| Issue |
A&A
Volume 686, June 2024
|
|
|---|---|---|
| Article Number | A209 | |
| Number of page(s) | 9 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/202348811 | |
| Published online | 12 June 2024 | |
A precise symbolic emulator of the linear matter power spectrum
1
CNRS & Sorbonne Université, Institut d’Astrophysique de Paris (IAP), UMR 7095, 98 bis bd Arago, 75014 Paris, France
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Heuristic and Evolutionary Algorithms Laboratory, University of Applied Sciences Upper Austria, Hagenberg, Austria
3
Institute of Cosmology & Gravitation, University of Portsmouth, Dennis Sciama Building, Portsmouth PO1 3FX, UK
4
Astrophysics, University of Oxford, Denys Wilkinson Building, Keble Road, Oxford OX1 3RH, UK
5
Center for Computational Astrophysics, Flatiron Institute, 162 5th Avenue, New York, NY 10010, USA
Received:
1
December
2023
Accepted:
3
April
2024
Abstract
Context. Computing the matter power spectrum, P(k), as a function of cosmological parameters can be prohibitively slow in cosmological analyses, hence emulating this calculation is desirable. Previous analytic approximations are insufficiently accurate for modern applications, so black-box, uninterpretable emulators are often used.
Aims. We aim to construct an efficient, differentiable, interpretable, symbolic emulator for the redshift zero linear matter power spectrum which achieves sub-percent level accuracy. We also wish to obtain a simple analytic expression to convert As to σ8 given the other cosmological parameters.
Methods. We utilise an efficient genetic programming based symbolic regression framework to explore the space of potential mathematical expressions which can approximate the power spectrum and σ8. We learn the ratio between an existing low-accuracy fitting function for P(k) and that obtained by solving the Boltzmann equations and thus still incorporate the physics which motivated this earlier approximation.
Results. We obtain an analytic approximation to the linear power spectrum with a root mean squared fractional error of 0.2% between k = 9 × 10−3 − 9 h Mpc−1 and across a wide range of cosmological parameters, and we provide physical interpretations for various terms in the expression. Our analytic approximation is 950 times faster to evaluate than CAMB and 36 times faster than the neural network based matter power spectrum emulator BACCO. We also provide a simple analytic approximation for σ8 with a similar accuracy, with a root mean squared fractional error of just 0.1% when evaluated across the same range of cosmologies. This function is easily invertible to obtain As as a function of σ8 and the other cosmological parameters, if preferred.
Conclusions. It is possible to obtain symbolic approximations to a seemingly complex function at a precision required for current and future cosmological analyses without resorting to deep-learning techniques, thus avoiding their black-box nature and large number of parameters. Our emulator will be usable long after the codes on which numerical approximations are built become outdated.
Key words: methods: numerical / cosmological parameters / cosmology: theory / large-scale structure of Universe
© The Authors 2024
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
Machine learning (ML) methods have great potential for simplifying and accelerating the analysis of astrophysical data sets. The primary focus has been on what one might dub “advanced numerical methods” using, for example, Gaussian processes or neural networks. In these cases, one tries to construct efficient algorithms which can be used to either infer specific physical properties from complex data sets or emulate complex processes which can then be extrapolated to new situations. Typically these methods involve constructing a set of pre-established basis functions and then inferring their weights, or building complex, expressible functions, with parameters that can be optimised via efficient gradient descent methods. These methods can be easily incorporated in Bayesian inference frameworks that have achieved significant success, becoming the standard practice in astrostatistics.
The drawback of the more traditional, numerical ML techniques is their opaqueness; it is not always clear what information is being used and how methods trained on (necessarily imperfect) simulations will perform when applied to real-world data. A somewhat overlooked branch of machine learning which has tremendous promise for the types of problems being considered in astrophysics is symbolic regression (SR). With SR one tries to infer the mathematical expressions that best capture the properties of the physical system one is trying to study. The process is an attempt to mimic and systematise the practice that physicists have always used: to infer simple physical laws (i.e., formulae) from data. The field of SR has developed over the years into a vibrant and active field of research in ML, typically associated with evolutionary methods such as Genetic Programming. It has been shown that it can be used to infer some well-established laws of physics from data and infer new ones (e.g., Lemos et al. 2023; Bartlett et al. 2023a,b; Desmond et al. 2023; Kamerkar et al. 2023; Sousa et al. 2024; Delgado et al. 2022; Miniati & Gregori 2022; Wadekar et al. 2023; Koksbang 2023a,b,c; Alestas et al. 2022; Lodha et al. 2024).
Within the field of cosmology, one often compresses observations from galaxy surveys into two-point correlation functions (or their Fourier transforms, power spectra), which are compared to theory through Markov chain Monte Carlo methods to constrain cosmological parameters. As cosmological surveys become increasingly vast and precise, a fundamental limitation to the feasibility of such inferences has been the speed at which one can make this theoretical prediction, since it involves solving a complex set of coupled, highly non-linear differential equations. Recently, instead of directly solving these equations (Lewis et al. 2000; Blas et al. 2011; Hahn et al. 2023) and adding non-linear corrections (Smith et al. 2003), emulation techniques such as Neural Networks, Gaussian Processes or polynomial interpolation schemes have been used to accelerate these calculations to directly output the matter power spectrum as a function of cosmological parameters (Fendt & Wandelt 2007a,b; Heitmann et al. 2014; Winther et al. 2019; Angulo et al. 2021; Aricò et al. 2022; Euclid Collaboration 2021; Spurio Mancini et al. 2022; Mootoovaloo et al. 2022; Zennaro et al. 2023). These methods act as black boxes and require up to several hundreds of parameters to be optimised.
However, through perturbation theory, one knows analytic limits of the power spectrum and, through visual inspection, it does not appear to be an extremely complex function. As such, one wonders whether an analytic approximation exists. Indeed, for many years, the leading method of accelerating this calculation has been an analytic approximation (Eisenstein & Hu 1998, 1999), however it is insufficiently precise for modern experiments. Analytic approximations to beyond ΛCDM power spectra have been proposed in the context of modified gravity (Orjuela-Quintana et al. 2024), although these still only achieve a precision of between 1 and 2%.
Such an emulator has the advantage that it will not become deprecated when the codes on which current numerical methods are built become outdated, whereas other methods require the transfer of the inferred weights and biases as well as the model architecture, hindering longevity. Even in the short term, an analytic expression using standard operators is more portable, since it can be more easily be incorporated into the user’s favourite programming language without the need to install or write wrappers for the model. Moreover, having an analytic expression allows one to interpret such a fit, and potentially identify physical processes which could lead to certain terms, contrary to the black-box numerical methods. Additionally, such expressions often contain fewer free parameters to optimise than numerical ML methods.
In Sect. 2 we briefly describe the matter power spectrum and the Eisenstein & Hu approximation, and in Sect. 3 we detail the SR method we use in this work. We present an analytic emulator for σ8 as a function of other cosmological parameters in Sect. 4 (which is easily invertible to obtain As as a function of cosmological parameters), and in Sect. 5 we give our emulator for the linear matter power spectrum. The main results of this paper are given in Eqs. (4) and (6). We conclude and discuss future work in Sect. 6. Throughout this paper ‘log’ denotes the natural logarithm.
2. The matter power spectrum
2.1. Definition
We would like to construct an efficient, differentiable and (if at all possible) interpretable emulator for the power spectrum of the matter distribution in the Universe, P(k; θ), for wavenumber k and cosmological parameters θ.
The power spectrum is defined as follows: the matter density of the Universe, ρ(x) can be decomposed into a constant (in space) background density, 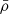 , and a density contrast, δ(x) such that
, and a density contrast, δ(x) such that ![Mathematical equation: $ \rho(\boldsymbol{x})={\bar{\rho}}[1+\delta(\boldsymbol{x})] $](/articles/aa/full_html/2024/06/aa48811-23/aa48811-23-eq2.gif) . If
. If 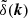 is the Fourier Transform of δ(x), and the matter distribution is statistically homogeneous and isotropic, we have that
is the Fourier Transform of δ(x), and the matter distribution is statistically homogeneous and isotropic, we have that
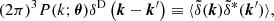 (1)
(1)
where ⟨⋯⟩ denotes an ensemble average and δD is the Dirac delta function.
From observations of the cosmic microwave background (CMB; Planck Collaboration VI 2020), it is known that the density fluctuations at early times were approximately Gaussian and thus fully described by P(k; θ). At these early times, the power spectrum of the comoving curvature perturbations is proportional to Askns − 4, where ns ≈ 0.9665 (Planck Collaboration VI 2020). Although structure formation through gravity makes the present-day density field non-Gaussian (e.g., the intricate structure of the cosmic web is typically associated with higher order statistics), the power spectrum still holds a central role in modern cosmological analyses.
The current cosmological model is described by only six parameters: the baryonic, Ωb, and total matter, Ωm, density parameters, the Hubble constant, H0 = 100 h km s−1 Mpc−1, the scalar spectral index, ns, the curvature fluctuation amplitude, As, and the reionisation optical depth, τ. All other parameters can be derived from these six, and thus sometimes a different set of parameters is chosen. For example, instead of As, one often quotes σ8 which is the root-mean-square density fluctuation when the linearly evolved field is smoothed with a top-hat filter of radius 8 h−1 Mpc. Specifically, one defines for a top-hat of radius R
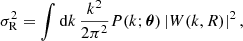 (2)
(2)
where θ is the set of cosmological parameters and the Fourier transfer of the top-hat filter is
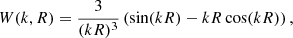 (3)
(3)
and σ8 is simply σR for R = 8 h−1 Mpc. Throughout this paper we ignore the small dependence of the power spectrum on the reionisation optical depth parameter, and focus on the remaining five parameters. We set the neutrino mass to zero in all calculations.
2.2. Eisenstein & Hu approximation
Since each evaluation of a Boltzmann solver to compute P(k; θ) can be expensive, the ability to emulate this procedure and replace this solver with a surrogate model has long been desirable. The most notable attempt to do this in an analytic manner is given in a series of papers by Eisenstein & Hu (1998, 1999). In these works, an approximation is constructed based on physical arguments including baryonic acoustic oscillations (BAO), Compton drag, velocity overshoot, baryon infall, adiabatic damping, Silk damping, and cold dark matter (CDM) growth suppression. Rather than repeat their findings, we refer the reader to these papers to inspect the structure of the equations. Such a model is accurate to a few percent which, although invaluable at the time of writing, is insufficiently accurate for modern cosmological analyses. It is thus the goal of this work to build upon this analytic emulator to provide sub-percent level predictions. We note that alternative symbolic approximations also exist to P(k), such as the earlier, less accurate approximation by Bardeen et al. (1986; BBKS). More recently, Orjuela-Quintana et al. (2023) found simple expressions using genetic programming which can achieve similar accuracy to the Eisenstein & Hu (1998) expression, but we choose to use Eisenstein & Hu (1998)’s approximation due to its physical motivation and widespread use.
3. Symbolic regression
To extract analytic approximations from sampled data, we use the symbolic regression package OPERON1 (Burlacu et al. 2020). This package leverages the most popular (e.g., Lemos et al. 2023; Cranmer et al. 2020; Cranmer 2020, 2023; Schmidt & Lipson 2009; Schmidt et al. 2011; Virgolin et al. 2021; de Franca & Aldeia 2021; La Cava et al. 2019; Kommenda et al. 2020; Arnaldo et al. 2014) approach to SR, namely genetic programming (Turing 1950; David 1989; Haupt & Haupt 2004). Genetic programming describes the evolution of “computer programs”, in our case mathematical expressions encoded as expression trees. Following the principle of natural selection, over several iterations the worst performing equations (given some fitness metric) are discarded and new equations are produced by combining sub-expressions of the current population (crossover) or by randomly inserting, replacing or deleting a subtree in an expression (mutation). Over the course of several generations, the expectation is that the population of equations evolve to become fitter and thus we obtain increasingly accurate analytic expressions.
We note that many other techniques exist for SR, such as supervised or reinforcement learning with neural networks (Petersen et al. 2021; Landajuela et al. 2022; Tenachi et al. 2023; Biggio et al. 2021), deterministic approaches (Worm & Chiu 2013; Kammerer et al. 2021; Rivero et al. 2022; McConaghy 2011), Markov chain Monte Carlo (Jin et al. 2019), physics-inspired searches (Udrescu & Tegmark 2020; Udrescu et al. 2020; René Broløs et al. 2021), and exhaustive searches (Bartlett et al. 2023a). However, we choose OPERON and thus genetic programming due to its speed, high memory efficiency and its strong performance in benchmark studies (Cava et al. 2021; Burlacu 2023).
To improve the search, every time a terminal node appears in an expression tree (i.e., k or one of the cosmological parameters), a scaling parameter is introduced, which is then optimised (Kommenda et al. 2020) using the Levenberg–Marquardt algorithm (Levenberg 1944; Marquardt 1963). We denote the total number of nodes in the expression excluding the scaling as the “length” of the model, and the “complexity” refers to the total number of nodes, including these.
When comparing objective values during non-dominated sorting (NSGA2), OPERON implements the concept of ϵ-dominance (Laumanns et al. 2002), where the parameter ϵ is defined such that two objective values which are within ϵ of each other are considered equal. This parameter therefore affects the number of duplicate equations in the population and is designed to promote convergence to a representative well distributed approximation of the global Pareto front: the set of solutions which cannot be made more accurate without being made more complex. We choose different values for this parameter when searching for our two emulators, and these were found after some experimentation with different values to find settings which produced accurate yet compact models.
Model selection is an essential part of any SR search. Since one optimises both accuracy and simplicity during the search, SR is often a Pareto-optimisation problem. In the presence of statistical errors, one can combine simplicity and accuracy in a principled, information theory motivated way into a single objective to optimise under the minimum description length principle (Bartlett et al. 2023a). In this case, the task of picking the optimum function is unambiguous, and one can incorporate prior information into the functional form using language models (Bartlett et al. 2023b) to obtain more physically motivated functions. In our problem, however, we do not have noise in our data and thus have to rely on heuristic methods.
To choose a model, we first generate the Pareto front of candidate expressions. We then consider only those models for which the loss is below some predefined level (to ensure sufficiently accurate solutions for our applications) and those for which the loss on the training and validation sets do not differ significantly (and indicator of over-fitting). At this point one could automate model selection; for example, in the code PYSR (Cranmer et al. 2020; Cranmer 2020) the best model is the one with the best “score”, which is the one with largest negative of the derivative of the loss with respect to complexity. However, given we wish to have interpretable and physically-reasonable functions, we instead visually inspect the most accurate solution found for each model length and make a qualitative judgement as to the function which is sufficiently compact to be interpretable yet is accurate enough for our applications.
Further details are given in Sects. 4 and 5.
4. Analytic emulator for σ8
We begin by considering the simplest emulator one may want for power spectrum related quantities: an emulator for σ8 as a function of other cosmological parameters (As, Ωb, Ωm, h, ns) or, equivalently, an emulator for As given σ8 and the other cosmological parameters. Although the set of neural network emulators BACCO contains a function to do this (Aricò et al. 2022), to the best of the authors’ knowledge an analytic approximation is not currently in common use. The standard approach is to compute the linear matter power spectrum with a Boltzmann code assuming some initial guess of As, then compute the integral in Eq. (2) to obtain σ8. For a target σ8 of 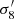 , one should then use
, one should then use 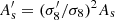 .
.
We wish to accelerate this process with a symbolic emulator. To compute this, we constructed a Latin hypercube (LH) of 100 sets of cosmological parameters, using uniform priors in the ranges given in Table 1, which are the same as those used in Euclid Collaboration (2021). We constructed a second LH of 100 points to be used for validation. For these parameters, we computed σ8 using CAMB (Lewis et al. 2000) and attempted to learn this mapping using a mean squared error loss function with OPERON.
Cosmological parameters used for analytic emulators.
For the equation search, we used a population size of 1000 with a brood size of 10 and tournament size of 5, optimising both the mean squared error and the length of the expression simultaneously, with ϵ = 10−6 (see Sect. 3). From Eq. (2), one would expect that As only appears in the expression for σ8 as 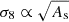 since As linearly scales the power spectrum. As such, we chose to fit for
since As linearly scales the power spectrum. As such, we chose to fit for 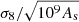 , where we use 109As instead of As so that all cosmological parameters and the target variable are 𝒪(1). Parameters were optimised during the search using a nonlinear least squared optimiser with up to 1000 iterations per optimisation attempt. We set the maximum allowed model length to 40 and maximum number of iterations to 108, although we found that both of these are much larger than the required values needed to converge to a desirable solution.
, where we use 109As instead of As so that all cosmological parameters and the target variable are 𝒪(1). Parameters were optimised during the search using a nonlinear least squared optimiser with up to 1000 iterations per optimisation attempt. We set the maximum allowed model length to 40 and maximum number of iterations to 108, although we found that both of these are much larger than the required values needed to converge to a desirable solution.
The candidate expressions were comprised of standard arithmetic operations (addition, subtraction, multiplication), as well as the natural logarithm, square and square root operators. It is somewhat difficult to predict the exact effect the function set has on the quality of the results. The efficiency of the algorithm is only affected insofar as the transcendental functions (sin, cos, log, exp,  , etc.) are slower to evaluate than arithmetic operators. The effect is minor, however. Increasing the number of basis functions inflates the total search space, making it potentially less likely that well-fitting expressions are found, yet too small a basis set could remove compact approximations to the functions of interest. For both this section and Sect. 5 we experimented with alternative basis sets and found that those chosen gave accurate yet compact expressions within a reasonable run time.
, etc.) are slower to evaluate than arithmetic operators. The effect is minor, however. Increasing the number of basis functions inflates the total search space, making it potentially less likely that well-fitting expressions are found, yet too small a basis set could remove compact approximations to the functions of interest. For both this section and Sect. 5 we experimented with alternative basis sets and found that those chosen gave accurate yet compact expressions within a reasonable run time.
After 2 min of operation on one node of 56 cores, we found the Pareto front of expressions given in Fig. 1. We see that the training and validation losses are comparable at all model lengths, reaching a root mean squared error of around 10−3 by a model length of 14. We see that the difference between the training and validation losses increases after the model of length 27, so we take this model as our fiducial result. It is given by
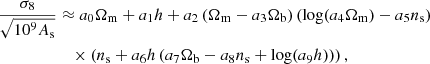 (4)
(4)
 |
Fig. 1. Pareto front of solutions obtained using OPERON when fitting |
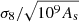
where the optimised parameters are a = [0.51172, 0.04593, 0.73983, 1.56738, 1.16846, 0.59348, 0.19994, 25.09218, 9.36909, 0.00011]. We note that we have removed a final additive term produced by OPERON since this has a value of 3 × 10−6 and is thus much smaller than the error in the fit so can be safely neglected.
We note several important features of this equation which make it desirable. First, we find that it is a highly accurate approximation, with a root mean squared fractional error on the validation set of only 0.1% which is far smaller than the precision to which one can measure this number with cosmological experiments. Second, one sees that As (by design) only appears once in this equation and as a multiplicative term. Thus, it is trivial to invert this equation to obtain As as a function of the other cosmological parameters, as is often needed.
5. Analytic emulator for the linear power spectrum
We now move on to the more challenging task of producing an analytic emulator for the linear matter power spectrum. Given the previous success of Eisenstein & Hu (1998, 1999), we believe it is sensible to build upon this work, not least due to the physically-motivated terms included in their fit and so that we must only have to fit a small residual (of the order of a few percent). Thus, instead of directly fitting for P(k, θ), we define
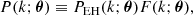 (5)
(5)
where PEH(k; θ) is the zero-baryon fit of Eisenstein & Hu (1998), which does not include an attempt to fit the BAO. We plot both P(k; θ) and log F(k; θ) in Fig. 2 for the best-fit cosmology obtained by Planck (Planck Collaboration VI 2020), where we see that dividing out the Eisenstein & Hu term retains the BAO part of the power spectrum and reduces the dynamic range required for the fit.
 |
Fig. 2. Linear matter power spectrum (upper), the residuals Eq. (5) from the Eisenstein & Hu fit without baryons (middle), and the fractional residuals on P(k) compared to the truth for the Planck 2018 (Planck Collaboration VI 2020) cosmology. In all panels we plot the truth computed with CAMB with solid red lines, and the analytic fit Eq. (6) obtained in this paper with dashed blue lines. We see that the fit is accurate within 0.3% across all k considered. |
As before, we obtained 100 sets of cosmological parameters on a LH using the priors in Table 1 and computed both P(k; θ) with CAMB and PEH(k; θ) with the COLOSSUS (Diemer 2018) implementation, using 200 logarithmically spaced values of k in the range 9 × 10−3 − 9 h Mpc−1. We note that this is an extremely small training set compared to many power spectrum emulators, but we find that it is sufficient to obtain sub-percent level fits.
We chose to symbolically regress log F(k; θ) using a mean squared error loss function, and thus wish to minimise the fractional error on this residual. We chose to fit for log F as this ensures that our final estimate of P(k; θ) is positive, as guaranteed by exponentiation, which is physically required. Additionally, we first multiplied log F by 100 so that the target was 𝒪(1). We used a further 100 sets of cosmological parameters, also arranged on a LH, for validation. We chose to fit using the cosmological parameters σ8, Ωb, Ωm, h and ns. We used the same settings for OPERON as in Sect. 4, except we chose ϵ = 10−3, terminated our search after 108 function evaluations and used a basis set comprising of addition, subtraction, multiplication, natural logarithm, cosine, power and analytic quotient operators (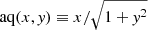 ).
).
The root mean squared error for the best function found at each model length is given in Fig. 3, where we see that we are able to achieve values of 𝒪(10−3) for log F. Unlike for the σ8 emulator, we obtain slightly worse losses for the validation set compared to training, however always by less than a factor of two.
 |
Fig. 3. Pareto front of solutions obtained using OPERON when fitting the linear matter power spectrum as a function of σ8, Ωb, Ωm, h and ns. We plot the root mean squared error on log F as a function of model length for the training and validation sets separately. The model given in Eq. (6) has a model length of 77, as indicated by the dotted line. |
Given this set of candidate solutions, we wish to choose one which is sufficiently accurate for current applications yet is sufficiently compact to be interpretable. In Fig. 3, one observes a plateau in accuracy between model lengths ∼65 − 80 and thus it seems reasonable to choose a solution in this regime, since doubling the model length only achieves approximately a factor of two improvement in fit beyond this point. Moreover, beyond this point the training and validation curves begin to deviate, suggesting a degree of overfitting.
We choose to report the model of length 77, as indicated by the dotted line in Fig. 3, since this provided one of the most interpretable solutions, and achieved a sub-percent error for 95% (2σ) of the cosmological parameters considered, for both the training and validation set. After some simplification, this can be written as
![Mathematical equation: $$ \begin{aligned} \log F&\approx b_0 h - b_{1} \nonumber \\&\quad + \left( \frac{b_2 \Omega _{\rm b}}{\sqrt{h^2 + b_3}} \right)^{b_4 \Omega _{\rm m}} \left[ \frac{b_5 k - \Omega _{\rm b}}{\sqrt{b_6 + (\Omega _{\rm b} - b_7 k)^2}} b_8 (b_9 k)^{-b_{10} k} \cos \left( b_{11} \Omega _{\rm m} \right.\right.\nonumber \\ &\left.\left.-\frac{b_{12} k}{\sqrt{b_{13} + \Omega _{\rm b}^2}} \right) - b_{14} \left( \frac{b_{15} k}{\sqrt{1 + b_{16} k^2}} - \Omega _{\rm m} \right) \cos \left( \frac{b_{17} h}{\sqrt{1 + b_{18} k^2}} \right) \right] \nonumber \\&\quad + b_{19} (b_{20} \Omega _{\rm m} + b_{21} h - \log (b_{22} k) + (b_{23} k)^{- b_{24} k}) \cos \left( \frac{b_{25}}{\sqrt{1 + b_{26} k^2}} \right) \nonumber \\&\quad + (b_{27} k)^{-b_{28} k} \left( b_{29} k - \frac{b_{30} \log (b_{31} k)}{\sqrt{b_{32} + (\Omega _{\rm m} - b_{33} h)^2}} \right) \cos \left( b_{34} \Omega _{\rm m} - \frac{b_{35} k}{\sqrt{b_{36} + \Omega _{\rm b}^2}} \right), \end{aligned} $$](/articles/aa/full_html/2024/06/aa48811-23/aa48811-23-eq16.gif) (6)
(6)
where the best-fit parameters for this function are given in Table 2. We find that there are 37 different parameters required for this fit, far fewer than would be used if one were to emulate this with a neural network. We note that, if we used a method based on the “score” approach of PYSR (Cranmer et al. 2020; Cranmer 2023; see Sect. 3) to choose our model – defining the loss to be the mean squared error on the training set and computing the derivative with respect to model length – then we would have chosen the model of length 80. This has an almost identical functional form to Eq. (6), so our results are not sensitive to the exact model selection method.
We plot this fit and the residuals compared to CAMB for the Planck 2018 cosmology in Fig. 2, which we note is not included in either our training or validation sets. One can see that the difference between the true power spectrum and our analytic fit is almost imperceptible, and in the residuals plot we see that for all k considered, the fractional error does not exceed 0.3%. This is smaller than the error on log F given in Fig. 3, since we compare at the level of the full P(k; θ), such that a moderate error on log F becomes very small once substituted into Eq. (5). This is shown in Fig. 4, where we plot the distribution of fractional residuals in P(k; θ) for all the cosmologies in the training and validations sets. We obtain sub-percent level predictions for all cosmologies and values of k considered, with a root mean squared fractional error of 0.2%.
 |
Fig. 4. Distribution of fractional errors as a function of k on the linear matter power spectrum across all cosmologies in the training and validation sets, as compared to the predictions of CAMB. The bands give the 1 and 2σ values. The dotted line corresponds to a 1% error, and we see that our expression achieves this for all cosmologies and values of k considered, with a root mean squared fractional error of 0.2%. |
Part of the appeal of a symbolic emulator is the possibility for interpretability and to easily identify what information used in the input is used to make the prediction. To begin, we note that, although we obtained our emulator by varying σ8, Ωb, Ωm, h and ns, we see that Eq. (6) contains neither σ8 nor ns. For the linear matter power spectrum, one expects that As and ns only appear as a multiplicative factor of Askns − 1, with all other terms independent of these parameters. Given that the Eisenstein & Hu (1998) term already contains this expression, it is unsurprising that log F is independent of ns. Indeed, if it did appear, this would indicate a degree of overfitting. Since σ8 is not proportional to As (see Eq. (4)), we cannot use the same argument to explain the lack of its appearance in our expression, but can conclude that a combination of the Eisenstein & Hu (1998) term and the first line of Eq. (6) can sufficiently approximate As, since this line is k independent and thus contributes to an overall offset for the emulator.
Turning to the remaining lines of Eq. (6), we observe that each term contains an oscillation modulated by a k- and cosmology-dependent damping. Despite there being four such terms across the remaining three lines, we find that we can split these into two pairs with the same structure of the oscillations. Firstly, we have cosines with an argument proportional to 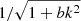 , for some constant b. This functional form (
, for some constant b. This functional form (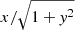 ) arises due to the inclusion of the analytic quotient operator, which also explains why the constant 1 appears multiple times in Eq. (6). These terms give oscillations which vary slowly as a function of k. In particular, as plotted in Fig. 5, the third line of Eq. (6) contains approximately one cycle of oscillation across the range of k considered, with a minimum during the BAO part of the power spectrum, and a maximum just afterwards. Beyond this point, this term fits the non-oscillatory, decaying part of the residual beyond k ∼ 1 h Mpc−1 (compare the middle panel of Fig. 2 to the third term plotted in Fig. 5).
) arises due to the inclusion of the analytic quotient operator, which also explains why the constant 1 appears multiple times in Eq. (6). These terms give oscillations which vary slowly as a function of k. In particular, as plotted in Fig. 5, the third line of Eq. (6) contains approximately one cycle of oscillation across the range of k considered, with a minimum during the BAO part of the power spectrum, and a maximum just afterwards. Beyond this point, this term fits the non-oscillatory, decaying part of the residual beyond k ∼ 1 h Mpc−1 (compare the middle panel of Fig. 2 to the third term plotted in Fig. 5).
 |
Fig. 5. Contributions to log F from our emulator as a function of k for the Planck 2018 cosmology. The line numbers indicated in the legend correspond to the line in Eq. (6). One sees that the first term provides an overall offset, the second and fourth capture the BAO signal, and the third term contains a broad oscillation and then matches on to the decaying residual at high k. |
The remaining oscillatory terms are of the form cos(ωk + ϕ). The phase, ϕ, of these oscillations is proportional to the total matter density, Ωm, such that changing this parameter at fixed Ωb shifts the BAOs to peak at different values of k. The frequency of these oscillations is 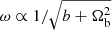 for some parameter b, such that cosmologies with a higher fraction of baryons have many more cycles of BAO in a given range of k, as one would physically expect. From Fig. 5, one can see how the second and fourth lines of Eq. (6) capture the BAO signal with opposite signs, such that they combine to give the familiar damped oscillatory feature. Using Ωbh2 = 0.02242 and h = 0.6766, as appropriate for the Planck 2018 cosmology (Planck Collaboration VI 2020), the frequency of the oscillations are
for some parameter b, such that cosmologies with a higher fraction of baryons have many more cycles of BAO in a given range of k, as one would physically expect. From Fig. 5, one can see how the second and fourth lines of Eq. (6) capture the BAO signal with opposite signs, such that they combine to give the familiar damped oscillatory feature. Using Ωbh2 = 0.02242 and h = 0.6766, as appropriate for the Planck 2018 cosmology (Planck Collaboration VI 2020), the frequency of the oscillations are 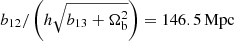 and
and 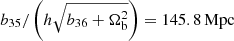 , and are thus approximately equal to the sound horizon, which is r* = 144.6 Mpc for this cosmology. One can therefore view these frequencies as symbolic approximations to the sound horizon, although we refer the reader to Aizpuru et al. (2021) for alternative SR fits.
, and are thus approximately equal to the sound horizon, which is r* = 144.6 Mpc for this cosmology. One can therefore view these frequencies as symbolic approximations to the sound horizon, although we refer the reader to Aizpuru et al. (2021) for alternative SR fits.
Thus, although we did not enforce physically motivated terms in the equation search, we see that simple oscillatory contributions for the BAOs have emerged and thus our symbolic emulator is not merely a high order series expansion, but contains terms which are both compact and interpretable. We find that such terms exist in many functions given in Fig. 3, however we find that using shorter run times for OPERON of only 2–4 h (compared to approximately 24 h on a single node of 128 cores for our fiducial analysis) do not provide as interpretable expressions as Eq. (6).
As a note of caution, one can identify a few terms in Eq. (6) which will become problematic if extrapolated to values of k much smaller than those used to train the emulator, namely those containing log(k) and k raised to a power proportional to k. For k ≲ 10−3 h Mpc−1 this can lead to an error on P(k) of more than one percent. Although one is likely cosmic-variance dominated in this regime so such errors should not be problematic, we know that the Eisenstein & Hu (1998) provide a very good approximation, and thus we suggest that Eq. (6) is included in a piece-wise fit, such that it is only used approximately in the range of k which were used to obtain it. A similar effect is seen if one extrapolates to higher k than considered here. Although this is far beyond the validity of the linear approximation, we caution that applying any parameterisation of the non-linear power spectrum that depends on the linear one may suffer from potentially catastrophic extrapolation failures at high k if used beyond the k range considered here. Again, it is potentially advisable to just use the Eisenstein & Hu (1998) fit in this regime.
In light of the potential for significant efficiency improvements in cosmological analyses through the use of symbolic approximations, it is informative to compare the run times of our approach to the standard computation of the linear matter power spectrum. To do this, we evaluated the redshift-zero linear matter power spectrum 1000 times on an Intel Xeon E5-4650 CPU at the Planck 2018 cosmology (Planck Collaboration VI 2020) using CAMB (Lewis et al. 2000), the BACCO (Angulo et al. 2021) neural network emulator and using our formulae, where we considered both a PYTHON3 and FORTRAN90 implementation, demonstrating the ease at which one can change programming language when using symbolic emulators. We found that CAMB takes an average of 0.18 s to evaluate P(k), which is significantly slower than the BACCO emulator, which requires just 6.9 ms. However, our approach is even faster, requiring just 850 μs when written in PYTHON3 and 190 μs in FORTRAN90. This is approximately 950 times faster than CAMB and 36 times faster than BACCO.
If the reader wishes to use a more accurate, yet less interpretable, emulator, we provide the most accurate equation found in Appendix A, which has a model length of 142, with 73 parameters and yields a root mean of squared fractional errors on P(k) of 0.1% for both the training and validation sets.
6. Discussion and conclusion
In this paper we have found analytic approximations to σ8 Eq. (4) and the linear matter power spectrum Eq. (6) as a function of cosmological parameters which are accurate to sub-percent levels. In the case of σ8, the simple yet accurate expression we have identified can be easily inverted to obtain As as a function of σ8 and the other cosmological parameters. Our approximation to P(k) is built by fitting the residuals between the output of a Boltzmann solved (CAMB) and the physics-inspired approximation of Eisenstein & Hu (1998). As such, unlike neural network or Gaussian process based approaches, our expression explicitly captures many physical processes (and is thus interpretable) whilst still achieving sub-percent accuracy.
This work is the first step in a programme of work dedicated to obtaining analytic approximations to P(k) which can be used in current and future cosmological analyses. In this paper we have focused on the linear P(k), i.e., the power spectrum of the linearly evolved density fluctuations. Although this approach is valid on large scales, the real Universe is non-linear, such that non-linear corrections are required at k ≳ 10−1 h Mpc−1 to accurately model the observed matter power spectrum across a wider range of scales. In Bartlett et al. (2024) we extend our framework to capture such non-linear physics and to include redshift dependence in our emulator. Finally, in our emulator we have considered a ΛCDM Universe with massless neutrinos. In the future we will add corrections to the expressions found in this work to incorporate the effects of massive neutrinos and include beyond ΛCDM effects, such as a w0 − wa parametrisation of dark energy.
We have demonstrated that, despite the temptation to blindly apply black-box methods such as neural networks to approximate physically useful functions, even in ostensibly challenging situations such as the matter power spectrum, one can achieve the required precision with relatively simple analytic fits. Given the unknown lifetime of current codes upon which numerical ML approximations are built and the ease of copying a few mathematical functions into your favourite programming language, finding analytic expressions allows one to more easily future-proof such emulators and should therefore be encouraged wherever possible.
Acknowledgments
We thank Bartolomeo Fiorini for useful comments and suggestions. DJB is supported by the Simons Collaboration on “Learning the Universe”. LK was supported by a Balzan Fellowship. HD is supported by a Royal Society University Research Fellowship (grant no. 211046). PGF acknowledges support from STFC and the Beecroft Trust. BDW acknowledges support from the Simons Foundation. DA acknowledges support from the Beecroft Trust, and from the Science and Technology Facilities Council through an Ernest Rutherford Fellowship, grant reference ST/P004474/1. MZ is supported by STFC. We made extensive use of computational resources at the University of Oxford Department of Physics, funded by the John Fell Oxford University Press Research Fund, and at the Institut d’Astrophysique de Paris. For the purposes of open access, the authors have applied a Creative Commons Attribution (CC BY) licence to any Author Accepted Manuscript version arising. The data underlying this article will be shared on reasonable request to the corresponding author. We provide PYTHON3 and FORTRAN90 implementations of Eqs. (4) to (6) and (A.1) at https://github.com/DeaglanBartlett/symbolic_pofk.
References
- Aizpuru, A., Arjona, R., & Nesseris, S. 2021, Phys. Rev. D, 104, 043521 [CrossRef] [Google Scholar]
- Alestas, G., Kazantzidis, L., & Nesseris, S. 2022, Phys. Rev. D, 106, 103519 [NASA ADS] [CrossRef] [Google Scholar]
- Angulo, R. E., Zennaro, M., Contreras, S., et al. 2021, MNRAS, 507, 5869 [NASA ADS] [CrossRef] [Google Scholar]
- Aricò, G., Angulo, R. E., & Zennaro, M. 2022, Open Res Europe, 1:152 [Google Scholar]
- Arnaldo, I., Krawiec, K., & O’Reilly, U. M. 2014, Proceedings of the 2014 Annual Conference on Genetic and Evolutionary Computation, GECCO ’14 (New York: Association for Computing Machinery), 879 [CrossRef] [Google Scholar]
- Bardeen, J. M., Bond, J. R., Kaiser, N., & Szalay, A. S. 1986, ApJ, 304, 15 [Google Scholar]
- Bartlett, D. J., Desmond, H., & Ferreira, P. G. 2023a, IEEE Transactions on Evolutionary Computation, 1 [Google Scholar]
- Bartlett, D. J., Desmond, H., & Ferreira, P. G. 2023b, The Genetic and Evolutionary Computation Conference 2023 [Google Scholar]
- Bartlett, D. J., Wandelt, B. D., Zennaro, M., Ferreira, P. G., & Desmond, H. 2024, A&A, 686, A150 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Biggio, L., Bendinelli, T., Neitz, A., Lucchi, A., & Parascandolo, G. 2021, in Proceedings of the 38th International Conference on Machine Learning, eds. M. Meila, & T. Zhang, Proc. Mach. Learn. Res., 139, 936 [Google Scholar]
- Blas, D., Lesgourgues, J., & Tram, T. 2011, J. Cosmol. Astropart. Phys., 2011, 034 [CrossRef] [Google Scholar]
- Burlacu, B. 2023, Proceedings of the Companion Conference on Genetic and Evolutionary Computation, GECCO ’23 Companion (New York: Association for Computing Machinery), 2412 [CrossRef] [Google Scholar]
- Burlacu, B., Kronberger, G., & Kommenda, M. 2020, Proceedings of the 2020 Genetic and Evolutionary Computation Conference Companion, GECCO ’20 (New York: Association for Computing Machinery), 1562 [CrossRef] [Google Scholar]
- Cava, W. G. L., Orzechowski, P., Burlacu, B., et al. 2021, arXiv e-prints [arXiv:2107.14351] [Google Scholar]
- Cranmer, M. 2020, https://doi.org/10.5281/zenodo.4041459 [Google Scholar]
- Cranmer, M. 2023, arXiv e-prints [arXiv:2305.01582] [Google Scholar]
- Cranmer, M., Sanchez Gonzalez, A., Battaglia, P., et al. 2020, arXiv e-prints [arXiv:2006.11287] [Google Scholar]
- David, E. 1989, Genetic Algorithms in Search, Optimization and Machine Learning (Addison-Wesley) [Google Scholar]
- de Franca, F. O., & Aldeia, G. S. I. 2021, Evolu. Comput., 29, 367 [CrossRef] [Google Scholar]
- de Franca, F. O., & Kronberger, G. 2023, in Proceedings of the Genetic and Evolutionary Computation Conference, GECCO ’23 (New York: Association for Computing Machinery), 1064 [CrossRef] [Google Scholar]
- Delgado, A. M., Wadekar, D., Hadzhiyska, B., et al. 2022, MNRAS, 515, 2733 [NASA ADS] [CrossRef] [Google Scholar]
- Desmond, H., Bartlett, D. J., & Ferreira, P. G. 2023, MNRAS, 521, 1817 [NASA ADS] [CrossRef] [Google Scholar]
- Diemer, B. 2018, ApJS, 239, 35 [NASA ADS] [CrossRef] [Google Scholar]
- Eisenstein, D. J., & Hu, W. 1998, ApJ, 496, 605 [Google Scholar]
- Eisenstein, D. J., & Hu, W. 1999, ApJ, 511, 5 [Google Scholar]
- Euclid Collaboration (Knabenhans, M., et al.) 2021, MNRAS, 505, 2840 [NASA ADS] [CrossRef] [Google Scholar]
- Fendt, W. A., & Wandelt, B. D. 2007a, ApJ, submitted [arXiv:0712.0194] [Google Scholar]
- Fendt, W. A., & Wandelt, B. D. 2007b, ApJ, 654, 2 [NASA ADS] [CrossRef] [Google Scholar]
- Hahn, O., List, F., & Porqueres, N. 2023, JCAP, submitted [arXiv:2311.03291] [Google Scholar]
- Haupt, R., & Haupt, S. 2004, Practical Genetic Algorithms, 2nd edn. (Wyley) [Google Scholar]
- Heitmann, K., Lawrence, E., Kwan, J., Habib, S., & Higdon, D. 2014, ApJ, 780, 111 [Google Scholar]
- Jin, Y., Fu, W., Kang, J., & Guo, J. 2019, arXiv e-prints [arXiv:1910.08892] [Google Scholar]
- Kamerkar, A., Nesseris, S., & Pinol, L. 2023, Phys. Rev. D, 108, 043509 [NASA ADS] [CrossRef] [Google Scholar]
- Kammerer, L., Kronberger, G., Burlacu, B., et al. 2021, arXiv e-prints [arXiv:2109.13895] [Google Scholar]
- Koksbang, S. M. 2023a, Phys. Rev. D, 107, 103522 [CrossRef] [Google Scholar]
- Koksbang, S. M. 2023b, Phys. Rev. D, 108, 043539 [NASA ADS] [CrossRef] [Google Scholar]
- Koksbang, S. M. 2023c, Phys. Rev. Lett., 130, 201003 [NASA ADS] [CrossRef] [Google Scholar]
- Kommenda, M., Burlacu, B., Kronberger, G., & Affenzeller, M. 2020, Genet. Program. Evol. Mach., 21, 471 [CrossRef] [Google Scholar]
- La Cava, W., Helmuth, T., Spector, L., & Moore, J. H. 2019, Evolu. Comput., 27, 377 [CrossRef] [Google Scholar]
- Landajuela, M., Lee, C. S., Yang, J., et al. 2022, A Unified Framework for Deep Symbolic Regression, 36th Conference on Neural Information Processing Systems [Google Scholar]
- Laumanns, M., Thiele, L., Deb, K., & Zitzler, E. 2002, Evol. Comput., 10, 263 [CrossRef] [Google Scholar]
- Lemos, P., Jeffrey, N., Cranmer, M., Ho, S., & Battaglia, P. 2023, Mach. Learn. Sci. Technol., 4, 045002 [CrossRef] [Google Scholar]
- Levenberg, K. 1944, Quart. Appl. Math., 2, 164 [Google Scholar]
- Lewis, A., Challinor, A., & Lasenby, A. 2000, ApJ, 538, 473 [Google Scholar]
- Lodha, K., Pinol, L., Nesseris, S., et al. 2024, MNRAS, 530, 1424 [NASA ADS] [CrossRef] [Google Scholar]
- Marquardt, D. W. 1963, J. Soc. Indust. Appl. Math., 11, 431 [CrossRef] [Google Scholar]
- McConaghy, T. 2011, in FFX: Fast, Scalable, Deterministic Symbolic Regression Technology, eds. R. Riolo, E. Vladislavleva, & J. H. Moore (New York: Springer), 235 [Google Scholar]
- Miniati, F., & Gregori, G. 2022, Sci. Rep., 12, 11709 [NASA ADS] [CrossRef] [Google Scholar]
- Mootoovaloo, A., Jaffe, A. H., Heavens, A. F., & Leclercq, F. 2022, Astron. Comput., 38, 100508 [NASA ADS] [CrossRef] [Google Scholar]
- Orjuela-Quintana, J. B., Nesseris, S., & Cardona, W. 2023, Phys. Rev. D, 107, 083520 [CrossRef] [Google Scholar]
- Orjuela-Quintana, J. B., Nesseris, S., & Sapone, D. 2024, Phys. Rev. D, 109, 063511 [NASA ADS] [CrossRef] [Google Scholar]
- Petersen, B. K., Larma, M. L., Mundhenk, T. N., et al. 2021, International Conference on Learning Representations [Google Scholar]
- Planck Collaboration VI. 2020, A&A, 641, A6 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- René Broløs, K., Vieira Machado, M., Cave, C., et al. 2021, arXiv e-prints [arXiv:2104.05417] [Google Scholar]
- Rivero, D., Fernandez-Blanco, E., & Pazos, A. 2022, Exp. Syst. Appl., 198, 116712 [CrossRef] [Google Scholar]
- Schmidt, M., & Lipson, H. 2009, Science, 324, 81 [CrossRef] [Google Scholar]
- Schmidt, M., & Lipson, H. 2011, in Age-Fitness Pareto Optimization (New York: Springer), eds. R. Riolo, T. McConaghy, & E. Vladislavleva, 129 [Google Scholar]
- Smith, R. E., Peacock, J. A., Jenkins, A., et al. 2003, MNRAS, 341, 1311 [Google Scholar]
- Sousa, T., Bartlett, D. J., Desmond, H., & Ferreira, P. G. 2024, Phys. Rev. D, 109, 083524 [NASA ADS] [CrossRef] [Google Scholar]
- Spurio Mancini, A., Piras, D., Alsing, J., Joachimi, B., & Hobson, M. P. 2022, MNRAS, 511, 1771 [NASA ADS] [CrossRef] [Google Scholar]
- Tenachi, W., Ibata, R., & Diakogiannis, F. I. 2023, ApJ, 959, 99 [NASA ADS] [CrossRef] [Google Scholar]
- Turing, A. M. 1950, Mind, LIX, 433 [CrossRef] [Google Scholar]
- Udrescu, S. M., & Tegmark, M. 2020, Sci. Adv., 6, eaay2631 [NASA ADS] [CrossRef] [Google Scholar]
- Udrescu, S. M., Tan, A., Feng, J., et al. 2020, AI Feynman 2.0: Pareto-optimal Symbolic Regression Exploiting Graph Modularity, 34th Conference on Neural Information Processing Systems [Google Scholar]
- Virgolin, M., Alderliesten, T., Witteveen, C., & Bosman, P. A. N. 2021, Evolu. Comput., 29, 211 [CrossRef] [Google Scholar]
- Wadekar, D., Thiele, L., Hill, J. C., et al. 2023, MNRAS, 522, 2628 [NASA ADS] [CrossRef] [Google Scholar]
- Winther, H. A., Casas, S., Baldi, M., et al. 2019, Phys. Rev. D, 100, 123540 [CrossRef] [Google Scholar]
- Worm, T., & Chiu, K. 2013, Proceedings of the 15th Annual Conference on Genetic and Evolutionary Computation, GECCO ’13 (New York: Association for Computing Machinery), 1021 [CrossRef] [Google Scholar]
- Zennaro, M., Angulo, R. E., Pellejero-Ibáñez, M., et al. 2023, MNRAS, 524, 2407 [Google Scholar]
Appendix A: Most accurate analytic expression found for linear power spectrum
The expression we report for an analytic approximation for the linear matter power spectrum Eq. (6) is not the most accurate one found, but the one which we deemed to appropriately balance accuracy, simplicity, and interpretability. It may be desirable to have a more accurate symbolic expression if interpretability is not a concern. In this case one may wish to use the most accurate equation found, which is
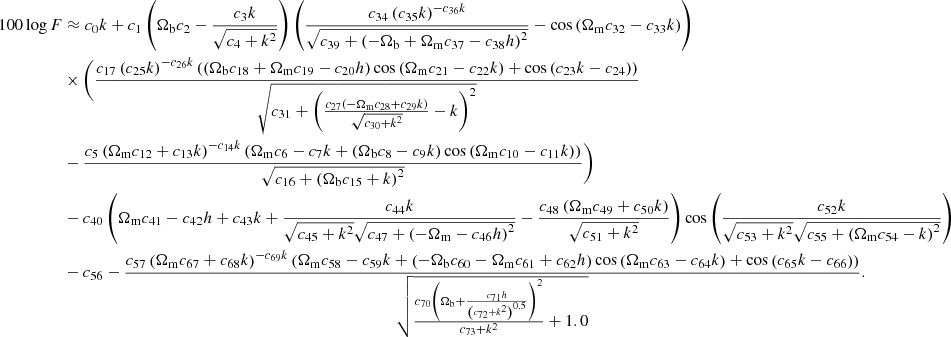 (A.1)
(A.1)
This equation has 73 parameters, which is approximately twice as many as Eq. (6), yet one only gains a factor of two in the fractional root mean squared error. The best-fit parameter values are reported in Table A.1. We note that this function is the direct output of OPERON and is thus over-parameterised so that some simplification could be applied. For example, one only needs two of c1, c2 and c3 as these only appear as c1c2 and c1c3. Since we only provide this expression as a precise emulator and do not attempt to interpret its terms, we choose not to apply any simplifications (although see de Franca & Kronberger (2023) for an automated method to do this).
Best-fit parameters for the most accurate linear matter power spectrum emulator found, reported in Appendix A.
All Tables
Best-fit parameters for the most accurate linear matter power spectrum emulator found, reported in Appendix A.
All Figures
|
Fig. 1. Pareto front of solutions obtained using OPERON when fitting |
| In the text | |
|
Fig. 2. Linear matter power spectrum (upper), the residuals Eq. (5) from the Eisenstein & Hu fit without baryons (middle), and the fractional residuals on P(k) compared to the truth for the Planck 2018 (Planck Collaboration VI 2020) cosmology. In all panels we plot the truth computed with CAMB with solid red lines, and the analytic fit Eq. (6) obtained in this paper with dashed blue lines. We see that the fit is accurate within 0.3% across all k considered. |
| In the text | |
|
Fig. 3. Pareto front of solutions obtained using OPERON when fitting the linear matter power spectrum as a function of σ8, Ωb, Ωm, h and ns. We plot the root mean squared error on log F as a function of model length for the training and validation sets separately. The model given in Eq. (6) has a model length of 77, as indicated by the dotted line. |
| In the text | |
|
Fig. 4. Distribution of fractional errors as a function of k on the linear matter power spectrum across all cosmologies in the training and validation sets, as compared to the predictions of CAMB. The bands give the 1 and 2σ values. The dotted line corresponds to a 1% error, and we see that our expression achieves this for all cosmologies and values of k considered, with a root mean squared fractional error of 0.2%. |
| In the text | |
|
Fig. 5. Contributions to log F from our emulator as a function of k for the Planck 2018 cosmology. The line numbers indicated in the legend correspond to the line in Eq. (6). One sees that the first term provides an overall offset, the second and fourth capture the BAO signal, and the third term contains a broad oscillation and then matches on to the decaying residual at high k. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.