| Issue |
A&A
Volume 582, October 2015
|
|
|---|---|---|
| Article Number | A79 | |
| Number of page(s) | 14 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/201526793 | |
| Published online | 12 October 2015 | |
X-ray galaxy clusters abundance and mass temperature scaling⋆
1
Université de Toulouse, UPS-OMP, IRAP, 31400
Toulouse, France
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
;
This email address is being protected from spambots. You need JavaScript enabled to view it.
2
CNRS, IRAP, 14
avenue Édouard Belin, 31400
Toulouse,
France
3
Institut d’Astrophysique Spatiale, Université Paris-Sud, UMR
8617, 91405
Orsay,
France
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
4
CNRS, 91405
Orsay,
France
Received: 19 June 2015
Accepted: 12 August 2015
Abstract
The abundance of clusters of galaxies is known to be a potential source of cosmological constraints through their mass function. In the present work, we examine the information that can be obtained from the temperature distribution function of X-ray clusters. For this purpose, the mass-temperature (M − T) relation and its statistical properties are critical ingredients. Using a combination of cosmic microwave background (CMB) data from Planck and our estimations of X-ray cluster abundances, we use Markov chain Monte Carlo (MCMC) techniques to estimate the ΛCDM cosmological parameters and the mass to X-ray temperature scaling relation simultaneously. We determine the integrated X-ray temperature function of local clusters using flux-limited surveys. A local comprehensive sample was build from the BAX X-ray cluster database, allowing us to estimate the local temperature distribution function above ~1 keV. We model the expected temperature function from the mass function and the M − T scaling relation. We then estimate the cosmological parameters and the parameters of the M − T relation (calibration and slope) simultaneously. The measured temperature function of local clusters in the range ~1–10 keV is well reproduced once the calibration of the M − T relation is treated as a free parameter, and therefore is self-consistent with respect to the ΛCDM cosmology. The best-fit values of the standard cosmological parameters as well as their uncertainties are unchanged by the addition of clusters data. The calibration of the mass temperature relation, as well as its slope, are determined with ~10% statistical uncertainties. This calibration leads to masses that are ~75% larger than X-ray masses used in Planck.
Key words: galaxies: clusters: general / large-scale structure of Universe / cosmological parameters / cosmic background radiation
Appendix A is available in electronic form at http://www.aanda.org
© ESO, 2015
1. Introduction
The quest for cosmological parameters has made dramatic progresses in recent years. The most spectacular progress has come from the evidence for accelerated expansion from the Hubble diagram of distant supernovae (Riess et al. 1998; Perlmutter et al. 1999). Although astrophysical evolution of the type Ia supernovae would easily explain their Hubble diagram (Drell et al. 2000; Wright 2002; Ferramacho et al. 2009), the measurements of the angular power spectrum of the cosmic microwave background (CMB) fluctuations and of the power spectrum of galaxy distribution on large scales have enabled the confirmation of several predictions of the dark energy dominated, cold dark matter picture (Blanchard 2010; Weinberg et al. 2013). The parameters of this model have now been estimated with impressive precision (Planck Collaboration XVI 2014), making alternative explanations rather contrived. The actual origin of the acceleration now appears as one of the most intriguing and challenging problem of modern cosmology and fundamental physics. While the simplest explanation is an Einstein cosmological constant presently dominating the energy density of the Universe, various options have been investigated in which the dark energy behaves like a fluid with its equation of state w, parametrised by p = wρ (ρ being the pressure and p the pressure of the fluid). For these so-called “quintessence” models, the dark energy is due to the presence of a scalar field, the evolution of its potential determining its equation of state. Modifying the Lagrangian of the field opens an almost unlimited range of possibilities for the properties of the dark energy fluid (Copeland et al. 2006). However, another explanation for the origin of the cosmic acceleration comes from the modification of the law of gravitation at large scales, i.e. a deviation from general relativity at cosmological scales (Jain & Khoury 2010; Amendola et al. 2013). In this kind of case, the dynamics of the expansion could be identical to that of a concordant model and all geometrical tests provide cosmological parameters identical to those inferred in a Friedman-Lemaître model, but the gravitational dynamics of matter fluctuations may differ, offering a possible signature of the modified gravity. There is, therefore, a specific interest in measuring the gravitational growing rate of fluctuations. The evolution of the abundance of clusters with redshift is exponentially sensitive to the growing rate of linear fluctuations (Blanchard & Bartlett 1998). This has motivated the use of cluster abundance evolution as a cosmological test (Oukbir & Blanchard 1992; Henry 1997; Eke et al. 1998; Viana & Liddle 1999; Borgani et al. 2001; Rosati et al. 2002; Voit 2005; Vikhlinin et al. 2014; Planck Collaboration XX 2014). X-ray instruments, such as HEAO1, Einstein, ROSAT, XMM, Chandra have enabled the construction of flux-limited surveys of X-ray clusters, the luminosity and temperature of which can be measured accurately. However, conclusions obtained from the analysis of these samples of X-ray clusters have lead to somewhat contradictory results. While some early works based on distant X-ray clusters (Oukbir & Blanchard 1997) indicated a significantly lower abundance of clusters at redshift 0.3−0.5, i.e. a sign of a high-density universe (Sadat et al. 1998; Borgani et al. 1999; Viana & Liddle 1999; Reichart et al. 1999), some recent analyses tend to favour a lower density concordance cosmology (Henry 2000; Borgani et al. 2001; Vikhlinin et al. 2009b). On the other hand, Vauclair et al. (2003) showed that the abundance in all existing ROSAT cluster surveys were consistently reproduced by Einstein de Sitter models, which were normalised to the local temperature distribution function using the XMM luminosity temperature evolution of X-ray clusters (Lumb et al. 2004). This result was shown to be insensitive to the calibration of the mass-temperature relation, but relies on standard scaling relations for its evolution. Alternatively, assuming that the mass-temperature relation evolves significantly from the standard scaling law, the X-ray cluster distribution was found to agree well with the concordance cosmology with an appropriate level of evolution. More recently, the Sunyaev-Zel’dovitch (SZ) effect has been used in microwave observations to build large samples of galaxy clusters (Hasselfield et al. 2013; Reichardt et al. 2013; Planck Collaboration XXIX 2014). Constraints obtained from cosmological samples of few hundred of objects are not limited by low number statistics, but by the calibration of the scaling laws (Planck Collaboration XX 2014, hereafter PXX). Depending on the normalisation of the Y − M scaling relation, the constraints go from low matter density and low σ8 (cf. PXX) to higher values consistent with Planck CMB results (Mantz et al. 2014).
In the present paper, we address the problem of the calibration of the mass-temperature relation of X-ray clusters, using their distribution function at low redshift. We perform a Markov chain Monte-Carlo (MCMC) analysis to constrain simultaneously the X-ray cluster scaling law and the standard cosmological parameters, with the help of the Planck CMB data. This allows us to derive the mass-temperature relation of clusters in the ΛCDM model consistently with the Planck CMB data. We compare our result with the calibration derived from pure X-ray analysis, which was used as a prior in the Planck analysis of SZ counts with Planck.
Our paper is structured as follows: in Sect. 2 we discuss the mass function used in theoretical predictions of cluster abundances. In Sect. 3 we introduce the clusters sample used in our analysis, and then detail how we construct the theoretical and observed temperature function. Finally, in Sect. 4 we present the results of our MCMC analysis and associated discussion.
2. Mass function and abundances
The halo mass function, i.e. the distribution function of objects relative to their mass, is widely used for cosmological constraints. A theoretical formalism has been proposed by Press & Schechter (1974), which allows us to relate the non-linear mass function of cosmic structures to the linear amplitude of the fluctuations, usually specified by the matter power spectrum P(k). We recall the basic assumptions of the derivation of the mass function as follows:
-
i) the abundance of non-linear haloes with mass greater than some mass M is essentially related to the probability that an elementary volume of the Universe lies in a region of the linear field1 that passes the density threshold δt corresponding to the condition for non-linear collapse, i.e.
 (1)with σ2(M) the variance of
the field smoothed by the window function. Usually, this function is a top-hat window
in real space, although Gaussian windows (and more rarely others) are occasionally
used. Any object that is formed has a contrast density above some (non-linear)
threshold Δ, which is
taken as a definition for the objects counted by the mass function.
(1)with σ2(M) the variance of
the field smoothed by the window function. Usually, this function is a top-hat window
in real space, although Gaussian windows (and more rarely others) are occasionally
used. Any object that is formed has a contrast density above some (non-linear)
threshold Δ, which is
taken as a definition for the objects counted by the mass function. -
ii) the aforementioned probability can be written as
 (2)and has been assumed to be independent of
the primordial spectrum, but might depend on the Gaussian or non-Gaussian nature of
the initial fluctuations.
(2)and has been assumed to be independent of
the primordial spectrum, but might depend on the Gaussian or non-Gaussian nature of
the initial fluctuations.
This limited set of generic assumptions leads to an universal self-similar form of the mass
function, which can be then computed for arbitrary models (Blanchard et al. 1992) without requiring the systematic use of numerical
simulations. The mass function can then be derived as  (3)and is commonly expressed as (see e.g. Jenkins et al. 2001):
(3)and is commonly expressed as (see e.g. Jenkins et al. 2001): 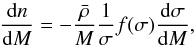 (4)where f(σ)
(=νg(ν)) is a
function that is usually fitted on numerical simulations, and
(4)where f(σ)
(=νg(ν)) is a
function that is usually fitted on numerical simulations, and
 is the mean matter density of the Universe2. When using
a top-hat filter for the smoothing of the initial fluctuations, the mass M corresponds directly to the
mass within a sphere of (comoving) radius R,
is the mean matter density of the Universe2. When using
a top-hat filter for the smoothing of the initial fluctuations, the mass M corresponds directly to the
mass within a sphere of (comoving) radius R,
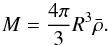 (5)The non-linear objects that the mass function
describes are those that present a (non-linear) density contrast Δ corresponding to the linear threshold
δt, i.e.
(5)The non-linear objects that the mass function
describes are those that present a (non-linear) density contrast Δ corresponding to the linear threshold
δt, i.e.
 (6)where we have
(6)where we have
 . Note that the non-linear density contrast
can also be defined relative to the critical density: Δc =
ΔΩm(z). A final simplifying assumption is
that the threshold δt and the non-linear contrast density
Δ can be deduced from a simple
spherical model.
. Note that the non-linear density contrast
can also be defined relative to the critical density: Δc =
ΔΩm(z). A final simplifying assumption is
that the threshold δt and the non-linear contrast density
Δ can be deduced from a simple
spherical model.
2.1. Reliable mass functions
Although the Press and Schechter approach was established in 1974, it is only after large N-body simulations were available that the validity of an universal self-similar mass function gained in strength (Efstathiou et al. 1988). New versions of the mass function based on extensive numerical simulations have since been developed, greatly improving the accuracy of the description of the halo mass function. Departures from universality have been claimed when the abundance is examined with an accuracy better than 20% (Warren et al. 2006; Courtin et al. 2011). We used two types of descriptions of the mass function, and in particular of the fitting function f from Eq. (4). The first variant of the function f considered is that obtained by Sheth et al. (2001, SMT hereafter), while the second is from Tinker et al. (2008). As we show in what follows, the difference between these mass functions is appreciable but not critical given the statistical uncertainties in current samples of X-ray clusters; nevertheless, the difference could be as large as the (1σ) errors in measured abundances. Furthermore, although the Tinker et al. (2008) mass function produces fewer structures than the SMT mass function, the recent and detailed investigations of Crocce et al. (2010) concludes that the SMT mass function seems to underestimate the actual abundance of cosmic structures, a claim comforted by Bhattacharya et al. (2011) even if a comprehensive comparison is delicate. A further source of uncertainty comes from the fact that current estimations of the mass function are derived from numerical simulations in which the gas physics is not included, whereas it may have an appreciable effect (see e.g. Cui et al. 2012).
We therefore compare the results derived from both the SMT and the Tinker mass functions.
Any difference that arises is thus considered an estimation of the magnitude of
systematics uncertainties that may remain because of the lack of knowledge of the
theoretical mass function. The SMT expression for the mass function, which is evaluated
for a top-hat filtering using virial quantities, is given by ![Mathematical equation: \begin{equation} \label{eq:SMT} f_{\rm ST}(\sigma) =A\sqrt{\frac{2a}{\pi}}\left[1+\left(\frac{\sigma^2}{a\delta_{\rm c}^2}\right)^p\right]\frac{\delta_{\rm c}}{\sigma}\exp\left[-\frac{a\delta_{\rm c}^2}{2\sigma^2}\right] \end{equation}](/articles/aa/full_html/2015/10/aa26793-15/aa26793-15-eq33.png) (7)where A = 0.3222, a = 0.707, p = 0.3, as determined
after fitting on N-body simulations results. The parameter
δc ≃
1.686 is the critical over-density for spherical collapse. The Tinker et al. (2008) mass function, on the other hand,
reads
(7)where A = 0.3222, a = 0.707, p = 0.3, as determined
after fitting on N-body simulations results. The parameter
δc ≃
1.686 is the critical over-density for spherical collapse. The Tinker et al. (2008) mass function, on the other hand,
reads ![Mathematical equation: \begin{equation} \label{eq:Tkmassfunction} f_{\rm T}(\sigma,z) =A\left(\left(\frac{b}{\sigma}\right)^a + 1\right) \exp\left[-\frac{c}{\sigma^2}\right] , \end{equation}](/articles/aa/full_html/2015/10/aa26793-15/aa26793-15-eq38.png) (8)where A, a, b, and c are also fitted
parameters, but are functions of the redshift and the over-density contrast
Δ (see Tinker et al. 2008, for more details).
(8)where A, a, b, and c are also fitted
parameters, but are functions of the redshift and the over-density contrast
Δ (see Tinker et al. 2008, for more details).
To illustrate the difference between the two mass functions, we calculated the haloes mass distribution functions for the best-fit cosmology as determined by Planck. Figure 1 shows the two mass functions at a local redshift of z = 0.05. In the presented cluster mass range (above 1014 M⊙), the difference between the two distributions increases with mass, reaching roughly a factor of two at a mass of ~3 × 1015 M⊙. We computed the Tinker mass function again, increasing the value of σ8 from 0.83 to 0.87. The difference between the mass functions then becomes very small, and the relative evolution behaves very similarly. This is an important point to notice, as it implies that constraints on the evolution of the clusters gas physics are almost independent of the choice of the mass function, while the uncertainty in the mass function is expected to make a noticeable difference in the estimation of the amplitude of matter fluctuations, with negligible impact on other parameters (at the level of present-day quality data).
 |
Fig. 1 Comparison of integrated mass functions computed for the Sheth et al. (2001, blue solid line) and the Tinker et al. (2008, green solid line) fitting function f(σ), in the Planck best-fit cosmology. The green dashed line corresponds to the Tinker mass function with a σ8 = 0.87 instead of the best-fit value of 0.83. All mass functions are estimated at virial mass and redshift of 0.05. |
2.2. Mass function and recent cosmological constraints
The mass function (Lilje 1992) is sensitive to the cosmological parameters, especially the matter density parameter Ωm and the present-day amplitude of the fluctuations σ8. In scenarios such as the Λ dominated cold dark matter (ΛCDM) paradigm, the matter power spectrum is well defined, and depends on a few parameters that can be constrained from the three standard cosmological data sets: the CMB, the type Ia Supernovae, and the galaxy power spectrum.
In the following, the determination of the cosmological parameters as well as the parameters describing cluster physics are performed by combining the CMB data from Planck (Planck Collaboration I 2014, more precisely, the so-called Planck+WP data combination described in the paper) and cluster abundance data. The estimations of the parameters are obtained through a MCMC analysis using the COSMOMC package (Lewis & Bridle 2002; Lewis 2013). Although we could in principle combine CMB data with other sets of data, such as the SNIa Hubble diagram or the BAO signal, this leads to essentially identical cosmological parameters; we therefore choose to keep only Planck CMB data to allow a more direct comparison with Planck clusters results. We then estimate the range of predicted abundances for models in which parameters fall within the 68% range. The results and the 68% error bars on cosmological parameters are given in the first column of Table 2.
Figure 2 shows the 1σ uncertainty region for the expected mass function determined for Δc = 500. We compared this result with the determination from (Vikhlinin et al. 2009a): their reference model is shown with the dashed line; their cosmological parameters are Ωm = 0.3, h = 0.72 and σ8 = 0.746. It is clear that the expected mass distribution function in ΛCDM with parameters and uncertainties determined from standard cosmological constraints leads to a much larger overall abundance of clusters. This is clearly related to the temperature mass relation used in (Vikhlinin et al. 2009a). We follow a different approach: we assume a standard ΛCDM model and fit the CMB data and the abundance of X-ray clusters simultaneously to infer constraints on the mass temperature relation required for consistency. This allows us to make a comparison with masses estimated by more observational approaches and examine what are the consequences for the interpretation of Planck SZ clusters counts.
 |
Fig. 2 1σ region for the Tinker mass function according to current cosmological constraints (CMB measurements; in blue). The red dashed line represents the mass function of Vikhlinin et al. (2009a) with Ωm = 0.3, h = 0.72 and σ8 = 0.746. All mass functions are computed at z = 0.05. |
3. Determination of the temperature distribution function
Existing surveys of X-ray clusters provide comprehensive sets of clusters for which the selection function is reasonably well understood. When the temperature is known for every cluster of a given survey, we can estimate the temperature distribution function at the typical redshift of the survey. The match between the mass function and temperature distribution function provide self-consistent information about clusters for ΛCDM models.
3.1. A new complete sample of low-redshift clusters
We built a new sample of X-ray selected clusters, with a strategy that is essentially the same as in Blanchard et al. (2000), who published the first temperature distribution function based on a sample selected from ROSAT fluxes. Currently, many measurements of clusters fluxes are often available and of good quality, coming from different instruments and sometimes estimated in different bands. It is preferable to have samples with flux estimations that are as homogeneous as possible. However, this is a rather complicated task: for instance, the conversion between counts and flux requires a spectral model of the source. This is generally done assuming a single temperature, which may not be available at the time of the flux measurement. Furthermore, the emissivity of X-ray clusters cannot be represented by a single temperature: occasionally, the central part of clusters are complex multi-components temperature systems, such as occurs in cooling flow clusters. For this reason, the emissivity in the central region is often corrected. We built our sample from the online database BAX3 (Sadat et al. 2004), which provides published fluxes that are homogenised to the same energy band. Therefore, for our selection we used the BAX working energy band corresponding to the ROSAT [0.1–2.4] keV energy band. We removed clusters that are too close to the galactic plane by discarding objects between 20 <b< −20, where b is the latitude in the galactic coordinate system; this results in a sky coverage of 7.96 sr (~63% of the sky). We did not apply any further geometrical selection. To limit the internal evolution of the abundance of objects, we restricted the redshift range of our sample and did not include clusters with redshift above z = 0.1.
To compute the detection volume for all selected clusters, we need a sample with a well-understood selection function. In our selection criterion, we limited our sample to objects known as bona fide clusters brighter than a minimal flux, such that at least one temperature measurement has been published for every selected cluster. In practice, this sets the minimal flux to fmin = 1.8 × 10-11 erg s-1 cm-2, at which the whole selected area is complete from the various ROSAT samples. We note that BAX contains objects brighter than this flux, which are no longer considered clusters and were removed from the final sample. With our selection criteria combined, we finally obtained a sample of 73 clusters covering a temperature range of [0.8−9] keV with a mean redshift of z ~ 0.05, making this sample the largest ever used for the determination of the local temperature distribution function (with actual temperature measurements).
X-ray temperatures (68% uncertainties), ROSAT 0.1–2.4 keV fluxes, and redshifts of the 73 X-ray clusters used in the present work.
3.2. Modelling the temperature function
An ideal situation would be to have a direct estimation of the mass function to compare with theoretical expectations, however, a direct detection of DM haloes based on their mass is not an easy task. Blind lensing surveys may allow this possibility in the future, such as with the Euclid project (Laureijs et al. 2011), but this seems out of reach with our currently available means. We are therefore restricted to cluster surveys based on techniques, such as velocity dispersion, X-ray, or SZ signal, and we then apply a relation between the observable and the mass of each cluster present in the survey. It is therefore necessary to have a good understanding of this mass-observable relation, in addition to a selection function that is well under control.
We focus on X-ray clusters and start with the assumption that clusters are self-similar
at some level, i.e. that their observable quantities (e.g. luminosity or temperature) can
be related to their mass through a simple expression, generally a power law. Hereafter, we
call these relations “scaling relations”. Kaiser
(1991) proposed that the dependence of these relations on mass and redshift can
be inferred from a simple collapse model; we refer to these as standard scaling relations.
Beyond these, it is important to take the effect of dispersion into account. In the
following, we work with the virial mass (unless specified otherwise), i.e. the mass inside
the radius that corresponds to a contrast density equal to Δv in the
standard spherical model. Hence, the virial radius is
 (9)To derive the gas temperature, provided the
gravitational collapse is the unique source of gas heating, we can assume that the average
thermal energy of a particle is related to its average kinetic energy in the gravitational
potential of the cluster (incomplete virialisation is accommodated by this assumption),
(9)To derive the gas temperature, provided the
gravitational collapse is the unique source of gas heating, we can assume that the average
thermal energy of a particle is related to its average kinetic energy in the gravitational
potential of the cluster (incomplete virialisation is accommodated by this assumption),
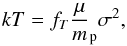 (10)with μ the average molecular
weight of the intracluster plasma, σ the (1D) velocity dispersion along the line of
sight
(10)with μ the average molecular
weight of the intracluster plasma, σ the (1D) velocity dispersion along the line of
sight  , and fT a parameter
accommodating for possible incomplete virialisation. For a single isothermal sphere, the
velocity dispersion is
, and fT a parameter
accommodating for possible incomplete virialisation. For a single isothermal sphere, the
velocity dispersion is 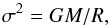 (11)allowing us to derive the (theoretical)
scaling law between temperature and mass, i.e.
(11)allowing us to derive the (theoretical)
scaling law between temperature and mass, i.e. 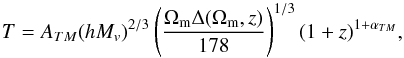 (12)with ATM the normalisation
constant, Mv the virial mass of
the cluster expressed in unit of 1015 solar mass, and Δ(Ωm,z) the
density contrast with respect to the total matter density of the Universe. The
αTM parameter is
introduced to account for a possible evolution of the scaling law with redshift; we do not
consider this additional parameter and fix αTM = 0, since our
local sample of clusters (all with redshifts lower than 0.1) is not able to constrain this
parameter.
(12)with ATM the normalisation
constant, Mv the virial mass of
the cluster expressed in unit of 1015 solar mass, and Δ(Ωm,z) the
density contrast with respect to the total matter density of the Universe. The
αTM parameter is
introduced to account for a possible evolution of the scaling law with redshift; we do not
consider this additional parameter and fix αTM = 0, since our
local sample of clusters (all with redshifts lower than 0.1) is not able to constrain this
parameter.
Some of the previous works in the literature used the L − M relation to derive cosmological constraints directly. The main advantage of this method is that the luminosity is much easier to obtain than temperature. As a consequence larger samples of clusters can be used with this kind of approach. However, the luminosity is proportional to the square of the gas density, which is concentrated in the core of the cluster and therefore less likely to follow a scaling relation with the total mass. Additionally, the L − T relation is known not to follow a standard scaling law, which is generally attributed to the sensitivity of the gas distribution to non-gravitational gas physics. If the L − T relation is not standard then it also implies that luminosity does not follow a standard scaling with mass.
For a given T −
M scaling relation assumed with no dispersion, the
number of objects that are hotter than a temperature threshold is equivalent to the number
of objects that are heavier than a corresponding mass threshold. The theoretical
temperature function can be written as  (13)where M(T) is
given by the scaling relation (12). The
last equation allows us to compute the integrated temperature function from the mass
function, i.e. the numerical density of clusters that are hotter than a given temperature.
(13)where M(T) is
given by the scaling relation (12). The
last equation allows us to compute the integrated temperature function from the mass
function, i.e. the numerical density of clusters that are hotter than a given temperature.
We have to take the effect of the dispersion in the T − M
scaling relation into account. In the absence of any dispersion, the Eq. (13) can be rewritten as follows:  (14)where θ(x) is
the Heaviside function. In practice, the threshold should be replaced by a smooth function
raising from zero to one. Assuming a log-normal dispersion in temperature with a variance
(14)where θ(x) is
the Heaviside function. In practice, the threshold should be replaced by a smooth function
raising from zero to one. Assuming a log-normal dispersion in temperature with a variance
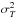 , the observed temperature distribution
function can be rewritten as
, the observed temperature distribution
function can be rewritten as  (15)For a power-law distribution n( >T) =
KT−
α(α> 0), the dispersion
causes an increase of the observed number of
clusters
(15)For a power-law distribution n( >T) =
KT−
α(α> 0), the dispersion
causes an increase of the observed number of
clusters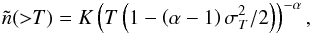 (16)i.e. the effect of dispersion is totally
absorbed by a shift in the value of the normalisation of the mass temperature relation
(16)i.e. the effect of dispersion is totally
absorbed by a shift in the value of the normalisation of the mass temperature relation
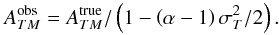 (17)The effective value of α in the range
3−10 keV is of the order of
3 (cf. Fig. 3), so that a 20% dispersion leads to a
measured value of ATM 4% higher than
the “true” underlying value of ATM. Numerical
simulations are indicative of a dispersion of this order. However, as the dispersion is
not directly accessible with observations, we do not attempt to correct the inferred value
of ATM in the following.
The value we derive is therefore be effective, and possibly biased by dispersion.
(17)The effective value of α in the range
3−10 keV is of the order of
3 (cf. Fig. 3), so that a 20% dispersion leads to a
measured value of ATM 4% higher than
the “true” underlying value of ATM. Numerical
simulations are indicative of a dispersion of this order. However, as the dispersion is
not directly accessible with observations, we do not attempt to correct the inferred value
of ATM in the following.
The value we derive is therefore be effective, and possibly biased by dispersion.
 |
Fig. 3 Observed temperature function of local clusters (red dots), with error bars defined as the sum of the inverse-square detection volumes of the clusters. The best-fit theoretical models are also shown, in the case of the mass function of SMT (blue dashed curve), and the mass function of Tinker et al. (2008), with and without a fixed index βTM (defined in Eq. (28)) for the M − T scaling law (solid green and dot-dashed purple curves, respectively). |
3.3. The observed temperature function
The value of ATM is a quantity providing a first constraint on clusters gas physics. It can be obtained by comparing an observed temperature distribution function with the expectation from some fiducial model. In this section, we describe how we estimate this temperature distribution function from existing samples of X-ray clusters as well as the uncertainty in these estimations.
The number of clusters N inside a luminosity range [L,L + ΔL]
is the realisation of a stochastic Poisson process with a mean value Φ(L)V(L)Δ(L),
with V(L) being the volume of detection
for an object with luminosity L and Φ(L) is the luminosity distribution function. For a
selection function specified by a flux dependent area A(fx,z),
the search (comoving) volume corresponding to a cluster of luminosity L can be written as
 (18)where
(18)where  is the comoving volume element per unit
area on the sky. By definition, N/V(L) is then an
unbiased estimation of Φ(L)ΔL and the integrated
luminosity function can be written
is the comoving volume element per unit
area on the sky. By definition, N/V(L) is then an
unbiased estimation of Φ(L)ΔL and the integrated
luminosity function can be written (19)where the sum is performed over all clusters
in the sample satisfying the criteria. In our case, we are interested in the temperature
distribution function. We can therefore define in a similar fashion a volume search for an
object with temperature T, i.e.
(19)where the sum is performed over all clusters
in the sample satisfying the criteria. In our case, we are interested in the temperature
distribution function. We can therefore define in a similar fashion a volume search for an
object with temperature T, i.e.
 (20)The temperature function is given by the
following unbiased estimator:
(20)The temperature function is given by the
following unbiased estimator: 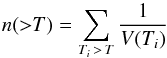 (21)However, in practice the selection function
A(kT,z) is not known. Attempts to
estimate the volume search V(kT) from the
temperature-luminosity relation (and from the search volumes V(L))
suffer from a systematic uncertainty due to the fact that the properties of the
luminosity-temperature relation is not perfectly known.
(21)However, in practice the selection function
A(kT,z) is not known. Attempts to
estimate the volume search V(kT) from the
temperature-luminosity relation (and from the search volumes V(L))
suffer from a systematic uncertainty due to the fact that the properties of the
luminosity-temperature relation is not perfectly known.
For a given flux limit, the maximum redshift of detection zmax of a
cluster can be determined from its actual flux. To accomplish this, the flux is first
converted into a rest-frame luminosity in the same band of observation, [0.1–2.4] keV in
the present case. The maximum redshift of detection is therefore the redshift at which the
flux of the cluster reaches the flux threshold. Note that this requires us to evaluate the
rest-frame luminosity in the band corresponding to the observation. In practice, we use a
Raymond-Smith code for this. The flux is then  (22)with Lx the luminosity in the
appropriate rest-frame band, i.e. [0.1(1 +
z),2.4(1
+ z)] keV, and dL(z)
the cosmological luminosity distance at a redshift z.
(22)with Lx the luminosity in the
appropriate rest-frame band, i.e. [0.1(1 +
z),2.4(1
+ z)] keV, and dL(z)
the cosmological luminosity distance at a redshift z.
Figure 3 shows the observed temperature function for local clusters, defined as those with a redshift below 0.1.
4. Parameters determination
4.1. The likelihood analysis
The use of the cluster population properties to constrain cosmological parameters has been widely used in the past. One fundamental limitation of this approach is that it usually relies on the knowledge of the scaling relations, including their calibration. For instance, the local abundance of clusters is a sensitive probe of the amplitude of matter fluctuations σ8. However, it is well known that the amplitude of σ8 is degenerated with the normalisation constant ATM (Blanchard & Douspis 2005). In the present work we follow a different strategy: we perform a self-consistent analysis to constrain both the cosmological parameters of the ΛCDM model and the parameters of the mass-temperature scaling law of X-ray clusters simultaneously.
To explore the full parameter space and to remove any degeneracy, we need to combine several relevant data sets. In this analysis, we adopted the standard ΛCDM cosmology as our reference and performed a MCMC analysis using the COSMOMC package (Lewis & Bridle 2002; Lewis 2013). We combined the constraining power of the CMB data from Planck (Planck Collaboration I 2014) as well as our measured temperature function through the use of a separate COSMOMC module of our design.
In practice, we do not use the measured temperature function as it is, i.e. as defined in
Eqs. (13) to (15) and shown as red points in Fig. 3. Instead, we binned the temperature range covered by
our sample of clusters, and define a binned version of the temperature function defined as
 (23)for a given temperature interval
[T1,T2].
This is equivalent to computing the sum of the inverse volumes of all the clusters
detected in a given [T1,T2]
temperature interval
(23)for a given temperature interval
[T1,T2].
This is equivalent to computing the sum of the inverse volumes of all the clusters
detected in a given [T1,T2]
temperature interval  (24)We used ten distinct temperature bins for the
likelihood analysis, defined such that each bin contains approximatively the same amount
of clusters from the sample.
(24)We used ten distinct temperature bins for the
likelihood analysis, defined such that each bin contains approximatively the same amount
of clusters from the sample.
 |
Fig. 4 Normalised histogram of the values of the temperature function (blue curve), in one of our ten temperature bins, as derived from our bootstrap process (see text for details). The histogram is very well fitted by a Weibull distribution (red curve). |
Statistical analysis of our MCMC runs.
In our analysis, we need to estimate the likelihood of any given set of cosmological parameters given the measured temperature function. The details of this likelihood is hard to determine analytically. To circumvent this problem, we perform a bootstrap analysis on our sample of 73 selected clusters, i.e.
-
we build a “new” sample by drawing randomly
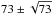 clusters from our original sample;
clusters from our original sample;
-
we recompute the binned temperature function, keeping the same T bins; and
-
we repeat the procedure a large number of times.
Therefore, for each temperature bin we can compute a histogram of all the values of the
temperature function coming from the bootstrap process (cf. Fig. 4). The mean value is obviously the measured density of clusters from
the original sample in the considered temperature bin. We find that for all bins, the
distribution of the values are very well fitted by a Weibull distribution, defined as
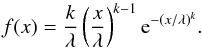 (25)The fitting is illustrated in Fig. 4 for one of our temperature bins. The mean value of
random variables following this distribution is related to the shape parameter
k and the
scale parameter λ by: ⟨
x ⟩ = λ Γ(1 + 1
/k) where Γ is the Gamma function.
(25)The fitting is illustrated in Fig. 4 for one of our temperature bins. The mean value of
random variables following this distribution is related to the shape parameter
k and the
scale parameter λ by: ⟨
x ⟩ = λ Γ(1 + 1
/k) where Γ is the Gamma function.
In this study, we assume that the shape k of this distribution (obtained by bootstrapping)
is a good approximation to the shape of the likelihood function corresponding to the real,
underlying temperature function. Therefore, if a given cosmological model predicts a value
of 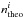 for the temperature function in a given
temperature bin i, then we define the likelihood of this model given
the measured value
for the temperature function in a given
temperature bin i, then we define the likelihood of this model given
the measured value 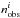 as
as 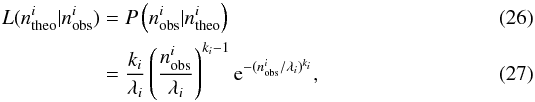 where ki was determined through
the bootstrap process and
where ki was determined through
the bootstrap process and  . Finally, the total likelihood for all
temperature bins can simply be written as the product of the individual likelihoods for
each bin.
. Finally, the total likelihood for all
temperature bins can simply be written as the product of the individual likelihoods for
each bin.
4.2. First results
When used alone, galaxy clusters cannot provide strong constraints on the cosmological parameters because of the degeneracy between Ωm, σ8, and the calibration of the mass temperature calibration ATM. Our approach allows us to infer these parameters in a self-consistent way in a given cosmological paradigm (the flat ΛCDM model in our case).
To do this, we combine the data from cosmological probes (Planck CMB data) and our estimation of the local temperature function of X-ray clusters, using the COSMOMC package. We performed our MCMC analysis in the following five different cases:
-
with the constraints from CMB data only (thus the masstemperature calibration is not evaluated);
-
with both CMB and clusters constraints, using the SMT mass function, which uses the virial mass of clusters;
-
with both CMB and clusters constraints, using the Tinker et al. (2008) mass function, which uses the virial masses when defining clusters;
-
with both CMB and clusters constraints, using the Tinker et al. (2008) mass function, which uses the critical M500 masses, and is our fiducial case; and, finally,
-
the same as above, with an additional degree of freedom, leaving the index of the M − T scaling law as a free parameter, i.e. Eq. (12) becomes
 (28)with βTM as a free
parameter.
(28)with βTM as a free
parameter.
We chose to use both the SMT and Tinker mass function to quantify the difference in the resulting estimated parameters. Indeed, as mentioned earlier (and shown in Fig. 1), for the same cosmological model the Tinker function predicts fewer objects than SMT’s, which have an effect on the best-fit parameters found by the MCMC analysis.
Figures A.1 and A.2 presents a summary of our MCMC analysis in the form of 1D likelihoods and 2D likelihood contours between the cosmological parameters Ωm and σ8, the calibration parameter ATM, and the scaling index βTM. The best-fit values and 68% confidence intervals of these parameters are summarised in Table 2 for all five scenarios. As we can see, for all of the cases cosmological parameters are nearly identical since their strongest constraints come from the standard CMB data (and not from the cluster abundance). The limits on the values of ATM reflect the uncertainty in the mass function. Its derived value when using either the SMT or the Tinker (Mvir version) mass function lies within the 1σ interval of the other one, with the SMT function producing a lower value of ATM. This was expected from the differences in the behaviour of the two mass functions. We note that adding an additional degree of freedom with the scaling index βTM does not degrade the constraints of ATM (1.5× larger 68% interval) too much, while it simultaneously constrains βTM fairly well. Our approach is therefore capable of determining with a relatively good accuracy the two main parameters of the M − T scaling law.
The comparison of the best-fit theoretical temperature functions with the data (shown in Fig. 3) shows a good agreement at all temperatures, although there seems to be some deficit in the observed abundance of clusters (around 2 keV). The SMT temperature function appears to be a better fit to the data, both at the lowest and highest temperature. However, one has to remember that the fit is performed on the binned observed temperature function: in practice for our ten temperature bins, the Δχ2 between the SMT and Tinker functions is only ~0.14 (in favour of SMT).
4.3. Implication for the Planck SZ clusters results
In the present section, we now check for consistency between our local sample of X-ray clusters (selected in flux and temperature) and the cluster sample detected through their SZ effect in the Planck CMB data (PXX).
The abundance of clusters as a function of redshift is a well-known probe and source of constraints for cosmological models. Although apparently inconsistent results have been obtained from the analyses of (small) X-ray samples (Vauclair et al. 2003; Vikhlinin et al. 2009b), the use of clusters detected thanks to their SZ signal was anticipated to be an efficient and reliable method (Barbosa et al. 1996). The reasons are twofold: first, the SZ signal does not decline as rapidly with redshift as the X-ray flux, and, second, it is more directly sensitive to the total mass of the clusters, whereas the X-ray flux is biased towards central regions (da Silva et al. 2004).
The Planck collaboration (PXX) has produced a cosmological SZ cluster sample selected on a signal-to-noise ratio basis, in the redshift range z ∈ [0, 1]. For their cosmological analysis, they build a scaling relation between the SZ flux Y and the mass M from X-ray observations and simulations. The slope of the scaling relation was obtained from the comparison, for a subsample of 71 clusters, of the SZ flux with the estimation of the mass derived from the hydrostatic equilibrium obtained from XMM-Newton observations (Planck Collaboration 2013; Planck Collaboration XXIX 2014). The normalisation of the Y − M relation was calibrated using simulations (PXX). The uncertainty in the determination of this normalisation led to the introduction of a mass bias factor (1 − b) in order to parametrise the scaling such that Y ∝ A [(1 − b)M] β. The mean value as determined by the aforementioned simulations gives a mass bias of (1 − b) = 0.8 with an assumed constant probability in the range [0.7−1]. The cosmological parameters, then derived from the Planck SZ clusters, are shown to be in tension with the CMB-only best-fit cosmology and depends highly on the assumption made on the mass bias. To recover the CMB parameters, it was shown by the Planck collaboration (PXX, and again recently in Planck Collaboration XXIV 2015) that a value of (1 − b) ~ 0.6 is required for the mass bias, showing the degeneracy between the cosmological parameter (mainly the amplitude of fluctuations, σ8) and the normalisation (or bias) of the Y − M relation.
For each Planck cluster with redshift, Planck Collaboration XXIX (2014) also provides a SZ mass estimate calibrated on the Y − M scaling relation, and for which no bias is assumed (i.e. b = 0). In our analysis, we were able to determine the TX − M scaling relation for a Planck CMB cosmology: this allows us to compute a TX based mass for each Planck cluster with a measured X-ray temperature. We then compare these masses to the Planck estimates for a subsample corresponding to the common clusters between our reference sample of 73 clusters and the 71 used by Planck to derive the scaling relation4 (amounting for 45 clusters, shown in Fig. 6). By fitting the relation between the two set of masses (using the BCES regression technique, see Akritas & Bershady 1996), we deduce the mass bias (1 − b). In practice, we did not obtain a single value of our ATM normalisation parameter, but a likelihood function over a range of ATM values. For any value of the ATM normalisation parameter, we can derive the associated mass bias (1 − b): we can therefore translate our ATM likelihood into a (1 − b) likelihood (see Fig. 5). Figure 6 shows an example for the fitting of the relation between mass estimates, for our best-fit value of ATM = 6.29 (in our fiducial case) leading to a value of (1 − b) = 0.569. This value is in very good concordance with the value derived by (PXX) when fitting Planck CMB and the SZ cosmological sample (1 − b = 0.6), thus showing good, indirect agreement between our sample (based on X-ray measurements of local clusters) and the Planck sample (selected by their SZ signal between z ∈ [0, 1]).
 |
Fig. 5 Top panel: in blue, the 1D likelihood of the ATM parameter derived from our MCMC analysis in our fiducial case (Tinker mass function, with M500c as a definition for the clusters masses. The dashed green and dot-dashed red curves correspond to the 1D likelihood of ATM when fixing all other cosmological and nuisance parameters to the Planck CMB and the Planck SZ clusters best-fit cosmology, respectively. Bottom panel: corresponding 1D likelihoods of the mass bias (1 − b) deduced from the ATM likelihood (see text for details). |
 |
Fig. 6 For 45 clusters in common between our sample and the Planck sample (see Sect. 6 for details), the blue crosses show the mass estimates from PXX as a function of the masses we derive from their X-ray temperature and our TX − M scaling relation in our fiducial case, with ATM = 6.29 (best-fit value). The red line corresponds to the best fit from the BCES regression technique, and its slope gives us the mass bias of the Planck masses (see text for the detail). |
5. Conclusion
The abundance of clusters found in Planck through their SZ signal has been identified as being somewhat surprisingly low. One possible origin of this “tension”, identified in the original dedicated Planck paper, is the calibration of the mass SZ signal used in the analysis (no tension subsists if the calibration is left free). Indeed, cluster masses were estimated from the use of the hydrostatic equation based on X-ray observations, the so-called hydrostatic masses. The accuracy of these estimates have been the subject of debate in the past for several reasons:
-
(i)
Hydrostatic solutions may allow for a wide range of masses for a given set of observations and their uncertainties (Balland & Blanchard 1997). Differences in X-ray instrument calibration and analysis pipelines might lead to additionnal uncertainties (Schellenberger et al. 2015).
-
(ii)
Gas in clusters might not be in hydrostatic equilibrium due for instance to residual turbulent motions of the gas (Bryan & Norman 1998; Nagai et al. 2007; Piffaretti & Valdarnini 2008; Meneghetti et al. 2010).
-
(iii)
The solution to the overcooling problem (Blanchard et al. 1992) most likely needs feedback physics, which are still very uncertain and translate into unknown uncertainties in mass estimations derived from X-ray data.
More recently, comparisons made to masses obtained from lensing confirmed that hydrostatic masses seem to yield underestimated values, but no real convergence on lensing masses has been achieved (see Applegate et al. 2014 versus Hoekstra et al. 2015 and Umetsu et al. 2015). Yet, the use of a larger sample of clusters detected by Planck (Planck Collaboration XXIV 2015) leads to essentially the same tension. The subject of masses, dispersion, and biases in cluster masses estimation is currently an actively discussed subject (Rozo et al. 2014; Sereno & Ettori 2015).
In this paper, we have explored the constraints that can be set on clusters masses in ΛCDM cosmology matching the Planck CMB data. Our approach was to use the local temperature distribution function of X-ray clusters, and to constrain the mass calibration of scaling laws by requiring that inferred theoretical abundance of local clusters are consistent with observations. This approach is essentially independent of that followed in Planck clusters analyses, and therefore offers an interesting cross-check. Our approach allows us to determine the calibration of the mass-temperature relation and its uncertainty, in ΛCDM cosmology, in a way that is fully consistent with CMB data. The addition of further cosmological constraints such as BAO of SNIa Hubble diagram would not significantly modify these figures, as they do not provide additional constraints on matter fluctuations. Using the Tinker et al. (2008) mass function, we derived the calibration of the mass-temperature at the virial radius as well as at the standard R500c radius. Our results are summarized in Table 2. As we tested the M − T scaling law, not only were we able to constrain its normalisation ATM but also its slope βTM, highlighting the constraining power of our approach and the consistency of the scaling law. It should be noted that during the refereeing process of the present article, the 2015 Planck CMB likelihood was publicly released. The resulting new constraints on the scaling law parameters are tighter, but only by a small margin (as illustrated in Fig. A.3), and do not change our conclusions presented here.
The main findings of our analysis is that masses of clusters are 75% higher (mass here referring to the M500c commonly used in scaling relations), translating in the so-called mass bias 1 − b = 0.569. Since this bias has been obtained from an analysis based on X-ray counts, and is thus independent of the Planck SZ counts, it is an important test of the consistency on the calibration needed in ΛCDM to fit the observed abundance of clusters. Indeed, our calibration based on the abundance of X-rays clusters is essentially consistent with that inferred from SZ counts in Planck. This leaves us with the conclusion that cluster counts need a significant revision of one the ingredients of the standard modelling of clusters in ΛCDM: the physics of clusters might be more complex than previously assumed and their mass have been systematically underestimated, or the mass function used – based only on dark matter simulations – significantly overestimates cluster abundance. A last possibility is that there is indeed a more serious problem in the cosmological model and the amplitude of the matter power spectrum σ8 is actually lower, calling for extensions of the ΛCDM model. In this respect, accurate observational calibration of the actual mass of clusters appears as an important clue for solving this issue.
Online material
Appendix A: MCMC likelihood
In this appendix, we present the results of our MCMC runs for all the scenarios considered in Sect. 4.2, through “triangle” plots showing the 1D and 2D posterior distributions for the calibration parameter ATM, scaling index βTM, the matter density Ωm, and the amplitude of the linear power spectrum σ8. Figure A.1 illustrates the differences between the various mass functions used throughout our work, while Fig. A.2 shows the impact of having the scaling index βTM as a additional free parameter. Figure A.1 presents the impact of the latest Planck 2015 data on our results obtained with the 2013 data.
 |
Fig. A.1 1D posterior distributions and 2D confidence (68% and 95%) contours for the parameters ATM, Ωm, and σ8, as derived from our MCMC analysis in three different cases: contraints from CMB+clusters using either the SMT mass function (red), the Tinker mass function with a virial mass definition (blue) or with M500 critical masses (black). The statistical analysis of the corresponding MCMC chains is given in Table 2. |
 |
Fig. A.2 1D posterior distributions and 2D confidence (68% and 95%) contours for the parameters ATM, βTM, Ωm, and σ8, as derived from our MCMC analysis in two different cases: contraints from CMB+clusters using the Tinker mass function with M500 critical masses, with a fixed scaling index βTM = 2 / 3 (red) or with βTM as a free parameter (black). The statistical analysis of the corresponding MCMC chains is given in Table 2. |
 |
Fig. A.3 1D posterior distributions and 2D confidence (68% and 95%) contours for the parameters ATM, Ωm, and σ8, as derived from our MCMC analysis using the Tinker mass function with M500 critical masses, with the Planck 2013 (black) and Planck 2015 (red) data sets. The 68% confidence limits of the scaling law calibration ATM are [6.04,6.80] when using the 2015 CMB data (to be compared to the slightly wider interval [5.97,6.93] with the 2013 data). |
Properly smoothed by a window function with a scale R, associated with the mass M enclosed by the window function.
“Base de Données Amas de Galaxies X”, http://bax.irap.omp.eu
Available at szcluster-db.ias.u-psud.fr
Acknowledgments
This work has been carried out thanks to the support of the OCEVU Labex (ANR-11-LABX-0060) and the A*MIDEX project (ANR-11-IDEX-0001-02) funded by the “Investissements d’Avenir” French government program managed by the ANR. Authors would like to thank M. Arnaud, E. Pointecouteau, and G. W. Pratt for providing tools for the BCES fit. This research has made use of the X-Rays Clusters Database (BAX), which is operated at the Institut de Recherche en Astrophysique et Planétologie (IRAP) and of the SZ-Cluster Database operated by the Integrated Data and Operation Center (IDOC) at the Institut d’Astrophysique Spatiale (IAS) under contract with CNES and CNRS.
References
- Akritas, M. G., & Bershady, M. A. 1996, ApJ, 470, 706 [NASA ADS] [CrossRef] [Google Scholar]
- Amendola, L., Appleby, S., Bacon, D., et al. 2013, Liv. Rev. Relativity, 16, 6 [NASA ADS] [CrossRef] [Google Scholar]
- Applegate, D. E., von der Linden, A., Kelly, P. L., et al. 2014, MNRAS, 439, 48 [NASA ADS] [CrossRef] [Google Scholar]
- Arnaud, M., Aghanim, N., Gastaud, R., et al. 2001, A&A, 365, L67 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Balland, C., & Blanchard, A. 1997, ApJ, 487, 33 [NASA ADS] [CrossRef] [Google Scholar]
- Barbosa, D., Bartlett, J. G., Blanchard, A., & Oukbir, J. 1996, A&A, 314, 13 [NASA ADS] [Google Scholar]
- Bhattacharya, S., Heitmann, K., White, M., et al. 2011, ApJ, 732, 122 [NASA ADS] [CrossRef] [Google Scholar]
- Blanchard, A. 2010, A&ARv, 18, 595 [NASA ADS] [CrossRef] [Google Scholar]
- Blanchard, A., & Bartlett, J. G. 1998, A&A, 332, L49 [NASA ADS] [Google Scholar]
- Blanchard, A., & Douspis, M. 2005, A&A, 436, 411 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Blanchard, A., Valls-Gabaud, D., & Mamon, G. A. 1992, A&A, 264, 365 [NASA ADS] [Google Scholar]
- Blanchard, A., Sadat, R., Bartlett, J. G., & Le Dour, M. 2000, A&A, 362, 809 [NASA ADS] [Google Scholar]
- Böhringer, H., Schuecker, P., Guzzo, L., et al. 2004, A&A, 425, 367 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Borgani, S., Rosati, P., Tozzi, P., & Norman, C. 1999, ApJ, 517, 40 [NASA ADS] [CrossRef] [Google Scholar]
- Borgani, S., Rosati, P., Tozzi, P., et al. 2001, ApJ, 561, 13 [NASA ADS] [CrossRef] [Google Scholar]
- Bryan, G. L., & Norman, M. L. 1998, ApJ, 495, 80 [NASA ADS] [CrossRef] [Google Scholar]
- Cavagnolo, K. W., Donahue, M., Voit, G. M., & Sun, M. 2008, ApJ, 682, 821 [NASA ADS] [CrossRef] [Google Scholar]
- Copeland, E. J., Sami, M., & Tsujikawa, S. 2006, Int. J. Mod. Phys. D, 15, 1753 [NASA ADS] [CrossRef] [MathSciNet] [Google Scholar]
- Courtin, J., Rasera, Y., Alimi, J.-M., et al. 2011, MNRAS, 410, 1911 [NASA ADS] [Google Scholar]
- Crocce, M., Fosalba, P., Castander, F. J., & Gaztañaga, E. 2010, MNRAS, 403, 1353 [Google Scholar]
- Cui, W., Borgani, S., Dolag, K., Murante, G., & Tornatore, L. 2012, MNRAS, 423, 2279 [NASA ADS] [CrossRef] [Google Scholar]
- da Silva, A. C., Kay, S. T., Liddle, A. R., & Thomas, P. A. 2004, MNRAS, 348, 1401 [NASA ADS] [CrossRef] [Google Scholar]
- De Grandi, S., & Molendi, S. 2002, ApJ, 567, 163 [NASA ADS] [CrossRef] [Google Scholar]
- de Plaa, J., Werner, N., Bleeker, J. A. M., et al. 2007, A&A, 465, 345 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Drell, P. S., Loredo, T. J., & Wasserman, I. 2000, ApJ, 530, 593 [NASA ADS] [CrossRef] [Google Scholar]
- Efstathiou, G., Frenk, C. S., White, S. D. M., & Davis, M. 1988, MNRAS, 235, 715 [NASA ADS] [CrossRef] [Google Scholar]
- Eke, V. R., Cole, S., Frenk, C. S., & Patrick Henry, J. 1998, MNRAS, 298, 1145 [NASA ADS] [CrossRef] [Google Scholar]
- Ferramacho, L. D., Blanchard, A., & Zolnierowski, Y. 2009, A&A, 499, 21 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Fujita, Y., Sarazin, C. L., & Sivakoff, G. R. 2006, PASJ, 58, 131 [NASA ADS] [CrossRef] [Google Scholar]
- Fukazawa, Y., Makishima, K., & Ohashi, T. 2004, PASJ, 56, 965 [NASA ADS] [Google Scholar]
- Fusco-Femiano, R., Landi, R., & Orlandini, M. 2005, ApJ, 624, L69 [NASA ADS] [CrossRef] [Google Scholar]
- Hasselfield, M., Hilton, M., Marriage, T. A., et al. 2013, J. Cosmol. Astropart. Phys., 7, 8 [Google Scholar]
- Henry, J. P. 1997, ApJ, 489, L1 [NASA ADS] [CrossRef] [Google Scholar]
- Henry, J. P. 2000, ApJ, 534, 565 [Google Scholar]
- Hoekstra, H., Herbonnet, R., Muzzin, A., et al. 2015, MNRAS, 449, 685 [NASA ADS] [CrossRef] [Google Scholar]
- Hudson, D. S., Mittal, R., Reiprich, T. H., et al. 2010, A&A, 513, A37 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ikebe, Y., Reiprich, T. H., Böhringer, H., Tanaka, Y., & Kitayama, T. 2002, A&A, 383, 773 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Jain, B., & Khoury, J. 2010, Ann. Phys., 325, 1479 [NASA ADS] [CrossRef] [Google Scholar]
- Jenkins, A., Frenk, C. S., White, S. D. M., et al. 2001, MNRAS, 321, 372 [NASA ADS] [CrossRef] [MathSciNet] [Google Scholar]
- Jones, C., & Forman, W. 1999, ApJ, 511, 65 [NASA ADS] [CrossRef] [Google Scholar]
- Kaiser, N. 1991, ApJ, 383, 104 [NASA ADS] [CrossRef] [Google Scholar]
- Kawaharada, M., Makishima, K., Takahashi, I., et al. 2003, PASJ, 55, 573 [NASA ADS] [CrossRef] [Google Scholar]
- Laureijs, R., Amiaux, J., Arduini, S., et al. 2011, ArXiv e-prints [arXiv:1110.3193] [Google Scholar]
- Lewis, A. 2013, Phys. Rev. D, 87, 103529 [NASA ADS] [CrossRef] [Google Scholar]
- Lewis, A., & Bridle, S. 2002, Phys. Rev. D, 66, 103511 [NASA ADS] [CrossRef] [Google Scholar]
- Lilje, P. B. 1992, ApJ, 386, L33 [NASA ADS] [CrossRef] [Google Scholar]
- Lumb, D. H., Bartlett, J. G., Romer, A. K., et al. 2004, A&A, 420, 853 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mantz, A. B., Allen, S. W., Morris, R. G., et al. 2014, MNRAS, 440, 2077 [NASA ADS] [CrossRef] [Google Scholar]
- Marini, F., Bardelli, S., Zucca, E., et al. 2004, MNRAS, 353, 1219 [NASA ADS] [CrossRef] [Google Scholar]
- Matsumoto, H., Tsuru, T. G., Fukazawa, Y., Hattori, M., & Davis, D. S. 2000, PASJ, 52, 153 [NASA ADS] [Google Scholar]
- Meneghetti, M., Rasia, E., Merten, J., et al. 2010, A&A, 514, A93 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Nagai, D., Kravtsov, A. V., & Vikhlinin, A. 2007, ApJ, 668, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Oukbir, J., & Blanchard, A. 1992, A&A, 262, L21 [NASA ADS] [Google Scholar]
- Oukbir, J., & Blanchard, A. 1997, A&A, 317, 1 [NASA ADS] [Google Scholar]
- Perlmutter, S., Aldering, G., Goldhaber, G., et al. 1999, ApJ, 517, 565 [NASA ADS] [CrossRef] [Google Scholar]
- Piffaretti, R., & Valdarnini, R. 2008, A&A, 491, 71 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration XI. 2011, A&A, 536, A11 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration. 2013, A&A, 550, A129 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration I. 2014, A&A, 571, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration XVI. 2014, A&A, 571, A16 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration XX. 2014, A&A, 571, A20 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration XXIX. 2014, A&A, 571, A29 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration XXIV. 2015, A&A, submitted [arXiv:1502.01597] [Google Scholar]
- Press, W. H., & Schechter, P. 1974, ApJ, 187, 425 [NASA ADS] [CrossRef] [Google Scholar]
- Rasmussen, J., & Ponman, T. J. 2007, MNRAS, 380, 1554 [NASA ADS] [CrossRef] [Google Scholar]
- Reichardt, C. L., Stalder, B., Bleem, L. E., et al. 2013, ApJ, 763, 127 [NASA ADS] [CrossRef] [Google Scholar]
- Reichart, D. E., Nichol, R. C., Castander, F. J., et al. 1999, ApJ, 518, 521 [NASA ADS] [CrossRef] [Google Scholar]
- Reiprich, T. H., & Böhringer, H. 2002, ApJ, 567, 716 [NASA ADS] [CrossRef] [Google Scholar]
- Riess, A. G., Filippenko, A. V., Challis, P., et al. 1998, AJ, 116, 1009 [NASA ADS] [CrossRef] [Google Scholar]
- Rosati, P., Borgani, S., & Norman, C. 2002, ARA&A, 40, 539 [NASA ADS] [CrossRef] [Google Scholar]
- Rozo, E., Bartlett, J. G., Evrard, A. E., & Rykoff, E. S. 2014, MNRAS, 438, 78 [NASA ADS] [CrossRef] [Google Scholar]
- Sadat, R., Blanchard, A., & Oukbir, J. 1998, A&A, 329, 21 [Google Scholar]
- Sadat, R., Blanchard, A., Kneib, J.-P., et al. 2004, A&A, 424, 1097 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schellenberger, G., Reiprich, T. H., Lovisari, L., Nevalainen, J., & David, L. 2015, A&A, 575, A30 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sereno, M., & Ettori, S. 2015, MNRAS, submitted [arXiv:1502.05413] [Google Scholar]
- Shang, C., & Scharf, C. 2009, ApJ, 690, 879 [NASA ADS] [CrossRef] [Google Scholar]
- Sheth, R. K., Mo, H. J., & Tormen, G. 2001, MNRAS, 323, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Simionescu, A., Werner, N., Böhringer, H., et al. 2009, A&A, 493, 409 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sun, M., Voit, G. M., Donahue, M., et al. 2009, ApJ, 693, 1142 [NASA ADS] [CrossRef] [Google Scholar]
- Tinker, J., Kravtsov, A. V., Klypin, A., et al. 2008, ApJ, 688, 709 [NASA ADS] [CrossRef] [Google Scholar]
- Umetsu, K., Zitrin, A., Gruen, D., et al. 2015, ArXiv e-prints [arXiv:1507.04385] [Google Scholar]
- Vauclair, S. C., Blanchard, A., Sadat, R., et al. 2003, A&A, 412, L37 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Viana, P. T. P., & Liddle, A. R. 1999, MNRAS, 303, 535 [NASA ADS] [CrossRef] [Google Scholar]
- Vikhlinin, A., Kravtsov, A., Forman, W., et al. 2006, ApJ, 640, 691 [NASA ADS] [CrossRef] [Google Scholar]
- Vikhlinin, A., Burenin, R. A., Ebeling, H., et al. 2009a, ApJ, 692, 1033 [NASA ADS] [CrossRef] [Google Scholar]
- Vikhlinin, A., Kravtsov, A. V., Burenin, R. A., et al. 2009b, ApJ, 692, 1060 [NASA ADS] [CrossRef] [Google Scholar]
- Vikhlinin, A. A., Kravtsov, A. V., Markevich, M. L., Sunyaev, R. A., & Churazov, E. M. 2014, Physics Uspekhi, 57, 317 [NASA ADS] [CrossRef] [Google Scholar]
- Voit, G. M. 2005, Rev. Mod. Phys., 77, 207 [NASA ADS] [CrossRef] [Google Scholar]
- Warren, M. S., Abazajian, K., Holz, D. E., & Teodoro, L. 2006, ApJ, 646, 881 [NASA ADS] [CrossRef] [Google Scholar]
- Weinberg, D. H., Mortonson, M. J., Eisenstein, D. J., et al. 2013, Phys. Rep., 530, 87 [NASA ADS] [CrossRef] [MathSciNet] [Google Scholar]
- Wright, E. L. 2002, ArXiv e-prints [arXiv:astro-ph/0201196] [Google Scholar]
- Yoshioka, T., Furuzawa, A., Takahashi, S., et al. 2004, Adv. Space Res., 34, 2525 [NASA ADS] [CrossRef] [Google Scholar]
All Tables
X-ray temperatures (68% uncertainties), ROSAT 0.1–2.4 keV fluxes, and redshifts of the 73 X-ray clusters used in the present work.
All Figures
|
Fig. 1 Comparison of integrated mass functions computed for the Sheth et al. (2001, blue solid line) and the Tinker et al. (2008, green solid line) fitting function f(σ), in the Planck best-fit cosmology. The green dashed line corresponds to the Tinker mass function with a σ8 = 0.87 instead of the best-fit value of 0.83. All mass functions are estimated at virial mass and redshift of 0.05. |
| In the text | |
|
Fig. 2 1σ region for the Tinker mass function according to current cosmological constraints (CMB measurements; in blue). The red dashed line represents the mass function of Vikhlinin et al. (2009a) with Ωm = 0.3, h = 0.72 and σ8 = 0.746. All mass functions are computed at z = 0.05. |
| In the text | |
|
Fig. 3 Observed temperature function of local clusters (red dots), with error bars defined as the sum of the inverse-square detection volumes of the clusters. The best-fit theoretical models are also shown, in the case of the mass function of SMT (blue dashed curve), and the mass function of Tinker et al. (2008), with and without a fixed index βTM (defined in Eq. (28)) for the M − T scaling law (solid green and dot-dashed purple curves, respectively). |
| In the text | |
|
Fig. 4 Normalised histogram of the values of the temperature function (blue curve), in one of our ten temperature bins, as derived from our bootstrap process (see text for details). The histogram is very well fitted by a Weibull distribution (red curve). |
| In the text | |
|
Fig. 5 Top panel: in blue, the 1D likelihood of the ATM parameter derived from our MCMC analysis in our fiducial case (Tinker mass function, with M500c as a definition for the clusters masses. The dashed green and dot-dashed red curves correspond to the 1D likelihood of ATM when fixing all other cosmological and nuisance parameters to the Planck CMB and the Planck SZ clusters best-fit cosmology, respectively. Bottom panel: corresponding 1D likelihoods of the mass bias (1 − b) deduced from the ATM likelihood (see text for details). |
| In the text | |
|
Fig. 6 For 45 clusters in common between our sample and the Planck sample (see Sect. 6 for details), the blue crosses show the mass estimates from PXX as a function of the masses we derive from their X-ray temperature and our TX − M scaling relation in our fiducial case, with ATM = 6.29 (best-fit value). The red line corresponds to the best fit from the BCES regression technique, and its slope gives us the mass bias of the Planck masses (see text for the detail). |
| In the text | |
|
Fig. A.1 1D posterior distributions and 2D confidence (68% and 95%) contours for the parameters ATM, Ωm, and σ8, as derived from our MCMC analysis in three different cases: contraints from CMB+clusters using either the SMT mass function (red), the Tinker mass function with a virial mass definition (blue) or with M500 critical masses (black). The statistical analysis of the corresponding MCMC chains is given in Table 2. |
| In the text | |
|
Fig. A.2 1D posterior distributions and 2D confidence (68% and 95%) contours for the parameters ATM, βTM, Ωm, and σ8, as derived from our MCMC analysis in two different cases: contraints from CMB+clusters using the Tinker mass function with M500 critical masses, with a fixed scaling index βTM = 2 / 3 (red) or with βTM as a free parameter (black). The statistical analysis of the corresponding MCMC chains is given in Table 2. |
| In the text | |
|
Fig. A.3 1D posterior distributions and 2D confidence (68% and 95%) contours for the parameters ATM, Ωm, and σ8, as derived from our MCMC analysis using the Tinker mass function with M500 critical masses, with the Planck 2013 (black) and Planck 2015 (red) data sets. The 68% confidence limits of the scaling law calibration ATM are [6.04,6.80] when using the 2015 CMB data (to be compared to the slightly wider interval [5.97,6.93] with the 2013 data). |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.