| Issue |
A&A
Volume 614, June 2018
|
|
|---|---|---|
| Article Number | A137 | |
| Number of page(s) | 10 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/201732170 | |
| Published online | 27 June 2018 | |
A statistical analysis of two-dimensional patterns and its application to astrometry
Institute of Physics of the Czech Academy of Sciences,
Na Slovance 2,
182 21 Prague 8, Czech Republic
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
25
October
2017
Accepted:
3
February
2018
Abstract
Here we develop a general statistical procedure for the analysis of finite two-dimensional (2D) patterns inspired by the analysis of heavy-ion data. The method is used in the study of publicly available data obtained by the Gaia-ESA mission. We prove that the procedure can be sensitive to the limits of accuracy of measurement, and can also clearly identify the real physical effects on the large background of random distributions. As an example, the method confirms the presence of binary and ternary star systems in the studied data. At the same time, the possibility of the statistical detection of the gravitational microlensing effect is discussed.
Key words: methods: statistical / methods: data analysis / surveys / astrometry / binaries: close / gravitational lensing: micro
© ESO 2018
1 Introduction
The motivation of the present study was to modify and generalize the known method for analyzing anisotropic flow in relativistic nuclear collisions (Voloshin & Zhang 1996; Poskanzer & Voloshin 1998), which has been effectively applied in many studies, for example, recently in Adam et al. (2016). The method is based on the use of the Fourier expansion of azimuthal distributions of produced particles and allows us to obtain important information on the mechanism of nuclear collisions. However, mathematical formalism of this method is more general and can be used after minor modifications even for quite different kinds of analysis. Our present idea is focused primarily on astrometry. Recently, some similarity between spiral structures in galactic patterns and heavy ion collisions has been discussed (Rustamov & Rustamov 2016). However, our approach is different. We make use of the formalism of the Fourier analysis of nuclear collisions simply as a tool and we do not consider a common physics that could bridge the two different fields. Moreover, Fourier analysis is only one of two methods that we work with.
In our approach the astrometric data are decomposed into a set of limited, finite star patterns whose parameters are statistically analyzed. These parameters define characteristics of the patterns and represent statistical deviations from the uniform distribution of stars; for example, a tendency to display scale-dependent clustering or anti-clustering. The aim is to find and interpret these deviations. The input data are taken from the Gaia DR1 catalog (Gaia Collaboration 2016b,a).
In Sect. 2.1 we define some useful terms and explain the essence of our task in more detail. The general description of the Fourier analysis modified for application to astrometry is presented in Sect. 2.2. Then in Sect. 2.3 we describe a complementary statistical method for analysis of the patterns of stars, which deals with angular distances and is important for identification of binary and ternary star systems. The results obtained from the application of both methods to the Gaia data are presented and discussed in Sect. 3.1. A discussion on the gravitational microlensing effect and the conditions of its observation is given in Sect. 3.2. A brief summary of the paper is presented in Sect. 4.
2 Methods
2.1 Subject of analysis
Let us consider a region of the sphere of the galactic reference frame. We study the patterns of the stars inside the circles of the same angular radius as in Fig. 1a that cover the chosen region. The circular shape is essential for application of our methods and the stars among the circles are not used for statistical analysis. First, in accordance with the figure, we define one event of the multiplicity M as a set of stars with angular positions 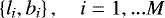 inside one circle with the center (l0, b0) and a small angular radius ρ (introduced terms are inspired by particle physics). The letter l(b) represents the galactic longitude (latitude). The positions inside the circle (event) can be represented equivalently by the three-dimensional (3D) unit vectors nα as sketched in Fig. 1b:
inside one circle with the center (l0, b0) and a small angular radius ρ (introduced terms are inspired by particle physics). The letter l(b) represents the galactic longitude (latitude). The positions inside the circle (event) can be represented equivalently by the three-dimensional (3D) unit vectors nα as sketched in Fig. 1b:
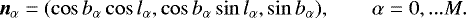 (1)
(1)
Subsequently, the event can be defined as the set of stars meeting the condition:
 (2)
(2)
One can define for each event its local orthonormal frame defined on the basis:
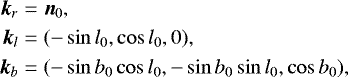 (3)
(3)
where kl(kb) represent local directions of the longitude (latitude). The local coordinates are defined as
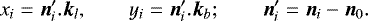 (4)
(4)
We work with the following representations of the star positions (Fig. 3a) inside the event circle:
1) Two-dimensional (2D) positions {xi, yi} (Sect. 2.3):
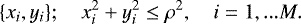 (5)
(5)
2) Azimuthal positions 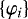 (Sect. 2.2):
(Sect. 2.2):
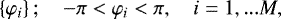 (6)
(6)
defined by xi, yi:
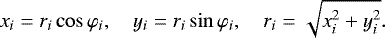 (7)
(7)
Here we use two sources of input data: (A) The simulated events generated by the Monte-Carlo (MC) code; Fig. 1a is an example of uniform generation of the star positions, and (B) the real star events obtained from the Gaia catalog. The methods for their analysis are described below. The final results of the analysis follow from the comparison of the parameters and distributions obtained from both sources of input data.
 |
Fig. 1 Patterns of the stars inside the grid of circles (a). Position n0 of the event defines its local reference frame (b). |
2.2 Fourier analysis
We start from the general formalism introduced in Voloshin & Zhang (1996) and Poskanzer & Voloshin (1998). The angular distribution P(φ) > 0 in (−π, π) can be expressed as the Fourier series
![Mathematical equation: \begin{align*} &P(\varphi) =\frac{1}{2\pi}\left( 1+2\sum_{n=1}^{\infty}v_{n}\cos\left[ n\left( \varphi-\mathrm{\Psi}_{n}\right) \right] \right) ,\\ &\int_{-\pi}^{\pi}P(\varphi)\textrm{d}\varphi =1,\nonumber \end{align*}](/articles/aa/full_html/2018/06/aa32170-17/aa32170-17-eq10.png) (8)
(8)
where the set of parameters 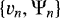 define the distribution. If we define the mean value of the function f as
define the distribution. If we define the mean value of the function f as
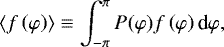 (9)
(9)
then the orthogonality of the terms in Eq. (8) implies:
![Mathematical equation: \begin{align}&v_{n} =\left\langle \cos\left[ n\left( \varphi-\mathrm{\Psi}_{n}\right) \right] \right\rangle ,\\[8pt] &\tan\left( n\mathrm{\Psi}_{n}\right) =\frac{\left\langle \sin\left( n\varphi\right) \right\rangle }{\left\langle \cos\left( n\varphi\right) \right\rangle },\end{align}](/articles/aa/full_html/2018/06/aa32170-17/aa32170-17-eq13.png)
for any n = 1, 2, 3, ... If we take event (6) in which the probability of φi is proportional to P(φi) and replace the average value defined by Eq. (9) with the summation
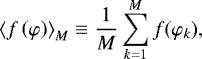 (12)
(12)
then insteadof Eqs. (10) and (11) we get
![Mathematical equation: \begin{align}&v_{n}(M) =\left\langle \cos\left[ n\left( \varphi-\mathrm{\Psi}_{n}\right) \right] \right\rangle _{M},\\[8pt] &\tan\left( n\mathrm{\Psi}_{n}(M)\right) =\frac{\left\langle \sin\left( n\varphi\right) \right\rangle _{M}}{\left\langle \cos\left( n\varphi\right) \right\rangle _{M}}.\end{align}](/articles/aa/full_html/2018/06/aa32170-17/aa32170-17-eq15.png)
Apparently, for any n = 1, 2, 3, ... and M →∞ one can expect:
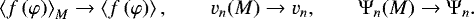 (15)
(15)
The Eqs. (13) and (14) do not have an unambiguous solution, as illustrated in Fig. 2.
The panels represent distributions
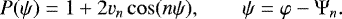 (16)
(16)
The relation in Eq. (14) gives the solutions
![Mathematical equation: \begin{equation*} n\mathrm{\Psi}_{n}(M)=\tan^{-1}\left[ \frac{\left\langle \sin\left( n\varphi\right) \right\rangle _{M}}{\left\langle \cos\left( n\varphi\right) \right\rangle _{M}}\right] +k\pi.\end{equation*}](/articles/aa/full_html/2018/06/aa32170-17/aa32170-17-eq18.png) (17)
(17)
The sign of the term ![Mathematical equation: $v_{n}\cos\left[ n\left( \varphi-\mathrm{\Psi}_{n}\right) \right] ~$](/articles/aa/full_html/2018/06/aa32170-17/aa32170-17-eq19.png) in Eq. (8) can be controlled either by the sign of vn or by the phase nΨn. Apparently the change vn →−vn is equivalent to nΨ n → nΨn ± kπ, k = 1, 2, 3, ... Nevertheless in the present paper we analyze only
in Eq. (8) can be controlled either by the sign of vn or by the phase nΨn. Apparently the change vn →−vn is equivalent to nΨ n → nΨn ± kπ, k = 1, 2, 3, ... Nevertheless in the present paper we analyze only 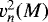 and not vn(M) with the phase Ψn(M). Therefore the sign ambiguity does not play a role.
and not vn(M) with the phase Ψn(M). Therefore the sign ambiguity does not play a role.
The relation in Eq. (13) implies
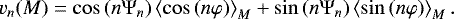 (18)
(18)
The relations
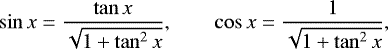 (19)
(19)
together with Eq. (14) give
![Mathematical equation: \begin{align} \sin\left( n\mathrm{\Psi}_{n}\right) & =\frac{\left\langle \sin\left( n\varphi\right) \right\rangle _{M}}{\sqrt{\left\langle \cos\left( n\varphi\right) \right\rangle _{M}^{2}+\left\langle \sin\left( n\varphi\right) \right\rangle _{M}^{2}}},\\[8pt] \cos\left( n\mathrm{\Psi}_{n}\right) & =\frac{\left\langle \cos\left( n\varphi\right) \right\rangle _{M}}{\sqrt{\left\langle \cos\left( n\varphi\right) \right\rangle _{M}^{2}+\left\langle \sin\left( n\varphi\right) \right\rangle _{M}^{2}}}.\end{align}](/articles/aa/full_html/2018/06/aa32170-17/aa32170-17-eq23.png)
Inserting of these latter two expressions into Eq. (18) after some algebra gives
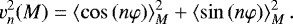 (22)
(22)
We note that 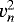 does not depend on the choice of k in Eq. (17). The last relation can be modified as
does not depend on the choice of k in Eq. (17). The last relation can be modified as
![Mathematical equation: \begin{equation*} v_{n}^{2}(M)=\frac{1}{M}\left[ 1+\frac{2}{M}\sum_{1\leq k<l\leq M}\cos(n\varphi_{k}-n\varphi_{l})\right] .\end{equation*}](/articles/aa/full_html/2018/06/aa32170-17/aa32170-17-eq26.png) (23)
(23)
There are two extreme cases:
1) All angles are in a narrow cone so that cos(nφi − nφj) ≈ 1; subsequently
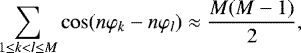 (24)
(24)
and
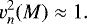 (25)
(25)
2) All angles are regularly distributed on the circle, so φk = 2πk∕M (anti-clustering). If we define q = exp(i2πn∕M), n∕M≠1, 2, 3, ..., then we get
![Mathematical equation: \begin{align*} \sum_{1\leq k<l\leq M}\cos(n\varphi_{k}-n\varphi_{l}) & =\operatorname{Re}\sum_{1\leq k<l\leq M}q^{k-l}\nonumber \\ & =-\operatorname{Re}\frac{q\left[ 1+M\left( q-1\right) -q^{M}\right] }{\left( q-1\right) ^{2}}\nonumber\\ & =M\operatorname{Re}\frac{q}{1-q}=-\frac{M}{2}, \end{align*}](/articles/aa/full_html/2018/06/aa32170-17/aa32170-17-eq29.png) (26)
(26)
which after inserting to Eq. (23) gives
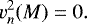 (27)
(27)
This result confirms an expectation that the regular distribution should not generate asymmetry terms in Eq. (8). In general, we can have NM events of the same multiplicity M
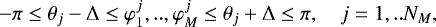 (28)
(28)
where θj can be different for various events. Subsequently, the average value of 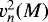 defined by Eq. (23) can be estimated as
defined by Eq. (23) can be estimated as
![Mathematical equation: \begin{equation*} \left\langle v_{n}^{2}(M)\right\rangle =\frac{1}{M}\left[ 1+\frac{2}{M}\sum_{1\leq k<l\leq M}\left\langle \cos(n\varphi_{k}^{j}-n\varphi_{l}^{j})\right\rangle \right] ,\end{equation*}](/articles/aa/full_html/2018/06/aa32170-17/aa32170-17-eq33.png) (29)
(29)
where
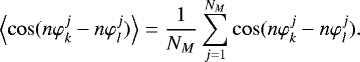 (30)
(30)
For uniform distribution of 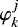 inside the intervals of Eq. (28), and with sufficiently great NM, one can estimate this value by the integral
inside the intervals of Eq. (28), and with sufficiently great NM, one can estimate this value by the integral
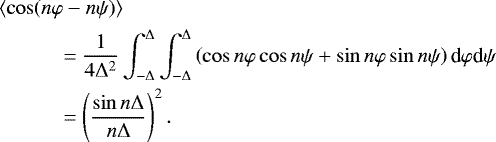 (31)
(31)
Subsequently, for any n = 1, 2, 3, ... we have
![Mathematical equation: \begin{equation*} \left\langle v_{n}^{2}(M)\right\rangle =\frac{1}{M}\left[ 1+\left( M-1\right) \left( \frac{\sin n\mathrm{\Delta}}{n\mathrm{\Delta}}\right) ^{2}\right] \geq\frac{1}{M},\end{equation*}](/articles/aa/full_html/2018/06/aa32170-17/aa32170-17-eq37.png) (32)
(32)
and therefore for Δ → 0 (clustering), we obtain
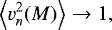 (33)
(33)
which corresponds to case (I) of Eq. (24). For Δ = π (uniform distribution) one obtains
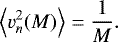 (34)
(34)
To explain the practical meaning of the relation in Eq. (33), let us assume the stars inside the circle in Fig. 3a are not distributed uniformly over this circle, but are concentrated in some smaller circle, which is located anywhere inside the greater one in Fig. 3b; their positions 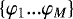 inside the greater circle fill up a narrower angular segment (statistically). Such a scenario is reflected in Eqs. (25) and (33). In general there can be a mixture uniform + clustering, something between (33) and (34):
inside the greater circle fill up a narrower angular segment (statistically). Such a scenario is reflected in Eqs. (25) and (33). In general there can be a mixture uniform + clustering, something between (33) and (34):
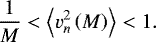 (35)
(35)
Furthermore, the relation in Eq. (34) corresponds to the uniform distribution, and for M →∞ gives
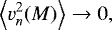 (36)
(36)
which is thecorrect result for uniform distribution defined by Eq. (8). But why does a finite M generate 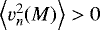 even for uniform generation? The reason is that the event of finite multiplicity, for example M = 3 of random stars, is usually better described with the use of higher harmonics. For increasing M the population becomes denser and more symmetric in terms of
even for uniform generation? The reason is that the event of finite multiplicity, for example M = 3 of random stars, is usually better described with the use of higher harmonics. For increasing M the population becomes denser and more symmetric in terms of 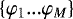 , in accordance with Eq. (36).
, in accordance with Eq. (36).
Here we also use the function Θn defined as
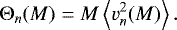 (37)
(37)
For illustration we present the toy examples of simulation:
a) Uniform distribution
We generate uniform sets of stars inside the circle of radius ρ, like the event in Fig. 3a.
For each event we use the relation in Eq. (22) to calculate 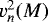 for n = 1, 2, 3. The functions
for n = 1, 2, 3. The functions
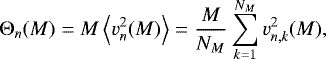 (38)
(38)
where NM is the number of events of multiplicity M, are displayed in the upper panels of Fig. 4. The resulting lines appa- rently satisfy Eq. (34). We note that throughout the paper, the error bars, if plotted, indicate only statistical errors.
b) Clustering
In a first step, we uniformly generate stars inside a smaller circle of radius δ. This circle is randomly located inside the greater circle of radius ρ, and we define λ = δ∕ρ (Fig. 3b). The functions Θn(ρ, δ, M) are calculated with the use of Eq. (38), equally as in the previous case. The results are displayed in the middle panels of Fig. 4.
c) Anti-clustering
We generate spots of the radius δ inside the circle of radius ρ, giving the ratio λ = δ∕ρ (Fig. 3c). The MC algorithm is the same as for uniform distribution, but with the additional constraint that the spots must not overlap. If two spots in uniform generation overlap, one of them is excluded. In other words, there is a rule that the distance between any two stars is greater than 2δ. The corresponding functions (38) are displayed in the lower panels of Fig. 4. Why do the curves decrease? Obviously, a denser population of spots inside the circle generates a more regular arrangement of φk, closer to case (II) above, so the function Θn(M) will tend to approach the minimum given by Eq. (27). The curves in the figure are linear for a small λ and M ≪ Mmax ≲ 1∕λ2 and one can approximate as
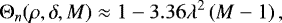 (39)
(39)
for n = 1, 2, 3.
Generally, for both algorithms mentioned above, the change of scale ρ → kρ, δ → kδ does not change distribution of angles in the event 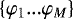 and
and 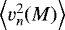 defined by Eq. (29); therefore
defined by Eq. (29); therefore
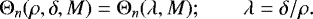 (40)
(40)
These algorithms are simple examples; one could think up other ones.
We summarize the main results of this section as follows.
1) The uniform field (like the events in Fig. 1a) generate the dependence Θ n (M) = 1 for any n = 1, 2, 3, ... The non-uniform distributions violate this rule. We have shown the examples, which generate relations Θ n (M) > 1 (clustering) and Θn(M) < 1 (anti-clustering).
2) In this way the functions Θn(M) give important information about the statistical character of the patterns, but the numbers 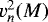 calculated only from a single event do not offer a significant amount of information.
calculated only from a single event do not offer a significant amount of information.
The functions Θn(M) are used in Sect. 3.1 for analysis and classification of the sets of real star events.
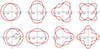 |
Fig. 2 Examples of deviations from uniform angular distribution defined by Eq. (16). The red curves are their representation in polar coordinates (P(ψ), ψ) as indicated in the lower left panel. The panels from left to right correspond to n = 1, 2, 3, 4. The upper (lower) panels correspond to the negative (positive) sign of vn = ∓1∕6. The black dot-dashed circles correspond to uniform distribution P(ψ) = 1. |
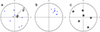 |
Fig. 3 Examples of the events generated by different algorithms: uniform distribution (a), clustering λ = 1∕3 (b), and anti-clustering λ = 1∕20 (c). |
2.3 Distributions of angular distances
Inside event (5) we define the angular distances:
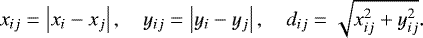 (41)
(41)
We also define the parameters characterizing the dimension of a triplet of stars:
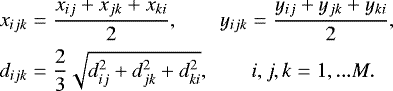 (42)
(42)
Let us consider a uniform field of stars (Fig. 1a). The example of a single event (5) is displayed in Fig. 3a. For the set of events we can calculate probability distributions of the parameters defined above. The distributions satisfy:
1) The shape of the (normalized) distribution of yij is the same as that of xij; similarly for xijk and yijk. Therefore for the uniform events, there are four different distributions,
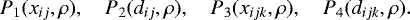 (43)
(43)
2) The shapes of these distributions do not depend on multiplicity. Since the numbers xj are independent, the distribution of xjk is the same for any j, k. Increasing M means only greater density, that is, greater numbers of xj and xjk, but proportion between different scales of xjk does not change. The same argument holds for the distribution of all the parameters (Eqs. (41),(42)).
3) Obviously, there is the similarity P(Δ, ρ) ~ P(kΔ, kρ) for the distributions above, Δ = xα, yα, dα. If we rescalethe distance parameters as
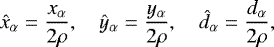 (44)
(44)
then one can check that 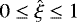 for
for 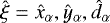 and α =ij or α =ijk. The corresponding normalized MC distributions
and α =ij or α =ijk. The corresponding normalized MC distributions 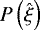 are together with the corresponding 3D plots
are together with the corresponding 3D plots 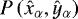 displayed in Fig. 5. These distributions can be approximated by the function
displayed in Fig. 5. These distributions can be approximated by the function
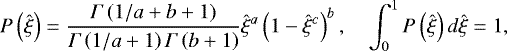 (45)
(45)
where the parameters a, b, c optimized by the fits in the whole region 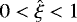 are listed in Table 1.
are listed in Table 1.
The universal plots in the figure, after rescaling 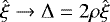 , will serve in the following section as the templates for comparison with the real events of angular radius ρ. We must point out that the functions Eq. (45) with the parameters in the table are only approximations of the MC distributions. The very good agreement in Fig. 5 is due to “flexibility” of this parameterization, which for a, b, c ≥ 0 satisfies needed boundary conditions:
, will serve in the following section as the templates for comparison with the real events of angular radius ρ. We must point out that the functions Eq. (45) with the parameters in the table are only approximations of the MC distributions. The very good agreement in Fig. 5 is due to “flexibility” of this parameterization, which for a, b, c ≥ 0 satisfies needed boundary conditions: 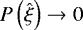 for
for  and
and 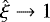 . The term with the Γ−functions provides normalization. Despite the simple MC algorithm for the definition of the distributions
. The term with the Γ−functions provides normalization. Despite the simple MC algorithm for the definition of the distributions 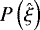 , we did not succeed in expressing their exact form in terms of the known standard or special functions. However, in principle we can calculate them with arbitrary precision, which is needed for the data analysis. We refer to the following rules of the MC technique. The statistical error of a simulated distribution in the kth bin is
, we did not succeed in expressing their exact form in terms of the known standard or special functions. However, in principle we can calculate them with arbitrary precision, which is needed for the data analysis. We refer to the following rules of the MC technique. The statistical error of a simulated distribution in the kth bin is 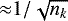 , where nk is bin population. For an accurate analysis, this error should be much less than the statistical error in the corresponding bin of the real data. In other words, the number of simulated events should be substantially greater than the number of the corresponding data events. In general, the precision of simulated distributions increases with the number of generated events.
, where nk is bin population. For an accurate analysis, this error should be much less than the statistical error in the corresponding bin of the real data. In other words, the number of simulated events should be substantially greater than the number of the corresponding data events. In general, the precision of simulated distributions increases with the number of generated events.
 |
Fig. 4 The functions Θn(M), n = 1, 2, 3 for Monte-Carlo events in the scenario of uniform distribution (upper panels). The remaining panels show clustering λ = 1∕3 (middle panels) and anti-clustering scenarios λ = 1∕20 (lower panels). Each multiplicity bin is generated by NM = 6000 events. The red lines correspond to the expected dependence for uniform distribution, Θ n (M) = 1 (Eq. (34)). |
 |
Fig. 5 Distributions of angular distances |
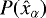
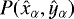
 |
Fig. 6 Analyzed regions in the Gaia catalog, where ρ is angular radius of the events, M is their multiplicity and Ne is the number of events. Analysis is done only for events 2 ≤ M ≤ 15. |
3 Application to the Gaia mission data
3.1 Violation of uniformity and bound star systems
The simulations described above have been applied to the analysis of the data from the recent Gaia catalog DR1 Gaia Collaboration (2016a). We present the results from the regions marked in Fig. 6. In the present paper we are starting this analysis from the simplest case, from the events of a small multiplicity. This condition refers to the small but different event radii in regions C and N&S (table in Fig. 6). In general, the scale of the possible structure violating uniformity should be less than the event radius ρ.
First, we applied the Fourier analysis described in Sect. 2.2. The corresponding functions Θ n (M) are shown in Fig. 7. The upper part corresponds to a dense region C and very similar results can be obtained over other regions at the galactic plane.
The result qualitatively corresponds to the scenario of anti-clustering simulated in the lower panels of Fig. 4, however the slope of Θ 1 appears to differ from the slopes of Θ2 and Θ 3. The lower panels correspond to sparse region N&S and the slopes Θn(M) suggest the presence of clustering.
To better understand these results, we have carried out a further analysis with the method described in Sect. 2.3. In Fig. 8 we show distributions of angular distances studied in region C, where we work with the events of radius ρ = 0.005deg = 18′′, which means dij max = xij max = yij max = 36′′, as seen in panel d. For comparison with simulation of uniform events we used the variables 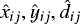 defined in Eq. (44). The MC curves are the same as in panels a and b of Fig. 5. For
defined in Eq. (44). The MC curves are the same as in panels a and b of Fig. 5. For 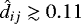 (or equivalently dij ≳ 4′′) the data agree perfectly with the MC simulation. However, the perfect agreement expected for uniform events is violated for dij ≲ 4′′. In fact we observe a 2D representation of the effect reported in (Arenou et al. 2017; Sect. 4.4.1., Fig. 17), which is due to reduced resolution oftwo sources in the same region of separation. Reduced efficiency at small distances imitates the anti-clustering scenario. If we take 2δ = dij min ≈ 2′′, then with the use of relation (39) one can predict the slope of the corresponding function Θ n (M) in the lower panels of Fig. 7 as
(or equivalently dij ≳ 4′′) the data agree perfectly with the MC simulation. However, the perfect agreement expected for uniform events is violated for dij ≲ 4′′. In fact we observe a 2D representation of the effect reported in (Arenou et al. 2017; Sect. 4.4.1., Fig. 17), which is due to reduced resolution oftwo sources in the same region of separation. Reduced efficiency at small distances imitates the anti-clustering scenario. If we take 2δ = dij min ≈ 2′′, then with the use of relation (39) one can predict the slope of the corresponding function Θ n (M) in the lower panels of Fig. 7 as
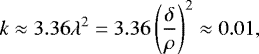 (46)
(46)
which gives a very reasonable agreement.
In the figure we also observe a peak at small separation dij ≲ 1′′. In Arenou et al. (2017) such a peak is observed only in the sparse region and is interpreted as the presence of binary stars. A simulation described in the same paper suggests that reduced efficiency at dij ≲ 4′′ correlates with fainter magnitudes G in the region. This is in agreement with our Fig. 9, where the sources with G > 15 mag are excluded and as a result the resolution dip is reduced.
A similar analysis for region N&S is demonstrated in Figs. 10 and 11. Now we work with the events of radius ρ = 0.020 deg = 72′′, which means dij max = xij max = yij max = 144′′. In the first figure, for 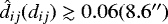 we see that the data agree perfectly with the MC simulation. Comparison of panel f from both Figs. 8 and 10 reveals that in the sparse region the efficiency drop is less pronounced. Further, in the latter figure, apart from the pronounced peak at dij ≲ 1′′, we observe a clear excess of pairs separated by
we see that the data agree perfectly with the MC simulation. Comparison of panel f from both Figs. 8 and 10 reveals that in the sparse region the efficiency drop is less pronounced. Further, in the latter figure, apart from the pronounced peak at dij ≲ 1′′, we observe a clear excess of pairs separated by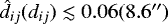 . In Fig. 11we display results for brighter stars, G ≤ 15. The panels are different representations of the very clear excess of pairs with a small separation. In panel a we observe a pronounced peak at small distances on the background, represented by the red curve in panel a. We note that the data and curve are equally normalized for
. In Fig. 11we display results for brighter stars, G ≤ 15. The panels are different representations of the very clear excess of pairs with a small separation. In panel a we observe a pronounced peak at small distances on the background, represented by the red curve in panel a. We note that the data and curve are equally normalized for 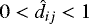 . The background is generated by uniform distribution of the star pairs. This background also naturally involves close pairs – but only double stars without the gravitational bond. The peak must be the result of some additional rule, which makes the close pairs more frequent. We interpret this surplus as the presence of the binary star systems (with gravitational bond). Panel c displays the excess most explicitly, as statistical ratio binaries/background. Further, we can observe some correspondence between Figs. 9c and 11c. For instance the positions of local minima of
. The background is generated by uniform distribution of the star pairs. This background also naturally involves close pairs – but only double stars without the gravitational bond. The peak must be the result of some additional rule, which makes the close pairs more frequent. We interpret this surplus as the presence of the binary star systems (with gravitational bond). Panel c displays the excess most explicitly, as statistical ratio binaries/background. Further, we can observe some correspondence between Figs. 9c and 11c. For instance the positions of local minima of 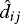 ≈ 0.05(0.0125) correspond to
≈ 0.05(0.0125) correspond to 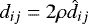 , which gives dij ≈ 1.8′′ for both event radii ρ = 18′′(72′′). This correspondence confirms that the results of the analysis should not be sensitive to ρ.
, which gives dij ≈ 1.8′′ for both event radii ρ = 18′′(72′′). This correspondence confirms that the results of the analysis should not be sensitive to ρ.
In a similar way we have analyzed distributions of the parameters (42) related to the triplets of stars in the region N&S. With the condition M ≥ 3 we have used the same events, ρ = 0.020deg = 72′′, which means dijk max = xijk max = yijk max = 144′′. The main results are presented in Fig. 12.
Again, we observe a peak in the region of smaller triplet distances; however the excess is broader and less dependent on G than for binaries. Weinterpret it as the presence of bound ternary star systems. Panels b and c display the statistical ratio ternaries/background.
The occurrence of the bound star systems is a manifestation of the clustering scenario. This scenario was suggested already by the function Θn(M) in the lower panels of Fig. 7 and followed from the Fourier analysis.
 |
Fig. 7 The functions Θn(M), n = 1, 2, 3 for events in the area C (upper panels) and N&S (lower panels). The green line is a linear fit of data taken in panel Θ 2. |
 |
Fig. 8 Distributions of angular distances in region C for all G. The blue points in the panels a, b, and c represent the data on |
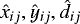
 |
Fig. 9 Distributions of angular distances in region C for G ≤ 15. The blue points in panel a represent the data on |
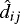
 |
Fig. 10 Distributions of angular distances in the region N&S for all G. The blue points in the panels a, b, and c represent the data on |

 |
Fig. 11 Distributions of angular distances in the region N&S for G ≤ 15. The blue points in panel a represent the data on |
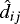
 |
Fig. 12 3D plot of angular ternary distances xijk, yijk
(unit is
1′′ ) in the region N&S for all G
(a) and ratios of measured distribution of relative distances |
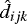
3.2 Gravitational microlensing
The principle of the gravitational microlensing effect is explained in Schneider et al. (1992). For a small angular separation β between two stars, the light beams from the more distant one (S2) and passing the gravitational field of the star on the way (S1) can reach the observer by the two pathways, as illustrated in Fig. 13a. The angles seen by the observer are
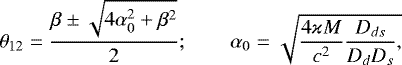 (47)
(47)
where ϰ is a gravitational constant, and M is the mass of the star S1. For β =0 the Einstein ring with angular radius θ = α0 is created. The relation in Eq. (47) implies
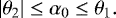 (48)
(48)
Therefore the necessary condition for observation of the splitting is that resolving power of the equipment is better than α0 . For estimation of α0, first of all the distance Dd is critical. For example Dd ≈ 10 − 102l.y., Ds ≈ 2D and M ≈ MS give roughly α0 ≈ 20 mas. Such a small separation is probably beyond present Gaia resolution. In fact the minimum separation we have registered in any of the regions C, N, and S is 59 mas. At the same time, for observation of the effect it is important that angular separation β of the pair is close to α0. For β < α0, the sources S 2 (θ2), S2(θ1) become strongly magnified, so the source S1 may not be resolved. On the other hand, brightness of S2(θ2) falls rapidly for β > α0 (Schneider et al. 1992).
There can be the following signature of the gravitational microlensing effect. The light sources S 2 (θ2), S1, S2(θ1) as seen by the observer, should have a small separation dijk (or 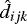 ) and should be aligned, or make a narrow triangle within the errors of measurement (Fig. 13b,c). Therefore, as a measure of the alignment we define the parameter κ:
) and should be aligned, or make a narrow triangle within the errors of measurement (Fig. 13b,c). Therefore, as a measure of the alignment we define the parameter κ:
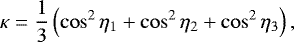 (49)
(49)
where ηi are angles in the observed triangle. For κ = 1 there is maximum alignment (e.g., η1, η2, η3 = 0, 0, π) and for η1 = η2 = η3 = π∕3 we have a minimum of κ = 1∕4. In the upper panels of Fig. 14 we have shown results of the uniform MC simulation. In the lower part we have shown its comparison with the data from the region N&S (we note the rescaled variable 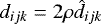 ). It is important that the shape of (normalized) MC distribution
). It is important that the shape of (normalized) MC distribution 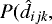 κ) does not depend on the multiplicity of events M ≥ 3. The reasons are the same as for distributions
κ) does not depend on the multiplicity of events M ≥ 3. The reasons are the same as for distributions 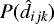 in Sect. 2.3. The same holds for the distribution P(κ) and the dependence
in Sect. 2.3. The same holds for the distribution P(κ) and the dependence 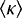 on dijk. One can observe a perfect agreement with the data for dijk ≳ 5′′. On contrary, for the smaller distances among the three sources there is a clear excess of the alignment. Could there be a connection between this effect and the gravitational microlensing – image splitting? Or, more probably, is the excess only another form of the distortion of measurement at small separations?
on dijk. One can observe a perfect agreement with the data for dijk ≳ 5′′. On contrary, for the smaller distances among the three sources there is a clear excess of the alignment. Could there be a connection between this effect and the gravitational microlensing – image splitting? Or, more probably, is the excess only another form of the distortion of measurement at small separations?
 |
Fig. 13 Geometry of gravitational microlensing effect (a). Alignment of three sources seen by observer: perfect (b) and partial (c). |
 |
Fig. 14 MC simulation of distribution |
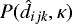
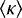
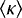
4 Summary and conclusion
We have proposed a general statistical method for the analysis of finite 2D patterns. Each pattern (event) consists of the stars located inside the circle of a given radius. We have demonstrated that the method can identify tiny deviations from uniform distributions; for example, a tendency to display clustering or anti-clustering.
The method has been applied to the analysis of astrometric data obtained by the Gaia mission. In parallel with the data, we have generated a large set of random uniform events using the MC code. In thepresent study we have focused on the events of a small radius and correspondingly small multiplicity (M ≲ 10). We have shown the functions Θn(ρ, M) representingdeviations from random uniform distribution are a useful tool for analysis. An equally important tool is the set of functions 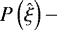 distributions of the parameters characterizing mutual positions and distances among the stars (doublets and triplets). The results of our analysis are based on the comparison of these functions from both the data and the MC simulation. The main results are as follows.
distributions of the parameters characterizing mutual positions and distances among the stars (doublets and triplets). The results of our analysis are based on the comparison of these functions from both the data and the MC simulation. The main results are as follows.
- 1)
In the dense region (C) we observe a 2D representation of reduced resolution power of two close sources (dij ≲ 4′′). Resolution improves for brighter pairs (G < 15).
- 2)
In the sparse region (N&S) we observe an evident excess of the close pairs (dij ≲ 9′′). The effect is very pronounced for the bright pairs (G < 15). A similar effect is observed for the triplets. We interpret these excesses as the presence of binary and ternary star systems.
- 3)
Apart from these effects we do not observe any violation of the uniformity on the scale of our events, which is defined by their radius ρ = 18′′(72′′) for the dense (sparse) region.
Special attention has been paid to the discussion on the possibility of detection of the gravitational microlensing and image splitting effect. Our present conclusion is that the statistical method suggested here can be a useful tool for detection of this effect. With the use of the alignment function 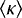 we have observed the excess of the three-source alignment at separation <5′′, which could accompany the gravitational image splitting. At the same time we are aware of some incompleteness in the Gaia survey reported by the Gaia team for this scale. We believe it will be possible to obtain more consistent results from the next Gaia data release (DR2).
we have observed the excess of the three-source alignment at separation <5′′, which could accompany the gravitational image splitting. At the same time we are aware of some incompleteness in the Gaia survey reported by the Gaia team for this scale. We believe it will be possible to obtain more consistent results from the next Gaia data release (DR2).
Acknowledgements
This work has made use of data from the European Space Agency (ESA) mission Gaia (https://www.cosmos.esa.int/gaia), processed by the Gaia Data Processing and Analysis Consortium (DPAC; https://www.cosmos.esa.int/web/gaia/dpac/consortium). Funding for the DPAC has been provided by national institutions, in particular the institutions participating in the Gaia Multilateral Agreement. The work was supported by the project LTT17018 of the MEYS (Czech Republic). Further, we are grateful to J. Grygar for deep interest and many valuable comments, J. Vondrak for critical reading of the manuscript and important comments, D. Heyrovsky and A. F. Zakharov for illuminating discussions on the gravitational microlensing effect and O. Teryaev for very useful discussions and inspiring comments.
References
- Adam, J., et al. (ALICE Collaboration) 2016, Phys. Rev. Lett., 116, 132302 [CrossRef] [PubMed] [Google Scholar]
- Arenou F., Luri X., Babusiaux C., et al. 2017, A&A, 599, A50 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Brown, A. G. A., et al.) 2016a, A&A, 595, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Prusti, T., et al.) 2016b, A&A, 595, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Poskanzer, A. M., & Voloshin, S. A. 1998, Phys. Rev. C, 58, 1671 [CrossRef] [Google Scholar]
- Rustamov, A., & Rustamov, J. N. 2016, Arxiv e-prints [arXiv: 1602.01812] [Google Scholar]
- Schneider, P., Ehlers, J., & Falco, E.E. 1992, Gravitational Lenses (Berlin: Springer Verlag), XIV, 560 [Google Scholar]
- Voloshin, S., & Zhang, Y. 1996, Z. Phys. C, 70, 665 [CrossRef] [Google Scholar]
All Tables
All Figures
|
Fig. 1 Patterns of the stars inside the grid of circles (a). Position n0 of the event defines its local reference frame (b). |
| In the text | |
|
Fig. 2 Examples of deviations from uniform angular distribution defined by Eq. (16). The red curves are their representation in polar coordinates (P(ψ), ψ) as indicated in the lower left panel. The panels from left to right correspond to n = 1, 2, 3, 4. The upper (lower) panels correspond to the negative (positive) sign of vn = ∓1∕6. The black dot-dashed circles correspond to uniform distribution P(ψ) = 1. |
| In the text | |
|
Fig. 3 Examples of the events generated by different algorithms: uniform distribution (a), clustering λ = 1∕3 (b), and anti-clustering λ = 1∕20 (c). |
| In the text | |
|
Fig. 4 The functions Θn(M), n = 1, 2, 3 for Monte-Carlo events in the scenario of uniform distribution (upper panels). The remaining panels show clustering λ = 1∕3 (middle panels) and anti-clustering scenarios λ = 1∕20 (lower panels). Each multiplicity bin is generated by NM = 6000 events. The red lines correspond to the expected dependence for uniform distribution, Θ n (M) = 1 (Eq. (34)). |
| In the text | |
|
Fig. 5 Distributions of angular distances |
| In the text | |
|
Fig. 6 Analyzed regions in the Gaia catalog, where ρ is angular radius of the events, M is their multiplicity and Ne is the number of events. Analysis is done only for events 2 ≤ M ≤ 15. |
| In the text | |
|
Fig. 7 The functions Θn(M), n = 1, 2, 3 for events in the area C (upper panels) and N&S (lower panels). The green line is a linear fit of data taken in panel Θ 2. |
| In the text | |
|
Fig. 8 Distributions of angular distances in region C for all G. The blue points in the panels a, b, and c represent the data on |
| In the text | |
|
Fig. 9 Distributions of angular distances in region C for G ≤ 15. The blue points in panel a represent the data on |
| In the text | |
|
Fig. 10 Distributions of angular distances in the region N&S for all G. The blue points in the panels a, b, and c represent the data on |
| In the text | |
|
Fig. 11 Distributions of angular distances in the region N&S for G ≤ 15. The blue points in panel a represent the data on |
| In the text | |
|
Fig. 12 3D plot of angular ternary distances xijk, yijk
(unit is
1′′ ) in the region N&S for all G
(a) and ratios of measured distribution of relative distances |
| In the text | |
|
Fig. 13 Geometry of gravitational microlensing effect (a). Alignment of three sources seen by observer: perfect (b) and partial (c). |
| In the text | |
|
Fig. 14 MC simulation of distribution |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.