| Issue |
A&A
Volume 670, February 2023
|
|
|---|---|---|
| Article Number | A76 | |
| Number of page(s) | 8 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202244424 | |
| Published online | 08 February 2023 | |
Constraining the polarisation flux density and angle of point sources by training a convolutional neural network
1
Departamento de Física, Universidad de Oviedo,
C. Federico García Lorca 18,
33007
Oviedo, Spain
2
Instituto Universitario de Ciencias y Tecnologías Espaciales de Asturias (ICTEA),
C. Independencia 13,
33004
Oviedo, Spain
e-mail: casasjm@uniovi.es
3
Departamento de Informática, Universidad de Oviedo,
Edificio Departamental 1, Campus de Viesques s/n,
33204,
Gijón, Spain
4
Escuela de Ingeniería de Minas,
Energía y Materiales Independencia 13,
33004
Oviedo, Spain
Received:
5
July
2022
Accepted:
24
December
2022
Context. Constraining the polarisation properties of extragalactic point sources is a relevant task not only because they are one of the main contaminants for primordial cosmic microwave background B-mode detection if the tensor-to-scalar ratio is lower than r = 0.001, but also for a better understanding of the properties of radio-loud active galactic nuclei.
Aims. We develop and train a machine learning model based on a convolutional neural network to learn how to estimate the polarisation flux density and angle of point sources embedded in cosmic microwave background images knowing only their positions.
Methods. To train the neural network, we used realistic simulations of patches of 32 × 32 pixels in area at the 217 GHz Planck channel with injected point sources at their centres. The patches also contain a realistic background composed of the cosmic microwave background signal, the Galactic thermal dust, and instrumental noise. We split our analysis into three parts: firstly, we studied the comparison between true and estimated polarisation flux densities for P, Q, and U simulations. Secondly, we analysed the comparison between true and estimated polarisation angles. Finally, we studied the performance of our model with the 217 GHz Planck map and compared our results against the detected sources of the Second Planck Catalogue of Compact Sources (PCCS2).
Results. We find that our model can be used to reliably constrain the polarisation flux density of sources above the 80 mJy level. For this limit, we obtain relative errors of lower than 30% in most of the flux density levels. Training the same network with Q and U maps, the reliability limit is above ±250 mJy when determining the polarisation angle of both Q and U sources. Above that cut, the network can constrain angles with a 1σ uncertainty of ±29° and ±32° for Q and U sources, respectively. We test this neural network against real data from the 217 GHz Planck channel, obtaining similar results to the PCCS2 for some sources; although we also find discrepancies in the 300–400mJy flux density range with respect to the Planck catalogue.
Conclusions. Based on these results, our model appears to be a promising tool for estimating the polarisation flux densities and angles of point sources above 80 mJy in any catalogue with very small computational time requirements.
Key words: techniques: image processing / submillimeter: galaxies / cosmic background radiation
© The Authors 2023
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. Subscribe to A&A to support open access publication.
1 Introduction
The impact of polarised extragalactic radio sources (ERSs), mainly blazars (de Zotti et al. 2010; Tucci et al. 2011), is not only important for research into active galactic nuclei but also because they are a contaminant for future cosmic microwave background (CMB) experiments as their properties are not yet well constrained.
ERSs are usually detected in total intensity signal I and in both Q and U maps of the microwave sky. However, it is better to work with the total polarisation of a source, 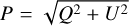 , not only because P is definite positively, but also because it is physically related to the real processes occurring along the path of photons from the ERS to Earth (Herranz et al. 2012). However, although blind and non-blind signal-processing techniques work by constraining the P polarisation, it is more common to present results of the total polarisation fraction, Π = P/S, where S is the source flux density in total intensity.
, not only because P is definite positively, but also because it is physically related to the real processes occurring along the path of photons from the ERS to Earth (Herranz et al. 2012). However, although blind and non-blind signal-processing techniques work by constraining the P polarisation, it is more common to present results of the total polarisation fraction, Π = P/S, where S is the source flux density in total intensity.
At present times, only a few sources are found to have a maximal polarisation fraction of ~ 10%, a fact predicted and explained by Tucci & Toffolatti (2012). Indeed, only 243 sources above the 99.99% C.L. are detected in the Second Planck Catalogue of Compact Sources (PCCS2, Planck Collaboration XXVI 2016), which corresponds to only 2.715% of the sources detected in total intensity.
The polarisation fraction value for HFI Planck channels has been studied by applying the stacking technique to the mission data in Bonavera et al. (2017a) for radio sources (mean value of 3.08% at 217 GHz) and in Bonavera et al. (2017b) for dusty galaxies (mean value of 3.10% and 3.65% at 217 and 353 GHz, respectively). More recently, Galluzzi et al. (2018) found a mean value of 2.91 ± 0.42% for flat-spectrum sources at 100 GHz and Trombetti et al. (2018) found a median value of 2.83% for radio sources and set upper limits (at 3.9% and 2.2%) for dusty galaxies (at 217 and 353 GHz, respectively) by exploiting the intensity distribution analysis. Furthermore, for the Atacama Cosmology Telescope Polarisation survey (ACTPol, Datta et al. 2019), the authors conclude that the polarisation of ERS could be defined by a Gaussian distribution instead of a log-normal one, presenting a mean fractional polarisation of 2.9 ± 0.5% at 148 GHz, while for the South Pole Telescope Polarisation survey (SPT- pol, Gupta et al. 2019), they obtain a weighted mean fractional polarisation of 2.63 ± 0.22% at 150 GHz.
The other physical quantity used to describe the behaviour of polarised ERS is the polarisation angle (also known as position angle), which is usually defined as
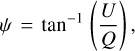 (1)
(1)
where 0 ≤ ψ ≤ 2π. As for the polarisation fraction, it is believed to be frequency independent (Saikia & Shastri 1984). Furthermore, although for lobe-dominated quasars the alignment between the core polarisation and the radio axis might be  (Saikia & Shastri 1984), no constraints have yet been made on the polarisation angle of core-dominated quasars (Pearson & Readhead 1984).
(Saikia & Shastri 1984), no constraints have yet been made on the polarisation angle of core-dominated quasars (Pearson & Readhead 1984).
Another important goal of the scientific community is to accurately constrain the polarised properties of ERSs as they directly affect primordial B mode detection, that is, the discovery of CMB patterns related to gravitational waves produced by cosmological perturbations at inflation era (Starobinskiî 1979; Linde 1982). Furthermore, following the simulations by Remazeilles et al. (2018), unresolved polarised ERS could be one of the main contaminants of such detections: as also confirmed by Puglisi et al. (2018), if the tensor-to-scalar ratio is lower than r = 0.001, ERSs affect the CMB power spectrum at multipoles l >50.
Several methods have been developed in recent years for the detection and flux density estimation of the polarisation of ERSs: Argüeso et al. (2009) developed Filtered Fusion (FF), which was applied by López-Caniego et al. (2009) to both WMAP and Planck data. More recently, Herranz et al. (2021) developed a Bayesian estimator (BFF), reaching reliable polarised estimations down to 0.01 Jy in realistic simulations of the QUIJOTE experiment (Rubiño-Martín et al. 2012). Furthermore, Diego-Palazuelos et al. (2021) proposed a method based on steerable wavelets, which is reliable down to 3.38 and 5.76 mJy for regions of faint galactic emission in simulations of the 30 and 155 GHz bands, respectively, of the PICO experiment (Hanany et al. 2019).
In this work, we present a new methodology based on a convolutional neural network (CNN, LeCun et al. 1989) called the POint Source Polarisation Estimation Network (POSPEN) trained with realistic simulations of polarisation data from the Planck mission. In Sect. 2, we present simulations for training and validating the network. Section 3 presents details of POSPEN. Section 4 discusses the results from simulations and real data and in Sect. 5 we outline our conclusions.
2 Simulations
For training and validating POSPEN, we use realistic simulations of the polarised sky at the 217 GHz Planck channel from the PR3 release, which can be downloaded from the Planck Legacy Archive (PLA1) database. Our goal is to develop a methodology to constrain both the polarisation emission and angle for each point source (PS) in a given catalogue (i.e. their positions are known). In particular, we randomly divide the sky maps into patches of 32 × 32 pixels in area and a pixel-side of 90 arcsec, which is reasonably close to the Planck 1.72 arcmin (corresponding to Nside = 2048 in the HEALPix all-sky pixelisation schema; Górski et al. 2005).
Each simulated patch has a central injected PS in order to mimic the future application of this methodology to real data where the PS position is known from its detection in total intensity (non-blind method). Its polarisation integrated value is kept to be used during the POSPEN training in the minimisation of the loss function. In addition, the patch contains realistic sky emission at the chosen frequency, a background consisting of the CMB signal, the Galactic thermal dust, and instrumental white noise at Planck levels.
Although polarised dusty galaxies are also present at 217 GHz (Planck Collaboration XXVI 2016), for simplicity we consider only radio sources. These sources are simulated in total intensity following the C2Ex model by Tucci et al. (2011) and the software CORRSKY (González-Nuevo et al. 2005); they are then convolved with a Gaussian filter using the 4.90 arcmin full width at half maximum value of Planck at this frequency. Their P polarisation is estimated by assuming a log-normal distribution with the parameters set to μ = 0.7 and σ = 0.9 (Bonavera et al. 2017a). The polarisation angle (ψ) is assumed to be randomly oriented in any direction of the sphere. Then, following the convention by Hamaker & Bregman (1996), P and ψ are used to calculate both Q and U values as
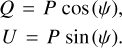 (2)
(2)
The Q and U CMB maps are the ones from the SEVEM component-separation method (Martínez-González et al. 2003) and the Galactic thermal dust map is a simulation from the Planck Sky Model (Delabrouille et al. 2013) based on the FFP10 sky model2. The instrumental noise is added to the patch as a random white noise using the Planck value of 1.75 μKCMB for this channel (Planck Collaboration I 2020), after re-scaling this value using the pixel area and the simulated beam.
In this work, we make two main groups of simulations: one in P and one in Q and U. First, we simulate 10 000 patches to train POSPEN in P which allow us to work with positive defined polarisation values for the simulated sources because it is unclear at this point whether or not the neural network can properly handle positive and negative data in the same dataset. Then, to take the possibility of overfitting into account, we also simulate 1000 extra patches for testing the data during training. Moreover, we prepare a validation dataset of 1000 additional patches not used in the POSPEN training. To prepare the second group of simulations, we repeat the same procedure for the train, test, and validation datasets formed by Q and U patches. An example of the simulated maps is shown in Fig. 1.
3 Methodology
In recent years, as the quantity of available data has continuously increased, the impact of machine learning (ML) has also increased across a vast range of technologies. One of the most popular ML methods is the neural network. These are models based on neuroscience and are specially designed to learn non-linear behaviours in data (see Goodfellow et al. 2016, and references therein). Neural networks are formed by layers of weighted computational units called neurons. Their weights are updated upon each step of training: once the information flowing forward reaches the last layer, a loss function is minimised and a gradient is computed in order to adjust the weights by flowing the information back and retrospectively updating each layer, one by one, back to the first layer. This process is called backpropagation (Rumelhart et al. 1986) and the whole process of forward and backward flows of information through the architecture is called an epoch of training. This process is iterated in order to optimise the network and several epochs can be required to train the network.
New methods based on neural networks and other ML methods have recently been developed in the field of CMB research, with promising results being obtained in both total intensity and polarisation. For example, Bonavera et al. (2021) and Casas et al. (2022b) compared their fully convolutional neural networks to commonly used filters in Planck for PS detection in singlefrequency (González-Nuevo et al. 2006) and multi-frequency (Herranz et al. 2009) realistic total-intensity simulations, obtaining more reliable results, and also at frequencies not used for training the networks.
In component separation, Casas et al. (2022a) recently developed a fully convolutional neural network for extracting the CMB signal in total intensity in realistic Planck simulations, reaching low residual values for multipoles up to 4000. These authors found that those types of architectures might be able to deal with both foreground and systematic non- gaussianities in future polarisation studies. A similar conclusion was derived by Krachmalnicoff & Puglisi (2021), who proposed a model based on generative adversarial networks capable of creating non-Gaussian simulations of polarised thermal dust extended to 12 arcmin using low-resolution input data. Moreover, Krachmalnicoff & Tomasi (2019) also investigated a methodology based on a neural network for extending a CNN to the sphere, and Puglisi & Bai (2020) developed a model based on convolutional neural networks for inpainting Galactic foregrounds.
Here, we propose the use of CNNs for estimating the polarisation flux density and angle values of sources previously detected in total-intensity maps. These kinds of networks are composed of blocks: each block convolves the input information into a space formed by a determined number of feature maps. The information is then computed for each block by a group of weights called kernels. After several convolutions, one or more layers of several neurons take into account the relevant convolved information by running a non-linear activation function, and a final neuron connected to them. provides an estimated value. At the end of this architecture, a loss function is minimised using the value given as the label and the gradient is computed using this loss information. With the gradient estimation, the weights of each convolutional block are updated on each layer of the architecture in the backpropagation (Rumelhart et al. 1986). This process (explained in detail in Goodfellow et al. 2016) is iterated for several epochs.
In our case, the input data are a patch of the microwave sky read by the first convolutional block as a 32×32 square matrix. The information is then convolved along five convolutional blocks, formed by 8, 32, 64, 128, and 256 kernels3, with sizes of 2, 2, 3, 5, and 5 and strides4 of 2, 2, 3, 5, and 5. After the convolutional blocks, there are two layers of 128 and 1 neurons, respectively’, which convert the previous information into numerical values. In all layers, the selected activation function is the leaky rectified linear unit (leaky ReLU, Nair & Hinton 2010), which not only allows the information to pass when the neurons of each block are active but also applies a small gradient when they are not active. This last behaviour is controlled by an alpha parameter, which in our case is 0.2. The other selected hyperparameters are the AdaGrad optimiser, 500 epochs, a batch size of 16, and a learning rate of 0.05. These have been selected bqsed on a preliminary study before the final training of the network. Finally, in the last part of the architecture, we use the mean squared error loss function, defined as
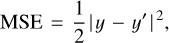 (3)
(3)
where y is the value estimated by the network and y’ is the true value we want to obtain. The architecture of POSPEN is shown in Fig. 2.
 |
Fig. 1 Example of one simulation used to train or validate POSPEN for P, Q, and U polarisation maps (left, middle, and right columns, respectively). Top panels show the input patch formed by all the emissions, where the network learns how to extract the polarisation of the PS. Bottom figures show an example of the simulated PS, where we use the integrated intensity as a label for the training. The units are in Jy. |
 |
Fig. 2 Architecture of POSPEN. The information in the 217 GHz patch is convolved into 8 filters in the first convolutional block. After that, several convolutions are made through four more layers of 32, 64, 128, and 256 filters. The information is then processed through a layer of 128 neurons. Finally, one last neuron gives the output value. |
 |
Fig. 3 Estimation of total polarisation flux density of the validation sources. Left panel: correlation between true and estimated polarisation flux density. Right panel: polarisation relative error against the input polarisation flux density. The error bars represent the uncertainty of each bin, which we considered to be equal to the standard deviation. In both cases, the dashed black lines show the ideal case. |
4 Results
4.1 Polarisation flux density estimation
In this section, we assess the results of our total polarisation flux density estimations, P, for the PS in the validation dataset. We compute the correlation between true and estimated polarisation, the polarisation relative error, and the source number counts in polarisation. In particular, the polarisation relative error is defined as
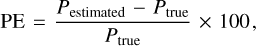 (4)
(4)
where Pestimated and Ptrue are the estimated and true polarisation values, respectively.
The left panel of Fig. 3 shows the correlation between true and estimated polarisation flux densities. The right panel plots the polarisation relative error against the true polarisation. In particular, we compute the mean relative error values for each bin (blue dots) and their uncertainty (standard deviation). In both panels, the ideal case is represented with dashed black lines.
Both figures show that the estimations by POSPEN for all simulated patches seem to be reliable above 80 mJy. More precisely, above that value, the CNN estimates the polarisation of the sources relatively well, with an error of less than 30% in most cases. Below 80 mJy, the results are affected by the Eddington bias: the estimated values are systematically overestimated, showing relative errors above 100% for polarised flux densities below 25 mJy.
As a comparison with other methods for polarisation flux density estimations, the Bayesian method by Herranz et al. (2021) provides reliable results down to 180 mJy when applied to realistic simulations with the QUIJOTE experiment characteristics. However, both the frequency analysed, namely 11 GHz, and the instrument sensitivity, 105 μKs1/2, are different from our case (217 GHz with a ~650 μKs1/2 sensitivity). The Bayesian method performs similarly well to more traditional techniques such as the FF filter from Argüeso et al. (2009), which was used in Planck (Planck Collaboration XXVI 2016).
In Fig. 4, we represent the true (blue area) and POSPEN- estimated (red area) source number counts in polarisation for the validation dataset. Both counts show a similar distribution, except in the 20–40 mJy flux density range, where the estimated counts are slightly higher with respect to the true ones. This is due to the Eddington bias, which also explains the fact that below 20 mJy, the estimated counts drop more rapidly than the true one.
4.2 Polarisation angle estimation
In this section, we follow a similar approach to that described in Sect. 4.1, but with the aim of constraining the polarisation angle of the target PS. To do so, the CNN is re-trained, firstly for Q and secondly for U maps with 10 000 simulated patches of PS and background, using the polarisation integrated values of Q and U central PS, respectively, to minimise the loss function. The CNN is then validated for each case with 1000 simulations not used for training.
The correlation between true and estimated Q sources is shown in the left panel of Fig. 5. The top panel represents sources with Q > 0, that is, sources with a polarisation angle of between 0° and 180°, while the bottom panel shows sources with Q < 0, which are the ones with a polarisation angle between –180° and 0°. In the right panel, we represent the Q relative error. The positive sources are represented as orange crosses and the negative as blue circles. In both cases, the uncertainty is taken as the standard deviation of each bin. For both figures, the black dashed lines represent the ideal case. The same statistical quantities for U sources are plotted in Fig. 6.
In both cases, we can see a similar behaviour to the previous section: POSPEN recovers reliable sources above ~80 mJy. As expected, due to the fact that the network has to deal with positive and negative quantities, the errors in Q and U are higher than the ones in total polarisation P, reaching maximal relative errors of 60% and 80% for Q and U sources, respectively.
Given these findings, in order to assess the performance of the CNN when estimating the polarisation angle, we consider only sources with reliable estimations above 80 mJy. We estimate the polarisation angle using Eq. (2), which is more suitable than Eq. (1) because good-quality detections of both Q and U flux densities are not strictly required. With this approach, we can estimate the polarisation angle even when Q is well estimated but not its corresponding U value, or vice versa. However, in order to get the actual polarisation angle, we need to compare the Q and U values of every source: when Q > 0 and U < 0, the actual angle is obtained by adding π/2 to the one from Eq. (2), while when Q < 0 and U < 0, we need to subtract π/2.
We also estimate the standard deviation of the relative error of the angle for each population in order to give the level of uncertainty of our method. This quantity depends on how well the polarisation flux of both Q and U sources is estimated. Therefore, to obtain the estimation for the polarisation angle with the minimum uncertainty, we examine the relation between the polarisation angle uncertainty and the polarised flux density cut for both Q and U sources, which we show in Fig. 7. We obtain that the minimal uncertainty that allows good statistics is ±29° and ±32° for a cut of ~250 mJy for Q and U sources, respectively. Obviously, this cut could also be applied independently for each map in order to obtain estimations for sources with low Q and high U values, and vice versa.
Considering this cut, we show in the left panel of Fig. 8 the correlation between true and estimated polarisation angles for sources in Q (top; orange) and U (bottom; green), with the black dashed line showing the 1:1 case. The coloured areas represent the 1σ uncertainty level computed as described above. As shown, most of the sources above the mentioned cut have their polarisation angles well recovered with an uncertainty of ~30°.
Furthermore, for assessing the quality of this correlation, we calculate the Pearson coefficient, defined as
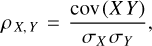 (5)
(5)
where cov(X Y) is the covariance between true and estimated angles and σX and σY are their standard deviations. We obtain a Pearson coefficient of 0.853 for Q sources and 0.91 for U ones. We also implement a test of null hypothesis, obtaining a probability value of 5.87×10−6% for Q sources and 1.03×10−10% for U ones.
In the right panels of Fig. 8, we plot the distribution of the input angles (blue area in both top and bottom panels) and Q (top; orange area) and U (bottom; green area) estimated ones. This shows on the one hand that the input sources have relatively random angles, as expected, and on the other hand that POSPEN estimates the distribution of the sources in most of the intervals relatively well.
 |
Fig. 4 Source number counts in polarisation of both true (blue area) and estimated (red area) catalogues. |
4.3 Comparison with the PCCS2
In this section, we apply our model to the 217 GHz Planck data. In particular, we extract patches of 32×32 pixels in area from the total 217 GHz Planck map. The patches are centred on the positions of the PCCS2 sources with polarisation detection. Thus, the resulting dataset is made up of 11 patches. We apply POSPEN to this dataset and obtain estimations of the corresponding total polarisation flux densities and angles. We compare our results against the PCCS2 estimated values.
Figure 9 shows the comparison between the estimations given in the PCCS2 by using the detection flux (DETFLUX, blue points) and aperture flux (APERFLUX, red crosses) methods5 and the estimations by POSPEN: the left panel compares the total polarisation flux densities and the right panel the polarisation angles. The corresponding horizontal error bars are the uncertainty given in the PCCS2, the vertical ones are the uncertainty of POSPEN, and the dashed black lines are the 1:1 case. The results obtained with simulations (described in the previous subsections) are used for assigning the POSPEN uncertainties to both polarisation flux densities and angles. More specifically, we use the relative error shown in the right panel of Fig. 3 for each flux density interval to assign the uncertainty to each source according to its polarisation level. The same procedure is applied to the polarisation angle, using the uncertainties shown in the right panels of Figs. 5 and 6.
Regarding the total polarisation, both for DETFLUX and APERTURE values, POSPEN tends to underestimate the flux densities of six of the detected PCCS2 sources, while overestimating the faintest one. Furthermore, all these sources were considered to be robustly detected in Planck and are relatively bright in polarisation, with a minimum polarisation of about 80 mJy. These results could simply indicate a potential issue with POSPEN in this polarisation flux density range. Indeed, a statistical underestimation can be seen in the 200–300 mJy range in the right panel of Fig. 3. The simulated sources with polarisation flux density brighter than 100 mJy constitute only ~20% of the whole sample. In fact, although we obtain interesting results, the fluctuations in the relative errors above 80 mJy that we see in Fig. 3 indicate that the training dataset has to be improved. We must also take into account the fact that, in real data, highly polarised sources are usually detected in polarisation maps, with it being very difficult to single out those sources with flux densities lower than 100 mJy. Our training set contains 10000 sources and only a few have flux densities above 100 mJy. Therefore, it might be worth injecting brighter sources into the training set when validating on real data.
Therefore, the performance of POSPEN could probably be improved when validating the hole PCCS2 catalogue by increasing the number of simulated sources brighter than 100 mJy, which are the most relevant ones when applied to the real maps. However, this is out of the scope of this work and will be tested in the future.
The polarisation angle is only underestimated for three sources by POSPEN in both DETFLUX and APERFLUX measurements, and the other eight estimations are consistent with Planck values. Therefore, although most of the results in total polarisation flux density underestimate Planck values, the polarisation angle obtained using Q and U data are mostly in agreement.
Finally, we also estimate the fractional polarisation, 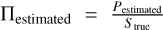 , of the sources detected in the PCCS2. We obtain a mean fractional polarisation of 4.78%, a value somewhat lower than the 5.3% in Planck Collaboration XXVI (2016), and a median of 2.82%, which is similar to the findings of other works in the literature that provide estimations using single-channel Planck data (as in Trombetti et al. 2018).
, of the sources detected in the PCCS2. We obtain a mean fractional polarisation of 4.78%, a value somewhat lower than the 5.3% in Planck Collaboration XXVI (2016), and a median of 2.82%, which is similar to the findings of other works in the literature that provide estimations using single-channel Planck data (as in Trombetti et al. 2018).
 |
Fig. 5 Estimation of polarisation flux density of Q sources. Left panel: correlation between true and estimated Q polarisation. The top part shows the Q > 0 sources in orange while the bottom part shows the Q < 0 ones in blue. Right panel: Q relative error against the polarisation flux of the validation catalogue. The error bars represent the uncertainty computed as the standard deviation of each bin. In both cases, the dashed black line shows the ideal case. |
 |
Fig. 6 Estimation of polarisation flux density of U sources. Left panel: correlation between true and estimated U polarisation. The top part shows the U > 0 sources in green while the bottom part shows the U < 0 ones in brown. Right panel: U relative error against the polarisation flux of the validation catalogue. The error bars represent the uncertainty computed as the standard deviation of each bin. In both cases, the dashed black line shows the ideal case. |
 |
Fig. 7 Relation between polarisation angle uncertainty for the estimations of POSPEN and the cut in polarisation flux density in both Q and U sources. The dashed red line shows the minimum uncertainty considering enough number of sources to have good statistics. |
 |
Fig. 8 Estimation of polarisation angles of Q and U sources. Left panel: correlation between true and estimated angles. The coloured areas represent a confidence interval of ±29° for Q sources and ±32° U ones, which are the standard deviation of the relative error of each population, respectively. Dashed black lines are the 1:1 case. Right panel: distribution of polarisation angles for both true and estimated Q and U catalogues, with the blue areas showing the true angles and orange and green areas showing the estimated angles for Q and U sources, respectively. |
 |
Fig. 9 Comparison of polarisation flux densities and angle estimations given by both POSPEN and the PCCS2. Left panel: comparison of PCCS2 with POSPEN polarisation flux density estimations. Right panel: comparison of PCCS2 with POSPEN polarisation angle estimations. In both cases, the horizontal error bars show the uncertainty given in the PCCS2, while the vertical ones show the uncertainty of POSPEN. The dashed orange line shows the systematic underestimation of POSPEN given by the simulations and the dashed black line is the 1:1 case. |
5 Conclusions
In this work, we aim to develop a new non-blind methodology for point-source polarisation flux density and angle estimation based on a CNN called the POint Source Polarisation Estimation Network (POSPEN). The CNN is trained with 10000 realistic simulations of 32 × 32 pixel patches (pixel size of 90 arcsec) composed of a central injected PS embedded in a realistic background with the 217 GHz Planck channel characteristics. The PSs are simulated following the C2Ex model by Tucci et al. (2011), and their polarisation is simulated assuming a log-normal distribution with μ and σ parameters from Bonavera et al. (2017a). The background is composed of a simulated map of Galactic thermal dust, the cosmic microwave background map from the SEVEM method, and injected instrumental white noise using the Planck value.
POSPEN is then validated with simulations not used for training, splitting our analysis into three parts. Firstly, we study the performance of the CNN on total polarisation data. We compute the correlation between true and estimated polarisation flux densities along with the relative error with respect to the input polarisation flux densities. We obtain that our method reliably recovers the polarisation flux density of sources above 80 mJy, where the Eddington bias starts to affect the results. Under these circumstances, we are able to recover the input polarisation flux density within a relative error of 30% in most of the flux-density intervals.
Subsequently, we re-train the neural network with 10000 simulations in both Q and U maps in order to obtain a constraint on the polarisation angle. We study the correlation between true and estimated Q and U values and their errors. We obtain similar results to in the previous case, reaching the Eddington bias at approximately the same flux-density level. For constraining the polarisation angle, we then use sources above this flux-density limit, obtaining minimal 1σ uncertainties of ±29° and ±32° for Q and U sources, respectively, above 250 mJy. For these, we analyse the correlation between these true and estimated angles and their distributions. We obtain a Pearson coefficient of 0.853 for Q sources and 0.91 for U sources with null-hypothesis probability values of 5.87 × 10−6% and 1.03 × 10−10%, respectively.
Finally, we study the performance of our model with real data from the 217 GHz Planck map and compare our estimations with the information in the PCCS2. We find that POSPEN recovers a similar polarisation flux density for 4 of the 11 sources in the PCCS2, but it tends to systematically underestimate the polarisation flux density of 6 sources and overestimate the value of the remaining one. For the polarisation angle, it recovers this quantity quite well for 8 sources, underestimating 3 of them. Finally, we compute the mean and median fractional polarisation values, obtaining 4.78% and 2.82%, respectively.
Based on these results, the methodology presented here appears to be promising for estimating polarisation flux density and angle in a non-blind way, especially considering the level of contamination in the simulations, the data we use (mimicking the Planck experiment), and the performance of other non-blind methods in similar conditions. In particular, the results that can be obtained by applying this method to real data can be useful not only for constraining the impact of polarised sources on the detection of primordial B-modes – if the tensor-to-scalar ratio is lower than r = 0.001 – but also for improving our knowledge of active galactic nuclei.
However, when considering the application of this method in conjunction with other instruments, in order to obtain a good performance, the network should be retrained with a training set consisting of realistic simulations that reproduce the characteristics and conditions of such instruments, such as the higher resolution ACTPol or SPTPol experiments. Moreover, this method can be further improved in order to detect sources in polarisation data in a blind way by subsequently applying the fully convolutional neural network by Casas et al. (2022b) to perform the detection in total intensity and then the methodology presented in this work to estimate the polarisation flux density and angle of the detected sources.
Acknowledgements
We warmly thank the anonymous referee for the very useful comments on the original manuscript. J.M.C., L.B., J.G.N., M.M.C. and D.C. acknowledge financial support from the PID2021-125630NB-I00 project funded by MCIN/AEI/10.13039/501100011033/FEDER, UE. J.M.C. also acknowledges financial support from the SV-PA-21-AYUD/2021/51301 project. M.M.C. also acknowledges to be granted by PAPI-21-PF-04 (Universidad de Oviedo). C.G.C., J.D.S., M.L.S. and F.J.D.C. acknowledge financial support from both PID2021- 127331NB-I00 and UE-18-SOLARNET-824135 projects. The authors thank Prof. José Alberto Rubino-Martín, Prof. Ricardo Tanasú Génova-Santos for valuable comments. They also thank Sergio Ena for helping with polarisation fraction results at the first stages of the original manuscript. This research has made use of the python packages Matplotlib (Hunter 2007), Pandas (McKinney 2010), Keras (Chollet 2015), and Numpy (Oliphant 2006), also the HEALPix (Górski et al. 2005) and Healpy (Zonca et al. 2019) packages.
References
- Argüeso, F., Sanz, J. L., Herranz, D., López-Caniego, M., & González-Nuevo, J. 2009, MNRAS, 395, 649 [Google Scholar]
- Bonavera, L., González-Nuevo, J., Argüeso, F., & Toffolatti, L. 2017a, MNRAS, 469, 2401 [Google Scholar]
- Bonavera, L., González-Nuevo, J., De Marco, B., Argüeso, F., & Toffolatti, L. 2017b, MNRAS, 472, 628 [Google Scholar]
- Bonavera, L., Suarez Gomez, S. L., González-Nuevo, J., et al. 2021, A&A, 648, A50 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Casas, J. M., Bonavera, L., González-Nuevo, J., et al. 2022a, A&A, 666, A89 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Casas, J. M., González-Nuevo, J., Bonavera, L., et al. 2022b, A&A, 658, A110 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Chollet, F. 2015, Keras, https://github.com/fchollet/keras [Google Scholar]
- Datta, R., Aiola, S., Choi, S. K., et al. 2019, MNRAS, 486, 5239 [NASA ADS] [CrossRef] [Google Scholar]
- de Zotti, G., Massardi, M., Negrello, M., & Wall, J. 2010, A&ARv, 18, 1 [CrossRef] [Google Scholar]
- Delabrouille, J., Betoule, M., Melin, J. B., et al. 2013, A&A, 553, A96 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Diego-Palazuelos, P., Vielva, P., & Herranz, D. 2021, JCAP, 2021, 048 [CrossRef] [Google Scholar]
- Galluzzi, V., Massardi, M., Bonaldi, A., et al. 2018, MNRAS, 475, 1306 [Google Scholar]
- González-Nuevo, J., Toffolatti, L., & Argüeso, F. 2005, ApJ, 621, 1 [Google Scholar]
- González-Nuevo, J., Argüeso, F., López-Caniego, M., et al. 2006, MNRAS, 369, 1603 [Google Scholar]
- Goodfellow, I. J., Bengio, Y., & Courville, A. 2016, Deep Learning (Cambridge, MA, USA: MIT Press) [Google Scholar]
- Górski, K. M., Hivon, E., Banday, A. J., et al. 2005, ApJ, 622, 759 [Google Scholar]
- Gupta, N., Reichardt, C. L., Ade, P. A. R., et al. 2019, MNRAS, 490, 5712 [NASA ADS] [CrossRef] [Google Scholar]
- Hamaker, J. P., & Bregman, J. D. 1996, Astron. Astrophys. Suppl. Ser., 117, 161 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hanany, S., Alvarez, M., Artis, E., et al. 2019, ArXiv e-prints [arXiv: 1902.10541] [Google Scholar]
- Herranz, D., López-Caniego, M., Sanz, J. L., & González-Nuevo, J. 2009, MNRAS, 394, 510 [NASA ADS] [CrossRef] [Google Scholar]
- Herranz, D., Argueso, F., & Carvalho, P. 2012, Adv. Astron., 2012, 410965 [CrossRef] [Google Scholar]
- Herranz, D., Argüeso, F., Toffolatti, L., Manjón-García, A., & López-Caniego, M. 2021, A&A, 651, A24 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hunter, J. D. 2007, Comput. Sci. Eng., 9, 90 [NASA ADS] [CrossRef] [Google Scholar]
- Krachmalnicoff, N., & Tomasi, M. 2019, A&A, 628, A129 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Krachmalnicoff, N., & Puglisi, G. 2021, ApJ, 911, 42 [Google Scholar]
- LeCun, Y., Boser, B., Denker, J. S., et al. 1989, Neural Comput., 1, 541 [NASA ADS] [CrossRef] [Google Scholar]
- Linde, A. 1982, Phys. Lett. B, 108, 389 [NASA ADS] [CrossRef] [Google Scholar]
- López-Caniego, M., Massardi, M., González-Nuevo, J., et al. 2009, ApJ, 705, 868 [Google Scholar]
- Martínez-González, E., Diego, J. M., Vielva, P., & Silk, J. 2003, MNRAS, 345, 1101 [Google Scholar]
- McKinney, W. 2010, in Proceedings of the 9th Python in Science Conference, eds. S. van der Walt, & J. Millman, 56 [Google Scholar]
- Nair, V., & Hinton, G. E. 2010, in Proceedings of the 27th International Conference on Machine Learning (ICML-10), 807 [Google Scholar]
- Oliphant, T. 2006, NumPy: A Guide to NumPy (USA: Trelgol Publishing) [Google Scholar]
- Pearson, T. J., & Readhead, A. C. S. 1984, ARA&A, 22, 97 [Google Scholar]
- Planck Collaboration XXVIII. 2014, A&A, 571, A28 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration XXVI. 2016, A&A, 594, A26 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration I. 2020, A&A, 641, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Puglisi, G., & Bai, X. 2020, ApJ, 905, 143 [Google Scholar]
- Puglisi, G., Galluzzi, V., Bonavera, L., et al. 2018, ApJ, 858, 85 [Google Scholar]
- Remazeilles, M., Banday, A. J., Baccigalupi, C., et al. 2018, JCAP, 2018, 023 [Google Scholar]
- Rubiño-Martín, J. A., Rebolo, R., Aguiar, M., et al. 2012, SPIE Conf. Ser., 8444, 84442Y [Google Scholar]
- Rumelhart, D. E., Hinton, G. E., & Williams, R. J. 1986, Nature, 323, 533 [Google Scholar]
- Saikia, D. J., & Shastri, P. 1984, MNRAS, 211, 47 [NASA ADS] [CrossRef] [Google Scholar]
- Starobinskiî, A. A. 1979, Sov. J. Exp. Theoret. Phys. Lett., 30, 682 [Google Scholar]
- Trombetti, T., Burigana, C., De Zotti, G., Galluzzi, V., & Massardi, M. 2018, A&A, 618, A29 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tucci, M., & Toffolatti, L. 2012, Adv. Astron., 2012, 624987 [Google Scholar]
- Tucci, M., Toffolatti, L., de Zotti, G., & Martínez-González, E. 2011, A&A, 533, A57 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Zonca, A., Singer, L. P., Lenz, D., et al. 2019, J. Open Source Softw., 4, 1298 [NASA ADS] [CrossRef] [Google Scholar]
These are extensively described in Planck Collaboration XXVIII (2014).
All Figures
|
Fig. 1 Example of one simulation used to train or validate POSPEN for P, Q, and U polarisation maps (left, middle, and right columns, respectively). Top panels show the input patch formed by all the emissions, where the network learns how to extract the polarisation of the PS. Bottom figures show an example of the simulated PS, where we use the integrated intensity as a label for the training. The units are in Jy. |
| In the text | |
|
Fig. 2 Architecture of POSPEN. The information in the 217 GHz patch is convolved into 8 filters in the first convolutional block. After that, several convolutions are made through four more layers of 32, 64, 128, and 256 filters. The information is then processed through a layer of 128 neurons. Finally, one last neuron gives the output value. |
| In the text | |
|
Fig. 3 Estimation of total polarisation flux density of the validation sources. Left panel: correlation between true and estimated polarisation flux density. Right panel: polarisation relative error against the input polarisation flux density. The error bars represent the uncertainty of each bin, which we considered to be equal to the standard deviation. In both cases, the dashed black lines show the ideal case. |
| In the text | |
|
Fig. 4 Source number counts in polarisation of both true (blue area) and estimated (red area) catalogues. |
| In the text | |
|
Fig. 5 Estimation of polarisation flux density of Q sources. Left panel: correlation between true and estimated Q polarisation. The top part shows the Q > 0 sources in orange while the bottom part shows the Q < 0 ones in blue. Right panel: Q relative error against the polarisation flux of the validation catalogue. The error bars represent the uncertainty computed as the standard deviation of each bin. In both cases, the dashed black line shows the ideal case. |
| In the text | |
|
Fig. 6 Estimation of polarisation flux density of U sources. Left panel: correlation between true and estimated U polarisation. The top part shows the U > 0 sources in green while the bottom part shows the U < 0 ones in brown. Right panel: U relative error against the polarisation flux of the validation catalogue. The error bars represent the uncertainty computed as the standard deviation of each bin. In both cases, the dashed black line shows the ideal case. |
| In the text | |
|
Fig. 7 Relation between polarisation angle uncertainty for the estimations of POSPEN and the cut in polarisation flux density in both Q and U sources. The dashed red line shows the minimum uncertainty considering enough number of sources to have good statistics. |
| In the text | |
|
Fig. 8 Estimation of polarisation angles of Q and U sources. Left panel: correlation between true and estimated angles. The coloured areas represent a confidence interval of ±29° for Q sources and ±32° U ones, which are the standard deviation of the relative error of each population, respectively. Dashed black lines are the 1:1 case. Right panel: distribution of polarisation angles for both true and estimated Q and U catalogues, with the blue areas showing the true angles and orange and green areas showing the estimated angles for Q and U sources, respectively. |
| In the text | |
|
Fig. 9 Comparison of polarisation flux densities and angle estimations given by both POSPEN and the PCCS2. Left panel: comparison of PCCS2 with POSPEN polarisation flux density estimations. Right panel: comparison of PCCS2 with POSPEN polarisation angle estimations. In both cases, the horizontal error bars show the uncertainty given in the PCCS2, while the vertical ones show the uncertainty of POSPEN. The dashed orange line shows the systematic underestimation of POSPEN given by the simulations and the dashed black line is the 1:1 case. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.