| Issue |
A&A
Volume 689, September 2024
|
|
|---|---|---|
| Article Number | A253 | |
| Number of page(s) | 17 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/202450266 | |
| Published online | 17 September 2024 | |
Bounds on galaxy stochasticity from halo occupation distribution modeling
1
University Observatory, Faculty of Physics, Ludwig-Maximilians-Universität, Scheinerstraße 1, 81679 Munich, Germany
2
Department of Physics, Stanford University, 382 Via Pueblo Mall, Stanford, CA 94305, USA
3
Kavli Institute for Particle Astrophysics & Cosmology, 452 Lomita Mall, Stanford, CA 94305, USA
4
SLAC National Accelerator Laboratory, 2575 Sand Hill Road, Menlo Park, CA 94025, USA
5
Excellence Cluster ORIGINS, Boltzmannstraße 2, 85748 Garching, Germany
Received:
5
April
2024
Accepted:
4
June
2024
The joint probability distribution of matter overdensity and galaxy counts in cells is a powerful probe of cosmology, and the extent to which variance in galaxy counts at fixed matter density deviates from Poisson shot noise is not fully understood. The lack of informed bounds on this stochasticity is currently the limiting factor in constraining cosmology with the galaxy–matter probability distribution function (PDF). We investigate stochasticity in the conditional distribution of galaxy counts along lines of sight with fixed matter density, and we present a halo occupation distribution (HOD)-based approach for obtaining plausible ranges for stochasticity parameters. To probe the high-dimensional space of possible galaxy–matter connections, we derive a set of HODs that conserve the galaxies’ linear bias and number density to produce REDMAGIC-like galaxy catalogs within the ABACUSSUMMIT suite of N-body simulations. We study the impact of individual HOD parameters and cosmology on stochasticity and perform a Monte Carlo search in HOD parameter space subject to the constraints on bias and density. In mock catalogs generated by the selected HODs, shot noise in galaxy counts spans both sub-Poisson and super-Poisson values, ranging from 80% to 133% of Poisson variance for cells with mean matter density. Nearly all of the derived HODs show a positive relationship between local matter density and stochasticity. For galaxy catalogs with higher stochasticity, modeling galaxy bias to second order is required for an accurate description of the conditional PDF of galaxy counts at fixed matter density. The presence of galaxy assembly bias also substantially extends the range of stochasticity in the super-Poisson direction. This HOD-based approach leverages degrees of freedom in the galaxy–halo connection to obtain informed bounds on nuisance model parameters and can be adapted to study other parametrizations of shot noise in galaxy counts, in particular to motivate prior ranges on stochasticity for cosmological analyses.
Key words: galaxies: statistics / dark matter / large-scale structure of Universe
© The Authors 2024
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. Subscribe to A&A to support open access publication.
1. Introduction
Understanding the statistical connection between galaxies and dark matter is essential to inferring the physics of the Universe from galaxy surveys. In the standard ΛCDM model of cosmology, the present large-scale structure is dominated by cold dark matter concentrated in gravitationally bound halos (White & Rees 1978; Cooray & Sheth 2002), with a constant vacuum energy density driving the acceleration of cosmic expansion (Weinberg et al. 2013). The ability to probe this dark sector hinges on models that relate observable tracers, including galaxies, to properties of the dark matter structures they inhabit (see Wechsler & Tinker 2018 for a comprehensive review). Several complementary cosmological probes require reliable models of the galaxy–matter connection, in particular galaxy clustering (Alam et al. 2017; Abbott et al. 2020), weak gravitational lensing (Tyson et al. 1984; Hoekstra et al. 2004; Mandelbaum et al. 2005; Asgari et al. 2021; Amon et al. 2022), and their cross-correlations (e.g., Heymans et al. 2021; DES Collaboration 2022; Pandey et al. 2022; Porredon et al. 2022).
As the volume and precision of galaxy surveys increase, so must the accuracy of models of the joint distribution of galaxies and matter, if systematic modeling errors are to remain below the level of statistical and observational systematic uncertainties. Current and upcoming surveys such as the Dark Energy Spectroscopic Instrument (DESI; Aghamousa et al. 2016), the Euclid space telescope (Euclid Collaboration 2022), and the Vera C. Rubin Observatory’s Legacy Survey of Space and Time (LSST; Ivezić et al. 2019) will surpass their predecessors by roughly an order of magnitude in terms of total galaxies cataloged. The associated increase in statistical power promises a major improvement in cosmological constraining power, provided that the models of the tracer–matter connection employed in cosmological analyses do not dominate their uncertainty budgets. Achieving this goal requires striking a balance between systematic errors that dominate when a model is too simple and statistical errors incurred when a model is overly flexible.
Developing reliable models directly from theory is challenging, as both the gravitational collapse of dark matter into halos and the assembly of baryonic matter into galaxies are substantially nonlinear. On physical scales for which the cosmic density field is linear or quasi-linear, perturbative galaxy bias expansions provide a rigorous and well-studied description of the statistical connection between galaxy density and matter density (see Desjacques et al. 2018 for a review). These expansions inevitably break down on smaller scales, including nonlinear regimes probed by observables such as galaxy clustering and galaxy–galaxy lensing.
A number of empirically motivated approaches address the need to model the galaxy–matter connection on nonlinear scales, including halo occupation distributions (HODs; Peacock & Smith 2000; Berlind & Weinberg 2002), which analytically relate expected galaxy counts to properties of host dark matter halos and introduce additional free parameters that must be constrained by observations. Galaxies and matter may also be modeled in terms of the joint distribution of their counts (in the case of galaxies) or density fields, in 2D or 3D, without the need to choose a specific halo definition. This approach appears in various counts-in-cells statistics for galaxies and matter, either separately or jointly, and these have proven useful for tasks such as constraining cosmology (e.g., Bel & Marinoni 2014; Codis et al. 2016; Uhlemann et al. 2017a,b, 2018; Friedrich et al. 2018, 2020; Gruen et al. 2018; Repp & Szapudi 2020; Uhlemann et al. 2020; Gough & Uhlemann 2022; Burger et al. 2023) and measuring galaxy bias parameters (Uhlemann et al. 2017c; Wang et al. 2019). In the broader context of probes of large-scale structure, these one-point probability density functions (PDFs) are complementary to standard two-point correlation functions (e.g., Bautista et al. 2020; Krause et al. 2021; Joachimi et al. 2021; Li et al. 2023) and higher-order statistics of the galaxy and matter density fields such as three-point functions (Schneider & Lombardi 2003; Takada & Jain 2003), integrated three-point functions (Chiang et al. 2014; Halder et al. 2021, 2023; Halder & Barreira 2022; Gong et al. 2023), and nearest-neighbor distributions (Banerjee & Abel 2020, 2021; Wang et al. 2022; Yuan et al. 2023a,b).
One obstacle to using one-point statistics in cosmological analyses is that accurate modeling of the galaxy–matter PDF may require the introduction of nuisance parameters that are neither well constrained by existing observations nor well described theoretically. This was the case for the Dark Energy Survey (DES) Year 1 density split statistics analysis (Friedrich et al. 2018; Gruen et al. 2018), which found the need for two additional parameters describing non-Poisson shot noise in galaxy counts. The lack of well-motivated bounds on these stochasticity parameters necessitated wide prior distributions that dominated the uncertainty budget of the density split analysis. A related agnostic approach to nonlinear galaxy bias and stochasticity is a limiting factor also for cosmological analyses of lensing and galaxy two-point correlation functions (Pandey et al. 2020; Sugiyama et al. 2020).
For statistics of the large-scale galaxy distribution, such as galaxy stochasticity, HODs provide a useful forward model for establishing well-motivated bounds or prior distributions. In its most general form, an HOD makes only the weak assumption that all galaxies are situated in dark matter halos and that the properties and formation history of a halo determine the number and properties of the galaxies it contains. If one can identify the subspace of HOD parameters that matches some chosen summary statistics of the galaxy catalog of interest, then these HODs can be used to generate mock galaxy catalogs in N-body simulations, from which measurements of stochasticity or any other nuisance parameter may be made directly.
In this work, we obtain such a set of HODs, with the aim being to probe the parameter space corresponding to a luminous red galaxy (LRG) sample selected by the REDMAGIC algorithm (Rozo et al. 2016). By producing mock catalogs with these HODs and measuring their stochasticity, we aim to set a plausible range on the parametrization of Friedrich et al. (2018) and Gruen et al. (2018). A companion paper (Ried Guachalla et al. 2024) presents a methodology for using these ranges to obtain stochasticity prior distributions that minimize error in a frequentist interpretation of the marginalized posterior distributions over cosmological parameters of interest.
The structure of this paper is as follows: in Sect. 2, we introduce the framework used to study galaxy bias and stochasticity in our analyses and review HODs and their extension to include galaxy assembly bias. In Sect. 3, we describe the rationale and computational methods (including simulations) used to select a set of realistic HODs, as well as the methods used to compute galaxy counts and matter densities in cells and measure bias and stochasticity. Section 4 presents our results, including the selected HODs, their stochasticity, and the effects of changing cosmology and cell geometry. In Sect. 5, we interpret our findings regarding the relationship between the galaxy–matter connection and stochasticity, and we discuss the implications of our results for modeling the galaxy–matter PDF and placing priors on stochasticity parameters. We conclude in Sect. 6 with a brief outlook on applying informed bounds on galaxy stochasticity in cosmological analyses.
2. Modeling the galaxy–matter connection
2.1. Stochasticity in galaxy counts
We consider the analysis of survey data consisting of galaxy counts Ng and matter overdensities δm along different lines of sight. Throughout this work, we assume a circular top-hat filter applied along each line of sight; such a filter is defined by an angular scale and redshift range, in the case of a galaxy survey, or a comoving radius and cylinder depth, in the case of a simulation snapshot. Each line of sight i thus corresponds to a comoving volume (cell) containing Ng, i galaxies and a mean matter overdensity δm, i. In galaxy survey applications, matter density cannot be measured directly and must be replaced by an observational proxy such as gravitational shear. Selecting cells of a given matter overdensity yields the discrete probability distribution P(Ng | δm), which contains information on the galaxy–matter connection and is part of several related probes of cosmology (Gruen et al. 2015, 2018; Friedrich et al. 2018, 2022; Uhlemann et al. 2020). A simple approach to modeling this distribution is to assume that it is approximately Poisson, with an expected galaxy count that varies linearly with the chosen matter density:
![$$ \begin{aligned} P(N_{\mathrm{g} } \,{\vert }\, \delta _{\mathrm{m} }) = \exp \left[-\bar{N}_{\mathrm{g} }(1+b\delta _{\mathrm{m} })\right]\times \left[\bar{N}_{\mathrm{g} }(1+b\delta _{\mathrm{m} })\right]^{\,N_{\mathrm{g} }}\times \left(N_{\mathrm{g} }!\right)^{-1}. \end{aligned} $$](/articles/aa/full_html/2024/09/aa50266-24/aa50266-24-eq1.gif)
Here 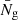 is the mean galaxy count across all cells (of all matter densities), and b is the linear galaxy bias.
is the mean galaxy count across all cells (of all matter densities), and b is the linear galaxy bias.
On physical scales for which galaxy counts in 3D are approximately Poisson-distributed and galaxies are linearly biased with respect to matter, galaxies will remain Poisson-distributed and linearly biased in a 2D projection as well. However, the assumption of strictly linear bias inevitably breaks down on sufficiently small scales, and there is also no a priori reason that the distribution must be exactly Poisson. Indeed, the density split analysis of Gruen et al. (2018) demonstrated that the mean and variance of P(Ng | δm) are not equal, as they would be for a simple Poisson distribution. Relative to the model of Eq. (1), Friedrich et al. (2018) and Gruen et al. (2018) found improved fits to simulations and survey data using a generalization of the Poisson distribution given by
![$$ \begin{aligned} P(N_{\mathrm{g} }\,{\vert }\,\delta _{\mathrm{m} }) &= \frac{1}{\mathcal{N} }\,\exp \left(-\,\frac{\bar{N}_{\mathrm{g} }(1+b\delta _{\mathrm{m} })}{\alpha (\delta _{\mathrm{m} })}\right)&\times \left(\frac{\bar{N}_{\mathrm{g} }(1+b\delta _{\mathrm{m} })}{\alpha (\delta _{\mathrm{m} })}\right)^{N_{\mathrm{g} }/\alpha (\delta _{\mathrm{m} })}\nonumber \\& \times \left[\,\Gamma \left(\frac{N_{\mathrm{g} }}{\alpha (\delta _{\mathrm{m} })}+1\right)\,\right]^{\,-1}, \end{aligned} $$](/articles/aa/full_html/2024/09/aa50266-24/aa50266-24-eq3.gif)
where Γ is the gamma function and α(δm)≡α0 + α1δm modulates the variance of the distribution in the following manner:
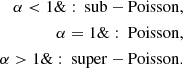
This distribution can be interpreted as one in which galaxies appear in sets of α, with the sets themselves exhibiting simple Poisson variance. We note that the probability on the right side of Eq. (2) corresponds to drawing a (generally noninteger) value Ng/α, not the value Ng itself. This requires a continuous analog of the Poisson distribution, which is achieved by replacing the factorial in the Poisson probability with the gamma function; this still yields a valid probability mass function over integer values of Ng. The distribution is normalized by 𝒩 ≃ 1/α, where the equality is exact for integer values of α (Friedrich et al. 2018) and close to exact for all α given a sufficiently large expectation value for P(Ng | δm), as is the case in this work.
In this parametrization, non-Poisson shot noise in galaxy counts (hereafter referred to as stochasticity) consists of a global component α0 that affects all cells equally and a parameter α1 that captures the dependence of stochasticity on local matter density. Pathological cases do arise when α(δm) or the quantity 1 + bδm is nonpositive; the numerical handling of such cells in our analysis is described in Sect. 3.2.6.
The HODs used in this work are derived to match specific values of galaxy density and linear bias as defined in Eq. (2), the same model applied to galaxy counts in cells and cosmic shear in Friedrich et al. (2018) and Gruen et al. (2018). However, in the mock catalogs produced by these HODs, linear galaxy bias alone is insufficient to fully describe P(Ng | δm) for some of the galaxy–matter connections probed at larger matter under- or overdensities. When analyzing stochasticity in the mock catalogs, we therefore model galaxy bias to second order by modifying Eq. (2) according to
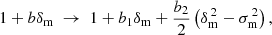
where b1 and b2 now denote the linear and quadratic galaxy bias, respectively, and 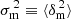 is the variance of matter overdensity across all cells. The full model for the conditional distribution of galaxy counts at fixed matter density, including quadratic bias, is then
is the variance of matter overdensity across all cells. The full model for the conditional distribution of galaxy counts at fixed matter density, including quadratic bias, is then
![$$ \begin{aligned} P(N_{\mathrm{g} }\,\vert \,\delta _{\mathrm{m} })&= \frac{1}{\alpha _0+\alpha _1\delta _{\mathrm{m} }}\,\exp \left(-\,\frac{\bar{N}_{\mathrm{g} }\,\Big [1+b_1\delta _{\mathrm{m} }+\frac{b_2}{2}\big (\delta _{\mathrm{m} }^{\,2}-\sigma _{\mathrm{m} }^{\,2}\big )\Big ]}{\alpha _0+\alpha _1\delta _{\mathrm{m} }}\right)\nonumber \\&\times \,\left(\frac{\bar{N}_{\mathrm{g} }\,\Big [1+b_1\delta _{\mathrm{m} }+\frac{b_2}{2}\big (\delta _{\mathrm{m} }^{\,2}-\sigma _{\mathrm{m} }^{\,2}\big )\Big ]}{\alpha _0+\alpha _1\delta _{\mathrm{m} }}\right)^{N_{\mathrm{g} }/(\alpha _0+\alpha _1\delta _{\mathrm{m} })}\nonumber \\&\times \,\left[\,\Gamma \left(\frac{N_{\mathrm{g} }}{\alpha _0+\alpha _1\delta _{\mathrm{m} }}+1\right)\,\right]^{\,-1}, \end{aligned} $$](/articles/aa/full_html/2024/09/aa50266-24/aa50266-24-eq7.gif)
where the 1/α(δm) normalization has been assumed. As a standard caution, we note that linear bias denoted by b or b1 is not an equivalent quantity across different models such as Eqs. (1), (2), and (4). In the remainder of this work, “bias” and “linear bias” refer to b1 as defined in the stochasticity model of Eq. (4), unless otherwise specified.
Galaxy stochasticity in the α0, α1 parametrization is not well understood from a physical perspective, nor has it been explored in depth via simulations. The density split statistics analysis of Gruen et al. (2018) used conservatively wide prior distributions for stochasticity parameters, with the authors noting that the cosmological constraining power of the model would improve significantly with even modestly tightened priors. In this work, we aim to better understand the plausible range of α0 and α1 and to develop a method for deriving this range given basic properties of a galaxy sample, such as its linear bias and galaxy number density. A companion paper (Ried Guachalla et al. 2024) presents a selection algorithm for obtaining informative priors on nuisance parameters such as α0 and α1, based on such ranges. These priors are optimized in the sense that the resulting marginalized 1D posteriors for cosmological parameters are minimally biased – that is, such that prior volume effects are minimized. These informed, total-error-minimizing (ITEM) priors enable us to assess the improvement in cosmological constraining power (Britt et al., in prep.) associated with a tightening of the plausible ranges for α0 and α1 via the methods described in Sect. 3.
2.2. Example: Modeling the counts-in-cells PDF
To illustrate the role of stochasticity and bias parameters in modeling P(Ng | δm), in Fig. 1 we fit three different models to measured counts-in-cells distributions for mock galaxies. The models are fit to two different sets of mock catalogs generated by different HODs, one with sub-Poisson scatter and one with super-Poisson scatter at δm = 0 (i.e., α0 < 1 and α0 > 1, respectively).1 Fig. 1 shows the measured counts-in-cells distributions at three different matter overdensities δm ∈ { − 0.3, 0.0, 0.38}, along with model fits for the PDFs defined in Eqs. (1), (2), and (4). The two nonzero values of δm are set at the most extreme values for which there exist at least 1000 cylinders whose matter overdensities fall in a narrow bin of width 0.05 in δm. For a given bin, each model is evaluated at each individual cylinder’s value of δm, and the resulting PDFs are averaged for comparison with the count histograms.
 |
Fig. 1. Comparison of different model predictions for P(Ng | δm) against measured counts-in-cells distributions in mock galaxy catalogs for a pair of example HODs that have sub-Poisson scatter (top row) and super-Poisson scatter (bottom row) at δm = 0. Within each row, the three panels show model fits (solid curves) for the different parametrizations of P(Ng | δm) given in Eqs. (1), (2), and (4). Left column: Best-fitting model with linear bias only; i.e., a simple Poisson distribution. Middle column: Model with linear bias b and density-dependent stochasticity α0, α1, which decouples the mean and variance of the distribution. Right column: Stochasticity model with galaxy bias modeled to second order in δm. Shaded histograms show the measured distributions of galaxy counts in cells for three narrow bins of width 0.05 in δm. Each histogram is an average over 200 mock galaxy catalogs. The underdense (−0.3) and overdense (0.38) bins are set to the most extreme values of δm for which each bin still contains at least 1000 of the 160 000 cylinders in the simulation box. Stochasticity values α0 and α1 for the two HODs (as measured in the model with quadratic bias) are given in the top right corner of the last panel in each row. |
The simplest model is a Poisson distribution whose expectation value incorporates linear bias only, and in the first column of Fig. 1, the histogram of counts in cells for the low-α0 HOD in the first row (α0 = 0.798, α1 = 0.221) has a smaller variance than the overplotted Poisson curve, while the counts in cells for the high-α0 HOD (second row, α0 = 1.327, α1 = 0.772) have super-Poisson scatter at δm = 0 (red histogram). Not only does the Poisson model fail to match the variance of the measured distributions, it also does not track the mean accurately as δm changes, suggesting that linear bias alone is insufficient to model the expectation value of the PDF for these HODs. The model with linear bias and stochasticity successfully matches the shape of the distribution, as it decouples the variance from the expectation value, but suffers from an offset to higher Ng for both nonzero values of δm. Finally, when quadratic bias is modeled in the third column of Fig. 1, both the width and mean of the distribution accurately track the measured PDFs.
2.3. Halo occupation distributions (HODs)
For a given galaxy sample, assessing the range of plausible α0 and α1 values requires a means of pushing the high-dimensional space of galaxy–matter connections to various limits while still respecting constraints imposed by a given cosmological model and the galaxy catalog. HODs are an efficient, empirically motivated, and thoroughly studied approach to modeling this connection and generating mock galaxy catalogs within halos identified in N-body simulations (Peacock & Smith 2000; Berlind & Weinberg 2002; Zheng et al. 2005, 2007). HOD modeling entails the assumptions that galaxies only exist inside dark matter halos and that the properties of a halo determine the expected number of galaxies it hosts. In its most commonly used form, an HOD is a function of halo mass that returns the expectation value of galaxy count for a halo. As such, HODs constitute both a modeling framework for cosmological analyses and a numerical method for painting galaxies into halos in dark matter-only simulations.
HODs are a natural choice for simulating and understanding galaxy stochasticity given their flexibility in describing a variety of galaxy distributions and the physical interpretability of their parameters. One of the most well-studied of these models is the five-parameter HOD of Zheng et al. (2005, 2007), which expresses the expected counts of central and satellite galaxies as sigmoid and power law functions of halo mass, respectively. Here we consider a modified Zheng HOD of the form
![$$ \begin{aligned} \Big \langle N_\mathrm{cen} \big (M_\mathrm{h} \big )\Big \rangle&= \frac{f_\mathrm{cen} }{2} \left[\,1+\mathrm{erf} \left( \frac{\log _{10} M_\mathrm{h} -\log _{10}M_\mathrm{min} }{\sigma _{\log M}}\right)\,\right]\end{aligned} $$](/articles/aa/full_html/2024/09/aa50266-24/aa50266-24-eq8.gif)
![$$ \begin{aligned} \Big \langle N_\mathrm{sat} \big (M_\mathrm{h} \big )\Big \rangle&= \Big \langle N_\mathrm{cen} \big (M_\mathrm{h} \big )\Big \rangle \,\times \,\left[\frac{M_\mathrm{h} }{M_1}\right]^{\,\alpha _{\,\mathrm{hod} }}, \end{aligned} $$](/articles/aa/full_html/2024/09/aa50266-24/aa50266-24-eq9.gif)
where masses are in units of h−1 M⊙ and erf is the error function:
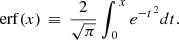
Relative to the canonical Zheng HOD, this version omits the cutoff mass M0 in the numerator of ⟨Nsat⟩ (as in, e.g., Clampitt et al. 2016; Zacharegkas et al. 2021) and includes fcen as a prefactor in ⟨Ncen⟩, keeping the total at five model parameters.
For central galaxies, Mmin sets the halo mass for which the probability of hosting a central is 0.5, and fcen is an incompleteness parameter introduced to account for the failure of some fraction of those central galaxies to pass catalog selection, even in very massive halos (Clampitt et al. 2016; Rodríguez-Torres et al. 2016; Leauthaud et al. 2016; Guo et al. 2018; Zacharegkas et al. 2021). The parameter σlog M describes the width of the mass range about Mmin over which ⟨Ncen⟩ transitions from zero to fcen/2.
For satellite galaxies, M1 plays a role analogous to that of Mmin, characterizing the halo mass above which satellites are expected to form, and αhod is the power-law slope describing the increase in satellite count with increasing halo mass. The subscript on αhod is used throughout this work to avoid confusion with the stochasticity parameters α0 and α1. We note that in our chosen form of the Zheng HOD, ⟨Nsat⟩ is modulated by ⟨Ncen⟩, suppressing the placement of satellites in halos that have lower probabilities of hosting a central. As a result, ⟨Nsat⟩ includes fcen as a prefactor, albeit one fully degenerate with M1. This HOD parametrization is therefore functionally equivalent to one in which fcen does not appear in the satellite component, and one must simply account for the presence or absence of fcen in ⟨Nsat⟩ when comparing values of M1 across models (e.g., Clampitt et al. 2016; Zacharegkas et al. 2021).
An HOD in the form of Eqs. (5) and (6) is useful both as a model for describing data and as a numerical method for placing mock galaxies in simulated halos. To generate a mock catalog using an HOD, an integer number of galaxies is placed in each halo, typically by drawing the central count (0 or 1) from a Bernoulli distribution with mean ⟨Ncen⟩ and the satellite count from a Poisson distribution with expectation value ⟨Nsat⟩. Central galaxies are placed at the centers of their host halos, and various approaches exist for positioning the satellites, including sampling from an analytical density profile such as Navarro–Frenk–White (NFW; Navarro et al. 1996) or assigning satellites to the positions of dark matter particles sampled from the halo (see, e.g., Yuan et al. 2021a and Sect. 3.1).
2.4. HOD extensions: Assembly bias
The Zheng HOD and variants such as Eqs. (5) and (6) have proven sufficiently flexible for modeling the moderate- to large-scale two-point correlation functions of LRG samples in current galaxy surveys such as DES (Clampitt et al. 2016; Zacharegkas et al. 2021). However, it has long been understood that secondary properties such as halo concentration can impact occupation statistics (Wechsler et al. 2002, 2006; Mao et al. 2017; Salcedo et al. 2018; Hadzhiyska et al. 2020; Xu et al. 2021). The dependence of galaxy count on any secondary (i.e., non-mass) halo properties is collectively referred to as galaxy assembly bias.
In this work, we consider two proxies for assembly bias: halo concentration c and the mean matter overdensity δenv of a halo’s local environment. Concentration is a measure of the radial mass distribution within a halo, typically defined as the ratio of two characteristic radii, and is indicative of a halo’s formation history. Here, we calculate concentration as implemented in AbacusHOD (Yuan et al. 2021a, see also Sect. 3.1 below), which defines it as c ≡ r90/r25, the ratio of the radii that contain 90% and 25% of the halo’s total mass, respectively. Environmental density is determined by the total mass of all nearby halos whose centers lie beyond r98 for the halo in question but within some outer radius, which we set at 5 h−1 Mpc (see Xu et al. 2021; Yuan et al. 2021a). To define an overdensity, this mass is normalized by the mean of all such environmental masses around all halos:

Dependence on secondary halo properties such as concentration and environmental overdensity can be added to an HOD in various ways. Again in keeping with the AbacusHOD implementation, we follow the approach of Xu et al. (2021), which preserves the explicit form of the HOD in Eqs. (5) and (6) by mixing assembly bias into the values of Mmin and M1 (see Walsh & Tinker 2019 for a similar approach):
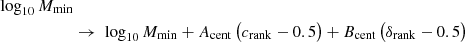
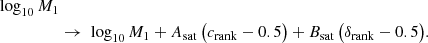
Here Acent, Asat, Bcent, and Bsat are additional HOD parameters capturing assembly bias. Concentration and environmental overdensity are converted to ranked quantities crank and δrank, respectively, by binning halos by mass, ranking c and δenv within each bin, and normalizing the ranks within bins to the range [0, 1]. In an HOD with Acent > 0, for example, a halo with above-median concentration for its mass bin (crank > 0.5) will see an increase in its effective value of Mmin and thus a decrease in ⟨Ncen⟩ relative to the case with no assembly bias.
In the context of studying galaxy stochasticity, the inclusion of assembly bias probes additional degrees of freedom in the galaxy–matter connection, in principle allowing the HOD to produce distributions P(Ng | δm) that are physically plausible but cannot be realized when halo occupation depends on halo mass alone.
3. Methods
Our approach to studying galaxy stochasticity, described in detail in this section, can be summarized as follows: we first optimize the Mmin and M1 parameters of the HOD to reproduce the galaxy bias and density of a REDMAGIC sample (Rozo et al. 2016), at fixed fiducial values of the other HOD parameters. We then allow one other HOD parameter at a time to vary from its baseline value until Mmin and M1 can no longer be optimized to achieve the desired bias and density. Having derived a set of REDMAGIC-like HODs in this way, we use them to produce mock galaxy catalogs and measure the resulting stochasticity. This approach allows us to determine relationships between individual HOD parameters and stochasticity at fixed bias and density, as well as to probe the allowed range of stochasticity when a limited number of HOD parameters are varied at once. We also assess the impact of cosmology on stochasticity by rederiving a baseline HOD in each of a set of alternate cosmologies. Finally, to more thoroughly probe the full HOD parameter space, we Monte Carlo sample additional HODs with all parameters free and measure stochasticity in the resulting galaxy catalogs.
3.1. Numerical simulations and HOD implementation
We employ the ABACUSSUMMIT2 suite of N-body simulations (Maksimova et al. 2021; Garrison et al. 2021) and associated halo catalogs produced by the COMPASO halo finder (Hadzhiyska et al. 2021), which are together designed to exceed DESI cosmological simulation requirements. We work with snapshots at z = 0.3 throughout; for reference, the density split analysis of Gruen et al. (2018) used a REDMAGIC LRG sample in the range 0.2 < z < 0.45. The snapshot halo catalogs used in this work have been ‘cleaned’ in a post-processing step described in Bose et al. (2022) by using merger trees to reassociate halos that are overdeblended by the halo finder. The base simulations of ABACUSSUMMIT consist of 69123 particles in boxes of side length 2 h−1 Gpc, with a particle mass of approximately 2 × 10 9 h−1 M⊙. Halos in the base simulations are resolved down to masses of roughly 1011 h−1 M⊙, which is more than sufficient for use with the HODs derived in this work. To reduce computing time, we apply a halo mass cut at log10(Mh/h−1 M⊙) = 11.35, which is conservative given that we additionally constrain our HODs (see Sect. 3.2.4) such that that none will place a meaningful fraction of galaxies in halos below log10(Mh/h−1 M⊙) = 11.5.
Our baseline analyses are performed in the primary cosmology (c000) of ABACUSSUMMIT, corresponding to Planck 2018 ΛCDM (Planck Collaboration VI 2020) Ωcdm = 0.2645, Ωb = 0.0493, ns = 0.9649, σ8, m = 0.8080, h = 0.6736, Neff = 3.046). For assessing the sensitivity of stochasticity to cosmology, we use the 52 additional cosmologies of the ABACUSSUMMIT emulator grid (c130-181; see Maksimova et al. 2021 Sect. 2.2 for details on the grid selection).
For all HOD implementations, we use the AbacusHOD code (Yuan et al. 2021a), which is part of the abacusutils3 package developed for working with ABACUSSUMMIT data products. AbacusHOD is a framework for rapidly generating mock galaxy samples in large simulation volumes and includes the Zheng et al. (2007) model and assembly bias extensions (Yuan et al. 2018) described in Sect. 2.3 (see Yuan et al. 2021b for a summary of these and other HOD extensions). In this implementation, central galaxies are placed at halo centers (see Hadzhiyska et al. 2021 Sect. 2.2.2 for details on center identification in COMPASO). Each satellite galaxy is placed at the position of a different dark matter particle drawn at random from the halo. All galaxy catalogs in this work implement redshift space distortions (RSDs) by adjusting galaxy positions in the line-of-sight direction (i.e., parallel to the cylinders used to compute counts in cells) according to the velocity of the halo center or particle to which the galaxy was assigned. In the context of this work, these shifts in position model the expected effect of peculiar velocities on counts-in-cells statistics in a galaxy survey, where counts are calculated using galaxies within a redshift bin. A galaxy whose comoving distance corresponds to a Hubble-flow redshift within the bin may be excluded if its peculiar velocity leads to an observed redshift outside the bin, and vice versa. For completeness, we also measure the impact of turning off RSD modeling and find a subpercent mean shift in galaxy count per cylinder and a similar subpercent effect on linear bias. The effect on the stochasticity parameters α0 and α1 is at the few percent level, which is subdominant to changes in stochasticity stemming from degrees of freedom in the galaxy–matter connection, as probed by the range of HODs we derive here.
3.2. Selecting plausible HODs
3.2.1. Constraining galaxy bias and density
Because we aim to study the stochasticity of LRGs, matching known properties of a REDMAGIC galaxy sample is a natural choice. Gruen et al. (2018) applied the stochasticity model of Eq. (2) to a REDMAGIC high-density sample, which by construction has a mean comoving density n = 10−3 h3 Mpc−3, and we set this as our target value of galaxy density. We simultaneously optimize our HODs for a baseline linear galaxy bias of b = 1.5 in the model of Eq. (2), similar to the b = 1.54 found by Friedrich et al. (2018) when applying the same model to mock LRGs across a range of smoothing scales from 10 to 30 arcmin. Although we select REDMAGIC-like values here, we emphasize that b and n in this method may be set to values corresponding to any desired galaxy population. To assess the impact of bias and density on stochasticity, we construct two additional sets of HODs that vary the target values of b and n themselves (see Sect. 3.2.5).
Optimizing for a specific bias and density requires a means of calculating these properties at different points in HOD parameter space. For an HOD that depends on halo mass only (i.e., no assembly bias), linear galaxy bias and number density may be estimated efficiently using analytic forms for the halo mass function dnh/dMh (e.g., Tinker et al. 2010) and halo bias bh as a function of mass (Tinker et al. 2008):
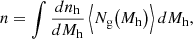
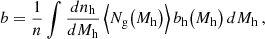
where ⟨Ng(Mh)⟩ is the expected galaxy count given by the HOD. However, we wish to construct HODs that include assembly bias, in which case analytic estimates analogous to those above would require integration over halo concentration and environmental overdensity – and therefore also approximations for dnh/dMh and bh that include dependence on these secondary halo properties. Lacking such functions, we instead estimate the bias and density of an HOD directly by using AbacusHOD to generate a single mock galaxy catalog. Calculating the number density of the catalog is straightforward given the simulation volume and the total galaxy count. To measure galaxy bias while optimizing HODs, we follow the approach of Friedrich et al. (2018) and Gruen et al. (2018) and fit the linear bias and stochasticity model of Eq. (2) to galaxy counts and matter overdensities in cells (see Sect. 3.2.6 for details on model fitting).
Given the above method for measuring linear bias and density, the optimization procedure begins by setting all parameters except Mmin and M1 to chosen baseline values (Sect. 3.2.2). The HOD then has two free parameters and can be optimized for the unique combination (Mmin, M1) that satisfies the two constraints (bias and density), under the assumption that a unique optimal HOD exists within a physically plausible range of (Mmin, M1).4 Both mass parameters are bounded between 1011 and 1016 h−1 M⊙, fully capturing the range of halo masses in the baseline cosmology of ABACUSSUMMIT (subject to our mass cut). The optimization itself consists of minimizing (over Mmin and M1) the sum of squared relative errors in bias and density given the goals of b = 1.5 and n = 10−3 h3 Mpc−3 – that is, minimizing the function,
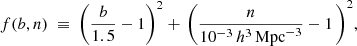
via Nelder-Mead simplex (Nelder & Mead 1965). Although measuring bias and density directly on a mock catalog is naturally more computationally expensive than an analytic estimate, optimizing an HOD to subpercent error in both b and n is generally possible in ∼50 function evaluations.
3.2.2. Fiducial HOD parameters
The optimization procedure described in Sect. 3.2.1 requires a specification of all HOD parameters other than Mmin and M1. In this section, we discuss the choice of fiducial values for these non-mass parameters. Optimizing an HOD at this set of values yields a baseline model relative to which other HODs can be derived.
Our fiducial value of fcen is a direct estimate from the DES Y3GOLD REDMAGIC high-density catalog, selecting only galaxies in the same redshift range (0.2 < z < 0.45) used by Gruen et al. (2018). The completeness of central galaxies in the sample is estimated by summing the probabilities that each of the selected REDMAGIC galaxies is a central in a REDMAPPER cluster, based on candidate centrals identified by REDMAPPER (Rykoff et al. 2014, 2016) in the same Y3GOLD photometric dataset (Sevilla-Noarbe et al. 2021). We select clusters of richness λ ≥ 50, corresponding to halos with masses well above Mmin (see, e.g., Fig. 9 in Abbott et al. 2020), so that ⟨Ncen⟩≃fcen for these clusters. The sum of these central probabilities divided by the number of clusters gives an estimate of fcen = 0.316, which we take as our fiducial value.
We set σlog M = 0.3 as a baseline value for the width of the ⟨Ncen⟩ part of the HOD, consistent with published constraints for REDMAGIC samples for lens bins of a similar redshift range (Clampitt et al. 2016; Zacharegkas et al. 2021). We find that stochasticity as parametrized by α0 and α1 is less sensitive to the choice of σlog M than to the other HOD parameters tested.
For the satellite galaxy component of the HOD, we set the fiducial power-law slope to αhod = 1. This value is a significant reduction relative to the DES Year 3 REDMAGIC HOD of Zacharegkas et al. (2021) for the lowest-redshift lens bin. We find that slopes much larger than αhod = 1 yield galaxy counts in the most massive halos of the baseline ABACUSSUMMIT simulation that are a factor of several larger than the highest REDMAGIC counts in clusters (see Sect. 3.2.3). A similar effect was noted by Kokron et al. (2022), who found that a reduction in αhod relative to the DES Y3 values was needed to match derived parameters such as the satellite fraction of their REDMAGIC-like HOD. The authors attributed the discrepancy in this case to differences between the halo mass function of their simulations and the Tinker et al. (2008) mass function used in constraining the DES Y3 HOD (see Sect. 3 of Kokron et al. 2022).
Finally, we define our baseline model without assembly bias, setting Acent, Asat, Bcent, and Bsat to zero. Table 1 lists the parameters of the baseline HOD after optimizing for Mmin and M1. To determine the extent to which each HOD parameter may vary in isolation, we choose one non-mass parameter at a time and shift it to values above and below its baseline, reoptimizing Mmin and M1 each time to obtain an HOD that conserves the target bias and density. For sufficiently extreme values of each parameter, the constraints can no longer be satisfied within the bounds set on Mmin and M1 (from 1011 to 1016 h−1 M⊙ for both mass parameters). The same applies when varying the target value of bias or density with all non-mass HOD parameters fixed at their baseline values. We use these ranges for the individual parameters (Table 1) to derive additional HODs in Sect. 3.2.5.
3.2.3. Constraining maximum halo occupation
With galaxy bias and density as constraints, the optimization procedure remains free to derive HODs whose mock galaxy catalogs may differ from those of a REDMAGIC sample in properties other than bias and density. In particular, we find that it is possible to obtain HODs that satisfy b ≃ 1.5 and n ≃ 10−3 h3 Mpc−3 but whose slopes αhod are high enough to yield ⟨Nsat⟩≳100 for the most occupied halos. For comparison to observations, we estimate the maximum number of galaxies in a REDMAGIC catalog (of the same density) that appear in any one galaxy cluster. For this we again use the DES Y3GOLD REDMAGIC catalog (high-density, n = 10−3 h3 Mpc−3) and the Y3GOLD REDMAPPER cluster catalog. To estimate the count of REDMAGIC galaxies in a given cluster, we sum the REDMAPPER membership probabilities for REDMAGIC galaxies identified as potential members of that cluster. The results are shown in Fig. 2, which includes the distribution of cluster occupations for all REDMAPPER clusters and for the subset in the redshift range 0.2 < z < 0.45, the same as in the density split analysis of DES Y1 REDMAGIC galaxies (Gruen et al. 2018).
 |
Fig. 2. Distribution of counts of DES Y3GOLD REDMAGIC galaxies (high-density sample) in REDMAPPER clusters. Count per cluster is calculated as the sum of membership probabilities for all REDMAGIC galaxies identified as possible members of the cluster. Shown are the distributions for all clusters in the catalog (blue) and for clusters in the redshift range 0.2 < z < 0.45 (red); this is identical to the range used in the density split analysis of DES Y1 REDMAGIC galaxies in Gruen et al. (2018). |
To keep our selected HODs consistent with the high end of the distribution in Fig. 2, we set an additional constraint on the single largest value of ⟨Ng⟩=⟨Ncen⟩+⟨Nsat⟩ across all halos, requiring that it fall in the range [25, 50]. We note that the constraint is on the expectation value ⟨Ng⟩ and that any individual realization of a mock catalog may place more than 50 or fewer than 25 galaxies in the halo with the highest galaxy count, due to the random drawing of satellite galaxy counts. We find that this constraint on ⟨Ng⟩ further tightens the bounds on the allowed values of the seven non-mass HOD parameters relative to those imposed by bias and density alone. Placing limits on ⟨Ng⟩ thus sets the extent to which each HOD parameter may vary in isolation as listed in Table 1 (with exceptions regarding the upper limit on σlog M and lower limit on Bsat, see Sect. 3.2.4).
With this restriction on the maximum value of ⟨Ng⟩ included, the full set of baseline constraints used in deriving HODs is:
![$$ \begin{aligned}&b = 1.5,\nonumber \\&n = 10^{-3}\,h^3\,\mathrm{Mpc} ^{-3},\nonumber \\&\max _i \Big \langle N_\mathrm{g} \big (M_{\mathrm{h} ,i}\big )\Big \rangle \,\in \,[25,50], \end{aligned} $$](/articles/aa/full_html/2024/09/aa50266-24/aa50266-24-eq17.gif)
where the first two constraints are imposed during optimization for the mass parameters (Mmin, M1) and the third limits the extent to which each non-mass parameter in isolation may deviate from its fiducial value.
3.2.4. Additional constraints: σlog M and assembly bias
For the one set of HODs that varies σlog M, we apply a further constraint due to the fact that if this parameter is sufficiently large, it will attempt to place galaxies in halos below our mass cut or even below the minimum mass resolved by the halo finder, regardless of the value of Mmin. We therefore set an upper limit on σlog M such that no HOD places a substantial fraction of galaxies (≳10−4) in halos below log10(Mh/h−1 M⊙) = 11.5. This condition corresponds to an upper bound of σlog M ≃ 0.38. Recall (Sect. 3.1) that we use a halo catalog that is complete down to log10(Mh/h−1 M⊙) = 11.35. Beyond being practical, this should also be a physically reasonable constraint on σlog M, as we do not expect halos below log10(Mh/h−1 M⊙) = 11.5 to host a meaningful number of galaxies that pass the luminosity threshold and other selection criteria for a REDMAGIC high-density sample, based on stellar mass to halo mass ratio considerations. We additionally verify that even without this constraint on σlog M, and using a lower halo mass cut at log10(Mh/h−1 M⊙) = 11, the highest-σlog M HODs consistent with all other constraints given in Eq. (14) still produce values of α0 and α1 within the range spanned by the HODs that vary other parameters.
Finally, we restrict each of the four assembly bias parameters Acent, Asat, Bcent, and Bsat to the range [ − 1, 1], which is generously wide relative to assembly bias values measured in observations and simulations (e.g., Xu et al. 2021; Yuan et al. 2021a,b, 2022; Hadzhiyska et al. 2023; Paviot et al. 2024). In practice, we find that it is only necessary to impose this restriction at Bsat = −1; all other assembly bias limits are set more tightly by the constraints in Eq. (14) as long as all other HOD parameters are kept at their baseline values.
3.2.5. HOD curves of constant bias and density
For each of the seven HOD parameters other than Mmin and M1, including assembly bias, we optimize HODs at 11 different values of that parameter, linearly spaced across its allowed range (see Sect. 3.2.2 and Table 1), with the other six non-mass parameters set to their baseline values. Each optimization determines the values of Mmin and M1 that produce the target galaxy bias and density. We execute the same procedure across the allowed ranges of the target values of bias and density themselves, with the HOD (excluding Mmin and M1) fixed at its baseline parameters. The result is a set of nine curves in HOD parameter space, all intersecting at the point corresponding to the baseline model. All HODs on the curves that vary the non-mass HOD parameters produce mock galaxy catalogs that conserve linear bias b = 1.5 in the model of Eq. (2) and number density n = 10−3 h3 Mpc−3, while the curves that vary bias or density have changing values of their respective parameter by construction.
3.2.6. Counts in cells and measuring stochasticity
To make stochasticity measurements on mock catalogs generated by our HODs, we count galaxies in cylindrical cells of radius 10 h−1 Mpc (as a transverse comoving distance, equivalent to ∼30 arcmin at z = 0.3) and depth 500 h−1 Mpc (roughly the comoving depth of a redshift bin between, e.g., z = 0.23 and z = 0.36; note of course that each mock catalog exists in a snapshot at z = 0.3). Each 2 h−1 Gpc simulation box is treated as four slabs of depth 500 h−1 Mpc, and counts in cells are performed in all slabs in order to utilize the full simulation volume. Across the (2 h−1 Gpc)2 face of each slab, cylinders are placed in a 200 × 200 grid with a 10 h−1 Mpc spacing between their centers, and periodic boundary conditions are enforced. Each mock catalog therefore yields a set of 160 000 counts in cells. Measurements of matter overdensity δm in cells are performed similarly by counting dark matter particles from the A subsample provided by ABACUSSUMMIT, which uniformly samples 3% of the total particles in the simulation. A downsampling of particles naturally contributes some variance to the values of δm in cells; however, even the most underdense cylinder (with radius 10 h−1 Mpc and depth 500 h−1 Mpc in the baseline cosmology) samples > 105 particles, and so any matter variance is subdominant to the stochasticity contributed by the galaxy–matter connections considered here.
To fit the stochasticity model to the resulting set of tuples (Ng, i, δm, i), we take our model likelihood to be the product over all cells of the PDF of Eq. (4). As noted in Friedrich et al. (2018, Sect. IV.C.2), although this likelihood is not exact given the correlations between counts and densities in nearby cells, it is nonetheless sufficient for the purpose of this analysis, namely obtaining conservative bounds on α0 and α1. The logarithm of our likelihood is then the sum over all cells of the logarithm of the PDF given by Eq. (4):
![$$ \begin{aligned} \ln \mathcal{L}&=\sum _i\left[{0em}{2em}\right. -\ln \big (\alpha _0+\alpha _1\delta _{\mathrm{m} ,i}\big )-\frac{\bar{N}_\mathrm{g} \,\Big [1+b_1\delta _{\mathrm{m} ,i}+\frac{b_2}{2}\big (\delta _{\mathrm{m} ,i}^{\,2}-\sigma _\mathrm{m} ^{\,2}\big )\Big ]}{\alpha _0+\alpha _1\delta _{\mathrm{m} ,i}}\nonumber \\&+ \frac{N_{\mathrm{g} ,i}}{\alpha _0+\alpha _1\delta _{\mathrm{m} ,i}}\ln \left(\frac{\bar{N}_{\mathrm{g} }\,\Big [1+b_1\delta _{\mathrm{m} ,i}+\frac{b_2}{2}\big (\delta _{\mathrm{m} ,i}^{\,2}-\sigma _\mathrm{m} ^{\,2}\big )\Big ]}{\alpha _0+\alpha _1\delta _{\mathrm{m} ,i}}\right)\nonumber \\&- \ln \Gamma \left(\frac{N_{\mathrm{g} ,i}}{\alpha _0+\alpha _1\delta _{\mathrm{m} ,i}}+1\right)\left.{0em}{2em}\right]. \end{aligned} $$](/articles/aa/full_html/2024/09/aa50266-24/aa50266-24-eq18.gif)
We note that this likelihood assumes the 1/α normalization for P(Ng | δm), which we find to be accurate for all stochasticity values measured for the HODs in this work.
For a given parameter combination b1, b2, α0, α1, it may be the case that some cells have δm, i such that the quantity 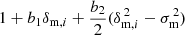 or α0 + α1δm, i is zero or negative. These cases may be handled in a number of ways, for instance by setting the offending quantity to a very small positive value or returning negative infinity for lnℒ. We use the latter option and verify that the two methods do not differ significantly in terms of the values of b1, b2, α0, and α1 that maximize the likelihood of Eq. (15).
or α0 + α1δm, i is zero or negative. These cases may be handled in a number of ways, for instance by setting the offending quantity to a very small positive value or returning negative infinity for lnℒ. We use the latter option and verify that the two methods do not differ significantly in terms of the values of b1, b2, α0, and α1 that maximize the likelihood of Eq. (15).
4. Results
4.1. Selected HODs
The HOD curves for varying αhod, σlog M, and fcen are shown in the M1-Mmin projection in HOD parameter space in the top panel of Fig. 3. Each curve consists of 11 HODs linearly spaced in the parameter being varied, with the endpoints occurring where it is no longer possible to meet the constraints on bias, number density, and the maximum value of ⟨Ng⟩ simultaneously. The maximum and minimum values for the parameter varied in each curve are listed in Table 1. We verify that these HODs, when used to generate new mock galaxy catalogs with unique random seeds, reproduce the target values of bias and density to subpercent precision. We note that the three curves in the top panel of Fig. 3 extend in orthogonal directions in the full HOD parameter space, as each varies a parameter that is fixed for the other curves.
 |
Fig. 3. Mmin versus M1 for the HODs produced when one non-mass parameter is varied and M1 and Mmin are optimized to achieve the target bias and density. The ends of each curve are marked with an open square for the lowest value of that parameter and a filled square for the highest (see Table 1 for the parameter ranges). All HOD curves intersect at the location of the baseline model. Top panel: HODs that vary the parameters αhod, σlog M, and fcen. Middle panel: HODs that vary the assembly bias parameters Acent, Asat, Bcent, and Bsat (inset: closeup of the curves for Acent and Asat). Bottom panel: HODs that vary the target values of bias and density while keeping the non-mass parameters fixed at baseline. Gray dashed curves in each panel correspond to the curves from the other two panels for reference. |
Analogous results for the assembly bias parameters Acent, Asat, Bcent, and Bsat are shown in the middle panel of Fig. 3. Unlike the curves for all other HOD parameters, those for Acent and Asat (parameters that modulate the effect of halo concentration) are U-shaped, with the HODs corresponding to negative and positive parameter values extending in somewhat similar directions in the M1-Mmin projection. The curve for Bsat is limited at the low-Bsat end by our conservatively wide lower bound of −1 for the assembly bias parameters, as noted in Sect. 3.2.4.
The bottom panel of Fig. 3 shows the HODs that result when the target bias and density values themselves are varied. For each curve, the target value of the other parameter remains fixed at its baseline value (b = 1.5 or n = 10−3 h3 Mpc−3), and the endpoints occur where the constraint on the maximum value of ⟨Ng⟩ given in Eq. (14) can no longer be satisfied for more extreme values of the parameter varied in that curve. The resulting ranges are [1.36, 1.54] for bias and [0.72, 1.08]×10−3 h3 Mpc−3 for density. Within these limits imposed by our constraints, varying the bias and density of the desired galaxy sample produces values of Mmin and M1 that fall roughly within the range spanned by the curves that vary HOD parameters in the first two panels of Fig. 3. However, this does not imply that the same should hold for the stochasticity values α0 and α1 that result when these HODs are used to generate mock galaxy catalogs.
4.2. Galaxy stochasticity
We evaluate stochasticity for the HODs of Fig. 3 by generating 100 mock galaxy catalogs with unique random seeds for each of the 11 HODs in each curve. We compute counts in cylinders and measure bias and stochasticity (b1, b2, α0, α1) as described in Sect. 3.2.6, averaging the results across the 100 samples to mitigate the Bernoulli and Poisson noise in the drawing of galaxy counts. Uncertainty estimates are obtained by measuring stochasticity on spatial jackknife resamplings of the counts in cells data, removing square jackknife patches of 20 × 20 cylinders at a time. Shown in the top panel of Fig. 4 are stochasticity curves corresponding to the HOD curves in the top panel of Fig. 3 for the parameters αhod, σlog M, and fcen. All HODs with varying σlog M and fcen have α0 < 1, corresponding to shot noise that is sub-Poisson for δm ≤ 0 but super-Poisson for cells with sufficiently positive δm, given that α1 > 0. HODs with values of αhod near the lower end of the allowed range do produce α0 > 1 and therefore super-Poisson shot noise even down to some negative matter overdensities. Among the three varying parameters shown in the top panel of Fig. 4, none produce α1 < 0, and so shot noise in galaxy counts increases with local matter density in all 33 of these HODs.
 |
Fig. 4. Stochasticity parameters α0 and α1 corresponding to the HOD curves of Fig. 3. Top panel: Stochasticity for the curves that vary the HOD parameters αhod, σlog M, and fcen. Middle panel: Stochasticity for the curves that vary the assembly bias parameters Acent, Asat, Bcent, and Bsat (inset: closeup of the curve for Acent). Bottom panel: Stochasticity for the curves that vary the target values of bias and density. Open and filled squares correspond to the HODs with the lowest and highest parameter values, respectively, for the parameter being varied in each curve. Error bars to the right of each panel indicate maximum spatial jackknife error in α0 and α1 across all 11 points in a curve. Errors are plotted point-by-point for galaxy bias (bottom panel) due to the larger range of error sizes for α1. Dashed lines at α0 = 1 and α1 = 0 indicate the stochasticity parameter values corresponding to Poisson shot noise. |
Analogous results for the four assembly bias parameters are shown in the middle panel of Fig. 4. When varying Bsat in particular, we obtain larger values of both α0 and α1 than in all other curves, with the highest-stochasticity HOD being that with the largest M1 and smallest Mmin in the curve (the Bsat = −1 HOD in the lower right corner of the middle panel of Fig. 3). Recall that the assembly bias prescription of Eqs. (9) and (10) modifies the effective values of Mmin and M1 on a per-halo basis depending on concentration and environmental density. In particular, Bsat < 0 leads to reduced effective M1 (and thus more satellites) in halos whose local environments are above median density for their halo mass bin. The result for Bsat = −1 therefore corresponds to stochasticity being largest (among these curves) when expected satellite galaxy count ⟨Nsat⟩ is positively correlated with the density of a halo’s local environment. For Acent and Asat, the U-shaped nature of the curves in M1-Mmin space is reproduced in the plot of α1 versus α0. Due to the relatively small extent of the stochasticity results for Acent, sample variance in the finite set of mock galaxy catalogs has a strong effect on the smoothness of the Acent curve in the middle panel of Fig. 4 (see inset).
Stochasticity results for the final two HOD curves, those that vary the target values of galaxy bias and density, are shown in the bottom panel of Fig. 4. The results for varying density roughly share a degeneracy direction in the α0-α1 plane with those for varying fcen (refer to the top panel of Fig. 4). Recall that the range of target density for these HODs is [0.72, 1.08]×10−3 h3 Mpc−3. We find that increasing galaxy density (while the non-mass HOD parameters remain at their baseline values) leads to a slight increase in global stochasticity α0 and a decrease in α1. In contrast, increasing the target bias (over its allowed range from 1.36 to 1.54) drives down both stochasticity parameters. As with the results for varying HOD parameters, we find that all points on the curves of varying bias and density have α1 > 0, corresponding to higher shot noise in galaxy counts at higher matter overdensity. Sufficiently low values of the target bias (again with the non-mass HOD parameters fixed at baseline) yield α0 > 1, corresponding to super-Poisson shot noise at δm = 0. This observation further favors the use of highly biased tracers for cosmological studies.
4.3. Stochasticity versus cosmology and cell geometry
To assess the extent to which uncertainty in the underlying cosmology affects galaxy stochasticity, we repeat the procedure for deriving the baseline HOD in each of 52 cosmologies from the ABACUSSUMMIT emulator grid (Maksimova et al. 2021). While the baseline HOD for the Planck cosmology is optimized for a linear bias of 1.5 and mean density of 10−3 h3 Mpc−3, in alternate cosmologies we modify the target density in a manner motivated by practical observational concerns. In each cosmology, we calculate the true comoving density that would result if an observer assumed the Planck cosmology when constructing a galaxy sample in the redshift range 0.2 < z < 0.45 with an intended density of 10−3 h3 Mpc−3. In a cosmology whose comoving volume in this redshift range is less than that for Planck, for example, a galaxy sample selected in this way will have a true galaxy number density greater than 10−3 h3 Mpc−3. We also test the effects of changing aperture geometry by halving or doubling the cylinder radii and depths (Sect. 3.2.6) when measuring stochasticity for the baseline HOD in the baseline cosmology.
The results of these tests are shown together in Fig. 5. For the baseline HODs derived in different cosmologies, we find that unlike the HOD curves presented so far, a small number of cosmologies produce α1 < 0, corresponding to an inverse relationship between local matter density and shot noise in galaxy counts. No cosmologies exceed the maximum value of α1 from the HODs in the curves, nor do any produce values of α0 outside the range spanned by the curves. We note again that these results correspond to each cosmology’s baseline HOD and that varying the HOD on top of cosmology could amplify or counteract the change in stochasticity due to cosmology alone.
 |
Fig. 5. Stochasticity values for baseline HODs derived in alternate cosmologies (black points) and for different cylinder radii (magenta circles) and cylinder depths (blue squares). The tests for alternate cylinder sizes use the baseline HOD in the baseline Planck 2018 cosmology, and radii and depths in the legend are given in h−1 Mpc. The 52 non-Planck cosmologies belong to the ABACUSSUMMIT emulator grid. All error bars are estimated via spatial jackknife resampling, and errors for radius 5 and depth 250 are of similar scale to the points as plotted. Dashed gray curves correspond to the results from Fig. 4 for reference, and the yellow star at the intersection of the curves indicates the stochasticity of the baseline HOD in the baseline cosmology. Dashed lines at α0 = 1 and α1 = 0 indicate the values corresponding to Poisson shot noise. |
Doubling or halving the depth of the cylinders used to measure galaxy count and matter density has a stronger impact on α0 than on α1, with shallower cylinders producing larger global stochasticity α0 and vice versa. Changing the physical smoothing scale by doubling or halving the cylinder radii affects both stochasticity parameters to a somewhat larger extent. We find that doubling the radius from 10 h−1 Mpc to 20 h−1 Mpc increases both stochasticity parameters and that halving the radius to 5 h−1 Mpc does the opposite. Nevertheless, the values of α0 and α1 produced by these changes in geometry lie within the range spanned by the other tests varying HOD parameters, bias, density, and cosmology. Taking into account the extent of cosmological parameter space spanned by the ABACUSSUMMIT emulator cosmologies (5–8σ from current cosmic microwave background plus large-scale structure constraints in any individual parameter, see Maksimova et al. 2021), the results in Fig. 5 suggest that uncertainty in the details of the galaxy–halo connection, rather than cosmological or geometrical effects, dominate the uncertainty of our prior knowledge on stochasticity in this parametrization.
4.4. Monte Carlo HOD search
The HODs presented in the preceding sections probe relationships between individual HOD parameters and galaxy stochasticity, and likewise for changes in the target bias or density of a galaxy sample, the underlying cosmology, or the scale and depth of the smoothing filter. However, because these HODs are all linked in some way to the choice of a baseline model, and because they vary a limited number of parameters simultaneously, they necessarily probe a restricted subvolume of the full HOD parameter space. To carry out a more thorough search and to assess the comprehensiveness of the tests presented thus far, we perform a Monte Carlo search for additional HODs, sampling uniformly from a wide volume of parameter space. The parameter ranges for this search are listed in Table A.1. We select the subset of the resulting HODs that are consistent with our target bias and density to within 2% while also satisfying the original constraint on the maximum value of ⟨Ng⟩ across all halos as specified in Eq. (14). This represents a slightly relaxed constraint relative to the optimization procedure for the previous HODs, all of which achieve the target values of bias and density to within ∼0.5%. However, given that this degree of uncertainty in bias has only a modest effect on stochasticity (bottom panel of Fig. 4, where each curve has 11 points total and neighboring points differ in bias by ∼1% or in density by ∼3%), we expect that any increase in the range of stochasticity for the Monte Carlo sampled HODs will be dominated by the increase in simultaneous degrees of freedom in the HOD parameters.
We first sample from the five-dimensional parameter space for the HOD of Eqs. (5) and (6) without assembly bias, allowing the sampler to run until 500 HODs satisfying our constraints have been found. We then expand the search to the nine-dimensional parameter space that includes the four assembly bias parameters, for which the search is less efficient and a similar runtime yields 200 HODs meeting the constraints on bias, density, and ⟨Ng⟩. The resulting stochasticity and quadratic bias for the selected HODs are plotted in Fig. 6, and a corner plot of all selected HOD parameters together with stochasticity is given in Fig. A.2.
 |
Fig. 6. Stochasticity and quadratic bias results for HODs obtained by Monte Carlo sampling from a wide volume of HOD parameter space. Separate searches are performed with assembly bias parameters set to zero (red points, 500 HODs) and with the four assembly bias parameters free (blue points, 200 HODs). Left panel: Stochasticity parameters α1 versus α0. Middle panel: α0 versus quadratic bias b2. Right panel: α1 versus b2, showing a tight degeneracy for the HODs without assembly bias (red points). The relation between b2 and α1 for these points is fit by the cubic polynomial |
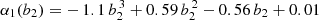
In this broader sample of HODs, we find that the overall range of stochasticity is expanded relative to the values spanned by the HOD curves. In particular, the inclusion of assembly bias has a substantial impact on the allowed range of global stochasticity α0. The majority of HODs without assembly bias (red points in Fig. 6) have α0 < 1, corresponding to sub-Poisson shot noise in galaxy counts at δm = 0, and some achieve slightly negative values of α1 (i.e., an inverse relationship between matter density and shot noise in galaxy counts). With assembly bias turned on, the allowed range of α0 increases at the upper end while the range of α1 remains similar. Another interesting feature of these results is that for an HOD to have a substantial amount of stochasticity overall, that stochasticity must include density dependence (α1). This can be seen in the relative scarcity of HODs with α0 ≠ 1 and α1 ≃ 0 in the left panel of Fig. 6, leading to the sharp V shape in the lower end of the cloud of points. We note that the HODs without assembly bias (red points) are simply a denser sample in a lower-dimensional subspace of the full parameter space that was used to draw the HODs with assembly bias (blue points).
The majority of the selected HODs produce galaxy catalogs with negative quadratic bias (middle and right panels of Fig. 6), corresponding to expected galaxy counts in cells that track slightly less than linearly with local matter density. When assembly bias is not present, there is a striking correlation between quadratic bias and α1 (red points in the right panel of Fig. 6) that is well-described by the cubic polynomial fit 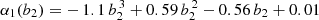 . The fact that this relation passes very nearly through b2 = α1 = 0 implies that in the absence of assembly bias, nonlinear galaxy bias is required in order to have non-Poisson shot noise, given that α0 is also close to 1 if α1 ≃ 0. The tightness of this relationship is disrupted when the assembly bias parameters are allowed to vary, as shown by the blue points in the same panel. This potential degeneracy between quadratic bias and the density dependence of stochasticity (α1) has implications for PDF modeling choices, if assembly bias can be constrained for a given galaxy catalog (see Sect. 5.2 for further discussion).
. The fact that this relation passes very nearly through b2 = α1 = 0 implies that in the absence of assembly bias, nonlinear galaxy bias is required in order to have non-Poisson shot noise, given that α0 is also close to 1 if α1 ≃ 0. The tightness of this relationship is disrupted when the assembly bias parameters are allowed to vary, as shown by the blue points in the same panel. This potential degeneracy between quadratic bias and the density dependence of stochasticity (α1) has implications for PDF modeling choices, if assembly bias can be constrained for a given galaxy catalog (see Sect. 5.2 for further discussion).
Taken together, the full set of 700 Monte Carlo sampled HODs spans stochasticity parameter ranges of α0 ∈ [0.798, 1.327] and α1 ∈ [ − 0.034, 0.788]. It is important to emphasize that these results are a test of the range of possible combinations of α0 and α1 in REDMAGIC-like galaxy samples and that Fig. 6 should not be interpreted as a probability distribution, as all regions of HOD parameter space are weighted equally during sampling.
5. Discussion
The ∼850 HODs and ∼30 000 mock galaxy catalogs produced in this work probe a nine-dimensional HOD parameter space (including assembly bias) as well as the additional dimensions of the target bias and number density of the catalogs, the underlying cosmology, and the depth and radius of the smoothing filter. We apply straightforward constraints on overall statistics of a galaxy sample in the form of linear bias, density, and the maximum expected count of galaxies in any halo. These properties describe the galaxy distribution on scales much larger than an individual halo, and we expect that the allowed range of stochasticity would be further restricted with additional constraints relevant on scales below our aperture radius of 10 h−1 Mpc. Small-scale probes of structure add significant constraining power with respect to the galaxy–matter connection, as demonstrated by analyses of galaxy two-point correlation functions (e.g., Coupon et al. 2012; Hatfield et al. 2016; Ishikawa et al. 2020; Yuan et al. 2021a, 2024), galaxy–galaxy lensing (e.g., Velander et al. 2013; Clampitt et al. 2016; Zacharegkas et al. 2021), higher-order lensing statistics (e.g., Linke et al. 2022), optically selected clusters (e.g., Hoshino et al. 2015), and combinations thereof (e.g., Coupon et al. 2015; Dvornik et al. 2018, 2023; Chaurasiya et al. 2023). Imposing further constraints on the mock catalogs in this one-halo regime would therefore likely reduce the allowed volume of HOD parameter space and the associated values of stochasticity.
In the combined results of our various tests, stochasticity values for the HODs extend both above and below α0 = 1, corresponding to super-Poisson and sub-Poisson variance in galaxy counts, respectively, in cells with δm = 0. Nearly all of our HODs have α1 > 0, indicating a positive relationship between local matter density and stochasticity. We note that this relationship can vary between tracer types; for example, Friedrich et al. (2022) find α1 to be negative for halos above 7.4 × 1012 h−1 M⊙ in the full-sky light-cone halo catalogs of the Takahashi N-body simulation (Takahashi et al. 2017) and for mock galaxies assigned to the same halos by an LRG-like HOD (see Fig. 9 of Friedrich et al. 2022).
When varying HOD parameters other than fcen, we find a generally positive relationship between α0 and α1, as seen in the relevant curves in the first two panels of Fig. 4. We find the same when varying the target galaxy bias with the HOD fixed at baseline, albeit with greater uncertainty on α1 (bottom panel of Fig. 4).
Among the stochasticity curves presented in Sect. 4.2 and Fig. 4, the fact that the two that vary fcen and galaxy density differ from the others in having an inverse relationship between α0 and α1 is noteworthy, as fcen and density can be constrained more tightly than many other properties of an HOD or galaxy sample. In the case of a REDMAGIC sample, number density is set by construction (Rozo et al. 2016), and fcen may be constrained by, for example, estimates of membership in high-richness clusters (see Sect. 3.2.2). A tighter upper bound on fcen in particular would raise the lower end of the range of α0 among the HOD curves (i.e., the high-fcen end of the dashed blue curve in the top panel of Fig. 4). Well-motivated constraints on the number density and incompleteness (fcen) of a galaxy catalog may therefore allow for significantly tightened bounds on stochasticity, potentially including the use of nonrectangular prior distributions for (α0, α1) to leverage the apparent degeneracy between the two when individual HOD parameters other than fcen are varied at fixed density.
Comparing the effects of changing the HOD (at fixed cosmology) to the effects of changing cosmology (with the non-mass HOD parameters fixed), we find that degrees of freedom in the galaxy–matter connection produce a range of α0 and α1 (left panel of Fig. 6) that fully covers the range due to changing cosmology, even across the very wide ABACUSSUMMIT emulator grid of cosmologies (Fig. 5). This suggests that with galaxy bias and density as constraints, uncertainty in the HOD remains the dominant concern when setting bounds on galaxy stochasticity, provided that the shift in stochasticity when changing cosmology is of similar size at different points in HOD parameter space. When changing cylinder size relative to the baseline radius of 10 h−1 Mpc and depth of 500 h−1 Mpc, we find that halving the radius and doubling the depth both decrease α0, despite their opposite effects on the total volume of the cylinder. This may be due to the smaller radius decreasing the fraction of halos that are fully covered by a given cylinder, thus reducing stochasticity as halos hosting multiple galaxies are less likely to be captured in cylinders as a single unit. Increasing the projection depth reduces the overall correlation between pairs of halos in a cylinder, again conceivably reducing stochasticity but via a two-halo effect. As described in Sect. 4.3, even these twofold changes in the radius or depth of the cylinders produce changes in stochasticity that are subdominant to those arising from the degrees of freedom in the HOD.
5.1. Assembly bias
A unique feature in the results for the assembly bias parameters Acent and Asat is the hooked shape of the curves both in HOD parameter space (middle panel of Fig. 3) and in the two stochasticity parameters (middle panel of Fig. 4). Acent and Asat control the influence of halo concentration on the effective values of Mmin and M1, respectively, and we find that pushing Asat away from zero in either the positive or negative direction produces somewhat similar results in terms of stochasticity, while changing Acent within its allowed range has little effect. The observed overall increase in stochasticity regardless of the sign of Asat is understandable if the added dependence on concentration simply introduces an additional source of variance in galaxy counts in cells across most or all of the halo mass bins within which concentration is ranked. In contrast, changing either Bcent or Bsat produces a more extended, monotonic curve in Mmin versus M1 and in α1 versus α0, with more negative values of either B parameter (i.e., more galaxies in halos with higher environmental density) leading to greater stochasticity (middle panel of Fig. 4). Conversely, shifting Bcent to positive values reduces both stochasticity parameters. The decrease in shot noise for Bcent > 0 implies that introducing a negative correlation between environmental density (ranked within mass bins) and ⟨Ncen⟩ somewhat counters the stochasticity arising from variation in the halo mass function alone, between cells of fixed matter density. It should be noted here that because of the optimization procedure for Mmin and M1, changing the value of an assembly bias parameter will require compensatory changes in the two mass parameters, in order to keep bias and number density fixed. This is expected to be the case, for example, as Bsat shifts to negative values, preferentially placing satellite galaxies in halos with higher-density environments (i.e., with greater halo bias). It is then reasonable to expect that as Bsat becomes more negative, M1 must increase to limit satellite galaxy counts in high-bias halos and keep galaxy bias constant, and this is indeed the case for the Bsat HOD curve in the middle panel of Fig. 3.
Our more thorough Monte Carlo search for REDMAGIC-like HODs reveals that the presence or absence of assembly bias has a significant impact on the allowed degree of stochasticity, specifically in the α0 direction (Fig. 6). Without assembly bias, the basic five-parameter HOD of Eqs. (5) and (6) does produce α0 > 1 to a limited extent, under our constraints on bias and density, but turning on the four additional assembly bias parameters extends the upper bound on α0 from ∼1.05 to ∼1.33. In contrast, the allowed range of α1 is effectively spanned by HODs with no assembly bias, indicating that the extent to which shot noise in galaxy counts may depend on local matter density is linked to the manner in which halo occupation depends on halo mass but not concentration or environmental density.
5.2. The galaxy–matter PDF
A broader question relevant to this work concerns the parametrization of P(Ng | δm). The importance of accounting for galaxy stochasticity in both simulations and observations was demonstrated in the DES Year 1 density split statistics analysis (Friedrich et al. 2018; Gruen et al. 2018), which modeled galaxy bias and stochasticity to linear order in δm. Our results from HODs derived in this work indicate that there exist galaxy–matter connections with REDMAGIC-like bias and density for which linear bias alone is not sufficient to accurately describe the PDF of galaxy counts in cells at different fixed matter densities. The comparison between model fits and measured PDFs in Fig. 1 illustrates the need to model both quadratic bias and density-dependent stochasticity, using the HODs with the two most extreme values of α0 as an example. However, we do find that the range of α0 and α1 across the full set of HODs is similar when fitting stochasticity models with or without quadratic bias (Fig. A.1 and Appendix A.1). For the specific purpose of placing conservative priors on stochasticity, then, it may be acceptable to model galaxy bias to linear order only, even if the resulting description of the galaxy–matter PDF is not necessarily accurate for all δm. Regarding the parametrization of stochasticity itself, the results of the Monte Carlo HOD search reinforce the need to model both global stochasticity (α0) and its density dependence (α1) when stochasticity is present in general, as combinations with significant amounts of the former but not the latter appear to be excluded (hence the V-shaped lower boundary in the left panel of Fig. 6).
A question to be addressed in future work is whether this parametrization can be improved upon, for example by identifying degeneracies between bias and stochasticity parameters in order to simplify the model. Our results from the set of Monte Carlo sampled HODs suggest that one such degeneracy exists when assembly bias is negligible, in the form of a tight relationship between quadratic bias b2 and the density dependence of stochasticity a1 (red points in the right panel of Fig. 6). This implies that for galaxies consistent with our overall constraints, one may model both density-dependent stochasticity and quadratic galaxy bias using only three parameters rather than four, if significant assembly bias can be ruled out. We do not find a similar relationship between any other pair of bias or stochasticity parameters (noting that b1 was tightly constrained by construction). It may, however, be possible to more systematically establish the minimum required dimensionality of the parameter space for P(Ng | δm) in other ways, such as learning a minimal disentangled representation of the PDF using neural networks.
Even in the absence of tight degeneracies between parameters, other informative features of our results may allow for improved priors on stochasticity. As mentioned in the discussion of the HOD curves in Sect. 5, we find an overall positive correlation between α0 and α1 when varying parameters other than fcen and density, opening the possibility of adopting a nonrectangular joint prior on α0 and α1 in a likelihood analysis, if fcen and density are well-constrained. Even when all HOD parameters are free, as in the Monte Carlo search of Sect. 4.4, we still find excluded regions in the joint distribution of stochasticity parameters, as seen in the left panel of Fig. 6. In this plot, all REDMAGIC-like HODs found in the search lie above a V-shaped boundary that could similarly form the basis for a more informed joint prior on α0 and α1.
5.3. Impact of constraining galaxy sample properties
The constraints on bias, density, and the maximum value of ⟨Ng⟩ used to select HODs naturally have an impact on the range of stochasticity parameters measured in the corresponding mock catalogs. The results in this work allow some insight into how our derived bounds on stochasticity would respond if these constraints were further tightened. For the galaxies studied here, the simulation volume and true galaxy density are known. In an observed catalog, in contrast, the true number density is degenerate with the comoving volume of the survey and therefore with the assumed cosmology. When varying the target density over its allowed range of [0.72, 1.08]×10−3 h3 Mpc−3 (while optimizing M1 and Mmin to keep the other constraints satisfied), we find that the resulting changes in stochasticity (bottom panel of Fig. 4) are very small relative to the range of stochasticity probed at fixed density when all HOD parameters are free (left panel of Fig. 6). The effect of changing bias over the range [1.36, 1.54] is larger than that for density (bottom panel of Fig. 4) but still a factor of a few smaller in either α0 or α1 than the range of stochasticity spanned by the degrees of freedom in the HOD itself, when bias is fixed at approximately 1.5. As with cosmology, then, modest uncertainties in bias and number density (which is, as mentioned, degenerate with cosmology) appear to be subdominant to uncertainty in the galaxy–matter connection, for catalogs constrained only by bias, density, and max⟨Ng⟩. We therefore do not expect that tightened constraints on bias and density, for example reducing the 2% threshold for selecting HODs in the Monte Carlo search, would significantly reduce the allowed ranges of α0 and α1.
In setting a constraint on max⟨Ng⟩, the maximum expectation value of the HOD across all halos, we estimated the distribution of REDMAGIC galaxy counts in REDMAPPER clusters (Fig. 2) and set max⟨Ng⟩∈[25, 50]. We note that because the constraint is only applied to an expectation value, the actual largest count of galaxies in any one halo is still free to be less than 25 or greater than 50 in any individual mock catalog generated by an HOD. Regarding whether tightening this constraint has a meaningful effect on the allowed range of stochasticity, we find that increasing the lower bound on max⟨Ng⟩ from 25 to 40 preferentially removes HODs from the central region of the left panel of Fig. 6 and therefore has no significant effect on the overall ranges of α0 and α1. Decreasing the upper bound from 50 to 40 excludes some – but crucially not all – HODs in the low-α0, low-α1 region of the same plot and so has little impact on the allowed range of stochasticity as well. Constraining max⟨Ng⟩ more tightly than the range used here therefore does little to limit stochasticity when all HOD parameters are free, although it remains possible that imposing, for example, scaling relationships between HOD parameters could make stochasticity more sensitive to the exact bounds on max⟨Ng⟩.
6. Summary and outlook
In this work, we use the flexibility of HOD modeling to assess the range of galaxy stochasticity that can plausibly exist for catalogs with REDMAGIC-like galaxy bias and density. For galaxies with b ≃ 1.5 and n ≃ 10−3 h3 Mpc−3, we obtain a stochasticity range of α0 ∈ [0.798, 1.327] and α1 ∈ [ − 0.034, 0.788] in the parametrization of Friedrich et al. (2018) and Gruen et al. (2018). In this parametrization, α0 + α1δm ≠ 1 corresponds to non-Poisson scatter in galaxy counts at fixed matter overdensity δm. The ranges quoted correspond to a model that includes quadratic galaxy bias, but the two stochasticity parameters remain similar when galaxy bias is modeled to linear order only, as in the original parametrization.
Notably, among the large set of HODs tested, the presence or absence of assembly bias strongly influences the upper bound on global stochasticity (α0). Additionally, we find that for galaxy–matter connections with significant amounts of non-Poisson shot noise, linear galaxy bias alone is insufficient to accurately model mean galaxy count as a function of matter density. The inclusion of quadratic bias in addition to α0, α1 leads to agreement of the model with the measured PDFs of mock galaxy count (conditioned on matter density) generated by our HODs.
The conservative bounds on stochasticity obtained through this HOD-based approach may be used to motivate priors on α0 and α1 for the purpose of a likelihood analysis that models the galaxy–matter PDF. A companion paper by Ried Guachalla et al. (2024) offers a natural application of our results, introducing a methodology for using plausible realizations of nuisance parameters (e.g., the galaxy stochasticity values obtained in this work) to select informative prior distributions for cosmological analyses.
Data availability
Parameters for the Monte Carlo sampled HODs and an example Python script for populating the ABACUSSUMMIT simulations are available at: https://github.com/dylan-britt/stochasticity_hods. The ABACUSSUMMIT data products used in this work are made publicly available by the Abacus authors and can be accessed via: https://abacusnbody.org.
We checked that this is indeed a reasonable assumption by using fitting functions for halo bias (Tinker et al. 2010) and the halo mass function (Tinker et al. 2008), together with our HODs, to analytically model galaxy bias and density as functions of Mmin and M1, at various combinations of the other HOD parameters.
Acknowledgments
We would like to thank Chun-Hao To, Risa Wechsler, Anik Halder, Yao-Yuan Mao, and members of the Astrophysics, Cosmology, and Artificial Intelligence (ACAI) group at LMU Munich for helpful discussions and feedback. This work was supported by the U.S. Department of Energy through grant DE-SC0013718 and under DE-AC02-76SF00515 to SLAC National Accelerator Laboratory, and by the Kavli Institute for Particle Astrophysics and Cosmology (KIPAC). DB acknowledges support provided by the KIPAC Giddings Fellowship, the Graduate Research & Internship Program in Germany (operated by The Europe Center at Stanford), the German Academic Exchange Service (Deutscher Akademischer Austauschdienst, DAAD, Short-Term Research Grant 2023 No. 57681230), and the Bavaria California Technology Center (BaCaTec). DG and OF were supported by the Excellence Cluster ORIGINS, which is funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under Germany’s Excellence Strategy (EXC 2094-390783311). OF was supported by the Fraunhofer-Schwarzschild Fellowship at the Universitäts-Sternwarte München (LMU Observatory). BRG was funded by the Chilean National Agency for Research and Development (ANID) – Subdirección de Capital Humano / Magíster Nacional / 2021 – ID 22210491 and by the German Academic Exchange Service (DAAD, Short-Term Research Grant 2021 No. 57552337). BRG also gratefully acknowledges support from the Program for Astrophysics Visitor Exchange at Stanford (PAVES). Computing for this project was performed using resources of the National Energy Research Scientific Computing Center (NERSC), a U.S. Department of Energy Office of Science User Facility located at Lawrence Berkeley National Laboratory, operated under Contract No. DE-AC02-05CH11231 using NERSC award HEP-ERCAP0023850. In addition to software cited in the main text, this work made use of IPython (Pérez & Granger 2007), Matplotlib (Hunter 2007), NumPy (Harris et al. 2020), SciPy (Virtanen et al. 2020), pathos (McKerns et al. 2011), halotools v0.8.1 (Hearin et al. 2017), and hmf (Murray 2014).
References
- Abbott, T. M. C., Aguena, M., Alarcon, A., et al. 2020, Phys. Rev. D, 102, 023509 [Google Scholar]
- Aghamousa, A., Aguilar, J., Ahlen, S., et al. 2016, arXiv e-prints [arXiv:1611.00036] [Google Scholar]
- Alam, S., Ata, M., Bailey, S., et al. 2017, MNRAS, 470, 2617 [Google Scholar]
- Amon, A., Gruen, D., Troxel, M. A., et al. 2022, Phys. Rev. D, 105, 023514 [NASA ADS] [CrossRef] [Google Scholar]
- Asgari, M., Lin, C.-A., Joachimi, B., et al. 2021, A&A, 645, A104 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Banerjee, A., & Abel, T. 2020, MNRAS, 500, 5479 [NASA ADS] [CrossRef] [Google Scholar]
- Banerjee, A., & Abel, T. 2021, MNRAS, 504, 2911 [NASA ADS] [CrossRef] [Google Scholar]
- Bautista, J. E., Paviot, R., Vargas Magaña, M., et al. 2020, MNRAS, 500, 736 [NASA ADS] [CrossRef] [Google Scholar]
- Bel, J., & Marinoni, C. 2014, A&A, 563, A36 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Berlind, A. A., & Weinberg, D. H. 2002, ApJ, 575, 587 [Google Scholar]
- Bose, S., Eisenstein, D. J., Hadzhiyska, B., Garrison, L. H., & Yuan, S. 2022, MNRAS, 512, 837 [NASA ADS] [CrossRef] [Google Scholar]
- Burger, P. A., Friedrich, O., Harnois-Déraps, J., et al. 2023, A&A, 669, A69 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Chaurasiya, N., More, S., Ishikawa, S., et al. 2023, MNRAS, 527, 5265 [NASA ADS] [CrossRef] [Google Scholar]
- Chiang, C.-T., Wagner, C., Schmidt, F., & Komatsu, E. 2014, JCAP, 2014, 048 [CrossRef] [Google Scholar]
- Clampitt, J., Sánchez, C., Kwan, J., et al. 2016, MNRAS, 465, 4204 [Google Scholar]
- Codis, S., Pichon, C., Bernardeau, F., Uhlemann, C., & Prunet, S. 2016, MNRAS, 460, 1549 [NASA ADS] [CrossRef] [Google Scholar]
- Cooray, A., & Sheth, R. 2002, Phys. Rep., 372, 1 [Google Scholar]
- Coupon, J., Kilbinger, M., McCracken, H. J., et al. 2012, A&A, 542, A5 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Coupon, J., Arnouts, S., van Waerbeke, L., et al. 2015, MNRAS, 449, 1352 [NASA ADS] [CrossRef] [Google Scholar]
- DES Collaboration (Abbott, T. M. C., et al.) 2022, Phys. Rev. D, 105, 023520 [CrossRef] [Google Scholar]
- Desjacques, V., Jeong, D., & Schmidt, F. 2018, Phys. Rep., 733, 1 [Google Scholar]
- Dvornik, A., Hoekstra, H., Kuijken, K., et al. 2018, MNRAS, 479, 1240 [Google Scholar]
- Dvornik, A., Heymans, C., Asgari, M., et al. 2023, A&A, 675, A189 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Euclid Collaboration (Scaramella, R., et al.) 2022, A&A, 662, A112 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Friedrich, O., Gruen, D., DeRose, J., et al. 2018, Phys. Rev., D, 98 [Google Scholar]
- Friedrich, O., Uhlemann, C., Villaescusa-Navarro, F., et al. 2020, MNRAS, 498, 464 [NASA ADS] [CrossRef] [Google Scholar]
- Friedrich, O., Halder, A., Boyle, A., et al. 2022, MNRAS, 510, 5069 [NASA ADS] [CrossRef] [Google Scholar]
- Garrison, L. H., Eisenstein, D. J., Ferrer, D., Maksimova, N. A., & Pinto, P. A. 2021, MNRAS, 508, 575 [NASA ADS] [CrossRef] [Google Scholar]
- Gong, Z., Halder, A., Barreira, A., Seitz, S., & Friedrich, O. 2023, JCAP, 2023, 040 [CrossRef] [Google Scholar]
- Gough, A., & Uhlemann, C. 2022, Universe, 8, 55 [CrossRef] [Google Scholar]
- Gruen, D., Friedrich, O., Amara, A., et al. 2015, MNRAS, 455, 3367 [Google Scholar]
- Gruen, D., Friedrich, O., Krause, E., et al. 2018, Phys. Rev. D, 98, 023507 [Google Scholar]
- Guo, H., Yang, X., & Lu, Y. 2018, ApJ, 858, 30 [NASA ADS] [CrossRef] [Google Scholar]
- Hadzhiyska, B., Bose, S., Eisenstein, D., Hernquist, L., & Spergel, D. N. 2020, MNRAS, 493, 5506 [NASA ADS] [CrossRef] [Google Scholar]
- Hadzhiyska, B., Eisenstein, D., Bose, S., Garrison, L. H., & Maksimova, N. 2021, MNRAS, 509, 501 [NASA ADS] [CrossRef] [Google Scholar]
- Hadzhiyska, B., Eisenstein, D., Hernquist, L., et al. 2023, MNRAS, 524, 2507 [NASA ADS] [CrossRef] [Google Scholar]
- Halder, A., & Barreira, A. 2022, MNRAS, 515, 4639 [NASA ADS] [CrossRef] [Google Scholar]
- Halder, A., Friedrich, O., Seitz, S., & Varga, T. N. 2021, MNRAS, 506, 2780 [CrossRef] [Google Scholar]
- Halder, A., Gong, Z., Barreira, A., et al. 2023, JCAP, 2023, 028 [CrossRef] [Google Scholar]
- Harris, C. R., Millman, K. J., van der Walt, S. J., et al. 2020, Nature, 585, 357 [NASA ADS] [CrossRef] [Google Scholar]
- Hatfield, P. W., Lindsay, S. N., Jarvis, M. J., et al. 2016, MNRAS, 459, 2618 [NASA ADS] [CrossRef] [Google Scholar]
- Hearin, A. P., Campbell, D., Tollerud, E., et al. 2017, AJ, 154, 190 [Google Scholar]
- Heymans, C., Tröster, T., Asgari, M., et al. 2021, A&A, 646, A140 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hoekstra, H., Yee, H. K. C., & Gladders, M. D. 2004, ApJ, 606, 67 [Google Scholar]
- Hoshino, H., Leauthaud, A., Lackner, C., et al. 2015, MNRAS, 452, 998 [NASA ADS] [CrossRef] [Google Scholar]
- Hunter, J. D. 2007, Comput. Sci. Eng., 9, 90 [NASA ADS] [CrossRef] [Google Scholar]
- Ishikawa, S., Kashikawa, N., Tanaka, M., et al. 2020, ApJ, 904, 128 [NASA ADS] [CrossRef] [Google Scholar]
- Ivezić, Z., Kahn, S. M., Tyson, J. A., et al. 2019, ApJ, 873, 111 [NASA ADS] [CrossRef] [Google Scholar]
- Joachimi, B., Lin, C.-A., Asgari, M., et al. 2021, A&A, 646, A129 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kokron, N., DeRose, J., Chen, S.-F., White, M., & Wechsler, R. H. 2022, MNRAS, 514, 2198 [NASA ADS] [CrossRef] [Google Scholar]
- Krause, E., Fang, X., Pandey, S., et al. 2021, arXiv e-prints [arXiv:2105.13548] [Google Scholar]
- Leauthaud, A., Bundy, K., Saito, S., et al. 2016, MNRAS, 457, 4021 [Google Scholar]
- Li, X., Zhang, T., Sugiyama, S., et al. 2023, Phys. Rev. D, 108, 123518 [CrossRef] [Google Scholar]
- Linke, L., Simon, P., Schneider, P., et al. 2022, A&A, 665, A38 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Maksimova, N. A., Garrison, L. H., Eisenstein, D. J., et al. 2021, MNRAS, 508, 4017 [NASA ADS] [CrossRef] [Google Scholar]
- Mandelbaum, R., Tasitsiomi, A., Seljak, U., Kravtsov, A. V., & Wechsler, R. H. 2005, MNRAS, 362, 1451 [NASA ADS] [CrossRef] [Google Scholar]
- Mao, Y.-Y., Zentner, A. R., & Wechsler, R. H. 2017, MNRAS, 474, 5143 [Google Scholar]
- McKerns, M. M., Strand, L., Sullivan, T., Fang, A., & Aivazis, M. A. G. 2011, Proceedings of the 10th Python in Science Conference, 67 [Google Scholar]
- Murray, S. 2014, Astrophysics Source Code Library [record ascl:1412.006] [Google Scholar]
- Navarro, J. F., Frenk, C. S., & White, S. D. M. 1996, ApJ, 462, 563 [Google Scholar]
- Nelder, J. A., & Mead, R. 1965, Comput. J., 7, 308 [Google Scholar]
- Pandey, S., Krause, E., Jain, B., et al. 2020, Phys. Rev. D, 102, 123522 [CrossRef] [Google Scholar]
- Pandey, S., Krause, E., DeRose, J., et al. 2022, Phys. Rev. D, 106, 043520 [NASA ADS] [CrossRef] [Google Scholar]
- Paviot, R., Rocher, A., Codis, S., et al. 2024, arXiv e-prints [arXiv:2402.07715] [Google Scholar]
- Peacock, J. A., & Smith, R. E. 2000, MNRAS, 318, 1144 [Google Scholar]
- Pérez, F., & Granger, B. E. 2007, Comput. Sci. Eng., 9, 21 [Google Scholar]
- Porredon, A., Crocce, M., Elvin-Poole, J., et al. 2022, Phys. Rev. D, 106, 103530 [NASA ADS] [CrossRef] [Google Scholar]
- Planck Collaboration VI. 2020, A&A, 641, A6 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Repp, A., & Szapudi, I. 2020, MNRAS, 498, L125 [NASA ADS] [CrossRef] [Google Scholar]
- Ried Guachalla, B., Britt, D., Gruen, D., & Friedrich, O. 2024, A&A, submitted [arxiv:2405.00261] [Google Scholar]
- Rodríguez-Torres, S. A., Chuang, C.-H., Prada, F., et al. 2016, MNRAS, 460, 1173 [CrossRef] [Google Scholar]
- Rozo, E., Rykoff, E. S., Abate, A., et al. 2016, MNRAS, 461, 1431 [NASA ADS] [CrossRef] [Google Scholar]
- Rykoff, E. S., Rozo, E., Busha, M. T., et al. 2014, ApJ, 785, 104 [Google Scholar]
- Rykoff, E. S., Rozo, E., Hollowood, D., et al. 2016, ApJS, 224, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Salcedo, A. N., Maller, A. H., Berlind, A. A., et al. 2018, MNRAS, 475, 4411 [NASA ADS] [CrossRef] [Google Scholar]
- Schneider, P., & Lombardi, M. 2003, A&A, 397, 809 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sevilla-Noarbe, I., Bechtol, K., Kind, M. C., et al. 2021, ApJS, 254, 24 [NASA ADS] [CrossRef] [Google Scholar]
- Sugiyama, S., Takada, M., Kobayashi, Y., et al. 2020, Phys. Rev. D, 102, 083520 [Google Scholar]
- Takada, M., & Jain, B. 2003, MNRAS, 344, 857 [Google Scholar]
- Takahashi, R., Hamana, T., Shirasaki, M., et al. 2017, ApJ, 850, 24 [Google Scholar]
- Tinker, J., Kravtsov, A. V., Klypin, A., et al. 2008, ApJ, 688, 709 [Google Scholar]
- Tinker, J. L., Robertson, B. E., Kravtsov, A. V., et al. 2010, ApJ, 724, 878 [NASA ADS] [CrossRef] [Google Scholar]
- Tyson, J. A., Valdes, F., Jarvis, J. F., Mills, A. P. J., 1984, ApJ, 281, L59 [NASA ADS] [CrossRef] [Google Scholar]
- Uhlemann, C., Codis, S., Hahn, O., Pichon, C., & Bernardeau, F. 2017a, MNRAS, 469, 2481 [NASA ADS] [CrossRef] [Google Scholar]
- Uhlemann, C., Pajer, E., Pichon, C., et al. 2017b, MNRAS, 474, 2853 [Google Scholar]
- Uhlemann, C., Feix, M., Codis, S., et al. 2017c, MNRAS, 473, 5098 [Google Scholar]
- Uhlemann, C., Pichon, C., Codis, S., et al. 2018, MNRAS, 477, 2772 [NASA ADS] [CrossRef] [Google Scholar]
- Uhlemann, C., Friedrich, O., Villaescusa-Navarro, F., Banerjee, A., & Codis, S. 2020, MNRAS, 495, 4006 [NASA ADS] [CrossRef] [Google Scholar]
- Velander, M., van Uitert, E., Hoekstra, H., et al. 2013, MNRAS, 437, 2111 [Google Scholar]
- Virtanen, P., Gommers, R., Oliphant, T. E., et al. 2020, Nat. Meth., 17, 261 [Google Scholar]
- Walsh, K., & Tinker, J. 2019, MNRAS, 488, 470 [NASA ADS] [CrossRef] [Google Scholar]
- Wang, K., Mao, Y.-Y., Zentner, A. R., et al. 2019, MNRAS, 488, 3541 [NASA ADS] [CrossRef] [Google Scholar]
- Wang, Y., Banerjee, A., & Abel, T. 2022, MNRAS, 514, 3828 [NASA ADS] [CrossRef] [Google Scholar]
- Wechsler, R. H., & Tinker, J. L. 2018, Ann. Rev. Astron. Astrophys., 56, 435 [CrossRef] [Google Scholar]
- Wechsler, R. H., Bullock, J. S., Primack, J. R., Kravtsov, A. V., & Dekel, A. 2002, ApJ, 568, 52 [NASA ADS] [CrossRef] [Google Scholar]
- Wechsler, R. H., Zentner, A. R., Bullock, J. S., Kravtsov, A. V., & Allgood, B. 2006, ApJ, 652, 71 [NASA ADS] [CrossRef] [Google Scholar]
- Weinberg, D. H., Mortonson, M. J., Eisenstein, D. J., et al. 2013, Phys. Rep., 530, 87 [Google Scholar]
- White, S. D. M., & Rees, M. J. 1978, MNRAS, 183, 341 [Google Scholar]
- Xu, X., Zehavi, I., & Contreras, S. 2021, MNRAS, 502, 3242 [NASA ADS] [CrossRef] [Google Scholar]
- Yuan, S., Eisenstein, D. J., & Garrison, L. H. 2018, MNRAS, 478, 2019 [NASA ADS] [CrossRef] [Google Scholar]
- Yuan, S., Garrison, L. H., Hadzhiyska, B., Bose, S., & Eisenstein, D. J. 2021a, MNRAS, 510, 3301 [Google Scholar]
- Yuan, S., Hadzhiyska, B., Bose, S., Eisenstein, D. J., & Guo, H. 2021b, MNRAS, 502, 3582 [NASA ADS] [CrossRef] [Google Scholar]
- Yuan, S., Garrison, L. H., Eisenstein, D. J., & Wechsler, R. H. 2022, MNRAS, 515, 871 [NASA ADS] [CrossRef] [Google Scholar]
- Yuan, S., Abel, T., & Wechsler, R. H. 2023a, MNRAS, 527, 1993 [NASA ADS] [CrossRef] [Google Scholar]
- Yuan, S., Zamora, A., & Abel, T. 2023b, MNRAS, 522, 3935 [NASA ADS] [CrossRef] [Google Scholar]
- Yuan, S., Zhang, H., Ross, A. J., et al. 2024, MNRAS, 530, 947 [CrossRef] [Google Scholar]
- Zacharegkas, G., Chang, C., Prat, J., et al. 2021, MNRAS, 509, 3119 [NASA ADS] [CrossRef] [Google Scholar]
- Zheng, Z., Berlind, A. A., Weinberg, D. H., et al. 2005, ApJ, 633, 791 [NASA ADS] [CrossRef] [Google Scholar]
- Zheng, Z., Coil, A. L., & Zehavi, I. 2007, ApJ, 667, 760 [Google Scholar]
Appendix A: Monte Carlo HOD search results
A.1. Quadratic bias modeling: Impact on stochasticity
To illustrate the impact of quadratic bias modeling on measured stochasticity values, in Fig. A.1 we plot α0 and α1 for the full set of Monte Carlo sampled HODs with and without quadratic bias – Eqs. (4) and (2), respectively. Shifting from the model with quadratic bias to the one with only linear bias causes very little change in the range of α0: [0.798, 1.327]→[0.800, 1.333] and a slight increase in the upper end of the range for α1: [ − 0.034, 0.788]→[−0.034, 0.823].
 |
Fig. A.1. Comparison of stochasticity measurements with and without accounting for quadratic galaxy bias, shown for the full set of Monte Carlo sampled HODs. Plotted are the best fitting values (α0, α1) for the stochasticity model of Eq. (2) with linear bias only (open circles) and for the model of Eq. (4), which includes quadratic galaxy bias (solid circles). As in Figs. 6 and A.2, red points correspond to HODs without assembly bias, and blue points correspond to HODs sampled with the assembly bias parameters free. |
A.2. Full results in HOD and stochasticity parameter space
Table A.1 lists the HOD parameter ranges that define the sample space for the Monte Carlo search described in Sect. 4.4. Points are drawn uniformly within this volume, and as the search proceeds, various cuts on the parameter space are made to exclude regions that fail to satisfy relaxed versions of our constraints (e.g., failing to achieve the target bias or density to within 50 percent). Fig. A.2 shows the selected points in HOD parameter space, together with their quadratic bias and stochasticity. The lower-dimensional search without assembly bias (red points) is more efficient in sampling points that satisfy the constraints and is run until 500 HODs have been found. The higher-dimensional search including the four assembly bias parameters (blue points) is less efficient and is run for a similar total number of samples (∼10 6) until 200 HODs have been found.
 |
Fig. A.2. Results of the HOD Monte Carlo sampling procedure described in Sect. 4.4. Separate searches were performed with assembly bias (blue points) and without (i.e., all assembly bias parameters set to zero, red points) in the baseline cosmology. The HODs shown achieve the target values of linear galaxy bias (1.5) and density (10−3 h3 Mpc−3) to within 2 percent and satisfy the additional constraint that the maximum of ⟨Ng⟩ across all halos falls in the range [25, 50], as specified in Eq. (14). The values of stochasticity (α0, α1) and quadratic bias (b2) shown here are the mean of measurements on 20 mock galaxy catalogs generated by each HOD, as in Fig. 6. The lower-dimensional search without assembly bias was allowed to run until 500 such HODs were sampled; the search including assembly bias was run until 200 HODs were found. Parameter ranges for the sampling procedure are given in Table A.1. |
HOD parameter ranges for the Monte Carlo sampling procedure of Sect. 4.4.
All Tables
All Figures
|
Fig. 1. Comparison of different model predictions for P(Ng | δm) against measured counts-in-cells distributions in mock galaxy catalogs for a pair of example HODs that have sub-Poisson scatter (top row) and super-Poisson scatter (bottom row) at δm = 0. Within each row, the three panels show model fits (solid curves) for the different parametrizations of P(Ng | δm) given in Eqs. (1), (2), and (4). Left column: Best-fitting model with linear bias only; i.e., a simple Poisson distribution. Middle column: Model with linear bias b and density-dependent stochasticity α0, α1, which decouples the mean and variance of the distribution. Right column: Stochasticity model with galaxy bias modeled to second order in δm. Shaded histograms show the measured distributions of galaxy counts in cells for three narrow bins of width 0.05 in δm. Each histogram is an average over 200 mock galaxy catalogs. The underdense (−0.3) and overdense (0.38) bins are set to the most extreme values of δm for which each bin still contains at least 1000 of the 160 000 cylinders in the simulation box. Stochasticity values α0 and α1 for the two HODs (as measured in the model with quadratic bias) are given in the top right corner of the last panel in each row. |
| In the text | |
|
Fig. 2. Distribution of counts of DES Y3GOLD REDMAGIC galaxies (high-density sample) in REDMAPPER clusters. Count per cluster is calculated as the sum of membership probabilities for all REDMAGIC galaxies identified as possible members of the cluster. Shown are the distributions for all clusters in the catalog (blue) and for clusters in the redshift range 0.2 < z < 0.45 (red); this is identical to the range used in the density split analysis of DES Y1 REDMAGIC galaxies in Gruen et al. (2018). |
| In the text | |
|
Fig. 3. Mmin versus M1 for the HODs produced when one non-mass parameter is varied and M1 and Mmin are optimized to achieve the target bias and density. The ends of each curve are marked with an open square for the lowest value of that parameter and a filled square for the highest (see Table 1 for the parameter ranges). All HOD curves intersect at the location of the baseline model. Top panel: HODs that vary the parameters αhod, σlog M, and fcen. Middle panel: HODs that vary the assembly bias parameters Acent, Asat, Bcent, and Bsat (inset: closeup of the curves for Acent and Asat). Bottom panel: HODs that vary the target values of bias and density while keeping the non-mass parameters fixed at baseline. Gray dashed curves in each panel correspond to the curves from the other two panels for reference. |
| In the text | |
|
Fig. 4. Stochasticity parameters α0 and α1 corresponding to the HOD curves of Fig. 3. Top panel: Stochasticity for the curves that vary the HOD parameters αhod, σlog M, and fcen. Middle panel: Stochasticity for the curves that vary the assembly bias parameters Acent, Asat, Bcent, and Bsat (inset: closeup of the curve for Acent). Bottom panel: Stochasticity for the curves that vary the target values of bias and density. Open and filled squares correspond to the HODs with the lowest and highest parameter values, respectively, for the parameter being varied in each curve. Error bars to the right of each panel indicate maximum spatial jackknife error in α0 and α1 across all 11 points in a curve. Errors are plotted point-by-point for galaxy bias (bottom panel) due to the larger range of error sizes for α1. Dashed lines at α0 = 1 and α1 = 0 indicate the stochasticity parameter values corresponding to Poisson shot noise. |
| In the text | |
|
Fig. 5. Stochasticity values for baseline HODs derived in alternate cosmologies (black points) and for different cylinder radii (magenta circles) and cylinder depths (blue squares). The tests for alternate cylinder sizes use the baseline HOD in the baseline Planck 2018 cosmology, and radii and depths in the legend are given in h−1 Mpc. The 52 non-Planck cosmologies belong to the ABACUSSUMMIT emulator grid. All error bars are estimated via spatial jackknife resampling, and errors for radius 5 and depth 250 are of similar scale to the points as plotted. Dashed gray curves correspond to the results from Fig. 4 for reference, and the yellow star at the intersection of the curves indicates the stochasticity of the baseline HOD in the baseline cosmology. Dashed lines at α0 = 1 and α1 = 0 indicate the values corresponding to Poisson shot noise. |
| In the text | |
|
Fig. 6. Stochasticity and quadratic bias results for HODs obtained by Monte Carlo sampling from a wide volume of HOD parameter space. Separate searches are performed with assembly bias parameters set to zero (red points, 500 HODs) and with the four assembly bias parameters free (blue points, 200 HODs). Left panel: Stochasticity parameters α1 versus α0. Middle panel: α0 versus quadratic bias b2. Right panel: α1 versus b2, showing a tight degeneracy for the HODs without assembly bias (red points). The relation between b2 and α1 for these points is fit by the cubic polynomial |
| In the text | |
|
Fig. A.1. Comparison of stochasticity measurements with and without accounting for quadratic galaxy bias, shown for the full set of Monte Carlo sampled HODs. Plotted are the best fitting values (α0, α1) for the stochasticity model of Eq. (2) with linear bias only (open circles) and for the model of Eq. (4), which includes quadratic galaxy bias (solid circles). As in Figs. 6 and A.2, red points correspond to HODs without assembly bias, and blue points correspond to HODs sampled with the assembly bias parameters free. |
| In the text | |
|
Fig. A.2. Results of the HOD Monte Carlo sampling procedure described in Sect. 4.4. Separate searches were performed with assembly bias (blue points) and without (i.e., all assembly bias parameters set to zero, red points) in the baseline cosmology. The HODs shown achieve the target values of linear galaxy bias (1.5) and density (10−3 h3 Mpc−3) to within 2 percent and satisfy the additional constraint that the maximum of ⟨Ng⟩ across all halos falls in the range [25, 50], as specified in Eq. (14). The values of stochasticity (α0, α1) and quadratic bias (b2) shown here are the mean of measurements on 20 mock galaxy catalogs generated by each HOD, as in Fig. 6. The lower-dimensional search without assembly bias was allowed to run until 500 such HODs were sampled; the search including assembly bias was run until 200 HODs were found. Parameter ranges for the sampling procedure are given in Table A.1. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.