| Issue |
A&A
Volume 659, March 2022
|
|
|---|---|---|
| Article Number | A165 | |
| Number of page(s) | 12 | |
| Section | The Sun and the Heliosphere | |
| DOI | https://doi.org/10.1051/0004-6361/202142018 | |
| Published online | 22 March 2022 | |
Bayesian Stokes inversion with normalizing flows
1
Institute for Solar Physics, Dept. of Astronomy, Stockholm University, AlbaNova University Centre, 10691 Stockholm, Sweden
e-mail: carlos.diaz@astro.su.se
2
Instituto de Astrofísica de Canarias, C/Vía Láctea s/n, 38205 La Laguna, Tenerife, Spain
3
Departamento de Astrofísica, Universidad de La Laguna, 38206 La Laguna, Tenerife, Spain
Received:
13
August
2021
Accepted:
19
December
2021
Stokes inversion techniques are very powerful methods for obtaining information on the thermodynamic and magnetic properties of solar and stellar atmospheres. In recent years, highly sophisticated inversion codes have been developed that are now routinely applied to spectro-polarimetric observations. Most of these inversion codes are designed to find an optimum solution to the nonlinear inverse problem. However, to obtain the location of potentially multimodal cases (ambiguities), the degeneracies and the uncertainties of each parameter inferred from the inversions algorithms – such as Markov chain Monte Carlo (MCMC) – require evaluation of the likelihood of the model thousand of times and are computationally costly. Variational methods are a quick alternative to Monte Carlo methods, and approximate the posterior distribution by a parametrized distribution. In this study, we introduce a highly flexible variational inference method to perform fast Bayesian inference, known as normalizing flows. Normalizing flows are a set of invertible, differentiable, and parametric transformations that convert a simple distribution into an approximation of any other complex distribution. If the transformations are conditioned on observations, the normalizing flows can be trained to return Bayesian posterior probability estimates for any observation. We illustrate the ability of the method using a simple Milne-Eddington model and a complex non-local thermodynamic equilibrium (NLTE) inversion. The method is extremely general and other more complex forward models can be applied. The training procedure need only be performed once for a given prior parameter space and the resulting network can then generate samples describing the posterior distribution several orders of magnitude faster than existing techniques.
Key words: Sun: atmosphere / line: formation / methods: data analysis / Sun: activity / radiative transfer
© ESO 2022
1. Introduction
Through the analysis of spectra and their polarization, we have been able to infer the properties of the solar and stellar atmospheres. To infer the stratification of physical properties as a function of depth, we compare the emergent spectra given by a solar model with observations. By modifying the physical parameters that define the model atmosphere, we can find a specific configuration that resembles the observations and obtain a physical interpretation of the origin of the observed phenomena. This process is commonly known as spectropolarimetric inversion and nowadays is routinely used in solar physics to extract physical information from spectropolarimetric observations.
At present, there are various different methods for obtaining the most probable atmospheric structure responsible for producing the observed spectra (see del Toro Iniesta & Ruiz Cobo 2016 and de la Cruz Rodríguez & van Noort 2017 for extensive reviews). The traditional way to find the optimum solution is to use a gradient search minimization algorithm – normally of second order –, such as the Levenberg-Marquardt method (Levenberg 1944; Marquardt 1963). There are a collection of techniques that use the gradient of the merit function to drive the solution in the direction of the minimum by reducing the difference between the forward-calculated spectrum and the observed one. These usually require only a few forward calculations of the synthetic spectra to converge, but the global minimum can only be guaranteed if the merit function is convex.
The Bayesian framework must be used to obtain detailed knowledge of the parameter space (the location of the global minimum if it exists, whether there are degeneracies or multiple solutions that can equally reproduce the observations, and to have a proper estimation of the uncertainty in the solution). The posterior distribution of the model parameters conditioned on the observations encodes all the relevant information of the inference. Computing this high-dimensional posterior distribution turns out to be complex and one has to rely on efficient stochastic sampling techniques such as Markov chain Monte Carlo (MCMC; Metropolis et al. 1953) and nested sampling (Skilling 2004).
These sampling methods have been one of the pillars of Bayesian analysis in solar physics (Asensio Ramos et al. 2007; Arregui 2018) not only for sampling complicated posterior distributions for parameter inference but also for computing marginal posterior for model comparison. Even though they are compelling and new algorithms have been developed to obtain the overall shape of the parameter space when multiple solutions exist (Díaz Baso et al. 2019b), they require many forward calculations and are therefore computationally very costly, which limits their applicability even in relatively simple atmospheric models.
Currently, although successful, gradient-based methods struggle when applied to two-dimensional fields of view (FOVs) with millions of pixels. Inverting such large maps often requires the use of supercomputers running parallelized inversion codes for many hours (e.g., Sainz Dalda et al. 2019). This is especially relevant for inversions in non-local thermodynamicd equilibrium (NLTE) for which the forward problem is computationally heavy. The use of artificial neural networks (ANNs) to learn the nonlinear mapping between the observed Stokes parameters and the stratification of solar physical parameters has shown a large improvement in speed and robustness to noise compared to classic gradient-search inversion codes (Carroll & Staude 2001; Socas-Navarro 2005; Asensio Ramos & Díaz Baso 2019; Socas-Navarro & Asensio Ramos 2021). Given that the inverse problem is often not bijective (there are very similar spectra that emerge from very different physical parameters), traditional neural networks struggle in cases where multiple solutions exist. A solution to this is to use neural networks as emulators that mimic the forward modeling and accelerate standard MCMC posterior sampling methods in Bayesian inversions (e.g., Asensio Ramos & Ramos Almeida 2009).
A very promising alternative method for Bayesian inference is variational inference, where the true distribution of the solution is approximated with a simpler analytical distribution (Asensio Ramos et al. 2017; Díaz Baso et al. 2019a) that is more convenient to work with. By assuming a distribution instead of a single solution for the physical parameters, we can capture the uncertainties and, for instance, whether several solutions are compatible with the observations. To improve this approximation, mixture models are usually used as a composition of many components of the same or different families. However, these require the evaluation of each component, their optimization is not always stable, and they only work well in cases where the posterior is simple.
In this study, we leverage a variational inference method known as normalizing flows (Tabak & Turner 2013; Rippel & Prescott Adams 2013; Dinh et al. 2014; Jimenez Rezende & Mohamed 2015) to perform Bayesian inference for the physical atmospheric parameters from spectropolarimetric data. Normalizing flows are a set of parametrized transformations that can convert a simple and analytically known distribution (e.g., a standard normal distribution) into a more complex distribution. Normalizing flows use neural networks to represent this complex relation. When these normalizing flows are conditioned on the observations, they can approximate the posterior distribution for every observation very efficiently. They also provide all the tools to rapidly sample from the posterior and compute the ensuing probability of every sample.
Given their recent conception and development, there are only a few examples of astrophysical applications, such as estimating continua spectra of quasars (Reiman et al. 2020), constraining distance estimates of nearby stars (Cranmer et al. 2019b), and inferring physical properties of black holes using gravitational waves (Green & Gair 2020). In solar physics, Osborne et al. (2019) showed the use of invertible neural networks, a particular modification of normalizing flows where the inverse and forward models are learned at the same time. The information that is lost during the forward model (which makes the inverse model ill-defined) is re-injected again using an ad hoc latent vector. The forward and inverse models are made consistent by imposing a cycle consistency. In our experience, although it is a promising direction, the cycle consistency makes both models somewhat difficult to train. In this study, we prefer to approximate both models separately. The inverse problem is treated probabilistically with a normalizing flow, while the forward model is approximated with a standard neural network. We find this approach to be stable and quick to train.
Therefore, we propose to apply normalizing flows to spectro-polarimetric observations in order to perform Bayesian inference faster than the classical gradient-search algorithms with all the added information of the parameter space given by the posterior distribution. We present an automated inference framework based on neural density estimation, where the fundamental task is to estimate a posterior distribution from pre-computed samples from a physical forward model. The paper is organized as follows. We start with a brief introduction to normalizing flows (Sect. 2), their basic principles, and how we implement the new approach with solar observations. Subsequently, we show the application of the normalizing flow for Bayesian inference to two examples of different complexity (Sects. 3 and 4) and verify the accuracy of this approach (Sects. 5 and 6). Finally, we provide a brief discussion of the implications of this work and outline potential extensions and improvements (Sect. 7).
2. Normalizing flows
2.1. Amortized variational inference
Bayesian inference relies on calculating the posterior probability distribution function p(θ|x) of a set of M physical model parameters θ that are used to describe a given observation x with N data points. This quantity can be obtained by direct application of the Bayes theorem (Bayes & Price 1763):
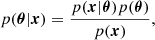
where p(x|θ) is the likelihood, which measures the probability that the data x were obtained (measured) assuming given values for the model parameters θ, while p(θ) is the prior distribution of all possible model parameters. The quantity p(x) is the so-called evidence or marginal posterior, which normalizes the posterior probability distribution.
As mentioned, the calculation of the posterior can be complex and one must rely on efficient stochastic sampling techniques, such as MCMCs, which require many model evaluations. On the other hand, variational inference is a faster alternative that tries to approximate the posterior with a simpler parametrized distribution, translating the inference problem into an optimization problem. However, both methods work on a single instance of the problem. This means that when we want to perform inference on a large number of observations, we have to run the same method several times which, in the end, can be significant in terms of computing time. In this way, we are not exploiting the global knowledge of the problem and evaluating the same model many times with different data.
Recent advances in deep learning have promoted the development of new algorithms based on amortized neural posterior estimation (ANPE; Cranmer et al. 2019a), i.e., we can find a function that maps the observed data to the variational parameters of our approximation. Once we have this function, performing inference on a new observation is as simple as evaluating this function and plugging the output into our variational approximation. This function must be flexible enough to learn the global representation of the data and neural networks are good at learning features from the data directly. Thus, neural networks can be optimized to approximate the posterior distribution p(θ|x) by conditioning the resulting distribution on observations that have been precomputed over our prior parameter space p(θ). After training the density estimator, we can evaluate the posterior of new observations efficiently. The approach presented in this paper belongs to the ANPE framework.
2.2. Normalizing flows
Normalizing flows approximate the posterior distribution p(θ|x) by transforming a simple probability distribution pz(z) into a complex one by applying an invertible and differentiable transformation θ = f(z). In practice, we can construct a flow-based model by implementing f = fϕ with a neural network with parameters ϕ and take the base distribution pz(z) to be simple, typically a multivariate standard normal distribution. This base distribution will act as a latent space of hidden independent variables. If the observed variables are also independent, the transformation will simply be a scaling of each of them. On the contrary, if the joint distributions of the observed variables show high complexity (correlations, multiple maxima, etc.), the latent variables will be mixed to reproduce such distributions. More precisely, the resulting probability distribution is computed by applying the change of variables formula from probability theory (Rudin 2006):
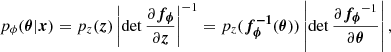
where the first factor represents the probability density for the base distribution (pz) evaluated at fϕ−1(θ), while the second factor is the absolute value of the Jacobian determinant and accounts for the change in the volume due to the transformation. This factor forces the total integrated probability of the new distribution to be unity. The transformation fϕ expands, contracts, deforms, and shifts the probability space to morph the initial (base) distribution into the target.
A flexible transformation can be obtained by composing several simple transformations, which can produce a very complex distributions. An important property of invertible and differentiable transformations is that if we compose K transforms f = (f1° f2° ⋯° fK), their inverse can also be decomposed into the components 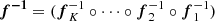 and the Jacobian determinant is the product of the determinant of each component. Therefore, the log-probability of the overall transformation is then
and the Jacobian determinant is the product of the determinant of each component. Therefore, the log-probability of the overall transformation is then
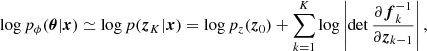
where zk = fk(zk − 1). The term normalizing flow is intimately related to the compositional character described above. The term “flow” refers to the trajectory that a collection of samples follow as they are gradually transformed. The term “normalizing” refers to the inverse trajectory that transforms a collection of samples from a complex distribution and makes them converge toward a prescribed distribution, often taken to be the normal distribution.
Figure 1 illustrates the difference between the classical neural-assisted Stokes inversion methods (e.g., Asensio Ramos & Díaz Baso 2019) (upper panel) and the probabilistic approach that normalizing flows offer (lower panel). In the classical case, a neural network produces a point estimate of the parameters 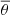 from the observed Stokes parameters. This point estimate is not really representative of any of the potential solutions in degenerate cases. In the probabilistic case, a normalizing flow transforms a standard-normal base distribution together with the observations into a complex target posterior density through several simple transformations. This final distribution properly captures all solutions compatible with the observations, even if they are multimodal.
from the observed Stokes parameters. This point estimate is not really representative of any of the potential solutions in degenerate cases. In the probabilistic case, a normalizing flow transforms a standard-normal base distribution together with the observations into a complex target posterior density through several simple transformations. This final distribution properly captures all solutions compatible with the observations, even if they are multimodal.
 |
Fig. 1. Comparison between an ANN and a conditional normalizing flow with parameters ϕ. The output of the classical ANN is an average value over all the solutions |
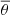
Normalizing flows are trained by minimizing the discrepancy (or divergence) between the posterior distribution and the variational approximation of Eq. (3). The most popular choice is the Kullback-Leibler divergence (Kullback & Leibler 1951). Assuming that our dataset has D samples {θi, xi} with physical parameters drawn from the prior p(θ) and observations generated from our physics-based forward model p(x|θ), minimizing the Kullback-Leibler divergence is equivalent to minimizing the negative log-likelihood:
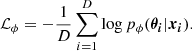
The minimization is carried out using gradient-based optimization methods by calculating the gradient of ℒϕ with respect to the parameters of the normalizing flows, ϕ. During the training, the normalizing flow will be optimized to map the samples from the unknown distributions to a standard normal distribution. If that is performed successfully, the inverse transformation enables us to sample the posterior by simply extracting values from the normal distribution and applying the learned inverse transformations.
From this result, we can already appreciate the power of normalizing flows on density estimation: we do not need to evaluate the likelihood of our data p(x|θ) (or the model) during training, we only need to provide samples. This is also the goal of simulation-based inference (SBI, Cranmer et al. 2019a), that is, to perform Bayesian inference when the evaluation of the likelihood is not possible because of mathematical or computational reasons.
2.3. Invertible transformations
A normalizing flow should satisfy several conditions to be of practical application. It should be (1) invertible, (2) expressive enough to model any desired distribution, and (3) computationally efficient for calculating both forward and inverse transforms and the associated Jacobian determinants. Among the different families of transformations fϕ, we use a transformation known as coupling neural splines flows (Dinh et al. 2014; Müller et al. 2018; Durkan et al. 2019) which have been demonstrated to be effective at representing complex densities and are quick to train and quick to evaluate (see Papamakarios et al. 2021 and Kobyzev et al. 2019 for extensive reviews).
The idea behind the coupling transform was introduced by Dinh et al. (2014) and consists of dividing the input variable (of dimension Q) into two parts and applying an invertible transformation g to the second half (zq + 1 : Q), whose parameters are a function of the first half (i.e., z1 : q). Such transformations have a lower triangular Jacobian whose determinant is just the product of the diagonal elements, allowing us to create faster normalizing flows. The output vector o of a coupling flow is given by
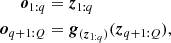
where g(z1 : q) is an invertible, element-wise transformation whose internal parameters have been computed based on z1 : q and in our case (conditionals flows) also on the observed data x. The final output of the transformation is then o = [o1 : q, oq + 1 : Q]. As coupling layers leave unmodified z1 : q, one needs to shuffle the order of the input in each step using a permutation layer so that these two halves do not remain independent throughout the network.
For the coupling transformation g, we have chosen a family of very expressive functions based on monotonically increasing splines (Müller et al. 2018; Durkan et al. 2019). They have shown large flexibility when modeling multi-modal or quasi-discontinuous densities. A spline is a piece-wise function that is specified by the value at some key points called knots. The location, value, and derivative of the spline at the knots for each dimension in oq + 1 : Q are calculated with a neural network. Each resulting distribution (and therefore each transformation) will depend on the observed data, and so the neural network will have the input [z1 : q, x].
2.4. Network architecture and training details
We use the implementation of normalizing flows in PyTorch (Paszke et al. 2019) available in nflows (Durkan et al. 2020) which allows for a wide variety of transformations to be used, among them the neural spline flows for coupling transforms. As suggested by Green & Gair (2020), we include invertible linear transforms together with a permutation layer before each coupling transform allowing all of the parameters to interact with each other. In summary, we used an architecture that is a concatenation of blocks of an invertible linear transformation using the LU-decomposition (Kingma & Dhariwal 2018) with a rational–quadratic spline transform (RQ, Durkan et al. 2019) where a residual network (ResNet, He et al. 2015) is used to calculate the parameters of the splines1.
For the first simple case, a flow with 5 coupling transformations, 5 residual blocks, and 32 neurons per layer was enough. In the second case, we need at least 15 coupling layers, 10 residual blocks, and 64 neurons per layer. We trained the models for 500 epochs with a batch size of 100. We used a learning rate of 10−4 and the Adam optimizer (Kingma & Ba 2014). During training, we reserved 10% of our training set for validation. An augmentation scheme based on applying different realizations of Gaussian noise to the data is applied during training, thus increasing the effective size of the training set.
3. Simple case: Milne–Eddington atmosphere
As a first example, we show the capabilities of the normalizing flows in a case where the forward modeling is fast enough to allow comparison with the exact solution obtained with an MCMC method. For this case, we choose the Milne–Eddington (Auer et al. 1977) solution of the radiative transfer problem as a baseline. Focusing only on Stokes I, θ is five-dimensional and contains the physical parameters of relevance that describe the intensity profile of a spectral line: the macroscopic velocity vLOS, the Doppler width ΔvD, the line-to-continuum opacity ratio η0, and the two parameters of the source function S0 and S1.
The normalizing flow is trained using an appropriate training set. To this end, we generate 106 training pairs (θi, xi) by drawing θi using a uniform prior for all the variables in the following ranges: vLOS = [ − 3.0, 3.0] km s−1, ΔvD = [0.05, 0.2] Å, η0 = [0.0, 5.0], S0 = [0.0, 1.0], and S1 = [0.0, 1.0]. We simulated the photospheric Fe I 6301.5 Å line using the Milne–Eddington model2 and assuming Gaussian noise of σ = 8 × 10−3 in continuum units. Once the normalizing flow is trained, we can carry out Bayesian inference for arbitrary observations. In order to demonstrate the speed of the inference, we point out that the normalizing flow produces samples of the posterior at a rate of 20 000 per second. In the following; we show the result for a synthetic profile with input parameters vLOS = −1.0 km s−1, ΔvD = 0.15 Å, η0 = 2.5, S0 = 0.35, and S1 = 0.7. This profile was specifically chosen in order to highlight the flexibility of the neural network when working with complex distributions and strong degeneracies. To verify the accuracy of the posterior inference, we compare the result of the normalizing flow against a Markov chain Monte Carlo computed with the emcee sampler (Foreman-Mackey et al. 2013) using a Gaussian likelihood.
The comparison of the posterior distributions generated by the neural network (light orange) and emcee (dark orange) is shown in Fig. 2. The normalizing flow is doing a very good job at approximating the posterior, with both distributions clearly in very close agreement. For strongly degenerate parameters, such as ΔvD and η0, we recover a typical joint banana-shaped posterior. For highly correlated parameters, as in S0 and S1, we find ridge-shaped distributions. Given these strong degeneracies, a classical inversion method based on ANNs will not perform correctly as there are multiple solutions for the same profile. The upper right panel of the same figure shows the synthetic spectra using samples from the posterior distribution of both methods. This test is known as the posterior predictive check and helps us understand whether the model is appropriate. It is clear from these results that the predictive profiles of each color are almost indistinguishable from one another; they also lie within the uncertainty produced by the noise on the intensity profile we have evaluated.
 |
Fig. 2. Joint (below the diagonal) and marginal (in the diagonal) posterior distributions for the physical parameters involved in the Milne-Eddington model. The label at the top of each column provides the median and the uncertainty defined by the percentiles 16 and 84 (equivalent to the standard 1σ uncertainty in the Gaussian case). Also, the contours are shown at 1 and 2 sigmas. The original values of the parameters are indicated with gray dots and vertical/horizontal lines. |
4. Complex case: NLTE with stratification
Computing the posterior distribution in complex and realistic models turns out to be particularly difficult, for several reasons. First, complex models often require lots of computing power, and so the number of samples of any MCMC method will be limited by the available computing time. An example of this is the formation of chromospheric spectral lines under NLTE conditions, which requires the joint solution of the radiative transfer and statistical equilibrium equations for the atoms under consideration. Second, complex models also require more model parameters (such as the whole atmospheric stratification with height), which increases the dimensionality of the posterior distribution. Finally, complex problems often contain nonlinear calculations that can lead to very cumbersome posterior distributions, with strong degeneracies and ambiguities. In the case of the NLTE problem, the information encoded in the posterior strongly depends on the specific observed spectral line. Some heights in the atmosphere are constrained by the observations, while other heights remain partially or completely unconstrained. This produces a posterior distribution with very different widths for different parameters of the model.
In order to showcase our approach, in this second example, we simulate a case in which we simultaneously observed the photospheric Fe I 6301.5 Å line and the chromospheric Ca II 8542 Å line. This configuration is commonly used because it facilitates studying events occurring both in the photosphere and the lower chromosphere (Esteban Pozuelo et al. 2019; Vissers et al. 2019; Kianfar et al. 2020; Díaz Baso et al. 2021; Yadav et al. 2021). It is also widespread because it is one of the most common instrumental configurations of the CRISP instrument on the Swedish 1-m Solar Telescope (SST, Scharmer et al. 2003, 2008).
The normalizing flow model needs to be trained for this specific problem. To this end, and to create a diverse set of samples of solar-like stratifications and intensity profiles, we start from the solar stratifications inferred in Díaz Baso et al. (2021). These models were inferred from spectropolarimetric observations under some model assumptions. Therefore, the posterior distributions produced by our model will be dependent on this specific a priori information (more details below). In any case, we consider that the assumption of a prior is beneficial because it will act as a guide to avoid nonrealistic stratifications. The model can always be trained with a different prior extracted, for example, from state-of-the-art numerical simulations.
The stratifications of the training set were extracted at nine equidistant locations from log(τ500) = − 7.0 to log(τ500) = + 1.0, where τ500 is the optical depth measured at 500 nm. These are the locations at which we infer the posterior distributions. We computed the mean and covariance matrix of the temperature, velocity, and microturbulent velocity obtained from the results of Díaz Baso et al. (2021) at these locations. We created 106 new stratifications by sampling from multivariate normal distributions with the computed means and covariances. Each physical quantity is drawn independently. To increase the diversity of the dataset, we increased the standard deviation at each log(τ500) location by a factor of between two and six. The samples were then interpolated to 54 depth points using Bezier splines and encapsulated in a model with zero magnetic field. The gas pressure at the upper boundary is assumed to be Ptop = 1 dyn cm−2. The density and gas pressure stratifications are computed assuming hydrostatic equilibrium (HE). The spectra were synthesized using the multi-atom, multi-line, NLTE inversion code STiC (de la Cruz Rodríguez et al. 2016, 2019). This code is built on top of an optimized version of the RH code (Uitenbroek 2001) to solve the atom population densities assuming statistical equilibrium and plane-parallel geometry. The radiative transport equation is solved using cubic Bezier solvers (de la Cruz Rodríguez & Piskunov 2013) and includes an equation of state extracted from the SME code (Piskunov & Valenti 2017). We treated the Ca II atom in NLTE with the Ca II 8542 Åline in complete frequency redistribution (CRD). The Fe I 6301.5 Å line was also modeled in NLTE, and therefore accounts for a complex atmosphere that could affect its formation. We then degraded each spectral line to the spectral resolution of the CRISP instrument at the SST telescope and added an uncorrelated Gaussian noise with a standard deviation of 10−2 in units of the continuum intensity.
We train two different models to capture the improvement in the inference of the stratification when more spectral lines are included. The first model only uses observations of the Fe I line, while the second model uses both the Fe I and Ca II lines together. The trained models are used to infer the stratification of physical properties for two different examples: one with strong emission in the chromospheric line produced by an increase in the temperature in this region and another example with the core of both lines in absorption.
The results of the inference are shown in Fig. 3. The left panels refer to the case in emission, while the case in absorption is displayed in the right panels. The top three panels show the stratification with optical depth of the temperature, line-of-sight velocity, and turbulent velocity. Black squares indicate the original stratification used to synthesize the line profiles. The solid orange and dashed brown lines show the median value estimated from the posterior distribution when considering only the photospheric line or both lines, respectively. The shaded regions mark the corresponding 68% confidence interval. As expected, the inference that considers both lines can recover the whole stratification with high accuracy, whereas using only the Fe I line yields a model where only the photosphere is recovered, with a large uncertainty toward the upper atmosphere. This result shows that the normalizing flow is able to learn the range of sensitivity of each spectral line simply by looking at the examples of the database. This sensitivity is model-dependent and a direct consequence is the presence of a larger uncertainty in the upper atmosphere when the profile is in emission with respect to that found when the profile is in absorption. This difference in the width of the distribution comes from the fact that large temperatures ionize the Ca II atoms and the line becomes less sensitive to the local physical conditions in the upper layers where the temperature is large (Díaz Baso et al. 2021). Although the Fe I line contains very limited information about the upper chromosphere, the inference outputs an increasing temperature and not a completely uncertain posterior. The reason for this is that the posterior is simply recovering the prior we used, which has larger temperatures toward the upper atmosphere. As in any Bayesian inference, the prior gives an important constraint on our expectations as to the nature of the solar-like stratifications, giving low probabilities to unrealistic values where the line contains no information.
 |
Fig. 3. Atmospheric stratification inferred by the normalizing flow for two examples. In each column, the orange solution is inferred using only the Fe I line while the brown solution also uses the Ca II profile. The lowest row shows the original intensity values together with the synthetic calculation from the maximum a posteriori solution. |
Although uncertainties are easy to visualize in the marginal posterior distributions at each location, the joint distributions are difficult to visualize for a multidimensional model. Joint distributions give interesting information about how different parameters are correlated in the inference, clearly pointing out the presence of ambiguities. To obtain an approximate insight, the joint distribution can be summarized by showing the correlation matrix. These correlation matrices are shown in Fig. 4 for the two examples of Fig. 3. Nonzero correlation is found both inside the same physical parameter (intra-parameter) and between different parameters (inter-parameter). Part of the intra-parameter correlation is a consequence of the assumed prior, which forces smooth stratifications. The checkerboard pattern found in the temperature indicates that reductions in the temperature at some locations can be compensated by increases in other locations. This oscillatory behavior can appear during the classical inversion process if too many degrees of freedom are used, and regularization is usually used to avoid erratic behavior (de la Cruz Rodríguez et al. 2019; de la Cruz Rodríguez 2019).
 |
Fig. 4. Correlation matrices calculated for the inferred atmospheric stratification for the emission (left) and absorption (right) profiles. Blue/red indicates positive/negative correlations, respectively. The optical depth increases towards the right and downwards so that each pair of physical quantities has the top of the atmosphere in the upper left corner and the bottom in the lower right corner. |
Arguably the most visible inter-parameter correlation happens between the temperature and the microturbulent velocity. This correlation is different in amplitude and sign between the two examples because it depends on the particular model stratification and the nonlinear effect of the physical parameters in the spectra. In this case, the difference comes from the fact that an increase of temperature in the chromosphere when the line profile is in absorption will produce a narrower core and an increase in the microturbulence compensates for this difference (positive correlation). However, an increase in temperature in the emission profile will broaden the profile, and the microturbulence needs to be decreased (negative correlation). The location of this correlation also indicates that the absorption profile displays the response higher in the atmosphere when compared with the emission profile. In summary, the Bayesian inference with normalizing flows allows us to obtain a complete picture of the inferred stratification and the degeneracy between parameters.
5. Validation and performance
Normalizing flows have the combined advantages of Bayesian inference and deep learning, by gaining access to the posterior distribution and being able to sample from it very quickly. However, it also inherits some of the limitations of the classical MCMC methods. For example, to obtain a sufficiently good representation of the posterior distribution with a standard MCMC method, it is required to densely sample the parameter space around the location of the mode, first to properly find it and then to estimate its shape. The samples from the training set have to be closer or similar to the expected width of the posterior distribution so that the normalizing flow is able to work properly. This is especially critical when the uncertainty in the observations is low because one expects very narrow posteriors. In this case, using a sparse training set leads to overestimation of the posterior width.
We have quantified how the accuracy of our models depends on the size of the training set. To this end, we use the fact that, when the models extracted from the posterior distribution are used to re-synthesize the line profiles, they should be distributed according to the assumed sampling distribution. In our case, this sampling distribution is Gaussian with a standard deviation of 8 × 10−3 and 10−2 in units of the continuum intensity for the ME and NLTE case, respectively. The upper panel of Fig. 5 shows these results for the ME case.
 |
Fig. 5. Statistical properties of the posterior predictive check. Upper panel: results for the ME case. The blue curve averages over the full posterior distribution and the orange curve shows the difference with respect to the mode of the posterior. Lower panel: same results but for the NLTE case. We also display the effect of compressing the model with an autoencoder and applying the resampling strategy. |
The blue curve was calculated as follows. First, we produced the corresponding posterior distributions of 1000 different spectra from the database, and then for each posterior distribution we extracted 1000 models and calculated the standard deviation between the original and the synthesized profiles. Finally, we calculated the average between all the standard deviation values. This was done for each normalizing flow that was trained with a different training set, producing all blue curve points. The orange curve shows the same quantity but only for the maximum a posteriori solution (evaluating only the solution with the highest probability).
The average error of the normalizing flow model decreases asymptotically with the size of the dataset towards the noise level of the target spectra (shown as a horizontal dashed black line). The speed at which this convergence takes place strongly depends on the complexity of the forward problem. In the Milne-Eddington example, the orange curve reaches the expected error already for a training set of 103 examples, although this number needs to be much higher when we check for convergence of the full posterior distribution. In the NLTE case, the model requires many more simulated examples to reach a similar error (see lower panel of Fig. 5). This behavior can also be witnessed during training: while the validation loss in the ME case saturates, the validation loss in the NLTE starts to worsen after 500 epochs, indicating that the number of samples is probably not large enough to avoid overfitting. This behavior is less noticeable with the largest training dataset indicating that we are reaching the right number of samples. This overfitting disappears when a larger standard deviation is used in the Gaussian noise added to the profiles. In this case, the model is able to correctly reproduce the width of the posterior distribution with a smaller amount of training examples. We note that the size of the training set for a normalizing flow model for Fe I only is similar to that of the ME case.
We considered two possible procedures to reduce the effect of the size of the training set on the results of the model. The first procedure relies on using compression to reduce the dimensionality of the forward model. To this end, we use an autoencoder (Hinton & Salakhutdinov 2006) to compress the 27 nodes (9 nodes for three physical variables) into a vector of dimension 20. After trial and error, we found this value to be the minimum size of the bottleneck layer so that the error in the reconstruction of the stratifications is still smaller than the width of the posterior distributions. This autoencoder consists of an encoder, a bottleneck of dimension 20, and a decoder. Both the encoder and the decoder are fully connected ResNets with five residual blocks and 64 neurons per layer. The autoencoder is trained with the physical stratifications of the training set by minimizing the difference between the input and output of the autoencoder. Once trained, we use the encoder to produce compressed representations for the stratifications, which are used to train the normalizing flow. After training the normalizing flow, one can use the decoder of the autoencoder to produce physical stratifications from the samples of the flow. A more compact representation helps the normalizing flow to train faster, also performing better (see orange lines in Fig. 5).
The second procedure reuses the samples from the normalizing flow and reweights them using importance sampling to produce a better approximation to the posterior distribution. This requires access to the forward modeling, which is time consuming in complex NLTE cases. One can also use a pre-trained neural network that works as an emulator of the forward modeling and produces much faster synthesis. In such a case, the posterior distribution can be further improved by resampling according to the likelihood of the observations, producing the results of the green lines in Fig. 5. To this end, we re-weight our posterior samples so that the sampling distribution approaches the correct posterior. The importance sampling weights are therefore
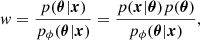
where the likelihood is given by
![$$ \begin{aligned} \log p(\boldsymbol{x}|\boldsymbol{\theta }) = -\frac{1}{2} \sum _{j=1}^{N_\lambda } \left[ \frac{\left( S(\lambda _j,\boldsymbol{\theta }) - I(\lambda _j) \right)^2}{\sigma _{j}^2} - \frac{1}{2} \log 2 \pi \sigma _{j}^2 \right], \end{aligned} $$](/articles/aa/full_html/2022/03/aa42018-21/aa42018-21-eq10.gif)
where  is the wavelength-dependent noise variance, S(λ, θ) is the synthetic line profile for parameters θ, and I(λ) is the observed line profile. The number of wavelength points we consider is Nλ. We point out that this resampling process only works well when the posterior samples from the normalizing flow overlap with those of the real posterior distribution and the sampling of the real posterior is not very sparse. This is almost guaranteed in our case because our normalizing flow tends to overestimate the width of the posterior distribution but not for a large margin.
is the wavelength-dependent noise variance, S(λ, θ) is the synthetic line profile for parameters θ, and I(λ) is the observed line profile. The number of wavelength points we consider is Nλ. We point out that this resampling process only works well when the posterior samples from the normalizing flow overlap with those of the real posterior distribution and the sampling of the real posterior is not very sparse. This is almost guaranteed in our case because our normalizing flow tends to overestimate the width of the posterior distribution but not for a large margin.
Given that the precision of the normalizing flow model increases with the size of the training set, one should consider this trade-off for a particular problem. For complex problems for which the difficulty of generating a large simulated training set is dominating, one should consider reducing the maximum achievable accuracy using a larger standard deviation of the noise. This automatically produces broader posteriors. In any case, we are confident that the normalizing flow model is an improvement over more classical MCMC methods. Any MCMC sampling method would require 104 − 105 forward calculations to be performed in order to correctly sample the posterior distribution for any new observation that needs to be analyzed. The amortized character of our model allows it to be applied seamlessly to new observations.
6. Validation on large FOVs
We also tested the trained normalizing flows on large FOVs. To qualitatively challenge this method on real data, we chose the observations analyzed in Leenaarts et al. (2018). The data were taken at a heliocentric angle μ = 1 and its wavelength sampling is the same used in the creation of the training set. This region was observed with the SST on 2016-09-19 at around 09:30 UT using the CRISP instrument. The field of view target is an active region with elongated granulation indicating ongoing flux emergence and enhanced brightness in the core of the chromospheric lines above the flux emergence (see Leenaarts et al. 2018 for more details).
Assuming that our database contains a sufficiently diverse sample of observed profiles, we applied the normalizing flow to a FOV of approximately 42 × 42 arcsec (smaller than the original size for optimal visualization). The normalizing flow was applied pixel by pixel, and to speed up the inference only 50 samples were obtained; enough to roughly estimate the width of the distribution. The left and right columns of Fig. 6 show the mean stratification and standard deviation of the samples at each pixel for each physical magnitude, respectively. The lower half of each panel shows the quantity at log(τ500) = − 1 which shows the photosphere, and the upper half at log(τ500) = − 4, which provides a view of the chromosphere. In the line-of-sight velocity maps, the blue color represents motions toward the observer while the red color represents motions away from the observer.
 |
Fig. 6. Atmospheric structure of the FOV as inferred from the inversion. Left column: the temperature, the LOS velocity, and the microturbulent velocity at two layers for half of the FOV. Right column: the associated uncertainty for the same quantities and layers. |
The model performs well overall, generating coherent maps and reproducing the patterns previously found in gradient-based inversions (Leenaarts et al. 2018; Díaz Baso et al. 2021). We note that, as our model does not include a magnetic field, all of the nonthermal broadening is reproduced with a higher value of the microturbulent velocity. The uncertainties tend to increase from the photosphere to the chromosphere, on average 80 → 500 K in temperature, 0.5 → 1.2 km s−1 in LOS velocity, and 0.4 → 1.0 km s−1 in microturbulent velocity. At first glance, in the two columns there seems to be a clear correlation between the magnitudes and their uncertainty. This could be understood from the examples in the previous sections, as emission profiles have higher chromospheric temperatures and therefore lower sensitivity in the upper layers. These locations also coincide with regions with high velocities and turbulent motions as a result of the interaction of the flux emergence with the pre-existing magnetic field. There are also exceptions such as the low photospheric velocity field in the umbra with higher uncertainty, probably caused by the difficulty to extract an accurate value from very wide profiles broadened due to the magnetic field. However, a more detailed analysis of each region is beyond the scope of this work.
To estimate the performance of the network on these data we re-synthesized the spectral lines from the mean stratification of each pixel. Figure 7 shows a histogram of the average error of each pixel for the FOV. On average, the result is very good, with a peak value around 10−2, although with an extended tail in the distribution reaching higher values. These points with a higher error are associated with the most complex profiles in the interior of the region. This behavior is to be expected because although the training set has a large diversity of profiles, more complex profiles have stronger gradients in temperature and velocity and therefore would require a finer sampling of heights than the one used here.
 |
Fig. 7. Distribution of the error in intensity between the synthetic and the observed profiles for the inversion of the FOV in Fig. 6. |
We want to note that for this particular set we did not find significant differences among the synthetic spectra coming from the mean, median, and maximum a posteriori stratification (MAP). The reason could be the following: the posterior distribution is narrow where the spectral lines are very sensitive and all these values are very close; while for the regions of the atmosphere where the posterior is much wider and asymmetric (and so MAP, median, and mean are different), the lines do not show a clear imprint of the solar conditions at those locations. This result cannot be generalized to other multimodal cases such as the magnetic field solutions under the Zeeman or Hanle effects.
7. Summary and conclusions
In this study, we explored the use of normalizing flows to accurately infer the posterior distribution of a solar model atmosphere (parameters, correlations, and uncertainties) from the interpretation of observed photospheric and chromospheric lines. Once the normalizing flow model is trained, the inference is extremely fast. We also show that the quality of the approximate posterior distribution depends on the size of the training set and that applying dimensionality reduction techniques makes the normalizing flow perform better. Rapid parameter estimation is critical if complex forward models are used to analyze the large amount of data that the next generation of telescopes such as the Daniel K. Inouye Solar Telescope (DKIST; Tritschler et al. 2015) and the European Solar Telescope (EST; Matthews et al. 2016) will produce.
Compared with a classical inversion approach, which computes only single-point estimations of the solution, models based on normalizing flows have the ability to estimate uncertainties and multi-modal solutions. The latter is usually the case when a single spectral line is used and its shape can be explained by different combinations of the parameters. It is therefore crucial to use multi-line observations and characterize how they can constrain the inferred properties, as we have shown here.
There are still many ways in which we could improve the current implementation. First, a natural extension of this work would be to include the four Stokes parameters to infer the magnetic properties of our target of interest, while also setting more constraints on the other physical parameters. As ambiguous solutions often plague the inference of magnetic properties, the Bayesian framework is ideal. Second, our normalizing flow only works with a particular noise level, but it can be easily generalized to arbitrary uncertainties by, for example, passing it as input in the conditioning of the normalizing flow (Dax et al. 2021). An arguably better option would be to let the model infer its value (e.g., Díaz Baso et al. 2019b). Third, a more general model can be built by adding metadata such as the spectral resolution or the solar location as additional conditioning alongside the observation. We are actively working on a version of the model that uses a summary network to condition the normalizing flow. This will enable the use of arbitrary wavelength grids (Asensio Ramos et al. 2022). All of the above combined will allow us to create a general Bayesian inference tool for almost any arbitrary observation.
Another problem we demonstrate is the difficulty in generating an appropriate training set. Recently, alternative training methods were developed that sequentially propose samples from the training set to maximize model performance with a smaller number of samples (see Lueckmann et al. 2021 for a comparison of different approaches), and this is an idea that we plan to explore in the future. Finally, the ability of normalizing flows to model probability distributions makes this method versatile, and other applications such as anomaly detection or learning complex priors for more traditional Bayesian sampling methods (Alsing & Handley 2021) are also being considered.
Our PyTorch implementation can be found in the following repository: https://github.com/cdiazbas/bayesflows. We also include a basic example to illustrate the method.
Acknowledgments
We would like to thank the anonymous referee for their comments and suggestions. CJDB thanks Adur Pastor Yabar, Flavio Calvo and Roberta Morosin for their comments. AAR acknowledges financial support from the Spanish Ministerio de Ciencia, Innovación y Universidades through project PGC2018-102108-B-I00 and FEDER funds. This project has received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation program (SUNMAG, grant agreement 759548). The Swedish 1-m Solar Telescope is operated on the island of La Palma by the Institute for Solar Physics of Stockholm University in the Spanish Observatorio del Roque de los Muchachos of the Instituto de Astrofísica de Canarias. The Institute for Solar Physics is supported by a grant for research infrastructures of national importance from the Swedish Research Council (registration number 2017-00625). We acknowledge the community effort devoted to the development of the following open-source packages that were used in this work: numpy (numpy.org), matplotlib (matplotlib.org), scipy (scipy.org), astropy (astropy.org) and sunpy (sunpy.org). This research has made use of NASA’s Astrophysics Data System Bibliographic Services.
References
- Alsing, J., & Handley, W. 2021, MNRAS, 505, L95 [NASA ADS] [CrossRef] [Google Scholar]
- Arregui, I. 2018, Adv. Space Res., 61, 655 [NASA ADS] [CrossRef] [Google Scholar]
- Asensio Ramos, A., & Díaz Baso, C. J. 2019, A&A, 626, A102 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Asensio Ramos, A., & Ramos Almeida, C. 2009, ApJ, 696, 2075 [NASA ADS] [CrossRef] [Google Scholar]
- Asensio Ramos, A., Martínez González, M. J., & Rubiño-Martín, J. A. 2007, A&A, 476, 959 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Asensio Ramos, A., de la Cruz Rodríguez, J., Martínez González, M. J., & Socas-Navarro, H. 2017, A&A, 599, A133 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Asensio Ramos, A., Diaz Baso, C., & Kochukhov, O. 2022, A&A, 658, A162 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Auer, L. H., Heasley, J. N., & House, L. L. 1977, Sol. Phys., 55, 47 [Google Scholar]
- Bayes, M., & Price, M. 1763, Philos. Trans. R. Soc. London Ser. I, 53, 370 [Google Scholar]
- Carroll, T. A., & Staude, J. 2001, A&A, 378, 316 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cranmer, M. D., Galvez, R., Anderson, L., Spergel, D. N., & Ho, S. 2019b, ArXiv e-prints [arXiv:1908.08045] [Google Scholar]
- Cranmer, K., Brehmer, J., & Louppe, G. 2019a, ArXiv e-prints [arXiv:1911.01429] [Google Scholar]
- Dax, M., Green, S. R., Gair, J., et al. 2021, Phys. Rev. Lett., 127 [CrossRef] [Google Scholar]
- de la Cruz Rodríguez, J. 2019, A&A, 631, A153 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- de la Cruz Rodríguez, J., & Piskunov, N. 2013, ApJ, 764, 33 [Google Scholar]
- de la Cruz Rodríguez, J., & van Noort, M. 2017, Space Sci. Rev., 210, 109 [Google Scholar]
- de la Cruz Rodríguez, J., Leenaarts, J., & Asensio Ramos, A. 2016, ApJ, 830, L30 [Google Scholar]
- de la Cruz Rodríguez, J., Leenaarts, J., Danilovic, S., & Uitenbroek, H. 2019, A&A, 623, A74 [Google Scholar]
- del Toro Iniesta, J. C., & Ruiz Cobo, B. 2016, Liv. Rev. Solar Phys., 13, 4 [CrossRef] [Google Scholar]
- Díaz Baso, C. J., de la Cruz Rodríguez, J., & Danilovic, S. 2019a, A&A, 629, A99 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Díaz Baso, C. J., Martínez González, M. J., & Asensio Ramos, A. 2019b, A&A, 625, A128 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Díaz Baso, C. J., de la Cruz Rodríguez, J., & Leenaarts, J. 2021, A&A, 647, A188 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dinh, L., Krueger, D., & Bengio, Y. 2014, ArXiv e-prints [arXiv:1410.8516] [Google Scholar]
- Durkan, C., Bekasov, A., Murray, I., & Papamakarios, G. 2019, ArXiv e-prints [arXiv:1906.04032] [Google Scholar]
- Durkan, C., Bekasov, A., Murray, I., & Papamakarios, G. 2020, https://doi.org/10.5281/zenodo.4296287 [Google Scholar]
- Esteban Pozuelo, S., de la Cruz Rodríguez, J., Drews, A., et al. 2019, ApJ, 870, 88 [Google Scholar]
- Foreman-Mackey, D., Hogg, D. W., Lang, D., & Goodman, J. 2013, PASP, 125, 306 [Google Scholar]
- Green, S. R., & Gair, J. 2020, ArXiv e-prints [arXiv:2008.03312] [Google Scholar]
- He, K., Zhang, X., Ren, S., & Sun, J. 2015, ArXiv e-prints [arXiv:1512.03385] [Google Scholar]
- Hinton, G. E., & Salakhutdinov, R. R. 2006, Science, 313, 504 [Google Scholar]
- Jimenez Rezende, D., & Mohamed, S. 2015, ArXiv e-prints [arXiv:1505.05770] [Google Scholar]
- Kianfar, S., Leenaarts, J., Danilovic, S., de la Cruz Rodríguez, J., & José Díaz Baso, C. 2020, A&A, 637, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kingma, D. P., & Ba, J. 2014, ArXiv e-prints [arXiv:1412.6980] [Google Scholar]
- Kingma, D. P., & Dhariwal, P. 2018, ArXiv e-prints [arXiv:1807.03039] [Google Scholar]
- Kobyzev, I., Prince, S. J. D., & Brubaker, M. A. 2019, ArXiv e-prints [arXiv:1908.09257] [Google Scholar]
- Kullback, S., & Leibler, R. 1951, Ann. Math. Stat., 22, 22 [Google Scholar]
- Leenaarts, J., de la Cruz Rodríguez, J., Danilovic, S., Scharmer, G., & Carlsson, M. 2018, A&A, 612, A28 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Levenberg, K. 1944, Q. Appl. Math., 2, 2 [Google Scholar]
- Lueckmann, J. M., Boelts, J., Greenberg, D. S., Gonçalves, P. J., & Macke, J. H. 2021, ArXiv e-prints [arXiv:2101.04653] [Google Scholar]
- Marquardt, D. W. 1963, SIAM J. Appl. Math., 11, 11 [Google Scholar]
- Matthews, S. A., Collados, M., Mathioudakis, M., & Erdelyi, R. 2016, SPIE Conf. Ser., 9908, 990809 [Google Scholar]
- Metropolis, N., Rosenbluth, A. W., Rosenbluth, M. N., Teller, A. H., & Teller, E. 1953, J. Chem. Phys., 21, 1087 [Google Scholar]
- Müller, T., McWilliams, B., Rousselle, F., Gross, M., & Novák, J. 2018, ArXiv e-prints [arXiv:1808.03856] [Google Scholar]
- Osborne, C. M. J., Armstrong, J. A., & Fletcher, L. 2019, ApJ, 873, 128 [NASA ADS] [CrossRef] [Google Scholar]
- Papamakarios, G., Nalisnick, E., Jimenez Rezende, D., Mohamed, S., & Lakshminarayanan, B. 2021, J. Mach. Learn. Res., 22, 1 [Google Scholar]
- Paszke, A., Gross, S., Massa, F., et al. 2019, ArXiv e-prints [arXiv:1912.01703] [Google Scholar]
- Piskunov, N., & Valenti, J. A. 2017, A&A, 597, A16 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Reiman, D. M., Tamanas, J., Prochaska, J. X., & Ďurovčíková, D. 2020, MNRAS, submitted [arXiv:2006.00615] [Google Scholar]
- Rippel, O., & Prescott Adams, R. 2013, ArXiv e-prints [arXiv:1302.5125] [Google Scholar]
- Rudin, W. 2006, Real and Complex Analysis, 3rd edn. (New Delhi: Tata McGraw-Hill) [Google Scholar]
- Sainz Dalda, A., de la Cruz Rodríguez, J., De Pontieu, B., & Gošić, M. 2019, ApJ, 875, L18 [Google Scholar]
- Scharmer, G. B., Bjelksjo, K., Korhonen, T. K., Lindberg, B., & Petterson, B. 2003, in Innovative Telescopes and Instrumentation for Solar Astrophysics, eds. S. L. Keil, & S. V. Avakyan, Proc. SPIE, 4853, 341 [NASA ADS] [CrossRef] [Google Scholar]
- Scharmer, G. B., Narayan, G., Hillberg, T., et al. 2008, ApJ, 689, L69 [Google Scholar]
- Skilling, J. 2004, in Am. Inst. Phys. Conf. Ser., eds. R. Fischer, R. Preuss, & U. V. Toussaint, 735, 395 [NASA ADS] [Google Scholar]
- Socas-Navarro, H. 2005, ApJ, 621, 545 [Google Scholar]
- Socas-Navarro, H., & Asensio Ramos, A. 2021, A&A, 652, A78 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tabak, E. G., & Turner, C. V. 2013, Commun. Pure Appl. Math., 66, 66 [Google Scholar]
- Tritschler, A., Rimmele, T. R., Berukoff, S., et al. 2015, Cambridge Workshop on Cool Stars Stellar Systems, and the Sun, 18, 933 [NASA ADS] [Google Scholar]
- Uitenbroek, H. 2001, ApJ, 557, 389 [Google Scholar]
- Vissers, G. J. M., de la Cruz Rodríguez, J., Libbrecht, T., et al. 2019, A&A, 627, A101 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Yadav, R., Díaz Baso, C. J., de la Cruz Rodríguez, J., Calvo, F., & Morosin, R. 2021, A&A, 649, A106 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
All Figures
|
Fig. 1. Comparison between an ANN and a conditional normalizing flow with parameters ϕ. The output of the classical ANN is an average value over all the solutions |
| In the text | |
|
Fig. 2. Joint (below the diagonal) and marginal (in the diagonal) posterior distributions for the physical parameters involved in the Milne-Eddington model. The label at the top of each column provides the median and the uncertainty defined by the percentiles 16 and 84 (equivalent to the standard 1σ uncertainty in the Gaussian case). Also, the contours are shown at 1 and 2 sigmas. The original values of the parameters are indicated with gray dots and vertical/horizontal lines. |
| In the text | |
|
Fig. 3. Atmospheric stratification inferred by the normalizing flow for two examples. In each column, the orange solution is inferred using only the Fe I line while the brown solution also uses the Ca II profile. The lowest row shows the original intensity values together with the synthetic calculation from the maximum a posteriori solution. |
| In the text | |
|
Fig. 4. Correlation matrices calculated for the inferred atmospheric stratification for the emission (left) and absorption (right) profiles. Blue/red indicates positive/negative correlations, respectively. The optical depth increases towards the right and downwards so that each pair of physical quantities has the top of the atmosphere in the upper left corner and the bottom in the lower right corner. |
| In the text | |
|
Fig. 5. Statistical properties of the posterior predictive check. Upper panel: results for the ME case. The blue curve averages over the full posterior distribution and the orange curve shows the difference with respect to the mode of the posterior. Lower panel: same results but for the NLTE case. We also display the effect of compressing the model with an autoencoder and applying the resampling strategy. |
| In the text | |
|
Fig. 6. Atmospheric structure of the FOV as inferred from the inversion. Left column: the temperature, the LOS velocity, and the microturbulent velocity at two layers for half of the FOV. Right column: the associated uncertainty for the same quantities and layers. |
| In the text | |
|
Fig. 7. Distribution of the error in intensity between the synthetic and the observed profiles for the inversion of the FOV in Fig. 6. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.