| Issue |
A&A
Volume 605, September 2017
|
|
|---|---|---|
| Article Number | A59 | |
| Number of page(s) | 19 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/201730522 | |
| Published online | 11 September 2017 | |
Chempy: A flexible chemical evolution model for abundance fitting
Do the Sun’s abundances alone constrain chemical evolution models?
1 Max Planck Institute for Astronomy, Königstuhl 17, 69117 Heidelberg, Germany
e-mail: rybizki@mpia.de
2 Astronomisches Rechen-Institut, Zentrum für Astronomie der Universität Heidelberg, Mönchhofstr. 12-14, 69120 Heidelberg, Germany
Received: 30 January 2017
Accepted: 10 April 2017
Elemental abundances of stars are the result of the complex enrichment history of their galaxy. Interpretation of observed abundances requires flexible modeling tools to explore and quantify the information about Galactic chemical evolution (GCE) stored in such data. Here we present Chempy, a newly developed code for GCE modeling, representing a parametrized open one-zone model within a Bayesian framework. A Chempy model is specified by a set of five to ten parameters that describe the effective galaxy evolution along with the stellar and star-formation physics: for example, the star-formation history (SFH), the feedback efficiency, the stellar initial mass function (IMF), and the incidence of supernova of type Ia (SN Ia). Unlike established approaches, Chempy can sample the posterior probability distribution in the full model parameter space and test data-model matches for different nucleosynthetic yield sets. It is essentially a chemical evolution fitting tool. We straightforwardly extend Chempy to a multi-zone scheme. As an illustrative application, we show that interesting parameter constraints result from only the ages and elemental abundances of the Sun, Arcturus, and the present-day interstellar medium (ISM). For the first time, we use such information to infer the IMF parameter via GCE modeling, where we properly marginalize over nuisance parameters and account for different yield sets. We find that 11.6+ 2.1-1.6% of the IMF explodes as core-collapse supernova (CC-SN), compatible with Salpeter (1955, ApJ, 121, 161). We also constrain the incidence of SN Ia per 103M⊙ to 0.5−1.4. At the same time, this Chempy application shows persistent discrepancies between predicted and observed abundances for some elements, irrespective of the chosen yield set. These cannot be remedied by any variations of Chempy’s parameters and could be an indication of missing nucleosynthetic channels. Chempy could be a powerful tool to confront predictions from stellar nucleosynthesis with far more complex abundance data sets and to refine the physical processes governing the chemical evolution of stellar systems.
Key words: methods: statistical / nuclear reactions, nucleosynthesis, abundances / stars: luminosity function, mass function / supernovae: general / Sun: abundances / Galaxy: evolution
© ESO, 2017
1. Introduction
The observed abundances of chemical elements in stars and interstellar medium (ISM) exhibit distinct patterns that correlate with the mass of a galaxy, the position within a galaxy, and the birth epoch of the stars (Baade 1944; Wallerstein 1962). Such chemical abundance patterns are by far best investigated in the Milky Way (MW), where the detailed photospheric composition of individual stars can be studied through spectroscopy. Galactic chemical evolution (GCE) models are a geometrically simplified approach to predicting the temporal evolution of abundance patterns arising from the interplay of the Galaxy’s star-formation history (SFH) and star-formation physics with its nucleosynthetic yield, and the inflow and re-processing of the ISM (Tinsley 1980; Matteucci 2003, 2012). The geometric simplification of GCE’s in many cases has been the assumption of a “leaky box”, or one-zone model, that is, considering a volume of interest, surrounded by a reservoir and repository of gas.
Since the seminal work of Schmidt (1959), chemical evolution arguments have been used to infer fundamental Galactic parameters. The one-zone approach was refined to include many elements (e.g., Tinsley 1979; Chiappini et al. 1997) and was extended to multi-zone models including dynamical constraints (Schönrich & Binney 2009; Kubryk et al. 2015). This not only increases the parameter space but at the same time makes the models computationally more expensive, in practice prohibiting a full parameter exploration. This places GCE’s in between analytical (e.g., Weinberg et al. 2017; Spitoni et al. 2017) models (with strong simplifying assumption) and hydrodynamical simulations including detailed chemical enrichment as well as galactic dynamics (e.g., Stinson et al. 2006; Few et al. 2012; Grand et al. 2015). Because of the complexity of those simulations usually only a limited parameter space or aspect of chemical evolution can be studied (e.g., Jiménez et al. 2015). Simple and flexible GCE models on the other hand are ideal to employ large chemical evolution parameter studies.
 |
Fig. 1 Schematic summary of Chempy: the left portion of this figure illustrates the sampling of the model parameter posteriors within the Bayesian framework (see Sect. 4); the right hand portion sketches how Chempy calculates a “system state”, for any one set of (hyper-)parameters, which produces observable predictions: (1) for a chosen set of parameters, θ, Chempy calculates the system state from initial conditions for all time steps (2, cf. Fig. 5), resulting in the observational predictions (3). These predictions are then compared to a predefined subset of our observations (see Table 3); here τ⋆ is the age of the tracers, whose abundance measurements we fit. In our sample application, this is the age of the Sun or Arcturus. We can now calculate the likelihood (4) of any set of observations ( |
The current revolution in data quality and quantity on stellar abundances, with the far greater ability to constrain stellar ages from spectra (Martig et al. 2016; Ness et al. 2016; Valls-Gabaud 2014; Feuillet et al. 2016) calls for a flexible model framework to interpret, and eventually fit these data. Recent advances towards this goal have been open-source releases by Côté et al. (2016a), Andrews et al. (2017) and statistical measures and sampling techniques to infer, for example, the MW SFH (Snaith et al. 2014) or Sculptor chemical evolution parameters (Côté et al. 2017).
GCE models encompass galactic (SFH, gas flows), star formation (stellar initial mass function, kinetic feedback, star formation efficiency), and stellar physics (yields, lifetimes). Modeling, even for only a single-zone, therefore inevitably draws on many free or fit parameters and hyperparameters. Many of them are poorly constrained a priori (Côté et al. 2016a), yet need to be marginalized out for simple astrophysical inferences. Perhaps the most important external or theoretical input for GCE models are nucleosynthetic yields for the various enrichment channels (Romano et al. 2010; Côté et al. 2016b). In the past, theoretical yields have produced mismatches with the observations, leading to the concept of “empirical yields” (François et al. 2004; Henry et al. 2010). Yet, many abundance trends are not reproduced (Argast et al. 2002; Kobayashi et al. 2006) and the physical shortcomings of stellar nucleosynthetic yield models are still under debate (Nomoto et al. 2013; Fink et al. 2014; Pignatari et al. 2016; Müller 2016).
In this paper, we lay out an approach to GCE modeling, dubbed Chempy, and illustrate its capabilities with a “toy case”: trying to match the abundances of the Sun, Arcturus, and local B-stars. At its heart, Chempy is an open box model, and per se relatively conventional; the new aspect is the flexible data fitting which marginalizes over free parameters and accounts for different yield sets. We also introduce a multi-zone scheme which allows us to use several stellar abundances to constrain the same parameters (this will be necessary, for example, when trying to produce empirical yield sets or relax the assumption of a universal stellar initial mass function, IMF).
We begin by introducing the model in Sect. 2, followed by a data description in Sect. 3. The Bayesian method will be explained in Sect. 4 and the results including a mock data test and the multi-zone scheme will be presented in Sect. 5. We will conclude with a summary and an outlook, Sect. 6.
2. Chempy and its chemical evolution parameters
A Python implementation of the current version of Chempy can be downloaded from https://github.com/jan-rybizki/Chempy. It was designed to be modular and fast in order to explore a high-dimensional parameter space via Markov chain Monte Carlo (MCMC).
Generally speaking, Chempy is a means of linking the parameters of a chemical evolution model θ (e.g., the IMF high-mass slope) together with underlying hyperparameters λ (e.g., a specific yield set) to the likelihood of the observations 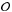 (e.g., stellar abundances) via its model predictions d. This is schematically shown in Fig. 1, which can provide guidance through the methodological description.
(e.g., stellar abundances) via its model predictions d. This is schematically shown in Fig. 1, which can provide guidance through the methodological description.
We start by introducing the main parameters, (θ), needed to specify the chemical evolution model (see Table 1). Each of these is parameterizing a specific aspect of the GCE model. This list of parameters is of course not exhaustive (e.g., it could include the mass of the most massive stars, mmax), but we limit ourselves to nθ = 7 parameters, for the sake of simplicity. We distinguish between parameters governing the physics of the stellar component (nθSSP = 3, global parameters) and parameters that affect the ISM (nθISM = 4, local parameters).
Each parameter (in some cases its logarithm) has a Gaussian prior distribution assigned to it, based on broad insights from published work (Table 1). The prior is specified by the mean 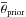 (i.e., the maximum or peak of the prior distribution) and the standard deviation σprior. In the following we will illustrate how each parameter affects Chempy by plotting its functional form or resulting predictions for a range of parameter values.
(i.e., the maximum or peak of the prior distribution) and the standard deviation σprior. In the following we will illustrate how each parameter affects Chempy by plotting its functional form or resulting predictions for a range of parameter values.
Free Chempy parameters, θ, and their priors with assumed Gaussian error model.
2.1. Stellar physics parameters
Chempy’s central module calculates the yield for a simple stellar population (SSP). This routine is governed by three parameters, which set the stellar physics of the chemical evolution model.
The stellar component of Chempy is modeled as a composite stellar population (CSP), a sum of simple stellar populations (SSPs) separated equidistantly in time. An SSP is fully characterized by its time of birth, its mass, and element composition ![\hbox{$\mathrm{SSP}\left({t}_\mathrm{birth},\mathrm{mass},[\mathrm{X/H}]\right)$}](/articles/aa/full_html/2017/09/aa30522-17/aa30522-17-eq44.png) , which also fixes its feedback when assuming some IMF, stellar lifetimes, and nucleosynthetic yields. The total mass of an SSP for a specific time step is determined by the star formation rate (SFR) and its initial elemental abundance is given by the composition of the ISM at that time.
, which also fixes its feedback when assuming some IMF, stellar lifetimes, and nucleosynthetic yields. The total mass of an SSP for a specific time step is determined by the star formation rate (SFR) and its initial elemental abundance is given by the composition of the ISM at that time.
 |
Fig. 2 Illustrating the first free parameter (θ1 = αIMF), the high-mass slope of the IMF. Showing the number of stars per mass interval. We use a Chabrier (2001, Table 1, IMF 3) functional form as in Eq. (1) with αIMF = − 2.29 as |
The stellar masses are distributed on a constant grid from 0.08 to 100 M⊙ with a mass step that can be adjusted. We found a mass resolution of about 0.02 M⊙ to be sufficient. The functional form of the IMF is Chabrier (2001, Table 1, IMF 3)![\begin{equation} \label{eq:imf} \frac{\mathrm{d}n}{\mathrm{d}m}=m^{-\left(1+\alpha_\mathrm{IMF}\right)}\exp\left[\left(-\frac{716.4}{m}\right)^{0.25}\right], \end{equation}](/articles/aa/full_html/2017/09/aa30522-17/aa30522-17-eq50.png) (1)where the high-mass slope (αIMF = θ1) is one of Chempy’s basic parameters; we assume the IMF slope to be universal. The parameter αIMF is crucial as it sets the ratio of low-mass to high-mass stars and it also alters the number distribution of the high-mass stars which influences the elemental composition of the feedback. The range of IMFs, spanned by this parametrization, is shown in Fig. 2 where we plot it for the mean prior value (
(1)where the high-mass slope (αIMF = θ1) is one of Chempy’s basic parameters; we assume the IMF slope to be universal. The parameter αIMF is crucial as it sets the ratio of low-mass to high-mass stars and it also alters the number distribution of the high-mass stars which influences the elemental composition of the feedback. The range of IMFs, spanned by this parametrization, is shown in Fig. 2 where we plot it for the mean prior value (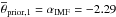 ) and its 2σprior deviations, also comparing to the Salpeter (1955) and the Kroupa et al. (1993) IMF. The values of the prior are taken from Côté et al. (2016a, Table 7), albeit their high-mass slope parameter is not exactly applicable to our IMF functional form. The stellar lifetimes are calculated according to Argast et al. (2000) in order to have the mass and the mass range of dying stars for all remaining time steps of the simulation.
) and its 2σprior deviations, also comparing to the Salpeter (1955) and the Kroupa et al. (1993) IMF. The values of the prior are taken from Côté et al. (2016a, Table 7), albeit their high-mass slope parameter is not exactly applicable to our IMF functional form. The stellar lifetimes are calculated according to Argast et al. (2000) in order to have the mass and the mass range of dying stars for all remaining time steps of the simulation.
We differentiate between three nucleosynthetic channels: Supernova of type Ia (SN Ia), core-collapse supernova (CC-SNe), and asymptotic giant branch stars (AGB). For the latter two, the elemental feedback and remnant mass depend on the mass of dying stars (see Fig. 4) and we assume that all relevant feedback materials of a star (including winds) are ejected only at the end of its lifetime. The elemental feedback is calculated according to yield tables from the literature. For our default yield set (see Table 2) the AGB feedback is calculated according to Karakas (2010); for the CC-SN feedback we use the table and prescription of Nomoto et al. (2013) where 50% of CC-SN more massive than 25 M⊙ explode as Hypernova. We use the net yields (i.e., only the newly synthesized material appears in the table and the missing ejecta mass is filled with unprocessed material from the stellar birth elemental composition, which is the predicted model ISM composition at the formation time of the corresponding SSP) which are calculated for a grid of masses and metallicities. The interpolation scheme can be switched from linear to logarithmic in metallicity and we use the latter here.
Yield sets for which we test our inference.
For the SN Ia, we use the Seitenzahl et al. (2013) yields (their model N100), which best reproduces observables (Sim et al. 2013), without metallicity dependence, and in Chempy SN Ia always explode with the same mass, calculated from 3D models superseding the W7 model of Iwamoto et al. (1999), which was calculated in 1D and had old electron capture rates. Because of that, Ni was over- and Mn underproduced, which is remedied with Seitenzahl et al. (2013). The choice of a specific yield set can be treated as a hyperparameter and we will test the impact that using different yield sets has on our inference.
What fraction of stars and in what mass range do they explode as SN Ia, is less well understood, and we treat this empirically. The delay time distribution (DTD) of the SN Ia explosions are parameterized as in Maoz et al. (2010) with a power-law of t-1.12. Free parameters are the number of SN Ia per solar mass over a time of 15 Gyr (NIa = θ2) and the time delay for the first SN Ia events to occur (τIa = θ3). In Fig. 3 the 2σ variation of those parameters are shown compared to the default model and the data on SN Ia explosions by Maoz et al. (2010, Table 1) and Maoz et al. (2012, Table 2). The prior of the SN Ia normalisation (NIa) is based on Maoz & Mannucci (2012, Table 1) and the prior on the time delay (τIa) is estimated from the bin size of Maoz et al. (2012) data.
 |
Fig. 3 Impact of the model parameters θ2,3 = NIa,τIa, the SN Ia normalization, and the SN Ia delay time. We show the distribution functions of SN Ia explosions for an SSP of 1 M⊙ using a Maoz et al. (2010) functional form with a mass normalization of NIa = 0.00178 and a time-delay of τIa ≈ 160 Myr. We show ± 2σprior variations from |
The distribution of stars along the IMF and the SN Ia explosions can be calculated as stochastic processes in Chempy. But this converges rapidly to the analytic solution, as soon as the SSP masses reach ~105M⊙, therefore we employed the faster analytic version here.
The yield is illustrated in Fig. 4 for an SSP of 1 M⊙ and Z⊙ with parameters comparing the default yield set with the alternative yield set (i.e., Chieffi & Limongi 2004; Ventura et al. 2013; and Thielemann et al. 2003, for CC-SN, AGB, and SN Ia respectively), where the cumulative yield over time for O, Fe, N, and C are displayed for the three different nucleosynthetic feedback processes1.
This feedback table is stored for each SSP of the simulation on the grid of the remaining time steps such that the feedback material of the previous stellar generations can be added to the respective latest time step by simple matrix calculation. Together with the effective use of numpy arrays (van der Walt et al. 2011), this diminishes the time per Chempy evaluation to the order of seconds.
 |
Fig. 4 Cumulative net yield in M⊙ for C, N, O and Fe over time for an SSP of 1 M⊙ and solar metallicity Z⊙, using Chempy’s |
 |
Fig. 5 Chempy (one-zone, open-box) mass flow of one time step t → t + Δt, illustrating how Chempy is integrating over time from the initial system state, Sθ(t = 0) (see Fig. 1). Each box represents a subsystem with its current state and the changes to the next time step. The numbered arrows show the sequence of Chempy time integration and the mathematical prescriptions with their parameter dependence. The quantities characterizing the resulting CSP (see Sect. 2.1) are given in gray. The chemical composition [X/H] of each subsystem is tracked. Initial conditions are: no stars, no ISM gas, and |
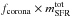
2.2. ISM physics: mass flow and time evolution
The mass flow of the open box model is sketched out in Fig. 5. The open box consists of a well-mixed gas phase representing the ISM from which new stars are formed. So far Chempy does not separate the warm and atomic gas phase, even though our linear Schmidt law only holds for the molecular gas component (Bigiel et al. 2008). The ISM infall is fed from a well-mixed “corona” gas reservoir, which is slowly enriched by the stellar feedback and on the other hand diluted by an inflow of primordial gas. Each time step consists of the following intermediate time steps:
- 1.
Inflow of primordial gas into the corona. The inflow mass per time step is, somewhat ad hoc, set to equal the SFR, minflow(t) = mSFR(t).
- 2.
Stellar feedback material from previous stellar generations is added up for the particular time step and the “outflow fraction” (xout = θ6) is presumed to add to the corona. The remaining fraction is mixed into the local ISM. This determines the new corona abundances.
- 3.
Infall from the corona until enough gas is in the ISM so that mSFR = SFE × mISM, given the star formation efficiency (SFE) parameter (=θ4). This sets the ISM abundances.
- 4.
New stars form with abundances that equal those of the ISM, and their individual masses are distributed following the IMF; the total amount of new stellar mass is set by the prescribed SFR.
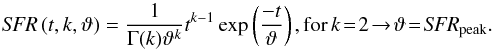 (2)We fix the shape parameter k = 2 such that the scale parameter (ϑ) determines the peak of the SFR. This makes θ5 = SFRpeak( = ϑ) Chempy’s fifth free parameter. The default distribution is depicted in Fig. 6 together with the distributions resulting from σprior deviations, showing that this parametrization is highly non-linear. Still we chose this parametrization and prior distribution in order to obtain a smooth SFR, peaking early as observed in L⋆ galaxies (van Dokkum et al. 2013, Fig. 4b). Whether the SFR should emulate the total SFR of the Milky Way, or the one near the solar radius can be debated, and explored with Chempy. Consequently we use an un-normalized SFR only being interested in the relative change of the SFR with time.
(2)We fix the shape parameter k = 2 such that the scale parameter (ϑ) determines the peak of the SFR. This makes θ5 = SFRpeak( = ϑ) Chempy’s fifth free parameter. The default distribution is depicted in Fig. 6 together with the distributions resulting from σprior deviations, showing that this parametrization is highly non-linear. Still we chose this parametrization and prior distribution in order to obtain a smooth SFR, peaking early as observed in L⋆ galaxies (van Dokkum et al. 2013, Fig. 4b). Whether the SFR should emulate the total SFR of the Milky Way, or the one near the solar radius can be debated, and explored with Chempy. Consequently we use an un-normalized SFR only being interested in the relative change of the SFR with time.
At the beginning of a Chempy run the ISM starts out with no mass, acquiring gas from the corona. In determining the gas infall needed to sustain a certain SFR, we generally assume a linear Schmidt law (nSchmidt = 1), for which our SFE parameter literally is the star formation efficiency: 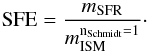 (3)Using different power law exponents is possible and we illustrate the commonly used case of nSchmidt = 1.4 in Fig. 7, where the dependence of the infall and the ISM- and corona gas mass onto the SFE parameter can be inspected. We center our prior on the SFE at the value established by Bigiel et al. (2008),
(3)Using different power law exponents is possible and we illustrate the commonly used case of nSchmidt = 1.4 in Fig. 7, where the dependence of the infall and the ISM- and corona gas mass onto the SFE parameter can be inspected. We center our prior on the SFE at the value established by Bigiel et al. (2008), 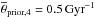 , with a variance of a factor of two (see Table 1).
, with a variance of a factor of two (see Table 1).
After the enrichment of the ISM by the stellar feedback material from the previous SSPs the next SSP generation is formed, reducing the mass of the ISM. Not all feedback material is returned to the ISM, as there is some outflow fraction (xout = θ6). The outflow fraction, which is added to the corona, can be varied per process but we apply the same to all three enrichment processes for the sake of simplicity. We note that this parametrization is different from the commonly used mass-loading factor. As there are no meaningful observational constraints, we use a relatively broad prior peaking at an outflow fraction of 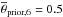 .
.
 |
Fig. 6 Model parameter θ5 = SFRpeak, the epoch of the peak of the star formation rate (SFR), shown here in arbitrary units. As functional form for the SFR, we use the gamma distribution with k = 2 (see Eq. (2)). Variations in the epoch of peak star formation of ± 1,2σprior from |
 |
Fig. 7 Illustration of how the gas infall and the gas masses (of ISM and corona) are governed by the model parameter “star formation efficiency”, θ4 = SFE. The upper panel shows the infall over time for |
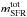
 |
Fig. 8 Illustration of impact of model parameters θ6,7 = xout,fcorona, the mass loading or outflow fraction and the corona mass factor on the ISM metallicity. The resulting metallicity of ISM gas (upper panel) and corona gas (lower panel) is shown over time assuming the default yields. The results for |
The corona gas starts out with primordial abundances and its initial mass equals 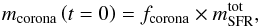 (4)where
(4)where 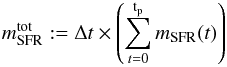 (5)is the total stellar mass formed over the Chempy run, and the corona mass factor is the last free parameter (fcorona = θ7). Since the SFR is un-normalized and could represent, for example, the solar birth chemical evolution zone, the corona gas can usually not be identified with a galactic halo (only if we were modeling whole galaxies as a Chempy single-zone, which could approximate the evolution of dwarf galaxies). Instead we must think of the corona as a gas reservoir, surrounding the chemical zone which we are modeling and diluting its outflows. Therefore an outer thin disk zone would probably have a larger surrounding gas reservoir than an inner disk zone.
(5)is the total stellar mass formed over the Chempy run, and the corona mass factor is the last free parameter (fcorona = θ7). Since the SFR is un-normalized and could represent, for example, the solar birth chemical evolution zone, the corona gas can usually not be identified with a galactic halo (only if we were modeling whole galaxies as a Chempy single-zone, which could approximate the evolution of dwarf galaxies). Instead we must think of the corona as a gas reservoir, surrounding the chemical zone which we are modeling and diluting its outflows. Therefore an outer thin disk zone would probably have a larger surrounding gas reservoir than an inner disk zone.
The corona is replenished with primordial gas (cosmic inflow) at the rate of the SFR; it loses mass to the ISM and it is chemically enriched by the outflowing fraction of the feedback material from the stellar component. Observational evidence from analysis of L⋆ galaxies (Stern et al. 2016; Werk et al. 2014) has shown that the corona to stellar mass ratio at the present-day ranges from 0.5 to 2. Because fcorona is not directly identifiable with those data, we chose a relatively broad prior centered around two with a variance of a factor of two (see Table 1). In Chempy, the corona is a simplified gas-reservoir surrounding the ISM, which is not available for star formation. It could also be interpreted as a hot gas phase that is slowly cooling down, but we use the corona gas terminology throughout. The effect of the parameters xout and fcorona is shown in Fig. 8. The default model is compared to the 2σprior deviations in each parameter and data points from observations are included as well.
The four above steps are iterated over the course of 13.5 Gyr (tp) over a number of equidistant time steps. We use 136 here (time resolution of Δt = 0.1 Gyr) which proves sufficient (even 28 time steps yield similar results). Since Chempy is very flexible, other mass flow as well as feedback prescriptions can be tested and more free parameters can easily be included (e.g., k, the shape parameter of the SFR or nSchmidt). Tests were made and a reasonable set of parameters chosen so that the most important parameters should be included without over-fitting the problem. Other prescriptions and parameters can be tested by the interested reader using a documented user-case from the Chempy github repository.
3. Observational constraints
We want to constrain the parameters of chemical evolution in the Galaxy by comparing Chempy’s synthesized output (predictions) to data. It is not trivial to chose a priori the observations that are best suited to constrain the Chempy’s model parameters. In the following we describe our fiducial set of observational evidence; this is in some sense a set of minimal data, geared at demonstrating which aspects of abundance measurements matter most.
3.1. Solar abundances
Arguably, the most accurate and precise stellar element abundances are the present-day solar photospheric abundances, [ X / H ] ⊙, by Asplund et al. (2009, Table 1). Still the abundance determination from spectroscopy relies on theoretical models and their systematic error is probably underestimated (Jofre et al. 2017), as illustrated by the ongoing debate regarding the solar oxygen abundance (Steffen et al. 2015). But the solar abundances have been verified using meteorites (Lodders et al. 2009), the elemental abundances of other solar system bodies (Lawler et al. 1989; McDonough 1995), as well as helioseismological inference (Basu & Antia 2004). At the same time, the age of the Sun is very well constrained (e.g., Dziembowski et al. 1999), hence we can map the Chempy ISM abundances from ~4.5 Gyr ago ![\hbox{$\left({[\mathrm{X}/\mathrm{H}]}_\mathrm{ISM}({t}_\mathrm{p}-4.5)={[\mathrm{X}/\mathrm{H}]}_\mathrm{SSP}({t}_\mathrm{p}-\tau_\odot)\right)$}](/articles/aa/full_html/2017/09/aa30522-17/aa30522-17-eq99.png) onto the solar birth abundances (protosolar), [ X / H ] ⊙ ,birth. We adopt protosolar abundances by adding 0.04 dex (0.05 dex for He) to the photospheric abundances, which is the depletion of heavy elements due to diffusion processes (Turcotte & Wimmer-Schweingruber 2002) in the Sun; and we add 0.01 dex to the abundance uncertainty, accounting for this imperfect correction.
onto the solar birth abundances (protosolar), [ X / H ] ⊙ ,birth. We adopt protosolar abundances by adding 0.04 dex (0.05 dex for He) to the photospheric abundances, which is the depletion of heavy elements due to diffusion processes (Turcotte & Wimmer-Schweingruber 2002) in the Sun; and we add 0.01 dex to the abundance uncertainty, accounting for this imperfect correction.
This leaves the decision of how many elements one can sensibly include in Chempy’s prediction and data comparison. For our analysis we consider the elements up to Ni (for both yield sets CC-SN and SN Ia tables provide all those elements and the AGB tables provide elements at least up to Si). We exclude Li, Be, and B because other nucleosynthetic channels (i.e., cosmic ray spallation and nova outbursts), which we do not model, contribute substantially to the enrichment of these elements (Reeves 1970; Romano et al. 1999). Similarly Li can easily be destroyed in the solar photosphere altering its abundance compared to the initial solar composition (Asplund et al. 2009). We also excluded Cl and Sc because the mismatch between predictions and observations was too large2. We use all remaining elements for our analysis: He, C, N, O, F, Ne, Na, Mg, Al, Si, P, S, Ar, K, Ca, Ti, V, Cr, Mn, Fe, Co, and Ni. Changing the solar abundances to Lodders et al. (2009, Table 6), which are based on meteoritic data, does not affect our results significantly.
Observations,  , used to constrain the Chempy parameters.
, used to constrain the Chempy parameters.
3.2. The present-day ISM abundances, with early B-stars as proxy
The present-day ISM abundances are a crucial anchor for GCE models. One of the best measurements is Nieva & Przybilla (2012, Table 9), who determined He, C, N, O, Ne, Mg, Si and Fe abundances for 20 nearby (within 0.5 kpc) early B-stars, with a star-to-star scatter comparable and often lower than the solar abundance precision of Asplund et al. (2009). This suggests that the present-day ISM is well mixed and establishes a “cosmic abundance standard”, [ X / H ] B − stars, which we use to constrain the ISM abundance at the end of the simulation, [ X / H ] ISM(tp).
3.3. Arcturus as the best-studied α-enhanced star
Arcturus is a well-studied giant star with α-enhanced abundances and an age of about 7 Gyr. Ramírez & Allende Prieto (2011) find an [ Fe / H ] of − 0.52 ± 0.04 dex and provide abundances for C, O, Na, Mg, Al, Si, K, Ca, Ti, V, Cr, Mn, Co, and Ni, in common with our elemental choice for the Sun. We exclude C, since the photospheric value in a giant does not represent the initial abundance because of dredge-up (Iben 1965). We do not apply any “proto-Arcturus” correction to its present-day photospheric abundances, [ X / Fe ] Arcturus, which we assume to reflect the ISM composition at the time of its birth, [ X / Fe ] ISM(tp − τArcturus). Arcturus’ age of 7.1 Gyr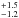 by Ramírez & Allende Prieto (2011) is less well-known than the Sun’s but that uncertainty turns out not to affect our results significantly.
by Ramírez & Allende Prieto (2011) is less well-known than the Sun’s but that uncertainty turns out not to affect our results significantly.
3.4. Observed incidence of supernovae
A more global observational constraint is the ratio of CC-SNe to SNe Ia, CC / Ia. The supernova-ratio contains information about the SFR (since CC-SNe trace the SFR directly and SNe Ia with a delay), about the IMF (number of CC-SN), and the number of SN Ia exploding per solar mass. Since data for the Milky Way are not available, we use Sbc/d galaxies from Mannucci et al. (2005). For SN Ia they measure 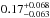 and
and 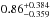 for CC-SN. This corresponds to a ratio of
for CC-SN. This corresponds to a ratio of 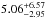 for which we use log 10(CC / Ia(tp)) = 0.7 ± 0.37, simplifying to a Gaussian error model.
for which we use log 10(CC / Ia(tp)) = 0.7 ± 0.37, simplifying to a Gaussian error model.
3.5. Corona metallicity
Observational constraints on the abundances of the corona gas turn out to be important to reduce parameter covariances (or even degeneracies) in Chempy. We know from Smith (1963) and Fox et al. (2016) that the material, falling onto the Galactic disk, is enriched, not pristine. As an observational constraint for the present-day corona gas metallicity we use the Smith cloud value of about half solar: 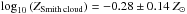 . Recent re-analysis of observational data by Stern et al. (2016, Fig. 3) fitting individual metallicities in the circum-galactic medium (CGM) of L∗-galaxies in the Cosmic Origins Spectrograph (COS)-halos survey yields similar corona abundances with a range of
. Recent re-analysis of observational data by Stern et al. (2016, Fig. 3) fitting individual metallicities in the circum-galactic medium (CGM) of L∗-galaxies in the Cosmic Origins Spectrograph (COS)-halos survey yields similar corona abundances with a range of 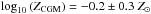 .
.
3.6. Combination of observational data
As observational constraints we will usually use a combination of stellar abundance, corona metallicity, and SN-ratio and indicate this by adding a “+” to the star’s name (e.g., Sun+ for {1,4,5}, cf. Table 3). The reason for adding the latter two constraints (which are, strictly speaking, not Milky Way data) is that we demand our model to reproduce a few basic, globally observed properties of L⋆ galaxies; they also constrain the otherwise ill-determined and degenerate ISM parameters xout and fcorona.
3.7. Comparative data set: APOGEE giants
In order to compare our predictions with Galactic stellar populations we use an APO Galactic Evolution Experiment (APOGEE) (Majewski et al. 2016) giant sample with data release 13 APOGEE Stellar Parameter and Chemical Abundance Pipeline (ASPCAP; SDSS Collaboration et al. 2016) abundances, for which ages have been derived from C/N ratios (Ness et al. 2016). We only chose stars for which the Ness et al. (2016)χ2 fit is better than 0.9, leaving us with a sample of ≈20 000 stars to which we compare our resulting chemical evolution tracks in Fig. 17.
Another important prediction is the metallicity distribution function (MDF). We will compare Chempy predictions with the APOGEE DR13 red-clump catalog (Bovy et al. 2014) for which good distance estimates are available.
3.8. Omitted observational constraints
We are not using the APOGEE data as constraints for our inference because the Chempy solar zone (the chemical enrichment of the ISM leading to the abundances of the Sun) cannot be identified with the ISM evolution at the solar neighborhood (the gas which is present here now could have experienced chemical enrichment at different places in the Galaxy). Conversely, a stellar sample from the solar neighborhood will also not be representative of the ISM evolution at solar Galactic radius because the stellar birth radius is not preserved.
Similarly we are not using present-day stellar or gas densities as observational constraints. The Chempy SFR can always be re-normalized to match a specific stellar density. But since the ISM gas mass is tight to the SFR via the SFE, a constraint on the gas density will force a specific present-day SFR value, which will bias our SFRpeak inference, even more so, since we are using a very simple SFR parametrization.
4. Constraining parameters via Bayesian inference
As depicted in Fig. 1, a single Chempy run evaluates the un-normalized posterior probability density function (PDF) for a specified set of observations 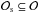 , at a specific point θ in parameter space (steps 1−5). The complete posterior PDF can be approximated using Chempy within an MCMC scheme (step 6). The steps are as follows:
, at a specific point θ in parameter space (steps 1−5). The complete posterior PDF can be approximated using Chempy within an MCMC scheme (step 6). The steps are as follows:
-
A point in parameter space (θ) is chosen. This sets the log prior:
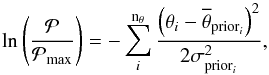 (6)normalized by its maximum
(6)normalized by its maximum 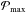 ; nθ is the number of free parameters (i.e., seven, the dimensions of θ). The analytic values for the prior mean (
; nθ is the number of free parameters (i.e., seven, the dimensions of θ). The analytic values for the prior mean ( ) and the standard deviation (σpriori) of the prior distribution are given in Table 1. Because of the imposed limits on the parameter values, the real prior distribution is slightly distorted, which has a negligible effect as can be seen in the first and second rows of Table 4. Table 4
) and the standard deviation (σpriori) of the prior distribution are given in Table 1. Because of the imposed limits on the parameter values, the real prior distribution is slightly distorted, which has a negligible effect as can be seen in the first and second rows of Table 4. Table 4Inferred parameters (16, 50, 84 percentiles of θposterior), for different observational subsets (
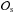 ), and different yield sets (default, alternative).
), and different yield sets (default, alternative). -
2.
Chempy then integrates the system state, Sθ(t), from the initial condition (Sθ(t = 0)) to the final epoch, usually the present time at 13.5 Gyr (Sθ(t = tp)) in steps of Δt = 0.1 Gyr. The system state keeps track of the chemical composition and mass of each component:
![\begin{equation} \mathrm{Chempy}({\theta}) \!=\! {{S}}_{{\theta}}(t)\!=\!\left\{{m}_{\mathrm{ISM,corona,CSP}}(t),{[\mathrm{X/H}]}_\mathrm{ISM,corona,CSP}(t) \right\}\cdot \end{equation}](/articles/aa/full_html/2017/09/aa30522-17/aa30522-17-eq233.png) (7)Additionally derived quantities from stellar evolution (e.g., feedback per process, mass in remnants, number of feedback events) are saved for the stellar component (cf. Fig. 5).
(7)Additionally derived quantities from stellar evolution (e.g., feedback per process, mass in remnants, number of feedback events) are saved for the stellar component (cf. Fig. 5). -
3.
The previously chosen set of observations (
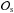 ) is compared to the corresponding predictions (ds(θ)) which are derived from the system state (Sθ(t)),
) is compared to the corresponding predictions (ds(θ)) which are derived from the system state (Sθ(t)), ![\begin{equation} {{S}}_{{\theta}}(t)\rightarrow{{d}}_\mathrm{s}({\theta})\subseteq \left( \begin{matrix} {[\mathrm{X}/\mathrm{H}]}_\mathrm{SSP}({t}_\mathrm{p}-\tau_\odot)\\ {[\mathrm{X}/\mathrm{H}]}_\mathrm{ISM}({t}_\mathrm{p})\\ {[\mathrm{X}/\mathrm{Fe}]}_\mathrm{SSP}({t}_\mathrm{p}-\tau_\mathrm{Arc})\\ \mathrm{CC}/\mathrm{Ia}({t}_\mathrm{p})\\ \mathrm{Z}_\mathrm{corona}({t}_\mathrm{p}) \end{matrix} \right) \leftrightarrow {\mathcal{O}}_\mathrm{s}\subseteq \left( \begin{matrix} {[\mathrm{X}/\mathrm{H}]}_{\odot,\mathrm{birth}}\\ {[\mathrm{X}/\mathrm{H}]}_\mathrm{B-stars}\\ {[\mathrm{X}/\mathrm{Fe}]}_\mathrm{Arc}\\ \mathrm{CC}/\mathrm{Ia}\\ \mathrm{Z}_\mathrm{Smith\,cloud} \end{matrix} \right)\cdot \end{equation}](/articles/aa/full_html/2017/09/aa30522-17/aa30522-17-eq236.png) (8)In our case the age of the star τ⋆ is 4.5 Gyr for the Sun and 7.1 Gyr for Arcturus, and all other observations are compared to the predictions at the end of the simulation, tp = 13.5 Gyr.
(8)In our case the age of the star τ⋆ is 4.5 Gyr for the Sun and 7.1 Gyr for Arcturus, and all other observations are compared to the predictions at the end of the simulation, tp = 13.5 Gyr. -
4.
The (log) likelihood of the observational constraint given the model predictions
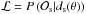 , is also normalized to its maximum value (ℒmax) resulting in the log likelihood being written as
, is also normalized to its maximum value (ℒmax) resulting in the log likelihood being written as 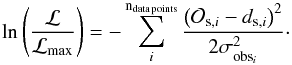 (9)The index i goes over all data points within , each with their associated standard deviation (reported observational error, σobsi). For Sun+ ndata points would be 24, that is, 22 elemental abundances and one data point each for the SN-ratio and the corona metallicity.
(9)The index i goes over all data points within , each with their associated standard deviation (reported observational error, σobsi). For Sun+ ndata points would be 24, that is, 22 elemental abundances and one data point each for the SN-ratio and the corona metallicity. - 5.
The un-normalized log posterior (P), that is, the probability of the parameters given the data
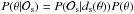 , is then:
, is then: 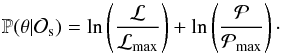 (10)In essence the posterior is a product of normal distributions, with nθ = 7 terms from the prior and ndata points (depending on the set of observations used) terms from the likelihood. For clarification, the log posterior
(10)In essence the posterior is a product of normal distributions, with nθ = 7 terms from the prior and ndata points (depending on the set of observations used) terms from the likelihood. For clarification, the log posterior 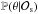 values with these definitions are:
values with these definitions are:
-
0, if parameters are at their peak values (
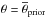 ) and the predictions reproduce the data perfectly (
) and the predictions reproduce the data perfectly (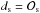 ).
). -
− 0.5 ( − 2, − 4.5, − 8) if only one parameter or one data point would be one (two, three, four) standard deviation (σprior,σobs) away from its maximum value (
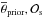 ).
). -
− 0.5 × (n + m) if n parameter and m data points would be one standard deviation away from its default.
-
6.
A single evaluation of the posterior function (oneChempy run) with a specific set of observations,
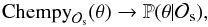 (11)requires a few seconds on a modern CPU. Since we are
interested in the complete posterior PDF of the Chempy parameters, we use MCMC
sampling to approximate it. We employ emcee (Foreman-Mackey et al. 2013), which can easily
parallelize the process. For each MCMC run we initialise 64 walkers in a small cloud
around . In each iteration each walker evaluates the
posterior function at a new position and rejects or accepts it depending on how the
new posterior compares to the posterior of the last accepted evaluation. After a
burn-in phase, the walkers then actually sample the PDF. We check whether the mean
posterior of those walkers converges (which usually happens after 100 burn-in
iterations) and leave the MCMC chain to stabilize for 200 more steps. The parameter
distribution of the 5000 last entries, j, of the flattened MCMC chain,
(11)requires a few seconds on a modern CPU. Since we are
interested in the complete posterior PDF of the Chempy parameters, we use MCMC
sampling to approximate it. We employ emcee (Foreman-Mackey et al. 2013), which can easily
parallelize the process. For each MCMC run we initialise 64 walkers in a small cloud
around . In each iteration each walker evaluates the
posterior function at a new position and rejects or accepts it depending on how the
new posterior compares to the posterior of the last accepted evaluation. After a
burn-in phase, the walkers then actually sample the PDF. We check whether the mean
posterior of those walkers converges (which usually happens after 100 burn-in
iterations) and leave the MCMC chain to stabilize for 200 more steps. The parameter
distribution of the 5000 last entries, j, of the flattened MCMC chain,
 (12)is used as a representation for the posterior PDF over
the parameter space. The hyperparameters λ are now written explicitly, because for each
subset of
(12)is used as a representation for the posterior PDF over
the parameter space. The hyperparameters λ are now written explicitly, because for each
subset of 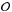 for which we will do our inference, we will also
derive parameter distributions when using Chempy with an alternative set of yields.
for which we will do our inference, we will also
derive parameter distributions when using Chempy with an alternative set of yields. 
Fig. 9 Illustration of model parameter constraints that can be excepted from observational constraints that are like Sun+ (Table 3). We generated Sun+ synthetic data from
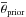 parameters (black triangles) with the default
yield set. We then generated ten realizations of such Sun+-like synthetic data,
with errors σobs, and inferred Chempy
parameter PDFs for each, using the default (green) and the alternative (red)
yield set. The marginalized parameter distributions are plotted on the prior
scale, with the absolute parameter values noted on the left side of each box in
gray. The median and the 15.9 and 84.1 (2.3 and 97.7) PDF percentiles are shown
in solid (transparent) lines for each parameter. The maximum posterior value of
all ten MCMC runs is given in the bottom of the SFE box. The gray area indicates
the limits of the parameter space. This figure illustrates that the Sun+
abundances already provide constraints on αIMF
and log 10(NIa).
parameters (black triangles) with the default
yield set. We then generated ten realizations of such Sun+-like synthetic data,
with errors σobs, and inferred Chempy
parameter PDFs for each, using the default (green) and the alternative (red)
yield set. The marginalized parameter distributions are plotted on the prior
scale, with the absolute parameter values noted on the left side of each box in
gray. The median and the 15.9 and 84.1 (2.3 and 97.7) PDF percentiles are shown
in solid (transparent) lines for each parameter. The maximum posterior value of
all ten MCMC runs is given in the bottom of the SFE box. The gray area indicates
the limits of the parameter space. This figure illustrates that the Sun+
abundances already provide constraints on αIMF
and log 10(NIa).
An example of the posterior PDF for Chempy used with Sun+ as observational constraint and the default yield set, that is, θj(Sun + ,default), can be seen in Fig. 12, together with the prior distribution in dashed lines. One such MCMC run takes approximately one hour on a 64 core machine, which allows us to extensively test our results.
5. Results
We will now present and discuss the inferred Chempy parameters (Table 1), when using Chempy with different subsets of our observations ( 3) and with the two different yield sets (Table 2).
5.1. Test with synthesized observations
We synthesize data for Sun+ observational constraints by taking Chempy’s predictions as observations, assuming the default parameter configuration (see in Table 1). We perturb the predictions by the observational uncertainties, σobs, to obtain mock observations. Then we start a parameter inference (an MCMC run) on these synthetic data and see how well the injected parameters, , can be retrieved and how large the uncertainty is. If we did not perturb the predictions by σobs, the initial parameters would be inferred almost perfectly. By perturbing the predictions by σobs we can estimate the internal error of our method for Sun+ as observational constraint. At the same time we test how well the parameters are inferred when using the alternative yield set on synthesized data produced by the default yield set. In Fig. 9 we show the combined parameter distributions of ten such MCMC inferences (mock data creation and inference is repeated ten times) for each yield set.
Figure 9 shows that the inferred parameter distributions (green crosses) are consistent with the input parameters (black triangles) if we use the default yield set (from which the mock data was synthesized). We can also see how well each parameter is constrained by the few observational constraints, essentially only the Sun’s element abundances, the corona metallicity, and the observed SN-ratio. In units of σprior, the parameters’ PDF variance is only 0.34 for αIMF and NIa, and 0.6 for xout; it is ~0.8 for SFE, SFRpeak, and fcorona, implying that the observational constraints place only weak constraints on those parameters. Only for τIa is there no constraining signal, because Sun+ alone has limited information on the delay time of SN Ia. We also see that the SFRpeak (and to a lesser degree SFE and fcorona) has a distorted distribution. The reason is that the SFR is a highly non-linear function of our SFRpeak parameter by which it is parametrized. The effective change of the SFR is much stronger for lower values of SFRpeak which is why the inferred parameter distribution spreads out to higher values (cf. Fig. 6).
For the alternative yield set (red diamonds) the inference is fairly consistent with small biases for NIa (− 1.2σprior), SFE (+1.5σprior), and SFRpeak (− 1σprior). The uncertainties of the inferred marginalized posterior distribution is very similar except for the SFRpeak, the reason being the non-linearity of this parameter. When looking at the feedback of the two yield sets in Fig. 4, we can qualitatively explain the behavior of inferred NIa. Since the Chieffi & Limongi (2004) CC-SN yields produce more Fe, Chempy decreases the number of SN Ia in order to match the α/Fe abundances. In practice it is much more complicated to establish a causal connection between model assumptions (like the yield) and inferred parameters. It could be that the decreased NIa is just a consequence of the decreased SFRpeak, as both parameters are positively correlated (see Fig. 12). The best (worst) maximum posterior values from ten MCMC inferences are − 5.5 (− 13.7) for the default yield set, and significantly worse, − 34.4 (− 70.4), when using the alternative yield set: the mock data clearly prefer the default yield set, from which they were synthesized.
5.2. Chempy parameters constrained by Sun+
We now proceed to apply Chempy to different subsets of the actual data. In Fig. 10 the inferred parameter distributions are shown when using the following subsets of our observational constraints: SN-ratio together with corona metallicity (4, 5 of Table 3, blue), Sun-only (1, in orange) and Sun+ (1,4,5, in green). The upper (lower) panel shows the results for the default (alternative) yield set.
 |
Fig. 10 As in Fig. 9, Chempy parameter constraints that can be derived from simple observational constraints, but now using real data: the SN ratio in external galaxies and Zcorona (blue, “+”); the Sun’s abundances alone (orange), and Sun+ (green). The top and bottom rows show the results for the default and alternative yield set respectively, as listed in Table 4. |
For Sun+ with the default yield set, the inferred median parameter values are compatible with except for αIMF, NIa, and fcorona where it is ≈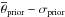 . The achieved precision is remarkable with the number of CC-SN (SN Ia) per 1000 M⊙ being constrained to 6.6 ± 0.7 (0.9 ± 0.2) and similarly the mass fraction of the IMF that is turned into CC-SNe (m> 8 M⊙) being constrained to 10.3% ± 1.2%. We note that both yield sets obtain comparable results (when accounting for the offset already seen in the synthetic data test, cf. Fig. 9).
. The achieved precision is remarkable with the number of CC-SN (SN Ia) per 1000 M⊙ being constrained to 6.6 ± 0.7 (0.9 ± 0.2) and similarly the mass fraction of the IMF that is turned into CC-SNe (m> 8 M⊙) being constrained to 10.3% ± 1.2%. We note that both yield sets obtain comparable results (when accounting for the offset already seen in the synthetic data test, cf. Fig. 9).
 |
Fig. 11 Metallicity distribution function (MDF) of APOGEE RC (Bovy et al. 2014) stars (black) within 1 kpc of the Sun compared to Chempy predictions for the default (green) and alternative yield set (red) with Sun+ as observational constraint. The Chempy ISM abundances were weighted with the corresponding SFR and the RC age distribution to obtain synthetic observations. The APOGEE MDF was not used during the fitting procedure. |
If we only use SN-ratio and corona metallicity as constraints (black triangles), we see that the posterior distribution of the parameters does not depart much from the prior distribution, . A small shift is visible for the corona mass normalization, fcorona, which influences the corona metallicity, and for the high-mass slope of the IMF, αIMF, and the SFRpeak which influence the SN-ratio. The effect of SN-ratio and corona metallicity is small because only two data points (with large uncertainties) are competing with seven parameter priors. Still, when adding these additional constraints to the Sun (i.e., comparing Sun to Sun+), we see that for both yield sets the precision of xout and fcorona increases. At the same time the former increases and the latter decreases by 1σprior.
With respect to our sub-title, it is in particular remarkable that the solar elemental abundances (i.e., the orange marker in Fig. 10) alone put very tight constraints on the high-mass slope of the IMF and the incidence of SN Ia. This means that within our Chempy framework the posterior distributions of these parameters are much narrower than their respective priors. However this comes with the caveat that we have to trust our assumptions, especially the applied yield sets which visibly bias our results (cf. the two panels of Fig. 10).
In Fig. 11 we compare the histograms of predicted MDF of the default (in green) and alternative yield set (in red) with APOGEE red clump (RC) stars (Bovy et al. 2014) from within 1 kpc of the Sun (in black). In order to produce synthetic observations we weight Chempy ISM abundances with the associated SFR and the age distribution of RC stars, as described in Just & Rybizki (2016). Both predicted distributions qualitatively match the local APOGEE RC sample, which peaks around solar metallicity. The default yield set peaks slightly higher and both predicted MDFs peter out later at about − 1 dex, whereas the observations only reach to about − 0.6 dex. As mentioned in Sect. 3.8, we do not believe that there exists a one-to-one mapping between the Chempy solar zone and the solar neighborhood. For example, the low metallicity tail containing old stars could be lost to the present-day solar neighborhood due to dynamical processes.
5.2.1. Parameter correlations
In Fig. 12 the corner plot for the inferred parameter distribution is shown when using Chempy with the default yield set and Sun+ as observational constraint. This allows us to investigate the mechanics of Chempy via parameter correlations.
 |
Fig. 12 Marginalized parameter distribution derived from the Sun+ constraints, in comparison to the prior distribution. Each contour plot in the lower left shows the projected 2D parameter density distribution with 1, 2, and 3σ contours, with individual PDF sample points beyond (Foreman-Mackey 2016). The 3σ ellipse from the prior run is shown in dashed black. The respective correlation coefficients (Pearson’s r) are given at the upper right together with the standard deviation from ten identical inferences. Histograms of the marginalized parameter distributions are given on the diagonal together with the Gaussian distribution of the prior which is shown in dashed black. The median and the 16 and 84 percentiles of each parameter PDF are given above the histogram and indicated as solid and dashed gray lines. |
The strongest correlation (0.73 ± 0.05) is between αIMF and NIa, with more CC-SNe also demanding more SNe Ia in order to get the abundance plateaus of α-elements and iron-peak elements right. Both parameters are also positively correlated with SFRpeak because a later peak of SFR means that more material is turned into low metallicity stars which themselves produce less metals. Likewise, the estimates of the outflow fraction and of the corona mass are anti-correlated with the SFRpeak (− 0.54, − 0.26) because a larger outflow can be compensated by earlier enrichment.
For xout and fcorona only αIMF has a positive correlation (0.27, 0.44) so that more produced metals can be compensated by more outflow and a larger corona mass with which to be mixed, in order to satisfy the solar abundance and the corona metallicity data. The αIMF and the NIa have a small negative correlation with SFE (− 0.29, − 0.37) due to more ISM gas requiring more feedback for the same enrichment. Similarly the SFE is negatively correlated with SFRpeak (− 0.23) and positively correlated with xout (0.28). By re-running our inference ten times we can give standard deviations for the correlation coefficients and at the same time we find that the inferred median parameter values,  , are very stable (to within 0.1σposterior) most likely due to parameter correlations.
, are very stable (to within 0.1σposterior) most likely due to parameter correlations.
5.2.2. Inferred element production by the different nucleosynthetic processes
In order to see the contribution from each nucleosynthetic channel to each element, we have plotted their fractions in Fig. 13 for the default (upper panel) and the alternative (lower panel) yield set (both optimized for Sun+). In the middle panel, the mass fraction of each element’s contribution to the total feedback is shown for the default yield set. Contributions from CC-SNe, SNe Ia, and AGB stars are given in blue, green, and red, respectively. There are 100 transparent lines from the posterior distribution that are plotted, with the most probable posterior fractions shown in the solid line. The fractions when using parameter values are given in black (they should be used to see differences between the two yield sets as the colored lines in the upper and lower panel have parameter changes superimposed onto the change in yield set). Because we marginalize out Chempy parameters we can see a more realistic range of possible fractional element production per nucleosynthetic process than any other study before. Andrews et al. (2017, Fig. 10) describes a nucleosynthetic contribution per element over metallicity, albeit for a single set of (hyper-)parameters.
 |
Fig. 13 Fraction of light elements that are produced by which nucleosynthetic channel when the Chempy parameters are constrained by the Sun+ observations. The fractional yield of CC-SN, SN Ia, and AGB is shown in blue, green, and red, respectively (in solid for the maximum posterior parameters and transparently for 100 results from the converged MCMC). The upper (lower) panel shows the result using the default (alternative) yield set. The bars in the middle panel indicate each element’s contribution to the total net yield (for the maximum posterior of the default yield set, for comparison, the prior feedback contribution is given in black lines but the difference is hardly visible on the log scale). The results from |
 |
Fig. 14 Chempy abundance predictions (for the medians of the marginalized posterior PDFs, |
From Fig. 13 we learn that AGB stars mainly contribute to He, C, N, and F enrichment (if our yield tables are applicable and if we neglect the s-process elements). The contribution to carbon varies strongly between the two yield sets, because of the very high C production from the Chieffi & Limongi (2004) CC-SNe yields (cf. Fig. 4), but is never as low as found in Henry et al. (2000, Fig. 5), who use Maeder (1992) CC-SN and van den Hoek & Groenewegen (1997) AGB yields. Similarly the 90% N contribution from AGB stars in Henry et al. (2000, Fig. 5) is a bit higher than our 75−80% range. Our Chempy modeling also provides theoretical evidence that the main source of cosmic F are AGB stars (cf. Recio-Blanco et al. 2012; Jönsson et al. 2014; Pilachowski & Pace 2015), with minor contributions from CC-SN.
For CC-SNe we see that only O and Mg are the most pure α-elements, in the sense that their feedback comes almost exclusively from CC-SNe. We see that Si, S, Ca, and Ti have a non-negligible contribution from SNe Ia. Of interest is also the fractional contribution of iron-peak elements from SNe Ia. Their Fe contribution ranges from 30 to 50% as in Timmes et al. (1995). The difference is mainly due to lower SN Ia normalization of the alternative yield set, though the difference between the more physically motivated Seitenzahl et al. (2013) versus the older Thielemann et al. (2003) SN Ia yields is also strong. We also see that Mn or Ni are better indicators for SN Ia incidence than Fe.
Overall we find a large uncertainty for each element’s origin: especially for C, V, Cr, Mn, and Ni the fractional contribution differs strongly between the different yield sets. Figure 4 together with Fig. 14 show the potential diagnostic power of Chempy in confronting nucleosynthetic yields and chemical evolution models with observations (cf. Mikolaitis et al. 2017).
5.2.3. Chempy constraints from B-stars+ and Arcturus+
In Fig. 16 the inferred parameter distributions are shown for B-stars+ ({2,4,5} of Table 3, in blue) and Arcturus+ ({3,4,5}, in red) and can be compared to the Sun+ constraints in green. Overall the inferred parameters for default and alternative yield sets for B-stars+ and Arcturus+ are comparable and mostly within 1σprior. Exceptions are the lower SN Ia normalization for Arcturus+ with the default yield set and the longer SN Ia delay for Arcturus+, with the alternative yield set illustrating how Chempy is struggling to fit an α-enhanced star within its physical model. Even though the B-star and Arcturus constraints involve fewer element abundances (i.e., fewer constraining data points), the precision of inferred parameters is comparable to the one from solar abundances, indicating that redundant information is contained in different elements.
The inferred ISM parameters of all three cases show an interesting trend for both yield sets. The SFE is lowest with Arcturus+, higher for B-star+, and highest for the Sun+. The SFRpeak is earlier for Sun+ and later for B-stars+ (Arcturus+ being undecided). The outflow fraction is high for B-star+ and Arcturus+ but low for Sun+. And also the corona normalization is similar for B-stars+ and Arcturus+ and only half as big for Sun+. These differences may be affected by the cross-correlation of parameters (the reaction of the ISM parameters to having different SSP parameters, cf. Fig. 12), but it would also mesh with the commonly invoked narrative:
-
The Sun originated further inside the Galaxy (inner thin disk), where the SFE and the gravitational potential were higher and stars formed earlier than at its present day position.
-
B-stars (i.e., the local ISM) originate at a larger radius, with a later peak in SFR, less retention of feedback material in the ISM, and an overall lower SFE (outer thin disk).
-
Arcturus originated in an environment with many CC-SNe and few SNe Ia, a large outflow and a lowered SFE (thick disk).
5.2.4. How well are stellar abundances reproduced?
In Figure 14 we want to investigate how well Chempy predictions do reproduce the observational constraints. We show the stellar abundance data and predictions coming from the median marginalized parameter values of the posterior PDF, , when optimizing for the respective stellar abundance and the additional observational constraints (i.e., Sun+, B-stars+, Arcturus+) with the default (green lines) and the alternative (red lines) yield set.
Figure 14 shows that many element abundances can be reproduced well, by both yield sets. However, some abundances cannot be explained (within a factor of two) by either the default, or the alternate yield set, even with the fitting flexibility that Chempy otherwise affords. Overall, the maximum obtained posterior is always somewhat better when using the alternative yields, implying that the abundances (together with the SN-ratio and the corona metallicity) are better reproduced. We attribute this to the solar scaled feedback of unprocessed material from Chieffi & Limongi (2004) CC-SNe yields whereas for Nomoto et al. (2013) we use net yields (i.e., the unprocessed feedback is composed of the stellar birth material), though the selection of elements can also change the posterior ranking of the yield tables. Remarkably the best posterior of Arcturus+ is lower than from Sun+ with both yield sets, even though the Arcturus constraints encompass fewer elements. This may be attributable to the formally higher precision of the Arcturus data. But it may also imply that Chempy’s implementation lacks the ability to produce α-enhanced abundance patterns at such late times. Other authors circumvent this by, for example, invoking metallicity dependent SN Ia rates (Kobayashi et al. 2006).
If we perturbed the protosolar abundances by their observational error and calculated the likelihood with itself 105 times, the median and 16 and 84 percentiles of the log likelihood would be 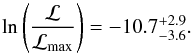 (13)Since our log likelihood with the default yield set is − 104.2 we are far away from reproducing the protosolar abundances precisely (or accurately), even though we marginalize out all Chempy parameters. The range of possible reasons: shortcomings of the yield tables (Rauscher et al. 2016), inaccurately determined abundances (Bergemann et al. 2012), inhomogeneous mixing of the ISM metals (Venn et al. 2012), or nucleosynthetic channels which we have not included, for example, sub-luminous SN Ia (Pakmor et al. 2010), or sub-Chandrasekhar SN Ia (Woosley & Weaver 1994). Additionally Chempy is a very simple model (with its one-zone) and most of the parameters are assumed to be constant over time (xout, αIMF, NIa, SFE). These model assumptions may not be good approximations for the whole Milky Way evolution. Also the functional form of the SFR, the IMF, and the SN Ia DTD are quite restrictive. Nevertheless, we can infer problems with the yield sets from the consistent inability of Chempy to reproduce certain elemental abundances which we will discuss next.
(13)Since our log likelihood with the default yield set is − 104.2 we are far away from reproducing the protosolar abundances precisely (or accurately), even though we marginalize out all Chempy parameters. The range of possible reasons: shortcomings of the yield tables (Rauscher et al. 2016), inaccurately determined abundances (Bergemann et al. 2012), inhomogeneous mixing of the ISM metals (Venn et al. 2012), or nucleosynthetic channels which we have not included, for example, sub-luminous SN Ia (Pakmor et al. 2010), or sub-Chandrasekhar SN Ia (Woosley & Weaver 1994). Additionally Chempy is a very simple model (with its one-zone) and most of the parameters are assumed to be constant over time (xout, αIMF, NIa, SFE). These model assumptions may not be good approximations for the whole Milky Way evolution. Also the functional form of the SFR, the IMF, and the SN Ia DTD are quite restrictive. Nevertheless, we can infer problems with the yield sets from the consistent inability of Chempy to reproduce certain elemental abundances which we will discuss next.
Optimizing the parameters for Sun+ with the default yield set and using the predictions from the median posterior parameter values, the following elements are more than 3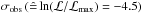 away from the observations and will be given in units of σobs: K (− 7.4), Ti (− 6.7), Si (+ 4.7), Na (+ 4.3), Co (− 4.1), and S (+ 4.0). Looking at Fig. 13, we see that all of those elements are at least produced to 2/3 by CC-SN and all of those except Na have a 1/5 contribution from SN Ia.
away from the observations and will be given in units of σobs: K (− 7.4), Ti (− 6.7), Si (+ 4.7), Na (+ 4.3), Co (− 4.1), and S (+ 4.0). Looking at Fig. 13, we see that all of those elements are at least produced to 2/3 by CC-SN and all of those except Na have a 1/5 contribution from SN Ia.
For the alternative yield set the obtained likelihood is somewhat better (− 81.1 compared to − 104.2). Here the elements with high deviations are: K (− 5.9), Na (+ 4.4), Ti (− 4.4), Ni (+ 4.2), F (− 3.7), V (− 3.3), and N (− 3.2). The contributions to those elements from CC-SNe are significantly higher (except for F) partly due to smaller SN Ia normalization and also due to Chieffi & Limongi (2004) only being implemented as gross yields in Chempy so far, including solar scaled feedback.
We note that Chempy slightly over-predicts O, and Ne for the Sun. These elements are part of the solar abundance problem (Serenelli 2016) and our adopted values (Asplund et al. 2009) are at the lower limit of the debated abundance range (Caffau et al. 2011), meaning that an increase could remedy our over-prediction. Vice versa, Chempy could potentially identify offsets in abundance determination, provided the yield sets were accurate.
In the middle panel of Fig. 14 the same is plotted for B-stars+ (using a smaller set of elements). Again the log likelihood of the default yield set is worse, with Si (+ 4.0) and He (− 4.0) showing the largest deviations. For the alternative yield set only He is off (− 4.5) more than 3σ and otherwise the predictions would be consistent with the B-stars abundances. Interestingly, the He predictions are a bit low for the Sun and strongly under-abundant in B-stars for both yield sets. Again this could be remedied by an increase in the solar He abundance, which would also be more consistent with results from helioseismology (Basu & Antia 2004).
Arcturus+ results are plotted in the lower panel of Fig. 14 (beware that [X/Fe] was used in the likelihood calculation, though [X/H] is depicted here). The alternative yield set gives better results and the deviation from the observations for both yield sets is stronger than for the Sun+ and B-stars+. More than half of the elements are 3σ outliers for both yield sets. For the default yield set the largest deviations come from K (− 11.7), Ti (− 9.0), Na (+ 8.3), V (− 7.9), Co (− 6.6), Cr (+ 4.5), Ni (− 3.9), and Al (− 3.6). For the alternative yield set the outliers are Na (+ 11.6), K (− 9.2), V (− 7.5), Ti (− 6.1), Mg (− 5.4), Cr (+ 4.0), and Mn (+ 3.1).
Since uncertainties of the abundances are expected to be much lower, we attribute the consistent (for both yield sets) under-prediction of K, Ti, and V and the over-prediction of Na to the yield tables. Alternatively it could mean that we are missing a non-negligible nucleosynthetic channel (Mernier et al. 2016). Battistini & Bensby (2015) found for V that it should behave as an SN II-like element, so that the deficiency could be attributed to the Nomoto et al. (2013) CC-SNe yields. As for K, Ventura et al. (2012) speculate that super-AGB stars could be an important source. From Fig. 13 we see that neither of our yield sets has K contribution from AGB stars.
The under abundance of K, Ti, and V is also found in other chemical evolution studies (Goswami & Prantzos 2000; Henry et al. 2010; Kobayashi et al. 2006; Andrews et al. 2017). Similarly, François et al. (2004) found an under abundance of Ti using the Woosley & Weaver (1995) and Iwamoto et al. (1999) yields, though K works for them. Looking at Sukhbold et al. (2016, Fig. 29) K, Ti, and V seem to fit in newer CC-SNe models as well as Na, albeit only for solar metallicity yields.
The maximum of the posterior PDF can be used as an indicator of which yield set best reproduces observations. This could help to discriminate between different nucleosynthetic feedback models and could also be used to infer empirical yields sets.
5.3. Multi-zone scheme
The advent of big spectroscopic surveys, eventually providing the abundances for millions of stars, in principle holds the key to constrain all parameters involved in the chemical enrichment. Yet matching the abundances of stars across the Milky Way with a single one-zone model must be a poor model approximation. This limitation already manifests itself in the MCMC runs where we put all three stars in the same zone (mutual single-zone run, cyan in Fig. 16). We see that the best achieved posteriors for both yield sets are much worse than if we just added the posteriors of the individual runs. The retrieved parameters depart strongly from illustrating the tension arising from the assumption that the Sun’s and Arcturus’s abundance patterns were produced in the same chemical enrichment zone. Also for the default yield set, the MCMC only finds a pathological parameter configuration, where the SFR ceases after ~8 Gyr and the α-enhancement decreases due to a few remaining SNe Ia (see solid cyan line Fig. 17).
We explore one obvious step to overcome this unrealistic assumption by generalizing Chempy to a multi-zone model, as depicted in Fig. 15. We run three Chempy models simultaneously, one for each star, where we require that all three zones share the same SSP parameters (i.e., share the same global stellar physics, cf. Table 1) but each zone can have their individual ISM parameters (i.e., their own local ISM history). Then we add up their log likelihoods and sample their common posterior PDF over the increased parameter space (2 × NθISM = 8 additional parameters)3.
 |
Fig. 15 Multi-zone scheme to use constraints from multiple stars. |
In Fig. 16 we show results from the multi-zone scheme in magenta using Sun+, Arcturus+, and B-stars+ simultaneously as observational constraint. We find that the (joint) SSP parameters αIMF and NIa are tightly constrained and consistent with the single-zone runs: we get 7.0 ± 0.5 (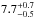 ) CC-SNe and 1.0 ± 0.4 (
) CC-SNe and 1.0 ± 0.4 (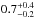 ) SNe Ia per 1000 M⊙ for the default (alternative) yield set; for our IMF that means
) SNe Ia per 1000 M⊙ for the default (alternative) yield set; for our IMF that means 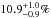 (
(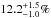 ) of the mass fraction will explode as CC-SNe for the default (alternative) yield set (cf. Fig. 2).
) of the mass fraction will explode as CC-SNe for the default (alternative) yield set (cf. Fig. 2).
The SN Ia time delay departs from demanding an implausibly long delay of 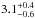 Gyr (
Gyr (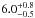 Gyr) for the default (alternative) yield set. This shows that it is hard to reconcile the three abundance patterns within the physics and parametrization of Chempy. Either the SN Ia rate (Kobayashi et al. 2006) or the IMF need to become metallicity dependent. Alternatively the delay time distribution could be improved by using a more realistic functional form (Matteucci & Recchi 2001) and more SN Ia channels (Ruiter et al. 2009), though many more stars with different ages will be needed to reliably constrain the additional free parameters.
Gyr) for the default (alternative) yield set. This shows that it is hard to reconcile the three abundance patterns within the physics and parametrization of Chempy. Either the SN Ia rate (Kobayashi et al. 2006) or the IMF need to become metallicity dependent. Alternatively the delay time distribution could be improved by using a more realistic functional form (Matteucci & Recchi 2001) and more SN Ia channels (Ruiter et al. 2009), though many more stars with different ages will be needed to reliably constrain the additional free parameters.
Remarkably, our multi-zone inference based on either yield set has consistent, within 1σposterior, results for all parameters, except for τIa and Arcturus’ fcorona. The resulting ISM parameters still support the idea of the three stellar abundances stemming from a different birth environment, that is, inner thin disk, outer thin disk, and thick disk (albeit for Arcturus+ xout and fcorona the trend no longer holds, probably due to correlations stemming from the changed SSP parameters).
In order to compare Chempy predictions to observations in Fig. 17 we plot the multi-zone (upper panels) and the single-zone (lower panels) predictions together with our constraining data in the [Mg/Fe] versus [Fe/H] plane (left panels). We show the same in the [Mg/Fe] versus time plane (right panels) and in both cases we add independent observation of ~20 000 APOGEE giant stars (Ness et al. 2016) to guide the eye.
 |
Fig. 16 Comparison of the inferred model parameters (PDFs) when fitting the three sets of observational constraints separately (Sun+, B-star+, Arcturus+), to the case when these constraints are fit simultaneously. For fitting the constraints simultaneously, we consider two regimes: first fitting a single-zone model, that is, a single set of SSP and ISM parameters (cyan); or fitting a multi-zone model, where there is a single set of stellar physics parameters, but Sun+, B-stars+, and Arcturus+ each (can) have their own ISM pre-history (magenta). For the SN Ia delay parameter some results are outside of the plotted 3σprior range but their values are given and can also be checked in Table 4. |
 |
Fig. 17 Tracks of the ISM abundances evolution implied by the Chempy fits, represented by a track in the [Mg/Fe]–[Fe/H] (left) and the [Mg/Fe]–time (right) panels. Shown are the predictions for the median inferred parameters |
We see that Chempy is flexible enough to more or less fulfill the observational constraints, which actually happens in the time domain (right panels). Chempy’s strong sensitivity to the SSP parameters (as evident from their small σposterior/σprior compared to the ISM parameters) manifests in the similarity of the chemical enrichment patterns for the multi-zone approach. There the differences between the individual zones can to first order be explained by the different timing set by the (also quite sensitive) SFRpeak parameter. In both yield sets, the plateau ends with the onset of the SNe Ia (≈3 Gyr for the default and ≈6 Gyr for the alternative yield set), which are mostly prompt for the single-zone runs.
For the single-zone cases the evolutionary tracks look consistent with the behavior of the APOGEE data. Even the cyan tracks, which incorporate Sun+, B-star, and Arcturus, fit well, but the overall fit of this mutual single-zone to the other elements is much worse as apparent from the best posterior values. Naturally, the multi-zone case scores better when fitting all three abundance patterns simultaneously, albeit the solar zone gets too metal-rich and too [Mg/Fe] poor. Additionally the track of the solar zones take an alpha-enhanced route in the [Mg/Fe] vs. [Fe/H] plane, though this picture changes in the [Mg/Fe] versus time plane where the solar zones decrease α-enhancement faster than the other zones. This points to the solar zone being produced in an inner disk environment (Wielen et al. 1996).
Similarly, while we see an increase of Mg in the [Mg/Fe] versus [Fe/H] plane for the APOGEE data, this does not hold when plotting in the [Mg/Fe] versus time plane. This strongly points towards radial migration bringing old [Mg/Fe] and [Fe/H]-rich stars from the inner disk into the APOGEE sample. We learn that when using only chemical evolution modeling we must carefully deconvolve the elemental abundance data from kinematic biases (e.g., Minchev et al. 2013).
6. Summary and conclusion
In this paper, we have presented and applied a new modeling tool for galactic chemical evolution studies, Chempy. In its basic version, Chempy is a conventional chemical evolution model: a single-zone open box. Its new and innovative aspects are centered around efficient Bayesian inference of the model parameters, accounting for a wide range of prior constraints and observations at hand. Chempy can also be generalized to a multi-zone model, combining universal stellar physics with local and diverse ISM histories. There is a need for such modeling tools if we are to systematically exploit the ever-growing number of stars with elemental abundance measurements in order to trace, and ultimately understand, the chemical evolution of galactic systems.
To illustrate the capabilities of Chempy, we used a very limited set of high-quality observational constraints: the element abundances of Sun, Arcturus, and the local, present-day ISM, traced by B-stars. We augmented these Galactic constraints with broader galaxy population inferences about present-day L⋆ galaxies: their relative incidence of different supernova types and the typical metallicity of their gaseous corona. Using Chempy we could then show that these data alone already constrain strongly some of fundamental parameters in the Milky Way’s chemical evolution. With respect to the question from the sub-title, even the Sun’s abundances and its age already precisely determine the IMF and the incidence of SN Ia (as can be seen from Fig. 10).
In practice, we derive these constraints by placing Chempy observational predictions into a Bayesian framework, where we marginalize out the model parameters using sampling techniques. We concentrate on three parameters governing the SSP physics (high-mass slope of the IMF, SN Ia normalization, and time delay) and four parameters determining the ISM environment (SFE, peak of the SFR, outflow fraction, and corona mass), though the method can be easily expanded to constrain more parameters.
We extensively test input and modeling restrictions that inevitably affect any such modeling, putting a special focus on Chempy’s most important hyperparameter: the yield sets, which translate the chemical evolution prescription of Chempy into elemental abundance predictions. We implement two different yield sets, consisting of up-to-date yields for the three nucleosynthetic channels: CC-SNe, SNe Ia, and AGB-winds. Even though the predicted abundance patterns are different for the two yield sets, the retrieved chemical evolution parameters are comparable. However, there are persistent discrepancies between the predicted and observed abundances for a number of elements: for example, we find that K, Ti, and V are under-abundant and that Na is over-abundant, irrespective of the chosen yield set and the data sets we try to reproduce. This could hint at a missing nucleosynthetic process (Mernier et al. 2016), or simply reflect shortcomings of the existing yield tables; or it could imply that the net yields are not homogeneously mixed into the ISM. Chempy can also rank different yield tables by their ability to reproduce elemental abundance data. If the abundances of many stars are used simultaneously, this could be extended to infer yield uncertainty parameters for each element or even to produce metallicity and mass dependent empirical yields.
The basic version of Chempy can be straightforwardly extended to a multi-zone scheme, where different single-zones share the same SSP physics, but can have separate ISM evolution. We apply this scheme to our set of three stellar abundances and retrieve extremely well-constrained SSP parameters (which we had presumed here to be universal within the Milky Way), together with parameters describing the ISM histories for each star(s): this application of Chempy implies – unsurprisingly – that the Sun, B-stars, and Arcturus have been experiencing diverse enrichment histories; one might be tempted to associate these with the inner thin disk, outer thin disk, and thick disk, respectively.
With this multi-zone scheme we are, for the first time, able to precisely constrain the IMF high-mass slope from chemical evolution modeling, while properly marginalizing over nuisance parameters and covariances, and accounting for the systematic effects of yield tables. The resulting value and achieved precision of 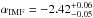 (common uncertainty range of both yield sets) are compatible with the most recent star count analysis in M31 by Weisz et al. (2015), though we rely on much less data (essentially a few elemental abundances of only three stars), showing the power of the Chempy approach.
(common uncertainty range of both yield sets) are compatible with the most recent star count analysis in M31 by Weisz et al. (2015), though we rely on much less data (essentially a few elemental abundances of only three stars), showing the power of the Chempy approach.
Our αIMF matches the Kroupa et al. (1993) IMF for the low mass stars (cf. Fig. 2) and translates to an IMF mass fraction exploding as CC-SNe (i.e., being heavier than 8 M⊙) of 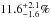 compatible with
compatible with 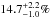 (Weisz et al. 2015) and 12.1% (Salpeter 1955). This rules out very steep high-mass slopes (Czekaj et al. 2014; Rybizki & Just 2015) as well as very shallow ones like the often-used Chabrier (2003).
(Weisz et al. 2015) and 12.1% (Salpeter 1955). This rules out very steep high-mass slopes (Czekaj et al. 2014; Rybizki & Just 2015) as well as very shallow ones like the often-used Chabrier (2003).
The SN Ia normalization from both yield sets ranges from 0.5 to 1.4 events per 1000 M⊙, which is compatible, but more precise, than the meta-analysis of Côté et al. (2016a, Table 7). The delay time deviates strongly from the prior and turns out very long (3−6 Gyr), which is the only sensible way within Chempy’s physical framework to conciliate the α-low and α-rich abundances. In our particular case, this implication may be driven by the strong α-enhancement of Arcturus, despite that fact that it is only ~7 Gyr old. But this may also point towards the necessity to include new physics, for example, more types of SNe (Pakmor et al. 2010).
On the path to fully exploit the chemical imprint of stellar abundance data from large spectroscopic surveys, the nucleosynthetic yields will have to be updated and uncertainties added to them, a good start being Rauscher et al. (2016). Another step will be to take dynamical parameters of the stars into account and understand the age uncertainty, though a statistical age distribution of stellar populations (Just & Rybizki 2016) can be utilized as well. The code is publicly available and the IMF weighted yield output over time (SSP feedback) can be plugged into n-body simulations to use a flexible stellar feedback model. Furthermore, new yield tables can be tested quickly and the author is readily available when help with yield-table implementation is needed.
Additional yield tables implemented in Chempy are: Portinari et al. (1998, gross), Pignatari et al. (2016, gross) for CC-SNe, Iwamoto et al. (1999) for SN Ia and Pignatari et al. (2016, gross, only provide solar and half solar metallicity, which is not enough for our simulation), Karakas (2010, gross), Karakas & Lugaro (2016, net) for AGB stars.
This is of course an arbitrary choice and biases our results (though the bias is small because we use many elements). Conceptually, it would seem attractive to include all available elements but that would require us to model the effects of changing photospheric elemental abundances and we would need to include all nucleosynthetic channels and have uncertainties on the yield tables as well.
Acknowledgments
We would like to thank the anonymous referee for a thorough reading of the manuscript and many useful comments. The authors would also like to thank David Hogg, Coryn Bailer-Jones, Morgan Fouesneau, Melissa Ness, Fritz Röpcke, Robert Grand, Greg Stinson, Ivo Seitenzahl, and Sam Jones for helpful discussions and valuable feedback on the topic. J.R. was partly supported by the DFG Research Centre SFB 881 “The Milky Way System” through project A6. During part of this work J.R. was a fellow of the International Max Planck Research School for Astronomy and Cosmic Physics at the University of Heidelberg (IMPRS-HD). H.W.R. and J.R. acknowledge funding from the European Research Council under the European Union’s Seventh Framework Programme (FP 7) ERC Advanced Grant Agreement No. [321035]. H.W.R. acknowledges support of the Miller Institute at UC Berkeley through a visiting professorship during part of this work.
References
- Andrews, B. H., Weinberg, D. H., Schönrich, R., & Johnson, J. A. 2017, ApJ, 835, 224 [NASA ADS] [CrossRef] [Google Scholar]
- Argast, D., Samland, M., Gerhard, O. E., & Thielemann, F.-K. 2000, A&A, 356, 873 [NASA ADS] [Google Scholar]
- Argast, D., Samland, M., Thielemann, F.-K., & Gerhard, O. E. 2002, A&A, 388, 842 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Asplund, M., Grevesse, N., Sauval, A. J., & Scott, P. 2009, ARA&A, 47, 481 [NASA ADS] [CrossRef] [Google Scholar]
- Baade, W. 1944, ApJ, 100, 137 [NASA ADS] [CrossRef] [Google Scholar]
- Basu, S., & Antia, H. M. 2004, ApJ, 606, L85 [NASA ADS] [CrossRef] [Google Scholar]
- Battistini, C., & Bensby, T. 2015, A&A, 577, A9 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bergemann, M., Lind, K., Collet, R., Magic, Z., & Asplund, M. 2012, MNRAS, 427, 27 [NASA ADS] [CrossRef] [Google Scholar]
- Bigiel, F., Leroy, A., Walter, F., et al. 2008, AJ, 136, 2846 [NASA ADS] [CrossRef] [Google Scholar]
- Bovy, J., Nidever, D. L., Rix, H.-W., et al. 2014, ApJ, 790, 127 [NASA ADS] [CrossRef] [Google Scholar]
- Caffau, E., Ludwig, H.-G., Steffen, M., Freytag, B., & Bonifacio, P. 2011, Sol. Phys., 268, 255 [NASA ADS] [CrossRef] [Google Scholar]
- Chabrier, G. 2001, ApJ, 554, 1274 [NASA ADS] [CrossRef] [Google Scholar]
- Chabrier, G. 2003, PASP, 115, 763 [NASA ADS] [CrossRef] [Google Scholar]
- Chiappini, C., Matteucci, F., & Gratton, R. 1997, ApJ, 477, 765 [NASA ADS] [CrossRef] [Google Scholar]
- Chiappini, C., Matteucci, F., & Romano, D. 2001, ApJ, 554, 1044 [NASA ADS] [CrossRef] [Google Scholar]
- Chieffi, A., & Limongi, M. 2004, ApJ, 608, 405 [NASA ADS] [CrossRef] [Google Scholar]
- Côté, B., Ritter, C., O’Shea, B. W., et al. 2016a, ApJ, 824, 82 [NASA ADS] [CrossRef] [Google Scholar]
- Côté, B., West, C., Heger, A., et al. 2016b, MNRAS, 463, 3755 [NASA ADS] [CrossRef] [Google Scholar]
- Côté, B., O’Shea, B. W., Ritter, C., Herwig, F., & Venn, K. A. 2017, ApJ, 835, 128 [NASA ADS] [CrossRef] [Google Scholar]
- Czekaj, M. A., Robin, A. C., Figueras, F., Luri, X., & Haywood, M. 2014, A&A, 564, A102 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dziembowski, W. A., Fiorentini, G., Ricci, B., & Sienkiewicz, R. 1999, A&A, 343, 990 [NASA ADS] [Google Scholar]
- Feuillet, D. K., Bovy, J., Holtzman, J., et al. 2016, ApJ, 817, 40 [NASA ADS] [CrossRef] [Google Scholar]
- Few, C. G., Courty, S., Gibson, B. K., et al. 2012, MNRAS, 424, L11 [NASA ADS] [CrossRef] [Google Scholar]
- Fink, M., Kromer, M., Seitenzahl, I. R., et al. 2014, MNRAS, 438, 1762 [NASA ADS] [CrossRef] [Google Scholar]
- Foreman-Mackey, D. 2016, The Journal of Open Source Software, 24 [Google Scholar]
- Foreman-Mackey, D., Hogg, D. W., Lang, D., & Goodman, J. 2013, PASP, 125, 306 [CrossRef] [Google Scholar]
- Fox, A. J., Lehner, N., Lockman, F. J., et al. 2016, ApJ, 816, L11 [NASA ADS] [CrossRef] [Google Scholar]
- François, P., Matteucci, F., Cayrel, R., et al. 2004, A&A, 421, 613 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Goswami, A., & Prantzos, N. 2000, A&A, 359, 191 [NASA ADS] [Google Scholar]
- Grand, R. J. J., Kawata, D., & Cropper, M. 2015, MNRAS, 447, 4018 [NASA ADS] [CrossRef] [Google Scholar]
- Henry, R. B. C., Edmunds, M. G., & Köppen, J. 2000, ApJ, 541, 660 [NASA ADS] [CrossRef] [Google Scholar]
- Henry, R. B. C., Cowan, J. J., & Sobeck, J. 2010, ApJ, 709, 715 [NASA ADS] [CrossRef] [Google Scholar]
- Iben, Jr., I. 1965, ApJ, 142, 1447 [NASA ADS] [CrossRef] [Google Scholar]
- Iwamoto, K., Brachwitz, F., Nomoto, K., et al. 1999, ApJS, 125, 439 [NASA ADS] [CrossRef] [MathSciNet] [Google Scholar]
- Jiménez, N., Tissera, P. B., & Matteucci, F. 2015, ApJ, 810, 137 [NASA ADS] [CrossRef] [Google Scholar]
- Jofre, P., Heiter, U., Worley, C. C., et al. 2017, A&A, 601, A38 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Jönsson, H., Ryde, N., Harper, G. M., Richter, M. J., & Hinkle, K. H. 2014, ApJ, 789, L41 [NASA ADS] [CrossRef] [Google Scholar]
- Just, A., & Rybizki, J. 2016, Astron. Nachr., 337, 880 [NASA ADS] [CrossRef] [Google Scholar]
- Karakas, A. I. 2010, MNRAS, 403, 1413 [NASA ADS] [CrossRef] [Google Scholar]
- Karakas, A. I., & Lugaro, M. 2016, ApJ, 825, 26 [NASA ADS] [CrossRef] [Google Scholar]
- Kobayashi, C., Umeda, H., Nomoto, K., Tominaga, N., & Ohkubo, T. 2006, ApJ, 653, 1145 [NASA ADS] [CrossRef] [Google Scholar]
- Kroupa, P., Tout, C. A., & Gilmore, G. 1993, MNRAS, 262, 545 [NASA ADS] [CrossRef] [Google Scholar]
- Kubryk, M., Prantzos, N., & Athanassoula, E. 2015, A&A, 580, A126 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lawler, M. E., Brownlee, D. E., Temple, S., & Wheelock, M. M. 1989, Icarus, 80, 225 [NASA ADS] [CrossRef] [Google Scholar]
- Lodders, K., Palme, H., & Gail, H.-P. 2009, Landolt Börnstein, 4B [Google Scholar]
- Maeder, A. 1992, A&A, 264, 105 [NASA ADS] [Google Scholar]
- Majewski, S. R., APOGEE Team, & APOGEE-2 Team 2016, Astron. Nachr., 337, 863 [NASA ADS] [CrossRef] [Google Scholar]
- Mannucci, F., Della Valle, M., Panagia, N., et al. 2005, A&A, 433, 807 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Maoz, D., & Mannucci, F. 2012, PASA, 29, 447 [NASA ADS] [CrossRef] [Google Scholar]
- Maoz, D., Sharon, K., & Gal-Yam, A. 2010, ApJ, 722, 1879 [Google Scholar]
- Maoz, D., Mannucci, F., & Brandt, T. D. 2012, MNRAS, 426, 3282 [NASA ADS] [CrossRef] [Google Scholar]
- Martig, M., Fouesneau, M., Rix, H.-W., et al. 2016, MNRAS, 456, 3655 [NASA ADS] [CrossRef] [Google Scholar]
- Matteucci, F. 2003, The Chemical Evolution of the Galaxy (Dordrecht: Kluwer Academic Publishers), Astrophys. Space Sci. Lib., 253 [Google Scholar]
- Matteucci, F. 2012, Chemical Evolution of Galaxies, Astronomy and Astrophysics Library (Berlin, Heidelberg: Springer-Verlag) [Google Scholar]
- Matteucci, F., & Recchi, S. 2001, ApJ, 558, 351 [NASA ADS] [CrossRef] [Google Scholar]
- McDonough, W. F. 1995, in Lunar and Planetary Science Conference, 26 [Google Scholar]
- Mernier, F., de Plaa, J., Pinto, C., et al. 2016, A&A, 592, A157 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mikolaitis, Š., de Laverny, P., Recio-Blanco, A., et al. 2017, A&A, 600, A22 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Minchev, I., Chiappini, C., & Martig, M. 2013, A&A, 558, A9 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Müller, B. 2016, PASA, 33, e048 [NASA ADS] [CrossRef] [Google Scholar]
- Ness, M., Hogg, D. W., Rix, H.-W., et al. 2016, ApJ, 823, 114 [NASA ADS] [CrossRef] [Google Scholar]
- Nieva, M.-F., & Przybilla, N. 2012, A&A, 539, A143 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Nomoto, K., Kobayashi, C., & Tominaga, N. 2013, ARA&A, 51, 457 [NASA ADS] [CrossRef] [Google Scholar]
- Pakmor, R., Kromer, M., Röpke, F. K., et al. 2010, Nature, 463, 61 [NASA ADS] [CrossRef] [PubMed] [Google Scholar]
- Pignatari, M., Herwig, F., Hirschi, R., et al. 2016, ApJS, 225, 24 [Google Scholar]
- Pilachowski, C. A., & Pace, C. 2015, AJ, 150, 66 [NASA ADS] [CrossRef] [Google Scholar]
- Portinari, L., Chiosi, C., & Bressan, A. 1998, A&A, 334, 505 [NASA ADS] [Google Scholar]
- Ramírez, I., & Allen de Prieto, C. 2011, ApJ, 743, 135 [NASA ADS] [CrossRef] [Google Scholar]
- Rauscher, T., Nishimura, N., Hirschi, R., et al. 2016, MNRAS, 463, 4153 [NASA ADS] [CrossRef] [Google Scholar]
- Recio-Blanco, A., de Laverny, P., Worley, C., et al. 2012, A&A, 538, A117 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Reeves, H. 1970, Nature, 226, 727 [NASA ADS] [CrossRef] [PubMed] [Google Scholar]
- Romano, D., Matteucci, F., Molaro, P., & Bonifacio, P. 1999, A&A, 352, 117 [NASA ADS] [Google Scholar]
- Romano, D., Karakas, A. I., Tosi, M., & Matteucci, F. 2010, A&A, 522, A32 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ruiter, A. J., Belczynski, K., & Fryer, C. 2009, ApJ, 699, 2026 [NASA ADS] [CrossRef] [Google Scholar]
- Rybizki, J., & Just, A. 2015, MNRAS, 447, 3880 [NASA ADS] [CrossRef] [Google Scholar]
- Salpeter, E. E. 1955, ApJ, 121, 161 [Google Scholar]
- Schmidt, M. 1959, ApJ, 129, 243 [NASA ADS] [CrossRef] [Google Scholar]
- Schönrich, R., & Binney, J. 2009, MNRAS, 396, 203 [NASA ADS] [CrossRef] [Google Scholar]
- SDSS Collaboration, Albareti, F. D., Allende Prieto, C., et al. 2016, ApJ, submitted [arXiv:1608.02013] [Google Scholar]
- Seitenzahl, I. R., Ciaraldi-Schoolmann, F., Röpke, F. K., et al. 2013, MNRAS, 429, 1156 [Google Scholar]
- Serenelli, A. 2016, Eur. Phys. J. A, 52, 78 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sim, S. A., Seitenzahl, I. R., Kromer, M., et al. 2013, MNRAS, 436, 333 [NASA ADS] [CrossRef] [Google Scholar]
- Smith, G. P. 1963, Bull. Astron. Inst. Netherlands, 17, 203 [NASA ADS] [Google Scholar]
- Snaith, O. N., Haywood, M., Di Matteo, P., et al. 2014, ApJ, 781, L31 [CrossRef] [Google Scholar]
- Spitoni, E., Vincenzo, F., & Matteucci, F. 2017, A&A, 599, A6 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Steffen, M., Prakapavičius, D., Caffau, E., et al. 2015, A&A, 583, A57 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Stern, J., Hennawi, J. F., Prochaska, J. X., & Werk, J. K. 2016, ApJ, 830, 87 [NASA ADS] [CrossRef] [Google Scholar]
- Stinson, G., Seth, A., Katz, N., et al. 2006, MNRAS, 373, 1074 [NASA ADS] [CrossRef] [Google Scholar]
- Sukhbold, T., Ertl, T., Woosley, S. E., Brown, J. M., & Janka, H.-T. 2016, ApJ, 821, 38 [Google Scholar]
- Thielemann, F.-K., Argast, D., Brachwitz, F., et al. 2003, Nucl. Phys. A, 718, 139 [NASA ADS] [CrossRef] [Google Scholar]
- Timmes, F. X., Woosley, S. E., & Weaver, T. A. 1995, ApJS, 98, 617 [NASA ADS] [CrossRef] [Google Scholar]
- Tinsley, B. M. 1979, ApJ, 229, 1046 [NASA ADS] [CrossRef] [Google Scholar]
- Tinsley, B. M. 1980, Fund. Cosmic Phys., 5, 287 [Google Scholar]
- Turcotte, S., & Wimmer-Schweingruber, R. F. 2002, J. Geophys. Res. (Space Phys.), 107, 1442 [NASA ADS] [CrossRef] [Google Scholar]
- Valls-Gabaud, D. 2014, EAS Pub. Ser., 65, 225 [Google Scholar]
- van den Hoek, L. B., & Groenewegen, M. A. T. 1997, A&AS, 123 [Google Scholar]
- van der Walt, S., Colbert, C., & Varoquaux, G. 2011, Comput. Sci. Engin., 13, 22 [Google Scholar]
- van Dokkum, P. G., Leja, J., Nelson, E. J., et al. 2013, ApJ, 771, L35 [NASA ADS] [CrossRef] [Google Scholar]
- Venn, K. A., Shetrone, M. D., Irwin, M. J., et al. 2012, ApJ, 751, 102 [NASA ADS] [CrossRef] [Google Scholar]
- Ventura, P., D’Antona, F., Di Criscienzo, M., et al. 2012, ApJ, 761, L30 [NASA ADS] [CrossRef] [Google Scholar]
- Ventura, P., Di Criscienzo, M., Carini, R., & D’Antona, F. 2013, MNRAS, 431, 3642 [NASA ADS] [CrossRef] [Google Scholar]
- Vincenzo, F., Matteucci, F., & Spitoni, E. 2017, MNRAS, 466, 2939 [NASA ADS] [CrossRef] [Google Scholar]
- Wallerstein, G. 1962, ApJS, 6, 407 [NASA ADS] [CrossRef] [Google Scholar]
- Weinberg, D. H., Andrews, B. H., & Freudenburg, J. 2017, ApJS, 837, 183 [NASA ADS] [CrossRef] [Google Scholar]
- Weisz, D. R., Johnson, L. C., Foreman-Mackey, D., et al. 2015, ApJ, 806, 198 [NASA ADS] [CrossRef] [Google Scholar]
- Werk, J. K., Prochaska, J. X., Tumlinson, J., et al. 2014, ApJ, 792, 8 [NASA ADS] [CrossRef] [Google Scholar]
- Wielen, R., Fuchs, B., & Dettbarn, C. 1996, A&A, 314, 438 [NASA ADS] [Google Scholar]
- Woosley, S. E., & Weaver, T. A. 1994, ApJ, 423, 371 [NASA ADS] [CrossRef] [Google Scholar]
- Woosley, S. E., & Weaver, T. A. 1995, ApJS, 101, 181 [NASA ADS] [CrossRef] [Google Scholar]
All Tables
Inferred parameters (16, 50, 84 percentiles of θposterior), for different observational subsets (), and different yield sets (default, alternative).
All Figures
|
Fig. 1 Schematic summary of Chempy: the left portion of this figure illustrates the sampling of the model parameter posteriors within the Bayesian framework (see Sect. 4); the right hand portion sketches how Chempy calculates a “system state”, for any one set of (hyper-)parameters, which produces observable predictions: (1) for a chosen set of parameters, θ, Chempy calculates the system state from initial conditions for all time steps (2, cf. Fig. 5), resulting in the observational predictions (3). These predictions are then compared to a predefined subset of our observations (see Table 3); here τ⋆ is the age of the tracers, whose abundance measurements we fit. In our sample application, this is the age of the Sun or Arcturus. We can now calculate the likelihood (4) of any set of observations ( |
| In the text | |
|
Fig. 2 Illustrating the first free parameter (θ1 = αIMF), the high-mass slope of the IMF. Showing the number of stars per mass interval. We use a Chabrier (2001, Table 1, IMF 3) functional form as in Eq. (1) with αIMF = − 2.29 as |
| In the text | |
|
Fig. 3 Impact of the model parameters θ2,3 = NIa,τIa, the SN Ia normalization, and the SN Ia delay time. We show the distribution functions of SN Ia explosions for an SSP of 1 M⊙ using a Maoz et al. (2010) functional form with a mass normalization of NIa = 0.00178 and a time-delay of τIa ≈ 160 Myr. We show ± 2σprior variations from |
| In the text | |
|
Fig. 4 Cumulative net yield in M⊙ for C, N, O and Fe over time for an SSP of 1 M⊙ and solar metallicity Z⊙, using Chempy’s |
| In the text | |
|
Fig. 5 Chempy (one-zone, open-box) mass flow of one time step t → t + Δt, illustrating how Chempy is integrating over time from the initial system state, Sθ(t = 0) (see Fig. 1). Each box represents a subsystem with its current state and the changes to the next time step. The numbered arrows show the sequence of Chempy time integration and the mathematical prescriptions with their parameter dependence. The quantities characterizing the resulting CSP (see Sect. 2.1) are given in gray. The chemical composition [X/H] of each subsystem is tracked. Initial conditions are: no stars, no ISM gas, and |
| In the text | |
|
Fig. 6 Model parameter θ5 = SFRpeak, the epoch of the peak of the star formation rate (SFR), shown here in arbitrary units. As functional form for the SFR, we use the gamma distribution with k = 2 (see Eq. (2)). Variations in the epoch of peak star formation of ± 1,2σprior from |
| In the text | |
|
Fig. 7 Illustration of how the gas infall and the gas masses (of ISM and corona) are governed by the model parameter “star formation efficiency”, θ4 = SFE. The upper panel shows the infall over time for |
| In the text | |
|
Fig. 8 Illustration of impact of model parameters θ6,7 = xout,fcorona, the mass loading or outflow fraction and the corona mass factor on the ISM metallicity. The resulting metallicity of ISM gas (upper panel) and corona gas (lower panel) is shown over time assuming the default yields. The results for |
| In the text | |
|
Fig. 9 Illustration of model parameter constraints that can be excepted from
observational constraints that are like Sun+ (Table 3). We generated Sun+ synthetic data from |
| In the text | |
|
Fig. 10 As in Fig. 9, Chempy parameter constraints that can be derived from simple observational constraints, but now using real data: the SN ratio in external galaxies and Zcorona (blue, “+”); the Sun’s abundances alone (orange), and Sun+ (green). The top and bottom rows show the results for the default and alternative yield set respectively, as listed in Table 4. |
| In the text | |
|
Fig. 11 Metallicity distribution function (MDF) of APOGEE RC (Bovy et al. 2014) stars (black) within 1 kpc of the Sun compared to Chempy predictions for the default (green) and alternative yield set (red) with Sun+ as observational constraint. The Chempy ISM abundances were weighted with the corresponding SFR and the RC age distribution to obtain synthetic observations. The APOGEE MDF was not used during the fitting procedure. |
| In the text | |
|
Fig. 12 Marginalized parameter distribution derived from the Sun+ constraints, in comparison to the prior distribution. Each contour plot in the lower left shows the projected 2D parameter density distribution with 1, 2, and 3σ contours, with individual PDF sample points beyond (Foreman-Mackey 2016). The 3σ ellipse from the prior run is shown in dashed black. The respective correlation coefficients (Pearson’s r) are given at the upper right together with the standard deviation from ten identical inferences. Histograms of the marginalized parameter distributions are given on the diagonal together with the Gaussian distribution of the prior which is shown in dashed black. The median and the 16 and 84 percentiles of each parameter PDF are given above the histogram and indicated as solid and dashed gray lines. |
| In the text | |
|
Fig. 13 Fraction of light elements that are produced by which nucleosynthetic channel when the Chempy parameters are constrained by the Sun+ observations. The fractional yield of CC-SN, SN Ia, and AGB is shown in blue, green, and red, respectively (in solid for the maximum posterior parameters and transparently for 100 results from the converged MCMC). The upper (lower) panel shows the result using the default (alternative) yield set. The bars in the middle panel indicate each element’s contribution to the total net yield (for the maximum posterior of the default yield set, for comparison, the prior feedback contribution is given in black lines but the difference is hardly visible on the log scale). The results from |
| In the text | |
|
Fig. 14 Chempy abundance predictions (for the medians of the marginalized posterior PDFs, |
| In the text | |
|
Fig. 15 Multi-zone scheme to use constraints from multiple stars. |
| In the text | |
|
Fig. 16 Comparison of the inferred model parameters (PDFs) when fitting the three sets of observational constraints separately (Sun+, B-star+, Arcturus+), to the case when these constraints are fit simultaneously. For fitting the constraints simultaneously, we consider two regimes: first fitting a single-zone model, that is, a single set of SSP and ISM parameters (cyan); or fitting a multi-zone model, where there is a single set of stellar physics parameters, but Sun+, B-stars+, and Arcturus+ each (can) have their own ISM pre-history (magenta). For the SN Ia delay parameter some results are outside of the plotted 3σprior range but their values are given and can also be checked in Table 4. |
| In the text | |
|
Fig. 17 Tracks of the ISM abundances evolution implied by the Chempy fits, represented by a track in the [Mg/Fe]–[Fe/H] (left) and the [Mg/Fe]–time (right) panels. Shown are the predictions for the median inferred parameters |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.