| Issue |
A&A
Volume 609, January 2018
|
|
|---|---|---|
| Article Number | A17 | |
| Number of page(s) | 28 | |
| Section | Extragalactic astronomy | |
| DOI | https://doi.org/10.1051/0004-6361/201731448 | |
| Published online | 22 December 2017 | |
The AMIGA sample of isolated galaxies
XIII. The HI content of an almost “nurture free” sample⋆
1 Instituto de Astrofísica de Andalucía (CSIC), Apdo. 3004, 18008 Granada, Spain
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2 National Astronomical Observatory of Japan (NAOJ), 2-21-1 Osawa, Mitaka, 181-8588 Tokyo, Japan
3 The Graduate University for Advanced Studies (SOKENDAI), 2-21-1 Osawa, Mitaka, 181-0015 Tokyo, Japan
4 Max-Planck-Institut fuer Radioastronomie, Postfach 2024, 53010 Bonn, Germany
5 Departamento de Física Teórica y del Cosmos, Universidad de Granada, 18071 Granada, Spain
6 Instituto Carlos I de Física Teórica y Computacional, Universidad de Granada, 18071 Granada, Spain
7 Joint ALMA Observatory – ESO, Av. Alonso de Córdova, 3104 Santiago, Chile
8 Institute for Astronomy, University of Edinburgh, EH9 3 HJ Edinburgh, UK
9 SAMSI, 19 T.W. Alexander Drive, PO Box 110207, Research Triangle Park, NC 27709, USA
10 Department of Statistical Sciences, Duke University, PO Box 90251, Durham, NC 27708, USA
Received: 26 June 2017
Accepted: 7 October 2017
Abstract
Context. We present the largest catalogue of HI single dish observations of isolated galaxies to date, as part of the multi-wavelength compilation being performed by the AMIGA project (Analysis of the interstellar Medium in Isolated GAlaxies). Despite numerous studies of the HI content of galaxies, no revision focused on the HI scaling relations of the most isolated L∗ galaxies has been made since Haynes & Giovanelli (1984, AJ, 89, 758).
Aims. The AMIGA sample has been demonstrated to be almost “nurture free”, therefore, by creating scaling relations for the HI content of these galaxies we will define a metric of HI normalcy in the absence of interactions.
Methods. The catalogue comprises of our own HI observations with Arecibo, Effelsberg, Nançay and GBT, and spectra collected from the literature. In total we have measurements or constraints on the HI masses of 844 galaxies from the Catalogue of Isolated Galaxies (CIG). The multi-wavelength AMIGA dataset includes a revision of the B-band luminosities (LB), optical diameters (D25), morphologies, and isolation. Due to the large size of the catalogue, these revisions permit cuts to be made to ensure isolation and a high level of completeness, which was not previously possible. With this refined dataset we fit HI scaling relations based on luminosity, optical diameter and morphology. Our regression model incorporates all the data, including upper limits, and accounts for uncertainties in both variables, as well as distance uncertainties.
Results. The scaling relation of HI mass with D25 is in good agreement with that of Haynes & Giovanelli (1984), but our relation with LB is considerably steeper. This disagreement is attributed to the large uncertainties in the luminosities, which introduce a bias when fitting with ordinary least squares regression (as was done in previous works), and the different morphology distributions of the samples. We find that the main effect of morphology on the D25-relation is to increase the intercept towards later types, while for the LB-relation it is to flatten the slope. These trends were not evident in previous works due to the small number of detected early-type galaxies. Applying our relations to HI detected galaxies in the Virgo cluster we find that although the typical HI-deficiency is only ~0.3 dex, the tail of the distribution extends over an order of magnitude beyond that of the AMIGA sample. These results are in general agreement with previous studies of HI-deficiency in the Virgo cluster.
Conclusions. The HI scaling relations of the AMIGA sample define an up-to-date metric of the HI content of almost “nurture free” galaxies. These relations allow the expected HI mass, in the absence of interactions, of an individual galaxy to be predicted to within 0.25 dex (for typical measurement uncertainties). These relations are thus suitable for use as statistical measures of the impact of interactions on the neutral gas content of galaxies.
Key words: galaxies: evolution / galaxies: interactions / radio lines: ISM / surveys
The complete HI dataset is only available at the CDS via anonymous ftp to cdsarc.u-strasbg.fr (130.79.128.5) or via http://cdsarc.u-strasbg.fr/viz-bin/qcat?J/A+A/609/A17
© ESO, 2017
1. Introduction
Galaxies in and around high density environments such as clusters and compact groups undergo an array of environmental processes that impact their morphological type, gas content, and star formation rate. The effects of tidal forces and ram pressure stripping are ubiquitous in clusters (e.g. Kenney et al. 2004; Lucero et al. 2005; Chung et al. 2009; Abramson et al. 2011), and the impact of the former is detectable even for galaxy pairs by the elevation of their star formation rates (e.g. Patton et al. 2013), or in extreme cases by stellar or gaseous tidal tails.
HI is one of the most sensitive components of the ISM (interstellar medium) to environmental effects as it typically extends approximately twice as far as the stellar disc. HI-rich galaxies with close neighbours are frequently seen to have HI tails and bridges extending well beyond any detectable stellar component, in some cases ~500 kpc long (Serra et al. 2013; Leisman et al. 2016; Hess et al. 2017). In clusters ram pressure stripping depletes galaxies of much of their HI reservoir leaving the majority of them HI-deficient. Furthermore, the rate of gas-poor spirals increases towards the centre of clusters (Haynes et al. 1984; Solanes et al. 2001; Lah et al. 2009; Chung et al. 2009), and perhaps even in groups (Hess & Wilcots 2013; Odekon et al. 2016; Brown et al. 2017). One of the most extreme examples of environment is compact groups, small groups (4–10 members) with number densities comparable to cluster cores (Hickson 1982; Hickson et al. 1992). These groups are found to be HI-deficient, and while they show evidence of highly effective stripping events (Verdes-Montenegro et al. 2001; Rasmussen et al. 2008; Borthakur et al. 2015; Walker et al. 2016), their formation and evolution are not yet understood, in particular the fate of atomic gas. This highlights the need for up-to-date benchmark of the HI content of undisturbed galaxies to act as a fair reference with which to compare.
In order to understand the impact of environmental effects on a galaxy’s HI content in a statistical sense, rather than on a system by system basis, a predictor of the expected HI content for a given galaxy is required to act as a baseline. This predictor must be calibrated by HI observations of galaxies with as minimal impact from interactions and environmental effects as possible to ensure that the baseline represents the HI content of unperturbed systems. The AMIGA project (Analysis of the interstellar Medium of Isolated GAlaxies; Verdes-Montenegro et al. 2005) is an in depth study of isolated galaxies from a starting sample of 1050 CIG galaxies (Catalogue of Isolated Galaxies; Karachentseva 1973). AMIGA was initially focused on studying the ISM in isolated galaxies, but as well as collecting a rich, multi-wavelength dataset has made numerous refinements to the quantification of the isolation and environment of these galaxies and their properties in the radio, infrared, and optical. These quantifications have demonstrated AMIGA to be an almost “nurture free” sample with galaxies that have been isolated for 3 Gyr on average (Verdes-Montenegro et al. 2005), and have properties that are distinct even from those of field galaxies. Thus, AMIGA constitutes an ideal sample for calibration of a predictor of HI content.
While interferometric 21 cm observations can provide spatially resolved maps of the HI emission of a galaxy, they generally have poorer surface brightness sensitivity than single dish observations and can introduce bias due to scale dependent attenuation of features. Therefore, as the global properties of a system’s HI, including its mass and basic kinematics, can be found from its 21 cm spectral profile alone, and because single dish spectra are both more plentiful in the literature and require shorter observations, they represent the best way to measure the total HI content in this case.
As the optical properties of galaxies are thought to be less impacted, or at least impacted on a longer timescale, than HI properties, the optical luminosity and optical diameter are typically used as proxies for the HI mass. Haynes & Giovanelli (1984; hereafter HG84) performed the seminal study of the HI properties of isolated galaxies using 324 Arecibo spectra of CIG galaxies to calibrate their predictors of HI mass. These scaling relations are still widely used today to measure the quantity “HI-deficiency”: 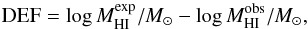 (1)where
(1)where 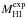 is the expected HI mass based on a predictor, and
is the expected HI mass based on a predictor, and 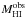 is the observed HI mass. This definition of HI-deficiency means that galaxies with positive DEF are poor in HI relative to what is expected.
is the observed HI mass. This definition of HI-deficiency means that galaxies with positive DEF are poor in HI relative to what is expected.
Solanes et al. (1996) extended the work of HG84 by assessing the correlation between galaxy size and HI mass for 532 field galaxies in the Pisces-Perseus region. As that region contains a chain of clusters the Sa-Sc spirals in their sample were selected to have low projected neighbour densities to ensure they were not cluster members, however, almost none of these galaxies would be considered isolated by the AMIGA criteria (see Appendix E). Hence, it is important to note that here “field” and “isolated” are two quantitatively separate categories. Solanes et al. (2001) then used the predictor calibrated in Solanes et al. (1996) to measure the HI-deficiency of galaxies in 18 nearby clusters, and mapped the HI-deficiency across the Virgo region.
More recently Toribio et al. (2011b,a) used ALFALFA (Arecibo Legacy Fast ALFA survey; Giovanelli et al. 2005; Haynes et al. 2011) to perform a principal component analysis of the HI and optical properties of 1624 field galaxies in low density environments (selected with weaker criteria than AMIGA’s) within the ALFALFA footprint in the direction of Virgo. Unlike the previous works (and this paper) the ALFALFA survey provides a blind HI-selected, rather than optically-selected, sample which means that the relations calculated by Toribio et al. (2011a) are optimal for the average HI-rich galaxy, however, this excludes parts of the population such as isolated early-type galaxies that are HI-poor and thus not detectable by ALFALFA.
Dénes et al. (2014) used HIPASS (HI Parkes All Sky Survey; Barnes et al. 2001; Meyer et al. 2004) and a compilation of optical and infrared properties to construct scaling relations of HI-selected galaxies. Their scaling relations were constructed from the HIPASS galaxies, excluding the highest 30% in neighbour density (out to the 7th optically-selected neighbouring galaxy). This sample contains many more galaxies than the previous samples, but this is a direct consequence of weaker isolation criteria. With these relations it was confirmed that HI-deficiency is seen to correlate with the densest environments.
Finally, Bradford et al. (2015) used a combination of ALFALFA data and their own HI observations to fit scaling relations between stellar masses (estimates from the NASA Sloan Atlas) and HI masses of isolated galaxies. This work focused on low-mass galaxies (mostly below the mass range covered by AMIGA) and therefore chose to define isolation as a minimum separation of 1.5 Mpc from a massive (potential) host galaxy. This definition was expanded to include non-dwarf galaxies, allowing the relations to be extended to higher masses. However, the sample suffers from incompleteness at higher masses and defining a consistent metric of isolation for both dwarf and L∗ galaxies is a challenge.
All of these related works, with the exception of HG84, are based on samples with significant numbers of field galaxies, not truly isolated galaxies. Therefore, they do not necessarily represent a galaxy population that has been without interactions for an extended period (the average AMIGA galaxy has been without substantial interaction for 3 Gyr, Verdes-Montenegro et al. 2005), and thus are not appropriate to act as the baseline for the expected HI content of galaxies in the absence of interactions.
Another growing use for HI scaling relations is in HI spectral line stacking experiments. With the imminent arrival of SKA precursor and pathfinder facilities the redshift range of HI galaxy surveys will be pushed to order unity through the use of stacking. HI scaling relations can be used to estimate the contribution of source confusion to such stacks (Delhaize et al. 2013; Jones et al. 2016; Elson et al. 2016), and to act as a comparison for the average properties of the stacked galaxies. Although these applications can both be (and likely will be) fulfilled by comparison with simulations, HI scaling relations offer not only an additional method that does not depend on the veracity of simulations, but also a method that can rapidly provide estimates with a minimal investment of computation time.
In this paper we use a collection of 844 spectra of CIG galaxies, both from the literature and AMIGA’s own observations, to measure a new baseline for the HI content of highly isolated galaxies. This measure has not been updated (for the most isolated galaxies) since HG84. Our larger sample of isolated galaxies with HI observations, combined with the ancillary dataset AMIGA has collected and characterised, allows us to make cuts to ensure both isolation and a high level of completeness, while still retaining a large enough sample to perform a statistical analysis. Furthermore, the regression model used here is more sophisticated than in previous works. It accounts for measurement uncertainties in all quantities (including the source distances), and incorporates the information contained in the upper limits. The retention of upper limits also means that our science sample covers the range of morphologies in a much more representative manner than HG84, as early types tend to be undetected in HI. The new baseline of HI content of the most isolated galaxies that we calculate here, will allow studies of the atomic gas in galaxies in terms of “nature versus nurture”, and for very gas-deficient systems will provide an up-to-date estimate of how much has been lost.
The paper is arranged as follows: in the next section we describe the AMIGA sample and the compiled optical properties, Sect. 3 details our HI observations and the HI data compiled from the literature, in Sect. 4 we describe how that data was uniformly reduced, Sect. 5 presents our regression model and the results of our analysis, and in Sect. 6 we discuss these results before summarising in Sect. 7.
2. Sample
The AMIGA (Verdes-Montenegro et al. 2005) sample is drawn from the CIG (Karachentseva 1973), which includes 1051 isolated galaxies (although CIG 781 has since been shown to be a globular cluster, Leon & Verdes-Montenegro 2003). AMIGA is an ongoing project to study the ISM of these galaxies and has observed and compiled a multi-wavelength database covering the optical, Hα, NIR, FIR, radio continuum, as well as HI and CO lines. AMIGA has made substantial contributions to updating and qualifying this catalogue of sources. Leon & Verdes-Montenegro (2003) used SExtractor and DSS (Digitized Sky Survey) to redefine the source positions of the CIG. Mostly these updated positions agreed within a few arcsec of the original position, but in certain cases there were deviations of over half an arcmin. Verdes-Montenegro et al. (2005) evaluated the completeness of the AMIGA sample using the V/Vmax test, finding it to be 80–95% complete for objects with B-band magnitudes brighter than 15.0. Verley et al. (2007a,b) measured the degree of isolation of the galaxies in this sample, estimating both the local number density and the strength of the tidal forces exerted by any neighbours. Criteria for both of these parameters were then chosen with the goal of removing any galaxies from the sample that could have their evolution impacted by the presence of neighbours. The isolation criteria were revised again in Argudo-Fernández et al. (2013) based on SDSS DR9 images and spectroscopy. However, because AMIGA is an all sky sample, restricting it to the SDSS footprint excludes much of the collected HI data. Therefore, we choose not to use this most recent revision and show in Appendix D that our results are mostly consistent with those of this more restricted sample.
The AMIGA sample has also been demonstrated to be the sample of galaxies with the lowest levels of all properties that are enhanced by interaction. Lisenfeld et al. (2007) found that the FIR luminosity of AMIGA galaxies falls over 0.2 dex below that of a random sample of galaxies (selected without constraints on environment), while the ratio of FIR to B-band luminosity is more than 0.1 dex lower, suggesting that the star formation rate (SFR) in an average galaxy is enhanced relative to that of an AMIGA galaxy. Lisenfeld et al. (2011) observed CO in 173 AMIGA galaxies and found them to be 0.2–0.3 dex poorer in molecular gas than interacting galaxies. The galaxies in the AMIGA sample are also radio-quiet, with most radio emission emanating from mild SF in the disc, and have a very low AGN-fraction as evidenced by the lack of excess (<1.5% of sources) above the radio continuum-FIR correlation (Leon et al. 2008; Sabater et al. 2008), although, curiously there is still a non-negligible fraction showing optical nuclear activity (Sabater et al. 2012). Finally, Espada et al. (2011) used a high signal-to-noise and velocity resolution subset of the HI dataset of this paper to show that AMIGA has the lowest level of HI-asymmetry of any galaxy sample. This body of evidence confirms the assertion that AMIGA is an excellent example of a “nurture free” galaxy sample which can act as the baseline control sample for studying the properties of non-interacting galaxies.
2.1. Optical properties
The optical properties of the sample were mostly taken directly from the AMIGA 2012 data release (Fernández Lorenzo et al. 2012) or compiled from HyperLeda1 (Makarov et al. 2014). Here we briefly describe the parameters used. For a full description consult the referenced articles.
2.1.1. Optical positions
The optical positions of the CIG were updated by Leon & Verdes-Montenegro (2003) who used DSS images and SExtractor. These new positions are used in this work to make corrections to observations that pointed at slightly incorrect locations.
2.1.2. Apparent magnitudes
The B-band magnitudes from the AMIGA 2012 release were compiled from HyperLeda and the standard corrections were applied to give the corrected magnitude as: 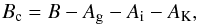 (2)where B is the observed B-band magnitude, Ag is the Galactic extinction, Ai in the galaxy’s internal extinction, and AK is the K-correction. Ag was taken directly from HyperLeda, as was Ai, except that it used the revised AMIGA morphologies. The K-correction was updated in this work to reflect the latest available heliocentric velocities of the sources (see Sect. 2.2).
(2)where B is the observed B-band magnitude, Ag is the Galactic extinction, Ai in the galaxy’s internal extinction, and AK is the K-correction. Ag was taken directly from HyperLeda, as was Ai, except that it used the revised AMIGA morphologies. The K-correction was updated in this work to reflect the latest available heliocentric velocities of the sources (see Sect. 2.2).
2.1.3. B-band luminosity
A physical property of the galaxy is required to act as a predictor of the HI mass, therefore, the corrected B-band apparent magnitudes must be converted to a luminosity. The luminosity is calculated in terms of the Sun’s bolometric luminosity. We use the Sun’s bolometric absolute magnitude, Mbol, ⊙ = 4.88 (as in Lisenfeld et al. 2011; Fernández Lorenzo et al. 2012), and the equation: 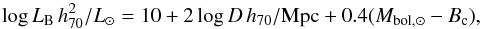 (3)where D is the calculated distance to the source.
(3)where D is the calculated distance to the source.
2.1.4. Morphologies
 |
Fig. 1 Morphology distributions of galaxy samples used in this work and the works with which we compare. The morphological types used for the AMIGA and HG84 samples are from the AMIGA database, while those for Solanes et al. (1996) are taken from the original article. The dark grey bars (detections) combined with the light grey bars (marginals and non-detections) make up the AMIGA HI science sample, which has a median type of 4 (Sbc). For comparison the white bars show the full CIG sample. The pink bars shown the field sample of Solanes et al. (1996), which has a median type of 6 (Scd), and the green bars the CIG-based sample of HG84, which has a median type of 5 (Sc). |
Morphologies given in Fernández Lorenzo et al. (2012) were used for this work. These morphologies are mostly based on SDSS images or AMIGA’s own optical images, for a much smaller number of sources the morphologies are from the original AMIGA revision of morphologies (Sulentic et al. 2006) based on POSS II images (Second Palomar Observatory Sky Survey; Reid et al. 1991), or in cases where no images were available the morphologies were taken from NED (NASA/IPAC Extragalactic Database) or HyperLeda. The numerical scale follows the RC3 system.
The morphology distributions of all the CIG and the AMIGA HI science sample (see Sect. 5.1) are shown in Fig. 1 along with the other galaxy samples with which we compare results (see Sect. 6.2).
2.1.5. Optical diameters, axis ratios, and inclinations
The major axis optical diameters at 25 mag/arcsec2 in B-band (D25), axial ratios (R25), and inclinations were taken directly from Fernández Lorenzo et al. (2012). D25 and R25 were compiled from HyperLeda in that work, whereas inclinations were estimated using AMIGA’s morphologies (but otherwise following the HyperLeda methodology).
2.1.6. Position angles
As position angles had not been compiled as part of the AMIGA 2012 release they were compiled for this work from HyperLeda. These angles are required for the beam corrections of the Nançay telescope as its beam is non-circular.
2.2. Distances and velocities
 |
Fig. 2 Calculated distances to all CIG galaxies with measurements of recession velocity (white). The subset of the CIG that is the AMIGA HI science sample (defined in Sect. 5.1) is shown in grey, the dark grey indicating detections and light grey the upper limits. Note that the science sample contains no sources with heliocentric velocities less than 1500 km s-1 due to the isolation requirements, as explained Sect. 5.1. |
To calculate distances from heliocentric velocities we extended the method of previous AMIGA releases which used Hubble flow and velocities corrected for Local Group motion. We adopt the model of Mould et al. (2000) which corrects for Local Group motion and then has separate attractor velocity fields for the Virgo cluster, the Shapley supercluster, and the Great Attractor. Each of these attractors is modelled as a spherical overdensity with symmetric infall. For a full description of the model refer to the original reference. The resulting distances are shown in Fig. 2. H0 is assumed to be 70 km s-1 Mpc-1 throughout this paper2.
Comparing the distances to sources in common with ALFALFA we find that the Mould-model distances are systematically higher than ALFALFA distances by about 3 Mpc. The scatter between the two methods is also about 3 Mpc, but the deviations are highly correlated with position on the sky, as would be expected because the positions and velocity fields of the attractors are different in the two methods (the ALFALFA flow model is described in Masters 2005).
Literature spectra used in this compilation.
Although no sources with heliocentric velocities less than 1500 km s-1 are used in the final regression analysis, the distances to sources with Vhelio< 1000km s-1 were replaced by literature values from primary and secondary distance indicators (as in Verdes-Montenegro et al. 2005), with the exception of CIGs 506, 657, 711, 748, and 753 for which no such distance estimates exist. Finally, the errors in the distances were estimated by assuming a normal distribution of galaxy peculiar velocities of width 200 km s-1 and a Gaussian uncertainty in H0 of 2 km s-1 Mpc-1. The Mould-model distances were then recalculated 10 000 times, with each iteration having a randomly drawn Hubble constant and a random selection of peculiar velocities for all the sources. The calculated distances to each galaxy were fit with a normal distribution and its standard deviation taken as the uncertainty in the distance. The uncertainty for sources with redshift independent distance measurements was assumed to be 10%, however, these low redshift sources are not used in the final regression sample. It should also be noted that the heliocentric velocity used for the distance determination was not necessarily the systemic HI velocity calculated in this work, but instead the best available velocity in the AMIGA dataset (see Appendix B for more information).
3. HI data
The 844 HI spectra compiled in this paper are from both the literature and our own observation, in approximately equal quantities. At the outset of the project, spectra of CIG galaxies were identified in the literature and all the remaining sources were observed where possible. From a starting sample of 1050 targets (the CIG) spectra of a total of 897 were compiled or observed (although not all observations resulted in usable data). In the cases where we used existing observations we required that the spectra were published (or made available to us) rather than just the spectral parameters. This requirement meant that all the spectral parameters of this compilation could be extracted using the same fitting method, allowing a highly uniform HI database of isolated galaxies to be created.
3.1. HI spectra from the literature
HI spectra were compiled from the literature using NED and the original articles. In most cases the spectra had been compiled (and digitised where necessary) by NED, however, for a small number (8) of spectra only the published plots were available and we performed the digitisation ourselves3. A complete list of the 26 original references and the total number of spectra taken from each is shown in Table 1.
3.2. HI observations
The AMIGA team performed HI observations of 488 CIG galaxies with the Arecibo, Effelsberg (ERT), Green Bank (GBT), and Nançay (NRT) radio telescopes. A full summary of these observations is displayed in Table 2 and here we outline the observing strategy used at each facility. All targets were observed using a total power switching mode (ON-OFF) at all telescopes and both polarisations were averaged together.
Summary of AMIGA’s HI observations of CIG galaxies.
3.2.1. Arecibo
A total of 34 CIG galaxies were observed with the Arecibo 305 m telescope using its Gregorian optics system and L-band wide receiver. The autocorrelator was configured either in a high or a low resolution mode, corresponding to a bandwidths of approximately 1400 or 5550 km s-1, depending on whether the source was of known or unknown redshift. Total integration times were about 30 min per galaxy and the system temperature was approximately 30 K.
3.2.2. Effelsberg
Observations of 186 galaxies were performed with the Effelsberg radio telescope. Most of these targets were selected because they fall outside of Arecibo’s declination range and therefore generally have declinations above 37° or below −1°. Observations were performed in 10 min ON-OFF pairs with a total bandwidth of 6.25 MHz across 256 channels, giving a typical channel width of ~5 km s-1 over a range of about 1200 km s-1. The system temperature was about 30 K.
3.2.3. Green Bank
A total of 51 CIG galaxies were observed with the GBT. Integration times of between 10 and 60 min were used for ON-OFF pairs of targets below 10 000 km s-1. Bandwidths of 5 or 10 MHz were used depending on the expected emission strength and width. The system temperature was approximately 20 K.
3.2.4. Nançay
During a total of 600 hours we observed 277 CIG galaxies. Sixty of these suffered from strong interference or severe baseline problems and had to be discarded. For sources of unknown redshift a total bandwidth of 50 MHz was used giving a velocity range of approximately 10 500 km s-1, which was centred at 7000 km s-1 to try to maximise the probability of detecting the target’s HI emission (as we anticipated that targets at very low velocities would have already been detected). For sources of known redshift a narrowed bandwidth of 12.5 MHz (~2500 km s-1) was used. The best system temperatures (at dec of 15°) was about 35 K.
3.3. Selection of spectra
Of the 488 CIG galaxies observed by the AMIGA team 429 are included in the final sample, along with 415 spectra from the literature. Our own observations were omitted in cases where there is still no known redshift (24 CIG galaxies) of an undetected source, or a redshift was obtained after our observations and it revealed that the source would not have been (completely) within the observed bandwidth (29 CIG galaxies). Without knowing the HI emission of a target should fall within the bandwidth, an upper limit of the flux cannot be confidently estimated. A small number of our observations were discarded because a literature spectrum was deemed preferable to our own spectrum (6 CIG galaxies).
In cases where there were multiple spectra with detections of the same target the preferred spectrum was selected by hand. As the comparison was performed by a person it did not follow an exact algorithm, but considered the following factors:
-
The rms noise of the spectrum.
-
The telescope beam size relative to the size of the optical disc of the target galaxy.
-
Spectral resolution.
-
Other problems such as RFI, unstable baselines, and proximity to the edge of the bandpass.
Generally the first two of these were the most important. When the angular size of the optical disc was comparable to the telescope beam, the observation with the largest beam was almost always preferred, even at the expense of some signal-to-noise. The rationale behind this choice is that it is better to incur a larger random error due to increased noise in the spectrum, than a larger systematic error due to flux residing outside the primary beam. In cases where beam size was unimportant, generally more recent and higher spectral resolution spectra were favoured. In the case of non-detections the spectrum with the lowest rms noise was favoured.
As much as was possible ALFALFA spectra were avoided (only one ALFALFA spectrum is used the final sample) such that an independent comparison could be made between the observed flux scales of our dataset and those CIG galaxies with ALFALFA spectra. This choice did not decrease the quality of our database because the rms noises in the overlapping spectra were typically similar to those from ALFALFA and no other telescope used had a beam size smaller than Arecibo.
4. HI data reduction
The HI single dish spectra of a total of 844 CIG galaxies were obtained through our own observations or compiled from the literature. The AMIGA collaboration observed 488 CIG galaxies with the Arecibo 305 m telescope, the Effelsberg radio telescope, the Green Bank telescope, and the Nançay radio telescope. The 415 spectra obtained from the literature predominantly came from Springob et al. (2005) and HG84 (see Table 1 for the complete list of sources). For many of the literature observations the original spectra were unavailable in digital format and were substituted for with the digitised spectra from NED. In addition, we digitised 8 spectra ourselves.
4.1. Determination of spectral and source parameters
The baselines of our own observations were fit with low order polynomials and the rms noise was estimated in an emission free region of each spectrum. The same procedure was applied to the literature spectra which were published without the baselines removed. All spectra were inspected by eye (and smoothed as necessary) to determine if there was a likely detection, or potential marginal detection, of the CIG galaxy. The spectra without a detection were retained to be used as upper limits only if the source had an existing redshift that fell in the observed bandpass. Upper limits on the source HI mass was estimated for the marginal and non-detected sources as described in Sect. 4.4. A threshold for the upper limits of 5σ was chosen because this is approximately when there is a transition from a mix of detections and marginals (identified by eye), to solely marginals.
The source parameters were extracted from the spectra with either detections or marginal detections, using our own implementation of the Springob et al. (2005) method to fit HI spectral profiles. This method was selected because it does not require a parametric form of the profiles to be assumed, but is found to be more resilient in cases of low S/N compared to using the observed datapoints themselves to define the source properties (e.g. Fouqué et al. 1990). Here we provide a brief description of the method. For a complete description refer to the original article (Springob et al. 2005).
The Springob-method assumes that HI profiles are double-horned in shape and begins by finding the peak flux density on the left and right edges of the profile. The two edges are then fit with straight lines using the datapoints between 15% and 85% of the peak flux density of that side of the profile minus the rms noise. The velocity width is then measured as the separation between the 50% levels (of the peak flux density minus rms) of the left and right sides (each calculated separately), while the centre velocity is taken as the mean of the velocities at the left and right 50% levels. Finally, the integrated flux is calculated by summing the flux density in the channels between the two zero points of the lines fitted to the left and right sides of the profile (and then multiplying by the mean channel width of the summed channels). The error in the integrated flux is estimated using the empirical relation 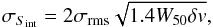 (4)where σrms is the rms noise, W50 is the velocity width at the 50% level, and δv is the spectrum channel width in km s-1. As the Springob-method assumes that the spectral profile is double horned in shape, it loses some of its objectivity when applied to profiles with only a single peak or cases where the highest point in the profile is not in either of the horns. These cases are flagged in the data reduction process, but generally were found to give similar results to the Fouqué-method. For spectra with the highest peak not falling in either horn, the peak signal-to-noise was adjusted after the initial fitting to reflex the true profile peak height.
(4)where σrms is the rms noise, W50 is the velocity width at the 50% level, and δv is the spectrum channel width in km s-1. As the Springob-method assumes that the spectral profile is double horned in shape, it loses some of its objectivity when applied to profiles with only a single peak or cases where the highest point in the profile is not in either of the horns. These cases are flagged in the data reduction process, but generally were found to give similar results to the Fouqué-method. For spectra with the highest peak not falling in either horn, the peak signal-to-noise was adjusted after the initial fitting to reflex the true profile peak height.
A complication with the Springob-method is that there must be at least 3 spectral channels with flux between the 15% and 85% levels within each horn in order for a straight line to be fitted. While Springob et al. (2005) mostly had high resolution spectra, preventing this from being a serious concern, a number of the compiled spectra are from older observations with relatively poor spectral resolution (>15 km s-1). If a straight line could not be fit due to there being too few points within the relevant interval then additional points were linearly interpolated between the true datapoints for the purposes of fitting only (these spectra were also flagged to indicate this had been done).
Finally, as some of the spectra required interpolation or were not double horned we decided not to use the uncertainties in the line fits to determine the errors in the widths. Instead we used the estimates of Fouqué et al. (1990), which gives the uncertainty in the systemic velocity, V50, as 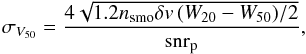 (5)where nsmo is the number of channels the final spectrum was smoothed over, δv is the channel width in km s-1, snrp is the peak signal-to-noise ratio, and W20 is the velocity width in km s-1 calculated as described above except at the 20% level. The uncertainty in the velocity width, W50, is taken to be
(5)where nsmo is the number of channels the final spectrum was smoothed over, δv is the channel width in km s-1, snrp is the peak signal-to-noise ratio, and W20 is the velocity width in km s-1 calculated as described above except at the 20% level. The uncertainty in the velocity width, W50, is taken to be 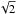 times this value.
times this value.
During this fitting process flags were also set if the method was thought to be potentially erroneous. This could occur if, for example, there was a substantial noise spike near the edge of the profile that obscured the true location of the profile edge.
It was also determined by eye whether a given target was considered detected, marginally detected, or not detected. Upon review it was found that the marginal detections almost all corresponded to profiles with signal-to-noise ratios of less than 5. This was then adopted as the quantitative threshold for a detection and all profiles with a signal-to-noise ratio of less than 5 were considered upper limits when deriving the scaling relations (see Sect. 4.4).
4.2. HI flux and width corrections
The HI integrated flux of a source can be suppressed below its true value by inaccurate pointing of the telescope, beam attenuation (if the angular size of emission is comparable to the telescope’s beam), or both. Inaccurate pointing can be caused by errors in the input source catalogue or due to the intrinsic uncertainty in the telescope’s pointing accuracy. The smaller the beam of the telescope the more severe both of these effects will be because the smaller the beam the greater the attenuation of the incoming signal for a given offset.
Leon & Verdes-Montenegro (2003) remeasured the optical positions of the CIG and found that there was a typical offset of 2′′ (although in some cases were as large as 38′′), while typical pointing uncertainties for radio telescopes are 5–15′′. HG84 estimated that Arecibo’s pointing uncertainty led to an average of 5% decrease in flux in target sources. The decrease is likely to be even smaller for other telescopes as Arecibo was the largest used by approximately a factor of 3 in diameter. As the centre of the beam has the highest gain, any offset from the centre results in a decrease in the measured flux. Therefore, HG84 corrected for this effect by multiplying by a constant correction factor. The updated positions calculated in AMIGA reveal that many of the original observations in our compilation were not targeting the centre of the source, meaning that the random pointing uncertainty would not always act to decrease the observed flux. Therefore, we choose not to make a correction for this effect. However, the systematic effect caused by the incorrect target positions is corrected for in the beam attenuation correction, as explained below.
When observed in HI, nearby galaxies cannot typically be treated as point sources because their distribution of HI frequently extends to angular scales comparable to the size of a radio telescope’s beam (e.g. Shostak 1978), this means that a correction must be applied for the beam filling factor, f, in order to get the corrected flux, Sc = fSobs, where Sobs is the observed flux and f is calculated as follows: 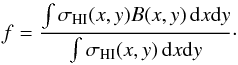 (6)Here x and y are the angular Cartesian coordinates on the sky, σHI is the neutral hydrogen surface density distribution, and B is the beam response pattern of the telescope. We followed the approach of Hewitt et al. (1983) using a circular Gaussian beam and a circular double Gaussian for the HI surface density. The characteristic length of the first Gaussian component of the HI surface density is assumed to be R1 = 0.65D25 (in B-band), the second Gaussian component has a magnitude of −0.6 times that of the first and a length scale of 0.23R1, in order to create the central HI hole. Finally, the whole distribution is compressed along one axis according to the inclination derived from the optical properties. The position angle is unimportant because the beam functions are circularly symmetric (with the exception of NRT, see below). Finally the centre of the distribution is offset by the difference between the revised position (Leon & Verdes-Montenegro 2003) and the target coordinates of the original observation4. The value of f is then calculated numerically.
(6)Here x and y are the angular Cartesian coordinates on the sky, σHI is the neutral hydrogen surface density distribution, and B is the beam response pattern of the telescope. We followed the approach of Hewitt et al. (1983) using a circular Gaussian beam and a circular double Gaussian for the HI surface density. The characteristic length of the first Gaussian component of the HI surface density is assumed to be R1 = 0.65D25 (in B-band), the second Gaussian component has a magnitude of −0.6 times that of the first and a length scale of 0.23R1, in order to create the central HI hole. Finally, the whole distribution is compressed along one axis according to the inclination derived from the optical properties. The position angle is unimportant because the beam functions are circularly symmetric (with the exception of NRT, see below). Finally the centre of the distribution is offset by the difference between the revised position (Leon & Verdes-Montenegro 2003) and the target coordinates of the original observation4. The value of f is then calculated numerically.
In the case of spectra observed with NRT there is the additional complication that the beam response cannot be assumed to be circular. We therefore use a double Gaussian beam that has a HPBW of 20′ in the North-South direction and 4′ in the East-West direction. This asymmetric beam also means that the position angle of the source is, in theory, important. Source position angles were obtained from HyperLeda for all objects and used to rotate the model HI distribution relative to the assumed telescope beam (only in the case of NRT). It should be noted that the uncertainties in the position angle can be very large, with different measurements in HyperLeda frequently varying by over 10°, however, given the large size of the NRT beam the impact that this is expected to have is minimal. The HPBWs assumed for other telescopes can be found in Table 3. The distribution of beam corrections is shown in Fig. 3. Over 90% of HI detections in this dataset have a beam correction factor of less than 20%
Telescope beam widths and codes.
 |
Fig. 3 Distribution of beam correction factors for all galaxies detected in HI. |
The velocity widths of all sources were corrected following the methodology of Springob et al. (2005). The first correction to the velocity width is for instrumental broadening, cinst. This is calculated following the empirical expressions given in Springob et al. (2005) Eqs. (3), (5)–(7), and their Table 2. We replace the channel width with the channel width times nsmo−2 (the expressions assume the spectra have already been Hanning smoothed across 2 channels). The next correction is for broadening due to the cosmological expansion. This term is simply ccosmo = (1 + z50)-1, where z50 is the heliocentric redshift measured at the 50% level. The instrumental effects have to be corrected first because corrections should be applied in the reverse order of how they impacted the originally emitted spectrum, starting with the impact of the instrument, then the expansion of the Universe, and finally the properties of the source itself. We do not make any of the third type of corrections (e.g. inclination and turbulent motions) as the velocity widths are not part of our statistical analysis.
4.3. HI masses
With the measurements of the HI fluxes and beam correction factors we use the normal equation to calculate the HI masses of the detected sources, 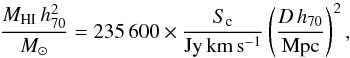 (7)where D is the estimated distance to the source in Mpc. The distribution of HI masses of all HI detections in shown in Fig. 4.
(7)where D is the estimated distance to the source in Mpc. The distribution of HI masses of all HI detections in shown in Fig. 4.
 |
Fig. 4 Distribution of HI masses for all sources detected in HI. |
4.4. HI mass upper limits
As a means to make a fair comparison of the sensitivity of all spectra the parameter σrms,10 was calculated for all spectra; the rms noise if the spectra all had 10 km s-1 channel widths. 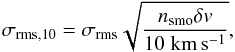 (8)where σrms is the spectrum’s measured rms noise for its given channel width (δv) and smoothing (nsmo). The integrated signal-to-noise ratio of all detections and marginal detections was calculated using a similar approach to ALFALFA (Giovanelli et al. 2005)
(8)where σrms is the spectrum’s measured rms noise for its given channel width (δv) and smoothing (nsmo). The integrated signal-to-noise ratio of all detections and marginal detections was calculated using a similar approach to ALFALFA (Giovanelli et al. 2005) 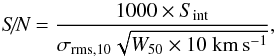 (9)where Sint is the integrated flux in Jy km s-1, and the rms noise in 10 km s-1 channels (σrms,10) is in mJy. A maximum value of 300 km s-1 was set for W50 (that is, widths above 300 km s-1 were set to 300 km s-1 for this calculation only) because, as confirmed by (Haynes et al. 2011), beyond this point smoothing the profile no longer results in the same improvement of signal-to-noise.
(9)where Sint is the integrated flux in Jy km s-1, and the rms noise in 10 km s-1 channels (σrms,10) is in mJy. A maximum value of 300 km s-1 was set for W50 (that is, widths above 300 km s-1 were set to 300 km s-1 for this calculation only) because, as confirmed by (Haynes et al. 2011), beyond this point smoothing the profile no longer results in the same improvement of signal-to-noise.
All spectra with S/N less that 5 were treated as upper limits. The distinction between non-detections and marginal detections is that marginal detections were originally identified by eye as marginal detections or detections (but have S/N< 5), whereas in the case of non-detections, no HI emission in the appropriate velocity range was identified. As 5σ is the threshold we have set to separate detections from upper limits, we will use 5σ upper limits on the HI mass for those sources not considered bona fide detections.
To calculate these upper limits the spectral profile of the source was assumed to be rectangular, with a flux density of 5σrms,10. The velocity widths of each source was estimated from the B-band Tully-Fisher relation (TFR). We used the relation for field galaxies calculated by Torres-Flores et al. (2010), which converted to our unit system is 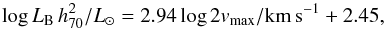 (10)where vmax is the maximum rotation velocity of the galaxy’s rotation curve. We assume that the velocity width is WTFR = 2vmax(1 + z)sini, where i is the inclination (see Sect. 2.1.5). A minimum width of 100 km s-1 was set because less than 5% of our final detection sample has widths this narrow and narrower widths make sources more likely to be detected. Finally, the distance to each source was used as calculated in Sect. 2.2, giving the upper limits on the HI mass as
(10)where vmax is the maximum rotation velocity of the galaxy’s rotation curve. We assume that the velocity width is WTFR = 2vmax(1 + z)sini, where i is the inclination (see Sect. 2.1.5). A minimum width of 100 km s-1 was set because less than 5% of our final detection sample has widths this narrow and narrower widths make sources more likely to be detected. Finally, the distance to each source was used as calculated in Sect. 2.2, giving the upper limits on the HI mass as 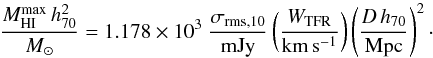 (11)Using widths based on the TFR steepens the final scaling relations that we calculate by about 5% compared to assuming a constant width. However, because for a given sensitivity per channel the flux (mass) limit of a non-detection grows with its velocity width, assuming a constant width introduces a non-physical dependence between LB and the limit on the HI mass. Instead, using the TFR to determine the widths introduces the natural relation between LB and the widths into the upper limits of the HI mass.
(11)Using widths based on the TFR steepens the final scaling relations that we calculate by about 5% compared to assuming a constant width. However, because for a given sensitivity per channel the flux (mass) limit of a non-detection grows with its velocity width, assuming a constant width introduces a non-physical dependence between LB and the limit on the HI mass. Instead, using the TFR to determine the widths introduces the natural relation between LB and the widths into the upper limits of the HI mass.
4.5. Comparison with ALFALFA integrated fluxes and velocity widths
 |
Fig. 5 Comparison between ALFALFA and AMIGA measurements of HI integrated flux. The orange and pink points show detections from NRT and ERT respectively, and the black points show detections from all other telescopes. The thin black line indicates equality, while the dotted red line shows the best fit to all the points. Statistical error bars are not shown as for the majority of the points these are comparable in size to the points themselves, indicating that absolute calibration is the cause of most of the scatter and offset. |
As only one of our compilation of spectra came from ALFALFA we can use the ALFALFA catalogue5 as a means to compare and verify our corrected integrated flux and velocity width measurements. The two catalogues were cross matched for agreement within 30′′ and 200 km s-1, using the optical counterpart positions and the HI recession velocities given in the ALFALFA catalogue. To estimate how likely a mismatch was with this automated procedure we integrated the ALFALFA correlation function (Papastergis et al. 2013; Jones et al. 2015) over the match volume to determine how many interlopers are expected. As essentially all our detections are above log MHI/M⊙ = 8, this was set as the minimum mass for a believable mismatch. This gave the chance of a mismatch as less than 1%. Therefore, we consider all automated matches to be correct. The comparison of the flux and velocity widths are shown in Figs. 5 and 6.
It appears that there is very good qualitative agreement between the two datasets. Indeed the relation between the velocity widths is log W50−ALFALFA = 1.03log W50−AMIGA−0.06. However, in the case of the fluxes the best fit line is at a small, but significant angle to the 1:1 line (log Sint−ALFALFA = 0.95log Sint−AMIGA + 0.06), indicating that there is a systematic disagreement of up to 20% (at the lowest and highest fluxes) in the flux between the AMIGA and ALFALFA measurements6.
 |
Fig. 6 Comparison between ALFALFA and AMIGA measurements of HI profile widths at the 50% level. The black line indicates equality and the dotted red line the best fit to the data. The highly outlying points are either from low signal-to-noise detections, or sources where the profile shapes in ALFALFA and AMIGA have differences for unknown reasons. |
Discrepancies at the highest fluxes are not surprising as these large and bright sources are often extended beyond the Arecibo beam, which can cause complications in determining the flux, especially with a multi-beam receiver such as ALFA (Arecibo L-band Feed Array). However, these sources were not found to be the main cause of the offset gradient. Instead sources observed with NRT and ERT were found to have systematically low integrated fluxes compared to ALFALFA, with a mean offset of ~0.2 dex. While the most obvious explanation for such an offset might be the beam correction factor, as the Arecibo beam is much smaller than both the NRT and ERT beams, all of the matched NRT and ERT sources have optical diameters of 1 arcmin or less, meaning their beam correction factors in ALFALFA would be approximately 10% or less and thus cannot explain the offset.
A similar discrepancy was noticed before by the NIBLES team in van Driel et al. (2016). They attributed this to a difference between single and multi-beam detectors, but our dataset does not appear to support this interpretation because the integrated fluxes measured from the 145 single beam spectra in our sample (excluding NRT and ERT) that overlap with ALFALFA are in good agreement with those of ALFALFA, despite it being a multi-beam survey. Furthermore, the NIBLES comparison was performed only against very high signal-to-noise sources in ALFALFA, which are not a representative sample of all the ALFALFA sources.
Even though NRT and ERT only contribute ~20% of the overlapping measurements, removing these data from the fit more than halved the magnitude of the deviation. Further investigation showed an apparent frequency (or redshift) dependence in the ratio of the ALFALFA fluxes to the AMIGA fluxes obtained with NRT and ERT. However, this trend had a poor correlation and although it could be an indication of a gain calibration issue, we were unable to identify the root cause of the apparent offset. Therefore, no correction was made to the NRT and ERT data to bring the flux scales in line with ALFALFA and the rest of our dataset, but we note that applying such a correction would steepen the final scaling relations that we calculate by a few percent. The implications of this choice for the final scaling relations are described in Appendix F.
The remaining scatter around the best fit line was measured along the length of the line and took values in the range 0.1–0.15 dex, with a mean of 0.12 dex across all the data. This is a better estimate of the uncertainty in the flux than the statistical error found during spectral fitting because for most sources uncertainties in the absolute calibration of the telescope dominate over the statistical uncertainty in a given spectrum. Therefore this value (0.12 dex) was set as the minimum possible uncertainty in the integrate flux and, later on, the HI mass.
5. Analysis
In this section we present our fundamental results, the HI scaling relations, but first we describe the selection of the final science sample, explain our regression model and discuss how the problems associated with previous regression methods used to fit HI scaling relations have been addressed.
5.1. Completeness and isolation
Sample size after each successive cut.
The ancillary data collected by the AMIGA team allows cuts to be made to the sample to ensure that the final scaling relations are fit to only galaxies with quantified isolation and a sample that is highly complete. Due to the substantially larger size of this dataset (compared to HG84), even after these significant cuts have been made there still remain sufficient sources to perform a statistical analysis.
The completeness of the CIG was assessed by Verdes-Montenegro et al. (2005) using a V/Vmax test and found to be 80–95% complete below a B-band magnitude of 15. The magnitudes of the AMIGA sample were revised by Fernández Lorenzo et al. (2012), which shifted this cut to a magnitude of 15.3. This threshold is applied to our HI sample which removes approximately 15% of the sources.
Next, isolation was ensured by following the recommended cuts of Verley et al. (2007a). The dimensionless local number density, ηk, calculated by the distance to the 5th neighbour, is cut at a maximum value of 2.4. The Q parameter, which signifies the strength of the tidal forces exerted by neighbours relative to the binding strength of the galaxy, is cut at a maximum value of −2, corresponding to an external tidal force of 1% of the galaxy’s internal forces. Neighbour density is frequently used alone to define isolation, but these two parameters are complementary because strong tidal forces can be caused by just one very nearby neighbour, without significantly impacting ηk. With both of these isolation criteria set the sample is ensured to be quite distinct to samples in higher density environments. It should also be noted that all sources with heliocentric velocities below 1500 km s-1 are removed in this step because it is extremely difficult to accurately quantify isolation for such nearby sources (Verley et al. 2007a). Hence, this cut also has the effect of removing any dwarf galaxies that were in the CIG, as these are only sufficiently bright when they are relatively nearby. Therefore, the relations calculated in this paper are not applicable to dwarf galaxies as there are none in our science sample.
Finally, any sources which had flags set during the spectral fitting procedure to indicate the spectral parameters are potentially spurious were also removed, which reduced the remaining detections by 5%. This leaves a final sample of 544 CIG galaxies (399 detections, 16 marginal detections, and 129 non-detections in HI) that we will refer to as the AMIGA HI science sample. This sample is used in all the following analysis unless explicitly stated otherwise. The exact sample size after each of the cuts explained above is shown in Table 4.
Applying the same isolation and completeness cuts described above to the full CIG leaves 618 galaxies. Therefore, although many galaxies have been cut from the HI sample there are still detections or upper limits on the HI content of almost 90% of the full isolated and complete sample.
5.2. Regression model
The data are expected to exhibit a good positive correlation between, for example, log MHI and log LB. However, this correlation most likely has a significant amount of intrinsic scatter due to covariates, such as galaxy morphology. In addition, the data contain errors in both the independent and dependent variables, and censorship of the dependent variable is common due to non-detection. Finally, the part of the errors that originate from the distance uncertainty is the same for both variables, making their errors correlated. Each of these properties of the dataset can erroneously impact the final regression line if not accounted for in the regression method.
The simplest methods, such as ordinary least squares (OLS), account only for scatter in the dependent variable, but can be straightforwardly extended to include the uncertainty in the measurements of the dependent variable. Therefore, both of these aspects of the data are usually modelled in the astronomy literature. All the works that we compare with used either the OLS method (Haynes & Giovanelli 1984; Solanes et al. 1996) or the OLS-bisector method (Dénes et al. 2014).
Measurement uncertainty in the independent variable is less straightforward to account for than uncertainty in the dependent variable, and is therefore frequently neglected. This is known as the “errors-in-variables” problem in statistics. Failing to account for these errors leads to a biasing of the regression line gradient (towards a flatter slope). Many methods also do not allow the incorporation of upper limits. However, upper limits can contain information about all the parameters of the regression fit and so simply ignoring them can make the results dependent on the sensitivity of the observations, or result in less precise estimates of the regression parameters than obtainable with the upper limits included. Finally, in the presence of correlated errors, standard regression methods can produce misleading results because they do not account for the fact that the measurements of the variables are not independent.
While there are many methods available in the literature to fit regression lines, they tend to be aimed at addressing a subset of these issues, but all are anticipated to be potentially important effects in this case. Therefore, we construct a parametric model designed for this particular situation and estimate the regression parameters by maximising the likelihood of the observed data given the model.
Assume that the data follow a linear trend with intrinsic scatter σξ: 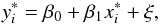 (12)where a star denotes the true value (as opposed to the observed value), i indicates simply the ith data point, and β0 and β1 are the regression coefficients that we wish to determine. Here we also use the notation that the greek letter ξ is a random variable and σξ is its standard deviation about a zero mean. This notation is also used for other random variables in this section. We have also taken care to consistently use the phrase “intrinsic scatter” to refer to estimates of σξ for the various relations calculated in this paper. Some of the scatter in the data is due to the measurement uncertainties (which can be large). Estimates of the measurement uncertainties for each datapoint are included in the method described below, which permits the fitting of an estimate of σξ, that is, the scatter intrinsic to the physical relation that is not accounted for by measurement uncertainty.
(12)where a star denotes the true value (as opposed to the observed value), i indicates simply the ith data point, and β0 and β1 are the regression coefficients that we wish to determine. Here we also use the notation that the greek letter ξ is a random variable and σξ is its standard deviation about a zero mean. This notation is also used for other random variables in this section. We have also taken care to consistently use the phrase “intrinsic scatter” to refer to estimates of σξ for the various relations calculated in this paper. Some of the scatter in the data is due to the measurement uncertainties (which can be large). Estimates of the measurement uncertainties for each datapoint are included in the method described below, which permits the fitting of an estimate of σξ, that is, the scatter intrinsic to the physical relation that is not accounted for by measurement uncertainty.
The independent variable is assumed to have a Gaussian measurement error, σηi, and a Gaussian error due to the distance uncertainty7, σδi, such that 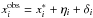 , where
, where 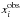 is the observed value of the ith data point. Similarly the dependent variable is assumed to have a Gaussian measurement error σϵi, giving
is the observed value of the ith data point. Similarly the dependent variable is assumed to have a Gaussian measurement error σϵi, giving 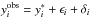 , where δi takes exactly the same value as in the previous equation. This means that the errors in the x- and y-directions are correlated, even though ηi and ϵi are independent.
, where δi takes exactly the same value as in the previous equation. This means that the errors in the x- and y-directions are correlated, even though ηi and ϵi are independent.
Due to this correlation the errors in the x- and y-directions cannot be modelled as two independent normal distributions and instead are treated as a bivariate normal with covariance matrix ![Mathematical equation: \begin{equation} \Sigma_{i} = \left[ {\begin{array}{cc} \sigma_{x_{i}}^{2} & \rho_{i}\sigma_{x_{i}}\sigma_{y_{i}} \\ \rho_{i}\sigma_{x_{i}}\sigma_{y_{i}} & \sigma_{y_{i}}^{2} \\ \end{array} } \right], \end{equation}](/articles/aa/full_html/2018/01/aa31448-17/aa31448-17-eq98.png) (13)where
(13)where 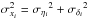 ,
, 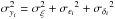 , and ρi = σδi2/σxiσyi.
, and ρi = σδi2/σxiσyi.
First consider only sources which are successfully detected. The observed independent variables will be normally distributed about their true values as indicated by σxi and the dependent variable will be normally distributed above and below the true regression line according to σyi, giving the likelihood of the detected data as ![Mathematical equation: \begin{eqnarray} \mathcal{L}_{\mathrm{det}} &= &\prod\limits_{i} \frac{1}{2 \pi \sigma_{x_{i}} \sigma_{y_{i}} \sqrt{1 - \rho_{i}^{2}} } \exp \left( \frac{-1}{2(1-\rho_{i}^{2})} \right. \nonumber \\ &&\quad\times \left. \left[ \frac{(x^{\mathrm{obs}}_{i}-x^{*}_{i})^{2}}{\sigma_{x_{i}}^{2}} + \frac{(y^{\mathrm{obs}}_{i}-\beta_{1}x^{*}_{i}-\beta_{0})^{2}}{\sigma_{y_{i}}^{2}} \right. \right. \nonumber \\ &&\quad\left. \left. - \frac{2 \rho_{i} (x^{\mathrm{obs}}_{i}-x^{*}_{i}) (y^{\mathrm{obs}}_{i}-\beta_{1}x^{*}_{i}-\beta_{0})}{\sigma_{x_{i}}\sigma_{y_{i}}} \right] \right) \cdot \end{eqnarray}](/articles/aa/full_html/2018/01/aa31448-17/aa31448-17-eq104.png) (14)When only considering the detected sources this is the likelihood that should be maximised by finding the optimal values of β0, β1, and σξ. This method also treats the true values of the observations of x as parameters and these are also found in the optimisation, but are discarded. In a more sophisticated treatment, such as a Bayesian hierarchical model, our prior knowledge of the intrinsic distribution of x∗ could be included rather than treating these as free parameters.
(14)When only considering the detected sources this is the likelihood that should be maximised by finding the optimal values of β0, β1, and σξ. This method also treats the true values of the observations of x as parameters and these are also found in the optimisation, but are discarded. In a more sophisticated treatment, such as a Bayesian hierarchical model, our prior knowledge of the intrinsic distribution of x∗ could be included rather than treating these as free parameters.
In the case where non-detections (or marginal detections) are also included, a different likelihood is required because  is unknown, there is only an upper limit on its value (here the indices have been changed to j rather than i to prevent confusion between detections and non-detections.). We assume that the unobserved values of the HI mass (y) follow the same conditional distribution at each value of x as the detections do, therefore, the appropriate weighting of each value of y for the upper limits is obtained by integrating the likelihood above over all possible values of . The values at which the non-detections become censored (the HI masses of the upper limits) are near random because they depend on which telescope the source was observed with, how long for, its distance, and its assumed velocity width. However, our assumption is somewhat uncertain because there is likely some morphological dependence on whether or not a source is detected, and the morphology distribution is not constant across all diameters and luminosities. This means that on some level our assumption is probably invalid. However, given the scope of our dataset this is a necessary simplification to proceed (although we explore the dependence on morphology in Sect. 5.4). When setting the upper limit for this integration we also make the simplifying assumption that it is absolute, i.e. that it is unaffected by the measurement and distance uncertainties. The upper limits are calculated at a level 5 times the rms noise in the spectra. The possibility that a signal at this level has been missed in our reduction process is remote. Furthermore, the fractional uncertainty in the distances is significantly less than 1 for all sources. Therefore, we are confident that the true HI mass of these sources falls below the stated limits. With these assumptions the likelihood for the non-detections becomes
is unknown, there is only an upper limit on its value (here the indices have been changed to j rather than i to prevent confusion between detections and non-detections.). We assume that the unobserved values of the HI mass (y) follow the same conditional distribution at each value of x as the detections do, therefore, the appropriate weighting of each value of y for the upper limits is obtained by integrating the likelihood above over all possible values of . The values at which the non-detections become censored (the HI masses of the upper limits) are near random because they depend on which telescope the source was observed with, how long for, its distance, and its assumed velocity width. However, our assumption is somewhat uncertain because there is likely some morphological dependence on whether or not a source is detected, and the morphology distribution is not constant across all diameters and luminosities. This means that on some level our assumption is probably invalid. However, given the scope of our dataset this is a necessary simplification to proceed (although we explore the dependence on morphology in Sect. 5.4). When setting the upper limit for this integration we also make the simplifying assumption that it is absolute, i.e. that it is unaffected by the measurement and distance uncertainties. The upper limits are calculated at a level 5 times the rms noise in the spectra. The possibility that a signal at this level has been missed in our reduction process is remote. Furthermore, the fractional uncertainty in the distances is significantly less than 1 for all sources. Therefore, we are confident that the true HI mass of these sources falls below the stated limits. With these assumptions the likelihood for the non-detections becomes ![Mathematical equation: \begin{eqnarray} \mathcal{L}_{\mathrm{lim}} &=& \prod\limits_{j} \frac{1}{2\sqrt{2 \pi} {\sigma_{x_{j}}}} \exp{\left( \frac{-(x^{\mathrm{obs}}_{j}-x^{*}_{j})^{2}}{2 {\sigma^{2}_{x_{j}}}} \right)} \nonumber \\ &&\quad\times \left[ 1 - \erf \left( \frac{1}{\sqrt{2 \left( 1-\rho^{2}_{j} \right) }} \right. \right. \nonumber \\ &&\quad\times \left. \left. \left( \frac{(x^{\mathrm{obs}}_{j}-x^{*}_{j})\rho_{j}}{\sigma_{x_{j}}} - \frac{y^{\mathrm{up}}_{j} - \beta_{0} - \beta_{1} x^{*}_{j}}{\sigma_{y_{j}}} \right) \right) \right] , \end{eqnarray}](/articles/aa/full_html/2018/01/aa31448-17/aa31448-17-eq108.png) (15)where
(15)where  is the upper limit for the jth non-detection. When calculating σyj we no longer have a measurement error (σϵj) because no signal was detected, however, in place of σϵj we use the scatter found in the calibration of the flux scales of our spectra (0.12 dex), which in practice was the relevant value for essentially all the detections as well. Finally, when performing the actual maximisation, log ℒdet for all the detections is added to log ℒlim for all the non-detections to give the complete log-likelihood.
is the upper limit for the jth non-detection. When calculating σyj we no longer have a measurement error (σϵj) because no signal was detected, however, in place of σϵj we use the scatter found in the calibration of the flux scales of our spectra (0.12 dex), which in practice was the relevant value for essentially all the detections as well. Finally, when performing the actual maximisation, log ℒdet for all the detections is added to log ℒlim for all the non-detections to give the complete log-likelihood.
Error estimates for each of the regression parameters can be calculated via the jackknife method. To jackknife a sample each datapoint is removed one at a time and the remaining N−1 datapoints are used to calculate the fit. The variance of each parameter can then be estimated by summing the squared deviations from the mean parameter value (across all N jackknife samples) and weighting by (N−1) /N.
5.3. HI scaling relations
 |
Fig. 7 Scatter plot of the HI mass of AMIGA galaxies as a function of their optical diameters (D25 in B-band). The black points indicate sources detected in HI while grey arrows indicate upper limits. The typical 1σ error ellipse of the data points is shown in the bottom right corner. The heavy blue lines show the regression fits of this work. The solid line corresponds to the full regression model including upper limits, while the dashed line is for the same model but only including detections (mostly hidden behind the solid line). The red dotted line is the ordinary least squares fit for the detections only. The green, purple, and orange dashed lines are from HG84, Solanes et al. (1996), and Dénes et al. (2014) respectively. |
 |
Fig. 8 Scatter plot of the HI mass of AMIGA galaxies as a function of their optical luminosities (in B-band). The black points indicate sources detected in HI while grey arrows indicate upper limits. The typical 1σ error ellipse of the data points is shown in the bottom right corner. The heavy blue lines show the regression fits of this work. The solid line corresponds to the full regression model including upper limits, while the dashed line is for the same model but only including detections (mostly hidden behind the solid line). The red dotted line is the ordinary least squares fit for the detections only. The green and orange dashed lines are from HG84 and Dénes et al. (2014). |
We selected log D25 and log LB to use as predictors of HI content because these have the strongest correlations with log MHI out of all of the available observational properties. The correlation coefficient between log D25 and log MHI (detections only) is 0.73, and 0.69 between log LB and log MHI. This is consistent with previous studies, which have generally found the optical diameter to be the best predictor of HI mass.
Regression fits between 2log D25/ kpc and log MHI/M⊙.
Regression fits between log LB/L⊙ and log MHI/M⊙.
The regression model described in the previous subsection was fit to the AMIGA HI science sample (described in Sect. 5.1) and is shown by the blue lines in Figs. 7 and 8, and the coefficients are given in Tables 5 and 6. For the purposes of comparison our regression model is fit both to all the data (shown by the solid blue line), including upper limits, and to just the detections (dashed blue line). An ordinary least squares (OLS) fit to the detections is also shown by the dotted red line. In both plots the OLS fit has a shallower gradient than those corresponding to our regression model. The reason for this is that the independent variable has considerable uncertainties (as shown by the typical error bars) which are not accounted for in the OLS method, causing an underestimate of the gradient. These plots also show fits from Haynes & Giovanelli (1984), Solanes et al. (1996) and Dénes et al. (2014) for comparison, which are discussed in detail in Sect. 6.2.
Tables 5 and 6 do not include values for the intrinsic scatter of the OLS fits because for this method only the total scatter about the relation can be calculated, which is 0.28 and 0.30 for the D25 and LB relations respectively. The corresponding values for our maximum likelihood method are 0.21 and 0.20, respectively. These are considerably smaller because our method accounts for the measurement uncertainties, excluding them from the scatter estimates, which are thus estimates only of the intrinsic scatter in the physical relation, not the total scatter.
The five exceptionally low HI-mass sources (two limits and three detections) that fall well below the main trend were excluded from the fitting process. To identify which points to exclude an iterative 3σ rejection algorithm was used. The relations were first fit using all the data, and the points and limits that were not consistent within 3σξ of the fitted relation were removed and the relation was fit again. This process was iterated until the fit remained unchanged.
All of the removed sources fall well below the relation. There are no strongly outlying detections above the relation, and although there are many limits well above the main relation, as these are upper limits they are still consistent with it. In total five sources were removed (from all subsequent fits): CIGs 13, 68, 358, 609, and 1042. These sources do not appear to follow the assumptions of the regression model and therefore should not be fit with it. CIGs 13, 358, and 1042 are all early types, so their low HI content is not particularly surprising, also the photometry of CIG 1042 is highly uncertain due to a bright foreground star. However, CIGs 68 and 609 are types Sab and Sc, respectively, and thus would normally be expected to be quite HI-rich.
The general action of the upper limits is to modestly improve the precision of the estimates of the regression parameters (see Tables 5 and 6). In this dataset the detections are numerous and cover the full ranges of both D25 and LB, which allows the regression parameters to be determined reasonably precisely with the detections alone. The upper limits are distributed in both D25 and LB in a similar way to the detections and the majority lie well above the relations, so they have minimal impact on the regression parameters.
An alternative fitting method was also considered where each term in the likelihood was weighted by 1 /Vmax, similarly to in Solanes et al. (1996). This produced the relations log MHI = 0.86 × 2log D25/ kpc + 7.30 and log MHI = 0.92log LB/L⊙ + 0.37, both with intrinsic scatters of 0.21 dex. The gradient and intercept parameters are easily within 1σ of the full HI science sample MLE values without the 1 /Vmax weighting. Therefore, we do not to use 1 /Vmax in the rest of this paper because it does no appear to have any significant effect.
The residuals of the relations were compared against various other properties to look for any residual correlations. The residuals of the D25-relation showed no correlation with LB and vice versa, indicating that both of these parameters are a proxy for the same underlying property of the galaxy, its mass. These two sets of residuals both had correlation coefficients of 0.02. There was also minimal residual correlation found with FIR luminosity (Lisenfeld et al. 2007), with the correlation coefficients being 0.15 and −0.11 for the D25 and LB relations respectively.
There was a slightly stronger suggestion of a residual correlation with morphology, with both relations producing residual correlation coefficients with morphological type of about 0.3. This residual correlation indicates that some of the intrinsic scatter in the relation is due to differences in morphological type.
5.4. HI scaling relations for different morphologies
 |
Fig. 9 Scaling relations with D25 split by morphological type; early and intermediate types (top), late types (middle), very late types (bottom). |
As morphology is a categorical variable it cannot be included in the regression model in the same manner that the numerical variables are. Ideally scaling relations would be fit individually for each morphological type, however, the currently existing sample of well isolated galaxies simply is not large enough to permit this approach. Therefore, we have split the sample into three bins of morphology that roughly correspond to early and intermediate types (T< 3, earlier than Sb), the main portion of AMIGA (3 ≤ T ≤ 5, i.e. late types from Sb to Sc), and very late types (T> 5, later than Sc). These relations are shown in Figs. 9 and 10 along with the relation of the full sample (thin grey line) and the HG84 relation of their full sample (green dashed line). The coefficients of the regression lines are shown in Tables 7 and 8.
As morphological type goes from early to late the gradient of the D25-relation (Fig. 9) changes very little, but the intercept increases by about 1 dex. This change is not unexpected because later types are usually found to be more HI-rich than earlier types. For the LB-relation the effect of morphology is quite different, with the most striking change being the gradient, which varies from ~1.5 for early types and late types, to 0.78 for very late types. The physical interpretation of this is that low-luminosity, late-type galaxies are more HI-rich than low-luminosity early types, which is again consistent with what would be expected.
It should also be noted that although the uncertainties in the intercepts of the relations are extremely large, the intercept and gradient uncertainties are over 99% negatively correlated (from our jackknife estimates), indicating that the uncertainties in the gradient and intercept should not be considered independently. The translational uncertainties in the y-position of the relation lines are considerably smaller than the quoted uncertainties in the intercepts, as these only represent the uncertainties at the origin of the x-axis, which lies far outside the range of the data (in both cases). This effect is much more pronounced for the LB-relation, than the D25-relation, because the data are considerably further from the origin of the x-axis in the chosen units, which causes a greater lever arm effect.
 |
Fig. 10 Scaling relations with LB split by morphological type; early and intermediate types (top), late types (middle), very late types (bottom). |
6. Discussion
In this section we discuss the interpretation of our results, focusing on two particular aspects: the impact of morphology and comparison with samples in different environments. The morphological dependence is discussed based on the split relations calculated above, although the different morphology distributions of the previous works that we compare with are also discussed. The AMIGA sample represents the most isolated environment, and we compare this with both field and cluster environments. We leave the comparison with compact groups for another paper.
6.1. Morphological dependence
As shown in Figs. 9 and 10 there is a definite dependence of the scaling relations on morphological type. This means that when comparing to a sample of mainly spiral galaxies (dominated by types 3–5, as is the population of isolated galaxies) the single relations shown in Tables 5 and 6 are the most appropriate scaling relations to use, but when considering a more morphologically diverse sample using just a single relation will result in biases for the early- and very late-type objects.
The three morphology bin relations (in both D25 and LB) can be made into a piece-wise relation to predict the HI mass of galaxies of different morphological types based on either D25 or LB. These piece-wise relations reduce the correlation coefficient between morphological type and the residual HI mass from ~0.3 to −0.05 for the D25-relation, and to −0.03 for the LB-relation, indicating that the dependence on morphology has been markedly reduced.
Although these piece-wise relations are somewhat ad hoc because the bins were chosen purely based on the morphology distribution of our sample, we nevertheless recommend they be used when a sample contains early types or very late types to address the bias in the predicted HI content that would otherwise arise. With a substantially larger dataset it would be possible to derive a more robust correction based on fitting the relations for each type, but this is not presently possible for isolated galaxies.
Another point to note is the estimated intrinsic scatter of the relations. As is shown in Table 7, all the D25-relations, regardless of morphology, have an estimated intrinsic scatter of 0.15–0.3 dex. However, the intrinsic scatter estimates for the LB-relations are all 0.15 dex or below, with the relations for early and late types being consistent with zero intrinsic scatter. While one should not over-interpret this result, it does suggest that if morphology was fully accounted for then the LB-relation may actually be intrinsically tighter than the D25-relation. If true, this might imply that if the contribution of the bulge to the overall luminosity was removed (as bulge-to-disc ratio is a key property in defining morphological class) then the disc luminosity could actually be a better predictor of MHI than the disc size.
The trends we observe with morphology are somewhat different than those of HG84. While we find that the intercept of the D25-relation increases with type, they find virtually no change. In the case of the LB-relation we see a definite flattening of the gradient for later types, which is again not evident in HG84. When comparing the samples used in the two papers these discrepancies are not surprising because their sample, after non-detections were excluded, included very few early types (see Fig. 1) and would therefore struggle to illuminate these trends.
Relations with D25 split by morphological type.
Relations with LB split by morphological type.
Gradients and intercepts of the comparison relations.
6.2. Comparison with previous scaling relations
Figures 7 and 8 include scaling relations from Haynes & Giovanelli 1984, Solanes et al. (1996), and Dénes et al. (2014) for comparison purposes8. These relations are based on HI datasets that span a range of low-density environments, but none as isolated as AMIGA. These relations had to be converted to the same unit system used here in order to facilitate a fair comparison. This means that the linear regression coefficients listed in Table 9 are not the same as in the original sources. Although we leave the details of these conversion for Appendix C, it should be noted that this is an essential step, without which our interpretation of the comparisons would change9. In particular, it is important to note that the optical properties of the HG84 sample were taken from the UGC (Nilson 1973), which means that they were measured by eye not digitally.
The HG84 sample, like ours, is based on the CIG and therefore the most similar comparison sample. However, despite coming from the same original catalogue that work did not have the refined information on isolation or completeness that AMIGA has, and thus is not quite as isolated or complete. In total they observed 324 CIG galaxies with the Arecibo telescope. Approximately 11% of their sample was not detected or only marginally detected, this fraction was omitted from the fits of the final scaling relations. Applying our own isolation and completeness criteria to the sources in common between our catalogue and that of HG84 has very much the same effect as on our own full dataset. This indicates that, as is the case for the full CIG, ~30% of the HG84 galaxies were not well isolated according to our definition. The HG84 scaling relations were also fit just to detections using the OLS method, so would not have accounted for the bias due to the uncertainties in the dependent variable.
In the D25-relation our fit is very similar to that of HG84, although our sample appears to be marginally less HI-rich. The LB-relations are more different, with our relation predicting that low mass galaxies are about 0.5 dex poorer in HI than the HG84 relation. The steeper gradient of our relation is likely in part due to the fact that the uncertainties in LB are large (see error ellipse in Fig. 8) and the OLS fitting method used in HG84 does not account for this. However, this does not appear to be a complete explanation because although our own OLS fit (red dotted line) has a shallower gradient than the main relation (solid blue line), it is not as shallow as the HG84 relation.
The next relation which we compare to is from Solanes et al. (1996). This relation was calculated based on a sample of 532 field spiral galaxies in the direction of the Pisces-Perseus supercluster. A threshold neighbour density was set to ensure that galaxies associated with the many clusters in the region were not selected, but this sample is a sample of field galaxies, not a sample of isolated galaxies, and therefore cannot be considered nearly “nurture free” as AMIGA can (see Appendix E). Their relation with D25 is shallower than ours and the other relations, which might suggest that in the environment of this sample there is already a small amount of HI-deficiency for the largest galaxies. The relation also indicates that the average galaxy in the Solanes et al. (1996) sample are considerably richer in HI than the AMIGA galaxies, and this is especially noticeable for the smallest galaxies.
The final relation that we compare with is also from a field sample, but in this case it is HI-selected rather than optically-selected. Dénes et al. (2014) used the HI detections of the HIPASS catalogue, excluding the galaxies in the 30% densest environments, to derive scaling relations between optical magnitudes and sizes, and HI mass. This isolation cut essentially only excludes the HI detections that were in relatively high density regions, such as the edge of clusters. The most striking difference between these relations and ours is that the sample they are based on is clearly more HI-rich, which is most apparent in the D25-relation (Fig. 7). This is not surprising as they were drawn from an HI-selected sample, however, it is important to remember that when using a scaling relation one should be conscious of the sample on which it was based and whether it is an appropriate sample to draw comparisons with.
Comparing all these relations against each other and our relations split by morphology illuminates some potential causes for their apparent differences. In Fig. 7 both the Solanes et al. (1996) and Dénes et al. (2014) relations have shallower slopes than our relation or that of HG84. As we have seen that changes in morphology do not appear to strongly alter the slope of this relation, this may be an indication that the difference in this slope is caused by environment, with both the samples of isolated galaxies having a steeper slope than the field samples. While, unsurprisingly, the most HI-rich is the HIPASS sample (an HI-selected sample).
In the case of the LB-relation the HG84 slope is shallower than that of our relation, with low-mass galaxies being found to be much more HI-rich than we find. However, the average morphological type of the HG84 sample is later than our sample (see Fig. 1) and there are almost no sources with early-type morphologies, which would have the effect of flattening the slope of the relation (see Fig. 10). Unfortunately, as we do not have the morphology distribution of the Dénes et al. (2014) sample we cannot tell if this fits with the same explanation, however, as the gradient is considerably flatter than any we measure, even for very late types, it may be that this is a consequence of the sample being HI-selected rather than being due to morphology.
To check this interpretation of the difference between the slopes of our LB-relation and that of HG84, we made OLS fits (the method HG84 used) to both the HG84 sources in our dataset and fits directly to their original sample, using their values. The OLS fit to the HG84 detections in our sample (using our values) has a gradient of 0.64, almost identical the gradient of 0.66 found in the original work. In contrast the OLS fit to all our detections, which increases the number of sources of types S0 or earlier from 8 to 23, has a gradient of 0.79, which is substantially steeper. This suggests that the morphology distribution is indeed the cause of the discrepancy. However, a possible confounding factor is that our sample has no sources below 1500 km s-1, which raises the possibility that it may be dwarf galaxies, rather than the morphology distribution, that are causing the HG84 fit to have a flatter slope. To test this we took the original HG84 dataset, removed all source with heliocentric velocities below 1500 km s-1 (46 sources), and then fit the OLS regression line again. Rather than steepening the fit, this flattened it further to 0.57, suggesting that the difference between the HG84LB-relation and our own may even be underestimated.
In summary, we find that the HG84LB-relation differs from the equivalent relation of this work, in part because our sample contains more detected early-type galaxies and includes even more through upper limits, and also because our fitting method accounts for uncertainties in LB. Both of these effects cause the gradient of the relation to steepen, which results in the final LB-relation being almost 50% steeper than that of HG84. In the case of the D25-relation it appears to be quite robust to both of these effects (although the resilience to the latter is expected because the uncertainties are smaller) and our final fit parameters agree within the uncertainties with those of HG84 (see Tables 5 and 9). However, there does appear to be a marginal decrease in the HI-richness of our sample relative to theirs, which is likely explained by the increased number of early types in the sample.
6.3. Broken scaling relations
In recent years several works have found trends with breaks in them between galaxies’ optical and HI properties (e.g. Catinella et al. 2010; Huang et al. 2012; Maddox et al. 2015), however, our relations do not appear to show evidence of any break.
Using the HI-selected population of ALFALFA, Huang et al. (2012) found that the scaling relation between stellar mass and HI mass has a slope change at a stellar mass of about 109M⊙, and this result was confirmed in Maddox et al. (2015) via a similar analysis of the ALFALFA dataset. The fact that such a break in the scaling relation is not apparent in our dataset does not indicate a conflict with these results because the break is expected to occur at M∗ ~ 109M⊙ and our dataset begins at LB ~ 109L⊙ (although stellar mass and B-band luminosity are not directly equivalent they should be the same order of magnitude). This reiterates the point that the AMIGA science sample does not contain a population of dwarf galaxies and the relations of this paper are likely inappropriate for such a population.
GASS (GALEX Arecibo SDSS Survey; Catinella et al. 2010) studied the scaling relation of gas fraction (MHI/M∗) with stellar mass surface density, of high stellar mass galaxies. They found that there is a break occurring at a stellar mass surface density of 108.5M⊙ kpc-2, with galaxies of higher surface densities having sharply reduced HI content. Using our B-band properties as a very rough proxy for stellar mass surface density, we find that the typical AMIGA galaxy has surface density 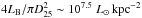 and none are above 108.5L⊙ kpc-2. Therefore, we again find that our sample does not extend into the range where this break is relevant.
and none are above 108.5L⊙ kpc-2. Therefore, we again find that our sample does not extend into the range where this break is relevant.
 |
Fig. 11 Left: scatter plot of the HI masses of isolated galaxy pairs as a function of their optical diameters (data from Zasov & Sulentic 1994), shown with black crosses. The light grey points in the background are the HI detections of the AMIGA HI science sample. The solid blue line shows the MLE regression fit of this work and the dashed green line shows the HG84 relation. Right: HI-deficiency of isolated galaxy pairs (diagonal hatching) compared to the AMIGA HI science sample (light grey). HI-deficiency here is calculated with the D25-relation (without use of morphological type). |
 |
Fig. 12 Left column: scatter plots of the HI masses of Virgo cluster galaxies from the VCC, shown with black crosses. The light grey points in the background are the HI detections of the AMIGA HI science sample. The solid blue line shows the MLE regression fit of this work and the dashed green line shows the HG84 relation. Right column: HI-deficiency of Virgo cluster galaxies from the VCC (diagonal hatching) compared to the AMIGA HI science sample (light grey). Top row: here the samples are compared based on D25. Bottom row: here the samples are compared based on LB. |
6.4. Comparison with isolated pairs
To facilitate a comparison with galaxies that are not entirely isolated, but also not field objects, we used the dataset of Zasov & Sulentic (1994) that was extracted from the Catalog of Isolated Pairs of Galaxies (CPG; Karachentsev 1972). The Zasov sample was selected to be pairs consisting of one early and one late-type galaxy. This was done such that the detected HI emission (typically with a spatial resolution that cannot separate the two galaxies) can be assumed to originate entirely from one component, the late-type galaxy. While this assumption is not entirely correct as there are HI-rich early types (e.g. Serra et al. 2012), in the vast majority of cases the late-type galaxy is expected to contain orders of magnitude more HI than the early-type galaxy. With this assumption the optical properties of the late type in each pair can then be compared with the HI content, and in turn contrasted with the relations of isolated galaxies.
The left panel of Fig. 11 shows the data from Zasov & Sulentic (1994) for the isolated pairs compared to the data and regression fit of the AMIGA HI science sample, as well as the HG84 fit shown as in previous plots. The right panel shows the HI-deficiency of the galaxy pairs (calculated with the D25-relation) along with the AMIGA HI-deficiencies. This comparison should be treated with caution because not only is the pairs dataset small, we were also only able to make a conversion for the different Hubble constants used, as there is no overlap with our dataset, so more detailed calibration (as was done for the previous comparisons) was not possible. Therefore, the reader should take under consideration that the exact positions of the points are somewhat uncertain in our unit system even though we compare them directly in Fig. 11.
While the distribution of HI-deficiency of the isolated pairs is peaked at zero, the wing towards positive HI-deficiencies is more heavily populated than for AMIGA. This results in the mean HI-deficiency being 0.2 dex, indicating that a minor amount of HI has been removed from these galaxies. A correlation between the HI-deficiency of the pair and the pair separation was investigated, but none was evident. Instead it appears to be the largest galaxies that are causing the pairs distribution to be slightly HI-deficient, as is apparent in the left panel of Fig. 11 because most of the paired galaxies with diameters above ~30 kpc fall below the regression line.
6.5. HI-deficiency of Virgo cluster galaxies
To contrast the HI content of the AMIGA galaxies with a cluster environment, Virgo cluster galaxies with HI measurements were obtained from HyperLeda. As the optical fluxes and diameters in our own compilation were collected from HyperLeda this ensured that at least the optical scales are directly comparable. The Virgo region is extremely complicated, so we also only selected sources which had redshift-independent distance measures placing them at less than 40 Mpc, and were identified as Virgo cluster members in the VCC (Virgo Cluster Catalog, Binggeli et al. 1985). These criteria produced a sample of 132 Virgo galaxies for comparison. Unfortunately the morphological types of these sources, with an equivalent definition was not available, and so they could only be compared against the global relations.
Figure 12 show the HI-deficiency of HI-detected galaxies in the Virgo cluster, with their deficiencies calculated by both the D25 and LB relations. We see that although the typical galaxy is only deficient by a factor of ~2 (or 0.3 dex) the distribution of HI-deficiencies in Virgo is highly skewed, with the high HI-deficiency tail of the distribution extended approximately an order of magnitude beyond that of the AMIGA sample. Furthermore, it should be noted that because the selection criteria require the galaxies to be detected in HI, the true level of HI-deficiency is likely to be higher than is shown here. Curiously, however, the outlying isolated galaxies that were excluded from the regression analysis have HI-deficiencies very similar to the most extremely deficient Virgo galaxies that are still detected in HI.
These results are generally consistent with previous studies of HI-deficiency in the Virgo cluster (e.g. Huchtmeier & Richter 1989; Solanes et al. 2001), which also find a typical deficiencies to be a factor of ~2, but also detected galaxies that are apparently missing over 90% of their initial HI content. VIVA (VLA Imaging survey of Virgo galaxies in Atomic gas, Chung et al. 2009) finds a mean HI-deficiency of about 0.5 dex, based on the D25-relation of HG84. This greater level of deficiency is likely because this sample was selected optically and then observed in HI, rather than requiring a prior HI detection (as we have here). However, the most extreme galaxies are also found to have HI-deficiencies of about 2 dex. Finally, Cortese et al. (2011) demonstrated that galaxies in Virgo are also HI-deficient for their stellar masses, but that the level of deficiency (anti-)correlates with other factors, such as stellar surface density.
The left panels of Fig. 12 also indicate an apparent advantage of our relations over those of HG84 (aside from those discussed earlier). It is straightforward to see that the HG84D25-relation would produce almost identical HI-deficiencies to our relation because the two lines fall in almost the same place in the top left panel. However, in the bottom left panel the HG84LB-relation would measure significantly higher levels of HI-deficiency in the least luminous galaxies compared to their D25-relation. This shows that the two relations we have calculated produce more self-consistent measures of HI-deficiencies.
This result is shown more clearly in Fig. 13 which compares the difference between the HI-deficiency of each galaxy calculated using either the D25 or the LB-relation, for both our relations and those of HG84. The HG84 values are clearly offset to the left indicating that their LB-relation produces larger estimates of HI-deficiency than their D25-relation. The mean value of the distribution is −0.16 dex, which is an 8σ deviation from zero based on the standard error in the mean. Our relations also result in an offset, though much smaller and in the opposite direction. The mean of the distribution is 0.04 dex, a 2σ deviation from zero. The width of the Gaussian fit to our values is 0.23 dex, which is an estimate of the 1σ random uncertainty in the value of HI-deficiency, and is also in agreement with the value of the intrinsic scatter fit in the original relations in Sect. 5.3. The deviation of the mean from zero indicates that there is also a systematic error in the estimates of HI-deficiency, of magnitude ~0.05 dex.
7. Summary
We have compiled a database of the global HI properties of 844 isolated galaxies (from the CIG) using our own single-dish observations and spectra from the literature, and a uniform method of profile characterisation. The large size and uniform nature of this dataset has allowed completeness and isolation cuts to be made while still retaining enough sources to perform a statistical analysis. Therefore, our final HI science dataset of 544 galaxies is not simply larger than previous HI datasets of isolated galaxies, it is also more complete and the galaxies are more isolated.
This dataset was used to measure scaling relations between HI mass and optical properties, in order to set an up-to-date baseline of the HI content of galaxies. As the AMIGA project has shown, these galaxies are isolated and represent, as near as possible, a “nurture free” sample that has been isolated on average for at least 3 Gyr (Verdes-Montenegro et al. 2005). Thus, these scaling relations are applicable to evolutionary scenarios addressing the impact of “nature” versus “nurture” on the neutral gas of a galaxy.
The regression model used to fit these relations is also more sophisticated than those of previous studies, incorporating measurement uncertainty in both variables, correlated distance errors, and upper limits from non-detections. We find that a galaxy’s HI mass is related to either its B-band luminosity or diameter with an intrinsic scatter of about 0.2 dex. With the inclusion of measurement uncertainties this means that the expected HI mass of an individual galaxy (in the absence of interactions) can be predicted with an accuracy of about 0.25 dex. This accuracy is very similar to that found by HG84, however, as described throughout the paper, our relations make numerous improvements, including increasing the number of sources, particularly for early-type morphologies, and incorporating HI upper limits and realistic uncertainties into the regression analysis.
Morphology is found to be an important covariate accounting for some of the intrinsic scatter. The trend with morphology indicates that at a given optical size or luminosity, later type galaxies are more HI-rich, and that this difference is most pronounced for low-luminosity galaxies. However, this effect manifests as a simple offset in the optical diameter scaling relations, but as a change to the gradient of luminosity scaling relations. These trends were not apparent in HG84 due to the small number of detected early-type galaxies.
Our relations were found to differ slightly from those in the literature, but in ways that likely have straightforward explanations. Previous samples were generally even more rich in late types than our sample, which led to those relations being slightly more HI-rich overall. This later average type was either an intentional selection to avoid contamination from galaxies in higher density regions or due to selection effects, but either way meant that the samples were a biased selection of isolated galaxies. Previous relations also typically had shallower gradients which can in part be attributed to the later morphologies, as well as to the lack of accounting for uncertainties in the dependent variable.
When contrasted with a cluster population from the VCC, we found that although the typical Virgo cluster galaxy was only HI-deficient by a factor of about 2, the tail of the distribution extended to more than an order of magnitude past that for isolated galaxies. Indicating that some cluster galaxies have lost ~90% of their HI gas. This comparison also revealed that the relations of this paper produce more consistent measures of HI-deficiency when estimated using either the optical diameter or optical luminosity, than the existing relations for isolated galaxies.
 |
Fig. 13 Comparison of the differences between the HI-deficiencies of Virgo cluster galaxies derived using the D25 and LB relations of this work (grey bars) and the differences using the HG84 relations (unfilled bars). The Gaussian fit to our values is shown with the grey solid line, the fit to the HG84 values is shown with the solid black line. A third Gaussian with zero mean and a width taken to be the average of the two fits, is shown for comparison by the dotted line. |
In conclusion, to predict the expected HI mass (in the absence of interaction) of a galaxy we recommend either the optical diameter (D25) relation 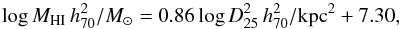 (16)or the B-band luminosity (LB) relation
(16)or the B-band luminosity (LB) relation 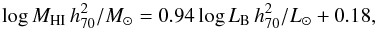 (17)should be used in cases where they is no morphology information, or where the sample is dominated by Sb-Sc galaxies. However, as morphology is a strong covariate, if the sample has morphological types that fall well outside this range it will lead to biases in the prediction of their HI content. In such cases it is recommended to use the piece-wise relations listed in Tables 7 and 8.
(17)should be used in cases where they is no morphology information, or where the sample is dominated by Sb-Sc galaxies. However, as morphology is a strong covariate, if the sample has morphological types that fall well outside this range it will lead to biases in the prediction of their HI content. In such cases it is recommended to use the piece-wise relations listed in Tables 7 and 8.
It should be noted that this is an update from previous AMIGA papers, which used H0 = 75 km s-1 Mpc-1, as both WMAP and Planck results now support a lower value of H0 (Hinshaw et al. 2013; Planck Collaboration XIII 2016).
The digitisation was performed by hand using WebPlotDigitizer v3.11 (http://arohatgi.info/WebPlotDigitizer/app/).
No positional offset was made for CIGs 68, 543, and 561 because of suspected typographical errors in target coordinates listed in the original reference.
Here we used the 70% ALFALFA catalogue which is available at http://egg.astro.cornell.edu/alfalfa/data/index.php
The deviation from unity of the slopes for both the flux and width comparison may be a similar magnitude, however, it is important to remember that the flux measurements span almost 3 orders of magnitude whereas the width measurements span only 1.
Note that σδ is twice the estimated uncertainty in the log distance because luminosity and mass both scale with the square of the distance.
We do not make a comparison with Toribio et al. (2011a) because their relations are based on SDSS r-band properties, which we were unable to reliably relate to our B-band properties.
This is also a note of caution that when using the relations calculated in this paper it is essential to ensure the definitions of luminosities, diameters, and morphological types used are equivalent to those of this work.
Acknowledgments
We thanks E. Battaner, J. Vilchez, E. Perez, and S. Verley for their useful comments, and to staff members of the different telescopes from which data are presented in this paper, especially to those where we have observed: Arecibo, Effelsberg, Nançay, and GBT. We also thank J. R. Fisher for his assistance in obtaining GBT spectra. M.G.J. and L.V.M. acknowledge support from the grant AYA2015-65973-C3-1-R (MINECO/FEDER, UE). D.E. was supported by a Marie Curie International Fellowship during this work (MOIF-CT-2006-40298) within the 6th European Community Framework Programme. This work is supported by DGI Grant AYA 2008-06181-C02 and the Junta de Andalucía (Spain) P08-FQM-4205. U.L. acknowledges support by the research projects AYA2014-53506-P from the Spanish Ministerio de Economía y Competitividad, from the European Regional Development Funds (FEDER)and the Junta de Andalucía (Spain) grants FQM108. J.S. is grateful for support from the UK STFC via grant ST/M001229/1. D.E.J. acknowledges support from the National Science Foundation under Grant DMS-1127914 to the Statistical and Applied Mathematical Sciences Institute. This work also received support from the Junta de Andalucía (Spain) grant TIC-114. This research has made use of the NASA/IPAC Extragalactic Database (NED), which is operated by the Jet Propulsion Laboratory, California Institute of Technology, under contract with the National Aeronautics and Space Administration. We also acknowledge the use of the HyperLeda database. This research has made use of the SDSS. Funding for SDSS-III has been provided by the Alfred P. Sloan Foundation, the Participating Institutions, the National Science Foundation, and the US Department of Energy Office of Science. The SDSS-III web site is http://www.sdss3.org/
References
- Abramson, A., Kenney, J. D. P., Crowl, H. H., et al. 2011, AJ, 141, 164 [NASA ADS] [CrossRef] [Google Scholar]
- Ahn, C. P., Alexandroff, R., Allende Prieto, C., et al. 2012, ApJS, 203, 21 [NASA ADS] [CrossRef] [Google Scholar]
- Argudo-Fernández, M., Verley, S., Bergond, G., et al. 2013, A&A, 560, A9 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Balkowski, C., & Chamaraux, P. 1981, A&A, 97, 223 [NASA ADS] [Google Scholar]
- Barnes, D. G., Staveley-Smith, L., de Blok, W. J. G., et al. 2001, MNRAS, 322, 486 [NASA ADS] [CrossRef] [Google Scholar]
- Bicay, M. D., & Giovanelli, R. 1986, AJ, 91, 705 [NASA ADS] [CrossRef] [Google Scholar]
- Binggeli, B., Sandage, A., & Tammann, G. A. 1985, AJ, 90, 1681 [NASA ADS] [CrossRef] [Google Scholar]
- Borthakur, S., Yun, M. S., Verdes-Montenegro, L., et al. 2015, ApJ, 812, 78 [NASA ADS] [CrossRef] [Google Scholar]
- Bothun, G. D., Beers, T. C., Mould, J. R., & Huchra, J. P. 1985, AJ, 90, 2487 [NASA ADS] [CrossRef] [Google Scholar]
- Bottinelli, L., Durand, N., Fouque, P., et al. 1992, A&AS, 93, 173 [NASA ADS] [Google Scholar]
- Bottinelli, L., Durand, N., Fouque, P., et al. 1993, A&AS, 102, 57 [NASA ADS] [Google Scholar]
- Brown, T., Catinella, B., Cortese, L., et al. 2017, MNRAS, 466, 1275 [NASA ADS] [CrossRef] [Google Scholar]
- Bradford, J. D., Geha, M. C., & Blanton, M. R. 2015, ApJ, 809, 146 [NASA ADS] [CrossRef] [Google Scholar]
- Catinella, B., Schiminovich, D., Kauffmann, G., et al. 2010, MNRAS, 403, 683 [NASA ADS] [CrossRef] [Google Scholar]
- Chung, A., van Gorkom, J. H., Kenney, J. D. P., Crowl, H., & Vollmer, B. 2009, AJ, 138, 1741 [NASA ADS] [CrossRef] [Google Scholar]
- Cortese, L., Catinella, B., Boissier, S., Boselli, A., & Heinis, S. 2011, MNRAS, 415, 1797 [NASA ADS] [CrossRef] [Google Scholar]
- Courtois, H. M., Tully, R. B., Fisher, J. R., et al. 2009, AJ, 138, 1938 [Google Scholar]
- Delhaize, J., Meyer, M. J., Staveley-Smith, L., & Boyle, B. J. 2013, MNRAS, 433, 1398 [NASA ADS] [CrossRef] [Google Scholar]
- Dénes, H., Kilborn, V. A., & Koribalski, B. S. 2014, MNRAS, 444, 667 [NASA ADS] [CrossRef] [Google Scholar]
- Elson, E. C., Blyth, S. L., & Baker, A. J. 2016, MNRAS, 460, 4366 [NASA ADS] [CrossRef] [Google Scholar]
- Espada, D., Verdes-Montenegro, L., Huchtmeier, W. K., et al. 2011, A&A, 532, A117 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Fernández Lorenzo, M., Sulentic, J., Verdes-Montenegro, L., et al. 2012, A&A, 540, A47 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Fouqué, P., Durand, N., Bottinelli, L., Gouguenheim, L., & Paturel, G. 1990, A&AS, 86, 473 [NASA ADS] [Google Scholar]
- Giovanelli, R., Haynes, M. P., Kent, B. R., et al. 2005, AJ, 130, 2598 [NASA ADS] [CrossRef] [Google Scholar]
- Haynes, M. P., & Giovanelli, R. 1980, ApJ, 240, L87 [NASA ADS] [CrossRef] [Google Scholar]
- Haynes, M. P., & Giovanelli, R. 1984, AJ, 89, 758 [NASA ADS] [CrossRef] [Google Scholar]
- Haynes, M. P., & Giovanelli, R. 1991, ApJS, 77, 331 [NASA ADS] [CrossRef] [Google Scholar]
- Haynes, M. P., Giovanelli, R., & Chincarini, G. L. 1984, ARA&A, 22, 445 [NASA ADS] [CrossRef] [Google Scholar]
- Haynes, M. P., Giovanelli, R., Martin, A. M., et al. 2011, AJ, 142, 170 [NASA ADS] [CrossRef] [Google Scholar]
- Hess, K. M., & Wilcots, E. M. 2013, AJ, 146, 124 [NASA ADS] [CrossRef] [Google Scholar]
- Hess, K. M., Cluver, M. E., Yahya, S., et al. 2017, MNRAS, 464, 957 [NASA ADS] [CrossRef] [Google Scholar]
- Hewitt, J. N., Haynes, M. P., & Giovanelli, R. 1983, AJ, 88, 272 [NASA ADS] [CrossRef] [Google Scholar]
- Hickson, P. 1982, ApJ, 255, 382 [NASA ADS] [CrossRef] [Google Scholar]
- Hickson, P., Mendes de Oliveira, C., Huchra, J. P., & Palumbo, G. G. 1992, ApJ, 399, 353 [NASA ADS] [CrossRef] [EDP Sciences] [MathSciNet] [PubMed] [Google Scholar]
- Hinshaw, G., Larson, D., Komatsu, E., et al. 2013, ApJS, 208, 19 [NASA ADS] [CrossRef] [Google Scholar]
- Huang, S., Haynes, M. P., Giovanelli, R., & Brinchmann, J. 2012, ApJ, 756, 113 [NASA ADS] [CrossRef] [Google Scholar]
- Huchtmeier, W. K., & Richter, O.-G. 1989, A&A, 210, 1 [NASA ADS] [Google Scholar]
- Huchtmeier, W. K., Sage, L. J., & Henkel, C. 1995, A&A, 300, 675 [NASA ADS] [Google Scholar]
- Jones, M. G., Papastergis, E., Haynes, M. P., & Giovanelli, R. 2015, MNRAS, 449, 1856 [NASA ADS] [CrossRef] [Google Scholar]
- Jones, M. G., Haynes, M. P., Giovanelli, R., & Papastergis, E. 2016, MNRAS, 455, 1574 [NASA ADS] [CrossRef] [Google Scholar]
- Karachentsev, I. D. 1972, Soobshcheniya Spetsial’noj Astrofizicheskoj Observatorii, 7 [Google Scholar]
- Karachentseva, V. E. 1973, Soobshcheniya Spetsial’noj Astrofizicheskoj Observatorii, 8 [Google Scholar]
- Kenney, J. D. P., van Gorkom, J. H., & Vollmer, B. 2004, AJ, 127, 3361 [NASA ADS] [CrossRef] [Google Scholar]
- Lah, P., Pracy, M. B., Chengalur, J. N., et al. 2009, MNRAS, 399, 1447 [NASA ADS] [CrossRef] [Google Scholar]
- Leisman, L., Haynes, M. P., Giovanelli, R., et al. 2016, MNRAS, 463, 1692 [NASA ADS] [CrossRef] [Google Scholar]
- Leon, S., & Verdes-Montenegro, L. 2003, A&A, 411, 391 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Leon, S., Verdes-Montenegro, L., Sabater, J., et al. 2008, A&A, 485, 475 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lewis, B. M. 1983, AJ, 88, 1695 [NASA ADS] [CrossRef] [Google Scholar]
- Lewis, B. M., Helou, G., & Salpeter, E. E. 1985, ApJS, 59, 161 [NASA ADS] [CrossRef] [Google Scholar]
- Lisenfeld, U., Verdes-Montenegro, L., Sulentic, J., et al. 2007, A&A, 462, 507 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lisenfeld, U., Espada, D., Verdes-Montenegro, L., et al. 2011, A&A, 534, A102 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lu, N. Y., Hoffman, G. L., Groff, T., Roos, T., & Lamphier, C. 1993, ApJS, 88, 383 [NASA ADS] [CrossRef] [Google Scholar]
- Lucero, D. M., Young, L. M., & van Gorkom, J. H. 2005, AJ, 129, 647 [NASA ADS] [CrossRef] [Google Scholar]
- Maddox, N., Hess, K. M., Obreschkow, D., Jarvis, M. J., & Blyth, S.-L. 2015, MNRAS, 447, 1610 [NASA ADS] [CrossRef] [Google Scholar]
- Makarov, D., Prugniel, P., Terekhova, N., Courtois, H., & Vauglin, I. 2014, A&A, 570, A13 [Google Scholar]
- Masters, K. L. 2005, Ph.D. Thesis, Cornell University, New York, USA [Google Scholar]
- Masters, K. L., Crook, A., Hong, T., et al. 2014, MNRAS, 443, 1044 [NASA ADS] [CrossRef] [Google Scholar]
- Meyer, M. J., Zwaan, M. A., Webster, R. L., et al. 2004, MNRAS, 350, 1195 [NASA ADS] [CrossRef] [Google Scholar]
- Mirabel, I. F., & Sanders, D. B. 1988, ApJ, 335, 104 [NASA ADS] [CrossRef] [Google Scholar]
- Mould, J. R., Huchra, J. P., Freedman, W. L., et al. 2000, ApJ, 529, 786 [NASA ADS] [CrossRef] [Google Scholar]
- Nilson, P. 1973, Uppsala general catalogue of galaxies (Uppsala: Astronomiske Observatorium) [Google Scholar]
- Odekon, M. C., Koopmann, R. A., Haynes, M. P., et al. 2016, ApJ, 824, 110 [NASA ADS] [Google Scholar]
- Papastergis, E., Giovanelli, R., Haynes, M. P., Rodríguez-Puebla, A., & Jones, M. G. 2013, ApJ, 776, 43 [NASA ADS] [CrossRef] [Google Scholar]
- Patton, D. R., Torrey, P., Ellison, S. L., Mendel, J. T., & Scudder, J. M. 2013, MNRAS, 433, L59 [NASA ADS] [CrossRef] [Google Scholar]
- Planck Collaboration XIII. 2016, A&A, 594, A13 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rasmussen, J., Ponman, T. J., Verdes-Montenegro, L., Yun, M. S., & Borthakur, S. 2008, MNRAS, 388, 1245 [NASA ADS] [CrossRef] [Google Scholar]
- Reid, I. N., Brewer, C., Brucato, R. J., et al. 1991, PASP, 103, 661 [NASA ADS] [CrossRef] [Google Scholar]
- Richter, O.-G., & Huchtmeier, W. K. 1987, A&AS, 68, 427 [NASA ADS] [Google Scholar]
- Rubin, V. C., Roberts, M. S., Graham, J. A., Ford, Jr., W. K., & Thonnard, N. 1976, AJ, 81, 687 [NASA ADS] [CrossRef] [Google Scholar]
- Sabater, J., Leon, S., Verdes-Montenegro, L., et al. 2008, A&A, 486, 73 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sabater, J., Verdes-Montenegro, L., Leon, S., Best, P., & Sulentic, J. 2012, A&A, 545, A15 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schneider, S. E., Thuan, T. X., Mangum, J. G., & Miller, J. 1992, ApJS, 81, 5 [NASA ADS] [CrossRef] [Google Scholar]
- Serra, P., Oosterloo, T., Morganti, R., et al. 2012, MNRAS, 422, 1835 [NASA ADS] [CrossRef] [Google Scholar]
- Serra, P., Koribalski, B., Duc, P.-A., et al. 2013, MNRAS, 428, 370 [NASA ADS] [CrossRef] [Google Scholar]
- Shostak, G. S. 1978, A&A, 68, 321 [NASA ADS] [Google Scholar]
- Solanes, J. M., Giovanelli, R., & Haynes, M. P. 1996, ApJ, 461, 609 [NASA ADS] [CrossRef] [Google Scholar]
- Solanes, J. M., Manrique, A., García-Gómez, C., et al. 2001, ApJ, 548, 97 [NASA ADS] [CrossRef] [Google Scholar]
- Springob, C. M., Haynes, M. P., Giovanelli, R., & Kent, B. R. 2005, ApJS, 160, 149 [Google Scholar]
- Staveley-Smith, L., & Davies, R. D. 1987, MNRAS, 224, 953 [NASA ADS] [CrossRef] [Google Scholar]
- Sulentic, J. W., Verdes-Montenegro, L., Bergond, G., et al. 2006, A&A, 449, 937 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Theureau, G., Bottinelli, L., Coudreau-Durand, N., et al. 1998, A&AS, 130, 333 [Google Scholar]
- Theureau, G., Coudreau, N., Hallet, N., et al. 2005, A&A, 430, 373 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Theureau, G., Hanski, M. O., Coudreau, N., Hallet, N., & Martin, J.-M. 2007, A&A, 465, 71 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tifft, W. G., & Cocke, W. J. 1988, ApJS, 67, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Toribio, M. C., Solanes, J. M., Giovanelli, R., Haynes, M. P., & Martin, A. M. 2011a, ApJ, 732, 93 [NASA ADS] [CrossRef] [Google Scholar]
- Toribio, M. C., Solanes, J. M., Giovanelli, R., Haynes, M. P., & Masters, K. L. 2011b, ApJ, 732, 92 [NASA ADS] [CrossRef] [Google Scholar]
- Torres-Flores, S., Mendes de Oliveira, C., Amram, P., et al. 2010, A&A, 521, A59 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- van Driel, W., van den Broek, A. C., & Baan, W. 1995, ApJ, 444, 80 [NASA ADS] [CrossRef] [Google Scholar]
- van Driel, W., Butcher, Z., Schneider, S., et al. 2016, A&A, 595, A118 [Google Scholar]
- Verdes-Montenegro, L., Yun, M. S., Williams, B. A., et al. 2001, A&A, 377, 812 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Verdes-Montenegro, L., Sulentic, J., Lisenfeld, U., et al. 2005, A&A, 436, 443 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Verley, S., Leon, S., Verdes-Montenegro, L., et al. 2007a, A&A, 472, 121 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Verley, S., Odewahn, S. C., Verdes-Montenegro, L., et al. 2007b, A&A, 470, 505 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Walker, L. M., Johnson, K. E., Gallagher, S. C., et al. 2016, AJ, 151, 30 [NASA ADS] [CrossRef] [Google Scholar]
- Zasov, A. V., & Sulentic, J. W. 1994, ApJ, 430, 179 [NASA ADS] [CrossRef] [Google Scholar]
- Zwicky, F., Herzog, E., Wild, P., Karpowicz, M., & Kowal, C. T. 1961, Catalogue of galaxies and of clusters of galaxies, Vol. I (Pasadena: California Institute of Technology) [Google Scholar]
Appendix A: Predicting HI mass
The relations calculated throughout this paper are designed to approximate the scaling between the “true” values of an isolated galaxy’s optical linear size or optical luminosity and its “true” HI mass. While the word “true” may seem redundant, but it makes the important distinction between the observed values of each of these properties and their actual physical values, which can never be known perfectly. Although the true values of these properties are unknown, by incorporating estimates of the uncertainties in their measured values into the fitting procedure, we have obtained the maximum likelihood estimate of the underlying physical relations (between the true values) for our dataset. This differs fundamentally from OLS regression, or similar methods that do not account for uncertainties in both variables, which find a relation between the observed values.
Typically OLS regression is used when one wishes to use observations of x to predict y, as this is the optimal linear predictor (in the least squares sense). Similarly, if each y value has a different variance then a form of weighted least squares is optimal. However, both approaches are only optimal for predicting the value of y (observed or true) from the observed value of x, under the assumption that x is observed either without error or that the errors in observing x have the same variance for every observation (and zero mean), and that the errors in future observations of x (to be used to predict y) also have the same variance as in the original dataset. If either assumption is violated then OLS is non-optimal. If the first assumption is violated then the physical interpretation of the relation is lost because the regression coefficients become dependent on the magnitude of the x error variance, which in turn can depend on the observation and reduction methods, which are unconnected with the physical properties of the galaxies. For our dataset neither of these assumptions hold. Therefore, the OLS relation (or more appropriately, the weighted least squares relation) is not optimal in our case. By taking the magnitude of the errors in each measurement into account we can construct a better method to predict y. Similarly, in quantifying the uncertainty in predictions of y from newly observed values of x, it is important to take into account the x error variance, see Eq. (A.2). In addition, failure to take into account the fact that the x and y errors are correlated would reduce prediction accuracy, although this would likely be a minor effect in this case.
By incorporating estimates of measurement and distance errors in the fitting procedure we have made an estimate of what the intrinsic scatter in the relations is (i.e. scatter which is not accounted for within the error budget), and similarly the slope and intercept of the relations are also estimates of their intrinsic values for the true values of D25, LB, and MHI. This presents a technical problem because when using the relations to predict MHI one cannot measure the true value of D25 or LB. To overcome this difficulty we consider how the quantity Δyest is distributed, where Δyest is the deviation between the true value of y and the value estimated by treating an observed value of x as the true value (which is what one must do in order to make a prediction of y using the scaling relation), i.e. 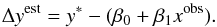 (A.1)The relation that we fitted was y∗ = β0 + β1x∗ + ξ (this is Eq. (12) restated), which can be substituted for y∗ in the above equation. We can also substitute xobs = x∗ + η + δ, where ση and σδ are the measurement and distance uncertainties as defined in Sect. 5.2. This gives Δyest = ξ−β1(η + δ), which implies
(A.1)The relation that we fitted was y∗ = β0 + β1x∗ + ξ (this is Eq. (12) restated), which can be substituted for y∗ in the above equation. We can also substitute xobs = x∗ + η + δ, where ση and σδ are the measurement and distance uncertainties as defined in Sect. 5.2. This gives Δyest = ξ−β1(η + δ), which implies 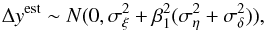 (A.2)where N(μ,σ2) indicates a normally distributed random variable with mean μ and variance σ2.
(A.2)where N(μ,σ2) indicates a normally distributed random variable with mean μ and variance σ2.
Therefore, by simply using our scaling relation and an observation of x as input, an unbiased prediction of the true value of y can be made and its confidence interval can be estimated from the above normal distribution. For the slopes of our regression fits and typical values of the uncertainties in log D25 and log LB, this gives estimates of the standard deviation of Δyest as 0.23 and 0.25 dex, respectively. These values match well with the width of the distribution in Fig. 13, showing self-consistency among our estimates of the precision of these relations as predictors of HI mass.
In other words, this approach allows for any future observation of either a galaxy’s D25 or LB to be used to make a prediction of the physical value of its HI mass and an estimate of the uncertainty, regardless of whether the uncertainties in those future measurements are similar to those in our dataset or not.
It should also be noted that this approach assumes that the relation is known, i.e. that our fit is both accurate and precise. This is a good approximation near the centre of the data range where there is an abundance of data points and the fit is tightly constrained (see Fig. F.1). At the extremes of the data the uncertainty in the position of the relation becomes larger, however, the standard deviation of Δyest about the relation is still several times larger. This shortcoming is not unique to our method, but applies to all approaches where the relation is not known exactly, but is treated as so. Ideally the extremes would be constrained with more data, but this is not presently possible.
Appendix B: Data table description
Observed properties of the full HI sample.
Derived properties of the full HI sample.
The complete HI dataset is available at the CDS. The data is displayed in three separate tables: 1) the observed HI properties; 2) the derived properties; and 3) various flags. Here we describe in detail the properties listed in each column of these tables.
Observed HI properties (Table B.1):
-
Column 1 – CIG: ID number corresponding to the assignment inthe original catalogue of isolated galaxies(Karachentseva 1973).
-
Column 2 – Sp: the peak flux density (mJy) of the emission profile. This is measured in the smoothed spectrum (see Col. 6).
-
Column 3 – σrms: the root mean squared noise (mJy) in the emission free parts of the spectrum. This is measured in the smoothed spectrum (see Col. 6).
-
Column 4 – σrms,10: the root mean squared noise (mJy) if the spectrum had channel widths of 10 km s-1 (see Eq. (8)).
-
Column 5 – δv: the average channel width across the emission profile in km s-1.
-
Column 6 – nsmo: the number of channels the spectrum is smoothed over using a Hanning window.
-
Column 7 – snrp: the peak signal-to-noise ratio of the profile (Sp/N = Sp/σrms).
-
Column 8 – snri: the integrated signal-to-noise ratio of the profile as calculated by Eq. (9).
-
Column 9 – Sint: the integrated flux (Jy km s-1) of the profile. This is measured between the two zero-crossings of the straight line fits to the left and right sides of the profile (see Sect. 4).
-
Column 10 – σSint: measurement error in Sint (Jy km s-1) as calculated in Eq. (4).
-
Column 11 – cbeam: the beam correction factor accounting for the beam response and flux that is outside the beam. This assumes a Gaussian beam response and a distribution of HI within the galaxy. See Sect. 4.2 for further details.
-
Column 12 – Sint,c: the corrected integrated flux (Jy km s-1). Sint,c = cbeamSint.
-
Column 13 – V50: the heliocentric velocity of the mid-point of the profile at the 50% level (km s-1). See Sect. 4.
-
Column 14 – σV50: the measurement error of the heliocentric velocity (km s-1) as estimated in Eq. (5).
-
Column 15 – z50: the heliocentric redshift of the source. Here we assume the velocities are small relative to c, i.e. z50 = V50/c.
-
Column 16 – W50: the full velocity width of the emission profile at the 50% level (km s-1). The half point velocity is identified independently on either side of the profile by fitting a straight line to the profile edge and taking the velocity where the line equals half the peak value (minus the rms noise) on that side. For further details see Sect. 4.
-
Column 17 – σW50: the measurement error of the velocity width (km s-1). Assumed to be
times the error in V50 (Col. 13). -
Column 18 – cinst: correction for instrumental broadening (km s-1). This correction is calculated exactly as in Springob et al. (2005) (Eqs. (3), (5)–(7), and Table 2) except that we replace the channel width with the channel width times nsmo−2, to account for any smoothing in addition to the 2 channels that method assumes have been smoothed over.
-
Column 19 – ccosmo: correction for the broadening of the velocity width due to cosmological expansion. ccosmo = 1/(1 + z50).
-
Column 20 – W50,c: the velocity width corrected for instrumental and cosmic broadening (km s-1). W50,c = (W50−cinst)ccosmo.
-
Column 21 – detection code: a code indicating whether the source was identified by eye to be confidently detected (0), not detected (1), or marginally detected (2).
-
Column 22 – Quality code: a code to identify spectra with features such as potentially spurious flux spikes that likely introduce major uncertainty into the measured parameters. 1 corresponds to a spectrum with complications, 0 to a good spectrum.
-
Column 23 – telescope code: a three character code to identify the telescope that the spectrum was observed with. See Table 3 for details.
-
Column 24 – Reference code: a four character code to identify the original article the spectrum was taken from (codes are matched to references in Table 1). If blank then the observations were performed as part of the AMIGA project.
Derived properties (Table B.2):
-
Column 1 – CIG: ID number corresponding to the assignment inthe original catalogue of isolated galaxies(Karachentseva 1973).
-
Column 2 – Vhelio: the heliocentric velocity chosen to be used to estimate the source distance (km s-1). This may or may not be the velocity measured from the HI spectrum. If V50 agreed within 2σ of the existing AMIGA preferred velocity then the one with the smaller measurement error was chosen. Otherwise the velocities were inspected by hand. Typically in these cases the measurement with the smaller uncertainty was chosen, except in cases where it disagreed with the majority of other measurements in the literature.
-
Column 3 – Vmod: the flow model corrected recession velocity of the source based on the Mould et al. (2000) flow model (km s-1).
-
Column 4 – Dmod: the flow model distance to the source (h70Mpc).
-
Column 5 – σD: estimate of the uncertainty in the flow model distance (Mpc). Calculated as described in Sect. 2.2.
-
Column 6 – log MHI: the log of the HI mass of the source (
 ), as calculated in Eq. (7).
), as calculated in Eq. (7). -
Column 7 – σlog MHI: the error in log MHI (dex). This was estimated as
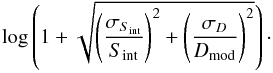 (B.1)However, the considerable scatter between the ALFALFA and AMIGA measures of Sint for the same sources suggests that the largest contribution to this error is in fact the absolute calibration, not the noise in the spectrum or the distance uncertainty. Therefore, this error was assigned a minimum value of 0.12 dex corresponding to the scatter between ALFALFA and AMIGA (see Sect. 4.5). In practice this is the relevant value for almost all the sources.
(B.1)However, the considerable scatter between the ALFALFA and AMIGA measures of Sint for the same sources suggests that the largest contribution to this error is in fact the absolute calibration, not the noise in the spectrum or the distance uncertainty. Therefore, this error was assigned a minimum value of 0.12 dex corresponding to the scatter between ALFALFA and AMIGA (see Sect. 4.5). In practice this is the relevant value for almost all the sources. -
Column 8 – WTFR: the estimate of the galaxy’s HI velocity width (km s-1) based on the Tully-Fisher relation of Torres-Flores et al. (2010), as described in Sect. 4.4.
-
Column 9 – log MHI−lim: the 5σ limit on the HI mass of the source (
), based on the velocity width above and the sensitivity of the spectrum. See Sect. 4.5 for more details. -
Column 10 – Limit code: this indicates whether the limit should be used. The limits should be used when this code is 1. Note that for marginal detections log MHI is still calculated, but it should not be used.
Flag table (Table B.3):
-
Column 1 – CIG: ID number corresponding to the assignment inthe original catalogue of isolated galaxies(Karachentseva 1973).
Table B.3Flags for the full HI sample.
-
Column 2 – isolation: if set to 1 the galaxy is not considered to be well isolated.
-
Column 3 – completeness: if set to 1 the galaxy does not meet the completeness requirements.
-
Column 4 – interpolation: if set to 1 this means that due to the low resolution of high noise of the spectrum some interpolation was necessary to obtain a meaningful fit to the edges of the HI profile.
-
Column 5 – single peak: if set to 1 the galaxy does not have a typical double horn profile, but is closer to a Gaussian.
-
Column 6 – middle peak: if set to 1 the galaxy HI profile is not peaked in on of the horned, but instead the maximum is somewhere between the horns.
-
Column 7 – offset spike: if set to 1 there is a sharp spike in the spectrum that may be contamination. In these cases the velocity widths are likely highly uncertain.
-
Column 8 – radio velocity: if set to 1 then the original spectrum was thought to be recorded in radio velocity and was converted to optical velocity accordingly.
-
Column 9 – digitised: if set to 1 then no digital version of the spectrum was available and a published image of the spectrum was digitised.
Appendix C: Conversion of previous scaling relations
We compare our trend lines between D25, LB and MHI with those of Haynes & Giovanelli (1984), Solanes et al. (1996), Dénes et al. (2014). However, these papers all use slightly different units systems or measures of galaxy diameter, luminosity or mass. Therefore, we must make corrections to facilitate a fair comparison.
HG84 correct their HI masses for internal absorption, which we make no correction for as it may introduce a bias depending on the galaxy type. Unfortunately as this correction was applied with a piece wise function that varied across different morphologies we cannot make a simple conversion factor to account for it. Therefore, no conversion is made for the HI masses. As the typical correction for internal absorption should be small (<10%) this is not expected to make a significant difference to the comparison.
The isophotal diameters they used were edited from the UGC values depending on the galaxy’s apparent surface magnitude. We took the overlapping 323 sources in the UGC and CIG and recalculated the HG84 correction to the UGC B-band diameters. An OLS linear trend line was then fit between these corrected UGC diameters and our B-band D25 values, giving the relation log (D25h70/ kpc) = 0.96log (ach/ kpc) + 0.12, where ac is the corrected UGC B-band diameter. HG84 also use h = 1 cosmology whereas we assume h = 0.7.
The original relation from HG84 is 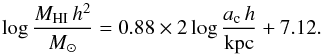 (C.1)After conversion to our unit system the gradient becomes 0.88/0.96 and the intercept 7.12−2log 0.7−(2 × 0.88 × 0.12)/0.96, making the final relation
(C.1)After conversion to our unit system the gradient becomes 0.88/0.96 and the intercept 7.12−2log 0.7−(2 × 0.88 × 0.12)/0.96, making the final relation 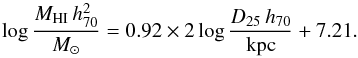 (C.2)HG84 also fit a relation based on LB. Their magnitudes are taken from the UGC and then corrected internal extinction, Galactic extinction, the K-correction and some systematic errors in the magnitude system used at the time. We do not duplicate their exact corrections, but make similar ones of our own. Also when our raw magnitudes were compared to those from the UGC for the 323 objects that overlap with the CIG, we found excellent agreement. Therefore, we do not make any conversion between the two papers’ magnitude systems. However, the difference in Hubble constant must be accounted for and HG84 used 5.37 as the bolometric absolute magnitude of the Sun, whereas we adopt the value 4.88. The original published relations was
(C.2)HG84 also fit a relation based on LB. Their magnitudes are taken from the UGC and then corrected internal extinction, Galactic extinction, the K-correction and some systematic errors in the magnitude system used at the time. We do not duplicate their exact corrections, but make similar ones of our own. Also when our raw magnitudes were compared to those from the UGC for the 323 objects that overlap with the CIG, we found excellent agreement. Therefore, we do not make any conversion between the two papers’ magnitude systems. However, the difference in Hubble constant must be accounted for and HG84 used 5.37 as the bolometric absolute magnitude of the Sun, whereas we adopt the value 4.88. The original published relations was 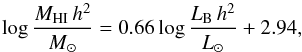 (C.3)which after conversion has the same gradient, but an intercept given by 2.94−2 × (1−0.66)log 0.7−(0.4 × 0.66)(4.88−5.37), making the final comparison relation
(C.3)which after conversion has the same gradient, but an intercept given by 2.94−2 × (1−0.66)log 0.7−(0.4 × 0.66)(4.88−5.37), making the final comparison relation 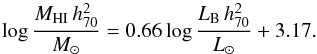 (C.4)Solanes et al. (1996) fit a relation based on the optical size of field galaxies based on by eye measurements from POSS blue prints. They state that these are in good agreement with the UGC diameters and that no corrections were made. We therefore again compare the matched sources between the UGC and CIG, but now do not make any corrections to the diameters. This gives the relation log (ah/ kpc) = 0.87log (D25h70/ kpc) + 0.12. The original relation from Solanes et al. (1996) is
(C.4)Solanes et al. (1996) fit a relation based on the optical size of field galaxies based on by eye measurements from POSS blue prints. They state that these are in good agreement with the UGC diameters and that no corrections were made. We therefore again compare the matched sources between the UGC and CIG, but now do not make any corrections to the diameters. This gives the relation log (ah/ kpc) = 0.87log (D25h70/ kpc) + 0.12. The original relation from Solanes et al. (1996) is 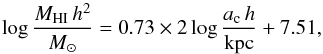 (C.5)which combined with the relation between the two diameter measurements gives the gradient as 0.73 × 0.87 and the intercept as 7.51−2log 0.7 + 2 × 0.73 × 0.12, making the final relation
(C.5)which combined with the relation between the two diameter measurements gives the gradient as 0.73 × 0.87 and the intercept as 7.51−2log 0.7 + 2 × 0.73 × 0.12, making the final relation 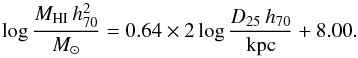 (C.6)Finally, we considered the two relations of Dénes et al. (2014), which are based on B-band magnitudes and diameters at the 25 mag arcsec-2 (as in this work), and HI masses from HIPASS. No conversion to a different unit system is required in this case and the scaling with size can be used directly,
(C.6)Finally, we considered the two relations of Dénes et al. (2014), which are based on B-band magnitudes and diameters at the 25 mag arcsec-2 (as in this work), and HI masses from HIPASS. No conversion to a different unit system is required in this case and the scaling with size can be used directly, 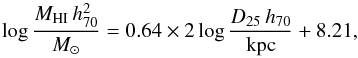 (C.7)while the B-band magnitude relation only requires conversion from a magnitude to a luminosity scale (using Eq. (3)). Which makes that relation
(C.7)while the B-band magnitude relation only requires conversion from a magnitude to a luminosity scale (using Eq. (3)). Which makes that relation 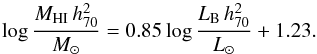 (C.8)
(C.8)
Appendix D: Scaling relations for SDSS-based isolation revision
Regression fits between 2log D25/ kpc and log MHI/M⊙ for the SDSS-defined isolated sample.
Argudo-Fernández et al. (2013) revised the AMIGA isolation criteria for those sources which fall within the SDSS footprint. Their photometric analysis produced a sample of well isolated galaxies that was 67% of the input sample of CIG objects. This represented a reduction from the 83% that Verley et al. (2007a) found to be isolated, with the difference arising due to faint neighbours being identified in SDSS that were not apparent in POSS I and II. However, there is considerable scatter in the estimates of neighbour density and tidal forces between the two works, therefore, a galaxy that is identified as isolated by the photometric criteria of Argudo-Fernández et al. (2013) may or may not be isolated according to the criteria of Verley et al. (2007a), although there is a definite correlation, and vice versa. When considering the SDSS spectroscopic sample Argudo-Fernández et al. (2013) found that 84% of the sources with good spectroscopic coverage were found to be isolated when neighbours separated by more than 500 km s-1 from the central object were excluded, which may suggest, contrary to the photometric findings, that the full CIG sample could contain slightly more well isolated galaxies than found by Verley et al. (2007a).
Regardless of which of the criteria from Argudo-Fernández et al. (2013) we choose to use it represents a major reduction in our sample size simply because their work is restricted to the SDSS footprint. This is the primary motivation for choosing the Verley et al. (2007a) criteria.
When we do employ the SDSS-based photometric criteria it produces a sample of 309 isolated objects with HI observations, a decrease of about 45% compared to using the Verley et al. (2007a) criteria. This more restricted sample results in the relations log MHI = 0.79 × 2log D25/ kpc + 7.56 and log MHI = 0.88log LB/L⊙ + 0.90, both with intrinsic scatter estimates of 0.17 dex. In the case of the SDSS spectroscopic isolation criteria, the sample available to us is only 243 objects. Here the relation fits become log MHI = 0.82 × 2log D25/ kpc + 7.44 and log MHI = 0.97log LB/L⊙−0.05, with intrinsic scatters of 0.18 and 0.17, respectively. The parameter values and error estimates are given in Tables D.1 and D.2, and the relations are plotted in Fig. F.1.
It is clear from Fig. F.1 that for both the D25 and LB relations that the relations based on the isolated SDSS spectroscopic sample are almost entirely consistent with the relations from the HI science sample. The relations from the isolated SDSS photometric sample appears to have a slightly flatter gradient and larger intercept, but agrees at high HI masses (for both relations). This might suggest that some of the smaller and less HI-rich AMIGA galaxies are not as well isolated when measured using SDSS rather than POSS I and II. However, this is a marginal result, and in fact the LB-relations are consistent at 1σ for the lowest HI masses.
A point to note is that the intrinsic scatter estimates for these fits are smaller by about 0.05 dex which could indicate that the Argudo-Fernández et al. (2013) criteria have removed the non-isolated galaxies more reliably and thus reduced scatter due to contamination by non-isolated objects. However, considerable caution is required in interpreting this result because there are many possible explanations. For example, not only is the sample size smaller, which will reduce the accuracy of the intrinsic scatter estimate, but also the SDSS footprint restricts the available sky area and the CIG is a local Universe sample, therefore, it is possible that some of the intrinsic scatter is related to the larger scale environment that the isolated galaxies reside in, but the range of possible environments has been restricted by not looking at the full northern sky.
Regression fits between log LB/L⊙ and log MHI/M⊙ for the SDSS-defined isolated sample.
Appendix E: Isolation comparison with Solanes et al. (1996)
Solanes et al. (1996) compiled a sample of field galaxies from the CGCG (Catalog of Galaxies and Galaxy Clusters; Zwicky et al. 1961) in the direction of Pisces-Perseus. In this paper we point out that this is a field sample which is quantitatively different from an isolated sample. To compare the degree of isolation we selected the ~2500 most isolated galaxies (from other CGCG sources) in the CGCG in the same area as Solanes et al. (1996). These sources were then cross matched with SDSS DR9 (Ahn et al. 2012) photometric sources with clean photometry that were identified as galaxies. A positional match of less than 5 arcsec was required, and if there were multiple matches within that radius the CGCG source was discarded. Next, all neighbouring SDSS photometric galaxies that had Petrosian radii (in r-band) within a factor of 4 of the Petrosian radius of the central object were selected from DR9. Using these neighbouring sources the dimensionless local number density was calculated (following Verley et al. 2007a) and the Karachentseva criteria were evaluated: a galaxy is considered isolated if there are no neighbours within an angular separation of 20 times their optical diameter, that have optical diameters within a factor of 4 of the central object. Originally the B-band diameter was used, however, for this approximate comparison we use the SDSS Petrosian diameters in r-band for simplicity. Due to the minimal SDSS DR9 coverage in this region, this process only returned usable results for 67 galaxies, therefore, we make our estimates based on this small sub-population. An equivalent exercise was performed with all of the CIG galaxies for which it was possible (451 sources).
It was found that while 20% of the CIG objects meet these adapted Karachentseva criteria, none of the Solanes-like sample do. Furthermore, the average projected neighbour density for the Solanes-like sample was found to be more than double that of the CIG sample. We therefore conclude that these two samples cover different environments and that almost all of the Solanes et al. (1996) galaxies would not be considered isolated by the AMIGA criteria, and thus are referred to a field objects rather than isolated objects.
Appendix F: Impact of NRT and ERT flux discrepancies
 |
Fig. F.1 The D25 (left) and LB (right) relations along with 1σ uncertainties (shaded regions) for the HI science sample (dashed black line), the sample with SDSS spectroscopic isolation criteria (light blue), the sample with SDSS photometric isolation criteria (green), the HI science sample with corrected NRT and ERT fluxes (purple), and with NRT and ERT observations removed (red). Offsets have been applied to the relations (except the central relation, the HI science sample) to aid readability. The HI science sample relation is duplicated each time for comparison. |
As detailed in Sect. 4.5 the data observed with NRT and ERT appear to have a frequency dependent discrepancy in their absolute flux calibration. We were unable to determine the source of this difference and decided to use the data unaltered. Here we describe what impact that decision has on the final relations which we calculate.
A straight line was fit using weighted least squares regression between the redshift (z50) and the logarithmic flux offset between the NRT and ERT observations and the ALFALFA fluxes for the same objects (considering only the uncertainty in the flux offset). This fit also included comparisons between our the NRT and ERT data and fluxes from Springob et al. (2005) as this doubled the number of available sources for the fit, making the total 64. The Springob et al. (2005) data were not used for comparisons when these were the same data as in our compilation. In this
scenario OLS is a reasonable method as the uncertainties in z50 are negligible in comparison to those in the flux. This fit was then used to alter all the NRT and ERT fluxes such that they fall in line with the ALFALFA and Springob et al. measurements. The resulting relations are listed in Tables F.1 and F.2, and plotted in Fig. F.1.
For both the D25 and LB relations, when the intercept and gradient are considered separately, they consistent (at 1σ) with the relations that we calculated in Tables 5 and 6. However, in all cases (including the OLS fits) the relations with the correction applied to the NRT and ERT fluxes are marginally steeper. This suggests that by not applying a correction to the fluxes in the main part of the paper the gradients may have been flattened by approximately 5%. Having said this, there is clearly substantial overlap between the 1σ uncertainties of the HI science sample relations with and without the flux corrections (Fig. F.1). In addition, the correction is both entirely empirical and quite uncertain. Therefore, we recommend using the relation given in Tables 5 and 6, not those in this section.
The other approach is to simply remove the spectra observed with NRT and ERT. This has the advantage of not necessitating the calculation of an uncertain and empirical relation to make a correction, however, it also removes almost half of the dataset. The relations calculated for this reduced dataset are also shown in Tables F.1 and F.2, and Fig. F.1.
In both relations removing the NRT and ERT sources caused a marginal flattening of the slope (and increase in the intercept), as opposed to the steepening found when the flux correction was applied. We suspect that, at least in part, this is caused by the different morphological distribution of the sources observed with NRT and ERT relative to the full population. For the detections approximately half of the sources that are S0 or earlier types were removed, whereas less than a third of sources later than S0 were removed. Hence, the remaining sample is richer in late types than the original sample. As the relations are found to be flatter for later types (which are also more HI-rich), this must contribute to the resulting flattening (and increase in the intercept). In addition, all but 17 of the marginal and non-detections were observed with NRT or ERT. These are also all removed, but this likely has minimal effects on the relations because the upper limits do not contain a lot of information.
Regression fits between 2log D25/ kpc and log MHI/M⊙ with NRT and ERT fluxes corrected or removed.
Regression fits between log LB/L⊙ and log MHI/M⊙ with NRT and ERT fluxes corrected or removed.
All Tables
Regression fits between 2log D25/ kpc and log MHI/M⊙ for the SDSS-defined isolated sample.
Regression fits between log LB/L⊙ and log MHI/M⊙ for the SDSS-defined isolated sample.
Regression fits between 2log D25/ kpc and log MHI/M⊙ with NRT and ERT fluxes corrected or removed.
Regression fits between log LB/L⊙ and log MHI/M⊙ with NRT and ERT fluxes corrected or removed.
All Figures
|
Fig. 1 Morphology distributions of galaxy samples used in this work and the works with which we compare. The morphological types used for the AMIGA and HG84 samples are from the AMIGA database, while those for Solanes et al. (1996) are taken from the original article. The dark grey bars (detections) combined with the light grey bars (marginals and non-detections) make up the AMIGA HI science sample, which has a median type of 4 (Sbc). For comparison the white bars show the full CIG sample. The pink bars shown the field sample of Solanes et al. (1996), which has a median type of 6 (Scd), and the green bars the CIG-based sample of HG84, which has a median type of 5 (Sc). |
| In the text | |
|
Fig. 2 Calculated distances to all CIG galaxies with measurements of recession velocity (white). The subset of the CIG that is the AMIGA HI science sample (defined in Sect. 5.1) is shown in grey, the dark grey indicating detections and light grey the upper limits. Note that the science sample contains no sources with heliocentric velocities less than 1500 km s-1 due to the isolation requirements, as explained Sect. 5.1. |
| In the text | |
|
Fig. 3 Distribution of beam correction factors for all galaxies detected in HI. |
| In the text | |
|
Fig. 4 Distribution of HI masses for all sources detected in HI. |
| In the text | |
|
Fig. 5 Comparison between ALFALFA and AMIGA measurements of HI integrated flux. The orange and pink points show detections from NRT and ERT respectively, and the black points show detections from all other telescopes. The thin black line indicates equality, while the dotted red line shows the best fit to all the points. Statistical error bars are not shown as for the majority of the points these are comparable in size to the points themselves, indicating that absolute calibration is the cause of most of the scatter and offset. |
| In the text | |
|
Fig. 6 Comparison between ALFALFA and AMIGA measurements of HI profile widths at the 50% level. The black line indicates equality and the dotted red line the best fit to the data. The highly outlying points are either from low signal-to-noise detections, or sources where the profile shapes in ALFALFA and AMIGA have differences for unknown reasons. |
| In the text | |
|
Fig. 7 Scatter plot of the HI mass of AMIGA galaxies as a function of their optical diameters (D25 in B-band). The black points indicate sources detected in HI while grey arrows indicate upper limits. The typical 1σ error ellipse of the data points is shown in the bottom right corner. The heavy blue lines show the regression fits of this work. The solid line corresponds to the full regression model including upper limits, while the dashed line is for the same model but only including detections (mostly hidden behind the solid line). The red dotted line is the ordinary least squares fit for the detections only. The green, purple, and orange dashed lines are from HG84, Solanes et al. (1996), and Dénes et al. (2014) respectively. |
| In the text | |
|
Fig. 8 Scatter plot of the HI mass of AMIGA galaxies as a function of their optical luminosities (in B-band). The black points indicate sources detected in HI while grey arrows indicate upper limits. The typical 1σ error ellipse of the data points is shown in the bottom right corner. The heavy blue lines show the regression fits of this work. The solid line corresponds to the full regression model including upper limits, while the dashed line is for the same model but only including detections (mostly hidden behind the solid line). The red dotted line is the ordinary least squares fit for the detections only. The green and orange dashed lines are from HG84 and Dénes et al. (2014). |
| In the text | |
|
Fig. 9 Scaling relations with D25 split by morphological type; early and intermediate types (top), late types (middle), very late types (bottom). |
| In the text | |
|
Fig. 10 Scaling relations with LB split by morphological type; early and intermediate types (top), late types (middle), very late types (bottom). |
| In the text | |
|
Fig. 11 Left: scatter plot of the HI masses of isolated galaxy pairs as a function of their optical diameters (data from Zasov & Sulentic 1994), shown with black crosses. The light grey points in the background are the HI detections of the AMIGA HI science sample. The solid blue line shows the MLE regression fit of this work and the dashed green line shows the HG84 relation. Right: HI-deficiency of isolated galaxy pairs (diagonal hatching) compared to the AMIGA HI science sample (light grey). HI-deficiency here is calculated with the D25-relation (without use of morphological type). |
| In the text | |
|
Fig. 12 Left column: scatter plots of the HI masses of Virgo cluster galaxies from the VCC, shown with black crosses. The light grey points in the background are the HI detections of the AMIGA HI science sample. The solid blue line shows the MLE regression fit of this work and the dashed green line shows the HG84 relation. Right column: HI-deficiency of Virgo cluster galaxies from the VCC (diagonal hatching) compared to the AMIGA HI science sample (light grey). Top row: here the samples are compared based on D25. Bottom row: here the samples are compared based on LB. |
| In the text | |
|
Fig. 13 Comparison of the differences between the HI-deficiencies of Virgo cluster galaxies derived using the D25 and LB relations of this work (grey bars) and the differences using the HG84 relations (unfilled bars). The Gaussian fit to our values is shown with the grey solid line, the fit to the HG84 values is shown with the solid black line. A third Gaussian with zero mean and a width taken to be the average of the two fits, is shown for comparison by the dotted line. |
| In the text | |
|
Fig. F.1 The D25 (left) and LB (right) relations along with 1σ uncertainties (shaded regions) for the HI science sample (dashed black line), the sample with SDSS spectroscopic isolation criteria (light blue), the sample with SDSS photometric isolation criteria (green), the HI science sample with corrected NRT and ERT fluxes (purple), and with NRT and ERT observations removed (red). Offsets have been applied to the relations (except the central relation, the HI science sample) to aid readability. The HI science sample relation is duplicated each time for comparison. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.