| Issue |
A&A
Volume 645, January 2021
|
|
|---|---|---|
| Article Number | A20 | |
| Number of page(s) | 7 | |
| Section | Planets and planetary systems | |
| DOI | https://doi.org/10.1051/0004-6361/202039040 | |
| Published online | 22 December 2020 | |
Spectral binning of precomputed correlated-k coefficients★
Laboratoire d’astrophysique de Bordeaux, Univ. Bordeaux, CNRS, B18N, allée Geoffroy Saint-Hilaire, 33615 Pessac, France
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
27
July
2020
Accepted:
26
October
2020
Abstract
With the major increase in the volume of the spectroscopic line lists needed to perform accurate radiative transfer calculations, disseminating accurate radiative data has become almost as much a challenge as computing it. Considering that many planetary science applications are only looking for heating rates or mid-to-low resolution spectra, any approach enabling such computations in an accurate and flexible way at a fraction of the computing and storage costs is highly valuable. For many of these reasons, the correlated-k approach has become very popular. Its major weakness has been the lack of ways to adapt the spectral grid/resolution of precomputed k-coefficients, making it difficult to distribute a generic database suited for many different applications. Currently, most users still need to have access to a line-by-line transfer code with the relevant line lists or high-resolution cross sections to compute k-coefficient tables at the desired resolution. In this work, we demonstrate that precomputed k-coefficients can be binned to a lower spectral resolution without any additional assumptions, and show how this can be done in practice. We then show that this binning procedure does not introduce any significant loss in accuracy. Along the way, we quantify how such an approach compares very favorably with the sampled cross section approach. This opens up a new avenue to deliver accurate radiative transfer data by providing mid-resolution k-coefficient tables to users who can later tailor those tables to their needs on the fly. To help with this final step, we briefly present Exo_k, an open-access, open-source Python library designed to handle, tailor, and use many different formats of k-coefficient and cross-section tables in an easy and computationally efficient way.
Key words: planets and satellites: general / planets and satellites: atmospheres
I wish to dedicated this paper to the memory of Adam P. Showman and Franck Hersant. You both were, each in your own way, an inspiration to me. Godspeed on your journey among the stars.
© J. Leconte 2020
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
1 Introduction
Despite the considerable increase in computing power, line-by-line radiative transfer is still considered a computationally intensive task in many cases of interest. One of the reasons for this state of affairs is that recent progress in spectroscopy has multiplied the size of molecular line lists by more than three orders of magnitude (Tennyson & Yurchenko 2012). We are at a point at which line list themselves, and a fortiori, high-resolution cross sections, represent a data volume that is not trivially handled and exchanged.
To face this while maintaining flexibility, some have opted for sampled or binned down cross-section tables1 (Line et al. 2015; Waldmann et al. 2015). But Garland & Irwin (2019) showed that this approach is inaccurate if the resolution used is not sufficiently high, and too computationally expensive if the resolution is high enough (we briefly revisit this question in Sect. 2 whose results are summarized in Figs. 1 and 2). It seems that for typical resolutions below ~1000, methods designed to group absorptions, such as the so-called correlated-k method (Liou 1980; Lacis & Oinas 1991), are more efficient while remaining accurate (Irwin et al. 2008; Amundsen et al. 2017; Garland & Irwin 2019; Zhang et al. 2020). It is especially true for multidimensional models that need a very fast radiative transfer and use only 10–30 bins for the whole spectrum (Showman et al. 2009; Wordsworth et al. 2011; Leconte et al. 2013; Amundsen et al. 2017).
For these reasons, it is interesting to directly distribute reference k-coefficients for each molecule instead of high-resolution cross sections. This is currently done for the ExoMol project (Chubb et al. 2020). This approach decreases the data volume necessary to handle while keeping an optimal accuracy. A current drawback with precomputed k-coefficients, however, is that the person computing the tables needs to choose a spectral resolution (or wavenumber grid) without knowing exactly what the table will be used for, while k-coefficients are used at their highest potential when tailored to the needed resolution.
To circumvent this problem we present a way to accurately bin down precomputed k-coefficients to an arbitrary spectral grid without any significant additional loss in accuracy. This method is faster than computing the k-coefficients directly from line-by-line data. It therefore opens up a new way of disseminating accurate, reference molecular opacities: spectroscopists only need to compute k-coefficients once with a resolution that is higher than the highest resolution they envision their users need (e.g., the resolution of the instrument you want to compare your model to). Users can then easily bin down the data to their spectral grid of choice, possibly even on the fly.
To help with the latter, we developed Exo_k2, an open-source Python 3 library that can directly load precomputed k-coefficient and cross-section tables, change their spectral resolution as well as pressure-temperature grids, and save them back on disk. The library can handle many different formats used in various codes: for example, TauREx (Al-Refaie et al. 2019; both pickle and HDF5), petitRADTRANS (Mollière et al. 2019), Nemesis (Irwin et al. 2008), ARCIS (Min et al. 2020), Exo transmit (Kempton et al. 2017), LMD Generic global climate model (Wordsworth et al. 2011; Leconte et al. 2013). Several of these formats are provided by the latest ExoMol release (Chubb et al. 2020). Other formats are being implemented and new ones can be added on request. It is also possible to compute k-coefficient tables from high-resolution spectra. One can also combine the opacities of several molecules using the random overlap method (Lacis & Oinas 1991) to create a table for a given atmospheric mix, which is very useful for climate models, for example. Finally, the library includes methods to directly interpolate and combine the opacities, and even compute transmission and emission spectra for 1D planetary atmospheres. Leveraging on the Numba library, these operations are performed in a very computationally efficient way. So Exo_k can be imported directly into any radiative transfer code to handle molecular opacities easily and efficiently.
In this article, we first briefly compare the relative accuracy and efficiency of the sampled cross section and correlated-k approaches in Sect. 2. After introducing the necessary concepts and notations, Sect. 3 demonstrates rigorously why and how to bin down precomputed k-coefficients to an arbitrary resolution. Then, in Sect. 4, we validate the numerical algorithm presented in this work and implemented in Exo_k.
2 Sampled cross sections versus correlated-k tables
To accurately compare the efficiency of various radiative transfer methods when a given resolution and precision are needed, we briefly estimate theaccuracy of atmospheric modeling when using the following types of input radiative data: sampled and binned cross section and k-coefficient tables.
We compare this for two different atmospheric configurations and observation geometries:
-
Transmission spectrum of a hot Jupiter with a 1000 K isothermal H2/H2O atmosphere in front of a Sun.
-
Emission spectrum of a pure CO2 Mars-like atmosphere.
The parameters for these two cases are given in Table 1.
Each time, we start by computing a reference spectrum using high-resolution monochromatic cross sections (with a typical step of 0.01 cm−1). For our CO2 atmosphere, we use spectra from Turbet & Tran (2017). For our hot-Jupiter case, we use water spectra produced by the Exomol project with H2 broadening (K. Chubb, private communication) based on the line list produced by Polyansky et al. (2018). Collision-induced-absorptions (CIA) are taken from the HITRAN database (Richard et al. 2011).
Then, the high-resolution cross sections are sampled at various resolutions (Rsp = {1000, 3000, 10 000, 30 000}) and a new set of spectra are computed at each of these resolutions.
The spectra obtained from the sampled cross sections are then binned (preserving area) at selected final resolutions (Rfin = {10, 20, 50, 100, 200, 500, 1000}). The transmission spectra computed in the hot-Jupiter case are shown in the left column of Fig. 2. Finally, these spectra are compared tothe properly binned reference spectrum (right column of Fig. 2). The root mean squared (RMS) error is shown for each (Rsp, Rfin) in Fig. 1. The emission spectra computed in the Mars-like case are shown in Fig. 3.
For the correlated-k approach, k-coefficient tables are computed from the high-resolution spectra directly at the final desired resolution (computed with 20 Gauss-Legendre quadrature points in g-space) and compared to the reference spectrum binned at the same resolution. This gives the black dashed curves in Fig. 2. The RMS error is shown by the black curve in Fig. 1.
For all the computations described above we used a standard algorithm to describe the transmission and emission spectra of a 1D atmosphere that have been implemented in the Exo_k library2.
We show that the correlated-k approach reaches an accuracy that is one to two orders of magnitude better than sampled cross sections, especially for resolutions bigger than 100. The relative drop in accuracy of the correlated-k method at Rfin = 10 is due to the low sampling of the CIA absorption, which is treated as constant in each spectral bin. This could be alleviated by applying the random overlap method to the CIA as well. To compare numerical efficiency, we focus on the Rfin = 10 case for which the Rsp = 30 000 roughly manages to reach an accuracy equivalent to the correlated-k method. Then, considering that our k-coefficients were computed using 20 quadrature points, the computation is still 150 times faster with the correlated-k method compared to the sampled cross sections.
We conclude this comparison by mentioning binned-down cross sections – in which the finely sampled cross sections are integrated over a coarser grid, thereby preserving area. Although it seems the most natural way to bin cross sections, this method performs even worse than the sampled cross sections (by about one order of magnitude; Fig. 4). This rather counterintuitive result stems from the nonlinear nature of radiative transfer: the opacity dilution due to the binning procedure is not sufficient to increase the transparency of the gas near optically thick lines, while decreasing it in the line wings. Overall, this systematically over estimates the opacity of the atmosphere and creates a systematic bias – on the order of 100 ppm in our hot-Jupiter test case.
Standard parameters used in our two fiducial cases.
 |
Fig. 1 Root mean square error on the transit spectrum of our fiducial hot Jupiter over the 1–2 μm window as a function of the final observed resolution. Dashed curves represent the error obtained with sampled cross-section tables at various sampling resolution (from top to bottom: Rsp = {1000, 3000, 10 000, 30 000}). The spectra are shown in Fig. 2. The black curve with dots represents the error using k-coefficients computed from high-resolution spectra directly at the final resolution. The gray curves show results when using binned down k-coefficients using natural (solid with stars) and non-integer (dotted) binning (see Sect. 3.4 for details). |
 |
Fig. 2 Effect of sampling resolution on the transit spectrum of a hot Jupiter. The various rows show the effect for different final observing resolutions (Rfin, specified in the top left corner of the panels). Left column: transit depth in the 1–2 μm window (with an offset of 11500 ppm). The various colors correspond to the four sampling resolutions (i.e., the resolution used in radiative transfer calculation before binning; Rsp) shown in the legend. The curve with dots shows the reference case computed from our very high-resolution cross sections (Δσ ≈ 0.01 cm−1). The high-resolution reference spectrum before binning is shown as the shading in the top left panel. Right column: difference (in ppm) between the spectra of the left panel and the reference case. The difference between the calculation with k-coefficients and the reference case is shown with the black dashed curve; the two spectra would be indistinguishable in the left panels. The RMS standard deviation over the spectral region is shown in Fig. 1. |
 |
Fig. 3 Effect of sampling resolution on the emission spectrum of our Mars-like case around the 15 μm CO2 band. The rows show the effect for different final observing resolutions (Rfin). Left column: flux. The various colors correspond to the four sampling resolutions (i.e., the resolution used in radiative transfer calculation before binning; Rsp) shown inthe legend. The reference case is computed from our very high-resolution cross sections (Δσ ≈ 0.01 cm−1). The high-resolution reference spectrum before binning is shown as the shading in the top left panel. Right column: relative error between the spectra of the left panel and the reference case. The error between the calculation with k-coefficients and the reference case is shown with the black dashed curve; the two spectra would be indistinguishable in the left panels. |
 |
Fig. 4 Effect of sampling resolution on the transit spectrum of a hot Jupiter using cross sections that have been binned by preserving the total area. The panels can be compared to the results for sampled cross sections in Fig. 2 (see the caption for details). The binning systematically overestimates the opacity. |
3 Method to bin down k-coefficients
3.1 Correlated-k formalism
Before demonstrating how to bin down k-coefficients, we briefly introduce the basic concepts we need. In the correlated-k method (see Liou 1980 for details), the wavenumber space, where ν is the wavenumber, is divided into Nb spectral bands of width 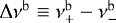 . In each band, the transmission through a slab of matter can be written as
. In each band, the transmission through a slab of matter can be written as
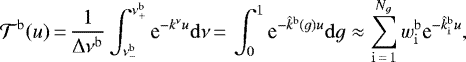 (1)
(1)
where Ng is the number of points (or abscissas) used to discretize the g-space and wb are the associated set of weights for each band. The symbol 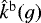 denotes the inverse of the cumulative density function of the opacity within band b – the so-called k-distribution – and should not be confused with kν, the absorption coefficient, which is a function of the wavenumber. The so-called correlated-k coefficients (or simply k-coefficients) are the
denotes the inverse of the cumulative density function of the opacity within band b – the so-called k-distribution – and should not be confused with kν, the absorption coefficient, which is a function of the wavenumber. The so-called correlated-k coefficients (or simply k-coefficients) are the 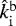 , which are the discretized version of the k-distribution (
, which are the discretized version of the k-distribution (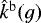 ).
).
An intuitive way to understand that is to say that now, in band b, the opacity can be described by Ng representative values (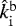 ) for each of the Ng points in g-space (gi), each of these values being affected a weight (wbi). Then any radiative transfer calculation can be computed separately in the Ng bins to be later summed up with the proper weights.
) for each of the Ng points in g-space (gi), each of these values being affected a weight (wbi). Then any radiative transfer calculation can be computed separately in the Ng bins to be later summed up with the proper weights.
An important, although often forgotten assumption of the correlated-k formalism is that both the spectral incoming flux impinging on our medium (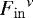 ) and the source function of the latter should be nearly constant within each spectral band (Lacis & Oinas 1991) so that it can be written
) and the source function of the latter should be nearly constant within each spectral band (Lacis & Oinas 1991) so that it can be written 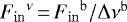 , where
, where 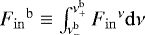 is the total flux within the band. Simply put in the context of a purely absorbing medium, which can be generalized, this ensures that the outgoing flux after a path u is given by
is the total flux within the band. Simply put in the context of a purely absorbing medium, which can be generalized, this ensures that the outgoing flux after a path u is given by
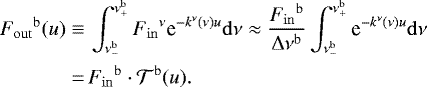 (2)
(2)
This assumption is important in our context because it is the only one that we need to make to be able to combine the k-coefficients of various bands. Finally, the bolometric flux can be obtained with
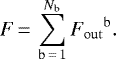 (3)
(3)
3.2 Combining k-coefficients of various bands
To reduce the resolution of precomputed k-coefficients, we essentially need to answer the following question: Can we determine the k-coefficients 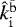 of a “super-band”
of a “super-band”  that is the union of two smaller, nonoverlapping “sub-bands”3, b1 and b2, for which we know the k-coefficients,
that is the union of two smaller, nonoverlapping “sub-bands”3, b1 and b2, for which we know the k-coefficients, 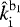 and
and 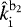 ?
?
In this form, the answer is not trivial. However, when computing k-coefficients, the crucial mathematical object is notthe k-distribution (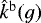 ) but its inverse, the cumulative density function (CDF) of the opacity within the band (hereafter called the g-distribution, ĝb (k)) defined as
) but its inverse, the cumulative density function (CDF) of the opacity within the band (hereafter called the g-distribution, ĝb (k)) defined as
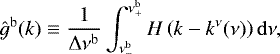 (4)
(4)
where H(x) is equal to 0 where x is positive and 1 elsewhere.
The question can thus be reframed to ask whether we can compute the g-distribution of the super-band, 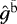 , if we know the g-distribution within the two sub-bands (ĝb1 and ĝb2). This is rather straightforward, because as long as the two smaller bands do not overlap, we have
, if we know the g-distribution within the two sub-bands (ĝb1 and ĝb2). This is rather straightforward, because as long as the two smaller bands do not overlap, we have 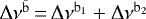 and
and
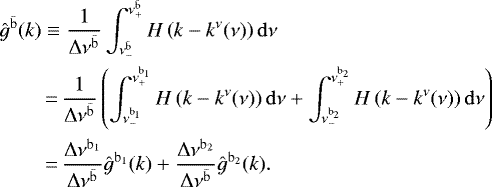 (5)
(5)
Therefore the g-distribution in the super-band is just the sum of the g-distributions in the sub-bands weighted by their spectral extent.
This can be understood more intuitively when discussing in terms of probability. We want to know if 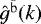 , that is, the probability that a monochromatic ray of light falls in a spectral region where the opacity kν is lower than k. To compute this, we have to sum, for each band, the probability of the ray falling in the given sub-band; this probability is
, that is, the probability that a monochromatic ray of light falls in a spectral region where the opacity kν is lower than k. To compute this, we have to sum, for each band, the probability of the ray falling in the given sub-band; this probability is 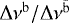 , as long as the incoming spectral flux is constant over the super-band, multiplied by the probability that kν < k within this sub-band, which is ĝb(k). So we recover Eq. (5) as long as we keep the essential assumption of the correlated-k method that the incoming flux and sources functions do not significantly vary over the wavelength range that we wish to describe by a single distribution.
, as long as the incoming spectral flux is constant over the super-band, multiplied by the probability that kν < k within this sub-band, which is ĝb(k). So we recover Eq. (5) as long as we keep the essential assumption of the correlated-k method that the incoming flux and sources functions do not significantly vary over the wavelength range that we wish to describe by a single distribution.
3.3 Numerical algorithm
As shown above, combining the g-distributions of various bands in a single g-distribution for a large band is straightforward. However, to use this in a radiative transfer code, we usually need the k-coefficients (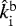 ) that are tabulated for fixed g-points (gi) with the associated weights (wbi). The difficulty is that although gi can be seen as the values of ĝb in band b for the points located at
) that are tabulated for fixed g-points (gi) with the associated weights (wbi). The difficulty is that although gi can be seen as the values of ĝb in band b for the points located at 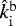 in opacity space, the distribution ĝb is sampled at different locations in opacity space in each sub-band.
in opacity space, the distribution ĝb is sampled at different locations in opacity space in each sub-band.
To circumvent this problem, we recommend the following approach, which is the one implemented in Exo_k. The whole process is illustrated in Fig. 5 with only two bands, but can be carried out for any numberof bands. For the moment, however, we restrict ourselves to the case in which the super-band 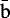 is composed ofan integer number of sub-bands (hereafter, natural binning). Once these sub-bands have been identified, we determine
is composed ofan integer number of sub-bands (hereafter, natural binning). Once these sub-bands have been identified, we determine
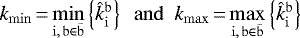 (6)
(6)
and compute an evenly log-distributed grid of Nk points (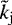 ) between these two values. Then, for each sub-band, we interpolate
) between these two values. Then, for each sub-band, we interpolate 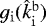 on this grid, which yields Nk values per band,
on this grid, which yields Nk values per band, 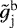 , representingall the ĝb on the same grid for all bands. It is thus now easy to compute the global g-distribution which is given by
, representingall the ĝb on the same grid for all bands. It is thus now easy to compute the global g-distribution which is given by
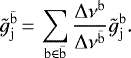 (7)
(7)
This generally yields an oversampled version of the distribution because we choose Nk > Ng (the black curve in the middle panel of Fig. 5). Recomputing the k-coefficients is thus now simply a matter of resampling 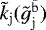 onto our original g-grid (gi) – going from the black to the gray curve in the right panel of Fig. 5 – as discussed in Lacis & Oinas (1991) and Amundsen et al. (2017). However, unlike those authors, we think that, to be consistent with the usual quadrature rules, the finely sampled k-distribution should not be weight-averaged over the final g-bins, but sampled at the precise abscissa of the g-point determined by the quadrature rule used, following Irwin et al. (2008).
onto our original g-grid (gi) – going from the black to the gray curve in the right panel of Fig. 5 – as discussed in Lacis & Oinas (1991) and Amundsen et al. (2017). However, unlike those authors, we think that, to be consistent with the usual quadrature rules, the finely sampled k-distribution should not be weight-averaged over the final g-bins, but sampled at the precise abscissa of the g-point determined by the quadrature rule used, following Irwin et al. (2008).
As longas we resample on the original grid, we keep the original quadrature with Ng points, and the weights are left unchanged. However, it is still possible at this point to use different g-points, especially if we need to use less g-points for computational reasons (as is often the case with 3D climate models). For this, we can simply resample 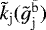 on a different g-grid and use the relevant weights, which is an option of Exo_k. In general, Exo_k works for any choice of g-space sampling specified by the user.
on a different g-grid and use the relevant weights, which is an option of Exo_k. In general, Exo_k works for any choice of g-space sampling specified by the user.
 |
Fig. 5 Example of the binning process for two bands. Left: k-coefficients on Ng = 20 Gauss-Legendre quadrature points for two bands ( |
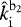
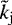
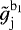
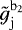
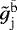
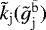
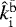
3.4 Non-integer binning
Up to now, we only considered the case in which the final super-band encompasses an integer number of sub-bands. This is required for our demonstration to be exact without any further assumptions.
In practice, it is still possible to bin k-coefficients on a spectral grid that does not exactly respect the limits of the sub-bands (hereafter, non-integer binning). To do that, we replace the spectral extent, Δνb, of the two bands at the boundaries of the super-band in Eq. (7) by their spectral extent inside the super-band. This is equivalent to binning a high-resolution spectrum to a low-resolution grid using a weighted average. In theory, this would remain perfectly accurate if the statistical distribution of the absorption coefficient were constant within the sub-band. As this is not true in general, we test the accuracy of this approach in the next section.
4 Validation
To validate our approach, we compute spectra in the two cases detailed in Sect. 2. As we do not want to test the accuracy of the correlated-k approach itself, which has already been done before, but whether the binning introduces additional errors, the comparison proceeds as follows:
-
Starting from very high-resolution spectra, we compute a first reference set of tables of k-coefficients with resolutions ranging from R = 1000 to R = 5 and a g-space sampled using 20 Gauss-Legendre quadrature points. The exact R values used do not matter. However, we make sure that the wavenumber points in the low-resolution grids can be found in the high-resolution grid to use only natural binning.
-
Starting from the R = 1000 table of k-coefficients4 we just computed, we use the binning approach described above to compute a new set of ten tables of k-coefficients with the exact same resolutions and wavenumber grids as the reference set.
-
The emitted or transmitted flux of our fiducial atmosphere is computed at each resolution with both the reference and the binned k-coefficients and the results are compared two by two.
The results of the comparison are shown in Fig. 6. For the Mars emission case, we compare the RMS standard deviation of the relative difference between the two spectra in the 1–200 μm range. For the Hot-jupiter in transmission test case, the comparison metric used is the RMS standard deviation of the relative difference between the two spectra in the 1–2 μm window.
All the k-coefficients computed in this work use 20 Gauss-Legendre quadrature points in g-space. Because the number of intermediate points used to resample the g-distribution in opacity space (Nk; see Sect. 3.3) is a free parameter, we tried different values of this parameter. We see that an insufficient intermediate sampling results in significant numerical errors, as could be anticipated. However, when Nk is a factor of a few larger than the initial number of g-points, the accuracy of the method asymptotes below 10−3−10−4, which is itself much lower than the error introduced by the correlated-k method in the first place (see for example Amundsen et al. 2017). We note that although choosing a larger Nk may slightly increase the binning time, this does not affect the efficiency of the subsequent radiative transfer calculations in any way. We thus used results with Nk = 5Ng as a baseline. We also found that using initial data with 40 Gauss-Legendre points did not significantly affect the performances of the binning procedure. Our algorithm is thus robust to the initial choice of g-space sampling.
The spectra obtained with this set of binned-down k-coefficients are also compared directly to the reference high-resolution spectrum as described in Sect. 2 to give the absolute difference shown in gray with stars in Fig. 1. Although not strictly equal because they are computed using a slightly different reference spectrum, the absolute difference shown in Fig. 1 and the relative difference from Fig. 6 can be shown to be consistent by multiplying the latter by the average transit depth as shown on the right axis of Fig. 6. In this particular case, we further wanted to test the impact of non-integer binning. For this a new set of k-coefficients were computed in the exact same way, but with a spectral grid that is slightly shifted in wavenumber to force non-integer binning. As shown by the dotted gray curve in Fig. 1, the accuracy is lower, although this method remains more accurate than sampled cross sections. In addition, the error decreases with the binning factor because the errors at the boundaries of our spectral bins are more diluted.
We therefore conclude that our binning method does not introduce any significant additional errors.
 |
Fig. 6 Numerical relative error introduced by the binning process as a function of the binning factor (ratio of the initial resolution, Rini, to the final one, Rfin) for four different values of the number of intermediate sampling points Nk (see Sect. 3.3; dotted: Nk = Ng; dashed: Nk = 1.5Ng; dot-dash: Nk = 2Ng; solid: Nk = 5Ng, where Ng = 20). Top: RMSrelative top-of-atmosphere flux error in our Mars-like case. Bottom: RMS relative transit depth error in our hot-Jupiter case. The right axis gives the absolute error to be compared to the results of Figs. 1 and 2. With a sufficient sampling, the errors are under the 10−3 − 10−4 level depending on the geometry, which is below the error introduced by the correlated-k method in the first place. |
5 Conclusions
We have demonstrated mathematically how the k-distribution of the opacity in a large band can be obtained from the k-distributions inside each of the smaller bands that it encompasses. Then we have presented a numerical algorithm to use this property to bin down precomputed tables of k-coefficients to any arbitrary resolution. Finally, we showed, in two concrete cases, that the numerical error added by this procedure is relatively small compared to the errors due to the more general use of the correlated-k approach.
To facilitate the implementation of this new method, we developed Exo_k, an open-source Python library that has been designed to handle many different sources of radiative data (including, of course, k-coefficient tables, but also cross section and collision-induced-absorption tables). Because this library is still rapidly evolving, see our extensive online documentation for tutorials, example notebooks, and a complete description of the library’s features2.
We think the flexibility that this approach brings to the correlated-k method opens up a completely new way of disseminating reference radiative data for use in atmospheric models: precomputed k-coefficients can now be directly distributed at a fraction of the data volume while providing fast and accurate results for any user that does not need a higher resolution. For example, R = 1000 k-coefficients computed on 20 gauss points such as that distributed by the ExoMol project take about 50 times less space on disk than the high-resolution spectra used to produce them. This is a considerable compression factor, and that does not include the hundreds of CPU hours that would be needed to compute the spectra.
This of course makes us wonder what would be the optimum resolution and quadrature for a flexible and versatile correlated-k database. Our test show that R = 1000 k-coefficients computed on 20 gauss points, when combined with the flexibility brought by a tool like Exo_k, seem to be sufficient for most 1D-3D atmospheric model applications5 as well as modeling synthetic spectroscopic observations of planetary atmospheres up to that resolution. This method can thus be used to model HST, Spitzer, Ariel (Tinetti et al. 2018), and low-resolution JWST data. For high-resolution JWST observation modes, higher resolution radiative data will be needed.
Acknowledgements
I thank F. Selsis for being, as always, an outstanding scientific sparring partner and the TauREx team at UCL for pointing out many important Python tricks and libraries. I am also indebted to K. Chubb and M. Turbet for making some radiative data available before their publication. This project has received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement n° 679030/WHIPLASH).
References
- Al-Refaie, A. F., Changeat, Q., Waldmann, I. P., & Tinetti, G. 2019, ArXiv e-prints [arXiv:1912.07759] [Google Scholar]
- Amundsen, D. S., Tremblin, P., Manners, J., Baraffe, I., & Mayne, N. J. 2017, A&A, 598, A97 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Chubb, K. L., Rocchetto, M., Yurchenko, S. N., et al. 2020, A&A, in press, https://doi.org/10.1051/0004-6361/202038350 [Google Scholar]
- Garland, R., & Irwin, P. G. J. 2019, MNRAS, in press [arXiv:1903.03997] [Google Scholar]
- Irwin, P. G. J., Teanby, N. A., de Kok, R., et al. 2008, J. Quant. Spectr. Rad. Transf., 109, 1136 [NASA ADS] [CrossRef] [Google Scholar]
- Kempton, E. M. R., Lupu, R., Owusu-Asare, A., Slough, P., & Cale, B. 2017, PASP, 129, 044402 [NASA ADS] [CrossRef] [Google Scholar]
- Lacis, A. A., & Oinas, V. 1991, J. Geophys. Res., 96, 9027 [Google Scholar]
- Leconte, J., Forget, F., Charnay, B., et al. 2013, A&A, 554, A69 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Line, M. R., Teske, J., Burningham, B., Fortney, J. J., & Marley, M. S. 2015, ApJ, 807, 183 [NASA ADS] [CrossRef] [Google Scholar]
- Liou, K. N. 1980, An introduction to atmospheric radiation (Boston: Academic Press) [Google Scholar]
- Min, M., Ormel, C. W., Chubb, K., Helling, C., & Kawashima, Y. 2020, A&A, 642, A28 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mollière, P., Wardenier, J. P., van Boekel, R., et al. 2019, A&A, 627, A67 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Polyansky, O. L., Kyuberis, A. A., Zobov, N. F., et al. 2018, MNRAS, 480, 2597 [NASA ADS] [CrossRef] [Google Scholar]
- Richard, C., Gordon, I., Rothman, L., et al. 2011, J. Quant. Spectr. Rad. Transf., 113, 1276 [Google Scholar]
- Showman, A. P., Fortney, J. J., Lian, Y., et al. 2009, ApJ, 699, 564 [NASA ADS] [CrossRef] [Google Scholar]
- Tennyson, J., & Yurchenko, S. N. 2012, MNRAS, 425, 21 [Google Scholar]
- Tinetti, G., Drossart, P., Eccleston, P., et al. 2018, Exp. Astron., 46, 135 [NASA ADS] [CrossRef] [Google Scholar]
- Turbet, M., & Tran, H. 2017, J. Geophys. Res. Planets, 122, 2362 [NASA ADS] [CrossRef] [Google Scholar]
- Waldmann, I. P., Tinetti, G., Rocchetto, M., et al. 2015, ApJ, 802, 107 [NASA ADS] [CrossRef] [Google Scholar]
- Wordsworth, R. D., Forget, F., Selsis, F., et al. 2011, ApJ, 733, L48 [NASA ADS] [CrossRef] [Google Scholar]
- Zhang, M., Chachan, Y., Kempton, E. M. R., Knutson, H. A., & Chang, W. H. 2020, ApJ, 899, 27 [CrossRef] [Google Scholar]
Here, sampled cross sections specifically refer to cross sections that are computed monochromatically but at a resolution that does not necessarily resolve the lines or their shape. Binned-down cross sections are computed on a finely sampled spectral grid and then integrated over a coarser grid, thereby preserving area.
See the online documentation for tutorials, example scripts and notebooks, and an extensive and up-to-date description of the (evolving) features of the library: http://perso.astrophy.u-bordeaux.fr/~jleconte/exo_k-doc/index.html
We restrict ourselves to the case of the combination of two bands. The generalization to an arbitrary number of bands is trivial.
This choice is motivated by the resolution chosen by the ExoMol project for their k-coefficient tables (Chubb et al. 2020).
Very cold and low pressure atmospheres, such as Pluto’s, may of course require special care because of their very narrow lines, which usually call for tailored quadrature rules.
All Tables
All Figures
|
Fig. 1 Root mean square error on the transit spectrum of our fiducial hot Jupiter over the 1–2 μm window as a function of the final observed resolution. Dashed curves represent the error obtained with sampled cross-section tables at various sampling resolution (from top to bottom: Rsp = {1000, 3000, 10 000, 30 000}). The spectra are shown in Fig. 2. The black curve with dots represents the error using k-coefficients computed from high-resolution spectra directly at the final resolution. The gray curves show results when using binned down k-coefficients using natural (solid with stars) and non-integer (dotted) binning (see Sect. 3.4 for details). |
| In the text | |
|
Fig. 2 Effect of sampling resolution on the transit spectrum of a hot Jupiter. The various rows show the effect for different final observing resolutions (Rfin, specified in the top left corner of the panels). Left column: transit depth in the 1–2 μm window (with an offset of 11500 ppm). The various colors correspond to the four sampling resolutions (i.e., the resolution used in radiative transfer calculation before binning; Rsp) shown in the legend. The curve with dots shows the reference case computed from our very high-resolution cross sections (Δσ ≈ 0.01 cm−1). The high-resolution reference spectrum before binning is shown as the shading in the top left panel. Right column: difference (in ppm) between the spectra of the left panel and the reference case. The difference between the calculation with k-coefficients and the reference case is shown with the black dashed curve; the two spectra would be indistinguishable in the left panels. The RMS standard deviation over the spectral region is shown in Fig. 1. |
| In the text | |
|
Fig. 3 Effect of sampling resolution on the emission spectrum of our Mars-like case around the 15 μm CO2 band. The rows show the effect for different final observing resolutions (Rfin). Left column: flux. The various colors correspond to the four sampling resolutions (i.e., the resolution used in radiative transfer calculation before binning; Rsp) shown inthe legend. The reference case is computed from our very high-resolution cross sections (Δσ ≈ 0.01 cm−1). The high-resolution reference spectrum before binning is shown as the shading in the top left panel. Right column: relative error between the spectra of the left panel and the reference case. The error between the calculation with k-coefficients and the reference case is shown with the black dashed curve; the two spectra would be indistinguishable in the left panels. |
| In the text | |
|
Fig. 4 Effect of sampling resolution on the transit spectrum of a hot Jupiter using cross sections that have been binned by preserving the total area. The panels can be compared to the results for sampled cross sections in Fig. 2 (see the caption for details). The binning systematically overestimates the opacity. |
| In the text | |
|
Fig. 5 Example of the binning process for two bands. Left: k-coefficients on Ng = 20 Gauss-Legendre quadrature points for two bands ( |
| In the text | |
|
Fig. 6 Numerical relative error introduced by the binning process as a function of the binning factor (ratio of the initial resolution, Rini, to the final one, Rfin) for four different values of the number of intermediate sampling points Nk (see Sect. 3.3; dotted: Nk = Ng; dashed: Nk = 1.5Ng; dot-dash: Nk = 2Ng; solid: Nk = 5Ng, where Ng = 20). Top: RMSrelative top-of-atmosphere flux error in our Mars-like case. Bottom: RMS relative transit depth error in our hot-Jupiter case. The right axis gives the absolute error to be compared to the results of Figs. 1 and 2. With a sufficient sampling, the errors are under the 10−3 − 10−4 level depending on the geometry, which is below the error introduced by the correlated-k method in the first place. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.