| Issue |
A&A
Volume 664, August 2022
|
|
|---|---|---|
| Article Number | A170 | |
| Number of page(s) | 20 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/202142083 | |
| Published online | 26 August 2022 | |
KiDS-1000: Cosmic shear with enhanced redshift calibration
1
Ruhr-University Bochum, Astronomical Institute, German Centre for Cosmological Lensing, Universitätsstr. 150, 44801 Bochum, Germany
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Argelander-Institut für Astronomie, Universität Bonn, Auf dem Hügel 71, 53121 Bonn, Germany
3
Center for Theoretical Physics, Polish Academy of Sciences, al. Lotników 32/46, 02-668 Warsaw, Poland
4
Institute for Astronomy, University of Edinburgh, Royal Observatory, Blackford Hill, Edinburgh EH9 3HJ, UK
5
E. A. Milne Centre, University of Hull, Cottingham Road, Hull HU6 7RX, UK
6
Waterloo Centre for Astrophysics, University of Waterloo, 200 University Ave W, Waterloo, ON N2L 3G1, Canada
7
Department of Physics and Astronomy, University of Waterloo, 200 University Ave W, Waterloo, ON N2L 3G1, Canada
8
Centre for Astrophysics & Supercomputing, Swinburne University of Technology, PO Box 218, Hawthorn, VIC 3122, Australia
9
Department of Astrophysical Sciences, Princeton University, 4 Ivy Lane, Princeton, NJ 08544, USA
10
Shanghai Astronomical Observatory (SHAO), Nandan Road 80, Shanghai 200030, PR China
11
University of Chinese Academy of Sciences, Beijing 100049, PR China
Received:
24
August
2021
Accepted:
4
April
2022
Abstract
We present a cosmic shear analysis with an improved redshift calibration for the fourth data release of the Kilo-Degree Survey (KiDS-1000) using self-organising maps (SOMs). Compared to the previous analysis of the KiDS-1000 data, we expand the redshift calibration sample to more than twice its size, now consisting of data of 17 spectroscopic redshift campaigns, and significantly extending the fraction of KiDS galaxies we are able to calibrate with our SOM redshift methodology. We then enhanced the calibration sample with precision photometric redshifts from COSMOS2015 and the Physics of the Accelerated Universe Survey (PAUS), allowing us to fill gaps in the spectroscopic coverage of the KiDS data. Finally we performed a Complete Orthogonal Sets of E/B-Integrals (COSEBIs) cosmic shear analysis of the newly calibrated KiDS sample. We found S8 = 0.748−0.025+0.021, which is in good agreement with previous KiDS studies and increases the tension with measurements of the cosmic microwave background to 3.4σ. We repeated the redshift calibration with different subsets of the full calibration sample and obtained, in all cases, agreement within at most 0.5σ in S8 compared to our fiducial analysis. Including additional photometric redshifts allowed us to calibrate an additional 6% of the source galaxy sample. Even though further systematic testing with simulated data is necessary to quantify the impact of redshift outliers, precision photometric redshifts can be beneficial at high redshifts and to mitigate selection effects commonly found in spectroscopically selected calibration samples.
Key words: cosmology: observations / gravitational lensing: weak / galaxies: distances and redshifts / surveys
© J. L. van den Busch et al. 2022
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe-to-Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
Over the past decade, gravitational lensing (Bartelmann & Schneider 2001) has emerged as one of the most powerful tools to study gravity and the dark sectors of the Universe, dark matter and dark energy, through the impact of these components on the density fluctuations of matter and their evolution with cosmic time (Peacock et al. 2006). In the limit of weak lensing, massive structures along the line of sight imprint a subtle shearing on the shapes of distant galaxies. This signal can be extracted by statistically analysing the ellipticity of galaxy images in large surveys (Refregier 2003). These cosmic shear surveys (Kilbinger 2015) face the challenge that they must accurately reconstruct the galaxy redshift distribution in order to interpret the cosmological signal correctly. Even small biases in the first moment of the redshift distribution may introduce significant biases in the recovered cosmological parameters (e.g. Huterer et al. 2006; Ma et al. 2006). There exists tension between constraints from cosmic shear and the cosmic microwave background, first seen between the Canada-France-Hawaii Telescope Lensing Survey (CFHTLenS, Heymans et al. 2013; MacCrann et al. 2015; Joudaki et al. 2017) and Planck (Planck Collaboration XVI 2014), but also between the Kilo-Degree Survey (KiDS, Kuijken et al. 2015) and Planck legacy (Planck Collaboration VI 2020) for example, and recently for KiDS-1000 (Asgari et al. 2021). The most recent cosmic shear results from the Dark Energy Survey (DES, Flaugher et al. 2015) are very similar to KiDS-1000 (Amon et al. 2022; Secco et al. 2022). albeit at a lower statistical tension with Planck1. In the light of these repeatedly reported tensions, redshift calibration has come under scrutiny as one of the systematics for cosmic shear experiments (e.g. Joudaki et al. 2020).
Due to the statistical nature of the shear measurements, current generation (stage-III) cosmic shear surveys, such as KiDS, DES, and the Hyper Suprime-Cam Subaru Strategic Program (HSC, Aihara et al. 2018), rely on the imaging of tens of millions of galaxies for which spectroscopic redshifts cannot be measured directly. Instead, galaxy redshifts are determined with secondary redshift estimates, the most notable ones are direct calibration with spectroscopic training samples (e.g. Lima et al. 2008; Hildebrandt et al. 2017, 2020; Buchs et al. 2019; Wright et al. 2020a), clustering redshifts (which infer redshift distributions by exploiting the gravitational clustering of galaxies at similar redshifts, e.g. Newman 2008; Matthews & Newman 2010; Schmidt et al. 2013; Ménard et al. 2013; van den Busch et al. 2020; Hildebrandt et al. 2021; Gatti et al. 2022), and methods that make use of a combination of both these approaches (Sánchez & Bernstein 2019; Alarcon et al. 2020; Myles et al. 2021).
The redshift calibration of the fourth data-release of KiDS (Kuijken et al. 2019; Hildebrandt et al. 2021) relies on an implementation of the direct calibration that utilises a self-organising map (SOM, Kohonen 1982; Wright et al. 2020a) based on work by Masters et al. (2016). The fundamental principle of this method is to re-weight a spectroscopic reference sample such that it is representative of a photometric dataset with an unknown redshift distribution. The weighted redshift distribution of the reference sample is then a direct estimate of the unknown distribution. Additionally, the SOM method allows for the removal of galaxies from the photometric dataset for which no similar galaxies exist in the reference sample. Their inclusion would otherwise bias the estimated redshift distribution. We call the subset of the remaining, well represented galaxies the ‘gold sample’. In this work we explore the redshift calibration of the KiDS data with a significantly enhanced reference sample that is composed of a variety of spectroscopic redshift campaigns and precision photometric redshifts. This allows us to expand the KiDS gold sample and calibrate redshifts in regions of the colour space that are difficult to access by direct spectroscopy. We then study how these additional calibration data influence our ability to calibrate the redshifts of the source sample, and how selection effects and changes in the calibration propagate to cosmological constraints. We compare our results to the original KiDS-1000 cosmic shear analysis by Asgari et al. (2021).
This paper is structured as follows: in Sect. 2 we describe the KiDS data and the redshift calibration sample (further details on this compilation in Appendix A), and in Sects. 3 and 4 we present the SOM redshift calibration and our cosmic shear analysis methods. We present and discuss the newly calibrated gold samples and cosmological constraints in Sects. 5 and 6. Finally we conclude and summarise in Sect. 7.
2. Data
This paper explores redshift calibration of the KiDS cosmic shear weak lensing sample (Sect. 2.1) with increasingly deep redshift calibration catalogues. Our fiducial analysis relies exclusively on spectroscopic data which was compiled from a variety of different spectroscopic surveys (Sect. 2.2 and Appendix A). We then added less accurate redshift estimates derived from narrowband photometry from the Physics of the Accelerated Universe Survey (PAUS, Padilla et al. 2019) and finally from medium- and broadband photometry from COSMOS2015 (Sect. 2.3). This approach is similar to the construction of the calibration sample for the DES Y3 redshift calibration (Myles et al. 2021), however the KiDS lensing and redshift calibration samples are both covered by the same nine bands which avoids mapping different photometries via a transfer function.
2.1. KiDS-1000 photometric data
The Kilo-Degree Survey (KiDS, Kuijken et al. 2015; de Jong et al. 2015, 2017; Kuijken et al. 2019) is a public European Southern Observatory (ESO) survey that has been designed particularly with weak gravitational lensing applications in mind. The complete survey will deliver about 1350 deg2 of ugri imaging split into an equatorial and a southern field. Combined with ZYJHKs imaging from its companion infrared survey, the VISTA Kilo-Degree Infrared Galaxy Survey (VIKING, Edge et al. 2013; Venemans et al. 2015), this constitutes a nine-band, matched-depth data-set with primary imaging in the r-band, observed at a mean seeing of 0.7″. This work is based on the fourth data release of KiDS which covers 1006 deg2. The weak lensing source catalogue (KiDS-1000, Giblin et al. 2021) is divided into five tomographic redshift bins, based on nine-band photometric redshifts (four bins with ΔZB = 0.2, starting from ZB = 0.1, and a fifth bin at 0.9 < ZB ≤ 1.2) computed with BPZ (Bayesian Photometric Redshift, Benítez 2000). It contains all objects with non-zero shear measurement weights obtained from lensfit (Miller et al. 2007; Fenech Conti et al. 2017), which effectively selects objects with r-band magnitudes between 20 ≤ r ≤ 25.
In addition to the main survey imaging there are observations of six fields dedicated primarily to redshift calibration. These ‘KiDZ’ fields cover approximately 1 deg2 each and target areas of the sky also observed by different spectroscopic campaigns, which are summarised in Sect. 2.2. Just like the main survey, KiDZ provides KiDS+VIKING nine-band imaging2 which reaches or exceeds the depth of the main survey. In the latter case we homogenise the data depth by applying Gaussian noise to obtain matched photometry.
2.2. Spectroscopic data for calibration
The most important spectroscopic campaigns that overlap with the six KiDZ fields are zCOSMOS (Lilly et al. 2009), VVDS (VIMOS VLT Deep Survey, Le Fèvre et al. 2005, 2013), DEEP2 (Newman et al. 2013), the GAMA (Galaxy And Mass Assembly, Driver et al. 2011) deep field G15deep (Kafle et al. 2018; Driver et al. 2022), and a compilation of spectra covering the Chandra Deep Field South (CDF-S, Appendix A). This data has been used in previous KiDS redshift calibration works (Wright et al. 2020a; Hildebrandt et al. 2021).
We extended this compilation by adding data from C3R2 (Complete Calibration of the Colour-Redshift Relation, Masters et al. 2017, 2019; Euclid Collaboration 2020; Stanford et al. 2021), DEVILS (Deep Extragalactic Visible Legacy Survey, Davies et al. 2018), VIPERS (VIMOS3 Public Extragalactic Redshift Survey, Scodeggio et al. 2018), and a variety of spectroscopic campaigns that target the CDF-S and COSMOS fields which are detailed in Appendix A. We also revised the selection of sources included for calibration by removing duplicates, both from spatial overlap as well as within the datasets, and by homogenising redshift quality flags based on the original information in the input samples. If, for a given source, there are redshifts from different surveys available, we assigned the most reliable measurement based on a specific ‘hierarchy’ of surveys (see Appendix A for details). For objects with multiple spectroscopic measurements within a particular survey, we either took the redshift with the highest quality flag or, if various entries for the same source have the same quality flag and the reported redshifts differ by no more than 0.005, we took the average. However, if the reported redshift differences exceed this threshold, we excluded such a source from the compilation. We restricted the selection to objects with high quality spectroscopic redshifts (approximately corresponding to ≥95% confidence or redshift quality code nQ ≥ 3). Figure 1 compares the number of galaxies and their mean redshift for all samples that enter the spectroscopic compilation. These values apply after removing duplicates between overlapping catalogues and only for those objects with photometric coverage in KiDZ (Sect. 2.1).
 |
Fig. 1. Sample size and mean redshift of the different surveys that are part of our spectroscopic compilation after matching to their counterparts in KiDS imaging. Objects with redshifts from multiple sources are assigned to the survey with the most reliable redshift estimate. |
2.3. Photometric data for calibration
The success rate of spectroscopically determined redshifts is very different from (typically flux-limited) imaging data. Therefore, it is very difficult to obtain a spectroscopic calibration sample that is representative of photometric data in magnitude and colour space, especially at faint magnitudes. Instead, we additionally included galaxy samples with high quality photometric redshifts to achieve a greater overall coverage of the KiDS data by the calibration sample which was beneficial for our redshift calibration technique of choice (Sect. 3.1).
2.3.1. COSMOS2015
The COSMOS2015 catalogue (Laigle et al. 2016) constitutes a sample of about half a million galaxies in the COSMOS field with precision photometric redshifts4 derived from up to 30 photometric bands, ranging from near ultra-violet to mid infrared, including 14 medium and narrow band filters. This sample extends to higher redshifts (zmax ≈ 6) and fainter magnitudes than our spectroscopic compilation, but at the cost of less secure redshift estimates with an outlier fraction ranging from 0.5% at low redshifts to 13.2% for 3 < z < 6 (Laigle et al. 2016).
2.3.2. PAUS
The PAUS photometric redshift sample5 (Alarcon et al. 2021) is a combination of 26 optical and near-infrared bands from COSMOS2015 that are matched against observations of the COSMOS field in 40 narrow band filters by the PAU survey. These PAU filters sample the optical regime between 450 nm to 850 nm at a bandwidth of Δλ = 12.5 nm (Padilla et al. 2019) and the combined photometric catalogue is limited to iAB < 23. Due to the relatively high spectral resolution of the dataset a new Bayesian spectral energy distribution (SED) fitting technique is required that accounts for individual emission lines (Alarcon et al. 2021). This allows the PAUS photo-z to achieve a 3× (1.7×) lower photo-z scatter at the bright (faint) end of the magnitude distribution and marginally smaller outlier fractions compared to the original COSMOS2015 photo-z at iAB < 23. The scaled photo-z bias is very low and has a |median(Δz)| < 0.001 over the whole redshift range of the PAUS sample. Therefore this sample positions itself right between the spectroscopic data and COSMOS2015 in terms of completeness and redshift precision.
2.4. Combined calibration sample
In this work we selected data from the full COSMOS2015 photometric catalogue and combined this data hierarchically with PAUS and the spectroscopic data. Finally we matched this unified catalogue to the KiDZ imaging to form our redshift calibration sample.
We prepared the full COSMOS2015 photometric catalogue similar to Laigle et al. (2016), that is, we selected only those sources which fall into the intersection of the footprint of the COSMOS field (flag_cosmos = 1) and the UltraVISTA observations (flag_hjmcc = 0), which provide essential infrared spectral coverage. We excluded data from saturated areas (flag_peter = 0) and additionally removed objects that are classified to be most likely stars (type ≠ 1) or have no photo-z estimate. This selection yields about half a million objects.
About 40 000 sources of the PAUS sample are, by design, matched against COSMOS2015 and therefore require no further preparation. Therefore we were able to directly combine the spectroscopic compilation, PAUS, and the subset of COSMOS2015 by matching objects within 1″. We maintained a hierarchy to ensure that we always chose the most reliable redshift estimate available: spec-z supersede PAUS photo-z which supersede the COSMOS2015 photo-z. Finally, we assigned nine-band KiDS magnitudes to this compilation by matching against the KiDZ data, again within 1″. This combination of spec-z (in all KiDZ fields), photo-z (only in COSMOS), and KiDS imaging represents our full redshift calibration sample.
The method to combine the two photometric redshift samples with our spectroscopic compilation in an hierarchical manner is very similar to the approach taken for the redshift calibration of the DES Y3 data (Myles et al. 2021). There are, however, two key differences to their approach. First, our compilation of spectroscopic redshifts covers a much wider range of the colour-redshift space than their selection of spectra. This allowed us to construct more representative calibration samples that consist purely of spectroscopic redshifts, photometric redshifts, or a combination thereof. Second, the primary KiDS imaging data and the calibration data are observed in all nine photometric bands at a comparable depth, which simplified the mapping from galaxy colour to redshift significantly (see Sect. 3).
2.4.1. Primary compilations
From this heterogeneous sample with redshift estimates from very different sources we selected three subsets, each with a higher redshift precision but lower completeness: Firstly the full compilation (to which we refer as spec-z+PAUS+COS15), secondly objects with either spectroscopic redshifts or PAUS photo-z (spec-z+PAUS), and finally our fiducial sample containing only those objects that have spectroscopic redshifts (spec-z fiducial). The main properties and redshift distributions of these three primary compilations are summarised in Table 1 and Fig. 2.
 |
Fig. 2. Redshift distribution of different calibration sample subsets (coloured, solid lines) and the one used by Hildebrandt et al. (2021) for KiDS-1000 (dashed black line). The bottom panel shows the excess of sources with photometric redshifts contributed by PAUS and PAUS + COSMOS2015 compared to the fiducial spectroscopic sample. |
Number counts and mean redshifts of the original KiDS-1000 redshift calibration sample and different subsets of the new redshift compilation.
The fiducial sample is already about twice as large as the calibration sample used previously by Hildebrandt et al. (2021) to calibrate the KiDS-1000 redshifts. Of the additional spectra we consider DEVILS and C3R2, the latter of which is designed to target regions of the galaxy colour-space with currently little spectroscopic coverage, to be the most important contributions. Similarly spec-z fiducial already contains about 66% of the matched PAUS sources, of which the majority has redshift z < 1. Due to its limited depth, the spec-z+PAUS sample presents only a small improvement over the fiducial case. The COSMOS2015 data, on the contrary, nearly doubles the compilation to its final size of about 112 000 objects. Due to the significantly higher depth of the COSMOS2015 photo-z, the fraction of sources with z > 1 nearly triples, pushing the mean redshift to ⟨z⟩≈1.0. Nevertheless this comes at the cost of a lower redshift accuracy compared to the rest of the sample.
2.4.2. Secondary compilations
In addition to the three primary compilations we also considered a subset that is restricted to only the most secure spectroscopic redshifts. This spec-z nQ ≥ 4 sample is, due to the large fraction of shared spectra, closest to the one of Hildebrandt et al. (2021) except that it lacks some low redshift sources (Fig. 2).
Finally, we created three subsets of the full redshift compilation that rely purely on photometric redshift estimates. We achieved this by recompiling the redshift compilation according to Sect. 2.4 but omitted all spectroscopic redshifts, therefore maintaining the usual hierarchy of PAUS and COSMOS2015 photo-z. These are objects from only the PAU survey (only-PAUS), all objects with photo-z (only-PAUS+COS15), and the pure COSMOS2015 subset (only-COS15, also discarding PAUS photo-z from the stack). Since the PAUS sample is essentially a subset of the COSMOS2015 catalogue, the latter two samples are almost identical except that for 30% of the sources the photo-z are augmented by the PAUS data (see Table 1). The PAUS sample is about half the size of the fiducial spectroscopic compilation and, while achieving a higher completeness at iAB < 23, lacks many important faint, high redshift objects.
3. Redshift calibration with self-organising maps
A self-organising map (SOM, Kohonen 1982) is a very powerful tool that allow us to calibrate the redshift distribution of the KiDS-1000 lensing sample using the redshift compilations defined in the previous section. We adopted the SOM methodology of Wright et al. (2020a) which additionally provides a metric to select only those parts of the KiDS colour space in which we can reliably map out the colour-redshift relation.
3.1. SOM redshift calibration methodology
The basic idea of the SOM methodology dates back to Lima et al. (2008) who introduced a redshift calibration strategy built on the assumption that two galaxy samples with the same colour-space distribution follow the same redshift distribution. Therefore they suggested to derive the unknown redshift distribution N(z) of a photometric galaxy sample from a calibration sample with accurate, preferentially spectroscopic redshifts Ncal(z) that is constructed such that it is representative of the photometric sample. This method is called ‘direct calibration’ (DIR). In practice, however, such a calibration sample has typically a substantially different selection function. Therefore Lima et al. (2008) proposed a re-weighting scheme to match the calibration to the photometric sample by computing the ratio of the local galaxy density of both samples in the high-dimensional colour-space spanned by the photometric observations. This can be achieved for example by counting neighbours in a fixed volume around a point in the colour-space or by computing the volume occupied by a fixed number of nearest neighbours. Provided that both samples initially cover the same volume of the colour-space this method should recover the true redshift distribution, even in the presence of colour-redshift degeneracies.
This method is still susceptible in particular to selection biases and incompleteness introduced by spectroscopic targeting strategies and success rates (e.g. Gruen & Brimioulle 2017; Hartley et al. 2020). Recent work by Wright et al. (2020a) shows that this can be alleviated by performing additional cleaning and selections (quality control, see Sect. 3.2) on the unknown sample, creating a gold sample containing only galaxies of the photometric sample that are sufficiently represented by the calibration sample. They implement this by training a SOM on the colour-space of the calibration sample and then parse the photometric sample into the same cells. Cells that are not occupied by objects from both samples are rejected, effectively removing those critical parts of the colour-space. They improve the cleaning procedure by applying hierarchical clustering on the SOM to find groups of cells with similar photometric properties instead of filtering individual cells. This allows a more fine-grained trade-off between the number of photometric sources rejected due to partitioning of the high-dimensional colour-space and the bias introduced by misrepresentation of the gold sample.
Finally, they compute the DIR weight for each of the n SOM groupings 𝒢 = {g1, …, gn} which is the ratio of calibration-to-gold sample objects. They obtain the redshift distribution of the gold sample
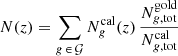 (1)
(1)
by calculating the DIR-weighted sum of the redshift distributions 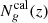 of the calibration sample in each SOM grouping.
of the calibration sample in each SOM grouping. 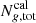 and
and 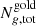 are the total number of calibration sample and gold sample objects of group g, respectively.
are the total number of calibration sample and gold sample objects of group g, respectively.
3.2. Application to KiDS-1000
For our analysis we largely followed Wright et al. (2020a) and trained a SOM with 101 × 101 hexagonal cells and periodic boundaries on the full calibration sample (spec-z+PAUS+COS15, see Sect. 2.4.1). The input features were the matched KiDS r-band magnitudes and all 36 possible KiDS-colours that can be formed from the ugriZYJHKs imaging. Next, we divided the calibration and the KiDS-1000 source sample into the five tomographic bins and parsed both samples into the SOM cells. We then ran the hierarchical clustering for which we used the same number of clusters per bin (4000, 2200, 2800, 4200, and 2000) as Wright et al. (2020a) since these numbers were calibrated using simulations6 (van den Busch et al. 2020). Even though each gold sample has a different optimal number of clusters, simulating the new redshift compilation and including realistic photo-z errors is beyond the scope of this work.
We used the same SOM for the remaining calibration samples defined in Sect. 2.4 and simply parsed the corresponding subset of the full calibration sample back into the SOM before running the hierarchical clustering. For each of these calibration samples we applied a final cleaning step to the SOM groupings by defining a quality cut
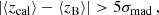 (2)
(2)
where σmad = nMAD(⟨zcal⟩−⟨zB⟩) is the normalised median absolute deviation from the median, where the normalisation ensures that the nMAD reproduces the traditional standard deviation in the limit of Gaussian noise. This selection rejects clusters of SOM cells in which the mean calibration sample redshift ⟨zcal⟩ and the mean KiDS photometric redshifts ⟨zB⟩ catastrophically disagree. Wright et al. (2020a) find that this additional cleaning significantly reduces the SOM redshift bias while the impact on the number density is small and does not exceed a few percent. The rejection threshold of σmad ≈ 0.12 was calculated for the spec-z fiducial case and was applied to all other samples. This choice was motivated by the fact that this value is very close to the one calibrated with mock data for KiDS-1000 by (Hildebrandt et al. 2021), whereas σmad would have been twice as large if we had calculated this threshold based on spec-z+PAUS+COS15. One reason for this difference in σmad is that the COSMOS2015 data allow the inclusion of additional populations of faint galaxies for which the calibration sample reference redshifts and the KiDS photo-z are more likely discrepant, increasing the spread of the distribution of ⟨zcal⟩−⟨zB⟩. We discuss this effect further in Sect. 6.1 and Appendix B.
This final selection step defines our gold sample for which we computed the redshift distributions according to Eq. (1). Since we required weighted redshift distributions for our cosmological analysis we substituted 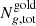 by
by 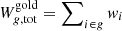 , which is the sum over the individual galaxy weights wi from shape measurements in the SOM group g.
, which is the sum over the individual galaxy weights wi from shape measurements in the SOM group g.
3.3. Clustering redshifts
There is one key difference to the calibration methodology of Hildebrandt et al. (2021) which is that we chose to omit the clustering redshift analysis in this work. While this choice limits our ability to validate the redshift distributions of our new gold samples, the SOM method is our fiducial calibration method and is therefore the focus of this work. In addition to that, the newly included calibration data does not increase the spatial overlap with KiDS significantly and is, due to its inhomogeneity, difficult to administer in a cross-correlation analysis. We leave this validation and joint analysis with the clustering redshifts to future work.
4. Cosmological analysis
In this section we summarise our cosmic shear analysis pipeline which we adopt from Asgari et al. (2021, A21 hereafter).
4.1. Cosmic shear
The primary observable of cosmic shear are the shear two-point correlation functions (2PCFs, Kaiser 1992)
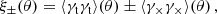 (3)
(3)
where γt and γ× are the tangential and the cross component of the shear, defined with respect to the line connecting a pair of galaxies (see e.g. Bartelmann & Schneider 2001). We used a weighted estimator for the shear correlations ξ± as a function of the separation angle θ between two tomographic redshift bins i and j:
![Mathematical equation: $$ \begin{aligned} \hat{\xi }_\pm ^{(ij)}(\bar{\theta }) = \frac{\sum _{ab} { w}_a { w}_b \left[ \epsilon _{\mathrm{t},a}^\mathrm{obs} \epsilon _{\mathrm{t},b}^\mathrm{obs} \pm \epsilon _{\times ,a}^\mathrm{obs} \epsilon _{\times ,b}^\mathrm{obs} \right] \Delta _{ab}^{(ij)}(\bar{\theta })}{\sum _{ab} { w}_a { w}_b (1 + \bar{m}_a) (1 + \bar{m}_b) \, \Delta _{ab}^{(ij)}(\bar{\theta })} \, . \end{aligned} $$](/articles/aa/full_html/2022/08/aa42083-21/aa42083-21-eq10.gif) (4)
(4)
Here, 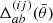 is a function that expresses whether a pair of galaxies, a and b, falls into an angular bin labelled by
is a function that expresses whether a pair of galaxies, a and b, falls into an angular bin labelled by 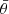 . Each galaxy has a weight w and measured ellipticities,
. Each galaxy has a weight w and measured ellipticities, 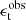 and
and 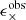 . The denominator applies the multiplicative shear bias m, which corrects the measured shear to match the true galaxy shear7.
. The denominator applies the multiplicative shear bias m, which corrects the measured shear to match the true galaxy shear7.
We extracted the cosmological information from the shear correlation signal using complete orthogonal sets of E/B-integrals (COSEBIs, Schneider et al. 2010). These present a method to cleanly decompose the shear 2PCFs into E- and B-modes by applying a set of oscillatory filter functions defined over a finite angular range between θmin and θmax. The filter functions T±n(θ) for the n-th COSEBI mode with
![Mathematical equation: $$ \begin{aligned} E_n = \frac{1}{2} \int _{\theta _{\rm min}}^{\theta _{\rm max}} \mathrm{d}{\theta } \, \theta \left[ T_{+n}(\theta ) \, \xi _+(\theta ) + T_{-n}(\theta ) \, \xi _-(\theta ) \right] \end{aligned} $$](/articles/aa/full_html/2022/08/aa42083-21/aa42083-21-eq15.gif) (5)
(5)
and
![Mathematical equation: $$ \begin{aligned} B_n = \frac{1}{2} \int _{\theta _{\rm min}}^{\theta _{\rm max}} \mathrm{d}{\theta } \, \theta \left[ T_{+n}(\theta ) \, \xi _+(\theta ) - T_{-n}(\theta ) \, \xi _-(\theta ) \right] \end{aligned} $$](/articles/aa/full_html/2022/08/aa42083-21/aa42083-21-eq16.gif) (6)
(6)
have exactly n + 1 roots.
One of the advantages of this formalism compared to the classical 2PCFs is that COSEBIs are less sensitive to small scales, where the complex physics of baryon feedback plays an important role, if a subset of the modes is chosen accordingly (Asgari et al. 2020).
4.2. Analysis pipeline
Our analysis pipeline is an upgraded version of CosmoPipe8 (Wright et al. 2020b) which is a wrapper for Cat_to_Obs9 (Giblin et al. 2021) and the KiDS Cosmology Analysis Pipeline10 (KCAP, Joachimi et al. 2021; Asgari et al. 2021; Heymans et al. 2021; Tröster et al. 2021) that have both been used previously to analyse the KiDS-1000 data. The pipeline measures the shear 2PCFs using TREECORR (Jarvis et al. 2004; Jarvis 2015) on angular scales between 0.5′ and 300′ from which we computed the first five COSEBI modes using the logarithmic versions of the filter functions T±n(θ). The logarithmic versions achieve a better compression of the cosmological signal onto fewer COSEBI modes.
We used the COSMOSIS framework (Zuntz et al. 2015) to compute theoretical predictions with the KCAP COSEBI module (Asgari et al. 2012). The linear matter power spectrum was modelled with CAMB (Code for Anisotropies in the Microwave Background, Lewis et al. 2000; Howlett et al. 2012) and its non-linear evolution with HMCODE (Mead et al. 2015, 2016), whereas intrinsic alignments were calculated based on the model of Hirata & Seljak (2004), Bridle & King (2007). We then compared these predictions to the measured COSEBIs by sampling a Gaussian likelihood with MULTINEST (Feroz et al. 2009) using the analytical covariance model and priors of Joachimi et al. (2021). From this we inferred constraints on the cosmological parameters of a spatially flat ΛCDM model. We additionally marginalised over a set of sample-dependent nuisance parameters which capture uncertainties in the shear and redshift calibration. Since Monte-Carlo samplers like MULTINEST are not designed to find the best fitting model parameters, we additionally ran a Nelder-Mead minimiser (Nelder & Mead 1965) starting from the maximum posterior point of all chains.
Based on this we quote parameter constraints and their uncertainty as the fit parameter value and the projected joint highest posterior density (PJ-HPD) that we obtained from the MULTINEST chains. It is important to note that both best fit parameters as well as the PJ-HPD have statistical uncertainties of about 0.1σ or 10% on the 1σ constraints due to the limited number of posterior samples (Joachimi et al. 2021).
4.2.1. Redshift uncertainty
We propagated uncertainties in the redshift calibration to the cosmological constraints by allowing the redshift distribution of each tomographic bin i to vary by a shift δzi. We used a set of correlated Gaussian priors δzi ∼ N(μi, σi) which allowed us to apply an empirical redshift bias correction by choosing offsets μi ≠ 0. These offsets and their correlations (Table 2) were calibrated from spectroscopic and KiDS-like mock data (van den Busch et al. 2020) in Hildebrandt et al. (2021). Since our analysis uses different calibration samples with altered sample selections, we would in principle need to perform a similar mock data analysis to recalibrate the priors for δzi. However, these new samples contain many new spectroscopic datasets and the inclusion of photometric redshifts presents an additional challenge when attempting to model realistic photo-z errors. Therefore, we assumed that the variance of the KiDS-1000 priors is conservative enough to absorb potential changes of the redshift biases from KiDS-1000 to the new gold samples.
The revised multiplicative shear bias mnew for the KiDS-1000 sample compared to the original values mold of Asgari et al. (2021).
4.2.2. Multiplicative shear uncertainty
The second set of sample-dependent nuisance parameters is the average multiplicative shear bias (m-bias, see Eq. (4)) in each tomographic bin. The effect of the m-bias and its uncertainty on the COSEBIs is captured in the covariance matrix and is calibrated by comparing the true galaxy ellipticities to those measured from a suite of image simulations generated by Kannawadi et al. (2019). The m-bias values vary little from sample to sample but are by up to 0.5σ larger than those of the KiDS-1000 sample (Giblin et al. 2021). This led to the discovery of an issue with the way KiDS galaxies were assigned to galaxies in the COSMOS field which provided us with accurate shape information. We recomputed the m-bias (Table 2, Fig. 3) and find that the revised values are in good agreement with those of the new gold samples. The updated values are also well within the uncertainty on m that was accounted for in A21.
 |
Fig. 3. m-bias values calculated for each gold sample per tomographic bin. Additionally, the values used by Asgari et al. (2021) are shown in black and their revised values in teal. |
5. Results
In this section we present the new KiDS gold samples and cosmological constraints from an analysis of COSEBIs.
5.1. New KiDS gold samples
Similar to the calibration samples (Sect. 2.4) we divide the gold samples in two categories: primary, which are based on the full compilation of spectroscopic data plus optionally photo-z (spec-z fiducial, spec-z+PAUS, and spec-z+PAUS+COS15, see Sect. 2.4.1), and secondary samples, which are calibrated with subsets of the spectroscopic calibration sample (spec-z nQ ≥ 4) or by using exclusively photo-z (only-PAUS, only-COS15, and only-PAUS+COS15, see Sect. 2.4.2).
5.1.1. Primary gold samples
We made a quantitative comparison of the selection of the three primary KiDS gold samples based on the representation fraction of each tomographic bin, the effective sample number density compared to the density of the full KiDS-1000 source sample. These are summarised for all gold samples in Fig. 4. The numbers show that our new spectroscopic redshift compilation provides a much greater coverage of the KiDS source sample since our fiducial gold sample has a 9% higher accumulated number density than the previous data set calibrated by Hildebrandt et al. (2021), increasing the total representation fraction from 80% to 89%. In comparison to the former, our spec-z fiducial gold sample and those constructed by the addition of the PAUS and COSMOS2015 photo-z steadily increase the coverage fraction of KiDS galaxies across all tomographic bins, rising from 73%, 81%, and 82% to 88%, 90%, and 95% in bins two, three, and four respectively. The fifth tomographic bin, which contributes most of the cosmological signal in the cosmic shear analysis, shows the least change in its representation fraction due to the already very high coverage of 95% reported by Hildebrandt et al. (2021).
 |
Fig. 4. Representation fractions, the effective number density of the different gold samples relative to the full KiDS-1000 source sample, per tomographic bin. The effective number density factors in the lensing weight of each object and is calculated according to Eq. (C.12) in Joachimi et al. (2021). |
The only exception to the steadily increasing representation fractions is the first bin of spec-z+PAUS+COS15, where the number density is about 2.5% lower compared to the fiducial case. This is the result of the quality control (Eq. (2)) removing some SOM groupings due to discrepancies in ⟨zcal⟩ and ⟨zB⟩, which arise when adding calibration sources and/or changing the gold selection. Expanding the calibration sample may shift ⟨zcal⟩ significantly, in particular in sparsely occupied SOM groupings, such that ⟨zcal⟩−⟨zB⟩ exceeds the quality control threshold 5σmad, which will flag and exclude the corresponding KiDS galaxies from the gold sample.
The SOM redshift distributions of the gold samples are shown in Fig. 5; it is important to note that these samples do not represent the same galaxies. A comparison reveals two effects when adding photo-z to the calibration sample: First, the bulk of the redshift distributions is skewed to lower redshifts as we added more data to the calibration sample which is most evident in the third tomographic bin. Secondly, COSMOS2015 added a significant portion of high redshift objects to the compilation that extends the coverage of KiDS galaxies to higher redshifts, enhancing the tails of the redshift distributions and significantly increasing the mean redshifts, in particular of bin five.
 |
Fig. 5. Comparison of the gold sample redshift distributions and their mean redshifts for all tomographic bins obtained from the different subsets of the calibration sample. All gold samples represent a different subset of the full KiDS-1000 source sample. |
Finally we compared the calibration sample redshift distributions in each tomographic bin to the resulting gold sample redshift distributions (Fig. 6). For most of the samples these distributions have very similar shapes and with mean redshifts agreeing within ±0.02, which indicates that the re-weighting (Eq. (1)) of the SOM groupings is very small on average. This changes once the COSMOS2015 redshifts are added to the calibration sample. Due to their significantly higher depth and mean redshifts, the redshift tails must be down-weighted significantly (up-weighted in bin one and two) to match the density of the KiDS source sample. The down-weighting of the low redshift tails in the upper three bins can be explained by the fact that COSMOS2015 adds faint galaxies at these redshifts. The corresponding KiDS galaxies have a low lensing weight, which must be compensated by the SOM cell weights.
 |
Fig. 6. Comparison of the tomographically binned calibration sample (black lines) to the gold sample redshift distributions (coloured lines). The greater the difference between the black and the coloured lines, the more weighting is applied by the SOM to match the calibration sample to the KiDS data. |
5.1.2. Secondary gold samples
The first of our secondary gold samples we calibrated using only those galaxies of the spectroscopic compilation that have the most secure spectroscopic redshifts of at least 99% confidence. Due to similarities to the SOM calibration sample used by Hildebrandt et al. (2021, see Sect. 2.4), this spec-z nQ ≥ 4 gold sample positions itself in between the latter and the spec-z fiducial sample in terms of representation fractions. In tomographic bin four and five however it is lacking some of the high redshift sources due to the more conservative spectroscopic flagging, reducing both the mean redshifts (Fig. 5) as well as the representation fractions (Fig. 4).
The remaining three gold samples exclusively rely on photometric redshifts from PAUS and COSMOS2015 (Sect. 2.4.2). Due to the great overlap of sources, both samples that contain the COSMOS2015 photo-z (only-COS15 and only-PAUS+COS15) achieve representation fractions which are just 2% smaller than those of the full redshift compilation, again due to the quality control (Eq. (2)). As seen for spec-z+PAUS+COS15, the effective density in the first bin is significantly reduced. The only-PAUS gold sample exhibits significantly suppressed tails in bin four and five due to a lack of high redshift sources that only the much deeper COSMOS2015 provides. This also imprints on the representation fractions which are similar to the fiducial gold sample in bin one and two but are about 10% lower in bin three and four, and 18% lower in the fifth tomographic bin. This example highlights the abilities of the SOM to flag and remove sources that cannot be calibrated by the DIR approach with the particular calibration sample.
5.2. Cosmological constraints
We present cosmological results for our primary KiDS gold samples, focusing on a relative comparison to A21 and other literature values. We summarise the numerical values of the most relevant cosmological parameters in Table 3. In Figs. 7 and 8 we highlight comparisons of the derived parameter S8 = σ8(Ωm/0.3)0.5, which is the primary measurable of weak lensing due to the degeneracy between Ωm, the dimensionless matter density parameter, and σ8, parameterising the amplitude of the linear power spectrum.
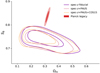 |
Fig. 7. Marginalised constraints for the joint distributions of S8 and Ωm (68% and 95% credible regions) obtained for different gold samples and Planck legacy (TT, TE, EE + lowE). Since the contours represent different galaxy samples, some deviation is expected. |
 |
Fig. 8. Comparison of the S8 constraints from our gold samples to other studies. We show the best fit (where available) and 68th-percentile PJ-HPD (circles, opaque data points), and the maximum of the marginal distribution and the associated 68th-percentile (diamonds, semi-transparent). We compare to Asgari et al. (2021), HSC-Y1 (Hikage et al. 2019), DES-Y3 (Amon et al. 2022), and Planck legacy. The coloured vertical line and outer bands indicate the constraints from the fiducial gold sample, the inner bands the expected variance of the sampler. |
Summary of the main cosmological parameter constraints (best fit and 68th-percentile PJ-HPD) from COSEBIs for all gold samples and their comparison to Asgari et al. (2021) and Planck legacy (TT, TE, EE + lowE).
5.2.1. Reanalysis of the KiDS-1000 data
First we ensured that our wrapper for the cosmological pipeline delivers results that are consistent with those of A21. We reanalysed the original KiDS-1000 data, running our pipeline with the same input parameters (‘Asgari reanalysis’). We find that the constraints on all cosmological parameters agree within the expected variance of the Monte-Carlo sampler. The best fit solution has a slightly larger χ2 of 83.8 compared to 82.2 for KiDS-1000 which is driven primarily by the slight change in the data vector (see Appendix C). Similarly, the correction of the m-bias values (Table 2) has no significant impact on the cosmological constraints either (Table C.1).
5.2.2. Primary gold samples
For our KiDS gold samples we find a tendency to lower S8-values, albeit at low significance (Figs. 7, 8 and Table 3). In particular we obtained 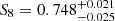 for the spec-z fiducial and
for the spec-z fiducial and 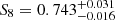 for the spec-z+PAUS gold samples, which is about 0.4σ lower compared to A21, and exceeds the expected statistical variance of the sampler (about 0.1σ). Deviations to some degree between these gold samples are expected, since they all represent different galaxy selections. The goodness of fit improves for all gold samples but in particular for spec-z fiducial, where it reduces to χ2 ≈ 63 compared to 82 in KiDS-1000. The spec-z+PAUS+COS15 sample on the other hand is in very good agreement with the original KiDS-1000 analysis.
for the spec-z+PAUS gold samples, which is about 0.4σ lower compared to A21, and exceeds the expected statistical variance of the sampler (about 0.1σ). Deviations to some degree between these gold samples are expected, since they all represent different galaxy selections. The goodness of fit improves for all gold samples but in particular for spec-z fiducial, where it reduces to χ2 ≈ 63 compared to 82 in KiDS-1000. The spec-z+PAUS+COS15 sample on the other hand is in very good agreement with the original KiDS-1000 analysis.
In addition to S8 we considered the more general Ωm–σ8-degeneracy case of Σ8 = σ8(Ωm/0.3)α, where α is a free parameter. We estimated the reference value for α by fitting the posterior samples of the fiducial chain and obtain αfid = 0.55 which is close to α = 0.54 for COSEBIs in A21. This projection optimises the signal-to-noise ratio compared to S8 and we find 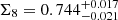 for spec-z fiducial compared to
for spec-z fiducial compared to 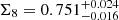 which we obtained for A21 with α = αfid. Furthermore, the scatter of Σ8 for the different gold samples is significantly smaller than the scatter in S8 (see Table 3).
which we obtained for A21 with α = αfid. Furthermore, the scatter of Σ8 for the different gold samples is significantly smaller than the scatter in S8 (see Table 3).
If we compare the marginal errors of S8 for the different gold samples (Table D.1), which have a smaller statistical variance than the PJ-HPD, we find that the constraints improve by 5% when including PAUS and another 4% when including COSMOS2015. Since the constraints on Σ8 are almost constant, these changes in S8 are most probably related to small changes in the Ωm–σ8-degeneracy. We also compared AIA, which is the dimensionless amplitude of the intrinsic alignment galaxy power spectrum, and find that its value is stable within the uncertainties in all our analyses.
6. Discussion
6.1. Gold sample selection and calibration
A side-by-side comparison of the different KiDS gold samples presented in Sect. 5.1 is non-trivial. On the one hand adding or removing galaxies from the calibration sample changes the redshift distribution of each of the SOM groupings that, according to Eq. (1), determine the sample’s redshift distribution. On the other hand two distinct gold samples are comprised of different galaxies since a modification of the calibration sample will also apply an implicit selection on the set of representative SOM groupings. Both of these effects combined determine the overall calibrated redshift distribution.
This is exemplified by the fact that, as we expand the calibration sample from the spec-z nQ ≥ 4 subset to spec-z+PAUS+COS15, we generally see that both the representation fractions and the mean redshifts increase across all bins. The galaxies added in each iteration are typically fainter (with the exception of PAUS) at the cost of lower redshift accuracy, which allowed us to calibrate additional KiDS galaxies, preferentially at the tails of the redshift distributions. At the same time we can observe in Fig. 5 that the redshift distributions are skewed to lower redshifts, which can be explained by the fact that there are disproportionately many more galaxies with z < 0.5 added in each iteration to the calibration sample (Fig. 2). These in turn increase the representation fraction of low and intermediate redshift galaxies in the gold sample (see also Fig. 4). This implies that we are changing the redshift calibration since the skewing applies to each individual SOM group. We were able to separate these two effects by splitting the spec-z fiducial and spec-z+PAUS+COS15 gold samples in two subsets, one containing those SOM groupings that are common to both samples (i.e. containing the same KiDS galaxies) and groupings that can only be calibrated using the full redshift compilation. The subset of KiDS galaxies that is common to both gold samples shows the same redshift skewing as seen with all galaxies (top panels of Fig. 9), whereas the additional COSMOS2015 galaxies contribute significantly at the low and high redshift tails of the tomographic bins (bottom panels of Fig. 9).
 |
Fig. 9. Comparison of the redshift distributions between the fiducial sample and the sample including the PAUS and COSMOS2015 photo-z. Top: SOM redshifts derived from the subset of SOM groupings present in both samples. Bottom: SOM redshift distributions of the groupings that are found only in the spec-z+PAUS+COS15 sample (dashed yellow) and the underlying redshift distribution in the calibration sample of the same groupings, i.e. not applying the SOM weighting in Eq. (1), scaled to the amplitude of the former for comparison. |
The final ingredient to the redshift calibration is the quality control cut (Eq. (2)) that we applied to remove potentially miscalibrated parts of the colour space. This becomes most obvious when comparing the representation fractions of the first tomographic bin (Fig. 4) which decreased whenever we added the COSMOS2015 data (compare spec-z+PAUS to spec-z+PAUS+COS15 and only-PAUS to only-PAUS+COS15). The low redshift of the KiDS galaxies in this bin makes the sample particularly susceptible to the addition of high redshift galaxies. These can significantly change the mean redshift of the calibration sample ⟨zcal⟩ compared to the KiDS photo-z in the SOM groupings which then may fail to pass the quality control (see also Appendix B). The great depth of the COSMOS2015 data compared to the spectroscopic data also explains why the SOM needs to apply more weighting to match the spec-z+PAUS+COS15 compilation to the KiDS colour-space (Fig. 6).
6.2. Cosmological constraints
The gold sample selection effects are, due to their redshift dependence, directly propagated to the cosmological constraints (Sect. 5.2), causing shifts in S8 of up to 0.5σ from sample to sample. One of the assumptions in our analysis is that we can adopt the same Gaussian priors for the δzi nuisance parameters (Sect. 4.2) that are used by A21. We therefore reanalysed the fiducial gold sample assuming no knowledge of the empirical redshift bias by centring the priors on μi = 0. For this run we find that the value of 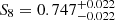 is in good agreement with the fiducial analysis.
is in good agreement with the fiducial analysis.
On the other hand, it may seem that our choice for the widths σi of the δzi priors may be insufficient to accommodate for the apparent variance in the mean redshifts of the different gold samples (see Fig. 5). This variance, however, is not only determined by potential systematic biases in the redshift calibration between any of these samples, but also by changes in the gold sample selection itself, as discussed above. Therefore, the question of the correct redshift prior can only be answered with realistic simulated data sets that are currently not available for our extended redshift calibration sample. Nevertheless, a comparison of the S8 values allows us to get an estimate of the variance induced by the selection effects in the calibration data and the resulting parameter constraints from the gold samples.
6.2.1. The fiducial gold sample
Next to the spec-z fiducial sample that is based on the full spectroscopic compilation we also defined the spec-z nQ ≥ 4 sample that relies only on the most secure redshifts. The estimated 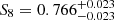 for the latter, arising from particularly low Ωm and high σ8 values, is about 0.5σ larger than in the fiducial case and surpasses all other gold samples (Table 3). In the Σ8 projection this difference reduces to 0.2σ.
for the latter, arising from particularly low Ωm and high σ8 values, is about 0.5σ larger than in the fiducial case and surpasses all other gold samples (Table 3). In the Σ8 projection this difference reduces to 0.2σ.
The shift in S8 between gold samples that are both calibrated with spectroscopic data begs the question which of these estimates is more reliable. The primary difference between the two calibration datasets is the selection using redshift quality flags. Selecting spectra based on the redshift confidence is a trade-off between constructing a sample that is confined to regions of the colour-redshift-space in which galaxies have distinct spectral features that allow secure redshift determination and a sample with an increasing fraction of galaxies with catastrophically misidentified redshifts. In the latter case the redshifts of the calibration sample themselves cause a biasing of the gold sample redshifts and in turn S8. In case of selecting only the highest quality redshifts, the biases arises from a misrepresentation of the imaging data by the calibration sample, as shown by Hartley et al. (2020). The redshift distribution of the calibration sample in each SOM grouping depends on the quality flag and thus the relative representation of different galaxy populations in the gold sample may change. We investigated the magnitude of both these effects by assuming two worst-case scenarios which shift down the S8 estimate obtained for spec-z fiducial and shift up S8 for spec-z nQ ≥ 4.
Scenario A assumes in the case of the spec-z fiducial sample that 5% of truly low redshift galaxies with 3 ≤ nQ < 4 (nominal 95% certainty), as well as 1% in case the of nQ ≥ 4 (99% certainty), are catastrophically misidentified as high redshift galaxies. Since both redshift flags are equally common in the fiducial sample we expect a combined spectroscopic failure rate of about 3%. We implemented this worst-case scenario on spec-z fiducial by truncating the top 3% of all redshift distributions which should increase the recovered S8 value. We calculated the redshift z97 corresponding to the 97-th percentile of the redshift distribution n(z), set n(z) = 0 at z > z97, and re-normalised to reproduce the original gold sample number density.
In scenario B we speculate that the calibration of the spec-z nQ ≥ 4 sample suffers from the same spectroscopic misrepresentation effects studied by Hartley et al. (2020, from Fig. 6 therein), who found redshift biases ⟨z⟩−⟨ztrue⟩ of 0.008, 0.022, −0.003, and −0.058 in the four tomographic redshifts bins of simulated DES and spectroscopic data, for the first time implementing a realistic, simulated nQ ≥ 4 sample selection. Since we currently do not have comparable spectroscopic mock data in KiDS, we assumed in this scenario that the bias applies at the same magnitude to the spec-z nQ ≥ 4 gold sample. We therefore corrected the assumed bias by interpolating the values from the four DES bins to the five tomographic bins of KiDS and shift the spec-z nQ ≥ 4 redshift distributions by −0.008, −0.015, −0.014, 0.003, and 0.058. We considered this to be an even more conservative assumption than scenario A, since the bias should be significantly smaller in case of KiDS thanks to the nine-band imaging and the improvements of the SOM calibration over the classical DIR approach (Sect. 3.1) that is used by Hartley et al. (2020).
With these modifications to the redshift distributions, scenario A (fiducial, truncated top 3%) yields a higher and scenario B (nQ ≥ 4, Hartley corrected) a lower estimate for S8 (Fig. 10, left). These results indicate that the combination of these two effects may explain the observed differences between S8 in spec-z fiducial and spec-z nQ ≥ 4. When comparing the projection Σ8 instead (Fig. 10, right), which is less susceptible to shifts along the Ωm–σ8-degeneracy, the difference between spec-z fiducial and spec-z nQ ≥ 4 is much smaller. However the shift, introduced when correcting the redshift distributions in scenario B, is about twice as big compared to the S8 case, indicating that the selection effects studied in Hartley et al. (2020) can have a significant impact on cosmological constraints. Furthermore the completeness, which determines the ability to correctly map out colour-redshift degeneracies in each SOM grouping, and the quality of the calibration sample redshifts should be balanced carefully to minimise biases in the redshift calibration and the cosmological analysis.
 |
Fig. 10. Comparison between constraints (best fit and 68th-percentile PJ-HPD) on S8 (left) and Σ8 (right) for spec-z fiducial, spec-z nQ ≥ 4, and the corresponding test scenario A and B. The grey arrows indicate shifts in S8 introduced in the tests by modifying the redshift distributions. |
6.2.2. Other gold samples
Finally, we made a relative comparison of the Σ8 constraints from the remaining gold samples, since Σ8 typically exhibits a smaller scatter than the corresponding S8 values. The gold samples that are calibrated using only photo-z from PAUS, COSMOS2015, or a combination of both, prefer smaller Σ8 values compared to spec-z fiducial (Fig. 11). While the cosmological constraints in a similar comparison between redshifts calibrated using spectroscopic data and COSMOS2015 (Hildebrandt et al. 2020) show a more pronounced shift in the opposite direction, this difference is caused by the gold sample selection (Wright et al. 2020b). In our analysis the shifts in Σ8 may be explained by the fact that COSMOS2015 tends to calibrate the KiDS galaxies to higher redshifts than the spectroscopic calibration data alone (see Fig. 9), translating to lower Σ8. The same reasoning does not explain why Σ8 reduces further when the PAUS data are included, therefore this behaviour is most likely owed to the quality control (Eq. (2)). When the photo-z data are combined with the spectroscopic compilation, it may result in a significantly different distribution of |⟨zcal⟩−⟨zB⟩| for the SOM groupings, which has non-trivial implications for the gold sample selection and the derived cosmological constraints.
 |
Fig. 11. Constraints on Σ8 (best fit and 68th-percentile PJ-HPD) for all primary and secondary gold samples. The coloured vertical line and outer bands indicate the constraints from the fiducial gold sample, the inner bands the expected variance of the sampler. |
7. Conclusion
We applied the SOM redshift calibration technique (Wright et al. 2020a) to define and calibrate the redshift distributions of a new set of KiDS-1000 gold samples by adopting a new spectroscopic calibration sample. Compared to previous work by Hildebrandt et al. (2021) we doubled the size of this calibration sample by adding more than ten additional spectroscopic campaigns such as C3R2 and DEVILS, which allowed us to calibrate an additional 9% of the KiDS galaxies.
We took this one step further by enhancing the calibration sample with precision photometric redshifts from the PAU survey and COSMOS2015, maintaining a hierarchy that prefers spectroscopic over PAUS and COSMOS2015 redshifts to resolve duplicates in the three catalogues. The resulting KiDS gold sample increases by additional 6% and covers nearly 98% of all KiDS galaxies in the fifth tomographic bin.
When comparing these gold samples we find changes in the mean redshifts of up to |Δz| = 0.026 which originate from selection effects in the calibration sample. First, there are residual modifications to the redshift calibration of those KiDS sources that are found in both gold samples. These modifications are a direct consequence of changing the redshift distribution of the calibration sample when adding the photo-z. Second and most important, the selection of KiDS sources itself changes since the faint COSMOS2015 data allows us to calibrate additional galaxies at both low and high redshifts. These results highlight the importance of quantifying and calibrating potential method dependent redshift biases arising from selection effects, as has been shown in previous work. This requires sophisticated galaxy mock data with sufficient redshift coverage, realistic galaxy colours and accurate modelling of photometric and spectroscopic galaxy samples, in particular if one aims to study the impact of photo-z outliers on the calibration sample.
In the second part of this study we performed a cosmic shear analysis using COSEBIs and find 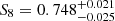 for our fiducial and v for the photo-z-enhanced gold sample which is slightly lower than, but still in excellent agreement with, previous work on KiDS-1000 by Asgari et al. (2021). As part of our additional systematic testing we created a third gold sample that we calibrated using only the most secure spectra of our spectroscopic compilation (nQ ≥ 4). We measure
for our fiducial and v for the photo-z-enhanced gold sample which is slightly lower than, but still in excellent agreement with, previous work on KiDS-1000 by Asgari et al. (2021). As part of our additional systematic testing we created a third gold sample that we calibrated using only the most secure spectra of our spectroscopic compilation (nQ ≥ 4). We measure 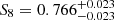 which corresponds to an increment of 0.5σ compared to the fiducial case. Our analysis speculates that this sample underestimates the true redshifts and overestimates S8 due to an implicit selection introduced when limiting the calibration to the most secure spectroscopic redshifts (Hartley et al. 2020). Therefore completeness and quality of the calibration sample can be optimised, this however requires realistic simulations to quantify the impact of this trade-off on the recovered redshift distributions.
which corresponds to an increment of 0.5σ compared to the fiducial case. Our analysis speculates that this sample underestimates the true redshifts and overestimates S8 due to an implicit selection introduced when limiting the calibration to the most secure spectroscopic redshifts (Hartley et al. 2020). Therefore completeness and quality of the calibration sample can be optimised, this however requires realistic simulations to quantify the impact of this trade-off on the recovered redshift distributions.
Finally we analysed four KiDS gold samples which are all calibrated from different subsets of our extended calibration sample or using only photo-z from PAUS and COSMOS2015. No matter how we calibrated the KiDS source galaxies, we find that all seven gold samples studied in this work scatter in the range of S8 = 0.743…0.766 around our fiducial analysis. This further confirms previously reported tensions of KiDS with measurements of the CMB by Planck Collaboration VI (2020) at 3.0σ to 3.6σ for a flat ΛCDM model.
In summary, there seems to be little benefit in using precision photometric redshifts for the SOM redshift calibration given the excellent coverage of the KiDS data by our spectroscopic compilation alone. The spec-z+PAUS+COS15 gold sample achieves, compared to our fiducial sample, a 6% improvement in terms of the number density, yet improvements on the cosmological constraints are marginal. Nevertheless, if the spectroscopic coverage is significantly lower or one wishes to target higher redshifts, photo-z samples are a valuable source of complementary calibration data. However, the greater the dependence on photometric redshifts is, the more attention must be paid to redshift outliers to guarantee a good balance between statistical uncertainties and systematic biases in the redshift calibration. Given their challenging calibration requirements this is in particular true for the next generation, stage IV surveys such as Euclid (Laureijs et al. 2011) or the Vera C. Rubin Observatory Legacy Survey of Space and Time (LSST, Ivezić et al. 2019). Despite photo-z outliers, photometric redshift samples have one significant advantage over spectroscopically selected samples: they achieve a much higher completeness, which can mitigate selection effects in the calibration sample and may improve the ability of the SOM to map out the full extent of colour-redshift-degeneracies.
Conclusions on the degree of tension differ primarily owing to the way tension is quantified and different prior choices for the neutrino mass in the Planck reanalysis.
In case of the COSMOS field we instead use existing data in the CFHT (Canada France Hawaii Telescope) z-band which is sufficiently similar to the VISTA InfraRed CAMera (VIRCAM) Z-band at the Visible and Infrared Survey Telescope for Astronomy (VISTA) given the photometric and redshift calibration uncertainties.
VIsible Multi-Object Spectrograph.
We used the median of the photo-z likelihood distribution (PHOTOZ column in the catalogue).
Available at cosmohub.pic.es
These simulations are tailored to fit the KiDS imaging data and are based on the MICE2 simulation (Fosalba et al. 2015a,b; Crocce et al. 2015; Carretero et al. 2015; Hoffmann et al. 2015).
In practice we did not apply the m-bias per galaxy in Eq. (4) but instead took the average value in each tomographic bin to avoid effects such as galaxy detection biases (Kannawadi et al. 2019).
Acknowledgments
We acknowledge support from the European Research Council under grant numbers 770935 (JvdB, AHW, HH) and 647112 (MA, CH, TT). HH is also supported by a Heisenberg grant (Hi1495/5-1) of the Deutsche Forschungsgemeinschaft. MB is supported by the Polish National Science Center through grants no. 2020/38/E/ST9/00395, 2018/30/E/ST9/00698 and 2018/31/G/ST9/03388, and by the Polish Ministry of Science and Higher Education through grant DIR/WK/2018/12. CH is additionally supported by the Max Planck Society and the Alexander von Humboldt Foundation in the framework of the Max Planck-Humboldt Research Award endowed by the Federal Ministry of Education and Research. HYS acknowledges the support from CMS-CSST-2021-A01, NSFC of China under grant 11973070, the Shanghai Committee of Science and Technology grant No.19ZR1466600 and Key Research Program of Frontier Sciences, CAS, Grant No. ZDBS-LY-7013. We are grateful to Mara Salvato and the zCOSMOS team to give us early access to additional deep spectroscopic redshifts that were not available in the public domain, as well as to Dan Masters for sharing pre-release C3R2 DR3 data. This work is based on observations made with ESO Telescopes at the La Silla Paranal Observatory under programme IDs 100.A-0613, 102.A-0047, 179.A-2004, 177.A-3016, 177.A-3017, 177.A-3018, 298.A-5015, and on data products produced by the KiDS consortium. This work has made use of CosmoHub (Carretero et al. 2017). CosmoHub has been developed by the Port d’Informació Científica (PIC), maintained through a collaboration of the Institut de Física d’Altes Energies (IFAE) and the Centro de Investigaciones Energéticas, Medioambientales y Tecnológicas (CIEMAT), and was partially funded by the "Plan Estatal de Investigación Científica y Técnica y de Innovación" program of the Spanish government. The figures in this work were produced with MATPLOTLIB (Hunter 2007) and GETDIST (Lewis 2019). Author Contributions: All authors contributed to the development and writing of this paper. The authorship list is given in three groups: the lead authors (JLvdB, AHW, HH, MB, and MA), followed by two alphabetical groups. The first alphabetical group includes those who are key contributors to both the scientific analysis and the data products. The second group covers those who have either made a significant contribution to the data products or to the scientific analysis.
References
- Aihara, H., Armstrong, R., Bickerton, S., et al. 2018, PASJ, 70, S8 [NASA ADS] [Google Scholar]
- Alarcon, A., Sánchez, C., Bernstein, G. M., & Gaztañaga, E. 2020, MNRAS, 498, 2614 [NASA ADS] [CrossRef] [Google Scholar]
- Alarcon, A., Gaztanaga, E., Eriksen, M., et al. 2021, MNRAS, 501, 6103 [NASA ADS] [CrossRef] [Google Scholar]
- Amon, A., Gruen, D., Troxel, M. A., et al. 2022, Phys. Rev. D, 105, 023514 [NASA ADS] [CrossRef] [Google Scholar]
- Asgari, M., Schneider, P., & Simon, P. 2012, A&A, 542, A122 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Asgari, M., Tröster, T., Heymans, C., et al. 2020, A&A, 634, A127 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Asgari, M., Lin, C.-A., Joachimi, B., et al. 2021, A&A, 645, A104 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Balestra, I., Mainieri, V., Popesso, P., et al. 2010, A&A, 512, A12 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bartelmann, M., & Schneider, P. 2001, Phys. Rep., 340, 291 [Google Scholar]
- Benítez, N. 2000, ApJ, 536, 571 [Google Scholar]
- Bridle, S., & King, L. 2007, New J. Phys., 9, 444 [Google Scholar]
- Buchs, R., Davis, C., Gruen, D., et al. 2019, MNRAS, 489, 820 [Google Scholar]
- Carretero, J., Castander, F. J., Gaztañaga, E., Crocce, M., & Fosalba, P. 2015, MNRAS, 447, 646 [NASA ADS] [CrossRef] [Google Scholar]
- Carretero, J., Tallada, P., Casals, J., et al. 2017, PoS, EPS-HEP2017, 488 [Google Scholar]
- Cooper, M. C., Yan, R., Dickinson, M., et al. 2012, MNRAS, 425, 2116 [NASA ADS] [CrossRef] [Google Scholar]
- Crocce, M., Castander, F. J., Gaztañaga, E., Fosalba, P., & Carretero, J. 2015, MNRAS, 453, 1513 [NASA ADS] [CrossRef] [Google Scholar]
- Damjanov, I., Zahid, H. J., Geller, M. J., Fabricant, D. G., & Hwang, H. S. 2018, ApJS, 234, 21 [NASA ADS] [CrossRef] [Google Scholar]
- Davies, L. J. M., Driver, S. P., Robotham, A. S. G., et al. 2015, MNRAS, 447, 1014 [Google Scholar]
- Davies, L. J. M., Robotham, A. S. G., Driver, S. P., et al. 2018, MNRAS, 480, 768 [NASA ADS] [CrossRef] [Google Scholar]
- de Jong, J. T. A., Verdoes Kleijn, G. A., Boxhoorn, D. R., et al. 2015, A&A, 582, A62 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- de Jong, J. T. A., Kleijn, G. A. V., Erben, T., et al. 2017, A&A, 604, A134 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Driver, S. P., Hill, D. T., Kelvin, L. S., et al. 2011, MNRAS, 413, 971 [Google Scholar]
- Driver, S. P., Bellstedt, S., Robotham, A. S. G., et al. 2022, MNRAS, 513, 439 [NASA ADS] [CrossRef] [Google Scholar]
- Edge, A., Sutherland, W., Kuijken, K., et al. 2013, The Messenger, 154, 32 [NASA ADS] [Google Scholar]
- Euclid Collaboration (Guglielmo, V., et al.) 2020, A&A, 642, A192 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Fenech Conti, I., Herbonnet, R., Hoekstra, H., et al. 2017, MNRAS, 467, 1627 [NASA ADS] [Google Scholar]
- Feroz, F., Hobson, M. P., & Bridges, M. 2009, MNRAS, 398, 1601 [NASA ADS] [CrossRef] [Google Scholar]
- Flaugher, B., Diehl, H. T., Honscheid, K., et al. 2015, AJ, 150, 150 [Google Scholar]
- Fosalba, P., Crocce, M., Gaztañaga, E., & Castander, F. J. 2015a, MNRAS, 448, 2987 [NASA ADS] [CrossRef] [Google Scholar]
- Fosalba, P., Gaztañaga, E., Castander, F. J., & Crocce, M. 2015b, MNRAS, 447, 1319 [NASA ADS] [CrossRef] [Google Scholar]
- Garilli, B., McLure, R., Pentericci, L., et al. 2021, A&A, 647, A150 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gatti, M., Giannini, G., Bernstein, G. M., et al. 2022, MNRAS, 510, 1223 [Google Scholar]
- Giblin, B., Heymans, C., Asgari, M., et al. 2021, A&A, 645, A105 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gruen, D., & Brimioulle, F. 2017, MNRAS, 468, 769 [Google Scholar]
- Hartley, W. G., Chang, C., Samani, S., et al. 2020, MNRAS, 496, 4769 [Google Scholar]
- Hasinger, G., Capak, P., Salvato, M., et al. 2018, ApJ, 858, 77 [Google Scholar]
- Heymans, C., Grocutt, E., Heavens, A., et al. 2013, MNRAS, 432, 2433 [Google Scholar]
- Heymans, C., Tröster, T., Asgari, M., et al. 2021, A&A, 646, A140 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hikage, C., Oguri, M., Hamana, T., et al. 2019, PASJ, 71, 43 [Google Scholar]
- Hildebrandt, H., Viola, M., Heymans, C., et al. 2017, MNRAS, 465, 1454 [Google Scholar]
- Hildebrandt, H., Köhlinger, F., van den Busch, J. L., et al. 2020, A&A, 633, A69 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hildebrandt, H., van den Busch, J. L., Wright, A. H., et al. 2021, A&A, 647, A124 [EDP Sciences] [Google Scholar]
- Hirata, C. M., & Seljak, U. 2004, Phys. Rev. D, 70, 063526 [Google Scholar]
- Hoffmann, K., Bel, J., Gaztañaga, E., et al. 2015, MNRAS, 447, 1724 [NASA ADS] [CrossRef] [Google Scholar]
- Howlett, C., Lewis, A., Hall, A., & Challinor, A. 2012, J. Cosmol. Astropart. Phys., 2012, 027 [CrossRef] [Google Scholar]
- Hunter, J. D. 2007, Comput. Sci. Eng., 9, 90 [NASA ADS] [CrossRef] [Google Scholar]
- Huterer, D., Takada, M., Bernstein, G., & Jain, B. 2006, MNRAS, 366, 101 [Google Scholar]
- Ivezić, Ž., Kahn, S. M., Tyson, J. A., et al. 2019, ApJ, 873, 111 [Google Scholar]
- Jarvis, M. 2015, Astrophysics Source Code Library [record ascl:1508.007] [Google Scholar]
- Jarvis, M., Bernstein, G., & Jain, B. 2004, MNRAS, 352, 338 [Google Scholar]
- Joachimi, B., Lin, C. A., Asgari, M., et al. 2021, A&A, 646, A129 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Joudaki, S., Blake, C., Heymans, C., et al. 2017, MNRAS, 465, 2033 [Google Scholar]
- Joudaki, S., Hildebrandt, H., Traykova, D., et al. 2020, A&A, 638, L1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kafle, P. R., Robotham, A. S. G., Driver, S. P., et al. 2018, MNRAS, 479, 3746 [Google Scholar]
- Kaiser, N. 1992, ApJ, 388, 272 [Google Scholar]
- Kannawadi, A., Hoekstra, H., Miller, L., et al. 2019, A&A, 624, A92 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kilbinger, M. 2015, Rep. Prog. Phys., 78, 086901 [Google Scholar]
- Kohonen, T. 1982, Biol. Cybern., 43, 59 [Google Scholar]
- Kuijken, K., Heymans, C., Hildebrandt, H., et al. 2015, MNRAS, 454, 3500 [Google Scholar]
- Kuijken, K., Heymans, C., Dvornik, A., et al. 2019, A&A, 625, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Laigle, C., McCracken, H. J., Ilbert, O., et al. 2016, ApJS, 224, 24 [Google Scholar]
- Laureijs, R., Amiaux, J., Arduini, S., et al. 2011, ArXiv e-prints [arXiv:1110.3193] [Google Scholar]
- Le Fèvre, O., Vettolani, G., Garilli, B., et al. 2005, A&A, 439, 845 [Google Scholar]
- Le Fèvre, O., Cassata, P., Cucciati, O., et al. 2013, A&A, 559, A14 [Google Scholar]
- Le Fèvre, O., Tasca, L. A. M., Cassata, P., et al. 2015, A&A, 576, A79 [Google Scholar]
- Lewis, A. 2019, ArXiv e-prints [arXiv:1910.13970] [Google Scholar]
- Lewis, A., Challinor, A., & Lasenby, A. 2000, ApJ, 538, 473 [Google Scholar]
- Lidman, C., Tucker, B. E., Davis, T. M., et al. 2020, MNRAS, 496, 19 [NASA ADS] [CrossRef] [Google Scholar]
- Lilly, S. J., Le Brun, V., Maier, C., et al. 2009, ApJS, 184, 218 [Google Scholar]
- Lima, M., Cunha, C. E., Oyaizu, H., et al. 2008, MNRAS, 390, 118 [Google Scholar]
- Ma, Z., Hu, W., & Huterer, D. 2006, ApJ, 636, 21 [Google Scholar]
- MacCrann, N., Zuntz, J., Bridle, S., Jain, B., & Becker, M. R. 2015, MNRAS, 451, 2877 [Google Scholar]
- Masters, D. C., Capak, P. L., Stern, D., et al. 2016, Am. Astron. Soc. Meeting Abstracts, 227, 139.14 [NASA ADS] [Google Scholar]
- Masters, D. C., Stern, D. K., Cohen, J. G., et al. 2017, ApJ, 841, 111 [Google Scholar]
- Masters, D. C., Stern, D. K., Cohen, J. G., et al. 2019, ApJ, 877, 81 [Google Scholar]
- Matthews, D. J., & Newman, J. A. 2010, ApJ, 721, 456 [Google Scholar]
- Mead, A. J., Peacock, J. A., Heymans, C., Joudaki, S., & Heavens, A. F. 2015, MNRAS, 454, 1958 [NASA ADS] [CrossRef] [Google Scholar]
- Mead, A. J., Heymans, C., Lombriser, L., et al. 2016, MNRAS, 459, 1468 [Google Scholar]
- Ménard, B., Scranton, R., Schmidt, S., et al. 2013, ArXiv e-prints [arXiv:1303.4722] [Google Scholar]
- Miller, L., Kitching, T. D., Heymans, C., Heavens, A. F., & van Waerbeke, L. 2007, MNRAS, 382, 315 [Google Scholar]
- Myles, J., Alarcon, A., Amon, A., et al. 2021, MNRAS, 505, 4249 [NASA ADS] [CrossRef] [Google Scholar]
- Nelder, J. A., & Mead, R. 1965, Comput. J., 7, 308 [Google Scholar]
- Newman, J. A. 2008, ApJ, 684, 88 [Google Scholar]
- Newman, J. A., Cooper, M. C., Davis, M., et al. 2013, ApJS, 208, 5 [Google Scholar]
- Padilla, C., Castander, F. J., Alarcón, A., et al. 2019, AJ, 157, 246 [NASA ADS] [CrossRef] [Google Scholar]
- Peacock, J. A., Schneider, P., Efstathiou, G., et al. 2006, ESA-ESO Working Group on "Fundamental Cosmology" [Google Scholar]
- Planck Collaboration XVI. 2014, A&A, 571, A16 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration VI. 2020, A&A, 641, A6 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Popesso, P., Dickinson, M., Nonino, M., et al. 2009, A&A, 494, 443 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Refregier, A. 2003, ARA&A, 41, 645 [NASA ADS] [CrossRef] [Google Scholar]
- Sánchez, C., & Bernstein, G. M. 2019, MNRAS, 483, 2801 [Google Scholar]
- Schmidt, S. J., Ménard, B., Scranton, R., Morrison, C., & McBride, C. K. 2013, MNRAS, 431, 3307 [Google Scholar]
- Schneider, P., Eifler, T., & Krause, E. 2010, A&A, 520, A116 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Scodeggio, M., Guzzo, L., Garilli, B., et al. 2018, A&A, 609, A84 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Secco, L. F., Samuroff, S., Krause, E., et al. 2022, Phys. Rev. D, 105, 023515 [NASA ADS] [CrossRef] [Google Scholar]
- Silverman, J. D., Kashino, D., Sanders, D., et al. 2015, ApJS, 220, 12 [NASA ADS] [CrossRef] [Google Scholar]
- Stanford, S. A., Masters, D., Darvish, B., et al. 2021, ApJS, 256, 9 [NASA ADS] [CrossRef] [Google Scholar]
- Tröster, T., Asgari, M., Blake, C., et al. 2021, A&A, 649, A88 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- van den Busch, J. L., Hildebrandt, H., Wright, A. H., et al. 2020, A&A, 642, A200 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- van der Wel, A., Noeske, K., Bezanson, R., et al. 2016, ApJS, 223, 29 [Google Scholar]
- Venemans, B. P., Verdoes Kleijn, G. A., Mwebaze, J., et al. 2015, MNRAS, 453, 2259 [Google Scholar]
- Wright, A. H., Hildebrandt, H., van den Busch, J. L., & Heymans, C. 2020a, A&A, 637, A100 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Wright, A. H., Hildebrandt, H., van den Busch, J. L., et al. 2020b, A&A, 640, L14 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Zuntz, J., Paterno, M., Jennings, E., et al. 2015, Astron. Comput., 12, 45 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: Updated spectroscopic compilation
Here we present the details of our extended and revised spectroscopic compilation discussed in Sect. 2.2. It includes redshifts from surveys covering a number of deep extragalactic fields for which we have nine-band VST+VISTA photometry of similar quality as the main KiDS+VIKING data (KiDZ). In this paper we used six such fields shown in Fig. A.1; three of them (COSMOS, CDF-S and VVDS-2h) are covered by a number of partly overlapping surveys and we merged them into our redshift calibration sample. In doing this, we translated the input redshift quality flags or assessments into our flag NQ, with NQ ≥ 4 indicating the most secure spectroscopic redshifts (confidence 99% or more), while 3 ≤ NQ < 4 indicate secure, but lower-confidence redshifts. The particular surveys are listed in Table A.1, in the ascending order of their mean redshift determined after removing multiples and cross-matching with our imaging. The details of the selection and quality assignment for the particular samples are as follows:
-
hCOSMOS (Damjanov et al. 2018): we used all the galaxies from the published dataset and assigned them redshift quality NQ = 4;
-
GAMA-G15Deep (Kafle et al. 2018; Driver et al. 2022): we selected galaxies with input redshift quality Z_QUAL ≥ 3 and with redshifts z > 0.001 to avoid stellar contamination. We assigned NQ = Z_QUAL;
-
G10-COSMOS (Davies et al. 2015): we used Z_BEST as the redshift value and followed the recommended selection for galaxy spectroscopic redshifts, that is Z_BEST > 0.0001, Z_USE < 3, and STAR_GALAXY_CLASS = 0. As the redshifts provided in that compilation do not always have a quality flag that could be easily translated into our NQ, we assigned all these galaxies a specific flag NQ = 3.5;
-
ACES (Cooper et al. 2012): we selected redshifts with Z_QUALITY ≥ 3 and with redshift errors below 1%. We assigned NQ = Z_QUALITY;
-
OzDES (Lidman et al. 2020): we used two patches partly overlapping with KiDZ imaging (around CDF-S and around VVDS-2h). We selected redshifts z > 0.002 (stellar contamination removal) and required quality qop ∈ {3, 4}. We assigned NQ = qop;
-
DEVILS (Davies et al. 2018): we selected spectroscopic redshifts only (zBestType = spec) and require the flags starFlag = 0, mask = 0, and artefactFlag = 0. As the DEVILS sample is a compilation including both own redshifts and external ones, we assigned NQ = 4 if zBestSource = DEVILS (redshift obtained from DEVILS observations) and NQ = 3 (external redshifts);
-
VIPERS (Scodeggio et al. 2018): we required sources with the flag 2 ≤ zflg < 10 or 22 ≤ zflg < 30. We assigned NQ = 4 if 3 ≤ zflg < 5 or 23 ≤ zflg < 25, and NQ = 3 otherwise;
-
VVDS (Le Fèvre et al. 2005, 2013): we joined the WIDE, DEEP, and UDEEP sub-samples and used only sources with ZFLAGS ∈ {3, 4, 23, 24}. We assigned NQ = 4 to these redshifts;
-
LEGA-C (van der Wel et al. 2016): we selected sources with the flag f_use = 1 and assigned NQ = 4 to them;
-
DEEP2 (Newman et al. 2013): as in the previous KiDS papers (Hildebrandt et al. 2017, 2020, 2021), we used sources from two equatorial fields (0226 & 2330), required sources with ZQUALITY ≥ 3 and with redshift errors smaller than 1%. We assigned NQ = Z_QUALITY;
-
C3R2: we combined four public datasets, DR1 (Masters et al. 2017), DR2 (Masters et al. 2019), DR3 (Stanford et al. 2021), and KMOS (Euclid Collaboration 2020) and excluded the Northern EGS field. We took sources with QFLAG ≥ 3 and assigned NQ = QFLAG;
-
DEIMOS (Hasinger et al. 2018): we required the quality flag Q = 2, while for assigning NQ we used the other flag provided, namely NQ = 4 for Qf ∈ {4, 14}, NQ = 3 otherwise;
-
GOODS/CDF-S: we used a public ESO compilation of spectroscopy in the CDF-S field11 (Popesso et al. 2009; Balestra et al. 2010). From the compilation, we chose secure redshifts (assigning NQ = 4 to them) and likely redshifts (NQ = 3) following the recommendations in the dataset description12;
-
FMOS-COSMOS (Silverman et al. 2015): we selected sources with the quality flag q_z ≥ 2 and assigned NQ = 4 if q_z = 4 or NQ = 3 otherwise;
-
zCOSMOS: we used this name for a proprietary compilation of various spectroscopic surveys in the COSMOS field, kindly provided to us by Mara Salvato, updated as of 01 September 2017. That dataset includes some of the surveys already included in our compilation, but it also provides redshifts from various other campaigns. We used the provided quality flag and select sources meeting the criteria 3 ≤ Q_f ≤ 5 or 13 ≤ Q_f ≤ 15 or 23 ≤ Q_f ≤ 25 or Q_f ∈ {6, 10}, do not use sources from lower-confidence determinations (e.g. grism), and limit the redshifts to z_spec > 0.002 to avoid stellar contamination. We assigned redshift quality as NQ = min((Qfmod10),4);
-
VUDS (Le Fèvre et al. 2015): we used sources with redshift flag zflags ending with {3, 4, 9} (reliability ≥80%) and assigned NQ = 4 if 3 ≤ zflags < 5 or 13 ≤ zflags < 25, otherwise NQ = 3;
-
VANDELS (Garilli et al. 2021): we selected sources for which (zflgmod10)∈{2, 3, 4} and assigned NQ = 4 if (zflgmod10)∈{3, 4} or NQ = 3 otherwise. The reassignment of the quality flags was motivated by the reportedly high redshift confidence of objects with flag values of two and three.
 |
Fig. A.1. On-sky distribution of spectroscopic sources matched against the six KiDZ fields. |
 |
Fig. A.2. Redshift distributions of the spectroscopic samples that enter the spectroscopic compilation, ordered by mean redshift (Table A.1). The distributions are calculated after removing duplicates between overlapping catalogues and matching with the KiDS imaging. |
Listing of the spectroscopic samples that enter the spectroscopic compilation summarising the sample sizes and mean redshifts. The values are calculated after removing duplicates between overlapping catalogues and matching with the KiDS imaging.
When joining the above samples into one dataset, we removed duplicates both from overlapping surveys as well as within the individual ones. In the former case, if for a given source there are redshifts from different surveys available, we assigned the most reliable measurement based on a specific ‘hierarchy’. Namely, we joined the catalogues by cross-matching objects within 1″ radius and apply the following order of preference:
-
COSMOS field: G10-COSMOS > DEIMOS > hCOSMOS > VVDS > Lega-C > FMOS > VUDS > C3R2 > DEVILS > zCOSMOS;
-
CDF-S field: ACES > VANDELS > VVDS > VUDS > GOODS/CDF-S > DEVILS > OzDES;
-
VVDS-2h field: VIPERS > VVDS > C3R2 > DEVILS > OzDES.
For objects with multiple spectroscopic measurements within a particular survey, we either took the redshift with the highest quality flag or, if various entries for the same source have the same quality flag and the reported redshifts differ by no more than 0.005, we calculated the average. If the reported redshifts have the same quality flag but differ by more than 0.005, we excluded such a source from the compilation.
Appendix B: SOM quality control
The original quality control (Eq. 2) was calibrated for the spectroscopic calibration data of Hildebrandt et al. (2021) with σmad = nMAD(⟨zcal⟩−⟨zB⟩) ≈ 0.12. Since this criterion may not be optimal for our new calibration dataset, we would in principle have needed to recalibrate the SOM cell rejection threshold to obtain the optimal trade-off between redshift bias and the size of the gold sample. It is, however, very challenging to simulate the photo-z errors and success rates of our new calibration dataset and therefore we chose to keep the threshold fixed for all gold sets.
Nevertheless, the addition of COSMOS2015 to the calibration data has a significant impact on the distribution of ⟨zcal⟩−⟨zB⟩ for the fully trained cells of the SOM (Fig. B.1). While the distribution is almost symmetrical for the case of spec-z fiducial, it is skewed to positive values for spec-z+PAUS+COS15. The effect is more distinct for those cells that are occupied exclusively by the COSMOS2015 data than for those that exist in both gold samples (compare the orange dotted and black lines in Fig. B.1). This is a clear indication that much of the additional calibration data are faint objects for which the KiDS nine-band photo-z catastrophically underestimates the redshift obtained from the much deeper COSMOS2015 data. This effect is responsible for the reduced representation fraction in the first tomographic bin, as discussed in Sect. 5.1.1.
 |
Fig. B.1. Comparison of the mean calibration sample redshift and KiDS nine-band photo-z in each SOM cell within the fiducial ±5σmad interval. The coloured solid lines represent the fiducial (purple) and the full (orange) gold sample. The black line is the subset of SOM cells that belong to both gold samples, whereas the dashed orange line represents those cells that are occupied only by data from COSMOS2015. |
Appendix C: Differences from the original KiDS-1000 analysis
The major difference between the analysis of the original KiDS-1000 data and this work is that our redshift calibration strategy focused exclusively on improving the SOM redshifts. We omitted revisiting the KiDS clustering redshifts, which Hildebrandt et al. (2021) used as a validation for the fiducial SOM redshift distributions. It is important to note, that the additional calibration data are only beneficial for the SOM calibration, since such inhomogeneous data, in particular photometric redshifts, cannot be applied easily in clustering redshifts.
Furthermore there are small differences in the cosmological analysis compared to A21, which are mostly related to small differences in the COSEBI data vector. We find that these differences originate from using a newer version of TREECORR; however, it has no impact on our cosmological constraints which agree within the expected statistical variance of the sampler. Differences in the measured COSEBIs also propagate to the covariance matrix, resulting in sub-percent differences between our covariance and the one used by A21. Finally, we assumed 99% correlation between m-bias values per tomographic bin instead of 100% (perfect correlation) as in A21. The effect of this choice is negligible compared to those introduced by the variations in the COSEBI data vector.
We also tested whether the correction of the m-bias (Table 2) has a significant impact on the cosmological constraints in A21 by analysing the same data (‘Asgari new m-bias’) with otherwise identical parameters (except for the differences summarised above). Our results show that the recovered primary cosmological parameters, in particular 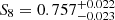 , are almost identical with those of our reanalysis of the KiDS-1000 data, performed with the old m-bias values (Table C.1). Given that the uncertainties of the m-biases are unchanged and the central value changes by less than 0.5σ in any of the tomographic bins, these results are as expected and have no further implication for the conclusions of A21.
, are almost identical with those of our reanalysis of the KiDS-1000 data, performed with the old m-bias values (Table C.1). Given that the uncertainties of the m-biases are unchanged and the central value changes by less than 0.5σ in any of the tomographic bins, these results are as expected and have no further implication for the conclusions of A21.
Summary of the main cosmological parameter constraints (best fit and 68th-percentile PJ-HPD) from COSEBIs for Asgari et al. (2021) and our reanalysis with and without the corrected m-bias values.
Appendix D: Marginal parameter constraints
Table D.1 lists an alternative representation of the parameter constraints of Table 3, showing the maximum of the marginal distribution and the associated 68th-percentile instead of the best fit and the 68th-percentile PJ-HPD.
Summary of the main cosmological parameter constraints (maximum of the marginal distribution and the associated 68th-percentile) from COSEBIs for all gold samples and the comparison to Asgari et al. (2021) and Planck legacy (TT, TE, EE + lowE).
Appendix E: Goodness of fit
We find that the cosmological model fits to the new gold samples achieve a better goodness-of-fit (χ2 between 62 and 74, Table 3) than those to the original KiDS-1000 gold sample with χ2 ≈ 83 as a reference. Since our methodology is identical in both cases, these differences stem from changes of the data vector that propagate also into the covariance matrix. We compared in particular the COSEBI data vectors with their respective best fit models for the spec-z fiducial and Asgari new m-bias (App. C) in Fig. E.1. Although a comparison by eye of the model and data is difficult due to the strong correlation between the different COSEBI modes, the most significant changes in the data vector occur between modes that involve bin one and two. In contrast to this the fitted models are very close in the first two bins and begin to deviate with increasing redshift.
 |
Fig. E.1. Comparison of the COSEBI data vector and the best fit model for spec-z fiducial and the reanalysis of Asgari et al. (2021) with corrected m-bias. The triangular arrangement of all 15 combinations of tomographic bins are labelled with their individual χ2-values. The COSEBIs modes are significantly correlated, therefore their goodness-of-fit cannot be estimated by eye. |
These changes propagate to the χ2, which becomes apparent when summing the individual χ2-values in each panel of Fig. E.1 for the two left-most columns. While the sum over the remaining three columns (dominated by bin three, four, and five) is almost identical for spec-z fiducial and Asgari new m-bias, the first two columns fully account for the smaller goodness-of-fit of Δχ2 ≈ 20. Since changing the m-bias seems to have a rather small impact on the χ2 (see Table C.1), this behaviour is most likely linked to the changes in the gold sample selection and redshift distributions, which are most significant for the first two bins. A21 report tensions between parameter constraints obtained from using only the second bin (including its cross-correlations) and the remainder of the data vector. A reduction of the χ2-value alone does not allow any conclusions on whether the improved calibration sample has an impact on the internal consistency of the cosmological analysis.
All Tables
Number counts and mean redshifts of the original KiDS-1000 redshift calibration sample and different subsets of the new redshift compilation.
The revised multiplicative shear bias mnew for the KiDS-1000 sample compared to the original values mold of Asgari et al. (2021).
Summary of the main cosmological parameter constraints (best fit and 68th-percentile PJ-HPD) from COSEBIs for all gold samples and their comparison to Asgari et al. (2021) and Planck legacy (TT, TE, EE + lowE).
Listing of the spectroscopic samples that enter the spectroscopic compilation summarising the sample sizes and mean redshifts. The values are calculated after removing duplicates between overlapping catalogues and matching with the KiDS imaging.
Summary of the main cosmological parameter constraints (best fit and 68th-percentile PJ-HPD) from COSEBIs for Asgari et al. (2021) and our reanalysis with and without the corrected m-bias values.
Summary of the main cosmological parameter constraints (maximum of the marginal distribution and the associated 68th-percentile) from COSEBIs for all gold samples and the comparison to Asgari et al. (2021) and Planck legacy (TT, TE, EE + lowE).
All Figures
|
Fig. 1. Sample size and mean redshift of the different surveys that are part of our spectroscopic compilation after matching to their counterparts in KiDS imaging. Objects with redshifts from multiple sources are assigned to the survey with the most reliable redshift estimate. |
| In the text | |
|
Fig. 2. Redshift distribution of different calibration sample subsets (coloured, solid lines) and the one used by Hildebrandt et al. (2021) for KiDS-1000 (dashed black line). The bottom panel shows the excess of sources with photometric redshifts contributed by PAUS and PAUS + COSMOS2015 compared to the fiducial spectroscopic sample. |
| In the text | |
|
Fig. 3. m-bias values calculated for each gold sample per tomographic bin. Additionally, the values used by Asgari et al. (2021) are shown in black and their revised values in teal. |
| In the text | |
|
Fig. 4. Representation fractions, the effective number density of the different gold samples relative to the full KiDS-1000 source sample, per tomographic bin. The effective number density factors in the lensing weight of each object and is calculated according to Eq. (C.12) in Joachimi et al. (2021). |
| In the text | |
|
Fig. 5. Comparison of the gold sample redshift distributions and their mean redshifts for all tomographic bins obtained from the different subsets of the calibration sample. All gold samples represent a different subset of the full KiDS-1000 source sample. |
| In the text | |
|
Fig. 6. Comparison of the tomographically binned calibration sample (black lines) to the gold sample redshift distributions (coloured lines). The greater the difference between the black and the coloured lines, the more weighting is applied by the SOM to match the calibration sample to the KiDS data. |
| In the text | |
|
Fig. 7. Marginalised constraints for the joint distributions of S8 and Ωm (68% and 95% credible regions) obtained for different gold samples and Planck legacy (TT, TE, EE + lowE). Since the contours represent different galaxy samples, some deviation is expected. |
| In the text | |
|
Fig. 8. Comparison of the S8 constraints from our gold samples to other studies. We show the best fit (where available) and 68th-percentile PJ-HPD (circles, opaque data points), and the maximum of the marginal distribution and the associated 68th-percentile (diamonds, semi-transparent). We compare to Asgari et al. (2021), HSC-Y1 (Hikage et al. 2019), DES-Y3 (Amon et al. 2022), and Planck legacy. The coloured vertical line and outer bands indicate the constraints from the fiducial gold sample, the inner bands the expected variance of the sampler. |
| In the text | |
|
Fig. 9. Comparison of the redshift distributions between the fiducial sample and the sample including the PAUS and COSMOS2015 photo-z. Top: SOM redshifts derived from the subset of SOM groupings present in both samples. Bottom: SOM redshift distributions of the groupings that are found only in the spec-z+PAUS+COS15 sample (dashed yellow) and the underlying redshift distribution in the calibration sample of the same groupings, i.e. not applying the SOM weighting in Eq. (1), scaled to the amplitude of the former for comparison. |
| In the text | |
|
Fig. 10. Comparison between constraints (best fit and 68th-percentile PJ-HPD) on S8 (left) and Σ8 (right) for spec-z fiducial, spec-z nQ ≥ 4, and the corresponding test scenario A and B. The grey arrows indicate shifts in S8 introduced in the tests by modifying the redshift distributions. |
| In the text | |
|
Fig. 11. Constraints on Σ8 (best fit and 68th-percentile PJ-HPD) for all primary and secondary gold samples. The coloured vertical line and outer bands indicate the constraints from the fiducial gold sample, the inner bands the expected variance of the sampler. |
| In the text | |
|
Fig. A.1. On-sky distribution of spectroscopic sources matched against the six KiDZ fields. |
| In the text | |
|
Fig. A.2. Redshift distributions of the spectroscopic samples that enter the spectroscopic compilation, ordered by mean redshift (Table A.1). The distributions are calculated after removing duplicates between overlapping catalogues and matching with the KiDS imaging. |
| In the text | |
|
Fig. B.1. Comparison of the mean calibration sample redshift and KiDS nine-band photo-z in each SOM cell within the fiducial ±5σmad interval. The coloured solid lines represent the fiducial (purple) and the full (orange) gold sample. The black line is the subset of SOM cells that belong to both gold samples, whereas the dashed orange line represents those cells that are occupied only by data from COSMOS2015. |
| In the text | |
|
Fig. E.1. Comparison of the COSEBI data vector and the best fit model for spec-z fiducial and the reanalysis of Asgari et al. (2021) with corrected m-bias. The triangular arrangement of all 15 combinations of tomographic bins are labelled with their individual χ2-values. The COSEBIs modes are significantly correlated, therefore their goodness-of-fit cannot be estimated by eye. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.