| Issue |
A&A
Volume 604, August 2017
|
|
|---|---|---|
| Article Number | A89 | |
| Number of page(s) | 14 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/201629971 | |
| Published online | 14 August 2017 | |
Calibrating the Planck cluster mass scale with CLASH
1 APC, AstroParticule et Cosmologie, Université Paris Diderot, CNRS/IN2P3, CEA/Irfu, Observatoire de Paris, Sorbonne Paris Cité, 10, rue Alice Domon et Léonie Duquet, 75205 Paris Cedex 13, France
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2 Centro Brasileiro de Pesquisas Físicas, rua Dr. Xavier Sigaud 150, 22290-180 Rio de Janeiro, RJ, Brazil
3 Jet Propulsion Laboratory, California Institute of Technology, Pasadena, California, CA91109, USA
4 Department of Physics, University of Arizona, Tucson, AZ 85721, USA
5 DRF/Irfu/SPP, CEA-Saclay, 91191 Gif-sur-Yvette Cedex, France
6 Department of Physics, University of Oxford, Keble Road, Oxford OX1 3RH, UK
7 Deparment of Physics and Michigan Center for Theoretical Physics, University of Michigan, Ann Arbor, MI 48109, USA
8 Department of Astronomy, University of Michigan, Ann Arbor, MI 48109, USA
9 Space Telescope Science Institute, 3700 San Martin Drive, Baltimore, MD 21208, USA
10 Kavli Institute for Particle Astrophysics & Cosmology, PO Box 2450, Stanford University, Stanford, CA 94305, USA
11 SLAC National Accelerator Laboratory, Menlo Park, CA 94025, USA
Received: 28 October 2016
Accepted: 12 June 2017
Abstract
We determine the mass scale of Planck galaxy clusters using gravitational lensing mass measurements from the Cluster Lensing And Supernova survey with Hubble (CLASH). We have compared the lensing masses to the Planck Sunyaev-Zeldovich (SZ) mass proxy for 21 clusters in common, employing a Bayesian analysis to simultaneously fit an idealized CLASH selection function and the distribution between the measured observables and true cluster mass. We used a tiered analysis strategy to explicitly demonstrate the importance of priors on weak lensing mass accuracy. In the case of an assumed constant bias, bSZ, between true cluster mass, M500, and the Planck mass proxy, MPL, our analysis constrains 1−bSZ = 0.73 ± 0.10 when moderate priors on weak lensing accuracy are used, including a zero-mean Gaussian with standard deviation of 8% to account for possible bias in lensing mass estimations. Our analysis explicitly accounts for possible selection bias effects in this calibration sourced by the CLASH selection function. Our constraint on the cluster mass scale is consistent with recent results from the Weighing the Giants program and the Canadian Cluster Comparison Project. It is also consistent, at 1.34σ, with the value needed to reconcile the Planck SZ cluster counts with Planck’s base ΛCDM model fit to the primary cosmic microwave background anisotropies.
Key words: galaxies: clusters: general / cosmology: observations / cosmological parameters / dark matter
© ESO, 2017
1. Introduction
Galaxy cluster mass measurements are the dominant source of systematic uncertainty in cosmological constraints derived from the space-time abundance of galaxy clusters. This was acutely illustrated by the Planck collaboration’s finding of tension between the Λ cold dark matter (ΛCDM) cosmology parameters favored by cluster counts and those derived by combining the primary cosmic microwave background (CMB) anisotropies with non-cluster data (PXX Planck Collaboration XX 2014; Planck Collaboration XXIV 2016). While the discrepant findings could reflect a relatively large neutrino mass or more exotic physics, the confidence in such statements is limited by systematic uncertainties in mass measurements (Rozo et al. 2013).
The fundamental issue is that cluster halo mass is not directly observable. While N-body simulations have calibrated the space density of massive halos to good precision (e.g., Bhattacharya et al. 2011; Murray et al. 2013, and references therein), application to cluster counts on the sky requires the use of scaling relations between halo mass and observable cluster properties, often termed mass proxies. In the case of Planck clusters detected through the Sunyaev-Zeldovich (SZ) effect, the required relation is between SZ signal strength and mass.
In principle, scaling relations can be calibrated with hydrodynamic simulations that properly account for most relevant physical processes. The approach is currently limited, however, by uncertainties in the baryon physics associated with galaxy feedback mechanisms (Ragone-Figueroa et al. 2013; Dubois et al. 2013; Le Brun et al. 2014; Martizzi et al. 2014; Genel et al. 2014). Nevertheless, the fidelity of the simulations is high enough to provide insights into the general form of the scaling relations and into important sources of systematic error.
In practice, empirical approaches are used to establish scaling relations. The Planck analysis employed X-ray observations from XMM-Newton to derive masses based on the assumption of hydrostatic equilibrium (HSE) of the intra-cluster medium (ICM) (Arnaud et al. 2010). For decades, hydrodynamic simulations have indicated that HSE is not exact, with expectations that HSE masses underestimate true values by typically tens of percent, depending on scale and the exact modeling of baryon physics (e.g., Evrard 1990; Rasia et al. 2006, 2012; Nagai et al. 2007; Piffaretti & Valdarnini 2008; Battaglia et al. 2013; Nelson et al. 2014). Combining XMM-Newton and Chandra data, Mahdavi et al. (2013) found a 15% systematic difference in HSE masses. Moreover, the X-ray instrument calibration errors can also affect masses at the ten-percent level (Donahue et al. 2014; Rozo et al. 2014c).
Gravitational lensing offers a powerful, independent alternative to HSE masses, but individual weak lensing mass estimates are noisy due to the sensitivity of the broad lensing kernel to material along the line-of-sight (Hoekstra 2003) and to halo triaxiality (Becker & Kravtsov 2011). Detailed lensing image simulations by Meneghetti et al. (2010) found that weak lensing mass estimates incur smaller bias than X-ray HSE values, with mean biases of a few percent. Independent work by Becker & Kravtsov (2011) supports this result, but mean underestimates of up to 10% have also been reported (Rasia et al. 2012). The bias depends in part on the method of extracting cluster mass from the lensing data, so precise estimates of systematic error require careful modeling of the full data acquisition and analysis workflow.
The Planck cluster cosmology findings motivate deeper investigation into the mass calibration for that sample. Here, we have relied on recent results from the Cluster Lensing and Supernova survey with Hubble (CLASH, Postman et al. 2012) collaboration, who have measured lensing masses from imaging data of exquisite depth and wavelength coverage for a sample of 25 X-ray and lensing selected galaxy clusters (Merten et al. 2015; Umetsu et al. 2014; Zitrin et al. 2015). In particular, we used the reconstruction method presented in (Merten et al. 2015) to obtain 22 CLASH mass estimates1. After cross-matching the CLASH and Planck cluster catalogs, we measured the SZ signal of 22 CLASH clusters in the publicly available Planck dataset for any CLASH clusters not included in the original Planck cluster catalog. We then used the CLASH cluster sample to place tight constraints on the SZ scaling relation of galaxy clusters, and discuss the import of our results for the cosmological interpretation of the Planck cluster counts.
The layout of the paper is as follows. In Sect. 2 we summarize the methods used to compute the CLASH and Planck mass estimates for the 21 clusters in common, while in Sect. 3 we compare these estimates. In Sect. 4 we introduce our models for the CLASH selection function and for the measurements, that is, the mass-observable distribution, including both observational uncertainties and intrinsic covariance between lensing and SZ signals. We construct the posterior probability distribution and perform different Bayesian analyses in Sect. 5 to constrain the model parameters. In Sects. 6 and 7 we discuss our results and then conclude with final remarks.
Unless otherwise specified, we have adopted a fiducial flat cosmology with ΩM = 0.3 = 1−ΩΛ (see Table 2), and all masses are given within R500, the radius at which the mean mass density within the cluster reaches 500 times the critical density at the redshift of the cluster:  , with ρc = 3H2(z) / 8πG. We refer to the Planck mass proxy (see below) as MPL and to the CLASH lensing mass as MCL. These measurements are noisy realizations of the true SZ mass proxy, MSZ, and true lensing mass, ML.
, with ρc = 3H2(z) / 8πG. We refer to the Planck mass proxy (see below) as MPL and to the CLASH lensing mass as MCL. These measurements are noisy realizations of the true SZ mass proxy, MSZ, and true lensing mass, ML.
2. Masses and mass proxies
2.1. CLASH lensing masses
The CLASH survey (Postman et al. 2012) is a Hubble Space Telescope (HST) multi-cycle treasury program targeting 25 massive galaxy clusters in the redshift range 0.18 < z < 0.89 and over a mass range 0.5 × 1015h-1M⊙ ≲ Mvir ≲ 2.0 × 1015h-1M⊙. The sample of 25 clusters was further subdivided into an X-ray selected sub-sample (20 clusters), and a strong-lensing selected sub-sample (five clusters, also referred to as the high-magnification sub-sample). For a complete definition of the two sub-sets, see Postman et al. (2012).
Each cluster was observed for 20 HST orbits in 16 broad photometric passbands. These data are supplemented with a three-to-five band Subaru/Suprime-Cam and ESO/WFI optical imaging to enable weak lensing measurements of the cluster profiles out to their virial radii. The combination of HST and ground-based wide-field data allows for a comprehensive weak-and strong-lensing analysis.
We have used a total of 22 CLASH clusters, of which 19 belong to the X-ray selected sub-sample and three belong to the high-magnification subset. The lensing reconstructions of the X-ray selected clusters have recently been presented in Merten et al. (2015) and Umetsu et al. (2014), while mass estimates for the high-magnification clusters have in part been presented in Medezinski et al. (2013) and Umetsu et al. (2014). Recently, Umetsu et al. (2016) and Zitrin et al. (2015) reconstructed the surface mass density profiles of 20 and 25 clusters (complete CLASH sample), respectively. In all cases, a combination of weak and strong lensing was used to derive reliable masses.
A thorough description of the input data and reconstruction techniques used in this work, is given by Merten et al. (2015). Here, we only provide a brief summary. Masses were derived with the SaWLens code (Merten et al. 2009) that consistently combines weak and strong lensing in a non-parametric fashion on adaptively refined grids. The method was thoroughly tested with realistic lensing scenarios and numerically simulated clusters (Meneghetti et al. 2010; Rasia et al. 2012), and has been used multiple times for the reconstruction of real galaxy clusters (Merten et al. 2009, 2011; Umetsu et al. 2012; Patel et al. 2014). For the CLASH analysis, SaWLens combines constraints from HST strong lensing, HST weak lensing and wide-field ground-based weak lensing (except for CLJ1226+3332 whose mass was reconstructed using HST data only) into a single reconstruction of the cluster’s gravitational potential from which it derives the surface-mass density. NFW fits to the surface-mass density provide the desired total 3-dimensional mass of the halo at any given radius.
Error bars for the lensing reconstruction were derived from 1000 bootstrap resamplings of the input weak-lensing shear catalogs, including their photometric redshift uncertainties2, and by randomly sampling the allowed redshift range of strong-lensing multiple image systems. Candidate systems are treated by random inclusion or exclusion in each bootstrap. From the bootstrap realizations, we have derived the covariance matrix of the surface-mass density bins, which is then taken into account during the NFW profile fitting (see Merten et al. 2015, for details).
In particular, as discussed in Merten et al. (2015), the mass estimate of the system CLJ1226+3332 shows only a mild tension within the errors with an independent study by Jee & Tyson (2009). The uncertainties in the source redshift distribution are taken into account by the error estimation of the SaWLens method, which is based on a combination of bootstrapping and a resampling of source redshifts within their uncertainties.
These CLASH mass errors account for a number of systematics in the lensing reconstruction, including shape scatter in the weak lensing catalogs, redshift uncertainties in the weak lensing background and strong-lensing multiple-image populations, mis-identifications of strong-lensing features and uncertainty in the central peak position of the mass distribution. Sources of systematic error not covered by this analysis include correlated and un-correlated structure within the cluster field, effects of tri-axiality and general error stemming from the fact that we fit a simplified 1D analytical form of the density profile to a complex mass distribution. These unaccounted sources of systematic error in CLASH mass estimates have recently been estimated by Umetsu et al. (2014) to be ~8%, and a detailed comparison of the SaWLens mass reconstructions to a set of numerical simulations that mimic the CLASH selection functions has been presented in Meneghetti et al. (2014). In Sect. 5 we will account for this systematic uncertainty using a Gaussian distribution with standard deviation of 8% Umetsu et al. (2014), and also the left-skewed distribution for the 3D and true mass ratio found by Meneghetti et al. (2014), as priors on the lensing mass scale.
 |
Fig. 1 Mass comparison and mass bias estimates. On the left, we plot the CLASH lensing masses as a function of the Planck SZ mass proxy. Red points represent clusters found in the PSZ1 (13 objects) and blue those of the remaining objects at lower signal-to-noise (eight clusters); open circles identify the three clusters in the high-magnification subsample. The solid line is the equality line. The strongest outlier in the upper left corner is CLJ1226 at z = 0.89, the highest redshift object in the sample. The right-hand panel plots ρ = MPL/MCL as a function of CLASH mass together with its uncertainty Δρ (see text) in the same color scheme. The green line and band correspond to the sample mean, ⟨ ρ ⟩ s, and its standard deviation obtained from a bootstrap analysis: E( ⟨ ρ ⟩ s) = 0.72 ± 0.059, where E indicates a calculation over the bootstrap and ⟨ ρ ⟩ s is calculated as the inverse-variance weighted mean. Similarly, the magenta line and band represent the bootstrap mean and uncertainty of the unweighted mean: E( ⟨ ρ ⟩ s) = 0.76 ± 0.052. The dashed line indicates zero mass bias. |
2.2. Planck SZ mass proxy
We attempted to measure the SZ mass proxy for each of the 22 CLASH clusters. Of these, 13 are found in the Planck Catalog of SZ Sources (PSZ1, Planck Collaboration XXIX 2014) and an additional eight are detected in the Planck temperature maps, albeit at lower significance than for clusters in the PSZ1. The remaining system, MACSJ1311-03, lies in a dusty region of the sky and has a negative signal-to-noise ratio in the Planck data. It is unusable, and we remove this system from our analysis, leaving 21 clusters.
The SZ mass proxy for each cluster is extracted following the same procedure as for the PSZ1. Here, we only provide a brief summary of the method. For each CLASH cluster, we extract 10deg × 10deg tangential maps centered on the cluster position for each of the six Planck High Frequency Instrument (HFI) channels. The maps were filtered with the SZ Matched MultiFilter (MMF3, Melin et al. 2006), varying the characteristic scale, θs, of the filter. For each system, the filter provided a degeneracy curve relating the SZ signal strength, Y500, to the characteristic scale, θs. We break this degeneracy curve with an X-ray prior on the signal-size relation (Eq. (20) of Planck Collaboration XX 2014), obtaining the cluster signal strength, Y500, and scale, θs, independently, and then convert the latter to MPL. The upper and lower values for MPL are obtained following the same method, but using Y500 ± σY500 versus θs for the degeneracy curve, where σY500 is the error on the signal provided by the MMF at each characteristic scale. Details are given in Sect. 7.2.2 of Planck Collaboration XXIX (2014).
We note that, in this work, the Planck masses were derived when centering the filters on the fiducial CLASH cluster position, irrespective of the PSZ1 location. This reflects the fact that Planck positions are more uncertain than those from the CLASH catalog. Because of this, our new SZ measurements differ slightly from, but remain consistent with, the values published in the PSZ1. The inverse-variance weighted average of the ratio of the masses inferred from the SZ between the PSZ1 and our CLASH-centered estimates is 0.99 ± 0.03.
Cluster redshifts, Planck and CLASH mass estimates.
3. Mass comparison
The left-hand panel of Fig. 1 compares the CLASH masses to the Planck SZ mass proxy, with the red points representing clusters in the PSZ1 and blue the additional lower signal-to-noise clusters. The three circled data points identify the CLASH clusters selected for their high lensing magnification. The redshift value and both Planck and CLASH mass estimates of each cluster are summarized in Table 1.
The CLASH lensing masses tend to be larger than the Planck proxy values, and there is a “wall” of clusters at low Planck mass (MPL = 2 × 1014h-1M⊙) reaching to high lensing masses and that would appear to be related to the CLASH selection function. Our subsequent analysis indeed finds an effective mass cutoff for CLASH selection around (4−5) × 1014h-1M⊙. The biggest outlier, in the upper left corner in blue, is CLJ1226 at z = 0.89, the highest redshift object in the CLASH sample.
Following other work (e.g., von der Linden et al. 2014; Hoekstra et al. 2015; Simet et al. 2017), we began by assuming that the sample mean mass ratio, ⟨ MPL/MCL ⟩ s, is an unbiased estimator of the mass bias, (1−bSZ), between the Planck mass and true halo mass, M500. The right-hand panel of Fig. 1 shows the mass ratio ρ = MPL/MCL for each of the clusters. Its uncertainty is calculated as (Δ(lnρ))2 = (Δ(lnMPL))2 + (Δ(lnMCL))2 and no correlation is assumed for the Planck and CLASH mass errors.
We first calculated the inverse-variance weighted mean: ⟨ ρ ⟩ s = 0.72 ± 0.057. We also estimate the uncertainty with a bootstrap, using the boot function from the Bootstrap R package (Canty & Ripley 2015), to obtain E( ⟨ ρ ⟩ s) = 0.72 ± 0.059, where E indicates a calculation over the bootstrap. The uncertainties on the cluster mass ratios are at best approximate, having been calculated using the measured ratios for each cluster, which tends to overweight (underweight) low (high) valued excursions and pull the inverse-variance weighted mean to smaller values. An unweighted mean with bootstrap errors, as per von der Linden et al. (2014), results in a slightly higher value of E( ⟨ ρ ⟩ s) = 0.76 ± 0.052 (magenta line and band). These initial results are all in agreement with those obtained by the Canadian Cluster Comparison Project (CCCP, Hoekstra et al. 2015) and the Weighing the Giants program (WtG, von der Linden et al. 2014).
We note that three of our CLASH clusters were selected for their previously known high magnification, rather than based on their X-ray properties, as is true for the bulk of the sample; these objects are indicated in Fig. 1. The X-ray selection would more naturally lend itself to our modeling of the selection function. To check for any sensitivity to these objects, we also performed our bootstrap analysis without them (i.e., on the other 18, X-ray selected, clusters). The results do not change significantly. Curiously, when eliminating these high magnification clusters, presumably more likely to have large masses, we find a slight increase in the mass bias, namely, E( ⟨ ρ ⟩ s) = 0.68 ± 0.066. This can be appreciated by eye from Fig. 1, where these three clusters all lie close to the equality line.
The simple analysis performed above is not completely satisfactory for a variety of reasons. Moreover, it is important to note that the average for this estimator is strictly over an ensemble including both measurement errors and intrinsic, potentially correlated astrophysical scatter at fixed true mass. Meneghetti et al. (2014) found that the intrinsic scatter in CLASH lensing-deduced masses is expected to be log-normal with a standard deviation of (10–15)%, although it is potentially larger due to the impact of correlated structure3, that was not fully accounted for in the Meneghetti et al. (2014) simulations (see also Becker & Kravtsov 2011). Intrinsic scatter in the Planck mass proxy is related to the scatter in SZ signal at fixed halo mass, estimated at ~10% according to numerical simulations (e.g., Nagai et al. 2007; Stanek et al. 2010). The exact way this propagates to the Planck mass is not quantified. One would also expect a positive correlation between the lensing and SZ signals because both are a linear projection along the line-of-sight (Noh & Cohn 2011; Angulo et al. 2012).
Finally, the simple analysis above has no means of accounting for selection criteria in the cluster sample (especially for a rather small and peculiar sample like CLASH), which is critical for interpreting the relation between the observed mass ratio and the mass bias of the SZ masses relative to true halo mass. The Bayesian approach presented in the next section aims to address these shortcomings and thereby provide a more robust result and error analysis.
4. Bayesian analysis
The goal of our Bayesian analysis is to constrain models for the distribution of lensing and Planck masses given true halo mass and, simultaneously, an approximate form of the CLASH selection function. Our primary objective is the mass bias parameter, (1−bSZ), quantifying the bias between the Planck mass proxy and true halo mass. With the Bayesian analysis, we can incorporate important astrophysical effects, such as the correlation between SZ and lensing signals, and evaluate their importance. The first task is to construct the posterior probability distribution for the model parameters given the data.
Our data consist of a set of Planck- and CLASH-determined masses and spectroscopic redshifts that we arrange into three data vectors, MPL, MCL and zspec, respectively. Each vector has as many elements as clusters in our sample, Nclus = 21. From these data and a model for the distribution of their uncertainties, we wish to determine the true cluster masses, M500, and the mass bias, (1−bSZ), as defined below.
4.1. Model
The observed Planck and CLASH masses are noisy Gaussian realizations of the underlying SZ and lensing masses, denoted MSZ and ML, respectively. That is, P(MPL | MSZ) is a Gaussian distribution of mean MSZ and variance given by the Planck measurement error. The same holds for P(MCL | ML). The masses MSZ and ML are in turn related to the true halo mass M500 via a bivariate log-normal distribution. We took the mean of these quantities to be  In these expressions, it is understood that MSZ and ML are in units of the pivot mass, M0. The intrinsic scatter in lnMSZ (lnML) at fixed mass is denoted via σSZ (σL), the correlation coefficient between the two scatters is rSZ,L | M500 (but for simplicity we denote it by r), and we adopt a pivot mass as the median of the CLASH lensing masses, i.e., M0 = 5.7 × 1014h-1M⊙.
In these expressions, it is understood that MSZ and ML are in units of the pivot mass, M0. The intrinsic scatter in lnMSZ (lnML) at fixed mass is denoted via σSZ (σL), the correlation coefficient between the two scatters is rSZ,L | M500 (but for simplicity we denote it by r), and we adopt a pivot mass as the median of the CLASH lensing masses, i.e., M0 = 5.7 × 1014h-1M⊙.
The parameter (1−bSZ) in Eq. (1) is the mass bias we seek to calibrate the mass scale of the Planck clusters. It accounts for any source of bias, instrumental (e.g., X-ray satellite calibration) or astrophysical (e.g., violation of hydrostatic equilibrium in the ICM). Although defined here through a different equation than in the Planck cluster counts analysis (Planck Collaboration XX 2014; Planck Collaboration XXIV 2016), we show in Appendix A that it is the same mass bias parameter. In fact, we view our parametrization as a formally more correct way of defining the bias parameter (1−bSZ), because it clearly identifies the connection of this parameter to the data within the context of a generative model. Our results will therefore be of direct relevance to the cluster cosmology analysis presented by Planck.
Similarly, the parameter (1−bL) characterizes any potential systematic bias in the CLASH lensing masses. Any such bias would depend on the method used to extract the lensing masses, as well as specifics of the observations themselves, and can only be accurately estimated through survey-specific numerical simulations. Generic simulations (Meneghetti et al. 2010; Becker & Kravtsov 2011) suggest that lensing masses for rich cluster systems, such as those in our sample, are unbiased at the few percent level, while Rasia et al. (2012) report underestimates of up to 10%. Meneghetti et al. (2014) simulated the CLASH sample in detail and concluded that lensing masses are unbiased, with ~(10−15)% scatter, although they did not simulate the complete strong+weak lensing measurement analysis. These studies provide a general idea of the level of possible bias and scatter, and we expect that in the near future simulations will improve the determination of these parameters and the slope of the mass dependence.
The probability of a CLASH cluster having data (MPL,MCL,zspec) is
 where
where  (3)p is the vector of scaling relation parameters (bSZ, αSZ, σSZ, bL, αL, σL, r) and P(zspec | z) is a delta function centered at zspec. We consider the true mass and redshift of a cluster (M500,z) as nuisance parameters. The posterior probability distribution of our model parameters is then
(3)p is the vector of scaling relation parameters (bSZ, αSZ, σSZ, bL, αL, σL, r) and P(zspec | z) is a delta function centered at zspec. We consider the true mass and redshift of a cluster (M500,z) as nuisance parameters. The posterior probability distribution of our model parameters is then  (4)where the product is over all galaxy clusters, the vector M comprises the true cluster masses, d the data (MPL,MCL,zspec), and we have dropped a normalization constant (the marginal probability of the data) that depends only on d. We adopted the priors listed in Table 3 on our scaling relation parameters, leaving only P0(M,z), the prior on the mass and redshift vectors, M and z, respectively.
(4)where the product is over all galaxy clusters, the vector M comprises the true cluster masses, d the data (MPL,MCL,zspec), and we have dropped a normalization constant (the marginal probability of the data) that depends only on d. We adopted the priors listed in Table 3 on our scaling relation parameters, leaving only P0(M,z), the prior on the mass and redshift vectors, M and z, respectively.
The prior P0(M,z) depends on the expected mass and redshift distribution of CLASH-detected clusters. Let ndet(M500,z) be this distribution. Assuming CLASH selects clusters in the redshift range zmin to zmax, the probability distribution of finding a cluster with mass M(i) and redshift z(i) ∈ [zmin,zmax] is  (5)where
(5)where  is the normalization factor defined by
is the normalization factor defined by 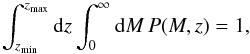 (6)which yields
(6)which yields  (7)Thus, we obtain that the prior is
(7)Thus, we obtain that the prior is  (8)and our posterior becomes
(8)and our posterior becomes  (9)We marginalized over our nuisance parameters by integrating over the vectors M and z to obtain
(9)We marginalized over our nuisance parameters by integrating over the vectors M and z to obtain  (10)where we defined
(10)where we defined  (11)Given that the redshift distribution is a delta function, Eq. (11)reduces to
(11)Given that the redshift distribution is a delta function, Eq. (11)reduces to  (12)where
(12)where  . Together with Eq. (10), this is our final expression for the posterior distribution over the parameter space. It is worth noting that this posterior is equivalent to the one built taking into account the Poisson distribution of the missing clusters and then marginalizing over the number of these undetected objects (see, e.g., Mantz et al. 2010).
. Together with Eq. (10), this is our final expression for the posterior distribution over the parameter space. It is worth noting that this posterior is equivalent to the one built taking into account the Poisson distribution of the missing clusters and then marginalizing over the number of these undetected objects (see, e.g., Mantz et al. 2010).
We then modeled the selection function, that is, the mass-redshift distribution of the CLASH sample. Despite the detailed study by Meneghetti et al. (2014) quantifying the effects of the CLASH selection criteria on the determination of the concentration-mass relation, it is difficult to extract a precise selection function in terms of cluster mass from their simulations. We therefore adopted the following approach.
We assumed that CLASH selection in mass is redshift independent over the range [zmin,zmax], and that the probability of a cluster being included in the sample is a function that goes to zero at low mass and to unity at high mass. We modeled this with an error function: ![Mathematical equation: \begin{equation} \label{eq:sel_func} f(\Mfive) = \frac{1}{2} \left[ 1 + \text{erf}\left( \frac{\ln \Mfive - \ln \Mcut}{\sqrt{2} \sigerf} \right) \right], \end{equation}](/articles/aa/full_html/2017/08/aa29971-16/aa29971-16-eq138.png) (13)and treated the low-mass cutoff, Mcut, and σcut, zmin and zmax as free parameters to be determined by the data themselves.
(13)and treated the low-mass cutoff, Mcut, and σcut, zmin and zmax as free parameters to be determined by the data themselves.
We took the mass-redshift distribution as  (14)where dn/ dlnM500 is the halo mass function and d2V/ dzdΩ is the comoving volume element per unit solid angle, dΩ. Throughout this paper, we have adopted the Tinker et al. (2008) multiplicity function with M500 defined in terms of the critical density, and the ΛCDM cosmological parameters used to estimate both Planck and CLASH masses as listed in Table 2.
(14)where dn/ dlnM500 is the halo mass function and d2V/ dzdΩ is the comoving volume element per unit solid angle, dΩ. Throughout this paper, we have adopted the Tinker et al. (2008) multiplicity function with M500 defined in terms of the critical density, and the ΛCDM cosmological parameters used to estimate both Planck and CLASH masses as listed in Table 2.
Fiducial cosmological parameters.
4.2. Priors
Our complete set of model parameters is  (15)comprising four scaling relation parameters for the mean mass values (αSZ,bSZ,αL,bL), three scatter parameters (σSZ,σL,r), and four selection function parameters (Mcut,σcut,zmin,zmax). The primary parameter of interest in this work is the bias, bSZ, of the SZ mass proxy and for which we adopted a flat prior. The parameter bL is the possible bias in the CLASH lensing masses, for which we adopt the same flat prior as for bSZ or a Gaussian prior with zero mean and standard deviation equal to 0.08 (Umetsu et al. 2014); we also performed analyses with fixed values of αL = 1, bL = 0.0, that is, unbiased lensing masses, and αSZ = 1. Table 3 summarizes the weak priors adopted on all other parameters.
(15)comprising four scaling relation parameters for the mean mass values (αSZ,bSZ,αL,bL), three scatter parameters (σSZ,σL,r), and four selection function parameters (Mcut,σcut,zmin,zmax). The primary parameter of interest in this work is the bias, bSZ, of the SZ mass proxy and for which we adopted a flat prior. The parameter bL is the possible bias in the CLASH lensing masses, for which we adopt the same flat prior as for bSZ or a Gaussian prior with zero mean and standard deviation equal to 0.08 (Umetsu et al. 2014); we also performed analyses with fixed values of αL = 1, bL = 0.0, that is, unbiased lensing masses, and αSZ = 1. Table 3 summarizes the weak priors adopted on all other parameters.
Summary of priors.
4.3. Algorithm
The posterior function is implemented in the Numerical Cosmology library (NumCosmo, Dias Pinto Vitenti & Penna-Lima 2014). The model and data objects are named NcClusterPseudoCounts and NcDataClusterPseudoCounts, respectively. The latter implements the −2lnℒ function and the former comprises, among other functions, f(M500), ndet, Ndet and the integral of Eq. (12). In order to optimize computation time, we numerically calculate the three-dimensional integral over lnM500, lnMSZ and lnML using the Divonne algorithm from the Cuba library4.
The Gaussian probability distributions for the Planck and CLASH masses, and the bivariate log-normal distribution for MSZ and ML (Eq. (3)) are written in the NcClusterMassPlCL object. A detailed description of the mass function calculation is presented in Penna-Lima et al. (2014). The python script (mass_calibration_planck_clash.py) to reproduce the analyses presented in this work is distributed and available with NumCosmo5. As an illustration, our code takes about 22 h to carry out a Markov chain Monte Carlo (MCMC) study with 106 points, using 100 chains and 40 cores.
Results – the mean and 68% CI of the marginal posterior distributions.
 |
Fig. 2 Results of the full-parameter MCMC analysis with 1.4 × 106 points (Case 1, Sect. 5.1). The contours correspond to the two-dimensional 68.3%, 95.4%, 99.7% confidence regions on parameter pairs after marginalizing over the other parameters and the true mass and redshift (see Eqs. (12)–(14)). The histograms show the one-dimensional posterior marginal distributions for each parameter. |
5. Results
We explored six cases with the Bayesian analysis and present the results in Table 4 and in Figs. 2 and 3. In the first full-parameter case, we leave all 11 parameters free and consider a flat prior on bL to understand the degeneracies inherent in the system. As there is nothing to tie-down the overall mass scale of the sample, degeneracies appear between the mass bias parameter, bSZ, the lensing mass calibration, bL, and the mass cut of the selection function. In our second study, we also perform a full-parameter analysis, but now applying the Gaussian prior on bL in order to evaluate the effect of the lensing systematics on the determination of bSZ. We then examined three other cases by progressively adding strong constraints on the slopes of the lensing and SZ relations and also on bL, namely: (i) αL = 1.0; (ii) αSZ = αL = 1.0; (iii) αSZ = αL = 1.0 and bL = 0.0. Overall, fixing these parameters changes little on the constraints of the others, as shown in Table 4.
Finally, we carried out a full-parameter study excluding the cluster CLJ1226 at z = 0.89. We observe an impact on SZ and lensing biases and scatters, but these results are consistent with the constraints of the other five cases within the 68.3% confidence interval (CI).
5.1. Case 1: all parameters free, flat prior on bL
For our first study, we computed the joint posterior distribution for the full parameter set describing the SZ- and lensing-mass distribution and the selection function. We ran 100 chains using the NcmFitESMCMC algorithm, an ensemble sampler with affine invariance for MCMC analysis from NumCosmo, requiring convergence of the variance of the fit parameters and −2lnℒ, and of the multivariate potential scale reduction factor (MPSRF). The latter should be at least smaller than 1.2, and Var(−2lnℒ) should be close to 22, since we are fitting 11 parameters.
We computed a total of 1.5 × 106 sampling points and considered a burn-in of 105 points, obtaining MPSRF ≃ 1.04 and Var(−2lnℒ) ≃ 19.5. As a consistency check, we also calculated these values for different burn-in sizes, namely 10 equally spaced points between [104,105], confirming the convergence status of the chains. Figure 2 shows the 68.3%, 95.4% and 99.7% confidence regions for parameter pairs, as well as the one-dimensional marginal distribution for each parameter.
It is worth noting that, in high-dimensional parameter space MCMC does not provide, in general, accurate estimates for the best fit6 (Lewis & Bridle 2002; Hobson et al. 2009). Therefore, in Table 4 we quote the mean and the 68.3% CI of the marginal posterior of each parameter. We determined the 68.3% CI of the i-th parameter pi by finding the points  and
and  such that the probability
such that the probability  (68.27%/2) and
(68.27%/2) and  , respectively, where
, respectively, where  is the mean of pi.
is the mean of pi.
In general, the marginal distributions are highly non-Gaussian. The parameters are very degenerate in this first, unconstrained exploration, most notably the slopes αSZ and αL, the correlation r and zmax. We see in Fig. 2 that their confidence regions cover the entire range of values defined by their flat priors, and that their errors are of the order of 50% and larger (see Table 4, column “none, flat”).
The mass bias parameter, (1−bSZ), is strongly correlated with the lensing mass calibration, (1−bL), and both are strongly anti-correlated with Mcut. The former correlation is easily understood, because the mass bias is obviously tied to halo mass through the lensing measurements; changing the lensing calibration correspondingly changes the mass bias parameter. The anti-correlation between bL and Mcut is a result of the lack of any absolute mass tie-down in this full parameter exploration: the system is attempting to calibrate the overall mass scale, and hence the lensing mass bias, through the selection function mass cut-off. This anti-correlation then spills into bSZ through its correlation with bL.
The SZ and lensing scatters are reasonably well constrained by the data, with large values, σSZ ≳ 0.6 and σL ≳ 0.4, disfavored. At 0.20, the mean for σL is consistent with expectations based on the simulations by Meneghetti et al. (2014). We also see from Fig. 2 that σSZ (σL) is moderately anti-correlated with αSZ (αL). We note this anti-correlation refers to the uncertainties in σSZ and σL, and not to the correlation coefficient between these two, which is unconstrained by the data.
5.2. Case 2: all parameters free, Gaussian prior on bL
Similarly to the previous study, we now fit the 11 parameters considering a Gaussian prior on bL = 0.0 ± 0.08 (Umetsu et al. 2014; Meneghetti et al. 2014). We performed an MCMC analysis generating 8.5 × 105 sample points. With a burn-in size of 105, we obtained MPSRF ≃ 1.03 and Var(−2lnℒ) ≃ 15.9. The marginal distributions and the 68.3%, 95.4% and 99.7% confidence regions are shown in Fig. 3. Given the lack of correlation between αSZ, σSZ, αL, σL, r, σcut, zmin and zmax with bL, there is no improvement in their constraints (see third column of Table 4).
The main differences concern bSZ and Mcut, which were strongly correlated with bL in Case 1. We drastically reduce the uncertainty on (1−bSZ), by about 70% with mean 0.73 and 68.3% CI of [0.64,0.83]. Similarly, for lnMcut the decrease in the 68.3% CI is ~60%. In addition, fixing the mass scale tightens the correlation between lnMcut and σcut.
Another effect of the bL prior is to weaken the correlation between bSZ and Mcut, confirming that their previous strong correlation leaks through from their relation to bL. This means that our constraints on the mass bias, bSZ, are relatively insensitive to the selection function as long as the lensing measurements robustly tie-down the mass scale.
 |
Fig. 3 Results of the full-parameter MCMC analysis assuming a Gaussian prior of bL = 0 ± 0.08, with 8.5 × 105 points (Case 2, Sect. 5.2) and following the format of Fig. 2. |
5.3. Other cases
We now consider more specific cases by fixing (i) αL = 1.0; (ii) αSZ = αL = 1.0; and (iii) αSZ = αL = 1.0 and bL = 0.0 in Eqs. (1), (2). This last corresponds the case of calibrating the overall scale of the Planck mass proxy assuming the CLASH masses are unbiased. We ran 100 chains, computing 5 × 105 points with a burn-in of 105 for each case. The respective results are given in the fifth, sixth and seventh columns of Table 4.
All three cases indicate that the constraints are limited by the small statistics of the sample. In general, the parameters are not correlated and, therefore, fixing the SZ and lensing slopes of the mass scaling relations do not tighten the constraints on the remaining parameters. The main difference is the reduction in ~30% of the 68.3% CI of (1−bSZ), when considering the extreme case (iii), in which there are no systematics in the lensing masses. In fact, the uncertainty on (1−bSZ) in Case 2 is the quadrature sum of the statistical uncertainty here and the Gaussian uncertainty on bL:  , as could be expected. It is worth mentioning that the regularity of these three (1−bSZ) estimates lends support to the conservative result presented in Sect. 5.2.
, as could be expected. It is worth mentioning that the regularity of these three (1−bSZ) estimates lends support to the conservative result presented in Sect. 5.2.
We also fit the 11 parameters removing the outlier CLJ1226 from the cluster catalog. Running also 100 chains, we generated 5 × 105 points to reach MPSRF ≃ 1.09 and Var(−2lnℒ) ≃ 22.06. From Fig. 1, we would expect an increase in the correlation, a decrease in the SZ and lensing scatters and in both bias parameters, since the outlier seems to require a spreader distribution to include it. The results, displayed in the fourth column of Table 4, confirm these expectancies. For instance, 1−bSZ = 0.78, σl = 0.13 and r = 0.16, although they are not statistically significant. We note that the results of all six cases are consistent, in part due to the broad constraints on the parameters, and that future applications of our methodology to larger catalogs promise to break the degeneracies.
5.4. Non-Gaussian prior
The results presented so far show that the constraints on bSZ are strongly dependent of bL. In addition to the flat and Gaussian priors on bL, and the unbiased case (bL = 0.0), we now consider one last case study with a non-Gaussian prior.
This new prior is based on the result presented in Meneghetti et al. (2014). The authors obtained the distribution of the 3D lensing-true mass ratio considering the NFW profile (among others). This is a left-skewed distribution in the interval (1−bL) ∈ [0.8,1.1], which we use as a prior on bL and show in Fig. 4 (blue dashed line) labeled as the Meneghetti prior.
In this case we ran 100 chains, computing 6 × 105 sampling points (burn-in size of 105). The posterior distributions of (1−bL) and (1−bSZ) are shown in Figs. 4 and 5, respectively. We compared them with the posteriors obtained from the MCMC analysis considering the flat prior. Similar to the previous cases, we see the strong effect on (1−bSZ) due to the prior on (1−bL).
Table 5 displays the mean and the 68.3% CI of all 11 parameters for the Gaussian and Meneghetti priors, second and third columns respectively. For instance, as the Meneghetti prior restricts bL to a narrower interval, naturally its error bar is accordingly reduced in comparison to the flat and Gaussian priors, namely,  . As expected, given the form of the Meneghetti prior (blue dashed line in Fig. 4), the lensing-mass proxy now presents a small bias. Consequently, the SZ bias increases by 3% to
. As expected, given the form of the Meneghetti prior (blue dashed line in Fig. 4), the lensing-mass proxy now presents a small bias. Consequently, the SZ bias increases by 3% to  , in comparison to the Gaussian prior centered in bL = 0, whereas the error bar decreases due to the narrower bL interval. It is worth mentioning that both results are in accordance within 68.3% CI.
, in comparison to the Gaussian prior centered in bL = 0, whereas the error bar decreases due to the narrower bL interval. It is worth mentioning that both results are in accordance within 68.3% CI.
On the other hand, the parameters of the selection function, Mcut and σcut, increase in both their mean values and their uncertainties even when compared to the flat-prior case (see Tables 4 and 5). This is due to the anti-correlation between bL and Mcut. The (1−bL) interval, [0.8, 1.1], favors larger values of Mcut and, consequently, σcut. The remaining parameters present no significant modification compared to the previous cases.
 |
Fig. 4 Prior distributions for the lensing mass bias parameter, bL. The blue dashed line represents the Meneghetti prior, i.e., the 3D lensing-true mass ratio distribution (Meneghetti et al. 2014). The other curves give the 1−bL posterior distributions in the case of flat (red line) and Meneguetti (black line) priors obtained from the MCMC analyses of the CLASH-Planck cluster sample (data). |
 |
Fig. 5 Results considering the Gaussian and Meneghetti priors: mean and 68% CI of the marginal posterior distributions. |
Results: mean and 68% CI of the marginal posterior distributions.
6. Discussion
Our basic result is a constraint on the Planck mass bias parameter of (1−bSZ) = 0.73 ± 0.10 ( ). This value applies at the median mass of our sample, M0 = 5.7 × 1014h-1, and our fit is consistent with no mass dependence, although with large uncertainty. Obtained by fitting all 11 parameters and assuming the Gaussian (Meneghetti) prior on bL (Cases 2 and 7, Sects. 5.2 and 5.4, second and third columns Table 5, respectively), these results agree within the uncertainties with the constraints in the five other case studies, as well as with the sample mean ratio from Sect. 3. They improve on the latter by folding in astrophysical effects, such as intrinsic, correlated scatter, and the influence of the CLASH selection function.
). This value applies at the median mass of our sample, M0 = 5.7 × 1014h-1, and our fit is consistent with no mass dependence, although with large uncertainty. Obtained by fitting all 11 parameters and assuming the Gaussian (Meneghetti) prior on bL (Cases 2 and 7, Sects. 5.2 and 5.4, second and third columns Table 5, respectively), these results agree within the uncertainties with the constraints in the five other case studies, as well as with the sample mean ratio from Sect. 3. They improve on the latter by folding in astrophysical effects, such as intrinsic, correlated scatter, and the influence of the CLASH selection function.
We have used Planck as a follow-up to the CLASH sample and, as a consequence, are not affected by the selection (Malmquist7) bias noted by Battaglia et al. (2016)8. This bias arises in the WtG and CCCP studies because some of their clusters do not have Planck detections9. Battaglia et al. (2016) attempted to correct the WtG and CCCP results for this effect by assigning Planck masses to the undetected clusters. Without knowing which masses to assign, however, this correction is of course uncertain, as they discuss (see also below).
Selection effects in our study would come through the CLASH sample definition. Our Bayesian approach aims to fully account for any such effects by incorporating the sample selection function into the analysis, and will do so to the extent that our model of the selection function is accurate. Ideally, we would like to know the sample selection function a priori. The CLASH sample selection is complex, and Meneghetti et al. (2014) use detailed numerical simulations to evaluate its impact on determination of the mass-concentration relation for clusters. Unfortunately, it is not straightforward to extract a selection function in terms of true halo mass from this work. We have instead opted to parameterize the CLASH selection function with the expected cosmological mass function and a smooth, but generic cutoff. By studying their relation to the other parameters, we conclude that the exact values for the selection function parameters do not significantly impact our final constraint on the SZ mass bias. This statement, however, is only as good as the generic form that we have employed for the selection function.
Our result improves on previous cluster mass calibrations by explicitly accounting for sample selection and associated uncertainties. Moreover, we consistently account for other statistical effects, such as Eddington bias, related to dispersion in the cluster observables and to their possible correlation. This is clear from our likelihood expression (Eq. (12)), which is a convolution of the steep prior on true mass (M500) with the multivariate cluster observable distribution.
The Bayesian analysis also provides information on the intrinsic dispersion of the SZ proxy and lensing masses, and their correlation. In all seven cases, we find a 13–20% scatter for the lensing mass, in good agreement with expectations (Meneghetti et al. 2014). The estimates also indicate a 30% scatter for the SZ mass proxy, notwithstanding, it is not well constrained, and remains consistent with the ~10% scatter expected from simulations (e.g., Nagai et al. 2007). Unfortunately, we are unable to establish a meaningful constraint on the correlation, r. We note that our results for the intrinsic lensing and SZ scatter masses are compatible with, respectively, the lensing and hydrostatic equilibrium scatters obtained by Sereno & Ettori (2015).
We find a value for the Planck SZ mass bias that is consistent with the constraints (1−bSZ) = 0.688 ± 0.072 and (1−bSZ) = 0.76 ± 0.05 (stat) ± 0.06 (syst) reported, respectively, by the WtG and CCCP lensing programs (von der Linden et al. 2014; Hoekstra et al. 2015). This agreement holds even after the correction to the WtG and CCCP values proposed by Battaglia et al. (2016), apart from the most extreme cases. This is satisfying because the samples and the lensing mass extraction methodologies differ significantly. The wide-field ground-based data for WtG and CCCP is augmented in CLASH by deep, 16-band HST data for weak -and strong-lensing, which the SaWLens reconstruction method combines into a single two-dimensional reconstruction. While doing so, it makes no assumption about the underlying mass distribution causing the lensing signal. This method differs to the aforementioned studies, which either rely on parametric fits or an aperture mass applied to the weak-lensing shear data only. The different mass estimates differ thus in both reconstruction methodology and input data.
The LoCuSS collaboration finds (1−bSZ) = 0.95 ± 0.04, based on their sample of 50 clusters at 0.15 < z < 0.3 (Smith et al. 2016). They show that within the uncertainties their result is consistent with both CCCP and WtG results discussed above, when the CCCP and WtG samples are restricted to clusters at z < 0.3. Moreover, the LoCuSS weak-lensing cluster masses for five clusters in the CLASH sample are in excellent agreement with CLASH measurements (Okabe & Smith 2016). This implies that 1−bSZ may evolve with redshift. Specifically, Smith et al. found (1−bSZ) = 0.6 ± 0.1 for WtG and (1−bSZ) = 0.7 ± 0.1 for CCCP, both at z > 0.3. These measurements at z > 0.3 are fully consistent with our basic results of (1−bSZ) = 0.73 ± 0.10 (), based on a sample that is dominated by clusters at z > 0.3.
The primary motivation for all these studies is to quantify the extent of the tension between constraints from the primary CMB and cluster counts found by Planck. The greatest source of uncertainty in this tension is presently the Planck cluster mass calibration. In Planck Collaboration XX (2014), Planck Collaboration XXIV (2016), the mass bias is defined through the SZ signal – halo mass relation, where no bias (bSZ = 0) corresponds to the mass calibration based on XMM-Newton X-ray observations, as detailed in the appendix of Planck Collaboration XX (2014). Our definition here is based on the Planck SZ mass proxy, MPL, described in Sect. 2.2. While not immediately obvious, Appendix A demonstrates that the two are equivalent and that the mass bias constrained here is in fact the same as that used in the Planck cluster cosmology analyses.
Figure 6 summarizes the implications for the Planck cluster cosmology results. In it we assemble a number of recent mass calibration results and compare them to the value of (1−bSZ) = 0.58 ± 0.04 required (yellow band) by the Planck primary CMB cosmology, as deduced in Planck Collaboration XXIV (2016) when leaving the mass bias parameter free. Measurements published before the 2013 Planck cosmology results are also included in the figure. These earlier studies do not report results in terms of the mass bias parameter, but rather the normalization of the Y–M relation. The mass bias parameter, (1−bSZ), is a parameterization of this amplitude that became standard afterwards when referring to the Planck cluster mass scale.
In the figure, P11 refers to the work by Planck Collaboration XI. (2011) that defines the reference point where bSZ = 0. The values labeled M10 and V09 are obtained by rewriting the amplitude of the Y–M relation of Rozo et al. (2014b) in terms of the (1−bSZ) parameter. These amplitudes were derived using a self-consistent method of propagating scaling relations that has since been improved upon by Evrard et al. (2014). The point R09 is the predicted amplitude for (1−bSZ) derived from the combined SZ and weak lensing signals of maxBCG galaxy clusters using the same methods of Rozo et al. (2014b). The R14 point corresponds to the preferred scaling relation of Rozo et al. (2014a), which combined the maxBCG and V09 Y-M scaling relation, correcting the former downwards in mass by 10%, and the latter upwards in mass by 21%. These two sets of scaling relations were then combined at the likelihood level to arrive at the R14 point. The PXX point corresponds to Planck Collaboration XX (2014), who took (1−bSZ) = 0.8 as their fiducial value, but adopted a top-hat systematic error budget (1−bSZ) ∈ [0.7,1], delineated here by the error bars.
 |
Fig. 6 Mass bias parameter, (1−bSZ), measured in different studies compared to the values preferred by the Planck base ΛCDM fit to the primary CMB anisotropies (Planck Collaboration XXIV 2016), shown as the yellow band. For reference, we translate results published before the Planck 2013 cosmological constraints became available to values for (1−bSZ). These are P11 (Planck Collaboration XI 2011), M10, V09, R09 (Rozo et al. 2014b) and R14 (Rozo et al. 2014a). PXX is the 2013 SZ cluster cosmology analysis by Planck (Planck Collaboration XX 2014) and represents the top-hat range used as a prior in that analysis. The WtG and CCCP points are, respectively, from von der Linden et al. (2014) and Hoekstra et al. (2015), with the red arrows showing the corrections estimated by Battaglia et al. (2016); the error bars increase to include the uncertainty on this correction. The Simet et al. (2017), based on lensing stacks of the MCXC catalog, and the LoCUSS (Smith et al. 2016) results are reproduced as labeled. See text for details. |
The WtG and CCCP points correspond to the work of von der Linden et al. (2014) and Hoekstra et al. (2015), who calibrated (1−bSZ) based on a comparison of the SZ masses from Planck with their weak lensing mass estimates using the subsample of Planck clusters with weak lensing follow up from each of these groups. Battaglia et al. (2016) noted that the incomplete overlap of the cluster samples introduces a bias in the recovered (1−bSZ) parameter (Malmquist bias), and we indicate the suggested corrections from Battaglia et al. (2016) in Fig. 6. The uncertainty on this correction increases the error bars. The Simet15 point comes from Simet et al. (2017), based on a stacked weak lensing analysis of the MCXC cluster catalog. Finally, the LoCUSS point is a (1−bSZ) estimate from the LoCUSS collaboration (Smith et al. 2016) that compares the Planck and lensing mass estimates.
The two main results from this paper are the points labeled CLASH(G) and CLASH(M), referring to the Gaussian and Meneghetti priors. Their error bars are larger than the comparable studies by WtG and CCCP because, in the Gaussian case, for instance, we have incorporated an 8% uncertainty, centered at zero, on any potential bias in lensing mass estimates. All of the mass calibrations lie above the range favored by the Planck primary CMB cosmology, although almost none of the more recent values does so with notable significance on its own. It is important to reduce the uncertainties in cluster mass calibration to obtain a more clear understanding of the existence of any tension between the cluster counts and the primary CMB constraints.
As a final note, we consider the effect of the lower reionization optical depth, τ, reported by Planck Collaboration Int. XLVII (2016) in an updated analysis of large angular scale polarization in Planck. The CMB determines the combination Ase− 2τ to high precision, where As is the power spectrum amplitude on large scales and is ∝ , assuming all other cosmological parameters are fixed. Lowering the optical depth therefore lowers σ8 from the primary CMB and moves the yellow band in Fig. 6 upwards. Taking the central value of τ = 0.058 given by Planck Collaboration Int. XLVII (2016), we estimate that the center line of the yellow band increases by ~8% to (1−bSZ) ≈ 0.63.
, assuming all other cosmological parameters are fixed. Lowering the optical depth therefore lowers σ8 from the primary CMB and moves the yellow band in Fig. 6 upwards. Taking the central value of τ = 0.058 given by Planck Collaboration Int. XLVII (2016), we estimate that the center line of the yellow band increases by ~8% to (1−bSZ) ≈ 0.63.
7. Conclusion
We are in the process of gaining considerable insight into the cluster mass scale thanks to recent samples of tens of clusters with high quality lensing mass determinations, now reaching statistical constraints of ~10%. These constraints are fundamental to cluster cosmology. Figure 6 summarizes recent determinations of the Planck cluster mass bias parameter and compares them to earlier mass bias estimates and to the value required by the Planck primary CMB cosmology.
The lensing based determinations (R09, R14, WtG, Simet, CCCP, CLASH) mostly display a coherent picture within the statistical uncertainties. While the value for 1−bSZ reported by LoCUSS is inconsistent with ours, LoCUSS sees a strong redshift evolution in 1−bSZ, and their final 1−bSZ value is dominated by clusters that are lower redshift than the bulk of the CLASH sample. Our result is consistent with LoCUSS for z> 0.3, see Fig. 6, as discussed in Sect. 3.2 of Smith et al. (2016). Malmquist and Eddington bias affect some of the points to an uncertain degree. Battaglia et al. (2016) estimated the Malmquist bias corrections on the WtG and CCCP determinations, which we indicate in the figure. Our constraint fully accounts for these, as well as astrophysical effects.
Other systematic effects may remain, however, at an important level. For example, in our study we adopted a generic form for the CLASH selection function. It would be far better to have a form that is well motivated from simulations, something that continued examination of the Meneghetti et al. (2014) simulations could afford. Similarly, detailed simulations are needed to evaluate the possible bias in lensing mass measurements (i.e., bL and αL). They must reproduce both the sample selection and the specific lensing mass extraction methodology. The technique to achieve such comprehensive simulations exists, but the studies have yet to be performed. It is important to emphasize in this light that each cluster cosmology sample must be analyzed in its own specific context.
With these recent advances we have perhaps learned more about how to calibrate the mass scale than we have actually improved understanding of the tension between the Planck primary CMB and cluster cosmology constraints. All mass scale determinations lie high relative to the preferred CMB value, although in each case the significance is low. This is also true of our measurement. In this context, it is important to note that the lower optical depth to reionization recently reported by Planck Collaboration Int. XLVII (2016) shifts the yellow band in Fig. 6 upwards from a center line of (1−bSZ) = 0.58 to (1−bSZ) ≈ 0.63, according to our approximate calculation.
Progress in understanding is encouraging and emphasizes the importance of improving constraints beyond the current level. With such progress on relatively small samples, the future looks promising with large lensing programs like Euclid (Laureijs et al. 2011), WFIRST (Spergel et al. 2013) and the Large Synoptic Survey Telescope (LSST Science Collaboration et al. 2009) that will produce samples of thousands of objects thanks to their wide-field surveying. In addition, CMB lensing, already observed over large sky areas by Planck, SPT and ACT, adds a powerful and independent method for mass measurements (Melin & Bartlett 2015; Baxter et al. 2015; Madhavacheril et al. 2015). The Bayesian methodology presented here will be important to extract the full potential of these large datasets.
There is not enough data for the remaining three CLASH clusters, namely, MACS0647+7015, MACS2129-0741 and Abell1423. For instance, there is no wide-field 3+-band Subaru data available for the cluster Abell1423.
During the bootstrap the redshift uncertainty of a given WL galaxy was also sampled. Then the angular distance ratio Ds/Dls for each individual galaxy was calculated, which was then averaged and used to convert the convergence map into a physical surface-density map.
Recently, Shirasaki et al. (2016) reported that the scatter of about 20% in the thermal SZ and weak lensing relation, found from observations (Marrone et al. 2012), is due to projections of correlated structures and the bias in the lensing determined cluster radius.
For instance, consider a n-dimensional unit Gaussian, whose maximum is at the origin. The probability of the number of samples to be close to the maximum is small, since the volume of a high-dimensional sphere is concentrated in a narrow annulus at the surface (Unpingco 2016).
Classical Malmquist bias applies to a flux limited sample and refers to the fact that intrinsically more luminous objects are over-represented because they can be seen over larger volumes than less luminous sources. In common practice, Malmquist bias is the term applied generally, but inaccurately, to effects related to sample selection.
The authors referred to this correction as an Eddington bias correction. Eddington bias is not a sample selection effect, but rather due to dispersion in an observable in the presence of a steep abundance function. While discussing Eddington bias at an earlier point in their paper, the correction made to WtG and CCCP results due to missing clusters is more appropriately referred to as Malmquist bias.
We note, however, that we are unable to use one cluster in our CLASH sample because of its negative signal-to-noise value.
Acknowledgments
M.P.L. was supported by National Council for Scientific and Technological Development – Brazil (CNPq grant 202131/2014-9 and PCI/MCTIC/CBPF program). M.P.L. and J.G.B. thank Sandro Vitenti for valuable discussions, and Graham Smith for suggestions. E.R. acknowledges support from DOE grant DE-SC0015975 and from the Sloan Foundation, grant FG-2016-6443. J.M. has received funding from the People Programme (Marie Curie Actions) of the European Unions Seventh Framework Programme (FP7/2007–2013) under REA grant agreement number 627288. Part of this research was carried out at the Jet Propulsion Laboratory, California Institute of Technology, under a contract with the National Aeronautics and Space Administration.
References
- Arnaud, M., Pratt, G. W., Piffaretti, R., et al. 2010, A&A, 517, A92 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Angulo, R. E., Springel, V., White, S. D. M., et al. 2012, MNRAS, 426, 2046 [CrossRef] [Google Scholar]
- Battaglia, N., Bond, J. R., Pfrommer, C., & Sievers, J. L. 2013, ApJ, 777, 123 [NASA ADS] [CrossRef] [Google Scholar]
- Battaglia, N., Leauthaud, A., Miyatake, H., et al. 2016, J. Cosmol. Astropart. Phys., 8, 013 [NASA ADS] [CrossRef] [Google Scholar]
- Baxter, E. J., Keisler, R., Dodelson, S., et al. 2015, ApJ, 806, 247 [NASA ADS] [CrossRef] [Google Scholar]
- Becker, M. R., & Kravtsov, A. V. 2011, ApJ, 740, 25 [NASA ADS] [CrossRef] [Google Scholar]
- Bhattacharya, S., Heitmann, K., White, M., et al. 2011, ApJ, 732, 122 [NASA ADS] [CrossRef] [Google Scholar]
- Canty, A., & Ripley, B. D. 2015, boot: Bootstrap R (S-Plus) Functions, r package version 1.3-17 [Google Scholar]
- Dias Pinto Vitenti, S., & Penna-Lima, M. 2014, Astrophysics Source Code Library [record ascl:1408.013] [Google Scholar]
- Donahue, M., Voit, G. M., Mahdavi, A., et al. 2014, ApJ, 794, 136 [NASA ADS] [CrossRef] [Google Scholar]
- Dubois, Y., Gavazzi, R., Peirani, S., & Silk, J. 2013, MNRAS, 433, 3297 [NASA ADS] [CrossRef] [Google Scholar]
- Evrard, A. E. 1990, ApJ, 363, 349 [NASA ADS] [CrossRef] [Google Scholar]
- Evrard, A. E., Arnault, P., Huterer, D., & Farahi, A. 2014, MNRAS, 441, 3562 [NASA ADS] [CrossRef] [Google Scholar]
- Genel, S., Vogelsberger, M., Springel, V., et al. 2014, MNRAS, 445, 175 [Google Scholar]
- Hobson, M. P., Jaffe, A. H., Liddle, A. R., Mukherjee, P., & Parkinson, D. 2009, Bayesian Methods in Cosmology (Cambridge University Press), Cambridge Books Online [Google Scholar]
- Hoekstra, H. 2003, MNRAS, 339, 1155 [NASA ADS] [CrossRef] [Google Scholar]
- Hoekstra, H., Herbonnet, R., Muzzin, A., et al. 2015, MNRAS, 449, 685 [NASA ADS] [CrossRef] [Google Scholar]
- Jee, M. J., & Tyson, J. A. 2009, ApJ, 691, 1337 [NASA ADS] [CrossRef] [Google Scholar]
- Laureijs, R., Amiaux, J., Arduini, S., et al. 2011, ArXiv e-prints [arXiv:1110.3193] [Google Scholar]
- Le Brun, A. M. C., McCarthy, I. G., Schaye, J., & Ponman, T. J. 2014, MNRAS, 441, 1270 [NASA ADS] [CrossRef] [Google Scholar]
- Lewis, A., & Bridle, S. 2002, Phys. Rev. D, 66, 103511 [NASA ADS] [CrossRef] [Google Scholar]
- LSST Science Collaboration, Abell, P. A., Allison, J., et al. 2009, ArXiv e-prints [arXiv:0912.0201] [Google Scholar]
- Madhavacheril, M., Sehgal, N., Allison, R., et al. 2015, Phys. Rev. Lett., 114, 151302 [NASA ADS] [CrossRef] [Google Scholar]
- Mahdavi, A., Hoekstra, H., Babul, A., et al. 2013, ApJ, 767, 116 [NASA ADS] [CrossRef] [Google Scholar]
- Mantz, A., Allen, S. W., Ebeling, H., Rapetti, D., & Drlica-Wagner, A. 2010, MNRAS, 406, 1773 [NASA ADS] [Google Scholar]
- Marrone, D. P., Smith, G. P., Okabe, N., et al. 2012, ApJ, 754, 119 [NASA ADS] [CrossRef] [Google Scholar]
- Martizzi, D., Jimmy, Teyssier, R., & Moore, B. 2014, MNRAS, 443, 1500 [NASA ADS] [CrossRef] [Google Scholar]
- Medezinski, E., Umetsu, K., Nonino, M., et al. 2013, ApJ, 777, 43 [NASA ADS] [CrossRef] [Google Scholar]
- Melin, J.-B., & Bartlett, J. G. 2015, A&A, 578, A21 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Melin, J.-B., Bartlett, J. G., & Delabrouille, J. 2006, A&A, 459, 341 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Meneghetti, M., Rasia, E., Merten, J., et al. 2010, A&A, 514, A93 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Meneghetti, M., Rasia, E., Vega, J., et al. 2014, ApJ, 797, 34 [NASA ADS] [CrossRef] [Google Scholar]
- Merten, J., Cacciato, M., Meneghetti, M., Mignone, C., & Bartelmann, M. 2009, A&A, 500, 681 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Merten, J., Coe, D., Dupke, R., et al. 2011, MNRAS, 417, 333 [NASA ADS] [CrossRef] [Google Scholar]
- Merten, J., Meneghetti, M., Postman, M., et al. 2015, ApJ, 806, 4 [NASA ADS] [CrossRef] [Google Scholar]
- Murray, S. G., Power, C., & Robotham, A. S. G. 2013, A&C, 3, 23 [Google Scholar]
- Nagai, D., Vikhlinin, A., & Kravtsov, A. V. 2007, ApJ, 655, 98 [NASA ADS] [CrossRef] [Google Scholar]
- Nelson, K., Lau, E. T., Nagai, D., Rudd, D. H., & Yu, L. 2014, ApJ, 782, 107 [NASA ADS] [CrossRef] [Google Scholar]
- Noh, Y., & Cohn, J. D. 2011, MNRAS, 413, 301 [NASA ADS] [CrossRef] [Google Scholar]
- Okabe, N., & Smith, G. P. 2016, MNRAS, 461, 3794 [NASA ADS] [CrossRef] [Google Scholar]
- Patel, B., McCully, C., Jha, S. W., et al. 2014, ApJ, 786, 9 [NASA ADS] [CrossRef] [Google Scholar]
- Penna-Lima, M., Makler, M., & Wuensche, C. A. 2014, J. Cosmol. Astropart. Phys., 5, 39 [NASA ADS] [CrossRef] [Google Scholar]
- Piffaretti, R., & Valdarnini, R. 2008, A&A, 491, 71 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration XI. 2011, A&A, 536, A11 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration XX. 2014, A&A, 571, A20 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration XXIX. 2014, A&A, 571, A29 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration XXIV. 2016, A&A, 594, A24 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration Int. XLVII. 2016, A&A, 596, A108 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Postman, M., Coe, D., Benítez, N., et al. 2012, ApJS, 199, 25 [NASA ADS] [CrossRef] [Google Scholar]
- Ragone-Figueroa, C., Granato, G. L., Murante, G., Borgani, S., & Cui, W. 2013, MNRAS, 436, 1750 [NASA ADS] [CrossRef] [Google Scholar]
- Rasia, E., Ettori, S., Moscardini, L., et al. 2006, MNRAS, 369, 2013 [NASA ADS] [CrossRef] [Google Scholar]
- Rasia, E., Meneghetti, M., Martino, R., et al. 2012, New J. Phys., 14, 055018 [NASA ADS] [CrossRef] [Google Scholar]
- Rozo, E., Rykoff, E. S., Bartlett, J. G., & Evrard, A. E. 2013, ArXiv e-print [arXiv:1302.5086] [Google Scholar]
- Rozo, E., Bartlett, J. G., Evrard, A. E., & Rykoff, E. S. 2014a, MNRAS, 438, 78 [NASA ADS] [CrossRef] [Google Scholar]
- Rozo, E., Evrard, A. E., Rykoff, E. S., & Bartlett, J. G. 2014b, MNRAS, 438, 62 [NASA ADS] [CrossRef] [Google Scholar]
- Rozo, E., Rykoff, E. S., Bartlett, J. G., & Evrard, A. 2014c, MNRAS, 438, 49 [NASA ADS] [CrossRef] [Google Scholar]
- Sereno, M., & Ettori, S. 2015, MNRAS, 450, 3633 [NASA ADS] [CrossRef] [Google Scholar]
- Shirasaki, M., Nagai, D., & Lau, E. T. 2016, MNRAS, 460, 3913 [NASA ADS] [CrossRef] [Google Scholar]
- Simet, M., Battaglia, N., Mandelbaum, R., & Seljak, U. 2017, MNRAS, 466, 3663 [NASA ADS] [CrossRef] [Google Scholar]
- Smith, G. P., Mazzotta, P., Okabe, N., et al. 2016, MNRAS, 456, L74 [NASA ADS] [CrossRef] [Google Scholar]
- Spergel, D., Gehrels, N., Breckinridge, J., et al. 2013, ArXiv e-prints [arXiv:1305.5425] [Google Scholar]
- Stanek, R., Rasia, E., Evrard, A. E., Pearce, F., & Gazzola, L. 2010, ApJ, 715, 1508 [NASA ADS] [CrossRef] [Google Scholar]
- Tinker, J., Kravtsov, A. V., Klypin, A., et al. 2008, ApJ, 688, 709 [NASA ADS] [CrossRef] [Google Scholar]
- Umetsu, K., Medezinski, E., Nonino, M., et al. 2012, ApJ, 755, 56 [NASA ADS] [CrossRef] [Google Scholar]
- Umetsu, K., Medezinski, E., Nonino, M., et al. 2014, ApJ, 795, 163 [NASA ADS] [CrossRef] [Google Scholar]
- Umetsu, K., Zitrin, A., Gruen, D., et al. 2016, ApJ, 821, 116 [Google Scholar]
- Unpingco, J. 2016, Python for Probability, Statistics, and Machine Learning (Springer International Publishing) [Google Scholar]
- von der Linden, A., Mantz, A., Allen, S. W., et al. 2014, MNRAS, 443, 1973 [NASA ADS] [CrossRef] [Google Scholar]
- Zitrin, A., Fabris, A., Merten, J., et al. 2015, ApJ, 801, 44 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: Connection to the Planck SZ Cosmology Analysis
The main result of this work is a constraint on the relation between a halo’s true mass M500 and the mass proxy MSZ. It is not necessarily obvious how this result is related to the parameter b used in PXX, a point that we discuss in some detail here.
Let us then define a parameter β such that  (A.1)We will show that β = b, where b is defined as in PXX. It is clear that it is the parameter β that we constrain in our analysis.
(A.1)We will show that β = b, where b is defined as in PXX. It is clear that it is the parameter β that we constrain in our analysis.
Now, PXX parameterizes the scaling relation between mass and YSZ – which we hereby denote Yb for reasons that will be made apparent momentarily – via  (A.2)The function A(z) is a known function of redshift whose specific form is irrelevant for this work. Likewise, α is some known constant whose value is irrelevant for this work. For the discussion below, it will be convenient to define the mass Mb ≡ (1−b)M500, so that
(A.2)The function A(z) is a known function of redshift whose specific form is irrelevant for this work. Likewise, α is some known constant whose value is irrelevant for this work. For the discussion below, it will be convenient to define the mass Mb ≡ (1−b)M500, so that  (A.3)Now, the detection probability of a halo of mass M500 in PXX is computed as follows: given b, one first computes Mb, which is to
(A.3)Now, the detection probability of a halo of mass M500 in PXX is computed as follows: given b, one first computes Mb, which is to
be thought of as an X-ray hydrostatic mass proxy. Since the mass dependence of the templates used by Planck are calibrated on X-ray hydrostatic masses, these templates are defined in terms of Mb. That is, the integrated Y profile can be expressed via  (A.4)where f(1) = 1, and f is a known function.
(A.4)where f(1) = 1, and f is a known function.
We contrast the above templates to how the observable MSZ is defined. Given an integrated SZ profile Y(R), the mass MSZ is given by the solution to the equation  (A.5)where RSZ is the radius of a cluster of mass MSZ.
(A.5)where RSZ is the radius of a cluster of mass MSZ.
Let us then assume that a cluster of mass MSZ corresponds to a cluster of mass Mb, so that the profile Y(R) is given by Eq. (A.4). The mass MSZ is given by the solution to:  (A.6)Setting MSZ = Mb, one has then that f = 1, while the right hand side reduces to the right hand side of Eq. (A.3). The equality is valid, and therefore MSZ = Mb is precisely the solution we were looking for. Since MSZ = Mb, it follows that β = b, and therefore our analysis is directly relevant to the Planck cosmological analysis without the need to introduce aperture corrections.
(A.6)Setting MSZ = Mb, one has then that f = 1, while the right hand side reduces to the right hand side of Eq. (A.3). The equality is valid, and therefore MSZ = Mb is precisely the solution we were looking for. Since MSZ = Mb, it follows that β = b, and therefore our analysis is directly relevant to the Planck cosmological analysis without the need to introduce aperture corrections.
All Tables
All Figures
|
Fig. 1 Mass comparison and mass bias estimates. On the left, we plot the CLASH lensing masses as a function of the Planck SZ mass proxy. Red points represent clusters found in the PSZ1 (13 objects) and blue those of the remaining objects at lower signal-to-noise (eight clusters); open circles identify the three clusters in the high-magnification subsample. The solid line is the equality line. The strongest outlier in the upper left corner is CLJ1226 at z = 0.89, the highest redshift object in the sample. The right-hand panel plots ρ = MPL/MCL as a function of CLASH mass together with its uncertainty Δρ (see text) in the same color scheme. The green line and band correspond to the sample mean, ⟨ ρ ⟩ s, and its standard deviation obtained from a bootstrap analysis: E( ⟨ ρ ⟩ s) = 0.72 ± 0.059, where E indicates a calculation over the bootstrap and ⟨ ρ ⟩ s is calculated as the inverse-variance weighted mean. Similarly, the magenta line and band represent the bootstrap mean and uncertainty of the unweighted mean: E( ⟨ ρ ⟩ s) = 0.76 ± 0.052. The dashed line indicates zero mass bias. |
| In the text | |
|
Fig. 2 Results of the full-parameter MCMC analysis with 1.4 × 106 points (Case 1, Sect. 5.1). The contours correspond to the two-dimensional 68.3%, 95.4%, 99.7% confidence regions on parameter pairs after marginalizing over the other parameters and the true mass and redshift (see Eqs. (12)–(14)). The histograms show the one-dimensional posterior marginal distributions for each parameter. |
| In the text | |
|
Fig. 3 Results of the full-parameter MCMC analysis assuming a Gaussian prior of bL = 0 ± 0.08, with 8.5 × 105 points (Case 2, Sect. 5.2) and following the format of Fig. 2. |
| In the text | |
|
Fig. 4 Prior distributions for the lensing mass bias parameter, bL. The blue dashed line represents the Meneghetti prior, i.e., the 3D lensing-true mass ratio distribution (Meneghetti et al. 2014). The other curves give the 1−bL posterior distributions in the case of flat (red line) and Meneguetti (black line) priors obtained from the MCMC analyses of the CLASH-Planck cluster sample (data). |
| In the text | |
|
Fig. 5 Results considering the Gaussian and Meneghetti priors: mean and 68% CI of the marginal posterior distributions. |
| In the text | |
|
Fig. 6 Mass bias parameter, (1−bSZ), measured in different studies compared to the values preferred by the Planck base ΛCDM fit to the primary CMB anisotropies (Planck Collaboration XXIV 2016), shown as the yellow band. For reference, we translate results published before the Planck 2013 cosmological constraints became available to values for (1−bSZ). These are P11 (Planck Collaboration XI 2011), M10, V09, R09 (Rozo et al. 2014b) and R14 (Rozo et al. 2014a). PXX is the 2013 SZ cluster cosmology analysis by Planck (Planck Collaboration XX 2014) and represents the top-hat range used as a prior in that analysis. The WtG and CCCP points are, respectively, from von der Linden et al. (2014) and Hoekstra et al. (2015), with the red arrows showing the corrections estimated by Battaglia et al. (2016); the error bars increase to include the uncertainty on this correction. The Simet et al. (2017), based on lensing stacks of the MCXC catalog, and the LoCUSS (Smith et al. 2016) results are reproduced as labeled. See text for details. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.