| Issue |
A&A
Volume 694, February 2025
|
|
|---|---|---|
| Article Number | A162 | |
| Number of page(s) | 15 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202452927 | |
| Published online | 11 February 2025 | |
Improvements to monoscopic analysis for imaging atmospheric Cherenkov telescopes: Application to H.E.S.S.
1
Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen Centre for Astroparticle Physics,
Nikolaus-Fiebiger-Str. 2,
91058
Erlangen,
Germany
2
Max-Planck-Institut für Kernphysik,
Saupfercheckweg 1,
69117
Heidelberg,
Germany
3
Indian Institute of Science Education and Research (IISER) Tirupati,
Tirupati
517507,
Andhra Pradesh,
India
★ Corresponding authors; This email address is being protected from spambots. You need JavaScript enabled to view it.
; This email address is being protected from spambots. You need JavaScript enabled to view it.
; This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
8
November
2024
Accepted:
8
January
2025
Abstract
Imaging atmospheric Cherenkov telescopes (IACTs) detect γ rays by measuring the Cherenkov light emitted by secondary particles in the air shower when the γ rays hit the atmosphere of the Earth. Given usual distances between telescopes in IACT arrays, at low energies (≲100 GeV), the limited amount of Cherenkov light produced typically implies that the event is registered by one IACT only. Such events are called monoscopic events, and their analysis is particularly difficult. Challenges include the reconstruction of the event’s arrival direction, energy, and the rejection of background events due to charged cosmic rays. Here, we present a set of improvements, including a machine-learning algorithm to determine the correct orientation of the image in the camera frame, an intensity-dependent selection cut that ensures optimal performance across all energies, and a collection of new image parameters. To quantify these improvements, we make use of simulations and data from the 28-m diameter central telescope of the H.E.S.S. IACT array. Knowing the correct image orientation, which corresponds to the arrival direction of the photon in the camera frame, is especially important for the angular reconstruction, which could be improved in resolution by 57% at 100 GeV. The event selection cut, which now depends on the total measured intensity of the events, leads to a reduction of the low-energy threshold for source analyses by ~50%. The new image parameters characterize the intensity and time distribution within the recorded images and complement the traditionally used Hillas parameters in the machine learning algorithms. We evaluate their importance to the algorithms in a systematic approach and carefully evaluate associated systematic uncertainties. We find that including subsets of the new variables in machine-learning algorithms improves the reconstruction and background rejection, resulting in a sensitivity improved by 41% at the low-energy threshold. Finally, we apply the new analysis to data from the Crab Nebula and estimate systematic uncertainties introduced by the new method.
Key words: methods: data analysis / gamma rays: general
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
Since the success of the first generation of ground-based γ-ray telescopes (Weekes et al. 1989), significant advances have been made in both hardware and software development (Funk 2015). The basic detection principle has remained the same: Cherenkov light, emitted by charged secondary particles in γ-ray induced air showers, is collected by imaging atmospheric Cherenkov telescopes (IACTs). Modern arrays, such as VERITAS (Weekes et al. 2002), MAGIC (Aleksić et al. 2016), and H.E.S.S. (Aharonian et al. 2006), employ stereoscopic event reconstruction techniques, where one shower is observed by at least two telescopes. This stereoscopic approach improves the reconstruction accuracy of the properties of the primary particle and improves the rejection of background events arising from interactions of charged cosmic rays (Konopelko et al. 1999).
However, not all γ-ray events are captured by multiple telescopes, which makes monoscopic (or mono) event reconstruction still crucial. This is particularly relevant for the H.E.S.S. array, where the large central telescope, with its 28 m mirror diameter, operates in mono-trigger mode and primarily detects low-energy events (≲100 GeV), often seen by this telescope alone. The importance and methodology for reconstructing these mono events are discussed in Murach et al. (2015). Their approach utilizes the traditional “Hillas parameters” (Hillas 1985), which characterize the first four moments of the intensity distribution within the shower images, as input to machine learning algorithms. Although other reconstruction techniques exist, such as template-based methods (Parsons & Hinton 2014), background rejection for mono events in H.E.S.S. is currently performed exclusively using image parameters. Using intensity information directly in machine learning models is an alternative (see, e.g., Holch et al. 2017; Parsons & Ohm 2020; Lyard et al. 2020; Miener et al. 2022; Glombitza et al. 2023), but poses challenges due to the sensitivity of the models to discrepancies between simulations and recorded data (Shilon et al. 2019; Parsons et al. 2022). Improving the reconstruction and background rejection for low-energy γ rays can further lower the energy threshold and increase the sensitivity of our observations.
By including the pixel time information in the analysis of monoscopic data from the MAGIC telescope, Aliu et al. (2009) could already achieve notable improvements in point-source sensitivity. The construction and usage of additional image parameters in reconstruction algorithms, as well as the optimization of the event selection cut, is discussed in Voigt (2014). A recent study by Abe et al. (2024) even included information from waveforms recorded by individual camera pixels in the reconstruction algorithms.
In this work, we explore the potential of incorporating additional image parameters that capture more detailed features of the amplitude and time distribution in the shower image. A systematic approach is used to assess the importance of each parameter for the reconstruction and background rejection algorithms, leading to an optimized subset of parameters tailored to each application. We also examine the systematic uncertainties arising from discrepancies between different observation conditions, both prior to and following the inclusion of these new image parameters. Moreover, we introduce a machine-learning algorithm trained to determine the direction of the shower development in the camera frame, enabling the calculation of the new image parameters based on a more accurate image orientation. Currently, the direction of the shower is determined solely using the Hillas-skewness (defined in Sect. 2.1.1), which is an unreliable parameter for both small and truncated images. We also implement a selection cut optimized for different event sizes (size here and in what follows stands for the total image intensity), which outperforms the standard constant selection cut used in Murach et al. (2015). This optimization is crucial because the performance of the classification algorithm improves significantly with event size, and a constant cut does not fully exploit the potential across all sizes (Voigt et al. 2014).
The new image parameters are introduced in Sect. 2.1, followed by the description of the machine learning model architecture for event reconstruction and classification in Sect. 2.2, and the optimization of the size-dependent selection cut in Sect. 2.3. Finally, we assess the performance of the new reconstruction chain and compare it to the previous one in Sects. 3.1–3.3, with an application to real Crab Nebula data presented in Sect. 3.4.
2 Implementation
This study is based on γ-ray events simulated and observed using the central large telescope (CT5) of the H.E.S.S. array, equipped with the FlashCam camera (van Eldik et al. 2016; Bi et al. 2021). Air showers are simulated using the CORSIKA package (Heck et al. 1998), and the telescope response is simulated using sim_telarray (Bernlöhr 2008). Simulated events follow a power-law distribution ∼ E−γ with a spectral index of 1.8 to increase statistics at higher energies and are then re-weighted to a spectral index of 2.5. After extracting the pixel amplitudes and times (i.e., integrated photoelectrons (p.e.) and peak signal times), noise pixels are set to zero by a cleaning procedure. A tail-cut image cleaning is used to classify core pixels, which have an amplitude above 14 p.e and at least 2 neighbor pixels above 7 p.e. Core and neighbor pixels are kept, while the time information is not considered during this step. Algorithms that use time information for image cleaning have been developed for H.E.S.S. Steinmaßl (2023) but are not yet adopted in the standard analysis pipeline. For this reason, we adhere to the standard tail-cut method to maintain consistency and minimize introducing correlated changes into the analysis pipeline. Future studies will explore potential enhancements to the image cleaning technique and the resulting improvements in source detection sensitivity. Based on the remaining signal pixels, image parameters are computed, forming the basis for event reconstruction and classification. All these steps (after simulation) are implemented in the H.E.S.S. analysis program (HAP). For this study, we apply preselection cuts, requiring a total image amplitude above 80 p.e. and a minimum of five pixels. This minimum image size is relatively close to the trigger threshold of the telescope at 69 p.e. (Bi et al. 2021), while maintaining a safe distance, to avoid systematic uncertainties due to mis-modeling of the camera response in this regime. The distance from the image center of gravity to the center of the camera (so-called Hillas-local-distance, see Sect. 2.1.1) is required to be smaller than 0.8 m to reduce image truncation effects at the camera edges, which are between 1.0m to 1.2 m.
In the following subsections, we define the image parameters investigated in this study before presenting the reconstruction framework and architecture of the machine learning models.
2.1 Definition of training variables
The variables described in this section characterize the spatial and temporal distribution of the pixel amplitudes and times, either for the whole image or parts of the image. To improve background rejection, they aim to be sensitive to differences between cosmic ray-induced (hereafter hadronic) background showers and γ ray-induced air showers. These differences are most prominently seen in the more irregular shower morphology for hadronic showers, caused by electromagnetic, muonic, and hadronic subshowers. In Appendix A, the distribution of each variable is shown for measured background data, together with proton and γ-ray simulations.
Even though one would not necessarily expect perfect agreement between background data and proton simulations due to various factors, such as the primary cosmic-ray composition or atmospheric and instrument conditions, a good agreement between these distributions indicates that the simulated atmosphere, telescope, and night sky background (NSB) light match reality. The consistency between the measured and simulated data for FlashCam in CT5 is discussed in detail by Leuschner et al. (2023). Since the background events are characterized by their isotropic arrival directions, we compare their distributions to those of diffuse γ-ray simulations1. These are available with a realistic NSB value, based on the average observed Galactic NSB, and a value that is ∼1.65 times higher than this. A difference between these sets of simulations indicates that the given variable is sensitive to the details of the NSB and therefore introduces systematic uncertainties, as the NSB values vary between observations but are typically kept at a fixed value for most simulations. Large differences between the hadronic and γ- ray distributions imply strong separation power for this variable, although some variables are correlated, which reduces the gain in separation power when combining these variables.
The camera image reflects the development of the shower in the atmosphere and is typically parameterized as an ellipse. The longitudinal development is encoded along the major axis of the image, the head reflecting the top part of the shower where the first interaction takes place, while the tail represents the bottom part of the shower where many shower particles contribute to the emission. Since the charged shower particles travel at a slightly higher speed compared to the Cherenkov photons in the atmosphere, the arrival times do not necessarily follow the sequence head-center-tail. They rather depend on the impact distance, the distance between the shower’s impact point on the ground and the telescope’s position, for geometrical reasons.
For the computation of the variables, we consider the position of pixel i in the camera frame (XCAM,i, YCAM,i), its amplitude Ai (integrated charge in the readout window), and time Ti (peak time of the charge time-evolution). The image coordinates (Xi, Yi) then follow as a translation plus rotation
![Mathematical equation: $\left[ {\matrix{ {{X_i}} \cr {{Y_i}} \cr } } \right] = \left[ {\matrix{ {\cos (\alpha )} & {\sin (\alpha )} \cr { - \sin (\alpha )} & {\cos (\alpha )} \cr } } \right]\left[ {\matrix{ {{X_{{\rm{CAM}},{\rm{i}}}} - \left\langle {{X_{{\rm{CAM}}}}} \right\rangle } \cr {{Y_{{\rm{CAM}},{\rm{i}}}} - \left\langle {{Y_{{\rm{CAM}}}}} \right\rangle } \cr } } \right],$](/articles/aa/full_html/2025/02/aa52927-24/aa52927-24-eq1.png) (1)
(1)
where α is the angle that minimizes the r.m.s. of the intensity distribution along the Y-direction and (<XCAM>, <YCAM>) is the center of gravity of the image in the camera frame. Consequently, the center of gravity lies at (0,0) in these coordinates, and the major axis of the ellipse is aligned with the X axis.
2.1.1 Hillas parameter-based variables
The first set of variables was introduced by Hillas (1985) and characterizes the second, third, and fourth moments of the amplitude distribution. These variables are widely referred to as “Hillas parameters,” and their calculation is described in Appendix A of Reynolds et al. (1993).
“ Hillas-image-amplitude” is the total amplitude summed over all pixels Σi Ai . It is mainly a function of the γ-ray energy and impact distance on the ground. Additionally, the atmospheric transparency and telescope efficiency affect the total light yield of the showers. Therefore, the distribution of the Hillas-image-amplitude (or size, cf. Fig. A.1) is very similar for different primary particle showers, in particular if they follow similar energy spectra. It cannot and should not be used as a separating variable. However, since the gamma-hadron separation works better for images with a larger total amount of light in the camera, information about the size is very useful for separation and is implicitly available through correlations with other variables.
“ Hillas-npix” is the number of pixels with Ai > 0 that pass the aforementioned image cleaning. Its distribution is shown in Fig. A.2. Hillas-npix is affected by the same shower properties as the Hillas-image-amplitude, and additionally by the shower morphology and the image cleaning.
“ Hillas-local-distance” is the distance from the image center of gravity to the center of the camera, defined as 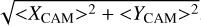 . This parameter is solely determined by the position of the shower in the camera’s field of view. Although it does not contain any physical information beyond the position, it is of interest to algorithms, as images recorded near the edges of the camera may require a different handling due to truncation effects.
. This parameter is solely determined by the position of the shower in the camera’s field of view. Although it does not contain any physical information beyond the position, it is of interest to algorithms, as images recorded near the edges of the camera may require a different handling due to truncation effects.
“Hillas-width” is defined as the r.m.s. along the Y-direction and can be computed as:
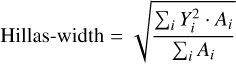 (2)
(2)
with the distribution shown in Fig. A.3. The characteristic dip located at ~2 cm, slightly below half of the camera pixel width (5 cm), occurs because images with only 5, 6, or 7 pixels have a sharp cutoff in their width distribution at this value. The vast majority of possible configurations for 5, 6, or 7 connected pixels in the hexagonal camera frame have their largest extent along one of the three symmetry axes, resulting in preferred directions of α. Therefore, most images with low pixel numbers have only two “rows” of pixels along the Y-direction, with a maximal r.m.s. of half the pixel width. For images with more pixels, the distribution shifts toward larger widths and becomes more and more continuous.
“Hillas-length” is defined analogously as the r.m.s. along the X-direction:
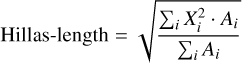 (3)
(3)
with the distributions shown in Fig. A.4. The length and, especially, the width distributions show differences between hadrons and γ rays, with the latter being more abundant at smaller values, as expected for more compact and regular showers.
The third and fourth moments along the major axis can be computed as:
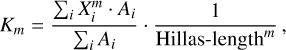 (4)
(4)
where Km is the m’th moment.
“ Hillas-skewness” is the third moment K3 with the distribution shown in Fig. A.5. There are minor differences in the distributions, as the more irregular proton showers feature larger absolute values of skewness, indicating a broader distribution.
“ Hillas-kurtosis” is the fourth moment K4 with the distribution shown in Fig. A.6. The more irregular proton showers with their broader intensity distribution feature lower values of kurtosis.
“ Hillas-logdensity” is a composite variable that includes the Hillas-image-amplitude and is defined as:
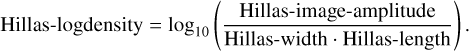 (5)
(5)
The Hillas-image-amplitude does not enter the separation training directly, to avoid a strong dependence of the algorithm on the simulated spectrum, but is implicitly available through the composite variables. The distribution is shown in Fig. A.7, where γ-ray showers have a tail toward higher densities, while hadronic showers tend toward lower densities. This matches the Hillas-npix distributions, where the latter tend toward higher pixel numbers.
“ Hillas-length-over-logsize” is also a composite variable and defined as:
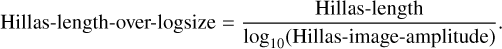 (6)
(6)
The distribution of the Hillas-length-over-logsize is shown in Fig. A.8 and is very similar to that of the Hillas-length.
2.1.2 Sector-based variables
The following image parameters (also those introduced in Sects. 2.1.3 and 2.1.4) are part of a set of novel variables that have not yet been utilized in any previous analyses. These parameters are specifically designed to enhance both the reconstruction accuracy and background rejection in monoscopic IACT images.
The idea behind the sector-based variables is to increase the sensitivity to asymmetries in the image that arise from the asymmetric development of the shower in the atmosphere, such as the head-tail asymmetry, or potential asymmetries in the hadronic shower development. For this, we divide the image into three sectors along the major axis: the head, center, and tail sectors, and compute moments of the charge distribution in these sectors separately. When L = Hillas-length, all pixels with Xi < −0.5 ⋅ L belong to the first sector, pixels with |Xi| < 0.5 ⋅ L belong to the center sector, and pixels with Xi > 0.5 ⋅ L belong to the third sector (cf. Fig. 1). Due to the random image orientation in the camera, the assignment of sectors one and three to the head and tail sectors occurs later, after the correct image orientation is estimated (see Sect. 2.2.1).
For each of the sectors, we compute <X> and <Y>, resulting in the variables “xhead,” “xcenter,” and “xtail,” and “yhead,” “ycenter,” and “ytail,” with the distributions shown in Figs. A.9–A.14.
Additionally, we compute the width according to Eq. (2) for each of the sectors, resulting in the variables “widthhead,” “widthcenter,” and “widthtail” (cf. Figs. A.15–A.17).
The peaks at zero for the distributions of the center sectors are caused by low-size events where the central sector has zero pixels. This corresponds to a division of the event into only two sectors. Variations of <Y> from zero indicate a curvature of the image along the major axis, which is typical for high-impact distance muons where only part of the characteristic muon ring is visible. However, this feature may be better captured by the continuous “kink-major” variable described in Sect. 2.1.3. While widthcenter is strongly correlated with the Hillas-width, a comparison of the head and tail widths allows the characterization of a gradient in the width along the major axis. This is then correlated with the continuous variable “kink-minor” (cf. Sect. 2.1.3). The <X> values for the head and tail sectors of the γ-ray showers are slightly closer to zero, which is connected to the larger kurtosis. Asymmetries between the head and tail values for one event are reflected in the skewness.
Finally, one can also compute the “charge-asymmetry” as:
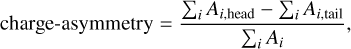 (7)
(7)
which is also correlated with the Hillas-skewness and has a very similar distribution for background data and γ-ray simulations (cf. Fig. A.18).
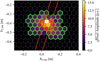 |
Fig. 1 Simulated γ-ray event in the camera frame overlaid with a red ellipse illustrating the Hillas parametrization (width and length), and the lines separating the sectors. The pixels marked in green belong to either the head or the tail sector, while pixels that are not marked belong to the central sector. |
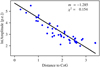 |
Fig. 2 Profile-gradient for a simulated γ-ray event. The distance to the CoG is computed according to Eq. (12) and is therefore unitless. |
2.1.3 Continuous variables
In the following, we aim to characterize additional features of the event images that the variables introduced up to here are not sensitive to. As the sector variables are not optimal, especially for low-size events, we no longer separate the pixels into three sectors but rather use all pixels to compute gradients and other correlations. The first set of variables is based on the gradient m between two pixel attributes x and y, which is computed via linear regression:
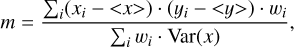 (8)
(8)
where <x>, <y> are the weighted averages of x and y, respectively, using the weights w. Var(x) is the weighted variance computed as follows:
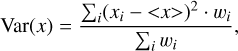 (9)
(9)
again with <x> being the weighted average of x. The y-value t at x = 0 is computed as:
 (10)
(10)
and the goodness-of-fit (GOF) or weighted squared deviation χ2 from the linear curve:
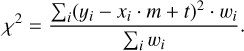 (11)
(11)
“ Profile-gradient” The first example is the profile-gradient, where we compute the slope with which the logarithm of the pixel amplitudes Ai changes with distance to the center of gravity (CoG) of the image (cf. Fig. 2). The distance to the CoG r is computed as:
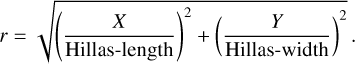 (12)
(12)
The profile-gradient follows as slope m of Eq. (8) with x = r, y = ln(A [p.e.]), and w = A. Using the same variables and the resulting m and t, one can also compute the spread around the profile-gradient as χ2 from Eq. (11), resulting in the “profile-gradient-GOF.”
Compared to Hillas-kurtosis, profile-gradient is sensitive not only to the charge distribution along the major axis but also along the minor axis. The distribution of profile-gradient in Fig. A.19 shows that γ-ray showers usually have larger negative gradients, typical for more compact showers. Very few, dominantly hadronic, showers have positive gradients, which are characteristic of muon rings where the intensity increases toward the edges. The distribution of the profile-gradient-GOF, shown in Fig. A.20, also indicates that proton showers are more irregular and therefore have a larger spread around the linear gradient. One can also compute the profile-gradient for pixels with Xi > 0, resulting in “profile-gradienthead,” and for pixels with Xi < 0, resulting in “profile-gradienttail .” For asymmetric events, these values can be quite different.
“Kink-major” is the gradient m from Eq. (8), with x = |X|, y = Y, and w = A, and is sensitive to the curvature of the ellipse along the major axis. When muons are recorded at large impact distances, only part of the muon ring is visible in the camera, which might be confused with a γ-ray ellipse, except for its curvature. Fig. A.21 shows that γ-ray events tend to have values of kink-major closer to zero, while some hadronic events show larger absolute values for kink-major. The calculation of the “kink-major-GOF” as χ2 of Eq. (11) is identical to the definition of the Hillas-width in the case of kink-major = 0. For values of kink-major, 0, the kink-major-GOF is smaller than the Hillas-width due to one more degree of freedom. To further reduce the correlation with Hillas-width and to make the distribution more similar for events of different sizes, we divide the kink-major-GOF additionally by Hillas-npix – 2, as m and t represent two additional degrees of freedom. With this computation, the distribution is smoothed and the characteristic dip present in the distribution of Hillas-width is eliminated.
“ Kink-minor” is defined similarly as m from Eq. (8) with x = Y2, y = X, and w = A, and represents a gradient in <X> for increasing offsets to the major axis. This is tightly connected to a change in the ellipse’s width along the major axis. We also tested the variable resulting from y = |Y| but found that the separation between γ-ray and hadronic events is not as good, as the influence of low-intensity pixels far away from the major axis is reduced. From Fig. A.23, one can see that hadronic showers tend to have values closer to zero, while the γ-ray simulations show larger tendencies for more asymmetric images. The sign of the kink-minor is especially interesting, as shower images are expected to have a larger width in the tail of the shower facing the ground, so the sign of kink-minor is useful in the angular reconstruction of the events. The “kink-minor-GOF” follows as χ2 /(Hillas-npix − 2) and is proportional to the Hillas-length. Figure A.24 shows that the distributions for γ rays and background events are similar.
“ Time-gradient-major” In the variables described so far, the time information in the pixels is not yet used. We compute the time-gradient-major as m from Eq. (8) with x = X, y = T, and w = A, and the “time-gradient-minor” with x = Y and y = T, and w = A. The distributions for the two time gradients are shown in Figs. A.25 and A.26. While the time-gradient-minor is expected to be close to zero for all showers, the time-gradient-major is expected to be mainly a function of the impact distance for geometrical reasons. Therefore, the difference between the distributions of γ-ray and hadronic showers is somewhat surprising. As we will see in Sect. 2.1.5, however, these variables do not pass our selection procedure.
The difference between the time spreads “time-gradient-major-GOF” and “time-gradient-minor-GOF,” shown in Figs. A.27 and A.28, is highly affected by different NSB rates. While this is expected for the tail-cut image cleaning, which is neglecting the pixel’s time information, we cannot use these variables without introducing large systematic uncertainties.
“ Roughness” The next set of variables is meant to be sensitive to the regularity or smoothness of the shower. One can compare a smoothed version of the image to the original by adding the differences for each pixel. This is done in the roughness variable, which is calculated as follows:
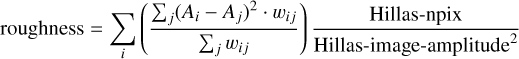 (13)
(13)
where wij represents weights of a Gaussian kernel with σ = 1 pixel width:
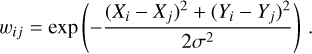 (14)
(14)
The roughness variable adds up differences in the pixel amplitude between neighboring pixels, while the “std-over-mean” variable adds differences to the mean from all shower pixels.
“ Std-over-mean” converges to the roughness parameter in the limit of large kernel widths. It is computed as:
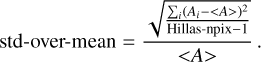 (15)
(15)
Therefore, the variables roughness and std-over-mean are correlated, but the strength of the correlation is different for γ rays (0.88) and background events (0.79). The distribution for both variables can be seen in Figs. A.29 and A.30. One can see that for both variables, the γ-ray simulations tend toward larger values due to their more compact shape, leading to larger differences in the amplitudes of neighboring pixels.
“ Spatial-auto-correlation” An attempt to characterize differences from the expected event morphology resulted in the computation of the spatial-auto-correlation (Moran’s I) of the residuals after subtracting the expected pixel amplitude based on the profile-gradient:
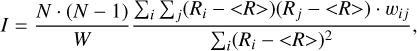 (16)
(16)
with N = Hillas-npix, wij the weights from Eq. (14), and W = Σi Σj wij. Ri is calculated from the previously determined profile-gradient m and the corresponding t (cf. Eqs. (8) and (10)):
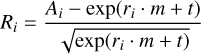 (17)
(17)
and
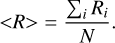 (18)
(18)
In the absence of any correlation, the expected value for I is −1, with more negative values indicating spatial anticorrelation and more positive values indicating spatial correlation. The distributions of the spatial-auto-correlation shown in Fig. A.31 are very similar between background and γ rays, with background events slightly more abundant at larger negative values.
2.1.4 Pixel variables
To improve gamma-hadron separation, especially for low-size images, we also examine distributions focusing on the two brightest pixels. From their amplitude values A1 and A2, we compute “fraction-top-1” and “fraction-top-1+2” as
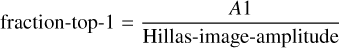 (19)
(19)
and
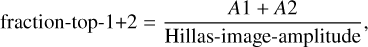 (20)
(20)
respectively. If the machine learning algorithm has access to both values, the ratio between the two brightest pixels is also accessible. The distributions in Figs. A.32 and A.33 show that γ-ray showers have a larger charge concentration in the brightest pixel(s).
The other three pixel parameters concern the position of the brightest two pixels with respect to the CoG and to each other:
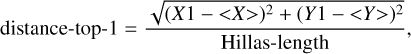 (21)
(21)
and
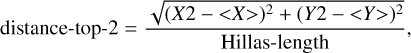 (22)
(22)
and
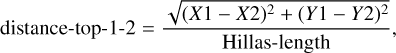 (23)
(23)
with (X1, Y1) being the coordinates of the brightest pixel, (X2, Y2) the coordinates of the second brightest pixel, and (<X>, <Y>) the coordinates of the CoG.
The distributions in Figs. A.34–A.36 show that for γ-ray showers, it is more likely to find the brightest, but also the second brightest, pixel closer to the CoG, which is expected for more regular showers. For the distance between the two brightest pixels, there is a plateau in the distributions around one Hillas-length, which is more concentrated for γ-ray showers, while there is a larger spread for hadronic showers.
Finally, simply counting the number of pixels that exceed the thresholds of 10 p.e. and 30 p.e. results in the variables “npix>10” and “npix>30,” respectively. Figures A.37 and A.38 show the distributions of these variables, where small γ-ray images tend to have brighter pixels, while for larger images, hadronic showers have a more homogeneous light distribution.
2.1.5 NSB sensitivity of the image parameters
By introducing additional variables, one not only increases sensitivity to physical differences between the shower types, but also to systematic differences between data and simulations. One possible source of systematic difference is the NSB level, which varies within the field of view (FoV) and between different observations, but is simulated at a constant averaged value. To obtain a more quantitative estimate of the NSB sensitivity per variable, we use point-source simulations for nominal and high NSB values. These simulations are more efficient than the diffuse simulations introduced earlier, which leads to a statistically more accurate estimate. As for the diffuse simulations, the high NSB value is 1.65 times larger compared to the nominal NSB value and exceeds the NSB values of the vast majority of observations.
For each variable, we employ an Anderson-Darling test for k-samples, which tests the null hypothesis that the two distributions are drawn from the same population. Figure 3 summarizes the results of these tests.
The danger of an NSB-sensitive distribution is that the separation training will perform differently on observations taken under different NSB conditions, introducing systematic uncertainties in the reconstructed γ-ray rates. Additionally, the performance might also change across the FoV introducing background artifacts, like gradients.
Compared to all other variables, the time variables show the most significant NSB dependence. This is because the image cleaning completely ignores the pixel times and their clustering for shower pixels. Consequently, higher NSB rates lead to a higher rate of noise pixels with larger amplitudes that survive the image cleaning, but which are randomly distributed in time. These pixels can drastically change the time gradient, if the random pixel time is very different from the shower time. Therefore, we do not use time-based variables for the separation training.
A time-based image-cleaning technique might solve this issue and would allow time variables to be used in the separation training. The exact influence of the NSB rates on the effective area and thus the flux systematics will be evaluated in Sect. 3.2.
2.2 Architecture of training algorithms
The event reconstruction used in this work is based on the current H.E.S.S. monoscopic analysis procedure. The first step involves determining the so-called “flip” (F), which specifies whether the image center is to the left or right of the true source position in the camera frame. The source is expected to be located along the major axis of the Hillas ellipse. However, for a monoscopic reconstruction, it is challenging to determine the direction along the axis.
Next, the distance between the center of gravity of the ellipse and the source location, called “disp” (δ), is reconstructed (Hofmann 1999). The reconstructed source position in the camera reference frame can then be obtained using the following equations:
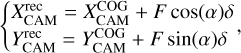 (24)
(24)
where F = ±1, and α is the angle of the major axis of the ellipse with respect to the camera frame.
In the standard H.E.S.S. analysis, the order in which flip and disp are determined is irrelevant. However, for this work, some of the new variables introduced depend on distinguishing the head and tail of the ellipse. Thus, the flip must be determined first and if it is positive, these variables change sign or are interchanged with their corresponding variables on the opposite side of the shower. The flipping behavior for each variable is detailed in Table B.1.
Moreover, the flip-dependent image parameters are also sensitive to the position of the source in the camera frame, while the simulations are always performed for a point source at XCAM = +0.5◦ . This would normally lead to an asymmetry in the flip distribution, since the region left to the source position is larger than that to the right. Therefore, we mirror half of the simulated events with respect to the YCAM axis (XCAM → −XCAM), randomizing the distributions. With that, we ensure a performance independent of the camera sector.
The subsequent steps involve energy regression and the estimation of the event’s gammaness, that is, a quantity reflecting the probability that the primary particle was a γ ray, compared to a hadronic particle. Also in these trainings, the flip determination and mirror operations described above are required beforehand due to the head- and tail-dependent variables being used. Aside from this, both reconstructions are independent of the other reconstruction steps. Here, we evaluate the performance of the separation as a function of the Hillas-image-amplitude, rather than the reconstructed energy typically used in stereoscopic analyses.
 |
Fig. 3 Anderson-Darling statistic for the distribution of nominal and high-NSB simulations. Larger values correspond to a more significant difference between the distributions. The vertical lines show four selected significance levels at 25%, 2.5%, 0.5%, and 0.1%. The numbers next to the variable names indicate the value of the Anderson-Darling statistic since some of the values extend beyond the plotted range. |
2.2.1 Flip determination algorithm
In Murach et al. (2015), the “flip” is determined by examining the sign of the Hillas-skewness. This asymmetry is a good first- order indicator of the orientation of the ellipse with respect to the source position. However, for truncated or small images with few pixels and a small Hillas-image-amplitude, the Hillas-skewness determination becomes less accurate, resulting in an increasing fraction of incorrectly flipped events.
In this work, we improve the flip determination by employing a boosted decision tree (BDT), a machine-learning algorithm known for its efficiency as a classifier and widely used in γ-ray astronomy for tasks such as gamma-hadron separation. We use the XGBRegressor from the XGBoost2 Python package (Chen & Guestrin 2016) with 100 trees, a maximum depth of 5 and a learning rate of 0.3.
The true flip for a simulated event, Ftrue, is defined as
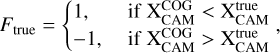 (25)
(25)
with  being the true position of the source in the camera reference frame. The simulated point-source γ-ray events were divided into two sets, where we used 80% for training and 20% for testing. The variables from Sect. 2.1 were given as input to the training, and the total fraction of wrongly flipped events after the BDT evaluation served as the score to be minimized. As BDTs return the relative variable importance for each input feature, we chose the following procedure for the selection of useful variables.
being the true position of the source in the camera reference frame. The simulated point-source γ-ray events were divided into two sets, where we used 80% for training and 20% for testing. The variables from Sect. 2.1 were given as input to the training, and the total fraction of wrongly flipped events after the BDT evaluation served as the score to be minimized. As BDTs return the relative variable importance for each input feature, we chose the following procedure for the selection of useful variables.
The selection process began by including all non-time-based variables, followed by an iterative process in which the least important variable was removed and the BDT was re-trained. This process continued until the false flip fraction over all energies increased by 2.5% with respect to the model trained with all variables. The final set of selected variables and their respective importance are shown in Figure 4.
2.2.2 Energy and disp regression algorithm
Energy and “disp” regression are currently performed in H.E.S.S. using two independent shallow neural networks (NNs) based on the tensorflow.keras framework, with two hidden layers with 20 nodes each and a sigmoid activation. The mean squared error of the predicted variable (energy or disp) for all events was used as the variable loss to be minimized. The NN were trained for up to 5000 epochs with a batch size of 1000. 90% of the data were used for training and 10% for validation, that is, estimation of the variable loss. For this work, the structure of the neural networks was kept, changing only the input variables. For the standard H.E.S.S. analyses, the variables used are: Hillas-image-amplitude, Hillas-length, Hillas-width, Hillas-skewness, Hillas-kurtosis, and Hillas-logdensity. Again, we explored the ideal subset of the variables from Sect. 2.1. As the variable importance is not available in NNs, the iterative procedure starts with all variables, conducting a training with N input variables. Subsequently, N individual trainings were performed, each omitting one of the N variables, and the final loss of each NN training with the (N − 1) variables was evaluated. The best-performing training indicated the least important variable and was used for the next iteration. This process was repeated until the performance (i.e., variable loss) dropped by 5% with respect to the model trained with all the variables. The same subset of variables was chosen for both energy and disp regression: Hillas-image-amplitude, Hillas-local-distance, Hillas-width, Hillas-length, Hillas-npix, Hillas-skewness, Hillas-kurtosis, Hillas-length-over-logsize, charge-asymmetry, time-gradient-major, and std-over-mean.
 |
Fig. 4 Relative variable importance for the flip training. |
2.2.3 Particle identification algorithm
Due to the large number of hadronic background events, which exceed the number of γ-ray events by typically three orders of magnitude, an efficient classification algorithm is necessary. Its task is to assign a “gammaness” score to each event that is maximally different for hadronic and γ-ray events. The differences in the gammaness distribution allows the signal to be separated from background events by rejecting events below a certain value of the gammaness score. We refer to this value as selection or BDT cut. Similar to the flip training, we employ a BDT trained on simulated point-source γ rays and measured background data across all energy and size ranges, with 10% of the data reserved for validation to prevent over-fitting. After exploring various settings for the number of trees, tree depth, and learning rate, we identified an optimal configuration with 200 trees, a maximum depth of 6, and a learning rate of 0.3, yielding a stable and robust performance. We also investigated the impact of segregating the training data by size ranges, but this approach did not result in significant performance improvements. This indicates that the algorithm has enough information about the event sizes to treat different sizes appropriately.
For the separation training, the events are re-weighted from the simulated spectrum with an index of −1.8 to a more typical γ-ray spectrum with an index of −2.5. We do not expect any bias for sources with different spectral shapes or offsets from the telescope’s pointing, as the instrument response functions (IRFs)3 are binned in energy and offset; however, the performance might decrease slightly.
For the selection of useful variables, we again employ an iterative procedure that starts with all variables (except the time variables) and removes the least important variable after each training iteration. The performance of each training is evaluated based on the signal efficiency, requiring a background rejection fraction of 95% over all events. Additionally, the training is also evaluated on simulations with a high NSB value, and the difference in signal efficiency between the two simulations serves as an indicator of the training’s sensitivity to NSB fluctuations. Figure 5 summarizes this procedure, where each bar, starting from the bottom, shows the result of the training after removing the respective variable. The result consists of two parts: the first is the relative improvement in signal efficiency compared to the reference training with the standard six Hillas variables  for the nominal NSB value. Secondly, the signal efficiency is compared between nominal and high-NSB simulations for all trainings. The ideal training maximizes improvement in signal efficiency compared to the reference training while not increasing the difference between the two NSB simulation sets.
for the nominal NSB value. Secondly, the signal efficiency is compared between nominal and high-NSB simulations for all trainings. The ideal training maximizes improvement in signal efficiency compared to the reference training while not increasing the difference between the two NSB simulation sets.
After removing the first four variables (charge-asymmetry, yhead, ycenter, ytail), the signal efficiency slightly increases, indicating confusion in the BDT due to too many correlated or unimportant variables. Continuing to remove variables does not affect the performance but increases the NSB sensitivity of the trainings. Only after removing distance-top-1 do both the performance and the NSB sensitivity decrease, with the difference in signal efficiency between the two NSB simulation sets ending up at values smaller than 1.6% – the value for the reference training – for most of the trainings. The following variables survived the selection process beyond the iterations shown in Fig. 5 (in ascending order of their importance): std-over-mean, kink-major-GOF, Hillas-local-distance, Hillas-npix, widthhead, Hillas-logdensity, Hillas-width, and profile-gradient.
Mainly because of the sensitivity to different NSB rates, we decided to keep all variables except charge-asymmetry, yhead, ycenter, ytail, although other selections could be justified as well. For the final training we remain with 31 input variables, with their relative variable importance given in Table B.1.
 |
Fig. 5 Relative change of the signal efficiency ϵsig during the iterative removal of the least important variable (from bottom to top). The signal efficiency for each training is compared to the signal efficiency of the reference training |
2.3 Size-dependent selection cut
To find the optimal BDT cut resulting in the best sensitivity, one can maximize the q-factor defined as 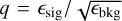 . This approach is effective because the observed significance σ for an on-off (i.e., aperture photometry) analysis is proportional to
. This approach is effective because the observed significance σ for an on-off (i.e., aperture photometry) analysis is proportional to
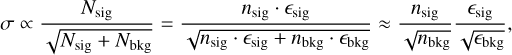 (26)
(26)
where N refers to counts after cuts and n refers to the number of events before cuts. The final approximation assumes Nsig << Nbkg which is a good approximation in the low signal-to-noise case where optimization is most critical. The ratio of 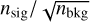 is fully determined by the source and background spectra together with the effective area, leaving the q-factor as the remaining quantity to optimize. Several tests carried out in the context of this study showed that the performance of the BDT within a certain size range is stable with respect to adding or removing events of different sizes4. However, the distribution of the BDT score changes, which can make the performance appear worse or better for the size range of interest if the BDT cut is optimized using events of all sizes. Therefore, we optimize the q-factor in different size bins by scanning through different BDT cuts (cf. Fig. 6). The optimal BDT cuts are then smoothed with a Gaussian kernel with width equal to one bin, which results in the red line in Fig. 6. Events can now be selected based on the BDT cut interpolated at their respective size and their BDT score.
is fully determined by the source and background spectra together with the effective area, leaving the q-factor as the remaining quantity to optimize. Several tests carried out in the context of this study showed that the performance of the BDT within a certain size range is stable with respect to adding or removing events of different sizes4. However, the distribution of the BDT score changes, which can make the performance appear worse or better for the size range of interest if the BDT cut is optimized using events of all sizes. Therefore, we optimize the q-factor in different size bins by scanning through different BDT cuts (cf. Fig. 6). The optimal BDT cuts are then smoothed with a Gaussian kernel with width equal to one bin, which results in the red line in Fig. 6. Events can now be selected based on the BDT cut interpolated at their respective size and their BDT score.
This approach allows for the retention of more low-size events, where due to poor separation, the best statistical significance is achieved by keeping nearly all events. While the sensitivity gain due to low-size events is limited by the high background contamination, it does lower the energy threshold and reduces the relative systematic uncertainty, which is highest for strict cuts in the distribution.
 |
Fig. 6 Scan of q-factors for different event sizes (x-axis) and BDT cuts (y-axis) using the 6 Hillas variables. For each size bin the color map shows the q-factors (normalized to 1) for different BDT cuts. The resulting optimal BDT cut (red) is shown together with the signal (green) and background (yellow) background efficiencies. The solid lines show the case for the size-dependent BDT cut while the dashed lines show the constant BDT cut. |
3 Performance evaluation
The performance evaluation is conducted for simulations at a zenith angle of 20° and an angular separation (offset) of 0.5° from the pointing direction of the telescopes. In the following, we compare the current standard analysis using the six Hillas variables and a constant BDT cut (labeled “Hillas variables (const. cut)”) to an intermediate analysis with the Hillas variables but a size-dependent BDT cut (labeled “Hillas variables (var. cut)”) and the new analysis with new variables and the sizedependent cut (labeled “New variables (var. cut)”). Details on how the size-dependent BDT cut is computed can be found in Sect. 2.3.
The performance presented in Murach et al. (2015) is based on different event (pre)selection cuts and the camera previously installed on CT5. In contrast to this study, they use a θ2-cut on the angular mis-reconstruction, considerably lowering the effective area but improving the energy resolution. For these reasons we do not directly compare to the results from Murach et al. (2015), but instead to the performance of current FlashCam analyses without θ2-cut.
3.1 Event reconstruction
In this section, we evaluate the performance of the event reconstruction using the machine learning models described in Sect. 2.2. First, the “flip” is determined, based on which the sign of variables like the Hillas-skewness is changed, and sector variables like xhead and xtail are interchanged according to Table B.1. The flipped variables then serve as input for the energy, direction, and particle type reconstruction.
 |
Fig. 7 Fraction of wrongly flipped events as function of true energy. The dashed lines show the performance evaluated on all events after preselection, while the solid lines only include selected events passing the size-dependent gamma-hadron separation cut. |
3.1.1 False flip fractions
The improvements in the flip determination are shown in Fig. 7, where the performance of the BDT model is compared with that of the flip determination based solely on the Hillas-skewness. At high energies, where an increasing fraction of the events is truncated at the camera edges, image skewness alone becomes an unreliable indicator. In contrast, the BDT model consistently demonstrates the expected behavior, with a decreasing false flip fraction as energy increases. For low-energy events with small images, determining the correct flip remains challenging. This is especially the case for highly symmetric events with their CoG close to the true source position. However, for these events, even an incorrect flip has only a minor effect on the reconstructed position and the associated parameters. As a result, the false flip fraction merely counts all events where the flip was incorrectly determined, while the angular resolution more accurately reflects the impact of the flip determination on the reconstruction.
3.1.2 Angular resolution
The angular resolution is defined as the 68% containment radius of the reconstructed position relative to the true one. It is important when disentangling sources close to each other and also affects the sensitivity of the instrument to isolated point-like sources, as the background increases with a larger integration area of the signal.
Based on the dashed lines in Fig. 8, the improvement achieved with the new variables is evident, lowering the angular resolution at 100 GeV by 57%. The dashed lines are always shown to represent the performance of the reconstruction independent of the BDT cut, while the solid lines represent the actual performance of the analysis including only events passing the gamma-hadron separation. Since the constant BDT cut removes most low-size events, the good angular resolution of this analysis at low energies is a natural but mostly irrelevant consequence, due to the low event statistics in this range. The enhancement in angular resolution is partly attributable to the improved “disp” estimation and partly to the improved flip training, as incorrectly flipped events are often reconstructed far from the true position, particularly when the impact distance is large.
As the direction determination of the new analysis also makes use of very NSB dependent variables such as the time-gradient-major, the angular resolution is also evaluated on the high-NSB simulations. Here, we use simulations of γ-ray events with an increased NSB value (scaled by 1.65), which is higher than expected for the vast majority of observations (cf. Sect. 2.1.5). The difference in angular resolution is very small and is shown in the barely visible red-shaded region in Fig. 8.
 |
Fig. 8 Angular resolution as a function of true energy. The blue curves show the performance for the current analysis, the orange ones for the intermediate analysis with the old training but the size-dependent BDT cut, and the red lines represent the new analysis. The red-shaded band shows the difference to high-NSB simulations. |
 |
Fig. 9 Energy bias as a function of true energy. |
3.1.3 Energy resolution
The energy bias is defined as the mean of the energy migration µ = (Ereco − Etrue)/Etrue and the energy resolution is the standard deviation of µ. For ideal reconstruction, the energy bias would be zero; however, if events with different true energies appear very similar to the algorithm, it assigns an average energy to minimize the loss. This leads to a positive bias for low-energy events and a negative bias for higher-energy events. The dip-like shape of the curves for a variable BDT cut in Fig. 9 can be understood when considering that events with low size are composed of events with low energies and small impact distance, as well as events with large energies and large impact distance. Compared to the other curves, the energy bias with the constant BDT cut appears shifted to the right, as only very few events with low sizes pass the BDT cut. The energy at which the bias exceeds a value of +10% is usually considered a safe choice for the energy threshold. Hence, we observe that the energy threshold can be lowered considerably using the size-dependent BDT cut. Comparing the dashed lines, for which no BDT cut is applied, one can see that the new variables help in moving the energy bias closer to zero.
The energy resolution, shown in Fig. 10, also shows significant improvement when evaluated on all events. Considering the BDT cuts, the improvement is most notable at higher energies ≳200 GeV.
The difference to high-NSB simulations is again illustrated based on the red-shaded regions. Although there is no significant difference in the energy bias, the energy resolution becomes clearly worse for low energies under high-NSB conditions. This is not unexpected, as during calibration, the pixel amplitudes are corrected on the basis of their average amplitude in the absence of a triggered event, leading to a minor effect of the NSB rates on the energy bias. However, the NSB fluctuations in the pixel amplitudes increase with the square root of the subtracted amplitude, causing also larger uncertainty in the energy reconstruction.
 |
Fig. 10 Energy resolution as a function of true energy. The red-shaded region shows the difference in energy resolution compared to the high-NSB simulations. |
3.2 Background rejection
The difference in separation performance between the three configurations, measured in terms of the q-factor (see Sect. 2.3), is shown in Fig. 11. Here, the constant BDT cut is optimized for medium sizes around 600 p.e., resulting in similar q-factors for the two configurations that use the standard Hillas variables. At lower or higher sizes the configurations employing the sizedependent cut achieve significantly higher q-factors. The benefit of the new variables is most pronounced for sizes around 200 p.e. (not considering the statistical fluctuations at larger sizes).
Finally, the effective areas shown in Fig. 12 also reflect the lower energy threshold for the configurations with a variable BDT cut, which is also often chosen as the energy at which the effective area drops below 10% of its maximum. This threshold is at 30 GeV for the configurations with a variable BDT cut and at 64 GeV for the configuration with the constant BDT cut.
In a real data analysis with the HAP framework, the corresponding IRFs are computed based on simulations at different zenith, azimuth, and offset angles, with atmospheric transparency also accounted for. One variable not considered is the rate of the night sky background light. In Fig. 13, the resulting effective area for the high-NSB simulations is compared to that from the default simulations. For observations taken under such high NSB rates, this difference would translate directly into a systematic error on the recovered flux. Since the number of events simulated for the high NSB value is considerably lower than for the default simulations, the ratio of the effective area is also affected by statistical fluctuations, especially toward the higher energies.
The shaded bands in Fig. 13 are constructed based on a systematic deviation of neighboring points from a value of 1 and therefore still include statistical fluctuations. Especially toward higher energies, the statistical fluctuations dominate and increase the difference between the two simulation sets. The width of the shaded bands can thus be interpreted as the maximum expected systematic uncertainty caused by different NSB values. This systematic effect resulting from high NSB rates is expected to be opposite for observations taken under lower NSB rates, although less strong.
Quantitatively, the systematic uncertainty due to NSB differences is ~2.5%, which is small compared to other systematic uncertainties, which are generally estimated to add up to ∼20% (see supplementary material of Aharonian et al. 2022). However, it is still informative to compare this systematic uncertainty between the new and the old variables. This comparison is made for the two configurations with the size-dependent BDT cut, as these have similar effective areas, and demonstrates that the systematic uncertainty is slightly increased by approximately one percentage point. This suggests that the increased performance in gamma-hadron separation comes at the expense of a slight increase in susceptibility to data-simulation mismatches, as for example introduced by different NSB values.
 |
Fig. 11 The absolute q-factors (upper panel) of the separation trainings as a function of event size, and their ratios (lower panel). The blue curves show the performance for the current analysis, the orange ones for the intermediate analysis with the old training but the size-dependent BDT cut, and the red lines represent the new analysis. |
 |
Fig. 12 Effective areas for the three configurations as function of true energy. |
 |
Fig. 13 Ratio of the effective areas computed from simulations with nominal and high NSB values. The points show the ratio for each energy bin while the shaded bands represent an estimate of the systematic uncertainty. For details see main text. |
3.3 Sensitivity
Using all the IRFs, we compute sensitivities for source detection in different energy bins. In each energy bin, the source flux (∝ E-2.5) is scaled such that it leads to a 5σ detection for 50 h of observation time. Since the absolute values of this differential sensitivity depend on the size of the energy bins, they primarily serve as a means of comparison between different configurations.
Scanning through various preselection cuts for image size and pixel number showed that small events, with five or six pixels, generally decrease the sensitivity. These events exhibit low resolution during reconstruction and perform especially poorly in gamma-hadron separation. Including such events in the analysis significantly increases the background without a comparable enhancement in the signal. For this reason, the following analysis is based on slightly stricter preselection criteria, where events must contain seven or more pixels. While applying even more stringent cuts could further enhance performance at higher energies, this comes at the cost of diminished performance at lower energies, which is the primary focus of this study.
Figure 14 highlights the improvement in sensitivity, which roughly follows the improvement in q-factor already discussed in Fig. 11. The constant BDT cut is optimized for medium energies around 100 GeV, where due to the strict cut on low-size events, the sensitivity is slightly better compared to the new configurations. Improvements from the variable cut are apparent at higher and lower energies. The new variables mainly increase the performance in the first few bins, where they mostly contribute to the increased background rejection and improved event reconstruction. At the threshold, an improvement of 41% could be achieved by adding the new variables.
 |
Fig. 14 Comparison of the differential sensitivities (upper panel) and their ratios (lower panel). The vertical lines show the energy threshold at which the effective area drops below 10% of its maximum. The sensitivities are computed for 50 h of observation time and 5σ detection per energy bin. The points for CTA - North rely on prod5 v0.1 IRFs5. |
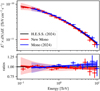 |
Fig. 15 Spectral energy distribution of the Crab Nebula as measured by CT5. The blue data points correspond to the H.E.S.S. mono data from Aharonian et al. (2024), reflecting the performance of the standard reconstruction method. The black line represents the Crab spectrum obtained from the mono + stereo analysis (extrapolated to 100 GeV) also from Aharonian et al. (2024). The red data points indicate the results from the new reconstruction method. In the upper panel, the shaded error bands represent the combined statistical and systematic uncertainties. The lower panel illustrates the ratios relative to the black spectrum, with the darker shaded regions showing the statistical uncertainty in addition to the total uncertainty. |
3.4 Application to test dataset
In this section, we apply the new reconstruction to 65 observations (~30 h) of the Crab Nebula, taken under zenith angles between 44° and 55°. The dataset used is identical to that in Aharonian et al. (2024) for the mono data, where the standard reconstruction technique was applied. For the current study, the background is estimated using reflected regions around the source position (Berge et al. 2007). A low-energy threshold of 100 GeV is chosen, which lies above the 10% effective area threshold and below the 10% energy bias threshold for this zenith range. At this energy threshold, the new analysis exhibits an energy bias of 41%, whereas the previous analysis demonstrated a bias of 128%. At the threshold energy of the previous analysis, 200 GeV, the new analysis shows a significantly reduced bias of 0.6%, compared to 27% for the old analysis.
Figure 15 provides a comparative overview of the spectra derived from the two analyses. The systematic uncertainty is estimated by grouping the observations into three different zenith and offset angle bins, respectively, and estimating the deviations beyond the statistical uncertainty. This kind of systematic can be regarded as lower limit of systematic uncertainties, particularly reliable at lower energies where statistical uncertainties are minimal. Overall, we find good agreement between the old and new analyses, with the latter extending to lower energies. As expected, systematic uncertainties increase at lower energies, primarily due to the inclusion of events near the instrument’s trigger threshold.
4 Conclusion
In this study, we introduced approximately 30 new image parameters and assessed their impact on the reconstruction and gamma-hadron separation of monoscopic IACT images. One of the primary challenges for monoscopic events is determining the correct image flip, that is, whether the arrival direction is to the left or right of the image’s center of gravity. By employing a boosted decision tree for this task, we improved the accuracy of the flip determination by approximately eight percent points up to 1 TeV, with even larger improvements at higher energies. The fraction of wrongly flipped events could be reduced from 38% to 32% at threshold and from 29% to 17% at 100 GeV. The most important parameter for the BDT was the new kink-minor variable, which describes the change in image width along the major shower axis.
Unlike the traditional Hillas parameters, many of the new parameters lack symmetry with respect to the image center. Consequently, if the image is mirrored along the y-axis, the sign of certain variables may change, or variables associated with the head and tail regions may be swapped. Correctly determining the flip is therefore crucial not only for angular reconstruction but also for the accurate interpretation of these new variables. Throughout this study we put great emphasis on removing any asymmetries between the distributions of γ-ray and background events by consistently mirroring half of the events. This approach ensures uniform performance regardless of the event’s position within the camera frame, while fully leveraging the information provided by the image parameters. As a result, both the energy and angular resolutions showed considerable improvement. Additionally, the gamma-hadron separation saw a notable enhancement, with an average 20% increase in the q-factor for low to medium-size events.
When combined with the new size-dependent BDT cut, these reconstruction improvements allow for the inclusion of more low-energy events in the analysis, significantly lowering the energy threshold. For observations at a zenith angle of 20° and an offset of 0.5°, the 10% energy bias threshold was reduced from 120 GeV to 50 GeV, and the 10% effective area threshold from 64 GeV to 30 GeV. Although background rejection at low energies remains a challenge, the sensitivity curves presented in this work are promising. We also carefully evaluated the systematic uncertainties introduced by varying NSB rates and found only a minor increase in the systematic error on the effective area based on the new image parameters.
These three improvements to the analysis of monoscopic events were successfully applied to H.E.S.S. data, demonstrating their potential for integration into the analysis of other IACT arrays. Like the H.E.S.S. array, the upcoming Cherenkov Telescope Array Observatory (CTAO) will feature telescopes of various sizes, with only the largest telescopes detecting the faint light signals from low-energy γ rays. Consequently, the relevance of monoscopic event analysis will persist, even with the superior performance of stereoscopic events. In fact, mono- and stereoscopic events may be classified into distinct event types, allowing for a combined analysis of all events without sacrificing sensitivity.
Future studies could explore the analysis of IACT data split into different event-types and the potential of time-cleaning for the shower images observed with FlashCam. The latter might reduce the susceptibility of the time-related parameters to NSB fluctuations, enabling their inclusion in the background rejection algorithms, and further minimizing systematic uncertainties. Template-based reconstruction methods for monoscopic events offer additional potential for enhancing event reconstruction; however, their performance is highly dependent on the quality of the initial seeds. In this context, the improvements presented in this work are expected to provide substantial value.
Data availability
Appendix A is available on Zenodo (https://doi.org/10.5281/zenodo.14640478).
Acknowledgements
We thank the H.E.S.S. Collaboration for providing the simulated data, common analysis tools, and valuable comments to this work. We also thank the H.E.S.S. Collaboration for allowing us to use the data on the Crab nebula in this publication. This research made use of the ASTROPY (https://www.astropy.org; Astropy Collaboration 2013, 2018, 2022), MATPLOTLIB (https://matplotlib.org; Hunter 2007), IMINUIT (https://iminuit.readthedocs.io; Dembinski et al. 2020) and GAMMAPY (https://gammapy.org/; Donath et al. 2023; Acero et al. 2024) software packages.
Appendix A Variable distribution plots
All the plots from this appendix are available on Zenodo (https://doi.org/10.5281/zenodo.14640478)
Appendix B Variables summary
In the following we list all variables investigated in this work, segmented in Hillas, sector, continuous, and pixel variables.
Summary table of the variables
References
- Abe, K., Abe, S., Abhishek, A., et al. 2024, A&A, 691, A328 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Acero, F., Bernete, J., Biederbeck, N., et al. 2024, Gammapy v1.2, Zenodo, https://doi.org/10.5281/zenodo.10726484 [Google Scholar]
- Aharonian, F., Akhperjanian, A. G., Bazer-Bachi, A. R., et al. 2006, A&A, 457, 899 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Aharonian, F., Ait Benkhali, F., Angüner, E. O., et al. 2022, Science, 376, 77 [NASA ADS] [CrossRef] [Google Scholar]
- Aharonian, F., Benkhali, F. A., Aschersleben, J., et al. 2024, A&A, 686, A308 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Aleksic, J., Ansoldi, S., Antonelli, L., Antoranz, P., et al. 2016, Astropart. Phys., 72, 61 [NASA ADS] [CrossRef] [Google Scholar]
- Aliu, E., Anderhub, H., Antonelli, L. A., et al. 2009, Astropart. Phys., 30, 293 [NASA ADS] [CrossRef] [Google Scholar]
- Astropy Collaboration (Robitaille, T. P., et al.) 2013, A&A, 558, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Astropy Collaboration (Price-Whelan, A. M., et al.) 2018, AJ, 156, 123 [Google Scholar]
- Astropy Collaboration 2022, ApJ, 935, 167 [NASA ADS] [CrossRef] [Google Scholar]
- Berge, D., Funk, S., & Hinton, J. 2007, A&A, 466, 1219 [CrossRef] [EDP Sciences] [Google Scholar]
- Bernlöhr, K. 2008, Astropart. Phys., 30, 149 [CrossRef] [Google Scholar]
- Bi, B., Barcelo, M., Bauer, C., et al. 2021, PoS, ICRC2021, 743 [Google Scholar]
- Chen, T., & Guestrin, C. 2016, in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 785 [Google Scholar]
- Dembinski, H., Ongmongkolkul, P., Deil, C., et al. 2020, scikit-hep/iminuit, Zenodo, https://doi.org/10.5281/zenodo.3949207 [Google Scholar]
- Donath, A., Terrier, R., Remy, Q., et al. 2023, A&A, 678, A157 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Funk, S. 2015, Annu. Rev. Nucl. Part. Sci., 65, 245 [NASA ADS] [CrossRef] [Google Scholar]
- Glombitza, J., Joshi, V., Bruno, B., & Funk, S. 2023, JCAP, 11, 008 [CrossRef] [Google Scholar]
- Heck, D., Knapp, J., Capdevielle, J., et al. 1998, CORSIKA: A Monte Carlo code to simulate extensive air showers, Tech. Rep. FZKA 6019, Forschungszentrum Karlsruhe [Google Scholar]
- Hillas, A. M. 1985, in 19th International Cosmic Ray Conference, 3, No. OG-9.5-3 [Google Scholar]
- Hofmann, W. 1999, Astropart. Phys., 12, 135 [NASA ADS] [CrossRef] [Google Scholar]
- Holch, T. L., Shilon, I., Büchele, M., et al. 2017, PoS, ICRC2017, 795 [Google Scholar]
- Hunter, J. D. 2007, Comput. Sci. Eng., 9, 90 [NASA ADS] [CrossRef] [Google Scholar]
- Konopelko, A., Hemberger, M., Aharonian, F., et al. 1999, Astropart. Phys., 10, 275 [NASA ADS] [CrossRef] [Google Scholar]
- Leuschner, F., Schäfer, J., Steinmassl, S., et al. 2023, arXiv e-prints [arXiv:2303.00412] [Google Scholar]
- Lyard, E., Walter, R., Sliusar, V., Produit, N., & for the CTA Consortium 2020, J. Phys.: Conf. Ser., 1525, 012084 [NASA ADS] [CrossRef] [Google Scholar]
- Miener, T., Nieto, D., López-Coto, R., et al. 2022, arXiv e-prints [arXiv:2211.16009] [Google Scholar]
- Murach, T., Gajdus, M., & Parsons, R. D. 2015, in Proc. 34th Int. Cosmic Ray Conf. – PoS(ICRC2015), 236, 1022 [Google Scholar]
- Parsons, R., & Hinton, J. 2014, Astropart. Phys., 56, 26 [NASA ADS] [CrossRef] [Google Scholar]
- Parsons, R. D., & Ohm, S. 2020, Eur. Phys. J. C, 80, 1 [CrossRef] [Google Scholar]
- Parsons, R. D., Mitchell, A. M. W., & Ohm, S. 2022, arXiv e-prints [arXiv:2203.05315] [Google Scholar]
- Reynolds, P. T., Akerlof, C. W., Cawley, M. F., et al. 1993, ApJ, 404, 206 [Google Scholar]
- Shilon, I., Kraus, M., Büchele, M., et al. 2019, Astropart. Phys., 105, 44 [NASA ADS] [CrossRef] [Google Scholar]
- Steinmaßl, S. F. 2023, PhD thesis, Ruperto-Carola-University Heidelberg, Germany [Google Scholar]
- van Eldik, C., Holler, M., Berge, D., et al. 2016, PoS, ICRC2015, 847 [Google Scholar]
- Voigt, T. 2014, PhD thesis, Technische Universität Dortmund, Germany [Google Scholar]
- Voigt, T., Fried, R., Backes, M., & Rhode, W. 2014, Adv. Data Anal. Classif., 8, 195 [Google Scholar]
- Weekes, T. C., Cawley, M. F., Fegan, D. J., et al. 1989, ApJ, 342, 379 [NASA ADS] [CrossRef] [Google Scholar]
- Weekes, T., Badran, H., Biller, S., et al. 2002, Astropart. Phys., 17, 221 [NASA ADS] [CrossRef] [Google Scholar]
Simulations with isotropic arrival directions, as opposed to pointsource simulations with only one arrival direction.
Version 1.7.4.
Collection of functions describing the response of the telescope to a true source flux (effective area, energy dispersion, point spread function, and background model).
This holds as long as the algorithm has access to (implicit) information about the event size.
Taken from: https://www.ctao.org/for-scientists/performance/
All Tables
All Figures
|
Fig. 1 Simulated γ-ray event in the camera frame overlaid with a red ellipse illustrating the Hillas parametrization (width and length), and the lines separating the sectors. The pixels marked in green belong to either the head or the tail sector, while pixels that are not marked belong to the central sector. |
| In the text | |
|
Fig. 2 Profile-gradient for a simulated γ-ray event. The distance to the CoG is computed according to Eq. (12) and is therefore unitless. |
| In the text | |
|
Fig. 3 Anderson-Darling statistic for the distribution of nominal and high-NSB simulations. Larger values correspond to a more significant difference between the distributions. The vertical lines show four selected significance levels at 25%, 2.5%, 0.5%, and 0.1%. The numbers next to the variable names indicate the value of the Anderson-Darling statistic since some of the values extend beyond the plotted range. |
| In the text | |
|
Fig. 4 Relative variable importance for the flip training. |
| In the text | |
|
Fig. 5 Relative change of the signal efficiency ϵsig during the iterative removal of the least important variable (from bottom to top). The signal efficiency for each training is compared to the signal efficiency of the reference training |
| In the text | |
|
Fig. 6 Scan of q-factors for different event sizes (x-axis) and BDT cuts (y-axis) using the 6 Hillas variables. For each size bin the color map shows the q-factors (normalized to 1) for different BDT cuts. The resulting optimal BDT cut (red) is shown together with the signal (green) and background (yellow) background efficiencies. The solid lines show the case for the size-dependent BDT cut while the dashed lines show the constant BDT cut. |
| In the text | |
|
Fig. 7 Fraction of wrongly flipped events as function of true energy. The dashed lines show the performance evaluated on all events after preselection, while the solid lines only include selected events passing the size-dependent gamma-hadron separation cut. |
| In the text | |
|
Fig. 8 Angular resolution as a function of true energy. The blue curves show the performance for the current analysis, the orange ones for the intermediate analysis with the old training but the size-dependent BDT cut, and the red lines represent the new analysis. The red-shaded band shows the difference to high-NSB simulations. |
| In the text | |
|
Fig. 9 Energy bias as a function of true energy. |
| In the text | |
|
Fig. 10 Energy resolution as a function of true energy. The red-shaded region shows the difference in energy resolution compared to the high-NSB simulations. |
| In the text | |
|
Fig. 11 The absolute q-factors (upper panel) of the separation trainings as a function of event size, and their ratios (lower panel). The blue curves show the performance for the current analysis, the orange ones for the intermediate analysis with the old training but the size-dependent BDT cut, and the red lines represent the new analysis. |
| In the text | |
|
Fig. 12 Effective areas for the three configurations as function of true energy. |
| In the text | |
|
Fig. 13 Ratio of the effective areas computed from simulations with nominal and high NSB values. The points show the ratio for each energy bin while the shaded bands represent an estimate of the systematic uncertainty. For details see main text. |
| In the text | |
|
Fig. 14 Comparison of the differential sensitivities (upper panel) and their ratios (lower panel). The vertical lines show the energy threshold at which the effective area drops below 10% of its maximum. The sensitivities are computed for 50 h of observation time and 5σ detection per energy bin. The points for CTA - North rely on prod5 v0.1 IRFs5. |
| In the text | |
|
Fig. 15 Spectral energy distribution of the Crab Nebula as measured by CT5. The blue data points correspond to the H.E.S.S. mono data from Aharonian et al. (2024), reflecting the performance of the standard reconstruction method. The black line represents the Crab spectrum obtained from the mono + stereo analysis (extrapolated to 100 GeV) also from Aharonian et al. (2024). The red data points indicate the results from the new reconstruction method. In the upper panel, the shaded error bands represent the combined statistical and systematic uncertainties. The lower panel illustrates the ratios relative to the black spectrum, with the darker shaded regions showing the statistical uncertainty in addition to the total uncertainty. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.