| Issue |
A&A
Volume 699, July 2025
|
|
|---|---|---|
| Article Number | A46 | |
| Number of page(s) | 14 | |
| Section | Stellar atmospheres | |
| DOI | https://doi.org/10.1051/0004-6361/202554675 | |
| Published online | 01 July 2025 | |
Signatures of planets and Galactic subpopulations in solar analogs
Precise chemical abundances with neural networks
1
Max-Planck-Institut für Astronomie,
Königstuhl 17,
69117
Heidelberg,
Germany
2
Fakultät für Physik und Astronomie, Universität Heidelberg,
Im Neuenheimer Feld 226,
69120
Heidelberg,
Germany
3
Department of Astronomy, Universidade de São Paulo,
Rua do Matão 1226,
05508-090
São Paulo,
Brazil
4
INAF-Osservatorio Astronomico di Padova,
Vicolo dell’Osservatorio 5,
35122
Padova,
Italy
5
INAF-Osservatorio Astrofisico di Arcetri,
Largo E. Fermi 5,
50125
Firenze,
Italy
★ Corresponding author: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
21
March
2025
Accepted:
23
May
2025
Abstract
Aims. The aim of this work is to obtain precise atmospheric parameters and chemical abundances automatically for solar twins and solar analogs to find signatures of exoplanets, as well as to assess how peculiar the Sun is compared to these stars and to analyze any possible fine structures in the Galactic thin disk.
Methods. We developed a neural network (NN) algorithm using Python to derive atmospheric parameters and chemical abundances for a sample of 99 solar twins and solar analogs previously studied in the literature from normalized high-quality spectra from HARPS, with a resolving power of R ~ 115 000 and a signal-to-noise ratio of S/N > 400.
Results. We obtained precise atmospheric parameters and abundance ratios [X/Fe] of 20 chemical elements (Li, C, O, Na, Mg, Al, Si, S, Ca, Sc, Ti, V, Cr, Mn, Co, Ni, Cu, Zn, Y, and Ba). The results we obtained are in line with the literature, with average differences and standard deviations of (2 ± 27) K for Teff, (0.00 ± 0.06) dex for log g, (0.00 ± 0.02) dex for [Fe/H], (−0.01 ± 0.05) km s−1 for microturbulence velocity (vt), (0.02 ± 0.08) km s−1 for the macro turbulence velocity (vmacro), and (−0.12 ± 0.26) km s−1 for the projected rotational velocity (vsini). Regarding the chemical abundances, most of the elements agree with the literature within 0.01 – 0.02 dex. The abundances were corrected from the effects of the Galactic chemical evolution through a fitting versus the age of the stars and analyzed with the condensation temperature (Tcond) to verify whether the stars presented depletion of refractories compared to volatiles.
Conclusions. We found that the Sun is more depleted in refractory elements compared to volatiles than 89% of the studied solar analogs, with a significance of 9.5σ when compared to the stars without detected exoplanets. We also found the possible presence of three subpopulations in the solar analogs: one Cu-rich, one Cu-poor, and the last one being slightly older and poor in Na.
Key words: planets and satellites: detection / stars: abundances / stars: fundamental parameters / stars: solar-type / Galaxy: abundances / Galaxy: disk
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model.
Open Access funding provided by Max Planck Society.
1 Introduction
Precise chemical abundances are key for the characterization of planet hosts, since the formation and the presence of planets around the stars can alter their chemical composition, leaving chemical fingerprints that can be revealed via detailed analyses of the spectrum. A widely accepted hypothesis in the field of star formation is that stars and planets are formed at approximately the same epoch, from the gravitational collapse of an unstable molecular cloud. In this way, the chemical elements used to form the planets are sequestered in smaller amounts by the star in the last stages of stellar formation, resulting in a slight deficit of these elements in the stellar convective zone.
The works of Meléndez et al. (2009), Ramírez et al. (2009), Gonzalez et al. (2010), Nissen (2015), Bedell et al. (2018), and more recently Rampalli et al. (2024) showed that the Sun presents a depletion of ~0.05–0.08 dex (12–20%) of refractory elements in relation to volatile elements when compared to solar twins or solar analogs. According to Meléndez et al. (2009), this difference in abundances is of the same order as the mass of refractory elements present in the rocky planets of the Solar System. They also found a strong correlation between this depletion and the Tcond of the elements in the protosolar nebula (Lodders 2003), with a higher depletion for the refractories, and a break in the trend in Tcond ~ 1200 K (Fig. 1 of Meléndez et al. 2009). This temperature is only found in the interior part of protoplanetary disks, where the rocky planets are located. Chambers (2010) showed that the peculiar solar abundance pattern relative to the average of solar twins could be erased by adding about four Earth masses of rocky material into the Sun’s convection zone.
The most plausible explanation for the chemical anomalies of the Sun is the presence of planets around it in a relatively stable configuration, preserving part of the deficiency of refractories imprinted from the formation of the planets, while other planetary systems could have had important engulfment events, enriching the star with refractory elements, resulting in no deficit. Among the alternative explanations for the depletion are the effects of the Galactic Chemical Evolution – GCE (for example, the contamination by supernovae), and the vanishing of the dust from the primordial cloud where the Sun was formed by the radiative pressure of luminous nearby stars (Gustafsson 2018). However, it is unknown why these events occurred with the Sun in particular.
Trends of the depletion of refractories with the condensation temperature were found by Ramírez et al. (2015), Teske et al. (2016), Maia et al. (2019), Yana Galarza et al. (2021), Jofré et al. (2021), and Miquelarena et al. (2024), among others, in binary systems of twins or similar stars. As these systems are formed from the same molecular cloud approximately at the same time, it is expected that both stars present similar chemical composition during the main sequence (except for lithium and beryllium, which are the lighter elements that are destroyed in the stellar interior), and should not be affected by GCE. Therefore, the chemical inhomogeneity between the stars of the system suggests the occurrence of physical processes not necessarily related to the stellar evolution, such as the formation of planets or the engulfment of planets by one of the components (Saffe et al. 2017; Oh et al. 2018; Liu et al. 2020; Flores et al. 2024), with less and more refractory material, respectively.
The chemical signatures of planets are on the order of few 0.01 dex (Maia et al. 2019). Thus, they can be revealed only from a thorough analysis of stellar spectra. The current precision of 0.01–0.02 dex is achieved employing the method of differential line-by-line spectroscopy (Bedell et al. 2014), where the equivalent width (EW) of a spectral line is measured in strictly the same manner for the star under study and the comparison star, by comparing each line in the spectrum of the star and in the reference spectrum. The differential approach diminishes the statistical (observational) errors and the uncertainties associated with the log (gf) of each line are totally erased, while the use of similar stars minimizes the systematic errors associated with stellar models, as they are mostly canceled in the comparison. Yet, it is necessary to employ spectra of high quality, with high resolution and high signal-to-noise ratio (S/N) and with attenuated contamination of telluric lines. The importance of revisiting high precision abundances is shown by the recent results of Cowley & Yüce (2022), who suggested that the Sun is not depleted in refractories. However, they analyze abundances from different works altogether, that introduces more errors on the analysis. As the line-by-line method is affected by subjective decisions, such as the definition of the continuum, as well as how the EW is measured, combining measurements made by different authors can increase the errors and suppress the subtle planetary effects. Also, the authors force the GCE trend to produce zero abundances for stars of solar age; hence, all stars will have similar abundance when compared to the Sun.
Although the line-by-line differential method provides precise chemical abundances, it is unfeasible to apply it to large samples, such as those from large-scale surveys with thousands of stars and many elements, since manual measurements are time consuming. Some codes, such as ARES (Sousa et al. 2015), can be used to measure EWs automatically. However, the results obtained using them lead to only moderate precision. This has a great impact on the study of very weak signatures, such as the planet’s imprint on the photosphere of the star. In the literature, some automatic codes such as the Cannon (Casey et al. 2016) and the Payne (Ting et al. 2019) are being used to improve the precision of abundances of catalogs with hundreds of thousands of stars, such as APOGEE, using machine learning and spectra with medium to moderately high resolution and low-to-medium S/N. They were able to refine the abundances calculated with dedicated pipelines for the surveys and even reproduce results from the literature for chemical evolution and globular clusters with higher significance. The typical precision achieved for individual abundances was of 0.03–0.04 dex, and up to 0.1 dex for some elements. Also, in a more recent paper, Angelo et al. (2024) used the Cannon to obtain the atmospheric parameters of main sequence stars from Gaia DR3, with precisions of 72 K in Teff, 0.09 dex in log g, 0.06 dex in [Fe/H] and 1.9 km s−1 in broadening velocity. However, they did not report chemical abundances. The performance of these codes should improve by employing data with higher resolution and S/N, resulting in more precise stellar parameters and abundances.
In this work, we developed a neural network algorithm to obtain chemical abundances automatically at the same level of precision (0.01–0.02 dex) as the manual differential method, allowing a refined analysis of the chemical composition of solar twins and analogs. We used the derived abundances to compare the Sun to the solar twins and analogs and also study possible subpopulations present in these stars.
2 Sample and data
The sample is composed of 99 solar twins and close analogs, with temperatures within Teff,⊙ ± 150 K and metallicities [Fe/H]⊙ ± 0.15 dex (Cayrel de Strobel 1996; Ramírez et al. 2009). Of these, 79 were previously studied by Bedell et al. (2018) and Spina et al. (2018), 6 by Martos et al. (2023), and 14 by Rathsam et al. (2023). The atmospheric parameters are around solar values, with the range of ages spanning the main sequence to permit the study of the GCE: 5600 ≤ Teff (K) ≤ 5900, 4.10 ≤ log g (dex) ≤ 4.60, −0.15 ≤ [Fe/H] (dex) ≤ 0.15, 0.9 ≤ vt (km s−1) ≤ 1.2, 0.95 ≤ Mass (M⊙) ≤ 1.08, and 0.45 ≤ Age (Gyr) ≤ 9.80. This limitation in stellar parameters is important in that it allows us to avoid possible anomalies found in the abundances that stem from systematic errors (and not due to the presence of planets). Finally, 11 stars of the sample have confirmed exoplanets.
We employed high-resolution (R ~ 115 000) and high-S/N (>400) spectra obtained with the High Accuracy Radial velocity Planet Searcher (HARPS) spectrograph, downloaded from the ESO Science Archive Facility1. Around 20–30 individual spectra of minimum S/N > 40 obtained in different dates were combined in order to achieve the highest S/N possible and mitigate the contamination of telluric lines. The spectra were corrected by the radial velocity of the star and normalized using IRAF (Tody 1986). We distinguished between spectra taken before and after the HARPS upgrade occurred in June 3rd 2015, when the optical fibers of the instrument were changed, as there are differences in the continuum. The spectra cover the region from 378 to 691 nm, where the spectral lines of many elements are observable.
We adopted the reflected spectrum from the asteroid Vesta as the reference solar spectrum. Also, the spectrum of the Moon and Ganymede were employed to obtain the uncertainties of the solar abundances, as explained in Section 4.1.
3 Method
3.1 The algorithm
The algorithm developed to obtain atmospheric parameters and chemical abundances automatically was divided in two parts. The first was a neural network (NN), employed as a fast interpolator between the stellar labels (atmospheric parameters and abundance ratios [X/Fe]) and the flux of the star. Instead of using the normalized flux directly, we used the differential flux of the star in relation to the Sun, given in Equation (2), where Fs and F⊙ are the flux of the star and the Sun at a certain pixel, respectively. In this way, we mimic the way that the abundances were obtained in the differential method, where the differential abundance is given approximately by Equation (1) and replacing the definition of equivalent width (![Mathematical equation: $\[E W=\int_{0}^{\infty}\left(1-\frac{F_{\lambda}}{F_{c}}\right) \mathrm{d} \lambda\]$](/articles/aa/full_html/2025/07/aa54675-25/aa54675-25-eq1.png) ), we obtain Equation (2). These equations are expressed as
), we obtain Equation (2). These equations are expressed as
![Mathematical equation: $\[\delta A_X \sim \log _{10} \frac{E W_{X, \lambda}^{s t a r}}{E W_{X, \lambda}^{\odot}},\]$](/articles/aa/full_html/2025/07/aa54675-25/aa54675-25-eq2.png) (1)
(1)
![Mathematical equation: $\[F_{\mathrm{diff}}=\log _{10} \frac{1-F_s}{1-F_{\odot}}.\]$](/articles/aa/full_html/2025/07/aa54675-25/aa54675-25-eq3.png) (2)
(2)
The NN was built using the Python libraries scikitlearn and tensorflow, and it was composed of three hidden layers with 300 neurons each. We used the LeakyReLu activation function for each layer, except for the output, where we chose a linear activation function. For the loss or cost function, we used mean absolute errors. The NN was trained using ten thousand synthetic spectra generated with iSpec (Blanco-Cuaresma et al. 2014; Blanco-Cuaresma 2019), separated as 80% for the training set and 20% for the test set. We adopted MARCS model atmospheres (Gustafsson et al. 2008) and TurboSpectrum (Plez 2012) as the synthetic spectra generator. The line list we adopted is version 6 of the Gaia-ESO Survey (GES) (Heiter et al. 2021), with hyperfine splitting and isotopic and molecular data included. The labels used as input parameters were randomly sampled from a linear distribution around solar values to reflect the parameters of solar-type stars, as follows: Teff = T⊙ ± 300 K; log g = log g⊙ ± 0.3 dex; [Fe/H] = [Fe/H]⊙ ± 0.3 dex; vt = vt,⊙ ± 0.5 km s−1; vsini = 0.1–10 km s−1 (the solar value being vsini⊙ = 1.9 km s−1); and [X/Fe] = [X/Fe]⊙ ± 0.3 dex. The macro turbulence velocity (vmac), was calculated using the relation obtained by dos Santos et al. (2016) for solar analogs: vmac = vmac⊙ − (0.00707 Teff) + (![Mathematical equation: $\[9.2422 \times 10^{-7} \mathrm{~T}_{\text {eff }}^{2}\]$](/articles/aa/full_html/2025/07/aa54675-25/aa54675-25-eq4.png) ) + 10+(k1(log g − 4.44)) + k2, where vmac⊙ = 3.1, k1 = −1.81 and k2 = 0. For the determination of the atmospheric parameters, we adopted model atmospheres with solar-scaled ratios.
) + 10+(k1(log g − 4.44)) + k2, where vmac⊙ = 3.1, k1 = −1.81 and k2 = 0. For the determination of the atmospheric parameters, we adopted model atmospheres with solar-scaled ratios.
The spectra used in the training of the NN were generated in a region of 500 pixels (5 Å) around the center of each spectral line. For the determination of the atmospheric parameters, 87 Fe I and 17 Fe II were employed, as these lines are sensitive indicators of effective temperature, gravity, and microturbulence (Gray 2008). To determine the abundance ratios, we computed the spectra around the lines of each element, based on the line list of Meléndez et al. (2014). The 20 elements considered were the ones with atomic number Z ≤ 30, to account for both volatile and refractory elements, and with lines present in the range of HARPS spectra: Li, C, O, Na, Mg, Al, Si, S, Ca, Sc, Ti, V, Cr, Mn, Co, Ni, Cu, Zn, and two heavier elements, Y and Ba.
The second part of the algorithm was a fitter, responsible for finding the labels that best reproduce the observed Fdiff of the star. For this, models resulting from the training of the NN were fitted to the observed data using the library lmfit. We used the Least Squares Method to minimize a residual function, defined as the difference between the model and the observed data, weighted by the errors in the data. The uncertainties in Fdiff are given by Eq. (3), obtained by propagating the errors of Fdiff. σFstar and σF⊙ are the errors of the fluxes of the star and the Sun. The adopted value for both σ s was 0.002, corresponding to a S/N = 500.
![Mathematical equation: $\[\sigma_F=\frac{1}{\left|\left(1-F_{star}\right)\left(1-F_{\odot}\right) ln 10\right|} \sqrt{\left(\frac{\sigma_{F_{star}}}{1-F_{star}}\right)^2\left(\frac{\sigma_{F_{\odot}}}{1-F_{\odot}}\right)^2}.\]$](/articles/aa/full_html/2025/07/aa54675-25/aa54675-25-eq5.png) (3)
(3)
A region of 30 pixels around the center of the line, corresponding to 0.3 Å, was considered in the fit. This was found to be the optimal range to work with, so that features surrounding the line that do not correspond to the chemical element are disregarded and yet a small portion of the continuum is considered. Also, the fluxes were interpolated in this range because a certain pixel may not correspond to the exact same wavelength in the spectrum of the star and the Sun, causing small shifts between both fluxes, which are increased when calculating the log of differential fluxes. In addition, line blends were masked automatically by assigning an infinite error to the flux to mitigate the contamination of other elements in the line of interest. A blend was identified as an extra region of absorption next to the central line, where the flux starts to decrease again after it was increasing towards the continuum. The blend masking was applied only for the abundances, as the Fe lines used to obtain the atmospheric parameters are well isolated.
The final labels were obtained in two steps. First, the data was fitted without any processing besides the interpolation, to have a first guess of the result. Next, the values were refined. The first guess of the parameters was used to generate a synthetic spectrum around the lines and the observed fluxes were re-normalized, considering the continuum of the synthetic spectrum as the reference. To do this, the value of the 95% percentile of a region of 50 pixels around the line, corresponding to 0.5 Å, was used as the continuum value for both the observed and synthetic spectrum. The ratio between these two values was the normalization factor used to multiply the observed fluxes to do the re-normalization.
The atmospheric parameters and abundances for each element were obtained separately, both generally and on a line-by-line basis, respectively. For the first, the Fdiff values for all Fe lines were concatenated and fitted as a single data array. This forces the fitting algorithm to obtain a set of atmospheric parameters that is appropriate for all Fe lines simultaneously. Indeed, when using spectroscopic equilibrium, it needs to be achieved while considering all the Fe lines. The values adopted as the parameter uncertainties were taken as the uncertainties of the fit.
To calculate the abundance ratios, the atmospheric parameters were fixed to the values fitted before and each line of the element was fitted individually. The final abundance adopted for the element was the average of all abundances obtained individually with each line, calculated in linear space. The uncertainties were calculated as the quadratic sum of the error associated with the fit and the systematic errors due to the uncertainties of the atmospheric parameters. The first one was calculated as the standard deviation of the abundances obtained with each line, divided by ![Mathematical equation: $\[\sqrt{N}\]$](/articles/aa/full_html/2025/07/aa54675-25/aa54675-25-eq6.png) , where N is the number of lines. For the second, the abundances were calculated again using the value of each parameter plus its error, for each parameter individually.
, where N is the number of lines. For the second, the abundances were calculated again using the value of each parameter plus its error, for each parameter individually.
To test the method, we fit 100 synthetic spectra from the test set to assess how well the NN can recover parameters from simulated data. The results are in excellent agreement with the original values. The average residuals and standard deviations are (−0.2 ± 3.9) K for Teff, (−0.001 ± 0.010) dex for log g, (0.000 ± 0.004) dex for [Fe/H], (0.000 ± 0.007) km s−1 for vt, (0.000 ± 0.015) km s−1 for vmacro, and (0.011 ± 0.064) km s−1 for vsini.
3.2 Obtaining the stellar labels
The fit of the concatenated 104 Fe lines for the first guess of the atmospheric parameters takes ~30 seconds for each star and the refined fit takes ~80 seconds. Thus, all the atmospheric parameters for one single star are obtained in ~2 minutes. If each line in the manual method is measured in 1 minute, our method is more than 50 times faster just considering the measurements, as the parameters would need to be further calculated using spectroscopic equilibrium.
The results for the atmospheric parameters (Table A.1) were compared with the 79 stars in common with Spina et al. (2018) (Figure A.1). The average residuals and standard deviations are (2.0 ± 27.1) K for Teff, (0.00 ± 0.06) dex for log g, (0.00 ± 0.02) dex for [Fe/H], (−0.01 ± 0.05) km s−1 for vt, (0.02 ± 0.08) km s−1 for vmacro, and (−0.12 ± 0.26) km s−1 for vsini. The dispersion (i.e., the standard deviation of the parameters calculated with NN in relation to the literature values) is similar and even smaller than typical dispersions reported in the literature. There are some outliers, for example, the star HIP 102040, for which the values of log g and vt found (4.18 dex and 0.716 km s−1) are much smaller than in the literature (4.48 dex and 1.05 km s−1). Overall, the global results follow the 1:1 expected behavior. In general, the NN is able to identify solar twins because the star-to-star scatter (e.g., 27 K in Teff) is smaller than the typical definition of solar twins (within 100 K of the Sun), and the case is similar for the other parameters.
Regarding the abundance ratios, the generation of the synthetic spectrum around a spectral line used to do the renormalization takes ~3–4 seconds and the fit of the line is done in ~0.3 seconds. An individual line is fitted in less than 5 seconds. Considering that we can take 1 minute to measure a line manually in the differential line-by-line method, our method is more than ten times faster. The abundance ratios obtained (Table A.2) were compared to the results of Bedell et al. (2018) and Nissen et al. (2020), with 79 and 27 stars in common, respectively. For approximately half of the elements (Na, Mg, Al, Si, Ca, Ti, Cr, Co, Ni, and Cu), we reached a dispersion on the order of 0.01 dex and 0.02 dex for the majority of the remaining elements. Figure A.2 shows the comparison of the abundances with the literature.
Higher dispersions, for Zn (0.028 dex) and S (0.031), for example, can be due to normalization issues and the small number of spectral lines available (three lines for Zn and two lines for S, while other elements usually have more than five lines available). In the case of O, the higher dispersion (0.058 dex) is due to the fact that the only line adopted was the forbidden line in 6300 Å, which is very weak and has a blend with Ni, making both the manual and automatic measurements difficult. The discrepancies in the comparison can also be due to the observational differences with other authors, as Bedell et al. (2018) used the O triplet in 7774 Å observed at a lower spectral resolution, R ~ 60 k.
The abundances of the heavier elements Y and Ba were compared with Spina et al. (2018). A larger dispersion of around 0.03 dex for these elements can be explained by the fact that they are affected by the hyperfine splitting, which could not be well described in the line list used to generate the synthetic spectra for the training. The Li abundance was compared with Martos et al. (2023). This is the element with the higher dispersion, ten times the dispersion of other elements (~0.1 dex). The Li line in 6707.8 Å is extremely shallow and the line region is affected by species of other elements, such as CN and C2, as shown in Figure 2 of Carlos et al. (2016), which could have influenced the results. The larger differences are also for the lower Li abundances, which have larger uncertainties, as the determination for the vanishing absorption line is more uncertain and sometimes it is only an upper limit. This difficulties in the calculation of low Li abundances is also reflected by the larger uncertainties in the results reported in Martos et al. (2023) for the stars with lower Li content.
The differences between our results and the literature may also be explained by the assumptions that were made by the respective authors. For example, they assume that the shape of the lines are Gaussian functions. However, the lines are closer to Voigt profiles or in some cases, neither of these functions are able to reproduce the observed profile, for example, due to blends. In this sense, the NN method is more robust, because no assumptions are made about the shape of the line; the pixels are fitted independent of any defined function, just using the weights provided by the training of the NN. It is also important to stress that the NN method is fully reproducible, while past works using the differential line-by-line method were subject to human assumptions and decisions on how to do the manual measurements; for example, the placement of the continuum. Nevertheless, the errors are minimized in the line-by-line technique, as the human assumptions made are the same for the star and the Sun. For example, as can be seen in Figure 1 from Carvalho-Silva et al. (2025), the human differential line-by-line results for the solar twin 18 Sco show excellent agreement among different authors using different spectra, agreeing in Teff within 6 K (1-sigma). Our NN result for 18 Sco also agrees within 6 K with that average value.
Figure 1 shows the median error of each element against the standard deviation of the residuals of the comparison with Bedell et al. (2018). For the elements located on the left of the blue line, such as Sc, our method may be overestimating the error bars. For the elements around the blue line, the error bars are comparable with σ, indicating that they are realistic, as the errors from the authors also contribute to the dispersion. On the other hand, for the elements more complicated to be measured, such as C, O, S, and Zn, our error bars could be underestimated.
 |
Fig. 1 Median error of the abundance ratios [X/Fe] of the elements versus the standard deviation of the residuals when comparing our automatic abundances with Bedell et al. (2018). |
3.3 Limitations of the method
Our results are affected by the synthetic gap, which is the difference that exists between real and synthetic data and that cannot be surpassed. It is introduced when we use synthetic spectra generated with models that are not the ideal representation of the atmospheres to train the NN instead of real data. In particular, the model used is a 1D LTE model. Thus, the 3D hydrodynamical structure of the atmosphere and non-LTE effects are disregarded, but corrections could be performed afterwards when necessary.
Besides that, the line list used to generate the spectra depends on atomic data that sometimes can be poorly estimated, as some regions were not identical to the observed spectrum. This particular issue did not impact our results in a significant way as the work was done in a differential way and the stars have comparable stellar parameters, so this type of difference was roughly canceled out in the calculations. In a few cases, the line list either introduced additional spectral lines that do not exist on real spectra (which had to be masked) or specific features of the region were not accounted for, such as the calcium autoionization feature around the Zn line in 6362.5 Å. These differences in the observed and synthetic spectrum affect the determination of the abundances because the NN learns what is present in the synthetic spectrum and when it fails to find a certain pattern or behavior in the observed spectrum, it provides an abundance value that may not be correct.
Possible improvements for this method are the use of more robust line lists, with more complete atomic and hyperfine splitting data for the spectral lines, along with with a detailed revision around each important region to remove spurious features. Also, the use of other codes or model atmospheres to generate the synthetic spectra (including 3D, magnetic, and NLTE effects when possible) to work as close as possible to a realistic scenario and to diminish the influence of the synthetic gap.
4 Results and analysis
4.1 Solar abundances
The reflected spectrum of Vesta was employed in this work as the reference solar spectrum. To assess the effect of using different solar spectra and the error due to the choice of Vesta as the reference, the solar abundances of the 20 elements were also obtained using the reflected spectrum of the Moon and Ganymede, both in relation to Vesta. The three solar spectra employed were obtained with the HARPS spectrograph and post-processed in the same manner as the stellar spectra. The results are shown in Table A.3. The last column shows the error in the solar abundances, calculated as the average of the absolute value of the abundance obtained from the Moon and Ganymede spectra. If the abundances were exactly zero, the error was assumed as the standard deviation of all the abundances obtained using the Vesta spectrum. The latter can also be considered as the error of the method itself.
All the abundances are compatible with the zero abundance expected for the Sun within the 3σ range defined by the uncertainties listed in the last column of Table A.3. The elements with higher standard deviations are C, S, Ca, Sc, Y, and Ba. The larger uncertainty is that of Li, being >0.10 dex. Apart from that case, most of the elements have errors of around 0.01 dex.
4.2 Galactic chemical evolution and the possible presence of Galactic thin-disk subpopulations
The abundance ratios obtained are in large part due to the evolution of the Milky Way, as they should reflect the chemical composition of the interstellar medium (ISM) when the star was born; in other words, the abundances depend on the age of the star. We refer to this effect as the Galactic chemical evolution (GCE). The effects of metallicity for GCE in this work are small, as the [Fe/H] of the stars of the sample span a limited range around solar values. Also, chemical evolution depends on the galactic location, with a faster enrichment occurring in the inner regions of the Galaxy. Our sample is in the solar neighborhood, thereby avoiding large variations due to the Galactic chemo-dynamics, but some of our sample stars may have suffered radial migration, meaning that they could have originated elsewhere and migrated towards near the solar vicinity (Prantzos et al. 2023; Plotnikova, A. et al. 2024).
The abundance ratios were correlated with the age of the stars to remove the influence of the GCE and minimize its influence on the detection of planetary signatures. First, the stars were separated between thin and thick disk populations using a chemical criterion according to their [Mg/Fe] abundance ratios in relation to [Fe/H], using the proposed equation from Adibekyan et al. (2011) as adapted by Shejeelammal et al. (2024). The eleven stars identified as part of the thick disk are shown as blue crosses in Figure 2 (HIP 14501, HIP 28066, HIP 30476, HIP 33094, HIP 65708, HIP 73241, HIP 74432, HIP99115, HIP 108158, HIP 109821, and HIP 115577). These stars had already been singled out by Bedell et al. (2018) as coming from the thick-disk population as part of their empirical selection of stars older than 8 Gyr and visual enhancement in α elements.
Only the stars of the thin disk were considered in the correlation with age. A linear fit ([X/Fe] = A × Age + B) was performed using the Python library scipy with the orthogonal distance method, which takes into account the error bars of both variables. The fits for all elements are plotted in Figure B.1 and the coefficients are shown in Table B.1), where the last column contains the standard deviation of the residuals. The GCE correction is valid for the entire range of metallicity of our sample (−0.15 ≤ [Fe/H] ≤ 0.15 dex). We also tried a quadratic fit. However, since both linear and quadratic fits presented similar χ2 values and a very similar behavior for some elements as well (based on a visual inspection), the linear fit was chosen for simplicity. The correction was done by subtracting the linear function from the abundances replacing the age of each star.
Figure 3 shows the standard deviation of the residuals of the fit for each element, for both linear and quadratic fits. Due to our high precision, we can discern better cosmic scatter from measurement errors. For Ca, Ti, Cr, and V, the errors of the method are about the same as the dispersion of the abundances, being thus harder to detect abundance peculiarities. On the other hand, other elements have a dispersion larger than the errors, singled out based on the evidence of scatter of an astrophysical nature – except in the cases where our measurement errors could be underestimated, such as in the case of oxygen. Considering our error bars, the somewhat larger scatter in some plots of Figure B.1 may be of astrophysical nature, rather than due to errors in our analysis.
From Figure 4, we noted the possible presence of three Galactic subpopulations in our sample of solar analogs. In the [Na/Fe] plot, we identified a group of older stars (age >6 Gyr) and lower abundances, represented as open circles. Other possible subpopulations were identified, as the richer stars above the linear fit in the [Cu/Fe] plot, represented by blue star markers, and the poor stars below the fit, shown as black diamonds. These groups can also be identified in equivalent regions in the plots of other elements, such as Al, Si, Mn, Co, Ni, and Zn (Figure B.1). It is interesting that for [Ba/Fe] the behavior is reversed. So far, these subpopulations have not been reported in the literature. From Figure 5, it is also possible to note the separation of the subgroups, with Cu and Mn varying in the same direction and Cu and Ba exhibiting an opposite behavior with respect to each other.
In Figure 4 of Nissen et al. (2020), there is a region with smaller [Na/Fe] ratios for older stars. However, the authors distinguish only two populations, based on a separation identified in a [Fe/H] versus age plot (their Figure 3). We did not find this separation in our sample, as shown in Figure 6. Also, in their subgroups, there is a overlap of the stars that would be part of our Na-poor group with some Cu-rich stars.
To investigate the origin of these groups, we generated the galactic parameters’ eccentricity (Ecce), energy, the z component of the angular momentum (Lz), galactocentric distance and maximum height above the Galactic plane using the Python code galpy (Bovy 2015), following the same procedure as Shejeelammal & Goswami (2024). Figures 7 and 8 show the cumulative distributions of Ecce and Lz of the stars. It is possible to note that the Na-poor and Cu-rich groups present higher Ecce and smaller Lz than the Cu-poor group, indicating that perhaps the stars are originated from the inner regions of the galactic disk and (due to the eccentric orbits together with migration) they were observed in the solar vicinity. Thus, their chemical composition could reflect the chemistry of thin-disk stars in the inner regions.
The Na-poor subpopulation seems to form a plateau along with older stars of the thick disk. Migration of the stars from the inner part of the disk, which is richer in metals and with a distinct abundance pattern due to a different supernova enrichment history, could also have contributed. The Sun itself may have been formed in the inner disk, around 5–6 kpc, and migrated to its current position (Nieva & Przybilla 2012; Tsujimoto & Baba 2020; Baba et al. 2023; Prantzos et al. 2023; Lu et al. 2024).
 |
Fig. 2 Separation of the stars of the sample between thin and thick disk according to their [Mg/Fe] ratio in relation to [Fe/H]. The stars above the red line and represented by blue crosses belong to the thick disk. |
 |
Fig. 3 Standard deviation of the residuals of the fit of [X/Fe] versus age and median error according to the atomic number (Z) of the elements. |
4.3 Comparison of the Sun with the solar twins and analogs and the signature of exoplanets
Refractory elements are the building blocks of rocky planets, whose signatures can be revealed by evaluating how the abundance of such species behave according to Tcond. If there is a decrease in the abundances of more refractory species, this may indicate that they were used to form planets and that the star accreted the refractory-depleted material from the protonebula.
In an attempt to find these signatures, the abundance ratios were analyzed with the 50% condensation temperature from Lodders (2003). We performed a linear fit using the Python library lmfit with the least squares method for each of the 88 stars of the thin disk. As mentioned above and in other papers (e.g., Bedell et al. (2018)), the highly volatile elements have larger uncertainties. Therefore, we followed Bedell et al. (2018) and considered in the fit only the elements with Tcond > 900 K (Ramírez et al. (2009) also took a similar approach). Thus, we started the fit with the semi-volatile element sodium (Tcond = 958 K) and included all elements of higher condensation temperature until the highly refractory elements (Tcond ~ 1650 K; Sc, Al). Since most elements included in the fit are refractories (Tcond ≥ 1300 K; Lodders 2003), we refer to both the semi-volatiles and refractories elements considered in the fit as refractories henceforth.
Before performing the fit, a correction was made to the abundances, so that they could reflect the abundance that the star would have if it had the solar age (4.6 Gyr), using the same linear fit of the GCE correction. The volatiles were excluded from the fit because the determination of their abundances is more uncertain: there are few spectral lines available and the line regions are more complicated to do the measurements at high precision (0.01–0.02 dex level). Also, Li, Ba, and Y were not considered in the fit. Overall, Li is a very sensitive element, varying significantly with stellar parameters such as age, [Fe/H] (Martos et al. 2023), Teff, and mass (Rathsam et al. 2023) and, thus, it is not reliable to study the global influence of exoplanets in the abundances. Regarding Y and Ba, at solar metallicity, they are s-process elements generated mainly in AGB stars, while the other elements are mostly produced through nuclear reactions and released by supernovae. The retrieval of the elements from AGBs is slower, as it is a less energetic event, and it could create inhomogeneities that are not specifically associated with any planets.
Figure 9 is an example plot for the star HIP 3203. For the volatiles (C, O, S, and Zn), the median value of the solar-age abundances is represented by the solid grey line and the median of the non-corrected abundances is shown by the dashed grey line. The blue star represents the oxygen abundance corrected by the offset of 0.033 dex between this work and Nissen et al. (2020). The blue dotted-dashed line is the median considering this value for the abundance of oxygen. This was done as an example to show the sensitivity of the volatiles, which have a significant impact on the median value and support the argument why the volatiles were not included in the fit.
The distribution of slopes resulting from the fit of the refractories versus Tcond is shown in Figure 10. The slope of the Sun, which is zero by definition, is smaller than 89% of the stars, meaning that the Sun is more depleted in refractories compared to volatiles than 89% of the studied stars. A negative slope, meaning a slope smaller than solar, indicates that a smaller amount of refractory material has been accreted compared to the mass of refractories in the planets of the Solar System.
In Figure 8 of Bedell et al. (2018), the authors provide a wider range of slopes, from −1 × 10−4 to 3.5 × 10−4, approximately, whereas in this work the slopes range from around −0.5 × 10−4 to 1.75 × 10−4, perhaps due to our consistent low uncertainties on the abundances. Also, the mean value of their slopes for the corrected (solar-age) and non-corrected abundances present a higher difference than this work. This happens because the sample of Bedell et al. (2018) is more populated with stars older than the Sun and the ages of our sample are more homogeneous, resulting in similar average values for the slopes for the cases with and without correction for the abundances. In their work, Bedell et al. (2018) found that the Sun is more depleted than 93% of the solar twins and close analogs, whereas we found 89%. These percentages are compatible, considering the uncertainties in the abundances in both works. Our sample has four additional planet hosts (HIP 669, HIP 70965, HIP 77358, and HIP 99115) and it is interesting to note that the number of stars more depleted than the Sun increased compared to the sample with fewer planets hosts from Bedell et al. (2018). However, we found no correlation between the slope and the presence of planets.
To assess how peculiar the Sun is compared to the solar twins and analogs, we analyzed the difference between the solar abundances and the abundance of an “average solar analog,” calculated as the average of the abundances of the stars in the linear space of number of atoms, given in Equation (4). The error adopted was the quadratic sum of the standard deviation of the average ![Mathematical equation: $\[\left(\sigma\left(10^{[X / F e]}\right) / \sqrt{N}\right)\]$](/articles/aa/full_html/2025/07/aa54675-25/aa54675-25-eq7.png) , where N is the number of stars whose abundances were considered in the sum, with the errors of the solar abundances, given in the last column of Table A.3. The equation is expressed as
, where N is the number of stars whose abundances were considered in the sum, with the errors of the solar abundances, given in the last column of Table A.3. The equation is expressed as
![Mathematical equation: $\[\left\langle\left[\frac{X}{F e}\right]\right\rangle=\log _{10}\left(\frac{1}{N} \sum_{n=0}^N 10^{\left[\frac{X}{F e}\right]_n}\right).\]$](/articles/aa/full_html/2025/07/aa54675-25/aa54675-25-eq8.png) (4)
(4)
The analysis was done in three cases: considering all the 88 stars of the thin disk, only the stars without planets, and only the stars with planets. For each case, the difference in the refractory abundances between the Sun (zero abundances, by definition) and the average solar twin was fitted against Tcond. Ten stars have confirmed exoplanets in orbit: HIP 669 (1), HIP 5301 (1), HIP 11915 (1), HIP 15527 (3), HIP 68468(2), HIP 70695 (1), HIP 77358 (2), HIP 96160(1), HIP 99115 (1), and HIP 116906(1). Figure 11 shows the case considering the stars without detected exoplanets the case for planet hosts. In the first, the significance of the correlation is of 9.5σ. Regarding the stars with planets, the depletion is less significant (4.6σ). This means that the composition of the Sun is more similar to the stars with detected planets, although they are not as depleted as the Sun.
 |
Fig. 4 Fit of [Na/Fe] and [Cu/Fe] versus age. The open circles indicate a possible older subpopulation poor in Na, and the blue stars and black diamonds represent possible subpopulations enhanced and reduced in Cu, respectively. The blue crosses correspond to thick disk stars that were not considered in the fit. The bottom panel shows the residuals, as well as their average and standard deviation. |
 |
Fig. 5 Relation of [Cu/Fe] abundances with [Mn/Fe] and [Ba/Fe], where it is also possible to note the separation of the stars into the subgroups. |
 |
Fig. 6 Distribution of [Fe/H] versus age for the stars of our sample, distinguished by the possible subgroups. |
 |
Fig. 7 Cumulative distribution of the eccentricity of the stars that belong to the Na-poor (open circles), Cu-rich (blue stars), and Cu-poor (black diamonds) samples. |
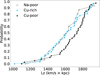 |
Fig. 8 Cumulative distribution of the z direction of the angular momentum (Lz) of the stars that belong to the Na-poor (open circles), Cu-rich (blue stars), and Cu-poor (black diamonds) samples. |
 |
Fig. 9 Example fit of the refractory elements of the star HIP 3203 versus Tcond. |
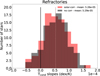 |
Fig. 10 Slopes of the fit of [X/Fe] versus Tcond for all stars. Here, “solar-corr” refers to the solar-age abundances and “no-corr” refers to the abundances without any GCE or age correction. The vertical line represents the Sun. |
 |
Fig. 11 Comparison of the abundances of the Sun with the average solar twin, considering the stars without detected exoplanets (upper panel) and the stars with planets (bottom panel). The refractory elements are shown as colored markers, and the volatiles, which were not fitted, are shown in grey. The solid circles are the solar-age abundances and the empty circles are the abundances without any correction. The red lines are linear fits to the solar-age abundances, and the black lines are the linear fits to the non-corrected abundances. In both cases, only the refractories were fitted. For the volatiles (C, O, S, and Zn), the median value of the solar-age abundances is represented by the solid grey line and the median of the non-corrected abundances is shown by the dashed grey line. The blue star represents the oxygen abundance corrected by the offset of 0.033 dex between this work and Nissen et al. (2020). The blue dotted-dashed line is the median when considering this value for the abundance of oxygen. |
5 Conclusions
We used neural networks (NNs) to obtain precise atmospheric parameters and abundance ratios [X/Fe] of 20 elements for a sample of 99 solar twins and analogs, using high-quality spectra from HARPS. The results obtained are in line with the literature, with average residuals and standard deviations of (2.0 ± 27.1) K for Teff, (0.00 ± 0.06) dex for log g, (0.00 ± 0.02) dex for [Fe/H], (−0.01 ± 0.05) km s−1 for vt, (0.02 ± 0.08) km s−1 for vmacro, and (−0.12 ± 0.26) km s−1 for vsini. It was possible to achieve the desired precision of 0.01 dex for approximately half of the elements (Na, Mg, Al, Si, Ca, Ti, Cr, Co, Ni, and Cu) and about 0.02 dex for the rest.
We identified the possible presence of three Galactic thin disk stellar subpopulations in our sample from the plots of [Na/Fe] and [Cu/Fe] versus age. The first is slightly older (age > 6 Gyr) and poor in Na, while the others are more and less enriched in Cu. These groups are also present in the plots of Al, Si, Mn, Co, Ni, and Zn. One possible explanation is that these stars belong to inner regions of the thin disk and, due to their eccentric orbits (associated with migration), they were observed in the solar vicinity. Due to radial migration, the stars actually reflect the local supernova+AGBs enrichment of their birthplace, resulting thus in a distinct chemistry.
Finally, the solar-age abundances of refractories were correlated with the condensation temperature of the elements to compare the Sun with the solar twins and close analogs. We found that the Sun is more depleted in refractories in relation to volatiles than 89% of the studied stars, with a significance of 9.5σ when comparing to the stars without detected exoplanets. When comparing the Sun with the stars that are planet hosts, the significance is 4.3σ. This means that the Sun’s composition is more similar to that of stars that have exoplanets, although they are not as depleted as the Sun. With the detection of new exoplanets in the following years, the results can be refined, clarifying the relationship between chemical abundances and exoplanets and potentially offering valuable insights into the uniqueness of the Solar System.
Data availability
Full Tables A.1–A.3 and B.1 are available at the CDS via anonymous ftp to cdsarc.cds.unistra.fr (130.79.128.5) or via https://cdsarc.cds.unistra.fr/viz-bin/cat/J/A+A/699/A46
Acknowledgements
We thank Shejeelammal Jamela for sharing the Galactic parameters computed with galpy and Chiaki Kobayashi for discussions on the observed abundance patterns. G.M. and J.M. acknowledges FAPESP (São Paulo State Research Foundation) for the MSc grants (processes 2022/05833-0, 2023/15044-5) and Temático research grant (2018/04055-8), respectively. This work made use of data collected at the European Southern Observatory under ESO programs: 072.C-0488, 183.C-0972, 192.C-0852, 188.C-0265, 188.C-0265, 188.C-0265, 183.D-0729, 188.C-0265, 188.C-0265, 188.C-0265, 092.C-0721, 188.C-0265, 093.C-0409, 077.C-0364, 188.C-0265, 188.C-0265, 188.C-0265, 188.C-0265, 188.C-0265, 188.C-0265, 188.C-0265, 188.C-0265, 188.C-0265, 0103.D-0445, 0103.D-0445, 0100.D-0444, 076.C-0155, 1102.C-0923, 188.C-0265, 074.C-0364, 188.C-0265, 183.D-0729, 089.C-0732, 091.C-0034, 087.C-0831, 090.C-0421, 111.24ZQ.001, 198.C-0836, 075.C-0202, 0102.C-0584, 0103.C-0206, 292.C-5004, 075.C-0332, 099.C-0491, 196.C-1006, 106.21TJ.001, 60.A-9036, 60.A-9709, 192.C-0852, 0104.C-0090, 106.215E.004, 098.C-0739, 106.215E.002, 105.20AK.002, 0104.C-0090, 192.C-0224, 0101.C-0275, 085.C-0019, 098.C-0366, 0103.C-0432, 0100.C-0097, 0102.C-0558, 106.21R4.001, 0101.C-0379, 095.C-0551, 099.C-0458, 108.222V.001, 096.C-0460, 091.C-0936, 097.C-0571, 0100.C-0474, 0101.C-0275.
Appendix A Atmospheric parameters and chemical abundances
Stellar parameters obtained automatically with NNs for the sample. Stars identified with p are planet hosts. The complete table is available at CDS.
Chemical abundances (dex) obtained automatically with NNs for the sample. Stars identified with p are planet hosts. The complete table is available at CDS.
Solar abundances obtained automatically with NNs using spectra of the Moon, Vesta, and Ganymede, with Vesta as the reference solar spectrum. The last column shows the zero point error adopted for the element. The complete table is available at CDS.
 |
Fig. A.1 Atmospheric parameters obtained automatically with the NN compared with the results of Spina et al. (2018). The bottom panel shows the residuals, as well as their average and standard deviation. |
 |
Fig. A.2 Comparison of the abundances obtained automatically with Martos et al. (2023) for Li, Spina et al. (2018) for Y and Ba and Bedell et al. (2018) for the other elements. The bottom panel shows the residuals, as well as their average and standard deviation. |
Appendix B Fits with stellar age
Coefficients of the linear fit of the chemical abundances versus age. The complete table is available at CDS.
 |
Fig. B.1 Linear fit of the abundance ratios [X/Fe] versus age for all 20 elements. The stars represented by blue crosses are from the thick disk and were not considered in the linear fit (red dashed line). The black empty circles are stars from the distinct population identified in the [Na/Fe] plot, and the blue filled circles and black diamonds are stars from the Cu-rich and Cu-poor populations, respectively. The bottom panel shows the residuals, as well as their average and standard deviation. |
References
- Adibekyan, V. Z., Santos, N. C., Sousa, S. G., & Israelian, G. 2011, A&A, 535, L11 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Angelo, I., Bedell, M., Petigura, E., & Ness, M. 2024, ApJ, 974, 43 [Google Scholar]
- Baba, J., Saitoh, T. R., & Tsujimoto, T. 2023, MNRAS, 526, 6088 [Google Scholar]
- Bedell, M., Meléndez, J., Bean, J. L., et al. 2014, ApJ, 795, 23 [Google Scholar]
- Bedell, M., Bean, J. L., Meléndez, J., et al. 2018, ApJ, 865, 68 [Google Scholar]
- Blanco-Cuaresma, S. 2019, MNRAS, 486, 2075 [Google Scholar]
- Blanco-Cuaresma, S., Soubiran, C., Heiter, U., & Jofré, P. 2014, A&A, 569, A111 [CrossRef] [EDP Sciences] [Google Scholar]
- Bovy, J. 2015, ApJS, 216, 29 [NASA ADS] [CrossRef] [Google Scholar]
- Carlos, M., Nissen, P. E., & Meléndez, J. 2016, A&A, 587, A100 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Carvalho-Silva, G., Meléndez, J., Rathsam, A., et al. 2025, ApJ, 983, L31 [Google Scholar]
- Casey, A. R., Hogg, D. W., Ness, M., et al. 2016, submitted to AAS (ApJ), [arXiv:1603.03040] [Google Scholar]
- Cayrel de Strobel, G. 1996, A&A Rev., 7, 243 [CrossRef] [Google Scholar]
- Chambers, J. E. 2010, ApJ, 724, 92 [NASA ADS] [CrossRef] [Google Scholar]
- Cowley, C. R., & Yüce, K. 2022, MNRAS, 512, 3684 [CrossRef] [Google Scholar]
- dos Santos, L. A., Meléndez, J., do Nascimento, J.-D., et al. 2016, A&A, 592, A156 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Flores, M., Yana Galarza, J., Miquelarena, P., et al. 2024, MNRAS, 527, 10016 [Google Scholar]
- Gonzalez, G., Carlson, M. K., & Tobin, R. W. 2010, MNRAS, 407, 314 [NASA ADS] [CrossRef] [Google Scholar]
- Gray, D. F. 2008, The Observation and Analysis of Stellar Photospheres (Cambridge: Cambridge University Press) [Google Scholar]
- Gustafsson, B. 2018, A&A, 616, A91 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gustafsson, B., Edvardsson, B., Eriksson, K., et al. 2008, A&A, 486, 951 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Heiter, U., Lind, K., Bergemann, M., et al. 2021, A&A, 645, A106 [EDP Sciences] [Google Scholar]
- Jofré, E., Petrucci, R., Maqueo Chew, Y. G., et al. 2021, AJ, 162, 291 [CrossRef] [Google Scholar]
- Liu, F., Yong, D., Asplund, M., et al. 2020, MNRAS, 495, 3961 [NASA ADS] [CrossRef] [Google Scholar]
- Lodders, K. 2003, ApJ, 591, 1220 [Google Scholar]
- Lu, Y. L., Minchev, I., Buck, T., et al. 2024, MNRAS, 535, 392 [NASA ADS] [CrossRef] [Google Scholar]
- Maia, M. T., Meléndez, J., Lorenzo-Oliveira, D., Spina, L., & Jofré, P. 2019, A&A, 628, A126 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Martos, G., Meléndez, J., Rathsam, A., & Carvalho Silva, G. 2023, MNRAS, 522, 3217 [NASA ADS] [CrossRef] [Google Scholar]
- Meléndez, J., Asplund, M., Gustafsson, B., & Yong, D. 2009, ApJ, 704, L66 [Google Scholar]
- Meléndez, J., Ramírez, I., Karakas, A. I., et al. 2014, ApJ, 791, 14 [Google Scholar]
- Miquelarena, P., Saffe, C., Flores, M., et al. 2024, A&A, 688, A73 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Nieva, M. F., & Przybilla, N. 2012, A&A, 539, A143 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Nissen, P. E. 2015, A&A, 579, A52 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Nissen, P. E., Christensen-Dalsgaard, J., Mosumgaard, J. R., et al. 2020, A&A, 640, A81 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Oh, S., Price-Whelan, A. M., Brewer, J. M., et al. 2018, ApJ, 854, 138 [NASA ADS] [CrossRef] [Google Scholar]
- Plez, B. 2012, Astrophysics Source Code Library [record ascl:1205.004] [Google Scholar]
- Plotnikova, A., Spina, L., Ratcliffe, B., Casali, G., & Carraro, G. 2024, A&A, 691, A298 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Prantzos, N., Abia, C., Chen, T., et al. 2023, MNRAS, 523, 2126 [NASA ADS] [CrossRef] [Google Scholar]
- Ramírez, I., Meléndez, J., & Asplund, M. 2009, A&A, 508, L17 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ramírez, I., Khanal, S., Aleo, P., et al. 2015, ApJ, 808, 13 [Google Scholar]
- Rampalli, R., Ness, M. K., Edwards, G. H., Newton, E. R., & Bedell, M. 2024, ApJ, 965, 176 [Google Scholar]
- Rathsam, A., Meléndez, J., & Carvalho Silva, G. 2023, MNRAS, 525, 4642 [CrossRef] [Google Scholar]
- Saffe, C., Jofré, E., Martioli, E., et al. 2017, A&A, 604, L4 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Shejeelammal, J., & Goswami, A. 2024, MNRAS, 527, 2323 [Google Scholar]
- Shejeelammal, J., Meléndez, J., Rathsam, A., & Martos, G. 2024, A&A, 690, A107 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sousa, S. G., Santos, N. C., Adibekyan, V., Delgado-Mena, E., & Israelian, G. 2015, A&A, 577, A67 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Spina, L., Meléndez, J., Karakas, A. I., et al. 2018, MNRAS, 474, 2580 [NASA ADS] [Google Scholar]
- Teske, J. K., Khanal, S., & Ramírez, I. 2016, ApJ, 819, 19 [NASA ADS] [CrossRef] [Google Scholar]
- Ting, Y.-S., Conroy, C., Rix, H.-W., & Cargile, P. 2019, ApJ, 879, 69 [Google Scholar]
- Tody, D. 1986, SPIE, 0627, 733 [NASA ADS] [Google Scholar]
- Tsujimoto, T., & Baba, J. 2020, ApJ, 904, 137 [Google Scholar]
- Yana Galarza, J., López-Valdivia, R., Meléndez, J., & Lorenzo-Oliveira, D. 2021, ApJ, 922, 129 [NASA ADS] [CrossRef] [Google Scholar]
All Tables
Stellar parameters obtained automatically with NNs for the sample. Stars identified with p are planet hosts. The complete table is available at CDS.
Chemical abundances (dex) obtained automatically with NNs for the sample. Stars identified with p are planet hosts. The complete table is available at CDS.
Solar abundances obtained automatically with NNs using spectra of the Moon, Vesta, and Ganymede, with Vesta as the reference solar spectrum. The last column shows the zero point error adopted for the element. The complete table is available at CDS.
Coefficients of the linear fit of the chemical abundances versus age. The complete table is available at CDS.
All Figures
|
Fig. 1 Median error of the abundance ratios [X/Fe] of the elements versus the standard deviation of the residuals when comparing our automatic abundances with Bedell et al. (2018). |
| In the text | |
|
Fig. 2 Separation of the stars of the sample between thin and thick disk according to their [Mg/Fe] ratio in relation to [Fe/H]. The stars above the red line and represented by blue crosses belong to the thick disk. |
| In the text | |
|
Fig. 3 Standard deviation of the residuals of the fit of [X/Fe] versus age and median error according to the atomic number (Z) of the elements. |
| In the text | |
|
Fig. 4 Fit of [Na/Fe] and [Cu/Fe] versus age. The open circles indicate a possible older subpopulation poor in Na, and the blue stars and black diamonds represent possible subpopulations enhanced and reduced in Cu, respectively. The blue crosses correspond to thick disk stars that were not considered in the fit. The bottom panel shows the residuals, as well as their average and standard deviation. |
| In the text | |
|
Fig. 5 Relation of [Cu/Fe] abundances with [Mn/Fe] and [Ba/Fe], where it is also possible to note the separation of the stars into the subgroups. |
| In the text | |
|
Fig. 6 Distribution of [Fe/H] versus age for the stars of our sample, distinguished by the possible subgroups. |
| In the text | |
|
Fig. 7 Cumulative distribution of the eccentricity of the stars that belong to the Na-poor (open circles), Cu-rich (blue stars), and Cu-poor (black diamonds) samples. |
| In the text | |
|
Fig. 8 Cumulative distribution of the z direction of the angular momentum (Lz) of the stars that belong to the Na-poor (open circles), Cu-rich (blue stars), and Cu-poor (black diamonds) samples. |
| In the text | |
|
Fig. 9 Example fit of the refractory elements of the star HIP 3203 versus Tcond. |
| In the text | |
|
Fig. 10 Slopes of the fit of [X/Fe] versus Tcond for all stars. Here, “solar-corr” refers to the solar-age abundances and “no-corr” refers to the abundances without any GCE or age correction. The vertical line represents the Sun. |
| In the text | |
|
Fig. 11 Comparison of the abundances of the Sun with the average solar twin, considering the stars without detected exoplanets (upper panel) and the stars with planets (bottom panel). The refractory elements are shown as colored markers, and the volatiles, which were not fitted, are shown in grey. The solid circles are the solar-age abundances and the empty circles are the abundances without any correction. The red lines are linear fits to the solar-age abundances, and the black lines are the linear fits to the non-corrected abundances. In both cases, only the refractories were fitted. For the volatiles (C, O, S, and Zn), the median value of the solar-age abundances is represented by the solid grey line and the median of the non-corrected abundances is shown by the dashed grey line. The blue star represents the oxygen abundance corrected by the offset of 0.033 dex between this work and Nissen et al. (2020). The blue dotted-dashed line is the median when considering this value for the abundance of oxygen. |
| In the text | |
|
Fig. A.1 Atmospheric parameters obtained automatically with the NN compared with the results of Spina et al. (2018). The bottom panel shows the residuals, as well as their average and standard deviation. |
| In the text | |
|
Fig. A.2 Comparison of the abundances obtained automatically with Martos et al. (2023) for Li, Spina et al. (2018) for Y and Ba and Bedell et al. (2018) for the other elements. The bottom panel shows the residuals, as well as their average and standard deviation. |
| In the text | |
|
Fig. B.1 Linear fit of the abundance ratios [X/Fe] versus age for all 20 elements. The stars represented by blue crosses are from the thick disk and were not considered in the linear fit (red dashed line). The black empty circles are stars from the distinct population identified in the [Na/Fe] plot, and the blue filled circles and black diamonds are stars from the Cu-rich and Cu-poor populations, respectively. The bottom panel shows the residuals, as well as their average and standard deviation. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.