| Issue |
A&A
Volume 597, January 2017
|
|
|---|---|---|
| Article Number | A134 | |
| Number of page(s) | 29 | |
| Section | Extragalactic astronomy | |
| DOI | https://doi.org/10.1051/0004-6361/201629139 | |
| Published online | 20 January 2017 | |
A large sample of Kohonen selected E+A (post-starburst) galaxies from the Sloan Digital Sky Survey ⋆
1 Türinger Landessternwarte, Sternwarte 5, 07778 Tautenburg, Germany
e-mail: meus@tls-tautenburg.de
2 Universität Leipzig, Fakultät für Physik und Geowissenschaften, Linnestraße 5, 04103 Leipzig, Germany
3 Texture-Editor GbR, Dornröschenstraße 48, 81739 Munich, Germany
Received: 17 June 2016
Accepted: 20 October 2016
Context. The galaxy population in the contemporary Universe is characterised by a clear bimodality, blue galaxies with significant ongoing star formation and red galaxies with only a little. The migration between the blue and the red cloud of galaxies is an issue of active research. Post starburst (PSB) galaxies are thought to be observed in the short-lived transition phase.
Aims. We aim to create a large sample of local PSB galaxies from the Sloan Digital Sky Survey (SDSS) to study their characteristic properties, particularly morphological features indicative of gravitational distortions and indications for active galactic nuclei (AGNs). Another aim is to present a tool set for an efficient search in a large database of SDSS spectra based on Kohonen self-organising maps (SOMs).
Methods. We computed a huge Kohonen SOM for ~ 106 spectra from SDSS data release 7. The SOM is made fully available, in combination with an interactive user interface, for the astronomical community. We selected a large sample of PSB galaxies taking advantage of the clustering behaviour of the SOM. The morphologies of both PSB galaxies and randomly selected galaxies from a comparison sample in SDSS Stripe 82 (S82) were inspected on deep co-added SDSS images to search for indications of gravitational distortions. We used the Portsmouth galaxy property computations to study the evolutionary stage of the PSB galaxies and archival multi-wavelength data to search for hidden AGNs.
Results. We compiled a catalogue of 2665 PSB galaxies with redshifts z < 0.4, among them 74 galaxies in S82 with EW(Hδ) > 3 Å and z < 0.25. In the colour-mass diagram, the PSB sample is clearly concentrated towards the region between the red and the blue cloud, in agreement with the idea that PSB galaxies represent the transitioning phase between actively and passively evolving galaxies. The relative frequency of distorted PSB galaxies is at least 57% for EW(Hδ) > 5 Å, significantly higher than in the comparison sample. The search for AGNs based on conventional selection criteria in the radio and MIR results in a low AGN fraction of ~ 2–3%. We confirm an MIR excess in the mean SED of the E+A sample that may indicate hidden AGNs, though other sources are also possible.
Key words: galaxies: interactions / galaxies: starburst / galaxies: active / surveys / virtual observatory tools
The catalogue is available at the CDS via anonymous ftp to cdsarc.u-strasbg.fr (130.79.128.5) or via http://cdsarc.u-strasbg.fr/viz-bin/qcat?J/A+A/597/A134
© ESO, 2017
1. Introduction
The bimodality of the galaxy distribution in the colour-luminosity (or colour-stellar mass) plane and the migration of galaxies between the red and the blue cloud is an important issue in galaxy evolution research (e.g. Strateva et al. 2001; Kauffmann et al. 2003b; Blanton et al. 2003; Baldry et al. 2004; Gabor et al. 2011; Rodríguez Del Pino et al. 2014; Knobel et al. 2015). E+A galaxies are thought to be best candidates for systems in that transformation stage towards early-type galaxies in the red sequence (Yang et al. 2008; Wong et al. 2012). The rare type of E+A galaxies is defined by optical spectra that indicate a combination of characteristics from old stellar populations typical of elliptical galaxies on the one hand and strong Balmer absorption lines, mostly from A stars indicating a recent episode of substantial star formation, on the other hand (Dressler & Gunn 1983, 1992; Couch & Sharples 1987; Kaviraj et al. 2007; Bergvall et al. 2016). Alternatively the term K+A galaxies is used (e.g. Melnick & De Propris 2013; Melnick et al. 2015) refering to spectra of an old stellar population dominated by K giants superimposed by a strong population of A stars, without restriction on morphology. In this paper, we will use the term E+A galaxies.
The absence of strong [O ii] or Hα emission lines in the spectra of E+A galaxies indicates that there is currently no substantial visible star formation (e.g. Couch & Sharples 1987; Quintero et al. 2004; Goto 2007b; Wu et al. 2014). The strong impact of A-type stars in the spectrum is a sign of a substantial stellar population with an age corresponding to or less than the main-sequence lifetime of A stars from a starburst less than about one Gyr ago. A significant part of about 10% to 60% of the stellar mass of the galaxy was created in that starburst (Kaviraj et al. 2007; Choi et al. 2009; Swinbank et al. 2012; Melnick & De Propris 2013). An alternative interpretation of the optical spectra could be a still on-going starburst that is obscured by dust (Poggianti & Wu 2000). Based on 20 cm radio continuum observations, Goto (2004) has shown that this dusty starburst scenario can be excluded for the majority of his sample of 34 E+A galaxies. A previous starburst, rather than just a truncation of the star formation, is also required by the optical and near-infrared colours (Balogh et al. 2005). E+A galaxies are therefore considered as prototypical post-starburst (PSB) galaxies, observed in a short-lived transition phase from the blue cloud towards the red sequence. For luminous E+A galaxies (M(z) < −22) the star formation rates (SFR) in the starburst seem to be high enough to qualify them as successors of luminous and ultra-luminous infrared galaxies (LIRGs and ULIRGs; Kaviraj et al. 2007; Liu et al. 2007). At least some ULIRGs may evolve to quasars and the intermediate stage may be represented by PSB quasars that show the spectral signatures of both a luminous active galactic nucleus (AGN) and a PSB stellar population (Brotherton et al. 1999; Cales & Brotherton 2015; Melnick et al. 2015).
It has long been recognised that tidal interactions and merging of gas-rich galaxies can act as triggers for star formation (Toomre & Toomre 1972; Larson & Tinsley 1978; Hopkins et al. 2008) and can be a major driver of starbursts (e.g. Barton et al. 2000; Snyder et al. 2011). In hierarchical models, galaxy mergers are a key mechanism of structure formation and evolution. Major mergers, minor mergers, and tidal interactions with close companions can all perturb the structure of the involved galaxies on time scales of the order of a Gyr (e.g. Mihos & Hernquist 1996; Di Matteo et al. 2007; Duc & Renaud 2013) where tidally induced star formation seems to be triggered very soon after the closest approach (Barton et al. 2000; Holincheck et al. 2016). Strong correlations have been found between the lopsidedness in the outer parts and the youth of the stellar population in the central regions (Reichard et al. 2009) and also between the proximity of a nearby neighbour and the average specific SFR (Li et al. 2008).
Gravitational interactions are expected to also play a role as trigger for E+A galaxies. The time scale of the spectral signature of A stars from a PSB stellar population coincides with the time scale of the appearance of strong tidal structures. The majority of the local PSB galaxy population have neither early- nor late-type galaxy morphologies (Wong et al. 2012) where tidal features have been found in many cases (e.g. Zabludoff et al. 1996; Goto 2005; Yang et al. 2008; Yamauchi et al. 2008; Sell et al. 2014). Using the largest sample studied till then, Goto (2005) has investigated the environment of 266 E+A galaxies from scales of a typical distance of satellite galaxies to the scale of large-scale structure. He found that E+A galaxies have an excess of local galaxy density only at scales of dynamical interaction with closely accompanying galaxies, but not at scales of galaxy clusters. About 30% of the galaxies in this sample were found to have dynamically disturbed signatures of interactions or mergers. In a sample of 21 E+A galaxies observed with the HST studied by Yang et al. (2008), at least 55% were found to show dramatic tidal features indicative of mergers. Most of the galaxies from this sample lie in the field, well outside of rich clusters. An even higher percentage (75%) of galaxies with distorted morphology was found by Sell et al. (2014) for a small sample of young PSB galaxies at z ~ 0.6.
While there is strong evidence that gravitational interactions trigger starbursts, the processes that lead to the quenching of star formation are poorly understood. The energetic output from an AGN triggered by a major merger is thought to be an effective quenching mechanism (e.g. Springel et al. 2005; Hopkins et al. 2006; Booth & Schaye 2013). The luminosity function of the PSB galaxy population seems to closely follow that of AGNs indicating a link between starburst and AGN activity, where AGNs are difficult to detect either because of dust obscuration or AGN domination (Bergvall et al. 2016). However, direct evidence for AGN-induced quenching is still sparse (Heckman & Best 2014). AGNs reside almost exclusively in massive galaxies, the fraction of galaxies with AGN strongly decreases at stellar masses below 1011M⊙ (Kauffmann et al. 2003a). Also the quenching efficiency seems to show a strong trend with stellar mass and luminosity consistent with the energetic feedback from supernovae for log M∗/M⊙ ≲ 10, while the major effect may come from AGNs at higher masses (Kaviraj et al. 2007). Empirical evidence for AGNs in PSB galaxies is sparse. Based on the analysis of line ratios Yan et al. (2006) suggested that most PSB galaxies may harbour AGN. Direct indications of AGNs in individual PSB galaxies was reported for a few cases only (Liu et al. 2007; Georgakakis et al. 2008). Other studies of samples of E+A galaxies did not confirm a substantial number of luminous AGNs. Swinbank et al. (2012) found 20–40% of their sample of 11 E+A galaxies to have 1.4 GHz radio emission suggestive of low-luminosity AGNs, but they concluded that AGNs do not play a dramatic role for the host galaxies, or the time scale of AGN feedback is short. De Propris & Melnick (2014) found that no E+A galaxy in their local sample hosts an AGN with substantial luminosity. Sell et al. (2014) concluded that their sample of 12 young PSB galaxies at z ~ 0.6, selected from a larger parent sample as the most likely to host AGNs, represent massive merger remnants with high-velocity gaseous outflows primarily driven by compact starbursts rather than AGNs. On the other hand, these studies do not conclusively rule out that AGNs may play a role in some point of the evolution and that the quenching of star formation and AGN activity rapidly follow each other (Melnick et al. 2015).
The creation of sufficiently large samples is crucial for statistical studies of E+A galaxies but is difficult because of the rarity of this object type. The situation has become strongly improved with the availability of large spectroscopic surveys, particularly the Sloan Digital Sky Survey (SDSS; York et al. 2000). Large and homogeneous samples of E+A galaxies from the SDSS were derived particularly by Goto et al. (2003), Goto (2005, 2007b). The tremendous amount of data produced by the SDSS requires efficient methods for browsing the huge archive. The search for narrowly defined spectral types in such a data set makes sophisticated tools desirable. Artificial neural network algorithms provide an efficient tool. We developed the software tool ASPECT to compute large Kohonen self-organising maps (SOMs; Kohonen 2001) for up to one million SDSS spectra (in der Au et al. 2012). In previous studies, we computed SOMs for the quasar spectra of the SDSS data release seven (DR7; Abazajian et al. 2009) to select unusual quasars (Meusinger et al. 2012; Meusinger & Balafkan 2014). Thereafter we applied this technique to galaxies, stars, and unknowns in the SDSS DR7, as well as to the quasar spectra in the SDSS DR10 (Ahn et al. 2014) to extend the unusual quasar search (Meusinger et al. 2016). SOMs computed from the SDSS DR12 (Alam et al. 2015) are currently being analysed.
Here we aim to create a selection of E+A galaxies from SDSS DR7 based on the SOM technique. We demonstrate the applicability of a large SOM for such a task and describe the newly developed user interface that allows for easy exploration of huge maps for example for comfortable visual examination, projecting input catalogues, tagging and collecting single or several objects, etc. The SOM and the user interface are made fully available for the astronomical community. The second aim of this study is to analyse the properties of our E+A sample, where the focus is on the position in the colour-mass plane, the morphological distortions, and possible indications of AGNs. The paper is structured as follows. The data sources are described in Sect. 2. The SOM, the user interface, and the selection method are presented in Sect. 3. In the following Sect. 4, the properties of our E+A sample are discussed. Finally, summary and conclusions are given in Sect. 5. The cosmological parameters ΩM = 0.27,ΩΛ = 0.73, and H0 = 70 km s-1 Mpc-1 were used throughout this paper.
2. Data sources
2.1. Sloan Digital Sky Survey
The original core science goal of the SDSS was obtaining CCD imaging over roughly a quarter of the high-Galactic latitude sky and spectroscopy of a million galaxies and quasars. The imaging part covers more than 10 000 deg2 in the five broad bands u,g,r,i, and z, mostly taken under good seeing conditions in moonless photometric nights. It includes a deep survey by repeated imaging in the Stripe 82 (S82) area along the Celestial Equator. The SDSS data have been made public in a series of cumulative data releases. The SDSS DR7 (Abazajian et al. 2009) includes all data accumulated up to the end of the phase known as SDSS-II that marks the completion of the original goals of the SDSS. The spectra database contains spectra of 930 000 galaxies and 120 000 quasars. The spectra were taken with the 2.5 m SDSS telescope at Apache Point Observatory equipped with a pair of double fibre-fed spectrographs. The wavelength range covered by the SDSS spectra is 3800 Å to 9200 Å with a resolution of ~ 2000 and sampling of ~ 2.4 pixels per resolution element. For a galaxy near the main sample limit, the typical signal-to-noise ratio (S/N) is ~ 10 per pixel. The spectra are calibrated in wavelength and flux and classified by a spectroscopic pipeline, including redshift determination.
The primary data set for the present study consists of a subset of about one million spectra downloaded from the SDSS DR7. Most of the spectroscopic data used in the present study where extracted from the SDSS fits files of the spectra downloaded from DR7. This includes in particular the equivalent widths (EWs) of the spectral lines. However, contrary to the definition in that database, we followed the convention in the literature to indicate the EWs of absorption lines by positive and those of emission lines by negative values. Other data like redshift z and object classification were taken from the SDSS DR12 (Alam et al. 2015).
In addition, morphological data from Galaxy Zoo are used. In Sect. 4.2, we make use of the data from the first Galaxy Zoo project (Lintott et al. 2011), where ~900 000 galaxies were included. Results from the complex classification system applied in Galaxy Zoo 2 (GZ2; Willett et al. 2013) for ~300 000 SDSS galaxies are discussed in Sect. 4.4.
Further, we exploited the database of galaxy properties from the Portsmouth stellarMassStarFormingPort1 (sMSP), which is available from the SDSS DR122. The Portsmouth galaxy property computations deliver stellar masses and other properties by applying stellar population models (Maraston et al. 2013) to all objects that the SDSS spectroscopic pipeline classifies as a galaxy with a reliable and positive definite redshift. The stellar population models were used to perform a best fit to the observed ugriz magnitudes with the spectroscopic redshift determined by the pipeline. The fit was carried out on extinction corrected model magnitudes that were scaled to the i band for two sets of models, a passively evolving galaxy or a galaxy with active star formation. The stellar mass, the SFR, and the age were computed from the best-fit spectral energy distribution (SED; Maraston et al. 2006, 2009).
In Sect. 4.4, we make use of the deep imaging in the SDSS S82 (Fliri & Trujillo 2016, see next Sect. 2.2 below).
 |
Fig. 1 Kohonen SOM of ~106 spectra from SDSS DR7 in its representation as a redshift map. Each pixel corresponds to one spectrum where the colour represents the redshift z from 0 (dark) to 6 (bright yellow). The grey dots are empty neurons. |
2.2. SDSS S82
The SDSS S82 is the 275 deg2 region of sky along the Celestial Equator in the southern Galactic cap at 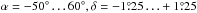 . Because of the combination of a high completeness level of SDSS spectroscopy and deep co-added images, this area is particularly attractive for the present study. In addition, the SDSS data in S82 are complemented by a broad multi-wavelength coverage by existing and planned wide-field surveys. A second-epoch 1.4 GHz survey of S82, conducted with the Very Large Array, achieves an angular resolution of
. Because of the combination of a high completeness level of SDSS spectroscopy and deep co-added images, this area is particularly attractive for the present study. In addition, the SDSS data in S82 are complemented by a broad multi-wavelength coverage by existing and planned wide-field surveys. A second-epoch 1.4 GHz survey of S82, conducted with the Very Large Array, achieves an angular resolution of 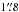 and a median rms noise of 52 μJy beam-1 over 92 deg2 (Hodge et al. 2011). Moreover, a wide-area X-ray survey endeavouring to achieve a survey area of ~ 100 deg2 in S82 (LaMassa et al. 2013, 2016) has detected 6181 unique X-ray sources so far.
and a median rms noise of 52 μJy beam-1 over 92 deg2 (Hodge et al. 2011). Moreover, a wide-area X-ray survey endeavouring to achieve a survey area of ~ 100 deg2 in S82 (LaMassa et al. 2013, 2016) has detected 6181 unique X-ray sources so far.
Co-adding the multi-epoch observations in S82 leads to the construction of images that are considerably deeper than typical observations from the SDSS legacy survey. Co-added images were made available in the Data Archive Server (DAS) of a database called Stripe82 as part of the SDSS DR7 (Abazajian et al. 2009). Annis et al. (2014) combined about one third of all available SDSS runs in S82 to co-adds that are ~ 1–2 mag deeper than the regular SDSS images, depending on the band. In another approach, Jiang et al. (2008) combined between 75 and 90% of the data and reported that the resulting images are 0.3–0.5 mag deeper than the previous co-adds. A new reduction of the S82 data was provided recently by Fliri & Trujillo (2016). Compared to the previous studies, these new images focus on the surface brightness depth rather than on faint point sources. The main intention was to prevent the destruction of low-surface brightness features in the process of co-addition by an optimal local sky brightness correction and to reduce the probability of confusing low-surface brightness features of galaxies and sky background. Averaging the g,r and i co-adds yields another gain in depth by ~ 0.2...0.3 mag in the so-called rdeep images. The co-adds reach 3σ surface brightness limits μr ~ 28.5 mag arcsec-2 with 50% completeness limits at (25, 26, 25.5, 25, 24) mag arcsec-2 for (u,g,r,i,z).
2.3. Self-organising map of the SDSS DR7 spectra
In a previous paper (in der Au et al. 2012) we described the software tool ASPECT3 that was developed to organise a large number of spectra by means of their relative similarity in a topological map. Similarity maps are generated using SOMs as proposed by Kohonen (2001). The SOM technique is an artificial neural network algorithm that uses unsupervised learning. The network consists of neurons represented by weight vectors, where the number n of neurons must be at least equal to the number k of source spectra. We found that good results are achieved for n/k ~ 1.2, that is about 20% of the neurons are empty (i.e. not linked to spectra).
ASPECT maps spectra (dis-)similarity to position in the resulting SOM. For the bulk of the SDSS sources, the spectral properties vary more or less smoothly over the SOM. The spectra thus form coherent areas interspersed with small areas of “no men’s land” that are often occupied by rare spectral types with pronounced spectral properties. Uncommon spectra often cluster to smaller structures between large coherent areas where the latter are occupied by the more common objects. For extragalactic objects, the shape of the observed spectra and the observed wavelengths of the characteristic spectral features change of course with redshift z so that the appearance of several clusters for different z intervals is natural. The very fact of such clustering properties makes the SOMs useful for efficiently selecting uncommon or rare objects from large data samples.
 |
Fig. 2 Six cutouts from different parts of the icon map, each five by five pixels in size. |
In the previous paper (in der Au et al. 2012), we discussed a SOM of ~ 5 × 105 spectra from the SDSS DR4. Afterwards, we computed and exploited a large number of smaller SOMs (several 104 spectra each) for different data sets of stars and z-binned quasars and galaxies from DR7 to DR12 with the main aim to search for different types of unusual quasars (Meusinger et al. 2012, 2016; Meusinger & Balafkan 2014). However, ASPECT was developed in particular to compute SOMs of sizes that existing implementations of the algorithm where not able to cope with. Here we present, for the first time, a SOM of about one million SDSS spectra. The SOM contains all useful spectra from the SDSS DR7 that were available for download, regardless of spectral type, redshift, or S/N. The procedure and the parameters of the neural network are essentially the same as in in der Au et al. (2012), the computation time was about eight months on a state-of-the-art personal computer.
Figure 1 shows a low-resolution image of the whole map. Each pixel corresponds to a neuron of the SOM. Colours indicate redshifts, the grey filamentary network represents empty neurons. In the resulting SOM, these empty neurons tend to settle at the borders of the coherently populated areas thus enhancing the clustering power of the method. Figure 2 shows six cutouts from different regions of the icon map of the same SOM. It illustrates how the algorithm implemented in ASPECT clusters spectra of the same type. The icon map is a representation of the SOM where each pixel is represented by the SDSS spectrum at low spectral resolution (icon).
2.4. SOM user interface
The selection of E+A galaxies presented below (Sect. 3) is based on the huge SOM of roughly one million spectra from SDSS DR7. The detailed analysis of such a large map is challenging. Several types of representations of the SOMs computed by ASPECT (e.g. U matrix, z map, type map, icon map) were discussed by in der Au et al. (2012), in combination with different methods of their analysis. The present study is focused on the selection of spectra from the icon map by means of an input catalogue.
ASPECT saves the computed SOM to a HTML document that can be viewed in its icon map version using a web browser. The output is internally structured as HTML tables containing the spectra icons. Rendering these tables results in a representation as a map of sorted spectra that can be explored using standard scrolling and zooming functionality of the web browser. While this is a practical method for smaller maps with some thousand spectra it becomes a straining user experience when the browser has to render a whole huge SOM at once and to keep it in memory. The latter becomes nearly impossible for SOMs consisting of several 105 spectra because of technical restrictions.
We developed the ASPECT user interface (AUI) for the efficient work with even very large icon maps. The AUI is publicly available together with the SDSS DR7 icon map4. So far, it is focused on the following features. Firstly, the map must be easily zoomable for a convenient work flow, that is it should provide representations of the SOM in different detail levels. Secondly, for the selection of objects from the icon map, specific data from SDSS or other sources can be very helpful. Therefore, it should be possible to overlay additional information. Thirdly, to compile lists of objects selected from the icon map, it should be possible to highlight already selected spectra and to tag spectra for later data export.
We applied modern web techniques and the framework leaflet.js5 to add data layers and interactivity to the rendered SOM. The original intention behind leaflet.js was to support development of online street maps. However, the principle of aligning smaller images to compile a large map is very well applicable to our use case. Speaking in terms of leaflet.js we organise the spectra icons in adjacent tiles, each icon occupying one tile in the highest detail level. In order to have the map available for different zoom levels it is necessary to rescale and re-size the spectra plots computed by ASPECT. To this end we start with the static ASPECT output as the highest zoom respective detail level Ld, meaning that one spectra icon fills one tile. The composition of tiles of the next lower detail level Ld−1 is achieved by combining four tiles of Ld into one new tile. In every such re-size step the number of tiles is divided by four compared to the predecessor zoom level. This process has to be repeated with lower detail levels as needed until all spectra are re-sized and rescaled into one remaining image tile at the lowest detail level. Figure 3 schematically illustrates the process. In the field of computational graphics, the approach to build such image pyramids is known as mipmapping. It was first described by Williams (1983).
 |
Fig. 3 Schematic illustration of two lower-detailed levels derived from an existing detail level Ld. |
The application of the previously described steps to the icon map of about one million spectra provided us with the necessary tool for the search for E+A galaxies. We extended our basic map view with several features that can be toggled on and off by adding or removing layers to the view to prevent information overload (see also the AUI homepage for a live demonstration):
Firstly, map controls, such as a zoom level switcher, a data layer selectors, and marker tools are available.
Secondly, additional data from the SDSS DR7 spectra FITS files, such as the object type or the EWs for Hα and Hδ, can be over plotted in each icon.
Thirdly, a click on an icon provides the SOM coordinates and hyperlinks to the SDSS explorer homepage of the object and, alternatively, to the redshift tool zshift, which was inspired by the interactive spectra tool from the SDSS DR12 Science Archive Server and is used here mainly for manually checking the redshift in case of a doubtful result from the SDSS spectroscopic pipeline.
Furthermore, several spectra icons within an area can be marked and tagged for later export. This works like rectangular selection tools in common graphics software. The list of selected objects can be exported to a csv file containing the SOM coordinates and SDSS identifiers (plate, MJD, fibre ID). A SOM pixel (icon) marked previously with the selection tool is indicated by a coloured margin. Layers of different colours and tag names can be created in a separate menu.
Finally, the AUI provides the opportunity for the import of an input catalogue. Given their presence in the SOM, objects from the input catalogue (again identified by MJD, plate ID, fibre ID) can be mapped to and highlighted in the icon map.
Depending on requirements and resources the overlay and tagging information can be stored in more or less sophisticated storage back-ends. For the present application, we extracted most of the additional data from the FITS files of the SDSS spectra and stored them in a database management system. We chose an SQL database server as storage back-end. The spectra were stored as image files in plain file system. Additional information was transferred from the SDSS DR7 1d spectra database6, in particular the EWs of spectral lines derived by the SDSS pipeline.
In the previous paper (in der Au et al. 2012), we demonstrated that the use of an input catalogue of known objects of a given spectral type can be very useful for an efficient search of further objects of the same or similar types in a large SOM. Here, we illustrate this approach by another example.
3. Selecting E+A galaxies
3.1. Input catalogue
The most comprehensive compilation of E+A galaxies was performed by Tomotsugu Goto, published in several updates. Goto et al. (2003) presented a catalogue of galaxies with strong Hδ absorption from SDSS DR1. In the following, Goto (2005) provided a list of 266 E+A galaxies, picked from the SDSS DR2. Subsequently, that number was roughly doubled with an update after SDSS DR5 (Goto 2007b) and was eventually increased again after the SDSS DR7. Goto’s latest catalogue7 compiles 837 E+A galaxies found in the SDSS DR7. The criteria for objects to qualify for the catalogue are EW(Hδ) > 5 Å, EW(Hα) > −3 Å, EW([O ii])>−2.5 Å, and redshift not in the range 0.35 <z< 0.37 in order to exclude intervening sky lines. In the following, the objects from this catalogue will be referred to as “Goto galaxies”. We identified Goto galaxies in our SOM by the plate – MJD – fiberID combination using the skyserver8 links provided in the catalogue. All entries of the input catalogue could be mapped to spectra in our data base. The arithmetic median composite rest-frame spectrum of the Goto sample is shown in Fig. 9b.
3.2. Selection of new candidates
 |
Fig. 4 Distribution of Goto galaxies (black open circles) over the SOM. The clusters identified by dbscan clustering are shown as red squares and labelled by the cluster ID. The axis are the pixel coordinates of the SOM. |
The input catalogue is used as seed for the search for further E+A galaxies in the DR7 SOM. Figure 4 shows the distribution of the input galaxies over the map. The labelling of the axis indicates the coordinate system of the SOM with 1104 by 1104 neurons. Every black dot indicates the position of a galaxy from the input catalogue, larger red symbols mark concentrations, referred to as “clusters” throughout this paper. On the one hand, the clustering is an eye-catching feature of the SOM. On the other hand, it is remarkable that E+A galaxies do not form a single cluster, a substantial part of the input sample is scattered across the map.
As a first step, we had to find out which of the aggregations of input galaxies could be considered to be clusters. In the next step, each cluster should be used to define an environment where the probability is high for finding further galaxies with similar spectral properties. We intended to inspect all spectra within the resulting areas for E+A features. To define a cluster, we applied the data clustering tool dbscan (density-based spatial clustering of applications with noise; Ester et al. 1998) in its implementation for the statistics software R9.
dbscan is a commonly used clustering algorithm. Compared to simpler algorithms, the advantage is its ability to locate clusters of arbitrary shape. The basic principle is to find aggregations of a defined minimum number of objects with defined maximum distances and to recognise them as clusters: Let M ∈N and ϵ ∈R be the input parameters (named MinPts and Eps respectively in Ester et al. 1998). M defines the minimum number of members constituting a cluster, whereas ϵ is the radius of an epsilon ball Nϵ around points in the cluster space. Using these input parameters, dbscan clusters objects in a given map by their relative distance and categorises them as directly density reachable, density reachable, density connected, and neither density reachable nor density connected.
To approach the problem of Goto galaxy clusters in the SOM, we assumed a two-dimensional grid. Assuming that a subset of n grid points is occupied by the objects O1,O2,...,On with the corresponding two-dimensional position vectors o1,o2,...,on, we define for two objects Ok and Ol that Ok is directly density reachable from Ol if ok lies within Nϵ around ol and the number of objects within this epsilon ball is greater or equal to M.
Ok is density reachable from Ol if there is a chain of grid points occupied by the elements of a subset { Pi } ⊂ { O1,O2...On } ,i = 1,...,q connecting Ok and Ol such that ∀i:Pi + 1 is directly density reachable from Pi and Ok = P1 and Ol = Pq.
Ok is density connected to Ol if there is a grid point g such that Ok and Ol are both density reachable from an object at g.
These definitions allow us to define a cluster as the set of density connected objects with maximised density reachability with respect to the parameters M and ϵ, which have to be fixed in advance (Ester et al. 1998). The Euclidean distance was used as distance function.
We ran dbscan with a set of various combinations of M and ϵ. The analysis of the results led to the conclusion that solutions with 8 to 12 clusters were meaningful. Solutions with less clusters missed some of the clearly visible accumulations. On the other hand, solutions with more than 12 clusters assigned the cluster status to very small groups merely scattered throughout the map, or even to single galaxies. Considering the fraction of objects bound in clusters and the visual appearance of the solutions’ plots, we finally chose the parameter values ϵ = 18 and M = 5. The dbscan run then resulted in nine clusters of altogether 645 objects from the input catalogue (Fig. 4). Another 192 galaxies were found to be scattered across the SOM and were not assigned to a cluster. Following Ester et al. (1998) we refer to the latter as “noise” in this context.
Mean properties of the galaxies from the input catalogue clusters 1 to 9 and noise.
Table 1 lists mean properties of the seed galaxies from the input catalogue in the nine clusters and the noise: the sample-averaged redshift, the mean EW(Hδ), and the mean ratio fe/s = Pe/Ps, where Pe and Ps are the probabilities for being an elliptical galaxy or a spiral galaxy, respectively, from the Galaxy Zoo project (Lintott et al. 2011, see Sect. 4.2). The three largest clusters correspond to three different z intervals, though there is some overlap. The noise contains galaxies from all redshifts. As expected, the ratio fe/s increases with z due to the Malmquist bias. The S/N was measured in the continuum around Hδ at rest-frame wavelengths λ = 4030−4080 Å and λ = 4122−4170 Å.
The next step was the eyeball examination of the neighbourhood of the Goto clusters. The properties of Kohonen maps imply that it is likely to find there more objects with similar spectra. To keep the effort at a manageable level we restricted the search area in the following way. Assuming that  is the set of objects Oi that do not belong to any cluster and oi are their corresponding position vectors in the map,
is the set of objects Oi that do not belong to any cluster and oi are their corresponding position vectors in the map,  is the set of the n objects that belong to cluster k and ck,l are their corresponding vectors (k = 1...9,l = 1...n), and
is the set of the n objects that belong to cluster k and ck,l are their corresponding vectors (k = 1...9,l = 1...n), and 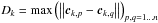 is the largest distance between any two members of cluster k, we defined the neighbourhood
is the largest distance between any two members of cluster k, we defined the neighbourhood 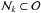 of cluster k as the subset of all objects Oi with
of cluster k as the subset of all objects Oi with 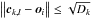 for at least one value of l. The resulting set
for at least one value of l. The resulting set 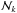 takes into account the varying sizes of clusters but prevents too large samples. Nevertheless, the joint set of all clusters and their neighbourhoods comprised a still fair number of 14 828 E+A galaxy candidates that had to be examined “manually”. The panels on the left hand side of Fig. 5 show the cutouts from the icon map for the clusters 1 to 5. The seed of input galaxies is marked blue, the cluster neighbourhood is red.
takes into account the varying sizes of clusters but prevents too large samples. Nevertheless, the joint set of all clusters and their neighbourhoods comprised a still fair number of 14 828 E+A galaxy candidates that had to be examined “manually”. The panels on the left hand side of Fig. 5 show the cutouts from the icon map for the clusters 1 to 5. The seed of input galaxies is marked blue, the cluster neighbourhood is red.
 |
Fig. 5 Cutouts from the icon map containing the E+A clusters 1 to 5 (top to bottom; first selection on the left side, final selection on the right side). Galaxies from the input catalogue are marked blue. The red background colour indicates the newly selected E+A galaxies. |
3.3. Final selection
After the sampling of E+A galaxy candidates described above, we added a coloured overlay to the Kohonen map indicating all objects from the input catalogue in blue and all objects added to the sample in the steps described in Sect. 3.2 in red. Afterwards we made use of the tool set described in Sect. 2.4 to sort out contaminant spectra. Roughly the following routine was applied to any single spectrum in the red area: firstly, are there spectral features indicative of E+A galaxies? Secondly, exclude stars that can have spectra more or less similar to PSB galaxies. (In fact, galaxies and stars are mixed in some areas of the SOM.) Thirdly, a strong Hα emission line is usually easy to spot. Is EW(Hα) ≳ −3? If yes, it can be a candidate. Next, click on the spectrum for more information. Is Balmer absorption dominant? Is the [O ii] line weak in emission? Check for Hδ absorption. Is EW(Hδ) ≳ 3? Finally, if in doubt, open the link to the SDSS DR12 sky server and inspect the original spectrum.
The outcome of the “manual” selection and rejection process for each of the nine clusters from Fig. 4 is the following:
-
Cluster 1: this is the biggest aggregation of inputgalaxies. Although a substantial number of furtherE+A galaxies were found, most had to beexcluded. The shape of the final cluster resembles structures ofthe underlying SOM very well. What remains after selection canbe seen as two distinct clusters. (Another ϵ value could probably have led to less work.)
-
Cluster 2: with an exception of a small area in the lower left region this cluster fits an island in the Kohonen landscape very well. Here we see that “ditches” of empty neurons are congruent with E+A cluster borders. The final relative outcome is quite large compared to the clusters 3 through 9.
-
Cluster 3: compared to the most other clusters, the area occupied by the outcome for this cluster is less clearly constrained by the Kohonen map landscape.
-
Cluster 4: this cluster provides a rather small outcome. However it is well observable that the E+A galaxies strongly cluster in the SOM.
-
Cluster 5: the small distances between the seed objects led to a small cluster neighbourhood, and only a few of the pre-selected candidates remained after closer examination.
-
Cluster 6: the outcome is similar to that of cluster 5, which also lies in the same region of the SOM.
-
Cluster 7: the large M and small ϵ parameters resulted in a relatively large cluster and included a large neighbourhood compared to the actual seed size.
-
Cluster 8: this cluster can be seen as a false positive. It has the minimum number of Goto galaxies as seed to meet the dbscan ϵ parameter. After examination the Goto galaxies and only one additional E+A galaxy were left.
-
Cluster 9: after detailed inspection of the preselected galaxies, almost nothing remained.
The results of the visual inspection of clusters 1 to 5 are illustrated in the panels on the right hand side of Fig. 5 for the clusters 1 to 5. As in the panels on the left hand side, galaxies from the input catalogue are marked blue, selected E+A galaxies from the present study are marked red. The clusters are shown at different zoom levels because of the huge differences in cluster sizes. It is clearly visible that the neighbourhood of at least some Goto clusters includes a substantial number of further E+A galaxies that were not selected as such before. Table 2 lists the corresponding numbers for the nine clusters and the noise: galaxies from the input catalogue, selected by the 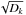 criterion, manually rejected, and final number.
criterion, manually rejected, and final number.
Result of dbscan clustering of the galaxies from the input catalogue, number of rejected galaxies, and final numbers per cluster and noise.
3.4. Selection effects
 |
Fig. 6 Top: histogram distribution of redshifts for the final E+A sample (black) and the input sample (red). Middle: mean Petrosion radius in redshift bins. Bottom: mean stellar mass in redshift bins. |
 |
Fig. 7 Top: EW(Hδ) as a function of redshift in four different size categories. Middle: mean coverage factor Rf/RP for the E+A galaxies in redshift intervals. Bottom: median of EW(Hδ) in different intervals of the coverage factor. |
Selection effects are induced by various processes, mainly the target selection, plate definition, and fibre spectroscopy in the SDSS (Stoughton et al. 2002), the definition of the input sample of Goto galaxies, the selection from the SOM, and the use of the EWs from the SDSS spectroscopic pipeline for the final selection. The biases in the final E+A sample are complex and a quantitative description is barely achievable. Here, we focus on the effects from the SDSS and from the SOMs
3.4.1. SDSS
The redshift distribution of the E+A sample is shown in the top panel of Fig. 6. As a direct consequence of the flux limitation of the SDSS in combination with the z distribution, the galaxy sample suffers from the Malmquist bias: at each redshift, the galaxy luminosities show a broad distribution with a lower limit increasing with increasing z. Properties correlated with the luminosity must also show a trend with z, such as the mean size (Fig. 6, middle) and the mean stellar mass (Fig. 6, bottom). The size is expressed here by the Petrosian radius, RP, in the r band from the SDSS Photometric Catalog, DR7 (Abazajian et al. 2009). The Petrosian radius is the radial distance R from the centre of a galaxy where the mean local surface brightness in an annulus at R is equal to 20 per cent of the mean surface brightness within R. Theoretically, RP recovers essentially all of the flux of a galaxy with an exponential profile and about 80% for a de Vaucouleurs profile. The stellar mass is taken from the Portsmouth sMSP data base (see Sect. 4.3). To take account of the Malmquist bias we will compare our sample with a control sample of the same z distribution in the Sects. 4.4 and 4.5 below, or we consider the sample in different z bins separately (Sect. 4.3).
There is still another selection effect caused by the range of redshifts observed with a fibre spectrograph, as in the SDSS. As a consequence of the fixed size of the entrance aperture of the fibre, the observed spectrum probes different parts of the galaxies at different z (e.g. Brinchmann et al. 2004; Bergvall et al. 2016). For the SDSS fibre (3″), the linear radius Rf of the covered field changes from ≈2 kpc at lowest redshifts to 10 kpc at z = 0.2. If the starburst is strongly concentrated in a small central region of a more or less constant size the PSB spectrum is expected to be more and more diluted by the light from the underlying stellar population in the galaxy with increasing z. Bergvall et al. (2016) analysed how EW(Hα) changes with z in a sample of local starburst and PSB galaxies. They found a significant trend at z< 0.02 and argued that a sample with a lower redshift limit z low = 0.02 is less affected by aperture losses. It should be noted that the lower limit is 0.02 in our sample. The top panel of Fig. 6 shows EW(Hδ) as a function of z for four different size catagories of our E+A galaxies. We do not see a significant trend.
The Malmquist effect leads to a selection bias against smaller galaxies with increasing z. The middle panel of Fig. 6 shows the mean ratio Rf/RP averaged in z bins of the width 0.02 as a function of z. The ratio Rf/RP is a measure of the coverage of the galaxy by the aperture. There is a moderate increase at lowest redshifts, but the ratio changes only weakly over the interval 0.06 ≲ z ≲ 0.3 that contains 90% of the E+A sample. If the starburst is not strictly confined to the nuclear region (Swinbank et al. 2012) and if the size of the starburst region scales with the galaxy size, the aperture effect may thus be essentially compensated by the Malmquist bias. The bottom panel of Fig. 6 indicates that there is no significant trend of EW(Hδ) with the coverage ratio Rf/RP.
 |
Fig. 8 Median composite (black) and standard deviations (yellow) from the rest-frame spectra of the Goto galaxies in cluster 1 (left) and in the noise (right). |
3.4.2. SOM
The Kohonen method is expected to produce selection biases mainly because the clustering power depends on several properties of the spectra, such as the strength of the characterising spectral features, the diversity of the underlying spectral components, the redshift distribution, and the S/N.
A first way to check the selection effects from the SOM is to compare the redshift distribution of the final sample with that of the input sample. The top panel of Fig. 6 clearly indicates that the two distributions are very similar. As for the input sample the redshift range is from z ≈ 0.02 to 0.4, with 96% below z = 0.25.
As described in detail in the ASPECT paper (in der Au et al. 2012), the computation of a SOM of this size requires the reduction of the overall size of the data pool to a necessary minimum. The spectra had to be smoothed and rebinned in order to reduce the number of pixels. Initial tests have shown that the reduction of the spectral resolution caused by the rebinning does not significantly affect the quality of the clustering results as long as spectral features are considered that are clearly broader than the spectral resolution of the original SDSS spectra, for example quasar broad absorption lines. Compared to such spectra, the characterising spectral features of E+A galaxies are relatively narrow. For weak and narrow features, the clustering is of course stronger dominated by the underlying spectral components and is thus less efficient. One solution would be trading spectral coverage against spectral resolution. However, though the main intention for the construction of the SOM described in Sect. 2.3 was to search for extreme BAL quasars (Meusinger et al. 2012, 2016), it was originally not designed for any special application. In addition, the selection of E+A galaxies requires the wide wavelength coverage from O ii to (redshifted) Hα.
The clustering strength of the E+A galaxies depends on the EW of the Hδ line, the S/N of the continuum near Hδ, and the spectrum of the underlying stellar population. Table 1 compares mean properties of the nine clusters and the noise. While the mean redshift of the noise is very similar to that of the richest cluster, the other properties are different. The lowest mean EW(Hδ) is found for the (poor) cluster 9 and the noise. The mean S/N is smallest and its scatter is largest for the noise. In addition, the composite spectra from the noise and the rich clusters show some differences. The top panels of Fig. 8 compare the median rest-frame composite spectra of the Goto galaxies from cluster 1 on the left-hand side with that of the noise galaxies on the right-hand side. The noise composite is redder and shows a much larger standard deviation. We subdivided each of the two samples into a blue and a red subsample defined by Fλ(4030−4080 Å ) /Fλ(5200−5800 Å ) ≥ 1 or <1, respectively, and computed the composites for these subsamples. The comparison shows (middle and bottom raw of Fig. 8) that the composite of the red noise spectra is redder, that of the blue ones is bluer, and in both cases the scatter is larger than for the cluster. This means that the noise galaxies show a considerably larger variety of spectral slopes. If dust obscuration is one of the reasons for these differences, this could mean that our sample is biased against dusty E+A galaxies.
The last column of Table 2 lists the ratio of the number of newly selected galaxies to the number of seed galaxies, which is a proxy for the efficiency of the search. For the seven clusters with ni > 10, the mean ratio is 3.4, compared to 1.0 for the combination of the noise and the clusters 8 and 9. If we assume complete selection around the rich clusters, that means each seed galaxy corresponds, on average, to 3.4 galaxies in our sample, we find that 482 galaxies are missed from the poor clusters and the noise. This corresponds to ~ 15% of the entire sample, with the largest part lost in the noise.
4. Properties of the E+A sample
4.1. The final catalogue
As a result of the thorough examination of the SOM neighbourhood of the input galaxies, both of the nine clusters and the noise (Fig. 4), we selected altogether 3060 E+A galaxies. The subsample fulfilling Goto’s selection criteria (Sect. 3.1) consists of 774 galaxies, among them 539 Goto galaxies. The lack of 35% of the Goto galaxies in this subsample is caused by small differences in the values for the EWs from the data used by Goto, most likely due to differences in the output of the spectroscopic pipeline of the SDSS from rerun to rerun.
The final selection was used to compile a catalogue of 2665 galaxies defined by the following properties: EW(Hδ) > 3 Å, EW(Hα) > −5 Å, EW([O ii]) >−5 Å, z< 0.35 or >0.37. This sample is referred to as our E+A sample throughout this paper. The catalogue will be published in electronic form in the Vizier service of the CDS Strasbourg. The galaxy redshifts cover the range z ≈ 0.02−0.4, with a mean value at 0.13. The vast majority (84%) of the galaxies have z < 0.2. The catalogue includes 803 galaxies from the input catalogue (96%). Applying Goto’s stronger selection criteria to the line EW data used in the present study leads to a reduced sample of 916 E+A galaxies, among them 615 Goto galaxies.
 |
Fig. 9 Median composite (black) and standard deviations (yellow) from the rest-frame spectra of a) the whole set of the E+A galaxies from the present study with EW(Hδ) > 3 Å; b) the subset of the galaxies from the input catalogue; c) the subset of newly selected galaxies fulfilling the selection criteria of the input catalogue EW(Hδ) > 5 Å, EW(Hα) > −3 Å, and EW(O ii) >−2.5 Å. |
In Fig. 9, we compare the rest-frame arithmetic median composite spectrum of the E+A sample (upper panel) with that of the galaxies from the input catalogue (middle panel). In addition, the bottom panel shows the composite of the new E+A galaxies fulfilling the selection criteria of the input catalogue. There is no substantial difference between the three spectra. The weak emission line close to the right margin is N iiλ6584, Hα is seen as a weak absorption line.
4.2. Morphological types
Morphological type classification of the SDSS galaxies is available from the Galaxy Zoo project. The first version of Galaxy Zoo (Lintott et al. 2011) provided the most fundamental morphological types (spiral or elliptical systems) for nearly 9 × 105 galaxies based on the contributions from more than 2 × 105 online volunteer citizen scientists. More detailed morphological information is available from Galaxy Zoo 2 (GZ2; Willett et al. 2013) for the brightest 25 per cent of the resolved SDSS DR7 galaxies in the north Galactic cap region. At this point, we restrict the discussion to the fundamental morphological types from the original Galaxy Zoo because only one third of our E+A galaxies were identified in the GZ2 sample. The results of the classifications are expressed by weighted probabilities Pe,Ps,Pm for being an elliptical galaxy, a spiral, or a galaxy merger, respectively. The fraction of gravitationally distorted galaxies and mergers will be the subject of Sect. 4.4 where we will discuss, among others, classifications from GZ2.
The morphological type probabilities are available for 94% of the galaxies from our sample. The top panel of Fig. 10 shows Ps versus Pe as black symbols for galaxies with merger probabilities Pm < 0.1, galaxies with Pm = 0.1...0.3 are highlighted blue, those with Pm > 0.3 are red. Although there is a concentration towards large Pe and small Ps, only a small fraction are clearly attributed to one of the two types. Usually a minimum 80% majority agreement is required for a clean classification. This is found for only 12% of the galaxies in the sample, where ~ 11% are classified as ellipticals and ~ 1% as spirals. The overwhelming majority of the E+A galaxies have intermediate morphologies. The median values for the three probabilities are (Pe,Ps,Pm) = (0.62,0.17,0.00).
For comparison we created a randomly selected control sample of “normal” galaxies from the SDSS DR7. The control sample has the same redshift distribution as the E+A sample but is twice as large. The distribution of the comparison galaxies in the Ps versus Pe diagram (bottom panel of Fig. 10) appears similar to that of the E+A galaxies and the median values are also similar (0.65, 0.20, 0.00). However, the percentage of comparison galaxies with a minimum 80% majority agreement is clearly larger: 28% have Pe ≥ 0.8 and 10% have Ps ≥ 0.8.
4.3. Colour-mass diagram
Wong et al. (2012) analysed the distribution of a local sample of 80 PSB galaxies with z = 0.02−0.05 in the u−r colour-mass diagram. They found that the majority reside within the lower mass part of the “green valley” between the red sequence and the blue cloud. Here, we exploited the data from the Portsmouth sMSP (Sect. 2.1) to study the distribution of the galaxies from our E+A sample on the colour-mass plane. We used the data set portsmouth_stellarmass_starforming_krou-26-sub for the galaxies from SDSS DR8 adopting the Kroupa initial mass function. We identified 96% of the galaxies from our E+A sample in the Portsmouth data base.
Figure 11 shows the distribution of all SDSS galaxies in the u−r versus log M diagram represented by equally-spaced local point density contours. Because of the heavy Malmquist bias we plotted the diagrams for four different z bins (top to bottom): z = 0.02−0.05, 0.05−0.10, 0.10−0.15, 0.15−0.25. In the panels on the left-hand side, the galaxies from the E+A sample are over-plotted as coloured symbols with Hδ-strong galaxies (EW(Hδ) > 5 Å) in red, the others (EW(Hδ) = 3−5 Å) in blue. The mean uncertainties are ~ 0.1 mag in u−r and <0.3 in log M. E+A galaxies are scattered over a relatively wide area of the colour-mass plane. The main conclusion from Fig. 11 is, however, that there is clearly a strong concentration of the E+A sample in the region between the blue cloud and the red sequence, independent of z. This is in agreement with Wong et al. (2012), who argued that their finding is consistent with the idea that E+A galaxies are in the transformation stage between actively evolving galaxies from the blue cloud into passively evolving members of the red sequence. In fact, there is a tendency for stronger Hδ absorption galaxies to be on average somewhat closer to the blue cloud and those with weaker Hδ lines to be closer to the red sequence. However, this trend is significant only in the highest z bin and not seen at lowest z.
 |
Fig. 10 Morphological type probabilities from Galaxy Zoo for the E+A sample (top) and the comparison sample (bottom). The colours indicate different merger probablilities: Pm < 0.1 (black), Pm = 0.1...0.3 (blue), and Pm> 0.3 (red). |
 |
Fig. 11 Colour-mass diagram for the galaxies from the SDSS DR8 (contours) and our E+A galaxies (symbols) for four different redshift ranges (top to bottom). The redshifts are given in the top left corner of each panel. Left column: entire E+A sample, middle and right columns: S82 E+A sample. The histogram on the right-hand side of each panel shows the distribution of u−r. The colours are explained in the insets in the top raw. |
4.4. Merger fraction
4.4.1. Classification of morphological distortions
Galaxy-wide shock fronts in merging gas-rich disks are thought to be a major trigger of starburst activity. According to the Galaxy Zoo data, the fraction of E+A galaxies classified as mergers is remarkably low, only 3% have Pm> 0.3. However, detecting the fine structures that most unambiguously indicate a gravitational perturbation induced by a close encounter or merger event in the past history of a galaxy requires deep imaging. The characteristics of such fine structures depend on the properties of the parent galaxies and the details of the encounter (for details see e.g. Duc & Renaud 2013). Extended tidal structures, remarkable anisotropies, shells, rings, or simply close galaxy pairs are usually taken as indicators of ongoing or past collisions. Tidal tails are considered the most direct signpost of a previous merger, particularly of major mergers of disk galaxies. Such tails are short lived with fall-back times between a few hundred Myr and a few Gyr and can be of very low surface brightness. Generally, a deep surface brightness limit is a basic requirement for the evaluation of such faint morphological structures. The SDSS S82 is perfectly suited for such a task thanks to the combination of the remarkable depth of the co-adds from the multi-epoch imaging, the large field, and the dense spectroscopic coverage (see Sect. 2.2).
Our catalogue of E+A galaxies contains 74 systems in S82. The redshifts are between z = 0.02 and 0.22. Throughout this section, this sample is referred to as the S82 E+A sample. Among them are 18 galaxies from the input catalogue, that is 77% of the sample comes from the present search. The arithmetic median composite spectrum is very similar to the composite spectrum from the input catalogue (Fig. 12). We subdivided this sample into the three subsamples with EW(Hδ) > 5 Å (sample A), 4...5 Å (sample B), and 3...4 Å (sample C). The threshold for EW(Hδ) in sample A corresponds to the stronger selection criterion used by Goto (2007b), but it is worth mentioning that only 17 of the 28 galaxies in that subsample are also in the Goto catalogue, 11 galaxies (39%) are new. Table A.1 lists the galaxies in the three subsamples sorted by increasing z.
We analysed the morphology on the cutouts from the sky-rectified co-added rdeep images provided by Fliri & Trujillo (2016; see Sect. 2.2). The size of the cutouts was set to n·Rp, where Rp is the Petrosian radius of the galaxy and n = 4 turned out to be a good choice in most cases. Figure 13 shows four examples of E+A galaxies with faint tidal structures to illustrate the gain in surface brightness depth by the co-addition.
In some studies (e.g. Reichard et al. 2009), methods for automatic measurements of morphological asymmetries were applied to huge numbers of galaxies. However, if the data set is not too large, the human visual system still remains the most efficient and complete system for pattern recognition. To determine the fraction of mergers or otherwise morphologically distorted galaxies in the E+A sample, we classified the galaxies according to morphological peculiarities recognised by a simple visual inspection.
 |
Fig. 12 Median composite (black) and standard deviations (yellow) from the rest-frame spectra of the subsamples A, B, and C (top to bottom) from the PB-S82 sample. |
Peculiarity types.
 |
Fig. 13 Cutouts from the normal-depth images provided by the SDSS DR12 navigator (left) and from the co-adds provided by Fliri & Trujillo (2016; right, inverted grey scale) for four E+A galaxies. |
As a result of the inspection each galaxy was assigned to one of the types listed in Table 3 and coded by the flag tm. A nearby neighbour galaxy is considered indicative of a perturbation only if the two galaxies are either embedded in a common halo or connected with each other by a light bridge. Types 2 and 3 are the best candidates for mergers. In a few cases (e.g. J211230.60−005022.4 and J223006.83−004031.3 in sample A, and J015012.99+000504.8 and J215738.85+000416.9 in sample B), the intermediate stage of a major merger is clearly indicated. Other galaxies classified as type tm ≥ 2 may represent either minor mergers or older major mergers. In general it is difficult to distinguish faint stellar streams in minor mergers from faded tidal debris in major mergers. Figures B.1 to B.3 show the contrast-enhanced image cutouts for the galaxies assigned to types tm ≥ 2 from the S82 E+A samples A, B, and C. The structure in the bright inner parts of the galaxies is indicated by isophotes equally spaced on a logarithmic scale.
The median values of the morphological type probabilities from the first Galaxy Zoo project (Lintott et al. 2011) are (Pe,Ps,Pm) = (0.64,0.16,0.00) for the S82 E+A sample. These values are very similar to those for the entire E+A sample (Sect. 4.2). Because of its higher completeness in SDSS S82, compared to the SDSS Legacy survey, we can make use of the more detailed classifications from Galaxy Zoo 2 (GZ2; Willett et al. 2013) for the S82 sample. GZ2 includes classifications from co-added images in S82 in addition to the normal-depth images, where two different sets of co-adds were used (co-add1, co-add2). The GZ2 decision tree consists of 11 classification tasks with a total of 37 possible responses. Most relevant for the classification of distorted morphology are task 6 (Is there anything odd?), task 8 (Is the odd feature a ring, or is the galaxy disturbed or irregular?), and task 11 (How many spiral arms are there?).
We used the VizieR catalogue search page at CDS10 to match the S82 E+A sample with the catalogue of morphological types from GZ2. We identified 59 galaxies (80%) from the S82 E+A sample. We restricted the analysis to the following weighted fractions of votes:
-
a14 “something odd”;
-
a21 “odd feature is a disturbed galaxy”;
-
a22 “odd feature is an irregular galaxy”;
-
a23 “odd feature is something else”;
-
a24 “odd feature is a merger”;
-
a31-1 “one spiral arm”.
Table 4 lists the mean weighted fractions for the five different types tm from the present study, defined in Table 3. There is a trend of increasing a14 from tm = 1 to tm = 3, as expected. The trend is stronger for co-add2 than for co-add1. Willett et al. (2013) found that either set of co-adds can likely be used for science, but they recommend using co-add2 if choosing between them. In the following we will use co-add2 data only. Individual values for a14 to a21 are listed in Table A.1 along with tm from the present analysis of the Fliri & Trujillo co-adds.
Mean weighted fractions from GZ2 for different peculiarity types.
No clear-cut correlation with tm is seen for the other GZ2 parameters. In addition, the values of a14,a21,a22, and a24 for the tm = 3 subsample are surprisingly small. For the four galaxies shown in Fig. 13, we find the mean co-add2 values (a14,a21,a22,a24) = (0.48,0.16,0.18,0.20). Similarly, the mean values for the four intermediate-stage mergers mentioned above in Sect. 4.4.1 are (a14,a21,a22,a24) = (0.66,0.12,0.12,0.38). We conclude that the faint morphological distortions found in the E+A galaxies are not adequately reflected by the GZ2 data for a substantial fraction of our sample. The database from the Galaxy Zoo project is definitely of outstanding importance for statistical studies in a wide area of applications, particularly for large samples. For the analysis of low-surface brightness features in small samples, on the other hand, it can eventually not completely supersede a target-oriented detailed visual inspection. The following analysis will be focused on the tm classification.
4.4.2. E+A sample versus control sample
A limitation of the “eyeball” classification of morphology is of course its subjective nature. Drawing conclusions on the relative frequency of distorted morphology of E+A galaxies requires therefore the comparison with a control sample. We defined a control sample of 149 galaxies randomly selected from the SOM in such a way that its z distribution is the same as for the E+A sample. To reduce the risk of a subjective bias towards overestimating peculiarities in the E+A sample it is important to guarantee an unprejudiced evaluation of the images from both samples. Therefore, the image cutouts of the E+A galaxies and the comparison galaxies were put into the same archive and then randomly selected in such a way that the examiner did not know to which sample a galaxy belongs when its image was inspected.
 |
Fig. 14 Merger fractions fm,i in EW(Hδ) bins for the E+A sample (filled squares) and the control sample (open squares). Vertical bars indicate the errors from the Poisson statistics; due to clarity reasons, error bars are given only for the case tm ≥ 1. The colour coding is described in the inset. |
After the classification of the morphological peculiarities, we computed relative “merger fractions” fm = Nm/Ntot, where Nm is the number of mergers and Ntot is the total number of galaxies in the sample. To discuss trends with EW(Hδ) we subdivide also the comparison sample in Comp A with EW(Hδ) > 1 Å and Comp B with EW(Hδ) < 1 Å. Table 6 lists statistical properties of the three S82 E+A samples and the comparison samples: the number N of galaxies and the mean values (with standard deviation) of redshift z, stellar mass log M∗/M⊙, and stellar age τ∗. The latter two quantities were taken from the Portsmouth sMSP data base (see Sect. 4.3). In the bottom part of Table 6, the different measurements of the relative frequency of mergers fm are listed.
In Fig. 14, we plotted fm,i (i = 1,2,3 and 1,ul) versus the mean EW(Hδ) for the five samples from Table 6. The data points were interconnected just to guide the eye. The main result is that E+A galaxies with EW(Hδ) > 4 Å have a higher merger fraction fm, though the formal error bars are large. To check whether the difference is significant or not we applied the statistical test for the comparison of two relative frequencies described by Sachs (1982). The null hypothesis, 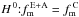 is tested against the alternative hypothesis
is tested against the alternative hypothesis 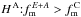 at an error probability α. The null hypothesis H 0 is rejected in favour of H A if the test statistics
at an error probability α. The null hypothesis H 0 is rejected in favour of H A if the test statistics ![\begin{equation} \hat{z} = \frac{f_{\rm m}^{\rm \, E+A}-f_{\rm m}^{\rm \, C}}{\sqrt{f_{\rm m}^{\rm \, T}\cdot \Big[1-f_{\rm m}^{\rm \, T}\Big]}}\cdot \sqrt{\frac{N_{\rm m}^{\rm \, E+A}\cdot N_{\rm m}^{\rm C}}{N_{\rm m}^{\rm \, T}}}, \label{eq:statistics} \end{equation}](/articles/aa/full_html/2017/01/aa29139-16/aa29139-16-eq214.png) (1)is larger than a critical value ẑα. The upper indices indicate the sample with C = comparison and T = total (i.e. E+A plus comparison sample). For the statistical test we excluded the subsample C and considered only E+A galaxies with EW(Hδ) > 4 Å. We combined the S82 E+A subsamples A and B and compared that test sample with the control sample.
(1)is larger than a critical value ẑα. The upper indices indicate the sample with C = comparison and T = total (i.e. E+A plus comparison sample). For the statistical test we excluded the subsample C and considered only E+A galaxies with EW(Hδ) > 4 Å. We combined the S82 E+A subsamples A and B and compared that test sample with the control sample.
Table 5 lists the relative fractions fm and the test statistics ẑ based on tm in the upper part and on GZ2 S82 co-add2 weighted fractions in the bottom part. In the upper part, the number of distorted galaxies (“mergers”) is defined as Nm = N(tm ≥ i). As an upper limit for the observed relative merger frequency we consider the case i = 1; ul with Nm = N(tm ≥ 1) + N(tm = −1). For the GZ2 data we used Nm(a) = N(a>acrit) with the liberal criterion acrit = 0.5. The relative frequency of mergers is fm = fm,i = N(tm ≥ i) /Ntot where i = 1; ul means fm,1;ul = [N(tm ≥ 1) + N(tm = −1)] /Ntot, which can be considered as a kind of an upper limit for the observed relative merger frequency. The relative merger frequencies from the GZ2 data are defined as fm(a) = Nm(a>acrit) /Ntot using the moderate criterion acrit = 0.5. We found ẑ> 3 for the four selections based on tm and also for the GZ2 parameters a14 and a22. These ẑ values are clearly larger than ẑα = 2.58 for the (low) error probability α = 0.01. Consequently, H 0 has to be rejected in favour of H A at an error probability less than 1% for these tests. We conclude that both our tm classifications and the GZ2 data support the view that the E+A sample has a significantly higher merger fraction than the control sample.
Comparison of relative fractions of morphological distortions in the E+A samples A and B with the control sample C.
Statistical properties in dependence on EW(Hδ) for the S82 E+A samples (PSB) and the comparison sample (Comp).
4.4.3. Trends with age
In a simple one-generation starburst population, the Hδ absorption line reaches a maximum at an age of 0.1–1 Gyr when the continuum is dominated by the A stars. The strength of the Hδ line is thus an age indicator (e.g. Reichard et al. 2009). The Portsmouth sMSP database provides information on the ages of the stellar population in the SDSS galaxies derived by the fit of stellar population models to the observed SDSS photometry. On the basis of a set of single stellar populations, composite population models were created adopting different star formation histories. Exponentially declining SFRs are parametrised as SFR(t) = SFR(t0) × exp−(t−t0) /τ, where the SFR starts at the time t0. At a cosmic time t, the age derived for a galaxy from the best fit is then defined as the time t−t0 elapsed since the beginning of star formation in the best-fitting population model. This value is not necessarily identical with the true age of the galaxy, but can be taken as a measure of the age of the stellar population dominating the optical luminosity. As in Sect. 4.3, we used the data set portsmouth_stellarmass_starforming_krou-26-sub for the galaxies from SDSS DR8.
 |
Fig. 15 Stellar age versus EW(Hδ) for the galaxies from the E+A sample (filled squares) and from the control sample (open squares). The two filled squares with downward arrows indicate ages <0.25 Gyr. The red asterisks are mean ages in the EW(Hδ) bins indicated by the horizontal bars, the vertical bars are 1σ standard deviations. |
 |
Fig. 16 Merger fraction fm,i in age bins for the combined S82 sample (E+A sample plus comparison sample). Colours and error bars as in Fig. 14. |
Figure 15 shows the sMSP age as a function of EW(Hδ) for the combined sample of E+A galaxies plus the galaxies from the comparison sample. Most of the E+A galaxies have ages <2 Gyr. For the vast majority in the S82 E+A sample A, the age is slightly smaller than 1 Gyr, which is consistent with previous results (Poggianti et al. 1999; Goto 2007a). For the galaxies with EW(Hδ) = 0–3 Å from the comparison sample, on the other hand, the scatter is much larger. This sample includes both systems dominated by old stars and such systems dominated by a young stellar population. The mean age increases from 0.93 ± 0.72 Gyr for sample A, to 1.14 ± 0.59 Gyr for sample B, 1.46 ± 0.59 Gyr for sample C, and more than 3 Gyr for the comparison sample (Table 6). In Fig. 15, we over plotted the ages averaged in EW(Hδ) bins of the width 1 Å, starting at EW(Hδ) = 0.5 ± 0.5. The mean ages continuously decrease with EW(Hδ) from ~ 5 Gyr to ~ 800 Myr, though the scatter is large.
We used the sMSP ages to study the dependence of the merger fraction on the stellar population age. Figure 16 shows fm in six age bins, again for the combined sample of S82 E+A plus comparison galaxies. The merger fraction increases with decreasing age for ages ≲2 Gyr. The coincidence with the characteristic relaxation time of a galaxy after a merger (e.g. Bournaud et al. 2005; Duc & Renaud 2013) hints at a causal connection between the starbursts and the morphological perturbations. In the youngest age bin (<0.5 Gyr), the percentage of distorted galaxies reaches 71% (82%) for tm ≥ 2 (tm ≠ 0), compared to ≲20% (30%) for the old (>2 Gyr) subsample that is dominated by the galaxies from the comparison sample. There are 17 galaxies with age <0.5 Gyr in the combined sample, among them 11 E+A galaxies (65%). For the E+A galaxies with age <0.5 Gyr we find 73% (91%), which is comparable with 75% found by Sell et al. (2014) for a sample of 12 massive, young PSB galaxies at z ~ 0.6 studied on HST images. The high merger fraction of 67% (67%) for the comparison galaxies in that age bin is not surprising, given that a young sMSP age may indicate an ongoing starburst.
The panels in the middle row and on the right-hand side of Fig. 11 show the locations of the S82 E+A galaxies in the colour-mass plane. With very few exceptions, the galaxies populate the area between the blue cloud and the red cloud, as was found already for the entire E+A sample. In the middle row, sample A galaxies are shown in red, sample B and C in blue. There is a weak trend for galaxies with stronger Hδ lines to be on average slightly bluer. Because of the correlation of EW(Hδ) with the age of the stellar population (Fig. 15), this is consistent with the idea that E+A galaxies are in a rapid transition phase from the blue cloud towards the red cloud. No such trend is seen in the morphological distortions on the right-hand side of Fig. 11.
The Portsmouth sMSP also provides estimates of the SFR. However, only three galaxies from the S82 E+A sample have SFR> 0 (J020505.99−004345.1, J025850.52 + 003458.7, J225506.79 + 005840.0), all three belong to sample A. Their specific star formation rates sSFR = SFR/ (M∗/M⊙) = 0.04,0.003, and 0.025 Gyr-1 place them into the transition region between the blue cloud of star forming galaxies and the red sequence in the sSFR-M∗ diagram (see Heckman & Best 2014, Fig. 2). For log M∗/M⊙ ≈ 10.1 (Table 6), this transition occurs at sSFR ≈ 0.02 Gyr-1, corresponding to a SFR ≈ 0.2 M⊙ yr-1. The zero SFR from the Portsmouth data for the vast majority of the galaxies in our sample is thus in agreement with the idea that we selected galaxies where the star formation is quenched.
4.5. Hidden AGNs
Interactions and mergers are believed to provide an important channel for fuelling the central supermassive black hole and triggering AGNs. The energetic feedback from the AGN is thought to play a role in the co-evolution of galaxies and supermassive black holes (see for reviews Fabian 2012; Heckman & Best 2014). There are two categories of AGN feedback: the radiative mode and the jet mode.
A classical radiative-mode AGN of type 1 is characterised by a blue continuum and strong and broad emission lines. As a consequence of the selection criteria (Sect. 4.1), the E+A sample is lacking luminous type 1 AGNs. However, the central region of a galaxy can be hidden by dust, especially when the sight line is near to the plane of the putative obscuring torus (type 2 AGN) or crosses dense molecular clouds in the host galaxy. The latter case is particularly relevant in the context of the merger driven AGN scenario with “wet” mergers where lots of gas and dust are concentrated towards the central region (Sanders et al. 1988; Hopkins et al. 2006; Bennert et al. 2008). The integrated energy density of the cosmic X-ray background suggests that supermassive black holes grow mostly during phases when the AGN is obscured (Fabian & Iwasawa 1999). Highly obscured AGNs seem to prefer infrared luminous galaxies (Symeonidis et al. 2013) and were found in morphologically disturbed hosts (Urrutia et al. 2008; Koss et al. 2011).
In this Section, the final catalogue of all E+A galaxies is used to search for candidates of optically hidden AGNs.
4.5.1. Mid infrared selection
The presence of an optically hidden AGN can be indicated by the thermal emission in the infrared. Luminous AGNs are robustly differentiated from galaxies and stars by their red mid-infrared (MIR) colours. We exploited the database from the Wide-field Infrared Survey Explorer (WISE; Wright et al. 2010). WISE performed an all-sky survey with images in four broad bands W1 to W4 around the central wavelengths 3.4, 4.6, 12, and 22 μm. The difference of the magnitudes W1 and W2 is typically ~ 1 mag for low-redshift quasars. An efficient selection threshold for quasars is provided by the colour criterion W1−W2 ≥ 0.8 (Assef et al. 2010; Stern et al. 2012). For a low-luminosity AGN the spectrum is diluted by stellar radiation from the host galaxy and the MIR colours depend on the AGN-to-host ratio. For early-type hosts W1−W2 becomes smaller with a decreasing ratio. A modestly extincted AGN in an early-type galaxy of the same luminosity is still expected to produce W1−W2 ≈ 0.7 at z ≲ 0.3 (see Figs. 1 and 2 in Stern et al. 2012). However, if the flux from the AGN is less than half of the host flux in the WISE bands, the integrated colour index will hardly exceed W1−W2 ≈ 0.5.
 |
Fig. 17 WISE mid infrared two-colour diagram for the E+A galaxies (blue crosses for EW(Hδ) = 3−5 Å, red squares for EW(Hδ) > 5 Å). The contour curves indicate the distributions of 9468 SDSS galaxies with 0.02 ≤ z ≤ 0.25 (green) and of 2373 SDSS quasars with z< 0.5 (black), respectively. Dashed vertical line: AGN selection threshold. |
We identified counterparts in the AllWISE Source Catalogue for 95% of the E+A galaxies from our catalogue within a search radius of 3 arcsec. The size of the WISE detected subsample is strongly reduced, however, when a good S/N is required. Figure 17 shows the W1−W2 versus W3−W4 two-colour diagram for the 310 galaxies with S/N> 5 for W1,W2,W3, and >2 for W4. The E+A galaxies from our catalogue are plotted as blue plus signs, filled red squares represent the 126 E+A galaxies fulfilling the stronger selection criteria from Goto’s catalogue (in particular EW(Hδ) > 5 Å). The distribution of quasars and normal galaxies is over-plotted for comparison. Among the 6231 quasars with z< 0.5 from the SDSS DR7 quasar catalogue (Schneider et al. 2010; Shen et al. 2011), 2373 have reliable measurements in W3 and W4 (sigma < 0.3 mag). Their locus on the two-colour plane is shown by the black equally spaced local point density contours. We identified WISE counterparts of 83 844 SDSS galaxies with z = 0.02−0.25 from the Portsmouth sMSP database. The green contour curves show the 9468 galaxies with S/N> 5 for W1,W2,W3, and >3 for W4. The dashed vertical line indicates the demarcation W1−W2 = 0.8.
The vast majority of our E+A galaxies with reliable WISE measurements populate the region below the AGN demarcation line, the mean colour is W1−W2 = 0.27 ± 0.20. Only 10 sources are classified as AGN candidates based on the W1−W2 criterion corresponding to 3% of the plotted E+A galaxies, their mean colour is W1−W2 = 0.92 ± 0.11. The WISE E+A sample becomes much larger (2 569 galaxies) when there are no restrictions made on S/N in the W3 and W4 bands, which are not necessary for the AGN selection. However, there is no additional E+A galaxy with W1−W2 > 0.8 in this larger sample, and the corresponding fraction of AGN candidates becomes as small as 0.4%. There is no obvious trend of W1−W2 with EW(Hδ). None of the AGN candidates is lying in S82.
The depth of WISE at 22 μm is significantly shallower than in the other bands. Non-detection and low S/N in the W4 band are the main reasons for the strong reduction of the galaxy sample in Fig. 17. Mateos et al. (2012) presented an AGN selection criterion based on the first three WISE bands. It was defined using a large complete flux-limited sample of bright hard-X-ray-selected AGNs of types 1 and 2. Figure 18 shows the E+A sample in the log(F4.6 μm/F3.4 μm) versus log(F12 μm/F4.6 μm) two-colour diagram in the same style as presented by Mateos et al. (2012), where F = Fν is the monochromatic flux density per frequency interval. The selection criteria for the E+A galaxies are the same as in Fig. 17, but without restriction on S/N in the W4 band. The number of galaxies is now 596 (blue plus signs), among them 232 fulfilling the stronger Goto selection criteria (red squares). The “AGN wedge” is indicated by the green solid lines. 18 galaxies (3%) are located in the AGN wedge. The dashed line illustrates the MIR power-law locus for different spectral indices (taken from Mateos et al. 2012, Fig. 6). Mateos et al. (2012) found a strong dependence of log(F4.6 μm/F3.4 μm) on the X-ray luminosity. Luminous quasars, expected to dominate the MIR emission, are preferentially located above the power-law locus. Less powerful AGNs, where the contribution from the host galaxy emission becomes significant, have bluer colours at the shortest WISE wavelengths, consistent with normal galaxies. As found by Mateos et al. (2012) for their sample of X-ray AGNs, the log(F12 μm/F4.6 μm) colour of the E+A sample shows a large scatter at blue log(F4.6 μm/F3.4 μm) colours. They argued that such a broad range is expected for AGNs of lower luminosities with an important host galaxy contribution.
 |
Fig. 18 WISE mid infrared two-colour diagram for the E+A galaxies based on the three WISE bands at 3.4, 4.6, and 12 μm. Symbols as in Fig. 17. The green lines indicate the AGN selection suggested by Mateos et al. (2012). |
 |
Fig. 19 SED of E+A samples with EW(Hδ) > 5 Å (red) and 3–5 Å (blue), and of AGNs from WISE (black). Magenta curves: two-component model from Melnick & De Propris (2013) for PSB galaxies (solid) and three-component model from Melnick et al. (2015) for post-starburst quasars (dashed). Green line: power law Fλ ∝ λ-1.5. |
The distribution of the E+A galaxies in the W1−W2 versus W3−W4 diagram (Fig. 17) is shifted towards redder W3−W4 compared to the distribution of the typical SDSS galaxies. Melnick & De Propris (2013) found that all galaxies in their PSB sample show significant excess at MIR wavelengths, in particular in W3 and W4, compared to the galaxy model SED. Figure 19 shows the composite rest-frame MIR SEDs of our E+A subsamples with EW(Hδ) > 5 Å (red) and EW(Hδ) = 3−5 Å (blue), normalised at the de-redshifted wavelength of the W1 band. The coloured squares with vertical error bars are the mean values and 1σ standard deviations in the four WISE bands, the horizontal bars indicate the wavelength range covered by the rest-frame central wavelengths in each band. The selection criteria are the same as in Fig. 17. We also plotted the individual SEDs of the 18 AGN candidates from the WISE three-band selection, where the data points in the four bands where interconnected solely to guide the eye. For comparison we over-plotted the MIR part of the best-fit two-component model SEDs used by Melnick & De Propris (2013) to analyse a sample of PSB galaxies with EW(Hδ) > 5 Å (solid magenta) and the three-component model presented by Melnick et al. (2015) to fit the SED of PSB quasars (dashed magenta). The former invokes, in addition to the modelled star light, a 300 K blackbody from hot dust to fit the MIR excess. The dust may be heated by an embedded AGN, though other sources are possible as well (young star clusters or asymptotic giant branch stars). For the PSB quasars Melnick et al. (2015) added a power law component with Fλ ∝ λ-1.5 (green diagonal line) to match the flatter MIR SED. The best-fit two-component model perfectly fits the WISE data of our E+A subsample with stronger Hδ (red). The E+A galaxies with EW(Hδ) = 3−5 Å (blue) have on average a weaker MIR bump. The situation is less clear for the AGN candidates. At short WISE wavelengths, the decline is weaker because of the selection criterion, and the SED is fitted by the three-component model, which is dominated there by the power-law component. Contrary to the whole E+A sample, the majority (~ 72%) of the AGN candidates do obviously not require a substantial blackbody component.
 |
Fig. 20 WISE colour index W1−W3 as a function of the EW of Hδ (left) and Hα (right). The blue diagonal lines are the linear regression curves. |
Melnick & De Propris (2013) found that the MIR excess is correlated with the intrinsic reddening. In Fig. 20, we show that the excess, expressed by the colour index W1−W3, is also correlated with the strength of the optical lines. Stronger excesses are observed in galaxies with larger EW(Hδ) and smaller EW(Hα). These correlations can be explained by a reddened emission line component (AGN or starburst) in addition to the PSB stellar component.
4.5.2. Radio selection
For a jet-mode AGN optical emission lines can be weak or absent, but the AGN can still be detected at moderate or weak radio luminosity. We exploited the source catalogue from the Faint Images of the Radio Sky at Twenty Centimeters (FIRST; Becker et al. 1995; Helfand et al. 2015). There was no E+A galaxy in Stripe 82 identified with a FIRST source. Also the inspection of the radio images from the High-Resolution VLA Imaging of the SDSS Stripe 82 (Hodge et al. 2011) did not reveal any radio counterpart.
Next we matched the entire E+A catalogue with the FIRST source catalogue. Using a search radius of 5′′ we identified FIRST counterparts of 47 E+A galaxies. All identified FIRST galaxies appear unresolved in the FIRST image cutouts. Because of the (by definition) weak or missing emission lines in the spectra of E+A galaxies, it is difficult to distinguish AGNs from starburst origin of the radio emission in terms of diagnostic line ratios. In a statistical sense, the different radio luminosity functions of AGNs and star forming galaxies can be used for the discrimination, because AGNs become more frequent with increasing radio luminosity. We used the integrated FIRST fluxes F1.4,int to compute the monochromatic luminosity at 1.4 GHz (rest frame) 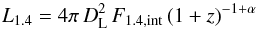 (2)(see e.g. Morrison et al. 2003; Nielsen et al. 2012), where a power law Fν ∝ ν−α was adopted with α = 0.8 in the radio domain; DL is the luminosity distance.
(2)(see e.g. Morrison et al. 2003; Nielsen et al. 2012), where a power law Fν ∝ ν−α was adopted with α = 0.8 in the radio domain; DL is the luminosity distance.
 |
Fig. 21 Histogram distribution of the monochromatic 1.4 GHz luminosities (black: all, red: radio-loud) for the E+A sample. |
The distribution of L1.4 is shown in Fig. 21. All FIRST E+A galaxies have log L1.4> 23, the mean value is 24.9 ± 0.7, where L1.4 is in Ws. Eight galaxies (17%) are classified as radio-loud when the criterion Ri> 1 is applied to the radio-loudness parameter Ri from Ivezić et al. (2002)11. Their radio luminosity distribution is clearly shifted to higher values (mean value log L1.4 = 25.6 ± 0.5). Following Sadler et al. (2002), AGNs dominate the radio luminosity distribution for L1.4> 1023 Ws. All 47 FIRST E+A galaxies have luminosities above that threshold. This result remains qualitatively unchanged when we correct for the different cosmological model used by Sadler et al. (2002). We conclude that the majority of the FIRST E+A galaxies likely host AGNs.
4.5.3. X-ray selection
For completeness we briefly mention that X-rays provide an alternative way to identify AGNs, complementing the optical, MIR, and radio identification techniques. X-ray surveys have identified thousands of AGNs, contributing significantly to our knowledge of this object class and may lead to the discovery of otherwise hidden AGNs (e.g. Mateos et al. 2012; Civano et al. 2014; Paggi et al. 2016). With the exception of the most heavily obscured AGNs, surveys with the X-ray satellite missions XMM-Newton and Chandra are sensitive to all types of AGNs. Based on the analysis of XMM-Newton and Chandra data overlapping ~ 16.5 deg2 of S82, LaMassa et al. (2013) presented a compilation of 3362 unique X-ray sources detected at high significance. We matched our S82 E+A list to this X-ray catalogue with a search radius of 10 arcsec. In no case an X-ray counterpart was found.
4.5.4. E+A sample versus control sample
The relative fractions of AGN candidates in the E+A sample have to be compared with those in a control sample. We constructed a comparison sample in the following way. For each galaxy i from the E+A sample with redshift zi and mass log Mi we selected a galaxy in the Portsmouth sMSP catalogue with z ∈ (zi−0.015,zi + 0.015) and log M ∈ (log Mi−0.1,log Mi + 0.1). Thus, the E+A sample and the control sample have the same distribution on the z-log M plane. The control sample was matched with the AllWISE Source Catalogue and with the FIRST catalogue in the same way as the E+A sample.
We applied the statistical test from Sect. 4.4.2 to compare the relative AGN frequencies from the E+A sample with the control sample. The results are listed in Table 7. The null hypothesis, H 0: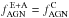 is tested against the alternative hypothesis H A:
is tested against the alternative hypothesis H A: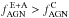 at an error probability α = 0.01. The null hypothesis H 0 is retained for the WISE two-band selection. On the other hand, H 0 is rejected in favour of H A for the WISE three-band selection. The fraction of AGN candidates selected by the two-colour AGN wedge in Fig. 18 is significantly larger for the E+A galaxies.
at an error probability α = 0.01. The null hypothesis H 0 is retained for the WISE two-band selection. On the other hand, H 0 is rejected in favour of H A for the WISE three-band selection. The fraction of AGN candidates selected by the two-colour AGN wedge in Fig. 18 is significantly larger for the E+A galaxies.
Comparison of relative AGN fractions in the E+A sample and the control sample.
The opposite is found for the radio selection: The control sample shows a significantly larger relative fraction of FIRST sources than the E+A sample. For the brightness range of our sample (z-band magnitude ≲18), Ivezić et al. (2002) found that FIRST galaxies represent about 5% of all SDSS galaxies, in agreement with ~4% found here for the control sample. The fraction of 1.8% FIRST galaxies among the E+A galaxies is thus rather small. However, the direct comparison of these values is difficult because of the different nature of the samples. FIRST SDSS galaxies are dominated by galaxies from the red sequence (u−g ≈ 3, Ivezić et al. 2002), whereas the E+A galaxies typically lie between the blue cloud and the red sequence (Fig. 11). The mean age of the FIRST E+A galaxies is 1.7 Gyr compared to 2.3 Gyr for FIRST galaxies in the control sample. On the other side, the distribution of the radio luminosities is very similar for the two samples (compare Figs. 21 and 22). The difference between the radio-loudness fractions is statistically insignificant (Table 7).
4.5.5. Properties of the AGN candidates
The combination of the WISE selection and the FIRST selection yields a sample of 62 AGN candidates (2.3%) among the E+A sample: 18 objects from WISE and 47 from FIRST with an overlap of three objects in both samples.
Figure 23 compares the composite spectrum of the WISE AGN candidates (top) with that of the FIRST E+A galaxies, where we distinguish between radio-quiet (middle) and radio-loud ones (bottom). The differences are only subtle. What is most conspicuous is the somewhat stronger emission from [N ii]λ6584 and [O iii]λ5007 in the WISE-selected composite (top).
Some properties of the AGN subsamples are listed in Table 8, compared with the whole E+A sample. The distribution on the colour-mass plane is shown in Fig. 24. The strongest difference is the higher mean redshift of the FIRST E+A galaxies. Both AGN subsamples have somewhat higher mean masses compared to the entire E+A sample. The percentage of galaxies with log M/M⊙ > 10.3 is 51% for all E+A, but 68% for the radio-detected and 88% for the radio-loud sources. It is known that radio galaxies in optical and radio flux limited samples tend to be biased towards higher z and thus towards higher optical luminosities and stellar masses (Ivezić et al. 2002). However, the tendency to be related to higher stellar masses is indicated for both AGN candidate samples and is seen in each panel of Fig. 24. In each z bin, the distribution of the AGN candidates is centred on a somewhat higher mass than the corresponding E+A sample. The stellar ages show a wide scatter, the median values are 1.14, 0.90, and 1.14 Gyr for the FIRST, the WISE, and the total sample, respectively. Both AGN candidate samples have on average stronger Hδ absorption and stronger O ii emission lines. No significant differences are seen in the morphological type probabilities from Galaxy Zoo.
Statistical properties of the AGN candidates from FIRST and WISE compared with the entire E+A sample.
Finally, we briefly discuss whether the E+A galaxies in our sample are massive enough for a supermassive black hole in the centre. The expected mean black hole mass MBH can be estimated from the scaling relation between MBH and the mass Msph of the spheroidal component of a galaxy. The mean stellar mass from the Portsmouth sMSP database is log M∗/M⊙ = 10.22 (Table 8). We assumed a ratio Msph/M∗ = 0.5...1 because the deep S82 co-adds clearly indicate the presence of a significant spheroidal component for many E+A galaxies. The empirical MBH−Msp relation for galaxies with log Msph/M⊙ ≲ 10.5 derived by Scott et al. (2013) yields log MBH/M⊙ = 7.0...7.7. Masses in this range are typical of AGNs in the local Universe. Greene & Ho (2007) reported a characteristic mass of log MBH/M⊙ = 7.0 for the local populations of broad and narrow-line AGNs. Recently, Kara et al. (2016) listed BH masses for 11 Seyfert galaxies with reverberation detections, the mean mass is log MBH/M⊙ = 7.0 ± 0.6. Even values as small as MBH ≈ 106M⊙ are not unreasonable for Seyfert galaxies (e.g. Greene & Ho 2007; Bentz et al. 2016a,b).
5. Summary and conclusions
E+A galaxies are thought to represent PSB galaxies in the transition from the blue cloud to the red sequence of galaxies (and perhaps back). We created a large sample of local E+A galaxies from the spectra database of the SDSS. The selection is based on a Kohonen SOM for ~ 106 spectra from SDSS DR7. The process takes advantage of the clustering behaviour of Kohonen maps. We developed an interactive user interface based on modern web techniques for navigating through huge SOMs. Both the SDSS DR7 Kohonen map and the user interface are made available for the community. Using the catalogue of 837 E+A galaxies with EW(Hδ) > 5 Å from Goto as input catalogue, we selected a large sample of similar galaxies from the Kohonen map and compiled a new list of 2665 E+A galaxies with EW(Hδ) > 3 Å in the redshift range z = 0−0.4.
We used the galaxy data from the Portsmouth galaxy property computations to study particularly the distribution of the E+A galaxies in the colour-mass diagram. We have shown that the E+A galaxy sample is clearly concentrated towards the green valley between the red sequence and the blue cloud, independent of the redshift. There is a weak tendency for strong Hδ galaxies to be closer to the blue cloud. These findings are in agreement with the idea that PSB galaxies represent the transitioning phase between actively and passively evolving galaxies.
 |
Fig. 23 Median composite (black) and standard deviations (yellow) for a) 18 AGN candidates from the WISE three-band selection; b) 39 radio-quiet FIRST sources; c) 8 radio-loud FIRST sources. |
 |
Fig. 24 Colour-mass diagrams for the AGN candidates with z< 0.25 from WISE (green) and FIRST (magenta) in four redshift bins. The FIRST sources are subdivided in radio-loud (RL = filled squares) and radio-quiet (RQ = open squares). The contour curves show the distributions of all SDSS galaxies (black) and of our E+A galaxies (blue, dashed). |
It is commonly believed that galaxy interactions and wet mergers play a major role for triggering starburst activity. It was one of the main aim of this study, to create a sizable sample of E+A galaxies in the SDSS S82 that can be used to investigate the morphological peculiarities on the deep co-added images of the SDSS multi-epoch observations in S82. We exploited the new deep co-adds from Fliri & Trujillo (2016) to analyse 74 local E+A galaxies found in S82 along with galaxies from a randomly selected control sample with the same z distribution. We identified morphological peculiarities in many E+A galaxies. The relative frequency of distorted galaxies in the E+A sample is significantly higher than in the control sample and indicates a trend with the age of the stellar population. In the youngest age bin (<0.5 Gyr), at least 73% of the E+A galaxies are classified as distorted or merger.
Our study confirms that AGNs are rare in E+A galaxies, unless they are heavily obscured or Compton thick. We identified 18 E+A galaxies in the AGN wedge of the WISE three-band colour-colour diagram and 47 galaxies selected as FIRST 1.4 GHz sources, with only a small overlap of these two samples. Based on the 1.4 GHz luminosities we argue that the majority of the FIRST sources are related to AGNs rather than star formation. The corresponding AGN fractions are 2.8% for the MIR selection and 1.8% for the radio selection. The radio AGN fraction is significantly lower than in the comparison sample, whereas the MIR AGN fraction is higher. We also confirm the MIR excess found by Melnick & De Propris (2013) for the majority of our E+A galaxies. The origin of this excess may be dust heated by young stars or low-luminosity AGNs. These results are not in contradiction with a scenario where stellar mass and black hole mass grow simultaneously in massive galaxies and where suppression of star formation and AGN activity rapidly follow each other.
Acknowledgments
The anonymous referee is thanked for helpful comments and suggestions. This research has made use of data products from the Sloan Digital Sky Survey (SDSS). Funding for the SDSS and SDSS-II has been provided by the Alfred P. Sloan Foundation, the Participating Institutions (see below), the National Science Foundation, the National Aeronautics and Space Administration, the US Department of Energy, the Japanese Monbukagakusho, the Max Planck Society, and the Higher Education Funding Council for England. The SDSS Web site is http://www.sdss.org/. The SDSS is managed by the Astrophysical Research Consortium (ARC) for the Participating Institutions. The Participating Institutions are: the American Museum of Natural History, Astrophysical Institute Potsdam, University of Basel, University of Cambridge (Cambridge University), Case Western Reserve University, the University of Chicago, the Fermi National Accelerator Laboratory (Fermilab), the Institute for Advanced Study, the Japan Participation Group, the Johns Hopkins University, the Joint Institute for Nuclear Astrophysics, the Kavli Institute for Particle Astrophysics and Cosmology, the Korean Scientist Group, the Los Alamos National Laboratory, the Max-Planck-Institute for Astronomy (MPIA), the Max-Planck-Institute for Astrophysics (MPA), the New Mexico State University, the Ohio State University, the University of Pittsburgh, University of Portsmouth, Princeton University, the United States Naval Observatory, and the University of Washington. This publication has made extensive use of the VizieR catalogue access tool, CDS, Strasbourg, France and of data obtained from the NASA/IPAC Infrared Science Archive (IRSA), operated by the Jet Propulsion Laboratories/California Institute of Technology, founded by the National Aeronautic and Space Administration. In particular, this publication makes use of data products from the Wide-field Infrared Survey Explorer, which is a joint project of the University of California, Los Angeles, and the Jet Propulsion Laboratory/California Institute of Technology, funded by the National Aeronautics and Space Administration.
References
- Abazajian, K., Adelman-McCarthy, J., Agüeros, M., et al. 2009, ApJS, 182, 543 [NASA ADS] [CrossRef] [Google Scholar]
- Ahn, C. P., Alexandroff, R., Allen de Prieto, C., et al. 2014, ApJS, 211, 17 [NASA ADS] [CrossRef] [Google Scholar]
- Alam, S., Albareti, F. D., Allen de Prieto, C., et al. 2015, ApJS, 219, 12 [NASA ADS] [CrossRef] [Google Scholar]
- Annis, J., Soares-Santos, M., Strauss, M., et al. 2014, ApJ, 794, 120 [NASA ADS] [CrossRef] [Google Scholar]
- Assef, R. J., Kochanek, C. S., Brodwin, M., et al. 2010, ApJ, 713, 970 [NASA ADS] [CrossRef] [Google Scholar]
- Baldry, I. K., Glazebrook, K., Brinkmann, J., et al. 2004, ApJ, 600, 681 [NASA ADS] [CrossRef] [Google Scholar]
- Balogh, M. L., Miller, C., Nichol, R., Zabludoff, A., & Goto, T. 2005, MNRAS, 360, 587 [NASA ADS] [CrossRef] [Google Scholar]
- Barton, E. J., Geller, M. J., & Kenyon, S. J. 2000, ApJ, 530, 660 [NASA ADS] [CrossRef] [Google Scholar]
- Becker, R. H., White, R. L., & Helfand, D. J. 1995, ApJ, 450, 559 [NASA ADS] [CrossRef] [Google Scholar]
- Bennert, N., Canalizo, G., Jungwiert, B., et al. 2008, ApJ, 677, 846 [NASA ADS] [CrossRef] [Google Scholar]
- Bentz, M. C., Batiste, M., Seals, J., et al. 2016a, ApJ, 831, 2 [NASA ADS] [CrossRef] [Google Scholar]
- Bentz, M. C., Cackett, E. M., Crenshaw, D. M., et al. 2016b, ApJ, 830, 136 [NASA ADS] [CrossRef] [Google Scholar]
- Bergvall, N., Marquart, T., Way, M. J., et al. 2016, A&A, 587, A72 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Blanton, M. R., Hogg, D. W., Bahcall, N. A., et al. 2003, ApJ, 594, 186 [NASA ADS] [CrossRef] [Google Scholar]
- Booth, C. M., & Schaye, J. 2013, Sci. Rep., 1738 [Google Scholar]
- Bournaud, F., Jog, C. J., & Combes, F. 2005, A&A, 437, 69 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Brinchmann, J., Charlot, S., White, S. D. M., et al. 2004, MNRAS, 351, 1151 [NASA ADS] [CrossRef] [Google Scholar]
- Brotherton, M. S., van Breugel, W., Stanford, S. A., et al. 1999, ApJ, 520, L87 [NASA ADS] [CrossRef] [Google Scholar]
- Cales, S. L., & Brotherton, M. S. 2015, MNRAS, 449, 2374 [NASA ADS] [CrossRef] [Google Scholar]
- Choi, Y., Goto, T., & Yoon, S.-J. 2009, MNRAS, 395, 637 [NASA ADS] [CrossRef] [Google Scholar]
- Civano, F., Fabbiano, G., Pellegrini, S., et al. 2014, ApJ, 790, 16 [NASA ADS] [CrossRef] [Google Scholar]
- Couch, W. J., & Sharples, R. M. 1987, MNRAS, 229, 423 [NASA ADS] [CrossRef] [Google Scholar]
- De Propris, R., & Melnick, J. 2014, MNRAS, 439, 2837 [NASA ADS] [CrossRef] [Google Scholar]
- Di Matteo, P., Combes, F., Melchior, A.-L., & Semelin, B. 2007, A&A, 468, 61 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dressler, A., & Gunn, J. E. 1983, ApJ, 270, 7 [NASA ADS] [CrossRef] [Google Scholar]
- Dressler, A., & Gunn, J. E. 1992, ApJS, 78, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Duc, P.-A., & Renaud, F. 2013, Lect. Notes Phys. 861, eds. J. Souchay, S. Mathis, & T. Tokieda (Berlin: Springer Verlag), 327 [Google Scholar]
- Ester, M., Kriegel, H.-P., Sander, J., & Xu, X. 1998, Data Min. Knowl. Discov., 2, 169 [CrossRef] [Google Scholar]
- Fabian, A. C. 2012, ARA&A, 50, 455 [NASA ADS] [CrossRef] [Google Scholar]
- Fabian, A. C., & Iwasawa, K. 1999, MNRAS, 303, L34 [NASA ADS] [CrossRef] [Google Scholar]
- Fliri, J., & Trujillo, I. 2016, MNRAS, 456, 1359 [NASA ADS] [CrossRef] [Google Scholar]
- Gabor, J. M., Davé, R., Oppenheimer, B. D., & Finlator, K. 2011, MNRAS, 417, 2676 [NASA ADS] [CrossRef] [Google Scholar]
- Georgakakis, A., Nandra, K., Yan, R., et al. 2008, MNRAS, 385, 2049 [NASA ADS] [CrossRef] [Google Scholar]
- Goto, T. 2004, A&A, 427, 125 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Goto, T. 2005, MNRAS, 357, 937 [NASA ADS] [CrossRef] [Google Scholar]
- Goto, T. 2007a, MNRAS, 381, 187 [NASA ADS] [CrossRef] [Google Scholar]
- Goto, T. 2007b, MNRAS, 377, 1222 [NASA ADS] [CrossRef] [Google Scholar]
- Goto, T., Nichol, R., Okamura, S., et al. 2003, PASJ, 55, 771 [NASA ADS] [CrossRef] [Google Scholar]
- Greene, J. E., & Ho, L. C. 2007, in The Central Engine of Active Galactic Nuclei, eds. L. C. Ho, & J.-W. Wang, ASP Conf. Ser., 373, 33 [Google Scholar]
- Heckman, T. M., & Best, P. N. 2014, ARA&A, 52, 589 [Google Scholar]
- Helfand, D. J., White, R. L., & Becker, R. H. 2015, ApJ, 801, 26 [NASA ADS] [CrossRef] [Google Scholar]
- Hodge, J. A., Becker, R. H., White, R. L., Richards, G. T., & Zeimann, G. R. 2011, AJ, 142, 3 [NASA ADS] [CrossRef] [Google Scholar]
- Holincheck, A. J., Wallin, J. F., Borne, K., et al. 2016, MNRAS, 459, 720 [NASA ADS] [CrossRef] [Google Scholar]
- Hopkins, P. F., Hernquist, L., Cox, T. J., et al. 2006, ApJS, 163, 1 [Google Scholar]
- Hopkins, P. F., Cox, T. J., Kereš, D., & Hernquist, L. 2008, ApJS, 175, 390 [NASA ADS] [CrossRef] [MathSciNet] [Google Scholar]
- in der Au, A., Meusinger, H., Shalldach, P., & Newholm, M. 2012, A&A, 547, A115 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ivezić, Ž., Menou, K., Knapp, G. R., et al. 2002, AJ, 124, 2364 [NASA ADS] [CrossRef] [Google Scholar]
- Jiang, L., Fan, X., Annis, J., et al. 2008, AJ, 135, 1057 [NASA ADS] [CrossRef] [Google Scholar]
- Kara, E., Miller, J. M., Reynolds, C., & Dai, L. 2016, Nature, 535, 388 [Google Scholar]
- Kauffmann, G., Heckman, T. M., Tremonti, C., et al. 2003a, MNRAS, 346, 1055 [Google Scholar]
- Kauffmann, G., Heckman, T. M., White, S. D. M., et al. 2003b, MNRAS, 341, 54 [Google Scholar]
- Kaviraj, S., Kirkby, L., Silk, J., & Sarzi, M. 2007, MNRAS, 382, 960 [NASA ADS] [CrossRef] [Google Scholar]
- Knobel, C., Lilly, S. J., Woo, J., & Kovač, K. 2015, ApJ, 800, 24 [NASA ADS] [CrossRef] [Google Scholar]
- Kohonen, T. 2001, Self-organizing maps (Springer) [Google Scholar]
- Koss, M., Mushotzky, R., Veilleux, S., et al. 2011, ApJ, 739, 57 [NASA ADS] [CrossRef] [Google Scholar]
- LaMassa, S. M., Urry, C. M., Cappelluti, N., et al. 2013, MNRAS, 436, 3581 [NASA ADS] [CrossRef] [Google Scholar]
- LaMassa, S. M., Urry, C. M., Cappelluti, N., et al. 2016, ApJ, 817, 172 [NASA ADS] [CrossRef] [Google Scholar]
- Larson, R. B., & Tinsley, B. M. 1978, ApJ, 219, 46 [NASA ADS] [CrossRef] [Google Scholar]
- Li, C., Kauffmann, G., Heckman, T. M., White, S. D. M., & Jing, Y. P. 2008, MNRAS, 385, 1915 [NASA ADS] [CrossRef] [Google Scholar]
- Lintott, C., Schawinski, K., Bamford, S., et al. 2011, MNRAS, 410, 166 [NASA ADS] [CrossRef] [Google Scholar]
- Liu, C. T., Hooper, E. J., O’Neil, K., et al. 2007, ApJ, 658, 249 [NASA ADS] [CrossRef] [Google Scholar]
- Maraston, C., Daddi, E., Renzini, A., et al. 2006, ApJ, 652, 85 [NASA ADS] [CrossRef] [Google Scholar]
- Maraston, C., Strömbäck, G., Thomas, D., Wake, D. A., & Nichol, R. C. 2009, MNRAS, 394, L107 [NASA ADS] [CrossRef] [Google Scholar]
- Maraston, C., Pforr, J., Henriques, B. M., et al. 2013, MNRAS, 435, 2764 [NASA ADS] [CrossRef] [Google Scholar]
- Mateos, S., Alonso-Herrero, A., Carrera, F. J., et al. 2012, MNRAS, 426, 3271 [NASA ADS] [CrossRef] [Google Scholar]
- Melnick, J., & De Propris, R. 2013, MNRAS, 431, 2034 [NASA ADS] [CrossRef] [Google Scholar]
- Melnick, J., Telles, E., De Propris, R., & Chu, Z.-H. 2015, A&A, 582, A37 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Meusinger, H., & Balafkan, N. 2014, A&A, 568, A114 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Meusinger, H., Schalldach, P., Scholz, R.-D., et al. 2012, A&A, 541, A77 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Meusinger, H., Schalldach, P., Mirhosseini, A., & Pertermann, F. 2016, A&A, 587, A83 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mihos, J. C., & Hernquist, L. 1996, ApJ, 464, 641 [NASA ADS] [CrossRef] [Google Scholar]
- Morrison, G. E., Owen, F. N., Ledlow, M. J., et al. 2003, ApJS, 146, 267 [NASA ADS] [CrossRef] [Google Scholar]
- Nielsen, D. M., Ridgway, S. E., De Propris, R., & Goto, T. 2012, ApJ, 761, L16 [NASA ADS] [CrossRef] [Google Scholar]
- Paggi, A., Fabbiano, G., Civano, F., et al. 2016, ApJ, submitted [arXiv:1507.03170v2] [Google Scholar]
- Poggianti, B. M., & Wu, H. 2000, ApJ, 529, 157 [NASA ADS] [CrossRef] [Google Scholar]
- Poggianti, B. M., Smail, I., Dressler, A., et al. 1999, ApJ, 518, 576 [NASA ADS] [CrossRef] [Google Scholar]
- Quintero, A. D., Hogg, D. W., Blanton, M. R., et al. 2004, ApJ, 602, 190 [Google Scholar]
- Reichard, T. A., Heckman, T. M., Rudnick, G., et al. 2009, ApJ, 691, 1005 [NASA ADS] [CrossRef] [Google Scholar]
- Rodríguez Del Pino, B., Bamford, S. P., Aragón-Salamanca, A., et al. 2014, MNRAS, 438, 1038 [NASA ADS] [CrossRef] [Google Scholar]
- Sachs, L. 1982, Applied Statistics. A Handbook of Techniques (New York: Springer) [Google Scholar]
- Sadler, E. M., Jackson, C. A., Cannon, R. D., et al. 2002, MNRAS, 329, 227 [NASA ADS] [CrossRef] [Google Scholar]
- Sanders, D. B., Soifer, B. T., Elias, J. H., et al. 1988, ApJ, 325, 74 [NASA ADS] [CrossRef] [Google Scholar]
- Schneider, D. P., Richards, G. T., Hall, P. B., et al. 2010, AJ, 139, 2360 [NASA ADS] [CrossRef] [Google Scholar]
- Scott, N., Graham, A. W., & Schombert, J. 2013, ApJ, 768, 76 [NASA ADS] [CrossRef] [Google Scholar]
- Sell, P. H., Tremonti, C. A., Hickox, R. C., et al. 2014, MNRAS, 441, 3417 [NASA ADS] [CrossRef] [Google Scholar]
- Shen, Y., Richards, G. T., Strauss, M. A., et al. 2011, ApJS, 194, 45 [NASA ADS] [CrossRef] [Google Scholar]
- Snyder, G., Cox, T., Hayward, C., Hernquist, L., & Jonsson, P. 2011, ApJ, 741, 77 [NASA ADS] [CrossRef] [Google Scholar]
- Springel, V., Di Matteo, T., & Hernquist, L. 2005, ApJ, 620, L79 [NASA ADS] [CrossRef] [Google Scholar]
- Stern, D., Assef, R. J., Benford, D. J., et al. 2012, ApJ, 753, 30 [NASA ADS] [CrossRef] [Google Scholar]
- Stoughton, C., Lupton, R. H., Bernardi, M., et al. 2002, AJ, 123, 485 [NASA ADS] [CrossRef] [Google Scholar]
- Strateva, I., Ivezić, Ž., Knapp, G. R., et al. 2001, AJ, 122, 1861 [Google Scholar]
- Swinbank, A. M., Balogh, M. L., Bower, R. G., et al. 2012, MNRAS, 420, 672 [NASA ADS] [CrossRef] [Google Scholar]
- Symeonidis, M., Kartaltepe, J., Salvato, M., et al. 2013, MNRAS, 433, 1015 [NASA ADS] [CrossRef] [Google Scholar]
- Toomre, A., & Toomre, J. 1972, ApJ, 178, 623 [NASA ADS] [CrossRef] [Google Scholar]
- Urrutia, T., Lacy, M., & Becker, R. H. 2008, ApJ, 674, 80 [NASA ADS] [CrossRef] [Google Scholar]
- Willett, K. W., Lintott, C. J., Bamford, S. P., et al. 2013, MNRAS, 435, 2835 [NASA ADS] [CrossRef] [Google Scholar]
- Williams, L. 1983, SIGGRAPH ’83 Proc. 10th annual conference on Computer graphics and interactive techniques, 1 [Google Scholar]
- Wong, O. I., Schawinski, K., Kaviraj, S., et al. 2012, MNRAS, 420, 1684 [NASA ADS] [CrossRef] [Google Scholar]
- Wright, E. L., Eisenhardt, P. R. M., Mainzer, A. K., et al. 2010, AJ, 140, 1868 [NASA ADS] [CrossRef] [Google Scholar]
- Wu, P.-F., Gal, R., Lemaux, B., et al. 2014, ApJ, 792, 16 [NASA ADS] [CrossRef] [Google Scholar]
- Yamauchi, C., Yagi, M., & Goto, T. 2008, MNRAS, 390, 383 [NASA ADS] [CrossRef] [Google Scholar]
- Yan, R., Newman, J. A., Faber, S. M., et al. 2006, ApJ, 648, 281 [NASA ADS] [CrossRef] [Google Scholar]
- Yang, Y., Zabludoff, A. I., Zaritsky, D., & Mihos, J. C. 2008, ApJ, 688, 945 [NASA ADS] [CrossRef] [Google Scholar]
- York, D. G., Adelman, J., Anderson, Jr., J. E., et al. 2000, AJ, 120, 1579 [Google Scholar]
- Zabludoff, A. I., Zaritsky, D., Lin, H., et al. 1996, ApJ, 466, 104 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: List of E+A galaxies in S82
E+A galaxies in SDSS S82.
Appendix B: Images of morphologically peculiar E+A galaxies in S82
 |
Fig. B.1 Distorted galaxies with tm ≥ 2 from sample A (left to right, than top to bottom in the same order as in Table A.1). |
 |
Fig. B.1 continued. |
All Tables
Mean properties of the galaxies from the input catalogue clusters 1 to 9 and noise.
Result of dbscan clustering of the galaxies from the input catalogue, number of rejected galaxies, and final numbers per cluster and noise.
Comparison of relative fractions of morphological distortions in the E+A samples A and B with the control sample C.
Statistical properties in dependence on EW(Hδ) for the S82 E+A samples (PSB) and the comparison sample (Comp).
Statistical properties of the AGN candidates from FIRST and WISE compared with the entire E+A sample.
All Figures
|
Fig. 1 Kohonen SOM of ~106 spectra from SDSS DR7 in its representation as a redshift map. Each pixel corresponds to one spectrum where the colour represents the redshift z from 0 (dark) to 6 (bright yellow). The grey dots are empty neurons. |
| In the text | |
|
Fig. 2 Six cutouts from different parts of the icon map, each five by five pixels in size. |
| In the text | |
|
Fig. 3 Schematic illustration of two lower-detailed levels derived from an existing detail level Ld. |
| In the text | |
|
Fig. 4 Distribution of Goto galaxies (black open circles) over the SOM. The clusters identified by dbscan clustering are shown as red squares and labelled by the cluster ID. The axis are the pixel coordinates of the SOM. |
| In the text | |
|
Fig. 5 Cutouts from the icon map containing the E+A clusters 1 to 5 (top to bottom; first selection on the left side, final selection on the right side). Galaxies from the input catalogue are marked blue. The red background colour indicates the newly selected E+A galaxies. |
| In the text | |
|
Fig. 6 Top: histogram distribution of redshifts for the final E+A sample (black) and the input sample (red). Middle: mean Petrosion radius in redshift bins. Bottom: mean stellar mass in redshift bins. |
| In the text | |
|
Fig. 7 Top: EW(Hδ) as a function of redshift in four different size categories. Middle: mean coverage factor Rf/RP for the E+A galaxies in redshift intervals. Bottom: median of EW(Hδ) in different intervals of the coverage factor. |
| In the text | |
|
Fig. 8 Median composite (black) and standard deviations (yellow) from the rest-frame spectra of the Goto galaxies in cluster 1 (left) and in the noise (right). |
| In the text | |
|
Fig. 9 Median composite (black) and standard deviations (yellow) from the rest-frame spectra of a) the whole set of the E+A galaxies from the present study with EW(Hδ) > 3 Å; b) the subset of the galaxies from the input catalogue; c) the subset of newly selected galaxies fulfilling the selection criteria of the input catalogue EW(Hδ) > 5 Å, EW(Hα) > −3 Å, and EW(O ii) >−2.5 Å. |
| In the text | |
|
Fig. 10 Morphological type probabilities from Galaxy Zoo for the E+A sample (top) and the comparison sample (bottom). The colours indicate different merger probablilities: Pm < 0.1 (black), Pm = 0.1...0.3 (blue), and Pm> 0.3 (red). |
| In the text | |
|
Fig. 11 Colour-mass diagram for the galaxies from the SDSS DR8 (contours) and our E+A galaxies (symbols) for four different redshift ranges (top to bottom). The redshifts are given in the top left corner of each panel. Left column: entire E+A sample, middle and right columns: S82 E+A sample. The histogram on the right-hand side of each panel shows the distribution of u−r. The colours are explained in the insets in the top raw. |
| In the text | |
|
Fig. 12 Median composite (black) and standard deviations (yellow) from the rest-frame spectra of the subsamples A, B, and C (top to bottom) from the PB-S82 sample. |
| In the text | |
|
Fig. 13 Cutouts from the normal-depth images provided by the SDSS DR12 navigator (left) and from the co-adds provided by Fliri & Trujillo (2016; right, inverted grey scale) for four E+A galaxies. |
| In the text | |
|
Fig. 14 Merger fractions fm,i in EW(Hδ) bins for the E+A sample (filled squares) and the control sample (open squares). Vertical bars indicate the errors from the Poisson statistics; due to clarity reasons, error bars are given only for the case tm ≥ 1. The colour coding is described in the inset. |
| In the text | |
|
Fig. 15 Stellar age versus EW(Hδ) for the galaxies from the E+A sample (filled squares) and from the control sample (open squares). The two filled squares with downward arrows indicate ages <0.25 Gyr. The red asterisks are mean ages in the EW(Hδ) bins indicated by the horizontal bars, the vertical bars are 1σ standard deviations. |
| In the text | |
|
Fig. 16 Merger fraction fm,i in age bins for the combined S82 sample (E+A sample plus comparison sample). Colours and error bars as in Fig. 14. |
| In the text | |
|
Fig. 17 WISE mid infrared two-colour diagram for the E+A galaxies (blue crosses for EW(Hδ) = 3−5 Å, red squares for EW(Hδ) > 5 Å). The contour curves indicate the distributions of 9468 SDSS galaxies with 0.02 ≤ z ≤ 0.25 (green) and of 2373 SDSS quasars with z< 0.5 (black), respectively. Dashed vertical line: AGN selection threshold. |
| In the text | |
|
Fig. 18 WISE mid infrared two-colour diagram for the E+A galaxies based on the three WISE bands at 3.4, 4.6, and 12 μm. Symbols as in Fig. 17. The green lines indicate the AGN selection suggested by Mateos et al. (2012). |
| In the text | |
|
Fig. 19 SED of E+A samples with EW(Hδ) > 5 Å (red) and 3–5 Å (blue), and of AGNs from WISE (black). Magenta curves: two-component model from Melnick & De Propris (2013) for PSB galaxies (solid) and three-component model from Melnick et al. (2015) for post-starburst quasars (dashed). Green line: power law Fλ ∝ λ-1.5. |
| In the text | |
|
Fig. 20 WISE colour index W1−W3 as a function of the EW of Hδ (left) and Hα (right). The blue diagonal lines are the linear regression curves. |
| In the text | |
|
Fig. 21 Histogram distribution of the monochromatic 1.4 GHz luminosities (black: all, red: radio-loud) for the E+A sample. |
| In the text | |
 |
Fig. 22 As Fig. 21, but for the comparison sample. |
| In the text | |
|
Fig. 23 Median composite (black) and standard deviations (yellow) for a) 18 AGN candidates from the WISE three-band selection; b) 39 radio-quiet FIRST sources; c) 8 radio-loud FIRST sources. |
| In the text | |
|
Fig. 24 Colour-mass diagrams for the AGN candidates with z< 0.25 from WISE (green) and FIRST (magenta) in four redshift bins. The FIRST sources are subdivided in radio-loud (RL = filled squares) and radio-quiet (RQ = open squares). The contour curves show the distributions of all SDSS galaxies (black) and of our E+A galaxies (blue, dashed). |
| In the text | |
|
Fig. B.1 Distorted galaxies with tm ≥ 2 from sample A (left to right, than top to bottom in the same order as in Table A.1). |
| In the text | |
|
Fig. B.1 continued. |
| In the text | |
 |
Fig. B.2 As Fig. B.1 but for sample B. |
| In the text | |
 |
Fig. B.3 As Fig. B.1 but for sample C. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.