| Issue |
A&A
Volume 687, July 2024
|
|
|---|---|---|
| Article Number | A258 | |
| Number of page(s) | 24 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202449654 | |
| Published online | 22 July 2024 | |
Improved source classification and performance analysis using Gaia DR3
Max-Planck Institute für Astronomy,
Königstuhl 17,
69117
Heidelberg,
Germany
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
19
February
2024
Accepted:
26
April
2024
Abstract
The Discrete Source Classifier (DSC) provides probabilistic classification of sources in Gaia Data Release 3 (GDR3) using a Bayesian framework and a global prior. The DSC Combmod classifier in GDR3 achieved for the extragalactic classes (quasars and galaxies) a high completeness of 92%, but a low purity of 22% (all sky, all magnitudes) due to contamination from the far larger star class. However, these single metrics mask significant variation in performance with magnitude and sky position. Furthermore, a better combination of the individual classifiers that comprise Combmod is possible. Here we compute two-dimensional (2D) representations of the completeness and the purity as a function of Galactic latitude and source brightness, and also exclude the Magellanic Clouds where stellar contamination significantly reduces the purity. Reevaluated on a cleaner validation set and without introducing changes to the published GDR3 DSC probabilities themselves, we here achieve for Combmod average 2D completenesses of 92% and 95% and average 2D purities of 55% and 89% for the quasar and galaxy classes, respectively. Since the relative proportions of extragalactic objects to stars in Gaia is expected to vary significantly with brightness and latitude, we then introduce a new prior that is a continuous function of brightness and latitude, and compute new class probabilities from the GDR3 DSC component classifiers, Specmod and Allosmod. Contrary to expectations, this variable prior only improves the performance by a few percentage points, mostly at the faint end. Significant improvement, however, is obtained by a new additive combination of Specmod and Allosmod. This classifier, Combmod-α, achieves average 2D completenesses of 82% and 93% and average 2D purities of 79% and 93% for the quasar and galaxy classes, respectively, when using the global prior. Thus, we achieve a significant improvement in purity for a small loss of completeness. The improvement is most significant for faint quasars (G≥20) where the purity rises from 20% to 62%.
Key words: methods: data analysis / methods: statistical / surveys / stars: general / galaxies: general / quasars: general
© The Authors 2024
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model.
Open Access funding provided by Max Planck Society.
1 Introduction
The Gaia ESA mission (Gaia Collaboration 2016, 2023) maps with micro-arcsecond astrometry more than 109 sources in the sky into a 6D phase-space of positions and velocities, allowing us to trace the Galactic acceleration field (Malhan et al. 2018; Ibata et al. 2021), infer the 3D distribution of interstellar matter (Dharmawardena et al. 2022, 2023), characterise the kinematics of stellar clusters and associations (Soubiran et al. 2018; Kuhn et al. 2019) and improve the calibration of the cosmic distance scale ladder (Riess et al. 2018, 2021), to mention just a few examples. Through Gaia, the distribution and the kinematics of matter (dark+visible) provides important insights into the formation history and the structure of the Milky Way components, from the Galactic centre extending to the outermost parts of the discs and into the halo. The distances derived from the Gaia parallaxes (Bailer-Jones et al. 2021), complemented with photometry, allow us to populate the Hertzsprung-Russell diagram highlighting different stellar populations (Babusiaux et al. 2023; Creevey et al. 2023). Primarily designed to map the stars in the Milky Way, Gaia observes a large scope of extragalactic sources such as quasars and galaxies (Bailer-Jones et al. 2023).
Large samples of galaxies and quasars are used in statistical studies to constrain key cosmological parameters. Quasars are extremely luminous sources powered by a supermassive black hole at the centre of their host galaxy. The most distant quasars at redshifts z ≳ 6 are thought to have formed before the epoch of reionisation and are therefore useful probes of the early Universe and the epoch of reionisation (Fan et al. 2006; Mortlock et al. 2011; Bañados et al. 2018). Quasars are also used to investigate supermassive black hole formation and evolution history (Volonteri & Rees 2006). Cosmological probes such as the baryon acoustic oscillations (BAOs) and the redshift distortions space (RSD) are key observables for constraining different cosmological models and for investigating the role of the dark energy in the late-time acceleration of the expansion of the Universe. The distributions of galaxies and quasars over large volumes across the Universe at different cosmic times carry an imprint on the growth rate of cosmic structures and emerge as an anisotropic clustering in the redshift space. The measurement of the RSD is used to constrain dark energy models through measurements of the linear growth rate of large-scale structures f(z)σ8(z) (Beutler et al. 2012; Zarrouk et al. 2018). Likewise, signatures of baryons, seen in the large-scale distribution of galaxies at low redshifts, are used to trace the expansion history through measurements of the Hubble distance H(z) and the co-moving angular distances DA(z) (Beutler et al. 2011). Together with direct measurements from galaxy samples, BAOs can also be measured from the spatial distribution of the neutral hydrogen in the Lyman-α forest in quasars spectra (Busca et al. 2013; Font-Ribera et al. 2014; Delubac et al. 2015; Ata et al. 2018).
The construction of catalogues of quasars and galaxies with a high level of purity is therefore essential to cosmological studies aiming at a better understanding of the evolution history of the Universe and probing the role of the dark components, namely the dark energy and dark matter, in the late acceleration of the expansion. Classification of sources relies on information from spectra, photometry, astrometry, and image reconstructions to discriminate between different types. Quasar spectra are characterised by a featureless continuum with noticeable emission lines such as the Balmer lines and Lyα (Berk et al. 2001), while galaxy spectra display a strong continuum component with absorption lines indicative of the stellar population as well as emission lines from the ionised gas in galaxies with an active star formation. Galaxy spectra are a composite of different contributions, from stellar populations, HII regions, active galactic nuclei, as well as contributions from the interstellar medium such as reddening (Conroy 2013). In stellar spectra, the shape of the continuum is a direct proxy to the star’s temperature and the characteristics of the absorption lines (e.g. ratio, strength and broadening) inform about the evolutionary phase of the star. Colour information and astrometry are also used to identify a source as a quasar, a galaxy, or a star.
Historical methods for the quasar-galaxy-star classification employ direct approaches such as colour cuts to optical or infrared photometry to identify aggregates of sources sharing similar properties (Newberg & Yanny 1997; Fan 1999). For instance, quasars appear bluer compared to stars in the optical, and point-like sources such as single stars are fairly concentrated along a stellar locus. However, despite their simplicity, such methods are hampered by the reduced dimensionality of the segmentation and the (inherent) subjectivity in selecting the separating planes through visual inspection, especially down to fainter magnitudes. With the rapid growth of astronomical data sets from large-scale surveys, traditional classification methods are unable to efficiently process the information space. Therefore, we use automated techniques such as machine learning (ML) for a repeatable, robust, and efficient way to classify the data and dive into finer details at levels beyond visual inspection or colour cuts. ML has been applied to the quasar-galaxy-star classification using a diverse range of techniques such as random forests (Weir et al. 1995; Bai et al. 2018; Nakazono et al. 2021; Zhang et al. 2021; Rimoldini et al. 2023), extremely randomised trees (Baqui et al. 2021; Delchambre et al. 2023), support-vectors machines (Peng et al. 2012; Małek et al. 2013; Nakazono et al. 2021; Wang et al. 2022), Bayesian kernel density estimators (Peters et al. 2015; Bailer-Jones et al. 2019), convolutional neural networks (Kim & Brunner 2017; Burke et al. 2019; He et al. 2021; Stoppa et al. 2023; Merz et al. 2023; Rodrigues et al. 2023; Chaini et al. 2023), and dense neural networks (Martínez-Solaeche et al. 2023). Unsupervised approaches have also been proposed in the literature such as the Hierarchical Density-Based Spatial Clustering of Applications with Noise (HDBSCAN) algorithm (Logan & Fotopoulou 2020) and contrastive learning networks (Guo et al. 2022). More recently, several contributions have exploited boosted trees classifiers such as extreme gradient boosting (XGBoost) (Golob et al. 2021; Li et al. 2021; Hughes et al. 2022; Stoppa et al. 2023; Rimoldini et al. 2023) that proved to be highly performing in separating point-like sources (quasars and stars) from extended sources (galaxies).
By scanning the entire sky down to faint magnitudes, Gaia observes millions of extragalactic sources that require classification methods to identify quasar and galaxy candidates (Bailer-Jones et al. 2023). Within the Gaia Data Processing and Analysis Consortium (DPAC), several modules are responsible for the classification and the characterisation of the Gaia sources. Among the classification modules, the Discrete Source Classifier (DSC) provides probabilistic classifications into five classes, namely the quasar, galaxy, star, white dwarf, and binary star classes (Creevey et al. 2023). DSC exploits a decision tree-based classifier and a density-based model in a supervised approach trained on Gaia astrometry and spectro-photometric data (Delchambre et al. 2023). In the latest Gaia Data Release 3 (GDR3; Gaia Collaboration, 2023), DSC classification reports for the extragalactic classes a high completeness (~92%) owing to the classifiers’ ability in identifying the true classes, but a low purity (~22%) due to large numbers of stellar detections erroneously classified as a quasar or a galaxy candidate. However, single metrics to summarise the performance for all types of sources do not constitute a fair assessment. For instance, low performance is unsurprisingly correlated to fainter magnitudes and crowded regions. Moreover, a reduced purity implies a limited use of the catalogue for cosmological studies. In this work, our goal is two-fold, first to quantify DSC performance as a function of brightness and Galactic latitude in order to identify the range of the best results and limitations, and second to improve the purity of the extragalactic classes. To assess the performance, we define a two-dimensional (2D) representation of the purities and the completenesses at different magnitudes across the sky. To improve the purity, we apply to the GDR3 DSC probabilities a continuous variable prior based on the expected distribution of brightness and Galactic latitude and provide a new approach for combining the DSC classifiers. In this work, we concentrate our efforts in assessing the performance of the extragalactic classes and briefly discuss the white dwarf class.
The paper is structured as follows. Section 2 succinctly presents the data. Section 3 summarises the classification results from DSC in GDR3 and introduces the 2D assessment of the performance. In Sec. 4, we present the continuous variable prior function of brightness and Galactic latitude and outline a new approach for combining DSC classifiers to improve the purity of the extragalactic classes. We finally conclude in Sec. 5, and provide an Appendix with additional information.
2 Data
The Gaia data collected by the satellite between the period of 2014 and 2017 was published in the latest catalogue on June 2022, the Gaia Data Release 3 (GDR3; Gaia Collaboration, 2023), for ~1.9 billion sources down to faint magnitudes G≃20, providing ~1.6 billion sources with classifications and 470 million sources with astrophysical parameters such as effective temperatures, surface gravity, metallicity, extinction, and abundances. Gaia provides measurements of astrometry, photometry, and spectroscopy for billions of sources. The low-resolution spectro-photometry, namely the XP spectra, cover a wavelength range in the blue BP band at 330-680 nm and in the red RP band at 640-1050 nm (~220 million mean spectra in GDR3; Angeli et al. 2023). In GDR3, DSC computes probabilistic classification into the quasar, galaxy, star, white dwarf, and binary star classes using the parallaxes, the proper motions, the Galactic latitude, the colours, the magnitudes in the G-band, and the low-resolution XP spectra (Bailer-Jones et al. 2019; Delchambre et al. 2023). The main source table (gaiadr3.gaia_source) reports the posterior probabilities of the quasar, galaxy, and star classes from the DSC combined classifier, while the astrophysical parameters table (gaiadr3.astrophysical_parameters) reports the posterior probabilities of all classes from the DSC classifiers. The GDR3 extragalactic tables (gaiadr3.qso_candidates, gaiadr3.galaxy_candidates) provide a list of quasar and galaxy candidates identified by different classification modules within DPAC including DSC candidates. A purer sub-sample of the GDR3 extragalactic tables, presented in Bailer-Jones et al. (2023), is obtained by imposing a joint condition on the probabilities of the DSC classifiers. In this work, we use the DSC posterior probabilities from the astrophysical parameters table in GDR3.
3 Reassessment of classification results in GDR3
3.1 An outline of DSC in GDR3
DSC architecture in GDR3 is composed of three classifiers computing posterior probabilities: two baseline classifiers trained using a set of labelled sources, Specmod and Allosmod, complemented with a third classifier, Combmod. Specmod is trained using low-resolution XP spectra and computes posterior probabilities across the five classes, while Allosmod is trained using discretised features from the Gaia astrometry and photometry to discriminate between the quasar, galaxy, and anonymous classes, with the latter referring to the stellar types of the single star, white dwarf and binary star classes combined. Combmod combines the probabilities of the baseline classifiers and provides posterior probabilities over the five classes. The baseline classifiers are trained on the same sources, thus requiring the availability of all input data for the joint training. However, at the prediction stage, the architecture with separate classifiers offers more flexibility in processing sources with missing information. For instance, sources without parallax measurements but with a valid XP spectrum are classified through Specmod and not processed through Allosmod.
Specmod is a decision tree-based classifier Extratrees (Geurts et al. 2006) and Allosmod is a Gaussian Mixture Model (Reynolds 2015). The Extratrees algorithm is an ensemble-based algorithm combining class predictions from a collection of randomised decision trees trained on bootstrap samples of the data. Compared to the Random Forest algorithm, Extratrees is similar in the randomisation of the input features at the nodes level, but differs by adding a randomisation of the thresholds applied to the selected features. The Gaussian Mixture Model is a probabilistic model assuming that the data are a mixture of Gaussian distributions. Training the algorithm aims to find the best model parameters, the mean and variance of the gaussian components. DSC classifies sources using a Bayesian framework and a global prior to account for the rarity of the extragalactic classes. The global prior πglob is defined such that for one source to be identified as a star, the probabilities to observe a quasar and a galaxy are, respectively, one over 1000 and one over 5000.
3.2 Performance metrics
To assess the performance of a classifier in predicting the correct labels, we compute the completeness and the purity from the confusion matrix. By definition, the completeness is the ability of the classifier to retrieve the true labels while the purity depicts its ability to filter out false detections. The two metrics are defined as
![Mathematical equation: $\[\text { completeness }=\frac{\mathrm{TP}}{\mathrm{TP}+\mathrm{FN}}, \quad \text { purity }=\frac{\mathrm{TP}}{\mathrm{TP}+\mathrm{FP}} \text {, }\]$](/articles/aa/full_html/2024/07/aa49654-24/aa49654-24-eq1.png) (1)
(1)
where TP, FN, and FP refer to true positives, false negatives and false positives, respectively. A high completeness and a high purity are indicative of a satisfactory performance. However, a trade-off between completeness versus purity is a known compromise. A low completeness and a high purity suggest that the classifier is able to reject false positives (i.e. sources from other classes erroneously classified as the target class) at the cost of missing true predictions, while a high completeness coupled to a low purity emphasises the ability of the classifier to correctly predict the true labels to the expense of introducing large numbers of false detections. DSC assigns class labels by identifying the class with the largest probability above a fixed threshold. A higher threshold entails a more stringent condition to assign a source to a target class, otherwise the source is marked as unclassified. A high threshold typically produces a purer sample from rejecting more false detections, to the detriment of a reduced completeness from rejecting the true positives with probabilities below the threshold.
Classification results, when evaluated on a limited number of test objects, are not indicative of the performance on the overall distribution across the sky as the number of stars overly exceeds the number of extragalactic sources. Therefore, if stars are under-represented in the test set compared to reality, there will not be a correct estimate of the fraction of potential stellar contaminants and the purity will be underestimated. To illustrate this point, we consider a simple example of a 2-class classifier able to correctly predict class-1 but completely misclassifies the class-2. For a balanced test set, the completeness of class-1 is 100% and the purity is 50%. For an imbalanced test set where class-2 is at least 100 times larger, the completeness of the class-1 remains 100% but its purity is ~1% (=1/101). For DSC, the problem of the class imbalance was addressed in Bailer-Jones et al. (2019) in two folds, firstly by applying the class prior to compute posterior probabilities, and secondly by applying an adjustment to the confusion matrix to scale the test set to the overall class distribution in the sky. The adjustment, applied per target class to the confusion matrix, affects only the purities and not the completenesses. Throughout this work, the classification metrics are the metrics after adjustment.
3.3 Performance of DSC as reported in GDR3
In Delchambre et al. (2023), the classification performance of DSC in GDR3 is evaluated on a validation data set. Specmod reports a completeness of 41% and 83% and a purity of 23% and 40%, and Allosmod reports a higher completeness of 84% and 92% and a purity of 41% and 30%, for the quasars and the galaxies, respectively. Combmod combines the probabilities of the baseline classifiers and reports a high completeness of 92% and 94% and a low purity of 24% and 22% for the quasars and the galaxies respectively, showing the ability of the classifier to achieve a higher prediction rate (higher completeness) to the disadvantage of introducing the false detections (lower purity). Low purity values result from increased numbers of the stellar false positives, a contribution largely inflated due to the strong prior of the star class. At higher latitudes, farther from the Galactic plane where most single star contaminants lie, the purity of the extragalactic classes increases by ~20% for all classifiers, which pinpoints anew to the contamination from the star class as the main factor affecting the purity. In GDR3, DSC Combmod reports a completeness of 99%, 43% and 0.2% and a purity of 99%, 25% and 7.5% for the stars, white dwarfs and physical binaries, respectively. For the extragalactic classes, a conditional conjunction of Specmod and Allosmod probabilities is introduced through the label classlabel_dsc_joint such that the two classifiers jointly identify the same class with a maximum probability larger than 0.5. This combination reports the highest purities (~62%) for the extragalactic classes but the lowest completeness for the quasar class (38%).
In this work, we use the same validation data set of DSC in GDR3, which comprises 308 526 quasars, 52 359 galaxies, 717 252 single stars, 47 245 white dwarfs and 331 526 physical binary stars. This validation set was built from SDSS spectroscopic candidates for the extragalactic classes, from the Montreal White Dwarf database1 for the white dwarfs, and from a selection of Gaia data for the single star and physical binary star classes. In this work, we omit the analysis of the binary class, due to the poor performance of DSC in GDR3 on this class. Figure 1 shows the distribution of the number of sources in the validation data set per target class as a function of the Galactic latitude and magnitude. The relative density of quasars and galaxies peaks at higher latitudes at the faint end while the density of stars is higher close to the Galactic plane. The density of the white dwarfs across the 2D space peaks at higher latitudes at the faint end, but such agglomeration could be due to a selection effect from the constructed sample.
Using the validation data set, we first reproduce the GDR3 results (the overall completeness and purity for all three classifiers and the posterior probabilities from Combmod computed from Allosmod and Specmod). The overall performance evaluated on the full validation data set is summarised in Table 1 under the label ‘original’. The confusion matrix is provided in Fig. B.1a for reference.
 |
Fig. 1 Representation in 2D of the distribution of sources as a function of Galactic latitude and brightness of the original validation data set. Each distribution is normalised by the total number of sources in that panel. The colour scale is set such that bright colours indicate a higher density of sources compared to dark regions. The 2D representation of the density of sources is defined on a grid in | sin b| and G of 50×91 bins. As a design choice, the binning in magnitude bins compresses the range at G<14. Contours (green lines) are used in the regions of highest density to indicate the normalised density in log scale. |
Summary of the overall classification performance evaluated on the validation data set.
3.4 An cleaned validation data set
The reported performance assumes that the labels in the validation data set are correct. However, through cross-matches using public tools2,3 with external non-Gaia catalogues at a maximum radius of 1 arcsec, we identify, in the stellar classes of the validation data set, quasar and galaxy candidates from Milliquas v7.2-v8 (Flesch 2015, 2023), LAMOST DR7 (Luo et al. 2022), SDSS DR 17 photometry (Abdurro’uf et al. 2022), UKIDSS DR9 (Lawrence et al. 2007), DES DR2 (Abbott et al. 2021), Assef R90 and C75 WISE AGN catalogues (Assef et al. 2018), and SIMBAD (Wenger et al. 2000). We further filter out the sources with unreliable classifications in SIMBAD. We remove these sources from the stellar classes to build a cleaner validation data set and assess the performance of the classifiers without a bias. The filtering amounts in total to 1.6% removal of sources (22 912 sources) applied to the star, white dwarf, and binary classes. Table A.1 summarises the selection criteria applied to the results in order to filter contaminants from the stellar classes in the validation data set. We also remove the sources located in the Magellanic Clouds4 from the stellar classes, about 0.8% of sources (11 837 sources), and filter the galaxy class from sources that deviate from the expected distribution of galaxies in the colour-colour diagram and fall in the stellar locus as defined in Bailer-Jones et al. 2019 (~103 sources). After accounting for duplicates, the total removal from the original validation data set amounts to 2.5% (35 753 sources). The cleaned validation data set contains 308 526 quasars, 51 347 galaxies, 702 450 stars, 45 005 white dwarfs and 313 827 binaries. Table A.2 summarises the total number of sources in the validation data set.
Summary of the average 2D classification performance evaluated on the validation data set.
3.5 Two-dimensional representation of results
Classification performance typically summarises results averaged over a diverse validation data set. However, the performance of a classifier is expected to vary as a function of source parameters, such as magnitude and Galactic latitude that are strongly linked to the signal-to-noise (S/N) level and possible crowding. For instance, in crowded regions, classification is limited either by a reduced data quality or by a higher density of stellar contaminants.
Similar to Hughes et al. (2022), we explore a 2D representation of the classification performance. We compute a 2d grid of a total of 4550 bins (50×91) in | sin b| and G. The magnitude binning is composed of a coarse grid for G < 14 and a finer grid for 14 ≤ G < 22, while the binning in | sin b| is defined on a uniform grid between 0 and 1. Using the prior and the number of sources per bin, we apply the adjustment to the confusion matrices in each bin and compute the completeness and the purity. We intuitively expect a better performance for brighter sources, especially in low-density regions farther from the Galactic plane.
Representations of the 2D completenesses and 2D purities of the DSC Combmod classifier evaluated on the original validation data set are provided in Figs. 2a–3a, respectively. Similar representations evaluated on the cleaned validation data set are reported in Figs. 2b–3b. To assess the performance, we also compute 1D representations of the completenesses and purities as a function of Galactic latitude in Figs. 2c–3c. We exclude from our assessment the star class as its purity and completeness remain very close to 1. For the quasar, galaxy, and white dwarf classes, the completenesses and the purities decrease with decreasing magnitudes. From the 2D representations, we identify regions with zero completenesses (TP=0) indicative of the inability of the classifier to correctly identify sources. However, these regions have low occupancy (i.e. few sources per bin), and thus do not affect the overall assessment of the performance. We also identify regions with an undefined purity (TP=0 and FP=0) and a zero completeness (TP=0) due to the absence of correct predictions and false positives (no source is mislabelled but no true class is correctly identified). Such regions correspond to the gaps in the 2D representations of the purity, as identified for the white dwarf class in the strip at G > 20.5 across all latitudes and the bulk region close to the Galactic plane at | sin b| < 0.2 and G > 18.5, totalling 4742 sources.
Overall, the 2D representations of the completenesses indicate a good performance across all magnitudes (Figs. 2a–3a). The 2D representations of the purities show that the false positives of the quasar class are mainly localised at the faint end with noticeable aggregates at | sin b| = −0.54 and | sin b| = −0.70, in addition to a few bright stellar contaminants at G < 14. The false detections of the galaxy class are distributed across the 2D space mostly at fainter magnitudes G > 19 and at lower latitudes (i.e. close to the Galactic plane). The false positives of the white dwarf class are similarly distributed across the 2D space with noticeable aggregates at the fainter magnitudes at | sin b| = −0.54 and | sin b| = −0.70. These aggregates of false positives are traced back to the Magellanic Clouds5, identifiable in the distribution of the star class in Fig. 1. The performance of DSC in the LMC and SMC is dominated by the stellar contaminants that strongly affects the overall purity. To assess the completeness and purity outside these regions, we chose to remove the LMC and SMC regions from the validation data set (Figs. 2b–3b).
Reevaluated on the cleaned validation set and without introducing changes to the published GDR3 DSC probabilities, the overall performance set is summarised in Table 1 under the label ‘cleaned’. The confusion matrix is provided in Fig. B for reference. Figures 2b and 3b report the 2D performance of Combmod evaluated on the cleaned validation data. Comparing Figs. 3a and 3b, the absence of the contaminants is easily noticeable in the 2D purities. This is also apparent in the smoothed representations of the purities in Fig. 3c at different magnitude limits.
To summarise the 2D representations, we compute the average 2D metrics over magnitude and latitude bins, defined as the weighted sum across all bins. Per target class, the average 2D completenesses are weighted by the number of true sources per bin and the average 2D purities are weighted by the number of predictions per bin. Table 2 reports the summary of the 2D performance evaluated on the cleaned validation set showing higher 2D purities for the quasars, galaxies and white dwarfs, compared to the original validation data set. In Table 3, the comparison at different magnitude limits shows that the improvement in purity is more pronounced at fainter magnitudes, by 33, 17 and 11 percentage points at magnitudes 19≤G<20, and 13, 35, and 9 percentage points at magnitudes G≥20, for the quasars, galaxies and white dwarfs, respectively.
 |
Fig. 2 Completeness of DSC Combmod. Predicted labels are obtained from the class with the largest posterior probability using the global prior. (a) Variation of completeness with magnitude and absolute Galactic latitude for each of the three classes using the original validation data set. (b) As (a), but using the cleaned validation set (i.e. after removal of the Magellanic Clouds and mislabelled sources). (c) Completeness as a function of absolute Galactic latitude for three brightness ranges (columns) for each class (rows). In each panel the dashed line shows the performance on the original validation data set and the solid line the cleaned validation data set. These one-dimensional plots are essentially a marginalisation of the 2D representations in panels a and b but weighting by the number of sources in each bin. The curves have been smoothed with a Gaussian filter to remove noise. The shaded region encompasses the LMC at | sin b| = −0.54 and the SMC | sin b| = −0.70 (which are excluded from the cleaned set). |
Summary of the average 2D classification performance evaluated on the validation data set at different magnitude limits.
3.6 A closer look at white dwarfs
We now examine the distribution of the white dwarfs (WDs) predictions. Figure 4a shows the distributions of the correct predictions (TPs), the WDs falsely classified as stars (FNs), and the stars falsely classified as WDs (FPs). We build the Gaia Hertzsprung-Russell diagram (HRD) by estimating the absolute magnitude from the G band and the parallax in millarcseconds. The absolute magnitude is plotted against the colour GBP − GRP. On the HRD, most TPs lie in the expected WDs sequence. Within the TPs, a subset of hot subdwarfs can be identified. However, since hot subdwarfs and white dwarfs share similar characteristics in their black-body emission spectra, these sources can be misclassified. In GDR3, DSC training of the white dwarf class used the MWDD that contains hot subdwarf candidates in addition to white dwarfs. The stellar FNs are distributed over the full sky with small clusterings of faint sources at higher latitudes or close to the Galactic plane. On the HRD, the faint FNs show a large scatter and the bright FNs extend towards redder colours (higher GBP − GRP) in comparison to the TPs. The distribution of the few FPs from the star class follows the WD sequence on the HRDs. These sources can possibly be true WDs candidates, although misclassified in the validation data set as stars.
To investigate the stellar FNs we apply a quality cut on Gaia data similar to Gentile Fusillo et al. (2021) using features from the Gaia main source table (gaiadr3.gaia_source) as
![Mathematical equation: $\[\begin{array}{rr} & \text { parallax_over_error } \geq 4, \\\text { and } &\qquad \text { ruwe }<1.1, \\\text { and } &\qquad \text { astrometric_sigma5d_max }<1.5, \\\text { and } &\qquad \text { ipd_gof_harmonic_amplitude }<1, \\\text { and } &\qquad \text { phot_[bp,rp]_n_obs }>2,\end{array}\]$](/articles/aa/full_html/2024/07/aa49654-24/aa49654-24-eq2.png) (2)
(2)
where parallax_over_error is the parallax divided by its error, astrometric_sigma5d_max the longest semi-major axis of the 5-d error ellipsoid, ruwe the renormalised unit weight error, ipd_gof_harmonic_amplitude the amplitude of the goodness-of-fit of the Image Parameter Determination (IPD) versus the position angle of the scan direction, phot_[bp,rp]_n_obs the number of observations in BP and RP, respectively. In Fig. 4b, the quality cut rejects the bright subdwarfs and the faint sources from the TPs, and the faint sources from the FNs. The clusterings of the faint FNs are rejected and the large dispersion on the HRD is corrected. This shows that the data quality contributes to the misclassification. After the quality cut, the remaining FNs mislabelled by DSC as stars result from inherent limitations of the GDR3 DSC classifiers. In GDR3, Combmod achieves for the white dwarf class average 2D completenesses of 43% and average 2D purities of 95% (Table 2). At different magnitude limits, the average 2D completenesses and 2D purities are 59% and 95% at G < 19, 34% and 94% at 19≤G<20 and 20% and 93% at G≥20, respectively (Table 3). Although incomplete, the GDR3 DSC WD candidates constitute a pure set of candidates that can be useful for follow-up studies. We advise to apply quality cuts and discard DSC predictions in the LMC and SMC regions.
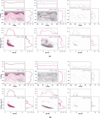 |
Fig. 4 DSC Combmod classifications for the white dwarf class on the cleaned validation data set using the global prior. (a) DSC WDs predictions on the full sample. (b) DSC WDs predictions after the quality cut on Gaia data. Each panel shows, from left to right, the true positives (i.e. correct predictions), the stellar false negatives (i.e. sources from the white dwarf class classified as stars), and the stellar false positives (i.e. sources from the star class classified as white dwarfs). Faint sources G ≥ 18 (grey) and bright sources G < 18 (magenta) are plotted separately. |
4 New classifications based on the published DSC probabilities
4.1 A magnitude- and latitude-dependent prior
4.1.1 Method
DSC exploits a Bayesian framework to compute posterior probabilities per target class, and uses a global prior to account for the overall distribution of classes over the entire data set (Delchambre et al. 2023). The global prior is set to πglob = [0.000989, 0.000198, 0.988728, 0.000198, 0.009887] for the quasar, galaxy, star, white dwarf, and physical binary classes, respectively. Following the work by Hughes et al. (2022), we compute a variable prior πvari function of Galactic latitude and brightness from the expected class distribution across the sky. Stars dominate over the whole sky, but their number density decreases towards higher latitudes and fainter magnitudes where the contribution from the quasars and galaxies increases. Ideally, a deeper and complete survey would provide the relative numbers of stars, quasars, galaxies as a function of Galactic latitude and brightness. However, we do not have access in reality to a deep survey covering the whole sky at all magnitudes. We compute the prior from a selected data set and assume that the ratios computed in the constructed 2D space are representative of the expected class distributions across all magnitudes and latitudes. The variable prior πvari for class k (quasar, galaxy, stellar class) is defined as
![Mathematical equation: $\[\pi_k^{\text {vari }}(x)=\pi_k^{\mathrm{glob}} \frac{F_k(x)}{N_k},\]$](/articles/aa/full_html/2024/07/aa49654-24/aa49654-24-eq3.png) (3)
(3)
where x refers to the parameters (Galactic latitude and brightness), k the class, Fk(x) the total number of sources per class k evaluated at x, Nk the total number of sources per class k, and ![Mathematical equation: $\[\pi_k^{\text {glob }}\]$](/articles/aa/full_html/2024/07/aa49654-24/aa49654-24-eq4.png) the global prior at class k. We expand the variable prior from the three classes to the five classes by adjusting the fraction of the stellar types as
the global prior at class k. We expand the variable prior from the three classes to the five classes by adjusting the fraction of the stellar types as
![Mathematical equation: $\[\pi_j^{\text {vari }}=\pi_{\text {stellar }}^{\text {vari }}\left(\frac{\pi_j^{\text {glob }}}{\pi_{\text {stellar }}^{\text {glob }}}\right),\]$](/articles/aa/full_html/2024/07/aa49654-24/aa49654-24-eq5.png) (4)
(4)
where j refers to the star, white dwarf and binary classes and ![Mathematical equation: $\[\pi_{\text {stellar }}^{\text {glob }}=\pi_{\text {star }}^{\text {glob }}+\pi_{\text {whitedwarf }}^{\text {glob }}+\pi_{\text {binary }}^{\text {glob }}\]$](/articles/aa/full_html/2024/07/aa49654-24/aa49654-24-eq6.png) .
.
Finally, the variable prior is normalised across the five classes using
![Mathematical equation: $\[\pi_k^{\mathrm{vari}}=\pi_k^{\mathrm{vari}} / \sum_{k^{\prime} \text { classes }} \pi_{k^{\prime}}^{\mathrm{vari}}.\]$](/articles/aa/full_html/2024/07/aa49654-24/aa49654-24-eq7.png) (5)
(5)
To build the variable prior, we select quasar and galaxy sources from SDSS DR17 with spectral types class=‘GALAXY’ or class=‘QSO’ and a redshift quality flag zWarning=0 indicative of a reliable redshift estimation and spectroscopic classification. The stellar class is a random selection from Gaia cleaned from the selected extragalactic sources and any match to quasar and galaxy candidates from cross-matches with external non-Gaia catalogues (Milliquas v7.2-v8 Flesch 2015, Flesch 2023; SDSS DR 17 photometry Abdurro’uf et al. 2022; and the Assef R90 and C75 WISE AGN catalogues Assef et al. 2018). Since SDSS does not cover the full sky nor the full magnitude and latitude range of Gaia, we extrapolate the prior outside this magnitude range to the values at the boundary. The selected extragalactic classes cover a magnitude range of 14≤G≤21. Priors at magnitudes fainter than 21 are extrapolated to the prior at G=21, and at magnitudes brighter than 14 extrapolated to the prior at G=14. Moreover, to compensate for the disparity in the SDSS footprint between the northern versus the southern Galactic hemispheres, we build the prior in latitudes using the absolute values in | sin b|.
We compute the variable prior from a discretised 10×10 grid across magnitudes and latitudes using Eq. (3), compute the variable prior for the stellar classes using Eq. (4) and then normalise using Eq. (5). We expand the discretised mapping to a continuous representation ![Mathematical equation: $\[\hat{\boldsymbol{\pi}}^{\text {vari }}\]$](/articles/aa/full_html/2024/07/aa49654-24/aa49654-24-eq8.png) by fitting a bivariate spline to the prior of the quasar and galaxy classes. To ensure the sum of the prior across all classes to be equal to 1 at every point, the continuous variable prior for the stellar class is obtained by subtracting the priors of the extragalactic classes
by fitting a bivariate spline to the prior of the quasar and galaxy classes. To ensure the sum of the prior across all classes to be equal to 1 at every point, the continuous variable prior for the stellar class is obtained by subtracting the priors of the extragalactic classes ![Mathematical equation: $\[\hat{\pi}_{\text {stellar }}^{\text {var }}=1-\hat{\pi}_{\text {quasar }}^{\text {vuas }}-\hat{\pi}_{\text {galaxi }}^{\text {vari }}\]$](/articles/aa/full_html/2024/07/aa49654-24/aa49654-24-eq9.png) . The individual stellar contributions are obtained using Eq. (4). The fitting is performed using the implementation of the RectBivariateSpline from the python package scipy.interpolate. As previously stated, priors outside the grid are extrapolated from the values estimated at the boundary. Computing DSC probabilities using a new prior does not require re-training nor re-applying DSC to the data (Bailer-Jones et al. 2019). The posterior probability using the variable prior Pkvari for class k is defined as
. The individual stellar contributions are obtained using Eq. (4). The fitting is performed using the implementation of the RectBivariateSpline from the python package scipy.interpolate. As previously stated, priors outside the grid are extrapolated from the values estimated at the boundary. Computing DSC probabilities using a new prior does not require re-training nor re-applying DSC to the data (Bailer-Jones et al. 2019). The posterior probability using the variable prior Pkvari for class k is defined as
![Mathematical equation: $\[P_k^{\text {vari }}=P_k \frac{\hat{\pi}_k^{\text {vari }}}{\pi_k^{\text {glob }}} / \sum_{k^{\prime} \text { classes }}\left(P_{k^{\prime}} \frac{\hat{\pi}_{k^{\prime}}^{\text {vari }}}{\pi_{k^{\prime}}^{\text {glob }}}\right),\]$](/articles/aa/full_html/2024/07/aa49654-24/aa49654-24-eq10.png) (6)
(6)
where Pk refer to the posterior probability using the global prior, ![Mathematical equation: $\[\pi_k^{\text {glob }}\]$](/articles/aa/full_html/2024/07/aa49654-24/aa49654-24-eq11.png) the global prior at class k and
the global prior at class k and ![Mathematical equation: $\[\hat{\pi}_k^{\text {vari }}\]$](/articles/aa/full_html/2024/07/aa49654-24/aa49654-24-eq12.png) the variable prior at class k. We apply Eq. (6) to compute new posterior probabilities for all classifiers in DSC. For reference, Fig. C.1 reports the variable prior for the quasar, galaxy, and stellar classes.
the variable prior at class k. We apply Eq. (6) to compute new posterior probabilities for all classifiers in DSC. For reference, Fig. C.1 reports the variable prior for the quasar, galaxy, and stellar classes.
4.1.2 Performance
We compute 1D representations of the completenesses and purities as a function of Galactic latitude in Figs. 5a–5b. Results of the Combmod classifier using the variable prior show a slightly higher purity and completeness at fainter magnitudes at high latitudes. Figure 6 reports in the 2D performance of the extra-galactic classes the removal of the few bright contaminants in the quasar class. Overall, the application of the variable prior shows overall no significant improvement in the completeness and the purity of any of the three classes.
The confusion matrix is provided in Fig. B.1 for reference. Table 2 summarises the 2D performance evaluated on the cleaned validation data set (as described in Sec. 3.4). Using the variable prior does not strongly modify (improve nor decrease) the average 2D completenesses and purities compared to the GDR3 Combmod using the global prior. The comparison at different magnitude limits (Table 3) shows the highest improvement at magnitudes G≥20, although small (under ~7 percentage points in the 2D completenesses and ~2-3 percentage points in the 2D purities).
To summarise, the application of a continuous variable prior on Combmod improves by a small fraction the average 2D completenesses and purities of the target classes compared to the GDR3 results using the global prior. The highest improvement is seen at fainter magnitudes G≥20 for quasars, where the average 2D completeness increases from 86% to 93% and the average 2D purity from 19% to 24%. The effect of the variable prior on the galaxies and the white dwarfs remains not significant (~2 percentage points).
4.2 Combmod-α: A new combination of classifiers
4.2.1 Method
In GDR3, Combmod is obtained from a weighted combination of the DSC classifiers Specmod and Allosmod to compute probabilities for the five classes. Since Specmod and Allosmod have the same prior, the combination of the posterior probabilities removes the prior from one contribution (Ulla et al. 2022). The posterior probability of Combmod for class k is defined as
![Mathematical equation: $\[P_k^c= \begin{cases}P_k^s P_k^a \frac{1}{\pi_k^s} & \text { for the quasar and galaxy classes, } \\ P_k^s P_k^a \frac{\pi_k^s}{\left(\pi_{\text {star }}^a\right)^2} & \text { for the stellar classes },\end{cases}\]$](/articles/aa/full_html/2024/07/aa49654-24/aa49654-24-eq13.png) (7)
(7)
and normalised across all five classes
![Mathematical equation: $\[P_k^c=P_k^c / \sum_{k^{\prime}} P_{k^{\prime}}^c,\]$](/articles/aa/full_html/2024/07/aa49654-24/aa49654-24-eq14.png) (8)
(8)
where ![Mathematical equation: $\[P_k^s\]$](/articles/aa/full_html/2024/07/aa49654-24/aa49654-24-eq15.png) and
and ![Mathematical equation: $\[P_k^a\]$](/articles/aa/full_html/2024/07/aa49654-24/aa49654-24-eq16.png) are the posterior probabilities for Specmod and Allosmod respectively, and the priors
are the posterior probabilities for Specmod and Allosmod respectively, and the priors ![Mathematical equation: $\[\left\{\pi_k^s, \pi_k^a\right\}\]$](/articles/aa/full_html/2024/07/aa49654-24/aa49654-24-eq17.png) refer, respectively, to the 5-class prior used in Specmod and the 3-class prior used in Allosmod, such that
refer, respectively, to the 5-class prior used in Specmod and the 3-class prior used in Allosmod, such that ![Mathematical equation: $\[\pi_{\text {star }}^a=\pi_{\text {star }}^s+\pi_{\text {whitedwarf }}^s+\pi_{\text {binary }}^s\]$](/articles/aa/full_html/2024/07/aa49654-24/aa49654-24-eq18.png) .
.
We investigate how a different combination of the DSC baseline classifiers performs in terms of completeness and purity. We report in this work results of a parametric weighted sum combination. We compute a new classifier, Combmod-α, from a weighted sum of the GDR3 Allosmod and Specmod posterior probabilities. The posterior probability of Combmod-α for class k is defined as
![Mathematical equation: $\[P_k^{c_\alpha}= \begin{cases}\left(1-\alpha_k\right) P_k^s+\alpha_k P_k^a & \text { for the quasar and galaxy classes, } \\ \left(1-\alpha_k\right) P_k^s+\alpha_k P_k^a \frac{\pi_k^s}{\pi_{\text {star }}^a} & \text { for the stellar classes, }\end{cases}\]$](/articles/aa/full_html/2024/07/aa49654-24/aa49654-24-eq19.png) (9)
(9)
and normalised across all five classes
![Mathematical equation: $\[P_k^{c_\alpha}=P_k^{c_\alpha} / \sum_{k^{\prime}} P_{k^{\prime}}^{c_\alpha},\]$](/articles/aa/full_html/2024/07/aa49654-24/aa49654-24-eq20.png) (10)
(10)
where the parameters {αk} control the contribution of each classifier, subject to αk≥0. We explore the optimal values of these parameters over a uniform grid between 0 and 1, and set the contribution of the stellar classes to αstar=αwhitedwarf=αbinary.
For different configurations of the {αk}, we compute the posterior probabilities of the classifier and assess its performance through the geometric score. We define the geometric score as the geometric mean of the completeness and purity of the extragalactic classes, as follows:
![Mathematical equation: $\[\text { score}_{\text {geometric} }=\left(\text { completeness }_{\text {quasar }} \times \text { completeness }_{\text {galaxy }}\right.\\\left.\qquad\quad\times \text { purity }_{\text {quasar }} \times \text { purity }_{\text {galaxy }}\right)^{1 / 4} \text {. }\]$](/articles/aa/full_html/2024/07/aa49654-24/aa49654-24-eq21.png) (11)
(11)
The extreme case of αk = 0 for all k has only Specmod contributing to the posterior probabilities, while the case of αk=1 has only Allosmod contributing. When αstar > 0.5, the contribution from Allosmod is increased compared to Specmod. Since the GDR3 Allosmod did not discriminate between the three stellar types, we limit the contribution αstar to values below 0.5, in order to balance out the contributions of Specmod and Allosmod across the five classes.
4.2.2 Performance
For different configurations of the {αk}, the configuration with the highest geometric score (~0.76) is obtained for αquasar≥0.7, αgalaxy=0.6 and αstar=0.5. This configuration can be interpreted as boosting Allosmod predictions for the quasar and galaxy classes, while keeping the contribution from both classifiers for the stellar classes equal. A similar evaluation of different αk combinations of Allosmod and Specmod using the variable prior, where we identify the best configuration with the highest geometric score (~0.74) for αquasar≥0.5, αgalaxy,=0.6 and αstar=0.5. The best classifiers Combmod-α correspond to αglob=[1.0, 0.6, 0.5] using the global prior and αvari=[0.6, 0.6, 0.5] using the variable prior. Figures D.1a–D.1b summarise the results obtained for different parametric combinations of Allosmod and Specmod using the global prior and the variable prior, respectively.
The overall performance evaluated on the cleaned validation data set (as described in Sec. 3.4) is summarised in Table 1 under the label ‘Combmod-α’. Confusion matrices are provided in Figs. B.2a and B.2c for reference. The 2D performance of the Combmod-α classifier is compared to the GDR3 Combmod in Fig. 6. To facilitate the comparison, we also compute 1D representations of the completenesses and purities as a function of Galactic latitude in Figs. 7–8. Table 2 summarises the 2D performance evaluated on the cleaned validation data set. Combmod-α using the global prior achieves average 2D purities of the quasar and galaxy classes of 79% and 93%, compared to 55% and 88% in the GDR3 Combmod. The average 2D completenesses for the quasar and galaxy classes are 82% and of 93%, respectively, compared to 92% and 95% in the GDR3 Combmod. Similarly, Combmod-α using the variable prior reports higher 2D completenesses for the quasars (an increase by 7 percentage points) but reduced 2D purities for the extragalactic classes (a drop by 3 percentage points). In Table 3, the comparison at different magnitude limits shows that the highest increase in purity is obtained at fainter magnitudes. For quasars at G≥20, Combmod-α using the global prior increases the average 2D purities by 42 percentage points but reduces the average 2D completenesses by 15 percentage points. Similarly, Combmod-α using the variable prior increases the 2D purities by 31 percentage points but reduces the average 2D completenesses by 5 percentage points. At magnitudes G < 20, the new combined classifiers show a similar performance across all target classes, with a drop in the 2D completenesses by 2-5 percentage points and an increase in the 2D purities by 2-5 percentage points.
To summarise, the new combined classifier improves the purity of the extragalactic classes, particularly the quasar class (Table 2). Compared to the GDR3 Combmod, Combmod-α increases the average 2D purities by 23 percentage points and 18 percentage points using the global prior and the variable prior, respectively. In contrast, the new combined classifier reduces the average 2D completenesses by 10 percentage points and 3 percentage points using the global prior and the variable prior, respectively. Therefore, the new classifier achieves a significant improvement in purity for a small loss of completeness.
 |
Fig. 5 As Figs. 2c and 3c, but comparing the DSC Combmod using the variable prior and the global prior on the clean validation data set. In each panel the solid line shows the performance of the Combmod using the global prior and the dash dot line using the variable prior. (a) Smoothed average of the 2D completenesses. (b) Smoothed average of the 2D purities. |
 |
Fig. 6 Representation in 2D of DSC classification results of the Combmod classifier compared to new combination of the DSC classifiers Combmod-α evaluated on the cleaned validation data set as a function of Galactic latitude and brightness. In each subplot, left and right two panels refer to the completenesses and the purities of the extragalactic classes, respectively. The number of sources per target class in the cleaned validation set are reported in Table A.2. (a) Combmod using the global prior (average 2D completenesses of 92% and 95%, and 2D purities of 55% and 88%, for the quasar and galaxy classes, respectively). (b) Combmod-α using the global prior (average 2D completenesses of 82% and 93%, and 2D purities of 79% and 93%). (c) Combmod using the variable prior (average 2D completenesses of 95% and 96%, and 2D purities of 57% and 86%). (d) Combmod-α using the variable prior (average 2D completenesses of 89% and 94%, and 2D purities of 74% and 90%). |
 |
Fig. 7 As Figs. 2c and 3c, but comparing the DSC Combmod and the new classifier Combmod-α using the global prior on the clean validation data set. In each panel the solid line shows the performance of the Combmod and the dash line the Combmod-α, using the global prior. (a) Smoothed average of the 2D completenesses. (b) Smoothed average of the 2D purities. |
 |
Fig. 8 As Fig. 7, but using the variable prior instead of the global prior. In each panel the dash dot line shows the performance of the Combmod and the dash line the Combmod-α, using the variable prior. (a) Smoothed average of the 2D completenesses. (a) Smoothed average of the 2D purities. |
Quasar and galaxy candidates classified by GDR3 DSC Combmod and Combmod-α excluding the LMC and the SMC.
4.2.3 Application to all of GDR3
We now compute Combmod-α probabilities for the ~1.4 billion sources with published6 GDR3 DSC Specmod and Allosmod probabilities.
Table 4 reports the total numbers of the extragalactic candidates classified by Combmod and Combmod-α excluding the LMC and the SMC. Figures 9a and 9c show the Galactic sky distributions of the quasar and galaxy candidates obtained from maximum probabilities of Combmod-α using the global prior.
Across the full sky, Combmod-α predicts 2 041 979 quasars and 3 031 885 galaxies, compared to 5 254 959 quasars and 3 575 099 galaxies from the GDR3 Combmod. We exclude the LMC and SMC regions from this analysis due to the large stellar contamination, and find 1719 638 quasars and 2971 433 galaxies classified by Combmod-α, compared to 2909 081 quasars and 3 419 626 galaxies classified by the GDR3 Combmod. The difference in numbers in the classifications between the two classifiers is due, on one hand to the improved purity of Combmod-α by rejecting far more stellar contaminants, and on the other hand to the bright magnitude limit in Combmod-α. In GDR3, DSC Allosmod assignes a star label to all sources brighter than G=14.5. By design, Combmod-α inherits this characteristic.
The distributions of Gaia astrometry and photometry for the quasar and galaxy candidates are reported in Fig. 10. Compared to the GDR3 Combmod, the features distributions in the Combmod-α extragalactic candidates show a smaller scatter suggesting a lower level of stellar contaminants that is even more reduced for quasars. In general, the distribution of normalised parallaxes and proper motions (PM) is expected to agree with noise for quasars and follow a normal distribution with a zero mean and a unit variance. For the Combmod-α quasars, the normalised parallaxes are closer to a normal distribution compared to the GDR3 Combmod quasars. The colour distribution shows no significant difference between the Combmod and Combmod-α quasars, only bluer galaxies (lower GBP − GRP) are filtered out by Combmod-α. The G-band magnitude distribution of classified quasars and galaxies by Combmod-α is restricted to magnitudes fainter than 14.5, which corresponds to the magnitude limit set by Allosmod in GDR3. In the current configuration, Combmod-α uses exclusively the GDR3 Allosmod for quasars (αquasar=1). Despite reducing the parameter αquasar from 1 to 0.9, so that Specmod contributes for the quasar class, we obtain similar results in the features distributions. This means the majority of bright sources at G = 14.5 classified by Specmod as quasar or galaxy candidates are likely stellar contaminants now ejected by Combmod-α.
The quasar and galaxy candidates classified as such only by Combmod and not by Combmod-α (1230 071 quasars and 459 835 galaxies) are reported in Figs. 9b–9d. Their sky distribution shows an excess of sources close to the Galactic plane, especially for galaxies. We also notice a higher density close to the LMC in the distribution of the quasar candidates of the GDR3 Combmod. From the performance of Combmod-α in Sect. 4.2.2, a large fraction of the ~1.2 million sources classified exclusively by Combmod are likely stellar contaminants now rejected by Combmod-α.
To summarise, compared to the GDR3 Combmod, the DSC extragalactic candidates from the new combination of the GDR3 Specmod and Allosmod constitute a purer sample, although incomplete, up to magnitudes of G = 14.5.
5 Conclusions
We have reassessed the performance of the DSC classification results in GDR3, and use a new combination of the Specmod and Allosmod classifiers to significantly improve the purity of the extragalactic classifications.
Classification results summarised through global metrics do not reflect how the performance of a classifier depends on the properties of the sources. We have therefore assessed the completeness and purity as a function of magnitude and Galactic latitude. This reveals a significant variation in the performance allowing us, among other things, to identify regions most affected by stellar contamination. Unsurprisingly, completeness and purity are lowest at the faintest magnitudes. In Table 2, we report the 2D completenesses and purities (i.e. averaged over magnitude and latitude bins), excluding the Magellanic Clouds where the contribution of the stellar contaminants heavily affects the purity. Over all magnitudes and latitudes, the average 2D completenesses for quasars, galaxies and white dwarfs are 92%, 95%, and 43%, and the average 2D purities are 55%, 88%, and 94%, respectively. This is a significant improvement over what was published and claimed in GDR3. This improvement comes primarily from the cleaned validation set. For G<20 the average 2D purities are 86% for quasars and 92% for galaxies; for G≥20 the average 2D purities is 20% for quasars and 83% for galaxies (Table 3).
We have also examined the impact of a variable prior on the results. Rather than a single number reflecting the prior probability of a source being a quasar (for example), we modified this to be a function of G magnitude and Galactic latitude. Compared to GDR3 Combmod, the application of the variable prior improves the 2D completenesses and purities of the quasars, galaxies, and white dwarfs only by a small amount (2-3 percentage points), mainly at fainter magnitudes.
More significantly, we introduced a new additive parametric combination of the GDR3 DSC baseline classifiers Specmod and Allosmod. The new combined classifier, which we call Combmod-α, increases the overall purities by about 20 percentage points for the extragalactic classes, at the cost of only a small decrease in completeness (about 10 and 2 percentage points for the quasars and galaxies, respectively). Combmod-α achieves, for the quasar and galaxy classes, respectively, average 2D completenesses of 82% and 93%, and average 2D purities of 79% and 93% using the global prior. Using the variable prior, the average 2D completenesses are 89% and 94%, and the average 2D purities are 74% and 90%. Even for faint sources, the improvement with Combmod-α is significant: at G≥20 the average 2D purities for the quasar class are 62% using the global prior, and 51% using the variable prior. This compares to the average 2D purities of just 20% in the GDR3 Combmod. The newly introduced combination of the baseline classifiers is therefore able to produce much purer catalogues of extragalactic objects using the existing GDR3 results, without having to train or apply new classifiers.
We plan to implement the presented approaches – the continuous variable prior and a parametric combination of the baseline classifiers – in future versions of DSC for the next Gaia Data Release. We expect that a new combined classifier would reach a similar performance to those presented here to provide higher purity catalogues of extragalactic candidates. We also publish our software implementing the continuous variable prior and new Combmod-α classifier applied to the GDR3 DSC results as open source software.
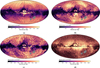 |
Fig. 9 Galactic sky distribution of sources classified from maximum probabilities as quasars (top row) and galaxies (bottom row) by Combmod and Combmod-α using the global prior at HEALpixel level 7 in Mollweide projection. (a) Quasar candidates identified by Combmod-α (1 719 638 sources). (b) Quasar candidates identified only by Combmod (1 230 071 sources). (c) Galaxy candidates identified by Combmod-α (2971 433 sources). (d) Galaxy candidates identified only by Combmod (459 835 sources). The LMC and SMC regions are masked in grey. |
 |
Fig. 10 Features distributions of extragalactic candidates from maximum probabilities classified by the GDR3 Combmod and Combmod-α using the global prior. (a) Quasar candidates. (b) Galaxy candidates. Excluding the LMC and SMC regions, class predictions from maximum probabilities of Combmod-α give 1 719 638 quasars and 2 971 433 galaxies compared to 2 909 081 quasars and 3 419 626 galaxies classified by the GDR3 Combmod. Combmod results are indicated in (a) blue for quasars and (b) orange for galaxies. Combmod-α results are showed in black. |
Acknowledgements
We would like to thank René Andrae, Morgan Fouesneau, and Ruth Carballo for their constructive comments and helpful suggestions during the realisation of this work. We sincerely thank the referee for their detailed comments and suggestions that helped improve the manuscript. This work has made use of data from the European Space Agency (ESA) mission Gaia (https://www.cosmos.esa.int/gaia), processed by the Gaia Data Processing and Analysis Consortium (DPAC, https://www.cosmos.esa.int/web/gaia/dpac/consortium). Funding for the DPAC has been provided by national institutions, in particular the institutions participating in the Gaia Multilateral Agreement. This work was funded in part by the DLR (German space agency) via grant 50 QG 2102.
Appendix A Validation data set
This section summarises the validation data set used in the study. Table A.1 provides the list of the cross match catalogues used to identify mislabelled sources in the stellar classes (star, white dwarf and binary star classes) of the validation data set. The selection criteria are applied to the best match (minimal crossmatch radius of 1 arcsecond). Table A.2 reports a brief summary of the number of sources per target class after removal of the identified contaminants (i.e. mislabelled sources) and the Magellanic Clouds.
Summary of the cross-match catalogues and the criteria for contaminant removal from the stellar classes.
Summary of the number of sources in the validation data set.
Appendix B DSC classification results in GDR3
To quantify the performance in multi-class classification, the purity (precision) and the completeness (recall) are computed from the confusion matrices. In this section, we report the confusion matrices used to compute the overall metrics discussed throughout this study. Figures B.1a and B.1b refer to the confusion matrices of the DSC Combmod classifier using the global prior on the original validation data set and the cleaned validation data set, respectively. Figure B.2a reports the confusion matrix of the new combined classifier Combmod-α using the global prior on the cleaned validation data set. Figures B.2b and B.2c report the confusion matrices of the DSC Combmod and the new combined classifier Combmod-α using the variable prior on the cleaned validation data set.
The completeness and the purity before the adjustment to the class fractions (cf. Section 3.1) are listed in the leading diagonal of the confusion matrix, in blue and in red, respectively. For example, the unadjusted purity and completeness of the quasar class in B.1a are ~0.976 (= 282 464 / 289 431) and ~0.916 (= 282 464 / 308 526), respectively. After adjusting to account for the class fractions, the completenesses are unchanged while the purities are recomputed. For the extragalactic classes, we note that the purities before the adjustment are ~96% and after the adjustment are decreased to ~21% to account for the reevaluated contribution of the stellar contaminants in the sky (Table 1).
 |
Fig. B.1 Unadjusted confusion matrices of DSC classifiers computed on the validation data set over the five classes. (a) Confusion matrix computed over the full validation data set of 1 456 908 sources of DSC Combmod using the global prior. (b) Confusion matrix computed on the cleaned validation data set of 1 421 155 sources of DSC Combmod using the global prior. ‘Unadjusted’ means that confusion matrices have not yet been adjusted to represent the expected class fractions. Indicated in blue colours are the fractions of the number of predictions per class normalised by the total number of true labels in this class (last row in grey), and in red colours the fractions of the predictions per class normalised by the total number of the predictions (last column in grey). The diagonal elements of the matrix in blue refer to the unadjusted completeness TP/(TP+FN) and in red to the unadjusted purity TP/(TP+FP). The colour scheme of the background is defined such that dark colours refer to higher number of sources and white colours to lower values. |
 |
Fig. B.2 As B.1 but for Combmod using the variable prior and the new Combmod-α classifiers. (a) Unadjusted confusion matrix computed on the cleaned validation data set of 1 421 155 sources for Combmod-α with {αquasar=1.0, αgalaxy=0.6, αstar=0.5}, using the global prior. (b) Unadjusted confusion matrix computed on the cleaned validation data set of 1 421 155 sources for DsC Combmod after application of the continuous variable prior. (c) Unadjusted confusion matrix computed on the cleaned validation data set of 1 421 155 sources for Combmod-α with {αquasar=0.6, αgalaxy=0.6, αstar=0.5} after application of the continuous variable prior. |
Appendix C Variable prior
The section provides a representation of the variable prior de fined in Section 4.1. Figure C.1 shows the prior as a function of Galactic latitude and brightness for the quasar, galaxy, and stellar classes.
 |
Fig. C.1 Representation of the variable prior for the quasar, galaxy, and stellar classes. For visualisation, the viewing angle is adapted to distinguish regions of interest in the mapping. The x-axis and y-axis refer to the Galactic latitude and brightness, and the z-axis reports to the prior. The grid corresponds to the discretised 10×10 definition of the prior. The coloured surface represents the fitted spline expanding outside of the boundaries of the grid. The colour scheme is defined such that red colours refer to higher values and blue colours to lower values. Left to right, are represented the priors for the quasar, galaxy, and star classes. |
Appendix D Parametric combination of DSC classifiers
This section reports the geometric score evaluated at different configurations of the parametric combination of DSC classifiers Specmod and Allosmod. The parameters α=[αquasar, αgalaxy, αstar] are computed on a coarse grid where αquasar and αgalaxy are set to vary between 0 and 1, while αstar is fixed between 0 and 0.5. For each combination of the α parameters, we compute the posterior probabilities and evaluate the classification metrics. Figures D.1a and D.1b present the results obtained using the global prior and the variable prior, respectively.
 |
Fig. D.1 Geometric score of the extragalactic classes for different parametric combinations of DSC Specmod and Allosmod. (a) Results of all combinations using the global prior. (b) As (a) but using the variable prior. The parameters α=[αquasar, αgalaxy, αstar] are computed on a coarse grid. The geometric score of the extragalactic classes is computed at each combination. The evolving sequence can be followed from top to bottom, left to right, where αquasar and αgalaxy are set to vary between 0 and 1 while αstar is fixed between 0 and 0.5. Each panel reports the geometric score evaluated at each αstar as a function of the other two parameters. The colour scheme of the mapping is defined such that bright colours refer to higher geometric score values and dark colours to lower values. |
References
- Abbott, T. M. C., Adamów, M., Aguena, M., et al. 2021, ApJS, 255, 20 [NASA ADS] [CrossRef] [Google Scholar]
- Abdurro’uf, Accetta, K., Aerts, C., et al. 2022, ApJS, 259, 35 [NASA ADS] [CrossRef] [Google Scholar]
- Angeli, F. D., Weiler, M., Montegriffo, P., et al. 2023, A&A, 674, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Assef, R. J., Stern, D., Noirot, G., et al. 2018, ApJS, 234, 23 [Google Scholar]
- Ata, M., Baumgarten, F., Bautista, J., et al. 2018, MNRAS, 473, 4773 [NASA ADS] [CrossRef] [Google Scholar]
- Babusiaux, C., Fabricius, C., Khanna, S., et al. 2023, A&A, 674, A32 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bai, Y., Liu, J., Wang, S., & Yang, F. 2018, AJ, 157, 9 [NASA ADS] [CrossRef] [Google Scholar]
- Bailer-Jones, C. A. L., Fouesneau, M., & Andrae, R. 2019, MNRAS, 490, 5615 [CrossRef] [Google Scholar]
- Bailer-Jones, C. A. L., Rybizki, J., Fouesneau, M., Demleitner, M., & Andrae, R. 2021, AJ, 161, 147 [Google Scholar]
- Bailer-Jones, C. A. L., Teyssier, D., Delchambre, L., et al. 2023, A&A, 674, A41 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bañados, E., Venemans, B. P., Mazzucchelli, C., et al. 2018, Nature, 553, 473 [Google Scholar]
- Baqui, P. O., Marra, V., Casarini, L., et al. 2021, A&A, 645, A87 [EDP Sciences] [Google Scholar]
- Berk, D. E. V., Richards, G. T., Bauer, A., et al. 2001, AJ, 122, 549 [NASA ADS] [CrossRef] [Google Scholar]
- Beutler, F., Blake, C., Colless, M., et al. 2011, MNRAS, 416, 3017 [NASA ADS] [CrossRef] [Google Scholar]
- Beutler, F., Blake, C., Colless, M., et al. 2012, MNRAS, 423, 3430 [NASA ADS] [CrossRef] [Google Scholar]
- Burke, C. J., Aleo, P. D., Chen, Y.-C., et al. 2019, MNRAS, 490, 3952 [NASA ADS] [CrossRef] [Google Scholar]
- Busca, N. G., Delubac, T., Rich, J., et al. 2013, A&A, 552, A96 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Chaini, S., Bagul, A., Deshpande, A., et al. 2023, MNRAS, 518, 3123 [Google Scholar]
- Conroy, C. 2013, ARA&A, 51, 393 [NASA ADS] [CrossRef] [Google Scholar]
- Creevey, O. L., Sarro, L. M., Lobel, A., et al. 2023, A&A, 674, A39 [CrossRef] [EDP Sciences] [Google Scholar]
- Delchambre, L., Bailer-Jones, C. A. L., Bellas-Velidis, I., et al. 2023, A&A, 674, A31 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Delubac, T., Bautista, J. E., Busca, N. G., et al. 2015, A&A, 574, A59 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dharmawardena, T. E., Bailer-Jones, C. A. L., Fouesneau, M., & Foreman-Mackey, D. 2022, A&A, 658, A166 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dharmawardena, T. E., Bailer-Jones, C. A. L., Fouesneau, M., et al. 2023, MNRAS, 519, 228 [Google Scholar]
- Fan, X. 1999, AJ, 117, 2528 [CrossRef] [Google Scholar]
- Fan, X., Strauss, M. A., Becker, R. H., et al. 2006, AJ, 132, 117 [NASA ADS] [CrossRef] [Google Scholar]
- Flesch, E. W. 2015, PASA, 32, e010 [Google Scholar]
- Flesch, E. W. 2023, Open J. Astrophys., 6, 49 [NASA ADS] [CrossRef] [Google Scholar]
- Font-Ribera, A., Kirkby, D., Busca, N., et al. 2014, JCAP, 2014, 027 [Google Scholar]
- Gaia Collaboration (Prusti, T., et al.) 2016, A&A, 595, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Vallenari, A., et al.) 2023, A&A, 674, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gentile Fusillo, N. P., Tremblay, P.-E., Cukanovaite, E., et al. 2021, MNRAS, 508, 3877 [NASA ADS] [CrossRef] [Google Scholar]
- Geurts, P., Ernst, D., & Wehenkel, L. 2006, Mach. Learn., 63, 3 [Google Scholar]
- Golob, A., Sawicki, M., Goulding, A. D., & Coupon, J. 2021, MNRAS, 503, 4136 [NASA ADS] [CrossRef] [Google Scholar]
- Guo, X., Liu, C., Qiu, B., et al. 2022, MNRAS, 517, 1837 [NASA ADS] [CrossRef] [Google Scholar]
- He, Z., Qiu, B., Luo, A.-L., et al. 2021, MNRAS, 508, 2039 [NASA ADS] [CrossRef] [Google Scholar]
- Hughes, A. C. N., Bailer-Jones, C. A. L., & Jamal, S. 2022, A&A, 668, A99 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ibata, R., Malhan, K., Martin, N., et al. 2021, ApJ, 914, 123 [NASA ADS] [CrossRef] [Google Scholar]
- Kim, E. J., & Brunner, R. J. 2017, MNRAS, 464, 4463 [Google Scholar]
- Kuhn, M. A., Hillenbrand, L. A., Sills, A., Feigelson, E. D., & Getman, K. V. 2019, ApJ, 870, 32 [CrossRef] [Google Scholar]
- Lawrence, A., Warren, S. J., Almaini, O., et al. 2007, MNRAS, 379, 1599 [Google Scholar]
- Li, C., Zhang, Y., Cui, C., et al. 2021, MNRAS, 506, 1651 [NASA ADS] [CrossRef] [Google Scholar]
- Logan, C. H. A., & Fotopoulou, S. 2020, A&A, 633, A154 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Luo, A. L., Zhao, Y. H., Zhao, G., et al. 2022, VizieR Online Data Catalog, V/156 [Google Scholar]
- Malhan, K., Ibata, R. A., & Martin, N. F. 2018, MNRAS, 481, 3442 [Google Scholar]
- Martínez-Solaeche, G., Queiroz, C., Delgado, R. M. G., et al. 2023, A&A, 673, A103 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Małek, K., Solarz, A., Pollo, A., et al. 2013, A&A, 557, A16 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Merz, G., Liu, Y., Burke, C. J., et al. 2023, MNRAS, 526, 1122 [NASA ADS] [CrossRef] [Google Scholar]
- Mortlock, D. J., Warren, S. J., Venemans, B. P., et al. 2011, Nature, 474, 616 [Google Scholar]
- Nakazono, L., Mendes de Oliveira, C., Hirata, N. S. T., et al. 2021, MNRAS, 507, 5847 [CrossRef] [Google Scholar]
- Newberg, H. J., & Yanny, B. 1997, ApJS, 113, 89 [NASA ADS] [CrossRef] [Google Scholar]
- Peng, N., Zhang, Y., Zhao, Y., & Wu, X.-b. 2012, MNRAS, 425, 2599 [NASA ADS] [CrossRef] [Google Scholar]
- Peters, C. M., Richards, G. T., Myers, A. D., et al. 2015, ApJ, 811, 95 [NASA ADS] [CrossRef] [Google Scholar]
- Reynolds, D. 2015, in Encyclopedia of Biometrics, eds. S. Z. Li, & A. K. Jain, 827 [CrossRef] [Google Scholar]
- Riess, A. G., Casertano, S., Yuan, W., et al. 2018, ApJ, 861, 126 [NASA ADS] [CrossRef] [Google Scholar]
- Riess, A. G., Casertano, S., Yuan, W., et al. 2021, ApJ, 908, L6 [NASA ADS] [CrossRef] [Google Scholar]
- Rimoldini, L., Holl, B., Gavras, P., et al. 2023, A&A, 674, A14 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rodrigues, N. V. N., Raul Abramo, L., Queiroz, C., et al. 2023, MNRAS, 520, 3494 [NASA ADS] [CrossRef] [Google Scholar]
- Soubiran, C., Cantat-Gaudin, T., Romero-Gómez, M., et al. 2018, A&A, 619, A155 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Stoppa, F., Bhattacharyya, S., Austri, R. R. d., et al. 2023, A&A, 680, A109 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ulla, A., Creevey, O. L., Álvarez, M. A., et al. 2022, Gaia DR3 documentation, European Space Agency; Gaia Data Processing and Analysis Consortium. Online at https://gea.esac.esa.int/archive/documentation/GDR3/index.html, 11 [Google Scholar]
- Volonteri, M., & Rees, M. J. 2006, ApJ, 650, 669 [NASA ADS] [CrossRef] [Google Scholar]
- Wang, C., Bai, Y., López-Sanjuan, C., et al. 2022, A&A, 659, A144 [Google Scholar]
- Weir, N., Fayyad, U. M., & Djorgovski, S. 1995, AJ, 109, 2401 [NASA ADS] [CrossRef] [Google Scholar]
- Wenger, M., Ochsenbein, F., Egret, D., et al. 2000, A&AS, 143, 9 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Zarrouk, P., Burtin, E., Gil-Marín, H., et al. 2018, MNRAS, 477, 1639 [NASA ADS] [CrossRef] [Google Scholar]
- Zhang, Y., Zhao, Y., & Wu, X.-B. 2021, MNRAS, 503, 5263 [NASA ADS] [CrossRef] [Google Scholar]
Excluding sources with coordinates (ra,dec) within a radius of 9° and 6° around the LMC and the SMC, respectively.
Coordinates of the Large Magellanic Cloud (LMC) and the Small Magellanic Cloud (SMC) are (RA 80.8942°, Dec −69.7561°) and (RA 13.1583°, Dec −72.8003°), respectively.
All Tables
Summary of the overall classification performance evaluated on the validation data set.
Summary of the average 2D classification performance evaluated on the validation data set.
Summary of the average 2D classification performance evaluated on the validation data set at different magnitude limits.
Quasar and galaxy candidates classified by GDR3 DSC Combmod and Combmod-α excluding the LMC and the SMC.
Summary of the cross-match catalogues and the criteria for contaminant removal from the stellar classes.
All Figures
|
Fig. 1 Representation in 2D of the distribution of sources as a function of Galactic latitude and brightness of the original validation data set. Each distribution is normalised by the total number of sources in that panel. The colour scale is set such that bright colours indicate a higher density of sources compared to dark regions. The 2D representation of the density of sources is defined on a grid in | sin b| and G of 50×91 bins. As a design choice, the binning in magnitude bins compresses the range at G<14. Contours (green lines) are used in the regions of highest density to indicate the normalised density in log scale. |
| In the text | |
|
Fig. 2 Completeness of DSC Combmod. Predicted labels are obtained from the class with the largest posterior probability using the global prior. (a) Variation of completeness with magnitude and absolute Galactic latitude for each of the three classes using the original validation data set. (b) As (a), but using the cleaned validation set (i.e. after removal of the Magellanic Clouds and mislabelled sources). (c) Completeness as a function of absolute Galactic latitude for three brightness ranges (columns) for each class (rows). In each panel the dashed line shows the performance on the original validation data set and the solid line the cleaned validation data set. These one-dimensional plots are essentially a marginalisation of the 2D representations in panels a and b but weighting by the number of sources in each bin. The curves have been smoothed with a Gaussian filter to remove noise. The shaded region encompasses the LMC at | sin b| = −0.54 and the SMC | sin b| = −0.70 (which are excluded from the cleaned set). |
| In the text | |
 |
Fig. 3 As Fig. 2, but for the 2D purities. |
| In the text | |
|
Fig. 4 DSC Combmod classifications for the white dwarf class on the cleaned validation data set using the global prior. (a) DSC WDs predictions on the full sample. (b) DSC WDs predictions after the quality cut on Gaia data. Each panel shows, from left to right, the true positives (i.e. correct predictions), the stellar false negatives (i.e. sources from the white dwarf class classified as stars), and the stellar false positives (i.e. sources from the star class classified as white dwarfs). Faint sources G ≥ 18 (grey) and bright sources G < 18 (magenta) are plotted separately. |
| In the text | |
|
Fig. 5 As Figs. 2c and 3c, but comparing the DSC Combmod using the variable prior and the global prior on the clean validation data set. In each panel the solid line shows the performance of the Combmod using the global prior and the dash dot line using the variable prior. (a) Smoothed average of the 2D completenesses. (b) Smoothed average of the 2D purities. |
| In the text | |
|
Fig. 6 Representation in 2D of DSC classification results of the Combmod classifier compared to new combination of the DSC classifiers Combmod-α evaluated on the cleaned validation data set as a function of Galactic latitude and brightness. In each subplot, left and right two panels refer to the completenesses and the purities of the extragalactic classes, respectively. The number of sources per target class in the cleaned validation set are reported in Table A.2. (a) Combmod using the global prior (average 2D completenesses of 92% and 95%, and 2D purities of 55% and 88%, for the quasar and galaxy classes, respectively). (b) Combmod-α using the global prior (average 2D completenesses of 82% and 93%, and 2D purities of 79% and 93%). (c) Combmod using the variable prior (average 2D completenesses of 95% and 96%, and 2D purities of 57% and 86%). (d) Combmod-α using the variable prior (average 2D completenesses of 89% and 94%, and 2D purities of 74% and 90%). |
| In the text | |
|
Fig. 7 As Figs. 2c and 3c, but comparing the DSC Combmod and the new classifier Combmod-α using the global prior on the clean validation data set. In each panel the solid line shows the performance of the Combmod and the dash line the Combmod-α, using the global prior. (a) Smoothed average of the 2D completenesses. (b) Smoothed average of the 2D purities. |
| In the text | |
|
Fig. 8 As Fig. 7, but using the variable prior instead of the global prior. In each panel the dash dot line shows the performance of the Combmod and the dash line the Combmod-α, using the variable prior. (a) Smoothed average of the 2D completenesses. (a) Smoothed average of the 2D purities. |
| In the text | |
|
Fig. 9 Galactic sky distribution of sources classified from maximum probabilities as quasars (top row) and galaxies (bottom row) by Combmod and Combmod-α using the global prior at HEALpixel level 7 in Mollweide projection. (a) Quasar candidates identified by Combmod-α (1 719 638 sources). (b) Quasar candidates identified only by Combmod (1 230 071 sources). (c) Galaxy candidates identified by Combmod-α (2971 433 sources). (d) Galaxy candidates identified only by Combmod (459 835 sources). The LMC and SMC regions are masked in grey. |
| In the text | |
|
Fig. 10 Features distributions of extragalactic candidates from maximum probabilities classified by the GDR3 Combmod and Combmod-α using the global prior. (a) Quasar candidates. (b) Galaxy candidates. Excluding the LMC and SMC regions, class predictions from maximum probabilities of Combmod-α give 1 719 638 quasars and 2 971 433 galaxies compared to 2 909 081 quasars and 3 419 626 galaxies classified by the GDR3 Combmod. Combmod results are indicated in (a) blue for quasars and (b) orange for galaxies. Combmod-α results are showed in black. |
| In the text | |
|
Fig. B.1 Unadjusted confusion matrices of DSC classifiers computed on the validation data set over the five classes. (a) Confusion matrix computed over the full validation data set of 1 456 908 sources of DSC Combmod using the global prior. (b) Confusion matrix computed on the cleaned validation data set of 1 421 155 sources of DSC Combmod using the global prior. ‘Unadjusted’ means that confusion matrices have not yet been adjusted to represent the expected class fractions. Indicated in blue colours are the fractions of the number of predictions per class normalised by the total number of true labels in this class (last row in grey), and in red colours the fractions of the predictions per class normalised by the total number of the predictions (last column in grey). The diagonal elements of the matrix in blue refer to the unadjusted completeness TP/(TP+FN) and in red to the unadjusted purity TP/(TP+FP). The colour scheme of the background is defined such that dark colours refer to higher number of sources and white colours to lower values. |
| In the text | |
|
Fig. B.2 As B.1 but for Combmod using the variable prior and the new Combmod-α classifiers. (a) Unadjusted confusion matrix computed on the cleaned validation data set of 1 421 155 sources for Combmod-α with {αquasar=1.0, αgalaxy=0.6, αstar=0.5}, using the global prior. (b) Unadjusted confusion matrix computed on the cleaned validation data set of 1 421 155 sources for DsC Combmod after application of the continuous variable prior. (c) Unadjusted confusion matrix computed on the cleaned validation data set of 1 421 155 sources for Combmod-α with {αquasar=0.6, αgalaxy=0.6, αstar=0.5} after application of the continuous variable prior. |
| In the text | |
|
Fig. C.1 Representation of the variable prior for the quasar, galaxy, and stellar classes. For visualisation, the viewing angle is adapted to distinguish regions of interest in the mapping. The x-axis and y-axis refer to the Galactic latitude and brightness, and the z-axis reports to the prior. The grid corresponds to the discretised 10×10 definition of the prior. The coloured surface represents the fitted spline expanding outside of the boundaries of the grid. The colour scheme is defined such that red colours refer to higher values and blue colours to lower values. Left to right, are represented the priors for the quasar, galaxy, and star classes. |
| In the text | |
|
Fig. D.1 Geometric score of the extragalactic classes for different parametric combinations of DSC Specmod and Allosmod. (a) Results of all combinations using the global prior. (b) As (a) but using the variable prior. The parameters α=[αquasar, αgalaxy, αstar] are computed on a coarse grid. The geometric score of the extragalactic classes is computed at each combination. The evolving sequence can be followed from top to bottom, left to right, where αquasar and αgalaxy are set to vary between 0 and 1 while αstar is fixed between 0 and 0.5. Each panel reports the geometric score evaluated at each αstar as a function of the other two parameters. The colour scheme of the mapping is defined such that bright colours refer to higher geometric score values and dark colours to lower values. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.