| Issue |
A&A
Volume 690, October 2024
|
|
|---|---|---|
| Article Number | A325 | |
| Number of page(s) | 19 | |
| Section | Extragalactic astronomy | |
| DOI | https://doi.org/10.1051/0004-6361/202451341 | |
| Published online | 21 October 2024 | |
The SLACS strong lens sample, debiased
1
Department of Astronomy, School of Physics and Astronomy, Shanghai Jiao Tong University, Shanghai, 200240
China
2
Shanghai Key Laboratory for Particle Physics and Cosmology, Shanghai Jiao Tong University, Shanghai, 200240
China
3
Key Laboratory for Particle Physics, Astrophysics and Cosmology, Ministry of Education, Shanghai Jiao Tong University, Shanghai, 200240
China
Received:
2
July
2024
Accepted:
16
August
2024
Abstract
Strong gravitational lensing observations can provide extremely valuable information on the structure of galaxies, but their interpretation is made difficult by selection effects, which, if not accounted for, introduce a bias between the properties of strong lens galaxies and those of the general population. A rigorous treatment of the strong lensing bias requires, in principle, to fully forward model the lens selection process. However, doing so for existing lens surveys is prohibitively difficult. With this work we propose a practical solution to the problem: using an empirical model to capture the most complex aspects of the lens finding process, and constraining it directly from the data together with the properties of the lens population. We applied this method to real data from the SLACS sample of strong lenses. Assuming a power-law density profile, we recovered the mass distribution of the parent population of galaxies from which the SLACS lenses were drawn. We found that early-type galaxies with a stellar mass of log M*/M⊙ = 11.3 and average size have a median projected mass enclosed within a 5 kpc aperture of log M5/M⊙ = 11.332 ± 0.013, and an average logarithmic density slope of γ = 1.99 ± 0.03. These values are respectively 0.02 dex and 0.1 lower than inferred when ignoring selection effects. According to our model, most of the bias is due to the prioritisation of SLACS follow-up observations based on the measured velocity dispersion. As a result, the strong lensing bias in γ reduces to ∼0.01 when controlling for stellar velocity dispersion.
Key words: gravitational lensing: strong / galaxies: elliptical and lenticular / cD / galaxies: fundamental parameters
Corresponding author; This email address is being protected from spambots. You need JavaScript enabled to view it.
© The Authors 2024
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
Strong gravitational lensing is a unique tool for measuring galaxy masses at cosmological distances. Strong lensing constraints have enabled us to gain insight on the mass structure of the most massive galaxies, as well as on cosmology (see Shajib et al. 2022, and references therein). Strong lenses, however, are a special subset of the general galaxy population, for two reasons. First, the probability of a galaxy to act as a strong lens varies as a function of its properties: for example, the more massive and more concentrated a galaxy is, the more likely it is to be a lens. Second, lenses of different properties have different probabilities of being discovered by a strong lensing survey: in general, lenses with a larger Einstein radius (and hence a larger mass, everything else being fixed) are more likely to be identified (see e.g. Herle et al. 2024). The ratio between the probability distribution of galaxy properties that is sampled by a strong lens survey and that of the parent population from which the lenses are drawn is referred to as the strong lensing bias. This bias, if not accounted for, makes it difficult to compare strong lensing measurements to other measurements or models.
One possible approach to mitigate the strong lensing bias is to control for observed galaxy properties when comparing lenses with non-lens galaxies. For example, the stellar mass distribution of strong lens galaxies is very different from that of the rest of the population. However, if a given property X correlates with stellar mass, differences in X between the lens and non-lens sample are reduced when comparing them at a fixed stellar mass.
In practice, even at a fixed stellar mass strong lens galaxies are noticeably different from non-lens galaxies: for example, they are on average more compact (see e.g. Auger et al. 2010). Controlling for central velocity dispersion appears to be a better choice: lens galaxies from the Sloan Lens ACS Survey (SLACS, Bolton et al. 2006) have been shown to be indistinguishable from non-lens galaxies in terms of their fundamental plane1 (Treu et al. 2006) and environment (Treu et al. 2009), at fixed velocity dispersion. This can be explained by noting that, under the assumption of an isothermal density profile, the probability of a galaxy to create multiple lensed images of a background source is a function of velocity dispersion alone. Thus, to first approximation, strong lens samples can be viewed as being velocity dispersion-selected. However, galaxies are not exactly isothermal systems, and the selection of lenses involves more criteria than the simple production of multiple images (as we discuss below). Therefore we expect that not all of the strong lensing bias can be captured by velocity dispersion alone.
In general, finding analogues to galaxies acting as strong lenses is an ill-posed problem, because the strong lensing bias depends on the mass structure of galaxies, which is difficult to know exactly (and usually is the very property that one seeks to constrain with strong lensing). Instead, a more productive approach to dealing with the strong lensing bias is to forward model the selection process of lenses in a survey. Sonnenfeld (2022) showed an example of how this can be done when working with a complete sample of lenses and well-defined selection criteria. For most of the strong lensing surveys carried out so far, however, it has been very challenging to model the selection function from first principles. This is because existing lens samples are partly the result of human decisions on the classification of lens candidates, which are difficult to reproduce and include in a model.
In this paper we propose a practical solution to the problem of correcting for the strong lensing bias in the analysis of a strong lens sample. We tackled the problem by making some simplifying assumptions on the lens detection probability, and by using empirical models to describe those aspects of the problem that are most difficult to predict. These empirical models are to be inferred from the data along with the mass properties of the population of galaxies. We first explain our methodology in general terms, then show its application to the SLACS strong lens sample.
We used our technique to revisit measurements of the total density profile of massive galaxies. Strong lensing and stellar dynamics observations based on the SLACS sample have revealed how, under the assumption of a power-law density profile, ρ(x)∝x−γ, the average density slope of early-type galaxies is ⟨γ⟩ = 2.09, corresponding to a distribution slightly steeper than isothermal, and scales positively with stellar surface mass density (Koopmans et al. 2006; Auger et al. 2010; Sonnenfeld et al. 2013). The trend with stellar surface mass density can be easily explained with the dark matter halo contributing to a smaller fraction of the total mass within the half-light radius in more compact galaxies (Shankar et al. 2017). However, when combining SLACS with other lens samples at higher redshift, such as the BOSS Emission-Line Lens Survey (BELLS, Bolton et al. 2012) or the Strong Lens Legacy Survey (SL2S, Gavazzi et al. 2012), lensing and dynamics constraints indicate that the average slope γ increases from z = 1 to the present (Ruff et al. 2011; Bolton et al. 2012; Sonnenfeld et al. 2013), in a way that is difficult to reconcile with theory. Hydrodynamical simulations and empirical models tend to predict opposite trends (Remus et al. 2013; Xu et al. 2017; Shankar et al. 2018), with the exception of HORIZON-AGN (Peirani et al. 2019). The issue of the evolution in γ is related to the late growth history of massive galaxies: these objects are generally believed to grow as a result of dissipationless mergers, which tend to make the density slope shallower (Sonnenfeld et al. 2014). One possible way to reconcile theory and observations is then to allow for some amount of dissipation and related gas infall associated with mergers (Sonnenfeld et al. 2014). As an alternative to the dissipational merger scenario, it has been suggested that strong lensing selection effects are responsible for the observed trend (e.g. Remus et al. 2013). With this work we aim to bring new insight to the problem, by re-analysing the SLACS sample while accounting for the strong lensing bias.
The structure of this paper is as follows. In Section 2 we describe the lens sample that we use for our case study, with a focus on the lens selection process. In Section 3 we introduce a formal definition of the strong lensing bias and describe the general methodology that we adopt to account for it. In Section 4 we describe the model that we fit to the lensing data. In Section 5 we show the results of our analysis. We discuss the results in Sect. 6 and draw conclusions in Sect. 7.
The Python code used for the simulation and analysis of the lens sample can be found in a dedicated section of a GitHub repository. Throughout this work we assumed a flat Λ cold dark matter model, with H0 = 70 km s−1 Mpc−1, and Ωm = 0.3.
2. The strong lens sample
Our study focuses on lenses drawn from the SLACS survey. In this section we first describe the selection process of these lenses, and then their associated data.
2.1. The selection process
SLACS lenses were discovered as follows. Foreground galaxies were selected among the main and the luminous red galaxy (LRG) spectroscopic samples (Eisenstein et al. 2001; Strauss et al. 2002) of the Sloan Digital Sky Survey (SDSS, York et al. 2000). The SDSS spectra of the foreground galaxies were scanned for the presence of emission lines associated with objects at higher redshift. Among the systems with a spectroscopic detection of a background galaxy, those expected to have the largest strong lensing cross-section (we explain below how it was estimated) were followed-up with the Hubble Space Telescope (HST) for high-resolution imaging (Bolton et al. 2006). Lenses with a clear detection of a set of strongly lensed arcs were then modelled for the purpose of measuring their Einstein radius.
The resulting selection function of the SLACS sample is rather complex. In order for the source redshift to be measured, multiple emission lines had to be detected. These lines are typically [OIII], Hβ and the [OII] doublet. Since the wavelength coverage of the SDSS spectrograph extends only up to ∼ 9200 Å, only sources up to redshift ∼0.9 could effectively be discovered. At fixed source redshift, the lens detection probability also depends on the source emission line strength and surface brightness distribution. Additionally, the finite size of the SDSS spectroscopic fibre, 1.5″ in radius, put constrains on the Einstein radius and image configuration of the lens. For instance, lenses with a very large Einstein radius have a main arc that falls outside of the fibre, and could only be detected if one of the counter-images is sufficiently close to the centre, or if sufficient flux is brought into the fibre by the point spread function (PSF). We refer to the simulation study of Arneson et al. (2012) for more details on fibre size effects.
Finally, the prioritisation in terms of lensing cross-section applied by Bolton et al. (2006) introduced another non-trivial selection effect. Bolton et al. (2006) estimated the lensing cross-section of each lens candidate as follows. First, they assumed a singular isothermal density profile for each lens. Then, they used the observed stellar velocity dispersion measured by the SDSS, σap(obs), as a proxy for the velocity dispersion of the singular isothermal mass distribution. Under this assumption, they estimated the Einstein radius of a lens as
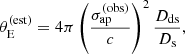 (1)
(1)
where c is the speed of light, Dds is the angular diameter distance between the lens and the source, and Ds is the angular diameter distance between the observer and the source. Finally, they defined the strong lensing cross-section as the area in the source plane that is mapped into sets of multiple images2, which for a singular isothermal sphere is equal to πθE2. We indicate this quantity as σSL(B06). In summary, σSL(B06) is a combination of observed stellar velocity dispersion, lens redshift and source redshift. The way that σSL(B06) enters the SLACS selection function, however, is rather subtle: it was used to rank candidates identified via spectroscopy for the purpose of scheduling follow-up HST observations. This means that the probability of a lens being included in the SLACS sample depended on the size of the parent sample of lens candidates and on the number of systems with HST data: in the limit of infinite HST time, all candidates would have been followed-up. Explicitly incorporating these aspects in a model of the SLACS selection function can be cumbersome. Moreover, a selection based on the observed velocity dispersion, as opposed to its true value (which is not directly accessible), can lead to the velocity dispersion of the sample to be systematically overestimated.
In principle, the selection function of the SLACS sample is also determined by the finite resolution of the photometric data: lenses with an image separation that is close to the size of the PSF may not be recognised as such. In the case of the SLACS sample, however, we argue that resolution does not play a primary role. This is because the smallest Einstein radius in the SLACS sample is θE = 0.79″, much larger than the FWHM of HST photometric data. Indeed, the same search methodology at the base of the SLACS selection has been used by Shu et al. (2017) to discover lenses with significantly smaller Einstein radii, down to θE ≈ 0.5″. Shu et al. (2017) used a different criterion to prioritise spectroscopically detected candidates for HST follow-up, compared to SLACS. We then concluded that the main source of selection on the Einstein radius distribution of the SLACS sample is the lensing cross-section prioritisation, which depends on the observed velocity dispersion. In Section 3 we explain how we can model the overall selection function of the SLACS sample.
2.2. Sample definition and data
We took 59 lenses from the SLACS survey, for our study. These are the systems for which Auger et al. (2010) carried out a joint lensing and dynamical analysis, measuring their mass density slope. All of the lenses were selected to be early-type galaxies: although the SLACS campaign also led to the discovery of late-type lenses (Treu et al. 2011), these were not included in the Auger et al. (2010) study and are not considered here either. The lenses span the redshift range 0.06 < z < 0.36, with a median redshift of 0.19. For the purposes of our analysis, we needed measurements of the lens redshift, Einstein radius, stellar mass, half-light radius and velocity dispersion, as well as the redshift of the source. We took these data from Auger et al. (2009). Einstein radii were measured by fitting singular isothermal ellipsoid models to HST images of the lenses. Stellar masses were obtained by fitting stellar population synthesis models to broad band photometric measurements. Auger et al. (2009) provided measurements of the stellar mass under the assumption of a Chabrier or a Salpeter stellar initial mass function (IMF). We used Chabrier stellar masses for our analysis (though all of our results can be converted to a Salpeter IMF by rescaling stellar masses upwards by 0.25 dex). Rest-frame V-band half-light radii were obtained by Auger et al. (2009) by fitting a de Vaucouleurs profile to the HST images. Figure 1 (grey dots) show the distribution in redshift, observed stellar mass, half-light radius and stellar velocity dispersion of the SLACS lenses.
 |
Fig. 1. SLACS lenses and parent population. Distribution in redshift, observed stellar mass, half-light radius, and stellar velocity dispersion. The green contours and histograms are obtained by weighting the parent sample distribution by σap4. Vertical dashed or dotted lines indicate the median of the distributions of the corresponding colour. Contours enclose 68% and 95% of the distribution. Half-light radius measurements of the parent population were not used in our analysis. Instead, we assumed a stellar mass-size relation from Hyde & Bernardi (2009), which is shown as a dashed red line. The black line in the redshift-stellar mass panel is the inferred truncation stellar mass mt, introduced in section 4.2. |
2.3. The parent population
As we explained in Section 2.1, the first step in the selection of SLACS lenses consisted in scanning SDSS spectra of a large sample of early-type galaxies3. We refer to that sample as the parent population of foreground galaxies, or simply the parent sample. The goals of our are analysis are to (1) understand the strong lensing bias of SLACS with respect to the parent population, and (2) recover the mass structure of the parent population galaxies. To achieve both goals, it is necessary to obtain an accurate description of the parent sample. Obtaining the exact sample that was used originally for the SLACS search is nearly impossible, because Bolton et al. (2006) carried out the search in internal data releases of the SDSS, which may not correspond to any of the public data releases available today. For this reason, we built our fiducial SLACS parent sample on the SDSS data release 18 (DR18, Almeida et al. 2023) instead, under the assumption that it samples the same galaxy population studied by Bolton et al. (2006). Starting from the main and LRG spectroscopic samples, we first applied a redshift cut, limiting the sample to galaxies in the range 0.05 < z < 0.40. Then, in order to select early-type galaxies, we removed objects with Hα emission, by applying an upper limit of 0 Å to the Hα equivalent width (positive values corresponding to emission). Finally, we removed galaxies with blue colour. For this purpose, we used the rest-frame absolute magnitudes provided by the Granada Flexible Stellar Population Synthesis (FSPS, Conroy et al. 2009) value-added catalogue of DR18 (Montero-Dorta et al. 2016), which are K- and E-corrected to z = 0.55, and imposed a minimum u − r value of 2.0. The resulting sample consists of 401576 galaxies.
Given this sample, our inference method required us to obtain a model for their distribution in redshift, stellar mass and half-light radius space. We obtained stellar mass measurements from the Granada FSPS catalogue, using the masses based on the early star-formation with dust model. The Granada FSPS masses for the SLACS lenses are on average 0.23 dex larger than the measurements of Auger et al. (2009), most likely as a result of a different assumption on the stellar IMF. In order to make these measurements consistent, we applied a −0.23 dex shift to the Granada FSPS masses of the entire parent sample.
Finally, we relied on a mass-size relation from the literature to describe the distribution in half-light radius of the parent sample. In particular, we used the quadratic fit of Hyde & Bernardi (2009), which describes the mass-size relation of early-type galaxies over the full stellar mass range of our parent sample. We also took half-light radius measurements directly from the SDSS, using the r-band de Vaucouleurs model from DR18. However, these can suffer from contamination from neighbouring objects and deblending issues (see e.g. Meert et al. 2015), and therefore cannot be used directly for precision measurements without significant additional work. We used these half-light radius measurements for illustrative purposes only.
Figure 1 shows the distribution of the parent sample in redshift, stellar mass, half-light radius and stellar velocity dispersion, along with that of the SLACS lenses. Stellar velocity dispersion measurements were taken from DR18. In Section 1 we argued that, to first approximation, strong lens samples are selected in velocity dispersion. To verify the validity of this assertion, we also plot in Figure 1 the distribution of the parent sample weighted by σap4, which is proportional to the estimated lensing cross-section of a singular isothermal sphere with velocity dispersion equal to σap. The medians of the four quantities for the σap4-weighted distribution are remarkably close to those of the SLACS lenses. However, the detailed shapes of the distributions are significantly different. This suggests that a σap4-weighting can account for large part of the strong lensing bias, but not its entirety.
3. Methods
In this section we develop a formalism to correct for the strong lensing bias in a strong lensing inference. First we examine the problem in its full complexity, then we apply a few approximations to make it more tractable in practice.
3.1. The problem
Sonnenfeld et al. (2023) developed a formalism describing how strong lenses differ from their parent galaxy population. We follow the same notation in this paper. We considered a population of foreground galaxies and a population of background sources. Each foreground galaxy is described by a set of parameters ψg, drawn from a probability distribution Pg(ψg). These parameters describe all aspects that are relevant for predicting the lensing properties (i.e. the mass structure) and the selection of lens candidates (e.g. the stellar mass or the redshift). Each background source is described by parameters ψs, drawn from a probability distribution Ps(ψs). These parameters describe all aspects necessary to predict its observed features, when lensed by a foreground object (i.e. its redshift, position, surface brightness distribution and spectrum). Then the joint probability distribution in (ψg, ψs) of a sample of strong lenses from a given survey is
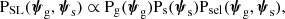 (2)
(2)
where Psel(ψg, ψs) is the probability for a galaxy-source pair to produce a strong lens that is identified as such and included in the survey. The term Psel, in other words, describes the selection function of a strong lens sample.
Equation (2) describes how the distribution in the properties of lens galaxies and lensed sources (the left-hand side of the equation) differ from that of their parent populations (Pg and Ps on the right-hand side). If we are exclusively interested in the foreground galaxies, we can marginalise over the source distribution to obtain
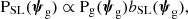 (3)
(3)
where bSL is the formal definition of the strong lensing bias and is given by
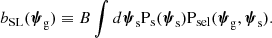 (4)
(4)
The constant B is set by the condition that PSL(ψg) is normalised to unity. In order to compare a strong lens sample with non-lens galaxies in an accurate way, it is necessary to either invert Equation (3) and obtain Pg, or to multiply the distribution of non-lenses by bSL, each approach requiring good knowledge of the strong lensing bias. However, bSL depends on survey-specific details, such as the distribution of background sources (in particular their redshift, as we discuss later) and the lens finding probability. In other words, two different strong lensing surveys targeting the same population of foreground galaxies have in general different strong lensing biases.
We can address the problem by modelling the properties of the foreground population of galaxies, of the background sources, and of the lens finding process. We can assume that all of these aspects of the problem can be fully described by a set of parameters η, and try to infer the values of these parameters from the data of a strong lens survey, d. The posterior probability distribution of the parameters η is
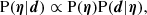 (5)
(5)
where P(η) is the prior probability and P(d|η) the likelihood of observing the data given the model. Assuming that measurements on individual lenses are independent of each other, the likelihood can be factorised as
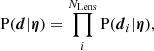 (6)
(6)
where NLens is the total number of lenses.
In order to evaluate individual factors in Equation (6), it is necessary to introduce parameters describing each system and average over them. That allows us to expand the likelihood of an individual lens as
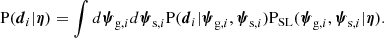 (7)
(7)
Assuming that the lens selection process can be forward modelled completely, then it is possible to compute integrals of the kind of Equation (7), and thus evaluate the likelihood. Unfortunately, that is not the case for virtually all existing lens surveys, including SLACS. In the next section we provide a strategy for substantially simplifying Equation (7).
3.2. A solution
The first step consists of simplifying the data vector di. The data can be though of as the sum of source- and lens-related observables. The former are the redshift, emission line flux, and surface brightness distribution of the lensed images; the latter are the redshift, stellar mass distribution and velocity dispersion of the lens galaxy. First, we dropped the source emission line flux from di. This does not mean that we ignored the spectroscopic detection process: as we explain below, we described it in an approximate way. Rather, we gave up modelling explicitly the spectroscopic selection from first principles. Second, we compressed the information from the source surface brightness into a model-independent summary observable: the Einstein radius. This means that, similarly to the spectroscopic selection, also the photometric detection is not fully modelled, but is described in an approximate way. The data related to a single lens then becomes
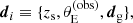 (8)
(8)
where dg includes all of the observables related to the lens galaxy. From here onward we omit the subscript i on individual observables and parameters for ease of notation. These assumptions allowed us to simplify the first factor in the integrand of Equation (7), P(di|ψg, ψs), as now the only source-related parameter on which the data depends explicitly is the redshift.
As the next step, we proceeded to simplify the strong lens population distribution term PSL. We began by expanding Psel as follows:
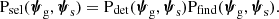 (9)
(9)
In the above equation, Pdet is the probability of a galaxy-source pair to produce a detectable lens in the survey considered. The term Pfind is instead the probability of the lens being found in the survey, given that it is detectable. The concept of detectability is rather subtle and deserves further explanation. First of all, we defined a detected strong lens as a system with at least two images of the same source that are detected and spatially resolved in photometric data, and a spectroscopic measurement of the lens and source redshift. Therefore, our definition of detection covers both photometry and spectroscopy. Second, we defined a lens as detectable if the survey data and hypothetical follow-up observations would yield a detection according to our definition. Crucially, Pdet is different from the probability of a lens being actually detected: the latter depends on the availability of data, which in turn is determined by human decisions on which candidates are followed-up with high-resolution imaging. These human factors are captured by the factor Pfind in Equation (9).
The SLACS sample constitutes only a subset of the strong lenses with a spectroscopic detection in SDSS data. Some of those lenses that are not in SLACS would have been detected photometrically if followed-up with HST (many, in fact, have been detected by Shu et al. 2017). The difference between the pool of detectable lenses and the actual SLACS sample is due to the criteria used for the prioritisation of targets for follow-up, which can be described with Pfind.
The use of the concept of detectability might appear like a nuisance, but is made necessary by the fact that the SLACS lens finding process cannot be split cleanly into a detection and a search phase. Equation (9) instead allowed us to separate the problem into a part that depends purely on data, Pdet, and a part that describes human decision processes, Pfind. In the rest of this section, we provide a practical way to describe the factors entering Equation (9) explicitly.
We began by writing the source parameters as
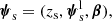 (10)
(10)
where zs is the redshift, β the angular position in the source plane and 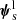 encodes all information on the light distribution (flux, surface brightness profile and spectrum). We then simplified the probability of finding a detectable lens, Pfind, by making the following approximation:
encodes all information on the light distribution (flux, surface brightness profile and spectrum). We then simplified the probability of finding a detectable lens, Pfind, by making the following approximation:
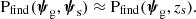 (11)
(11)
That is, we assumed that the lens finding probability does not depend on any source property other than the redshift. In the case of SLACS, this is a very good approximation: the decision process that led to the follow-up and subsequent discovery of the SLACS lenses was based purely on the measured values of the lens redshift, lens velocity dispersion, and source redshift (source flux and spectrum only enter Pdet).
With the approximations introduced so far, Equation (7) could be rewritten as
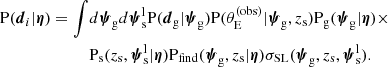 (12)
(12)
In writing Equation (12) we used Equation (9), we introduced the strong lensing cross-section,
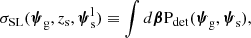 (13)
(13)
we carried out the integral over the source redshift (because it is known spectroscopically), and we implicitly assumed that the sources are distributed uniformly in the sky.
To further simplify the problem, we assumed that the strong lensing cross-section can be separated into a geometric factor g that depends purely on the lens properties and source redshift, and a factor l that depends only on the source light distribution:
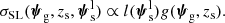 (14)
(14)
The geometric factor g can be thought of as the strong lensing cross-section computed for a reference value of the source light distribution. The ansatz of Equation (14) is, in general, not true. We discuss the limitations of this approximation in Section 4.4.
Nevertheless, assuming Equations (11) and (14) to hold, we could compute the integral over the source light parameters in Equation (12) to obtain
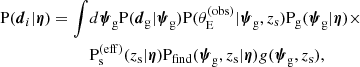 (15)
(15)
where
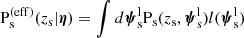 (16)
(16)
is an effective probability distribution of the redshift of sources that can be strongly lensed. One subtlety with this last definition is that Ps(eff)(zs) is neither the redshift distribution of the background source population, which describes all sources regardless of whether they are detectable or not, nor the redshift distribution of the lensed sources. So it cannot be trivially inferred from the data without taking selection effects into account.
The factors that do not depend on the data in the integrand of Equation (15) can be written in compact form, to indicate the effective distribution of strong lens parameters (averaged over the source light distribution):
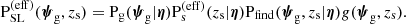 (17)
(17)
An important point is that the above probability must be properly normalised:
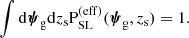 (18)
(18)
The normalisation can be absorbed by the geometric cross-section factor g (hence the proportionality sign in Equation (14)). With these approximations the strong lensing bias was also simplified to
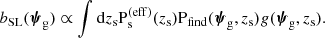 (19)
(19)
In summary, we have approximated the expression for the lens finding probability and we have eliminated the explicit dependence of the model on the source light distribution. The price to pay for this choice is losing sensitivity to the total number of lenses: had we known the number of spectroscopic detections and photometric non-detections from the SLACS search, together with the distribution of sources in redshift, surface brightness and emission line flux space, we could have used that information to further constrain the model (in a similar vein to the approach of Zhou & Sonnenfeld 2024). We chose not to treat that aspect of the problem explicitly, for the sake of simplicity.
To compute the likelihood, one still has to evaluate the integrand of Equation (15). The geometric factor g can be computed by means of simulation. The factors Ps(eff)(zs) and Pfind can be inferred directly from the data. In Section 4 we show a practical example of how this can be done.
4. The model
4.1. Mass density profile and individual lens parameters
Our goal was to infer the mass density profile of the population of massive galaxies, using strong lensing and stellar kinematics constraints. We did so under the assumption of a spherical power-law density profile. Although the true density profile of galaxies might not be a perfect power law, deviations larger than ∼10% are inconsistent with stellar kinematics and strong lensing constraints (Cappellari et al. 2015; Tan et al. 2024).
A power-law profile has two degrees of freedom in the radial direction. We chose to parameterise it in terms of the total mass within a cylinder of radius 5 kpc, M5, and the three-dimensional density slope γ. The choice of M5 was motivated by the fact that lensing directly constraints the projected mass, and the value of 5 kpc is very close to the median Einstein radius of the SLACS lenses (which is 4.2 kpc). Therefore we expected it to be relatively well constrained by the data, without the need for major extrapolations. Expressed in terms of M5 and γ, the three-dimensional density profile of a galaxy reads
![Mathematical equation: $$ \begin{aligned} \rho (x) = \frac{3-\gamma }{2\pi ^{3/2}}\frac{\Gamma [\gamma /2]}{\Gamma [(\gamma -1)/2]}\frac{M_{5}}{(5\mathrm{kpc} )^{3-\gamma }}x^{-\gamma }, \end{aligned} $$](/articles/aa/full_html/2024/10/aa51341-24/aa51341-24-eq21.gif) (20)
(20)
where x is the three-dimensional distance from the lens centre and Γ is the Gamma function.
In addition to the two parameters of the power-law, we described each foreground galaxy by means of its redshift zg, its stellar mass M*, and its half-light radius Re (for simplicity also referred to as size). We needed the redshift, first of all, to compute the lensing properties. We also needed redshift and size (more generally, the stellar distribution) to predict the stellar velocity dispersion, to be compared with stellar kinematics measurements. Finally, as we explain in the next section, our model for the population distribution allows for a scaling of M5 and γ with M* and Re. We used the stellar mass purely as a label: in our model, the value of the stellar mass of a galaxy does not directly translate into a mass density profile. In summary, the set of individual galaxy parameters ψg is
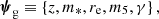 (21)
(21)
where
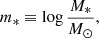 (22)
(22)
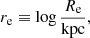 (23)
(23)
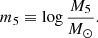 (24)
(24)
4.2. Foreground galaxies distribution
In this section we introduce the probability distribution Pg describing the population of foreground galaxies.
We began by writing Pg(ψg) as follows:
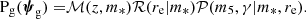 (25)
(25)
The first factor on the right-hand side of the above equation is the distribution in redshift and stellar mass of the parent sample. This sample is the sum of galaxies from the main and the LRG spectroscopic samples, and modelling the corresponding distribution from first principles is challenging. Nevertheless we expected, at any given redshift, the distribution to be volume-limited at the high-mass end, and to drop to zero at lower masses. Therefore we assumed the following functional form:
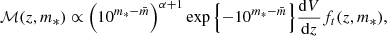 (26)
(26)
where dV/dz is the derivative of the comoving volume with respect to the redshift, and ft is a function that truncates the distribution at low values of m*. We chose the following form for ft:
![Mathematical equation: $$ \begin{aligned} f_t(z,m_*) = \frac{1}{\pi }\arctan {\left[\frac{m_* - m_t(z)}{\sigma _t}\right]} + \frac{1}{2}, \end{aligned} $$](/articles/aa/full_html/2024/10/aa51341-24/aa51341-24-eq28.gif) (27)
(27)
where mt is a redshift-dependent truncation mass, which we modelled with a fifth-order polynomial function. Because the strong lenses occupy the high-mass end of the stellar mass distribution, the exact details of the stellar mass distribution at low M* are not critical for the accuracy of the model.
The factor ℛ in Equation (25) describes the distribution in half-light radius as a function of redshift and stellar mass. Following Sonnenfeld et al. (2019), we modelled it as
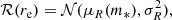 (28)
(28)
where the notation 𝒩(μ, σ2) indicates a Gaussian distribution with mean μ and variance σ2. We set the mean μR to scale quadratically with log M* as
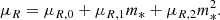 (29)
(29)
We fixed the values of the coefficients in Equation (29) to those measured by Hyde & Bernardi (2009): μR, 0 = 7.55, μR, 1 = −1.84, μR, 2 = 0.11. Then, we set the intrinsic scatter in size to σR = 0.112, which is the value measured by Sonnenfeld et al. (2019) on a large sample of elliptical galaxies at z = 0.55 (Hyde & Bernardi 2009, did not provide an estimate of the intrinsic scatter around the mass-size relation).
The last factor in Equation (25) describes the distribution in the power-law parameters, which is the main quantity of interest for our measurement. We assumed a Gaussian functional form in both m5 and γ:
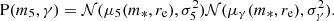 (30)
(30)
We let the average of m5 and γ to scale with stellar mass and size as
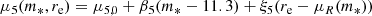 (31)
(31)
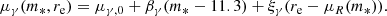 (32)
(32)
This model is similar to that adopted by Sonnenfeld et al. (2013), but differs from it in a few aspects. First, here we modelled explicitly the normalisation of the total density profile, described by means of m5, while Sonnenfeld et al. (2013) focused only on γ. Second, the coefficients ξ5 and ξγ describe a scaling with excess size, that is the ratio between the half-light radius of a galaxy and the average size of a galaxy of the same stellar mass (the definition of ξγ in Sonnenfeld et al. 2013, is different). Third, we did not allow for a redshift evolution, since our sample spans a much smaller redshift range than that of Sonnenfeld et al. (2013). As we show in Section 5, this model is sufficiently complex to provide a good fit to the available data.
4.3. Source galaxy distribution
The next ingredient needed for our analysis was the redshift probability distribution of the sources that can be strongly lensed, Ps(eff)(zs), introduced in Section 3.2. According to Equation (16), this quantity is the redshift distribution of the background source population, marginalised over the source light parameters, and weighted by the light-dependent component of the lens finding probability, l. Our approach was to directly model Ps(eff)(zs) empirically, so a full characterisation of l was not needed. Our model is a Gaussian distribution, with mean μzs and dispersion σzs:
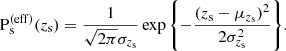 (33)
(33)
4.4. Lensing cross-section
A key ingredient for correcting our inference for selection effects is the strong lensing cross-section, σSL. In Section 3.2 we split σSL into a part that depends on the source brightness, and a geometric factor g. This factor is the strong lensing cross-section of a source with a reference light distribution. In order to compute g, then, we needed to define exactly what a detection of a strong lens consists of, and what the light distribution of this reference source is. The detection of SLACS lenses is both spectroscopic and photometric. We then defined the spectroscopic detection on the basis of the total emission line flux within a circular aperture of 1.5″ (the spectroscopic fibre), after convolution with the PSF of the SDSS, and the photometric detection based on whether there are multiple images in the HST data. This entailed specifying both the spectrum and surface brightness distribution of the reference source.
To simplify the problem, we approximated the mass of the lenses as circular and the sources as point-like. The first assumption is justified by the fact that the strong lensing cross-section is a weak function of ellipticity; the second is a good approximation of cases in which the source size is smaller than the Einstein radius of the lens (see Figs. 8 and 9 of Sonnenfeld et al. 2023). Under these assumptions, we defined the emission line flux of the reference source to be 1/3 of the total fibre flux needed for a spectroscopic detection, and the broad-band flux to be the same as that needed for a photometric detection of an image. In other words, our reference source would be classified as strongly lensed if (1) the total emission line flux within the fibre, from all images and smeared by the PSF, is magnified by at least a factor of three with respect to the intrinsic flux; and (2) at least two images with magnification larger than one are produced.
Figure 2 shows the strong lensing cross-section of a power-law lens with θE = 1.2″ with respect to the reference source (green curve), as a function of the density slope γ. We computed this quantity from Equation (13) by simulating lensed sources, solving the lens equation, predicting image fluxes, convolving the emission line flux by the SDSS PSF, which we took to have an FWHM of 1.5″, and averaging over the source position. Along with it, we also computed σSL for sources with both emission line and broadband flux rescaled up to a factor of two with respect to the reference. This allowed us to assess the accuracy of the separability assumption of Equation (14). For values of γ > 1.8, σSL increases with the brightness of the source in a way that is weakly dependent on the density slope, roughly confirming our ansatz. For smaller values, however, σSL becomes independent of the source brightness: this is because lenses with a shallow density profile produce sets of highly magnified images, which can be detected regardless of the intrinsic brightness of the source (down to some limiting flux). The approximation of Equation (14) therefore breaks down for very bright sources or for lenses with a very shallow density profile. More generally, the accuracy of our approximation is higher the more similar our reference source is to the typical strongly lensed source of the SLACS sample. Since the choice of the reference source is arbitrary, we also carried out the analysis with a different definition of it, by setting its emission line flux to half of that necessary for a spectroscopic detection (instead of a third). The results did not change appreciably.
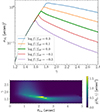 |
Fig. 2. Strong lensing cross-section of a circular power-law lens and a point source. A lensing event is defined as the detection of an emission line within an aperture of 1.5″, and of at least two images in photometric data. Top: σSL of a lens with θE = 1.2″ as a function of the slope γ. The thick green line corresponds to a source with intrinsic emission line flux equal to one third of the flux required for a spectroscopic detection, and a broadband flux equal to that needed for a photometric detection. Different lines were obtained by rescaling both the emission line and broadband flux by the amount indicated in the legend. Bottom: geometric factor of the lensing cross-section, that is the value of σSL for the reference source (corresponding to the green line in the top panel), as a function of both θE and γ. |
The bottom panel of Figure 2 shows the geometric factor of the lensing cross-section, as a function of θE and γ, that is σSL of our reference source. For γ > 2, the lensing cross-section peaks at values of the Einstein radius close to the fibre size, then drops to zero for larger values of θE. This is a distinct signature of the spectroscopic detection requirement: for lenses with a steep density profile and large Einstein radius, any images that form within the spectroscopic fibre are not sufficiently magnified to lead to a detection (see also Arneson et al. 2012).
4.5. Lens finding probability
Finally, we needed to prescribe a model for the probability of finding a detectable lens. As we explained in Section 2.1, the main quantity that determined the discovery of a SLACS lens was the estimated lensing cross-section, which is the square of Equation (1). Therefore, we asserted that
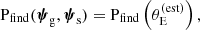 (34)
(34)
which is a special case of Equation (11), since 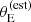 depends only on lens properties and on the source redshift (see Equation (1)). Our choice for the functional form of Pfind is the following sigmoid, described by two parameters:
depends only on lens properties and on the source redshift (see Equation (1)). Our choice for the functional form of Pfind is the following sigmoid, described by two parameters:
![Mathematical equation: $$ \begin{aligned} \mathrm{P}_\mathrm{find} (\theta _{\mathrm{E} }^{(\mathrm{est} )}) = \frac{1}{1 + \exp {\left[-a(\theta _{\mathrm{E} }^{(\mathrm{est} )} - \theta _0)\right]}}. \end{aligned} $$](/articles/aa/full_html/2024/10/aa51341-24/aa51341-24-eq37.gif) (35)
(35)
According to our model, the lens finding probability is zero for small values of the estimated Einstein radius, and reaches one for values of 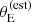 larger than θ0.
larger than θ0.
Predicting 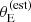 for the parent population of lenses requires accounting for the effects of observational noise on the velocity dispersion measurements. We adopted a 6.25% uncertainty on all σap measurements, which is the median relative uncertainty on σap of the SLACS lenses. By comparison, Bolton et al. (2008) quoted a value of 7% as representative of the uncertainty on σap measurements of the SLACS lenses. Birrer et al. (2020) argued, on the basis of a mismatch between the inferred properties of the SLACS and a different set of lenses, that the velocity dispersion measurements of SLACS lenses have been underestimated. They allowed for a systematic uncertainty, which they constrained to be approximately 6%, to be added in quadrature to the SLACS values. We repeated the analysis with these added uncertainties, but found that the goodness-of-fit worsened. Therefore we stuck with the uncertainties provided by Auger et al. (2009) for our analysis.
for the parent population of lenses requires accounting for the effects of observational noise on the velocity dispersion measurements. We adopted a 6.25% uncertainty on all σap measurements, which is the median relative uncertainty on σap of the SLACS lenses. By comparison, Bolton et al. (2008) quoted a value of 7% as representative of the uncertainty on σap measurements of the SLACS lenses. Birrer et al. (2020) argued, on the basis of a mismatch between the inferred properties of the SLACS and a different set of lenses, that the velocity dispersion measurements of SLACS lenses have been underestimated. They allowed for a systematic uncertainty, which they constrained to be approximately 6%, to be added in quadrature to the SLACS values. We repeated the analysis with these added uncertainties, but found that the goodness-of-fit worsened. Therefore we stuck with the uncertainties provided by Auger et al. (2009) for our analysis.
4.6. Fundamental plane constraint
Our goal was to infer the properties of the parent population of galaxies, and we could use information on the non-lens galaxies for this purpose. The model that we introduced so far makes use of the stellar mass-redshift distribution of the parent population of the lenses, and of the mass-size relation of early-type galaxies. A natural extension would have been to also consider the velocity dispersion distribution. Our model makes predictions for the velocity dispersion of a galaxy, by means of Jeans modelling. Therefore, it is in principle possible to fit the model directly to the observed velocity dispersion measurements of the entire parent population. We chose not to, for the following reasons. First, with a sample of ∼4 × 105 objects, the constraints from the dynamical model of the parent population would dominate over the lensing data. Second, the simplified assumptions on which our dynamical analysis is based would end up completely dominating the error budget: we would need to adopt a much more complex model of the stellar orbits and of the measurement systematics to properly fit such a large dataset. Third, the inference is sensitive to the input values of the stellar mass, size and velocity dispersion of the galaxies, and to their uncertainties. Since the stellar mass and half-light radius of the lenses and non-lenses have been measured with different procedures, separate dynamical analyses of the two samples can easily produce inconsistent posterior probabilities, which therefore cannot be combined.
In light of these difficulties, our compromise solution was to adopt a prior on the velocity dispersion distribution of the parent population that matches the observations, but allowing for some degree of flexibility. In particular, we set a prior on the coefficients of the stellar mass fundamental plane, the observed correlation between stellar mass, half-light radius and central velocity dispersion of early-type galaxies (see e.g. Bernardi et al. 2020). We defined the stellar mass fundamental plane as follows:
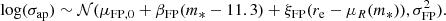 (36)
(36)
We could not fit directly Equation (36) to the parent sample galaxies, because we lacked measurements of their half-light radius (or rather, we lacked measurements that are consistent with those of the SLACS lenses). So, we fitted the stellar mass-velocity dispersion relation instead, to constrain the first two coefficients in Equation (36). We assumed a quadratic dependence of log σap on m* for the fit. We obtained μFP, 0 = 2.342 and βFP = 0.258 for galaxies with stellar mass close to the pivot value of m* = 11.3, and adopted a Gaussian prior centred on these values. The statistical errors on these coefficients are very small, but we allowed for a 0.03 dispersion to accommodate possible inconsistencies between the measurement on the SLACS sample and the parent population. Finally, we put a prior on the intrinsic scatter parameter σFP. This is an important quantity that defines the tightness of the fundamental plane relation. We defined our prior on σFP in a way to accommodate both measurements from the literature and from the SLACS sample. Sonnenfeld (2020) measured σFP = 0.047 ± 0.02 on a sample of early-type galaxies at z = 0.2, and, when fitting Equation (36) to the SLACS data used in this paper, we obtained σFP = 0.039 ± 0.008. On the basis of these results, we chose the following prior:
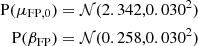 (37)
(37)
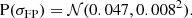 (38)
(38)
In practice, for a given value of the model parameters η we fitted Equation (36) to a large mock population of galaxies, then weighted the corresponding posterior probability by Equation (37). Since we were mostly interested in obtaining an accurate model for the high-mass end of the galaxy distribution, where the bulk of the SLACS lenses lie, we restricted this fit to the stellar mass range m* > 11.0.
We found that the prior of Equation (37) had a significant impact on our inference. Therefore, in Section 5, we show results obtained when both including or excluding it.
4.7. Inference procedure
Our fiducial model is described by the following set of free parameters:
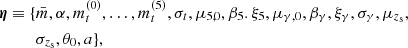 (39)
(39)
where mt(0), …, mt(5) are the coefficients of the polynomial function describing the truncation mass mt in Equation (27). We first constrained the stellar mass function parameters, by fitting the model of Equation (26) to the stellar mass measurements of the parent population. The inferred values are reported in Table 1. In virtue of the very large sample size, formal uncertainties are very small. Therefore we fixed these parameters to their best-fit value and proceeded to infer the remaining parameters by fitting the model to the SLACS lenses.
Parent sample. Stellar mass and redshift distribution parameters.
The data vector of each SLACS lens consists of the lens redshift, source redshift, lens stellar mass, half-light radius, stellar velocity dispersion, and Einstein radius:
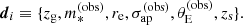 (40)
(40)
Stellar mass and velocity dispersion have associated uncertainties, on the order of 25% and 6% respectively. Redshift and half-light radius are instead measured very precisely, and we neglected their uncertainties. Einstein radii are measured with a precision of a few percent (Etherington et al. 2022). To further simplify the inference procedure, we neglected their uncertainties as well. We justified this approximation after the inference, by noting that our measurement on the average mass within 5 kpc has a larger relative uncertainty, which is therefore dominated by other aspects of the data (most likely the velocity dispersion measurements).
We assumed a Gaussian form for the likelihood of the stellar mass and velocity dispersion measurements. We calculated the model stellar velocity dispersion, σap, using the spherical Jeans equation under the assumption of isotropic orbits. We discuss the possible implications of these assumptions in Section 6.
From Equations (15) and (17) we could write the likelihood term for a SLACS lens as
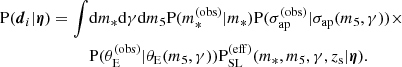 (41)
(41)
In the factor P(σap(obs)|σap(m5, γ)), which describes the likelihood of the observed velocity dispersion, the model-predicted velocity dispersion is obtained via the spherical Jeans equation with isotropic orbits. Under the assumption of negligible uncertainty on the Einstein radius, the likelihood term in  became a Dirac delta function, which we could integrate over after a variable change:
became a Dirac delta function, which we could integrate over after a variable change:
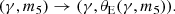 (42)
(42)
The result is
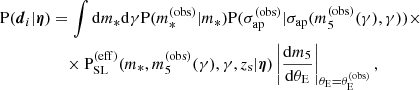 (43)
(43)
where 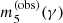 is the value of m5 that reproduces the observed Einstein radius, for a given γ.
is the value of m5 that reproduces the observed Einstein radius, for a given γ.
We assumed a uniform prior in all model hyper-parameters, multiplied by the fundamental plane prior of Equation (37). We sampled the posterior probability distribution with a Markov chain Monte Carlo (MCMC). We carried out the integrals of Equation (40), as well as the integral of Equation (18) to normalise PSL(eff), via Monte Carlo integration.
4.8. Lens-only inference
One of the goals of this work was to quantify the impact of selection effects on a strong lensing measurement of the mass-structure of galaxies. To do this, we also carried out the inference while ignoring all lensing selection terms. We did this by taking the prior factor PSL(eff) in Equation (42) to simply be the product between the distribution in (m5, γ) of Equation (30) and a Gaussian distribution in m*, meant to describe solely the SLACS lenses.
5. Results
5.1. Individual lens constraints
As a first thing we examined the constraining power of each individual lens. A power-law model has two free parameters: m5 and γ. Each lens provided two constraints: the Einstein radius, which we assumed to be measured exactly, and the stellar velocity dispersion within the spectroscopic aperture, σap. Therefore, the range of parameter values allowed by the data is a line in m5 − γ space. These constraints are shown in Figure 3, along with the values of the velocity dispersion corresponding to the model. Each line spans the 68% credible region of the posterior probability, assuming a flat prior on both m5 and γ.
 |
Fig. 3. Constraints on m5 and γ, and predicted values of the velocity dispersion, for individual lenses. Each line covers the 68% credible region of the posterior probability. Lines are colour-coded by the physical size of the Einstein radius. Dots mark the maximum posterior probability values. |
The mass enclosed within 5 kpc is generally very well constrained: the median uncertainty on m5 is as small as 0.013. The uncertainty is largest for the lenses with Einstein radius that differs the most from 5 kpc: for these lenses, obtaining m5 requires an extrapolation of the power-law profile, which introduces a correlation between γ and m5. In all cases, γ is strongly correlated with the velocity dispersion: given the Einstein radius of a lens, the steeper the density profile the larger the value of σap. Together with the velocity dispersion selection criterion that we described in Section 2.1, this has important implications for the selection function of the SLACS sample.
5.2. Parameter inference
In Table 2 we report the median and 68% credible region of the marginal posterior probability of each model parameter. We list the values obtained with and without the fundamental plane prior of Equation (37), as well as the values obtained when fitting the SLACS lenses while not accounting for selection effects. In Figures 4, 5 and 6 we show projections of the posterior probability on selected pairs of model parameters. Given the large number of free parameters, we avoid showing all possible pairwise correlations. The MCMC samples that we used to make these figures is available online for further analysis.
Results.
 |
Fig. 4. Posterior probability distribution of the model. Parameters shown: average log M5 and γ at fixed stellar mass and half-light radius, and intrinsic scatter around the average. Filled contours: model describing SLACS lenses, without correction for selection effects (see Section 4.8). Thick solid curves: fiducial model. Thin solid curves: model with no fundamental plane prior of Equation (37). Contour levels correspond to 68% and 95% enclosed probability. |
 |
Fig. 5. Same as Figure 4, but showing parameters describing the scaling of m5 and γ with stellar mass and size. Dashed lines indicate values of the parameters corresponding to the case in which galaxies are homologous systems with an average density slope of γ = 2.00. |
 |
Fig. 6. Same as Figure 4, but showing parameters describing the lens finding probability, defined in Equation (35), and the average density slope parameter. |
Figure 4 focuses on the mean m5 and γ at fixed stellar mass and size, and scatter around the average. According to the lens-only inference (cyan filled contours), SLACS lenses of m* = 11.3 and average size for their mass have an average density slope of μγ, 0 = 2.091 ± 0.024. This value is in good agreement with the measurement of Auger et al. (2010) on the same dataset. Once corrected for selection effects, the same quantity for the parent sample galaxies (magenta solid curves) is μγ, 0 = 1.99 ± 0.03. The average projected mass within 5 kpc, at the pivot stellar mass and average size, is inferred to be μ5, 0 = 11.358 ± 0.010 in the lens-only analysis and μ5, 0 = 11.332 ± 0.013 after the selection effects correction. Based on these results, we can say that SLACS lenses are on average slightly more massive than parent sample galaxies (they have a larger m5 at fixed stellar mass), and have an overall steeper density profile. The larger mass can be easily explained by the increase in lensing cross-section with m5. The bias on γ is less intuitive, because, as the bottom panel of Figure 2 shows, the lensing cross-section is generally larger for values of γ < 2: this alone would lead to the lenses having a shallower profile than the non-lenses. Instead, as we show in Section 5.4, the main reason for the bias in γ lies in the lens finding probability term, Pfind.
When comparing the inference based on the fiducial model (magenta curves) with that without the fundamental plane prior (black curves), we can see that the strong lensing bias (the difference with respect to the SLACS-only posterior probability) is larger in the latter case. To understand this fact, it is useful to consider the intrinsic scatter parameters. We can see that σγ and σ5 are anti-correlated with the respective average parameters, μγ, 0 and μ5, 0. This means that the strong lensing data can be reproduced both with an underlying population that has a relatively large bias and intrinsic scatter, or with a smaller bias and scatter. But a larger scatter in m5 and γ translates into a larger scatter around the fundamental plane. Therefore the solution with the larger bias is disfavoured by the prior of Equation (37).
Figure 5 shows the posterior probability distribution in the parameters describing how m5 and γ scale with stellar mass and size. In order to gain intuition on how to interpret these measurements, it is useful to first predict the values of these parameters in an ideal case. For instance, we can make the assumption that early-type galaxies are homologous systems, which is to say that galaxies with different values of the stellar mass and half-light radius are scaled-up versions of one another. Although strict homology is already ruled out by dynamical observations, such as the tilt of the fundamental plane (see e.g. Bertin et al. 2002), we can still use it as a reference limiting case. Under the homology assumption, the average density slope γ is a constant, the total projected mass within the half-light radius is also a constant, and, at fixed half-light radius, the total mass within any aperture scales linearly with stellar mass. The values of the parameters of our model under the homology assumption are β5 = 0.35, ξ5 = −1.00, βγ = 0 and ξγ = 0.
Our measured values are inconsistent with the homology assumption. In particular, β5 = 0.59 ± 0.05, which means that the mass enclosed within 5 kpc grows more rapidly than it would in the case of perfect homology. It could be explained with the dark matter mass within the half-light radius growing more than linearly with stellar mass, or also with the ratio between the true stellar mass and our estimate m* being an increasing function of m*. This is not a new result, but was previously noted by Auger et al. (2010) in their analysis of SLACS lenses. Our work demonstrates that it holds also when accounting for selection effects.
The dependence of m5 on excess size is also very different from that of homologous systems: ξ5 = −0.11 ± 0.13, instead of −1. This means that m5 responds relatively mildly to a change in half-light radius. One possible explanation is that the dark matter distribution is roughly independent of galaxy size. Weak lensing observations have shown that halo mass is a weak function of size, at fixed stellar mass (Sonnenfeld et al. 2018, 2019, 2022), so they support this hypothesis (though see Charlton et al. 2017, for a counter-example). Finally, we put an upper limit on the correlation between the density slope γ and stellar mass, βγ = 0.03 ± 0.08, and found a negative correlation with galaxy size at fixed stellar mass: ξγ = −0.67 ± 0.31. This is consistent with the measurements of Sonnenfeld et al. (2013).
Among the model parameters are those describing the effective source redshift distribution, Ps(eff), introduced in Section 4.3. The mean and dispersion of the Gaussian of Equation (16) are constrained to be μzs = 0.48 ± 0.04 and σzs = 0.22 ± 0.02, and the two parameters are anti-correlated. By comparison, the mean and standard deviation of the redshift of the SLACS sources is 0.61 and 0.18, respectively. The fact that we inferred a broader distribution, centred at a smaller redshift, was expected: as we explained in section 3.2, Ps(eff) describes the redshift distribution of unlensed sources that can be detected. Because the lensing cross-section increases for higher-redshift sources, the distribution of SLACS sources is shifted to higher redshifts. We found no signs of correlation between μzs or σzs and any of the other parameters of the model. From this we concluded that the exact choice of parameterisation of Ps(eff) is not a critical element in our model.
Finally, we constrained the lens finding probability parameters, defined in Equation (35). Figure 6 shows the posterior probability in the cutoff radius θ0 and log a, defined in Equation (35), as well as in the average density slope μγ, 0. The cutoff on 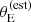 is θ0 = 0.93 ± 0.08, meaning that lenses with an estimated Einstein radius smaller than this value had a small probability of being selected for photometric follow-up in the SLACS survey. The parameters θ0 and a are anti-correlated. This indicates that the data cannot constrain the detailed shape of the lens finding probability function, but can allow either a Pfind with a sharp cutoff at a smaller
is θ0 = 0.93 ± 0.08, meaning that lenses with an estimated Einstein radius smaller than this value had a small probability of being selected for photometric follow-up in the SLACS survey. The parameters θ0 and a are anti-correlated. This indicates that the data cannot constrain the detailed shape of the lens finding probability function, but can allow either a Pfind with a sharp cutoff at a smaller 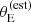 , or one with a more progressive increase centred at a larger value of
, or one with a more progressive increase centred at a larger value of 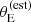 . Neither θ0 nor log a are strongly correlated with the average density slope parameter μγ, 0, as can be seen in Figure 6, or with any other parameter of the model.
. Neither θ0 nor log a are strongly correlated with the average density slope parameter μγ, 0, as can be seen in Figure 6, or with any other parameter of the model.
5.3. Goodness of fit
We assessed the goodness of fit of the model with posterior predictive tests, as follows. We sampled sets of values of the model parameters η from the posterior probability distribution. For each set of values, we randomly drew a set of 59 lenses (the same as the SLACS sample) from the strong lens distribution PSL(eff). For each lens, we predicted the set of observables that we used in the analysis, adding observational noise to the velocity dispersion. We adopted a Gaussian noise with a 6.25% relative uncertainty for this purpose. We then defined an ensemble of test quantities {Ti} based on observations, and quantified the probability of drawing more extreme values of each test quantity from a posterior predicted sample. Very small (P < 5%) or very large (P > 95%) probabilities would mean that it is unlikely that the observed sample has been drawn from the model. The choice of test quantities is not unique, but must be made on the basis of what aspects of the data we want the model to successfully reproduce. We chose them to be the mean, standard deviation, 10%- and 90%-ile of the distribution in observed Einstein radius, velocity dispersion and density slope γ.
Figure 7 shows the posterior predicted distributions of these twelve test quantities. The probability of producing samples of lenses with more extreme values of each test quantity is shown in the corresponding panel of Figure 7. None of the observed test quantities correspond to very small or very large percentiles of the posterior predicted distribution. Therefore our model is able to reproduce these data.
 |
Fig. 7. Posterior predictive tests of goodness of fit. Each panel shows the posterior predicted (histogram) and observed value (dashed line) of the test quantity indicated at the bottom. Units of Einstein radius are in arcsec and of the velocity dispersion are in km s−1. |
We also checked whether the model can recover the velocity dispersion distribution of the parent sample. The bottom panel of Figure 8 shows the posterior predicted average σap (magenta band) as a function of stellar mass, and our quadratic fit to the m* − σap distribution of the parent sample (green curve). The model matches the data over a broad range in stellar mass, but departs from it at the high-mass end. This is not a goodness-of-fit issue: as we explained in Section 4.6, we only used observations around the pivot stellar mass m* = 11.3 to constrain the model. Nevertheless, it could mean that the model does not extrapolate well at large stellar masses, where it tends to overpredict the stellar velocity dispersion. However, the source of the discrepancy could more simply be an inconsistency between the way stellar mass is defined for the SLACS lenses and the parent sample galaxies. Although we rescaled the m* measurements of the parent sample galaxies so that the stellar masses of the SLACS lenses would be consistent on average, we cannot exclude a mass-dependent offset, for instance as a result of different choices in the photometric measurement or stellar population synthesis phase. It could also be that a quadratic model is not sufficiently flexible to describe the high-mass end of the m* − σap relation. Our main goal is to understand the properties of galaxies at m* ≈ 11.3, where the bulk of the SLACS lenses lie. Therefore we did not investigate this issue further.
 |
Fig. 8. Posterior predicted trends with stellar mass, for galaxies of average size. Top: average projected mass enclosed within 5 kpc. Middle: average density slope. Bottom: average stellar velocity dispersion. Each band marks the 68% credible region. The magenta band shows the prediction for the parent population. The cyan band shows the prediction from the lens-only analysis, without accounting for selection effects. Dashed blue lines show the prediction for the population of SLACS lenses. Solid black lines show the prediction for the population of detectable lenses (obtained by removing the lens finding probability Pfind from the posterior prediction). Error bars are the values measured for the SLACS lenses, assuming a flat prior on both m5 and γ. Uncertainties on the stellar mass are uncorrelated with those on m5, γ and σap. In the bottom panel, the green line shows our quadratic fit to the m* − σap relation of the parent sample. |
5.4. Insight from the model
Figure 8 shows the inferred trend of m5, γ and velocity dispersion with stellar mass, as predicted from the posterior probability of the model parameters, along with the data. In the middle panel we can see a significant difference between the average γ of the parent population (magenta band), and that inferred from the lens-only analysis (cyan band). According to these results, the average density slope of the SLACS lenses appears to be ∼0.1 larger than the corresponding value of their parent population, at the pivot stellar mass m* = 11.3. This raises the question of whether this bias is intrinsic to strong lenses in general, or is a peculiarity of SLACS.
One aspect that makes the SLACS sample unique is the pre-selection of targets for photometric follow-up based on the estimated Einstein radius, which we described empirically with the lens finding probability term Pfind. We can assess the impact of this choice with posterior prediction. For a given galaxy population drawn from the posterior probability, we considered the population of detectable lenses: these are strong lens systems that are detected spectroscopically and that would be detected photometrically if followed-up with HST. We obtained such a sample by setting Psel = Pdet, dropping Pfind in Equation (9). We measured the average m5 and γ of detectable lenses in bins of stellar mass. The resulting 68% credible regions are shown in Figure 8, enclosed within the black lines. At stellar masses around m* ∼ 11.3, where the bulk of the SLACS data lies, the posterior predicted average γ of detectable lenses is indistinguishable from the value inferred for the lens population (magenta band). This means that, according to our model, the strong lensing bias on the density slope is entirely attributable to the 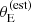 -based target prioritisation criterion. At fixed lens and source redshift, selecting lenses with larger
-based target prioritisation criterion. At fixed lens and source redshift, selecting lenses with larger 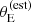 means selecting preferentially lens galaxies with larger velocity dispersion. Since velocity dispersion correlates positively with γ, this results in lenses with steeper density profiles on average.
means selecting preferentially lens galaxies with larger velocity dispersion. Since velocity dispersion correlates positively with γ, this results in lenses with steeper density profiles on average.
The above argument explains part of the difference in the average density slope that we inferred with or without taking selection effects into account, but not its entirety. From our model, we predicted the average γ of SLACS lenses, this time using the full expression for Psel. The corresponding 68% confidence region is show by the dashed blue lines in Figure 8. This is indeed larger than the corresponding value for the lens population, but is also smaller than the value that we inferred from the lens-only analysis (cyan band in Figure 8). The difference in γ is about 0.04 at the pivot stellar mass m* = 11.3. This result might seem counterintuitive, especially given that the posterior predicted tests showed no sign of inconsistency with the observed values of γ (bottom panels of Figure 7).
The root of this residual discrepancy is observational errors. Not only the selection in 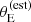 tends to favour galaxies with intrinsically larger velocity dispersion, but also those for which σap has been systematically overestimated. The probability of a detected lens being included in the SLACS sample increases with
tends to favour galaxies with intrinsically larger velocity dispersion, but also those for which σap has been systematically overestimated. The probability of a detected lens being included in the SLACS sample increases with 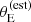 . This means that, at fixed lens and source redshift and velocity dispersion, lenses with a larger σap(obs) are more likely to be selected. Due to the correlation between σap and γ, such lenses have also a larger observed value of the density slope. Figure 9 illustrates this effect. The top panel shows the values of
. This means that, at fixed lens and source redshift and velocity dispersion, lenses with a larger σap(obs) are more likely to be selected. Due to the correlation between σap and γ, such lenses have also a larger observed value of the density slope. Figure 9 illustrates this effect. The top panel shows the values of 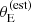 and γ of the SLACS lenses that are allowed by the velocity dispersion measurements. The bottom panel shows the inferred Pfind distribution, which describes the probability of a detected lens to be included in the SLACS sample, and which depends on
and γ of the SLACS lenses that are allowed by the velocity dispersion measurements. The bottom panel shows the inferred Pfind distribution, which describes the probability of a detected lens to be included in the SLACS sample, and which depends on 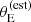 . The uncertainties on the velocity dispersion translate into relatively large errors on
. The uncertainties on the velocity dispersion translate into relatively large errors on 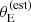 , compared to the scale where Pfind varies. Therefore, observational errors can play an important role in shaping the lens sample, particularly at low values of
, compared to the scale where Pfind varies. Therefore, observational errors can play an important role in shaping the lens sample, particularly at low values of 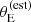 .
.
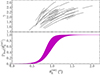 |
Fig. 9. Estimated Einstein radius, density slope and lens finding probability. Top: 68% probable values of |
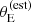
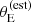
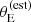
To verify this conjecture, we carried out the following test. Given a posterior predicted sample of SLACS-like lenses, we considered the estimated Einstein radius under the assumption of a singular isothermal profile and perfect knowledge of the stellar velocity dispersion:
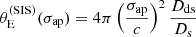 (44)
(44)
(the difference with Equation (2) is in the value of the velocity dispersion that is used). Then, we looked at the relative error on σap and the error on γ as a function of  . These are shown in Figure 10, marginalised over the values of the parameters η. As expected, both quantities are positively biased at small values of
. These are shown in Figure 10, marginalised over the values of the parameters η. As expected, both quantities are positively biased at small values of  . The average posterior predicted observed γ is, on average (i.e. when marginalising over the model parameters), 2.10, which is larger than the true value by 0.04. This bias disappears for the population of detectable lenses. In conclusion, SLACS lenses have on average a steeper density slope than their parent sample, and the value of γ of some of their lenses has likely been overestimated.
. The average posterior predicted observed γ is, on average (i.e. when marginalising over the model parameters), 2.10, which is larger than the true value by 0.04. This bias disappears for the population of detectable lenses. In conclusion, SLACS lenses have on average a steeper density slope than their parent sample, and the value of γ of some of their lenses has likely been overestimated.
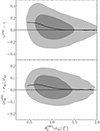 |
Fig. 10. Bias on velocity dispersion and density slope of SLACS-like lenses. Top: error on γ as a function of |


Observational errors aside, SLACS lenses have on average a larger velocity dispersion than parent sample galaxies of the same stellar mass, as can be seen in the bottom panel of Figure 8. The difference is most obvious at stellar masses m* < 11.5. This is again due to the 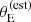 -based selection, because the posterior predicted distribution in σap of all detectable lenses (black lines in Figure 8) is instead very close to that of the parent population. Since the velocity dispersion is related to both stellar mass and size through the fundamental plane relation, it is interesting to determine whether the SLACS lenses lie on the fundamental plane or not. If they do, then their larger σap must be due to them being more compact than the average at fixed stellar mass. If not, then their values of σap are genuinely larger for their stellar mass and size. We found the latter to be the main reason.
-based selection, because the posterior predicted distribution in σap of all detectable lenses (black lines in Figure 8) is instead very close to that of the parent population. Since the velocity dispersion is related to both stellar mass and size through the fundamental plane relation, it is interesting to determine whether the SLACS lenses lie on the fundamental plane or not. If they do, then their larger σap must be due to them being more compact than the average at fixed stellar mass. If not, then their values of σap are genuinely larger for their stellar mass and size. We found the latter to be the main reason.
To illustrate this point, we show in Figure 11 the posterior predicted distribution of the stellar mass-size relation (top), and the fundamental plane relation (bottom). SLACS lenses have indeed smaller sizes than the parent population, on average, but only at the low-mass end, and only by 0.04 dex at m* = 11. When fitting the fundamental plane relation of Equation (36) to the model for the parent population, we inferred an average value of the coefficient describing the scaling of σap with excess size of ξFP ≈ −0.20. This means that a 0.04 dex offset in size translates into an average difference in velocity dispersion of 0.008 dex (2%), corresponding to 3.5 km s−1 at σap = 180 km s−1. This is much smaller than the difference in σap between SLACS lenses and the parent population seen in the bottom panel of Figure 8. At the bottom of Figure 11 we show the posterior predicted distribution of the stellar velocity dispersion, as a function of the position on the fundamental plane (the mean of the distribution of Equation (36)), marginalised over the model parameters η. SLACS lenses lie on average above the fundamental plane: their velocity dispersion is 0.035 dex (8%) higher at values of stellar mass and size corresponding to σap = 200 km s−1, and the bias increases towards lower velocity dispersions. Thus, this is the main reason for SLACS lenses having higher values of σap at fixed stellar mass. This conclusion depends to some extent on our choice of adopting the mass-size relation of Hyde & Bernardi (2009), which lies very close to that of the SLACS lenses (see also Auger et al. 2010). For a more robust assessment of the relative position of SLACS lenses and their parent population in (M*, Re, σap) space we need consistent measurements of the three quantities, which we do not have. Nevertheless, the main point of this investigation is that, although the fundamental plane is a relatively tight relation, it is sufficiently thick to allow for a significant bias in velocity dispersion between the SLACS lenses and the parent population.
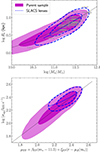 |
Fig. 11. Posterior predicted mass-size and fundamental plane relation. Top: distribution in stellar mass and half-light radius of the parent population (magenta regions) and the SLACS lenses (dashed contours), marginalised over the model parameters η. The dotted black line is the mass-size relation from Hyde & Bernardi (2009). The solid blue line indicates the average size of SLACS lenses as a function of stellar mass. Bottom: distribution in velocity dispersion, as a function of the predicted average given the stellar mass and size (the mean of the distribution in Equation (36)). The solid blue line indicates the average velocity dispersion of the SLACS lenses. |
Another interesting question, related to the point above, is to what extent SLACS lenses are similar to galaxies from their parent population, once controlling for velocity dispersion. In Figure 12 we show the posterior predicted average true values of m5 and γ of parent sample galaxies, SLACS lenses and detectable lenses, measured in bins of velocity dispersion. Strong lenses are remarkably similar to the parent population from this point of view: for instance, the average m5 of SLACS lenses at σap = 250 km s−1 is smaller than that of the parent sample by only 0.02. Differences in γ are for the most part smaller than 0.01. These results corroborate previous claims that SLACS lenses are representative of galaxies of the same stellar velocity dispersion Treu et al. (2006, 2009), despite occupying a different region in (M*, Re, σap) space. However, as shown previously in Figure 10, SLACS lenses have slightly biased velocity dispersion measurements. This bias needs to be taken into account when comparing them to other samples of galaxies.
 |
Fig. 12. Posterior predicted trends with stellar velocity dispersion. Top: average projected dark matter mass within 5 kpc. Bottom: average density slope. The magenta band marks the 68% credible region for the parent population of galaxies. The dashed blue lines enclose the 68% credible region for the SLACS lenses. Grey lines in the top two panels span the values of the SLACS lenses that are allowed with 68% probability. |
As a last thing, we computed the strong lensing bias bSL of the SLACS survey. We introduced bSL in Section 3.1: it is the function by which the distribution of parent sample galaxies is multiplied to produce the sample of strong lens galaxies observed in a survey. We computed bSL from Equation (19) for an example galaxy at redshift z = 0.2 and with half-light radius Re = 7 kpc, as a function of m5 and γ. Figure 13 shows the result, marginalised over the model parameters η. The strong lensing bias peaks on a relatively narrow band in m5 − γ space, which can be seen as a window function of the SLACS survey: galaxies that lie on that band are more likely to be selected as SLACS lenses, while those outside of it are missed. In Figure 13 we also overplotted lines of constant velocity dispersion, which are nearly parallel to the lines of constant bSL. This matches our view that the selection function of SLACS is mostly one in velocity dispersion: at fixed σap, the strong lensing bias does not vary much with either m5 or γ, hence SLACS lenses have a similar density profile to regular early-type galaxies with the same velocity dispersion.
 |
Fig. 13. SLACS Strong lensing bias bSL for a galaxy at z = 0.2 with Re = 7 kpc, as a function of m5 and γ. White lines connect points of constant velocity dispersion, with σap equal to the value indicated. We computed bSL from Equation (19), while marginalising over the model parameters η. |
The expression for the strong lensing bias is independent of the distribution of the parent galaxy population Pg. One could then consider a different parent sample from the one used by SLACS, and use bSL to predict what kind of lenses would be discovered in a SLACS-like campaign with this different sample. In general this could be a valid use of bSL, but not in our case. This is because our model for the lens finding probability, which is meant to describe the prioritisation of targets for follow-up observations, depends explicitly on the observed velocity dispersion. But in a hypothetical sample with a different distribution in σap, a SLACS-like prioritisation that selects a fixed number of targets at the top of the 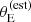 distribution would correspond to a different selection in σap, and consequently different Pfind. The question of what a SLACS-like survey would look like with a different parent population is then an ill-posed one: more details on the follow-up strategy need to be provided.
distribution would correspond to a different selection in σap, and consequently different Pfind. The question of what a SLACS-like survey would look like with a different parent population is then an ill-posed one: more details on the follow-up strategy need to be provided.
6. Discussion
Joint lensing and dynamics studies of the SLACS lenses carried out so far have found that the average density slope of the 59 lenses in the sample is ⟨γ⟩≈2.1. According to our analysis, this value of the average γ is larger than that of regular early-type galaxies of the same stellar mass, by about 0.1. This result can have important implications for studies of the evolution in the density profile of massive early-type galaxies.
Ruff et al. (2011), Bolton et al. (2012), Sonnenfeld et al. (2013) showed how, when combining SLACS with other samples of lenses, the average γ tends to be larger at lower redshift, pointing towards a steepening of the total density profile with time. The common feature among these studies is that they all rely on the SLACS sample as a low-redshift pivot. Thus, if ⟨γ⟩ of SLACS were to be lowered, the conclusions would change dramatically. For instance, Sonnenfeld et al. (2013) measured d⟨γ⟩/dz = −0.31 ± 0.10 when combining SLACS with SL2S lenses. The average redshift of the SL2S sample is ⟨z⟩≈0.5, larger than that of SLACS by ≈0.3. This means that a systematic offset in ⟨γ⟩ of the SLACS lenses by 0.1 could account for the detected trend entirely. A similar argument can be made for the study of Bolton et al. (2012), which is based on the BELLS sample. BELLS lenses were discovered spectroscopically with a very similar method employed for SLACS, including a criterion for the prioritisation of photometric follow-up observations based on the estimated Einstein radius 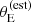 . Crucially, however, BELLS did not rely on the observed velocity dispersion in the estimate of
. Crucially, however, BELLS did not rely on the observed velocity dispersion in the estimate of 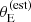 , due to the low signal-to-noise ratio of the available spectroscopic measurements: instead, they assigned a fixed value of σap = 250 km s−1 to all lens candidates (Brownstein et al. 2012). As a result, the BELLS sample is immune from the selection in velocity dispersion that causes the bias in γ of the SLACS lenses.
, due to the low signal-to-noise ratio of the available spectroscopic measurements: instead, they assigned a fixed value of σap = 250 km s−1 to all lens candidates (Brownstein et al. 2012). As a result, the BELLS sample is immune from the selection in velocity dispersion that causes the bias in γ of the SLACS lenses.
In light of these findings, the evidence for a steepening with time of the total density profile of massive early-type galaxies needs to be revisited. SLACS lenses cannot be simply compared to lenses at higher redshift from different samples, but their velocity dispersion selection needs to be taken into account. It is possible that the value of d⟨γ⟩/dz will be revised upwards after correcting for selection effects. That would help reconcile lensing and dynamics measurements with some lensing-only studies (Tan et al. 2024; Sahu et al. 2024) and with theoretical predictions (Remus et al. 2013; Sonnenfeld et al. 2014; Xu et al. 2017; Shankar et al. 2018). Nevertheless, in order to know with certainty whether the steepening in γ is real or not, it is necessary to correct for selection effects also the other samples of lenses mentioned above. That, however, is beyond the scope of this work.
Our findings have implications for time-delay cosmography studies as well. Birrer et al. (2020) used the SLACS sample to put a prior on the lens mass model of time-delay lenses from the TDCOSMO sample (Millon et al. 2020), under the assumption that any differences between the SLACS and the TDCOSMO sample can be accounted for by scalings with the ratio between Einstein radius and half-light radius. Given the peculiar selection function of SLACS lenses, which tends to pick objects that are offset from the fundamental plane of early-type galaxies, it seems unlikely that the two samples can be combined in such a way without introducing biases. However, we are unable to quantify such a bias, which might well be within the statistical uncertainties, because the mass model used by Birrer et al. (2020) is more complex than the simple power-law on which our study is based.
All of our analysis was carried out under the assumption of a spherical mass distribution and isotropic orbits for the stars. This assumption allowed us to convert directly the Einstein radius and stellar velocity dispersion of each lens into an inference on the two free parameters of the power-law mass profile, (m5, γ). Although the amount of flattening and anisotropy of the SLACS lenses has been found to be modest (Barnabè et al. 2011), high precision measurements would require us to allow for a departure from spherical symmetry and from the isotropy assumption. At fixed mass and tracer density profile, radial orbits tend to increase the stellar velocity dispersion. Fitting an isotropic power-law model to a radially anisotropic lens galaxy would then lead to an overestimate of the density slope γ (see Koopmans et al. 2006, for a quantification of this effect). We expect the orbital anisotropy to vary from galaxy to galaxy: this is a source of scatter in the velocity dispersion at fixed mass profile that we are absorbing into the inferred distribution in γ. As a result, we likely overestimated the strength of the correlation between γ and the velocity dispersion. Because, as we established, the nature of the bias in γ between the SLACS lenses and the parent population is entirely due to the selection in velocity dispersion, an intrinsic scatter in orbital anisotropy would mean that what we interpreted exclusively as a bias in γ is partly a bias in anisotropy: SLACS lenses are not as biased in γ with respect to the parent population, but have on average more radially anisotropic orbits. Appendix A explores the degeneracy between density slope and orbital anisotropy in more detail. A similar argument can be made regarding the three-dimensional structure. This does not change the main point of our analysis, which is that the way that SLACS galaxies were selected makes them different from galaxies with similar stellar mass and size, in terms of their internal structure.
One of the limiting factors in our analysis is the lack of consistent measurements of the stellar mass profile of galaxies of the SLACS lenses and the parent population galaxies. This prevented us from taking full advantage of the information available on the parent sample, and forced us to adopt the more relaxed prior on the fundamental plane described in Section 4.6. For future studies, it would be beneficial to have access to the same photometric data for both the lenses and the non-lenses. We expect that strong lens studies based on data from Euclid (Euclid Collaboration 2024) will satisfy this requirement.
7. Conclusions
We carried out a joint lensing and dynamical analysis of the SLACS sample of lenses. Our study differed from previous analyses of the same sample (Auger et al. 2010; Sonnenfeld et al. 2013; Posacki et al. 2015; Shajib et al. 2021) under one crucial aspect: we corrected the inference for selection effects. Our model for the selection function describes both the probability of detecting a lensed source in the spectroscopic and photometric data on which the survey was based, and the probability of a lens candidate being included in the final SLACS sample. This constitutes a step forward in complexity and fidelity with respect to earlier attempts (Sonnenfeld et al. 2015, 2018).
We constrained the distribution in the mass structure of massive early-type galaxies, under the assumption of a spherically symmetric power-law mass density profile and isotropic orbits. We found that galaxies with a stellar mass of log(M*/M⊙) = 11.3 and average size for their mass have on average a total projected mass enclosed within 5 kpc of log M5 = 11.332 ± 0.013, and an average density slope of γ = 1.99 ± 0.03. By contrast, a fit of the same mass model to the SLACS lenses gives a larger average density slope by approximately 0.1. We identified the source of this bias to lie entirely in the way that the SLACS lens candidates were prioritised for photometric follow-up observations, which relied on the observed velocity dispersion. As a result, SLACS lenses have larger velocity dispersion than regular early-type galaxies at fixed stellar mass and size, and their velocity dispersion measurements are likely biased towards larger values. Nevertheless, they are fairly representative of galaxies of similar velocity dispersion (though they have slightly lower masses). We also corroborated evidence towards early-type galaxies not being homologous systems: their total mass grows more strongly with stellar mass and decreases less strongly with half-light radius than a purely homologous structure would suggest.
Because the source of the bias of the SLACS lenses is in the target prioritisation, which is a peculiarity of SLACS, we do not expect other lens samples to be similarly biased. This could have implications for previous claims of an evolution in the total density profile of massive early-type galaxies that relied on the combination of SLACS data with other lens samples.
Our study provides a reference on which to base future investigations that require knowledge of the selection function of a strong lens sample. One immediate use case is testing the predictions of theoretical models on the mass structure of early-type galaxies: this can be done directly by taking the model distribution in (m5, γ) that we inferred from the data and comparing it with theory. If the goal is building a large sample of galaxies with similar internal structure as the SLACS lenses, for instance to carry out weak lensing measurements (such as in the study of Sonnenfeld et al. 2018), this can be done by matching the two samples in velocity dispersion, provided that differences in mass of 0.02 dex are deemed not important. If one wishes to use information from the SLACS sample as a prior for different samples of lenses, as done in the time-delay lensing analysis of Birrer et al. (2020), additional work is needed: the strong lensing bias of each strong lens sample needs to be determined separately. Finally, by applying the method developed in this paper to more complex models and different samples of lenses, we can remove the strong lensing bias on other properties of the mass structure of galaxies, such as the stellar mass-to-light ratio, the dark matter distribution, and their time evolution.
Data availability
Additional data for this article are available in a public data repository at: https://zenodo.org/records/13366012. The code and accompanying documentation are publicly available on GitHub at: https://github.com/astrosonnen/strong_lensing_tools/tree/main/papers/slacs_selection.
The fundamental plane is a scaling relation between half-light radius, central surface brightness and central stellar velocity dispersion of early-type galaxies (Dressler et al. 1987; Djorgovski & Davis 1987).
This definition differs from the one that we adopt in our paper (which we introduce in Section 4.4).
To be precise, the morphology selection was only applied after the lens search, but it is convenient to consider it as part of the initial cut.
Acknowledgments
This work was initiated at the 2023 KICP workshop “Lensing at different scales: strong, weak, and synergies between the two”. I thank Tommaso Treu, Tom Collett, Tian Li, Anowar Shajib, Natalie Hogg, Birendra Dhanasingham and Raphael Gavazzi for their useful comments and suggestions.
References
- Almeida, A., Anderson, S. F., Argudo-Fernández, M., et al. 2023, ApJS, 267, 44 [NASA ADS] [CrossRef] [Google Scholar]
- Arneson, R. A., Brownstein, J. R., & Bolton, A. S. 2012, ApJ, 753, 4 [CrossRef] [Google Scholar]
- Auger, M. W., Treu, T., Bolton, A. S., et al. 2009, ApJ, 705, 1099 [Google Scholar]
- Auger, M. W., Treu, T., Bolton, A. S., et al. 2010, ApJ, 724, 511 [NASA ADS] [CrossRef] [Google Scholar]
- Barnabè, M., Czoske, O., Koopmans, L. V. E., Treu, T., & Bolton, A. S. 2011, MNRAS, 415, 2215 [Google Scholar]
- Bernardi, M., Domínguez Sánchez, H., Margalef-Bentabol, B., Nikakhtar, F., & Sheth, R. K. 2020, MNRAS, 494, 5148 [Google Scholar]
- Bertin, G., Ciotti, L., & Del Principe, M. 2002, A&A, 386, 149 [CrossRef] [EDP Sciences] [Google Scholar]
- Birrer, S., Shajib, A. J., Galan, A., et al. 2020, A&A, 643, A165 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bolton, A. S., Burles, S., Koopmans, L. V. E., Treu, T., & Moustakas, L. A. 2006, ApJ, 638, 703 [NASA ADS] [CrossRef] [Google Scholar]
- Bolton, A. S., Burles, S., Koopmans, L. V. E., et al. 2008, ApJ, 682, 964 [Google Scholar]
- Bolton, A. S., Brownstein, J. R., Kochanek, C. S., et al. 2012, ApJ, 757, 82 [NASA ADS] [CrossRef] [Google Scholar]
- Brownstein, J. R., Bolton, A. S., Schlegel, D. J., et al. 2012, ApJ, 744, 41 [NASA ADS] [CrossRef] [Google Scholar]
- Cappellari, M., Romanowsky, A. J., Brodie, J. P., et al. 2015, ApJ, 804, L21 [NASA ADS] [CrossRef] [Google Scholar]
- Charlton, P. J. L., Hudson, M. J., Balogh, M. L., & Khatri, S. 2017, MNRAS, 472, 2367 [NASA ADS] [CrossRef] [Google Scholar]
- Conroy, C., Gunn, J. E., & White, M. 2009, ApJ, 699, 486 [Google Scholar]
- Djorgovski, S., & Davis, M. 1987, ApJ, 313, 59 [Google Scholar]
- Dressler, A., Lynden-Bell, D., Burstein, D., et al. 1987, ApJ, 313, 42 [Google Scholar]
- Eisenstein, D. J., Annis, J., Gunn, J. E., et al. 2001, AJ, 122, 2267 [Google Scholar]
- Etherington, A., Nightingale, J. W., Massey, R., et al. 2022, MNRAS, 517, 3275 [CrossRef] [Google Scholar]
- Euclid Collaboration (Mellier, Y. et al.) 2024, A&A, in press, https://doi.org/10.1051/0004-6361/202450810 [Google Scholar]
- Gavazzi, R., Treu, T., Marshall, P. J., Brault, F., & Ruff, A. 2012, ApJ, 761, 170 [Google Scholar]
- Herle, A., O’Riordan, C. M., & Vegtti, S. 2024, ArXiv e-prints [arXiv:2307.10355] [Google Scholar]
- Hyde, J. B., & Bernardi, M. 2009, MNRAS, 394, 1978 [NASA ADS] [CrossRef] [Google Scholar]
- Koopmans, L. V. E., Treu, T., Bolton, A. S., Burles, S., & Moustakas, L. A. 2006, ApJ, 649, 599 [Google Scholar]
- Meert, A., Vikram, V., & Bernardi, M. 2015, MNRAS, 446, 3943 [NASA ADS] [CrossRef] [Google Scholar]
- Millon, M., Galan, A., Courbin, F., et al. 2020, A&A, 639, A101 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Montero-Dorta, A. D., Bolton, A. S., Brownstein, J. R., et al. 2016, MNRAS, 461, 1131 [CrossRef] [Google Scholar]
- Peirani, S., Sonnenfeld, A., Gavazzi, R., et al. 2019, MNRAS, 483, 4615 [NASA ADS] [CrossRef] [Google Scholar]
- Posacki, S., Cappellari, M., Treu, T., Pellegrini, S., & Ciotti, L. 2015, MNRAS, 446, 493 [Google Scholar]
- Remus, R.-S., Burkert, A., Dolag, K., et al. 2013, ApJ, 766, 71 [NASA ADS] [CrossRef] [Google Scholar]
- Ruff, A. J., Gavazzi, R., Marshall, P. J., et al. 2011, ApJ, 727, 96 [NASA ADS] [CrossRef] [Google Scholar]
- Sahu, N., Tran, K.-V., Suyu, S. H., et al. 2024, ApJ, 970, 86 [CrossRef] [Google Scholar]
- Shajib, A. J., Treu, T., Birrer, S., & Sonnenfeld, A. 2021, MNRAS, 503, 2380 [Google Scholar]
- Shajib, A. J., Vernardos, G., Collett, T. E., et al. 2022, ArXiv e-prints [arXiv:2210.10790] [Google Scholar]
- Shankar, F., Sonnenfeld, A., Mamon, G. A., et al. 2017, ApJ, 840, 34 [Google Scholar]
- Shankar, F., Sonnenfeld, A., Grylls, P., et al. 2018, MNRAS, 475, 2878 [NASA ADS] [CrossRef] [Google Scholar]
- Shu, Y., Brownstein, J. R., Bolton, A. S., et al. 2017, ApJ, 851, 48 [Google Scholar]
- Sonnenfeld, A. 2020, A&A, 641, A143 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sonnenfeld, A. 2022, A&A, 659, A132 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sonnenfeld, A., Treu, T., Gavazzi, R., et al. 2013, ApJ, 777, 98 [Google Scholar]
- Sonnenfeld, A., Nipoti, C., & Treu, T. 2014, ApJ, 786, 89 [NASA ADS] [CrossRef] [Google Scholar]
- Sonnenfeld, A., Treu, T., Marshall, P. J., et al. 2015, ApJ, 800, 94 [Google Scholar]
- Sonnenfeld, A., Leauthaud, A., Auger, M. W., et al. 2018, MNRAS, 481, 164 [Google Scholar]
- Sonnenfeld, A., Wang, W., & Bahcall, N. 2019, A&A, 622, A30 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sonnenfeld, A., Tortora, C., Hoekstra, H., et al. 2022, A&A, 662, A55 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sonnenfeld, A., Li, S.-S., Despali, G., et al. 2023, A&A, 678, A4 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Strauss, M. A., Weinberg, D. H., Lupton, R. H., et al. 2002, AJ, 124, 1810 [Google Scholar]
- Tan, C. Y., Shajib, A. J., Birrer, S., et al. 2024, MNRAS, 530, 1474 [NASA ADS] [CrossRef] [Google Scholar]
- Treu, T., Koopmans, L. V., Bolton, A. S., Burles, S., & Moustakas, L. A. 2006, ApJ, 640, 662 [NASA ADS] [CrossRef] [Google Scholar]
- Treu, T., Gavazzi, R., Gorecki, A., et al. 2009, ApJ, 690, 670 [NASA ADS] [CrossRef] [Google Scholar]
- Treu, T., Dutton, A. A., Auger, M. W., et al. 2011, MNRAS, 417, 1601 [Google Scholar]
- Xu, D., Springel, V., Sluse, D., et al. 2017, MNRAS, 469, 1824 [NASA ADS] [CrossRef] [Google Scholar]
- York, D. G., Adelman, J., Anderson, J. E. Jr, et al. 2000, AJ, 120, 1579 [Google Scholar]
- Zhou, Q., Sonnenfeld, A., & Hoekstra, H., 2024, A&A, in press, https://doi.org/10.1051/0004-6361/202451227 [Google Scholar]
Appendix A: Orbital anisotropy
Our measurements of the density profile of early-type galaxies rely mainly on strong lensing and stellar kinematics information. In particular, we used the spherical Jeans equation to fit dynamical models to the observed velocity dispersion data. The entire analysis was carried out under the assumption of isotropic orbits. Here we explore briefly how some of the results would change if we were to relax that assumption.
Orbital anisotropy in spherical systems is defined in terms of the tangential and radial components of the velocity dispersion, as
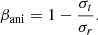 (A.1)
(A.1)
For isotropic orbits, σt = σr and βani = 0. For radially anisotropic orbits, βani > 0, while βani < 0 indicates tangential anisotropy.
One effect of fitting an isotropic power-law model to the velocity dispersion of a galaxy with non-zero anisotropy is to bias the inferred value of the density slope γ: at fixed mass profile, the velocity dispersion increases with βani, and so does the inferred value of γ. Therefore, to first approximation, a non-zero anisotropy produces an overall shift on the inferred γ, the amplitude of which depends on the average value of βani of the population of galaxies.
However, we also expect a bias between the distribution in anisotropy of the SLACS lenses and that of the parent sample, similar to the bias in γ that we uncovered in this paper. This is because anisotropy affects the observed velocity dispersion, which enters the lens selection probability by means of the estimated Einstein radius 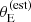 . Figure A.1 illustrates this effect, by showing how the value of
. Figure A.1 illustrates this effect, by showing how the value of 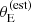 varies as a function of both γ and βani, for a lens with fixed true value of the Einstein radius and a spatially constant anisotropy. Qualitatively speaking,
varies as a function of both γ and βani, for a lens with fixed true value of the Einstein radius and a spatially constant anisotropy. Qualitatively speaking, 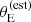 increases both with γ and β. Coupled with the fact that lenses with a larger
increases both with γ and β. Coupled with the fact that lenses with a larger 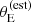 were more likely to be selected, this means that galaxies with more radially anisotropic orbits are likely over-represented in the SLACS sample. For a quantitative assessment of the amplitude of the bias, knowledge of the intrinsic distribution in βani of the general population is needed. That quantity, however, is not known very well.
were more likely to be selected, this means that galaxies with more radially anisotropic orbits are likely over-represented in the SLACS sample. For a quantitative assessment of the amplitude of the bias, knowledge of the intrinsic distribution in βani of the general population is needed. That quantity, however, is not known very well.
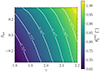 |
Fig. A.1. Estimated Einstein radius of a power-law lens with θE = 1″, as a function of density slope and orbital anisotropy. The lens is at zg = 0.2, with a half-light radius Re = 7 kpc, and the Einstein radius is computed with respect to a source at zs = 0.6. White lines connect points of constant |
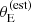
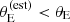
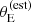
All Tables
All Figures
|
Fig. 1. SLACS lenses and parent population. Distribution in redshift, observed stellar mass, half-light radius, and stellar velocity dispersion. The green contours and histograms are obtained by weighting the parent sample distribution by σap4. Vertical dashed or dotted lines indicate the median of the distributions of the corresponding colour. Contours enclose 68% and 95% of the distribution. Half-light radius measurements of the parent population were not used in our analysis. Instead, we assumed a stellar mass-size relation from Hyde & Bernardi (2009), which is shown as a dashed red line. The black line in the redshift-stellar mass panel is the inferred truncation stellar mass mt, introduced in section 4.2. |
| In the text | |
|
Fig. 2. Strong lensing cross-section of a circular power-law lens and a point source. A lensing event is defined as the detection of an emission line within an aperture of 1.5″, and of at least two images in photometric data. Top: σSL of a lens with θE = 1.2″ as a function of the slope γ. The thick green line corresponds to a source with intrinsic emission line flux equal to one third of the flux required for a spectroscopic detection, and a broadband flux equal to that needed for a photometric detection. Different lines were obtained by rescaling both the emission line and broadband flux by the amount indicated in the legend. Bottom: geometric factor of the lensing cross-section, that is the value of σSL for the reference source (corresponding to the green line in the top panel), as a function of both θE and γ. |
| In the text | |
|
Fig. 3. Constraints on m5 and γ, and predicted values of the velocity dispersion, for individual lenses. Each line covers the 68% credible region of the posterior probability. Lines are colour-coded by the physical size of the Einstein radius. Dots mark the maximum posterior probability values. |
| In the text | |
|
Fig. 4. Posterior probability distribution of the model. Parameters shown: average log M5 and γ at fixed stellar mass and half-light radius, and intrinsic scatter around the average. Filled contours: model describing SLACS lenses, without correction for selection effects (see Section 4.8). Thick solid curves: fiducial model. Thin solid curves: model with no fundamental plane prior of Equation (37). Contour levels correspond to 68% and 95% enclosed probability. |
| In the text | |
|
Fig. 5. Same as Figure 4, but showing parameters describing the scaling of m5 and γ with stellar mass and size. Dashed lines indicate values of the parameters corresponding to the case in which galaxies are homologous systems with an average density slope of γ = 2.00. |
| In the text | |
|
Fig. 6. Same as Figure 4, but showing parameters describing the lens finding probability, defined in Equation (35), and the average density slope parameter. |
| In the text | |
|
Fig. 7. Posterior predictive tests of goodness of fit. Each panel shows the posterior predicted (histogram) and observed value (dashed line) of the test quantity indicated at the bottom. Units of Einstein radius are in arcsec and of the velocity dispersion are in km s−1. |
| In the text | |
|
Fig. 8. Posterior predicted trends with stellar mass, for galaxies of average size. Top: average projected mass enclosed within 5 kpc. Middle: average density slope. Bottom: average stellar velocity dispersion. Each band marks the 68% credible region. The magenta band shows the prediction for the parent population. The cyan band shows the prediction from the lens-only analysis, without accounting for selection effects. Dashed blue lines show the prediction for the population of SLACS lenses. Solid black lines show the prediction for the population of detectable lenses (obtained by removing the lens finding probability Pfind from the posterior prediction). Error bars are the values measured for the SLACS lenses, assuming a flat prior on both m5 and γ. Uncertainties on the stellar mass are uncorrelated with those on m5, γ and σap. In the bottom panel, the green line shows our quadratic fit to the m* − σap relation of the parent sample. |
| In the text | |
|
Fig. 9. Estimated Einstein radius, density slope and lens finding probability. Top: 68% probable values of |
| In the text | |
|
Fig. 10. Bias on velocity dispersion and density slope of SLACS-like lenses. Top: error on γ as a function of |
| In the text | |
|
Fig. 11. Posterior predicted mass-size and fundamental plane relation. Top: distribution in stellar mass and half-light radius of the parent population (magenta regions) and the SLACS lenses (dashed contours), marginalised over the model parameters η. The dotted black line is the mass-size relation from Hyde & Bernardi (2009). The solid blue line indicates the average size of SLACS lenses as a function of stellar mass. Bottom: distribution in velocity dispersion, as a function of the predicted average given the stellar mass and size (the mean of the distribution in Equation (36)). The solid blue line indicates the average velocity dispersion of the SLACS lenses. |
| In the text | |
|
Fig. 12. Posterior predicted trends with stellar velocity dispersion. Top: average projected dark matter mass within 5 kpc. Bottom: average density slope. The magenta band marks the 68% credible region for the parent population of galaxies. The dashed blue lines enclose the 68% credible region for the SLACS lenses. Grey lines in the top two panels span the values of the SLACS lenses that are allowed with 68% probability. |
| In the text | |
|
Fig. 13. SLACS Strong lensing bias bSL for a galaxy at z = 0.2 with Re = 7 kpc, as a function of m5 and γ. White lines connect points of constant velocity dispersion, with σap equal to the value indicated. We computed bSL from Equation (19), while marginalising over the model parameters η. |
| In the text | |
|
Fig. A.1. Estimated Einstein radius of a power-law lens with θE = 1″, as a function of density slope and orbital anisotropy. The lens is at zg = 0.2, with a half-light radius Re = 7 kpc, and the Einstein radius is computed with respect to a source at zs = 0.6. White lines connect points of constant |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.