| Issue |
A&A
Volume 642, October 2020
|
|
|---|---|---|
| Article Number | A90 | |
| Number of page(s) | 17 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/202038638 | |
| Published online | 09 October 2020 | |
Constraining the origin and models of chemical enrichment in galaxy clusters using the Athena X-IFU
1
European Space Agency (ESA), European Space Research and Technology Centre (ESTEC), Keplerlaan 1, 2201 AZ Noordwijk, The Netherlands
e-mail: francois.mernier@esa.int
2
MTA-Eötvös University Lendület Hot Universe Research Group, Pázmány Péter sétány 1/A, Budapest 1117, Hungary
3
Institute of Physics, Eötvös University, Pázmány Péter sétány 1/A, Budapest 1117, Hungary
4
SRON Netherlands Institute for Space Research, Sorbonnelaan 2, 3584 CA Utrecht, The Netherlands
5
IRAP, Université de Toulouse, CNRS, CNES, UPS, Toulouse, France
6
INAF, Osservatorio Astronomico di Trieste, Via Tiepolo 11, 34131 Trieste, Italy
7
Universitäts-Sternwarte München, Fakultät für Physik, LMU Munich, Scheinerstr. 1, 81679 München, Germany
8
IFPU – Institute for Fundamental Physics of the Universe, Via Beirut 2, 34014 Trieste, Italy
9
CNES, 18 Avenue Edouard, Belin, 31400 Toulouse, France
10
Dipartimento di Fisica dell’Universitä di Trieste, Sezione di Astronomia, via Tiepolo 11, 34131 Trieste, Italy
11
INFN – National Institute for Nuclear Physics, Via Valerio 2, 34127 Trieste, Italy
12
Max-Planck-Institut für extraterrestrische Physik, Gießenbachstraße 1, 85748 Garching, Germany
13
Harvard-Smithsonian Center for Astrophysics, 60 Garden Street, Cambridge, MA 02138, USA
14
Dr. Karl Remeis-Observatory, Erlangen Centre for Astroparticle Physics, Sternwartstr. 7, 96049 Bamberg, Germany
15
University Observatory Munich, Scheinerstr. 1, 81679 Munich, Germany
16
Max Plank Institut für Astrophysik, Karl-Schwarzschield Strasse 1, 85748 Garching bei Munchen, Germany
17
INAF, Osservatorio di Astrofisica e Scienza dello Spazio, via Piero Gobetti 93/3, 40129 Bologna, Italy
18
INFN, Sezione di Bologna, Viale Berti Pichat 6/2, 40127 Bologna, Italy
19
Department of Astrophysical Sciences, Princeton University, Princeton, NJ 08544, USA
20
Dipartimento di Fisica e Astronomia, Universitá di Bologna, Via Gobetti 93, 40127 Bologna, Italy
Received:
11
June
2020
Accepted:
30
July
2020
Chemical enrichment of the Universe at all scales is related to stellar winds and explosive supernovae phenomena. Metals produced by stars and later spread throughout the intracluster medium (ICM) at the megaparsec scale become a fossil record of the chemical enrichment of the Universe and of the dynamical and feedback mechanisms determining their circulation. As demonstrated by the results of the soft X-ray spectrometer onboard Hitomi, high-resolution X-ray spectroscopy is the path to differentiating among the models that consider different metal-production mechanisms, predict the outcoming yields, and are a function of the nature, mass, and/or initial metallicity of their stellar progenitor. Transformational results shall be achieved through improvements in the energy resolution and effective area of X-ray observatories, allowing them to detect rarer metals (e.g. Na, Al) and constrain yet-uncertain abundances (e.g. C, Ne, Ca, Ni). The X-ray Integral Field Unit (X-IFU) instrument onboard the next-generation European X-ray observatory Athena is expected to deliver such breakthroughs. Starting from 100 ks of synthetic observations of 12 abundance ratios in the ICM of four simulated clusters, we demonstrate that the X-IFU will be capable of recovering the input chemical enrichment models at both low (z = 0.1) and high (z = 1) redshifts, while statistically excluding more than 99.5% of all the other tested combinations of models. By fixing the enrichment models which provide the best fit to the simulated data, we also show that the X-IFU will constrain the slope of the stellar initial mass function within ∼12%. These constraints will be key ingredients in our understanding of the chemical enrichment of the Universe and its evolution.
Key words: X-rays: galaxies: clusters / galaxies: clusters: intracluster medium / galaxies: abundances / supernovae: general / galaxies: fundamental parameters / methods: numerical
© F. Mernier et al. 2020
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
1. Introduction
The processes that lead to chemical enrichment of the Universe remain one of the major open questions in astrophysics. Most of the light elements (H, He, Li) were produced in the very first minutes of the Universe, during the primordial nucleosynthesis (Cyburt et al. 2016). Metals (i.e. elements heavier than Li) are instead more recent, as most of this enrichment is related to supernovae events (SNe) and to stellar winds (Burbidge et al. 1957). In fact, different types of stellar sources do not produce the same elements. Elements from O to Si are predominantly produced by fusion reactions in the outer shells of massive stars (M ≥ 10 M⊙) during core-collapse supernovae (SNcc, see Nomoto et al. 2013 for a review), while heavier elements (i.e. Si to Fe) are mostly related to thermonuclear explosions of white dwarfs (WDs) – former remnants of low-mass stars (M ≤ 8 M⊙) – that is, type-Ia supernovae (SNIa, see Maoz et al. 2014 for a review). Lighter elements (e.g. C, N, O) can also be related to radiative stellar winds when low-mass stars enter their asymptotic giant branch (AGB) phase (Iben & Renzini 1983).
Though understood to some extent, the physics of these mechanisms is not fully constrained. For instance, two main scenarios compete to explain SNIa events: the explosive C-burning onto a WD (triggering the SNIa explosion) may be ignited either by (i) the accretion of matter from a companion star when the WD mass approaches the Chandrasekhar mass (single-degenerate model, Whelan & Iben 1973), or (ii) the merger with another WD far below its Chandrasekhar mass (double-degenerate model, Webbink 1984). The nature of the WD explosion itself also remains unclear (Hillebrandt et al. 2013) and end-of-life models invoke either deflagration or delayed-detonation scenarios to explain observations (Iwamoto et al. 1999). Similarly, for SNcc, metal production depends on the initial mass (hence lifetime) and metallicity of the star, Zinit, the estimation of which is challenging. Beyond the progenitor mass, chemical enrichment at all scales is strongly coupled to the initial mass function (IMF), i.e. the relative proportion of low- and high- mass stars that are born within a given single stellar population. In fact, different IMFs result in different (relative) numbers of AGBs, SNcc, and SNIa, affecting not only the chemical properties of galaxies, but also their entire evolution and feedback (for a review, see e.g. Bastian et al. 2010). However, whether the IMF is the same for all galaxies or constant with time is still an open question (e.g. De Masi et al. 2019), and therefore observational signatures of the IMF at galactic scales and beyond are valuable in this respect.
Measurements through X-ray spectroscopy of the intra-cluster medium (ICM) performed by missions such as XMM-Newton, Chandra, or Suzaku provide outstanding results in recovering the chemical composition of the ICM and in probing the enrichment of the largest scales of the Universe (for recent reviews, see Werner et al. 2008; Mernier et al. 2018a). In fact, the investigation of radial metallicity profiles in the outskirts of these systems (Werner et al. 2013; Urban et al. 2017) highlighted strong evidence of an early metal-production scenario (z > 2–3), which predates the formation of clusters (Fabjan et al. 2010; McCarthy et al. 2010; Biffi et al. 2017, 2018a, for a review on metallicity profiles in numerical simulations, see Biffi et al. 2018b) and is likely contemporary to the stelliferous epoch of the Universe (Madau & Dickinson 2014). Although active galactic nucleus (AGN) feedback of the dominant galaxy can in principle induce significant central metallicity variations as a function of outflow and/or jet events (e.g. Gaspari et al. 2011), the remarkable similarity in the spatial distribution of SNIa and SNcc products even within the central metallicity peaks suggests a similar “early-enrichment” scenario for clusters (and groups) cores (Simionescu et al. 2009; Million et al. 2011; Mernier et al. 2017). Nevertheless, the exact diffusion and transport mechanisms of metals from stars to the interstellar medium and beyond remains an open question in both observations (Kirkpatrick et al. 2011; De Grandi et al. 2016; Urdampilleta et al. 2019) and simulations (e.g. Schindler & Diaferio 2008; Greif et al. 2009).
Additional information can be derived from the abundance ratios measured in the ICM. For example, the Mn/Fe and Ni/Fe ratios are both sensitive to the electron capture rates during SNIa explosions, and are therefore crucial indicators of their progenitor channels (Seitenzahl et al. 2013a; Mernier et al. 2016a; Hitomi Collaboration 2017), while ratios of lighter elements can in principle provide constraints on the IMF and the initial metallicity of the SNcc progenitors (e.g. de Plaa et al. 2007; Mernier et al. 2016a). By pushing current observatories to their limit, recent studies derived constraints on the relative fraction of SN events that effectively contribute to the ICM enrichment. These measurements showed that SNIa and SNcc contribute relatively equally to the overall chemical enrichment in the ICM (Werner et al. 2006; de Plaa et al. 2006, 2017; Bulbul et al. 2012; Mernier et al. 2016a). The comprehensive study of Simionescu et al. (2019) compiled the most accurate abundance measurements of the Perseus cluster (taken with the XMM-Newton RGS and Hitomi SXS instruments) and compared them to state-of-the-art SNIa and SNcc yield models. Their surprising conclusion is that no current set of models is able to reproduce all the observed abundance ratios at once. In particular, the measured Si/Ar ratio tends to be systematically overpredicted by models, even when taking calibration and atomic uncertainties into account. Whereas further improvement of stellar nucleosynthesis models is expected, the non-negligible systematic errors associated to these observations and the lack of highly sensitive, spatially resolved high-resolution spectroscopy prevents us from steering any considerable change in the paradigm (see also de Grandi & Molendi 2009). In fact, measurements from currently flying missions are performed with moderate collective area, either over the whole X-ray band (0.4–10 keV) with modest spectral resolution (> 100 eV), or with higher resolution dispersive spectroscopy but over the low E band (0.3–2 keV) and without any spatial resolution, which considerably limits interpretations.
As revealed by Hitomi SXS (Takahashi et al. 2018), more accurate measurements of rare elements (e.g. Ne, Cr or Mn) will be key to constraining SN models. These steps forward are expected through the successor of the SXS, Resolve, on the X-Ray Imaging and Spectroscopy Mission (XRISM, XRISM Science Team 2020), but definitive answers will require instruments such as the X-ray Integral Field Unit (X-IFU, Barret et al. 2016, 2018) which will fly onboard Athena (Nandra et al. 2013). With more than 3000 micro-calorimeter pixels, the X-IFU will provide high-resolution spectroscopy on the 0.2–12 keV energy band (2.5 eV FWHM energy resolution out to 7 keV) over an equivalent diameter of 5′ with 5″ pixel size. This will (i) allow us to measure for the first time abundances of rare elements (Ettori et al. 2013a), (ii) provide unprecedented constraints on the spatial distribution of metals through the ICM (Cucchetti et al. 2018, hereafter, Paper I), and (iii) allow us to further explore the chemical evolution of the ICM down to z ∼ 2 (Pointecouteau et al. 2013). Other astrophysical questions on the ICM, specifically its level and distribution of turbulence (e.g. Roncarelli et al. 2018; Clerc et al. 2019; Cucchetti et al. 2019), will also be explored by the X-IFU in unprecedented detail.
In this paper, we perform a first investigation of the capabilities of the X-IFU in constraining the sources of the ICM chemical enrichment and the associated stellar IMF in galaxy clusters. To do so, we use inputs from hydrodynamical cosmological simulations as already adopted in Paper I. The methods are described in Sect. 2. Using the large number of theoretical models at our disposal, we first demonstrate the capabilities of the X-IFU in recovering the underlying enrichment mechanisms assumed in the simulations (Sect. 3). By fixing the best-fit models to the data, a second study is performed to analyse the capabilities of the instrument in constraining important parameters linked to the IMF, such as its slope, shape, and the high-mass cut-off (Sect. 4). Results obtained in both cases are then discussed and future prospects are addressed (Sect. 5). Finally, we conclude our findings in Sect. 6.
Throughout this paper, we assume that metals showing emission lines in the X-ray band are produced by three independent astrophysical sources: AGBs, SNcc, and SNIa. The abundances and their associated ratios (i.e. normalised to the Fe abundance) are given in the solar units of Anders & Grevesse (1989). Although other reference tables are available in the literature (e.g. the proto-solar, meteoritic abundances of Lodders et al. 2009), the choice of units here has no impact on our results, as long as they are used self-consistently from the simulations to the mock data analysis. We also assume a Λ-CDM cosmology with ΩM = 0.24, Ωb = 0.04, H0 = 72 km s−1 Mpc−1, σ8 = 0.8 and ns = 0.96 as used in the original hydrodynamical simulations (Rasia et al. 2015). Unless stated otherwise, the quoted errors consider a 68% confidence level.
2. Methods and simulations
2.1. Simulation setup and mock data
As current measurements are not adequate in terms of joint spatial and spectral resolution to build a representative toy model and perform a feasibility study of the afore-presented science case by X-IFU, this study relies on input numerical simulations, which are then converted into mock X-IFU datasets. The full method is described extensively in Paper I (to which we refer the reader for more details).
In summary, four Lagrangian regions are extracted from a parent large-scale cosmological simulation and re-simulated at higher resolution including the treatment of hydrodynamical processes with sub-grid physics models (using the tree-PM smoothed particle hydrodynamics code GADGET-3; see Rasia et al. 2015). Of these four systems, two are “cool-core” and two are “non-cool-core”, and each class contains both a low- and a high-mass cluster. Each of these four clusters is traced back successively to z = 0.1 and z = 1. Metal enrichment by AGBs, SNcc, and SNIa is implemented following the approach of Tornatore et al. (2007), in which yields for H, He, C, N, O, Ne, Na, Mg, Al, Si, S, Ar, Ca, Fe, and Ni are injected and tracked during the clusters evolution (Biffi et al. 2018a; Truong et al. 2019). These elements are assumed to be produced by (i) AGBs, (ii) SNcc, and (iii) SNIa following the yields of, respectively, (i) Karakas (2010), (ii) Woosley & Weaver (1995) with updates from Romano et al. (2010), and (iii) Thielemann et al. (2003).
These yield models are listed in boldface in Tables A.1–A.3. They are used as input in our cosmological simulations to estimate the abundance of the different metal species produced during the evolution of the stellar component, assuming proper lifetimes (Padovani & Matteucci 1993) and depending on its metallicity and mass distributions. For the latter, the simulations assume a Chabrier IMF of the stellar population (Chabrier 2003, see also Sect. 4). For this reason, most of the produced α-elements are the result of a complex distribution of AGB and SNcc initial metallicities (Tornatore et al. 2007), from which we aim further to recover the dominant contribution only. X-ray photons ultimately emitted by these simulations are then projected and converted into event lists suitable for synthetic observations with the X-IFU for fixed exposure time of 100 ks. This is done using the end-to-end simulator SIXTE (Dauser et al. 2019)1 and assuming a vvapec model for the parameters of each emitting particle (for a similar approach, see also Roncarelli et al. 2018). As SIXTE is the official simulator for the X-IFU, the up-to-date response files of the instrument are used. For each of the nearby (z = 0.1) systems, we simulate seven adjacent X-IFU pointings in order to fully cover their R500 limits.
We analyse the mock data following Paper I. Specifically, the projected mock spectra are extracted within R500 for each cluster, and are then fitted with XSPEC (Arnaud 1996) within 0.2–12 keV, using the same vvapec as in the input simulations for consistency (with the normalisation, temperature, redshift, and relevant abundances as free parameters). This approach thus neglects the impact of the uncertainties in the atomic models, which could be ultimately a limiting factor at the sensitivity to be reached by the X-IFU (for further discussion on systematic uncertainties and our approach to dealing with them, see Sects. 3.2 and 5.3). Other typical observational effects are taken into account. In particular, the implementation of the background relies on a modelling of the astrophysical foreground (consisting of the local hot bubble and the Milky Way hot gaseous content, modelled by an unabsorbed and absorbed thermal plasma, respectively), the cosmic X-ray background (unresolved AGNs, modelled by a power law), and the instrumental background (directly implemented within SIXTE). More details about this procedure are given in Paper I. The obtained best-fit abundance ratios are shown in Table 1 for each individual cluster as well as for the sample average (which are used throughout this paper). They can be directly compared to their corresponding input values from the simulations described above (listed on the same table). Results for other parameters, in particular the temperature, are further detailed in Paper I.
Mean abundance ratios with respect to iron, obtained from the simulation input values (“i” in the second column) and the analysis of the mock X-IFU data (“o” in the second column) of the z ∼ 0.1 simulated clusters of Paper I (100 ks of mock exposure for each system, labelled as cool-core [CC] or non-cool-core [NCC]).
2.2. Production yields and principle of the comparison
The origin of metals in the ICM can be traced by K distinct stellar sources of enrichment k (in our case, K = 3 and k refers successively to AGBs, SNcc, and SNIa). As such, the total number of atoms, NX, tot, of a given chemical element X produced over time can be expressed as (Gastaldello & Molendi 2002):
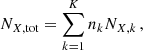
where nk are multiplicative constants representing the total number of each source needed to obtain the observed enrichment (i.e. number of SNe or AGBs), and NX, k represents the number of atoms produced by each source. This number can easily be related to the mass MX, k of a produced element as usually provided by yield models from the literature:
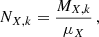
where μX is the atomic weight of the element X (in the same units as MX, k). Usually, however, AGBs and SNcc yield models are provided for a specific progenitor mass m and need to be integrated over a single stellar population with a given IMF. Such an integrated mass 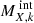 , assuming a power-law IMF, can be written as:
, assuming a power-law IMF, can be written as:
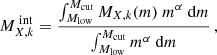
where α is the slope of the IMF, Mlow is the lowest stellar mass assumed for each source of enrichment (depending on the yield models, though typically ∼1 M⊙ and ∼10 M⊙ for AGBs and SNcc, respectively2), and Mcut is the upper mass cut-off for the integration (yet uncertain, though typically assumed to be ∼40 M⊙). In the input numerical simulations, the actual IMF is represented by a Chabrier-like piece-wise power-law function with Mcut = 40 M⊙ and the following slopes: α = −1.2 for M ∈ [0.1, 0.3] M⊙, α = −1.8 for M ∈ [0.3, 1.3] M⊙, and α = −2.3 for M ∈ [1.3, 40] M⊙. The Salpeter-like IMF (often used in previous literature as well as in this paper) follows the slope α = −2.35 and is very similar to the Chabrier-like IMF beyond ∼1 M⊙.
The respective “absolute” (i.e. relative to H) abundance 𝒜X, k of a given element X is defined as:
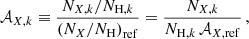
where 𝒜X, ref ≡ (NX/NH)ref are the selected solar (or proto-solar) reference abundances (in our case, Anders & Grevesse 1989).
Given the above equations, the associated X/Fe abundance ratio (i.e. relative to Fe) can be expressed as:
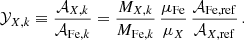
Considering now all the sources of enrichment, and similar to Eq. (1), the overall abundance ratio 𝒴X, tot can be written
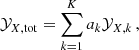
where ak is another multiplicative constant (linked to nk with appropriate normalisation). By definition 𝒴Fe, tot = 1.
The previous equations are valid in the case of an overall study of the abundances, which accounts for the total number of atoms produced in stars, galaxies, and the ICM (Matteucci & Chiappini 2005). However, X-ray observations provide a direct measurement of the ICM content in heavy elements. In addition, while the previous approach is rather insensitive to the spatial variation of metals within the ICM itself (due to, e.g. turbulence or diffusion – as clusters within R500 are considered as closed-boxes), it does not consider the circulation timescale of metals from stars into the ICM (see also de Grandi & Molendi 2009), nor the possibly different locations of AGB, SNcc, and SNIa due to the different lifetimes of their progenitors. It does not account either for any potential difference in the metal distribution (relative and spatial differences) between the ICM phase and the stellar phase. A usual caveat, assumed here, is to consider that the fractions ak derived from ICM studies are representative of the number of events enriching the ICM-only system, rather than the total galaxy cluster system (i.e. stellar and ICM phases). In this case, the previous formula can be applied treating 𝒴X, k as “effective” yields, which describe the fractions of the stellar sources enriching the hot gas (equivalent if and only if the metal distribution is the same in galaxies and the ICM, Humphrey & Buote 2006).
Using X-ray measurements of abundance ratios, 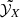 , the consistency of a theoretical prediction of abundance ratios can be tested at the ICM level by fitting a linear combination of the integrated yields that minimises
, the consistency of a theoretical prediction of abundance ratios can be tested at the ICM level by fitting a linear combination of the integrated yields that minimises
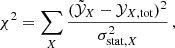
where the sum is performed over the total number of available elements X, and σstat is the statistical error of the measurements 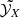 (our strategy to deal with potential systematic errors is explained further in Sect. 3.1). The recovered values of
(our strategy to deal with potential systematic errors is explained further in Sect. 3.1). The recovered values of 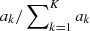 represent the corresponding fractions of each source k at play in the ICM enrichment.
represent the corresponding fractions of each source k at play in the ICM enrichment.
A generic way of quantifying the accuracy of a model in describing observations is to compute the reduced chi-squared of the fit, 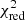 . If large values are obtained, the predicted yields are not likely to represent the observations of the chemical enrichment (at least at the ICM level) in a realistic way. These results can also be further refined by applying additional observational constraints on the ratio of SNIa-to-SNe (e.g. Mernier et al. 2016a). Current observational studies are limited in this comparison by the large (statistical and/or systematic) in the measured abundance ratios, and the limited number of elements observed (e.g. Mernier et al. 2015, 2016b). As shown in Table 1, X-IFU observations will provide a wealth of new constraints to discard or verify certain models. By comparing our mock data (Sect. 2.1) to a significant number of available models, in the following sections we derive which set of models matches the ratios in the most statistically accurate way, assessing whether it is ultimately possible to recover the models originally used in the input simulation (described in detail in Tornatore et al. 2007; Biffi et al. 2017).
. If large values are obtained, the predicted yields are not likely to represent the observations of the chemical enrichment (at least at the ICM level) in a realistic way. These results can also be further refined by applying additional observational constraints on the ratio of SNIa-to-SNe (e.g. Mernier et al. 2016a). Current observational studies are limited in this comparison by the large (statistical and/or systematic) in the measured abundance ratios, and the limited number of elements observed (e.g. Mernier et al. 2015, 2016b). As shown in Table 1, X-IFU observations will provide a wealth of new constraints to discard or verify certain models. By comparing our mock data (Sect. 2.1) to a significant number of available models, in the following sections we derive which set of models matches the ratios in the most statistically accurate way, assessing whether it is ultimately possible to recover the models originally used in the input simulation (described in detail in Tornatore et al. 2007; Biffi et al. 2017).
3. Constraining chemical enrichment models with the X-IFU
Besides the three distinct and independent sources of enrichment considered here – AGB, SNcc, or SNIa, we also assume that the bulk of the enrichment is completed at z = 0.1 and does not differ from local clusters, which is a fair hypothesis supported by numerical and observational results (e.g. Ettori et al. 2015; McDonald et al. 2016; Biffi et al. 2017, 2018b; Urban et al. 2017; Mantz et al. 2017; Liu et al. 2020). Section 3.4 further extends the comparison to the case of z = 1 clusters.
In the following sections, nucleosynthesis yields computed for various models from the literature are fitted to the averaged X/Fe abundance ratios measured by the synthetic X-IFU observations. This is done by using the abunfit package in python3, which solves the minimisation problem in Eq. (7) for aSNIa, aSNcc, aAGB (based on the approach of Ettori et al. 2002; Gastaldello & Molendi 2002; Werner et al. 2006; de Plaa et al. 2007; Mernier et al. 2016a, and Simionescu et al. 2019). The fit is then performed under the constraint:
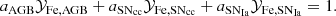
The full list of models (along with their relevant specifics) used for this comparison, and covering a significant fraction of the recent literature, is detailed in Appendix A. Most AGB and SNcc models are tested individually over the available range of initial metallicities Zinit. Among the tested SNcc models, we also include a set of hypernova and pair-instability SN predicted yields in order to explore the reproducibility of the abundance pattern through an enrichment from very massive, metal-poor stars. To ease the comparison, throughout this section AGB and SNcc yields are first integrated using the same Salpeter-like power-law IMF with a slope α = −2.35 (Salpeter 1955). Although, formally, not exactly the same as the Chabrier-like IMF used in the input simulations, the Salpeter-like parametrisation is reasonable as a first approximation, is the simplest one to use, and is usually considered in previous similar studies. Other choices of the IMF (including Chabrier-like, which marginally improves our fit) are explored in Sect. 4. A summary of our fits and methods is shown in Table 2.
Summary of the fits performed on our mock observations throughout this study.
3.1. Recovering the input simulated enrichment models
As a first safety check, we aim to recover our X-IFU mock observed ratios with the combinations of the yield models that were considered as input in the simulated clusters. This corresponds to all the “K10+Ro10+Th03” combinations as listed in Appendix A (4 AGB models × 5 SNcc models × 1 SNIa model = 20 combinations).
Figure 1 shows the best-fit abundance pattern under these assumptions, obtained with Zinit = 0.01 Z⊙ for SNcc yields and Zinit = 1 Z⊙ for AGB yields4. With only two element ratios not perfectly recovered (Mg/Fe and Ni/Fe), the agreement between the mock ratios and best-fit models is good, leading to 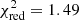 . This is particularly reassuring as under our assumptions it demonstrates the remarkable ability of the X-IFU to reproduce the true chemical composition of the ICM. We note that the exquisite precision achieved on most ratios naturally inflates
. This is particularly reassuring as under our assumptions it demonstrates the remarkable ability of the X-IFU to reproduce the true chemical composition of the ICM. We note that the exquisite precision achieved on most ratios naturally inflates 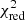 for the elements whose yields are not perfectly recovered. In fact, when ignoring the Mg/Fe and Ni/Fe ratios, the fit further improves with
for the elements whose yields are not perfectly recovered. In fact, when ignoring the Mg/Fe and Ni/Fe ratios, the fit further improves with 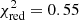 . The precise reasons of the > 1σ discrepancies on these two specific ratios may be various (e.g. numerical issues, projection effects5, contribution from less dominant Zinit as initially implemented) and are left for investigation in future work.
. The precise reasons of the > 1σ discrepancies on these two specific ratios may be various (e.g. numerical issues, projection effects5, contribution from less dominant Zinit as initially implemented) and are left for investigation in future work.
 |
Fig. 1. Average abundance ratio X/Fe within R500 over the cluster sample for z = 0.1 recovered using 100 ks observations. These values are fitted using the enrichment yields derived from the references provided in Paper I. The corresponding fitted contributions of SNIa (blue), SNcc (magenta), and AGB stars (yellow) are shown as histograms. |
3.2. Constraints on various enrichment models
Going one step further, though still assuming that each source of enrichment can be described by one single model, we aim to test whether the observed abundance pattern can be (mis-) interpreted with other combinations of AGB+SNcc+SNIa yield models available from the literature. This is particularly important in order to demonstrate the ability of the X-IFU to constrain relevant astrophysical parameters on the stellar population itself (e.g. average initial metallicity of SNcc progenitors, favoured explosion channel of SNIa).
For each combination of models (i.e. a total of 4 AGB models × 24 SNcc models × 182 SNIa models = 17 472 combinations), we computed the reduced chi-squared of the fit with 8 degrees of freedom (corresponding to 12 elements – 3 models – 1). The corresponding 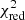 of each combination, along with the associated best-fit SNIa fraction – i.e. SNIa/SNe or, more formally, aSNIa/(aSNcc + aSNIa) – is shown in Fig. 2 (left). All these combinations are also counted in histograms and their distribution is shown in Fig. 2 (right). We define a combination as “statistically acceptable” if it verifies
of each combination, along with the associated best-fit SNIa fraction – i.e. SNIa/SNe or, more formally, aSNIa/(aSNcc + aSNIa) – is shown in Fig. 2 (left). All these combinations are also counted in histograms and their distribution is shown in Fig. 2 (right). We define a combination as “statistically acceptable” if it verifies 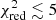 . Such a conservative value is chosen arbitrarily to account for systematic error in the models or in the IMF and to avoid ruling out potentially significant models. The distribution indicates that, in the vast majority of cases (17 383), the fit does not provide a good description of the mock measurements (
. Such a conservative value is chosen arbitrarily to account for systematic error in the models or in the IMF and to avoid ruling out potentially significant models. The distribution indicates that, in the vast majority of cases (17 383), the fit does not provide a good description of the mock measurements (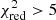 ). In fact we can distinguish two different features. A first peak (
). In fact we can distinguish two different features. A first peak (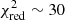 ) corresponds to a fit in which one out of the fitted models (either SNc or SNIa) is different from the input family of models used to perform the cosmological simulations. In that case, two of the models are close to reproducing correct metal production yields but the third one is not. Likewise, the second peak (
) corresponds to a fit in which one out of the fitted models (either SNc or SNIa) is different from the input family of models used to perform the cosmological simulations. In that case, two of the models are close to reproducing correct metal production yields but the third one is not. Likewise, the second peak (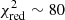 ) corresponds to the case where both the SNccand the SNIa models are different from the input family of models. In that case, none of them is consistent with the data set, thus providing a poorly accurate description of our mock abundance pattern.
) corresponds to the case where both the SNccand the SNIa models are different from the input family of models. In that case, none of them is consistent with the data set, thus providing a poorly accurate description of our mock abundance pattern.
 |
Fig. 2. Left: best-fit |
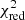
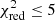
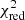
From the list of models presented in Appendix A, only 89 AGB+SNcc+SNIa combinations provide statistically acceptable results (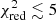 ). This represents only 0.5% of the total number of combinations. The X-IFU is therefore able to reject more than ≥99% of the theoretical combinations of models tested here. A further refinement can be performed by analysing the results of the fit, in particular the relative contribution of each mechanism. From previous observations, we know that the observed SNIa fraction is, very conservatively, comprised between 0.1 and 0.6 (see Tables 5 and 6 in de Grandi & Molendi 2009). As such, we can constrain the number of statistically accurate fits even further by requesting that aSNIa/(aSNIa + aSNcc) remains within these limits (Fig. 2, left). Following this second selection, 53 combinations satisfy
). This represents only 0.5% of the total number of combinations. The X-IFU is therefore able to reject more than ≥99% of the theoretical combinations of models tested here. A further refinement can be performed by analysing the results of the fit, in particular the relative contribution of each mechanism. From previous observations, we know that the observed SNIa fraction is, very conservatively, comprised between 0.1 and 0.6 (see Tables 5 and 6 in de Grandi & Molendi 2009). As such, we can constrain the number of statistically accurate fits even further by requesting that aSNIa/(aSNIa + aSNcc) remains within these limits (Fig. 2, left). Following this second selection, 53 combinations satisfy 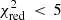 . In Table 3, we show the ten best-fit combinations satisfying this criterion.
. In Table 3, we show the ten best-fit combinations satisfying this criterion.
Top ten best-fit combinations of AGB+SNcc+SNIa models with our X-IFU mock observed abundance ratios at z = 0.1, with 0.1 < SNIa/SNe < 0.6 (see text).
While the combination of models used in the numerical simulations and recovered in Sect. 3.1 is remarkably situated among the top of all these best-fit combinations (black arrow in Fig. 2, left), we note that two other combinations (using respectively the 100-3-c3 and 500-5-c3 SNIa models from Leung & Nomoto 2018) provide a slightly better 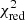 . We discuss the reasons for this mis-interpretation in Sect. 5.1 and further demonstrate that in more realistic conditions the X-IFU will be easily able to refine the discriminations between these combinations and strongly favour the one corresponding to the genuine sources of enrichment.
. We discuss the reasons for this mis-interpretation in Sect. 5.1 and further demonstrate that in more realistic conditions the X-IFU will be easily able to refine the discriminations between these combinations and strongly favour the one corresponding to the genuine sources of enrichment.
Among these statistically acceptable results, we also note that all the combinations predict correctly the input family of SNcc models. In fact, the yellow circles of Fig. 2 (left) below the dashed red line are all combinations in which only the SNIa model was not consistent with the input simulations. This means that our fits are more inclined to recover an accurate SNcc (family of) model(s) rather than an accurate SNIa model. However, the ability of the X-IFU to measure more ratios than presented here (Sect. 5.1) will eventually result in a much tighter filtering on the SNIa models.
Despite the conservative treatment of the systematic uncertainties considered above, one may wonder how our results would be altered if the X-IFU abundance measurements of one of the key elements turns out to be unreliable. To check this scenario, we re-fit our 17 472 combinations ignoring successively one given X/Fe ratio. The main effect is a slight decrease of 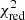 without significantly altering the SNIa fraction, resulting in a horizontal left shift of the pattern seen in Fig. 2 (left). Ignoring Ni/Fe has the most noticeable impact, with a total of 443 combinations becoming statistically acceptable (i.e. ∼2.5% of the total number of combinations). This is not surprising as, among all the ratios tested here, Ni/Fe is by far the most efficient at separating different SNIa models (see our discussion in Sect. 5.1). Ignoring other key ratios, such as Si/Fe or O/Fe (respectively 138 and 126 “statistically acceptable” combinations), has a much less pronounced impact on our results. Providing that the X-IFU will be able to measure the abundances of other key heavy elements (e.g. Cr, Mn; Sect. 5.1), our conclusions therefore hold even if not all ratios were considered as reliable.
without significantly altering the SNIa fraction, resulting in a horizontal left shift of the pattern seen in Fig. 2 (left). Ignoring Ni/Fe has the most noticeable impact, with a total of 443 combinations becoming statistically acceptable (i.e. ∼2.5% of the total number of combinations). This is not surprising as, among all the ratios tested here, Ni/Fe is by far the most efficient at separating different SNIa models (see our discussion in Sect. 5.1). Ignoring other key ratios, such as Si/Fe or O/Fe (respectively 138 and 126 “statistically acceptable” combinations), has a much less pronounced impact on our results. Providing that the X-IFU will be able to measure the abundances of other key heavy elements (e.g. Cr, Mn; Sect. 5.1), our conclusions therefore hold even if not all ratios were considered as reliable.
3.3. Lifting model degeneracies: the case of two SNIa models
In theory, multiple sources of the same type may co-exist and enrich the ICM in comparable amounts. This might be notably the case for SNIa, whose end of life can be significantly different depending on the single-degenerate versus double-degenerate scenario of their progenitors (and/or their deflagration vs. delayed-detonation thermonuclear explosions). Although this possibility is worth exploring, the use of multiple models to represent one class of physical events introduces one additional degree of freedom, which can be degenerate if the number and accuracy of the observed ratios is limited. In fact, this is one of the major limitations of current observatories when testing enrichment scenarios (Mernier et al. 2016a). To verify whether the accuracy expected from future X-IFU measurements is able to lift this degeneracy, we included an additional SNIa model to the fit to represent a more complex stellar reality. The same method as in Eq. (8) (Sect. 3) is applied, considering two scalars, aSNIa, 1 and aSNIa, 2, in the fit. Specifically, one SNIa model is chosen to be near-Chandrasekhar (near-MCh, corresponding predominantly to the single-degenerate progenitor channel) while the other is chosen to be sub-Chandrasekhar (sub-MCh, corresponding predominantly to the double-degenerate progenitor channel; see also Table A.3). Assuming the same diversity of AGB and SNcc models as in the previous section, this corresponds to a total of 4 AGB models × 24 SNcc models × 78 SNIa, 1 models × 96 SNIa, 2 models = 718 848 combinations of models. Although our input simulations include only one (near-MCh) SNIa contribution (Sect. 2.1), this exercise is fully relevant as it shows whether or not the X-IFU measurement accuracies are good enough to avoid misinterpreting one dominant SNIa model with a combination of two SNIa models that would (incorrectly) contribute in comparable amounts to the enrichment.
We find that 472 of these AGB+SNcc+SNIa, 1+SNIa, 2 combinations offer a 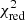 value below 1.5 (13 of which contain one input SNIa model), and are thus better at reproducing our X-IFU mock abundance pattern than the input AGB+SNcc+SNIa set of models (Sect. 3.1, Fig. 1). Although this seems to be a large number, this represents only ∼0.07% of the total number of our combinations including two SNIa models (near-MCh+sub-MCh). The more complex scenario where two SNIa models co-exist can be further constrained imposing a limit on the relative contributions from the two competing mechanisms. For instance, we can request the SNIa, 1/SNIa, 2 ratio (namely, aSNIa, 1/aSNIa, 2) not to exceed one order of magnitude, that is, that it lies between 0.1 and 10. These limits are arbitrarily chosen to satisfy the condition that both mechanisms remain quantitatively comparable (otherwise a single model should suffice at first order). When applying this criterion, together with the same criterion as in Sect. 3.2 (i.e. 0.1 < SNIa1 + 2/SNe < 0.6), the number of “realistic” combinations below
value below 1.5 (13 of which contain one input SNIa model), and are thus better at reproducing our X-IFU mock abundance pattern than the input AGB+SNcc+SNIa set of models (Sect. 3.1, Fig. 1). Although this seems to be a large number, this represents only ∼0.07% of the total number of our combinations including two SNIa models (near-MCh+sub-MCh). The more complex scenario where two SNIa models co-exist can be further constrained imposing a limit on the relative contributions from the two competing mechanisms. For instance, we can request the SNIa, 1/SNIa, 2 ratio (namely, aSNIa, 1/aSNIa, 2) not to exceed one order of magnitude, that is, that it lies between 0.1 and 10. These limits are arbitrarily chosen to satisfy the condition that both mechanisms remain quantitatively comparable (otherwise a single model should suffice at first order). When applying this criterion, together with the same criterion as in Sect. 3.2 (i.e. 0.1 < SNIa1 + 2/SNe < 0.6), the number of “realistic” combinations below 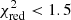 drops to 190 (i.e. ∼0.03% of the total number of combinations).
drops to 190 (i.e. ∼0.03% of the total number of combinations).
Admittedly, the present case includes more degeneracies than our previous, less complex attempts (i.e. simple AGB+SNcc+SNIa combinations). These numbers, and their interpretation as to the ability of the X-IFU to disentangle an ICM enrichment from one or two (or more) SNIa models, are further discussed in Sect. 5.1.
3.4. Best fits and extension to higher redshift
The results shown above offer very promising perspectives for the X-IFU. Through simple linear fits and physical considerations, we are able to accurately recover the underlying enrichment model implemented in the hydrodynamical simulations. As shown in Fig. 1 and Sect. 3.1, the best fit for the data set is obtained, at z = 0.1, for Zinit = 0.01 Z⊙ for SNcc yields and Zinit = 1 Z⊙ for AGB yields, with values of the reduced chi-squared of 1.49 for local clusters, nicely recovering the input yield models from the simulations.
The previous approach is also extended at z = 1 with excellent results (see Fig. 3). We find that the X-IFU is still capable of accurately recovering abundance ratios within R500 and the underlying input combination of models (same as Sect. 3.1) with good accuracy (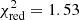 ). In addition, similarly to what has been reported in the input simulations (Biffi et al. 2018a), our mock X-IFU observations consistently show no significant changes in the measured ratios between our two tested redshifts.
). In addition, similarly to what has been reported in the input simulations (Biffi et al. 2018a), our mock X-IFU observations consistently show no significant changes in the measured ratios between our two tested redshifts.
 |
Fig. 3. Same as Fig. 1, over the cluster sample at z = 1 (instead of z = 0.1). Carbon and nitrogen are not shown as the lines are outside the energy bandpass of the X-IFU instrument. |
We note that the aim of this exercise is limited to recovering the yields used in our input simulations. A full constraint among all the other considered models (as in Sect. 3.2 and Sect. 3.3) is indeed less relevant at higher redshift if, as in our simulations, one assumes no substantial change in the physics of AGB, SNcc, and SNIa within the last 7–8 Gyr of ICM enrichment. Moreover, In the case of high-redshift systems, low-mass elements such as C and N can no longer be detected (as their emission lines fall outside the X-ray energy window) and measuring the abundance of rarer elements (e.g. Ne, Na, and Al) with sufficient statistical accuracy will require exposures deeper than 100 ks. At those high redshifts and for 100 ks exposures (or less), the derived AGB fraction is characterised by large uncertainties because the weight of those key low-mass elements becomes minimal in the fit. More accurate results call for better-adapted exposure strategies and larger sample studies in order to optimise the results for distant objects and to investigate the chemical enrichment of the AGB (in addition to SNe) across cosmic time.
4. Recovering the IMF with the X-IFU
4.1. Effect of the IMF on yields
Nucleosynthesis yields for AGB and SNcc are usually given for a specific progenitor mass. As a consequence, they need to be integrated in a consistent (and realistic) way before fitting the result to our measurements (together with SNIa models). In the approach described above, in order to be consistent with the large majority of previous observational strategies (de Plaa et al. 2007; Mernier et al. 2016a; Simionescu et al. 2019), full integration of these yields is performed using a Salpeter-like power law. Though representative at first order, more advanced models can be used (e.g. Chabrier-like, as in our input simulations; Chabrier 2003) to provide a more accurate description of the low-mass parts of the IMF in the integration. Similarly, the mass cut-off beyond which a massive star directly collapses into a black hole (i.e. without ejecting freshly produced elements, and therefore not influencing AGB and SNcc products) can be varied in the integration. Since all our models are integrated using the same IMF and mass cut-off (for consistency), no such related effects are expected in the above results. However, for a given AGB+SNcc+SNIa combination, one can vary α and Mcut and study their effects on the fits. This is particularly relevant to verify whether (and to which extent) the X-IFU will be able to provide constraints on the shape, the slope, and the mass cut-off of the IMF.
4.2. Recovering the IMF parameters for a fixed set of models
The original IMF proposed by Salpeter assumes a value of α = − 2.35 (Salpeter 1955). As our simulations initially assumed a Chabrier-like IMF, we aim to explore the effects of such changes on our best-fit combination of input yields (i.e. K10_0.02+Ro10_2E-4+Th03, see Sect. 3.1) at z = 0.1. To do so, we re-integrate the total AGB and SNcc yields over various arbitrary values of the IMF (Eq. (3)), with α ∈ [ − 1.5, −3.0], and using cut-off values of Mcut ∈ [25, 50] M⊙. We then successively re-fit these modified models on our mock measurements. The results – namely the variation of 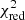 on the {α, Mcut} parameter plane – are provided in Fig. 4. For the given degrees of freedom, we notice that only a limited region of this plane provides results that are statistically consistent (i.e. within the 68% and 95% confidence intervals, corresponding respectively to Δχ2 values of 9.30 and 15.51 for 8 degrees of freedom) with our initial assumptions.
on the {α, Mcut} parameter plane – are provided in Fig. 4. For the given degrees of freedom, we notice that only a limited region of this plane provides results that are statistically consistent (i.e. within the 68% and 95% confidence intervals, corresponding respectively to Δχ2 values of 9.30 and 15.51 for 8 degrees of freedom) with our initial assumptions.
 |
Fig. 4. Value of |
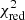
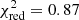
Clearly, the slope of the IMF has a significant effect on the consistency of the fit. Depending on its value, the reduced chi-square rises from ∼1 to more than 10. The confidence interval contours show little dependence on the mass cut-off, such that the best-fit value is given by α = −1.97 ± 0.24 (±0.47 at the 95% level). Around these values, the mass cut-off of the IMF at low progenitor masses has a large effect on the yields. This is expected, as a low Mcut implies that an appreciable fraction of massive stars is not considered in the integration, thereby causing a bias toward low values some low-mass elements. When Mcut ≥ 40 M⊙, the effect on the integration becomes negligible. This is related to the treatment of high-mass stars in the cosmological simulations (Rasia et al. 2015), which are considered to collapse directly into black-holes beyond 40 M⊙, hence creating no chemical elements.
This best-fit value of the IMF slope (α ≃ −2) can also be explained (Fig. 5). When fitting the Chabrier-like piece-wise function (Sect. 2.2) with a single slope power-law, the slope coefficient is indeed close to α ∼ −2. Although yields from AGBs (and by extension SNcc) contribute only for progenitors above 0.9 M⊙, the same study as for the Salpeter-like IMF can in principle be performed also on Chabrier-like IMFs. When manually re-integrating the baseline yields (Sect. 3.1) with such a Chabrier-like IMF (as initially assumed in the original hydrodynamical simulations; Tornatore et al. 2007), we find slight improvements with respect to the best fits obtained so far (Sect. 3.1; Table 3). In fact, 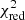 improves from 1.49 to 1.32 at z = 0.1 (with the S/Fe and Ni/Fe ratios becoming < 1σ consistent with the yield predictions, as well as a slight improvement on the Mg/Fe ratio), and from 1.53 to 1.41 at z = 1 (with improvements essentially on the Na/Fe and Al/Fe ratios).
improves from 1.49 to 1.32 at z = 0.1 (with the S/Fe and Ni/Fe ratios becoming < 1σ consistent with the yield predictions, as well as a slight improvement on the Mg/Fe ratio), and from 1.53 to 1.41 at z = 1 (with improvements essentially on the Na/Fe and Al/Fe ratios).
 |
Fig. 5. Comparison of assumed slopes of the IMF throughout this study (normalised for their integral within [0.9–50] M⊙ to be unity). The input Chabrier IMF (piece-wise function) as used in our input simulations is well reproduced by a power-law IMF of slope α = −1.97 ± 0.24 (see text). Stars with < 0.9 M⊙ are not expected to directly enrich their surroundings, and therefore IMFs are not considered below that mass limit. |
Using very simple considerations on the IMF, we showed that the X-IFU will be able to provide useful constraints on the (average) IMF of the stellar population(s) responsible for the enrichment. To some extent, it will be capable of distinguishing the mass cut-off of this function and to provide refinements on the value of the power slope (especially in the high-mass regime of SNcc progenitors, where presumably the IMF is close to a single-slope power law). The observation of multiple clusters with the X-IFU and the accuracy of the recovered abundance ratios will provide an interesting tool for future IMF studies. Further discussion on this point and the ability of the X-IFU to favour different functional shapes of the IMF is provided in Sect. 5.2.
5. Discussion
5.1. Ability of the X-IFU to constrain nucleosynthesis models
In Sects. 3.1 and 3.2, we show that the combination of AGB+SNcc+SNIa models representing the enrichment processes as injected in our cosmological simulations (blue stars in Fig. 2 left) are remarkably well recovered through the abundance ratios measured by the X-IFU. However, it also appeared that two other combinations (using SNIa models that were not initially considered in our simulations) provide a better fit to our mock abundance pattern.
At first glance, this may appear as a source of concern regarding the ability of the X-IFU to correctly isolate the dominant physical and environmental mechanisms at play for stellar sources responsible for the enrichment. Nevertheless, one should keep in mind that in the present exercise we limit our study to the elements individually tracked within the numerical simulations, while the capabilities of X-IFU (e.g. Ettori et al. 2013a) extend to the abundance measurement of other Fe-peak elements as well, such as Ti, V, Cr, and Mn. Although these elements were not tracked in the original simulations (Tornatore et al. 2007), they play a crucial role in the different SNIa explosion and progenitor scenarios. We illustrate this effect in Fig. 6, where the predicted X/Fe ratios of the five most favoured SNIa models from our AGB+SNcc+SNIa fits (Table 3) are compared. It clearly appears that the Ti/Fe, V/Fe, Cr/Fe, and Mn/Fe ratios offer a powerful way to favour and/or rule out specific models. On the other hand, it is quite remarkable to note that, in this work, the (already impressive) ability of the X-IFU to efficiently favour our input model (namely, Th03) among 181 other ones from the literature was based solely on the Si/Fe, S/Fe, Ar/Fe, Ca/Fe, and Ni/Fe ratios, which individually exhibit limited model-to-model differences.
 |
Fig. 6. Comparison of various X/Fe abundance ratios predicted by the SNIa yield models used in our top five “SNIa model” best fits (Table 3). Upper and lower horizontal axes mark respectively the odd- and even-Z elements. For comparison, we also show the relative (i.e. normalised to 1) observational uncertainties on the X/Fe ratios derived (i) in this work using the X-IFU (12 ratios, as tracked by our input simulations, C and N are not shown here), and (ii) using ∼300 ks of Hitomi/SXS (in synergy with ∼200 ks of XMM-Newton/RGS) exposure (Simionescu et al. 2019). |
These additional constraints expected from Ti, V, Cr, and Mn will depend on the typical uncertainties that the X-IFU will measure for these abundances. While a complete re-run of cosmological simulations including these elements (along with a thorough mock spectral re-analysis) is out of the scope of this paper (see below), we highlight the remarkable constraints on Cr/Fe and Mn/Fe that were already achieved by the Hitomi SXS observations of the Perseus cluster (Hitomi Collaboration 2017; Simionescu et al. 2019, red areas in Fig. 6). Given the factor ∼10–12 improvement in weak-line sensitivity offered by the X-IFU in that energy band (Barret et al. 2018) and the results presented in this work, it becomes clear that the X-IFU will ultimately be capable of isolating the most realistic physical and environmental constraints of SN progenitors responsible for the ICM enrichment.
The same reasoning could in principle be applied to the question of disentangling one from two SNIa models (Sect. 3.3). Although the X-IFU is fully capable of favouring our input (single-SNIa) enrichment model over more than 99.97% of all the combinations including two SNIa (i.e. near-MCh+sub-MCh) models, an ideal goal would consist of isolating the former while disfavouring all the two-SNIa combinations. The inclusion of Cr/Fe and Mn/Fe ratios (and likely Ti/Fe and V/Fe) will certainly help to approach this limit. As mentioned earlier, this is particularly relevant given the high sensitivity of Mn to disentangle between near-MCh and sub-MCh models (e.g. Seitenzahl et al. 2013a; Mernier et al. 2016a; Hitomi Collaboration 2017).
Admittedly, a complete demonstration of the X-IFU to favour one or two co-existing SNIa models would require not only the inclusion of these additional elements in the input simulations, but also the testing of the inverse exercise as proposed here – i.e. inject two SNIa progenitor channels in the simulations and test whether combinations with one SNIa model all fail to reproduce the resulting abundance pattern. Due to limited computing capacity, such re-runs are beyond the scope of this study and deeper investigation is therefore left to future work.
Another point of importance has been mentioned in Simionescu et al. (2019), where the authors show that no combination of the current models can simultaneously reproduce all the measured abundance ratios in the Perseus cluster. This suggests that the current nucleosynthesis models need to be further improved to include more realistic physical processes that may have an impact on their ejected yields (see also de Grandi & Molendi 2009). Such improvements will be crucial for the era of exquisite ICM abundance accuracies that will be unveiled by XRISM and Athena. They will also help to reduce the number of models that can be considered as physically realistic, further improving the constraints presented here.
5.2. Constraints on the IMF
The investigation on the IMF performed here (Sect. 4.2) demonstrates the breadth of possibilities that will be accessible through the X-IFU. In fact, most of the possible caveats come essentially from our choice of the enrichment models rather than the capabilities of the instrument. Specifically, we notice that with slight changes in the IMF parameters, 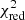 can easily go above the previous threshold of five for our set of input models. The question of whether other sets of models could provide more accurate fits when integrated with slightly different IMFs thus naturally arises. However, integrating other models using modified IMFs (using the abunfit package) confirms the results seen in Sect. 4, that is, a best-fit slope typically around α ∼ −2 and Mcut ∼ 40 M⊙. This can be explained by the very simple shape of the IMF considered here, but could provide significantly different results with more complex functions.
can easily go above the previous threshold of five for our set of input models. The question of whether other sets of models could provide more accurate fits when integrated with slightly different IMFs thus naturally arises. However, integrating other models using modified IMFs (using the abunfit package) confirms the results seen in Sect. 4, that is, a best-fit slope typically around α ∼ −2 and Mcut ∼ 40 M⊙. This can be explained by the very simple shape of the IMF considered here, but could provide significantly different results with more complex functions.
In fact, the IMF considered in the fits is simplistic, but ensures that we have only two parameters (slope and mass cut-off) to ease the interpretation. Other shapes can be considered, especially those with lower solar mass roll-offs (notably Chabrier-like, Fig. 5), which assume a (realistic) finite number of stars at low masses. However, in this case, interpreting the contribution of each part of the IMF to the final integrated yields becomes more challenging. Furthermore, as most of these IMFs (see a few examples in Chabrier 2003) are approximated at high solar masses by a power law (similar to that of Salpeter 1955), no substantial change in the results is expected (mostly second-order changes are observed when using a Chabrier-like IMF).
As shown in Sect. 4.2, the typical uncertainties on the ICM abundance ratios obtained with the 100 ks of X-IFU exposure on four nearby clusters will therefore allow us to derive constraints on the slope of the IMF of the order of ∼12% (i.e. Δα = 0.24). For comparison, while various measurements of the slope of the high-mass end of the IMF in the Galactic field, star-forming regions, associations, and star clusters show individual reported errors from ∼50% down to a few percent, they scatter with deviations up to ∼60–70% of the Salpeter value (e.g. Fig. 2 in Bastian et al. 2010). It becomes therefore evident that the Athena mission will play a key role in substantially improving our understanding of the IMF, its global properties, and the question of its universality. Given that elliptical galaxies show hot atmospheres even in compact, isolated halos (e.g. Reiprich & Böhringer 2002; Kim et al. 2019; Lakhchaura et al. 2019a; Gaspari et al. 2019), and under the condition that plasma emission codes will further provide the necessary accuracy, similar IMF studies can be expanded to the low-mass regime with similar statistics (e.g. lower luminosity is compensated by higher line emissivity of α-elements due to cooler plasma temperature).
Because successive generations of stars become continuously enriched with metals (which may in turn affect their masses and lifetimes), it is also possible that the IMF evolves with cosmic time, with more weight toward massive stars at higher redshifts (van Dokkum 2008; Wang & Dai 2011). For instance, van Dokkum (2008) reports a change of Δα ≃ 1.6 between a sample of 0.02 < z < 0.83 cluster galaxies and the canonical value around 1 M⊙. Although at a different mass range, this is larger than the typical uncertainty reported in Sect. 4.2. The question of how such a possible IMF evolution would affect the results presented here is not trivial, as it depends on (i) exactly how the IMF evolves with time and (ii) at which exact redshift range the metals seen today in the ICM were produced. While it is clear that good knowledge of the former will allow the X-IFU to bring constraints on the latter (or inversely), such constraints are difficult to quantify with the present simulations. Future work, with a time-changing IMF included in the input simulations, will certainly help to address this question.
As another consequence of stellar metallicities potentially evolving during the main epoch of enrichment, the simple assumption of using one Zinit in our models may limit the interpretation of the above results. While in such a case one can reasonably expect that Zinit represents the bulk of initial metallicities of SNcc progenitors, the precise impact on the derived IMF is less clear. As shown in Mernier et al. (2016a), the change of initial metallicity rather impacts the O/Ne ratio (see their Fig. 2 right) while the effect of the IMF is rather reflected on the Ne/Mg and Ne/Si ratios (see their Fig. 8). Although at first order we speculate that these effects are therefore limited, dedicated studies will be necessary to further quantify them.
5.3. Possible improvements of the current approach
From the above results, it is clear that the exquisite accuracy of the X-IFU in deriving ICM abundance ratios will allow us to favour and/or rule out various nucleosynthesis scenarios and conditions to explain the enrichment in galaxy clusters. This will considerably improve the constraints offered by the current missions (e.g. de Plaa et al. 2007; Mernier et al. 2016a, 2018b) as well as with the available Hitomi observations (Simionescu et al. 2019). As this work is the first attempt to quantify such constraints with the X-IFU, a few more points of discussion should be addressed, specifically in the context of improving our future observing strategies.
First, and as outlined above, the obtained numbers (which are used to draw our conclusions) depend on the choice of the input yields in the hydrodynamical simulations used to generate synthetic X-IFU observations (described in Paper I and references therein). Different results might be expected if for instance the yields assumed in the hydrodynamical simulations produce a truly unique chemical signature while on the contrary a large fraction of all the other model combinations happen to produce very similar abundance patterns. Although this is in practice unlikely to be the case here (see the rather large spread in the 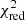 of Fig. 2), a proper validation would require tests with other input models, which we defer to future studies. We also note that no uncertainties are associated with these yields, simply because none are directly available in the current literature (although de Grandi & Molendi 2009 reported some yield uncertainties on the order of tens of percent).
of Fig. 2), a proper validation would require tests with other input models, which we defer to future studies. We also note that no uncertainties are associated with these yields, simply because none are directly available in the current literature (although de Grandi & Molendi 2009 reported some yield uncertainties on the order of tens of percent).
In this study, abundance ratios were derived within R500 over four clusters. Although no strong observational evidence has been reported so far, the internal dynamical structure of clusters (e.g. turbulence, diffusion, AGN feedback) could to some extent affect the abundance ratios with radial and/or azimuthal inhomogeneities. This would naturally induce biases as a function of the spatial scale over which measurements are performed. However, this effect can be safely neglected in our case. Indeed, Figs. 3, 4, and 5 of Paper I clearly show that despite mild spatial metallicity inhomogeneities for a given system (and mild cluster-to-cluster differences in their metallicity profiles), the abundance ratios remain spatially uniform within uncertainties. It should be noted that, even though this picture is actually consistent with the absence of radial variation in abundance ratios reported on several observed systems (e.g. Ezer et al. 2017; Mernier et al. 2017) and in simulations (Biffi et al. 2017), future X-IFU observations will be able to simultaneously measure abundance ratios integrated over large regions with very high accuracy (as shown in this paper) and investigate abundance ratios on much smaller (1D or 2D) scales. These local variations and anisotropies will also be key to constraining other important ICM observables, such as X-ray cavities and jets (driven via AGN feedback; e.g. Gaspari et al. 2020) or the halo structure (shaped by mergers and sloshing; e.g. Ettori et al. 2013b).
Moreover, we cannot exclude the possibility that different elements do not enrich their surroundings with the same efficiency. For instance, specific elements freshly produced by SNe could be more (or less) easily depleted into dust than others before (or even after) ending up in the ICM. Multi-phase gas, which were not included in the present simulations due to sub-grid physics limitations, could also play an important role in this respect. The question of the interplay between hot gas and dust phases of metals (and their enrichment) in the central regions of galactic and cluster hot atmospheres has indeed only just begun to be explored (e.g. Panagoulia et al. 2015; Lakhchaura et al. 2019b; Liu et al. 2019). If this were the case, the observed abundance pattern should be reproduced with comprehensive chemo-dynamical models rather than linear fits of yield model combinations.
Despite our conservative approach to consider all fits with 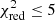 as statistically acceptable, a proper and thorough quantification of all the possible systematic uncertainties (e.g. instrumental response and calibration, spectral code uncertainties, background reproducibility, and subtle residual scatter in the ratios of different systems) that might affect future real observations will be important for the next steps of such studies. In high-redshift clusters, cosmic variance and AGN contamination might also require us to adapt the spatial and spectral analysis. While these systematic errors will contribute to increasing the total uncertainties, dedicated observing strategies (via e.g. larger samples or deeper exposures) will very likely help to compensate for this effect, in addition to optimising the ability of the X-IFU to constrain SN models. Future dedicated work on the total error budget, on the 12 abundance ratios studied here as well as additional ones (Sect. 5.1), will help to refine our results and predict the abilities of distinction between more subtle models.
as statistically acceptable, a proper and thorough quantification of all the possible systematic uncertainties (e.g. instrumental response and calibration, spectral code uncertainties, background reproducibility, and subtle residual scatter in the ratios of different systems) that might affect future real observations will be important for the next steps of such studies. In high-redshift clusters, cosmic variance and AGN contamination might also require us to adapt the spatial and spectral analysis. While these systematic errors will contribute to increasing the total uncertainties, dedicated observing strategies (via e.g. larger samples or deeper exposures) will very likely help to compensate for this effect, in addition to optimising the ability of the X-IFU to constrain SN models. Future dedicated work on the total error budget, on the 12 abundance ratios studied here as well as additional ones (Sect. 5.1), will help to refine our results and predict the abilities of distinction between more subtle models.
Finally, the approach adopted in this work relies on simple linear fits using χ2 statistics, allowing comparison with the previous observational studies – using XMM-Newton (e.g. Ettori et al. 2002; de Plaa et al. 2007; Mernier et al. 2016a) and/or Hitomi (Simionescu et al. 2019). Such a methodology will naturally tend to preferentially reproduce ratios that have the smallest error bars. While this is not a problem for the context of this work, better approaches (e.g. using a Bayesian formalism) might be more appropriate for future real data, especially if some specific ratios suffer from additional systematic uncertainties (calibration, spectral codes, etc.) and/or if future nucleosynthesis calculations are provided with formal uncertainties on their predicted yields. A thorough, comprehensive comparison between different statistical methods – listing advantages and drawbacks that are relevant for our goals – is left for future work.
6. Summary and conclusions
In this paper, which naturally follows Paper I, we use synthetic observations of clusters extracted from hydrodynamical simulations (Rasia et al. 2015) to demonstrate the capabilities of the X-IFU in constraining the chemical composition of the ICM. These mock observations were obtained using the X-IFU end-to-end simulator SIXTE (Dauser et al. 2019). The measured abundance ratios were then compared to various combinations of existing AGB, SNcc, and SNIa yields from the literature. Our main results can be summarised as follows.
-
The AGB+SNcc+SNIa combination of yield models that was used as input in the hydrodynamical simulations (Tornatore et al. 2007) is successfully recovered by the X-IFU, both at low (z = 0.1) and high (z = 1) redshifts. With
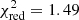 for local systems, this combination constitutes the third best fit (out of more than 17 000 combinations) with our mock abundance ratios.
for local systems, this combination constitutes the third best fit (out of more than 17 000 combinations) with our mock abundance ratios. -
Complementary to the previous result, we show that a very large number of model combinations (> 99.5%) could be excluded as they provide a significantly worse fit. Expecting even further improvements when accounting for additional crucial ratios (e.g. Cr/Fe, Mn/Fe), this demonstrates that the X-IFU will be able to efficiently favour or rule out specific yield models, therefore providing valuable physical constraints on AGB, SNcc, and SNIa and their progenitors. These conclusions are essentially unchanged when the assumption of two co-exisiting SNIa models is considered.
-
For a fixed AGB+SNcc+SNIa model combination (i.e. the one that was recovered as input yields in the simulations), we tried to determine the possible constraints the X-IFU could provide on the stellar IMF, which is a critical parameter to understand the stellar and chemical evolution of the Universe. Through a simple integration of the yields using a Salpeter-like IMF (i.e. power-law like, see Salpeter 1955), we demonstrate that the X-IFU will provide accurate values on the slope (within less than ∼12%) and the upper mass cut-off of this function. Even further, the Chabrier-like shape of the IMF as used in our input simulations is recovered and favoured in the observations as well. Coupled with other observational evidence, the ability of the X-IFU to pick up a sensible IMF will help to better characterise it and test its (non-)universality.
This study assesses – for the first time – the feasibility of a future instrument in providing constraints on the metal enrichment of the Universe by measuring the chemical composition of the ICM to an unprecedented level. Quite remarkably, most limitations are generally related to our current methodology (which should be considered as a first step) and/or model uncertainties rather than to the X-IFU capabilities. With multiple cluster observations at very high accuracy (which will also help in estimating the total metal budget in the entire cluster volume; e.g. Molendi et al. 2016), and provided that the upcoming XRISM observations will motivate continuous improvements on (i) nucleosynthesis calculations and (ii) spectral atomic codes (as done already with the Hitomi observation of Perseus; Hitomi Collaboration 2018), the X-IFU will provide astronomers with new ways to investigate quantities such as metal production yields in stars, end-of-life models of compact objects, or the mass distribution of stars in the Universe.
Below ∼1 M⊙, stellar mass losses are negligible compared to the AGB wind losses above that limit. Below ∼10 M⊙, the core of a star is not massive enough to collapse and trigger a SNcc explosion (e.g. Nomoto et al. 2013).
As seen from Figs. 5 and 8 of Paper I, the simulation-to-data discrepancies of the Mg/Fe ratio are mainly present in Cluster 3 (cool-core), while the other systems do not seem to be affected. While this may suggest that projection effects play a role in such simulations-to-data discrepancies (especially if Cluster 3 is affected by large-scale motions or substructures), the absence of such discrepancies for other ratios originating from the same source of enrichment (e.g. O/Fe) prevents us from excluding the other possibilities mentioned in the text.
Acknowledgments
The authors thank the anonymous referee for useful suggestions that helped to improve this paper, as well as A. Simionescu for insightful discussions. This work is supported by the Lendület LP2016-11 grant awarded by the Hungarian Academy of Sciences. V.B. acknowledges support by the DFG project nr. 415510302. V.B., S.B. and E.R. acknowledge financial contribution from the contract ASI-INAF n.2017-14-H.0. E.R. and S.B. acknowledge the ExaNeSt and Euro Exa projects, funded by the European Union’s Horizon 2020 research and innovation programme, under grant agreement No 754337. S.B. also acknowledges support from the INFN INDARK grant. K.D. acknowledges support through ORIGINS, founded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under Germany’s Excellence Strategy – EXC-2094 – 390783311. S.E. acknowledges financial contribution from the contracts ASI-INAF Athena 2015-046-R.0, ASI-INAF Athena 2019-27-HH.0, “Attività di Studio per la comunità scientifica di Astrofisica delle Alte Energie e Fisica Astroparticellare” (Accordo Attuativo ASI-INAF n. 2017-14-H.0), and from INAF “Call per interventi aggiuntivi a sostegno della ricerca di main stream di INAF”. M.G. is supported by the Lyman Spitzer Jr. Fellowship (Princeton University) and by NASA Chandra GO8-19104X/GO9-20114X and HST GO-15890.020-A grants. Our French and CNES colleagues are grateful to CNES for their outstanding support in developing the X-IFU for Athena. SRON is supported financially by NWO, the Netherlands Organization for Scientific Research.
References
- Anders, E., & Grevesse, N. 1989, Geochim. Cosmochim. Acta, 53, 197 [Google Scholar]
- Arnaud, K. A. 1996, in Astronomical Data Analysis Software and Systems V, eds. G. H. Jacoby, & J. Barnes, ASP Conf. Ser., 101, 17 [Google Scholar]
- Badenes, C., Borkowski, K. J., Hughes, J. P., Hwang, U., & Bravo, E. 2006, ApJ, 645, 1373 [NASA ADS] [CrossRef] [Google Scholar]
- Barret, D., Lam Trong, T., den Herder, J. W., et al. 2016, in Space Telescopes and Instrumentation 2016: Ultraviolet to Gamma Ray, Proc. SPIE, 9905, 99052F [CrossRef] [Google Scholar]
- Barret, D., Lam Trong, T., den Herder, J. W., et al. 2018, in Space Telescopes and Instrumentation 2018: Ultraviolet to Gamma Ray, SPIE Conf. Ser., 10699, 106991G [Google Scholar]
- Bastian, N., Covey, K. R., & Meyer, M. R. 2010, ARA&A, 48, 339 [NASA ADS] [CrossRef] [Google Scholar]
- Biffi, V., Planelles, S., Borgani, S., et al. 2017, MNRAS, 468, 531 [NASA ADS] [CrossRef] [Google Scholar]
- Biffi, V., Planelles, S., Borgani, S., et al. 2018a, MNRAS, 476, 2689 [NASA ADS] [CrossRef] [Google Scholar]
- Biffi, V., Mernier, F., & Medvedev, P. 2018b, Space Sci. Rev., 214, 123 [NASA ADS] [CrossRef] [Google Scholar]
- Bulbul, E., Smith, R. K., & Loewenstein, M. 2012, ApJ, 753, 54 [NASA ADS] [CrossRef] [Google Scholar]
- Burbidge, E. M., Burbidge, G. R., Fowler, W. A., & Hoyle, F. 1957, Rev. Mod. Phys., 29, 547 [NASA ADS] [CrossRef] [Google Scholar]
- Chabrier, G. 2003, PASP, 115, 763 [Google Scholar]
- Clerc, N., Cucchetti, E., Pointecouteau, E., & Peille, P. 2019, A&A, 629, A143 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cucchetti, E., Pointecouteau, E., Peille, P., et al. 2018, A&A, 620, A173 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cucchetti, E., Clerc, N., Pointecouteau, E., Peille, P., & Pajot, F. 2019, A&A, 629, A144 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cyburt, R. H., Fields, B. D., Olive, K. A., & Yeh, T.-H. 2016, Rev. Mod. Phys., 88, 015004 [NASA ADS] [CrossRef] [Google Scholar]
- Dauser, T., Falkner, S., Lorenz, M., et al. 2019, A&A, 630, A66 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- de Grandi, S., & Molendi, S. 2009, A&A, 508, 565 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- De Grandi, S., Eckert, D., Molendi, S., et al. 2016, A&A, 592, A154 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- De Masi, C., Vincenzo, F., Matteucci, F., et al. 2019, MNRAS, 483, 2217 [NASA ADS] [CrossRef] [Google Scholar]
- de Plaa, J., Werner, N., Bykov, A. M., et al. 2006, A&A, 452, 397 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- de Plaa, J., Werner, N., Bleeker, J. A. M., et al. 2007, A&A, 465, 345 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- de Plaa, J., Kaastra, J. S., Werner, N., et al. 2017, A&A, 607, A98 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ettori, S., Fabian, A. C., Allen, S. W., & Johnstone, R. M. 2002, MNRAS, 331, 635 [NASA ADS] [CrossRef] [Google Scholar]
- Ettori, S., Pratt, G. W., de Plaa, J., et al. 2013a, ArXiv e-prints [arXiv:1306.2322] [Google Scholar]
- Ettori, S., Gastaldello, F., Gitti, M., et al. 2013b, A&A, 555, A93 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ettori, S., Baldi, A., Balestra, I., et al. 2015, A&A, 578, A46 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ezer, C., Bulbul, E., Nihal Ercan, E., et al. 2017, ApJ, 836, 110 [NASA ADS] [CrossRef] [Google Scholar]
- Fabjan, D., Borgani, S., Tornatore, L., et al. 2010, MNRAS, 401, 1670 [NASA ADS] [CrossRef] [Google Scholar]
- Fink, M., Kromer, M., Seitenzahl, I. R., et al. 2014, MNRAS, 438, 1762 [NASA ADS] [CrossRef] [Google Scholar]
- Gaspari, M., Melioli, C., Brighenti, F., & D’Ercole, A. 2011, MNRAS, 411, 349 [NASA ADS] [CrossRef] [Google Scholar]
- Gaspari, M., Eckert, D., Ettori, S., et al. 2019, ApJ, 884, 169 [NASA ADS] [CrossRef] [Google Scholar]
- Gaspari, M., Tombesi, F., & Cappi, M. 2020, Nat. Astron., 4, 10 [CrossRef] [Google Scholar]
- Gastaldello, F., & Molendi, S. 2002, ApJ, 572, 160 [NASA ADS] [CrossRef] [Google Scholar]
- Greif, T. H., Glover, S. C. O., Bromm, V., & Klessen, R. S. 2009, MNRAS, 392, 1381 [NASA ADS] [CrossRef] [Google Scholar]
- Heger, A., & Woosley, S. E. 2002, ApJ, 567, 532 [NASA ADS] [CrossRef] [Google Scholar]
- Heger, A., & Woosley, S. E. 2010, ApJ, 724, 341 [NASA ADS] [CrossRef] [Google Scholar]
- Hillebrandt, W., Kromer, M., Röpke, F. K., & Ruiter, A. J. 2013, Front. Phys., 8, 116 [Google Scholar]
- Hitomi Collaboration (Aharonian, F., et al.) 2017, Nature, 551, 478 [NASA ADS] [CrossRef] [Google Scholar]
- Hitomi Collaboration (Aharonian, F., et al.) 2018, PASJ, 70, 12 [NASA ADS] [Google Scholar]
- Humphrey, P. J., & Buote, D. A. 2006, ApJ, 639, 136 [NASA ADS] [CrossRef] [Google Scholar]
- Iben, I., Jr, & Renzini, A. 1983, ARA&A, 21, 271 [NASA ADS] [CrossRef] [Google Scholar]
- Iwamoto, K., Brachwitz, F., Nomoto, K., et al. 1999, ApJS, 125, 439 [NASA ADS] [CrossRef] [MathSciNet] [Google Scholar]
- Karakas, A. I. 2010, MNRAS, 403, 1413 [NASA ADS] [CrossRef] [Google Scholar]
- Kim, D.-W., Anderson, C., Burke, D., et al. 2019, ApJS, 241, 36 [NASA ADS] [CrossRef] [Google Scholar]
- Kirkpatrick, C. C., McNamara, B. R., & Cavagnolo, K. W. 2011, ApJ, 731, L23 [NASA ADS] [CrossRef] [Google Scholar]
- Kromer, M., Fink, M., Stanishev, V., et al. 2013, MNRAS, 429, 2287 [NASA ADS] [CrossRef] [Google Scholar]
- Kromer, M., Ohlmann, S. T., Pakmor, R., et al. 2015, MNRAS, 450, 3045 [NASA ADS] [CrossRef] [Google Scholar]
- Lakhchaura, K., Truong, N., & Werner, N. 2019a, MNRAS, 488, L134 [CrossRef] [Google Scholar]
- Lakhchaura, K., Mernier, F., & Werner, N. 2019b, A&A, 623, A17 [CrossRef] [EDP Sciences] [Google Scholar]
- Leung, S.-C., & Nomoto, K. 2018, ApJ, 861, 143 [NASA ADS] [CrossRef] [Google Scholar]
- Liu, A., Zhai, M., & Tozzi, P. 2019, MNRAS, 485, 1651 [CrossRef] [Google Scholar]
- Liu, A., Tozzi, P., Ettori, S., et al. 2020, A&A, 637, A58 [CrossRef] [EDP Sciences] [Google Scholar]
- Lodders, K., Palme, H., & Gail, H.-P. 2009, Landolt Börnstein, 712 [Google Scholar]
- Madau, P., & Dickinson, M. 2014, ARA&A, 52, 415 [NASA ADS] [CrossRef] [Google Scholar]
- Maeda, K., Röpke, F. K., Fink, M., et al. 2010, ApJ, 712, 624 [NASA ADS] [CrossRef] [Google Scholar]
- Mantz, A. B., Allen, S. W., Morris, R. G., et al. 2017, MNRAS, 472, 2877 [NASA ADS] [CrossRef] [Google Scholar]
- Maoz, D., Mannucci, F., & Nelemans, G. 2014, ARA&A, 52, 107 [NASA ADS] [CrossRef] [Google Scholar]
- Marquardt, K. S., Sim, S. A., Ruiter, A. J., et al. 2015, A&A, 580, A118 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Matteucci, F., & Chiappini, C. 2005, PASA, 22, 49 [NASA ADS] [CrossRef] [Google Scholar]
- McCarthy, I. G., Schaye, J., Ponman, T. J., et al. 2010, MNRAS, 406, 822 [NASA ADS] [Google Scholar]
- McDonald, M., Bulbul, E., de Haan, T., et al. 2016, ApJ, 826, 124 [NASA ADS] [CrossRef] [Google Scholar]
- Mernier, F., de Plaa, J., Lovisari, L., et al. 2015, A&A, 575, A37 [Google Scholar]
- Mernier, F., de Plaa, J., Pinto, C., et al. 2016a, A&A, 595, A126 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mernier, F., de Plaa, J., Pinto, C., et al. 2016b, A&A, 592, A157 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mernier, F., de Plaa, J., Kaastra, J. S., et al. 2017, A&A, 603, A80 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mernier, F., Biffi, V., Yamaguchi, H., et al. 2018a, Space Sci. Rev., 214, 129 [NASA ADS] [CrossRef] [Google Scholar]
- Mernier, F., Werner, N., de Plaa, J., et al. 2018b, MNRAS, 480, L95 [NASA ADS] [CrossRef] [Google Scholar]
- Million, E. T., Werner, N., Simionescu, A., & Allen, S. W. 2011, MNRAS, 418, 2744 [NASA ADS] [CrossRef] [Google Scholar]
- Molendi, S., Eckert, D., De Grandi, S., et al. 2016, A&A, 586, A32 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Nandra, K., Barret, D., Barcons, X., et al. 2013, ArXiv e-prints [arXiv:1306.2307] [Google Scholar]
- Nomoto, K., & Hashimoto, M. 1988, Phys. Rep., 163, 13 [NASA ADS] [CrossRef] [Google Scholar]
- Nomoto, K., Kobayashi, C., & Tominaga, N. 2013, ARA&A, 51, 457 [NASA ADS] [CrossRef] [Google Scholar]
- Ohlmann, S. T., Kromer, M., Fink, M., et al. 2014, A&A, 572, A57 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Padovani, P., & Matteucci, F. 1993, ApJ, 416, 26 [NASA ADS] [CrossRef] [Google Scholar]
- Pakmor, R., Kromer, M., Röpke, F. K., et al. 2010, Nature, 463, 61 [NASA ADS] [CrossRef] [PubMed] [Google Scholar]
- Pakmor, R., Kromer, M., Taubenberger, S., et al. 2012, ApJ, 747, L10 [Google Scholar]
- Panagoulia, E. K., Sanders, J. S., & Fabian, A. C. 2015, MNRAS, 447, 417 [NASA ADS] [CrossRef] [Google Scholar]
- Pointecouteau, E., Reiprich, T. H., Adami, C., et al. 2013, ArXiv e-prints [arXiv:1306.2319] [Google Scholar]
- Rasia, E., Borgani, S., Murante, G., et al. 2015, ApJ, 813, L17 [NASA ADS] [CrossRef] [Google Scholar]
- Reiprich, T. H., & Böhringer, H. 2002, ApJ, 567, 716 [NASA ADS] [CrossRef] [Google Scholar]
- Romano, D., Karakas, A. I., Tosi, M., & Matteucci, F. 2010, A&A, 522, A32 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Roncarelli, M., Gaspari, M., Ettori, S., et al. 2018, A&A, 618, A39 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Salpeter, E. E. 1955, ApJ, 121, 161 [Google Scholar]
- Schindler, S., & Diaferio, A. 2008, Space Sci. Rev., 134, 363 [NASA ADS] [CrossRef] [Google Scholar]
- Seitenzahl, I. R., Cescutti, G., Röpke, F. K., Ruiter, A. J., & Pakmor, R. 2013a, A&A, 559, L5 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Seitenzahl, I. R., Ciaraldi-Schoolmann, F., Röpke, F. K., et al. 2013b, MNRAS, 429, 1156 [Google Scholar]
- Seitenzahl, I. R., Kromer, M., Ohlmann, S. T., et al. 2016, A&A, 592, A57 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Shen, K. J., Boubert, D., Gänsicke, B. T., et al. 2018, ApJ, 865, 15 [Google Scholar]
- Sim, S. A., Röpke, F. K., Hillebrandt, W., et al. 2010, ApJ, 714, L52 [Google Scholar]
- Sim, S. A., Fink, M., Kromer, M., et al. 2012, MNRAS, 420, 3003 [NASA ADS] [CrossRef] [Google Scholar]
- Simionescu, A., Werner, N., Böhringer, H., et al. 2009, A&A, 493, 409 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Simionescu, A., Nakashima, S., Yamaguchi, H., et al. 2019, MNRAS, 483, 1701 [NASA ADS] [CrossRef] [Google Scholar]
- Sukhbold, T., Ertl, T., Woosley, S. E., Brown, J. M., & Janka, H.-T. 2016, ApJ, 821, 38 [Google Scholar]
- Takahashi, T., Kokubun, M., Mitsuda, K., et al. 2018, J. Astron. Telescopes Instrum. Syst., 4, 021402 [Google Scholar]
- Thielemann, F.-K., Argast, D., Brachwitz, F., et al. 2003, From Twilight to Highlight: The Physics of Supernovae, eds. W. Hillebrandt, & B. Leibundgut, 331 [CrossRef] [Google Scholar]
- Tornatore, L., Borgani, S., Dolag, K., & Matteucci, F. 2007, MNRAS, 382, 1050 [NASA ADS] [CrossRef] [Google Scholar]
- Truong, N., Rasia, E., Biffi, V., et al. 2019, MNRAS, 484, 2896 [NASA ADS] [CrossRef] [Google Scholar]
- Urban, O., Werner, N., Allen, S. W., Simionescu, A., & Mantz, A. 2017, MNRAS, 470, 4583 [NASA ADS] [CrossRef] [Google Scholar]
- Urdampilleta, I., Mernier, F., Kaastra, J. S., et al. 2019, A&A, 629, A31 [CrossRef] [EDP Sciences] [Google Scholar]
- Utrobin, V. P., Wongwathanarat, A., Janka, H.-T., & Müller, E. 2015, A&A, 581, A40 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- van Dokkum, P. G. 2008, ApJ, 674, 29 [NASA ADS] [CrossRef] [Google Scholar]
- Waldman, R., Sauer, D., Livne, E., et al. 2011, ApJ, 738, 21 [NASA ADS] [CrossRef] [Google Scholar]
- Wang, F. Y., & Dai, Z. G. 2011, ApJ, 727, L34 [NASA ADS] [CrossRef] [Google Scholar]
- Webbink, R. F. 1984, ApJ, 277, 355 [NASA ADS] [CrossRef] [Google Scholar]
- Werner, N., de Plaa, J., Kaastra, J. S., et al. 2006, A&A, 449, 475 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Werner, N., Durret, F., Ohashi, T., Schindler, S., & Wiersma, R. P. C. 2008, Space Sci. Rev., 134, 337 [NASA ADS] [CrossRef] [Google Scholar]
- Werner, N., Urban, O., Simionescu, A., & Allen, S. W. 2013, Nature, 502, 656 [NASA ADS] [CrossRef] [Google Scholar]
- Whelan, J., & Iben, I., Jr 1973, ApJ, 186, 1007 [Google Scholar]
- Woosley, S. E., & Weaver, T. A. 1995, ApJS, 101, 181 [NASA ADS] [CrossRef] [Google Scholar]
- XRISM Science Team 2020, ArXiv e-prints [arXiv:2003.04962] [Google Scholar]
Appendix A: List of nucleosynthesis yield models
AGB yield models used in this work via the abunfit package (see below for references).
SNcc yield models used in this work via the abunfit package (see below for references).
SNIa yield models used in this work via the abunfit package (continues on next pages, see below for references).
All Tables
Mean abundance ratios with respect to iron, obtained from the simulation input values (“i” in the second column) and the analysis of the mock X-IFU data (“o” in the second column) of the z ∼ 0.1 simulated clusters of Paper I (100 ks of mock exposure for each system, labelled as cool-core [CC] or non-cool-core [NCC]).
Top ten best-fit combinations of AGB+SNcc+SNIa models with our X-IFU mock observed abundance ratios at z = 0.1, with 0.1 < SNIa/SNe < 0.6 (see text).
AGB yield models used in this work via the abunfit package (see below for references).
SNcc yield models used in this work via the abunfit package (see below for references).
SNIa yield models used in this work via the abunfit package (continues on next pages, see below for references).
All Figures
|
Fig. 1. Average abundance ratio X/Fe within R500 over the cluster sample for z = 0.1 recovered using 100 ks observations. These values are fitted using the enrichment yields derived from the references provided in Paper I. The corresponding fitted contributions of SNIa (blue), SNcc (magenta), and AGB stars (yellow) are shown as histograms. |
| In the text | |
|
Fig. 2. Left: best-fit |
| In the text | |
|
Fig. 3. Same as Fig. 1, over the cluster sample at z = 1 (instead of z = 0.1). Carbon and nitrogen are not shown as the lines are outside the energy bandpass of the X-IFU instrument. |
| In the text | |
|
Fig. 4. Value of |
| In the text | |
|
Fig. 5. Comparison of assumed slopes of the IMF throughout this study (normalised for their integral within [0.9–50] M⊙ to be unity). The input Chabrier IMF (piece-wise function) as used in our input simulations is well reproduced by a power-law IMF of slope α = −1.97 ± 0.24 (see text). Stars with < 0.9 M⊙ are not expected to directly enrich their surroundings, and therefore IMFs are not considered below that mass limit. |
| In the text | |
|
Fig. 6. Comparison of various X/Fe abundance ratios predicted by the SNIa yield models used in our top five “SNIa model” best fits (Table 3). Upper and lower horizontal axes mark respectively the odd- and even-Z elements. For comparison, we also show the relative (i.e. normalised to 1) observational uncertainties on the X/Fe ratios derived (i) in this work using the X-IFU (12 ratios, as tracked by our input simulations, C and N are not shown here), and (ii) using ∼300 ks of Hitomi/SXS (in synergy with ∼200 ks of XMM-Newton/RGS) exposure (Simionescu et al. 2019). |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.