| Issue |
A&A
Volume 622, February 2019
|
|
|---|---|---|
| Article Number | A177 | |
| Number of page(s) | 14 | |
| Section | Extragalactic astronomy | |
| DOI | https://doi.org/10.1051/0004-6361/201732480 | |
| Published online | 21 February 2019 | |
J-PLUS: Morphological star/galaxy classification by PDF analysis
1
Centro de Estudios de Física del Cosmos de Aragón,
Plaza San Juan 1,
44001
Teruel,
Spain
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
APC, AstroParticule et Cosmologie, Université Paris Diderot, CNRS/IN2P3, CEA/lrfu, Observatoire de Paris,
Sorbonne Paris Cité, 10 rue Alice Domon et Léonie Duquet,
75205
Paris Cedex 13,
France
3
Departamento de Astronomia, Instituto de Física, Universidade Federal do Rio Grande do Sul,
Porto Alegre,
R.S,
Brazil
4
Instituto de Astronomia, Geofísica e Ciências Atmosféricas, Universidade de São Paulo,
05508-090
São Paulo,
Brazil
5
Observatório Nacional/MCTIC,
Rua Gen. José Cristino 77,
20921-400,
Rio de Janeiro,
Brazil
6
Department of Astronomy, University of Michigan,
Ann Arbor,
MI
48109-1107,
USA
7
PITT PACC, Department of Physics and Astronomy, University of Pittsburgh,
Pittsburgh,
PA
15260,
USA
8
Department of Physics and JINA Center for the Evolution of the Elements, University of Notre Dame,
Notre Dame,
IN
46556,
USA
Received:
17
December
2017
Accepted:
3
May
2018
Abstract
Aims. Our goal is to morphologically classify the sources identified in the images of the J-PLUS early data release (EDR) as compact (stars) or extended (galaxies) using a dedicated Bayesian classifier.
Methods. J-PLUS sources exhibit two distinct populations in the r-band magnitude versus concentration plane, corresponding to compact and extended sources. We modelled the two-population distribution with a skewed Gaussian for compact objects and a log-normal function for the extended objects. The derived model and the number density prior based on J-PLUS EDR data were used to estimate the Bayesian probability that a source is a star or a galaxy. This procedure was applied pointing-by-pointing to account for varying observing conditions and sky positions. Finally, we combined the morphological information from the g, r, and i broad bands in order to improve the classification of low signal-to-noise sources.
Results. The derived probabilities are used to compute the pointing-by-pointing number counts of stars and galaxies. The former increases as we approach the Milky Way disk, and the latter are similar across the probed area. The comparison with SDSS in the common regions is satisfactory up to r ~ 21, with consistent numbers of stars and galaxies, and consistent distributions in concentration and (g−i) colour spaces.
Conclusions. We implement a morphological star/galaxy classifier based on probability distribution function analysis, providing meaningful probabilities for J-PLUS sources to one magnitude deeper (r ~ 21) than a classical Boolean classification. These probabilities are suited for the statistical study of 150 thousand stars and 101 thousand galaxies with 15 < r ≤ 21 present in the 31.7 deg2 of the J-PLUS EDR. In a future version of the classifier, we will include J-PLUS colour information from 12 photometric bands.
Key words: methods: data analysis / Galaxy: stellar content / galaxies: statistics
© ESO 2019
1. Introduction
The study of Milky Way stars and the understanding of extragalactic sources have greatly benefited from large (≳5000 deg2) and systematic photometric surveys, such as the second Palomar Observatory Sky Survey (POSS-II) with three optical gri broad bands (Gal et al. 2004), the Sloan Digital Sky Survey (SDSS) with five optical ugriz broad bands (Abazajian et al. 2009), or the VISTA Hemisphere Survey (VHS) with three near-infrared HJKs bands (McMahon et al. 2013). The studies will move forward in the following years with next-generation surveys such as the Dark Energy Survey (DES) with five optical ugriz broad bands (Flaugher 2012); the UKIRT Hemisphere Survey (UHS) with two near-infrared JKs bands (Dye et al. 2018); Euclid with three near-infrared Y HJ broad bands (Laureijs et al. 2011); the Large Synoptic Survey Telescope (LSST) with six optical ugrizY broad bands (Ivezic et al. 2008); the Javalambre Local Universe Survey (J-PLUS1) with five ugriz broad and seven narrow optical bands (Cenarro et al. 2019); the Southern Local Universe Survey (S-PLUS), the southern counterpart of J-PLUS (Mendes de Oliveira, 2018 in prep.); and the Javalambre Physics of the accelerating universe Astrophysical Survey (J-PAS2) with 56 narrow optical bands (Benítez et al. 2014).
Becauseof their photometric nature, the above surveys image all the astronomical sources down to a limiting magnitude without any pre-selection. Thus, one of the main steps in the analysis of these rich photometric datasets is the classification of the observed sources into stars, galaxies, or other objects of interest.
The star/galaxy classification of astronomical sources is usually performed following two complementary approaches, based on morphology and colours. Morphological classifiers use the different concentration properties of stars (point-like sources) and galaxies (extended sources) to separate them (e.g. Kron 1980; Reid et al. 1996; Bertin & Arnouts 1996; Odewahn et al. 2004; Vasconcellos et al. 2011), and colour classifiers take advantage of the different location of stars, galaxies, and quasi-stellar objects (QSOs) in colour–colour diagrams, using one or more of them to perform the classification (e.g. Huang et al. 1997; Elston et al. 2006; Baldry et al. 2010; Saglia et al. 2012; Małek et al. 2013). The combination of the two approaches is also possible, maximising the use of the available information (e.g. Molino et al. 2014; Kim et al. 2015; Soumagnac et al. 2015; Kim & Brunner 2017).
From the technical point of view, there are several ways to address the source classification problem. We highlight those based on the modelling of the observed spectral energy distribution (SED; e.g. Wolf et al. 2004; Robin et al. 2007; Saglia et al. 2012; Preethi et al. 2014), the application of machine learning codes and neural networks (e.g. Cortiglioni et al. 2001; Ball et al. 2006; Małek et al. 2013; Miller et al. 2017), or the inclusion of prior information from a Bayesian framework (e.g. Sebok 1979; Scranton et al. 2002; Henrion et al. 2011; Molino et al. 2014).
In the present paper, we implement a morphological Bayesian classifier that accounts for the observational errors in the concentration measurements and applies a magnitude prior to deal with the greater number of galaxies expected at fainter magnitudes. The classifier was developed in the context of the PROFUSE3 project, that uses probabiliy functions for unbiased statistical estimations in multi-filter surveys, and was applied to classify the sources of the J-PLUS early data release (EDR) dataset. J-PLUS is a multi-filter survey of thousands of square degrees in the northern hemisphere with a set of 12 optical filters (5 broad and 7 narrow) particularly defined to provide reliable SEDs of Milky Way stars and nearby galaxies, and to photometrically calibrate J-PAS. The J-PLUS survey and its EDR are completely described in Cenarro et al. (2019).
The paper is organised as follows. In Sect. 2, we present the J-PLUS EDR dataset. The Bayesian classifier and its application to J-PLUS EDR data are described in Sect. 3. We test the performance of our classification in Sect. 4, and present the star and galaxy number counts of the J-PLUS EDR in Sect. 5. We discuss our results in Sect. 6, and present our conclusions in Sect. 7. Magnitudes are given in the AB system (Oke & Gunn 1983).
J-PLUS filter system and limiting magnitudes (3σ, 3′′ aperture) of J-PLUS and the EDR.
2. J-PLUS early data release
As previously mentioned, J-PLUS is a photometric survey of several thousand square degrees that is being conducted from the Observatorio Astrofísico de Javalambre (OAJ, Teruel, Spain; Cenarro et al. 2014) using the 83 cm Javalambre Auxiliary Survey Telescope (JAST/T80) and T80Cam, a panoramic camera that provides a 2 deg2 field of view (FoV) with a pixel scale of 0.55′′. The J-PLUS filter system, composed of twelve bands, is summarised in Table 1. The J-PLUS observational strategy, image reduction, photometric calibration, and main scientific goals are presented in Cenarro et al. (2019).
The 18 pointings that comprise the J-PLUS EDR are representative of the 205 J-PLUS pointings gathered in a similar production stage (i.e. reduction and calibration) in September 2017. The limiting magnitudes targeted by J-PLUS and those of the EDR are presented in Table 1 for reference. The median point spread function (PSF) full width at half maximum (FWHM) in the EDR r-band images is 1.1′′. Source detection was done in the r band using SExtractor (Bertin & Arnouts 1996), and the flux measured in the 12 J-PLUS bands at the position of the detected sources using its dual mode capability. The EDR is publicly available at the J-PLUS website4.
In addition to the present paper, the J-PLUS EDR and science verification data have been used to refine the membership in the nearby galaxy clusters A2589 and A2593 (Molino et al. 2019), to analyse the globular cluster M15 (Bonatto et al. 2019), and to study the Hα emission (Logroño-García et al. 2019) and the stellar populations (San Roman et al. 2019) of several local galaxies.
2.1. Masking and final J-PLUS EDR area
To perform our study, we were restricted to the high signal-to-noise (S/N) areas covered by the J-PLUS EDR. We defined the best area for each pointing as those pixels with relative exposure higher than 0.7 with respect to the maximum in the r-band detection image5. Hence, the 0.7 exposure condition selects areas covered by the three acquired images at each position. This avoids the borders of the images and provides a well-defined area of ~2 deg2 per pointing, with 36 deg2 covered by the J-PLUS EDR without accounting for the overlaps between adjacent pointings.
We masked the areas surrounding bright stars that are affected by spikes and luminous haloes, compromising the photometry of the sources. This was done by searching for the Tycho2 stars (Høg et al. 2000) and masking a circular area centred in the position of the star with radius
![Mathematical equation: \begin{equation*} 0.075\,(12 - V_{\textrm{T}})^{2.4} + 1.5\ \ \textrm{[arcmin]}, \end{equation*}](/articles/aa/full_html/2019/02/aa32480-17/aa32480-17-eq1.png) (1)
(1)
where VT is the V -band magnitude of the star in the Tycho photometric system. The masking was only applied to stars brighter than VT = 12. The circular area was estimated empirically to minimise the impact of bright stars, improving the reliability of the photometry. The area masked because of bright stars is 4 deg2, 11% of the initial J-PLUS EDR area.
Finally, we masked the areas affected by reflections and artefacts. The artefacts mask was defined by visual inspection of the J-PLUS EDR images. The area masked because of artefacts is only 0.02 deg2, less than 0.1% of the initial area.
The final high-quality area of the J-PLUS EDR after masking is 31.98 deg2. Accounting for the overlapping areas between adjacent pointings, the effective area is reduced to 31.70 deg2. The former refers to pointing-by-pointing studies that include duplicated sources observed in more than one pointing, and the latter to the J-PLUS EDR studies that include only unique sources. The present paper performs a pointing-by-pointing morphological classification to cope with the varying conditions of the observations (Sect. 3.2). The masks are available at the public J-PLUS data base.
The J-PLUS EDR comprises a total of 292 thousand unique detections in the r-band images with 15 < r ≤ 21, which is reduced to 251 thousand (84%) after masking.
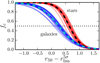 |
Fig. 1. Completeness curves referenced to the 5σ
detection in the J-PLUS r-band magnitude ( |
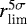
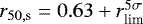
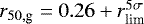
2.2. Detection completeness of stars and galaxies
We used SDSS photometry as a reference to estimate the star and galaxy completeness of the J-PLUS EDR pointings in the r band. We compared the number of stars and galaxies in the general SDSS catalogue with those from the sources detected in the J-PLUS r-band images. To avoid biases related to the lower S/N of J-PLUS images close to the limiting magnitude, we used the star/galaxy classification and the model magnitudes from SDSS, which is typically one magnitude deeper than J-PLUS images in the r band.
The measured r-band completeness is then parametrised with the function
![Mathematical equation: \begin{equation*} f_{\textrm{c}}\,(r) = 1 - \frac{1}{1 + \textrm{exp}[ -\kappa\,(r - r_{50}) ]} , \end{equation*}](/articles/aa/full_html/2019/02/aa32480-17/aa32480-17-eq2.png) (2)
(2)
where r50 is the magnitude at 50% completeness and κ the decay rate of the completeness. The obtained curves in each pointing for both stars and galaxies with respect to the 5σ detection in the J-PLUS r-band AUTO magnitude (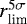 ), computed as the median magnitude of those sources with photometric error σr ~ 0.22 (S∕N ~ 5), are presented in Fig. 1. We find evident similarities among the completeness curves of different pointings after normalising them to the depth of the corresponding image, with stars being detected to fainter magnitudes and presenting a steeper decay rate. Hence, for simplicity, in the following we assume a common decay rate κs = 4.7 for stars and κg = 3.0 for galaxies, and define the 50% completeness magnitude of each EDR pointing as
), computed as the median magnitude of those sources with photometric error σr ~ 0.22 (S∕N ~ 5), are presented in Fig. 1. We find evident similarities among the completeness curves of different pointings after normalising them to the depth of the corresponding image, with stars being detected to fainter magnitudes and presenting a steeper decay rate. Hence, for simplicity, in the following we assume a common decay rate κs = 4.7 for stars and κg = 3.0 for galaxies, and define the 50% completeness magnitude of each EDR pointing as 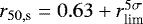 for stars and
for stars and 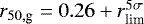 for galaxies. The median 50% completeness of the J-PLUS EDR is reached at r = 21.51 for stars and at r = 21.10 for galaxies, magnitudes that change to r = 20.88 and r = 20.12, respectively, for 95% completeness.
for galaxies. The median 50% completeness of the J-PLUS EDR is reached at r = 21.51 for stars and at r = 21.10 for galaxies, magnitudes that change to r = 20.88 and r = 20.12, respectively, for 95% completeness.
The above procedure is valid for J-PLUS pointings in shared areas with SDSS and only for the broad bands in common. We plan to estimate the completeness for stars and galaxies in all the J-PLUS filters and pointings by injecting realistic fake sources and studying their recovery rate (see Molino et al. 2019 for details about the procedure).
3. Morphological classification by PDF analysis
Given an image with a set of properties (i.e. pixel size, PSF FWHM, photometric depth, position in the sky, etc.), we can classify the detected sources in different astronomical categories using their morphological properties. The most basic distinction is between compact (e.g. stars and QSOs) and extended (e.g. galaxies and nebulae) sources.
To perform a morphological separation, we need to define a compactness indicator for each detection in our images. Such an indicator can be based on the comparison between properly selected magnitudes (e.g. Yasuda et al. 2001). In our case, we defined the concentration cr as the difference between the r-band magnitudes estimated at 1.5′′ (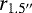 ) and 3.0′′ (
) and 3.0′′ (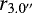 ) diameter apertures:
) diameter apertures:
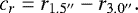 (3)
(3)
The concentration cr is lower for more compact point-like sources, and higher for extended less concentrated objects. We note that our definition approximates the light growth curve of the sources with only two points, which in this case roughly corresponds to one and two PSF FWHM in J-PLUS EDR r-band images. We checked that this combination of aperture magnitudes provides the best results for our purpose.
The distribution of the concentration parameter with respect to the r-band AUTO magnitude, a proxy for the total magnitude of the sources, for J-PLUS pointing 00857 is presented in the top panel of Fig. 2. We note that this pointing has a PSF FWHM of 1.1′′, similar to the median of the J-PLUS EDR, and we use it as a representative example throughout this paper. Two populations are evident in the concentration versus magnitude plane: a tight sequence of compact sources at cr ~ 0.55 and a cloud of extended sources at cr ~ 1, with concentrations spanning a range between 0.2 and 2.0. Both populations are well separated at r ≲ 19.5, and merge at fainter magnitudes. The vast majority of compact sources in our magnitude range (r ≤ 21) are Milky Way stars, whereas nearly all the extended sources are galaxies. Hence, we denote compact sources as stars and extended sources as galaxies in the following.
The SDSS provides a morphological classification based on the comparison between a PSF magnitude, computed assuming a compact PSF-like light profile, and a model magnitude, computed assuming a combination of Sérsic profiles. The model and the PSF magnitudes are similar for compact star-like sources, and different for extended sources (Yasuda et al. 2001; Strauss et al. 2002). The SDSS classification is reliable up to r ~ 21, and it is used as a reference throughout the present paper. We used SDSS classification to colour-code the J-PLUSsources in Fig 2. As expected, sources classified as compact in SDSS are located in the sequence of lower concentrations, and the extended ones populate the cloud at higher cr values. Because of the uncertainties in our measurements, both distributions broaden at r ≳ 19, making it difficult to define a clear separation between stars and galaxies at fainter magnitudes. This is further illustrated in the bottom panel of Fig. 2, where the concentration distribution of stars and galaxies following SDSS classification at 20 < r ≤ 21 is shown. Both distributions overlap, with their tails crossing at cr ~ 0.75, and a significant number of compact sources have higher cr values than some extended sources. Hence, it does not seem feasible to define a criterion to classify J-PLUS EDR sources with r > 19.5 based on the parameter cr alone.
We analysed J-PLUS EDR sources with a Bayesian star/galaxy classifier (Sebok 1979; Scranton et al. 2002; Henrion et al. 2011; Molino et al. 2014), providing the probability that each source is a star or a galaxy. This method was designed to provide meaningful probabilities for low S/N sources, pushing the study of stars and galaxies in J-PLUS EDR to magnitudes fainter than r ~ 19.5. We used the SDSS classification to test the quality of our results in Sect. 4, but we note that the derived classification is based solely on J-PLUS information.
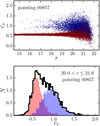 |
Fig. 2. Concentration vs. r-band magnitude for the J-PLUS EDR pointing 00857 (top panel), and distribution of 20 < r ≤ 21 sources in concentration space (black histogram in the bottom panel). In both panels, sources classified as stars by SDSS are in red, and those classified as galaxies are in blue. |
3.1. Probability distribution function of compact and extended sources
In this section we present the mathematical formalism and the main ingredients of the Bayesian star/galaxy classifier. Further details can be found in Scranton et al. (2002) and Henrion et al. (2011), so we focus on its application to the J-PLUS EDR dataset.
We want to estimate the probability distribution function (PDF) in type t space for stars (s) and galaxies (g), t = (s, g), given a measured concentration c and its errorσc. Formally,
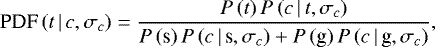 (4)
(4)
where P (t) is the prior information for type t, and P (c | t, σc) is the probability of getting the observed concentration under the hypothesis that the source is of type t. The PDF is normalised to one by definition:
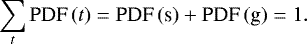 (5)
(5)
Henrion et al. (2011) present all the details of the general estimation of the terms in Eq. (4). In our case, we estimated the probability of the observations as
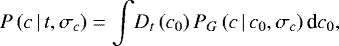 (6)
(6)
where Dt is the intrinsic distribution (i.e. unaffected by observational errors) of type t sources, and c0 is the real value of the concentration affected by a Gaussian uncertainty:
![Mathematical equation: \begin{equation*} P_G\,(x\,|\,x_0, \sigma_x) = \frac{1}{\sqrt{2 \pi} \sigma_x} \exp\bigg[-\frac{(x - x_0)^2}{2\sigma_x^2}\bigg]. \end{equation*}](/articles/aa/full_html/2019/02/aa32480-17/aa32480-17-eq12.png) (7)
(7)
We have no access to the real value of the concentration c0, so we marginalise over it in Eq. (6) and the probability is therefore expressed with measured quantities.
The uncertainty in the concentration parameter is
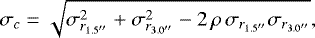 (8)
(8)
where ρ is the covariance between the two magnitudes. We note that the flux of the 1.5′′ aperture is included in the 3.0′′ aperture, so the two measurements are correlated. We have estimated the best covariance value empirically by studying the properties of the stellar locus at different magnitudes (Sect. 3.2), and find ρ = 0.72. Hereafter we assume this covariance value in our analysis.
Some simplifications were made in the estimation of the PDF. We neglected the uncertainty in the reference r-band AUTO magnitude, which also correlates with the measured concentration as both share common flux. With this simplification, we downgraded the dimensionality of the analysis, passing from a joint 2D estimation in r − c space to a 1D estimation in c, and speed up the numerical efficiency of the process. In addition, we did not use the multi-filter colour information from the twelve J-PLUS bands. Such information is highly valuable, and will be included in future versions of the classifier. Despite the above simplifications, our results demonstrate that the implemented version of the classifier has reached a fair compromise between mathematical rigour and computational resources.
The next sections are devoted to the estimation, using J-PLUS EDR data, of the intrinsic distributions for compact (Ds; Sect. 3.2) and extended sources (Dg; Sect. 3.3). The prior probability P (t) is estimated in Sect. 3.4. The final PDF is defined as the combination of the morphological information in the g, r, and i broad bands, as detailed in Sect. 3.5.
 |
Fig. 3. Variation in the parameters defining the stellar locus (position μs in the left panel and dispersion σs in the right panel) as a function of the PSF FWHM of the J-PLUS EDR r-band image. The dotted line in each panel is the error-weighted linear fit to the points. |
3.2. Definition of the stellar locus
The first step of our classifier is to estimate the intrinsic distribution of compact sources in concentration space. We call this distribution the stellar locus and denote it Ds. As shown in Fig. 2, the compact population presents a clear narrow distribution with an extended tail towards higher values of cr. This extended component is present at all magnitudes and it is a common feature in astronomical images (see Henrion et al. 2011, for details). To account for this fact, we parametrised the stellar locus as
![Mathematical equation: \begin{equation*} D_{\textrm{s}}\,(c_0\,|\,\boldsymbol{\uptheta}_{\textrm{s}}) = P_G\,(c_0\,|\,\mu_{\textrm{s}}, \sigma_{\textrm{s}})\,\bigg[1 + \textrm{erf}\,\bigg(\alpha_{\textrm{s}}\,\frac{c_0 - \mu_{\textrm{s}}}{\sqrt{2} \sigma_{\textrm{s}}}\bigg)\bigg],\end{equation*}](/articles/aa/full_html/2019/02/aa32480-17/aa32480-17-eq14.png) (9)
(9)
where θs = (μs, σs, αs) are the three parameters that define the distribution, and erf (x) is the error function. The parameter αs determines the skewness of the distribution, which accounts for the extended tail at higher concentration values.
The stellar locus distribution is affected by the uncertainties in the measured concentrations. To derive the parameters θs, we maximised the likelihood
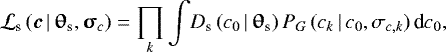 (10)
(10)
where c = (c1, c2, …, ck) is the data vector with associated uncertainty vector σc, and the index k spans the sources in the sample. We used J-PLUS sources with 15 < r ≤ 18 to model the stellar locus because at these magnitudes photometric errors are small and the extended population is sparse. We performed an initial Gaussian fit to the histogram of these sources, and discarded those with high cr values beyond 5σ to avoid the few extended sources that exist at these magnitudes. The stellar locus distribution in Eq. (9) has three parameters, but we found that the value of αs is similar in all the pointings. Hence, we fixed it to the J-PLUS EDR median value, αs = 4.1, and estimated the values of μs and σs in each pointing independently.
We present the dependence of the stellar locus position (μs) and dispersion (σs) with the PSF FWHM of the J-PLUS EDR r-band images in Fig. 3. We found correlations with the FWHM, as expected. The position of the stellar locus increases with the FWHM, implying a less concentrated distribution of light. However, this correlation is affected by a significant scatter, meaning that other factors (e.g. the FWHM of the individual combined images and the stability of the PSF across the large T80Cam FoV) are also modifying μs from pointing to pointing.
We found that the value of σs seems to decrease with the PSF FWHM. This trend is caused by the different impact of the PSF depending on the compactness of the source. The concentration of an extended source is less affected by the PSF, so the larger the FWHM, the smaller the difference between compact and extended sources, and the smaller the dispersion of the distribution (i.e. the PSF tends to homogenise the concentration of the imaged sources). We confirm this interpretation with the study of the galaxy locus in Sect. 3.3. We also note that three pointings are clearly above the general trend, with σs ~ 0.08 (Fig. 3). These pointings were observed on the same night and present a larger PSF FWHM dispersion across the FoV (σFWHM ~ 0.06) than the other 15 fields (σFWHM ~ 0.03). This highlights the importance of a pointing-by-pointing analysis and the flexibility of our modelling.
We conclude this section by testing the impact of the observational errors in our analysis. The intrinsic (i.e. unaffected by uncertainties) stellar locus must be independent of the magnitude for a given pointing. However, the observed stellar locus broadens towards fainter magnitudes because our concentration measurements have larger uncertainties. We illustrate this in Fig. 4 by using the estimated position and dispersion of the stellar locus at different magnitudes, normalised to the fiducial value estimated at 15 < r ≤ 18 for comparison. We found that the stellar locus position and dispersion are consistent over the whole magnitude range only if the concentration uncertainty is included in the analysis via Eq. (10). Disregarding the effect of the errors produces a bias in the position (~2% underestimation at r ~ 19) and the dispersion (~60% overestimation at r ~ 19) of the stellar locus. We also find that leaving out the covariance term in the estimation of the concentration error also biases the results by producing a much lower σs than expected because of the overestimated uncertainties. In practice, we used this to empirically estimate the best value for the covariance term in Eq. (8), ρ = 0.72, so it is an extra parameter in our modelling. We conclude that a rigorous treatment of the concentration uncertainties is fundamental to perform a robust analysis and obtain a meaningful PDF.
With the stellar locus properly defined, the next step is to repeat the above procedure to estimate the intrinsic distribution of extended sources.
 |
Fig. 4. Variation in the normalised stellar locus position (circles in the left panels) and dispersion (squares in the right panels) with r-band magnitude. The coloured symbols mark the measurements in each J-PLUS EDR pointing. The white symbols show the median and the dispersion of the pointing-based values. The dashed lines mark identity. The top panels show the results assuming no concentration uncertainties (σc = 0), and the bottom panels with the uncertainties, computed assuming a covariance ρ = 0.72, properly accounted for. |
3.3. Definition of the galaxy locus
The second step of our classifier is to estimate the intrinsic distribution of extended sources in concentration space. We call this distribution the galaxy locus and denote it Dg. We return to Fig. 2 to define the shape of the galaxy locus. As Henrion et al. (2011), we found that a log-normal distribution is a fair representation of the observations,
![Mathematical equation: \begin{equation*} D_{\textrm{g}}\,(c_0\,|\,\boldsymbol{\uptheta}_{\textrm{g}}) = \frac{1}{c_0 \sqrt{2 \pi} \sigma_{\textrm{g}}} \exp\bigg[-\frac{(\ln c_0 - \ln \mu_{\textrm{g}})^2}{2\sigma_{\textrm{g}}^2}\bigg], \end{equation*}](/articles/aa/full_html/2019/02/aa32480-17/aa32480-17-eq16.png) (11)
(11)
where θg = (μg, σg) are the two parameters that define the distribution. We assume that these parameters do not depend on source magnitude. This seems a good approximation in our magnitude range, r < 21, but it is not guaranteed at fainter magnitudes. Thus, a magnitude-dependent parametrisation of the galaxy locus could be needed for deeper surveys.
We derived the parameters θg by maximising the likelihood
![Mathematical equation: \begin{align*} {\mathcal L}_{\textrm{g}}\,&(\vec{c}\,|\,\boldsymbol{\uptheta}_{\textrm{g}}, f_{\textrm{g}}, \boldsymbol{\upsigma}_{c}) \nonumber\\ & =\prod_k \!\! \int \!\! \big[(1 - f_{\textrm{g}})\,D_{\textrm{s}}\,(c_0) + f_{\textrm{g}}\,D_{\textrm{g}}\,(c_0\,|\,\boldsymbol{\uptheta}_{\textrm{g}})\big]\,P_G\,(c_k\,|\,c_0, \sigma_{c,k})\,\textrm{d}c_0,\end{align*}](/articles/aa/full_html/2019/02/aa32480-17/aa32480-17-eq17.png) (12)
(12)
where fg is the fraction of galaxies in the sample, and the parameters of the stellar locus were fixed to the values derived in Sect 3.2. In the modelling of the galaxy locus, we used sources with 18 < r ≤ 20, where both compact and extended sources exists. This magnitude range ensures well-controlled uncertainties, a significant separation between extended and compact populations, and a sufficient number of extended sources to derive the parameters with inferred values of fg between 0.20 and 0.55 at 18 < r ≤ 20. We show the location of the galaxy locus and its dispersion as a function of the pointing PSF FWHM in Fig. 5. As in the case of the stellar locus parameters, μg increases with FWHM and σg decreases.
We compared the location of the stellar and the galaxy loci in Fig. 6. We found that both variables are highly correlated with a slope below unity, dμg∕dμs = 0.48. This implies that the increase in the PSF FWHM affects the compact sources more, and for a large enough FWHM both populations would be indistinguishable in our images. This should occur with a FWHM larger than ~2.5′′. This effect also explains the decrease in σs and σg with FWHM, as argued in Sect. 3.2.
We conclude that our modelling with six parameters (three for the stellar locus, two for the galaxy locus, and the magnitude covariance) is general enough to retain the main properties of compact and extended sources. A pointing-by-pointing analysis is needed to account for the different observational conditions that modify the position and the dispersion of the stellar and galaxy loci. The PSF FWHM of the images is the main parameter involved, but it cannot explain all the observed variations alone. In the next section, we compute the final ingredient of our classifier, the prior in the fraction of stars and galaxies with magnitude.
 |
Fig. 5. Variation in the parameters defining the galaxy locus (position μg in left panel and dispersion σg in right panel) as a function of the PSF FWHM of the J-PLUS EDR r-band image. The dotted line in each panel is the error-weighted linear fit to the points. |
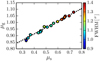 |
Fig. 6. Position of the galaxy locus, μg, as a function of the position of the stellar locus, μs. The colour scale shows the PSF FWHM of the r-band images. Thedotted line is the error-weighted linear fit to the points. |
3.4. Priorprobability by morphological type
We have defined the properties of the stellar and the galaxy loci in the previous sections at magnitudes brighter than r = 20, where both populations can be distinguished. We aim to define a probabilistic classification that can also be useful and statistically meaningful at magnitudes close to our detection limit, r ~ 21. To reach our goal, we have to include a priori information about the relative number of stars and galaxies with magnitude (Scranton et al. 2002; Henrion et al. 2011; Molino et al. 2014). This is the third step of our classifier.
We computed the fraction of galaxies at different magnitudes, from r = 15.25 to r = 19.75 in 0.5 mag steps, by minimising Eq. (12) with fg as the only free parameter (i.e. we fixed the stellar and galaxy loci parameters). The derived galaxy fractions for each J-PLUS EDR pointing are shown in Fig. 7. We found a variety of values, with pointings closer to the Milky Way disk having a lower fraction of galaxies. To have a continuum description with magnitude and prior information beyond r = 20, we fitted the dependence of fg on the r-band magnitude as
![Mathematical equation: \begin{equation*} f_{\textrm{g}}\,(r\,|\,\boldsymbol{\theta_{\textrm{p}}}) = \frac{1}{1 + \textrm{exp}[ -\kappa_{\textrm{p}}\,(r - \mu_{\textrm{p}}) ] }, \end{equation*}](/articles/aa/full_html/2019/02/aa32480-17/aa32480-17-eq18.png) (13)
(13)
where θp = (μp, κp) are the parameters of the function, μp is the magnitude with the same number density of stars and galaxies, and κp is the transition rate between both populations. We tested this parametrisation by comparing the expected fraction of galaxies at r ~ 21 with that measured using the SDSS data. We found that the difference between the two estimations is always under 10%, supporting our modelling.
We defined the prior probability of a source with magnitude r as P (g | r) = fg (r) for galaxies, and as P (s | r) = 1 − fg (r) for stars. The prior information ensures statistically meaningful probabilities at magnitudes fainter than r = 20, where less information is encoded in the concentration parameter because of observational uncertainties.
We show the derived values of μp as a function of the galactic latitude b of the J-PLUS EDR pointings in Fig. 8. We find that μp increases aswe approach the galactic plane, as expected. The parameter μp has no clear dependence on the PSF FWHM, supporting our modelling procedure. We note that with the pointing-by-pointing estimation of P (t), we had implicitly included in our prior probability the varying density of stars with the position in the sky (Scranton et al. 2002).
Finally, to avoid biases related to low-quality and undetected sources, we only assigned a probability to those detections with S∕N > 3. Below this S/N limit, measured fluxes are effected by the sky background fluctuations and the concentration measurements are compromised. The low S/N sources with S∕N ≤ 3 have PDF (s) = 0.5, irrespective of their likelihoods and magnitude.
3.5. Finalprobability from g-, r-, and i-band information
In addition to the concentration in the r band, we included in our final classification the valuable information from the g- and i-band images. These three broad bands are the deepest ones in our dataset, and provide most of the morphological J-PLUS information. The median PSF FWHM in the g and i bands is 1.2′′ and 1.0′′, respectively.
The stellar and the galaxy loci in the g and i bands were estimated following Sects. 3.2 and 3.3, adapting the analysed magnitude ranges to the depth and properties of each band.
We assumed uninformative flat priors for g and i bands, P (t | g) = P (t | i) = 0.5, in Eq. (4). Stars and galaxies have particular colour distributions with r-band magnitude, as we show in Sect. 4.3. Thus, g, r, and i magnitudes are not independent and a complete multi-filter study demands the inclusion of the colour distributions for different morphological types in the probability from Eq. (6), as shown by Henrion et al. (2011). This will include explicitly the colour information in the analysis, but we only considered here the morphological information by imposing flat priors and using no colours. The addition of the colour information from the twelve J-PLUS bands is beyond the scope of the present paper, and will be included in future versions of the classifier.
Regarding the quality cut at S∕N = 3, it was applied in each band independently. This allows a meaningful inclusion of uninformative bands, and only the relevant information was used to perform the final classification of the sources.
We estimated the final PDFs by multiplying the probabilities from each band and normalising to one. We illustrate the impact of the gri-derived classification with respect to that of the r-band in Fig. 9. We show the star probability in the magnitude versus concentration plane for the representative pointing 00857. The other pointings in the J-PLUS EDR present a similar behaviour, and all their relevant figures are accessible at the PROFUSE web page. In the single-band case, the classification performs well up to r ~ 19.5, the magnitude at which the uncertainties in the concentration parameter start to merge the two populations. At fainter magnitudes both distributions overlap, creating a continuous transition between stars and galaxies. This performance is common among Bayesian classifiers (Henrion et al. 2011). The inclusion of the extra morphological information from the g and i bands is evident in the right panel of Fig. 9, where the continuous transition in the overlapping area is diminished because those sources that appear compact in the g and i bands approach PDF (s) = 1. We further study the concentration distribution of stars and galaxies in Sect. 4.2.
At this point, we have a PDF-based probabilistic classification of J-PLUS EDR sources into star or galaxy. In the next sections, we test our classification by comparison with the SDSS dataset in the common areas.
 |
Fig. 7. Fraction of galaxies, fg, as a function of the r-band magnitude. The circles are the measurements in each J-PLUS EDR pointing, coloured with the galactic latitude b of the pointing. The dashed line marks fg = 0.5. As an illustration, the dotted lines show the best prior fitting curves, P (g | r), to the pointings with lower and higher galactic latitude. |
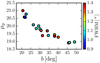 |
Fig. 8. Magnitude at which stars and galaxies have the same number density, μp, as a function of the galactic latitude b of the J-PLUS EDR pointings. The colour scale shows the FWHM of the r-band images. |
4. Stars and galaxies in the J-PLUS EDR
We tested the performance of our PDF-based morphological classifier implemented in Sect. 3 by comparing it to the SDSS dataset. The SDSS classification is reliable up to r ~ 21 (Yasuda et al. 2001; Scranton et al. 2002), and it is used as reference in the following sections. We note that our classification was based solely on J-PLUS information and it is independent of the SDSS classification.
As a first step, we performed a one-to-one comparison with the SDSS classification, defining the completeness and the contamination of our classifier (Sect 4.1). We note the probabilistic nature of our PDF-based classification by studying the distribution of stars and galaxies in both concentration (Sect. 4.2) and (g−i) colour space (Sect. 4.3) at different magnitudes.
4.1. Completeness and contamination for a Boolean classification
The usual way to test the performance of a classifier is by analysing the completeness and contamination of its output classes. The completeness is defined as the fraction of sources classified with type t over the total number of actual sources of type t. The contamination is the fraction of sources incorrectly classified as type t.
We present the completeness and contamination of our Bayesian classifier in Fig. 10. To construct this figure, we used a Boolean classification with stars as PDF (s) > 0.5 sources. We found that this Boolean classification is reliable up to r ~ 20, with a completeness of ~95% and a contamination of ~5% both for stars and galaxies. Thus, for those studies that need a secure source type t, J-PLUS data provide a reliable morphological classification at r ≲ 20. However, our PDF-based classifier is suitable for statistical studies, and we demonstrate its good performance up to r = 21 in the following sections.
4.2. Distribution of stars and galaxies in concentration space
We present the PDF-weighted distribution of star and galaxies in pointing 00857 for different magnitude ranges in Fig. 11. We also present the distribution obtained with the SDSS classification of our sources, similar to the bottom panel in Fig. 2. We found that the SDSS distribution is well recovered by our probabilistic approach. This agreement is remarkable at the fainter magnitude range with 20 < r ≤ 21. The stellar locus in concentration space is broad at these magnitudes and stellar sources extend to higher than expected concentrations because of the uncertainties on cr. This is confirmed by the SDSS-based classification, and correctly accounted for with our statistical analysis.
The previous qualitative comparison based on pointing 00857 is quantitatively explored in Fig. 12. We compared at different magnitudes ranges the number of SDSS-based stars and galaxies, 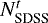 , with the number estimated from the addition of the morphological type PDFs,
, with the number estimated from the addition of the morphological type PDFs,
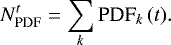 (14)
(14)
We carried out a Student’s t-test to state the significance of the difference between both estimations, assuming 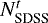 as the right one. The estimator is defined as
as the right one. The estimator is defined as
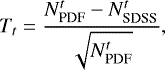 (15)
(15)
where Poissonian uncertainties were assumed. We accepted that 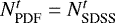 with α = 0.01 significance at |Tt| ≤ 2.6 (i.e. 99% of the time two similar distributions randomly sampled fulfils this criteria). We found that nearly all the measurements are compatible, with only two discrepant pointings at the faint end. Thus, we conclude that the PDF-based classifier statistically obtains the right number of stars and galaxies up to r = 21, in contrast with the limit r = 20 imposed by a Boolean classification (Sect. 4.1). Hence, by relying on the Bayesian classification and weighting sources with the morphological type PDF instead of using the Boolean one, we can extend the analysis by one magnitude. To highlight this, we study the (g − i) colour distributions of J-PLUS EDR stars and galaxies in the next section.
with α = 0.01 significance at |Tt| ≤ 2.6 (i.e. 99% of the time two similar distributions randomly sampled fulfils this criteria). We found that nearly all the measurements are compatible, with only two discrepant pointings at the faint end. Thus, we conclude that the PDF-based classifier statistically obtains the right number of stars and galaxies up to r = 21, in contrast with the limit r = 20 imposed by a Boolean classification (Sect. 4.1). Hence, by relying on the Bayesian classification and weighting sources with the morphological type PDF instead of using the Boolean one, we can extend the analysis by one magnitude. To highlight this, we study the (g − i) colour distributions of J-PLUS EDR stars and galaxies in the next section.
 |
Fig. 9. Stellar probability in the magnitude vs. concentration plane for the J-PLUS EDR pointing 00857. The left panel shows the classification derived with the r-band image alone, PDFr (s), and the right panel the final classification combining the morphological information from g, r, and i bands, PDFgri (s). |
 |
Fig. 10. Completeness (circles) and contamination (squares) of the J-PLUS EDR stars (left panel) and galaxies (right panel) as a function of the r-band magnitude. Sources were classified using PDFgri = 0.5 as boundary. The coloured symbols show the estimation on individual J-PLUS EDR pointings. The white symbols are the median values of the pointings. The grey areas mark the 95% completeness and 5% contamination tolerance regions used to define the performance of our classifier. |
4.3. Colour distribution of stars and galaxies
We further tested our classifier by computing the distribution of stars and galaxies in (g − i) colour space. As in the previous section, we compared our PDF-based distributions with those estimated from the SDSS classification of J-PLUS EDR sources. We present the distributions at different magnitude bins for pointing 00857 in Fig. 13. We found that our morphological classification recovers the expected (g − i) colour distributions with a bimodality in the stellar population at all magnitudes. We note that we are able to recover the expected colour distribution even at r > 20, confirming the goodness of our PDF probabilities.
The result of the quantitative comparison of the distributions with a Kolmogorov–Smirnov (KS) test is presented in Fig. 14. To avoid the different sample sizes, we defined the normalised KS parameter as
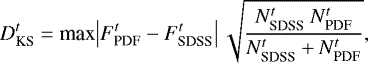 (16)
(16)
where Ft is the cumulative (g − i) colour distribution for type t using a given classification. This parameter is independent of the samples size and provides a common scale for all our measurements. We consider two distributions to be similar (α = 0.01) with DKS < 1.62. We found that all the PDF-based colour distributions are compatible with the SDSS-based ones, even at the fainter magnitudes. The inclusion of the g and i bands information improves DKS by a factor of two with respect to only using the r band, confirming the benefits of a multi-filter analysis of the data.
 |
Fig. 11. Distribution of stars (red) and galaxies (blue) in the r-band concentration space for different magnitude ranges (labelled in the panels) in the J-PLUS EDR pointing 00857. The coloured solid lines mark the PDF-weighted histograms estimated with our probabilistic PDF-based classifier. The coloured areas show the histograms estimated with the SDSS classification of J-PLUS sources. The black solid histogram is the total distribution, illustrating the confusion between compact and extended sources at the faintest magnitudes. |
 |
Fig. 12. Significance of the difference between the number of PDF-based stars (left panel) and galaxies (right panel) with respect to the number estimated from SDSS classification, Tt, as a function of r-band magnitude. The coloured symbols show the estimation of individual J-PLUS EDR pointings. The dotted lines mark zero difference. The dashed lines mark |T| = 2.6, the limit where the PDF-based and the SDSS-based numbers can be considered similar. The exclusion areas with |T| > 2.6 are shown in grey. |
4.4. Number density of stars and galaxies
From the results in the previous sections, we conclude that our PDF-based classifier provides a reliable Boolean classification at r ≤ 20, and a meaningful statistical classification at r ≤ 21. We recover statistically the right number of stars and galaxies, and also their colour (g − i) distributions. Any future study with J-PLUS EDR can benefit from our PDF classification by properly weighting the sources in the dataset.
Finally, we estimated the total PDF-weighted number of stars and galaxies with 15 < r ≤ 21 in the high-quality area covered by the J-PLUS EDR (31.70 deg2, Sect. 2.1). We found 150 thousand stars (4730 per deg2) and 101 thousand galaxies (3190 per deg2). Assuming that these number densities are representative, we expect the detection of ~40 million stars and ~25 million galaxies at J-PLUS completion. As a first application, we present the pointing-by-pointing stellar and galaxy number counts in the next section.
 |
Fig. 13. Distribution of stars (red) and galaxies (blue) in the g − i colour space for different r-band magnitude ranges (labelled in the panels) at J-PLUS EDR pointing 00857. The solid lines mark the PDF-weighted histograms estimated with our classifier. The coloured areas mark the histograms estimated with the SDSS classification. The black solid histogram is the total colour distribution. |
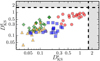 |
Fig. 14. Normalised Kolmogorov–Smirnov parameter for the (g − i) colour distribution of stars ( |
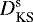
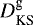
5. Stellar and galaxy number counts
In this section, we study the number counts in the J-PLUS EDR using our PDF-based classification. We define the r-band stellar number counts in pointing j as the PDF-weighted histogram normalised by area and magnitude,
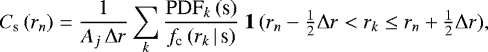 (17)
(17)
where r = rn is the r-band magnitude vector that defines the histogram, Δr = 0.5 the magnitude bin size, the index k spans the sources in the pointing, 1 (⋅) is the indicator function with value unity if the defined condition is fulfilled and zero otherwise, Aj the area subtended by the pointing, and fc the detection completeness for stars (Sect. 2.2). The dimensions of the number counts are [# deg−2 mag−1]. We defined the galaxy number counts in the same way, but we weighted with PDF (g) and used the detection completeness for galaxies. We note that some sources count as stars and galaxies simultaneously in the analysis because of the probabilistic nature of our classification. The uncertainties on the number counts were estimated using the bootstrapping technique (Davison & Hinkley 1997).
We present the J-PLUS EDR stellar and galaxy number counts of four representative pointings in Fig. 15. These pointings span the range of μp covered by the data (Sect. 3.4). The derived stellar and galaxy number counts are in good agreement with SDSS counts up to r = 21. Our results are also compatible with the galaxy number counts from the literature and with the stellar number counts from the default TRILEGAL model of the Milky Way (Girardi et al. 2005). The derived number counts can be found at the PROFUSE web page together with their uncertainties.
We further explore the properties of the derived number counts in the following. We focus first on the stellar counts, that are gathered together in the left panel of Fig. 16. There is a large variation in the normalisation of the counts. Using r = 19.75 as reference, the median stellar counts in the J-PLUS EDR is Cs (19.75) = 1175 ± 526, with ~45% dispersion. Following the results from Fig. 8, we found that the number count decreases with galactic latitude b, as we move away from the galactic plane. Moreover, the higher-latitude pointings seem to present a double power-law shape. This could be interpreted as the dominance of halo stars in these fields (e.g. Gao et al. 2013), but a detailed study is beyond the scope of the present paper.
Regarding the galaxy number counts, the pointing-to-pointing variation is much smaller, with the median counts at r = 19.75 being Cg (19.75) = 1082 ± 125, only a ~ 10% dispersion. The pointing-to-pointing scatter is larger at brighter magnitudes, reaching 75% at r = 15.25. This reflects the larger cosmic variance and points to galaxy clustering as the dominating source of scatter. Indeed, we note that pointings 01488 and 01588 present a clear excess of bright (r < 17) sources (bottom right panel in Fig. 15). We checked that this excess is due to a large-scale structure at z ~ 0.07, confirmed with SDSS spectroscopy.
We planto perform a detailed modelling of the galaxy number counts with the first J-PLUS data release which comprises more than one thousand square degrees (Cenarro et al. 2019).
 |
Fig. 15. Stellar (red dots) and galaxy (blue squares) number counts as a function of r-band magnitude in four J-PLUS EDR pointings (labelled in the panels). Coloured solid histograms are the stellar (yellow) and galaxy (green) number counts from SDSS in the same area. Black solid histograms are the stellar number counts at the pointing position estimated with the default TRILEGAL model of the Milky Way (Girardi et al. 2005). White symbols are galaxy number counts from the literature: Yasuda et al. (2001; circles); Huang et al. (2001; triangles); Kümmel & Wagner (2001; inverted triangles); and Kashikawa et al. (2004; diamonds). The dashed vertical line marks the value of μp estimated for each pointing, showing the expected magnitude with the same number density of stars and galaxies. |
6. Discussion and future prospects
From the analysis presented in previous sections, we conclude that statistically meaningful studies of stars and galaxies at r ≤ 21 with J-PLUS data can be performed by PDF-weighting the observed sources (Sect. 5). Those studies that demand an absolute classification or the spectroscopic follow-up of particular sources, should either restrict to r ≤ 20 or use high-probability sources with PDF (t) > 0.9. The latter approach permits the identification of reliable candidates up to r ~ 21, but penalises the completeness of the targeted morphological population (see Viironen et al. 2015 for an example of this issue regarding the study of high-z galaxies with redshift PDFs).
Our classifier could be improved and further tested by the following:
-
Including J-PLUS colour information, with 12 available bands from 3500 to 9000 Å (Table 1), providing 11 independent colours with valuable information for classifying sources. Following the Bayesian SED-fitting classification presented in Fadely et al. (2012), we plan to define the J-PLUS stellar locus in several colour–colour diagrams, using (g − i) as a fixed colour and comparing the other 11 J-PLUS bands with the reference r band. The galaxy locus will be estimated from a template library. Once both loci are defined, the likelihood betweenthe objects’ photometry and the loci will be computed. The likelihoods will be supplemented by a (g − i) colour prior, computed to account for the different density of stars and galaxies as a function of colour and magnitude. By the end of the process, the probability of having stellar or galaxy colours will be produced, complementing the morphological probability derived in the present work. As an example, the colour information will be useful for identifying close stars that appear to be a single extended object in the catalogues, and thus contaminate the galaxy sample.
-
Calibrating with deeper and better defined star/galaxy classifications. Our derived PDFs can be further compared against other classifications to provide well-defined probabilities. This will additionally improve the statistical information of the classifier.
-
Including external secure classifications, like those based on Gaia proper motions (Gaia Collaboration 2018) or Euclid morphologies. We would need only to add a new prior in Eq. (4) to properly include this extra information in our PDFs.
These improvements will be explored in future versions of the classifier.
 |
Fig. 16. Stellar (dots in the left panel) and galaxy (squares in the right panel) number counts as a function of r-band magnitude of each J-PLUS EDR pointing. The colour scale shows the galactic latitude of the pointings. White symbols in the right panel are galaxy number counts from the literature, as in Fig. 15. |
7. Conclusions
We have implemented a probabilistic morphological classification of the 251 thousand J-PLUS EDR sources over 31.7 deg2. Our Bayesian classifier is based on the distribution of J-PLUS sources in the concentration versus magnitude space, where two populations are present: a compact sequence of point-like sources (stars) and a cloud of extended sources (galaxies). We modelled these distributions, including uncertainties, with a skewed Gaussian for compact objects and a log-normal function for the extended ones. The derived model and the number density prior based on J-PLUS EDR data were used to estimate the Bayesian probability that a source is a star or a galaxy. This procedure was applied pointing-by-pointing to account for varying observing conditions and sky position, with stars being more numerous closer to the Milky Way disc. Finally, we combined the morphological information from g, r, and i broad bands to have the morphological type PDF of each source.
We find that our PDF-based classifier provides a reliable Boolean classification at r ≤ 20, and a meaningful statistical classification at r ≤ 21. This extra magnitude gained by Bayesian analysis was also estimated by Scranton et al. (2002) using the SDSS dataset. The comparison with SDSS in the common areas is satisfactory up to r ~ 21, with consistent numbers of stars and galaxies, and consistent distributions in concentration and (g− i) colour spaces. Future versions of the classifier will include colour information from the twelve photometric J-PLUS bands, improving the classification of low S/N sources.
The derived probabilities were used to compute the pointing-by-pointing number counts of 150 thousand stars and 101 thousand galaxies in the J-PLUS EDR with 15 < r ≤ 21. The normalisation of the stellar number counts increases as we approach the Milky Way disc. Moreover, the higher latitude pointings seem to present a double power-law shape, that could be interpreted as the dominance of halo stars at r ≳ 19 in these fields (e.g. Gao et al. 2013). Regarding galaxy number counts, our values are in good agreement with previous results in the literature. The pointing-to-pointing scatter increases at brighter magnitudes, reflecting the larger cosmic variance.
Using the stellar and galaxy number densities in the EDR as representative, we expect to detect ~40 millions stars and ~25 million galaxies at J-PLUS completion, significantly improving the study of the Milky Way halo structure and our knowledge about galaxy formation and evolution in the nearby Universe (Cenarro et al. 2019).
Acknowledgements
We dedicate this paper to the memory of our six IAC colleagues and friends who met with a fatal accident in Piedra delos Cochinos, Tenerife, in February 2007, with special thanks to Maurizio Panniello, whose teachings of python were so important for this paper. We thank the anonymous referee for useful comments and suggestions. Based on observations made with the JAST/T80 telescope at the Observatorio Astrofísico de Javalambre (OAJ), in Teruel, owned, managed and operated by the Centro de Estudios de Física del Cosmos de Aragón. We acknowledge the OAJ Data Processing and Archiving Unit (UPAD) for reducing and calibrating the OAJ data used in this work. Funding for the J-PLUS Project has been provided by the Governments of Spain and Aragón through the Fondo de Inversiones de Teruel, the Aragón Government through the Reseach Groups E96 and E103, the Spanish Ministry of Economy and Competitiveness (MINECO; under grants AYA2015-66211-C2-1-P, AYA2015-66211-C2-2, AYA2012-30789, and ICTS-2009-14), and European FEDER funding (FCDD10-4E-867, FCDD13-4E-2685). B.A. acknowledges funding received from the European Union’s Horizon 2020 research and innovation programme under the Marie Sklodowska-Curie grant agreement No. 656354. V.M.P. and D.D.W. acknowledgepartial support from grant PHY 14-30152; Physics Frontier Center/JINA Center for the Evolution of the Elements (JINA-CEE), awarded by the US National Science Foundation. K.V. acknowledges the Juan de la Cierva - Incorporación fellowship, IJCI-2014-21960, of the Spanish government. Funding for the SDSS and SDSS-II has been provided by the Alfred P. Sloan Foundation, the Participating Institutions, the National Science Foundation, the U.S. Department of Energy, the National Aeronautics and Space Administration, the Japanese Monbukagakusho, the Max Planck Society, and the Higher Education Funding Council for England. The SDSS Web Site is www.sdss.org. The SDSS is managed by the Astrophysical Research Consortium for the Participating Institutions. The Participating Institutions are the American Museum of Natural History, Astrophysical Institute Potsdam, University of Basel, University of Cambridge, Case Western Reserve University, University of Chicago, Drexel University, Fermilab, the Institute for Advanced Study, the Japan Participation Group, Johns Hopkins University, the Joint Institute for Nuclear Astrophysics, the Kavli Institute for Particle Astrophysics and Cosmology, the Korean Scientist Group, the Chinese Academy of Sciences (LAMOST), Los Alamos National Laboratory, the Max-Planck-Institute for Astronomy (MPIA), the Max-Planck-Institute for Astrophysics (MPA), New Mexico State University, the Ohio State University, University of Pittsburgh, University of Portsmouth, Princeton University, the United States Naval Observatory, and the University of Washington. This research made use of Astropy, a community-developed core Python package for Astronomy (Astropy Collaboration 2013), and Matplotlib, a 2D graphics package used for Python for publication-quality image generation across user interfaces and operating systems (Hunter 2007).
References
- Abazajian, K. N., Adelman-McCarthy, J. K., Agüeros, M. A., et al. 2009, ApJS, 182, 543 [NASA ADS] [CrossRef] [Google Scholar]
- Astropy Collaboration (Robitaille, T. P., et al.) 2013, A&A, 558, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Baldry, I. K., Robotham, A. S. G., Hill, D. T., et al. 2010, MNRAS, 404, 86 [NASA ADS] [Google Scholar]
- Ball, N. M., Brunner, R. J., Myers, A. D., & Tcheng, D. 2006, ApJ, 650, 497 [NASA ADS] [CrossRef] [Google Scholar]
- Benítez, N., Dupke, R., Moles, M., et al. 2014, ArXiv e-prints, [arXiv:1403.5237] [Google Scholar]
- Bertin, E. & Arnouts, S. 1996, A&AS, 117, 393 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bonatto, C., Chies-Santos, A. L., Coelho, P. R. T., & J-PLUS Collaboration 2019, A&A, 622, A179 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cenarro, A. J., Moles, M., Marín-Franch, A., et al. 2014, in Observatory Operations: Strategies, Processes, and Systems V, Proc. SPIE, 91491I [Google Scholar]
- Cenarro, A. J., Moles, M., Cristóbal-Hornillos, D., & J-PLUS Collaboration 2019, A&A, 622, A176 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cortiglioni, F., Mähönen, P., Hakala, P., & Frantti, T. 2001, ApJ, 556, 937 [NASA ADS] [CrossRef] [Google Scholar]
- Davison, A. C., & Hinkley, D. V. 1997, Bootstrap Methods and Their Applications (Cambridge: Cambridge University Press) [CrossRef] [Google Scholar]
- Dye, S., Lawrence, A., Read, M. A., et al. 2018, MNRAS, 473, 5113 [NASA ADS] [CrossRef] [Google Scholar]
- Elston, R. J., Gonzalez, A. H., McKenzie, E., et al. 2006, ApJ, 639, 816 [NASA ADS] [CrossRef] [Google Scholar]
- Fadely, R., Hogg, D. W., & Willman, B. 2012, ApJ, 760, 15 [NASA ADS] [CrossRef] [Google Scholar]
- Flaugher, B. 2012, in APS April Meeting Abstracts, D7.007 [Google Scholar]
- Gaia Collaboration (Brown, A. G. A., et al.) 2018, A&A, 616, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gal, R. R., de Carvalho, R. R., Odewahn, S. C., et al. 2004, AJ, 128, 3082 [NASA ADS] [CrossRef] [Google Scholar]
- Gao, S., Just, A., & Grebel, E. K. 2013, A&A, 549, A20 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Girardi, L., Groenewegen, M. A. T., Hatziminaoglou, E., & da Costa L. 2005, A&A, 436, 895 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Henrion, M., Mortlock, D. J., Hand, D. J., & Gandy, A. 2011, MNRAS, 412, 2286 [NASA ADS] [CrossRef] [Google Scholar]
- Høg, E., Fabricius, C., Makarov, V. V., et al. 2000, A&A, 355, L27 [Google Scholar]
- Huang, J.-S., Cowie, L. L., Gardner, J. P., et al. 1997, ApJ, 476, 12 [NASA ADS] [CrossRef] [Google Scholar]
- Huang, J.-S., Thompson, D., Kümmel, M. W., et al. 2001, A&A, 368, 787 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hunter, J. D. 2007, Compu. Sci. Eng., 9, 90 [Google Scholar]
- Ivezic, Z., Tyson, J. A., Acosta, E., et al. 2008, ArXiv e-prints, [arXiv:0805.2366] [Google Scholar]
- Kashikawa, N., Shimasaku, K., Yasuda, N., et al. 2004, PASJ, 56, 1011 [NASA ADS] [CrossRef] [Google Scholar]
- Kim, E. J., & Brunner, R. J. 2017, MNRAS, 464, 4463 [NASA ADS] [CrossRef] [Google Scholar]
- Kim, E. J., Brunner, R. J., & Carrasco Kind M. 2015, MNRAS, 453, 507 [NASA ADS] [CrossRef] [Google Scholar]
- Kron, R. G. 1980, ApJS, 43, 305 [NASA ADS] [CrossRef] [Google Scholar]
- Kümmel, M. W. & Wagner, S. J. 2001, A&A, 370, 384 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Laureijs, R., Amiaux, J., Arduini, S., et al. 2011, ArXiv e-prints, [arXiv:1110.3193] [Google Scholar]
- Logroño-García, R. Vilella-Rojo, G., López-Sanjuan, C., & J-PLUS Collaboration 2019, A&A, 622, A180 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Małek, K., Solarz, A., Pollo, A., et al. 2013, A&A, 557, A16 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- McMahon, R. G., Banerji, M., Gonzalez, E., et al. 2013, The Messenger, 154, 35 [NASA ADS] [Google Scholar]
- Miller, A. A., Kulkarni, M. K., Cao, Y., et al. 2017, AJ, 153, 73 [NASA ADS] [CrossRef] [Google Scholar]
- Molino, A., Benítez, N., Moles, M., et al. 2014, MNRAS, 441, 2891 [NASA ADS] [CrossRef] [Google Scholar]
- Molino, A., Costa-Duarte, M. V., Mendes de Oliveira, C., & J-PLUS Collaboration 2019, A&A, 622, A178 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Odewahn, S. C., de Carvalho, R. R., Gal, R. R., et al. 2004, AJ, 128, 3092 [NASA ADS] [CrossRef] [Google Scholar]
- Oke, J. B., & Gunn, J. E. 1983, ApJ, 266, 713 [NASA ADS] [CrossRef] [Google Scholar]
- Preethi, K., Gudennavar, S. B., Bubbly, S. G., Murthy, J., & Brosch, N. 2014, MNRAS, 437, 771 [NASA ADS] [CrossRef] [Google Scholar]
- Reid, I. N., Yan, L., Majewski, S., Thompson, I., & Smail, I. 1996, AJ, 112, 1472 [NASA ADS] [CrossRef] [Google Scholar]
- Robin, A. C., Rich, R. M., Aussel, H., et al. 2007, ApJS, 172, 545 [NASA ADS] [CrossRef] [Google Scholar]
- Saglia, R. P., Tonry, J. L., Bender, R., et al. 2012, ApJ, 746, 128 [NASA ADS] [CrossRef] [Google Scholar]
- San Roman, I., Sánchez-Blázquez, P., Cenarro, A. J., & J-PLUS Collaboration 2019, A&A, 622, A181 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Scranton, R., Johnston, D., Dodelson, S., et al. 2002, ApJ, 579, 48 [NASA ADS] [CrossRef] [Google Scholar]
- Sebok, W. L. 1979, AJ, 84, 1526 [NASA ADS] [CrossRef] [Google Scholar]
- Soumagnac, M. T., Abdalla, F. B., Lahav, O., et al. 2015, MNRAS, 450, 666 [NASA ADS] [CrossRef] [Google Scholar]
- Strauss, M. A., Weinberg, D. H., Lupton, R. H., et al. 2002, AJ, 124, 1810 [NASA ADS] [CrossRef] [Google Scholar]
- Vasconcellos, E. C., de Carvalho, R. R., Gal, R. R., et al. 2011, AJ, 141, 189 [NASA ADS] [CrossRef] [Google Scholar]
- Viironen, K., Marín-Franch, A., López-Sanjuan, C., et al. 2015, A&A, 576, A25 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Wolf, C., Meisenheimer, K., Kleinheinrich, M., et al. 2004, A&A, 421, 913 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Yasuda, N., Fukugita, M., Narayanan, V. K., et al. 2001, AJ, 122, 1104 [NASA ADS] [CrossRef] [Google Scholar]
J-PLUS pointings comprise three exposures with a relatively small dithering displacement of 10′′.
All Tables
J-PLUS filter system and limiting magnitudes (3σ, 3′′ aperture) of J-PLUS and the EDR.
All Figures
|
Fig. 1. Completeness curves referenced to the 5σ
detection in the J-PLUS r-band magnitude ( |
| In the text | |
|
Fig. 2. Concentration vs. r-band magnitude for the J-PLUS EDR pointing 00857 (top panel), and distribution of 20 < r ≤ 21 sources in concentration space (black histogram in the bottom panel). In both panels, sources classified as stars by SDSS are in red, and those classified as galaxies are in blue. |
| In the text | |
|
Fig. 3. Variation in the parameters defining the stellar locus (position μs in the left panel and dispersion σs in the right panel) as a function of the PSF FWHM of the J-PLUS EDR r-band image. The dotted line in each panel is the error-weighted linear fit to the points. |
| In the text | |
|
Fig. 4. Variation in the normalised stellar locus position (circles in the left panels) and dispersion (squares in the right panels) with r-band magnitude. The coloured symbols mark the measurements in each J-PLUS EDR pointing. The white symbols show the median and the dispersion of the pointing-based values. The dashed lines mark identity. The top panels show the results assuming no concentration uncertainties (σc = 0), and the bottom panels with the uncertainties, computed assuming a covariance ρ = 0.72, properly accounted for. |
| In the text | |
|
Fig. 5. Variation in the parameters defining the galaxy locus (position μg in left panel and dispersion σg in right panel) as a function of the PSF FWHM of the J-PLUS EDR r-band image. The dotted line in each panel is the error-weighted linear fit to the points. |
| In the text | |
|
Fig. 6. Position of the galaxy locus, μg, as a function of the position of the stellar locus, μs. The colour scale shows the PSF FWHM of the r-band images. Thedotted line is the error-weighted linear fit to the points. |
| In the text | |
|
Fig. 7. Fraction of galaxies, fg, as a function of the r-band magnitude. The circles are the measurements in each J-PLUS EDR pointing, coloured with the galactic latitude b of the pointing. The dashed line marks fg = 0.5. As an illustration, the dotted lines show the best prior fitting curves, P (g | r), to the pointings with lower and higher galactic latitude. |
| In the text | |
|
Fig. 8. Magnitude at which stars and galaxies have the same number density, μp, as a function of the galactic latitude b of the J-PLUS EDR pointings. The colour scale shows the FWHM of the r-band images. |
| In the text | |
|
Fig. 9. Stellar probability in the magnitude vs. concentration plane for the J-PLUS EDR pointing 00857. The left panel shows the classification derived with the r-band image alone, PDFr (s), and the right panel the final classification combining the morphological information from g, r, and i bands, PDFgri (s). |
| In the text | |
|
Fig. 10. Completeness (circles) and contamination (squares) of the J-PLUS EDR stars (left panel) and galaxies (right panel) as a function of the r-band magnitude. Sources were classified using PDFgri = 0.5 as boundary. The coloured symbols show the estimation on individual J-PLUS EDR pointings. The white symbols are the median values of the pointings. The grey areas mark the 95% completeness and 5% contamination tolerance regions used to define the performance of our classifier. |
| In the text | |
|
Fig. 11. Distribution of stars (red) and galaxies (blue) in the r-band concentration space for different magnitude ranges (labelled in the panels) in the J-PLUS EDR pointing 00857. The coloured solid lines mark the PDF-weighted histograms estimated with our probabilistic PDF-based classifier. The coloured areas show the histograms estimated with the SDSS classification of J-PLUS sources. The black solid histogram is the total distribution, illustrating the confusion between compact and extended sources at the faintest magnitudes. |
| In the text | |
|
Fig. 12. Significance of the difference between the number of PDF-based stars (left panel) and galaxies (right panel) with respect to the number estimated from SDSS classification, Tt, as a function of r-band magnitude. The coloured symbols show the estimation of individual J-PLUS EDR pointings. The dotted lines mark zero difference. The dashed lines mark |T| = 2.6, the limit where the PDF-based and the SDSS-based numbers can be considered similar. The exclusion areas with |T| > 2.6 are shown in grey. |
| In the text | |
|
Fig. 13. Distribution of stars (red) and galaxies (blue) in the g − i colour space for different r-band magnitude ranges (labelled in the panels) at J-PLUS EDR pointing 00857. The solid lines mark the PDF-weighted histograms estimated with our classifier. The coloured areas mark the histograms estimated with the SDSS classification. The black solid histogram is the total colour distribution. |
| In the text | |
|
Fig. 14. Normalised Kolmogorov–Smirnov parameter for the (g − i) colour distribution of stars ( |
| In the text | |
|
Fig. 15. Stellar (red dots) and galaxy (blue squares) number counts as a function of r-band magnitude in four J-PLUS EDR pointings (labelled in the panels). Coloured solid histograms are the stellar (yellow) and galaxy (green) number counts from SDSS in the same area. Black solid histograms are the stellar number counts at the pointing position estimated with the default TRILEGAL model of the Milky Way (Girardi et al. 2005). White symbols are galaxy number counts from the literature: Yasuda et al. (2001; circles); Huang et al. (2001; triangles); Kümmel & Wagner (2001; inverted triangles); and Kashikawa et al. (2004; diamonds). The dashed vertical line marks the value of μp estimated for each pointing, showing the expected magnitude with the same number density of stars and galaxies. |
| In the text | |
|
Fig. 16. Stellar (dots in the left panel) and galaxy (squares in the right panel) number counts as a function of r-band magnitude of each J-PLUS EDR pointing. The colour scale shows the galactic latitude of the pointings. White symbols in the right panel are galaxy number counts from the literature, as in Fig. 15. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.