| Issue |
A&A
Volume 694, February 2025
|
|
|---|---|---|
| Article Number | A228 | |
| Number of page(s) | 14 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202452224 | |
| Published online | 18 February 2025 | |
Breaking the degeneracy in stellar spectral classification from single wide-band images
1
Université Paris-Saclay, Université Paris Cité, CEA, CNRS, AIM,
91191
Gif-sur-Yvette,
France
2
Institutes of Computer Science and Astrophysics, Foundation for Research and Technology Hellas (FORTH),
Greece
3
IRFU, CEA, Université Paris-Saclay,
91191
Gif-sur-Yvette,
France
4
IMT Atlantique, École Mines-Télécom,
Bretagne-Pays de la Loire,
France
★ Corresponding author; ezequiel.centofanti@cea.fr
Received:
12
September
2024
Accepted:
16
December
2024
The spectral energy distribution (SED) of observed stars in wide-field images is crucial for chromatic point spread function (PSF) modelling methods, which use unresolved stars as integrated spectral samples of the PSF across the field of view. This is particularly important for weak gravitational lensing studies, where precise PSF modelling is essential to get accurate shear measurements. Previous research has demonstrated that the SED of stars can be inferred from low-resolution observations using machine-learning classification algorithms. However, a degeneracy exists between the PSF size, which can vary significantly across the field of view, and the spectral type of stars, leading to strong limitations of such methods. We propose a new SED classification method that incorporates stellar spectral information by using a preliminary PSF model, thereby breaking this degeneracy and enhancing the classification accuracy. Our method involves calculating a set of similarity features between an observed star and a preliminary PSF model at different wavelengths and applying a support vector machine to these similarity features to classify the observed star into a specific stellar class. The proposed approach achieves a 91% top-two accuracy, surpassing machine-learning methods that do not consider the spectral variation of the PSF. Additionally, we examined the impact of PSF modelling errors on the spectral classification accuracy.
Key words: techniques: image processing / stars: general
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. Subscribe to A&A to support open access publication.
1 Introduction
Significant efforts have been made in recent decades to study the stars in our galaxy in detail. For this purpose, several spectroscopic surveys have been carried out, which provide very high-resolution catalogues of stellar spectra (Bagnulo et al. 2003; Baranne et al. 1996; Pickles 1998; Sánchez-Blázquez et al. 2006; Valdes et al. 2004). Stars are generally categorised according to the Morgan-Keenan (MK) system (Morgan et al. 1943). This system segments stars in descending order of temperature, with O-type stars being the hottest and M-type stars the coolest. Each of these stellar classes has a distinctive spectrum, the main characteristics of which are shared between stars of the same class. Stellar classification is crucial for studying the composition of stars and their properties, and for understanding the evolution of the galactic stellar population. One particularly interesting case where stellar spectra play a significant role is in modelling the instrumental response of wide-field, single-band telescopes.
Current space telescopes such as Euclid (Euclid Collaboration: Mellier et al. 2025; Laureijs et al. 2011) or upcoming telescopes such as the Nancy Grace Roman space telescope (Akeson et al. 2019; Spergel et al. 2015) and the Vera C. Rubin Observatory (Ivezic et al. 2019; LSST Science Collaboration 2009) will observe the Universe with unprecedented accuracy and coverage, providing vast amounts of data in the coming decades that will drive cosmology forward and enable new discoveries to be made. Given their depth and coverage, these surveys will be able to examine the large-scale structure of the late-time Universe using statistical probes, such as Weak gravitational Lensing (WL). The WL signal is measured by correlating the shape and orientation of large numbers of galaxies. The apparent shape of the observed galaxies is corrupted by the instrumental response of the telescope, which directly limits the quality of the measured WL signal (Massey et al. 2012). Hence, an accurate model of the point spread function (PSF), that is, the instrumental response of the optical system, is a fundamental requirement for obtaining unbiased and competitive constraints on cosmological parameters. Cutting-edge space telescopes have such low aberrations that the instrumental response is diffraction limited and is mainly driven by the optical system (Euclid Collaboration: Cropper et al. 2025). Even so, in addition to having a spatial and temporal dependence, the PSF is also strongly wavelength-dependent, which is particularly challenging for wide single-passband instruments. Most PSF modelling methods (for a review see e.g. Liaudat et al. 2023b), in particular data-driven methods, such as PSFEx (Bertin 2011), RCA (Ngolè et al. 2016), MCCD (Liaudat et al. 2021), and WaveDiff (Liaudat et al. 2023a), make use of observations of unresolved stars to sample the underlying instrumental response of the telescope. These samples allow the PSF model to be constrained at various positions in the field of view (FOV). Chromatic PSF models (e.g. Liaudat et al. 2023a) additionally require knowledge of the SED of the stars that are used to fit the model to account for the spectral dependence of the PSF of Euclid-like (i.e. optical single-band wide-field) telescopes.
Given the temporal variation caused by temperature fluctuations and the resulting mechanical stress on the optical system of space telescopes, the PSF model has to be recalibrated for each individual exposure using only the unresolved stars present in that exposure. Additionally, stellar spectra are typically measured for a small number of stars (at most several hundred), which is largely insufficient for chromatic PSF modelling. Astrometric missions, such as GAIA (Gaia Collaboration 2016; Perryman et al. 2001), can provide spectral information for a considerably larger number of stars, albeit at a lower spectral resolution. Nevertheless, these complementary surveys will only measure the brightest stars in the FOV of a Euclid-like exposure. Therefore, the availability of spectral information for the observed stars is a limiting factor in the estimation of data-driven chromatic PSF models.
Stellar classification from photometric observations provides a way to increase the number of available stars for PSF modelling. There are numerous methods to classify stellar spectra with spectroscopic data, such as in Sharma et al. (2019) and Chaini et al. (2023). Other studies, such as Yang & Li (2024), propose classification from multi-band photometric observations. Previous work by Kuntzer et al. (2016) introduced a stellar classifier that assigns spectral templates to single-band star observations. Their method is based on a principal component analysis (PCA) decomposition of the observed stars followed by a fully connected neural network classifier. Each star to be classified is projected onto the PCA feature space and the associated coefficients are fed into a multi-layer perceptron (MLP) network (Bishop 1995). The MLP classifies the coefficients into a given stellar class, assigning a specific spectral template to the observation. Their work demonstrated that it is possible to perform stellar classification with single wide-band star images. However, the methodology they propose does not account for the degeneracy between the size of the PSF and the spectral type of the star. This degeneracy (detailed in Sect. 4) refers to the fact that stars at different positions in the sky with different stellar types can have very similar image properties (i.e. size and shape) due to variations in the PSF across the field of view. As the classification method only has access to the image properties, there is an inherent limitation in the accuracy that can be achieved.
In this work, we consider stellar classification from singleband photometric images for a Euclid-like survey. We propose a stellar spectral classification method from single-band star observations that takes into account the PSF spectral variation by using a preliminary PSF model, thus breaking the degeneracy between the size of the PSF and the spectral type of the star. We only consider the WaveDiff PSF model since it is the sole data-driven model that accounts for the chromatic variation of the PSF. Firstly, we apply the PCA+MLP classification method introduced by Kuntzer et al. (2016) to Euclid-like simulated stellar images to establish a baseline for comparison. Secondly, we introduce a modified version of their method, where the PCA decomposition is replaced by a convolutional neural network (CNN) that takes the single-band stellar image pixels and outputs a feature vector, which is then similarly fed into an MLP network that assigns the stellar type. Finally, we introduce our new PSF-aware classification method and compare it to the previous solutions. The structure of this paper is the following: in Sect. 2 we describe stellar observations in the context of PSF modelling, in Sect. 3 we introduce the pixel-only stellar classification algorithms, in Sect. 4 we present the PSF-aware classification method, in Sect. 5 we explain the simulated star observations and the PSF modelling details, in Sect. 6 we show the results of the classification methods and finally, Sect. 7 summarises this work and outlines future steps that could be taken.
Notation. In this paper, we adopt the notation for PSF modelling and astronomical imaging defined in Liaudat et al. (2023b). A summary of the chosen notation can be found in Table A.1.
Terminology. In this article, the terms polychromatic PSF or PSF sample are equivalent to a star observation (or simulation) since they include the spectral information of the star. The term PSF by itself refers to the underlying instrumental response of the instrument or a simulated PSF model, a function of the FOV coordinates and the wavelength. A monochromatic PSF is the PSF model evaluated at a single wavelength for a specific FOV position. The wavefront error (WFE) is the phase difference between the incoming light wavefront and an ideal hemispherical wavefront at the pupil plane of the optical system.
2 Stellar image model
PSF modelling for Euclid-like telescopes involves several key challenges. First, the observations are integrated over the passband of the telescope (i.e. single-band or polychromatic observations), thus blending the spectral variation of the PSF with the SED of the star. Second, the observation is subsampled on the detector (High et al. 2007; Lauer 1999) and contains observational noise that encompasses thermal noise, readout noise (Basden et al. 2004), and dark-current shot noise (Baer 2006). Finally, the number of stars for which the SED is known is very limited (Gillis et al. 2020). Thus, PSF modelling from low- resolution star observations proves to be a challenging task that would benefit from an increase in spectral information (SEDs) of distant stars in the FOV.
Distant stars can be considered as point sources whose intensity varies with wavelength according to the SED of each star. The observational model of a distant star at the position (ui, vi) in the FOV is as follows
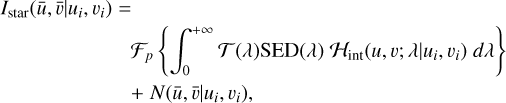 (1)
(1)
where 𝓗int(u, v; λ|ui, vi) is the PSF of the telescope with its centre at the position of the star1. The PSF is positively valued and has two spatial coordinates (u, v) and one spectral coordinate λ. The PSF sample is integrated over the passband of the telescope, given by the transmission function 𝒯(λ), together with the SED of the star. The 𝓕p operator is a discretisation function that models the pixelisation of the detector (sampling) and N represents the observational noise. The observed image Istar, with pixel coordinates 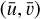 , is a single-band discrete version of the star corrupted by the PSF of the telescope and the observational noise.
, is a single-band discrete version of the star corrupted by the PSF of the telescope and the observational noise.
Measuring stellar spectra to high precision is a challenging task that can only be carried out for a limited number of stars, generally reserved for the brightest stars in the FOV. Deep and wide space-based optical surveys can observe hundreds to thousands of unresolved stars in one exposure (Laureijs et al. 2011). However, only a fraction of the observed stars will have complementary SED information from spectroscopic surveys. Thus, estimating the spectra of the remaining stars is crucial for improving PSF modelling and maximising the scientific returns of these observations.
Equation (1) describes the observational model of an unresolved star. The PSF of a telescope at the position of the star in the FOV is integrated alongside the SED of the given star. Thus, the observation is directly affected by the spectrum of the star. O-type stars, being hotter and bluer, have higher flux at shorter wavelengths. Conversely, M-type stars, being cooler and redder, have a higher flux at longer wavelengths. The fact that the PSF has a chromatic variation allows some of the spectral information of the stars to permeate into the observations, meaning that different types of stars at the same position in the FOV will produce different observations. Hence, a spectral classification of stars from their polychromatic (wavelength integrated or single-band) observations is physically supported.
3 Star classification from a single wide band
In the following, we present some methods of stellar classification from single wide-band star observations. The objective of these classification methods is to assign SED templates to the stars without spectral information using the pixels in the corresponding postage stamps. For all of the methods, we assume a scenario in which, given an exposure of a Euclid-like telescope, source detection is performed with a tool, such as SExtractor (Bertin & Arnouts 1996), SFIND (Hopkins et al. 2002) or IMSAD (Sault et al. 1995). Then, these sources are efficiently classified as stars or galaxies, and postage stamps are extracted at the positions of the stars. For the purpose of this work, sources of contamination in the star selection such as galaxies, binaries, or other misclassifications are not considered. We expect only small fraction of the detected stars to have spectral information (SEDs) available from complementary measurements.
3.1 PCA MLP
The method proposed by Kuntzer et al. (2016) can be separated into two steps: the preprocessing of the input data and the actual spectral classification. The first step aims to extract relevant structure from the observations by compressing the input into a reduced number of coefficients. This is done by applying PCA to project the input onto 24 orthogonal components (i.e. the PCA coefficients). The second step implements a fully connected MLP neural network (Bishop 1995) classifier that takes as input the 24 PCA coefficients associated with the star image to be classified, and outputs the predicted spectral class among the 13 spectral classes considered (Pickles 1998). We implemented this method from scratch2 and adapted it to our synthetic star observations (see Sect. 5). We use 10 000 simulated stars to obtain the PCA components and train the MLP classifier. We present the first seven PCA components as well as the dataset mean in the top panel a of Figure 1. In the bottom panel b, we show a star observation and its reconstruction from the first 24 PCA components. The relative values of the 24 coefficients are shown in the last figure in the lower panel. The reconstruction maintains the overall shape of the observed star filtering out the high frequency variations. In other words, the observation is denoised. This process significantly reduces the size of the data, compressing the 32 × 32 px images (1024 pixels) into 24 coefficients. As in Kuntzer et al. (2016), we train a committee of 48 networks from which we compute the ensemble average of the predictions, allowing us to obtain a more robust classification. Each MLP classifier has two hidden layers of 26 nodes each.
 |
Fig. 1 PCA decomposition of input stars. (a) First seven PCA components and PCA mean. (b) Original star observation and its reconstruction from the first 24 PCA components. The last figure in the lower panel shows the relative values of the coefficients associated with the 24 PCA components. |
 |
Fig. 2 CNN+MLP model diagram. In light blue, the convolutional blocks. In yellow, the multi-layer perceptron classifier. |
3.2 CNN MLP
Convolutional neural networks (Krizhevsky et al. 2012; LeCun et al. 1989) are widely used for recognising structure in twodimensional data and have been widely applied to astronomical data (Akhaury et al. 2022; Farrens et al. 2022; Schaefer et al. 2018; Schuldt et al. 2021). It has been shown that the first convolutional filters of properly trained CNNs resemble classical image processing filters (Zeiler et al. 2011; Zeiler & Fergus 2013), and are able to identify patterns and the multi-scale structure of images. Auto-encoder networks (Baldi 2012; Kramer 1991) extract relevant features of the data, encoding the input into a reduced number of values. In a similar approach, we propose to replace the PCA preprocessing step in the Kuntzer et al. (2016) approach with an encoder-like CNN network, keeping the same two-step process: preprocessing and classification.
Figure 2 shows the proposed architecture for the classifier. The first layer centre-crops the star observations to get rid of pixels that only contain noise, reducing the size of the input. Then, the cropped image passes through six convolutional layers. Each layer has 32 channels and gradually reduces the width and height of the data. The convolutional kernel size is 3 × 3, thus reducing the data dimension by 2 pixels per layer. The last convolutional layer kernel size is 2 × 2 given the size of the input data in this layer. The output of the last convolutional layer is a 32-dimensional vector that encodes the main structural features of the input. These features are fed into a multi-layer perceptron with two hidden layers of 32 neurons each and an output layer of 13 neurons that correspond to the 13 stellar classes. Every layer (CNN and MLP) uses a ReLU activation function, except for the output layer which has a softmax activation function. This activation function enforces the output to be a probability vector, that is, the i-th element of the output vector represents the probability that the input belongs to the i-th stellar class. We compare the performance of these two pixel-only classification methods on simulated data in Sect. 6.
 |
Fig. 3 Ilustrative example of the degeneracy between the PSF size and spectral type of stars. (a) Middle rows: monochromatic PSFs for two positions in the FOV. The PSFs are shown for eight equally spaced wavelength values. Top and bottom: eight-bin spectral energy distribution of two stars, a M5 star (top) and an O5 star (bottom), located at positions 1 and 2 respectively. The wavelength axis is shared between all rows. (b) Observation of the respective stars. |
4 Breaking the degeneracy
A significant challenge for the methods described in Sect. 3 is the degeneracy between the PSF size and the spectral type of the star. This degeneracy is not addressed since these methods rely solely on the star image pixels for the classification, and do not include any information on the underlying PSF model corresponding to the observations. As a result, this degeneracy sets a cap on the classification accuracy of these types of methods. To illustrate this issue, consider the example shown in Fig. 3. The left-hand side (a) of the figure presents two different monochromatic PSFs (PSF1 and PSF2) at two different positions in the FOV. The chromatic variation of the PSFs is shown for eight different equally spaced wavelength values. Suppose that in each FOV position we observe an unresolved star. At FOV position 1 (top half of the figure) a M5-type (red) star is observed, whose eight-bin SED is shown in the top panel. At FOV position 2 (bottom half of the figure) an O5-type (blue) star is found, with its corresponding eight-bin SED in the bottom panel. According to a discrete version of Eq. (1), where the integral is approximated by a summation, the star observations are the sum of the monochromatic PSFs weighted by the corresponding SED values (see Eq. (2)). The fact that PSF1 at long wavelengths is similar in size to PSF2 at shorter wavelengths produces observations of similarly shaped stars, even if they correspond to completely different stellar types. The right-hand side of the figure (b) shows the corresponding observed stars. The observed star at position 2 has a similar, if not larger, size than star at position 1. In principle, we would associate a larger shape with a redder (M-type) star3, which is the opposite of what is shown in this example.
This example highlights that it is very difficult, if not improbable, to make a highly accurate spectral classification of stars from single-band observations alone. While many stars can be correctly classified, the confusion introduced by this degeneracy can only be overcome if the spatial and spectral variation of the PSF are considered along with the single-band observations. Two key issues must be considered in this regard. On the one hand, we need to know with a good level of precision the PSF (including its spatial and spectral variations) of the telescope with which the observations are obtained. On the other hand, we have to come up with an architecture capable of taking as input both the star observation and the approximate PSF model at the corresponding star position. We elaborate on these two issues in the following subsections.
4.1 Approximate PSF model
To generate the simulated observations (see Sect. 5) we model a ground truth (GT) PSF representing the instrumental response of the telescope. This GT model is assumed to be completely unknown when processing the simulated observations (i.e. performing the classification). To obtain an approximation of this GT model we have to fit a PSF model to the simulated observations. The approximate PSF model 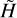 is estimated with a reduced number of observations since the SEDs are not available for all the observed stars prior to the stellar classification. In this work, we use the WaveDiff PSF modelling software (Liaudat et al. 2023a). Details about the WaveDiff PSF model can be found in Appendix C.
is estimated with a reduced number of observations since the SEDs are not available for all the observed stars prior to the stellar classification. In this work, we use the WaveDiff PSF modelling software (Liaudat et al. 2023a). Details about the WaveDiff PSF model can be found in Appendix C.
4.2 Similarity features
There are many ways in which one could envision adapting the classification models already presented to take into account the PSF. Our approach is perhaps the simplest and is based on the approximate star observation model, where the integral in Equation (1) is approximated by the sum of the monochromatic PSFs weighted by the SED of the star
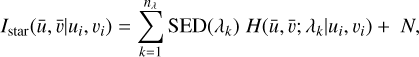 (2)
(2)
where nλ is the number of wavelength bins centred at λk. We can expand this summation for each bin as follows
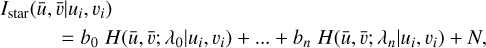 (3)
(3)
where 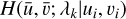 are the monochromatic PSFs (i.e. evaluated at a single wavelength) at the position of the star and bk are the SED values. We use the approximate PSF model
are the monochromatic PSFs (i.e. evaluated at a single wavelength) at the position of the star and bk are the SED values. We use the approximate PSF model 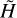 , evaluated at the position of the star, to compute a similarity metric, referred to as similarity features (SF), for each wavelength λk by comparing the approximate monochromatic PSFs with the observation,
, evaluated at the position of the star, to compute a similarity metric, referred to as similarity features (SF), for each wavelength λk by comparing the approximate monochromatic PSFs with the observation,
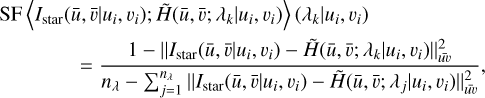 (4)
(4)
where 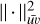 is the Frobenius matrix squared norm over the image pixels,
is the Frobenius matrix squared norm over the image pixels,
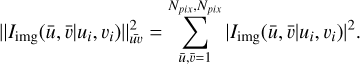 (5)
(5)
The resulting similarity features serve as a proxy for the SED values bk . Therefore, we expect higher similarity in the bins that contributed the most to the star observation, that is, to the weighted sum of monochromatic PSFs (Eq. (3)).
Figure 4 shows the similarity features, coloured according to the corresponding stellar class, of the full classification dataset (10000 simulated stars) using the ground truth PSF model. The visible distinction between the curves for each stellar type demonstrates a clear correlation between spectral type and similarity features. This strongly suggests that the similarity metric extracts relevant spectral information from the single-band observations. The dispersion in the similarity feature distribution (Fig. 4) for stars of the same spectral class is driven by the spectral variation of the PSF for each star, and more specifically how alike the monochromatic PSFs are to each other at that position in the FOV.
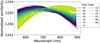 |
Fig. 4 Normalised similarity features as a function of monochromatic PSF wavelength for the 10000 stars. Each set of features is coloured according to the corresponding observation stellar type. |
4.3 SVM classifier
We use the similarity features as the input to our SED classifier. This greatly reduces the complexity of the classifier and thus the computational needs for training and inference. We use the C-Support Vector Classification model from the sklearn.svm (Pedregosa et al. 2018) Python library. This algorithm allows us to find optimal boundaries in the nλ-dimensional similarity feature space for classifying the data into the 13 stellar classes. If the data are linearly separable, the algorithm finds optimal separating hyperplanes by maximising the distance from the nearest data points of each class to the given hyperplane. When the data are not linearly separable, kernel transformations are used to map the data points onto a higher dimensional space where they can be separated by hyperplanes.
We use radial basis functio (RBF) kernels, also known as Gaussian kernels, which tend to cluster close points (with respect to the Euclidean distance) to the same class. This is based on the fact that we consider that the distribution of similarity features is directly related to the SED and therefore the same types of stars will have comparable similarity features.
5 Simulated data
To simulate synthetic star observations we use the WaveDiff4 PSF model. WaveDiff provides a wavefront-based parametric PSF simulator that addresses the spectral and spatial dependence of the PSF across the FOV. This makes it possible to evaluate the PSF model at any desired wavelength, for any arbitrary position in the FOV. See Appendix C for details on WaveDiff PSF modelling. With the WaveDiff PSF simulator we can simulate observations of distant stars at any position in the FOV. To do so, we approximate the integral in Eq. (1) by Eq. (2). We note that the SED of the star and the simulated PSF of the telescope are discretised in this approximation. In the following paragraphs we provide further details regarding the PSF model and the selection of SEDs and stellar types.
5.1 WaveDiff PSF simulator
Figure 5 shows different components of the PSF simulator: the WFE, the monochromatic PSFs, and the star observations (with and without noise). First, the WFE for a random position in the FOV is shown in the first column of the top panel. Then, eight monochromatic PSFs computed from the aforementioned WFE are shown in the bottom panel. Finally, the middle and righthand side columns of the top panel show an example of a star observation with and without added noise.
The noise is modelled pixel-wise by an additive independent Gaussian random variable of zero mean and standard deviation σS/N. The total amount of noise added to a simulated observation depends on the desired signal-to-noise ratio S /N (defined as Liaudat et al. 2023a) as follows,
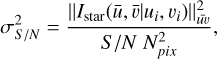 (6)
(6)
where Npix is the stamp size (width and height) of the simulated star observations and 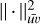 is the Frobenius matrix squared norm as defined in Eq. (5).
is the Frobenius matrix squared norm as defined in Eq. (5).
 |
Fig. 5 WaveDiff simulations. (a) Wavefront error, noiseless star observation, and noisy star observation at a particular position in the FOV for a simulated PSF field. (b) Monochromatic PSFs for multiple wavelength values. |
5.2 SED templates
The PSF simulator allows us to obtain monochromatic PSFs from the simulated WFE at any position in the FOV. To simulate a stellar observation, we sum the monochromatic PSFs over the wavelength weighted by the SED of the star as described by Eq. (2). Therefore, we need the spectral information of the stars. For this, we use 13 SED templates from Pickles (1998) corresponding to the following star types: O5, B0, B5, A0, A5, F0, F5, G0, G5, K0, K5, M0, and M5. The spectra are limited to the passband of the Euclid VIS instrument (Euclid Collaboration: Cropper et al. 2025), from 550 to 900 nm, to simulate Euclid - like star observations. In Fig. 6, we present the flux-normalised spectrum template fstar(λ) for each stellar type. To obtain the observed star simulation as described in Eq. (2), we compute the discrete SED of the star by integrating the spectrum over nλ regular wavelength bins bk, matching the number of monochromatic PSFs. The centre of each bin corresponds to the wavelength of each monochromatic PSF. The bins, of size ∆bk are computed as follows,
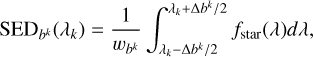 (7)
(7)
where 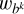 normalises the bin such that
normalises the bin such that 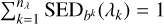 .
.
 |
Fig. 6 Spectral templates for the 13 stellar classes taken from Pickles (1998). Spectra are limited to a Euclid-like passband [550–900] nm, with a resolution of 1 nm. Spectra are flux normalised to unit sum. |
5.3 Simulation parameters
The simulations used in this work are built from a random realisation of a WaveDiff PSF field, mainly governed by the following parameters: nZ, the maximum Zernike order in the WFE representation; dmax, the degree of the polynomial variation of the Zernike coefficients Ck(x,y) across the FOV; nλ, the number of spectral bins, which corresponds to the number of monochromatic PSFs and SED bins; and S /N, the signal-tonoise-ratio range for the stellar observations. The selection of these parameters depends mainly on the telescope that is taken as a reference for simulating the PSF and corresponding observations. The trade-off between the closeness of the simulations to real observations, and the available memory resources and computing power is also taken into consideration. We consider for the WFE a maximum Zernike order dZ = 45 and a polynomial spatial variation of its coefficients of degree dmax = 4. The number of spectral bins to be used is limited by the computational resources and the resolution of the available SEDs. For each wavelength value of the SED, the monochromatic PSF must be computed. Therefore, a larger number of bins requires a linear increase in time and memory resources. However, a larger number of bins allows for more realistic simulations, thereby making Eq. (2) a closer approximation to Eq. (1). Simulated observations are generated with eight spectral bins to speed up the computation time for both the generation of the observations and the training of the PSF models. For the results shown in the following sections, we consider that eight bins are sufficient to capture the spectral information of the star in the single-band simulated observation. Furthermore, Fig. 4 demonstrates a clear visual separation of spectral classes based on the computed similarity features, further supporting that eight spectral bins provide sufficient resolution for our simulations. Finally, we vary the additive noise level for each simulated star so that the signal-to-noise ratio falls in the range [20–110], which corresponds to the standard deviation of the Gaussian additive noise σ falling approximately in the range (10−3; 2 × 10−3). The pre-noise observations produced by WaveDiff are flux-normalised to one (i.e. the sum of the pixels is equal to one). Table 1 summarises the values selected for the simulation parameters, as well as other relevant features of the simulations. The parameters concerning the dimensions and optics of the telescope and its characteristics, such as focal length, aperture radius, obscurations, passband, etc., are set as in Liaudat et al. (2023a) considering a Euclid-like telescope.
6 Experiments
Using the WaveDiff PSF simulator we generate a total of 13 000 star observations from a single ground truth PSF model.
The star positions (ui, vi) are selected randomly over the FOV with a uniform distribution. The associated SED for each simulated observation is chosen randomly from the 13 spectral classes Ci . The choice of a flat stellar type distribution is intended to mitigate any classification bias due to sample imbalance. Figure 7 summarises all the models and simulation tools presented in this article. Star observation images are directly used to train (10 000 stars) and test (1000 stars) the pixel-only classification models (PCA+MLP and CNN+MLP). The remaining 2000 stars are divided into six nested datasets used to train six approximate PSF models, which are tested with the 1000 test stars. We compute the monochromatic PSFs for every approximate PSF model at every star position in the FOV and we use them to compute the similarity features for the PSF-aware model.
In this section, we present the classification results for each method. First, we define the metrics used to compare the models. Then, we show the classification results of the pixel- only algorithms, validating Kuntzer et al. (2016) results and contrasting them with our CNN approach. Finally, we present the performance of our novel PSF-aware classification method.
 |
Fig. 7 Project workflow: 13 000 star observations were simulated with the WaveDiff PSF simulator. Each star observation is located at a particular FOV position (ui, vi), has a random noise level S /N and belongs to a spectral class Ci. 10000 stars are directly used for training the pixel-only classification models, and 1000 stars to test them. 2000 stars are used to optimise the approximate PSF models required to calculate similarity features. The quality of the PSF models is evaluated with the 1000 test stars. Once the train and test similarity features have been computed, the PSF-aware stellar classifier is trained with 10 000 stars and tested with 1000 stars. |
WaveDiff simulation parameters.
6.1 Classification metrics
To assess the performance of multi-class classification tasks, there exists a large variety of metrics, such as F-score, precision, recall, accuracy, cross entropy, etc. (Grandini et al. 2020).
Many of these metrics are based on the confusion matrix (CM); we will therefore devote special attention to it.
6.1.1 Confusion matrix
The CM is a cross table that for each available class enumerates the number of assignments to the output classes. Each row of the table corresponds to the predicted labels 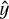 for a specific class Ci of the input data. The diagonal of the table, or matrix, shows the number of correctly classified elements per class
for a specific class Ci of the input data. The diagonal of the table, or matrix, shows the number of correctly classified elements per class 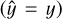 . Formally, the elements of the CM are defined as follows,
. Formally, the elements of the CM are defined as follows,
![${\rm{C}}{{\rm{M}}_{ij}} = \sum\limits_{x \in {{\cal C}_i}} 1 [\hat y = i],$](/articles/aa/full_html/2025/02/aa52224-24/aa52224-24-eq18.png) (8)
(8)
where 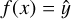 is the predicted class for the element x.
is the predicted class for the element x.
6.1.2 Precision, recall, & F1-score
Precision and recall are the main building blocks of binary classification metrics. In binary classification, precision is the fraction of correctly retrieved elements (true positives) and the total number of retrieved (claimed positives, that is true positives plus false positives) instances; and recall is the ratio between the true positives and the total number of relevant elements.
 (9)
(9)
The F1-score is widely used in binary classification because it leverages the number of correctly detected instances, true positives (TP) and true negatives (TN), and the number of missed instances, false positives (FP) and false negatives (FN). The F1-score is the harmonic mean of precision and recall,
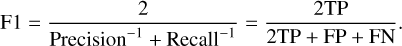 (10)
(10)
The precision and recall, and thus the F1-score, can be generalised to multi-class classification by computing them class by class in an one-vs-all scenario, and then averaging over every class.
6.1.3 Accuracy
Another relevant multi-class classification metric we consider is the accuracy, defined as the ratio between the number of correctly classified elements and the sample size. This metric is derived from the trace of the confusion matrix,
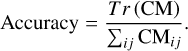 (11)
(11)
Given the proximity between neighbouring stellar types, which have a difference of half a spectral class, a top-two accuracy metric is considered. This is mainly motivated by the similarity between two spectra of neighbouring classes (see Fig. 6), which when discretised into 8 wavelength bins the difference between two neighbouring spectral classes lies in the range of the SEDs photometric measurement noise. The top-two accuracy allows for neighbouring stellar type misclassification. These cases are located on the super diagonal and sub diagonal of the CM, defining the top-two accuracy metric as follows,
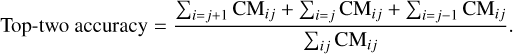 (12)
(12)
In Kuntzer et al. (2016), this metric is referred to as the success rate.
6.2 Pixel-only classification
We train, evaluate, and compare the pixel-only classification methods: PCA+MLP and CNN+MLP. Both methods were trained with the same dataset of 10 000 simulated star observations. We evaluate both methods on the 1000 test dataset using the aforementioned classification metrics. The results are presented in Table 2. Each row of the table corresponds to a different model, and the first two rows correspond to the pixel-only methods. The first column corresponds to the one-vs-all F1-score averaged over all the classes, the second column is the accuracy of each model, and the third one is the top-two accuracy.
We note that the metrics for the PCA+MLP method are consistent with those of Kuntzer et al. (2016). The performance of the model is slightly lower, but this is expected as the data we are using has a higher complexity in the spatial variation of the PSF, higher noise levels, and the total number of samples used for training is lower.
While using a convolutional network instead of the PCA decomposition uses state-of-the-art deep learning techniques and gives more flexibility to the extraction of spatial features, we do not observe a significant improvement in classification. We believe this is primarily due to the degeneracy between PSF and spectral type, which imposes a limit on the accuracy of pixel-only classification, regardless of which technique is used.
In addition to the metrics shown in Table 2, which are averaged across all stellar classes, we show the one-vs-all metrics for each class in Fig. 8. The exact values are detailed in Appendix D. We observe that the one-vs-all F1-score accuracy and top-two accuracy have a similar distribution for both the PCA+MLP model (in red dot-dashed line) and the CNN+MLP model (in violet dashed line). We note that these metrics are higher for the redder stars. This is expected when examining the spectra shown in Fig. 6. The figure demonstrates that the spectral differences between adjacent stellar types are larger for red stars (M-type) compared to blue stars (O-type). This is also consistent with the distribution of similarity features shown in Fig. 4, where we see that the red stars (and neighbouring types) have a similarity feature distribution that is easily distinguishable by eye from the other types.
Classification metrics for the PCA+MLP, CNN+MLP, and SVM+PSF models.
 |
Fig. 8 F1 score, accuracy, and top-two accuracy by stellar type for the PCA+MLP, CNN+MLP, and SVM+PSF models. The |
6.3 PSF-aware classification
Before training the PSF-aware stellar classifier, we compute the approximate PSF models with differently sized datasets. We present below the estimated PSF models and then the results of the PSF-aware stellar classifier.
 |
Fig. 9 Relative error at observation resolution for each approximate PSF model as a function of the number of training stars. The error bars represent the standard deviation of the relative errors of the stars in the test dataset. |
List of nested datasets with the corresponding number of stars.
6.3.1 Approximated PSF models
As mentioned in Sect. 4.1, we need to produce an approximate model of the PSF to compute the similarity features of each star, as the ground truth PSF is in principle unknown. We use WaveDiff to compute an approximate PSF model from the star observations. We employ 2000 simulated star observations for training the approximate PSF model. To assess various levels of PSF modelling uncertainty and analyse the impact on stellar SED classification, we subdivide the 2000 stars into six datasets with increasing number of stars, where each dataset is contained in the next 𝒮1 ⊂ 𝒮2 ⊂ … ⊂ 𝒮6. Since each star observation is a sample of the GT PSF, we expect that a larger number of stars will lead to a more accurate PSF model. We fit a WaveDiff PSF model 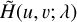 to each of the datasets listed in Table 3. Figure 9 shows the relative error of each PSF model as a function of the number of training stars contained in the dataset. The relative error is defined as
to each of the datasets listed in Table 3. Figure 9 shows the relative error of each PSF model as a function of the number of training stars contained in the dataset. The relative error is defined as
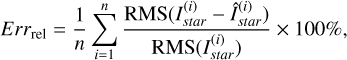 (13)
(13)
where Istar is the target PSF, Îstar is the predicted PSF, n is the total number of test stars and RMS(⋅) is the root mean square of a matrix as defined in Liaudat et al. (2023a). For each PSF model in Fig. 9 the relative error is averaged over the 1000 test stars. These six approximate PSF models provide the basis for computing the similarity features used in the classification algorithm. The resulting PSF relative error at observation resolution5 is around 2.5% for dataset 𝒮1 containing 50 stars, and 0.7% for dataset 𝒮6 containing 2000 stars. The relative error range of the PSF models is consistent with what is shown in Fig. 9 of Liaudat et al. (2023a) therefore we assume that we cover a sufficient range of PSF model accuracy for our analysis.
6.3.2 Classification results
With each approximated PSF model we evaluate the eight monochromatic PSFs, 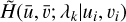 , at each star position (ui, vi) in the classification dataset. From the monochromatic PSFs and the star observations we compute the similarity features following Eq. (4). We fit the proposed SVM algorithm to the similarity features, independently for each dataset 𝒮, and make the predictions for each star in the test dataset. We also consider the scenario in which we have perfect knowledge of the PSF by using the ground truth PSF for computing the similarity features. This sets a baseline for the best possible performance of the PSF-aware classification method.
, at each star position (ui, vi) in the classification dataset. From the monochromatic PSFs and the star observations we compute the similarity features following Eq. (4). We fit the proposed SVM algorithm to the similarity features, independently for each dataset 𝒮, and make the predictions for each star in the test dataset. We also consider the scenario in which we have perfect knowledge of the PSF by using the ground truth PSF for computing the similarity features. This sets a baseline for the best possible performance of the PSF-aware classification method.
The classification accuracy and top-two accuracy are presented in Fig. 10. The detailed F1-score and accuracy values are provided in Table E.1. The PSF-aware method, SVM+PSF, outperforms both pixel-only classifiers (PCA+MLP and CNN+MLP) for every considered error level of the PSF. We obtain a 91% top-two accuracy with perfect knowledge of the PSF, and 76% top-two accuracy with the least precise PSF model we tested. We recall that this model was trained with only 50 stars in the FOV, which is much less than what we expect for a Euclid-like survey (Laureijs et al. 2011). In addition, we note that the approximate PSF model trained with the 2000 fiducial stars allows for a 89% top-two classification accuracy, which is very close to that obtained with the ground truth PSF model. Also, models trained with fewer stars (between 200 and 2000) lead to a similar classification performance. These approximate PSF models, although not accurate enough for weak-lensing analyses (Cropper et al. 2013; Massey et al. 2012; Paulin-Henriksson et al. 2008), are able to assist stellar classification methods by breaking the degeneracy between PSF size and spectral type, and outperforming pixel-only classification methods.
 |
Fig. 10 Accuracy (dashed blue line) and top-two accuracy (continuous blue line) metrics for the PSF-aware model (SVM+PSF) as a function of the PSF model error. In red and violet (horizontal lines), corresponding metrics for the pixel-only classification methods (PCA+MLP and CNN+MLP) are plotted as a reference. |
6.3.3 Improving the final PSF model
To demonstrate a potential application of our novel PSF-aware classifier we test how much of an impact additional stars with classified SEDs in a given FOV would have on improving the final PSF model. The aim is to extract more information from the observations and improve the quality of the PSF model.
Figure 11 shows a diagram of the proposed PSF improvement scenario. We assume a single Euclid-like wide-band exposure. A fraction of the unresolved stars present in this exposure have known SEDs from complementary measurements (in yellow) and the remaining do not (in blue). We propose to obtain an approximate PSF model from the stars with known SEDs. Then, to use this approximate PSF model with our PSF-aware classifier to assign SEDs to the remaining stars. Finally, we can attempt to improve the PSF model considering both the stars with measured SEDs and the ones with assigned SED templates. We expect the final PSF model to have a lower error as it uses more samples of the underlying PSF and the spatial distribution of the additional samples better captures the spatial variation of the PSF in the FOV.
As a proof of concept, we test the proposed PSF improvement scenario using a sample of 2050 simulated star observations. We train WaveDiff using 50 stars with GT SEDs and obtain an approximate PSF model with a relative error of 2.4% at observation resolution. We then use the approximate PSF in our PSF-aware classifier to assign SED templates to the remaining 2000 stars. For this purpose we employ an SVM classifier pre-trained on 8000 similarity feature samples. We obtain a classification accuracy of 41% and a top-two accuracy of 76%, which is consistent with the results presented in Sect. 6. Finally, the 2000 newly classified stars are used together with the original 50 stars to train new WaveDiff PSF models. We study how the PSF error varies as we increase the total number of training stars. Figure 12 shows the relative error, at observation resolution, of the PSF model as a function of the number of training stars. In dark yellow, we present the baseline relative error of the approximate PSF model (i.e. trained on the 50 stars with GT SEDs). The relative error of subsequent PSF models that use the additional sample of spectrally classified stars is plotted in blue. We show that, as we increase the number of stars with classified SEDs, the relative error of the PSF decreases. Using the full sample of 2000 spectrally classified stars, we achieve a relative error of 0.78%. This represents a PSF error reduction of almost 70%. Finally, the dotted line (in green) represents the relative error obtained by training the PSF model with 2000 stars and the corresponding GT SEDs (i.e. an idealised performance assuming unlimited spectroscopic counterparts) for comparison. The minimum error is 0.65%, only slightly lower than that obtained using the sample of stars with classified SEDs.
We emphasise that this is a highly idealised and simplified test case and significant work would still need to be carried out to conclusively demonstrate the applicability of this approach to real survey data. However, the initial results are promising and indicate that it may be possible to improve PSF modelling performance in single wide-band images by increasing the star sample with classified SED stars.
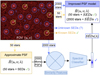 |
Fig. 11 PSF improvement scenario. The observed exposure contains 2050 stars, of which 50 have complementary spectral information (in yellow) and 2000 do not (in blue). An approximate PSF model is trained from 50 stars with known SEDs. The approximate PSF is used in the context of the PSF-aware classifier to spectrally classify the remaining 2000 stars. The classified stars are assigned a SED template and can be used to train an improved PSF model. |
 |
Fig. 12 Relative PSF error, at observation resolution, as a function of the number of training stars. The baseline is set to the performance of the approximate PSF trained with 50 stars and ground truth SEDs (dark yellow). The subsequent PSF models (blue points) are trained using the 50 baseline stars in addition to increasing numbers of stars with SEDs assigned by our PSF-aware classifier. The error bars represent the standard deviation of the relative errors of the test dataset. The green dashed line shows the idealised minimum relative PSF error that can be obtained when using 2000 stars with ground truth SEDs, and the green shaded area represents the standard deviation of the relative errors. |
7 Conclusions
The SED of observed stars is crucial for chromatic PSF modelling of wide-field single-band telescopes. However, SED measurements are often expensive and scarce for low-brightness stars, limiting the number of stars available for PSF modelling. A reliable spectral classification method using survey data could significantly benefit PSF modelling. Assigning SED templates to observed stars would increase the number of stars available for constraining the PSF model. This approach could enhance the accuracy of PSF modelling and, consequently, improve various astronomical studies, particularly weak gravitational lensing analysis.
In this paper, we propose a novel method for spectral classification from single wide-band observations of stars. This new method, referred to as the PSF-aware classifier, incorporates the spectral variation of an approximate PSF model of the telescope in order to break the degeneracy between the size of the PSF and the spectral type of stars. To evaluate the performance of our PSF-aware method, we compare it with pixel-only classifiers that rely solely on the star image pixel values. We implement and validate the results of the pixel-only classifier presented in Kuntzer et al. (2016) and propose an update based on a convolutional neural network. We find that the CNN method performs about the same as the Kuntzer et al. (2016) approach. We emphasise that these classifiers, since they use only the pixel values of the observed stars, do not address the degeneracy between the PSF size and the spectral type of the star. Consequently, we introduce the PSF-aware stellar classification method and address how the PSF modelling error impacts the spectral classification accuracy.
We show how the PSF-aware model breaks the aforementioned degeneracy, pushing the classification accuracy further and outperforming both pixel-only classification methods by around 10%. We obtain a top-two accuracy of 91% with the proposed model and perfect knowledge of the PSF. We also study how the level of fidelity of the PSF model impacts the classification metrics, resulting in a top-two accuracy of 87% with a PSF model trained with 500 stars (1% relative error over the low-resolution PSF samples), and a top-two accuracy of 76% with a PSF model trained with only 50 stars (2.4% relative error over the low-resolution PSF samples). This shows that the approximate PSF models, which assist the classifier, although not sufficiently precise for WL analyses, are useful for breaking the degeneracy and improving the classification accuracy. We use WaveDiff (Liaudat et al. 2023a) to obtain approximate PSF models for the purposes of the work presented. However, we expect similar performance from any PSF modelling method, provided it can model the spectral variation of the PSF.
We then test the PSF-aware classifier in a proof-of-concept study, where we evaluate how much the additional stars with classified SEDs in a given FOV improve the modelling of the final PSF. We show that PSF models trained with complementary classified stars allow the relative PSF error to be reduced by almost 70%. The inclusion of spectrally classified stars reduces the relative error of the PSF from 2.5%, for an approximate reference model trained with 50 stars and their GT SEDs, to an error of 0.78% when using 2000 complementary stars spectrally classified with our PSF-aware classifier. While this experiment is rather simplistic and does not fully represent the complexity of PSF modelling from real data, the results obtained are promising and illustrate a potential use of the proposed spectral classifier.
Future studies can explore improvements to the PSF-aware classifier, such as replacing the SVM classifier with a neural network or using convolutional networks to compute custom features optimised for the stellar classification problem. The next steps for the work presented would include making more realistic simulations by adding redshift information to the star observations and increasing the number of wavelength bins used for stellar observations generation (Eq. (2)). In this case, we would need to study the selection of the number of similarity features, which we set equal to the number of spectral bins, in more detail. By addressing these issues, we would move significantly closer to applying our PSF-aware classifier to real survey data. This could be of interest for space missions such as Euclid, where the spectral information (SEDs) of the observed stars is crucial for training the PSF model.
Acknowledgements
This work was supported by the TITAN ERA Chair project (contract no. 101086741) within the Horizon Europe Framework Program of the European Commission, and the Agence Nationale de la Recherche (ANR-22- CE31-0014-01 TOSCA). This work is additionally supported by the European Community through the grant ARGOS (contract no. 101094354). This work was granted access to the HPC resources of IDRIS under the allocation 2023-AD011012983R2 made by GENCI.
Appendix A PSF modelling notation
Coordinates and notation used throughout this article. (Liaudat et al. (2023b)).
Appendix B PSF modelling
PSF modelling (Liaudat et al. 2023b) can be divided into two main categories: parametric models and data-driven models. Parametric models rely on building a physical representation of the optical system. After the physical model is built there is a reduced set of parameters to adjust, but it can be very challenging to tune them properly, requiring costly measurements of the instrument, precise calibrations, and time-consuming optical simulations. Data-driven or non-parametric models do not necessarily represent the physics of the instrument and have a higher degree of freedom, which allows optimal parameter combinations to be found using optimisation techniques. Such models typically use observations to constrain the PSF representation.
This approach is based on the observational model for an image centred at the position (ui, vi) in the FOV,
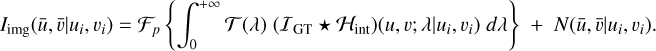 (B.1)
(B.1)
The ground truth image 𝐼GT is convolved with the PSF of the telescope ℋint (intensity impulse response) and integrated over the passband of the telescope, which is given by the transmission function (λ). The ℱp operator is a discretisation function that models the pixelisation of the detector (sampling) and N embodies the observational noise. The observed image Iimg, with pixel coordinates 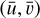 , is a discrete version of the ground truth image corrupted by the PSF of the telescope and the observational noise.
, is a discrete version of the ground truth image corrupted by the PSF of the telescope and the observational noise.
Observations of distant stars are particularly interesting for PSF modelling. Unresolved stars can be considered as point sources represented by a 2-dimensional delta distribution with a chromatic dependence described by the spectral energy distribution of the star,
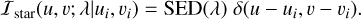 (B.2)
(B.2)
The convolution between the delta function and the PSF will result in a sample of the PSF at the (ui, vi) position. Therefore each observation of an unresolved star provides a sample of the PSF of the telescope at the corresponding position in the FOV (Mandelbaum 2018; Jarvis et al. 2020). The observational model of a distant star is as follows
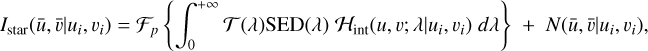 (B.3)
(B.3)
where ℋint(u, v; λ|ui, vi) is the PSF of the telescope with its centre at the position of the star. The PSF has two spatial coordinates (u, v) and one spectral coordinate λ. The PSF sample is integrated together with the star SED over the passband of the telescope given by the transmission function 𝒯 (λ). The ℱp operator is a discretisation function that models the pixelisation of the detector (sampling) and N embodies the observational noise. The observed image Istar, with pixel coordinates 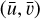 , is a single-band discrete version of the star corrupted by the PSF of the telescope and the observational noise.
, is a single-band discrete version of the star corrupted by the PSF of the telescope and the observational noise.
Appendix C WaveDiff
WaveDiff (Liaudat et al. 2023a) is a data-driven PSF model that operates in the wavefront space and is based on a differentiable optical module that models the physics of the optical process to go from the wavefront error (WFE) to the pixel-level PSF. By simplifying the optical system of the telescope to a single converging lens, the Fraunhofer diffraction approximation can be applied, thus relating the PSF at the focal plane and the wavefront error at the pupil plane as follows (Liaudat et al. 2023a, Eq. 5),
![$H\left( {\bar u,\bar \v ;\lambda \mid {u_i},{\v _i}} \right) \propto {\left| {{\rm{FT}}\left\{ {\exp \left[ {{{2\pi i} \over \lambda }{\mathop{\rm WFE}\nolimits} \left( {x,y\mid {u_i},{\v _i}} \right)} \right]} \right\}\left[ {{{\bar u} \over {\lambda {f_L}}},{{\bar \v } \over {\lambda {f_L}}}} \right]} \right|^2},$](/articles/aa/full_html/2025/02/aa52224-24/aa52224-24-eq41.png) (C.1)
(C.1)
where FT is the Fourier transform, u and v are the focal plane coordinates, x and y are the pupil plane coordinates and fL is the focal length of the optical system.
The WaveDiff WFE parametric representation is composed of a weighted sum of Zernike polynomials (Noll 1976), which are widely used by the optics community to represent the phase of spherical wavefronts. Zernike polynomials are two-dimensional functions that are orthogonal to each other over the unit disc. The Zernike amplitudes vary across the FOV coordinates (u, v) for each Zernike order l and are represented by a two-dimensional function 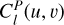 . In addition, the WFE has a non-parametric contribution, whose features,
. In addition, the WFE has a non-parametric contribution, whose features, 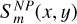 , are trained together with the spatial variation coefficients,
, are trained together with the spatial variation coefficients, 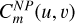 , using unresolved stars observations. The WFE as a function of the FOV coordinates (u, v) can be modelled as follows,
, using unresolved stars observations. The WFE as a function of the FOV coordinates (u, v) can be modelled as follows,
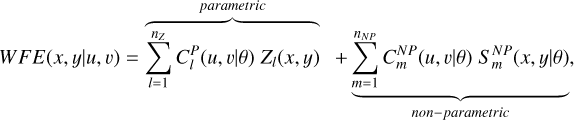 (C.2)
(C.2)
where Zl is the l-th order Zernike polynomial and nZ is the maximum order considered for the WFE representation. In this model, the spatial variation of the Zernike coefficients is a polynomial of degree dmax.
WaveDiff employs single-band star observations to optimise the parameters θ, modelling both the spatial and spectral variations of the GT PSF.
Appendix D One-vs-all metrics
F1-score for each classification model, for each individual class.
Accuracy for each classification model, for each individual class.
Top-two accuracy for each classification model, for each individual class.
Appendix E SVM+PSF results
Classification results for the SVM+PSF classifier.
References
- Akeson, R., Armus, L., Bachelet, E., et al. 2019, arXiv e-prints [arXiv:1902.05569] [Google Scholar]
- Akhaury, U., Starck, J.-L., Jablonka, P., Courbin, F., & Michalewicz, K. 2022, Front. Astron. Space Sci., 9, 357 [NASA ADS] [CrossRef] [Google Scholar]
- Baer, R. L. 2006, SPIE Conf. Ser., 6068, 37 [NASA ADS] [Google Scholar]
- Bagnulo, S., Jehin, E., Ledoux, C., et al. 2003, The Messenger, 114, 10 [Google Scholar]
- Baldi, P. 2012, in Proceedings of Machine Learning Research, 27, Proceedings of ICML Workshop on Unsupervised and Transfer Learning, eds. I. Guyon, G. Dror, V. Lemaire, G. Taylor, & D. Silver (Bellevue, Washington, USA: PMLR), 37 [Google Scholar]
- Baranne, A., Queloz, D., Mayor, M., et al. 1996, A&AS, 119, 373 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Basden, A., Tubbs, B., & Mackay, C. 2004, in Scientific Detectors for Astronomy, eds. P. Amico, J. W. Beletic, & J. E. Beletic (Dordrecht: Springer Netherlands), 599 [CrossRef] [Google Scholar]
- Bertin, E. 2011, in Astronomical Society of the Pacific Conference Series, 442, Astronomical Data Analysis Software and Systems XX, eds. I. N. Evans, A. Accomazzi, D. J. Mink, & A. H. Rots, 435 [NASA ADS] [Google Scholar]
- Bertin, E., & Arnouts, S. 1996, A&AS, 117, 393 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bishop, C. 1995, Neural Networks for Pattern Recognition (USA: Oxford University Press) [Google Scholar]
- Chaini, S., Bagul, A., Deshpande, A., et al. 2023, MNRAS, 518, 3123 [Google Scholar]
- Cropper, M., Hoekstra, H., Kitching, T., et al. 2013, MNRAS, 431, 3103 [Google Scholar]
- Euclid Collaboration (Cropper, M. S., et al.) 2025, A&A, in press, https://doi.org/10.1051/0004-6361/202450996 [Google Scholar]
- Euclid Collaboration (Mellier, Y., et al.) 2025, A&A, in press, https://doi.org/10.1051/0004-6361/202450810 [Google Scholar]
- Farrens, S., Lacan, A., Guinot, A., & Vitorelli, A. Z. 2022, A&A, 657, A98 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Prusti, T., et al.) 2016, A&A, 595, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gillis, B. R., Schrabback, T., Marggraf, O., et al. 2020, MNRAS, 496, 5017 [NASA ADS] [CrossRef] [Google Scholar]
- Grandini, M., Bagli, E., & Visani, G. 2020, arXiv e-prints [arXiv:2008.05756] [Google Scholar]
- High, F. W., Rhodes, J., Massey, R., & Ellis, R. 2007, PASP, 119, 1295 [NASA ADS] [CrossRef] [Google Scholar]
- Hopkins, A. M., Miller, C. J., Connolly, A. J., et al. 2002, AJ, 123, 1086 [NASA ADS] [CrossRef] [Google Scholar]
- Ivezic, Z., Kahn, S. M., Tyson, J. A., et al. 2019, ApJ, 873, 111 [NASA ADS] [CrossRef] [Google Scholar]
- Jarvis, M., Bernstein, G. M., Amon, A., et al. 2020, MNRAS, 501, 1282 [NASA ADS] [CrossRef] [Google Scholar]
- Kramer, M. A. 1991, AIChE J., 37, 233 [CrossRef] [Google Scholar]
- Krizhevsky, A., Sutskever, I., & Hinton, G. E. 2012, in Advances in Neural Information Processing Systems, 25, eds. F. Pereira, C. Burges, L. Bottou, & K. Weinberger (Curran Associates, Inc.) [Google Scholar]
- Kuntzer, T., Tewes, M., & Courbin, F. 2016, A&A, 591, A54 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lauer, T. R. 1999, PASP, 111, 1434 [NASA ADS] [CrossRef] [Google Scholar]
- Laureijs, R., Amiaux, J., Arduini, S., et al. 2011, arXiv e-prints [arXiv:1110.3193] [Google Scholar]
- LeCun, Y., Boser, B., Denker, J. S., et al. 1989, Neural Computat., 1, 541 [CrossRef] [Google Scholar]
- Liaudat, T., Bonnin, J., Starck, J.-L., et al. 2021, A&A, 646, A27 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Liaudat, T., Starck, J.-L., Kilbinger, M., & Frugier, P.-A. 2023a, Inverse Probl., 39, 035008 [NASA ADS] [CrossRef] [Google Scholar]
- Liaudat, T. I., Starck, J.-L., & Kilbinger, M. 2023b, Front. Astron. Space Sci., 10 [CrossRef] [Google Scholar]
- LSST Science Collaboration (Abell, P. A., et al.) 2009, arXiv e-prints [arXiv:0912.0201] [Google Scholar]
- Mandelbaum, R. 2018, ARA&A, 56, 393 [Google Scholar]
- Massey, R., Hoekstra, H., Kitching, T., et al. 2012, MNRAS, 429, 661 [Google Scholar]
- Morgan, W. W., Keenan, P. C., & Kellman, E. 1943, An Atlas of Stellar Spectra, with an Outline of Spectral Classification (The University of Chicago press) [Google Scholar]
- Ngolè, F., Starck, J.-L., Okumura, K., Amiaux, J., & Hudelot, P. 2016, Inverse Probl., 32, 124001 [CrossRef] [Google Scholar]
- Noll, R. J. 1976, J. Opt. Soc. Am., 66, 207 [Google Scholar]
- Paulin-Henriksson, S., Amara, A., Voigt, L., Refregier, A., & Bridle, S. L. 2008, A&A, 484, 67 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pedregosa, F., Varoquaux, G., Gramfort, A., et al. 2018, arXiv e-prints [arXiv:1201.0490] [Google Scholar]
- Perryman, M. A. C., de Boer, K. S., Gilmore, G., et al. 2001, A&A, 369, 339 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pickles, A. J. 1998, PASP, 110, 863 [NASA ADS] [CrossRef] [Google Scholar]
- Sánchez-Blázquez, P., Peletier, R. F., Jiménez-Vicente, J., et al. 2006, MNRAS, 371, 703 [Google Scholar]
- Sault, R. J., Teuben, P. J., & Wright, M. C. H. 1995, in Astronomical Society of the Pacific Conference Series, 77, Astronomical Data Analysis Software and Systems IV, eds. R. A. Shaw, H. E. Payne, & J. J. E. Hayes, 433 [NASA ADS] [Google Scholar]
- Schaefer, C., Geiger, M., Kuntzer, T., & Kneib, J. P. 2018, A&A, 611, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schuldt, S., Suyu, S. H., Cañameras, R., et al. 2021, A&A, 651, A55 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sharma, K., Kembhavi, A., Kembhavi, A., et al. 2019, MNRAS, 491, 2280 [Google Scholar]
- Spergel, D., Gehrels, N., Baltay, C., et al. 2015, arXiv e-prints [arXiv:1503.03757] [Google Scholar]
- Valdes, F., Gupta, R., Rose, J. A., Singh, H. P., & Bell, D. J. 2004, ApJS, 152, 251 [Google Scholar]
- Yang, Y., & Li, X. 2024, Universe, 10, 214 [CrossRef] [Google Scholar]
- Zeiler, M. D., & Fergus, R. 2013, arXiv e-prints [arXiv:1311.2901] [Google Scholar]
- Zeiler, M. D., Taylor, G. W., & Fergus, R. 2011, in 2011 International Conference on Computer Vision, 2018 [Google Scholar]
In the adopted notation (Appendix A) the symbol | means centred at the given position.
The code is available here: https://github.com/CentofantiEze/sed_spectral_classification
In this study, we evaluate the PSF only at observation resolution and not at super-resolution as is done in Liaudat et al. (2023a).
All Tables
Coordinates and notation used throughout this article. (Liaudat et al. (2023b)).
All Figures
|
Fig. 1 PCA decomposition of input stars. (a) First seven PCA components and PCA mean. (b) Original star observation and its reconstruction from the first 24 PCA components. The last figure in the lower panel shows the relative values of the coefficients associated with the 24 PCA components. |
| In the text | |
|
Fig. 2 CNN+MLP model diagram. In light blue, the convolutional blocks. In yellow, the multi-layer perceptron classifier. |
| In the text | |
|
Fig. 3 Ilustrative example of the degeneracy between the PSF size and spectral type of stars. (a) Middle rows: monochromatic PSFs for two positions in the FOV. The PSFs are shown for eight equally spaced wavelength values. Top and bottom: eight-bin spectral energy distribution of two stars, a M5 star (top) and an O5 star (bottom), located at positions 1 and 2 respectively. The wavelength axis is shared between all rows. (b) Observation of the respective stars. |
| In the text | |
|
Fig. 4 Normalised similarity features as a function of monochromatic PSF wavelength for the 10000 stars. Each set of features is coloured according to the corresponding observation stellar type. |
| In the text | |
|
Fig. 5 WaveDiff simulations. (a) Wavefront error, noiseless star observation, and noisy star observation at a particular position in the FOV for a simulated PSF field. (b) Monochromatic PSFs for multiple wavelength values. |
| In the text | |
|
Fig. 6 Spectral templates for the 13 stellar classes taken from Pickles (1998). Spectra are limited to a Euclid-like passband [550–900] nm, with a resolution of 1 nm. Spectra are flux normalised to unit sum. |
| In the text | |
|
Fig. 7 Project workflow: 13 000 star observations were simulated with the WaveDiff PSF simulator. Each star observation is located at a particular FOV position (ui, vi), has a random noise level S /N and belongs to a spectral class Ci. 10000 stars are directly used for training the pixel-only classification models, and 1000 stars to test them. 2000 stars are used to optimise the approximate PSF models required to calculate similarity features. The quality of the PSF models is evaluated with the 1000 test stars. Once the train and test similarity features have been computed, the PSF-aware stellar classifier is trained with 10 000 stars and tested with 1000 stars. |
| In the text | |
|
Fig. 8 F1 score, accuracy, and top-two accuracy by stellar type for the PCA+MLP, CNN+MLP, and SVM+PSF models. The |
| In the text | |
|
Fig. 9 Relative error at observation resolution for each approximate PSF model as a function of the number of training stars. The error bars represent the standard deviation of the relative errors of the stars in the test dataset. |
| In the text | |
|
Fig. 10 Accuracy (dashed blue line) and top-two accuracy (continuous blue line) metrics for the PSF-aware model (SVM+PSF) as a function of the PSF model error. In red and violet (horizontal lines), corresponding metrics for the pixel-only classification methods (PCA+MLP and CNN+MLP) are plotted as a reference. |
| In the text | |
|
Fig. 11 PSF improvement scenario. The observed exposure contains 2050 stars, of which 50 have complementary spectral information (in yellow) and 2000 do not (in blue). An approximate PSF model is trained from 50 stars with known SEDs. The approximate PSF is used in the context of the PSF-aware classifier to spectrally classify the remaining 2000 stars. The classified stars are assigned a SED template and can be used to train an improved PSF model. |
| In the text | |
|
Fig. 12 Relative PSF error, at observation resolution, as a function of the number of training stars. The baseline is set to the performance of the approximate PSF trained with 50 stars and ground truth SEDs (dark yellow). The subsequent PSF models (blue points) are trained using the 50 baseline stars in addition to increasing numbers of stars with SEDs assigned by our PSF-aware classifier. The error bars represent the standard deviation of the relative errors of the test dataset. The green dashed line shows the idealised minimum relative PSF error that can be obtained when using 2000 stars with ground truth SEDs, and the green shaded area represents the standard deviation of the relative errors. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.