Fig. A.2.
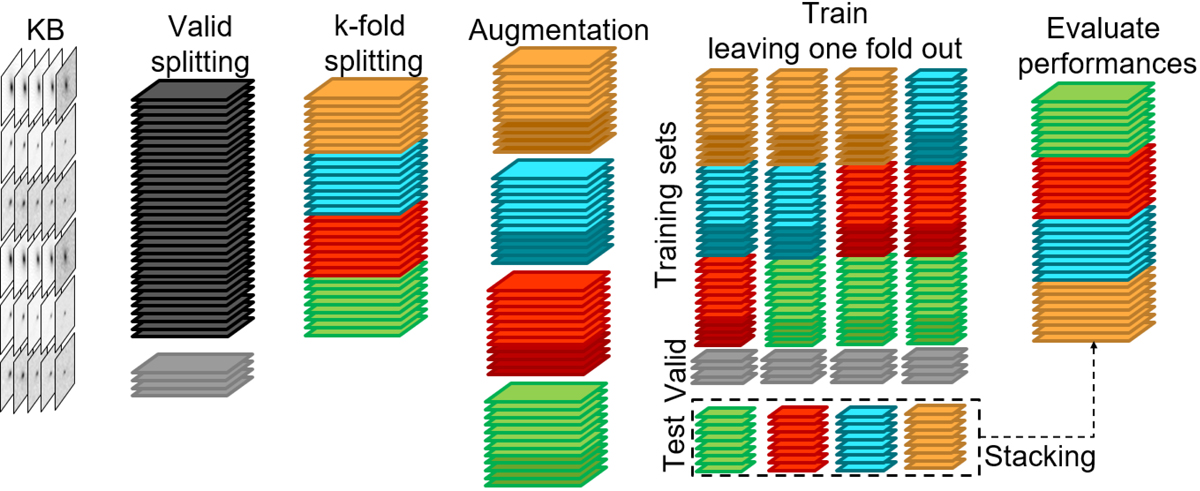
Data preparation flow: from the whole dataset (i.e. the knowledge base) a validation set is extracted. The rest of the dataset is split through a k-fold partitioning process (in this image, we simplified the figure assuming k = 4 folds, while in reality we used k = 10). The training samples are then arranged, by permuting the involved augmented folds, while the test samples dof not include the artefact images generated by the augmentation process. These sets are finally stacked in order to evaluate the global training performances.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.