| Issue |
A&A
Volume 698, May 2025
|
|
|---|---|---|
| Article Number | A25 | |
| Number of page(s) | 13 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/202553707 | |
| Published online | 26 May 2025 | |
Impact of weak-lensing mass-mapping algorithms on cosmology inference
1
University of Crete, Department of Physics, GR-70013 Heraklion, Greece
2
Institutes of Computer Science and Astrophysics, Foundation for Research and Technology – Hellas (FORTH), N. Plastira 100, Voutes GR-70013 Heraklion, Greece
3
Université Paris-Saclay, Université Paris Cité, CEA, CNRS, AIM, 91191 Gif-sur-Yvette, France
4
Dipartimento di Fisica – Sezione di Astronomia, Università di Trieste, Via Tiepolo 11, 34131 Trieste, Italy
5
INAF-Osservatorio Astronomico di Trieste, Via G. B. Tiepolo 11, 34143 Trieste, Italy
⋆ Corresponding author: atersenov@physics.uoc.gr
Received:
8
January
2025
Accepted:
31
March
2025
Context. Weak gravitational lensing is a powerful tool for probing the distribution of dark matter in the Universe. Mass-mapping algorithms, which reconstruct the convergence field from galaxy shear measurements, play a crucial role in extracting higher-order statistics from weak-lensing data to constrain cosmological parameters. However, only limited research has been done on whether the choice of mass-mapping algorithm affects the inference of cosmological parameters from weak-lensing higher-order statistics.
Aims. This study aims to evaluate the impact of different mass-mapping algorithms on the inference of cosmological parameters measured with weak-lensing peak counts.
Methods. We employed Kaiser-Squires, inpainting Kaiser-Squires, and MCALens mass-mapping algorithms to reconstruct the convergence field from simulated weak-lensing data, generated from cosmo-SLICS simulations. Using these maps, we computed the peak counts and multi-scale wavelet peak counts as our data vectors. We performed Bayesian analysis with Markov chain Monte Carlo sampling to estimate the posterior distributions of cosmological parameters, including the matter density, amplitude of matter fluctuations, and dark energy equation of state parameter.
Results. Our results indicate that the choice of mass-mapping algorithm significantly affects the constraints on cosmological parameters, with the MCALens method improving constraints by up to 157% compared to the standard Kaiser-Squires method. This improvement arises from MCALens’s ability to better capture small-scale structures. In contrast, inpainting Kaiser-Squires yields constraints similar to Kaiser-Squires, indicating a limited benefit from inpainting for cosmological parameter estimation with peaks.
Conclusions. The accuracy of mass-mapping algorithms is critical for cosmological inference from weak-lensing data. Advanced algorithms like MCALens, which offer superior reconstruction of the convergence field, can substantially enhance the precision of cosmological parameter estimates. These findings underscore the importance of selecting appropriate mass-mapping techniques in weak-lensing studies to fully exploit the potential of higher-order statistics for cosmological research.
Key words: gravitational lensing: weak / large-scale structure of Universe
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. Subscribe to A&A to support open access publication.
1. Introduction
Weak gravitational lensing, or the distortion of distant galaxy images due to intervening mass along the line of sight, is a powerful cosmological probe (Kilbinger 2015). In the past decade, weak-lensing surveys, namely the Kilo Degree Survey (KiDS; Kuijken et al. 2019), the Dark Energy Survey (DES; Flaugher 2005; DES Collaboration 2022), and the Hyper Suprime Camera Survey (HSC; Aihara et al. 2017), and the Ultraviolet Near Infrared Optical Northern Survey (UNIONS, Guinot et al. 2022; Li et al. 2024), have imaged large areas of the extra-galactic sky to study the nature of dark matter, dark energy, and the sum of neutrino masses. The launch of the Euclid satellite (Euclid Collaboration: Mellier et al. 2025) heralds a new generation of so-called Stage-IV weak-lensing surveys, which will soon include the Vera C. Rubin Legacy Survey of Space and Time (LSST; LSST Dark Energy Science Collaboration 2012), and the Nancy Grace Roman telescope (Spergel et al. 2015). These instruments will conduct weak-lensing measurements over an unprecedented area and depth.
Weak-lensing surveys extract cosmological information primarily by measuring two-point summary statistics: the two-point galaxy shear correlation function and its Fourier equivalent, the power spectrum. However, current and future surveys are probing small angular scales with increasing precision. At these scales, weak-lensing measurements contain non-Gaussian information due to non-linear structure formation that two-point statistics fail to capture (Weinberg et al. 2013). This has motivated the development of new summary statistics, known as higher-order statistics (HOS), designed to exploit the non-Gaussian information encoded in the matter density field. Some examples include peak counts (Marian et al. 2009; Dietrich & Hartlap 2010; Lin & Kilbinger 2015a,b; Harnois-Déraps et al. 2021, 2024; Ayçoberry et al. 2023), Minkowski functionals (Mecke et al. 1994; Kratochvil et al. 2012; Grewal et al. 2022), Betti numbers (Feldbrugge et al. 2019; Parroni et al. 2021), scattering transform coefficients (Cheng et al. 2020; Cheng & Ménard 2021), three-point statistics and the bispectrum (Takada & Jain 2003, 2004; Semboloni et al. 2011; Fu et al. 2014), map-level inference (Porqueres et al. 2022; Boruah & Rozo 2024), and the starlet-ℓ1 norm (Ajani et al. 2021, 2023). Euclid Collaboration: Ajani et al. (2023) performed forecasts of ten different HOS with a unified framework and found that they all outperform two-point statistics in terms of constraining power on the cosmological matter density parameter, Ωm, the amplitude of the matter power spectrum, σ8, and the dark energy equation of state parameter, w0. While forecasts show the very promising potential constraining power of HOS, additional studies are required to demonstrate that systematic measurement errors can be controlled for these observables in practice.
Several HOS are computed from the two-dimensional convergence, κ, which is not directly observable. Instead, κ must be reconstructed from galaxy shears, in a process called “mass-mapping”. This reconstruction is an ill-posed inverse problem, first because of galaxy shape noise and second because of missing data from observational artefacts such as bright stars, cosmic rays, and CCD defects. As a result, the fidelity of map reconstruction differs depending on the method used (see e.g. Jeffrey et al. 2021).
In the literature, metrics for comparing mass-mapping methods are typically based on the quality of the map reconstruction, with the implicit assumption that methods with a higher fidelity produce tighter cosmological contours. However, the effects of mass-mapping methods on cosmological parameters measured with HOS have not yet been fully quantified. Furthermore, Grewal et al. (2024), using Minkowski functionals, found that different choices in the inversion method alter cosmological contours in a Fisher-forecast analysis.
In this work we go a step further and measure the effect of different mass-mapping methods on cosmological constraints from peak counts in a full inference pipeline. We focused on the following mass-mapping methods: Kaiser-Squires (KS; Kaiser & Squires 1993), inpainting Kaiser-Squires (iKS; Pires et al. 2009), and MCALens (Starck et al. 2021). KS is a linear method that is fast but implements no de-noising, and does not account for missing data or boundary effects; iKS is an improvement upon KS that provides an iteratively applied inpainting scheme to reduce the effect of missing data. Finally, MCALens combines a sparsity-based method that captures non-Gaussian information on small scales with a Gaussian random field to replicate Gaussian behaviour on large scales (Starck et al. 2021).
We examined the effects of these three inversion methods on peak counts and wavelet peak counts. These summary statistics offer several unique advantages. They are fast to compute and have been shown to break the degeneracy between the standard model and fifth forces in the dark sector (Peel et al. 2018). Wavelet peak counts also have the advantages of peak counts but offer additional constraining power. In Stage-IV survey forecasts, Ajani et al. (2020) find that multi-scale wavelet peak counts yield tighter parameter constraints than a power spectrum analysis. This method is in fact so powerful that adding a power spectrum analysis does not further improve constraints compared to wavelet peak counts alone. Moreover, wavelet peak counts conveniently exhibit a covariance matrix that is nearly diagonal.
The structure of this paper is as follows: In Sect. 2 we describe the cosmo-SLICS simulations and their associated mock data, as developed in Harnois-Déraps et al. (2021), that are used our inference pipeline. We review the HOS that we measure (peaks and wavelet peaks) in Sect. 3, which is followed by a description of our cosmological inference pipeline in Sect. 4. We then compare the cosmological contours derived using each mass-mapping reconstruction in Sect. 5. Finally, we conclude the paper in Sect. 6.
2. Simulations
One method for computing a theoretical prediction of HOS as a function of cosmological parameters is to forward-model the HOS from cosmological simulations. In the following, we introduce the SLICS N-body simulations (Harnois-Déraps et al. 2019), and describe how they are used to construct mock galaxy catalogues of the DES Y1 footprint (Harnois-Déraps et al. 2021). We employed these mock galaxy catalogues to apply our mass-mapping algorithms and compute the HOS.
2.1. Cosmology training set
In this work we used the version of cosmo-SLICS described in Harnois-Déraps et al. (2021). These simulations are designed for the HOS analysis of weak-lensing data, covering points over a wide range of the [Ωm,σ8,h,w0] parameter space, where h is the Hubble parameter. They sample this space at 25 w cold dark matter (CDM) points as well as one ΛCDM point, arranged in a Latin Hypercube. At each of these points, a pair of N-body simulations with 15363 particles in a (505 h−1 Mpc)3 co-moving volume is run, providing 2D projections of the matter density field. The precise mass of each particle is determined by the simulation volume and matter density and, therefore, varies with h and Ωm, covering the range from 1.42 to 7.63 × 109 M⊙. The 2D projections are afterward organised into 10 (5 for each of the 2 random seeds) past light-cone density maps, δ2D(θ, z), with a field of view of 100 deg2 at different redshifts z. Those maps are in turn used to obtain convergence and shear maps, κ(θ, zs) and γ(θ, zs), for a number of source redshifts zs, as described in Section 2.3. The mean source redshift in each tomographic bin is ⟨zs⟩ = 0.403, 0.560, 0.773, 0.984.
2.2. Covariance mocks
The covariance matrix, which expresses the sample variance of our HOS, is evaluated from the SLICS suite of simulations, described in Harnois-Déraps et al. (2018). This set comprises 124 fully independent N-body simulations, run at a fixed ΛCDM cosmology1, but with different random phases in the initial conditions. The specifications of this set (volume, number of particles, resolution) are the same as those of the cosmology training set. We further increases the effective number of simulations by a factor of 10, by generating 10 different shape noise realisations for each of the 124 simulations. The covariance matrix is then computed from the 1240 realisations of this covariance training set.
2.3. Matching survey properties
Harnois-Déraps et al. (2021) adapted the SLICS simulations to the DES Y1 survey by overlaying the simulated light cones with the data in a way that the resulting mock surveys have the (κ, γ) values from the simulations at the positions and intrinsic ellipticities of the galaxies in the data. This was implemented by segmenting the DES Y1 catalogues into 19 tiles, each with a size of 100  , and populating every simulated map with the galaxy samples from the corresponding tile. In particular, the positions of the individual observed galaxies were replicated in every simulated survey realisation. Every simulated galaxy was assigned a redshift by sampling from the redshift distribution n(z) corresponding to its tomographic bin.
, and populating every simulated map with the galaxy samples from the corresponding tile. In particular, the positions of the individual observed galaxies were replicated in every simulated survey realisation. Every simulated galaxy was assigned a redshift by sampling from the redshift distribution n(z) corresponding to its tomographic bin.
In summary, each simulated light cone from the cosmology and covariance training sets is replicated 19 times and linked to a full survey realisation. As a final product, for the cosmology training set we have 10 mock galaxy catalogue realisations for each of the 19 tiles that cover the DES Y1 footprint, at each of the 25 wCDM cosmologies and the single ΛCDM cosmology. For the covariance training set, we have 124 fully independent mock galaxy catalogue realisations at the fixed cosmology, for each of the 19 tiles.
3. Higher-order statistics on weak-lensing mass maps
3.1. Mass-mapping
The weak-lensing mass-mapping problem is the task of reconstructing the convergence field κ from the measured shear field γ. This is possible because κ and γ are not independent, and can both be expressed as second-order derivatives of the lensing potential ψ:

where γ1 and γ2 are the two orthogonal components of the shear.
Rewriting the above equations in Fourier space, under the flat-sky approximation, we obtain the relation between convergence and shear:

where k is the wave vector in Fourier space. This estimator of the convergence field, however, is only optimal in the case of zero noise, missing (or masked) data, and periodic boundary conditions. Moreover, Eq. (2) is only defined for k ≠ 0, which means that the mean κ cannot be recovered from γ alone. This problem is known as mass-sheet degeneracy.
To address these issues, several mass-mapping algorithms have been proposed in the literature. These techniques are based on different assumptions and methods and have been shown to produce different results in terms of the fidelity of the reconstructed maps. In this work we compared the performance of the following mass-mapping techniques: the KS method, the iterative iKS, and the MCALens method. We provide a detailed description of these methods in Appendix A.
The original KS method is a direct linear inversion of the shear field to the convergence field, using the relation Eq. (2). Since this method is very fast, it has been widely used in weak-lensing studies (e.g. Ayçoberry et al. 2023; Euclid Collaboration: Ajani et al. 2023; Dutta et al. 2024; Jeffrey et al. 2025). However, its simplicity leads to strong artefacts in the reconstructed convergence due to boundary effects, creates leakage between the E and B modes of the convergence field, and is not optimal in the presence of noise. The iKS algorithm is a variation of the KS method that iteratively applies the KS inversion along with an inpainting scheme that reduces the effects of missing data. The inpainting scheme uses the morphological component analysis (MCA) iterative thresholding algorithm, introduced in Starck et al. (2005a), to fill in the missing convergence field data. This algorithm has been shown to improve the reconstruction of the convergence field in the presence of masks. Finally, the MCALens method is a non-linear mass-mapping algorithm that combines a Gaussian component to capture large-scale behaviour and a non-Gaussian component, constructed with sparsity priors, to recover the strong peaks in the convergence field at small scales. As a non-linear method, MCALens is computationally more expensive, but it provides a more accurate reconstruction of the convergence field, especially at small scales, where the non-Gaussian features of the matter distribution are more pronounced (Starck et al. 2021).
While there has been recent development of deep machine learning methods for mass-mapping (e.g. Jeffrey et al. 2020; Remy et al. 2023), here we focus on unsupervised methods and leave comparison with deep learning methods for future work. Supervised methods, while promising, introduce issues such as training dataset representativity (i.e. the generalisation problem). Moreover, in terms of mean square error, deep learning techniques have been shown to achieve results similar to those of MCALens (Remy et al. 2023). Additionally, although all of the above methods can be applied to data on the sphere, we instead took the approach of tiling the sky into small regions where the flat-sky approximation holds to ease comparison with the SLICS simulations during parameter inference, which are given in Cartesian coordinates.
3.2. Higher-order statistics
In this section, we describe the HOS in our pipeline: peak counts and wavelet peak counts. Weak-lensing peaks are defined as local maxima of the convergence field; in particular, we defined peaks as pixels with a value larger than that of their eight neighbours in the image. These peaks trace projected overdensities in the matter distribution, and thus often indicate the presence of massive cosmic structures, although the precise relation between peaks and halos is complex due to projection effects and potential noise-induced false detections (Sabyr et al. 2022).
Peak count analysis is performed by calculating the peak function, which represents the number of peaks in a convergence map or signal-to-noise map as a function of the peak height (the respective pixel value). In this work we counted the peaks in signal-to-noise maps, obtained by dividing the noisy convergence maps κ, convolved with a filter 𝒲θ, by its corresponding rms map, σnfilt:

Here, * denotes the convolution operator, and σnfilt is derived from the rms map r of the shear field by  .
.
Filtering of the convergence maps is necessary to reduce noise, especially at smaller scales where noise is dominant, and to assist in the detection of peaks. For the filtering, we employed two different approaches: a mono-scale and a multi-scale filtering, corresponding to a single Gaussian and a set of starlet (wavelet) filters, respectively.
The mono-scale approach consists of simply convolving the convergence maps with a single Gaussian kernel of size θ. The kernel size is chosen as a compromise between the need to reduce the noise and the need to preserve the signal. The multi-scale peak count analysis is performed by employing a wavelet decomposition to the map, namely the isotropic un-decimated wavelet transform, commonly referred to as the starlet transform (Starck et al. 2007). This transform enables one to extract the information encoded in different spatial scales quickly and simultaneously by decomposing the convergence maps into a set of wavelet bands of different scales. Specifically, the starlet filter decomposes the original N × N convergence map κ into a sum of images with the same number of pixels at different resolution scales j:

where cJ is a coarse, highly smoothed version of the original map, and wj are the wavelet bands representing the details of the original map at scale 2j pixels, jmax is the maximum scale considered, and J = jmax + 1. An important advantage of this analysis over other multi-scale approaches is that each wavelet band covers a different frequency range, resulting in a nearly diagonal peak count covariance matrix (Lin & Kilbinger 2018; Ajani 2021), which does not occur, for example, in the application of a multi-scale Gaussian analysis on the convergence map. In this starlet multi-scale approach, the standard deviation of noise σnfilt must be assessed separately for each wavelet band. In our analysis, we assumed that the noise in the convergence maps is non-stationary (i.e. it depends on the number of galaxies per pixel) but Gaussian, as described in Sect. 4.1. Thanks to the linearity of the starlet transform, this pixel-level noise propagates directly to the wavelet domain, allowing us to derive a spatially dependent noise level for each wavelet coefficient at every scale and position. It has been shown (Starck et al. 2015) that for starlet-decomposed images, the standard deviation of the noise at scale j can be estimated from the standard deviation of the noise of the original image σI and some coefficients σje that represent the behaviour of the noise in wavelet space, as σj = σjeσI. The coefficients σje are equal to the standard deviation at scale j of the starlet transform of a normal distribution with a standard deviation of one.
4. Inference pipeline
4.1. Shear maps
The output of the simulations described in Sect. 2 is a set of galaxy catalogues, each containing the positions, redshifts, simulated shear components, and simulated convergence of the galaxies. We first concatenated the four redshift bins into one, so that each catalogue contained galaxies of all redshifts. We then projected the galaxy right ascension and declination to Cartesian coordinates (x, y) onto a grid with a pixel size of 1 arcmin. This resulted in 600 × 600 pixel maps. To create the mask, we constructed a galaxy number density map by binning the galaxy positions into the pixel grid, (M = 0 where there are no galaxies, M = 1 where there are galaxies).
Next, we binned the simulated shear components in the pixel grid to create the shear maps and generated a noise map for each shear component using

where ⟨σint2⟩ = 0.44 is the average global intrinsic ellipticity dispersion of the source galaxies, and ngal is the number of galaxies in the pixel. Here, we did not assume a constant galaxy number density but instead used the actual number of galaxies in each pixel, to create a more realistic noise map. This noise map was added to the shear maps to create the mock observed shear maps.
Some studies (e.g. Marques et al. 2024; Cheng et al. 2025) chose to apply some smoothing to the shear maps before the mass-mapping inversion. Our approach primarily involves filtering the reconstructed mass maps with various filters before calculating the HOS (see Section 3.2). However, we also incorporated a preprocessing step where the shear maps are smoothed using a Gaussian kernel with a small standard deviation of 0.4 arcmin. This additional shear smoothing aims to reduce edge effects in the mass maps, particularly in the KS method, caused by pixels with no shear information. As shown in Section 4.2, this smoothing slightly improves the reconstruction accuracy of certain mass maps. Since we subsequently convolved the reconstructed mass maps with larger filters, this initial smoothing is not expected to bias our results. Ultimately, we conducted our analysis with both smoothed and unsmoothed shear maps but find no significant difference in the resulting cosmological parameter estimation. Consequently, we report only the results obtained with shear smoothing in this paper.
4.2. Mass-mapping
To create mass maps, we applied the KS, iKS, and MCALens methods to the noisy shear maps. For the iKS and MCALens methods, which include an internal iterative process, we set the number of iterations to 50, since this provides a good compromise between achieving sufficient convergence and managing computational time. We also set the internal parameter of the peak detection threshold in MCALens to 5σ.
In Figure 1, we show the mass maps obtained using the KS, iKS, and MCALens methods from a single tile of the simulated footprint. The KS and iKS maps have been smoothed with a Gaussian kernel with a standard deviation of 2 arcmin, to render the structures more visible. Without smoothing, the KS and iKS maps are dominated by noise. The MCALens maps, however, are already noise-suppressed by the mass-mapping algorithm, so they do not require additional smoothing for visualisation purposes.
 |
Fig. 1. Mass maps obtained using different reconstruction techniques, from a specific tile of the simulated footprint. Upper left: True convergence map derived directly from the simulated κ field (after pixelising the per-object convergence). Upper right and lower left: Mass maps generated by the KS and iKS methods, respectively, both smoothed with a Gaussian kernel (standard deviation of 2 arcmin) for visualisation purposes. Lower right: MCALens mass map. The iKS method implements inpainting of the missing data, and the unmasked regions of the patch are outlined in white. Note that the white line outlines only the large unmasked areas, for better visualisation purposes. |
The iKS map uses inpainting to fill in the missing data in the convergence field (see Sect. 3.1), effectively reducing the edge effects visible in the KS map. For reference, large masked regions are outlined in white in the plots of the reconstructed mass maps. Additionally, we see that the MCALens method removes noise, while keeping the stronger peaks in the convergence field, as expected from the method.
Table 1 presents a quantitative comparison of the reconstructed mass maps generated using the KS, iKS, and MCALens methods. The comparison evaluates shear maps processed with or without Gaussian smoothing (standard deviation 0.4 arcmin). The reconstruction accuracy is measured using the root mean square error (RMSE) between the true convergence map, κtrue, and the reconstructed map, κrec, calculated as:

RMSE comparison for mass map reconstruction.
where i is the pixel index, Nmask is the total number of unmasked pixels (i.e., where Mi = 1), and M is the binary mask. The RMSE values reported in the table are computed as the mean over all independent realisations and all cosmologies. The table also lists the error on this mean RMSE. As shown in the table, applying Gaussian smoothing to the shear maps reduces the RMSE for the KS and iKS methods, indicating improved reconstruction accuracy. However, shear smoothing has minimal effect on the MCALens method, which consistently outperforms the others by achieving the lowest RMSE.
4.3. Statistics calculation
Once the mass maps are generated, we calculated our HOS on S/N maps, derived from the mass maps, as described in Section 3.2. We calculated the peak counts and wavelet peak counts only in regions where M = 1, for both inpainted and non-inpainted maps, as the inpainted parts do not contain real signal. For both analyses, the S/N maps were constructed using Eq. (3), and peaks were counted and binned into 20 linearly spaced bins over the range −2 < S/N < 6, following Ajani et al. (2020).
For the mono-scale peak counts, we used a Gaussian kernel as the filter 𝒲 in Eq. (3). We tested various kernel sizes and selected the size that yielded the best cosmological constraints for each method. The optimal kernel sizes were θker = 2 arcmin for the KS and iKS methods and θker = 1 arcmin for the MCALens method. We then counted the peaks in the resulting S/N maps. Figure 2 displays the log-scaled histograms of the peak counts for the KS, iKS, and MCALens methods, averaged over all tiles and realisations for each of the 25 simulated cosmologies. The histograms are colour-coded as a function of the input S8 showing the sensitivity of peak counts to cosmology as well as the difference between the mass-mapping methods. MCALens produces a significantly narrower peak distribution with a higher mode. This is a consequence of its de-noising process, which suppresses both noise and part of the signal, resulting in a lower-amplitude reconstructed κ field compared to KS and iKS (see Fig. 1). However, the S/N maps are computed using a noise level derived directly from the noise in the input shear field, Eq. (3), regardless of the mass-mapping method. As a result, the reduced amplitude of the MCALens κ map translates into a peak distribution that is more concentrated around zero.
 |
Fig. 2. Log-scaled histograms of the peak counts as a function of the signal-to-noise ratio. The three panels (from left to right) correspond to the KS, iKS, and MCALens methods, for the 25 simulated cosmologies. The histograms are colour-coded by their S8 value. |
For the wavelet peak counts, we first decomposed the convergence maps into wavelet scales using the starlet transform, as described in Sect. 3.2. We used five wavelet scales, which correspond to resolutions [2, 4, 8, 16, 32] arcmin, along with the coarse map. We then calculated the S/N maps for each wavelet band separately, according to Eq. (3), and counted the peaks in each S/N map. Figure 3 shows the log-scaled histograms of the wavelet peak counts for the KS, iKS, and MCALens methods, for the 25 simulated cosmologies. As expected, scales corresponding to smaller wavelet filters contain more peaks, as they capture smaller, more abundant structures in the convergence field. As in the mono-scale case, for most scales, MCALens results in a narrower distribution of peak counts, which again is a consequence of its de-noising approach that suppresses both noise and part of the signal.
 |
Fig. 3. Log-scaled histograms of the wavelet peak counts as a function of the signal-to-noise ratio for the Kaiser-Squires (KS), iterative Kaiser-Squires (iKS), and MCALens methods, for the 25 simulated cosmologies. The four rows correspond to the three wavelet scales, [8, 16, 32] arcmin and the coarse map, and the columns correspond to the three mass-mapping methods. The histograms are colour coded by their S8 value. |
4.4. Covariance matrices
We calculated the covariance matrices for the HOS, using the covariance training set described in Sect. 2.2. To avoid unphysical large-scale mode-coupling that arises from replicating the same light cone across tiles, we randomised the selection of light cones during the survey construction, following Harnois-Déraps et al. (2021). For each of the 124 full survey realisations, we drew the 19 tiles from different, randomly selected light cones. We applied this process to all 10 realisations and averaged them to create our final covariance matrix. The covariance matrix elements were calculated as
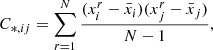
where N = 1240 is the number of realisations in the covariance training set, xir is the value of the statistic in the i-th bin of the r-th realisation, and  is the mean of the i-th bin over all realisations:
is the mean of the i-th bin over all realisations:

To account for the finite number of bins and realisations, we used the de-biased estimator for an inverse Wishart distribution (Siskind 1972; Hartlap et al. 2007) for the inverse of the covariance matrix:

where nbins is the number of bins in the histogram of the HOS under consideration, and [BOLD]C*−1 is the inverse of the respective covariance matrix calculated according to Eq. (7). In Fig. 4, we show the correlation matrices for the single-scale peak counts, for the different mass-mapping methods. Fig. 5 shows the correlation matrices for the wavelet peak counts.
 |
Fig. 4. Correlation matrices for the single-scale peak counts, for the KS, iKS, and MCALens methods. |
 |
Fig. 5. Correlation matrices for the wavelet peak counts, for the KS, iKS, and MCALens methods. The dashed white lines separate the different wavelet scales, which are positioned in increasing order of resolution from left to right, i.e. [2′, 4′, 8′, 16′, 32′, coarse]. |
4.5. Emulator
To obtain a prediction for our HOS for any given point in the parameter space [Ωm,σ8,h,w0] within the range of our simulations, we constructed an emulator using the Gaussian process regression (GPR) method2. For each bin of the HOS histograms, we trained a separate GPR model on all realisations of the HOS from the cosmology training set. We find that training the GPR models on the full set of realisations, rather than just the mean HOS histograms, improved the emulator’s performance. This approach enables the GPR models to predict the scaled HOS values in each histogram bin as a function of the cosmological parameters while simultaneously capturing the variability across realisations through a Gaussian likelihood.
The GPR training involves optimising the model hyperparameters by maximising the marginal log-likelihood using the Adam optimiser. We employed a radial basis function kernel with automatic relevance determination, allowing the model to learn different length scales for each cosmological parameter. To ensure stability and efficiency, the HOS values are rescaled by their mean value in each bin during training, and the scaling factors are recorded for subsequent use in predictions.
We then validated the emulator by performing a leave-one-out cross-validation, where we trained the GPR on all but one of the 25 cosmologies in the cosmology training set, and then predicted the HOS for the left-out cosmology. We repeated this process for all the cosmologies in the cosmology training set, and we calculated the percentage error between the predicted and the true HOS. Because the training is done on one fewer cosmology than the full set, the leave-one-out cross-validation provides an upper limit on the error of the emulator. In particular, the error is over-estimated in the case that the left-out cosmology is on the edge of the training volume, since in this case the emulator has to extrapolate from the other training points, instead of interpolating. We find that overall the emulator has percentage errors of less than 5% for all the HOS, which is acceptable for our purposes.
However, as discussed in Harnois-Déraps et al. (2024), the small number of available cosmologies in the cosmo-SLICS simulations used for training the emulator can lead to significant biases in the posterior distributions of the cosmological parameters. To mitigate these biases arising from the Gaussian process emulator altogether, following Davies et al. (2024), we used the emulator’s prediction of HOS at the given fiducial cosmology as our mock ‘observed’ data vector. This choice is also made for simplicity and presentation purposes, as it assures that the contours will be centred around the fiducial cosmology, making it easier to compare the constraining power of the HOS for the different mass-mapping methods. To ensure that this choice does not significantly alter the results of the analysis, we also perform the inference analysis using a mock data vector calculated from a cosmo-SLICS simulation at the fiducial cosmology, but in a simpler setting where the GPR is more robust. The results of this analysis are presented in Appendix B.
4.6. Likelihood
To perform Bayesian inference and to estimate the posterior distributions of the cosmological parameters, we model the likelihood function by assuming that our HOS follow a multivariate Gaussian distribution at each cosmology point in the parameter space:

where d is the data vector of the HOS, μ(θ) is the vector of the predicted HOS from the emulator at the point θ in the parameter space, and [BOLD]C is the covariance matrix of the HOS.
4.7. MCMC and posterior distributions
We performed a Markov chain Monte Carlo (MCMC) analysis employing the emcee3 Python package. We assumed flat priors for the parameters Ωm ∈ [0.1019, 0.5482], σ8 ∈ [0.4716, 1.3428], h ∈ [0.6034, 0.8129], and w0 ∈ [ − 1.9866, −0.5223], which are the boundaries of the training volume. We used the Gaussian likelihood function in Eq. (10) and a model-independent covariance, as described in Sect. 4.4. To verify the convergence of the chains, we used the Gelman-Rubin diagnostics (Gelman & Rubin 1992).
5. Results
In this section we present the results of our inference analysis for the parameters Ωm, σ8, h, and w0, using the pipeline described in the previous section. We show the parameter constraints, estimated from peak counts and wavelet peak counts, and we investigate the impact of the choice of the mass-mapping method on these constraints.
5.1. Mono-scale peak counts
Figure 6 shows the constraints obtained from single-scale peak counts for the KS, iKS, and MCALens methods. We observe a substantial difference in the constraints obtained from the different mass-mapping methods, with the MCALens method providing the tightest constraints, followed by the KS and the iKS method.
 |
Fig. 6. Constraints on the parameters Ωm, σ8, h, and w0 from the single-scale peak counts, for the KS (grey), iKS (red), and MCALens (blue) methods. The contours represent the 68% and 95% confidence levels, and the dashed black lines indicate the true parameter values of our fiducial (ΛCDM) cosmology. |
We further quantified these results by calculating the figure of merit (FoM) for each pair of parameters, defined as

where  is the marginalised Fisher matrix, estimated as the inverse of the covariance matrix among the parameters of interest, calculated from our MCMC chains, and n is the number of parameters. The FoM is a measure of the constraining power of the data on the parameters, with higher values indicating tighter constraints. Table 2 shows the FoM for each subset of parameters, as well as for the full set of parameters, for the KS, iKS, and MCALens methods.
is the marginalised Fisher matrix, estimated as the inverse of the covariance matrix among the parameters of interest, calculated from our MCMC chains, and n is the number of parameters. The FoM is a measure of the constraining power of the data on the parameters, with higher values indicating tighter constraints. Table 2 shows the FoM for each subset of parameters, as well as for the full set of parameters, for the KS, iKS, and MCALens methods.
FoMs for parameters from single-scale peak counts, for the KS, iKS, and MCALens methods.
We can see that using MCALens instead of KS improves the FoM by 17%. This improvement can be attributed primarily to the de-noising strategy employed by MCALens. Specifically, MCALens’s wavelet-based de-noising technique is more effective at preserving true peaks at small scales, which are critical for constraining cosmology. In contrast, KS and iKS rely more on Gaussian smoothing, which reduces noise but sacrifices some of the small-scale signal. Moreover, iKS does not provide a clear improvement over KS, sometimes performing slightly worse than KS. This is likely because the inpainting applied by iKS primarily affects the masked areas, which are excluded from the peak count analysis. This may also indicate that the optimal Gaussian smoothing for iKS was not fully reached with the kernel sizes we explored, leading to suboptimal performance with our current choices. We note that for other HOS, such as the bispectrum computed in Fourier space (which uses the full area including masked regions), the performance differences between KS and iKS could be more pronounced.
5.2. Wavelet peak counts
Figure 7 shows the constraints obtained from the wavelet peak counts, for the KS, iKS, and MCALens methods. As in the case of the single-scale peak counts, we observe a clear difference in the constraints obtained from the different mass-mapping methods, with the MCALens method delivering the tightest constraints, followed by the KS and the iKS method. Notably, KS and iKS produce very similar contours, indicating again that the inpainting applied by iKS has only a minimal effect for peak counts. Table 3 shows the FoM for each pair of parameters, as well as for the full set of parameters, for the KS, iKS, and MCALens methods.
 |
Fig. 7. Constraints on the parameters Ωm, σ8, h, and w0 from the wavelet peak counts with six wavelet scales [2′, 4′, 8′, 16′, 32′, coarse], for the KS (grey), iKS (red), and MCALens (blue) methods. The contour lines are described in Fig. 6. |
FoMs for parameters from wavelet peak counts, for the KS, iKS, and MCALens methods.
As expected, the constraints produced from the wavelet peak counts are tighter than those from the single-scale peak counts, across all methods. However, the MCALens method shows a significantly greater relative improvement in the FoM when using wavelet peak counts, with a 157% enhancement compared to the KS method with wavelet peak counts. Furthermore, the combination of wavelet peak counts with the MCALens method enhances the FoM by 296% compared to single-scale peak counts with the KS method. These results underscore the critical importance of adopting a multi-scale approach, both in the mass-map reconstruction and in the statistical analysis of the convergence field.
To assess the contribution of different wavelet scales across various methods, we also performed the inference analysis incrementally by including an increasing number of scales. We began by obtaining constraints using the [16′, 32′, coarse] scales. Next, we successively added finer scales to this set, starting with the 8′ scale, followed by the 4′ scale, and, finally the 2′ scale.
The results are shown in Figs. 8 and 9 for the KS and MCALens methods, respectively. In Fig. 8, we observe that KS constraints improve significantly when including the 8′ scale, while the 4′ and 2′ scales do not provide significant additional information. In contrast, Fig. 9 shows that the MCALens constraints improve significantly with the inclusion of every smaller scale. This result highlights that the MCALens method is able to extract more information from the smaller scales of the convergence field, and that is where it gains most of its constraining power over the KS and iKS methods.
 |
Fig. 8. Constraints on the parameters Ωm, σ8, h, and w0 from the wavelet peak counts using KS inversion and including different numbers of wavelet scales. The green contours were obtained with three scales: [16′, 32′, coarse]. The grey contours were obtained by adding a fourth scale at 8′. The red contours were obtained by adding a fifth scale at 4′, and the blue contours include a sixth scale at 2′. The contour lines are described in Fig. 6. |
 |
Fig. 9. Constraints on the parameters Ωm, σ8, h, and w0 from the wavelet peak counts using MCALens inversion and including different numbers of wavelet scales. The green contours were obtained with three scales: [16′, 32′, coarse]. The grey contours were obtained by adding a fourth scale at 8′, the red contours a fifth scale at 4′, and the blue contours a sixth scale at 2′. The contour lines are described in Fig. 6. |
6. Conclusions
We investigated the impact of various mass-mapping algorithms on cosmological inference using HOS derived from weak-lensing data. We used a set of 25 simulated cosmologies to train an emulator for the HOS, and we used a set of 1240 realisations of the HOS for a fixed cosmology to estimate the covariance matrices. We then performed a Bayesian analysis with an MCMC method to estimate the posterior distributions of the parameters Ωm, σ8, h, and w0, using peak counts and wavelet peak counts as our data vectors.
Our analysis shows that the choice of the mass-mapping method has a significant impact on the constraints on the cosmological parameters, with the MCALens method providing the tightest constraints. The improvement gained by using MCALens is ∼17% in the FoM compared to the KS method for the mono-scale analysis, and ∼157% for the multi-scale analysis. We find no significant difference in the contours created with the iKS and KS methods, indicating that forward-modelling the inversion is sufficient to account for edge effects for both peak counts and multi-scale peak count statistics. However, we note that this conclusion does not necessarily generalise to all HOS. Certain HOS, such as the bispectrum, are much more sensitive to masked regions because they rely on information across Fourier modes that can be significantly impacted by missing data. In such cases, a dedicated study would be required to determine whether an inpainting approach or another treatment of the masked area is necessary to ensure reliable results. Finally, we confirm previous results, that wavelet peak counts provide tighter constraints than single-scale peak counts. Constraints from MCALens are tightest when using a multi-scale approach because it captures additional information from smaller scales compared to KS.
These results highlight that a careful choice of mass-mapping method when attempting to accurately reconstruct the convergence field can significantly improve constraints on the cosmological parameters from HOS.
We used the GPyTorch (version 1.12) Python package (Gardner et al. 2018) to implement the GPR.
Acknowledgments
This work was supported by the TITAN ERA Chair project (contract no. 101086741) within the Horizon Europe Framework Program of the European Commission, and the Agence Nationale de la Recherche (ANR-22-CE31-0014-01 TOSCA). LB is supported by the PRIN 2022 project EMC2 - Euclid Mission Cluster Cosmology: unlock the full cosmological utility of the Euclid photometric cluster catalog (code no. J53D23001620006). This work used the CANDIDE computer system at the IAP supported by grants from the PNCG, CNES, and the DIM-ACAV and maintained by S. Rouberol. The authors thank Nicolas Martinet, Virginia Ajani and Joachim Harnois-Deraps for useful discussions. The authors also thank Joachim Harnois-Deraps for providing the simulations used in this work.
References
- Aihara, H., Arimoto, N., Armstrong, R., et al. 2017, PASJ, 70, S4 [NASA ADS] [Google Scholar]
- Ajani, V. 2021, Ph.D. Thesis, Université Paris Cité, France [Google Scholar]
- Ajani, V., Peel, A., Pettorino, V., et al. 2020, Phys. Rev. D, 102, 103531 [Google Scholar]
- Ajani, V., Starck, J.-L., & Pettorino, V. 2021, A&A, 645, L11 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ajani, V., Harnois-Déraps, J., Pettorino, V., & Starck, J.-L. 2023, A&A, 672, L10 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ayçoberry, E., Ajani, V., Guinot, A., et al. 2023, A&A, 671, A17 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bobin, J., Starck, J. L., Sureau, F., & Fadili, J. 2012, AdAst, 2012, 703217 [Google Scholar]
- Boruah, S. S., & Rozo, E. 2024, MNRAS, 527, L162 [Google Scholar]
- Cheng, S., & Ménard, B. 2021, MNRAS, 507, 1012 [NASA ADS] [CrossRef] [Google Scholar]
- Cheng, S., Ting, Y.-S., Ménard, B., & Bruna, J. 2020, MNRAS, 499, 5902 [Google Scholar]
- Cheng, S., Marques, G. A., Grandón, D., et al. 2025, JCAP, 2025, 006 [Google Scholar]
- Davies, C. T., Harnois-Déraps, J., Li, B., et al. 2024, MNRAS, 533, 3546 [NASA ADS] [CrossRef] [Google Scholar]
- DES Collaboration (Abbott, T. M. C., et al.) 2022, Phys. Rev. D, 105, 023520 [CrossRef] [Google Scholar]
- Dietrich, J. P., & Hartlap, J. 2010, MNRAS, 402, 1049 [Google Scholar]
- Dutta, A., Peterson, J. R., Rose, T., et al. 2024, ApJ, 977, 87 [Google Scholar]
- Euclid Collaboration (Ajani, V., et al.) 2023, A&A, 675, A120 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Euclid Collaboration (Mellier, Y., et al.) 2025, A&A, 697, A1 [Google Scholar]
- Feldbrugge, J., van Engelen, M., van de Weygaert, R., Pranav, P., & Vegter, G. 2019, JCAP, 2019, 052 [CrossRef] [Google Scholar]
- Flaugher, B. 2005, IJMPA, 20, 3121 [Google Scholar]
- Fu, L., Kilbinger, M., Erben, T., et al. 2014, MNRAS, 441, 2725 [Google Scholar]
- Gardner, J. R., Pleiss, G., Bindel, D., Weinberger, K. Q., & Wilson, A. G. 2018, arXiv e-prints [arXiv:1809.11165] [Google Scholar]
- Gelman, A., & Rubin, D. B. 1992, Stat. Sci., 7, 457 [Google Scholar]
- Grewal, N., Zuntz, J., Tröster, T., & Amon, A. 2022, OJAp, 5, 13 [Google Scholar]
- Grewal, N., Zuntz, J., & Tröster, T. 2024, OJAp, 7, 52 [Google Scholar]
- Guinot, A., Kilbinger, M., Farrens, S., et al. 2022, A&A, 666, A162 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Harnois-Déraps, J., Amon, A., Choi, A., et al. 2018, MNRAS, 481, 1337 [Google Scholar]
- Harnois-Déraps, J., Giblin, B., & Joachimi, B. 2019, A&A, 631, A160 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Harnois-Déraps, J., Martinet, N., Castro, T., et al. 2021, MNRAS, 506, 1623 [CrossRef] [Google Scholar]
- Harnois-Déraps, J., Heydenreich, S., Giblin, B., et al. 2024, MNRAS, 534, 3305 [CrossRef] [Google Scholar]
- Hartlap, J., Simon, P., & Schneider, P. 2007, A&A, 464, 399 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Heydenreich, S., Brück, B., & Harnois-Déraps, J. 2021, A&A, 648, A74 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Jeffrey, N., Lanusse, F., Lahav, O., & Starck, J.-L. 2020, MNRAS, 492, 5023 [Google Scholar]
- Jeffrey, N., Gatti, M., Chang, C., et al. 2021, MNRAS, 505, 4626 [NASA ADS] [CrossRef] [Google Scholar]
- Jeffrey, N., Whiteway, L., Gatti, M., et al. 2025, MNRAS, 536, 1303 [Google Scholar]
- Kaiser, N., & Squires, G. 1993, ApJ, 404, 441 [Google Scholar]
- Kilbinger, M. 2015, Rep. Prog. Phys., 78, 086901 [Google Scholar]
- Kratochvil, J. M., Lim, E. A., Wang, S., et al. 2012, Phys. Rev. D, 85, 103513 [Google Scholar]
- Kuijken, K., Heymans, C., Dvornik, A., et al. 2019, A&A, 625, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lanusse, F., Starck, J.-L., Leonard, A., & Pires, S. 2016, A&A, 591, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Li, Q., Kilbinger, M., Luo, W., et al. 2024, ApJ, 969, L25 [Google Scholar]
- Lin, C.-A., & Kilbinger, M. 2015a, A&A, 576, A24 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lin, C.-A., & Kilbinger, M. 2015b, A&A, 583, A70 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lin, C.-A., & Kilbinger, M. 2018, A&A, 614, A36 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- LSST Dark Energy Science Collaboration 2012, arXiv e-prints [arXiv:1211.0310] [Google Scholar]
- Marian, L., Smith, R. E., & Bernstein, G. M. 2009, ApJ, 698, L33 [NASA ADS] [CrossRef] [Google Scholar]
- Marques, G. A., Liu, J., Shirasaki, M., et al. 2024, MNRAS, 528, 4513 [NASA ADS] [CrossRef] [Google Scholar]
- Mecke, K. R., Buchert, T., & Wagner, H. 1994, A&A, 288, 697 [NASA ADS] [Google Scholar]
- Parroni, C., Tollet, É., Cardone, V. F., Maoli, R., & Scaramella, R. 2021, A&A, 645, A123 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Peel, A., Pettorino, V., Giocoli, C., Starck, J.-L., & Baldi, M. 2018, A&A, 619, A38 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pires, S., Starck, J.-L., Amara, A., et al. 2009, MNRAS, 395, 1265 [NASA ADS] [CrossRef] [Google Scholar]
- Porqueres, N., Heavens, A., Mortlock, D., & Lavaux, G. 2022, MNRAS, 509, 3194 [Google Scholar]
- Remy, B., Lanusse, F., Jeffrey, N., et al. 2023, A&A, 672, A51 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sabyr, A., Haiman, Z., Matilla, J. M. Z., & Lu, T. 2022, Phys. Rev. D, 105, 023505 [Google Scholar]
- Semboloni, E., Schrabback, T., van Waerbeke, L., et al. 2011, MNRAS, 410, 143 [Google Scholar]
- Siskind, V. 1972, Biometrika, 59, 690 [Google Scholar]
- Spergel, D., Gehrels, N., Baltay, C., et al. 2015, arXiv e-prints [arXiv:1503.03757] [Google Scholar]
- Starck, J. L., Moudden, Y., Bobin, J., Elad, M., & Donoho, D. L. 2005a, in Wavelets XI, eds. M. Papadakis, A. F. Laine, & M. A. Unser, Society of Photo-Optical Instrumentation Engineers (SPIE) Conference Series, 5914, 209 [Google Scholar]
- Starck, J.-L., Elad, M., & Donoho, D. 2005b, IEEE Trans. Image Process., 14, 1570 [Google Scholar]
- Starck, J.-L., Fadili, J., & Murtagh, F. 2007, IEEE Trans. Image Process., 16, 297 [Google Scholar]
- Starck, J. L., Murtagh, F., & Fadili, J. 2015, Sparse Image and Signal Processing: Wavelets and Related Geometric Multiscale Analysis (Cambridge University Press) [Google Scholar]
- Starck, J.-L., Themelis, K. E., Jeffrey, N., Peel, A., & Lanusse, F. 2021, A&A, 649, A99 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Takada, M., & Jain, B. 2003, MNRAS, 344, 857 [Google Scholar]
- Takada, M., & Jain, B. 2004, MNRAS, 348, 897 [Google Scholar]
- Weinberg, D. H., Mortonson, M. J., Eisenstein, D. J., et al. 2013, Phys. Rep., 530, 87 [Google Scholar]
Appendix A: Mass-mapping algorithms
A.1. Kaiser-Squires
In general, mass-mapping can be formulated as an inverse problem,

where A is the convolution matrix (which corresponds to the linear transformation from ideal κ-field to ideal γ-field), and n is the noise vector. The matrix A can be decomposed in Fourier space as A = F*PF, where F is the discrete Fourier transform matrix, and P is the Fourier-space filter that relates the pure shear signal (in the absence of noise) to the convergence

Here,  and
and  are the complex representations of the two shear components and the convergence E and B modes, in Fourier space, respectively.
are the complex representations of the two shear components and the convergence E and B modes, in Fourier space, respectively.
The original method for solving the mass-mapping problem was proposed by Kaiser & Squires (1993). This method directly inverts the relation between the observed shear γ and the convergence κ in Fourier space, as given by Eq. (2). In practice, this is done by directly applying the Fourier-space filter P−1 to the shear field:

This is the relation that was used for the standard KS reconstruction in our analysis.
While the KS method is the simplest and computationally fastest mass-mapping technique, it does not account for the noise, missing data, or the boundaries of the survey. This makes it suboptimal in the application to real data, leading to significant noise amplification, edge effects, and internal artefacts in the reconstructed maps, along with leakage between the E and B modes of the convergence field. Typically, to reduce the noise in the reconstructed maps, some Gaussian smoothing is applied to the map. This, however, also leads to a loss of information at small scales and suppression of peaks.
To rigorously account for the noise covariance matrix Σn and the mask M, we needed to minimise the following equation:

This can be solved using the following iterative process:

where μ = min(Σn). This iterative algorithm generalises the standard KS solution, to take into account the noise covariance matrix and the mask. For the special case of a diagonal covariance matrix with all diagonal elements equal to 1 and no mask (i.e. M = 1) this iterative algorithm converges to the standard KS solution. In particular, if we set μ = 1/2, the update simplifies to the KS inversion in one iteration. More details can be found in Starck et al. (2021), Appendix B.1.
A.2. Iterative Kaiser-Squires with DCT inpainting
Inpainting methods are techniques used to fill in missing data in an image or signal by estimating the missing values from known data. Sparse inpainting based on the discrete cosine transform (DCT) was proposed in Starck et al. (2005b,a) and used in the context of mass-mapping by Pires et al. (2009) to fill in areas of missing data in the convergence field.
Inpainting can be very easily included in Eq. A.4, so that one now minimises the following equation:

where p = 0 or 1,  is the DCT, and λ is a Lagrangian parameter. The solution can be obtained using the forward-backward algorithm:
is the DCT, and λ is a Lagrangian parameter. The solution can be obtained using the forward-backward algorithm:


where  is the proximal operator defined in Pires et al. (2009), which consists of applying a DCT transform to t, thresholding the DCT coefficients, reconstructing an image from the thresholded coefficients, and normalising the values of the filled-in pixels so that their standard deviation matches the standard deviation of the observed parts. This normalisation can also be performed at every scale of the wavelet transform of the solution. Areas for which we possess information were processed as in the iterative KS case, while the inpainting regularisation affects areas with missing data (i.e. when M = 0).
is the proximal operator defined in Pires et al. (2009), which consists of applying a DCT transform to t, thresholding the DCT coefficients, reconstructing an image from the thresholded coefficients, and normalising the values of the filled-in pixels so that their standard deviation matches the standard deviation of the observed parts. This normalisation can also be performed at every scale of the wavelet transform of the solution. Areas for which we possess information were processed as in the iterative KS case, while the inpainting regularisation affects areas with missing data (i.e. when M = 0).
A.3. MCALens
MCALens method was developed in Starck et al. (2021) to combine the advantages of two different methods with complementary strengths: the Wiener filter and sparsity-based methods. The Wiener filter models the convergence field as a Gaussian random field. It effectively reconstructs the large-scale Gaussian features of the convergence field, but it is suboptimal in reconstructing the small-scale features, such as peaks. On the other hand, methods based on sparsity priors (e.g. Lanusse et al. 2016) assume that the convergence field is sparse when represented in a certain basis. Sparsity-based methods excel in capturing these peak structures but can struggle to retrieve the Gaussian-like statistical properties that emerge on larger scales.
To combine these two methods, MCALens models the convergence field as a sum of two components: a Gaussian component κG and a non-Gaussian component κS, sparse in a wavelet dictionary,

MCALens then estimates κG and κS by applying the MCA algorithm, which is designed to separate different components mixed within a single signal or image, provided these components have distinct morphological properties. Specifically, MCA takes advantage of the sparsity of the different components in different dictionaries, which in the case of MCALens are a weighted Fourier basis ΦG for the Gaussian component,
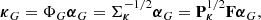
and a wavelet basis ΦS for the sparse component,

The MCA algorithm is then solving the following optimisation problem:

where 𝒞G and 𝒞S are regularisation terms for the Gaussian and sparse components, respectively. The solution to this problem is found by iteratively applying the following steps:
-
Estimate κG by assuming that κS is known, minimising:
-
Estimate κS by assuming that κG is known, minimising:


To estimate the Gaussian component, the algorithm uses the Wiener filter, performing an iteration of the proximal Wiener filtering algorithm, as described in Starck et al. (2021), Section 2, at each MCA step. The proximal Wiener filtering is a variant of the standard Wiener filter (Bobin et al. 2012) which is designed to handle non-stationary noise, through the use of a Forward-Backward iterative algorithm. Thus, the penalty term 𝒞G in this case is

For the sparse component, the algorithm cannot follow the typical ℓ1 of ℓ0-norm regularisation used in the standard sparse recovery algorithms, as the large-scale wavelet coefficients overlap with low-frequency Fourier coefficients of the Gaussian field, complicating their separation. Instead, the algorithm adopts an alternative two-step approach:
-
Identify the set of active wavelet coefficients by applying a threshold, typically 3-5 times the noise level at each scale j and position x. This results in a binary mask Ω, defined as:
The mask isolates the sparse features, distinguishing them from the Gaussian component.
-
Estimate the sparse component by solving the following minimisation problem:
where ⊙ denotes the element-wise multiplication, ΦS† is the adjoint operator of the wavelet transform, and the penalty term 𝒞S is given by:
where iℝ is an indicator function to enforce real-valued solutions.

![$$ \begin{aligned} \min _{\boldsymbol{\kappa }_S} \left\{ \big \Vert \Omega \odot \mathbf \Phi _S^\dagger \left[ \left( \boldsymbol{\gamma } - \mathbf A \boldsymbol{\kappa }_G \right) - \mathbf A \boldsymbol{\kappa }_S \right] \big \Vert ^2_{\boldsymbol{S}_n} + \mathcal{C} _S (\boldsymbol{\kappa }_S) \right\} , \end{aligned} $$](/articles/aa/full_html/2025/06/aa53707-25/aa53707-25-eq36.gif)

This approach offers the advantage that when Ω is fixed, the algorithm behaves almost linearly, with the only non-linearity being the positivity constraint imposed on κS. This enables the straightforward derivation of an approximate error map by simply propagating noise and relaxing the positivity constraint. The positivity constraint ensures that the reconstructed peaks are positive, which is not guaranteed in general, since peaks in the convergence field can be on top of voids and thus have negative values. The higher the non-Gaussianity of the convergence field, the more MCALens is expected to outperform linear methods like the Wiener filter.
Appendix B: Inference with simulated observations
In this appendix, we present the results of the inference analysis using as mock data the forward-modelled HOS from the cosmo-SLICS simulations at the fiducial (ΛCDM) cosmology. The forward model applied to generate these fiducial data vectors is the same as the one used to generate the data vectors for the emulator training, described in Sections 4.1-4.3.
We then used the fiducial data vectors to estimate the size of the emulator’s interpolation error that was not captured by our covariance matrix. To measure this, we trained an additional GPR model on the mean values of the HOS histograms across realisations at the 25 cosmologies. From this model, we obtained the prediction uncertainties from the GPR at the fiducial cosmology. We then incorporated these interpolation errors into our error budget by adding them to the diagonal of the covariance matrix of the HOS data vectors, following Heydenreich et al. (2021).
The results for single-scale peak counts are shown in Fig. B.1. The constraints on the cosmological parameters are overall larger than those obtained using the emulator predictions as mock data, shown in Fig. 6, mainly due to the inclusion of the GPR interpolation error. Nevertheless, the contours still show that using MCALens instead of KS or iKS leads to significant improvements in the constraining power.
The results for wavelet peak counts are shown in Fig. B.2. These constraints were obtained using only three different scales: 16′,32′, coarse. Including additional scales overly biased the GPR predictions due to the small number of cosmologies in the training set, leading to unreliable results. As in the case of single-scale peak counts, the resulting constraints are larger than those obtained using the emulator predictions as mock data, shown in Fig. 7 (both due to the use of only three scales, and the inclusion of the GPR interpolation error) but the improvement in the constraining power of MCALens over KS and iKS is still evident.
Regarding the bias in the cosmological parameters, the results show that the true values of the parameters are within the 68% confidence intervals for all mass-mapping methods and summary statistics. However, a more detailed analysis with a larger number of cosmologies in the training set would be necessary to draw more robust conclusions.
 |
Fig. B.1. Constraints on the parameters Ωm, σ8, h, and w0 from single-scale peak counts, for simulated fiducial histograms. The contour lines are described in Fig. 6. |
 |
Fig. B.2. Constraints on the parameters Ωm, σ8, h, and w0 from wavelet peak counts using the [16′,32′,coarse] scales, for simulated fiducial histograms. The contour lines are described in Fig. 6. |
All Tables
FoMs for parameters from single-scale peak counts, for the KS, iKS, and MCALens methods.
FoMs for parameters from wavelet peak counts, for the KS, iKS, and MCALens methods.
All Figures
|
Fig. 1. Mass maps obtained using different reconstruction techniques, from a specific tile of the simulated footprint. Upper left: True convergence map derived directly from the simulated κ field (after pixelising the per-object convergence). Upper right and lower left: Mass maps generated by the KS and iKS methods, respectively, both smoothed with a Gaussian kernel (standard deviation of 2 arcmin) for visualisation purposes. Lower right: MCALens mass map. The iKS method implements inpainting of the missing data, and the unmasked regions of the patch are outlined in white. Note that the white line outlines only the large unmasked areas, for better visualisation purposes. |
| In the text | |
|
Fig. 2. Log-scaled histograms of the peak counts as a function of the signal-to-noise ratio. The three panels (from left to right) correspond to the KS, iKS, and MCALens methods, for the 25 simulated cosmologies. The histograms are colour-coded by their S8 value. |
| In the text | |
|
Fig. 3. Log-scaled histograms of the wavelet peak counts as a function of the signal-to-noise ratio for the Kaiser-Squires (KS), iterative Kaiser-Squires (iKS), and MCALens methods, for the 25 simulated cosmologies. The four rows correspond to the three wavelet scales, [8, 16, 32] arcmin and the coarse map, and the columns correspond to the three mass-mapping methods. The histograms are colour coded by their S8 value. |
| In the text | |
|
Fig. 4. Correlation matrices for the single-scale peak counts, for the KS, iKS, and MCALens methods. |
| In the text | |
|
Fig. 5. Correlation matrices for the wavelet peak counts, for the KS, iKS, and MCALens methods. The dashed white lines separate the different wavelet scales, which are positioned in increasing order of resolution from left to right, i.e. [2′, 4′, 8′, 16′, 32′, coarse]. |
| In the text | |
|
Fig. 6. Constraints on the parameters Ωm, σ8, h, and w0 from the single-scale peak counts, for the KS (grey), iKS (red), and MCALens (blue) methods. The contours represent the 68% and 95% confidence levels, and the dashed black lines indicate the true parameter values of our fiducial (ΛCDM) cosmology. |
| In the text | |
|
Fig. 7. Constraints on the parameters Ωm, σ8, h, and w0 from the wavelet peak counts with six wavelet scales [2′, 4′, 8′, 16′, 32′, coarse], for the KS (grey), iKS (red), and MCALens (blue) methods. The contour lines are described in Fig. 6. |
| In the text | |
|
Fig. 8. Constraints on the parameters Ωm, σ8, h, and w0 from the wavelet peak counts using KS inversion and including different numbers of wavelet scales. The green contours were obtained with three scales: [16′, 32′, coarse]. The grey contours were obtained by adding a fourth scale at 8′. The red contours were obtained by adding a fifth scale at 4′, and the blue contours include a sixth scale at 2′. The contour lines are described in Fig. 6. |
| In the text | |
|
Fig. 9. Constraints on the parameters Ωm, σ8, h, and w0 from the wavelet peak counts using MCALens inversion and including different numbers of wavelet scales. The green contours were obtained with three scales: [16′, 32′, coarse]. The grey contours were obtained by adding a fourth scale at 8′, the red contours a fifth scale at 4′, and the blue contours a sixth scale at 2′. The contour lines are described in Fig. 6. |
| In the text | |
|
Fig. B.1. Constraints on the parameters Ωm, σ8, h, and w0 from single-scale peak counts, for simulated fiducial histograms. The contour lines are described in Fig. 6. |
| In the text | |
|
Fig. B.2. Constraints on the parameters Ωm, σ8, h, and w0 from wavelet peak counts using the [16′,32′,coarse] scales, for simulated fiducial histograms. The contour lines are described in Fig. 6. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.