| Issue |
A&A
Volume 687, July 2024
|
|
|---|---|---|
| Article Number | A81 | |
| Number of page(s) | 27 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202347492 | |
| Published online | 02 July 2024 | |
Statistics of magnification for extremely lensed high redshift stars★
1
Instituto de Física de Cantabria (CSIC-UC),
Avda. Los Castros s/n,
39005
Santander,
Spain
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Facultad de Ciencias, Universidad de Cantabria,
Avda. Los Castros s/n,
39005
Santander,
Spain
Received:
18
July
2023
Accepted:
2
November
2023
Abstract
Microlensing of stars in strongly lensed galaxies can lead to temporary extreme magnification factors (μ> 1000), enabling their detection at high redshifts. Following the discovery of Icarus, several stars at cosmological distances (z > 1) have been observed using the Hubble Space Telescope (HST) and the James Webb Space Telescope (JWST). This emerging field of gravitational lensing holds promise to study individual high redshift stars. It also offers the opportunity to study the substructure in the lens plane with implications for dark matter models, as more lensed stars are detected and analysed statistically. Due to the computational demands of simulating microlensing at large magnification factors, it is important to develop fast and accurate analytical approximations for the probability of magnification in such extreme scenarios. In this study, we consider different macro-model magnification and microlensing surface mass density scenarios and study how the probability of extreme magnification factors depends on these factors. To achieve this, we created state-of-the-art large simulations of the microlensing effect in these scenarios. Through the analysis of these simulations, we derived analytical scaling relationships that can bypass the need for expensive numerical simulations. Our results are useful to interpret current observations of stars at cosmic distances which are extremely magnified and under the influence of microlenses.
Key words: gravitation / gravitational lensing: strong / gravitational lensing: micro / dark matter
A public code based on our results for analytically computed magnification PDFs can be found here: https://github.com/ChemaPalencia/M_SMiLe.
© The Authors 2024
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
The discovery of Icarus (Kelly et al. 2018), a strongly magnified star at redshift z=1.49, recently opened the door to a new branch of gravitational lensing, the study of distant stars at extreme magnification factors (μ > 1000). Icarus was being magnified by a large factor (of several hundred) by a galaxy cluster. In addition to the magnification from the cluster, a microlens in the cluster (most likely a star) boosted the amplification by another factor ![Mathematical equation: $\[\boldsymbol{\mathcal{O}}\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq1.png) (10), bringing the net magnification to several thousand. This large magnification was maintained for only a few weeks, but it allowed for Icarus to be identified as a varying source, and for it to be monitored further with additional Hubble Space Telescope (HST) observations that allowed for its nature to be confirmed. After Icarus, a series of blue luminous stars have been discovered with similar magnification factors with HST (Chen et al. 2019; Kaurov et al. 2019; Welch et al. 2022a; Diego et al. 2022; Meena et al. 2023a), culminating with the discovery of Earen-del, the farthest star ever observed at z ≈ 6 (Welch et al. 2022a,b). More recently, the James Webb Space Telescope (JWST) has expanded this list with additional blue supergiants (Chen et al. 2022; Meena et al. 2023b), and the first red supergiants, which are the most luminous in the infrared (IR) bands beyond the reach of HST (Diego et al. 2023). Dedicated programmes with HST to search for these extremely magnified stars near cluster critical curves, and undergoing microlensing events, such as Flashlights (Kelly et al. 2019), have recently proven to be very successful with the discovery of over a dozen new stars at cosmic distances (Kelly et al. 2022). New programmes with JWST, such as the Prime Extragalactic Areas for Reionization and Lensing Science (PEARLS; Windhorst et al. 2023), are taking over, and are finding new examples of extremely magnified stars, specially colder ones (T < 10 000 K). With the number of individual stars beyond redshift z = 1 rapidly increasing, we are approaching the point where the statistical significance of such detections may be sufficient to discriminate between different models of the following: (i) the underlying population of luminous stars at cosmic distances, and (ii) the amount of a small-scale substructure in the lens plane that is responsible for the microlensing fluctuations.
(10), bringing the net magnification to several thousand. This large magnification was maintained for only a few weeks, but it allowed for Icarus to be identified as a varying source, and for it to be monitored further with additional Hubble Space Telescope (HST) observations that allowed for its nature to be confirmed. After Icarus, a series of blue luminous stars have been discovered with similar magnification factors with HST (Chen et al. 2019; Kaurov et al. 2019; Welch et al. 2022a; Diego et al. 2022; Meena et al. 2023a), culminating with the discovery of Earen-del, the farthest star ever observed at z ≈ 6 (Welch et al. 2022a,b). More recently, the James Webb Space Telescope (JWST) has expanded this list with additional blue supergiants (Chen et al. 2022; Meena et al. 2023b), and the first red supergiants, which are the most luminous in the infrared (IR) bands beyond the reach of HST (Diego et al. 2023). Dedicated programmes with HST to search for these extremely magnified stars near cluster critical curves, and undergoing microlensing events, such as Flashlights (Kelly et al. 2019), have recently proven to be very successful with the discovery of over a dozen new stars at cosmic distances (Kelly et al. 2022). New programmes with JWST, such as the Prime Extragalactic Areas for Reionization and Lensing Science (PEARLS; Windhorst et al. 2023), are taking over, and are finding new examples of extremely magnified stars, specially colder ones (T < 10 000 K). With the number of individual stars beyond redshift z = 1 rapidly increasing, we are approaching the point where the statistical significance of such detections may be sufficient to discriminate between different models of the following: (i) the underlying population of luminous stars at cosmic distances, and (ii) the amount of a small-scale substructure in the lens plane that is responsible for the microlensing fluctuations.
Future observations, especially with JWST, will soon increase the number of strongly lensed stars to ![Mathematical equation: $\[\boldsymbol{\mathcal{O}}\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq2.png) (100), allowing for studies that constrain not only the nature of the distant star, but also the intervening population of microlenses. Of particular interest is the study of the most distant lensed stars, since at large redshifts the critical curves of gravitational lenses move outwards, where the role of stellar microlenses is smaller. However, the role of possible compact dark matter (DM) candidates – such as primordial black holes (PBHs) – is, in relative terms, greatest. In interacting clusters, critical curves can form in regions in between the different cluster components, where the stars responsible for the intracluster light have the smallest lensing effects. In addition, if the cluster is relatively at large redshifts (z > 0.6), the intracluster medium is still in its early stages of formation resulting in a relative pristine medium (in terms of stellar microlensing contamination), and hence offering a unique opportunity to constrain models of compact DM. High redshift galaxies that are strongly lensed produce counter images in regions relatively far away from the centre of galaxy clusters, and where the abundance of stellar microlenses is smallest compared with the contribution from DM. Interacting clusters offer a unique opportunity to constrain models of compact dark matter due to the lower contamination from stellar microlensing in the region between the two clusters, thus offering a clearer view of the DM component. Such arcs already exist in the literature, for instance the giant arc at z = 2.83 nicknamed La Flaca, which is strongly magnified by the merging galaxy cluster El Gordo at z = 0.87 (Diego et al. 2023). At least one lensed star candidate has been identified in this arc. If confirmed, its interpretation will demand an accurate modelling of the probability of magnification on a wide range of scenarios that involve different contributions to the microlensing signal from compact DM models.
(100), allowing for studies that constrain not only the nature of the distant star, but also the intervening population of microlenses. Of particular interest is the study of the most distant lensed stars, since at large redshifts the critical curves of gravitational lenses move outwards, where the role of stellar microlenses is smaller. However, the role of possible compact dark matter (DM) candidates – such as primordial black holes (PBHs) – is, in relative terms, greatest. In interacting clusters, critical curves can form in regions in between the different cluster components, where the stars responsible for the intracluster light have the smallest lensing effects. In addition, if the cluster is relatively at large redshifts (z > 0.6), the intracluster medium is still in its early stages of formation resulting in a relative pristine medium (in terms of stellar microlensing contamination), and hence offering a unique opportunity to constrain models of compact DM. High redshift galaxies that are strongly lensed produce counter images in regions relatively far away from the centre of galaxy clusters, and where the abundance of stellar microlenses is smallest compared with the contribution from DM. Interacting clusters offer a unique opportunity to constrain models of compact dark matter due to the lower contamination from stellar microlensing in the region between the two clusters, thus offering a clearer view of the DM component. Such arcs already exist in the literature, for instance the giant arc at z = 2.83 nicknamed La Flaca, which is strongly magnified by the merging galaxy cluster El Gordo at z = 0.87 (Diego et al. 2023). At least one lensed star candidate has been identified in this arc. If confirmed, its interpretation will demand an accurate modelling of the probability of magnification on a wide range of scenarios that involve different contributions to the microlensing signal from compact DM models.
To extract useful information (with cosmological significance) from these events, it is necessary to understand the role that microlenses play in the magnification for objects discovered near the critical curves of gravitational lenses. This has been done so far by means of simulating the lens plane after populating it with microlenses from the gravitational lens. These microlenses include stars and remnants form the lens itself but also sometimes more exotic microlenses such as primordial black holes (Diego et al. 2018). Given the extreme values of the magnification factors, a target-simulated area A in the source plane needs to be simulated first in an area a factor μ times larger in the image plane. Combined with the fact that the source to be resolved (a star) is very small in nature, this usually results in simulations that are very computationally demanding. If one wants to perform a statistical study of the detected stars, a wide range of magnifications and microlens parameters needs to be explored making this task a daunting one if performed through simulations. A more efficient approach is to approximate the probability of magnification by analytical forms that are flexible and accurate enough so they can reproduce a wide range of scenarios. The present work aims to find these analytical forms which will set the basis for future studies on the probability of finding these stars. This probability involves several ingredients such as the number density of luminous stars, the probability of having magnification factors greater than 100 (by a galaxy or galaxy cluster)1, and the probability of magnification when microlenses are present in a region magnified over a factor 100 by a galaxy or galaxy cluster. This paper hence focusses on this last point, and we leave the much more complex full calculation of the probability of observing a particular type of star and at a given redshift for future work.
One direct application of our work is the study of certain models of DM that could act as microlenses. Among these, primordial black holes (PBHs) have gained significant attention as a potential candidate for DM (see Green & Kavanagh 2021 for a recent review). These black holes are believed to have formed through the gravitational collapse of mass overdensities in the early Universe, predating the epoch of matter-radiation equality. Importantly, PBHs are non-baryonic and did not play a role in primordial nucleosynthesis. PBHs can potentially interact with baryonic matter through two mechanisms. Firstly, the lightest PBHs could undergo evaporation via Hawking radiation, leading to the release of energy and particles. Secondly, the heaviest PBHs could interact with baryons through the transfer of energy from their accretion disks. PBHs with initial masses MPBH ≳ 1011 kg are expected to have completely evaporated by the present time (MacGibbon et al. 2008). On the other hand, massive PBHs (MPBH ≳ 100 M⊙) would have left an inprint on the cosmic microwave background (Serpico et al. 2020) or interact with their surroundings heating the medium (Lu et al. 2021). In the range of a few tens of M⊙, PBHs could offer a natural explanation for the abundance of massive black hole mergers found by gravitational wave experiments (The LIGO Scientific Collaboration 2023). If PBHs with these masses exist in relatively large numbers, they contribute to the microlensing signal. Current constraints based on microlensing signatures set an upper limit on the abundance of PBHs at the 1% level of the total amount of DM. Future observations of distant lensed stars are expected to lower this upper limit even further.
This paper is organised as follows: in Sec. 2, we describe the basic properties of microlensing embedded in a region of high magnification. In Sect. 3, we introduce the methodology to follow and present the simulation procedure. Section 4 presents the results for isolated lens simulations and a study on how a simple parameter scale in terms of the macro- and micro-model parameters. Section 5 generalises this to a set of N microlenses and presents our numerical simulations. We present in Sec. 6 the modelling of the magnification probability. In Sec. 7, we develop the methodology to constraint compact DM with caustic crossing events (CCEs) using our newly obtained analytical tool. Our results and some prospects on the use of the approximations derived here are discussed in Sect. 8, and we conclude in Sec. 9.
Unless noted otherwise, we adopt a flat cosmology with Ωm = 0.3, Λ = 0.7, and h = 0.7 (100 km s−1 Mpc−1). We use the term macrolens or macromodel when we refer to a lens with the mass of a galaxy or a galaxy cluster. The term microlens or micromodel is used to refer to much smaller lenses with masses comparable to stellar masses. The caustics associated with microlenses are referred to as microcaustics.
2 Simple notions of gravitational lensing
In this section, we provide a brief overview of the formalism of gravitational lensing, a fundamental tool in studying many astro-physical phenomena. We focus specifically on the gravitational lensing effect caused by the perturbation of a set of point-like lenses located in a region of high magnification near a critical curve (or CC). This regions of extreme magnification map into the source plane into similar regions of extreme magnification known as caustics. A source with infinitesimal size has divergent magnification when is place at the exact position of the caustic. Stars are very small but have a limited size. In this case, the maximum magnification scales as ![Mathematical equation: $\[1 / \sqrt{R_*}\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq3.png) , where R* is the star radius.
, where R* is the star radius.
As mentioned in the introduction, we refer to the components of the microlensing, the lensing effects caused by the point-like lenses, with the prefix ‘micro-’ (e.g. micro-images, micro-caustics, etc.). In contrast, we use the prefix ‘macro-’ for those effects associated with the galaxy cluster.
The position of a lensed image θ, and its actual position in the sky β are related through the lens equation (Schneider et al. 1992; Narayan & Bartelmann 1996)
![Mathematical equation: $\[\boldsymbol{\beta}=\boldsymbol{\theta}-\boldsymbol{\alpha}(\Sigma, \boldsymbol{\theta}),\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq4.png) (1)
(1)
where α is the deflection angle at the position θ produced by a lens of surface mass density ∑(θ). As α is a function of θ, Eq. (1) is generally non-linear leading to multiple solutions θ for the same β, and usually forbidding an analytical solution. The deflection angle can be obtained from the derivatives of the effective lensing potential
![Mathematical equation: $\[\psi(\boldsymbol{\theta})=\frac{D_{\mathrm{ds}}}{D_{\mathrm{d}} D_{\mathrm{s}}} \frac{2}{c^2} \int \phi\left(D_{\mathrm{d}} \boldsymbol{\theta}, z\right) \mathrm{d} z,\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq5.png) (2)
(2)
where Dd, Ds and Dds are the angular diameter distances to the lens, the source, and between the lens and the source, respectively, and ϕ is the Newtonian potential of the lens. The deflection angle is the gradient of ψ with respect to θ
![Mathematical equation: $\[\boldsymbol{\alpha}=\boldsymbol{\nabla}_{\boldsymbol{\theta}} \psi,\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq6.png) (3)
(3)
while its Laplacian is related to Σ(θ) as
![Mathematical equation: $\[\boldsymbol{\nabla}_\theta^2 \psi=2 \frac{D_{\mathrm{d}} D_{\mathrm{d} s}}{D_{\mathrm{s}}} \frac{4 \pi G}{c^2} \Sigma(\boldsymbol{\theta})=2 \frac{\Sigma(\boldsymbol{\theta})}{\Sigma_{\text {crit }}} \equiv 2 \kappa(\boldsymbol{\theta}),\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq7.png) (4)
(4)
where κ is known as the convergence and is the ratio between the surface mass density and the critical surface mass density, ∑crit.
The lensing distortion can be described by the Jacobian matrix
![Mathematical equation: $\[\mathrm{A} \equiv \frac{\partial \boldsymbol{\beta}}{\partial \boldsymbol{\theta}}=\left(\delta_{i j}-\frac{\partial \alpha_i(\boldsymbol{\theta})}{\partial \theta_j}\right)=\left(\delta_{i j}-\frac{\partial^2 \psi(\boldsymbol{\theta})}{\partial \theta_i \partial \theta_j}\right)=\left(\delta_{i j}-\psi_{i j}\right)=\mathrm{M}^{-1},\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq8.png) (5)
(5)
which is the inverse of the magnification tensor M. Since the convergence is half of the Laplacian of ψ, we have that
![Mathematical equation: $\[\kappa(\boldsymbol{\theta})=\frac{1}{2}\left(\psi_{11}+\psi_{22}\right)=\frac{1}{2} \operatorname{tr} \psi_{i j}.\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq9.png) (6)
(6)
Another important quantity is the shear tensor γ(θ), whose components can be also expressed as linear combinations of ψij,
![Mathematical equation: $\[\begin{aligned}& \gamma_1(\boldsymbol{\theta})=\frac{1}{2}\left(\psi_{11}-\psi_{22}\right), \\& \gamma_2(\boldsymbol{\theta})=\psi_{12}=\psi_{21},\end{aligned}\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq10.png) (7)
(7)
the modulus of the shear tensor is ![Mathematical equation: $\[\gamma^2=\left(\gamma_1^2+\gamma_2^2\right)^{1 / 2}\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq11.png) , where γ is known as the shear. We can rewrite the Jacobian matrix in terms of the convergence and the shear
, where γ is known as the shear. We can rewrite the Jacobian matrix in terms of the convergence and the shear
![Mathematical equation: $\[\mathrm{A}=\left(\begin{array}{cc}1-\kappa-\gamma_1 & -\gamma_2 \\-\gamma_2 & 1-\kappa+\gamma_1\end{array}\right).\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq12.png) (8)
(8)
Gravitational lensing preserves the surface brightness of an object while altering its apparent size. The magnification, which represents the ratio between the total observed flux of a lensed image and that of the unaltered image, is determined by the ratio between the solid angles of the image and the original, unlensed source. The CC of a lens system refers to a collection of positions in the lens plane where the magnification diverges. By utilising Eq. (1), we can trace the origins of these critical curves back to the source plane, thereby obtaining their corresponding complementary caustic curves.
Combining Eqs. (5) and (8), the magnification μ is
![Mathematical equation: $\[\mu=\mu_{\mathrm{t}} \mu_{\mathrm{r}}=\operatorname{det} \mathrm{M}=\frac{1}{\operatorname{det} \mathrm{A}}=\frac{1}{(1-\kappa)^2-\gamma^2} \text {, }\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq13.png) (9)
(9)
where μt and μr are the tangential and radial components of the magnification, ![Mathematical equation: $\[\mu_{\mathrm{t}}^{-1}=1-\kappa-\gamma\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq14.png) , and
, and ![Mathematical equation: $\[\mu_{\mathrm{r}}^{-1}=1-\kappa+\gamma\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq15.png) . We note that similar to A and M, μ is a function of the position θ in the lens plane.
. We note that similar to A and M, μ is a function of the position θ in the lens plane.
Despite the non-linearity of Eq. (1), the deflection angle remains linear. Thus, we can express α as the sum of the individual components of the lens system. In our case of interest
![Mathematical equation: $\[\boldsymbol{\alpha}=\sum_{i=0}^{\mathrm{N}} \boldsymbol{\alpha}_{*, i}+\boldsymbol{\alpha}_{\mathrm{m}}=\boldsymbol{\alpha}_*+\boldsymbol{\alpha}_{\mathrm{m}},\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq16.png) (10)
(10)
where α*,i is the deflection angle caused by each of the N pointlike lenses, α* is their combined deflection angle, and αm is the contribution from the galaxy cluster. For a point-like lens substituting the corresponding Newtonian potential into Eq. (2), the deflection angle for a lens of mass Mi at the position θi is
![Mathematical equation: $\[\boldsymbol{\alpha}_{*, i}=\frac{D_{\mathrm{ds}}}{D_{\mathrm{d}} D_{\mathrm{s}}} \frac{4 G M_i}{c^2} \frac{\boldsymbol{\theta}-\boldsymbol{\theta}_{\boldsymbol{i}}}{\left|\boldsymbol{\theta}-\boldsymbol{\theta}_{\boldsymbol{i}}\right|^2}.\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq17.png) (11)
(11)
To obtain αm, we consider a region near the tangential CC of the cluster. By definition a tangential CC forms where 1 − κ − γ = 0 and |1 − κ + γ| > 0. For simplicity we assume γ2 = 0 and so γ = γ1. This is equivalent to considering a portion of the CC where the deflection field is aligned in a direction perpendicular to the CC, which is a common situation in many real lenses. The high magnification arises from the tangential component of the macro-magnification μt ≫ μr. Depending on which side of the CC we consider we might have a positive or negative parity. The convergence and shear values of the macro-lens are given by
![Mathematical equation: $\[\begin{aligned}& \gamma_{\mathrm{m}}=\frac{1}{2}\left(\frac{1}{\mu_{\mathrm{r}}} \mp \frac{1}{\mu_{\mathrm{t}}}\right), \\& \kappa_{\mathrm{m}}=1-\gamma_{\mathrm{m}} \mp \frac{1}{\mu_{\mathrm{t}}},\end{aligned}\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq18.png) (12)
(12)
where the minus and plus sign refer to the positive and negative parities respectively. If (1 − κ)2 − γ2> 0, the parity is positive, otherwise if this factor is negative we are in a negative parity region. This subtle change in the form of the convergence and the shear allows for completely different phenomena occurring at each parity. The deflection angle caused by a smooth potential such as that of the macrolens increases linearly as we approach the macro-CC, thus we have that the deflection angles from the macro model in the tangential and radial directions is
![Mathematical equation: $\[\begin{aligned}& \alpha_{\mathrm{m}, \mathrm{t}} \propto\left(\tilde{\kappa}+\gamma_{\mathrm{m}}\right), \\& \alpha_{\mathrm{m}, \mathrm{r}} \propto\left(\tilde{\kappa}-\gamma_{\mathrm{m}}\right).\end{aligned}\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq19.png) (13)
(13)
It is important to note that we have not used the macroconvergence but its modified value ![Mathematical equation: $\[\tilde{\kappa}=K_{\mathrm{m}}-K_*\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq20.png) , taking into account the modification of the point-like lenses on the macro-potential (Diego et al. 2018). As the point-like lenses are isotropically (and randomly) distributed they do not contribute a shear, so there is no need for a correction in the macro-shear. Including Eqs. (11) and (13) in Eq. (10), we obtain the total deflection angle, thus allowing us to solve numerically any lens problem related to our given configuration.
, taking into account the modification of the point-like lenses on the macro-potential (Diego et al. 2018). As the point-like lenses are isotropically (and randomly) distributed they do not contribute a shear, so there is no need for a correction in the macro-shear. Including Eqs. (11) and (13) in Eq. (10), we obtain the total deflection angle, thus allowing us to solve numerically any lens problem related to our given configuration.
3 Numerical simulations
Extreme magnification near a CC gives rise to very crowded source planes. The microlens surface mass density, ∑*, is effectively re-scaled by the large macromodel magnification μ, resulting in a large effective surface mass density ∑eff = μt∑*. The value of the effective surface mass density often surpasses the critical density, leading to optically thick lenses where continuous microlensing events occur. Earlier work has relied on expensive simulations to study the statistical properties of the observed flux (Diego et al. 2018; Venumadhav et al. 2017). A recent paper by Meena et al. (2022) presents a new simulation method to circumvent the large computing time required for inverse ray shooting. This method provides a new and faster approach to obtain magnification in the source plane, and thus the light curves of compact sources under microlensing. However, the aim of this work is to obtain statistics of magnification bypassing the simulation step which is the most resource consuming. These two methods are complementary. If only statistics of magnification are required, our approach is faster; however, if light curves are required, our method cannot provide them, while that of Meena et al. (2022) can.
To approximate the changes in flux properties over time for an extremely lensed source, caused by a specific microlens population with surface mass density ∑, at a given distance from a tangential macro-CC (μm = μtμr), a series of simulations must be conducted by varying these parameters. Subsequently, the d(area)/dμ or probability distribution function of the total magnification needs to be modelled, which will be discussed in more detail in Sect. (6). The model function’s parameters will be studied in relation to the physical parameters, establishing their underlying relation. Once this step is completed, it becomes possible to bypass the numerical simulations that currently consume the majority of time in these analysis, thereby eliminating this bottleneck. Previous works have obtained analytical approximations for the magnifications (Deguchi & Watson 1987; Seitz & Schneider 1994; Seitz et al. 1994; Neindorf 2003; Tuntsov et al. 2004). However, these methods fail at large macro-magnifications and high surface mass densities, where this work is focussed. Thus the need to derive analytical methods in this regime.
The computation of magnification in the source plane is accomplished using the inverse ray-shooting technique (Kayser et al. 1986). This method uses the lens equation as shown in Eq. (1) to trace back an image observed in the lens plane to its original position in the source plane. By discretising the lens plane over a sufficiently large area and performing this tracing, a reasonably accurate approximation of the magnification in the source plane can be obtained. The accuracy of this magnification probability with respect to pixel size and other resolution effects is extensively discussed in Appendix A.
In order to utilise the inverse ray-shooting technique effectively, it is necessary to determine the deflection angle at each pixel of the simulated lens plane, considering both the contributions from the micro and macro components. Initially, we compute the deflection angle generated by the microlensing population, denoted as α*. To accomplish this, we randomly distribute a set of point-like lenses within a circular region with a radius of Nx, where Nx corresponds to the size in pixels of our simulated lens plane in the tangential direction of the macro-magnification. The masses of these lenses are randomly picked from a Spera initial–final mass function (Spera et al. 2015), with the constraint that they do not exceed 1.5 M⊙. We only compute the deflection angle from the lenses within a circle of radius Nx By utilising Eq. (11) and considering the position and mass of each microlens, we can calculate the corresponding deflection angle α*,,i(θ) for each individual microlens. Next, we proceed to calculate the corresponding deflection angle associated with the galaxy cluster αm(θ). To begin, we calculate the convergence and shear of the macro-model based on the macro-magnification, as described in Eq. (12). The specific choice of parity will depend on the simulation being conducted. Subsequently, we proceed to correct the convergence, κ, by considering the influence of the microlenses,that is the effective convergence is κeff = κ − κ*. Although this correction may be negligible in cases where the surface mass density of microlenses is small, it becomes crucial in crowded regions characterised by large stellar populations. In such scenarios, the effect of microlenses becomes significant and must be accounted for in the analysis. Using Eqs. (13) and (10), we can proceed to calculate the total deflection angle at each position required for the inverse ray-shooting method. These equations allow us to combine the contributions from the macromodel and the microlenses to obtain the complete deflection angle necessary for the analysis. Since the total deflection angle is the sum of independent contributions from each component, we can exploit this property by utilising the same deflection angle obtained from a set of microlenses with different macromodel configurations. This approach allows us to save both time and computational resources by avoiding redundant calculations of the microlens deflection angles for each specific macro-model configuration. In this study, we conducted simulations using a computational grid consisting of approximately Nx ≈ 3 × 106 pixels in the tangential direction and Ny ≈ 0.15 × 106 pixels in the radial direction. This area gets remapped into a region (3 × 106/μt) × (0.15 × 106/μr) in the source plane. Each pixel in the simulation corresponds to a size of 2 nas. Consequently, the total size of the simulation area amounted to 6 × 0.3 mas2, with a lens plane redshift of zd = 0.7 and a source plane redshift of zs = 1.3. For this particular system, the critical surface mass density was estimated to be approximately ∑crit ≈ 3.1 × 103 M⊙/pc2. We conducted 39 distinct simulations for each parity, where we varied the values of ∑*, μt, and μr. As a result, we obtained a range of effective surface mass densities spanning from 0.01 to 66.5 times the critical density. Furthermore, in order to gain a deeper understanding of the statistics related to the negative parity regime and investigate additional effects associated with low effective surface mass densities, we conducted a few additional realisations alongside the main simulations. On average, it takes 32 CPU-hours to simulate the deflection angle for a single microlens of the aforementioned size and resolution that occupies 1.4 TB of disk space. Complex simulations with thousands of microlenses can reach hundreds of thousands of CPU-hours. Detailed explanations of these supplementary simulations can be found in Sec. 6 and Appendix B. As far as we are aware, these state-of-the-art simulations represent the largest scale simulations conducted at this resolution level for the purpose of studying microlensing by compact lenses around a cluster-CC. The substantial size of the simulations provides us with a significant amount of statistical data, enabling a comprehensive analysis of the probability of magnification for background sources across a wide range of values.
To simplify the modelling of magnification probabilities and ease a direct comparison between different simulations, the final magnification is normalised by a factor of 1000/μm. Unless specifically stated otherwise, this normalisation has been consistently applied throughout our analysis. As a result, a pixel in our simulations with a magnification value of μ will now be represented as ![Mathematical equation: $\[\tilde{\mu}=1000 \times \mu / \mu_{\mathrm{m}}\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq21.png) . The PDF of the magnification after being re-scaled this way peaks around values close to μ = 1000, but not exactly at this value as we describe below. For ease of notation, we continue to refer to the re-scaled magnification as μ in our discussions.
. The PDF of the magnification after being re-scaled this way peaks around values close to μ = 1000, but not exactly at this value as we describe below. For ease of notation, we continue to refer to the re-scaled magnification as μ in our discussions.
The inverse ray-shooting technique is a computationally intensive numerical method that relies on the total number of pixels (a combination of the simulated area and pixel size) and the number of microlenses. Simulating scenarios with high surface mass densities can be exceptionally expensive, necessitating the development of tools that offer an alternative to the costly numerical simulations. The main objective of this work is to develop and present a tool that serves as a shortcut from the lens parameters to the magnification probability. Providing an alternative approach that eliminates the requirement for time-consuming and computationally expensive simulations. By offering this tool, researchers can efficiently estimate the magnification probability based on the lens parameters, streamlining their analyses and reducing the reliance on extensive numerical simulations.
It is crucial to emphasise that despite the development of shortcut tools, the spatial distribution of the micro-caustic network remains an important factor in many analyses. Therefore, numerical simulations continue to play a vital role in understanding and studying the intricate details of the micro-caustic structure.
Given the large size of the simulations, we used a computer cluster. To facilitate the development of this work, a parallelised version of the inverse ray-shooting technique was employed, thus allowing us to fully exploit the resources of the computer cluster ALTAMIRA.
 |
Fig. 1 Magnification in the source plane of a single microlens near a macro-CC where μm = 1000. The darkest blue indicates a lower magnification, while the whites show where the magnification diverges (i.e. the micro-caustics). Left: single microlens on the positive parity side of the CC. The caustics have the familiar diamond shape. Right: same, but in the negative parity region, crossing the macro-CC. Now the shape of the micro-caustics is broken into two distorted triangles with a demagnification area in between, but increasing the maximum achievable magnification at the tips of these triangles. Outside the caustics, the average magnification is that of the macro model μm. The vertical direction has been scaled down a factor ~10 for better visualisation. The probability of magnification for both examples is shown in Fig. 2. |
4 Microlenses near a CC
The primary objective of this work is to model the statistical properties of the flux emitted by a background source as it traverses the micro-caustic network created by microlenses, such as stars from the intracluster light (ICL) and compact DM candidates like PBHs, in a region of high magnification near a CC associated with a galaxy cluster. This problem is inherently complex due to the non-linear nature of the lens equation. To gain insights into the flux statistics arising from the perturbation of the galaxy cluster’s smooth potential by numerous microlenses, it is beneficial to analyse the case of an isolated microlens near a CC.
 |
Fig. 2 Probability of magnification (in log10 bins) for the two single lenses. The purple dashed line represents the microlens on the negative parity side of the macro-CC, while the orange solid line represents the positive parity case on the right and left panels of Fig. 1, respectively. The dotted lines represents the power-laws that always appear for isolated microlenses near macro-CCs, and for N microlenses with low ∑eff. The variation in the value of the ∑−2 power-law amplitude is shown in Fig. 3. |
4.1 Single microlens case
This analysis of a single microlens near a CC provides valuable information for scenarios characterised by low optical depths, where a microlens can be treated as an isolated entity. This was the case for Icarus and its counter image Iapyx (Kelly et al. 2018), and generally applies for images not too close to the macro-CC and within regions of low ∑* (∑eff ≪ ∑crit). In addition, the single microlens case can be used to test limitations of the numerical simulation, such as the limited spatial resolution, or pixel size.
The outcome of the inverse ray-shooting technique applied to a single microlens situated near a macro-CC is presented in Fig. 1. This illustration showcases the results for both positive and negative parities. To exemplify the magnification probability for a single microlens within positive and negative macro-model regions, we refer to Fig. 2.
This visualisation offers insights into several key observations. Firstly, the size of the critical curves is scaled down by factors μt and μr in the tangential and radial directions, respectively (refer to Oguri et al. 2018 for further details). Furthermore, both parities exhibit a prominent peak in the probability of magnification around the value of the macro-model magnification μm. As magnification increases beyond this peak, the probability decreases following a power-law scaling of μ−3 (or μ−2 if logarithmic bins are considered, as in our analysis). This behaviour is well-established in the literature (see Rauch 1991) and serves as a means to assess the resolution of our simulations (see Appendix A). When the probability of magnification no longer adheres to this power-law decline, it indicates the limit of our simulation’s resolution. Additionally, the negative parity introduces a demagnification relative to μm, with the probability of demagnification exhibiting a decreasing slope of −1/2 for lower magnifications. These findings shed light on the behaviour and characteristics of magnification probabilities associated with a single microlens near a macro-CC at both positive and negative parities.
This straightforward scenario provides valuable insights into the impact of various parameters on the magnification probability. Parameters such as the lens mass, the macro-model magnification, and the reduced distance D = Dds/(DsDd) play crucial roles in shaping the magnification probability. To examine these effects, we perform a fitting procedure to the power-law function, μ−2, on the right tail of the PDF of the magnification, and investigate the relationship between the amplitude of the power-law and these variables. The results of this analysis are illustrated in Fig. 3. The amplitude of the power-law (dotted lines in Fig. 3) increases cuadratically with the mass and the macromagnification, and it increases linearly with the reduced distance.
 |
Fig. 3 Extrapolated value of the power-law ∝ μ−2 at μ = 1 from the probability distribution function of a system of N microlenses in the vicinity of a macro-CC. The case of one microlens is shown in the top row. The case for two microlenses is shown in the bottom row. We have changed the total mass of the microlenses, the magnification from the macro model and the reduced distance in the first, second and third columns respectively, while keeping the other parameters fixed. Note that for both systems the amplitude scales at the same rate for each parameter. All these lens systems have ∑eff ≪ ∑crit. Dashed lines represent the best fit to a powerlaw obtained by χ2 minimisation. We found that the amplitude scales linearly with the reduced distance and it scales cuadratically with the macro-magnification and the mass of the lenses. |
4.2 Double microlens case
Before delving into the realistic scenario of a distribution of N microlenses, it is insightful to examine the case of two microlenses. This analysis will elucidate the fundamental scalings that will be further explored and elucidated throughout the remainder of this paper. We consider a second microlens with half the mass of the first microlens, centred at a distance equal to half the size of the original microcaustic in each direction, exactly on top of the microcaustic, maximising the overlapping (if placed closer it would behave as a single microlens whose mass is the combination of each sub-mass).
The scenario of two nearby microlenses in a high magnification region exhibits similarities to the single lens scenario. The linearity shown in Fig. 3 persists even for larger number of microlenses as long as the effective surface mass density remains below 0.1 ∑crit. However, once the micro-caustics start to overlap, resulting in ∑eff values beyond this threshold, the magnification probability undergoes a transformation. At this point, the power-law decrease in the probability for higher magnifications vanishes, and a log-normal behaviour starts to emerge. In the most extreme scenarios of ∑eff >> 1, the log-normal shape of the PDF of the magnification gets narrower the larger the value of ∑eff. This phenomenon, known as the “more is less effect”, has been previously observed and studied (see Welch et al. 2022a; Diego et al. 2018) and is studied in more detail in Sec. 6. The scalings of the probability of magnification are exactly the same as the ones observed for the case of a single microlens. These scalings are shown in the bottom row of Fig. 3.
This simple test demonstrates that increasing the mass of the lens or lenses, increasing the magnification of the macro-model (i.e. reducing the distance to the macro-CC), or increasing the reduced distance all lead to an increase in the probability of magnification at higher values.
Building upon these insights, a similar procedure is applied to the general case of N microlenses in Sec. 6, which is the main objective of this work.
5 Generalisation to N microlenses
Here, we consider a more realistic scenario that is more likely to be found in real observations. In this scenario, we consider a large population of microlenses with different surface mass densities and macro-model magnifications. The simulations consist of nearly 90 cases with different effective surface mass densities and parities, and the computational resources required for these simulations amount to approximately 0.5 × 106 CPU-hours.
A significant finding is that the magnification statistics exhibit distinct behaviours depending on whether the ratio ∑eff/∑crit is smaller or greater than one. We refer to these cases as the low surface mass density and medium-high surface mass density scenarios, respectively. These two cases display different characteristics in terms of the magnification statistics. Figures 4–7 show some of the simulated magnification maps and statistics at the source plane for each surface mass density regime, low and high respectively, increasing the surface mass density towards the right at each parity (column).
To increase the effective surface mass density, there are two approaches. Firstly, one can increase the surface mass density of the microlenses by either including more microlenses or by having more massive ones. This results in larger micro-caustics, which in turn contribute to an increase in ∑eff. Secondly, one can approach the macro-CC more closely, effectively increasing the macro-magnification. This mapping of micro-caustics into a smaller region enhances the likelihood of overlap between micro-caustics, thereby increasing the probability of a microlensing event due to caustic crossings.
The overlapping micro-caustics distorts the probability of magnification in the high-end. A simple way to understand this is by realising that locally, each microlens can perturb the magnification acting over nearby microlenses, perturbing the magnification from the macromodel. Alternatively, the maximum magnification is inversely proportional to the smoothness of the deflection field. Very corrugated deflection fields naturally result in smaller maximum magnifications. In the negative parity case, there is still a tail of demagnification, but as the surface mass density increases, this tail disappears, and the magnification probability becomes similar to that of the positive case. This effect is evident in Fig. 6, where for an effective surface mass density 48 times larger than the critical value, the micro-caustics for the negative parity are indistinguishable from those of the positive case. In these high-density scenarios, the areas of demagnification have been completely eliminated. This more is less effect leads to a decrease in the probability of higher magnifications. The effects of micro-caustic overlap and the more-is-less effect can be observed in Figs. 4 and 6.
5.1 Low surface mass density
In the low surface mass density case, where the combined effect of the macro-model and microlenses does not exceed the critical surface mass density, the micro-caustics do not heavily overlap. As a result, they maintain a similar shape to the isolated microlens case, and the magnification probability resembles that shown in Fig. 2. As the effective surface mass density increases, both positive and negative parity cases exhibit a broadening of the main peak and a shift towards smaller magnification values. Additionally, the power-law tails of the probability distributions increase in amplitude and begin to transition to a log-normal distribution at smaller magnifications due to the increased overlap of micro-caustics. In the case of the negative parity, there is an excess probability of lower magnifications compared to the macro-magnification value. This demagnification effect follows a power-law distribution, with an increasing amplitude and a broadening peak structure as the surface mass density increases. This behaviours can be observed in Fig. 5 for the positive (right panel) and negative (left panel) macro-magnification parity cases.
 |
Fig. 4 High resolution view of the magnification at the source plane. Top panels: positive parity side of the macro-CC. Bottom panels: negative parity side of the macro-CC. The effective surface mass density increases from left to right. The value of the macro magnification and the ratio of the effective surface density to the critical value are shown for each column. Note that the y-direction has been compressed a factor 10 for better visualisation. For the same reason, the two rightmost columns have been compressed a factor 2 in the x-direction. |
5.2 Medium-high surface mass density
In the medium-high surface mass density case, the effective surface mass density exceeds the critical value, leading to the inevitable overlap of micro-caustics. The microlenses affect the macro-model magnification considerably and form a complex web of deformed micro-caustics that covers the entire plane, as depicted in Fig. 6. The magnification probabilities for the medium-high surface mass density simulations are shown in Fig. 7 for the positive (right panel) and negative (left panel) macro-magnification parity cases.
As ∑eff increases, the probability distribution of the re-scaled magnification becomes more concentrated within a smaller range and around smaller magnification values2. Both parities exhibit a peak-shaped distribution that saturates to a constant width. In the negative parity case, there is still a tail of demagnification, but as the surface mass density increases, this tail becomes less relevant and eventually it disappears. For the most extreme values of ∑eff, the magnification probability becomes similar to that of the positive case. This effect is evident in Fig. 6, where for an effective surface mass density 48 times larger than the critical value, the micro-caustics for the negative parity are indistinguishable from those of the positive case. In these high-density scenarios, the areas of demagnification have been completely eliminated.
 |
Fig. 5 Probability of magnification for a set of simulations with different ∑eff in the low surface mass density regime. Left panel: negative parity side of the macro-CC. Right panel: positive parity side of the macro-CC. |
 |
Fig. 6 High resolution view of the magnification at the source plane. Top panels: positive parity side of the macro-CC. Bottom panels: negative parity side of the macro-CC. The effective surface mass density increases from left to right. The value of the macro magnification and the ratio of the effective surface density to the critical value are shown for each column. Note that the y-direction has been compressed a factor 25 (50 for the last column) for better display. |
6 Analytical modelling
In this section, we describe the analytical functions employed to fit the magnification probabilities in each simulation. We differentiate between the low and medium-high surface mass density regimes as well as the positive and negative parities. Additionally, we demonstrate how each model parameter scales in relation to the physical properties of the lens system. To account for resolution effects, as described in Appendix A, we have carefully considered them in each simulation. All best-fit data points are presented in Appendix C.
The process we follow is straightforward. For each case study, we fitted the simplest analytical functions that not only offer a good approximation to the magnification probability distribution but also exhibit function parameters that demonstrate a discernible trend with respect to the lens model parameters. These trends can be easily extrapolated. We fitted the model parameters to simple models via χ2 minimisation. The model parameter value according to the best fit can be found in a Github repository3. As a result, we can work in the inverse direction: by utilising the lens characteristics, we can determine their corresponding model parameters. These parameters can then be incorporated to obtain a analytical approximation of the magnification probability distribution. This approach allows us to bypass the need for extensive numerical simulations, saving us time and computational resources.
Before delving into the analytical modelling that links the properties of the microlenses and the macro-model to the magnification probability, it is important to acknowledge a degeneracy present in the magnification probability with respect to ∑eff. Specifically, two different simulations with the same ∑eff but different values of ∑*, and μt can yield the same magnification probability (see Fig. 8).
Under certain circumstances, as described in Appendix B, this degeneracy can be broken. Additionally, if we undo the previous normalisation, different values of μr can also break this degeneracy. Furthermore, we observe that, in general, μr does not significantly influence the magnification probability. In the most extreme cases of surface mass density, and for high magnifications regardless of the surface mass density, this parameter does not have a significant impact on the probability of attaining such magnifications.
 |
Fig. 7 Probability of magnification for a set of simulations with different ∑eff in the medium-high surface mass density regime. Left panel: negative parity side of the macro-CC. Right panel: positive parity side of the macro-CC. |
 |
Fig. 8 Probability of magnification for two simulations with different ∑* and μt but the same ∑eff. Positive parities are shown as solid lines, while dashed lines represent negative parities. A difference in the position of the probability excess in the low magnification regime is due to a difference in μr between the simulations. |
6.1 Low effective surface mass density
This case is similar to the isolated microlens studied previously. It describes the probability of magnification, which is important in scenarios with a low density of microlenses, important for high redshift stars whose CC will be in the outermost parts of the cluster, where stellar microlenses are reduced. It also describes sources at lower macro-magnifications, or larger distances to the macro-CC. Furthermore, it serves as a useful bridge, linking the single microlens case to the high-density regime scenarios that are computationally more demanding. In this regime, we observe slight differences in magnifications between the positive and negative parities. As mentioned earlier, we now present the modelling of each case to provide a comprehensive understanding of the magnification behaviour in this regime.
The magnification probability functions in this study are characterised by a combination of power-law and log-normal functions. To facilitate the understanding of the parameter scalings in each case, we adopt the following notation:
Capital letters are used to represent the parameters of the log-normal functions.
Lowercase letters are used to denote the parameters of the power-law functions.
The alphabetical ordering of the parameters corresponds to their appearance in the probability distribution function from lower to higher magnification values, progressing from left to right in the PDF figures.
A superscript “+” or “-” is added to indicate the positive or negative parity case, respectively.
By employing this notation, we can succinctly represent and communicate the parametrisation of the magnification probability functions in a clear and organised manner.
6.1.1 Positive parity
A positive parity is obtained when (1 − κ)2 − γ2 > 0, indicating that the image retains the same parity as the source. This regime has been extensively investigated in previous studies. However, the understanding of probabilities at the highest magnification factors has been limited by the constraints of past simulations. The large field of view and high resolution of our simulations enable us to provide a precise description of the highest magnification factors, where the more-is-less effect comes into play.
The modelling of the magnification probability in this regime is straightforward and resembles that of a single microlens embedded in a highly magnified region. The probability distribution exhibits a peak structure centred around values similar to the magnification of the macro-model at that specific distance from the macro-CC. With our re-scaling of the magnification, these peaks are centred at μ = 1000. This central peak smoothly transitions into the well-known power-law decay that characterises the probability distribution over the remaining range of magnification values. However, the presence of overlapping micro-caustics leads to a decrease in the probability at the highest magnification values. This decrease occurs more rapidly than the power-law decay, resulting in a distinctive behaviour in the tail of the magnification probability distribution.
As the effective surface mass density increases, several notable changes occur in the magnification probability distribution. Firstly, the peaks in the distribution decrease in amplitude, become broader, and shift towards values smaller than the macromodel magnification. Additionally, these initially symmetrical peaks begin to exhibit a skewness towards larger magnification values.
Conversely, the power-law components of the distribution experience an increase in amplitude as the effective surface mass density increases. However, the range of magnifications described by these power-laws gets reduced, and the suppression of extreme magnification factors starts at smaller magnification values compared to lower surface mass density regimes.
To effectively model these magnification probabilities, we have divided the probability density functions into three distinct magnification regimes: (i) the low magnification regime, which is characterised by the presence of peaks, including the main one at the mode of the distribution; (ii) an intermediate region, which is described by the classic μ−2 power-law; (iii) the saturation extreme regime, where the power-law gets suppressed by microlenses. By breaking down the PDFs into these three regimes, we can provide a comprehensive and accurate representation of the magnification probabilities across the entire range of magnification values.
-
Low magnification regime: For the main peak of the PDF, we utilise a skewed log-normal distribution to capture the shape and characteristics of the magnification probabilities (part of the Eq. (14) with normalisation factor B+). In addition to the skewed log-normal distribution for the peak, we incorporate another log-normal distribution to account for the slight excess of probability at magnification values smaller than the peak (A+ term in the same equation).
![Mathematical equation: $\[\begin{aligned}\operatorname{PDF}\left(\log _{10}(\mu)\right)= & \mathrm{A}^{+} \exp \left(-\frac{\left(\log _{10}(\mu)-\log _{10}\left(\mu_{\mathrm{A}}^{+}\right)\right)^2}{2 \sigma_{\mathrm{A}}^{+2}}\right) \\& +\mathrm{B}^{+} \exp \left(-\frac{\left(\log _{10}(\mu)-\log _{10}\left(\mu_{\mathrm{B}}^{+}\right)\right)^2}{2 \sigma_{\mathrm{B}}^{+2}}\right) \\& \times\left[1+\operatorname{erf}\left(\alpha_{\mathrm{B}}^{+} \frac{\log _{10}(\mu)-\log _{10}\left(\mu_{\mathrm{B}}^{+}\right)}{\sqrt{2} \sigma_{\mathrm{B}}^{+}}\right)\right].\end{aligned}\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq22.png) (14)
(14)By combining these analytical functions, we can effectively model the peak structure and the slight excess of probability at lower magnification values observed in the PDFs for the lowest surface mass densities. From now on, in the context of this paper, a capital letter “X” refers specifically to the amplitude of the X-log-normal distribution, where X stands for A, B, C, etc. μx represents the centre of distribution without skewness, σx represents its width, and αx represents its skewness amplitude. In Fig. 9, we present the scaling of these model parameters with respect to the effective surface mass density.
-
Intermediate magnification regime: In the intermediate magnification regime, we model the magnification probability using a combination of two power-law functions with a fixed relation between their amplitudes. These power-laws capture the smooth transition from the peak region to the power-law decay with a fixed index of −2. The amplitude of the free index power-law is obtained by fitting the ratio of the amplitudes from a first fit of two independent power-laws. We use this model function to reduce the number of parameters. This procedure is repeated for the power-laws in the negative parity case.
![Mathematical equation: $\[\operatorname{PDF}\left(\log _{10}(\mu)\right)=\mathrm{a}^{+}\left(\frac{\sqrt{\sum_{\mathrm{eff}}}}{591}\left(\frac{\mu}{10^{3.5}}\right)^{\beta_{\mathrm{a}}^{+}}+\left(\frac{\mu}{10^{3.5}}\right)^{-2}\right).\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq23.png) (15)
(15)

Fig. 10 Scaling of the model parameters for the intermediate magnification regime at the low surface mass density and positive parity scenario. Point colours represent the ∑eff over the critical value as shown in Fig. 5.
This analytical model provides a convenient way to approximate the magnification probability in the intermediate magnification regime. Similarly to our previous notation for log-normal functions, we adopt a notation for power-law distributions. The lowercase letter “x” represents the amplitude of the x-power-law distribution, while βx denotes the index or exponent of the power-law. Figure 10 shows the scaling of these model parameters with ∑eff.
-
Extreme magnification regime: The suppression of the magnification probability at extreme magnification factors due to the microlenses can be described by a log-normal,
![Mathematical equation: $\[\operatorname{PDF}\left(\log _{10}(\mu)\right)=\mathrm{C}^{+} \exp \left(\frac{-\left(\log _{10}(\mu)-\log _{10}\left(\mu_{\mathrm{C}}^{+}\right)\right)^2}{2 \sigma_{\mathrm{C}}^{+2}}\right)\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq24.png) (16)
(16)These parameter scaling are shown at Fig. 11.
An example of a magnification probability curve fitted using this model is shown in Fig. 12. The figure showcases the agreement between the fitted model (dot-dashed line) and the simulated data (solid line). This exemplifies how our analytical approach can accurately capture the magnification probability distribution over a wide range of magnifications.
6.1.2 Negative parity
The negative magnification regime, where (1 − κ)2 − γ2 <0, corresponds to cases where the magnification μ is negative, resulting in an image with reversed parity compared to the source. While this regime has often been overlooked in the literature, it plays a significant role in understanding certain features observed in caustic crossing events. The unique characteristics of the negative parity regime can offer a better explanation for some observed events (such as the non-observation of Icarus’ counter-image), making a thorough modelling of this regime crucial for a comprehensive understanding of extreme magnification events.
In the negative parity regime, the magnification probability exhibits similar characteristics to the positive parity case at the highest magnifications. However, there are unique features observed at lower magnifications. We still observe a peak close to the macromodel value (μ = 1000 after re-scaling), followed by a power-law decrease that transitions to a log-normal behaviour at the highest magnification values. At the lowest magnifications, we observe a mild increase in the probability from a power-law component, which is much less steep compared to the power-law at higher magnifications. Additionally, there is a “bump” or excess in the probability of the lowest magnifications. Interestingly, the position of this bump does not seem to follow a specific dependence on ∑eff. These characteristics of the magnification probability in the negative parity regime provide important insights into the unique features and behaviours of caustic crossing events in gravitational lensing.
In the negative parity regime, similar to the positive regime, the width of the log-normals increases with increasing effective surface mass density. The range of the power-law component decreases, and the amplitude of the central peak decreases while the amplitudes of the other log-normals increase, similar to the amplitudes of the power-law components. However, there is a slight difference in the behaviour of the central peaks. Initially, they shift towards higher magnification values, but as the surface mass density further increases, they start moving towards lower magnification values, mimicking the trend observed in the positive parity case. This behaviour, alongside the demagnification components, reflects the unique characteristics of the negative magnification regime and provides important insights into the magnification probability in caustic crossing events with negative parities.
Here we also break the modelling into three regimes based on magnification values. Thus, providing a comprehensive description of the magnification probability distribution in the negative magnification regime: i) The low magnification or demagnification regime featuring the main differences with respect to the positive parity; ii) The intermediate magnification, covering the central peak; iii) The high magnification regime, spawning the power-law decrease and log-normal decrease at the highest magnification factors.
-
Low magnification regime: In the negative magnification regime, we model the probability distribution using a combination of power-law functions and a skewed log-normal distribution. An interesting finding is the presence of a constant index of 0.5 in the low magnification regime power-law, similar to the index of −2 observed in the high magnification regime. This modelling approach allows us to capture the unique characteristics of the negative magnification regime, including a smooth transition to the peaks. The skewed log-normal appears as a bump or excess of probability on top of the power-law at the lowest magnifications. To the left of this excess, the decrease is only that of the log-normal. Analytically this model is described as follows:
![Mathematical equation: $\[\begin{aligned}\operatorname{PDF}\left(\log _{10}(\mu)\right)= & \mathrm{a}^{-}\left(\left(\frac{\Sigma_{\text {eff }}}{1928}\right)^{1.7678}\left(\frac{\mu}{10^{2.4}}\right)^{\beta_{\mathrm{a}}^{-}}+\left(\frac{\mu}{10^{2.4}}\right)^{0.5}\right) \\& +\mathrm{A}^{-} \exp \left(-\frac{\left(\log _{10}(\mu)-\log _{10}\left(\mu_{\mathrm{A}}^{-}\right)\right)^2}{2 \sigma_{\mathrm{A}}^{-2}}\right) \\& \times\left[1+\operatorname{erf}\left(\alpha_{\mathrm{A}}^{-} \frac{\log _{10}(\mu)-\log _{10}\left(\mu_{\mathrm{A}}^{-}\right)}{\sqrt{2} \sigma_{\mathrm{A}}^{-}}\right)\right].\end{aligned}\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq25.png) (17)
(17)These parameter scalings are shown in Fig. 13. We have observed that unlike other parameters, the characteristics of this excess in the probability distribution, that appear at low magnification factors for the negative parity only, do not scale directly with ∑eff. This distinction arises because the position of the excess is solely determined by the μr parameter, independent of ∑eff. Consequently, the normalisation of the distribution places this peak at different positions relative to μm. This observation becomes apparent when examining Fig. 8, where the negative parity probability distributions are identical for the entire range of magnifications except for the lowest factors where these bumps occur. To gain further insight into these peaks at low magnification factors, we conducted an additional set of 12 simulations with varying μt, μr, and ∑*, in addition to the previous simulations. This comprehensive data-set helps us better understand the characteristics of these peaks. We proceed to fit the position of the peak before normalisation as a function of μr:
![Mathematical equation: $\[\tilde{\mu}_{\mathrm{A}}^{-}=\mu_{\mathrm{A}}^{-} \frac{\mu_{\mathrm{m}}}{1000}.\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq26.png) (18)
(18)

Fig. 13 Scaling of the model parameters for the low magnification regime at the low surface mass density and negative parity scenario. Point colours represent the ∑eff over the critical value as shown in Fig. 5.
Similarly, we perform a fitting procedure to determine the width of the peak at each ∑eff and μr. We use the same scaling of the width with respect to ∑eff, but with different scaling factors determined by μr (see Fig. 14). We define this scaling factor in terms of μr as follows:
![Mathematical equation: $\[R_{\sigma_4}\left(\mu_{\mathrm{r}}\right)=\frac{\sigma_{\mathrm{A}}^{-}\left(\mu_{\mathrm{r}}\right)}{\sigma_{\mathrm{A}}^{-}(4)}.\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq27.png) (19)
(19)The dependence of this quantity with respect to μr is shown in Fig. 15. Furthermore, we observe that the amplitude does not exhibit a simple scaling with ∑eff, regardless of the peak position corrections. To characterise the amplitude, we introduce a new quantity:
![Mathematical equation: $\[\tilde{\mathrm{A}}^{-}=\mathrm{A}^{-} \mu_{\mathrm{m}},\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq28.png) (20)
(20)that shows a clear trend with ∑eff. Figure 14 illustrates the scaling of the peak parameters, with the corrections applied, as a function of ∑eff.
-
Intermediate magnification regime: This regime encompasses the central peak, which can be effectively modelled as a log-normal distribution:
![Mathematical equation: $\[\operatorname{PDF}\left(\log _{10}(\mu)\right)=\mathrm{B}^{-} \exp \left(-\frac{\left(\log _{10}(\mu)-\log _{10}\left(\mu_{\mathrm{B}}^{-}\right)\right)^2}{2 \sigma_{\mathbf{B}}^{-2}}\right).\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq29.png) (21)
(21)The scaling for these parameters is illustrated in Fig. 16.
-
High magnification regime: This regime can be modelled similarly to the positive parity case, with two power-laws and a log-normal. However, in this case, the log-normal is added to the power-laws instead of being a piecewise function. At the right end of the log-normal, the contribution of the power-laws becomes negligible. This analytical model is:
![Mathematical equation: $\[\begin{aligned}\operatorname{PDF}\left(\log _{10}(\mu)\right)= & \mathrm{b}^{-}\left(\left(\frac{\Sigma_{\mathrm{eff}}}{995}\right)^2\left(\frac{\mu}{10^{3.5}}\right)^{\beta_{\mathrm{b}}^{+}}+\left(\frac{\mu}{10^{3.5}}\right)^{-2}\right) \\& +\mathrm{C}^{-} \exp \left(-\frac{\left(\log _{10}(\mu)-\log _{10}\left(\mu_{\mathrm{C}}^{-}\right)\right)^2}{2 \sigma_{\mathrm{C}}^{-2}}\right).\end{aligned}\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq30.png) (22)
(22)

Fig. 14 Scaling of the model parameters for the low magnification excess at the low magnification regime for the low surface mass density and negative parity scenario. As in Fig. 13 point rainbow colours represent the ∑eff over the critical value as shown in Fig. 5.
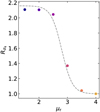
Fig. 15 Ratio between the width of the peak (at low magnifications for low surface mass density and negative parity) at a given μr and its corresponding width at μr = 4. Point colours represent the μr over the critical value as shown in Fig. 14.
Figure 17 shows the scaling of this parameters with respect to ∑eff.
Figure 18 showcases the modelling of the magnification probability in the negative parity regime, as previously developed.
 |
Fig. 11 Scaling of the model parameters for the extreme magnification regime at the low surface mass density and positive parity scenario. Point colours represent the ∑eff over the critical value as shown in Fig. 5. |
 |
Fig. 12 Magnification probability function for a simulation within the low surface mass density regime and positive parity. The dashed lines represent each of the fitting model components and their total contribution. |
 |
Fig. 16 Scaling of the model parameters for the intermediate magnification regime at the low surface mass density and negative parity scenario. Point colours represent the ∑eff over the critical value as shown in Fig. 5. |
 |
Fig. 17 Scaling of the model parameters for the extreme magnification regime at the low surface mass density and negative parity scenario. Point colours represent the ∑eff over the critical value as shown in Fig. 5. |
6.2 High effective surface mass density
This regime is expected to be more prevalent in realistic scenarios, where the combination of factors such as the distance to the macro-CCs, the surface mass densities of stars derived from the ICL, and the presence of a hypothetical population of compact DM can lead to higher values of ∑eff. These elevated values often exceed the critical surface mass density, making the occurrence of this regime more likely.
In this regime, the magnifications for positive and negative parity differ, similar to what is observed in the low surface scenario. However, as the effective surface mass density increases, the magnification probabilities for both parity regimes tend to become more similar. In fact, for larger values of surface mass density, the modelling for both parity scenarios becomes identical. Following the previous approach, we now explain the modelling for both parity scenarios.
It is worth mentioning that even though this scenario is relatively straightforward in terms of modelling, the scaling of parameters exhibits more complexity and displays distinct regime behaviours. Nonetheless, we have successfully captured the entire range of effective surface mass densities included in our simulations. Moreover, we observe a saturation regime in the magnification probability at the highest densities, allowing for straightforward extrapolation to larger values. This enables us to fully describe the magnification statistics and behaviour across the entire range of effective surface mass densities in our study.
 |
Fig. 18 Magnification probability function for a simulation within the low surface mass density regime and negative parity. The dashed lines represent each of the fitting model components and their total contribution. |
6.2.1 Positive parity
In this regime, we observe a transition from the low surface mass density regime, where the power-law distribution is dominant, to a regime characterised by a high-magnification log-normal distribution. The magnification probability in this regime can be effectively modelled as the sum of two log-normal distributions, with both distributions exhibiting skewness. Analytically, this can be represented as the sum of two skewed log-normal distributions:
![Mathematical equation: $\[\begin{aligned}\operatorname{PDF}\left(\log _{10}(\mu)\right)= & \mathrm{A}^{+} \exp \left(-\frac{\left(\log _{10}(\mu)-\log _{10}\left(\mu_{\mathrm{A}}^{+}\right)\right)^2}{2 \sigma_{\mathrm{A}}^{+2}}\right) \\& \times\left[1+\operatorname{erf}\left(\alpha_{\mathrm{A}}^{+} \frac{\log _{10}(\mu)-\log _{10}\left(\mu_{\mathrm{A}}^{+}\right)}{\sqrt{2} \sigma_{\mathrm{A}}^{+}}\right)\right] \\& +\mathrm{B}^{+} \exp \left(-\frac{\left(\log _{10}(\mu)-\log _{10}\left(\mu_{\mathrm{B}}^{+}\right)\right)^2}{2 \sigma_{\mathrm{B}}^{+2}}\right) \\& \times\left[1+\operatorname{erf}\left(\alpha_{\mathrm{B}}^{+} \frac{\log _{10}(\mu)-\log _{10}\left(\mu_{\mathrm{B}}^{+}\right)}{\sqrt{2} \sigma_{\mathrm{B}}^{+}}\right)\right].\end{aligned}\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq31.png) (23)
(23)
The scaling of the parameters in this model with respect to ∑eff, as well as an example of a probability density function obtained from our simulations and fitted using this model, are depicted in Figs. 19 and 20, respectively. These figures provide a visual representation of how the model parameters evolve with increasing ∑eff and demonstrate the individual components of the fitted compound distribution.
 |
Fig. 19 Scaling of the model parameters at the high surface mass density and positive parity scenario. Point colours represent the ∑eff over the critical value as shown in Fig. 7. |
6.2.2 Negative parity
In this regime, the probability distribution at the highest magnification factors is conceptually similar to that of the positive parity regime. The power-law distribution is no longer an accurate description of the probability, and instead, the sum of two log-normal distributions provides a more appropriate magnification probability approximation. However, at the lowest magnification factors, the power-law distribution still persists. The crucial difference is that the power-law index is no longer fixed at 0.5. As the effective surface mass density increases, the power-law index grows, while the amplitude of the distribution remains constant. This variation in the power-law index reflects the changing behaviour of the magnification probability distribution compared to the low surface mass density regime. The range of magnification values for which the power-law distribution remains a valid description covers all values up to the magnification at which the log-normal and power-law distributions yield the exact same probability. However, as ∑eff approaches a value of approximately 5 ∑crit, the power-law distribution returns extremely low probabilities, rendering its contribution negligible. In contrast to the positive parity regime, the most suitable model that we have found to fit our simulations in this regime consists of three log-normal distributions, which are fully symmetrical and do not exhibit any skewness.
Additionally, we have observed a peak at the lowest magnification factors in this regime, which is likely the same excess that we observed in the low density regime. However, due to limitations in our simulation statistics, we do not have sufficient data to fully describe this peak in detail. Given that the excess peak at the lowest magnification factors is unlikely to be observed due to the known luminosity functions of stars, high redshift considerations, and limitations of current telescopes, we can omit the modelling of this peak and approximate the magnification as a power-law distribution in this regime. Qualitatively, we have observed that these peaks exhibit growth in both width and amplitude as well as a shift towards larger magnification values. Additionally, there is a correlation between the position of the peak and μr, similar to what was observed in the low density regime. Further investigations and simulations would be required to better understand and characterise this feature at the lowest magnification values, we left this task for a future work. The analytical model we have employed for the probability distribution is expressed as follows:
![Mathematical equation: $\[\begin{aligned}\operatorname{PDF}\left(\log _{10}(\mu)\right)= & \mathrm{A}^{-} \exp \left(-\frac{\left(\log _{10}(\mu)-\log _{10}\left(\mu_{\mathrm{A}}^{-}\right)\right)^2}{2 \sigma_{\mathrm{A}}^{-2}}\right) \\& +\mathrm{B}^{-} \exp \left(-\frac{\left(\log _{10}(\mu)-\log _{10}\left(\mu_{\mathrm{B}}^{-}\right)\right)^2}{2 \sigma_{\mathrm{B}}^{-2}}\right) \\& +\mathrm{C}^{-} \exp \left(-\frac{\left(\log _{10}(\mu)-\log _{10}\left(\mu_{\mathrm{C}}^{-}\right)\right)^2}{2 \sigma_{\mathrm{C}}^{-2}}\right).\end{aligned}\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq32.png) (24)
(24)
The power-law distribution, which is valid only for lower magnification factors until it becomes overtaken by the log-normal distributions, is described by the equation:
![Mathematical equation: $\[\operatorname{PDF}\left(\log _{10}(\mu)\right)=\mathrm{a}^{-}\left(\frac{\mu}{10^{2.4}}\right)^{\beta_{\mathrm{a}^{-}}}.\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq33.png) (25)
(25)
Regarding the negative parity regime, we have also depicted the dependence of the model parameters on ∑eff in Fig. 21, and we have also provided an example of a simulation magnification probability fitted according to this models in Fig. 22.
 |
Fig. 20 Magnification probability function for a simulation within the high surface mass density regime and positive parity. The dashed lines represent each of the fitting model components and their total contribution. |
 |
Fig. 21 Scaling of the model parameters at the high surface mass density and negative parity scenario. Point colours represent the ∑eff over the critical value as shown in Fig. 7. |
 |
Fig. 22 Magnification probability function for a simulation within the high surface mass density regime and negative parity. The dashed lines represent each of the fitting model components and their total contribution. |
7 Constraining compact DM with CCE
During caustic crossing events, the flux of the background stars can increase by factors of several thousands, to tens of thousands. This translates in magnitude changes of ![Mathematical equation: $\[\boldsymbol{\mathcal{O}}\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq34.png) (10) compared to fluxes without magnification. This change in their apparent magnitude allows the detection of these sources, as well as a characterisation of the underlying microlensing population causing such events. Here we outline how the tools we have developed can be used to constrain compact DM with caustic crossing events, and provide an illustration of the expected magnification as a function of time, which illustrates how we can estimate the magnification probability.
(10) compared to fluxes without magnification. This change in their apparent magnitude allows the detection of these sources, as well as a characterisation of the underlying microlensing population causing such events. Here we outline how the tools we have developed can be used to constrain compact DM with caustic crossing events, and provide an illustration of the expected magnification as a function of time, which illustrates how we can estimate the magnification probability.
Microlensing of small sources within a strongly lensed galaxy is responsible for the extremely lensed events such as Icarus, Earendel, or Godzilla (Kelly et al. 2018; Welch et al. 2022a; Diego et al. 2022). These lensing events result in a significant enhancement of the observed fluxes from these objects, enabling their detection and facilitating detailed studies of their properties. This scientific scenario in itself presents an intriguing subject of investigation and has led to the development of dedicated scientific programmes like Flashlights (Kelly et al. 2019). However, these extremely lensed events hold particular importance in the field of DM studies. They offer unique opportunities to probe the nature and distribution of DM, as the lensing effects depend on the underlying DM distribution within the lensing system (Oguri et al. 2018).
As seen in the previous section the magnification probability in microlensing events is primarily determined by two factors: ∑* and μt. The latter can be obtained from the strong-lensing models of the cluster, taking into account the distance of the image to the macro-CC. But even when the magnification cannot be accurately described, the scaling of the magnification with distance, d, to the CC, μ ∝ d−1 allows to study the relative detection rate as a function of distance. On the other hand, ∑* can be further divided into two components: ∑b, which accounts for baryonic matter such as stars, and ∑DM, which represents the contribution from DM.
The estimation of ∑b can be derived from the ICL, which provides valuable information about the distribution of stars within the cluster. The remaining unknown parameter is ∑DM, which represents the contribution of DM. This parameter can be inferred from the observed rate of microlensing events in a statistical sense, after a sufficiently large number of lensed stars has been observed. Of particular interest are lensed stars observed in regions where the contribution from ∑b is lowest. This includes the CC forming between two merging clusters, specially during the first core passage, since the intermediate region in between the two clusters is expected to have very small contributions from stars in the intracluster light.
Monitoring the change of flux over time in the magnified images as the source moves in the source plane provides valuable information about the magnification probability. By comparing these observed flux variations with the analytical models derived from the previous section, we can perform statistical inference to estimate the parameter ∑DM that best fits the data. This statistical analysis allows us to obtain an approximation of the density of compact DM in the microlensing population. Specifically, we can update the fraction of DM made up of our model of interest, denoted as “X”, by determining the ratio of its density to the total density of DM, represented by fx = Ωx/ΩDM. This provides insights into the contribution of the specific model of interest to the overall DM content in the microlensing population.
The characteristic timescales of microlensing events are influenced by several factors, including the distance to the source and its transverse motion relative to the micro-caustics. To illustrate this, we can consider a simulated caustic pattern in which the source is located at a redshift of zs = 1.3. The transverse velocity of a star with respect to the caustics at this distance can be estimated using the formula (see Miralda-Escude 1991)
![Mathematical equation: $\[v_{\perp}=\left|\frac{v_{\mathrm{s}}-v_{\mathrm{o}}}{\left(1+z_{\mathrm{s}}\right)}-\frac{D_{\mathrm{s}}\left(v_{\mathrm{d}}-v_{\mathrm{o}}\right)}{D_{\mathrm{d}}\left(1+z_{\mathrm{d}}\right)}\right| \text {. }\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq35.png) (26)
(26)
The transverse velocity depends on the distances to the lens plane, and the source plane through their angular diameter distances, and their redshifts, and depends also on the transverse velocities of the cluster, the source, and the observer, υd, υs, and υo, respectively. To fix the transverse velocity υ⊥, a typical value of ~1000 km s−1 can be used as suggested by (Kelly et al. 2018). Finally, the angular transverse velocity at the source plane (see Oguri et al. 2018) is
![Mathematical equation: $\[u_{\mathrm{s}}=\frac{v_{\mathrm{s}}}{1+z_{\mathrm{s}}} \frac{1}{D_{\mathrm{s}}}.\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq36.png) (27)
(27)
Plugging the transverse velocity value of ~1000 km s−1 into the equation, assuming a distance corresponding to a source at a red-shift ~1.3, we can calculate the transverse velocity in angular units. This yields a value of approximately 52 nas per year. In the context of our simulation, this corresponds to a crossing time of approximately 40 yr. Figure 23 illustrates an example of such a microlensing event, showing the evolution of the magnification over time due to the motion of the source.
Monitoring an arc close to a macro-CC allows us to observe flux changes in the sources within the arc, which can be attributed to microlensing events. By characterising the source properties, such as its intrinsic flux, we can translate the observed flux changes into magnification values. With longer exposure times, we can monitor the flux changes of more sources over extended periods, which improves the accuracy of the magnification probability estimation. By combining the flux changes from multiple sources, we can obtain a better estimate of the magnification probability distribution. Using the analytical approximations that we have establish in the previous section and the estimated magnification probabilities, we can quickly obtain an estimate of the magnification probability in terms of parameters such as ∑*, μt, and μr. This approach allows us to bypass the need for time-consuming simulations, which would require significant computational resources and subsequent analysis to obtain the magnification probability. Furthermore, by employing Markov chain Monte Carlo methods, we can perform parameter estimation and identify the most favoured combination of parameters that best explain the observed data. This enables us to derive constraints on the physical properties of the lensing system, such as the surface mass density of the microlenses and the macro-magnification factors, by comparing the observed flux variations with the estimated magnification probabilities. Independent estimations of the macro-magnification factors μt and μr, as well as the baryon surface mass density ∑b constrain the parameter space reducing the number of free parameters to one, ∑DM, the contribution from compact DM.
Studying the outskirts of clusters is a promising approach for probing the role of DM in microlensing effects. In these regions, the contribution of stellar populations to the microlensing population is diminished, allowing the potential dominance of DM objects, if present. This offers an opportunity to investigate the properties of DM in the form of compact objects. Arcs farther from the cluster centre are associated with source planes at larger redshifts. To probe larger redshifts, it becomes necessary to observe intrinsically brighter objects. By comparing the observed probabilities of magnification to what would be expected solely from the stellar populations, we can set lower limits on the contribution of compact DM. Setting lower limits on the fraction of compact DM, fx, requires careful analysis and comparison between observed magnification probabilities and our analytical predictions. By constraining the minimum amount of compact DM necessary to explain the lack of higher magnification events, we gain valuable insights into the presence and properties of DM in the form of compact objects within galaxy clusters.
Figure 24 shows the magnification probability from a hypothetical population of microlenses made of 5 M⊙/pc2 in the form of stars, and 20 M⊙/pc2 made of PBHs which corresponds to approximately a 1% of the total DM in realistic scenarios. For completeness the magnification probability for the same scenario with no PBHs is displayed as a dashed line. The macro-model tangential magnification, μt, is 200 which makes ∑eff = 2∑crit = 5000 M⊙/pc2. Being the macro-images at a distance of approximately 0.2 arcseconds from a macro-CC, a powerful telescope like the JWST would have the capability to resolve both the positive parity image and the negative parity image. By comparing the flux differences between these two images, we can estimate the probability distribution functions of magnification at both parities. If we can observe both parities we have even more constraining power, usually the negative parity image is more constraining. In this particular scenario, the observed flux differences can be used to infer the presence of an underlying surface mass density of approximately 20 M⊙ pc−2 composed of primordial black holes (PBHs) or other compact objects. This analysis can be carried out with only one image, but adding a second image of the same source in the reverse parity regime greatly increases the constraining power on the surface mass density of the microlensing population.
 |
Fig. 23 Magnification of a source at redshift 1.3 and angular size 2 nas sweeping the micro-caustic web at a constant speed of 1000 km s−1. Top panel: magnification pattern in the source plane. Bottom panel: magnification over time. The dashed line represents the magnification from the macro model. |
 |
Fig. 24 Magnification probability for a case with ∑eff/∑crit = 2, in both parity regimes. This mimics the magnification probability of a hypothetical microlensing population consisting of 5 M⊙/pc2 stars and 20 M⊙ pc−2 PBHs. The critical density is ∑crit = 2500 M⊙ pc−2. μt = 200 and μr = 4. Left panel: negative macro-magnification. Right panel: positive macro-magnification. The dashed curve represents the magnification probability for the same system with no PBHs. |
8 Discussion
In this paper, we have used the inverse ray-shooting technique to generate very large simulations of extragalactic microlensing phenomena caused by compact objects within galaxy clusters, and near the caustic region. These microlensing effects occur alongside the strong lensing effects generated by the gravitational field of the cluster, resulting in a combined lensing scenario. This emerging field of gravitational lensing provides a unique opportunity to investigate and study background sources. Furthermore these microlensing events allow us to constrain the surface mass density of the microlenses and provide valuable information about their luminous and non-luminous constituents. The non-luminous components are particularly interesting as they are directly linked to the presence and properties of compact DM.
In our study, we have focussed on the simulation of microlensing near tangential CCs, where μt ≫ μr. This choice is motivated by the fact that radial CCs are located closer to the centre of the cluster, where the influence of DM compact objects is comparatively smaller. In contrast, tangential CCs offer a more favourable scenario for studying the effects of DM, as the population of microlenses in this region is expected to be predominantly composed of DM. Furthermore, higher red-shift sources provide an additional advantage in probing the DM population associated with microlensing. As the redshift of the source increases, the tangential CCs move further outwards from the centre of the cluster. Consequently, the contribution from the cluster’s light becomes less significant, enhancing the relative impact of the DM population. This makes higher redshift sources more effective in isolating and studying the effects of DM compact objects within the microlensing framework.
In our simulations, we replicate the magnification effects experienced by stars or compact objects passing through an arc that intersects the perturbed gravitational potential of the cluster. This occurs due to the presence of a population of microlenses near a macro-caustic, considering both parity configurations. We have obtained the magnification probabilities for each combination of μt, μr, and ∑* simulated for both parity configurations, considering scenarios where ∑eff is below the critical value and scenarios where it is equal to or greater than this value. In the presence of increasing surface mass density and a stronger influence of perturbations from microlenses, the most frequently observed magnification deviates from the macro-model’s magnification at the simulated distance to the macro-CC. Specifically, it tends to shift towards smaller values as the disruption of the cluster’s smooth potential becomes more dominated by the perturbation effects of microlenses. We have found previously unknown effects such as the power-law decay in magnification at negative parities, along with the bump or excess at the lowest magnifications. Using our newly developed tool, we have the capability to generate probability density functions for magnification within the range of effective surface mass densities ∑eff spanning from 0.01 to 66.5 M⊙ pc−2. Furthermore, we can extrapolate these magnification probabilities for even larger effective surface mass densities as needed.
 |
Fig. 25 Analytical approximation for the probability of magnification for a fixed μm = 1000, and varying ∑*. By increasing ∑eff the more-is-less and saturation effects appear, obtaining a thicker log-normal centred at lower magnifications. |
8.1 Saturation regime and log-normal behaviour
The extreme saturation regime, characterised by ∑eff/∑crit ≫ 1, poses significant computational demands and thus it is the more interesting to describe with analytical models. Remarkably, we observe that in this regime, the well-established power-law behaviour that typically characterises the magnification probability for sparsely overlapping caustics gets completely eradicated. Instead, we find that the magnification probability follows a log-normal distribution. While the log-normal behaviour has been previously noted in the literature (Diego et al. 2018, Welch et al. 2022a), its complete understanding or comprehensive explanation has remained elusive due to limitations in microlensing simulations. Our simulations provide a sufficiently large area in the source plane with high resolution, enabling us to place confidence in the statistical properties of magnification in this regime.
Figure 25 shows how increasing ∑eff results in the more-is-less effect, which reduces the spread of variability in flux when more and more microlenses are added. Such small variability in flux has been already observed in highly magnified stars such as Earendel (Welch et al. 2022a,b). The lack of variability due to microlensing in Earendel can be explained if the probability of magnification is already well into the log-normal regime.
Log-normal distributions are common in nature, in particular in multiplicative processes that transform into small additive increments in log-scale. The superposition of many microcaustics mimics a multiplicative process in which each microcaustic multiplies the flux of the background source by some amount. An increase in ∑eff can be attributed to two factors: either an increase in μt or in ∑*. At higher macro-magnifications, the lens plane is mapped onto smaller regions in the source plane, so the probability of caustics overlapping increases. To better understand the log-normal behaviour and the saturation regime, it is useful to understand how the micro-caustics are shaped and how increasing ∑* and μm affects in the probability of overlap. In their paper, Oguri et al. (2018) derive an analytical approximation for the shape of a micro-caustic by solving the equation where the inverse of the magnification equals zero. They determined the sizes of a micro-caustic located near the tangential CC, in the positive regime, in both the tangential and radial directions to be
![Mathematical equation: $\[\begin{aligned}& \beta_{\mathrm{caus}, \mathrm{t}} \approx \frac{\sqrt{\mu_{\mathrm{t}}}}{\mu_{\mathrm{r}}} \theta_{\mathrm{E}}, \\& \beta_{\mathrm{caus}, \mathrm{r}} \approx \frac{\theta_{\mathrm{E}}}{\sqrt{\mu_{\mathrm{r}}}},\end{aligned}\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq37.png) (28)
(28)
respectively. For the negative parity the caustic size is similar but reduced by a factor of ![Mathematical equation: $\[2 \sqrt{2}\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq38.png) in the tangential direction, and it exhibits a demagnification region in the centre of the caustics. θE is the Einstein radius of the lens defined as
in the tangential direction, and it exhibits a demagnification region in the centre of the caustics. θE is the Einstein radius of the lens defined as
![Mathematical equation: $\[\theta_{\mathrm{E}}=\left(\frac{4 G M}{c^2} \frac{D_{\mathrm{d} s}}{D_{\mathrm{s}} D_{\mathrm{d}}}\right).\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq39.png) (29)
(29)
A similar solution for the sizes of the micro-CCs was also obtained by Diego et al. (2018).
Increases in μm result in larger caustics concentrated in smaller regions, while larger ∑* results from more microlenses, more massive microlenses resulting in larger micro-caustics, or a combination of both effects. These aforementioned effects promote the overlapping of micro-caustics, particularly at the tips of the caustics where higher magnification is concentrated. Consequently, these regions are the first to experience distortion as a result of overlapping. This phenomenon explains why the more-is-less effect becomes prominent at larger values of ∑eff. The log-normal behaviour of the magnification probability can be understood as the manifestation of the central limit theorem in the logarithmic domain, arising from the overlapping of caustics.
Figure 26 depicts the presence of a saturation regime for ∑eff/∑crit ≳ 30 for the positive parity and ∑eff/∑crit ≳ 25 for the negative parity. Within this regime, the magnification probability follows a log-normal distribution, with a shift in its central value as ∑eff increases (the changes in width and amplitude are almost negligible). It should be noted that the centre of the log-normal distribution requires subsequent correction, taking into account the value of μm. At the highest simulated effective surface mass densities, both parities exhibit the same log-normal distribution shifted towards higher magnifications for the negative parity. This can be observed in Fig. 7.
8.2 Constraints on PBHs
In Sec. 7, we considered a hypothetical scenario where the microlenses, consisting of 25% stars and 75% primordial black holes (PBHs), constituted 1% of the system’s critical density. The macro-model predicted a magnification of μm = 200, resulting in an effective surface mass density twice the critical density value. In this setup, background sources would undergo microlensing events following the probability distributions illustrated in Fig. 24. We would observe these events when the product of the intrinsic luminosity of the source and the magnification (Lμ) exceeds the detection threshold of our telescopes.
The HST and the JWST have already observed numerous microlensing events, and the number of such observations will continue to increase over time. Continuous monitoring of arcs located in the outskirts of large galaxy clusters, will eventually accumulate sufficient data to perform statistical inference on the surface mass density of microlenses in these regions. Additionally, photometric measurements of the ICL in the same area will allow us to estimate the contribution of stars to the population of microlenses. Our current methodology provides a rapid estimation of the magnification probability, which can be compared against observational data. This allows us to determine the most likely value of ∑* based on the experimental results. Moreover, since ∑b can be measured independently, the DM surface mass density (∑DM) can be obtained simply by taking the difference between the inferred total density (from microlensing flux fluctuations) and the contribution from baryonic matter (from SED fitting of the observed photometry).
The data release by the LIGO-Virgo-KAGRA collaboration in 2016 (Abbott et al. 2016) has brought renewed interest in the in primordial black holes as a potential candidate for DM. While observational searches for the extra-galactic γ-ray background (Page & Hawking 1976), have ruled out the mass range of PBHs with initial masses Mpbh ≲ 10−17 M⊙, CMB and dynamical constraints have ruled out massive PBHs (Mpbh ≳ 100 M⊙; Serpico et al. 2020; Lu et al. 2021). The remaining window of PBH masses, where they could potentially constitute a significant fraction of the DM content in the Universe, is an elusive range where only gravitational interactions play a significant role in possible observations.
Several methods have been suggested to constrain the abundance of PBHs in this open window (see Carr et al. 2021 and Green & Kavanagh 2021 for an extended review), in particular gravitational microlensing. The EROS-2 and MACHO surveys (Tisserand et al. 2007; Alcock et al. 2000), which focussed on, microlensing observations of stars in the Magellanic Clouds, and the OGLE survey (Niikura et al. 2019b), which conducted microlensing studies of the galactic bulge, have provided valuable constraints on the mass range of primordial black holes (PBHs) within the Milky Way. These studies have placed constraints on the presence of PBHs in the mass range of 10−6 ≲ Mpbh ≲ 10 M⊙ at the (1–0.1)% level around 1 M⊙. The Subaru Hyper Suprime-Cam has played a crucial role in further constraining the mass range of primordial black holes within the Milky Way and the Andromeda galaxy (M31; Niikura et al. 2019a). In particular, the Subaru Hyper Suprime-Cam has extended the constraints to even lower PBH masses, specifically for Mpbh ≳ 10−11 M⊙, through the microlensing observations of stars from M31.
Quasar microlensing involves a similar mechanism to extreme magnification events, where compact objects within a galaxy act as lenses that magnify the flux of background quasars images, resulting in flux changes in these images. Mediavilla et al. (2017) used optical and X-ray data from 24 lensed quasars. The results indicated that ~ 20% of the mass of the lens galaxies consisted of compact objects within the mass range of 0.05 M⊙ ≳ M ≳ 0.45 M⊙. Similarly to quasar microlensing, extremely lensed events offer a novel approach to constraining the amount of compact DM present in galaxy clusters. In 2018, Oguri et al. (2018) utilised the Icarus data (Kelly et al. 2018) to constrain the abundance of compact DM in the presence of the intracluster light.
By combining the results obtained from the aforementioned studies and incorporating future data collected by space telescopes such as the JWST, it will be possible to establish new constraints on the fraction of DM composed of PBHs, potentially even setting lower limits on their abundance. These ongoing investigations hold promise for advancing our understanding of the nature and contribution of PBHs to the overall DM content of the Universe.
 |
Fig. 26 Probability of magnification for two simulations with the same |μt|, μr, ∑*, and different parities in the saturation regime ∑eff/∑crit = 66.5. |
8.3 Early stars, GWs, and high redshift SNe
The analytic approximation of the magnification probability presented in this paper not only provides a valuable method for constraining compact DM, but it also opens up possibilities for constraining the abundances of lensed sources at higher redshifts. In a recent study Diego et al. (2024) quantified the probability of observing a supergiant star due to the crossing of a micro-caustic, which amplifies the star’s intrinsic luminosity above the detection threshold of the HST. To achieve this, the authors employed both a macro-model and a micro-model of the lensing system, along with the characterisation of the background galaxy, the Spock arc. This, and previous investigations relied on computationally expensive numerical simulations to account for the variability of the macro-model magnification and the contribution of microlenses within the arc. However, with the development of our new tool, these types of analyses can be significantly accelerated, providing faster and more efficient estimations. In their study, Diego et al. (2024) also presented forecasts for the constraints on these stars using the JWST. By incorporating the improved magnification probability obtained from our analytic approach, future observations with the JWST will enable more precise constraints on the presence and characteristics of lensed supergiant stars.
The rate of extreme magnification events depends on both the number of background sources and the probability of magnification that produces detectable events. Since we can now infer the later, by observing the number of events over a certain period of time, we can extract information about the abundance of the background sources.
Among the sources whose combined intrinsic luminosity and maximum magnifications achievable can lead to extreme magnification events, we discuss the following: high redshift stars, high redshift supernovae (SNe), gravitational waves (GWs) from binary black hole systems, and population III stars.
The discussion of microlensing effects on quasars (QSOs) will not be addressed here, as they have already been extensively investigated, and their typical sizes surpass those of the previously described sources, thereby limiting the maximum magnification to the order of ![Mathematical equation: $\[\boldsymbol{\mathcal{O}}\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq40.png) (10). However, it is worth noting that certain regions within QSOs exhibit smaller sizes, which can enhance the maximum magnification. The detection of such variations may be possible through multi-wavelength studies of these objects.
(10). However, it is worth noting that certain regions within QSOs exhibit smaller sizes, which can enhance the maximum magnification. The detection of such variations may be possible through multi-wavelength studies of these objects.
8.3.1 Luminous stars at cosmological distances
Although the probability of extreme magnification events for individual stars may be low, the vast number of stars in the Universe makes them ideal candidates to undergo such events.
The probability of a source intersecting a micro-caustic and experiencing extreme magnification increases with the number of background sources available. When considering cosmological distances (z > 1), it becomes challenging to detect stars unless they are particularly luminous. Telescopes such as the HST and JWST are capable of observing the most massive and bright stars at these distances.
In general, the mass-luminosity relation for main sequence stars follows a relationship, where the luminosity L is correlated with the stellar mass M as follows:
![Mathematical equation: $\[\frac{L}{L_{\odot}}=A\left(\frac{M}{M_{\odot}}\right)^\alpha,\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq41.png) (30)
(30)
where the slope α typically ranges from 3 to 4, with slightly lower values observed for the most massive stars. This mass-luminosity relation indicates that the most massive stars are capable of attaining the highest levels of luminosity within the main sequence. Stars outside the main sequence exhibit different mass-luminosity relations. However, the population of stars outside the main sequence is generally smaller in number compared to main sequence stars. Therefore, they are expected to contribute to a lower rate of extremely lensed events.
Smaller stars have a higher maximum magnification due to their smaller radius, but their intrinsic luminosity is also lower compared to larger stars. The luminosity of a star is generally correlated with its radius, and the exponent a in the scaling relation L ∝ Ra is typically greater than 1. As a result, the maximum luminosity Lmax scales with the radius as Lmax ∝ Ra−0.5. This implies that larger stars are more likely to be observed in extreme magnification events because their intrinsic luminosity exceeds the decrease in maximum magnification with respect to smaller stars. Therefore, as a general rule, larger and more massive stars are more commonly observed in caustic crossing events due to their higher intrinsic luminosity.
8.3.2 Population III stars
The existence and properties of Pop. III stars (Bromm et al. 2001) are of great interest in astrophysics and cosmology. These hypothetical stars, which are believed to have formed in the early universe and have very low or negligible metallicity, could provide crucial insights into the early stages of cosmic evolution. In their paper Windhorst et al. (2018) discuss the luminosity-mass relation for Pop. III stars as well as a similar population called “Pop. II.5” stars, which have a modest metallicity. They found that this relation is close to the Eddington limit, where the luminosity is proportional to the mass (L ∝ M).
Due to their short lifespan, Pop. III stars are primarily expected to exist at high redshifts (z ≳ 6–7). The study of caustic crossing events with the JWST may lead to the first direct observations of Pop. III stars and significantly advance our understanding of the early Universe, including the re-ionisation process and the formation of the first galaxies.
8.3.3 GWs from binary black holes
Gravitational waves can also experience deflections in their paths as they propagate through regions with large distributions of matter. This gravitational lensing effect on GWs can lead to magnification or demagnification of the waves, similar to the lensing effect on light.
Broadhurst et al. (2018) proposes that a subset of the low-frequency GWs detected by the LIGO-Virgo collaboration could be attributed to GWs originating from sources at redshifts greater than one (z > 1) and magnified by a factor greater μ > 100. These magnified GWs are hypothesised to arise from binary black hole systems with chirp masses around 30 M⊙. At these magnifications microlensing events will only be important for small sources, but the large wavelengths of the GWs suggest that wave optics might need to be considered.
8.3.4 High redshift SNe
Supernovae are extremely compact and luminous objects prone to microlensing effects. If the progenitor is located within a few astronomical units (AU) from a micro-caustic, the expansion of its photosphere can lead to extreme magnification increasing over time (typical rate of expansion ~6 AU/day). As the photosphere expands, it can intersect the micro-caustic, resulting in a maximum increase in the observed brightness of the SNe. However, as the photosphere continues to expand and move away from the micro-caustic, the magnification gradually decreases. This effect will leave an in-print on the light curve of the SNe.
All SNe can be observed through this mechanism, but we focus on type Ia SNe. These SNe are extremely important in the field of cosmology, as they serve as standard candles for measuring astronomical distances. The origin of the initial Type Ia SNe could potentially be traced back to the initial generation of white dwarfs. Consequently, their abundance at high redshifts (z ≳ 6) remains uncertain, given the time required for the formation of binary systems. The JWST has the capability to provide data of Type Ia SNe at redshifts ranging from z = 6 to 12, which would considerably augment our understanding of the abundance of these entities as well as their properties at high redshifts.
Readers can refer to Diego (2019) for a more extensive analysis on the methodologies employed for measuring these phenomena and their corresponding likelihood of occurrence.
9 Conclusions
Giant arcs intersecting a cluster’s CC provides an exceptional scenario for caustic crossing events to arise. If small and bright sources happen to lay close to the cluster caustic, they undergo extreme magnification boosting their fluxes by factors of hundreds or even thousands. This magnification can momentarily be even larger when the star crosses a microcaustic, providing a boost of ![Mathematical equation: $\[\boldsymbol{\mathcal{O}}\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq42.png) (10) magnitudes and making a luminous star at red-shift z > 1 detectable with current telescopes. This new branch of gravitational lensing opens the door to answer some questions about the nature and abundances of the magnified sources, providing a natural telescope to detect them. Moreover, monitoring these arcs allows for the characteristics of the underlying population of microlenses to be inferred, constraining their surface mass density and possibly their nature. This is particularly interesting in the context of DM, where certain DM candidates, such as primordial black holes, can contribute to the microlensing signal.
(10) magnitudes and making a luminous star at red-shift z > 1 detectable with current telescopes. This new branch of gravitational lensing opens the door to answer some questions about the nature and abundances of the magnified sources, providing a natural telescope to detect them. Moreover, monitoring these arcs allows for the characteristics of the underlying population of microlenses to be inferred, constraining their surface mass density and possibly their nature. This is particularly interesting in the context of DM, where certain DM candidates, such as primordial black holes, can contribute to the microlensing signal.
This type of analysis requires the probability distribution function of the magnification to be known. Previous works have relied on expensive numerical simulations, with one simulation per set of parameters to be tested. Furthermore, accurate approximations of the magnification probability require large areas A in the source plane (increased by a factor μm in the lens plane) and small pixel scales. These three effects combined result in thousands of CPU hours per simulation, making it extremely difficult to carry out such an analysis. We have developed an approximation tool that enables a straightforward and efficient estimation of magnification probabilities by considering the scaling properties associated with the lens parameters. To develop our magnification probability approximation tool, we conducted an extensive series of simulations on microlensing near macro-CCs, involving approximately 0.5 million CPU hours. These simulations explored the parameter space for both macro- and micro-models. We obtained the magnification probability distributions and subsequently derived analytical models to represent these distributions. We derived the scaling relations between the model parameters and physical parameters such as the effective surface mass density of microlenses. These scaling relations allowed us to quickly compute the probability of magnification in a wide range of scenarios. As a result, we can now determine the magnification probability directly from the system’s physical parameters, eliminating the need for extensive simulations, offering a viable alternative to time-consuming numerical simulations. This analytical approximation can be obtained in less than one second, thereby enabling the aforementioned studies.
During our modelling process, we observed that in extreme scenarios where ∑eff ≳ 1 the magnification probability deviates from the well-known power-law distribution with an index of −3 (−2 when considering probabilities in logarithmic bins). Instead, it exhibits a log-normal behaviour when the micro-caustics overlap in the source plane. This effect becomes prominent when either the surface mass density of the microlenses increases or when approaching the cluster-CC as the microlens magnification, μm, grows. Interestingly, we discovered a degeneracy in the magnification probability between the surface mass density of microlenses and the tangential magnification. Many parameters scale in terms of the effective surface mass density, ∑eff = ∑* × μt. The aforementioned degeneracy can be broken by the radial magnification, denoted as μr. In particular, we find that two simulations with the same ∑eff but different ∑* and μt have the same shape but are shifted relative to each other. Furthermore, our simulations confirm the more-is-less effect discussed by Welch et al. (2022a), as well as the concept of the effective microlens mass, μtM, mentioned by Diego et al. (2018).
By delving into the study of the negative parity case, which has often been overlooked in the literature, we have made intriguing observations. We have found that this regime exhibits similarities to the positive parity regime, but with two distinct differences: (1) A demagnification effect emerges relative to the most likely magnification value. This probability of demagnification follows a negative power-law scaling (μ−1/2), which can even be observed for isolated lenses. Additionally, there is a probability excess at the lower end of the magnification distribution, and its position is solely determined by the radial magnification, μr. (2) Although the probability of magnification at the most likely factor is smaller compared to its positive parity counterpart, the probability at the largest magnification values is slightly higher in the negative parity regime.
We have identified two distinct regimes based on the effective surface mass density. When ∑eff is smaller than the critical value of the system, the magnification probability follows a similar model as that of isolated lenses near macro-CCs. The only additional component is the power-law transition to a log-normal distribution at the high magnification end of the probability distribution. When ∑eff is comparable to or significantly greater than its critical value, the magnification probability functions are modelled as the sum of two log-normal distributions for the positive parity case. In this regime, the negative parity exhibits a power-law demagnification but no longer follows a fixed slope as observed in the low-∑ regime. As the effective surface mass density increases, the contribution of the power-law demagnification becomes negligible. In the negative parity regime, when 3 < ∑eff/∑crit < 9, the magnification probability is effectively modelled by three log-normal distributions.
When the effective surface mass density exceeds a certain threshold of approximately 30–40 times the critical surface mass density, the magnification probability enters the saturation regime. In this regime, the probability distribution is predominantly described by a single log-normal distribution. Interestingly, for values of ∑eff/∑crit above approximately 55, the parameters of the log-normal distribution coincide for both the positive and negative parity regimes. However, there is a slight shift towards higher magnifications in the negative parity side of the main-CC. At this point the perturbation from the microlenses have completely erased the main-CC and both parities are virtually indistinguishable.
Acknowledgements
J.M.P. acknowledges financial support from the Formación de Personal Investigador (FPI) programme, ref. PRE2020-096261, associated with the Spanish Agencia Estatal de Investigación project MDM-2017-0765-20-2. J.M.D. acknowledges the support of project PGC2018-101814-B-100 (MCIU/AEI/MINECO/FEDER, UE) Ministerio de Ciencia, Investigación y Universidades. B.J.K. acknowledges funding from the Ramón y Cajal Grant RYC2021-034757-I, financed by MCIN/AEI/10.13039/501100011033 and by the European Union “NextGenerationEU”/PRTR. We acknowledge Santander Supercomputacion support group at the University of Cantabria who provided access to the supercomputer Altamira Supercomputer at the Institute of Physics of Cantabria (IFCA-CSIC), member of the Spanish Supercomputing Network, for performing simulations.
Appendix A Resolution effects
The inverse ray-shooting technique, despite its effectiveness, is not without limitations. In this appendix, we address the impact of resolution effects on our estimation of the magnification probability. We found three key factors that have an impact on the derived magnification probability from the simulations. These factors include the pixel size, the masses of the microlenses, and the limited statistics at the lowest magnification factors.
 |
Fig. A.1 Magnification probability approximation for an inverse ray tracing simulation of an isolated microlens of 1M⊙ near a macro-CC. Each curve represents a different pixel size. Larger pixels reach smaller maximum magnifications. |
A.1 Pixel size
When the pixel size in our simulations is increased, it imposes limitations on accurately representing the intricate structures within the micro-caustics web. A larger pixel size mimics a larger source, which affects the maximum magnification experienced. As discussed earlier, the maximum magnification is inversely proportional to the source size (![Mathematical equation: $\[\mu_{\max } \propto 1 / \sqrt{R}\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq43.png) ), meaning larger sources experience lower maximum magnifications. Most of the peak magnification is mostly produced by the narrow tips of the micro-caustics. With larger pixels, these specific regions cannot be properly sampled, smoothing out the extreme magnification values near the caustics. Consequently, the magnification values provided by larger pixels tend to reflect an average rather than capturing the enhanced magnification in the localised tips of the micro-caustics. We expect to observe a decrease in the maximum magnification obtained in our simulations as the pixel size increases.
), meaning larger sources experience lower maximum magnifications. Most of the peak magnification is mostly produced by the narrow tips of the micro-caustics. With larger pixels, these specific regions cannot be properly sampled, smoothing out the extreme magnification values near the caustics. Consequently, the magnification values provided by larger pixels tend to reflect an average rather than capturing the enhanced magnification in the localised tips of the micro-caustics. We expect to observe a decrease in the maximum magnification obtained in our simulations as the pixel size increases.
To quantitatively evaluate this effect, we conducted multiple simulations using identical parameters while varying only the pixel size. By obtaining the approximated magnification probability for each simulation, we can compare the results at the high magnification end to analyse the impact of the pixel size. In our study, we focussed on simulating an isolated microlens that follows the well-established power-law behaviour, A> μ ∝ μ−2. This choice allowed us to investigate the effect of pixel size and its influence on the resulting magnification probability.
Fig. (A.1) illustrates the magnification probability obtained for three distinct pixel sizes. It is evident that smaller pixel sizes yield better approximations of the magnification probability, particularly at higher magnifications. For our purposes, the most relevant finding is the fact that increasing the pixel size reduces the maximum magnification while maintaining the power-law behaviour up to the maximum magnification. This means that the power-law cutoff observed at extreme magnification values when ∑eff approaches 1 is not a resolution effect, but a real property of the probability of magnification.
 |
Fig. A.2 Magnification probability approximation for an inverse ray-shooting simulation of an isolated microlens near a macro-CC. Each curve represents a different microlens mass. For a fixed pixel size (2 nas), the maximum magnification we can measure increases with he mass of the microlens. The dashed lines represents the μ−2 power-law that govern the magnification probability at high magnification factor in this regime. The amplitude of this power-law increases cuadratically as seen in Sec. (4). |
It is important to consider the computational time required for numerical simulations, which scales as ![Mathematical equation: $\[\boldsymbol{\mathcal{O}}\]$](/articles/aa/full_html/2024/07/aa47492-23/aa47492-23-eq44.png) (N2), where N represents the number of pixels in one of the dimensions of the simulated region. Reducing the pixel size by a factor of 1/2 increases the computational time by a factor of 4. Therefore, a trade-off exists between the desired simulation time and the accuracy of the magnification probability. After careful analysis, we have determined that a pixel size of 2 nas is well-suited for our specific task, of microlenses at cosmological distances and in realistic scenarios, striking a balance between computational efficiency and the required level of accuracy for the magnification estimates. A pixel size of 2 nas represents well the high magnification tail of the magnification PDF up to magnifications where the probability is negligible, while smaller pixels require much larger simulation times and disk space. For larger pixel sizes that are less resource consuming to simulate we observe resolution effects at non-negligible probabilities.
(N2), where N represents the number of pixels in one of the dimensions of the simulated region. Reducing the pixel size by a factor of 1/2 increases the computational time by a factor of 4. Therefore, a trade-off exists between the desired simulation time and the accuracy of the magnification probability. After careful analysis, we have determined that a pixel size of 2 nas is well-suited for our specific task, of microlenses at cosmological distances and in realistic scenarios, striking a balance between computational efficiency and the required level of accuracy for the magnification estimates. A pixel size of 2 nas represents well the high magnification tail of the magnification PDF up to magnifications where the probability is negligible, while smaller pixels require much larger simulation times and disk space. For larger pixel sizes that are less resource consuming to simulate we observe resolution effects at non-negligible probabilities.
A.2 Mass of the microlenses
An additional resolution effect arises from the mass of the microlens itself. Smaller microlenses exhibit smaller micro-caustics, as the size of the caustics scales linearly with the Einstein angle (θE), which is proportional to the mass (M) of the lens. Consequently, lighter lenses have smaller caustics, and for a fixed pixel size, the maximum magnification achievable from these lenses is reduced. In our simulations, we consider microlens masses obtained from a distribution derived by Spera et al. (2015), which mimics an old stellar population with masses not exceeding 1.5 M⊙, while remnants and ordinary stars are not lighter than 0.1 M⊙. Our primary focus is on the smallest lenses within this distribution. Similar to our previous analysis, we simulate isolated masses ranging from 0.1 to 2 M⊙ and analyse their respective magnification probabilities. The results, presented in Fig. (A.2), confirm our expectations, with larger masses exhibiting higher maximum magnification values. However, it is worth noting that even in the case of the smallest lenses from our simulations, this resolution effect does not significantly impact our findings. The figure shows the scaling discussed in the main paper, where the amplitude of the power-law scales cuadratically with the mass of the microlens.
A.2 Magnification approximation at the lowest values
The inverse ray-shooting technique employed in our study approximates the magnification in the source plane pixels based on the number of photons traced from the lens plane. By utilising the deflection angle in the lens plane and solving the lens equation, we can determine the corresponding position in the source plane for each position in the lens plane. This approach yields accurate results when the lens plane has a sufficiently large area and good resolution. However, a limitation of this method arises from the fact that we can only obtain integer values for the magnification, while in reality, the magnification can be any real number. Therefore, this technique effectively rounds the magnification value to the closest integer. This limitation does not significantly impact our results when the magnification values differ by large factors (e.g. 104 versus 104 + 1). However, it becomes more significant when the magnification values are of order 1, as the rounding leads to a noisier estimate of the probability of magnification.
In our positive parity simulations, the magnifications fall within the range of ≳ μm. When the effective surface density increases, there is a slight reduction in this range. However, since μm is typically large, the minimum magnifications in our observations are not affected by this effect.
In simulations with negative parity, a demagnification effect relative to μm appears. This demagnification exhibits also a power-law behaviour, and its parameters can be constrained by studying larger magnifications where this effect is negligible. Additionally, a distinctive feature in the form of a skewed lognormal bump emerges in the magnification distribution at the lowest magnification values. The position of this bump decreases as μr (as shown in Fig. (14)), and it is influenced by this demagnification effect. It is important to note that characterising these peaks in the magnification distribution is challenging, and our accuracy in this regard may not be as precise as in other parts of the probability density functions. Nevertheless, our fitting procedure successfully captures the main elements of this portion of the model. In the super-critical simulations with negative parity, the combination of the demagnification effect and reduced statistics due to a smaller area in the source plane (scaled by a factor of μm, which is larger for these simulations) has hindered our ability to accurately model the low magnification excess observed in these specific cases. Despite this limitation, we have observed an interesting trend: the fixed position of these peaks begins to shift towards larger magnification values as ∼eff increases.
Appendix B Sub-structure in the central peak
In our simulations, we have discovered an intriguing feature characterised by the emergence of substructure around the mode of the magnification probability. This effect is observed primarily at low values of ∑eff, and does not significantly impact the probability distribution at the largest magnifications, which is the driving force our current study. However, it is important to note that this substructure may have implications in other cases or scenarios. While we do not provide a detailed modelling of this substructure in the present paper, we offer a brief qualitative description.
In contrast to the previous description of a single peak characterised by a log-normal distribution, our recent observations reveal the presence of two distinct peaks around the expected value μm. Moreover, the width, amplitude, and centre of these newly discovered peaks do not exhibit a clear scaling relationship with ∑eff as observed in previous analyses, although we observe that this effect manifests itself only when ∑eff < 0.3,
To gain a better understanding of the observed substructure in the magnification probability, we conducted a series of simulations where two out of the three main model parameters, namely μt, μr, and ∑*, were fixed while varying the third parameter. The results of these simulations are presented in Fig. (B.1).
Our main findings can be summarised as follows:
The parameter μt plays a crucial role in determining the positions of the peaks in the magnification probability. Increasing μt leads to a shift of both peaks towards each other. However, the lower magnification peak experiences a larger shift compared to the other peak. The ratio between the heights or amplitudes of the peaks remains constant, although the amplitude of both peaks decreases as a result of the increased ∑eff.
The parameter ∑* is correlated with the width of the peaks. Larger ∑eff values result in broader peaks. The centres of the peaks remain constant, and the ratio of amplitudes also remains constant. Similar to the case of varying μt, the increase in ∑eff leads to a reduction in the amplitude of both peaks.
The ratio of amplitudes is controlled by the parameter μr. For lower radial magnifications, the peak with higher magnification dominates. The ratio between the amplitude of this peak and its lower magnification counterpart decreases as μr increases. At μr ≈ 1.5, the ratio is approximately 1. For radial magnifications larger than 2.5, only one peak is observed. The position of the peaks may also be slightly influenced by μr.
The observed substructure in the magnification probability manifests itself primarily for low radial magnifications and low ∑eff values, typically of the order of ≲ 10% of the critical surface density. In our simulations, where the critical surface density is approximately ∑crit ≈ 3100 M⊙/pc2, we found that this effect is at it highest for μt = 1000, ∑* = 0.31 M⊙/pc2, and μr = 1.5. For the sake of simplicity, we have presented the observed substructure effect only in the context of negative parity simulations. However, it is important to note that we have also observed this effect in simulations with both positive and negative parity.
To the best of our knowledge, the substructure effect that we have observed in our simulations represents a newly discovered phenomenon whose modelling is left for future work.
 |
Fig. B.1 Zoom in on the magnification probability around the mode. We show the substructure of this peak and its changes as we fixed two parameters and allowed the remaining one to change. μt (left panel) controls the position of each peak, while its width is only scaled with ∑* (middle panel). The ratio of peak amplitudes depends on μr (Right panel). |
Appendix C Fitting data points
This appendix contains the best-fit parameters obtained via χ2 minimisation of the models described in section 6 against the simulated data. The data points shown in tables (C.1 - C.4) are fitted to simple models easily extrapolated (powerlaws, lognormals, constants...). More info can be found in the Github repository4.
References
- Abbott, B. P., Abbott, R., Abbott, T. D., et al. 2016, Phys. Rev. Lett., 116, 061102 [Google Scholar]
- Alcock, C., Allsman, R. A., Alves, D. R., et al. 2000, ApJ, 542, 281 [NASA ADS] [CrossRef] [Google Scholar]
- Broadhurst, T., Diego, J. M., & Smoot, G. III. 2018, arXiv e-prints [arXiv:1802.05273] [Google Scholar]
- Bromm, V., Kudritzki, R. P., & Loeb, A. 2001, ApJ, 552, 464 [NASA ADS] [CrossRef] [Google Scholar]
- Carr, B., Kohri, K., Sendouda, Y., & Yokoyama, J. 2021, Rep. Progr. Phys., 84, 116902 [Google Scholar]
- Chen, W., Kelly, P. L., Diego, J. M., et al. 2019, ApJ, 881, 8 [NASA ADS] [CrossRef] [Google Scholar]
- Chen, W., Kelly, P. L., Treu, T., et al. 2022, ApJ, 940, L54 [NASA ADS] [CrossRef] [Google Scholar]
- Deguchi, S., & Watson, W. D. 1987, Phys. Rev. Lett., 59, 2814 [NASA ADS] [CrossRef] [Google Scholar]
- Diego, J. M. 2019, A&A, 625, A84 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Diego, J. M., Kaiser, N., Broadhurst, T., et al. 2018, ApJ, 857, 25 [NASA ADS] [CrossRef] [Google Scholar]
- Diego, J. M., Pascale, M., Kavanagh, B. J., et al. 2022, A&A, 665, A134 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Diego, J. M., Meena, A. K., Adams, N. J., et al. 2023, A&A, 672, A3 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Diego, J. M., Kei Li, S., Meena, A. K., et al. 2024, A&A, 681, A124 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Green, A. M., & Kavanagh, B. J. 2021, J. Phys. G Nucl. Part. Phys., 48, 043001 [NASA ADS] [CrossRef] [Google Scholar]
- Kaurov, A. A., Dai, L., Venumadhav, T., Miralda-Escudé, J., & Frye, B. 2019, ApJ, 880, 58 [NASA ADS] [CrossRef] [Google Scholar]
- Kayser, R., Refsdal, S., & Stabell, R. 1986, A&A, 166, 36 [NASA ADS] [Google Scholar]
- Kelly, P. L., Diego, J. M., Rodney, S., et al. 2018, Nat. Astron., 2, 334 [NASA ADS] [CrossRef] [Google Scholar]
- Kelly, P., Acebron, A., Alfred, A., et al. 2019, Flashlights: Many Extremely Magnified Individual Stars as Probes of Dark Matter and Stellar Populations to Redshift z 2, HST Proposal. Cycle 27, 15936 [Google Scholar]
- Kelly, P. L., Chen, W., Alfred, A., et al. 2022, arXiv e-prints [arXiv:2211.02670] [Google Scholar]
- Lu, P., Takhistov, V., Gelmini, G. B., et al. 2021, ApJ, 908, L23 [NASA ADS] [CrossRef] [Google Scholar]
- MacGibbon, J. H., Carr, B. J., & Page, D. N. 2008, Phys. Rev. D, 78, 064043 [NASA ADS] [CrossRef] [Google Scholar]
- Mediavilla, E., Jiménez-Vicente, J., Muñoz, J. A., Vives-Arias, H., & Calderón-Infante, J. 2017, ApJ, 836, L18 [NASA ADS] [CrossRef] [Google Scholar]
- Meena, A. K., Arad, O., & Zitrin, A. 2022, MNRAS, 514, 2545 [CrossRef] [Google Scholar]
- Meena, A. K., Chen, W., Zitrin, A., et al. 2023a, MNRAS, 521, 5224 [NASA ADS] [CrossRef] [Google Scholar]
- Meena, A. K., Zitrin, A., Jiménez-Teja, Y., et al. 2023b, ApJ, 944, L6 [NASA ADS] [CrossRef] [Google Scholar]
- Miralda-Escude, J. 1991, ApJ, 379, 94 [NASA ADS] [CrossRef] [Google Scholar]
- Narayan, R., & Bartelmann, M. 1996, arXiv e-prints [arXiv:astro-ph/9606001] [Google Scholar]
- Neindorf, B. 2003, A&A, 404, 83 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Niikura, H., Takada, M., Yasuda, N., et al. 2019a, Nat. Astron., 3, 524 [NASA ADS] [CrossRef] [Google Scholar]
- Niikura, H., Takada, M., Yokoyama, S., Sumi, T., & Masaki, S. 2019b, Phys. Rev. D, 99, 083503 [NASA ADS] [CrossRef] [Google Scholar]
- Oguri, M., Diego, J. M., Kaiser, N., Kelly, P. L., & Broadhurst, T. 2018, Phys. Rev. D, 97, 023518 [NASA ADS] [CrossRef] [Google Scholar]
- Page, D. N., & Hawking, S. W. 1976, ApJ, 206, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Rauch, K. P. 1991, ApJ, 374, 83 [NASA ADS] [CrossRef] [Google Scholar]
- Schneider, P., Ehlers, J., & Falco, E. E. 1992, Gravitational Lenses [Google Scholar]
- Seitz, C., & Schneider, P. 1994, A&A, 288, 1 [NASA ADS] [Google Scholar]
- Seitz, C., Wambsganss, J., & Schneider, P. 1994, A&A, 288, 19 [Google Scholar]
- Serpico, P. D., Poulin, V., Inman, D., & Kohri, K. 2020, Phys. Rev. Res., 2, 023204 [NASA ADS] [CrossRef] [Google Scholar]
- Spera, M., Mapelli, M., & Bressan, A. 2015, MNRAS, 451, 4086 [NASA ADS] [CrossRef] [Google Scholar]
- The LIGO Scientific Collaboration, the Virgo Collaboration, the KAGRA Collaboration (Abbott, R., et al.) 2023, Phys. Rev. X, 13, 041039 [Google Scholar]
- Tisserand, P., Le Guillou, L., Afonso, C., et al. 2007, A&A, 469, 387 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tuntsov, A. V., Lewis, G. F., Ibata, R. A., & Kneib, J. P. 2004, MNRAS, 353, 853 [NASA ADS] [CrossRef] [Google Scholar]
- Venumadhav, T., Dai, L., & Miralda-Escudé, J. 2017, ApJ, 850, 49 [NASA ADS] [CrossRef] [Google Scholar]
- Welch, B., Coe, D., Diego, J. M., et al. 2022a, Nature, 603, 815 [NASA ADS] [CrossRef] [Google Scholar]
- Welch, B., Coe, D., Zackrisson, E., et al. 2022b, ApJ, 940, L1 [NASA ADS] [CrossRef] [Google Scholar]
- Windhorst, R. A., Timmes, F. X., Wyithe, J. S. B., et al. 2018, ApJS, 234, 41 [NASA ADS] [CrossRef] [Google Scholar]
- Windhorst, R. A., Cohen, S. H., Jansen, R. A., et al. 2023, AJ, 165, 13 [NASA ADS] [CrossRef] [Google Scholar]
In general, all lensed stars involve magnification factors, μ, from galaxies or clusters of galaxies above μ = 100.
We recall that all magnification values in this plot have been re-scaled by the factor 1000/μm.
All Tables
All Figures
|
Fig. 1 Magnification in the source plane of a single microlens near a macro-CC where μm = 1000. The darkest blue indicates a lower magnification, while the whites show where the magnification diverges (i.e. the micro-caustics). Left: single microlens on the positive parity side of the CC. The caustics have the familiar diamond shape. Right: same, but in the negative parity region, crossing the macro-CC. Now the shape of the micro-caustics is broken into two distorted triangles with a demagnification area in between, but increasing the maximum achievable magnification at the tips of these triangles. Outside the caustics, the average magnification is that of the macro model μm. The vertical direction has been scaled down a factor ~10 for better visualisation. The probability of magnification for both examples is shown in Fig. 2. |
| In the text | |
|
Fig. 2 Probability of magnification (in log10 bins) for the two single lenses. The purple dashed line represents the microlens on the negative parity side of the macro-CC, while the orange solid line represents the positive parity case on the right and left panels of Fig. 1, respectively. The dotted lines represents the power-laws that always appear for isolated microlenses near macro-CCs, and for N microlenses with low ∑eff. The variation in the value of the ∑−2 power-law amplitude is shown in Fig. 3. |
| In the text | |
|
Fig. 3 Extrapolated value of the power-law ∝ μ−2 at μ = 1 from the probability distribution function of a system of N microlenses in the vicinity of a macro-CC. The case of one microlens is shown in the top row. The case for two microlenses is shown in the bottom row. We have changed the total mass of the microlenses, the magnification from the macro model and the reduced distance in the first, second and third columns respectively, while keeping the other parameters fixed. Note that for both systems the amplitude scales at the same rate for each parameter. All these lens systems have ∑eff ≪ ∑crit. Dashed lines represent the best fit to a powerlaw obtained by χ2 minimisation. We found that the amplitude scales linearly with the reduced distance and it scales cuadratically with the macro-magnification and the mass of the lenses. |
| In the text | |
|
Fig. 4 High resolution view of the magnification at the source plane. Top panels: positive parity side of the macro-CC. Bottom panels: negative parity side of the macro-CC. The effective surface mass density increases from left to right. The value of the macro magnification and the ratio of the effective surface density to the critical value are shown for each column. Note that the y-direction has been compressed a factor 10 for better visualisation. For the same reason, the two rightmost columns have been compressed a factor 2 in the x-direction. |
| In the text | |
|
Fig. 5 Probability of magnification for a set of simulations with different ∑eff in the low surface mass density regime. Left panel: negative parity side of the macro-CC. Right panel: positive parity side of the macro-CC. |
| In the text | |
|
Fig. 6 High resolution view of the magnification at the source plane. Top panels: positive parity side of the macro-CC. Bottom panels: negative parity side of the macro-CC. The effective surface mass density increases from left to right. The value of the macro magnification and the ratio of the effective surface density to the critical value are shown for each column. Note that the y-direction has been compressed a factor 25 (50 for the last column) for better display. |
| In the text | |
|
Fig. 7 Probability of magnification for a set of simulations with different ∑eff in the medium-high surface mass density regime. Left panel: negative parity side of the macro-CC. Right panel: positive parity side of the macro-CC. |
| In the text | |
|
Fig. 8 Probability of magnification for two simulations with different ∑* and μt but the same ∑eff. Positive parities are shown as solid lines, while dashed lines represent negative parities. A difference in the position of the probability excess in the low magnification regime is due to a difference in μr between the simulations. |
| In the text | |
 |
Fig. 9 Scaling of the model parameters for the low magnification regime at the low surface mass density and positive parity scenario. Point colours represent the ∑eff over the critical value as shown in Fig. 5. |
| In the text | |
|
Fig. 10 Scaling of the model parameters for the intermediate magnification regime at the low surface mass density and positive parity scenario. Point colours represent the ∑eff over the critical value as shown in Fig. 5. |
| In the text | |
|
Fig. 11 Scaling of the model parameters for the extreme magnification regime at the low surface mass density and positive parity scenario. Point colours represent the ∑eff over the critical value as shown in Fig. 5. |
| In the text | |
|
Fig. 12 Magnification probability function for a simulation within the low surface mass density regime and positive parity. The dashed lines represent each of the fitting model components and their total contribution. |
| In the text | |
|
Fig. 13 Scaling of the model parameters for the low magnification regime at the low surface mass density and negative parity scenario. Point colours represent the ∑eff over the critical value as shown in Fig. 5. |
| In the text | |
|
Fig. 14 Scaling of the model parameters for the low magnification excess at the low magnification regime for the low surface mass density and negative parity scenario. As in Fig. 13 point rainbow colours represent the ∑eff over the critical value as shown in Fig. 5. |
| In the text | |
|
Fig. 15 Ratio between the width of the peak (at low magnifications for low surface mass density and negative parity) at a given μr and its corresponding width at μr = 4. Point colours represent the μr over the critical value as shown in Fig. 14. |
| In the text | |
|
Fig. 16 Scaling of the model parameters for the intermediate magnification regime at the low surface mass density and negative parity scenario. Point colours represent the ∑eff over the critical value as shown in Fig. 5. |
| In the text | |
|
Fig. 17 Scaling of the model parameters for the extreme magnification regime at the low surface mass density and negative parity scenario. Point colours represent the ∑eff over the critical value as shown in Fig. 5. |
| In the text | |
|
Fig. 18 Magnification probability function for a simulation within the low surface mass density regime and negative parity. The dashed lines represent each of the fitting model components and their total contribution. |
| In the text | |
|
Fig. 19 Scaling of the model parameters at the high surface mass density and positive parity scenario. Point colours represent the ∑eff over the critical value as shown in Fig. 7. |
| In the text | |
|
Fig. 20 Magnification probability function for a simulation within the high surface mass density regime and positive parity. The dashed lines represent each of the fitting model components and their total contribution. |
| In the text | |
|
Fig. 21 Scaling of the model parameters at the high surface mass density and negative parity scenario. Point colours represent the ∑eff over the critical value as shown in Fig. 7. |
| In the text | |
|
Fig. 22 Magnification probability function for a simulation within the high surface mass density regime and negative parity. The dashed lines represent each of the fitting model components and their total contribution. |
| In the text | |
|
Fig. 23 Magnification of a source at redshift 1.3 and angular size 2 nas sweeping the micro-caustic web at a constant speed of 1000 km s−1. Top panel: magnification pattern in the source plane. Bottom panel: magnification over time. The dashed line represents the magnification from the macro model. |
| In the text | |
|
Fig. 24 Magnification probability for a case with ∑eff/∑crit = 2, in both parity regimes. This mimics the magnification probability of a hypothetical microlensing population consisting of 5 M⊙/pc2 stars and 20 M⊙ pc−2 PBHs. The critical density is ∑crit = 2500 M⊙ pc−2. μt = 200 and μr = 4. Left panel: negative macro-magnification. Right panel: positive macro-magnification. The dashed curve represents the magnification probability for the same system with no PBHs. |
| In the text | |
|
Fig. 25 Analytical approximation for the probability of magnification for a fixed μm = 1000, and varying ∑*. By increasing ∑eff the more-is-less and saturation effects appear, obtaining a thicker log-normal centred at lower magnifications. |
| In the text | |
|
Fig. 26 Probability of magnification for two simulations with the same |μt|, μr, ∑*, and different parities in the saturation regime ∑eff/∑crit = 66.5. |
| In the text | |
|
Fig. A.1 Magnification probability approximation for an inverse ray tracing simulation of an isolated microlens of 1M⊙ near a macro-CC. Each curve represents a different pixel size. Larger pixels reach smaller maximum magnifications. |
| In the text | |
|
Fig. A.2 Magnification probability approximation for an inverse ray-shooting simulation of an isolated microlens near a macro-CC. Each curve represents a different microlens mass. For a fixed pixel size (2 nas), the maximum magnification we can measure increases with he mass of the microlens. The dashed lines represents the μ−2 power-law that govern the magnification probability at high magnification factor in this regime. The amplitude of this power-law increases cuadratically as seen in Sec. (4). |
| In the text | |
|
Fig. B.1 Zoom in on the magnification probability around the mode. We show the substructure of this peak and its changes as we fixed two parameters and allowed the remaining one to change. μt (left panel) controls the position of each peak, while its width is only scaled with ∑* (middle panel). The ratio of peak amplitudes depends on μr (Right panel). |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.