| Issue |
A&A
Volume 632, December 2019
|
|
|---|---|---|
| Article Number | A37 | |
| Number of page(s) | 15 | |
| Section | Stellar structure and evolution | |
| DOI | https://doi.org/10.1051/0004-6361/201935520 | |
| Published online | 25 November 2019 | |
Radial-velocity jitter of stars as a function of observational timescale and stellar age⋆⋆⋆
1
Zentrum für Astronomie der Universität Heidelberg, Landessternwarte, Königstuhl 12, 69117 Heidelberg, Germany
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Max Planck Institut für Astronomie, Königstuhl 17, 69117 Heidelberg, Germany
Received:
22
March
2019
Accepted:
8
October
2019
Abstract
Context. Stars show various amounts of radial-velocity (RV) jitter due to varying stellar activity levels. The typical amount of RV jitter as a function of stellar age and observational timescale has not yet been systematically quantified, although it is often larger than the instrumental precision of modern high-resolution spectrographs used for Doppler planet detection and characterization.
Aims. We aim to empirically determine the intrinsic stellar RV variation for mostly G and K dwarf stars on different timescales and for different stellar ages independently of stellar models. We also focus on young stars (≲30 Myr), where the RV variation is known to be large.
Methods. We use archival FEROS and HARPS RV data of stars which were observed at least 30 times spread over at least two years. We then apply the pooled variance (PV) technique to these data sets to identify the periods and amplitudes of underlying, quasiperiodic signals. We show that the PV is a powerful tool to identify quasiperiodic signals in highly irregularly sampled data sets.
Results. We derive activity-lag functions for 20 putative single stars, where lag is the timescale on which the stellar jitter is measured. Since the ages of all stars are known, we also use this to formulate an activity–age–lag relation which can be used to predict the expected RV jitter of a star given its age and the timescale to be probed. The maximum RV jitter on timescales of decades decreases from over 500 m s−1 for 5 Myr-old stars to 2.3 m s−1 for stars with ages of around 5 Gyr. The decrease in RV jitter when considering a timescale of only 1 d instead of 1 yr is smaller by roughly a factor of 4 for stars with an age of about 5 Myr, and a factor of 1.5 for stars with an age of 5 Gyr. The rate at which the RV jitter increases with lag strongly depends on stellar age and reaches 99% of the maximum RV jitter over a timescale of a few days for stars that are a few million years old, up to presumably decades or longer for stars with an age of a few gigayears.
Key words: stars: activity / methods: data analysis / techniques: radial velocities
Table E.1 is only available at the CDS via anonymous ftp to cdsarc.u-strasbg.fr (130.79.128.5) or via http://cdsarc.u-strasbg.fr/viz-bin/cat/J/A+A/632/A37
Based on data obtained from the ESO Science Archive Facility under request number sbrems392771.
© ESO 2019
1. Introduction
Of the almost 4000 exoplanets known today, more than 3700 were discovered via the radial-velocity (RV) or transit methods1. According to the database, only three of them (V830 Tau b, Donati et al. 2016; K2-33 b, David et al. 2016, and TAP 26 b, Yu et al. 2017) are younger than 100 Myr. The main reason for this is the strong stellar activity of young stars, which makes it hard to find the subtle planetary signal in the large stellar variations. This is unfortunate for two reasons: first, planet formation takes place in young systems and at least gas giants need to form before the disk has dissipated after less than a few tens of millions of years (e.g., Ercolano & Pascucci 2017). Second, planets at large orbital distances (≳50 AU) are almost exclusively detected via direct imaging (DI), which is best applicable to young systems where the planets are still hot from their formation. Thus, in order to discover all planets in a system, one either needs to image old stars – which seems currently impossible given the already low detection rate around young stars probed by large DI surveys (e.g., Desidera et al. 2015; Lannier et al. 2016; Tamura 2016; Stone et al. 2018) – or try to minimize the impact of the stellar activity of young stars. A lot has been done to understand and characterize stellar activity (e.g., Dumusque 2018). Lindegren & Dravins (2003) further estimate the effects of stellar activity such as oscillation, granulation, meridional flow, long-term magnetic cycle, surface magnetic activity and rotation, gravitational redshift and many more on the RV measurement. Meunier & Lagrange (2019) then try to model the effect of this kind of activity signal on RV data of mature stars. With our data probing activity timescales of days to years, we are mainly probing the combined effect of stellar rotation, reconfiguration of active regions, and long-term magnetic cycles. Still, large uncertainties remain in the prediction and interpretation of any RV signal, in particular for young pre-main sequence stars. But since this is what we measure, knowledge about the typical RV variability is important, for example for developing and testing RV activity models or planning RV surveys. In this paper we therefore derive a model-free analytic relation between stellar jitter, stellar age, and lag, where lag denotes the timescale on which the jitter is measured.
In order to derive this relation, we systematically analyze precise Doppler measurements from FEROS (Kaufer et al. 1999) and HARPS (Mayor et al. 2003) of mainly G and K dwarfs with ages between 3 Myr and 7 Gyr using the pooled variance (PV) technique (Donahue et al. 1997a,b; Kürster et al. 2004).
This paper is organized as follows: in Sect. 2 we introduce the input target list as well as target selection and data cleaning. Section 3 explains the PV technique, the activity modeling for individual stars, and the uncertainty estimation. Section 4 presents two analytic activity–age–lag functions to the pooled data of all stars. In Sect. 5 we discuss the strengths, weaknesses, and limits of this analysis and give example values of the empirical activity–age–lag function. Section 6 then concludes on the main findings of this paper.
2. Target sample
Our goal is to characterize RV jitter as a function of stellar age and probed timescale. Therefore, we need to put together a sample of young and old stars with known ages that have been part of RV monitoring programs.
We assemble our input target list from three different surveys which all focus on young stars in the southern hemisphere: first, the ongoing Imaging Survey for Planets around Young stars (NaCo-ISPY)2 survey (Launhardt et al., in prep.; 443 targets). Second the recently started Radial-velocity Survey for Planets around Young stars (RV SPY) survey (Zakhozhay et al., in prep.; 180 targets). And third the RV survey to find planets around young stars from Weise (2010) and Mohler-Fischer (2013; 214 targets). NaCo-ISPY is a 120-night guaranteed time observations (GTO) L′-band direct imaging survey using the NaCo instrument (Lenzen et al. 2003; Rousset et al. 2003) at the VLT. Its target list contains mostly two subcategories: first, young, nearby stars with debris disks showing significant infrared excess, and second, stars with protoplanetary disks. RVSPY is a RV survey currently spanning 40 nights that is complementary to NaCo-ISPY, as it searches for close-in planets around debris disk stars older than about 10 Myr. Its target list has an intentionally large overlap with the NaCo-ISPY target list, but is extended especially for older, less active stars. Since the second and third surveys use the FEROS instrument and young stars are mostly avoided in RV surveys, the young stars (≤45 Myr) are uniquely observed with FEROS; see Table 1. However, since their intrinsic RV variation is at least one order of magnitude larger than the instrumental precision, we do not expect any significant bias in our results from this selection effect. Since there are overlaps in the catalogs, we end up with 699 targets. Figure 1 shows the age distribution of those stars. One can see that most stars in the input catalog are younger than 100 Myr. Almost all of the older stars come from the RV SPY survey, which also included older stars to avoid the issues of young and active stars as RV targets.
Properties of the 27 stars that qualified for further analysis.
 |
Fig. 1. Age distribution of the stars in the input catalog (blue) and the remaining 20 single stars (red) after applying the selection criteria described in the text. The remaining sample has a wide age distribution, slightly skewed towards younger stars. Young stars (≤100 Myr) are especially important for this analysis and are in general rarely observed in RV surveys. |
We searched the archives for public data from the ESO-instruments HARPS (Mayor et al. 2003) and FEROS (Kaufer et al. 1999) for all 699 stars in our input catalog. The RVs were derived using the CERES pipeline (Brahm et al. 2017) for FEROS and the SERVAL pipeline (Zechmeister et al. 2018) for HARPS data. We removed bad observations with formal errors as returned by the pipelines above 20 m s−1 and 50 m s−1 for HARPS and FEROS respectively, and via iterative 10σ-clipping on all data of a star simultaneously. In order to qualify for our final analysis, the remaining data need to be sufficiently evenly distributed for each star and instrument. We ensured this by requiring a minimum of 30 observations, at least a two-year baseline, no gap larger than 50%, and a maximum of two gaps larger than 20% of the baseline. Since HARPS underwent a major intervention, including a fiber change in June 2015 (Lo Curto et al. 2015), these criteria needed to be fulfilled for one of the data sets before or after the intervention.
Finally stars with known companions (stellar or substellar) listed in the Washington Double Star catalog (Mason et al. 2001), the Spectroscopic Binary Catalog (9th edition Pourbaix et al. 2004), or the NASA Exoplanet Archive1 were also removed. This is done so we can make the assumption that we are left only with stellar noise. As a consistency check with increased statistics, we additionally analyzed seven of the removed wide binary systems (≥27 AU projected separation). They are not used to obtain the main results given in Table 2 and are marked with a binary flag in Tables 1 and 2.
Parameters and formal errors of the 27 stars, where HD 25457 has sufficient data in HARPS and FEROS.
After this selection we were left with 27 stars (including the 7 binaries): 9 with sufficient HARPS data and 19 with sufficient FEROS data, where HD 25457 (single) had good data from both instruments. Table 2 lists their basic properties and Fig. C.1 shows the RV data for all 27 stars. The individual measurements, including the barycentric Julian date (BJD), the RV signal, and the RV error, are given in Table E.1. These data are only available at the CDS.
3. Method
3.1. Models
In order to determine the typical RV scatter over different observing timescales (lags), several methods were applied.
First, the variogram or structure function (Hughes et al. 1992) using different estimators as described in Rousseeuw & Croux (1993) and Eyer & Genton (1999) was tried: the idea here is to create all possible differences between the measured RV data points. Those points are then sorted by the time differences (lags) and compared to theoretical predictions of a sinusoidal signal. Second, self-created, automated block-finding algorithms with random selection of single observation in clustered observations: The algorithm identifies clustered observations on different timescales. For clusters shorter than an arbitrarily chosen fraction of the lag probed, one random observation will be picked, while longer blocks will be split into sub-blocks of the according size. For each block, the variance is determined and used as the typical variance for that timescale. Third, consecutive binning was tried, where the observations are binned on the timescale chosen. This is similar to the second method, but there is no upper limit on the block size and one takes the mean instead of a random representative of that bin. This is done for all lags to be probed. And finally the PV was used.
Since only the latter method turned out to be robust enough to identify signals in sparse and irregularly sampled data, we used it for our analysis. The remainder of this section is dedicated to describing the method in more detail.
3.2. Pooled variance
We use the PV or pooled variance diagram (PVD) method, which was first introduced for the analysis of time series of astronomical data by Dobson et al. (1990) to analyze the CaII emission strength of active late-type stars. Dobson et al. (1990), Donahue et al. (1995, 1997a,b), Donahue & Dobson (1996), and Kürster et al. (2004) demonstrated the capability of this technique to detect timescales pertaining to stellar activity such as the stellar rotation period, the typical timescale of active region reconfiguration or the stellar activity cycle. The PV is a combined variance estimate from k different sets of measurements yi, j, i = 1, …, Nj, j = 1, …, k each of which has a different mean 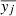 . If it can be assumed that all the individual sets of measurements have the same variance (despite the different mean), then the PV σp is defined as
. If it can be assumed that all the individual sets of measurements have the same variance (despite the different mean), then the PV σp is defined as
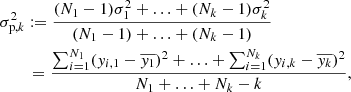 (1)
(1)
with σp, j being the variance of the jth data set, that is, the PV is the weighted mean of the variances of the individual data sets.
In this paper we make the assumption of (on average) equal RV variances in spite of different mean RV for data sets that were obtained within time intervals of equal length. In particular we assume this to be true for the data taken by HARPS before and after the intervention in June 2015 (Lo Curto et al. 2015), even though the formal errors increase from a mean of 0.9 m s−1 to 1.3 m s−1 for our data. This decreased precision after the intervention seems to affect all HARPS data (Trifonov, in prep.), but since we probe jitter values typically much larger than these formal errors, the assumption still holds. The only significant effect is the offset of several meters per second in the absolute RV values. To account for this, we split the data into pre- and post-data sets. Furthermore, we assume that the RV variance on a given timescale does not change over time (e.g., due to activity cycles). For these data sets the PV can be calculated and is used as an estimate of the true variance for this timescale. As long as the lag probed is shorter than the observational baseline, the PV is more precise than the variance of a single data set due to the larger number of measurements as several data sets are combined. If the length of the time intervals differs we expect different variances in general.
3.3. Block sizes
As the integer k to split our observations in smaller blocks is arbitrary, we run k = 1, …, B, where B is the number of days covered by the observations. In other words, we split our data into blocks, starting from one block having the full baseline length, to B blocks with a length of one day each. We define the lag τ := B/k, which corresponds to the length of each bin in days for a given k. For each value of k, or equivalent lag τ, we then obtain a different variance 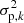 as defined in Eq. (1). We note that due to the HARPS fiber change in June 2015 (Lo Curto et al. 2015), we removed HARPS data taken during this procedure (2457173.0–2457177.0 JD) and did not allow blocks to combine data taken before and after the intervention. We therefore had two data sets with shortened baselines. After applying the PV, we then treat the two datasets as one again.
as defined in Eq. (1). We note that due to the HARPS fiber change in June 2015 (Lo Curto et al. 2015), we removed HARPS data taken during this procedure (2457173.0–2457177.0 JD) and did not allow blocks to combine data taken before and after the intervention. We therefore had two data sets with shortened baselines. After applying the PV, we then treat the two datasets as one again.
It is difficult to assign absolute error bars to each pooled data point, as the formal RV precision (a few m s−1) is typically much smaller than the PV (a few hundred m s−1). We therefore decided to assign a weight wk to each measurement σp, k. In contrast to errors, weights only have a relative meaning and thus do not need to be calibrated absolutely. Since more points yield in general a more significant result, we use the square root of the number of individual points minus the number of filled boxes that were used to compute this point. We subtract the number of filled boxes because each box takes one degree of freedom (the mean):
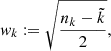 (2)
(2)
where 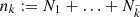 is the number of individual data points contributing, and
is the number of individual data points contributing, and 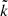 is the number of blocks where the variance could be calculated, that is, the number of boxes with at least two measurements. This formula, and especially the subtraction of
is the number of blocks where the variance could be calculated, that is, the number of boxes with at least two measurements. This formula, and especially the subtraction of 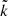 , are further motivated by the relative uncertainty of the variance estimator for N points, which is
, are further motivated by the relative uncertainty of the variance estimator for N points, which is 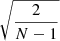 (e.g., Squires 2001, p. 22). Thus, under the assumption of k independent blocks with N/k measurements in each block, the uncertainty is
(e.g., Squires 2001, p. 22). Thus, under the assumption of k independent blocks with N/k measurements in each block, the uncertainty is
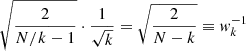 (3)
(3)
for k independent blocks with N/k measurements in each block (compare also Brown & Levine 2007).
3.4. Activity modeling
Now that we know the variance on different timescales, we want to find the periods P and amplitudes K of the underlying modulations. Under the assumption of an underlying, infinitely sampled sinusoidal signal 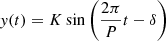 with semi-amplitude K, period P, and phase δ, the analytic PV for timescale τ is given in Eq. (B.4), which is independent of δ.
with semi-amplitude K, period P, and phase δ, the analytic PV for timescale τ is given in Eq. (B.4), which is independent of δ.
Since there might be no, one, or multiple periodic signals of this kind, we fit four different curves to each PV data point of a star:
![Mathematical equation: $$ \begin{aligned} \sigma _{\rm p}^2(\tau ) = A^2 + \sum _{i=1}^m K_i^2\left[ \frac{1}{2} + \frac{\cos (2\pi \tau /P_i)-1}{(2\pi \tau /P_i)^2} \right], \end{aligned} $$](/articles/aa/full_html/2019/12/aa35520-19/aa35520-19-eq127.gif) (4)
(4)
where m ∈ [0, 1, 2, 3] is the number of sinusoidal signals and τ is the timescale or lag probed. In other words, only white noise or white noise plus up to three underlying sinusoidal signals are fitted using χ2-minimization, where the formal squared errors are given by the reciprocal of the weight from Eq. (2). We note that the models have 2m + 1 free parameters. In order to decide how many signals are significant, we used an F-test (Rawlings et al. 1998), which is often used in nested models. We highlight the fact that the number of independent measurements required in this test is the number of observations and not the number of points in the PVD. This approach has one value α to be chosen arbitrarily. This α acts as a threshold in rejecting the null hypothesis, which is that the model with fewer parameters describes the data as well as the model with more parameters. It is typically chosen to be around α ≈ 0.01 − 0.05, where a larger value favors the model with fewer parameters. We select α = 0.05.
3.5. Uncertainty estimation
Finally we want to assign confidence intervals to each of the 2m + 1 parameters we found for each star to best describe its activity. We tried the following methods:
First, we tried to apply Markov chain Monte Carlo (MCMC) on the RV data as well as on the pooled data. Then we tried a Monte Carlo (MC)-like method on the pooled data: we removed the modeled signal from the pooled data, binned seven neighboring data points, for example, and determined their mean and variance. This mean and variance were then used to create seven new, random data points, assuming a Gaussian distribution. We then re-added the modeled signal and re-performed the fitting routine. And finally we tried bootstrap resampling on the RV data as well as on the pooled data.
Quantifying these methods not only by eye but also using artificially generated data where we know the true periods and amplitudes of the underlying signals, we found the last method to give the most realistic results. By “realistic”, we mean that the true value lies within the error bars of the estimated values and that the sampled values spread roughly equally around the original estimate. The MCMC methods underestimated the errors, whereas in the MC-like method one often has the problem of non-Gaussian distributed residuals, which will then lead to skewed and shifted results if those are approximated and redistributed by Gaussians. Bootstrapping the original data leads to issues when bins often contain identical data, returning a variance of zero, seemingly skewing the results to smaller absolute variances.
For the last method, we pooled the data using Eq. (1) as described in Sects. 3.2 and 3.3, resulting in k pairs of lag τ and variance 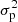 . Subsequently, we determined the model capable of best describing the data using the F-test; see Sect. 3.4. We randomly redrew k pairs of lag τ and variance
. Subsequently, we determined the model capable of best describing the data using the F-test; see Sect. 3.4. We randomly redrew k pairs of lag τ and variance 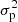 with placing back, meaning the same pair can be drawn multiple times. This is the method known as bootstrapping. Fixing the model to the one found for the original data, we fit this model to the new data. Repeating the last two steps 5000 times yields an estimate of the robustness of the model parameters. The original fit is used as the best fit and the standard deviations left and right of that are used as the asymmetric error bars. An example of this distribution for HD 45184 is shown in Fig. E.1 (bottom left), where the lines indicate the best fits and confidence intervals. However, bootstrapping assumes the underlying data points to be mutually independent and well sampled. Since the statistical independence of the PVs is not fulfilled here and additional systematic errors might be present, the errors should be seen as lower limits to the real uncertainties.
with placing back, meaning the same pair can be drawn multiple times. This is the method known as bootstrapping. Fixing the model to the one found for the original data, we fit this model to the new data. Repeating the last two steps 5000 times yields an estimate of the robustness of the model parameters. The original fit is used as the best fit and the standard deviations left and right of that are used as the asymmetric error bars. An example of this distribution for HD 45184 is shown in Fig. E.1 (bottom left), where the lines indicate the best fits and confidence intervals. However, bootstrapping assumes the underlying data points to be mutually independent and well sampled. Since the statistical independence of the PVs is not fulfilled here and additional systematic errors might be present, the errors should be seen as lower limits to the real uncertainties.
4. Results
We derived an analytic activity–lag–function for the 27 stars (including the 7 binaries) that were selected by the criteria described in Sect. 2. The analytic function fitted to the PV data of each star is given by Eq. (4). This equation describes constant noise plus up to three independent sinusoidal signals as they would show up in the PVD in the case of infinite sampling. It has one free parameter for the constant plus two more for each signal identified. Those parameters represent the period and amplitude of the assumed underlying sinusoid. As it was integrated over the phase and we assume all phases to be covered roughly equally, no parameter for the phase or potential phase jumps is needed; see Appendix B. The results of the fits are presented in Table 2. Figure 2 shows those fits graphically as well as the PV for all stars and Fig. 3 then compares those to the age of the stars. With the exception of HD 51062 (highest dotted line), a clear spectroscopic binary (SB) as seen in the cross-correlation function (CCFs) returned by CERES, a clear correlation between age and RV scatter σ is found. We excluded HD 51062 as well as the other six visual binaries from further analysis, and only use the six wide binaries as a consistency check with increased statistics below. As shown in Table 2, on average there were 1.6 individual signals with periods between 2.1 and 114 days identified for those 20 stars. These signals cause an increase of the stellar noise by roughly a factor of two when comparing the variance at the smallest lags with those at the largest lags, as can be seen in the PVDs in Fig. 2. This means that if one is looking for planetary signals, not only does the amplitude of the signal of the planet Kpl decrease with Kpl ∝ P−1/3, but also the underlying noise doubles when probing months instead of days.
 |
Fig. 2. Pooled results for the first 6 stars. Find plots for the remaining 21 stars in Fig. D.1. Blue symbols denote FEROS data and green symbols HARPS data. The lines show the best fits for the different numbers of sinusoidal signals fitted: dotted: zero signal (constant), dash-dotted: one signal, dashed: two signals, dash-dot-dotted: three signals. The solid line replaces the line which qualified as best fit using the F-test described in Sect. 3.4. The dotted vertical lines represent the periods of the identified signals and the number in the bottom right corner the number of identified signals. The model parameters are shown in Table 2. We note that σp and not |
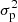
 |
Fig. 3. Top: fitted RV jitter of the 28 RV datasets of the 27 stars using the procedure described in Sect. 3.4. The color indicates the age of the star, showing a clear correspondence between RV jitter and age. The dotted lines corresponds to the binaries and are not used to fit the age–lag–activity model. The outlier at the top is HD 51062, the newly identified SB. Bottom: residuals of the above, ignoring HD 51062, from the more complex age–lag–activity model (b), divided by the model value. The model is described in Sect. 4, Eq. (6). We highlight the linear scale between −1 and 1 and a log-scale for values greater than 1. HD 51062 is excluded from the residuals. |
In order to quantify this further and to make it possible for surveys to predict the amount of RV jitter before starting the observations, we fitted an empirical model, now adding a dependence on age to the model. Since the systematic errors are much larger than the formal errors on the curves, we did not account for those errors, or for the uncertainties of the ages. Instead, we reused the weights for each point derived earlier, but normalized them such that the sum of the weights equals one for each star. This procedure ensures that each star gets assigned the same weight, but still keeps the different weights for the individual points. The fitting is done using the python scipy.optimize.curve_fit least-square fitting routine, where we fit with all three parameters (age, lag, and standard deviation) in log space, decreasing the impact of extreme values. The errors are then determined using the square root of the diagonal entries of the covariance matrix of the fit results. This can be done since the weights are scaled such that the reduced χ2 equals unity. We used a shifted and stretched error function as our model. We chose the error function, since it asymptotically approaches different constant values in the positive and negative directions, similar to the PV signal of a sine wave; see Eq. (B.4). It is analytically described by
![Mathematical equation: $$ \begin{aligned} \log \,\sigma (\hat{T}, \hat{\tau }) = \kappa _{0}\cdot \hat{T}^{\kappa _{1}} \cdot \left[ \mathrm{erf} \left(\omega _{0}+\hat{\tau }\cdot \omega _1 \right)\right] -\epsilon , \end{aligned} $$](/articles/aa/full_html/2019/12/aa35520-19/aa35520-19-eq131.gif) (5)
(5)
where 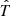 and
and 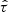 are the respective decadic logarithms of the stellar age T in years and lag τ in days and σ is returned in meters per second. κ0, κ1, ω0, ω1 and ϵ are free parameters of the model and erf is defined by
are the respective decadic logarithms of the stellar age T in years and lag τ in days and σ is returned in meters per second. κ0, κ1, ω0, ω1 and ϵ are free parameters of the model and erf is defined by 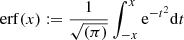 . The respective κi and ωi describe amplitude and angular frequency of the model, similar to K and 2π/P in the one-dimensional case given in Eq. (B.4). The parameter ω1 describes how steeply the noise σ increases with lag τ, and ϵ is a simple offset since the error function goes through the origin. We call this model (a). The fitted parameter values and errors are given in Table 3 and the contours of the 2D function are plotted in Fig. 4 as white dotted lines. The most striking feature is the very strong dependence of the RV scatter on stellar age. Although this behavior was already known qualitatively, to the authors’ knowledge the dependence is quantified for the first time here. In addition, the stellar noise increases when going to longer baselines: by a factor of 3.4 for stars with an age of 5 Myr years, and 1.6 for stars with an age of 5 Gyr, when comparing a baseline of 10 yr with a baseline of 1 d. With this model, this increase happens on average such that 99% of the maximum activity is reached after approximately 10 d. Thus, especially for young stars, the already very high noise level is increasing from 190 m s−1 for a lag of 1 d to 640 m s−1 for a lag of 10 d or longer.
. The respective κi and ωi describe amplitude and angular frequency of the model, similar to K and 2π/P in the one-dimensional case given in Eq. (B.4). The parameter ω1 describes how steeply the noise σ increases with lag τ, and ϵ is a simple offset since the error function goes through the origin. We call this model (a). The fitted parameter values and errors are given in Table 3 and the contours of the 2D function are plotted in Fig. 4 as white dotted lines. The most striking feature is the very strong dependence of the RV scatter on stellar age. Although this behavior was already known qualitatively, to the authors’ knowledge the dependence is quantified for the first time here. In addition, the stellar noise increases when going to longer baselines: by a factor of 3.4 for stars with an age of 5 Myr years, and 1.6 for stars with an age of 5 Gyr, when comparing a baseline of 10 yr with a baseline of 1 d. With this model, this increase happens on average such that 99% of the maximum activity is reached after approximately 10 d. Thus, especially for young stars, the already very high noise level is increasing from 190 m s−1 for a lag of 1 d to 640 m s−1 for a lag of 10 d or longer.
 |
Fig. 4. Fitted activity model to the PV data excluding HD 51062. This model has been subtracted in Fig. 3. The color code and white solid lines with contour levels show the more complex model (b) of Eq. (6). As expected, the most important parameter is age. The increase of significant activity timescales with age can also be seen: 99% of the final activity is reached after ∼5 d for a 10 Myr-old star, but only after ∼30 yr for a 10 Gyr-old star. The black dashed lines show the simpler model (a) of Eq. (5) where the timescales are forced to be the same for all ages. |
 |
Fig. 5. Four slices for different lags through the activity model (b) presented in Fig. 4 with solid lines. The slices show the strong dependance on age, but also on lag, in particular for the older stars. |
Additionally, it would be interesting to know whether younger stars typically have longer or shorter periodic signals than older stars. To answer this, another free parameter δ was introduced, slightly changing Eq. (5) to
![Mathematical equation: $$ \begin{aligned} \log \,\sigma (\hat{T}, \hat{\tau }) = \kappa _{0}\cdot \hat{T}^{\kappa _{1}} \cdot \left[ \mathrm{erf} \left(\omega _{0}+\frac{\hat{\tau }\cdot \omega _{1}}{\hat{T}^{\delta }}\right)\right] -\epsilon , \end{aligned} $$](/articles/aa/full_html/2019/12/aa35520-19/aa35520-19-eq135.gif) (6)
(6)
which we now refer to as model (b). As shown in Table 3, we derive a value of δ = 8.00 ± 0.12. The positive value of δ means that younger stars have shorter activity timescales than older ones, as can clearly be seen in the 2D function with solid white contours shown in Fig. 4. With this dependence, 99% of the maximum activity will be reached after 2.5 d for stars with ages of 5 Myr and after 14 d, 800 d, and 10 yr for stars with ages of 50 Myr, 500 Myr, and 5 Gyr, respectively. The total increase with lag is a factor of 4 for 5 Myr-old stars and a factor of 1.8 for 5 Gyr-old stars. At the same time, the absolute jitter values for a lag of 10 d decrease from 516 m s−1 for a 5 Myr-old star to 41 m s−1, 6.7 m s−1, and 1.9 m s−1 for stars with ages of 50 Myr, 500 Myr, and 5 Gyr, respectively.
5. Discussion
Without making use of any stellar models, we were able to determine the RV jitter as function of lag for 27 stars and to describe it with an analytic function for all of those using PV. However, since the assumption of statistical independence is violated in the pooled points, the F-test used to determine the number of sinusoidal signals identified is strictly speaking not applicable. Thus, even though the results appear convincing, one cannot put numbers on the significance of an identified signal, one of the original plans to characterize stars even further. Consequently, the errors determined using bootstrapping need to be considered as lower limits because of this lack of statistical independence. For the future, a MC simulation on the original data with scaled error bars would perhaps return more realistic errors. But since we neither make use of the number of signals identified nor of the errors, we did not pursue this further.
This lack of statistical independence has the largest influence when little and clustered data is present. This is often the case in the HARPS data taken after the intervention, resulting in a horizontal line of pooled data, as seen for example in HD 30495 in Fig. D.1. This is because often only a few or even one “box” has at least two data points, allowing calculation of the variance. In the case of HD 30495, multiple data points were taken in one night, with the shortest time period between two nights of data capture being 44 d. Thus, the PV only changes for a lag of 44 d or larger, sometimes resulting in a jump in the PVD. Fortunately, fewer data points are used in these cases, down-weighting the influence of these cases. Also, the selection criteria presented in Sect. 2 try to limit the occurrence of these phenomena.
For stellar activity there are three main characteristic timescales involved (e.g., Borgniet et al. 2015): first, the stellar rotation causing rotational modulation of active regions and their effects with typical timescales of days to a few weeks. Second, the reconfiguration of active regions with typical timescales of several weeks. And third, the stellar activity cycle with typical timescales of several years or decades. Of those three, the second is the least periodic and has a rather unsharp timescale; furthermore, it overlaps with the stellar rotation timescale, meaning that the two are difficult to disentangle; see for example Giles et al. (2017). Many stars show an increase of the RV jitter up to a few days or weeks followed by a plateau. This is probably due to the stellar rotation and reconfiguration of the active regions. In addition, especially the older, more quiet stars show another strong increase with a lag of a few years. This is probably related to the stellar activity cycle. However, since this increase is often close to the probed baseline, we might often only probe a part of this additional noise term.
For very active stars, the white noise term A of Eq. (4) is often consistent with zero, taking the error bars into account. This probably means that the periodic signal dominates the fit and therefore A cannot be determined very well numerically instead of truly being zero.
Since the ages of all stars are known, we could determine an empirical but still analytic model of the age–lag–activity relation based on the 20 presumably single stars. This model shows that the typical RV jitter of a star depends strongly on the age of the star, ranging from 516 m s−1 for a 5 Myr-old star down to 2.5 m s−1 for a 5 Gyr-old star – when probing lags of 10 yr. When considering a timescale of 1 d only, the RV jitter is smaller by roughly a factor of 4 for stars with ages of 5 Myr and a factor of 1.7 for stars with an age of 5 Gyr. The rate by which this jitter then increases with lag strongly depends on the age of the stars, where according to the model younger stars reach their maximum in a few days and older stars take up to thousands of years. We note that the maximum baseline of our measurements is about 13 yr, meaning that we cannot say anything about the contribution of activity cycles that operate on even longer timescales. The ages of the single stars probed reach from 5 Myr to 5 Gyr and cover spectral types from F6 to M0; see Table 1 and Fig. 1. By construction, each star is assigned the same weight, and since 14 of the 20 stars are younger than 100 Myr, the result is skewed towards relatively young stars and thus is also most robust for those young stars. We also note that the individual scatter of σp of the stars is about a factor of two, as can be seen in the residuals of Fig. 4. This might hint towards another dependence of the activity on spectral type or metallicity. However, more data are needed to analyze this dependence.
To test our model with increased statistics, we derived the age–lag relationship of model (b) with the six additional wide (≥27 AU projected separations) binary systems, that is, all stars except the SB HD 51062. Since the activity of these stars is on average slightly lower than that of the similar-aged single stars (see Fig. 3) the RV data for these stars are likely not dominated by the binary companions, justifying this approach. The derived values are κ0 = 98.4 ± 4.1, κ1 = −1.544 ± 0.029, ω0 = 1.1612 ± 0.0071, ω1 = (3.17 ± 1.56)×106, δ = 7.36 ± 0.25 and ϵ = 2.471 ± 0.066 m s−1. Despite individual values changing more than the formal errors (e.g., κ0 from 312 to 98), the typical scatter σ does not change by more than 20% in the probed parameter space (ages from 5 Myr−10 Gyr, lags from 1 d −104 d). Also the trend of longer activity timescales for older stars, quantified by the δ parameters, remains of the same order and clearly positive. The major change is a decrease of the RV scatter by slightly less than 20% for 5 Myr-old stars and by 10% for 5 Gyr-old stars. It remains the same within a few percent for stars of intermediate ages (∼50 Myr−1 Gyr). Therefore, this test strengthens our confidence in the robustness of our model.
This means that for RV exoplanet-hunting surveys using state of the art instruments for example, one should be aware that for stars younger than a few hundred million years the limit is set by the stellar jitter and not by instrumental precision and the age is a crucial parameter. For example, the RV SPY survey excludes stars younger than about 5 Myr although its goal is to find planets around young stars. Additionally, RV SPY focuses on searching for hot Jupiters, where the stellar jitter is slightly smaller and the signal of the planet is larger than for longer periodic planets (Zakhozhay et al., in prep.).
6. Conclusions
Here, we show that the PV method can be used to model and determine stellar activity timescales and amplitudes. We applied PV to 28 data sets of 27 different stars. We find an empirical relation between RV scatter, stellar age, and lag τ. We found a very strong dependence of RV jitter on age. Further, the RV scatter roughly doubles with the lag τ when probing over timescales of months instead of a few days.
This relation is not only important for stellar modeling, but also for developing an observing strategy for RV exoplanet surveys, especially if young stars are involved, such as predicting the RV jitter for young K/G dwarfs common in the TESS survey. Also, in searches for hot Jupiters, dense sampling is approximately twice as sensitive as long-term random sampling. One survey making use of the findings in this paper is the RV SPY survey with FEROS, looking for hot Jupiters around young stars (Zakhozhay et al., in prep.).
Acknowledgments
This research has made use of the NASA Exoplanet Archive, which is operated by the California Institute of Technology, under contract with the National Aeronautics and Space Administration under the Exoplanet Exploration Program. This research made use of Astropy (http://www.astropy.org), a community-developed core Python package for Astronomy (Astropy Collaboration 2013, 2018). This research has made use of the SIMBAD database, operated at CDS, Strasbourg, France Thanks also to Diana Kossakowski for fruitful discussions about Gaussian processes and its limitations on this application and to Peter Markowski for his help on statistical issues. We would also like to thank the anonymous referee for his or her helpful comments and ideas, which helped to improve the paper.
References
- Astropy Collaboration (Robitaille, T. P., et al.) 2013, A&A, 558, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Astropy Collaboration (Price-Whelan, A. M., et al.) 2018, AJ, 156, 123 [Google Scholar]
- Borgniet, S., Meunier, N., & Lagrange, A.-M. 2015, A&A, 581, A133 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Brahm, R., Jordán, A., & Espinoza, N. 2017, PASP, 129, 034002 [NASA ADS] [CrossRef] [Google Scholar]
- Brown, L. D., & Levine, M. 2007, Ann. Stat., 35, 2219 [CrossRef] [Google Scholar]
- Chen, C. H., Mittal, T., Kuchner, M., et al. 2014, ApJS, 211, 25 [NASA ADS] [CrossRef] [Google Scholar]
- David, T. J., Hillenbrand, L. A., Petigura, E. A., et al. 2016, Nature, 534, 658 [NASA ADS] [CrossRef] [PubMed] [Google Scholar]
- Desidera, S., Covino, E., Messina, S., et al. 2015, A&A, 573, A126 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dobson, A. K., Donahue, R. A., Radick, R. R., & Kadlec, K. L. 1990, in Cool Stars, Stellar Systems, and the Sun, ed. G. Wallerstein, ASP Conf. Ser., 9, 132 [NASA ADS] [Google Scholar]
- Donahue, R. A., & Dobson, A. K. 1996, in Cool Stars, Stellar Systems, and the Sun, eds. R. Pallavicini, & A. K. Dupree, ASP Conf. Ser., 109, 599 [NASA ADS] [Google Scholar]
- Donahue, R. A., Dobson, A. K., & Baliunas, S. L. 1995, in American Astronomical Society Meeting Abstracts #186, BAAS, 27, 843 [Google Scholar]
- Donahue, R. A., Dobson, A. K., & Baliunas, S. L. 1997a, Sol. Phys., 171, 191 [NASA ADS] [CrossRef] [Google Scholar]
- Donahue, R. A., Dobson, A. K., & Baliunas, S. L. 1997b, Sol. Phys., 171, 211 [NASA ADS] [CrossRef] [Google Scholar]
- Donati, J. F., Moutou, C., Malo, L., et al. 2016, Nature, 534, 662 [NASA ADS] [CrossRef] [Google Scholar]
- Dumusque, X. 2018, A&A, 620, A47 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ercolano, B., & Pascucci, I. 2017, R. Soc. Open Sci., 4, 170114 [Google Scholar]
- Eyer, L., & Genton, M. G. 1999, A&AS, 136, 421 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Foreman-Mackey, D. 2016, https://doi.org/10.5281/zenodo.45906 [Google Scholar]
- Giles, H. A. C., Collier Cameron, A., & Haywood, R. D. 2017, MNRAS, 472, 1618 [Google Scholar]
- Hughes, P. A., Aller, H. D., & Aller, M. F. 1992, ApJ, 396, 469 [NASA ADS] [CrossRef] [Google Scholar]
- Ibukiyama, A., & Arimoto, N. 2002, A&A, 394, 927 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kaufer, A., Stahl, O., Tubbesing, S., et al. 1999, The Messenger, 95, 8 [Google Scholar]
- Kürster, M., Endl, M., Els, S., et al. 2004, in Planetary Systems in the Universe, ed. A. Penny, IAU Symp., 202, 36 [NASA ADS] [Google Scholar]
- Lachaume, R., Dominik, C., Lanz, T., & Habing, H. J. 1999, A&A, 348, 897 [NASA ADS] [Google Scholar]
- Lannier, J., Delorme, P., Lagrange, A. M., et al. 2016, A&A, 596, A83 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lenzen, R., Hartung, M., Brandner, W., et al. 2003, in Instrument Design and Performance for Optical/Infrared Ground-based Telescopes, eds. M. Iye, & A. F. M. Moorwood, Proc. SPIE, 4841, 944 [NASA ADS] [CrossRef] [Google Scholar]
- Lindegren, L., & Dravins, D. 2003, A&A, 401, 1185 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lo Curto, G., Pepe, F., Avila, G., et al. 2015, The Messenger, 162, 9 [NASA ADS] [Google Scholar]
- Maldonado, J., Martínez-Arnáiz, R. M., Eiroa, C., Montes, D., & Montesinos, B. 2010, A&A, 521, A12 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mason, B. D., Wycoff, G. L., Hartkopf, W. I., Douglass, G. G., & Worley, C. E. 2001, AJ, 122, 3466 [Google Scholar]
- Mayor, M., Pepe, F., Queloz, D., et al. 2003, The Messenger, 114, 20 [NASA ADS] [Google Scholar]
- Meunier, N., & Lagrange, A.-M. 2019, A&A, 628, A125 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mohler-Fischer, M. 2013, PhD Thesis, University of Heidelberg, Germany [Google Scholar]
- Pourbaix, D., Tokovinin, A. A., Batten, A. H., et al. 2004, A&A, 424, 727 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rawlings, J. O., Pantula, S. G., & Dickey, D. A. 1998, in Applied Regression Analysis, 2nd edn. (Berlin: Springer), Springer Texts Stat., XVIII, 657 S [Google Scholar]
- Rousseeuw, P. J., & Croux, C. 1993, J. Am. Stat. Assoc., 88, 1273 [CrossRef] [Google Scholar]
- Rousset, G., Lacombe, F., Puget, P., et al. 2003, in Adaptive Optical System Technologies II, eds. P. L. Wizinowich, & D. Bonaccini, Proc. SPIE, 4839, 140 [NASA ADS] [CrossRef] [Google Scholar]
- Squires, G. L. 2001, Practical Physics, 4th edn. (Cambridge: Cambridge University Press), XI, 212 S [Google Scholar]
- Stone, J. M., Skemer, A. J., Hinz, P. M., et al. 2018, AJ, 156, 286 [NASA ADS] [CrossRef] [Google Scholar]
- Tamura, M. 2016, Proc. Jpn. Acad. Ser. B, 92, 45 [Google Scholar]
- Tucci Maia, M., Ramírez, I., Meléndez, J., et al. 2016, A&A, 590, A32 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Vican, L. 2012, AJ, 143, 135 [NASA ADS] [CrossRef] [Google Scholar]
- Weise, P. 2010, PhD Thesis, University of Heidelberg, Germany [Google Scholar]
- Weise, P., Launhardt, R., Setiawan, J., & Henning, T. 2010, A&A, 517, A88 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Yu, L., Donati, J.-F., Hébrard, E. M., et al. 2017, MNRAS, 467, 1342 [NASA ADS] [Google Scholar]
- Zechmeister, M., Reiners, A., Amado, P. J., et al. 2018, A&A, 609, A12 [CrossRef] [Google Scholar]
Appendix A: Analytic description of the PV
The variance of a data set yi = 1, …, n is given by
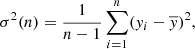 (A.1)
(A.1)
where 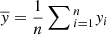 . For sufficiently large n, we have
. For sufficiently large n, we have
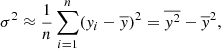 (A.2)
(A.2)
where 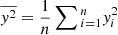 .
.
In the limit of equidistant and infinitely dense sampling of the data, we can replace the sums by integrals; Eq. (A.2) then becomes
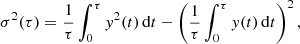 (A.3)
(A.3)
where τ is the timescale over which the variance is to be evaluated.
As we see below, for periodic functions the shape of σ2(τ) depends strongly on the phase of the periodic function. In practice however, the phase of a signal is often sampled repeatedly in a random fashion, thus also averaging over potential variations in the phase. Therefore, we consider the phase-averaged variance, with δ ∈ [0, 2π) the phase of the signal y(δ)
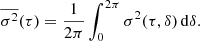 (A.4)
(A.4)
We note that we take averages over the signal 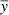 with respect to the selected time scale τ, whereas we take the average over the variance
with respect to the selected time scale τ, whereas we take the average over the variance 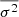 with respect to the phase of the signal δ.
with respect to the phase of the signal δ.
In the analytic case (infinitely dense sampling) the PV of a data set is given by inserting Eq. (A.3) into Eq. (A.4). In reality one might see effects of transient oscillations if the signal is not sampled densely at all phases. To minimize the influence of those effects, the selection criteria for the sampling described in Sect. 2 were applied.
Appendix B: Analytic PV of sinusoids
As an example we consider the PV of a sine wave:
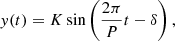 (B.1)
(B.1)
where K is the (semi-) amplitude, P is the period, and δ ∈ [0, 2π) the phase.
Evaluating Eq. (A.3) for the sine function of Eq. (B.1) yields the scaled variance
![Mathematical equation: $$ \begin{aligned} \Omega ^2(\theta ) =&\frac{1}{2} - \frac{\sin (2\theta -2\delta )+\sin (2\delta )}{4\theta }\nonumber \\& - \left[ \frac{\cos \delta - \cos (\theta -\delta )}{\theta } \right]^2, \end{aligned} $$](/articles/aa/full_html/2019/12/aa35520-19/aa35520-19-eq145.gif) (B.2)
(B.2)
where Ω2 := σ2/K2 and θ = 2πτ/P. Inserting Eq. (B.2) into Eq. (A.4) yields the normalized, analytic PV of a sine wave
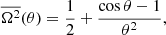 (B.3)
(B.3)
or
![Mathematical equation: $$ \begin{aligned} \overline{\sigma ^2}(\tau ) = K^2\left[ \frac{1}{2} + \frac{\cos (2\pi \tau /P)-1}{(2\pi \tau /P)^2} \right] \cdot \end{aligned} $$](/articles/aa/full_html/2019/12/aa35520-19/aa35520-19-eq147.gif) (B.4)
(B.4)
We have 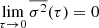 and
and 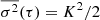 for τ = P and also for τ ≫ P.
for τ = P and also for τ ≫ P.
Appendix C: Radial-velocity data
 |
Fig. C.1. Radial velocity data for all 27 stars after removing the bad data as described in Sect. 2 and subtracting the mean of each data set. Green symbols denote HARPS and blue symbols FEROS data. The offset of the Julian Date on the x-axis is given in the bottom right of each plot. The green vertical lines mark the fiber change of HARPS where the data sets were split. One can see how some data show clear jumps there while others do not. Jumps in the PVD in Fig. 2 as in HD 51062 or HD 25457 can be explained by clustered (e.g., HD 25457) or relatively sparse (e.g., HD 51062) data. |
 |
Fig. C.2. continued. |
Appendix D: Pooled variance diagrams
 |
Fig. D.1. continued. |
Appendix E: Pooled variance error estimate
 |
Fig. E.1. Bottom left: results of the bootstrapping procedure shown as an example for HD 45184. Shown is a corner plot using the Foreman-Mackey (2016) python package. A denotes the offset where as Ki and Pi show the amplitudes and periods of the ith signal, as defined in Eq. (4). The solid green bars denote the fit to the original data, whereas the dashed lines denote the 1σ-confidence levels. In the case of HD 45184, three signals were identified as significant by the F-test, which are shown here. Top right: PV plot: the points mark the results of the PV and the curves the fits with different numbers of sinusoidal signals modeled: dotted: zero (constant), dash-dotted: one sinusoid, dashed: two sinusoids, solid: three sinusoids (best fit). The flat line of points at the bottom are due to the sparse sampling after the HARPS intervention, where only two times two observations are taken within less than 20 days, and those were respectively taken on the same nights; see Fig. C.1. |
All Tables
Parameters and formal errors of the 27 stars, where HD 25457 has sufficient data in HARPS and FEROS.
All Figures
|
Fig. 1. Age distribution of the stars in the input catalog (blue) and the remaining 20 single stars (red) after applying the selection criteria described in the text. The remaining sample has a wide age distribution, slightly skewed towards younger stars. Young stars (≤100 Myr) are especially important for this analysis and are in general rarely observed in RV surveys. |
| In the text | |
|
Fig. 2. Pooled results for the first 6 stars. Find plots for the remaining 21 stars in Fig. D.1. Blue symbols denote FEROS data and green symbols HARPS data. The lines show the best fits for the different numbers of sinusoidal signals fitted: dotted: zero signal (constant), dash-dotted: one signal, dashed: two signals, dash-dot-dotted: three signals. The solid line replaces the line which qualified as best fit using the F-test described in Sect. 3.4. The dotted vertical lines represent the periods of the identified signals and the number in the bottom right corner the number of identified signals. The model parameters are shown in Table 2. We note that σp and not |
| In the text | |
|
Fig. 3. Top: fitted RV jitter of the 28 RV datasets of the 27 stars using the procedure described in Sect. 3.4. The color indicates the age of the star, showing a clear correspondence between RV jitter and age. The dotted lines corresponds to the binaries and are not used to fit the age–lag–activity model. The outlier at the top is HD 51062, the newly identified SB. Bottom: residuals of the above, ignoring HD 51062, from the more complex age–lag–activity model (b), divided by the model value. The model is described in Sect. 4, Eq. (6). We highlight the linear scale between −1 and 1 and a log-scale for values greater than 1. HD 51062 is excluded from the residuals. |
| In the text | |
|
Fig. 4. Fitted activity model to the PV data excluding HD 51062. This model has been subtracted in Fig. 3. The color code and white solid lines with contour levels show the more complex model (b) of Eq. (6). As expected, the most important parameter is age. The increase of significant activity timescales with age can also be seen: 99% of the final activity is reached after ∼5 d for a 10 Myr-old star, but only after ∼30 yr for a 10 Gyr-old star. The black dashed lines show the simpler model (a) of Eq. (5) where the timescales are forced to be the same for all ages. |
| In the text | |
|
Fig. 5. Four slices for different lags through the activity model (b) presented in Fig. 4 with solid lines. The slices show the strong dependance on age, but also on lag, in particular for the older stars. |
| In the text | |
|
Fig. C.1. Radial velocity data for all 27 stars after removing the bad data as described in Sect. 2 and subtracting the mean of each data set. Green symbols denote HARPS and blue symbols FEROS data. The offset of the Julian Date on the x-axis is given in the bottom right of each plot. The green vertical lines mark the fiber change of HARPS where the data sets were split. One can see how some data show clear jumps there while others do not. Jumps in the PVD in Fig. 2 as in HD 51062 or HD 25457 can be explained by clustered (e.g., HD 25457) or relatively sparse (e.g., HD 51062) data. |
| In the text | |
|
Fig. C.2. continued. |
| In the text | |
 |
Fig. D.1. Continued from Fig. 2. |
| In the text | |
|
Fig. D.1. continued. |
| In the text | |
|
Fig. E.1. Bottom left: results of the bootstrapping procedure shown as an example for HD 45184. Shown is a corner plot using the Foreman-Mackey (2016) python package. A denotes the offset where as Ki and Pi show the amplitudes and periods of the ith signal, as defined in Eq. (4). The solid green bars denote the fit to the original data, whereas the dashed lines denote the 1σ-confidence levels. In the case of HD 45184, three signals were identified as significant by the F-test, which are shown here. Top right: PV plot: the points mark the results of the PV and the curves the fits with different numbers of sinusoidal signals modeled: dotted: zero (constant), dash-dotted: one sinusoid, dashed: two sinusoids, solid: three sinusoids (best fit). The flat line of points at the bottom are due to the sparse sampling after the HARPS intervention, where only two times two observations are taken within less than 20 days, and those were respectively taken on the same nights; see Fig. C.1. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.