| Issue |
A&A
Volume 595, November 2016
|
|
|---|---|---|
| Article Number | A50 | |
| Number of page(s) | 8 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/201629070 | |
| Published online | 28 October 2016 | |
A method to deconvolve stellar rotational velocities II
The probability distribution function via Tikhonov regularization
1 Instituto de Estadística, Pontificia Universidad Católica de Valparaíso, 2950 Valparaíso, Chile
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2 Centro Avanzado de Ingeniería Eléctrica y Electrónica, Universidad Técnica Federico Santa María, 1680 Valparaíso, Chile
3 Large Binocular Telescope Observatory, Steward Observatory, Tucson, AZ 85546, USA
4 Instituto de Física y Astronomía, Universidad de Valparaíso, Chile
5 Departamento de Matemáticas, Facultad de Ciencias Exactas y Naturales, Universidad de Buenos Aires, 1053 Buenos Aires, Argentina
6 Universidad Nacional de General Sarmiento, Buenos Aires, 1613 Buenos Aires, Argentina
Received: 7 June 2016
Accepted: 12 September 2016
Abstract
Aims. Knowing the distribution of stellar rotational velocities is essential for understanding stellar evolution. Because we measure the projected rotational speed v sin i, we need to solve an ill-posed problem given by a Fredholm integral of the first kind to recover the “true” rotational velocity distribution.
Methods. After discretization of the Fredholm integral we apply the Tikhonov regularization method to obtain directly the probability distribution function for stellar rotational velocities. We propose a simple and straightforward procedure to determine the Tikhonov parameter. We applied Monte Carlo simulations to prove that the Tikhonov method is a consistent estimator and asymptotically unbiased.
Results. This method is applied to a sample of cluster stars. We obtain confidence intervals using a bootstrap method. Our results are in close agreement with those obtained using the Lucy method for recovering the probability density distribution of rotational velocities. Furthermore, Lucy estimation lies inside our confidence interval.
Conclusions. Tikhonov regularization is a highly robust method that deconvolves the rotational velocity probability density function from a sample of v sin i data directly without the need for any convergence criteria.
Key words: stars: rotation / methods: statistical / methods: numerical / methods: data analysis / stars: fundamental parameters
© ESO, 2016
1. Introduction
Understanding how stars rotate is essential in describing and modelling many aspect of stellar evolution. From spectroscopy observations we can only get the projected velocity, v sin i, where i is the inclination angle with respect to the line of sight. Furthermore, in order to deconvolve (disentangle or unfold) the rotational velocity distribution function, an assumption on the distribution of rotational axes is required. The standard practice is to assume that the distribution of stellar axes is uniformly (randomly) distributed over the sphere. Using this assumption Chandrasekhar & Münch (1950) studied the integral equation that describes the distribution of “true” (v) and apparent (v sin i) rotational velocities, deriving a formal solution, which is proportional to a derivative of an Abel’s Integral. Chandrasekhar & Münch (1950) method is not usually applied, because the differentiation of the formal solution can lead to misleading results due to intrinsic numerical problems associated to the derivative of the Abel’s integral.
Curé et al. (2014) extended the work of Chandrasekhar & Münch (1950) integrating the formal solution, and obtained the cumulative distribution function (CDF) for the rotational velocities. This CDF is attained in only one step demonstrating the robustness to this method.
While the CDF identifies the distribution of the speed of rotation, it is sometimes useful to have the probability density function (PDF) for easy handling and to directly appreciate certain properties of the distribution (e.g., the maximum, its symmetry and its variability, etc.). It is also known that the observed values of the projected rotational velocities are provided with measurement error. The aim of this work is to propose a methodology that directly provides the PDF, taking into account the measurement errors and avoiding numerical problems arising from the derivative of the CDF. Regularization methods are techniques widely used to deconvolve inverse problems. Image processing, geophysics and machine learning are some of the areas where they are usually applied (Bouhamidi 2007; Deng et al. 2013; Fomel 2007). Among the regularization methods we find: truncated singular value decomposition (TSVD), selective singular value decomposition (SSVD) and the Tikhonov regularization method (Hansen 2010).
In this article we obtain the estimated probability distribution function directly from the Fredholm integral by means of the Tikhonov regularization method.
After its introduction by Tikhonov (1943) to solve integral equation problems, this method (known as Ridge Regression in statistics) has been developed and extensively used ever since (see, e.g., Tikhonov 1963, 1995; Tikhonov & Arsenin 1977; Eggermont 1993; and Hansen 2010). It allows for an increase in the numerical stability and for errors of measurement to be taken into account.
This article is structured as follows: in Sect. 2 we briefly present the mathematical description of the method and describe a procedure for calculating the Tikhonov factor. In Sect. 3, we perform Monte Carlo simulations to show the robustness of this method. In Sect. 4, a real sample of cluster stars is deconvolved using Tikhonov regularization, confidence intervals are calculated using a bootstrap method, and a comparison is made between our PDF results and both those obtained with the Lucy (1974) method and CDF results from the work of Curé et al. (2014). Our conclusions and plans for future work are presented in the final section.
2. Tikhonov regularization method
Many inverse problems in physics and astronomy are given in terms of the Fredholm integral of the first kind (Lucy 1994; Hansen 2010). Namely: 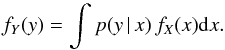 (1)Here fY is a function accessible to observation and fX is the function of interest. The kernel p(y | x) of this integral is related to the remoteness of the measurement process; in this case, the projection of the distribution of stellar axes.
(1)Here fY is a function accessible to observation and fX is the function of interest. The kernel p(y | x) of this integral is related to the remoteness of the measurement process; in this case, the projection of the distribution of stellar axes.
Chandrasekhar & Münch (1950) were the first to consider the integral equation governing the distribution of “true” and apparent (projected) rotational velocities of stars, y = x sin i, where x = v is the rotational speed and i is the inclination angle with respect to the line of sight. Assuming a uniform distribution of stellar axes over the sphere (see Curé et al. 2014, for details), this integral equation (Eq. (1)) reads as follows: 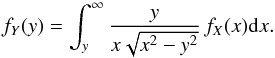 (2)Expressing Eq. (2) in matrix form (by a quadrature discretization of the problem), we get:
(2)Expressing Eq. (2) in matrix form (by a quadrature discretization of the problem), we get: 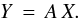 (3)Now, A is a matrix representing the kernel p(y | x), Y is a vector representing the density of projected rotational velocities fY(y) and X is the unknown vector representing the density of “true” rotational velocities fX(x).
(3)Now, A is a matrix representing the kernel p(y | x), Y is a vector representing the density of projected rotational velocities fY(y) and X is the unknown vector representing the density of “true” rotational velocities fX(x).
Since the observed data are measured with error, the last equation is an example of a discrete ill-posed problem, that is, small errors in the measured data can produce large variations in the recovered function which make the solution unstable (Ivanov et al. 2002, and references therein). Nevertheless, in the decades following the work of Chandrasekhar & Münch (1950), much mathematical theory on this kind of problem has been developed. Among others, one of the most common methods is the Tikhonov regularisation method (Tikhonov & Arsenin 1977; Tikhonov et al. 1995; Hansen 2010).
The standard method to solve Eq. (3) is to apply ordinary least squares (OLS), that is, min { | | AX−Y | | 2 }, where ||·|| represents the euclidean norm. However, for ill-posed problems this method fails in the sense that it can produce unstable estimators. In order to avoid this problem the Tikhonov regularization method imposes a regularization term to be included in the minimization process, namely: 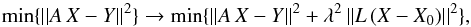 (4)where λ is the Tikhonov factor. The standard definition for the L matrix is L = I, where I is the identity matrix and X0 is an initial estimation, setting X0 = 0, when there is no previous information. There exist different quantitative approaches to obtain the Tikhonov factor, for example, Generalized Cross-Validation (GCV), L-curve Method, Discrepancy Principle, and Restricted Maximum Likelihood. More details of these are explained in, Press et al. (2007), Hansen (2010) and Tikhonov & Arsenin (1977), for example. Once the λ-value is attained, the solution Xλ of the regularized problem by the Tikhonov method is given by:
(4)where λ is the Tikhonov factor. The standard definition for the L matrix is L = I, where I is the identity matrix and X0 is an initial estimation, setting X0 = 0, when there is no previous information. There exist different quantitative approaches to obtain the Tikhonov factor, for example, Generalized Cross-Validation (GCV), L-curve Method, Discrepancy Principle, and Restricted Maximum Likelihood. More details of these are explained in, Press et al. (2007), Hansen (2010) and Tikhonov & Arsenin (1977), for example. Once the λ-value is attained, the solution Xλ of the regularized problem by the Tikhonov method is given by: 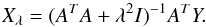 (5)In this article we use the Tikhonov regularization method using singular value decomposition (see Appendix A for details) to deconvolve the distribution of the rotational stellar velocities.
(5)In this article we use the Tikhonov regularization method using singular value decomposition (see Appendix A for details) to deconvolve the distribution of the rotational stellar velocities.
In the data analyzed in this article the L-curve method failed, that is, we do not obtain the “L” shape in the L-curve plot, but only the horizontal part of it (see details in Appendix B). For this reason we propose the method described below to select the Tikhonov factor based on the fact that, when λ → 0, Xλ tends to the exact solution X, the difference between two regularized solutions tends to 0. In Monte Carlo runs (Sect. 3) the Tikhonov factor has been calculated with our proposed method (see below). We proved (Sect. 3) empirically that the Tikhonov estimator we obtained is unbiased and consistent; both desirable properties of any statistical estimator.
We determine the value of the Tikhonov factor, λ, using the following iterative procedure, which turned out to be fast and efficient in obtaining the regularization parameter in the case of smooth solutions:
-
i)
We start with an initial value of λ (λ = λ0).
-
ii)
In each following iteration we reduce the value of λ by a factor f, (λj = fjλ0), we use typically f = 0.99.
-
iii)
At iteration step j we calculate the difference between the corresponding regularization solutions: φ = | | Xλj−Xλj−1 | |.
-
iv)
If φ is small enough, that is, φ<ϵ, we stop the iterative process and get the value of λ. Typically a value of ϵ = 10-7 has been used in this procedure.
In Appendix B, we show the criteria for selecting λ0 and factor f.
 |
Fig. 1 Upper panels: univariate Maxwellian distribution, with parameter σ = 8, is shown with a solid line in all upper panels; black squares connected by dashed lines represent the mean of the nMC = 1000 samples of Tikhonov regularization. Results are for: ns = 30 with σϵ = 0.5 (upper left), ns = 100 with σϵ = 1 (upper center) and ns = 1000 with σϵ = 2 (upper right). Lower panels: bivariate Maxwellian distributions are shown by a solid line in all lower panels, with parameters σ1 = 5 and σ2 = 15 and amplitudes A = 0.7 and B = 0.3. Black squares connected by a dashed line show the estimated PDFs obtained by Tikhonov regularization. Results are for: ns = 30 with σϵ = 0.5 (lower left), ns = 300 with σϵ = 1 (lower center) and ns = 1000 with σϵ = 2 (lower right). |
3. Monte Carlo simulation
In this section we present the results of Monte Carlo numerical simulations to assess the performance of the Tikhonov regularization method in deconvolving rotational velocity distribution from the Fredhoml integral. Our Monte Carlo runs consist of nMC = 1000 independent replications for each chosen scenario, where we considered two specific distributions of rotational velocities. Therefore, we simulate 30 different cases, described as follows:
-
a)
Unimodal distribution: we chose a Maxwellian distribution
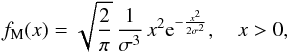 (6)with parameter σ = 8, which is the same distribution used in Curé et al. (2014). Furthermore, we considered three different cases, each one including an additive error from a uniform distribution U [−σϵ,σϵ], with PDF given by fU(x) = 1/(2σϵ) for −σϵ ≤ x ≤ σϵ. The chosen values of σϵ are σϵ = 0.5,1,2 (km s-1).
(6)with parameter σ = 8, which is the same distribution used in Curé et al. (2014). Furthermore, we considered three different cases, each one including an additive error from a uniform distribution U [−σϵ,σϵ], with PDF given by fU(x) = 1/(2σϵ) for −σϵ ≤ x ≤ σϵ. The chosen values of σϵ are σϵ = 0.5,1,2 (km s-1). -
b)
Bimodal distribution: for a mix of two Maxwellian distributions
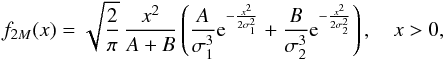 (7)dispersion parameters are: σ1 = 5 and σ2 = 15, and amplitudes: A = 0.3 and B = 0.7. We consider the same additive error cases as for the unimodal distribution.
(7)dispersion parameters are: σ1 = 5 and σ2 = 15, and amplitudes: A = 0.3 and B = 0.7. We consider the same additive error cases as for the unimodal distribution.
Furthermore, for both uni- and bimodal cases, we consider five sample lengths ns: ns = 30,100,300,1000,10 000.
For each independent Monte Carlo sample two samples needed to be simulated, one from the distribution of the rotational velocities (uni- or bimodal) and another for the kernel, p(y | x), representing the distribution of the inclination angles in the Fredholm integral (Eq. (2)). Then, we multiplied each element of the first sample with the corresponding element of the second sample and added the error term. This gave the final sample of v sin i for each scenario. The following step was to estimate the PDF of the projected rotational velocities with a Kernel Density Estimator (KDE, Silverman 1986). Using a grid of ng points we discretized the Fredholm integral obtaining the linear system (Eq. (4)). With this data we calculated the Tikhonov factor λ using the procedure described above and obtained the Tikhonov regularization solution, Xλ, which is the estimated PDF of rotational speeds.
Figure 1 upper panels show, using a solid line, the original Maxwellian distribution (Eq. (6)) together with the mean estimated PDF of all Monte Carlo simulations (black squares connected by a dashed line) for different values of σϵ and ns. It is clearly shown that sample lengths of order ns ~ 30 give acceptable results when compared with the original sample. For larger sample lengths, ns ≳ 100, the agreement between the original distribution and the mean of the estimated PDFs is almost exact. Although the mean estimated distribution is slightly shifted to lower velocities. Lower panels of Fig. 1 show the original bimodal mixed Maxwellian distributions (in a solid line) together with the mean estimated PDF (black squares connected by a dashed line). When a sample length is of the order ns ~ 30, a difference between the estimated PDF and the original PDF is observed. Nevertheless, the Tikhonov regularized solution retrieves the bimodality and delivers ther approximate position of the maximum of both components, but gives a false estimate of the tail of the original distribution.
In the other cases (ns ≳ 100) the mean of the Tikhonov regularization solutions is very close to the original mixture of Maxwellian distributions, although the estimated value of the amplitudes is slightly lower (first distribution) and slightly higher (second distribution) than the original one.
In order to quantify the error of the estimated PDF, we calculated (following Curé et al. 2014) the mean integrated square error (MISE), that is: 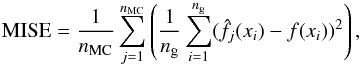 (8)where f(x) represents the original distribution function of rotational speeds and
(8)where f(x) represents the original distribution function of rotational speeds and 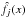 represents the estimated Tikhonov regularization density of the j-run in Monte Carlo simulations.
represents the estimated Tikhonov regularization density of the j-run in Monte Carlo simulations.
In the left panel of Fig. 2 we plotted the MISE as a function of sample length for σϵ = 0.5. In the other cases (σϵ = 1, 2) the MISE value is very similar to values MISE ≲ 10-4. Also it can be seen that as the sample size increases, MISE tends to zero, that is,  when ns → ∞.
when ns → ∞.
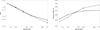 |
Fig. 2 Left panel: value of MISE (black dots) from the estimated PDF for univariate distributions (solid line) and bivariate distributions (dashed line) both using σϵ = 0.5. Right panel: value of Tikhonov factor λ as a function of sample size for the cases where σϵ = 2. See text for details. |
The right panel in Fig. 2 shows Tikhonov factor as a function of sample size. These factors are of the same order of magnitude for both types of distribution (uni- and bimodal). Our simulations confirm for all sample lengths and different σϵ values that the Tikhonov factor (λ) is almost independent of the magnitude of the error σϵ. Furthermore, since the Tikhonov parameter changes only slightly as a function of sample size, we can consider the Tikhonov factor as being almost independent of the sample length, ns.
To confirm this result, we performed MC simulations with a fixed value of λ. The range of λ was from 0.002 to 0.01 with a step of Δλ = 0.001. We calculated the MISE from nMC = 1000 samples, each with a size of ns = 1000 for each value of λ. For the unimodal Maxwellian distribution the values of the MISE vary, increasing from 7.319 × 10-5 to 7.320 × 10-5 for this range of λ, an almost negligible difference. In the case of a bimodal Maxwellian distribution the scenario is very similar. Using the same range of λ, the MISE values vary, increasing from 4.717 × 10-5 to 4.718 × 10-5. Similar behaviour is found when ns = 30,100,300,10 000, supporting our claim that the Tikhonov factor (λ) is almost independent of the sample size.
By means of the average of the estimated PDFs we can estimate the expected value for the Tikhonov regularization solution. In all cases, the mean of the estimated PDFs is very close to the original unimodal or bimodal distributions, and this mean probability density function is closer to the true PDF when increasing the sample size.
This fact shows, empirically, that the studied estimator is asymptotically unbiased. Therefore, since MISE tends to zero when ns tends to infinity, it is implied that the variance of the Tikhonov regularization estimator tends to zero as well and hence is a consistent estimator.
4. Deconvolving a real sample
In this section, we perform the following steps: (i) apply the Tikhonov regularization method to a sample of measured v sin i data of cluster stars in order to estimate the rotational velocity probability density distribution; and (ii) compare the application of different methods to deconvolve the velocity distribution together with previous non-parametric results from the literature.
4.1. Tarantula sample
We select the Tarantula sample for single O-type stars from the VLT Flames Tarantula Survey, where Ramírez-Agudelo et al. (2013) deconvolved the rotational velocity distribution using the Lucy (1974) method (see also Richardson 1972). This sample contains 216 stars with v sin i data from 40 km s-1 up to 610 km s-1. Following Ramírez-Agudelo et al. (2013) for comparison purposes, we also omitted the two largest values (outliers) of the sample. To build the Y vector, we used the KDE method with the following bandwidths (Silverman 1986, pages 45 and 47): 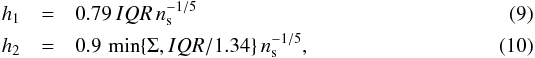 here, IQR is the interquartile range, Σ is the standard deviation of the sample and ns is the sample length.
here, IQR is the interquartile range, Σ is the standard deviation of the sample and ns is the sample length.
Figure 3 shows, by a solid line, the rotational velocity distribution after Tikhonov regularization. Our procedure for Tikhonov factor determination gives a value of λ = 0.0174 for a step of Δx = 2 km s-1. Figure 3 also shows the confidence intervals calculated using a bootstrap method (nBS = 3000, Efron & Tibshirani 1993). The lower is the bandwidth, the wider is the confidence interval. The “bump” around 400 to 450 km s-1 is wider in our case ranging from 340 km s-1 to 480 km s-1. This discrepancy is probably due to the use of the KDE method with a Gaussian kernel in Y.
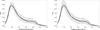 |
Fig. 3 Estimated PDF from the Tarantula sample (solid lines). Both panels with λ = 0.0174 and Δx = 2 km s-1, Left panel with bandwidth h1 = 35.676 and right panel with bandwidth h2 = 30.313. Gray-shaded regions represent the 2.5% (lower) and 97.5% (upper) confidence intervals calculated using a bootstrap method. Dashed lines show the PDF (from Ramírez-Agudelo et al. 2013) obtained using the Lucy (1974) method. |
4.2. Comparing results
For the Tarantula sample, we calculate the CDF by direct integration of the PDF obtained via the Tikhonov regularization method and compare this to the CDF calculated using the method described by Curé et al. (2014). Figure 4 shows both CDFs. Their agreement is remarkable. In addition to our results for the PDF, Fig. 3 also shows the PDF (dashed lines) obtained from Ramírez-Agudelo et al. (2013, see their Fig. 17) calculated using the Lucy (1974) method. It can clearly be seen that Lucy-PDF lies inside our confidence interval.
In order to evaluate whether or not both estimated PDFs correspond to the same distribution, we obtained the q–q plot and calculated the respective quantiles. Figure 5 shows the q–q plot of these densities, confirming that both come from the same probability distribution.
 |
Fig. 4 Estimated cumulative rotational velocity distribution function for the Tarantula sample (solid line) obtained using Tikhonov regularization using a spacing of Δx = 2 km s-1 for the velocities. Dots connected by dashed lines show the CDF calculated using the Curé et al. (2014) method with a spacing of Δx = 10 km s-1. |
 |
Fig. 5 q-q plot from the Tarantula sample, black dots represent the quantiles of each distribution, one calculated using the Tikhonov regularization method and the other calculated using the Lucy method (data from Ramírez-Agudelo et al. 2013). |
5. Conclusions
In this work we have obtained the estimated probability distribution function of “true” rotational velocities using the Tikhonov regularization method. Furthermore, this estimated PDF uses a Tikhonov parameter λ obtained by means of an iterative method with a specific stopping criterion in comparison to the widely used iterative method of Lucy (1974).
Through Monte Carlo numerical simulations we assess the proposed method in two cases: when the rotational velocity distribution is described by a Maxwell distribution and for a mixture of two Maxwell distributions. For each situation different scenarios were evaluated obtaining satisfactory results for all of them, except for ns = 30, when the velocities are described by a mixture of two Maxwellian distributions.
This method retrieves the typical rotational velocity distribution for uni- and bimodal distributions. We showed, empirically, that the studied estimator is asymptotically unbiased and its variance tends to zero. Furthermore, we use the MISE as a measure of goodness of fit of the estimated PDF, which is approximately equal to or less than 10-4 for all sample sizes and tends to zero when ns tends to infinity.
We apply this method to a set of observed data from the Tarantula cluster (Ramírez-Agudelo et al. 2013). The estimated PDF from the Tikhonov regularization method agreed very well with the PDF obtained using the Lucy method, as shown by the q-q plot, demonstrating the method’s ability to deconvolve rotational velocities distribution.
In comparison with the method that delivers the CDF described by Cure et al. (2014), Tikhonov regularization solution gives, by direct integration of the PDF, almost the same non–parametric estimation of the true underlying cumulative distribution function of rotational velocities.
To summarize, we previously developed a method to obtain the CDF of “true” rotational velocities (Curé et al. 2014). This current publication presents the Tikhonov regularization method for obtaining the corresponding PDF directly from the Fredhoml integral. Both methods calculate in a simple and straightforward way (PDF, CDF), without any assumptions of the underlying distribution.
Future work: we would like to develop a general function of the kernel of the Fredholm integral, p(y | x), in order to describe an arbitrary orientation of rotational axes. Thus, we can study the distribution of rotational speeds relaxing the standard assumption of uniformity of stellar axes.
Acknowledgments
A.C. thanks the support from the Instituto de Estadística, Pontificia Universidad Católica de Valparaíso. P.E. thanks the support from the Advanced Center for Electrical and Electronic Engineering, AC3E, Basal Fund Conicyt FB0008. M.C. thanks the support from the Centro de Astrofísica de Valparaíso and the Centro Interdiciplinario de Estudios Atmosféricos y Astroestadística. J.C. and D.R. thanks project “Métodos de deconvolución aplicados a la astronomía”, Ministerio de Educación – Secretaría de Políticas and Universitarias, the Universidad Nacional de General Sarmiento and the Universidad de Buenos Aires for their financial support. D.R. also acknowledges the support of the project PIP11420090100165, CONICET.
References
- Bouhamidi, A., & Jbilou, K. 2007, J. Comput. Appl. Math., 206, 86 [NASA ADS] [CrossRef] [Google Scholar]
- Burger, M. 2007, Inverse Problems, Lecture Notes, Winter 2007/08 (University Muenster) [Google Scholar]
- Chandrasekhar, S., & Münch, G. 1950, ApJ, 111, 142 [NASA ADS] [CrossRef] [MathSciNet] [Google Scholar]
- Curé, M., Rial, D. F., Christen, A., & Cassetti, J. 2014, A&A, 565, A85 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Deng, L.-J., Huang, T.-Z., Zhao, L., & Wang, S. 2013, J. Opt. Soc. Am. A, 30, 5 [Google Scholar]
- Efron, B., & Tibshirani, R. J. 1993, An Introduction to the Bootstrap (Chapman & Hall CRC) [Google Scholar]
- Eggermont, P. P. B. 1993, SIAM J. Math. Anal., 24, 6 [CrossRef] [Google Scholar]
- Fomel, S. 2007, Geophysics, 72, 29 [NASA ADS] [Google Scholar]
- Hansen, P. C. 2010, Discrete Inverse Problems: Insight and Algorithms (SIAM) [Google Scholar]
- Ivanov, V., Vasin, V., & Tanana, V. 2002, Theory of linear ill-posed problems and its applications (Utrecht, Boston: VSP) [Google Scholar]
- Lucy, L. B. 1974, AJ, 79, 745 [NASA ADS] [CrossRef] [Google Scholar]
- Lucy, L. B. 1994, Rev. Mod. Astron., 7, 31 [NASA ADS] [Google Scholar]
- Press, W. H., Teukolsky, S. A., Vetterling, W. T., & Flannery, B. P. 2007, Numerical recipes (Cambridge University Press) [Google Scholar]
- Ramírez-Agudelo, O. H., Simón-Díaz, S., Sana, H., et al. 2013, A&A, 560, A29 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Richardson, W. H. 1972, J. Opt. Soc. America, 62, 55 [Google Scholar]
- Silverman, B. W. 1986, Density estimation for statistics and data analysis. Monographs on Statistics and Applied Probability No. 26 (London: Chapman and Hall) [Google Scholar]
- Tikhonov, A. N. 1943, C. R. (Doklady) Acad. Sci. URSS (N. S.), 39, 176 [Google Scholar]
- Tikhonov, A. N. 1963, Soviet Math Dokl 4, 1035, English translation of Dokl Akad Nauk SSSR, 151, 501 [Google Scholar]
- Tikhonov, A. N., & Arsenin, V. Y. 1977, Solution of Ill-posed Problems (Washington: Winston & Sons) [Google Scholar]
- Tikhonov, A. N., Goncharsky, A. V., Stepanov, V. V., & Yagola, A. G. 1995, Numerical Methods for the Solution of Ill-Posed Problems (Kluwer Academic Publishers) [Google Scholar]
Appendix A: The Tikhonov regularization method
In this Appendix we give a brief description of the Tikhonov regularization method closely following Burger (2007) and Eggermont (1993). Suppose that we have a linear system of the form 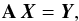 (A.1)with a matrix A ∈ Rn × n, and vectors X,Y ∈ Rn. Suppose additionally that A is a symmetrical, positive definite matrix. In this case, from spectral theory for symmetrical matrices there exist eigenvalues, 0 <μ1 ≤ ··· ≤ μn and corresponding eigenvectors ui ∈ Rn, with the euclidean norm | | ui | | = 1, such that
(A.1)with a matrix A ∈ Rn × n, and vectors X,Y ∈ Rn. Suppose additionally that A is a symmetrical, positive definite matrix. In this case, from spectral theory for symmetrical matrices there exist eigenvalues, 0 <μ1 ≤ ··· ≤ μn and corresponding eigenvectors ui ∈ Rn, with the euclidean norm | | ui | | = 1, such that 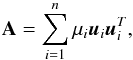 (A.2)where we consider ui ∈ Rn × 1. Since the solution of (A.1) is given by:
(A.2)where we consider ui ∈ Rn × 1. Since the solution of (A.1) is given by: 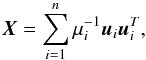 (A.3)small eigenvalues of A can cause numerical difficulties when they are arbitrarily close to zero and the problem is ill-posed. The condition number κ: = μn/μ1, is a measure of the stability of the system. For simplicity we shall assume that μn = 1 then κ = 1 /μ1. When we have data with error Yδ instead of Y, satisfying | | Yδ−Y | | <δ, we obtain a solution Xδ and the error in the solution is:
(A.3)small eigenvalues of A can cause numerical difficulties when they are arbitrarily close to zero and the problem is ill-posed. The condition number κ: = μn/μ1, is a measure of the stability of the system. For simplicity we shall assume that μn = 1 then κ = 1 /μ1. When we have data with error Yδ instead of Y, satisfying | | Yδ−Y | | <δ, we obtain a solution Xδ and the error in the solution is: 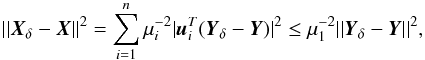 (A.4)then | | Xδ−X | | 2 ≤ κδ.
(A.4)then | | Xδ−X | | 2 ≤ κδ.
One observes that with increasing condition number the error amplification increases simultaneously. Often the nature of the error is unknown, then it is necessary used a method to solve the linear system that deals with error effects. The regularization methods face this problem efficiently. If matrix A is positive semi-definite, its eigenvalues are non-negative, but it can have a zero eigenvalue. In this case, let μm be the smallest positive eigenvalue, then the solution of (A.1) becomes: 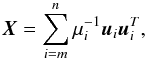 (A.5)and the problem is solvable if and only if
(A.5)and the problem is solvable if and only if 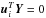 for i<m.
for i<m.
For data with error, we can use the projection PYδ onto the range of A. This analysis can be extended to a general matrix A ∈ Rn × m by considering the associated system AT AX = AT Y, being that the matrix AT A is always symmetrical, positive and semi-definite.
In order to shift away from zero the smallest eigenvalues of this matrix AT A, it seems natural to approximate AT A for a family of matrices Aλ: = AT A + λI, whose eigenvalues are μi + λ, where μis are the eigenvalues of AT A.
We obtain an approximated solution 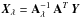 and for data with error we have
and for data with error we have 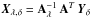 . The error of the estimation is then
. The error of the estimation is then 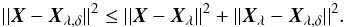 (A.6)The first term on the right side corresponds to the approximation error and the second term corresponds to the error in data. Using spectral theory (Burger 2007), we obtain:
(A.6)The first term on the right side corresponds to the approximation error and the second term corresponds to the error in data. Using spectral theory (Burger 2007), we obtain: 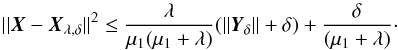 (A.7)The first term on the right side decreases when λ tends to zero while the second term on the right side increases when λ tends to zero. Thus, we have to find an estimation of λ that is a compromise between the error of the approximation and the error from measurements.
(A.7)The first term on the right side decreases when λ tends to zero while the second term on the right side increases when λ tends to zero. Thus, we have to find an estimation of λ that is a compromise between the error of the approximation and the error from measurements.
The solution of the Tikhonov regularization can be obtained also from the Singular Value Descomposition (SVD) of matrix A. In this case, we write a general matrix A ∈ Rm × n with rank n in the form: 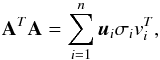 (A.8)where ui and vi are orthonormal vectors of dimensions m and n respectively, and σi ≥ 0 are the singular values of AT A such that σ1 ≥ σ2 ≥ ··· ≥ σn> 0. Under this decomposition the Tikhonov solution is given by:
(A.8)where ui and vi are orthonormal vectors of dimensions m and n respectively, and σi ≥ 0 are the singular values of AT A such that σ1 ≥ σ2 ≥ ··· ≥ σn> 0. Under this decomposition the Tikhonov solution is given by: 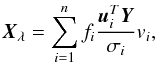 (A.9)where fi, i = 1,··· ,n are defined by fi = σi/ (σi + λ2).
(A.9)where fi, i = 1,··· ,n are defined by fi = σi/ (σi + λ2).
As we mentioned in Sect. 2 there are several methods to estimate λ. The most frequently used are the L-curve Criterion, the Discrepancy Principle and Generalized Cross Validation.
The L-curve is a plot of 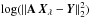 versus
versus 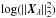 , the logarithm of two square euclidean norm, for different values of the Tikhonov factor λ. This plot has the characteristic “L” shape (see Fig. B.1). According to Hansen (2010) the Tikhonov solution Xλ can be decomposed as
, the logarithm of two square euclidean norm, for different values of the Tikhonov factor λ. This plot has the characteristic “L” shape (see Fig. B.1). According to Hansen (2010) the Tikhonov solution Xλ can be decomposed as 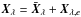 , where
, where 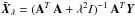 is the regularized version of the exact solution X, and Xλ,e = (AT A + λ2I)-1AT e is the solution obtained by applying Tikhonov regularization to the error component e. For small values of λ, the error dominates the L-curve because the regularized solution Xλ is dominated by Xλ,e and for large values of λ, Xλ is dominated by
is the regularized version of the exact solution X, and Xλ,e = (AT A + λ2I)-1AT e is the solution obtained by applying Tikhonov regularization to the error component e. For small values of λ, the error dominates the L-curve because the regularized solution Xλ is dominated by Xλ,e and for large values of λ, Xλ is dominated by 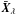 , the unperturbed term. The λ chosen achieves a compromise between the two parts, allocated in the corner of the L-curve. The L-curve criterion for choosing the regularization factor is one of the most frequently used methods. The advantages are robustness and ability to manage observations with correlated errors. The limitations of the L-curve are the reconstruction of very smooth, exact solutions and treatment with a large amount of data (Hansen 2010).
, the unperturbed term. The λ chosen achieves a compromise between the two parts, allocated in the corner of the L-curve. The L-curve criterion for choosing the regularization factor is one of the most frequently used methods. The advantages are robustness and ability to manage observations with correlated errors. The limitations of the L-curve are the reconstruction of very smooth, exact solutions and treatment with a large amount of data (Hansen 2010).
Appendix B: Determination of regularization parameters
When we apply the L-curve method to different v sin i samples, the obtained values of the Tikhonov factor (λ) are “large”. The large size of these values is due to the small values of the coefficients in singular value decomposition with almost constant singular values around 1, requiring the addition of too many terms to increase the norm of X (the vertical part of the “L” shape, see Fig. B.1). We suspect that the reason for this is the smoothness of the solution (Hansen 2010). For the Tarantula sample (Sect. 4), the Tikhonov parameter delivered by the L-Curve, and the GCV methods, are the same, λ = 0.2956.
 |
Fig. B.1 L-curve plot for the data obtained by the Monte Carlo sample for a unimodal distribution. Horizontal axis shows |
Here we show how to determine the value of λ0 and the choice of factor (f) to select the parameters λ of the Thikhonov method.
As we stated at the end of Sect. 2, we start with an initial value of λ0 and calculate the Tikonov method to obtain the PDF, (Xλ(1)), then we multiply λ0 by a factor f and obtain a new value of λ = λ(1) = λ0 × f, and another PDF (Xλ(2)), after applying Tikhonov method. After “m” iterations we have a set of {λ(1),λ(2),...,λ(m)}.
Defining φ(j) as: 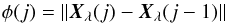 (B.1)where ∥·∥ represents the euclidian norm. After these “m” iterations we also have a set of {φ(2),φ(3),...,φ(m)}. The iteration stops when the value of φ(m) is less than a certain value of ϵ. In our case we chose ϵ = 10-7.
(B.1)where ∥·∥ represents the euclidian norm. After these “m” iterations we also have a set of {φ(2),φ(3),...,φ(m)}. The iteration stops when the value of φ(m) is less than a certain value of ϵ. In our case we chose ϵ = 10-7.
Figure B.2 shows, log (λ) versus log (φ) for different values of λ0 and f, for the Tarantula sample. The initial values of λ0 are: λ0 = 10, shown as a dotted line in all three curves; λ0 = 1, shown as dashed lines and λ0 = 0.1, as solid lines.
For a given value of f, all three curves are superimposed, showing that the final value of λ is independent of the starting value λ0. Therefore we chose to start our calculations with λ0 = 0.1. On the other hand, the critical parameter here is f; the lower this value, the lower the final value of λ, when φ(m) ≤ ϵ. Considering that λ is of the order λ2 in Eq. (5), a very small parameter λ should be avoided in order to have a non-zero regularization term. Thus we select f = 0.99 as our default value to obtain the Tikhonov parameter λ.
 |
Fig. B.2 log (λ) versus log (φ). Factor f varies from f = 0.99 (left), f = 0.75 (center) to f = 0.5 (right). Each of these curves starts with three initial values of λ0, dotted line (λ0 = 10), dashed line (λ0 = 1) and solid line (λ0 = 0.1). See text for details. The vertical gray solid line shows the selected value of ϵ = 10-7 as a criterion to finish the iteration process. The horizontal gray solid line shows the value of λ = 0.2956 (log (λ) = −0.53) obtained using the L–Curve or GCV methods. |
It is clearly seen in Fig. B.2, that for log (λ) = −0.53, that is, the value obtained by the L–Curve or GCV method (horizontal gray line) corresponds to a very “high” value of ϵ. If f = 0.99 then ϵ = 1.8 × 10-4, value much larger than ϵ = 10-7, which is our criterion to stop this iteration process.
All Figures
|
Fig. 1 Upper panels: univariate Maxwellian distribution, with parameter σ = 8, is shown with a solid line in all upper panels; black squares connected by dashed lines represent the mean of the nMC = 1000 samples of Tikhonov regularization. Results are for: ns = 30 with σϵ = 0.5 (upper left), ns = 100 with σϵ = 1 (upper center) and ns = 1000 with σϵ = 2 (upper right). Lower panels: bivariate Maxwellian distributions are shown by a solid line in all lower panels, with parameters σ1 = 5 and σ2 = 15 and amplitudes A = 0.7 and B = 0.3. Black squares connected by a dashed line show the estimated PDFs obtained by Tikhonov regularization. Results are for: ns = 30 with σϵ = 0.5 (lower left), ns = 300 with σϵ = 1 (lower center) and ns = 1000 with σϵ = 2 (lower right). |
| In the text | |
|
Fig. 2 Left panel: value of MISE (black dots) from the estimated PDF for univariate distributions (solid line) and bivariate distributions (dashed line) both using σϵ = 0.5. Right panel: value of Tikhonov factor λ as a function of sample size for the cases where σϵ = 2. See text for details. |
| In the text | |
|
Fig. 3 Estimated PDF from the Tarantula sample (solid lines). Both panels with λ = 0.0174 and Δx = 2 km s-1, Left panel with bandwidth h1 = 35.676 and right panel with bandwidth h2 = 30.313. Gray-shaded regions represent the 2.5% (lower) and 97.5% (upper) confidence intervals calculated using a bootstrap method. Dashed lines show the PDF (from Ramírez-Agudelo et al. 2013) obtained using the Lucy (1974) method. |
| In the text | |
|
Fig. 4 Estimated cumulative rotational velocity distribution function for the Tarantula sample (solid line) obtained using Tikhonov regularization using a spacing of Δx = 2 km s-1 for the velocities. Dots connected by dashed lines show the CDF calculated using the Curé et al. (2014) method with a spacing of Δx = 10 km s-1. |
| In the text | |
|
Fig. 5 q-q plot from the Tarantula sample, black dots represent the quantiles of each distribution, one calculated using the Tikhonov regularization method and the other calculated using the Lucy method (data from Ramírez-Agudelo et al. 2013). |
| In the text | |
|
Fig. B.1 L-curve plot for the data obtained by the Monte Carlo sample for a unimodal distribution. Horizontal axis shows |
| In the text | |
|
Fig. B.2 log (λ) versus log (φ). Factor f varies from f = 0.99 (left), f = 0.75 (center) to f = 0.5 (right). Each of these curves starts with three initial values of λ0, dotted line (λ0 = 10), dashed line (λ0 = 1) and solid line (λ0 = 0.1). See text for details. The vertical gray solid line shows the selected value of ϵ = 10-7 as a criterion to finish the iteration process. The horizontal gray solid line shows the value of λ = 0.2956 (log (λ) = −0.53) obtained using the L–Curve or GCV methods. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.