| Issue |
A&A
Volume 673, May 2023
|
|
|---|---|---|
| Article Number | A141 | |
| Number of page(s) | 10 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202244657 | |
| Published online | 23 May 2023 | |
Astronomical image time series classification using CONVolutional attENTION (ConvEntion)
1
Laboratory of Computer Science, Robotics and Microelectronics of Montpellier, University of Montpellier,
161 rue Ada,
34095
Montpellier,
France
e-mail: anass.bairouk@lirmm.fr
2
Aix Marseille Univ, CNRS/IN2P3, Centre of Particle Physics of Marseilles,
163 avenue de Luminy, Case 902,
13009
Marseille,
France
3
University of Nimes,
5 rue du Docteur Georges Salan, CS 13019,
30021
Nîmes,
France
4
Groupe AMIS, Paul Valéry University Montpellier
3, Rte de Mende,
34090
Montpellier,
France
5
Land, Environment, Remote Sensing and Spatial Information – UMR TETIS, INRAE/CIRAD/CNRS,
500 rue Jean François Breton,
34000
Montpellier,
France
Received:
2
August
2022
Accepted:
13
March
2023
Aims. The treatment of astronomical image time series has won increasing attention in recent years. Indeed, numerous surveys following up on transient objects are in progress or under construction, such as the Vera C. Rubin Observatory Legacy Survey for Space and Time (LSST), which is poised to produce huge amounts of these time series. The associated scientific topics are extensive, ranging from the study of objects in our galaxy to the observation of the most distant supernovae for measuring the expansion of the universe. With such a large amount of data available, the need for robust automatic tools to detect and classify celestial objects is growing steadily.
Methods. This study is based on the assumption that astronomical images contain more information than light curves. In this paper, we propose a novel approach based on deep learning for classifying different types of space objects directly using images. We named our approach ConvEntion, which stands for CONVolutional attENTION. It is based on convolutions and transformers, which are new approaches for the treatment of astronomical image time series. Our solution integrates spatio-temporal features and can be applied to various types of image datasets with any number of bands.
Results. In this work, we solved various problems the datasets tend to suffer from and we present new results for classifications using astronomical image time series with an increase in accuracy of 13%, compared to state-of-the-art approaches that use image time series, and a 12% increase, compared to approaches that use light curves.
Key words: techniques: image processing / supernovae: general / surveys
© The Authors 2023
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. Subscribe to A&A to support open access publication.
1 Introduction
The astronomical community has been facing a considerable challenge in the last few years as tools for observing the universe continue to improve. Telescopes are becoming more powerful, with the capacity to observe a huge part of the universe and generate a massive amount of data. Processing and analyzing these data are very demanding steps in terms of their computational and human resource requirements. With the promises of The Vera C. Rubin Observatory Legacy Survey for Space and Time (LSST; Ivezić et al. 2019), the field will see the discovery of 10 to 100 times more astronomical sources that fluctuate in the night sky. Some of these sources will be entirely new. LSST is prepared to alert the community to 10 million new objects per night, and these objects all need to be classified. There are many types of objects, including active galactic nuclei (AGNs), variables, cepheids, RR Lyrae, and supernovae. The latter stands the most important transient object for cosmology because increasingly large samples of Type Ia supernovae (SNe Ia) are being used to measure luminosity distances as a function of redshift in order to understand the origin of the acceleration of the expansion of the universe.
Traditionally, the classification of these objects goes through many processes in a complex pipeline. First, the preprocessing phase known as photometry is conducted on a series of images to extract the flux per band, each band corresponding to a passband-like color filter. The number of bands can vary, depending on the survey, for example SDSS survey (Holtzman et al. 2008; Sako et al. 2014; Frieman et al. 2007) has five bands and the Catalina survey (Drake et al. 2011) has only one band. Then, a time series of brightness changes is generated over time, called the light curves. Afterwards, the light curve is fed to a machine-learning classifier to determine the class of the object. Among all the methods developed to perform such a classification, Möller & de Boissière (2020) introduced a model called SuperNNova: a supernova photometric classification framework that uses a recurrent neural network (RNN; Rumelhart et al. 1985; Hochreiter & Schmidhuber 1997; Cho et al. 2014) to classify different types of supernovas such as SNIa, SNIb, SNIIP, and others using only light curves. The proposition yields good results because while Bayesian neural networks (BNN) are known to be robust to overfitting and can easily learn from small datasets, they are still significantly more complex than standard neural networks and computationally expensive. Boone (2019) (winner of the photometric classification challenge PLAs-TiCC (PLAsTiCC-team et al. 2018; Hložek et al. 2020)) presented a model based on Gaussian process augmentation of the light curve and then train it on boosted decision tree classifier. Pasquet et al. (2019) created a deep architecture called PELICAN that accepts only light curves and redshifts as input. PELICAN can handle light curves with sparsity and irregular sampling. Some can choose to add more preprocessing before training a model. For instance, Qu et al. (2021) proposed a novel approach where they generated a 2D image heatmap from light curves using 2D Gaussian process regression, which they fed to convolutional neural networks to classify different types of supernovae. The approach yields great results on PLAsTiCC data, with an accuracy of 99.73% on the binary classification of SNIa and non-SNIa. The methods that use light curves for classification still have some limitations. In order to generate a light curve, we should correctly align the two consecutive images and we must lower the quality of one of the two images to subtract them to get the flux, which could lead to a loss of information. Some dedicated algorithms called scene modeling can mitigate such issues on blended objects but are very demanding in terms of computer resources. Most importantly, the scene information, namely, the background of the transient object, is in general not taken into account in the classification. Several recent works have proposed to eliminate the feature extraction and light curve phase and focus on classifying the objects using only images. Carrasco-Davis et al. (2019) and Gómez et al. (2020) used a RNN to classify the sequences after passing the images through a CNN to extract the spatial features. They forwarded the output to the RNN (GRU/LSTM) to extract the temporal characteristics and classify the object, while (Gómez et al. 2020) applied their model to only transient objects and Carrasco-Davis et al. (2019) classified variables and transient. These two papers showed promising results for the astronomical image time series (AITS). Therefore, we followed the same path to improve the classification and also solve some challenges posed by AITS, which have not been tackled before.
In particular, image time series (ITS) classification has always been one of the challenging areas of deep learning. In addition to spatial characteristics, you also need to give importance to the temporal aspects, which makes traditional feedforward networks ineffective. Due to the lack of research carried out on ITS in astronomy, we need to import new technics from other fields of research. Most of the research in ITS classification is done in two major domains: action recognition, where the goal is to classify the type of human action (Shi et al. 2015; Ji et al. 2013), and landscape classification using satellite images (Ozgur Turkoglu et al. 2021). These two fields have covered many of the essential methods to handle ITS. Then, RNN-based approaches use recurrent neural networks to manage the aspect of time in the classification. These approaches are split into two main categories. The first one handles the spatial features separately from the temporal features. Carrasco-Davis et al. (2019) and Gómez et al. (2020) used precisely this method at the point when the CNN handles the spatial characteristics to pass it later to the RNN, which might be LSTM (Hochreiter & Schmidhuber 1997) or GRU (Cho et al. 2014). The second category combines convolution inside the RNN cell, thus maintaining the spatial structure of the input, which leads to extracting spatial-temporal features in the sequence. This method was first introduced by Shi et al. (2015). These authors demonstrated how to create an end-to-end trainable model using the convolutional LSTM (ConvLSTM). Experiments indicate that their ConvLSTM network regularly exceeds fully connected LSTM (FC-LSTM) in capturing Spatiotemporal correlations. Using satellite images, Ozgur Turkoglu et al. (2021) proposed a new type of RNN called ConvSTAR, which has fewer parameters than the LSTM and GRU. Another way of achieving the classification of ITS is by using convolution neural networks. Ji et al. (2013) created a new 3D CNN model for action recognition. This model pulls features from spatial and temporal dimensions, collecting motion information contained in several consecutive frames. Meanwhile, some of the latest developments have abandoned convolutions and RNNs to replace them with only transformers. Liu et al. (2022) and Yan et al. (2022) proposed an improved supervised transformer for image classification. On the other hand, Zhou et al. (2022) and Bao et al. (2021) proposed more complex transformers that are self-supervised.
In this work, we develop a new deep learning transformer-based architecture to classify AITS. Unlike other works that separate spatial and temporal feature extraction, we combine these two steps by performing a spatio-temporal feature extraction in one step. It improves the capacity of the network to recognize the objects. We also propose a solution for the missing observations problem, which demonstrates a significant improvement in the accuracy of the model. To illustrate the performances of our model, we tested it with actual data from the SDSS survey (Holtzman et al. 2008; Sako et al. 2014; Frieman et al. 2007). In Sect. 2, we describe the dataset that we used in our work. Section 3 introduces our architecture ConvEntion and describes the role of each component of the model. In Sect. 4, we present the results of our work with some statistics about the performance and some comparisons with other architectures used for image time series classification. Finally, in Sect. 5, we present our conclusions and perspectives on this work.
2 Dataset
2.1 Database description
The Sloan Digital Sky Survey (SDSS; Holtzman et al. 2008; Frieman et al. 2007) is a very ambitious and successful large-scale survey program using a dedicated 2.5-m telescope at Apache Point Observatory, New Mexico, equipped with photometric and spectroscopic instruments that have released images, spectra, and catalog information for several hundred million celestial objects. The dataset used in this paper was collected during the SDSS Supernova Survey (Sako et al. 2014), one of three components (along with the Legacy and SEGUE surveys) of SDSS-II, a three-year extension of the original SDSS that operated from July 2005 to July 2008. The Supernova Survey is a time-domain survey, involving repeat imaging of the same region of the sky every other night, weather permitting.
The images are obtained through five wide-band filters (Fukugita et al. 1996) named u′, g′, r′, i′, and z′, simplified as u, g, r, i, and z in the following, which corresponds to an effective mid-point wavelength of u (365 nm), g (475 nm), r (658 nm), i (806 nm), and z (900 nm). The survey region observed repeatedly over three years is a 2.5-degree-wide stripe centered on the celestial equator in the Southern Galactic Cap that has been imaged numerous times in the last twenty years, allowing for the construction of a big image database for the discovery of new celestial objects. Most of the sources have included galactic variable stars, active galactic nuclei (AGN), supernovae (SNe), and other astronomical transients, all of which have been processed to generate multi-band (ugriz) light curves. The imaging survey is reinforced by an extensive spectroscopic follow-up program that uses spectroscopic diagnostics to identify SNe and measure their redshifts. Light curves were evaluated during the survey to provide an initial photometric type of the SNe and a selected sample of sources was targeted for spectroscopic observations.
In order to investigate the classification from images rather than light curves, we acquired the images from the public SDSS dataset through their platform. Our dataset contains many types of supernovas (see Table 1 and Sako et al. 2014). The label of “unknown” mainly represents very sparse or poorly measured transient candidates, “variables” have signals spanning over two seasons, and “AGNs” have a spectral signature. The three other classes are supernovae of types Ia, Ib/c, and II. Among supernovae, the typing is performed from spectroscopy or from the light curve using different machine learning techniques (see Sako et al. 2014). We grouped the non-Ia supernovas because our focus in this study only on the Ia type for their interest in cosmology as standard candles and also because of the small number of non-Ia with spectral signatures. The very small class of three SLSN bright objects has been added to the non-Ia super-novae. Figure 1 shows an example of astronomical image time taken from the SDSS dataset.
 |
Fig. 1 Sample of some objects present in our dataset. Each image in filter g/i corresponds to a different observation with the same filter. |
2.2 Challenges
Most of the astronomical dataset suffers from a number of problems that should be dealt with before feeding it to the classification algorithm. Among difficulties contributing to the challenging nature of AITS, we can mention class imbalance (as shown in Table 1 of our dataset). In particular, we can clearly see that the classes we have are not balanced where the number of samples for variables is much bigger than SNIa. This imbalance significantly impacts machine learning models due to their higher prior probability, which means they tend to over-classify the larger class(es). As a result, instances belonging to the smaller class(es) are more likely to be misclassified than those belonging to the larger class(es). Another problem that impacts the model is missing bands. Indeed, each time an image is acquired in an AITS it is captured through one filter among a set of up to five or more channels. So, an image of a celestial object can be taken in many channels, but not necessarily at the same time. This results in missing bands for a given time of observation (see Fig. 2). It is well known that the missing data negatively impacts the performance of the model if it is not dealt with. Gill et al. (2007) stated that an increasingly missing percentage of training data resulted in an increased testing error, which requires a solution to mitigate the impact of missing data.
Number of objects per class in the SDSS dataset.
 |
Fig. 2 Each image has five filters (u, g, r, i, z), The black channel represents the missing observation. |
3 Methods
In this section, we propose a neural network based on a combination of convolution and self-attentions. The goal of the model is to handle the challenges that we mentioned previously, such as class imbalance, data sparsity, and missing observations. Figure 3 represents the general architecture of the ConvEntion model. The model takes as its input the sequence of images that have been rearranged to embed the band information (See Sect. 3.1 and Fig. 4). The sequence first passes through a 3DCNN to downsize its length. It allows for the reduction of the computation complexity of the model and also captures the local characteristics of the objects. The newly constructed sequence by the 3DCNN is fed to a convolutional BERT which then extracts the spatio-temporal features with high-level representation from the input. Finally, we pass the output of the convolutional BERT, which is a projection of our input into a high-level representation subspace, through a 3D max-pooling to downsample it, then it goes on to the final classifier to make the prediction. In the following subsections, we explain each component in depth.
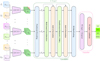 |
Fig. 3 General architecture of the ConvEntion network. The image time series are first rearranged to embed the band information. Then each 3DCNN is fed with a sub-sequence of K inputs of the time series J(∊ ℝM×H×W×2 for M elements of images of size HxW) to create the new downsized sequence S (∊ ℝN×H′×W′×D). S is fed to the positional encoder in order to add the information about the position, which outputs F(∊ ℝN×H′×W′×D). Then F is passed to ConvBERT which has L layers. The 3D max-pooling is used to downsize the output of ConvBERT for the classifier. |
3.1 Data modeling
First, we note that throughout the paper, vectors are given in bold capital letters, sizes in capital letters, and indices in lowercase. To start with the missing data problem, a network dedicated to image time series is usually fed a sequence of images I ∊ ℝH×W×5, where H and W are, respectively, the height and width of the image and 5 is the number of channels representing the bands (u, g, r, i, z). However, we know, as explained earlier, some bands are missing in the dataset. To fix this issue, instead of giving the model images with empty channels, thus introducing a bias to the network, we decided to separate the channels as individual images (X ∊ ℝH×W) simply by skipping the empty channels. As a consequence, the information about the type of filter, which holds a crucial value for the network to accurately discriminate between objects, is also eliminated. In an image with different channels, the order of the channels usually represents the type of filter (see Fig. 2).
In order to preserve this valuable information, we should add the band type to the new 2D images X. Knowing that the information about the type of the filter is a categorical feature, thus we need to adapt it to the model 2D input representation. To do so, we propose using an embedding layer to encode the channel type before passing the input to the model. For each band (u, g, r, i, z), we assign a unique number id ∊ {1, 2, 3, 4, 5}. Then, an embedding layer BandEmbed converts the band type id, which is a categorical feature, into 2D dense representation Eid with Eid ∊ ℝH×W (see Fig. 4):
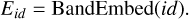 (1)
(1)
The embedding layer is a fully connected layer that is reshaped to a 2D representation. The weights of BandEmbed are learnable. After getting the band embedding, we concatenate it with the new image to get our new input J ∊ ℝM×H×W×2 that contains the band information, where M is the length of the sequence:
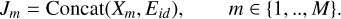 (2)
(2)
The problem of class imbalance is one of the major challenges for any machine learning project. Some tried to solve this problem by adding a new loss function to mitigate the impact of the class imbalance. For example Lin et al. (2017) proposed a loss function called “focal loss” which applies a modulating term to the cross-entropy loss in order to focus the learning on hard mis-classified examples. However, this approach tends to produce a vanishing gradient during backpropagation (Hossain et al. 2021). Other solutions propose the use of oversampling such as SMOTE (Chawla et al. 2002). Those authors proposed an approach where they synthesize new samples of the minority class. However, this solution was proposed mainly for tabular data. Knowing that our data are images that contain a much higher number of features than tabular data, it appears obvious that using SMOTE may not be optimal in our case. Dablain et al. (2021) introduced a solution based on SMOTE dedicated to images called DeepSMOTE. It is aimedat generating new images for the minority class. Once again, this approach is unsuitable in our case as our dataset is not composed of images, but of a sequence of images, and it is too expensive to generate a whole new sequence. So, instead of generating a new one, we used data augmentation and weighted random sampling (WRS; Efraimidis 2010) on our database. We oversampled the dataset, which translates to simply altering the dataeet to remove such an imbalance by increasing the number of minority classes and undersampling the data by decreasing themajority classes until we have reached a balanced dataset. In our case, the WRS was applied nn a batch level. We generate balanced batches based on the probability of a sample being selected. We weighted each samp le according to the inverse frequency of its label's occurrence and then sampled mini-batches from a multinomial distribution based on these weights. This means that samples with high weights are sampled more often for each mini-batch. The same sample can be reused in other mini-batcOes of the same epoch to increase the minority class, but with a daia augmentation applied to it. Different methods of data augmentation were used: for example a random drop of some steps from the whole sequence to create a new one or a sequence rotation, horizontal and vertical flips, and sequence shifting, where we construct a smaller sequence from the original one which has a bigger length than the input length of ConvEntion. In our implementation, we recall the dataset at every epoch, the transforms operºtion (augmentation) is executed and then we get different augmented data. Using this oversampling approach has drastically improved the performance of the model. We used the function Weighted Random Sampler from PyTorch (Paszke et al. 2019) as an implementation of WRS.
 |
Fig. 4 Illustration of the handling of missing information by separating the bands. The empty channels are dropped, then we concatenate each image with a 2D representation of the band used to capture the image. The band embedding contains five band representations. The black channel represents the missing observation. |
3.2 3D convolution network
In several deep learning applications, large transformer models have demonstrated fantastic success in obtaining state-of-the-art results. However, because the original transformer’s self-attention mechanism consumes O(M2) time and space with respect to the sequence length, M, training the model for a long sequence is so expensive, it causes the problem called “attention bottleneck” (Wang et al. 2020; Choromanski et al. 2021). The problem is more severe for us because we use con-volutions and 3D tensors inside the attention mechanism; for instance, the attention map is of a size H × W, so the complexity of the attention will be O(M2 × H × W). Thus, our model would then be prohibitively expensive to train. In the last few years, there have been numerous proposals aimed at solving this issue. Wang et al. (2020) demonstrated that a low-rank matrix could approximate the sele-attention mechanism. They suggested a new self-attention method that minimizes total self-attention complexity. Choromanski et al. (2021) presented a novel transformer architecture that uses linear space and time complexity to estimate regular (softmax) full-rank-attention Transformers with proven accuracy. However, all these propositions remain irrelevant in our case because we do not use the standard self-attention mechanism, as the (convolutions make it an arduous task. So, the soiution we preferred to go with is to reduce the length of the sequence before feeding it to the transformer block. Reducing the sequence must be done without losing relevant information. Thus, we propose using a 3D convolution neural network (3D CNN). A 3D CNN is an improved type version of CNN first proposed by Tran et al. (2014), where it applies a 3D filter to the dataset and the filter moves in three directions to calculate the low-level feature representations. Their output shape is in a 3D volume space. We applied 3DCNN where we input the sequence J to get the reduced new sequence S following the equation:
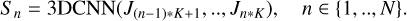 (3)
(3)
We let M be the length of the series, J and we fed K inputs of J to the 3DCNN to generate one entry, S, for our transformer. So, in the end, the new sequence, S, will be S ∊ ℝN×H′×W′×D, where N = M/K, D is the number of channels and H′ and W′ are the new height and width. By using the 3DCNN, we reduced the length of the sequence by a factor of K, which also reduced the complexity of the model. The 3DCNN does not just reduce the length of the input sequence, it also captures local spatio-temporal low-level features. The 3DCNN captures these particulate features due to its focus on the local characteristics (space and time) of the sequence, while the transformer focuses on the global characteristics. On the whole, we have reduced the computation without losing essential information that is important for classification. Table 2 summarizes the architecture used inside the 3DCNN.
3D CNN architecture where Conv3D is a 3D convolutional element and BN3d is a 3D batch normalization element.
3.3 Convolutional BERT
After getting the new output S of the 3DCNN, it is time to feed it to what we call convolutional BERT which stands for Convolutional Bidirectional Encoder Representations from Transformers. Transformer and self-attention have become one of the main models that revolutionize deep learning in the last few years, especially in neural language processing (NLP). Self-attention (Bahdanau et al. 2014), also known as intra-attention, is an attention mechanism that connects different positions in a single sequence to compute a representation of the sequence. Here, “attention” refers to the fact that in real life, when viewing a video or listening to a song, we frequently pay more attention to certain details while paying less attention to others, based on the importance of the details. Deep learning uses a similar flow for its attention mechanism, giving particular parts of the data more focus as it is processed. Our intention in using this mechanism is for the model to focus more on the changes happening in the image sequence to better discriminate between astronomical objects. Self-attention layers are the foundation of the transformer block design. Transformers were first introduced by Vaswani et al. (2017), using model-based attention dispensing with recurrence and convolutions entirely. Their work inspired others who used the concept of transformers to achieve even better results. For example, in BERT (Devlin et al. 2018) the authors used only the encoder block by stacking many of them. Even though transformers were widely used in NLP in the last two years, people started implementing these blocks in other domains like image classification. Dosovitskiy et al. (2020) presented a model free from convolutions by using only a transformer to classify images. Sainte Fare Garnot et al. (2019) also suggested that they are able to extract temporal characteristics using a custom neural architecture based on self-attention instead of recurrent networks. Their use was not limited to image classification; action recognition was also investigated as in Sharir et al. (2021), where the authors used a transformer-based approach inspired by the work of Dosovitskiy et al. (2020). Liu et al. (2021) did propose a new transformer where they added convolution to the attention mechanisms, making it able to apply convolutions while extracting the temporal features.
3.3.1 Positional encoding
Because transformers have no recurrence throughout the thumbnail sequence, some information about each thumbnail's relative or absolute position must be injected into the feature map obtained by the 3DCNN to inform the model about the order in the sequence. Similarly to the original transformer paper (Vaswani et al. 2017), we use positional encoding at each layer in the encoder to achieve this. The only difference is that our positional encoding is a 3D tensor, where P ∊ ℝN×H′×W′×D. Because the positional encoding and the new feature maps have the same dimension, they can be added together. We use sine and cosine functions to encode the position (Vaswani et al. 2017):
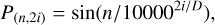 (4)
(4)
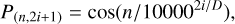 (5)
(5)
where n denotes the position in the sequence of length, N, and i is the channel dimension, while D represent the total number of channel gotten by the 3DCNN. The sinusoidal positional encoding is chosen to make it easy for the model to learn to attend to relative positions. To get the new input for the convolutional BERT, we conducted an element-wise addition between the positional encoding and the feature maps obtained from 3DCNN to obtain the new tensor F ∊ ℝN×H′×W′×D.
 (6)
(6)
In this study, we only used information about the position of the image in a sequence. While the observation date could be used as an alternative to the position, this would require adjusting the positional encoding function. Our experiments on the SDSS dataset did not reveal any improvement in the model when using the observation date, as opposed to just using the position. This can be understood because we do the training and the test with the same observation sequence and the network can therefore learn this sequence. On the other hand, not incorporating any information regarding the order of the sequence greatly degraded the performance of the model. As a result, we ultimately chose to use only the position in our model (see Sect. 4.2 for a discussion).
The newly obtained sequence F is fed to a multi-head con-volutional attention, which is an improved self-attention that has convolution. Then the multi-head convolutional attention is followed by the second component which is a tiny feed-forward network (FFN) that has convolutions applied to every attention map. Its primary purpose is to transform the attention map into a form acceptable by the next convolutional BERT layer, with the FFN consisting of two convolutional layers with ReLU activation in between.
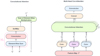 |
Fig. 5 Convolutional attention (left). Multi-head convolutional attention (right). To obtain the query, key, and value maps, we applied a convolution layer on the feature map obtained from 3DCNN. |
3.3.2 Multi-head convolutional self-attention
For this process, we used the model proposed by Liu et al. (2021), with a few modifications where we replaced the last linear layer with a convolution layer. We believe that convolution in self-attention is better than the dot product between the query and the key because the convolution will accurately calculate the similarity, especially when we have 3D feature maps. A query map and a set made up of a pair of key maps and value maps that are encoded to an output using convolutional self-attention. The query map, key maps, value maps, and output are all 3D tensors. Figure 5 represent the general architecture of the multi-head ConvAttention.
We used a convolution layer to generate the attention model’s query, value, and key. The input to the attention model is F ∊ ℝN×H′×W′×D. We pass each map through a convolution layer to get {Q, K, V} ∊ ℝN×H′×W′×D′, where D′ = D/T and T represent the number of attention heads. Then we appled a subnetwork, Μθ, on the query and the key maps, which consists of an element-wise sum of the query and the key maps followed by another convolution layer to generate our attention map H(n,m) ∊ ℝH′×W′×1:
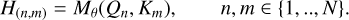 (7)
(7)
After getting all the map attentions, Hn = {H(n,1), H(n,2),…,H(n,N)}, where Hn ∊ ℝH′×W′×N, we applied a softmax operation along the third dimension of size, N. Then we conducted an element-wise product between the attention map and the value map following the equation:
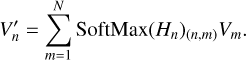 (8)
(8)
We concatenated the new value representation, 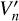 , obtained from the different attention heads. The multi-head attention is used to attend to input from various representation subspaces jointly:
, obtained from the different attention heads. The multi-head attention is used to attend to input from various representation subspaces jointly:
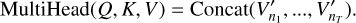 (9)
(9)
Finally, we applied a convolution layer for merging the output of the multi-head and obtaining a high-level representation that groups all the heads. At the end of the network, we pass the encoded sequence to 3D max-pooling and finally to the classifier to make a prediction.
3.4 Evaluation metrics
Accuracy is the probability that an object will be correctly classified. It is defined as the sum of the true positives plus true negatives divided by the total number of individuals tested:
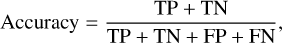 (10)
(10)
where TP, TN, FP, and FN are, respectively, the true positive, true negative, false positive, and false negative.
The F1 score is a classification accuracy metric that combines precision and recall. It is a suitable measure of models tested with imbalanced datasets:
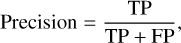 (11)
(11)
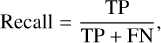 (12)
(12)
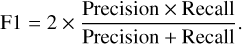 (13)
(13)
4 Experiments
4.1 Implementation details
The supernovae in our data are not all spectroscopically confirmed, which means that the unconfirmed ones might contain some misclassified objects due to errors from the photometric typing. The model may not generalize due to this data bias. To ensure that our model performs a generalization only on spec-troscopically confirmed data, we split up the training process into two steps. We divided the data into two datasets. The first one contains only the photometrically typed data and the second contains spectroscopically confirmed data. We trained the model at first with the photometrically typed data, then we used transfer learning to fine-tune the model on only spectroscopically confirmed data (Table 3 summarizes the partition of the data). The models are trained using cross-validation of five folds and three ensembles in each fold. All the architectures presented in this paper follow this same process and are implemented using PyTorch (Paszke et al. 2019).
We performed an extensive hyperparameter tuning of over 20 models to specify the best hyperparameters for our architecture, which contains 1.3 Million parameters. We conducted a hyperparameter optimization using only a non-confirmed dataset with different parameters, such as sequence length, M, learning rate, lr, 3DCCN sub-sequence length, K, classifier layers’ size, number of ConvBERT layers, L, number of Multi-head ConvAt-tention, T, batch size, and dropout. We used an Adam optimizer (Kingma & Ba 2014), with a value of the learning rate of 10−3, and we trained the model with cross-entropy loss and a dropout of 0.3. Hyperparameter tuning involves the number of images K that feed the 3DCNN and the maximum length of the sequence. The best values were K = 3 and M = 99, which means the number of sequences for the convolutional BERT is N = 33. The batch size was 128 sequences which we ran over 100 epochs. We chose the number of convolutional BERT layers to be L = 2 and the number of attention heads T = 4. Also, the images were normalized band-wise, as each band has different characteristics. We used only four classes (AGN, SNIa, Variable, SNOther) to train all the models. The class marked as “unknown” has not been considered in the study. It corresponds to noisy or very sparse data. It can easily be tagged from sparsity or noise in the image metrics and we do not expect any improvement in the classification if such objects are added to the training. We trained all models with 4 GPUs GeForce RTX 2080 Ti, Each model takes about three hours to complete training. The implementation will be released upon publication in our Github page1.
Count of every object in a dataset of each step in training protocol.
4.2 Results
This section provides studies on SDSS comparing the accuracy and F1 score of our proposed solution with other works. Table 4 summarizes the result of different models from different deep learning areas to diversify our benchmark as it contains RNN architectures (SuperNNova, LSTM), CNN-based models such as SCONE, Hybrid models that have CNN and RNN such as Carrasco-Davis et al. (2019) and Gómez et al. (2020), and, finally, a transformer-based model. Also, we compared the result using two types of datasets: first, the image dataset and, second, the same dataset object but with the light curves; the goal is to highlight the advantage of using images instead of light curves. Moreover, the different works mentioned in Table 4 were initially proposed for different datasets with different classes and training protocols. Hence, the results do not reflect the quality of these works on other datasets. The goal of the comparison is to give visibility into the performance of our model from a deep learning standpoint and the importance of using image time series from an astronomy perspective.
Overall, our model ConvEntion obtains the highest accuracy of 79.83% and F1 score of 70.62%, 13 points higher in accuracy than the best results on images by Gómez et al. (2020) and 12 points higher in accuracy than the best model using light curves. This confirms the advantage of using images over light curves. This advantage can be explained by the fact that the image contains more information than a single value of flux in a light curve. Hence, a model can learn robustly with the existence of more high-level feature maps. Also, ConvEntion performed better compared to the other image-based models, such as Carrasco-Davis et al. (2019). Additionally, transformers give a remarkable computational advantage because transformers avoid recursion and allow for parallel computation, thus reducing the training time. Our model took only three hours to train, compared to other image-based models which took five hours of training on our GPUs. Our model achieved better results using fewer parameters, compared to the other models trained on image sequences. The main benefit of using a transformer is that it reduces the drop in performance due to long dependencies. Transformers do not rely on past hidden states to capture dependencies with previous features such as RNNs. They instead process a sequence as a whole. Therefore, there is no risk of losing past information. Also, the integration of a spatiotemporal feature extraction helped in getting a better high-level representation of the sequence, in comparison to separating the spatial features from the temporal ones. The two types of features have correlations that may help the model to better discriminate between objects. We can also highlight the importance of separating the band to mitigate the impact of missing observations. Our model performed well, in comparison to that of Gómez et al. (2020) which uses multiple bands, which shows that separating the bands and adding band embedding works better than feeding the network with empty bands.
In the study of Carrasco-Davis et al. (2019), the authors trained their model on a dataset that only has a “g” band and they noted that the model can be adapted to classify the image sequence combining information using multiple bands. For the sake of comparison, we trained the image models with all the bands “ugriz” at first and then with only one “g” band. Our model achieved an accuracy of 76.89% and 63.20% in the F1 score using one band (“g”) which dropped 7% in comparison to using multiple bands. Meanwhile, Carrasco-Davis et al. (2019) achieved 63% in accuracy and 60% in their F1 score. This shows that our model is more efficient when using multiple bands. This also highlights the impact of band separation to mitigate the impact of the missing observations.
Figure 6 illustrates the obtained confusion matrix by ConvEntion and it shows that the model has well classified the supernovas. Most of the misclassified SNIa are associated with SNOther and vice versa, which is not a serious error. This is even an expected behavior, especially since all types of supernovas share a lot of similarities which may confuse the model. Additionally, with a small dataset like ours, it is normal to have such behavior because the model does not have enough samples to totally discriminate among objects. Meanwhile, variables were the best-classified class in our dataset, with just a bit of confusion with the AGN; this misclassification between AGN and variable can be explained by the class imbalance in our dataset based on the knowledge that the number of variables is higher than in the other classes.
Table 5 summarizes the results of different models trained only on three classes (AGN, SN, Variable), where classes SNIa and SNOther are combined into a single class. The goal of this experiment is to see the behavior of our model in discriminating between transient and non-transient objects. We got the best results with an accuracy of 83.90% with an F1 Score of 75.77%. The model was able to classify the SN accurately, with a score of 86% (as shown in Fig. 7).
The model is able to effectively process a given survey without any loss in performance and without the requirement of providing it with the time information for each image. However, when there is a covariate shift, or a mismatch, between the training set and the test set as when using a different dataset with a different observation sequence), incorporating the time information can improve the results. This experimental finding will be further studied and reported in future work using other datasets.
Performance comparison in terms of average F1 score and the average of the accuracy of five folds of cross-validation.
Performance comparison in terms of average F1 score and the average of the accuracy of five folds of cross-validation.
 |
Fig. 6 Confusion matrix showing the average accuracy and standard deviation of the predictions generated by ConvEntion over cross-validation of five folds on test data. |
 |
Fig. 7 Confusion matrix of three classes showing the average accuracy and standard deviation of the predictions generated by ConvEntion over cross-validation of five folds on test data. |
5 Conclusion
In this work, we present a method for efficient astronomical image time series classification that is entirely based on the combination of convolutional networks and transformers. Inspired by action recognition and satellite image time series classification, we propose a model ConvEntion that utilizes convolutions and transformers jointly to capture complex spatio-temporal dependencies between distinct steps, leading to accurate predictions based on different observations of an object. The accuracy of our model is better with a high margin of 13%, in comparison to state-of-the-art methods using image data – and even better compared to approaches using light curves.
Our model achieves good results on the SDSS dataset, while also being faster thanks to using fewer parameters and parallel computational processes, making it a good candidate for latency-sensitive applications such as the real-time thumbnail classifier of astronomical events. Meanwhile, our benchmark stands as clear evidence of the importance of images in the domain of astronomy. Indeed, the images contain more information than the normal light curves, even if they present more difficulties. In the future, we plan to scale up ConvEntion using self-supervised learning to investigate whether the model can generalize even better. With a large amount of unlabeled data in astronomy, we believe that the next step to advance AITS classification is creating self-supervised models.
Acknowledgements
This work has been carried out thanks to the support of the DEEPDIP ANR project (ANR-19-CE31-0023). This work makes use of Sloan Digital Sky Survey (SDSS) data. Funding for SDSS-III has been provided by the Alfred P. Sloan Foundation, the Participating Institutions, the National Science Foundation, and the U.S. Department of Energy Office of Science. The SDSS-III website is http://www.sdss3.org/. SDSS-III is managed by the Astrophysical Research Consortium for the Participating Institutions of the SDSS-III Collaboration including the University of Arizona, the Brazilian Participation Group, Brookhaven National Laboratory, Carnegie Mellon University, University of Florida, the French Participation Group, the German Participation Group, Harvard University, the Instituto de Astrofisica de Canarias, the Michigan State/Notre Dame/JINA Participation Group, Johns Hopkins University, Lawrence Berkeley National Laboratory, Max Planck Institute for Astrophysics, Max Planck Institute for Extraterrestrial Physics, New Mexico State University, New York University, Ohio State University, Pennsylvania State University, University of Portsmouth, Princeton University, the Spanish Participation Group, University of Tokyo, University of Utah, Vanderbilt University, University of Virginia, University of Washington, and Yale University.
References
- Bahdanau, D., Cho, K., & Bengio, Y. 2014, ArXiv e-prints [arXiv:1409.0473] [Google Scholar]
- Bao, H., Dong, L., Piao, S., & Wei, F. 2021, ArXiv e-prints [arXiv:2106.08254] [Google Scholar]
- Boone, K. 2019, AJ, 158, 257 [NASA ADS] [CrossRef] [Google Scholar]
- Carrasco-Davis, R., Cabrera-Vives, G., Förster, F., et al. 2019, PASP, 131, 108006 [NASA ADS] [CrossRef] [Google Scholar]
- Chawla, N. V., Bowyer, K. W., Hall, L. O., & Kegelmeyer, W. P. 2002, J. Artif. Intell. Res., 16, 321 [CrossRef] [Google Scholar]
- Cho, K., van Merrienboer, B., Gulcehre, C., et al. 2014, ArXiv e-prints [arXiv:1406.1078] [Google Scholar]
- Choromanski, K. M., Likhosherstov, V., Dohan, D., et al. 2021, in International Conference on Learning Representations [Google Scholar]
- Dablain, D., Krawczyk, B., & Chawla, N. V. 2021, ArXiv e-prints [arXiv:2105.02340] [Google Scholar]
- Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. 2018, ArXiv e-prints [arXiv:1810.04805] [Google Scholar]
- Dosovitskiy, A., Beyer, L., Kolesnikov, A., et al. 2020, ArXiv e-prints [arXiv:2010.11929] [Google Scholar]
- Drake, A. J., Djorgovski, S. G., Mahabal, A., et al. 2011, Proc. Int. Astron. Union, 7, 306 [CrossRef] [Google Scholar]
- Efraimidis, P. S. 2010, ArXiv e-prints [arXiv:1012.0256] [Google Scholar]
- Frieman, J. A., Bassett, B., Becker, A., et al. 2007, AJ, 135, 338 [Google Scholar]
- Fukugita, M., Ichikawa, T., Gunn, J. E., et al. 1996, AJ, 111, 1748 [Google Scholar]
- Gill, M. K., Asefa, T., Kaheil, Y., & McKee, M. 2007, Water Resour. Res., 43, W07416 [CrossRef] [Google Scholar]
- Gómez, C., Neira, M., Hernández Hoyos, M., Arbeláez, P., & Forero-Romero, J. E. 2020, MNRAS, 499, 3130 [CrossRef] [Google Scholar]
- Hložek, R., Ponder, K. A., Malz, A. I., et al. 2020, ArXiv e-prints [arXiv:2012.12392] [Google Scholar]
- Hochreiter, S., & Schmidhuber, J. 1997, Neural Comput., 9, 1735 [CrossRef] [Google Scholar]
- Holtzman, J. A., Marriner, J., Kessler, R., et al. 2008, AJ, 136, 2306 [NASA ADS] [CrossRef] [Google Scholar]
- Hossain, M. S., Betts, J. M., & Paplinski, A. P. 2021, Neurocomputing, 462, 69 [Google Scholar]
- Ivezić, Ž., Kahn, S. M., Tyson, J., et al. 2019, ApJ, 873, 111 [NASA ADS] [CrossRef] [Google Scholar]
- Ji, S., Xu, W., Yang, M., & Yu, K. 2013, IEEE Trans. Pattern Anal. Mach. Intell., 35, 221 [Google Scholar]
- Kingma, D. P., & Ba, J. 2014, ArXiv e-prints [arXiv:1412.6980] [Google Scholar]
- Lin, T.-Y., Goyal, P., Girshick, R. B., He, K., & Dollár, P. 2017, ArXiv e-prints [arXiv:1708.02002] [Google Scholar]
- Liu, Z., Luo, S., Li, W., et al. 2021, ArXiv e-prints [arXiv:2011.10185] [Google Scholar]
- Liu, Z., Ning, J., Cao, Y., et al. 2022, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) [Google Scholar]
- Möller, A., & de Boissière, T. 2020, MNRAS, 491, 4277 [CrossRef] [Google Scholar]
- Ozgur Turkoglu, M., D’Aronco, S., Perich, G., et al. 2021, ArXiv e-prints [arXiv:2102.08820] [Google Scholar]
- Pasquet, J., Pasquet, J., Chaumont, M., & Fouchez, D. 2019, A&A, 627, A21 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Paszke, A., Gross, S., Massa, F., et al. 2019, ArXiv e-prints [arXiv:1912.01703] [Google Scholar]
- PLAsTiCC-team (Allam, T. Jr., et al.) 2018, ArXiv e-prints [arXiv:1810.00001] [Google Scholar]
- Qu, H., Sako, M., Möller, A., & Doux, C. 2021, AJ, 162, 67 [NASA ADS] [CrossRef] [Google Scholar]
- Rumelhart, D. E., Hinton, G. E., & Williams, R. J. 1985, Learning internal representations by error propagation, Tech. rep. (San Diego La Jolla Inst for Cognitive Science: California Univ.) [CrossRef] [Google Scholar]
- Sainte Fare Garnot, V., Landrieu, L., Giordano, S., & Chehata, N. 2019, ArXiv e-prints [arXiv:1911.07757] [Google Scholar]
- Sako, M., Bassett, B., Becker, A. C., et al. 2014, PASP, 130, 064002 [Google Scholar]
- Sharir, G., Noy, A., & Zelnik-Manor, L. 2021, ArXiv e-prints [arXiv:2103.13915] [Google Scholar]
- Shi, X., Chen, Z., Wang, H., et al. 2015, ArXiv e-prints [arXiv:1506.04214] [Google Scholar]
- Tran, D., Bourdev, L., Fergus, R., Torresani, L., & Paluri, M. 2014, ArXiv eprints [arXiv:1412.0767] [Google Scholar]
- Vaswani, A., Shazeer, N., Parmar, N., et al. 2017, ArXiv e-prints [arXiv:1706.03762] [Google Scholar]
- Wang, S., Li, B. Z., Khabsa, M., Fang, H., & Ma, H. 2020, ArXiv e-prints [arXiv:2006.04768] [Google Scholar]
- Yan, S., Xiong, X., Arnab, A., et al. 2022, ArXiv e-prints [arXiv:2201.04288] [Google Scholar]
- Yuan, Y., & Lin, L. 2021, IEEE J. Sel. Top. Appl. Earth Observ. Rem. Sensing, 14, 474 [NASA ADS] [CrossRef] [Google Scholar]
- Zhou, J., Wei, C., Wang, H., et al. 2022, ArXiv e-prints [arXiv:2111.07832] [Google Scholar]
All Tables
3D CNN architecture where Conv3D is a 3D convolutional element and BN3d is a 3D batch normalization element.
Performance comparison in terms of average F1 score and the average of the accuracy of five folds of cross-validation.
Performance comparison in terms of average F1 score and the average of the accuracy of five folds of cross-validation.
All Figures
|
Fig. 1 Sample of some objects present in our dataset. Each image in filter g/i corresponds to a different observation with the same filter. |
| In the text | |
|
Fig. 2 Each image has five filters (u, g, r, i, z), The black channel represents the missing observation. |
| In the text | |
|
Fig. 3 General architecture of the ConvEntion network. The image time series are first rearranged to embed the band information. Then each 3DCNN is fed with a sub-sequence of K inputs of the time series J(∊ ℝM×H×W×2 for M elements of images of size HxW) to create the new downsized sequence S (∊ ℝN×H′×W′×D). S is fed to the positional encoder in order to add the information about the position, which outputs F(∊ ℝN×H′×W′×D). Then F is passed to ConvBERT which has L layers. The 3D max-pooling is used to downsize the output of ConvBERT for the classifier. |
| In the text | |
|
Fig. 4 Illustration of the handling of missing information by separating the bands. The empty channels are dropped, then we concatenate each image with a 2D representation of the band used to capture the image. The band embedding contains five band representations. The black channel represents the missing observation. |
| In the text | |
|
Fig. 5 Convolutional attention (left). Multi-head convolutional attention (right). To obtain the query, key, and value maps, we applied a convolution layer on the feature map obtained from 3DCNN. |
| In the text | |
|
Fig. 6 Confusion matrix showing the average accuracy and standard deviation of the predictions generated by ConvEntion over cross-validation of five folds on test data. |
| In the text | |
|
Fig. 7 Confusion matrix of three classes showing the average accuracy and standard deviation of the predictions generated by ConvEntion over cross-validation of five folds on test data. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.