| Issue |
A&A
Volume 668, December 2022
|
|
|---|---|---|
| Article Number | A99 | |
| Number of page(s) | 20 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202244859 | |
| Published online | 13 December 2022 | |
Quasar and galaxy classification using Gaia EDR3 and CatWise2020★
1
Max Planck Institute for Astronomy,
Königstuhl 17,
69117
Heidelberg, Germany
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
School of Mathematical and Physical Sciences, Macquarie University,
Sydney, NSW
2109, Australia
3
Research Centre in Astronomy, Astrophysics & Astrophotonics, Macquarie University,
Sydney, NSW
2109, Australia
Received:
1
September
2022
Accepted:
8
October
2022
Abstract
In this work, we assess the combined use of Gaia photometry and astrometry with infrared data from CatWISE in improving the identification of extragalactic sources compared to the classification obtained using Gaia data. Here we perform a comprehensive study in which we assess different input feature configurations and prior functions to identify extragalactic sources in Gaia, with the aim of presenting a classification methodology that integrates prior knowledge stemming from realistic class distributions in the Universe. In our work, we compare different classifiers, namely Gaussian mixture models (GMMs) and the boosted decision trees, XGBoost and CatBoost, in a supervised approach, and classify sources into three classes, namely star, quasar, and galaxy, with the target quasar and galaxy class labels obtained from the Sloan Digital Sky Survey Data release 16 (SDSS16) and the star label from Gaia EDR3. In our approach, we adjust the posterior probabilities to reflect the intrinsic distribution of extragalactic sources in the Universe via a prior function. In particular, we introduce two priors, a global prior reflecting the overall rarity of quasars and galaxies, and a mixed prior that incorporates in addition the distribution of the extragalactic sources as a function of Galactic latitude and magnitude. Our best classification performances, in terms of completeness and purity of the extragalactic classes, namely the galaxy and quasar classes, are achieved using the mixed prior for sources at high latitudes and in the magnitude range G = 18.5–19.5. We apply our identified best-performing classifier to three application datasets from Gaia Data Release 3 (GDR3), and find that the global prior is more conservative in what it considers to be a quasar or a galaxy compared to the mixed prior. In particular, when applied to the quasar and galaxy candidate tables from GDR3, the classifier using a global prior achieves purities of 55% for quasars and 93% for galaxies, and purities of 59% and 91%, respectively, using the mixed prior. When compared to the performances obtained on the GDR3 pure quasar and galaxy candidate samples, we reach a higher level of purity, 97% for quasars and 99.9% for galaxies using the global prior, and purities of 96% and 99%, respectively, using the mixed prior. When refining the GDR3 candidate tables via a cross-match with SDSS DR16 confirmed quasars and galaxies, the classifier reaches purities of 99.8% for quasars and 99.9% for galaxies using a global prior, and 99.9% and 99.9% using the mixed prior. We conclude our work by discussing the importance of applying adjusted priors that portray realistic class distributions in the Universe and the effect of introducing infrared data as ancillary inputs in the identification of extragalactic sources.
Key words: methods: statistical / surveys / quasars: general / galaxies: general / stars: general / methods: data analysis
Full Table 8 is only available at the CDS via anonymous ftp to cdsarc.cds.unistra.fr (130.79.128.5) or via https://cdsarc.cds.unistra.fr/viz-bin/cat/J/A+A/668/A99
© A. C. N. Hughes et al. 2022
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe-to-Open model.
Open Access funding provided by Max Planck Society.
1 Introduction
Classification of galactic and extragalactic sources is fundamental for statistical analyses of large populations, as well as for probing the properties of individual objects. For instance, quasars (quasi-stellar objects) refer to highly luminous active galactic nuclei (AGNs), which are used as probes to investigate fundamental questions in Cosmology such as galaxy evolution (e.g., Harrison et al. 2018), the composition of the interstellar medium (e.g., Li et al. 2022), and supermassive black-hole formation and evolution (e.g., Croom et al. 2009).
All-sky surveys, such as the Sloan-Digital Sky Survey (SDSS; York et al. 2000) and the Wide-field Infrared Survey Explorer (WISE; Wright et al. 2010), have created detailed maps of the Universe at optical and infrared wavelengths. Infrared data is highly informative for the classification of stars, quasars, and galaxies. As demonstrated in the work by Kurcz et al. (2016), the authors exploited the infrared colours from WISE and reported a 90–95% classification accuracy across all object types despite the limitations observed for galaxy sources with a high dust component. The combined use of infrared data with optical photometry should, in principle, enhance the classification accuracy and reduce the number of false positives across all object types.
However, a large fraction of work on classification fails to consider the intrinsic distribution of sources of different classes, and only reports results – in particular the accuracy (i.e., the fraction of correct predictions per target class) – using a test set that is typically not representative of the observable Universe. Moreover, such test sets often under-represent the stellar contaminants that would, in practice, lower the purity of extragalactic classification. To account for the actual distribution, we introduce a prior (discussed in detail in Sect. 3.3) which, in a Bayesian framework, is used to adjust the estimated model posterior probabilities in order to reflect the class distribution of sources we would expect to exist. Furthermore, after a model has been applied, we apply an adjustment factor to the distribution of sources, such that the performance metrics are computed as if the model had been applied to the dataset with a realistic expected distribution. Applying both the prior and the adjustment factor result in classification performances that are more representative of what we can achieve – although inevitably lower – than the performances obtained when the prior and adjustment factor are not applied. Despite the lower results of some models, applying the prior correction is a necessary step because it will reveal the real classification performances, especially for large-scale surveys for which the observed sources are unknown.
The Gaia mission is an optical mapping survey designed to focus on stars in our Galaxy (Gaia Collaboration 2016). During Gaia’s scan of the entire sky, the satellite observes all point-source-like objects down to a magnitude limit of G ≃ 21, including extragalactic objects (Gaia Collaboration 2022a). A reliable methodology to identify extragalactic sources would benefit the construction of comprehensive catalogues useful for addressing fundamental questions in astronomy.
To design this method, we followed a similar approach to that of Bailer-Jones et al. (2019), who obtained a classification of extragalactic sources using Gaussian mixture models (GMMs; Fraley & Raftery 2002) applied to Gaia Data Release 2 (DR2) photometry and astrometry. In this study, we consider photometry and astrometry from Gaia Early Data Release 3 (GeDR3) and the addition of infrared photometry from CatWISE2020 (Marocco et al. 2021), as well as the application of gradient-boosting decision trees, namely XGBoost (Chen & Guestrin 2016) and CatBoost (Dorogush et al. 2017) to construct a three-class classifier (quasar, galaxy, star). The objective of our work is to assess the effects of additional information from infrared photometry and the omission of parallax and proper motions on the classification of extragalactic sources. We also aim to evaluate different classification algorithms and the appropriate use of different priors to ensure that the reported performance results are reflective of reality.
2 Data
Our input data comprise astrometry and photometry from the GeDR3 catalogue and infrared photometry from the CatWISE2020 catalogue. The training and test datasets for the quasars and galaxies are based on the sixteenth data release of SDSS (SDSS-DR16, Ahumada et al. 2020) while the star sample is built from the Gaia GeDR3 catalogue. We are aware that SDSS is not complete and does not cover the same magnitudes as Gaia; however, we accept these limitations when building our class samples.
The Gaia GeDR3 catalogue (Gaia Collaboration 2021) was published on 3 December 2020 for observations acquired between 25 July 2014 and 28 May 2017, spanning a period of 34 months. GeDR3 consists of astrometry, and broad band photometry in the G, GBP, and GRP bands for about 1.8 billion sources. In this work, we set a limit in magnitude up to G > 14.5 mag. This work commenced prior to Gaia Data Release 3 (GDR3) and therefore made use of the public data in GeDR3. However, as the photometry and astrometry remain unchanged between GeDR3 and GDR3, our findings are applicable to DR3.
The CatWISE2020 catalogue consists of about 1.8 billion sources observed across the entire sky selected from the WISE and NEOWISE survey data in the W1 and W2 (3.4 µm and 4.6 µm) bands (Marocco et al. 2021). In our study, we chose CatWISE2020 instead of All/unWISE as the CatWISE2020 catalogue extends to fainter magnitudes and the associated data processing pipeline uses the full-depth unWISE co-addition of AllWISE and NEOWISE 2019 Data Release for aperture photometry (Marocco et al. 2021), which results in a significant improvement over the AllWISE data. A five-arcsecond positional cross-match of CatWISE2020 with GeDR3 identifies about 1.5 billion sources.
2.1 Classes
The goal of our classification is to identify objects in the target star, quasar, and galaxy classes. The definitions of the target classes are similar to those used by Bailer-Jones et al. (2019), but are augmented with the aforementioned CatWISE2020 cross-match. However, in our application we do not use – and therefore do not require the availability of – parallax and proper motions. This approach results in a much larger set of galaxies, because most galaxies observed by Gaia lack published parallax and proper motions due to a poor fit of the astrometric model on account of their physical extent. As these may indicate a different type of galaxy, this effectively changes our class definition. We ensure there are no common sources between the three class datasets.
2.1.1 Quasars
The SDSS-DR16 quasar catalogue (Lyke et al. 2020) contains 750 414 quasars confirmed by optical spectroscopy. Its authors estimate the contamination to be around 0.5%. We select objects with a zWarning flag equal to zero, indicating a higher reliability in the classification or the redshift estimation. We cross-match the selected sample to GeDR3 by sky position with a one-arcsecond search radius using the CDS X-match tool, finding 489 581 matches in total. This constructed sample is then compared with the cross-matched sample from GeDR3 and the CatWISE2020 catalogue, resulting in 484 749 objects with GeDR3 features and CatWISE2020 magnitude measurements in the W1 and W2 bands.
2.1.2 Galaxies
The sample of galaxies in our train and test datasets is constructed from SDSS-DR16 (Ahumada et al. 2020; Blanton 2017). We select 777409 objects from the SDSS SpecObjAll table on the SDSS Skyserver identified as GALAXY with zWarning equal to zero, and are identified as neither AGN nor AGN BROADLINE in the subclass field. The selected sample is similarly crossmatched with GeDR3, finding all objects. In our selection, we relax the requirement of the parallax and proper motions, as such information may be unavailable for several sources in Gaia, particularly amongst galaxy sources. Applying the defined criterion, we retain about 90% of the galaxy sources. Furthermore, supplementing the CatWISE2020 colours to our constructed sample results in a total of 766 310 objects. Following the work by Bailer-Jones et al. (2019), we apply a colour cut to the galaxy sources using the same colour-edge locus as shown in Fig. 1. Objects below this locus represent stellar contaminants within the galaxy sample. Potential sources of contamination include errors in the SDSS classification or the Gaia BP/RP spectra affected by blends of nearby objects (De Angeli et al. 2022). The colour cut removes 1061 contaminants from our galaxy sample.
2.1.3 Stars
The spectroscopic selection for stars from SDSS data is complex, ill-defined, and likely affected by a biased distribution of stellar types. We therefore do not use SDSS to define the star class. We exploit the fact that the majority of observed sources in Gaia are expected to be stars. We therefore construct our star sample via a random subset of 3 million sources from the Gaia catalogue in which known galaxies and quasars are filtered out. We augment the sample with the CatWISE2020 cross-match, resulting in 1.8 million sources identified as stars. In our constructed star sample, we could expect a non-zero level of contamination from non-stellar sources. This contamination level is unknown, but our prior defined in Sect. 3.3 is our expectation. Ideally, our classifier trained on the cleaned sample would be robust to contamination.
 |
Fig. 1 Colour-colour diagram of the galaxy class. Sources below the dashed line are contaminants that are removed from the galaxy sample. |
2.2 Training, validation, and test sets
The full dataset is the combination of the quasar, galaxy, and star samples. The data are split into two equal parts at random. The first part is then split again into ten equal parts, with nine being used for training, and one part for validation, to monitor the performance during the training. For brevity, we often refer to these two together as the ‘training data’. The second part is the test set which is kept back to assess the fixed models.
During the training phase, the training dataset is used to train the statistical model while the validation set is used to assess the performance of the trained model. After convergence, the trained model is stored and the test set, that is, a subset of the data unseen during training, is used to evaluate the performances of the classifier.
For the classifier trained on the balanced dataset, we select a random subset of 200 000 sources of each class for the training (90 000 for training and 10 000 for validation) and test datasets. By constructing a balanced classifier, we are able to directly compare the intrinsic performance of the models trained on different feature configurations and classification methods and identify the best performing method. The class imbalance is addressed in the discussion of the priors in Sect. 3.3.
Having selected the best-performing model using the balanced training and test dataset discussed in Sect. 4.1, we re-define our training and test datasets to use as many of the available sources in the quasar and galaxy class as possible by sampling a random subset of 900 000 stars, 200 000 quasars, and 370 000 galaxies from the full dataset. We train the feature configuration and classification method identified using the balanced dataset on this imbalanced training and test set in Sect. 4.2. This resulting classifier is applied to the application sets in Sect. 5.
2.3 Application sets
We use three datasets derived from GDR3 (Gaia Collaboration 2022b) to demonstrate the application of our best-performing classifier.
A subset of 50 million randomly selected GDR3 sources that have CatWISE2020 photometry.
Quasar candidate table from GDR3: the quasar tables described in Gaia Collaboration (2022a) represent datasets where there is an estimation of the number of quasars within GDR3. The quasar candidate table contains 6649162 sources with a purity of 0.52, and is refined further in the pure subsample (1 942 825 sources) with a purity of 0.96.
Galaxy candidate table from GDR3: similarly defined in Gaia Collaboration (2022a), the full table reports 4 842 342 candidates with a purity of 0.69, and the pure sample (2 891 132 sources) reaches a purity of 0.94.
There are 144 109 sources in common between the quasar and galaxy candidates (Gaia Collaboration 2022a). For ease of interpretation of our results on these tables, we therefore choose to remove these sources from the subsequent analysis.
2.4 Feature selection
In feature selection, an important condition is the completeness of each feature, as missing data often cause many statistical methods to fail. As noted in Sect. 2.1, a large fraction of galaxies do not have published parallaxes and proper motions in GeDR3. We therefore disregard both as input features in order to retain as many sources as possible. As inputs to the classifier, we test various combinations of eight features: six of the eight features are defined in Bailer-Jones et al. (2019), which we refer to as ‘Gaia_f’, and the other two features are W1-W2 and the G-W1 colours constructed from the CatWISE2020 catalogue. The six features from Gaia_f are apparent magnitude (G), sine of the Galactic latitude (sin b), g-rp (G-RP), bp-g (G-RP), relative variability in the G-band (relvarg), and the astrometric unit weight error (UWE). We report the distribution of each feature in Fig. 2 and their descriptions below:
Figure 2 shows the distribution of the broadband G magnitude in Gaia and the colours BP-G, G-RP, W1-W2, and G-W1. Quasars have characteristic optical-infrared colours. In the colour-colour and colour-magnitude space, quasars can be discerned from other stellar objects as well as from galaxies; see Fig. 3. Additionally in Fig. 3, we can see the clear distinction from the galaxy class. Due to the clear separation between the distinct classes seen in Figs. 2 and 3, we consider the colour information as one of the main discriminating features of the target classes.
Galactic longitude and latitude (l, b) can also be useful discriminants. Compared to stars, for which the distribution is concentrated towards the Galactic disk and the bulge, extragalactic objects are expected to be uniformly distributed across the entire sky (Copernican principle). However, such distribution is not observed due to the strong interstellar extinction in the disk of the Galaxy concealing extragalactic sources at low latitudes. Due to the SDSS sky coverage, the extragalactic objects in our training and test datasets follow a non-uniform distribution. We corrected our sample from this selection effect by randomising the latitude of these objects in our training and test datasets with values drawn from a uniform distribution in sin b. This approach may not be a perfect solution because, as mentioned, we do not expect to see a large fraction of extragalactic objects at low latitudes. While this may help us find otherwise-difficult-to-detect extragalactic objects at low latitudes, it may also lead to a higher number of false positives. We accept this limitation. Galactic longitude is a problematic parameter because it wraps at l = 0° = 360° and is not used as a model feature. However, we do use v when computing our priors to account for the footprint of SDSS in comparison with Gaia (see Sect. 3.3.2).
The relative variability in the G-band, which we call ‘relvarg’ following the work by Bailer-Jones et al. (2019), is defined as the ratio of the standard deviation of the epoch photometry to its mean. Relvarg can be computed from the fields in GeDR3 as phot_g_n_obs/phot_g_mean_flux_over_error. Figure 2 shows a higher variability in quasars compared to stars. Galaxies also show large levels of variability, although in Gaia this effect is a spurious artefact due to galaxies being extended in their surface-brightness profile. At each epoch scan, Gaia will determine a slightly different photocentre possibly related to a different photometry. However, we can exploit this behaviour to help distinguish galaxies.
The astrometric unit weight error, UWE, is defined as the square root of the χ2 multiplied by the number of degrees of freedom of the astrometric solution. A larger UWE value correlates to a weak fit to the astrometric solution and generally an enhanced value for some galaxies. We do not use the re-normalised UWE (RUWE), which also removes dependencies on colour and magnitude, because RUWE is not defined when the parallax and proper motions are missing.
 |
Fig. 2 Distribution of the features from the training dataset, coloured according to their true classes. Black: stars. Blue: quasars. Orange: galaxies. Each distribution is separately normalised and the sin b has been randomised for quasars and galaxies (constant probability per unit sky area). |
3 Classification
In our work, the goal of the classification task is to find an optimal mapping between a class label (i.e. star, quasar, or galaxy) and a set of features characteristic of a given object. Several methods proposed in the literature have exploited supervised classification to determine the best mapping between input features and discrete classes. In our work, we seek a probabilistic classification, whereby a trained classifier generates a probability that an object belongs to a class, offering more flexibility in the determination of the final class prediction. Moreover, exploiting a Bayesian framework allows, on one hand, to define the posterior probability for an object to belong to a specific class, and on the other hand to incorporate the use of a highly informative prior function on the target classes, such as the expected distribution of objects across the Universe.
The following section introduces the terminology and the classification metrics used in our evaluation, the probabilistic models used to identify extragalactic sources, and the prior functions we exploit to address the issue of class imbalance.
3.1 Terminology and metrics
In this section, we define key terms and the metrics used to assess a classifier performance. Classes may be defined as true and predicted. The true class refers to what has been defined in the training and testing datasets as the object’s assumed class as defined by SDSS (for galaxies and quasars) or Gaia (for stars), and is therefore bound to have some inherent misclassification errors which will add noise to our classifier. The predicted class refers to the class that has been assigned using the probabilities outputted from our estimated classifier, which may be taking the maximum posterior probability or by considering a probability threshold. We define our predicted class as being the maximum posterior probability for a given source. To compare the predicted and true classes, we construct a confusion matrix, where entry row i and column j of the matrix refer to the number of objects with the true class i classified into predicted class j. The confusion matrix is of dimension K × K, with K2 numbers when classified using the maximum posterior probability.
During training, we seek to minimise a loss function and monitor the performances of the model across all iterations using an evaluation metric. In multiclass classification, the standard loss function is the cross-entropy, defined in Eq. (1), for which an ideal model would be able to correctly predict all objects (i.e. a cross entropy loss value equal to 0), in contrast with the opposite case of a larger value when the predictions diverge from the true class:
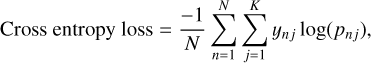 (1)
(1)
where N refers to the sample size, K the number of classes, ynj the outcome equal to 1 for the true class and 0 otherwise, and pnj the probability that object n belongs to class j.
Classification performances are evaluated on a dataset unseen during the training phase, that is, the test dataset. Performances are evaluated through metrics such as purity, completeness, and the F1-score. The purity, also known as precision (cf. Eq. (2)), refers to the number of true positives (TPs) over the full count of objects in the target class. Purity can also be considered as a measure of contamination (1 – purity), representing the false positive (FP) rate. The higher the purity, the lower the contamination.
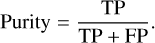 (2)
(2)
The completeness, also known as the recall or sensitivity (cf. Eq. (3)), refers to the number of TPs over the number of objects in the target class, that is, the total sum of correct predictions and true non-detections (false negatives (FNs)). A perfect model has purity and completeness both equal to 1.
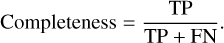 (3)
(3)
The F1-score is computed as the harmonic mean of a model’s completeness and purity:
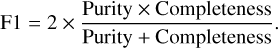 (4)
(4)
We define the objective function during training as the cross-entropy (Eq. (1)), but we use the F1-score as the evaluation metric applied to the validation dataset for the statistical methods described in Sect. 3.2. A perfect model has an F1-score of 1.
We report the completeness and purities in the discussion of each of our classifiers, as these metrics are of the greatest interest when considering the rare classes, quasars and galaxies, and because these objects are harder to classify in comparison to the large number of stars observed in Gaia.
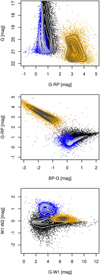 |
Fig. 3 Colour-magnitude diagram (top) and two colour-colour (middle αnd bottom) diagrams highlighting the distribution of each class, with contours designating the density on a linear-scale for a random sample of 10 000 observations. The colour black corresponds to stars, blue to quasars, and gold to galaxies. Distinct aggregates can be identified for each class, although a significant interclass overlap still occurs. |
3.2 Statistical methods
Gaussian mixture models and gradient-boosting methods have been shown to be effective in numerous classification tasks, such as the works by Lee et al. (2012); de Souza et al. (2017) and Möller et al. (2016); Chao et al. (2019); Golob et al. (2021), respectively. In the current section, we describe both methods as well as their known limitations when applied to our classification problem.
3.2.1 Gaussian mixture models
GMMs (Fraley & Raftery 2002), as used in the work by Bailer Jones et al. (2019) for the supervised classification of extragalactic sources in Gaia, are defined in this work as our baseline classifier. In the training phase, for each class of the training set, the GMMs fit the distribution of the data as a sum of M Gaussians defined in a multi-dimensional feature space by maximum likelihood. In the prediction phase, for an unclassified object, the trained classifier computes a probability density function normalised for each class to provide posterior class probabilities, which nominally is equivalent to adopting an equal class prior. The final class prediction is obtained from the highest posterior probability across all classes.
GMMs are known to reach their limitations when dealing with overlapping classes and sparse data. To prevent such limitations, we introduced an adjustment to the likelihood by setting a fraction n of the lowest values to zero, which sets the final densities computed by the GMMs to zero. By forcing the Gaussian distributions to truncate to zero, sources at the boundaries of a class distribution (the potential overlap between classes) should be directly assigned to the most prevalent class (for our purposes, the star class), resulting in an increase in the purity and completeness of the rarer classes. We considered four different values for the threshold value n of {1,5,20,50} applied to all models trained on the different input configurations (i.e. with and without infrared features). We found that the purity in the quasar and galaxy classes marginally improves (an increase of 0.02) when using n = 50 for the model trained without the infrared features compared to a standard GMM. However, this correction does not induce any improvement for the models trained on the dataset including infrared features. Furthermore, we find that the GMMs subject to the likelihood trimming method perform better than the standard GMM classifier, but attain lower performances compared to the boosted decision tree methods. We therefore do not consider the correction via likelihood trimming any further.
3.2.2 Gradient boosting methods
Gradient boosting is a popular and powerful ensemble technique within supervised machine learning, where the ensemble technique refers to building a model from a collection of weaker learners. There are additional ensemble methods such as bagging, which splits the dataset into N subsets with replacement, builds a model on each subset in parallel, and finally combines their individual predictions to compute the final class. Bagging is the basis of the random forest method (Breiman 2001). By contrast, gradient boosting builds a model by sequentially fitting the weak learners in order to correct the residual errors at each iteration. The algorithm re-weights the data towards the most difficult cases at each training step, such that subsequent learners prioritise solving them. Typically, the learners used in gradient-boosting methods are decision trees, and the method is known as gradient-boosting decision trees (GBDT; Friedman 2001).
The extreme gradient-boosting (XGBoost) method is a boosting algorithm presented by Chen & Guestrin (2016) that refers to one of the fastest implementations of GBDT. In particular, XGBoost improves upon GBDT in that it includes the second derivative of the loss function, which provides complementary information on the direction of gradients essential to solving the optimisation problem. Furthermore, the XGBoost method includes L1 and L2 regularisation used to prevent the model from overfitting.
A second gradient-boosting method, used in our work, is categorical boosting (CatBoost; Dorogush et al. 2017). The key properties of CatBoost (which are lacking in XGBoost) are balanced (symmetric) trees and ordered boosting. Balanced trees, by definition, are built such that, at every step, the trees are split using the same feature criterion. By using a balanced tree architecture, CatBoost runs more efficiently and controls for overfitting as the balanced tree serves as regularisation. In general, classic boosting methods are prone to overfitting and CatBoost circumvents this limitation via ordered boosting, which refers to the process of training a model on a subset of the data and computing the residuals on a different subset.
In the following, we train two classifiers, using XGBoost and CatBoost, with the same set of input features used to train the GMM in order to assess the classification performances of all classifiers. We select the optimal hyperparameters by performing a five-fold grid search cross-validation that minimises the cross entropy loss function for finding the best hyperparameters. We then maximise the evaluation metric, the F1 score, when fitting the model with the best hyperparameters on the validation set. The hyperparameters we choose to optimise are max_depth or depth (in the case of CatBoost), learning_rate, and n_estimators, with the remaining set at their default values. Here, max_depth represents the maximum number of nodes allowed on a tree and is used to control for over-fitting, as a higher depth will make the model more complex and representative of the training dataset and thus more likely to be overfitted. The max_depth parameter ranges from zero to infinity and we consider the values of 3, 6, 8, and 10. The learning_rate is the step size taken by the model at each iteration to reach the minimum of the loss function; it takes a value of between 0 and 1, and is used to control for overfitting by modifying the weights of new trees added to the model. We consider the values 0.01, 0.03, 0.05, and 0.1. The last hyperparameter we consider tuning is the number of trees, specified by n_estimators. There is often a point of diminishing returns once there is a large number of trees, and each subsequent tree barely reduces the loss function. We considered the values of 100, 500, and 1000 for the n_estimators in our testing. The optimal values for the hyperparameters obtained from our grid search are a max_depth of 8, a learning_rate of 0.1, and a total number of trees n_estimators of 100 for XGBoost, and a depth of 6, a learning_rate of 0.03, and a total number of trees n_estimators of 1000 for CatBoost.
3.3 Prior
The class imbalance problem, that is, when the class distributions are highly skewed and we are interested in the least frequent class, is not unique to classification within astronomy. The problem is often encountered in various areas such as credit fraud detection where fraud is considerably less frequent than regular transactions. Multiple classification algorithms in this context attain low predictive accuracy for the rare class. Several data augmentation methods have been developed to address the imbalance problem from oversampling the rare classes, under-sampling the most prevalent class, and generating synthetic observations using techniques such as SMOTE (Chawla et al. 2002). In this work, we attempt to correct for the class imbalance by applying a model correction exploiting prior knowledge that can be physically attributed, as introduced in Bailer-Jones et al. (2019). Lake & Tsai (2022) offer a similar approach which likewise proposes replacing the implicit prior of the classifier with one representative of the target population. The model correction is applied in two phases of the modelling process. First by adjusting the posterior probabilities by the class prior, as described in Eq. (5), and second via the modification of the confusion matrix by an adjustment factor, λk, shown in Eq. (6). The approach is thoroughly explained in section 3.4 of Bailer-Jones et al. (2019), but we summarise the key points in the following section for convenience.
First, the prior adjustment is done by re-weighting the posterior probabilities using a prior distribution to reflect the expected real class distribution:
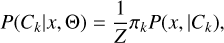 (5)
(5)
where Θ refers to any prior information, Z = ∑k πkP(x, |Ck), and πk is the class prior for class k.
Second, when applying the model to a test dataset, the confusion matrix is modified using the adjustment factor in Eq. (6). This approach ensures that the results reflect the expected (prior) distribution of all classes, in particular the larger number of potential star contaminants to the quasar and galaxy classes. This step is necessary because the actual test dataset generally does not portray the class distribution expected in reality; in particular, it will tend to have too few stellar contaminants. The factor λk scales the actual number of objects in each row to the number of objects expected within a dataset. Given the definition of the adjustment factor, the correction only affects the purity and not the completeness estimated from the confusion matrix.
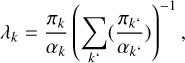 (6)
(6)
where αk is the class fraction within a dataset.
In this work, we describe three different priors and apply two of them: first the global prior reflecting a general class distribution, then a joint prior dependent upon latitude and magnitude, and lastly a mixed prior that combines the two aforementioned priors.
3.3.1 The global prior
The global prior of 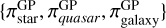 , which was introduced in the work by Bailer-Jones et al. (2019), outlines the scarcity of quasar and galaxy objects compared to stars across the sky. The prior sets the probabilities of observing a quasar or a galaxy to 1/1000 and 1/5000, respectively, from a sample of extragalactic sources with parallaxes and proper motion measurements. However, as discussed in Sect. 2.1.2, the majority of the galaxies observed in Gaia lack reported parallaxes and proper motions. To define our global prior, we count the number of sources across each class in the Stripe82 region from SDSS DR16, and extrapolate the distribution across the entire sky. The SDSS region Stripe 82 was chosen given the large sample of spectroscopic observations available for the majority of sources, thus providing a more complete count of identified targets. We find twice the number of galaxies compared to quasars and based on this we define our global prior as 1/1000 for quasars and re-adjusted to 1/500 for galaxies.
, which was introduced in the work by Bailer-Jones et al. (2019), outlines the scarcity of quasar and galaxy objects compared to stars across the sky. The prior sets the probabilities of observing a quasar or a galaxy to 1/1000 and 1/5000, respectively, from a sample of extragalactic sources with parallaxes and proper motion measurements. However, as discussed in Sect. 2.1.2, the majority of the galaxies observed in Gaia lack reported parallaxes and proper motions. To define our global prior, we count the number of sources across each class in the Stripe82 region from SDSS DR16, and extrapolate the distribution across the entire sky. The SDSS region Stripe 82 was chosen given the large sample of spectroscopic observations available for the majority of sources, thus providing a more complete count of identified targets. We find twice the number of galaxies compared to quasars and based on this we define our global prior as 1/1000 for quasars and re-adjusted to 1/500 for galaxies.
3.3.2 The joint latitude and magnitude prior
Extragalactic sources are expected to have an intrinsic uniform distribution across the sky, but will not be observed due to dust extinction in the disk. At low latitudes closer to the Galactic plane, we would expect a higher number density of stars in comparison to galaxies and quasars. As the (absolute) latitude increases, the number density of galaxies and quasars with respect to stars increases. This information can be used to generate a latitude-based prior derived from densities at different latitudes.
We can also construct a prior based on apparent magnitude as we would expect the number of quasars and galaxies to increase towards the fainter brightness end. The G-band magnitude distribution in Fig. 2 supports this expectation. Exploiting such characteristics in the latitude and the G magnitude distributions, we have the functionality to represent what we consider to be true variations in latitude and magnitude as a prior to improve the performance of our classifier over a two-dimensional (2D) latitude and magnitude space.
To construct the joint class prior, we chose the overlapped region 50° ≤ l ≤ 200° in Gaia and SDSS DR16 in order to ensure that we are counting sources over the same area of the sky. We assume that SDSS DR16 includes all galaxies and quasars in this region, and that Gaia includes all stars within. Here the denomination ‘all’ refers to a randomly generated application data set (i.e. our randomly selected 50 million GDR3 sources). Using the compiled list of sources, we now further define bins in both sin b and G-mag, count the number of stars, quasars, and galaxies and finally normalise in order to compute frequencies. The distributions for the different class priors can be seen in Fig. A.1. The top panel shows a large number of stars within the plane and a lower density of stars at higher latitudes and towards lower magnitudes. The middle panel reports the distribution observed for the quasars, for which the lowest density is identified within the lowest latitude bin, and a majority of quasar sources at G = 18 mag and higher latitudes. For galaxy sources, the bottom panel reports the majority of sources at the highest magnitudes and those uniformly distributed across latitudes excluding the lowest latitude regions.
3.3.3 The mixed prior
The mixed prior refers to the latitude- and magnitude-dependent prior that accounts for the overall sky distribution of classes represented by the global prior. We define the mixed prior as follows:
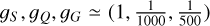 , the (un-normalised) target global prior.
, the (un-normalised) target global prior.FS, FQ, FG are the measured fractions of sources by star, quasar, and galaxy class in the overlap of SDSS and Gaia over the region 50° ≤ l ≤ 200°, over all latitudes and magnitudes.
In a specific latitude and magnitude bin, the number of sources from each class is counted to be nS, nQ, nG.
The number of sources we should have in each latitude and magnitude bin according to our target prior are therefore
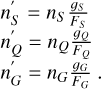
Normalising these across the classes gives the target prior for each latitude and magnitude bin:
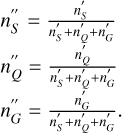
The distribution of this prior across latitude and magnitude is shown in Fig. 4. We see the dominance of stars in the lower latitudes and a gradual increase in the prevalence of quasars and galaxies at higher latitudes and fainter magnitudes. As the prior is discontinuous in magnitudes G and latitudes b, we expect discontinuities in the classification probabilities and counts.
4 Results of different models and feature combinations on the test set
Section 4.1 presents the results of classification obtained with four different feature combinations using the GMM, XGBoost, and CatBoost methods applied to the balanced data set (for training and testing). We identify the best feature combination and method for the classification of extragalactic sources. Section 4.2 shows the results of the chosen model and feature combination fitted and assessed on the larger unbalanced training and test datasets, respectively. The effect of applying the priors to the model probabilities is discussed in Sect. 4.3. The selected classifier is applied to our application datasets in Sect. 5. Our tests were run on an Ubuntu server, with 344GB of RAM and an Intel Xeon CPU E5-2695 v3 at 2.30 GHZ with 30 threads.
Classification performances obtained for different balanced classifiers using different algorithms and input features.
Classification performances adjusted by the global prior and adjustment factor for different balanced classifier models using the XGBoost algorithm and different input features.
Classifier using XGBoost with two feature set configurations as applied to the imbalanced test dataset.
4.1 Classifier trained on a balanced set
By considering a balanced class distribution across the training and test datasets with 200 000 sources in each class, as defined in Sect. 2.2, the intrinsic performances of each method applied to different input feature combinations are higher compared to those obtained when we subsequently apply the appropriate prior and allow for a higher level of contamination from stellar objects.
Table 1 reports the different methods GMM, XGBoost, and CatBoost, where each model is tested using four combinations of input features: Feature Set 1: Gaia_f, Feature Set 2: Gaia_f + W1-W2, Feature Set 3: Gaia_f + W2 + G-W1, and Feature Set 4: Gaia_f + W1-W2 + G-W1.
When performing model fitting, we search for the best input configuration with the highest purity and completeness in the quasar and galaxy classes. We add the colour difference of W1-W2 and G-W1 for long colour wavelength span to the original Gaia features. We do not consider colours such as BP-W2, as W2 is less sensitive than W1 and G has a higher signal-noise ratio than BP. From Table 1, we can see that across all feature combinations, the GMM has a lower classification performance for the two extragalactic classes compared to the gradient boosted methods. Moreover, the addition of infrared-derived features increases the purity and completeness for the quasar and galaxy classes. In Table 2, we apply a global prior and the adjustment factor, and report the purity and completeness for each class. We find that Feature sets 3 and 4 give comparable performances, and are better than sets 1 and 2. Given Tables 1 and 2 we choose an XGBoost model with Gaia features and the W1-W2 and G-W1 infrared colours (Feature Set 4).
Confusion matrix on the test set predictions using an XGBoost classifier trained on Feature Set 4.
 |
Fig. 4 Heat map of the mixed prior distribution. In this representation, the number of stars at lower latitudes exceeds the number of observed quasars and galaxies. Whereas, at higher latitudes and fainter magnitudes, the number of quasars and galaxies surpasses the number of stars. Values of ‘0.0000’ are not necessarily exactly zero, but could be below the numerical precision shown. |
4.2 Classifier trained on an imbalanced set
Using the statistical model and features identified in Sect. 4.1, we now train a classifier using all available sources. This enables the design of a classifier that is more representative of the true class distribution, as discussed in Sect. 2.2. As introduced in Sect. 3.3, the global prior is set to 1, 1/1000, or 1/500, for star, quasar, and galaxy targets, respectively, which differs from the class fractions in the training and test sets. Given the available data, it would be infeasible to use this prior and have a representative number of objects in the extragalactic classes. Furthermore, the intrinsic prior of a model is not necessarily equal to the class fractions in the data initially used for training. Application of the adjustment to the posterior probabilities is discussed in Sect. 4.3.
The results of our classifier trained using Feature Set 4 are reported in Table 3 and Table 4. We compare the final model with an XGBoost model trained exclusively on Feature Set 1 and find a significant improvement in the completeness and purity for the quasar class, from 0.9040 to 0.9799 in the completeness, and from 0.9091 to 0.9705 in the purity. However, for the galaxy class, only an insignificant improvement is seen in the classification metrics, from 0.9914 to 0.9922 in the completeness and from 0.9759 to 0.9784 in the purity. Compared to the balanced classifier in Sect. 4.1, the current classifier exploits a larger dataset, and therefore the decrease in the classification performances is to be expected, particularly in terms of purity, which is due to the fact that the larger dataset likely has more contaminants. For the remainder of this work, we retain the classifier trained on the imbalanced dataset using Feature Set 4 to assess the use of different priors applied to the models and apply the classifier to the application sets in Sect. 5.
4.3 Classifier adjusted using the priors
We now consider the effect of applying different prior probability distributions to the posterior probabilities estimated by the classifier in Sect. 4.2. In the figures discussed in this section, the left panels represent results obtained for the Feature Set 1 model, whereas the right-panels report the results associated to the Feature Set 4, both with XGBoost.
The results using the global prior are reported in Table 5. The top half of the table (‘Adj’) shows results for a realistic level of stellar contamination by using the adjustment factor λk in Eq. (6); the bottom half shows raw unadjusted results, that is, with the lower level of contamination seen in the test set (‘Unadj’). Using the global prior gives a lower completeness overall in comparison to the results obtained before applying the prior in Table 3. On average, similar results are observed in the purity for the unadjusted case. Applying the adjustment factor results in lower purities across both the quasar and galaxy classes; however, the addition of infrared colour information clearly results in a better classifier in terms of performance.
Having assessed the impact of the global prior on the final classification. We now consider a more highly tuned prior, namely the ‘mixed’ prior introduced in Sect. 3.3.3, and assess the performance as a function of latitude and magnitude, while also applying the adjustment of the confusion matrix in order to incorporate the expected class fractions at each latitude and magnitude into the performance metrics. In Fig. 5, the completeness for the quasar class improves with higher latitudes and most significantly when we add infrared colour information as an input feature. However adding infrared data and moving to higher latitudes marginally improves the completeness in the galaxy class. As an illustration, there is an 18% increase in completeness for very faint quasars at high latitudes (top right bin) and only a 0.7% increase in completeness for galaxies in the equivalent bin when adding infrared data. The purities for the quasar and galaxy classes are shown in Figs. 6 and 7, respectively. We would like to point out that the exact values of 1 and 0 are due to a rounding precision. The effect of the adjustment factor is reported in the top panels. For the quasar class, we observe a significant improvement in purity when adding the infrared colours, and as a function of latitude. For the galaxy class, the addition of infrared colours has only a marginal improvement on the purities as a function of latitude and magnitude. The application of the adjustment factor induces an expected decrease in purity for both the quasar and galaxy target classes.
Imbalanced Classifier Global Prior.
 |
Fig. 5 Imbalanced classifier mixed prior: completeness evaluated for the three target classes in the test set from predictions obtained by the best-performing models, i.e. XGBoost trained on Feature Set 1 (left panel) and Feature Set 4 (right panel). |
5 Results of the best-performing model and feature combination on the application sets
To evaluate how our selected classifier performs and what distribution of the predicted classes is obtained on datasets with representative distributions, we apply the classifier to three datasets selected from the 1.8 billion sources observed in Gaia at the intersection between GDR3 and the CatWISE2020 catalogue. With our first application, we aim to predict the classes for a randomly selected subset of 50 million sources, without prior information on the target classes or their distribution. However, this application set has the distribution that our global and mixed priors are designed for. The second dataset is constructed from the GDR3 quasar and galaxy candidate tables defined in Gaia Collaboration (2022a), which are quoted as having purities of 0.52 and 0.69, respectively. The third data set is the purer sub-sample of the GDR3 quasar and galaxy candidate tables defined in Gaia Collaboration (2022a), which are quoted as having purities of 0.95 for the quasar class and 0.94 for the galaxy class. In addition to assessing the accuracy of our classifier, we wish to identify whether adding infrared colours to Gaia data improves the reliability of these candidate tables, despite having removed parallax and proper motion as features.
Our priors, both global and mixed, are designed for a sample of sources drawn at random from the Gaia/CatWISE2020 all-sky sample. These priors are not appropriate for the classification of the GDR3 extragalactic tables in Sects. 5.2 and 5.3, where we have 50–95% extragalactic objects, rather than 0.1–0.2% as expected by the prior. For application to these, we redefine our global priors by taking the purity of each GDR3 extragalactic table as defined in Gaia Collaboration (2022a), which we denote p. Considering the case of the quasar table, the normalised global prior becomes (1 – p – e, p, e), where e is an estimation of the contamination from the galaxy class. The prior would be defined as (1 – p – e, e, p) in the case of the galaxy class. The normalised global priors are (0.454, 0.520, 0.026) and (0.274, 0.036, 0.690), with the re-adjusted mixed priors shown in Figs. 8 and 9 for the GDR3 quasar and galaxy candidate tables, respectively.
 |
Fig. 6 Imbalanced classifier mixed prior: purity evaluated for the quasar class in the test set from predictions obtained by the best-performing models, i.e. XGBoost trained on Feature Set 1 (left panel) and Feature Set 4 (right panel). Top panels show the classification performances modified by the adjustment factor. The near unit purity at low latitudes in the right panels is not meaningful as there are very few objects, as shown in Fig. 4 |
5.1 Application on a random subset of the overlap of GDR3 and CatWISE2020
For the 50 million sources at the intersection of GDR3 and CatWISE2020, the true class of the source is unknown and therefore reliable performance metrics cannot be computed. However, we can compare the number of sources classified with the different priors, and compare the counts to expectations. We find 12607 quasars and 41153 galaxies, or 1/4000 and 1/1200, using the global prior. When compared to the global prior values of 1/1000 for quasars and 1/500 for galaxies, we find that our results give a factor of 4 fewer quasars and a factor of 2 fewer galaxies. Using the mixed prior, we find 97294 quasars and 192231 galaxies, or 1/500 and 1/300. The mixed prior finds nearly eight times as many quasars (97294/12607 = 7.7) and roughly five times more galaxies (192231/41153 = 4.7) than the global prior. This may be attributed to the mixed prior being very non-uniform in magnitude and latitude, similar to the true distribution. Furthermore, by construction the mixed prior is better matched to the data.
In Fig. 10, we show the sky distributions of the sources by assigned class. For both priors, in a random sample of 50 million sources observed by Gaia, we classify less than 1% of the sample as either a galaxy or a quasar, highlighting the scarcity of the extragalactic sources.
It is interesting to compare our results with those used from the DSC-Combmod classifier, which was used to identify many quasars and galaxies published in the GDR3 extragalactic candidate tables (Gaia Collaboration 2022a). Combmod is the combination of the class posterior probabilities from two classifiers, DSC-Specmod and DSC-Allosmod (Delchambre et al. 2022). Specmod classifies objects using BP/RP spectra, whereas Allosmod uses a GMM to classify objects using several astrometric and photometric features (the features being our Gaia_f set plus parallax and proper motion; see also Bailer-Jones et al. 2019). We use the quasar and galaxy class probabilities from Combmod, but take the star class probabilities to be one minus the sum of the quasar and galaxy probabilities (because Combmod reports more than three classes), and assign the class label to the class with the largest probability. When applying the global prior, we identify 7% of the Combmod quasars as quasars with the remaining 92.9% identified as stars and 0.1% as galaxies. We identify 21% of the Combmod galaxies as galaxies, with the remaining 78.9% identified as stars and 0.1% as galaxies. Using the mixed prior, we classify 40% of the Combmod quasars as quasars with the remaining 59.8% identified as stars and 0.2% as galaxies. For the Combmod galaxies using the mixed prior, we find 56% to be galaxies with the remaining fraction being 43.6% stars and 0.4% quasars.
We now refine the 50 million sources by considering those that are classified as a quasar or a galaxy in the pure samples defined in the GDR3 quasar and galaxy candidate tables, respectively. We aim to see whether the proportion of identified quasars and galaxies increases when the sample is refined. We find that our classifier identifies 12% of the quasars in the pure quasar candidate table using the global prior, an improvement of 5% compared to quasars classified in Combmod. Using the mixed prior, we identify 69% of the quasars in the pure quasar candidate table, which is over 25% better than the Combmod quasars. When considering the pure galaxy candidate table, we identify 18% as galaxies using the global prior which is a reduction of 3% when compared to the Combmod galaxies. A 2% reduction is seen when applying the mixed prior, where we identify 54% of galaxies in the pure galaxy candidate table. Using the three different classifications – DSC-Combmod, the pure subsample from the GDR3 candidate table, and our classifier – we illustrate the density of the predicted sources in colour-colour diagrams and a colour-magnitude diagram, with the contours representing the classifications from DSC-Combmod and the purer subsamples. Figure 11 shows the sources classified as quasars using the global prior in our classifier. We see that considerably fewer sources are classified as extragalactic when using the global prior compared to the mixed prior in Fig. 12, but are focused towards the redder magnitude. In contrast to the global prior, the mixed prior allows for more freedom in the identification of sources that are quasars, closely resembling the contours of the pure sample. Figures 13 and 14 represent the density of the galaxy class with the global prior and mixed prior adjustment, respectively. The global prior results are a subset of the mixed prior, with the mixed prior extending to bluer G-RP but the global prior not extending redder.
 |
Fig. 8 Heat map of the mixed prior distribution for the GDR3 Quasar Candidate Table. In this representation, the number of stars at the lowest latitude exceeds the number of observed quasars and galaxies. |
 |
Fig. 9 Heat map of the mixed prior distribution for the GDR3 Galaxy Candidate Table. In this representation, the number of stars at the lowest latitude exceeds the number of observed quasars and galaxies. |
 |
Fig. 10 Log10 of counts for sources classified on the random Gaia DR3 sample on a healpix at level 6 (HPX6). As described in Sect. 3.3.3, the mixed prior is discretised by latitude and magnitude, this giving rise to the banded structure in the right panels. The white colour indicates a source density below the scale and anything above the scale is yellow. |
5.2 Application to quasar candidates from GDR3
The GDR3 quasar candidate table defined in Gaia Collaboration (2022a) contains 6.6 million potential quasars with a purity of 52%, and is further refined into a pure subsample containing 1.9 million quasars with a purity of 95%. The overlap with Cat-WISE2020 results in 4048 626 GDR3 quasars and 1822 922 pure subsample quasars.
We applied our trained classifier from Sect. 4.2 to the GDR3 quasar candidates that overlap with CatWISE2020 and estimated the probabilities of the three classes. We assess the classification performance of our model by considering the proportion of quasars identified by our classifier using the global prior and the mixed prior redefined for this application dataset (as explained at the beginning of this section), on the assumption that the quasar candidate overlap is entirely quasars.
The results are shown in Table 6, where in the global prior case we identify 55% of quasars in the GDR3 candidate table. If we further constrain the sample by considering the pure sub-sample only, or the pure subsample and the SDSS16 quasar table together, we see the proportion of quasars identified by our classifier is considerably higher than the GDR3 candidate sample, reaching 99.8%. A similar trend is reported in the mixed prior case, this time identifying 58% of quasars in the GDR3 candidate table and 99.9% when restricting the sample to the pure subsample or the pure subsample plus the SDSS16 quasar table. Given that both global prior and mixed prior have the same global prior behind them, adding the highly non-uniform distribution of the latitude and G dependencies to the prior makes it slightly more suited to finding quasars and galaxies where we expect to find them. We can deconstruct this results table further by considering the entire GDR3 quasar candidate sample in Fig. 15 for the global prior and Fig. 16 for the mixed prior. Comparing the two priors, we see a higher proportion of quasars identified in the fainter and higher magnitude end in the mixed prior case than the global prior, but the distribution on average is quite similar.
We visualise the application of the mixed prior to the quasar candidate table in Fig. 17, and the considerable overlap between the pure sample contours in the most dense region of the mixed prior classifier is evident. The same distribution can be seen in the case of the global prior.
By splitting the sample into two subsets based on the availability of parallax or proper motions in Fig. 18, we observe a higher density distribution for sources with parallaxes compared to the sources without parallax measurements. Furthermore, for the sources classified with parallax we see a shift in the density of the colour distribution, with more sources extending to BP − G = 1, whereas the sources without parallax and proper motions are centred around BP − G = 0 with a few outliers when G − RP > 2 for sources without parallax or proper motions in the case of the global prior. For the mixed prior, the distribution in colour space is similar; however, in the top-left panel for sources with G − RP > 2 the probabilities are lower than in the case of the global prior. Overall, the application of our classifier to the quasar candidates from GDR3 identifies 96–97% of the pure quasar subsample as quasars. Moreover, when requiring the source to have a SDSS16 quasar classification, we identify 99.9% of them as quasars, irrespective of whether the source was in the GDR3 pure subsample or not.
 |
Fig. 11 Results of the classifier when applied to the randomly selected set of 50 million Gaia DR3 and catWISE2020 sources using the global prior: colour-magnitude and colour-colour diagrams for the quasars. Sources from the classifier adjusted by the global prior are given by the density scale where black is zero density and yellow is high density. DSC-Combmod sources are identified by the cyan contours and the GDR3-defined pure quasar sample by the white contours. This colour code is used for all subsequent colour-magnitude and colour-colour diagrams. |
 |
Fig. 12 Results of the classifier when applied to the randomly selected set of 50 million Gaia DR3 and catWISE2020: As in Fig. 11, but using the mixed prior in our classifier. |
 |
Fig. 13 Results of the classifier when applied to the randomly-selected set of 50 million Gaia DR3 and catWISE2020: colour-magnitude and colour-colour diagrams for the galaxies derived from DSC-Combmod, the GDR3-defined pure galaxy sample, and from the classifier adjusted by the global prior. |
 |
Fig. 14 Results of the classifier when applied to the randomly-selected set of 50 million Gaia DR3 and catWISE2020: colour-magnitude & colour-colour diagrams for the galaxies using DSC-Combmod, the GDR3 defined pure galaxy sample and the classifier adjusted by the mixed prior. |
 |
Fig. 15 Heat map of the distribution for quasars identified using the global prior for the GDR3 Quasar Candidates as function of magnitude and latitude. Each mag/lat cell is normalised across the three classes. |
 |
Fig. 16 Heat map of the distribution for quasars as in Fig. 15 but using the mixed prior in our classifier. |
 |
Fig. 17 GDR3 quasar candidate table mixed prior: colour-magnitude & colour-colour diagrams for the quasars using the mixed prior. The sources identified by the classifier are represented by the density scale, where black is zero density and yellow is high density. GDR3 quasar sources are identified by the cyan contours and the GDR3 pure quasar sample by the white contours. |
 |
Fig. 18 GDR3 quasar candidate table mixed prior: probability and density distributions for sources classified as a quasar. The left hand side panels correspond to sources with parallax while the right-hand side panels represent the distribution for sources without parallax. |
 |
Fig. 19 Heat map of the distribution for galaxies identified using the global prior for the GDR3 Galaxy Candidates by magnitude and latitude. |
5.3 Application to galaxy candidates from GDR3
In analogy to Sect. 5.2, here we apply our classifier to the galaxy candidate table in GDR3, which comprises 4.8 million candidates with a purity of 69%, and includes a purer subsample of 2.8 million candidates with a purity of 94%. The overlap with CatWISE2020 reduces the counts to 4 194 100 and 2 824 570, respectively.
From Table 7, we find the proportion of galaxies identified by our classifier in the full galaxy candidate table to be 93% when using the global prior and if we apply the mixed prior to this table we find 91%. If we further constrain the sample by considering the pure subsample or the pure subsample plus the SDSS16 galaxy table, we see the proportion of galaxies identified by our classifier is higher, at 99% for both priors. Exploring the entire GDR3 galaxy candidate sample further in Fig. 19 for the global prior and Fig. 20 for the mixed prior. Comparing the two priors, we see a higher proportion of galaxies identified in the fainter and higher magnitude end in the global prior case than with the mixed prior, but the distribution on average is quite similar. Furthermore the mixed prior considers more galaxy sources to be quasars, particularly at the bright end and at higher latitudes, whereas the global prior considers more galaxy sources to be stars at the bright end but at lower latitudes.
We can see this distribution for the mixed prior results in Table 7 and in Fig. 21. We see closer contours for the GDR3 pure sample centred around the highest density region when using the mixed prior classifier and wider contours for the GDR3 sample as expected. A similar result is seen when applying the global prior. In contrast to the work by Bailer-Jones et al. (2019), our classifier was fit without using parallax or proper motions in order to retain as many galaxy sources as possible. We assess in Fig. 22 whether our classifier has a different distribution in either the count or probability spaces for sources with parallax and proper motions and for those that do not. We see a tendency towards redder magnitudes for the sources classified using the mixed prior without parallax and proper motions. The probability distributions are unperturbed and follow a similar trend with higher probabilities towards the lower magnitudes.
 |
Fig. 20 Heat map of the distribution for galaxies as in Fig. 19 but using the mixed prior in our classifier. |
6 Conclusions
Building large catalogues of well-classified extragalactic sources is useful for large-scale statistical analyses in astronomy. In this paper, we look at how adding infrared colour information improves the classification of extragalactic sources compared to simply using Gaia. Our results indicate an improved classification performance when adding the infrared colour information from CatWISE2020. The purities of the quasar and galaxy class improve from 0.9091 and 0.9759 to 0.9705 and 0.9784, respectively. We discuss how using a prior and adjusting the confusion matrix to reflect the expected (high) level of stellar contamination in a real application are necessary steps in ensuring that the reported results are representative of the performance of the classifier when test or application datasets do not reflect the true class distribution. Significantly, we find that using a prior that varies with latitude and magnitude gives higher purity and completeness for extragalactic objects: Looking at Fig. 6 in the adjusted case, and taking the bin where sin b = (0.6, 0.8] and G = (18.5, 19.5], we observe an improvement in the purity of the quasar class from 0.51 to 0.58. This result is coupled with a higher completeness seen in Fig. 5, from 0.84 to 0.97 in this bin. The published probabilities for the mixed prior classifier applied to the quasar and galaxy extragalactic candidate tables are available at the CDS. Table 8 illustrates the format of the tables. Exploiting the results of our classifications would be useful to scientific studies focusing on extragalactic sources as well as investigating stellar populations in the Milky Way as observed by Gaia and CatWise2020. Finally, when testing different statistical models, we find that decision-tree-based methods, in particular XGBoost, are more effective than Gaussian mixture models for this type of classification task.
 |
Fig. 21 GDR3 Galaxy candidate table mixed prior: colour-magnitude & colour-colour diagrams for the galaxies using the mixed prior. The sources identified by the classifier are represented by the density scale, where black is zero density and yellow is high density. GDR3 galaxy sources are identified by the cyan contours and the GDR3 pure galaxy sample by the white contours. |
 |
Fig. 22 GDR3 Galaxy candidate table mixed prior: probability and density distributions for sources classified as a galaxy The right hαnd side pαnels correspond to sources with parallax while the left hand side panels represent the distribution for sources without parallax. We find in the bottom-right panel a similar colour excess factor locus at BP-G =−0.5 and G-RP = 2, as in Fig. 3 of Bailer-Jones et al. (2019) and Fig. 31 of Gaia Collaboration (2022a). This locus is however not evident in the case which has parallax and proper motions. |
Quasar candidates.
Acknowledgements
We thank Morgan Fouesneau and Rene Andrae for their useful comments that helped to improve this work. We also thank the referee for their suggestions and helpful comments. The modelling and plots were done using R (http://www.r-project.org) and Python (https://www.python.org). This research made use of the cross-match service provided by CDS, Strasbourg. This work was funded in part by the DLR (German space agency) via grant 50 QG 2102. Authors report the use of data from the European Space Agency (ESA) mission Gaia (http://www.cosmos.esa.int/gaia), processed by the Gaia Data Processing and Analysis Consortium (DPAC, http://www.cosmos.esa.int/web/gaia/dpac/consortium). Funding for the DPAC has been provided by national institutions, in particular the institutions participating in the Gaia Multilateral Agreement.
Appendix A Prior counts, and latitude and magnitude priors
Prior Table Counts
The following section shows the counts of sources in SDSS 16 as a function of latitude and magnitude as well as the distribution of the prior.
 |
Fig. A.1 Heat map of the joint latitude and magnitude prior for each class. The top panel refers to the star class, middle panel to the quasar class, and the lower panel to the galaxy class. A higher density of stars is noticeable at lower latitudes, while more quasars and galaxies clusters are seen at higher magnitudes. |
References
- Ahumada, R., Allende Prieto, C., Almeida, A., et al. 2020, ApJS, 249, 21 [Google Scholar]
- Bailer-Jones, C. A. L., Fouesneau, M., & Andrae, R. 2019, MNRAS, 490, 5615 [CrossRef] [Google Scholar]
- Blanton, M. R. 2017, AJ, 154, 35 [Google Scholar]
- Breiman, L. 2001, Mach. Learn., 45, 5 [Google Scholar]
- Chao, L., Wen-hui, Z., & Ji-ming, L. 2019, Chinese Astron. Astrophys., 43, 539 [Google Scholar]
- Chawla, N. V., Bowyer, K. W., Hall, L. O., & Kegelmeyer, W. P. 2002, J. Artif. Intell. Res., 16, 321 [CrossRef] [Google Scholar]
- Chen, T., & Guestrin, C. 2016, in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD’16 (New York, NY, USA: Association for Computing Machinery), 785 [CrossRef] [Google Scholar]
- Croom, S. M., Fine, S., & Team, t. S. S. 2009, Proc. Int. Astron. Union, 5, 223 [Google Scholar]
- De Angeli, F., Weiler, M., Montegriffo, P., et al. 2022, A&A, in press, https://doi.org/10.1051/0004-6361/202243680 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- de Souza, R. S., Dantas, M. L. L., Costa-Duarte, M. V., et al. 2017, MNRAS, 472, 2808 [Google Scholar]
- Delchambre, L., Bailer-Jones, C. A. L., Bellas-Velidis, I., et al. 2022, A&A, in press, https://doi.org/10.1051/0004-6361/202243423 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dorogush, A. V., Ershov, V., & Gulin, A.. 2017, Comput. Sci., 7 [Google Scholar]
- Fraley, C., & Raftery, A. E. 2002, J. Am. Stat. Assoc., 97, 611 [CrossRef] [Google Scholar]
- Friedman, J. H. 2001, Ann. Stat., 29, 1189 [Google Scholar]
- Gaia Collaboration (Prusti, T., et al.) 2016, A&A, 595, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Brown, A. G. A., et al.) 2021, A&A, 649, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Bailer-Jones, C. A. L., et al.) 2022a, A&A, in press, https://doi.org/10.1051/0004-6361/202243232 [Google Scholar]
- Gaia Collaboration (Vallenari, A., et al.) 2022b, A&A, in press, https://doi.org/10.1051/0004-6361/202243940 [Google Scholar]
- Golob, A., Sawicki, M., Goulding, A. D., & Coupon, J. 2021, MNRAS, 503, 4136 [NASA ADS] [CrossRef] [Google Scholar]
- Harrison, C. M., Costa, T., Tadhunter, C. N., et al. 2018, Nat. Astron., 2, 198 [Google Scholar]
- Kurcz, A., Bilicki, M., Solarz, A., et al. 2016, A&A, 592, A25 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lake, S. E., & Tsai, C. W. 2022, Astron. Comput., 40, 100617 [NASA ADS] [CrossRef] [Google Scholar]
- Lee, K. J., Guillemot, L., Yue, Y. L., Kramer, M., & Champion, D. J. 2012, MNRAS, 424, 2832 [Google Scholar]
- Li, J., Venemans, B. P., Walter, F., et al. 2022, ApJ, 930, 27 [NASA ADS] [CrossRef] [Google Scholar]
- Lyke, B. W., Higley, A. N., McLane, J. N., et al. 2020, ApJS, 250, 8 [NASA ADS] [CrossRef] [Google Scholar]
- Marocco, F., Eisenhardt, P. R. M., Fowler, J. W., et al. 2021, ApJS, 253, 8 [Google Scholar]
- Möller, A., Ruhlmann-Kleider, V., Leloup, C., et al. 2016, J. Cosmol. Astropart. Phys., 2016, 008 [CrossRef] [Google Scholar]
- Wright, E. L., Eisenhardt, P. R. M., Mainzer, A. K., et al. 2010, AJ, 140, 1868 [Google Scholar]
- York, D. G., Adelman, J., John E. Anderson, J., et al. 2000, AJ, 120, 1579 [NASA ADS] [CrossRef] [Google Scholar]
All Tables
Classification performances obtained for different balanced classifiers using different algorithms and input features.
Classification performances adjusted by the global prior and adjustment factor for different balanced classifier models using the XGBoost algorithm and different input features.
Classifier using XGBoost with two feature set configurations as applied to the imbalanced test dataset.
Confusion matrix on the test set predictions using an XGBoost classifier trained on Feature Set 4.
All Figures
|
Fig. 1 Colour-colour diagram of the galaxy class. Sources below the dashed line are contaminants that are removed from the galaxy sample. |
| In the text | |
|
Fig. 2 Distribution of the features from the training dataset, coloured according to their true classes. Black: stars. Blue: quasars. Orange: galaxies. Each distribution is separately normalised and the sin b has been randomised for quasars and galaxies (constant probability per unit sky area). |
| In the text | |
|
Fig. 3 Colour-magnitude diagram (top) and two colour-colour (middle αnd bottom) diagrams highlighting the distribution of each class, with contours designating the density on a linear-scale for a random sample of 10 000 observations. The colour black corresponds to stars, blue to quasars, and gold to galaxies. Distinct aggregates can be identified for each class, although a significant interclass overlap still occurs. |
| In the text | |
|
Fig. 4 Heat map of the mixed prior distribution. In this representation, the number of stars at lower latitudes exceeds the number of observed quasars and galaxies. Whereas, at higher latitudes and fainter magnitudes, the number of quasars and galaxies surpasses the number of stars. Values of ‘0.0000’ are not necessarily exactly zero, but could be below the numerical precision shown. |
| In the text | |
|
Fig. 5 Imbalanced classifier mixed prior: completeness evaluated for the three target classes in the test set from predictions obtained by the best-performing models, i.e. XGBoost trained on Feature Set 1 (left panel) and Feature Set 4 (right panel). |
| In the text | |
|
Fig. 6 Imbalanced classifier mixed prior: purity evaluated for the quasar class in the test set from predictions obtained by the best-performing models, i.e. XGBoost trained on Feature Set 1 (left panel) and Feature Set 4 (right panel). Top panels show the classification performances modified by the adjustment factor. The near unit purity at low latitudes in the right panels is not meaningful as there are very few objects, as shown in Fig. 4 |
| In the text | |
 |
Fig. 7 Similar to Fig. 6 for the galaxy target class in the test set. |
| In the text | |
|
Fig. 8 Heat map of the mixed prior distribution for the GDR3 Quasar Candidate Table. In this representation, the number of stars at the lowest latitude exceeds the number of observed quasars and galaxies. |
| In the text | |
|
Fig. 9 Heat map of the mixed prior distribution for the GDR3 Galaxy Candidate Table. In this representation, the number of stars at the lowest latitude exceeds the number of observed quasars and galaxies. |
| In the text | |
|
Fig. 10 Log10 of counts for sources classified on the random Gaia DR3 sample on a healpix at level 6 (HPX6). As described in Sect. 3.3.3, the mixed prior is discretised by latitude and magnitude, this giving rise to the banded structure in the right panels. The white colour indicates a source density below the scale and anything above the scale is yellow. |
| In the text | |
|
Fig. 11 Results of the classifier when applied to the randomly selected set of 50 million Gaia DR3 and catWISE2020 sources using the global prior: colour-magnitude and colour-colour diagrams for the quasars. Sources from the classifier adjusted by the global prior are given by the density scale where black is zero density and yellow is high density. DSC-Combmod sources are identified by the cyan contours and the GDR3-defined pure quasar sample by the white contours. This colour code is used for all subsequent colour-magnitude and colour-colour diagrams. |
| In the text | |
|
Fig. 12 Results of the classifier when applied to the randomly selected set of 50 million Gaia DR3 and catWISE2020: As in Fig. 11, but using the mixed prior in our classifier. |
| In the text | |
|
Fig. 13 Results of the classifier when applied to the randomly-selected set of 50 million Gaia DR3 and catWISE2020: colour-magnitude and colour-colour diagrams for the galaxies derived from DSC-Combmod, the GDR3-defined pure galaxy sample, and from the classifier adjusted by the global prior. |
| In the text | |
|
Fig. 14 Results of the classifier when applied to the randomly-selected set of 50 million Gaia DR3 and catWISE2020: colour-magnitude & colour-colour diagrams for the galaxies using DSC-Combmod, the GDR3 defined pure galaxy sample and the classifier adjusted by the mixed prior. |
| In the text | |
|
Fig. 15 Heat map of the distribution for quasars identified using the global prior for the GDR3 Quasar Candidates as function of magnitude and latitude. Each mag/lat cell is normalised across the three classes. |
| In the text | |
|
Fig. 16 Heat map of the distribution for quasars as in Fig. 15 but using the mixed prior in our classifier. |
| In the text | |
|
Fig. 17 GDR3 quasar candidate table mixed prior: colour-magnitude & colour-colour diagrams for the quasars using the mixed prior. The sources identified by the classifier are represented by the density scale, where black is zero density and yellow is high density. GDR3 quasar sources are identified by the cyan contours and the GDR3 pure quasar sample by the white contours. |
| In the text | |
|
Fig. 18 GDR3 quasar candidate table mixed prior: probability and density distributions for sources classified as a quasar. The left hand side panels correspond to sources with parallax while the right-hand side panels represent the distribution for sources without parallax. |
| In the text | |
|
Fig. 19 Heat map of the distribution for galaxies identified using the global prior for the GDR3 Galaxy Candidates by magnitude and latitude. |
| In the text | |
|
Fig. 20 Heat map of the distribution for galaxies as in Fig. 19 but using the mixed prior in our classifier. |
| In the text | |
|
Fig. 21 GDR3 Galaxy candidate table mixed prior: colour-magnitude & colour-colour diagrams for the galaxies using the mixed prior. The sources identified by the classifier are represented by the density scale, where black is zero density and yellow is high density. GDR3 galaxy sources are identified by the cyan contours and the GDR3 pure galaxy sample by the white contours. |
| In the text | |
|
Fig. 22 GDR3 Galaxy candidate table mixed prior: probability and density distributions for sources classified as a galaxy The right hαnd side pαnels correspond to sources with parallax while the left hand side panels represent the distribution for sources without parallax. We find in the bottom-right panel a similar colour excess factor locus at BP-G =−0.5 and G-RP = 2, as in Fig. 3 of Bailer-Jones et al. (2019) and Fig. 31 of Gaia Collaboration (2022a). This locus is however not evident in the case which has parallax and proper motions. |
| In the text | |
|
Fig. A.1 Heat map of the joint latitude and magnitude prior for each class. The top panel refers to the star class, middle panel to the quasar class, and the lower panel to the galaxy class. A higher density of stars is noticeable at lower latitudes, while more quasars and galaxies clusters are seen at higher magnitudes. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.