| Issue |
A&A
Volume 621, January 2019
|
|
|---|---|---|
| Article Number | A69 | |
| Number of page(s) | 18 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/201834117 | |
| Published online | 11 January 2019 | |
Cosmological inference from Bayesian forward modelling of deep galaxy redshift surveys
1
Sorbonne Université, CNRS, UMR 7095, Institut d’Astrophysique de Paris, 98 bis bd Arago, 75014 Paris, France
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Sorbonne Universités, Institut Lagrange de Paris (ILP), 98 bis bd Arago, 75014 Paris, France
3
The Oskar Klein Centre, Department of Physics, Stockholm University, AlbaNova University Centre, 106 91 Stockholm, Sweden
4
Center for Computational Astrophysics, Flatiron Institute, 162 5th Avenue, 10010 New York, NY, USA
Received:
22
August
2018
Accepted:
7
November
2018
Abstract
We present a large-scale Bayesian inference framework to constrain cosmological parameters using galaxy redshift surveys, via an application of the Alcock-Paczyński (AP) test. Our physical model of the non-linearly evolved density field, as probed by galaxy surveys, employs Lagrangian perturbation theory (LPT) to connect Gaussian initial conditions to the final density field, followed by a coordinate transformation to obtain the redshift space representation for comparison with data. We have implemented a Hamiltonian Monte Carlo sampler to generate realisations of three-dimensional (3D) primordial and present-day matter fluctuations from a non-Gaussian LPT-Poissonian density posterior given a set of observations. This hierarchical approach encodes a novel AP test, extracting several orders of magnitude more information from the cosmic expansion compared to classical approaches, to infer cosmological parameters and jointly reconstruct the underlying 3D dark matter density field. The novelty of this AP test lies in constraining the comoving-redshift transformation to infer the appropriate cosmology which yields isotropic correlations of the galaxy density field, with the underlying assumption relying purely on the geometrical symmetries of the cosmological principle. Such an AP test does not rely explicitly on modelling the full statistics of the field. We verified in depth via simulations that this renders our test robust to model misspecification. This leads to another crucial advantage, namely that the cosmological parameters exhibit extremely weak dependence on the currently unresolved phenomenon of galaxy bias, thereby circumventing a potentially key limitation. This is consequently among the first methods to extract a large fraction of information from statistics other than that of direct density contrast correlations, without being sensitive to the amplitude of density fluctuations. We perform several statistical efficiency and consistency tests on a mock galaxy catalogue, using the SDSS-III survey as template, taking into account the survey geometry and selection effects, to validate the Bayesian inference machinery implemented.
Key words: methods: data analysis / methods: statistical / cosmology: observations / large-scale structure of Universe / galaxies: statistics
© ESO 2019
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
1. Introduction
The past few decades have witnessed the advent of an array of galaxy redshift surveys, with the state-of-the-art catalogues mapping millions of galaxies with precision positioning and accurate redshifts. The Sloan Digital Sky Survey (SDSS; York et al. 2000; Abazajian et al. 2009; Ahn et al. 2014; Alam et al. 2015) and the Six Degree Field Galaxy Redshift Survey (6dFGRS; Jones et al. 2009) are two notable examples. Future cutting-edge surveys from the Euclid (Laureijs et al. 2011; Racca et al. 2016; Amendola et al. 2018) and Large Synoptic Survey Telescope (LSST; Ivezic et al. 2008) missions, currently under construction, further highlight the wealth of galaxy redshift data sets which would be available within a five to ten year time frame. Sophisticated and optimal data analysis techniques, in particular large-scale structure analysis methods, are in increasing demand to cope with the present and upcoming avalanches of cosmological and astrophysical data, and therefore optimise the scientific returns of the missions.
With the metamorphosis of cosmology into a precision (and data-driven) science, the three-dimensional (3D) large-scale structures have emerged as an essential probe of the dynamics of structure formation and evolution to further our understanding of the Universe. The two-point statistics of the 3D matter distribution have developed into key tools to investigate various cosmological models and test different inflationary scenarios. Various techniques to measure the power spectrum and several reconstruction methods attempting to recover the underlying density field from galaxy observations are described in literature (e.g. Bertschinger & Dekel 1989; Bertschinger et al. 1991; Hoffman et al. 1994; Lahav et al. 1994; Fisher et al. 1995; Sheth 1995; Webster et al. 1997; Bistolas & Hoffman 1998; Schmoldt et al. 1999; Saunders et al. 2000; Zaroubi et al. 1999; Zaroubi 2002; Erdoǧdu et al. 2004, 2006), with the recent focus being on large-scale Bayesian inference methods (e.g. Kitaura & Enßlin 2008; Kitaura et al. 2009; Jasche & Kitaura 2010; Jasche et al. 2010a; Jasche & Wandelt 2012, 2013b; Jasche & Lavaux 2015, 2018). A formal and rigorous Bayesian framework provides the ideal setting to solve the ill-posed problem of inferring signals from noisy observations, while quantifying the corresponding statistical uncertainties.
The potential of such Bayesian algorithms to jointly infer cosmological constraints, nevertheless, has not yet been exploited. We present, for the first time, a non-linear Bayesian inference framework for cosmological parameter inference from galaxy redshift surveys via an implementation of the Alcock-Paczyński (AP, Alcock & Paczynski 1979) test. We extend the hierarchical Bayesian inference machinery of Bayesian Origin Reconstruction from Galaxies (BORG; Jasche & Wandelt 2013a), originally developed for the non-linear reconstruction of large-scale structures, to constrain cosmological parameters. BORG encodes a physical model for gravitational structure formation, yielding a highly non-trivial Bayesian inverse problem. This consequently allows us to reformulate the standard problem of present 3D density field reconstruction as an inference problem for initial conditions at an earlier epoch from current galaxy observations. BORG builds upon the implementation of the Hamiltonian Monte Carlo (HMC) method (Neal 1993), initially introduced in the HAmiltonian Density Estimation and Sampling (HADES) algorithm (Jasche & Kitaura 2010), for efficiently sampling the high dimensional and non-linear parameter space of possible initial conditions at an earlier epoch.
In this work, the conceptual framework is to constrain the comoving-redshift coordinate transformation and therefore infer the appropriate cosmology which would result in isotropic correlations of the galaxy density field. The key aspect of this application of the AP test consequently lies in its robustness to a misspecified model and the approximations therein, yielding a near-optimal exploitation of the model predictions, without relying on its accuracy in modelling the scale dependence of the correlations of the density field. Here, we employ Lagrangian perturbation theory (LPT) as a physical description for the non-linear dynamics and perform a joint inference of initial conditions, and consequently the corresponding non-linearly evolved density fields and associated velocity fields, and cosmological parameters, from incomplete observations. This augmented framework with cosmological applications is designated as ALTAIR (ALcock-Paczyński consTrAIned Reconstruction).
The paper is organised as follows. In Sect. 2, the underlying principles of the AP test are outlined, followed by a description of the forward modelling approach and data model implemented in Sect. 3. We then test the algorithm in Sect. 5 on an artificially generated galaxy survey, with the mock generation procedure described in the preceding Sect. 4, by investigating its performance via statistical efficiency and consistency tests. In Sect. 6, we summarise the main aspects of our work and discuss further possible extensions to our algorithm in order to fully exploit its potential in deriving cosmological constraints. In Appendix A, we describe the LPT-Poissonian posterior implemented in this work, followed by the computation of the Jacobian of the comoving-redshift transformation in Appendix B. We provide a brief overview of the Hamiltonian sampling approach in Appendix C, and follow up by deriving the required equations of motion in Appendix D, with the numerical implementation outlined in Appendix E. We subsequently describe how we increase the efficiency of our cosmological parameter sampler via a rotation of the parameter space in Appendix F. Finally, we outline the derivation of the adjoint gradient for a generic 3D interpolation scheme in Appendix G.
2. The Alcock-Paczyński test
The Alcock-Paczyński (AP) test (Alcock & Paczynski 1979) is a cosmological test of the expansion of the Universe and its geometry. The main advantage of this test is that it is independent of the evolution of galaxies but depends only on the geometry of the Universe. The assumption of incorrect cosmological parameters in data analysis produces distortions in the appearance of any spherical object or isotropic statistical distribution. The AP test provides a pathway to exploit this resulting spurious anisotropy to constrain the cosmological parameters. Here, we invoke the AP test to ensure that the underlying geometrical properties of isotropy of the Universe (Friedmann 1922, 1924; Lemaître 1927, 1931, 1933; Robertson 1935; 1936a,b; Walker 1937; Saadeh et al. 2016) are maintained. As such, the key underlying assumption adopted in this work relies purely on the geometrical symmetries of the cosmological principle. As a result, such a test does not employ the growth of structures to constrain cosmology, unlike cluster abundance (e.g. Wang & Steinhardt 1998).
The AP test, and various formulations thereof, have been studied extensively in the context of galaxy and quasar surveys (e.g. Phillipps 1994; Ryden 1995; Ballinger et al. 1996; Matsubara & Suto 1996; Popowski et al. 1998; de Laix & Starkman 1998; López-Corredoira 2014; Li et al. 2014, 2016). Variants of the AP test have also been successfully applied to cosmic voids (e.g. Sutter et al. 2012, 2014; Lavaux & Wandelt 2012; Hamaus et al. 2014, 2015, 2016) and also to other cosmological observables like supernovae (Blake et al. 2011), the Lyman-α forest (Hui et al. 1999) and 21 centimetre emission maps (Nusser 2005; Barkana 2006).
With baryon acoustic oscillations (BAOs) being a robust standard ruler, the AP test has been utilised for the simultaneous measurement of the Hubble parameter and angular diameter distance of distant galaxies (e.g. Seo & Eisenstein 2003; Blake & Glazebrook 2003; Glazebrook & Blake 2005; Padmanabhan & White 2008; Shoji et al. 2009). In Fig. 1, we depict the 1σ confidence region of the cosmological constraints inferred via our implementation of the AP test. As a comparison, we also indicate the corresponding confidence region obtained via BAO measurements from the SDSS-III (Data Release 12; Alam et al. 2017). These BAO constraints have not been combined with Planck measurements, which would significantly tighten the constraints. Nevertheless, this highlights the significant potential constraining power of our AP test compared to standard BAO analyses, while being at least as robust. While this improvement is extremely substantial for the mock SDSS-III survey considered here, we will investigate to what extent the above promise holds when applied to actual SDSS-III data in a follow-up work, as unknown systematics represent a potential caveat. We discuss Fig. 1 in more depth in Sect. 5.
 |
Fig. 1. Comparison of cosmological constraints from BAO measurements and our implementation of AP test in ALTAIR. The grey and green lines denote the 1σ confidence region, centred on the fiducial cosmological parameters, obtained from our AP test and BAO constraints from SDSS-III (DR 12; Alam et al. 2017), respectively. The BAO constraints have not been combined with Planck CMB measurements. This demonstrates the potentially unprecedented constraining power of our AP test compared to standard BAO analyses, as discussed in Sect. 2, with the inset focusing on the ALTAIR constraints where the fiducial cosmology is depicted in dashed lines. This error forecast is validated on a simulated analysis (cf. Fig. 6). |
The crucial aspect of our AP test is that it does not assume that the correlation function is correctly modelled. This robustness to a misspecified model is illustrated explicitly in Sect. 5, where we demonstrate that the shape of the prior power spectrum adopted in the inference framework does not impact on the inferred cosmological constraints (cf. Fig. 10). As a result of this robustness, our AP test has a definite edge over standard approaches. Moreover, it has been pointed out that other cosmological tests, such as the luminosity distance – redshift relation, can be considered as generalised formulations of the AP test (Mukherjee & Wandelt 2018), further underlining the strength of the approach presented in this work.
3. The forward modelling approach
The large-scale structure (LSS) posterior implemented in this work, based on the BORG framework (Jasche & Wandelt 2013a), is described in depth in Appendix A. A key component of the inference framework is the forward model ℳp which links the initial conditions 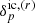 to the redshift space representation of the evolved density field
to the redshift space representation of the evolved density field 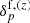 as follows:
as follows:
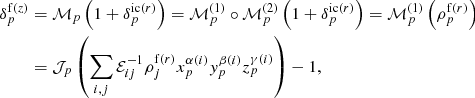 (1)
(1)
where 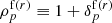 is the final density field in comoving space. The forward model consists of two components,
is the final density field in comoving space. The forward model consists of two components, 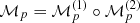 . The first component,
. The first component, 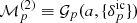 , contains a physical description of the non-linear dynamics, and consequently propagates the initial conditions forward in time using LPT, yielding a non-linearly evolved final density field in comoving space,
, contains a physical description of the non-linear dynamics, and consequently propagates the initial conditions forward in time using LPT, yielding a non-linearly evolved final density field in comoving space, 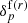 .
.
To encode the AP test, we incorporate another component in the forward model that takes care of the coordinate transformation from comoving (r) to redshift (z) space, encoded in 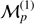 (cf. Fig. 2). Schematically, we construct a second grid in redshift space, which involves a triquintic interpolation (fifth order interpolation scheme in three dimensions) on the comoving grid. This interpolation scheme is described in Appendix G, with the notation employed in Eq. (1) clearly laid out. The corresponding Jacobian factor of this transformation,
(cf. Fig. 2). Schematically, we construct a second grid in redshift space, which involves a triquintic interpolation (fifth order interpolation scheme in three dimensions) on the comoving grid. This interpolation scheme is described in Appendix G, with the notation employed in Eq. (1) clearly laid out. The corresponding Jacobian factor of this transformation, 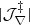 (cf. Appendix B), entails cosmological dependence and is consequently included in the AP test as well as through the direct coordinate dependence ℰij.
(cf. Appendix B), entails cosmological dependence and is consequently included in the AP test as well as through the direct coordinate dependence ℰij.
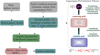 |
Fig. 2. Schematic representation of the reconstruction pipeline. The forward model consists of a chain of various components for the non-linear evolution from initial conditions and the subsequent transformation from comoving to redshift space for the application of the AP test. This consequently transforms the initial density field into a set of predicted observables, i.e. a galaxy distribution in redshift space, for comparison with data via a likelihood or posterior analysis. |
The redshift space representation then allows for comparison with data via the likelihood or posterior. The essence of this AP test to constrain cosmological parameters can be summarised as follows: The Bayesian inference machinery explores the various cosmological expansion histories and selects the cosmology-dependent evolution pathways which result in isotropic correlations of the galaxy density field.
Figure 2 illustrates the reconstruction scheme implemented in ALTAIR. First, galaxies are projected from the survey onto a 3D grid, such that we have a distribution of galaxies in redshift space and this constitutes our observable. We then generate a 3D density field according to Gaussian initial conditions (homogeneous prior) with a reference power spectrum, typically ΛCDM cosmology. The forward model subsequently transforms the initial density field into a set of predicted observables which are then compared to data via a likelihood or posterior analysis. And conversely, given the position of galaxies, we can infer this density field.
While we implement LPT to approximately describe gravitational non-linear structure formation in this work, other more adequate physical descriptions such as 2LPT or the non-perturbative particle mesh (see recent upgrade of BORG in Jasche & Lavaux 2018) can be straightforwardly employed, within the flexible block sampling approach described in Appendix A.3, by upgrading the first component, 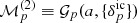 , of our forward model (cf. Fig. 2). Nevertheless, our implementation of the AP test exploits essentially the isotropy of the correlation function, such that there is no explicit dependence on the accuracy of modelling the scale dependence of the correlations, rendering this method robust to a misspecified model and the approximations therein.
, of our forward model (cf. Fig. 2). Nevertheless, our implementation of the AP test exploits essentially the isotropy of the correlation function, such that there is no explicit dependence on the accuracy of modelling the scale dependence of the correlations, rendering this method robust to a misspecified model and the approximations therein.
3.1. The galaxy data model
Galaxies can be considered as tracers of the matter fluctuations since they follow the gravitational potential of the underlying matter distribution, with the statistical uncertainty due to the discrete nature of the galaxy distribution usually modelled by a Poissonian distribution (e.g. Layzer 1956; Peebles 1980). Poissonian likelihoods have emerged as the standard for non-linear LSS inference (e.g. Jasche et al. 2010b; Jasche & Kitaura 2010; Kitaura et al. 2010). The Poissonian likelihood distribution implemented in ALTAIR, for multiple subcatalogues or galaxy observations labelled by the index g, can be expressed as follows:
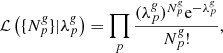 (2)
(2)
where 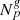 is the observed galaxy number counts in redshift space in the given voxel p.
is the observed galaxy number counts in redshift space in the given voxel p. 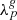 is the expected number of galaxies at this given position and is related to the final density field
is the expected number of galaxies at this given position and is related to the final density field 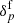 , in redshift space, via
, in redshift space, via
![Mathematical equation: $$ \begin{aligned} \lambda ^{\textit{g}}_{p} \left( \{ {\delta }_{p}^{\mathrm{f}} \}, \{ \theta _{i} \} \right) = {R}^{\textit{g}}_{p} (\theta _{i}) \mathcal{T} \left[ 1 + \delta ^{\mathrm{f}}_{p} \right] , \end{aligned} $$](/articles/aa/full_html/2019/01/aa34117-18/aa34117-18-eq15.gif) (3)
(3)
where 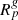 is the overall linear response operator of the survey that incorporates the survey geometry and selection effects, and θi corresponds to a set of cosmological parameters. 𝒯 is the galaxy biasing model which accounts for the fact that galaxies do not trace exactly the underlying matter distribution, and are therefore biased tracers with clustering properties that do not exactly mirror those of dark matter (Kaiser 1984). This is currently one of the most challenging and unresolved issues hindering the analysis of galaxy distributions in non-linear regimes (e.g. see the review by Desjacques et al. 2018; Schmidt et al. 2018).
is the overall linear response operator of the survey that incorporates the survey geometry and selection effects, and θi corresponds to a set of cosmological parameters. 𝒯 is the galaxy biasing model which accounts for the fact that galaxies do not trace exactly the underlying matter distribution, and are therefore biased tracers with clustering properties that do not exactly mirror those of dark matter (Kaiser 1984). This is currently one of the most challenging and unresolved issues hindering the analysis of galaxy distributions in non-linear regimes (e.g. see the review by Desjacques et al. 2018; Schmidt et al. 2018).
In this work, we adopt the standard approach of a local, but non-linear bias function, in particular, the phenomenological model proposed by Neyrinck et al. (2014), such that the above Poisson intensity field can be expressed as
![Mathematical equation: $$ \begin{aligned} \lambda ^{\textit{g}}_{p} \left( \{ {\delta }_{p}^{\mathrm{f}} \}, \{ \theta _{i} \}, \{ \bar{N}^{\textit{g}} \}, \{ {b}^{\textit{g}}_{i} \} \right) = {R}^{\textit{g}}_{p} \bar{N}^{\textit{g}} \left[ 1 + \delta ^{\mathrm{f}}_{p} \right]^{\beta } \mathrm{e}^{- \rho ^{\textit{g}} [1 + \delta ^{\mathrm{f}}_{p}]^{-\epsilon ^{\textit{g}}}} , \end{aligned} $$](/articles/aa/full_html/2019/01/aa34117-18/aa34117-18-eq17.gif) (4)
(4)
where the bias function, described by four parameters, N̄g, the mean density of tracers, and 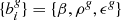 , is a truncated power law bias model with the additional exponential function suppressing galaxy clustering in under dense regions. This bias model, with a power law and an exponential at low densities, were found to be in good agreement with standard excursion set and local-growth-factor models (for more details, see Neyrinck et al. 2014). The main limitation of this bias model is that it is purely local. Nevertheless, it is more adequate than a simplistic linear bias model and mitigates in practice the deficiencies of our physical model (LPT) at the considered resolution. The expected number of galaxies can subsequently be related to the initial conditions
, is a truncated power law bias model with the additional exponential function suppressing galaxy clustering in under dense regions. This bias model, with a power law and an exponential at low densities, were found to be in good agreement with standard excursion set and local-growth-factor models (for more details, see Neyrinck et al. 2014). The main limitation of this bias model is that it is purely local. Nevertheless, it is more adequate than a simplistic linear bias model and mitigates in practice the deficiencies of our physical model (LPT) at the considered resolution. The expected number of galaxies can subsequently be related to the initial conditions 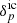 via the forward model ℳp, as described above, due to the deterministic nature of structure formation, as implied by the Dirac delta function in Eq. (A.2).
via the forward model ℳp, as described above, due to the deterministic nature of structure formation, as implied by the Dirac delta function in Eq. (A.2).
The logarithm of the likelihood from Eq. (2) can therefore be expressed, in terms of the initial conditions, as
![Mathematical equation: $$ \begin{aligned}&\ln \mathcal{L} \left[ \{ {N}^{\textit{g}}_{p} \} \big | {\mathcal{M} }_{p} \left(\{ {\delta }_{p}^{\mathrm{ic}} \}\right), \{ \theta _{i} \}, \{ \bar{N}^{\textit{g}} \}, \{ {b}^{\textit{g}}_{i} \} \right] \nonumber \\&\qquad \qquad = - \sum _{p} \left\{ \lambda ^{\textit{g}}_{p} \left( \{ {\delta }_{p}^{\mathrm{f}} \}, \{ \theta _{i} \}, \{ \bar{N}^{\textit{g}} \}, \{ {b}^{\textit{g}}_{i} \} \right)\right. \nonumber \\&\qquad \qquad \left.- {N}^{\textit{g}}_{p} \ln \left[ \lambda ^{\textit{g}}_{p} \left( \{ {\delta }_{p}^{\mathrm{f}} \}, \{\theta _{i} \}, \{ \bar{N}^{\textit{g}} \}, \{ {b}^{\textit{g}}_{i} \} \right) \right] + \ln \left( {{N}^{\textit{g}}_{p} !} \right) \right\} . \end{aligned} $$](/articles/aa/full_html/2019/01/aa34117-18/aa34117-18-eq20.gif) (5)
(5)
We therefore have a likelihood distribution that encodes the statistical process describing the generation of galaxy observations given a specific realisation of 3D initial conditions. This data model is inherently non-linear as a result of the galaxy biasing model employed and also due to the signal dependence of Poissonian noise, which does not behave as an additive nuisance.
3.2. The augmented joint posterior distribution
The augmented joint posterior distribution corresponds to the following:
![Mathematical equation: $$ \begin{aligned}&\mathcal{P} \left(\{ {\delta }_{p}^{\mathrm{ic}} \}, \{\bar{N}^{\textit{g}}\}, \{b_{i}^{\textit{g}}\}, \{ \theta _{i} \} |\{{N}^{\textit{g}}_{p}\}, \mathbf S \right)\nonumber \\&\qquad \quad \propto \mathcal{L} \left[\{{N}^{\textit{g}}_{p}\}\big |{\mathcal{M} }_{p} (\{ {\delta }_{p}^{\mathrm{ic}} \}), \{ \theta _{i} \}, \{\bar{N}^{\textit{g}}\}, \{b_{i}^{\textit{g}}\} \right] \nonumber \\&\qquad \quad \times \Pi \left(\{ {\delta }_{p}^{\mathrm{ic}} \}| \, \mathbf S \right) \Pi \left( \{\bar{N}^{\textit{g}} \}, \{b_{i}^{\textit{g}}\} \right) \Pi \left( \{\theta _{i} \}\right), \end{aligned} $$](/articles/aa/full_html/2019/01/aa34117-18/aa34117-18-eq21.gif) (6)
(6)
where the Π’s correspond to the respective priors for each parameter. Hence, given our forward model ℳ, which incorporates sequential components of structure formation and coordinate transformation, as described above, the complex task of modelling accurate priors for the statistical behaviour of present-day matter fluctuations can be recast into a Bayesian inference problem for the initial conditions. From this joint posterior distribution, we can construct the various conditional posterior distributions for each parameter of interest. The modular statistical programming approach adopted in outlined in Appendix A.3.
Since the non-linear LSS analysis has been reformulated as an initial conditions statistical inference problem, as described by the joint posterior distribution Eq. (6), this method depends solely on forward evaluations, and consequently has a definite edge over traditional approaches of initial conditions inference that require backward integration of the equations of motion or the inversion of the flow of time (e.g. Nusser & Dekel 1992). The latter methods are prone to erroneous fluctuations in the initial density and velocity fields, resulting from spurious growth of decaying modes. Moreover, such schemes are hindered by survey incompleteness which requires the knowledge of the complex and, as yet, unknown multi-variate probability distribution for the matter fluctuations, to render the backward integration of non-linear models physically meaningful via constrained realisations. In comparison, the forward modelling approach here conveniently accounts for survey masks and statistical uncertainties in the initial conditions, which amounts to modelling straightforward uncorrelated Gaussian processes, to generate data constrained realisations of the initial and evolved density fields.
3.3. The cosmological parameter posterior distribution
In this work, we sample the present-day values of matter density and dark energy equation of state parameters, {θi}={Ωm, w0}, via the following conditional posterior distribution,
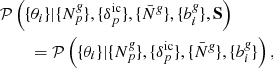 (7)
(7)
assuming conditional independence of the cosmological power spectrum, that is, Fourier transform of the covariance matrix S, once the density field is known. This assumption holds as we are only probing the cosmological expansion in this work, with the power spectrum anchored with a fiducial cosmology. We quantitatively demonstrate the validity of this assumption in Sect. 5 by comparing the entropy of prior information against that of posterior information (cf. Fig. 9). We defer power spectrum sampling to a future work. Applying Bayes’ identity, and using the joint posterior distribution from Eq. (6), we obtain
![Mathematical equation: $$ \begin{aligned} \mathcal{P} \Big ( \{ \theta _{i} \}&| \{{N}^{\textit{g}}_{p}\}, \{ {\delta }_{p}^{\mathrm{ic}} \}, \{\bar{N}^{\textit{g}}\}, \{b_{i}^{\textit{g}}\} \Big ) \nonumber \\&= \frac{\mathcal{P} \left( \{ \theta _{i} \}, \{ {\delta }_{p}^{\mathrm{ic}} \}, \{\bar{N}^{\textit{g}}\}, \{b_{i}^{\textit{g}}\} |\{{N}^{\textit{g}}_{p}\} \right)}{\mathcal{P} \left( \{ {\delta }_{p}^{\mathrm{ic}} \}, \{\bar{N}^{\textit{g}}\}, \{b_{i}^{\textit{g}}\} |\{{N}^{\textit{g}}_{p}\} \right)} \nonumber \\&= \frac{\mathcal{L} \left[\{{N}^{\textit{g}}_{p}\}\big | {\mathcal{M} }_{p} \left(\{ {\delta }_{p}^{\mathrm{ic}} \} \right), \{ \theta _{i} \}, \{\bar{N}^{\textit{g}}\}, \{b_{i}^{\textit{g}}\} \right] }{\mathcal{P} \left( \{ {\delta }_{p}^{\mathrm{ic}} \}, \{\bar{N}^{\textit{g}}\}, \{b_{i}^{\textit{g}}\} |\{{N}^{\textit{g}}_{p}\} \right)} \nonumber \\&\; \; \; \; \; \; \; \; \; \times \Pi \left(\{ {\delta }_{p}^{\mathrm{ic}} \} | \, \mathbf S \right) \Pi \left( \{\bar{N}^{\textit{g}} \}, \{b_{i}^{\textit{g}}\} \right) \Pi \left( \{\theta _{i} \}\right) \nonumber \\&\propto \mathcal{L} \left[\{{N}^{\textit{g}}_{p}\}\big | {\mathcal{M} }_{p} \left(\{ {\delta }_{p}^{\mathrm{ic}} \} \right), \{ \theta _{i} \}, \{\bar{N}^{\textit{g}}\}, \{b_{i}^{\textit{g}}\} \right] \times \Pi \left( \{\theta _{i} \}\right) , \end{aligned} $$](/articles/aa/full_html/2019/01/aa34117-18/aa34117-18-eq23.gif) (8)
(8)
after omitting the terms without any cosmological parameter dependence.
Since this work attempts to demonstrate the capabilities of ALTAIR to constrain the cosmological parameters, as proof of concept, we set uniform prior distributions on θi. To sample from the above marginal posterior distribution, we make use of a slice sampling procedure (e.g. Neal 2000, 2003). After obtaining a realisation of θi, we need to update the comoving-redshift coordinate transformation in the forward model.
We adopt a dynamical dark energy model, in particular, the standard Chevallier-Polarski-Linder (CPL) parameterisation (Chevallier & Polarski 2001; Linder 2003), where the evolution of the dark energy equation of state parameter w is a linear function of the scale factor a, as follows:
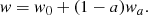 (9)
(9)
In this work, we set wa = 0 and infer the present-day value w0. Moreover, we impose the assumption of flatness, that is, Ωk = 0, such that the dark energy density is Ωde = 1 − Ωm.
Due to the correlation between Ωm and w0, we perform a rotation of the (Ωm, w0) parameter space, using orthonormal basis transformations derived from the covariance matrix, to improve the efficiency of the slice sampler. This procedure is outlined in Appendix F, with the significant gain in efficiency illustrated in Fig. F.1. The corresponding sampler for the bias parameters is outlined in Appendix A.4.
4. Generation of a mock galaxy catalogue
We describe the generation of an artificial galaxy survey using as template the Sloan Digital Sky Survey (SDSS-III), consisting of four galaxy subcatalogues, to validate the methodology described in the previous sections. The procedure implemented here for the mock generation is essentially based on the descriptions provided in Jasche & Kitaura (2010) and Jasche & Wandelt (2013a).
At first, we generate a realisation for the initial density contrast 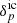 from a normal distribution with zero mean and covariance corresponding to an underlying cosmological power spectrum for the matter distribution. This power spectrum, including baryonic wiggles, is computed following the prescription provided in Eisenstein & Hu (1998, 1999), assuming a standard Λ cold dark matter (ΛCDM) cosmology with the set of cosmological parameters (Ωm = 0.3089, ΩΛ = 0.6911, Ωb = 0.0486, h = 0.6774, σ8 = 0.8159, ns = 0.9667) from Planck (Planck Collaboration XIII 2016). This yields a 3D Gaussian initial density field in an equidistant Cartesian grid with Nside = 128, consisting of 1283 voxels, where each voxel corresponds to a discretised volume element with a physical voxel size of 15.6 h−1 Mpc, and comoving box length of 4000 h−1 Mpc. As a result, this implies a total of ∼2.1 × 106 inference parameters, corresponding to the amplitude of the primordial density fluctuations at the respective grid nodes.
from a normal distribution with zero mean and covariance corresponding to an underlying cosmological power spectrum for the matter distribution. This power spectrum, including baryonic wiggles, is computed following the prescription provided in Eisenstein & Hu (1998, 1999), assuming a standard Λ cold dark matter (ΛCDM) cosmology with the set of cosmological parameters (Ωm = 0.3089, ΩΛ = 0.6911, Ωb = 0.0486, h = 0.6774, σ8 = 0.8159, ns = 0.9667) from Planck (Planck Collaboration XIII 2016). This yields a 3D Gaussian initial density field in an equidistant Cartesian grid with Nside = 128, consisting of 1283 voxels, where each voxel corresponds to a discretised volume element with a physical voxel size of 15.6 h−1 Mpc, and comoving box length of 4000 h−1 Mpc. As a result, this implies a total of ∼2.1 × 106 inference parameters, corresponding to the amplitude of the primordial density fluctuations at the respective grid nodes.
To ensure a sufficient resolution of inferred final density fields, we oversample the initial density field by a factor of eight, thereby evaluating the LPT model with 2563 particles in every sampling step. The following step is to scale this 3D distribution of initial conditions to a cosmological scale factor of ainit = 0.001 via multiplication with a cosmological growth factor D+(ainit). These initial conditions are subsequently evolved forward in time, in non-linear fashion, with LPT providing an approximate description of gravitational LSS formation. We then construct a final 3D non-linearly evolved density field 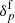 from the resulting particle distribution via the cloud-in-cell (CIC) method (e.g. Hockney & Eastwood 1988).
from the resulting particle distribution via the cloud-in-cell (CIC) method (e.g. Hockney & Eastwood 1988).
To generate the mock galaxy survey, we essentially need to simulate the inhomogeneous Poissonian process described by Eq. (2), by drawing random samples from the distribution, on top of the final density field 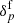 . In this work, we generate a mock data set with realistic features emulating the highly structured survey geometry and selection effects of the SDSS-III survey, with the observed sky completeness depicted in the left and right panels of Fig. 3, respectively, for the CMASS and LOW-Z components of the SDSS-III survey. To account for the different selection effects in the northern and southern galactic planes, each component is further divided into two subcatalogues, corresponding to north/south galactic caps (NGC/SGC). The respective radial selection functions for these four subcatalogues are illustrated in Fig. 4. Here, the selection functions are numerical estimates obtained by binning the corresponding distribution of tracers N(d) in the CMASS and LOW-Z components (e.g. Ross et al. 2017), where d is the comoving distance from the observer.
. In this work, we generate a mock data set with realistic features emulating the highly structured survey geometry and selection effects of the SDSS-III survey, with the observed sky completeness depicted in the left and right panels of Fig. 3, respectively, for the CMASS and LOW-Z components of the SDSS-III survey. To account for the different selection effects in the northern and southern galactic planes, each component is further divided into two subcatalogues, corresponding to north/south galactic caps (NGC/SGC). The respective radial selection functions for these four subcatalogues are illustrated in Fig. 4. Here, the selection functions are numerical estimates obtained by binning the corresponding distribution of tracers N(d) in the CMASS and LOW-Z components (e.g. Ross et al. 2017), where d is the comoving distance from the observer.
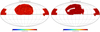 |
Fig. 3. Observed sky completeness, used to generate and analyse the mock catalogue in this work, are illustrated in the left and right panels, corresponding to the CMASS and LOW-Z components of the SDSS-III survey, respectively. |
 |
Fig. 4. Radial selection functions for the CMASS sample, in solid and dashed lines for the north galactic cap (NGC) and south galactic cap (SGC), respectively. The corresponding radial selection functions for the LOW-Z sample are depicted in dash-dotted (NGC) and dotted lines (SGC). These selection functions are used to generate the mock data to emulate features of the actual SDSS-III BOSS data. |
The projection of the completeness functions into the 3D volume produces the 3D observation mask 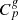 . The survey properties are described by the galaxy selection function and the 3D completeness function, with the product of these two functions yielding the survey response operator
. The survey properties are described by the galaxy selection function and the 3D completeness function, with the product of these two functions yielding the survey response operator 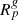 . More specifically, it is the average of the product of the 2D survey geometry
. More specifically, it is the average of the product of the 2D survey geometry 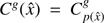 and the selection function f(x) at each volume element of the 3D grid:
and the selection function f(x) at each volume element of the 3D grid:
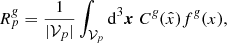 (10)
(10)
where the volume occupied by the pth voxel is indicated by 𝒱p, with |𝒱| the volume of the set 𝒱.
Finally, we generate the four artificial galaxy subcatalogues, labelled by g, by Poisson sampling on the grid with 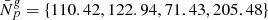 , resulting in a total number of 997828 galaxies. The values of
, resulting in a total number of 997828 galaxies. The values of 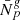 are chosen such that the mock catalogue reflects the characteristics of the actual SDSS-III data which contains around one million tracers.
are chosen such that the mock catalogue reflects the characteristics of the actual SDSS-III data which contains around one million tracers.
5. Results
We perform a series of tests to evaluate the performance of our algorithm in a realistic context by applying ALTAIR on the simulated SDSS-III-like galaxy catalogue described in the previous section. In particular, the focus is on the burn-in and convergence behaviour of our method, which are key indicators of the overall numerical feasibility and statistical efficiency for real data applications. To validate the conceptual framework for cosmological parameter inference and the robustness of our implementation of the AP test, the reproducibility of the input cosmology and the correlations with the other inferred quantities such as galaxy bias are also of interest.
The Markov chains for the cosmological parameters, displayed in Fig. 5, were initialised with an over-dispersed state. This figure consequently illustrates an initial burn-in phase, lasting ∼250 MCMC steps, where the Markov chains follow a persistent drift towards the high probability region of the parameter space. The rotation of the (Ωm, w0) parameter space before slice sampling, as described in Appendix F, reduces the burn-in period significantly, by roughly a factor of five, as shown in the right panel of Fig. F.1, resulting in improved sampling efficiency.
 |
Fig. 5. MCMC chains for the cosmological parameters, for the first 1000 samples, with the reference cosmology employed in the mock generation indicated by the horizontal dashed lines. An initial burn-in phase lasting ∼250 Markov transitions is illustrated by the coherent drift of the Markov chain towards the preferred region in parameter space. |
The corresponding marginal and joint posterior distributions for the cosmological parameters are displayed in Fig. 6, demonstrating the capability of ALTAIR to infer tight constraints from galaxy redshift surveys. This robust AP test fully exploits the high information content from the cosmic expansion as a result of probing a deep redshift range, where the distortion is more pronounced, yielding the following cosmological constraints: Ωm = 0.3080 ± 0.0036 and w0 = −0.998 ± 0.008. As a comparison, the SDSS-III (DR12, BAO + Planck) constraints are as follows: Ωm = 0.310 ± 0.005 and w0 = −1.01 ± 0.06 (Alam et al. 2017), further highlighting the significant constraining power of our AP test. We acknowledge the significant difference in the size of uncertainties. A back of the envelope computation of the information gain is as follows: Considering a sphere of 100 h−1 Mpc for BAO against all voxels in 4000 h−1 Mpc, NBAO = 40003/(4π × 1003/3) = 15 278, compared to Nvox = 1283, yields an improvement of 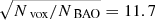 , which provides an order of magnitude of our uncertainties on the cosmological parameters. This is an approximate attempt to quantify the information gain from including smaller scales (in our work, ∼0.17 h−1 Mpc) than the BAO scale by essentially counting the number of modes. However, the above argument does not imply that employing finer resolutions will result in an infinite gain of information. There is a saturation of information at a certain resolution due to the slow variation in the density fields across neighbouring voxels, such that further refinement beyond this limit will not yield any additional information.
, which provides an order of magnitude of our uncertainties on the cosmological parameters. This is an approximate attempt to quantify the information gain from including smaller scales (in our work, ∼0.17 h−1 Mpc) than the BAO scale by essentially counting the number of modes. However, the above argument does not imply that employing finer resolutions will result in an infinite gain of information. There is a saturation of information at a certain resolution due to the slow variation in the density fields across neighbouring voxels, such that further refinement beyond this limit will not yield any additional information.
 |
Fig. 6. Marginal posteriors for Ωm (left panel) and the dark energy equation of state, w0 (middle panel), for ∼3000 MCMC realisations, ignoring the burn-in phase of ∼250 Markov steps. The corresponding mean and standard deviation for each parameter are indicated in the top right corner of each plot. The joint posterior (right panel) for Ωm and w0, depicting the high level of correlation between these two parameters. The highly informative distortion due to the cosmic expansion, as a result of probing a deep redshift range, yields extremely tight constraints on the above cosmological parameters. As a consistency test, this validates our implementation of the AP test to correctly recover the input cosmology. |
To verify that the cosmological information stems purely from the geometric distortion due to the cosmic expansion, that is, the AP test, we perform the following experiment: We deactivate the cosmic expansion component in our forward model and sample the cosmological parameters using only the LPT evolved density field. We consequently recover the corresponding prior distributions for the marginal posteriors of the cosmological parameters. As a result, this implies that the information derives purely from the geometry and not from the clustering of the non-linearly evolved density field, at least for the test case with the physical voxel size considered in this work.
The mean initial and final density fields computed from ∼4000 realisations (ignoring the burn-in phase) are illustrated in the left panel of Fig. 7 for a particular slice of the 3D field. The maps reveal that on average we can recover highly detailed and well-defined structures in the observed regions. In particular, the filamentary nature of the non-linearly evolved density field can be clearly seen, while the Gaussian nature of the initial conditions can also be deduced visually. However, in poorly or not observed regions, the ensemble mean density field approaches the cosmic mean density, as expected, since regions lacking any observational information should on average reflect the cosmic mean. The uncertainty in these regions is accurately accounted for in the inference process, as demonstrated by the right panel, since each sampled density field is a constrained realisation, which means that these regions are augmented with statistically correct information.
 |
Fig. 7. Mean and standard deviation maps for the initial (top panels) and final density fields (bottom panels), computed from the MCMC realisations, with the same slice through the 3D density fields being illustrated above. In unobserved or masked regions, the density fields are not constrained by data, and they average out to the cosmic mean density. However, in observed regions, the Gaussian nature of the initial conditions and the filamentary nature of the non-linearly evolved density field is manifest. The corresponding variance is therefore higher in regions devoid of data. |
In the top panel of Fig. 8, we illustrate the power spectra reconstructed from all the realisations of 3D initial density field, obtained from the posterior via the HMC sampler. This is a self-consistency test to confirm that the sampled density fields are in agreement with the reference (prior) power spectrum adopted for the mock generation, as substantiated quantitatively in the bottom panel, where the ratio of the a posteriori power spectra to the prior distribution is shown. The measured power spectra therefore demonstrate that the individual realisations possess the correct power throughout the entire domain of Fourier modes considered in this work. Moreover, they do not exhibit any spurious power artefacts typically resulting from erroneous treatment of survey characteristics, such as survey geometry and selection effects, and galaxy biases, implying that such effects have been properly accounted for.
 |
Fig. 8. Top panel: reconstructed power spectra from the inferred posterior initial density field realisations for all sampling steps of the Markov chain. The MCMC samples are colour-coded according to their sample number, as indicated by the colour bar. This is a self-consistency test to verify whether the sampled density fields are in accordance with the reference power spectrum, depicted in dashed lines, employed in the mock generation. Bottom panel: deviation from the true underlying solution, with the thick dashed lines representing the prior power spectrum. The thin grey and black dotted lines correspond to the Gaussian 1σ and 2σ limits, respectively. |
In order to verify the impact of the prior power spectrum on the actual inference of cosmological parameters, we illustrate, in Fig. 9, the distributions of power spectra computed using the inferred cosmology and the prior analytic prescription (Eisenstein & Hu 1998, 1999) and the reconstructed power spectra from Fig. 8, via their respective summary statistics, normalised with respect to the fiducial power spectrum. The scatter in the latter a posteriori power spectra reconstructed from the sampled density field realisations is significantly higher than distribution of the former prior spectra. This implies that the entropy of prior information is much lower than that of posterior information, thereby demonstrating that the prior power spectrum does not influence the cosmological parameter inference via the AP test and justifying the assumption made in Sect. 3.3.
 |
Fig. 9. Summary statistics of the reconstructed power spectra from the inferred posterior initial density field realisations depicted in Fig. 8, with the ensemble mean indicated by a solid green line. The solid blue line corresponds to the ensemble mean of the power spectra realisations generated using the inferred cosmological parameters. The shaded regions indicate their respective 1σ confidence region, i.e. 68% probability volume. This plot shows that the prior information entropy is inferior to the posterior information entropy, due to the narrower distribution of the former. The prior power spectrum adopted, as a result, does not impact significantly on the cosmological parameter inference via the AP test. |
We further demonstrate this robustness of our AP test by employing a modified prior power spectrum in the inference procedure. By adopting a different cosmology (Ωm = 0.40, w0 = −0.85), we modify the shape of the power spectrum, and subsequently apply ALTAIR on the same mock catalogue from Sect. 4. As shown in Fig. 10, we recover the fiducial cosmological parameters employed in the mock generation, although with slightly larger uncertainties than for the original run by roughly 15%. This test case therefore explicitly highlights the robustness of our implementation of the AP test to a misspecified model since it does not optimise the information from the scale dependence of the correlations of the density field, but rather from the isotropy of the field.
 |
Fig. 10. Same as Fig. 6, but employing a different prior power spectrum (Ωm = 0.40, w0 = −0.85), for ∼3000 MCMC realisations. By recovering the fiducial cosmological parameters employed in the mock generation, this test case explicitly highlights the robustness of our approach to the shape of the prior power spectrum adopted. The corresponding uncertainties are slightly larger than for the original run by around 15%. |
From the correlation matrix of Ωm, w0 and the galaxy bias parameters for each of the four subcatalogues, illustrated in Fig. 11, we deduce the extremely weak correlation between the cosmological constraints and the bias. This is a key positive aspect of our method, as galaxy bias remains nevertheless a highly active and challenging field of research (see, for e.g., Desjacques et al. 2018), due to its complex non-linear behaviour on intermediate and small scales, which may potentially limit the effectiveness of traditional methods of cosmological parameter inference (Pollina et al. 2018).
 |
Fig. 11. Correlation matrix of the galaxy bias and cosmological parameters, normalised using their respective variance. This illustrates the weak correlation between the inferred cosmological constraints and the galaxy bias. The lack of dependence on the currently unknown phenomenon of galaxy biasing is therefore a key highlight of our implementation of the AP test for cosmological parameter inference. |
Moreover, this insensitivity to the galaxy bias implies that our method does not rely on absolute density fluctuation amplitudes, but on the actual location of matter. This entails that our AP test exploits the geometrical structure of the density field and not its absolute amplitude since the power spectrum does not influence the inferred cosmological constraints. To the best of our knowledge, this is a novel aspect of cosmological inference, with most of our current understanding of cosmology based on measurements of density contrast amplitudes. We present, therefore, one of the first methods which extracts a large fraction of information from statistics other than that of direct density contrast correlations, without relying on the power spectrum or bispectrum. Our method consequently yields complementary information to state-of-the-art methods.
6. Summary and conclusions
We presented the implementation of a robust AP test that performs a detailed fit of the cosmological expansion via a non-linear and hierarchical Bayesian LSS inference framework. This forward modelling approach employs LPT as a physical description for the non-linear dynamics and sequentially encodes the cosmic expansion effect for joint inference of the cosmological parameters and underlying 3D density fields, while also fitting the mean density of tracers and bias parameters. In essence, this inference machinery explores the various cosmological expansion histories and selects the cosmology-dependent evolution pathways which yield isotropic correlations of the galaxy density field, thereby constraining cosmology.
We demonstrated the application of our algorithm ALTAIR on an artificially generated galaxy catalogue, consisting of four subcatalogues, that emulates the highly structured survey geometry and selection effects of SDSS-III. We performed a series of statistical efficiency and consistency tests to validate the methodology adopted and showcased its potential to yield tight constraints on cosmological parameters from current and future galaxy redshift surveys. The main strength of our implementation of the AP test lies in its robustness to a misspecified model and its inherent approximations, thereby near-optimally exploiting the model predictions, without relying on its accuracy in modelling the scale dependence of the correlations of the field.
Moreover, another key aspect of our approach, resulting from the robustness to a misspecified model, is that the cosmological constraints show extremely weak dependence on galaxy bias. This yields two crucial advantages. First, this is especially interesting as the lack of a sufficient physical description of this bias remains a potential limiting factor for standard approaches of cosmological parameter inference from such redshift surveys. Furthermore, this lack of sensitivity to the bias also implies that our method does not depend on the absolute density fluctuation amplitudes. This is therefore among the first methods to extract a large amount of information from statistics other than that of direct density contrast correlations, without relying on the power spectrum or bispectrum, thereby providing complementary information to state-of-the-art techniques.
There is scope for further development of the ALTAIR framework, such as incorporating power spectrum inference, which is a highly non-trivial undertaking. We also intend to augment the current formalism to include the treatment of redshift space distortions, which is key for unbiased constraints on the cosmological parameters, and apply ALTAIR on state-of-the-art galaxy redshift catalogues for cosmological inference1.
Acknowledgments
We express our appreciation to the anonymous reviewer for their constructive comments that helped us to improve the manuscript. We are grateful to Franz Elsner, Florent Leclercq and Natalia Porqueres for interesting discussions and/or for their comments on a draft version of the paper. We thank Tom Charnock for his help with coining the name ALTAIR in a coherent context. We also thank Jeremy Tinker for his assistance in interpreting the SDSS-III (DR12) science products. We acknowledge financial support from the ILP LABEX (under reference ANR-10-LABX-63) which is financed by French state funds managed by the ANR within the Investissements d’Avenir programme under reference ANR-11-IDEX-0004-02. This work was supported by the ANR BIG4 project, grant ANR-16-CE23-0002 of the French Agence Nationale de la Recherche. BDW is supported by the Simons Foundation. This work has made use of the Horizon/Beyond cluster at the Institut d’Astrophysique de Paris. This work is supported, through the maintenance of Horizon/Beyond cluster, under the name ORIGIN by the Domaine d’Intérêt Majeur (DIM) Astrophysique et Conditions d’Apparition de la Vie (ACAV), and received financial support from Région Île-de-France. We thank Stéphane Rouberol for running smoothly this cluster for us. This work is done within the Aquila Consortium.
References
- Abazajian, K. N., Adelman-McCarthy, J. K., Agüeros, M. A., et al. 2009, ApJS, 182, 543 [NASA ADS] [CrossRef] [Google Scholar]
- Ahn, C. P., Alexandroff, R., Allende Prieto, C., et al. 2014, ApJS, 211, 17 [NASA ADS] [CrossRef] [Google Scholar]
- Alam, S., Albareti, F. D., Allende Prieto, C., et al. 2015, ApJS, 219, 12 [NASA ADS] [CrossRef] [Google Scholar]
- Alam, S., Ata, M., Bailey, S., et al. 2017, MNRAS, 470, 2617 [NASA ADS] [CrossRef] [Google Scholar]
- Alcock, C., & Paczynski, B. 1979, Nature, 281, 358 [NASA ADS] [CrossRef] [Google Scholar]
- Amendola, L., Appleby, S., Avgoustidis, A., et al. 2018, Liv. Rev. Rel., 21, 2 [Google Scholar]
- Ballinger, W. E., Peacock, J. A., & Heavens, A. F. 1996, MNRAS, 282, 877 [NASA ADS] [CrossRef] [Google Scholar]
- Barkana, R. 2006, MNRAS, 372, 259 [NASA ADS] [CrossRef] [Google Scholar]
- Bertschinger, E., & Dekel, A. 1989, ApJ, 336, L5 [NASA ADS] [CrossRef] [Google Scholar]
- Bertschinger, E., & Dekel, A. 1991, in Large-scale Structures and Peculiar Motions in the Universe, eds. D. W. Latham, & L. A. N. da Costa, ASP Conf. Ser., 15, 67 [NASA ADS] [Google Scholar]
- Bistolas, V., & Hoffman, Y. 1998, ApJ, 492, 439 [NASA ADS] [CrossRef] [Google Scholar]
- Blake, C., & Glazebrook, K. 2003, ApJ, 594, 665 [NASA ADS] [CrossRef] [Google Scholar]
- Blake, C., Glazebrook, K., Davis, T. M., et al. 2011, MNRAS, 418, 1725 [NASA ADS] [CrossRef] [Google Scholar]
- Bouchet, F. R., Colombi, S., Hivon, E., & Juszkiewicz, R. 1995, A&A, 296, 575 [NASA ADS] [Google Scholar]
- Buchert, T., Melott, A. L., & Weiss, A. G. 1994, A&A, 288, 349 [NASA ADS] [Google Scholar]
- Chevallier, M., & Polarski, D. 2001, Int. J. Mod. Phys. D, 10, 213 [NASA ADS] [CrossRef] [Google Scholar]
- Coles, P., & Jones, B. 1991, MNRAS, 248, 1 [NASA ADS] [CrossRef] [Google Scholar]
- de Laix, A. A., & Starkman, G. 1998, ApJ, 501, 427 [NASA ADS] [CrossRef] [Google Scholar]
- Desjacques, V., Jeong, D., & Schmidt, F. 2018, Phys. Rep., 733, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Duane, S., Kennedy, A. D., Pendleton, B. J., & Roweth, D. 1987, Phys. Lett. B, 195, 216 [NASA ADS] [CrossRef] [Google Scholar]
- Eisenstein, D. J., & Hu, W. 1998, ApJ, 496, 605 [NASA ADS] [CrossRef] [Google Scholar]
- Eisenstein, D. J., & Hu, W. 1999, ApJ, 511, 5 [NASA ADS] [CrossRef] [Google Scholar]
- Erdoǧdu, P., Lahav, O., Zaroubi, S., et al. 2004, MNRAS, 352, 939 [NASA ADS] [CrossRef] [Google Scholar]
- Erdoǧdu, P., Lahav, O., Huchra, J. P., et al. 2006, MNRAS, 373, 45 [NASA ADS] [CrossRef] [Google Scholar]
- Fisher, K. B., Lahav, O., Hoffman, Y., Lynden-Bell, D., & Zaroubi, S. 1995, MNRAS, 272, 885 [NASA ADS] [Google Scholar]
- Friedmann, A. 1922, Z. Angew. Phys., 10, 377 [Google Scholar]
- Friedmann, A. 1924, Z. Angew. Phys., 21, 326 [Google Scholar]
- Frigo, M., & Johnson, S. G. 2005, Proc. IEEE, 93, 216 [Google Scholar]
- Galassi, M., Davies, J., Theiler, J., et al. 2009, GNU Scientific Library reference manual Network Theory (UK: Bristol) [Google Scholar]
- Gaztanaga, E., & Yokoyama, J. 1993, ApJ, 403, 450 [NASA ADS] [CrossRef] [Google Scholar]
- Glazebrook, K., & Blake, C. 2005, ApJ, 631, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Hamaus, N., Sutter, P. M., Lavaux, G., & Wandelt, B. D. 2014, J. Cosmol. Astropart. Phys., 12, 013 [NASA ADS] [CrossRef] [Google Scholar]
- Hamaus, N., Sutter, P. M., Lavaux, G., & Wandelt, B. D. 2015, J. Cosmol. Astropart. Phys., 11, 036 [NASA ADS] [CrossRef] [Google Scholar]
- Hamaus, N., Pisani, A., Sutter, P. M., et al. 2016, Phys. Rev. Lett., 117, 091302 [NASA ADS] [CrossRef] [Google Scholar]
- Hastings, W. K. 1970, Biometrika, 57, 97 [Google Scholar]
- Hockney, R. W., & Eastwood, J. W. 1988, Computer simulation using particles (New York, London: Taylor & Francis) [Google Scholar]
- Hoffman, Y. 1994, in Unveiling Large-Scale Structures Behind the Milky Way, eds. C. Balkowski, & R. C. Kraan-Korteweg, ASP Conf. Ser., 67, 185 [Google Scholar]
- Hubble, E. 1934, ApJ, 79, 8 [NASA ADS] [CrossRef] [Google Scholar]
- Hui, L., Stebbins, A., & Burles, S. 1999, ApJ, 511, L5 [NASA ADS] [CrossRef] [Google Scholar]
- Ivezic, Z., Tyson, J. A., & Abel, B. 2008, ArXiv e-prints [arXiv:0805.2366] [Google Scholar]
- Jasche, J., & Kitaura, F. S. 2010, MNRAS, 407, 29 [NASA ADS] [CrossRef] [Google Scholar]
- Jasche, J., & Lavaux, G. 2015, MNRAS, 447, 1204 [NASA ADS] [CrossRef] [Google Scholar]
- Jasche, J., & Lavaux, G. 2018, ArXiv e-prints [arXiv:1806.11117] [Google Scholar]
- Jasche, J., & Wandelt, B. D. 2012, MNRAS, 425, 1042 [NASA ADS] [CrossRef] [Google Scholar]
- Jasche, J., & Wandelt, B. D. 2013a, MNRAS, 432, 894 [NASA ADS] [CrossRef] [Google Scholar]
- Jasche, J., & Wandelt, B. D. 2013b, ApJ, 779, 15 [NASA ADS] [CrossRef] [Google Scholar]
- Jasche, J., Kitaura, F. S., Wandelt, B. D., & Enßlin, T. A. 2010a, MNRAS, 406, 60 [NASA ADS] [CrossRef] [Google Scholar]
- Jasche, J., Kitaura, F. S., Li, C., & Enßlin, T. A. 2010b, MNRAS, 409, 355 [NASA ADS] [CrossRef] [Google Scholar]
- Jasche, J., Leclercq, F., & Wandelt, B. D. 2015, J. Cosmol. Astropart. Phys., 1, 036 [CrossRef] [Google Scholar]
- Jones, D. H., Read, M. A., Saunders, W., et al. 2009, MNRAS, 399, 683 [NASA ADS] [CrossRef] [Google Scholar]
- Kaiser, N. 1984, ApJ, 284, L9 [NASA ADS] [CrossRef] [Google Scholar]
- Kayo, I., Taruya, A., & Suto, Y. 2001, ApJ, 561, 22 [NASA ADS] [CrossRef] [Google Scholar]
- Kitaura, F.-S. 2012, MNRAS, 420, 2737 [NASA ADS] [CrossRef] [Google Scholar]
- Kitaura, F. S., & Enßlin, T. A. 2008, MNRAS, 389, 497 [NASA ADS] [CrossRef] [Google Scholar]
- Kitaura, F. S., Jasche, J., Li, C., et al. 2009, MNRAS, 400, 183 [NASA ADS] [CrossRef] [Google Scholar]
- Kitaura, F.-S., Jasche, J., & Metcalf, R. B. 2010, MNRAS, 403, 589 [NASA ADS] [CrossRef] [Google Scholar]
- Kitaura, F.-S., Gallerani, S., & Ferrara, A. 2012, MNRAS, 420, 61 [NASA ADS] [CrossRef] [Google Scholar]
- Komatsu, E., Smith, K. M., Dunkley, J., et al. 2011, ApJS, 192, 18 [NASA ADS] [CrossRef] [Google Scholar]
- Lahav, O., Fisher, K. B., Hoffman, Y., Scharf, C. A., & Zaroubi, S. 1994, ApJ, 423, L93 [NASA ADS] [CrossRef] [Google Scholar]
- Laureijs, R., Amiaux, J., & Arduini, S. 2011, ArXiv e-prints [arXiv:1110.3193] [Google Scholar]
- Lavaux, G., & Jasche, J. 2016, MNRAS, 455, 3169 [NASA ADS] [CrossRef] [Google Scholar]
- Lavaux, G., & Wandelt, B. D. 2012, ApJ, 754, 109 [NASA ADS] [CrossRef] [Google Scholar]
- Layzer, D. 1956, AJ, 61, 383 [NASA ADS] [CrossRef] [Google Scholar]
- Lekien, F., & Marsden, J. 2005, J. Numer. Methods Eng., 63, 455 [Google Scholar]
- Lemaître, G. 1927, Ann Soc. Sci. Bruxelles, 47, 49 [Google Scholar]
- Lemaître, G. 1931, MNRAS, 91, 483 [NASA ADS] [Google Scholar]
- Lemaître, G. 1933, Ann Soc. Sci. Bruxelles, 53 [Google Scholar]
- Li, X.-D., Park, C., Forero-Romero, J. E., & Kim, J. 2014, ApJ, 796, 137 [NASA ADS] [CrossRef] [Google Scholar]
- Li, X.-D., Park, C., Sabiu, C. G., et al. 2016, ApJ, 832, 103 [NASA ADS] [CrossRef] [Google Scholar]
- Linde, A. 2008, Inflationary cosmology (Berlin, Heidelberg: Springer), 1 [Google Scholar]
- Linder, E. V. 2003, Phys. Rev. Lett., 90, 091301 [NASA ADS] [CrossRef] [PubMed] [Google Scholar]
- López-Corredoira, M. 2014, ApJ, 781, 96 [NASA ADS] [CrossRef] [Google Scholar]
- Matsubara, T., & Suto, Y. 1996, ApJ, 470, L1 [NASA ADS] [CrossRef] [Google Scholar]
- Matsumoto, M., & Nishimura, T. 1998, ACM Trans. Modeling Comput. Simulation, 8, 3 [CrossRef] [Google Scholar]
- Moutarde, F., Alimi, J.-M., Bouchet, F. R., Pellat, R., & Ramani, A. 1991, ApJ, 382, 377 [NASA ADS] [CrossRef] [Google Scholar]
- Mukherjee, S., & Wandelt, B. D. 2018, Phys. Rev. Lett. submitted [arXiv:1808.06615] [Google Scholar]
- Neal, R. 2000, Ann. Stat., 31, 705 [CrossRef] [Google Scholar]
- Neal, R. M. 1993, Technical Report CRG-TR-93-1 [Google Scholar]
- Neal, R. M. 2003, Ann. Stat., 705 [Google Scholar]
- Neyrinck, M. C., Aragón-Calvo, M. A., Jeong, D., & Wang, X. 2014, MNRAS, 441, 646 [NASA ADS] [CrossRef] [Google Scholar]
- Nusser, A. 2005, MNRAS, 364, 743 [NASA ADS] [CrossRef] [Google Scholar]
- Nusser, A., & Dekel, A. 1992, ApJ, 391, 443 [NASA ADS] [CrossRef] [Google Scholar]
- Padmanabhan, N., & White, M. 2008, Phys. Rev. D, 77, 123540 [NASA ADS] [CrossRef] [Google Scholar]
- Peebles, P. J. E. 1980, The large-scale structure of the universe (Princeton: Princeton University Press) [Google Scholar]
- Phillipps, S. 1994, MNRAS, 269, 1077 [NASA ADS] [CrossRef] [Google Scholar]
- Planck Collaboration XIII. 2016, A&A, 594, A13 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration XVII. 2016, A&A, 594, A17 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pollina, G., Hamaus, N., & Paech, K. 2018, MNRAS, submitted [arXiv:1806.06860] [Google Scholar]
- Popowski, P. A., Weinberg, D. H., Ryden, B. S., & Osmer, P. S. 1998, ApJ, 498, 11 [NASA ADS] [CrossRef] [Google Scholar]
- Racca, G. D., Laureijs, R., & Stagnaro, L. 2016, in SPIE Conf. Ser., Proc. SPIE, 9904, 99040O [Google Scholar]
- Robertson, H. P. 1935, ApJ, 82, 284 [NASA ADS] [CrossRef] [Google Scholar]
- Robertson, H. P. 1936a, ApJ, 83, 187 [NASA ADS] [CrossRef] [Google Scholar]
- Robertson, H. P. 1936b, ApJ, 83, 257 [NASA ADS] [CrossRef] [Google Scholar]
- Ross, A. J., Beutler, F., Chuang, C.-H., et al. 2017, MNRAS, 464, 1168 [NASA ADS] [CrossRef] [Google Scholar]
- Ryden, B. S. 1995, ApJ, 452, 25 [NASA ADS] [CrossRef] [Google Scholar]
- Saadeh, D., Feeney, S. M., Pontzen, A., Peiris, H. V., & McEwen, J. D. 2016, Phys. Rev. Lett., 117, 131302 [NASA ADS] [CrossRef] [PubMed] [Google Scholar]
- Saunders, W., & Ballinger, W. E. 2000, in Mapping the Hidden Universe: The Universe behind the Mily Way - The Universe in HI, eds. R. C. Kraan-Korteweg, P. A. Henning, & H. Andernach, ASP Conf. Ser., 218, 181 [NASA ADS] [Google Scholar]
- Schmidt, F., Elsner, F., Jasche, J., Nguyen, N. M., & Lavaux, G. 2018, ArXiv e-prints [arXiv:1808.02002] [Google Scholar]
- Schmoldt, I. M., Saar, V., Saha, P., et al. 1999, AJ, 118, 1146 [NASA ADS] [CrossRef] [Google Scholar]
- Scoccimarro, R. 2000, ApJ, 544, 597 [NASA ADS] [CrossRef] [Google Scholar]
- Scoccimarro, R., & Sheth, R. K. 2002, MNRAS, 329, 629 [NASA ADS] [CrossRef] [Google Scholar]
- Seo, H.-J., & Eisenstein, D. J. 2003, ApJ, 598, 720 [NASA ADS] [CrossRef] [Google Scholar]
- Sheth, R. K. 1995, MNRAS, 277, 933 [NASA ADS] [CrossRef] [Google Scholar]
- Shoji, M., Jeong, D., & Komatsu, E. 2009, ApJ, 693, 1404 [NASA ADS] [CrossRef] [Google Scholar]
- Sutter, P. M., Lavaux, G., Wandelt, B. D., & Weinberg, D. H. 2012, ApJ, 761, 187 [NASA ADS] [CrossRef] [Google Scholar]
- Sutter, P. M., Pisani, A., Wandelt, B. D., & Weinberg, D. H. 2014, MNRAS, 443, 2983 [NASA ADS] [CrossRef] [Google Scholar]
- Taylor, J. F., Ashdown, M. A. J., & Hobson, M. P. 2008, MNRAS, 389, 1284 [NASA ADS] [CrossRef] [Google Scholar]
- Tegmark, M., Blanton, M. R., Strauss, M. A., et al. 2004, ApJ, 606, 702 [NASA ADS] [CrossRef] [Google Scholar]
- Walker, A. G. 1937, Proc. London Math. Soc., 42, 90 [NASA ADS] [CrossRef] [Google Scholar]
- Wang, L., & Steinhardt, P. J. 1998, ApJ, 508, 483 [NASA ADS] [CrossRef] [Google Scholar]
- Webster, M., Lahav, O., & Fisher, K. 1997, MNRAS, 287, 425 [NASA ADS] [CrossRef] [Google Scholar]
- York, D. G., Adelman, J., Anderson, Jr., J. E., et al. 2000, AJ, 120, 1579 [CrossRef] [Google Scholar]
- Zaroubi, S. 2002, MNRAS, 331, 901 [NASA ADS] [CrossRef] [Google Scholar]
- Zaroubi, S., Hoffman, Y., & Dekel, A. 1999, ApJ, 520, 413 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: The LPT-Poissonian posterior
In this section, we describe the large-scale structure (LSS) posterior distribution implemented in this work. We demonstrate how the complex problem of exploring the high dimensional joint posterior distribution can be reduced to a set of distinct steps via a multiple block sampling scheme.
A.1. The density posterior distribution
The primary objective is to fully characterise the 3D cosmic LSS in observations via a numerical representation of the corresponding LSS posterior using sophisticated Markov chain Monte Carlo (MCMC) techniques, in particular to provide data constrained realisations of a set of plausible 3D density contrast amplitudes underlying a given set of galaxy observations. The posterior distribution for the evolved density field fluctuation 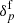 can be formulated, in a general context, via Bayes’ identity as:
can be formulated, in a general context, via Bayes’ identity as:
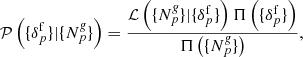 (A.1)
(A.1)
where 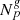 is the observed number of galaxies in voxel p, at position xp in the sky, in redshift space, for the gth galaxy sample, with the prior
is the observed number of galaxies in voxel p, at position xp in the sky, in redshift space, for the gth galaxy sample, with the prior 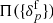 incorporating our a priori knowledge of the present-day matter fluctuations in the Universe, the likelihood
incorporating our a priori knowledge of the present-day matter fluctuations in the Universe, the likelihood 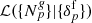 and the normalizing factor given by the evidence
and the normalizing factor given by the evidence 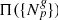 .
.
A major stumbling block consequently arises, as discussed extensively in Jasche & Wandelt (2013a), since the inference framework requires a suitable prior 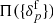 which adequately describes the physical behaviour of the gravitationally evolved density field. Nevertheless, as elaborated in the following section, most attempts made in this direction so far have been based on heuristic approximations and the absence of a closed form description of the present day matter fluctuations encoded in a multi-variate probability density distribution still persists.
which adequately describes the physical behaviour of the gravitationally evolved density field. Nevertheless, as elaborated in the following section, most attempts made in this direction so far have been based on heuristic approximations and the absence of a closed form description of the present day matter fluctuations encoded in a multi-variate probability density distribution still persists.
However, Jasche & Wandelt (2013a) proposed an elegant approach to circumvent this key impediment based on the following assertions: There is substantial evidence that primordial seed fluctuations at redshifts z ∼ 1000 can be modelled as a Gaussian random field to great accuracy (e.g. Linde 2008; Komatsu et al. 2011; Planck Collaboration XVII 2016), consistent with inflationary theories and CMB observations. Moreover, the evolution of the initial conditions relies solely on deterministic gravitational structure formation processes. Therefore, a conceptually reasonable alternative to modelling the complex statistical behaviour of the non-linear matter distribution is to formulate the inference problem at the level of the initial conditions adequately described by Gaussian statistics. This constitutes the conceptual foundation of the BORG framework (Jasche & Wandelt 2013a).
Given a forward model ℳp that connects the initial conditions 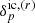 , in comoving (r) space, to the redshift (z) space representation of the final density field
, in comoving (r) space, to the redshift (z) space representation of the final density field 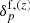 , we can therefore express the conditional posterior for the evolved density field as
, we can therefore express the conditional posterior for the evolved density field as
![Mathematical equation: $$ \begin{aligned} \mathcal{P} \left( \{ \delta ^{\mathrm{f}}_{p} \} | \{ {\delta }_{p}^{\mathrm{ic}} \} \right) = \prod _{p} \delta ^{\mathrm{D}} \left[ \delta ^{\mathrm{f}}_{p} - {\mathcal{M} }_{p} \left( \{ {\delta }_{p}^{\mathrm{ic}} \} \right) \right] , \end{aligned} $$](/articles/aa/full_html/2019/01/aa34117-18/aa34117-18-eq44.gif) (A.2)
(A.2)
where δD(x) denoting the Dirac delta distribution encapsulates the assumption that the structure formation process is deterministic. Within this generic framework, the forward model may be generalised to a chain of arbitrary components linking the primordial density fluctuations to the present-day density contrast. Nevertheless, at its crux lies a cosmic structure formation model 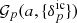 for the non-linear evolution of initial conditions into a final density field at a given scale factor a, that is,
for the non-linear evolution of initial conditions into a final density field at a given scale factor a, that is, 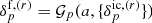 . The forward model implemented in this work to encode the AP test is described in Sect. 3 above.
. The forward model implemented in this work to encode the AP test is described in Sect. 3 above.
We can then obtain a prior distribution for 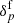 via a two-step sampling procedure: First, a realisation of
via a two-step sampling procedure: First, a realisation of 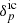 is generated from the prior distribution
is generated from the prior distribution 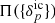 and subsequently evolved with a given forward model
and subsequently evolved with a given forward model 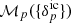 . This essentially implies generating samples from the joint prior distribution of
. This essentially implies generating samples from the joint prior distribution of 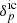 and
and 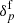 :
:
![Mathematical equation: $$ \begin{aligned} \mathcal{P} \left( \{ \delta ^{\mathrm{f}}_{p} \} , \{ {\delta }_{p}^{\mathrm{ic}} \} \right)&= \Pi \left( \{ {\delta }_{p}^{\mathrm{ic}} \} \right) \mathcal{P} \left( \{ \delta ^{\mathrm{f}}_{p} \} | \{ {\delta }_{p}^{\mathrm{ic}} \} \right) \nonumber \\&= \Pi \left( \{ {\delta }_{p}^{\mathrm{ic}} \} \right) \prod _{p} \delta ^{\mathrm{D}} \left[ \delta ^{\mathrm{f}}_{p} - {\mathcal{M} }_{p} \left( \{ {\delta }_{p}^{\mathrm{ic}} \} \right) \right] , \end{aligned} $$](/articles/aa/full_html/2019/01/aa34117-18/aa34117-18-eq53.gif) (A.3)
(A.3)
after plugging in the conditional posterior distribution from Eq. (A.2).
Assuming a normal distribution with zero mean and covariance S corresponding to an underlying cosmological power spectrum for the initial conditions 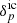 , the joint prior distribution can be expressed as
, the joint prior distribution can be expressed as
![Mathematical equation: $$ \begin{aligned} \mathcal{P} \left( \{ \delta ^{\mathrm{f}}_{p} \} , \{ {\delta }_{p}^{\mathrm{ic}} \} |\, \mathbf S \right)&= \Pi \left( \{ {\delta }_{p}^{\mathrm{ic}} \} |\, \mathbf S \right) \prod _{p} \delta ^{\mathrm{D}} \left[ \delta ^{\mathrm{f}}_{p} - {\mathcal{M} }_{p} \left( \{ {\delta }_{p}^{\mathrm{ic}} \} \right) \right] \nonumber \\&= \frac{\mathrm{e}^{- \frac{1}{2} \sum _{p,q} {\delta }_{p}^{\mathrm{ic}} \mathbf S ^{-1}\delta _q^{\mathrm{ic} }}}{\mathrm{det}(2 \pi \, \mathbf S )} \prod _{p} \delta ^{\mathrm{D}} \left[ \delta ^{\mathrm{f}}_{p} - {\mathcal{M} }_{p} \left( \{ {\delta }_{p}^{\mathrm{ic}} \} \right) \right] . \end{aligned} $$](/articles/aa/full_html/2019/01/aa34117-18/aa34117-18-eq55.gif) (A.4)
(A.4)
Reformulating the statistical inference problem in terms of the initial conditions 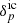 results in the following joint posterior distribution of
results in the following joint posterior distribution of 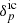 and
and 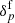 , conditional on the observed galaxy number counts
, conditional on the observed galaxy number counts 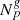 ,
,
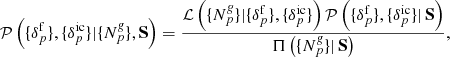 (A.5)
(A.5)
after making the dependence on the underlying power spectrum explicit. Assuming that the galaxy observations are conditionally independent of the initial conditions once the final density field is known, that is, 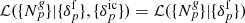 and using the joint prior distribution from Eq. (A.4) leads to the LSS posterior distribution:
and using the joint prior distribution from Eq. (A.4) leads to the LSS posterior distribution:
![Mathematical equation: $$ \begin{aligned} \mathcal{P} \left( \{ {\delta }_{p}^{\mathrm{f}} \}, \{ {\delta }_{p}^{\mathrm{ic}} \} | \{ {N}^{\textit{g}}_{p} \}, \mathbf S \right)&= \mathcal{L} \left( \{ {N}^{\textit{g}}_{p} \} | \{ {\delta }_{p}^{\mathrm{f}} \} \right) \frac{\Pi \left( \{ {\delta }_{p}^{\mathrm{ic}} \} |\, \mathbf S \right)}{\Pi \left( \{ {N}^{\textit{g}}_{p} \} |\, \mathbf S \right)} \nonumber \\&\times \prod _{p} \delta ^{\mathrm{D}} \left[ \delta ^{\mathrm{f}}_{p} - {\mathcal{M} }_{p} \left( \{ {\delta }_{p}^{\mathrm{ic}} \} \right) \right] . \end{aligned} $$](/articles/aa/full_html/2019/01/aa34117-18/aa34117-18-eq62.gif) (A.6)
(A.6)
By marginalizing over the final density field 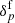 , we finally obtain our posterior distribution as follows:
, we finally obtain our posterior distribution as follows:
![Mathematical equation: $$ \begin{aligned} \mathcal{P} \left( \{ {\delta }_{p}^{\mathrm{ic}} \} | \{ {N}^{\textit{g}}_{p} \}, \mathbf S \right) = \mathcal{L} \left[ \{ {N}^{\textit{g}}_{p} \} \big | {\mathcal{M} }_{p} \left(\{ {\delta }_{p}^{\mathrm{ic}} \}\right) \right] \frac{\Pi \left( \{ {\delta }_{p}^{\mathrm{ic}} \} |\, \mathbf S \right) }{\Pi \left( \{ {N}^{\textit{g}}_{p} \} | \, \mathbf S \right)} , \end{aligned} $$](/articles/aa/full_html/2019/01/aa34117-18/aa34117-18-eq64.gif) (A.7)
(A.7)
thereby connecting present galaxy observations 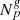 to their corresponding primordial density fields
to their corresponding primordial density fields 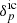 via a given forward model,
via a given forward model, 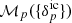 . We must therefore sample from the highly non-linear and non-Gaussian posterior above to obtain realisations of the 3D initial density fields conditioned on the galaxy observations via the sophisticated HMC method described below in Appendix C.
. We must therefore sample from the highly non-linear and non-Gaussian posterior above to obtain realisations of the 3D initial density fields conditioned on the galaxy observations via the sophisticated HMC method described below in Appendix C.
A.2. Choice of density prior
Standard Wiener filtering approaches employ isotropic Gaussian priors on the present-day density contrast which is justified for inference on the largest scales (e.g. Zaroubi et al. 1999; Zaroubi 2002; Erdoǧdu et al. 2004, 2006; Kitaura & Enßlin 2008; Kitaura et al. 2009; Jasche et al. 2010a; Jasche & Lavaux 2015), where the density field can be reasonably approximated as a Gaussian random field. Although the exact probability distribution for the density field in the mildly and strongly non-linear regimes is not known, the deviation from Gaussianity is well-established and we therefore require a non-Gaussian prior to effectively capture the details of the highly complex filamentary nature of the present day cosmic web.
Lognormal density priors were subsequently proposed (Coles & Jones 1991) and this proved to be an adequatephenomenological choice (e.g. Hubble 1934; Peebles 1980; Gaztanaga & Yokoyama 1993; Kayo et al. 2001), albeit withsome limitations, for modelling the evolved matter field in the mildly non-linear regime (Kitaura et al. 2009; Jasche et al. 2010; Jasche et al. 2010b). The use of Edgeworth expansions to construct prior distributions involving third order moments has also been proposed in the literature (Kitaura 2012).
In this work, we rely on Lagrangian perturbation theory (LPT) to model cosmic structure formation, which accounts for non-local effects of gravitational mass transport from initial to final positions. It has been extensively shown that LPT provides a sufficient description of the cosmic LSS on large scales, where it is capable of reproducing the exact one-, two- and three-point statistics of the evolved field, while still being a reasonable approximation to the higher order statistics (e.g. Moutarde et al. 1991; Buchert et al. 1994; Bouchet et al. 1995; Scoccimarro 2000; Scoccimarro & Sheth 2002).
The essence of the above approach is that it provides a pathway to recover the high-order statistics of the matterdistribution using only the 2-point statistics of the initial conditions, obviating the need for additional parameters to describe higher order statistics for the matter inference problem.Moreover, since our model encodes the dynamics, the reconstruction of the large-scale velocity field is automatically generated without incurring the expense of an increased parameter space.
A.3. Modular statistical programming
In this work, we exploit the modular statistical programming framework inherent in the BORG algorithm to encode the AP test as an additional component to the original block sampling machinery. This approach allows us to model any Bayesian hierarchical problem to take into account any observational systematics via data models of higher complexity. Here, we account for the unknown parameters 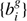 of the galaxy bias model described in Sect. 3.1 and unknown normalisations {N̄g} for distinct galaxy samples, as illustrated in Fig. A.1. These last normalisations, in practice, scale as the noise amplitudes as we are using a per-voxel Poissonian likelihood.
of the galaxy bias model described in Sect. 3.1 and unknown normalisations {N̄g} for distinct galaxy samples, as illustrated in Fig. A.1. These last normalisations, in practice, scale as the noise amplitudes as we are using a per-voxel Poissonian likelihood.
Conceptually, within such a framework, the overall aim is to characterise fully the augmented joint posterior 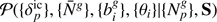 of different tracer populations labelled by the index g. Since it is not computationally feasible and advisable to sample directly from the high dimensional joint posterior distribution, we make use of an important theorem on Metropolis-Hastings block sampling which allows us to break the high dimensional sampling problem into a series of lower dimensional ones (Hastings 1970). We therefore dissect the exploration of the full joint parameter space into a sequence of conditional sampling procedures. The block sampling approach consists of drawing samples from the following conditional probability distributions:
of different tracer populations labelled by the index g. Since it is not computationally feasible and advisable to sample directly from the high dimensional joint posterior distribution, we make use of an important theorem on Metropolis-Hastings block sampling which allows us to break the high dimensional sampling problem into a series of lower dimensional ones (Hastings 1970). We therefore dissect the exploration of the full joint parameter space into a sequence of conditional sampling procedures. The block sampling approach consists of drawing samples from the following conditional probability distributions:
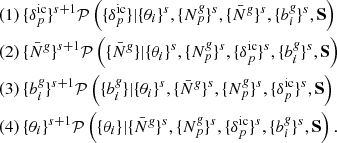 (A.8)
(A.8)
 |
Fig. A.1. Schematic representation of the multi-step iterative block sampling procedure implemented in ALTAIR. Initially, a realisation of the 3D density contrast is obtained conditional on galaxy observations, followed by the other parameters being sampled conditional on the respective previous samples. Subsequent iterations of this procedure yield samples from the full joint posterior distribution within a modular statistical programming framework. |
In the above expressions, s denotes the sampling step and the symbol ↶ indicates sampling from the distribution on the right hand side. A series of iterations of the individual sampling steps above will converge to the target distribution which corresponds the full joint posterior distribution (Hastings 1970). Hence, by simultaneously exploring the 3D initial density field 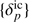 , the galaxy bias parameters
, the galaxy bias parameters 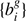 , the galaxy density contrast normalisations {N̄g} and the cosmological parameters {θi} via an implementation of high dimensional MCMC methods in a multiple block sampling procedure, we can obtain samples from the desired joint posterior distribution.
, the galaxy density contrast normalisations {N̄g} and the cosmological parameters {θi} via an implementation of high dimensional MCMC methods in a multiple block sampling procedure, we can obtain samples from the desired joint posterior distribution.
A.4. The bias posterior distribution
The formalism for the data model is presented in a generic context in Sect. 3.1, such that it can be implemented for two or more different galaxy surveys, distinct subsamples of a given catalogue or even different cosmological probes of the LSS. The advantage of splitting a galaxy sample into various subsamples is that we can treat the respective systematic and statistical uncertainties of each subsample separately, thereby allowing us to account for the distinct clustering behaviour of galaxy populations in the LSS sample via their respective bias parameters.
These additional parameters can be trivially incorporated in the flexible block sampling approach adopted here, as described in Sect. A.3. The mean numbers of galaxies, N̄g, for the various subsamples are essential for defining the density contrast of the galaxy distribution, with an erroneous value of N̄g resulting in a non-zero value of the mean, yielding spurious large-scale power in the inferred density fields (Jasche & Wandelt 2013b). Due to a lack of a priori knowledge, we must perform a joint inference of the set of four N̄g and  bias parameters, together with initial and final density fields, to take into account possible cross-correlations and interdependencies. Unlike traditional approaches (e.g. Tegmark et al. 2004), here we infer the bias factors directly from the relation between the data and the density field.
bias parameters, together with initial and final density fields, to take into account possible cross-correlations and interdependencies. Unlike traditional approaches (e.g. Tegmark et al. 2004), here we infer the bias factors directly from the relation between the data and the density field.
The conditional posterior distribution for the bias parameters, given a realisation of the density field and galaxy number counts for the respective subcatalogues, can be expressed as:
![Mathematical equation: $$ \begin{aligned} \mathcal{P} \left( \{\bar{N}^{\textit{g}}\}, \{b_{i}^{\textit{g}}\} | \{ \theta _{i} \}, \{{N}^{\textit{g}}_{p}\}, \{ {\delta }_{p}^{\mathrm{ic}} \} \right)&\propto \mathcal{L} \left[\{{N}^{\textit{g}}_{p}\}\big | {\mathcal{M} }_{p} \left(\{ {\delta }_{p}^{\mathrm{ic}} \} \right), \{ \theta _{i} \}, \{\bar{N}^{\textit{g}}\}, \{b_{i}^{\textit{g}}\} \right] \nonumber \\&\quad \times \Pi \left( \{\bar{N}^{\textit{g}}\}, \{b_{i}^{\textit{g}}\} \right), \end{aligned} $$](/articles/aa/full_html/2019/01/aa34117-18/aa34117-18-eq74.gif) (A.9)
(A.9)
following an analogous reasoning to that described in Sect. 3.3. Adopting a standard maximally agnostic philosophy, we set uniform prior distributions for the bias parameters:
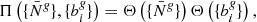 (A.10)
(A.10)
where the Heaviside function Θ(x) ensures that the parameters are positive, as required by the bias model. The non-linear shape of the galaxy biasing function, as given in Eq. (4), poses a particular challenge as no straightforward sampling procedure can be derived. We therefore sample from the above conditional bias posterior distribution via sequential slice sampling steps (e.g. Neal 2000, 2003) to ensure unit acceptance rates.
Appendix B: Jacobian of comoving-redshift transformation
The derivation of the Jacobian, 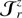 , of the coordinate transformation between comoving (r) and redshift (z) transformation is described below.
, of the coordinate transformation between comoving (r) and redshift (z) transformation is described below.
Since we desire the redshift space representation of the density field,
![Mathematical equation: $$ \begin{aligned} \rho _{z} [{\boldsymbol{z}}({\boldsymbol{r}})] = \rho _r({\boldsymbol{r}}) \left| \frac{\partial z}{\partial r} \right|^{-1} = \rho _r({\boldsymbol{r}}) \big | {\boldsymbol{\mathcal{J} }}^{r}_{z} \big |^{-1} = \rho _r({\boldsymbol{r}}) \big | \boldsymbol{\mathcal{J} }^{z}_{r} \big | , \end{aligned} $$](/articles/aa/full_html/2019/01/aa34117-18/aa34117-18-eq77.gif) (B.1)
(B.1)
or in terms of the density contrast,
![Mathematical equation: $$ \begin{aligned} \delta _{z} [{\boldsymbol{z}}({\boldsymbol{r}})] = [1 + \delta _r({\boldsymbol{r}})] \big | \boldsymbol{\mathcal{J} }^{z}_{r} \big | - 1 , \end{aligned} $$](/articles/aa/full_html/2019/01/aa34117-18/aa34117-18-eq78.gif) (B.2)
(B.2)
where 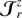 is the corresponding Jacobian for the converse (redshift to comoving) transformation.
is the corresponding Jacobian for the converse (redshift to comoving) transformation.
The set of three indices {i, j, k} below are spatial coordinates {1, 2, 3}. With the functional dependence of z = f(r), we have
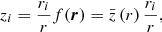 (B.3)
(B.3)
where we defined 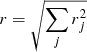 , and z̄ is the cosmological redshift. Taking the derivative yields
, and z̄ is the cosmological redshift. Taking the derivative yields
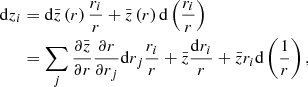 (B.4)
(B.4)
after applying the chain rule. Differentiating with respect to the comoving coordinate, and using d(1/r) = −∑j(1/r3)rjdrj,
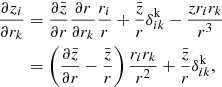 (B.5)
(B.5)
where we made use of rdr = ∑krkdrk which follows from the definition 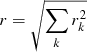 . To compute ∂z̄/∂r, we start from the definition of comoving distance,
. To compute ∂z̄/∂r, we start from the definition of comoving distance,
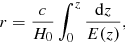 (B.6)
(B.6)
with the conventional definition for ℰ(z),
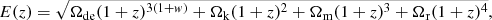 (B.7)
(B.7)
where c is the speed of light and H0 is the Hubble constant today, such that
 (B.8)
(B.8)
Finally, the Jacobian matrix can be expressed as follows:
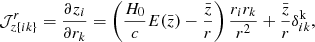 (B.9)
(B.9)
and we obtain the desired  by taking the reciprocal of
by taking the reciprocal of 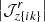 .
.
Appendix C: Hamiltonian sampling
The exploration of the LPT-Poissonian posterior, described by Eq. (6), requires highly non-linear reconstruction methods and is therefore numerically intensive. From the Bayesian viewpoint considered in this work, a single estimate of the density field is not of particular interest, with the desired scientific output being a sampled representation of the multi-dimensional LSS posterior. Extracting any relevant statistical summary, such as mean, mode or variance, given this posterior representation, is then straightforward. Furthermore, the propagation of uncertainties to the final inferred quantities is smooth and coherent.
In the absence of a known procedure to directly sample from a LPT-Poissonian distribution, a Metropolis-Hastings sampling scheme with an accept-reject step must be implemented. But such a mechanism suffers from the well-known drawback of possible high rejection rate, where a low acceptance rate of proposed samples will render the method numerically inefficient. This is especially significant since the inference of 3D density fields typically involves extremely high number of inference parameters. For instance, in this work, there are over 2 × 106 free parameters, which correspond to primordial density fluctuation amplitudes 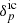 at respective grid nodes. Exploring this high dimensional parameter space via a random walk, as in conventional MCMC methods, consequently results in a high rejection rate. This is an understatement, as in practice, the acceptance rate is virtually zero, with one chance over 106 of going in the right direction, without taking into account the step size.
at respective grid nodes. Exploring this high dimensional parameter space via a random walk, as in conventional MCMC methods, consequently results in a high rejection rate. This is an understatement, as in practice, the acceptance rate is virtually zero, with one chance over 106 of going in the right direction, without taking into account the step size.
To limit the number of samples and alleviate the numerical scaling of the method, we implement a Hamiltonian Monte Carlo (HMC) scheme. This method guarantees an acceptance rate of unity in the absence of numerical errors. The numerical efficiency of the Hamiltonian sampling lies in deterministically proposing new samples to the Metropolis-Hastings algorithm, based on techniques to follow dynamical particle motion in potentials. The HMC algorithm therefore maintains a reasonable sampling efficiency in high dimensional spaces by suppressing the dominant random walk behaviour.
The HMC method has been successfully implemented for the inference of density fields in the non-linear regime, and has been found to be very efficient (e.g. Jasche & Kitaura 2010; Jasche et al. 2010b; Kitaura et al. 2012; Jasche & Wandelt 2013a,b). Moreover, this approach is less prone to spurious effects induced by numerical inaccuracies due to the final accept/reject step of the Metropolis-Hastings sampler ensuring correctness of the target density. Numerical inaccuracies would only be detrimental to the efficiency, without comprimising the correctness.
We briefly review the underlying framework and rationale of the HMC method. An excellent in-depth review of this approach is provided in Duane et al. (1987) and Neal (1993), with its application to LSS inference illustrated in Jasche & Kitaura (2010), Jasche et al. (2010b), Jasche & Wandelt (2013a,b) and Jasche & Lavaux (2018).
The essence of the HMC method is as follows: If we want to generate random variates according to a desired probability distribution 𝒫({xi}), with {xi} being a set of N elements xi, then we may interpret the negative logarithm of the distribution as a potential ψ(x),
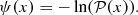 (C.1)
(C.1)
We can subsequently formulate a corresponding Hamiltonian that describes the dynamics in the multi-dimensional phase space by adding a kinetic term to the above potential. To this end, we introduce a “momentum” variable pi and a “mass matrix” M as nuisance parameters, as follows:
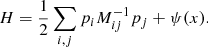 (C.2)
(C.2)
This Hamiltonian, as in classical mechanics, describes the dynamics in a high dimensional parameter space. We then obtain the new target probability distribution by exponentiating the above Hamiltonian:
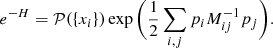 (C.3)
(C.3)
The form of the Hamiltonian ensures that the new joint distribution can be separated into a Gaussian distribution for the momenta {pi} and the target distribution 𝒫({xi}). This implies that the two sets of variables {xi} and {pi} are independent, and hence, we can obtain samples from the target distribution 𝒫({xi}) simply by marginalizing over the auxiliary momenta.
The next step is to generate a random variate from the joint distribution, which is proportional to exp(−H). We must first draw a set of momenta from the distribution defined by the kinetic energy term, which is an N-dimensional Gaussian with covariance M. To obtain a new sample from the joint distribution, we allow the system to evolve deterministically, from a given initial point in the high dimensional parameter space ({xi},{pi}), according to Hamilton’s equations:
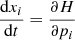 (C.4)
(C.4)
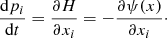 (C.5)
(C.5)
Integrating the above equations of motion for the time variable t up to a fixed pseudo-time τ results in the new position (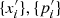 ) in phase space. This new point in phase space is accepted according to the standard Metropolis-Hastings acceptance rule:
) in phase space. This new point in phase space is accepted according to the standard Metropolis-Hastings acceptance rule:
![Mathematical equation: $$ \begin{aligned} \mathcal{P} _{{A}} = \mathrm{min}\left\{ 1, \exp {\left[ -\left(H\left(\{ x^{\prime }_{i} \}, \{ p^{\prime }_{i} \}\right) - H\left(\{ x_{i} \}, \{ p_{i} \}\right) \right) \right]} \right\} . \end{aligned} $$](/articles/aa/full_html/2019/01/aa34117-18/aa34117-18-eq98.gif) (C.6)
(C.6)
Since the equations of motion provide a solution to a Hamiltonian system, the energy or the Hamiltonian described by Eq. (C.2) must be conserved. A direct consequence of this conservation of the Hamiltonian is that the HMC approach yields an acceptance rate of unity. In practice, however, the acceptance rate may be lower due to numerical inaccuracies in the integration scheme. After accepting a new sample, the mechanism proceeds by discarding the momentum counterpart and restarts the sampling procedure by randomly drawing a new set of momenta. The individual momenta {pi} do not have to be stored in memory which is numerically convenient, and marginalisation simply implies discarding them.
The HMC sampling scheme can therefore be summarised in two steps. The first step is essentially a Gibbs sampling step which results in a new set of Gaussian distributed momenta. The second step involves computing the deterministic dynamical trajectory on the posterior surface. We obtain samples of the desired target distribution by marginalizing over the nuisance parameters, that is, by discarding the auxiliary momenta {pi}.
Appendix D: Equations of motion for LSS inference
As described in Appendix C, the Hamiltonian Monte Carlo (HMC) approach allows the exploration of the non-linear LSS posterior via the study of the Hamiltonian dynamics in the high dimensional parameter space. To ensure a high acceptance rate, the HMC exploits the gradient of the logarithmic posterior distribution to optimally explore this parameter space, such that the algorithm also requires the derivatives of the posterior distribution, as outlined below.
From the LSS posterior illustrated in Eq. (6), we can derive the corresponding forces required to evaluate the Hamiltonian trajectories. The Hamiltonian potential ψ(δic) can be written as
![Mathematical equation: $$ \begin{aligned} \psi (\delta ^{\mathrm{ic}})&= - \ln \left[ \mathcal{P} \left(\{\delta ^{\mathrm{ic}}_{p}\}, \{\bar{N}^{\textit{g}}\}, \{b^{\textit{g}}\}, \{\theta _{i}\} |\{{N}^{\textit{g}}_{p}\}, \mathbf S \right) \right] \nonumber \\&= \psi _{\mathrm{likelihood}}(\delta ^{\mathrm{ic}}) + \psi _{\mathrm{prior}}(\delta ^{\mathrm{ic}}) , \end{aligned} $$](/articles/aa/full_html/2019/01/aa34117-18/aa34117-18-eq99.gif) (D.1)
(D.1)
where the potential ψprior(δic) corresponds to
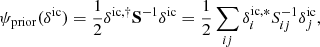 (D.2)
(D.2)
while ψlikelihood(δic) is given by
![Mathematical equation: $$ \begin{aligned} \psi _{\mathrm{likelihood}}(\delta ^{\mathrm{ic}})&= \sum _{p} \left\{ \lambda ^{\textit{g}}_{p} \left( \{ {\delta }_{p}^{\mathrm{f}} \}, \{ \theta _{i} \}, \{ \bar{N}^{\textit{g}} \}, \{ {b}^{\textit{g}}_{i} \} \right)\right. \nonumber \\&\left.- {N}^{\textit{g}}_{p} \ln \left[ \lambda ^{\textit{g}}_{p} \left( \{ {\delta }_{p}^{\mathrm{f}} \}, \{ \theta _{i} \}, \{ \bar{N}^{\textit{g}} \}, \{ {b}^{\textit{g}}_{i} \} \right) \right] \right\} . \end{aligned} $$](/articles/aa/full_html/2019/01/aa34117-18/aa34117-18-eq101.gif) (D.3)
(D.3)
Using the definition of the Hamiltonian potential ψ(δic) from Eq. (D.1), we obtain the corresponding equations describing the Hamiltonian forces by differentiating with respect to δic:
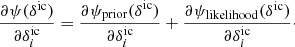 (D.4)
(D.4)
The prior term is trivially obtained as
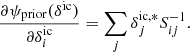 (D.5)
(D.5)
The corresponding likelihood term, however, cannot be derived in straightforward fashion. We compute this adjoint gradient as a sequential application of linear operations, as follows:
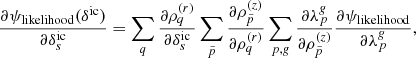 (D.6)
(D.6)
where we explicitly expressed the coordinate transformation from comoving (r) to redshift (z) space, and 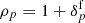 is the density field. Equation (D.6) constitutes a sequence of matrix vector applications, as follows:
is the density field. Equation (D.6) constitutes a sequence of matrix vector applications, as follows:
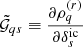 (D.7)
(D.7)
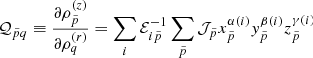 (D.8)
(D.8)
![Mathematical equation: $$ \begin{aligned}&\mathcal{K} _{p \tilde{p}} \equiv \sum _\textit{g} \frac{\partial \lambda ^{\textit{g}}_{p}}{\partial \rho ^{(z)}_{\tilde{p}}} = \sum _\textit{g} \delta ^{\mathrm{k}}_{p,\tilde{p}} \frac{\lambda ^{\textit{g}}_{p}}{ \rho ^{(r)}_{\tilde{p}} } \left[ \rho ^{\textit{g}} \epsilon ^{\textit{g}} \rho ^{-\epsilon _\textit{g},(r)}_{\tilde{p}} + \beta \right] \end{aligned} $$](/articles/aa/full_html/2019/01/aa34117-18/aa34117-18-eq108.gif) (D.9)
(D.9)
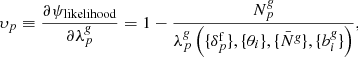 (D.10)
(D.10)
where 𝒥 is the Jacobian of the comoving-redshift transformation, 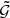 indicates the derivative of LPT (cf. Appendix D in Jasche & Wandelt 2013a) and
indicates the derivative of LPT (cf. Appendix D in Jasche & Wandelt 2013a) and 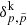 is the Kronecker delta. The derivation of the adjoint gradient for the triquintic interpolation is illustrated in Appendix G.
is the Kronecker delta. The derivation of the adjoint gradient for the triquintic interpolation is illustrated in Appendix G.
Using the above results, the two equations of motion (C.4) and (C.5) for the Hamiltonian system can be expressed as follows:
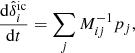 (D.11)
(D.11)
and
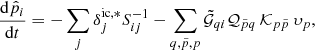 (D.12)
(D.12)
where the hats denote Fourier space representation. We can now obtain new samples from the LSS posterior by following the dynamical evolution of the Hamiltonian system, governed by Eqs. (D.11) and (D.12), in phase space.
Appendix E: Numerical implementation
Our numerical implementation of the augmented version of BORG, that incorporates cosmological parameter inference, while assuming a more realistic non-linear bias model, is designated as ALTAIR. It employs the FFTW3 library for fast Fourier transforms (Frigo & Johnson 2005), whose feature of parallel transforms allows for straightforward parallelisation of our code. For random number generation, we make use of the GNU scientific library (gsl; Galassi et al. 2009), in particular, the Mersenne Twister MT19937, with 32-bit word length, from the gsl_rng_mt19937 routine. The use of the Mersenne Twister algorithm as a pseudo-random number generator for Monte Carlo simulations has been proven to be efficient and dependable (Matsumoto & Nishimura 1998).
E.1. The leapfrog scheme
In order to obtain samples from the LSS posterior, we must integrate the equations of motion (D.11) and (D.12) numerically over a pseudo-time interval τ by means of a leapfrog scheme. Ideally, we want to solve the equations exactly for an optimal acceptance rate. As such, the choice of this integrator is motivated by several reasons. Primarily, the leapfrog scheme is convenient as it is a symplectic integrator and is therefore exactly reversible, thereby maintaining detailed balance (Duane et al. 1987) of the Markov chain. The high accuracy of such an integration scheme is conducive to the conservation of the total Hamiltonian along a given trajectory, within the limit of numerical errors, resulting in high acceptance rates. It is also numerically stable and allows for simple propagation of errors. To avoid resonant trajectories, τ is drawn from a uniform distribution. The numerical implementation of the “kick-drift-kick” leapfrog scheme here follows closely the descriptions provided in Jasche & Kitaura (2010) and Jasche & Wandelt (2013a), which we refer the reader to for more elaborate and complementary explanations.
E.2. Hamiltonian mass
The mass matrix M contains a large number of parameters that must be tuned to optimise the performance of the HMC sampler. Conceptually, this Hamiltonian mass characterises the inertia of individual parameters as they move through the parameter space. As a result, the choice of M is a compromise to limit slow exploration efficiency due to extremely large masses and avoid large numerical errors of the integration scheme due to extremely light masses, and is therefore a trade-off between efficiency and acceptance rate.
A general prescription for the Hamiltonian masses, when the density fluctuations 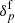 can be characterised as a Gaussian random field, is to set them inversely proportional to the variance of that specific
can be characterised as a Gaussian random field, is to set them inversely proportional to the variance of that specific 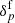 (Taylor et al. 2008). However, this prescription has been found to be effective even for the case of non-Gaussian distributions, such as the LPT-Poissonian posterior encountered in this work (Jasche & Wandelt 2013a; Jasche et al. 2015; Lavaux & Jasche 2016). Since the leapfrog scheme requires the inversion of M, a diagonal representation of M is numerically convenient, given the extremely high dimensionality of the problem. We therefore choose M to be inversely proportional to the cosmological power spectrum, M = S−1, which is diagonal in its Fourier basis. This choice, moreover, improves the efficiency of the HMC sampler and results in faster convergence since it accounts for the correlation structure of the underlying density field (Jasche & Wandelt 2013a).
(Taylor et al. 2008). However, this prescription has been found to be effective even for the case of non-Gaussian distributions, such as the LPT-Poissonian posterior encountered in this work (Jasche & Wandelt 2013a; Jasche et al. 2015; Lavaux & Jasche 2016). Since the leapfrog scheme requires the inversion of M, a diagonal representation of M is numerically convenient, given the extremely high dimensionality of the problem. We therefore choose M to be inversely proportional to the cosmological power spectrum, M = S−1, which is diagonal in its Fourier basis. This choice, moreover, improves the efficiency of the HMC sampler and results in faster convergence since it accounts for the correlation structure of the underlying density field (Jasche & Wandelt 2013a).
Appendix F: Rotation of cosmological parameter space
To increase the efficiency of the cosmological parameter sampler, we rotate the (Ωm, w0) parameter space, using orthogonal basis transformations, before slice sampling. The corresponding covariance matrix can be orthonormally decomposed as C = Q† ΔQ, where Q† Q = 1.
We perform a rotation of the θ vector of cosmological parameters, about the mean  , using the transformation:
, using the transformation:
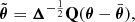 (F.1)
(F.1)
where the tilde denotes the transformed variable. A key point is that we must rotate back to the original frame when computing the logarithm of the posterior via
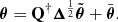 (F.2)
(F.2)
This is implemented at each step of the Markov chain, such that the covariance used to compute the orthogonal basis operators must be learnt progressively as follows:
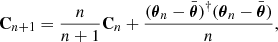 (F.3)
(F.3)
at the given nth step. The above transformation helps to decorrelate the variables involved when sampling, thereby reducing the burn-in period significantly. This procedure is especially effective with highly correlated parameters, as is the case for (Ωm, w0) (cf. Fig. 6).
We investigate the statistical efficiency of our cosmological parameter sampler by computing the correlation length of the Markov chain. Subsequent samples in the chain are generally correlated and hence do not qualify as independent samples of the target posterior distribution. The correlation length characterises the statistical efficiency of generating independent samples of a given parameter θ, as follows:
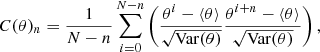 (F.4)
(F.4)
where n is the number of transition steps in the chain, ⟨θ⟩ and Var(θ) correspond to the mean and variance, respectively, ⟨θ⟩ = 1/N∑i θi and Var(θ) = 1/N∑i(θi − ⟨θ⟩)2, while N is the total number of realisations in the chain. This correlation length therefore indicates the number of independent realisations that can be drawn from the MCMC chain with a given number of transition steps. For an unbiased comparison, we computed the correlation length using the same chain length for both scenarios, while ignoring their respective burn-in phases. From the left panel of Fig. F.1, we deduce that the correlation length for the Ωm chain is of the order of 25 samples. Without the rotation of (Ωm, w0) parameter space, the correlation length is longer by nearly a factor of five, further demonstrating the gain in efficiency obtained with the more sophisticated sampler.
 |
Fig. F.1. Left panel: correlation length of the Ωm Markov chain. The chain has a correlation length of the order of 25 samples. The dashed-dotted lines depict the longer correlation length without the rotation of the cosmological parameter space, by nearly a factor of five. Right panel: burn-in phase for both scenarios, illustrated via the deviation from the reference cosmology. The dashed-dotted lines depict the MCMC chains obtained without rotating the parameter space, where the burn-in phase consequently requires around five times more iterations. The longer correlation length and burn-in phase highlight the loss in efficiency compared to the more sophisticated sampler. |
Appendix G: Adjoint gradient for generic 3D interpolation
The 3D interpolation can be expressed generally, for any arbitrary nth order of interpolation, as:
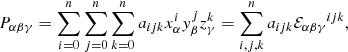 (G.1)
(G.1)
where P is the interpolated surface and ℰ is a (n + 1)3 × (n + 1)3 matrix required for computing the vector of interpolation coefficients a. In this work, we implement a triquintic interpolation scheme, which corresponds to n = 5, with the indices {i, j, k},{α, β, γ}={0, 1, 2, 3, 4, 5} constituting the particular indexing scheme employed to denote the voxels involved. ℰ is therefore a 216 × 216 matrix for the triquintic scheme.
The above system of equations can be reformulated as a matrix for the linear system described by P = ℰa, such that the vector of interpolation coefficients can be computed in straightforward fashion through matrix inversion, a = ℰ−1 P. The advantage of this approach is that ℰ−1 can computed only once and stored, and then used for interpolation at any location inside the cube (e.g. Lekien & Marsden 2005).
The derivative of the generic 3D interpolation is required as a component of the adjoint gradient at the core of the HMC sampler described in Appendix C. The 3D interpolated density field, in redshift space (cf. Eq. (B.1)), can be written explicitly as:
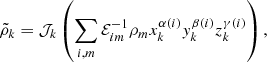 (G.2)
(G.2)
where 𝑅 is the Jacobian of the comoving-redshift transformation from Appendix B, evaluated at the location of the mesh element k. Here, we employed a compact notation, where {x, y, z} correspond to the fractional steps with respect to a reference node in the grid, that is, interpolation weights, and {α, β, γ} label the powers of the elements of ℰ via:
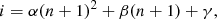 (G.3)
(G.3)
with the index m ∈ {i, j, k} from Eq. (G.1). Using the chain rule, the resulting gradient w, after application of the incoming gradient υ from the previous components in the forward model, is obtained as follows:
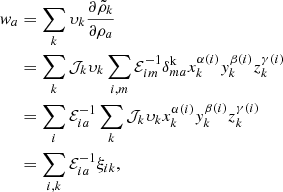 (G.4)
(G.4)
where 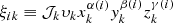 represents the contribution to the adjoint gradient from a specific voxel labelled by the indexing scheme adopted. This is convenient as ℰ−1 is already available from the execution of the 3D interpolation in the forward model.
represents the contribution to the adjoint gradient from a specific voxel labelled by the indexing scheme adopted. This is convenient as ℰ−1 is already available from the execution of the 3D interpolation in the forward model.
All Figures
|
Fig. 1. Comparison of cosmological constraints from BAO measurements and our implementation of AP test in ALTAIR. The grey and green lines denote the 1σ confidence region, centred on the fiducial cosmological parameters, obtained from our AP test and BAO constraints from SDSS-III (DR 12; Alam et al. 2017), respectively. The BAO constraints have not been combined with Planck CMB measurements. This demonstrates the potentially unprecedented constraining power of our AP test compared to standard BAO analyses, as discussed in Sect. 2, with the inset focusing on the ALTAIR constraints where the fiducial cosmology is depicted in dashed lines. This error forecast is validated on a simulated analysis (cf. Fig. 6). |
| In the text | |
|
Fig. 2. Schematic representation of the reconstruction pipeline. The forward model consists of a chain of various components for the non-linear evolution from initial conditions and the subsequent transformation from comoving to redshift space for the application of the AP test. This consequently transforms the initial density field into a set of predicted observables, i.e. a galaxy distribution in redshift space, for comparison with data via a likelihood or posterior analysis. |
| In the text | |
|
Fig. 3. Observed sky completeness, used to generate and analyse the mock catalogue in this work, are illustrated in the left and right panels, corresponding to the CMASS and LOW-Z components of the SDSS-III survey, respectively. |
| In the text | |
|
Fig. 4. Radial selection functions for the CMASS sample, in solid and dashed lines for the north galactic cap (NGC) and south galactic cap (SGC), respectively. The corresponding radial selection functions for the LOW-Z sample are depicted in dash-dotted (NGC) and dotted lines (SGC). These selection functions are used to generate the mock data to emulate features of the actual SDSS-III BOSS data. |
| In the text | |
|
Fig. 5. MCMC chains for the cosmological parameters, for the first 1000 samples, with the reference cosmology employed in the mock generation indicated by the horizontal dashed lines. An initial burn-in phase lasting ∼250 Markov transitions is illustrated by the coherent drift of the Markov chain towards the preferred region in parameter space. |
| In the text | |
|
Fig. 6. Marginal posteriors for Ωm (left panel) and the dark energy equation of state, w0 (middle panel), for ∼3000 MCMC realisations, ignoring the burn-in phase of ∼250 Markov steps. The corresponding mean and standard deviation for each parameter are indicated in the top right corner of each plot. The joint posterior (right panel) for Ωm and w0, depicting the high level of correlation between these two parameters. The highly informative distortion due to the cosmic expansion, as a result of probing a deep redshift range, yields extremely tight constraints on the above cosmological parameters. As a consistency test, this validates our implementation of the AP test to correctly recover the input cosmology. |
| In the text | |
|
Fig. 7. Mean and standard deviation maps for the initial (top panels) and final density fields (bottom panels), computed from the MCMC realisations, with the same slice through the 3D density fields being illustrated above. In unobserved or masked regions, the density fields are not constrained by data, and they average out to the cosmic mean density. However, in observed regions, the Gaussian nature of the initial conditions and the filamentary nature of the non-linearly evolved density field is manifest. The corresponding variance is therefore higher in regions devoid of data. |
| In the text | |
|
Fig. 8. Top panel: reconstructed power spectra from the inferred posterior initial density field realisations for all sampling steps of the Markov chain. The MCMC samples are colour-coded according to their sample number, as indicated by the colour bar. This is a self-consistency test to verify whether the sampled density fields are in accordance with the reference power spectrum, depicted in dashed lines, employed in the mock generation. Bottom panel: deviation from the true underlying solution, with the thick dashed lines representing the prior power spectrum. The thin grey and black dotted lines correspond to the Gaussian 1σ and 2σ limits, respectively. |
| In the text | |
|
Fig. 9. Summary statistics of the reconstructed power spectra from the inferred posterior initial density field realisations depicted in Fig. 8, with the ensemble mean indicated by a solid green line. The solid blue line corresponds to the ensemble mean of the power spectra realisations generated using the inferred cosmological parameters. The shaded regions indicate their respective 1σ confidence region, i.e. 68% probability volume. This plot shows that the prior information entropy is inferior to the posterior information entropy, due to the narrower distribution of the former. The prior power spectrum adopted, as a result, does not impact significantly on the cosmological parameter inference via the AP test. |
| In the text | |
|
Fig. 10. Same as Fig. 6, but employing a different prior power spectrum (Ωm = 0.40, w0 = −0.85), for ∼3000 MCMC realisations. By recovering the fiducial cosmological parameters employed in the mock generation, this test case explicitly highlights the robustness of our approach to the shape of the prior power spectrum adopted. The corresponding uncertainties are slightly larger than for the original run by around 15%. |
| In the text | |
|
Fig. 11. Correlation matrix of the galaxy bias and cosmological parameters, normalised using their respective variance. This illustrates the weak correlation between the inferred cosmological constraints and the galaxy bias. The lack of dependence on the currently unknown phenomenon of galaxy biasing is therefore a key highlight of our implementation of the AP test for cosmological parameter inference. |
| In the text | |
|
Fig. A.1. Schematic representation of the multi-step iterative block sampling procedure implemented in ALTAIR. Initially, a realisation of the 3D density contrast is obtained conditional on galaxy observations, followed by the other parameters being sampled conditional on the respective previous samples. Subsequent iterations of this procedure yield samples from the full joint posterior distribution within a modular statistical programming framework. |
| In the text | |
|
Fig. F.1. Left panel: correlation length of the Ωm Markov chain. The chain has a correlation length of the order of 25 samples. The dashed-dotted lines depict the longer correlation length without the rotation of the cosmological parameter space, by nearly a factor of five. Right panel: burn-in phase for both scenarios, illustrated via the deviation from the reference cosmology. The dashed-dotted lines depict the MCMC chains obtained without rotating the parameter space, where the burn-in phase consequently requires around five times more iterations. The longer correlation length and burn-in phase highlight the loss in efficiency compared to the more sophisticated sampler. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.