| Issue |
A&A
Volume 628, August 2019
|
|
|---|---|---|
| Article Number | A129 | |
| Number of page(s) | 14 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/201935211 | |
| Published online | 20 August 2019 | |
Convolutional neural networks on the HEALPix sphere: a pixel-based algorithm and its application to CMB data analysis
1
SISSA, Via Bonomea 265, 34136 Trieste, Italy
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
IFPU, Institute for Fundamental Physics of the Universe, Via Beirut 2, 34014 Trieste, Italy
3
Dipartimento di Fisica “Aldo Pontremoli”, Università degli Studi di Milano, Via Celoria 16, 20133 Milano, Italy
4
Istituto Nazionale di Fisica Nucleare (INFN), Sezione di Milano, Via Celoria 16, 20133 Milano, Italy
Received:
5
February
2019
Accepted:
28
June
2019
Abstract
We describe a novel method for the application of convolutional neural networks (CNNs) to fields defined on the sphere, using the Hierarchical Equal Area Latitude Pixelization scheme (HEALPix). Specifically, we have developed a pixel-based approach to implement convolutional and pooling layers on the spherical surface, similarly to what is commonly done for CNNs applied to Euclidean space. The main advantage of our algorithm is to be fully integrable with existing, highly optimized libraries for NNs (e.g., PyTorch, TensorFlow, etc.). We present two applications of our method: (i) recognition of handwritten digits projected on the sphere; (ii) estimation of cosmological parameter from simulated maps of the cosmic microwave background (CMB). The latter represents the main target of this exploratory work, whose goal is to show the applicability of our CNN to CMB parameter estimation. We have built a simple NN architecture, consisting of four convolutional and pooling layers, and we have used it for all the applications explored herein. Concerning the recognition of handwritten digits, our CNN reaches an accuracy of ∼95%, comparable with other existing spherical CNNs, and this is true regardless of the position and orientation of the image on the sphere. For CMB-related applications, we tested the CNN on the estimation of a mock cosmological parameter, defining the angular scale at which the power spectrum of a Gaussian field projected on the sphere peaks. We estimated the value of this parameter directly from simulated maps, in several cases: temperature and polarization maps, presence of white noise, and partially covered maps. For temperature maps, the NN performances are comparable with those from standard spectrum-based Bayesian methods. For polarization, CNNs perform about a factor four worse than standard algorithms. Nonetheless, our results demonstrate, for the first time, that CNNs are able to extract information from polarization fields, both in full-sky and masked maps, and to distinguish between E and B-modes in pixel space. Lastly, we have applied our CNN to the estimation of the Thomson scattering optical depth at reionization (τ) from simulated CMB maps. Even without any specific optimization of the NN architecture, we reach an accuracy comparable with standard Bayesian methods. This work represents a first step towards the exploitation of NNs in CMB parameter estimation and demonstrates the feasibility of our approach.
Key words: methods: data analysis / methods: numerical / cosmic background radiation
© ESO 2019
1. Introduction
The field of astrophysics and cosmology is experiencing a rapidly increasing interest in the use of machine learning (ML) algorithms to analyze and efficiently extract information from data coming from experiments. This is happening because of two main factors: (i) the more and more extensive size of astronomical datasets and the ever-increasing requirements in instrumental sensitivities encourage the development of new algorithms to do the job; and (ii) ongoing research in ML continuously produces new concepts, approaches, algorithms, to classify and regress data. ML methods can demonstrate outstanding performance, and the astrophysical community is promptly taking the challenge to adapt them to the problems typically tackled in the field.
One of the most fruitful fields of ML is the domain of artificial neural networks (or neural networks for short, NNs). Roughly speaking, NNs are non-linear mathematical operators that can approximate functions that map inputs onto outputs through a process called training. NNs have already been applied in many fields of science, such as biology (Cartwright 2008; Lodhi 2012; Angermueller et al. 2016), economics (Lam 2004; Hyun-jung & Kyung-shik 2007; Yan & Ouyang 2017; Tamura et al. 2018), medicine (Virmani et al. 2014; Kasabov 2014; Cha et al. 2016; Liu et al. 2017; Cascianelli et al. 2017), and of course astrophysics (Collister & Lahav 2004; Dieleman et al. 2015; Baccigalupi et al. 2000; Graff et al. 2014; Auld et al. 2007).
In this paper, we present a novel algorithm that extends commonly-used NN architectures to signals projected on the sphere. Spherical domains are of great interest for the astrophysical and cosmological community, which often observe vast portions of the celestial sphere whose curvature is not always negligible. The latter statement applies to several fields, for example: (i) the study of the cosmic microwave background (CMB), the relic thermal radiation coming from the early Universe, which carries crucial information concerning very high energy physical processes occurred just after the Big Bang, and (ii) the analysis of the Universe Large Scale Structure, that is, the mapping of the location and properties of galaxies over large portions of the sky, which yields fundamental clues about the dark cosmological components.
Given our background in the analysis of data coming from experiments observing the CMB radiation, we propose applications of our algorithm to the problem of estimating cosmological parameters from CMB observations. While we provide only a proof-of-concept of such an application, this work demonstrates for the first time the feasibility of using deep CNNs for CMB parameter estimation on the very large angular scales, in both temperature and polarization. An implementation of the proposed algorithm, developed in Python, is available online1.
The paper is structured as follows: in Sect. 2, we introduce the basic concepts underlying the way standard and convolutional NNs (CNNs) work; in Sect. 3, we explain the problem of the application of CNNs on signals projected on the sphere and present our algorithm. Section 4 briefly describes the working environment used to develop and run our algorithm, as well as the NN architecture we have used in our analysis. Sections 5 and 6 deal with possible applications. In Sect. 5, we show the performance of our algorithm on a classification problem (recognition of hand-written digits from the MNIST dataset) on a spherical domain. Section 6 describes the application of our algorithm to CMB-related examples, namely the estimation of cosmological parameters applying CNNs to simulated CMB maps. Lastly, in Sect. 7 we discuss our main results and draw our conclusions.
2. Basic concepts of neural networks
In this section, we provide a brief introduction to the basic concepts of NNs. We stick to the two most common types of NNs, which are fully-connected networks and CNNs.
A NN is a computational tool able to approximate a non-linear function f that maps some inputs x ∈ ℝn into outputs y ∈ ℝm: y = f(x). The advantage of NNs is the lack of requirements on any a priori information for the function f, as the network can learn it from a (sufficiently large) set of labeled data, that is, a training set of inputs for which the corresponding outputs are known. Given this requirement, NNs fall into the category of supervised machine learning algorithms. NNs can approximate even extremely complicated mappings by recursively applying a non-linear function (called activation function) to linear combinations of the input elements.
2.1. Fully connected NN
Several network architectures have been developed in the last years; a particularly simple type builds on so-called fully connected layers. In this kind of NN, the architecture tries to approximate some function f : ℝn → ℝm via a sequence of multiple groups of artificial neurons; each group is called layer. Neurons of consecutive layers are linked to each other by connections. Each connection between neuron i in layer K and neuron j in layer K + 1 is quantified by a scalar weight 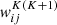 , with
, with 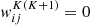 if the two neurons are not connected directly. The first layer of a NN, called the input layer, contains n neurons and is fed with the input. The last layer, the output layer, produces the result of the computation and contains m neurons. All the other layers, sandwiched between the first and last, are called hidden layers. NNs are called shallow if they have few hidden layers, or deep if they contain several layers (up to a thousand and more He et al. 2016).
if the two neurons are not connected directly. The first layer of a NN, called the input layer, contains n neurons and is fed with the input. The last layer, the output layer, produces the result of the computation and contains m neurons. All the other layers, sandwiched between the first and last, are called hidden layers. NNs are called shallow if they have few hidden layers, or deep if they contain several layers (up to a thousand and more He et al. 2016).
The network processes the input and produces the output via the following procedure:
-
1.
The n elements of the input vector x ∈ ℝn are associated to each neuron in the input layer (K = 0);
-
2.
For every neuron j in the (K + 1)th hidden layer, the following value is computed2, considering all the neurons of the Kth layer pointing to j:
 (1)
(1)where gj is the non-linear activation function for neuron j,
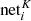 is the value associated with neuron i of the Kth layer, and the sum is done over all the neurons i that are connected to j.
is the value associated with neuron i of the Kth layer, and the sum is done over all the neurons i that are connected to j. -
3.
The output
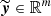 is the vector associated with the m neurons of the output layer, obtained after the computation of the previous step in all the hidden layers.
is the vector associated with the m neurons of the output layer, obtained after the computation of the previous step in all the hidden layers.
In order for the network to be able to approximate the function f, the connection weights must be optimized. This is done through the network training: starting from initialized values of the weights 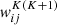 , the network is fed with the elements xi of the training set and the output values
, the network is fed with the elements xi of the training set and the output values 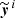 are obtained. A cost function 𝒥 is computed:
are obtained. A cost function 𝒥 is computed:
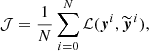 (2)
(2)
where, ℒ is a loss function that measures the distance between the true known output value yi and the one computed by the network 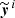 , for the ith element of the training set; the sum is done over N elements of the training set. The minimum of the cost function is found in the following way: (i) the network runs over N elements of the training set; (ii) the cost function is computed; (iii) the values of the weights are updated moving towards the minimum of the loss function, usually with a gradient descent algorithm that requires the computation of the derivative of 𝒥 with respect to the weights; (iv) the full computation is iterated until the value of 𝒥 converges to its minimum. The application of steps (i)–(iii) on the entire training set is called epoch. Depending on the approach, N can be equal to one, to the total number of elements in the training set, or to a sub-fraction of it (randomly changing the training set elements included in this fraction at every iteration). In the latter case, the training set is divided in so-called mini-batches.
, for the ith element of the training set; the sum is done over N elements of the training set. The minimum of the cost function is found in the following way: (i) the network runs over N elements of the training set; (ii) the cost function is computed; (iii) the values of the weights are updated moving towards the minimum of the loss function, usually with a gradient descent algorithm that requires the computation of the derivative of 𝒥 with respect to the weights; (iv) the full computation is iterated until the value of 𝒥 converges to its minimum. The application of steps (i)–(iii) on the entire training set is called epoch. Depending on the approach, N can be equal to one, to the total number of elements in the training set, or to a sub-fraction of it (randomly changing the training set elements included in this fraction at every iteration). In the latter case, the training set is divided in so-called mini-batches.
The NN parameters (e.g., the number of layers and neurons, the loss function, the dimension of mini-batches, the learning rate for the gradient descent algorithm, etc.) are optimized by evaluating the performance of the network over the validation set for which the outputs y are also known. The final assessment of the ability of the NN to approximate the mapping f is done over the test set. Depending on the characteristics of the output and the function f, NNs can be used, for example, to solve classification problems or to perform parameter regression.
2.2. Convolutional NNs
A peculiar type of NN is the so-called convolutional neural network (Krizhevsky et al. 2012), which is the main topic of this paper. In CNNs, convolutional layers take the place of some or all of the fully connected hidden layers. A convolutional layer convolves its input with one or more kernels (filters), and the coefficients of these kernels are the weights that are optimized during training.
We show a sketch of convolution in Fig. 1: the convolutional kernel is represented by a 3 × 3 matrix, thus containing nine weights wij. The kernel scans the input coming from the previous layer, which, in this case, is a 3 × 5 pixels image. The kernel is applied to each sub-region of 3 × 3 pixels of the input image, and the result of the dot product between the two is saved in each pixel of the output layer:
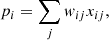 (3)
(3)
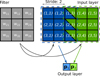 |
Fig. 1. Application of CNN convolutional filter to 2D image. The input image (shown as a colored matrix) contains 3 × 5 pixels, while the convolutional filter (in gray) is a 3 × 3 matrix. The filter moves across the input image and each time a dot product between the filter and the sub 3 × 3 portion of the image is performed. The result of the product is stored in the output. In this example the filter is not applied to all the possible 3 × 3 partitions of the input image but jumps one pixel at every move (the way the filter moves across the image is controlled by the stride parameter, which in this case is equal to 2 as the filter is translated by two pixels at every move). The filter elements wij represent the weights of the network which are optimized during training, and do not change while the filter moves. In this example, the value of each pixel in the output layer is the result of the dot product between the filter and the image pixels in the two squares centered on (2, 2) and (2, 4). |
where indices xij are the elements of the 3 × 3 portion of the input image. The number of pixels in the output depends on the dimension of the input, the dimension of the kernel, and the way the kernel moves across the input image (see caption of Fig. 1). Once the output is computed, the non-linear activation function is applied to its elements, and this becomes the input of the following layer. In CNNs, training is done as for the fully connected ones, by minimizing a cost function through the application of the network on a training set.
In Fig. 1, we applied the convolutional layer to a 2D image. Nevertheless, CNN can be applied to inputs with other dimensionality, such as 3D images (where, typically, the third dimension deals with the color channels) or to 1D vectors. In the latter case, the kernel is a 1D vector as well, scanning the input vector and applying the dot product on a portion of it.
The fact that CNNs retain the local information of the inputs while performing the convolution on adjacent pixels makes them an extremely powerful tool for pattern recognition. In classification and regression problems, CNNs are often used to extract synthetic information from input data. Typically, this requires some operation that reduces the dimensionality of the input, which is usually done using pooling layers. A pooling layer partitions the input coming from the previous layer into sets of contiguous pixels and applies some operation on each set. Therefore, a pooling layer performs some down-sampling operation; typical examples are: (1) the computation of the average over the pixels within the partition (average pooling), or (2) the extraction of the pixel with the minimum/maximum value in the partition (min or max pooling).
3. CNNs on the HEALPix sphere
The CNN concepts and examples introduced in Sect. 2 are typically applied to Euclidean domains (e.g., 1D vectors and planar images). Nevertheless, it is of great interest to extend the method to signals projected on the sphere. This would have general applications3 and would also be extremely interesting for those astrophysical and cosmological fields that need to study large parts of the celestial sphere.
In this work, we present a novel pixel-based algorithm to build spherical CNNs, having in mind applications related to cosmological studies. Our implementation relies on the HEALPix (Hierarchical Equal Area iso-Latitude Pixelization) tessellation scheme, which we briefly introduce in the next section.
3.1. The HEALPix spherical projection
The HEALPix tessellation of the sphere was presented by Górski et al. (2005). HEALPix partitions off the spherical surface into 12 base-resolution pixels, and it recursively divides each of them into 4 sub-pixels till the desired resolution is reached. The number of time a sub-division is applied to the base pixels is equal to log2(Nside), where the parameter Nside is linked to the resolution of the map. The value of Nside must be a power of 2, and the number of pixels on the map is 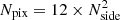 .
.
A signal projected on the sphere with the HEALPix scheme is usually encoded in the computer’s memory as a vector, with each element being associated to a single pixel on the map, following a specific order. Two ordering schemes exist; (a) ring order sorts pixels according to iso-latitude rings, and (b) nested order makes use of the hierarchical structure of the tessellation to enumerate pixels. Once the ordering scheme is picked, and for a fixed value of the Nside parameter, the association between the vector elements and the map pixels is uniquely defined4.
HEALPix has been widely used, with applications not only in multiple branches of astronomy and astrophysics (e.g. analysis of CMB maps Planck Collaboration I 2016, high-energy sources Fermi Collaboration 2015, large-scale structure Percival et al. 2007; Anderson et al. 2012, astroparticle physics IceCube Collaboration 2014, exoplanetary searches Robinson et al. 2011; Majeau et al. 2012; Sullivan et al. 2015, astrohydrodynamics Bryan et al. 2014, gravitational-wave astronomy Singer & Price 2016, etc.) but also in other fields, such as the geophysical one (Westerteiger et al. 2012; Shahram & Donoho 2007). Algorithms able to apply CNNs on spherical maps projected with the HEALPix scheme, as the one presented in this work, have therefore the potential of being of large interest, with possible applications in several different contexts.
3.2. Description of the HEALPix CNN algorithm
The algorithm that we propose implements CNNs over HEALPix maps preserving the local information of the signal by applying kernels to pixels close to each other. We describe the details of this process in the following sections.
3.2.1. Convolutional layers on a sphere
The majority of pixels in the HEALPix scheme has eight adjacent neighbors (structured with a “diamond” shape). Standard HEALPix libraries implement algorithms to find and enumerate them. In particular, for a given pixel labeled by the index p, these functions return the indices of its eight closest neighbors following some pre-defined ordering (N-W, N, N-E, E, S-E, S, S-W, and W). However, a few pixels (24 for Nside ≥ 2) have only 7 neighbors: this happens for those pixels along some of the borders of the 12 base-resolution ones, as shown in Fig. 2.
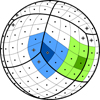 |
Fig. 2. Tessellation of a sphere according the HEALPix scheme. In this figure the pixel resolution corresponds to Nside = 4 (Npix = 192). Almost every pixel in a HEALPix map has 8 neighbors; however, a few pixels only have 7 of them. In this figure, the blue pixel has 7 neighbors, while the green one has 8. Black dots represent pixel centers; seven-neighbor pixels are highlighted with grey diamonds. These pixels are at the intersection of three base-pixels (delimited using thick lines); this kind of intersection occurs only near the two polar caps, and in any map with Nside ≥ 2 there are exactly 8 of them. Thus, the number of seven-neighbor pixels is always 24 (because of the nature of the orthographic projection used in this sketch, only 9 seven-neighbor pixels are visible). |
Our convolutional algorithm makes use of the possibility to quickly find neighbor pixels in the following way (see Fig. 3):
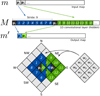 |
Fig. 3. Sketch of the convolution algorithm developed in this work. The elements p1 and p2 of the vector m correspond to two pixels on map (in this case 0 and 4). p1 and p2 are associated to nine elements each, in vector M. The first of this nine elements corresponds to the pixel itself, while the subsequent ones corresponds to its eight neighbors. The neighbors are visited, and unrolled in the M vector, following a clockwise order staring from the NW direction. The filter (in grey) is also unrolled in a nine element long vector, using the same convention. Convolution is then implemented as a standard 1D convolutional layer with a stride of 9, and the output is the m′ convolved vector (map), which has the same number of elements (pixels) as the input m. In the figure, numbers over the pixels do not represent the values of the pixels but their unique index: in practical applications, these indices will be those associated to an ordering scheme and a map resolution Nside. Colors are the same as in Fig. 1, to underline the similarity. |
1. The input of the convolutional layer is a map (or a set of maps) at a given Nside, which is stored in a vector m of Npix elements.
2. Before applying the convolution, the vector m is replaced by a new vector M with 9 × Npix elements. We associate each element p in m with nine elements 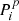 of M (i = 0…8), setting
of M (i = 0…8), setting 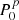 equal to the value of the pixel p itself and the others equal to the values of the eight neighbors of p, following the clockwise order specified above. Pixels with 7 neighbors are still associated with 9 elements of M, but the element corresponding to the missing pixel is set to zero.
equal to the value of the pixel p itself and the others equal to the values of the eight neighbors of p, following the clockwise order specified above. Pixels with 7 neighbors are still associated with 9 elements of M, but the element corresponding to the missing pixel is set to zero.
3. Once the vector M is generated, a 1D convolution is done in the standard way: a nine element long 1D kernel, with elements wi, is applied to M. This convolution is done with a stride parameter equal to 9, meaning that the kernel is not applied to all the elements of the M vector, but it makes a jump of nine of them at each move. This is equivalent to the convolution of each pixel with its 8 closest neighbors. The elements wi of the kernel represent the weights that the network needs to optimize during the training phase.
4. The output of this operation is a new vector m′ with Npix elements, corresponding to the convolved map.
To visualize how convolution works we have prepared a simple example described in Appendix A.
The algorithm presented above has a few interesting properties. Firstly, the search of pixel neighbors needs to be done only once for each Nside value: the re-ordering scheme that brings a map m into M is always the same once Nside is fixed, and re-ordering operation of a vector is computationally extremely fast. Secondly, the convolution is pixel based, therefore there is an immediate analogy between standard Euclidean convolution and this implementation of a spherical one. Lastly, since the operation is the 1D convolution between a kernel and a vector, it can be performed using the highly-optimized NN libraries commonly available today (e.g., TensorFlow, PyTorch, Theano, Flux, etc.)
On the other hand, our algorithm suffers from one main downside: unlike other spherical CNNs recently introduced in literature (e.g. Cohen et al. 2018; Perraudin et al. 2019), we lose the notation of rotation equivariance. This makes our network less efficient, meaning that it needs a larger set of data to be properly trained and that its final accuracy could be sub-optimal. We discuss this point in Sect. 3.2.2.
3.2.2. Pooling layers on a sphere
As we have seen for standard CNNs (Sect. 2.2), pooling layers are useful for lowering the resolution of the network inputs. The hierarchical nature of the HEALPix scheme naturally supports pooling operations, as each pixel in a low-resolution map is mapped to four (or more) sub-pixels in a higher resolution map. In our algorithm, pooling is easily implemented in one dimension using the same approach described in Sect. 3.2.1 for convolution. For each pooling layer, the input vector m containing a map with Npix pixels is converted to HEALPix nested ordering, and a standard 1D pooling (either min, max, or average) is applied with a stride of 4. This process turns a map with resolution Nside to a map with Nside/2 Fig. 4 sketches the process.
 |
Fig. 4. Sketch for the implementation of pooling layers on HEALPix maps. Since a map with Nside > 1 can be degraded to a map with Nside/2, thanks to HEALPix hierarchical construction, pooling can be implemented naturally using standard 1D pooling layers, if pixels of the input vector (map) m are properly ordered and a stride equal to 4 is used. |
3.2.3. Related works on spherical CNNs
In the last few years, several works have studied the possibility to apply CNNs to extract informations from signals projected on the sphere. The simplest idea for achieving the goal relies on using standard 2D Euclidean CNNs on planar projection of the sphere, such as the equirectangular one (e.g., Hu et al. 2017; Boomsma & Frellsen 2017). These approaches are easy to implement, but they suffer from the fact that any planar projection of the sphere causes distortions. This problem has been addressed by the CNN implementation described in Coors et al. (2018) where the sampling location of the convolutional filters is adapted in order to compensate distortions. A second approach described in literature requires to project the spherical signal to tangent planes around the sphere, and then to apply standard 2D CNNs to each of these planes (e.g., Xiao et al. 2012). In the limit of making the projection on every tangent plane, this strategy is accurate, but requires large computational resources. Su et al. (2017) proposed a combination of the two approaches by processing spherical signals in their equirectangular projection and mimicking the filter response as if they were applied to the tangent planes.
All the methods described above propose CNNs that are not rotationally equivariant. Rotational equivariance means that if R ∈ SO(3) is a rotation and f is the convolution operation applied to some input x, its output y = f(x) is such that f(R(x)) = R(y), ∀R. A non-equivariant CNN architecture causes the learning process to be sub-optimal, as the efficiency in filter weight sharing is reduced.
Cohen et al. (2018) proposes the first spherical CNN with the property of being rotational equivariant. Its approach uses a generalized fast Fourier Transform (FFT) algorithm to implement convolutional layers in harmonic domain. Their network is very accurate in 3D model recognition; however, it is computationally expensive, as the computation of spherical harmonics is a O(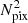 ) operation.
) operation.
While we were in implementing the spherical CNN described in this paper, Perraudin et al. (2019) presented an algorithm to apply the HEALPix tessellation of the sphere to CNNs. Their implementation, called DeepSphere, uses graphs to perform convolutions. It has the advantage of being computationally efficient, with a computational complexity of O(Npix) and to be adaptable to the analysis of signals that only partially cover the spherical surface. Moreover, by restricting to filters with radial symmetry, their network is close to be rotational equivariant.
Our CNN is specifically built to run on HEALPix, without requiring any other projection of sphere. Similarly to DeepShpere, it is computational efficient, scaling as O(Npix), and it is applicable to partially-covered spherical surfaces. Moreover, since the convolution operation ends up in being a traditional 1D convolution, our algorithm has the advantage of being fully integrated in exiting libraries for NNs, like TensorFlow, and can therefore rely on years of algorithmic optimization of the convolution in the context of deep learning. On the other hand, the main drawback is the lack of rotation equivariance, which is due to three factors. Firstly, although covering all the same area, pixels in the HEALPix tessellation have different shapes, depending on their position on the sphere (see Fig. 2). This causes some degree of distortion, especially close to the poles. Secondly, as described in Sect. 3.2.1 and Fig. 2, in every HEALPix sphere there are 24 pixels with only seven neighbors instead of eight. This causes distortions that mostly affects convolution on low resolution maps (i.e., small values of Nside). Lastly, in this first implementation of our algorithm we do not force filters to have radial symmetry. This makes the efficiency of our network sub-optimal. However, the good performance of our algorithm in the applications that we present in Sects. 5 and 6 shows the validity of our approach in the present case.
It would be interesting to compare our results with the ones of other networks that encode equivariance. However, the spherical CNN introduced by Cohen et al. (2018) is not developed to run on HEALPix; adapting the code would require an amount of work that is outside the scope of this paper. On the other hand, DeepSphere computes convolutions on the HEALPix sphere, similarly to our approach. Nevertheless, the main goal of this paper is to test the feasibility of our algortihm in estimating cosmological parameters that affect the large scales of CMB polarized maps (tensor fields), as described in Sect. 6.2. DeepSphere has not been tested on this kind of analysis yet, as Perraudin et al. (2019) only applied their code to a classification problem performed on scalar fields. Therefore, we defer this comparison to some future works.
4. Working environment and NN architecture
In this section we briefly describe the working environment used to develop and train the NNs that implement the spherical convolutional layers introduced previously. We also present the network architecture used in the applications described in Sects. 5 and 6.
4.1. Working environment
We have implemented the algorithm to apply CNNs on the HEALPix sphere in the Python programming language. We have taken advantage of the existing healpy package5, a Python library specifically built to handle HEALPix maps.
As we emphasized in Sect. 3, our implementation of convolutional and pooling layers ends up in being a sequence of operations on 1D vectors, which can applied using existing NN libraries. In our work, we have employed the Keras package6, with TensorFlow backend7 to build, test, and train CNNs.
We have used the computing facilities provided by the US National Energy Resource Scientific Computing Center (NERSC) to perform training. As NERSC does not provide GPU computing nodes at the moment, we relied on CPU-based training architectures. In order to parallelize the computation and make the training more efficient, we used the Horovod package (Sergeev & Balso 2018) to distribute the workload over cluster nodes using MPI8.
4.2. Network architecture
Using the convolutional and pooling layers described in Sects. 3.2.1 and 3.2.2, we have built a full deep CNN that we have applied to the examples reported in the following sections. For all our applications we have used a single network architecture, changing only the output layer depending on the problem addressed.
We have implemented this CNN architecture by stacking several instances of a Network Building Block (NBB) with the following structure (see left panel of Fig. 5):
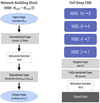 |
Fig. 5. Left panel: basic Network Building Block (NBB). Right panel: full deep CNN architecture. |
1. The first layer in the NBB accepts one or more HEALPix maps with the same resolution parameter Nside and performs a convolution with N filters, according to the algorithm described in Sect. 3.2.1 and Fig. 3, then applying an activation function;
2. The next layer contains an average-pooling operation (see Sect. 3.2.2 and Fig. 4);
3. As a result, the NBB lowers the resolution of the input maps from Nside to Nside/2.
In all our applications, the input of the network is a set of HEALPix maps at Nside = 16 (each map has 3072 pixels, each of which covers an area of about 13 deg2 on the sphere). We have built the full deep CNN by stacking together four NBBs, going from maps at Nside = 16 to Nside = 1. In each convolutional layer, we convolve the input maps with N = 32 filters. We use a rectified linear unit (ReLU) as the activation function in the NBB.
After the four building blocks, we include a dropout layer, with a dropout rate set to 0.2, in order to avoid overfitting9. Subsequently, the 32 output maps are flattened into one vector, which is fed to a fully connected layer with 48 neurons activated via a ReLU function. The shape of the output layer and its activation function depend on the kind of problem considered. The full CNN architecture is shown on the right panel of Fig. 5.
This architecture, which convolves maps at decreasing angular resolution while moving forward in the network, makes each layer sensitive to features on map laying at different angular scales. As it will be described in the following, this is an important property for the proposed applications.
5. Application to the MNIST dataset
The first application of the algorithms presented in this work is the classification of handwritten digits projected over the sphere. We have used images from the MINST image database10, a publicly available database containing 70 000 grayscale 28 × 28 pixels images with handwritten digits (having a repartition between training and test set with a proportion 6 : 1).
We have chosen this example, despite being of little relevance for astrophysics, because the MNIST dataset is widely used to test the performance of machine learning algorithms, and it is currently considered one of the standard tests to check how well automatic classifiers perform. Moreover, the performance of CNNs depends critically on the existence of a large and reliable training set, and MNIST satisfies this requirement.
5.1. Projection
To use MNIST images in our tests we need to project them on the HEALPix maps. We have therefore developed a simple algorithm to project a rectangular image over a portion of the sphere, as shown in Fig. 6. We consider the image as placed on a plane in 3D space, perpendicular to the Equatorial plane of the celestial sphere; the point at the center of the image is on the Equatorial plane. We use a ray tracing technique, firing rays from the center of the sphere against pixels in the plane and finding their intersection with the sphere. We fill each pixel on the HEALPix map hit by a ray with the value of the corresponding pixel in the plane figure. We fire a number of rays sufficient to cover all the HEALPix pixels in the portion of the sphere where we want to project the image, and we bin multiple hits that fall in the same spherical pixel with an average. In this way, the image on the sphere is smooth and has no holes. After the image has been projected with its center on the Equator, the code applies a rotation, in order to center the image on a user-defined point on the sphere.
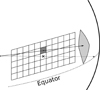 |
Fig. 6. Method used to project MNIST images on the sphere. The image is aligned so that the center of the pixel in the middle (marked with a ×) is on the Equatorial plane. A number of rays are fired, originating from the center of the sphere, targeting each of the pixels in the image, and the intersection with each pixel on the sphere is computed. In order to cover all the pixels on the sphere, the angular separation among rays is 1/2 of the angular resolution of the HEALPix map. |
5.2. Training and results
We have performed the training of the NN on the Cori cluster at NERSC, with the working environment and network architecture described in Sect. 4. In particular, since this application of our algorithm is a classification problem the last layer of the CNN contains 9 densely-connected neurons, corresponding to the nine different classes of our problem11. We have used a Softmax activation function for the last layer, as this is the typical choice for classifiers.
To generate the training set, we have taken 40 000 images out of the MNIST database, and we have projected them on the HEALPix sphere, randomizing on the position, rotation, and size of each image. Each projected image has random dimensions with 120 ° < θ < 180° and 120 ° < φ < 360°, therefore covering a large portion of the sphere. We have used this basic data-augmentation to produce a training set of 100 000 different images. The validation set is composed by 10 000 randomly projected images, taken from the remaining 10 000 ones of the MNIST training set.
We have adopted the mean squared error as the loss function for training, and categorical accuracy as the metric to assess the NN performance. We have used the Adam optimizer on mini-batches of 32 samples, with learning rate equal to 10−3 in the first step and then divided by 10 every time the validation loss has not improved for 5 consecutive epochs. We stopped the training after twenty epochs without improvement. Each epoch required ∼350 s; training stopped after 50 epochs, for a total of less than 5 h of wall-clock time. Figure 7 reports the training history of the network. The accuracy achieved on the validation set is ∼95%. The network did not show overfitting, but it generalized well the performance from the training set to the validation one.
 |
Fig. 7. Learning history for the CNN applied to the MNIST dataset projected on the sphere. |
We have generated 10 000 randomly projected images from the MNIST database to be used as test set, using the same data-augmentation described above. The error we achieved on the test set is about 4.8%. This error is comparable to the one obtained for the classification of the MNIST dataset projected on the sphere by Cohen et al. (2018).
As discussed in Sect. 3.2.2 our CNN is not rotationally equivariant and distortions, due to the different pixel shapes, could affect the network performance, especially close to the poles. For this reason we have checked that, once trained, the network is able to classify handwritten digits with the same accuracy, independently from their position on the sphere. To do so, we have tested the network on three different groups of images, each containing 100 different sets of 300 images for a total of 30 000 samples for group. The three groups differed only in the region of the sphere where we projected the image:
-
1.
images in the first group were projected at random points along the Equator;
-
2.
images in the second group were projected near the North Pole;
-
3.
images in the third group were projected in random positions on the sphere.
We show examples from each group in the first, second and third raw of Fig. 8 respectively. We report results in Fig 9 for each group, we provide the histogram of the final error for the one hundred different test sets. The three distributions are close to each other, showing that the network performs equally and independently on the position of the object on the sphere.
 |
Fig. 8. Projection of a MNIST image (upper panel) on the HEALPix sphere. The same image is projected along the Equator (first row), around the north pole (second row) and at a random position on the sphere (third row). For each case, we show the map using the Mollweide projection (first column), an Orthographic projection centered on the Equator and at the north and south poles. The resolution of the projected maps corresponds to Nside = 16. |
 |
Fig. 9. Distribution of NN error on three groups of test sets, where MNIST images have been projected: (i) at the north pole (blue), (ii) at the equator (purple) and (iii) on random positions on the sphere (black). Each group is composed by 100 test sets of 300 images each. |
6. Parameter estimation for CMB
As a second application of our algorithm, we have applied CNNs on the sphere to a regression problem. Our objective was to assess the performance of the NN when applied to the estimation of parameters defining the properties of a Gaussian scalar or tensor field on the sphere. This represents the main goal of this explorative work: to understand whether our spherical CNN implementation is suitable to be applied to this kind of problem.
The CMB represents the relic radiation from the Big Bang, emitted when the universe was about 380 000 years old, after the decoupling of matter and photons. It has a blackbody spectrum at the temperature of ∼2.7 K and it shows a high level of isotropy in the sky. Anisotropies in its temperature, which represent the trace of primordial fluctuations, are of the order of ΔT/T ≃ 10−5. The CMB signal is linearly polarized due to Thomson scattering of photons with free electrons in the primordial universe. A net linear polarization can be generated only when this scattering occured in the presence of a quadrupole anisotropy in the incoming radiation. Since only a small fraction of photons lastly scattered under this condition the polarization fraction of the CMB radiation is rather small, at the level of about 10%.
In the last decades, several experiments have measured the CMB anisotropies12, in both total intensity and polarization, making the study of the CMB radiation one of the fundamental branches of modern observational cosmology. In particular, information on the origin, evolution and composition of our Universe can be extracted with a statistical analysis of the CMB temperature and polarization fields used to estimate the values of the cosmological parameters). As primordial CMB fluctuations can be considered as a Gaussian field all the information is encoded in their angular power spectrum. Classical methods for parameter fitting rely on Bayesian statistics: the values of cosmological parameters, defining the properties of our Universe, are typically extracted through the maximization of a likelihood function computed from the angular power spectra of CMB sky maps.
Recently, several works have explored the possibility to estimate cosmological parameters directly from CMB maps using NNs without the computation of angular power spectra. He et al. (2018) have successfully used deep residual CNNs to estimate the value of two cosmological parameters from CMB temperature sky maps, in the flat sky approximation. the DeepSphere algorithm presented by Perraudin et al. (2019) have been tested to classify weak lensing convergence maps (which are scalar fields similarly to CMB temperature maps) generated from two sets of different cosmological parameters. Caldeira et al. (2019) also have applied CNNs to the field of CMB science, extracting the projected gravitational potential from simulated CMB maps whose signal is distorted by the presence of gravitational lensing effect.
As pointed out by the authors of these papers, the possibility to complement traditional Bayesian methods for cosmological parameter estimations with innovative network-based alternatives could represent an important tool to cross-check results, especially in the case where the hypothesis of signal Gaussianity does not hold. This happens if the CMB primordial radiation is contaminated by non-Gaussian spurious signals, such as residual instrumental systematic effects or Galactic emissions.
In the following sections, we demonstrate that the algorithm presented in this work has the potentiality to be used for this purpose. We have first applied the NN to a “mock” cosmological parameter, in order to asses its ability to perform regression and estimate it directly from maps (Sect. 6.1). We have then tested the NN performance on the estimation of the value of τ, one of the six fundamental cosmological parameters of the ΛCDM model, which quantifies the Thomson scattering optical depth at reionization, on simulated maps (Sect. 6.2).
6.1. Position of a peak in the power spectrum
We have assessed the ability of our CNN to estimate the value of a mock cosmological parameter in pixel-space. This parameter, ℓp, defines the angular scale of the peak of a random Gaussian field in the power spectrum. We have constructed simulated maps starting from power spectra having the following form:
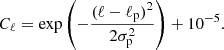 (4)
(4)
The peak in the power spectrum is centered around multipole ℓp, with standard deviation13σp. We have fixed the value of σp = 5, while we have varied the value of the parameter ℓp in the range of multipoles between 5 and 20. Examples of these power spectra, for different values of ℓp, are shown in Fig. 10.
 |
Fig. 10. Power spectra computed according to Eq. (4). The ℓp parameter, defining the position of the peak, varies in the multipole range 5−20. |
To assess the feasibility of CNNs to retrieve cosmological parameters under different conditions, we have estimated the value of ℓp in the following cases: on scalar and tensor fields, with or without noise, in the case of full or partial sky coverage, as described in the following sections.
6.1.1. Application to a scalar field
We have constructed the training, validation and test sets by simulating maps as random Gaussian realizations of the power spectra defined in Eq. (4) using the synfast module in the healpy package. We have generated a scalar field projected on the sphere for each spectrum, corresponding to a temperature map in the CMB terminology. Maps have been simulated from spectra with ℓp randomly chosen from a uniform distribution in the interval 5−20 at the resolution corresponding to Nside = 16. We have not included noise in this first test.
We have used the working environment described in Sect. 4. We have used 100 000 maps for the training set, and 10 000 maps for the validation set; we have considered different seeds and ℓp values for each each map. The network architecture is the same as the one applied to the MNIST example (see Sect. 4.2), with the only exception of the last layer: as our goal was to estimate the parameter ℓp, the output layer contained one single neuron. We have trained the network using a mean squared error as loss function, and we have monitored the accuracy of the network using the mean percentage error on the validation set. Training has been done with Adam optimizer and learning rate decay, as for the MNIST case, on mini-batches of 32 sample. The convergence took place after 70 epochs14, for a total of about 6 wall-clock hours of training.
We have applied the trained network on a test set, composed by 1000 maps simulated as before, and we have compared the results reached with the network with those obtained with standard Bayesian method. In the latter case, we have estimated the ℓp parameter from the power spectrum of each map of the test set (computed with the anafast module within healpy), using a Markov chain Monte Carlo (MCMC) algorithm to maximize the following χ2 likelihood:
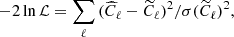 (5)
(5)
where 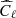 is derived from the reference model (in this case,
is derived from the reference model (in this case, 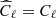 from Eq. (4)),
from Eq. (4)), 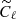 are computed from the simulated map and
are computed from the simulated map and 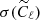 represent their uncertainties. Since we have been running on simulations, we assume that
represent their uncertainties. Since we have been running on simulations, we assume that 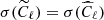 , with the signal variance equal to
, with the signal variance equal to
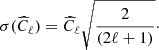 (6)
(6)
We fit the power spectra up to ℓmax = (3Nside − 1) = 47.
The mean error obtained with CNN on the test set is ∼1.3%, while the error of the MCMC fit is ∼0.7%. Although the standard Bayesian method performs about twice as good as the NN, there are two important considerations to be made, which make the network performance remarkable:
i. We have not optimized our network architecture, as we have used the same architecture described in Sect. 4.2 adapted to the regression problem. Indeed, as already emphasized, the goal of our work is not to find the best architecture for a given problem, but to prove the feasibility of our approach. An optimized architecture could therefore lead to better results in the estimation of the ℓp parameter.
ii. Contrary to the standard maximum likelihood approach applied to power spectra to fit for the value of ℓp, the estimation with the network does not make any assumption on the Gaussianity of the signal.
We have also tested the network performance in the presence of white noise. We have considered three levels of noise on maps, with standard deviation σn = 5, 10, 15, corresponding to a signal-to-noise ratio15 of about 1, 1/2 and 1/3. For each of the three noise levels, we have trained a new NN, with the same architecture defined above and a training set containing 100 000 signal+noise maps. We have generated each map as a Gaussian realization of the power spectrum of Eq. (4) plus Gaussian noise. The training strategy has been the same used for the noiseless case.
As in the previous case, we have compared the results from CNN with the ones coming from standard MCMC fitting on a test set of 1000 maps, for each of the three noise levels. When fitting for the value of ℓp from the power spectra, we have taken into account the fact that the presence of noise on maps induces a bias on the auto-spectra 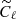 , which must be considered while maximizing the likelihood in Eq. (5). Therefore, in this case, the reference model becomes:
, which must be considered while maximizing the likelihood in Eq. (5). Therefore, in this case, the reference model becomes:
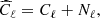 (7)
(7)
with Cℓ from Eq. (4) and Nℓ being the noise power spectrum. In the case of homogeneous white noise with standard deviation σn on a map with Npix = 12 × 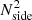 , the noise power spectrum is:
, the noise power spectrum is:
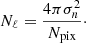 (8)
(8)
We present a summary of the results obtained with the NN and with the MCMC approach in Table 1. For each noise level used in the simulation, we report the mean percentage error on the estimated values of the ℓp parameter computed over the entire test set. In Fig. 11, we show the distribution of the estimated values of ℓp around the true ones for each noise level, considering both approaches. Even in the presence of noise, the accuracy is comparable with the one reached with the MCMC fit.
Summary of the results obtained in the estimation of the ℓp parameter from the neural network and the MCMC fit, for the noiseless case and the three considered noise levels.
 |
Fig. 11. Comparison of the results obtained in the estimation of the ℓp parameter with the neural network and with the MCMC fit, for the noiseless case and for the three considered noise levels. |
6.1.2. Application to a tensor field
We have tested the ability of the network to estimate ℓp also in the case of a tensor field projected on the sphere. This is analog to the case of CMB polarization measurements, and it is of great importance, as current CMB experiments are mainly focusing on polarization observations.
The CMB signal is linearly polarized, with a polarization fraction of about 10%, and with amplitude and orientation defined by the Stokes parameter Q and U. Although CMB experiments directly measure the amplitude of Stokes parameters across the sky, producing Q and U maps, these quantities are coordinate-dependent. Therefore, it is more convenient to describe the CMB field using a different basis, dividing the polarization pattern according to its parity properties and using the so-called E-modes (even) and B-modes (odd). The use of the (E, B) basis is convenient also from a physical point of view, as these modes are sourced by different types of perturbations in the primordial universe, with B-modes produced by tensor (metric) perturbations.
Using tensor spherical harmonics, the polarization tensor field can be described in terms of E and B power spectra, which, as for the case of a scalar (temperature) field, give a complete description of the signal statistics in case of a Gaussian field.
For our exercise, we have used the model in Eq. (4) to build E and B-mode power spectra: from those, we derive Stokes Q and U maps with Nside = 16. For each pair of maps we have considered polarization power spectra with values of the parameters 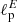 and
and 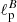 different from each other and randomly draw from a uniform distribution in the multipole interval 5−20.
different from each other and randomly draw from a uniform distribution in the multipole interval 5−20.
In this application, the purpose of the NN was to estimate the values of both 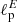 and
and 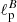 having as input a pair of Q and U maps. In order to do so, we slightly change the input and output layers of the network: the input layer accepts two maps (Q and U) instead of one, and the output layer emits two scalar values (
having as input a pair of Q and U maps. In order to do so, we slightly change the input and output layers of the network: the input layer accepts two maps (Q and U) instead of one, and the output layer emits two scalar values (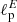 and
and 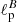 ). The other network layers share the same architecture used for the recognition of the MNIST dataset in Sect. 5 and for the regression problem on a scalar field in Sect. 6.1.1.
). The other network layers share the same architecture used for the recognition of the MNIST dataset in Sect. 5 and for the regression problem on a scalar field in Sect. 6.1.1.
The training set was composed by 100 000 pairs of Q and U maps, generated from 100 000 pairs of E and B spectra, and the validation set contained 10 000 pairs of maps. We have trained the network using the same procedure described in Sect. 6.1.1: we have minimized a mean squared error loss function, reaching convergence on the validation set after about 7 h of training.
As before, we have assessed the performance of the NN on a test set of 1000 samples. The mean percentage error on the estimation of 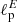 and
and 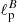 is about 2.7% on the test set. This number needs to be compared with the accuracy that can be reached with standard MCMC fitting. In this case we have estimated
is about 2.7% on the test set. This number needs to be compared with the accuracy that can be reached with standard MCMC fitting. In this case we have estimated 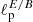 by computing the E and B-mode power spectra of the test maps, and by minimizing, separately for the two spectra, a chi squared likelihood (see Eqs. (5) and (6)) as we did for the scalar case. The mean percentage error that we get in on both
by computing the E and B-mode power spectra of the test maps, and by minimizing, separately for the two spectra, a chi squared likelihood (see Eqs. (5) and (6)) as we did for the scalar case. The mean percentage error that we get in on both 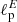 and
and 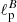 from this standard fitting procedure is about 0.7% (analogous to the scalar case).
from this standard fitting procedure is about 0.7% (analogous to the scalar case).
Although it is true that for polarization field the NN performs worse than the standard MCMC approach, it is important to notice that, with this simple exercise, we demonstrate for the first time that the network can still discern between E and B-modes and fit for two parameters that independently affect the statistics of the two polarization states. Also, as already emphasized, we have not optimized the network architecture, but have stuck to the one used also for the other examples presented in this work. However, as in this case the network needs to map a more complicated function to distinguish the two polarization modes, it is worth expecting that lager network could perform better, possibly approaching the MCMC accuracy.
Another important test that can be done with tensor fields projected on the sphere, is the evaluation of parameters from partially covered maps. Ideally, one would expect the uncertainty on cosmological parameter to scale as 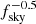 , at the first order. However, the computation of power spectra on patches of the sky is problematic, as masking induces correlation between Fourier modes and mixing between polarization states. These effects can lead to biases in the estimation of cosmological parameters from spectra, as well as to an increase variance, especially when large scales (low multipoles) are considered. Sophisticated power spectrum estimators, correcting for multipole and polarization state mixing, are currently used to mitigate this problem (Tristram et al. 2005; Grain et al. 2009). It is therefore interesting to understand how the NN accuracy scales as a function of the considered sky fraction.
, at the first order. However, the computation of power spectra on patches of the sky is problematic, as masking induces correlation between Fourier modes and mixing between polarization states. These effects can lead to biases in the estimation of cosmological parameters from spectra, as well as to an increase variance, especially when large scales (low multipoles) are considered. Sophisticated power spectrum estimators, correcting for multipole and polarization state mixing, are currently used to mitigate this problem (Tristram et al. 2005; Grain et al. 2009). It is therefore interesting to understand how the NN accuracy scales as a function of the considered sky fraction.
In our test, we have considered four sky masks, obtained as circular patches in the sky, with retained sky fraction16 varying between ∼50% and ∼5% (Fig. 12). For each of the four masks, we have trained a new CNN, where the input simulated maps have been obtained as described before, but the Q/U signal outside the mask have been set to zero. The output of the networks is, as before, the pair of estimates for 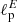 and
and 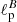 .
.
 |
Fig. 12. Four circular masks applied to the estimation of the |
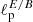
Results of are summarized in Table 2. The mean percentage error on the recovered 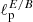 parameter scales roughly as
parameter scales roughly as 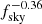 , meaning, therefore, that the NN accuracy is closer to the optimal one for smaller masks (this could be due to the smaller amount of data that it needs to process) and that mixing between different modes and polarization states does not affect its performance.
, meaning, therefore, that the NN accuracy is closer to the optimal one for smaller masks (this could be due to the smaller amount of data that it needs to process) and that mixing between different modes and polarization states does not affect its performance.
6.2. Estimation of τ
In Sect. 6.1.2, we have showed that our network can estimate the value of simple parameters defined in Fourier space using data in pixel space as input. This proves that the spherical CNN algorithm presented in this paper works well for this kind of regression problems, making it suitable for estimating real cosmological parameters directly from CMB maps (either in total intensity or in polarization). Consequently, we have tested our network architecture on a more realistic case: the estimation of the value of the Thomson scattering optical depth at reionization.
CMB photons, released at the last scattering surface in the early universe, interact with free electrons of the intergalactic medium, ionized by the first emitting objects, at a redshift z between about 11 and 6, during the so-called reionization epoch. This causes modifications in the CMB signal both in total intensity and in polarization. In particular, for what concern the polarized signal, the effect is visible especially at the larger angular scales (for multipoles ℓ ≲ 20) as a bump in the E-mode power spectrum, caused by the new Thomson scattering events experienced by the CMB photons. The optical depth of Thomson scattering at reionization, usually indicated with the letter τ, parametrizes the amplitude and shape of this low-ell bump.
In order to constrain the value of τ, high sensitivity polarization observations on large portion of the sky are needed. Moreover, at the large angular scales affected by the reionization bump, spurious signals, coming either from instrumental systematic effects or from residual foreground emission, can strongly contaminate the measurements, making the estimation of this parameter particularly tricky. Currently, the tightest constraint available on the value of τ comes from the full sky observation of the Planck satellite, with τ = 0.054 ± 0.007 (68% confidence level; Planck Collaboration VI 2018). Among the six cosmological parameters of the standard ΛCDM model, τ is the parameter whose value is currently constrained with the largest uncertainty.
The peculiarity of τ makes it an interesting test case for parameter estimation using the algorithm presented in this work. Firstly, the fact that τ affects the large angular scales requires algorithms defined on the sphere, as the flat-sky approximation cannot be applied. Secondly, since mainly multipoles at ℓ ≲ 20 are affected by the parameter, low resolution maps (at Nside = 16) are sufficient to fit for τ: this makes the problem computationally feasible for CNNs. Lastly, the complexity in the estimation of τ calls for new analysis techniques that can complement standard parameter estimation routines, thus increasing the confidence on the results.
To estimate τ we have used a similar approach as the one described for the ℓp parameter, generating training, validation, and test sets from simulations. We have computed a set of five thousands E-mode power spectra, using the CAMB code (Lewis & Bridle 2002). Each spectrum has a different value of τ, uniformly distributed in the range 0.03−0.08, while the other cosmological parameters are fixed to the best ΛCDM model from Planck (Planck Collaboration VI 2018) (we show a subset of these spectra in Fig. 13). From these spectra, we have generated 100 000 pairs of full sky Q and U maps with Nside = 16 for the training set, and 10 000 and 1000 for the validation and test sets respectively17. We have not included any primordial or lensing B-mode signal.
 |
Fig. 13. Subset of the E-modes power spectra used to generate to polarization maps for training, validation and test set on which we run the neural network. The value of τ changes in the range 0.03−0.08 while all the other cosmological parameters are fixed to the best ΛCDM model from Planck results. |
We have used the same network architecture, working environment and training procedure described in Sect. 4, feeding the network with the simulated Q and U maps and producing an estimate for τ as the output. By running the CNN on full sky maps, we have obtained a network accuracy of about 4% (mean percentage error of τ values over the test set).
We have compared this number with the accuracy reachable through standard MCMC method. As for the previous example, we have maximized the simple chi-squared likelihood of Eq. (5) to fit for the best value of τ, where the model 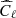 represents the theoretical E-mode power spectrum, and
represents the theoretical E-mode power spectrum, and 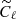 are computed from the test set polarization maps. The accuracy reached with this method is about 2.8%, a factor ∼1.5 better than the NN one.
are computed from the test set polarization maps. The accuracy reached with this method is about 2.8%, a factor ∼1.5 better than the NN one.
Although the NN average error is larger, we believe that this result demonstrates that our CNN algorithm could be a feasible approach to constraint the value of τ. Obviously, a complete analysis to understand its real potentiality is needed, including the addition of realistic noise, sky masking, optimization of the NN architecture, error estimation, and so on. However, this is outside the objective of the present work and is hence deferred to a dedicated paper.
7. Discussion and conclusions
In this work, we have presented a novel algorithm for the application of CNNs to signals projected on the sphere. We considered the HEALPix tessellation, which allowed us to easily implement convolutional and pooling layers on a pixel domain. The HEALPix pixelization scheme is used in several scientific fields; therefore, the implementation of efficient and compatible CNN algorithms can be of great interest in several contexts.
Our algorithm presents some main advantages. Firstly, convolution is done in the pixel domain, as for standard 1D Euclidean cases: this allows the construction, training, and testing of the CNNs using the existing highly-optimized neural network libraries, such as PyTorch and TensorFlow. Moreover, the algorithm is computationally efficient, with a computational complexity that scales as O(Npix). Lastly, the process can be easily optimized to run only on portion of the sphere.
On the other hand and contrary to other spherical CNNs recently introduced in literature (Perraudin et al. 2019; Cohen et al. 2018), our implementation is not rotationally equivariant. Although this makes the network sub-optimal, the good results obtained on our applications show that training makes the CNN able to overcame this deficiency.
We have built a simple network architecture, which includes four convolutional and pooling layers. Therefore, convolution is applied to maps at decreasingly lower resolutions, making the network sensitive to feature at different angular scales. The same architecture has been used for all the applications presented in this work.
We have first tested the feasibility of our approach on the recognition of handwritten digits (MNIST dataset) projected on the HEALPix sphere. Results show that the trained CNN can recognize handwritten digits that cover large portion of the sphere, with an accuracy of about 95%, a performance comparable with other kinds of spherical NNs. As our network is not spherical invariant, it must be trained with images projected at different positions and orientations on the sphere. When properly done, the performance of the CNN is independent on the position and orientation of images.
We have then moved to applications related to the Cosmology field. In particular, we have applied CNNs to the estimation of cosmological parameters from CMB simulated observations, impacting the very large angular scales (ℓ ≲ 20), directly from temperature or polarization sky maps. This work represents the first one in which NNs are tested on such a task.
We have started with the estimation of a mock parameter, ℓp, defining the angular scales at which the power spectrum of a Gaussian field projected on the sphere peaks. We have used the same network architecture applied the MNIST recognition, changing only input and output layers depending on whether we fit for the value of ℓp in temperature or polarization.
For the temperature case (scalar field projected on the sphere) we have applied the network to both noiseless or noisy maps, showing that it is able to correctly retrieve the value of ℓp. The reached accuracy is comparable with the one obtained from the estimation with standard bayesian methods applied to the angular power spectra computed from maps. In particular, for the noiseless case, CNNs preform about a factor two worse then standard methods, but this factor move close to one for the noisy maps.
We have applied the same CNN architecture also to maps in polarization (tensor field projected on the sphere). In this case we fed the network with pairs of Stokes Q and U maps, retrieving the values of two parameters 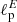 and
and 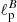 , representing the angular scales at which the polarization E and B-mode power spectra peak. The accuracy reached is about four times worse than for the standard bayesian estimation (percentage error on the retrieved
, representing the angular scales at which the polarization E and B-mode power spectra peak. The accuracy reached is about four times worse than for the standard bayesian estimation (percentage error on the retrieved 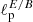 values is ∼2.7% against ∼0.7%). Although not being optimal, this result is indeed remarkable, as it proves for the first time that CNNs are able to distinguish and separate E/B polarization in pixel space. We have repeated the test in case of partial sky coverage, applying sky masks, with retained sky fraction between 50 and 5%, to the input Q and U maps. The network performs well also under these conditions, with achieved accuracy closer to the optimal one for the smaller masks. This shows that mixing between multipoles and polarization states, due to the sky cut, does not impact the network performance.
values is ∼2.7% against ∼0.7%). Although not being optimal, this result is indeed remarkable, as it proves for the first time that CNNs are able to distinguish and separate E/B polarization in pixel space. We have repeated the test in case of partial sky coverage, applying sky masks, with retained sky fraction between 50 and 5%, to the input Q and U maps. The network performs well also under these conditions, with achieved accuracy closer to the optimal one for the smaller masks. This shows that mixing between multipoles and polarization states, due to the sky cut, does not impact the network performance.
Lastly, we have tested the network on the estimation of a real cosmological parameter: the optical depth of Thomson scattering at reionization (τ). Although in this work we only present preliminary results on the estimation of τ as a proof-of-concept of our approach, this represents one possible concrete and important application of our network, to be fully explored in the future. The τ parameter mostly impacts the large angular scales of E-mode polarized emission. Its estimation is complicated by the fact that spurious signals, coming from instrumental systematic effects or Galactic residual emissions, can strongly contaminate the cosmological one at low multipoles. As a matter of fact, among the six cosmological parameters of the standard ΛCDM model, τ is the parameter whose value is currently constrained with the largest uncertainty (Planck Collaboration VI 2018). For these reasons, pairing standard estimation methods with new ones based on NNs, would be of great importance to achieve a better constraint and cross check results.
We have applied the same CNN architecture used in the previous examples to simulated maps, with values of τ in the range 0.03−0.08. We have tested the performance of the network in the simplest case of full sky and noiseless observations, and without applying any specific optimization to the CNN architecture. Results shows that the network is able to reach an accuracy on the estimation of τ that is ∼1.5 worse than standard Bayesian fitting.
Our findings represent a first step towards the possibility to estimate τ with NNs, and show that our implementation of CNNs on the sphere is a valid tool to achieve the goal. Obviously, a more sophisticated analysis is needed, including complications to make simulations more representative of real data, such as the introduction of realistic noise, instrumental systematic effects and foreground signals. In order to have a reliable estimate of τ, a full characterization if the results obtained with NNs is also needed, especially regarding the estimation of uncertainties. Moreover, specific optimization of the CNN architecture is necessary. We defer all these studies to a subsequent work.
The formula in Eq. (1) is called the weighted-average formula, and it is the most common. Depending on the domain and the purpose of the NN, other formulae can be used.
One example is the use of computer vision applied to images taken using 4π cameras mounted on flying drones.
For a complete description of the HEALPix features and related libraries, we refer to https://healpix.sourceforge.io
For a tutorial on how to work with this environment at NERSC see https://docs.nersc.gov/analytics/machinelearning/tensorflow/
The dropout regularization randomly drops neurons and their connections in a NN layer during training. The dropout rate represents the percentage of the neurons of the layers randomly switched off in each training epoch.
The MNIST (Modified National Institute of Standards and Technology) database can be downloaded from http://yann.lecun.com/exdb/mnist/
Once projected on the sphere with random rotation, numbers 6 and 9 cannot be distinguished. Therefore, we drop out all images containing digit 9 from the MNIST dataset and only use nine classes, corresponding to integer numbers from 0 to 8.
See https://lambda.gsfc.nasa.gov/product/expt/ for a list of all previous and operating experiments.
We have added a constant small plateau at 10−5 in order to avoid convergence issues.
The code stopped training after 20 epochs without improvement of the validation loss.
The signal amplitude is defined as the standard deviation of the noiseless maps computed on the whole training set of 100 000 maps. This means that the signal-to-noise ratio is slightly different on each map of the training set, as the signal is generated from spectra with different value of ℓp, while the noise standard deviation is the same for all maps.
Masks are obtained by retaining the portions of the sky included in circular regions, centered on the central pixel of a map at Nside = 16, with radii equal to 90, 53, 37 and 26° and have sky fraction of about 50, 20, 10 and 5% respectively.
Each pair of maps is simulated by randomly choosing one of the 5000 spectra with different τ and with a different seed.
Acknowledgments
This research was supported by the he ASI-COSMOS Network (http://cosmosnet.it). We acknowledge support from the RADIOFOREGROUNDS project, funded by the European Commission’s H2020 Research Infrastructures under the Grant Agreement 687312. The authors thank Prof. Carlo Baccigalupi for useful discussion and early paper review. We acknowledge the use of NERSC for the simulations done in this work.
References
- Anderson, L., Aubourg, E., Bailey, S., et al. 2012, MNRAS, 427, 3435 [Google Scholar]
- Angermueller, C., Pärnamaa, T., Parts, L., & Stegle, O. 2016, Mol. Syst. Biol., 12, 878 [Google Scholar]
- Auld, T., Bridges, M., Hobson, M. P., & Gull, S. F. 2007, MNRAS, 376, L11 [NASA ADS] [CrossRef] [Google Scholar]
- Baccigalupi, C., Bedini, L., Burigana, C., et al. 2000, MNRAS, 318, 769 [NASA ADS] [CrossRef] [Google Scholar]
- Boomsma, W., & Frellsen, J. 2017, in Advances in Neural Information Processing Systems 30, eds. I. Guyon, U. V. Luxburg, S. Bengio, et al. (Curran Associates, Inc.), 3433 [Google Scholar]
- Bryan, G. L., Norman, M. L., O’Shea, B. W., et al. 2014, ApJS, 211, 19 [NASA ADS] [CrossRef] [Google Scholar]
- Caldeira, J., Wu, W. L. K., Nord, B., et al. 2019, Astron. Comput., 28, 100307 [CrossRef] [Google Scholar]
- Cartwright, H. M. 2008, Methods in Molecular Biology™ (Humana Press), 1 [Google Scholar]
- Cascianelli, S., Scialpi, M., Amici, S., et al. 2017, Curr. Alzheimer Res., 14, 198 [CrossRef] [Google Scholar]
- Cha, K. H., Hadjiiski, L., Samala, R. K., et al. 2016, Med. Phys., 43, 1882 [NASA ADS] [CrossRef] [Google Scholar]
- Cohen, T. S., Geiger, M., Koehler, J., & Welling, M. 2018, ArXiv e-prints [arXiv:1801.10130] [Google Scholar]
- Collister, A. A., & Lahav, O. 2004, PASP, 116, 345 [NASA ADS] [CrossRef] [Google Scholar]
- Coors, B., Condurache, A. P., & Geiger, A. 2018, European Conference on Computer Vision (ECCV) [Google Scholar]
- Dieleman, S., Willett, K. W., & Dambre, J. 2015, MNRAS, 450, 1441 [NASA ADS] [CrossRef] [Google Scholar]
- Fermi Collaboration 2015, ApJS, 218, 23 [Google Scholar]
- Górski, K. M., Hivon, E., Banday, A. J., et al. 2005, ApJ, 622, 759 [NASA ADS] [CrossRef] [Google Scholar]
- Graff, P., Feroz, F., Hobson, M. P., & Lasenby, A. 2014, MNRAS, 441, 1741 [NASA ADS] [CrossRef] [Google Scholar]
- Grain, J., Tristram, M., & Stompor, R. 2009, Phys. Rev. D, 79, 123515 [Google Scholar]
- He, K., Zhang, X., Ren, S., & Sun, J. 2016, in Computer Vision – ECCV 2016, eds. B. Leibe, J. Matas, N. Sebe, & M. Welling (Cham: Springer International Publishing), 630 [CrossRef] [Google Scholar]
- He, S., Ravanbakhsh, S., & Ho, S. 2018, International Conference on Learning Representations [Google Scholar]
- Hu, H. N., Lin, Y. C., Liu, M. Y., et al. 2017, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) [Google Scholar]
- Hyun-jung, K., & Kyung-shik, S. 2007, Appl. Soft Comput., 7, 569 [CrossRef] [Google Scholar]
- IceCube Collaboration 2014, Phys. Rev. Lett., 113, 101101 [NASA ADS] [CrossRef] [PubMed] [Google Scholar]
- Kasabov, N. K. 2014, Neural Netw., 52, 62 [CrossRef] [Google Scholar]
- Krizhevsky, A., Sutskever, I., & Hinton, G. E. 2012, Proceedings of the 25th International Conference on Neural Information Processing Systems – Volume 1, NIPS’12 (USA: Curran Associates Inc.), 1097 [Google Scholar]
- Lam, M. 2004, Decis. Support Syst., 37, 567 [CrossRef] [Google Scholar]
- Lewis, A., & Bridle, S. 2002, Phys. Rev. D, 66, 103511 [NASA ADS] [CrossRef] [Google Scholar]
- Liu, F., Zhou, Z., Jang, H., et al. 2017, Magn. Reson. Med., 79, 2379 [CrossRef] [Google Scholar]
- Lodhi, H. 2012, Comput. Stat., 4, 455 [CrossRef] [Google Scholar]
- Majeau, C., Agol, E., & Cowan, N. B. 2012, ApJ, 747, L20 [NASA ADS] [CrossRef] [Google Scholar]
- Percival, W. J., Cole, S., Eisenstein, D. J., et al. 2007, MNRAS, 381, 1053 [NASA ADS] [CrossRef] [MathSciNet] [Google Scholar]
- Perraudin, N., Defferrard, M., Kacprzak, T., & Sgier, R. 2019, Astron. Comput., 27, 130 [NASA ADS] [CrossRef] [Google Scholar]
- Planck Collaboration I. 2016, A&A, 594, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration VI. 2018, A&A, submitted [arXiv:1807.06209] [Google Scholar]
- Robinson, T. D., Meadows, V. S., Crisp, D., et al. 2011, Astrobiology, 11, 393 [NASA ADS] [CrossRef] [Google Scholar]
- Sergeev, A., & Balso, M. D. 2018, ArXiv e-prints [arXiv:1802.05799] [Google Scholar]
- Shahram, M., & Donoho, D. 2007, Proceedings of SPIE – The International Society for Optical Engineering, 6701 [Google Scholar]
- Singer, L. P., & Price, L. R. 2016, Phys. Rev. D, 93, 024013 [NASA ADS] [CrossRef] [Google Scholar]
- Su, Y. C., & Grauman, K. 2017, in Advances in Neural Information Processing Systems 30, eds. I. Guyon, U. V. Luxburg, S. Bengio, et al. (Curran Associates, Inc.), 529 [Google Scholar]
- Sullivan, P. W., Winn, J. N., Berta-Thompson, Z. K., et al. 2015, ApJ, 809, 77 [NASA ADS] [CrossRef] [Google Scholar]
- Tamura, K., Uenoyama, K., Iitsuka, S., & Matsuo, Y. 2018, Trans. Jpn. Soc. Artif. Intell., 33, A [CrossRef] [Google Scholar]
- Tristram, M., Macías-Pérez, J. F., Renault, C., & Santos, D. 2005, MNRAS, 358, 833 [NASA ADS] [CrossRef] [Google Scholar]
- Virmani, J., Kumar, V., Kalra, N., & Khandelwal, N. 2014, J. Digit. Imaging, 27, 520 [CrossRef] [Google Scholar]
- Westerteiger, R., Gerndt, A., & Hamann, B. 2012, in OpenAccess Series in Informatics (OASIcs), Vol. 27, Visualization of Large and Unstructured Data Sets: Applications in Geospatial Planning, Modeling and Engineering – Proceedings of IRTG 1131 Workshop 2011, eds. C. Garth, A. Middel, & H. Hagen (Dagstuhl, Germany: Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik), 13 [Google Scholar]
- Xiao, J., Ehinger, K., Oliva, A., & Torralba, A. 2012, Proceedings, IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2695 [Google Scholar]
- Yan, H., & Ouyang, H. 2017, Wirel. Pers. Commun., 102, 683 [CrossRef] [Google Scholar]
Appendix A: Detecting stripes in a map
 |
Fig. A.1. Filters used in the example of convolution described in Sect. 3.2.1. Black pixels are set to 1, white pixels to −1, gray pixels to zero. The filter on the left is designed to pick vertical features, i.e., stripes that are aligned with meridians. The filter on the right picks features running along parallels. These filters are here shown with a diamond shape, but practically they are applied as 1D vectors to maps, following the algorithm sketched in Fig. 3. The unrolling into vectors is done clockwise, starting from the NW direction. |
 |
Fig. A.2. Maps used in the explanation of convolution in Sec. 3.2.1. All the maps have Nside = 16. Each map is shown using two orthographic projections: in the upper row, maps are represented as seen from the Equatorial plane; in the lower row, maps are centered around the poles. |
In this appendix, we show a pedagogical application of the convolution algorithm presented in Sect. 3.2.1. We have created two nine-elements filters, shown in Fig. A.1. In this figure, filters are shown with a diamond shape, but they are flattened into a nine-element vector to compute the convolution, following the clockwise order of elements. The sum of the values of the weights wi is zero in both filters, and the only non-zero pixels are aligned along vertical or horizontal lines. In this way, the application of a filter to a block of nine pixels on a map will be significantly different from zero only if the pixels in this block show some vertical or horizontal features.
 |
Fig. A.3. Result of the application of the two filters in Fig. A.1 to the three maps shown in Fig. A.2. |
We have produced three maps m1, m2, m3, where the value associated with each pixel p is given, respectively, by:
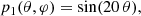 (A.1)
(A.1)
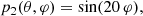 (A.2)
(A.2)
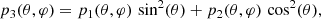 (A.3)
(A.3)
with (θ, φ) being the colatitude and longitude of the pixel center (0 ≤ θ ≤ π, 0 ≤ φ < 2π). The maps are shown in Fig. A.2; map m3 is a weighted combination of m1 and m2, where the weights sin2(θ) and cos2(θ) make horizontal stripes (from m1) and vertical stripes (from m2) negligible at the Equator and at the poles, respectively.
The application of the horizontal and vertical filters in Fig. A.1 to the maps in Fig. A.2 is shown in Fig. A.3. The result of applying the horizontal filter to the vertically striped map is a map with almost no feature: the only residuals are shaped like a plus sign around the pole and correspond to those pixels that only have 7 neighbors instead of 8 (see Fig. 2), as the sum of the weights is no longer zero in this case. Similar results occur in the other maps. In the case of map m3, which contains both horizontal and vertical stripes, the two filters correctly pick the right feature depending on the latitude, as expected.
All Tables
Summary of the results obtained in the estimation of the ℓp parameter from the neural network and the MCMC fit, for the noiseless case and the three considered noise levels.
All Figures
|
Fig. 1. Application of CNN convolutional filter to 2D image. The input image (shown as a colored matrix) contains 3 × 5 pixels, while the convolutional filter (in gray) is a 3 × 3 matrix. The filter moves across the input image and each time a dot product between the filter and the sub 3 × 3 portion of the image is performed. The result of the product is stored in the output. In this example the filter is not applied to all the possible 3 × 3 partitions of the input image but jumps one pixel at every move (the way the filter moves across the image is controlled by the stride parameter, which in this case is equal to 2 as the filter is translated by two pixels at every move). The filter elements wij represent the weights of the network which are optimized during training, and do not change while the filter moves. In this example, the value of each pixel in the output layer is the result of the dot product between the filter and the image pixels in the two squares centered on (2, 2) and (2, 4). |
| In the text | |
|
Fig. 2. Tessellation of a sphere according the HEALPix scheme. In this figure the pixel resolution corresponds to Nside = 4 (Npix = 192). Almost every pixel in a HEALPix map has 8 neighbors; however, a few pixels only have 7 of them. In this figure, the blue pixel has 7 neighbors, while the green one has 8. Black dots represent pixel centers; seven-neighbor pixels are highlighted with grey diamonds. These pixels are at the intersection of three base-pixels (delimited using thick lines); this kind of intersection occurs only near the two polar caps, and in any map with Nside ≥ 2 there are exactly 8 of them. Thus, the number of seven-neighbor pixels is always 24 (because of the nature of the orthographic projection used in this sketch, only 9 seven-neighbor pixels are visible). |
| In the text | |
|
Fig. 3. Sketch of the convolution algorithm developed in this work. The elements p1 and p2 of the vector m correspond to two pixels on map (in this case 0 and 4). p1 and p2 are associated to nine elements each, in vector M. The first of this nine elements corresponds to the pixel itself, while the subsequent ones corresponds to its eight neighbors. The neighbors are visited, and unrolled in the M vector, following a clockwise order staring from the NW direction. The filter (in grey) is also unrolled in a nine element long vector, using the same convention. Convolution is then implemented as a standard 1D convolutional layer with a stride of 9, and the output is the m′ convolved vector (map), which has the same number of elements (pixels) as the input m. In the figure, numbers over the pixels do not represent the values of the pixels but their unique index: in practical applications, these indices will be those associated to an ordering scheme and a map resolution Nside. Colors are the same as in Fig. 1, to underline the similarity. |
| In the text | |
|
Fig. 4. Sketch for the implementation of pooling layers on HEALPix maps. Since a map with Nside > 1 can be degraded to a map with Nside/2, thanks to HEALPix hierarchical construction, pooling can be implemented naturally using standard 1D pooling layers, if pixels of the input vector (map) m are properly ordered and a stride equal to 4 is used. |
| In the text | |
|
Fig. 5. Left panel: basic Network Building Block (NBB). Right panel: full deep CNN architecture. |
| In the text | |
|
Fig. 6. Method used to project MNIST images on the sphere. The image is aligned so that the center of the pixel in the middle (marked with a ×) is on the Equatorial plane. A number of rays are fired, originating from the center of the sphere, targeting each of the pixels in the image, and the intersection with each pixel on the sphere is computed. In order to cover all the pixels on the sphere, the angular separation among rays is 1/2 of the angular resolution of the HEALPix map. |
| In the text | |
|
Fig. 7. Learning history for the CNN applied to the MNIST dataset projected on the sphere. |
| In the text | |
|
Fig. 8. Projection of a MNIST image (upper panel) on the HEALPix sphere. The same image is projected along the Equator (first row), around the north pole (second row) and at a random position on the sphere (third row). For each case, we show the map using the Mollweide projection (first column), an Orthographic projection centered on the Equator and at the north and south poles. The resolution of the projected maps corresponds to Nside = 16. |
| In the text | |
|
Fig. 9. Distribution of NN error on three groups of test sets, where MNIST images have been projected: (i) at the north pole (blue), (ii) at the equator (purple) and (iii) on random positions on the sphere (black). Each group is composed by 100 test sets of 300 images each. |
| In the text | |
|
Fig. 10. Power spectra computed according to Eq. (4). The ℓp parameter, defining the position of the peak, varies in the multipole range 5−20. |
| In the text | |
|
Fig. 11. Comparison of the results obtained in the estimation of the ℓp parameter with the neural network and with the MCMC fit, for the noiseless case and for the three considered noise levels. |
| In the text | |
|
Fig. 12. Four circular masks applied to the estimation of the |
| In the text | |
|
Fig. 13. Subset of the E-modes power spectra used to generate to polarization maps for training, validation and test set on which we run the neural network. The value of τ changes in the range 0.03−0.08 while all the other cosmological parameters are fixed to the best ΛCDM model from Planck results. |
| In the text | |
|
Fig. A.1. Filters used in the example of convolution described in Sect. 3.2.1. Black pixels are set to 1, white pixels to −1, gray pixels to zero. The filter on the left is designed to pick vertical features, i.e., stripes that are aligned with meridians. The filter on the right picks features running along parallels. These filters are here shown with a diamond shape, but practically they are applied as 1D vectors to maps, following the algorithm sketched in Fig. 3. The unrolling into vectors is done clockwise, starting from the NW direction. |
| In the text | |
|
Fig. A.2. Maps used in the explanation of convolution in Sec. 3.2.1. All the maps have Nside = 16. Each map is shown using two orthographic projections: in the upper row, maps are represented as seen from the Equatorial plane; in the lower row, maps are centered around the poles. |
| In the text | |
|
Fig. A.3. Result of the application of the two filters in Fig. A.1 to the three maps shown in Fig. A.2. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.