| Issue |
A&A
Volume 693, January 2025
|
|
|---|---|---|
| Article Number | A46 | |
| Number of page(s) | 12 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/202450499 | |
| Published online | 03 January 2025 | |
The cosmological analysis of X-ray cluster surveys
VI. Inference based on analytically simulated observable diagrams
1
Department of Theoretical Physics and Astrophysics, Faculty of Science, Masaryk University, Kotlářská 2, Brno 611 37, Czech Republic
2
Université Paris-Saclay, Université Paris Cité, CEA, CNRS, AIM, 91191 Gif-sur-Yvette, France
3
Dipartimento di Fisica, Università degli Studi di Torino, Via Pietro Giuria 1, I-10125 Torino, Italy
4
Université Paris Cité, Université Paris-Saclay, CEA, CNRS, AIM, F-91191 Gif-sur-Yvette, France
5
Max Planck Institute for Extraterrestrial Physics, Giessenbachstrasse 1, D-85748 Garching, Germany
6
Laboratoire Univers et Théories, Observatoire de Paris, CNRS, Université PSL, F-92190 Meudon, France
⋆ Corresponding author; This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
24
April
2024
Accepted:
13
August
2024
Abstract
Context. The number density of galaxy clusters across mass and redshift has been established as a powerful cosmological probe, yielding important information on the matter components of the Universe. Cosmological analyses with galaxy clusters traditionally employ scaling relations, which are empirical relationships between cluster masses and their observable properties. However, many challenges arise from this approach as the scaling relations are highly scattered, maybe ill-calibrated, depend on the cosmology, and contain many nuisance parameters with low physical significance.
Aims. For this paper, we used a simulation-based inference method utilizing artificial neural networks to optimally extract cosmological information from a shallow X-ray survey, solely using count rates, hardness ratios, and redshifts. This procedure enabled us to conduct likelihood-free inference of cosmological parameters Ωm and σ8.
Methods. To achieve this, we analytically generated several datasets of 70 000 cluster samples with totally random combinations of cosmological and scaling relation parameters. Each sample in our simulation is represented by its galaxy cluster distribution in a count rate (CR) and hardness ratio (HR) space in multiple redshift bins. We trained convolutional neural networks (CNNs) to retrieve the cosmological parameters from these distributions. We then used neural density estimation (NDE) neural networks to predict the posterior probability distribution of Ωm and σ8 given an input galaxy cluster sample.
Results. Using the survey area as a proxy for the number of clusters detected for fixed cosmological and astrophysical parameters, and hence of the Poissonian noise, we analyze various survey sizes. The 1σ errors of our density estimator on one of the target testing simulations are 1000 deg2, 15.2% for Ωm and 10.0% for σ8; and 10 000 deg2, 9.6% for Ωm and 5.6% for σ8. We also compare our results with a traditional Fisher analysis and explore the effect of an additional constraint on the redshift distribution of the simulated samples.
Conclusions. We demonstrate, as a proof of concept, that it is possible to calculate cosmological predictions of Ωm and σ8 from a galaxy cluster population without explicitly computing cluster masses and even the scaling relation coefficients, thus avoiding potential biases resulting from such a procedure.
Key words: galaxies: clusters: general / cosmological parameters / cosmology: observations
© The Authors 2024
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
Galaxy clusters are the largest virialized systems in the Universe, sitting on the peaks of the primordial density fluctuation field (Bahcall 1988). The mass distribution and number density of galaxy clusters across space and redshift are governed by the cosmological parameters of the Universe, making them potentially powerful cosmological probes Eke et al. (1996). Clusters in X-rays are less prone to projection effects than galaxy over-densities in the optical (Bhatiani et al. 2022) and provide key physical information on the intra-cluster medium (ICM), which is a good tracer of the underlying dark matter distribution (for example, Holland et al. 2015; Fischer et al. 2023).
However, cluster cosmology is usually considered a delicate enterprise, given that the cluster mass, a key parameter that enters the cosmological analysis, is not a directly observable parameter. Rather than using mass proxies, such as the X-ray temperature, luminosity, or gas mass, our approach is to forward model a set of observed properties. More specifically, we consider the distribution of the count rates (CR) and hardness ratios (HR) observed by the XMM-Newton satellite in several redshift bins – X-ray observable diagrams (XODs). The main idea is that the CR and HR values are analogous quantities to the X-ray fluxes and the temperatures of the galaxy clusters. Together with the redshift information, these quantities thus carry both physical and cosmological information. This method, ASpiX, has proven an efficient way of performing cluster cosmological analyses (Clerc et al. 2012). It enables easy modeling of the cluster selection function and has the merit of cleaning several potential systematic uncertainties that are otherwise cosmology-dependent. Moreover, it enables the inclusion of all detected clusters in the analysis because HR measurements require many fewer photons than when measuring a temperature.
To date, the method has been tested on simulations (Pierre et al. 2017; Valotti et al. 2018) and used to extract the cosmological constraints from the XMM-XXL cluster sample (Garrel et al. 2022, 2023) All of these applications used a Markov chain Monte Carlo (MCMC) algorithm to infer the cosmological parameters and related uncertainties. Moreover, cosmology-dependent priors derived from the same cluster sample were imposed on the cluster scaling relations, linking the mass with the cluster luminosity, temperature, size, and associated scatter values.
The present paper is the sixth of the series investigating the potential of the ASpiX concept. Our goal for this work was to use a deep learning approach to explore to what extent we can infer cosmology without any prior knowledge of the cluster evolutionary physics, that is, on the coefficients of the scaling relations. We started by creating XODs for a wide range of Ωm and σ8 values, assuming random values for the scaling relation coefficients, which will be handled as nuisance parameters: this allows us to produce an unbiased simulated XOD sample. We then trained a sequential neural posterior estimation (SNPE) (Papamakarios & Murray 2016) network, a novel machine learning (ML)-based technique of the simulation-based inference family (SBI), to infer the cosmological parameters Ωm and σ8 from the XODs. We considered several survey sizes independently to estimate the effect of the shot noise on cluster counts, and thus on the representation of the XODs and subsequently on the inferred cosmological parameters.
This paper is structured as follows: Section 2 describes the formalism used to create the XOD sample. Section 3 describes the SNPE method. We present our main results in Sect. 4. In Sect. 5 we discuss the impact of various factors on our cosmological predictions: the size of the training set for the neural networks, as well as the effect of imposing a prior on the cluster redshift distribution and of decreasing the number of free parameters by assuming self-similar evolution. We discuss here also what steps would need to be taken when using this method on a real observed XOD of our Universe. We conclude in Sect. 6.
In this paper, we shall consider uniform XMM-Newton extragalactic surveys of various sizes, all performed with an exposure time of 10 ks at any sky position. We take WMAP9 (Hinshaw et al. 2013) as our fiducial cosmology.
2. Creating the set of X-ray observable diagrams
Given an XMM-Newton extragalactic survey area, size, and exposure time, the XOD is a summary statistic of the entire detected cluster population. Namely, a 3D representation of the HR, CR, and z observed parameters. CR is the total (MOS1+MOS2+pn) count rate in the [0.5−2] keV band, HR is the ratio of the number of counts in the [1.0−2.0]/[0.5−1.0] bands; while measurement errors can be attributed to CR and HR, we consider that spectroscopic redshifts are available with negligible uncertainty. The XODs thus represent the cluster number counts in the CR-HR-z parameter space.
To create the XOD set for the cosmological inference, one needs to populate the cluster multi-parameter space (cosmology and cluster physics) in a way that is tractable for this 3-dimensional summary statistics. In the XOD formalism, cluster properties have to be expressed in terms of CR, HR, and z. To compute the first two quantities, one must know, as a function of cluster mass and redshift, the cluster luminosity and temperature. The fact that clusters follow scaling relations is an intrinsic property, physically motivated by the theory of structure formation and observationally verified. Consequently, we make use of scaling relations to create our XOD set. For this, we use simple power laws because, in the survey regime that we are modeling (10 ks XMM observations), we collect an average of 200 photons per cluster (Lieu et al. 2016). This does not allow measurements of T (and L) with sufficient accuracy to implement broken power laws. Similarly, we cannot quantify the effect of the cool core, as we mostly detect the cluster central region. Both effects can be considered as integrated in the very wide range assumed for the scaling relation coefficients.
2.1. Cosmological model and galaxy cluster mass function
To simulate the X-ray cluster population, we assume a flat ΛCDM cosmology (w = −1) and the Tinker et al. (2008) halo mass function (HMF). This, multiplied by the comoving volume element, provides us with the number of galaxy clusters (dn) formed per unit mass (dM) per redshift bin (dz) per unit solid angle (dΩ). The ranges of considered Ωm and σ8 values are given in Table 1.
Sampling range for parameters used to simulate the CR-HR-z diagrams.
2.2. Scaling relation formalism
The next step is to attribute to each halo an X-ray luminosity and a temperature; this is done through scaling relations. We adopt the formalism described by Pacaud et al. (2018):
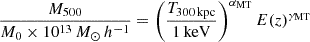 (1)
(1)
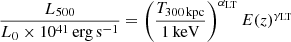 (2)
(2)
where L500 is the rest-frame luminosity in the [0.5−2] keV band, within R500; T300 kpc stands for a generic measure of the temperature within a radius of 300 kpc. The ranges adopted for the six free parameters (normalization, slope, evolution) are given in Table 1. Following Pacaud et al. (2018), we encapsulate all the scatter in the L−T relation, that is σLT = 0.67, and σMT = 0. The scatter in the scaling relations is fixed to a value obtained from standard survey observations (Pacaud et al. 2018). We could have also let this parameter free, but we feel that this would unnecessarily increase the degeneracy with the other scaling relation parameters, on which we do not put any constraint.
2.3. X-ray observable properties
After each (M, z) halo is assigned a luminosity and a temperature, we derive the corresponding observed total XMM-Newton count rates in the three [0.5–2], [1–2], and [0.5–1] keV bands of interest; this is done using the APEC plasma model folded with the XMM-Newton responses for the three EPIC detectors as described, for example, in Garrel et al. (2022).
2.4. XMM-Newton survey design and selection function
In the present study, we consider several (hypothetic) survey sizes ranging from 1000 deg2 to infinity (see Sects. 2.6 and 5.3). This allows us to study the impact of the shot noise in the XODs: the larger the survey, the larger the number of clusters in the dCR/dHR/dz bins, hence the smaller the statistical fluctuations in each bin.
To simulate the survey selection function, we assume a simple CR cut. This allows us to significantly simplify the modeling of the selection process, which in reality depends on both the CR and the cluster apparent size (Pacaud et al. 2006). This hypothesis has no incidence for the purpose of the present study. We set the cut to CR = 0.02 c/s, which corresponds to ∼200 counts for a 10 ks XMM-Newton exposure; this is a safe limit inspired by the XXL survey statistics (Adami et al. 2018) and yields for the fiducial cosmology and the Pacaud et al. (2018) scaling relations around 4 clusters/deg2.
2.5. Construction of the XOD sample and the dn/dz selection
The CR-HR-z XODs are defined as 64 × 64 × 10 arrays for the CR, HR, and z dimensions, respectively (Fig. 1) and are later compressed to a 16 × 16 × 10 resolution used for the SNPE ML model (Fig. 2). To create an XOD, firstly, a set of two cosmological and six scaling relation parameters are drawn from the allowed parameter space (Table 1) based on random-uniform prior distributions. We then compute the number of halos in the survey volume for a 1000 deg2 area, derive the CR for each halo, and apply the CR selection, to include or not the halo in our simulated detected sample. Because the analytical derivation of the dn/dM/dz distribution is computer-time demanding, we apply an intermediate test to exclude a priori unphysical combinations of the eight free parameters – this has a high probability of occurring given that the parameters are drawn independently at random. For this, we use the fiducial XOD based on the observed cluster distribution in our Universe. We calculate the number of clusters that pass the CR cut in the second redshift bin (i.e., the most populated one). If this number is incompatible within 3σ with the real-life value (i.e., that of our fiducial diagram), the combination is discarded and we consider another set of eight parameters. If this number is compatible with the observed cluster counts, we compute the number of clusters that pass the CR cut in the fourth redshift bin; we perform the same comparison as for the second bin and, similarly, decide whether to keep the set of eight parameters. We perform this test every two redshift bins to validate a parameter combination as plausible quickly. We stop when we have identified 70 000 combinations of the eight parameters that verify the dn/dz constraint for every two bins over the full redshift range. We find that this only occurs for 1.7% of the random combinations. The entire process takes about 12 hours to simulate, running in parallel on ∼110 cores. The sample size of 70 000 was arbitrarily chosen and later proved to be a sufficiently large number to ensure good performance (Sect. 5.1). Figure 3 (left) shows the distribution of the Ωm and σ8 values of the 70 000 dn/dz accepted XODs.
 |
Fig. 1. XOD visualization integrated over the redshift dimension for a 64 × 64 × 10 resolution. Left: Fiducial XOD for a 1000 deg2 survey area (simulated for central values of Table 1. Right: a particular Poisson realization of the left-hand-side image. |
 |
Fig. 2. XOD visualization integrated over the redshift dimension for a downsampled XOD to a 16 × 16 × 10 resolution, the shape used for the ML model. Left: Fiducial XOD for a 1000 deg2 survey area (simulated for central values of Table 1). Right: a particular Poisson realization of the left-hand-side image. |
 |
Fig. 3. Comparison of the Ωm and σ8 distribution for XODs from the D1 and D3 datasets. Left: D1 with eight free parameters. Right: D3 with six free parameters, having fixed cluster evolution to be self-similar. Both datasets verify the dn/dz test. Each dataset contains 70 000 XODs. The white zones show the regions excluded by each selection. Fixing cluster evolution does not significantly restrict the a priori range of possible cosmological values. |
2.6. Modeling the impact of survey area and of stochastic noise
In average, the number of detected clusters scales proportionally to the survey area, but the true number of clusters in each XOD pixel is affected by shot noise. (In all this study, we neglect the effect of sample variance on the cluster number counts). We describe below, how noise is implemented in the diagrams.
The XODs are first simulated for a 1000 deg2 survey area with a 64 × 64 × 10 resolution, for a given set of cosmological + cluster physics parameters. The dn/dz 3σ test is applied on this realization. If the XOD passes the test, the pixel values are multiplied 10, to obtain the XOD for 10 000 deg2. After that, the XODs are downsampled to the 16 × 16 × 10 resolution used for the ML model and we apply a Poisson noise model on every XOD pixel with the Numpy (Harris et al. 2020) Python (Van Rossum & Drake 2009) library. Figure 2 shows an XOD before noising (left) and after the noise (right) at a 16 × 16 × 10 resolution.
In addition, for the purpose of investigating the limits and possible biases of our modeling, we consider two other – unrealistic – survey sizes: 100 000 deg2 and “infinite”. The infinite realization is not affected by noise, while the noising of 100 000 deg2 follows the same principles as that of 1000 deg2 and 10 000 deg2, meaning that the noise in the 100 000 deg2 is equivalent to what noise we would receive if we had such a survey even though it is unrealistic in a real case scenario. We note that since the dn/dz test is applied on the 1000 deg2 realization only, it is more permissive for the parameter sets compatible with the 10 000 deg2 and 100 000 deg2 surveys.
2.7. Datasets
In addition to the main dataset described previously, we also created three other datasets of XODs (Table 2) to examine how the dn/dz selection and how decreasing the number of free parameters by fixing cluster evolution parameters at fiducial values impacts the final accuracy of the cosmological predictions. The main dataset for this work is the 70 000 dn/dz accepted XODs created by the steps described previously (D1 dataset). The distribution of its parameters is shown in Fig. 4. The distribution of the parameter values in the dataset shows some forbidden regions in the parameter space, because of the dn/dz selection.
 |
Fig. 4. Prior distribution of the two cosmological and six scaling relation parameters after dn/dz subselection for D1 dataset. The blue dots represent parameters of XODs that were accepted by the dn/dz selection on this dataset. We can see that the dn/dz selection flags forbidden regions compared to the initial random uniform selection from this parameter space. |
Four datasets used for training the networks.
The second XOD dataset inhibits the dn/dz subselection (D2 dataset). We do not show the corresponding parameter distribution as it is just the input random uniform one.
The third XOD dataset uses the dn/dz subselection and, in addition, assumes that cluster evolution is self-similar (i.e., γLT and γMT are fixed at their central fiducial values). this is the D3 dataset (Table 1). Figure 5 shows the distribution of this dataset’s dn/dz accepted XOD parameters.
 |
Fig. 5. Prior distribution with two cosmological and four scaling relation parameters after dn/dz subselection for the ResNet4 training dataset with fixed γMT and γLT scaling relation parameters (D3 dataset). The data points represent XODs accepted in this dataset by the dn/dz selection. There are no new forbidden regions compared to the distribution of the D1 dataset (Fig. 4). |
The last dataset (D4) inhibits the dn/dz subselection and assumes cluster self-similar evolution.
Thanks to these four datasets, we can investigate the effect of restricting the possible ranges of XOD by applying well-justified constraints on the cluster scaling relation coefficients, otherwise totally random: (i) the XOD must verify the observed detected-cluster redshift distribution and (ii) clusters evolve self-similarly.
The datasets are listed in Table 2. They all contain 70 000 XODs.
3. Sequential neural posterior estimation
Simulation-based inference (SBI) is a broad domain encompassing various models. We use the Sequential Neural Posterior Estimation model, SNPE (Papamakarios & Murray 2016), from the Python sbi package (Tejero-Cantero et al. 2020). This model uses neural density estimation (NDE) techniques (Magdon-Ismail & Atiya 1998) to conduct likelihood-free inference. In this section we give a non-exhausting basic overview of the SNPE method, and we kindly refer interested readers for more in-depth details to Papamakarios & Murray (2016).
The SNPE and SBI methods, in general, usually work with a compressed version of the data. This is done to preserve a significant amount of relevant information about the data while reducing the dimensionality of the data as much as possible. Compressing the data also keeps the data size for the inference manageable.
We compress our XODs by training a small ResNet model with two resolution levels and two ResNet blocks per level trained under mean square error regression loss as a regressor to estimate the Ωm and σ8 from the XODs. These estimates are our new parameter space. The XODs enter the SNPE method, which is represented as their compressed version provided by our trained ResNet model. For a detailed description of the ResNet architecture, we refer interested readers to He et al. (2015).
We aim to estimate the posterior probability distribution of the Ωm and σ8 for a given XOD. We want to get the posterior probability distribution p(θ | x = x0), where x0 corresponds to our target XOD diagram. The posterior probability distribution is proportional as
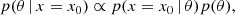 (3)
(3)
where p(θ) is our prior and p(x = x0 | θ) is the likelihood of our simulator model. In this sense, the simulator model is the pipeline simulating XODs plus the regressor neural network compressing them into the new parameter space. The data, x, in our work, represents the compressed version of the XOD.
With the simulation-based approach of the SNPE, we avoid the explicit computation of the likelihood and its necessary assumptions. The SNPE implements a Mixture Density Network (MDN) (Bishop 1994) trained to output a posterior probability distribution as a mixture of 10 Gaussian components. The MDN consists of feed-forward neural networks trained to compute the components’ mixing coefficients, means, and covariance matrices. In this work, we use the SNPE-a (Papamakarios & Murray 2016). After the training procedure, the MDN models the posterior distribution.
In our analysis, we used the MDN in a single Gaussian component regime, outputting the posterior probability as a Gaussian to better compare our results with the traditional approach of the Fisher analysis, which predictions are Gaussian.
Our XOD simulations are not sampled from a simple prior. We estimate the empirical proposal prior distribution of the simulations and account for it in the NDE procedure to be able to set our desired prior.
4. Results
In this section we present the main results of this work as an estimation of cosmological parameters, Ωm and σ8 for a target XOD for a survey size of 1000 deg2. The dataset used for this experiment is the D1 (see Sect. 2.7). Figure 6 shows the neural density estimator’s cosmological prediction based on this data for a target test XOD. We compare the NDE’s prediction with a well-established method, a Fisher analysis, focusing on the same setting as the D1 dataset, with dn/dz, and including evolution parameters. We compute the Fisher information matrix on the fiducial model parameters. Here, we note an XOD as a set of bins λi(θ), with i running over z-CR-HR bins, and its likelihood ℒ can be expressed, assuming that the bins are independent and follow a Poisson distribution, as:
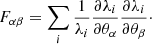 (4)
(4)
 |
Fig. 6. Left: Comparison of the NDE’s cosmological prediction with a Fisher prediction on the same target XOD corresponding to a 1000 deg2 survey area. Right: Comparison of the NDE’s cosmological results for four different survey areas. The NDE’s was trained on our D1 dataset, with dn/dz selection and free γ parameters. The y-axis in the 1D posterior probability distribution plots indicates the probability density at each parameter value shown on the x-axis. Each 1D probability density function is normalized in a way that the total area under its curve equals 1. |
The derivatives are numerically computed following the methodology presented in Cerardi et al. (2024), ensuring the output’s stability. As the Fisher matrix is computed around a particular point in the parameter space, it does not take account of any proposal distribution. Thus, to represent the effect of the dn/dz selection, we compute the covariance matrix of the dn/dz training sample and invert it to obtain the Fisher Proposal matrix. Naturally, this induces a loss of information as it only keeps the multivariate Gaussian signal in the proposal distribution, but it is sufficient for the test we intend to perform here. The Fisher matrices can be added together and then inverted to recover the constraints on Ωm and σ8. We show the corresponding ellipse in Fig. 6 and an estimated posterior from the NDE for an XOD with its Ωm and σ8 near the fiducial model. The contours agree well, although the Fisher contours are slightly broader. This could be caused by (i) the prior information drawn from the proposal information being degraded and (ii) the Fisher computation only reflecting the properties of the local derivatives. While the Fisher prediction is anchored to the fiducial model and then well-centered, it is normal that the noisy realization of the target diagram offsets the SBI contours. The general agreement between the two constraining methods makes us more confident in the main results of this paper.
5. Discussion
In this section we first discuss the impact of the size of the training sample on the neural network performances. Next, we show what levels of accuracy can be expected as a function of the survey area. We discuss the effect of the dn/dz selection and of the self-similar evolution assumption. Lastly, we discuss which steps would be taken when using this method on a real observed XOD instead of a simulated one.
5.1. Training data size
In deep learning studies, the larger the training set, the better in principle. However, simulating XOD is expensive, we thus investigate the trade-off between the size of the training samples and the returned cosmological accuracy. Our neural network training consists of two steps (ResNet and NDE) and we thus have to validate the training data size for each of them. First, the ResNet regressor compresses the XODs in a new parameter space, and second, the NDE estimates the posterior probability distribution of Ωm and σ8 for a given ResNet-compressed XOD. To do this, we fix the training size of one network on a larger volume while varying the size of the other. The results are presented in the next two figures.
Figure 7 shows how the accuracy on the final prediction varies with the ResNet’s training dataset size while keeping the NDE’s training size set as 10 000 XODs. The quality of the final prediction does not significantly improve beyond 10 000 training samples.
 |
Fig. 7. Amplitude of the 1σ errors as a function of the ResNet’s training size, for a training size of the NDE set fixed at 10 000 XODs. We can see that the precision does not significantly improve after 20 000 training XODs. |
Figure 8 shows how the error on the final prediction varies with the NDE’s training dataset size while keeping the ResNet training size set to 40 960 XODs.
 |
Fig. 8. Amplitude of the 1σ errors as a function of the NDE’s training size, for a fixed training size of the ResNet set at 40 960 XODs. We can see that the NDE already performs well with a few hundred XODs as a training size. This was to be expected as it was intentionally developed to work in this way. Even though working already with smaller training XODs, we conservatively decided to use 10 000 XODs as our final training sample, given that we already simulated 70 000 XODs. |
The quality of the final prediction is more sensitive to the ResNet’s training size, while the NDE can already perform well even with a few hundred training examples. This is expected because Papamakarios & Murray (2016) designed the NDE to perform well even with a few hundred training samples. Based on these results, we concluded that our initial guess of creating 70 000 XODs per dataset is enough and that we do not need to enlarge the sample. We set as default values 20 480 for the ReNet4’s training size and 10 000 XODs for the NDE’s training size. If not stated otherwise, the results presented in this paper are always produced with these training sizes.
5.2. Testing the NDE’s calibration
To test whether the neural density estimator is well-trained and calibrated, we retrain it eight times with the same settings of all hyperparameters, and let it make predictions for the same target XOD. This is done for all four survey areas. In these tests, its training data size is set at 10 000, and the XODs are always compressed with the same ResNet of the corresponding survey size that is not retrained. The only difference between these tests is the seed used to draw random numbers from distributions when initializing the NDE’s network’s layers. If the ML model is adequately trained, it will not have any significant deviations from its predictions when retrained in this fashion. Figure 9 shows four calibration tests for four different models, each trained for a different noise level represented as a survey size. We can see that the results are very consistent.
 |
Fig. 9. Calibration tests of the density estimator on four different survey areas. Each contour represents an output of a newly retrained NDE with the same training parameters. The only difference is in the seeds used for generating random numbers, for example, initialization of weights in the neural network. The tests are done for the same testing XOD. We can see that the NDE is well-trained in that regard it produces consistent results and does not show large deviations only due to small differences in the initialization of its neural networks. |
5.3. Survey area
As described in Sect. 2.6, we are working with four different survey sizes, that is, noise levels in the XOD pixels: namely 1000 deg2, 10 000 deg2, 100 000 deg2, and an infinite survey area (no noising at all). Even though the last two settings are ‘thought experiments’, they are potentially useful in understanding possible biases in our methodology. We perform these tests to see what levels of accuracy we can expect for a different survey area and to probe the effect of noise on the accuracy of our cosmological predictions.
Figure 6 (right) shows how, within our framework, the accuracy of the cosmological parameters depends on the survey size. Table 3 summarises the cosmological constraints. Considering the first three columns, it appears that the cosmological accuracy roughly scales as the square root of the area, that is, as the square root of the number of clusters, which is sound. We observe that no noise at all in the XOD (infinite area) still results in nonzero errors. We may interpret this as a possible limitation of the numerical accuracy when constructing the XODs. Alternatively, it could also be due to keeping the same 16 × 16 × 10 resolution for all noise levels. Improving the resolution in the case of an infinite survey area should lead to smaller errors in this regime. We tested this hypothesis by retraining the ML models for a 32 × 32 × 10 XOD resolution. Figure 10 shows the final posterior probability cosmological predictions for ML models trained on 32 × 32 × 10 XOD resolution (blue) and the standard 16 × 16 × 10 XOD resolution (yellow) for two target XODs (left and right figures). Figure 11 shows the same but for a setting with no Poisson noise (infinite deg2). Table 4 shows the relative 1σ accuracy of these predictions. We can see that increasing the resolution does not significantly change the accuracy of our cosmological predictions. For the T1 XOD, the relative 1σ has a bit better accuracy for the 16 × 16 × 10 resolution in the case of 100 000 deg2 survey area and only for Ωm. However, we observe an opposite trend for the T2 target XOD, which had a bit better accuracy on the Ωm but for the case of 32 × 32 × 10 resolution of 100 000 deg2 survey area. For the T2 target XOD, there was also a small improvement in the accuracy of our cosmological prediction for the 16 × 16 × 10 resolution in the case of no noise at all (infinite deg2 survey area). Based on these results, we conclude that increasing the resolution to 32 × 32 × 10 does not play a significant role in the accuracy of our cosmological predictions, when shot noise becomes negligible. The plausible interpretation is that, given that we work at the CR level, cluster spectral features (in particular emission lines) are somewhat erased by the rather low XMM-EPIC spectral resolution, containing itself sharp discontinuities1. This may cause the observed remaining weak degeneracy.
 |
Fig. 10. Tests of the accuracy of our cosmological predictions based on the resolution of the XODs in the case of a 100 000 deg2 survey area for two target testing XODs T1 (left) and T2 (right). The XOD resolution is color-coded. |
 |
Fig. 11. Tests of the accuracy of our cosmological predictions based on the resolution of the XODs in the case of no Poisson noise (infinite deg2 survey area) for two target testing XODs T1 (left) and T2 (right). The XOD resolution is color-coded. |
Relative 1σ errors (in percent) from NDE for a single target diagram.
Relative 1σ errors of our resolution tests.
5.4. dn/dz subselection
In this section we explore how the dn/dz selection improves the accuracy of our cosmological predictions. This selection effectively excludes all XODs whose redshift distribution is incompatible with the observations (i.e., here, with the dn/dz of our fiducial model) at the 3σ level. However, the test is rather permissive, so XODs that pass the dn/dz test can show very different combinations of the eight free parameters due to the high level of degeneracy for such a large number of free parameters. Compared to a normal uniform prior distribution, the dn/dz restricts the range of possible parameter combinations (Fig. 4), introducing forbidden areas in the parameter space.
To understand how the dn/dz selection improves the final predictions, we compare the ResNet and the NDE trained on the D1 and D2 sets. (see Sect. 2.7). A separate density estimator must be trained on the corresponding dataset for each survey area. The predictions are made for the same target XOD modulated by the noise level pertaining to the survey area. The results are displayed in Fig. 12. The relative errors are reported in Table 3. We can see that plugging the dn/dz selection decreases the size of the error bars on cosmological parameters. This difference is most prominent for smaller noise levels corresponding to larger survey areas. Hence, filtering out unrealistic distributions at the dn/dz level is a quick and efficient method to improve the constraining power of this technique.
 |
Fig. 12. Posterior probability distribution, trained on the D1 dataset (dn/dz selection, left) and on the D2 dataset (no dn/dz selection, right) (Table 2). These datasets have fixed γ cluster evolution parameters. Four MDNs are trained per dataset each on a different survey area. These results are computed for the same target testing XOD, always of the appropriate survey size, that was produced letting all 8 parameters free and verifying the dn/dz selection. |
5.5. Constraining scaling relations – Fixing gammas
In this section we investigate how the performance of our cosmological predictions improves when reducing the number of free parameters to six, assuming cluster self-similar evolution (i.e., γMT and γLT are fixed to their fiducial values). By doing this, the potential degeneracy between cluster physics and cosmology is lowered. The test uses datasets D3 and D4. Figures 13 and 14 show the outcome, compared with the 8-parameter realizations, including or excluding the dn/dz selection, respectively. Table 3 shows the relative 1σ errors. Clearly, as expected, fixing cluster evolution improves the accuracy of our cosmological predictions. We also note a change in the direction of the degeneracy.
 |
Fig. 13. Posterior probability distribution estimated trained on the D1 dataset (left) and training on the D3 dataset (right) (Table 2). These datasets both have the dn/dz selection but differ in the choice of fixing the cluster evolution γ parameters on their fiducial values. Four MDNs are trained per dataset each on a different survey area. These results are computed for the same target testing XOD, always of the appropriate survey size, that was produced having all 8 parameters free and with the dn/dz selection. We can see that fixing the γ parameters improves the accuracy of the NDE’s cosmological predictions. |
 |
Fig. 14. Posterior probability distribution estimated trained on the D2 dataset (left) and training on the D4 dataset (right) (Table 2). These datasets both come with no dn/dz selection but differ in the choice of fixing the γ parameters. Four MDNs are trained per dataset each on a different survey area. These results are computed for the same target testing XOD, always of the appropriate survey size, that was produced having all 8 parameters free and with the dn/dz selection. We can again observe that using the dn/dz selection and fixing the γ parameters improves the accuracy of the NDE’s cosmological predictions. |
5.6. Applying the method to real observations
Now let us consider what steps would be necessary to apply our method to a real observed XOD. So far in the paper, we showcased the method performance on testing XODs which have been inside the parameter range used to create the training simulations (Table 1). When used on an XOD composed from an observed galaxy cluster sample, with the underlying true Ωm and σ8 being well within the range of the training simulations parameters, we would see results similar to those demonstrated in this work. Given the current constraints on Ωm and σ8 from various probes, we can confidently expect a real XOD to lie well within the boundaries of our study. However, in principle, we have to address the case where the true cosmological parameters would be located outside of the simulation training range. Since neural regression models are known to extrapolate badly, the posterior estimation would probably fail in this situation. This could result in a final estimated posterior being placed toward the edges of the training sample distribution in the direction of the true underlying cosmological parameters. If we obtained results like this on a real observed XOD, we would need to create a second training sample, now centered on the central values of the estimated posterior probability distribution, and to retrain the neural networks involved, the ResNet regressor as well as the MDN density estimator on this new dataset. These newly trained networks would give us a new estimate of the cosmological parameter posterior probability distribution. We would need to repeat this process until the final estimated posterior would be well-centered within the training sample range. We show such a situation in Fig. 15 where the true Ωm and σ8 cosmological parameters used to simulate this testing XOD are close to the borders of our simulation box.
 |
Fig. 15. NDE’s cosmological results for four different survey areas computed for a target XOD with its Ωm and σ8 values close to the borders of our simulation box. The regressor and density estimator neural networks were trained on our D1 dataset, with dn/dz selection and free γ parameters. |
Other effects will have to be considered when applying this method to a real sample. Firstly, using a CR cut to mimic the selection function is very simplistic and does not correctly render the detection probability within an X-ray survey, which is two-dimensional (flux versus apparent size) (Pacaud et al. 2006; Clerc et al. 2024). However, the high flexibility of the ResNet regression models should make the training just as efficient on more complex selection functions. Secondly, measurement errors will have to be included. For X-ray surveys, the number of photons for individual clusters can be as low as a few tens of counts, and hence, the observed CR and HR are noisy estimates of the true quantities. Implementing an error model is not a showstopper for the inference method: basically, this can be modeled by two-dimensional filtering of the XOD (Clerc et al. 2012).
6. Conclusions
This paper is a proof of concept investigating the cosmological constraining power of simulation-based inference utilizing artificial neural networks with a shallow (∼200 photons per cluster) X-ray cluster survey using only three observed parameters: the X-ray flux in a given band (XMM-Newton CR), an X-ray color (XMM-Newton HR), and the redshift. Our simulated cluster populations are thus represented in this CR-HR-z parameter space, an XOD.
The neural networks in our cosmological inference are trained on a large number of simulated XODs. To simulate a sample of XODs, we forward-modeled cluster X-ray observables from their mass through scaling relation parameters. The scaling-relation parameters were selected randomly from the prior distribution, and they neither never directly entered our regressor neural network that compresses the XODs nor the density estimator neural network that subequently estimated the posterior probability distribution of the Ωm and σ8 for a target XOD.
This process allowed us to perform a likelihood-free cosmological inference. The size of the posterior is governed by the regressor compression (limited by the Poison noise in the XODs and the parametrization used to model the CR-HR-z observational quantities).
The performances of our approach are sensible. Cosmological constraints scale roughly as the square root of the surveyed area – imposing that the simulated XODs verify the observed dn/dz cluster distribution, and fixing the cluster evolutionary parameters – leads to better constraints.
The absolute constraining power of our method can be compared to the recent eROSITA cosmological results (Ghirardini et al. 2024). Their cosmological sample has 5259 massive clusters over 12 791 deg2; our 1000 deg2 realization yields about 4000 clusters. Our predicted uncertainties on Ωm and σ8 are ∼2.2 and ∼4.3 times larger, respectively. This is not surprising because (i) the eROSITA clusters are more massive compared to our 1000 deg2 because our sample has a flux cut based on the XXL analysis, thus having a similar cluster mass distribution, also with ∼4000 clusters on a 1000 deg2 compared to the similar 5259 eROSITA clusters over 12 791 deg2 and (ii) several assumptions are made on the eROSITA cluster scaling relations (from optical datasets) to calibrate the individual cluster masses (Ghirardini et al. 2024).
Applying our method to real data would require implementing a two-dimensional selection function in the CR versus cluster-apparent-size plane. Practically, this means that we need to introduce a supplementary scaling relation (M500 − Rc) in the formalism that produces the XODs; this is not a problem as long as the coefficients of this new relation would be drawn at random, the same way we have done with the scaling relations in this study. Modeling the measurement errors would also be needed.
The present study treats the scaling relation coefficients as nuisance parameters; this is a fair approach, but because these parameters amount to six, and we excluded any a priori knowledge on them, there remains a significant degeneracy with the cosmological parameters. This explains why our predicted errors on the cosmological parameters appear rather large. A much more efficient approach is to create the XOD training sample from numerical simulations spanning a large range of cosmologies and for various feedback assumptions (e.g., the CAMELS simulations, Villaescusa-Navarro et al. 2021). In this case, the number of parameters ruling the cluster’s physical properties is drastically reduced (two AGN feedback parameters) and, moreover, these parameters should not be considered as nuisance parameters. In the end, the SBI, relying on such a training sample, faces much less degeneracy and delivers the cosmological parameters plus the feedback parameters, which are the truly relevant physics parameters (Paper VII, Cerardi et al., in prep.).
https://xmm-tools.cosmos.esa.int/external/xmmusersupport/documentation/uhb/effareaonaxis.html
Acknowledgments
We are very grateful for Tom Charnock’s huge help and contribution to this project in its early stages. M. K. and N. W. are supported by the GACR grant 21-13491X. M. K.’s stays in France and Italy were supported by the French Alternative Energies and Atomic Energy Commission internship, the ERASMUS program, and the Italian Government Scholarship issued by the Italian MAECI.
References
- Adami, C., Giles, P., Koulouridis, E., et al. 2018, A&A, 620, A5 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bahcall, N. A. 1988, ARA&A, 26, 631 [NASA ADS] [CrossRef] [Google Scholar]
- Bhatiani, S., Dai, X., Griffin, R. D., et al. 2022, ApJS, 259, 9 [NASA ADS] [CrossRef] [Google Scholar]
- Bishop, C. 1994, Mixture Density Networks, Workingpaper (Birmingham: Aston University) [Google Scholar]
- Cerardi, N., Pierre, M., Valageas, P., Garrel, C., & Pacaud, F. 2024, A&A, 682, A138 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Clerc, N., Pierre, M., Pacaud, F., & Sadibekova, T. 2012, MNRAS, 423, 3545 [NASA ADS] [CrossRef] [Google Scholar]
- Clerc, N., Comparat, J., Seppi, R., et al. 2024, A&A, 687, A238 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Eke, V. R., Cole, S., & Frenk, C. S. 1996, MNRAS, 282, 263 [CrossRef] [Google Scholar]
- Fischer, M. S., Durke, N.-H., Hollingshausen, K., et al. 2023, MNRAS, 523, 5915 [CrossRef] [Google Scholar]
- Garrel, C., Pierre, M., Valageas, P., et al. 2022, A&A, 663, A3 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Garrel, C., Pierre, M., Umetsu, K., et al. 2023, A&A, submitted [Google Scholar]
- Ghirardini, V., Bulbul, E., Artis, E., et al. 2024, A&A, 689, A298 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Harris, C. R., Millman, K. J., van der Walt, S. J., et al. 2020, Nature, 585, 357 [NASA ADS] [CrossRef] [Google Scholar]
- He, K., Zhang, X., Ren, S., & Sun, J. 2015, ArXiv e-prints [arXiv:1512.03385] [Google Scholar]
- Hinshaw, G., Larson, D., Komatsu, E., et al. 2013, ApJS, 208, 19 [Google Scholar]
- Holland, J. G., Böhringer, H., Chon, G., & Pierini, D. 2015, MNRAS, 448, 2644 [NASA ADS] [CrossRef] [Google Scholar]
- Lieu, M., Smith, G. P., Giles, P. A., et al. 2016, A&A, 592, A4 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Magdon-Ismail, M., & Atiya, A. 1998, in Advances in Neural Information Processing Systems, eds. M. Kearns, S. Solla, & D. Cohn, 11 [Google Scholar]
- Pacaud, F., Pierre, M., Refregier, A., et al. 2006, MNRAS, 372, 578 [NASA ADS] [CrossRef] [Google Scholar]
- Pacaud, F., Pierre, M., Melin, J. B., et al. 2018, A&A, 620, A10 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Papamakarios, G., & Murray, I. 2016, ArXiv e-prints [arXiv:1605.06376] [Google Scholar]
- Pierre, M., Valotti, A., Faccioli, L., et al. 2017, A&A, 607, A123 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tejero-Cantero, A., Boelts, J., Deistler, M., et al. 2020, J. Open Source Softw., 5, 2505 [NASA ADS] [CrossRef] [Google Scholar]
- Tinker, J., Kravtsov, A. V., Klypin, A., et al. 2008, ApJ, 688, 709 [Google Scholar]
- Valotti, A., Pierre, M., Farahi, A., et al. 2018, A&A, 614, A72 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Van Rossum, G., & Drake, F. L. 2009, Python 3 Reference Manual (Scotts Valley: CreateSpace) [Google Scholar]
- Villaescusa-Navarro, F., Anglés-Alcázar, D., Genel, S., et al. 2021, ApJ, 915, 71 [NASA ADS] [CrossRef] [Google Scholar]
All Tables
All Figures
|
Fig. 1. XOD visualization integrated over the redshift dimension for a 64 × 64 × 10 resolution. Left: Fiducial XOD for a 1000 deg2 survey area (simulated for central values of Table 1. Right: a particular Poisson realization of the left-hand-side image. |
| In the text | |
|
Fig. 2. XOD visualization integrated over the redshift dimension for a downsampled XOD to a 16 × 16 × 10 resolution, the shape used for the ML model. Left: Fiducial XOD for a 1000 deg2 survey area (simulated for central values of Table 1). Right: a particular Poisson realization of the left-hand-side image. |
| In the text | |
|
Fig. 3. Comparison of the Ωm and σ8 distribution for XODs from the D1 and D3 datasets. Left: D1 with eight free parameters. Right: D3 with six free parameters, having fixed cluster evolution to be self-similar. Both datasets verify the dn/dz test. Each dataset contains 70 000 XODs. The white zones show the regions excluded by each selection. Fixing cluster evolution does not significantly restrict the a priori range of possible cosmological values. |
| In the text | |
|
Fig. 4. Prior distribution of the two cosmological and six scaling relation parameters after dn/dz subselection for D1 dataset. The blue dots represent parameters of XODs that were accepted by the dn/dz selection on this dataset. We can see that the dn/dz selection flags forbidden regions compared to the initial random uniform selection from this parameter space. |
| In the text | |
|
Fig. 5. Prior distribution with two cosmological and four scaling relation parameters after dn/dz subselection for the ResNet4 training dataset with fixed γMT and γLT scaling relation parameters (D3 dataset). The data points represent XODs accepted in this dataset by the dn/dz selection. There are no new forbidden regions compared to the distribution of the D1 dataset (Fig. 4). |
| In the text | |
|
Fig. 6. Left: Comparison of the NDE’s cosmological prediction with a Fisher prediction on the same target XOD corresponding to a 1000 deg2 survey area. Right: Comparison of the NDE’s cosmological results for four different survey areas. The NDE’s was trained on our D1 dataset, with dn/dz selection and free γ parameters. The y-axis in the 1D posterior probability distribution plots indicates the probability density at each parameter value shown on the x-axis. Each 1D probability density function is normalized in a way that the total area under its curve equals 1. |
| In the text | |
|
Fig. 7. Amplitude of the 1σ errors as a function of the ResNet’s training size, for a training size of the NDE set fixed at 10 000 XODs. We can see that the precision does not significantly improve after 20 000 training XODs. |
| In the text | |
|
Fig. 8. Amplitude of the 1σ errors as a function of the NDE’s training size, for a fixed training size of the ResNet set at 40 960 XODs. We can see that the NDE already performs well with a few hundred XODs as a training size. This was to be expected as it was intentionally developed to work in this way. Even though working already with smaller training XODs, we conservatively decided to use 10 000 XODs as our final training sample, given that we already simulated 70 000 XODs. |
| In the text | |
|
Fig. 9. Calibration tests of the density estimator on four different survey areas. Each contour represents an output of a newly retrained NDE with the same training parameters. The only difference is in the seeds used for generating random numbers, for example, initialization of weights in the neural network. The tests are done for the same testing XOD. We can see that the NDE is well-trained in that regard it produces consistent results and does not show large deviations only due to small differences in the initialization of its neural networks. |
| In the text | |
|
Fig. 10. Tests of the accuracy of our cosmological predictions based on the resolution of the XODs in the case of a 100 000 deg2 survey area for two target testing XODs T1 (left) and T2 (right). The XOD resolution is color-coded. |
| In the text | |
|
Fig. 11. Tests of the accuracy of our cosmological predictions based on the resolution of the XODs in the case of no Poisson noise (infinite deg2 survey area) for two target testing XODs T1 (left) and T2 (right). The XOD resolution is color-coded. |
| In the text | |
|
Fig. 12. Posterior probability distribution, trained on the D1 dataset (dn/dz selection, left) and on the D2 dataset (no dn/dz selection, right) (Table 2). These datasets have fixed γ cluster evolution parameters. Four MDNs are trained per dataset each on a different survey area. These results are computed for the same target testing XOD, always of the appropriate survey size, that was produced letting all 8 parameters free and verifying the dn/dz selection. |
| In the text | |
|
Fig. 13. Posterior probability distribution estimated trained on the D1 dataset (left) and training on the D3 dataset (right) (Table 2). These datasets both have the dn/dz selection but differ in the choice of fixing the cluster evolution γ parameters on their fiducial values. Four MDNs are trained per dataset each on a different survey area. These results are computed for the same target testing XOD, always of the appropriate survey size, that was produced having all 8 parameters free and with the dn/dz selection. We can see that fixing the γ parameters improves the accuracy of the NDE’s cosmological predictions. |
| In the text | |
|
Fig. 14. Posterior probability distribution estimated trained on the D2 dataset (left) and training on the D4 dataset (right) (Table 2). These datasets both come with no dn/dz selection but differ in the choice of fixing the γ parameters. Four MDNs are trained per dataset each on a different survey area. These results are computed for the same target testing XOD, always of the appropriate survey size, that was produced having all 8 parameters free and with the dn/dz selection. We can again observe that using the dn/dz selection and fixing the γ parameters improves the accuracy of the NDE’s cosmological predictions. |
| In the text | |
|
Fig. 15. NDE’s cosmological results for four different survey areas computed for a target XOD with its Ωm and σ8 values close to the borders of our simulation box. The regressor and density estimator neural networks were trained on our D1 dataset, with dn/dz selection and free γ parameters. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.