| Issue |
A&A
Volume 630, October 2019
|
|
|---|---|---|
| Article Number | A71 | |
| Number of page(s) | 19 | |
| Section | Extragalactic astronomy | |
| DOI | https://doi.org/10.1051/0004-6361/201935743 | |
| Published online | 23 September 2019 | |
Survey of gravitationally-lensed objects in HSC imaging (SuGOHI)
III. Statistical strong lensing constraints on the stellar IMF of CMASS galaxies⋆
1
Leiden Observatory, Leiden University, Niels Bohrweg 2, 2333 Leiden, The Netherlands
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Kavli IPMU (WPI), UTIAS, The University of Tokyo, Kashiwa, Chiba 277-8583, Japan
3
Faculty of Science and Engineering, Kindai University, Higashi-Osaka 577-8502, Japan
4
Astronomical Institute, Tohoku University, Aramaki, Aoba, Sendai 980-8578, Japan
5
Institute of Physics, Laboratory of Astrophysics, École Polytechnique Fédérale de Lausanne (EPFL), Observatoire de Sauverny, 1290 Versoix, Switzerland
6
The Inter-University Center for Astronomy and Astrophysics, Post bag 4, Ganeshkhind, Pune 411007, India
7
Max-Planck-Institut für Astrophysik, Karl-Schwarzschild Str. 1, 85741 Garching, Germany
8
Physik-Department, Technische Universität München, James-Franck-Straße 1, 85748 Garching, Germany
9
Institute of Astronomy and Astrophysics, Academia Sinica, 11F of ASMAB, No.1, Section 4, Roosevelt Road, Taipei 10617, Taiwan
10
National Astronomical Observatory of Japan, 2-21-1 Osawa, Mitaka, Tokyo 181-8588, Japan
11
Department of Physics, University of Tokyo, 7-3-1 Hongo, Bunkyo-ku, Tokyo 113-0033, Japan
12
Research Center for the Early Universe, University of Tokyo, 7-3-1 Hongo, Bunkyo-ku, Tokyo 113-0033, Japan
13
National Optical Astronomy Observatory, 950 N Cherry Ave, Tucson, AZ 85719, USA
Received:
21
April
2019
Accepted:
11
July
2019
Abstract
Context. The determination of the stellar initial mass function (IMF) of massive galaxies is one of the open problems in cosmology. Strong gravitational lensing is one of the few methods that allow us to constrain the IMF outside of the Local Group.
Aims. The goal of this study is to statistically constrain the distribution in the IMF mismatch parameter, defined as the ratio between the true stellar mass of a galaxy and that inferred assuming a reference IMF, of massive galaxies from the Baryon Oscillation Spectroscopic Survey (BOSS) constant mass (CMASS) sample.
Methods. We took 23 strong lenses drawn from the CMASS sample, measured their Einstein radii and stellar masses using multi-band photometry from the Hyper Suprime-Cam survey, then fitted a model distribution for the IMF mismatch parameter and dark matter halo mass to the whole sample. We used a prior on halo mass from weak lensing measurements and accounted for strong lensing selection effects in our model.
Results. Assuming a Navarro Frenk and White density profile for the dark matter distribution, we infer a value μIMF = −0.04 ± 0.11 for the average base-10 logarithm of the IMF mismatch parameter, defined with respect to a Chabrier IMF. A Salpeter IMF is in tension with our measurements.
Conclusions. Our results are consistent with a scenario in which the region of massive galaxies where the IMF normalisation is significantly heavier than that of the Milky Way is much smaller than the scales 5 − 10 kpc probed by the Einstein radius of the lenses in our sample, as recent spatially-resolved studies of the IMF in massive galaxies suggest.
Key words: galaxies: elliptical and lenticular, cD / gravitational lensing: strong / galaxies: fundamental parameters
The Monte Carlo chains describing the posterior probability distribution of the model are available at https://github.com/astrosonnen/sugohi3_inference, together with the code used to obtain them.
Marie Skłodowska-Curie Fellow.
© ESO 2019
1. Introduction
The stellar initial mass function (IMF) is one of the fundamental properties of stellar populations. Within the Milky Way, the stellar IMF is observed to be a relatively constant function across a wide range of environments (see e.g. Bastian et al. 2010). For other galaxies, however, it is difficult to obtain direct (i.e. based on star counts) measurements of the IMF, especially outside the Local Group.
The question of whether the stellar IMF is a universal function or not is an important one: detecting a variation, or lack thereof, of the IMF with galaxy properties can give us insight into the physics of star formation. Moreover, the vast majority of the measurements of stellar masses of galaxies at cosmological distances used in the literature rely on the assumption of a particular form of the IMF. If the IMF is not universal, these measurements are biased. Not knowing the IMF limits our ability to match observations with theoretical predictions: for instance, varying the IMF will shift the stellar mass function and the stellar mass-size relation, two distributions that are commonly used to assess the accuracy of hydrodynamical cosmological simulations.
The past decade has seen a relatively large number of observational studies aimed at constraining the stellar IMF in massive early-type galaxies (ETGs). Many of these studies suggest that the IMF of these objects is different from that observed in the Milky Way, resulting in a higher stellar mass-to-light ratio at fixed age and metallicity. These include works based on the analysis of IMF-sensitive absorption lines in integrated spectra of massive galaxies (van Dokkum & Conroy 2010; Spiniello et al. 2012; Ferreras et al. 2013), on the combination of strong lensing and stellar dynamics (Auger et al. 2010a; Barnabè et al. 2013; Sonnenfeld et al. 2015), on dynamical modelling of nearby galaxies with integrated field unit spectroscopic data (Cappellari et al. 2012; Lyubenova et al. 2016; Li et al. 2017), and on gravitational microlensing of strongly lensed quasars (Schechter et al. 2014). There are, however, massive ETGs known for having an IMF similar to that of the Milky Way, in terms of mass-to-light ratio (Smith & Lucey 2013; Smith et al. 2015; Collier et al. 2018).
From the theoretical point of view, a number of models have been proposed to explain the observed shape of the IMF and its variation across the galaxy population (see Krumholz 2014, and references therein). However, as recently shown by Guszejnov et al. (2019), finding models that can simultaneously reproduce the near-universality of the IMF in the Milky Way and the bottom-heavy IMFs suggested by observations of massive ETGs is very challenging.
The picture is complicated by the possible presence of radial gradients in the IMF, detected in some spatially resolved studies of IMF-sensitive absorption features (though some other studies find contrasting results. See Martín-Navarro et al. 2015; La Barbera et al. 2016; van Dokkum et al. 2017; Sarzi et al. 2018; Parikh et al. 2018; Zieleniewski et al. 2017; Alton et al. 2017; Vaughan et al. 2018, for a complete picture), suggested by observations of mass-to-light ratio gradients from lensing and dynamics (Smith et al. 2017; Oldham & Auger 2018a,b; Sonnenfeld et al. 2018a; Collett et al. 2018), and predicted in cosmological simulations with a non-universal IMF (Barber et al. 2019). With gradients in the IMF, more care is required when comparing observations with models, since the interpretation of a given measurement will depend on the spatial scale over which it is carried out.
Strong gravitational lensing is one of the few available methods for constraining the stellar IMF in objects outside of the Local Group. Strong lensing can provide a very precise measurement of the total projected mass enclosed within the Einstein radius of a galaxy, the radius enclosing an average surface mass density equal to the lensing critical density, which typically probes scales around 5 − 10 kpc from the centre. This mass measurement can be converted into a mass-to-light ratio, which can then be compared to IMF-dependent predictions from stellar population synthesis modelling.
The presence of dark matter, however, complicates the interpretation of strong lensing measurements. Typically, the degeneracy between the dark matter mass enclosed within the Einstein radius and the stellar mass-to-light ratio (M*/L from now on) is broken by combining lensing with other probes, such as stellar dynamics (Treu et al. 2010), by statistically combining a large set of lenses (Oguri et al. 2014), or by combining both approaches (Sonnenfeld et al. 2015). In this work, the third paper of the Survey of Gravitationally-lensed Objects in Hyper Suprime-Cam (HSC) Imaging (Sonnenfeld et al. 2018b; Wong et al. 2018, SuGOHI), we use strong lensing measurements in combination with weak lensing information to constrain the IMF of a statistical sample of galaxies at z ∼ 0.6.
We focus on massive galaxies drawn from the constant mass (CMASS) subset of the Baryon Oscillation Spectroscopic Survey (BOSS; Schlegel et al. 2009; Dawson et al. 2013) in the Sloan Digital Sky Survey III (SDSS-III; Eisenstein et al. 2011). We use photometric data from the HSC (Miyazaki et al. 2018) Subaru Strategic Program (Aihara et al. 2018) to measure Einstein radii and stellar masses of 23 CMASS strong lenses. This sample includes lenses presented in Sonnenfeld et al. (2018b; hereafter Paper I) and Wong et al. (2018; hereafter Paper II), as well as lens systems from the literature that are covered by the HSC survey.
We then take advantage of the recent weak lensing study of Sonnenfeld et al. (2019; hereafter S19), who used HSC data to constrain the stellar-to-halo mass relation (SHMR) of CMASS galaxies, to put a prior on the halo mass distribution of our strong lens sample and thus break the degeneracy between the dark matter distribution and the stellar IMF. An important caveat is that our CMASS strong lenses, although drawn from the general population of CMASS galaxies, are not a representative sample of the latter, due to selection effects: galaxies with a larger lensing cross-section are more likely to be lenses, and lenses with different properties have different probabilities of being detected by a lensing survey. We explicitly take these effects into account as part of our model. This is one of the most important features of our method, which enables us to use information obtained from the CMASS sample as a whole as a prior on the strong lens sample.
For all CMASS galaxies, central stellar velocity dispersion measurements are available from BOSS spectroscopy. In principle, we could use these measurements as additional constraints on the gravitational potential of the lens. We choose not to for two reasons: firstly, BOSS velocity dispersion measurements of CMASS galaxies are very noisy; secondly, carrying out a joint lensing and stellar dynamics study with single aperture velocity dispersion measurements requires making a series of additional assumptions on the geometry and the orbital structure of each lens (typically spherical symmetry, isotropic orbits, and a spatially constant M*/L. See e.g. Auger et al. 2010a; Sonnenfeld et al. 2015). Some of these assumptions might bias the results (see Sonnenfeld et al. 2018a; Bernardi et al. 2018, for discussions on the effect of assuming a spatially constant M*/L on the stellar IMF inferred from lensing and dynamics). We decide instead to use purely lensing data to constrain our model. As a result, our observational constraints on individual lenses are rather limited, and the ability to statistically combine our measurements in a meaningful and accurate way plays a central role in our inference. To emphasise these features, we label our method statistical strong lensing.
The structure of this work is as follows. In Sect. 2 we describe the sample of lenses and the data used for this study. In Sect. 3 we perform lens modelling and a stellar population synthesis analysis to obtain measurements of the Einstein radius and estimates of the stellar mass of each lens. In Sect. 4 we introduce the model distribution used to fit the population of lenses. We first carry out our analysis with a simplified version of the model. Then, in Sect. 5, we repeat the analysis with the full model. We discuss our findings in Sect. 6 and summarise our results in Sect. 7. We assume a flat ΛCDM cosmology with ΩM = 0.3 and H0 = 70 km s−1 Mpc−1. Magnitudes are in AB units. All images are oriented with north up and east left.
2. Data
2.1. Lens sample
Our starting sample consists of strong lenses from the CMASS sample of BOSS galaxies for which HSC imaging data in grizy bands is available. As of the S17A internal data release of the HSC survey, there are 84 between definite and probable lenses (grade A and B, using the notation of Paper I) that satisfy this requirement. Seventy-two of these were recently discovered using HSC data (see Tanaka et al. 2016; Paper I and Paper II for details). Nine belong to the Strong Lensing Legacy Survey (SL2S; Ruff et al. 2011; Gavazzi et al. 2012; More et al. 2012; Sonnenfeld et al. 2013a), while three are part of the BOSS Emission-Line Lens Survey (BELLS; Brownstein et al. 2012). Hyper Suprime-Cam and SL2S lenses have been selected by means of searches for arc-like images of strongly lensed sources in photometric data, while the selection of the BELLS sample is based on a search for emission lines from strongly lensed objects in the BOSS spectra of luminous red galaxies.
In order to carry out our strong lensing analysis, we require systems for which the redshift of both the lens and the background source are known. For all CMASS lenses, the spectroscopic redshift of the lens galaxy is available from the BOSS catalogue. Of the 84 lenses from the starting sample, 16 have spectroscopic redshifts of the source from the literature. We measured source redshifts for an additional seven systems, thanks to a spectroscopic follow-up campaign on the Very Large Telescope (VLT), the details of which are given in Sect. 2.3.
Finally, for a more straightforward modelling and interpretation of the strong lensing data, we require lenses to consist of only one massive deflector, excluding systems with two or more galaxies of comparable mass acting as lenses. Although this requirement is already satisfied by all the lens systems in our sample for which we have source redshifts, it is important to take this condition into account when discussing selection effects (see Sect. 5). Our final sample then consists of 23 CMASS strong gravitational lenses with HSC imaging and spectroscopic redshifts of both the lens and the source. These lenses are listed in Table 1 with their coordinates, lens and source redshifts, lens stellar velocity dispersion as obtained from the SDSS data release 12 (DR12; Alam et al. 2015), and references.
Sample of strong lenses used for our study.
The typical velocity dispersion of our lenses is in the range 200 − 300 km s−1, with some outliers, including a galaxy with a nominal value of σBOSS = 709 ± 86 km s−1. These are most likely the result of systematic effects in the measurements of the stellar velocity dispersion, related to the low signal-to-noise ratio of BOSS spectra.
2.2. Hyper Suprime-Cam photometry
We use photometric data from the S17A internal release of the HSC survey to obtain stellar mass and Einstein radius measurements of the lens galaxies in our sample. Data from S17A has been processed with the HSC data reduction pipeline HSCPIPE version 5.4 (Bosch et al. 2018), a version of the Large Synoptic Survey Telescope pipeline (Ivezić et al. 2019; Axelrod et al. 2010; Jurić et al. 2017). The end products of HSCPIPE include sky-subtracted coadded images, variance maps, and models of the point spread function (PSF), which we use for our analysis. In particular, in each of the g, r, i, z, y bands, we obtain 101 × 101 pixel cutouts (16.4″×16.4″) centred on the lens, as well as samples of the PSF on a 37 × 37 grid, with the same pixel size as the data. Colour-composite images in g, r, i bands of the 23 lenses subject of our study are shown in the left column of Fig. 1.
 |
Fig. 1. Twenty-three CMASS galaxy strong lenses in our sample. First column: colour-composite HSC images in g, r, i bands. Second column: best-fit lens + source model. Third column: data with the best-fit model of the lens light subtracted. Fourth column: best-fit source model. Fifth column: residuals. |
2.3. Very Large Telescope spectroscopy
We observed nine CMASS lens candidates from the SuGOHI sample (Paper I) with the X-shooter spectrograph (Vernet et al. 2011) on the VLT (ESO programme 099.A-0220, PI Suyu), with the main goal of measuring the redshift of the lensed background source. Each target was observed in slit mode during either one or two observation blocks (OBs), depending on the brightness of the source. Each OB corresponds to roughly one hour of telescope time, and consists of 10 × 285 s exposures obtained in an ABBA nodding pattern, to optimise background subtraction in the near-infrared (NIR) arm. Exposure times in the ultraviolet (UVB) and visible (VIS) arms are slightly shorter due to the longer readout time. We used slit widths of 1.0″, 0.9″, and 0.9″ in the UVB, VIS, and NIR arms, respectively, and applied a 2 × 2 pixel binning to the UVB and VIS CCDs. We positioned the slit so that it covered both the centre of the lens galaxy and the brightest feature of the lensed source. Observations were executed with a seeing full width at half maximum FWHM < 0.9″ on target position.
We used 2D spectra for our analysis, as provided by the ESO Quality Control Group, obtained by processing the data with the X-shooter pipeline (Modigliani et al. 2010). We visually inspected the spectra of each system, looking for emission lines from the source. For seven of the nine observed lens candidates we see multiple emission lines, which enable us to measure the source redshift. No emission lines are visible in the spectrum of HSC J140705−011256 and HSC J142053+005620, therefore we do not use these systems for our lensing study.
We summarise the spectroscopic observations in Table 2, where, in the last column, we list the emission lines from the lensed source that are detected in the spectrum of each system. Small cutouts of the 2D spectrum of each lens around the two emission lines with the highest signal-to-noise ratio are shown in Fig. 2, together with a colour-composite image of the lens and a box indicating the position of the slit. Only lenses with detected emission lines are shown. Three of the lenses in this sample, HSC J142720+001916, HSC J222801+012805, and HSC J223733+005015, were classified as grade B lens candidates in Paper I, meaning that their lens nature could not be determined with certainty with the available data, which consisted only of HSC photometry. X-shooter observations confirmed that the blue arcs are indeed at a higher redshift compared to the main galaxy, and therefore lensed by it. This additional piece of information, together with the fact that we are able to reproduce the observed image configuration with a simple model, as we will show in Sect. 3.1, allows us to upgrade these candidates to grade A lenses.
Spectroscopic observations of nine CMASS lens candidates from the SuGOHI sample.
 |
Fig. 2. X-shooter observations of seven CMASS lenses with detected emission lines from the lensed source. Left panel: HSC gri colour-composite image of the lens. The green box indicates the position of the slit used during the spectroscopic observation. Middle and right panels: small cutouts of the 2D spectrum around the two source emission lines with the highest signal-to-noise ratio. |
3. Lens models and stellar mass measurements
We wish to measure the Einstein radius and the stellar mass, or, more specifically, the stellar mass density profile, of the 23 lenses in our sample. Our strategy consists of (1) fitting a parameterised model for the lens and source galaxy system to grizy HSC images, (2) fitting a stellar population synthesis model to the lens galaxy fluxes measured in step 1. These two steps are described separately in the next two subsections.
3.1. Lens modelling
Our model consists of two light components, describing the lens and source galaxy respectively, and one mass component associated with the lens. The surface brightness distribution of the lens is described with a Sérsic profile (Sersic 1968) with elliptical isophotes, while the source is modelled as an exponential profile (i.e. a Sérsic profile with index n = 1), also elliptical. For each component, we assume the structural parameters (the centroid, half-light radius, axis ratio, position angle, and Sérsic index) to have the same values in all bands, allowing only the total flux to vary with wavelength. This corresponds to a model with spatially constant colours.
We model the lens mass with a singular isothermal ellipsoid (SIE; Kormann et al. 1994). Although the true density profiles of the lenses in our sample may in general be different from isothermal, the measurement of the Einstein radius is robust to the particular choice of the lens model to a few percent accuracy (Bolton et al. 2008). We impose the centroid of the mass to be coincident with that of the lens light component, but allow the axis ratio and position angle to be different.
For each system, we search for the set of values of the model parameters that minimises the χ2 between the seeing-convolved model surface brightness distribution and the observed data in each band. For the fit, we use a circular region extending out to a radius where the lens surface brightness falls below the level of the sky fluctuations (typically between 3″ and 5″). Objects not associated with either the lens or the source are masked out or explicitly modelled as an extra Sérsic component.
We explore the parameter space by running a Markov chain Monte Carlo (MCMC), using the software EMCEE (Foreman-Mackey et al. 2013). At each step of the chain, we draw a set of values of the structural parameters of the lens and source light, of the lens mass (Einstein radius, axis ratio, and position angle), as well as the four colours of the lens and the source, defined with respect to the i-band. We then run an optimiser to find the lens and source i-band magnitudes that minimise the χ2. We assume a flat prior on all model parameters.
In Fig. 1, we show, for each lens, colour-composite gri images of the observed data, the best-fit model, the data with the best-fit model of the lens light subtracted, the best-fit model of the source galaxy only, and the residual image. In Table 3 we report the best-fit values of the parameters describing the surface brightness distribution of the lens galaxy, while the parameters describing the lens mass and the source surface brightness are listed in Table 4. We define the Einstein radius as the circularised radius of the elliptical isodensity curve that encloses an average surface mass density equal to the lensing critical density.
Best-fit values of the lens light Sérsic profile model parameters.
The median Sérsic index of the lens galaxies is 5.6, with four galaxies with n > 8. While these are relatively large values of the Sérsic index, compared to the canonical picture of quiescent galaxies being described by n = 4 models, this distribution is very similar to that measured by S19 on CMASS galaxies. Although errors on the Sérsic index propagate into measurements of the total flux and the half-light radius of a galaxy, we point out that, for the purposes of constraining the stellar IMF with strong lensing, it is sufficient to obtain an accurate description of the stellar profile in the region enclosed by the Einstein radius. This is very well constrained by HSC photometry and robust to changes in the surface brightness profile. The estimate of the total stellar mass of a galaxy only matters for the purpose of assigning a prior on the dark matter halo mass, using the SHMR measured by S19. Since both the data and the analysis method we employ here are the same as those used by S19, this procedure is insensitive to possible systematics in the surface brightness profile fitting process.
The Einstein radius is, in most cases, well constrained by HSC data, owing to the presence of extended arcs and/or counter-images detected with high signal-to-noise ratio. The only exception is HSC J094427−014742, a lens from the BELLS sample: for this system, only one image of the source is visible, and is not sufficient to obtain a robust lens model. We then fix the lens model parameters to the values measured by Brownstein et al. (2012) with Hubble Space Telescope (HST) data, in which the counter-image is visible.
One of the lenses in the sample is the double source plane lens HSC J142449−005321, the “Eye of Horus” lens (Tanaka et al. 2016). For consistency with the rest of the sample, we only model the lensing effect on the source closer to us, forming the inner ring, while masking out the light from the outer ring. The value of the Einstein radius reported in Table 4 then refers to a source redshift of zs = 1.302.
Best-fit values of the lens mass and source surface brightness model parameters.
The values of the typical statistical uncertainty on each parameter, defined as the median across the sample of the 68% enclosed probability interval, as obtained from the MCMC, are given at the bottom of Tables 3 and 4. These are typically very small, thanks to the depth of HSC imaging data. In practice, however, systematic uncertainties related to the choice of model are larger than statistical ones. Bolton et al. (2008) have estimated systematic uncertainties on the Einstein radius to be on the order of a few percent, when high resolution HST imaging data is used to constrain θEin. In our case, we are using lower resolution ground-based data, which could lead to larger systematic errors on the lens model. In addition to HSC J094427−014742, models obtained using HST data are available from the literature for three more lenses in our sample: SL2S lenses HSC J021411−040502 and HSC J021737−051329, and BELLS lens HSC J230335+003703. We can use these lenses to get a rough estimate of the robustness of our HSC-based measurements of θEin. Sonnenfeld et al. (2013a) measured θEin = 1.41″ for HSC J021411−040502 and θEin = 1.27″ for HSC J021737−051329, while Brownstein et al. (2012) measured θEin = 1.01″ for HSC J230335+003703. Our estimates are respectively 11% smaller, 2% smaller, and 2% larger than their values. Given the outcome of this comparison, we assume a 10% systematic uncertainty on θEin for all the lenses in our sample.
3.2. Stellar population synthesis
We measure the stellar mass of the lens galaxies by fitting composite stellar population (CSP) models to the observed g, r, i, z, y magnitudes, following a Bayesian procedure similar to that used by Auger et al. (2009). We use the stellar population synthesis code BC03 (Bruzual & Charlot 2003) to generate CSP models with an exponentially decaying star formation history and a Chabrier IMF (Chabrier 2003). In particular, we obtain model spectra over a grid of values of the following parameters: age (i.e. time since the first burst of star formation), star formation decay time, metallicity, and dust attenuation. Then, for each lens galaxy, we calculate the predicted flux in each HSC filter at each point of the grid.
We sample the parameter space defined by the stellar mass and the other parameters of the CSP model by running an MCMC. We assume flat priors on age, star formation decay time, on the logarithm of the dust attenuation parameter, and on the logarithm of the stellar mass, while we assume a Gaussian prior on the logarithm of the metallicity at fixed stellar mass, following the observational study by Gallazzi et al. (2005). We obtain the model magnitudes at any point within the grid by interpolation. We correct the observed magnitudes for galactic extinction using the dust reddening map of Schlafly & Finkbeiner (2011), as provided by the NASA Infrared Science Archive.
Typical uncertainties on the observed fluxes are ∼0.02 magnitudes. Our CSP models are unable to fit such precise data down to the noise level, despite having the same number of degrees of freedom (five) as the number of data points, for each galaxy. This is shown in Fig. 3, where we plot the difference between the observed and predicted magnitudes for the CSP model that maximises the likelihood. As can be seen, the deviations are often larger than the statistical uncertainty on the observed magnitudes, especially for the redder bands. In order to obtain a reliable estimate of the uncertainty on the stellar mass, following S19 we add in quadrature a 0.05 mag uncertainty to the data, which is the typical standard deviation between the data and the magnitudes predicted by the best-fit CSP model. This procedure allows us to take into account, to some extent, systematic errors associated with the model.
 |
Fig. 3. Difference between magnitudes predicted by the CSP model that maximises the likelihood and the observed magnitudes, as a function of the latter. Different colours correspond to different HSC filters. The typical observational uncertainty on the observed magnitudes, from Sérsic profile fitting, is 0.02. |
The inferred values of the stellar mass, with their 1σ uncertainty, are listed in Table 5. Throughout this paper, we indicate the stellar mass obtained from stellar population synthesis modelling as 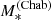 , to highlight the fact that this measurement relies on the assumption of a Chabrier IMF. Also in Table 5, we list the value of the Einstein radius in physical units of each lens, REin, the corresponding enclosed total projected mass, MEin, and the stellar mass enclosed within REin, obtained assuming a constant M*/L throughout the galaxy.
, to highlight the fact that this measurement relies on the assumption of a Chabrier IMF. Also in Table 5, we list the value of the Einstein radius in physical units of each lens, REin, the corresponding enclosed total projected mass, MEin, and the stellar mass enclosed within REin, obtained assuming a constant M*/L throughout the galaxy.
Mass measurements on the strong lenses in our sample.
Finally, in Fig. 4, we plot the derived fraction of the mass enclosed within the Einstein radius that is accounted for by stellar mass, as derived from stellar population synthesis modelling. The lenses with the largest Einstein radii have a comparatively smaller stellar mass fraction, meaning that dark matter dominates the mass within the Einstein radius for these systems. In particular, HSC J142449−005321 is the lens with both the largest Einstein radius and the smallest stellar mass fraction. As first pointed out by Tanaka et al. (2016), this lens is identified as the most probable brightest galaxy of a rich (∼50 members) cluster, according to the HSC cluster catalogue of Oguri et al. (2018). One of the lenses, HSC J023817−054555, appears to have a significantly larger value of the stellar mass fraction, compared to the rest of the sample. This lens has simultaneously one of the smallest half-light radii and Einstein radii of the whole sample: Re = 0.71″ and θEin = 0.93″. The large value of f* is then due to the fact that strong lensing is probing the inner regions of a compact galaxy, which we expect to be dominated by stars.
 |
Fig. 4. Ratio between the stellar mass enclosed within the Einstein radius, as inferred from stellar population synthesis modelling assuming a Chabrier IMF, and the total mass within the Einstein radius, as a function of the Einstein radius. The horizontal dashed line corresponds to the limit of 100% mass fraction within the Einstein radius. Values above this limit are non-physical. |
4. Population analysis
In this section, we carry out a Bayesian hierarchical inference of the distribution of the stellar IMF, as well as other galaxy properties entering the problem, of CMASS galaxies, given the strong lensing and stellar population synthesis measurements presented in the previous section.
4.1. Individual object parameters
Let us introduce the IMF mismatch parameter, αIMF, defined as the ratio between the true stellar mass of a galaxy and the value of the stellar mass inferred assuming a Chabrier IMF and having an otherwise perfect knowledge of the remaining stellar population parameters:
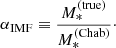 (1)
(1)
We wish to infer the distribution of αIMF of CMASS galaxies, given the measurements of REin and 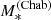 on our 23 strong lenses.
on our 23 strong lenses.
In order for us to evaluate the likelihood of these measurements, we need to propose a model for the mass distribution of the lenses in our sample, with αIMF being one of the model parameters. We describe each lens as the sum of a stellar and a dark matter mass component. We assume that the stellar surface mass density follows a Sérsic profile, with half-light radius Re and Sérsic index n fixed to the values inferred from the fit of Sect. 3 and total mass 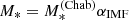 . We are implicitly assuming that the stellar population parameters, including the stellar IMF, are constant throughout a given galaxy. We will discuss the implications of this assumption for our inference, in light of existing evidence in favour of gradients in the stellar IMF, in Sect. 6.1. We then assume that the dark matter density follows a Navarro Frenk and White profile (NFW; Navarro et al. 1997),
. We are implicitly assuming that the stellar population parameters, including the stellar IMF, are constant throughout a given galaxy. We will discuss the implications of this assumption for our inference, in light of existing evidence in favour of gradients in the stellar IMF, in Sect. 6.1. We then assume that the dark matter density follows a Navarro Frenk and White profile (NFW; Navarro et al. 1997),
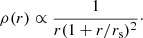 (2)
(2)
We define the halo mass as the mass enclosed within a sphere with average density equal to 200 times the critical density of the Universe. We then describe the profile in terms of the concentration parameter, defined as the ratio between the radius of the shell enclosing a mass equal to Mh, r200, and the scale radius rs:
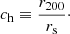 (3)
(3)
For a gravitational lens, the value of the Einstein radius depends not only on the mass distribution of the lens, but also on the geometry of the system, that is, the redshift of the lens and the source, zd and zs. We can then fully describe a strong lens system with the set of parameters
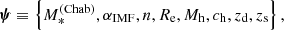 (4)
(4)
to which we will often refer collectively as “individual object parameters” (as opposed to parameters describing the whole population) and which we summarise with the symbol ψ.
It is not possible to constrain the exact values of ψ for each lens, given our data: the Einstein radius determines only the total enclosed mass, so that the same value of θEin can be reproduced with different relative amounts of stellar and dark matter. Our goal, however, is to infer how the individual object parameters are distributed across the population of galaxies, with particular attention paid to the IMF mismatch parameter αIMF. For this purpose, we introduce a population distribution described by a set of hyper-parameters η, which can be interpreted as a prior on the individual lens parameters:
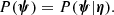
Our goal is to infer the posterior probability distribution of the hyper-parameters given the data, P(η|d).
4.2. Population distribution
Our strong lenses are drawn from the CMASS sample of galaxies. We then describe the population distribution of the individual object parameters of the lenses as the product between the distribution of the whole CMASS sample, PCMASS(ψ|η), and a selection function term ℱsel(ψ|η), which takes into account the fact that some objects (e.g. more massive galaxies) are more likely to be strong lenses, depending on the value of ψ:
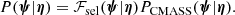 (5)
(5)
In this subsection, we focus on the term PCMASS, while we discuss the selection function term ℱsel in Sect. 4.3. Strictly speaking, PCMASS is not a probability distribution: it is not normalised to unity, only the product ℱselPCMASS is. Nonetheless, it can be considered as such when studied on its own.
We assume that PCMASS factorises as
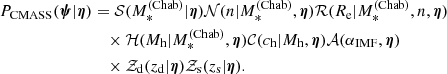 (6)
(6)
The product 𝒮𝒩ℛ describes the distribution of stellar mass, Sérsic index, and half-light radius of CMASS galaxies. Following S19, we assume 𝒮 to be a skew-Gaussian distribution in log 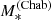 , 𝒩 a Gaussian distribution in log n with mean that scales linearly with log
, 𝒩 a Gaussian distribution in log n with mean that scales linearly with log 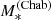 , and ℛ a Gaussian distribution in log Re with mean that scales linearly with log
, and ℛ a Gaussian distribution in log Re with mean that scales linearly with log 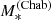 and log n. We refer to Sect. 3.2 of S19 for a detailed description of this part of the model. A total of ten hyper-parameters describes these three terms. These hyper-parameters have been measured with a high precision by S19, owing to their large sample size of ∼10 000 CMASS galaxies. In order to reduce the dimensionality of the problem and simplify calculations, we fix them to the values reported in Table 2 of S19.
and log n. We refer to Sect. 3.2 of S19 for a detailed description of this part of the model. A total of ten hyper-parameters describes these three terms. These hyper-parameters have been measured with a high precision by S19, owing to their large sample size of ∼10 000 CMASS galaxies. In order to reduce the dimensionality of the problem and simplify calculations, we fix them to the values reported in Table 2 of S19.
The term ℋ describes the distribution in halo mass of CMASS galaxies. Again, following S19, we assume this to be a log-Gaussian distribution,
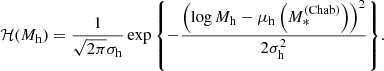 (7)
(7)
In their analysis, S19 let the mean of this Gaussian scale with stellar mass and half-light radius. However, they did not find any evidence for a dependence of halo mass on Re. In light of their results, we assume the following form for the mean of log Mh:
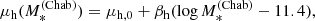 (8)
(8)
where βh is the slope of the power-law relation between halo and stellar mass, and μh, 0 is the average value of log Mh at the pivot stellar mass log 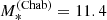 . The term 𝒞 describes the halo mass–concentration relation, which we describe as a Gaussian in log ch,
. The term 𝒞 describes the halo mass–concentration relation, which we describe as a Gaussian in log ch,
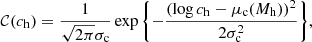 (9)
(9)
with mean
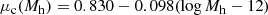 (10)
(10)
and dispersion σc = 0.1. The values of the coefficients of the above equation are the same used by S19 and are taken from the Macciò et al. (2008) study. We are implicitly assuming that the mass–concentration relation is independent of redshift. This is a reasonable approximation, because the predicted change in concentration over the narrow redshift range spanned by our lenses is smaller than the intrinsic scatter around the mean relation (Macciò et al. 2008).
The distribution in the IMF mismatch parameter is described by the term 𝒜, which we model as a Gaussian in logαIMF,
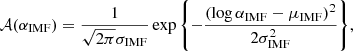 (11)
(11)
with mean μIMF and dispersion σIMF. These are the main parameters of interest in our study.
The term 𝒵d is the redshift distribution of CMASS galaxies, which we approximate as a Gaussian:
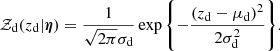 (12)
(12)
Fitting this distribution to the full set of CMASS galaxies, we infer μd = 0.558 and σd = 0.085 with very small errors. We then keep these hyper-parameters fixed, as done for the hyper-parameters describing the distribution in stellar mass, Sérsic index, and half-light radius.
Finally, 𝒵s describes the distribution of source redshifts, which must be interpreted as the redshift distribution of sources that, if lensed by CMASS galaxies, are sufficiently bright to be detected in a strong lensing survey like ours. It is, therefore, a term related to the strong lensing selection function. As such, we could in principle express it as the product of two terms: one describing the redshift distribution of all possible source galaxies, multiplied by a sensitivity function, to be included in the term ℱsel, which cuts off objects that are too faint to be detected. In practice, we choose to only model the product of these two terms, for the sake of convenience. By doing so, we are assuming that the selection in source redshift due to the sensitivity limit of our survey can be separated in a term that is independent of the lens model parameters (which is implicitly included in 𝒵s) and a term that depends on the properties of the lens galaxy. This latter term is not included in the simplest version of our model, but will be introduced in Sect. 5. The term 𝒵s, too, is modelled as a Gaussian distribution in zs:
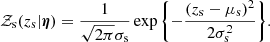 (13)
(13)
In summary, we model the distribution of individual object parameters of CMASS galaxies as the product of eight terms, listed in Eq. (6). The values of some of these hyper-parameters, those that have been measured with high precision, are kept fixed for the sake of reducing the dimensionality of the problem. The list of free hyper-parameters then reduces to the set
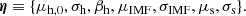 (14)
(14)
We refer to this as the “base model”.
4.3. Strong lensing selection
The 23 galaxies in our sample are not randomly selected from the general distribution of CMASS galaxies: they are strong lenses. The probability of a galaxy being a strong lens increases with increasing mass and, at fixed mass, with increasing concentration. The term ℱsel then, which re-weights the distribution of CMASS galaxies by the probability of a galaxy-source pair to be included in a strong lens survey, must be proportional to σSL:
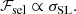 (15)
(15)
The strong lensing cross-section of a lens-source pair is proportional to the area of the source plane that gets mapped into multiple images that are detectable by a strong lens survey.
To calculate σSL in the context of our model we make a series of simplifying assumptions. We first assume circular symmetry. Secondly, following Sonnenfeld et al. (2018a), we define σSL as the angular size of the region of the source plane that gets mapped into sets of at least two images with magnification larger than a minimum value |μmin| = 0.5. We verified that changing the value of μmin does not change our results significantly. Finally, we ignore any additional selection effect due to the lens-finding efficiency of the strong lens surveys on which our sample is based. We will relax this assumption in Sect. 5.
4.4. Inferring the hyper-parameters
We wish to infer the posterior probability distribution of the hyper-parameters η given the data. Using Bayes’ theorem, this is
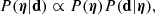 (16)
(16)
where P(η) is the prior probability distribution of the hyper-parameters, to be assigned, and P(d|η) is the likelihood of observing the data given the hyper-parameters. Since the measurements on individual galaxies are all independent from each other, the latter can be expanded as
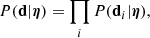 (17)
(17)
where 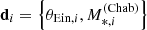 is the measurement of the Einstein radius and stellar mass of the ith lens, inclusive of their uncertainties. With ψi being the set of individual parameters of the ith lens, listed in Eq. (4), each term of the product in the right-hand side of the above equation can then be written as
is the measurement of the Einstein radius and stellar mass of the ith lens, inclusive of their uncertainties. With ψi being the set of individual parameters of the ith lens, listed in Eq. (4), each term of the product in the right-hand side of the above equation can then be written as
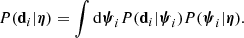 (18)
(18)
In other words, the likelihood of the data given the hyper-parameters is obtained by marginalising over all possible values of the individual parameters of the ith lens, with a weight P(ψi|η) given by the hyper-parameters, which effectively acts as a prior on ψi. This last term is the product of Eq. (5) between the distribution of individual object parameters of CMASS galaxies and the strong lensing selection term, which, as discussed in the previous subsection, is proportional to the strong lensing cross-section:
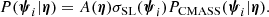 (19)
(19)
The factor A(η) is a multiplicative constant ensuring that P(ψ|η) is normalised to unity.
We sample the posterior probability distribution with an MCMC, using EMCEE. At each step of the chain, we calculate the multi-dimensional integral of Eq. (18) with importance sampling and Monte Carlo integration. The full procedure is described in Appendix A.
4.5. The prior
We assume flat priors on μIMF and σIMF, describing the distribution in the IMF mismatch parameter. The remaining free hyper-parameters are μh, 0, σh, and βh, describing the distribution in halo mass. For these, we set a prior based on the weak lensing study of S19.
The S19 measurement was obtained assuming a Chabrier IMF for all CMASS galaxies, while here we let the IMF normalisation to be a free parameter. We expect the inference of the halo mass distribution from weak lensing to be mostly insensitive to the particular choice of the IMF, since this only affects the mass in the very inner regions of each lens, while the weak lensing data used for their analysis extends out to 300 kpc. To verify this conjecture, we repeat the S19 analysis assuming different, but fixed, values for αIMF of CMASS galaxies. A 0.1 dex increase in αIMF results in a 0.03 decrease in the maximum-likelihood value of μh, 0, while the inference on σh and βh is unchanged.
Given the small effect of a varying IMF on the weak lensing-based inference on the halo mass distribution, as a prior on {μh, 0, σh, βh} we use the posterior probability distribution inferred from weak lensing by assuming an IMF normalisation logαIMF = 0.1. We then iteratively repeat the weak lensing measurement by setting αIMF to the maximum-likelihood value of μIMF obtained in our inference, until the result is stable (in practice, the procedure converges at the first iteration). For consistency with the model used in this work, we also assume that the average halo mass depends only on stellar mass, as specified by Eq. (8), and not on the half-light radius as was assumed by S19. This is justified by the fact the S19 did not find any evidence for an additional dependence of halo mass on size at fixed stellar mass. Under these assumptions, the new inference on the three hyper-parameters describing the halo mass distribution is μh, 0 = 12.75 ± 0.03, σh = 0.33 ± 0.03, and βh = 1.82 ± 0.11. We approximate the posterior probability distribution of this weak lensing-based inference as a tri-variate Gaussian, with covariance matrix set equal to the covariance of the samples of the MCMC in the three parameters, and use it as a prior for our strong lensing inference.
4.6. Results
In Fig. 5, we show the posterior probability distribution on the model hyper-parameters. The median and 68% enclosed marginal probabilities of each hyper-parameter are listed in the first column of Table 6.
 |
Fig. 5. Posterior probability distribution of the model hyper-parameters. Contour levels correspond to the 68% and 95% enclosed probability regions. The two vertical dashed lines on the first column, parameter μIMF, indicate an average IMF normalisation corresponding to a Chabrier and a Salpeter IMF, respectively. |
Inferred values of the hyper-parameters, with 68% credible intervals.
Our data, combined with the weak lensing prior, result in an inferred value of the average logαIMF of μIMF = 0.14 ± 0.05. This value is in between that of a Chabrier IMF (corresponding to logαIMF = 0 by definition) and a Salpeter IMF (corresponding to logαIMF ≈ 0.25, for quiescent galaxies like the ones in our sample).
4.7. Goodness-of-fit evaluation
In Bayesian hierarchical inference studies, goodness-of-fit is evaluated by means of posterior predictive tests: we use the posterior probability distribution of the model to generate mock data, then compare this generated data with observations on the basis of test quantities summarising the mismatch between the datasets. In our case, the key observable is the sample of Einstein radii, {θEin, i}. We then generate sets of 23 lens-source pairs, calculate their Einstein radii, and compare them to the distribution of the observed values.
We consider four test quantities T1, …, T4: T1 and T2 are the mean and standard deviation of the Einstein radius distribution, while T3 and T4 are the minimum and maximum value of the Einstein radius in the sample. The observed values of these test quantities are 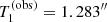 ,
, 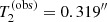 ,
, 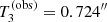 , and
, and 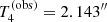 . For each test quantity Tn, we wish to determine the probability of the model predicting a more extreme value than the observed one:
. For each test quantity Tn, we wish to determine the probability of the model predicting a more extreme value than the observed one:
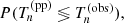 (20)
(20)
where 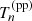 stands for the posterior predicted test quantity, and the probability must be calculated by averaging over the posterior probability distribution.
stands for the posterior predicted test quantity, and the probability must be calculated by averaging over the posterior probability distribution.
We proceed as follows: we randomly draw 1000 points from the MCMC sample of the posterior probability distribution, then, for each point, generate a large sample of galaxy-source pairs from the model distribution PCMASS. We then assign a probability proportional to ℱsel to each galaxy-source pair in this sample and draw 23 lenses. For each set of mock lenses, we calculate the posterior predictive test quantities.
In Fig. 6, we plot the posterior predictive distribution of the four test quantities. Under the assumption that our model is an accurate description of reality, the value of the observed average Einstein radius is typical, with the posterior predicted values exceeding it 46.1% of the time. The predicted values of the standard deviation in the Einstein radius, though, are mostly larger than the observed value: if the model is correct, the probability of observing a value of the standard deviation equal to 0.319″ or smaller is only 4.8%. This low probability casts a doubt on the ability of the model to accurately describe this aspect of the data, although there is a non-negligible possibility that our sample of lenses has an unusually small value of the standard deviation in θEin by pure chance.
 |
Fig. 6. Posterior predictive tests. Four panels: predicted distributions in the average, standard deviation, minimum, and maximum θEin (in arcseconds) in samples of 23 strong lens systems drawn from the posterior. The vertical line in each panel corresponds to the observed value of each test quantity. Posterior predicted distributions obtained from the base model are shown as filled histograms in blue. The black solid line and red dotted line histograms correspond to the “Arctan” and “Gaussian” lens detection efficiency models introduced in Sect. 5. The percentage to the left (right) side of each panel indicates the fraction of times the predicted value is smaller (larger) than the observed one, with the top value corresponding to the base model and the middle and bottom values corresponding to the “Arctan” and “Gaussian” models, respectively. |
The posterior prediction on the minimum value of the Einstein radius of the sample (T3, bottom left panel of Fig. 6) shows that the model typically predicts smaller values than 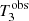 : the observed value of 0.724″ is exceeded in only 10.0% of the posterior draws. Finally, the test on the maximum value of the Einstein radius, T4, is less conclusive, with the model predicting smaller values than the observed one 16.9% of the time.
: the observed value of 0.724″ is exceeded in only 10.0% of the posterior draws. Finally, the test on the maximum value of the Einstein radius, T4, is less conclusive, with the model predicting smaller values than the observed one 16.9% of the time.
5. Inferring the lens detection efficiency
The posterior predictive tests carried out in Sect. 4.7 suggest that the model, when used to generate mock observations of samples of 23 strong lenses, tends to predict a broader distribution in θEin than observed, with more than 95% significance. Additionally, the minimum value of θEin of the observed sample, 0.724″, is relatively large when compared to the posterior predicted distribution of the same quantity.
We wish to add complexity to our model in order to alleviate these mild tensions between posterior predicted quantities and observations. One important aspect of the problem that has not yet been taken into account is observational selection effects related to differences in the detection efficiency of lenses with different properties. For example, strong lenses with a small Einstein radius are more difficult to identify in ground-based imaging data, where most of the systems used for this study have been discovered, due to the effects of atmospheric blurring. The observed narrow distribution in θEin and the relatively large value of the minimum Einstein radius of the sample could be the result of this observational effect. We then modify the strong lensing selection term, ℱsel, by multiplying the lensing cross-section by a detection efficiency term,
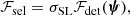 (21)
(21)
which, in general, can be a function of all the model parameters. Strictly speaking, it is not appropriate to define a single detection efficiency for the whole sample of lenses. This is because not all lenses have been selected homogeneously from a single survey. Some of them have been discovered in data from the Canada-France-Hawaii Telescope (Gavazzi et al. 2014), some from the HSC survey, while for some others, those belonging to the BELLS survey, HST data have been used for their confirmation. Moreover, the properties of the sample depend also on the spectroscopic data used to measure the redshift of the background source. For a good fraction of our lenses, the source redshift is obtained directly from the BOSS spectrum: since the BOSS fibre has a 1″ radius, lenses with a much larger value of θEin are less likely to have their source detected (Arneson et al. 2012). Finally, we have required in Sect. 2.1 that all the lenses consist of a single galaxy as the deflector. This condition tends to exclude lenses with a large Einstein radius, because these are more likely to have close multiplets of galaxies acting as a lens.
It is prohibitively difficult to write down an analytical form for ℱdet(ψ) that takes into account all of these different selection effects. Instead, we make the simplifying assumption that the detection efficiency of the whole lens sample can be described by an analytical function of the Einstein radius:
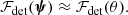 (22)
(22)
An implicit assumption in this approach is that, at fixed θ, any additional dependence of the detection efficiency on the source redshift zs is fully captured by the term 𝒵s in PCMASS. We explore two different choices for the form of ℱdet, as described below:
![Mathematical equation: $$ \begin{aligned} \mathcal{F} _{\mathrm{det}}(\theta ) \propto \left\{ \begin{array}{ll} \dfrac{1}{\pi } \arctan {\left[m(\theta _{\mathrm{Ein}} - \theta _0)\right]} + \dfrac{1}{2}&{\text{``Arctan''}}\,{\mathrm{model}} \\ \exp {\left\{ -\dfrac{(\theta _{\mathrm{Ein}} - \mu _\theta )^2}{2\sigma _\theta ^2}\right\} }&{\text{``Gaussian''}}\,{\mathrm{model}} \end{array}\right.\!\!\!. \end{aligned} $$](/articles/aa/full_html/2019/10/aa35743-19/aa35743-19-eq42.gif) (23)
(23)
The “Arctan” detection efficiency model goes to zero for values of θEin smaller than θ0 and reaches a constant for large θEin. The steepness of the transition between the two regimes depends on the parameter m. The “Gaussian” model goes to zero both for small and large values of the Einstein radius. The rationale for the low-θEin cutoff present in both models is to capture the loss of lenses due to the resolution limit of HSC data. The “Gaussian” model has an additional cutoff at large values of θEin, which is meant to describe a loss due to our selection of isolated galaxies as lenses, and the decrease in the success rate of source redshift measurements from BOSS spectroscopy at large θEin. Each of these models is described by two parameters, which we infer from the data. We assume a flat prior on θ0, log m, μθ, and σθ. With the addition of the multiplicative term ℱdet, the probability distribution ℱselPCMASS = σSLℱdetPCMASS now describes the distribution of CMASS strong lenses that can be detected in a survey like ours. From here on, we will refer to this distribution as that of SuGOHI lenses.
In Fig. 7 we show the new inference on the pair of hyper-parameters describing the mean and intrinsic scatter in logαIMF, obtained with the two different prescriptions for the lens detection efficiency. For comparison, we also plot the inference obtained in the previous section, with no detection efficiency correction (filled contours). The median values and 68% credible regions of the full set of hyper-parameters, including those describing the detection efficiency, are reported in the second and third column of Table 6.
 |
Fig. 7. Posterior probability distribution of the hyper-parameters describing the IMF normalisation of the CMASS sample, marginalised over the other hyper-parameters. Filled contours: base model. Black solid lines: model with “Arctan” detection efficiency function. Red dotted lines: model with “Gaussian” detection efficiency function. Contour levels mark the 68% and 95% enclosed probability regions. The vertical dashed lines correspond to an average IMF normalisation equal to that of a Chabrier and Salpeter IMF, respectively. |
The main effects of adding a lens detection efficiency correction ℱdet are to broaden and to shift towards smaller values the distribution of allowed values of the average IMF normalisation parameter μIMF. Remarkably, the inferences obtained with the two different forms for ℱdet are very similar to each other. This is reassuring as it indicates that the result is not particularly sensitive to the specific choice of functional form for ℱdet. For the “Arctan” model, the marginal posterior distribution in μIMF has a median and 68% confidence interval of −0.04 ± 0.11, while the 95th percentile of the distribution is 0.13. Numbers relative to the “Gaussian” model are very similar. These result are inconsistent with an average IMF normalisation equal to that of a Salpeter IMF.
We now assess the goodness-of-fit of these two new models, with the same method used in Sect. 4.7. The posterior predictive distributions of the four test quantities T1, …, T4 obtained from the “Arctan” and “Gaussian” model are plotted in Fig. 6. For both of these models, in none of the test quantities the observed value is more extreme than the lowest or highest 10% tail of the posterior predicted distribution. This indicates that (1) both models are able to reproduce all four aspects of the observed distribution in θEin and (2) the data do not give us strong reasons to favour one model of the lens detection efficiency over the other.
6. Discussion
The statistical combination of strong lensing measurements on a sample of 23 CMASS galaxies and weak lensing constraints on the distribution of halo mass as a function of stellar mass of the parent sample, allows us to infer the average IMF mismatch parameter of CMASS galaxies. We find a value consistent with that of a Chabrier IMF, while a normalisation as heavy as that of a Salpeter IMF is in clear tension with our inference. In the following subsections we discuss how sensitive these results are to the various assumptions made in our analysis, how they compare with similar studies from the literature, and implications for the relative distribution of strong lenses and non-lenses, given our model.
6.1. Sensitivity to model assumptions
One of the key assumptions in our model is that of an NFW density profile for the dark matter halos in the sample, which allows us to use weak lensing information, obtained on scales larger than ∼50 kpc, to predict the projected dark matter mass enclosed within the Einstein radius of the lenses in our sample and thus separate the contribution of luminous and dark matter to the observed lensing masses. If we were to lift this assumption, the inferred IMF mismatch parameter would be highly degenerate with the inner dark matter distribution. In particular, for the same total mass, a halo with an overall steeper density profile, such as an adiabatically contracted one, corresponds to a higher central density of dark matter, implying that a lower stellar mass (and therefore a lower IMF normalisation) would be required to reproduce the observed value of the Einstein radius of a lens (see also Auger et al. 2010a). This would increase the tension between our measurement and a scenario with an IMF normalisation equal to that of a Salpeter IMF. Vice versa, this tension would decrease by allowing for the inner slope of the dark matter halo to be shallower than that of an NFW profile.
There is some observational evidence suggesting that the inner dark matter density profile of massive galaxies is generally steeper than the NFW model predicted by dark-matter-only simulations (Sonnenfeld et al. 2012; Oldham & Auger 2018b). A similar behaviour is seen in the latest cosmological hydrodynamical simulations (Xu et al. 2017; Peirani et al. 2017). There are, however, also measurements indicating inner dark matter profiles flatter than NFW for some massive ETGs (Barnabè et al. 2013; Oldham & Auger 2018b). The issue of whether dark matter halos of massive ETGs are more or less concentrated than standard dark-matter-only NFW halos of the same mass is therefore still subject to debate.
Our results depend also, in principle, on the assumed functional form of the distribution of structural parameters across the population of CMASS galaxies, Eq. (6). In particular, the dark matter halo mass distribution term, ℋ(Mh), plays an important role in our analysis, because the dark matter mass is not directly constrained by the strong lensing data and we rely on our prior knowledge of ℋ, that is, the SHMR of CMASS galaxies inferred from weak lensing, to disentangle the luminous and dark matter contribution to the strong lensing mass. In our model, ℋ(Mh) is a power-law relation between halo mass and stellar mass, with scatter. This is an approximation: the SHMR is typically described by a more flexible model, with a change in slope around stellar mass ∼1011 M⊙ (see e.g. Leauthaud et al. 2012). However, in the stellar mass range covered by CMASS galaxies, deviations from a pure power-law SHMR are smaller than the width of our prior (and the posterior) on ℋ (i.e. varying the slope of the SHMR, parameter βh, within its uncertainty has a bigger impact on the SHMR). We then conclude that our results are not sensitive to our particular choice for the parameterisation of the SHMR.
Another assumption in our model is that of a spatially constant stellar IMF, which is in contrast with some recent spatially resolved studies of the IMF in massive galaxies (see Sect. 1). In order to assess the impact of this assumption on our inference, it is useful to generalise the definition of the IMF mismatch parameter αIMF by introducing the enclosed IMF mismatch parameter profile, αIMF(< R), defined as the ratio between the true stellar mass enclosed within radius R and the stellar mass measured in the same region from stellar population synthesis modelling, assuming a Chabrier IMF (see also Sect. 5 of Sonnenfeld et al. 2018a). Strong lensing data is only sensitive to αIMF(< REin), where REin is the Einstein radius in physical units. If the true IMF mismatch parameter of a galaxy is declining with radius, then αIMF(< R) is also a decreasing function of R, meaning that, on average, αIMF(< REin) is larger for lenses with a smaller Einstein radius and vice-versa. In our population model we do not allow for such a trend. As a result, this signal, if present, would translate into a larger intrinsic scatter in the αIMF distribution. However, our inference on the IMF mismatch parameter intrinsic scatter σIMF is consistent with zero, meaning that if a signal from a spatially varying IMF is present in our sample, our measurements are not sensitive to it.
6.2. Comparison with other IMF studies
Under the assumption of an NFW dark matter density profile, we find an IMF mismatch parameter consistent with that of a Chabrier IMF, while a normalisation as heavy as that of a Salpeter IMF is excluded at more than 2σ level. This value appears to be in tension with some measurements of the stellar IMF in strong lenses from the literature. For instance, Treu et al. (2010), combining strong lensing with stellar dynamics on a set of 56 lenses from the Sloan Lenses ACS Survey (SLACS), claimed an average IMF normalisation higher than that of a Salpeter IMF. A similar result was found by Sonnenfeld et al. (2015), using a similar method on a sample of 80 lenses drawn from the SLACS and the SL2S survey, and by Cappellari et al. (2012) from a spatially resolved dynamical study of a sample of nearby ETGs.
The recent re-analysis of the SLACS sample by Sonnenfeld et al. (2018a), however, showed how stellar dynamics is particularly sensitive to the presence of gradients in the M*/L in the inner regions of galaxies. In particular, negative gradients in M*/L can bias the inferred IMF normalisation towards larger values than the truth: this is because, at fixed mass enclosed within the Einstein radius, a negative gradient in M*/L increases the central velocity dispersion, in a similar way as increasing the global IMF mismatch parameter does (see also Bernardi et al. 2018).
When allowing for M*/L gradients and including weak lensing information, Sonnenfeld et al. (2018a) inferred an average IMF normalisation μIMF = 0.11 ± 0.04 for the SLACS lenses, which translates into even lower values when accounting for lensing selection effects. Our inference is then consistent with that of Sonnenfeld et al. (2018a), and in general with a series of recent studies based on spatially-resolved kinematics and strong lensing (Oldham & Auger 2018a,b; Collett et al. 2018), which show that the region in massive galaxies where the IMF normalisation is significantly heavier than that of a Chabrier IMF is limited to R ≲ 1 kpc.
If the sensitivity of stellar dynamics to M*/L gradients is the main reason for the discrepancy between our results and previous estimates of the IMF normalisation from strong lensing and dynamics, and if M*/L gradients are also present in CMASS galaxies, we would expect our gradient-less model to under-predict the central velocity dispersion of our lenses, compared to the values measured by BOSS. We can verify this conjecture with a posterior predictive test and by making additional assumptions on the dynamical state of our lenses.
We take the same mock realisations of sets of 23 lenses used for the posterior predictive tests of Fig. 6, drawn from the posterior probability distribution of the “Arctan” and “Gaussian” models. Then, for each lens, we use the spherical Jeans equation, assuming isotropic orbits, to predict the surface brightness-weighted line-of-sight stellar velocity dispersion, integrated within a circular aperture of radius Re: σe1. For a fair comparison with the noisy distribution in observed velocity dispersion, we add random errors to the mock distribution in σe, with a 46 km s−1 scatter, which is the median value of the uncertainty on the BOSS velocity dispersion of our sample. For each mock realisation, we then compare the median value of σe with the median σBOSS of our sample, which is 271 km s−1. We choose the median rather than the mean, because it is less sensitive to the presence of catastrophic outliers, such as the value of σBOSS for HSC J121504+004726. In Fig. 8 we plot the posterior predicted distribution of the median σe, based on 1000 random realisations. As expected, our model tends to under-predict the velocity dispersion of the sample, with a large (∼95%) probability. Adding a negative gradient in M*/L would bring our model into better agreement with the observations.
 |
Fig. 8. Posterior predictive distribution in the median value of the central stellar velocity dispersion σe, from mock realisations of sets of 23 SuGOHI lenses, generated from the posterior probability distribution inferred for the “Arctan” (black solid) and “Gaussian” (red dotted) models. The vertical line marks the median value of the stellar velocity dispersion of the lenses in our sample, as measured by BOSS. The percentages left and right of the vertical line indicate the fraction of mock realisations with a median σe smaller or larger than the observed value, for the two models. |
6.3. Differences between strong lenses and the general population
An important part of our analysis is the separation of the probability distribution of the strong lenses into a term describing the distribution of the parent sample and a term proportional to the strong lensing cross-section and the lens detection efficiency, which allows us to correct for selection effects. For a set of values of the hyper-parameters η, the term PCMASS(ψi|η) describes the general population of CMASS galaxies. If multiplied by the strong lensing cross-section σSL, we obtain the distribution of CMASS lenses. Finally, multiplication by the lens detection efficiency ℱdet gives the population of SuGOHI lenses. Each of these three populations will in general occupy different regions of parameter space. We can use a posterior predictive procedure to investigate these possible differences.
We are interested in studying the posterior probability distribution of the individual galaxy parameters ψ, marginalised over all possible values of the hyper-parameters allowed by the data. For the distribution of CMASS galaxies, this is given by
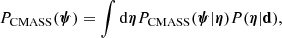 (24)
(24)
while analogous distributions of the samples of strong lenses can be obtained by multiplying PCMASS by the appropriate strong lensing selection terms (σSL for CMASS lenses and σSLℱdet for SuGOHI lenses). We sample from PCMASS(ψ) as follows: we first draw a set of values of the hyper-parameters η from the posterior probability distribution, then draw a set of values of ψ from P(ψ|η), for a large number of iterations. The resulting distribution for the CMASS galaxies, the CMASS strong lenses and the SuGOHI lenses, is shown Fig. 9, as obtained from the “Arctan” detection efficiency model (the “Gaussian” model produces very similar results).
 |
Fig. 9. Posterior predictive distribution in stellar mass, halo mass, halo concentration, IMF mismatch parameter, half-light radius, and Sérsic index of CMASS galaxies, CMASS strong lenses and SuGOHI lenses, obtained from our inference based on the “Arctan” model. Observed values in |
We focus on the following quantities: stellar mass, IMF mismatch parameter, halo mass and concentration, half-light radius, and Sérsic index. The most obvious difference between the strong lens subsamples and the general population is that the former are on average more massive than the latter, in terms of both stellar and dark matter mass. This is true for the population of strong lenses compared to all CMASS galaxies, but also for the SuGOHI lenses compared to the population of strong lenses, indicating that selection effects play an important role in the definition of our sample of lenses.
We can also see that the predicted stellar mass-size relation of the strong lenses appears to be steeper than that of the general population (see the panel in the first column from the left and second row from the bottom of Fig. 9), with the lowest mass lenses being more compact compared to regular galaxies of the same mass. This prediction appears to match the observed distribution of lenses in  − Re space. A similar behaviour is seen, with higher statistical significance, in the SLACS sample of strong lenses when compared to the population of SDSS quiescent galaxies from which that sample is drawn (Auger et al. 2010b).
− Re space. A similar behaviour is seen, with higher statistical significance, in the SLACS sample of strong lenses when compared to the population of SDSS quiescent galaxies from which that sample is drawn (Auger et al. 2010b).
The posterior predicted IMF mismatch parameter has a broad distribution, as a result of the large observational uncertainty (the posterior predicted distribution is obtained by marginalising over the whole posterior distribution for the model hyper-parameters), but we can still see how lenses tend to have higher values of αIMF compared to the general population. We point out, however, that models with no intrinsic scatter in αIMF are allowed by the data: the probability distribution in σIMF, shown in Fig. 7, is consistent with the value 0. For those models, the IMF normalisation is the same for all galaxies, regardless of their strong lens nature. Models with σIMF = 0 are not represented in the posterior predicted distribution of Fig. 9 as a result of our choice of prior, which is uniform on values of σIMF > 0. If we were to impose a much more restrictive prior, for instance asserting a universal IMF (i.e. σIMF = 0), then the difference in αIMF between the general population of galaxies and the strong lenses would disappear by construction, while the model would still be providing a good fit to the data.
Finally, the model predicts a higher average halo mass at fixed stellar mass for the strong lenses. This is best seen in Fig. 10, where we plot histograms of the distribution in Mh of posterior predicted galaxies and strong lenses selected in a narrow bin in stellar mass centred on log 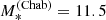 . The halo mass of the strong lenses is on average 0.17 dex higher than that of the general population of galaxies. This model prediction can in principle be verified by carrying out a weak lensing analysis of CMASS strong lenses. In practice, this requires a much larger sample of lenses to reach the necessary precision to measure the signal.
. The halo mass of the strong lenses is on average 0.17 dex higher than that of the general population of galaxies. This model prediction can in principle be verified by carrying out a weak lensing analysis of CMASS strong lenses. In practice, this requires a much larger sample of lenses to reach the necessary precision to measure the signal.
 |
Fig. 10. Posterior predictive distribution in halo mass, for CMASS galaxies, CMASS strong lenses, and SuGOHI lenses with stellar masses in the range |
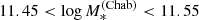
We can also investigate the differences in the posterior predicted distribution in the Einstein radius between the SuGOHI lenses and all CMASS strong lenses. This is shown in Fig. 11 for the “Arctan” model, together with the corresponding detection efficiency function ℱdet, as inferred from the data. Because of the sharp cutoff in ℱdet around θEin ≈ 0.8″, the distribution in θEin of SuGOHI lenses is shifted towards larger values compared to that of all strong lenses: the medians of the two distributions are 1.18″ and 0.88″, respectively. According to our model, then, half of the existing strong lenses in the CMASS sample have values of the Einstein radius smaller than 0.88″, but many of these lenses are missed by our survey.
 |
Fig. 11. Posterior predictive distribution in the Einstein radius of CMASS strong lenses and SuGOHI lenses, based on the “Arctan” model inference. The shaded curve corresponds to the 68% credible region of the lens detection efficiency function, ℱdet, as inferred from our data. |
We can qualitatively test this prediction by considering the BELLS lens sample, which consists mostly of CMASS galaxy lenses and has minimal overlap with SuGOHI. The BELLS sample has been assembled by means of a spectroscopic search, and the lens detection efficiency of this survey extends to lower values of θEin compared to ours (Arneson et al. 2012). This implies that, if the population of small Einstein radius lenses predicted by our model exists, these lenses should be part of the BELLS sample. Indeed, half of the BELLS lenses have values of θEin ≤ 0.75″, in agreement with our prediction. For a more quantitative comparison between our SuGOHI sample-based inference and the BELLS sample, it is necessary to model the lens detection efficiency of BELLS. This, however, is beyond the scope of this work.
7. Conclusions
We used photometric data from HSC and spectroscopic measurements from VLT to analyse a sample of 23 strong lenses drawn from the CMASS sample of BOSS galaxies. We measured the Einstein radius and the stellar mass of each lens, then carried out a statistical analysis to infer the distribution in IMF normalisation of the CMASS sample of galaxies. We used a prior on halo mass from a previous weak lensing analysis of the CMASS sample and assumed an NFW density profile for the dark matter distribution to break the degeneracy between the stellar IMF and the contribution of dark matter to the strong lensing mass. We also accounted for strong lensing selection effects to generalise the constraints obtained on the 23 strong lenses to the parent sample. In particular, our model accounts for the facts that (1) the probability of a galaxy being a lens is proportional to its strong lensing cross-section and (2) lenses with different Einstein radius have different probabilities of being detected by our lensing survey.
We constrain the average base-10 logarithm of the IMF normalisation of CMASS galaxies to be −0.04 ± 0.11, where logαIMF = 0 corresponds to a Chabrier IMF, while a Salpeter IMF is in tension with our measurement. This tension can be made more (less) severe by allowing the inner slope of the dark matter halo to be steeper (shallower) than that of an NFW profile. Our inferred IMF normalisation is significantly lower than previous studies based on stellar dynamics, used either alone or in combination with strong lensing. This discrepancy can be explained by the presence of radial gradients in the stellar mass-to-light ratio, to which stellar dynamics is particularly sensitive. Ours is an estimate of the mass-weighted average IMF normalisation measured over a region of 5 − 10 kpc in projection. As such, our measurement cannot rule out the presence of a stellar population with a heavier IMF confined to the very inner regions of the CMASS galaxies.
We investigated differences between the general population of CMASS galaxies, CMASS strong lenses, and lenses that can be detected by our survey, by means of posterior prediction. Our model correctly predicts a steeper stellar mass-size relation for the strong lenses compared to the general population of galaxies, matching existing observations, and also predicts a higher average halo mass at fixed stellar mass for the lenses.
The current number of CMASS strong lenses (grade B or above) with HSC data, as of the 17A internal release, is 84, and is expected to at least double by the end of the HSC survey. Our sample size of 23 was limited by the availability of spectroscopic measurements of the redshift of the background source. With a larger sample of HSC lenses we expect to be able to relax some of our assumptions and test more complex models than the ones considered so far, such as models with a free inner density slope for the dark matter halo.
In the next decade, the Euclid space telescope2 and the Large Synoptic Survey Telescope3 (LSST) will enable the discovery of tens of thousands of new strong lenses (Collett 2015). Together with a significant shrinkage in the statistical errors, such a dramatic increase in sample size will allow us to precisely infer the distribution of halo masses of the strong lenses directly from weak lensing, as opposed to using weak lensing information obtained on a separate sample as a prior for the strong lens sample as done in the present work. This will then allow us to remove one source of potential systematic uncertainty, the strong lensing selection correction (although an accurate understanding of selection effects will still be needed to generalise results obtained on strong lenses to the general galaxy population). Additionally, thanks to the high cadence of its planned observations, the LSST will provide time-delay measurements for hundreds of strongly lensed quasars (Oguri & Marshall 2010). Time-delay measurements are sensitive to higher order derivatives of the lens potential, compared to the image position data on which our work is based, and will then provide additional constraints on the density profile of the lens population. We expect the statistical strong lensing method developed in this work to be an essential tool to take full advantage of the wealth of strong lensing data coming from the next generation of surveys.
The code used for the calculation of the velocity dispersion through the spherical Jeans equation is available at the following link: https://github.com/astrosonnen/spherical_jeans
Acknowledgments
AS acknowledges funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement No 792916, as well as a KAKENHI Grant from the Japan Society for the Promotion of Science (JSPS), MEXT, Number JP17K14250. ATJ is supported by JSPS KAKENHI Grant number JP17H02868. MO acknowledges support from JSPS KAKENHI Grants Number JP15H05892 and JP18K03693. SHS thanks the Max Planck Society for support through the Max Planck Research Group. KCW is supported in part by an EACOA Fellowship awarded by the East Asia Core Observatories Association, which consists of the Academia Sinica Institute of Astronomy and Astrophysics, the National Astronomical Observatory of Japan, the National Astronomical Observatories of the Chinese Academy of Sciences, and the Korea Astronomy and Space Science Institute. This work was supported by World Premier International Research Center Initiative (WPI Initiative), MEXT, Japan. The Hyper Suprime-Cam (HSC) collaboration includes the astronomical communities of Japan and Taiwan, and Princeton University. The HSC instrumentation and software were developed by the National Astronomical Observatory of Japan (NAOJ), the Kavli Institute for the Physics and Mathematics of the Universe (Kavli IPMU), the University of Tokyo, the High Energy Accelerator Research Organization (KEK), the Academia Sinica Institute for Astronomy and Astrophysics in Taiwan (ASIAA), and Princeton University. Funding was contributed by the FIRST programme from Japanese Cabinet Office, the Ministry of Education, Culture, Sports, Science, and Technology (MEXT), the Japan Society for the Promotion of Science (JSPS), Japan Science and Technology Agency (JST), the Toray Science Foundation, NAOJ, Kavli IPMU, KEK, ASIAA, and Princeton University. Funding for SDSS-III has been provided by the Alfred P. Sloan Foundation, the Participating Institutions, the National Science Foundation, and the U.S. Department of Energy Office of Science. The SDSS-III web site is http://www.sdss3.org/. SDSS-III is managed by the Astrophysical Research Consortium for the Participating Institutions of the SDSS-III Collaboration including the University of Arizona, the Brazilian Participation Group, Brookhaven National Laboratory, Carnegie Mellon University, University of Florida, the French Participation Group, the German Participation Group, Harvard University, the Instituto de Astrofisica de Canarias, the Michigan State/Notre Dame/JINA Participation Group, Johns Hopkins University, Lawrence Berkeley National Laboratory, Max Planck Institute for Astrophysics, Max Planck Institute for Extraterrestrial Physics, New Mexico State University, New York University, Ohio State University, Pennsylvania State University, University of Portsmouth, Princeton University, the Spanish Participation Group, University of Tokyo, University of Utah, Vanderbilt University, University of Virginia, University of Washington, and Yale University.
References
- Aihara, H., Arimoto, N., Armstrong, R., et al. 2018, PASJ, 70, S4 [NASA ADS] [Google Scholar]
- Alam, S., Albareti, F. D., Allende Prieto, C., et al. 2015, ApJS, 219, 12 [NASA ADS] [CrossRef] [Google Scholar]
- Alton, P. D., Smith, R. J., & Lucey, J. R. 2017, MNRAS, 468, 1594 [NASA ADS] [Google Scholar]
- Arneson, R. A., Brownstein, J. R., & Bolton, A. S. 2012, ApJ, 753, 4 [NASA ADS] [CrossRef] [Google Scholar]
- Auger, M. W., Treu, T., Bolton, A. S., et al. 2009, ApJ, 705, 1099 [NASA ADS] [CrossRef] [Google Scholar]
- Auger, M. W., Treu, T., Gavazzi, R., et al. 2010a, ApJ, 721, L163 [NASA ADS] [CrossRef] [Google Scholar]
- Auger, M. W., Treu, T., Bolton, A. S., et al. 2010b, ApJ, 724, 511 [NASA ADS] [CrossRef] [Google Scholar]
- Axelrod, T., Kantor, J., Lupton, R. H., & Pierfederici, F. 2010, in Software and Cyberinfrastructure for Astronomy, Proc. SPIE, 7740, 774015 [CrossRef] [Google Scholar]
- Barber, C., Schaye, J., & Crain, R. A. 2019, MNRAS, 483, 985 [NASA ADS] [CrossRef] [Google Scholar]
- Barnabè, M., Spiniello, C., Koopmans, L. V. E., et al. 2013, MNRAS, 436, 253 [NASA ADS] [CrossRef] [Google Scholar]
- Bastian, N., Covey, K. R., & Meyer, M. R. 2010, ARA&A, 48, 339 [NASA ADS] [CrossRef] [Google Scholar]
- Bernardi, M., Sheth, R. K., Dominguez-Sanchez, H., et al. 2018, MNRAS, 477, 2560 [NASA ADS] [CrossRef] [Google Scholar]
- Bolton, A. S., Burles, S., Koopmans, L. V. E., et al. 2008, ApJ, 682, 964 [NASA ADS] [CrossRef] [Google Scholar]
- Bosch, J., Armstrong, R., Bickerton, S., et al. 2018, PASJ, 70, S5 [NASA ADS] [CrossRef] [Google Scholar]
- Brownstein, J. R., Bolton, A. S., Schlegel, D. J., et al. 2012, ApJ, 744, 41 [NASA ADS] [CrossRef] [Google Scholar]
- Bruzual, G., & Charlot, S. 2003, MNRAS, 344, 1000 [NASA ADS] [CrossRef] [Google Scholar]
- Cappellari, M., McDermid, R. M., Alatalo, K., et al. 2012, Nature, 484, 485 [NASA ADS] [CrossRef] [Google Scholar]
- Chabrier, G. 2003, PASP, 115, 763 [NASA ADS] [CrossRef] [Google Scholar]
- Collett, T. E. 2015, ApJ, 811, 20 [NASA ADS] [CrossRef] [Google Scholar]
- Collett, T. E., Oldham, L. J., Smith, R. J., et al. 2018, Science, 360, 1342 [NASA ADS] [CrossRef] [Google Scholar]
- Collier, W. P., Smith, R. J., & Lucey, J. R. 2018, MNRAS, 478, 1595 [NASA ADS] [CrossRef] [Google Scholar]
- Dawson, K. S., Schlegel, D. J., Ahn, C. P., et al. 2013, AJ, 145, 10 [Google Scholar]
- Eisenstein, D. J., Weinberg, D. H., Agol, E., et al. 2011, AJ, 142, 72 [Google Scholar]
- Ferreras, I., La Barbera, F., de la Rosa, I. G., et al. 2013, MNRAS, 429, L15 [NASA ADS] [CrossRef] [Google Scholar]
- Foreman-Mackey, D., Hogg, D. W., Lang, D., & Goodman, J. 2013, PASP, 125, 306 [CrossRef] [Google Scholar]
- Gallazzi, A., Charlot, S., Brinchmann, J., White, S. D. M., & Tremonti, C. A. 2005, MNRAS, 362, 41 [NASA ADS] [CrossRef] [Google Scholar]
- Gavazzi, R., Treu, T., Marshall, P. J., Brault, F., & Ruff, A. 2012, ApJ, 761, 170 [NASA ADS] [CrossRef] [Google Scholar]
- Gavazzi, R., Marshall, P. J., Treu, T., & Sonnenfeld, A. 2014, ApJ, 785, 144 [NASA ADS] [CrossRef] [Google Scholar]
- Guszejnov, D., Hopkins, P. F., & Graus, A. S. 2019, MNRAS, 485, 4852 [NASA ADS] [CrossRef] [Google Scholar]
- Ivezić, Ž., Kahn, S. M., Tyson, J. A., et al. 2019, ApJ, 873, 111 [NASA ADS] [CrossRef] [Google Scholar]
- Jurić, M., Kantor, J., Lim, K., et al. 2017, in Astronomical Data Analysis Software and Systems XXV, ASP Conf. Ser., 512, 279 [NASA ADS] [Google Scholar]
- Kormann, R., Schneider, P., & Bartelmann, M. 1994, A&A, 284, 285 [NASA ADS] [Google Scholar]
- Krumholz, M. R. 2014, Phys. Rep., 539, 49 [NASA ADS] [CrossRef] [Google Scholar]
- La Barbera, F., Vazdekis, A., Ferreras, I., et al. 2016, MNRAS, 457, 1468 [NASA ADS] [CrossRef] [Google Scholar]
- Leauthaud, A., Tinker, J., Bundy, K., et al. 2012, ApJ, 744, 159 [NASA ADS] [CrossRef] [Google Scholar]
- Li, H., Ge, J., Mao, S., et al. 2017, ApJ, 838, 77 [NASA ADS] [CrossRef] [Google Scholar]
- Lyubenova, M., Martín-Navarro, I., van de Ven, G., et al. 2016, MNRAS, 463, 3220 [NASA ADS] [CrossRef] [Google Scholar]
- Macciò, A. V., Dutton, A. A., & van den Bosch, F. C. 2008, MNRAS, 391, 1940 [NASA ADS] [CrossRef] [Google Scholar]
- Martín-Navarro, I., Barbera, F. L., Vazdekis, A., Falcón-Barroso, J., & Ferreras, I. 2015, MNRAS, 447, 1033 [NASA ADS] [CrossRef] [Google Scholar]
- Miyazaki, S., Komiyama, Y., Kawanomoto, S., et al. 2018, PASJ, 70, S1 [NASA ADS] [Google Scholar]
- Modigliani, A., Goldoni, P., Royer, F., et al. 2010, in Observatory Operations: Strategies, Processes, and Systems III, Proc. SPIE, 7737, 773728 [CrossRef] [Google Scholar]
- More, A., Cabanac, R., More, S., et al. 2012, ApJ, 749, 38 [Google Scholar]
- Navarro, J. F., Frenk, C. S., & White, S. D. M. 1997, ApJ, 490, 493 [NASA ADS] [CrossRef] [Google Scholar]
- Oguri, M., & Marshall, P. J. 2010, MNRAS, 405, 2579 [NASA ADS] [Google Scholar]
- Oguri, M., Rusu, C. E., & Falco, E. E. 2014, MNRAS, 439, 2494 [NASA ADS] [CrossRef] [Google Scholar]
- Oguri, M., Lin, Y.-T., Lin, S.-C., et al. 2018, PASJ, 70, S20 [NASA ADS] [Google Scholar]
- Oldham, L., & Auger, M. 2018a, MNRAS, 474, 4169 [NASA ADS] [CrossRef] [Google Scholar]
- Oldham, L. J., & Auger, M. W. 2018b, MNRAS, 476, 133 [NASA ADS] [CrossRef] [Google Scholar]
- Parikh, T., Thomas, D., Maraston, C., et al. 2018, MNRAS, 477, 3954 [NASA ADS] [CrossRef] [Google Scholar]
- Peirani, S., Dubois, Y., Volonteri, M., et al. 2017, MNRAS, 472, 2153 [CrossRef] [Google Scholar]
- Ruff, A. J., Gavazzi, R., Marshall, P. J., et al. 2011, ApJ, 727, 96 [NASA ADS] [CrossRef] [Google Scholar]
- Sarzi, M., Spiniello, C., La Barbera, F., Krajnović, D., & van den Bosch, R. 2018, MNRAS, 478, 4084 [NASA ADS] [CrossRef] [Google Scholar]
- Schechter, P. L., Pooley, D., Blackburne, J. A., & Wambsganss, J. 2014, ApJ, 793, 96 [NASA ADS] [CrossRef] [Google Scholar]
- Schlafly, E. F., & Finkbeiner, D. P. 2011, ApJ, 737, 103 [NASA ADS] [CrossRef] [Google Scholar]
- Schlegel, D., White, M., & Eisenstein, D. 2009, ArXiv e-prints [arXiv:0902.4680] [Google Scholar]
- Sersic, J. L. 1968, Atlas de galaxias australes (Cordoba, Argentina: Observatorio Astronomico) [Google Scholar]
- Smith, R. J., & Lucey, J. R. 2013, MNRAS, 434, 1964 [NASA ADS] [CrossRef] [Google Scholar]
- Smith, R. J., Lucey, J. R., & Conroy, C. 2015, MNRAS, 449, 3441 [NASA ADS] [CrossRef] [Google Scholar]
- Smith, R. J., Lucey, J. R., & Edge, A. C. 2017, MNRAS, 471, 383 [NASA ADS] [CrossRef] [Google Scholar]
- Sonnenfeld, A., Treu, T., Gavazzi, R., et al. 2012, ApJ, 752, 163 [NASA ADS] [CrossRef] [Google Scholar]
- Sonnenfeld, A., Gavazzi, R., Suyu, S. H., Treu, T., & Marshall, P. J. 2013a, ApJ, 777, 97 [NASA ADS] [CrossRef] [Google Scholar]
- Sonnenfeld, A., Treu, T., Gavazzi, R., et al. 2013b, ApJ, 777, 98 [NASA ADS] [CrossRef] [Google Scholar]
- Sonnenfeld, A., Treu, T., Marshall, P. J., et al. 2015, ApJ, 800, 94 [NASA ADS] [CrossRef] [Google Scholar]
- Sonnenfeld, A., Leauthaud, A., Auger, M. W., et al. 2018a, MNRAS, 481, 164 [Google Scholar]
- Sonnenfeld, A., Chan, J. H. H., Shu, Y., et al. 2018b, PASJ, 70, S29 [NASA ADS] [CrossRef] [Google Scholar]
- Sonnenfeld, A., Wang, W., & Bahcall, N. 2019, A&A, 622, A30 (S19) [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Spiniello, C., Trager, S. C., Koopmans, L. V. E., & Chen, Y. P. 2012, ApJ, 753, L32 [NASA ADS] [CrossRef] [Google Scholar]
- Tanaka, M., Wong, K. C., More, A., et al. 2016, ApJ, 826, L19 [NASA ADS] [CrossRef] [Google Scholar]
- Treu, T., Auger, M. W., Koopmans, L. V. E., et al. 2010, ApJ, 709, 1195 [NASA ADS] [CrossRef] [Google Scholar]
- van Dokkum, P. G., & Conroy, C. 2010, Nature, 468, 940 [NASA ADS] [CrossRef] [Google Scholar]
- van Dokkum, P., Conroy, C., Villaume, A., Brodie, J., & Romanowsky, A. J. 2017, ApJ, 841, 68 [NASA ADS] [CrossRef] [Google Scholar]
- Vaughan, S. P., Davies, R. L., Zieleniewski, S., & Houghton, R. C. W. 2018, MNRAS, 475, 1073 [NASA ADS] [CrossRef] [Google Scholar]
- Vernet, J., Dekker, H., D’Odorico, S., et al. 2011, A&A, 536, A105 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Wong, K. C., Sonnenfeld, A., Chan, J. H. H., et al. 2018, ApJ, 867, 107 [NASA ADS] [CrossRef] [Google Scholar]
- Xu, D., Springel, V., Sluse, D., et al. 2017, MNRAS, 469, 1824 [NASA ADS] [CrossRef] [Google Scholar]
- Zieleniewski, S., Houghton, R. C. W., Thatte, N., Davies, R. L., & Vaughan, S. P. 2017, MNRAS, 465, 192 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: Marginalisation over individual lens parameters
In order to sample the posterior probability distribution of the hyper-parameters, P(η|d), we need to marginalise over the individual object parameters of each lens, evaluating the integrals in Eq. (18) at each step of the MCMC. Although ψ is a vector in the eight-dimensional space defined by the parameters listed in Eq. (4), some of these parameters are assumed to be known exactly: the lens and source redshift, the Sérsic index, and the half-light radius of the lens. As a result, the likelihood term in these variables reduces to a delta function, which effectively transforms Eq. (18) into an integral over the four-dimensional space in  .
.
The basic idea for computing the integrals in Eq. (18) is the following: given a normalised probability distribution g(ψ) and a function h(ψ), we can compute the integral over ψ of the product g(ψ)h(ψ) by drawing a large sample {ψ(k)} from g(ψ) and approximate the integral with the average value of h(ψ) over this sample:
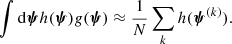 (A.1)
(A.1)
For the purpose of calculating the integral in Eq. (18), we could in principle set g(ψi) = P(ψi|η) and h(ψi) = P(di|ψi). However, drawing samples from P(ψi|η) is complicated by the presence of the lensing cross-section term σSL, which is not an analytic function of ψi. Instead, we set the sampling distribution to
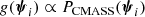 (A.2)
(A.2)
and move the term dependent on the lensing cross-section, the product A(η)σSL in Eq. (19), to h(ψi):
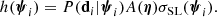 (A.3)
(A.3)
With this choice, g(ψi) is a product of seven Gaussians and a skew Gaussian, 𝒮, as summarised in Eq. (6).
We draw samples in (Mh, ch,  , αIMF) from it as follows: given a set of hyper-parameters η, we first draw values of
, αIMF) from it as follows: given a set of hyper-parameters η, we first draw values of  from 𝒮(
from 𝒮( |η) and values of logαIMF from 𝒜(αIMF|η), then draw values of log Mh from ℋ(Mh|
|η) and values of logαIMF from 𝒜(αIMF|η), then draw values of log Mh from ℋ(Mh| , η) and finally draw values of log ch from 𝒞(ch|Mh). In practice, it is sufficient to sample
, η) and finally draw values of log ch from 𝒞(ch|Mh). In practice, it is sufficient to sample  from 𝒮 only once, since we keep the hyper-parameters describing the stellar mass distribution term fixed. For each lens i, given a sample
from 𝒮 only once, since we keep the hyper-parameters describing the stellar mass distribution term fixed. For each lens i, given a sample 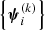 drawn from g(ψi), we calculate the product in Eq. (A.3) for each point of the sample and use the approximation in Eq. (A.1) to calculate the integral in Eq. (18). In order to speed up the evaluation of the likelihood term and the lensing cross-section, we pre-compute, for each lens, the model Einstein radius and σSL on a grid of values of stellar mass, halo mass, and halo concentration and obtain the quantities of interest at any point ψi by interpolation.
drawn from g(ψi), we calculate the product in Eq. (A.3) for each point of the sample and use the approximation in Eq. (A.1) to calculate the integral in Eq. (18). In order to speed up the evaluation of the likelihood term and the lensing cross-section, we pre-compute, for each lens, the model Einstein radius and σSL on a grid of values of stellar mass, halo mass, and halo concentration and obtain the quantities of interest at any point ψi by interpolation.
We calculate the normalisation A(η) of the probability distribution Eq. (19) as follows. Since Eq. (19) must be normalised to unity, A(η) is defined as
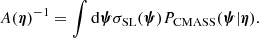 (A.4)
(A.4)
This is the lensing cross-section averaged over the distribution PCMASS(ψ), up to a constant that does not depend on the free hyper-parameters. We can calculate it by approximating the integral with an average over a sample 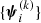 drawn from PCMASS(ψi). This time, however, the sample of ψ must span the whole eight-dimensional space defined by Eq. (4). Grid interpolation does not help in the evaluation of σSL, because the high dimensionality of the problem makes it unfeasible. Instead, we adopt an importance sampling approach. We choose a fixed value of the hyper-parameters, η0, draw a large sample
drawn from PCMASS(ψi). This time, however, the sample of ψ must span the whole eight-dimensional space defined by Eq. (4). Grid interpolation does not help in the evaluation of σSL, because the high dimensionality of the problem makes it unfeasible. Instead, we adopt an importance sampling approach. We choose a fixed value of the hyper-parameters, η0, draw a large sample 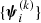 from PCMASS(ψ|η0), and approximate the integral in Eq. (A.4) by the mean of σSL over the sample, weighted by the ratio between PCMASS(ψ|η) and PCMASS(ψ|η0):
from PCMASS(ψ|η0), and approximate the integral in Eq. (A.4) by the mean of σSL over the sample, weighted by the ratio between PCMASS(ψ|η) and PCMASS(ψ|η0):
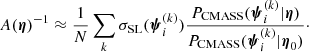 (A.5)
(A.5)
All Tables
Spectroscopic observations of nine CMASS lens candidates from the SuGOHI sample.
Best-fit values of the lens mass and source surface brightness model parameters.
All Figures
|
Fig. 1. Twenty-three CMASS galaxy strong lenses in our sample. First column: colour-composite HSC images in g, r, i bands. Second column: best-fit lens + source model. Third column: data with the best-fit model of the lens light subtracted. Fourth column: best-fit source model. Fifth column: residuals. |
| In the text | |
|
Fig. 2. X-shooter observations of seven CMASS lenses with detected emission lines from the lensed source. Left panel: HSC gri colour-composite image of the lens. The green box indicates the position of the slit used during the spectroscopic observation. Middle and right panels: small cutouts of the 2D spectrum around the two source emission lines with the highest signal-to-noise ratio. |
| In the text | |
|
Fig. 3. Difference between magnitudes predicted by the CSP model that maximises the likelihood and the observed magnitudes, as a function of the latter. Different colours correspond to different HSC filters. The typical observational uncertainty on the observed magnitudes, from Sérsic profile fitting, is 0.02. |
| In the text | |
|
Fig. 4. Ratio between the stellar mass enclosed within the Einstein radius, as inferred from stellar population synthesis modelling assuming a Chabrier IMF, and the total mass within the Einstein radius, as a function of the Einstein radius. The horizontal dashed line corresponds to the limit of 100% mass fraction within the Einstein radius. Values above this limit are non-physical. |
| In the text | |
|
Fig. 5. Posterior probability distribution of the model hyper-parameters. Contour levels correspond to the 68% and 95% enclosed probability regions. The two vertical dashed lines on the first column, parameter μIMF, indicate an average IMF normalisation corresponding to a Chabrier and a Salpeter IMF, respectively. |
| In the text | |
|
Fig. 6. Posterior predictive tests. Four panels: predicted distributions in the average, standard deviation, minimum, and maximum θEin (in arcseconds) in samples of 23 strong lens systems drawn from the posterior. The vertical line in each panel corresponds to the observed value of each test quantity. Posterior predicted distributions obtained from the base model are shown as filled histograms in blue. The black solid line and red dotted line histograms correspond to the “Arctan” and “Gaussian” lens detection efficiency models introduced in Sect. 5. The percentage to the left (right) side of each panel indicates the fraction of times the predicted value is smaller (larger) than the observed one, with the top value corresponding to the base model and the middle and bottom values corresponding to the “Arctan” and “Gaussian” models, respectively. |
| In the text | |
|
Fig. 7. Posterior probability distribution of the hyper-parameters describing the IMF normalisation of the CMASS sample, marginalised over the other hyper-parameters. Filled contours: base model. Black solid lines: model with “Arctan” detection efficiency function. Red dotted lines: model with “Gaussian” detection efficiency function. Contour levels mark the 68% and 95% enclosed probability regions. The vertical dashed lines correspond to an average IMF normalisation equal to that of a Chabrier and Salpeter IMF, respectively. |
| In the text | |
|
Fig. 8. Posterior predictive distribution in the median value of the central stellar velocity dispersion σe, from mock realisations of sets of 23 SuGOHI lenses, generated from the posterior probability distribution inferred for the “Arctan” (black solid) and “Gaussian” (red dotted) models. The vertical line marks the median value of the stellar velocity dispersion of the lenses in our sample, as measured by BOSS. The percentages left and right of the vertical line indicate the fraction of mock realisations with a median σe smaller or larger than the observed value, for the two models. |
| In the text | |
|
Fig. 9. Posterior predictive distribution in stellar mass, halo mass, halo concentration, IMF mismatch parameter, half-light radius, and Sérsic index of CMASS galaxies, CMASS strong lenses and SuGOHI lenses, obtained from our inference based on the “Arctan” model. Observed values in |
| In the text | |
|
Fig. 10. Posterior predictive distribution in halo mass, for CMASS galaxies, CMASS strong lenses, and SuGOHI lenses with stellar masses in the range |
| In the text | |
|
Fig. 11. Posterior predictive distribution in the Einstein radius of CMASS strong lenses and SuGOHI lenses, based on the “Arctan” model inference. The shaded curve corresponds to the 68% credible region of the lens detection efficiency function, ℱdet, as inferred from our data. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.