| Issue |
A&A
Volume 633, January 2020
|
|
|---|---|---|
| Article Number | A26 | |
| Number of page(s) | 13 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/201936163 | |
| Published online | 03 January 2020 | |
High-precision Monte Carlo modelling of galaxy distribution
1
Aix Marseille Université, CNRS/IN2P3, CPPM, Marseille, France
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Aix Marseille Univ, Université de Toulon, CNRS, CPT, Marseille, France
3
LAL, Univ. Paris-Sud, CNRS/IN2P3, Université Paris-Saclay, Orsay, France
4
Institut de Physique Nucléaire de Lyon, 69622 Villeurbanne, France
Received:
24
June
2019
Accepted:
1
November
2019
Abstract
We revisit the case of fast Monte Carlo simulations of galaxy positions for a non-Gaussian field. More precisely, we address the question of generating a 3D field with a given one-point function (e.g. log-normal) and some power spectrum fixed by cosmology. We highlight and investigate a problem that occurs in the log-normal case when the field is filtered, and we identify a regime where this approximation still holds. However, we show that the filtering is unnecessary if aliasing effects are taken into account and the discrete sampling step is carefully controlled. In this way we demonstrate a sub-percent precision of all our spectra up to the Nyquist frequency. We extend the method to generate a full light cone evolution, comparing two methods for this process, and validate our method with a tomographic analysis. We analytically and numerically investigate the structure of the covariance matrices obtained with such simulations which may be useful for future large and deep surveys.
Key words: large-scale structure of Universe / methods: statistical
© P. Baratta et al. 2020
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
1. Introduction
Fast Monte Carlo methods are essential tools to design analyses over large datasets. Widely used in the cosmic microwave background (CMB) community, thanks to the high-quality Healpix software (Górski et al. 2005), they are less frequently used in galactic surveys where analyses often rely on mock catalogues following a complicated and heavy process chain. The reason is that the problem is more complex since, with respect to the CMB,
-
the galaxy distribution follows a 3D stochastic point process;
-
the underlying continuous field is non-Gaussian.
The first point, which leads to shot noise, can be accommodated, although a Monte Carlo tool cannot provide universal “window functions” for correcting voxel effects since the data do not lie on a sphere, but on some complicated 3D domain.
The matter distribution field cannot be Gaussian. A very simple way to see it is to note that even in the so-called linear regime (i.e. for scales above ≃8 h−1 Mpc) the value measured is σ8 ≃ 0.8, which represents the standard deviation of the matter density contrast 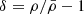 . If the one-point distribution P(δ) followed a Gaussian with such a standard deviation, the energy density
. If the one-point distribution P(δ) followed a Gaussian with such a standard deviation, the energy density 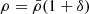 would become negative in about P(δ ≤ −1) = 10% of the cases. This very obvious argument demonstrates that even in what is known as the linear regime, the field is non-Gaussian and follows some more involved distribution.
would become negative in about P(δ ≤ −1) = 10% of the cases. This very obvious argument demonstrates that even in what is known as the linear regime, the field is non-Gaussian and follows some more involved distribution.
This is a serious problem because non-Gaussian fields are difficult to characterise (Adler 1981) and shooting samples according to their characterisations is a Herculean task. Cosmologists focussed essentially on the subset of fields obtained by applying a transformation to a Gaussian field (Coles & Barrow 1987). Remarkably, in some (rare) cases the auto-correlation function of the transformed field can be expressed analytically from the Gaussian field. This happens for the log-normal (LN) field, obtained essentially by taking the exponential of a Gaussian field (Coles & Jones 1991), which largely explains the reason for its success in cosmology.
Hubble conjectured the LN distribution in 1934 (Hubble 1934), and it still describes surprisingly well the one-point distribution of galaxies in the σ < 1 regime (Clerkin et al. 2017), given that it has no theoretical foundations. A closer look, based on numerous N-body simulations, reveals it is not perfect, in particular for higher variances, which lead to extensions with more freedom such as the skewed LN (Colombi 1994) or gamma expansion (Gaztañaga et al. 2000). More recently, Klypin et al. (2018) propose some more refined parameterisations. A more physical description may be preferred, like the one based on a large deviation principle and spherical infall model (Uhlemann et al. 2016) that provides a fully deterministic formula for the probability distribution function (PDF) in the mildly non-linear regime (Codis et al. 2016).
Boltzmann codes such as CLASS (Blas et al. 2011), by numerically solving the perturbation equations in the linear regime and adding some contributions describing small scales, predict the matter power spectrum for a given cosmology. For any field, this quantity is always defined as the Fourier transform of the auto-correlation function. Only in the Gaussian case does it contain all the available information. Then if we want to study cosmological parameters we need to provide realisations that follow a given spectrum.
In the following we present a method for generating a density field (and subsequent catalogues) following any one-point function and some target power-spectrum. Although it is similar to standard methods for generating a LN field (e.g. Chiang et al. 2013; Greiner & Enßlin 2015; Agrawal et al. 2017; Xavier et al. 2016), it is more general and solves an important issue. The method for generating a LN distribution with a target power-spectrum by locally transforming a Gaussian field is ill-defined when the field is smoothed, since it actually requires an input power spectrum with some negative parts. We show in Sect. 2 how this problem can be partially cured by properly including aliasing effects. We will use the Mehler transform to show how any form of the PDF can be achieved still keeping a positive input power spectrum. We then give an analytical expression of the general tri-spectrum and compare it to the output of the simulations. In Sect. 3 we consider the production of a discrete catalogue and how the cell window function affects the result. We discuss a linear interpolation scheme that reduces discontinuities between cells. We also consider and compare two methods to account for the redshift evolution, one with the full light-cone reconstruction and the other evolving the perturbation. To qualify our catalogues, we then apply in Sect. 4 a tomographic analysis to compare the simulated results to the expected theoretical values and focus on the covariance matrices.
The appendices give more technical details about some properties of the LN distribution, the Mehler transform, and the associated tri-spectrum computation. Throughout the paper we target a sub-percent precision of all our spectra up to the Nyquist frequency.
2. Sampling a field with a target PDF and spectrum
We consider the sampling of an isotropic field over a regular cubic grid of step size
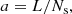 (1)
(1)
Ns being the number of sampling points per dimension1 and L the comoving box size fixed by the cosmology and the maximum wanted redshift. Our goal is to obtain a proper power spectrum up to the maximum accessible frequency which is the Nyquist value:
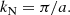 (2)
(2)
Getting the spectrum under control up to such a high k value is actually challenging because of a subtlety that will be discussed in the next parts.
For any PDF, the power spectrum is defined as the Fourier transform of the auto-correlation function, which for an isotropic 3D field reads
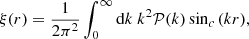 (3)
(3)
where 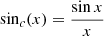 , and a similar formula can be expressed for the other way round2. Figure 1 shows a typical k2𝒫(k) linear spectrum computed with the Boltzmann code CLASS for a standard cosmology. Such a spectrum does not decrease rapidly and its variance (defined by the integral of this quantity) is not band-limited, and is even infinite when considering either a linear or a non-linear spectrum (e.g. Coles & Lucchin 2003). When sampling such a field up to some fixed kN value, we then encounter a problem of energy: aliasing. This is why we sometimes explicitly filter the field, for instance with a Gaussian window
, and a similar formula can be expressed for the other way round2. Figure 1 shows a typical k2𝒫(k) linear spectrum computed with the Boltzmann code CLASS for a standard cosmology. Such a spectrum does not decrease rapidly and its variance (defined by the integral of this quantity) is not band-limited, and is even infinite when considering either a linear or a non-linear spectrum (e.g. Coles & Lucchin 2003). When sampling such a field up to some fixed kN value, we then encounter a problem of energy: aliasing. This is why we sometimes explicitly filter the field, for instance with a Gaussian window 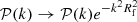 which band-limits the spectrum to
which band-limits the spectrum to 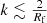 , where Rf is defined as the filtering radius. An example is shown as the full line in Fig. 1. Unfortunately this leads to a problem that is discussed next.
, where Rf is defined as the filtering radius. An example is shown as the full line in Fig. 1. Unfortunately this leads to a problem that is discussed next.
 |
Fig. 1. Linear power spectrum (dashed line) computed by CLASS for a standard cosmology and smoothed by a Gaussian window of radius Rf = 4 h−1 Mpc (solid line). The vertical dotted line corresponds to |
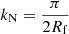
2.1. Problem with filtering
Let us consider the case of a LN field (see Appendix A) that is obtained from a Gaussian field (ν(x)) applying the following local transform to each location:
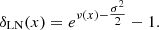 (4)
(4)
Remarkably, in this case the transformed auto-correlation function is analytical:
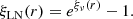 (5)
(5)
This suggests a straightforward way for generating an LN field with some target power-spectrum: just log-transform (i.e. apply Eq. (4)) a Gaussian field with a spectrum 𝒫ν(k) corresponding to
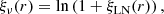 (6)
(6)
that we will call an inverse-log transform. By construction, the LN field should then have the desired spectrum.
As shown in Fig. 2, when we do so and compute the power spectrum 𝒫ν(k) corresponding to Eq. (6), its high k part becomes negative where the spectrum is cut by the window. This prohibits any standard Gaussian shooting method.
 |
Fig. 2. Close-up of Fig. 1. Shown are the smoothed power spectrum (solid line) and the one reconstructed by applying the Eq. (6) inverse-log transform (dash-dotted line). |
Indeed any function cannot represent an auto-correlation function since it must be positive definite, which in practical terms is checked by looking at the positivity of its Fourier transform (for an extensive discussion, see Yoglom 1986). This is clearly not the case here where we implicitly assumed that (1+ξLN(r)) represents an auto-correlation function. This is very different from the direct log case (Eq. (5)) where the auto-correlation function is constructed from classical statistical rules. This is a small effect, but we cannot be satisfied by clipping all negative values to zero since then the variance of the field would be incorrect and the spectrum biased for high k values.
Let us investigate when the problem happens. Postponing the details to the next section, we compute the 3D power spectrum given by Eq. (6). We count the fraction of modes with negative values with respect to the smoothing size Rf for three Ns samplings (256, 512, and 1024) with a fixed box size corresponding to three values of the grid size a. The outcome of this test is presented in Fig. 3, which shows that in each case modes with negative power appear when Rf ≳ a/2. This means that we can reconstruct a proper LN field as far as Rf > a/2. This is only partially satisfactory since we may adjust the step size (with Ns) to the smoothing radius, but we will only be able to reconstruct the spectrum up to the Nyquist frequency
 |
Fig. 3. Fraction f− of negative values in the three-dimensional 𝒫ν(k) as a function of the relative filtering Rf/a for three different grid samplings. The ratio Rf/a represents the relative scale between the smoothing scale Rf of the filtered power spectrum and the size of a grid unity a. |
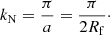 (7)
(7)
As illustrated in Fig. 1 (dashed vertical line), we do not sample the spectrum entirely and thus miss a small amount of power. This should affect the variance of the field; however, the power is restituted through aliasing.
There is no fully satisfactory solution to this problem since the procedure itself is mathematically ill defined whenever the spectrum reaches small values. The exact LN sampling of a filtered field cannot be achieved by transforming a Gaussian field.
Fortunately, we do not need to explicitly filter the field. From the density field we generate a discrete set of galaxies, a process that introduces some filtering, but if we exactly control this filtering (as is demonstrated in Sect. 3) we do not need to perform it explicitly at the very start. Then we can work with an unfiltered field (like the dashed one in Fig. 1) that is well-behaved for the transforms. However as Fig. 1 clearly shows, there will always be some extra power above the Nyquist frequency, and thus the key point discussed next is the proper handling of aliasing.
2.2. Taking into account aliasing
Although our method’s grounds are somewhat standard (e.g. Chiang et al. 2013; Greiner & Enßlin 2015; Agrawal et al. 2017; Xavier et al. 2016), we introduce two new aspects:
-
We generalise the PDF to any distribution;
-
We take into account aliasing to deal with the residual power.
The idea to obtain any PDF (for the density contrast δ) is to go into configuration space and apply a non-linear local transform to the Gaussian field ν:
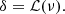 (8)
(8)
The ℒ function can be found easily by applying standard probability transformation rules (Bel et al. 2016) and may need to be computed numerically. In the LN case, the transformation is analytical and is given in Eq. (4).
From now on, δ(x) is assumed to be a real, L periodic, and translational invariant field with null expectation value. Let us define δk as its Fourier transform. On the one hand, the translational invariance imposes that the covariance between wave modes is diagonal, ⟨δkδk′⟩ = δD(k + k′)𝒫(k); on the other hand, the periodicity implies that the Fourier transform δk is non-zero only for k = nkf, where kf = 2π/L is the fundamental frequency of the field and n is an integer vector. Adding the fact that the field is real, it follows that the expectation value of the square modulus of the Fourier transform is directly related to the power spectrum
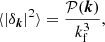 (9)
(9)
while the covariance between modes remains null. This property allows us to set up a Gaussian field νk, following a power spectrum 𝒫ν(k), in Fourier space by generating two uncorrelated centred Gaussian random variables (the real and the imaginary part of the Fourier density field νk). They must have the same variance, which should be equal to half the value of the power spectrum evaluated at the considered k-mode. This is equivalent to generating the square of the modulus of δk following an exponential distribution with parameter 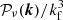 and a random phase peaked from a uniform distribution between 0 and 2π. Thus, in practice the Fourier transform of a Gaussian field can be generated on a Fourier grid as
and a random phase peaked from a uniform distribution between 0 and 2π. Thus, in practice the Fourier transform of a Gaussian field can be generated on a Fourier grid as
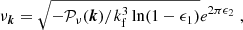 (10)
(10)
with ϵ1 and ϵ2 being two uncorrelated random variables uniformly distributed between 0 and 1. In addition to the appealing property of having a null correlation between different modes, generating a Gaussian field in Fourier space allows us to take avantage of the 3D FFT algorithm. The novel ingredient is to consider that since we are using here a raw (i.e. unfiltered) cosmological spectrum, more power is leaking around the Nyquist frequency.
Then to be coherent with our process of generating the Gaussian field with the required input power spectrum 𝒫ν(k) we must add the aliased power as an input in Fourier space (see Hockney & Eastwood 1988, for a detailed review), which can be performed by summing the power spectrum aliases
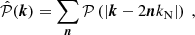 (11)
(11)
where n runs over the 3D Fourier wavenumbers. These terms are taken into account at the beginning of the method, as soon as the theoretical power spectrum  is provided by CLASS. We note that since the aliasing effect mixes modes that are uncorrelated, the phases remain uniformly distributed in Fourier space while the effective amplitude of the power spectrum changes according to Eq. (11). In our analysis we find that using only the first 125 contributions from n = ( − 2, −2, −2) to n = (2, 2, 2) is enough to reach a percent-level accuracy on the power spectrum of the catalogue at the Nyquist frequency. A more computationally efficient choice would be to take only the first 27 aliases, but it would lead to an accuracy of around 5–6%. In turn, if all alias contributions are discarded, then nearly 2% of the modes would be required to have a negative variance. Clipping these pathological modes to 0 power would lead to a significant deviation of the power spectrum of the generated field with respect to the expected one, even below the Nyquist frequency. In the following we consider the first 125 alias contributions.
is provided by CLASS. We note that since the aliasing effect mixes modes that are uncorrelated, the phases remain uniformly distributed in Fourier space while the effective amplitude of the power spectrum changes according to Eq. (11). In our analysis we find that using only the first 125 contributions from n = ( − 2, −2, −2) to n = (2, 2, 2) is enough to reach a percent-level accuracy on the power spectrum of the catalogue at the Nyquist frequency. A more computationally efficient choice would be to take only the first 27 aliases, but it would lead to an accuracy of around 5–6%. In turn, if all alias contributions are discarded, then nearly 2% of the modes would be required to have a negative variance. Clipping these pathological modes to 0 power would lead to a significant deviation of the power spectrum of the generated field with respect to the expected one, even below the Nyquist frequency. In the following we consider the first 125 alias contributions.
As detailed in Bel et al. (2016) any local transform ℒ applied to a centred Gaussian field ν(x) corresponds to a one-to-one mapping λ of its two-point correlation function ξν(r)≡⟨ν(x)ν(x + r)⟩ such that δ(x) = ℒ[ν(x)] and ξδ(r) = λ[ξν(r)]. The λ function is given explicitly in Appendix B (Eqs. (B.12) and (B.13)). As a result, using an inverse Fourier transform we can find the 3D two-point correlation of the target non-Gaussian field δ(x), from which, using the inverse mapping λ−1, we are able to compute the corresponding two-point correlation of the Gaussian field ν(x). In the end we only need to perform an inverse Fourier transform in order to get the input power spectrum 𝒫ν(k) that characterises the input Gaussian field. We can see that being obtained from the Fourier transform of a regularly (grid) sampled two-point correlation, it already contains aliasing effects. Thus, the input Gaussian field can be generated on the corresponding Fourier grid from Eq. (10). A summary of the steps involved in the process computation of the power spectrum 𝒫ν of the Gaussian field are shown in Fig. 4. Those steps do not require reevaluation for each realisation of the density field. This process can be time consuming so it is better to avoid repeating it when it is not necessary. Both computational time and memory of each array involved in the chain shown in Fig. 4 are summarised in Table 1. We call alias27 and alias125 the number of alias elements added to the raw power spectrum in Eq. (11) (respectively 27 and 125 terms). For ease of comparison, we use a single thread on a 2,4 GHz processor (without considering multiprocessing).
 |
Fig. 4. Schematic view of the method used to build the power spectrum involved in the sampling of the Gaussian field, prior to its local transformation. The grey box means that three dimensions are considered. |
Finally, we can inverse Fourier transform the realisation of the Gaussian field and apply to it a local transformation, which will automatically turn both the PDF and the power spectrum into the expected ones. It is clear that if the input power spectrum was not aliased (as it naturally is) then the corresponding inverse Fourier transform could not be interpreted as a regularly sampled Gaussian field, thus the process would not be self-consistent.
Figure 5 illustrates the power spectra involved in the generation of the non-Gaussian density field. The raw input power spectrum obtained from the CLASS code and its corresponding aliased version ( )) can be seen. We note that the aliasing needs to be applied on the 3D Fourier grid, while we represent only the averaged power spectrum in each Fourier shell of size kf. In addition, the same Figure shows the corresponding power spectrum of the Gaussian field that we use to generate Monte Carlo realisations. We note an excess of power at large k, which corresponds to the aliasing contribution.
)) can be seen. We note that the aliasing needs to be applied on the 3D Fourier grid, while we represent only the averaged power spectrum in each Fourier shell of size kf. In addition, the same Figure shows the corresponding power spectrum of the Gaussian field that we use to generate Monte Carlo realisations. We note an excess of power at large k, which corresponds to the aliasing contribution.
 |
Fig. 5. Power spectra involved in the Monte Carlo process. Shown is the theoretical 1D matter power spectrum computed by CLASS (dashed black line). Also shown (in red and blue, respectively) are the shell-averaged power spectra (in shells of width |k|−kf/2 < |k|< |k|+kf/2) showing the aliased version of the input power spectrum computed by the Boltzmann code and the corresponding power spectrum after transformation (B.12) (see Fig. 4 for details). All of them are plotted up to Nyquist frequency kN ∼ 0.67 h Mpc−1 with a setting of Ns = 256 and L = 1200 h−1 Mpc. |
In order to verify the coherency of the method, we generated 1000 realisations of LN non-Gaussian fields in a periodic box of size L = 1200 h−1 Mpc with two different spatial resolutions corresponding to a number of sampling per side of Ns = 256 and 512.
From the definition of the power spectrum (Eq. (9)), we estimated the power spectrum on the 3D Fourier grid by computing the ensemble average of the 1000 realisations and compared it to the true expected power spectrum (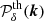 ). In Fig. 6, we represent the k-shell-averaged relative difference between the estimated and expected power spectrum for each individual wave modes. We can safely conclude that the accuracy of the proposed method is better than 0.1% for wave modes close to the Nyquist frequency. In addition, no significant bias can be detected at the sub-percent level on the whole range of wave modes present in the density field independently from the choice of the spatial resolution.
). In Fig. 6, we represent the k-shell-averaged relative difference between the estimated and expected power spectrum for each individual wave modes. We can safely conclude that the accuracy of the proposed method is better than 0.1% for wave modes close to the Nyquist frequency. In addition, no significant bias can be detected at the sub-percent level on the whole range of wave modes present in the density field independently from the choice of the spatial resolution.
 |
Fig. 6. Averaged 3D power spectrum compared to the expected 3D power spectrum, for 1000 realisations of the density field. The shell-averaged monopoles of this residuals in shells of width |k|−kf/2 < |k|< |k|+kf/2 were then computed. The result is presented as percentage with error bars. The setting used is a sampling number per side of 256 in the top panel and 512 for the other, all in a box of size L = 1200 h−1 Mpc at redshift z = 0. Both results are computed up to the Nyquist frequency. |
2.3. Covariance matrix
A possible interest of being able to generate non-Gaussian fields with a Monte Carlo method is related to generating a large number of realisations in order to estimate the covariance matrix (and its inverse) of a cosmological observable with a high level of statistical precision. In the following we define the shell-averaged power spectrum as our observable, and we estimate its covariance matrix between two shells centred around wave numbers ki and kj as
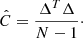 (12)
(12)
Here Δ is a matrix formed by the residual between the estimated power spectrum in each realisation and the estimated ensemble average of the power spectrum in each k-shell, and 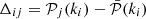 and
and 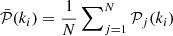 , where the j index refers to the j-th realisation. If the deviation elements Δij follow a Gaussian distribution then we can show that the estimated covariance matrix elements Cij follow a Wishart distribution. As a result, the estimator (12) is unbiased and the variance of the covariance matrix elements (see Anderson 1984) is given by
, where the j index refers to the j-th realisation. If the deviation elements Δij follow a Gaussian distribution then we can show that the estimated covariance matrix elements Cij follow a Wishart distribution. As a result, the estimator (12) is unbiased and the variance of the covariance matrix elements (see Anderson 1984) is given by
![Mathematical equation: $$ \begin{aligned} \mathbb{V} \left[{C_{ij}}\right] = (C_{ij}^2 + C_{ii}C_{jj})/(N-1). \end{aligned} $$](/articles/aa/full_html/2020/01/aa36163-19/aa36163-19-eq25.gif) (13)
(13)
In the following we show that the statistical behaviour of the variance of the estimator of the power spectrum is in agreement with what we expected to find.
Having control of both the target PDF and the power spectrum, we can predict to some extent the expected covariance matrix C of our power spectrum estimator. Since the density field generated with a Monte Carlo process is non-Gaussian, the covariance matrix of the estimator of the power spectrum involves contribution of the Fourier space four-point correlation function. For a translational invariant density field it reduces to
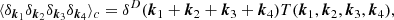 (14)
(14)
where T is defined as the tri-spectrum which is the Fourier transform of the four-point correlation function in configuration space. As shown by Scoccimarro et al. (1999), the covariance matrix elements of the power spectrum estimator can be expressed as
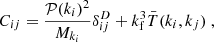 (15)
(15)
where Mki is the number of independent modes in shell i and
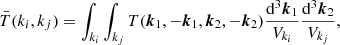 (16)
(16)
where the integral is made over two shells of thickness kf centred and encapsulating ki and kj. The volume (in Fourier space) of each shell containing independent modes is denoted as Vki and Vkj; in the limit of thin shells we have that Vk = 2πk2kf thus 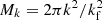 .
.
In Appendix C we show how to predict in a perturbative way the tri-spectrum of the generated non-Gaussian density field for any local transform. In particular, for the contribution of the tri-spectrum to the diagonal elements of the covariance matrix we obtain the expression
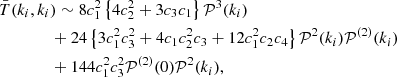 (17)
(17)
where 𝒫(2)(ki ≡ ℱ[ξ2] = ∫𝒫(q)𝒫(|q + ki|)d3q and the cn are the coefficients of the Hermite transform of the function ℒ:
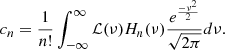 (18)
(18)
Here Hn denotes the probabilistic Hermite polynomial of order n. From Eq. (17) we can see that the covariance matrix elements are expected to depend on both the chosen target power spectrum and the probability density distribution of density fluctuations.
We generate 7375 realisations of a LN density field characterised by a ΛCDM power spectrum at redshift z = 0, the cn are thus given analytically. We can evaluate the covariance matrix elements of the power spectrum estimator as a simple matrix product (see Eq. (12)). In Fig. 7 we show the diagonal elements, namely the variance at each wave mode compared to the Gaussian contribution and the expected non-Gaussian contribution coming from Eq. (17). It shows a better correspondance between perturbation theory and simulations up to k ∼ 10−1 confirming that for intermediate-wave modes the non-Gaussian correction starts being relevant; however, as expected, it fails to reproduce the full k-dependance because expression (17) was obtained in a perturbative way. In Fig. 8 we show some combinations of modes ki and kj of the covariance matrix elements; they exhibit a clear dependance in such combination showing that due to the non-Gaussian nature of the created density field long- and short-wave modes are correlated in our power spectrum estimator.
 |
Fig. 7. Measured diagonal of the covariance matrix for 7375 power spectra realisations of the density field using the Monte Carlo method (black line) up to kN ∼ 0.67 h Mpc−1. The other curves represent their predictions taking into account the Gaussian part alone (G) or by adding some non-Gaussian contributions of Eq. (15). For example in (1-NG) only the term in 𝒫3(ki) is kept in the tri-spectrum development presented in Eq. (17), while in (3-NG) all of them are kept. |
 |
Fig. 8. Off-diagonal elements of the covariance matrix estimated with N = 7375 realisations, showing the dependance of the Cij with respect to kj at various fixed ki (see labels on the right). The error bars are computed from Eq. (13). |
In the following we extend the case of the continuous sampled density field to the creation of a catalogue of discrete objects, which could be galaxies, clusters, haloes, or simply dark matter particles.
3. Production of a catalogue
3.1. Poisson sampling
Simulating a galaxy catalogue implies transforming the sampled continuous density field δ(x) into a point-like distribution. The density field must therefore be translated into a number of objects (galaxies, haloes, or dark matter particles) per cell imposing an average number density ρ0 in the comoving volume such that ρ(x) = ρ0[1 + δ(x)] and performing a Poisson sampling (Layzer 1956). To do so, we must choose an interpolation scheme in order to be able to define a continuous density field ρ(i)(x) between the sampling nodes xj surrounding a cell centred on position xi. In this way, for each cell i we are able to compute the expected number of object Λi as
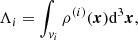 (19)
(19)
where in practice the integration domain vi corresponds to the volume of a cell.
Finally, we assign to the cell the corresponding number of galaxies Ni such that the probability of observing N objects given the value of the underlying field Λ is given by a Poisson distribution 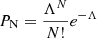 . This means that we can distribute the right number Ni of objects in each cell volume with a spacial probability distribution function proportional to the interpolated density field ρ(i)(x) within the cell.
. This means that we can distribute the right number Ni of objects in each cell volume with a spacial probability distribution function proportional to the interpolated density field ρ(i)(x) within the cell.
The most straightforward interpolation scheme consists in populating cells uniformly with the corresponding number of objects, which is called the Top-Hat scheme. We can guess that on scales comparable to the size of the randomly populated cells the power spectrum of the Poisson sample will not match the expected power spectrum.
When 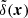 is the sampled density contrast field (the true density contrast field multiplied by a Dirac comb), the corresponding interpolated density contrast within the cell
is the sampled density contrast field (the true density contrast field multiplied by a Dirac comb), the corresponding interpolated density contrast within the cell 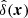 is obtained by convolving the sampled density field with a window function W(x) leading in Fourier space to the power spectrum relevant for the Poisson process as
is obtained by convolving the sampled density field with a window function W(x) leading in Fourier space to the power spectrum relevant for the Poisson process as 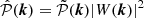 , where
, where 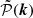 is the power spectrum of the sampled density field, namely the aliased power spectrum. We can thus finally obtain that the expected power spectrum of the created catalogue is
is the power spectrum of the sampled density field, namely the aliased power spectrum. We can thus finally obtain that the expected power spectrum of the created catalogue is
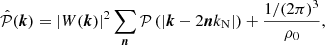 (20)
(20)
where the additional term on the right corresponds to the shot noise contribution due to the auto-correlation of particles with themselves. As anticipated in the previous section, we note that the Fourier transform of the chosen convolution function W is cutting the power on a small scale, which is equivalent to smoothing the density field on the size of the cells.
The interpolation scheme for the number density within each cell defines the form of the smoothing kernel W; in the following we consider two different interpolation schemes. The first (the first order) is the Top-Hat scheme which consists in defining cells around each node of the grid and assigning the corresponding density within the cell. The second (the second order) is a natural extension, which consists in defining a cell as the volume within eight grid nodes and adopting a tri-linear interpolation scheme between the nodes. In any of the two cases the window function (see Sefusatti et al. 2016, for higher order smoothing functions) takes the general form W(n)(k) = [j0(kxa/2)j0(kya/2)j0(kza/2)]n, where j0 is the spherical Bessel function of order 0 and the index n corresponds to the order of the interpolation scheme.
We estimate the power spectrum of the catalogues with the method described by Sefusatti et al. (2016) employing a particle assignment scheme of order four (piecewise cubic spline) and the interlacing technique to reduce aliasing effects. We note that these choices are intrinsic to the way we estimate the power spectrum of the distribution of generated objects and has nothing to do with the way we generate the catalogues. In Fig. 9, we compare the power spectra of the catalogues of objects for the two interpolation schemes described above. As expected, on small scales the linear interpolation scheme reduces the extra power more efficiently, due to aliasing.
 |
Fig. 9. Top: measured power spectra averaged over 100 realisations of the Poissonian LN field for the Top-Hat interpolation scheme (blue curve with prediction in dash-dotted black line) and for the linear interpolation scheme (red curve and prediction in dashed line). The shot noise is subtracted from measures (solid horizontal black line) and is about 3.48 × 10−2 h3 Mpc3. The dotted black curve represents the alias-free theoretical power spectrum computed by CLASS. Bottom: relative deviation in percentage between the averaged realisations (with shot noise contribution) and prediction (with the same shot noise added) in blue line with error bar in grey for the Top-Hat interpolation scheme. Snapshots are computed for a grid of size L = 1200 h−1 Mpc and parameter Ns = 512. Here comparisons are made well beyond the Nyquist (vertical line) frequency at kN ∼ 1.34 h Mpc−1. |
In the same figure we also show the expected power spectra computed with Eq. (20) and corresponding to the two mentioned interpolation schemes. We demonstrate in both cases that we control precisely the smoothing of the spectrum up to the Nyquist frequency and even above.
3.2. Light cone
In the following we describe how we build a light cone from our catalogue, and we compare two methods.
Shell method. The first idea is to glue a series of comoving volume at constant time in order to reconstruct the past light cone shell by shell (Fosalba et al. 2015; Crocce et al. 2015). However we take care of keeping track of the cross-correlation between shells by starting with the same Gaussian field for all the shells. In practice, we first select a redshift interval Δz labelled by zmin and zmax and a number Nshl of shells within it. For each of these shells, we generate a point-like distribution in a comoving volume at constant cosmic time. Obviously, we perform the Poisson sampling only of the cells contributing to the considered redshift shell. In addition, we keep only the objects belonging to the comoving volume spanned by the redshift shell, defined by [R(zi − dz/2),R(zi + dz/2)], where zi corresponds to the redshift of the comoving volume, dz = Δz/Nshl, and R(z) is the radial comoving distance. The light cone method is designed to cover 4π steradians on the sky.
In the next section we show the effect of the choice of the number of shells Nshl used to build the light cone, on the angular power spectrum.
Cell method. The second method is faster. Rather than simulating many redshift shells, we select a single redshift z0 chosen at the middle of the radial comoving space spanned by the light cone. We generate the corresponding Gaussian field in a comoving volume on a grid at z = z0. At this level we needs to include some evolution in the radial direction from the point of view of an observer located at the centre of the box. To do so, there are two possibilities.
– We can simply think of rescaling the Gaussian field at a comoving radial distance x(z) (from the observer) with the corresponding growth factor D(z), which rules the evolution of linear matter perturbations (Peebles 1980). In this way it is clear that on large scales the power spectrum of the density field will follow the expected evolution in D2(z); however, the small scales will be affected in a non-trivial way leading to a modification of the shape of the power spectrum.
– We can change the contrast field so that the evolution of the density field will follow the growth factor D(z). For the LN case this would read
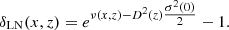 (21)
(21)
The second option is particularly well suited when generating a density field following a linear evolution. However the first option, although not exact, can allow for the fast computation of spectra evolution for more complex cases as when D(k, z) depends on k. In the following section we compare, in the linear regime, the shell method and the two cell methods in the case of the LN density field.
We conclude this section by providing the running time for the generation of a catalogue of ∼110 million galaxies with the second method considering that the chain in Fig. 4 has already been computed. We get 1.7 min for Ns = 256, 11 min for Ns = 512 and 1.7 h for Ns = 1024 using a single thread on a 2,4 GHz processor.
4. Application to tomography
In cosmology, several arguments can be put forward to justify a tomographic approach. Unlike the estimation of the power spectrum or the two-point correlation function, no fiducial cosmology needs to be assumed in order to estimate the observable (see Bonvin & Durrer 2011; Montanari & Durrer 2012; Asorey et al. 2012). Only angular observed positions and measured redshift are required, thus making it a true observable quantity. In addition, the observable is defined on a sphere simplifying its combinations with other cosmological probes such as lensing (Cai & Bernstein 2012; Gaztañaga et al. 2012) or CMB and Hα intensity mapping.
4.1. Angular power spectrum Cℓ
So far we have worked on a Fourier basis, but it is useful to expand the matter perturbations into spherical harmonics (Peebles 1980) and consider its coefficients:
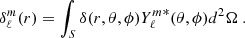 (22)
(22)
Assuming that the field is statistically invariant by rotation, i.e. its angular two-point correlation function only depends on the angular separation and not on the absolute angular position (the analogue of translational invariance in 3D) on the sky, the two-point correlation of the harmonic coefficient depends only on the order ℓ, thus 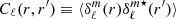 is defined as the angular power spectrum between shells r and r′. We may relate this spectrum to the isotropic 3D spectrum as
is defined as the angular power spectrum between shells r and r′. We may relate this spectrum to the isotropic 3D spectrum as
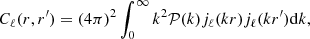 (23)
(23)
where jℓ is the spherical Bessel function of order ℓ. However, in this expression there is an explicit dependence on the radial comoving distances r and r′.
We can project the density field of a thick redshift shell with a given weighting function W(z) and define our observable density field as
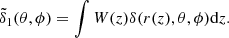 (24)
(24)
The corresponding angular power spectrum3 can be predicted from
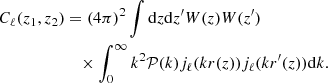 (25)
(25)
In practice, the numerical evaluation of Eq. (25) is not simple and we use the Angpow software (Neveu & Plaszczynski 2018), which is fully optimised for this task.
This theoretical quantity may then be compared to our simulations by considering the number counts within pixels from samples in the z1 < z < z2 range (i.e. using for W a Top-Hat window) since in our case the only source of fluctuations is due to the overdensity field. We then simply project the objects of the catalogue on the sky, count them, normalise by the mean value within pixels 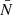 , and compute the spherical power-spectrum
, and compute the spherical power-spectrum 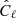 with the Healpix (Górski et al. 2005) software using the parameter nside = 211. The shot-noise contribution is classically
with the Healpix (Górski et al. 2005) software using the parameter nside = 211. The shot-noise contribution is classically 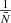 . We note that as in the Fig. (9), we compute the angular power spectrum on scales smaller than the grid pitch. On a spherical basis, the equivalent of the Nyquist mode is obtained using ℓN ∼ R[zmean]kN, where zmean is the averaged redshift of the particles composing the catalogue.
. We note that as in the Fig. (9), we compute the angular power spectrum on scales smaller than the grid pitch. On a spherical basis, the equivalent of the Nyquist mode is obtained using ℓN ∼ R[zmean]kN, where zmean is the averaged redshift of the particles composing the catalogue.
In Fig. 10 we compare the estimated angular power spectrum in the [0.2, 0.3] redshift range to the predicted one (Eq. (25)) with the shell method described in Sect. 3 (Nshl = 250) for one thousand generated light cones. In the lower panel of the same figure we display the relative difference between the two showing that the agreement is better than the percent level.
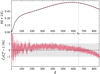 |
Fig. 10. Top panel: one thousand averaged Cℓ values for simulated light cones using the shell method with error bars (red curve) and corresponding prediction (dashed black curve). We simulate here a light cone between redshifts 0.2 and 0.3 in a sampling Ns = 512 and a number of shells Nshl = 250 to ensure a sufficient level of continuity in the density field. The spherical Nyquist mode is situated around ℓN ∼ 650 and represented by the vertical reference. Bottom panel: relative deviation in percent of the averaged predicted Cℓ values with error bars in red. |
In order to quantify the impact of the choice of the number of shells in the shell method, we run a test comparison between the cell method and various number of shells Nshl in the cell method. We note that since we are using a power spectrum that is evolving linearly across cosmic time, we know that the shell method is expected to converge to cell method if we rescale the density field with the linear growing mode D(z), as described in Sect. 3. Figure 11 shows the outcome of this analysis, which shows that in the considered redshift range the shell method is indeed converging to the cell method below the percent level as long as the number of shells is greater than 200.
 |
Fig. 11. Relative difference in percent between shell method and cell method for varying numbers of shells. The spherical Nyquist mode is situated around ℓN ∼ 650 and represented by the vertical reference. |
Finally, we make a comparison within the cell method, rescaling the Gaussian field instead of rescaling the density field. This way we can quantify the deviation when assuming that the Gaussian field evolves linearly when instead it is the density field that is evolving linearly. In Fig. 12, we show the relative deviation in the two cases with respect to the expected power spectrum. We can see that the deviation, despite being systematic, remains small (around the percent level). Therefore, considering these two cell methods, and as stated in the previous section, only the one offering better results will be recommended: the rescaling of the density field (top panel).
 |
Fig. 12. Relative deviation in percent with error bars for 10 000 averaged realisations of Cℓ values in the context of the cell method. In the top panel, the density field (non-Gaussian) is rescaled using linear growth function, while in the bottom panel the Gaussian field following the virtual power spectrum is rescaled. The spherical Nyquist mode is situated around ℓN ∼ 650 and is represented by the vertical reference. |
4.2. Covariance matrix
In this section we consider the cell method with linear rescaling of the density field. Our aim is to estimate the covariance matrix of the 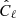 estimator defined as
estimator defined as
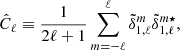 (26)
(26)
with a high level of precision. Let us first show that the covariance matrix has a structure similar to the power spectrum estimator studied in Sect. 2. By definition the covariance of 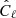 is
is
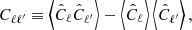 (27)
(27)
where we can substitue 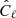 with its expression (see Eq. (26)). We immediately see that the first term of Eq. (27) will let a four-point moment appear, which can be expanded (Fry 1984a,b) in terms of cumulative moments (or connected expectation values). It follows that it takes the general form
with its expression (see Eq. (26)). We immediately see that the first term of Eq. (27) will let a four-point moment appear, which can be expanded (Fry 1984a,b) in terms of cumulative moments (or connected expectation values). It follows that it takes the general form
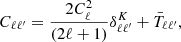 (28)
(28)
where 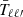 accounts for non-Gaussian contribution. Instead, when
accounts for non-Gaussian contribution. Instead, when 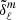 is a Gaussian field we can see that the covariance matrix is diagonal.
is a Gaussian field we can see that the covariance matrix is diagonal.
We generate N = 10 000 realisations and measure the angular power spectrum in each of them in order to finally estimate the covariance matrix in the same way as described in Sect. 2. In Fig. 13 we represent the diagonal of the covariance matrix; the errors on the covariance matrix elements are computed with Eq. (13). Since in the Gaussian case the relative error expected on the diagonal of the covariance matrix elements is given by 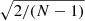 , the interest of using such a large number of realisations is that we expect a 1.4% precision on the estimation of the diagonal of the covariance matrix and an absolute precision on the correlation coefficients
, the interest of using such a large number of realisations is that we expect a 1.4% precision on the estimation of the diagonal of the covariance matrix and an absolute precision on the correlation coefficients 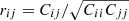 of roughly 0.02. In the bottom panel of Fig. 13 we show the relative deviation between the Gaussian prediction and the measured variance of the angular power spectrum, we see that the maximum of deviation is about 45% at ℓ ∼ 600. It appears that deviations from Gaussianity remain small compared to the deviation obtained for the power spectrum covariance matrix, which was about two orders of magnitude bigger (see Sect. 2).
of roughly 0.02. In the bottom panel of Fig. 13 we show the relative deviation between the Gaussian prediction and the measured variance of the angular power spectrum, we see that the maximum of deviation is about 45% at ℓ ∼ 600. It appears that deviations from Gaussianity remain small compared to the deviation obtained for the power spectrum covariance matrix, which was about two orders of magnitude bigger (see Sect. 2).
 |
Fig. 13. Top: measured diagonal of the covariance matrix (blue curve) over N = 10 000 realisations of different light cones. The red curve represents the associated prediction in the case of a Gaussian field with errors computed using Eq. (13). Here we keep the shot noise (SN) effect in the measures and include it in the prediction. The spherical Nyquist mode is situated around ℓN ∼ 650. Bottom: relative difference in percent following the same colour-coding. |
In addition, in Fig. 14 we display some off-diagonal covariance elements with their error bars. Despite some fluctuations it is consistant with zero, indicating that the covariance matrix is close to diagonal, as expected in the Gaussian case (at least for the 300 first elements of the matrix by counting them following the description in the caption). In order to make sure that this is indeed the case, in Fig. 15 we show the correlation coefficients 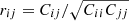 ; we see that the matrix is close to diagonal only considering ℓ < 200. It therefore confirms that projecting a thick redshift shell onto the sky tends to turn the density field more Gaussian. This is compatible with what we would naively expect from the central limit theorem since the projection is made by summing over many values of a non-Gaussian field with some weights. It appears that the resulting distribution should tend to a Gaussian as the volume of the projection increases. However, for large ℓ-values we measure a significant amount of correlation typically of order 10% reaching 30% at ℓ ∼ 600.
; we see that the matrix is close to diagonal only considering ℓ < 200. It therefore confirms that projecting a thick redshift shell onto the sky tends to turn the density field more Gaussian. This is compatible with what we would naively expect from the central limit theorem since the projection is made by summing over many values of a non-Gaussian field with some weights. It appears that the resulting distribution should tend to a Gaussian as the volume of the projection increases. However, for large ℓ-values we measure a significant amount of correlation typically of order 10% reaching 30% at ℓ ∼ 600.
 |
Fig. 14. First 300 elements measured for the off-diagonal part of the covariance matrix over n = 10 000 realisations of light cone with Gaussian errors computed using Eq. (13). The elements are labelled by the index m and are ordered column by column in the lower half of the matrix without passing by the diagonal, i.e. Cij, i > j. |
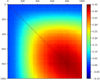 |
Fig. 15. Correlation matrix for 10 000 realisations of Cℓ in a simulated universe between redshifts 0.2 and 0.3 and a sampling Ns = 512. The (ℓ×ℓ′) = (1000 × 1000) of the matrix are represented here. |
5. Conclusion
In this paper we refined a known process allowing us to generate a non-Gaussian density field with a given PDF and power spectrum.
We first pointed out the current main mathematical issue arising when we want to generate a density field with a cut-off scale by filtering its power spectrum. We demonstrated that the power spectrum of the Gaussian field that will eventually be transformed into a non-Gaussian is likely to be undefined (i.e. with negative values) on some bandwidth. Even though we noted that there is, in principle, no way of mathematically sorting this problem, we showed that a simple criterion allows a work-around: for a Gaussian filtering, a spatial sampling rate a, which is larger than twice the cut-off scale Rf, needs to be used.
We demonstrated that taking into account aliasing at the stage of generating the density field in Fourier space is of paramount importance in order to maintain the output power spectrum under control. In addition, we showed that without imposing an explicit cut-off scale, at the stage of producing a catalogue with a local Poisson process we introduce an effective filtering of the density field which can be predicted with a sub-percent level accuracy. Regarding the Poisson sampling, we proposed a natural extension of the usual Top-Hat method consisting in populating the cubical cells uniformly with objects: we can linearly interpolate the density field between nodes and populate the cells with a probability distribution following the interpolated density field. The interest of this extension is that it allows us to get closer to the ideal power spectrum by strongly decreasing the amplitude of aliasing.
Regarding the density field, we showed that we can predict in a perturbative way the expected bi-spectrum and tri-spectrum, and we provided an analytical approximation allowing us to predict the variance of the power spectrum estimated for the non-Gaussian density field. This allowed us to check that the statistical behaviour of our method was going in the expected direction.
At the end of Sect. 3 we discussed two different methods to build a light cone out of our catalogues. The shell method can be used whether the evolution of the power spectrum is linear or not, but it involves a large number of redshift shells, which is time consuming. The other method is much faster; the cell method is particularly suitable when the power spectrum evolves linearly, but does not allow us to keep a perfect control on the power spectrum when it presents a non-linear evolution.
Finally, we presented a possible application of this kind of Monte Carlo catalogue of objects to tomographic analysis. We showed that the estimated angular power spectrum is in agreement at the percent level with the expected one. This validated the shell and cell methods used to build the light cones. Thanks to the numerical efficiency of this Monte Carlo we were able to generate 10 000 realisations, allowing us to estimate the covariance matrix elements with a percent accuracy. Despite the reduction of non-Gaussianity involved in the projection of the catalogue on the sky, we were still able to detect a clear signature on small scales, coming from the fact that the catalogues were generated out of a non-Gaussian density field.
Such a Monte Carlo method might be useful in investigating the dependance of the covariance matrix on the cosmological parameter. As recently done by Lippich et al. (2019) and Blot (2019), in a future work we plan to compare the covariance matrix obtained with this method to the one estimated from cosmological N-body simulations and we will include the treatment of redshift space distortions.
From numerical considerations concerning fast Fourier transform (FFT), a power of 2 is generally preferred.
Technically, such integrals can be computed efficiently with an FFTLog algorithm (Hamilton 2000), which is the approach we use in the following, or simply with an FFT by noticing that (rξ(r), k𝒫(k)) form a Fourier (sine) pair.
In the following we only consider auto-correlations between shells.
References
- Adler, R. J. 1981, The Geometry of Random Fields (London: Wiley) [Google Scholar]
- Agrawal, A., Makiya, R., Chiang, C.-T., et al. 2017, JCAP, 2017, 003 [CrossRef] [Google Scholar]
- Anderson, T. W. 1984, An Introduction to Multivariate Statistical Analysis, 2nd edn. (Wiley Series in Probability and Mathematical Statistics) [Google Scholar]
- Asorey, J., Crocce, M., Gaztañaga, E., & Lewis, A. 2012, MNRAS, 427, 1891 [NASA ADS] [CrossRef] [Google Scholar]
- Bel, J., Branchini, E., Di Porto, C., et al. 2016, A&A, 588, A51 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Blas, D., Lesgourgues, J., & Tram, T. 2011, JCAP, 1107, 034 [NASA ADS] [CrossRef] [Google Scholar]
- Blot, L., Crocce, M., Sefusatti, E., et al. 2019, MNRAS, 485, 2806 [NASA ADS] [CrossRef] [Google Scholar]
- Bonvin, C., & Durrer, R. 2011, Phys. Rev. D, 84, 063505 [NASA ADS] [CrossRef] [Google Scholar]
- Cai, Y.-C., & Bernstein, G. 2012, MNRAS, 422, 1045 [NASA ADS] [CrossRef] [Google Scholar]
- Carlitz, L. 1970, Collect. Math., 21, 117 [Google Scholar]
- Chiang, C.-T., Wullstein, P., Jeong, D., et al. 2013, JCAP, 2013, 030 [NASA ADS] [CrossRef] [Google Scholar]
- Clerkin, L., Kirk, D., Manera, M., et al. 2017, MNRAS, 466, 1444 [NASA ADS] [CrossRef] [Google Scholar]
- Codis, S., Pichon, C., Bernardeau, F., Uhlemann, C., & Prunet, S. 2016, MNRAS, 460, 1549 [NASA ADS] [CrossRef] [Google Scholar]
- Coles, P., & Barrow, J. D. 1987, MNRAS, 228, 407 [NASA ADS] [CrossRef] [Google Scholar]
- Coles, P., & Jones, B. 1991, MNRAS, 248, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Coles, P., & Lucchin, F. 2003, Cosmology, the Origin and Evolution of Cosmic Structure (London: Wiley) [Google Scholar]
- Colombi, S. 1994, ApJ, 435, 536 [NASA ADS] [CrossRef] [Google Scholar]
- Crocce, M., Castander, F. J., Gaztañaga, E., Fosalba, P., & Carretero, J. 2015, MNRAS, 453, 1513 [NASA ADS] [CrossRef] [Google Scholar]
- Fosalba, P., Crocce, M., Gaztañaga, E., & Castander, F. J. 2015, MNRAS, 448, 2987 [NASA ADS] [CrossRef] [Google Scholar]
- Fry, J. N. 1984a, ApJ, 277, L5 [NASA ADS] [CrossRef] [Google Scholar]
- Fry, J. N. 1984b, ApJ, 279, 499 [NASA ADS] [CrossRef] [Google Scholar]
- Gaztañaga, E., Fosalba, P., & Elizalde, E. 2000, ApJ, 539, 522 [NASA ADS] [CrossRef] [Google Scholar]
- Gaztañaga, E., Eriksen, M., Crocce, M., et al. 2012, MNRAS, 422, 2904 [NASA ADS] [CrossRef] [Google Scholar]
- Górski, K. M., Hivon, E., Banday, A. J., et al. 2005, ApJ, 622, 759 [NASA ADS] [CrossRef] [Google Scholar]
- Greiner, M., & Enßlin, T. A. 2015, A&A, 574, A86 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hamilton, A. J. S. 2000, MNRAS, 312, 257 [NASA ADS] [CrossRef] [Google Scholar]
- Hockney, R. W., & Eastwood, J. W. 1988, Computer Simulation Using Particles (Bristol, PA, USA: Taylor & Francis, Inc.) [CrossRef] [Google Scholar]
- Hubble, E. 1934, ApJ, 79, 8 [NASA ADS] [CrossRef] [Google Scholar]
- Klypin, A., Prada, F., Betancort-Rijo, J., & Albareti, F. D. 2018, MNRAS, 481, 4588 [CrossRef] [Google Scholar]
- Layzer, D. 1956, AJ, 61, 383 [NASA ADS] [CrossRef] [Google Scholar]
- Lippich, M., Sánchez, A. G., Colavincenzo, M., et al. 2019, MNRAS, 482, 1786 [NASA ADS] [CrossRef] [Google Scholar]
- Montanari, F., & Durrer, R. 2012, Phys. Rev. D, 86, 063503 [NASA ADS] [CrossRef] [Google Scholar]
- Neveu, J., & Plaszczynski, S. 2018, Astrophysics Source Code Library [record ascl:1807.012] [Google Scholar]
- Peebles, P. J. E. 1980, The Large-scale Structure of the Universe (Princeton: Princeton University Press) [Google Scholar]
- Scoccimarro, R., Zaldarriaga, M., & Hui, L. 1999, ApJ, 527, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Sefusatti, E., Crocce, M., Scoccimarro, R., & Couchman, H. M. P. 2016, MNRAS, 460, 3624 [NASA ADS] [CrossRef] [Google Scholar]
- Simpson, F., Heavens, A. F., & Heymans, C. 2013, Phys. Rev. D, 88, 083510 [NASA ADS] [CrossRef] [Google Scholar]
- Uhlemann, C., Codis, S., Pichon, C., Bernardeau, F., & Reimberg, P. 2016, MNRAS, 460, 1529 [NASA ADS] [CrossRef] [Google Scholar]
- Xavier, H. S., Abdalla, F. B., & Joachimi, B. 2016, MNRAS, 459, 3693 [NASA ADS] [CrossRef] [Google Scholar]
- Yoglom, A. 1986, Correlation Theory of Stationary and Related Random Functions, Volume I: Basic Results (Spinger Series in Statistics) [Google Scholar]
Appendix A: Some properties of the LN field
Let X follow a Gaussian distribution X ∼ 𝒩(μ,σ2); then Y = eX follows a LN distribution. For simplicity we consider in the following that the Gaussian has a null mean μ = 0. Its moments can be immediately computed:
![Mathematical equation: $$ \begin{aligned} \mathbb{E} \left[{y^k}\right]&= \int _0^\infty y^k f_Y(y) \mathrm{d}y=\int _0^\infty e^{k \ln y} f_Y(y) \mathrm{d}y \nonumber \\&= \int _{-\infty }^{+\infty } e^{k x} \mathcal{N}(x;0,\sigma ^2) \mathrm{d}x \nonumber \\&= e^{k^2 \sigma ^2/2}. \end{aligned} $$](/articles/aa/full_html/2020/01/aa36163-19/aa36163-19-eq59.gif) (A.1)
(A.1)
In particular,
![Mathematical equation: $$ \begin{aligned} \mathbb{E} \left[{y}\right]&=e^{\sigma ^2/2} \end{aligned} $$](/articles/aa/full_html/2020/01/aa36163-19/aa36163-19-eq60.gif) (A.2)
(A.2)
![Mathematical equation: $$ \begin{aligned} \mathbb{V} \left[{y}\right]&=e^{\sigma ^2}(e^{\sigma ^2}-1). \end{aligned} $$](/articles/aa/full_html/2020/01/aa36163-19/aa36163-19-eq61.gif) (A.3)
(A.3)
The idea for cosmology is to ensure a positive energy density (denoted ρ in the following) by transforming a Gaussian density contrast ν into
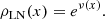 (A.4)
(A.4)
We recover the LN contrast using Eq. (A.2)
![Mathematical equation: $$ \begin{aligned} \delta _{\rm LN}=\dfrac{\rho _{\rm LN}}{\mathbb{E} \left[{\rho _{\rm LN}}\right]}-1 = e^{\nu -\tfrac{\sigma ^2}{2}} -1. \end{aligned} $$](/articles/aa/full_html/2020/01/aa36163-19/aa36163-19-eq63.gif) (A.5)
(A.5)
This is a linear transformation of the pure LN distribution eν, so we can compute immediately its first two moments:
![Mathematical equation: $$ \begin{aligned} \mathbb{E} \left[{\delta _{\rm LN}}\right]&=0\end{aligned} $$](/articles/aa/full_html/2020/01/aa36163-19/aa36163-19-eq64.gif) (A.6)
(A.6)
![Mathematical equation: $$ \begin{aligned} \mathbb{V} \left[{\delta _{\rm LN}}\right]&=[e^{-\sigma ^2/2}]^2 \mathbb{V} \left[{\rho _{\rm LN}}\right]=e^{\sigma ^2}-1 \end{aligned} $$](/articles/aa/full_html/2020/01/aa36163-19/aa36163-19-eq65.gif) (A.7)
(A.7)
The random field is created by considering it a function of spatial coordinates xi, and from now on we use the shorthand δi = δ(xi), νi = ν(xi) and ρi = ρ(xi), dropping the “LN” subscript. Its auto-correlation function, assuming isotropy, reads
![Mathematical equation: $$ \begin{aligned} \xi (r)=\mathbb{E} \left[{\delta _1 \delta _2}\right]=\dfrac{\mathbb{E} \left[{(\rho _1-\bar{\rho })(\rho _2-\bar{\rho })}\right]}{\mathbb{E} \left[{\rho }^2\right]}=\dfrac{\mathbb{E} \left[{\rho _1\rho _2}\right]}{\mathbb{E} \left[{\rho }\right]^2}-1 \end{aligned} $$](/articles/aa/full_html/2020/01/aa36163-19/aa36163-19-eq66.gif) (A.8)
(A.8)
Calling f2(ρ1, ρ2) the 2D density distribution of the LN energy density random field, probability conservation yields
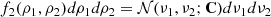 (A.9)
(A.9)
The covariance matrix of the Gaussian field being
![Mathematical equation: $$ \begin{aligned} \mathbf C =\mathbb{E} \left[{\nu _1 \nu _2}\right]= \begin{pmatrix} \sigma ^2&\xi _\nu \\ \xi _\nu&\sigma ^2 \end{pmatrix}, \end{aligned} $$](/articles/aa/full_html/2020/01/aa36163-19/aa36163-19-eq68.gif) (A.10)
(A.10)
we can then compute its two-point function in a way similar to moments
![Mathematical equation: $$ \begin{aligned} \mathbb{E} \left[{\rho _1 \rho _2}\right]&=\int \int e^{\ln \rho _1} e^{\ln \rho _2} f_2(\rho _1,\rho _2) d\rho _1 d\rho _2 \end{aligned} $$](/articles/aa/full_html/2020/01/aa36163-19/aa36163-19-eq69.gif) (A.11)
(A.11)
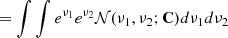 (A.12)
(A.12)
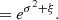 (A.13)
(A.13)
The last line can be obtained from a direct computation or by recalling that the generative functional of a multi-dimensional Gaussian is
![Mathematical equation: $$ \begin{aligned} \mathbb{E} \left[{e^{xt}}\right]=e^{\tfrac{1}{2}t^T\mathbf C t}, \end{aligned} $$](/articles/aa/full_html/2020/01/aa36163-19/aa36163-19-eq72.gif) (A.14)
(A.14)
where x, t represent vectors.
Finally, using Eqs. (A.4) and (A.2), we obtain for the contrast density of the LN field the result that
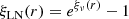 (A.15)
(A.15)
We can check that the variance (ξ(r = 0)) indeed follows Eq. (A.7).
Appendix B: The Mehler formalism
The Mehler transform for bivariate distributions is not a well-known tool, while it is particularly convenient to ease computations of 2D integrals involving Gaussian distributions, as was demonstrated in Simpson et al. (2013) or more recently in Bel et al. (2016).
Let (X1, X2) follow a central bivariate distribution
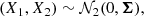 (B.1)
(B.1)
with a covariance matrix
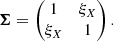 (B.2)
(B.2)
For convenience we restrict the variance term to 1, so that the covariance term ξν is the correlation coefficient, and we show at the end of this appendix how to treat the general case. By denoting, in loose notation, 𝒩(x) as the 1D normal distribution, the transform reads
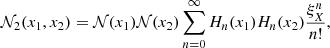 (B.3)
(B.3)
where Hn are the (probabilistic) Hermite polynomials which are orthogonal with respect to the Gaussian measure
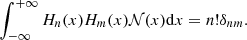 (B.4)
(B.4)
The interest here is that when applying some local transform to a Gaussian field Y = ℒ(X) the covariance of the transformed field becomes
![Mathematical equation: $$ \begin{aligned} \xi _Y=\mathbb{E} \left[{y_1y_2}\right]&=\int _{-\infty }^\infty \int _{-\infty }^\infty y_1 y_2 f_Y(y_1,y_2) \mathrm{d}y_1 \mathrm{d}y_2 \nonumber \\&=\int _{-\infty }^\infty \int _{-\infty }^\infty \mathcal{L} (x_1)\mathcal{L} (x_2) \mathcal{N} _2(x_1,x_2) \mathrm{d}x_1 \mathrm{d}x_2. \end{aligned} $$](/articles/aa/full_html/2020/01/aa36163-19/aa36163-19-eq78.gif) (B.5)
(B.5)
Then if we decompose the local field onto the Hermite polynomials,
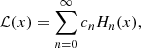 (B.6)
(B.6)
and use the orthogonality properties, we obtain the simple expansion
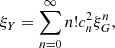 (B.7)
(B.7)
where
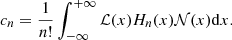 (B.8)
(B.8)
An important point to notice is that all the coefficients in the expansion are positive. Compare this to the series expansion of the inverse log-transform (Eq. (6)). We see immediately that a field with a ln(1 + ξX) covariance cannot be obtained from a Gaussian one.
Let us now reconsider the classical LN field (but with σ = 1). The local transform reads
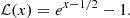 (B.9)
(B.9)
Then
![Mathematical equation: $$ \begin{aligned} c_n&=\dfrac{1}{n!}\int _{-\infty }^{+\infty } (e^{x-1/2}-1) \mathcal{N} (x) H_n(x) \mathrm{d}x \nonumber \\&=\dfrac{1}{n!} \left[ \int _{-\infty }^{+\infty } \mathcal{N} (x-1) H_n(x) \mathrm{d}x - \int _{-\infty }^{+\infty } \mathcal{N} (x) H_n(x) \mathrm{d}x \right] \nonumber \\&=\dfrac{1}{n!}[1-\delta _{n0}], \end{aligned} $$](/articles/aa/full_html/2020/01/aa36163-19/aa36163-19-eq83.gif) (B.10)
(B.10)
where we used the 𝒩(x) expression, H0(x) = 1 and 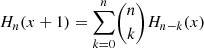 .
.
From Eq. (B.7) the autocorrelation of the LN field is
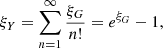 (B.11)
(B.11)
in agreement with the more classical way to derive it shown in Appendix A. While unnecessary in the LN case, such an approach is very powerful in computing numerically the auto-correlation of any transformed Gaussian field.
When the Gaussian field does not have a unit variance σ2 = ξX(0)≠1 which is generally the case, we works with rescaled variables leading to
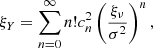 (B.12)
(B.12)
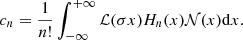 (B.13)
(B.13)
Then using the more general local transform discussed in Appendix A,
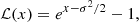 (B.14)
(B.14)
we recover Eq. (B.11).
Appendix C: Higher order correlation functions
In this appendix we show how to predict in a perturbative way the bi-spectrum and tri-spectrum, a non-Gaussian density field generated from the local transformation of a Gaussian field.
Let us consider a density field ϵ(x) in configuration space. We can therefore define its Fourier transform as
![Mathematical equation: $$ \begin{aligned} \epsilon _{{\boldsymbol{k}}} = \mathcal{F} \left[ \epsilon ({\boldsymbol{x}})\right] \equiv \frac{1}{(2\pi )^3}\int \epsilon ({\boldsymbol{x}}) e^{-{\boldsymbol{k}} \cdot {\boldsymbol{x}}}\mathrm{d}^3{\boldsymbol{x}}. \end{aligned} $$](/articles/aa/full_html/2020/01/aa36163-19/aa36163-19-eq89.gif) (C.1)
(C.1)
As explained is Sect. 2.2 we generate a Gaussian random field in Fourier space (assuming a power spectrum), we perform an inverse Fourier transform to get its analogue in configuration space. We further apply a local transform ℒ to map the Gaussian field into a stochastic field that is characterised by a target PDF. Thus, the N-point moments can in principle be predicted as soon as the local transform and the target power spectrum have been specified.
Let ν be a stochastic field following a centred (⟨ν⟩ = 0) reduced (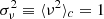 ) Gaussian distribution. From a realisation of this field, we can generate a non-Gaussian density field δ by applying a local mapping ℒ between the two, hence
) Gaussian distribution. From a realisation of this field, we can generate a non-Gaussian density field δ by applying a local mapping ℒ between the two, hence
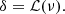 (C.2)
(C.2)
Without a lake of generality, we can express the N-point moments of the transformed density field with respect to the two-point correlation of the Gaussian field as
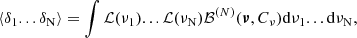 (C.3)
(C.3)
where ℬ(N) is a N-variate Gaussian distribution with a N × N covariance matrix Cν and sub-indexes are referring to positions δ1 ≡ δ(x1). In practice, the computation of Eq. (C.3) can be numerically expensive; however, as shown in Appendix B it can be efficiently computed thanks to the Mehler expansion, at least in the case of the two-point moment (see Eq. (B.7)). Assuming that in the local transform ℒ the amplitude of the coefficients of its Hermite transform (see Eq. (B.8)) is decreasing by the order n, it offers the possibility of ordering the various contributions to the total moment.
In order to evaluate Eq. (C.3) we can use extensions of the Mehler formula (Carlitz 1970); for example, the third order leads to
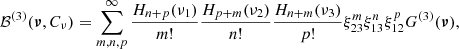 (C.4)
(C.4)
where the correlation functions ξ12, ξ13, and ξ23 are the three off-diagonal elements of the covariance matrix Cν and the function GN is defined as an N-variate Gaussian distribution with a diagonal covariance matrix whose values are all set to unity
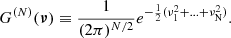 (C.5)
(C.5)
At fourth order (N = 4), the four-variate Gaussian can be expressed as
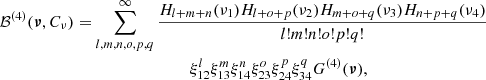 (C.6)
(C.6)
where again ξ12, ξ13, ξ14, ξ23, ξ24, and ξ34 are the six off-diagonal elements of the covariance matrix Cν. By replacing Eqs. (C.4) and (C.6) in expression C.3, we can integrate over the N variables ν1 to νN and express the three- and four-point moments as a sum over the product of the two-point correlation function of the Gaussian field
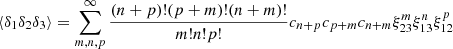 (C.7)
(C.7)
and
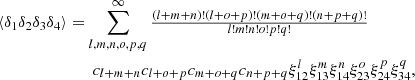 (C.8)
(C.8)
where the coefficients ci are still the coefficients of the Hermite expansion defined by Eq. (B.8). Equations (C.7) and (C.8) are particularly useful when we wants to evaluate the three- and four-point correlation functions of the density field δ or their Fourier counterparts, the bi-spectrum and tri-spectrum.
Let us express first the power spectrum of the density field δ with respect to the power spectrum of the Gaussian field ν. By performing a Fourier transform on Eq. (B.7) we can obtain
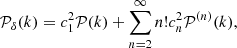 (C.9)
(C.9)
where 𝒫(n)(k) represents what we call loop corrections of order n − 1 and are defined as ![Mathematical equation: $ \mathcal P^{(n)}(k) \equiv \mathcal{F} [\xi_{\nu}^n] $](/articles/aa/full_html/2020/01/aa36163-19/aa36163-19-eq99.gif) . The leading order or tree-level contribution is given by
. The leading order or tree-level contribution is given by 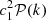 , which is just a change in amplitude of the power spectrum of the Gaussian field. It represents the change in the power spectrum that we would expect if the local transformation ℒ were linear.
, which is just a change in amplitude of the power spectrum of the Gaussian field. It represents the change in the power spectrum that we would expect if the local transformation ℒ were linear.
We now express the three-point correlation function ζδ, 123 ≡ ⟨δ1δ2δ3⟩c, dropping terms higher than one-loop corrections that we would obtain:
![Mathematical equation: $$ \begin{aligned} \zeta _{\delta , 123}&\simeq 2c_2c_1^2\left[ \xi _{12}\xi _{13} + \xi _{12}\xi _{23} + \xi _{13}\xi _{23} \right] \nonumber \\&\quad + 6c_3c_1c_2 \left[ \xi _{12}\xi _{13}^2 + \xi _{12}\xi _{23}^2 + \xi _{13}\xi _{23}^2 + \xi _{12}^2\xi _{13} + \xi _{12}^2\xi _{23} + \xi _{13}^2\xi _{23} \right] \nonumber \\&\quad + 8c_2^3\xi _{12}\xi _{13}\xi _{23}. \end{aligned} $$](/articles/aa/full_html/2020/01/aa36163-19/aa36163-19-eq101.gif) (C.10)
(C.10)
Taking the Fourier transform of the above Eq. (C.10) we can obtain the expression of the bi-spectrum of the density field as
![Mathematical equation: $$ \begin{aligned} B_\delta (k_1, k_2)&\simeq 2c_2c_1^2\left[ \mathcal{P} (k_1)\mathcal{P} (k_2) + \mathcal{P} (k_1)\mathcal{P} (k_{12}) + \mathcal{P} (k_2)\mathcal{P} (k_{12}) \right] \nonumber \\&\quad + 6c_3c_1c_2 \left[ \mathcal{P} (k_1)\mathcal{P} ^{(2)}(k_2) + \mathcal{P} (k_1)\mathcal{P} ^{(2)}(k_{12}) + \mathcal{P} (k_2)\mathcal{P} ^{(2)}(k_{12}) \right. \nonumber \\&\left. \quad + \mathcal{P} ^{(2)}(k_1)\mathcal{P} (k_2) + \mathcal{P} ^{(2)}(k_1)\mathcal{P} (k_{12}) + \mathcal{P} ^{(2)}(k_2)\mathcal{P} (k_{12}) \right] \nonumber \\&\quad + 8c_2^3B^{(3)}(k_1, k_2), \end{aligned} $$](/articles/aa/full_html/2020/01/aa36163-19/aa36163-19-eq102.gif) (C.11)
(C.11)
where we use the shorthand notations ki = ki, kij = |ki + kj| and
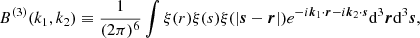 (C.12)
(C.12)
which can also be expressed in terms of a triple product of the power spectrum at different wave modes
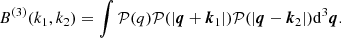 (C.13)
(C.13)
In the very same way, we can also express the one-loop prediction of the tri-spectrum; we need to start from the four-point correlation function ηδ, 1234 ≡ ⟨δ1δ2δ3δ4⟩c = ⟨δ1δ2δ3δ4⟩−ξδ, 12ξδ, 34 − ξδ, 13ξδ, 24 − ξδ, 14ξδ, 23 (Fry 1984b), where we need to express the products of two-point correlation functions at fourth order, and it follows that
![Mathematical equation: $$ \begin{aligned} \xi _{\delta , 12}\xi _{\delta , 34}&\simeq c_1^4 \xi _{12}\xi _{34} + 2c_2^2c_1^2\left[ \xi _{12}^2\xi _{34} + \xi _{12}\xi _{34}^2\right] + 4 c_2^4\xi _{12}^2\xi _{34}^2 \nonumber \\&\quad + 6c_3^2 c_1^2 \left[ \xi _{12}^3\xi _{34} + \xi _{12}\xi _{34}^3 \right]. \end{aligned} $$](/articles/aa/full_html/2020/01/aa36163-19/aa36163-19-eq105.gif) (C.14)
(C.14)
Keeping terms of order lower or equal to four in terms of ξ in Eq. (C.8) and subtracting permutations of Eq. (C.14) we can obtain the one-loop expression of the four-point correlation function
![Mathematical equation: $$ \begin{aligned} \eta _{\delta , 1234}&\simeq 6c_3c_1^3 \left[ \xi _{12}\xi _{13}\xi _{14}+ 3\; \mathrm{perm.} \right] + 4c_2^2c_1^2 \left[ \xi _{12}\xi _{23}\xi _{34}+ 11\; \mathrm{perm.} \right] \nonumber \\&\quad + 18c_1^2c_3^2 \left[ \xi _{12}\xi _{13}^2\xi _{34} + 11\; \mathrm{perm.} \right] \nonumber \\&\quad + 12c_3c_2^2c_1 \left[ \xi _{12}\xi _{13}\xi _{34} ( \xi _{12} + \xi _{34} ) + 11\; \mathrm{perm.} \right] \nonumber \\&\quad + 24 c_4c_2c_1^2 \left[ \xi _{12}\xi _{13}\xi _{14} ( \xi _{12} + \xi _{13} + \xi _{14} ) + 3\; \mathrm{perm.} \right] \nonumber \\&\quad + 24c_1c_2^2c_3\left[ \xi _{12}\xi _{34} ( \xi _{13}\xi _{14} + \xi _{23}\xi _{24} +\xi _{13}\xi _{23}+\xi _{14}\xi _{24} ) + 2\; \mathrm{perm.} \right]\nonumber \\&\quad + 16 c_2^4\left[ \xi _{12}\xi _{14}\xi _{23}\xi _{34} + 2\; \mathrm{perm.} \right]. \end{aligned} $$](/articles/aa/full_html/2020/01/aa36163-19/aa36163-19-eq106.gif) (C.15)
(C.15)
In order to recover the correct permutations, it should be noted that ξ12 and ξ34, ξ13 and ξ24, ξ14 and ξ23 can be interchanged without modification of the coefficients in front, thus in the second line we have four permutations involving the product ξ12ξ34 and we can iterate three times by taking the mentioned specific pairs (ξ12ξ34, ξ13ξ24, and ξ14ξ23). The above expression can be transformed into the tri-spectrum by just taking its Fourier transform, which reads
![Mathematical equation: $$ \begin{aligned} T_\delta (k_1, k_2, k_3)&\simeq 4c_2^2c_1^2 \left\{ \mathcal{P} (k_1)\mathcal{P} (k_2)\left[ \mathcal{P} (k_{13}) + \mathcal{P} (k_{14})\right] + 5\; \mathrm{perm.} \right\} \nonumber \\&\,\, + 6c_3c_1^3 \left\{ \mathcal{P} (k_1)\mathcal{P} (k_2)\mathcal{P} (k_3) + 3\; \mathrm{perm.} \right\} \nonumber \\&\,\, + 18c_1^2c_3^2 \left\{ \mathcal{P} ^{(2)}(k_{12})\mathcal{P} (k_1)\mathcal{P} (k_3) + 11\; \mathrm{perm.} \right\} \nonumber \\&\,\, + 12c_3c_2^2c_1 \left\{ \mathcal{P} (k_{12})\left[ \mathcal{P} ^{(2)}(k_1)\mathcal{P} (k_3) +\mathcal{P} (k_1)\mathcal{P} ^{(2)}(k_3) \right]+ 11\; \mathrm{perm.} \right\} \nonumber \\&\,\, + 24c_4c_2c_1^2 \left\{ \mathcal{P} (k_1)\mathcal{P} (k_2)\mathcal{P} ^{(2)}(k_3)+ 11\; \mathrm{perm.} \right\} \nonumber \\&\,\, + 24c_3c_2^2c_1 \left\{ \mathcal{P} (k_1)B^{(3)}(k_2, k_{3}) + 11\; \mathrm{perm.} \right\} \nonumber \\&\,\, + 16c_2^4 \left\{ T^{(4)}(k_1, k_{2}, k_{14})+T^{(4)}(k_1, k_{3}, k_{12}) + T^{(4)}(k_1, k_{4}, k_{13}) \right\} , \end{aligned} $$](/articles/aa/full_html/2020/01/aa36163-19/aa36163-19-eq107.gif) (C.16)
(C.16)
where we define the fourth order tri-spectrum as
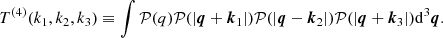 (C.17)
(C.17)
The practical evaluation of all the terms in Eq. (C.16) is not easy to get; however, in order to predict the covariance matrix we only need specific configuration of the tri-spectrum. The problem can simplified when trying to predict only the diagonal contribution (ki = kj). This has been already considered in the literature (Scoccimarro et al. 1999) at the tree-level and we obtain the same expression, which is
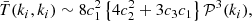 (C.18)
(C.18)
where as in Scoccimarro et al. (1999) we approximate the angular averages the power spectrum of the sum of two wave modes as being equal to the power spectrum evaluated at half the modulus of the two wave modes. A simple extension of the previous result can be obtained by neglecting the B(3) and T(4) terms in Eq. (C.17), and we would get
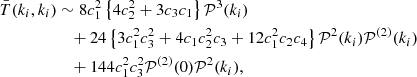 (C.19)
(C.19)
which can be used to control the statistical behaviour of our Monte Carlo density fields.
All Tables
All Figures
|
Fig. 1. Linear power spectrum (dashed line) computed by CLASS for a standard cosmology and smoothed by a Gaussian window of radius Rf = 4 h−1 Mpc (solid line). The vertical dotted line corresponds to |
| In the text | |
|
Fig. 2. Close-up of Fig. 1. Shown are the smoothed power spectrum (solid line) and the one reconstructed by applying the Eq. (6) inverse-log transform (dash-dotted line). |
| In the text | |
|
Fig. 3. Fraction f− of negative values in the three-dimensional 𝒫ν(k) as a function of the relative filtering Rf/a for three different grid samplings. The ratio Rf/a represents the relative scale between the smoothing scale Rf of the filtered power spectrum and the size of a grid unity a. |
| In the text | |
|
Fig. 4. Schematic view of the method used to build the power spectrum involved in the sampling of the Gaussian field, prior to its local transformation. The grey box means that three dimensions are considered. |
| In the text | |
|
Fig. 5. Power spectra involved in the Monte Carlo process. Shown is the theoretical 1D matter power spectrum computed by CLASS (dashed black line). Also shown (in red and blue, respectively) are the shell-averaged power spectra (in shells of width |k|−kf/2 < |k|< |k|+kf/2) showing the aliased version of the input power spectrum computed by the Boltzmann code and the corresponding power spectrum after transformation (B.12) (see Fig. 4 for details). All of them are plotted up to Nyquist frequency kN ∼ 0.67 h Mpc−1 with a setting of Ns = 256 and L = 1200 h−1 Mpc. |
| In the text | |
|
Fig. 6. Averaged 3D power spectrum compared to the expected 3D power spectrum, for 1000 realisations of the density field. The shell-averaged monopoles of this residuals in shells of width |k|−kf/2 < |k|< |k|+kf/2 were then computed. The result is presented as percentage with error bars. The setting used is a sampling number per side of 256 in the top panel and 512 for the other, all in a box of size L = 1200 h−1 Mpc at redshift z = 0. Both results are computed up to the Nyquist frequency. |
| In the text | |
|
Fig. 7. Measured diagonal of the covariance matrix for 7375 power spectra realisations of the density field using the Monte Carlo method (black line) up to kN ∼ 0.67 h Mpc−1. The other curves represent their predictions taking into account the Gaussian part alone (G) or by adding some non-Gaussian contributions of Eq. (15). For example in (1-NG) only the term in 𝒫3(ki) is kept in the tri-spectrum development presented in Eq. (17), while in (3-NG) all of them are kept. |
| In the text | |
|
Fig. 8. Off-diagonal elements of the covariance matrix estimated with N = 7375 realisations, showing the dependance of the Cij with respect to kj at various fixed ki (see labels on the right). The error bars are computed from Eq. (13). |
| In the text | |
|
Fig. 9. Top: measured power spectra averaged over 100 realisations of the Poissonian LN field for the Top-Hat interpolation scheme (blue curve with prediction in dash-dotted black line) and for the linear interpolation scheme (red curve and prediction in dashed line). The shot noise is subtracted from measures (solid horizontal black line) and is about 3.48 × 10−2 h3 Mpc3. The dotted black curve represents the alias-free theoretical power spectrum computed by CLASS. Bottom: relative deviation in percentage between the averaged realisations (with shot noise contribution) and prediction (with the same shot noise added) in blue line with error bar in grey for the Top-Hat interpolation scheme. Snapshots are computed for a grid of size L = 1200 h−1 Mpc and parameter Ns = 512. Here comparisons are made well beyond the Nyquist (vertical line) frequency at kN ∼ 1.34 h Mpc−1. |
| In the text | |
|
Fig. 10. Top panel: one thousand averaged Cℓ values for simulated light cones using the shell method with error bars (red curve) and corresponding prediction (dashed black curve). We simulate here a light cone between redshifts 0.2 and 0.3 in a sampling Ns = 512 and a number of shells Nshl = 250 to ensure a sufficient level of continuity in the density field. The spherical Nyquist mode is situated around ℓN ∼ 650 and represented by the vertical reference. Bottom panel: relative deviation in percent of the averaged predicted Cℓ values with error bars in red. |
| In the text | |
|
Fig. 11. Relative difference in percent between shell method and cell method for varying numbers of shells. The spherical Nyquist mode is situated around ℓN ∼ 650 and represented by the vertical reference. |
| In the text | |
|
Fig. 12. Relative deviation in percent with error bars for 10 000 averaged realisations of Cℓ values in the context of the cell method. In the top panel, the density field (non-Gaussian) is rescaled using linear growth function, while in the bottom panel the Gaussian field following the virtual power spectrum is rescaled. The spherical Nyquist mode is situated around ℓN ∼ 650 and is represented by the vertical reference. |
| In the text | |
|
Fig. 13. Top: measured diagonal of the covariance matrix (blue curve) over N = 10 000 realisations of different light cones. The red curve represents the associated prediction in the case of a Gaussian field with errors computed using Eq. (13). Here we keep the shot noise (SN) effect in the measures and include it in the prediction. The spherical Nyquist mode is situated around ℓN ∼ 650. Bottom: relative difference in percent following the same colour-coding. |
| In the text | |
|
Fig. 14. First 300 elements measured for the off-diagonal part of the covariance matrix over n = 10 000 realisations of light cone with Gaussian errors computed using Eq. (13). The elements are labelled by the index m and are ordered column by column in the lower half of the matrix without passing by the diagonal, i.e. Cij, i > j. |
| In the text | |
|
Fig. 15. Correlation matrix for 10 000 realisations of Cℓ in a simulated universe between redshifts 0.2 and 0.3 and a sampling Ns = 512. The (ℓ×ℓ′) = (1000 × 1000) of the matrix are represented here. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.