| Issue |
A&A
Volume 671, March 2023
|
|
|---|---|---|
| Article Number | A5 | |
| Number of page(s) | 17 | |
| Section | Extragalactic astronomy | |
| DOI | https://doi.org/10.1051/0004-6361/202244693 | |
| Published online | 27 February 2023 | |
Clustering dependence on Lyα luminosity from MUSE surveys at 3 < z < 6
1
Leibniz-Institut für Astrophysik Potsdam (AIP), An der Sternwarte 16, 14482 Potsdam, Germany
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Universidad Nacional Autónoma de México, Instituto de Astronomía (IA-UNAM-E), AP 106, Ensenada, 22860 BC, Mexico
3
Leiden Observatory, Leiden University, PO Box 9513 2300 RA Leiden, The Netherlands
4
Department of Physics, ETH Zurich, Wolfgang-Pauli-Strasse 27, 8093 Zurich, Switzerland
5
Observatoire de Genève, Université de Genève, 51 Chemin de Pégase, 1290 Versoix, Switzerland
Received:
5
August
2022
Accepted:
23
December
2022
Abstract
We investigate the dependence of Lyα emitter (LAE) clustering on Lyα luminosity and connect the clustering properties of ≈L⋆ LAEs with those of much fainter ones, namely, ≈0.04L⋆. We use 1030 LAEs from the MUSE-Wide survey, 679 LAEs from MUSE-Deep, and 367 LAEs from the to-date deepest ever spectroscopic survey, the MUSE Extremely Deep Field. All objects have spectroscopic redshifts of 3 < z < 6 and cover a large dynamic range of Lyα luminosities: 40.15 < log(LLyα/erg s−1) < 43.35. We apply the Adelberger et al. K-estimator as the clustering statistic and fit the measurements with state-of-the-art halo occupation distribution (HOD) models. We find that the large-scale bias factor increases weakly with an increasing line luminosity. For the low-luminosity (log⟨LLyα/[erg s−1]⟩ = 41.22) and intermediate-luminosity (log⟨LLyα/[erg s−1]⟩ = 41.64) LAEs, we compute consistent bias factors blow = 2.43−0.15+0.15 and binterm. = 2.42−0.09+0.10, whereas for the high-luminosity (log⟨LLyα/[erg s−1]⟩ = 42.34) LAEs we calculated bhigh = 2.65−0.11+0.13. Consequently, high-luminosity LAEs occupy dark matter halos (DMHs) with typical masses of log(Mh/[h−1 M⊙]) = 11.09−0.09+0.10, while low-luminosity LAEs reside in halos of log(Mh/[h−1 M⊙]) = 10.77−0.15+0.13. The minimum masses to host one central LAE, Mmin, and (on average) one satellite LAE, M1, also vary with Lyα luminosity, growing from log(Mmin/[h−1M⊙]) = 10.3−0.3+0.2 and log(M1/[h−1 M⊙]) = 11.7−0.2+0.3 to log(Mmin/[h−1 M⊙]) = 10.7−0.3+0.2 and log(M1/[h−1 M⊙]) = 12.4−0.6+0.4 from low- to high-luminosity samples, respectively. The satellite fractions are ≲10% (≲20%) at 1σ (3σ) confidence level, supporting a scenario in which DMHs typically host one single LAE. We next bisected the three main samples into disjoint subsets to thoroughly explore the dependence of the clustering properties on LLyα. We report a strong (8σ) clustering dependence on Lyα luminosity, not accounting for cosmic variance effects, where the highest luminosity LAE subsample (log(LLyα/erg s−1) ≈ 42.53) clusters more strongly (bhighest = 3.13−0.15+0.08) and resides in more massive DMHs (log(Mh/[h−1M⊙] )= 11.43−0.10+0.04) than the lowest luminosity one (log(LLyα/erg s−1) ≈ 40.97), which presents a bias of blowest = 1.79−0.06+0.08 and occupies log(Mh/[h−1M⊙]) = 10.00−0.09+0.12 halos. We discuss the implications of these results for evolving Lyα luminosity functions, halo mass dependent Lyα escape fractions, and incomplete reionization signatures.
Key words: large-scale structure of Universe / galaxies: high-redshift / galaxies: evolution / cosmology: observations / dark matter
© The Authors 2023
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
Dark matter halos (DMHs) serve as sites of galaxy formation but their co-evolution is still a matter of investigation. Observations deliver snapshots of the luminosities of galaxies at given redshifts, while numerical analyses succeed at simulating the evolution and copiousness of DMHs. Linking these two constituents is not straightforward but, because the spatial distribution of baryonic matter is biased against that of dark matter (DM), the former indirectly traces the latter. The evolutionary stage of the two distributions depends on both the epoch of galaxy formation and the physical properties of galaxies (see Wechsler & Tinker 2018 for a review). Thus, studying the dependence of the baryonic-DM relation on galaxy properties is essential for better understanding the evolution of the two components.
Exploring the spatial distribution of high-redshift (z > 2) galaxies and its dependence on physical properties provides an insight into the early formation and evolution of the galaxies we observe today. Clustering statistics yield observational constraints on the relationship between galaxies and DMHs, as well as on their evolution. Traditional studies of high-z galaxies (Steidel et al. 1996; Hu et al. 1998; Ouchi et al. 2003, 2010; Gawiser et al. 2007; Khostovan et al. 2019) model the large-scale (R ≳ 1 − 2 h−1cMpc) clustering statistics with a two parameter power-law correlation function that takes the form ξ = (r/r0)−γ (Davis & Peebles 1983) to derive the large-scale linear galaxy bias and the associated typical DMH mass. To make full use of the clustering measurements, the smaller separations of the nonlinear regime (R ≲ 1 − 2 h−1cMpc) are modeled by relating galaxies to DMHs within the nonlinear framework of halo occupation distribution (HOD) modeling. In this context, the mean number of galaxies in the DMH is modeled as a function of DMH mass, further assessing whether these galaxies occupy the centers of the DMHs or whether they are satellite galaxies.
Although clustering studies of high-redshift galaxies are plentiful, HOD modeling has been rarely used to interpret the results. While several works have focused on Lyman-break galaxy (LBG) surveys, only one study fit a sample of Lyman-α emitters (LAEs) with HOD models (Ouchi et al. 2018). Durkalec et al. (2014), Madau et al. (2017), Hatfield et al. (2018), Harikane et al. (2018) applied the full HOD framework to sets of LBGs to put constraints on the central and satellite galaxy populations, while Ouchi et al. (2018) partially exploited the power of HOD models in a sample of LAEs to infer the threshold DMH mass for central galaxies.
The number of studies that have investigated the correlations between clustering strength and physical properties of high-redshift galaxies is slightly higher. In [O II] and [O III] emission-line-selected galaxy samples, Khostovan et al. (2018) found a strong halo mass dependence on the line luminosity and stellar mass. Durkalec et al. (2018) also observed a correlation with stellar mass, together with a further dependence on UV luminosity, in a sample of LBGs. However, these correlations become somewhat unclear near the epoch of reionization (z ≈ 6). Based on LAEs surveys, Ouchi et al. (2003), Bielby et al. (2016), Kusakabe et al. (2018) revealed tentative trends (≈1σ) between luminosity (both UV and Lyα) and clustering strength, while only Khostovan et al. (2019) reported a clear (5σ) correlation between inferred DMH mass and Lyα luminosity.
In a previous study (Herrero Alonso et al. 2021), we used 68 MUSE-Wide fields to measure the LAE clustering with the K-estimator method presented in Adelberger et al. (2005). We computed the clustering at large scales (R > 0.6 h−1Mpc) to derive the linear bias factor and the typical DMH mass of LAEs. By splitting our main sample into subsets based on physical properties of LAEs, we also found a tentative 2σ dependence on Lyα luminosity. Here, we extend this work with larger and more deeply spectroscopically confirmed samples and a refined set of analysis methods. We measured the clustering at smaller scales, applied full HOD modeling, and studied the dependence of the clustering properties on Lyα luminosity.
The paper is structured as follows. In Sect. 2, we describe the data used for this work and we characterize the LAE samples. In Sect. 3, we explain our method for measuring and analyzing the clustering properties of our galaxy sets. We present the results of our measurements in Sect. 4. In Sect. 5, we discuss our results and their implications, and we investigate the clustering dependence on Lyα luminosity. We give our conclusions in Sect. 6.
Throughout this paper, all distances are measured in comoving coordinates and given in units of h−1Mpc (unless otherwise stated), where h = H0/100 = 0.70 km s−1 Mpc−1. We assume the same h to convert line fluxes to luminosities. Thus, there are implicit 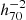 factors in the line luminosities. We use a ΛCDM cosmology and adopt ΩM = 0.3, ΩΛ = 0.7, and σ8 = 0.8 (Hinshaw et al. 2013). All uncertainties represent 1σ (68.3%) confidence intervals.
factors in the line luminosities. We use a ΛCDM cosmology and adopt ΩM = 0.3, ΩΛ = 0.7, and σ8 = 0.8 (Hinshaw et al. 2013). All uncertainties represent 1σ (68.3%) confidence intervals.
2. Data
The MUSE spectroscopic surveys are based on a wedding cake design, namely: a first spatially wide region (bottom of the cake) is observed with a short exposure time (1 h), while deeper observations (10 h exposure) are carried out within the first surveyed area (middle tier of the cake). Contained in the last observed region, an even deeper survey (140 h) is then built up (at the top of the cake). These three surveys are known as: MUSE-Wide (Herenz et al. 2017; Urrutia et al. 2019), MUSE-Deep (Bacon et al. 2017, 2023; Inami et al. 2017), and MUSE Extremely Deep Field (MXDF; Bacon et al. 2023). Each of them can be seen as a different layer of a wedding cake, where higher layers become spatially smaller and correspond to deeper observations. In what follows, we give further details on survey and galaxy sample construction.
2.1. MUSE-Wide
The spectroscopic MUSE-Wide survey (Herenz et al. 2017; Urrutia et al. 2019) comprises 100 MUSE fields distributed in the CANDELS/GOODS-S, CANDELS/COSMOS and the Hubble Ultra Deep Field (HUDF) parallel field regions. Each MUSE field covers 1 arcmin2. While 91 fields were observed with an exposure time of one hour, nine correspond to shallow (1.6 h) reduced subsets of the MUSE-Deep data (see next section; as well as Bacon et al. 2017), located within the HUDF in the CANDELS/GOODS-S region. However, we do not include the objects from this region since they overlap with the MUSE-Deep sample (see next section and gap in the left panel of Fig. 1). The slight overlap between adjacent fields leads to a total spatial coverage of 83.52 arcmin2. The red circles in Fig. 1 display the spatial distribution of the LAEs from the MUSE-Wide survey. We refer to Urrutia et al. (2019) for further details on the survey build up, reduction and flux calibration of the MUSE data cubes.
 |
Fig. 1. Spatial distribution of the LAEs from the MUSE-Wide survey (red circles), MUSE-Deep (green squares) and MXDF (blue stars). The overlapping objects between the MXDF and MUSE-Deep samples have been removed from the MUSE-Deep LAE set, while those LAEs overlapping in MUSE-Deep and MUSE-Wide have been removed from the MUSE-Wide LAE sample. The MUSE-Wide survey covers part of the CANDELS/GOODS-S region and the HUDF parallel fields (left panel) as well as part of the CANDELS/COSMOS region (right panel). See Fig. 1 in Urrutia et al. (2019) for the layout of the MUSE-Wide survey without individual objects, Fig. 1 in Bacon et al. (2017) for that of MUSE-Deep, and Fig. 2 in Bacon et al. (2023) for that of MUSE-Deep (MOSAIC) and MXDF together. |
In this paper, we extend (x2 spatially, 50% more LAEs) the sample used in Herrero Alonso et al. (2021) and include all the 1 h exposure fields from the MUSE-Wide survey. Despite the somewhat worse seeing (generally) in the COSMOS region (right panel of Fig. 1), we demonstrate in Appendix A that adding these fields does not significantly impact our clustering results but helps in minimizing the effects of cosmic sample variance.
We also expanded the redshift range of the sample. While MUSE spectra cover 4750–9350 Å, implying a Lyα redshift interval of 2.9 ≲ z ≲ 6.7, we limited the redshift range to 3 < z < 6 (differing from the more conservative range of Herrero Alonso et al. 2021; 3.3 < z < 6) as the details of the selection function near the extremes are still being investigated. Section 2 of Herrero Alonso et al. (2021) describes the aspects relevant to our analysis on the construction of a sample of LAEs, as well as the strategy to measure line fluxes and redshifts. The redshift distribution of the sample is shown in red in the top panel of Fig. 2. Systematic uncertainties introduced in the redshift-derived 3D positions of the LAEs have negligible consequences for our clustering approach (see Sect. 2.2 in Herrero Alonso et al. 2021).
 |
Fig. 2. Lyα luminosity-redshift for the LAEs in MUSE-Wide (red circles), MUSE-Deep (green squares) and MXDF (blue stars). The dashed colored lines correspond to the median log LLyα values of the corresponding samples. The redshift and LLyα distributions are shown in the top and right panel, respectively. |
Within 83.52 arcmin2 and in the selected redshift interval, we detected a total of 1030 LAEs. This implies a LAE density of more than 13 objects per arcmin2 or n ≈ 1 × 10−3 h3 Mpc−3 (for 3 < z < 6). At the median redshift of the sample ⟨z⟩ = 4.0, the transverse extent of the footprint is ≈43 h−1Mpc. The range of Lyα luminosities is 40.92 < log(LLyα/[erg s−1]) < 43.35 (see red circles in Fig. 2), with a median value of log⟨LLyα/[erg s−1]⟩ = 42.34 (or ≈L⋆ in terms of characteristic luminosity L⋆; Herenz et al. 2019), which makes this sample the highest luminosity data set of our three considered surveys. The Lyα luminosity distribution is shown in red in the right panel of Fig. 2. The main properties of the MUSE-Wide LAEs are summarized in Table 1.
Properties of the LAE samples.
2.2. MUSE-Deep
MUSE-Deep (10 h MOSAIC; Bacon et al. 2017, 2023; Inami et al. 2017) encompasses nine fields located in the CANDELS/GOODS-S region of the HUDF, each spanning 1 arcmin2 and observed with a 10 h exposure time. The total spatial coverage is 9.92 arcmin2. We represent the spatial distribution of the survey in green in Fig. 1. We did, however, remove the MUSE-Deep objects that are selected in the deepest survey, described in the next section. We refer to Bacon et al. (2017, 2023) for a detailed description on survey construction and data reduction.
The sources in MUSE-Deep were blindly detected and extracted using ORIGIN (Mary et al. 2020), based on a matched filtering approach and developed to detect faint emission lines in MUSE datacubes. While the redshift measurements and line classifications were carried out with pyMarZ, a python version of the redshift fitting software MarZ (Hinton et al. 2016), the line flux determination was conducted with pyPlatefit, which is a python module optimized to fit emission lines of high-redshift spectra. The redshift distribution of the sample is shown in green in the top panel of Fig. 2, also within 3 < z < 6.
The LAE density of the MUSE-Deep sample is 8 × 10−3 h3 Mpc−3 (68 LAE per arcmin2 in the whole redshift range). The survey spans ≈8.7 h−1Mpc transversely. The range of Lyα luminosities is 40.84 < log(LLyα/[erg s−1]) < 43.12, represented with green squares in Fig. 2, together with its distribution (right panel). MUSE-Deep is our intermediate luminous dataset, with a median luminosity of log⟨LLyα/[erg s−1]⟩ = 41.64. The sample properties are recorded in Table 1.
2.3. MUSE Extremely Deep
The MUSE Extremely Deep Field (Bacon et al. 2023) is situated in the CANDELS/GOODS-S region and overlaps with MUSE-Deep and MUSE-Wide. It is composed of a single quasi circular field with inner and outer radii of 31″ and 41″, respectively. While a 140 h exposure was employed to observe the totality of the field, the inner field is 135 h deep, decreasing to 10 h depth at the outer radius. This makes MXDF the deepest spectroscopic survey to date. For further details see Bacon et al. (2023) and the blue data points in Fig. 1, where the MXDF field is overplotted on the previous surveys.
The survey assembly and data reduction is described in Bacon et al. (2023) and is similar to the one applied to MUSE-Deep (Bacon et al. 2017). The source extraction in MXDF and the redshift and flux measurements are conducted following the same procedure as was done for MUSE-Deep. The redshift distribution of the sample is shown in blue in the top panel of Fig. 2.
Contained within ≈1.47 arcmin2 and over the same redshift range as for the previous catalogues, we detected 367 LAEs, corresponding to a LAE density of n ≈ 3 × 10−2 h3 Mpc−3 (432 LAEs per arcmin2 at 3 < z < 6). With a median redshift of ⟨z⟩ = 4.2, the footprint covers ≈2.8 h−1Mpc (transversely). The Lyα luminosities span 40.15 < log(LLLyα/[erg s−1] < 43.09 (see blue stars in Fig. 2 and its distribution in the right panel). The median Lyα luminosity is log⟨LLyα/[erg s−1]⟩ = 41.22 (or ≈0.08L⋆), more than one order of magnitude fainter than for MUSE-Wide. This makes MXDF the faintest ever observed sample of non-lensed LAEs. The main properties are listed in Table 1.
2.4. LAE subsamples
We bisected the main samples into disjoint subsets based on their median Lyα luminosity to investigate the clustering dependence on this quantity. We did not merge the main LAE datasets because their distinct Lyα luminosities, together with their slightly different location on the sky, might introduce systematics in the clustering measurements. The subsample properties are summarized in Table 2 and described in the following.
Properties of the LAE subsamples.
We split the MUSE-Wide sample at the median Lyα luminosity log⟨LLyα/[erg s−1]⟩ = 42.34. The two subsamples consist of 515 LAEs each. The low-luminosity subset has a median redshift and Lyα luminosity of ⟨zlow⟩ = 3.7 and log⟨LLyαlow/[erg s−1]⟩ = 42.06, while the high-luminosity subsample has ⟨zhigh⟩ = 4.1 and log⟨LLyαhigh/[erg s−1]⟩ = 42.53. The median redshift of the number of galaxy pairs for the low-luminosity subset is zpair ≈ 3.4, and that for the high-luminosity one is zpair ≈ 4.1.
We next bisected the MUSE-Deep set at the median Lyα luminosity log⟨LLyα/[erg s−1]⟩ = 41.64. The low-luminosity subsample has 340 LAEs and presents a median redshift and Lyα luminosity of ⟨zlow⟩ = 3.7 and log⟨LLyαlow/[erg s−1]⟩ = 41.46. The high-luminosity subset is formed by 339 LAEs with ⟨zhigh⟩ = 4.5 and log⟨LLyαhigh/[erg s−1]⟩ = 41.89. While for the low-luminosity subsample zpair ≈ 3.5, for the high-luminosity one zpair ≈ 4.4.
We also divide the sample with the largest dynamic range of Lyα luminosities (MXDF) at the median Lyα luminosity log⟨LLyα/[erg s−1]⟩ = 41.22. While the lower luminosity subset contains 183 LAEs with ⟨zlow⟩ = 4.0 and log⟨LLyαlow/[erg s−1]⟩ = 40.97, the higher luminosity subsample consists of 184 LAEs with ⟨zhigh⟩ = 4.5 and log⟨LLyαhigh/[erg s−1]⟩ = 41.54. For the low-luminosity subset, we have zpair ≈ 3.9, and for the high-luminosity one, we have zpair ≈ 4.8.
The redshift distribution of each subsample is shown in Fig. 3. The corresponding median redshifts are represented with a vertical dashed line. Despite the similar median redshifts between the subsample pairs, the redshift distributions are significantly different, with a higher amount of spike-trough contrasts in the high-luminosity subsets.
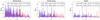 |
Fig. 3. Redshift distribution of the subsamples bisected at the median Lyα luminosity of MUSE-Wide, MUSE-Deep and MXDF (panels from left to right). Blue (red) colors show the low- (high-) luminosity subsets. The vertical dashed lines represent the median redshift of the corresponding subsample. |
3. Methods
3.1. K-estimator
Galaxy clustering is commonly measured by two-point correlation function (2pcf) statistics. Samples investigated by this method typically span several square degrees on the sky. With MUSE, we encounter the opposite scenario. By design, MUSE surveys cover small spatial extensions on the sky and provide a broad redshift range. Although the MUSE-Wide survey is the largest footprint of all MUSE samples, its nature is still that of a pencil-beam survey. Its transverse scales are of the order of 40 h−1Mpc, while in redshift space it reaches almost 1500 h−1Mpc. If we consider the deeper samples, the difference is even more prominent: 8.7 vs. 1500 h−1Mpc for MUSE-Deep and 2.8 versus 1500 h−1Mpc for MXDF. It is thus paramount to exploit the radial scales and utilize alternative methods to the traditional 2pcf.
In Herrero Alonso et al. (2021) we applied the so-called K-estimator, introduced by Adelberger et al. (2005), to a subset of our current sample. Here, we build on our previous work by extending the dataset and measuring the small-scale clustering required to perform full HOD modeling. The details of the K-estimator are given in Sect. 3.1 of Herrero Alonso et al. (2021). In the following, we provide a brief description of the method.
The K-estimator measures the radial clustering along line-of-sight distances, Zij, by counting galaxy pairs (formed by galaxy i and galaxy j) in redshift space at fixed transverse separations, Rij. Although the K-estimator does not need a random sample to carry out the clustering measurements, its nature is very similar to that of the projected two-point correlation function. We bin by Rij, shown with distinct radii in the cylinders of Fig. 4, and count the number of pairs within individual transverse bins, for two different ranges of Zij, represented in red and blue in Fig. 4. The K-estimator as a function of Rij is then defined as the ratio of galaxy pairs within the first Zij interval (blue cylinder) and the total Zij range (red and blue cylinder), quantifying the excess of galaxy pairs in the first Zij bin with respect to the total one. We optimize the choice of the Zij ranges, and thus the K-estimator, by seeking out the estimator that delivers the best sensitivity for the clustering signal (i.e., the highest signal-to-noise ratio, S/N; see Sect. 3.1.2 in Herrero Alonso et al. 2021). Although slightly different than in Herrero Alonso et al. (2021), we find nearly identical K-estimators for each of the current samples (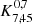 for MUSE-Wide,
for MUSE-Wide, 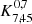 for MUSE-Deep, and
for MUSE-Deep, and 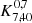 for MXDF), whose clustering signals only differ in their S/N. We chose the same K-estimator for the three data sets,
for MXDF), whose clustering signals only differ in their S/N. We chose the same K-estimator for the three data sets, 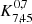 .
.
 |
Fig. 4. Sketch of the K-estimator, representing the relative geometry that probe the one- and two-halo term scales. The empty blue and filled red cylinders, delimited by |a2| = 7 h−1 Mpc and |a3| = 45 h−1 Mpc respectively, illustrate the line-of-sight distance Zij intervals within which we count galaxy pairs at fixed transverse separations Rij, represented by nested cylinders. Pairs of LAEs connected with green lines within the same DMH (filled gray circle) contribute to the one-halo term (small Rij scales), while pairs belonging to two different DMHs (yellow lines) probe the two-halo term (larger Rij separations). |
The K-estimator is directly related to the average underlying correlation function (see Eq. (2) in Herrero Alonso et al. 2021). In fact, its definition is proportional to a combination of projected two-point correlation functions corresponding to the blue and red cylinders of Fig. 4. While the traditional 2pcf method integrates the correlation function ξ(Rij, Zij) over line-of-sight separations up to a maximum line-of-sight distance πmax, the K-estimator integrates up to a2 and a3. The correlation function ξ(Rij, Zij) can be approximated with a power-law following Limber (1953) equations as we did in Herrero Alonso et al. (2021), or modeled with a halo occupation distribution (HOD) model (see Sect. 3.3). For reference, randomly distributed galaxies in space (ξ(Rij, Zij) = 0) provide 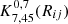 values equal to 7/45 (see Eq. (2) in Herrero Alonso et al. 2021). Samples with data points significantly above 7/45 dispense clustering signals.
values equal to 7/45 (see Eq. (2) in Herrero Alonso et al. 2021). Samples with data points significantly above 7/45 dispense clustering signals.
3.2. Error estimation
3.2.1. Error estimation for the MUSE-Wide survey
Applying clustering statistics delivers correlated data points. One single galaxy might be part of more than one galaxy pair and can therefore contribute to several Rij bins, especially if they are adjacent. In order to quantify the actual correlation between data points, we applied the jackknife resampling technique, followed by the computation of the covariance matrix (see e.g., Krumpe et al. 2010; Miyaji et al. 2011). For the MUSE-Wide sample, we employed ten logarithmic bins in the range 0.16 < Rij < 27.5 h−1Mpc, discarding lower Rij scales since they host very few galaxy pairs.
We then found a compromise between the number of independent regions (jackknife zones) and the size of the jackknife zones and divide the sky coverage into Njack = 10 regions, each of which extends ≈4 h−1Mpc in both RA and Dec directions (see Appendix B for a visual representation of the sky division). The limited spatial extent of the survey does not allow for a higher number of jackknife zones. We then constructed Njack jackknife subsamples, excluding one jackknife zone at a time, and computed the K-estimator for each of the subsets. The K-estimator measurements are then used to derive the covariance matrix Mij, which quantifies the correlation between bins i and j. The matrix is expressed as
![Mathematical equation: $$ \begin{aligned}&M_{ij} = \frac{N_{\rm {jack}}-1}{N_{\rm {jack}}} \left[ \displaystyle \sum _{k=1}^{N_{\rm {jack}}}\Bigg (K_k(R_i) \,\,-\left< K(R_i)\right>\Bigg )\, \right. \nonumber \\&\qquad \qquad \qquad \times \left. \Bigg (\,K_k(R_j)\,\,-\langle K(R_j)\rangle \Bigg ) \right], \end{aligned} $$](/articles/aa/full_html/2023/03/aa44693-22/aa44693-22-eq20.gif) (1)
(1)
where Kk(Ri), Kk(Rj) are the K-estimators from the kth jackknife samples and ⟨K(Ri)⟩, ⟨K(Rj)⟩ are the averages over all jackknife samples in the i, j bins, respectively. The error bar for the K-estimator at the ith bin comes from the square root of the diagonal element (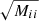 ) of the covariance matrix, our so-called “jackknife uncertainty”. This approach could not be followed in Herrero Alonso et al. (2021) because of the smaller sky coverage. Instead, we used a galaxy bootstrapping approach. In Appendix C, we compare the two techniques and show that bootstrapping uncertainties are ≈50% larger than the jackknife error bars, in agreement with Norberg et al. (2009), who found that boostrapping overestimates the uncertainties.
) of the covariance matrix, our so-called “jackknife uncertainty”. This approach could not be followed in Herrero Alonso et al. (2021) because of the smaller sky coverage. Instead, we used a galaxy bootstrapping approach. In Appendix C, we compare the two techniques and show that bootstrapping uncertainties are ≈50% larger than the jackknife error bars, in agreement with Norberg et al. (2009), who found that boostrapping overestimates the uncertainties.
We next search for the best-fit parameters by minimizing the correlated χ2 values according to
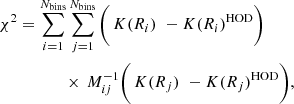 (2)
(2)
where Nbins = 10 is the number of Rij bins, K(Ri), K(Rj) are the measured K-estimators and K(Ri)HOD, K(Rj)HOD are the K-estimators predicted by the HOD model for each i, j bin, respectively.
Regardless of the larger sample considered in this work, we are still limited by the spatial size of the survey, which only permits a small number of jackknife zones. The insufficient statistics naturally lead to a higher noise contribution in the covariance matrix, which cause the χ2 minimization to mathematically fail (i.e., cases of χ2 < 0) when the full covariance matrix is included. Hence, we only incorporated the main diagonal of the matrix and its two contiguous diagonals. In Appendix B, we discuss the high level of noise in the matrix elements corresponding to bins that are significantly apart from each other. We also verify the robustness of our approach and show that our clustering results are not altered (within 1σ) by this choice.
3.2.2. Error estimation for the deeper surveys
The small sky coverage of the deeper surveys does not allow us to follow the same error estimation approach as for the MUSE-Wide survey. In Appendix C, we not only compare the bootstrapping technique applied in Herrero Alonso et al. (2021) to the jackknife approach performed in MUSE-Wide, but we also consider the Poisson uncertainties. We demonstrate that Poisson and jackknife errors are comparable in our sample. In fact, we show that while bootstrapping uncertainties are ≈50% larger than jackknife errors, Poisson uncertainties are only ≈7% higher. Thus, and similarly to Adelberger et al. (2005), Diener et al. (2017), Khostovan et al. (2018), we stick to Poisson uncertainties for the MUSE-Deep and MXDF samples. For these datasets, we measure the K-estimator in eight and six logarithmic bins in the ranges 0.09 < Rij/[h−1Mpc] < 4.75 and 0.09 < Rij/[h−1Mpc] < 1.45, respectively, constrained by the spatial extent of the surveys.
We then perform a standard χ2 minimization to find the best fitting parameters to the K-estimator measurements. Namely,
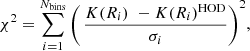 (3)
(3)
where K(Ri), K(Ri)HOD, and σi denote the measured K-estimator, the HOD modeled K-estimator and the Poisson uncertainty in the ith bin, respectively.
We note that the standard χ2 minimization does not account for the correlation between bins. Although in Appendix B we show that only contiguous bins are moderately correlated, we should take the resulting fit uncertainties with caution.
3.3. Halo occupation distribution modeling
The clustering statistics can be approximated with a power-law or modeled with state-of-the-art HOD modeling. Traditional clustering studies make use of power laws to derive the correlation length and slope, from which they infer large-scale bias factors and typical DMH masses. This simple approach deviates from the actual shape of the clustering statistic curve, even in the linear regime, and its inferred DMH masses suffer from systematic errors (e.g., Jenkins et al. 1998 and references therein). To overcome these concerns, physically motivated HOD models do not treat the linear and nonlinear regime alike but differentiate between the clustering contribution from galaxy pairs that reside in the same DMH and pairs that occupy different DMHs.
In Herrero Alonso et al. (2021) we only modeled the two-halo term of the K-estimator with HOD modeling, which only delivered the large-scale bias factor and the typical DMH mass of the sample. We now extend into the nonlinear regime (i.e., Rij < 0.6 h−1Mpc) of the one-halo term. We can then model the clustering measured by the K-estimator with a full HOD model, combining the separate contributions from the one- (1 h, i.e., galaxy pairs residing in the same DMH) and the two-halo (2 h, i.e., galaxy pairs residing in different DMHs) terms:
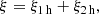 (4)
(4)
where ξ is the correlation function.
The HOD model we used is the same as in Herrero Alonso et al. (2021), an improved version of that described by Miyaji et al. (2011), Krumpe et al. (2012, 2015, 2018). We assumed that LAEs are associated with DMHs, linked by the bias-halo mass relation from Tinker et al. (2005). From Tinker et al. (2005), we also included the effects of halo-halo collisions and scale-dependent bias. The mass function of DMHs, which is denoted by ϕ(Mh)dMh, is based on Sheth et al. (2001), and the DMH profile is taken from Navarro et al. (1997). We use the concentration parameter from Zheng et al. (2007), and the weakly redshift-dependent collapse overdensity from Navarro et al. (1997), Van Den Bosch et al. (2013). We further incorporated redshift space distortions (RSDs) in the two-halo term using linear theory (Kaiser infall; Kaiser 1987 and Van Den Bosch et al. 2013). We did not model RSDs in the one-halo term because the peculiar velocity has negligible effects to our K-estimator as demonstrated in the following. The velocity dispersion (σv) of satellites in a Mh halo can be estimated by 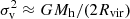 , where Rvir is the virial radius (Tinker 2007). Its effect on the line-of-sight physical distance estimate is then σv/H(z). For 1011 − 12 h−1 M⊙ DMH masses, which are typical for our sample, with virial radii of ≈0.02 − 0.05 (physical) h−1Mpc, the line-of-sight distance estimation is deviated by ≈0.15 − 0.30 h−1Mpc, corresponding to a peculiar velocity dispersion of σv ≈ 80 − 170 km s−1. This is significantly small compared to our a2 = 7 h−1Mpc. We thus assume that the one-halo term contributes only to the Zij = 0 − 7 h−1Mpc bin. We evaluated the HOD model at the median redshift of N(z)2, where N(z) is the redshift distribution of the sampled galaxy pairs. For our three main datasets, zpair ≈ 3.8.
, where Rvir is the virial radius (Tinker 2007). Its effect on the line-of-sight physical distance estimate is then σv/H(z). For 1011 − 12 h−1 M⊙ DMH masses, which are typical for our sample, with virial radii of ≈0.02 − 0.05 (physical) h−1Mpc, the line-of-sight distance estimation is deviated by ≈0.15 − 0.30 h−1Mpc, corresponding to a peculiar velocity dispersion of σv ≈ 80 − 170 km s−1. This is significantly small compared to our a2 = 7 h−1Mpc. We thus assume that the one-halo term contributes only to the Zij = 0 − 7 h−1Mpc bin. We evaluated the HOD model at the median redshift of N(z)2, where N(z) is the redshift distribution of the sampled galaxy pairs. For our three main datasets, zpair ≈ 3.8.
The mean halo occupation function is a simplified version of the five parameter model by Zheng et al. (2007). We fixed the halo mass at which the satellite occupation becomes zero to M0 = 0 and the smoothing scale of the central halo occupation lower mass cutoff to σ log M = 0, due to sample size limitations. We define the mean occupation distribution of the central galaxy ⟨Nc(Mh)⟩ as
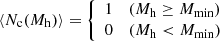 (5)
(5)
and that of satellite galaxies ⟨Ns(Mh)⟩ as
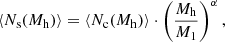 (6)
(6)
where Mmin is the minimum halo mass required to host a central galaxy, M1 is the halo mass threshold to host (on average) one satellite galaxy, and α is the high-mass power-law slope of the satellite galaxy mean occupation function. The total halo occupation is given by the sum of central and satellite galaxy halo occupations, N(Mh) = Nc(Mh)+Ns(Mh).
The dependencies of the HOD parameters on the shape of the K-estimator are detailed in Appendix D. In short, for the HOD parameters there selected, the clustering amplitude of the two-halo term is ascertained by the hosting DMHs and is thus very sensitive to their mass, Mmin, and to the fraction of galaxies in massive halos with respect to lower-mass halos, linked to α. The clustering in the one-halo term regime, however, is affected by the three parameters in a complex manner; roughly Mmin and α vary the amplitude, and α as well as (moderately) M1 modify the slope.
To find the best-fit HOD model, we construct a 3D parameter grid for Mmin, M1, and α. We vary log(Mmin/[h−1 M⊙]) in the range 9.5 − 11.2, log(M1/Mmin) from 0.5 to 2.5, and α within 0.2 − 4.3, all in steps of 0.1. For each parameter combination, we computed ξ (Eq. (4)), converted it to the K-estimator using Eq. (2) in Herrero Alonso et al. (2021), and computed a χ2 value (Eq. (2) or (3)). We then used the resulting 3D χ2 grid to estimate the confidence intervals for the HOD parameters. For each point on a 2D plane, we search for the minimum χ2 for the contouring along the remaining parameter. The contours we plot are at Δχ2 = 3.53 and 8.02, which correspond to Gaussian 68% (1σ) and 95% (2σ) confidence levels, respectively, applying the χ2 distribution for three degrees of freedom. The projections of the 68% probability contours on the three interesting parameters are then used to compute the uncertainty of each HOD parameter.
For each point in the three parameter grid, we also computed the large-scale galaxy bias factor, b, and the fraction of satellite galaxies per halo, fsat, as follows:
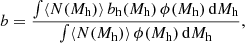 (7)
(7)
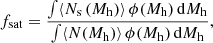 (8)
(8)
where bh(Mh) denotes the large-scale halo bias. The typical DMH mass is determined by the large-scale galaxy bias factor. We ultimately compute the bias and fsat distributions from the HOD models that fall within the 68% confidence (for the three-parameter space) contours. These distributions are then used to assess the uncertainties in the bias and fsat.
4. Results from HOD modeling
4.1. Fit results from the MUSE-Wide survey
Using the K-estimator 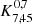 , we compute the clustering of our LAE sample in ten logarithmic bins in the range 0.16 < Rij/[h−1Mpc] < 27.5, with error bars calculated following the jackknife resampling technique described in Sect. 3.2.1. In the left top panel of Fig. 5, we show the measured clustering signal, with all MUSE-Wide data points significantly above the 7/45 baseline, which represents the expected clustering of an unclustered population.
, we compute the clustering of our LAE sample in ten logarithmic bins in the range 0.16 < Rij/[h−1Mpc] < 27.5, with error bars calculated following the jackknife resampling technique described in Sect. 3.2.1. In the left top panel of Fig. 5, we show the measured clustering signal, with all MUSE-Wide data points significantly above the 7/45 baseline, which represents the expected clustering of an unclustered population.
 |
Fig. 5. Best-fit HOD models to the LAE clustering measurements (blue data points) from MUSE samples. Top left: blue dashed, red dotted, and black continuous curves show the one-halo, two-halo, and total clustering terms from the MUSE-Wide sample, respectively. The black straight line shows the expected K value of an unclustered sample. The residuals are shown below. The uncertainties are computed with the jackknife technique described in Sect. 3.2.1. Top right: best-fit HODs for central (red dotted), satellite (blue dashed), and total LAEs (black continuous) from the MUSE-Wide survey. Shaded regions correspond to 1σ confidence space. Middle: Same but for MUSE-Deep and using Poisson error bars. Bottom: same but for MXDF and Poisson uncertainties. |
Following the procedure laid out in Sect. 3.3, we obtain constraints on the HOD parameters. From the grid search and the χ2 minimization, we find the best HOD fit to the K-estimator, colored in black in the same figure and dissected into the one- and two-halo term contributions. It can be seen from the residuals (bottom) that the model is in remarkable agreement with the measurements.
A somewhat intriguing feature, at least at first sight, is the kink in the two-halo term profile at 0.2 < Rij/[h−1Mpc] < 0.4. This reflects the effect of the halo-halo collision introduced in the HOD model formalism by Tinker et al. (2005), where the galaxy pairs within the same DMH cannot contribute to the two-halo term.
Our fitting allows us to find the best-fit HOD from Eqs. (5) and (6). In the right top panel of Fig. 5, we represent the best HODs for the central, satellite, and total LAEs from the MUSE-Wide survey. While the halo mass needed to host one (central) LAE is log(Mh/[h−1 M⊙]) > 10.6, satellite galaxies are only present if the DMHs are at least one order of magnitude more massive (log(Mh/[h−1 M⊙]) > 11.6).
As described in Sect. 3.3, we also compute the confidence regions for the HOD parameters. We show the probability contours (red) in Fig. 6. The wobbliness of the curves, especially those involving α, is caused by making use of a discrete grid. For our sample, the contours are constrained to have α > 1, log(M1/Mmin) > 1, and log(Mmin/[h−1 M⊙]) > 10.4.
 |
Fig. 6. Confidence contours in the three HOD parameter space. Red corresponds to MUSE-Wide, green to MUSE-Deep, and blue to MXDF. The thick (dashed) contours represent the 68.3% (95.5%) confidence, at Δχ2 = 3.53 (8.02) level. The crosses stand for best-fit ( |
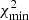
We list the best-fit HOD parameters in Table 3. While the minimum DMH mass required to host a central galaxy is ![Mathematical equation: $ \log (M_\mathrm{{min}}/[h^{-1}M_\odot])=10.7^{+0.2}_{-0.3} $](/articles/aa/full_html/2023/03/aa44693-22/aa44693-22-eq32.gif) , that needed to host one central and (on average) one satellite is
, that needed to host one central and (on average) one satellite is ![Mathematical equation: $ \log (M_1/[h^{-1}M_\odot])=12.4^{+0.4}_{-0.6} $](/articles/aa/full_html/2023/03/aa44693-22/aa44693-22-eq33.gif) (i.e.,
(i.e., 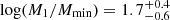 ). The power-law slope of the number of satellites is found to be
). The power-law slope of the number of satellites is found to be 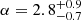 . The inferred typical DMH mass is
. The inferred typical DMH mass is ![Mathematical equation: $ \log( M_\mathrm{{h}}/[h^{-1}M_\odot])=11.09^{+0.10}_{-0.09} $](/articles/aa/full_html/2023/03/aa44693-22/aa44693-22-eq36.gif) , corresponding to a large-scale bias factor of
, corresponding to a large-scale bias factor of 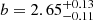 . The high values of log M1 and α, considering the typical DMH mass of LAEs, suggest a low number of satellite galaxies detected in our sample.
. The high values of log M1 and α, considering the typical DMH mass of LAEs, suggest a low number of satellite galaxies detected in our sample.
Best-fit HOD parameters for the main samples of LAEs.
Seeking robust information about the number of satellite galaxies, we compute the satellite fraction fsat (Eq. (8)) for each parameter combination. We find fsat ≲ 0.10 at the 3σ confidence level, being 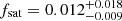 . That is, ≈3% (1σ upper limit) of the LAEs in the MUSE-Wide survey are satellites. In other words, at most ≈2 out of ≈65 DMHs in our sample host one satellite LAE.
. That is, ≈3% (1σ upper limit) of the LAEs in the MUSE-Wide survey are satellites. In other words, at most ≈2 out of ≈65 DMHs in our sample host one satellite LAE.
4.2. Fit results from MUSE-Deep
We measure the clustering of the MUSE-Deep LAE sample with the same K-estimator in eight logarithmic bins within 0.09 < Rij/[h−1Mpc] < 4.75. We compute Poisson uncertainties as laid out in Sect. 3.2.2 and display the result in the middle left panel of Fig. 5. Overplotted on the clustering signal, we show the best HOD fit, split into the one- and two-halo term contributions. The good quality of the fit is quantified with the residuals in the bottom panel of the figure.
Following the procedure described in Sect. 3.2.2, we compute the confidence intervals for the HOD parameters and list them in Table 3. We plot the probability contours (green) in Fig. 6, which overlap significantly with those from the MUSE-Wide sample. Central LAEs can occupy DMHs if these are at least as massive as ![Mathematical equation: $ \log (M_\mathrm{{min}}/[h^{-1}\rm{Mpc}])=10.5^{+0.2}_{-0.1} $](/articles/aa/full_html/2023/03/aa44693-22/aa44693-22-eq57.gif) , whereas, in order to host satellite LAEs, the halos must have masses
, whereas, in order to host satellite LAEs, the halos must have masses ![Mathematical equation: $ \log (M_1/[h^{-1}\rm{Mpc}])=12.4^{+0.3}_{-0.2} $](/articles/aa/full_html/2023/03/aa44693-22/aa44693-22-eq58.gif) (
(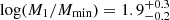 ). These values correspond to a large-scale bias and typical DMH mass
). These values correspond to a large-scale bias and typical DMH mass 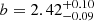 and
and ![Mathematical equation: $ \log (M_\mathrm{{h}}/[h^{-1}{M}_{\odot}])=10.89^{+0.09}_{-0.09} $](/articles/aa/full_html/2023/03/aa44693-22/aa44693-22-eq61.gif) , which are similar to those found in the MUSE-Wide survey. The derived satellite fraction is
, which are similar to those found in the MUSE-Wide survey. The derived satellite fraction is 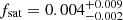 , consistent with that from the MUSE-Wide LAE sample.
, consistent with that from the MUSE-Wide LAE sample.
We then compute the best-fit HOD for central, satellite and total LAEs (middle right panel of Fig. 5). In line with the best-fit HOD parameters and somewhat lower than the values found for the MUSE-Wide survey, the smallest DMH that can host a central LAE has a mass of log(Mh/[h−1 M⊙]) > 10.4, more than one order of magnitude lower than that required to host one additional LAE (satellite).
4.3. Fit results from the MUSE Extremely Deep Field
We make use of six logarithmic bins in the range 0.09 < Rij/[h−1Mpc] < 1.45 and Poisson errors (see Sect. 3.2.2) to quantify the clustering of the sample of LAEs from MXDF. We show the K-estimator measurements in the bottom left panel of Fig. 5, along with the corresponding best HOD fit.
The probability contours are plotted in blue in Fig. 6, significantly apart from those of MUSE-Wide and MUSE-Deep. While the minimum DMH mass to host a central LAE is ![Mathematical equation: $ \log (M_\mathrm{{min}}/[h^{-1}\rm{Mpc}])=10.3^{+0.2}_{-0.3} $](/articles/aa/full_html/2023/03/aa44693-22/aa44693-22-eq63.gif) , that to host one central and one satellite LAE is
, that to host one central and one satellite LAE is ![Mathematical equation: $ \log (M_1/[h^{-1}\rm{Mpc}])=11.7^{+0.3}_{-0.2} $](/articles/aa/full_html/2023/03/aa44693-22/aa44693-22-eq64.gif) (
(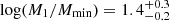 ). These values are somewhat lower than those found for the MUSE-Wide survey and correspond to a bias factor and typical halo mass of
). These values are somewhat lower than those found for the MUSE-Wide survey and correspond to a bias factor and typical halo mass of 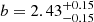 and
and ![Mathematical equation: $ \log (M_\mathrm{{h}}/[h^{-1}{M}_{\odot}])=10.77^{+0.13}_{-0.15} $](/articles/aa/full_html/2023/03/aa44693-22/aa44693-22-eq67.gif) , respectively. The inferred satellite fraction is
, respectively. The inferred satellite fraction is 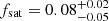 (fsat ≲ 0.2 at the 3σ confidence level), tentatively higher than that found in the MUSE-Wide survey.
(fsat ≲ 0.2 at the 3σ confidence level), tentatively higher than that found in the MUSE-Wide survey.
From the best-fit HOD parameters, we calculate the HODs for central, satellite and total LAEs and show them in the bottom right panel of Fig. 5. Significantly lower than in the MUSE-Wide survey, central LAEs reside in DMHs if these are more massive than log(Mh/[h−1 M⊙]) > 10.2. For the satellite case, and similarly to the previous LAE samples, they only exist if the halos are around one order of magnitude more massive.
It is worth pointing out that the three HOD parameters have some degree of degeneracy, printed out in the diagonally elongated probability contours in log M1/Mmin – α space in the bottom right panel of Fig. 6. This can be understood as follows: a higher α in the models causes an increase of satellites at high mass halos, but this can be compensated by producing less satellites by increasing log M1/Mmin. While this correlation is clearly visible for the MUSE-Wide and MUSE-Deep samples, the MXDF dataset only seems to be affected in the 95% confidence contour. We did not observe clear correlations between other parameters with any of our samples. Appendix A shows how our K-estimator varies with the parameters. The causes of parameter degeneracies are also noticeable in Fig. D.1. We note however that while the correlation between the HOD parameters leads to the perturbed shape of the probability contours, the lowest (MXDF) and highest luminosity (MUSE-Wide) sample contours are detached from each other. Thus, for the purposes of this study, simultaneously fitting the three HOD parameters and showing their correlations is preferable over, for instance, fixing α to a dubious value.
5. Discussion
5.1. Clustering dependence on Lyα luminosity
The complex radiative transfer processes that the Lyα photons are subject to make the search for correlations between Lyα luminosity and other physical properties a difficult task. Despite this complication, Yajima et al. (2018) predicted a correlation between simulated LLyα and halo mass based on halo merger trees and Lyα radiative transfer calculations. Khostovan et al. (2019) is, however, the only study so far that has reported a clear (5σ) relation between these quantities using observational data. Motivated by these results, we exploited the large dynamic range of Lyα luminosities that we cover to investigate the relation between Lyα luminosity and DMH mass. As a first step, we compare the K-estimator measurements in the MUSE-Wide survey (highest luminosity LAE sample: ⟨LLyα⟩≈1042.34 erg s−1, but still fainter than those in Khostovan et al. 2019) and in MXDF (faintest LAE sample; ⟨LLyα⟩≈1041.22 erg s−1) and show the outcome of this comparison in the left panel of Fig. 7.
 |
Fig. 7. Clustering dependence on Lyα luminosity. Left: K-estimator measurements in the MUSE-Wide survey (red; ⟨LLyα⟩≈1042.34 erg s−1) and MXDF (blue; ⟨log LLyα⟩≈1041.22 erg s−1). The dotted curves represent the best HOD fits. The black straight line shows the expected K-estimator of an unclustered sample. Right: same for the high LLyα subset (red) from the MUSE-Wide survey and the low LLyα subsample (blue) from MXDF. |
The relatively luminous LAEs from the MUSE-Wide survey cluster slightly more strongly (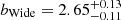 ) than the low-luminosity LAEs from MXDF (
) than the low-luminosity LAEs from MXDF (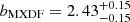 ). The clustering measurements and bias factor (
). The clustering measurements and bias factor (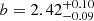 ) in MUSE-Deep (log(LLyα/[erg s−1]) = 41.64) fall between those from MUSE-Wide and MXDF. We convert the bias factors from the three main samples of this study into typical DMH masses and plot them as a function of their median Lyα luminosity with colored symbols in Fig. 8.
) in MUSE-Deep (log(LLyα/[erg s−1]) = 41.64) fall between those from MUSE-Wide and MXDF. We convert the bias factors from the three main samples of this study into typical DMH masses and plot them as a function of their median Lyα luminosity with colored symbols in Fig. 8.
 |
Fig. 8. Typical dark matter halo mass against observed median Lyα luminosity. Filled and unfilled symbols correspond to the values derived from the samples and subsamples described in Sect. 2, respectively. Red circles, green triangles and blue squares belong to MUSE-Wide, MUSE-Deep and MXDF, respectively. Gray crosses represent the results from Khostovan et al. (2019) in the Lyα luminosity interval relevant for this study. |
Although the three main datasets sample the same region of the sky, their transverse coverage is limited and somewhat differs. Therefore, our results are affected by cosmic sample variance. Ideally, this uncertainty is estimated from the variance of clustering measurements from simulated mocks in different lines of sight. Inferring cosmic variance from a large set of mocks that are able to reproduce the observed clustering of our LAEs is however beyond the scope of this paper.
We further investigate the possible dependence on LLyα by splitting the main LAE samples into disjoint subsets (see Table 2). We compute the K-estimator in each LLyα subsample, find the best HOD fit and list the large-scale bias factors and the typical DMH masses in Table 4. We also plot the typical DMH masses in Fig. 8 (empty symbols) as a function of the median LLyα of the subsamples. We find that typical halo mass increases from 1010.00 to 1011.43 M⊙ between 1040.97 and 1042.53 erg s−1 in line luminosity.
Best HOD fit large-scale bias factor and typical DMH mass for the LAE subsamples.
For each subsample pair, the high-luminosity subset always clusters more strongly than the low-luminosity one and, in this case, cosmic sample variance effects can be completely neglected because subset pairs span the exact same area on the sky. The most pronounced difference is found when splitting the MXDF sample, the dataset with the largest dynamic range of Lyα luminosity. The best HOD fits deliver 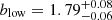 and
and 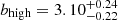 (3.9σ significant).
(3.9σ significant).
Despite its higher luminosity, we infer a less massive DMH for the MUSE-Deep high-luminosity subsample than for the main dataset. This is due to the higher zpair of the subset (see Sects. 2.4 and 3.3). Because we evaluate the HOD model at zpair, a higher redshift corresponds to HOD models in which the halo mass function presents a lower number density of massive halos and, thus, deliver less massive typical DMHs. The same reasoning applies when comparing the high-luminosity MXDF and low-luminosity MUSE-Deep subsamples and the high-luminosity MUSE-Deep and low-luminosity MUSE-Wide subsets. While each subsample pair presents similar median luminosities, the former also has similar zpair, unlike the latter one (see Sect. 2.4). This translates into similar DMH masses for the first pair but significantly distinct masses for the second.
We last consider the most extreme cases, the low-luminosity subset from MXDF and the high-luminosity one from the MUSE-Wide survey. We show the measured clustering in the two subsamples in the right panel of Fig. 7. The high-luminosity LAEs cluster 8σ more strongly than the low-luminosity LAEs, without accounting for cosmic variance. We find that LAEs with log(LLyα/[erg s−1]) ≈ 42.53 reside in DMHs of ![Mathematical equation: $ \log(M_\mathrm{{h}} / [h^{-1}{M}_{\odot}])=11.43^{+0.04}_{-0.10} $](/articles/aa/full_html/2023/03/aa44693-22/aa44693-22-eq86.gif) and that lower luminosity LAEs (log(LLyα/[erg s−1]) ≈ 40.97) are hosted by DMHs of masses ranging
and that lower luminosity LAEs (log(LLyα/[erg s−1]) ≈ 40.97) are hosted by DMHs of masses ranging ![Mathematical equation: $ \log(M_\mathrm{{h}} / [h^{-1}{M}_{\odot}])=10.00^{+0.12}_{-0.09} $](/articles/aa/full_html/2023/03/aa44693-22/aa44693-22-eq87.gif) . These results fit well within the assumed framework in which star-forming galaxies that reside in more massive halos present higher star formation rates and thus show more luminous nebular emission lines (Kusakabe et al. 2018). This dependence can then be weakened by low Lyα escape fractions in high mass halos.
. These results fit well within the assumed framework in which star-forming galaxies that reside in more massive halos present higher star formation rates and thus show more luminous nebular emission lines (Kusakabe et al. 2018). This dependence can then be weakened by low Lyα escape fractions in high mass halos.
Following Sect. 5.4.1 of Herrero Alonso et al. (2021), we matched the redshift distributions of the three main samples and of each subsample pair to verify that the difference in clustering amplitude is not driven by the different redshift distribution of the datasets. For each main sample, we compare individual bins between their corresponding z-distributions and select the one that contains a higher number of objects. We then randomly remove LAEs until we match the number counts of the non-selected samples in that bin. Once all bins have been inspected, we obtain “matched” z-distributions (i.e., equivalent), but with still different Lyα luminosity distributions. We ran the K-estimator in the three “matched” datasets and find consistent results with the original ones. We follow the same approach for the subsamples such that the low- and high-luminosity subsets have exactly the same z-distribution. We find that the clustering difference between the “matched” and original subsamples varies within 1σ. Besides, as we did for LLyα, we also searched for a possible clustering dependence on redshift and found no trend. Thus, we discarded the possibility of a possible clustering dependence on Lyα luminosity driven by z.
Our results are not driven by AGN or low-redshift emission line contamination either. The Lyα-emitting AGN fraction for LLyα < 1043 erg s−1 is close to zero (Spinoso et al. 2020 and references therein) and the four known X-ray detected AGNs (Luo et al. 2017), which only affect MUSE-Wide and MUSE-Deep, were not included in our datasets. Besides, Urrutia et al. (2019) performed a stacking experiment of X-ray images centered on MUSE-Wide LAEs, yielding no signal. The presence of low-redshift interlopers in our spectroscopic samples is also unlikely. [O II] emitters are the typical contaminants of high-redshift LAE samples but the high resolution of the MUSE instrument allows to distinguish the [O II] emission line doublet with high confidence.
These results are in line with the tentative trends seen in Ouchi et al. (2003), Kusakabe et al. (2018), Herrero Alonso et al. (2021) and the clear dependence found in Khostovan et al. (2019). While Ouchi et al. (2003) noted a slight difference in the correlation amplitude of two LLyα subsamples (30 and 57 LAEs in each subset at z = 4.86 with log(LLyα/[erg s−1]) > 42.2 and log(LLyα/[erg s−1]) < 42.2, respectively), Kusakabe et al. (2018) observed a tendency (< 2σ) of larger bias factors corresponding to higher luminosity LAEs. They used four deep survey fields at z = 2 with limiting Lyα luminosities within the range of 41.3 < log(LLyα/[erg s−1] < 42 computed from NB387 magnitudes.
More significant is the dependence found in Khostovan et al. (2019) and Herrero Alonso et al. (2021). While the latter measured a 2σ difference in bias factors or DMH masses between two subsets of 349 and 346 LAEs at z ≈ 4 with log LLyαlow/[erg s−1] ≈ 42.14 and log LLyαlow/[erg s−1] ≈ 42.57, the former used various surveys with discrete redshift slices between 2.5 < z < 6 and 42.0 < log(LLyα/[erg s−1]) < 43.6 to find that halo mass clearly (5σ) increases with increasing line luminosity. For a direct comparison, we plot in Fig. 8 (gray crosses) the DMH masses computed by Khostovan et al. (2019) from samples with similar redshifts (z ≈ 3) and Lyα luminosities (log(LLyαlow/[erg s−1]) ≈ 42) to our current LAE samples. Our results are in good agreement and extend to much fainter Lyα luminosities.
Our results, along with those from the literature, demonstrate that having a broad dynamic range of LLyα (nearly extending two orders of magnitude) and a large number of LAEs in the samples is crucial to detect the clustering dependence on LLyα.
5.2. Comparison to Herrero Alonso et al. (2021)
In this section we compare our results with the findings of our previous study (Herrero Alonso et al. 2021, hereafter HA21), where we measured the clustering of a subset (68 fields of the MUSE-Wide survey) of our current sample (91 fields of the MUSE-Wide survey) and fitted the corresponding signal with a two-halo term only HOD modeling. In order to envisage the methodological and statistical improvement of our new investigation, we applied our 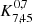 estimator to the sample considered in HA21 (695 LAEs at 3.3 < z < 6). We compare the outcome to our current clustering measurement in Fig. 9.
estimator to the sample considered in HA21 (695 LAEs at 3.3 < z < 6). We compare the outcome to our current clustering measurement in Fig. 9.
 |
Fig. 9. Clustering of the full MUSE-Wide sample (blue; this work) compared to the subset considered in HA21 (red). The former measurements show jackknife uncertainties (see Sect. 3.2.1) and the latter bootstrapping errors (see Sect. 3.1.3 in HA21). The blue dotted curve represents our best-fit from full HOD modeling. The red dotted curve displays the two-halo term only best HOD fit found in Sect. 4.3 of HA21. The black straight line shows the expected K value of an unclustered sample. |
The two datasets show good agreement within the uncertainties, with smaller errors for the current sample. Besides the higher number of LAEs and larger spatial coverage, the error estimation was carried out following different procedures. While the spatial coverage of the full MUSE-Wide survey allows us to compute the covariance matrix from the jackknife resampling technique, the smaller transverse extent covered by the 68 fields did not allow the split of the surveyed area into a significant number of jackknife zones. Thus, in HA21, we chose bootstrapping error bars as our next most conservative and realistic approach.
The slightly puzzling hump seen in Sect. 4 of HA21 at 4 ≲ Rij/[h−1Mpc] ≲ 7 is no longer visible in our new dataset. This confirms the judgement in HA21 that the feature was consistent with a statistical fluctuation resulting from the correlation between datapoints.
In HA21, we limited the range of transverse separations to Rij > 0.6 h−1Mpc, excluding the smallest scales of the one-halo term. Thus, we fitted the signal with a two-halo term only HOD model (red dotted curve in Fig. 9) in contrast to the full HOD modeling performed in this work (blue dotted curve). While the former only constrained the large-scale bias factor and the typical DMH mass of LAEs, the latter further determines the number of central and satellite galaxies, as well as the required DMH mass to host each type of galaxy. Despite these dissimilarities, the two fits are in good agreement: the bias factor (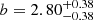 ) and the typical DMH mass of LAEs (log(MDMH /
) and the typical DMH mass of LAEs (log(MDMH / ![Mathematical equation: $ [\it{h}^{-1}{M}_{\odot}])=11.34^{+0.23}_{-0.27} $](/articles/aa/full_html/2023/03/aa44693-22/aa44693-22-eq90.gif) ) from HA21 are consistent with those derived in this work (
) from HA21 are consistent with those derived in this work (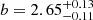 and log(MDMH /
and log(MDMH / ![Mathematical equation: $ [{h}^{-1}{M}_{\odot}])=11.09^{+0.10}_{-0.09} $](/articles/aa/full_html/2023/03/aa44693-22/aa44693-22-eq92.gif) ). The higher accuracy of our current measurements originates from the larger sample, the availability of more realistic error bars, and constraints from the one-halo term.
). The higher accuracy of our current measurements originates from the larger sample, the availability of more realistic error bars, and constraints from the one-halo term.
5.3. Comparison to the literature
A common way to infer the host DMH masses of LAEs is to quantify the galaxy clustering of the detected population through clustering statistics, which is then traditionally approximated with power-laws or fit with physically motivated HOD models.
Following the traditional approach, Gawiser et al. (2007), Ouchi et al. (2010) and Bielby et al. (2016) focused on the clustering of a few hundred LAEs at z = 3.1 − 6.6 to obtain typical DMH masses in the range 1010 − 1011 M⊙. Similar masses were found by Khostovan et al. (2018) in a much larger sample (≈5000 LAEs) in discrete redshift slices within 2.5 < z < 6, adopting the same procedure. A major improvement in terms of methodology was presented in Lee et al. (2006), Durkalec et al. (2014, 2018), Ouchi et al. (2018), who considered samples of high-z galaxies (2000–3000 mainly LAEs and Lyman-break galaxies, LBGs) and quantified the clustering with HOD modeling. While Ouchi et al. (2018) found that their LAEs at z = 5.7 (6.6) are hosted by DMHs with typical masses of 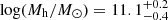 (
(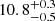 ), Lee et al. (2006) and Durkalec et al. (2014, 2018) computed log(Mh/h−1 M⊙)≈11.7 for their sample of galaxies at z = 4 − 5 and z = 3, respectively. Considering that we have performed a full HOD modeling at the median redshift of our number of galaxy pairs (zpair = 3.8) and that the DMH masses are predicted to evolve with cosmic time, our derived typical DMH masses log(Mh/h−1 M⊙)≈10.77 − 11.09 are in good agreement with the literature.
), Lee et al. (2006) and Durkalec et al. (2014, 2018) computed log(Mh/h−1 M⊙)≈11.7 for their sample of galaxies at z = 4 − 5 and z = 3, respectively. Considering that we have performed a full HOD modeling at the median redshift of our number of galaxy pairs (zpair = 3.8) and that the DMH masses are predicted to evolve with cosmic time, our derived typical DMH masses log(Mh/h−1 M⊙)≈10.77 − 11.09 are in good agreement with the literature.
Besides the computation of typical DMH masses, modeling the one-halo term of the clustering statistics with HOD models delivers the minimum DMH mass required to host a central galaxy, Mmin, that is needed for a satellite galaxy, M1, and the power-law slope of number of satellites, α. These three parameters constrain the satellite fraction, fsat. Ouchi et al. (2018) partially exploited the power of HOD models in a sample of ≈2000 LAEs to obtain 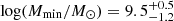 (
(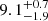 ) at z = 5.7 (6.6). Our derived minimum masses to host a central galaxy at zpair = 3.8 are considerably larger (log(Mmin/M⊙)≈10.3 − 10.7), which can be explained by the different Lyα luminosities covered in the two studies, and by the fact that several HOD parameters were fixed in Ouchi et al. (2018), namely, σ log M = 0.2, log M0 = 0.76M1 + 2.3, log M1 = 1.18 log Mmin − 1.28, and α = 1, which are not compatible with ours. This was the only previous study that performed HOD modeling in a sample of LAEs.
) at z = 5.7 (6.6). Our derived minimum masses to host a central galaxy at zpair = 3.8 are considerably larger (log(Mmin/M⊙)≈10.3 − 10.7), which can be explained by the different Lyα luminosities covered in the two studies, and by the fact that several HOD parameters were fixed in Ouchi et al. (2018), namely, σ log M = 0.2, log M0 = 0.76M1 + 2.3, log M1 = 1.18 log Mmin − 1.28, and α = 1, which are not compatible with ours. This was the only previous study that performed HOD modeling in a sample of LAEs.
Lee et al. (2006) and Durkalec et al. (2014) made use of the full potential of HOD models to reproduce the clustering of their LBG population at z = 4 − 5 and 2.9 < z < 5, respectively. Although it is still under debate whether LBGs and LAEs are the same galaxy population (Garel et al. 2015 and references therein), Lee et al. (2006) computed a minimum DMH mass to host a central LBG of log(Mmin/M⊙)≈10.8, to host a satellite LBG of log(M1/M⊙)≈12.0, and a power-law slope α for the number of satellites of α ≈ 0.7, with considerable uncertainties. Similarly, Durkalec et al. (2014) found 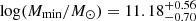 ,
, 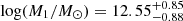 , and
, and 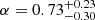 . While their halo masses are in agreement with our findings, their slope is somewhat shallower. This is partially expected given the dissimilarities in the galaxy populations (i.e., disparate observational selection techniques detect distinct galaxy populations).
. While their halo masses are in agreement with our findings, their slope is somewhat shallower. This is partially expected given the dissimilarities in the galaxy populations (i.e., disparate observational selection techniques detect distinct galaxy populations).
5.4. Satellite fraction
In the above discussions on HOD modeling, we limit ourselves to the HOD model form expressed by Eqs. (5) and (6), which is rather restrictive. The underlying assumption of the model is that the center of the halo with mass Mh > Mmin is always occupied by one galaxy in the sample (or at least at a Mh-independent constant probability). This form may be appropriate for instance, for luminosity or stellar mass thresholding samples, but there is no reason that this has to be the case for samples selected by other criteria.
We note that the inferred value of fsat is sensitive to the form of the parameterized model of the central and satellite HODs. In this work and in the literature, a power-law form of the satellite HOD is customarily assumed. In this case, a lower α would increase the model ⟨Ns(Mh)⟩ at the lower Mh end, near Mmin, and yield fewer satellites in higher mass halos. Since the halo mass function drops with increasing mass, fsat is mainly determined by the HOD behavior around Mh ∼ Mmin ∼ 1010.5 h−1 M⊙, where the halo mass function is large and the virial radius is rvir ≈ 0.08 h−1Mpc at z ∼ 3.8 (Zheng et al. 2007). These scales are too small to be well constrained by our observations. Our observed one-halo term mainly constrains the satellite fraction at larger mass halos (Mh ∼ Mmin ∼ 1013 h−1 M⊙, where rvir ≈ 0.5 h−1Mpc at the same redshift). Thus, the fsat values from the HOD modeling should be viewed with caution and may well reflect the artefacts of the assumed form of the model. On the other hand, the sheer presence of a significant one-halo term indicates the existence of some satellites at higher halo masses. The extent of the one-halo term up to Rij ≈ 0.5 h−1Mpc shows that there are indeed satellites up to Mh ∼ 1013 h−1 M⊙.
In spite of the above caveats, the small satellite fraction of the LAEs is likely to be robust. The small fsat values for the assumed HOD model indicate that not only central-satellite pairs are rare, but also satellite-satellite pairs are as well, suggesting that only a small fraction of halos contain multiple LAEs. The small Mmin values themselves are also an indication that a large majority of the halos (at the low mass end) that contain a LAE are indeed dominated by one galaxy and in this case, the LAE is probably the central galaxy.
5.5. Implications
The clustering results of this study do not only have implications on the baryonic-DM relation, but also on evolving Lyα luminosity functions, signatures of incomplete reionization, and halo mass-dependent Lyα escape fractions. We address these aspects in the following.
The relation between halo mass (or clustering strength) and Lyα luminosity (Table 4 and Fig. 8) demonstrates that high-luminosity LAEs tend to reside in higher density environments than lower luminosity ones. As a result, overdense regions contain a larger fraction of high-luminosity sources (and a lower fraction of less luminous ones) than environments of lower density. These inferences affect the Lyα LF measurements at 3 < z < 6. While we expect a shallower faint-end slope of the Lyα LF in overdense regions, the slope should steepen in average or low density environments. As a consequence, surveys for relatively high-luminosity (LLyα ≈ 1042 erg s−1) LAEs are implicitly biased against the lowest density regions and thus gives a biased shape for the LF, which should not be extrapolated towards lower Lyα luminosities.
Assuming that our LLyα − Mh relation still holds at higher redshifts, the Lyα LF at z ≥ 6 would be even more affected, not only because of the above discussion but also because higher redshift bins are mainly populated by high-luminosity sources, contrary to lower redshift bins (typical case for telescopes with higher sensitivity at bluer wavelengths). Thus, it is important to be careful when interpreting Lyα LFs, especially near the epoch of reionization (EoR), where a shallow to steep variation in the slope of the LF from higher (z ≈ 7) to lower redshifts (z ≈ 5.7) is commonly interpreted as a sign of incomplete reionization (Konno et al. 2014; Matthee et al. 2015; Santos et al. 2016).
Simulations at those higher redshifts also tend to find that high-luminosity LAEs are more likely to be observed than low-luminosity ones because they are able to ionize their surroundings and form H II regions around them (i.e., ionized bubbles; Matthee et al. 2015; Hutter et al. 2015; Yoshioka et al. 2022). These allow Lyα photons to redshift out of the resonance wavelength and escape the region. Lower luminosity LAEs are then observed if they reside within the ionized bubbles of higher luminosity LAEs or if they are able to transmit enough flux through the IGM (Matthee et al. 2015). If our LLyα − Mh relation is still valid at these redshifts, our results would support this simulation paradigm since high-luminosity LAEs (situated in overdense regions) could form large ionized bubbles more efficiently than low-luminosity sources which tend to be located in lower density environments (Tilvi et al. 2020).
Theoretical studies (e.g., Furlanetto et al. 2006; McQuinn et al. 2007) have modeled the size distribution of these H II regions and predicted an increase in the apparent clustering signal of LAEs towards the epoch of reionization (i.e., towards a more neutral IGM). Large ionized bubbles become rarer as the ionizing fraction declines. This patchy distribution of H II regions, which mostly surrounds large galaxy overdensities, boosts the apparent clustering of LAEs. This is commonly interpreted as another sign of incomplete reionization (e.g., Matthee et al. 2015; Hutter et al. 2015). Comparisons between observed intrinsic LAE clustering and model predictions have therefore been used to infer the fraction of neutral hydrogen at the EoR (e.g., Ouchi et al. 2018). Nevertheless, if the clustering dependence on Lyα luminosity continues to z ≈ 6, this comparison should be performed with caution. Because the observed high redshift bins (z ≥ 6) mainly contain high-luminosity LAEs, a strong clustering signal at z ≈ 6 may be wrongly interpreted as incomplete reionization when, in fact, it may only reflect the natural relation between Lyα luminosity and clustering strength.
We speculate that our results also play a role in the amount of escaping Lyα photons (Lyαfesc). Durkalec et al. (2018) observed a dependence between halo mass and absolute UV magnitude (MUV). The interpretation of their relation goes as follows: MUV traces star formation rate (SFR; e.g., Walter et al. 2012), which, in turn, tracks stellar mass (M*; e.g., Salmon et al. 2015), which correlates with halo mass (e.g., Moster et al. 2010). Because we observe a similar relation of Mh with LLyα, LLyα is presumably also a tracer of star formation. If this is correct, the object-to-object variations in Lyα escape fraction cannot be so large that they obscure the trend of SFR – M* − Mh. Given the typical Lyα luminosities of our sample, this is in agreement with the model suggestions of Schaerer et al. (2011), Garel et al. (2015), where the Lyαfesc is of the order of unity for sources with SFR ≈ 1 M⊙ yr−1. The Lyα luminosity would then be a good tracer of the SFR for less luminous LAEs.
6. Conclusions
We report a strong clustering dependence on Lyα luminosity from the clustering measurements of three MUSE Lyα emitting galaxy (LAE) samples at 3 < z < 6. Following the pencil-beam design of MUSE surveys from spatially large and shallow observation to spatially small and deep observation, we use 1030 LAEs from the full MUSE-Wide survey (1 h exposure time), 679 LAEs from MUSE-Deep (10 h), and 367 LAEs from MXDF (140 h). We thus connect the clustering properties of L⋆ LAEs with those of much fainter ones in the MXDF. We applied an optimized version of the K-estimator as the clustering statistic, coupled to state-of-the-art halo occupation distribution (HOD) modeling.
From our full HOD analysis, we derive constraints on the HOD of high-luminosity (log(LLyα/erg s−1) ≈ 42.34), intermediate (log(LLyα/erg s−1) ≈ 41.64) and low-luminosity (log(LLyα/erg s−1) ≈ 41.22) LAEs. We modeled the LAE HOD with three parameters: the threshold dark matter halo (DMH) mass for hosting a central LAE (Mmin), for hosting (on average) one satellite LAE (M1), and the power-law slope of the number of satellites per halo (α) as a function of halo mass. For the high-luminosity sample we derived a typical DMH mass of ![Mathematical equation: $ \log (M_{\mathrm{h}}/[h^{-1}M_\odot])=11.09^{+0.10}_{-0.09} $](/articles/aa/full_html/2023/03/aa44693-22/aa44693-22-eq100.gif) , corresponding to a bias factor of
, corresponding to a bias factor of 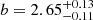 . These findings, although more accurate, are in agreement with the results based on the two-halo term only HOD modeling performed in Herrero Alonso et al. (2021) for a subset of our MUSE-Wide sample. For the lower luminosity samples we found lower DMH masses. While for the log(LLyα/erg s−1) ≈ 41.64 dataset we inferred
. These findings, although more accurate, are in agreement with the results based on the two-halo term only HOD modeling performed in Herrero Alonso et al. (2021) for a subset of our MUSE-Wide sample. For the lower luminosity samples we found lower DMH masses. While for the log(LLyα/erg s−1) ≈ 41.64 dataset we inferred ![Mathematical equation: $ \log (M_{\mathrm{h}}/[h^{-1}M_\odot])=10.89^{+0.09}_{-0.09} $](/articles/aa/full_html/2023/03/aa44693-22/aa44693-22-eq102.gif) (
(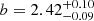 ), for the low-luminosity LAE sample we computed
), for the low-luminosity LAE sample we computed ![Mathematical equation: $ \log (M_{\mathrm{h}}/[h^{-1}M_\odot])=10.77^{+0.13}_{-0.15} $](/articles/aa/full_html/2023/03/aa44693-22/aa44693-22-eq104.gif) (
(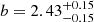 ).
).
We also derived threshold DMH masses for centrals and satellites for each sample. We found that the minimum DMH mass to host a central LAE is ![Mathematical equation: $ \log (M_\mathrm{{min}}/[h^{-1}M_\odot])\,{=}\,10.3^{+0.2}_{-0.3}, 10.5^{+0.2}_{-0.1}, 10.7^{+0.2}_{-0.3} $](/articles/aa/full_html/2023/03/aa44693-22/aa44693-22-eq106.gif) for low-, intermediate-, and high-luminosity LAEs, respectively. The threshold halo mass for satellites and the power-law slope of the number of satellite LAEs also increase with Lyα luminosity, from
for low-, intermediate-, and high-luminosity LAEs, respectively. The threshold halo mass for satellites and the power-law slope of the number of satellite LAEs also increase with Lyα luminosity, from ![Mathematical equation: $ \log (M_1/[h^{-1}M_\odot])\,{=}\,11.7^{+0.3}_{-0.2} $](/articles/aa/full_html/2023/03/aa44693-22/aa44693-22-eq107.gif) and α = 1.5 ± 0.5 to
and α = 1.5 ± 0.5 to ![Mathematical equation: $ \log (M_1/[h^{-1}M_\odot])\,{=}\,12.4^{+0.3}_{-0.2} $](/articles/aa/full_html/2023/03/aa44693-22/aa44693-22-eq108.gif) and
and 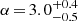 and to
and to ![Mathematical equation: $ \log (M_1/[h^{-1}M_\odot])\,{=}\,12.4^{+0.4}_{-0.6} $](/articles/aa/full_html/2023/03/aa44693-22/aa44693-22-eq110.gif) and
and 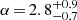 . These HOD constraints imply a decreasing number of detected satellite LAEs with luminosity. Indeed we infer satellite fractions of fsat ≲ 10, 20% (at 3σ confidence level) for high- and low-luminosity LAEs, respectively. This suggests that the most common scenario for current MUSE surveys is that in which DMHs mainly host a single detected LAE.
. These HOD constraints imply a decreasing number of detected satellite LAEs with luminosity. Indeed we infer satellite fractions of fsat ≲ 10, 20% (at 3σ confidence level) for high- and low-luminosity LAEs, respectively. This suggests that the most common scenario for current MUSE surveys is that in which DMHs mainly host a single detected LAE.
Motivated by these results, we aimed to further explore the clustering dependence on Lyα luminosity. Exploiting the large dynamic range of LLyα from MXDF, we split the main LAE sample at its median LLyα. We found a 3.9σ difference between the clustering of the low-luminosity (log(LLyα/erg s−1) ≈ 40.97, 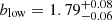 ) and the high-luminosity subset (log(LLyα/erg s−1) ≈ 41.54,
) and the high-luminosity subset (log(LLyα/erg s−1) ≈ 41.54, 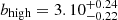 ). We then selected the highest luminosity LAE subset from the MUSE-Wide survey (log(LLyα/erg s−1) ≈ 42.53) and the lowest luminosity LAE subsample from MXDF (log(LLyα/erg s−1) ≈ 40.97), resulting in a clear clustering dependence where the high-luminosity LAEs from MUSE-Wide cluster more strongly (
). We then selected the highest luminosity LAE subset from the MUSE-Wide survey (log(LLyα/erg s−1) ≈ 42.53) and the lowest luminosity LAE subsample from MXDF (log(LLyα/erg s−1) ≈ 40.97), resulting in a clear clustering dependence where the high-luminosity LAEs from MUSE-Wide cluster more strongly (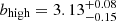 or
or ![Mathematical equation: $ \log(M_\mathrm{{h}} / [h^{-1}{M}_{\odot}])\,{=}\,11.43^{+0.04}_{-0.10} $](/articles/aa/full_html/2023/03/aa44693-22/aa44693-22-eq115.gif) ) than the low-luminosity ones from MXDF (
) than the low-luminosity ones from MXDF (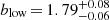 or log(Mh /
or log(Mh / ![Mathematical equation: $ [h^{-1}{M}_{\odot}])\,{=}\,10.00^{+0.12}_{-0.09} $](/articles/aa/full_html/2023/03/aa44693-22/aa44693-22-eq117.gif) ) at 8σ significance, excluding cosmic variance effects. The ongoing Hobby-Eberly Telescope Dark Energy Experiment (HETDEX; Gebhardt et al. 2021) survey will complement these results at the high-luminosity end and at somewhat lower redshifts (1.9 < z < 3.5).
) at 8σ significance, excluding cosmic variance effects. The ongoing Hobby-Eberly Telescope Dark Energy Experiment (HETDEX; Gebhardt et al. 2021) survey will complement these results at the high-luminosity end and at somewhat lower redshifts (1.9 < z < 3.5).
The implications of this framework are however not only relevant for LAE clustering studies, but also for reported measurements of evolving Lyα luminosity functions, detections of incomplete reionization at z ≈ 6, and the relation between Lyα escape fraction and halo mass. Our results are also crucial for the much debated relevance of unresolved satellite LAEs (fainter than those in MXDF) for the measured Lyα surface brightness profiles.
Acknowledgments
The authors give thanks to the staff at ESO for extensive support during the visitor-mode campaigns at Paranal Observatory. We thank the eScience group at AIP for help with the functionality of the MUSE-Wide data release webpage. T.M. and H.A. thank for financial support by CONACyT Grant Científica Básica #252531 and by UNAM-DGAPA (PASPA, PAPIIT IN111319 and IN114423). L.W. and T.U. by the Deutsche Forschungsgemeinschaft through grant Wi 1369/32-1. M.K. acknowledges support by DLR grant 50OR1904 and DFG grant KR 3338/4-1. The data were obtained with the European Southern Observatory Very Large Telescope, Paranal, Chile, under Large Program 185.A-0791. This research made use of Astropy, a community-developed core Python package for Astronomy (Adelberger et al. 2013).
References
- Adelberger, K. L., Steidel, C. C., Pettini, M., et al. 2005, ApJ, 619, 697 [NASA ADS] [CrossRef] [Google Scholar]
- Adelberger, K. L., Astropy Collaboration, Robitaille, T. P., et al. 2013, A&A, 558, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bacon, R., Conseil, D., Mary, D., et al. 2017, A&A, 608, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bacon, R., Brinchmann, J., Conseil, S., et al. 2023, A&A, 670, A4 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bielby, R. M., Tummuangpak, P., Shanks, T., et al. 2016, MNRAS, 456, 4061 [NASA ADS] [CrossRef] [Google Scholar]
- Davis, M., & Peebles, P. J. E. 1983, ApJ, 267, 465 [Google Scholar]
- Diener, C., Wisotzki, L., Schmidt, K. B., et al. 2017, MNRAS, 471, 3186 [NASA ADS] [CrossRef] [Google Scholar]
- Durkalec, A., Le Fèvre, O., Pollo, A., et al. 2014, A&A, 583, A128 [Google Scholar]
- Durkalec, A., Le Fèvre, O., Pollo, A., et al. 2018, A&A, 612, A42 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Furlanetto, S. R., Zaldarriaga, M., Hernquist, L., et al. 2006, MNRAS, 365, 1012 [CrossRef] [Google Scholar]
- Garel, T., Blaizot, J., Guiderdoni, B., et al. 2015, MNRAS, 450, 1279 [Google Scholar]
- Gawiser, E., Francke, H., Lai, K., et al. 2007, ApJ, 671, 278 [NASA ADS] [CrossRef] [Google Scholar]
- Gebhardt, K., Cooper, E. M., Ciardullo, R., et al. 2021, ApJ, 923, 217 [NASA ADS] [CrossRef] [Google Scholar]
- Hatfield, P. W., Bowler, R. A. A., Jarvis, M. J., et al. 2018, MNRAS, 477, 3760 [NASA ADS] [CrossRef] [Google Scholar]
- Herenz, E. C., Urrutia, T., Wisotzki, L., et al. 2017, A&A, 606, A12 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Herenz, E. C., Wisotzki, L., Saust, R., et al. 2019, A&A, 621, A107 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Harikane, Y., Ouchi, M., Ono, Y., et al. 2018, PASJ, 70, S11 [NASA ADS] [CrossRef] [Google Scholar]
- Herrero Alonso, Y., Krumpe, M., Wisotzki, L., et al. 2021, A&A, 653, A136 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hinshaw, G., Larson, D., Komatsu, E., et al. 2013, AJSS, 208, 19 [CrossRef] [Google Scholar]
- Hinton, S. R., Davis, T. M., Lidman, C., et al. 2016, Astron. Comput., 15, 61 [NASA ADS] [CrossRef] [Google Scholar]
- Hu, E. M., Cowie, L. L., & McMahon, R. G. 1998, ApJ, 502, L99 [NASA ADS] [CrossRef] [Google Scholar]
- Hutter, A., Dayal, P., & Müller, V. 2015, MNRAS, 450, 4025 [NASA ADS] [CrossRef] [Google Scholar]
- Inami, H., Bacon, R., Brinchmann, J., et al. 2017, A&A, 608, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Jenkins, A., Frenk, C. S., Pearce, F. R., et al. 1998, ApJ, 499, 20 [Google Scholar]
- Kaiser, N. 1987, MNRAS, 227, 1 [Google Scholar]
- Khostovan, A. A., Sobral, D., Mobasher, B., et al. 2018, MNRAS, 478, 2999 [NASA ADS] [CrossRef] [Google Scholar]
- Khostovan, A. A., Sobral, D., Mobasher, B., et al. 2019, MNRAS, 489, 555 [Google Scholar]
- Konno, A., Ouchi, M., Ono, Y., et al. 2014, ApJ, 797, 16 [Google Scholar]
- Krumpe, M., Miyaji, T., & Coil, A. L. 2010, ApJ, 713, 558 [NASA ADS] [CrossRef] [Google Scholar]
- Krumpe, M., Miyaji, T., Coil, A. L., & Aceves, H. 2012, ApJ, 746, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Krumpe, M., Miyaji, T., Husemann, B., et al. 2015, ApJ, 815, 21 [NASA ADS] [CrossRef] [Google Scholar]
- Krumpe, M., Miyaji, T., Coil, A. L., & Aceves, H. 2018, MNRAS, 474, 1773 [CrossRef] [Google Scholar]
- Kusakabe, H., Shimasaku, K., Ouchi, M., et al. 2018, PASJ, 70, 4 [Google Scholar]
- Lee, K.-S., Giavalisco, M., Gnedin, O., et al. 2006, ApJ, 642, 63 [NASA ADS] [CrossRef] [Google Scholar]
- Limber, D. N. 1953, ApJ, 117, 134 [NASA ADS] [CrossRef] [Google Scholar]
- Luo, B., Brandt, W. N., Xue, Y. Q., et al. 2017, ApJS, 228, 2 [Google Scholar]
- Madau, M. A., Cohen, D. P., Maruyama, M., et al. 2017, ApJ, 850, 5 [NASA ADS] [CrossRef] [Google Scholar]
- Mary, D., Bacon, R., Conseil, S., et al. 2020, A&A, 635, A194 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Matthee, J., Sobral, D., Santos, S., et al. 2015, MNRAS, 451, 400 [Google Scholar]
- McQuinn, M., Hernquist, L., Zaldarriaga, M., et al. 2007, MNRAS, 381, 75 [NASA ADS] [CrossRef] [Google Scholar]
- Miyaji, T., Krumpe, M., Coil, A., & Aceves, H. 2011, ApJ, 726, 83 [NASA ADS] [CrossRef] [Google Scholar]
- Moster, B. P., Somerville, R. S., Maulbetsch, C., et al. 2010, ApJ, 710, 903 [Google Scholar]
- Navarro, J. F., Frenk, C. S., & White, S. D. M. 1997, ApJ, 490, 493 [Google Scholar]
- Norberg, P., Baugh, C. M., Gaztañaga, E., & Croton, D. J. 2009, MNRAS, 396, 19 [Google Scholar]
- Ouchi, M., Shimasaku, K., Furusawa, H., et al. 2003, ApJ, 582, 60 [Google Scholar]
- Ouchi, M., Shimasaku, K., Furusawa, H., et al. 2010, ApJ, 723, 869 [Google Scholar]
- Ouchi, M., Harikane, Y., Shibuya, T., et al. 2018, PASJ, 70, S13 [Google Scholar]
- Salmon, B., Papovich, C., Finkelstein, S. L., et al. 2015, ApJ, 799, 183 [NASA ADS] [CrossRef] [Google Scholar]
- Santos, S., Sobral, D., & Matthee, J. 2016, MNRAS, 463, 1678 [Google Scholar]
- Schaerer, D., Hayes, M., Verhamme, A., et al. 2011, A&A, 531, A12 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sheth, R., Mo, H. J., & Tormen, G. 2001, MNRAS, 323, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Spinoso, D., Orsi, A., & López-Sanjuan, C. 2020, A&A, 643, A149 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Steidel, C. C., Giavalisco, M., & Pettini, M. 1996, ApJ, 462, L17 [NASA ADS] [CrossRef] [Google Scholar]
- Tilvi, V., Malhotra, S., Rhoads, J. E., et al. 2020, ApJ, 891, L10 [NASA ADS] [CrossRef] [Google Scholar]
- Tinker, J. L., Weinberg, D. H., & Zheng, Z. 2005, MNRAS, 368, 85 [Google Scholar]
- Tinker, J. L. 2007, MNRAS, 374, 477 [NASA ADS] [CrossRef] [Google Scholar]
- Urrutia, T., Wisotzki, L., Kerutt, J., et al. 2019, A&A, 624, A141 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Van Den Bosch, F. C., More, S., Cacciato, M., et al. 2013, MNRAS, 430, 725 [NASA ADS] [CrossRef] [Google Scholar]
- Walter, F., Decarli, R., Carilli, C., et al. 2012, ApJ, 752, 93 [CrossRef] [Google Scholar]
- Wechsler, R. H., & Tinker, J. L. 2018, ARA&A, 56, 435 [NASA ADS] [CrossRef] [Google Scholar]
- Yoshioka, T., Kashikawa, N., Inoue, A., et al. 2022, ApJ, 927, 32 [NASA ADS] [CrossRef] [Google Scholar]
- Yajima, H., Sugimura, K., & Hasegawa, K. 2018, MNRAS, 477, 5406 [NASA ADS] [CrossRef] [Google Scholar]
- Zheng, Z., Coil, A., & Zehavi, I. 2007, ApJ, 667, 760 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: Effect of different fields on the clustering measurements
In this work, we have analyzed the clustering of LAEs in the full MUSE-Wide sample, including the CANDELS/COSMOS fields and the HUDF parallel fields. Here, we explore the possible effects on the MUSE-Wide clustering results when including or excluding various sets of fields. In appendix A of Herrero Alonso et al. (2021), we showed that the HUDF parallel fields did not alter the clustering results, their exclusion or inclusion mainly affected the clustering uncertainties. We therefore explore the effect of including the CANDELS/COSMOS region by comparing the clustering of the full MUSE-Wide survey with that present in a subsample without the CANDELS/COSMOS fields. The number of LAEs in the CANDELS/COSMOS region is 250.
It is clear from Fig. A.1 that the clustering in both samples is in good agreement. The large-scales bias factors derived from the two curves are indistinguishable (within 1σ). The uncertainties corresponding to the smaller sample are (on average) 20% larger than in the full MUSE-Wide sample. We conclude that the inclusion of these fields has no notable effect on our clustering results but helps in reducing cosmic sample variance uncertainties.
 |
Fig. A.1. Clustering of the LAEs in the full MUSE-Wide sample (blue, see Fig. 1) and without the CANDELS/COSMOS fields (red, see right panel of Fig. 1). The black baseline represents the expected clustering of an unclustered sample. The error bars are Poissonian. The red measurements have been shifted along the x-axis for visual purposes. |
Appendix B: Covariance matrix
A common approach to quantify the correlation of the clustering data points is to resample the set of galaxies with the jackknife technique, followed by the calculation of the covariance matrix. To apply the jackknife method, we find a compromise between the number and the size of the jackknife zones. Thus, we split the sky area into ten independent regions (see Fig. B.1) with a spatial extent of ≈4 h−1Mpc in both RA and Dec directions. We then construct ten different subsamples, each of them excluding one jackknife zone, and compute the K-estimator in each subset. These measurements are then used to build up the covariance matrix using Eq. 1 (see Sect. 3.2.1).
 |
Fig. B.1. Ten Jackknife zones in the spatial coverage of the full MUSE-Wide survey (83.52 arcmin2). Each Jackknife zone has a spatial extent of ≈4 h−1Mpc in both RA and Dec directions. |
Considering that the probability of one galaxy pair to contribute to various adjacent bins is higher than that to contribute to several distant bins, one would naively expect a higher correlation in the former case. This is indeed what the (normalized) covariance matrix reflects in the left panel of Fig. B.2. In fact, the noise in the matrix elements corresponding to notably separate bins is substantial. In the right panel of Fig. B.2, we plot the normalized matrix elements as a function of bin i for each bin j to better illustrate the high level of noise in the matrix, especially for bins i > 6, where most curves become negative. This is likely due to the limited spatial size of the survey, which does not allow neither for a higher number of jackknife zones nor for spatially larger zones.
 |
Fig. B.2. Covariance matrix computed from ten independent K-estimator measurements from the jackknife resampling technique. Left: Normalized covariance matrix for bins i and j. The red region defines the main diagonal and the two adjacent diagonals used for our reduced covariance matrix. Right: Normalized covariance matrix elements as a function of bin i for each bin j (colored). |
As a result of the considerable noise in the matrix on account of barely correlated bins significantly apart from each other, the minimization of the χ2 values (Eq. 2) including the full covariance fails (i.e., various χ2 values become negative). We therefore limit the use of the covariance matrix to its main diagonal and two adjacent diagonals (see red section in the left panel of Fig. B.2; our so-called reduced covariance matrix). This means we set the negative part of the curves in the right panel of Fig. B.2 to zero (i.e., no correlation between those bins), in an attempt to smooth out the noise. While incorporating more diagonals results mathematically problematic for the χ2 minimization, we have verified that the number of adjacent diagonals (one or two) slightly modifies the χ2 values but the probability contours represented in Fig. 6 remain unaltered. Thus, so do the best-fit HOD parameters.
Despite current limitations, jackknife is still the most robust method to compute the K-estimator uncertainties. While galaxy bootstrapping or Poisson error bars do not account for bin to bin correlations, our reduced covariance matrix only neglects the correlation between bins remarkably separated (expected to be minimal), but accounts for the correlation between nearby bins.
Appendix C: Error estimation comparison
In order to quantify the correlation between the K-estimator bins, the covariance matrix must be computed. By splitting the sky area into independent regions, following the jackknife resampling technique, we create as many subsamples from the MUSE-Wide sample as jackknife zones (see Sect. 3.2.1). The K-estimator is then computed in each subset and the measurements are used to quantify the covariance matrix, whose diagonal provides the variance of each clustering data point. The square root of the diagonal represents the 1σ uncertainties and are represented in blue in Fig. C.1 (same along the main paper).
 |
Fig. C.1. Error estimation method comparison for the sample of LAEs in the MUSE-Wide survey. Uncertainties from the covariance matrix and the jackknife resampling technique described in Sect. 3.2.1 are colored in blue, those from the bootstrapping approach used in Herrero Alonso et al. (2021) in red, and Poisson uncertainties in green. |
The jackknife resampling method requires a division of the sky area into several independent regions, each of which should ideally be large enough to cover the full range of scales under consideration. Out of the three samples examined in this study, this can only be partially achieved in the MUSE-Wide dataset. MUSE-Deep and MXDF do not allow for a spatial split into independent zones. We are thus left with two options for the deeper samples: the bootstrapping technique applied in Herrero Alonso et al. (2021), shown in red in Fig. C.1, and Poisson uncertainties, shown in green.
We find that Poisson (bootstrapping) errors are, on average, 7% (46%) larger than those computed with the jackknife technique. These findings corroborate the results from Norberg et al. (2009), who found that the bootstrapping approach overestimates the uncertainties.
Similarly as for the MUSE-Wide survey, we find that bootstrapping uncertainties are ≈40% (on average) larger than Poisson in both MUSE-Deep and MXDF. We thus decide to use Poisson errors for the deeper samples in an attempt to least overvalue the uncertainties.
We verified that the error estimation method does not significantly affect our clustering results. The best-fit parameters from MUSE-Deep and MXDF using bootstrapping error bars and the χ2 minimization described in Sect. 3.1.3 of Herrero Alonso et al. (2021) are consistent with those delivered from Poisson statistics. Although in agreement, bootstrapping delivers ≈45% larger uncertainties than Poisson for the best-fit HOD parameters.
We last perform the same experiment in MUSE-Deep and MXDF but using scaled Poisson error bars. We decreased the Poisson in 7% (excess found in MUSE-Wide) and find that the best-fit parameters are ≈10% less uncertain than if Poisson errors are directly applied.
Appendix D: Dependence of HOD parameters on the shape of the K-estimator
Here we visualize and qualitatively describe the effect of the HOD parameters on the K-estimator. Figure D.1 shows the K-estimator for numerous HOD models. Each panel represents the result of varying one HOD parameter with the other two parameters fixed. Before detailing the major effects, it should be pointed out that the exact change in the shape of the K-estimator does not only depend on the varied parameter but also on the specific choice of the other two. Hence, these panels should merely be seen as illustrative examples.
 |
Fig. D.1. Effect of HOD parameters on the shape of the K-estimator. Left: Dependence on log(Mmin) for fixed log(M1/Mmin) = 1.2 and α = 2.4. Middle: Dependence on log(M1/Mmin) for fixed log(Mmin/[h−1 M⊙]) = 10.9 and α = 2.4. Right: Dependence on α for fixed log(Mmin/[h−1 M⊙]) = 10.9 and log(M1/Mmin) = 1.2. |
The left panel of Fig. D.1 shows the dependence of the K-estimator on Mmin. Higher values of log Mmin (i.e., more massive halos) raise the expected K-estimator at all Rij scales (one- and two- halo terms). At large scales, this occurs because more massive halos present larger bias factors, whereas at small scales, this is due to the decline in the contribution from less massive DMHs.
The middle panel of Fig. D.1 shows the dependence of the K-estimator on M1/Mmin. Larger log(M1/Mmin) values (i.e., more massive halos) reduce the one-halo term clustering amplitude because of the decrease in the contribution from less massive DMHs. The clustering in the two-halo term does not depend on M1.
The right panel of Fig. D.1 shows the dependence of the K-estimator on α. Higher values of α increase the fraction of galaxies in massive DMHs with respect to smaller mass DMHs. Given that more massive halos are more strongly biased, the amplitude of the two-halo term increases. The change observed in the one-halo term is explained because galaxies hosted by massive DMHs can contribute to the one-halo term on its largest scales, while galaxies residing in less massive halos can only contribute to the one-halo term at smaller Rij scales. Since α modifies the fraction of galaxies in massive DMHs to less mass DMHs, the corresponding fraction of the clustering contribution also varies. This alters the slope of the one-halo term.
All Tables
Best HOD fit large-scale bias factor and typical DMH mass for the LAE subsamples.
All Figures
|
Fig. 1. Spatial distribution of the LAEs from the MUSE-Wide survey (red circles), MUSE-Deep (green squares) and MXDF (blue stars). The overlapping objects between the MXDF and MUSE-Deep samples have been removed from the MUSE-Deep LAE set, while those LAEs overlapping in MUSE-Deep and MUSE-Wide have been removed from the MUSE-Wide LAE sample. The MUSE-Wide survey covers part of the CANDELS/GOODS-S region and the HUDF parallel fields (left panel) as well as part of the CANDELS/COSMOS region (right panel). See Fig. 1 in Urrutia et al. (2019) for the layout of the MUSE-Wide survey without individual objects, Fig. 1 in Bacon et al. (2017) for that of MUSE-Deep, and Fig. 2 in Bacon et al. (2023) for that of MUSE-Deep (MOSAIC) and MXDF together. |
| In the text | |
|
Fig. 2. Lyα luminosity-redshift for the LAEs in MUSE-Wide (red circles), MUSE-Deep (green squares) and MXDF (blue stars). The dashed colored lines correspond to the median log LLyα values of the corresponding samples. The redshift and LLyα distributions are shown in the top and right panel, respectively. |
| In the text | |
|
Fig. 3. Redshift distribution of the subsamples bisected at the median Lyα luminosity of MUSE-Wide, MUSE-Deep and MXDF (panels from left to right). Blue (red) colors show the low- (high-) luminosity subsets. The vertical dashed lines represent the median redshift of the corresponding subsample. |
| In the text | |
|
Fig. 4. Sketch of the K-estimator, representing the relative geometry that probe the one- and two-halo term scales. The empty blue and filled red cylinders, delimited by |a2| = 7 h−1 Mpc and |a3| = 45 h−1 Mpc respectively, illustrate the line-of-sight distance Zij intervals within which we count galaxy pairs at fixed transverse separations Rij, represented by nested cylinders. Pairs of LAEs connected with green lines within the same DMH (filled gray circle) contribute to the one-halo term (small Rij scales), while pairs belonging to two different DMHs (yellow lines) probe the two-halo term (larger Rij separations). |
| In the text | |
|
Fig. 5. Best-fit HOD models to the LAE clustering measurements (blue data points) from MUSE samples. Top left: blue dashed, red dotted, and black continuous curves show the one-halo, two-halo, and total clustering terms from the MUSE-Wide sample, respectively. The black straight line shows the expected K value of an unclustered sample. The residuals are shown below. The uncertainties are computed with the jackknife technique described in Sect. 3.2.1. Top right: best-fit HODs for central (red dotted), satellite (blue dashed), and total LAEs (black continuous) from the MUSE-Wide survey. Shaded regions correspond to 1σ confidence space. Middle: Same but for MUSE-Deep and using Poisson error bars. Bottom: same but for MXDF and Poisson uncertainties. |
| In the text | |
|
Fig. 6. Confidence contours in the three HOD parameter space. Red corresponds to MUSE-Wide, green to MUSE-Deep, and blue to MXDF. The thick (dashed) contours represent the 68.3% (95.5%) confidence, at Δχ2 = 3.53 (8.02) level. The crosses stand for best-fit ( |
| In the text | |
|
Fig. 7. Clustering dependence on Lyα luminosity. Left: K-estimator measurements in the MUSE-Wide survey (red; ⟨LLyα⟩≈1042.34 erg s−1) and MXDF (blue; ⟨log LLyα⟩≈1041.22 erg s−1). The dotted curves represent the best HOD fits. The black straight line shows the expected K-estimator of an unclustered sample. Right: same for the high LLyα subset (red) from the MUSE-Wide survey and the low LLyα subsample (blue) from MXDF. |
| In the text | |
|
Fig. 8. Typical dark matter halo mass against observed median Lyα luminosity. Filled and unfilled symbols correspond to the values derived from the samples and subsamples described in Sect. 2, respectively. Red circles, green triangles and blue squares belong to MUSE-Wide, MUSE-Deep and MXDF, respectively. Gray crosses represent the results from Khostovan et al. (2019) in the Lyα luminosity interval relevant for this study. |
| In the text | |
|
Fig. 9. Clustering of the full MUSE-Wide sample (blue; this work) compared to the subset considered in HA21 (red). The former measurements show jackknife uncertainties (see Sect. 3.2.1) and the latter bootstrapping errors (see Sect. 3.1.3 in HA21). The blue dotted curve represents our best-fit from full HOD modeling. The red dotted curve displays the two-halo term only best HOD fit found in Sect. 4.3 of HA21. The black straight line shows the expected K value of an unclustered sample. |
| In the text | |
|
Fig. A.1. Clustering of the LAEs in the full MUSE-Wide sample (blue, see Fig. 1) and without the CANDELS/COSMOS fields (red, see right panel of Fig. 1). The black baseline represents the expected clustering of an unclustered sample. The error bars are Poissonian. The red measurements have been shifted along the x-axis for visual purposes. |
| In the text | |
|
Fig. B.1. Ten Jackknife zones in the spatial coverage of the full MUSE-Wide survey (83.52 arcmin2). Each Jackknife zone has a spatial extent of ≈4 h−1Mpc in both RA and Dec directions. |
| In the text | |
|
Fig. B.2. Covariance matrix computed from ten independent K-estimator measurements from the jackknife resampling technique. Left: Normalized covariance matrix for bins i and j. The red region defines the main diagonal and the two adjacent diagonals used for our reduced covariance matrix. Right: Normalized covariance matrix elements as a function of bin i for each bin j (colored). |
| In the text | |
|
Fig. C.1. Error estimation method comparison for the sample of LAEs in the MUSE-Wide survey. Uncertainties from the covariance matrix and the jackknife resampling technique described in Sect. 3.2.1 are colored in blue, those from the bootstrapping approach used in Herrero Alonso et al. (2021) in red, and Poisson uncertainties in green. |
| In the text | |
|
Fig. D.1. Effect of HOD parameters on the shape of the K-estimator. Left: Dependence on log(Mmin) for fixed log(M1/Mmin) = 1.2 and α = 2.4. Middle: Dependence on log(M1/Mmin) for fixed log(Mmin/[h−1 M⊙]) = 10.9 and α = 2.4. Right: Dependence on α for fixed log(Mmin/[h−1 M⊙]) = 10.9 and log(M1/Mmin) = 1.2. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.