| Issue |
A&A
Volume 567, July 2014
|
|
|---|---|---|
| Article Number | A72 | |
| Number of page(s) | 15 | |
| Section | Stellar atmospheres | |
| DOI | https://doi.org/10.1051/0004-6361/201423590 | |
| Published online | 14 July 2014 | |
Atomic diffusion and mixing in old stars
V. A deeper look into the globular cluster NGC 6752⋆,⋆⋆
Division of Astronomy and Space Physics, Department of Physics and Astronomy, Uppsala University, Box 516, 75120 Uppsala, Sweden
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received: 6 February 2014
Accepted: 21 May 2014
Abstract
Context. Abundance trends in heavier elements with evolutionary phase have been shown to exist in the globular cluster NGC 6752 ([Fe / H] = −1.6). These trends are a result of atomic diffusion and additional (non-convective) mixing. Studying such trends can provide us with important constraints on the extent to which diffusion modifies the internal structure and surface abundances of solar-type, metal-poor stars.
Aims. Taking advantage of a larger data sample, we investigate the reality and the size of these abundance trends and address questions and potential biases associated with the various stellar populations that make up NGC 6752.
Methods. We perform an abundance analysis by combining photometric and spectroscopic data of 194 stars located between the turnoff point and the base of the red giant branch. Stellar parameters are derived from uvby Strömgren photometry. Using the quantitative-spectroscopy package SME, stellar surface abundances for light elements such as Li, Na, Mg, Al, and Si as well as heavier elements such as Ca, Ti, and Fe are derived in an automated way by fitting synthetic spectra to individual lines in the stellar spectra, obtained with the VLT/FLAMES-GIRAFFE spectrograph.
Results. Based on uvby Strömgren photometry, we are able to separate three stellar populations in NGC 6752 along the evolutionary sequence from the base of the red giant branch down to the turnoff point. We find weak systematic abundance trends with evolutionary phase for Ca, Ti, and Fe which are best explained by stellar-structure models including atomic diffusion with efficient additional mixing. We derive a new value for the initial lithium abundance of NGC 6752 after correcting for the effect of atomic diffusion and additional mixing which falls slightly below the predicted standard BBN value.
Conclusions. We find three stellar populations by combining photometric and spectroscopic data of 194 stars in the globular cluster NGC 6752. Abundance trends for groups of elements, differently affected by atomic diffusion and additional mixing, are identified. Although the statistical significance of the individual trends is weak, they all support the notion that atomic diffusion is operational along the evolutionary sequence of NGC 6752.
Key words: stars: abundances / stars: atmospheres / stars: fundamental parameters / globular clusters: individual: NGC 6752 / techniques: spectroscopic
Based on data collected at the ESO telescopes under programs 079.D-0645(A) and 081.D-0253(A).
Full Tables 2 and 8 are only available at the CDS via anonymous ftp to cdsarc.u-strasbg.fr (130.79.128.5) or via http://cdsarc.u-strasbg.fr/viz-bin/qcat?J/A+A/567/A72
© ESO, 2014
1. Introduction
Stellar spectroscopy of stars with spectral types F, G and K is a mature field of astrophysics. At least for simple atoms like lithium and sodium, the matter-light interaction taking place in stellar atmospheres can nowadays be modelled from first principles, with due consideration of hydrodynamics and departures from local thermodynamic equilibrium (LTE). Using long-lived stars as data carriers of different phases of Galactic evolution, much has been learned about the matter cycle and the general build-up of the Galactic inventory of chemical elements with time. However, our inferences are not free from uncertainties and limitations. One such inquietude is the theoretical expectation that the surface abundances of late-type stars with shallow outer convection zones are a direct function of time, due to element-separating effects collectively referred to as atomic diffusion (Michaud et al. 1984). Subject to the prevailing forces (gravity, radiation pressure), chemical elements will be pushed into/out of the atmosphere, leaving the visible surface somewhat enriched/depleted, to various degrees for different elements. Given that convection can efficiently counteract atomic diffusion, the effects are expected to lead to sizable surface effects only in hotter stars, i.e. in the context of this paper the F-type turnoff-point stars. During prior and subsequent evolution, the deep outer convection zone retains/restores the surface abundances (with the notable exception of lithium which is mostly destroyed during the course of the first dredge-up on the red-giant branch).
In this series of papers, we investigate to which extent careful spectroscopic studies can trace small yet systematic abundance differences between groups of stars representing different phases in the evolution of globular-cluster stars. The basic idea is simple: with sufficiently accurate spectroscopic modelling, inferred abundance differences can be compared to the predictions of stellar-structure models including the effects of atomic diffusion.
Earlier papers in the series have traced such effects in NGC 6397 at [Fe / H]1 = −2.1 (Korn et al. 2007; Lind et al. 2008; Nordlander et al. 2012) and NGC 6752 at [Fe / H] = −1.6 (Gruyters et al. 2013, hereafter Paper I). It was shown that the turnoff-point (TOP) stars do show systematically lower abundances (by 0.05–0.2 dex) than the red-giant branch (RGB) stars, with intermediate groups falling in between. But the predictions of atomic diffusion are not supported by these observations straight off. To achieve agreement between theory and observation, atomic diffusion needs to be counteracted by what is referred to as additional mixing, i.e. non-canonical mixing not provided by convection in the mixing-length formulation. Some mixing beyond the formal extent of the convection zone in the turnoff-point phase of evolution is also needed to explain the properties of the Spite plateau of lithium (Spite & Spite 1982) which at a given metallicity is found to be mono-valued and not a function of effective temperature (Richard et al. 2005). Such mixing can be prescribed in stellar-structure models by an extra term in the diffusion equation, adding a simple analytical function that accomplishes mixing down to layers of a specific temperature. The free parameter involved in this modelling, the efficiency relative to atomic diffusion, has to, at present, be determined empirically from the observations, i.e. from the amplitude of the elemental abundance trends.
For stars in NGC 6397, the efficiency of additional mixing is well-constrained and falls within the range that prevents lithium destruction which would be incompatible with the properties of the Spite plateau (see above). The agreement between theory and observation is very good and succeeds in describing abundance structures seen for the first time in lithium and calcium (Korn et al. 2006; Lind et al. 2009). There is, however, no complete consensus on the effective-temperature scale to be applied, with consequences for the abundance trends of e.g. lithium between main-sequence (MS) and subgiant-branch (SGB) stars (González Hernández et al. 2009).
For stars in NGC 6752, the results are less compelling, mainly because the abundance trends are weaker in this cluster. Nonetheless, with somewhat more efficient additional mixing, the trends can be reproduced and the diffusion-corrected lithium abundance raised to levels compatible with WMAP-calibrated predictions of standard Big-Bang Nucleosynthesis (Gruyters et al. 2013).
In this paper, we revisit NGC 6752 with additional observations obtained with the GIRAFFE spectrograph at the VLT. With improved stellar statistics, we can address questions and potential biases associated with the various stellar populations that make up NGC 6752. The paper is organized in the following manner: Sect. 2 describes the observations, both photometric and spectroscopic, and the data reduction providing the material for the analysis presented in Sect. 3. Section 4 describes the results, while Sect. 5 discusses their scientific significance. In Sect. 6, the results are summarized and some conclusions are drawn.
2. Observations and data reduction
2.1. Photometry
Photometric data was obtained using the DFOSC instrument on the 1.5 m telescope on La Silla, Chile, in 1997 and consist of uvby Strömgren photometry. The data is the same as used in Paper I, and details on the data reduction and photometric calibration procedures can be found in Grundahl et al. (1998, 1999).
The sample used for spectroscopic analysis consists of 194 stars located between the cluster turnoff point (TOP) at V = 17.0 and the base of the red giant branch (bRGB) up to V = 15.3. A colour-magnitude diagram (CMD) of the total sample is given in Fig. 1. We construct colour-magnitude fiducial sequences by averaging the colours of cluster members along the sequence. By interpolating colours at constant V-magnitude onto this sequence, we effectively remove the observational scatter, with residual errors dominated by uncertainties in the shape of the fiducial sequence. The best-fitting fiducial is found by trial and error. We find the most reliable method of constructing colour-magnitude fiducials to be quadratic interpolation between points placed manually such that the resulting residuals along the sequence were minimized. Finally, we apply a reddening correction of E(B − V) = 0.04 (Harris 1996, latest web update) with the relation coefficients given by Ramírez & Meléndez (2005), and E(v − y) = 1.7 × E(b − y).
 |
Fig. 1 Observed colour-magnitude diagram of NGC 6752. The spectroscopic targets are marked by black squares for the GIRAFFE sample. For comparison we have included the UVES targets from Gruyters et al. (2013) as red diamonds. |
2.2. Spectroscopy
The spectroscopic observations were obtained in Service Mode during ESO period 79 (Program ID: 079.D-0645(A)) and period 81 (Program ID: 081.D-0253(A)) using the multi-object spectrograph FLAMES/GIRAFFE mounted on the ESO VLT-UT2 Kueyen (Pasquini et al. 2003). Running in MEDUSA mode, FLAMES-GIRAFFE can simultaneously observe 132 objects. On average we dedicated 15 of the 132 fibres to a simultaneous monitoring of the sky background. As our faintest targets reach V ≈ 17, we typically coadded multiple long exposures (up to 4215 s) in order to reach spectra of sufficient quality with signal-to-noise ratios per pixel (S/N) above 30. Including overhead, we spent a total of 70 h under good seeing conditions (~0.7′′) during grey-to-bright lunar time periods using six high-resolution “B”-settings (HR9B, HR10B, HR11B, HR13B, HR14B, and HR15B).
Observational data of the NGC 6752 stars observed with FLAMES-GIRAFFE.
In this work we present the data of four of the six settings, covering a combined spectral range of 1100 Å. Stars in different evolutionary stages are distributed randomly across the field-of-view. We find no gradient in background light over the field and subtract a single, median averaged sky-spectrum from the stellar spectra obtained during each observation. The setup is summarised in Table 1 for the subset of spectra analysed in this work.
As UVES targets were prioritized during observations, fibre positioning limitations resulted in only 37 stars out of the full sample of 194 being observed in all six settings. The largest overlapping sample consists of 105 stars observed in HR11B covering e.g. the Mg i 5711 Å line and the Na i 5682–5688 Å doublet, and HR15B covering the Li i 6707 Å line and the Al i 6696–6698 Å doublet. Additionally, 99 stars were observed in both HR10B and HR11B, the former covering the Mg i 5528 Å line.
We executed basic data reduction on the spectroscopic data using the GIRAFFE pipeline maintained by ESO. Individual exposures, ranging between 1 and 11 per star, were coadded after sky-subtraction, normalization, radial-velocity correction and cosmic-ray rejection. As we have only a single exposure for some stars, we opted for a threshold-rejection method of affected pixels and their neighbours, and visually inspected all spectra before and after coaddition.
The minimum, maximum and median S/N-ratios per rebinned pixel of the coadded spectra are given in Table 1 for the different settings. These values are computed for each spectral order in the reasonably line-free continuum regions used for normalization, and are subsequently applied as flux error estimates.
3. Analysis
3.1. Effective temperature
A photometric effective temperature (Teff) scale was constructed from the (v − y) and (b − y) colour indices using relations for MS stars (Alonso et al. 1996; Korn et al. 2007) and giant stars (Alonso et al. 1999, 2001; Korn et al. 2007), assuming [Fe / H] = −1.60 for all stars. Both relations are calibrated on the infrared flux method. As our sample stretches from the TOP at the very end of the MS to the bRGB, we evaluate separately the dwarf and giant calibrations, and interpolate Teff linearly as a function of log g between them.
Comparing the (v − y) and (b − y) calibrations, differences are rather small: the former is hotter by 16 ± 57 K for the dwarf and 6 ± 55 K for the giant calibration. The difference is at most roughly 80 K in a narrow part of the SGB, which falls outside the colour ranges covered by the calibrations. Temperatures based on (v − y) and (b − y) exhibit a scatter about the fiducial sequences of 40 K and 80 K, respectively. Comparing the fiducial sequences on the two colour indices, we find a dispersion of just 23 K, including the aforementioned biases.
While the v-band is in principle sensitive to variations in chemical composition, i.e. different CN band strengths (Carretta et al. 2011), our fiducial sequence does not appear to be strongly affected by this. We judge potential errors in placement of the fiducial sequence due to such effects to be at most + 20 K, for our coolest stars where the sensitivity is greatest. We opt to base our temperature scale on the (v − y) relation as it exhibits less scatter, higher sensitivity on the RGB, and creating its fiducial appears to be less susceptible to systematic errors. Taking into account the statistical uncertainties present, we adopt a representative uncertainty of 40 K in Teff.
The calibration of Casagrande et al. (2010) on the (b − y) index produces higher temperatures by 120–150 K, with a slight dependence on colour. No corresponding calibration is available for (v − y). With the main difference to previous calibrations being in the zero-point (as indicated in that paper), we may assume a similar absolute uncertainty would apply to the (v − y) index.
3.2. Surface gravity
We employ photometric surface gravities, assuming a distance modulus of 13.13 (Harris 1996, latest web update). The bolometric corrections of Alonso et al. (1999, 2001) are applied to observed V-magnitudes, as a function of metallicity and Teff, to compute luminosities. Stellar masses are interpolated directly as a function of Teff from a 13.5 Gyr isochrone (from Gruyters et al. 2013), and range from 0.79 to 0.815 M⊙. The resulting values of log g range from 4.0 at Teff= 6050 K (TOP) to 3.0 at Teff = 5160 K (bRGB). The final stellar parameters, along with observational parameters, are given in Table 2.
The surface gravities are most sensitive to uncertainties in Teff, where a change of + 100 K propagates into log g changes of + 0.04 dex on the TOP, or + 0.03 dex on the bRGB. An effect of δlog g = + 0.01 dex would require, e.g., an increase in stellar mass of 0.02 M⊙, or an increase in V-magnitude by 0.025 mag, be it due to observational uncertainties or errors in distance modulus or bolometric correction. Sbordone et al. (2011) examined the effects of chemical composition variations on isochrones and photometry. Concerning isochrones, they found that only extreme increases in nitrogen or helium abundance could produce any discernible effects. Cassisi et al. (2013) expanded on this work and note a composition-driven increase in Teff of + 30 K and Δlog (L/L⊙) ≈ 0.017, where partial cancellation results in an effect δlog g = + 0.01 dex. On the bRGB on the other hand, δTeff≈ 0 K, giving an 0.01 dex net differential effect.
Thanks to the high precision in log g, gravity-sensitive (majority) species such as Fe ii and Ti ii are the least susceptible to errors in the primary stellar parameters, as shown in Sect. 3.6.
Photometry, data quality and stellar parameters.
3.3. Spectrum synthesis
For our heterogeneous sample of spectra of 194 stars, we opted for an automated spectrum analysis rather than the manual line-by-line approach employed for UVES spectra in Paper I. We use a modified version of the spectrum synthesis code Spectroscopy Made Easy (SME, Valenti & Piskunov 1996; Valenti & Fischer 2005), set to run without user interaction. Additionally, the code has been modified to allow non-LTE (NLTE) line formation, from a grid of precomputed corrections (tabulations of LTE departure coefficients). To run the code, one provides an input spectrum, stellar parameters (Teff, log g, [Fe / H] and vmic), a line list with line parameters, line and continuum masks, and a list of spectrum segments wherein the continuum is individually normalized. The code uses a grid of MARCS plane-parallel and spherically symmetric model atmospheres (Gustafsson et al. 2008), all with scaled solar abundances and alpha-enhancement of 0.4 dex. Interpolating models from this grid, spectra are then computed on the fly. The numerical comparison between synthetic and observed spectra is executed by a non-linear optimization algorithm (Marquardt 1963; Press et al. 1992). We apply NLTE corrections for Fe, Na and Li (Lind et al. 2009, 2011a, 2012) to the line formation using pre-computed departure coefficients. Finally, we apply NLTE corrections to our LTE abundances of Mg (Y. Osorio, priv. comm.) as in Paper I.
3.4. Microturbulence
As a large fraction of our stellar sample only has spectra of moderate quality in the rather line-poor spectral region covered in HR15B, vmic cannot be determined to acceptable precision for each star. We executed preliminary analyses where vmic was determined from a set of iron lines in the HR9B setting, and found an essentially linear dependence on effective temperature with an RMS error of 0.11 km s-1. Applying this linear relation to all stars, vmic values range between 1.8 km s-1 at Teff= 6000 K and 1.3 km s-1 at Teff= 5200 K. On our photometric temperature scales, the excitation equilibrium is not necessarily fulfilled. This could skew the determination of vmic due to the tendency for low-χ lines to be stronger, thus correlating Teff with vmic. We executed test runs where Teff was determined simultaneously with vmic from Fe i lines, resulting in overall significantly higher temperatures, as well as a somewhat expanded temperature scale. The difference is δTeff= 207 ± 143 K and 60 ± 48 K for the warm (Teff> 5800 K) and cool (Teff< 5450 K) stars of our sample, with corresponding increases δvmic= 0.10 ± 0.16 and 0.08 ± 0.07 km s-1, respectively. Deriving vmic from Fe ii lines, as was done in Paper I, we find only a minor difference δvmic= − 0.06 ± 0.20 km s-1 for the warm, and δvmic= 0.01 ± 0.06 km s-1 for the cool stars. With these considerations in mind, we adopt 0.10 km s-1 as our representative uncertainty. At this level, the vmic uncertainty does not add significantly to the error budget of derived abundances (cf. Sect. 3.6).
3.5. Deriving chemical abundances
We derive chemical abundances for each star independently from each available spectral order. This allows us to check the order-to-order consistency, and ensures internal homogeneity among abundances derived from a single spectral order. Only after ensuring consistent results do we average results from different spectral orders, where relevant. As spectral orders vary in the amount and quality of spectral information, they are weighted by statistical uncertainties in the averaging.
To further maintain consistency between settings and reduce (internal) line-to-line scatter, we determine abundances differentially to a high-quality averaged spectrum on the cool end of our sample for the α and iron-peak elements. We selected all 11 stars on the bRGB (Teff< 5420 K) with complete sets of observations in all spectral orders. By coadding these spectra, we achieve S/N well above 200 in all settings. We executed a preliminary abundance analysis on these spectra, and adopted these results as our reference abundance pattern. Line oscillator strengths were then adjusted to reproduce this abundance pattern, so that the baseline (at the bRGB) is the same for all lines, in all spectral orders. The reference stars are detailed in Table 3.
Coadded bRGB spectra used as reference in differential analysis.
When the chemical composition exhibits internal variations among the coadded stars, nontrivial problems may arise from the averaging of lines whose strengths and shapes are intrinsically different. For this reason, we do not adopt astrophysical oscillator strengths for the light elements where such variations are expected: Li, Na, Mg, and Al. Note however that most of these elemental abundances are derived from only one or two lines, and thus would anyway not be affected by this issue. The atomic data for these lines can be found in Table 4. The other atomic data for the lines used in the abundance analysis were obtained from the Vienna Atomic Line Database (Piskunov et al. 1995; Kupka et al. 1999).
Atomic line data.
Abundance sensitivity to stellar parameters.
3.6. Uncertainties
We consider systematic and statistical errors separately. Leading systematic error sources likely stem from uncertainties in the atmospheric parameters, which were discussed in Sects. 3.1 and 3.2. Systematic abundance uncertainties from the influence of stellar parameter perturbations on average abundance results are indicated in Table 5. We evaluate these effects for the hot and cool ends of our temperature range, for all chemical elements analysed in this work.
Modelling errors related to the use of 1D atmospheres were discussed in Paper I. Lines of the same ionisation stage respond, in general, in a similar way to changes in atmospheric parameters. Thus the systematic uncertainties related to the atmospheric parameters partially cancel when working with abundance ratios ([X/Y] = [X/ H] − [Y/ H]).
For statistical errors, we use those reported by the χ2 minimization algorithm of SME (Marquardt 1963; Press et al. 1992), which are based on photon-noise statistics. We shall refer to these as “SME errors”. As they do not fully take into account uncertainties in the continuum determination, we enforce a representative minimum error of 0.02 dex. Unless otherwise stated, uncertainties in this work refer to these statistical errors.
We examine the estimate of these statistical errors in more detail by running a Monte Carlo simulation, in which we derive the abundance from a single weak atomic line, representing the case of lithium. As reference, we use synthetic spectra generated for stellar parameters (Teff= 5400–6000 K) and abundances spanning the ranges of the stars observed (EW = 7–45 mÅ), with a wide range of Gaussian noise injected (S/N = 10–1000). We generated a total of 65 such sets of at least 10 000 spectra each. We averaged results from each set of abundance analyses, taking SME errors as uncertainties. The weighted standard deviation and the bias of the mean from these averages are compared in Fig. 2 to the SME error. Small errors appear to be dominated by the width of the distribution, such that averaging a large sample will generate an accurate estimate of the mean. Large errors on the other hand tend to become asymmetric, giving a significant positive bias, while underestimating the true dispersion. The figure can be interpreted as a decomposition of the SME error into these two components, for any single abundance result. Alternatively, the bias of an averaged abundance can be estimated from the size of its standard deviation. For instance, averaging a large sample of lithium abundances with 0.10 dex uncertainties would overestimate the mean value by 0.03 dex.
The cause of this behaviour is that noise produces errors in line equivalent widths which are symmetric and linear. For weak lines, the same is then true for the number of absorbers NX/NH. On the logarithmic abundance scale, log (NX/NH), these errors instead appear asymmetric, such that weighted averages always systematically overestimate the mean value. If instead lines are on the saturated or strong parts of the curve of growth, the corresponding error statistics apply. Finally, these considerations would not necessarily apply if uncertainties in stellar parameters dominate over those in line strengths.
As we analyse lines on various parts of the curve of growth, we choose not to apply linear averages. Tests indicate that the magnitude of these biases, if applicable, is less than 0.03 dex in this work.
 |
Fig. 2 Weighted standard deviations and biases of the weighted means as determined from weak lines analysed in Monte Carlo tests on synthetic spectra. |
 |
Fig. 3 Evolutionary abundance trends of Mg, Ca, Ti, and Fe. Mg and Ca abundances are derived from neutral lines while Ti and Fe are derived from singly ionised lines (see Table 6). The solid (green) line represents the running mean (weighted average), while dashed (blue) lines represent the standard deviation. Error bars represent statistical errors. Systematic errors are indicated in Fig. 10. Overplotted in diamonds are the UVES results from Paper I, which have been vertically shifted for easier comparison. |
4. Results
In what follows we address our derived chemical abundances for the total sample of 194 stars. As not all stars were observed with all settings, we do not have a complete set of abundances for the full sample. Results from different spectral orders have been averaged only after carefully verifying that they appear compatible. After describing our abundance results, we discuss the implications, and investigate the prospect of predicting population membership from photometry.
4.1. Chemical abundances
4.1.1. Lithium
Lithium abundances A(Li) are given in Table 8 and are derived from the 7Li resonance line at 6707.8 Å. The line has two fine-structure components which are separated by only 0.15 Å and thus are indistinguishable at the resolution of GIRAFFE (R = 19 300). The atomic data for the Li doublet takes into account this fine structure and isotopic splitting and is given in Table 4. The abundances are corrected for NLTE effects by interpolation on the grid by Lind et al. (2009). As lithium is almost completely ionised, A(Li) is primarily sensitive to Teff, which thus dominates the systematic errors. Our estimated precision of 40 K in Teff corresponds to an abundance uncertainty of 0.03 dex. Compared to this, errors due to uncertainties in gravity, metallicity and microturbulence are generally negligible (~0.01 dex).
Combining these systematic uncertainties, with the expected bias stemming from the averaging process, we estimate 0.10 dex to be a suitable conservative error. The average Li abundance of the TOP sample (Teff> 5900 K) is 2.22 ± 0.08 in agreement with Paper I and Gratton et al. (2001). We will discuss lithium in greater depth in Sect. 5.2.
4.1.2. α and iron-peak elements
Average abundances obtained at two effective-temperature points.
Abundances of the α elements magnesium, calcium and titanium were derived along with the iron-peak elements scandium, chromium, iron and nickel. Figure 3 shows the derived chemical abundances of magnesium, calcium, titanium and iron as a function of the effective temperature. Results have been averaged on a running mean in bins of ±150 K, which has then been further smoothed by a Gaussian (σ = 100 K). We show also the group-averaged abundances derived from UVES spectra in Paper I, from a temperature scale based on the (b − y) colour index. We have shifted those results slightly to coincide with our abundance scale for the coolest stars.
Magnesium abundances were derived from the λλ5167–5184 triplet in the HR9 setting and the high-excitation λ5528 line in the HR10 setting. We average abundances between the two settings for the 50 stars which were observed in both settings, as we find rather consistent results when adopting laboratory oscillator strengths (Chang & Tang 1990; Aldenius et al. 2007) and applying NLTE corrections. The rather large observed dispersion, compared to the other elements, is further discussed in Sect. 4.1.3.
Calcium abundances were likewise determined from the HR9, HR10 and HR11 settings. When applicable, we average results between settings, resulting in abundances determined for a set of 176 stars. We investigated departures from LTE, following Mashonkina et al. (2007), for several of the Ca i lines used in the determination of the Ca abundance. Apart from the general effect of over-ionisation which raises all abundances by ~0.1 dex, the relative trends between TOP and RGB are only marginally affected, on average by 0.02 dex. This correction is well within the error budget of our analysis.
Titanium and iron abundances have been derived from ionized lines, which we selected exclusively from HR9. As only half the stars were observed with this setting, we also determined iron abundances for each star from the neutral lines available in every spectral order. These abundances were corrected for NLTE effects and averaged between settings, but are only used as a reference in computing [X/ Fe].
All elements exhibit clear evolutionary variations, summarized for the hot and cool ends of our temperature range in Table 6, where we also state explicitly which spectral lines have been used. Although these abundance variations are rather weak and of low significance (1–2σ), they are in good agreement with Paper I, despite the independent methods used here. The abundance variations are also rather robust regarding systematic errors in stellar parameters. For instance, removing the abundance trend in iron would require increasing temperatures of stars at the TOP by 200 K, implying an error in ΔTeff(TOP − bRGB) of 25%, which we consider unlikely. A similarly large adjustment to log g (+0.35 dex) or vmic (–0.4 km s-1) would be required. Systematic uncertainties of stellar parameters were further examined by Nordlander et al. (2012), indicating that no combination of stellar parameters can simultaneously render null trends in all elements. Errors due to hydrodynamical effects were investigated in Paper I. A full 3D treatment (in LTE) would in fact strengthen all observed trends.
We also derived abundances of scandium, chromium and nickel for the bRGB stars in our sample. Unfortunately, the quality of the dwarf star spectra did not allow to derive reliable abundances for these elements in these stars. An overview of the mean abundances and dispersion for the bRGB stars (Teff< 5450 K) is given in Table 7.
The abundances of Ca, Ti, Cr, Fe and Ni are in agreement with the abundances derived for the reference RGB bump star NGC 6752–11 from the Yong et al. (2013) sample. Unfortunately, they did not derive Mg or Sc abundances. The abundances show the typical pattern of halo field stars in which the α-elements are overabundant by 0.1 to 0.3 dex relative to the Fe-peak elements which are roughly solar, meaning [α / Fe] ≈ 0.1–0.3 and [X/ Fe] ≈ 0.
Three of the stars examined here (IDs 2844, 2795, 3035) exhibit suspiciously low abundances in calcium, titanium and iron, which could indicate binarity. For instance, an evolved low-mass companion would only moderately affect photometric parameters, but rather provide continuum flux filling in all spectral lines.
 |
Fig. 4 Evolutionary abundance trends of Na, Mg, Al, and Si. The different coloured symbols correspond to the chemical populations deduced from a photometric cluster analysis (see text). |
Average abundances and dispersions of Sc, Cr, Ni and Fe for the subsample of bRGB stars (Teff< 5450 K).
4.1.3. Na, Mg, Al, and Si
Distinct chemical populations in globular clusters have previously been addressed in a series of papers (on NGC 6752, e.g., by Gratton et al. 2001 and Carretta et al. 2007, 2012). In Paper I, we did the same for a set of FLAMES-UVES spectra, revealing three chemically distinct populations in agreement with Carretta et al. (2012). Based on the abundances of Al, Na and Mg we labelled stars to be first- or second-generation stars. First-generation stars are poor in Al and Na while rich in Mg, compared to the mean of the whole sample. This group of stars is referred to as the primordial population (P). Second-generation stars are characterised by average and high Al and Na abundances compared to the mean abundances for our sample. This second generation can be further split into two different populations: one with average abundances of Al, Na and Mg (intermediate population I), and one rich in Al and Na but poor in Mg (extreme population E). Si is not considered a discriminating element in this sense.
Figure 4 shows the abundances of sodium, magnesium, aluminium and silicon as a function of Teff. All elements exhibit a large dispersion, as expected from previous findings (e.g. Carretta et al. 2007, 2012; Paper I). Symbols and colours in this figure correspond to the different chemical populations, determined photometrically in Sect. 4.2.
Sodium abundances were derived for a set of 132 stars using the λλ5682–5688 doublet in HR11. We find a spread (tip-to-tip) of roughly 0.8 dex, which does not appear to vary significantly along the sequence, sans sampling effects. While Lind et al. (2011a) found a 0.2 dex difference between dwarf and giant stars in the cluster NGC 6397, we do not observe a clear difference in abundance between the two groups. Lind et al. (2011a) explain their observed difference as a result from atomic diffusion. At the present metallicity, the expected trend is shallower (~0.1 dex), while the star-to-star dispersion is similar. A potential trend is thus difficult to detect using the very weak lines available in our spectra. We will address atomic diffusion in more detail in Sect. 5.1.
By contrast, our magnesium abundances exhibit a smaller spread of just 0.3 dex. The spread again does not exhibit significant variation along the sequence. The abundance difference comparing warm to cool stars, 0.11 ± 0.12 dex (Table 6), is similar for the three populations, 0.16 ± 0.06, 0.16 ± 0.12 and 0.12 ± 0.14 dex, for the P, I and E populations, respectively. As the P and I populations exhibit similar abundances of magnesium, we note that their combined sample indicates an abundance trend of 0.15 ± 0.08 dex.
Aluminium abundances are derived from the weak Al i doublet at 6696–6698 Å and thus could only be derived from stars observed in HR15. Unfortunately, the doublet was too weak to be observed in most of the stars, and even upper limits were not meaningful for the bulk of (lower-S/N) spectra. In total, we could detect aluminium in 22 stars, and derived upper limits for another 48, indicating a spread of at least 1 dex.
Finally, we deduced silicon abundances from three Si I lines in HR11B at 5708, 5665 and 5690 Å. The spread in Si abundance is dominated by the observational uncertainty on the hotter end of our sample. This uncertainty also masks out any potential trend with evolutionary phase. We estimate an intrinsic spread in Si of about 0.3 dex.
The abundances ratios of Na, Mg, Al and Si relative to Fe (based on Fe i lines) for the individual stars are given in Table 8, and compared in Fig. 5. Using Mg as the discriminator, the usual anticorrelations are observed, a signature of element depletion in H burning at high temperature. We also see that Al is well correlated with elements which are enhanced by the Ne-Na and Mg-Al cycles. And like Carretta et al. (2012), we also seem to find a Al-Si correlation. The correlation stems from leakage from the Mg-Al cycle on 28Si. Such a leakage can only be obtained within a reaction network in which the temperature exceeds ~65 × 106 K. The Al-Si correlation can thus be explained as a direct result of pollution by the first generation of cluster stars burning H at high temperatures.
Light-element abundances and abundance ratios, compared to photometric population assignments.
 |
Fig. 5 Anticorrelations between sodium, magnesium and aluminium. Different coloured symbols correspond to the chemical populations deduced from a photometric cluster analysis (see text). The faintest (V> 16.8) stars have been excluded from this comparison. |
In the next section we will address these distinct chemical populations in greater depth by investigating their photometric properties.
4.2. A cluster analysis
It has previously been demonstrated by Carretta et al. (2012) that one can couple abundance anticorrelations to photometric properties of RGB stars in NGC 6752. We shall here attempt to extend their findings for fainter stars, along the SGB toward the TOP region.
Using uvby Strömgren photometry for our complete data set, we created colour-magnitude fiducial sequences for the colour indices (u − v), (u − b), cy and δ4. Figure 6 shows the corresponding CMDs with the fiducial sequences overplotted. The cy index was defined by Yong et al. (2008) and combines three colour indices: cy = (u − v) − (v − b) − (b − y) = u − 2 × v + y. It is sensitive to N abundances, from the influence on NH bands near 3450 Å in the u filter, and CN bands at 4216 Å in the v filter. As the sensitivity on the latter is weaker, it is weighted twice. The δ4 = (u − v) − (b − y) index was introduced by Carretta et al. (2011) and combines the four Strömgren filters, each weighted only once. For further in-depth discussion of the cy and δ4 indices, the reader is referred to Carretta et al. (2011).
 |
Fig. 6 CMDs in (u − v) (upper left), (u − b) (upper right), δ4 (lower left), and cy (lower right). The solid lines represent the fiducial sequences from which distances (residuals) are used in the cluster analysis. Different coloured symbols correspond to the chemical populations deduced from a cluster analysis. |
We now pose the following question: based solely on photometry, can we predict membership of our globular cluster stars to different chemical populations? It was shown by Sbordone et al. (2011) and Cassisi et al. (2013) that the effect of anticorrelated Mg and Al variations on Johnson and Strömgren photometry is negligible. However, these anticorrelations appear intrinsically tied to variations in CNO and He, which affect the spectral energy distribution (SED) both directly via molecular band strengths, and indirectly via secondary effects on the stellar evolution. We here make an attempt to predict chemical population membership based on photometric information alone. In a next step we then compare these predictions to the derived abundances for Na, Mg, Al, and Si. This was done as follows.
With the photometric indices described above, we performed a cluster analysis using the k-means algorithm (Steinhaus 1956; MacQueen 1967) as implemented in the R statistical package (R Development Core Team 2013)2. We consider only photometric parameters for each star and take the residuals of colour indices with respect to the fiducial sequences at constant V magnitude as the parameters for the cluster analysis. We do not take into account the varying widths of the distributions as a normalizing factor. By the nature of the k-means method, uncertainties are not taken into account, and populations are assigned as definitive rather than probabilistic. The resulting average values of the photometric parameters for stars in three populations as determined by our cluster analysis are given in Table 9.
Average photometric parameters of cluster populations.
With all stars in our sample assigned to populations, we return to the light element abundances. In Fig. 5 we show the relations between abundances of sodium, magnesium and aluminium, colour-coded by population. We find stars low in sodium and aluminium but rich in magnesium to be generally correctly identified as first-generation stars. Stars rich in sodium and aluminium but low in magnesium are labeled as extreme stars belonging to the second generation. There is, however, some crosstalk between the primordial and intermediate population on the one hand, and between the extreme and intermediate populations on the other. Since many of our abundance results for these elements are only upper limits, it is difficult to say definitively whether stars have truly been mislabeled. From Fig. 6, more crosstalk is seen among the faintest (V> 16.8), warmest (Teff> 5900 K) stars of the sample. This should be expected due to weaker correlation between photometry and chemistry on the merit of weaker CN-bands. Spectroscopic assignments are unfortunately similarly difficult as a result of limited S/N for these faint stars, making it difficult to derive precise abundances from weak lines (see Fig. 2 in Paper I).
Comparing the statistics of our population assignments to those by Carretta et al. (2012), we find overall similar results. The primordial population comes out the smallest at 24%, at a similar fraction to the 21% of Carretta et al. (2012) and 25% of Milone et al. (2013). A general fraction of ~30% primordial stars in globular clusters was determined by Carretta (2013) by comparing the Na abundances of field stars with globular cluster stars.
We find a twice larger intermediate than extreme population, while Carretta et al. (2012) find the two to be roughly comparable, and Milone et al. (2013) find a 3:2 ratio. Our result may be somewhat inflated due to shortcomings in our analysis relating to the weaker photometric sensitivity to chemical composition toward the TOP. Firstly, the photometric variations are simply weaker in relation to the observational uncertainty. Secondly, the fact that the variations weaken toward higher temperature leads to any warm star regardless of chemical composition appearing more similar to an intermediate (cool) star.
We have also directly compared to Carretta et al. (2012) by including their stars in the cluster analysis. Crossmatching our photometric catalogue to their sample of stars, the three populations are identified in the same proportions, to within 1%. Among the stars they assigned to the P, I, and E populations, we misidentify 20, 31 and 17%, respectively. Most mismatches are between the I and E populations, while only one star in the E population is assigned P membership.
We conclude that a cluster analysis based solely on uvby Strömgren photometry can indeed separate globular cluster stars into first- and second-generation populations on the subgiant branch, with some success even down toward the TOP. We explore this possibility further in Sect. 5.2. As expected though, significant crosstalk arises when the photometric response to chemical composition weakens to a level comparable to photometric uncertainties. Finally, we would like to note that the separation of globular cluster stars in populations based on uvby Strömgren photometry is the direct result of abundance variations in C, N and O, and in He. However, since O correlates with Mg but anticorrelates with N, stars rich in O/Mg will be poor in N and vice versa. This variation in N abundance is then responsible for the separation in colour index upon which we base our method of identifying chemical populations. Besides the effect of varying N abundances in the different populations, Milone et al. (2013) also discussed the influence of different He fractions, Y. However, as we have no direct information on the He content of our stars, we can only refer to their results that the first generation of stars is characterised by a primordial He abundance (Y ~ 0.246), is rich in C/O/Mg and poor in N/Na/Al. The extreme population is made up of second-generation stars enhanced in He (ΔY ~ 0.03) and N/Na/Al but depleted in C/O/Mg. Finally the intermediate population also represents second-generation stars, but with intermediate He (ΔY ~ 0.01), C/O/Mg and N/Na/Al abundances.
 |
Fig. 7 CMDs in (u − v) (upper left), (u − b) (upper right), δ4 (lower left), and cy (lower right). The solid (blue) lines represent the fiducial sequences from which distances (residuals) are used in the cluster analysis. Blue diamonds indicate points between which the sequence has been interpolated. Yellow squares represent the selected stars for the cluster analysis. |
 |
Fig. 8 Left: cumulative radial distribution of the different populations as a function of distance from the cluster center. Right: spatial distribution of the stars in NGC 6752. The different symbols represent the populations as deduced from the cluster analysis. The black triangle marks the cluster center. |
4.3. Radial distribution
Finally, we also performed the same cluster analysis on the full uvby photometric catalogue after selecting all stars with V magnitude brighter than 16.8 and located within a distance of 0.1 mag from the chosen fiducials in all four colours. These criteria select 1100 stars, as shown in Fig. 7. The cumulative radial distribution for each population is given in the left panel of Fig. 8, while the right panel displays the spatial distribution on the sky, with different symbols corresponding to the different populations.
A Kolmogorov-Smirnov test indicates a 4.5% probability that the radial distributions of the primordial (green curve) and the extreme populations (blue curve) are drawn from the same parent distribution. The largest difference between the primordial and extreme population is found at a distance of roughly 3 arcmin from the cluster center. We also divided the full sample into subgroups: RGB stars (16 <V< 13), SGB stars (16.8 <V< 16), and proper motion members (V> 13; proper motion data from Zloczewski et al. 2012). We divided each group into five bins of radial distance to the cluster center. For each bin we calculated the mean distance to the cluster center for each population, and computed their number ratios. The radial distribution of the ratio between primordial and extreme stars is given in Fig. 9. Overplotted are the uncertainties given by the Poisson statistic, 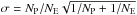 , where NP and NE represent, respectively, the number of primordial and extreme stars within each bin. The dotted line indicates the half-mass radius rh = 2.34 arcmin (Harris 1996).
, where NP and NE represent, respectively, the number of primordial and extreme stars within each bin. The dotted line indicates the half-mass radius rh = 2.34 arcmin (Harris 1996).
 |
Fig. 9 Radial distributions of the ratio of primordial stars to extreme stars as a function of the distance from the cluster center. The diamonds give the mean value of the radial bin whose range is indicated by the horizontal bar through the symbol. The dotted vertical line gives the half-mass radius of the cluster. |
We compare our radial distribution with that of Kravtsov et al. (2011). They claim a strong radial segregation between the primordial and extreme populations, based on ground-based broadband UBVI photometry of RGB stars. They conclude that RGB stars redder in (U − B) are centrally concentrated within the rh, while the radial distribution of RGB stars bluer in (U − B) peaks outside this region. This rather extreme bimodality is incompatible with our results, which merely indicate that the primordial population falls off faster than the extreme population between a radial distance of 2 and 5 arcmin (see e.g. left panel of Figs. 8, and 9) (within our sample). We do not see a radial segregation around the half-mass radius of the cluster. Our results are instead compatible with those of Milone et al. (2013), who analysed multi-band Hubble Space Telescope (HST) photometry, indicating no significant radial trend in the relative numbers of the three stellar populations within 6 arcmin of the cluster center. Milone et al. (2010) executed a Kolmogorov-Smirnov test on the radial distributions of different photometric populations on the SGB, indicating a 4% probability that the primordial and extreme population have the same radial distribution, which they considered far from conclusive.
Recently, Kravtsov et al. (2014) finalised the study of the NGC 6752 broadband photometry from Kravtsov et al. (2011), including the radial distribution of blue horizontal branch (BHB) stars. They found that the brighter BHB (BBHB) stars are more centrally concentrated than the faint (FBHB), thus suggesting nitrogen enhanced red giants as the progenitors of BBHB stars, on the basis of qualitatively similar radial distributions. The ratio of BBHB to FBHB stars of Kravtsov et al. (2014, Fig. 11) exhibits a similar morphology to our primordial-to-extreme star ratios in Fig. 9, with a minimum appearing at R ≈ 5 arcmin. They also find that the nitrogen enhanced extreme stars, RGBs redder in U − B and the U-faint SGBs, are centrally concentrated (essentially within rh) while their blue and U-faint counterparts exhibit flatter radial distributions in the field. This is contrary to our results indicating smooth distributions of extreme stars, while the primordial stars appear more centrally concentrated, falling off more rapidly outside rh.
 |
Fig. 10 Averaged abundance trends from Fig. 3 (green bullets), compared to the predictions from stellar structure models including atomic diffusion with additional mixing with two different efficiencies, at an age of 13.5 Gyr. Horizontal, dashed lines represent the initial abundances of the models, which have been adjusted so that predictions match the observed abundance level of the coolest stars. The groups of three arrows in each panel indicate the influence on averaged abundances from increasing the effective temperature by 40 K (left), surface gravity by 0.1 dex (middle) and microturbulence by 0.1 km s-1 (right) – see also Table 5. |
Both observed radial distributions can be argued for in terms of build-up scenarios for the cluster. On the one hand, 1D hydrodynamical simulations show that second-generation stars are formed more centrally than first-generation stars. This follows from the assumption that second-generation stars are made up of the ejecta from first-generation AGB stars. These ejecta accumulate in a cooling flow into the cluster core where the second-generation stars then form. Follow-up N-body simulations show that a large fraction of first-generation stars is lost early on. This because the cluster expands and early mass loss due to first-generation supernovae strips of the outer layers populated by first-generation stars (D’Ercole et al. 2008; Vesperini et al. 2013). During the dynamical evolutionary phase, both stellar generations mix and the ratio of second-to-first generation stars will settle into a morphology which is similar to the one observed by Kravtsov et al. (2014).
On the other hand, we know that He-enhanced stars (i.e. second-generation stars) are slightly less massive than their He-normal counterparts (i.e. first-generation stars) when they evolve off the MS. The cluster will be driven toward equipartition of kinetic energy if one assumes that the dynamical evolutionary phase is dominated by two-body relaxation. As a result, the He-enhanced red giants can end up having a more extended distribution than He-normal ones after a Hubble time or several relaxation times. This is actually what we seem to find in our data sample: the primordial, i.e. He-normal, population falls off faster than their He-enhanced counterparts (see Fig. 9). There is no obvious explanation to reconcile both observations. We suggest further investigation of a consistent HST data set which extends to larger radial distance from the cluster center.
5. Discussion
We now return to the observed abundance trends and discuss their implications.
5.1. Diffusion trends
Figure 10 compares the averaged trends of magnesium, calcium, titanium and iron from Fig. 3 (bullets) to predictions from stellar evolution models computed at the cluster’s metallicity [Fe / H] = −1.6 (Paper I). These models, introduced in Sect. 1, take into account the effects of atomic diffusion (AD), meaning radial transport of chemical elements, modelled from first principles, with the addition of a parametrised additional mixing (AddMix) of unknown physical origin.
AddMix is parametrised as a function of temperature and density (i.e., depth), and its efficiency is set by a free parameter representing a rescaling to the efficiency at a reference temperature T0. Figure 10 compares observations to AD model predictions at two different efficiencies of AddMix, where the model T6.0 (log T0 = 6.0) represents a low efficiency of AddMix, while T6.2 (log T0 = 6.2) represents high efficiency. Dashed horizontal lines indicate the initial model composition, which has been slightly adjusted so that predictions match the abundances of the cooler stars, where models coincide. This in turn is an effect of the convective envelope reaching deeper into the star, until it surpasses the region affected by AddMix.
Overall, we find good agreement between observations and predictions. The best correspondence is again found for the T6.2 model, as was the conclusion from the UVES analysis in Paper I.
In Sect. 4.2 we argued that the chemical populations in NGC 6752 differ in helium fraction by ΔY ~ 0.03. Lind et al. (2011b) showed, however, that such a change in helium fraction has negligible influence on Teff and log g at a given evolutionary phase. We thus assume that the variation in Y between stars of different populations does not influence the predictions from our stellar-structure models (cf. the contrasting case of NGC 6397, Korn et al. 2007). We also note that we find no significant abundance difference between stars of different populations in Ca, Ti, Cr, Fe, and Ni, except for the evolutionary trends discussed here. In the case of Mg, we find an insignificant tendency for the first-generation stars to exhibit a stronger trend than the second-generation stars, which is likely due to sampling of low-number statistics.
The confirmation of the diffusion trends from Paper I brings further support to the assumption that AD is operational along the evolutionary sequence of NGC 6752. Together with NGC 6397 we now have two globular clusters in which effects of AD have been observed. Adding to this list the old, solar-metallicity open cluster M 67, we can start to form a better picture about the rôle of AddMix and its behaviour with metallicity. Comparing the results in these three clusters with metallicities ranging from [Fe / H] = −2.1 (NGC 6397) over −1.6 (NGC 6752) to + 0.06 (M 67, Önehag et al. 2014), we find a decreasing effect of AD. One might have to make a differentiation between the metal-poor clusters and the solar-like ones as the degree of Addmix is found to increase with metallicity, i.e. decreasing the efficiency of AD, for the metal-poor clusters while AddMix seems unnecessary to explain the abundance trends in M 67. As a final note we would like to comment on yet another metal-poor cluster which was studied by Mucciarelli et al. (2011), namely M4 (NGC 6121) at [Fe / H] = −1.16. Abundances of Fe and Li were derived for stars between the TOP and RGB. Although no trend in Fe was observed, the authors argue that the primordial lithium abundance (see Sect. 5.2) can be reproduced assuming very efficient AddMix (T6.30). If this is true, the efficiency of AddMix is correlated with metallicity in the metal-poor regime. On the metal-rich side of the metallicity scale, however, AddMix does not seem to be required. One possible explanation is the fact that the outer convection zone extends further inside the star, surpassing the region where AddMix can operate. Continuing on this line of thought, one would expect the efficiency of AddMix to decrease with decreasing metallicity, as AddMix scales with the extent of the outer convection zone. Further analyses on globular clusters bridging the metallicity range between the metal-poor and the metal-rich regimes will shed light on the physical origin of AddMix. This is of utmost importance since any physical effects that alter the surface elemental composition of stars during their evolution must be taken into consideration in detailed studies of Galactic chemical evolution.
5.2. Evolution of lithium
Figure 11 compares our derived lithium abundances to model predictions, with stars identified by their chemical population membership as determined in Sect. 4.2. Compared to the traditional Spite plateau identified among field stars, surface lithium abundances of these globular cluster stars are known to be dramatically affected both by internal and external processes. Firstly, surface layers of more evolved stars are diluted by essentially lithium-free processed material dredged up as the surface convection zone deepens along the subgiant branch. Secondly, star-to-star scatter is caused by processed material from short-lived massive stars mixing with the gas from which second-generation stars are forming, in what is known as intra-cluster pollution (see Sect. 4.1.3). Even selecting the least evolved, least polluted stars of our sample, the same type of mostly non-destructive surface depletion by gravitational settling as has been discussed for other elements is at work for lithium (as in all Spite plateau stars). As a matter of fact, lithium is the metal affected the most by gravitational settling.
Selecting the least processed stars in the cluster is however not straightforward. Surface dilution sets in after the TOP at Teff ≈ 5900 K, which happens to coincide with the limit below which our photometric identification technique becomes less reliable (see Sect. 4.2). Only four TOP stars (out of 43) are identified as belonging to the primordial population. Correcting their measured lithium abundances for the effect of atomic diffusion predicted by the T6.2 model (~+ 0.25 dex), we find an average initial lithium abundance log ε(Li) = 2.52 ± 0.03 (statistical error).
 |
Fig. 11 Observed lithium abundances (coloured symbols as in Fig. 4), compared to stellar evolution model predictions for two different efficiencies of AddMix (see text). The initial abundance of the models (horizontal dashed line and shaded region), log ε(Li) = 2.53 ± 0.10, compares well to the predicted primordial lithium abundance (dotted horizontal line and shaded region), log ε(Li) = 2.69 ± 0.04. |
 |
Fig. 12 Initial abundances (corrected for atomic diffusion and dredge-up) of lithium, compared to the anticorrelation elements magnesium (left), sodium (middle) and aluminium (right). The dotted line and shaded region refer to the predicted primordial abundance based on the CMB-calibrated BBN predictions (see text). The faintest (V> 16.8) stars have been excluded from the comparison. Different coloured symbols correspond to the chemical populations deduced from the cluster analysis. |
Figure 4 indicates first-generation stars to be poor in sodium, with log ε(Na) < 4.7, in agreement with (Carretta 2013). Selecting instead on this chemical criterion, matches 23 out of 30 TOP stars with observations of both sodium and lithium, indicating an initial abundance log ε(Li) = 2.50 ± 0.07.
Applying these two selection criteria separately to the full sample of stars, including those affected by dredge-up, indicates log ε(Li) = 2.54 ± 0.05 (25 stars) and log ε(Li) = 2.52 ± 0.06 (52 stars). The strongest constraint is found when combining the two criteria, giving log ε(Li) = 2.53 ± 0.05 (21 stars). We adopt this as our best estimate of the initial lithium abundance, but enlarge the error bar to 0.10 dex in accordance with the uncertainty in selection and the systematic uncertainties discussed in Sect. 4.1.1. These results are in good agreement with Paper I, where an initial level of log ε(Li) = 2.58 ± 0.10 was deduced from two TOP stars.
Continuing this line of reasoning, we compare in Fig. 12 the initial abundances of lithium to magnesium, sodium and aluminium, after correcting for evolutionary effects (AD and dredge-up). While magnesium abundances appear smoothly correlated with lithium, both sodium and aluminium exhibit a two-zone behaviour. In both Figs. 11 and 12, the predicted primordial Li abundance based on Big Bang nucleosynthesis (BBN) calibrated on the cosmological background radiation (CMB) as observed by Planck, is given by the shaded area at log ε(Li)CMB + BBN = 2.69 ± 0.04 (Coc et al. 2013). The independent analysis of Nollett & Steigman (2014) prefers an insignificantly higher value of 2.72 ± 0.04.
6. Conclusions
Our differential 1D-LTE/NLTE based spectroscopic analysis of 194 stars observed at medium-high resolution indicates weak (~0.1 dex) systematic abundance trends of heavy elements with evolutionary phase along the subgiant branch, in magnesium, calcium, titanium and iron. Although these trends are of low statistical significance taken individually, they are found to be in good agreement with those determined by independent methods in Paper I, as well as predictions from stellar structure models including atomic diffusion with efficient additional mixing (the T6.2 model). The trends are not likely to be caused by systematic errors on, e.g., effective temperature, as flattening the abundance trend in iron would require an increase of 200 K on the turnoff point, implying an unrealistically large error in ΔTeff(TOP − bRGB) of 25%.
Abundances of lithium, sodium, magnesium, aluminium and silicon exhibit intrinsic (anti)correlated variations, indicating the presence of multiple stellar populations in the cluster. It has previously been shown that these can be identified – predicted – using uvby Strömgren photometry of stars on the RGB (Carretta et al. 2011). We have here extended this work to fainter, less evolved stars on the subgiant branch down to V ≈ 16.8, (Teff ≈ 5900 K) close to the TOP. It seems there is a genuine colour index for every population with a given abundance pattern in the sense that the polluted chemical composition of second-generation stars makes them appear redder than first-generation stars. We have investigated the radial distribution of the different stellar populations by use of uvby Strömgren photometry. We find a marginally significant indication of a weak radial segregation where the center of the globular cluster is slightly overpopulated by the primordial population, compared to the outskirts.
Combining photometric and spectroscopic information, we have attempted to identify the least polluted (primordial) stars in the cluster. Correcting their abundance patterns for the expected effects of atomic diffusion, we predict an initial lithium abundance of log ε(Li) = 2.53 ± 0.10. This is in good agreement with the results of Paper I, log ε(Li) = 2.58 ± 0.10, and similar to the initial composition of the less massive globular cluster NGC 6397, log ε(Li) = 2.57 ± 0.10 (Nordlander et al. 2012). For both clusters, the initial lithium abundance compares reasonably well with Planck-calibrated predictions of standard BBN, log ε(Li)CMB + BBN = 2.69 ± 0.04 (Coc et al. 2013).
Lithium is but one element affected by atomic diffusion and additional mixing, as all elements are affected to varying degree by these physical processes. With recent constraints on atomic diffusion in M 67 (Önehag et al. 2014), it is now important to bridge the gap between metal-poor globular clusters and the regime of solar-metallicity stars. This will help to shed light on the physical nature of additional mixing such that surface abundances of late-type stars can systematically be corrected for atomic diffusion and their initial abundances reliably recovered, for the benefit of such diverse science cases as studies of planet-hosting stars or the chemical evolution of the Galaxy.
We adopt here the usual spectroscopic notations that [X/Y] ≡ log (NX/NY)∗ − log (NX/NY)⊙, and that log ε(X) ≡ log (NX/NH) + 12 for elements X and Y. We assume also that metallicity is equivalent to the stellar [Fe/H] value.
Acknowledgments
We thank O. Richard for providing stellar-structure models, F. Grundahl for providing the uvby Strömgren photometric data, and Y. Osorio for computing NLTE corrections for magnesium. P.G. and A.K. thank the European Science Foundation for support in the framework of EuroGENESIS. T.N. and A.K. acknowledge support by the Swedish National Space Board.
References
- Aldenius, M., Tanner, J. D., Johansson, S., Lundberg, H., & Ryan, S. G. 2007, A&A, 461, 767 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Alonso, A., Arribas, S., & Martinez-Roger, C. 1996, A&A, 313, 873 [NASA ADS] [Google Scholar]
- Alonso, A., Arribas, S., & Martínez-Roger, C. 1999, A&AS, 140, 261 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Alonso, A., Arribas, S., & Martínez-Roger, C. 2001, A&A, 376, 1039 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Carretta, E. 2013, A&A, 557, A128 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Carretta, E., Bragaglia, A., Gratton, R. G., Lucatello, S., & Momany, Y. 2007, A&A, 464, 927 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Carretta, E., Bragaglia, A., Gratton, R., D’Orazi D’Orazi, V., & Lucatello, S. 2011, A&A, 535, A121 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Carretta, E., Bragaglia, A., Gratton, R. G., Lucatello, S., & D’Orazi, V. 2012, ApJ, 750, L14 [NASA ADS] [CrossRef] [Google Scholar]
- Casagrande, L., Ramírez, I., Meléndez, J., Bessell, M., & Asplund, M. 2010, A&A, 512, A54 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cassisi, S., Mucciarelli, A., Pietrinferni, A., Salaris, M., & Ferguson, J. 2013, A&A, 554, A19 [EDP Sciences] [Google Scholar]
- Chang, T. N., & Tang, X. 1990, J. Quant. Spectr. Rad. Transf., 43, 207 [NASA ADS] [CrossRef] [Google Scholar]
- Coc, A., Uzan, J.-P., & Vangioni, E. 2013 [arXiv:1307.6955] [Google Scholar]
- D’Ercole, A., Vesperini, E., D’Antona, F., McMillan, S. L. W., & Recchi, S. 2008, MNRAS, 391, 825 [NASA ADS] [CrossRef] [Google Scholar]
- González Hernández, J. I., Bonifacio, P., Caffau, E., et al. 2009, A&A, 505, L13 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gratton, R. G., Bonifacio, P., Bragaglia, A., et al. 2001, A&A, 369, 87 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Grundahl, F., Vandenberg, D. A., & Andersen, M. I. 1998, ApJ, 500, L179 [NASA ADS] [CrossRef] [Google Scholar]
- Grundahl, F., Catelan, M., Landsman, W. B., Stetson, P. B., & Andersen, M. I. 1999, ApJ, 524, 242 [NASA ADS] [CrossRef] [Google Scholar]
- Gruyters, P., Korn, A. J., Richard, O., et al. 2013, A&A, 555, A31 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gustafsson, B., Edvardsson, B., Eriksson, K., et al. 2008, A&A, 486, 951 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Harris, W. E. 1996, AJ, 112, 1487 [NASA ADS] [CrossRef] [Google Scholar]
- Korn, A. J., Grundahl, F., Richard, O., et al. 2006, Nature, 442, 657 [Google Scholar]
- Korn, A. J., Grundahl, F., Richard, O., et al. 2007, ApJ, 671, 402 [NASA ADS] [CrossRef] [Google Scholar]
- Kravtsov, V., Alcaíno, G., Marconi, G., & Alvarado, F. 2011, A&A, 527, L9 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kravtsov, V., Alcaíno, G., Marconi, G., & Alvarado, F. 2014, ApJ, 783, 56 [NASA ADS] [CrossRef] [Google Scholar]
- Kupka, F., Piskunov, N., Ryabchikova, T. A., Stempels, H. C., & Weiss, W. W. 1999, A&AS, 138, 119 [NASA ADS] [CrossRef] [EDP Sciences] [MathSciNet] [PubMed] [Google Scholar]
- Lind, K., Korn, A. J., Barklem, P. S., & Grundahl, F. 2008, A&A, 490, 777 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lind, K., Primas, F., Charbonnel, C., Grundahl, F., & Asplund, M. 2009, A&A, 503, 545 [NASA ADS] [CrossRef] [EDP Sciences] [MathSciNet] [Google Scholar]
- Lind, K., Asplund, M., Barklem, P. S., & Belyaev, A. K. 2011a, A&A, 528, A103 [Google Scholar]
- Lind, K., Charbonnel, C., Decressin, T., et al. 2011b, A&A, 527, A148 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lind, K., Bergemann, M., & Asplund, M. 2012, MNRAS, 427, 50 [NASA ADS] [CrossRef] [Google Scholar]
- MacQueen, J. B. 1967, in Berkley Symp. on Math. Statistics, and Probability, Proc. of the Fifth Symposium on Math. Statistics, and Probability (Berkley: Univ California Press), 11, 281 [Google Scholar]
- Marquardt, D. W. 1963, SIAM J. Appl. Math., 11, 431 [Google Scholar]
- Mashonkina, L., Korn, A. J., & Przybilla, N. 2007, A&A, 461, 261 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Michaud, G., Fontaine, G., & Beaudet, G. 1984, ApJ, 282, 206 [NASA ADS] [CrossRef] [Google Scholar]
- Milone, A. P., Piotto, G., King, I. R., et al. 2010, ApJ, 709, 1183 [NASA ADS] [CrossRef] [Google Scholar]
- Milone, A. P., Marino, A. F., Piotto, G., et al. 2013, ApJ, 767, 120 [NASA ADS] [CrossRef] [Google Scholar]
- Mucciarelli, A., Salaris, M., Lovisi, L., et al. 2011, MNRAS, 412, 81 [NASA ADS] [CrossRef] [Google Scholar]
- Nollett, K. M., & Steigman, G. 2014, Phys. Rev. D, 89, 083508 [NASA ADS] [CrossRef] [Google Scholar]
- Nordlander, T., Korn, A. J., Richard, O., & Lind, K. 2012, ApJ, 753, 48 [NASA ADS] [CrossRef] [Google Scholar]
- Önehag, A., Gustafsson, B., & Korn, A. 2014, A&A, 562, A102 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pasquini, L., Alonso, J., Avila, G., et al. 2003, in SPIE Conf. Ser. 4841, eds. M. Iye, & A. F. M. Moorwood, 1682 [Google Scholar]
- Piskunov, N. E., Kupka, F., Ryabchikova, T. A., Weiss, W. W., & Jeffery, C. S. 1995, A&AS, 112, 525 [NASA ADS] [Google Scholar]
- Press, W. H., Teukolsky, S. A., Vetterling, W. T., & Flannery, B. P. 1992, Numerical recipes in FORTRAN. The art of scientific computing (Cambridge University Press) [Google Scholar]
- R Development Core Team 2013, R: A Language and Environment for Statistical Computing [Google Scholar]
- Ramírez, I., & Meléndez, J. 2005, ApJ, 626, 465 [NASA ADS] [CrossRef] [Google Scholar]
- Richard, O., Michaud, G., & Richer, J. 2005, ApJ, 619, 538 [NASA ADS] [CrossRef] [Google Scholar]
- Sbordone, L., Salaris, M., Weiss, A., & Cassisi, S. 2011, A&A, 534, A9 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Spite, F., & Spite, M. 1982, A&A, 115, 357 [NASA ADS] [Google Scholar]
- Steinhaus, H. 1956, Bull. Acad. Polon. Sci., 4 [Google Scholar]
- Valenti, J. A., & Fischer, D. A. 2005, ApJS, 159, 141 [NASA ADS] [CrossRef] [MathSciNet] [Google Scholar]
- Valenti, J. A., & Piskunov, N. 1996, A&AS, 118, 595 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Vesperini, E., McMillan, S. L. W., D’Antona, F., & D’Ercole, A. 2013, MNRAS, 429, 1913 [NASA ADS] [CrossRef] [Google Scholar]
- Yong, D., Grundahl, F., Johnson, J. A., & Asplund, M. 2008, ApJ, 684, 1159 [NASA ADS] [CrossRef] [Google Scholar]
- Yong, D., Meléndez, J., Grundahl, F., et al. 2013, MNRAS, 434, 3542 [NASA ADS] [CrossRef] [Google Scholar]
- Zloczewski, K., Kaluzny, J., Rozyczka, M., Krzeminski, W., & Mazur, B. 2012, Acta Astron., 62, 357 [NASA ADS] [Google Scholar]
All Tables
Average abundances and dispersions of Sc, Cr, Ni and Fe for the subsample of bRGB stars (Teff< 5450 K).
Light-element abundances and abundance ratios, compared to photometric population assignments.
All Figures
|
Fig. 1 Observed colour-magnitude diagram of NGC 6752. The spectroscopic targets are marked by black squares for the GIRAFFE sample. For comparison we have included the UVES targets from Gruyters et al. (2013) as red diamonds. |
| In the text | |
|
Fig. 2 Weighted standard deviations and biases of the weighted means as determined from weak lines analysed in Monte Carlo tests on synthetic spectra. |
| In the text | |
|
Fig. 3 Evolutionary abundance trends of Mg, Ca, Ti, and Fe. Mg and Ca abundances are derived from neutral lines while Ti and Fe are derived from singly ionised lines (see Table 6). The solid (green) line represents the running mean (weighted average), while dashed (blue) lines represent the standard deviation. Error bars represent statistical errors. Systematic errors are indicated in Fig. 10. Overplotted in diamonds are the UVES results from Paper I, which have been vertically shifted for easier comparison. |
| In the text | |
|
Fig. 4 Evolutionary abundance trends of Na, Mg, Al, and Si. The different coloured symbols correspond to the chemical populations deduced from a photometric cluster analysis (see text). |
| In the text | |
|
Fig. 5 Anticorrelations between sodium, magnesium and aluminium. Different coloured symbols correspond to the chemical populations deduced from a photometric cluster analysis (see text). The faintest (V> 16.8) stars have been excluded from this comparison. |
| In the text | |
|
Fig. 6 CMDs in (u − v) (upper left), (u − b) (upper right), δ4 (lower left), and cy (lower right). The solid lines represent the fiducial sequences from which distances (residuals) are used in the cluster analysis. Different coloured symbols correspond to the chemical populations deduced from a cluster analysis. |
| In the text | |
|
Fig. 7 CMDs in (u − v) (upper left), (u − b) (upper right), δ4 (lower left), and cy (lower right). The solid (blue) lines represent the fiducial sequences from which distances (residuals) are used in the cluster analysis. Blue diamonds indicate points between which the sequence has been interpolated. Yellow squares represent the selected stars for the cluster analysis. |
| In the text | |
|
Fig. 8 Left: cumulative radial distribution of the different populations as a function of distance from the cluster center. Right: spatial distribution of the stars in NGC 6752. The different symbols represent the populations as deduced from the cluster analysis. The black triangle marks the cluster center. |
| In the text | |
|
Fig. 9 Radial distributions of the ratio of primordial stars to extreme stars as a function of the distance from the cluster center. The diamonds give the mean value of the radial bin whose range is indicated by the horizontal bar through the symbol. The dotted vertical line gives the half-mass radius of the cluster. |
| In the text | |
|
Fig. 10 Averaged abundance trends from Fig. 3 (green bullets), compared to the predictions from stellar structure models including atomic diffusion with additional mixing with two different efficiencies, at an age of 13.5 Gyr. Horizontal, dashed lines represent the initial abundances of the models, which have been adjusted so that predictions match the observed abundance level of the coolest stars. The groups of three arrows in each panel indicate the influence on averaged abundances from increasing the effective temperature by 40 K (left), surface gravity by 0.1 dex (middle) and microturbulence by 0.1 km s-1 (right) – see also Table 5. |
| In the text | |
|
Fig. 11 Observed lithium abundances (coloured symbols as in Fig. 4), compared to stellar evolution model predictions for two different efficiencies of AddMix (see text). The initial abundance of the models (horizontal dashed line and shaded region), log ε(Li) = 2.53 ± 0.10, compares well to the predicted primordial lithium abundance (dotted horizontal line and shaded region), log ε(Li) = 2.69 ± 0.04. |
| In the text | |
|
Fig. 12 Initial abundances (corrected for atomic diffusion and dredge-up) of lithium, compared to the anticorrelation elements magnesium (left), sodium (middle) and aluminium (right). The dotted line and shaded region refer to the predicted primordial abundance based on the CMB-calibrated BBN predictions (see text). The faintest (V> 16.8) stars have been excluded from the comparison. Different coloured symbols correspond to the chemical populations deduced from the cluster analysis. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.