| Issue |
A&A
Volume 694, February 2025
|
|
|---|---|---|
| Article Number | A183 | |
| Number of page(s) | 15 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202347461 | |
| Published online | 12 February 2025 | |
Multiband embeddings of light curves
1
John A. Paulson School of Engineering and Applied Sciences, Harvard University,
Cambridge,
MA,
02138,
USA
2
Millennium Institute of Astrophysics,
Nuncio Monseñor Sotero Sanz 100, Of. 104, Providencia,
Santiago,
Chile
3
Computer Science Department, School of Engineering, Pontificia Universidad Católica de Chile,
Av. Vicuña Mackenna 4860,
7820436
Macul, Santiago,
Chile
4
Instituto de Astrofísica, Facultad de Física, Pontificia Universidad Católica de Chile,
Av. Vicuña Mackenna 4860,
7820436
Macul, Santiago,
Chile
5
Centro de Astroingeniería, Pontificia Universidad Católica de Chile,
Av. Vicuña Mackenna 4860,
7820436
Macul, Santiago,
Chile
★ Corresponding author; iebecker@fas.harvard.edu
Received:
13
July
2023
Accepted:
9
January
2025
In this work, we propose a novel ensemble of recurrent neural networks (RNNs) that considers the multiband and non-uniform cadence without having to compute complex features. Our proposed model consists of an ensemble of RNNs, which do not require the entire light curve to perform inference, making the inference process simpler. The ensemble is able to adapt to varying numbers of bands, tested on three real light curve datasets, namely Gaia, Pan-STARRS1, and ZTF, to demonstrate its potential for generalization. We also show the capabilities of deep learning to perform not only classification, but also regression of physical parameters such as effective temperature and radius. Our ensemble model demonstrates superior performance in scenarios with fewer observations, thus providing potential for early classification of sources from facilities such as Vera C. Rubin Observatory’s LSST. The results underline the model’s effectiveness and flexibility, making it a promising tool for future astronomical surveys. Our research has shown that a multitask learning approach can enrich the embeddings obtained by the models, making them instrumental to solve additional tasks, such as determining the orbital parameters of binary systems or estimating parameters for object types beyond periodic ones.
Key words: methods: data analysis / astronomical databases: miscellaneous / stars: variables: general
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. Subscribe to A&A to support open access publication.
1 Introduction
Variable objects have a unique place in astronomy, as they provide additional information which is absent in the non-variable counterparts. They allow the measurement of distances, the study of physical processes that occur inside the objects, and the study of stellar populations (for a review, see Catelan & Smith 2015). Classifying these variable objects into distinct types has posed a recurring challenge in astronomy. In the past decades, the landscape of light curve acquisition has been transformed with the advent of numerous observatories (for a review, see Catelan 2023), altering the methodology employed. Traditionally, light curves were obtained primarily in a single band to maximize temporal coverage. However, this approach led to traditional classifiers relying on hand-crafted features specific to a single band, often incurring high computational expenses and necessitating the computation of the entire light curve. Consequently, the process became computationally intensive. Various Python packages have been developed to streamline this task, such as Feature Analysis for Time Series (FATS, Nun et al. 2015), offering automation capabilities.
Instead of multiple observations in one band, most modern telescopes have been observing in multiple bands, such as Gaia (Gaia Collaboration 2023), the Panoramic Survey Telescope and Rapid Response System (Pan-STARRS, Chambers et al. 2016), the Zwicky Transient Facility (ZTF, Bellm et al. 2019b), the Sloan Digital Sky Survey’s (SDSS, Almeida et al. 2023) Stripe 82 (Ivezic et al. 2007), the Asteroid Terrestrial-impact Last Alert System (ATLAS, Tonry et al. 2018), the SkyMapper survey (Onken et al. 2019), among others. Modern single-band telescopes are still operating, such as the Gravitational-wave Optical Transient Observer (GOTO, Steeghs et al. 2022) or the AllSky Automated Survey for SuperNovae (ASAS-SN, Shappee et al. 2014), as the generated light curves are of great scientific importance.
A revolution will begin in astronomy when the Vera C. Rubin Observatory Legacy Survey of Space and Time (LSST, Ivezic et al. 2019) begins science operations. It will scan the sky every three days, observing using one of six filters, and produce 20 TB of data per night. The relatively high cadence of observations will enable the differentiation of various variable phenomena, including transients, periodic sources, and moving sources. Any time a variable event is detected with respect to a reference image by the Rubin/LSST image pipeline, an alert will be distributed to the Alert Brokers (Bellm et al. 2019a). It is estimated that ~10 million alerts will be generated per night.
Brokers are systems that ingest, process, and distribute alerts to the scientific community. The seven brokers are Automatic Learning for the Rapid Classification of Events (ALeRCE, Förster et al. 2021), AMPEL (Nordin et al. 2019), ANTARES (Matheson et al. 2021), BABAMUL, Fink (Möller et al. 2021), Lasair (Smith et al. 2019) and Pitt-Google1.
One of the most important roles of brokers is to classify the alerts into different classes. One of the main challenges is the multiband nature of the light curves since an observation is only done in one filter at a time. There is no straightforward way to combine the information into a unified representation informative enough to classify with a few observations. Additionally, any solution has to be fast to process the alerts in real-time and needs to adapt to different observing strategies. This is an open problem that has yet to be solved conclusively. The training and deployment of a classifier is even more challenging at the start of the survey, when only a small number of observations per object are available, and training data is scarce.
In recent years, deep learning approaches have emerged as an alternative to feature-based methods. These approaches automatically extract their own representations, eliminating the reliance on predefined features (for a review, see Smith & Geach 2023). By avoiding the need for handcrafted features, deep learning methods tend to provide faster and less computationally expensive solutions. However, to date, these methods have not surpassed feature-based Random Forest (RF, Breiman 2001) approaches (e.g. Förster et al. 2021). This highlights the fact that expert knowledge contained in the features is critical in the development of any automated classifier. As such, even deep learning methods can benefit from domain-specific design.
Convolutional neural networks (CNNs) have been widely used to analyze multiband time series data. However, one of the primary challenges in this domain is to construct appropriate input representations for these networks. Pasquet et al. (2019) tackled this challenge by transforming supernova (SN) multiband time series into a 2D representation. Their approach organized the magnitudes in different bands as rows and represented the corresponding time information as columns. To extract meaningful features from unlabeled data, they employed an encoder-decoder architecture. This representation was then utilized to classify simulated Rubin/LSST light curves. Similarly, Brunel et al. (2019) developed a one-dimensional CNN classification model based on the inception module (Szegedy et al. 2015). Their study focused on simulated data captured at a daily cadence across four bands. They also adopted the same matrix representation, filling in missing values with zeros.
In Muthukrishna et al. (2022), a CNN was developed to detect anomalies in SN light curves. Training was carried out using simulated data, and testing was performed on real ZTF light curves. Linear interpolation addressed missing observations, followed by binning to achieve a cadence of three days.
The interpolation or binning approach to handle missing observations can pose challenges due to limited data points or large gaps between observations that exceed the characteristic time of the object. This effect becomes more pronounced with an increasing number of bands, as it requires more interpolations. Moreover, the number of observations per band is typically non-uniform, as they adhere to broader requirements set by the science objectives (Bianco et al. 2022) and the meteorological conditions.
Recurrent neural networks (RNNs) can naturally handle sequences, utilizing learned weights and the last hidden states to update embeddings and perform classification. However, RNNs tend to have slower training compared to their CNN counterparts, as they require sequential training. This sequential nature becomes advantageous during inference, as RNNs only need the last hidden state and the new observations, rather than the entire light curve, to make predictions. Despite some benefits, the Balanced Random Forest (BRF, Chen et al. 2004) is used in state-of-the-art classification scenarios, such as the ALeRCE broker.
Becker et al. (2020) introduced a model based on Gated Recurrent Units (GRU; Cho et al. 2014) for analyzing single-band light curves. Building on this work, Donoso-Oliva et al. (2021) enhanced the methodology employing a combination of Long Short-term Memory (LSTM; Hochreiter & Schmidhuber 1997) and Phased-LSTM (Neil et al. 2016), resulting in promising results across six real datasets. Both approaches demonstrated the ability of RNNs to work without interpolation. In another study by Charnock & Moss (2017), a deep bidirectional LSTM network was trained on simulated multiband light curves of supernovae. To address sparsity, the authors binned the light curve into 1-hour windows to ensure simultaneous observations. To impute missing values, they sampled random values between the observed points.
In the work of Möller & de Boissière (2020), a Bayesian RNN was employed to classify simulated SN light curves and obtain uncertainty in the predictions. The observations were grouped into 8-hour windows to handle the irregular cadence, and the multiband information was incorporated by using one- hot-encoded vectors and included the time difference between observations.
In a ground-breaking work, Vaswani et al. (2017) introduced the idea of self-attention and applied it to train an encoderdecoder called Transformer, removing the need for RNNs. The main benefit of this architecture is that it leverages the entire sequence in parallel, enabling the model to extract informative representations for each element in the sequence2.
The same concept has been employed in extracting light curve representations, as demonstrated by ASTROMER (Donoso-Oliva et al. 2023), which uses a pre-training strategy on unlabeled data. Recent studies, such as Pimentel et al. (2023), have utilized self-attention architectures for the multiband classification of supernovae. The models were tested on both synthetic and real ZTF data. Their approach for constructing the input involved binning the observations into 12-hour windows and concatenating the band information as a one-hot vector. Allam & McEwen (2024) developed a model based on self-attention to classify simulated multiband light curves of variable, transient, and stochastic objects. They employed interpolation using a Gaussian process to fill in the missing observations and utilized a global average pooling layer to explain the model’s output.
Supervised training can also be extended to regression tasks. Various relations involving light curve information and astrophysical quantities have been developed throughout history. For example, the Leavitt law (Leavitt & Pickering 1912) established a relation between Cepheids’ light curve properties and their absolute magnitude. In a study by Fernie (1992), a relation between periods and radii was obtained for δ Scuti stars. Additionally, Fernie (1995) fitted a period-gravity relation for radially pulsating stars. Fourier coefficients have also been utilized to establish relations between metallicity ([Fe/H]) and pulsation period (Morgan et al. 2007). Relationships of this type are not limited to pulsating stars; for instance, late-type eclipsing binaries also exhibit period-luminosity and period-luminosity-color relations (Ngeow et al. 2021, and references therein). Deep learning methods have been applied to perform similar regressions in recent years (e.g. Dékány & Grebel 2022).
In this work, we propose an ensemble of RNNs that incorporates the non-uniform sampling of multiband light curves into its design to extract their representations. This approach preserves the inherent relation between different bands, irrespective of the survey’s cadence. The extracted representations are obtained through training a classifier and a regression simultaneously when the data are available. This training methodology, also known as multi-task learning (for a review, see Crawshaw 2020), serves as a regularization mechanism while providing additional information to train the network. Consequently, it can enhance the performance of the models. We trained the models using three real light curve datasets, namely Gaia, Pan-STARRS1, and ZTF, to demonstrate their potential for generalization.
In Section 2, we describe the real light curves used in this work. In Section 3, we describe the single and multiband models used in this work. In Section 5, we show the results of the multiband classification and the regression of physical parameters. Finally, in Sections 6 and 7, we present the analysis and main conclusions of this work.
2 Datasets
This work used multiple single-band light curves to represent each object. The dataset consisted of modified Julian Date (MJD) values sorted in ascending order, the corresponding magnitudes with their respective uncertainties, and the bands in which the observations were conducted. Any flux values that exceeded their associated uncertainties were discarded, to remove low S/N measurements and ensure accurate photometry.
As is common in many deep learning approaches, a large training set with an adequate number of examples per class and sufficient observations per band is necessary. To fulfill these requirements, this study utilized real photometry data from Gaia, Pan-STARRS1, and ZTF. The following sections present comprehensive descriptions and explanations of the main pre-processing steps carried out on each dataset.
Histograms of the number of observations per light curve in each band are shown in Figure 1. Figure 2 illustrates a folded light curve of an RRab star, highlighting the inconsistent number of observations across the surveys.
2.1 Gaia
The Gaia DR2 variable star catalog, as described by Holl et al. (2018), consists of 550 737 variable objects cataloged using machine learning models. The available photometry includes three bands, with two of them being independent (Jordi et al. 2010). The telescope’s optics divide the light beam into two, allowing simultaneous measurements of red GRP and blue GBP magnitudes. For the purposes of this study, the G filter’s photometry is omitted since it is redundant as G = GBP + GRP. Our objective is to obtain light curves with bands sampling different sections of the electromagnetic spectrum.
To simulate an alternating cadence, we sub-sample the real light curves. If two observations from different bands are within 15 minutes of each other, one of the observations is removed to maintain the alternating cadence. We selected objects with a minimum of four observations per band. Table 1 displays the total number of examples per class.
For this dataset, the classes used were RR Lyrae fundamental-mode (RRab) and first-overtone (RRc), Mira and semi-regular variables (MIRA_SR); δ Scuti and SX Phoenicis (DSCT_SXPHE); classical Cepheid (CEP) and type II Cepheid (T2CEP).
We sampled a maximum of 40000 objects per class to construct the final training set to prevent classifier bias. This sampling strategy primarily limits the number of RRab and MIRA_SR stars. Categories with fewer samples than the threshold were used entirely, without any sampling.
 |
Fig. 1 Histograms of the number of observations on each band, per survey. Each band is identified by a color and a hatch style. Gaia filters GBP and GRP are identified with blue solid and orange hatched bars, respectively. Pan-STARRS1 bands are identified with solid green for ɡ, red right diagonal hatch for r, purple horizontal hatch for i, brown left diagonal hatch for z, and pink dotted bar for y. Both Gaia and ZTF are balanced but differ in the number of observations per light curve by one order of magnitude. Pan-STARRS1 is not balanced, showing longer sequences on the i band. As such, not all the bands will be available for some objects. |
Gaia dataset class numbers.
2.2 Pan-STARRS1
Pan-STARRS1 (Chambers et al. 2016; Flewelling et al. 2020; Magnier et al. 2020) is the first telescope of the Pan-STARRS Observatory, which is an imaging and data processing facility primarily used for the 3πsr and Medium Deep Surveys. It features a 1.8-meter telescope equipped with a 1.4 gigapixel camera, which captures observations through filters ɡP1, rP1, iP1, zP1, and yP1. To select a sample of variable objects, we conducted a crossmatch with the Gaia DR2 objects (Marrese et al. 2019). The classes were the same as in Gaia, with the addition of RR Lyrae double-mode pulsator (RRd).
For the second data release, the photometry was obtained from the Detections table on the MAST CasJobs3. Specifically, columns containing MJD, flux, flux uncertainty, and band information were queried.
The fluxes were transformed into AB magnitudes using
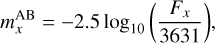 (1)
(1)
where x represents the band, and 3631 Jy is the zero point for the AB photometric system (Tonry et al. 2012).
Furthermore, the columns psfQfPerfect, infoFlags, infoFlags2, and infoFlags3 were extracted to ensure the selection of clean photometry. The criteria for filtering observations are outlined in Appendix A.
Following the pre-processing steps, we imposed a requirement of a minimum of four observations per band. The final catalog is described in Table 2. Similar to the Gaia dataset, we sampled a maximum of 10 000 objects per class to reduce overfitting, reducing the number of RR Lyrae objects in the dataset. The threshold value differs from the Gaia dataset because of the huge class imbalance, where RR Lyrae examples are 91% of the total number of samples. As such, a lower value had to be selected to avoid overfitting to only one object type.
 |
Fig. 2 Light curves of the same RRab star with a period of 0.658936 days. The identifiers are 839368005575354240, 169841701110866261 and ZTF17aaajjtn, for Gaia DR2, Pan-STARRS1 DR2 and ZTF DR10, respectively. For Gaia, the observation in the GBP filter is shown in blue circles and orange triangles for GRP. For Pan-STARRS1 on the second panel, the filters ɡP1, rP1, iP1, zP1, yP1 are identified by green circles, red triangles, purple inverted triangles, brown squares, and gray diagonal crosses, respectively. For ZTF, g is shown in olive circles and r in cyan diamonds. |
Pan-STARRS1 dataset class numbers.
2.3 ZTF
ZTF (Bellm et al. 2019b) is an optical time-domain survey that uses the Palomar 48-inch Schmidt telescope. This telescope has a field of view of 43.56 deg2 and uses a 576 megapixel camera. This survey uses ZTF’s alert photometry in the ɡ, r, and i filters. The alert light curves were obtained from ALeRCE’s Database service4 up to May 2022, where only ɡ and r bands are available for the alerts. The public data releases contain all three bands.
In this work, the labeled training set objects were obtained from Sánchez-Sáez et al. (2021), as it contains a curated sample of variable stars, transients, and stochastic variables. Transients are represented by SN of types Ia, Ibc, II and super luminous supernova (SLSN). The stochastic classes are blazars, type 1 Seyfert galaxy (AGN), type 1 quasar (QSO), young stellar object (YSO) and cataclysmic variable/nova (CV/Nova). The main categories for periodic variables are long-period variable (LPV), RR Lyrae (RRL), Cepheid (CEP), eclipsing binary (E), δ Scuti (DSCT), and Periodic-Other, which are periodic classes not considered in the previous ones. For training purposes, we sampled up to 10 000 objects per class, affecting mainly E, QSO, and RRL type objects. Table 3 displays the total number of examples per class.
2.4 Physical parameters
Physical parameters play a crucial role as they provide fundamental descriptions of objects. However, for variable stars, these parameters often undergo changes over time. Consequently, it is only realistic to study the mean values of these parameters, when large sample sizes are involved. Otherwise, a large investment in follow-up resources would be required, which is not feasible for a large sample size.
In this study, we utilized the values obtained from the Transiting Exoplanet Survey Satellite (TESS) Input Catalog (TIC, Stassun et al. 2019), which is employed by the TESS mission (Ricker et al. 2015) for target selection, and the Gaia astrophysical parameters inference system (Apsis, Andrae et al. 2018). Both catalogs are products of systematic analyses of objects. Apsis derives stellar parameters using an ensemble of machine learning models. The physical parameters of TIC sources are mainly inferred from Teff, which is obtained from a spline fit as a function of GBP − GRP based on spectroscopic data. The radius is derived from the Stefan–Boltzmann relation, and the mass is obtained from a fitted mass versus Teff spline function. The rest of the quantities are obtained directly.
After performing a cross-match, if a measurement was available in both catalogs, the measurement from the TIC took precedence as it reported smaller uncertainties in its estimations. It is worth noting that, while a more extensive search might have yielded additional measurements, we intentionally maintained a smaller set of sources to avoid introducing unnecessary sources of uncertainty.
Given the limitations of photometric and spectral observations, not every object will have measurements for these parameters, let alone measurements for all of them.
This model utilized the reported central values without considering the uncertainties, which are likely underestimated for TIC. In its current form, the regression was only used to enhance the information contained in the embeddings and improve the classification performance.
Table 4 provides an overview of each survey’s number of objects with measurements of Teff and radius. To avoid numerical artifacts, we kept values of Teff between 3400 and 8000 K, and radii between 10 and 200 R⊙.
ZTF dataset class numbers.
Physical parameters measured on each dataset.
3 Multiband RNN classifier
In this work, we built on the ideas proposed by Becker et al. (2020) to create a novel model inspired by the Local-Global Hybrid Memory Architecture (Liu et al. 2016). This model incorporates modular single-band interconnect components to facilitate information flow, thereby increasing flexibility and adaptability.
A single multiband model’s limitation lies in its inflexibility to include new information post-training. To overcome this, we developed a model that uses the neural network’s capacity to generate its own representations and harnesses its modular nature to extend the architecture, integrating new filters into the data. Consequently, the model can adapt to different surveys, accommodate additional bands, and even assimilate data from various telescopes.
We constructed our proposed model from interlinked singleband models based on LSTMs. Each of these models uniquely learns the behavior of the light curves in its respective band. These single-band models feed into another LSTM, which then develops a unified multiband vector representation. We used this consolidated representation for subsequent tasks, such as variable star classification and the regression of stellar physical parameters.
This section provides a detailed description of the preprocessing stage, the creation of single-band inputs, the architecture of the model that learns the unified representation, and the training strategy employed to train the model effectively.
3.1 Pre-processing
Our encoding of single-band light curves followed a similar method to Becker et al. (2020), with some additional steps. We used an integer b to identify the band and to store the uncertainties ub related to the measurements. We assigned each time measurement in the multiband light curve an integer denoting the observation order, which we stored in the vector ob.
For each band, we calculated the differences in time and magnitude between the current and previous observations, excluding the first observation. We then grouped these differences using a sliding window of size w and stride s. In this work, we set w = 2 to allow predictions from the third observation and s = 1 to predict after each subsequent observation. We maintained these values across all datasets. While this representation omitted the first observation per band, the difference became negligible as we accumulated sufficient observations.
The resulting single-band input Xb is,
![${{\bf{X}}^b} = \left( {\left[ {\matrix{ {\Delta {t_2}} & {\Delta {t_3}} & {\Delta {m_2}} & {\Delta {m_3}} \cr {\Delta {t_3}} & {\Delta {t_4}} & {\Delta {m_3}} & {\Delta {m_4}} \cr \vdots & {} & {} & \vdots \cr {\Delta {t_{N - 1}}} & {\Delta {t_N}} & {\Delta {m_{N - 1}}} & {\Delta {m_N}} \cr } } \right]\,\,\,\,,\,\,\,\,\,\left[ {\matrix{ {{u_3}} \cr {{u_4}} \cr \vdots \cr {{u_N}} \cr } } \right]\,\,\,\,,\,\,\,\,\left[ {\matrix{ {{o_3}} \cr {{o_4}} \cr \vdots \cr {{o_N}} \cr } } \right]} \right).$](/articles/aa/full_html/2025/02/aa47461-23/aa47461-23-eq2.png) (2)
(2)
We also stored non-sequential data per band, such as the number of observations and the first measurements of time and magnitude.
3.2 Single-band representation
This work used a multi-layer LSTM as the primary mechanism for learning representations. We considered each row of the matrix Xb as a step in the sequence and used it as input for the b-th single-band model. Additionally, we applied residual connections (He et al. 2016), as demonstrated in Wu et al. (2016), between the recurrent layers to promote the flow of gradients and augment the model’s expressivity. We also applied Layer Normalization (Ba et al. 2016) between each recurrent layer.
The hidden state encodes the light curve information from each recurrent layer up to that specific time step. Adding recurrent layers can incur an increased computational cost and yield diminishing returns, a pattern we observed in preliminary experiments and corroborated by previous works (Zhang et al. 2016). To merge the hidden states without substantially increasing the number of parameters, we used a linear combination of the hidden states, adhering to the method proposed by Peters et al. (2018).
For each step i in the sequence, we combined the L hidden states using
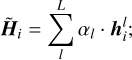 (3)
(3)
we softmax-normalized the trainable parameters αl. This normalization allowed the model to merge the information without concatenating the hidden states or adding more layers. In this work, we selected L = 3 for all three datasets. We set the hidden state size to 128 for Gaia and ZTF, and 64 for Pan-STARRS1. The values for the hidden state sizes were defined based on preliminary experimentation and were not fine-tuned. The sizes correlated with the length of the light curves. A larger hidden state implied a larger number of parameters, which required more training data. Pan-STARRS1 light curves were smaller compared to the other two surveys.
Following the methodology in Donoso-Oliva et al. (2021), we performed classification at each time step to encourage early sequence predictions by the model. We used the categorical cross-entropy loss function. However, we excluded the first Nskip predictions to compensate for the model’s limited early performance with sparse observations. We always set Nskip to be less than the shortest sequence in the dataset. Specifically, we set Nskip to 8 for Gaia, 2 for Pan-STARRS1, and 3 for ZTF.
Light curves include the uncertainty of each observation, which can be used to prioritize them. In a survey setting, fainter stars often have larger uncertainties due to lower signal-to-noise ratios than brighter stars. If not addressed, the model might give undue weight to certain observations tied to brighter objects.
To counteract this bias, we normalized the weights of the observations within each light curve to a total of one. This process minimized the impact of uncertain observations on the predictions for each light curve and treated every example in the dataset equally. For each example, we computed a weighted average of the individual step losses. We chose the weight of each time step as the inverse of the uncertainty value. The weight of the l-th step for a single light curve is
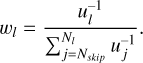 (4)
(4)
In this equation, Nl represents the length of the l-th light curve, and the subscript j corresponds to the j-th element of the sequence. We calculated the loss of each batch as the average across the different training examples within the batch. A diagram of a single-band model is shown in Figure 3.
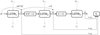 |
Fig. 3 Single-band representation of a single time step. Solid lines represent the inputs and outputs of the LSTM cells across a single time step. Dashed lines represent the residual connections between recurrent steps. The dotted lines represent the operations to construct the final representation, given in Equation (3). The gray connections represent the inputs and outputs across different time steps. |
3.3 Multiband representation
We employed an additional LSTM to merge information from the single-band representations, whose architecture is similar to the single-band ones. The inputs to this network were the hidden states of each single-band LSTM, sorted using the order information o detailed in Sect. 3.1.
We applied a distinct linear combination, using Eq. (3), to create a unified vector input for each band. The central model learned the weights of this transformation, enabling it to attend to the hidden states in a manner distinct from the single-band models.
Given that the single-band RNNs are trained independently, the embeddings 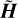 cannot be directly compared. To overcome this, we trained a three-layer Feed Forward Neural Network (FFNN) with Rectified Linear Unit (ReLU) activation to map the outputs of each single-band RNN to a new representation
cannot be directly compared. To overcome this, we trained a three-layer Feed Forward Neural Network (FFNN) with Rectified Linear Unit (ReLU) activation to map the outputs of each single-band RNN to a new representation 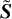 . We refer to these FFNNs as translation layers, and their weights are trained by the central model. After this step, we applied Layer Normalization.
. We refer to these FFNNs as translation layers, and their weights are trained by the central model. After this step, we applied Layer Normalization.
We set the number of recurrent levels to two for Gaia and ZTF, and three for Pan-STARRS1, while maintaining the hidden state size consistent with that used in the single-band counterparts. The resulting multiband representation is captured in the vectors H . Figure 4 provides an example diagram of the ensemble of models, depicting a two-band survey configuration.
3.4 Color
In any astrophysical scenario, color information is critical. We understand color as the difference between two magnitudes, providing an approximation of an object’s spectral shape. Typically, corrections due to extinction have to be applied to obtain the object’s intrinsic color. Since the filters towards the blue part of the spectrum are most affected, objects appear redder than they truly are. In this work, we did not perform those corrections to make the pipelines simpler and not introduce any other source of uncertainty to the observations.
We transformed the single-band representations Xb to obtain the mean magnitudes at each time step. From the magnitude differences, the magnitude at each time step is recovered. From there, the mean magnitudes in every band were obtained using forward fill imputation. The process is explained in Appendix B, which does not consider uncertainty propagation.
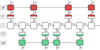 |
Fig. 4 Representation of the multiband ensemble of models. Mr and Mɡ represent single-band models. Tr and Tɡ correspond to the translation layers that project the data to a common representation. C is the central model with a similar architecture as shown in Figure 3, trained on the outputs of the single-band models. The final classification is done with the output of the last step. |
3.5 Final multiband representation
The multiband time differences were included to provide the central model with a general view of the information. First, the single-band ∆MJD were concatenated and sorted using the order information ob. Then, following the same method used for mean magnitudes detailed in Appendix B, the original MJD was recovered and used to compute the multiband time differences.
We appended the colors and time differences to the vectors H to provide more information about the object. The final representation was fed into a three-layer FFNN that featured batch normalization (Ioffe & Szegedy 2015) and ReLU activation.
One of the main advantages of our multiband approach is its simplicity when making predictions. If a new observation arrives on any band the model was trained on – regardless of the number of bands – only two model evaluations are necessary: one for the observed band and another for the central model. The singleband models can be obtained by training band-specific models on multiple datasets or applying additional machine learning techniques, such as Transfer Learning.
3.6 Training strategy
This study introduces a methodology involving b + 1 interacting models, encompassing the single-band and a central unifying model. We applied backpropagation using the AdamW optimizer (Loshchilov & Hutter 2019), coupled with an exponential decay learning rate of 0.95 every 60 training steps. We also employed early stopping with a patience of 20 epochs.
We independently trained each single-band network on the cross-entropy loss weighted by uncertainty, as depicted below:
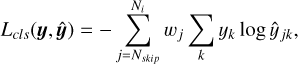 (5)
(5)
where ŷjk are the predicted probabilities for the k-th class of the j-th step in the sequence and yk the ground truth, the same for the entire sequence. The class with the highest probability determined the final classification.
We trained the central network using the same classification loss. This network independently trained its weights, the weights associated with the b linear combinations of hidden states as described in Eq. (3), and the translation layers.
In this work, we aim to include the entire multiband observations in the model, as the single-band light curves are complementary. The information contained in the unified multiband representations is tied to the quality of the single-band embeddings. For machine learning models, the information contained on a light curve cannot be measured by using traditional features, as these models can extract information even from apparently noisy light curves (Donoso-Oliva et al. 2023). Additionally, the number of examples has a higher impact on the quality of the single-band representations than the noise characteristics (Becker et al. 2020).
As such, the central network is able to combine and enhance the provided information, even if the characteristics of the light curves are not ideal from a traditional standpoint. It is not in the scope of this work to explore the characteristics that a light curve might possess to be considered informative.
Moreover, comparing the quality of single-band light curves depends on many factors, such as the specific filters, extinction, different physical behaviors, or errors that might affect the hardware at different wavelengths. The criteria to balance the quantity and quality of the information will depend on the specific task to solve.
The uncertainties were used to weigh each observation’s importance. Different bands can have drastically different uncertainty behavior. For simplicity, we ensured equal weighting of uncertainties across different bands to prevent undue prioritization of bands with smaller uncertainties. To achieve this, the uncertainties of each single-band light curve were normalized to add up to one. Then, we concatenated and sorted the values using the order information ob. Finally, we computed the loss weights using Equation (4).
This strategy was intended to be used for surveys with a similar number of observations per band. In a different scenario, other strategies could be adopted, such as normalizing the single-band uncertainties to have a mean of one.
During each training batch, we performed backpropagation once in the single-band models and twice in the central model with half the learning rate.
The training process began with the single-band models, which we trained for 500 batches. We then start training the central model. This strategy allowed the single-band models to approximate a local minimum while still permitting minor parameter adjustments in the generation of their embeddings. These slight modifications in the input helped the central model alleviate overfitting. Allowing the single-band models to converge before training the central one resulted in poorer performance.
The number of trainable weights for the Gaia model was 383 113 for the single-band models and 1 198 114 for the central representation, totaling 1964 340. For Pan-STARRS1, the single-band models contained 110 153 trainable parameters, and the central model 744 645, totaling 1 295 410. For ZTF, these are 383 500 for the single-band models, and 1 197 993 for the central model, totaling 1964 993.
3.7 Multi-task training
To obtain more general embeddings, we trained the central network for classification using cross-entropy and mean squared error (MSE) for regression of physical parameters.
For the regression task, only the last hidden state of the central model was used to predict the physical parameters. We created the final representation using a two-layer FFNN with batch normalization and ReLU activation.
The final loss function L is the sum of the classification and regression losses for one example is
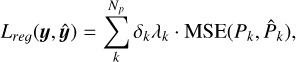 (6)
(6)
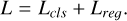 (7)
(7)
The regression loss, Lreɡ, was calculated for each physical parameter using the MSE, weighted by λk, which represents the relative importance of each parameter. Here, Np is the number of physical parameters, and Pk is the prediction for the k-th physical parameter. Without proper weighting, the different dynamic ranges of the parameters could bias the learning process.
Since not all objects have multiband light curves or measurements for all physical parameters, we use the parameter δk to mask the missing ground truth values from the loss update. It took the value of 1 when the physical parameter had a valid measurement and 0 otherwise. This ensured that the model could be trained with all available information while accounting for the missing data.
The same final representation discussed in Sect. 3.5 was used for the regression branch. It was fed into a two-layer FFNN with 128 neurons per layer, employing ReLU activation and batch normalization after each layer. This architecture was applied consistently across all datasets and physical parameters.
4 Baselines
This section introduces the baselines used as points of comparison for the proposed model. The first baseline is the BRF, which is based on the work of Sánchez-Sáez et al. (2021). This model is already utilized in the real-time classification of variable objects, making it a suitable candidate for comparison. A detailed description of the BRF model is provided in Section 4.1.
To assess the advantages of our proposed model’s architecture and to evaluate an additional baseline, we utilized the concatenation of the representations generated by the single-band RNN models, as discussed in Sect. 3.2. This baseline approach allowed us to investigate the performance of a straightforward combination of single-band representations without the additional modeling and training steps introduced in our proposed model.
4.1 RF baseline
We trained a BRF classifier for classification tasks and a RF for regression, utilizing the Python packages Imbalanced-learn (Lemaître et al. 2017) and scikit-learn (Pedregosa et al. 2011), respectively.
To provide the input for the baseline model, we used the code provided by Sánchez-Sáez et al. (2021), computing a total of 105 features. However, not all of these features were used since our data contained only time, band, magnitude, and uncertainty measurements. We independently computed the color features as the subtraction of two mean magnitudes. We followed the same methodology, imputing missing values with −999.
We discarded the mean magnitudes and computed the periods with single-band light curves to avoid biasing the model, given that multiband period estimation yields superior results (Mondrik et al. 2015).
We trained two versions of the BRF classification baselines: one limiting the maximum number of objects per class to replicate the training conditions of our model, and another without any restrictions, to study if that limitation hinders the performance of the model. In this way, the performance could be compared directly.
For each experiment, we performed a grid search in five stratified folds to determine the optimal hyper-parameters, utilizing the scikit-learn library. We optimized the macro F-score for classification and MSE for regression. Our search spanned between 100 and 4000 trees. Initially, we explored tree counts starting at 100 and increasing in increments of 100, up to 500. Beyond this, the numbers began at 750 and increased by 250 until we reached 4000.
4.2 Mixture of experts
We evaluated the merits of our proposed ensemble model in comparison to a similar architecture without the central network. Each single-band LSTM in this setup was constructed as detailed in Section 3.2.
The resultant embeddings from these single-band LSTMs were concatenated to form a multiband representation. Subsequently, we appended the color information to this multiband representation. The training process used the same data and hyper-parameters as those used in our proposed model.
All of the RNNs were trained together as a single network, since the multiband observations are not simultaneous. The gradient backpropagation was performed from a single classification loss into each of the single-band RNNs.
F-score for Gaia experiments results.
F-score for Pan-STARRS1 experiments results.
5 Results
This section presents the results of the proposed multiband model and the baselines. We split the data into 70% for training, 10% for validation, and 20% for testing. We perform seven of such stratified splits, maintaining the same test set. We use the same data for our model and the baselines. For the RF-based models, the training and validation splits are combined, as these models do not need validation data.
5.1 Baselines
A grid search was performed for both classification and regression tasks, and the optimal number of trees was selected. For the two BRF experiments, the number of trees for Gaia was 2750 and 2750; for Pan-STARRS1, 1000 and 200; and for ZTF, 3250 and 3500, for the capped and uncapped experiments, respectively.
Upon evaluation on the test set, the capped experiment achieved median macro-averaged recall values of 0.800, 0.420, and 0.778 for Gaia, Pan-STARRS1 and ZTF, respectively. The uncapped experiment attained median macro-averaged recall values of 0.801, 0.417, and 0.779, respectively.
In the RNN baseline model, the median macro-averaged recall values were 0.520 for Gaia, 0.358 for Pan-STARRS1, and 0.516 for ZTF.
The F-score for each class is detailed in Tables 5, 6, and 7.
We used only the datasets with a capped maximum number of objects per class for the regression baseline. The aim is to evaluate how much information can the RF and MTL models extract from the data to predict the measured physical parameters. The number of trees was calculated separately for each physical parameter.
For Gaia, 2250 and 400 trees were used for Teff and radius, respectively. Pan-STARRS1 used 3000 and 200, while ZTF used 3250 and 2250 trees for these parameters. The results are in Tables 8, 9, and 10. The best results are highlighted in bold font.
Post-training feature importance analysis, obtained as the normalized total reduction of the Gini impurity, highlighted the significant role of color information in the RF. For Gaia, color features accounted for 84 and 63% of the importance in the Teff and radius predictions, respectively. For Pan-STARRS1, color features held a combined importance of 75% for Teff and 79% for radius predictions. For ZTF, color features held a combined importance of 62% for Teff and 56% for radius predictions.
F-score for ZTF experiments results.
Regression R2 metric for the Gaia, Pan-STARRS1 and ZTF datasets.
Regression RMSE metric for the Gaia, Pan-STARRS1 and ZTF datasets.
5.2 Multiband RNN model
Our proposed multiband ensemble yielded median macroaveraged recall values of 0.745 for the Gaia data, 0.588 for Pan-STARRS1, and 0.828 for ZTF. The median F-scores for each class, obtained in the seven cross-validation folds, are presented in Tables 5, 6, and 7. In the tables, Base denotes the baseline RNN model, Multi corresponds to our multiband model, and MTL signifies the multi-task learning model. The terms BRF and BRFAll pertain to the models trained on capped and uncapped training sets, respectively. We highlight in bold the highest results per class. Notably, across all categories and throughout all three surveys, our ensemble of RNNs outperforms the Base model. Moreover, it generally surpasses the BRF models, with only two exceptions – the T2CEP in Gaia and the SNIa class for ZTF.
Figures 5, 6, and 7 display confusion matrices, showcasing the median results among the seven trained models. The rows do not sum to one, as the information is derived from different matrices. The values at the lower and upper end represent the 25th and 75th percentiles, respectively, with black lines grouping objects of the same type. The matrices are primarily diagonal, suggesting that most mistakes occur within larger classes.
As for the multi-task learning setup, the macro-averaged recall values for Gaia are 0.742, 0.582 for Pan-STARRS1, and 0.807 for ZTF. The outcomes of the physical parameters prediction are depicted in Tables 8, 9, and 10 for the R2, root mean square error (RMSE) and mean absolute percentage error (MAPE) metrics, respectively.
For clarity purposes, we report the approximated value of Teff to the nearest integer and the radius to the first decimal since the uncertainties generally fall within this order of magnitude. For training purposes, the data was used with all the reported decimals.
To expand on the aggregated metrics, we report the distribution of predictions for our model and the RF in Fig. 8. It shows that the RNN systematically predicts similar but shifted distributions compared to the RF.
MAPE for the Gaia and Pan-STARRS1 datasets regressions.
 |
Fig. 5 Confusion matrix for the Gaia Multi model. Cepheids and RR Lyrae are confused inside the hierarchy. A bias towards the RRab class can be seen, as this class dominates the dataset. |
 |
Fig. 6 Confusion matrix for the Pan-STARRS1 Multi model. RRd stars pulsate in the fundamental and first overtone simultaneously, with the latter being the dominant mode most of the time Braga et al. (2022, and references therein). The same behavior can be seen in the fraction of misclassified RRd stars, which are assigned either RRab or RRc labels. |
 |
Fig. 7 Confusion matrix for ZTF Multi model. The main mistakes are between QSO, AGN and Blazars, given their similar source and a bias towards QSO as one of the most numerous classes. |
 |
Fig. 8 Distribution of the physical parameter estimations. Each column corresponds to the parameters of a survey. |
5.3 Sequence classification
The classification performance through time is important for any survey, as the classifier should provide stable and more reliable classifications as new observations arrive. Inspecting the model’s predictions as a function of the observation number provides evidence of the overall performance.
Figure 9 presents the classification evolution with respect to the number of multiband observations for a single DSCT_SXPHE object in the Pan-STARRS1 data. Initially, classification fluctuated between DSCT_SXPHE and RRc classes, while the other classes maintained a low probability. After approximately 40 observations, the classification probability improves with new data, regardless of the band. At the final step, the predicted class stabilizes, but this behavior may vary for different light curves.
Our data representation precludes predictions for the first two observations in each band. Therefore, the plot demonstrates the performance based on our representation and does not precisely represent the actual performance as an alert classification mechanism.
 |
Fig. 9 Example of the models’ output of the classification probabilities as a function of the number of observations for the Pan-STARRS1 DSCT_SXPHE star 86363087019643005. The symbols on the lower axis identify the filters used for each observation. Filter g is represented with a green circle, r with a red square, i with an orange triangle, z with a purple cross, and y with a blue diamond. The model’s main confusion was among DSCT_SXPHE (blue solid line) and the RRc class (orange dashed line). The rest of the classes, represented as Other (green dotted line) are assigned a low probability. |
5.4 Classification performance
Feature-based classifiers depend on informative features, such as the period, which cannot be calculated when only a few observations exist. However, the sequential nature of an RNN- based classifier enables classification even with a limited number of observations per band. Figure 10 provides histograms of the mean F-score in bins based on the total number of observations. Generally, the RNN model outperforms the BRF. The significant difference in Pan-STARRS1’s performance can be attributed to the large number of bands, which shortens the single-band light curve lengths and consequently diminishes the quality of the features.
 |
Fig. 10 F-score as a function of the total number of observations. The results of the RNN model are shown in solid blue, while the values for the BRF are shown in diagonal hatched orange. The bins are not uniform as some of them were merged to increase the number of objects per bin. Bins with less than 20 examples were removed to avoid showing unrepresentative results. The vertical black lines show the standard deviation for each bin. |
6 Analysis
Analysis of our multiband ensemble model reveals its adaptability across varied surveys, signified by its performance with different numbers of bands and cadences. This adaptability is anchored in the model’s modular architecture, composed of single-band networks that function independently but are united by another central network. This independence allows the models to be individually trained on similar datasets, providing a considerable degree of flexibility.
The preprocessing used in this work is not refined for the early classification of transient objects, which requires a prediction from a small set of single-band observations. We note that the single-band models can be changed to a better-suited model, such as Donoso-Oliva et al. (2021), which does not drop any observations.
The multiband RNN ensemble demonstrates a high degree of accuracy in multiband classification, as evidenced in Figures 5, 6, and 7 for Gaia, Pan-STARRS1, and ZTF data, respectively.
In the case of Gaia, a primarily diagonal confusion matrix indicates strong classification performance, with the model adeptly identifying main classes such as Cepheids and RR Lyrae. While the model shows a slight bias towards RRab objects, high- amplitude δ Scutis present a challenge, often being misclassified as RR Lyrae. In spite of the difference in their period distributions, the light curves of RRab objects may resemble that of a δ Scuti pulsating in the fundamental radial mode; in like vein, RRc light curves may resemble those of δ Scutis pulsating in the first radial overtone. This could point to the model’s deficiency in characterizing objects with shorter periods, in contrast with its higher efficiency at longer periods, as revealed by the high scores that are found in the case of MIRA_SRs.
The Pan-STARRS1 results mirror those from Gaia, with RRab stars being the most populous class and δ Scutis objects maintaining a similar proportion of misclassifications. A significant issue occurs with the RRd stars, most of which are misclassified due to the fact that they pulsate simultaneously in both the fundamental and first overtone, with the network assigning the class corresponding to the most dominant pulsation mode.
For the ZTF data, which extends to transients, stochastic, and periodic variables, the classification accuracy remains high. The primary confusion arises among QSO, AGN, and Blazar categories due to their shared source properties, also observed in Sánchez-Sáez et al. (2021). Notably, a degree of overfitting is observed in Fig. 7, as vertical patterns emerge from the predicted QSO and E classes. The model is biased towards those classes, as they are some of the largest categories in the dataset. In specific cases, such as ZTF SNIa, the BRF outperforms our model, as some of the features are specifically designed to identify SNe.
In general, our multiband ensemble of models matches or surpasses the performance of the standard BRF, delivering higher F-scores across multiple surveys. Our proposed model outperforms the BRF in all experiments except Gaia T2CEP and ZTF SNIa, where the feature-based method achieves a better F- score. The differences are minimal, as the former is a class with few examples where both models perform poorly, and the latter shows a difference of 0.01 in F-score, which can be increased with careful hyper-parameter tuning. The results underline the model’s effectiveness and flexibility, making it a promising tool for future astronomical surveys. In terms of design, our model can adapt to any survey’s cadence, regardless of the number of filters. This flexibility is illustrated in Fig. 9.
Our multiband model is specifically adept at providing solid classification performance even for light curves with few observations, as shown in Figure 10. The BRF faced difficulties as not all features could be accurately computed, as the imputation scheme negatively impacts the classifier’s performance as not all features are well-defined.
In the regime of longer light curves, our model continues to provide correct classifications, even for long sequences where the features are well defined, outperforming the baselines. However, as seen in Figure 10, our model’s performance does decrease slightly for longer sequences. This is a characteristic limitation of RNNs that tend to lose track of information over extended sequences (Pascanu et al. 2013). However, for the expected number of observations from the Rubin/LSST, the results are stable, and no significant impact should be expected.
In the context of multi-task learning, the performance of the MTL model remains comparable to the pure classifier (Multi) model. In most instances, it manages to achieve similar performance, and in some classes even surpasses it, such as in the case of Gaia DSCT_SXPHE and Pan-STARRS1 RRc. In some classes, the classification performance of the MTL model decreases, such as T2CEP stars in Pan-STARRS1, Gaia RRab class or the entire ZTF data. For the first two datasets, the differences are at most 0.02 in F-score (with the exception of Pan-STARRS1 T2CEP), and with proper hyper-parameter tuning, the score should at least equalize. For ZTF, the scores are consistently lower, but with much better physical parameter estimation.
We note that training the models for classification and regression simultaneously has the added advantage of improving the quality of the embeddings. These enriched embeddings can subsequently be leveraged to resolve other downstream tasks, such as the regression of other astrophysical quantities.
When it comes to the regression of physical parameters, the results in Tables 8, 9, and 10 show the RF as the best model. Nonetheless, our model was able to extract representations used to perform classification and regression simultaneously. While RFs can be trained to perform individual tasks, they are built from a predefined representation of the objects, cannot extract a new one from the data, and do not benefit from the information of other tasks. This highlights the importance of flexible models and informative embeddings that can be used as a foundation for more task-specific models (Touvron et al. 2023; Donoso-Oliva et al. 2023).
A plausible explanation for this could be the strong dependence of the parameters on the color information. Although both models had equal access to this information, the more straightforward approach adopted by RF appears to be better suited for this task. It is conceivable that a more specialized model could potentially match the RF results. The development of such a model extends beyond the purview of this study.
7 Conclusion
The aim of this work was to develop an ensemble of RNNs capable of extracting informative representations from multiband light curves, in order to perform tasks such as classification of variable objects or regression of physical parameters.
The presented ensemble of multiband models was tested on real light curves from Gaia, Pan-STARRS1, and ZTF surveys, demonstrating its ability to adapt to varying numbers of bands. This unique model ingests multiple single-band light curves per object, eliminating the need for interpolation or binning, and lets the model itself extract a multiband representation.
Our model architecture allows it to maximize single-band information extraction, which is then combined into a unified multiband embedding, independent of each band’s cadence. This gives our approach significant flexibility, as new single-band models can be trained on different datasets and included in the ensemble without requiring retraining of existing individual band models. Only the central RNN needs to be retrained to incorporate the new information.
Our ensemble approach demonstrates superior performance in scenarios with fewer observations, thus providing potential for early classification of sources from facilities such as Vera C. Rubin Observatory’s LSST. Remarkably, even in cases like Pan-STARRS1, where six interacting models are trained, only two model evaluations are needed at prediction time: one for the observed band and one for the central representation.
This method outperforms standard approaches, particularly those based on BRF implementations, especially in scenarios with more bands and sparser single-band light curves.
In addition, our research showed that a multi-task learning approach could enrich the embeddings obtained by the model. These improved embeddings can further be utilized in various astrophysical tasks, such as the regression of physical parameters like the temperature or radius of stars. We note that the features correlate strongly with the regressed parameters, which explains the edge of the RF. In this work, the multi-task learning approach increased the information contained in the embeddings. The regression task served as a regularization tool and was not fine-tuned for performance, as doing so would hurt the performance of the classifier, as seen in the ZTF case. Alternatively, it would require implementing a metric to balance the regression and classification tasks, which falls outside the scope of this work.
In future work, our model can be trained on more extensive datasets such as Gaia DR3, which offers improved photometry and longer light curves. In addition to this, we can incorporate metadata from an expanded array of sources, including but not limited to extinction maps, coordinates, and redshifts. This enriched data pool could significantly boost the model’s predictive power and versatility. However, incorporating diverse datasets will require careful treatment to address potential systematics, inconsistencies, and errors inherent in the data, ensuring robust and reliable model performance.
Moreover, including a wider variety of tasks in our model – be it classification or regression – may further improve the quality of the embeddings. Such advancements could prove particularly beneficial in applications like determining the orbital parameters of binary systems or estimating parameters for diverse object types that extend beyond periodic ones.
There is considerable potential to adopt advanced training techniques from the Natural Language Processing domain, such as self-supervised pre-training followed by supervised finetuning as in Devlin et al. (2018). This approach could enrich the learned data representations, paving the way for effective transfer learning, particularly considering the minor discrepancies in the filter systems used by ZTF, Pan-STARRS1, and Rubin/LSST.
Such strategies could facilitate model training on datasets from different surveys, such as ZTF, necessitating fewer training epochs for adaptation to Rubin/LSST conditions. This would considerably reduce the time required to develop a specific Rubin/LSST classifier, thus promoting efficiency and expediency in future astronomical studies.
Data availability
The code to create the data representation, and to train and test the multiband model is available in GitHub at https://github.com/iebecker/ScalableMultiband_RNN.
Acknowledgements
This research was supported by CONICYT- PFCHA/Doctorado nacional/2018-21181990. Additional support for this project is provided by ANID’s Millennium Science Initiative through grant ICN12_009, awarded to the Millennium Institute of Astrophysics (MAS); by ANID/FONDECYT Regular grant 1231637; and by ANID’s Basal grant FB210003.
Appendix A Pan-STARRS1 cleaning
To clean invalid or noisy observations for the Pan-STARRS1 dataset, the following criteria is used, taken from Table 2 in Magnier et al. (2013):
psfQfPerfect>0.9
psfFlux>0 and psfFluxErr>0
psfFlux>psfFluxErr
infoFlag ∉ {8, 16, 32, 128, 256, 1024, 2048, 4096, 8192, 32768, 65536, 131072, 262144, 4194304, 268435456, 536870912, 1073741824, 2147483648}
infoFlag2 ∉ {8, 16, 32, 64, 4096, 8192, 16384, 4194304}
infoFlag3 ∉ {8192, 16384}
Appendix B Color information
The process to obtain the color information from multiple single-band representations is described below. This process is computed at each time step and will be referred to as the cumulative mean magnitude. For simplicity, the process for one object is shown.
The magnitude differences are extracted from the last column of the matrix Xb and from the third element of the first row. We form a vector whose components range from ∆m2 to ∆mN. This vector is multiplied by a lower triangular matrix of ones, obtaining an expression containing the vector of magnitudes, shown below:
![$\left[ {\matrix{ 1 & 0 & 0 & \cdots & 0 \cr 1 & 1 & 0 & \cdots & 0 \cr 1 & 1 & 1 & \cdots & 0 \cr \vdots & \vdots & \vdots & {} & \vdots \cr 1 & 1 & 1 & \cdots & 1 \cr } } \right]\,\,\,\left[ {\matrix{ {\Delta {m_2}} \cr {\Delta {m_3}} \cr {\Delta {m_4}} \cr \vdots \cr {\Delta {m_N}} \cr } } \right] = \left[ {\matrix{ {{m_2} - {m_1}} \cr {{m_3} - {m_1}} \cr {{m_4} - {m_1}} \cr \vdots \cr {{m_N} - {m_1}} \cr } } \right] = \left[ {\matrix{ {{m_2}} \cr {{m_3}} \cr {{m_4}} \cr \vdots \cr {{m_N}} \cr } } \right] - {m_1}\left[ {\matrix{ 1 \cr 1 \cr 1 \cr \vdots \cr 1 \cr } } \right].$](/articles/aa/full_html/2025/02/aa47461-23/aa47461-23-eq10.png) (B.1)
(B.1)
The vector of magnitudes can be obtained by adding to the latter the first magnitude m1. This resulting vector is multiplied by another lower triangular matrix, which results in the sum of the magnitudes, as follows:
![$\left[ {\matrix{ 1 & 0 & 0 & \cdots & 0 \cr 1 & 1 & 0 & \cdots & 0 \cr 1 & 1 & 1 & \cdots & 0 \cr \vdots & \vdots & \vdots & {} & \vdots \cr 1 & 1 & 1 & \cdots & 1 \cr } } \right]\,\,\left[ {\matrix{ {{m_2}} \cr {{m_3}} \cr {{m_4}} \cr \vdots \cr {{m_N}} \cr } } \right] + \left[ {\matrix{ {{m_1}} \cr {{m_1}} \cr {{m_1}} \cr \vdots \cr {{m_1}} \cr } } \right] = \left[ {\matrix{ {{m_1} + {m_2}} \cr {{m_1} + {m_2} + {m_3}} \cr {{m_1} + {m_2} + {m_3} + {m_4}} \cr \vdots \cr {\sum\nolimits_{i = 1}^N {{m_i}} } \cr } } \right].$](/articles/aa/full_html/2025/02/aa47461-23/aa47461-23-eq11.png) (B.2)
(B.2)
To obtain the cumulative mean magnitudes, the result of Equation B.2 is divided by the number of observations considered,
![$\left[ {\matrix{ {{{\bar m}_2}} \cr {{{\bar m}_3}} \cr \vdots \cr {{{\bar m}_N}} \cr } } \right] = \left[ {\matrix{ {{m_1} + {m_2}} \cr {{m_1} + {m_2} + {m_3}} \cr \vdots \cr {\sum\nolimits_{i = 1}^N {{m_i}} } \cr } } \right]/\left[ {\matrix{ 2 \cr 3 \cr \vdots \cr N \cr } } \right].$](/articles/aa/full_html/2025/02/aa47461-23/aa47461-23-eq12.png) (B.3)
(B.3)
These operations can be computed efficiently using tensor operations on an entire batch of light curves.
The observations are taken only in one band at a time. As our model necessitates the computation of all colors at every step in the sequence, we have to use an imputation method to compensate for missing mean magnitudes.
The imputation method involves propagating the most recently computed value of the mean magnitude. This propagated value is used until a new observation provides an updated mean magnitude. This method ensures continuity and offers a plausible fill-in for missing values, thereby maintaining the integrity of the model’s performance.
This process can be visualized as follows, for a three-band example:
![$\left[ {\matrix{ {^1{{\bar m}_2}} & {^1{{\bar m}_2}} & {^1{{\bar m}_2}} & {^1{{\bar m}_3}} & {^1{{\bar m}_3}} & {^1{{\bar m}_3}} \cr {} & {^2{{\bar m}_2}} & {^2{{\bar m}_2}} & {^2{{\bar m}_2}} & {^2{{\bar m}_3}} & {^2{{\bar m}_3}} \cr {} & {} & {^3{{\bar m}_2}} & {^3{{\bar m}_2}} & {^3{{\bar m}_2}} & {^3{{\bar m}_3}} \cr } } \right].$](/articles/aa/full_html/2025/02/aa47461-23/aa47461-23-eq13.png) (B.4)
(B.4)
Each row corresponds to single-band mean magnitudes, labeled from 1 to 3 superscripts. The subscript indicates the observation number on each band. In this example, as the observations are taken sequentially, band 1 is updated first, then band 2, and finally band 3. The cumulative mean magnitudes are carried forward until a new observation is made available. In this case, the fourth observation is used to update the band 1 mean magnitude.
References
- Allam, T., & McEwen, J. D. 2024, RAS Techniques and Instruments, 3, 209 [NASA ADS] [CrossRef] [Google Scholar]
- Almeida, A., Anderson, S. F., Argudo-Fernández, M., et al. 2023, ApJS, 267, 44 [NASA ADS] [CrossRef] [Google Scholar]
- Andrae, R., Fouesneau, M., Creevey, O., et al. 2018, A&A, 616, A8 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ba, J. L., Kiros, J. R., & Hinton, G. E. 2016, arXiv e-prints [arXiv:1607.06450] [Google Scholar]
- Becker, I., Pichara, K., Catelan, M., et al. 2020, MNRAS, 493, 2981 [NASA ADS] [CrossRef] [Google Scholar]
- Bellm, E., Blum, R., Graham, M., et al. 2019a, Large Synoptic Survey Telescope (LSST) Data Management (USA: NASA) [Google Scholar]
- Bellm, E. C., Kulkarni, S. R., Graham, M. J., et al. 2019b, PASP, 131, 018002 [Google Scholar]
- Bianco, F. B., Ivezic, Ž., Jones, R. L., et al. 2022, ApJS, 258, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Braga, V. F., Fiorentino, G., Bono, G., et al. 2022, MNRAS, 517, 5368 [NASA ADS] [CrossRef] [Google Scholar]
- Breiman, L. 2001, Mach. Learn., 45, 5 [Google Scholar]
- Brown, T., Mann, B., Ryder, N., et al. 2020, in Advances in Neural Information Processing Systems, eds. H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, & H. Lin, (New York: Curran Associates, Inc.), 33, 1877 [Google Scholar]
- Brunel, A., Pasquet, J., Pasquet, J., et al. 2019, Electronic Imaging, 31, 90 [Google Scholar]
- Catelan, M. 2023, Mem. Soc. Astron. It., 94, 56 [NASA ADS] [Google Scholar]
- Catelan, M., & Smith, H. A. 2015, Pulsating Stars (Hoboken: Wiley-VCH) [Google Scholar]
- Chambers, K. C., Magnier, E. A., Metcalfe, N., et al. 2016, arXiv e-prints [arXiv:1612.05560] [Google Scholar]
- Charnock, T., & Moss, A. 2017, ApJ, 837, L28 [NASA ADS] [CrossRef] [Google Scholar]
- Chen, C., Liaw, A., Breiman, L., et al. 2004, Using random forest to learn imbalanced data, University of California, Berkeley, 110, 24 [Google Scholar]
- Cho, K., Van Merriënboer, B., Gulcehre, C., et al. 2014, arXiv e-prints [arXiv:1406.1078] [Google Scholar]
- Crawshaw, M. 2020, arXiv e-prints [arXiv:2009.09796] [Google Scholar]
- Dékány, I., & Grebel, E. K. 2022, ApJS, 261, 33 [CrossRef] [Google Scholar]
- Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. 2018, arXiv e-prints [arXiv:1810.04805] [Google Scholar]
- Donoso-Oliva, C., Cabrera-Vives, G., Protopapas, P., Carrasco-Davis, R., & Estevez, P. A. 2021, MNRAS, 505, 6069 [CrossRef] [Google Scholar]
- Donoso-Oliva, C., Becker, I., Protopapas, P., et al. 2023, A&A, 670, A54 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Fernie, J. D. 1992, AJ, 103, 1647 [Google Scholar]
- Fernie, J. D. 1995, AJ, 110, 2361 [Google Scholar]
- Flewelling, H. A., Magnier, E. A., Chambers, K. C., et al. 2020, ApJS, 251, 7 [NASA ADS] [CrossRef] [Google Scholar]
- Förster, F., Cabrera-Vives, G., Castillo-Navarrete, E., et al. 2021, AJ, 161, 242 [CrossRef] [Google Scholar]
- Gaia Collaboration (Vallenari, A., et al.) 2023, A&A, 674, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- He, K., Zhang, X., Ren, S., & Sun, J. 2016, in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770 [Google Scholar]
- Hochreiter, S., & Schmidhuber, J. 1997, Neural Comput., 9, 1735 [CrossRef] [Google Scholar]
- Holl, B., Audard, M., Nienartowicz, K., et al. 2018, A&A, 618, A30 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ioffe, S., & Szegedy, C. 2015, in Proceedings of the 32nd International Conference on International Conference on Machine Learning, ICML’15 (JMLR.org), 37, 448 [Google Scholar]
- Ivezic, Ž., Smith, J. A., Miknaitis, G., et al. 2007, AJ, 134, 973 [Google Scholar]
- Ivezic, Ž., Kahn, S. M., Tyson, J. A., et al. 2019, ApJ, 873, 111 [NASA ADS] [CrossRef] [Google Scholar]
- Jordi, C., Gebran, M., Carrasco, J. M., et al. 2010, A&A, 523, A48 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Leavitt, H. S., & Pickering, E. C. 1912, Harvard College Observ. Circ., 173, 1 [NASA ADS] [Google Scholar]
- Lemaître, G., Nogueira, F., & Aridas, C. K. 2017, J. Mach. Learn. Res., 18, 1 [Google Scholar]
- Liu, P., Qiu, X., & Huang, X. 2016, in Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (Austin, Texas: Association for Computational Linguistics), 118 [CrossRef] [Google Scholar]
- Loshchilov, I., & Hutter, F. 2019, in International Conference on Learning Representations [Google Scholar]
- Magnier, E. A., Schlafly, E., Finkbeiner, D., et al. 2013, ApJS, 205, 20 [Google Scholar]
- Magnier, E. A., Schlafly, E. F., Finkbeiner, D. P., et al. 2020, ApJS, 251, 6 [NASA ADS] [CrossRef] [Google Scholar]
- Marrese, P., Marinoni, S., Fabrizio, M., & Altavilla, G. 2019, A&A, 621, A144 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Matheson, T., Stubens, C., Wolf, N., et al. 2021, AJ, 161, 107 [NASA ADS] [CrossRef] [Google Scholar]
- Möller, A., & de Boissière, T. 2020, MNRAS, 491, 4277 [CrossRef] [Google Scholar]
- Möller, A., Peloton, J., Ishida, E. E. O., et al. 2021, MNRAS, 501, 3272 [CrossRef] [Google Scholar]
- Mondrik, N., Long, J. P., & Marshall, J. L. 2015, ApJ, 811, L34 [NASA ADS] [CrossRef] [Google Scholar]
- Morgan, S. M., Wahl, J. N., & Wieckhorst, R. M. 2007, MNRAS, 374, 1421 [NASA ADS] [CrossRef] [Google Scholar]
- Muthukrishna, D., Mandel, K. S., Lochner, M., Webb, S., & Narayan, G. 2022, MNRAS, 517, 393 [NASA ADS] [CrossRef] [Google Scholar]
- Neil, D., Pfeiffer, M., & Liu, S.-C. 2016, in Proceedings of the 30th International Conference on Neural Information Processing Systems, NIPS’16 (Red Hook, NY, USA: Curran Associates Inc.), 3889 [Google Scholar]
- Ngeow, C.-C., Liao, S.-H., Bellm, E. C., et al. 2021, AJ, 162, 63 [Google Scholar]
- Nordin, J., Brinnel, V., van Santen, J., et al. 2019, A&A, 631, A147 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Nun, I., Protopapas, P., Sim, B., et al. 2015, arXiv e-prints [arXiv:1506.00010] [Google Scholar]
- Onken, C. A., Wolf, C., Bessell, M. S., et al. 2019, PASA, 36, e033 [Google Scholar]
- Pascanu, R., Mikolov, T., & Bengio, Y. 2013, in Proceedings of the 30th International Conference on International Conference on Machine Learning, ICML’13 (JMLR.org), 28, III–1310–III–1318 [Google Scholar]
- Pasquet, J., Pasquet, J., Chaumont, M., & Fouchez, D. 2019, A&A, 627, A21 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pedregosa, F., Varoquaux, G., Gramfort, A., et al. 2011, J. Mach. Learn. Res., 12, 2825 [Google Scholar]
- Peters, M. E., Neumann, M., Iyyer, M., et al. 2018, in Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) (New Orleans, Louisiana: Association for Computational Linguistics), 2227 [CrossRef] [Google Scholar]
- Pimentel, Ó., Estévez, P. A., & Förster, F. 2023, AJ, 165, 18 [NASA ADS] [CrossRef] [Google Scholar]
- Ricker, G. R., Winn, J. N., Vanderspek, R., et al. 2015, J. Astron. Teles. Instrum. Syst., 1, 014003 [Google Scholar]
- Sánchez-Sáez, P., Reyes, I., Valenzuela, C., et al. 2021, AJ, 161, 141 [CrossRef] [Google Scholar]
- Shappee, B. J., Prieto, J. L., Grupe, D., et al. 2014, ApJ, 788, 48 [Google Scholar]
- Smith, M. J., & Geach, J. E. 2023, R. Soc. Open Sci., 10, 221454 [NASA ADS] [CrossRef] [Google Scholar]
- Smith, K. W., Williams, R. D., Young, D. R., et al. 2019, RNAAS, 3, 26 [NASA ADS] [Google Scholar]
- Stassun, K. G., Oelkers, R. J., Paegert, M., et al. 2019, AJ, 158, 138 [Google Scholar]
- Steeghs, D., Galloway, D. K., Ackley, K., et al. 2022, MNRAS, 511, 2405 [NASA ADS] [CrossRef] [Google Scholar]
- Szegedy, C., Liu, W., Jia, Y., et al. 2015, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) [Google Scholar]
- Tonry, J. L., Stubbs, C. W., Lykke, K. R., et al. 2012, ApJ, 750, 99 [Google Scholar]
- Tonry, J. L., Denneau, L., Heinze, A. N., et al. 2018, PASP, 130, 064505 [Google Scholar]
- Touvron, H., Martin, L., Stone, K., et al. 2023, arXiv e-prints [arXiv:2307.09288] [Google Scholar]
- Vaswani, A., Shazeer, N., Parmar, N., et al. 2017, in Advances in Neural Information Processing Systems, eds. I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, & R. Garnett (New York: Curran Associates, Inc.), 30 [Google Scholar]
- Wu, Y., Schuster, M., Chen, Z., et al. 2016, arXiv e-prints [arXiv:1609.08144] [Google Scholar]
- Zhang, S., Wu, Y., Che, T., et al. 2016, in Advances in Neural Information Processing Systems, eds. D. Lee, M. Sugiyama, U. Luxburg, I. Guyon, & R. Garnett (Curran Associates, Inc.), 29 [Google Scholar]
Language Models have been developed using this idea, obtaining state-of-the-art results trained on a massive amount of unlabeled data (Devlin et al. 2018; Brown et al. 2020; Touvron et al. 2023).
All Tables
All Figures
|
Fig. 1 Histograms of the number of observations on each band, per survey. Each band is identified by a color and a hatch style. Gaia filters GBP and GRP are identified with blue solid and orange hatched bars, respectively. Pan-STARRS1 bands are identified with solid green for ɡ, red right diagonal hatch for r, purple horizontal hatch for i, brown left diagonal hatch for z, and pink dotted bar for y. Both Gaia and ZTF are balanced but differ in the number of observations per light curve by one order of magnitude. Pan-STARRS1 is not balanced, showing longer sequences on the i band. As such, not all the bands will be available for some objects. |
| In the text | |
|
Fig. 2 Light curves of the same RRab star with a period of 0.658936 days. The identifiers are 839368005575354240, 169841701110866261 and ZTF17aaajjtn, for Gaia DR2, Pan-STARRS1 DR2 and ZTF DR10, respectively. For Gaia, the observation in the GBP filter is shown in blue circles and orange triangles for GRP. For Pan-STARRS1 on the second panel, the filters ɡP1, rP1, iP1, zP1, yP1 are identified by green circles, red triangles, purple inverted triangles, brown squares, and gray diagonal crosses, respectively. For ZTF, g is shown in olive circles and r in cyan diamonds. |
| In the text | |
|
Fig. 3 Single-band representation of a single time step. Solid lines represent the inputs and outputs of the LSTM cells across a single time step. Dashed lines represent the residual connections between recurrent steps. The dotted lines represent the operations to construct the final representation, given in Equation (3). The gray connections represent the inputs and outputs across different time steps. |
| In the text | |
|
Fig. 4 Representation of the multiband ensemble of models. Mr and Mɡ represent single-band models. Tr and Tɡ correspond to the translation layers that project the data to a common representation. C is the central model with a similar architecture as shown in Figure 3, trained on the outputs of the single-band models. The final classification is done with the output of the last step. |
| In the text | |
|
Fig. 5 Confusion matrix for the Gaia Multi model. Cepheids and RR Lyrae are confused inside the hierarchy. A bias towards the RRab class can be seen, as this class dominates the dataset. |
| In the text | |
|
Fig. 6 Confusion matrix for the Pan-STARRS1 Multi model. RRd stars pulsate in the fundamental and first overtone simultaneously, with the latter being the dominant mode most of the time Braga et al. (2022, and references therein). The same behavior can be seen in the fraction of misclassified RRd stars, which are assigned either RRab or RRc labels. |
| In the text | |
|
Fig. 7 Confusion matrix for ZTF Multi model. The main mistakes are between QSO, AGN and Blazars, given their similar source and a bias towards QSO as one of the most numerous classes. |
| In the text | |
|
Fig. 8 Distribution of the physical parameter estimations. Each column corresponds to the parameters of a survey. |
| In the text | |
|
Fig. 9 Example of the models’ output of the classification probabilities as a function of the number of observations for the Pan-STARRS1 DSCT_SXPHE star 86363087019643005. The symbols on the lower axis identify the filters used for each observation. Filter g is represented with a green circle, r with a red square, i with an orange triangle, z with a purple cross, and y with a blue diamond. The model’s main confusion was among DSCT_SXPHE (blue solid line) and the RRc class (orange dashed line). The rest of the classes, represented as Other (green dotted line) are assigned a low probability. |
| In the text | |
|
Fig. 10 F-score as a function of the total number of observations. The results of the RNN model are shown in solid blue, while the values for the BRF are shown in diagonal hatched orange. The bins are not uniform as some of them were merged to increase the number of objects per bin. Bins with less than 20 examples were removed to avoid showing unrepresentative results. The vertical black lines show the standard deviation for each bin. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.