| Issue |
A&A
Volume 536, December 2011
|
|
|---|---|---|
| Article Number | A37 | |
| Number of page(s) | 12 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/201116761 | |
| Published online | 05 December 2011 | |
Do X-ray dark or underluminous galaxy clusters exist?
INAF-Osservatorio Astronomico di Brera, via Brera 28, 20121 Milano, Italy
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
; This email address is being protected from spambots. You need JavaScript enabled to view it.
Received: 22 February 2011
Accepted: 11 September 2011
Abstract
We study the X-ray properties of a color-selected sample of clusters at 0.1 < z < 0.3, to quantify the real aboundance of the population of X-ray dark or underluminous clusters and at the same time the spurious detection contamination level of color-selected cluster catalogs. Starting from a local sample of color-selected clusters, we restrict our attention to those with sufficiently deep X-ray observations to probe their X-ray luminosity down to very faint values and without introducing any X-ray bias. This allowed us to have an X-ray- unbiased sample of 33 clusters to measure the LX-richness relation. Swift 1.4 Ms X-ray observations show that at least 89% of the color-detected clusters are real objects with a potential well deep enough to heat and retain an intracluster medium. The percentage rises to 94% when one includes the single spectroscopically confirmed color-selected cluster whose X-ray emission is not secured. Looking at our results from the opposite perspective, the percentage of X-ray dark clusters among color-selected clusters is very low: at most about 11 per cent (at 90% confidence). Supplementing our data with those from literature, we conclude that X-ray- and color- cluster surveys sample the same population and consequently that in this regard we can safely use clusters selected with any of the two methods for cosmological purposes. This is an essential and promising piece of information for upcoming surveys in both the optical/IR (DES, EUCLID) and X-ray (eRosita). Richness correlates with X-ray luminosity with a large scatter, 0.51 ± 0.08 (0.44 ± 0.07) dex in lgLX at a given richness, when Lx is measured in a 500 (1070) kpc aperture. We release data and software to estimate the X-ray flux, or its upper limit, of a source with over-Poisson background fluctuations (found in this work to be ~20% on cluster angular scales) and to fit X-ray luminosity vs richness if there is an intrinsic scatter. These Bayesian applications rigorously account for boundaries (e.g., the X-ray luminosity and the richness cannot be negative).
Key words: galaxies: clusters: intracluster medium / X-rays: galaxies: clusters / methods: statistical / galaxies: clusters: general / dark matter
© ESO, 2011
1. Introduction
Statistical studies of galaxy cluster samples are important for cosmological studies. The effectiveness of cluster samples critically depends on several factors, among which is the accuracy of the knowledge of the selection function and biases. Cluster samples suited for these studies are collected by means of surveys in optical, X-ray, or radio energy bands. Albeit Sunyaev-Zeldovich surveys are now producing samples useful for cosmological purposes, currently the most efficient methods to compile cluster catalogs for cosmological purposes are still based on optical and X-ray data. Indeed, in the future the two most promising telescopes in this field seem to be in the X-ray (eRosita) and in the optical (e.g., DES).
A critical problem for the use of clusters for cosmological studies is whether optical and X-ray surveys provide fair samples of the dark matter halo mass distribution predicted by the perturbation evolution theories or, equivalently, how far the selection biases in these surveys are known and under control. An important piece of information can be provided by the relation between the optical richness (n200) and the X-ray luminosity (LX), which are the fundamental parameters for cluster detection and are, at the same time, useful mass proxies. This relation has been previously measured by studying the X-ray properties of large optically selected cluster samples and it is usually parametrized by a power law with a (large) intrinsic scatter (Donahue et al. 2001; Gilbank et al. 2004; Rykoff et al. 2008). The amplitude of the LX scatter is commonly explained by the wide range in the dynamical state of the clusters and by the presence of cooling gas, whereas from the optical point of view, the scatter can be ascribed to projection effects or different efficiencies in the galaxy formation (Gilbank et al. 2004).
The existence of an X-ray dark or underluminous, physically distinct population, whose X-ray luminosity is much lower than expected from their optical richness has been also invoked several times in literature. The large differences in X-ray and optical properties of these clusters have been explained by some extreme feedback mechanism (e.g., Castellano et al. 2011). Recently, Balogh et al. (2011) studied a mass-selected sample of 18 moderatly massive (3−6 × 1014 M⊙) nearby (z < 0.1) clusters and found a bimodality in ICM properties, with a higlhly significant part of X-ray underluminous or dark objects (~30%). Therefore, an accurate measurement of the LX-richness relation and its scatter is surely useful for a better understanding of the selection biases at different wavelengths and, at the same time, to probe the cluster non-gravitational physics and the very existence of X-ray dark or underluminous clusters.
In this work, we study of the X-ray properties and the LX-richness relation relation of a small and well-controlled optical sample. Previous works (Donahue et al. 2001; Gilbank et al. 2004; Rykoff et al. 2008) assembled extensive cluster optical catalogs and studied their X-ray properties using the ROSAT shallow observations, mostly the ROSAT All Sky Survey. Their use of shallow X-ray data (in the cluster rest-frame) resulted in a large number of almost uninformative upper limits, only ruling out that the observed cluster has a flux much brighter than other similar clusters of the same richness and which is of little use in ascertaining the existence of dark or underluminous clusters. Some of these works (e.g., Rykoff et al. 2008) are also affected by some systematics such as point-source contamination and centring biases. Here we overcome these limitations through deep X-ray observations of a well-controlled optically selected cluster sample whose depth is appropriate to find an X-ray dark population, if this exist.
In Sect. 2 we describe the sample selection; in Sects. 3 and 4 we describe the optical and X-ray data analysis. In Sect. 5 we describe the fit procedure we used to parametrize the LX-richness relation. In Sect. 6 we revisit previous statements about the existence of underluminous clusters. In Sect. 7 we briefly discuss our results. We summarize and conclude our work in Sect. 8. Throughout this paper we assume ΩM = 0.3, ΩΛ = 0.7 and H0 = 70 km s-1 Mpc-1. For the statistical analysis, we adopt a Bayesian framework with uniform priors, unless otherwise stated.
2. Sample selection
We start from the maxBCG cluster catalog (Koester et al. 2007), which is an optically selected, quasi-volume-limited sample of clusters with 0.1 < z < 0.3, with very accurate photometric redshifts (δz ~ 0.01).
We searched for all Swift X-Ray Telescope (XRT) observations within 8 arcmin from any maxBCG cluster and with an exposure time longer than 3 ks. This yielded 180 observations out of 14 000 in the Swift archive at the start of this work.
We restricted our analysis to the clusters with high-quality X-ray observations. We keep those of the 180 selected clusters, whose 3σ flux limit is at least 30 times fainter than the expected X-ray cluster flux. We calculated the 3σ flux limit (for a point-like source) as in Moretti et al. (2007) and the expected X-ray flux assuming the LX − n200 relation reported in Rykoff et al. (2008)1. This filter can be expressed by 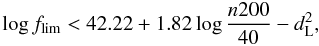 (1)where the flux limit is expressed in erg s-1 cm-2 and dL is the cluster luminosity distance in cm. This selection is such that an average cluster of a given richness n200 is very well detectable in X-ray and allows us to exclude most uninformative upper limits. For example, the poorest cluster cataloged in maxBCG catalog (richness n200 = 10), at the typical redshift of our sample, z = 0.2, is included in the sample only if it has been observed for at least 15 ks with the Swift XRT, corresponding to a 3σ flux limit of 2 × 10-14 erg s-1 cm-2. Equation (1) leaves us with 43 clusters. We emphasize that a cluster was kept or removed from the sample independently of its own LX (in this phase, X-ray data were not even downloaded), which is essential to avoid X-ray biases, as discussed in Sect. 6.
(1)where the flux limit is expressed in erg s-1 cm-2 and dL is the cluster luminosity distance in cm. This selection is such that an average cluster of a given richness n200 is very well detectable in X-ray and allows us to exclude most uninformative upper limits. For example, the poorest cluster cataloged in maxBCG catalog (richness n200 = 10), at the typical redshift of our sample, z = 0.2, is included in the sample only if it has been observed for at least 15 ks with the Swift XRT, corresponding to a 3σ flux limit of 2 × 10-14 erg s-1 cm-2. Equation (1) leaves us with 43 clusters. We emphasize that a cluster was kept or removed from the sample independently of its own LX (in this phase, X-ray data were not even downloaded), which is essential to avoid X-ray biases, as discussed in Sect. 6.
In the XRT archive we found three clusters, MS1006+1202, MS1455.0+232 and Abell 1835, which are the target of the observations. To search for underluminous clusters they are not useful, because they are known to be X-ray-bright sources, and leaving them in the sample would introduce a bias in the LX-richness relation. Therefore we removed them from the statistical sample, but we kept them in tables and figures.
Three more clusters are aligned with an unrelated bright point X-ray sources, making the measurement of the cluster X-ray emission useless for our purposes. We discarded them. Two more clusters fall too near to the Swift XRT field-of-view boundary to make the X-ray data reliable. We discarded these as well. Finally, two maxBCG clusters are (or might be) multiple detections of clusters already present in the maxBCG catalog. To avoid any ambiguity, we also discarded these, which left us with a final sample of 33 (+3) clusters.
Again we stress that these selections do not introduce any selection effect on the X-ray axis: the cluster X-ray flux is not used, directly or indirectly, to decide if the cluster has to be kept in the sample. The final cluster sample is formed by either serendipitously observed clusters (in the field of a source at a fairly different redshift), or, in 50% of the cases, belong to our own Swift observational program targeting all rich maxBCG clusters.
Observed galaxy counts, solid angle ratios, and cluster masses.
3. Cluster center, richness, mass
We started from the maxBCG catalog to improve the center and richness of our clusters.
The maxBCG catalog reports the coordinates of the brightest galaxy (BCG) in the region as the cluster center. In 10 cases (#3, 4, 7, 12, 19, 21, 23, 34, 37, 38), the BCG has been mis-identified in the maxBCG catalog, and the quoted cluster center is offset by both the peak of the galaxy density and by the X-ray emission barycenter (which is centered on the galaxy overdensity, see Sect. 4) by more than 30 arcsec. Therefore, we updated the cluster center. We note that the fraction of miscentered clusters, 0.28 ± 0.07, derived from our observations of 10 offset in a sample of 33, agrees with the rough expectations based on simulations (Johnston et al. 2007; Hilbert & White 2010). We emphasize that both the value and the error of this fraction are essential parameters for estimating cosmology parameters (Hilbert & White 2010) or for forecasting their precision in future surveys (Oguri & Takada 2010) using galaxy clusters. Up to now, a rough estimate for the value was taken, and no error on it was considered. The values directly measured for the first time here on real data allow future analyses to provide more realistic estimates.
We derived the cluster richness, n200, using the Sloan Digital Sky Survey (SDSS) 6th data release (Adelman-McCarthy et al. 2008), strictly following the Andreon & Hurn (2010) procedure, which rigorously accounts for the finite sample size, uncertainties, and existence of boundaries (e.g., clusters galaxies do not come in negative units, while the usual total minus background difference may be negative because of Poisson fluctuations). We counted the net number of red galaxies within r200. This radius is estimated from the net number of red galaxies within 1.43 Mpc from the cluster center, obsn( < 1.43), using Eq. (18) in Andreon & Hurn (2010), which calibrates this relation with a sample of 54 clusters with kwown r200.
Moreover, we used the Andreon & Hurn (2010) measured richness-mass scaling to estimate the masses of our clusters. The quoted mass uncertainty accounts for a number of error sources including the larger calibration uncertainty at the extremes of the richness range, as detailed in Andreon & Hurn (2010). This point has relevance for the richest cluster of our sample, #38, which has a larger mass error because in the calibrating sample only few clusters are as rich as it is. At the other richness extreme, the error of the poorest cluster in our sample, #9, accounts for the extrapolation in going from the range where the richness-mass is well calibrated, from seven galaxies on, to its richness, about four galaxies. The model is described in detail in Andreon & Hurn (2010), who also give its coding in a user-friendly way.
Table 1 lists the results of the optical analysis. Column 1 lists the cluster id; Cols. 2 and 3 list updated coordinates; Col. 4 lists the net observed number of galaxies in the cluster line-of-sight within an aperture of 1.43 Mpc, obsn(<1.43); Col. 5 lists the observed number of galaxies in the cluster line of sight within r200, obsgaltoti; Col. 6 gives the observed number of galaxies in the background line-of-sight obsgalbkgi; Col. 7 lists the ratio between the cluster and background solid angles, Cgal; Col. 8 gives the cluster richness (posterior mean and highest posterior 68% interval); Col. 9 gives the inferred mass (posterior mean and standard deviation), on a log scale in solar mass units. Finally, Col. 10 lists other known identifications of the studied clusters when their reported coordinates is within 1.5 arcmin from the center determined by us. The angular offset is reported in parenthesis.
Figure 1 shows the distribution in mass of clusters in our sample: most of them are in the range 1 to 5 × 1014 solar masses, and all are included in the range 0.6 to 8 × 1014 solar masses.
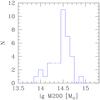 |
Fig. 1 Distribution of cluster masses. |
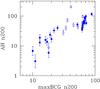 |
Fig. 2 Comparison of the richness as determined by us (ordinate) and in the maxBCG catalog. Open points marks miscentered clusters in the maxBCG catalog. There is no error on the abscissa because none is listed in the maxBCG catalog. |
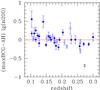 |
Fig. 3 Redshift dependence of richness residuals. Open points indicate miscentered clusters in the maxBCG catalog. Error bars only consider errors on our richness estimate, because there is no such measurement for the maxBCG. |
Figure 2 compares the Koester et al. (2007) and our measurements of richness. There is no errorbar in Fig. 2 on maxBCG richness because none is listed in their catalog. Figure 2 shows that our sample explores a richness range that goes from the richest (maxBCG richness ~ 80) to the poorest (maxBCG richness 10) clusters in the 0.1 < z < 0.3 volume (and in the SDSS area). The two richness estimates broadly agree, although they were derived in slightly different ways: a) Koester et al. count galaxies in different color and luminosity ranges and in different filters; b) we account for background galaxies, whereas Koester et al. do not; c) we adopt different centers (in 30% of the cases) and also r200 values (Koester et al. count galaxies within a radius, unfortunately named r200, which is on average 2r200, e.g., Sheldon et al. 2009; Becker et al. 2007; Johnston et al. 2007). Therefore, it is not surprising that a scatter is present between the two richnesses. The outlier point in Fig. 2 (the point with highest ordinate) is cluster #38, and it is one of those that have a wrong maxBCG estimate of the cluster center. In particular, the area explored by maxBCG (i.e. the circle centered on their center and of radius given by their r200) misses about half the cluster.
Figure 3 compares residuals between Koester et al. (2007, maxBCG) and our (AH) richnesses vs. redshift. There is a small but clear trend with redshift, in the sense that maxBCG richnesses are underestimated at high redshift. Indeed, residuals tend to be positive for the lower half of the redshift range and negative for the upper half. The redshift dependency of the maxBCG richness has already been indirectly pointed out (Reyes et al. 2008; Rykoff et al. 2008; Becker et al. 2007; Rozo et al. 2009). By directly comparing two richness estimates, Fig. 3 confirms that the maxBCG richness is redshift-dependent. A redshift trend introduces a systematic bias on the mass estimate and therefore on estimates of cosmological parameters.
 |
Fig. 4 Montage of the Swift XRT [0.5 − 2] keV images of clusters in our sample, convolved with a Gaussian kernel with σ = 18 arcsec. The ruler indicates 1 arcmin. North is up, east is to the left. The cluster is marked by a green circle. Red circles mark other sources masked in our analysis. |
4. X-ray data
The XRT on board the Swift satellite (Gehrels et al. 2004) uses a Wolter I mirror set, originally designed for the JET-X telescope (Citterio et al. 1994), to focus X-rays (0.2 − 10 keV) onto a XMM-Newton/EPIC MOS CCD detector (Burrows et al. 2005). The effective area of the telescope (~120 cm2 at 1.5 keV) is ~ 3.5 smaller than 1 XMM-Newton MOS module. The PSF, similar to XMM, is characterized by a half-energy-width (HEW) of ~ 18′′ at 1.5 keV (Moretti et al. 2005).
XRT data were reduced using the standard data reduction procedures as outlined in Moretti et al. (2009). Two of our clusters, #12 and 34, are angularly not far from a background gamma-ray-burst. In these cases, we removed the first segments of the observations to reduce the noise associated with the bright gamma-ray-burst.
The total Swift XRT integration time on our cluster sample is 1.4 Ms.
Figure 4 shows [0.5 − 2] keV images, convolved with a Gaussian kernel with σ = 18 arcsec. The extended X-ray emission of most of them is fairly obvious in this figure.
To estimate the cluster count rate, we measured counts (in the [0.5 − 2] keV band) in the cluster direction, obstoti, within a 500 kpc aperture at the cluster redshift, centered on the revised cluster center. To estimate the background and its fluctuations, we measured the counts in a number (nboxi) of regions of the same solid angle as the cluster, spread over the XRT field-of-view.
 |
Fig. 5 Expected (red error bars) and observed (black points) spread in background values vs median background value. The upper panel assumes purely Poisson background fluctuations, whereas the lower panel allow a 20% scatter in the mean background value. |
To eliminate the contamination by point sources, we ran the wavedetect CIAO task and we masked X-ray point sources associated to galaxies or optical point objects. This left us with only the signal coming from the ICM. We used exposure maps to calculate the effective exposure time accounting for vignetting, CCD defects, and excised regions.
To estimate possible over-Poisson fluctuations of background counts, we computed the 16th, 50th (median) and 84th percentiles of the distribution of background values and from these the spread, Ibkg(84) − Ibkg(16), plotted in the abscissa of Fig. 5. We then computed the same percentiles for a sample of simulated nboxi background values drawn from a Poisson distribution of mean intensity μ. The upper panel of Fig. 5 shows that the observed spread (solid points) is larger than the simulated one (error bar, showing the 68% range of simulated spreads) assuming Poisson fluctuations only. Note that the observed spread is noisy and has a systematic bias because we measured it from a finite number of elements. Noise and systematic are both addressed by our simulation. The lower panel shows simulations that better match the observed spread: we allowed the background to have a 20% Gaussian fluctuation on the top of the Poisson fluctuations. The agreement between observed and simulated spread is fairly good, and therefore, we allowed 20% over-Poisson background fluctuations throughout.
Of course, we kept separate data from different pointings in our calculation because we are interested in background variations on cluster angular scales.
To summarize, we found that the nboxi background values scatter more than expected if the only source of background fluctuations were Poisson i.e. we detected over-Poisson fluctuations of background counts consistent with a 20% amplitude. Some over-Poisson fluctuation is expected (Moretti et al. 2011).
Modeling this term is important for low surface brightness objects whose intensity is heavily affected by a 20% background variation. In particular, our modeling of the over-Poisson fluctuations of the background is important for the three faintest clusters, #9, 36 and 40, which otherwise would have their luminosity error underestimated by about 0.2 dex.
Figure 6 shows X-ray counts in the direction of the clusters in units of the mean background value measured all around them, together with background errors and 20% over-Poisson fluctuations. All clusters, except #9, display a significant excess of X-ray counts in a 500 kpc aperture. For cluster #9, we measured a flux excess higher than expected Poisson fluctuations, but well consistent with a 20% background fluctuation. Clusters #36 and #40 have also low S/N X-ray counts in the 500 kpc aperture, but their detection is secure adopting an optimized aperture.
To ascertain the extension of the X-ray emission, we calculated for each cluster the half-power-radius (HPR), defined as the radius enclosing 50% of the fluence within a 1 arcmin (25 pixels) circle radius, which corresponds to the ~95% of the PSF encircled energy fraction. We assessed the significance of the extension of each cluster simulating 1000 PSFs with the same counts, the same spectrum and same off-axis angle. To each simulated PSF we added a background, accounting for its whole variance (Poisson and over Poisson). The typical HPR of a point-like source is 3 pixels (7 arcsec) with a distribution tail that mostly depends on the signal-to-noise ratio. Figure 7 shows that for all the clusters of our sample the HPR lies well beyond the 90th percentile of the HPR PSF simulation distributions, except #40, which barely exceeds it. In this case a significance near 100% is precluded by small number statistics and high allowed (Poisson plus over-Poisson) fluctuations.
We computed the X-ray count rate of the clusters in our sample using the fitting model in Appendix A, which accounts for the Poisson nature of counts, over-Poisson background fluctuations, uncertainty on the mean value of the background, and the existence of boundaries in the data and parameter space. Cluster counts were converted into X-ray luminosities accounting for the exposure map and assuming a thermal spectrum (APEC) of T = 1.5 keV, 0.3 times the solar value metallicity, at the cluster redshift and the Galactic absorption (Kalberla et al. 2005). We checked that using a T = 3.5 keV temperature does not alter our conclusions. Figure 8 shows the (posterior) probability distribution of LX for our clusters. Sharp distributions indicate precisely determined LX. Note the asymmetry and general non-Gaussian shape of clusters with lower quality determinations of LX.
We detail the fitting model in Appendix A in a user-friendly way for computing the flux, and/or its upper limit, of whatever source. Again, the use of this model is particularly important for the faintest elements of our catalog, which are the most interesting cases for the purposes of this work. The fitting model returns physically acceptable values in all situations, including when observed counts in the cluster direction are lower than the average measured background, a situation that occurs, for example, when a faint cluster is on the top of a negative background fluctuation. Returned uncertainties behave as expected: they do not include non-physical (negative) X-ray luminosities and are large when the X-ray flux is low, which is not guaranteed in other approaches (as illustrated in Kraft et al. 1991).
 |
Fig. 6 X-ray counts in the direction of the clusters (points) in units of the mean background value measured all around them. The error bars indicate heuristic ( |
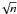
 |
Fig. 7 Half power radius of clusters (black circle) compared with the 50th (square) and 90th (orange triangle) percentile of the distribution of PSFs simulated in the same conditions (off-axis, spectrum, counts and background). |
 |
Fig. 8 (Posterior) LX probability distribution for clusters in our sample. Curves are offset vertically to improve readibility. Note the non-Gaussian shape (e.g., asymmetry) of the several of them, as also indicated by asymetric errors in Table 2. |
Table 2 lists cluster id (Col. 1), Swift exposure time on source (Col. 2), total number of photons in the cluster direction, obstoti (Col. 3), and in the background direction, obsnbkgi (Col. 4). The latter is measured in a solid angle nboxi times larger. Column 6 gives the number needed to convert counts into X-ray luminosity. Column 7 lists derived X-ray luminosities and their 68% (highest posterior) intervals.
To summarize, all clusters, except #9, display a significant extended X-ray emission, as shown in Figs. 6 and 7. As mentioned, the X-ray emission of cluster #9 is not secured. The X-ray detection of 32 clusters out of 33 implies that the 90% upper limit fraction of X-ray dark clusters is 0.11. This number should be read as pessimistic because cluster #9 is likely an X-ray emitting system. Therefore we can infer that X-ray surveys do not systematically miss a significant population of X-ray dark halos, which is an essential assumption for any cosmological use of X-ray cluster surveys such as those that will be performed e-Rosita and, possibly, WFXT.
The fraction of color-detected clusters that are real objects is even higher, 0.935 (at 90% confidence), because cluster #9, for which our X-ray data provide no compelling evidence, is spectroscopically confirmed. In other words, we find that all color-selected clusters are real (the 90% upper limit to spurious detection is 0.065); this is an essential and promising piece of information for incoming surveys as DES or EUCLID.
Our finding of a tight upper limit to the fraction of X-ray dark clusters agrees with the results of Donahue et al. (2001), but offers a more stringent constraint. While up to 75% of the optically selected clusters in Donahue et al. (2001) might be dark because X-ray undetected, our 90% upper limit is around 5 to 10%. We find a tight upper limit because our observation strategy has been tailored to avoid little informative upper limits to the X-ray flux, i.e. values brighter than, or comparable to, the mean LX-richness relation.
Our upper limit to the fraction of X-ray dark cluster agrees with the fraction one can derive from the X-ray observations of 13 clusters at much higher redshift, 0.6 < z < 1.1 reported in Hicks et al. (2008) and Bignamini et al. (2008). Counting as possibly dark all clusters that do not have a clear X-ray detection, one in our sample and three in theirs, the 90% upper limit to the fraction of X-ray dark clusters is 11% in our sample, and 42% in theirs. The latter value is higher because their sample size is small, only 13 systems, and their X-ray upper limits are little informative.
X-ray data.
We stress that our conclusions are applicable to color-detected clusters in the local Universe (0.1 < z < 0.3) using a filter pair that brackets the 4000 Å break, of richness comparable to the clusters listed in the maxBCG catalog (>10 galaxies counted as they do, or ≥ 4 as we do). As just mentioned, there are indications that the same results may hold true at higher redshift.
We note that the fraction of spurious detection that we find in the MaxBCG catalog (<6.5%) is consistent with the typical contamination level of X-ray and SZ catalogs. For example, 1 in 34 of the REFLEX (i.e. X-ray) selected clusters have subsequently been discovered to be AGNs (Boheringer et al. 2007); a similar fraction of objects are expected to be false positives in the 400d survey (Burenin et al. 2007). Four out of 21 new cluster candidates identified in the Planck ESZ sample are known not to be single clusters and are instead double or triple systems from XMM follow-up observations (Planck collaboration et al. 2011). Note that prior to publication both these X-ray and SZ selected samples were subject to attentive scrutiny in the optical, whereas our sample of maxBCG clusters were not filtered out by any X-ray data inspection.
5. LX-richness relation
As we have said, the 90% (pessimistic) upper limit fraction of X-ray dark clusters is 11%. We will now to address a finer question, namely whether a significant population of underluminous clusters exists at all. They may, of course, exist without being dark (at least in principle), and may thus have been counted as X-ray emitters in the previous section. Therefore, we looked for outliers in the regression between richness and X-ray luminosity.
For this regression, our fitting model assumes a linear relation between (the log of) the true richness and true X-ray flux (with some intrinsic scatter), but rather than these true values, we have noisy measurements of both richness and X-ray flux, with noise amplitude different from point to point. We account for the Poisson nature of counts, the non-Poisson nature of X-ray flux and richness, for higher than Poisson fluctuations in the X-ray background and covariance for all modeled quantities. This computation requires the use of the full probability distribution for intervening quantities, not just the point estimates of X-ray flux and richness given in Tables 1 and 2. The fitting model is fully described in Appendix B, where we also give its coding. To our best knowledge, this model and the one of in Appendix A have never been published before.
Using the fitting model, we found for our sample of 33 color-selected clusters 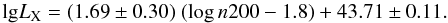 (2)Figure 9 shows the scaling between richness and X-ray luminosity, observed data, the mean scaling (solid line) and its 68% uncertainty (shaded yellow region) and the mean intrinsic scatter (dashed lines) around the mean relation. The 1σscatt band is not expected to contain 68% of the data points because of the measurement errors. All points are, however, within twice the intrinsic scatter. The upper abscissa also gives the cluster mass.
(2)Figure 9 shows the scaling between richness and X-ray luminosity, observed data, the mean scaling (solid line) and its 68% uncertainty (shaded yellow region) and the mean intrinsic scatter (dashed lines) around the mean relation. The 1σscatt band is not expected to contain 68% of the data points because of the measurement errors. All points are, however, within twice the intrinsic scatter. The upper abscissa also gives the cluster mass.
Figure 10 shows the posterior probability distribution of the intercept, slope, and intrinsic scatter σscat. These probability distributions are reasonably well approximated by Gaussians. The intrinsic LX scatter at a given richness, σscat = σlgLX|log n200, is very large, 0.51 ± 0.08 dex. In other terms, a whole 1 dex in LX is needed to bracket 68% of clusters of a given richness.
Figure 9 also shows that the three (out of three) X-ray selected clusters (for this reason not fitted) are much brighter than the mean regression, as expected for X-ray selected objects. Figure 9 shows that the data of cluster #9 (the object with the lowest n200 and an X-ray flux excess higher than the Possion fluctuation, but still consistent with a 20% background fluctuation) are also compatible with the X-ray luminosity expected for its richness.
 |
Fig. 9 X-ray luminosity-richness scaling. The solid line indicates the mean fitted regression line of log LX, measured within a 500 kpc aperture, on log n200, while the dashed line shows this mean plus or minus the intrinsic scatter σscat. The shaded region marks the 68% highest posterior credible interval for the regression. Error bars on the data points represent observed errors for both variables (computed following the usual astronomical practice). The distances between the data and the regression line is partly caused by the measurement error and partly by the intrinsic scatter. The upper abscissa indicates the cluster mass. |
 |
Fig. 10 Posterior probability distribution for the parameters of the X-ray luminosity-richness scaling. The black jagged histogram shows the posterior as computed by MCMC, marginalized over the other parameters. The red curve is a Gaussian approximation of it. The shaded (yellow) range shows the 95% highest posterior credible interval. The jagged nature of the histogram is caused by the finite sampling of the posterior. |
Figure 9 allows us to address the question mentioned at the start of this section, whether there is a population of clusters with much lower X-ray luminosity at a given richness or mass, i.e. underluminous. None of them has been found in our sample, because no point is much off from the regression, the farthest one being about 1.5 times the intrinsic scatter. Indeed, the current data allow us to set an upper limit to the fraction of underluminous clusters. Because no outlier is present in a sample of 33, this sets a 90% upper limit of 0.065.
We used a 500 kpc aperture as a good compromise between the physical dimensions of the cluster and the typical apparent size in our observation. To test the robustness of our results we also measured the relation using an aperture of 1.07 Mpc (adopted by Rykoff et al. 2008). We found 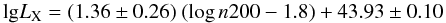 (3)and an intrinsic scatter of 0.44 ± 0.07. Figure 11 shows the scaling between richness and X-ray luminosity with this larger aperture. These parameters are consistent with those derived using the small aperture. If anything, the intercept is slightly larger than using a smaller aperture because there is some cluster flux outside 0.5 Mpc. As in the case of the smaller aperture, there are no outliers and no cluster qualifies itself as underluminous.
(3)and an intrinsic scatter of 0.44 ± 0.07. Figure 11 shows the scaling between richness and X-ray luminosity with this larger aperture. These parameters are consistent with those derived using the small aperture. If anything, the intercept is slightly larger than using a smaller aperture because there is some cluster flux outside 0.5 Mpc. As in the case of the smaller aperture, there are no outliers and no cluster qualifies itself as underluminous.
Slope and intercept agree with the values reported in Rykoff et al. (2008). Our intrinsic scatter, which formally agrees, is larger than the total scatter they report, even though we expect the contrary because their (total) scatter does not account for point-source contamination, for miscentering (30% of clusters with wrong coordinates), redshift dependence of their definition of richness, and richness errors2. We checked to find a larger scatter also adopting the MaxBCG n200 definition. We emphasize that while these observed differences are within the errors, our work gives the first robust measurement of the intrinsic scatter of LX at a given richness, previous attemps (e.g., Rykoff et al. 2008) do not have completely removed all observationally-related effects from its estimate.
6. Do we know any underluminous clusters?
We found no underluminous clusters. However, other works (e.g., Bignamini et al. 2008; Hicks et al. 2008; Castellano et al. 2011; Dietrich et al. 2009; Balogh et al. 2011) do. What is the reason for this? To claim that a cluster is underluminous, it is critical
a): to account for the intrinsic scatter. If none is assumed, a cluster isclaimed to be underluminous when instead it is normal, i.e. justone (true) σintr below from the mean relation. Once the intrinsic scatter is allowed, the putative Dietrich et al. (2009) X-ray underluminous cluster becomes a normal cluster;
b): to use a non-biased relation as reference to determine the underluminous nature of a putative cluster. Indeed, if a reference relation is (mis)taken biased-high, one may wrongly classify normal clusters as underluminous. The reference relation may be easily biased as high if the comparison sample is formed by X-ray selected clusters or by an uncontrolled sample, as is now well known from the literature (e.g., for the LX − T relation: Pacaud et al. 2007; Stanek et al. 2006; Nord et al. 2008; Andreon et al. 2011; Andreon & Hurn 2011). The bias occurs when the probability that a cluster is included in the sample depends on its own LX. This is the case for an X-ray selected sample, but also for every sample for which there is a selection based on (individual) cluster luminosity, flux or counts, (e.g., at least n photons for a temperature measurement, with n often in the range 200 − 1000). Indeed, in an X-ray selected sample, the bias comes from the larger Universe volume over which a cluster brighter-than-average at a given richness can be seen compared to fainter-than-average clusters. Therefore, in an X-ray selected sample, at a given richness the upper half of the LX distribution will be more populated than the lower half, biasing high the mean, and underestimating the dispersion (if the effect is not accounted for). A similar bias is also likely present in cluster samples assembled from pointed observations of X-ray selected clusters like the ones built by, amongst others, Ettori et al. (2004) and Branchesi et al. (2007). On the contrary, a purely optically (or color, as in this work) selected sample of clusters does not introduce any bias in the LX-richness relation, because the average LX at a given richness will not be biased high (or low).
Bignamini et al. (2008), Hicks et al. (2008) conclude that color-selected clusters are underluminous. Castellano et al. (2011) claim the existence of an underluminous cluster. However, their claim is based on the comparion with a biased-high mean LX − T.Finally, Balogh et al. (2011) asses the X-ray properties of their sample using Chandra or XMM observations for all but two clusters (both undetected in X-ray), and claim the existence of five X-ray underluminous clusters in a sample of 18 of mass in the range considered in our sample. However, a) their X-ray upper limits are all equal irrespective of the cluster redshift, exposure time, or XRT used (ROSAT vs. Chandra or XMM); b) four out five of them are within 2 sigma (1 dex) of the mean LX-richness relation, not enough to call them underluminous (outlier); c) the authors note that three of the five underluminous clusters, objects 13, 17 and 18, are possibly fake objects (chance projections), not truly existing clusters.
Older claims about the existence of underluminous clusters are rebutted in Andreon et al. (2009). That paper shows that underestimated errors may incorrectly lead to classify a cluster as underluminous even when it agrees with the mean relation, for example when it is, say, 3 (wrong) σ below the mean relation.
7. Discussion
The analysis of our sample of 33 clusters at 0.1 < z < 0.3 and our revision of the recent literature results presented in Sect. 6, joined to our revision of older works in Andreon et al. (2009), confirms that X-ray underluminous clusters are rare enough that we are still looking for an example. Some scenarios of cluster formation predict the existence of underluminous clusters, objects in which the gas has been expelled (e.g., Bower et al. 2008; McCarthy et al. 2011). As we found none in a sample of 33, our 90% upper limit to this type of objects is 0.065.
This work, which is based on a color-selected sample of clusters, does not address the fraction of clusters without a red sequence. However, past works have shown the absence of X-ray selected clusters without red galaxies, for example 54 out 54 X-ray selected clusters studied in Andreon & Hurn (2010) have red galaxies and all 32 clusters in Garilli et al. (1996) and in Puddu et al. (2001) of the Einstein Medium Sensitivity Surveys have a red sequence. Overall, the general picture that emerges from this work, when joined to the absence of X-ray selected clusters without red galaxies, is that outliers in the dark (X-ray or low richness) side are quite rare and that the X-ray and color selection sample the same population of objects. This conclusion is supported indeed at much higher redshift by the smaller sample analyzed in Bignamini et al. (2008) and Hicks et al. (2008), in which no believable outliers from the mean relation is found, and by the detection of a red sequence (Andreon et al. 2004, 2005) in all X-ray selected clusters of the XMM-LSS survey (Pierre et al. 2004).
8. Summary and conclusions
We studied the X-ray properties of a color-selected sample of clusters at 0.1 < z < 0.3 and we critically discussed previous works claiming the existence of underluminous clusters.
Two important guidelines have been strictly followed in the sample selection. First, the sample has been selected to have sufficiently deep X-ray observations to probe their X luminosity down to very faint values and, second, at the same time we did not use any criterium that depends directly or indirectly on the X luminosity, at a given richness, of the single objects. Our sample consist of 33 clusters that fall in sky regions where deep Swift XRT X-ray observations are available.
Using SDSS data, we refined the cluster centers and richnesses and we estimated cluster masses using richness as mass proxy. These clusters have masses in the range between 5 × 1013 and 8 × 1014 solar masses. This allowed an unbiased measure of the LX-n200 relation for a small, but representative, sample of galaxy clusters.
Using 1.4 Ms Swift XRT data, we measured the X-ray luminosity within an aperture of 500 kpc. In these calculations, we accounted for terms usually neglected, such as over-Poisson fluctuations of X-ray background counts, which turned out to be on the order of 20%, cluster miscentering (i.e. that the cluster center is in 30% of the cases at a sky location different from what is listed in the catalog), the positively defined nature of measured quantities (richness and X-ray luminosity), etc.
Thirty-two out of our 33 color-selected clusters are obvious X-ray detections. The remaining cluster shows an X-ray excess in the cluster direction compatible with a possible background fluctuation but also with the expected X-ray luminosity of a cluster of the same richness. Therefore, the fraction of X-ray dark clusters (if any of them exist) is low: 11% (at 90% confidence level).
Since 32 out 33 color-detected clusters are X-ray emitting, then at least 89% of color-detected clusters are real objects with a potential well deep enough to heat and retain an intracluster medium. Because the system with suggestive, but not compelling evidence of an X-ray emission is spectroscopically confirmed, the fraction of false positive in color-selected searches has most probably an upper limit of 6.5%. The low contamination of color-selected clusters is a requirement for the use of color-selected clusters for cosmological aims and this work directly shows that this requirement is fulfilled in the mass and redshift ranges considered here.
The quite strict upper limit to the fraction of X-ray dark or underluminous clusters, 6.5 to 11%, depending on the status of our system without compelling evidence of an X-ray emission, also justifies the widespread use of X-ray selected clusters (e.g., Pacaud et al. 2007), in the sense that X-ray surveys do not systematically miss halos with (red) galaxies inside them. Broadly speaking, X-ray and color (galaxy) cluster searches detect the same population: no X-ray dark cluster is found (in this work and in our revision of other works), and no X-ray selected cluster is found (in other works) not to have red galaxies (of course, in the mass range and in the portion of the Universe volume explored by the considered data).
X-ray luminosity, measured within a 500 (1070) kpc aperture, scales with richness with a proportional factor 1.69 (1.36), with a noticeable scatter, 0.51 ± 0.07 (0.44 ± 0.07) dex. The intrinsic scatter is compatible, but larger, than previously reported scatters. Nevertheless, we emphasize that previous attemps (e.g., Rykoff et al. 2008) do not have completely removed all observational-related effects from the scatter estimate, and thus are not quoting a measurement of scatter entirely related to the object under study, i.e. intrinsic to clusters, but a mix of intrinsic scatter and observer-related effects (such as having no flagged point-sources or having centered the X-ray aperture away from the cluster).
Finally, we found that the observed fraction of miscentered clusters is 0.28 ± 0.07. This parameter and its uncertainty are required to estimate cosmological parameters or to perform cosmological forecasts using richness as mass proxy.
Our results are very promising for cosmological estimates based on galaxy-detected clusters at least for the redshift and mass ranges considered in this work: surveys as DES or EUCLID will image a large part of the sky, returning color-selected clusters with the same low contamination of X-ray selected clusters (as shown in this work), with a mass proxy of equal quality (Andreon & Hurn 2010), but with an at least 10 times larger sample (Andreon & Hurn 2010). Galaxy-detected clusters are also promising when compared to current SZ-detected clusters: current SZ surveys return one hundred to one thousand fewer clusters than optical searches (e.g., one cluster per 8 to 19 deg2, Vanderlinde et al. 2010; Marriage et al. 2011), with a mass proxy that has an observationally determined scatter of about 0.5 dex (Rines et al. 2010), i.e. much worser than n200 performances (0.3 dex, Andreon & Hurn 2010). Forecasts specifically for EUCLID will be presented in Trotta et al. (in prep.).
n200 is a measure of the cluster richness, and it is given by the number of cluster galaxies measured in some standard conditions, see Sect. 3 for details.
Rozo et al. (2011) prefer to use the term “intrinsic scatter” to indicate richness errors.
Acknowledgments
We acknowledge financial contribution from the agreement ASI-INAF I/009/10/0 and ASI-INAF I/011/07/0. For the standard SDSS acknowledgement see: http://www.sdss.org/dr6/coverage/credits.html.
References
- Andreon, S. 2003, A&A, 409, 37 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Andreon, S. 2010, MNRAS, 407, 263 [NASA ADS] [CrossRef] [Google Scholar]
- Andreon, S., & Hurn, M. A. 2010, MNRAS, 404, 1922 [NASA ADS] [Google Scholar]
- Andreon, S., & Hurn, M. A. 2011, Statistical Analysis and Data Mining, submitted [Google Scholar]
- Andreon, S., Willis, J., Quintana, H., et al. 2004, MNRAS, 353, 353 [NASA ADS] [CrossRef] [Google Scholar]
- Andreon, S., Valtchanov, I., Jones, L. R., et al. 2005, MNRAS, 359, 1250 [NASA ADS] [CrossRef] [Google Scholar]
- Andreon, S., de Propris, R., Puddu, E., Giordano, L., & Quintana, H. 2008, MNRAS, 383, 102 [NASA ADS] [CrossRef] [Google Scholar]
- Andreon, S., Maughan, B., Trinchieri, G., & Kurk, J. 2009, A&A, 507, 147 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Andreon, S., Trinchieri, G., & Pizzolato, F. 2011, MNRAS, 412, 2391 [NASA ADS] [CrossRef] [Google Scholar]
- Becker, M. R., McKay, T. A., Koester, B., et al. 2007, ApJ, 669, 905 [NASA ADS] [CrossRef] [Google Scholar]
- Bower, R. G., McCarthy, I. G., & Benson, A. J. 2008, MNRAS, 390, 1399 [NASA ADS] [Google Scholar]
- Balogh, M. L., Mazzotta, P., Bower, R. G., et al. 2010, MNRAS, 412, 947 [Google Scholar]
- Bignamini, A., Tozzi, P., Borgani, S., Ettori, S., & Rosati, P. 2008, A&A, 489, 967 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Böhringer, H., Schuecker, P., Pratt, G. W., et al. 2007, A&A, 469, 363 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Burenin, R. A., Vikhlinin, A., Hornstrup, A., et al. 2007, ApJS, 172, 561 [NASA ADS] [CrossRef] [Google Scholar]
- Burrows, D. N., Hill, J. E., Nousek, J. A., et al. 2005, SSRv, 120, 165 [Google Scholar]
- Castellano, M., Pentericci, L., Menci, N., et al. 2011, A&A, 530, A27 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Citterio, O., & O’Dell, S. L. 2004, SPIE, 5168 [Google Scholar]
- D’Agostini, G. 2003, Bayesian reasoning in data analysis: A critical introduction (World Scientific Publishing) [Google Scholar]
- Dai, X., Kochanek, C. S., & Morgan, N. D. 2007, ApJ, 658, 917 [NASA ADS] [CrossRef] [Google Scholar]
- Dellaportas, P., & Stephens, D. 1995, Biometrics, 51, 1085 [CrossRef] [Google Scholar]
- Dietrich, J. P., Biviano, A., Popesso, P., et al. 2009, A&A, 499, 669 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Donahue, M., Mack, J., Scharf, C., et al. 2001, ApJ, 552, L93 [NASA ADS] [CrossRef] [Google Scholar]
- Ettori, S., Tozzi, P., Borgani, S., & Rosati, P. 2004, A&A, 417, 13 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gehrels, N., Chincarini, G., Giommi, P., et al. 2004, ApJ, 611, 1005 [NASA ADS] [CrossRef] [Google Scholar]
- Gladders, M. D., & Yee, H. K. C. 2000, AJ, 120, 2148 [NASA ADS] [CrossRef] [Google Scholar]
- Gladders, M. D., Yee, H. K. C., Majumdar, S., et al. 2007, ApJ, 655, 128 [NASA ADS] [CrossRef] [Google Scholar]
- Hicks, A. K., Ellingson, E., Bautz, M., et al. 2008, ApJ, 680, 1022 [NASA ADS] [CrossRef] [Google Scholar]
- Hilbert, S., & White, S. D. M. 2010, MNRAS, 404, 486 [NASA ADS] [Google Scholar]
- Holder, G. P., McCarthy, I. G., & Babul, A. 2007, MNRAS, 382, 1697 [NASA ADS] [Google Scholar]
- Kalberla, P. M. W., Burton, W. B., Hartmann, D., et al. 2005, A&A, 440, 775 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Koester, B. P., McKay, T. A., Annis, J., et al. 2007, ApJ, 660, 239 [NASA ADS] [CrossRef] [Google Scholar]
- Kraft, R. P., Burrows, D. N., & Nousek, J. A. 1991, ApJ, 374, 344 [NASA ADS] [CrossRef] [Google Scholar]
- McCarthy, I. G., Schaye, J., Bower, R. G., et al. 2011, MNRAS, 412, 1965 [NASA ADS] [CrossRef] [Google Scholar]
- Majumdar, S., & Mohr, J. J. 2004, ApJ, 613, 41 [NASA ADS] [CrossRef] [Google Scholar]
- Marriage, T. A., Acquaviva, V., Ade, P. A. R., et al. 2011, ApJ, 737, 61 [NASA ADS] [CrossRef] [Google Scholar]
- Moretti, A., Campana, S., Mineo, T., et al. 2005, SPIE, 5898, 348 [Google Scholar]
- Moretti, A., Perri, M., Capalbi, M., et al. 2007, Proc. SPIE, 6688, 66880 [Google Scholar]
- Moretti, A., Pagani, C., Cusumano, G., et al. 2009, A&A, 493, 501 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Moretti, A., Gastaldello, F., Ettori, S., & Molendi, S. 2011, A&A, 528, A102 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Nord, B., Stanek, R., Rasia, E., & Evrard, A. E. 2008, MNRAS, 383, L10 [NASA ADS] [CrossRef] [Google Scholar]
- Oguri, M., & Takada, M. 2011, Phys. Rev. D, 83, 023008 [NASA ADS] [CrossRef] [Google Scholar]
- Pacaud, F., Pierre, M., Adami, C., et al. 2007, MNRAS, 382, 1289 [NASA ADS] [CrossRef] [Google Scholar]
- Planck Collaboration 2011, A&A, 536, A9 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Plummer, M. 2008, JAGS Version 1.0.3 user manual3 [Google Scholar]
- Puddu, E., Andreon, S., Longo, G., et al. 2001, A&A, 379, 426 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Stanek, R., Evrard, A. E., Böhringer, H., Schuecker, P., & Nord, B. 2006, ApJ, 648, 956 [NASA ADS] [CrossRef] [Google Scholar]
- Reyes, R., Mandelbaum, R., Hirata, C., Bahcall, N., & Seljak, U. 2008, MNRAS, 390, 1157 [NASA ADS] [CrossRef] [Google Scholar]
- Rines, K., Geller, M. J., & Diaferio, A. 2010, ApJ, 715, L180 [NASA ADS] [CrossRef] [Google Scholar]
- Rykoff, E. S., McKay, T. A., Becker, M. R., et al. 2008, ApJ, 675, 1106 [NASA ADS] [CrossRef] [Google Scholar]
- Rozo, E., Rykoff, E. S., Koester, B. P., et al. 2009, ApJ, 703, 601 [NASA ADS] [CrossRef] [Google Scholar]
- Rozo, E., Wechsler, R. H., Rykoff, E. S., et al. 2010, ApJ, 708, 645 [NASA ADS] [CrossRef] [Google Scholar]
- Vanderlinde, K., Crawford, T. M., de Haan, T., et al. 2010, ApJ, 722, 1180 [NASA ADS] [CrossRef] [Google Scholar]
- Wu, H.-Y., Rozo, E., & Wechsler, R. H. 2008, ApJ, 688, 729 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: Model for the X-ray flux, accounting for over-Poisson background fluctuations
The aim of this section is to present a Bayesian analysis of the X-ray luminosity fitting model. In particular, we wish to acknowledge the uncertainty in all measurements, including the background estimation.
Because of errors, observed and true values are not identical. We call nclusi and nbkgi the true cluster and the true background counts in the studied solid angles. We measured the number of photons in both cluster and background regions, obstoti and obsbkgi respectively, for each of our 36 clusters (i.e. for i = 1,...,36). The background solid angle is nboxi times larger than the cluster solid angle. We assume a Poisson likelihood for both and that all measurements are conditionally independent. 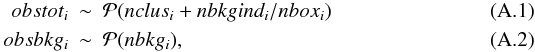 where the symbols ~ reads “is distributed as” and and
where the symbols ~ reads “is distributed as” and and 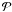 stands for the Poisson distribution.
stands for the Poisson distribution.
nbkgindi is allowed to fluctuate by 20% around the global background value, so that the predicted scatter of background values matches the observed one inside each XRT field: 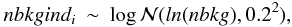 (A.3)where the symbol
(A.3)where the symbol 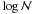 stands for the lognormal distribution.
stands for the lognormal distribution.
We assume uniform priors on cluster and background counts, zero-ed to un-physical values:  Finally, cluster net counts, nclusi, are converted into X-ray luminosities as usual:
Finally, cluster net counts, nclusi, are converted into X-ray luminosities as usual: 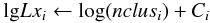 (A.6)where the arrow symbol reads “take the value of”, and Ci is the usual conversion from counts to Lx.
(A.6)where the arrow symbol reads “take the value of”, and Ci is the usual conversion from counts to Lx.
Equations (A.1) to (A.6) find an almost literal translation in JAGS (Plummer 2008), Poisson, normal, lognormal and uniform distributions become dpois, dnorm, dlnorm, dunif, respectively. JAGS, following BUGS (Spiegelhalter et al. 1995), uses precisions, prec = 1/σ2, in place of variances σ2. Furthermore, it uses neperian logarithms, instead of decimal ones.
This model (set of equations) reads in JAGS:
model
{
for (i in 1:length(obstot)) {
obstot[i] ~ dpois(nclus[i]+nbkgind[i]/nbox[i])
nbkgind[i] ~ dlnorm(log(nbkg[i]),1/0.2/0.2)
obsbkg[i] ~ dpois(nbkg[i])
nbkg[i] ~ dunif(1,1.0E+7)
nclus[i] ~ dunif(0,1.0E+7)
# optional, JAGS is not needed to do it
lgLx[i] <- log(nclus[i])/2.30258 +C[i]
}
}
This model (and code) gives the posterior distribution of the cluster X-ray luminosity, given the observed values of cluster and background counts. Data, posterior mean and (highest posterior) 68% intervals of the X-ray luminosity are listed in Table 2.
Note that a different prior for cluster and background counts may be more appropriate and valuable in other contexts. In Appendix B we adopt the prior inherited from the cluster richness for the cluster signal.
Appendix B: Model for the X-ray luminosity vs. richness/mass
The aim of this section is to present a Bayesian analysis of the X-ray luminosity-richness fitting model. In particular, we wish to acknowledge the uncertainty in all measurements, including background estimation. Basically, our model regresses two quantities, each one given by the difference of two Poisson deviates (photons or galaxy counts). We allow the existence of an intrinsic scatter between regressed quantities, and higher than Poisson fluctuations of the X-ray background. In the statistics literature, such a model is know as an “errors-in-variables regression” (Dellaportas & Stephens 1995). Our model is an extension of the model in Andreon & Hurn (2010), accounting for the different nature of one of the modeled quantities (X-ray luminosity instead of mass) and for the presence of over-Poisson fluctuations.
First of all, because of errors, observed and true values are not identically equal. The variables n200i and ngalbkgi represent the true richness and the true background galaxy counts in the studied solid angles. We measured the number of galaxies in both cluster and control field regions, obsgaltoti and obsgalbkgi respectively, for each of our 33 clusters (i.e. for i = 1,...,33). We assumed a Poisson likelihood for both and that all measurements are conditionally independent. The ratio between the cluster and control field solid angles, Cgali, is exactly known. In formulae: 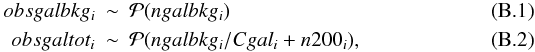 for the X-ray photons a similar construct holds, as detailed in the section above, with Eq. (A.4) removed (the prior on LX is inherited from n200 and σscatt ones), and Eq. (A.6) replaced by
for the X-ray photons a similar construct holds, as detailed in the section above, with Eq. (A.4) removed (the prior on LX is inherited from n200 and σscatt ones), and Eq. (A.6) replaced by 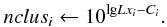 (B.3)We assume a linear relation between the unobserved LX and n200 on the log scale, with intercept α + 44.0, slope β and intrinsic scatter σscat:
(B.3)We assume a linear relation between the unobserved LX and n200 on the log scale, with intercept α + 44.0, slope β and intrinsic scatter σscat: 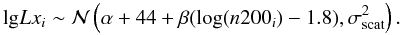 (B.4)Note that log (n200) is centered at an average value of 1.8 and α is centred at 44.0, purely for computational advantages in the MCMC algorithm used to fit the model (it speeds up convergence, improves chain mixing, etc.), and that the relation is between true values, not between observed values.
(B.4)Note that log (n200) is centered at an average value of 1.8 and α is centred at 44.0, purely for computational advantages in the MCMC algorithm used to fit the model (it speeds up convergence, improves chain mixing, etc.), and that the relation is between true values, not between observed values.
The priors on the slope and the intercept of the regression line in Eq. (B.4) are taken to be quite flat, a zero mean Gaussian with very large variance for α and a Students t distribution with 1 degree of freedom for β. The latter choice is made to avoid that properties of galaxy clusters depend on humans rules to measure angles (from the x axis anticlockwise or from the y axis clockwise). This agrees with the model choices in Andreon (2006 and later works) but differs from most other works. Our t distribution on β is mathematically equivalent to a uniform prior on the angle b.  Finally, we need to specify the prior for the intrinsic scatter, σscat, which is positively defined. Following Andreon & Hurn (2010) and Andreon (2010), we impose a quite weak prior information: a Gamma distribution on
Finally, we need to specify the prior for the intrinsic scatter, σscat, which is positively defined. Following Andreon & Hurn (2010) and Andreon (2010), we impose a quite weak prior information: a Gamma distribution on 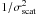 ,
, 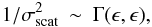 (B.7)with ϵ taken to be a very small number.
(B.7)with ϵ taken to be a very small number.
In JAGS, our model reads
model
{
intrscat <- 1/sqrt(prec.intrscat)
prec.intrscat ~ dgamma(1.0E-5,1.0E-5)
alpha ~ dnorm(0.0,1.0E-4)
beta ~ dt(0,1,1)
for (i in 1:length(obstot)) {
# modelling X-ray photons
obstot[i] ~ dpois(nclus[i]+nbkgind[i]/nbox[i])
nbkgind[i] ~ dlnorm(log(nbkg[i]),1/0.2/0.2)
obsbkg[i] ~ dpois(nbkg[i])
nbkg[i] ~ dunif(0,10000)
# convert nclus in Lx
nclus[i] <- exp(2.30258*(lgLx[i]-C[i]))
# modelling galaxy counts
# n200 term
obsgalbkg[i] ~ dpois(ngalbkg[i])
obsgaltot[i] ~ dpois(ngalbkg[i]/Cgal[i]+n200[i])
n200[i] ~ dunif(1,3000)
ngalbkg[i] ~ dunif(0,3000)
# modeling Lx -n200 relation
z[i] <- alpha+44+beta*(log(n200[i])/2.30258-1.8)
lgLx[i] ~ dnorm(z[i], prec.intrscat)
}
}
All Tables
All Figures
|
Fig. 1 Distribution of cluster masses. |
| In the text | |
|
Fig. 2 Comparison of the richness as determined by us (ordinate) and in the maxBCG catalog. Open points marks miscentered clusters in the maxBCG catalog. There is no error on the abscissa because none is listed in the maxBCG catalog. |
| In the text | |
|
Fig. 3 Redshift dependence of richness residuals. Open points indicate miscentered clusters in the maxBCG catalog. Error bars only consider errors on our richness estimate, because there is no such measurement for the maxBCG. |
| In the text | |
|
Fig. 4 Montage of the Swift XRT [0.5 − 2] keV images of clusters in our sample, convolved with a Gaussian kernel with σ = 18 arcsec. The ruler indicates 1 arcmin. North is up, east is to the left. The cluster is marked by a green circle. Red circles mark other sources masked in our analysis. |
| In the text | |
|
Fig. 5 Expected (red error bars) and observed (black points) spread in background values vs median background value. The upper panel assumes purely Poisson background fluctuations, whereas the lower panel allow a 20% scatter in the mean background value. |
| In the text | |
|
Fig. 6 X-ray counts in the direction of the clusters (points) in units of the mean background value measured all around them. The error bars indicate heuristic ( |
| In the text | |
|
Fig. 7 Half power radius of clusters (black circle) compared with the 50th (square) and 90th (orange triangle) percentile of the distribution of PSFs simulated in the same conditions (off-axis, spectrum, counts and background). |
| In the text | |
|
Fig. 8 (Posterior) LX probability distribution for clusters in our sample. Curves are offset vertically to improve readibility. Note the non-Gaussian shape (e.g., asymmetry) of the several of them, as also indicated by asymetric errors in Table 2. |
| In the text | |
|
Fig. 9 X-ray luminosity-richness scaling. The solid line indicates the mean fitted regression line of log LX, measured within a 500 kpc aperture, on log n200, while the dashed line shows this mean plus or minus the intrinsic scatter σscat. The shaded region marks the 68% highest posterior credible interval for the regression. Error bars on the data points represent observed errors for both variables (computed following the usual astronomical practice). The distances between the data and the regression line is partly caused by the measurement error and partly by the intrinsic scatter. The upper abscissa indicates the cluster mass. |
| In the text | |
|
Fig. 10 Posterior probability distribution for the parameters of the X-ray luminosity-richness scaling. The black jagged histogram shows the posterior as computed by MCMC, marginalized over the other parameters. The red curve is a Gaussian approximation of it. The shaded (yellow) range shows the 95% highest posterior credible interval. The jagged nature of the histogram is caused by the finite sampling of the posterior. |
| In the text | |
 |
Fig. 11 As Fig. 9, but for an LX measured in an aperture of 1070 kpc. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.