| Issue |
A&A
Volume 577, May 2015
|
|
|---|---|---|
| Article Number | A47 | |
| Number of page(s) | 15 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/201425232 | |
| Published online | 29 April 2015 | |
Testing the chemical tagging technique with open clusters ⋆
1 CNRS/Univ. Bordeaux, LAB, UMR 5804, 33270 Floirac, France
2 Observatoire de Genève, Université de Genève, 1290 Versoix, Switzerland
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
3 Department of Physics and Astronomy, Uppsala University, Box 516, 75120 Uppsala, Sweden
4 Research School of Astronomy and Astrophysics, Australian National University, ACT 2601, Australia
5 ESO, Alonso de Cordova 3107, Casilla 19001, Santiago de Chile, Chile
6 Instituto de Astrofísica de Andalucía-CSIC, Apdo. 3004, 18080 Granada, Spain
7 Lund Observatory, Department of Astronomy and Theoretical Physics, Box 43, 221 00 Lund, Sweden
8 Dpto. Astrofísica, Facultad de CC. Físicas, Universidad Complutense de Madrid, 28040 Madrid, Spain
9 Instituto de Astrofísica de Canarias, 38205 La Laguna, Tenerife, Spain
10 Universidad de La Laguna, Dept. Astrofísica, 38206 La Laguna, Tenerife, Spain
11 Centro de Astrobiología (INTA-CSIC), Dpto. de Astrofísica, PO Box 78, 28691 Villanueva de la Cañada, Madrid, Spain
12 Suffolk University, Madrid Campus, C/ Valle de la Viña 3, 28003 Madrid, Spain
13 Centro de Estudios de Física del Cosmos de Aragon, Plaza San Juan 1, Planta-2, 44001 Teruel, Spain
14 Institute of Theoretical Physics and Astronomy, Vilnius University, Gostauto 12, 01108 Vilnius, Lithuania
Received: 28 October 2014
Accepted: 20 February 2015
Abstract
Context. Stars are born together from giant molecular clouds and, if we assume that the priors were chemically homogeneous and well-mixed, we expect them to share the same chemical composition. Most of the stellar aggregates are disrupted while orbiting the Galaxy and most of the dynamic information is lost, thus the only possibility of reconstructing the stellar formation history is to analyze the chemical abundances that we observe today.
Aims. The chemical tagging technique aims to recover disrupted stellar clusters based merely on their chemical composition. We evaluate the viability of this technique to recover co-natal stars that are no longer gravitationally bound.
Methods. Open clusters are co-natal aggregates that have managed to survive together. We compiled stellar spectra from 31 old and intermediate-age open clusters, homogeneously derived atmospheric parameters, and 17 abundance species, and applied machine learning algorithms to group the stars based on their chemical composition. This approach allows us to evaluate the viability and efficiency of the chemical tagging technique.
Results. We found that stars at different evolutionary stages have distinct chemical patterns that may be due to NLTE effects, atomic diffusion, mixing, and biases. When separating stars into dwarfs and giants, we observed that a few open clusters show distinct chemical signatures while the majority show a high degree of overlap. This limits the recovery of co-natal aggregates by applying the chemical tagging technique. Nevertheless, there is room for improvement if more elements are included and models are improved.
Key words: stars: abundances / techniques: spectroscopic / Galaxy: abundances
Based on observations obtained at the Telescope Bernard Lyot (USR5026) operated by the Observatoire Midi-Pyrénées, Université de Toulouse (Paul Sabatier), Centre National de la Recherche Scientifique of France, and on public data obtained from the ESO Science Archive Facility under requests number 81252 and 81618.
© ESO, 2015
1. Introduction
Understanding the formation and evolution of galaxies and their structure (e.g., disks) is an open issue in near-field cosmology. One approach to tackle this problem is to study our own Galaxy by unravelling the sequence of events that took place in the formation of the Galactic disk (where most star formation occurs). Unfortunately, most of the dynamical information is lost since the disk was formed in a dissipative process and it evolved dynamically. Nevertheless, the chemical composition of the stars can potentially help us to recover the history of our Galaxy (Freeman & Bland-Hawthorn 2002).
Stars are born in aggregates from molecular clouds (Shu et al. 1987; Meyer et al. 2000; Lada & Lada 2003). Hydrody namical simulations indicate that the progenitor cloud undergoes fragmentation preventing contraction onto a single star (Jappsen et al. 2005; Tilley & Pudritz 2004; Larson 1995). Hundreds to thousands of stars can be formed from one single cloud. If we assume that the progenitor cloud was chemically well-mixed (Feng & Krumholz 2014), then we expect to observe homogeneous chemical composition in the stars formed from this cloud (Bland-Hawthorn et al. 2010). With this information, we could use the method of chemical tagging to track individual stars back to their common formation sites as proposed by Freeman & Bland-Hawthorn (2002).
The viability of this approach depends on two critical issues: do stars born together have the same chemical signature? And, are the chemical signatures different enough to distinguish stars formed from different molecular clouds?
In this context, open clusters are a fantastic laboratory to investigate their homogeneity and validate that their progenitor clouds were uniformly mixed. Most of the stars formed in clusters in our Galaxy have already been dispersed into the field, but a few of them managed to stay gravitationally bound, probably, thanks to a higher formation rate and/or galactic orbits that avoided high-density regions and giant molecular clouds (Friel 1995; Finlay et al. 1995; van den Bergh & McClure 1980). Thus, old and intermediate-age clusters (age >~100 Myr) are the leftovers of star forming aggregates in the Galactic disk that have managed to survive until the present day. We can be certain that their stars were born from the same molecular cloud at roughly the same period.
Additionally, since each molecular cloud has its own history of pollution by ejecta from core-collapse supernovae (i.e., Type II, Ib, and Ic Supernovae where most of the α-elements are produced), Type Ia supernovae (SNe Ia where most iron peak elements are created), and asymptotic giant branch stars (AGB where a s-process takes place), we expect different open clusters to have different chemical patterns.
There is some observational evidence for chemical homogeneity in open clusters. For instance, De Silva et al. (2006) present an abundance analysis of the heavy elements Zr, Ba, La, Ce, and Nd (their abundances are not thought to be modified during normal stellar evolution) for F-K dwarfs in the Hyades open cluster. They claimed that the abundances of member stars are highly uniform and they showed a scatter on the order of 0.06 dex for Zr; 0.05 dex for Ba; 0.03 dex for Ce, La, and Nd.
In a subsequent study, De Silva et al. (2007) measured the lighter elements Na, Mg, Si, Ca, Mn, Fe, and Ni (but not for Zr and Ba) for 12 red giants of the old open cluster Collinder 261. They demonstrated again a high chemical homogeneity for this cluster finding a dispersion of 0.07 dex for Na, 0.05 dex for Mg and Ca, 0.06 dex for Si, 0.03 dex for Mn, 0.02 dex for Fe, and 0.04 dex for Ni. Additionally, they compared Collinder 261, the Hyades, and the HR 1614 moving group and were able to show that the three have unique chemical signatures.
This last study was extended in De Silva et al. (2009), where the authors compiled abundances of 24 open clusters from the literature and showed that different clusters seem to have different chemical patterns (from the average values). They observe significant dispersion for some elements; however, one possible reason is systematic uncertainties among the different studies (e.g., use of different methods, atomic data, model atmospheres).
Mitschang et al. (2013) quantified the level to which chemical tagging can distinguish between co-natal stars (stars born at the same period and formation site) by developing a metric and deriving an empirical probability function based on chemical abundances for 35 clusters collected from the literature. The authors showed that achieving a high clustering detection efficiency is difficult and that depends on the level of uniqueness of the co-natal stars’ chemical signatures.
Although abundances are now available in the literature for many stars in open clusters, it is not appropiate to mix them into a single dataset to study the chemical patterns in the open cluster population (as it was done in most of the previous studies). The abundances have been obtained by diverse observers using different instruments and methods, resulting in possible systematic differences. The use of different methods (e.g., equivalent width or synthetic spectral fitting), atomic data, model atmospheres, and continuum normalization processes can lead to systematic errors. Other studies derive very accurate chemical abundances but in a non-automatic way (e.g., manual continuum and/or line fitting). Manual analysis is affected by subjective criteria that can vary with time and is not easily used when a huge quantity of spectra must be analyzed. For instance, the on-going Gaia-ESO Public Spectroscopic Survey (GES; Gilmore et al. 2012) will target approximately 100 000 field and open cluster stars in the Galaxy, and the GALactic Archaeology (GALAH; De Silva et al. 2015) with HERMES (Barden et al. 2010) survey will target a million disk stars at high resolution in a relatively short time-span.
It is worth noting that we do not intend to build an exhaustive compilation of past and on-going studies in this introduction. We note, however, some other examples of significant contributions to the determination of chemical abundances for large samples of open clusters: the Bologna Open Clusters Chemical Evolution project (BOCCE, Bragaglia & Tosi 2006); the WIYN Open Cluster Study (Mathieu 2000; Jacobson et al. 2011); and recent papers from GES such as Magrini et al. (2014), where the chemical homogeneity of the inner-disk open clusters Trumpler 20, NGC 4815, and NGC 6705 from the first GES data was shown.
To evaluate the potential of chemical tagging when using our own homogeneous and automatic analysis, we have
-
1.
collected high-resolution spectra of open clusters’ starsobserved by different instruments and homogenized them;
-
2.
implemented a completely automatic process to derive atmospheric parameters and chemical abundances;
-
3.
applied machine learning algorithms to try to recover the original clusters from the homogeneously derived chemical abundances.
We describe the collected data in Sect. 2. The spectral analysis developed to derive the atmospheric parameters and chemical abundances is presented in Sect. 3. In Sect. 4 we explore the results of our analysis to validate the viability of the chemical tagging technique and, finally, the conclusions can be found in Sect. 5.
2. Sample selection and observations
We compiled 2133 high-resolution spectra of which 146 come from the NARVAL instrument, 1630 from HARPS, and 357 from UVES. The initial selection criteria were that the spectral resolution had to be at least 47 000 (to match the setup of the GES) and the star had to be located in the field of view of a cluster (i.e., inside a given radius around the cluster center). We mainly looked for clusters discussed in Paunzen et al. (2010) and Heiter et al. (2014), although we did not strictly limit the selection to these. Based on this dataset, a further selection process was performed according to cluster membership and spectrum quality as described in Sect. 2.4.
2.1. NARVAL spectra
The NARVAL spectropolarimeter is mounted on the 2 m Telescope Bernard Lyot (Aurière 2003) located at Pic du Midi (France). The data from NARVAL were reduced with the Libre-ESpRIT pipeline (Donati et al. 1997). These spectra were taken within a large program proposed as part of the “Ground-based observations for Gaia” (P.I.: C. Soubiran).
NARVAL spectra cover a large wavelength range (~300−1100 nm), with a resolution1 that varies for different observation dates and along the wavelength range, typically from 75 000 around 400 nm to 85 000 around 800 nm. However, it is acceptable to initially assume a constant resolution of R ≃ 81 000 as we showed in Blanco-Cuaresma et al. (2014b).
2.2. HARPS spectra
HARPS is the ESO facility for the measurement of radial velocities with very high accuracy. It is fiber-fed from the Cassegrain focus of the 3.6 m telescope in La Silla (Mayor et al. 2003). The spectra were originally reduced by the HARPS Data Reduction Software (version 3.1). The data used in this work were taken from the public HARPS archive by selecting observed stars in the clusters’ field of view.
The spectral range covered is 378–691 nm, but as the detector consists of a mosaic of two CCDs, one spectral order (from 530 nm to 533 nm) is lost in the gap between the two chips.
2.3. UVES spectra
The UVES spectrograph is hosted by unit telescope 2 of ESO’s VLT (Dekker et al. 2000). We took the spectra available from the Advanced Data Products collection of the ESO Science Archive Facility2 (made available in October 2013) by selecting observed stars in clusters’ field of view.
The setup used for each observation (CD#3, centered around 580 nm) provides a spectrum with two different parts which approximately cover the ranges from 476 to 580 nm (lower part) and from 582 to 683 nm (upper part).
Analyzed clusters with the number of co-added spectra per instrument and other known cluster properties from the literature.
2.4. Data homogenization
The wavelength range varies from one set of observations to another. We chose to limit the spectral analysis to the range between 480 and 680 nm, where all the spectra provide their best signal-to-noise ratio (S/N).
To increase the overall S/N, we co-added spectra corresponding to the same star when they were observed by the same instrument and with the same setup (i.e., same resolution). After co-addition, we discarded spectra with S/N lower than 40, which is an optimal level for determining atmospheric parameters with iSpec (Blanco-Cuaresma et al. 2014a).
All the spectra were convolved to 47 000, which is the minimum resolution from our initial selection of spectra.
Observations were cross-correlated with a zero point template corresponding to a solar spectrum observed by NARVAL (Blanco-Cuaresma et al. 2014b). The derived radial velocities were used to shift and align all the spectra.
We assume that cluster members share the same velocity vector with a small random dispersion, thus we discarded stars with a radial velocity higher or lower than the cluster’s reference velocity ±2 km s-1 (see Table 1), which is a reasonable limit considering the observed dispersion by previous studies such as Mermilliod et al. (2009). We did not detect any double lined spectroscopic binary stars in our dataset.
After co-addition and the second selection criteria (i.e., S/N higher than 40 and membership validation by radial velocity), the dataset is reduced to 447 spectra that correspond to 392 different stars.
3. Spectral analysis
An automatic computational process was developed to derive atmospheric parameters and chemical abundances. The process is based on the integrated spectroscopic framework named iSpec (Blanco-Cuaresma et al. 2014a).
For the atmospheric parameters derivation we used the atomic data kindly provided by the GES line-list sub-working group prior to publication (Heiter et al., in prep.). The line-list covers our wavelength range of interest and it also provides a selection of middle-3 and high-quality lines (based on the reliability of the oscillator strength and the blend level) for iron and other elements (e.g., Na, Mg, Al, Si, Ca, Sc, Ti, V, Cr, Mn, Co, Ni, Cu, Zn, Sr, Y, Zr, Ba, Nd, and Sm).
We adopted the MARCS4 model atmosphere (Gustafsson et al. 2008) with the solar abundances from Grevesse et al. (2007). It is worth noting that the model atmosphere grid is formed of a combination of plane-parallel and spherical models. The first is reasonable for modeling the atmosphere of dwarf stars (where the extent of the atmosphere is smaller than the stellar radius), while the second is more appropriate for giant stars. However, the synthesizer used by iSpec (SPECTRUM; Gray & Corbally 1994) will interpret the spherical models as plane-parallel. The differences that may be introduced for F, G, and K giants are below 0.03 dex in terms of iron abundances as shown by Heiter & Eriksson (2006).
3.1. Atmospheric parameters
The determination of atmospheric parameters forms part of an iterative process, based on iSpec, where the continuum normalization also takes place. It consists of the following steps.
-
1.
Blind normalization. At this stage we do not know the kind ofstar we are analyzing, thus we fit the continuum by using thedefault iSpec algorithm where the following generalsubprocesses are executed:
-
(a)
reduction of the noise effects by applying a median filter with awindow of 0.10 nm;
-
(b)
application of a maximum filter with a window of 1.0 nm to select those fluxes that have a larger probability to belong to the continuum;
-
(c)
fitting of second degree splines every 1.0 nm to the filtered points and dividing the original observed spectrum by the fitted model.
-
(a)
-
2.
Line fitting. For each spectrum, we fit the selected absorptionlines with Gaussian profiles and we automatically discard linesthat fall into one of these cases:
-
(a)
fitted Gaussian peak too far away from the expected position(more than 0.0005 nm). Convection couldproduce shifts, but it is also possible that a strong nearbyabsorption line is dominating the region and blendingconsiderably the original targeted line. The analysis wouldrequire manual inspection, thus we reject those lines.
-
(b)
Bad fits with a root mean square bigger than 1.0 (e.g., extreme values due to a cosmic ray).
-
(c)
Absorption lines potentially affected by telluric lines (previously identified by cross-correlating with a telluric line mask).
-
(d)
Invalid fluxes (i.e., negative or inexistent due to gaps in the observation).
This verification process allows us to adapt the analysis to thepeculiarities of each observation, ensuring that only the bestquality regions are used.
-
(a)
-
3.
Fast atmospheric parameter estimation. We use the synthetic spectral fitting technique implemented in iSpec, where a least-square algorithm compares the observed spectra with synthetic spectra. The compared regions correspond to the selected absorption lines from step 2 together with the wings of H-α, H-β and the Mg triplet (around 515−520 nm). The process estimates the following atmospheric parameters: effective temperature, surface gravity, metallicity, microturbulence, and macroturbulence. The rotational velocity is fixed to 2.0 km s-1 since it generally degenerates with the macroturbulence. To speed up this first estimation, we limit the minimization algorithm to one iteration and we use a small pre-computed synthetic grid with key spectra (i.e., metal-rich/poor dwarf/giant). This process allows us to quickly distinguish dwarfs from giants and overall metallicities.
-
4.
Guided normalization. The same steps described in the blind normalization stage are executed, but after ignoring all the fluxes that have a value below 0.98 in their respective synthetic spectra (computed with the fast estimation of atmospheric parameters from step 3). This way, we reduce the effect of strong lines in the normalization process.
-
5.
Line re-fitting. Step 2 is repeated with the new normalized spectra obtained from step 3.
-
6.
Final atmospheric parameter determination: the same analysis described in step 3 is repeated, but now the maximum number of iterations is increased to six, which is an optimal value as shown in Blanco-Cuaresma et al. (2014a).
To reduce the dataset to mainly FGK stars in the main sequence and red giant branch, we discarded spectra for which we found an effective temperature higher than 6500 K or lower than 4500 K, and a surface gravity higher than 4.60 dex or lower than 2.00 dex (same limits as in Heiter et al. 2014).
After this third selection criterion, 389 spectra remain, which correspond to 339 stars. The selection covers the 35 clusters listed in Table 1, where we included their coordinates, radial velocity, spectroscopic metallicity, and age from the literature.
3.2. Chemical abundances
The metallicity obtained in the atmospheric parameter determination process (Sect. 3.1) corresponds to a global scaling factor that is applied to all the elements (taking the solar abundance as the reference point). In a subsequent step, individual abundances are derived.
It has been shown that line-by-line differential analysis with a manual selection of lines can reach precision of 0.003 dex for solar twins (Meléndez et al. 2012). In our case, the whole analysis is automatized and stars cover a wider parameter space, thus we cannot expect such a level of precision. Nevertheless, we developed a differential analysis where we have derived the solar absolute abundances of all the absorption lines that were selected for 7 solar spectra included in the Gaia FGK Benchmark Stars library (Blanco-Cuaresma et al. 2014b). The process follows these steps for each element and spectrum:
-
1.
derivation of the absolute abundances for each of the selectedlines by using the synthetic spectral technique implemented iniSpec.
-
2.
Calculation of the relative abundances by subtracting the solar absolute abundances from the absolute abundances for each line.
-
3.
Derivation of the final abundance for the spectrum by calculating the weighted average
 (1)where the weight is the inverse of the abundance error
(1)where the weight is the inverse of the abundance error  reported by iSpec, which is influenced by the spectral S/N and the goodness of fit.
reported by iSpec, which is influenced by the spectral S/N and the goodness of fit. -
4.
Derivation of the error associated with the final abundance from the unbiased weighted sample dispersion
 (2)where
(2)where 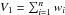 and
and  .
.
We analyzed 779 422 lines from which we discarded extreme values which are clearly outliers (i.e., relative abundances bigger than 1.0 dex and smaller than −5.0 dex) and elements with only one measured line (we required at least two lines to be able to calculate the weighted sample dispersion). As an order of magnitude, the typical dispersion of the abundance of a single element is ~0.10 dex.
The abundances that were successfully measured in all the spectra cover 17 species corresponding to 14 different elements. The list includes iron peak elements (V I, Cr I/II, Mn I, Fe I/II, Co I, Ni I), alpha elements (Mg I, Si I, Ca I, Ti I/II), odd-Z elements (Na I, Sc II), and s-process elements (Ba II, Y II). We discarded stars for which we do not have any of the previous abundances, thus the final dataset was reduced to 206 stars covering 32 clusters.
3.3. Chemical outliers
Assuming that stars born together share the same chemical signature, we used the 17 abundances to identify outliers in each cluster. However, the low number of stars per cluster is a limiting factor for the detection of outliers. To overcome this limitation, we first compressed the 17 dimensions (abundance values) by using the statistical procedure named principal component analysis (PCA), where the abundances are converted into a set of linearly uncorrelated variables (named components) by applying an orthogonal transformation. The first principal component has the largest possible variance, and each subsequent component has the highest variance possible under the constraint that it is orthogonal to (i.e., uncorrelated with) the preceding components. Ting et al. (2012) illustrated the power of PCA to study and interpret stellar element abundances.
Second, using the first two components, we estimated and subtracted the central location in the PCA space for each independent cluster. Thus, all the clusters share the same central location (i.e., origin of coordinates in the PCA space) and outlying stars are placed farther away. It is important to minimize the impact of deviant values in the determination of clusters’ central locations in the PCA space. Therefore, we used a robust estimator named minimum covariance determinant (MCD) and the Mahalanobis distance (Mahalanobis 1936), which can tolerate the effect of nearly 50% of contamination in the data (Rousseeuw 1984) and for which there is a computationally fast and well-known algorithm (Rousseeuw & Driessen 1999).
Finally, we redetermined the central location and scatter of all the stars applying again the same algorithm and assuming that all the cluster have similar dispersion. For multivariate normally distributed data, the Mahalanobis distances to the central location are approximately chi-square distributed with p degrees of freedom ( where p = 2 in our case since we use the first two principal components; Filzmoser 2004). We tagged as outliers those stars with a squared distance higher than the 80% quantile of the chi-squared distribution (see Fig. 1).
where p = 2 in our case since we use the first two principal components; Filzmoser 2004). We tagged as outliers those stars with a squared distance higher than the 80% quantile of the chi-squared distribution (see Fig. 1).
 |
Fig. 1 Dwarf (left) and giant stars (right) from all clusters represented using the first two components of the PCA with the central cluster location subtracted. Stars chemically identified as outliers are shown in red. |
After executing this procedure and discarding the identified outliers (see Fig. 2), the dataset was reduced to 177 stars corresponding to 31 clusters. The discarded stars could be chemically peculiar or simply not belong to the cluster. In the case of NGC 3114, the two stars of the cluster were classified as outliers by this method, probably only one of them is a real outlier, but because of the lack of statistics (if there is an outlier in a cluster of only two stars, the mean abundances are strongly affected) we prefer to be conservative and discard the complete cluster. We decided not to perform any further detailed analysis of these stars since this would fall outside of the scope of this work. Detailed abundances per cluster and stellar type can be found in Tables 8 and 9.
 |
Fig. 2 Abundances (top) and mean number of lines used (bottom) in function of species (element code at top, atomic number, and ionization state in Kurucz format at bottom where “0” is neutral and “1” is ionized) for Melotte 111 dwarfs showing all the analyzed stars (left) and after filtering outliers (right). All the abundance ratios are referenced to iron except iron itself, which is relative to hydrogen. Each color represents a star with an identification name shown in the legend. |
4. Chemical tagging
4.1. Continuum normalization effects
As pointed out in the introduction, some of the chemical studies found in the literature are based on non-homogeneous compilations of abundances, obtained from different sources and by different methods (e.g., equivalent width/synthetic spectra) and ingredients (e.g., atomic data, model atmospheres). This inhomogeneity implies systematic uncertainties that can mislead our scientific conclusions.
To illustrate the impact of those changes on the metallicity, we repeated our full analysis changing only one parameter in the continuum normalization process (see Sect. 3.1). We decreased the median filter window from 0.10 to 0.01 nm, which raises the continuum placement.
We used the iron abundance [Fe/H] as a pertinent tracer of the metallicity, and we compared the values obtained from both slightly different normalization procedures. A small change in the normalization criteria produces a systematic average difference of −0.07 ± 0.04 dex.
When we compared both results (median filter window of 0.10 and 0.01 nm) with open cluster metallicities found in the literature, we obtained the average differences of −0.07 ± 0.07 dex and 0.01 ± 0.08 dex, respectively (details in Table 2). The large dispersion confirms the inadequacy of mixing chemical abundances from different literature sources to draw solid scientific conclusions.
Iron abundances from neutral lines when using two slightly different normalization processes, and comparison to literature metallicities.
For the rest of the abundances, we chose to work in terms of [X/Fe]5 since this way we can partially cancel out the effect of different continuum placements.
4.2. Abundance and astrophysical parameter correlations
Previous works have already detected trends in chemical abundances with effective temperature and surface gravity for metal poor globular clusters, measuring iron abundances smaller in the turnoff stars than in the red giants on the order of the order of 30% or 0.13 dex (Korn et al. 2007; Lind et al. 2008; Nordlander et al. 2012; Gruyters et al. 2013).
Systematic differences were also found for open clusters with metallicities closer to solar such as M 67 (Önehag et al. 2014), NGC 5822, or IC 4756 (differences higher than 0.15 dex for Na, Si, and Ti; Pace et al. 2010).
The assumption of local thermodynamic equilibrium (LTE) may introduce systematic errors and abundance trends when analyzing stars covering large intervals of effective temperatures, surface gravities and metallicities. For instance, Randich et al. (2006) exposes that the Na difference between dwarfs and giants in M 67 can be explained by NLTE effects that are larger for cool giants than for warm dwarfs (Mashonkina et al. 2000).
The depletion of some elements could also be caused by the atomic diffusion (pushing heavier elements in the direction of increasing pressure and temperature) that takes place during the main sequence lifetime of the star and modifies the chemical composition of the stellar atmosphere. The effect is element-specific since radiative levitation reduces the gravitational acceleration (caused by the interaction of photons with gas particles) and acts selectively on different atoms and ions. When the star evolves toward the red giant branch, elements previously drained from the surface are mixed up again as the outer convection zone gradually reaches deeper layers.
Additionally, as shown in Blanco-Cuaresma et al. (2014a), when simultaneously deriving the effective temperature, surface gravity and metallicity from spectra, degeneracies among those parameters lead to correlations where lower metallicities are found for lower surface gravities and vice versa.
Consequently, chemical abundances derived for stars in different evolutionary stages might be affected by NLTE effects, atomic diffusion processes, and correlations from atmospheric parameter determinations. The NLTE effects can be partly canceled out only for solar dwarfs by performing differential analysis (see Sect. 3.2), and the effects from parameter determinations can be reduced by working with [X/Fe] ratios6. Additionally, to control these effects in our work, we decided to divide each cluster into two subgroups formed of dwarfs and giant stars (i.e., log (g) ≤ 3.5 dex).
It is worth noting that the outlier detection process (see Sect. 3.3) was executed at this subgroup level for each cluster, otherwise we would have detected a significant number of false outliers due to these stellar processes.
In Fig. 5 we present the chemical pattern for M 67, one of the clusters with a high number of spectra in our dataset. The signature is different for each subgroup and the elemental abundance dispersion is slightly lower when we subdivide clusters per evolutionary stages.
 |
Fig. 3 Hertzsprung-Russell diagram for M 67 with Yonsei-Yale isochrones (three different ages; Demarque et al. 2004), color scale corresponding to the neutral iron abundance, and size represents abundance dispersion. |
 |
Fig. 4 Hertzsprung-Russell diagram for M 67 with Yonsei-Yale isochrones (three different ages; Demarque et al. 2004), color scale corresponding to the silicon abundance, and size represents abundance dispersion. |
The chemical differences for IC 4651, M 67, NGC 2447, NGC 2632, and NGC 3680 stars in various evolutionary stages for each analyzed element are shown in Table 3. We observe that Si I, and Na I are enhanced for evolved stars with increases higher than 0.10 dex. We priorize abundances for neutral elements when possible since we have more lines for them. The rest present smaller variations that in most of the cases fall inside the error margins (~0.05 dex). For a better visual inspection, the iron and silicon abundances for M 67 are shown in Figs. 3 and 4, respectively.
 |
Fig. 5 Average chemical abundances (top), dispersion (middle), and mean number of lines (bottom) used for M 67 stars (left) and divided into two stellar-type groups (right). All the abundance ratios are referenced to iron except iron itself, which is relative to hydrogen. |
Chemical differences for stars in different evolutionary stages.
An alternative approach to visually evaluating the chemical differences between subgroups is to reduce the 17 dimensions to two components using PCA as shown in Fig. 6. Dwarfs reside in a clearly different parameter space from giants, showing that the subgroups have distinct chemical patterns.
 |
Fig. 6 Abundances represented by the first two principal components. The surface gravity of each star is indicated by the color scale bar. |
Regardless of whether these abundance enhancements are real or due to systematic errors (e.g., model assumptions, data treatment), they have implications that we cannot ignore for the chemical tagging technique when applied to stars in very different evolutionary stages, which is the reason why we decided to separate dwarfs from giants in our experiment.
4.3. Cluster homogeneity
To evaluate the viability of the chemical tagging technique, we performed a blind chemical tagging experiment designed to recover the initial stellar groups by only using the chemical abundances and the total number of clusters. We note that we discarded stars considered outliers based on their chemical signature, which should make the task easier than a real scenario with unknown stellar groups (i.e., field stars).
The K-Means method (also known as Lloyd’s algorithm, Lloyd 1982) is a well-established machine learning/clustering algorithm for which the benefits and drawbacks have already been widely studied. Its simplicity and the use of the number of clusters that we want to find as an input parameter makes this algorithm ideal for our experiment.
K-Means aims to partition the observations (one observation would be one star with its measured abundances) into K clusters in which each observation belongs to the cluster with the nearest mean (called centroid). Given a fixed number of clusters, K-Means clustering is reduced to an optimization problem where it finds the K centroids and assigns the observations to the nearest one, such that the squared distances are minimized.
The election of the number of clusters is usually a limitation if no a priori information is available, but in our case we provided the real number of clusters. Other known drawbacks are that this algorithm tends to find clusters of comparable spatial extent, it often incorrectly cuts the borders in between clusters (the algorithm optimizes cluster centers, not cluster borders), and the final results might depend on the initial position of the centroids. To address the last drawback, we used a variation of the algorithm named K-Means++ which optimizes the position of the initially random centroid with a probability proportional to its squared distance from the closest observation (Arthur & Vassilvitskii 2007).
To evaluate the goodness of the clustering, we used the following well-known metrics
-
1.
V-measure7 (Hirschberg& Rosenberg 2007) is a harmonicmean between homogeneity and completeness:
 (3)
(3)
-
(a)
Homogeneity: a clustering result satisfies homogeneity if all ofits predicted clusters contain only data points that are members ofone real open cluster. Score is between 0.0 and 1.0 and the latterstands for perfectly homogeneous labeling.
-
(b)
Completeness: a clustering result satisfies completeness if all the data points that are members of a given real open cluster are elements of the same predicted cluster. Score is between 0.0 and 1.0 and the latter stands for perfectly complete labeling.
-
(a)
-
2.
Silhouette coefficient (Rousseeuw 1987):measures the concepts of cluster cohesion (favoringmodels that contain tightly cohesive clusters) and clus-ter separation (favoring models that contain highlyseparated clusters). The coefficient is calculated as
 (4)where dintra is the mean intra-cluster distance and dinter is the mean nearest-cluster distance. Negative values (never smaller than −1) indicate that most of the stars are assigned to a incorrect cluster, values close to zero indicate the existence of overlapping clusters, and values close to 1.0 indicate that the stars of a given cluster are similar to each other and well-separated from other clusters.
(4)where dintra is the mean intra-cluster distance and dinter is the mean nearest-cluster distance. Negative values (never smaller than −1) indicate that most of the stars are assigned to a incorrect cluster, values close to zero indicate the existence of overlapping clusters, and values close to 1.0 indicate that the stars of a given cluster are similar to each other and well-separated from other clusters.
The clustering configurations that maximizes the V-measure and the mean silhouette coefficient is the best although it should be taken into account that the silhouette is usually reduced when adding more dimensions. We found the best results when the clustering algorithm is run separately in groups divided by stellar types (i.e., dwarfs and giants) and with the first five principal components (built from the 17 abundances; see Table 4).
It is interesting to see that we cover 85% of the variance with four or five principal components, contrary to Ting et al. (2012) where six or seven components are needed. Our abundances were derived homogeneously, but our sample is smaller. We have 31 clusters and Ting et al. (2012) analyze 78 clusters, which can lead to a bigger diversity and thus, more components are needed to cover the same amount of variance.
For all the configurations, the silhouette coefficient is under 0.50, indicating that the structure found is reasonable but weak. There is a non-negligible chemical overlapping among stars of different clusters.
K-Means++ clustering metrics for different stellar groups and dimensions.
Benchmark of different clustering algorithms separated by stellar group.
The clustering analysis groups together stars from different open clusters (see Tables 6 and 7; Figs. 7 and 8) pointing out that, for the analyzed elemental abundances, the clusters’ chemical signature are not significantly different. The abundance patterns change relatively smoothly in the chemical space as shown in Figs. 9 and 10 (especially considering that the typical uncertainty is ~0.05 dex), complicating the separation of stars that belong to different clusters.
 |
Fig. 7 Dwarfs represented using the first two components of PCA. Background colors correspond to the clusters found by the K-Means algorithm. Centroids are marked with white crosses. |
 |
Fig. 8 Giants represented using the first two components of PCA. Background colors correspond to the clusters found by the K-Means algorithm. Centroids are marked with white crosses. |
 |
Fig. 9 Stellar abundances averaged per cluster using only dwarf stars. |
 |
Fig. 10 Stellar abundances averaged per cluster using only giant stars. |
In addition to the K-Means method, we tested other known machine learning algorithms such as affinity propagation (Frey & Dueck 2007) and DBSCAN (Ester et al. 1996). These do not require specifying the number of clusters to be found as an input, but need other distance parameters that are going to have a significant impact on the number of clusters automatically found by the algorithm. In our case, to do a fair comparison with K-Means we have fine-tuned the input parameters to obtain a number of clusters close to the real one. As input values, we used the first five principal components, which cover approximately 85% of the variance. To complement the comparison, we also implemented the classification algorithm developed by Mitschang et al. (2013) which does not need any extra input parameters and it also automatically finds the number of clusters. For this method we use the 17 elements directly because this approach was calibrated with real abundances and not principal components. Four different configurations have been executed using the following criteria: limiting the probability of belonging to the cluster to be higher than 68% or 90%; discarding clusters found with only two stars or not discarding any resulting cluster. The results are shown in Table 5; all the methods have a similar behavior in terms of V-Measure except DBSCAN, which is the worse behaving with dwarf stars (it might be more sensitive to the lower number of stars).
To estimate an order of magnitude of the star contamination level, we linked each group (found by the clustering algorithms) to the open cluster that contains the highest number of stars (unless the open cluster was already assigned) and we found that around 30−50% of the stars are not assigned to their expected cluster. The higher the number of open clusters included in the analysis, the higher the contamination percentage. Considering that it has been estimated that about 108 clusters were dissolved in the Galaxy (Bland-Hawthorn & Freeman 2004), we expect a severe contamination when applying the chemical tagging technique to field stars in order to recover co-natal aggregates.
For the giant case, where the number of stars is higher, there might be a correlation between the first two principal components and the stellar ages (i.e., cluster ages). In Fig. 11 we see that the stars with a lower value in the first two components belong to younger clusters, while older stars have lower values in the first component but higher in the second one. The correlation seems to follow a semi-circular path in that visualization of the PCA space (although the correlation seems stronger for the first component). Thus, this keeps open the possibility of finding co-eval aggregates (stars born at the same period although not necessarily from the same molecular cloud) by using the chemical tagging technique.
 |
Fig. 11 Stars represented in the PCA space using the first two principal components. The stellar ages are indicated by the color scale bar. |
Clusters found for dwarf stars and their real open clusters using five components.
Clusters found for giant stars and their real open clusters using five components.
4.4. The role of different elements
The selection of measured abundances also has an impact on the clustering algorithms, hence on the potential of the chemical tagging technique. The best elements among those included in this study are those that can be measured with high precision (i.e., low dispersion) and show no correlation among them (e.g., alpha elements have similar trends). It is also important to have elements produced in different processes with significantly different yields.
Working with high-resolution and high S/N spectra contributes to better precision, even though not all the elements can be easily measured for all kinds of stellar types because their absorption lines can be too weak or highly blended. In this context, high-quality atomic data and reliable physical models are fundamental.
A principal component analysis can help us to understand the role of the measured abundances by looking at the weights assigned to each one. Elements with similar weights have similar behaviors and they do not contribute significantly to differentiate between clusters. In Fig. 12 we observe that the elements that contribute more to differentiate stars are the heavier elements (Y II, Ba II), Fe I, Mg I, Si I, and Na I. To fully take advantage of this information, it is desirable to include a higher number of stars in future studies, especially for the dwarf subgroup, to extend the analysis to include other elements and to correct NLTE effects.
 |
Fig. 12 PCA weights of the elements per stellar subgroup. |
5. Conclusions
We compiled 2133 high-resolution spectra acquired with different instruments (i.e., NARVAL, HARPS, UVES) in the field of view of known open clusters. We implemented an automatic process based on iSpec to homogenize the observations, co-add them, derive atmospheric parameters and determine chemical abundances using a differential approach. After filtering low S/N spectra, non-members by radial velocity, non-FGK and/or chemically peculiar stars, we were left with a dataset of 177 stars covering 31 open clusters with abundances for 17 species corresponding to 14 different elements.
Weighted mean abundances and dispersion per cluster and stellar subgroup.
By slightly varying our continuum normalization process, we show how inhomogeneities in the spectral analysis imply systematic uncertainties in, for instance, the derived chemical abundances. Using the heterogeneous compilations from the literature to draw scientific conclusions about extensive topics such as the chemical history of our Galaxy is not recommended.
Weighted mean abundances and dispersion per cluster.
We identified distinct chemical signatures for stars in different evolutionary stages that belong to the same open cluster. The origin of these differences may be explained by NLTE effects (minimized for solar dwarfs thanks to the applied differential approach in the abundance determination), atomic diffusion, mixing processes and correlations from atmospheric parameter determinations. Regardless of whether these abundance enhancements are real or artificial, they have important implications for the chemical tagging technique when applied to stars in different evolutionary stages.
To evaluate the viability of the chemical tagging technique when analyzing a huge quantity of spectra in an automatized fashion, we performed experiments where we applied machine learning algorithms to blindly group stars based on their chemical abundances. We should note that our analysis was mainly limited to nearby clusters and it covers a narrow metallicity range. We found that the analyzed open clusters overlap in the chemical space for the 17 elemental abundances analyzed and it is not possible to completely recover co-natal stars (born from the same cloud at the same time). It is worth noting that chemical outliers were already discarded and the clustering analysis was performed individually in subgroups with stars in similar evolutionary stages. Thus, in a real scenario where the chemical tagging technique would be applied to a greater number of field stars, we expect to have a high level of overlapping that would severely affect the success rate of this technique for recovering co-natal aggregates.
In Mitschang et al. (2014), the authors conducted the first blind chemical tagging experiment to find stellar groups from 714 field stars. They also found that the viability of finding co-natal groups was doubtful, but they claimed that the technique can still identify co-eval groups of stars (stars born at the same period). In our study, we observed a possible correlation between the first principal components and the stellar ages for giant stars. The door remains open for the possibility of using the chemical tagging technique to find co-eval aggregates.
It is intuitive to conclude that increases in chemical dimensionality lead to improvements in the clustering experiments, although the difficulty in deriving abundances for some elements (e.g., weak absorption lines, fewer lines, blended regions) at a given resolution could also yield greater uncertainties and potential scatter. We showed that not all the elements have the same discriminatory power (as previous studies have forseen, such as Freeman & Bland-Hawthorn 2002; Mitschang et al. 2013), some tend to act in concert while others contribute significantly such as the heavy n-capture element Ba. For future analysis, it would be interesting to include other elements such as La, Nd, and Eu, which are formed through similar processes that produce Ba (slow and rapid n-capture processes in low-mass AGB stars, Busso et al. 2001; and core-collapse supernovae, Kratz et al. 2007). It would be also necessary to explore open clusters with lower metallicities, where less line blending could make different elements accessible.
There is also room to improve automatic analysis and spectral modeling, for instance, incorporating NLTE effects and averaged 3D model atmosphere. Time dependent 3D hydrodynamical models (Pereira et al. 2013) are still computationally too expensive as to use them for massive analysis, thus the averaged 3D models are a good compromise. These improvements could reduce discrepancies among stars in different evolutionary stages and achieve a higher degree of success when recovering clusters using chemical abundances (Bergemann et al. 2012; Lind et al. 2012).
In this text, the term “resolution” refers to  where λ is the wavelength.
where λ is the wavelength.
Lines that might be slightly more blended for hotter or colder stars.
By definition, [X/Y] ≡ log 10(NX/NY)star − log 10(NX/NY)⊙, where NX and NY are the abundances of element X and element Y respectively.
[X/Fe] = [X/H] − [Fe/H].
The “V” stands for “validity”, in the sense of the goodness of a clustering solution.
Acknowledgments
This work was partially supported by the Gaia Research for European Astronomy Training (GREAT-ITN) Marie Curie network, funded through the European Union Seventh Framework Programme [FP7/2007-2013] under grant agreement n. 264895. U.H. and A.J.K. acknowledge support from the Swedish National Space Board (Rymdstyrelsen). I.S.R. gratefully acknowledges the support provided by the Gemini-CONICYT project 32110029. All the software used in the data analysis were provided by the Open Source community.
References
- Anderson, E., & Francis, C. 2012, Astron. Lett., 38, 331 [NASA ADS] [CrossRef] [Google Scholar]
- Anguiano, B., Freeman, K., Bland-Hawthorn, J., et al. 2014, in IAU Symp. 298, eds. S. Feltzing, G. Zhao, N. A. Walton, & P. Whitelock, 322 [Google Scholar]
- Arthur, D., & Vassilvitskii, S. 2007, in Proc. eighteenth annual ACM-SIAM symp. on Discrete algorithms, SIAM, 1027 [Google Scholar]
- Aurière, M. 2003, in EAS Pub. Ser. 9, eds. J. Arnaud, & N. Meunier, 105 [Google Scholar]
- Barden, S. C., Jones, D. J., Barnes, S. I., et al. 2010, in SPIE Conf. Ser., 7735 [Google Scholar]
- Bergemann, M., Lind, K., Collet, R., Magic, Z., & Asplund, M. 2012, MNRAS, 427, 27 [NASA ADS] [CrossRef] [Google Scholar]
- Blanco-Cuaresma, S., Soubiran, C., Heiter, U., & Jofré, P. 2014a, A&A, 569, A111 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Blanco-Cuaresma, S., Soubiran, C., Jofré, P., & Heiter, U. 2014b, A&A, 566, A98 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bland-Hawthorn, J., & Freeman, K. C. 2004, PASA, 21, 110 [NASA ADS] [CrossRef] [Google Scholar]
- Bland-Hawthorn, J., Krumholz, M. R., & Freeman, K. 2010, ApJ, 713, 166 [NASA ADS] [CrossRef] [Google Scholar]
- Bragaglia, A., & Tosi, M. 2006, AJ, 131, 1544 [NASA ADS] [CrossRef] [Google Scholar]
- Busso, M., Gallino, R., Lambert, D. L., Travaglio, C., & Smith, V. V. 2001, ApJ, 557, 802 [NASA ADS] [CrossRef] [Google Scholar]
- Carraro, G., Geisler, D., Villanova, S., Frinchaboy, P. M., & Majewski, S. R. 2007, A&A, 476, 217 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- De Silva, G. M., Sneden, C., Paulson, D. B., et al. 2006, AJ, 131, 455 [NASA ADS] [CrossRef] [Google Scholar]
- De Silva, G. M., Freeman, K. C., Asplund, M., et al. 2007, AJ, 133, 1161 [NASA ADS] [CrossRef] [Google Scholar]
- De Silva, G. M., Freeman, K. C., & Bland-Hawthorn, J. 2009, PASA, 26, 11 [NASA ADS] [CrossRef] [Google Scholar]
- De Silva, G. M., Freeman, K. C., Bland-Hawthorn, J., et al. 2015, MNRAS, 449, 2604 [NASA ADS] [CrossRef] [MathSciNet] [Google Scholar]
- Dekker, H., D’Odorico, S., Kaufer, A., Delabre, B., & Kotzlowski, H. 2000, in SPIE Conf. Ser. 4008, eds. M. Iye, & A. F. Moorwood, 534 [Google Scholar]
- Demarque, P., Woo, J.-H., Kim, Y.-C., & Yi, S. K. 2004, ApJS, 155, 667 [NASA ADS] [CrossRef] [Google Scholar]
- Dias, W. S., Alessi, B. S., Moitinho, A., & Lépine, J. R. D. 2002, A&A, 389, 871 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Donati, J., Semel, M., Carter, B. D., Rees, D. E., & Collier Cameron, A. 1997, MNRAS, 291, 658 [NASA ADS] [CrossRef] [MathSciNet] [Google Scholar]
- Ester, M., Kriegel, H.-P., Sander, J., & Xu, X. 1996, KDD, 96, 226 [Google Scholar]
- Feng, Y., & Krumholz, M. R. 2014, Nature, 513, 523 [NASA ADS] [CrossRef] [Google Scholar]
- Filzmoser, P. 2004, Proc. 7th Int. Conf. Computer Data Analysis and Modeling, eds. S. Aivazian et al., Vol. 1, 18 [Google Scholar]
- Finlay, J., Noriega-Crespo, A., Friel, E. D., & Cudworth, K. M. 1995, in BAAS 27, Am. Astron. Soc. Meet. Abstr., 107.02 [Google Scholar]
- Freeman, K., & Bland-Hawthorn, J. 2002, ARA&A, 40, 487 [NASA ADS] [CrossRef] [Google Scholar]
- Frey, B. J., & Dueck, D. 2007, Science, 315, 972 [Google Scholar]
- Friel, E. D. 1995, ARA&A, 33, 381 [NASA ADS] [CrossRef] [Google Scholar]
- Gilmore, G., Randich, S., Asplund, M., et al. 2012, The Messenger, 147, 25 [NASA ADS] [Google Scholar]
- Gray, R. O., & Corbally, C. J. 1994, AJ, 107, 742 [NASA ADS] [CrossRef] [Google Scholar]
- Grevesse, N., Asplund, M., & Sauval, A. J. 2007, Space Sci. Rev., 130, 105 [Google Scholar]
- Gruyters, P., Korn, A. J., Richard, O., et al. 2013, A&A, 555, A31 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gustafsson, B., Edvardsson, B., Eriksson, K., et al. 2008, A&A, 486, 951 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Heiter, U., & Eriksson, K. 2006, A&A, 452, 1039 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Heiter, U., Soubiran, C., Netopil, M., & Paunzen, E. 2014, A&A, 561, A93 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hirschberg, J. B., & Rosenberg, A. 2007, Proc. EMNLP [Google Scholar]
- Jacobson, H. R., Pilachowski, C. A., & Friel, E. D. 2011, AJ, 142, 59 [NASA ADS] [CrossRef] [Google Scholar]
- Jappsen, A.-K., Klessen, R. S., Larson, R. B., Li, Y., & Mac Low, M.-M. 2005, A&A, 435, 611 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kharchenko, N. V., Piskunov, A. E., Röser, S., Schilbach, E., & Scholz, R.-D. 2005, A&A, 438, 1163 [NASA ADS] [CrossRef] [EDP Sciences] [MathSciNet] [Google Scholar]
- Korn, A. J., Grundahl, F., Richard, O., et al. 2007, ApJ, 671, 402 [NASA ADS] [CrossRef] [Google Scholar]
- Kratz, K.-L., Farouqi, K., Pfeiffer, B., et al. 2007, ApJ, 662, 39 [NASA ADS] [CrossRef] [MathSciNet] [Google Scholar]
- Lada, C. J., & Lada, E. A. 2003, ARA&A, 41, 57 [NASA ADS] [CrossRef] [Google Scholar]
- Larson, R. B. 1995, MNRAS, 272, 213 [NASA ADS] [Google Scholar]
- Lind, K., Korn, A. J., Barklem, P. S., & Grundahl, F. 2008, A&A, 490, 777 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lind, K., Bergemann, M., & Asplund, M. 2012, MNRAS, 427, 50 [NASA ADS] [CrossRef] [Google Scholar]
- Lloyd, S. 1982, Information Theory, IEEE Transactions, 28, 129 [Google Scholar]
- Magrini, L., Randich, S., Romano, D., et al. 2014, A&A, 563, A44 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mahalanobis, P. C. 1936, Proc. National Institute of Sciences, Calcutta, 2, 49 [Google Scholar]
- Mashonkina, L. I., Shimanskiĭ, V. V., & Sakhibullin, N. A. 2000, Astron. Rep., 44, 790 [NASA ADS] [CrossRef] [Google Scholar]
- Mathieu, R. D. 2000, in Stellar Clusters and Associations: Convection, Rotation, and Dynamos, eds. R. Pallavicini, G. Micela, & S. Sciortino, ASP Conf. Ser., 198, 517 [Google Scholar]
- Mayor, M., Pepe, F., Queloz, D., et al. 2003, The Messenger, 114, 20 [NASA ADS] [Google Scholar]
- Meléndez, J., Bergemann, M., Cohen, J. G., et al. 2012, A&A, 543, A29 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mermilliod, J.-C., Mayor, M., & Udry, S. 2009, A&A, 498, 949 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Meyer, M. R., Adams, F. C., Hillenbrand, L. A., Carpenter, J. M., & Larson, R. B. 2000, Protostars and Planets IV, 121 [Google Scholar]
- Mitschang, A. W., De Silva, G., Sharma, S., & Zucker, D. B. 2013, MNRAS, 428, 2321 [NASA ADS] [CrossRef] [Google Scholar]
- Mitschang, A. W., De Silva, G., Zucker, D. B., et al. 2014, MNRAS, 438, 2753 [NASA ADS] [CrossRef] [Google Scholar]
- Molenda-Żakowicz, J., Brogaard, K., Niemczura, E., et al. 2014, MNRAS, 445, 2446 [NASA ADS] [CrossRef] [Google Scholar]
- Montalto, M., Villanova, S., Koppenhoefer, J., et al. 2011, A&A, 535, A39 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Netopil, M., & Paunzen, E. 2013, A&A, 557, A10 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Nordlander, T., Korn, A. J., Richard, O., & Lind, K. 2012, ApJ, 753, 48 [NASA ADS] [CrossRef] [Google Scholar]
- Önehag, A., Gustafsson, B., & Korn, A. 2014, A&A, 562, A102 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pace, G., Danziger, J., Carraro, G., et al. 2010, A&A, 515, A28 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Paunzen, E., & Netopil, M. 2006, MNRAS, 371, 1641 [NASA ADS] [CrossRef] [Google Scholar]
- Paunzen, E., Heiter, U., Netopil, M., & Soubiran, C. 2010, A&A, 517, A32 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pereira, T. M. D., Asplund, M., Collet, R., et al. 2013, A&A, 554, A118 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pöhnl, H., & Paunzen, E. 2010, A&A, 514, A81 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Randich, S., Sestito, P., Primas, F., Pallavicini, R., & Pasquini, L. 2006, A&A, 450, 557 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rousseeuw, P. J. 1984, J. Am. Statistical Association, 79, 871 [Google Scholar]
- Rousseeuw, P. J. 1987, J. Comput. Appl. Math., 20, 53 [Google Scholar]
- Rousseeuw, P. J., & Driessen, K. V. 1999, Technometrics, 41, 212 [CrossRef] [Google Scholar]
- Shu, F. H., Adams, F. C., & Lizano, S. 1987, ARA&A, 25, 23 [Google Scholar]
- Tilley, D. A., & Pudritz, R. E. 2004, MNRAS, 353, 769 [NASA ADS] [CrossRef] [Google Scholar]
- Ting, Y.-S., Freeman, K. C., Kobayashi, C., De Silva, G. M., & Bland-Hawthorn, J. 2012, MNRAS, 421, 1231 [NASA ADS] [CrossRef] [Google Scholar]
- van den Bergh, S., & McClure, R. D. 1980, A&A, 88, 360 [NASA ADS] [Google Scholar]
All Tables
Analyzed clusters with the number of co-added spectra per instrument and other known cluster properties from the literature.
Iron abundances from neutral lines when using two slightly different normalization processes, and comparison to literature metallicities.
Clusters found for dwarf stars and their real open clusters using five components.
Clusters found for giant stars and their real open clusters using five components.
All Figures
|
Fig. 1 Dwarf (left) and giant stars (right) from all clusters represented using the first two components of the PCA with the central cluster location subtracted. Stars chemically identified as outliers are shown in red. |
| In the text | |
|
Fig. 2 Abundances (top) and mean number of lines used (bottom) in function of species (element code at top, atomic number, and ionization state in Kurucz format at bottom where “0” is neutral and “1” is ionized) for Melotte 111 dwarfs showing all the analyzed stars (left) and after filtering outliers (right). All the abundance ratios are referenced to iron except iron itself, which is relative to hydrogen. Each color represents a star with an identification name shown in the legend. |
| In the text | |
|
Fig. 3 Hertzsprung-Russell diagram for M 67 with Yonsei-Yale isochrones (three different ages; Demarque et al. 2004), color scale corresponding to the neutral iron abundance, and size represents abundance dispersion. |
| In the text | |
|
Fig. 4 Hertzsprung-Russell diagram for M 67 with Yonsei-Yale isochrones (three different ages; Demarque et al. 2004), color scale corresponding to the silicon abundance, and size represents abundance dispersion. |
| In the text | |
|
Fig. 5 Average chemical abundances (top), dispersion (middle), and mean number of lines (bottom) used for M 67 stars (left) and divided into two stellar-type groups (right). All the abundance ratios are referenced to iron except iron itself, which is relative to hydrogen. |
| In the text | |
|
Fig. 6 Abundances represented by the first two principal components. The surface gravity of each star is indicated by the color scale bar. |
| In the text | |
|
Fig. 7 Dwarfs represented using the first two components of PCA. Background colors correspond to the clusters found by the K-Means algorithm. Centroids are marked with white crosses. |
| In the text | |
|
Fig. 8 Giants represented using the first two components of PCA. Background colors correspond to the clusters found by the K-Means algorithm. Centroids are marked with white crosses. |
| In the text | |
|
Fig. 9 Stellar abundances averaged per cluster using only dwarf stars. |
| In the text | |
|
Fig. 10 Stellar abundances averaged per cluster using only giant stars. |
| In the text | |
|
Fig. 11 Stars represented in the PCA space using the first two principal components. The stellar ages are indicated by the color scale bar. |
| In the text | |
|
Fig. 12 PCA weights of the elements per stellar subgroup. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.