| Issue |
A&A
Volume 698, May 2025
|
|
|---|---|---|
| Article Number | A276 | |
| Number of page(s) | 14 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/202453576 | |
| Published online | 20 June 2025 | |
Hybrid-z: Enhancing the Kilo-Degree Survey bright galaxy sample photometric redshifts with deep learning
1
Center for Theoretical Physics, Polish Academy of Sciences, al. Lotników 32/46, 02-668 Warsaw, Poland
2
National Centre for Nuclear Research (NCBJ), ul. Pasteura 7, 02-093 Warsaw, Poland
3
Division of Physics, Mathematics and Astronomy, California Institute of Technology, 1200 E California Blvd, Pasadena, CA 91125, USA
⋆ Corresponding authors: anjithajm@cft.edu.pl, bilicki@cft.edu.pl
Received:
21
December
2024
Accepted:
5
May
2025
We employed deep learning to improve the photometric redshifts (photo-zs) in the Kilo-Degree Survey Data Release 4 bright galaxy sample (KiDS-DR4 Bright). This dataset, used as foreground for KiDS lensing and clustering studies, is flux-limited to r < 20 mag with mean z = 0.23 and covers 1000 deg2. Its photo-zs were previously derived with artificial neural networks from the ANNz2 package trained on the Galaxy And Mass Assembly (GAMA) spectroscopy. Here, we considerably improve on these previous redshift estimations by building a deep learning model, Hybrid-z, that combines an inception-based convolutional neural network operating on four-band KiDS images with an artificial neural network using nine-band magnitudes from KiDS+VIKING. The Hybrid-z framework provides state-of-the-art photo-zs for KiDS-Bright with negligible mean residuals of O(10−4) and scatter at a level of 0.014(1 + z) – representing a reduction of 20% compared to the previous nine-band derivations with ANNz2. Our photo-zs are robust and stable independently of galaxy magnitude, redshift, and color. In fact, for blue galaxies, which typically have more pronounced morphological features, Hybrid-z provides a larger improvement over ANNz2 than for red galaxies. We checked our photo-z model performance on test data drawn from GAMA as well as from other KiDS-overlapping wide-angle spectroscopic surveys, namely SDSS, 2dFLenS, and 2dFGRS. We found stable behavior and consistent improvement over ANNz2 throughout. Finally, we applied Hybrid-z trained on GAMA to the entire KiDS-Bright DR4 sample of 1.2 million galaxies. For these final predictions, we designed a method of smoothing the input redshift distribution of the training set in order to avoid propagation of features present in GAMA related to its small sky area and large-scale structure imprint in its fields. Our work paves the way toward the best-possible photo-zs achievable with machine learning for any galaxy type for both the final KiDS-Bright DR5 data and for future deeper imaging, such as from the Legacy Survey of Space and Time.
Key words: techniques: miscellaneous / catalogs / surveys / galaxies: distances and redshifts / galaxies: photometry / cosmology: observations
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. Subscribe to A&A to support open access publication.
1. Introduction
Redshift is a key quantity for cosmological analyses. As the basic proxy for galaxy distances, it allows one to map the large-scale structure of the Universe in time and three-dimensional space. Redshift can be measured to a sub-percent accuracy only via spectroscopy. For such spectroscopic redshifts (spec-zs), one first collects the spectrum of an object and then identifies the shift in spectral lines with respect to the rest frame. However, even in the current era of fast measurements, such as with the Dark Energy Spectroscopic Instrument (DESI Collaboration 2016), spec-zs can be obtained only for a small fraction of all detected galaxies.
On the other hand, redshifts can be estimated for a much larger sample from photometric measurements. Such photometry-based redshifts (photo-z) provide an alternative method to the spec-zs and are based on the correlation between redshift and apparent galaxy magnitudes. This approach was originally pointed out by Baum (1957) and first applied to obtain photoelectric magnitudes in nine passbands by Baum (1962). The two main attractive factors of photo-zs are that they allow one to obtain redshifts for galaxies fainter than generally possible with spectroscopy and that the number of objects with redshift estimates per unit telescope time is also much larger (Hildebrandt et al. 2010). Notably, photo-zs cannot provide redshift accuracy and precision as good as spec-zs. Nevertheless, they are indispensable in today’s massive imaging surveys cataloging millions and billions of galaxies.
Photo-zs are based on a complicated mapping from photometry to redshift space, and they are difficult to handle analytically since this mapping depends on observational, computational, and statistical factors. Photo-z estimation methods can be generally categorized into template fitting and empirical approaches. In the latter case, which is our focus in this paper, the relation between photometric quantities and redshift is very commonly found by machine learning (ML) algorithms, although we note that simpler approaches of using functional fitting have also been proposed (e.g., Connolly et al. 1995; Krone-Martins et al. 2014).
In supervised ML techniques, the algorithm derives the empirical relation between observed quantities and labels from appropriate training on labeled data. Therefore, their main challenge and limitation lies in extrapolating the results beyond a representative training set. However, if such appropriate training data exist, ML methods can excel, and this has led to numerous approaches being proposed for photo-zs based on the newest developments in computer science. Some examples include support vector machines (Wadadekar 2004), random forest (Carliles et al. 2010; Li et al. 2021), artificial neural networks (ANNs; e.g., Tagliaferri et al. 2003; Collister & Lahav 2004; Oyaizu et al. 2008), ensemble learning (Cunha & Humphrey 2022), Gaussian processes (Way & Srivastava 2006; Bonfield et al. 2010), self-organizing maps (Way & Klose 2012), k-nearest neighbors (Graham et al. 2017), mixture density networks (Ansari et al. 2021), and finally deep neural networks (e.g., Hoyle 2016; D’Isanto & Polsterer 2018).
Among the various supervised ML techniques for photo-z derivation, deep learning (DL) has emerged as a particularly promising one. Deep learning makes it possible to entirely skip “higher-level” quantities such as galaxy magnitudes or sizes derived from photometric post-processing and build the ML model using multi-band imaging directly. In such frameworks, “deep” indicates that the models usually have compounded multi-layer architectures. Their usage for photo-zs was pioneered by Hoyle (2016) and then studied by, for example, D’Isanto & Polsterer (2018), Menou (2019), Pasquet et al. (2019), Dey et al. (2022), Henghes et al. (2022), Treyer et al. (2024) for Sloan Digital Sky Survey (SDSS) data; Schuldt et al. (2021) for Hyper-Suprime Cam (HSC); Li et al. (2022) for the Kilo-Degree Survey (KiDS); and by Roster et al. (2024) for DESI Imaging. These papers have demonstrated that using images directly, or in combination with magnitudes (e.g., Li et al. 2022; Jones et al. 2024; Roster et al. 2024), allows one to derive photo-zs of better performance than those based on tabular galaxy data such as magnitudes.
A particular realization of DL is convolutional neural networks (CNNs). They are a type of ANN suitable for computer vision problems, such as image feature detection or classification, and are inspired by the human vision system. Similar to real neurons, which receive input and pass electrochemical signals (McCulloch 1943), artificial neurons are used in CNNs. The significance of CNNs is evidenced by their vast use in image recognition tasks (e.g., LeCun et al. 1998). These networks are appropriate for processing data that have grid-like topology, such as images, because of their local connectivity, parameter sharing, and translational invariance. We chose CNNs to extract the galaxy image patterns by detecting features such as edges, textures, and shapes, which are expected to improve photo-z derivations compared to methods that do not employ such information.
In this paper, we present a photo-z estimation in which we incorporate both fluxes (magnitudes) and multichannel galaxy images by using DL techniques for KiDS (de Jong et al. 2013). KiDS is a multiband imaging survey covering about 1350 deg2 of the sky, of which we employ ∼1000 deg2 from its fourth data release (Kuijken et al. 2019). The DL photo-zs within KiDS have already been studied in detail by Li et al. (2022), where various setups using both images and magnitudes were compared for a general selection of galaxies spanning 0 < z ≲ 3. However, until now, such imaging-based photo-z approaches have not been employed in KiDS in the regime where they are expected to bring the most improvement over “shallow” ML, namely, for relatively bright and well-resolved galaxies. Here, we fill this gap and focus only on the bright end of the KiDS data.
We studied the performance of DL for photo-zs in the flux-limited “KiDS-Bright DR4 sample,” which includes all the KiDS galaxies within the magnitude cut of r < 20 mag (Bilicki et al. 2018, 2021, hereafter B18, B21). This sample is particularly useful for such an analysis, as by design it is selected to mimic the spectroscopic Galaxy And Mass Assembly dataset (GAMA; Driver et al. 2011). As GAMA is flux limited and highly complete spectroscopically, it constitutes a very well matched training set for empirical photo-z models. In the DL context, this aspect has been taken advantage of in the recent work by Treyer et al. (2024), where photo-z derivation for a sample of SDSS galaxies at r < 20 mag was presented. The previous KiDS analysis by Li et al. (2022) at the low-redshift end using DL as well as the dedicated studies by B18, B21 with “shallow” ML and GAMA training gave state-of-the-art photo-z results for the respective selections in KiDS. Therefore, here we aim to build on and extend these previous successful endeavors. Among our goals is to check if the current KiDS-Bright DR4 sample redshift estimates could be further improved. This is relevant, for instance, in view of the forthcoming Legacy Survey of Space and Time (LSST Science Collaboration 2009), where high-resolution multi-wavelength imaging of a depth greater than in KiDS will be available for the entire southern sky. Improvements in photo-z accuracy and precision of foreground galaxies are important in this context, as they help minimize related systematics of photometric clustering and lensing analyses.
The default photo-zs in KiDS data releases are derived with the Bayesian photometric redshifts (BPZ; Benítez 2000) template-fitting tool. In particular, this tool is used to bin the weak lensing sources in redshift shells, and their true redshift distribution is then calibrated with self-organizing maps and via the clustering redshift technique (Hildebrandt et al. 2021). However, several studies have demonstrated that for bright low-redshift galaxies, empirical photo-z methods can outperform the default BPZ solution when selecting galaxy samples from KiDS (e.g., Cavuoti et al. 2015; Bilicki et al. 2018; Vakili et al. 2019; Li et al. 2022). This is possible if relevant training or calibration data are available to build a model mapping the photometric space to redshift using ML, but also other approaches such as red-sequence fitting (Rozo et al. 2016; Vakili et al. 2019, 2023) can be used as well. For the KiDS-DR4 Bright galaxy sample (B21) we are concerned with in this paper, the redshifts were estimated using ANNs from the public package ANNz2 (Sadeh et al. 2016). The ANNs used photometric quantities (magnitudes, colors) as input and were trained with spectroscopic redshifts from GAMA. A number of tests have shown that such photo-zs are statistically accurate and precise (i.e., have low mean bias and scatter; B18; B21) not only for the KiDS-DR4 Bright sample as a whole but also for the sub-populations such as red and blue galaxies. In particular, this was possible thanks to the already mentioned intentional very good match of the galaxy selection in the KiDS-Bright DR4 sample to the GAMA training set.
In this work, we extend the previous feature-based ML efforts to build a successful DL model that we call “Hybrid-z.” The model integrates both images and features for KiDS-DR4 Bright photo-z estimations. We used the same GAMA training set as in B21 and constructed a photo-z model that is conceptually similar to one tested in Li et al. (2022). Namely, it combines a deep convolutional network, employing ugri imaging, with an ordinary ANN that is fed by nine-band galaxy magnitudes. An analogous configuration was also studied by Henghes et al. (2022) for SDSS, and inspired by their results, we also use “inception” as our basic architecture for the DL part.
This paper is organized in the following manner. In Sect. 2 we describe the data used. Next, in Sect. 3 we explain the basic concepts of CNNs and the special CNN architecture that we used, called inception. In Sect. 4, we describe our Hybrid-z model to estimate the photo-zs and the statistics that we used to measure the performance of the network. Sect. 5 presents our results, and in Sect. 6, we conclude and discuss future prospects.
2. Data
In this section, we discuss the data used in this study. We employed the KiDS-Bright DR4 sample images supplemented with photometry (i.e., magnitudes). The required training and testing data are labeled using the spectroscopic redshifts from the GAMA survey.
2.1. KiDS images and photometry
Kilo-degree survey is an optical wide-field imaging survey of the European Southern Observatory (ESO) at the Very Large Telescope (VLT) Survey (VST, Capaccioli & Schipani 2011), having at the focal plane a 268 million pixel Charge-Coupled Device (CCD) mosaic camera called OmegaCAM (Kuijken 2008). VST is an alt-az mounted modified Ritchey-Cretien telescope located in the ESO Paranal Observatory, Chile. The images were taken in four broad bands (ugri), and the survey covers 1350 square degrees of the extragalactic sky. The final footprint of the survey is shown in Fig. 3 of Wright et al. (2024); here we use its publicly available subset.
KiDS-ESO Data Release 4 (KiDS DR4; (Kuijken et al. 2019)), is the fourth public release of KiDS. The ASTRO-WISE optical pipeline and data reduction environment (McFarland et al. 2013) is used to produce stacked (or co-added) composite images created by combining multiple individual exposures of the same sky area, one in each of the four bands. As a result, KiDS DR4 optical data are organized into 4 × 1006 one square-degree tiles.
KiDS DR4 products consist of astrometrically and photometrically calibrated co-added images with a uniform pixel scale of 0.2 arcsec. The pixel units are fluxes relative to the 0th magnitude (de Jong et al. 2015). We have downloaded the KiDS DR4 tiles1 and made cutouts of galaxies with a size of 7.2″ × 7.2″ (36 × 36 pixels), since most of the objects we use are smaller than this. In particular, this cutout size is above the 99-percentile level of the half-light diameter (i.e., 2 × FLUX_RADIUS) in KiDS-Bright. The largest galaxies, not fitting within our cutouts, are likely of little interest for our work anyway: they will be very nearby and will have had spec-z from wide-angle surveys or otherwise will not be useful for lensing studies.
We have also tried bigger cutouts such as 20.2″×20.2″ and 8″×8″, motivated receptively by Grespan et al. (2024) and Li et al. (2022), but our finally adopted size gave the best results. The smaller size reduces the noise in images without losing galaxy flux information. Too large cutouts could also lead to frequent situations when more than one galaxy appears in the image. This type of contamination could adversely affect the performance of the model, although it has been argued in the literature that CNNs for photo-z estimation could in fact benefit from physically close pairs in the images (e.g., Pasquet et al. 2019). In our case we also use magnitudes of individual galaxies, which should mitigate this effect, be it positive or negative. In any case, for our fiducial cutout size, more than one object is present in the image very rarely, in less than 1% cases.
Finally, we normalized the pixel values to the range [0, 1] galaxy-wise, i.e. jointly for all the ugri bands for a given galaxy cutout. The normalization formula is
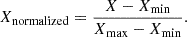
The minimum value of the pixels for the 4-band per-galaxy images (cutouts) is denoted as Xmin and the maximum value as Xmax. In occasional cases when the image has (a) saturated pixel(s), this normalization will not work properly. Dealing with this problem would be beyond the scope of our work as it would require building an extra framework to pre-analyze all the 4.8 million cutouts and cleaning them up of such artifacts. We note that in most cases, objects located in such corrupted areas will not be useful for science anyway, as they will bear an appropriate KiDS MASK value indicating that their photometry is not reliable (see next Section). According to our estimates, for the ‘clean’ data (i.e., those not affected by the mask), the presence of artifacts in the images is very infrequent, at a fraction of a percent level. Last but not least, the usage of magnitudes together with images in the model, will minimize their influence on the derived photo-zs.
KiDS DR4 photometric data consists of optical ugri and near-infrared (NIR) data from the VISTA Kilo-degree INfrared Galaxy survey (VIKING, Edge et al. 2013) with observations in five bands: ZYJHKs. In KiDS the magnitudes are by default derived with the Gaussian Aperture And Point spread function (GAAP, Kuijken 2008) methodology. GAAP magnitudes are meant to provide robust galaxy colors irrespective of PSF differences in various bands, which makes them optimal for photo-z derivation. This is an important asset for general weak lensing tomographic studies (Kuijken et al. 2015). GAAP magnitudes were also shown to be optimal for low-redshift photo-z estimates in KiDS, as compared to other galaxy magnitude measurements available in this survey (B18). The GAAP magnitudes in KiDS are provided in the AB system and their zero-point calibration is achieved by using coadd overlaps and stellar locus regression. They are corrected for Galactic extinction (Schlegel et al. 1998) E(B − V) map with (Schlafly & Finkbeiner 2011) coefficients.
We standardized these 9-band magnitude features using the StandardScaler class from the scikit-learn Python library (Pedregosa et al. 2011), which computes the mean (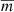 ) and standard deviation (σm) for each band independently. The magnitude values (m) in each band are transformed as
) and standard deviation (σm) for each band independently. The magnitude values (m) in each band are transformed as
In comparison to the optical ugri images from KiDS, “coadds” are not readily available for the VIKING NIR, as these data are not processed by the ASTRO-WISE pipeline. Because of this, here we employ only the 4-band optical images, leaving the possible extension with NIR imaging to future work.
2.2. KiDS-DR4 Bright galaxy sample
In this work, we derive DL photo-zs for the KiDS-DR4 Bright galaxy sample, introduced in B21. This dataset contains galaxies selected from KiDS DR4 with the flux limit rauto < 20 mag, where “auto” stands for SExtractor-derived estimate of the total flux via automatic aperture photometry (Bertin & Arnouts 1996). The selection of the sample is designed to have the best possible match with overlapping GAMA-equatorial spectroscopic data, which originally were selected using SDSS Petrosian magnitudes in the r band (Liske et al. 2015). As it was discussed in B21, among the various r-band magnitude measurements in KiDS, a cut in rauto provides the best correspondence to the GAMA original rPetro < 19.8 limit.
In addition to the flux limit, the KiDS-Bright dataset uses various flags from the KiDS input catalog to remove point sources (stars, quasars) and artifacts. These in particular were CLASS_STAR < 0.5 & SG2DPHOT = 0 & SG_FLAG = 1 to select extended sources and IMAFLAGS_ISO = 0 & (MASK & 28668) > 0 to remove imaging artifacts. However, we note that the published KiDS-Bright catalog also includes the objects without this final criterion applied, and in Sect. 5.1 we test how the masking affects our photo-z derivation.
2.3. GAMA spectroscopic data
In the training and testing phase, we used KiDS galaxies that have counterparts in the GAMA catalog (Driver et al. 2011), giving us the true redshift labels. GAMA is a multi-wavelength and spectroscopic survey in five fields2 (three equatorial: G09, G12, and G15, and two southern ones: G02 and G23), with a total ∼286 deg2 area. Spectra were collected using the AAOmega fiber-fed spectrograph facility on the 3.9-m Anglo-Australian Telescope. GAMA provides spectra, redshifts, their quality marks, and other ancillary information.
KiDS DR4 fully overlaps with four GAMA fields (all but G02). Of these, the equatorial ones present the largest flux-limited spectroscopic completeness, originally estimated as 98.5% at rSDSS < 19.8 mag (Liske et al. 2015) but subsequently revised to 98% at rKiDS < 19.58 (Driver et al. 2022) after ingestion of KiDS photometry into the GAMA database (Bellstedt et al. 2020). Following the results of B21, where the addition of the shallower and less complete G23 data did not lead to improvement in photo-z estimates, also here we used only the equatorial fields to train the model, and it is tested on both equatorial and G23 fields. Similarly, other datasets such as for instance SDSS or DESI Early Data Release, are not sufficiently complete at our flux limit of r < 20 mag to provide useful training sets for the overall galaxy sample (see, e.g., Jalan et al. 2024). Some of them, however, are useful for a posteriori tests of our photo-z model, and this is discussed in Sect. 5.2.
In this work, we employ the GAMA-II spectroscopic redshift catalog of galaxies from the final GAMA DR4 (Driver et al. 2022)3. For secure redshifts, we select galaxies with a normalized quality parameter NQ ≥ 3 (see Liske et al. 2015, for details) and z > 0.001. We have identified galaxies within KiDS tiles that are shared between the GAMA and KiDS-Bright samples based on their right ascension and declination coordinates, assuming a 1″ matching radius between KiDS and GAMA. Then we made cutouts of size 7.2″×7.2″ from KiDS images with these galaxies positioned at the center.
3. Methodology
3.1. Convolutional neural networks
A CNN is a sequence of layers: convolutional, pooling, and fully connected layers. The convolution takes place between input images and a small matrix of weights called a kernel or filter. Initially, the weights are small random values. In a CNN, the learning is hierarchical. The first convolutional layers are responsible for extracting the lower-level features of images, such as edges, corners, and textures (Goodfellow et al. 2016). The kernels adjust their weights to extract these features. The filters in the following layers help integrate more complex features of input data. The network is trained by non-linear optimization of weights and biases through a gradient-descent algorithm. Input data is transformed by convolution operation, producing linear activation.
The relationship between input data and output labels is usually non-linear. The linear relations are limited for this complex mapping from input to output spaces. To introduce non-linearity, the convoluted output passes through a non-linear function in hidden and output layers. This decides which neurons should activate. Without using the activation function, the output would be linearly dependent on the input, since the convolution output is a linear combination of input pixels within the receptive field. Rectified Linear unit (ReLu) and its variants such as peaky ReLu and leaky ReLu, hyperbolic tangent, and sigmoid functions are the common activation functions (Jentzen et al. 2023). The output of CNN is multidimensional (a tensor) and referred to as a feature map; it is another representation of the input data.
The next stage is the pooling operation to modify the output. The pooling function replaces the output of the network at a certain location with a summary statistic of the nearby outputs (Goodfellow et al. 2016). We experimented with various pooling operations, including average pooling and max pooling (Gholamalinezhad & Khosravi 2020). Based on evaluation metrics, we found that average pooling enhances model performance, which might be thanks to the fact that it deals better with noise in the images than max pooling. Average pooling computes the average of a rectangular neighborhood.
3.2. Training
The training of a neural network involves several key steps and considerations. Initially, the dataset is divided into three subsets in a random manner using scikit-learn python library: training, validation, and testing set, in our case in a ratio of 70:15:15. The validation set serves to monitor the performance of the network during the training process. Also, there is no selection bias in magnitudes or redshifts in any subset. The final cutout catalog contains ∼173k galaxies in the equatorial fields and ∼125k of these are used to train the model. The model is validated on ∼26k galaxies in the equatorial fields, and the remaining data are used for testing. Finally, it is applied to the entire KiDS-DR4 Bright sample of about 1.2 million galaxies.
During training, the network updates its kernel values based on feedback signals. This iterative process aims to minimize the loss function, which represents the discrepancy between the predicted values and the true value. In the case of a CNN, the loss function is dependent on the weights. The weights are multiplied by the input values during the forward pass of the network to produce the output.
To minimize the loss function and approach the global minimum, the weights need to be updated in the opposite direction of the gradient. This optimization process involves gradient-based techniques. Thelearning rate, a crucial hyperparameter, determines the size of the step taken along the negative gradient direction. A too-small learning rate can result in slow convergence, while a too-large one can lead to divergent behavior of loss function.
The training process iterates over the dataset in batches, where the number of iterations is referred to as epochs, and the number of samples per batch is the batch size. At each epoch, the network computes the gradients of the weights with respect to the loss on the batch and updates the weights (Chollet 2017).
3.3. Data augmentation
Optimization and generalization play important roles in ML problems. Optimization is the process of adjusting the model parameters to get the best performance on training data, while generalization determines the model performance on unseen data. If the ML model is too simple to capture the underlying structure of the data, it performs poorly not only on the training data but also on unseen data. This is because it fails to learn relevant patterns from the training, leading to underfitting. On the other hand, overfitting happens when a model learns not only the underlying patterns but also the noise and random fluctuations present in the training (Xia 2024). As a result, it performs very well on the training data but poorly on unseen data because it has essentially memorized the training data instead of generalizing from it.
One of the solutions for over- and underfitting is generating a large training dataset using data augmentation. Data augmentation is commonly used in ML, particularly in the context of image classification and computer vision tasks (Shorten & Khoshgoftaar 2019). It involves generating additional training data by applying various transformations (rotation, width and height shift, flipping, etc.) to the existing training samples. After learning a certain pattern in an image, a CNN can recognize it anywhere due to its translational invariance.
We experimented with various data augmentation approaches in the training sample images and selected those that were most efficient for our case. We applied 5% shifts in both width and height. Also, we performed horizontal and vertical flipping on the images. By these four variations, we extended our training set to ∼484k objects and were able to considerably improve model performance. We also tried image rotations, but these did not lead to any improvements.
3.4. Inception module
In this section, we discuss a CNN architecture referred to as “inception” that we employ in photo-z prediction. Increasing the depth of the network improves the performance at a cost of high computation time. Inception, a deep CNN architecture developed for image detection and classification tasks. It was first used in GoogLeNet architecture (Szegedy et al. 2015). The smaller number of weights, and biases compared to its predecessors reduces the computation time and makes it appropriate for big-data handling. There are various versions of Inception available, differing by the use of regularization, reduction of overfitting when the training sample is limited, and the inclusion of additional DL architectures such as Resnet (He et al. 2015) in the Inception module. In our model, we used the Inception v1 module illustrated in Fig. 1. We also tested other versions and we found that Inception v1 gives the best performance for our dataset.
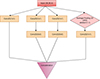 |
Fig. 1. Inception module used in this study to estimate the photo-z. The input layer has size (36,36,4). Conv2D is a two-dimensional convolution layer, with the kernel size specified in brackets. Average Pooling 2D is a two-dimensional pooling operation that uses a kernel of size 3 × 3. Each operation is represented using boxes of distinct colors. Concatenation is the combined feature maps from parallel convolutions. |
Choosing the right kernel is very important for feature extraction. On the one hand, a larger kernel is suitable for images where the information is distributed globally. However, a smaller-sized kernel is good for locally distributed information extraction. This selection becomes highly important as the galaxies in our sample have a wide range of apparent sizes, and hence our dataset contains both kinds of distributions. We used both larger and smaller-sized kernels in the Inception module. This is shown in Fig. 1.
The most straightforward way of improving the performance of deep neural networks is by increasing the complexity. This includes both increasing the depth (number of layers) of the network and its width: the number of units at each layer. The inception module uses parallel convolution operation with multiple filter sizes. Inception v1 uses 1 × 1, 3 × 3, and 5 × 5 spatial filters.
The concatenation process combines all the feature maps from the parallel convolutions. This merging takes place along the channel axis (depth-wise concatenation) which enables the network to efficiently process and extract information from complex visual data. Based on prior research in photo-z estimation, such as Henghes et al. (2022), Li et al. (2022), and the performance of our model, we decided to include Inception in our framework.
3.5. Metrics
In this Section, we discuss the metrics to evaluate the performance of our model and photo-zs. Here we discriminate the two types of metrics into those which are evaluated and optimized when building the model (during training and validation), and those computed a posteriori to quantify the behavior of the photo-zs. For the former, we mainly used three metrics: mean squared error (MSE), mean absolute error (MAE), and the R squared error (R2). The MSE and MAE are defined as follows:
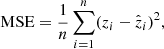
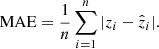
Here, n is the number of samples used for training, zi is the predicted value and 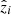 is the true value. The R2 is a statistical measure that shows how well a model predicts the outcome in a regression analysis. It is the proportion between the variance explained by the model and the total variance:
is the true value. The R2 is a statistical measure that shows how well a model predicts the outcome in a regression analysis. It is the proportion between the variance explained by the model and the total variance:
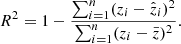
Here, 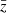 is the mean of the spectroscopic redshift values from the GAMA×KiDS crossmatch. For an ideal case, the value of this metric would be unity.
is the mean of the spectroscopic redshift values from the GAMA×KiDS crossmatch. For an ideal case, the value of this metric would be unity.
The MSE is more sensitive to outliers than MAE. Due to the squaring part, MSE puts more weight on larger errors. MAE, on the other hand, treats all errors with equal importance, which can be advantageous when the dataset contains extreme values or noisy observations – which is common for galaxy images. Therefore, MSE is more appropriate for learning outliers, and MAE is better for ignoring them. To include the benefits of both these loss functions, we use the Huber (1964) loss function, similarly as in the previous KiDS analysis by Li et al. (2022). This function is quadratic when the absolute error is small, and linear when the absolute error exceeds a threshold δ. This makes it robust to outliers because the impact of large errors is reduced compared to using a purely quadratic loss function such as MSE. The Huber loss is defined as
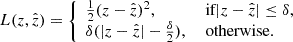
A very low δ value means that the transition region between the quadratic and linear parts of the loss function is extremely narrow. As a result, even points that are not true outliers but are slightly distant from the predicted values may significantly impact the loss. This can lead to overfitting to outliers. A high value (δ > 0.01 for our case) makes the loss function less sensitive to outliers. These will affect the model generalization. We tried a range of values between 10−5 and 0.01, and found that δ = 0.001 shows the lowest values for Huber loss, MSE, and MAE. Thus we chose this value of δ for our models.
We evaluated the resulting photo-z performance using the following standard statistics:
-
Bias,
-
Normalized (rescaled) bias,
-
Standard deviation of normalized bias, σΔz;
-
Scaled median absolute deviation (SMAD) of Δz, where
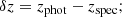
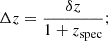
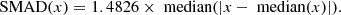
The first two of these metrics quantify the average residuals of the photo-zs from the true value, i.e. their statistical accuracy. The two others measure the scatter, i.e. statistical precision. The factor 1.4826 in the SMAD definition allows it to converge to one standard deviation for the Gaussian.
4. Photometric redshift model
Here, we explain the photometric redshift model, Hybrid-z, used in this study. It incorporates two types of input: galaxy images and magnitudes.
The model was trained using a dataset comprising 173k × 4 KiDS galaxy images from the GAMA equatorial fields and with data augmentation techniques applied, as outlined in Sect. 3.3. Together with the 4-band images, also 9-band magnitudes of the same galaxies were used. Then the model was validated with 26k galaxy samples and tested on an additional set of 26k galaxies also from GAMA equatorial × KiDS. Finally, we estimated photo-zs for all the KiDS-DR4 Bright sample galaxies.
We used the Rectified linear unit (Relu, Jentzen et al. 2023) as the activation function in all the layers except in the output one where the sigmoid function (i.e., logistic curve) is used, which enforces all the predictions to lie in the range 0 < zphot < 1. For the layers other than the last (output) one, we also tried other activation functions such as leaky Relu (Jentzen et al. 2023), peaky Relu, softmax, swish, and tanh, but Relu gave the best performance.
For the output layer, the sigmoid function gives the best results in our redshift range where practically all the galaxies have z < 1 due to the r < 20 mag flux limit. For instance, in the entire GAMA spectroscopic sample, objects with z > 1 constitute less than 0.1% of the total and these are typically very bright and rare AGNs. For such sparse sources, empirical methods such as ours would not be able to render reliable redshift predictions unless some special approach to anomaly handling is taken. We therefore sacrificed a very small number of objects that lie at true z > 1 to have zphot < 1 in order to avoid a gross redshift overestimation for others, which could happen if the model had more freedom. The latter is for instance the case for ANNz2, where some of the photo-zs from B21 are predicted significantly above unity. Similar logic applies to photo-zs with non-physical predictions of z < 0 which are equally avoided in our model, while were present in the ANNz2 results. We note, however, that both cases were rare already in B21. In the clean KiDS-Bright sample, there were 82 galaxies with zANNz2 > 1 and 444 with zANNz2 < 0.
The architecture of the Hybrid-z model is shown in Fig. 2. The left-hand side is the CNN part, where images are processed, while to the right we have the ONN section using magnitudes. For CNNs, the input is 36 × 36 pixels (7.2″×7.2″) galaxy cutouts in four optical bands. When training the network, we used the Adam optimizer (Kingma & Ba 2014). One of its key features is the adaptive learning rate, updated during iteration based on previous steps. 10−4 is selected as the initial learning rate after various iterative tests with it from [10−5, 10−2]. The loss function is the Huber loss with the δ hyperparameter value of 10−3 as mentioned in Sect. 3.5. During training, we calculate MAE and MSE in each epoch. When the epoch progresses, their values decrease.
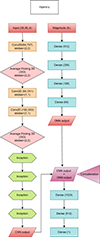 |
Fig. 2. Architecture of the Hybrid-z model, which employs four-band KiDS galaxy images together with nine-band KiDS+VIKING magnitudes for photo-z derivation. For the CNN part (left-hand side), the symbols used are as in Fig. 1, while inception modules are represented as hexagons. In the fully connected part (right-hand side), dense layers are given as blue rectangles, and the number of neurons is shown in parentheses. |
The features extracted by the convolutional and average pooling layers are passed through the Inception module before reaching the final dense layers. We found that the performance of the model improves with the inclusion of Inception, with notable improvement found in the reduction of the loss function value. We conducted tests with different numbers of Inception modules, ranging from three to five. Our findings suggest that using four Inception modules with varying numbers of filters is optimal for our data. The first inception module receives input from the Average Pooling 2D layer, while each subsequent inception module takes its input from the output of the preceding inception module. The initial inception modules extract low-level features and the final inception layers capture the global patterns in the image. Padding is applied before the convolutional and pooling operations for each Conv2D and AveragePooling2D layer using the ‘same’ padding (He et al. 2015). This ensures that the spatial dimensions (height and width) of the output feature maps are maintained as much as possible relative to the input. When the kernel is applied to the input, padding is added around the edges as necessary to keep the spatial dimensions consistent after each convolution and pooling operation.
As in Li et al. (2022) and Henghes et al. (2022), for our photo-z model, we combined two different types of networks, “shallow” (fully connected) ANN, that we will denote as ordinary neural networks (ONNs) and CNN, hence the name Hybrid-z. There are ∼13.8 million trainable parameters in our model. An important aspect of the Hybrid-z model is the concatenation step. The nine-band magnitudes of galaxies are the additional information for the network. These are processed by dense layers. The flattened feature map and ONN output are combined via depth-wise concatenation. ONN output has 64 features. However, when we include images, the number of features increases to 12 064. Then this concatenated information is passed through final layers for the prediction of photo-zs. This significant increase in features for final dense layers after concatenation highlights the substantial contribution of the image data.
In Fig. 3, the performance of the Huber loss function for the Hybrid-z is shown. The addition of supplementary information enhances the model’s performance with respect to using only 4-band images. We find that for this model, we can achieve R2 value greater than 0.93. We used early stopping criteria (Prechelt 1996) for determining the number of epochs. The threshold for considering an improvement is zero, meaning that any decrease in the validation loss would count as an improvement. Early stopping will be triggered after ten consecutive epochs where the validation loss does not improve and the training will automatically stop.
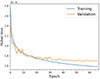 |
Fig. 3. Performance of the Huber loss function during the training and validation stage of the Hybrid-z. |
5. Results and discussion
Here we present the results of applying the model described in the previous Section to the KiDS-Bright data discussed in Sect. 2. We benchmark our findings against the results obtained previously in B21 using ‘shallow’ neural-network software ANNz2. We then analyze the Hybrid-z results for the test sample in more detail. Finally, we apply our best model to the entire KiDS-Bright DR4 photometric sample and discuss the properties of the resulting photo-zs. To reiterate, our training and testing samples with redshift labels have been selected from GAMA equatorial data.
5.1. Hybrid-z performance on test data
The comparison of the main statistics of Hybrid-z versus ANNz2 results are provided in Table 1. Our new model employing jointly optical imaging and KiDS+VIKING magnitudes performs clearly better than ANNz2 which used 9-band magnitudes. In the first block of the Table, we provide statistics of a general test sample, which consists of GAMA galaxies crossmatched with KiDS-Bright including both ‘clean’ (masked = 0) and ‘contaminated’ (masked = 1) data, where the ‘masked’ flag was derived in B21 based on the KiDS-internal ‘MASK’ bit-wise column. The compared methods have comparable mean residuals – that is, they are similarly accurate – but Hybrid-z outperforms ANNz2 in its photo-z precision, quantified as the scatter in Δz. Both in terms of standard deviation and SMAD, our combined CNN+ONN approach performs better, be it for the overall or clean (masked = 0) test data. Hybrid-z provides about 20% smaller scatter than the ANNz2-based derivations of B21, where 9-band magnitudes were used. In the case of the fiducial clean data that are recommended for science, we achieve SMAD(Δz)≃0.014, as compared to 0.018 in B21. Our result is at the same level as that by Treyer et al. (2024) where CNNs were used for photo-zs based on SDSS images at similar depths as in our case.
Statistics of photometric redshift performance obtained for the KiDS-GAMA test sample.
To further evaluate the performance and stability of Hybrid-z, we used the k-fold cross-validation technique. We employ k = 5 folds, and the dataset was systematically divided into five distinct subsets. In each iteration of the cross-validation process, one fold was reserved for validation, another for testing, and the remaining three folds were used for training the model. This procedure was repeated five times, each fold taking a turn as the validation and testing set. This ensures that each data point is used for validation, testing, and training, providing a comprehensive evaluation of the model’s performance across different subsets of data. The photo-z statistics for each of the folds were very similar, we therefore quote in the tables numbers from only one such runs.
We visualize the performance of the Hybrid-z model in Figs. 4 and 5, where we limit the range of redshift shown to z < 0.6 as beyond that value there are practically no galaxies in our samples (for instance, there are only 18 objects with z > 0.6 in the test data). Figure 4 directly compares the true redshifts from the test set with our photo-z predictions. The running median (depicted by the thick red line) closely follows the diagonal for most of the 0 < z < 0.6 range, deviating only at the lowest and highest redshifts. This behavior is typical for ML photo-z derivations, which are unbiased as a function of photometric, but not spectroscopic redshifts. This is further illustrated in panels (a) and (b) of Fig. 5, where photo-z residuals (rescaled by 1 + z as typically done) are plotted as a function of respectively predicted photo-z (panel a) and of the true spectroscopic redshift (panel b).
 |
Fig. 4. Comparison of the true spectroscopic redshifts with the photometric ones derived with our framework, Hybrid-z, using four-band KiDS images and nine-band KiDS+VIKING magnitudes. The test data were taken from a subset of GAMA crossmatched with KiDS. The thick red line depicts the median while the thin lines show the scatter (SMAD) around the median. |
 |
Fig. 5. Photometric redshift errors of Hybrid-z as a function of four quantities, from left to right, (a) photometric redshift as derived in this work; (b) true spectroscopic redshift from the clean sample; (c) apparent r-band magnitude; and (d) observed u − g color. The thick solid red line represents the running median, while the thin red lines illustrate the scatter (SMAD), based on a blind test sample derived from GAMA. |
In panels (c) and (d) of Fig. 5 we illustrate the behavior of photo-z errors of our Hybrid-z model as a function of two observables: the r-band apparent magnitude and the observed u − g color. The former is shown for the ‘auto’ flux measurement, which approximates the total light of a galaxy and was used by B21 to select the flux-limited KiDS-Bright sample. We observe slightly growing scatter (thin red lines indicating SMAD in Fig. 5 (c)) at the faintest end of the sample (r ≲ 20). Otherwise, photo-zs are stable as a function of magnitude, with practically zero bias at most of the range. The u − g color shown in panel (d) can be used to split galaxies into red and blue populations (similarly as u − r, Strateva et al. 2001). Indeed, we see the bimodality in the plot, with bluer galaxies to the left and redder to the right. As expected for photo-zs, the former has a wider scatter with respect to the true value than the latter. The difference is, however, not substantial, and again the median biases for the whole range of the u − g color are very close to zero.
We further quantify the performance of Hybrid-z for blue and red galaxies in the two bottom blocks of Table 1. Here, for a direct comparison between this work and B21, the selection of the two galaxy types was based on their intrinsic rather than observed properties, namely via their positioning on the absolute r-band magnitude versus rest-frame u − g color diagram4 as discussed in B21. Similarly as for the full sample, also for these subsets, Hybrid-z provides considerable improvement in precision over ANNz2. Interestingly, this reduction in SMAD(Δz) is greater for blue galaxies (by ∼22%) than for red ones (∼17%). This is consistent with the fact that, as compared to the approaches relying solely on summary measurements such as magnitudes, the DL-based methods, which directly extract features from images to estimate redshifts, are expected to show larger improvement for galaxies with intricate morphologies such as spirals, that typically have bluer colors (e.g., Schuldt et al. 2021; Treyer et al. 2024). In contrast, for red galaxies – typically ellipticals with fewer features in images – the reduction in scatter for Hybrid-z is smaller than for the overall sample, although we would such as to emphasize that it still does perform better than ANNz2 for the same galaxy selection. In addition, it is worth noting that SMAD(Δz) of 0.0154 for blue galaxies as obtained by Hybrid-z is even smaller than the same statistic of ANNz2 for red ones (cf. blocks #3 and #4 of Table 1).
The final comparison between ANNz2 and Hybrid-z performance is provided in Fig. 6, where we show the distributions of photo-z errors Δz as calibrated on the GAMA test data. As discussed in B21, following earlier work (e.g., Bilicki et al. 2014), such a distribution presents non-Gaussian features in the wings and is therefore better fit with a “generalized Lorentzian” of the form5
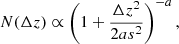
 |
Fig. 6. Comparison of photometric redshift error distributions between Hybrid-z (blue, this work) and ANNz2 (B21, red) shown as normalized counts based on the test sample results. Solid lines illustrate the best-fit Gaussian (with σ = 0.0145 and μ = 2.56 × 10−4, yellow) and generalized Lorentzian (Eq. 10, with a = 2.332 and s = 0.0116, black). The inset compares the histogram of Hybrid-z photo-z residuals with the fit models in logscale of the y-axis. |
where the mean bias is assumed to be negligible (but see Hang et al. 2021 on including non-zero mean). For our Hybrid-z model in the test sample, the best-fitting values are a = 2.332 and s = 0.0116. If we instead fit a Gaussian, this time allowing the mean to depart from 0, we get best-fit values of σ = 0.0145 and μ = 2.56 × 10−4. As visible in Fig. 6, the Gaussian is a worse fit to the residuals than Eq. (10). In the same plot, we also show the histogram for ANNz2 residuals as derived by B21, which is clearly broader. Quantitatively, the above numbers can be compared with best-fit {a, s}B21 = {2.613, 0.0149} and σB21 = 0.0180. For the Gaussian, the reduction in scatter of Hybrid-z is by 24%. For the modified Lorentzian, the width is encoded in the s parameter while a quantifies the extent of the wings; we see a reduction in both for Hybrid-z in comparison to ANNz2.
To summarize this subsection, the Hybrid-z model using CNNs on KiDS optical images together with ONNs on KiDS+VIKING magnitudes provides considerably better results than the previous 9-band ANNz2 derivations of B21. The improvement from ANNz2 to Hybrid-z is at the level of 20% reduction in photo-z scatter (better precision) while maintaining almost zero bias (very good accuracy). Thanks to our new model, we observe smaller photo-z errors for various subsamples of test data, and most remarkably for blue galaxies, where SMAD(Δz) is lowered by about 22% from what was obtained in B21. As such, these are state-of-the-art results for the KiDS-Bright galaxies and in line with independent derivations for SDSS at the same depth (Treyer et al. 2024).
5.2. Validation of Hybrid-z across external spectroscopic samples
In addition to the standard evaluation of Hybrid-z performance from Sect. 5.1 done on test samples statistically consistent with the training data (as both were randomly sampled from input GAMA equatorial catalogs), we have done a further validation of our photo-zs. Still using GAMA-Equatorial for training, we checked Hybrid-z predictions for a number of spectroscopic samples overlapping with the KiDS DR4 area and covering appropriate magnitude ranges and sky areas to provide sufficient statistics. These include GAMA Equatorial and G23 fields (Driver et al. 2022), 2dFGRS (Colless et al. 2001), SDSS DR16 (Ahumada et al. 2020), and 2dFLenS (Blake et al. 2016). Among these, GAMA G23 and 2dFLenS are disjoint with our GAMA-Equatorial training set, as they cover only the southern patch of KiDS (at δ < −25°)6. The surveys SDSS and 2dFGRS do have common objects with GAMA in its equatorial patches. However, they extend to the much wider KiDS area, so their overlap with GAMA-eq is also small.
In Table 2 we present the statistics derived from crossmatching the above-mentioned datasets with the full KiDS-Bright ‘clean’ sample. For each spectroscopic dataset, we compare the performance of Hybrid-z with previous ANNz2 results from B21. For each of these test sets, Hybrid-z performs considerably better in terms of scatter than ANNz2, while generally the former displays larger bias than the latter. This indicates that our new model loses some of the accuracy that ANNz2 had while gaining in precision (typical ML trade-off). We note, however, that in all the inspected cases, for Hybrid-z the mean biases in δz or Δz are much smaller than the scatter, meaning that the model is still highly accurate in its photo-z predictions. In the future, we plan to inspect this further with KiDS DR5 (Wright et al. 2024) 9-band imaging and extending the training with, for example, DESI DR1 (DESI Collaboration 2025), to see if we can minimize both precision and accuracy at the same time.
Statistics of photometric redshift performance for KiDS-Bright crossmatched with various spectroscopic samples.
What is worth noticing is the very small SMAD of Hybrid-z (∼0.012) for the SDSS DR16 crossmatch. This dataset, due to the r < 20 flux limit of KiDS-Bright, includes galaxies from the SDSS main sample (flux-limited to r < 17.77), as well as a subset of BOSS LOWZ and CMASS, dominated by luminous red galaxies. This combination leads to the photo-z statistics for such a SDSS × KiDS-Bright crossmatch being overall better than for the general red galaxies specified in Table 1. However, the same is not the case for ANNz2, which performs only marginally better for such a mixture of SDSS galaxies than it did for the general red galaxy selection.
Among the datasets included in Table 2, GAMA G23 and 2dFLenS are genuinely ‘blind’ test samples, as they are separated on-sky by many degrees from the area where the GAMA-Equatorial training sets are. Photo-z statistics derived from these catalogs should therefore be robust against possible overfitting thanks to their independence from the training data. While one should remember that neither G23 nor 2dFLenS are as complete and flux-limited samples as KiDS-Bright and GAMA-Equatorial, it is reassuring to find that for both of the former Hybrid-z gives considerable improvement over ANNz2, namely reduction in scatter by respectively 17% and 20%.
To summarize, in addition to evaluating the Hybrid-z model on test samples similar to the training data, we validated its photo-z predictions using several independent spectroscopic datasets within the KiDS DR4 survey area. Results show that Hybrid-z outperforms the previous ANNz2 model in terms of scatter across all test datasets, indicating robust performance also on datasets statistically different from the training.
5.3. Application to the KiDS-DR4 Bright sample
The Hybrid-z model trained on the full GAMA equatorial data, as discussed above, provides satisfactory results when tested on various overlapping spectroscopic datasets. However, applying it directly to the KiDS-Bright sample introduces artifacts in the final photo-z distribution, which we believe are related to the specific properties of the GAMA training set. Namely, GAMA sky coverage of 180 deg2 is small enough that the survey is affected by cosmic variance, manifesting itself by enhanced effects of the cosmic web, such as voids and filaments (e.g., Eardley et al. 2015). This results in significant ‘peaks’ and ‘dips’ in the GAMA redshift distribution, which should average out for larger sky area. However, these kind of features are still imprinted onto our photo-z predictions. Namely, training the Hybrid-z model directly on the full GAMA dataset leads to dN/dzphot of KiDS-Bright which mimics some of the LSS-related properties of GAMA dN/dzspec.
As discussed in previous papers (e.g., Bilicki et al. 2016, B21), the redshift distribution of GAMA has strong features, and in particular, there is an under-abundance of galaxies at zspec ∼ 0.25. This redshift is close to the median of the sample, which is where ML models typically work optimally. If we then train on such a specific distribution, our model becomes biased toward this input dN/dz, which results in a ‘dip’ at zphot ∼ 0.25 and two peaks below and above this value (see panel (a) of Fig. 7). As photo-zs dilute the structures in the radial direction, for a sample covering ∼1000 deg2 such as ours, this kind of strong features in its dN/dzphot are unlikely to be physical but rather originate from ‘redshift focusing’ of the model. However, this behavior was not observed in B21, where photo-zs were derived with ANNz2.
 |
Fig. 7. Photo-z distribution of the KiDS-DR4 Bright sample (r < 20 mag) as predicted by ANNz2 (blue, B21) compared with photo-z estimates from Hybrid-z (this work) trained on the spec-z distribution of (a) KiDS x GAMA bright sources (original training sample) (b) smoothed KiDS x GAMA bright sources. |
Our interpretation is that our new model is more sensitive to such strong features in the training data and this needs to be mitigated. One possibility would be to include training sets covering more of the sky, and hence they would be less affected by cosmic variance. This will be possible thanks to, for example, DESI7. Another option is to train several models, with for instance different random seeds and/or architectures, and appropriately combine their outputs into the final prediction. Such an approach is implemented in ANNz2, but it uses much less computationally demanding ONNs. Employing a similar framework with DL would be beyond our scope of research. Below we propose another mitigation strategy consisting of appropriately resampling (“smoothing”) the available training set.
The second effect we observe is related to the mismatch between the training and target photometric datasets at the faint end. Namely, GAMA is complete to a brighter magnitude than the KiDS-Bright selection, which will lead to some extrapolation of model predictions at the faint end. As quantified in the recent paper by Jalan et al. (2024), the GAMA-equatorial sample becomes considerably incomplete with respect to KiDS-Bright at r ≳ 19.5 mag. For a supervised ML model such as ours, this leads to extrapolation resulting from the so-called covariate shift. ML models tend to perform well when the test and training data share a well-matched feature space and distribution of the target quantity. When this distribution shifts or a covariate shift occurs, model performance can be adversely affected (Y et al. 2019). In our case, this affects the predictions at the faintest magnitudes of the sample. In particular, as was already the case for ANNz2, many galaxies with r > 19.5 are assigned zphot > 0.35 where training data is sparser. For Hybrid-z, training directly on the full GAMA dataset introduces additionally a new peak at zphot ∼ 0.38, revealing a redshift focusing effect in our model’s predictions as evident from panel (a) of Fig. 7).
In order to solve the above-discussed issues, for the final training of the full-sample photo-zs, we decided to subsample the spectroscopic redshifts from the GAMA equatorial dataset in such a way as to smooth out the peaks and dips originally present. The subsampling was done in such a way to not affect the color-redshift relation but instead provide a ‘smoother’ (more regular) input redshift distribution in GAMA without the strong features discussed above. We create this smoothed subsample of training data by iteratively adjusting the distribution of redshift values to achieve a more uniform histogram. Starting with an initial histogram of true z values, bins with counts that significantly exceed their neighboring bins are identified as spikes, based on a decreasing threshold. In each iteration, if a bin exceeds the count of its neighbors by this threshold, its count is reduced to either the average of its neighbors or its original count, whichever is lower. Randomly selected data points are then drawn from each bin according to the adjusted counts, preserving the dataset’s structure but smoothing out extreme values. This iterative process results in a more evenly distributed subsample, which is useful for downstream tasks, by reducing overrepresented regions. Finally, the resulting ‘KiDS ID’ values and their corresponding z values for this subsample are output, with a calculation of the subsample size as a percentage of the original dataset. This gave us an output of 118k galaxies from the GAMA training set (about 66%of the original one) and their redshift distribution is shown as red bars in panel (b) in Fig. 7. Using these smoothed data we retrained the Hybrid-z model and then applied it to the full r < 20 mag dataset of ∼1.2 million KiDS DR4 galaxies. Among these, about 996k have the flag ‘masked = 0’ indicating their usefulness for science (see B21 for details).
In panel (b) of Fig. 7 we compare the dN/dzphot of the full sample from our model (Hybrid-z) and ANNz2 from B21. We also show the spec-z distribution of the smoothed training sample. Differences in the photo-z distributions are notable between Hybrid-z and ANNz2, particularly at z ∼ 0.24 and within the redshift range of (0.3, 0.4). Otherwise, they are very consistent, despite the fact that ANNz2 redshifts were trained on the full GAMA sample as shown in panel (a), while Hybrid-z used the smoothed GAMA subsample for training, as shown in panel (b). What persists in our derivations is the peak at zphot ∼ 0.38, which is present whether we train on original or smoothed GAMA data. We note that the comparison between Hybrid-z and ANNz2 dN/dzphot serves here just as a cross-check, but the aim is not to make them overlapping. While some consistency between the two approaches is expected, as the models use the same input training data and were applied to the same inference sample, direct comparisons between two photo-z approaches should be done with care. For science applications of such data, further redshift calibration is needed to either reproduce the underlying dN/dztrue or to build a photo-z error model.
To summarize, the Hybrid-z model, trained on the full GAMA equatorial dataset, performs well on overlapping spectroscopic surveys, but introduces artifacts when applied directly to the KiDS-Bright sample, due to the specific properties of the GAMA training set. To mitigate these problems, a smoothed subsample of the training data was created to achieve a more uniform redshift distribution, which was then used to retrain the model. As a result, we obtain photo-z predictions for the full KiDS-DR4 Bright galaxy sample, which displays improved performance over previous derivations and also gives a generally artifact-free redshift distribution.
We release the photometric redshifts generated with our Hybrid-z model for the entire KiDS-DR4 Bright Sample as a supplement to the original dataset which was accompanying B21. This is available from the KiDS webpage at https://kids.strw.leidenuniv.nl/DR4/brightsample.php.
6. Conclusions and future prospects
This work presents the first DL photometric redshift (photo-z) derivations for the flux-limited KiDS-Bright galaxy sample with the selection threshold r < 20 mag (Bilicki et al. 2021). Previously, photo-zs for this catalog were estimated using “shallow” learning methods, specifically the ANNz2 neural network package (Sadeh et al. 2016). Our new model, Hybrid-z, is built on recent studies, including Li et al. (2022), where DL was applied for photo-zs in a deeper KiDS galaxy sample, and Treyer et al. (2024), who used a similar training set as us to obtain CNN-based redshifts for an SDSS-selected catalog with the same flux limit.
We built and tested a DL model for photo-z derivation called Hybrid-z that uses four-band KiDS images (ugri) processed by CNNs, which are combined with nine-band magnitudes from KiDS+VIKING, processed by an ONN. Rather than simply averaging the outputs of the two networks, we concatenated their outputs before the final three dense layers. This approach was inspired by the previous works of, for example, Li et al. (2022) and Henghes et al. (2022), and it yielded significantly improved photo-z performance compared to the previous ANNz2 derivations of B21, where nine-band KiDS+VIKING magnitudes were used. The Hybrid-z model reduces the scatter (SMAD) of Δz by 20% as compared to ANNz2 for the same test samples. This is true for multiple spectroscopic test datasets, of which some can be considered entirely “blind” in terms of being fully disjointed with the training data. When tested on the fiducial “clean” KiDS-Bright sample, Hybrid-z achieves a SMAD(Δz) of approximately 0.014(1 + z), representing a clear improvement over the prior ANNz2 results giving ∼0.018(1 + z) while maintaining the same minimal bias in δz of at most a few times 10−4.
The Hybrid-z model shows even greater improvement in photo-z precision when we separate out blue galaxies from the KiDS-Bright sample. For these objects, Hybrid-z reduces the SMAD of Δz by 22% as compared to ANNz2, resulting in a scatter comparable to that which ANNz2 attained for red galaxies. This of course, means that at the same time, the photo-z performance for red galaxies improves less than on average (by 17% in SMAD) after adding DL as compared to the ordinary “shallow” networks. This is consistent with expectations, as CNNs can leverage the detailed varied features in blue (typically spiral) galaxies more effectively than in the smoother elliptical red galaxies. In a flux-limited sample at low redshift, as ours, blue galaxies are more abundant than red galaxies, so such a property of the photo-z model is very useful to improve the overall quality of the derivations. These advancements pave the way for more refined astrophysical and cosmological analyses using KiDS-Bright data, such as of the stellar-to-halo-mass relation (B21) or multi-probe analyses (Dvornik et al. 2023).
Our new photo-z model trained on the GAMA equatorial dataset performs reliably on KiDS overlapping spectroscopic data, but it introduces artifacts in the redshift distribution when directly applied to the KiDS-Bright sample. These artifacts stem from GAMA’s limited sky coverage and cosmic variance, which affect the resulting dN/dzphot and introduce specific patterns that mimic GAMA characteristics, such as a notable dip at zphot ∼ 0.25, and extrapolation issues at faint magnitudes and where r > 19.5 mag. To overcome these limitations, we created a smoothed subsample of the GAMA training data by reducing sharp peaks and dips in its redshift distribution and achieving a more uniform dN/dzspec for final model training. This approach mitigates artifacts in the output dN/dzphot, thus enhancing the reliability of our photo-z estimates. These improved photo-zs for the KiDS-DR4 Bright sample (∼1.2M galaxies) are available publicly online8.
In this work, our DL analysis focused on the four-band KiDS optical images, while the full nine-band KiDS+VIKING photometry was used only in the form of magnitudes. Moving forward, we plan to build an extended DL model incorporating images from all nine bands, from KiDS u to VIKING Ks, once the NIR coadds are available; currently, they are being prepared for the 4MOST WAVES target selection (Driver et al. 2019). We anticipate that this expansion will improve CNN-based photo-z precision and will mirror the gains seen from KiDS DR3 ugri (Bilicki et al. 2018) to nine-band inclusion in DR4 (Bilicki et al. 2021). We plan to apply such an enhanced Hybrid-z model to the final KiDS Data Release 5 (Wright et al. 2024) for state-of-the-art bright-end photometric redshifts. Additional improvement in DR5 is expected thanks to the second i-band pass, which deepens effective imaging and should help further refine our photo-z estimates. Last but not least, our approach holds promise for even deeper imaging applications in the forthcoming Legacy Survey of Space and Time (LSST Science Collaboration 2009), paving the way for robust photo-zs in future large-scale sky surveys.
Data availability
The photometric redshift catalog based on the Hybrid-z DL model, containing redshifts for over 1.2 million galaxies in the KiDS-Bright DR4 sample, is available at the CDS via anonymous ftp to cdsarc.cds.unistra.fr (130.79.128.5) or via https://cdsarc.cds.unistra.fr/viz-bin/cat/J/A+A/698/A276
See https://www.astro.ljmu.ac.uk/~ikb/research/gama_fields/ for the GAMA field locations.
It is interesting to note that also spectroscopic redshifts may present Lorentizan rather than Gaussian uncertainties, e.g., Yu et al. (2024).
DESI Data Release 1 (DESI Collaboration 2025) was released after this work had been completed; hence, we do not include it here.
Acknowledgments
We would like to thank Elisa Chisari, Rui Li, Nicola Napolitano & Angus Wright for their valuable comments and suggestions on the manuscript. Based on data products from observations made with ESO Telescopes at the La Silla Paranal Observatory under program IDs 177.A-3016, 177.A-3017 and 177.A-3018, and on data products produced by Target/OmegaCEN, INAF-OACN, INAF-OAPD and the KiDS production team, on behalf of the KiDS consortium. OmegaCEN and the KiDS production team acknowledge support by NOVA and NWO-M grants. Members of INAF-OAPD and INAF-OACN also acknowledge the support from the Department of Physics & Astronomy of the University of Padova, and of the Department of Physics of Univ. Federico II (Naples). GAMA is a joint European-Australasian project based around a spectroscopic campaign using the Anglo-Australian Telescope. The GAMA input catalog is based on data taken from the Sloan Digital Sky Survey and the UKIRT Infrared Deep Sky Survey. Complementary imaging of the GAMA regions is being obtained by a number of independent survey programs including GALEX MIS, VST KiDS, VISTA VIKING, WISE, Herschel-ATLAS, GMRT, and ASKAP providing UV to radio coverage. GAMA is funded by the STFC (UK), the ARC (Australia), the AAO, and the participating institutions. The GAMA website is http://www.gama-survey.org/. This work is supported by the Polish National Science Center through grants no. 2020/38/E/ST9/00395, and 2018/31/G/ST9/03388. We have made use of TOPCAT (Taylor 2005) and STILTS (Taylor 2006) software, as well as of PYTHON (www.python.org), including the packages NUMPY (Harris et al. 2020), SCIPY (Virtanen et al. 2020), and MATPLOTLIB (Hunter 2007).
References
- Ahumada, R., Allende Prieto, C., Almeida, A., et al. 2020, ApJS, 249, 3 [NASA ADS] [CrossRef] [Google Scholar]
- Ansari, Z., Agnello, A., & Gall, C. 2021, A&A, 650, A90 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Baum, W. A. 1957, AJ, 62, 6 [NASA ADS] [CrossRef] [Google Scholar]
- Baum, W. A. 1962, in Problems of Extra-Galactic Research, ed. G. C. McVittie, 15, 390 [Google Scholar]
- Bellstedt, S., Driver, S. P., Robotham, A. S. G., et al. 2020, MNRAS, 496, 3235 [NASA ADS] [CrossRef] [Google Scholar]
- Benítez, N. 2000, ApJ, 536, 571 [Google Scholar]
- Bertin, E., & Arnouts, S. 1996, A&AS, 117, 393 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bilicki, M., Jarrett, T. H., Peacock, J. A., Cluver, M. E., & Steward, L. 2014, ApJS, 210, 9 [Google Scholar]
- Bilicki, M., Peacock, J. A., Jarrett, T. H., et al. 2016, ApJS, 225, 5 [Google Scholar]
- Bilicki, M., Hoekstra, H., Brown, M. J. I., et al. 2018, A&A, 616, A69 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bilicki, M., Dvornik, A., Hoekstra, H., et al. 2021, A&A, 653, A82 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Blake, C., Amon, A., Childress, M., et al. 2016, MNRAS, 462, 4240 [NASA ADS] [CrossRef] [Google Scholar]
- Bonfield, D. G., Sun, Y., Davey, N., et al. 2010, MNRAS, 405, 987 [Google Scholar]
- Capaccioli, M., & Schipani, P. 2011, The Messenger, 146, 2 [NASA ADS] [Google Scholar]
- Carliles, S., Budavári, T., Heinis, S., Priebe, C., & Szalay, A. S. 2010, ApJ, 712, 511 [NASA ADS] [CrossRef] [Google Scholar]
- Cavuoti, S., Brescia, M., De Stefano, V., & Longo, G. 2015, Exp. Astron., 39, 45 [Google Scholar]
- Chollet, F. 2017, Deep Learning with Python (New York, NY: Manning Publications) [Google Scholar]
- Colless, M., Dalton, G., Maddox, S., et al. 2001, MNRAS, 328, 1039 [Google Scholar]
- Collister, A. A., & Lahav, O. 2004, PASP, 116, 345 [NASA ADS] [CrossRef] [Google Scholar]
- Connolly, A. J., Csabai, I., Szalay, A. S., et al. 1995, AJ, 110, 2655 [NASA ADS] [CrossRef] [Google Scholar]
- Cunha, P. A. C., & Humphrey, A. 2022, A&A, 666, A87 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- de Jong, J. T. A., Verdoes Kleijn, G. A., Kuijken, K. H., & Valentijn, E. A. 2013, Exp. Astron., 35, 25 [Google Scholar]
- de Jong, J. T. A., Verdoes Kleijn, G. A., Boxhoorn, D. R., et al. 2015, A&A, 582, A62 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- DESI Collaboration (Aghamousa, A., et al.) 2016, arXiv e-prints [arXiv:1611.00036] [Google Scholar]
- DESI Collaboration (Abdul-Karim, M., et al.) 2025, arXiv e-prints [arXiv:2503.14745] [Google Scholar]
- Dey, B., Andrews, B. H., Newman, J. A., et al. 2022, MNRAS, 515, 5285 [NASA ADS] [CrossRef] [Google Scholar]
- D’Isanto, A., & Polsterer, K. L. 2018, A&A, 609, A111 [Google Scholar]
- Driver, S. P., Hill, D. T., Kelvin, L. S., et al. 2011, MNRAS, 413, 971 [Google Scholar]
- Driver, S. P., Liske, J., Davies, L. J. M., et al. 2019, The Messenger, 175, 46 [NASA ADS] [Google Scholar]
- Driver, S. P., Bellstedt, S., Robotham, A. S. G., et al. 2022, MNRAS, 513, 439 [NASA ADS] [CrossRef] [Google Scholar]
- Dvornik, A., Heymans, C., Asgari, M., et al. 2023, A&A, 675, A189 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Eardley, E., Peacock, J. A., McNaught-Roberts, T., et al. 2015, MNRAS, 448, 3665 [NASA ADS] [CrossRef] [Google Scholar]
- Edge, A., Sutherland, W., Kuijken, K., et al. 2013, The Messenger, 154, 32 [NASA ADS] [Google Scholar]
- Gholamalinezhad, H., & Khosravi, H. 2020, arXiv e-prints [arXiv:2009.07485] [Google Scholar]
- Goodfellow, I., Bengio, Y., & Courville, A. 2016, Deep Learning (MIT Press) [Google Scholar]
- Graham, M. L., Connolly, A. J., Željko Ivezic, et al. 2017, AJ, 155, 1 [Google Scholar]
- Grespan, M., Thuruthipilly, H., Pollo, A., et al. 2024, A&A, 688, A34 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hang, Q., Alam, S., Peacock, J. A., & Cai, Y.-C. 2021, MNRAS, 501, 1481 [Google Scholar]
- Harris, C. R., Millman, K. J., van der Walt, S. J., et al. 2020, Nature, 585, 357 [NASA ADS] [CrossRef] [Google Scholar]
- He, K., Zhang, X., Ren, S., & Sun, J. 2015, arXiv e-prints [arXiv:1512.03385] [Google Scholar]
- Henghes, B., Thiyagalingam, J., Pettitt, C., Hey, T., & Lahav, O. 2022, MNRAS, 512, 1696 [NASA ADS] [CrossRef] [Google Scholar]
- Hildebrandt, H., Arnouts, S., Capak, P., et al. 2010, A&A, 523, A31 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hildebrandt, H., van den Busch, J. L., Wright, A. H., et al. 2021, A&A, 647, A124 [EDP Sciences] [Google Scholar]
- Hoyle, B. 2016, Astron. Comput., 16, 34 [NASA ADS] [CrossRef] [Google Scholar]
- Huber, P. J. 1964, Ann. Math. Stat., 35, 73 [CrossRef] [Google Scholar]
- Hunter, J. D. 2007, Comput. Sci. Eng., 9, 90 [NASA ADS] [CrossRef] [Google Scholar]
- Jalan, P., Bilicki, M., Hellwing, W. A., et al. 2024, A&A, 692, A177 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Jentzen, A., Kuckuck, B., & von Wurstemberger, P. 2023, arXiv e-prints [arXiv:2310.20360] [Google Scholar]
- Jones, E., Do, T., Li, Y. Q., et al. 2024, ApJ, 974, 159 [NASA ADS] [CrossRef] [Google Scholar]
- Kingma, D. P., & Ba, J. 2014, arXiv e-print [arXiv:1412.6980] [Google Scholar]
- Krone-Martins, A., Ishida, E. E. O., & de Souza, R. S. 2014, MNRAS, 443, L34 [NASA ADS] [CrossRef] [Google Scholar]
- Kuijken, K. 2008, A&A, 482, 1053 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kuijken, K., Heymans, C., Hildebrandt, H., et al. 2015, MNRAS, 454, 3500 [Google Scholar]
- Kuijken, K., Heymans, C., Dvornik, A., et al. 2019, A&A, 625, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. 1998, Proc. IEEE, 86, 2278 [Google Scholar]
- Li, C., Zhang, Y., Cui, C., et al. 2021, MNRAS, 509, 2289 [CrossRef] [Google Scholar]
- Li, R., Napolitano, N. R., Feng, H., et al. 2022, A&A, 666, A85 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Liske, J., Baldry, I. K., Driver, S. P., et al. 2015, MNRAS, 452, 2087 [Google Scholar]
- LSST Science Collaboration (Abell, P. A., et al.) 2009, arXiv e-prints [arXiv:0912.0201] [Google Scholar]
- McCulloch, W. S. P., 1943, Bull. Math. Biophys., 5, 115 [CrossRef] [Google Scholar]
- McFarland, J. P., Verdoes-Kleijn, G., Sikkema, G., et al. 2013, Exp. Astron., 35, 45 [Google Scholar]
- Menou, K. 2019, MNRAS, 489, 4802 [NASA ADS] [CrossRef] [Google Scholar]
- Oyaizu, H., Lima, M., Cunha, C. E., et al. 2008, ApJ, 674, 768 [Google Scholar]
- Pasquet, J., Bertin, E., Treyer, M., Arnouts, S., & Fouchez, D. 2019, A&A, 628, A10 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pedregosa, F., Varoquaux, G., Gramfort, A., et al. 2011, J. Mach. Learn. Res., 12, 2825 [Google Scholar]
- Prechelt, L. 1996, Neural Networks, 9, 457 [Google Scholar]
- Roster, W., Salvato, M., Krippendorf, S., et al. 2024, A&A, 692, A260 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rozo, E., Rykoff, E. S., Abate, A., et al. 2016, MNRAS, 461, 1431 [NASA ADS] [CrossRef] [Google Scholar]
- Sadeh, I., Abdalla, F. B., & Lahav, O. 2016, PASP, 128, 104502 [NASA ADS] [CrossRef] [Google Scholar]
- Schlafly, E. F., & Finkbeiner, D. P. 2011, ApJ, 737, 103 [Google Scholar]
- Schlegel, D. J., Finkbeiner, D. P., & Davis, M. 1998, ApJ, 500, 525 [Google Scholar]
- Schuldt, S., Suyu, S. H., Cañameras, R., et al. 2021, A&A, 651, A55 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Shorten, C., & Khoshgoftaar, T. M. 2019, J. Big Data, 6, 1 [CrossRef] [Google Scholar]
- Strateva, I., Ivezić, Ž., Knapp, G. R., et al. 2001, AJ, 122, 1861 [CrossRef] [Google Scholar]
- Szegedy, C., Liu, W., Jia, Y., et al. 2015, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 1 [Google Scholar]
- Tagliaferri, R., Longo, G., Andreon, S., et al. 2003, Lect. Notes Comput. Sci., 2859, 226 [NASA ADS] [CrossRef] [Google Scholar]
- Taylor, M. B. 2005, in Astronomical Data Analysis Software and Systems XIV, eds. P. Shopbell, M. Britton, & R. Ebert, ASP Conf. Ser., 347, 29 [Google Scholar]
- Taylor, M. B. 2006, in Astronomical Data Analysis Software and Systems XV, eds. C. Gabriel, C. Arviset, D. Ponz, & S. Enrique, ASP Conf. Ser., 351, 666 [Google Scholar]
- Treyer, M., Ait Ouahmed, R., Pasquet, J., et al. 2024, MNRAS, 527, 651 [Google Scholar]
- Vakili, M., Bilicki, M., Hoekstra, H., et al. 2019, MNRAS, 487, 3715 [Google Scholar]
- Vakili, M., Hoekstra, H., Bilicki, M., et al. 2023, A&A, 675, A202 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Virtanen, P., Gommers, R., Oliphant, T. E., et al. 2020, Nat. Methods, 17, 261 [Google Scholar]
- Wadadekar, Y. 2004, PASP, 117, 79 [Google Scholar]
- Way, M. J., & Klose, C. D. 2012, PASP, 124, 274 [NASA ADS] [CrossRef] [Google Scholar]
- Way, M. J., & Srivastava, A. N. 2006, ApJ, 647, 102 [Google Scholar]
- Wright, A. H., Kuijken, K., Hildebrandt, H., et al. 2024, A&A, 686, A170 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Xia, Z. 2024, Appl. Comput. Eng., 37, 212 [Google Scholar]
- Y, G. D., Nair, N. G., Satpathy, P., & Christopher, J. 2019, in 2019 Global Conference for Advancement in Technology (GCAT), 1 [Google Scholar]
- Yu, J., Ross, A. J., Rocher, A., et al. 2024, arXiv e-prints [arXiv:2405.16657] [Google Scholar]
All Tables
Statistics of photometric redshift performance obtained for the KiDS-GAMA test sample.
Statistics of photometric redshift performance for KiDS-Bright crossmatched with various spectroscopic samples.
All Figures
|
Fig. 1. Inception module used in this study to estimate the photo-z. The input layer has size (36,36,4). Conv2D is a two-dimensional convolution layer, with the kernel size specified in brackets. Average Pooling 2D is a two-dimensional pooling operation that uses a kernel of size 3 × 3. Each operation is represented using boxes of distinct colors. Concatenation is the combined feature maps from parallel convolutions. |
| In the text | |
|
Fig. 2. Architecture of the Hybrid-z model, which employs four-band KiDS galaxy images together with nine-band KiDS+VIKING magnitudes for photo-z derivation. For the CNN part (left-hand side), the symbols used are as in Fig. 1, while inception modules are represented as hexagons. In the fully connected part (right-hand side), dense layers are given as blue rectangles, and the number of neurons is shown in parentheses. |
| In the text | |
|
Fig. 3. Performance of the Huber loss function during the training and validation stage of the Hybrid-z. |
| In the text | |
|
Fig. 4. Comparison of the true spectroscopic redshifts with the photometric ones derived with our framework, Hybrid-z, using four-band KiDS images and nine-band KiDS+VIKING magnitudes. The test data were taken from a subset of GAMA crossmatched with KiDS. The thick red line depicts the median while the thin lines show the scatter (SMAD) around the median. |
| In the text | |
|
Fig. 5. Photometric redshift errors of Hybrid-z as a function of four quantities, from left to right, (a) photometric redshift as derived in this work; (b) true spectroscopic redshift from the clean sample; (c) apparent r-band magnitude; and (d) observed u − g color. The thick solid red line represents the running median, while the thin red lines illustrate the scatter (SMAD), based on a blind test sample derived from GAMA. |
| In the text | |
|
Fig. 6. Comparison of photometric redshift error distributions between Hybrid-z (blue, this work) and ANNz2 (B21, red) shown as normalized counts based on the test sample results. Solid lines illustrate the best-fit Gaussian (with σ = 0.0145 and μ = 2.56 × 10−4, yellow) and generalized Lorentzian (Eq. 10, with a = 2.332 and s = 0.0116, black). The inset compares the histogram of Hybrid-z photo-z residuals with the fit models in logscale of the y-axis. |
| In the text | |
|
Fig. 7. Photo-z distribution of the KiDS-DR4 Bright sample (r < 20 mag) as predicted by ANNz2 (blue, B21) compared with photo-z estimates from Hybrid-z (this work) trained on the spec-z distribution of (a) KiDS x GAMA bright sources (original training sample) (b) smoothed KiDS x GAMA bright sources. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.