| Issue |
A&A
Volume 667, November 2022
|
|
|---|---|---|
| Article Number | A132 | |
| Number of page(s) | 10 | |
| Section | The Sun and the Heliosphere | |
| DOI | https://doi.org/10.1051/0004-6361/202244206 | |
| Published online | 17 November 2022 | |
FarNet-II: An improved solar far-side active region detection method
1
Instituto de Astrofísica de Canarias, C/ Vía Láctea, s/n, 38205 La Laguna, Tenerife, Spain
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Departamento de Astrofísica, Universidad de La Laguna, 38205 La Laguna, Tenerife, Spain
Received:
7
June
2022
Accepted:
16
July
2022
Abstract
Context. Activity on the far side of the Sun is routinely studied through the analysis of the seismic oscillations detected on the near side using helioseismic techniques such as phase-shift sensitive holography. Detections made through those methods are limited to strong active regions due to the need for a high signal-to-noise ratio. Recently, the neural network FarNet was developed to improve these detections. This network extracts more information from helioseismic far-side maps, enabling the detection of smaller and weaker active regions.
Aims. We aim to create a new machine learning tool, FarNet-II, which further increases FarNet’s scope, and to evaluate its performance in comparison to FarNet and the standard helioseismic method for detecting far-side activity.
Methods. We developed FarNet-II, a neural network that retains some of the general characteristics of FarNet but improves the detections in general, as well as the temporal coherence among successive predictions. The main novelties of the new neural network are the implementation of attention and convolutional long short-term memory (ConvLSTM) modules. A cross-validation approach, training the network 37 times with a different validation set for each run, was employed to leverage the limited amount of data available. We evaluate the performance of FarNet-II using three years of extreme ultraviolet observations of the far side of the Sun acquired with the Solar Terrestrial Relations Observatory (STEREO) as a proxy of activity. The results from FarNet-II were compared with those obtained from FarNet and the standard helioseismic method using the Dice coefficient as a metric. Given that the application of the ConvLSTM modules can affect the accuracy as a function of the position on the sequence, we take this potential dependency into account in the evaluation.
Results. FarNet-II achieves a Dice coefficient that improves that of FarNet by over 0.2 points for every output position on the sequences from the evaluation dates. Its improvement over FarNet is higher than that of FarNet over the standard method.
Conclusions. The new network is a very promising tool for improving the detection of activity on the far side of the Sun given by pure helioseismic techniques. Space weather forecasts can potentially benefit from the higher sensitivity provided by this novel method.
Key words: Sun: activity / Sun: helioseismology / Sun: oscillations / sunspots / Sun: UV radiation
© E. G. Broock et al. 2022
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe-to-Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
Helioseismology is the branch of heliophysics that uses measurements of the surface oscillations of the Sun to infer the properties of the solar interior. Global helioseismology, the study of the eigenfrequencies of the resonant oscillatory modes, has shed some light on the solar internal structure and its rotation (Christensen-Dalsgaard 2002). The techniques of global helioseismology are, unfortunately, limited to the inference of the global properties of the Sun. As a natural evolution of global helioseismology, local helioseismology (Braun et al. 1987, 1992; Hill 1988; Duvall et al. 1993) was developed to infer the properties of local regions of the solar interior or its surface. This is accomplished by studying the whole wave field, instead of just the eigenfrequencies (see Gizon & Birch 2005, for a review).
One of the main techniques under the local helioseismology umbrella is helioseismic holography (Lindsey & Braun 1990). Helioseismic holography applies helioseismic observations of the surface to a solar interior model with no local structure in time reverse, and then it samples the results of the model at various depths. This technique relies on the coherence of the waves on smooth acoustic media to detect structures that disturb their path. Phase-sensitive holography, the technique used in this work, is a specific version of holography that uses the measurement of time-travel perturbations to study active regions that are not directly visible. A more detailed description can be found in Lindsey & Braun (2000b).
Phase-sensitive holography has been applied to the far-side imaging problem, resulting in a technique that is capable of detecting active regions in the non-visible solar hemisphere from the analysis of the near-side wave field (Lindsey & Braun 2000a; Braun & Lindsey 2001). Using the seismic data of a region in the visible hemisphere (the so-called “pupil”), the technique infers the wave field in a region of the far side or “focus point” (see Lindsey & Braun 2017, for further details). The success of this technique is made possible by the phase shift that active regions introduce between ingoing and outgoing waves from a range of frequencies. This phase shift is fundamentally caused by the Wilson depression (Lindsey et al. 2010; Felipe et al. 2017). Waves that arrive at regions on the far side where a Wilson depression is present are reflected into the Sun at a deeper layer than those that arrive at the quiet Sun’s surface. This shortening of the wave path imprints a negative phase shift upon the arrival of the waves to the near side. The disturbance in the travel time can then be associated with the presence of magnetic activity. We point out that time-distance helioseismology is also being used to perform far-side activity detection (Duvall & Kosovichev 2001; Zhao 2007; Ilonidis et al. 2009).
Although the results are impressive, far-side helioseismic methods are only able to detect strong sunspots due to the low signal-to-noise ratio of the seismic signal from most of the active regions. Smaller and fainter activity is left undetected (González Hernández et al. 2007; Liewer et al. 2014, 2017). To bypass the limitations of these techniques, Felipe & Asensio Ramos (2019) developed the deep neural network FarNet, a U-net (Ronneberger et al. 2015) that improves the sensitivity of phase-sensitive holography, opening the way for the detection of small active regions on the far side. Recently, Broock et al. (2021) confirmed FarNet’s reliability and its superior performance to that of the standard method. The goal of this paper is to present FarNet-II, a new architecture that further improves FarNet predictions by implementing convolutional long short-term memory (LSTM) modules and attention mechanisms into a U-net architecture.
The LSTM architectures (Hochreiter & Schmidhuber 1997) are recursive neural networks that were developed as an improvement over plain recurrent neural networks (RNNs; Rumelhart et al. 1986). Recurrent neural networks are architectures used to compute predictions over time series of data. They are especially useful for cases where temporal coherence is important (i.e., for forecasting problems). These types of networks take inputs recursively and use weights extracted from operations with previous inputs to compute the next outputs. Since RNNs are especially susceptible to the vanishing gradient problem, particularly when used over long time series (Hochreiter 1998), LSTMs were proposed.
The second main novelty of FarNet-II is the use of attention mechanisms. They are a variety of algorithms that focus on weighting the importance of different parts of the data running through a neural network, and on using their relative importance to optimize the performance of the network. These tools started by being applied to translation neural networks (Bahdanau et al. 2016; Vaswani et al. 2017), but their range of applicability has since become much wider. One of the fields in which these mechanisms have been used is computer vision, improving models for image classification (Hu et al. 2019a,b) and semantic segmentation (Fu et al. 2019; Li et al. 2019).
The paper is organized as follows: Sect. 2 explains methods of detecting far-side activity, including FarNet-II; Sect. 3 presents the obtained results; and those results are discussed in Sect. 4, along with the conclusions of the paper.
2. Detection of far-side activity
2.1. Phase-sensitive seismic method
The detection of activity on the far side of the Sun is founded on the analysis of far-side phase-shift maps. Helioseismic holography is employed to compute these maps from continuous near-side Doppler data. The latter are acquired from synoptic observations (the Global Oscillation Network Group, GONG, Harvey et al. 1996) or space-based observatories (Helioseismic and Magnetic Imager, HMI; Schou et al. 2012). In this work, we focus on HMI far-side seismic maps, which are regularly published by the Joint Science Operation Center (JSOC)1. Two different data products with a cadence of 12 h are available: one that uses 24 h of Doppler data for its generation and another one that uses five days of Doppler data instead.
The detection of active regions on the far side is routinely carried out by Stanford’s Strong Active Region Discriminator (SARD)2. This process uses the phase-shift maps computed with five days of Doppler data from HMI, and searches for those regions with a phase-shift lower than −0.085 rad. Then, the integral over the region’s area, in millionths of a hemisphere (μHem), is calculated. This magnitude is the so-called seismic strength (S). The presence of a seismically detected far-side active region is claimed for regions with S > 400 μHem rad (Liewer et al. 2017).
2.2. FarNet
FarNet was the first successful attempt at using deep learning to improve the interpretation of far-side phase-shift maps for activity detection. Activity detection can be seen as a binary semantic segmentation task, in which every pixel of the output needs to be classified as active or non-active. It is usually achieved by using deep convolutional neural networks (DCNNs). One of the architectures that is more commonly employed to pursue this task is the U-net. This architecture is based on an encoder-decoder structure that uses tools such as convolutional layers, batch normalization (BN; Ioffe & Szegedy 2009), and rectified linear unit activation functions (ReLU; Nair & Hinton 2010). The encoder reduces the spatial size of the images in successive steps via max-pooling (Goodfellow et al. 2016), while the number of channels is increased. This is done to extract and combine spatial information at many scales. On the decoder, the opposite happens, and the channel dimension is reduced while the spatial size is gradually increased to the spatial size of the input, via interpolation. The U-net uses skip connections between the encoder and the decoder to better utilize multiscale information, and improve performance during training and evaluation.
FarNet takes, as input, sequences of 11 phase-shift maps with a temporal cadence of 12 h, each of them computed in a 24-hour window of Doppler data (in contrast to SARD detections, which are currently based on phase-shift maps obtained from five days of Doppler data). A region spanning 120° in longitude and 144° in latitude is included in each map. The output is a probability map of the same far-side region from the central date of the input. Its values are constrained to the [0, 1] range using a sigmoid function at the output of the U-net. As proposed by Felipe & Asensio Ramos (2019), and later verified by Broock et al. (2021), it is important to post-process the output of FarNet to infer which features of the output are reliable active region detections. First, a Gaussian filter is applied over the outputs, with a full width at half maximum of 1.5 pixels. Then, regions with five contiguous pixels with a probability value higher than 0.2 are selected. Finally, for each detected region, the integrated probability (Pi) is calculated. This quantity is the integral of the probability over the regions’ area, measured in deg2. A region with an integrated probability of Pi > 100 is taken as a reliable detection.
2.3. FarNet-II
In this paper, we develop FarNet-II, an evolution of FarNet that greatly enhances its capabilities. It maintains some structural properties of FarNet, but it introduces some improvements, such as bidirectional convolutional LSTM modules, attention mechanisms, and dropout. One of the most relevant improvements is that FarNet-II can now produce one activity prediction per input date, instead of one only prediction for the central date of the input. This is achieved through the application of bidirectional ConvLSTM modules on specific parts of the network, which exploit the time coherence both forward and backward in time.
Figure 1 shows a graphical representation of our new model. It resembles a standard U-net architecture, but with the addition of the attention and ConvLSTM blocks in the decoder. We use, as input, sequences of 11 phase-shift maps of spatial size H × W. The encoder is applied in parallel to all the input maps of the sequences. For this reason, we combine the batch and sequence dimensions to fully exploit the parallelization capabilities of the hardware we use for training. The encoder increases the number of channels per map from one to C. Spatial dimensions are reduced by the consecutive application of a max-pooling and two convolutional layers with a ReLU activation function. Once the encoder operations are fully applied, the output of the encoder is passed through the decoder. Every operation, except those of the ConvLSTM layers, is applied in parallel to all elements in the input sequences. The decoder upsamples the information in the lowest spatial scale and combines it with the information obtained from the encoder at the same spatial resolution thanks to an attention layer. This process goes on until the decoder is applied over every scale. Figure 2 shows how the decoder uses the ConvLSTM layer, which keeps memory from the previous elements of the sequence during prediction, in a bidirectional way, keeping also memory from the next elements. We explain the details of these two innovations in the following sections. Dropout is also applied to two locations in the network, one on the encoder and the other on the decoder. The output of the network goes through a sigmoid to limit its values to the [0, 1] range before exiting the U-net architecture. The described model and an example of usage can be found online3.
 |
Fig. 1. General representation of FarNet-II. Original dimensions are batch (B), sequence (S), height (H), and width (W). Channel dimension (C) is additionally used in the following steps. Batch and sequence dimensions are joined together for every operation in the network, except for the application of the ConvLSTM modules. The red arrows symbolize simple convolutions, the light blue arrows symbolize the downward operation that reduces the spacial size of the images while increasing the number of channels, the violet arrows symbolize the bidirectional convolutional LSTM modules, and the dark blue arrows symbolize attention mechanisms. ⊗ symbolizes a dropout of 0.5. |
 |
Fig. 2. Bidirectional ConvLSTM module. Before the application of this module, the batch and sequence dimensions are split, and the input is duplicated but inverted in the sequence dimension. A ConvLSTM module is applied over both tensors, and the result of the application over the inverted one is re-inverted and concatenated with the result in the forward direction. The output of the module is obtained with a convolution over the concatenated tensors, which gives an output with the same dimension as the input. |
2.3.1. LSTM and convolutional LSTM
As a recursive network, the main innovation of the LSTM (Hochreiter & Schmidhuber 1997) over the RNN is the presence of a memory cell, ct, which modulates the information from previous inputs used to compute the next output. The memory cell is modified thanks to three self-parameterized gates: the input, the forget, and the output gates. Information of the input currently being processed by the layer is included in the cell if the input gate is open. Likewise, the values from the previous cell state are forgotten according to the value of the forget gate. The output gate controls if the latest cell state is propagated onto the next hidden state. The status of all gates (open or closed) is determined by sigmoid activation functions.
The LSTM modules have been used for a variety of purposes, including computer vision, with high success, but as their algorithm was not purposefully developed to tackle that task, their initial implementations did not take into account the possible existence of spatial correlations between different positions of the image. Long short-term memory was initially applied to computer vision in a fully connected manner, having to unfold the inputs into one-dimensional vectors, losing important spatial information. Architectures as convolutional layers naturally take into account these relations, especially when used over various resolutions of the inputs, as in encoder-decoder architectures.
Shi et al. (2015) developed an encoder-decoder architecture for the task of predicting the future rainfall intensity in a local region over a short time period (precipitation nowcasting), in which convolutions are directly introduced as an intrinsic part of LSTM layers. Since its conception, ConvLSTM modules have been used in machine learning architectures for multiple applications, such as the detection of violence in videos (Hanson et al. 2019) or predictions of urban expansion (Boulila et al. 2021).
For our work, we use a bidirectional version of the ConvLSTM proposed by Shi et al. (2015), which consists of two ConvLSTM layers. As shown in Fig. 2, the first layer is applied to the sequence in the original order, while the second is applied to the reversed sequence. After reversing again the result of the application of this second layer, both sequences are concatenated and a convolutional layer reduces the output to the input size.
2.3.2. Attention
Attention mechanisms on FarNet-II are used to modulate the skip connections before using them at each step of the decoder. The module uses the tensor on the decoder previous to its application and the corresponding skip connection. Both tensors are processed through convolutions, ReLU activations, and a final sigmoid, which produces a mask. This mask is then applied to the original skip connection, which is used on the decoder in the traditional manner of a U-net. For this work, we used the implementation given by Fillioux (2017) of the attention module proposed by Oktay et al. (2018).
2.3.3. Dropout
Dropout is a regularization method developed by Srivastava et al. (2014), whose goal is to improve the generalization of neural network capabilities, reducing overfitting to a specific training set. This is achieved by randomly ignoring some nodes on certain layers of the model during the training process. For FarNet-II, we applied dropout to 50% of the nodes in two different stages of the data flow.
2.3.4. Post-processing
As in FarNet, filtering was applied to the outputs of FarNet-II to get rid of small disturbances in the background that do not correspond to active regions. We applied Gaussian filtering with a full width at half maximum of 1.5 pixels, and every pixel in regions with five contiguous pixels with a probability higher than 0.2 was set to one, while the rest of the pixels were set to zero. This made the comparison with STEREO masks more rigorous. The difference in the training metrics before and after applying the filtering is negligible.
2.3.5. Extreme ultraviolet data
FarNet-II goes through supervised training by forcing the output to be as close to the desired target as possible. These targets are obtained from a binarization process of 304 Å Carrington maps from the Solar Museum Server of NASA (Liewer et al. 2017). These maps join together images from the Extreme Ultraviolet Imager (EUVI; Wuelser et al. 2004) on board the Solar Terrestrial Relations Observatory (STEREO; Kaiser 2004), and from the Atmospheric Imaging Assembly (AIA; Lemen et al. 2012) on board the Solar Dynamics Observatory (SDO; Pesnell et al. 2012). The training only employs the region of the maps corresponding to the far-side hemisphere, that is, the data acquired with STEREO. Precedents of extreme ultraviolet (EUV) image usage as a proxy of far-side activity can be found in Liewer et al. (2012), Liewer et al. (2014), and Zhao et al. (2019). The process through which the EUV maps were binarized is explained in detail by Broock et al. (2021).
2.3.6. Training
Dates from December 4, 2011 to August 18, 2014, were included in the training. The inputs were sequences of 11 consecutive far-side phase-shift maps, from which a region of 144° in latitude and 180° in longitude was taken, centered on the far side. As a target, we used the corresponding 11 binarized EUV masks of the same region. The total number of available input-target pairs with good far-side coverage was 2253. We note that the size of this training set is very limited. We partially solved this issue by using augmenting. It consisted of vertically flipping the images and the expected values. Due to the lack of a larger dataset, we carried out the study using a cross-validation method, dividing the training set into segments of 60 elements and choosing one of those elements as validation on each run. In total, 37 independent trainings were performed, each of them with 4340 input-target pairs for training and 120 input-target pairs for validation (including augmenting). We made evaluations on the validation set of each training, and then we averaged the resulting metrics among them.
The training of the model was done by minimizing the Dice loss computed between the outputs and the EUV binary masks. The Dice loss derived from the Dice coefficient. The Dice coefficient is a measure of the superposition of arrays of data with binary labels. For this specific scenario, it accounts for the accuracy of pixel labeling and can take values from 0 (no overlapping between pixel values on the output and on the associated EUV activity mask) to 1 (complete overlapping of output and the EUV activity mask). Since the values of both the outputs and the EUV masks are restricted to lying between 0 and 1, the Dice coefficient is given by:
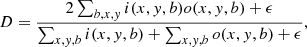 (1)
(1)
where i(x,y,b) and o(x,y,b) are the values of the output and target images for all pixels (x and y coordinates) and elements of the minibatch (b coordinate), while ϵ is a small quantity (0.001 in our case) that prevents the Dice coefficient from being undefined. To use the Dice coefficient as an efficient loss function for the training of a model, the simplest way is subtracting it from the unit, computing the Dice loss, given by:
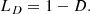 (2)
(2)
We implemented the model and trained it using the open-source PyTorch library (Paszke et al. 2019), and optimized the Dice loss using the Adam optimizer (Kingma & Ba 2017) with a learning rate of 3 × 10−4 during ten epochs and a batch size of 10. These ten epochs were sufficient for the Dice loss to stop increasing on validation data.
3. Results
To characterize the reliability of all the methods (standard phase-sensitive holography, FarNet, and FarNet-II) and compare their performance, we analyzed the values of the Dice coefficient between the EUV binary masks and the outputs of each method for each validation set. While FarNet-II produces a prediction spanning 180° in longitude, FarNet infers a shorter range. For this reason, the comparison was only made on the far-side section common to every method, spanning 120°.
In our previous paper (Broock et al. 2021), we used a different metric, in which each blob detected on the output of the model was assumed to be a different object. By comparison with the STEREO activity masks, we distinguished whether it was a true or a false detection. However, FarNet-II outputs tend to be less segmented, with various blobs merged, which makes the previous method of comparison less optimal.
3.1. Qualitative comparisons
We start by qualitatively comparing the outputs of all methods for two sequences, shown in Figs. 3 and 4. Each output batch of ten sequences takes between 13 and 14 s to be produced by the trained network on a CPU. The first columns show the square root of the STEREO EUV maps, with the second column displaying the STEREO masks defined using our procedure. The third, fourth, and fifth columns show the results obtained by FarNet-II, FarNet, and the standard phase-sensitive helioseismic method, respectively. Each row shows data of an element of the sequence, representing an instant in the temporal evolution of the far side for the dates of study. The solar rotation can be seen in the masks and also in the predictions. It is clear from these figures that the predictions of FarNet-II are much more accurate than those of the other methods when compared with the STEREO activity masks. FarNet-II can correctly predict small activity regions while also detecting many of the large regions. We speculate that the prediction of these regions is possible thanks to the time coherence exploited by the ConvLSTM in FarNet-II. The results of FarNet-II displayed in Figs. 3 and 4 show an excellent prediction ability, which is in strong contrast with the poorer results from FarNet and the classical phase-sensitive helioseismic method.
 |
Fig. 3. Comparison of an output sequence, centered on December 12, 2013, for each method. The first column shows the square root of the STEREO data used to compute the activity masks. The second column shows the activity masks. Third to fifth columns show outputs from FarNet-II, FarNet, and the phase-sensitive method, respectively, for the region corresponding to the EUV masks on the second column. In Cols. 2–5, the color gradient goes from purple for zero or values near zero to yellow for values near one or one. Outputs from FarNet are only valid on the central range of 120 degrees of longitude (vertical blue lines). Seismic strength and integrated probability were not taken into account to select the regions on the outputs from FarNet and the phase-sensitive method. Every region that passed the post-processing was included. |
3.2. Quantitative comparisons
The visual inspection of FarNet-II predictions demonstrates a very good prediction ability. In this section, we employ quantitative comparison methods to show that this is true for the large majority of cases in the validation sets.
This quantitative comparison is made using the Dice coefficient as a metric, which is then averaged over the validation sets of every training. We analyzed how the metric behaves for all of the considered methods. For an in-depth comparison, we checked the metrics when the thresholds in Pi and S (seismic strength) proposed for a reliable detection were considered or not. The global results are shown in Table 1. The global prediction capabilities of all methods were measured with the Dice coefficient averaged over every element of the sequences and all validation sets. FarNet-II clearly has improved performance, with the Dice coefficient increasing by more than 0.2 points over the most performant of all previous methods.
Average of the Dice coefficients over every sequence element, for each method and model, including variations in the filtering on outputs from FarNet (Pi value) and the phase-sensitive method (S value).
Since FarNet-II produces a prediction for all times using the information of previous and later input images of the sequence, we expect the reliability of the prediction to be potentially different for different times inside the sequence. We analyzed this in detail by calculating the Dice coefficient for each element of the sequence on the validation set. Since FarNet and the standard phase-sensitive method do not make use of this temporal information, the results of each index were computed with the appropriate window of phase-shift maps centered on the specific date of each element of the sequence. The results are shown in Fig. 5 when no special threshold is used. When the optimal thresholds are considered (Pi > 100 for FarNet and S > 400 for the phase-sensitive method), the results are those shown in Fig. 6. It is important to note that very restrictive values were selected for these optimal thresholds (Broock et al. 2021). They guarantee the presence of an EUV emission counterpart to the seismic active region with a 96% confidence level. When they are taken into account, the Dice coefficient exhibits poorer values since actual detections are discarded due to their lower confidence. According to these results, FarNet-II produces a Dice coefficient that is almost a factor of two larger than those of the other methods, on average. Additionally, this consistency is maintained for all indices of the sequence, with only a small improvement in the predictions for the central frames.
 |
Fig. 5. Dice coefficient per method, as a function of the position of the images on the output sequences of 11 elements. Thresholds for reliable detection for FarNet (Pi > 100) and the phase-sensitive method (S > 400) were not taken into account. Every region on outputs from FarNet with more than five contiguous pixels and a probability over 0.2 was used to compute the value. The vertical bars represent the standard deviation of the mean Dice coefficient over the 37 validation sets used in the study. |
 |
Fig. 6. Dice coefficient per method, as a function of the position of the images on the output sequences of 11 elements. Only regions with Pi > 100, for FarNet, and with S > 400, for the phase-sensitive method, are taken into account. The vertical bars represent the standard deviation of the mean Dice coefficient over the 37 validation sets used in the study. |
3.3. Ablation study
We carried out an ablation study to determine the relative importance of each of the new layers added to FarNet-II concerning the previous FarNet neural network. This study, although limited, demonstrates that the final architecture arguably produces the best predictions. To this end, we trained different models: (1) using unidirectional ConvLSTM layers instead of the bidirectional ones employed in the final model; (2) removing the attention layers; and (3) removing the regularizing effect of dropout. The average Dice coefficients computed on the validation sets for each model are represented in Figs. 7 and 8. The production time of outputs does not vary significantly for ablated versions of FarNet-II. The total averaged Dice coefficient achieved by each model can be found in Table 2. The results demonstrate that adding recursion produces the largest improvement over the baselines, with attention and dropout increasing the prediction ability only marginally, although still monotonically. In the case of using the unidirectional ConvLSTM, we see that the prediction for the elements at the end of the sequence is better than those at the beginning, demonstrating that exploiting the time correlation in the two directions is important.
 |
Fig. 7. Dice coefficient per method, as a function of the position of the images on the output sequences of 11 elements. This figure includes the ablated versions of FarNet-II. Thresholds for reliable detection for FarNet (Pi > 100) and the phase-sensitive method (S > 400) were not taken into account. Every region on outputs from FarNet with more than five contiguous pixels and a probability over 0.2 was used to compute the value. The vertical bars represent the standard deviation of the mean Dice coefficient over the 37 validation sets used in the study. |
 |
Fig. 8. Dice coefficient per method, as a function of the position of the images on the output sequences of 11 elements. This figure includes the ablated versions of FarNet-II. Only regions with Pi > 100, for FarNet, and with S > 400, for the phase-sensitive method, are taken into account. The vertical bars represent the standard deviation of the mean Dice coefficient over the 37 validation sets used in the study. |
Average of the Dice coefficients of every sequence element for FarNet-II and its ablated models (U: unidirectional ConvLSTM; WA: without attention; WD: without dropout).
3.4. Performance as a function of longitude
Figure 9 illustrates the dependence of the performance of FarNet-II on longitude. This study was individually performed for every index in the sequence of outputs. Additionally, the total average, including all the outputs from the sequence, is shown for completeness.
 |
Fig. 9. Average over every validation set of the Dice coefficient on FarNet-II’s outputs as a function of the longitude range in degrees. Each range covers 20°. Each panel represents the Dice coefficient on the sequence element indicated above it. The bottom right panel represents the average of all sequence elements. A longitude of 0° corresponds to the west limb, 90° to the center of the far-side hemisphere, and 180° to the east limb. |
The results exhibit a marked variation with the sequence index. At the beginning of the series (indices 0–2), far-side regions with a lower longitude (that is, the solar region that has just rotated onto the far-side hemisphere) show a higher Dice coefficient. In contrast, a low Dice coefficient is retrieved at high longitudes (regions that are about to rotate onto the visible hemisphere). A progressive change in this trend is found as higher indices are considered. The variation in the Dice coefficient with the longitude exhibits a mostly flat profile at the middle of the series (indices 3–5), whereas in the last steps of the sequence (indices 6–10), the Dice coefficient increases with the longitude.
This dependence on the longitude is consistent with the displacement of the active regions across the far-side hemisphere due to the solar rotation. Active regions located at high longitudes in the first elements of the series quickly rotate onto the visible hemisphere, and their presence is no longer tracked by seismic far-side maps. Similarly, active regions with a low longitude in the last steps of the series have just rotated onto the far side and only appear in those last steps. In summary, a weaker performance is found in those two extremes (high longitude and low index, low longitude and high index) due to the limited information available in the input sequence of far-side seismic maps. These results also support the relevance of exploiting the bidirectional temporal correlation.
4. Discussion and conclusions
We have presented a new neural architecture, FarNet-II, which combines some characteristics of the original FarNet (Felipe & Asensio Ramos 2019) with the use of bidirectional ConvLSTM, attention modules, and dropout. We have proven that this model further improves the capabilities of FarNet in the detection of far-side activity.
FarNet-II was trained using activity masks extracted from EUV data from the far side as expected values. This is an improvement over FarNet’s training, where we used near-side binarized magnetograms from half a rotation later than the inputs to the network. Even though these magnetograms were processed to eliminate every active region emerging on the near side, they do not provide an accurate characterization of the far-side activity at the temporal period when the seismic maps were computed, since the size and shape of the regions can vary between both dates, and regions may have decayed before rotating onto the near side. In these new training sets, far-side activity fed to the network is obtained from direct far-side observations, and it is strictly co-temporal to the seismic maps, leading to higher accuracy.
The enhanced performance of FarNet-II, as compared with other methods, has been proven through the visual inspection of their outputs in comparison with the actual far-side activity captured by EUV observations from STEREO (Figs. 3 and 4). We have also performed a quantitative comparison by employing the Dice coefficient as a metric to evaluate the similarity between the predicted far-side regions and the actual activity in EUV maps. The results show a remarkably higher value of the Dice coefficient for FarNet-II, strongly supporting its improved performance.
We have evaluated the individual contribution from each of the new ingredients implemented in FarNet-II. The analysis clearly points to the ConvLSTM modules as the main driver of the increased reliability of the new architecture. Interestingly, the version of FarNet-II with only unidirectional ConvLSTM modules (forward in time) exhibits an upward trend of the Dice coefficient as the sequence index increases (Fig. 7). This is due to the increase in information that later elements on the sequence receive from previous iterations. When bidirectional ConvLSTM is implemented (full FarNet-II), the performance is similarly good for the whole sequence, except for longitudes near the limb at the beginning and the end of the sequence (Fig. 9). The other novel modules implemented in FarNet-II (attention modules and dropout) provide a modest improvement in its performance. All in all, the best results are found when all these new layers act together. Although not shown explicitly in this work, we checked the coherence of the differential rotation for the sequence of FarNet-II’s outputs. The results are consistent with the measured solar differential rotation.
We consider this work as a new step forward to improve the imaging of the far side of the Sun. Nowadays, direct far-side images can only be acquired by Solar Orbiter (Müller et al. 2020) during some periods of its orbit, even though they are fundamental for space weather applications (the branch of astrophysics dedicated to studying the Sun and the state of the interplanetary space on the Solar System). The global photospheric magnetic field, not only in the visible hemisphere, is necessary in order to model the heliospheric magnetic field and solar wind. Currently, synoptic maps that complete the magnetism in the non-visible hemisphere with near-side observations obtained many days in advance are generally employed. This approximation of the far-side magnetism can be updated with sophisticated flux transport models (Schrijver & De Rosa 2003). However, these models cannot account for new active regions emerging on the far side or active regions that keep growing after rotating onto the non-visible hemisphere. The detection of activity on the far side is important to completely characterize the global photospheric magnetic field and, thus, the heliosphere. Arge et al. (2013) proved that incorporating seismically detected far-side active regions into the modeling of the heliosphere produces results that better match in situ measurements of the solar wind. Our study provides a remarkable improvement of the capabilities of local helioseismology to characterize the far-side magnetism, getting us closer to the goal of implementing these techniques in space weather forecasting applications. The main limitation of this study is the lack of data to construct bigger training sets. We have been forced to work with small validation sets that can lead to somehow noisy statistics. We plan to bypass this limitation with new data in future works.
GitHub repository: https://github.com/EBroock/FarNet-II
Acknowledgments
We thank P.C. Liewer and collaborators for making publicly available the composite STEREO/EUVI and SDO/AIA maps necessary to carry out this research. We also thank C. Cid, from Universidad de Alcalá de Henares (UAH), for her invaluable ideas for future projects using FarNet-II. Financial support from grants PGC2018-097611-A-I00 and PID2021-127487NB-I00, funded by MCIN/AEI/10.13039/501100011033 and by “ERDF A way of making Europe”, and grant PROID2020010059 funded by Consejería de Economísa, Conocimiento y Empleo del Gobierno de Canarias and the European Regional Development Fund (ERDF) is gratefully acknowledged. T.F. acknowledges grant RYC2020-030307-I funded by MCIN/AEI/10.13039/501100011033 and by “ESF Investing in your future”. We acknowledge the community effort devoted to the development of the following open-source packages that were used in this work: numpy (numpy.org, Harris et al. 2020), matplotlib (matplotlib.org, Hunter 2007), PyTorch (pytorch.org, Paszke et al. 2019), SunPy (sunpy.org, The Sun Py Community 2020), einops (Rogozhnikov 2022), and h5py (Koziol & Robinson 2017).
References
- Arge, C. N., Henney, C. J., Hernandez, I. G., et al. 2013, Sol. Wind, 13, 11 [Google Scholar]
- Bahdanau, D., Cho, K., & Bengio, Y. 2016, arXiv e-prints [arXiv:1409.0473v7] [Google Scholar]
- Boulila, W., Ghandorh, H., Khan, M. A., Ahmed, F., & Ahmad, J. 2021, Ecol. Inf., 64, 101325 [CrossRef] [Google Scholar]
- Braun, D. C., & Lindsey, C. 2001, ApJ, 560, L189 [NASA ADS] [CrossRef] [Google Scholar]
- Braun, D. C., Duvall, T. L., Jr., & Labonte, B. J. 1987, ApJ, 319, L27 [NASA ADS] [CrossRef] [Google Scholar]
- Braun, D., Lindsey, C., Fan, Y., & Jefferies, S. 1992, ApJ, 392, 739 [NASA ADS] [CrossRef] [Google Scholar]
- Broock, E. G., Felipe, T., & Asensio Ramos, A. 2021, A&A, 652, A132 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Christensen-Dalsgaard, J. 2002, Rev. Mod. Phys., 74, 1073 [Google Scholar]
- Duvall, T. L., Jr., & Kosovichev, A. G. 2001, in Recent Insights into the Physics of the Sun and Heliosphere: Highlights from SOHO and Other Space Missions, eds. P. Brekke, B. Fleck, & J. B. Gurman, IAU Symp., 203, 159 [NASA ADS] [Google Scholar]
- Duvall, T. L., Jr., Jefferies, S. M., Harvey, J. W., & Pomerantz, M. A. 1993, Nature, 362, 430 [Google Scholar]
- Felipe, T., & Asensio Ramos, A. 2019, A&A, 632, A82 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Felipe, T., Braun, D. C., & Birch, A. C. 2017, A&A, 604, A126 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Fillioux, L.https://gist.github.com/leofillioux/22f021a8606d67bf6a3481820654601a (accessed: 2021-11-30) [Google Scholar]
- Fu, J., Liu, J., Tian, H., et al. 2019, IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 3141 [Google Scholar]
- Gizon, L., & Birch, A. C. 2005, Liv. Rev. Sol. Phys., 2, 6 [Google Scholar]
- González Hernández, I., Hill, F., & Lindsey, C. 2007, ApJ, 669, 1382 [CrossRef] [Google Scholar]
- Goodfellow, I., Bengio, Y., & Courville, A. 2016, Deep Learning (Cambridge: MIT Press) [Google Scholar]
- Hanson, A., Pnvr, K., Krishnagopal, S., & Davis, L. 2019, Bidirectional Convolutional LSTM for the Detection of Violence in Videos: Subvolume B, 280 [Google Scholar]
- Harris, C. R., Millman, K. J., van der Walt, S. J., et al. 2020, Nature, 585, 357 [NASA ADS] [CrossRef] [Google Scholar]
- Harvey, J. W., Hill, F., Hubbard, R. P., et al. 1996, Science, 272, 1284 [Google Scholar]
- Hill, F. 1988, ApJ, 333, 996 [Google Scholar]
- Hochreiter, S. 1998, Int. J. Uncertain. Fuzziness Knowl. Based Syst., 6, 107 [CrossRef] [Google Scholar]
- Hochreiter, S., & Schmidhuber, J. 1997, Neural Comput., 9, 1735 [CrossRef] [Google Scholar]
- Hu, H., Zhang, Z., Xie, Z., & Lin, S. 2019a, in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 3463 [CrossRef] [Google Scholar]
- Hu, J., Shen, L., Albanie, S., Sun, G., & Wu, E. 2019b, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 7132 [Google Scholar]
- Hunter, J. D. 2007, Comput. Sci. Eng., 9, 90 [NASA ADS] [CrossRef] [Google Scholar]
- Ilonidis, S., Zhao, J., & Hartlep, T. 2009, Sol. Phys., 258, 181 [NASA ADS] [CrossRef] [Google Scholar]
- Ioffe, S., & Szegedy, C. in Proceedings of the 32nd International Conference on Machine Learning (ICML-15), eds. D. Blei, & F. Bach, JMLR Workshop and Conference Proceedings, 448 [Google Scholar]
- Kaiser, M. 2004, Adv. Space Res., 36, 1483 [Google Scholar]
- Kingma, D. P., & Ba, J. 2017, arXiv e-prints [arXiv:1412.6980v9] [Google Scholar]
- Koziol, Q., & Robinson, D. HDF5. Computer Software, https://doi.org/10.11578/dc.20180330.1 [Google Scholar]
- Lemen, J. R., Title, A. M., Akin, D. J., et al. 2012, Sol. Phys., 275, 17 [Google Scholar]
- Li, X., Zhong, Z., Wu, J., et al. 2019, in 2019 IEEE/CVF International Conference on Computer Vision (ICCV), 9166 [Google Scholar]
- Liewer, P., Hernandez, I., Hall, J., Thompson, W., & Misrak, A. 2012, Sol. Phys., 281, 3 [NASA ADS] [Google Scholar]
- Liewer, P. C., González Hernández, I., Hall, J. R., Lindsey, C., & Lin, X. 2014, Sol. Phys., 289, 3617 [NASA ADS] [CrossRef] [Google Scholar]
- Liewer, P. C., Qiu, J., & Lindsey, C. 2017, Sol. Phys., 292, 146 [NASA ADS] [CrossRef] [Google Scholar]
- Lindsey, C., & Braun, D. C. 1990, Sol. Phys., 126, 101 [NASA ADS] [CrossRef] [Google Scholar]
- Lindsey, C., & Braun, D. C. 2000a, Sol. Phys., 192, 261 [Google Scholar]
- Lindsey, C., & Braun, D. C. 2000b, Science, 287, 1799 [Google Scholar]
- Lindsey, C., & Braun, D. 2017, Space Weather, 15, 761 [NASA ADS] [CrossRef] [Google Scholar]
- Lindsey, C., Cally, P. S., & Rempel, M. 2010, ApJ, 719, 1144 [NASA ADS] [CrossRef] [Google Scholar]
- Müller, D., St. Cyr, O. C., Zouganelis, I., et al. 2020, A&A, 642, A1 [Google Scholar]
- Nair, V., & Hinton, G. E. 2010, in Proceedings of the 27th International Conference on Machine Learning (ICML-10), 807 [Google Scholar]
- Oktay, O., Schlemper, J., Folgoc, L. L., et al. 2018, arXiv e-prints [arXiv:1804.03999v3] [Google Scholar]
- Paszke, A., Gross, S., Massa, F., et al. 2019, in Advances in Neural Information Processing Systems 32, 8024 [Google Scholar]
- Pesnell, W. D., Thompson, B. J., & Chamberlin, P. C. 2012, Sol. Phys., 275, 3 [Google Scholar]
- Rogozhnikov, A. 2022, in 2022 International Conference on Learning Representations (ICLR), https://openreview.net/forum?id=oapKSVM2bcj [Google Scholar]
- Ronneberger, O., Fischer, P., & Brox, T. 2015, arXiv e-prints [arXiv:1505.04597] [Google Scholar]
- Rumelhart, D. E., Hinton, G. E., & Williams, R. 1986, Parallel Distributed Processing: Explorations in the Microstructure of Cognition: Foundations (MIT Press), 318 [Google Scholar]
- Schou, J., Scherrer, P. H., Bush, R. I., et al. 2012, Sol. Phys., 275, 229 [Google Scholar]
- Schrijver, C. J., & De Rosa, M. L. 2003, Sol. Phys., 212, 165 [Google Scholar]
- Shi, X., Chen, Z., Wang, H., et al. 2015, in Proceedings of the 28th International Conference on Neural Information Processing Systems, eds. C. Cortes, N. Lawrence, D. Lee, M. Sugiyama, & R. Garnett, 802 [Google Scholar]
- Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. 2014, J. Mach. Learn. Res., 15, 1929 [Google Scholar]
- The Sun Py Community, Barnes, W. T., Bobra, M. G., et al. 2020, ApJ, 890, 68 [NASA ADS] [CrossRef] [Google Scholar]
- Vaswani, A., Shazeer, N., Parmar, N., et al. 2017, in NIPS’17: Proceedings of the 31st International Conference on Neural Information Processing Systems, Curran Associates Inc, 6000 [Google Scholar]
- Wuelser, J. P., Lemen, J. R., Tarbell, T. D., et al. 2004, in Telescopes and Instrumentation for Solar Astrophysics, eds. S. Fineschi, & M. S. Gummin, International Society for Optics and Photonics (SPIE), 5171, 111 [NASA ADS] [CrossRef] [Google Scholar]
- Zhao, J. 2007, ApJ, 664, L139 [NASA ADS] [CrossRef] [Google Scholar]
- Zhao, J., Hing, D., Chen, R., & Hess Webber, S. 2019, ApJ, 887, 216 [NASA ADS] [CrossRef] [Google Scholar]
All Tables
Average of the Dice coefficients over every sequence element, for each method and model, including variations in the filtering on outputs from FarNet (Pi value) and the phase-sensitive method (S value).
Average of the Dice coefficients of every sequence element for FarNet-II and its ablated models (U: unidirectional ConvLSTM; WA: without attention; WD: without dropout).
All Figures
|
Fig. 1. General representation of FarNet-II. Original dimensions are batch (B), sequence (S), height (H), and width (W). Channel dimension (C) is additionally used in the following steps. Batch and sequence dimensions are joined together for every operation in the network, except for the application of the ConvLSTM modules. The red arrows symbolize simple convolutions, the light blue arrows symbolize the downward operation that reduces the spacial size of the images while increasing the number of channels, the violet arrows symbolize the bidirectional convolutional LSTM modules, and the dark blue arrows symbolize attention mechanisms. ⊗ symbolizes a dropout of 0.5. |
| In the text | |
|
Fig. 2. Bidirectional ConvLSTM module. Before the application of this module, the batch and sequence dimensions are split, and the input is duplicated but inverted in the sequence dimension. A ConvLSTM module is applied over both tensors, and the result of the application over the inverted one is re-inverted and concatenated with the result in the forward direction. The output of the module is obtained with a convolution over the concatenated tensors, which gives an output with the same dimension as the input. |
| In the text | |
|
Fig. 3. Comparison of an output sequence, centered on December 12, 2013, for each method. The first column shows the square root of the STEREO data used to compute the activity masks. The second column shows the activity masks. Third to fifth columns show outputs from FarNet-II, FarNet, and the phase-sensitive method, respectively, for the region corresponding to the EUV masks on the second column. In Cols. 2–5, the color gradient goes from purple for zero or values near zero to yellow for values near one or one. Outputs from FarNet are only valid on the central range of 120 degrees of longitude (vertical blue lines). Seismic strength and integrated probability were not taken into account to select the regions on the outputs from FarNet and the phase-sensitive method. Every region that passed the post-processing was included. |
| In the text | |
 |
Fig. 4. Same as for Fig. 3, but for data centered on July 2, 2012. |
| In the text | |
|
Fig. 5. Dice coefficient per method, as a function of the position of the images on the output sequences of 11 elements. Thresholds for reliable detection for FarNet (Pi > 100) and the phase-sensitive method (S > 400) were not taken into account. Every region on outputs from FarNet with more than five contiguous pixels and a probability over 0.2 was used to compute the value. The vertical bars represent the standard deviation of the mean Dice coefficient over the 37 validation sets used in the study. |
| In the text | |
|
Fig. 6. Dice coefficient per method, as a function of the position of the images on the output sequences of 11 elements. Only regions with Pi > 100, for FarNet, and with S > 400, for the phase-sensitive method, are taken into account. The vertical bars represent the standard deviation of the mean Dice coefficient over the 37 validation sets used in the study. |
| In the text | |
|
Fig. 7. Dice coefficient per method, as a function of the position of the images on the output sequences of 11 elements. This figure includes the ablated versions of FarNet-II. Thresholds for reliable detection for FarNet (Pi > 100) and the phase-sensitive method (S > 400) were not taken into account. Every region on outputs from FarNet with more than five contiguous pixels and a probability over 0.2 was used to compute the value. The vertical bars represent the standard deviation of the mean Dice coefficient over the 37 validation sets used in the study. |
| In the text | |
|
Fig. 8. Dice coefficient per method, as a function of the position of the images on the output sequences of 11 elements. This figure includes the ablated versions of FarNet-II. Only regions with Pi > 100, for FarNet, and with S > 400, for the phase-sensitive method, are taken into account. The vertical bars represent the standard deviation of the mean Dice coefficient over the 37 validation sets used in the study. |
| In the text | |
|
Fig. 9. Average over every validation set of the Dice coefficient on FarNet-II’s outputs as a function of the longitude range in degrees. Each range covers 20°. Each panel represents the Dice coefficient on the sequence element indicated above it. The bottom right panel represents the average of all sequence elements. A longitude of 0° corresponds to the west limb, 90° to the center of the far-side hemisphere, and 180° to the east limb. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.