| Issue |
A&A
Volume 693, January 2025
|
|
|---|---|---|
| Article Number | A12 | |
| Number of page(s) | 20 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202348362 | |
| Published online | 23 December 2024 | |
Kalkayotl 2.0
Bayesian phase-space modelling of star-forming regions, stellar associations, and open clusters
1
Departamento de Inteligencia Artificial, Universidad Nacional de Educación a Distancia (UNED),
c/Juan del Rosal 16,
28040
Madrid,
Spain
2
Laboratoire d’astrophysique de Bordeaux, Univ. Bordeaux, CNRS,
B18N, allée Geoffroy Saint-Hilaire,
33615
Pessac,
France
3
The Observatories of the Carnegie Institution for Science,
813 Santa Barbara Street,
Pasadena,
CA
91101,
USA
4
Depto. Estadística e Investigación Operativa, Universidad de Cádiz, Avda. República Saharaui s/n,
11510
Puerto Real, Cádiz,
Spain
★ Corresponding author; This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
23
October
2023
Accepted:
31
October
2024
Abstract
Context. Star-forming regions, stellar associations, and open clusters are fundamental stellar systems where predictions from star-formation theories can be robustly contrasted with observations.
Aims. We aim to provide the astrophysical community with a free and open-source code to infer the phase-space (i.e. positions and velocities) parameters of stellar systems with ≲1000 stars based on Gaia astrometry and possibly observed radial velocities.
Methods. We upgrade an existing Bayesian hierarchical model and extend it to model 3D (positions) and 6D (positions and velocities) stellar coordinates and system parameters with a flexible variety of statistical models, including a linear velocity field. This velocity field allows for the inference of internal kinematics, including expansion, contraction, and rotation.
Results. We extensively validated our statistical models using realistic simulations that mimic the properties of the Gaia Data Release 3. We applied Kalkayotl to β-Pictoris, the Hyades, and Praesepe, recovering parameter values compatible with those from the literature. In particular, we found an expansion age of 19.1 ± 1.0 Myr for β-Pictoris and rotational signal of 32 ± 11 m s−1 pc−1 for the Hyades and that Praesepe’s rotation reported in the literature comes from its periphery.
Conclusions. The robust and flexible Bayesian hierarchical model that we make publicly available here represents a step forward in the statistical modelling of stellar systems. The products it delivers, such as expansion, contraction, rotation, and velocity dispersions, can be directly contrasted with predictions from star-formation theories.
Key words: methods: statistical / stars: kinematics and dynamics / open clusters and associations: general / open clusters and associations: individual: β Pictoris / open clusters and associations: individual: Hyades / open clusters and associations: individual: Praesepe
© The Authors 2024
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
Open clusters, stellar associations, and star-forming regions, referred to as low-number stellar systems (LNSS), are laboratories where theories of star formation, stellar evolution, and stellar dynamics can be tested and validated. Often, the predictions of these theories are stated in physical spaces rather than in observational ones. Therefore, comparing theoretical predictions to observations requires translating operations that keep biases at the minimum and thoroughly propagate the uncertainty from the observed space to the physical one. The proper handling of this uncertainty propagation is fundamental for hypotheses testing.
The kinematics of stellar systems are one of their fundamental properties that allows for the testing of theories about their formation, evolution, and disaggregation. Because the kinematic predictions are often stated in the joint space of 3D positions and 3D velocities rather than in the observed space of sky coordinates, parallax, proper motions, and radial velocity, the testing of these theories requires an inference process as a mandatory bridging step.
The problem of inferring the kinematic parameters1 of stellar systems is commonly addressed in the literature from at least three different perspectives. The most common approach is to translate the observations of the ensemble of members to the physical space, and then perform the inference in that space. In contrast, in an alternative approach, the inference is done in the observed space, and then the population parameters are translated to the physical one. Finally, in the third and most computationally expensive approach, the inference of the parameters is done in the physical space by proposing parameter values that are transformed to the observed space, where they are compared to the observations. This last approach is known as forward-modelling because it proposes a model in the space of interest and moves it forward to the observed space, where the likelihood is computed (see, for example, Luri et al. 2018). Unfortunately, none of these perspectives is free of caveats and their application depends on the particular objective of the researcher. We now describe what we consider are the most concerning caveats of these approaches.
The transformation of the data from the observed space to the physical one demands sources with fully observed entries (i.e. radial velocity and all astrometric entries). However, radial velocities are usually only present for a small fraction of the bright stellar system’s members. Therefore, the practitioners of this approach tend to discard sources with missing radial velocity despite the quality of their astrometry. The caveat of this approach is that the parameters inferred based on such cropped samples will be biased towards the properties of the brightest observed members and will have larger uncertainties due to a smaller sample. The second approach is usually unaffected by the previous caveat given that the population parameters can be inferred independently in each feature of the observed space, despite missing values. However, transforming the resulting distributions of the population parameters from the observed space to the physical one requires the Jacobian of the transformation, which, for non-linear transformations, heavily depends on the precision of the measurements.
Moreover, the transformation of either measurements, as done in the first approach, or population parameters, as done in the second one, from the observed space to the physical one, is a non-trivial problem that unavoidably requires prior assumptions. Even in the presence of high signal-to-noise measurements or low-uncertainty parameters, the choice of the prior is of critical importance (see Bailer-Jones 2015, for the archetypical case of transforming parallaxes into distances).
The forward-modelling approach is free of the previous caveats but is often time-consuming for both human modellers and computing machines. We now present a brief review of the literature works that use this methodological approach for the task of inferring the internal kinematics of LNSS.
In their pioneering series of articles, Dravins et al. (1999) proposed, Lindegren et al. (2000) developed, and Madsen et al. (2002) applied a new method to estimate the space velocity and internal velocity dispersion of stellar clusters based on astrometric data alone. This method infers the cluster velocity parameters using a maximum-likelihood formulation together with Monte Carlo simulations. Their basic cluster model includes only the cluster’s velocity vector and an internal and isotropic velocity dispersion as population parameters and the parallax of each star as source-level parameters. In their complete model, the entries of a linear-velocity tensor were also inferred as population parameters. One of the advantages of this model is that it produces as output the kinematically improved parallaxes of each star together with its predicted astrometric radial velocity.
Building upon the previous method, Oh & Evans (2020) created the open code Kinesis, which fits the internal kinematics of open clusters with astrometry and (possibly missing) radial velocity data of its members. The inclusion of radial velocities allowed them to break the degeneracy between expansion or contraction and approaching or receding perspective effects present in the original method by Lindegren et al. (2000). Although their method continues to infer the velocity population- and source-level parameters, it relaxes the previous authors’ assumption on the isotropy of the velocity dispersion and infers its full covariance matrix. Therefore, their Bayesian forward-model for the velocity field allows for the inference of full velocity dispersion; a linear gradient that incorporates, expansion, rotation, and shear; and a background model for decontamination.
Crundall et al. (2019) created the Chronostar open code, which uses astrometry and radial velocities (when available) of sources within a specified sky region, to simultaneously identify the LNSS present in the region, deliver a list of their candidate members, infer their phase-space parameters (i.e. positions, velocities, and their dispersion), and estimate kinematic age. However, its application for estimating kinematic age is restricted to young stellar systems (see Sect. 3.4 of Žerjal et al. 2023). The code infers the stellar system’s phase-space parameters of location and dispersion assuming that the dispersion is isotropic but independent in positions and velocities.
Wen et al. (2024) developed a Bayesian hierarchical model for studying Galactic globular clusters that allows for the inference of source-level (i.e. heliocentric phase-space coordinates of individual stars) and population-level (i.e. distribution function) parameters, which include, among others, the cluster’s position and velocity dispersions. Rather than assuming a classical statistical distribution for the population-level parameters, the authors assume a lower isothermal distribution function. Although designed for globular clusters, the authors validate their method on datasets containing up to a thousand stars. We include this method in our review because it shares similar characteristics to the method presented in this work.
In this work, we aim to provide the astrophysical community with a free and open-source code that simplifies the implementation of forward-models of the phase-space of stellar systems. The methodological and practical implementation (i.e. the source code) that we present here is the multi-dimensional extension of the 1D Kalkayotl code (Olivares et al. 2020, hereafter Paper I). Thus we continue using the same name and online address2. The new version of the code will allow its users to infer the 3D Cartesian or 6D phase-space parameters of LNSS with a variety of flexible models. However, we warn its users that its main caveat is that it remains computationally expensive (see Appendix B).
This work is organised as follows. In Sect. 2, we introduce the theoretical and practical frameworks to infer the 3D positions and the 6D phase-space parameters of LNSS. Then, in Sect. 3, we validate these frameworks with synthetic datasets. In Sect. 4, we exemplify the use of Kalakyotl by applying it to benchmark stellar systems where other literature methods have been applied, particularly, Chronostar in β-Pictoris and Kinesis in the Hyades. Finally, in Sect. 5, we present our conclusions. Appendices A and B show a compilation of the method’s assumptions and the code’s time scalability, respectively.
2 Methodology
Kalkayotl infers the internal positions and kinematics of LNSS by creating flexible Bayesian hierarchical models with domains in the distance space (i.e. the 1D model), the Cartesian positional space (i.e. the 3D model), or Cartesian phase-space (i.e. the 6 D model). These Cartesian coordinates represent source-level parameters from the bottom-level hierarchy of the model, while the population-level parameters represent the upper-layer hierarchy of the model. The space of Cartesian coordinates can be selected to correspond either to the ICRS or Galactic reference systems3, for which we followed the PyGaia4 conventions and definitions.
In the rest of this section, we describe each of the dimensionalities of Kalkayotl’s models (i.e. 1D, 3D, and 6D) and the families of statistical distributions it provides to describe the data. Throughout this section we undertake the assumptions specified in Appendix A. Later on, we specify our choice of prior distributions for the population-level parameters and the probabilistic programming language that we use to sample the posterior distributions. We retain the central and non-central parametrisations introduced in Paper I and follow the recommendations therein: central parametrisation for distances up to 500 pc and non-central beyond. Finally, we end the section by describing our strategies to diagnose the prior specification, the convergence of the Markov chains, and the predictive power of the inferred models.
2.1 The 1D distance models
The 1D distance models are described in Paper I. Briefly, in those models, we constructed a Bayesian hierarchical model in which the stellar distances (source-level parameters) were sampled from distributions of statistical (e.g. uniform, Gaussian) or astrophyscial (e.g. King’s) origin whose (global-level) parameters were inferred hierarchically from the data as well. In this new version of the code, we keep the same 1D models as in Paper I and, following Bailer-Jones et al. (2021), include, as a prior for the distance r > 0, the generalised Gamma distribution (GGD; Stacy 1962) which is defined as p(r∣a, d, p) = (p/ad)rd−1e−(r/a)p/Γf(d/p), with shape parameters d > 0 and p > 0, scale parameter a > 0, and Γf the gamma function, respectively. Then, Eq. (3) of Bailer-Jones et al. (2021) is recovered, by setting a = L, d = β + 1, and p = α as
![Mathematical equation: $\[\mathcal{G G D}(r {\mid} L, \alpha, \beta)=\frac{1}{\Gamma_{f}\left(\frac{\beta+1}{\alpha}\right)} \frac{\alpha}{L^{\beta+1}} r^{\beta} e^{-(r / L)^{\alpha}}.\]$](/articles/aa/full_html/2025/01/aa48362-23/aa48362-23-eq1.png) (1)
(1)
We note that the exponentially decreasing space density (EDSD) prior introduced by Bailer-Jones (2015, Eq. (17)) is a special case of the 𝒢𝒢𝒟(r∣L, α, β), and corresponds to α = 1 and β = 2. When implementing this prior within Kalkayotl, we assume the following hyperpriors: for α and β, we assume uniform distributions with a width of 100, and lower limits set to 0 and −1 respectively. The length scale L is assumed to be Gammadistributed, with L ~ Γ(α = 2, β = 2/c) such that c > 0 is a user-defined hyper-parameter that corresponds to the mean of the length scale L.
2.2 The 3D position models
We modelled the 3D positions (i.e. the X, Y, and Z source-level parameters) of individual stars (either in ICRS or Galactic coordinates) as independent and identically distributed (iid) random variables drawn from the same multivariate parent distribution in the hierarchy, which comprises Gaussian, Student-T, and Gaussian mixture models (GMM). For the GMM, we included two special cases: the concentric GMM (CGMM) and the field GMM (FGMM). In the CGMM all Gaussian distributions in the mixture share the same mean or location parameter. The FGMM also has concentric mean parameters and a component representing the field in which the covariance matrix is diagonal and fixed to the values provided by the user. Specific details on the number of parameters and their dimensionality is given in the following sections.
2.3 The 6D phase-space models
We modelled the 6D coordinates (i.e. X, Y, Z, U, V, W source-level parameters) of individual stars as either joint distributions of positions and velocities or as a linear velocity field. In the linear velocity field, the velocities are expressed as a linear combination of the positions plus a peculiar velocity. As in the 3D models, the user can choose to infer the model parameters in the Cartesian ICRS or Galactic reference systems.
2.3.1 Joint models
The phase-space joint models are generalisations of the 3D models (see Sect. 2.2) in which the dimensionality simply goes from 3 to 6, with its consequent increase in the total number of model parameters. For example, the Gaussian and GMM models now have 6 × n + 27 and 6 × n + 27 × m + m − 1 free parameters, respectively.
2.3.2 Linear velocity field
In addition to the joint model of positions and velocities described above, Kalkayotl allows for the construction of a linear5 velocity field model. Following Lindegren et al. (2000), we modelled the velocity of a star as the addition of the system’s velocity (together with its internal dispersion) plus the velocity expected by a linear field:
![Mathematical equation: $\[\boldsymbol{v}_{i}=\boldsymbol{T} \cdot\left(\boldsymbol{x}_{i}-\boldsymbol{x}_{0}\right)+\mathcal{D}(\boldsymbol{v}_{0}, \Sigma_{v}),\]$](/articles/aa/full_html/2025/01/aa48362-23/aa48362-23-eq2.png) (2)
(2)
where T is a 3 × 3 tensor representing the linear velocity gradient, xi and x0 are the 3D positions of the star and the system, respectively, and 𝒟(v0, Σv) is either a multivariate Gaussian or multivariate Student-T distribution (see Sects. 2.4.1 and 2.4.2, respectively) centred at the system’s velocity v0 and with velocity dispersion given by the covariance matrix Σv. The entries of tensor T correspond to the nine partial derivatives of the velocity components (U, V, W) with respect to the position components (X, Y, Z).
Here, we represent the diagonal, lower-triangular, and upper-triangular entries of tensor T with vectors κ, Ω0, and Ω1, respectively, as follows:
![Mathematical equation: $\[\boldsymbol{T}=\left(\begin{array}{lll}T_{x x} & T_{x y} & T_{x z} \\ T_{y x} & T_{y y} & T_{y z} \\ T_{z x} & T_{z y} & T_{z z}\end{array}\right)=\left(\begin{array}{ccc}\kappa_{x} & \Omega_{00} & \Omega_{01} \\ \Omega_{10} & \kappa_{y} & \Omega_{02} \\ \Omega_{11} & \Omega_{12} & \kappa_{z}\end{array}\right).\]$](/articles/aa/full_html/2025/01/aa48362-23/aa48362-23-eq3.png) (3)
(3)
With this notation, the mean of vector κ expresses the internal contraction or expansion of the system, with ![Mathematical equation: $\[|\boldsymbol{k}|=\frac{1}{3}\left(T_{x x}+\right. \left.T_{y y}+T_{z z}\right)=\frac{1}{3}\left(\kappa_{0}+\kappa_{1}+\kappa_{2}\right)\]$](/articles/aa/full_html/2025/01/aa48362-23/aa48362-23-eq4.png) while the rotational velocity vector ω can be expressed as:
while the rotational velocity vector ω can be expressed as: ![Mathematical equation: $\[\boldsymbol{\omega}=\left[\omega_{x}, \omega_{y}, \omega_{z}\right]=\frac{1}{2}\left[T_{z y}-T_{y z}, T_{x z}-\right. \left.T_{z x}, T_{y x}-T_{x y}\right]\]$](/articles/aa/full_html/2025/01/aa48362-23/aa48362-23-eq5.png) (see Eq. (4) of Lindegren et al. 2000). We notice that a simpler and constant6 velocity model can be obtained by neglecting the contributions of vectors Ω0 and Ω1 which effectively reduce tensor T to a diagonal matrix.
(see Eq. (4) of Lindegren et al. 2000). We notice that a simpler and constant6 velocity model can be obtained by neglecting the contributions of vectors Ω0 and Ω1 which effectively reduce tensor T to a diagonal matrix.
Thanks to the previous definitions, objective criteria can be defined to establish if a stellar system is expanding, contracting or rotating. We use the following definitions throughout the rest of this work. Expansion or contraction is said to be detected at the α level if the α-quantile of the high-density interval (HDI) from the posterior distribution of |κ| does not contain zero. For example, expansion (contraction) is said to be detected at the 2σ level if the 95% HDI of the posterior distribution of |κ| is positive (negative) and does not contain zero. Similarly, we define a detectability criterion for rotation. We said to detect rotation at the α level if the α-quantile HDI of the posterior distribution of at least one of the entries of the ω vector does not contain zero. We notice that our restrictive criterion applies to each independent component given that a set of rotation vectors with random orientations may also have a magnitude that could be significantly positive without implying an ordered motion. In the case of expansion or contraction, given that the important quantity, |κ|, is defined as the average of the trace of tensor T and there are only two directions (contraction or expansion) there is no issue in defining its significance over the posterior distribution of |κ| rather than on the components of κ.
The previous velocity model is essentially the same that Lindegren et al. (2000) originally proposed and then Oh & Evans (2020) augmented by a background modelling. There are nonetheless the following differences. First, our model lacks an integrated decontamination mechanism (see Assumption 4), as the iterative outliers rejection of Lindegren et al. (2000) or the background modelling of Oh & Evans (2020). Second, the 3D positions in our model are inferred using a system-oriented hierarchical model (see Sect. 2.4), which offers more robust estimates than the improper 1D distance prior assumed by Oh & Evans (2020). Third, observed radial velocities are also included as part of the data; thus the perspective expansion or contraction effects affecting the Lindegren et al. (2000) model are no longer present. As stated in Appendix A of Oh & Evans (2020), a few radial velocity measurements across the system serve to anchor its systemic velocity and remove these perspective effects. Finally, the major difference between the previous models and ours is the correction of the angular (spatial) correlations present in both proper motions and parallaxes of Hipparcos (Perryman et al. 1997) and Gaia (Gaia Collaboration 2016) data. Correcting for these correlations results in improved parameter precision and credibility (see Paper I).
Regarding contamination, we believe that due to the multitude of origins that it may have (e.g. observation conditions, reduction pipeline, catalogue creation, selection function, membership methods, cherry-pick selection) a single decontamination model will not be optimal for a particular research objective given that an object may be considered a contaminant in some cases but not in others. The clearest example of this type of objects is an unresolved binary star, which could be considered a contaminant for some objectives (e.g. trace-back age dating) and not in others (e.g. mass function determination). For the previous reasons, we decided to leave the decontamination process to the criteria of the user. Nonetheless, we provide a simple decontamination method similar to that of Oh & Evans (2020) but constructed in the joint space of positions and velocities, which can be run independently from the rest of the models (see Sect. 2.4.5). The user can access this model through the FGMM family and the specific field_scale parameter. The probabilistic classification resulting from this model can be used to clean the list of system members.
2.4 Families of statistical distributions
In Paper I, we use two types of families to describe the distance distributions of stellar systems: the purely statistical and the astrophysical ones. Here, we only provide purely statistical distributions and leave the inclusion of astrophysical ones for future work. The purely statistical distributions that we implemented here are Gaussian, Student-T, and GMM, together with two specific cases of the GMM: the concentric Gaussian mixture model and the field Gaussian mixture model.
We notice that in all our model families, their parameters can be held fixed to a user-provided value during the inference process. This proved particularly useful in those cases where the user wants to reproduce the inference process given all or some parameter values from the literature or from a previous run. For example, if the user is interested in inferring the parameters of a single star that is known to be a member of the stellar system for which its parameters are known. Thus, instead of running a full analysis with the previous members plus the new one, the user can assume that this new member has a negligible contribution to the population-level parameters and hold them fixed when inferring its source-level parameters, which will certainly speed up the inference process.
2.4.1 Gaussian distribution
The Gaussian distribution describes the multivariate coordinates (i.e. 3D or 6 D) x of each star as x ~ 𝒩(μ, Σ), with 𝒩 the multivariate normal distribution, μ its vector of central location (i.e. mean or median), and Σ the symmetric positive semi-definite covariance matrix. The number of free parameters of the Gaussian distribution equals D + (D × (D + 1))/2, with D the model’s dimension (i.e. 3 or 6).
2.4.2 Student-T distribution
Similar to the Gaussian distribution, the Student-T distribution describes the multivariate coordinates (i.e. 3D or 6D) x of each star as x ~ 𝒯(μ, ν, Σ), with μ and Σ defined as in the Gaussian distribution, but now, the ν parameter describes the degrees of freedom. We notice that when ν → ∞ the Student-T distribution converges to the Gaussian distribution. Its number of free parameters is only one more than those of the Gaussian distribution with the same dimensionality. When this family distribution is used in combination with the linear velocity model, the ν parameter is a vector of dimension two with the first one used for positions and the second one for velocities.
We decided to include the Student-T distribution because it describes variations from normality using a single parameter (ν) with clear interpretability and simplicity. The smaller the value of the ν parameter, the larger the discrepancy with respect to the Gaussian distribution. Its heavy tails for small values of ν allow for a simple and robust modelling of possible outliers while maintaining a symmetric distribution.
2.4.3 Gaussian mixture
The Gaussian mixture distribution describes the multivariate coordinates (i.e. 3D or 6D) x of each star as drawn from a mixture of Gaussian distribution with a fixed number of components m set by the user, that is
![Mathematical equation: $\[\boldsymbol{x} \sim \boldsymbol{\mathcal{G M M}}\left(\left\{w_{i}, \boldsymbol{\mu}_{i}, \Sigma_{i}\right\}_{i=1}^{m}\right) \equiv \sum_{i=1}^{m} w_{i} \cdot \boldsymbol{\mathcal{N}}(\boldsymbol{\mu}_{i}, \Sigma_{i}),\]$](/articles/aa/full_html/2025/01/aa48362-23/aa48362-23-eq6.png)
with wi, μi and Σi the weight, mean, and covariance matrix of the i-th Gaussian component, where ![Mathematical equation: $\[\sum_{i=1}^{m} w_{i}=1\]$](/articles/aa/full_html/2025/01/aa48362-23/aa48362-23-eq7.png) . The total number of free parameters for the GMM distribution equals m × [(2 × D) + (D × (D + 1))/2] − 1, with D the model’s dimensionality.
. The total number of free parameters for the GMM distribution equals m × [(2 × D) + (D × (D + 1))/2] − 1, with D the model’s dimensionality.
We decided to include this family distribution to model complex stellar regions composed of more than one structure. We notice that each component in the mixture has its own location and dispersion, thus representing the most flexible of our models. In addition, this family allowed for a probabilistic posterior classification of individual stars into the components of the mixture, thus enabling probabilistic disentanglement of stellar populations (assuming that the Gaussian distribution is a good model for each of these populations).
2.4.4 Concentric Gaussian mixture
The concentric Gaussian mixture (CGMM) as its name says, is a special case of GMM in which the Gaussian components are concentric, this is, they all share the same and unique mean μ. Fixing this unique mean effectively reduces the number of free parameters to D + m × [D + (D × (D + 1))/2] − 1, with D the model’s dimensionality.
We included this special case of the GMM to describe complex distributions of stellar systems having tails heavier than those of the Student-T distribution but that are symmetric with respect to the centre (i.e. they are concentric). This distribution proved to be useful for describing the long tidal tails of open clusters (see, for example, Olivares et al. 2023b).
2.4.5 Field Gaussian mixture
The field plus Gaussian mixture (FGMM) distribution is a further special case of the CGMM in which the last component of the mixture has a fixed and user-provided diagonal covariance matrix. This last component is used to model possible field contaminants whose large dispersion may be known a priori by the user. Therefore, the 6D field_scale vector parameter that represents the standard deviations of the field component should be supplied by the user based on existing a prior information about possible contaminants. The number of free parameters of this model is thus reduced to D + (m − 1) × [D + (D × (D + 1))/2] − 1, with D the model’s dimensionality.
We included this special case to allow for the decontamination of the input list of members. Given the probabilistic classification provided by Gaussian mixtures, the user can make a first run using this decontamination model, and then use its output classification to remove from the input list of members those sources classified as field stars. An example of this procedure is shown in Sect. 4.
2.5 Prior specification
All the family distributions implemented in Kalkayotl share two types of parameters: locations and scales. Other parameters, such as the weights in the mixture distributions or the degrees of freedom in the Student-T distribution, are family specific and are discussed below.
The location parameter corresponds to the single D-dimensional vector μ in the Gaussian, Student-T, CGMM, and FGMM families, and to the set of m D-dimensional vectors ![Mathematical equation: $\[\{\boldsymbol{\mu}\}_{i=1}^{m}\]$](/articles/aa/full_html/2025/01/aa48362-23/aa48362-23-eq8.png) in the GMM family. Similarly, the scale parameter corresponds to the single DxD covariance matrix Σ in the Gaussian and Student-T families and to the set of m DxD covariance matrices
in the GMM family. Similarly, the scale parameter corresponds to the single DxD covariance matrix Σ in the Gaussian and Student-T families and to the set of m DxD covariance matrices ![Mathematical equation: $\[\left\{\Sigma_{i}\right\}_{i=1}^{m}\]$](/articles/aa/full_html/2025/01/aa48362-23/aa48362-23-eq9.png) in the mixture models (m − 1 in the case of the FGMM).
in the mixture models (m − 1 in the case of the FGMM).
For the location parameter (μ or ![Mathematical equation: $\[\{\boldsymbol{\mu}\}_{i=1}^{m}\]$](/articles/aa/full_html/2025/01/aa48362-23/aa48362-23-eq10.png) ) we used a Gaussian prior. In each entry (coordinate), μ, of this vector parameter we imposed a univariate Gaussian prior so that μi ~ 𝒩(μ = αi,0, σ = αi,1), with fixed hyper-parameters αi,0 and αi,1, corresponding to the median and standard deviation of the Gaussian distribution. The values of these hyper-parameters are either provided by the user or set to its default values.
) we used a Gaussian prior. In each entry (coordinate), μ, of this vector parameter we imposed a univariate Gaussian prior so that μi ~ 𝒩(μ = αi,0, σ = αi,1), with fixed hyper-parameters αi,0 and αi,1, corresponding to the median and standard deviation of the Gaussian distribution. The values of these hyper-parameters are either provided by the user or set to its default values.
For the scale parameter (Σ or ![Mathematical equation: $\[\left\{\Sigma_{i}\right\}_{i=1}^{m}\]$](/articles/aa/full_html/2025/01/aa48362-23/aa48362-23-eq11.png) ) we used independent prior distributions over the correlation matrices, Corr, and the diagonal standard-deviation matrix, S d, and reconstructed the scale parameters as Σ = S d · Corr · S d. We imposed a Lewandowski et al. (2009) distribution (hereafter LKJ) as prior for the correlation matrices, Corr ~ ℒ𝒦𝒥(η), with fixed hyper-parameter η, which controls the degree of correlation between entries (coordinates), with η = 1 resulting in uniform correlations (i.e. ρ ~ 𝒰(0, 1)) and increasingly larger values producing decreasing correlations. The value of this η parameter can be provided by the user or left to its default value of one. In each entry of the diagonal standard-deviation matrix we imposed a Gamma prior, σi ~ Γ(α = 2, β = βi) with fixed hyper-parameter βi either to a user-provided value or to its default of 10 pc in positions and 2 km s−1 in velocities, which result in modes at 10 pc and 2 km s−1, respectively. The combination of these two hyper-parameters can help users to flexibly infer the shape of the stellar system in both positions and velocities or, on the contrary, to impose spherical symmetry on it.
) we used independent prior distributions over the correlation matrices, Corr, and the diagonal standard-deviation matrix, S d, and reconstructed the scale parameters as Σ = S d · Corr · S d. We imposed a Lewandowski et al. (2009) distribution (hereafter LKJ) as prior for the correlation matrices, Corr ~ ℒ𝒦𝒥(η), with fixed hyper-parameter η, which controls the degree of correlation between entries (coordinates), with η = 1 resulting in uniform correlations (i.e. ρ ~ 𝒰(0, 1)) and increasingly larger values producing decreasing correlations. The value of this η parameter can be provided by the user or left to its default value of one. In each entry of the diagonal standard-deviation matrix we imposed a Gamma prior, σi ~ Γ(α = 2, β = βi) with fixed hyper-parameter βi either to a user-provided value or to its default of 10 pc in positions and 2 km s−1 in velocities, which result in modes at 10 pc and 2 km s−1, respectively. The combination of these two hyper-parameters can help users to flexibly infer the shape of the stellar system in both positions and velocities or, on the contrary, to impose spherical symmetry on it.
For the weight parameter w of the mixture distributions (i.e. GMM, CGMM and FGMM), we used a Dirichlet prior distribution so that w ~ 𝒟(δ), with δ a fixed hyper-parameter whose value is provided by the user. This hyper-parameter controls the amount of mass distribution going to each component, with small magnitude vectors resulting in more relaxed priors. For the degrees-of-freedom parameter, ν, of the Student-T distribution we use a Gamma prior distribution so that ν ~ Γ(α = να, β = νβ), with hyper-parameters να and νβ fixed to either the user-provided values or να = 1 and νβ = 0.1.
For the parameters κ and Ω of the linear velocity field, we use the following prior distributions. The components of both, κ and Ω are expected to be small and centred on zero. Thus we used zero-centred normal distributions with standard deviations as user-defined hyper-parameters σκ and σΩ, both having a default value of 0.1km s−1 pc−1.
In Table 1, we provide a summary of the shared and family-specific parameters together with their prior distributions. The right column of the table also provides the default hyper-parameter values for cases in which the user does not provide input values. In the default values of the hyper-parameters, the ![Mathematical equation: $\[\bar{X}\]$](/articles/aa/full_html/2025/01/aa48362-23/aa48362-23-eq13.png) vector corresponds to the mean vector of observables after transformation into the ICRS or Galactic reference system.
vector corresponds to the mean vector of observables after transformation into the ICRS or Galactic reference system.
Prior distributions and its hyper-parameters.
2.6 Likelihood
We assumed that the likelihood of the N stars in the input list of the system’s members is a multivariate Gaussian distribution. The dimensionality of this Gaussian corresponds to the total number of effectively observed features in the input list of members Ne f f. For example, the likelihood of a dataset with N = 100 stars with fully observed astrometry and radial velocity will be a multivariate Gaussian of Ne f f = 600 dimensions in the 6D model and Ne f f = 300 dimensions in the 3D model. However, the likelihood of a dataset with the same number of stars (N = 100) but with only 50 of them having radial velocity measurements would be a multivariate Gaussian with Ne f f = 550 and Ne f f = 300 dimensions in the 6D and 3D models, respectively. This single high dimensionality Gaussian results from dropping the usual assumption that observations are independent and identically distributed. Instead, we assume that the data is heteroscedastic and spatially correlated in the sky, as is the case of the Hipparcos (e.g Lindegren 1988; Lindegren et al. 2000) and Gaia (e.g. Lindegren et al. 2021) data. We model these spatial (angular) correlations using Equations 24 and 25 of Lindegren et al. (2021) (Assumption 3).
In the previous multivariate Gaussian likelihood, the median value corresponds to the flattened vector of the measurements of all the members in the input list. The covariance matrix of this Gaussian likelihood is constructed as follows. First, the covariance matrix of each source is reconstructed from its provided uncertainties (i.e. the _error suffix) and correlations (i.e. the _corr suffix). These N covariances are used to populate the block diagonal entries of the Ne f f × Ne f f covariance matrix. The inter-source covariances (off-block entries) of the parallax and proper motions features are populated with the values provided by the spatial correlation functions mentioned above (see Assumption 3). We notice that the entries of this covariance matrix corresponding to radial velocities and sky coordinates have zero inter-source correlations.
We noticed that the tiny sky uncertainties (typically of the order of 50 μas) of the Gaia data difficult the sampling of the model parameters. In a Markov chain, the probability of rejecting a proposed step increases with a diminished likelihood value. Therefore, the tiny uncertainties result in Markov chains with very few accepted transitions, large autocorrelations, and low effective sample sizes. The solution to this problem is to run longer chains at the cost of a higher computing time. We provide an alternative and more practical solution which is to increase the sky uncertainties to a value that results in an acceptable compromise between computing time and convergence of the Markov chains. We heuristically find that increasing the sky uncertainties by factors of the order of 105−106 (which effectively results in sky uncertainties of the order of 5–50 arcseconds) improves the convergence of the chains with negligible impact on the recovered parameter values. We set the default value of this scaling factor to 106, which renders the best compromise between computing time and convergence assurance.
2.7 Posterior sampling
We specify our models and sample their posterior distributions given the input list of members using the probabilistic programming language PyMC (Salvatier et al. 2016). To sample the posterior distributions, Kalkayotl finds suitable initial solutions for each Markov chain through auto-differentiable variational inference (ADVI; Kucukelbir et al. 2017). This fast initial solution serves to reduce the computation time that otherwise the chains would need to reach the target region of the parameter space. These initial solutions (one per chain) are passed to the No-U-Turn sampler (NUTS; Hoffman & Gelman 2011), which is used for efficient sampling of high-dimensionality spaces. Further sampling acceleration can be achieved using graphical processor units (GPUs) through the high-performance computing library JAX7.
The sampler default parameters were established as follows. The ADVI search for the initial solution runs for 5 × 105 steps or an absolute tolerance of 5 × 10−3. The sampling is done by running two chains with 3000 and 2000 iterations each for tuning and sampling, respectively. The default parameters for NUTS are a target acceptance of 0.65 (see Hoffman & Gelman 2011) and step sizes of 10−1, 10−2 and 10−3 for models of 1D, 3D, and 6D, respectively. These values were found after extensive validation and they probed to effectively reduce the tuning iterations without compromising the convergence. Nonetheless, the 3000 tuning iterations are used to refine this value at each run.
2.7.1 Convergence and statistics
Convergence of the NUTS chains is automatically assessed by PyMC at the end of each run. We recommend users to carefully read the output messages of the sampler, which generally provide useful diagnose. Nonetheless, Kalkayotl computes its convergence assessment through the following statistics. The potential scale reduction (Gelman & Rubin 1992), known as the Gelman–Rubin ![Mathematical equation: $\[\hat{R}\]$](/articles/aa/full_html/2025/01/aa48362-23/aa48362-23-eq14.png) statistic, is intended to measure the factor by which the posterior would shrink if the number of iterations will go to infinity. It is intended for multiple chains and its value should be ≲1, with values of
statistic, is intended to measure the factor by which the posterior would shrink if the number of iterations will go to infinity. It is intended for multiple chains and its value should be ≲1, with values of ![Mathematical equation: $\[\hat{R}>1.1\]$](/articles/aa/full_html/2025/01/aa48362-23/aa48362-23-eq15.png) indicating convergence issues. The effective sample size (ESS) measures the number of independent samples with the same statistical power as the N autocorrelated samples from the Markov chain (see Sect. 11.5 of Gelman et al. 2013), and thus the Markov chain standard error (MCSE) of the parameters is
indicating convergence issues. The effective sample size (ESS) measures the number of independent samples with the same statistical power as the N autocorrelated samples from the Markov chain (see Sect. 11.5 of Gelman et al. 2013), and thus the Markov chain standard error (MCSE) of the parameters is ![Mathematical equation: $\[\sigma / \sqrt{\mathrm{ESS}}\]$](/articles/aa/full_html/2025/01/aa48362-23/aa48362-23-eq16.png) rather than
rather than ![Mathematical equation: $\[\sigma / \sqrt{N}\]$](/articles/aa/full_html/2025/01/aa48362-23/aa48362-23-eq17.png) , with σ the standard deviation. These three statistics are reported for each model parameter as part of the standard output files. In addition, the terminal output of Kalkayotl also reports the step size value of the NUTS algorithm used by each chain, which can be used to further refine its value in consecutive runs and to diagnose convergence issues when different chains provide highly discrepant step size values.
, with σ the standard deviation. These three statistics are reported for each model parameter as part of the standard output files. In addition, the terminal output of Kalkayotl also reports the step size value of the NUTS algorithm used by each chain, which can be used to further refine its value in consecutive runs and to diagnose convergence issues when different chains provide highly discrepant step size values.
2.7.2 Model criticism: Prior and posterior checks
Model criticism is a fundamental step of the knowledge extraction process. Although it lies beyond the inference process itself, it is important to diagnose possible biases associated with the model itself rather than with the sampling algorithm. For this reason, model criticism must be done once the convergence of the sampling algorithm has been warranted.
The most straightforward element to criticise in a Bayesian parametric model is its set of prior distributions. This criticism of the prior in most cases can be done by visual comparison of the prior and posterior distributions. Upon user’s requests, Kalkayotl samples from the prior predictive distribution and thus generates samples from the prior distribution of the model parameters. Then, the code provides output files with plots of these prior distributions together with the inferred posterior ones. Inspecting these plots, the user can easily spot problematic prior distributions. In principle, the prior distribution should allow, with a non-negligible probability, the expected intervals of the parameter value without being overly restrictive to avoid biasing the posterior distribution towards specific parameter regions.
The second and sometimes most difficult element to criticise in a model is its set of prior assumptions (i.e. the assumptions that the modeller made when constructing the model). Assessing the fitness of these assumptions is dataset specific and far from simple. One diagnostic that aids in this criticism, particularly when comparing different models, is the ability of the model and its inferred parameter distributions to predict observed data, which could be sources observed or unobserved by the model. Kalkayotl provides, as part of the output files, the posterior predictive distributions of the model’s observed sources (i.e. those used to infer the posterior distributions). These synthetic observed data can be used to judge the model’s ability to predict the real observed data. And thus, by comparing the predictive posterior distributions of different models, the user can decide the specific model that better suits the particular needs of the scientific objective at hand.
We notice that these posterior predictive distributions may have further astrophysical uses. For example, by comparing the radial velocities posterior predictive distributions with the observed ones, the user can discriminate between single stars and possible binaries or multiples. Also, when working with 6 D models, the posterior predictive distributions of the parallaxes would in general shrink with respect to the observed ones due to the effect of the kinematically improved parallaxes (see Lindegren et al. 2000, and its Sect. 4.1.2, particularly). One further use could be to obtain kinematic parallaxes by adding to the system’s input dataset the data of candidate members with missing parallaxes but measured sky positions and proper motions (in the same reference system as Gaia), as those provided by the DANCe (Bouy et al. 2013) and VISIONS (Meingast et al. 2023) surveys.
3 Validation
We validated our methodology using synthetic data sets with Gaia data release 3 (DR3, Gaia Collaboration 2023) properties created with the Amasijo8 code. For detailed explanations of this code, we refer the reader to the works of Casamiquela et al. (2022) and Olivares et al. (2023b). Briefly, the code creates a synthetic population of stars from the user-provided kinematic parameters (location and dispersion in the ICRS or Galactic reference systems, optionally a linear velocity tensor can also be provided) together with the fixed population’s age, metallicity, and extinction. These true values are transformed into the observed space (astrometry plus photometry) and then resampled from the observational uncertainties given by PyGaia9 for Gaia DR3. The radial velocities are masked as missing according to PyGaia criteria, which roughly correspond to sources fainter than 14 mag in G band. Therefore, the percentage of sources with missing radial velocities varies from 10% for clusters at 100 pc to 50% for those at 1.5 kpc.
For each model family, we created synthetic clusters in a grid with varying numbers of stars n_stars ∈ [100, 200, 400], distances d ∈ [50, 100, 200, 400, 800, 1500] pc, and random seeds s ∈ [0, 1, 2, 3, 4, 5]. We fixed the population’s age, metallicity and extinction to 100 Myr, z = 0.012, and Av = 0.0, respectively. The system’s location in space and velocity space was fixed to XYZ = [1, 1, 1] · d/ ![Mathematical equation: $\[\sqrt{3}\]$](/articles/aa/full_html/2025/01/aa48362-23/aa48362-23-eq18.png) pc and UVW = [10, 10, 10] km s−1 whilst its scale (dispersion) fixed to 3 pc in position and 1 km s−1 in velocity, both isotropic with zero correlations.
pc and UVW = [10, 10, 10] km s−1 whilst its scale (dispersion) fixed to 3 pc in position and 1 km s−1 in velocity, both isotropic with zero correlations.
We generated stellar systems with five statistical models: Gaussian joint, Gaussian linear, Student-T joint, Student-T linear, and GMM joint. The joint models are multivariate in the joint space of positions and velocities (XYZUVW) while the linear ones are disjoint in positions (XYZ) and velocities (UVW). In the linear velocity field, the velocities are expressed as a linear field of the positions (see Eq. (2)) with a tensor T fixed to
![Mathematical equation: $\[\boldsymbol{T}=C \cdot\left(\begin{array}{rrr}1 & -1 & 1 \\1 & 1 & -1 \\-1 & 1 & 1\end{array}\right) \mathrm{ms}^{-1} ~\mathrm{pc}^{-1}\]$](/articles/aa/full_html/2025/01/aa48362-23/aa48362-23-eq19.png) (4)
(4)
with C as a constant taking values in C ∈ [10, 50, 100]. Such tensor produces stellar systems that expand isotropically at a rate |κ| = C m s−1 pc−1 and rotate with an angular velocity ω = [C, C, C] m s−1 pc−1. The chosen values of C are similar to the expansion and rotation signals found in the literature for the benchmark stellar systems of the β-Pictoris stellar association and the Hyades and Praesepe open clusters (see Sect. 4). In the Student-T and GMM, we fixed the parameter values to ν = 10 and w = [0.6, 0.4] with two components, respectively. We notice that in all cases we use the same location and scale parameters as described above, although in the GMM case, the second component is always located 50 pc above the first component in the Z direction.
We inferred the stellar system parameter of each synthetic data set using its corresponding model family. The posterior distribution was sampled, analysed, and criticised as described in Sects. 2.7, 2.7.1, and 2.7.2, respectively. Appendix B shows some examples of the typical execution time that Kalkyotl takes as a function of the number of stars in the system.
In the following, we validate and assess the quality of the recovered parameters with three metrics: error, uncertainty, and credibility. The error measures the parameter’s relative deviation from its true value and is computed as the difference between the mean of the parameter’s posterior distribution and the true value divided by the true value. The uncertainty metric corresponds to the standard deviation of the parameter’s posterior distribution divided by the parameter’s true value. These error and uncertainty metrics correspond to the ones typically known as accuracy and precision, although here we express them in relative terms. Finally, the credibility metric measures the fraction of the simulations in which the true parameter’s value was contained within the 95% HDI of the parameter’s inferred posterior distribution. All of these metrics are expressed in percentage units.
In the next two sections, we present the validation of the population-level parameters and the source-level parameters. Finally, we end this section with a discussion about our models’ characteristics.
3.1 Population-level parameters
We validate the population-level parameters of our set of models with the error, uncertainty, and credibility metrics mentioned above. First, we assess the performance of our method to recover the set of parameters that are common to all models (i.e. the location and standard deviation). Then, we continue the validation and discussion of the model-specific parameters, particularly those from the linear velocity field.
3.1.1 Common parameters
Figures 1 and 2 show the error and uncertainty, respectively, of the population-level parameters of location and standard deviation, which are common to all our models, as a function of the cluster’s distance. The solid lines and shaded regions depict, respectively, the mean and standard deviation of the random cluster realisations at each distance value. The figures show only the results on synthetic clusters with 100 stars given that the metrics of clusters with 200 and 400 stars are better, as expected, and thus, for the sake of simplicity, we do not show them. In the case of the GMM model, we only show the result of one component and up to a distance of 800 pc. Beyond this limit, the parameter’s recovery shows large errors, large uncertainties and negligible credibility. From these figures, we draw the following conclusions.
First, the errors and uncertainties are isotropic showing similar values in the position and in the velocity coordinates. The isotropy of our results indicate that our models can recover the true phase-space geometry of stellar systems with errors ≲10% up to 800 pc and ≲20% up to 1.5 kpc, which implies that up to 800 pc there is a minimal “fingers of God” effect (for a description of this effect, see, for example, Fig. 2 of Zucker et al. 2020). The only exception to this trend is the GMM model, which shows larger std errors, particularly in the X and Z directions. These large errors most likely result from the combination of both the lower number of stars (the shown GMM component has only 60 stars compared to the rest of the cases having 100 stars each) and the entanglement between components in the Z direction resulting from the second component being displaced 50 pc in this direction.
Second, concerning the errors, we observe that all our models, except for the GMM one, have negligible errors in the location parameters of position (≲0.5%) and velocity (≲3%), with the former having larger values in the closest clusters and the latter in the farthest ones. The errors in the standard deviation parameters of all models are ≲20% for both positions and velocities, with their values increasing from 5–10% at the closest clusters and up to 20% for the farthest ones. The GMM model shows the largest dispersion error in the X and Z directions for the reasons explained in the previous paragraph.
Third, concerning uncertainties, the 3D location of the clusters are recovered with uncertainties in the 0.5–1.5% range for clusters up to 200 pc and ≲0.2% for clusters up to 1.5 kpc. The relatively larger uncertainties at the closest distances indicate that our models struggle to infer the 3D centre of the nearest clusters despite the excellent precision and accuracy with which the 3D positions of their stars are recovered (at the 0.1% level, see Sects. 3.3 and 4.1). In the rest of the parameters and models, the uncertainties grow with distance, as expected, from 1% to 5% in the velocity location, and from 10% to 35% in the rest of the dispersion parameters.
Concerning the parameter’s credibility, the median value of this metric for all location and standard deviation parameters in all models is 100%, except for the GMM one beyond 800 pc, where it drops to zero as mentioned above. The high credibility indicates that our method can recover the true parameters values within the 95% HDI for distances up to 800 pc for the GMM model and up to 1.5 kpc for the rest of the models.
Finally, the low error, low uncertainty, and high credibility prove that our method is able to recover the true parameters of location and standard deviation of stellar systems with excellent accuracy and acceptable precision in the GMM model up to 800 pc and up to 1.5 kpc in the rest of models. Most probably, the subset of the location parameters could still be recovered with excellent accuracy and precision beyond 1.5 kpc. However, we are interested in showing the validity of the model as a whole rather than subsets of it.
 |
Fig. 1 Relative error of the population-level parameters common to all our models as a function of distance. The lines and shaded regions depict the mean and standard deviation of the synthetic clusters with 100 stars. |
 |
Fig. 2 Relative uncertainty of the population-level parameters common to all our models as a function of distance. Captions as in Fig. 1. |
3.1.2 Model-specific parameters
There are three sets of additional model-specific parameters: the ν parameter of the Student-T distribution, the weight parameters of the GMM model, and the nine entries of the T tensor in the linear velocity field models. In the following, we briefly discuss those of the GMM and Student-T, and then we discuss in more detail the parameters of linear velocity field models, particularly their detectability.
The ν parameter in the Student-T models is recovered with large errors for the closest clusters (200% in the joint model and 60% and 40% in the position and velocity of the linear field model) but these errors diminish with distance and stabilise at 800 pc with values of 100% for the joint model and <5% for the linear field model. This parameter is recovered with large uncertainties (~100%) in both the joint and linear field models for all distances. In spite of the large errors, the credibility reaches 100% due to the large uncertainties, except in the case of the joint model at closer distances (≲100 pc), where the credibility is lower than 60% due to the large errors. Therefore, we recommend caution when using the Student-T model and either disregarding the inferred values of the ν parameter or fixing it to a certain a priori value before the inference.
The weights of the GMM model are recovered with negligible errors, ≲2%, low uncertainties, ≲12%, and 100% credibility for distances up to 800 pc. Beyond this limit, the errors and uncertainties increase and the credibility goes to zero. Therefore, we conclude that our method can accurately and precisely recover the true weights of the GMM model to distances up to 800 pc.
The entries of the linear velocity tensor T (see Eq. (3)) are all recovered with almost identical metrics. Thus, the following description is valid for any of the entries.
Concerning errors, these vary mostly with the C value and are almost independent of the number of stars. For the lowest value of C = 10, the errors are independent of distance and their absolute values are, on average, ≲200%. For C = 50, the errors remain independent of distance in general, but this time, their absolute values are ≲50%. For the largest value of C = 100, the errors show a linear trend with distance that varies between 0% at 50 pc to −50% at 1.5 kpc.
Concerning the uncertainties, these grow with distance and diminish with an increasing number of stars, as expected. For C = 10, they vary between 200% at 50 pc to 800% at 1.5 kpc, while for C = 50 they vary between 40% at 50 pc to 160% at 1.5 kpc. Finally, for C = 100, the uncertainties vary between 20% at 50 pc to 80% at 1.5 kpc. Despite the large errors, the large uncertainties result in a high 100% credibility for all C values, distances and number of stars.
In the light of the previous results, we recommend proceeding with caution whenever an entry of the linear velocity tensor is inferred with a value ≲50 m s−1 pc−1, particularly when it is lower than ≲10 m s−1 pc−1. The criteria for the detection of such low signals should be based on their full posterior distribution rather than only on their mean value.
Usually, the detection of a signal is based on its significance level, with 3σ to 5σ being common criteria to establish a discovery. Moreover, the significance level of a signal can be related to the well-known term of signal-to-noise ratio (S/N), in which an S/N=n is roughly equivalent to a nσ significance level.
To aid the users of Kalkyotl to estimate the detectability of the entries in the linear velocity tensor, we use our set of Gaia DR3 simulations to compute the S/N of the inferred T tensor entries. In Fig. 3, we show the S/N of these entries as a function of the cluster distance, and colour-coded with the number of stars for the three values of the C constant (shown with different line style). As can be observed, the S/N improves with signal value and number of stars and diminishes with distance up to a maximum distance of 800 pc, beyond this limit, it remains almost constant independent of the number of stars. Moreover, the figure shows that given the current Gaia DR3 data (i.e. astrometry and radial velocity) a 5σ detection can only be achieved in the nearest (50 pc) and most populated clusters (>400 stars). However, if the criteria would be relaxed to 1σ significance level, then the detection of signals ~50 m s−1 pc−1 could be achieved up to distances of 800 pc even for clusters with 100 stars. We noticed that these S/N improve with the improving quality of the radial velocities. Thus, complementing Gaia DR3 astrometry with precise radial velocity surveys could significantly improve the detection of low T entry signals.
 |
Fig. 3 Signal-to-noise ratio of the entries in the linear velocity tensor as a function of the distance and the number of stars for the three values of the C constant in units of metre per second per parsec (see Eq. (4)). The lines and shaded regions depict the median and standard deviation of the synthetic simulations with varying random seed. |
3.2 Source-level parameters
We validate the source-level parameters (i.e. the phase-space coordinates of individual stars) with the same metrics used for the population-level parameters. However, in this case, we first averaged over the entire system’s population and then over simulations. The error and uncertainty in the source-level parameters of the six phase-space coordinates are shown in Figs. 4 and 5, respectively. The figures show the metrics value as a function of distance colour-coded according to the model. As with the figures of the group-level parameters, the ones here do not show the values of the GMM model for distances beyond 800 pc nor the results of clusters having 200 and 400 stars. The metrics of clusters having larger populations remain similar to those of having 100 stars except for a mild error reduction in the clusters at 1.5 kpc. In the case of the GMM model, as discussed in the previous section, the maximum distance at which it can be reliably applied is 800 pc. Thus, we do not show values beyond this limit. In the rest of the distances and models, the credibility remains high at 100%, and thus, for the sake of simplicity, their figures are not shown. In the following, we discuss the properties of the previous metrics.
As in the case of the population-level parameters, the source-level ones do not show signs of the “fingers of God” effect. The errors and uncertainties are isotropic with similar values for the 3D positions and 3D velocities.
Concerning errors, we observe that the X, Y, and Z coordinates are recovered with excellent accuracy, having errors ≲0.1%. Although the U, V, and W velocities are recovered with larger errors, ≲2%, these are still negligible.
The uncertainty of the source-level parameters is also remarkable, with values ≲0.4% for 3D positions and ≲8% for 3D velocities. These later behave as expected, growing at a constant rate of 4% at 50 pc to 8% at 1.5 kpc. On the contrary, the uncertainty of the 3D positions shows two distinct behaviours. First, it grows with a high slope from values ≲0.1% at 50 pc to 0.45% at 400 pc. Then, it decreases to 0.3% at 800 pc and remains constant at this value. These two behaviours result from the use of the central and non-central parametrisations (see Sect. 2), in which the former is used for clusters up to 500 pc and the latter for farther away ones. As can be seen in Fig. 5, the use of these parametrisations ensures that the uncertainty remains minimal.
In Paper I, we observed that the distance errors of the individual sources showed an anti-correlation with their true position within the cluster (see Sect. 4.2 and Fig. 2 of Paper I). In our phase-space models, this anti-correlation remains, although much less pronounced. For the 3D positions, it is negligible at 50 pc, grows up to −0.5 at 500 pc and remains at this value for larger distances. On the contrary, for the 3D velocities, it remains at −0.5 for all distances. The explanation for this anti-correlation remains the same as in the 1D case. It results from the ratio between the size of the source uncertainty to that of the cluster, coordinate by coordinate. When the source’s uncertainty is much smaller than the cluster’s dispersion, then there is enough information to pinpoint the source position within the cluster and the anti-correlation is negligible, as in the case of the 3D positions at 50 pc. As the source’s uncertainty increases and gets similar or larger than the cluster’s dispersion, then there is not enough information to pinpoint the source’s position within the cluster and its posterior gets attracted towards the cluster’s mode, thus resulting in the anti-correlation.
Finally, we can conclude that despite the previously described anti-correlations, the low errors, small uncertainties, and high credibility prove that our method can recover the phase-space coordinate of stars in LNSS with excellent accuracy and precision.
3.3 Discussion
The results of the previous sections show that Kalkayotl is able to recover the true values of the population-level and source-level parameters from various phase-space family distributions and velocity models with varying degrees of accuracy and precision. Despite the remarkable similarities in the metrics values, we notice the following important differences amongst models.
First, the GMM model has a lower applicability domain, with a recommended maximum distance of 800 pc. This reduced domain results from increasing entanglement of the GMM Gaussian components with increasing dataset uncertainties. We recommend that the users of this model do a thorough exploration of the chain’s traces to spot possible label switching. Moreover, when the uncertainties are large and the population is scarce, the model can fail to detect one of the components. For this reason, we recommend running the code with several chains or more than only one time. In addition, this model faces convergence difficulties beyond 500 pc. Whenever this occurs, we recommend increasing the number of iterations in the initialisation and tuning phases.
Second, the Student-T family, with both joint and linear velocity fields, shows good metrics values in the common parameters of location and standard deviation. However, the low credibility of the ν parameter must be kept in mind when using this model.
Third, due to its excellent accuracy and precision, our recommended model is the Gaussian one. In those cases where the use of the GMM model is unavoidable, we recommend nonetheless performing a run of the Gaussian model on each of the identified GMM components.
Finally, we observe that when the linear velocity field is applied to clusters at close distances or with a large number of sources, the sampling algorithm faces difficulties in the convergence of the chains. These difficulties result from both the model’s large number of parameters (nine more than the joint model) and its lack of flexibility (given that velocities are assumed to follow Eq. (2)). Although these issues can easily be solved by increasing the number of iterations in the initialisation and tuning phases, we recommend informing the model on the system’s velocity dispersion by setting its prior to sensible values, for example, to those obtained after running the joint velocity model on the same system.
 |
Fig. 4 Relative error of the source-level parameters as a function of distance. Captions as in Fig. 1. |
4 Application to real stellar systems
As part of the validation process and to exemplify the use of Kalkayotl in real data, we use it to infer the 6D phase-space source- and population-level parameters of the β-Pictoris stellar association and the Hyades and Praesepe open clusters. We select these systems because they have ample literature works describing their internal kinematics and relatively low (≲1000) numbers of members, which keeps the computation time at a reasonable value (see Appendix B). In β-Pictoris we use both the Gaussian joint and Gaussian linear velocity models, whereas in the open clusters we only use the Gaussian linear velocity one. Other examples of the application of Kalkayotl’s Gaussian, GMM, and CGMM family distributions with the joint velocity model to open clusters and star-forming regions can be found in Olivares et al. (2023a) and Olivares et al. (2023b). The users of Kalkayotl can find all the associated routines to infer and analyse the following stellar systems in the same online address as the source code (see footnote 2, specifically the folder article/v2.0/Code).
4.1 The β-Pictoris stellar association
Young stellar associations are one of the fundamental products of star formation. As such, studying their kinematics is paramount to understanding their origin and evolution. The β-Pictoris (β-Pic) stellar association, due to its proximity and young age (28 pc and 18–20 Myr for dynamical ages Couture et al. 2023; Miret-Roig et al. 2020; Crundall et al. 2019, 24 ± 3 Myr from isochrones Bell et al. 2015 and 24–25 Myr from Lithium depletion boundary Galindo-Guil et al. 2022; Messina et al. 2016), has been the focus of several studies and, as a result, its kinematic properties are well constrained. Here, we use the Gaia DR3 data of the lists of members from Couture et al. (2023), Miret-Roig et al. (2020), and Crundall et al. (2019). In the case of Crundall et al. (2019), we use the Gaia DR3 data of their 46 members in component A with a membership probability greater than 0.9. In the cases of Miret-Roig et al. (2020) and Couture et al. (2023), we use the Gaia DR3 data of their 26 and 25 members, respectively, complemented by the radial velocities provided in each work.
The previous works report the parameter values in the Galactic reference systems, and thus, for comparison, we used it as well. We notice though that Crundall et al. (2019) report their parameters with respect to a spatial origin located 25 pc above the Galactic plane and a velocity origin coinciding with the local standard of rest10. We subtracted this origin to put their values in the same reference frame as the other two works. We also notice that Couture et al. (2023) do not report uncertainties to any of their parameters, while Miret-Roig et al. (2020) only report those of the location parameters.
Table 2 shows the group-level parameters (i.e. location and standard deviation together with their ±σ uncertainties) of the β-Pic stellar association as reported in the aforecited literature works (i.e. Couture et al. 2023; Miret-Roig et al. 2020; Crundall et al. 2019) and inferred here using Kalkayotl’s 6D Gaussian joint model. For each of the selected literature works, the table shows the reported parameter’s values and those inferred here with the Gaia DR3 data of the corresponding authors’ membership list.
As can be observed, there is a general agreement between the values inferred here and those reported in the literature works, with the majority being compatible within the 2σ uncertainty (i.e. the 95% HDI). However, the largest exceptions correspond to the X parameters (both location and standard deviation) reported by Miret-Roig et al. (2020), and those corresponding to the standard deviation in Y, Z, and U as reported by Crundall et al. (2019). Given the large X location and low X dispersion reported by Miret-Roig et al. (2020) as compared to the rest of the estimates, we consider that these large deviations are probably an artefact resulting from either the membership list or the authors’ method. Similarly, the discrepant standard deviations values reported by Crundall et al. (2019) in the Y, Z, and U coordinates are most likely the result of their method, given that in the same membership list as those authors we find parameters’ values perfectly compatible with those reported by Couture et al. (2023) and Miret-Roig et al. (2020). Therefore, we conclude that our parameters estimates are generally compatible with those from the literature at the 2σ level.
Concerning our parameter’s uncertainty, we observe that these are generally similar to those reported by the literature works. In particular, there is a remarkable similarity between our uncertainties and those reported by Crundall et al. (2019). With respect to the parameters reported by Miret-Roig et al. (2020), we observe that in the location velocities both works have similar uncertainties. However, we notice that their uncertainties in the X, Y, and Z locations are smaller by one and two orders of magnitude. Given that our uncertainty values are similar to those of other parameters and literature works, we conclude that those reported by Miret-Roig et al. (2020) in the location of the X, Y, and Z coordinates are most likely underestimated.
It is interesting to highlight that, in spite of the different samples of members used by the previous works, our methodology renders all the inferred parameters (loc and std) compatible within the 2σ (95% HDI) uncertainties, except in the case of loc[U] were the values inferred from the samples of Miret-Roig et al. (2020) and Couture et al. (2023) are mutually exclusive.
In Fig. 6, we show a one-to-one comparison of the source-level parameters (i.e. the coordinate values of each star) as inferred here against those reported in Couture et al. (2023) and Miret-Roig et al. (2020). As can be observed, we recover with excellent accuracy and precision the values reported by those authors. The X, Y, and Z, coordinates have an average error ≲0.1–0.2 pc while in the U, V, and W it is ≲0.5 km s−1.
We fit the linear velocity model (see Sect. 2.3.2) to the β-Pic members from Miret-Roig et al. (2020), Crundall et al. (2019), and Couture et al. (2023). However, in these two membership lists, we increased the scaling factor of the sky uncertainties to 107 due to convergence failures with the default value of 106 (see Sect. 2.6). The most likely reason for these convergence issues is the presence of outliers and the lack of flexibility of the linear velocity model (see Sect. 3.3).
Table 3 shows the result of our inference with the linear velocity model (last three rows) together with the literature values of the Galactic components of expansion reported by Mamajek & Bell (2014) and Miret-Roig et al. (2020). As can be observed, our inferred values are comparable to those of the previous authors, except for the κZ components reported by Miret-Roig et al. (2020) and inferred here on the members by Crundall et al. (2019). Regarding rotation, we observe only mild evidence of it, with significance values in the order of ≲1σ.
The expansion rates can be used to compute the expansion age of the system, τ, using the relation τ = γ−1 κ−1, where γ = 1.022712165s pc km−1 Myr−1; see for example Mamajek & Bell (2014) and Miret-Roig et al. (2020). Following Mamajek & Bell (2014), we discard the κz component and compute expansion ages not only from κX and κY independently, but also from their weighted average. The last three columns of Table 3 show the expansion ages computed with this method as reported in the literature (first two rows) and obtained here (last three rows). As can be observed, the expansion age computed from the weighted average of κX and κY results in values that agree with the dynamical trace-forward age of 17.8 ± 1.2 Myr by Crundall et al. (2019) and the dynamical trace-back ages of ![Mathematical equation: $\[18.5_{-2.4}^{+2.0}\]$](/articles/aa/full_html/2025/01/aa48362-23/aa48362-23-eq33.png) Myr by Miret-Roig et al. (2020) and 20.4 ± 2.5 Myr by Couture et al. (2023). Combining the expansion ages inferred here (last column of Table 3) through a weighted average, we obtain a dynamical expansion age of 19.1 ± 1.0 Myr.
Myr by Miret-Roig et al. (2020) and 20.4 ± 2.5 Myr by Couture et al. (2023). Combining the expansion ages inferred here (last column of Table 3) through a weighted average, we obtain a dynamical expansion age of 19.1 ± 1.0 Myr.
The excellent agreement and the similar or even better uncertainties of our expansion ages shows that our comprehensive statistical model combined with a simple inversion of the expansion rate gives age estimates that are as accurate and precise as the literature trace-back and trace-forward values. Nonetheless, we notice that this inversion method is highly sensitive to the uncertainties of the expansion rate, in a similar way that distance determination is sensitive to the parallax uncertainty when distance is computed as the inverse of the parallax. Therefore, in the presence of large uncertainties in the expansion rates, we recommend the use of more sophisticated methods, such as dynamical trace-back (e.g. Miret-Roig et al. 2020).
Summarising, Kalkayotl was able to recover the source-level and population-level parameters of β-Pic reported in the literature with good accuracy and precision. The observed discrepancies in the population level parameters can be explained by the different statistical models assumed in the literature. Furthermore, we detect expansion at 12σ, 3σ, and 1σ levels in the X, Y, and Z, directions, respectively, which results in expansion ages which are as precise and accurate as the literature ones that use more sophisticated methodologies. Moreover, we detect, for the first time, some hints of rotation in this system at the 1σ level. Future work will be needed to confirm the existence of this rotation signal.
Location and standard deviation parameters of the β-Pic stellar association as reported in the literature and inferred in this work with the Gaussian joint model.
Expansion, rotation, and age of β-Pic.
 |
Fig. 6 One-to-one comparison of the source-level parameters inferred here and those reported by Couture et al. (2023) and Miret-Roig et al. (2020). The grey line depicts the identity relation. The root-mean-squared value of the differences is also shown on the lower right side of each panel. |
4.2 The Hyades open cluster
The Hyades open cluster is the closest to the Sun and has hundreds of members (710 members at 47 ± 0.2 pc, ![Mathematical equation: $\[640_{-49}^{+67}\]$](/articles/aa/full_html/2025/01/aa48362-23/aa48362-23-eq34.png) Myr, Lodieu et al. 2019b), which makes it an excellent benchmark for kinematic analyses. Several works have analysed the internal kinematics of this cluster (e.g. Jadhav et al. 2024; Hao et al. 2024; Oh & Evans 2020; Leão et al. 2019; Vereshchagin et al. 2013; Lindegren et al. 2000; Perryman et al. 1998; Gunn et al. 1988; Hanson 1975; Wayman 1967) and recently its elongated tidal tails (e.g. Lodieu et al. 2019b; Meingast & Alves 2019; Röser et al. 2019). Despite being thoroughly analysed in the literature, its internal rotation is still under debate. Wayman (1967) studied the influence that internal motions such as contraction and rotation had on distance determinations made with the convergent point method. Using a combined analysis with proper motions, parallaxes, and radial velocities, he measured a contraction of −13 ± 15 m s−1 pc−1 and a total rotation of |ω| = 30 ± 40 m s−1 pc−1, thus concluding that their effect was negligible, in the case of rotation, and could amount up to 0.14 mag in the distance modulus, in the case of contraction. Hanson (1975) also studied the impact that rotation may have on distance determinations made with the convergent point method but now employing numerical simulations. He generated Hyades-like clusters with varying degrees of rotation values and orientations that were transformed to the observed space of proper motions, parallaxes, and radial velocities where he applied the convergent point method. He concluded that when |ω| = 50 m s−1 pc−1 no significant effect was observed in the stellar motions, the convergent point solution, or the cluster distance. On the other hand, in the case of |ω| = 500 m s−1 pc−1 the effects on the proper motions and radial velocities were so large that they would be easily spotted if the Hyades possessed such rotation.
Myr, Lodieu et al. 2019b), which makes it an excellent benchmark for kinematic analyses. Several works have analysed the internal kinematics of this cluster (e.g. Jadhav et al. 2024; Hao et al. 2024; Oh & Evans 2020; Leão et al. 2019; Vereshchagin et al. 2013; Lindegren et al. 2000; Perryman et al. 1998; Gunn et al. 1988; Hanson 1975; Wayman 1967) and recently its elongated tidal tails (e.g. Lodieu et al. 2019b; Meingast & Alves 2019; Röser et al. 2019). Despite being thoroughly analysed in the literature, its internal rotation is still under debate. Wayman (1967) studied the influence that internal motions such as contraction and rotation had on distance determinations made with the convergent point method. Using a combined analysis with proper motions, parallaxes, and radial velocities, he measured a contraction of −13 ± 15 m s−1 pc−1 and a total rotation of |ω| = 30 ± 40 m s−1 pc−1, thus concluding that their effect was negligible, in the case of rotation, and could amount up to 0.14 mag in the distance modulus, in the case of contraction. Hanson (1975) also studied the impact that rotation may have on distance determinations made with the convergent point method but now employing numerical simulations. He generated Hyades-like clusters with varying degrees of rotation values and orientations that were transformed to the observed space of proper motions, parallaxes, and radial velocities where he applied the convergent point method. He concluded that when |ω| = 50 m s−1 pc−1 no significant effect was observed in the stellar motions, the convergent point solution, or the cluster distance. On the other hand, in the case of |ω| = 500 m s−1 pc−1 the effects on the proper motions and radial velocities were so large that they would be easily spotted if the Hyades possessed such rotation.
Gunn et al. (1988) used precise radial velocities to determine a convergent point solution that was later used in combination with the full astrometric and radial velocity data to infer a dynamical model that included elongation and cluster rotation among other parameters. They inferred a distance of 45.4 ± 2.1 pc, a velocity dispersion of 230 m s−1, and a rotation gradient of 1.3 ± 0.53 km s−1 radians−1(28 ± 11 m s−1 pc−1). Interestingly, they concluded that the cluster centre rotates faster than the outside but they were unable to determine the sense of the rotation (i.e. left-handed or right-handed).
The HIPPARCOS data of this cluster was used by Perryman et al. (1998), Lindegren et al. (2000) and Vereshchagin et al. (2013), among others, to analyse the internal kinematics of the cluster. Perryman et al. (1998) concluded that the cluster members move with parallel space motions and an internal velocity dispersion of 0.3 km s−1. They analysed the residuals of the space motions (see their Fig. 9) and concluded that although suggestive of a pattern of rotation or shearing motion, they were fully compatible within 3σ of the cluster motion. Lindegren et al. (2000) studied the cluster kinematics with a reduced version of their linear velocity model (see Sect. 1) that does not incorporate rotation. Vereshchagin et al. (2013) applied a geometric model and measured, in the plane of the sky, a total internal rotation of 40 ± 30 m s−1 pc−1. These authors also concluded that the rotation axis does not lie in the plane of the sky, and thus, that the study of the cluster’s rotation demands not only proper motions and parallaxes but also radial velocities.
Leão et al. (2019) use the spatial correlation of the differences between spectroscopic high-precision (160 m s−1) radial velocities with those predicted by Eq. (2) of Madsen et al. (2002), and measure the cluster’s velocity gradient, in the right ascension coordinate. This gradient translates into a rotation signal of 42.3 ± 4.0 m s−1 pc−1.
Oh & Evans (2020) use an improved version of the general model of Lindegren et al. (2000) and apply it to the Gaia Data Release 2 (DR2; Gaia Collaboration 2018) of the Hyades members from Meingast & Alves (2019) and Röser et al. (2019). They find no evidence of rotation.
Hao et al. (2024) used Gaia DR3 data from the Hyades members by Lodieu et al. (2019b) to analyse its internal rotation They found a mean rotational velocity of 90 ± 30 m s−1 within the cluster tidal radius of 9 pc. To compare with the common units of rotation, we use instead the peak value of their rotational curve (see their Table 8 and Fig. 14), which is located at 3 pc with a value of 0.61 ± 0.06 km s−1 which corresponds to 203 ± 20 m s−1 pc−1.
Jadhav et al. (2024) used Gaia DR3 data from the members by Hunt & Reffert (2023) to study the internal kinematic the Hyades. However, they do not find evidence for rotation.
Given that our Gaussian linear velocity model is similar to that of Oh & Evans (2020), we compare our results of rotation and expansion with those of the previous authors using their list of members with data from both the second and third releases of Gaia. In particular, we work with the list of members from the cluster core, which is expected to be less subject to Galactic shear forces. In addition, we expect the core list of members to have fewer contaminants than that of the tails, given that the tails are more confused with the Galactic field than the high-contrast and dense region of the core. We notice that Oh & Evans (2020) report their values in the ICRS reference frame, and thus, when comparing with those authors, we adopted this same frame.
First, we work with the Gaia DR2 data (i.e. the same astrometry of Oh & Evans 2020) to which we applied our decontamination algorithm (see Sect. 2.4.5). We identified 13 outliers representing a fraction of members of 0.968 ± 0.008. This fraction overlaps at the 95% HDI with the 0.953 ± 0.013 value reported by Oh & Evans (2020). Then, we applied the Gaussian linear velocity model (see Sect. 2.3.2) to the remaining 387 core members. The inferred posterior distributions of our linear model parameters are shown and compared to those of Oh & Evans (2020) in Table 4. We notice that the model of those authors is only for the velocity field; thus it lacks the loc and std parameters of the X, Y, and Z dimensions.
As can be observed from Table 4, in the same data as Oh & Evans (2020), this is column Gaia DR2, we recover the location parameters of the 3D velocities (U, V, W) with similar precision, while their standard deviations (std[U] and std[W]) and correlations with better ones. Only the dispersion in the V coordinate is recovered with lower precision but it is, nonetheless, compatible with the uncertainties as the rest of the parameters. Furthermore, all of the linear velocity parameters (i.e. |κ|, ω, and ω) are consistent within the uncertainties with those of Oh & Evans (2020) although with varying precision.
Then, we proceed to analyse the Gaia DR3 data of the same 387 core members with the Gaussian linear velocity model. The results of this inference are also shown in Table 4, under the column Gaia DR3. These results show that there is only a mild improvement in the precision of the correlation parameters (ρUV and ρVW). However, the most relevant result is the detection, at the 2σ level, of rotation in ωz.
To compare with other works from the literature, we also inferred the parameters of the linear velocity model in the Galactic reference frame. Unfortunately, from the literature works that report the cluster parameters in this frame, we found that only Lodieu et al. (2019b) provides the associated uncertainties. These authors report the cluster location parameters for sources located within two radii: 10 pc and 20 pc. We use the value 10 pc because it coincides with the selection criteria of Oh & Evans 2020, from which we take the list of members for the cluster core. In Table 5, we compare the location parameters reported by Lodieu et al. (2019b) with those inferred here using the Gaia DR3 data and the linear velocity model. As can be observed, the parameters show an overall good agreement despite being inferred from different lists of members and data sets.
In the Galactic reference frame the rotation signal remains at the 2σ level; however it is now in ωx alone, with a value of ω = [−13.61 ± 6.21, 19.87 ± 11.82, 15.93 ± 10.30] m s−1 pc−1. Unfortunately, this rotation signal cannot be directly compared to the values reported in the literature given that the majority of these were obtained by analysing the velocity gradients in the plane of the sky, whereas our model returns a vector of gradients in the 3D space. Nonetheless, the norm of the rotation vector we infer here is perfectly compatible, within the 95% HDI, with the total rotation values of the literature works (see Table 6), except with the recent value of Hao et al. (2024), which exceeds the literature values by more than five times. We notice that if the Hyades has a rotation signal ~200 m s−1 pc−1, then our method would detect it on the Gaia DR3 data with a significance level higher than 5σ (see Fig. 3).
Summarising, the Gaussian linear velocity model implemented here recovers, with excellent accuracy and slightly better precision, the cluster’s parameters reported by Oh & Evans 2020 in the ICRS frame and those of Lodieu et al. (2019b) in the Galactic frame. Furthermore, when applied over the Gaia DR3 data, it unravels, at the 2σ level, the rotational signal of this cluster and confirms most of the rotation values from the literature. More precise and complete radial velocity measures are needed to claim the discovery of the Hyades rotation at a higher significance level.
Parameters of the Hyades open cluster as reported by Oh & Evans (2020) and inferred here with data from Gaia DR2 and DR3.
Location parameters of the Hyades cluster in the Galactic frame.
Literature values of the Hyades rotational signal.
4.3 The Praesepe open cluster
The Praesepe open cluster (187.4 ± 3.9 pc, ![Mathematical equation: $\[673_{-39}^{+55}\]$](/articles/aa/full_html/2025/01/aa48362-23/aa48362-23-eq35.png) Myr, and more than 2000 members, Lodieu et al. 2019a), has recently been at the centre of a controversy about its rotational velocity. The works by Jadhav et al. (2024), Loktin & Popov (2020), Hao et al. (2022), and Guilherme-Garcia et al. (2023) have analysed this cluster with independent data and methodologies, finding contradictory results. Loktin & Popov (2020) find a possible rotation velocity of 400 m s−1 in the periphery of the cluster. Hao et al. (2022) find a clear rotation signal with a velocity of 200 ± 50 m s−1 within their cluster’s tidal radius of 10 pc. Guilherme-Garcia et al. (2023) do not find rotation and suggest that when found, it results from uncorrected projection effects (see their Appendix B and Fig. B.1). Finally, based only on radial velocity data, Jadhav et al. (2024) find a non-significant (0.5σ) rotational signal of 9 ± 18 cy Gyr−1, equivalent to 9.2 ± 18.4 m s−1 pc−1.
Myr, and more than 2000 members, Lodieu et al. 2019a), has recently been at the centre of a controversy about its rotational velocity. The works by Jadhav et al. (2024), Loktin & Popov (2020), Hao et al. (2022), and Guilherme-Garcia et al. (2023) have analysed this cluster with independent data and methodologies, finding contradictory results. Loktin & Popov (2020) find a possible rotation velocity of 400 m s−1 in the periphery of the cluster. Hao et al. (2022) find a clear rotation signal with a velocity of 200 ± 50 m s−1 within their cluster’s tidal radius of 10 pc. Guilherme-Garcia et al. (2023) do not find rotation and suggest that when found, it results from uncorrected projection effects (see their Appendix B and Fig. B.1). Finally, based only on radial velocity data, Jadhav et al. (2024) find a non-significant (0.5σ) rotational signal of 9 ± 18 cy Gyr−1, equivalent to 9.2 ± 18.4 m s−1 pc−1.
Here, we explore the internal kinematics of Praesepe with the Gaussian linear velocity model applied to the Gaia DR3 data of the list of members utilised by Hao et al. (2022), Guilherme-Garcia et al. (2023) and Jadhav et al. (2024). Given the controversial results of these works, we run the Gaussian linear velocity model directly on their list of members as well as in the cleaned subsamples resulting after applying our decontamination algorithm and restricting the analysis to sources within the tidal radius of 10.7 pc reported by Lodieu et al. (2019a). After applying our decontamination algorithm with a field scale of 20 pc in position and 5 km s−1 in velocity (and further restricting to the cluster’s tidal radius), we remove 12 (10), 30 (7), and 3 (0) sources from the membership lists by Hao et al. (2022), Guilherme-Garcia et al. (2023), and Jadhav et al. (2024), respectively. We notice that all original members by Jadhav et al. (2024) were contained within the cluster’s tidal radius. Table 7 shows summaries of the posterior distributions from the parameters of the Gaussian linear velocity model as inferred in all previous cases.
In the original samples, all the location parameters agree with themselves within the uncertainties. However, the standard deviations in the positions X, Y, and Z are discrepant, with those inferred from the members by Hao et al. (2022) being almost two times larger than those of the other cases. On the contrary, the standard deviations in the velocities U, V, and W are similar in the three cases. On the other hand, in the samples that were cleaned and restricted to the tidal radius, we observe that the location parameters continue to be in agreement with all previous cases and the velocity dispersion also show similar although more consistent values <1 km s−1. However, contrary to what was observed in the original samples, the standard deviations in positions X, Y, and Z are all now similar, with values ≲3 pc.
The internal motions in the original samples show the following results. First, expansion is only detected at 2σ level in the sample from Hao et al. (2022), the other two samples show spurious detections (<1σ). Second, rotation in ωx and ωy is detected at 4σ on the sample by Hao et al. (2022) and at 2σ in ωy on the sample by Guilherme-Garcia et al. (2023). The sample by Jadhav et al. (2024) shows a spurious detection (~1σ) of rotation in ωy alone although with opposite sign.
The results of the inference on the samples that were clean and restricted to the tidal radius indicate no significant detections of rotation and only some hints of contraction along the Z component. The rotational signal we found in all cases shows nosignificant rotations in the three components, which is consistent with the recent findings by Jadhav et al. (2024) along the line of sight.
We conclude that the signals of expansion and rotation, and rotation found on the original lists of members used by Hao et al. (2022) and Guilherme-Garcia et al. (2023), respectively, result from the cluster members beyond the tidal radius. We found no conclusive evidence for the rotation of the cluster’s central region within its tidal radius. Thus, we confirm that Praesepe’s rotational signal reported in the literature comes from its periphery (i.e. halo or tails). Moreover, our analysis shows that the apparent contradiction in the literature results roots in the contaminants present in the various membership lists.
5 Conclusions
In this work, we introduce, develop, and validate a free and open-source code for the inference of the phase-space parameters of star-forming regions, stellar associations, and open clusters. This code is the multidimensional extension of an already published methodology that enables its users to simultaneously infer global-level and source-level parameters of LNSS based on Gaia data.
This new code offers several methodological improvements with respect to similar ones from the literature, among which we mention the simultaneous modelling of positions, velocities, and their correlations, the treatment of parallax and proper motions angular correlations, the flexibility of its statistical models, the treatment of sources with missing values, particularly radial velocities, decontamination algorithms to clean up the input list of members, and the modelling of kinematic substructures. Furthermore, the comprehensive modelling enables the improvement of radial velocities and parallaxes through astrometric radial velocities and kinematically improved parallaxes (see Lindegren et al. 2000).
Our validation with real data shows that the linear velocity model that we present here offers similar accuracy and slightly better precision than the one implemented by Oh & Evans (2020). Nonetheless, Kalkayotl includes an improved version of this linear velocity model with Gaussian and Student-T distributions both in the spatial and velocity components. Moreover, thanks to the efficient Hamiltonian Monte Carlo sampling of the full posterior distribution of the improved Lindegren et al. (2000) linear velocity model our methodology can provide objective detectability criteria for internal kinematic patterns. Thus, the methodology present here provides the community with a free and open source code that delivers objective and reproducible criteria for the detection of patterns of expansion, contraction, and rotation.
We applied our newly developed methodology on benchmark stellar systems where extensive kinematic information is available in the literature. Our results show good accuracy and precision, resulting in agreement with the parameter values reported in the literature. We notice that the results of the internal kinematic patterns are sensitive to contaminants or outliers in the input list of members. After applying our decontamination methodology, we found the following results.
In the β-Pic stellar association, Kalkayotl joint velocity model recovers the source- and group-level parameters from the literature with excellent accuracy and slightly better precision. The Gaussian linear velocity models detects expansion at the 2σ level. By simple inversion, these expansion values translate into ages that are as accurate and precise as those from the literature.
In the Hyades open cluster, the Gaussian linear velocity model recovers the literature parameter values with similar accuracy and slightly better precision. Furthermore, it detects rotation at the 2σ level in the ωz component, with a total rotational magnitude compatible with the literature values.
In the Praesepe open cluster, we find no evidence of rotation within the cluster tidal radius but only in its outskirts. Thus, we conclude that the rotation and expansion signals reported in the literature come from the periphery of the cluster.
Although the mechanisms producing the expansion and rotation of stellar systems are well understood (see, for example, the introduction of Jadhav et al. 2024), the relative contribution of these different mechanisms is still poorly characterised. To improve this characterisation, both numerical N-body simulations with varying initial conditions (Jadhav et al. 2024) and observational surveys that minimise biases arising from contaminants, incomplete membership lists, and kinematic substructures are still needed. The robust statistical methodology that we present here offers ways to characterise and minimise these biases in LNSS up to 1.5 kpc.
Finally, we notice that although our methodology offers several advantages over those from the literature, it is still computationally expensive and requires further statistical modelling of the physical properties of stellar systems, including their spatial distribution (Olivares et al. 2018), differential rotation (Jadhav et al. 2024), or the tidal tails of open clusters. Future steps will be taken to continue improving Kalkayotl’s models.
Parameters of the Praesepe open cluster as inferred here with Gaia DR3 data from the samples of members (original and restricted to the tidal radius) reported by Hao et al. (2022), Guilherme-Garcia et al. (2023), and Jadhav et al. (2024).
Acknowledgements
We thank the anonymous referee for providing comments that greatly improved the quality of this work. JO acknowledge financial support from “Ayudas para contratos postdoctorales de investigación UNED 2021”. “La publicación es parte del proyecto PID2022-142707NA-I00, financiado por MCIN/AEI/10.13039/501100011033/FEDER, UE”. A. Berihuete was also funded by TED2021-130216A-I00 (MCIN/AEI/10.13039/501100011033 and European Union NextGenerationEU/PRTR). This research has received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No 682903, P.I. H. Bouy), and from the French State in the framework of the “Investments for the future” Program, IdEx Bordeaux, reference ANR-10-IDEX-03-02. This work has made use of data from the European Space Agency (ESA) mission Gaia (https://www.cosmos.esa.int/gaia), processed by the Gaia Data Processing and Analysis Consortium (DPAC, https://www.cosmos.esa.int/web/gaia/dpac/consortium). Funding for the DPAC has been provided by national institutions, in particular the institutions participating in the Gaia Multilateral Agreement. We express our gratitude to Anthony Brown, Jos de Bruijne, the Gaia Project Scientist Support Team, and the Gaia Data Processing and Analysis Consortium (DPAC) for providing the PyGaia code. We thank the PyMC team for making publicly available this probabilistic programming language. This research has made use of the VizieR catalogue access tool, CDS, Strasbourg, France.
Appendix A Assumptions
Assumption 1. Same as Paper I. Briefly, the Gaia measurements are normally distributed.
Assumption 2. Same as Paper I but extended to all astrometry and radial velocities. Briefly, the Gaia measurements have zero point values for all its observables and these are specified by the user.
Assumption 3. Same as Paper I but extended to proper motions as well. Briefly, the Gaia parallax and proper motions are spatially correlated in the sky. To correct for these spatial correlations, we now use Eqs. (24) and (25) of Lindegren et al. (2021).
Assumption 4. Same as Paper I. Briefly, the input list of members is not biased.
In the 3D and 6D models presented here, the Assumption 4 of Paper I is no longer needed.
Appendix B Time scalability
In this Appendix, we aim at giving the users of Kalkayotl a rough idea of the typical amount of time that an execution of the code may take. To this end, Figs. B.1 and B.2 show the amount of time, in hours, as a function of the number of stars in the system for the Student-T family with linear velocity model and GMM family with joint velocity model, respectively. This graphs were computed from the simulations created in Sect. 3 and inferred with the NUTS (Hoffman & Gelman 2011) samplers numpyro for the Student-T family and the pymc native for the GMM family. The numpyro implementation of the NUTS sampler (see PyMC documentation11) is faster than the native pymc one. However, the current version of PyMC fails at sampling 6D GMM with the numpyro sampler. We run the code using two parallel Markov chains in a machine with 2.1 GHz CPUs. The execution time takes into account not only the MCMC inference but all the auxiliary pre-processing of the data and post-processing of the chains.
As expected and observed from Figs. B.1 and B.2, the execution time grows with the number of stars. In addition, the figures show that for a fixed number of stars, the execution time is smaller for systems at farther distances (colour code), with this difference being less pronounced in the GMM case. The smaller running time of faraway systems is explained by the large uncertainty of their observables, which simplifies the job of finding the initial parameter values and, thus, the subsequent sampling of the chains.
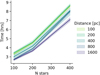 |
Fig. B.1 Time scalability of Kalkayotl’s runs done with the numpyro NUTS sampler as a function of the number of stars. The lines and shaded regions depict the mean and 2σ percentiles, respectively, from the grid of stellar systems created using the Student-T family with the linear velocity model (see Sect. 3). |
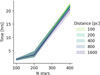 |
Fig. B.2 Time scalability of Kalkayotl’s runs done with the native pymc NUTS sampler as a function of the number of stars. The lines and shaded regions depict the mean and 2σ percentiles, respectively, from the grid of stellar systems created using the GMM family with velocity model (see Sect. 3). |
References
- Bailer-Jones, C. A. L. 2015, PASP, 127, 994 [Google Scholar]
- Bailer-Jones, C. A. L., Rybizki, J., Fouesneau, M., Demleitner, M., & Andrae, R. 2021, AJ, 161, 147 [Google Scholar]
- Bell, C. P. M., Mamajek, E. E., & Naylor, T. 2015, MNRAS, 454, 593 [Google Scholar]
- Bouy, H., Bertin, E., Moraux, E., et al. 2013, A&A, 554, A101 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Casamiquela, L., Olivares, J., Tarricq, Y., et al. 2022, A&A, 664, A31 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Couture, D., Gagné, J., & Doyon, R. 2023, ApJ, 946, 6 [NASA ADS] [CrossRef] [Google Scholar]
- Crundall, T. D., Ireland, M. J., Krumholz, M. R., et al. 2019, MNRAS, 489, 3625 [Google Scholar]
- Dravins, D., Lindegren, L., & Madsen, S. 1999, A&A, 348, 1040 [NASA ADS] [Google Scholar]
- Gaia Collaboration (Prusti, T., et al.) 2016, A&A, 595, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Brown, A. G. A., et al.) 2018, A&A, 616, A [NASA ADS] [Google Scholar]
- Gaia Collaboration (Vallenari, A., et al.) 2023, A&A, 674, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Galindo-Guil, F. J., Barrado, D., Bouy, H., et al. 2022, A&A, 664, A70 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gelman, A., & Rubin, D. B. 1992, Statist. Sci., 7, 457 [NASA ADS] [Google Scholar]
- Gelman, A., Carlin, J., Stern, H., et al. 2013, Bayesian Data Analysis, 3rd edn., Chapman & Hall/CRC Texts in Statistical Science (Taylor & Francis) [Google Scholar]
- Guilherme-Garcia, P., Krone-Martins, A., & Moitinho, A. 2023, A&A, 673, A128 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gunn, J. E., Griffin, R. F., Griffin, R. E. M., & Zimmerman, B. A. 1988, AJ, 96, 198 [NASA ADS] [CrossRef] [Google Scholar]
- Hanson, R. B. 1975, AJ, 80, 379 [NASA ADS] [CrossRef] [Google Scholar]
- Hao, C. J., Xu, Y., Bian, S. B., et al. 2022, ApJ, 938, 100 [NASA ADS] [CrossRef] [Google Scholar]
- Hao, C. J., Xu, Y., Hou, L. G., et al. 2024, ApJ, 963, 153 [NASA ADS] [CrossRef] [Google Scholar]
- Hoffman, M. D., & Gelman, A. 2011, arXiv e-prints [arXiv:1111.4246] [Google Scholar]
- Hunt, E. L., & Reffert, S. 2023, A&A, 673, A114 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Jadhav, V. V., Kroupa, P., Wu, W., Pflamm-Altenburg, J., & Thies, I. 2024, A&A, 687, A89 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kucukelbir, A., Tran, D., Ranganath, R., Gelman, A., & Blei, D. M. 2017, J. Mach. Learn. Res., 18, 1 [Google Scholar]
- Leão, I. C., Pasquini, L., Ludwig, H. G., & de Medeiros, J. R. 2019, MNRAS, 483, 5026 [Google Scholar]
- Lewandowski, D., Kurowicka, D., & Joe, H. 2009, J. Multivariate Anal., 100, 1989 [CrossRef] [Google Scholar]
- Lindegren, L. 1988, A Correlation Study of Simulated Hipparcos Astrometry, The European astrometry satellite HIPPARCOS. Scientific aspects of the Input Catalogue preparation II, 179 [Google Scholar]
- Lindegren, L., Madsen, S., & Dravins, D. 2000, A&A, 356, 1119 [NASA ADS] [Google Scholar]
- Lindegren, L., Klioner, S. A., Hernández, J., et al. 2021, A&A, 649, A2 [EDP Sciences] [Google Scholar]
- Lodieu, N., Pérez-Garrido, A., Smart, R. L., & Silvotti, R. 2019a, A&A, 628, A66 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lodieu, N., Smart, R. L., Pérez-Garrido, A., & Silvotti, R. 2019b, A&A, 623, A35 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Loktin, A. V., & Popov, A. A. 2020, Astron. Nachr., 341, 638 [NASA ADS] [CrossRef] [Google Scholar]
- Luri, X., Brown, A. G. A., Sarro, L. M., et al. 2018, A&A, 616, A9 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Madsen, S., Dravins, D., & Lindegren, L. 2002, A&A, 381, 446 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mamajek, E. E., & Bell, C. P. M. 2014, MNRAS, 445, 2169 [Google Scholar]
- Meingast, S., & Alves, J. 2019, A&A, 621, L3 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Meingast, S., Alves, J., Bouy, H., et al. 2023, A&A, 673, A58 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Messina, S., Lanzafame, A. C., Feiden, G. A., et al. 2016, A&A, 596, A29 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Miret-Roig, N., Galli, P. A. B., Brandner, W., et al. 2020, A&A, 642, A179 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Oh, S., & Evans, N. W. 2020, MNRAS, 498, 1920 [Google Scholar]
- Olivares, J., Moraux, E., Sarro, L. M., et al. 2018, A&A, 612, A70 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Olivares, J., Sarro, L. M., Bouy, H., et al. 2020, A&A, 644, A7 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Olivares, J., Bouy, H., Miret-Roig, N., et al. 2023a, A&A, 671, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Olivares, J., Lodieu, N., Béjar, V. J. S., et al. 2023b, A&A, 675, A28 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Perryman, M. A. C., Lindegren, L., Kovalevsky, J., et al. 1997, A&A, 323, L49 [Google Scholar]
- Perryman, M. A. C., Brown, A. G. A., Lebreton, Y., et al. 1998, A&A, 331, 81 [NASA ADS] [Google Scholar]
- Röser, S., Schilbach, E., & Goldman, B. 2019, A&A, 621, L2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Salvatier, J., Wiecki, T. V., & Fonnesbeck, C. 2016, PeerJ Comput. Sci., 2, e55 [Google Scholar]
- Stacy, E. W. 1962, Ann. Math. Statist., 33, 1187 [CrossRef] [Google Scholar]
- Vereshchagin, S. V., Reva, V. G., & Chupina, N. V. 2013, Astron. Rep., 57, 52 [CrossRef] [Google Scholar]
- Wayman, P. A. 1967, PASP, 79, 156 [Google Scholar]
- Wen, R. Y., Speagle, J. S., Webb, J. J., & Eadie, G. M. 2024, MNRAS, 527, 4193 [Google Scholar]
- Žerjal, M., Ireland, M. J., Crundall, T. D., Krumholz, M. R., & Rains, A. D. 2023, MNRAS, 519, 3992 [CrossRef] [Google Scholar]
- Zucker, C., Speagle, J. S., Schlafly, E. F., et al. 2020, A&A, 633, A51 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
Through this work, we refer to the parameters of the stellar system as group-level or population-level, parameters, whereas to star-level or source-level parameters to those of individual stars.
By specifying the reference_system argument.
By including κ and ω as model parameters.
By including only κ and not ω as model parameter.
There is a typo in the sign of their V⊙ velocity component.
All Tables
Location and standard deviation parameters of the β-Pic stellar association as reported in the literature and inferred in this work with the Gaussian joint model.
Parameters of the Hyades open cluster as reported by Oh & Evans (2020) and inferred here with data from Gaia DR2 and DR3.
Parameters of the Praesepe open cluster as inferred here with Gaia DR3 data from the samples of members (original and restricted to the tidal radius) reported by Hao et al. (2022), Guilherme-Garcia et al. (2023), and Jadhav et al. (2024).
All Figures
|
Fig. 1 Relative error of the population-level parameters common to all our models as a function of distance. The lines and shaded regions depict the mean and standard deviation of the synthetic clusters with 100 stars. |
| In the text | |
|
Fig. 2 Relative uncertainty of the population-level parameters common to all our models as a function of distance. Captions as in Fig. 1. |
| In the text | |
|
Fig. 3 Signal-to-noise ratio of the entries in the linear velocity tensor as a function of the distance and the number of stars for the three values of the C constant in units of metre per second per parsec (see Eq. (4)). The lines and shaded regions depict the median and standard deviation of the synthetic simulations with varying random seed. |
| In the text | |
|
Fig. 4 Relative error of the source-level parameters as a function of distance. Captions as in Fig. 1. |
| In the text | |
 |
Fig. 5 Relative uncertainty of the source-level parameters. Captions as in Fig. 1. |
| In the text | |
|
Fig. 6 One-to-one comparison of the source-level parameters inferred here and those reported by Couture et al. (2023) and Miret-Roig et al. (2020). The grey line depicts the identity relation. The root-mean-squared value of the differences is also shown on the lower right side of each panel. |
| In the text | |
|
Fig. B.1 Time scalability of Kalkayotl’s runs done with the numpyro NUTS sampler as a function of the number of stars. The lines and shaded regions depict the mean and 2σ percentiles, respectively, from the grid of stellar systems created using the Student-T family with the linear velocity model (see Sect. 3). |
| In the text | |
|
Fig. B.2 Time scalability of Kalkayotl’s runs done with the native pymc NUTS sampler as a function of the number of stars. The lines and shaded regions depict the mean and 2σ percentiles, respectively, from the grid of stellar systems created using the GMM family with velocity model (see Sect. 3). |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.