| Issue |
A&A
Volume 612, April 2018
|
|
|---|---|---|
| Article Number | A70 | |
| Number of page(s) | 39 | |
| Section | Galactic structure, stellar clusters and populations | |
| DOI | https://doi.org/10.1051/0004-6361/201731996 | |
| Published online | 27 April 2018 | |
The seven sisters DANCe
III. Projected spatial distribution
1
Dpt. de Inteligencia Artificial, UNED,
Juan del Rosal, 16,
28040
Madrid, Spain
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Univ. Grenoble Alpes, CNRS, IPAG,
38000
Grenoble, France
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
3
Laboratoire d’astrophysique de Bordeaux, Univ. Bordeaux, CNRS,
B18N, allée Geoffroy Saint-Hilaire,
33615
Pessac, France
4
Depto. Astrofísica, Centro de Astrobiología (INTA-CSIC),
ESAC campus, Camino bajo del castillo s/n,
28692
Villanueva de la Cañada, Spain
5
Dpt. Statistics and Operations Research, University of Cádiz,
Campus Universitario Río San Pedro s/n,
11510
Puerto Real,
Cádiz, Spain
6
Institut d’Astrophysique de Paris, CNRS UMR 7095 and UPMC,
98bis bd Arago,
75014
Paris, France
Received:
26
September
2017
Accepted:
23
November
2017
Abstract
Context. Membership analyses of the DANCe and Tycho + DANCe data sets provide the largest and least contaminated sample of Pleiades candidate members to date.
Aims. We aim at reassessing the different proposals for the number surface density of the Pleiades in the light of the new and most complete list of candidate members, and inferring the parameters of the most adequate model.
Methods. We compute the Bayesian evidence and Bayes Factors for variations of the classical radial models. These include elliptical symmetry, and luminosity segregation. As a by-product of the model comparison, we obtain posterior distributions for each set of model parameters.
Results. We find that the model comparison results depend on the spatial extent of the region used for the analysis. For a circle of 11.5 parsecs around the cluster centre (the most homogeneous and complete region), we find no compelling reason to abandon King’s model, although the Generalised King model introduced here has slightly better fitting properties. Furthermore, we find strong evidence against radially symmetric models when compared to the elliptic extensions. Finally, we find that including mass segregation in the form of luminosity segregation in the J band is strongly supported in all our models.
Conclusions. We have put the question of the projected spatial distribution of the Pleiades cluster on a solid probabilistic framework, and inferred its properties using the most exhaustive and least contaminated list of Pleiades candidate members available to date. Our results suggest however that this sample may still lack about 20% of the expected number of cluster members. Therefore, this study should be revised when the completeness and homogeneity of the data can be extended beyond the 11.5 parsecs limit. Such a study will allow for more precise determination of the Pleiades spatial distribution, its tidal radius, ellipticity, number of objects and total mass.
Key words: astrometry / open clusters and associations: individual: M 45 / infrared: stars / methods: data analysis / methods: statistical
© ESO 2018
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
1 Introduction
The projected spatial distribution (PSD), also known as number surface density, of a stellar cluster is the two dimensional (2D) projection, in the plane of the sky, of its three dimensional (3D) space distribution. Because celestial coordinates are far more easily measured than parallaxes (at least before Gaia), only a small fraction of the objects with stellar positions have distance estimates. Furthermore, the relative uncertainties in the celestial coordinates yield far more precise measurements (by a factor of 104) of distances perpendicular to the line of sight than those achieved by parallaxes along this line so far (except perhaps for very close objects). This explains why most of the previous works devoted to studying the spatial distribution of stars in clusters have been done using the PSD.
In the case of the Pleiades, cross-matching the HIPPARCOS catalogue (Perryman et al. 1997) with the 2109 candidate members of Bouy et al. (2015), shows that only 70 of them have parallax measurements. This figure has roughly doubled with the first Gaia data release DR1 (Gaia Collaboration 2016), and is expected to improve based on the longer time baselines and hence more accurate measurements of subsequent Gaia releases. In preparation for the analysis of these upcoming data sets and to narrow down the set of models that will be tested in the context of 3D studies, we have initiated a re-examination of the current analytical alternatives to describe the PSD of the Pleiades cluster.
The Pleiades PSD has been thoroughly studied in the past. Pinfield et al. (1998) fitted King’s (King 1962, hereafter King’s) empirical profiles to the positions of 1194 candidate members from the literature, which were contained in a 3° radius area. For their fitted King profiles, they used different mass ranges, with bins centred at 5.2, 1.65, 0.83 and 0.3 M⊙. Using tidal forces1, they iteratively constrained the tidal radius to a value of 13.1 pc ( ~5.6°). They infer a core radii in the 0.9–2.91 pc range in the different mass bins, and a total mass of 735 M⊙. They interpreted the gradual increase in the core radii for decreasing mass ranges as evidence of mass segregation.
The same year, Raboud & Mermilliod (1998) also fitted a King’s profile to a list of 270 candidate members with masses in the range 0.74–7.04 M⊙, which were contained within a 5° radius area. They found a coreradius of 1.5 pc and a tidal radius of 17.5 pc (7.5°). Using different approaches, they derived a total mass within the range of 500–8000 M⊙. They also measured anellipticity of ϵ = 0.17. However, they did not make any explicit mention of the position angle of the axis of the ellipse, and simply state that it is roughly parallel to the galactic equator.
Later, Adams et al. (2001) also fitted a King’s profile to objects with membership probabilities p > 0.3 within a radius of 10°. They founda core radius of 2.35–3.0 pc and a tidal radius of 13.6–16 pc (5.8–6.8°). They estimate a total mass of ~800 M⊙, and their measured ellipticities are in the range 0.1–0.35.
Converse & Stahler (2008) fitted a King’s profile to a sample of 1245 candidate members from the Stauffer et al. (2007) compilation. These objects have masses greater than 0.08 M⊙ and are contained within a 5° radius. They obtained a tidal radius of 18 pc (7.7°) and a core radius of 1.3 pc. They found unambiguous evidence of mass segregation using a method they devised inspired by econometrics. Later, Converse & Stahler (2010) refined their previous study (Converse & Stahler 2008) and obtained a core radius of 2.0 ± 0.1 pc, a tidal radius of 19.5 ± 1.0 pc ( ~8.3°), a total number of systems of 1256 ± 35, and a total mass of 870 ± 35 M⊙.
The previous summary of results shows at least two interesting points. In the first place, the King’s profile has been the preferred choice for the Pleiades cluster, although it was created to fit the PSD of globular clusters. Since globular clusters are farther away than open clusters and in a low-density environment, the end of their PSD is usually well within the survey area, which is not the case for the Pleiades. The second point concerns the increasing trend of the tidal radius with the size of the survey and the publication date (Table 1); as the surveys increase in area, the derived tidal radii increase as well. This may indicate that truncation has not been accounted for (see Appendix A and Fig. A.3 particularly). The exception to this trend is the work of Adams et al. (2001), in which the tidal radius is well within the survey radius. Since these authors used low-membership-probability ( ≥ 0.3) objects, their results may be affected by a significant contamination rate, which these authors acknowledge for their >5° sample.
The two points mentioned above are tightly related. With the exception of the work of Adams et al. (2001), the coverages of the rest of the surveys have not reached their estimated tidal radius. This indicates that the previously used samples of members were spatially truncated. They only contain objects from the inner parts of the cluster. Thus, estimates of the tidal radius may have been biased, and were, in any case, highly correlated with the contamination rate.
With Gaia data coming up soon, we will have very accurate measurements of the spatial distribution of all the brightest (G ≤20 mag) members of nearby clusters. Therefore, it is important to define sufficiently complex models to describe these measurements. The early and simple formulations of the PSD (e.g. King) were perfect when a dozen or a few tens of dozens of members were known. But the accuracy and completeness of future surveys will allow us to look in finer detail.
The study of the spatial distribution also has implications that go beyond its intrinsic interest. One of them is the existence of mass segregation as a result of star formation and dynamical interactions in the cluster. This effect has been predicted by numerical simulations of the internal cluster dynamics; see, for example, Terlevich (1987), Kroupa et al. (2001), Moraux et al. (2004) and Converse & Stahler (2010). Confirming and quantifying its dependence on various parameters (e.g. initial mass function, core mass function, total mass of the cluster, presence or absence or massive stars, T- or OB-association) shall provide important input to the models and simulations of star formation and dynamical evolution.
In the specific case of the Pleiades, mass segregation has been reported in the works of Raboud & Mermilliod (1998), Pinfield et al. (1998), Kroupa et al. (2001), Adams et al. (2001), Moraux et al. (2004) and Converse & Stahler (2008, 2010). Yet, Loktin (2006), using radial and tangential velocity dispersions, found no hint of mass segregation in a sample of 340 stars contained in the central 2.3°. However, his results may arise from the low number and extent of his sample. All the mentioned works performed their analyses by binning the stellar samples in mass or distance ranges. It is well known however that fitting a function to a binned data set can introduce biases (Bevington & Robinson 2003; Nousek & Shue 1989), and that modifying the bin width could improve the fitting to a preferred model (Towers 2012). Thus, the use of bins in previous works and the contradictory mass-segregation results found by Loktin (2006) may suggest that the hypothesis of mass segregation in the Pleiades requires a more solid reexamination.
In this work we aim at addressing this hypothesis on the basis of the largest and least contaminated sample of Pleiades candidate members found to date: the combined list of candidate members from Bouy et al. (2015) and Olivares et al. (2017). We avoid the binning biases by using Bayesian inference methods applied to continuous and thus non-binned distributions. In addition, these Bayesian methods allow a quantitative comparison of the competing models, including those with and without mass segregation. This will allow us to establish on firm grounds the analytical expression of the Pleiades PSD, and its potential dependence on stellar mass.
In Sect. 2 we briefly describe the data set that forms the basis of our analysis. In Sect. 3 we present the set of radially symmetric analytical models we used, as well as their extension to biaxially symmetric (elliptical) profiles. We also include a luminosity dependence of the core radius (as a proxy to the investigation of mass segregation). In Sect. 4 we describe the foundations of model selection in the Bayesian framework. We then discuss and compare the results that we obtain for the posterior distributions of the various models in Sect. 5, where we also briefly describe our estimates on the total mass and number of members in the cluster. Finally, in Sect. 6 we summarise the conclusions drawn from the study.
Survey, and derived core and tidal radius for recent studies in the literature.
2 The data sample
The data set used to compare the models in Sect. 3 corresponds to the high-membership-probability candidate members of Olivares et al. (2017), in the middle and faint luminosity end, with the addition of the Tycho-2 Pleiades high-luminosity candidate members from Bouy et al. (2015). This joint data set comprises the equatorial coordinates RA and Dec (in the following α and δ), proper motions, photometry, and membership probabilities of 2060 sources. In this analysis we work only with the positions, membership probabilities, and J photometric band. The latter is the reddest most available band for this list of members, and is used as a proxy for the mass and to explore evidence of mass segregation.
2.1 Completeness of the sample
To properly establish the probabilistic framework, it is necessary to take into account the observational constraints of the data. The Pleiades DANCe catalogue is constrained by its sky coverage and the different degrees of completeness (see Bouy et al. 2013, 2015, for details). Although the data set extends up to a radius of 6.5°, Bouy et al. (2015) conservatively assume that the census is homogeneous in coverage and limiting magnitude only in the central 3° radius area.
Here, we estimate the completeness of the whole of the joint Tycho + DANCe survey in terms of the J band luminosity and spatial coverage, which also applies to our list of candidate members. In Fig. 1 we show the distributions of the number of sources in the combined DANCe + Tycho catalogue as a function of the radial position for different limiting magnitudes and bins in the J band. The radial position is computed assuming a distance of 134.4 pc to the Pleiades cluster (Galli et al. 2017) and a centre at α, δ = [56.65, 24.13]. As can be seen from the top panel of this figure, the DANCe + Tycho catalogue is spatially complete until a radial distance of 11.5 pc ( ~5°). The latter corresponds roughly to the sky coverage of the UKIDSS survey (Lawrence et al. 2007). Above this limit, the density of sources drops with two different slopes. The first one is created by the sawtooth pattern at the edge of the DANCe survey, while the last one corresponds to the more extended selection box used for the Tycho survey. To evaluate the photometric completeness, we assume that the distribution of sources in the sky region of the Pleiades is uniform (this simplistic assumption is sufficient for our current purpose). We compare the radial density of sources of different J magnitude bins with that of a synthetic sample uniformly distributed in space and truncated at the completeness radius of 11.5 pc. The radial distribution of this synthetic sample and those of the three magnitude bins are shown in the bottom panel of Fig. 1. As can be seen from the latter, the joint Tycho + DANCe survey is expected to be complete until magnitude ~ 19 in the J band. Above this limit, the distribution of sources departs significantly from the expected one. Hence, we restrict our list of candidate members to those with: (i) J band observed and less than 19 mag, and (ii) radial distances less than 11.5 pc. This results in 1954 candidate members, which represents more than 50% more candidate members than those of Converse & Stahler (2010), who did thelatest analysis of the Pleiades PSD. Accounting for completeness and the previous truncation in the data set is essential to avoid possible bias in the inferred parameters (see Appendix A). Nevertheless, we remind the reader that the inhomogeneities (e.g. spatial resolutions, gaps in luminosity) of the DANCe + Tycho data set are so complex (and some of them only partially understood) that they can indeed bias the sample of candidate members in unknown ways. For example, the gap in luminosity coverage between the faint end of the Tycho-2 catalogue and the bright end of the DANCe survey (see Fig. 8 of Bouy et al. 2015) may result in undetected sources, therefore unmeasured proper motions and, finally, an incomplete list of candidate members.
Another important constraint is the number of cluster stars observed within the survey area coverage. Truncating the probability distributions properly accounts for the cluster members left outside the truncation radius. However, due to the several artefacts surrounding the images of bright sources (e.g. halos, spikes, saturation), potential cluster members could also remain undetected. Furthermore, these artefacts can severely bias any evidence of mass segregation, as the most massive and brightest stars are located at the centre of the cluster. However, the statistical treatment of the impact of these artefacts lays beyond the scope of this work.
The information provided by the observational constraints, which we call I, consists of the maximum radius, Rmax = 11.5 pc, and the number of stars observed within this radius, N = 1954. These constraints will be incorporated into the model through the likelihood.
 |
Fig. 1 Density of sources in the combined DANCe + Tycho catalogue as a function of the radial distance to the cluster centre and the J magnitude. Top panel: all sources contained within the limiting magnitudes. Bottom panel: sources within the 11.5 pc radius of spatial completeness (vertical grey line), and binned in magnitudes. The black line represents the density of two million sources uniformly distributed in the plane of the sky. |
2.2 Contamination
Olivares et al. (2017) estimate a contamination rate of 4.3 ± 0.2% in their sample of candidate members at the probability threshold of p84%2 > 0.84. This would amount to 84 of their 1963 candidate members. Also, Sarro et al. (2014) estimate that the contamination rate of their methodology is 11.0 ± 2.0% for a probability threshold of p = 0.5, similar to that used by Bouy et al. (2015) to classify the candidate members of their Tycho + DANCe data set. Thus, in our combined Tycho + DANCe list of candidate members, we acknowledge a mean contamination rate of ~ 8% (approx. 156 objects). We expect these contaminating sources to be uniformly distributed in right ascension and declination because the position on the sky was explicitly removed from the calculation of membership probabilities. Nevertheless, there may be a mild positive gradient of the density towards the Galactic centre. In addition, these contaminants may not be uniformly distributed in J band, with possible concentrations around 14 and 17 mag, where the entanglement of field and cluster populations is higher. The quantification of this possible dependency of contaminants with photometric magnitude and its consequences lay beyond the objective of this work and will be analysed in future studies.
3 Spatial density models
3.1 Spherical models
In this section we consider spherically symmetric models of the spatial distribution of Pleiades members. In the following paragraphs we give a brief description of each model, its analytical parameterisation, and the corresponding references.
Our starting point is the classical King’s profile. Although it was introduced as an empirical law to describe the number surface density of globular clusters, it has also been used to describe open clusters (see Alonso-Santiago et al. 2017; Panwar et al. 2017, for recent applications), globular clusters (Myeong et al. 2017) and even to study galaxies (Robotham et al. 2017), halo substructure (Sohn et al. 2007) and the dark matter distribution (Jiang & van den Bosch 2016). The analytical description of the surface number density of stars n is given by
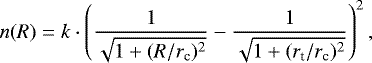 (1)
(1)
where rc, the core radius, is a scale factor, rt is the tidal radius, and k is a constant related (but not equal) to the central surface density. In the following we use R instead of r (as is often commonly done in the literature) to refer to the distance from the system centre projected on the celestial sphere.
In addition to the classical King’s profile we have tested two extensions of it. We define the Generalised King’s profile (hereafter GKing) as the classical King’s profile without fixing the exponents of the analytical expression. Instead of Eq. (1), we have
![Mathematical equation: \begin{equation*} n(R)= k \cdot \left[ \left(1+(R/r_{\textrm{c}})^{\frac{1}{\alpha}}\right)^{-\alpha} - \left(1+(r_{\textrm{t}}/r_{\textrm{c}})^{\frac{1}{\alpha}}\right)^{-\alpha} \right]^{\beta},\end{equation*}](/articles/aa/full_html/2018/04/aa31996-17/aa31996-17-eq2.png) (2)
(2)
where the classical King’s profile is recovered for α = 0.5 and β = 2. To the best of our knowledge, only in the work of Robotham et al. (2017) has a similarly modified King’s profile been used. However, the profile used by those authors is more restrictive than the one presented here, requiring that β = α−1, and that both terms (R∕rc), and (rt∕rc) are at the power of 2.
The optimised generalised King’s profile (hereafter OGKing) is the GKing profile with the values of α and β fixed at the maximum-a-posteriori (MAP) values of the GKing parameters. This maximises the Bayesian evidence and reduces the dimensionality of the parameter space.
To avoid the use of a tidal radius in the radial profile, we have also considered the model proposed by Elson et al. (1987), henceforth EFF, to describe young open clusters in the Large Magellanic Cloud. Their surface density (in star counts per solid angle) is given by
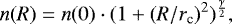 (3)
(3)
with rc the core radius, and γ the slope of the profile at radii much larger than the core radius.
Finally, we analyse a more general parameterisation introduced in Lauer et al. (1995), Byun et al. (1996) and Zhao (1997), where the projected mass density is given as
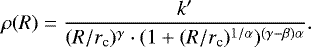 (4)
(4)
Equation (4) represents a double power law, with rc being the so-called core or break radius, γ and β the exponents of the inner and outer regions, respectively, α the width of the transition region, and k′ a scale constant. Meaningful values of these parameters fulfil the following conditions: α > 0 and 0 ≤ γ ≤ β. The aforementioned works assume this functional form for the projected surface brightness, the projected mass density ρ, and the volume density v, although the latter two are related by integration:
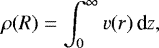 (5)
(5)
where z is the distance along the line of sight.
In this work we use the same analytical expression as in Eq. (4) but for the number density n(R). We call this model the generalised density profile3 (hereafter GDP), as it comprises many simpler models, each of which corresponding to particular choices of the model parameters. Several density profiles proposed to describe galaxies can indeed be grouped by parameter values. For example, α = 1 includes models by Navarro et al. (1997), Hernquist (1990), Jaffe (1983) and Moore et al. (1999). Similarly, α = 1∕2, γ = 0 includes the models by Plummer (1911) (with β = 5), by Sackett & Sparke (1990) and by de Zeeuw (1985). The EFF model corresponds also to α = 1∕2, γ = 0. King’s profile, however, cannot be cast into this general model unless the tidal radius rt is fixed at infinity.
For our spatial analysis, we also considered the restricted generalised profile (RGDP), corresponding to the generalised profile with the value γ fixed at 0.
We note that we have used similar names for parameters rc and γ in all the aforementioned formulations. However, these parameters do not share the same meaning amongst models. The latter is distinctively specified by each model relation 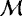 .
.
In all cases, the R coordinate is defined with respect to the cluster centre. The actual values of R then depend on the choice of this origin (see Sect. 3.2).
3.2 Central symmetry constraint
In the above, we have defined six models: King, GKing, OGKing, EFF, GDP and RGDP. Each of them has a different set of parameters. For example, the King’s model depends on two parameters (rc and rt ), the EFF model depends on two other parameters (rc and γ), and the generalised profile GDP depends on four parameters (α, β, γ and rc ).
In reality, there are always two more parameters that do not appear explicitly in any of the above analytical formulations of the number density profiles. These are the cluster centre coordinates from which all radial distances R are measured. It is not a minor question because the problem is degenerate, and there is a maximum likelihood solution for each choice of the cluster centre. In principle, one could even choose a poor cluster centre estimate that renders the angular distribution of members asymmetric, and obtain a maximum likelihood fit better than those obtained with a better centred estimate. The models assume central symmetry, but this can only be ensured approximately. There is a region of non-negligible extent, where the cluster centre may be, and any particular choice of its position will influence the posterior distribution inferred. Thus, in order to propagate appropriately this uncertainty about the cluster centre position in our posterior inferences, we have included the two cluster centre coordinates, αc and δc, as further parameters of our models (their allowed intervals will be described in Sect. 4.3).
For any given choice of the central coordinates, we calculate the radial distance, R, and the position angle θ of each star in our data set. To avoid biases introduced by projection effects of objects located far from the cluster centre, we project each object’s coordinates into the plane of the sky along the line-of-sight vector (see for example, Eq. (1) of van de Ven et al. 2006).
These projected coordinates are
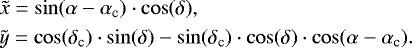 (6)
(6)
From these projected coordinates, the radial distance, R, and the position angle, θ, are computed as
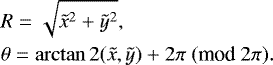 (7)
(7)
The requirement of central symmetry is enforced by the inclusion of a multiplicative term in the likelihood. For a given set of parameter values of αc, δc, we divide the computed polar angles of individual stars, θ, into four symmetric quadrants (divisions at [0, π∕2, π, 3π∕2]) and require that the number of stars in each quadrant be Poisson distributed with a mean rate given by Nq = Ntot∕4. Under this model, the likelihood of any given proposal for the model parameters (αc, δc ) will be
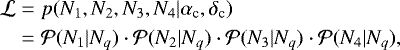 (8)
(8)
where Ni, i = 1, 2, 3, 4 is the number of sources in each quadrant, and 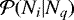 is the Poisson distribution with mean rate Ntot∕4 evaluated atNi.
is the Poisson distribution with mean rate Ntot∕4 evaluated atNi.
3.3 Elliptical models
In this section we extend the aforementioned spherical models to allow for deviations from radial symmetry. We do this by allowing variations of the radial profile that depend on the angular coordinate but still maintain biaxial symmetry. This can be done in many ways. In this work we focus on the simplest one: the analytical expression of the radial profile is maintained along any radial direction but the profile parameters (e.g. rc and rt in the King profile) have an ellipse-like dependence on the angular coordinate.
This requires the definition of a coordinate system centred at the cluster centre (parameters αc and δc ), and potentially rotated from the RA–Dec system of axes. Thus, we further include the angle ϕ between the principal axes of the ellipse and RA–Dec system as a parameter of these models. The coordinates 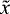 and ỹ of Eq. (6) are rotated by angle ϕ to obtain coordinates x and y. Then, R and θ are computed from the latter by means of Eq. (7).
and ỹ of Eq. (6) are rotated by angle ϕ to obtain coordinates x and y. Then, R and θ are computed from the latter by means of Eq. (7).
The radially symmetric parameters of the previous section have now an angular dependency, which is now expressed by means of the characteristic radii at the semi-major and semi-minors axes (denoted by subscripts a and b, respectively). These new radii are expressed as
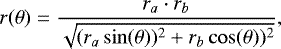 (9)
(9)
where θ is the position angle measured from the semi-major axis, and ra and rb are the parameters representing the characteristic radius at the semi-major and -minor axis, respectively.
We illustrate this new biaxial dependency in the King’s profile. The surface number density is now
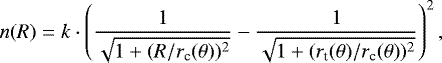 (10)
(10)
where rc and rt are obtained from Eq. (9). Explicitly they are,
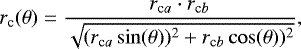 (11)
(11)
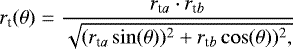 (12)
(12)
where rca and rt a are the core and tidal semi-major axis of the ellipse, and rcb and rtb correspond to the semi-minor axis. We highlight that we do not constrain the two ellipses to have the same aspect ratio, but they are co-aligned.
For the other model, the surface densities are similarly obtained. We do not incorporate any angle dependence for the exponents α, β or γ.
The position angle of the semi-major axis with respect to the Right Ascension axis (ϕ) is constrained using the equivalent of the radial symmetry likelihood term, except that now the position angle has its origin at the semi-major axis.
3.4 Segregated models
Finally, in this section we introduce another set of profiles to revisit the problem of mass segregation in the context of the Pleiades.
We consider the previous biaxially symmetric models to which we add a dependence of the core radius with the J magnitude. We select the J magnitude because it is the reddest of the magnitudes that are available for all candidate members. We assume that stars of the same mass have approximately the same magnitude and that distance differences (due to the 3D spatial extent of the Pleiades) average out. The core radius dependence with the J magnitude is modelled as
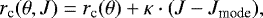 (13)
(13)
where Jmode is the mode of the J band distribution.
The slope of the relationship, κ, is independent of the angle θ. Therefore, for J = Jmode = 13.6 the model reduces to the elliptic profile described in Sect. 5.2. A positive value of κ corresponds to smaller values of the core radius for stars brighter than Jmode = 13.6; in other words, it describes a system where the more massive stars are more concentrated than the less massive ones.
4 Bayesian analysis
As mentioned in Sect. 2, our data set may be contaminated. Thus, in an effort to minimise the possible impact that these contaminants may have on our inference, we also model their spatial distribution. Hence, our model of the spatial distribution of stars not only includes the model of the Pleiades cluster, but also a field component which is modelled by a uniform spatial distribution  within the maximum radius Rmax.
within the maximum radius Rmax.
The measured properties of each of star in our data set can be assumed to be unaffected by the measured properties of any other star in the data set (this assumption is called statistical independence). Under this assumption, the probability that the data set was generated by the mixture of cluster and field is the product of the probabilities that each of the stars was generated by this mixture.
Allowing 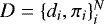 to denote our data set,with d comprising the sky coordinates and J magnitude, and π the cluster membership probability of each object, the probability or likelihood of the data set D, given the model
to denote our data set,with d comprising the sky coordinates and J magnitude, and π the cluster membership probability of each object, the probability or likelihood of the data set D, given the model 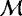 , constraints I, and parameters q, is
, constraints I, and parameters q, is
![Mathematical equation: \begin{equation*} \mathcal{L}(D|\boldsymbol{q},\mathcal{M},I)= \prod_i^N \left[\pi_i\cdot p(d_i|\boldsymbol{q},\mathcal{M},I)+(1-\pi_i)\cdot \mathcal{U}(d_i|I) \right]. \end{equation*}](/articles/aa/full_html/2018/04/aa31996-17/aa31996-17-eq20.png) (14)
(14)
The probability 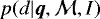 depends on the profile under consideration and is described in the following section.
depends on the profile under consideration and is described in the following section.
4.1 Probabilistic framework
To avoid the use of bins and to properly infer the parameters of the models presented in Sect. 3, we need to convert the projected stellar densities into probability density functions that describe the probability of finding a star between R and R + dR, under the assumption of spherical symmetry. The probability density function p(R) is constructed from the definition:
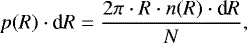 (15)
(15)
where N is the total number of stars in the system.
This probability is renormalised to integrate to unity at the truncation radius Rmax, which in our data set corresponds to 11.5 pc. Thus,
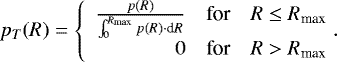 (16)
(16)
All the probabilities rendered by our set of models are renormalised according to the previous equation. However, in the following and for the sake of simplicity, we only present the non-truncated probabilities.
Applying Eq. (15) to the spherically symmetric King’s profile, we obtain
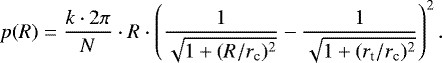 (17)
(17)
Actually, in probabilistic inference we write this probability function as:
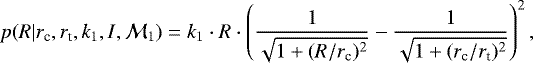 (18)
(18)
where we have defined a new constant, 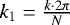 , and made explicit the dependence of the probability on the underlying analytical expression (
, and made explicit the dependence of the probability on the underlying analytical expression (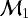 ), the constraints I, and the values of the parameter set (k1, rc and rt). In practice, k1 is treated as a normalisation constant (to enforce unit integral) and there is no need to know the total number of stars in the system.
), the constraints I, and the values of the parameter set (k1, rc and rt). In practice, k1 is treated as a normalisation constant (to enforce unit integral) and there is no need to know the total number of stars in the system.
For the generalised King’s profile, this becomes
![Mathematical equation: \begin{eqnarray*} && p(R|r_{\textrm{c}}, r_{\textrm{t}}, \alpha, \beta, k_2, I, \mathcal{M}_2) \nonumber \\ &&\quad = k_1\cdot R \cdot \left[ \left(1+(R/r_{\textrm{c}})^{\frac{1}{\alpha}}\right)^{-\alpha} - \left(1+(r_{\textrm{t}}/r_{\textrm{c}})^{\frac{1}{\alpha}}\right)^{-\alpha} \right]^{\beta}. \end{eqnarray*}](/articles/aa/full_html/2018/04/aa31996-17/aa31996-17-eq28.png) (19)
(19)
Likewise, the expression for the EFF model is
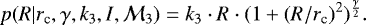 (20)
(20)
And finally, the GDP model is given by
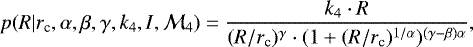 (21)
(21)
with γ = 0 for the RGDP model.
For the elliptical and luminosity segregated density profiles, the likelihoods are obtained similarly by adding ϕ and replacing rc and rt by rc a, rcb and rt a, rtb in the model parameters, and introducing the dependence on θ and J in the relations. For example, the likelihood of the biaxial King’s profile is
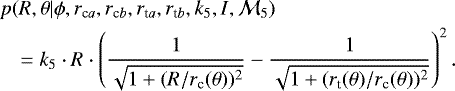 (22)
(22)
4.2 Model selection
In this section we aim at comparing the aforementioned analytical parameterizations of the projected stellar densities in the light of the currently available data. In order to do so, we use the Bayesian evidence, also known as marginal likelihood. In the following, we use evidence (and its plural evidences4) to refer to the Bayesian evidence. The evidence is the key for model comparison in the Bayesian framework. In this framework, the model comparison is done on the basis of the model posterior probability 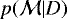 . This is the probability of model
. This is the probability of model 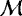 given the collected data D. In our opinion, this is the most natural way to compare and select (if needed) models in the scientific context. The posterior probability can be expressed as
given the collected data D. In our opinion, this is the most natural way to compare and select (if needed) models in the scientific context. The posterior probability can be expressed as
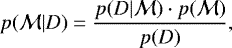 (23)
(23)
using Bayes’ theorem. The ratio of posterior probabilities can then be expressed as
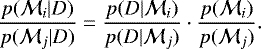 (24)
(24)
If there is no difference in the prior probabilities for models i and j, then the posterior ratio is equal to the marginal likelihood ratio (also known as Bayes Factor), where the marginal likelihood (i.e. the evidence) is the full likelihood marginalised over the model parameters q, as follows
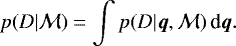 (25)
(25)
It is important to remark that the Bayesian model comparison naturally incorporates a preference towards the less complex models if they are equally supported by the data. In fact, the preference is towards models with less effective parameters (understood as parameters that the data can constrain).
The computation of the posterior probability distributions and the evidence of each model is carried out in practice using the Nested Sampling (Skilling 2006) algorithm as implemented in PyMultiNest (Buchner et al. 2014).
4.3 Priors
In the spherical models, we have assumed exponential priors, with a scale value of 1, and truncated at 100, for all exponent parameters α, β, γ, normal priors for the central coordinates (with mean at [56.65°, 24.13°] and standard deviation of 1°), and half-Cauchy priors for radial parameters (with scale parameter at 10 pc). These priors fall in the category of weakly informative ones (see Gelman 2006).
In the biaxially symmetric models, we use the same priors as for the radially symmetric ones but we restrict the semi-major axes of the core and tidal radii to be larger than, or at least equal to, their corresponding semi-minor axis. We also include a uniform prior for the angle ϕ ∈ [−π∕2, π∕2].
In the luminosity segregated models, in addition to the previous priors, we use a normal, 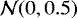 , as a prior for κ, which represents our prior beliefs of almost negligible luminosity segregation.
, as a prior for κ, which represents our prior beliefs of almost negligible luminosity segregation.
The code to perform the analysis of the present work, together with the data set described in Sect. 2, is available at https://github.com/olivares-j/PyAspidistra
5 Results and discussion
We apply the Bayesian formalism described in Sect. 4 to the data set detailed in Sect. 2. Thus, for each of our models we obtain the posterior distribution of its parameters, together with its evidence. Appendix B contains thedetails of the inferred posterior distributions, figures of the fitted densities and marginal distributions, together with the uncertainties of the parameters in each analysed model. Table 2 summarises the evidences and Bayes Factors resulting from all our models and their extensions. In the following we use these evidences to discuss the model comparison.
The boundaries for decision making from Bayes Factors should be set ab initio. We mostly discuss our results following the classical scale by Jeffreys (1961). In this scale, the strength of the evidence5 is said to be: inconclusive if the Bayes Factor is ≲3:1, weak if it is ~3:1, moderate if it is ~12:1, and strong if it is ≳150:1. Nevertheless, we hope that our conclusions can be shared by the reader independently of the scale used to categorise the Bayes Factors.
5.1 Models with radial symmetry
The upper-left panel of Table 2 summarises the evidences and Bayes Factors obtained from our radially symmetric models. In addition, Table 3 shows the MAP estimate of each parameter in the radially symmetric models (uncertainties are shown in Appendix B in the form of covariance matrices).
We observe that the evidences cluster in two groups. On one hand there is the family of King’s models, where the evidence to compare between them is inconclusive and weak in favour of OGKing over GKing. On the other hand there are the EFF, GDP, and RGDP, where there is weak evidence supporting EFF over GDP and RGDP. There is inconclusive evidence supporting RGDP over GDP.
Comparing the two groups shows that models in King’s family provide evidence that is: inconclusive and weak over the EFF, weak and moderate over RGDP, and moderate over GDP. Using this information only, we conclude that the tidal radius is an important parameter.
In addition, we observe that in GDP and RGDP, parameters rc and β show large correlations (0.85 and 0.92 for GDP and RGDP, respectively) and are relatively unconstrained with large uncertainties; see Appendix B. Despite this fact, the models still provide evidences comparable to those of the other models, suggesting that these two parameters, although necessary for the model, are unconstrained by the data, and therefore not penalised by the evidence. Aiming at eliminating this source of degeneracy, we tested models in which one of these two parameters was removed. However, the fits and evidence resulting from them were poorer than that of the RGDP. Thus, we consider these parameters as necessary for this model.
We find that the introduction of more flexibility in the analytical expressions of the classical radially symmetric profiles does not provide an increased amount of evidence, and results, in some cases, in unconstrained parameters and a loss of the interpretability associated to the original formulations. Therefore, the competing models are within the King’s family, with insufficient evidence to select amongst them. Only additional, perfectly acceptable prejudices like physical interpretability or the ability to compare with previous results can be invoked to choose one (e.g. King’s profile) over the rest.
The Bayes Factors seem to indicate (with inconclusive evidence however) that the best model is the OGKing. However, the fact that this profile has a larger evidence than any of the remaining models should come as no surprise since it results from fixing the values of α and β of the GKing model to their MAP values.
Comparing the rest of the models, we see that the poorest model is GDP with moderate evidence against it. The best models are again in King’s family, followed by EFF and RGDP.
The conclusion from the comparison of these radially symmetric profiles is that (i) there is no compelling reason to abandon the widely used King profile, and (ii) there are slightly better models, but we lack evidence to prove if they truly represent a requirement to make the King’s profile more flexible to accommodate the data.
Natural logarithm of the evidence for each profile density (diagonal) and Bayes Factors (off-diagonal elements, with the evidence for the model specified in the column header placed in the denominator, i.e. 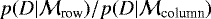 ).
).
Maximum-a-posteriori estimates of the inferred parameters in each radially symmetric model.
5.2 Biaxially symmetric models
The central panel of Table 2 contains the logarithm of the evidences and Bayes Factors of the biaxially symmetric models. The evidences follows a pattern similar to that observed for the radially symmetric models, with the exception of those that are against the GDP model. We can conclude that there is strong evidence for the family of King’s models and against the GDP one. The evidence is still moderate and too weak to compare the rest of the models.
Additionally, we compute a posteriori (from the MCMC chains) the ellipticities6 ϵrc and ϵrt, which are defined as,
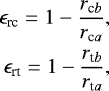
with the latter available only for the King’s family of models.
Table 4 shows the MAP estimate for the parameters in the models of this section, together with the mode ofthe distributions of ellipticities. Uncertainties for the latter are given in Appendix B.
We can observe that models with no tidal radius have similar ϵrc ellipticities with a mean value of 0.23 ± 0.01. This value is similar to the 0.17 found by Raboud & Mermilliod (1998), who use a multicomponent analysis to derive the directions (although its value is not given) and the aspect ratio of the ellipse’s axes. However, it is very interesting to see that the models within King’s family result in lower values of the ellipticity in the central region and larger values in the outer one. This result is expected from the interaction with the galactic potential and is predicted by numerical simulations of open clusters (see, e.g. Terlevich 1987).
By comparing the evidences of the biaxially symmetric models to those of the radially symmetric ones, we can conclude that in all cases there is strong evidence in favour of the biaxial models.
5.3 Models with luminosity segregation
The lower-right panel of Table 2 summarises the evidences and Bayes Factors of models with luminosity segregation. Also, Table 5 shows the MAP of the inferred distributions for this set of models, together with the derived ellipticities.
We observe that the ellipticities follow the same pattern as those of the previous section. This is expected because we explicitly model the luminosity segregation as independent of the position angle.
The luminosity segregation inferred here is non-negligible with κ in the range 0.1–0.25 pc mag−1, thus indicating that it is indeed an important parameter. However, in all the models, the marginal posterior distribution of κ does not discard the zero value (see the marginal posterior of κ in Appendix B).
The evidences provided by the models with luminosity segregation follow a similar pattern as those from radial symmetry. However, in this case the best model is the classical King’s, which shows only moderate evidence against the EFF, RGDP, and GDP models. The evidence of King’s model over GKing and OGKing is weak.
The evidences provided by the luminosity segregated models lead to them being strongly favoured over the radially andbiaxially symmetric ones in all cases. We can conclude that, despite having a small value of κ, the luminosity segregation is an important parameter regardless of the model used.
Maximum-a-posteriori estimates of the inferred parameters in each biaxially symmetric model.
Maximum-a-posteriori estimates of the inferred parameters in each luminosity segregated model.
5.4 Totalmass and number of members
In this section we use the inferred values of the parameters in King’s family of models to derive simple estimates of the total number of members and mass of the Pleiades cluster.
For each model and extension within the King’s family, we estimate the total number of cluster members by integrating the surface density profile until the tidal radii inferred for the model. This is done for each set of parameters returned by PyMultiNest. The resulting distributions of the total numbers fore each model and extension in the King’s family are shown in Fig. 2. Additionally, Table 6 shows the mode of these distributions. As can be seen from this table, our current data set (with 1954 members), although twice as large as previous studies in the literature, still lacks almost one fifth of the predicted number of objects in the cluster.
We also estimated the total mass of the cluster using the posterior samples of the parameters returned by PyMultiNest. To gain an estimate of the total mass we use the tidal force resulting from the interaction of the self-gravitating cluster with the galactic potential. A detailed derivation of the Jacobi radius under the Hill’s approximation can be found at p. 681 of Binney & Tremaine (2008). Following the mentioned authors, the Jacobi radius is given by,
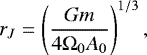 (26)
(26)
where G is the gravitational constant, m the total mass of the cluster, and Ω0 the circular frequency of the cluster around the galactic centre, which can be expressed in terms of the Oort’s constants A0 and B0 as Ω0 = A0 − B0.
In the following, we assume an over-simplistic correspondence between the tidal radius of the King’s family of models and Jacobi radius. Binney & Tremaine (2008, p. 677) provide a detailed list of reasons why this correspondence is only approximate. Thus, using the Oort’s constant values given by Bovy (2017, A =15.3 ± 0.4 km s−1 kpc−1 and B = −11.9 ± 0.4 km s−1 kpc−1), we can derive an estimate of the total mass of the cluster for each inferred value of the tidal radius.
Figure 3 shows the distributions of the total mass derived from the posterior distributions of the parameters of the King’s family of models with biaxial symmetry and luminosity segregation (the distributions of total mass resulting from the radial and biaxial models are shown in Appendix B). As a summary, Table 7 shows the mode of each of these total mass distributions.
As can be seen from this figure and table, inferring the total mass by means of the poorly constrained tidal radius leads to large uncertainties and probably biased estimators. This effect has already been observed by Raboud & Mermilliod (1998), who derived a total mass of 4000 M⊙ with a confidence interval ranging from 1600 M⊙ to 8000 M⊙. These values are in good agreement with the ones reported in Table 7 and observed in Fig. 3.
Given the large ellipticity of the cluster, we also investigated the possibility of deriving the total mass by means of the tidal elongation effect. However, the values determined are even more poorly constrained than those determined using Eq. (26).
The results of this section show that: (i) there is still a large fraction (up to 20%) of cluster members that lay beyond the spatial coverage of our data set, and (ii) although poorly unconstrained, the distributions of the total mass of the cluster seem to suggest that it is highly unlikely that the total mass of the cluster lays below the 1000 M⊙ limit, as commonly stated in the literature. However, the large and unconstrained mass distribution could also be an artefact resulting from: (i) the poor correspondence between the Jacobi radius and the tidal radius, (ii) the poorly constrained values of the tidal radius, and (iii) dynamical effects not taken into account to derive Eq. (26) (e.g. the cluster is not a point mass but a self gravitating and rotating system).
Mode of the distribution of total number of stars in the cluster.
Mode of the distribution of total mass of the cluster.
 |
Fig. 2 Distribution of the total number of systems within the tidal radius in each model and extension of the King’s family. The abbreviations Ctr, Ell, and Seg stand for the radial and biaxial symmetric models, and those with luminosity segregation, respectively. |
 |
Fig. 3 Distribution of the total mass of the cluster derived from each biaxially symmetric and luminosity segregated model of the King’s family. |
6 Conclusions
In this work we have formulated the existing radially symmetric alternatives for the spatial distribution of stars in open clusters in a probabilistic framework. The set of distributions reviewed include (i) the classical King’s profile with two variants put forward by us, (ii) the EFF model, and (iii) a general profile inspired by galactic profiles together with a more restricted version of it. We have used Bayesian techniques to both obtain posterior probability distributions for the parameters, and evidences for each model. With them, we compare and select the best model, given the data (and its possible biases). Furthermore, we have computed Bayes Factors for all pairwise model comparisons. Due to high correlations among their rc and β parameters, the GDP and RGDP models loose their physical interpretability. The result of the comparison amongst models with radial symmetry is that the King’s family of models is only mildly superior, with weak and moderate evidence, to those models without the tidal radius parameter.
Furthermore, we have analysed biaxially symmetric extensions of our set of models. The results indicate that deviations from spherical symmetry have strong evidence when compared to the more simple radially symmetric models. Additionally, the distribution of ellipticities derived from the EFF, GDP, and RGDP models peak at 0.22± 0.01, which is similar to the value of 0.17 found by Raboud & Mermilliod (1998). Within the King’s family, the models return ellipticities that are small (mean ϵrc = 0.07 ± 0.02) and large (mean ϵrt = 0.44 ± 0.14) in the innerand outer parts of the cluster, respectively. This effect is expected from the dynamical interaction of the cluster with the galactic potential, and is also predicted by numerical simulations.
We use Bayesian model selection with Bayes Factors to analyse mass segregation. We prefer to remain in the domain of direct observables and study potential differences in the parameters of the spatial distribution as a function not of mass, but of the apparent J-band magnitude. The Bayes Factors show strong evidence in favour of the luminosity segregated models, and against the simpler biaxially symmetric ones. We interpret this result as strong evidence for mass segregation.
The above conclusions heavily depend on the sample of Pleiades members selected for the analysis. In our probabilistic analysis we took into account the possibility that our sample is contaminated, but a J-band-dependent contamination rate (J-band contamination gradient) could mimic a mass segregation such as the one observed here. In addition, the halos and artefacts in the images of the central and bright stars can induce a spatial incompleteness that could also artificially enhance the slope of the luminosity segregation. Thus, our results must be taken with care. In the near future, we expect to conduct similar studies given the more homogenous and well characterised data sets (e.g. new releases of Gaia’s data).
Although the GKing and OGKing models introduced here have greater evidences and fitting properties than the classical King’s profile, there is no strong evidence supporting an abandonment of the latter. Nevertheless, the GKing profile is a good alternative to the King’s classical profile and should be compared with it in light of new and more complete data sets.
From the model selection process, we can conclude that the classical King’s profile extended to include biaxial symmetry and mass/luminosity segregation should be the starting point in future analyses of the spatial distribution of open clusters.
Finally, we use the posterior distributions of the parameters in King’s model family to obtain rough estimates of the total mass and number of systems in the cluster. We observe that even the largest census of candidate members (Bouy et al. 2015; Olivares et al. 2017) may lack up to 20% of the predicted number of stellar systems. The probability distribution function of the cluster total mass, which is determined using approximations of the tidal force exerted by the galactic and cluster potentials, reveals that it is highly unlikely that the true cluster total mass lays below the 1000 M⊙ limit.
The results of this work suggest that, although the Pleiades cluster is one of the most studied in the literature, the daughters of Atlas still keep many of their secrets within the oceans of the sky; probably awaiting the arrival of the final Gaia’s data.
Acknowledgements
We express our gratitude to the referee Anthony G. A. Brown for his kind and assertive comments which greatly improved the quality of this work. This research has received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No. 682903, P. I. H. Bouy), and from the French State in the framework of the “Investments for the future” Program, IdEx Bordeaux, reference ANR-10-IDEX-03-02. D. Barrado acknowledges the support by the Spanish project ESP2015-65712-C5-1-R. E. Moraux acknowledges financial support from the “StarFormMapper” project funded by the European Union’s Horizon 2020 Research and Innovation Action (RIA) programme under grant agreement number 687528. This work has been partially supported by a cooperative PICS project between CNRS and CSIC.
Appendix A: Effects of truncation on King’s profile
Statistical truncation occurs when an unknown number of sources lay beyond a threshold value. This threshold value can originate in the measuring process or in the post-processing of the data. The resulting data set does not contain any information about objects beyond the threshold.
 |
Fig. A.1 Mixture of the ten posterior distributions of the core and tidal radius (rc and rt, respectively) inferred under different sample sizes (line styles) and truncation radii (colours). The true parameter values are shown with the vertical grey lines. |
 |
Fig. A.2 Mean relative error (rc and rt, respectively) of the MAP statistic inferred from ten random realisations of different sample sizes (line styles) and truncation radii (colours). The uncertainties correspond to the standard deviation of the ten inferred MAPs. |
Performing inference on truncated data can bias the recovered parameters if the truncation mechanism is not included in the analysis. Nevertheless, bias can still appear if poor statistics are used to summarise the results. Practically speaking, if the truncation is too restrictive it could also lead to bias due to a reduced sample size. To estimate the impact of these effects, we generated synthetic data sets from the King’s profile, at true values of rc = 2.0 pc and rt = 20.0 pc, and infer the parameters under different sample sizes (1000, 2000, and 3000 objects) and truncation radii (5, 10, 15, 20 pc). We repeat each estimation ten times to account for randomness in the sample. Figure A.1 shows the posterior distributions inferred at each sample size and truncation radius. As can be seen, accounting for truncation results in posterior distribution that correctly recovers the true parameter values. However, due to the large asymmetry in the posterior distributions of the tidal radius at the lower truncation radius (5 pc), the MAP statistic can be severely biased. Figure A.2 shows the mean relative error of this statistic as a function of the truncation radius. As can be seen, the larger biases appear at the extreme case where the truncation radius is only one fourth of the true tidal radius. We note that although the MAP estimates ofeach of the ten realisations are biased, estimates are made in a similar way above and below the true value; except at the truncation radius of 5 pc, where they slightly over estimate the value. Also, the MAP is unbiased above truncation radii of half the tidal radius, in spite of the number of stars (at least for the tested values).
 |
Fig. A.3 Mixture of the ten posterior distributions of the core and tidal radius (rc and rt, respectively) inferred under different sample sizes (line styles) and truncation radii (colours) without correcting for truncation. The true parameter values are shown with the vertical grey lines. |
This example shows that the inference of the parameters in the King’s profile can be biased even after truncation has been accounted for. In particular, the tidal radius can be severely affected by truncation radius below one half of the tidal radius. Since this phenomenon is observed under the weakly informative priors used (half-Cauchy centred at zero and scale parameter of 100), this effect can be generalised to any maximum-likelihood estimator, the χ2 statistic particularly.
Finally, as can be seen in Fig. A.3, inferring King’s profile parameters without properly accounting for truncation leads to even larger biases.
Appendix B: Posterior distributions
This appendix contains the details of the inference performed for each of the models and extensions presented in Sect. 3. It is structured in the same way as that section. It starts with the radial models, then continues with the biaxial extensions, and finishes with the luminosity segregated ones. For each extension we give: (i) the uncertainties of the MAP for each model, and (ii) figures depicting: (a) the number surface density (i.e. the number of stars per square parsec), and (b) the univariate and bivariate marginal posterior distributions obtained from PyMultiNest in the form of a corner plot (Foreman-Mackey 2016). Since the MAP is computed in the joint posterior, it does not necessarily coincides with the modes of the marginal distributions.
The MAP uncertainties and correlations are summarised by covariance matrices. These are computed using the 68.2% of samples from the MCMC that were the closest to the MAP value. They represent the 2σ uncertainties and correlations of the parameters at the vicinity of the MAP.
Covariance matrix of the radially symmetric EFF model.
Covariance matrix of the radially symmetric GDP model.
Covariance matrix of the radially symmetric GKing model.
Covariance matrix of the radially symmetric King model.
Covariance matrix of the radially symmetric OGKing model.
Covariance matrix of the radially symmetric RGDP model.
Covariance matrix of the biaxially symmetric EFF model.
Covariance matrix of the biaxially symmetric GDP model.
Covariance matrix of the biaxially symmetric GKing model.
Covariance matrix of the biaxially symmetric King model.
Covariance matrix of the biaxially symmetric OGKing model.
Covariance matrix of the biaxially symmetric RGDP model.
Covariance matrix of the luminosity segregated EFF model.
Covariance matrix of the luminosity segregated GDP model.
Covariance matrix of the luminosity segregated GKing model.
Covariance matrix of the luminosity segregated King model.
Covariance matrix of the luminosity segregated OGKing model.
Covariance matrix of the luminosity segregated RGDP model.
 |
Fig. B.1 Inferred density of the radially symmetric profiles shown by means of the MAP value (red line) and 100 samples from the posterior distribution (grey lines). For comparison the data has been binned with Poissonian uncertainties (black dots). |
 |
Fig. B.2 Projections of the posterior distribution for the radially symmetric EFF model. |
 |
Fig. B.3 Projections of the posterior distribution for the radially symmetric GDP model. |
 |
Fig. B.4 Projections of the posterior distribution for the radially symmetric GKing model. |
 |
Fig. B.5 Projections of the posterior distribution for the radially symmetric King’s model. |
 |
Fig. B.6 Projections of the posterior distribution for the radially symmetric OGKing model. |
 |
Fig. B.7 Projections of the posterior distribution for the radially symmetric RGDP model. |
 |
Fig. B.8 Inferred density of the biaxially symmetric profiles shown by means of the MAP value (red line) and 100 samples from the posterior distribution (grey lines). For comparison the data has been binned with Poissonian uncertainties (black dots). |
 |
Fig. B.9 Projections of the posterior distribution for the biaxially symmetric EFF model. |
 |
Fig. B.10 Projections of the posterior distribution for the biaxially symmetric GDP model. |
 |
Fig. B.11 Projections of the posterior distribution for the biaxially symmetric GKing model. |
 |
Fig. B.12 Projections of the posterior distribution for the biaxially symmetric King’s model. |
 |
Fig. B.13 Projections of the posterior distribution for the biaxially symmetric OGKing model. |
 |
Fig. B.14 Projections of the posterior distribution for the biaxially symmetric RGDP model. |
 |
Fig. B.15 Ellipticity distributions of the biaxially symmetric models. The numbers shown in brackets represent the 16th percentile, the mode, and the 84th percentile (also shown by means of vertical grey lines). |
 |
Fig. B.16 Inferred density of the luminosity segregated models. The data are binned in three bins of the J band: J < 12, 12 ≲ J ≲ 15, and 15 < J (with colours green, cyan and magenta, respectively). The MAP is shown by means of three coloured solid lines, the colours correspond to those of the J band bins. In these MAPs, the core radius is increased accordingly to Eq. (13) using the mean value of the J band in each bin. Also shown are 100 samples from the posterior distribution (grey lines). |
 |
Fig. B.17 Projections of the posterior distribution for the luminosity segregated EFF model. |
 |
Fig. B.18 Projections of the posterior distribution for the luminosity segregated GDP model. |
 |
Fig. B.19 Projections of the posterior distribution for the luminosity segregated GKing model. |
 |
Fig. B.20 Projections of the posterior distribution for the luminosity segregated King’s model. |
 |
Fig. B.21 Projections of the posterior distribution for the luminosity segregated OGKing model. |
 |
Fig. B.22 Projections of the posterior distribution for the luminosity segregated RGDP model. |
 |
Fig. B.23 Ellipticity distributions of the luminosity segregated models. The numbers shown in brackets represent the 16th percentile, the mode, and the 84th percentile (also shown by means of vertical grey lines). |
 |
Fig. B.24 Distribution of the total mass of the cluster derived from each radially symmetric model of the King’s family. |
 |
Fig. B.25 Distribution of the total mass of the cluster derived from each biaxially symmetric model of the King’s family. |
For the biaxial and luminosity segregated models we also give the ellipticity distributions computed a posteriori from the core and tidal (when available) semi-major and semi-minor axes resulting from the PyMultiNest samples.
Finally, this appendix also contains the distributions of the total mass of the cluster derived from the radial and biaxial models in the King’s family.
References
- Adams, J. D., Stauffer, J. R., Monet, D. G., Skrutskie, M. F., & Beichman, C. A. 2001, AJ, 121, 2053 [NASA ADS] [CrossRef] [Google Scholar]
- Alonso-Santiago, J., Negueruela, I., Marco, A., et al. 2017, MNRAS, 469, 1330 [NASA ADS] [CrossRef] [Google Scholar]
- Bevington, P. R., & Robinson, D. K. 2003, Data Reduction and Error Analysis for the Physical Sciences (McGraw-Hill) [Google Scholar]
- Binney, J., & Tremaine, S. 2008, Galactic Dynamics, 2nd edn. (Princeton University Press) [Google Scholar]
- Bouy, H., Bertin, E., Moraux, E., et al. 2013, A&A, 554, A101 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bouy, H., Bertin, E., Sarro, L. M., et al. 2015, A&A, 577, A148 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bovy, J. 2017, MNRAS, 468, L63 [NASA ADS] [CrossRef] [Google Scholar]
- Buchner, J., Georgakakis, A., Nandra, K., et al. 2014, A&A, 564, A125 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Byun, Y.-I., Grillmair, C. J., Faber, S. M., et al. 1996, AJ, 111, 1889 [NASA ADS] [CrossRef] [Google Scholar]
- Converse, J. M., & Stahler, S. W. 2008, ApJ, 678, 431 [NASA ADS] [CrossRef] [Google Scholar]
- Converse, J. M., & Stahler, S. W. 2010, MNRAS, 405, 666 [NASA ADS] [Google Scholar]
- de Zeeuw, T. 1985, MNRAS, 216, 273 [NASA ADS] [CrossRef] [Google Scholar]
- Elson, R. A. W., Fall, S. M., & Freeman, K. C. 1987, ApJ, 323, 54 [NASA ADS] [CrossRef] [Google Scholar]
- Foreman-Mackey, D. 2016, The Journal of Open Source Software, DOI: 10.21105/joss.00024 [Google Scholar]
- Gaia Collaboration (Prusti, T., et al.) 2016, A&A, 595, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Galli, P. A. B., Moraux, E., Bouy, H., et al. 2017, A&A, 598, A48 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gelman, A. 2006, Bayesian Anal., 1, 515 [CrossRef] [Google Scholar]
- Hernquist, L. 1990, ApJ, 356, 359 [NASA ADS] [CrossRef] [Google Scholar]
- Jaffe, W. 1983, MNRAS, 202, 995 [NASA ADS] [Google Scholar]
- Jeffreys, H. 1961, Theory of Probability, 3rd edn. (Oxford: Oxford Univrsity Press) [Google Scholar]
- Jiang, F., & van den Bosch, F. C. 2016, MNRAS, 458, 2848 [NASA ADS] [CrossRef] [Google Scholar]
- King, I. 1962, AJ, 67, 471 [NASA ADS] [CrossRef] [Google Scholar]
- Kroupa, P., Aarseth, S., & Hurley, J. 2001, MNRAS, 321, 699 [NASA ADS] [CrossRef] [Google Scholar]
- Küpper, A. H. W., Kroupa, P., Baumgardt, H., & Heggie, D. C. 2010, MNRAS, 407, 2241 [NASA ADS] [CrossRef] [Google Scholar]
- Lauer, T. R., Ajhar, E. A., Byun, Y.-I., et al. 1995, AJ, 110, 2622 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lawrence, A., Warren, S. J., Almaini, O., et al. 2007, MNRAS, 379, 1599 [NASA ADS] [CrossRef] [MathSciNet] [Google Scholar]
- Loktin, A. V. 2006, Astron. Rep., 50, 714 [NASA ADS] [CrossRef] [Google Scholar]
- Moore, B., Quinn, T., Governato, F., Stadel, J., & Lake, G. 1999, MNRAS, 310, 1147 [NASA ADS] [CrossRef] [Google Scholar]
- Moraux, E., Kroupa, P., & Bouvier, J. 2004, A&A, 426, 75 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Myeong, G. C., Jerjen, H., Mackey, D., & Da Costa, G. S. 2017, ApJ, 840, L25 [NASA ADS] [CrossRef] [Google Scholar]
- Navarro, J. F., Frenk, C. S., & White, S. D. M. 1997, ApJ, 490, 493 [NASA ADS] [CrossRef] [Google Scholar]
- Nousek, J. A., & Shue, D. R. 1989, ApJ, 342, 1207 [NASA ADS] [CrossRef] [Google Scholar]
- Olivares, J., Sarro, L., Moraux, E., et al. 2017, A&A, submitted [Google Scholar]
- Panwar, N., Samal, M. R., Pandey, A. K., et al. 2017, MNRAS, 468, 2684 [NASA ADS] [CrossRef] [Google Scholar]
- Perryman, M. A. C., Lindegren, L., Kovalevsky, J., et al. 1997, A&A, 323, L49 [NASA ADS] [Google Scholar]
- Pinfield, D. J., Jameson, R. F., & Hodgkin, S. T. 1998, MNRAS, 299, 955 [NASA ADS] [CrossRef] [Google Scholar]
- Plummer, H. C. 1911, MNRAS, 71, 460 [CrossRef] [Google Scholar]
- Raboud, D., & Mermilliod, J.-C. 1998, A&A, 329, 101 [NASA ADS] [Google Scholar]
- Robotham, A. S. G., Taranu, D. S., Tobar, R., Moffett, A., & Driver, S. P. 2017, MNRAS, 466, 1513 [NASA ADS] [CrossRef] [Google Scholar]
- Sackett, P. D., & Sparke, L. S. 1990, ApJ, 361, 408 [NASA ADS] [CrossRef] [Google Scholar]
- Sarro, L. M., Bouy, H., Berihuete, A., et al. 2014, A&A, 563, A45 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Skilling, J. 2006, Bayesian Anal., 1, 833 [CrossRef] [MathSciNet] [Google Scholar]
- Sohn, S. T., Majewski, S. R., Muñoz, R. R., et al. 2007, ApJ, 663, 960 [NASA ADS] [CrossRef] [Google Scholar]
- Stauffer, J. R., Hartmann, L. W., Fazio, G. G., et al. 2007, ApJS, 172, 663 [NASA ADS] [CrossRef] [Google Scholar]
- Terlevich, E. 1987, MNRAS, 224, 193 [NASA ADS] [CrossRef] [Google Scholar]
- Towers, S. 2012, ArXiv e-prints [arXiv:1209.2690] [Google Scholar]
- van de Ven, G., van den Bosch, R. C. E., Verolme, E. K., & de Zeeuw, P. T. 2006, A&A, 445, 513 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Zhao, H. 1997, MNRAS, 287, 525 [NASA ADS] [CrossRef] [Google Scholar]
We highlight that their Eqs. (10) and (12) seem to be slightly different from those reported Binney & Tremaine (2008).
In Olivares et al. (2017), individual membership probabilities are themselves probability distributions. Thus, p84% stands for the 84th percentile of those distributions.
Although it is also called Nuker profile by Küpper et al. (2010).
Since the Bayesian evidence is a number that can be computed for each model and/or data set (see Eq. (25)), we use the plural evidences to address any set containing the Bayesian evidence of more than one model.
The Jeffreys scale is used to relate the Bayes Factors, which contain the Bayesian evidences of the two models, to the possible shared understanding of the word evidence.
The ellipticity used here is also known as “flattening”.
All Tables
Natural logarithm of the evidence for each profile density (diagonal) and Bayes Factors (off-diagonal elements, with the evidence for the model specified in the column header placed in the denominator, i.e. ).
Maximum-a-posteriori estimates of the inferred parameters in each radially symmetric model.
Maximum-a-posteriori estimates of the inferred parameters in each biaxially symmetric model.
Maximum-a-posteriori estimates of the inferred parameters in each luminosity segregated model.
All Figures
|
Fig. 1 Density of sources in the combined DANCe + Tycho catalogue as a function of the radial distance to the cluster centre and the J magnitude. Top panel: all sources contained within the limiting magnitudes. Bottom panel: sources within the 11.5 pc radius of spatial completeness (vertical grey line), and binned in magnitudes. The black line represents the density of two million sources uniformly distributed in the plane of the sky. |
| In the text | |
|
Fig. 2 Distribution of the total number of systems within the tidal radius in each model and extension of the King’s family. The abbreviations Ctr, Ell, and Seg stand for the radial and biaxial symmetric models, and those with luminosity segregation, respectively. |
| In the text | |
|
Fig. 3 Distribution of the total mass of the cluster derived from each biaxially symmetric and luminosity segregated model of the King’s family. |
| In the text | |
|
Fig. A.1 Mixture of the ten posterior distributions of the core and tidal radius (rc and rt, respectively) inferred under different sample sizes (line styles) and truncation radii (colours). The true parameter values are shown with the vertical grey lines. |
| In the text | |
|
Fig. A.2 Mean relative error (rc and rt, respectively) of the MAP statistic inferred from ten random realisations of different sample sizes (line styles) and truncation radii (colours). The uncertainties correspond to the standard deviation of the ten inferred MAPs. |
| In the text | |
|
Fig. A.3 Mixture of the ten posterior distributions of the core and tidal radius (rc and rt, respectively) inferred under different sample sizes (line styles) and truncation radii (colours) without correcting for truncation. The true parameter values are shown with the vertical grey lines. |
| In the text | |
|
Fig. B.1 Inferred density of the radially symmetric profiles shown by means of the MAP value (red line) and 100 samples from the posterior distribution (grey lines). For comparison the data has been binned with Poissonian uncertainties (black dots). |
| In the text | |
|
Fig. B.2 Projections of the posterior distribution for the radially symmetric EFF model. |
| In the text | |
|
Fig. B.3 Projections of the posterior distribution for the radially symmetric GDP model. |
| In the text | |
|
Fig. B.4 Projections of the posterior distribution for the radially symmetric GKing model. |
| In the text | |
|
Fig. B.5 Projections of the posterior distribution for the radially symmetric King’s model. |
| In the text | |
|
Fig. B.6 Projections of the posterior distribution for the radially symmetric OGKing model. |
| In the text | |
|
Fig. B.7 Projections of the posterior distribution for the radially symmetric RGDP model. |
| In the text | |
|
Fig. B.8 Inferred density of the biaxially symmetric profiles shown by means of the MAP value (red line) and 100 samples from the posterior distribution (grey lines). For comparison the data has been binned with Poissonian uncertainties (black dots). |
| In the text | |
|
Fig. B.9 Projections of the posterior distribution for the biaxially symmetric EFF model. |
| In the text | |
|
Fig. B.10 Projections of the posterior distribution for the biaxially symmetric GDP model. |
| In the text | |
|
Fig. B.11 Projections of the posterior distribution for the biaxially symmetric GKing model. |
| In the text | |
|
Fig. B.12 Projections of the posterior distribution for the biaxially symmetric King’s model. |
| In the text | |
|
Fig. B.13 Projections of the posterior distribution for the biaxially symmetric OGKing model. |
| In the text | |
|
Fig. B.14 Projections of the posterior distribution for the biaxially symmetric RGDP model. |
| In the text | |
|
Fig. B.15 Ellipticity distributions of the biaxially symmetric models. The numbers shown in brackets represent the 16th percentile, the mode, and the 84th percentile (also shown by means of vertical grey lines). |
| In the text | |
|
Fig. B.16 Inferred density of the luminosity segregated models. The data are binned in three bins of the J band: J < 12, 12 ≲ J ≲ 15, and 15 < J (with colours green, cyan and magenta, respectively). The MAP is shown by means of three coloured solid lines, the colours correspond to those of the J band bins. In these MAPs, the core radius is increased accordingly to Eq. (13) using the mean value of the J band in each bin. Also shown are 100 samples from the posterior distribution (grey lines). |
| In the text | |
|
Fig. B.17 Projections of the posterior distribution for the luminosity segregated EFF model. |
| In the text | |
|
Fig. B.18 Projections of the posterior distribution for the luminosity segregated GDP model. |
| In the text | |
|
Fig. B.19 Projections of the posterior distribution for the luminosity segregated GKing model. |
| In the text | |
|
Fig. B.20 Projections of the posterior distribution for the luminosity segregated King’s model. |
| In the text | |
|
Fig. B.21 Projections of the posterior distribution for the luminosity segregated OGKing model. |
| In the text | |
|
Fig. B.22 Projections of the posterior distribution for the luminosity segregated RGDP model. |
| In the text | |
|
Fig. B.23 Ellipticity distributions of the luminosity segregated models. The numbers shown in brackets represent the 16th percentile, the mode, and the 84th percentile (also shown by means of vertical grey lines). |
| In the text | |
|
Fig. B.24 Distribution of the total mass of the cluster derived from each radially symmetric model of the King’s family. |
| In the text | |
|
Fig. B.25 Distribution of the total mass of the cluster derived from each biaxially symmetric model of the King’s family. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.