| Issue |
A&A
Volume 624, April 2019
|
|
|---|---|---|
| Article Number | A115 | |
| Number of page(s) | 7 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/201834844 | |
| Published online | 22 April 2019 | |
Explicit Bayesian treatment of unknown foreground contaminations in galaxy surveys
1
Max-Planck-Institut für Astrophysik (MPA), Karl-Schwarzschild-Strasse 1, 85741 Garching, Germany
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Excellence Cluster Universe, Technische Universität München, Boltzmannstrasse 2, 85748 Garching, Germany
3
Sorbonne Université, CNRS, UMR 7095, Institut d’Astrophysique de Paris, 98 bis bd Arago, 75014 Paris, France
4
Sorbonne Universités, Institut Lagrange de Paris (ILP), 98 bis bd Arago, 75014 Paris, France
5
The Oskar Klein Centre, Department of Physics, Stockholm University, AlbaNova University Centre, 106 91 Stockholm, Sweden
Received:
12
December
2018
Accepted:
14
March
2019
Abstract
The treatment of unknown foreground contaminations will be one of the major challenges for galaxy clustering analyses of coming decadal surveys. These data contaminations introduce erroneous large-scale effects in recovered power spectra and inferred dark matter density fields. In this work, we present an effective solution to this problem in the form of a robust likelihood designed to account for effects due to unknown foreground and target contaminations. Conceptually, this robust likelihood marginalizes over the unknown large-scale contamination amplitudes. We showcase the effectiveness of this novel likelihood via an application to a mock SDSS-III data set subject to dust extinction contamination. In order to illustrate the performance of our proposed likelihood, we infer the underlying dark-matter density field and reconstruct the matter power spectrum, being maximally agnostic about the foregrounds. The results are compared to those of an analysis with a standard Poissonian likelihood, as typically used in modern large-scale structure analyses. While the standard Poissonian analysis yields excessive power for large-scale modes and introduces an overall bias in the power spectrum, our likelihood provides unbiased estimates of the matter power spectrum over the entire range of Fourier modes considered in this work. Further, we demonstrate that our approach accurately accounts for and corrects the effects of unknown foreground contaminations when inferring three-dimensional density fields. Robust likelihood approaches, as presented in this work, will be crucial to control unknown systematic error and maximize the outcome of the decadal surveys.
Key words: methods: data analysis / methods: statistical / galaxies: statistics / cosmology: observations / large-scale structure of Universe
© N. Porqueres et al. 2019
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access funding provided by Max Planck Society.
1. Introduction
The next generation of galaxy surveys such as Large Synoptic Survey Telescope (LSST; Ivezić et al. 2019) or Euclid (Laureijs et al. 2011; Amendola et al. 2018; Racca et al. 2016) will not be limited by noise but by systematic effects. In particular, deep photometric observations will be subject to several foreground and target contamination effects, such as dust extinction, stars, and seeing (e.g. Scranton et al. 2002; Ross et al. 2011; Ho et al. 2012, 2015; Huterer et al. 2013).
In the past, such effects have been addressed by generating templates for such contaminations and accounting for their overall template coefficients within a Bayesian framework. Leistedt & Peiris (2014), for example, compiled a total set of 220 foreground contaminations for the inference of the clustering signal of quasars in the Sloan Digital Sky Survey (SDSS-III) Baryon Oscillation Spectroscopic Survey (BOSS; Bovy et al. 2012). Foreground contaminations are also dealt with in observations of the cosmic microwave background, where they are assumed to be an additive contribution to observed temperature fluctuations (e.g. Tegmark & Efstathiou 1996; Tegmark et al. 1998; Hinshaw et al. 2007; Eriksen et al. 2008; Ho et al. 2015; Vansyngel et al. 2016; Sudevan et al. 2017; Elsner et al. 2017). In the context of large-scale structure analyses, Jasche & Lavaux (2017) presented a foreground sampling approach to account for multiplicative foreground effects which can affect the target and the number of observed objects across the sky.
All these methods rely on a sufficiently precise estimate of the map of expected foreground contaminants to be able to account for them in the statistical analysis. These approaches exploit the fact that the spatial and spectral dependence of the phenomena generating these foregrounds are well-known. But what if we are facing unknown foreground contaminations? Can we make progress in robustly recovering cosmological information from surveys subject to yet-unknown contaminations? In this work, we describe an attempt to address these questions and develop an optimal and robust likelihood to deal with such effects. The capability to account for ‘unknown unknowns’ is also the primary motivation behind the blind method for the visibility mask reconstruction recently proposed by Monaco et al. (2018).
The paper is organised as follows. We outline the underlying principles of our novel likelihood in Sect. 2, followed by a description of the numerical implementation in Sect. 3. We illustrate a specific problem in Sect. 4 and subsequently assess the performance of our proposed likelihood via a comparison with a standard Poissonian likelihood in Sect. 5. The key aspects of our findings are finally summarised in Sect. 6.
2. Robust likelihood
We describe the conceptual framework for the development of the robust likelihood which constitutes the crux of this work. The standard analysis of galaxy surveys assumes that the distribution of galaxies can be described as an inhomogeneous Poisson process (Layzer 1956; Peebles 1980; Martínez & Saar 2003) given by
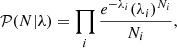 (1)
(1)
where Ni is the observed number of galaxies at a given position in the sky i and λi is the expected number of galaxies at that position. The expected number of galaxies is related to the underlying dark-matter density field ρ via
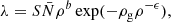 (2)
(2)
where S encodes the selection function and geometry of the survey, 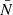 is the mean number of galaxies in the volume, and {b, ρg, ϵ} are the parameters of the non-linear bias model proposed by Neyrinck et al. (2014).
is the mean number of galaxies in the volume, and {b, ρg, ϵ} are the parameters of the non-linear bias model proposed by Neyrinck et al. (2014).
The key contribution of this work is to develop a more robust likelihood than the standard Poissonian likelihood by marginalizing over the unknown large-scale foreground contamination amplitudes. We start with the assumption that there is a large-scale foreground modulation that can be considered to have a constant amplitude over a particular group of voxels. Assuming that A is the amplitude of this large-scale perturbation, we can write 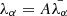 , where the index α labels the voxels over which the perturbation is assumed to have constant amplitude. The likelihood consequently has the following form:
, where the index α labels the voxels over which the perturbation is assumed to have constant amplitude. The likelihood consequently has the following form:
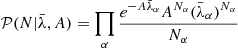 (3)
(3)
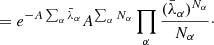 (4)
(4)
We can marginalize over the unknown foreground amplitude A as follows:
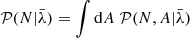 (5)
(5)
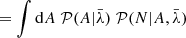 (6)
(6)
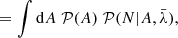 (7)
(7)
where, in the last step, we assumed conditional independence, 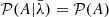 . This assumption is justified since the processes which generate the foregrounds are expected to be independent of the mechanisms involved in galaxy formation. As a result of this marginalization over the amplitude A, and using a power-law prior for A, 𝒫(A) = κA−γ where γ is the power-law exponent and κ is an arbitrary constant, the likelihood simplifies to:
. This assumption is justified since the processes which generate the foregrounds are expected to be independent of the mechanisms involved in galaxy formation. As a result of this marginalization over the amplitude A, and using a power-law prior for A, 𝒫(A) = κA−γ where γ is the power-law exponent and κ is an arbitrary constant, the likelihood simplifies to:
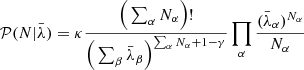 (8)
(8)
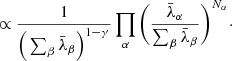 (9)
(9)
We employ a Jeffreys prior for the foreground amplitude A, which implies setting γ = 1. Jeffrey’s prior is a solution to a measure invariant scale transformation (Jeffreys 1946) and is therefore a scale-independent prior, such that different scales have the same probability and there is no preferred scale. This scale invariant prior is optimal for inference problems involving scale measurements as this does not introduce any bias on a logarithmic scale. Moreover, this is especially interesting because this allows for a total cancellation of unknown amplitudes in Eq. (9), resulting in the following simplified form of our augmented likelihood:
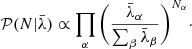 (10)
(10)
3. Numerical implementation
We implement the robust likelihood in BORG (Bayesian Origin Reconstruction from Galaxies, Jasche & Wandelt 2013), a hierarchical Bayesian inference framework for the non-linear inference of large-scale structures. It encodes a physical description for non-linear dynamics via Lagrangian Perturbation Theory (LPT), resulting in a highly non-trivial Bayesian inverse problem. At the core, it employs a Hamiltonian Monte Carlo (HMC) method for the efficient sampling of a high-dimensional and non-linear parameter space of possible initial conditions at an earlier epoch, with typically 𝒪(107) free parameters, corresponding to the discretized volume elements of the observed domain. The HMC implementation is detailed in Jasche & Kitaura (2010) and Jasche & Wandelt (2013). The essence of BORG is that it incorporates the joint inference of initial conditions, and consequently the corresponding non-linearly evolved density fields and associated velocity fields, from incomplete observations. An augmented variant, BORG-PM, employing a particle mesh model for gravitational structure formation, has recently been presented (Jasche & Lavaux 2019). An extension to BORG has also been developed to constrain cosmological parameters via a novel application of the Alcock–Paczyński test (Kodi Ramanah et al. 2019).
For the implementation of the robust likelihood, the HMC method that constitutes the basis of the joint sampling framework requires the negative log-likelihood and its adjoint gradient, which are given by
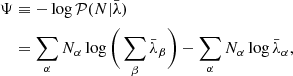 (11)
(11)
and
![Mathematical equation: $$ \begin{aligned} \frac{\partial \Psi }{\partial \bar{\lambda }_\gamma }\frac{\partial \bar{\lambda }_\gamma }{\partial \rho } = \frac{\bar{\lambda }_\gamma }{\rho } \Big (b + \epsilon \rho _{\rm g} \rho ^{-\epsilon } \Big ) \Bigg [\frac{\sum _\alpha N_\alpha }{\sum _\beta \bar{\lambda }_\beta } - \frac{N_\gamma }{\bar{\lambda }_\gamma }\Bigg ]\cdot \end{aligned} $$](/articles/aa/full_html/2019/04/aa34844-18/aa34844-18-eq15.gif) (12)
(12)
The labelling of voxels with the same foreground modulation is encoded via a colour indexing scheme that groups the voxels into a collection of angular patches. This requires the construction of a sky map which is divided into regions of a given angular scale, where each region is identified by a specific colour and is stored in HEALPix format (Górski et al. 2005), as illustrated in Fig. 1. An extrusion of the sky map onto a 3D grid subsequently yields a 3D distribution of patches, with a particular slice of this 3D coloured grid displayed in Fig. 2. The collection of voxels belonging to a particular patch is employed in the computation of the robust likelihood given by Eq. (11), where α corresponds to the colour index.
 |
Fig. 1. Schematic to illustrate the colour indexing of the survey elements. Colours are assigned to voxels according to patches of a given angular scale. Voxels of the same colour belong to the same patch, and this colour indexing is subsequently employed in the computation of the robust likelihood. |
 |
Fig. 2. Slice through the 3D coloured box. The extrusion of the colour indexing scheme (cf. Fig. 1) onto a 3D grid yields a collection of patches, denoted by a given colour, with a group of voxels belonging to a particular patch, to be employed in the computation of the robust likelihood. The axes indicate the comoving distances to the observer, who is located at the origin (0,0,0). |
This is a maximally ignorant approach to deal with unknown systematic errors where we enforce that every modulation above a given angular scale is not known. Since the colouring scheme does not depend on any foreground information, the numerical implementation of the likelihood is therefore generic. Moreover, another advantage of our approach is that the other components in our forward modelling scheme do not require any adjustments to encode this data model. However, we have not considered additive contaminations typically emanating from stars. We defer the extension of our data model to account for such additive contaminants to a future investigation.
4. Mock generation
We provide a brief description of the generation of the mock data set used to test the effectiveness of our novel likelihood, essentially based on the procedure adopted in Jasche & Kitaura (2010) and Jasche & Wandelt (2013). We first generate a realization for the initial density contrast 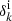 from a zero-mean normal distribution with covariance corresponding to the cosmological power spectrum, such that we have a 3D Gaussian initial density field in a cubic equidistant grid with Nside = 256, consisting of 2563 voxels, where each voxel corresponds to a discretized volume element, and comoving box length of 2000 h−1 Mpc. This 3D distribution of initial conditions must then be scaled to a cosmological scale factor of ainit = 0.001 using a cosmological growth factor D+(ainit).
from a zero-mean normal distribution with covariance corresponding to the cosmological power spectrum, such that we have a 3D Gaussian initial density field in a cubic equidistant grid with Nside = 256, consisting of 2563 voxels, where each voxel corresponds to a discretized volume element, and comoving box length of 2000 h−1 Mpc. This 3D distribution of initial conditions must then be scaled to a cosmological scale factor of ainit = 0.001 using a cosmological growth factor D+(ainit).
The underlying cosmological power spectrum, including baryonic acoustic oscillations, for the matter distribution is computed using the prescription described in Eisenstein & Hu (1998, 1999). We assume a standard Λ cold dark matter (ΛCDM) cosmology with the set of cosmological parameters (Ωm = 0.3089, ΩΛ = 0.6911, Ωb = 0.0486, h = 0.6774, σ8 = 0.8159, ns = 0.9667) from Planck Collaboration XIII (2016). We then employ LPT to transform the initial conditions into a non-linearly evolved field 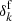 at redshift z = 0, which is subsequently constructed from the resulting particle distribution via the cloud-in-cell (CIC) method (e.g. Hockney & Eastwood 1988).
at redshift z = 0, which is subsequently constructed from the resulting particle distribution via the cloud-in-cell (CIC) method (e.g. Hockney & Eastwood 1988).
Given the final density field 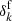 , we generate a mock galaxy redshift catalogue subject to foreground contamination. For the test case considered in this work, we generate a data set that emulates the characteristics of the SDSS-III survey, in particular the highly structured survey geometry and selection effects. We use a numerical estimate of the radial selection function of the CMASS component of the SDSS-III survey, shown in Fig. 3, obtained by binning the corresponding distribution of tracers N(d) in the CMASS sample (e.g. Ross et al. 2017), where d is the comoving distance from the observer. The CMASS radial selection function is therefore estimated from a histogram of galaxy distribution over redshift. The procedure to construct the CMASS sky completeness is less trivial however. We derive this CMASS mask, depicted in the left panel of Fig. 4, from the SDSS-III BOSS Data Release 12 (Alam et al. 2015) database by taking the ratio of spectroscopically confirmed galaxies to the target galaxies in each polygon from the mask.
, we generate a mock galaxy redshift catalogue subject to foreground contamination. For the test case considered in this work, we generate a data set that emulates the characteristics of the SDSS-III survey, in particular the highly structured survey geometry and selection effects. We use a numerical estimate of the radial selection function of the CMASS component of the SDSS-III survey, shown in Fig. 3, obtained by binning the corresponding distribution of tracers N(d) in the CMASS sample (e.g. Ross et al. 2017), where d is the comoving distance from the observer. The CMASS radial selection function is therefore estimated from a histogram of galaxy distribution over redshift. The procedure to construct the CMASS sky completeness is less trivial however. We derive this CMASS mask, depicted in the left panel of Fig. 4, from the SDSS-III BOSS Data Release 12 (Alam et al. 2015) database by taking the ratio of spectroscopically confirmed galaxies to the target galaxies in each polygon from the mask.
 |
Fig. 3. Radial selection function for the CMASS (north galactic cap) survey which is used to generate the mock data to emulate features of the actual SDSS-III BOSS data. |
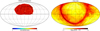 |
Fig. 4. Observed sky completeness (left panel) of the CMASS component of the SDSS-III survey for the north galactic cap and dust extinction map (right panel) used to generate the large-scale contamination. This reddening map has been generated from the SFD maps (Schlegel et al. 1998). |
In order to emulate a large-scale foreground contamination, we construct a reddening map that describes dust extinction, illustrated in the right panel of Fig. 4. This dust template is derived from the data provided by Schlegel et al. (1998) via straightforward interpolation, rendered in HEALPix format (Górski et al. 2005)1. The contamination is produced by multiplying the completeness mask of CMASS, shown in the left panel of Fig. 4, by a factor of (1 − ηF), where F is the foreground template rescaled to the angular resolution of the colour indexing scheme, and η controls the amplitude of this contamination. To obtain a mean contamination of 15% in the completeness, we arbitrarily chose η = 5 to ensure that the foreground contaminations are significant. This mean value corresponds to the average contamination per element of the sky completeness. Figure 5 shows the contaminated sky completeness and the percentage difference, with the edges of the survey being more affected by the contamination due to their proximity to the galactic plane where the dust is more abundant. The mock catalogue is produced by drawing random samples from the inhomogeneous Poissonian distribution described by Eq. (1) and using the modified completeness.
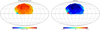 |
Fig. 5. Contaminated completeness mask (left panel) and percentage difference compared to the original completeness mask (right panel). The contamination is introduced by multiplying the original mask by a factor of (1 − 5F) where F is a foreground template, in this case, the dust extinction map downgraded to the angular resolution of the colour indexing map depicted in Fig. 1. The factor α = 5 is chosen such that the mean contamination is 15%, an arbitrary choice to ensure that the contaminations are significant in the completeness mask. The difference between the original and contaminated masks shows that the effect is stronger on the edges of the survey. |
5. Results and discussion
In this section, we discuss results obtained by applying the BORG algorithm with the robust likelihood to contaminated mock data. We also compare the performance of our novel likelihood with that of the standard Poissonian likelihood typically employed in large-scale structure analyses. In order to test the effectiveness of our likelihood against unknown systematic errors and foreground contaminations, the algorithm is agnostic about the contamination and assumes the CMASS sky completeness depicted in the left panel of Fig. 4.
We first study the impact of the large-scale contamination on the inferred non-linearly evolved density field. To this end, we compare the ensemble mean density fields and corresponding standard deviations for the two Markov chains with the Poissonian and novel likelihoods, respectively, illustrated in the top and bottom panels of Fig. 6, for a particular slice of the 3D density field. As can be deduced from the top-left panel of Fig. 6, the standard Poissonian analysis results in spurious effects in the density field, particularly close to the boundaries of the survey since these are the regions that are the most affected by the dust contamination. In contrast, our novel likelihood analysis yields a homogeneous density distribution through the entire observed domain, with the filamentary nature of the present-day density field clearly seen. While we can recover well-defined structures in the observed regions, the ensemble mean density field tends towards the cosmic mean density in the masked or poorly observed regions, with the corresponding standard deviation being higher to reflect the larger uncertainty in these regions. From this visual comparison, it is evident that our novel likelihood is more robust against unknown large-scale contaminations.
 |
Fig. 6. Mean and standard deviation of the inferred non-linearly evolved density fields, computed from the MCMC realizations, with the same slice through the 3D fields being depicted above for both the Poissonian (upper panels) and augmented (lower panels) likelihoods. The filamentary nature of the non-linearly evolved density field can be observed in the regions constrained by the data, with the unobserved or masked regions displaying larger uncertainty, as expected. Unlike our robust data model, the standard Poissonian analysis yields some artefacts in the reconstructed density field, particularly near the edges of the survey, where the foreground contamination is stronger. |
From the realizations of our inferred 3D initial density field, we can reconstruct the corresponding matter power spectra and compare them to the prior cosmological power spectrum adopted for the mock generation. The top panel of Fig. 7 illustrates the inferred power spectra for both likelihood analyses, with the bottom panel displaying the ratio of the a posteriori power spectra to the prior power spectrum. While the standard Poissonian analysis yields excessive power on the large scales due to the artefacts in the inferred density field, the analysis with our novel likelihood allows us to recover an unbiased power spectrum across the full range of Fourier modes.
 |
Fig. 7. Reconstructed power spectra from the inferred initial conditions from a BORG analysis with unknown foreground contamination for the robust likelihood (left panel) and the Poissonian likelihood (right panel) over the full range of Fourier modes considered in this work. The σ limit corresponds to the cosmic variance |
![Mathematical equation: $ \sigma=\sqrt[]{1/k} $](/articles/aa/full_html/2019/04/aa34844-18/aa34844-18-eq19.gif)
In addition, we tested the combined effects of the foreground and unknown noise amplitudes by estimating the covariance matrix of the Fourier amplitudes of the reconstructed power spectra. As depicted in Fig. 8, our novel likelihood exhibits uncorrelated amplitudes of the Fourier modes, as expected from ΛCDM cosmology. The strong diagonal shape of the correlation matrix indicates that our proposed data model correctly accounted for any mode coupling introduced by survey geometry and foreground effects.
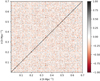 |
Fig. 8. Correlation matrix of power spectrum amplitudes with respect to the mean value for the robust likelihood, normalized using the variance of amplitudes of the power spectrum modes. The correlation matrix shows that our augmented data model does not introduce any spurious correlation artefacts, thereby implying that it has properly accounted for the selection and foreground effects. |
The above results clearly demonstrate the efficacy of our proposed likelihood in robustly dealing with unknown foreground contaminations for the inference of non-linearly evolved dark matter density fields and the underlying cosmological power spectra from deep galaxy redshift surveys. This method can be inverted to constrain foreground properties of the contamination. The inferred dark matter density allows for galaxy catalogues to be built without contaminations. These can be compared to the observed number counts to reconstruct the foreground properties as the mismatch between the two catalogues.
6. Summary and conclusions
The increasing requirement to control systematic and stochastic effects to high precision in next-generation deep galaxy surveys is one of the major challenges for the coming decade of surveys. If not accounted for, unknown foreground effects and target contaminations will yield significant erroneous artefacts and bias cosmological conclusions drawn from galaxy observations. A common spurious effect is an erroneous modulation of galaxy number counts across the sky, hindering the inference of 3D density fields and associated matter power spectra.
To address this issue, we propose a novel likelihood to implicitly and efficiently account for unknown foreground and target contaminations in surveys. We described its implementation in a framework of non-linear Bayesian inference of large-scale structures. Our proposed data model is conceptually straightforward and easy to implement. We illustrated the application of our robust likelihood to a mock data set with significant foreground contaminations and evaluated its performance via a comparison with an analysis employing a standard Poissonian likelihood to showcase the contrasting physical constraints obtained with and without the treatment of foreground contamination. We have shown that foregrounds, when unaccounted for, lead to spurious and erroneous large-scale artefacts in density fields and corresponding matter power spectra. In contrast, our novel likelihood allows us to marginalize over unknown large-angle contamination amplitudes, resulting in a homogeneous inferred density field, thereby recovering the fiducial power spectrum amplitudes.
We are convinced that our approach will contribute to optimising the scientific returns of current and coming galaxy redshift surveys. We have demonstrated the effectiveness of our robust likelihood in the context of large-scale structure analysis. Our augmented data model remains nevertheless relevant for more general applications with other cosmological probes, with applications potentially extending even beyond the cosmological context.
The construction of this template is described in more depth in Sect. 3 of Jasche & Lavaux (2017).
Acknowledgments
We express our appreciation to the anonymous reviewer for his comments which helped to improve the overall quality of the manuscript. NP would like to thank Torsten Enßlin for discussions and support. NP is supported by the DFG cluster of excellence “Origin and Structure of the Universe” ( www.universe-cluster.de ). This work has been done within the activities of the Domaine d’Intérêt Majeur (DIM) Astrophysique et Conditions d’Apparition de la Vie (ACAV), and received financial support from Région Ile-de-France. DKR and GL acknowledge financial support from the ILP LABEX, under reference ANR-10-LABX-63, which is financed by French state funds managed by the ANR within the Investissements d’Avenir programme under reference ANR-11-IDEX-0004-02. GL also acknowledges financial support from the ANR BIG4, under reference ANR-16-CE23-0002. This work is done within the Aquila Consortium (https://aquila-consortium.org).
References
- Alam, S., Albareti, F. D., Allende Prieto, C., et al. 2015, ApJS, 219, 12 [NASA ADS] [CrossRef] [Google Scholar]
- Amendola, L., Appleby, S., Avgoustidis, A., et al. 2018, Liv. Rev. Rel., 21, 2 [Google Scholar]
- Bovy, J., Myers, A. D., Hennawi, J. F., et al. 2012, ApJ, 749, 41 [NASA ADS] [CrossRef] [Google Scholar]
- Eisenstein, D. J., & Hu, W. 1998, ApJ, 496, 605 [NASA ADS] [CrossRef] [Google Scholar]
- Eisenstein, D. J., & Hu, W. 1999, ApJ, 511, 5 [NASA ADS] [CrossRef] [Google Scholar]
- Elsner, F., Leistedt, B., & Peiris, H. V. 2017, MNRAS, 465, 1847 [NASA ADS] [CrossRef] [Google Scholar]
- Eriksen, H. K., Dickinson, C., Jewell, J. B., et al. 2008, ApJ, 672, L87 [NASA ADS] [CrossRef] [Google Scholar]
- Górski, K. M., Hivon, E., Banday, A. J., et al. 2005, ApJ, 622, 759 [NASA ADS] [CrossRef] [Google Scholar]
- Hinshaw, G., Nolta, M. R., Bennett, C. L., et al. 2007, ApJS, 170, 288 [NASA ADS] [CrossRef] [Google Scholar]
- Ho, S., Cuesta, A., Seo, H.-J., et al. 2012, ApJ, 761, 14 [NASA ADS] [CrossRef] [Google Scholar]
- Ho, S., Agarwal, N., Myers, A. D., et al. 2015, JCAP, 5, 040 [NASA ADS] [CrossRef] [Google Scholar]
- Hockney, R. W., & Eastwood, J. W. 1988, Computer Simulation using Particles (CRC Press) [Google Scholar]
- Huterer, D., Cunha, C. E., & Fang, W. 2013, MNRAS, 432, 2945 [NASA ADS] [CrossRef] [Google Scholar]
- Ivezić, Ž., Kahn, S. M., Tyson, J. A., et al. 2019, ApJ, 873, 111 [NASA ADS] [CrossRef] [Google Scholar]
- Jasche, J., & Kitaura, F. S. 2010, MNRAS, 407, 29 [NASA ADS] [CrossRef] [Google Scholar]
- Jasche, J., & Lavaux, G. 2017, A&A, 606, A37 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Jasche, J., & Lavaux, G. 2019, A&A, in press, DOI: 10.1051/0004-6361/201833710 [EDP Sciences] [Google Scholar]
- Jasche, J., & Wandelt, B. D. 2013, MNRAS, 432, 894 [NASA ADS] [CrossRef] [Google Scholar]
- Jeffreys, H. 1946, Proc. R. Soc. London A, 186, 453 [Google Scholar]
- Kodi Ramanah, D., Lavaux, G., Jasche, J., & Wandelt, B. D. 2019, A&A, 621, A69 [CrossRef] [EDP Sciences] [Google Scholar]
- Laureijs, R., Amiaux, J., Arduini, S., et al. 2011, ArXiv e-prints [arXiv:1110.3193] [Google Scholar]
- Layzer, D. 1956, AJ, 61, 383 [NASA ADS] [CrossRef] [Google Scholar]
- Leistedt, B., & Peiris, H. V. 2014, MNRAS, 444, 2 [NASA ADS] [CrossRef] [Google Scholar]
- Martínez, V. J., & Saar, E. 2003, in Statistics of Galaxy Clustering, eds. E. D. Feigelson, & G. J. Babu, 143 [Google Scholar]
- Monaco, P., Di Dio, E., & Sefusatti, E. 2018, JCAP, submitted [arXiv:1812.02104] [Google Scholar]
- Neyrinck, M. C., Aragón-Calvo, M. A., Jeong, D., & Wang, X. 2014, MNRAS, 441, 646 [NASA ADS] [CrossRef] [Google Scholar]
- Peebles, P. J. E. 1980, The Large-Scale Structure of the Universe (Princeton University Press) [Google Scholar]
- Planck Collaboration XIII. 2016, A&A, 594, A13 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Racca, G. D., Laureijs, R., & Stagnaro, L. 2016, in Society of Photo-Optical Instrumentation Engineers (SPIE) Conference Series, Proc. SPIE, 9904, 99040O [Google Scholar]
- Ross, A. J., Ho, S., Cuesta, A. J., et al. 2011, MNRAS, 417, 1350 [NASA ADS] [CrossRef] [Google Scholar]
- Ross, A. J., Beutler, F., Chuang, C.-H., et al. 2017, MNRAS, 464, 1168 [NASA ADS] [CrossRef] [Google Scholar]
- Schlegel, D. J., Finkbeiner, D. P., & Davis, M. 1998, ApJ, 500, 525 [NASA ADS] [CrossRef] [Google Scholar]
- Scranton, R., Johnston, D., Dodelson, S., et al. 2002, ApJ, 579, 48 [NASA ADS] [CrossRef] [Google Scholar]
- Sudevan, V., Aluri, P. K., Yadav, S. K., Saha, R., & Souradeep, T. 2017, ApJ, 842, 62 [NASA ADS] [CrossRef] [Google Scholar]
- Tegmark, M., & Efstathiou, G. 1996, MNRAS, 281, 1297 [NASA ADS] [Google Scholar]
- Tegmark, M., Hamilton, A. J. S., Strauss, M. A., Vogeley, M. S., & Szalay, A. S. 1998, ApJ, 499, 555 [NASA ADS] [CrossRef] [Google Scholar]
- Vansyngel, F., Wandelt, B. D., Cardoso, J.-F., & Benabed, K. 2016, A&A, 588, A113 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
All Figures
|
Fig. 1. Schematic to illustrate the colour indexing of the survey elements. Colours are assigned to voxels according to patches of a given angular scale. Voxels of the same colour belong to the same patch, and this colour indexing is subsequently employed in the computation of the robust likelihood. |
| In the text | |
|
Fig. 2. Slice through the 3D coloured box. The extrusion of the colour indexing scheme (cf. Fig. 1) onto a 3D grid yields a collection of patches, denoted by a given colour, with a group of voxels belonging to a particular patch, to be employed in the computation of the robust likelihood. The axes indicate the comoving distances to the observer, who is located at the origin (0,0,0). |
| In the text | |
|
Fig. 3. Radial selection function for the CMASS (north galactic cap) survey which is used to generate the mock data to emulate features of the actual SDSS-III BOSS data. |
| In the text | |
|
Fig. 4. Observed sky completeness (left panel) of the CMASS component of the SDSS-III survey for the north galactic cap and dust extinction map (right panel) used to generate the large-scale contamination. This reddening map has been generated from the SFD maps (Schlegel et al. 1998). |
| In the text | |
|
Fig. 5. Contaminated completeness mask (left panel) and percentage difference compared to the original completeness mask (right panel). The contamination is introduced by multiplying the original mask by a factor of (1 − 5F) where F is a foreground template, in this case, the dust extinction map downgraded to the angular resolution of the colour indexing map depicted in Fig. 1. The factor α = 5 is chosen such that the mean contamination is 15%, an arbitrary choice to ensure that the contaminations are significant in the completeness mask. The difference between the original and contaminated masks shows that the effect is stronger on the edges of the survey. |
| In the text | |
|
Fig. 6. Mean and standard deviation of the inferred non-linearly evolved density fields, computed from the MCMC realizations, with the same slice through the 3D fields being depicted above for both the Poissonian (upper panels) and augmented (lower panels) likelihoods. The filamentary nature of the non-linearly evolved density field can be observed in the regions constrained by the data, with the unobserved or masked regions displaying larger uncertainty, as expected. Unlike our robust data model, the standard Poissonian analysis yields some artefacts in the reconstructed density field, particularly near the edges of the survey, where the foreground contamination is stronger. |
| In the text | |
|
Fig. 7. Reconstructed power spectra from the inferred initial conditions from a BORG analysis with unknown foreground contamination for the robust likelihood (left panel) and the Poissonian likelihood (right panel) over the full range of Fourier modes considered in this work. The σ limit corresponds to the cosmic variance |
| In the text | |
|
Fig. 8. Correlation matrix of power spectrum amplitudes with respect to the mean value for the robust likelihood, normalized using the variance of amplitudes of the power spectrum modes. The correlation matrix shows that our augmented data model does not introduce any spurious correlation artefacts, thereby implying that it has properly accounted for the selection and foreground effects. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.