| Issue |
A&A
Volume 614, June 2018
|
|
|---|---|---|
| Article Number | A129 | |
| Number of page(s) | 17 | |
| Section | Extragalactic astronomy | |
| DOI | https://doi.org/10.1051/0004-6361/201731797 | |
| Published online | 03 July 2018 | |
High redshift galaxies in the ALHAMBRA survey⋆
II. Strengthening the evidence of bright-end excess in UV luminosity functions at 2.5 ≤ z≤ 4.5 by PDF analysis
1
Centro de Estudios de Física del Cosmos de Aragón, Unidad Asociada al CSIC, Plaza San Juan 1, 44001 Teruel, Spain
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
APC, AstroParticule et Cosmologie, Université Paris Diderot, CNRS/IN2P3, CEA/lrfu, Observatoire de Paris, Sorbonne Paris Cité, 10 rue Alice Domon et Léonie Duquet, 75205 Paris CEDEX 13 France
3
IAA-CSIC, Glorieta de la Astronomía s/n, 18008 Granada, Spain
4
Instituto de Física de Cantabria (CSIC-UC), 39005 Santander, Spain
5
Unidad Asociada Observatorio Astronómico (IFCA-UV), 46980 Paterna, Spain
6
Ethiopian Space Science and Technology Institute (ESSTI), Entoto Observatory and Research Centre (EORC), Astronomy and Astrophysics Research Division, Addid Ababa, Ethiopia
7
Instituto de Astrofísica de Canarias, Vía Láctea s/n, 38200 La Laguna, Tenerife, Spain
8
Departamento de Astrofísica, Facultad de Física, Universidad de La Laguna, 38206 La Laguna, Spain
9
Observatório Nacional-MCT, Rua José Cristino, 77, CEP 20921-400 Rio de Janeiro, RJ, Brazil
10
Department of Theoretical Physics, University of the Basque Country UPV/EHU, 48080 Bilbao, Spain
11
IKERBASQUE, Basque Foundation for Science, María Díaz Haroko Kalea, 3, 48013 Bilbao, Spain
12
Departamento de Física Atómica, Molecular y Nuclear, Facultad de Física, Universidad de Sevilla, 41012 Sevilla, Spain
13
Institut de Ciències de l’Espai (IEEC-CSIC), Facultat de Ciències, Campus UAB, 08193 Bellaterra, Spain
14
Instituto de Astrofísica, Universidad Católica de Chile, Av. Vicuna Mackenna 4860, 782-0436, Macul, Santiago, Chile
15
Centro de Astro-Ingeniería, Universidad Católica de Chile, Av. Vicuna Mackenna 4860, 782-0436, Macul, Santiago, Chile
16
Observatori Astronòmic,Universitat de València, C/ Catedràtic José Beltrán 2, 46980 Paterna, Spain
17
Departament d’Astronomia i Astrofísica, Universitat de València, 46100 Burjassot, Spain
18
Instituto de Astronomía, Geofísica e Ciéncias Atmosféricas, Universidade de São Paulo, São Paulo, Brazil
Received:
18
August
2017
Accepted:
3
February
2018
Abstract
Context. Knowing the exact shape of the ultraviolet (UV) luminosity function (LF) of high-redshift galaxies is important to understand the star formation history of the early Universe. However, the uncertainties, especially at the faint and bright ends of the LFs, remain significant.
Aims. In this paper, we study the UV LF of redshift z = 2.5 – 4.5 galaxies in 2.38 deg2 of ALHAMBRA data with I ≤ 24. Thanks to the large area covered by ALHAMBRA, we particularly constrain the bright end of the LF. We also calculate the cosmic variance and the corresponding bias values for our sample and derive their host dark matter halo masses.
Methods. We have used a novel methodology based on redshift and magnitude probability distribution functions (PDFs). This methodology robustly takes into account the uncertainties due to redshift and magnitude errors, shot noise, and cosmic variance, and models the LF in two dimensions (z, MUV).
Results. We find an excess of bright * M*UV galaxies as compared to the studies based on broad-band photometric data. However, our results agree well with the LF of the magnitude-selected spectroscopic VVDS data. We measure high bias values, b ~ 8 – 10, that are compatible with the previous measurements considering the redshifts and magnitudes of our galaxies and further reinforce the real high-redshift nature of our bright galaxies.
Conclusions. We call into question the shape of the LF at its bright end; is it a double power-law as suggested by the recent broad-band photometric studies or rather a brighter Schechter function, as suggested by our multi-filter analysis and the spectroscopic VVDS data.
Key words: galaxies: evolution / galaxies: high-redshift / galaxies: luminosity function / mass function
Based on observations collected at the German-Spanish Astronomical Center, Calar Alto (CAHA), jointly operated by the Max-Planck-Institut fur Astronomie (MPIA) at Heidelberg and the Instituto de Astrofísica de Andalucía (CSIC).
© ESO 2018
Introduction
The ultraviolet (UV) continuum emission of galaxies is directly proportional to their star formation rate (SFR, see e.g. Kennicutt & Evans 2012), and is conveniently observed at optical wavelengths at z > 2.5. Hence, knowing the exact shape of the UV luminosity function (LF) at different redshifts is important to trace the star formation history of the early Universe. This, in turn, is an important piece of information to understand galaxy evolution and to constrain cosmological models.
The UV LF at redshift z ~ 2.5–4.5 is widely studied in the literature (e.g. Steidel et al. 1999; Reddy & Steidel 2009; van der Burg et al. 2010; Cucciati et al. 2012; Parsa et al. 2016; Mehta et al. 2017). However, the disagreement between different studies especially at the faint and bright ends of the LFs are still significant (see, e.g. Cucciati et al. 2012; Parsa et al. 2016). Ideally, one should derive the LFs from a deep spectroscopic sample of galaxies without pre-selection, and at a large area. In reality this is not achievable. Selection-wise a random magnitude- limited spectroscopic survey such as the VIMOS VLT Deep Survey (VVDS, Le Fèvre et al. 2013) basically does the same. However, achieving both area and depth is time consuming in general, and more so in spectroscopic surveys. Hence, to our knowledge the only z > 2.5 LF estimations based on spectroscopic data without colour pre-selection are those derived from the VVDS data (Paltani et al. 2007; Cucciati et al. 2012), while most of the high-z UV LFs have been derived from photometric surveys.
Commonly, the studies of z > 2.5 galaxies are based on samples pinpointed using the so-called drop-out technique (e.g. Guhathakurta et al. 1990; Steidel et al. 1996a, b; Bouwens et al. 2015; Mehta et al. 2017; Ono et al. 2018). The main limitation of these studies is that the redshift distribution of the selected objects is wide and the selection is affected by significant contamination and incompleteness. The contamination can be corrected by obtaining spectroscopic redshifts (see, e.g. Steidel et al. 1996a, b; Reddy et al. 2006). Incompleteness, however, is a more serious problem. As a matter of fact, it has been shown (Paltani et al. 2007; Le Fèvre et al. 2015; Inami et al. 2017) that the drop-out selection leaves out a significant fraction of genuine high-z galaxies.
A selection of high redshift objects based on photometric redshifts has also been used in the literature (e.g. Finkelstein et al. 2015; Parsa et al. 2016). The precision of the photometric redshifts depends strongly on the amount of filters used (Benítez et al. 2009) and can help to tighten the redshift distributions of the selected samples. However, the above studies use the redshift information to select a list of candidates instead of directly using all the information encoded in the redshift probability distribution functions (PDFs). Hence, the problem of contamination and incompleteness remains. As a matter of fact, Viironen et al. (2015) showed that in terms of colours a very conservative selection based on photometric redshifts, even when derived from various median bands leading to high-precision photo-zs, can closely resemble a drop-out selection. However, using all the information encoded in redshift PDFs allows us to exploit the colour spaces not considered in drop-out selections but which are shown to contain genuine high-z galaxies. To our knowledge the first attempt to fully exploit the redshift PDF information in LF analysis was made by McLure et al. (2009).
In this paper we derive the UV LFs for z = 2.5 – 4.5 galaxies observed by the Advanced Large, Homogeneous Area Medium Band Redshift Astronomical (ALHAMBRA, Moles et al. 2008) survey. We have previously studied the galaxy number counts based on redshift PDFs in Viironen et al. (2015). In this paper we derive the UV LFs considering both the redshift and the I-band selection magnitude PDFs. The methodology used here was developed as part of the PROFUSE (PRObability Functions for Unbiased Statistical Estimations in multi-filter surveys1) project and was introduced by López-Sanjuan et al. (2017, LS17 from now on) in the framework of B-band LFs of 0.2 ≤ z ≤ 1 ALHAMBRA galaxies.
The PROFUSE estimator of the LF has important advantages with respect to previous ones. It provides a posterior two-dimensional (2D) LF at the band of interest, in our case Ф(z, M UV). Taking into account both the redshift and magnitude PDFs it (i) naturally accounts for z and M UV uncertainties, (ii) ensures 100% completeness (up to the limiting magnitude of the survey) because it works with intrinsic magnitudes instead of the observed ones, and (iii) provides a reliable covariance matrix in redshift–magnitude space. Finally, instead of modelling the LF in redshift slices, a 2D z – M UV model is created with the same binning as the data, and the data is fitted in two dimensions.
The uncertainties in the derived LFs are derived considering both the shot noise and the cosmic variance. ALHAMBRA data is obtained in 48 sub-fields, allowing us to derive the latter. The cosmic variance of the galaxies is directly proportional to their bias, which in turn provides information about the mass of the hosting dark matter halo. Hence, we also derived the bias and halo masses for our sample of high-z galaxies.
The outline of this paper is as follows: Sect. 2 describes the ALHAMBRA data used for this study, the photometric red-shifts, and the photometric pre-selection of galaxies. Section 3 describes the absolute magnitude estimates. Section 4 describes the methodology employed to derive the LF and to model it. The corresponding error estimates are introduced in Sect. 5. The bias values and the modelling are introduced in Sect. 6. Section 7 presents the final ALHAMBRA LF and the corresponding luminosity density. In Sect. 8 the host halo masses for our sample galaxies are derived. Summary and conclusion are given in Sect. 9.
Where necessary, we have assumed a flat ΛCDM Universe with Ω m = 0.3, ΩΛ = 0.7, and H0 = 70 km s−1 Mpc−1. Magnitudes are given in the AB system (Oke & Gunn 1983).
2 The ALHAMBRA survey
The ALHAMBRA survey (Moles et al. 2008) has mapped a total of 4 deg2 of the northern sky in eight separate fields over a seven year period (2005–2012). Of the total surveyed area, 2.8 deg2 were completed with all the filters (2.38 deg2 after masking, see Sect. 2.2). ALHAMBRA uses a specially designed filter system (Aparicio Villegas et al. 2010) which covers the optical range from 3500 Å to 9700 Å with 20 contiguous, equal width (~300 Å FWHM), medium-band filters, plus the three standard broad bands, J, H, and K s, in the NIR. The photometric system has been specifically designed to optimise photometric redshift depth and accuracy (Benítez et al. 2009). The observations were carried out with the Calar Alto 3.5 m telescope using two wide field cameras: LAICA in the optical, and OMEGA-2000 in the NIR. The 5σ limiting magnitude reaches ≳ 24 for all filters below 8000 Å and decreases steeply towards redder medium band filters, down to m(AB) ~21.5 for the reddest optical filter at 9700 Å (see Fig. 37 of Molino et al. 2014). In the NIR the limiting magnitudes are J ~ 23, H ~ 22.5, and Ks ~ 22. For details about the NIR data reduction see Cristóbal-Hornillos et al. (2009), while the optical reduction will be described in Cristóbal-Hornillos et al. (in prep). The ALHAMBRA catalogues and the associated Bayesian photometric redshifts are described in Molino et al. (2014) and are publicly available through the ALHAMBRA webpage2.
2.1 ALHAMBRA photometric redshifts
For all the objects in the ALHAMBRA catalogue a redshift PDF is provided as detailed in Molino et al. (2014). These photometric redshifts were estimated using BPZ2, an updated version of the Bayesian photometric redshift (BPZ) code (Benítez 2000). BPZ uses Bayesian inference where a maximum likelihood, resulting from a χ 2 minimisation between the observed and predicted colours for a galaxy among a range of redshifts and templates, is weighted by a prior probability. Both maximum likelihood and Bayesian redshift probability distributions are available for all the ALHAMBRA sources. The BPZ2 spectral energy distribution (SED) library (see Molino et al. 2014) is composed of 11 SEDs: five templates for elliptical galaxies, two for spiral galaxies and four for starburst galaxies along with average emission lines and dust extinction. The opacity of the intergalactic medium has been applied as described in Madau (1995). The prior used gives the probability of a galaxy with apparent magnitude m0 having redshift z and spectral type T. The prior has been empirically derived for each spectral type and magnitude by fitting LFs provided by GOODS-MUSIC (Santini et al. 2009), COSMOS (Scoville et al. 2007) and UDF (Coe et al. 2006). In Viironen et al. (2015) we show that the use of prior hardly affects the high redshift galaxy number counts. We checked that the high-z LFs neither are affected by the use of the prior. Following Viironen et al. (2015) we opted for using the maximum likelihood PDFs in the present paper.
2.2 Photometric pre-selection
The photometric pre-selection was done following Viironen et al. (2015). The source detections for the ALHAMBRA catalogue, consisting of 441302 objects, are made in a synthetic F814W filter image, created to resemble the HST/F814W filter (Molino et al. 2014). To avoid spurious detections, we removed the areas of low quality data, meaning those affected by bright stars or image borders, using the masks created by Arnalte-Mur et al. (2014). The statistical separation between star and galaxy is encoded in the parameter Stellar_Flag in the ALHAMBRA catalogue. We selected galaxies by setting Stellar_Flag ≤ 0.5. This should remove the stars up to m < 22.5 in the reference filter, F814W. Above this magnitude the stellar flag is not defined, and slight contamination by faint stars may remain. However, for fainter magnitudes, the fraction of stars declines rapidly compared to that of galaxies, with a contribution of ~10% for magnitudes m(F814W) = 22.5, declining to ~1% for magnitudes m(F814W) = 23.5 (Molino et al. 2014). After these steps, our data consist of a total of 362788 galaxies in 2.38 deg2.
This is the only exclusive selection applied to the data. The rest of the catalogued objects are all included in the following study, but do not naturally influence the results if they either are so faint that even considering the magnitude errors they completely fall below the magnitude limit defined in Sect. 3.1 below, or if their probability to be at the redshift range of our interest is null.
3 Absolute magnitude estimates
In this section, we follow the methodology presented in LS17. These authors calculate the LF in a synthetic B-band filter. In this paper, we have created a synthetic 100 Å wide top-hat filter centred at 1500 Å restframe. First we introduce in Sect. 3.1 the I-band selection taking into account the magnitude errors and the correction for Eddington bias. The photometric redshift PDFs are taken into account in Sect. 3.2. Finally, with all these ingredients, the rest-frame UV absolute magnitudes are introduced in Sect. 3.3.
3.1 I-band selection
The ALHAMBRA catalogue is selected in the synthetic F814W images, which we refer to here as I band. Hence, all the studies based on this catalogue are affected by this selection. For each galaxy, we observe its magnitude I with an error σ
I
. Hence, the real magnitude, I
0, of the galaxy can be described as a Gaussian (in flux space) centred in I and with a standard deviation σ
1 (for the magnitude space description, see Eq. (3) in LS17). In addition, we know that the faint galaxies are more numerous than the bright ones. For this reason, the net effect of photometric errors is to slightly increase the number of bright galaxies at the expense of fainter ones, that is, to flatten the increasing trend of the number counts. This effect is generally known as Eddington bias (Eddington 1913; Teerikorpi 2004). To take into account these two factors, we describe each object in our catalogue by a posterior PDF: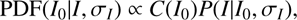 (1)
(1)
where the integral of PDF(I
0|I, σ
I
) is normalised to one and the number count term C(I
0) is obtained by fitting the intrinsic (I
0) galaxy number counts by an equation:![Mathematical equation: $$ {\mathrm{log}}_{10}\left[C\left({I}_0\right)\right]\propto -0.015{I}_0^2+1.00{I}_0. $$](/articles/aa/full_html/2018/06/aa31797-17/aa31797-17-eq3.gif) (2)
(2)
Here the intrinsic (I 0) number count distribution was deconvolved from the observed (I, σ I ) distribution using emcee (Foreman-Mackey et al. 2013) code, a Python implementation of the affine-invariant ensemble sampler for Markov chain Monte Carlo (MCMC) proposed by Goodman & Weare (2010).
The photometric error, σ
I
, accounts for three terms: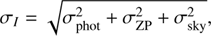 (3)
(3)
where σ phot is the photon counting error, σZP = 0.02 is the uncertainty in the zero point, and σ sky the sky background uncertainty. The last was estimated empirically by placing random apertures across the empty areas of the ALHAMBRA images (Molino et al. 2014).
With all these ingredients, the I-band selection is robustly taken into account by describing each galaxy with a source function: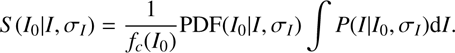 (4)
(4)
In this equation f c (I 0 ) is the completeness calculated by injecting sources of known I 0 magnitude in the I-band ALHAMBRA images and computing their detection rate (see LS17 for details), and the last term, ∫P(I|I 0, σ I )dI provides the probability that the object has a positive flux.
The final selection is then made by setting I
0 < 24, where a completeness of f
c
= 0.85 is reached on average in the 48 ALHAMBRA sub-fields (LS17). Formally, the selection is made by excluding the galaxies fulfilling the criterion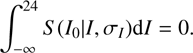 (5)
(5)
This means that even galaxies with observed magnitude I > 24 may partially enter the selection. As emphasised in LS17, this kind of selection in real magnitudes (instead of in the observed ones which is a normal practice in the literature) assures, once the completeness correction of Eq. (4) is applied, a 100% complete sample, with a well controlled selection function.
3.2 Photometric redshift information
The reliability of the ALHAMBRA photometric redshifts and redshift probability distribution functions are well demonstrated (e.g. Molino et al. 2014; López-Sanjuan et al. 2015b). Further following LS17, and along the line taken in several works related to ALHAMBRA (Viironen et al. 2015; Ascaso et al. 2015; López-Sanjuan et al. 2015a; Díaz-García et al. 2015), the redshifts of the galaxies are taken into account by considering their whole redshift probability distributions functions. The probability that a galaxy i is located at redshift z and has a spectral type T is PDF
i
(z, T). Hence, the probability that the galaxy i is located at redshift z is: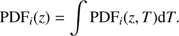 (6)
(6)
The integral of the PDF
i
(z) is normalised to one by definition, that is: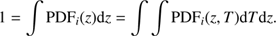 (7)
(7)
3.3 UV magnitudes
Armed with the source function, and bi-dimensional redshift probability distribution function, PDF(z, T), for each galaxy we can now obtain its magnitude, as a function of both redshift and template, in the target UV filter by the equation:![Mathematical equation: $$ {M}_{\rm{UV}}(z,T|{I}_0)={I}_0-5\thinspace{\mathrm{log}}_{10}[{D}_{\rm{L}(z)}]-k(z,T)-25, $$](/articles/aa/full_html/2018/06/aa31797-17/aa31797-17-eq9.gif) (8)
(8)
where DL(z) is the luminosity distance in Mpc and k(z, T) accounts for the k-correction between the observed I-band at redshift z and the targeted UV-filter at rest-frame for each template. Appendix A in LS17 gives the details of how to derive the k-correction for the rest frame B-band targeted in that study. In our case the methodology is exactly the same with the only difference being that we have created our own target UV-filter: a top-hat filter centred at rest-frame 1500 Å with a width of 100 Å.
Next, for each galaxy i, we constructed the probability P
i(z, M
UV|I
i
) by a PDF-weighted histogram of M
UV,
i
= MUV
(z, T\I
i
) with a very fine binning (dM
UV
= 0.02):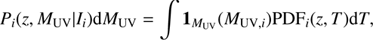 (9)
(9)
where 1 M UV (M UV,i ) is an indicator function whose value is one if the argument is between M UV and M UV + dM UV. This probability tracks the uncertainties of the observed colours, traced by the template space, to the z – M UV space, including the correlation between the two variables. As an example, we show the P i (z, M UV|I i) for an arbitrary high-redshift ALHAMBRA source in Fig. 1 (Top).
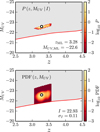 |
Fig. 1 Top panel: probability of an arbitrary high-redshift ALHAMBRA galaxy with observed magnitude I = 22.93 ± 0.11 in z – M UV space. Bottom: the above function convolved with the source function, S (I 0 |I, σ I ), gives the probability in z – M UV space for the real magnitude I 0. In both figures the white dot marks the maximum likelihood redshift, z ML, and the corresponding M UV,ML, labelled in the panel. The red line indicates the applied I 0 = 24 limiting magnitude, and the accessible total volume is shown as shaded grey area. |
Finally, to take into account the photometric errors, and the Eddington bias effects (see Sect. 3.1), we needed to convolve this matrix by the source function (Eq. (4)). Formally: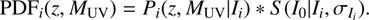 (10)
(10)
The final posterior PDF
i
(z, M
UV) for our example galaxy is shown in the bottom panel of Fig. 1. We note that the PDFs show sharp edges because, to reduce the calculation time, a cut was applied to small P
i
(z, M
UV|Ii
) values that were confirmed to be insignificant. To derive the limiting magnitude, M
UV,lim(z), corresponding to I
0 = 24, as a function of redshift (red line in Fig. 1), we calculated at each redshift the absolute magnitude for the template that, once normalised to I
0 = 24, gives the brightest absolute magnitude at that z:![Mathematical equation: $$ {M}_{\rm{UV},{lim}}(z)=\mathrm{min}[{M}_{\rm{UV}}(z,T|{I}_0=24)]. $$](/articles/aa/full_html/2018/06/aa31797-17/aa31797-17-eq12.gif) (11)
(11)
In this way we assured a 100% complete selection above M UV,lim(z). Finally, in the same Fig. 1, we also show how the same galaxy would be seen in a traditional approach in which only the BPZ2 redshift, z ML (Molino et al. 2014), and the corresponding UV magnitude (i.e. M UV corresponding to the observed I, z ML and the best fitting template), were taken into account.
4 Luminosity function derivation
In this section we derive the ALHAMBRA LF and model it in 2D, again following the scheme presented in LS17. The authors of LS17 calculate the LF separately for quiescent and star- forming galaxies. We use exactly the same code in this work. However, in the following text we skip the details related to the separation between quiescent and star-forming galaxies. This is because the integrated total number of quiescent galaxies in the ALHAMBRA catalogue at the redshift range of our interest is non-significant (0.7 to be more exact), and these galaxies can safely be ignored in our analysis. The low number of quiescent galaxies is understandable because these galaxies are too faint in their rest-frame UV to be detected by ALHAMBRA with F814W ≤ 24. Here we give a summary of the steps taken to calculate the LF. For more detailed description of the methodology, see LS17.
4.1 2D luminosity function
Having the PDF
i
(z, M
UV) for each ALHAMBRA galaxy, we are now in the position of constructing the LF simply by summing up the individual probability distributions, divided by the volumes they probe. To take into account the cosmic variance, we calculated the LF field by field. For an ALHAMBRA field j the LF is given by the equation:![Mathematical equation: $${{\Phi }_{j}}(z,{{M}_{\text{UV}}})=\frac{1}{{{\text{A}}_{j}}}\underset{i}{\mathop \sum }\,\text{PD}{{\text{F}}_{i}}(z,{{M}_{\text{UV}}}){{\left( \frac{\text{d}V}{\text{d}z} \right)}^{-1}}[\text{Mp}{{\text{c}}^{-3}}\,\text{ma}{{\text{g}}^{-1}}],$$](/articles/aa/full_html/2018/06/aa31797-17/aa31797-17-eq13.gif) (12)
(12)
where i runs over all the galaxies in the field j, A j is the area (in deg2) of the field j, PDF i (z, M UV) is given by the Eq. (10), and dV/dz is the differential cosmic volume probed by one square degree.
Next, we calculated the median value of the individual fields to obtain the total ALHAMBRA UV LF:![Mathematical equation: $$ {{\text{ }\!\!\Phi\!\!\text{ }}^{\text{tot}}}(z,{{M}_{\text{UV}}})=\text{med}\left[ {{\Phi }_{j}}(z,{{M}_{\text{UV}}}) \right], $$](/articles/aa/full_html/2018/06/aa31797-17/aa31797-17-eq14.gif) (13)
(13)
where the index j runs the N = 48 ALHAMBRA sub-fields. We note that we calculated the median value here, instead of the mean, because we consider this measurement more robust for the log-normally distributed number counts (see Sect. 5.2). The difference between mean and median becomes important at the brightest bins, which contain only a few galaxies, in which the mean would clearly bias the LF value towards the more populated fields.
Finally, to ensure a well controlled error budget for the LF, we degraded the resolution of each Φ
j
(z, M
UV) to create a binned LF. The LF was divided in K bins in the z-axis and L bins in the M
UV axis, where the optimal bin sizes, ∆z and ∆M
UV, are defined in Appendix A. Then for each bin [z
min = z
k
– 0.5∆z, z
max = z
k
+ 0.5∆z], [M
UV,min = M
UV,l – 0.5∆M
UV, M
UV,max = MUV,1 + 0.5∆M
UV], where k = (1,2, ...K), l = (1,2, ...L), the following formula was applied: (14)
(14)
where ΔV is the cosmic volume probed by one square degree at z
min ≤ z < z
max: (15)
(15)
The binned LF is then: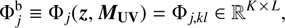 (16)
(16)
where z and
M
UV
are the vectors that define the binned histogram. Finally, the total binned LF is obtained with Eq. (13) by taking the median of the individual 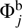 .
.
4.2 Luminosity function model
We modelled the ALHAMBRA LF with a Schechter function (Schechter 1976):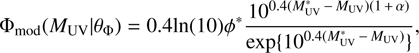 (17)
(17)
where ![Mathematical equation: $ {\theta }_{\mathrm{\Phi }}=[{{M}}_{\mathrm{UV}}^{\mathrm{*}},\enspace {\phi }^{\mathrm{*}},\alpha ]$](/articles/aa/full_html/2018/06/aa31797-17/aa31797-17-eq20.gif) are the parameters that define the model.
are the parameters that define the model. 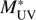 is the characteristic magnitude corresponding to the transition magnitude from a power law LF to an exponential LF, α* is the characteristic density, offering the normalisation of the LF, and α determines the slope of the power law variation at the faint end.
is the characteristic magnitude corresponding to the transition magnitude from a power law LF to an exponential LF, α* is the characteristic density, offering the normalisation of the LF, and α determines the slope of the power law variation at the faint end.
The modelling was done in 2D. For this purpose, we calculated a model LF using Eq. (17) at the same grid as our binned LF. The χ2 to be minimised is then given by the equation:![Mathematical equation: $$ {{\chi }^{2}}(\Phi |{{\theta }_{\Phi }},{{\Sigma }_{\Phi }})={{[\ln \Phi -\ln {{\Phi }_{\text{mod}}}]}^{\text{T}}}\sum\nolimits_{\Phi }^{-1}{[\text{ln}\Phi -\text{ln}{{\Phi }_{\text{mod}}}]}, $$](/articles/aa/full_html/2018/06/aa31797-17/aa31797-17-eq22.gif) (18)
(18)
where ΣΦ is the LF covariance matrix defined in Sect. 5 below, and the χ2 is defined in log-space because the LF values follow a log-normal distribution rather than a Gaussian one (see Sect. 6). The posterior distribution of the model parameters is then: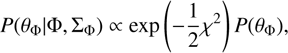 (19)
(19)
where the distribution is normalised to unity and (PθΦ) is the prior in the parameters. Here we have assumed an uninformative, flat prior, (PθΦ) = 1, for 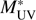 and ϕ*. We do not have enough data points at the faint end to accurately trace α Therefore, for α we needed to rely on a prior information. Parsa et al. (2016) offers a compilation of different α values found in the literature. From their table we selected the α values at the redshift range of our interest, ending up with 16 values in the range z = 2.7 − 4.0, and created a histogram of them. We fitted the histogram with a Gaussian function, resulting in median and standard deviation of α = –1.54 ± 0.15, see Fig. 2. Finally, we used this as a prior distribution for the α parameter.
and ϕ*. We do not have enough data points at the faint end to accurately trace α Therefore, for α we needed to rely on a prior information. Parsa et al. (2016) offers a compilation of different α values found in the literature. From their table we selected the α values at the redshift range of our interest, ending up with 16 values in the range z = 2.7 − 4.0, and created a histogram of them. We fitted the histogram with a Gaussian function, resulting in median and standard deviation of α = –1.54 ± 0.15, see Fig. 2. Finally, we used this as a prior distribution for the α parameter.
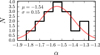 |
Fig. 2 Distribution of a values as compiled from the literature by Parsa et al. (2016) at redshifts z = 2.7 – 4.0. A Gaussian fit to this distribution is shown as a red line and the median and sigma of this Gaussian are labelled in the panel. |
4.3 Final modelling
The 2D LF modelling was then carried out by minimising the Eq. (18). This was done using the emcee code which provides a collection of solutions in the parameter space, with the density of the solutions being proportional to the posterior probability of the parameters, meaning that it empirically maps Eq. (19). The most probable values of the parameters and their uncertainties were then obtained as the median and the dispersion of the projected solutions.
5 Luminosity function uncertainty estimates
The LF uncertainty has two dominant terms: the statistical (i.e. the shot noise term), and the cosmic variance term (Robertson 2010; Smith 2012). Because of the uncertainties in both the redshifts and the magnitudes, the values of the LF in different bins are correlated in both dimensions. Following again LS17, we estimated both the shot noise and cosmic variance terms of the covariance matrix for the LF Φ. The covariance matrix is given in relative form, as the LF is finally fitted in logarithmic space.
5.1 Shot noise term
The shot noise term was derived with the bootstrapping technique (Davison & Hinkley 1997). For this purpose, 20000 bootstrap samples of the median LF were created, noted as 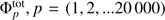 The shot noise term of the covariance matrix 2 is then given by the equation:
The shot noise term of the covariance matrix 2 is then given by the equation:
![Mathematical equation: $$ {\mathrm{\Sigma }}_S\equiv {\mathrm{\Sigma }}_S({z}_m,{z}_n,{M}_{\mathrm{UV},q},{M}_{\mathrm{UV},l})=\frac{\mathbb{E}[{\mathrm{\Phi }}_p^{\mathrm{tot}}({z}_m,{M}_{\mathrm{UV},q}){\mathrm{\Phi }}_p^{\mathrm{tot}}({z}_n,{M}_{\mathrm{UV},l})]}{{\mathrm{\Phi }}_p^{\mathrm{tot}}({z}_m,{M}_{\mathrm{UV},q}){\mathrm{\Phi }}_p^{\mathrm{tot}}({z}_n,{M}_{\mathrm{UV},l})}-1, $$](/articles/aa/full_html/2018/06/aa31797-17/aa31797-17-eq26.gif) (20)
(20)
where 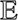 is the expected value (i.e. the mean) operator, the indices m and n run the redshift bins, and the indices q and l run the absolute magnitude bins. The covariance between luminosity bins at a given redshift is mapped by setting m = n, and the covariance between redshift bins at the given magnitude by setting q = l.
is the expected value (i.e. the mean) operator, the indices m and n run the redshift bins, and the indices q and l run the absolute magnitude bins. The covariance between luminosity bins at a given redshift is mapped by setting m = n, and the covariance between redshift bins at the given magnitude by setting q = l.
5.2 Cosmic variance term
The large scale density fluctuations of the Universe lead to field to field variations in the observed galaxy number counts. This cosmic variance often causes uncertainties larger than the shot noise term derived in the previous section. Here we have derived the cosmic variance term of the LF covariance matrix following the prescription given in LS17 and López-Sanjuan et al. (2015a).
The relative cosmic variance is defined as (Somerville et al. 2004):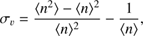 (21)
(21)
where 〈n〉 and 〈n 2〉 − 〈n〉2 are the mean and the variance, respectively, of the number density distribution of galaxies in the 48 ALHAMBRA subfields. The number density in each ALHAMBRA field and for each redshift-magnitude bin is obtained by Eq. (14). This is then fitted by a log-normal function, whose dispersion encodes both the dispersion due to the Poisson shot noise and the intrinsic dispersion due to the galaxy clustering. The latter, (i.e. the cosmic variance term), is separated from the former using a maximum likelihood estimator (MLE, see López-Sanjuan et al. 2015a, b). MLE offers both the value of the cosmic variance term and its error.
Ideally, one would derive the cosmic variance at exactly the same bins as the LF. However, due to the limited amount of galaxies in our sample, we have calculated the variance in two magnitude bins at z = 2.5 – 3.5, and one magnitude bin at z = 3.5 – 4.5, and derive from modelling the cosmic variance, σv,mod
, at the same resolution as our LF (see Sect. 6). The cosmic variance term of the covariance matrix is then given by the equation:![Mathematical equation: $$ {\mathrm{\Sigma }}_v\equiv {\mathrm{\Sigma }}_v\left({z}_m,{z}_n,{M}_{\mathrm{UV},q},{M}_{\mathrm{UV},l}\right)={\delta }_{mn}\frac{{\sigma }_{v,{\mathrm{mod}}}({z}_m,{M}_{\mathrm{UV},q}){\sigma }_{v,{\mathrm{mod}}}({z}_n,{M}_{\mathrm{UV},l})]}{\sqrt{{V}_{\mathrm{eff}}\left({\mathrm{z}}_m,{M}_{\mathrm{UV},q}\right){V}_{\mathrm{eff}}\left({z}_n,{M}_{\mathrm{UV},l}\right)}}\sqrt{\Delta {V}_m\Delta {V}_n}, $$](/articles/aa/full_html/2018/06/aa31797-17/aa31797-17-eq29.gif) (22)
(22)
where the Kronecker δ
mn
is one if m = n and zero otherwise, implying that the redshift bins are independent, and the effective volume, V
eff, takes into account the smaller cosmic volume probed by the bins affected by our selected magnitude limit I
0 = 24:![Mathematical equation: $$ {V}_{\mathrm{eff}}(\mathbf{z},{{M}}_{\mathbf{UV}})=\frac{1}{\Delta {M}_{\mathrm{UV},q}}{\int }_{{z}_{m,\mathrm{min}}}^{{z}_{m,\mathrm{max}}} {\int }_{{M}_{\mathrm{UV}},\mathrm{q},\mathrm{min}}^{\mathrm{min}[{M}_{\mathrm{UV}},\mathrm{q},\mathrm{max},{M}_{\mathrm{UV}},\mathrm{lim}]} \frac{\mathrm{d}V}{\mathrm{d}z}\mathrm{d}z\enspace \mathrm{d}{M}_{\mathrm{UV}}. $$](/articles/aa/full_html/2018/06/aa31797-17/aa31797-17-eq30.gif) (23)
(23)
5.3 Final covariance matrix
The final total covariance matrix was obtained by simply summing the shot noise and the cosmic variance terms: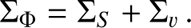 (24)
(24)
This covariance matrix provides the LF error estimate, mapping the correlations due to the redshift and magnitude uncertainties.
6 Galaxy bias
The galaxy bias, in addition to being an interesting result by itself, giving information about the clustering of the galaxies, is necessary for our LF modelling as it enters the LF covariance matrix calculation through its cosmic variance term. The galaxy linear bias can be derived from the cosmic variance (see Sect. 5.2 above) by the equation (Moster et al. 2011):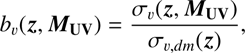 (25)
(25)
where σ v , dm is the cosmic variance of the dark matter calculated at the redshift bins of our interest, for an area of 0.051 deg2, the median area of the 48 ALHAMBRA sub-fields. This equation is based on an assumption that the bias does not depend on the scale of structure. This theoretical cosmic variance was computed in each volume using the code QUICKCV3 based on work published in Newman & Davis (2002). The code computes the cosmic variance from the dark-matter power spectrum using a window function which is one inside the volume of interest and zero otherwise. The dark-matter power spectrum at each redshift bin was obtained using the CAMB software (Lewis et al. 2000), including the nonlinear corrections of HALOFIT (Smith et al. 2003).
6.1 Observed bias values
In Appendix A we introduce the optimal binning for the bias calculation, ending up with three redshift-magnitude bins. The number density distributions of galaxies in the 48 ALHAMBRA subfields, the best MLE solutions, and the derived cosmic variances and biases together with their uncertainties in these three bins are shown in Fig. 3. We see that the bias values vary in the range bv ~ 8 – 10. These bias values are large, actually larger than any previous measurement at these redshifts. However, considering the high redshift and brightness of our galaxies these bias values are reasonable, as discussed in the following.
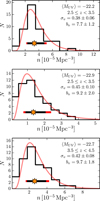 |
Fig. 3 Number density distribution in the 48 ALHAMBRA sub-fields in three magnitude-redshift bins. The mean magnitude and the redshift range of each bin are given in the panels. The total dispersion is shown as a red bar while the star and the black bar mark the median and the intrinsic dispersion retrieved by the MLE, respectively. The red solid lines show the best MLE solutions convolved with the Poisonian errors and are independent of the histogram binning. The derived values of the relative cosmic variance and the corresponding bias values are labelled in the panels. |
6.2 Bias function model
At the redshift range of our interest, the galaxy bias is found to increase both with redshift and with luminosity (e.g. Hildebrandt et al. 2009). Our data allows us to robustly estimate the bias in only three magnitude-redshift bins, while the magnitude dependence of bias at z ~ 3 is, to our knowledge, poorly studied in the literature. We opted for tracing the galaxy bias as a function of magnitude at z ~ 4, where previous studies provide data points at fainter magnitudes, and applying this dependence for both our redshift bins. We combined our data with the literature data at z ~ 4 where the bias information is given for magnitude bins (see Fig. 4, left) and fit a relation: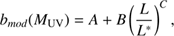 (26)
(26)
 |
Fig. 4 Left: bias values as a function of absolute UV magnitude. The blue filled square represents our data point at z ~ 4 and blue filled diamonds our data points at z ~ 3. The z ~ 3 points are shown as a comparison but are not used in the fit. The data points from Ouchi et al. (2004) and Cooray & Ouchi (2006) are shown as triangles and circles, respectively. Right: bias values as a function of the limiting absolute UV magnitude of each data set. The blue filled square shows our data point at z ~ 4. The results from the literature are shown as circles (Ouchi et al. 2005), pentagons (Allen et al. 2005), triangles (Ouchi et al. 2001), inverted triangles (Ouchi et al. 2004), diamonds (Arnouts et al. 2002), left-pointing triangles (Hildebrandt et al. 2009), stars (Harikane et al. 2016), and hexagons (Harikane et al. 2018). The black dashed line shows our best fit of Eq. (26) as also labelled in the figures. The 1-σ errors are shown as grey shaded areas. |
where L* is the luminosity corresponding to a normalisation magnitude M* = –21.7, and A, B, and C are the fitted constants, A = 2.5 ± 0.2, B = 1.1 ± 0.8, and C = 2.0 ± 0.8. To show that the z ~ 3 bias values are also well traced by this model, we have plotted them in Fig. 4, left. However, these points are not used in the fit. Most of the literature data is given as a function of the limiting magnitude of the corresponding survey, instead of the magnitude bin. For comparison, we also show this plot with our z ~ 4 data points included in Fig. 4, right. The constants for this fit are A = 2.7 ± 0.2, B = 3.2 ± 0.2, and C = 0.9 ± 0.1.
We see in both panels of Fig. 4 that the bias values we measure are higher than the values found in the literature. Considering the fact that our data traces brighter magnitudes than any of the previous studies, and considering the increasing trend of the bias with luminosity, the high values we measure are not surprising. We further study the reliability of the measured bias values in Sect. 8.
7 Results: ALHAMBRA UV luminosity function
In this section we present the final 2D and discretised z ~ 3 and z ~ 4 ALHAMBRA UV LFs and compare them with the LFs from the literature, Sect. 7.1. We discarded a strong influence of low-redshift galaxies (Sect. 7.2), and quasars (QSOs, Sect. 7.3) on our LFs and compare them with the recent LF estimates in radio, Sect. 7.4. Finally, we derived the FUV comoving luminosity density in z ~ 3 and z ~ 4, Sect. 7.5.
7.1 The luminosity function
The 2D ALHAMBRA LF for the whole redshift range of our interest, z = 2.5 – 4.5, consisting of an integrated total number of galaxies of 3861.5, is shown in Fig. 5. One can observe over-dense strips in redshift space, reflecting the presence of cosmic structures. Also the z – M UV correlations (Fig. 1) are visible especially at the brighter magnitudes where the density of objects is lower. The incompleteness at the faint end due to volume effect is evident, but is properly taken into account in the modelling.
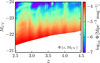 |
Fig. 5 Total differential LF of ALHAMBRA galaxies at z = 2.5 – 4.5. |
The optimal binning of this LF is derived in Appendix A. We find that Δz = 1 and ΔM
UV = 0.3 provide a proper error budget, both shot noise and cosmic variance. We show in Table 1 the values of the resultant LF in the two redshift bins, z = 2.5 – 3.5, and z = 3.5 – 4.5. For the magnitude bins, we show both the bin edges and the number weighted median values. The best fitting Schechter parameters are given in Table 2. We also show the correlation coefficients, ρ, between each pair of values 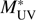 , ϕ*, and α. We see that while
, ϕ*, and α. We see that while 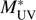 and ϕ
* are quite independent of each other, both
and ϕ
* are quite independent of each other, both 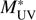 and ϕ* are highly correlated with α. We plot these LFs, together with the best fitting model, in Fig. 6. For comparison, we also show LF data given in the literature.
and ϕ* are highly correlated with α. We plot these LFs, together with the best fitting model, in Fig. 6. For comparison, we also show LF data given in the literature.
ALHAMBRA UV LF Φ (z; M UV).
Best fitting Schechter parameters, their correlation coefficients, and the luminosity density derived from the LFs at our two redshift bins.
One one hand, we compare our LFs with the literature data originating from works in which the galaxy selection is based on broad-band photometry, either applying drop-out selection or a selection made in photometric redshifts (left panels). On the other hand, we overplot the literature data derived from the spectroscopic VVDS survey (Cucciati et al. 2012, right panels).
In the left panels, we see a discrepancy between our LFs and the LFs from the literature, our data showing an excess of objects at the bright end. However, in the right panels we see that our data agree very well with the spectroscopic results. Hence, even though being discrepant at its bright end with most of the literature data, our results are compatible with those of the VVDS, to our knowledge the only magnitude-limited spectroscopic study at these redshifts.
It has already been discussed in the literature (e.g. Paltani et al. 2007; Le Fèvre et al. 2015; Inami et al. 2017) that the colour-colour selection leaves out a fraction of genuine high-z galaxies which might explain the disagreement of our results with these studies. On the other hand, a selection made in photometric redshifts can suffer from similar biases, the quality of the photo-zs depending strongly on, for example, the number of bands used for their derivation (Benítez et al. 2009). We showed in Viironen et al. (2015) that even in the case of ALHAMBRA with 23 bands, a strictly photo-z selected sample of galaxies lies within a typical LBG selection box and hence also misses the kind of galaxies shown to exist outside the box. In the same article, we also showed that when the information in the whole redshift PDFs is taken into account, an important fraction of galaxies is found outside the colour-colour selection boxes.
At the redshift bin 3.5 < z < 4.5, we observe that the volume probed by ALHAMBRA cannot explain the excess of bright galaxies, because the recent study by the GOLDRUSH project (Ono et al. 2018) covers a much larger area, ~100 deg2. On the other hand, our brightest bins with MUV ≲ –23.5 closely agree with those of Ono et al. (2018). Hence, the main difference between their results and ours is that our data points to a Schechter-shaped LF with a brighter 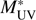 by ~0.75 magnitudes, while their data favours a double power-law. We also see in the left panels of Fig. 6 that at the faint end our data points approach those from the literature. This implies an excess of galaxies only at magnitudes close to the
by ~0.75 magnitudes, while their data favours a double power-law. We also see in the left panels of Fig. 6 that at the faint end our data points approach those from the literature. This implies an excess of galaxies only at magnitudes close to the 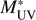 . We study in the following the possible causes of the observed excess. We concentrate here on the redshift range z ~ 4 where the recent Ono et al. (2018) results exist.
. We study in the following the possible causes of the observed excess. We concentrate here on the redshift range z ~ 4 where the recent Ono et al. (2018) results exist.
 |
Fig. 6 ALHAMBRA UV LF at two redshift bins as indicated in the panels. The ALHAMBRA measurements are shown as blue squares together with their 2-σ error bars, and the blue line shows our best median Schechter fit, shaded area enclosing 95% of the solutions. Left panels: comparison with literature data from photometrically selected samples of high-z galaxies is shown as follows: triangles (Reddy & Steidel 2009), upside-down triangles (van der Burg et al. 2010), diamonds (Mehta et al. 2017), pentagons and orange dashed-line (Parsa et al. 2016), open circles (Ono et al. 2018), left pointing triangles (Finkelstein et al. 2015), and hexagons (Bouwens et al. 2015). Right panels: comparison with the spectroscopic LF estimate of Cucciati et al. (2012) (black dots and red dotted line). |
7.2 Bright-end excess; low redshift galaxies
We observe in Fig. 6 an excess of objects close to 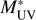 as compared to studies in which either drop-out or photo-z selected samples derived from broad-band data are used. Our results agree with the spectroscopic VVDS LF reinforcing our confidence on the ALHAMBRA redshift PDFs and on the methodology used in this paper.
as compared to studies in which either drop-out or photo-z selected samples derived from broad-band data are used. Our results agree with the spectroscopic VVDS LF reinforcing our confidence on the ALHAMBRA redshift PDFs and on the methodology used in this paper.
However, a natural concern is if low redshift galaxies could cause this excess. Some galaxies at low redshift can be confused with the high-redshift ones because of the Lyman/Lyman-α break vs. 4000 Å break degeneracy, causing, in simplified terms, double peaked redshift PDFs. The low-z galaxies are more numerous than the high-z ones, hence, one can worry if, in our approach of summing up the redshift PDFs, these double-peaked PDFs could cause a net flux of low-z objects towards high-z and explain the observed excess in our LF. We studied how the number of galaxies at z ~ 4 would change when we simply account for all the galaxies with the maximum likelihood photo-z, that is, ‘the primary peak’, in the range 3.5 < z < 4.5 and compare this to the same number derived from the LF calculated in this paper. The number we find is 1287 maximum likelihood photo-z objects vs. 1138.8 objects when the information from the whole redshift PDF is taken into account. In other words, our approach of integrating the PDFs, and hence taking into account also the “secondary peak objects”, or objects even with only very little probability to be at the redshift of interest, leads to a smaller number of high-z objects than the approach of selecting the “primary peak objects” and summing them up does. Hence, it seems clear that the secondary peak objects do not cause a net flux of low-z objects towards high-z.
To further quantify the different components influencing our LF at z ~ 4, we calculate the contribution from objects i) with primary peak – the peak corresponding to the maximum value of the redshift PDF – at 3.5 < z < 4.5, ii) with primary peak at z < 2, but secondary peak at 3.5 < z < 4.5, and iii) with primary peak at z > 2 and some probability (but not the peak) at 3.5 < z < 4.5. The contributions from the cases i), ii), and iii) are 60%, 30%, and 10%, respectively. Hence, our LF at z ~ 4 is dominated by objects with primary peak at the corresponding redshift interval, with an additional contribution of 30% caused by objects with primary peak at low-z. We recall here again, that it has been shown that genuine high-z objects may come out with redshift PDFs with primary peak at low-z (Paltani et al. 2007; Le Fèvre et al. 2015). Finally, a small contribution of 10% from objects with primary peak at z > 2, but outside the z ~ 4 redshift interval is also accounted for. This exercise shows us that our LF is not simply caused by accumulation of secondary peaks of (more numerous) low-z galaxies, but is indeed dominated by objects with primary redshift peak at the range of interest and an additional contribution from the less certain high-z objects (i.e. those with primary peaks outside the range of interest). Le Fèvre et al. (2015) discusses, in the framework of the spectroscopic VUDS (The Vimos Ultra-Deep) Survey that in their sample 17.5% of genuine high-z galaxies at z > 2 have a primary peak at low redshift. They also state that the actual fraction shows a variation with redshift. In addition to the redshift variation, the photometric redshift code used in their analysis is different from ours, so that an exact match in the percentages should not be expected.
Finally, we note that the large bias values we derived for our galaxies in Sect. 6 are not compatible with the observed biases at low-z (see e.g. Arnalte-Mur et al. 2014) and further support the genuine high-z nature of these galaxies.
7.3 Bright-end excess; quasar contamination
Of the above literature LF studies Reddy & Steidel (2009) and Ono et al. (2018) discuss the importance of QSO contamination of drop-out samples at the bright end of the LF and correct for it, while for the VVDS spectroscopic study (Cucciati et al. 2012) this is not an issue (only spectra with galaxy quality flags are used). As discussed in Viironen et al. (2015), we do not expect a significant contamination of QSOs in our data. This is because we removed the stellar-like objects from our sample and the BPZ templates do not include QSOs, and consequently the QSO red-shifts are poorly defined. However, if there were any QSOs contaminating our LF, this would occur mainly at the bright end where, on one hand, galaxy number counts are lower, and on the other hand, the faintest and thus the most numerous QSOs reside. For these reasons we further study here if these objects could be causing the bright-end excess.
Recently a catalogue of ALHAMBRA type I AGN reaching m(F814W) = 23 was presented in Chaves-Montero et al. (2017). We ran our photometric pre-selection and LF calculation code on this catalogue and corrected the numbers found by the completeness values given in Chaves-Montero et al. (2017). As the QSO redshifts are poorly defined, we might also have contamination by QSOs at other redshifts than those which are our focus here. It was shown in Viironen et al. (2015) that a small contamination from low-z QSOs can be expected. To be conservative, we used the lowest completeness value given by Chaves-Montero et al. (2017), 67%, given for the z < 2 QSOs with three detected emission lines. For QSOs at higher redshift and with only two detected lines the completeness is actually better. We find that some of the QSOs indeed enter our selection and contaminate the bright end. However, this contamination is always below ~20%, which corresponds to < 0.1 dex in our LF, hence being smaller than the symbol size in Fig. 6. Thus, the QSO contamination of our LFs is negligible and cannot explain the bright-end excess.
To further support this claim, we show in Fig. 7 our LF at z ~ 4, together with the corresponding LF from Ono et al. (2018) and the QSO LF from Akiyama et al. (2018). We also show the Schechter fit to our data and the Schechter resulting from subtracting the QSO LF from our fit. We note that this would be an absolute upper limit for the QSO contamination because only a fraction of the existing QSOs enter our sample as discussed above and in Viironen et al. (2015). However, even this absolute maximum contamination could not explain the observed excess around 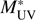 .
.
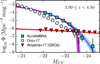 |
Fig. 7 ALHAMBRA UV LF of Fig. 6 at redshift z ~ 4 and the corresponding Schechter fit (blue squares and blue line). The LF from Ono et al. (2018) is shown as white circles. The QSO LF of Akiyama et al. (2018) at z ~ 4 is plotted as red upside-down triangles. The purple line shows the best Schechter fit when this (absolute maximum) QSO contamination is subtracted from our z ~ 4 LF fit. |
7.4 Comparison with radio data
We find above that our LFs predict an excess of bright objects as compared to most of the literature data, being however compatible with spectroscopic data. We also find that low-z galaxies nor QSOs cannot explain this excess. On the other hand, the UV LFs do not give a complete picture of the high redshift star-forming galaxies because part of the galaxies are probably missed, and all are faded, due to the presence of dust (see Mancuso et al. 2016, and references therein). In this section we compare our LF, once corrected for extinction, with the recent radio LF estimate of high-mass and highly star-forming galaxies (Novak et al. 2017). The non-thermal radio emission offers a dust-unbiased view of the star formation function and should offer the upper limit of the LF at its bright end.
To compare our z ~ 3 and z ~ 4 LFs with the Novak et al. (2017) radio LFs, we converted our UV luminosities to radio luminosities using the expression given by them: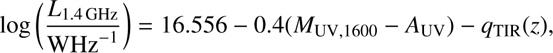 (27)
(27)
where L 1.4 GHz is the radio luminosity, q TIR = 2.78 × (1 + z)−0.14 links the radio luminosity to the total infrared luminosity (see Novak et al. 2017, and references therein), and AUV is the extinction at ultraviolet wavelength. As our luminosity distribution of galaxies is very similar to that of Cucciati et al. (2012), we use the extinction values given by them: for z = 2.5 – 3.5, A UV = 1.47, and for z = 3.5 – 4.5, A UV = 0.97. We also added a small correction, ΔM UV = +0.035 to our luminosity values in order to correct them from 1500 Å to 1600 Å. This was done by roughly defining the average β-slopes for our galaxies, giving β ∼ 1.7, and deriving the correction from there. The comparisons of the resultant radio LFs are shown in Fig. 8.
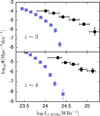 |
Fig. 8 Radio LF: The radio measurements of Novak et al. (2017) are shown as black dots. Our UV luminosities converted to radio following the prescription of Novak et al. (2017) are shown as blue squares. |
We see that our bright end prediction is still well below the radio based LF estimate at the bright end. This is not surprising, because the UV surveys under-sample the highest SFR galaxies (see Mancuso et al. 2016, and references therein). So, despite the fact that we observed more bright galaxies than most of the studies in the literature, comparison with radio data reveals that we still are missing a significant number of very bright galaxies obscured by dust.
7.5 The FUV comoving luminosity density
Generally the Schechter parameters fitted to describe LFs are highly correlated between each other. We showed this in the case of our Schechter parameters in Sect. 4.3. Hence, one by one comparison of these parameters in different studies is challenging. However, the integral of the LF is much more stable. The luminosity weighted integral of the LF at a given redshift gives the luminosity density at that redshift which in turn, once corrected for reddening, provides the star formation rate density at that cosmic age – an important measurement to understand galaxy evolution over cosmic times. An attempt to derive the extinction of our galaxies is beyond the scope of this paper. Hence, we settled for deriving the luminosity density, a quantity directly derivable from our LFs:![Mathematical equation: $$ {LD}={\int }_{{L}_{\mathrm{faint}}}^{{L}_{\mathrm{bright}}} \mathrm{\Phi }(L)L\mathrm{d}L\enspace [\mathrm{W}\enspace \mathrm{H}{\mathrm{z}}^{-1}\enspace \mathrm{Mp}{\mathrm{c}}^{-3}]. $$](/articles/aa/full_html/2018/06/aa31797-17/aa31797-17-eq49.gif) (28)
(28)
Following Cucciati et al. (2012), we set L
faint and L
bright to the luminosities corresponding to M
UV,faint = –3.4 and M
UV,bright = –28.4. To take into account the errors in the parameters, and the correlation between them, we calculated the integral for each set of parameters given by emcee walkers (see Eq. (19)). Our LD, and its error, are then given by the median and standard deviation of these individual integrations. The resulting LDs are 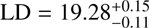 , and
, and 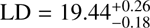 for z ∼ 3 and, z ∼4 respectively.
for z ∼ 3 and, z ∼4 respectively.
We also collected Schechter parameter information from the literature and, to be consistent, carried out ourselves the integration for these parameters using the same integration limits as for our data. Our recollection of literature Schechter parameters and the corresponding LDs calculated by us are given in Table C.1. We plot these together with our LD measurements as a function of redshift in Fig. 9. We did not calculate the error bars for the literature LDs as we lacked the information on the correlations of the individual Schechter parameters and a simple propagation of individual uncertainties would probably overestimate the errors. However, the scatter of the LD datapoints at similar redshifts gives an idea about the involved uncertainties.
 |
Fig. 9 Luminosity density derived integrating the Schechter functions given by us and given in the literature: Parsa et al. (2016), Bouwens et al. (2015), McLure et al. (2013, 2009), Cucciati et al. (2012), Oesch et al. (2010), Bouwens et al. (2007), Iwata et al. (2007), Paltani et al. (2007), Sawicki & Thompson (2006), Wyder et al. (2005), and Gabasch et al. (2004). |
We see that our LDs are compatible with the previous studies. However, we also remind the reader that the α parameter we derive heavily relies on the prior information from the literature because our data is not tracing the faint end of the LF, and the value of α has a strong influence on the derived LD. If we set the integration limits close to the values sampled by our data, MUV,faint = –22.0 and MUV,bright = –24.5, the luminosity densities would get down to 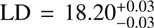 , and
, and 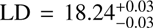 , for z ~ 3 and z ~ 4, respectively.
, for z ~ 3 and z ~ 4, respectively.
8 Results: halo masses
In this section we derive the masses of the dark matter halos hosting our galaxies from the bias values derived in Sect. 6. We compared the derived host halo mass at z ~ 4 to that predicted by abundance matching techniques for the galaxies of corresponding UV brightnesses (UV brightness being directly proportional to the SFR). In addition to gaining information about the host halo masses, this exercise serves to double check the bias values we have derived which are based on an assumption of scale independence and which are higher than in any previous study, preventing direct comparison with the literature.
8.1 Halo mass predicted from the bias
In the linear regime, the bias values we derived in Sect. 6 should directly reflect the bias of the dark matter halos hosting our galaxies. To derive the host halo masses from our bias estimates, we followed the modelling of Basilakos et al. (2008), as summarised in Appendix B. The host halo masses derived from Eq. (B.1) for our three luminosity-bias bins are listed in Table 3. We see that our galaxies are hosted by high mass dark matter halos, Mh ~ 0.5 – 3 x 1013h−1M⊙, as can be expected considering their high luminosities.
Host halo masses in 1013 h 1 M0 derived from our bias measurements in two luminosity bins at z ~ 3 and at one luminosity bin at z ~ 4.
8.2 Halo mass predicted from the SFR
We have derived our bias values assuming that they do not depend on scale. This assumption is necessary as we derived the bias from the cosmic variance, which in turn is a particular case of count-in-cell statistics in which all the scales inside the volume of interest are integrated. However, in reality, the bias is scale dependent. The observational studies at z ~ 4 find that the bias is nearly constant for scales larger than 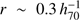 Mpc (the linear bias regime), while the bias values become larger at smaller scales (Ouchi et al. 2005). On the other hand, as discussed in López-Sanjuan et al. (2015a), the bigger is the area covered by the subfields used for the cosmic variance calculation, the smaller is the influence of the non-linear term. In this section we double check our bias value estimation to assure that the large values that we obtain are not dominated by the nonlinear regime. We do this indirectly by deriving the expected host halo mass from the median UV luminosity (assumed to be directly proportional to the SFR) of our galaxies and comparing the result with the bias-based halo mass estimate.
Mpc (the linear bias regime), while the bias values become larger at smaller scales (Ouchi et al. 2005). On the other hand, as discussed in López-Sanjuan et al. (2015a), the bigger is the area covered by the subfields used for the cosmic variance calculation, the smaller is the influence of the non-linear term. In this section we double check our bias value estimation to assure that the large values that we obtain are not dominated by the nonlinear regime. We do this indirectly by deriving the expected host halo mass from the median UV luminosity (assumed to be directly proportional to the SFR) of our galaxies and comparing the result with the bias-based halo mass estimate.
Mashian et al. (2016) employ abundance matching techniques to calibrate a relation between galaxy SFR and host halo mass by mapping the shape of the observed SFR function at z = 4 – 8 to that of the halo mass function. We show the relation given by them at redshift z ~ 4 in Fig. 10 together with our bias based halo mass estimate at z ~ 4 and the corresponding SFR derived from the median UV luminosity at the bin in question. In order to remove the uncertainties related to the conversion from the M UV to SFR, we do the conversion in the same way as was done in Mashian et al. (2016): we derive the SFR from the Kennicutt (1998) relation SFR[M ⊙ yr−1] = 1.25 × 10−28 L UV,corr[erg s−1Hz−1], where L UV,corr is the ultraviolet luminosity corrected for extinction, and we calculated the A UV from the Meurer et al. (1999) relation, A 1600 = 4.43 + 1.99β deriving the value of β from the relation given by Bouwens et al. (2014) at z ~ 4, β = –1.85 –0.11(M UV +19.5). We note that the extinction values and β slopes are not intended to be the ideal ones for our data, and are actually different than the ones used in Sect. 7.5 above. The idea is simply to strictly follow the Mashian et al. (2016) prescription in order to remove the systematics related to the conversion from M UV to SFR. For the value of M UV we adopted the median value of the magnitude bin used for the z ~ 4 bias calculation in Sect. 5.2. The error bars reflect the width of this bin. We applied a small correction, ΔM UV = +0.035 to correct from 1500 Å to 1600 Å (see Sect. 7.4). Our measurement is consistent, within the error bars, with the SFR−M h relation of Mashian et al. (2016).
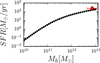 |
Fig. 10 SFR as a function of host halo mass. The Mashian et al. (2016) calibration at z ~ 4 is given as a dotted curve. Our bias-based halo mass estimate at z ~ 4 and the estimated SFR for the corresponding magnitude bin are given as a red point. |
To conclude, the high host halo mass at z ~ 4 derived from the large bias value (b v = 9.7 ± 1.8) is consistent with the halo mass expected from the luminosity of our galaxies. Hence, we can be confident that the influence of the non-linear regime on our bias values is not significant, and that the bias values we derive, which are larger than in any previous study at these redshifts, are reliable.
9 Summary and conclusions
In this work we have calculated the rest frame UV 1500 Å LF at the redshift range z = 2.5 – 4.5 from the data offered by the ALHAMBRA survey using a novel technique based on PDF analysis. We have also estimated the bias values and the corresponding host halo masses for our galaxies. Our main results are summarised as follows:
-
Our LF reveals an excess of bright objects as compared with most of the studies in the literature. However, our LF is compatible with the only magnitude limited spectroscopic LF estimate at these redshifts to date (Cucciati et al. 2012). Our best Schechter parameters at z = 2.5 – 3.5 are
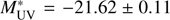 ,
, 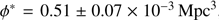 , α = −1.53±0.15, and at z = 3.5 – 4.5 are
, α = −1.53±0.15, and at z = 3.5 – 4.5 are 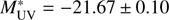 , ϕ* = 0.54 ± 0.08 × 10−3 Mpc3, α = −1.65 ± 0.17. We note that the αs we derive rely heavily on the prior information from the literature. We also derived the luminosity densities at the two redshift bins, giving
, ϕ* = 0.54 ± 0.08 × 10−3 Mpc3, α = −1.65 ± 0.17. We note that the αs we derive rely heavily on the prior information from the literature. We also derived the luminosity densities at the two redshift bins, giving 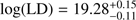 and
and 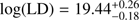 at z ~ 3 and z ~ 4 respectively.
at z ~ 3 and z ~ 4 respectively. -
From the cosmic variance we estimate the bias values for our galaxies. We calculate the bias for two magnitude bins at z ~ 3, giving b = 7.7 ± 1.2, and 9.2 ± 2.0 for 〈MUV〉, = −22.2, and 〈MUV〉 = −22.9, respectively, and at one bin at z ~ 4, giving 9.7 ± 1.8 for 〈MUV〉 = −22.7. These bias measurements are tracing brighter galaxies, on average, than in any of the previous studies at these redshifts. Consequently, the derived bias values are higher than in the previous studies.
-
Assuming that the bias values we derived are scale independent, we obtained the host dark matter halo masses corresponding to the measured biases. For the above magnitude bins, in the same order, we derived host halo masses of
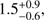 ,
, 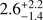 , and
, and 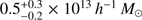 . We compared the host halo mass derived at z ~ 4 to that which would be expected from the SFR corresponding to the median UV magnitude of the bin in question using the SFR-M
h
calibration of Mashian et al. (2016). Our bias-based host halo mass estimate is compatible with that expected from our luminosities. Hence, the assumption of scale independence does not strongly affect the bias values we derive.
. We compared the host halo mass derived at z ~ 4 to that which would be expected from the SFR corresponding to the median UV magnitude of the bin in question using the SFR-M
h
calibration of Mashian et al. (2016). Our bias-based host halo mass estimate is compatible with that expected from our luminosities. Hence, the assumption of scale independence does not strongly affect the bias values we derive.
The results of this paper strengthen the evidence – previously observed in the spectroscopic VVDS data – of bright end excess in the UV LFs at z = 2.5 – 4.5 as compared to previous studies based on broad-band photometry. This bright-end excess can neither be explained by QSO contamination nor by miss-classified low-z galaxies, as the QSO contamination is shown to be insignificant and the large bias values derived for our galaxies would not be compatible with a low-z population. At the faintest bins our LF generally agrees with the literature data, while an agreement is also found at the very brightest bins with the recent wide area study of GOLDRUSH project (Ono et al. 2018) based on broad-band photometry. We call into question the shape of the z = 2.5 – 4.5 LF at its bright end; is it a double power-law as suggested by the recent broad-band photometric studies or rather a brighter Schechter function, as suggested by our multi-filter analysis and the spectroscopic VVDS data. Future studies based on the very large area J-PAS (Javalambre Physics of the Accelerating Universe Astrophysical Survey, Benítez et al. 2014) multi-filter data will, we hope, shed light on this topic.
Acknowledgments
We acknowledge the anonymous referee for helping us to improve the article. K. Viironen acknowledges the “Juan de la Cierva incorporación” fellowship, IJCI-2014-21960, of the Spanish government. This work has mainly been funded by the FITE (Fondos de Inversiones de Teruel) and the projects AYA2015-66211-C2-1 and AYA2012-30789. We also acknowledge support from the Aragón Government Research Group E103 and support from the Spanish Ministry for Economy and Competitiveness and FEDER funds through grants AYA2010-15081, AYA2010-15169, AYA2010-22111-C03-01, AYA2010-22111-C03-02, AYA2011-29517-C03-01, AYA2012-39620, AYA2013-40611-P, AYA2013-42227-P, AYA2013-43188-P, AYA2013-48623-C2-1, AYA2013-48623-C2-2, ESP2013-48274, AYA2014-58861-C3-1, AYA2016-76682-C3-1-P, Generalitat Valenciana projects Prometeo 2009/064 and PROMETEOII/2014/060, Junta de Andalucía grants TIC114, JA2828, P10-FQM-6444, and Generalitat de Catalunya project SGR-1398. BA has received funding from the European Union’s Horizon 2020 research and innovation programme under the Marie Sklodowska-Curie grant agreement No 656354. MP acknowledges financial supports from the Ethiopian Space Science and Technology Institute (ESSTI) under the Ethiopian Ministry of Science Science and Technology (MoST). This research made use of Astropy, a community-developed core Python package for Astronomy Astropy Collaboration (2013), and Matplotlib, a 2D graphics package used for Python for publication-quality image generation across user interfaces and operating systems Hunter (2007). Finally, K. Viironen thanks Isabel, without whom combining child care and research would be too demanding.
Appendix A: Defining the optimal binning
In this article, we have presented the method to derive the two dimensional, differential, and binned, luminosity and bias functions, and the covariance matrix of the LF. In this Appendix we show how the optimal binning of these functions are defined in order, on one hand, to not over-sample the data, and on the other hand, to not lose any information due to too aggressive binning. Once more, we followed the scheme presented in LS17. To ensure a meaningful analysis, we computed the median total and median cosmic variance at z = 2.5 – 4.5 within bins of size Δz, and studied their dependence on the adopted bin size. Both these quantities should decrease if the volume probed by each bin, i.e. the bin size, increases. In Fig. A.1 we see that the total variance starts decreasing at bin sizes close to the expected redshift uncertainty (〈δz〉 = 0.012(1 + 〈z〉), Molino et al. 2014). At bin sizes smaller than this the signal is dominated by the correlations between adjacent bins and the variance does not change with bin size. However, the cosmic variance only starts decreasing at Δz ≥ 1.0 and we set the redshift bin size to Δz = 1.0. We note that at bin sizes smaller than Δz ∼ 0.5 the cosmic variance decreases as well. However, we observed that at these small bin sizes the galaxy number counts are no more log-normally distributed, while log-normal distribution should be expected (Coles & Jones 1991), meaning that we are lacking statistics to robustly measure the cosmic variance.
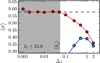 |
Fig. A.1 Median total variance (red dots) and the median cosmic variance (cyan pentagons) as a function of the redshift bin size Δz at z = 2.5 – 4.5. The dashed line marks the total variance in the constant regime. The grey area marks the bin sizes smaller than 〈δz〉, the ALHAMBRA photometric redshift precision. |
Finally, to study the optimal magnitude bin size, we first created the MUV posterior for each galaxy in our sample: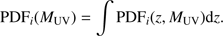 (A.1)
(A.1)
Then we summed the individual posterior distributions centred at zero![Mathematical equation: $$ \delta {M}_{\mathrm{UV}}=\sum_i \left[\mathrm{PDF}_i({M}_{\mathrm{UV}})-\left\langle \mathrm{PDF}_i({M}_{\mathrm{UV}}\right)\right\rangle], $$](/articles/aa/full_html/2018/06/aa31797-17/aa31797-17-eq67.gif) (A.2)where 〈PDFi(MUV)〉 is the median UV magnitude of the galaxy i. The resultant distribution is close to a Gaussian, see Fig. A.2. We fitted it with a Gaussian function and find a dispersion σ = 0.17, the mean being zero by definition. Finally, for the LF calculation, we set the magnitude bin size at ΔMUV = 0.3, roughly twice the sigma value of the above distribution.
(A.2)where 〈PDFi(MUV)〉 is the median UV magnitude of the galaxy i. The resultant distribution is close to a Gaussian, see Fig. A.2. We fitted it with a Gaussian function and find a dispersion σ = 0.17, the mean being zero by definition. Finally, for the LF calculation, we set the magnitude bin size at ΔMUV = 0.3, roughly twice the sigma value of the above distribution.
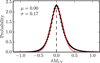 |
Fig. A.2 Sum of the individual MUV posterior distributions for all the galaxies in our sample normalised to be centred at zero. A Gaussian fit to this distribution is shown as a red line and the median and sigma of this Gaussian are labelled in the panel. |
To obtain large enough samples to calculate the bias values, much more coarse binning was used; we carried out some tests
with the objective of finding the finest possible binning without losing the log-normality of the number count distributions, and ended up calculating bias values at two magnitude bins at z = 2.5 – 3.5 and one bias value at z = 3.5 – 4.5.
Appendix B: Halo mass from galaxy bias
In this appendix we present the compilation of equations from Basilakos et al. (2008) that we have used to derive the host halo masses in Sect. 8. Basilakos et al. (2008) express the galaxy bias as a function of redshift and halo mass as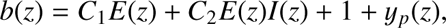 (B.1)where
(B.1)where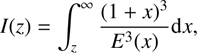 (B.2)
(B.2)
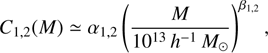 (B.3)and α1 = 3.29 ± 0.21,
β1 = 3.24 ± 0.07, α2 = −0.36 ± 0.01, and β2 = 0.32 ± 0.06. The term yp(z) is defined as
(B.3)and α1 = 3.29 ± 0.21,
β1 = 3.24 ± 0.07, α2 = −0.36 ± 0.01, and β2 = 0.32 ± 0.06. The term yp(z) is defined as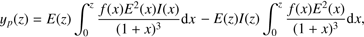 (B.4)where
(B.4)where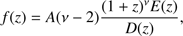 (B.5)and
(B.5)and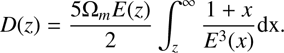 (B.6)
(B.6)
We derived the mass dependence of the constant A ourselves by using the values listed in Table 1 of Basilakos et al. (2008) and fitting a relation A = a + b × log10(M/1013h−1M⨀). This leads to a =3.93 ×10−3 and b =3.56 ×10−3. For the constant ν we adopted the average of its values listed in the same Table 1: ν = 2.57. The host halo masses are then obtained from Eq. (B.1).
Appendix C: Literature compilation of Schechter parameters and the corresponding LDs
In this appendix we present Table C.1 showing a compilation of UV LF Schechter parameters up to z = 6 from the literature and the LDs that we calculated by integrating the Schechter functions over the range − 28.4 ≤ MUV ≤ − 3.4.
Compilation of literature data for UV LF parameters and the corresponding luminosity densities calculated by us.
QuICKCV is available at www.phyast.pitt.edu/~janewman/quickcv
References
- Akiyama, M., He, W., Ikeda, H., et al. 2018, PASJ, 70, S34 [NASA ADS] [CrossRef] [Google Scholar]
- Allen, P. D., Moustakas, L. A., Dalton, G., et al. 2005, MNRAS, 360, 1244 [NASA ADS] [CrossRef] [Google Scholar]
- Aparicio Villegas, T., Alfaro, E. J., Cabrera-Caño,, J., et al. 2010, AJ, 139, 1242 [NASA ADS] [CrossRef] [Google Scholar]
- Arnalte-Mur, P., Martínez, V. J., Norberg, P., et al. 2014. MNRAS, 441, 1783 [NASA ADS] [CrossRef] [Google Scholar]
- Arnouts, S., Moscardini, L., Vanzella, E., et al. 2002, MNRAS, 329, 355 [NASA ADS] [CrossRef] [Google Scholar]
- Ascaso, B. Benítez, N., Fernández-Soto, A., et al. 2015, MNRAS, 452, 549 [NASA ADS] [CrossRef] [Google Scholar]
- Astropy Collaboration, Robitaille, T. P., Tollerud, E. J., et al. 2013, A&A, 558, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Basilakos, S., Plionis, M., & Ragone-Figueroa, C. 2008, ApJ, 678, 627 [NASA ADS] [CrossRef] [Google Scholar]
- Benítez, N. 2000, ApJ, 536, 571 [NASA ADS] [CrossRef] [Google Scholar]
- Benítez, N., Moles, M., Aguerri, J. A. L., et al. 2009, ApJ, 692, L5 [NASA ADS] [CrossRef] [Google Scholar]
- Benítez, N., Dupke, R., Moles, M., et al. 2014, ArXiv e-prints [arXiv: 1403.5237]. [Google Scholar]
- Bouwens, R. J., Illingworth, G. D., Franx, M., & Ford, H. 2007, ApJ, 670, 928 [NASA ADS] [CrossRef] [Google Scholar]
- Bouwens, R. J., Illingworth, G. D., & Oesch, P. A., et al. 2014, ApJ, 793, 115 [Google Scholar]
- Bouwens, R. J., Illingworth, G. D., & Oesch, P. A., et al. 2015, ApJ, 803, 34. [NASA ADS] [CrossRef] [Google Scholar]
- Chaves-Montero, J., Bonoli, S., Salvato, M., et al. 2017, MNRAS, 472, 2085 [NASA ADS] [CrossRef] [Google Scholar]
- Coe, D., Benítez, N., Sánchez, S. F., et al. 2006, AJ, 132, 926 [NASA ADS] [CrossRef] [Google Scholar]
- Coles, P., & Jones, B. 1991, MNRAS, 248, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Cooray, A., & Ouchi, M. 2006, MNRAS, 369, 1869 [NASA ADS] [CrossRef] [Google Scholar]
- Cristóbal-Hornillos, D., Aguerri, J. A. L., Moles, M., et al. 2009, ApJ, 696, 1554. [NASA ADS] [CrossRef] [Google Scholar]
- Cucciati, O., Tresse, L., Ilbert, O., et al. 2012, A&A, 539, A31 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Davison, A. C., & Hinkley, D. V. 1997, Bootstrap Methods and Their Application (Cambridge: Cambridge University Press) [CrossRef] [Google Scholar]
- Díaz-García, L. A., Cenarro, A. J., López-Sanjuan, C., et al. 2015, A&A, 582, A14 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Eddington, A. S. 1913, MNRAS, 73, 359 [Google Scholar]
- Finkelstein, S. L., Ryan, Jr. R. E., Papovich, C., et al. 2015, ApJ, 810, 71 [NASA ADS] [CrossRef] [Google Scholar]
- Foreman-Mackey, D., Hogg, D. W., Lang, D., & Goodman, J. 2013, PASP, 125, 306 [CrossRef] [Google Scholar]
- Gabasch, A., Bender, R., Seitz, S., et al. 2004, A&A, 421, 41 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Goodman, J., & Weare, J. 2010, Comm. App. Math. Comp. Sci., Vol. 5, 65 [NASA ADS] [CrossRef] [Google Scholar]
- Guhathakurta, P., Tyson, J. A., & Majewski, S. R. 1990, ApJ, 357, L9 [NASA ADS] [CrossRef] [Google Scholar]
- Harikane, Y., Ouchi, M., Ono, Y., et al. 2016, ApJ, 821, 123 [NASA ADS] [CrossRef] [Google Scholar]
- Harikane, Y., Ouchi, M., Ono, Y., et al. 2018, PASJ, 70, S11 [NASA ADS] [CrossRef] [Google Scholar]
- Hildebrandt, H., Pielorz, J., Erben, T., et al. 2009, A&A, 498, 725 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hunter, J. D. 2007, Comp. Sci. Eng., 9, 90 [Google Scholar]
- Inami, H., Bacon, R., Brinchmann, J., et al. 2017, A&A, 608, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Iwata, I., Ohta, K., Tamura, N., et al. 2007, MNRAS, 376, 1557 [NASA ADS] [CrossRef] [Google Scholar]
- Kennicutt, Jr. R. C. 1998, ARA&A, 36, 189 [Google Scholar]
- Kennicutt, R. C., & Evans, N. J. 2012, ARA&A, 50, 531 [NASA ADS] [CrossRef] [Google Scholar]
- Le Fèvre, O., Cassata, P., Cucciati, O., et al. 2013, A&A, 559, A14 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Le Fèvre, O., Tasca, L. A. M., Cassata, P., et al. 2015, A&A, 576, A79 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lewis, A., Challinor, A., & Lasenby, A. 2000, ApJ, 538, 473 [NASA ADS] [CrossRef] [Google Scholar]
- López-Sanjuan, C., Cenarro, A. J., Hernández-Monteagudo, C., et al. 2015a, A&A, 582, A16 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- López-Sanjuan, C., Cenarro, A. J., Varela, J., et al. 2015b, A&A, 576, A53 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- López-Sanjuan, C., Tempel, E., Benítez, N., et al. 2017, A&A, 599, A62 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Madau, P. 1995, ApJ, 441, 18 [NASA ADS] [CrossRef] [Google Scholar]
- Mancuso, C., Lapi, A., Shi, J., et al. 2016, ApJ, 823, 128 [NASA ADS] [CrossRef] [Google Scholar]
- Mashian, N., Oesch, P. A., Loeb, A. 2016, MNRAS, 455, 2101 [NASA ADS] [CrossRef] [Google Scholar]
- McLure, R. J., Cirasuolo, M., Dunlop, J. S., Foucaud, S., & Almaini, O. 2009, MNRAS, 395, 2196 [NASA ADS] [CrossRef] [Google Scholar]
- McLure, R. J., Dunlop, J. S., Bowler, R. A. A., et al. 2013, MNRAS, 432, 2696 [NASA ADS] [CrossRef] [Google Scholar]
- Mehta, V., Scarlata, C., Rafelski, M., et al. 2017, ApJ, 838, 29 [NASA ADS] [CrossRef] [Google Scholar]
- Meurer, G. R., Heckman, T. M., & Calzetti, D. 1999, ApJ, 521, 64 [NASA ADS] [CrossRef] [Google Scholar]
- Moles, M., Benítez, N., Aguerri, J. A. L., et al. 2008, AJ, 136, 1325 [Google Scholar]
- Molino, A., Benítez, N., Moles, M., et al. 2014, MNRAS, 441, 2891 [NASA ADS] [CrossRef] [Google Scholar]
- Moster, B. P., Somerville, R. S., Newman, J. A., & Rix, H.-W.. 2011, ApJ, 731, 113 [Google Scholar]
- Newman, J. A., & Davis, M. 2002, ApJ, 564, 567 [NASA ADS] [CrossRef] [Google Scholar]
- Novak, M., Smolcic, V., Delhaize, J., et al. 2017, A&A, 602, A5 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Oesch, P. A., Bouwens, R. J., Illingworth, G. D., et al. 2010, ApJ, 709, L16 [NASA ADS] [CrossRef] [Google Scholar]
- Oke, J.B., & Gunn, J. E. 1983, ApJ, 266, 713 [NASA ADS] [CrossRef] [Google Scholar]
- Ono, Y., Ouchi, M., Harikane, Y., et al. 2017, PASJ, 70, S10 [Google Scholar]
- Ouchi, M., Shimasaku, K., Okamura, S., et al. 2001, ApJ, 558, L83 [NASA ADS] [CrossRef] [Google Scholar]
- Ouchi, M., Shimasaku, K., Okamura, S., et al. 2004, ApJ, 611, 685 [NASA ADS] [CrossRef] [Google Scholar]
- Ouchi, M., Hamana, T., Shimasaku, K., et al. 2005, ApJ, 635, L117 [NASA ADS] [CrossRef] [Google Scholar]
- Paltani, S., Le Fèvre, O., Ilbert, O., et al. 2007, A&A, 463, 873 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Parsa, S., Dunlop, J. S., McLure, R. J., & Mortlock, A. 2016, MNRAS, 456, 3194 [Google Scholar]
- Reddy, N. A., & Steidel, C. C. 2009, ApJ, 692, 778 [NASA ADS] [CrossRef] [Google Scholar]
- Reddy, N. A., Steidel, C. C., Erb, D. K., Shapley, A. E., & Pettini, M. 2006, ApJ, 653, 1004 [Google Scholar]
- Robertson, B. E. 2010, ApJ, 713, 1266 [NASA ADS] [CrossRef] [Google Scholar]
- Santini, P., Fontana, A., Grazian, A., et al. 2009, VizieR On-line Data Catalog: J/A+A/504/751 [Google Scholar]
- Sawicki, M., & Thompson, D. 2006, ApJ, 642, 653 [NASA ADS] [CrossRef] [Google Scholar]
- Schechter, P. 1976, ApJ, 203, 297 [Google Scholar]
- Scoville, N., Abraham, R. G., Aussel, H., et al. 2007, ApJS, 172, 38 [NASA ADS] [CrossRef] [Google Scholar]
- Smith, R. E. 2012, MNRAS, 426, 531 [NASA ADS] [CrossRef] [Google Scholar]
- Smith, R. E., Peacock, J. A., Jenkins, A., et al. 2003, MNRAS, 341, 1311 [NASA ADS] [CrossRef] [Google Scholar]
- Somerville, R. S., Lee, K., Ferguson, H. C., et al. 2004, ApJ, 600, L171 [NASA ADS] [CrossRef] [Google Scholar]
- Steidel, C. C., Giavalisco, M., Dickinson, M., & Adelberger, K. L. 1996a, AJ, 112, 352 [NASA ADS] [CrossRef] [Google Scholar]
- Steidel, C. C., Giavalisco, M., Pettini, M., Dickinson, M., & Adelberger, K. L. 1996b, ApJ, 462, L17 [NASA ADS] [CrossRef] [Google Scholar]
- Steidel, C. C., Adelberger, K. L., Giavalisco, M., Dickinson, M., & Pettini, M. 1999, ApJ, 519, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Teerikorpi, P. 2004, A&A, 424, 73 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- van der Burg, R. F. J., Hildebrandt, H., & Erben, T. 2010, A&A, 523, A74 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Viironen, K., Marín-Franch, A., López-Sanjuan, C., et al. 2015, A&A, 576, A25 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Wyder, T. K., Treyer, M. A., Milliard, B., et al. 2005, ApJ, 619, L15 [Google Scholar]
All Tables
Best fitting Schechter parameters, their correlation coefficients, and the luminosity density derived from the LFs at our two redshift bins.
Host halo masses in 1013 h 1 M0 derived from our bias measurements in two luminosity bins at z ~ 3 and at one luminosity bin at z ~ 4.
Compilation of literature data for UV LF parameters and the corresponding luminosity densities calculated by us.
All Figures
|
Fig. 1 Top panel: probability of an arbitrary high-redshift ALHAMBRA galaxy with observed magnitude I = 22.93 ± 0.11 in z – M UV space. Bottom: the above function convolved with the source function, S (I 0 |I, σ I ), gives the probability in z – M UV space for the real magnitude I 0. In both figures the white dot marks the maximum likelihood redshift, z ML, and the corresponding M UV,ML, labelled in the panel. The red line indicates the applied I 0 = 24 limiting magnitude, and the accessible total volume is shown as shaded grey area. |
| In the text | |
|
Fig. 2 Distribution of a values as compiled from the literature by Parsa et al. (2016) at redshifts z = 2.7 – 4.0. A Gaussian fit to this distribution is shown as a red line and the median and sigma of this Gaussian are labelled in the panel. |
| In the text | |
|
Fig. 3 Number density distribution in the 48 ALHAMBRA sub-fields in three magnitude-redshift bins. The mean magnitude and the redshift range of each bin are given in the panels. The total dispersion is shown as a red bar while the star and the black bar mark the median and the intrinsic dispersion retrieved by the MLE, respectively. The red solid lines show the best MLE solutions convolved with the Poisonian errors and are independent of the histogram binning. The derived values of the relative cosmic variance and the corresponding bias values are labelled in the panels. |
| In the text | |
|
Fig. 4 Left: bias values as a function of absolute UV magnitude. The blue filled square represents our data point at z ~ 4 and blue filled diamonds our data points at z ~ 3. The z ~ 3 points are shown as a comparison but are not used in the fit. The data points from Ouchi et al. (2004) and Cooray & Ouchi (2006) are shown as triangles and circles, respectively. Right: bias values as a function of the limiting absolute UV magnitude of each data set. The blue filled square shows our data point at z ~ 4. The results from the literature are shown as circles (Ouchi et al. 2005), pentagons (Allen et al. 2005), triangles (Ouchi et al. 2001), inverted triangles (Ouchi et al. 2004), diamonds (Arnouts et al. 2002), left-pointing triangles (Hildebrandt et al. 2009), stars (Harikane et al. 2016), and hexagons (Harikane et al. 2018). The black dashed line shows our best fit of Eq. (26) as also labelled in the figures. The 1-σ errors are shown as grey shaded areas. |
| In the text | |
|
Fig. 5 Total differential LF of ALHAMBRA galaxies at z = 2.5 – 4.5. |
| In the text | |
|
Fig. 6 ALHAMBRA UV LF at two redshift bins as indicated in the panels. The ALHAMBRA measurements are shown as blue squares together with their 2-σ error bars, and the blue line shows our best median Schechter fit, shaded area enclosing 95% of the solutions. Left panels: comparison with literature data from photometrically selected samples of high-z galaxies is shown as follows: triangles (Reddy & Steidel 2009), upside-down triangles (van der Burg et al. 2010), diamonds (Mehta et al. 2017), pentagons and orange dashed-line (Parsa et al. 2016), open circles (Ono et al. 2018), left pointing triangles (Finkelstein et al. 2015), and hexagons (Bouwens et al. 2015). Right panels: comparison with the spectroscopic LF estimate of Cucciati et al. (2012) (black dots and red dotted line). |
| In the text | |
|
Fig. 7 ALHAMBRA UV LF of Fig. 6 at redshift z ~ 4 and the corresponding Schechter fit (blue squares and blue line). The LF from Ono et al. (2018) is shown as white circles. The QSO LF of Akiyama et al. (2018) at z ~ 4 is plotted as red upside-down triangles. The purple line shows the best Schechter fit when this (absolute maximum) QSO contamination is subtracted from our z ~ 4 LF fit. |
| In the text | |
|
Fig. 8 Radio LF: The radio measurements of Novak et al. (2017) are shown as black dots. Our UV luminosities converted to radio following the prescription of Novak et al. (2017) are shown as blue squares. |
| In the text | |
|
Fig. 9 Luminosity density derived integrating the Schechter functions given by us and given in the literature: Parsa et al. (2016), Bouwens et al. (2015), McLure et al. (2013, 2009), Cucciati et al. (2012), Oesch et al. (2010), Bouwens et al. (2007), Iwata et al. (2007), Paltani et al. (2007), Sawicki & Thompson (2006), Wyder et al. (2005), and Gabasch et al. (2004). |
| In the text | |
|
Fig. 10 SFR as a function of host halo mass. The Mashian et al. (2016) calibration at z ~ 4 is given as a dotted curve. Our bias-based halo mass estimate at z ~ 4 and the estimated SFR for the corresponding magnitude bin are given as a red point. |
| In the text | |
|
Fig. A.1 Median total variance (red dots) and the median cosmic variance (cyan pentagons) as a function of the redshift bin size Δz at z = 2.5 – 4.5. The dashed line marks the total variance in the constant regime. The grey area marks the bin sizes smaller than 〈δz〉, the ALHAMBRA photometric redshift precision. |
| In the text | |
|
Fig. A.2 Sum of the individual MUV posterior distributions for all the galaxies in our sample normalised to be centred at zero. A Gaussian fit to this distribution is shown as a red line and the median and sigma of this Gaussian are labelled in the panel. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.