| Issue |
A&A
Volume 535, November 2011
|
|
|---|---|---|
| Article Number | A119 | |
| Number of page(s) | 11 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/201117382 | |
| Published online | 23 November 2011 | |
Systematics in lensing reconstruction: dark matter rings in the sky?
1
IFCA, Instituto de Física de Cantabria (UC-CSIC), Av. de Los Castros s/n, 39005 Santander, Spain
e-mail: ponente@ifca.unican.es
2
Departamento de Física Moderna, Universidad de Cantabria, Av. de Los Castros s/n, 39005 Santander, Spain
Received: 31 May 2011
Accepted: 6 September 2011
Context. Non-parametric lensing methods are a useful way of reconstructing the lensing mass of a cluster without making assumptions about the way the mass is distributed in the cluster. These methods are particularly powerful in the case of galaxy clusters with a large number of constraints. The advantage of not assuming implicitly that the luminous matter follows the dark matter is particularly interesting in those cases where the cluster is in a non-relaxed dynamical state. On the other hand, non-parametric methods have several limitations that should be taken into account carefully.
Aims. We explore some of these limitations and focus on their implications for the possible ring of dark matter around the galaxy cluster CL0024+17.
Methods. We project three background galaxies through a mock cluster of known radial profile density and obtain a map for the arcs (θ map). We also calculate the shear field associated with the mock cluster across the whole field of view (3.3 arcmin). Combining the positions of the arcs and the two-direction shear, we perform an inversion of the lens equation using two separate methods, the biconjugate gradient, and the quadratic programming (QADP) to reconstruct the convergence map of the mock cluster.
Results. We explore the space of the solutions of the convergence map and compare the radial density profiles to the density profile of the mock cluster. When the inversion matrix algorithms are forced to find the exact solution, we encounter systematic effects resembling ring structures, that clearly depart from the original convergence map.
Conclusions. Overfitting lensing data with a non-parametric method can produce ring-like structures similar to the alleged one in CL0024.
Key words: cosmology: observations / gravitational lensing: weak / galaxies: clusters: general / dark matter / gravitational lensing: strong
© ESO, 2011
1. introduction
Gravitational lensing is one of the most powerful probes of dark matter. In particular, galaxy clusters host the strongest gravitational potentials in the Universe, hence they are rich in gravitational lensing effects. The distortions produced in the images of background galaxies by a galaxy cluster can be used to reconstruct the mass distribution of the cluster, which is believed to be largely dominated by dark matter. Two regimes are distinguished according to the strength of the lensing distortion. The weak lensing regime refers to small distortions that usually need to be studied in a statistical way. Large distortions, on the other hand, can be studied individually (or in pairs) and they are referred to as strong lensing. Strong lensing occurs when the projected surface mass density is on the order of the critical mass density Σcrit. In this scenario, a gravitational lens bends the light in such a way that it can produce multiple images (arcs) of the same background galaxy. Each multiple image can be used as a constraint of the mass distribution. The mass distribution has to be such that, when projected back into the source plane, the multiple images concentrate (or focus) into the same point. In most cases, the number of multiple images is small, which results in few constraints. If only strong lensing is available and the number of constraints is small, one needs to rely on parametric methods. However, more and more often new data reveals large numbers of multiple images around a single cluster. The cluster A1689 is probably the most spectacular example to date where hundreds of arcs can be seen around the cluster (Broadhurst et al. 2005a,b). When the number of constraints is sufficiently large, non-parametric methods become competitive with the parametric ones and with the advantage that no a priori assumption is made about the mass distribution of the cluster. Non-parametric methods applied to lensing mass reconstruction have been studied in the past (Saha & Williams 1997; Abdelsalam et al. 1998a; Bridle et al. 1998; Seitz et al. 1998; Kneib et al. 2003; Diego et al. 2005a,b; Smith et al. 2005; Bradač et al. 2005; Halkola et al. 2006; Cacciato et al. 2006). On the positive side, in cases where the number of constraints is large, the results obtained with the parametric and non-parametric methods agree well (Diego et al. 2005b) probing, among other things, that the dark matter does trace the luminous matter and the usefulness of non-parametric methods as a way of testing that the assumptions made in the parametric methods are well founded. Non-parametric methods have been used as well to combine weak and strong lensing data in the same analysis (Abdelsalam et al. 1998b; Bridle et al. 1998; Saha et al. 1999; Kneib et al. 2003; Smith et al. 2005; Bradač et al. 2005; Diego et al. 2007).
On the other hand, non-parametric methods have a series of limitations. In this paper we explore one of these limitations related to the limited resolution in the mass reconstruction and its connection with the accuracy in the reconstructed arc positions.
The results of this paper may have implications for the results of Jee et al. (2007), who use a non-parametric method and find an unusual ring of dark matter around the cluster. While we do not question the validity of these interesting results, we explore the possibility that spurious structures might appear when using non-parametric methods if the limitations of parametric methods are not taken into account in the analysis.
1.1. A ring of dark matter around CL0024+17?
The cluster CL0024+17 (z = 0.395) was one of the first for which strong lensing was observed (Wallington et al. 1992). Four strongly lensed arcs can be clearly seen around the tangential critical curve (see also, Smail et al. 1996; Broadhurst et al. 2000). These arcs have been used to constrain the mass in the central region of the cluster (Colley et al. 1996; Tyson et al. 1998; Broadhurst et al. 2000; Comerford et al. 2006). These mass constraints have been compared with those derived from X-ray measurements with Chandra (Ota et al. 2004) and XMM-Newton (Zhang et al. 2005). These authors estimated that the X-ray masses are a factor 3 − 4 lower than the lensing masses. This discrepancy has been interpreted as a sign that the cluster is not in hydrostatic equilibrium.
In Jee et al. (2007), the authors reconstruct the mass of the cluster out to 100 arcsec from its center. This corresponds to a physical size of 0.389 Mpc for an object located at z ≃ 0.4. In their analysis, they combine strong and weak lensing with a non-parametric method. The authors find a dark matter ring surrounding the cluster core, at r ≈ 75 arcsec from the center (Fig. 10 in Jee et al. 2007). The authors suggest that this ring might be the result of a high speed collision between two clusters along the line of sight (Czoske et al. 2001) in an scenario similar to the “bullet cluster” (Clowe et al. 2006) but with the difference that in that case the collision is perpendicular to the line of sight.
Whether the existence of the dark matter ring is real or not has been debated by many other authors (Milgrom & Sanders 2008; Qin et al. 2008; Liesenborgs et al. 2008; Zu Hone et al. 2009; Zitrin et al. 2009; Umetsu et al. 2010). Milgrom & Sanders (2008) reconstruct the radial profile of the mass assuming a model based on modified Newtonian dynamics (or MOND). The authors claim that a ringlike structure appears at the MOND transition region (see Figs. 3 and 4 in their paper). According to the authors, CL0024 can be considered as a robust probe of MOND. In Qin et al. (2008), the authors study the distribution of galaxies in CL0024, which, being collisionless, should exhibit a similar ring-like pattern. Based on a sample of 295 counts, the authors find no evidence of a ring in the distribution of galaxies. In a different paper, Zu Hone et al. (2009) use a hydrodynamical simulation of two collisioning clusters to compute the radial profiles after the collision. They find no evidence of either a dip or ring in the radial profile outside the core radius after the collision. They conclude that a ring-like feature could only be explained by an unlikely and highly tuned set of initial conditions before the collision.
To reanalyze the lensing data for CL0024, Zitrin et al. (2009) analyze this cluster using data from the Hubble Space Telescope (HST) instrument ACS/NIC3. The dark matter distribution profile was reconstructed using a SL parametric method based on six free parameters. The results presented in Figs. 1 and 2 of their paper reveal neither a dip nor ring in the profiles. Finally, Umetsu et al. (2010) combine a large field of view data set from the SUBARU telescope with data from HST ACS/NIC3, finding no evidence of the ringlike structure after the mass reconstruction (see Fig. 21 of their paper).
In this paper, we revisit the debate using a non-parametric method similar to that used in Jee et al. (2007) but applied to simulated data (weak and strong lensing). The advantage of using simulations is that the underlying dark matter distribution and the position and redshifts of the background sources are perfectly known. This offers the unique possibility of comparing the optimal solution with the multiple possible solutions obtained by the non-parametric method. We can also explore the space of solutions obtained when the minimization is done under different assumptions and compare with the original mass distribution.
In Sects. 2 and 3, we introduce the fundamentals of the gravitational lensing and the non-parametric method used in this paper for the mass reconstruction. In Sect. 4, we describe the mock data used in our analysis. In Sect. 5, we present the results obtained by our non-parametric method and compare the different solutions with the optimal one. Finally, in Sect. 6, we discuss our results and in Sect. 7 our conclusions.
2. Gravitational lensing basics
In gravitational lensing, it is usual to adopt the thin lens approximation because the cosmological distances between the observer, the lens, and the sources are much greater than the size of the lens. Hence, the lens can be treated as a plane. All the other elements in the lensing problem are also assumed to be located in planes. When there are multiple background galaxies, each one is assumed to be in a different plane with redshift zi (in the case of strong lensing) or in the same plane at the average redshift z (in the case of weak lensing). All these planes are perpendicular to the line of sight and the deflection is assumed to occur instantly when the light crosses the lens plane.
We define Dls as the angular diameter distance between the source plane and the lens plane and Dol and Dos as the angular diameter distances from the observer to the lens and from the observer to the sources, respectively. With respect to the line of sight, the sources are located at angular positions βi (i = 1,2,...,n with n the number of sources), while the lensed images are located at positions θi (i = 1,2,...,m with m the number of images). We define the equation of the lens 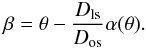 (1)We denote by ψ(θ) the two-dimensional potential produced by all the masses located at θ′
(1)We denote by ψ(θ) the two-dimensional potential produced by all the masses located at θ′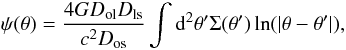 (2)where Σ(θ′) is the surface density of the cluster at the given position θ′. The part outside the integral is related to the critical density
(2)where Σ(θ′) is the surface density of the cluster at the given position θ′. The part outside the integral is related to the critical density 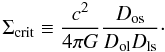 (3)The above equation is used in the definition of the convergence
(3)The above equation is used in the definition of the convergence 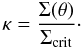 (4)The deflection angle α and the convergence can be expressed as derivatives of the two-dimension potential
(4)The deflection angle α and the convergence can be expressed as derivatives of the two-dimension potential  The magnification that the lens produces on the source is quantified by the determinant of the matrix describing the variation in the image position δθ for a small variation in the source position δβ
The magnification that the lens produces on the source is quantified by the determinant of the matrix describing the variation in the image position δθ for a small variation in the source position δβ![\begin{equation} \label{small_variation} \mu = \det \left | \frac{\partial \theta}{\partial \beta} \right | = \left [ \det \left | \frac {\partial \beta}{\partial \theta} \right | \right ]^{-1}\cdot \end{equation}](/articles/aa/full_html/2011/11/aa17382-11/aa17382-11-eq31.png) (7)From Eq. (1), we get
(7)From Eq. (1), we get 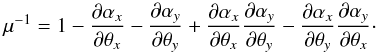 (8)The strong lens regime is most sensitive to the central mass of the cluster, where the mass surface density is normally higher than the critical surface mass density (κ > 1). When the surface mass density drops significantly below the critical density (κ ≪ 1), we are in the regime of weak lensing. Weak lensing cannot produce multiple images, but useful information about the distribution of the mass in the cluster can be extracted from the shear of the distortion (γ1 and γ2). Differentiating Eq. (1), we obtain
(8)The strong lens regime is most sensitive to the central mass of the cluster, where the mass surface density is normally higher than the critical surface mass density (κ > 1). When the surface mass density drops significantly below the critical density (κ ≪ 1), we are in the regime of weak lensing. Weak lensing cannot produce multiple images, but useful information about the distribution of the mass in the cluster can be extracted from the shear of the distortion (γ1 and γ2). Differentiating Eq. (1), we obtain 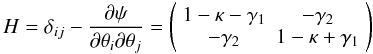 (9)where
(9)where 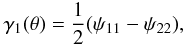 (10)
(10)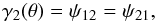 (11)where the double subscripts indicate the second order partial derivative. Equations (10) and (11) can be expressed in the complex notation
(11)where the double subscripts indicate the second order partial derivative. Equations (10) and (11) can be expressed in the complex notation 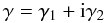 (12)to obtain the amplitude and the orientation of the deformation. The reduced shear is defined (in complex notation) g = γ/(1 − κ). The shear measures coherent shape distortions of source galaxies.
(12)to obtain the amplitude and the orientation of the deformation. The reduced shear is defined (in complex notation) g = γ/(1 − κ). The shear measures coherent shape distortions of source galaxies.
The detection of multiple images and/or the measurement of the shear can be used to constrain the mass distribution of the cluster. In cases where the number of constraints is large, the mass of the cluster expressed in Eq. (2) can be reconstructed using a non-parametric method.
2.1. Parameter-free lensing reconstruction
Here we adopt formalism and notation of Diego et al. (2005a) and Diego et al. (2007).
The mass reconstruction described in those papers is based on a parameter-free method where the lens plane is divided into a finite number of cells Nc and Eq. (1) can be written in algebraic form. The deflection angle α at a position θ is computed from the net contribution of the discretized mass distribution mi at the positions θi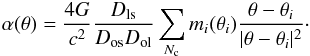 (13)The number of cells in the gridded mass must be carefully choosen. The discretization of the lens plane affects the spatial resolution of the mass reconstruction, as we discuss in more detail later.
(13)The number of cells in the gridded mass must be carefully choosen. The discretization of the lens plane affects the spatial resolution of the mass reconstruction, as we discuss in more detail later.
All the positions of the pixels hosting a strong lens image can be described by the vector θ of dimension Nθ. For each pixel in the θ vector and for a given discretized mass distribution, a corresponding β pixel can be traced back to the source plane. The relation between all these elements can be written in algebraic form 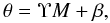 (14)where θ (and β) are vectors containing the x and y components of the Nθ pixels of the arcs (and sources), M is the vector of the masses inside the Nc cells, and the matrix Υ has the dimension of (2Nθ × Nc). The description of this matrix is given in Diego et al. (2005a).
(14)where θ (and β) are vectors containing the x and y components of the Nθ pixels of the arcs (and sources), M is the vector of the masses inside the Nc cells, and the matrix Υ has the dimension of (2Nθ × Nc). The description of this matrix is given in Diego et al. (2005a).
Equation (14) is a system of 2Nθ linear equations whose solution can be achieved using the methods described in Diego et al. (2005a). The unknowns of the problem are the masses in the M vector and the central positions of the background sources. Both vectors can be united into a single one X, rendering the simpler equation 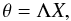 (15)where Λ is a matrix similar to Υ but with an extra sparse block containing 1 and 0.
(15)where Λ is a matrix similar to Υ but with an extra sparse block containing 1 and 0.
Weak lensing data can be modeled in a similar way. The two components of the shear are computed through the matrices that represent the contribution of each mass cell: 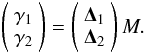 (16)A detailed description of the matrices Υ, Δ1 and Δ2 is presented in Appendix A.
(16)A detailed description of the matrices Υ, Δ1 and Δ2 is presented in Appendix A.
After including the weak lensing regime, the joint system of linear equations can be explicitly written down as 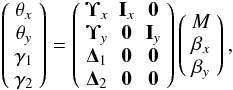 (17)where the element ij in the matrix Ix is 1 if the θi pixel comes from the βj source, and is 0 otherwise. The matrix 0 is the null matrix. Equation (17) can be written in the more compact form
(17)where the element ij in the matrix Ix is 1 if the θi pixel comes from the βj source, and is 0 otherwise. The matrix 0 is the null matrix. Equation (17) can be written in the more compact form 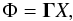 (18)where Φ is the vector containing the positions of the arcs and the shear measurements, Γ is a non-square matrix, and X is the vector of the unknowns.
(18)where Φ is the vector containing the positions of the arcs and the shear measurements, Γ is a non-square matrix, and X is the vector of the unknowns.
Written in this simple form, the lensing problem could, in principle, be resolved after the inversion of Eq. (18), X = Γ-1Φ.
3. Inversion of the lens equation
The vector X can be found by inverting Eq. (18). However, the matrix Γ is often non-invertible. This is actually not a problem as we seek an approximate solution with a more physical meaning than the exact solution. One of the assumptions made in the parametric method is that the background galaxies are infinitely small. The exact solution of the system of linear equations would reproduce an unphysical situation where the background galaxies are point-like. On the other hand, an approximate solution of the system has the benefit that the predicted background sources are not point-like but extended. In addition, an approximate solution allows for some error that is needed to compensate for the other wrong assumption made in non-parametric methods, namely, the assumption that the mass distribution is discretized. The predicted size of the background sources can be controlled in the solution by setting an error level or residual, R, in the system of linear equations 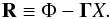 (19)In the case of WL, the physical meaning of the residual is the associated error in the determination of the reduced shear.
(19)In the case of WL, the physical meaning of the residual is the associated error in the determination of the reduced shear.
As discussed in Diego et al. (2005a), a powerful way to find an approximate solution to the system is through the bi-conjugate gradient algorithm, which minimizes the square of the residual 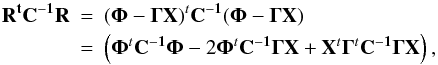 (20)where C is the covariance matrix of the residual R and among other things includes the relative weights of the SL and WL data. As discussed in Diego et al. (2007), this residual can be described (to first order) by a Gaussian distribution with a diagonal covariance matrix. This is however an approximation. The elements of the residual are correlated with each other, in particular those elements corresponding to the SL part of the data. The elements of the WL part of the residual are far more weakly correlated with each other and the diagonal approximation is a far more valid for this part. For the time being, we assume that the covariance matrix is diagonal and later discuss its implications. The diagonal approximation has been also assumed in previous works, including Jee et al. (2007). The elements of the diagonal corresponding to the SL data are set to σSL and the elements of the diagonal corresponding to the WL data are set to σWL. We adopt σSL ~ 1 arcsec (in radians) and σWL = 0.3 (or equivalently 30%). As discussed in Diego et al. (2007), the value of σSL has a physical meaning. Its value is connected with the angular size of the sources.
(20)where C is the covariance matrix of the residual R and among other things includes the relative weights of the SL and WL data. As discussed in Diego et al. (2007), this residual can be described (to first order) by a Gaussian distribution with a diagonal covariance matrix. This is however an approximation. The elements of the residual are correlated with each other, in particular those elements corresponding to the SL part of the data. The elements of the WL part of the residual are far more weakly correlated with each other and the diagonal approximation is a far more valid for this part. For the time being, we assume that the covariance matrix is diagonal and later discuss its implications. The diagonal approximation has been also assumed in previous works, including Jee et al. (2007). The elements of the diagonal corresponding to the SL data are set to σSL and the elements of the diagonal corresponding to the WL data are set to σWL. We adopt σSL ~ 1 arcsec (in radians) and σWL = 0.3 (or equivalently 30%). As discussed in Diego et al. (2007), the value of σSL has a physical meaning. Its value is connected with the angular size of the sources.
An alternative to the bi-conjugate gradient is the non-negative quadratic programming (QADP). A brief description of bi-conjugate and quadratic programming is given in Appendix B.
Both methods have advantages and disadvantages: the bi-conjugate gradient is extremely fast, although the final solution may contain unphysical negative masses. On the other hand, the non-negative quadratic programming algorithm does not produce a solution with negative masses, but it is significantly slower than the bi-conjugate gradient (its typical computation time is a few hours compared with a few minutes to reach similar accuracy). In both cases, a threshold R2 ≈ ϵ is defined to set the level at which the minimization stops.
The method has one drawback when applied to our problem: one can not choose ϵ to be arbitrary small. If one chooses ϵ to be very small, the algorithm will try to find a solution that focuses the arcs into Ns sources with unphysically small sizes. The mass distribution that accomplishes this, is usually very biased relative to the correct one: it usually has a lot of substructure with large mass fluctuations in the lens plane. One must then choose ϵ with some carefully selected criteria. Since the algorithm will stop when R2 < ϵ, we should choose ϵ to be an estimate of the expected error associated with the sources not being point-like and the reconstructed mass being discretized. Instead of defining ϵ in terms of R2, the parameter ϵ should be defined in terms of the residual of the conjugate gradient algorithm rk (see Eq. (B.7) in Appendix B). This would accelerate the minimization process significantly since we would not need to calculate R at each step but use the already estimated rk. Both residuals are connected by the relation 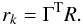 (21)Imposing a prior on the size of the sources means that we expect the residual of the lens equation, R, to take typical values on the order of the expected dispersion (or size) of the sources at the measured redshifts. Hence, we can define a Rprior of the form
(21)Imposing a prior on the size of the sources means that we expect the residual of the lens equation, R, to take typical values on the order of the expected dispersion (or size) of the sources at the measured redshifts. Hence, we can define a Rprior of the form 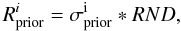 (22)where the index i runs from 1 to Nθ and σi is the dispersion (prior) assumed for the source associated with pixel i and RND is a random number normally distributed with zero mean and unity variance. We can then estimate ϵ as
(22)where the index i runs from 1 to Nθ and σi is the dispersion (prior) assumed for the source associated with pixel i and RND is a random number normally distributed with zero mean and unity variance. We can then estimate ϵ as 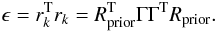 (23)Following Diego et al. (2005a), we construct Rprior assuming that the source galaxies can be described as Gaussians with σ = 30 h-1 kpc. In our particular problem (a grid with Nc = 32 × 32 cells), this results in a value ϵ ≈ 2 × 10-10. One has to be careful not to choose a too small σ. They should be larger than the typical size of a galaxy. Only when the number of grid points, Nc, is large enough, can the gridded version of the real mass distribution focus the arcs into sources that are similar in size to real ones. If Nc is not large enough, the gridded version of the true mass focuses the arcs into sources that are larger than the real sources. This is explained in more detail below.
(23)Following Diego et al. (2005a), we construct Rprior assuming that the source galaxies can be described as Gaussians with σ = 30 h-1 kpc. In our particular problem (a grid with Nc = 32 × 32 cells), this results in a value ϵ ≈ 2 × 10-10. One has to be careful not to choose a too small σ. They should be larger than the typical size of a galaxy. Only when the number of grid points, Nc, is large enough, can the gridded version of the real mass distribution focus the arcs into sources that are similar in size to real ones. If Nc is not large enough, the gridded version of the true mass focuses the arcs into sources that are larger than the real sources. This is explained in more detail below.
The choice of the threshold is a crucial point when performing the mass reconstruction. We illustrate in the next few sections how this affects both the final mass estimation and the positions of the sources.
4. Simulation of mock lensing data
We now describe the simulated data consisting of a simple cluster and lensing (both strong and weak) data set. The use of simulated data gives us the unique advantage of being able to compare the reconstructed mass with the true underlying simulated mass and check for biases and systematics.
For the cluster, we assume a single Navarro-Frenk-White (Navarro et al. 1996, NFW) profile for the radial density. We choose the simplest possible profile in order to avoid the effects of the uncertainties caused by the complexity of the mass distribution. We also assume the same redshift of CL0024 (z = 0.4), while the field of view corresponds to the field of view of the ACS field (FOV = 3.3 arcmin). The resulting mass in the whole field of view is M(FOV) ~ 4.8 × 1014 M⊙, while when we consider core radii within 30′′, we have M(<30′′) ~ 1.28 × 1014 M⊙ (the mass reconstruction in Jee et al. (2007) yields M(r < 30′′) ≈ (1.79 ± 0.13) × 1014 M⊙).
The strong and weak lensing data are computed using the full resolution of our simulated cluster (in the reconstruction process, the lens plane is divided with a grid that effectively reduces this resolution).
For the strong lensing data, we assume the same number of background sources (Ns = 3) identified in Jee et al. (2007) and that their redshifts are z1 = 1.675, z2 = 1.27, and z3 = 2.84. We carefully chose the position of the background sources in trying to mimic the strong lensing data set used by Jee et al. (2007), although this is not really relevant to our work. They identify five arcs from source 1, two arcs from source 2 and two arcs from source 3, making a total of nine. Most of the arcs are tangential, particularly those originating from source 1, which indicates that this source has to be positioned very close (in projection) to the density peak of the lens. In our case, our simulated strong lensing data set consists of seven arcs, three of which originate from source s1 (two tangential and one radial), two from source s2 (one tangential and one radial), and two from source s3 (one tangential and one radial). The map of the lensed images is represented in Fig. 1 (top panel), with the labels identifying the original sources.
The shear data is computed assuming that the density of available background galaxies is lower toward the center of the cluster, where the presence of the cluster itself makes it harder to estimate the reduced shear. For all the shear data points, we assume a Gaussian noise of 30%. In addition to the cluster itself, the magnification bias has to be taken into account. Magnification acts on galaxies (enhancing their flux) but also expanding the area of the sky behind the cluster. In Broadhurst et al. (2005b), the latter effect is estimated and showed that a net deficit of background galaxies is expected (see also Umetsu et al. 2011). The resulting shear field is shown in Fig. 1 (bottom panel).
 |
Fig. 1 Top panel: the lensed arcs (θ map) originated from three sources in the background (not shown in the figure). The total number of pixels forming the arcs is Nθ = 288. Bottom panel: shear field derived from the lens and used for the weak lensing computation. The inner points have been removed to mimic the contamination from cluster member galaxies. Total number of shear points is Nshear = 1301, needed to set the dimension of the lensing matrix. All points have a Gaussian noise of 30%. |
4.1. Simulated vs. real data
In Jee et al. (2007), the authors consider a FOV of 3.5 × 3.5 arcmin that is gridded in a 52 × 52 regular grid, but with the four corner points removed. We consider a slightly smaller FOV (3.3 × 3.3 arcmin) and divide the FOV using a 32 × 32 regular grid. We chose the side of the grid to be 32 to ensure that the number of constraints is comparable to the number of unknowns and hence have a more stable system of equations. A larger number of grid points will only introduce unnecessary noise in the reconstructed solution.
In Jee et al. (2007), the strong lensing constraints are derived from 132 knots identified in the lensed images and the weak lensing constraints are based on an ensemble of 1297 background galaxies with photometric redshifts zphot ≥ 0.8. In our simulated data, we instead consider all the pixels of our lensed images (288 pixels) for the strong lensing, while for the weak lensing we create a simulated vectorial field in 1301 positions.
The solution in Jee et al. (2007) is found after a minimization process involving the strong and weak lensing data, a regularization term and a model for the lensing potential. The regularization term improves the smoothness of the recovered solution and in principle helps to reduce the overfitting problem. The method is based on the maximum entropy method (MEM), which has a positive prior that forces the improved solution to remain positive. Here, we also use a minimization process but instead of a regularization term we stop the minimization process at a point that avoids overfitting the data. An interesting discussion of this point can be found in Jee et al. (2007). They perform a delensing of the arcs from one particular source. The resulting recovered sources are reported in Fig. 14 in their paper, where the orientation, parity, and size of the images are strongly consistent among the different recovered sources. Nonetheless, the positions of the the delensed images do not overlap. The same authors report: “when we forced the two locations to coincide in our mass reconstruction, the smoothness of the resulting mass map was compromised”. This might indicate a tension between the recovered solution and the corresponding goodness of fit. Formally the solution is not an optimal one in the sense that the recovered source positions do not coincide but seem to be good enough to ensure that the recovered sources resemble the real ones.
 |
Fig. 2 Simulated observed arcs (black) versus predicted ones from the optimal solution (white). The difference between the two sets of θ positions is representative of the error expected when recovering the solution. |
5. The optimal solution
With the simulated data, a very interesting exercise can be done before attempting the mass reconstruction. Since we know the true underlying mass and the positions of the background sources, we can predict where the arcs should appear when we assume the optimal solution possible for X assuming a uniform grid with 32 × 32 cells. This solution consists of the mean mass in each cell corresponding to the true underlying mass and the three real positions. In Fig. 2, we show the true strong lensing or θ-map used to reconstruct the mass, compared with the predicted one derived from the optimal solution X. The black arcs are obtained from the equation θ = ΓM + β, where the matrix Γ is built from the real θ positions and the 32 × 32 cells, the vector β contains the real positions of the background sources, and the vector M contains the mean mass sampled in the 32 × 32 cells.
The first interesting conclusion we can derive from this exercise is that the arcs predicted from the optimal solution differ significantly from the true observed arcs. This is unsurprising as the optimal solution lacks the resolution of the true underlying mass and hence we should expect a different set of strong lensed arcs. To reproduce the observed arcs, the solution has to bend the light in a different way. This can only be achieved with a mass distribution that is different (i.e. biased away) from the true one.
This exercise summarizes the entire philosophy behind this paper: using a non-parametric method with a uniform cell size, it is impossible to predict correctly the strong lensing data with an unbiased solution of the true underlying mass. By default, the non-parametric method makes the incorrect assumption that the mass distribution is discrete and ignores the details of the mass distribution on scales smaller than the cell size. Hence, the derived solution has to be biased by the method in order to fit the data and compensate for this incorrect assumption. The best we can hope for is a solution that resembles the true underlying mass distribution but is unable to fit the observed data perfectly. This margin of error in the description of the observed data will then compensate the original error made by assuming that the mass is discretized. However, we note that we seek a solution as close as possible to the true solution, which can only be achieved when a realistic error, R, is allowed in the minimization of the system of linear equations given in Eq. (19).
6. Mass reconstruction
To solve Eq. (18), the lens plane is divided into a regular grid of 32 × 32 cells. This number is smaller than the number of constraints provided by the weak and strong lensing data. The mass in each cell plus the positions of the background strong lensing galaxies form a vector of unknown variables X that has 1030 elements (1024 for the mass cells and 6 for the three sources, each one with the x and y coordinates of the position of the background galaxy).
6.1. The bi-conjugate gradient algorithm solution
The bi-conjugate gradient algorithm (BGA) is a fast and powerful algorithm for finding the solutions of a system of linear equations. As mentioned earlier, rather than finding the exact solution, we seek an approximated one with an error large enough to compensate for the discretized mass and that the background galaxies are not point-like. The minimization is stopped at a point where R2 ≈ ϵ. The choice of ϵ is based on the physical size of the background galaxies and also that the optimal solution should not reconstruct the data perfectly as discussed in the previous subsection. A value of ϵ can be computed from the equation 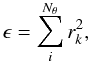 (24)where rk = ΓTRSL,prior + ΓTRWL,prior contains an estimate of the physical size of the background galaxies (RSL,prior) and the error in the weak lensing measurements (RWL,prior, see previous sections for the definition of ϵ and its relation to rk).
(24)where rk = ΓTRSL,prior + ΓTRWL,prior contains an estimate of the physical size of the background galaxies (RSL,prior) and the error in the weak lensing measurements (RWL,prior, see previous sections for the definition of ϵ and its relation to rk).
Once the value of ϵ is estimated, we can solve for the mass and position of the background sources. In Fig. 3, we show the mass reconstruction obtained with the BGA for a value of ϵ = 1 × 10-10 (computed in Eq. (24), corresponding to a σSL ~ 1.2 arcsec and σWL = 0.3 or 30%). The total recovered mass inside the FOV is M(<3.3′) = 6.1 × 1014 M⊙, while M(r < 30′′) = 1.39 × 1014 M⊙. The radial density profile is shown in the bottom panel of the figure, where it is compared with the true mass profile.
Values of ϵ significantly smaller than ~10-10 would produce an overfitting of the data, introducing systematics in the final mass reconstruction. A typical case of overfitting is shown in Fig. 4, where the threshold value of ϵ has been lowered several orders of magnitude (ϵ = 2 × 10-15). This value pushes the solution to the limit of the BGA and allows us to predict almost perfectly the observed data. However, this solution is clearly biased with respect to the true underlying mass as is clear when looking at the density profile (bottom panel).
 |
Fig. 3 Mass reconstruction obtained with the BGA and no overfitting ϵ = 2 × 10-10. Top panel: mass map after smoothing with a Gaussian. The mass inside the FOV is M3.3′ = 6.1 × 1014 M⊙, while the mass inside the core radius of 30′′ is M30′′ = 1.39 × 1014 M⊙. Bottom panel: surface mass density profile (in units of Σcrit) as a function of radius. Darker areas correspond to higher masses. |
 |
Fig. 4 Plots for M3.3′ = 4.34 × 1014 M⊙ and M30′′ ≈ 1.9 × 1014 M⊙. Overfitting case. It shows the solution obtained with the BGA when the method is forced to find a nearly exact solution to the problem (ϵ = 2 × 10-15). The density profile inside the core radius does not follow the profile of the input NFW cluster. Different density peaks and dips can be seen around the center of the FOV. Darker areas correspond to higher masses. |
 |
Fig. 5 Black color indicates the observed (or true) arcs and in white we show the predicted arcs obtained with the solution shown in Fig. 4. |
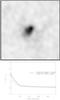 |
Fig. 6 Plots for M3.3′ = 5.92 × 1014 M⊙ and M30′′ = 1.22 × 1014 M⊙. Mass reconstruction obtained with the QADP after 100 iterations. This case corresponds to a reasonable value of ϵ and can be compared with the BGA solution shown in Fig. 3. The QADP recovers a higher mass in the central region (Σ/Σcrit) than the BGA. |
The mass map shown in Fig. 4 is obviously a poor solution in the sense that it deviates significantly from the underlying mass distribution. However, from the point of view of the system of linear equations it is a good solution because it is able to reproduce the data accurately. This is shown in Fig. 5, where the observed arcs are compared to the predicted ones by the overfitting solution. This result should be compared with the case in Fig. 2 showing the opposite situation where the closest representation of the mass distribution leads to an error in the predicted strongly lensed arcs. The conclusion we can extract from this example is that a simultaneous (unbiased) reconstruction of the mass and the lensing data is impossible with a non-parametric method that lacks the details of the mass distribution.
6.2. The quadratic programing algorithm solution
The solution X derived from the BGA might predict negative masses, which could lead to large fluctuations in the mass density profile as the negative fluctuations have to be compensated for by larger positive fluctuations. However, Hoekstra et al. (2011, and references within) report that cosmic noise (an induced shear effect by uncorrelated halos and large-scale structure) has to be taken into account when estimating the error bars in any cluster mass reconstruction that might lead to a negative convergence in the regime of the weak lensing. So a negative convergence is not completely unrealistic.
To avoid the large fluctuations at small radii exhibited by the biconjugate gradient, which can indicate a non-physical solution, we use the quadratic programming algorithm (QADP, see Appendix B), which prevents negative masses from appearing in the solution. This method resembles the maximum entropy method introduced in Jee et al. (2007), since both impose a positive prior on the mass.
The QADP has a smooth behavior in the inner regions, where no large fluctuations are found, even in the crucial areas of the lens plane where the transition between the WL and SL regimes is observed. In addition, QADP provides an independent solution that should agree with the one derived by the BGA.
The number of iterations of the algorithm can be directly related to ϵ. The overfitting solution obtained by the QADP algorithm converges only after a large number of iterations (~104 − 105) or equivalently after defining a small value for ϵ.
In Fig. 6, we show the solution obtained with QADP after 100 iterations. This result can be compared with the one in Fig. 3. The QADP recovers a higher mass than the BGA in the central region.
In Fig. 7, we show the overfitting case obtained with QADP with a large number of iterations (Niter = 105, or similarly, with a very small value for ϵ). In this case, the mass is pushed away from the center towards larger radii in a similar way to what was observed using the BGA. This is more clearly evident in the density profile. A peak in the density is observed at r = 20′′ and an additional bump at r = 50′′. The way in which the WL and SL are weighted is different in both methods. The overfitting solution differs significantly from the true mass (and also from Jee’s reconstruction in the central part). The overfitting solution is dominated in our case by the WL part of the data (as in Jee et al. 2007). As shown in Fig. 8, the WL alone case shows a mass deficit at the center that is compensated for by the ring in the outer regions. Whether a similar situation occurs in Jee et al. (2007) is unclear but we note that Jee’s mass reconstruction predicts a lower mass at the center than that of Zitrin et al. (2009; as seen in Fig. 21 of Umetsu et al. 2010) .
In Jee et al. (2007), their Fig. 10 shows the radial mass density profile of the cluster, with a Σc given at a fiducial redshift of zf = 3. The authors state that the resulting profile does not match any conventional analytic profile. The density, peaking at the center with the value of Σ/Σc = 1.3, rapidly decreases from the center to the end of the core radius at r = 50′′. The profile then remains almost constant around a value of Σ/Σc = 0.7. Only at radius r = 70′′ from the center is an increment observable, extending out to r = 80′′ with a peak at r = 75′′. This is what the authors refer to as the bump. In two dimensions, this bump appears like a ring structure, separated from the core by 20′′.
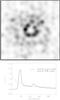 |
Fig. 7 M3.3′ = 6.81 × 1014 M⊙ and M30′′ = 1.59 × 1014. Mass reconstruction obtained with QADP and after 105 iterations (overfitting case). The density peaks at r ~ 15′′ and a bump is observed at r ~ 50′′. Darker areas correspond to higher masses. |
A plateau was detected by Jee et al. (2007) at r ~ 50′′, that was not found by Umetsu et al. (2010), who instead measured a monotonically decreasing density. This plateau might depend on the initial guess. The WL part of the data displays this plateau more than the SL data, especially in those regions where WL constraints are weaker. The role that the prior plays in determining the regularization term in the MEM has to be investigated in more detail and leaves questions open on how the choice of the prior could affect the radii outside the central core.
7. Discussion and conclusions
 |
Fig. 8 Reconstructed image for the case where only weak lensing data is used in the reconstruction. A clear ring of matter appears in the area where the density of weak lensing data gets reduced. Whiter colors indicate more mass. |
The interesting analysis of Jee et al. (2007) appears to detect a dark matter ring around the core of CL0024. This ring might have been caused by a recent high speed collision between two massive clusters along the line of sight. If confirmed, CL0024 would be an interesting laboratory to test different physical phenomena. We have explored the possibility that spurious ring-like structures might appear as a consequence of overfitting lensing data in a non-parametric way. We show how the optimal (unbiased) solution should produce a fit to the data significantly poorer than the minimal χ2 solution. This error is necessary to account for the initial error introduced when neglecting the impact of the small-scale fluctuations on the mass distribution. We demonstrate our argument by using a simulated data set where all the variables are known a priori and the reconstructed mass can be compared with the original one. The simulation shows how overfitting the data introduces artifacts in the reconstructed solution, which can resemble the ring-like structure found in Jee et al. (2007). The methods in Jee et al. (2007) and the one used in this work are different in some aspects but both methods share many common key features such as the lens plane is divided into a regular grid and the parameters to be constrained are basically those for convergence in the pixels. Hence both methods should also have the same systematic effects and in particular be sensitive in a similar way to overfitting.
Another interesting feature shown by the simulations that needs to be investigated more (with the actual data) is that when the density of weak lensing data is non-uniform across the field of view, there is a tendency for the overfitted solution to increase the mass density in the areas with fewer weak lensing data. We show one example in Fig. 8, where only the simulated weak lensing data is used to find the solution. The plot shows the WL data overlaid on the overfitted solution found for this case. In the case of CL0024, we expect a lower density of WL points toward the center of the cluster owing to contamination by the cluster members. While the SL data constraints the inner central region of the cluster, the outer regions are basically constrained by the WL data alone. In-between these two regions, the density of WL data points should show a gradient, and the effect of the non-uniformity of the WL data points might have a negative effect on the solution. The reality of the ringlike structure will need to be investigated in more detail.
We note that the covariance matrix of the residual might not necessarily be diagonal. As discussed in Sect. 7 of Diego et al. (2007), the elements of the residual are correlated with each other, in particular the strong lensing part of the residual. The elements of the WL portion of the residual are more weakly correlated with each other, and the diagonal approximation is in this case more valid. This is particularly true in our case where the error assigned to the WL measurements is the predominant one (30%). Since the WL data are more relevant to understanding the ring-like structure, we adopt the diagonal approximation for the covariance matrix. In addition, the second reason why we prefer to adopt this approximation in this paper is that Jee et al. (2007) assumed that the data are uncorrelated (the covariance matrix is diagonal for an uncorrelated residual). The issue of the effect of the covariance matrix in lensing reconstruction has not been addressed by any method (to the best of our knowledge) and we plan to do so in a future paper. Another interesting point that deserves discussion is that in Jee et al. (2007) a regularization term is included in the analysis, among other things, to prevent overfitting. This regularization term, however, does not guarantee that overfitting is prevented. The main objective of the regularization term is to favor solutions that are smooth by introducing a prior that represents a smoothed version of the solution. If we consider the extreme case where the reconstructed solution converges to the prior in their regularization term (this is not an unrealistic scenario because the prior is updated at each iteration and based on the previous solution), the regularization term tends to zero forcing the other terms in χ2 to be even smaller and hence closer to an overfitting situation. The SL and WL terms to be minimized are the ones that really constrain the model and can still be too small even for smooth solutions. Our work shows that a good solution obtained with our non-parametric method should predict arcs significantly different from the ones observed. Only when overfitting is allowed can the reconstructed data closely reproduce the observations (see Figs. 2 and 5 above).
Our work shows the validity and usefulness of non-parametric methods but also shows some of its limitations, in particular that one should not be too ambitious when fitting the data.
Acknowledgments
We acknowledge partial financial support from the Ministerio de Ciencia e Innovación project AYA2007-68058-C03-02. P.P.P. acknowledges support from the Spanish Ministerio de Educación y Ciencia and CSIC for an I3P grant.
References
- Abdelsalam, H. M., Saha, P., & Williams, L. L. R. 1998a, AJ, 116, 1541 [NASA ADS] [CrossRef] [Google Scholar]
- Abdelsalam, H. M., Saha, P., & Williams, L. L. R. 1998b, AJ, 116, 1541 [NASA ADS] [CrossRef] [Google Scholar]
- Bradač, M., Schneider, P., Lombardi, M., & Erben, T. 2005, A&A, 437, 39 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bridle, S. L., Hobson, M. P., Lasenby, A. N., & Saunders, R. 1998, MNRAS, 299, 895 [NASA ADS] [CrossRef] [Google Scholar]
- Broadhurst, T., Huang, X., Frye, B., & Ellis, R. 2000, ApJ, 534, L15 [NASA ADS] [CrossRef] [Google Scholar]
- Broadhurst, T., Benítez, N., Coe, D., et al. 2005a, ApJ, 621, 53 [NASA ADS] [CrossRef] [Google Scholar]
- Broadhurst, T., Takada, M., Umetsu, K., et al. 2005b, ApJ, 619, L143 [NASA ADS] [CrossRef] [Google Scholar]
- Cacciato, M., Bartelmann, M., Meneghetti, M., & Moscardini, L. 2006, A&A, 458, 349 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Clowe, D., Bradač, M., Gonzalez, A. H., et al. 2006, ApJ, 648, L109 [NASA ADS] [CrossRef] [Google Scholar]
- Colley, W. N., Tyson, J. A., & Turner, E. L. 1996, ApJ, 461, L83 [NASA ADS] [CrossRef] [Google Scholar]
- Comerford, J. M., Meneghetti, M., Bartelmann, M., & Schirmer, M. 2006, ApJ, 642, 39 [NASA ADS] [CrossRef] [Google Scholar]
- Czoske, O., Kneib, J., Soucail, G., et al. 2001, A&A, 372, 391 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Diego, J. M., Protopapas, P., Sandvik, H. B., & Tegmark, M. 2005a, MNRAS, 360, 477 [NASA ADS] [CrossRef] [Google Scholar]
- Diego, J. M., Sandvik, H. B., Protopapas, P., et al. 2005b, MNRAS, 362, 1247 [NASA ADS] [CrossRef] [Google Scholar]
- Diego, J. M., Tegmark, M., Protopapas, P., & Sandvik, H. B. 2007, MNRAS, 375, 958 [NASA ADS] [CrossRef] [Google Scholar]
- Halkola, A., Seitz, S., & Pannella, M. 2006, MNRAS, 372, 1425 [NASA ADS] [CrossRef] [Google Scholar]
- Hoekstra, H., Hartlap, J., Hilbert, S., & van Uitert, E. 2011, MNRAS, 412, 2095 [NASA ADS] [CrossRef] [Google Scholar]
- Jee, M. J., Ford, H. C., Illingworth, G. D., et al. 2007, ApJ, 661, 728 [NASA ADS] [CrossRef] [Google Scholar]
- Kneib, J., Hudelot, P., Ellis, R. S., et al. 2003, ApJ, 598, 804 [NASA ADS] [CrossRef] [Google Scholar]
- Liesenborgs, J., de Rijcke, S., Dejonghe, H., & Bekaert, P. 2008, MNRAS, 389, 415 [NASA ADS] [CrossRef] [Google Scholar]
- Milgrom, M., & Sanders, R. H. 2008, ApJ, 678, 131 [NASA ADS] [CrossRef] [Google Scholar]
- Navarro, J. F., Frenk, C. S., & White, S. D. M. 1996, ApJ, 462, 563 [NASA ADS] [CrossRef] [Google Scholar]
- Ota, N., Pointecouteau, E., Hattori, M., & Mitsuda, K. 2004, ApJ, 601, 120 [NASA ADS] [CrossRef] [Google Scholar]
- Press, W. H., Teukolsky, S. A., Vetterling, W. T., & Flannery, B. P. 1997, Numerical Recipes in Fortran, 77 [Google Scholar]
- Qin, B., Shan, H., & Tilquin, A. 2008, ApJ, 679, L81 [NASA ADS] [CrossRef] [Google Scholar]
- Saha, P., & Williams, L. L. R. 1997, MNRAS, 292, 148 [NASA ADS] [CrossRef] [Google Scholar]
- Saha, P., Williams, L. L. R., & AbdelSalam, H. 1999 [arXiv:astro-ph/9909249] [Google Scholar]
- Seitz, S., Schneider, P., & Bartelmann, M. 1998, A&A, 337, 325 [NASA ADS] [Google Scholar]
- Sha, F., Saul, L. K., & Lee, D. D. 2002, in Advances in Neural Information Processing Systems (MIT Press), 15, 1041 [Google Scholar]
- Smail, I., Dressler, A., Kneib, J., et al. 1996, ApJ, 469, 508 [NASA ADS] [CrossRef] [Google Scholar]
- Smith, G. P., Kneib, J., Smail, I., et al. 2005, MNRAS, 359, 417 [NASA ADS] [CrossRef] [Google Scholar]
- Tyson, J. A., Kochanski, G. P., & dell’Antonio, I. P. 1998, ApJ, 498, L107 [Google Scholar]
- Umetsu, K., Medezinski, E., Broadhurst, T., et al. 2010, ApJ, 714, 1470 [NASA ADS] [CrossRef] [Google Scholar]
- Umetsu, K., Broadhurst, T., Zitrin, A., Medezinski, E., & Hsu, L.-Y. 2011, ApJ, 729, 127 [NASA ADS] [CrossRef] [Google Scholar]
- Wallington, S., Kochanek, C. S., & Narayan, R. 1992, in BAAS, 24, 1192 [Google Scholar]
- Zhang, Y., Böhringer, H., Mellier, Y., Soucail, G., & Forman, W. 2005, A&A, 429, 85 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Zitrin, A., Broadhurst, T., Umetsu, K., et al. 2009, MNRAS, 396, 1985 [NASA ADS] [CrossRef] [Google Scholar]
- ZuHone, J. A., Lamb, D. Q., & Ricker, P. M. 2009, ApJ, 696, 694 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: How is built the Γ matrix
The Γ matrix is the basis of the Weak and Strong Lensing Analysis Package (WSLAP) and contains the information about how each cell in the grid contributes to either the jth deflection angle or the kth shear measurement. In the SL case, it also contains information about the source identity of the jth pixel in a given lensed arc. All this information is organized in rows, each row corresponding to one constraint (deflection angle for SL and shear for WL). The final structure of Γ is 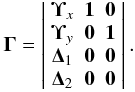 (A.1)The specific form of the Υ and Γ matrices depends on the choice of basis system. For clarity purposes, we assume that this system is based on Gaussians positioned on the grid. This grid is a division of the lens plane into cells, where the mass in a cell is assumed to be distributed as a Gaussian of dispersion σ, which is proportional to the size of the cell. A proportionality factor ~2 gives very satisfactory results in terms of reproducing the constraints. The integrated mass at a given distance δ from the center of the cell is then
(A.1)The specific form of the Υ and Γ matrices depends on the choice of basis system. For clarity purposes, we assume that this system is based on Gaussians positioned on the grid. This grid is a division of the lens plane into cells, where the mass in a cell is assumed to be distributed as a Gaussian of dispersion σ, which is proportional to the size of the cell. A proportionality factor ~2 gives very satisfactory results in terms of reproducing the constraints. The integrated mass at a given distance δ from the center of the cell is then 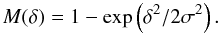 (A.2)Since the basis has circular symmetry, the x and y components of the deflection angle α at the same point can be estimated easily as
(A.2)Since the basis has circular symmetry, the x and y components of the deflection angle α at the same point can be estimated easily as ![\appendix \setcounter{section}{1} \begin{equation} \label{alpha_x} \alpha_{x} (\delta) = \Upsilon_{x} = \lambda\left[1-\exp \left(-\delta^2/1\sigma^2\right)\right]\frac{\delta_{x}}{\delta^2}, \end{equation}](/articles/aa/full_html/2011/11/aa17382-11/aa17382-11-eq167.png) (A.3)
(A.3)![\appendix \setcounter{section}{1} \begin{equation} \label{alpha_y} \alpha_{y} (\delta) = \Upsilon_{y} = \lambda\left[1-\exp \left(-\delta^2/1\sigma^2\right)\right]\frac{\delta_{y}}{\delta^2}, \end{equation}](/articles/aa/full_html/2011/11/aa17382-11/aa17382-11-eq168.png) (A.4)where the multiplying constant λ contains all the cosmological and redshift dependence
(A.4)where the multiplying constant λ contains all the cosmological and redshift dependence 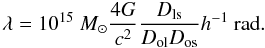 (A.5)The factor δx in Eq. (A.3) is just the difference (in radians) between the x position in the arc (x of pixel θx) and the x position of the cell j in the grid (
(A.5)The factor δx in Eq. (A.3) is just the difference (in radians) between the x position in the arc (x of pixel θx) and the x position of the cell j in the grid (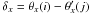 ). Similarly, we can define
). Similarly, we can define 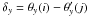 and
and 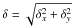 .
.
The Δ1 and Δ2 matrices can be computed in a similar way but in this case, since we need to calculate the derivatives, the deflection angles αx and αy have to be computed at three points δ1, δ2, and δ3. The first point, δ1, is the same as δ above. The second and third points (δ2 and δ3) are one (or a few) pixel(s) left (or right) and up (or down) the pixel at δ1, respectively. Then Δ1 is just the difference ![\appendix \setcounter{section}{1} \begin{eqnarray} {\mathbf \Delta}_1 &=& \frac{1}{2} \frac{[\alpha_{x}(\delta_3)-\alpha_{x}(\delta_1)]-[\alpha_{y}(\delta_3)-\alpha_{y}(\delta_1)]}{\mbox{pix2rad}},\\ {\mathbf \Delta}_2 &=&\frac{\alpha_{x}(\delta_3)-\alpha_{x}(\delta_1)}{\mbox{pix2rad}}= \frac{\alpha_{y}(\delta_3)-\alpha_{y}(\delta_1)}{\mbox{pix2rad}}, \end{eqnarray}](/articles/aa/full_html/2011/11/aa17382-11/aa17382-11-eq183.png) where pix2rad is the size of the pixel in radians. Since we included the factor 1015 M⊙ in λ (see Eq. (A.5)), the mass in the solution vector will be given in 1015 h-1 M⊙ units. The h-1 dependency exists because in λ we have the ratio Dls/(DolDos), which goes as h.
where pix2rad is the size of the pixel in radians. Since we included the factor 1015 M⊙ in λ (see Eq. (A.5)), the mass in the solution vector will be given in 1015 h-1 M⊙ units. The h-1 dependency exists because in λ we have the ratio Dls/(DolDos), which goes as h.
The 0 (null) and 1 (0’s and 1’s) matrices on the right side of Γ add 2Ns additional columns. The bottom part of thess columns consist entirely of 0’s since the shear measurements are independent of the position β of the sources. The Nθ × Ns dimensional matrices 1 contain 1’s in the ij positions (i ∈ [1,Nθ] ,j ∈ [1,Ns]), where the ith θ pixel comes from the j source and 0’s elsewhere.
Appendix B: Minimizing algorithms
B.1. Biconjugate gradient algorithm or BGA
The biconjugate gradient (Press et al. 1997) algorithm is one of the fastest and most powerful algorithms for solving systems of linear equations. It is also extremely useful for finding approximate solutions for systems where no exact solutions exists or where the exact solution is not the one we are interested in. The latter is our case. Given a system of linear equations 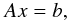 (B.1)a solution of this system can be found by minimizing the function
(B.1)a solution of this system can be found by minimizing the function 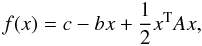 (B.2)where c is a constant. The gradient of Eq. (B.2) is 0 when the same equation is at its minima
(B.2)where c is a constant. The gradient of Eq. (B.2) is 0 when the same equation is at its minima 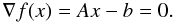 (B.3)That is, at the position of the minimum of the function f(x) we find a solution to Eq. (B.1). In most cases, finding the minimum of Eq. (B.2) is much easier than finding the solution of the system in B.1, especially when no exact solution exists for B.1 or A does not have an inverse.
(B.3)That is, at the position of the minimum of the function f(x) we find a solution to Eq. (B.1). In most cases, finding the minimum of Eq. (B.2) is much easier than finding the solution of the system in B.1, especially when no exact solution exists for B.1 or A does not have an inverse.
The biconjugate gradient finds the minimum of Eq. (B.2) (or equivalently, the solution of Eq. (B.1)) by following an iterative process that minimizes the function f(x) in a series of steps no longer than the dimension of the problem. The beauty of the algorithm is that the successive minimizations are carried out on a series of orthogonal conjugate directions, pk, with respect to the metric A. That is, 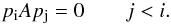 (B.4)This condition is useful when minimizing in a multidimensional space because it guarantees that successive minimizations do not spoil the minimizations in previous steps.
(B.4)This condition is useful when minimizing in a multidimensional space because it guarantees that successive minimizations do not spoil the minimizations in previous steps.
By comparising Eqs. (20) and (B.2), it is easy to identify the terms, c = (1/2)θTθ, b = ΓT and A = ΓTΓ. Minimizing the quantity R2 is equivalent to solving Eq. (19). To see this, we only have to realize that 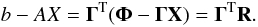 (B.5)If an exact solution for Eq. (19) does not exist, the minimum of R2 will be a more accuratly approximated solution to the system. The minimum can be found easily: in the case of symmetric matrices A, the algorithm constructs two sequences of vectors rk and pk and two constants, αk and βk. To begin the algorithm, we need to make a first guess of the solution, namely X0 and two vectors r0 and p0
(B.5)If an exact solution for Eq. (19) does not exist, the minimum of R2 will be a more accuratly approximated solution to the system. The minimum can be found easily: in the case of symmetric matrices A, the algorithm constructs two sequences of vectors rk and pk and two constants, αk and βk. To begin the algorithm, we need to make a first guess of the solution, namely X0 and two vectors r0 and p0 At every iteration, an improved estimate of the solution is given by
At every iteration, an improved estimate of the solution is given by 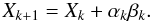 (B.10)The algorithm starts with an initial guess for the solution, X1, and chooses the residual and the new search direction in the first iteration to be
(B.10)The algorithm starts with an initial guess for the solution, X1, and chooses the residual and the new search direction in the first iteration to be 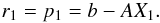 (B.11)We note that p1 is nothing but ∇R2. Thus, the algorithm chooses as a first minimization direction the gradient of the function to be minimized at the position of the first guess. It then minimizes in directions that are conjugate to the previous ones until either it reaches a minimum or the square of the residual R2 is smaller than ϵ.
(B.11)We note that p1 is nothing but ∇R2. Thus, the algorithm chooses as a first minimization direction the gradient of the function to be minimized at the position of the first guess. It then minimizes in directions that are conjugate to the previous ones until either it reaches a minimum or the square of the residual R2 is smaller than ϵ.
B.2. Quadratic programming algorithm (QADP)
The nonnegative quadratic programming algorithm used in this work has the peculiarity that it finds solutions, X, satisfying the condition X ≥ 0. That is, negative masses are not allowed in the solution by construction. We follow the multiplicative updates proposed by Sha et al. (2002).
The basic problem we wish to solve is to minimize the quadratic function 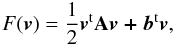 (B.12)subject to the constraint vi ≥ 0,∀i. In Eq. (B.12), the vector v is the unknown vector X, A = ΓTΓ and b = ΓTΦ. We note that the elements of X are all positive, since the βs can be chosen all positive with respect to an appropriate system of reference. The matrix A can be decomposed into its positive and negative parts: A = A + − A − , where
(B.12)subject to the constraint vi ≥ 0,∀i. In Eq. (B.12), the vector v is the unknown vector X, A = ΓTΓ and b = ΓTΦ. We note that the elements of X are all positive, since the βs can be chosen all positive with respect to an appropriate system of reference. The matrix A can be decomposed into its positive and negative parts: A = A + − A − , where 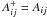 if Aij > 0 and 0 otherwise and
if Aij > 0 and 0 otherwise and 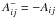 if Aij < 0 and 0 otherwise (nonnegative matrices). The solution is iteratively updated by the rule
if Aij < 0 and 0 otherwise (nonnegative matrices). The solution is iteratively updated by the rule 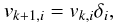 (B.13)where the updating term is defined as
(B.13)where the updating term is defined as 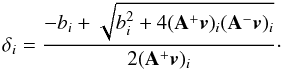 (B.14)It is easy to see that generic quadratic programming problems have a single unique minimum. We denote as v ∗ this global minimum of F(v). We attempt to prove that convergence of the iteration Eq. (B.14) corresponds to this minimum v ∗ . At this point, one of two conditions must apply for each component
(B.14)It is easy to see that generic quadratic programming problems have a single unique minimum. We denote as v ∗ this global minimum of F(v). We attempt to prove that convergence of the iteration Eq. (B.14) corresponds to this minimum v ∗ . At this point, one of two conditions must apply for each component 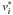 : either (i)
: either (i) 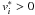 and
and 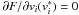 or (ii)
or (ii) 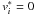 and
and 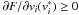 . Now since
. Now since 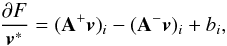 (B.15)the multiplicative updates in both cases (i) and (ii) take the value δi = 1, where the minimum is a fixed point. Conversely, a fixed point of the iteration must be the minimum v ∗ .
(B.15)the multiplicative updates in both cases (i) and (ii) take the value δi = 1, where the minimum is a fixed point. Conversely, a fixed point of the iteration must be the minimum v ∗ .
All Figures
|
Fig. 1 Top panel: the lensed arcs (θ map) originated from three sources in the background (not shown in the figure). The total number of pixels forming the arcs is Nθ = 288. Bottom panel: shear field derived from the lens and used for the weak lensing computation. The inner points have been removed to mimic the contamination from cluster member galaxies. Total number of shear points is Nshear = 1301, needed to set the dimension of the lensing matrix. All points have a Gaussian noise of 30%. |
| In the text | |
|
Fig. 2 Simulated observed arcs (black) versus predicted ones from the optimal solution (white). The difference between the two sets of θ positions is representative of the error expected when recovering the solution. |
| In the text | |
|
Fig. 3 Mass reconstruction obtained with the BGA and no overfitting ϵ = 2 × 10-10. Top panel: mass map after smoothing with a Gaussian. The mass inside the FOV is M3.3′ = 6.1 × 1014 M⊙, while the mass inside the core radius of 30′′ is M30′′ = 1.39 × 1014 M⊙. Bottom panel: surface mass density profile (in units of Σcrit) as a function of radius. Darker areas correspond to higher masses. |
| In the text | |
|
Fig. 4 Plots for M3.3′ = 4.34 × 1014 M⊙ and M30′′ ≈ 1.9 × 1014 M⊙. Overfitting case. It shows the solution obtained with the BGA when the method is forced to find a nearly exact solution to the problem (ϵ = 2 × 10-15). The density profile inside the core radius does not follow the profile of the input NFW cluster. Different density peaks and dips can be seen around the center of the FOV. Darker areas correspond to higher masses. |
| In the text | |
|
Fig. 5 Black color indicates the observed (or true) arcs and in white we show the predicted arcs obtained with the solution shown in Fig. 4. |
| In the text | |
|
Fig. 6 Plots for M3.3′ = 5.92 × 1014 M⊙ and M30′′ = 1.22 × 1014 M⊙. Mass reconstruction obtained with the QADP after 100 iterations. This case corresponds to a reasonable value of ϵ and can be compared with the BGA solution shown in Fig. 3. The QADP recovers a higher mass in the central region (Σ/Σcrit) than the BGA. |
| In the text | |
|
Fig. 7 M3.3′ = 6.81 × 1014 M⊙ and M30′′ = 1.59 × 1014. Mass reconstruction obtained with QADP and after 105 iterations (overfitting case). The density peaks at r ~ 15′′ and a bump is observed at r ~ 50′′. Darker areas correspond to higher masses. |
| In the text | |
|
Fig. 8 Reconstructed image for the case where only weak lensing data is used in the reconstruction. A clear ring of matter appears in the area where the density of weak lensing data gets reduced. Whiter colors indicate more mass. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.