| Issue |
A&A
Volume 587, March 2016
|
|
|---|---|---|
| Article Number | A18 | |
| Number of page(s) | 15 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/201527188 | |
| Published online | 12 February 2016 | |
A package for the automated classification of periodic variable stars⋆
Max-Planck Institute for Astronomy, Königstuhl 17, 69117 Heidelberg, Germany
Received: 13 August 2015
Accepted: 4 December 2015
Abstract
We present a machine learning package for the classification of periodic variable stars. Our package is intended to be general: it can classify any single band optical light curve comprising at least a few tens of observations covering durations from weeks to years with arbitrary time sampling. We use light curves of periodic variable stars taken from OGLE and EROS-2 to train the model. To make our classifier relatively survey-independent, it is trained on 16 features extracted from the light curves (e.g., period, skewness, Fourier amplitude ratio). The model classifies light curves into one of seven superclasses – δ Scuti, RR Lyrae, Cepheid, Type II Cepheid, eclipsing binary, long-period variable, non-variable – as well as subclasses of these, such as ab, c, d, and e types for RR Lyraes. When trained to give only superclasses, our model achieves 0.98 for both recall and precision as measured on an independent validation dataset (on a scale of 0 to 1). When trained to give subclasses, it achieves 0.81 for both recall and precision. The majority of misclassifications of the subclass model is caused by confusion within a superclass rather than between superclasses. To assess classification performance of the subclass model, we applied it to the MACHO, LINEAR, and ASAS periodic variables, which gave recall/precision of 0.92/0.98, 0.89/0.96, and 0.84/0.88, respectively. We also applied the subclass model to Hipparcos periodic variable stars of many other variability types that do not exist in our training set, in order to examine how much those types degrade the classification performance of our target classes. In addition, we investigate how the performance varies with the number of data points and duration of observations. We find that recall and precision do not vary significantly if there are more than 80 data points and the duration is more than a few weeks.
Key words: methods: data analysis / methods: statistical / stars: variables: general / techniques: miscellaneous
The classifier software of the subclass model is available (in Python) from the GitHub repository (https://goo.gl/xmFO6Q).
Current address: Institute of Astronomy and Astrophysics, Academia Sinica, PO Box 23-141, Taipei 10617, Taiwan.
© ESO, 2016
1. Introduction
Periodic variable stars have played a central role in our learning about the Universe. RR Lyrae stars, for instance, have been used to determine distances to globular clusters, to study Galactic structure, and also to trace the history of the formation of our Galaxy (Vivas et al. 2001; Carretta et al. 2000; Catelan 2009; Sesar 2011). Cepheid variables are important standard candles for measuring distances to external galaxies (Freedman et al. 2001; Riess et al. 2011). Eclipsing binaries are vital for estimating stellar masses (Torres et al. 2010), and δ Scuti are used in asteroseismological studies to learn about the internal structure of stars (Brown & Gilliland 1994).
As the volume of astronomical survey data grows, the reliable automated detection and classification of objects including periodic variable stars is becoming increasingly important. LSST, for instance, will produce about 20 TB of data per night, requiring robust and powerful automated methods to classify the sources and light curves (see Ivezic et al. 2008 and references therein). The Gaia satellite (Perryman et al. 2001) is scanning the whole sky to monitor a billion stars, and is using machine learning and statistical analysis techniques to classify the sources and to estimate the astrophysical parameters (effective temperature, extinction, etc.; Bailer-Jones et al. 2013) as well as to analyze the light curves (Eyer et al. 2014).
In this paper, we introduce UPSILoN: AUtomated Classification for Periodic Variable Stars using MachIne LearNing. This software package classifies a light curve into a class of a periodic variable star in an automatic manner. It can be applied to light curves from optical surveys regardless of survey-specific characteristics (e.g., photometric accuracy, sampling rate, duration, etc.) as long as the light curves satisfy a few broad conditions:
-
it contains at least a few tens of data points that sample thecharacteristic variability well;
-
the observation duration is more than a few weeks;
-
the light curve is obtained in an optical band.
If multiple optical bands are available, UPSILoN can classify them separately. It does not use – or rely on – color information. UPSILoN is currently trained to classify into six types of periodic variables: δ Scuti, RR Lyrae, Cepheid, Type II Cepheid, eclipsing binary, long-period variable, and their subclasses. UPSILoN can also separate non-variables from these periodic variables, which is important because the majority of light curves from most time-series surveys are non-variables.
Some previous studies have investigated the possibility of producing general purpose classifiers such as UPSILoN. For instance, Blomme et al. (2011) used a mixture of Hipparcos (Perryman et al. 1997), OGLE (Udalski et al. 1997), and CoRoT (Auvergne et al. 2009) sources to train a classification model, and then applied this to the TrES dataset (O’Donovan et al. 2009). Debosscher et al. (2009), Richards et al. (2012a) used Hipparcos and OGLE sources to train classification models and applied them to CoRoT and ASAS (Pojmanski 1997) data, respectively. The latest work of this kind was done by Paegert et al. (2014) who developed a periodic variable classifier optimized for eclipsing binaries based on neural networks (Mackay 2003). Most of these studies confirmed that their trained models successfully classified target sources from other surveys that were not included in their training sets.
UPSILoN differs from these previous works in several ways:
General purpose classifier UPSILoN has been trained to achieve the best classification quality for a broad set of periodic variables, rather than having been optimized for a specific type of variable.
Rich training set We use a mixture of the OGLE and EROS-2 periodic variable stars to provide a relatively complete set of periodic variables for training (see Sect. 2.1).
Simple and robust variability features We employ features that have been shown to quantify variability of both periodic and non-periodic light curves (Kim et al. 2011, 2012, 2014; Long et al. 2012). Most of these features are simple and easily calculated (see Sect. 2.2).
Random forest (Breiman 2001) We use the random forest algorithm, which is one of the most successful machine learning methods in many astronomical classification problems (e.g., Carliles et al. 2010; Pichara et al. 2012; Masci et al. 2014; Nun et al. 2014 and references therein). This is described in Sect. 2.3.
Application to MACHO, LINEAR, ASAS, and Hipparcos datasets To assess classification quality, we applied UPSILoN to the MACHO, LINEAR, ASAS, and Hipparcos periodic variables, as described in Sects. 3 and 4.
Experiments with resampled MACHO and ASAS light curves We resampled the MACHO and ASAS periodic variables’ light curves in order to build samples containing different number of measurements over different observation durations. Classification results using these samples are given in Sect. 5.
Ready-to-use Python package The UPSILoN package including the random forest model is available from the GitHub repository1.
2. UPSILoN classifier
2.1. Training set
Acronyms of the variable types.
As the quality of classification strongly depends on the training data, it is important to construct a rich and clean training set. We used a mixture of periodic variable stars from the OGLE (Udalski et al. 1997) and EROS-2 (Tisserand et al. 2007) Large Magellanic Cloud (LMC) databases. We chose these because they provide the most complete and well-sampled set of light curves in the optical for several types of periodic variable stars. We identified the OGLE periodic variables from several literature sources: Soszyński et al. (2008a,b, 2009a,b), Poleski et al. (2010), Graczyk et al. (2011). For the EROS-2 periodic variables, we used the training set of the periodic variable stars from Kim et al. (2014). As described in that paper, this data set was visually inspected and cleaned. From these source we complied a catalog of periodic variables comprising δ Scuti stars, RR Lyraes, Cepheids, Type II Cepheids, eclipsing binaries, and long-period variables (these are the superclasses). Table 1 gives the acronyms of each superclass. We also compiled subclasses (e.g., RR Lyrae ab, c, d, and e) of each class. We then added non-variable sources to the catalog, which is important because a given set of survey data that we want to classify will generally include many such sources. For these, we selected 5000 EROS-2 non-variables from Kim et al. (2014) and 5000 OGLE light curves randomly selected around the Large Magellanic Cloud2 (Szymanski 2005). We visually examined these light curves and removed light curves showing variability. Note, however, that it remains difficult for any general classifier to identify non-variables on account of the wide range of survey-dependent characteristics of such stars (e.g., due to systematic trends, variable noise levels). Thus although we added the OGLE and EROS-2 non-variable sources to our training set, this does not ensure that the classifier will efficiently exclude non-variables during the classification of light curves from other surveys.
Before extracting variability features (Sect. 2.2) from these training-set light curves, we first refined each light curve by
-
removing data points with bogus photometry (e.g., 99.999 in EROS-2). The EROS-2 light curves have many such measurements.
-
removing data points that lie more than 3σ above or below the mean (no iteration), where σ is the standard deviation of the light curve. This cut does not significantly alter light curves because it removes generally less than 1% of the data points per light curve.
In order to build the cleanest possible training set, we then excluded light curves from the training set if
-
the number of measurements was fewer than 100.
-
an estimated period was spurious, related to the mean sidereal day (~0.997 days), the mean sidereal month (~27.322 days), the mean synodic month (~29.531 days), and integer multiples thereof. We determined additional spurious periods by examining a period versus period signal-to-noise ratio (SNR) plot and a period histogram as done by Kim et al. (2014). Most of the additional spurious periods are close to the sidereal day.
The number of sources in each class in the training set.
The average number of data points in either an OGLE or an EROS-2 light curve is about 500. The observation duration is about seven years for the EROS-2 light curves, and about eight years for the OGLE light curves.
2.2. Survey-independent variability features
16 variability features.
We used a total of 16 variability features (Table 3) to quantify variability of a light curve. Note that we only chose features that are relatively survey-independent3 and excluded features that are only available in certain surveys (e.g., ones based on colors). This is important because our goal is to develop a general purpose classifier that can be applied to an essentially any long-duration time-series survey done in an optical band. Among these 16 features, 11 are taken from our previous work (Kim et al. 2011, 2012, 2014), and two are from Long et al. (2012). These publications show that these features are useful and robust to classify either periodic or non-periodic variables. We added three more features, A, H1, and W, defined as follows.
-
A The ratio of the squared sum of residuals of magnitudes that are either brighter than or fainter than the mean magnitude. This is defined as
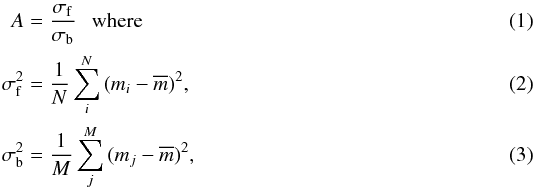
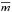 is the mean magnitude of a light curve, mi are measurements fainter than , and mj are measurements brighter than . If a light curve has a sinusoidal-like variability, A is close to 1. For EB-like variability, having sharp flux gradients around its eclipses, A is larger than 1.
is the mean magnitude of a light curve, mi are measurements fainter than , and mj are measurements brighter than . If a light curve has a sinusoidal-like variability, A is close to 1. For EB-like variability, having sharp flux gradients around its eclipses, A is larger than 1. -
H1 The rms amplitude of the first Fourier component of the Fourier decomposition of the light curve (Petersen 1986). This is
 (4)with the Fourier series defined as
(4)with the Fourier series defined as ![Mathematical equation: \begin{equation} m_0 + \sum_{k=1}^M [a_k \sin(2 \pi k f) + b_k \cos(2 \pi k f)] \end{equation}](/articles/aa/full_html/2016/03/aa27188-15/aa27188-15-eq25.png) (5)where M is the order of the Fourier series and f is the phase: 0 ≤ f< 1;j = 1,2,...,N, where N is the number of data points. m0, ak and bk are parameters to be fitted. In this work, the value of M is 5.
(5)where M is the order of the Fourier series and f is the phase: 0 ≤ f< 1;j = 1,2,...,N, where N is the number of data points. m0, ak and bk are parameters to be fitted. In this work, the value of M is 5. W The Shapiro-Wilk statistic, which tests the null hypothesis that the samples (e.g., measurements in the light curve) are from a normal distribution (Shapiro & Wilk 1965). The Shapiro-Wilk test is generally more powerful than other normality tests (e.g., Kolmogorov-Smirnov test, Anderson-Darling test, etc.) for different sample sizes (see Saculinggan & Balase 2013 and references therein).
 |
Fig. 1 Feature importance as estimated using the random forest algorithm. As expected, period is the most powerful feature for separating periodic variables, although the other 15 features are non unimportant. |
To extract variability features from the training-set light curves, we used EROS-2 blue-band, BE, light curves. For OGLE, we used I-band light curves. EROS-2 BE-band and OGLE I-band light curves generally have more data points and/or better photometric accuracy than EROS-2 red-band, RE, and OGLE V-band light curves, respectively.
 |
Fig. 2 F1 scores of the trained random forest models with different t and m. Note that the F1 scores are quite uniform over the parameter space, showing differences of less than 0.01. |
2.3. Training a classification model
A random forest classifier (Hastie et al. 2009; Breiman 2001) is based on an ensemble of decision trees (Quinlan 1993). Each decision tree is trained using a randomly selected subset of the features at each node. The random forest uses a majority voting strategy to assign probabilities to all labels (here the variability classes) for a given sample (here the light curve). We accept the variability class corresponding to the highest probability among those assigned probabilities. See Kim et al. (2014) for a more detailed description of the random forest algorithm.
To train a random forest model, two hyperparameters must be set. These are the number of trees, t, and the number of randomly selected features at each node of trees, m. Each tree is fully grown without pruning. Before tuning the parameters, we split the training set into two subsets, T1 and T2, each of which contains 50% of each class in the training set. We used T1 to optimize the hyperparameters by performing a brute-force search over a two-dimensional grid in t and m, using ten-fold cross-validation. The metric for model performance is the F1 score, which is the harmonic mean of the precision and recall, i.e.,  and F1 varies between 0 and 1. This is computed for each class separately, and the individual scores then averaged weighted by the number of objects in that class. Figure 2 shows the results of the grid search. The difference between the best and worst models is 0.009, so the exact choice of t and m is unimportant. The classification uncertainty derived during the ten-fold cross-validation is ±0.005, which is comparable to this difference.
and F1 varies between 0 and 1. This is computed for each class separately, and the individual scores then averaged weighted by the number of objects in that class. Figure 2 shows the results of the grid search. The difference between the best and worst models is 0.009, so the exact choice of t and m is unimportant. The classification uncertainty derived during the ten-fold cross-validation is ±0.005, which is comparable to this difference.
Classification quality of the trained model with subclasses.
 |
Fig. 3 Confusion matrix of the subclass model. Each cell shows the fraction of objects of that true class (rows) assigned to the predicted classes (columns) on a gray scale. Thus the values on the leading diagonal are the recall rate (Eq. (8)). We show the number only if it is larger than or equal to 0.01. See Table 4 for the numerical values of the recall and precision for each class. |
With t = 700 and m = 10 (the best values) we trained a classification model using the subset T1 and applied it to T2 in order to assess the classification quality. This is summarized in Table 4. Recall and precision for DSCT, RRL, CEPH, and their subclasses are generally higher than 0.90, sometimes as high as 0.99. The majority of misclassification is caused by confusion within a superclass, especially within EB and LPV, as can be seen in Fig. 3. In addition, if we train4 a classification model without the subclasses, the F1 score increases to 0.98 as shown in Table 5.
Finally, we trained a classifier using all 16 variability features, the entire training set (i.e., T1 + T2), and the subclasses (again with t = 700 and m = 10). Note that this model is the UPSILoN classifier that we use to classify the MACHO, LINEAR, ASAS, and Hipparcos periodic variables presented in the following sections.
3. Validation of the classifier on the MACHO, LINEAR, and ASAS datasets
We applied the UPSILoN classifier to light curves found as periodic variables from three time-series surveys: MACHO (Alcock et al. 1996a); ASAS (Pojmanski 1997); LINEAR (Palaversa et al. 2013). These each have different survey characteristics, such as the number of data points, observation duration, limiting magnitude, etc., so represent a suitable datasets to assess the UPSILoN classifier’s generalization performance. Before we applied the classifier to these three datasets, we refined each light curve by 3σ clipping, and by excluding light curves having spurious periods, as described in Sect. 2. We then extracted the 16 variability features from each light curve and used UPSILoN to predict a variability class.
3.1. MACHO
We obtained MACHO B-band light curves of periodic variables from Kim et al. (2011). The total number of light curves is 870 (Table 6). The number of data points in each light curve is between 200 and 1500, while 50% of the light curves have more than 1000 data points. The duration of the light curves (i.e., observation duration) is about 7 yr. The limiting magnitude of the MACHO survey is V ~ 21.
In the left panel of Table 7 we show the classification performance achieved by UPSILoN. MACHO does not provide subclass classifications so thus we merged predicted subclasses into corresponding superclasses. As the table shows, the average F1 score is 0.94, which confirms that the UPSILoN classifier is successful at classifying the MACHO periodic variables. Nevertheless, the recall of CEPH is only 0.75, meaning that 25% of CEPH were classified as another variability type. Almost all of these were classified as T2CEPH, which is not surprising since CEPH and T2CEPH are similar. Note that MACHO did not use the class T2CEPH, so it is quite possible that some of these sources are in fact of class T2CEPH. The recall for RRL is 0.85, i.e., 15% of true RRLs were misclassified. Many of these were classified as EB, and we visually confirmed that they indeed show EB-like variability (Fig. 4).
Table 7 also shows the classification performance using a random classifier with a training-set prior (middle panel), and an uniform prior (right panel). The term “random classifier” means that we randomly assigned a class to each MACHO light curve. The probability of assignment to a given class is proportional to the frequency of the class in the training set in the middle panel, and is equal for the classes in the right panel. We do these tests to get a measure of the minimum expected performance (which is not zero), and to quantify to what degree beyond “random” the data actually inform about the class. As expected, the precision and recall of both random classifiers are always considerably lower than that achieved by UPSILoN.
3.2. LINEAR
The light curves and catalog of LINEAR periodic variables are from Palaversa et al. (2013). We selected sources with the classification uncertainty flags of 1 and excluded others on the ground that their class assignment was ambiguous. The total number of sources after the selection is 5279 (Table 8). The number of data points of each light curve lies between 100 and 600, although most of the light curves have fewer than 300 data points. The duration of the light curves is about 5 yr and the faintest magnitude among these periodic variables is r ~ 17.
Classification quality of the trained model without subclasses.
Number of objects per true class in the MACHO dataset.
The left panel of Table 9 shows the UPSILoN classification performance. All classes except DSCT are successfully classified by UPSILoN. The low precision for DSCT occurs because 199 of the 1965 EBs were misclassified as DSCT, of which there are only 104 true ones. The reason for this is because 96% of the estimated periods of the LINEAR EBs are shorter than 0.25 days (Fig. 5), which is associated with the problem that the Lomb-Scargle algorithm typically returns half of the true period for EB-type variables in which the shapes of the primary and secondary eclipses are similar (see Graham et al. 2013 and references therein). Consequently, almost all of the LINEAR EB periods are within the period range for the DSCTs in the training set (i.e., ≤0.25 days), which could cause the misclassification. Despite the overlapping ranges of the estimated periods between LINEAR EB and DSCT, 88% of EBs (i.e., 1 734 among 1 965) were correctly classified.
Classification quality of the MACHO dataset.
 |
Fig. 4 Phased-folded light curves of the MACHO RRLs classified as EBs by the UPSILoN classifier. They show EB-like variability, implying that the MACHO classification might be incorrect. mV is the Johnson V-band magnitude derived from the MACHO magnitude using the conversion equation from Kunder & Chaboyer (2008). In each panel we show the periods of the light curves obtained from the Lomb-Scargle algorithm. We used twice these periods to plot the phase-folded light curves, because Lomb-Scargle occasionally returns half of the true period for EB-like variability. |
3.3. ASAS
We downloaded ASAS V-band light curves and the accompanying catalog (ASAS Catalog of Variable Stars version 1.1; hereafter ACVS) from the ASAS website5 (Pojmanski 1997). We selected only sources with a unique classification (e.g., DSCT), thereby excluding sources with multiple classifications (e.g., DSCT/RRC/EC). We also discarded MISC-type sources, which have unclear variability class. After this filtering, the number of remaining sources is 10 779 (Table 10). The number of data points in the light curves varies between 200 and 2000, while 60% of the light curves have more than 400 data points. The duration of the light curves is about 9 yr. The limiting magnitude of the ASAS survey is V ~ 14, which is substantially brighter than the limits for OGLE, EROS-2, MACHO, and LINEAR.
Number of objects per true class in the LINEAR dataset.
Table 11 (left panel) shows the UPSILoN classification performance. The average F1 score is 0.85, demonstrating that most ASAS periodic variables are successfully classified. However, F1 scores are relatively low for some classes such as RRL c and CEPH. This could be associated with the poor quality of the ACVS classification, which has been noted by previous studies also (Schmidt et al. 2009; Richards et al. 2012b). For instance, Schmidt et al. (2009) found that there exist serious biases in the CEPH classification of ACVS. Richards et al. (2012b) found the significant discrepancies between their classification and ACVS classification for RRL c and DSCT. We also find that our low precision for DSCT is mainly caused by the UPSILoN’s misclassification of EB EC (contact binaries) as DSCT. We visually checked the variability pattern of EB EC and DSCT classified by ACVS, and found that they are generally similar, as shown in Fig. 6. The low precision of EB ESD (semi-detached binary), 0.57, is likewise caused primarily by the confusion with EB EC, again due to their similar variability patterns. In contrast, the precision and recall of EB ED (detached binaries) are both fairly high: 0.93 and 0.96 respectively. This is because the variability pattern of EB ED – typically sharp flux gradients near its eclipses – is substantially different from that of EB EC or DSCT.
Classification quality of the LINEAR dataset.
4. Investigation of classification performance in the presence of other variability types: the HIPPARCOS periodic variable stars
We obtained a catalog of Hipparcos periodic variable stars and their corresponding light curves6 from Dubath et al. (2011). This dataset contains many variability types (e.g., rotational variability, eruptive variability) that are not in the UPSILoN training set, as well as types which are. Thus this dataset is suitable for examining the potential contamination to the UPSILoN classification by unaccounted for variability types. We refined each Hipparcos light curve by 3σ clipping, and by excluding light curves with spurious periods (see Sect. 2) as we did for the MACHO, LINEAR, and ASAS datasets (see Sect. 3). Table 12 gives the number of each Hipparcos variability type in the dataset after this refinement. The table also shows the corresponding UPSILoN classes. We then extracted the 16 features to predict a variability class. The average number of data points in the light curves is about 100, and the duration of the light curves varies from one to three years, which is much fewer and shorter than the other three datasets.
 |
Fig. 5 Period histograms of EB (solid line) from the LINEAR dataset. LINEAR EB have relatively shorter periods, which could cause misclassification of them into the short-period variables such as DSCT. The dashed line is a period histogram of the training set DSCT. |
 |
Fig. 6 Phase-folded ASAS light curves of EB EC (left) and DSCT (right) from the ACVS classification. As the figure shows, there are no clear variability differences between them, which could yield misclassification. Periods (in days) of the light curves are given in each panel. |
Number of objects per true class in the ASAS dataset.
In Fig. 7, we show the confusion matrix of the classification results. This is more informative than a table of recall/precision since many Hipparcos classes do not exist in the training set. As the matrix shows, the Hipparcos classes from DSCT to LPV (from top to middle row), which are those which correspond directly to UPSILoN classes, are relatively classified well by the UPSILoN classifier. The recall rates for those classes are generally high, up to 0.96, which indicates that UPSILoN successfully classifies the major types of periodic variables even though the number of data points is relatively small and the duration is relatively short. Nevertheless, we see the confusion between subclasses of eclipsing binaries, which is expected following what we showed ealrier for the UPSILoN classifier performance (see Fig. 3). About 40% of Hipparcos DCEPS (i.e., first overtone Cepheid) are misclassified as CEPH F (i.e., fundamental mode Cepheid).
Classification quality of the ASAS dataset.
Number of objects per true class in the Hipparcos dataset.
Dubath et al. (2011) also found a similar degree of confusion between these two classes and suggested that an overlap between the two classes in the period-amplitude space might be the reason. In addition, about half of the CEP(B) (i.e., multi-mode Cepheid) are classified as CEPH F rather than CEPH Other. The rest are classified as CEPH 1O (first overtone). In other words, all of the Hipparcos multi-mode Cepheid variables are misclassified. This confusion could be associated with their multi-period characteristics, because the UPSILoN classifier is trained using only a single period but not using multiple periods, as also suggested by Dubath et al. (2011). However this explanation might not clarify the confusion of this case because the recall/precision of CEPH Other is relatively high, as shown in Fig. 3. Thus we suspect that the training set might have an insufficient number of sources of the same variability type CEP(B). Most of the training sources in the CEPH Other class are double-mode Cepheids F/1O and 1O/2O, whereas we do not know which pulsation modes these 11 CEP(B) stars are in. Further investigation is therefore not possible.
 |
Fig. 7 Confusion matrix of the Hipparcos dataset classified by the UPSILoN classifier. Each cell-color represents the fraction of objects of that Hipparcos class (rows) assigned to the predicted UPSILoN classes (columns) on a gray scale. The value in each cell is the number of the Hipparcos sources. |
 |
Fig. 8 Fraction of sources (y-axis) whose probabilities of the accepted classes are lower than a certain probability (x-axis) for the Hipparcos periodic variables (left panel) and the OGLE/EROS-2 validation test-set, T2 (see Sect. 2.3), (right panel). The correctly classified sources (solid line) have generally higher probability than other two groups, each of which is 1) the misclassified sources (dashed line), and 2) the sources whose variability types are not in the training set (dotted line). |
 |
Fig. 9 Precision (left column) and recall (right column) of the resampled MACHO dataset as a function of length of light curves, l (horizontal axis), and the number of data points, n (different lines), for different variability classes (rows). |
The other Hipparcos classes, from ELL to RV, contaminate the classification results, which is not very surprising because the UPSILoN training set that defines its known class space does not contain those variability types. The most contaminated UPSILoN classes are DSCT, CEPH F, CEPH 1O, and EB ESD whereas other UPSILoN classes are less contaminated or almost entirely uncontaminated by them (i.e., all RRL subclasses, CEPH Other, EB ED, EB EC, all LPV subclasses, and T2CEPH). As the table shows, 24 of the 29 BCEP are misclassified as DSCT due to BCEP’s short periods and low amplitudes, which are also the characteristics of DSCT. In addition, contamination caused by SPB, ACV, RS+BY, GDOR, and ACYG to CEPH F, CEPH 1O and/or EB ESD is also high. For instance, 90% of SPB and 70% of ACV are classified as one of these UPSILoN classes. This might be because we did not use colors as a variability feature to train the UPSILoN classifier, which is one of the most useful features to separate different variability types. Training and validating an another model with survey-specific features (e.g., colors) is out of the scope of this paper. Nevertheless, most variable star surveys, being area and magnitude limited, will generally have a small fraction of variable stars of the rare “contaminating” classes considered here. Thus they would not be a significant source of contamination for the UPSILoN classes. Of course, UPSILoN will be unable to classify these rare classes, because it is not designed to do that.
 |
Fig. 10 continued. |
Figure 8 shows the cumulative distribution of the assigned class probabilities for both the Hipparcos periodic variables (left panel) and the OGLE/EROS-2 test-set periodic variables (T2 from Sect. 2.3, right panel)7. The solid line shows the sources whose variable types are in the training set and which are correctly classified by UPSILoN. The dashed line shows the sources of the same variability types but which are misclassified. As both panels show, the correctly classified sources tend to have higher probabilities than the misclassified sources. More importantly, the sources whose variability types are not in the training set (dotted line) generally have lower probabilities than other two groups (solid line and dashed line). This is not surprising, because UPSILoN does not know the data space which these variability types occupy. The data are poorly explained by several classes, no class dominates, so UPSILoN assigns all of them low probabilities (as the probabilities must sum to one). Thus, in order to reduce the contamination, one can set a probability cut. For instance, excluding sources with probabilities lower than 0.5 removes about 70% of the contaminating sources and also ~40% of the misclassified sources, as can be seen in the left panel of Fig. 8. Such cuts, however, will reduce the recall rate at the same time (16% loss of the correctly classified sources in this case).
5. Investigation of classifier performance as a function of light curve length and sampling
In this section we present the results of experiments to assess the classification performance of the UPSILoN classifier for light curves having different numbers of data points and different observation durations. To achieve this we constructed a set of light curves by resampling the MACHO and ASAS light curves from the previous sections based on two parameters: the length of a light curve, l (i.e., observation duration); and the number of data points, n. We chose l = 30, 60, 90, 180, 365, 730, and 1460 days, and also the full observation duration (i.e., 7 yr for MACHO and 9 yr for ASAS). For the number of data points, we chose n = 20, 40, 80, 100, 150, 200, and 300. The resampling procedures were as follows. For a given light curve we
-
1.
extract measurements observed between the starting epoch of the light curve and l days after the starting epoch. If the number of the selected measurements is fewer than n, skip the current light curve and move to the next light curve.
-
2.
randomly select n unique samples among these measurements.
These n unique samples give a resampled light curve of duration l. We did not resample the LINEAR and Hipparcos light curves because most of them have fewer than 300 data points.
We applied the UPSILoN classifier to these resampled MACHO and ASAS light curves. Figure 9 shows the precision and recall for each variability class for the MACHO data. Figure 10 show the same for ASAS. The horizontal-axis is the length of light curves, l, the vertical-axis is either precision or recall, and each line represents a different number of data points, n. In general, the more data points, the higher the precision and recall.
In the case of MACHO (Fig. 9), precision rapidly reaches its maximum value as the number of data points, n, reaches 80. Even when there are fewer data points (e.g., 20 and 40), precision is fairly high. Length, l, hardly affects precision. In contrast, recall is low for some classes (e.g., RRL) when n = 20 or 40. The reason for the low recall is because lots of light curves were classified as non-variables. This happens because the classification of variables with relatively short periods, such as RRL and CEPH, needs a sufficient number of data points over a short timescale. As the figure shows, the recall of RRL and CEPH slightly decreases as l increases when n = 20 or 40, for the same reason. In addition, to quantify EB-like variability, which has steep flux gradients around the eclipses, light curves have to be very well sampled to cover the area around the flux gradients. Therefore, recall for EB is also relatively low.
Figure 10 show the classification results of the resampled ASAS light curves. Precision and recall is generally lower than MACHO’s because ACVS provides subclasses whereas MACHO does not. We saw earlier that recovering subclasses is a harder problem than recovering superclasses, as we would expect. The poor quality of the ACVS classification could also contribute to the low recall and precision, as explained in the previous section. Nonetheless, when there are more than 40 data points, precision and recall are reasonably stable and rapidly reaches their maxima. We also found that recall and precision of most of the classes, namely DSCT, RRL ab, RRL c, CEPH, EB, and LPV, decreases as l increases when n = 20 or 40, as we saw from the resampled MACHO classification results.
From the experiments presented above, we see that if the number of data points, n, is larger than or equal to 80, precision and recall are not significantly lower than what we can achieve using more data points and longer duration light curves. More importantly, the duration of the light curves does not significantly alter the classification quality if n ≥ 80.
6. Summary
The quality of any supervised classification model depends strongly on the quality of the training data, and yet constructing a clean and reasonably complete training set is quite difficult. This is particularly the case in the early stages of a survey, when only a few known objects will have been observed, making it hard to build a classifier.
In this work, we have developed a general purpose classifier for periodic variable stars to help alleviate this problem. First of all, it is known that periodic variables are relatively straightforward to separate from non-periodic variables or non-variables because of the clear periodic patterns of their light curves. Second, lots of well-sampled light curves from different surveys are available that can be used as a training set. As the characteristics of periodic variables can be captured by survey-independent features (e.g., periods, amplitudes, shape of phase-folded light curves), it is possible to build a universal training set.
We constructed a training set using the OGLE and EROS-2 periodic variables consisting of 143 923 well-sampled light curves for a number of different types of periodic variable stars. We mixed two different surveys having different characteristics (sampling rates, observation durations, optical bands, etc.) in order to train a classification model that is relatively tolerant of the diverse characteristics that could be encountered in the application datasets from other surveys. We extracted 16 variability features that are relatively survey-independent and used these features to train a random forest classifier, the UPSILoN classifier. Using periodic variables identified in the MACHO, LINEAR, and ASAS surveys, we have shown that UPSILoN can successfully classify periodic variable types in the training set with high precision and recall. Using the Hipparcos periodic variables, we found that the UPSILoN classes, CEPH F, CEPH 1O, and EB ESD, can be contaminated by other variability types that are not in the training set. We also tested the classifier using the resampled MACHO and ASAS light curves, where we found that precision and recall were fairly stable regardless of the time sampling and duration, as long as there was a sufficient number of data points (≥80). The UPSILoN classifier should prove useful for performing an initial classification into the major periodic variability classes of light curves coming from a broad set of optical monitoring surveys.
Using the website http://ogledb.astrouw.edu.pl/~ogle/photdb/
The minimum requirements for a light curve are given in Sect. 1.
The hyperparameter optimization is done separately.
Periodic variables in Table 1 from Dubath et al. (2011).
Note that the probabilities for the OGLE/EROS-2 test-set were derived during the validation phase using the model trained on only T1 (Sect. 2.3).
Wall-clock time.
Acknowledgments
We thank P. Dubath and L. Rimoldini for providing the Hipparcos periodic variable stars and its catalog from their previous work (Dubath et al. 2011). The analysis in this work has been done using the multi-core machine, Mekong, equipped with eight AMD Opteron 6276 CPUs and 264 GB memory, at the Max-Planck Institute for Astronomy.
References
- Alcock, C., Allsman, R. A., Axelrod, T. S., et al. 1996a, ApJ, 461, 84 [NASA ADS] [CrossRef] [Google Scholar]
- Alcock, C., Allsman, R. A., Axelrod, T. S., et al. 1996b, AJ, 111, 1146 [NASA ADS] [CrossRef] [Google Scholar]
- Auvergne, M., Bodin, P., Boisnard, L., et al. 2009, A&A, 506, 411 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bailer-Jones, C. A. L., Andrae, R., Arcay, B., et al. 2013, A&A, 559, A74 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Blomme, J., Sarro, L. M., O’Donovan, F. T., et al. 2011, MNRAS, 418, 96 [NASA ADS] [CrossRef] [Google Scholar]
- Breiman, L. 2001, Machine Learning, 45, 5 [Google Scholar]
- Breiman, L., Friedman, J., Stone, C., & Olshen, R. 1984, Classification and Regression Trees, The Wadsworth and Brooks-Cole statistics-probability series (Taylor & Francis) [Google Scholar]
- Brown, T. M., & Gilliland, R. L. 1994, ARA&A, 32, 37 [NASA ADS] [CrossRef] [Google Scholar]
- Carliles, S., Budavári, T., Heinis, S., Priebe, C., & Szalay, A. S. 2010, ApJ, 712, 511 [NASA ADS] [CrossRef] [Google Scholar]
- Carretta, E., Gratton, R. G., Clementini, G., & Fusi Pecci, F. 2000, ApJ, 533, 215 [NASA ADS] [CrossRef] [Google Scholar]
- Catelan, M. 2009, Astrophys. Space Sci., 320, 261 [NASA ADS] [CrossRef] [Google Scholar]
- Debosscher, J., Sarro, L. M., López, M., et al. 2009, A&A, 506, 519 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dubath, P., Rimoldini, L., Süveges, M., et al. 2011, MNRAS, 414, 2602 [NASA ADS] [CrossRef] [Google Scholar]
- Eyer, L., Evans, D. W., Mowlavi, N., et al. 2014, in EAS Pub. Ser., 67, 75 [Google Scholar]
- Freedman, W. L., Madore, B. F., Gibson, B. K., et al. 2001, ApJ, 553, 47 [NASA ADS] [CrossRef] [Google Scholar]
- Graczyk, D., Soszyński, I., Poleski, R., et al. 2011, Acta Astron., 61, 103 [NASA ADS] [Google Scholar]
- Graham, M. J., Drake, A. J., Djorgovski, S. G., et al. 2013, MNRAS, 434, 3423 [NASA ADS] [CrossRef] [Google Scholar]
- Hastie, T., Tibshirani, R., & Friedman, J. 2009, The elements of statistical learning: data mining, inference and prediction, 2nd edn. (Springer) [Google Scholar]
- Ivezic, Z., Tyson, J. A., Abel, B., et al. 2008, ArXiv e-prints [arXiv:0805.2366] [Google Scholar]
- Kim, D.-W., Protopapas, P., Byun, Y.-I., et al. 2011, ApJ, 735, 68 [NASA ADS] [CrossRef] [Google Scholar]
- Kim, D.-W., Protopapas, P., Trichas, M., et al. 2012, ApJ, 747, 107 [NASA ADS] [CrossRef] [Google Scholar]
- Kim, D.-W., Protopapas, P., Bailer-Jones, C. A. L., et al. 2014, A&A, 566, A43 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kunder, A., & Chaboyer, B. 2008, AJ, 136, 2441 [NASA ADS] [CrossRef] [Google Scholar]
- Long, J. P., Karoui, N. E., Rice, J. A., Richards, J. W., & Bloom, J. S. 2012, PASP, 124, 280 [NASA ADS] [CrossRef] [Google Scholar]
- Mackay, D. J. C. 2003, Information Theory, Inference and Learning Algorithms (Cambridge University Press) [Google Scholar]
- Masci, F. J., Hoffman, D. I., Grillmair, C. J., & Cutri, R. M. 2014, AJ, 148, 21 [NASA ADS] [CrossRef] [Google Scholar]
- Nun, I., Pichara, K., Protopapas, P., & Kim, D.-W. 2014, ApJ, 793, 23 [NASA ADS] [CrossRef] [Google Scholar]
- O’Donovan, F. T., Charbonneau, D., Mandushev, G., et al. 2009, in NASA/IPAC/NExScI Star and Exoplanet Database, TrES Lyr1 Catalog, 6 [Google Scholar]
- Paegert, M., Stassun, K. G., & Burger, D. M. 2014, AJ, 148, 31 [NASA ADS] [CrossRef] [Google Scholar]
- Palaversa, L., Ivezić, Ž., Eyer, L., et al. 2013, AJ, 146, 101 [CrossRef] [Google Scholar]
- Perryman, M. A. C., Lindegren, L., Kovalevsky, J., et al. 1997, A&A, 323, L49 [NASA ADS] [Google Scholar]
- Perryman, M. A. C., de Boer, K. S., Gilmore, G., et al. 2001, A&A, 369, 339 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Petersen, J. O. 1986, A&A, 170, 59 [NASA ADS] [Google Scholar]
- Pichara, K., Protopapas, P., Kim, D.-W., Marquette, J.-B., & Tisserand, P. 2012, MNRAS, 427, 1284 [NASA ADS] [CrossRef] [Google Scholar]
- Pojmanski, G. 1997, Acta Astron., 47, 467 [NASA ADS] [Google Scholar]
- Poleski, R., Soszyñski, I., Udalski, A., et al. 2010, Acta Astron., 60, 1 [NASA ADS] [Google Scholar]
- Quinlan, J. R. 1993, C4.5: programs for machine learning (San Francisco: Morgan Kaufmann Publishers Inc.) [Google Scholar]
- Richards, J. W., Starr, D. L., Brink, H., et al. 2012a, ApJ, 744, 192 [NASA ADS] [CrossRef] [Google Scholar]
- Richards, J. W., Starr, D. L., Miller, A. A., et al. 2012b, ApJS, 203, 32 [NASA ADS] [CrossRef] [Google Scholar]
- Riess, A. G., Macri, L., Casertano, S., et al. 2011, ApJ, 730, 119 [NASA ADS] [CrossRef] [Google Scholar]
- Saculinggan, M., & Balase, E. A. 2013, J. Phys.: Conf. Ser., 435, 012041 [NASA ADS] [CrossRef] [Google Scholar]
- Schmidt, E. G., Hemen, B., Rogalla, D., & Thacker-Lynn, L. 2009, AJ, 137, 4598 [NASA ADS] [CrossRef] [Google Scholar]
- Sesar, B. 2011, in RR Lyrae Stars, Metal-Poor Stars, and the Galaxy, ed. A. McWilliam, 135 [Google Scholar]
- Shapiro, S. S., & Wilk, M. B. 1965, Biometrika, 52, 591 [Google Scholar]
- Soszyński, I., Poleski, R., Udalski, A., et al. 2008a, Acta Astron., 58, 163 [NASA ADS] [Google Scholar]
- Soszyński, I., Udalski, A., Szymański, M. K., et al. 2008b, Acta Astron., 58, 293 [NASA ADS] [Google Scholar]
- Soszyński, I., Udalski, A., Szymañski, M. K., et al. 2009a, Acta Astron., 59, 239 [NASA ADS] [Google Scholar]
- Soszyński, I., Udalski, A., Szymański, M. K., et al. 2009b, Acta Astron., 59, 1 [NASA ADS] [Google Scholar]
- Stokes, G. H., Evans, J. B., Viggh, H. E. M., Shelly, F. C., & Pearce, E. C. 2000, Icarus, 148, 21 [NASA ADS] [CrossRef] [Google Scholar]
- Szymanski, M. K. 2005, Acta Astron., 55, 43 [NASA ADS] [Google Scholar]
- Tisserand, P., Le Guillou, L., Afonso, C., et al. 2007, A&A, 469, 387 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Torres, G., Andersen, J., & Giménez, A. 2010, A&ARv, 18, 67 [Google Scholar]
- Udalski, A., Kubiak, M., & Szymanski, M. 1997, Acta Astron., 47, 319 [NASA ADS] [Google Scholar]
- Vivas, A. K., Zinn, R., Andrews, P., et al. 2001, ApJ, 554, L33 [NASA ADS] [CrossRef] [Google Scholar]
- von Neumann, J. 1941, Ann. Math. Statist., 12, 367 [CrossRef] [Google Scholar]
Appendix
Appendix A.1: How to use UPSILoN
The following pseudo-code shows how to use the UPSILoN library to extract features from light curves and then to classify them.
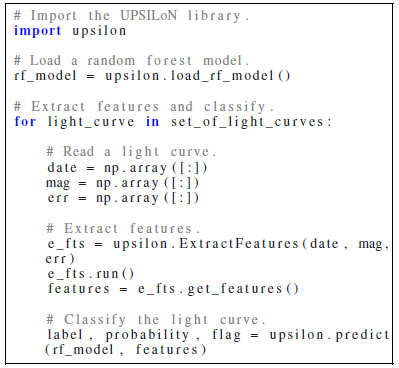
label and probability are a predicted class and a class probability, respectively. The flag gives additional information of the classification result. For details of how to use the UPSILoN library, visit the GitHub repository8. UPSILoN is released under the MIT license, so it is free to use, copy, and modify.
If you use UPSILoN in scientific publication, we would appreciate citations to this paper.
Appendix A.2: UPSILoN runtime
We used the Macbook Pro 13′′ equipped with 2.7 GHz Intel Core i5, 8 GB memory, and 256 GB SSD to measure the UPSILoN runtime9 using the EROS-2 light curves, which contains about 500 data points. The average runtime for feature extraction per light curve is ~1.1 s. The most time-consuming part of the feature extraction is the period estimation. UPSILoN can reduce the period estimation runtime by utilizing multiple cores to speed up the Fourier transform part in the Lomb-Scargle algorithm. We observed that the period estimation runtime is inversely scaled with the number of cores. The runtime for class prediction per light curve is less than 0.01 s, which is negligible when compared to the feature extraction runtime. In addition, loading the UPSILoN random forest model file takes ~4 s. Note that the loading is not a recurring task.
All Tables
All Figures
|
Fig. 1 Feature importance as estimated using the random forest algorithm. As expected, period is the most powerful feature for separating periodic variables, although the other 15 features are non unimportant. |
| In the text | |
|
Fig. 2 F1 scores of the trained random forest models with different t and m. Note that the F1 scores are quite uniform over the parameter space, showing differences of less than 0.01. |
| In the text | |
|
Fig. 3 Confusion matrix of the subclass model. Each cell shows the fraction of objects of that true class (rows) assigned to the predicted classes (columns) on a gray scale. Thus the values on the leading diagonal are the recall rate (Eq. (8)). We show the number only if it is larger than or equal to 0.01. See Table 4 for the numerical values of the recall and precision for each class. |
| In the text | |
|
Fig. 4 Phased-folded light curves of the MACHO RRLs classified as EBs by the UPSILoN classifier. They show EB-like variability, implying that the MACHO classification might be incorrect. mV is the Johnson V-band magnitude derived from the MACHO magnitude using the conversion equation from Kunder & Chaboyer (2008). In each panel we show the periods of the light curves obtained from the Lomb-Scargle algorithm. We used twice these periods to plot the phase-folded light curves, because Lomb-Scargle occasionally returns half of the true period for EB-like variability. |
| In the text | |
|
Fig. 5 Period histograms of EB (solid line) from the LINEAR dataset. LINEAR EB have relatively shorter periods, which could cause misclassification of them into the short-period variables such as DSCT. The dashed line is a period histogram of the training set DSCT. |
| In the text | |
|
Fig. 6 Phase-folded ASAS light curves of EB EC (left) and DSCT (right) from the ACVS classification. As the figure shows, there are no clear variability differences between them, which could yield misclassification. Periods (in days) of the light curves are given in each panel. |
| In the text | |
|
Fig. 7 Confusion matrix of the Hipparcos dataset classified by the UPSILoN classifier. Each cell-color represents the fraction of objects of that Hipparcos class (rows) assigned to the predicted UPSILoN classes (columns) on a gray scale. The value in each cell is the number of the Hipparcos sources. |
| In the text | |
|
Fig. 8 Fraction of sources (y-axis) whose probabilities of the accepted classes are lower than a certain probability (x-axis) for the Hipparcos periodic variables (left panel) and the OGLE/EROS-2 validation test-set, T2 (see Sect. 2.3), (right panel). The correctly classified sources (solid line) have generally higher probability than other two groups, each of which is 1) the misclassified sources (dashed line), and 2) the sources whose variability types are not in the training set (dotted line). |
| In the text | |
|
Fig. 9 Precision (left column) and recall (right column) of the resampled MACHO dataset as a function of length of light curves, l (horizontal axis), and the number of data points, n (different lines), for different variability classes (rows). |
| In the text | |
 |
Fig. 10 As Fig. 9, but for the resampled ASAS light curves. |
| In the text | |
|
Fig. 10 continued. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.