| Issue |
A&A
Volume 691, November 2024
|
|
|---|---|---|
| Article Number | A338 | |
| Number of page(s) | 8 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202451118 | |
| Published online | 26 November 2024 | |
Machine learning methods for automated interstellar object classification with LSST
Harvard-Smithsonian Center for Astrophysics,
60 Garden St., MS 15,
Cambridge,
MA
02138,
USA
★ Corresponding author; racsubs@gmail.com
Received:
14
June
2024
Accepted:
20
September
2024
Context. The Legacy Survey of Space and Time (LSST), to be conducted with the Vera C. Rubin Observatory, is poised to revolutionize our understanding of the Solar System by providing an unprecedented wealth of data on various objects, including the elusive interstellar objects (ISOs). Detecting and classifying ISOs is crucial for studying the composition and diversity of materials from other planetary systems. However, the rarity and brief observation windows of ISOs, coupled with the vast quantities of data to be generated by LSST, create significant challenges for their identification and classification.
Aims. This study aims to address these challenges by exploring the application of machine learning algorithms to the automated classification of ISO tracklets in simulated LSST data.
Methods. We employed various machine learning algorithms, including random forests (RFs), stochastic gradient descent (SGD), gradient boosting machines (GBMs), and neural networks (NNs), to classify ISO tracklets in simulated LSST data.
Results. Our results demonstrate that GBM and RF algorithms outperform SGD and NN algorithms in accurately distinguishing ISOs from other Solar System objects. RF analysis shows that many derived Digest2 values are more important than direct observables (right ascension, declination, and magnitude) in classifying ISOs from the LSST tracklets. The GBM model achieves the highest precision, recall, and F1 score, with values of 0.9987, 0.9986, and 0.9987, respectively.
Conclusions. These findings lay the foundation for the development of an efficient and robust automated system for ISO discovery using LSST data, paving the way for a deeper understanding of the materials and processes that shape planetary systems beyond our own. The integration of our proposed machine learning approach into the LSST data processing pipeline will optimize the survey’s potential for identifying these rare and valuable objects, enabling timely follow-up observations and further characterization.
Key words: methods: data analysis / methods: numerical / methods: statistical / astronomical databases: miscellaneous / astrometry / minor planets, asteroids: general
© The Authors 2024
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. Subscribe to A&A to support open access publication.
1 Introduction
The Vera C. Rubin Observatory, formally called the Large Synoptic Survey Telescope, is set to revolutionize the field of astronomy when it begins operations in 2025 (Ivezić et al. 2019) with its unprecedented wide-field survey capabilities. The survey will generate a vast amount of data, enabling research in diverse areas of astrophysics, including the discovery and characterization of new Solar System objects (Schwamb et al. 2023) such as interstellar objects (ISOs; Jones et al. 2009). To date, only two ISOs have been discovered (excluding interstellar meteors): 1I/‘Oumuamua and 2I/Borisov.
1I/‘Oumuamua was discovered coincidentally as an unknown object moving at a high apparent rate of motion. Due to its high near-Earth object (NEO) Digest2 score (Keys et al. 2019), the object was posted to the Near-Earth Object Confirmation Page1 (NEOCP) of the Minor Planet Center2 (MPC), which enabled rapid follow-up observations from multiple sites around the world. Within a few days, the heliocentric orbit was deemed to be undoubtedly hyperbolic. At the same time, 1I/‘Oumuamua was classified as an NEO due to its perihelion distance of less than 1.3 astronomical units (AU).
After its discovery, astronomers noticed 1I/‘Oumuamua’s peculiar physical properties, such as its extremely elongated shape (Meech et al. 2017; Jewitt et al. 2017; Bannister et al. 2017; Masiero 2017; Knight et al. 2017; Ye et al. 2017; Fraser et al. 2018; Bolin et al. 2018; Fitzsimmons et al. 2018; Mashchenko 2019) and its lack of cometary activity (Trilling et al. 2018). These characteristics sparked an intense debate about its origin and composition (Flekkøy et al. 2019; Hoang & Loeb 2020; Curran 2021; Jackson & Desch 2021; Siraj & Loeb 2022; Flekkøy & Brodin 2022; Loeb 2023). The motion of 1I/‘Oumuamua has not yet been fully explained, with several studies proposing different explanations for its nongravitational acceleration (Micheli et al. 2018; Bialy & Loeb 2018; Rafikov 2018; Loeb 2022; Bergner & Seligman 2023; Hoang & Loeb 2023).
Conversely, 2I/Borisov was discovered as a new comet (see Jewitt & Seligman 2023 and references therein), and like other new comet discoveries, the object was posted to the MPC’s Possible Comet Confirmation Page3 (PCCP). This again enabled rapid follow-up observations and early orbit determination, which proved that the comet has a highly hyperbolic orbit with respect to the Sun. Therefore, the second ISO was also a coincidental discovery, with its cometary activity drawing the attention of astronomers.
However, if an ISO’s orbit is not known and it is observed as a short intra-night object, it can be easily missed or misclassified as another type of object. This emphasizes the need for an automated approach for efficiently detecting and classifying ISOs. Additionally, the vast quantities of data that will be produced by LSST, especially in the first few years as new “background” objects – particularly main belt asteroids (MBAs) – are discovered, will further impede our ability to identify possible ISOs.
This will be particularly challenging in the first few years of LSST operations as most of the objects seen will be new discoveries, dominated by small MBAs. Traditional methods of data analysis cannot feasibly handle such massive datasets in a timely manner. This is where machine learning (ML) becomes crucial. Machine learning techniques are powerful tools for automatically processing and analyzing large volumes of data, identifying patterns, and making predictions with high accuracy and efficiency.
In the context of ISO detection and classification, ML algorithms can be trained to recognize the unique motion characteristics of ISOs amidst a vast sea of Solar System objects. These algorithms can rapidly sift through the data, flagging potential ISOs for further analysis and follow-up observations. By automating the identification process, ML not only accelerates the discovery of new ISOs but also improves the reliability and consistency of detections.
Therefore, to address the challenge of automatically flagging candidate ISOs for follow-up observation, we explored and evaluated several state-of-the-art ML algorithms for automated tracklet classification, including random forests (RFs; Breiman 2001), stochastic gradient descent (SGD; Bottou 2010), gradient boosting machines (GBMs; Friedman 2001), and neural networks (NNs; LeCun et al. 2015). By comparing the performance of these algorithms on simulated LSST data, we aim to identify the most effective approach to accurately classifying tracklets and distinguishing ISOs from other Solar System objects. The results of this study will facilitate the development of a robust and efficient automated system for ISO discovery and characterization using LSST data.
2 The search for interstellar objects
The existence of ISOs has been theorized for decades. In the early stages of the Solar System, a large quantity of planetesimals and debris was ejected due to the instability of the dynamical system and the gravity of the giant planets (Charnoz & Morbidelli 2003; Bottke et al. 2005; Raymond et al. 2018, 2020). Like small planetesimals, larger bodies such as planets (so-called free-floating planets) can be ejected from their parent systems (Scholz et al. 2012; Peña Ramírez et al. 2012; Miret-Roig et al. 2022).
Several studies derived upper estimates of the spatial density of ISOs around the Sun before the discovery of 1I/‘Oumuamua and 2I/Borisov (Torbett 1986; McGlynn & Chapman 1989; Sen & Rana 1993; Jewitt 2003; Moro-Martín et al. 2009; Cook et al. 2016). Some estimates relied on ongoing Solar System surveys, their pointing data and depth, such as LINEAR (Francis 2005) or Pan-STARRS (Engelhardt et al. 2017). However, without a single ISO discovered, the estimates varied by orders of magnitude, between 10−9 and 2.4 × 10−2 au−3 for a 1-km ISO.
The discovery of 1I/‘Oumuamua and 2I/Borisov allowed a better constraint to be placed on the spatial density of both active and inactive ISOs: Jewitt et al. (2017) predicted 1 × au−3 ‘Oumuamua-like objects closer than Neptune at any given time, while Levine et al. (2021) predicted the 3-sigma number density of similar sized ISOs between 2 × 10−4 and 0.8 au−3. Do et al. (2018) derived the number density to be similar to 0.2 au−3 and Portegies Zwart et al. (2018) derived a number density of 0.0040-0.24 au−3. Meanwhile, Bolin et al. (2020) used the data from both discovered ISOs and derived a density of ~1 au−3 for slightly larger, 250-meter ISOs, and determined the slope of the size-frequency distribution of ISOs N(> D), in terms of actual size (km), to be −3.38 ± 1.18.
Other works explored the potential of the LSST for discovering and characterizing ISOs and other unique Solar System objects. LSST’s unprecedented limiting magnitude of about +24.5 in g-band4 and sky-coverage of approximately half of the sky during the survey, offer a unique opportunity to detect the interstellar interlopers.
Hoover et al. (2022) predicted that LSST will detect 1–3 ISOs of 1I/‘Oumuamua’s size and properties per year. Marčeta & Seligman (2023) estimated that LSST could detect between 0 and 70 ISOs per year, depending on their albedo and sizefrequency distribution, thus covering a wide range of possibilities.
These studies collectively demonstrate the growing interest in the detection and characterization of ISOs, as well as the potential of the LSST to significantly advance this field. However, they fail to directly address the challenge of identifying ISOs in LSST data with high confidence and in a timely manner, which is critical for effective characterization. While ISO candidates can eventually be identified post-processing or through analysis by the MPC, rapid identification is crucial for follow-up observations, especially for objects on transient trajectories like 1I/‘Oumuamua, where early detection would have allowed for a more detailed characterization. By leveraging synthetic LSST data provided by the Rubin Science Platform (RSP)5, we aim to contribute to this ongoing research effort by employing ML algorithms as a means to automatically flag potential ISO candidates for follow-up observation among the large quantities of daily alerts. The next sections describe our methodology, model development, and evaluation.
3 Methodology
LSST Solar System products will be delivered in several forms: real-time alerts will provide large amounts of individual transients (400 000 to 5 million per night6), and a daily batch of tracklets will be shared with the MPC. Tracklets are short sequences of observations of the same object observed two or more times per night, and they can be used to determine the object’s approximate orbit (or range of potential orbits) and to classify them as NEOs, MBAs, or other types of objects (Denneau et al. 2013; Keys et al. 2019), such as ISOs.
LSST will submit to the MPC both individual tracklets and linkages of tracklets that represent an object that has been observed on three or more nights (Holman et al. 2018; Heinze et al. 2022), but they will not submit unlinked individual detections. Additionally, LSST will identify known objects and submit them with their designations to the MPC. The LSST catalog of derived orbits will also include photometric and light-curve information, although at present we have no plans to make use of such data. Although intra-night linking has been widely used by surveys such as WISE Moving Object Pipeline Subsystem (Dailey et al. 2010), Pan-STARRS Moving Object Processing System (Denneau et al. 2013), or Zwicky Transient Facility’s Moving Object Discovery Engine (Masci et al. 2019), the efficiency of the inter-night linking by LSST, which currently utilizes the HelioLinC method (Holman et al. 2018; Heinze et al. 2022), has not yet been proven for hyperbolic orbits. Consequently, the ability to link hyperbolic orbits and thus identify ISOs remains uncertain.
Our work focuses on analyzing the intra-night tracklets of unidentified objects as observed by LSST. Specifically, we used directly reported LSST “observables” – the right ascension, declination, and magnitude at a given epoch – and derived values such as the sky-plane velocity and motion direction and the apparent position with respect to the opposition. We also employed Digest2, using its output as additional input for our ML models. In this section we describe our data sources, processing, feature selection process, and their derived values employed by ML models for the purpose of automatically classifying ISO tracklets.
Number of tracklets and objects in the 1-year LSST simulation.
3.1 LSST input data
We utilized the LSST DP0.3 Solar System object simulation data, which contains a 1-year (d p03_catalogs_1yr) and 10- year (d p03_catalogs_10yr) quasi-realistic distribution of LSST pointings with simulated detections of Solar System objects, including both real (discovered) objects from the Minor Planet Center Orbit Database (MPCORB) and the synthetic Solar System model (Grav et al. 2011). The simulations collectively contain more than 13 million synthetic orbits, including approximately 12 000 hyperbolic (ISO) orbits. Data are distributed as Astronomical Data Query Language (ADQL) databases available through the RSP7, each with four tables: DiaSources (simulated astrometric and photometric measurements for detected Solar System objects), MPCORB (catalog of real and synthetic orbits), SSObject (table of LSST-linked Solar System objects), and SSSource (Solar System source information corresponding to specific difference image detections).
Table 1 illustrates the number of detections by category in the 1-year LSST simulation data. Although the synthetic model should realistically balance the ratio of different orbital types based on object size, the ISO population is significantly exaggerated in quantity (Grav et al. 2011). For this reason, we downloaded all data from the 1-year dataset and only the ISO detections from the 10-year dataset, thus boosting the total number of ISO samples from 3306 to 14 151. Figure 1 shows the size-frequency distribution of synthetic ISO orbits: synthetic ISOs have H in a range of 18–23, representing roughly objects of a size of between 100 meters to 1 kilometer for an assumed albedo of 0.1.
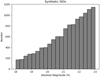 |
Fig. 1 Histogram of absolute magnitudes of synthetic ISOs used in this work. |
3.2 Boosting the sample count of synthetic ISO tracklets
Our initial dataset had about 6 million tracklets, of which only 14 151 (0.24%) were ISOs. The remaining tracklets were other celestial objects – a highly imbalanced dataset.
Highly imbalanced data in classification problems significantly impacts the performance and reliability of predictive models (Sun et al. 2009; Japkowicz & Stephen 2002; Chawla et al. 2002; He & Garcia 2009). In scenarios where the distribution of classes is skewed, traditional algorithms can exhibit a bias toward the majority class, leading to an inadequate representation and misclassification of the minority class. This imbalance can distort the learning process, as models may prioritize minimizing errors on the more prevalent class, consequently neglecting the rare yet potentially more critical class.
To address this imbalance, we sought to boost the number of ISO samples and then randomly sample an equal number of non-ISOs to form a new, balanced dataset. We downloaded the heliocentric ISO orbits from the dp03_catalogs_10yr simulation, which contain 12 148 Keplerian hyperbolic orbits.
To significantly increase the number of ISO tracklets, we created a simplistic LSST-like pseudo-survey. First, we propagated 12 148 ISO orbits to the initial epoch of the 10-year survey (to the local midnight) and then to a second epoch one our later, thus creating two-detection 1-hour tracklets for each orbit. This approach allowed us to generate a larger number of synthetic ISO tracklets that closely resembled the expected observations from the LSST survey.
Subsequently, we computed the ephemerides for each day over the next 10 years, using the following constraints to simulate a detection:
a limiting V -band magnitude of 24.5,
a minimum apparent lunar elongation of 90 degrees,
a minimum solar elongation of 60 degrees,
a minimum object altitude of 20 degrees,
allowing only detections with a negative declination or with a declination greater than 0 but an ecliptical latitude of less than 10 degrees, mimicking the LSST survey area as seen in Fig. 2.
We considered a tracklet valid when the same object fulfilled the mentioned constraints and was detected twice on the same night. To create a dataset independent from the original one but maintaining the same orbits, we shuffled the absolute magnitude H values, ensuring that the size-frequency distribution remained the same. This custom synthetic dataset of ISO tracklets was then added to the LSST-generated tracklets. The total number of generated ISO tracklets is displayed in Table 2.
 |
Fig. 2 Hammer-Aitoff sky-plane projection of synthetic positions of Solar System objects in downloaded LSST data. |
Low-fidelity simulation of ISO tracklets in 10 years of the LSST survey.
3.3 Digest2
Digest28 is a robust and efficient short-arc orbit classifier for small Solar System bodies, primarily utilized for the identification and prioritization of NEO candidates for follow-up observations (Keys et al. 2019). Digest2 operates by analyzing tracklets, employing statistical methods for motion analysis and initial orbit determination. Each object processed by Digest2 is assigned a “D2” score (often referred to as the NEO score) ranging from 0 to 100, representing a pseudo-probability that a tracklet belongs to an NEO. In addition to the D2 NEO score, Digest2 outputs scores for 14 additional orbit classes (see Table 8 in Keys et al. 2019). There are two independent scores for each class: “raw” is the score with respect to the entire model population as if all objects have been discovered; “noid” is the score with respect to the undiscovered portion of a given population (Keys et al. 2019).
Though Digest2 is regularly used to tag NEO candidates, the code has not been fully utilized to identify objects of other orbital categories despite its ability to do so. Therefore, we sought to build on Digest2 by exploring whether its output values could aid in the task of classifying ISOs.
One of the key questions we had was whether the output from Digest2 would be important in classifying ISOs. That is, would the orbital categories output by Digest2 serve as important input features for our ML models when determining whether a tracklet belongs to an ISO?
To explore this, we employed the RF algorithm to generate feature importances, which measure the contribution of each feature to the model’s predictive performance (Louppe et al. 2013). During our analysis, we noticed that indeed many of the features identified as having high importance were produced by Digest2, rather than those that were derived or obtained directly from the simulated LSST data. This is evident from Fig. 3, which shows that nine out of the ten most important features identified using the RF method were from Digest2. Among the highest-ranked features were those related to Jupiter-family comets (“raw” Digest2), Hildas (“noid” Digest2), inner main belt, and “Interesting” categories. Importantly, these features often relate to celestial objects with high eccentricity (Jupiter- family comets and Interesting) or to distant objects that have slow motion (Jupiter-family comets and Hildas). This suggests that these characteristics likely play a key role in identifying ISOs, which are known to have highly eccentric (hyperbolic) orbits and can have inclinations at any angle. Further explanation of the Digest2 algorithm and its output can be found in Keys et al. (2019).
Having confirmed that Digest2 output will serve as important input for our models, the next steps involved preprocessing our data and integrating the Digest2 output, which we describe next.
 |
Fig. 3 Digest2 output values ranked in the top nine our of ten features identified as important for ISO classification. |
3.4 Data preprocessing
As mentioned in Sect. 3.1, we downloaded all of the one-year LSST DP0.3 Solar System object simulation data and only ISOs from the ten-year simulation.
We then processed the downloaded individual detections using known object designations. Each detection was given a custom tracklet ID (trksub), which we derived by combining the modified mpcDesignation with the integer part of the modified Julian date (MJD) plus a constant offset of 0.5. Each trk sub has a length of 12 characters.
The data were then filtered to ensure that each object had a minimum of two detections per night, and then grouped by their trksub to form tracklets. That is, we define a tracklet as the same object observed two or more times per night. The tracklets were labeled by the nature of their orbits: ISOs and everything else. In our work, we assumed the tracklet linking efficiency is ideal, and we did not account for false tracklets (mislinked objects or object-noise linkages) such as discussed in Vereš & Chesley (2017).
The apparent magnitude in the observed filter band was converted to an approximate V -band magnitude (vmag) using a conversion factor specific to each filter9. The detections were then grouped by their unique trksub identifier.
For each tracklet (detection group), we selected the first and last detections (skipping those where the MJDs were the same) and derived quantities such as the rate of motion, position angle, ecliptical latitude, opposition-centered ecliptical longitude, and solar elongation. The orbtype column was created to indicate the class of the celestial object, with a value of 0 or a 1 assigned to each tracklet based on the leading characters of the modified mpcDesignation column, which we modified to start with an “I” for ISOs or a “1” for all other obit classes. The processed LSST data were compiled into a new dataset and merged with the pseudo ISO tracklets described in Sect. 3.2.
The next step involved using Digest2. Digest2 ingests track- lets, represented by observational data, in so-called MPC1992 format10. We converted previously prepared LSST observations to MPC1992 format, particularly the 12-character trksub, epoch, right ascension (α), declination (δ), magnitude, and band into the MPC1992 format, with the LSST observatory code X0511. The resulting format was generated with full-precision in α, δ, magnitude and the epoch. For this, the Digest2 source code was slightly altered so that the program could ingest 12-character trksubs. We computed 13 Digest2 parameters in both “raw” and “noid” modes for each of our synthetic tracklets, resulting in 26 features, and concatenated the output with our dataset (see Sect. 3.1 for the derived quantities).
Next, we removed duplicate entries based on the trksub column. During this data cleaning phase, we noticed that some detections had apparent magnitudes fainter than the limiting magnitudes12 and we therefore removed a few percent of the detections. The remaining data were sorted in ascending order by trksub and MJD to establish a consistent sequence of observations. Irrelevant columns, including trksub and MJD, were dropped, and the other columns were renamed for clarity. Our final dataset is described in Table 3.
Data sources and corresponding columns used in the analysis.
4 Model training and evaluation
Having identified the key features and completed data preprocessing, we split the dataset into training, testing, and validation subsets using a two-step process. The data were first divided into training (80%) and temporary (20%) sets using a fixed random seed of 42 for reproducibility. The temporary set was then further split equally into testing and validation sets using the same random seed.
Within each subset, we separated the target variable (orbtype) from the feature variables. The target variable represented the class or category we aimed to predict (i.e., non-ISO vs. ISO), while the feature variables encompassed all the remaining columns that would be used as input to the ML models.
4.1 Model selection
Using these data, we trained and evaluated several ML models for ISO detection: GBMs (Friedman 2001), RFs (Breiman 2001), SGD (Bottou 2010), and NNs (LeCun et al. 2015).
The GBM algorithm is an ensemble learning method that builds a series of weak learners, typically decision trees, sequentially to correct errors made by previous models. GBM is known for its high predictive accuracy and ability to handle complex, nonlinear relationships in data.
The RF algorithm is another ensemble method that constructs multiple decision trees and combines their outputs for prediction. RF is particularly effective at reducing overfitting through its use of bagging and random feature selection, making it robust across various types of datasets.
The SGD algorithm optimizes the model by updating weights incrementally using randomly chosen data points, making it computationally efficient for large datasets. Although it requires careful tuning, SGD can quickly converge to good solutions in high-dimensional spaces where other models may struggle.
Neural networks, with their layered architecture, are capable of capturing complex, nonlinear relationships. NNs learn hierarchical feature representations through back-propagation, making them particularly suited for tasks with intricate patterns, though they often require more data and computational resources to reach optimal performance.
4.2 Evaluation results
Figure 4 presents the confusion matrices for our chosen models, illustrating their classification performance.
The GBM model exhibited high accuracy with minimal false-positives and false-negatives, indicating strong performance in ISO detection. Similarly, the RF model performed well but showed slightly more false-positives. The SGD model had a higher false-positive rate compared to GBM and RF, suggesting a lower effectiveness in ISO detection. The NN model performed adequately but had a slightly lower accuracy than GBM and RF.
To assess the models’ effectiveness in identifying ISOs while minimizing false positives and false negatives, we measured key performance metrics for each model, including F1 score, precision, recall, and accuracy for both ISO and Not-ISO classes. Precision measures the proportion of true ISOs among all objects classified as ISOs by the model. Indeed, a high precision indicates that when the model classifies an object as an ISO, it is likely to be correct. Recall, however, measures the proportion of true ISOs that are correctly identified by the model out of all the actual ISOs in the dataset. A high recall suggests that the model is able to detect a large percentage of the ISOs present. The F1 score is the harmonic mean of precision and recall, providing a balanced measure of the model’s performance. It is particularly useful when the dataset has an uneven class distribution, as is the case with ISOs being rare compared to other celestial objects (although, we ensured that our data were balanced before model training). Accuracy measures the overall correctness of the model’s predictions, considering both true positives and true negatives.
As Table 4 illustrates, the GBM and RF models yielded the highest accuracy and balanced performance across all metrics, while the SGD and NN models showed lower accuracy. The results reveals that the GBM model was most effective in distinguishing ISOs from other Solar System objects.
 |
Fig. 4 Confusion matrices for GBM (upper left), SGD (upper right), RF (botton left), and NN (bottom right). |
Performance metrics for different models evaluated on the dataset.
4.3 Validation on nightly datasets
To assess the performance of our models in a realistic scenario, we validated them on three randomly selected nights from the simulated data, representing typical tracklet counts per year (around 20 000 tracklets per year). Our goal was to minimize confusion and false positives, given the vast quantity of unknown tracklets that LSST will produce. The nights chosen were:
Night 60313: no ISO, representing a typical night.
Night 60543: containing 13 ISOs, with a highly exaggerated number of ISOs.
Night 60358: containing exactly one ISO, simulating a prospective night where a single ISO could be discovered.
The selected data were excluded from the training, testing, and validation datasets, and the models were retrained using the same hyper parameters used in initial training. The results in Table 5 indicate that GBM consistently performed well across various datasets, while other models exhibited varying degrees of effectiveness. A closer look at the GBM results shows that on night 60313, where there were no ISOs in the dataset, the GBM correctly identified 0 ISOs and produced just 19 false positives. On night 60543, the GBM model labeled all 13 ISOs with only one false positive. On night 60358, where one ISO was present, it was correctly identified by the GBM, along with 4 false positives.
Confusion matrix results for different models evaluated on datasets.
Confusion matrix results for different models evaluated on ‘Oumuamua and Borisov datasets containing tracklets for one night.
4.4 1I/‘Oumuamua and 2I/Borisov
To evaluate the performance of our models on real-world examples of ISOs, we generated two new datasets containing tracklets from the first known ISOs, 1I/‘Oumuamua and 2I/Borisov, for a single night (Table 6). Despite the challenging nature of the data, the models demonstrated some ability to correctly identify the ISOs.The SGD model achieved the highest truepositive rate for ‘Oumuamua, correctly identifying 46 out of 50 instances, whereas the RF model performed best for Borisov, correctly identifying 103 out of 712 instances. However, the lack of true-negatives and the presence of false-negatives highlight the difficulty in confidently identifying ISOs from such limited observations. Additionally, the LSST dataset is very differ from current surveys that typically have limiting magnitudes down to +22.5, while LSST will survey significantly deeper (+24.5), thus providing an order of magnitude more unknown faint objects not seen by current surveys.
5 Discussion
Our models demonstrated strong performance on the simulated LSST data, and their application to real-world examples of 1I/‘Oumuamua and 2I/Borisov yielded promising results while highlighting areas for improvement. Notably, the models successfully flagged both ‘Oumuamua and Borisov as potential ISOs without generating any false positives. This achievement is significant as minimizing false positives is crucial to ensure that valuable telescope time is not wasted on follow-up observations of misclassified objects.
The models’ ability to correctly identify ‘Oumuamua and Borisov as ISOs, even with limited observations, underscores their potential for detecting these rare and significant celestial objects. However, the models struggled to achieve high truepositive rates and low false-negative rates for these specific cases, indicating the need for further enhancement to confidently identify ISOs from limited data.
These results emphasize the importance of collecting more comprehensive data on ISOs to improve the models’ performance and generalizability. The limited number of observations and the challenging nature of the data pose significant difficulties for the models in confidently identifying ISOs. With only a few detections available for each ISO, the models have limited information to learn from and make accurate predictions. This is evident in the results for 1I/‘Oumuamua and 2I/Borisov, where the models struggle to achieve high true-positive rates and low false-negative rates.
To enhance the models’ performance in confidently identifying ISOs, several improvements and additional data sources could be considered:
Collecting more observations of known ISOs: Increasing the number of observations for confirmed ISOs like 1I/‘Oumuamua and 2I/Borisov would provide the models with more examples to learn from, improving their ability to recognize the unique features of ISOs.
Collaborating with other observatories and surveys: Sharing data and combining observations from multiple telescopes and surveys could help create a more comprehensive dataset of ISO detections, increasing the diversity and quantity of examples available for training the models.
Incorporating additional features: Extending the feature set to include more physical and morphological properties of ISOs, such as color, spectral characteristics, and light curves, could provide the models with additional discriminating information to improve their classification performance.
Investigating the extendedness of ISOs: Extendedness can affect the quality of astrometry. For instance, typical comets exhibit activity by having a coma or extended tails that can shift the astrometric center, introducing uncertainties in position measurements. Understanding these effects is crucial, as the extended nature of an object can degrade the accuracy of the astrometric data and, consequently, affect the models’ ability to correctly link and identify ISOs. Importantly, moving detections made by LSST that are extended or differ significantly from the stellar point-spread-functions will be flagged immediately and distributed as LSST alerts13 well before any linking is made.
Exploring transfer learning techniques: leveraging knowledge gained from other asteroid and comet detection tasks could help improve the models’ performance on the limited ISO data available. Transfer learning techniques could be employed to adapt pretrained models to the specific task of ISO detection.
Evaluating uncertainties in the LSST pipeline: lssessing uncertainties in the LSST pipeline is critical, especially regarding their impact on ISO linking and identification. LSST data’s astrometric uncertainties may significantly challenge the differentiation between interstellar and Solar System objects. Even minor positional errors could result in inaccurate orbit determinations or object misclassifications. Furthermore, it is vital to analyze the correlations among orbit fit accuracy, determination, and linking precision. Errors in these areas can cascade through the ISO identification process, potentially complicating detection efforts. Comprehensive examination of these correlations will lead to refined, more reliable models. However, a complete evaluation of LSST uncertainties must await the publication and availability of actual observational data.
Continuously updating the models: as new ISOs are discovered and more data become available, regularly updating the models with the latest observations would help them stay current and improve their performance over time.
By addressing these challenges and incorporating additional data and techniques, the models’ ability to confidently identify ISOs could be significantly enhanced, enabling a more reliable detection and characterization of these rare and important celestial objects.
6 Conclusion
In this study we explored the application of ML algorithms for the automated classification of ISO tracklets in simulated data from the upcoming LSST survey. Our analysis with RFs shows that the Digest2 values are far more important for classifying ISOs than direct observables supplied by LSST data. The GBM and RF models outperform the SGD and NN models in accurately distinguishing ISOs from other Solar System objects. When evaluated on the simulated data, the GBM model achieved the highest precision, recall, and F1 score, making it the most effective approach for identifying these rare and elusive objects. The models were then applied to three randomly selected nights of LSST data and were able to identify all synthetic ISOs. The SGD and RF models performed best on ‘Oumuamua and Borisov, respectively. All models produced a relatively low false-positive rate (from a few to a few dozen). However, given that thousands of tracklets will be generated nightly, this low false-positive rate will be manageable. To further improve the performance and generalizability of our models, we have outlined several potential ways forward (see Sect. 5).
As LSST begins operations, it will generate an unprecedented wealth of data, presenting both challenges and opportunities for the astronomical community. The ability to quickly and accurately identify ISO candidates amidst the vast quantity of tracklets will be crucial for enabling timely follow-up observations and further characterization of these unique objects.
In conclusion, our work lays the foundation for the development of an automated ISO tracklet classification system that can be applied to new data collected in the upcoming LSST era. By developing and implementing efficient and robust classification systems, we can unlock the full potential of LSST in discovering and characterizing these rare and valuable objects, paving the way for advances in our understanding of the materials and processes that shape planetary systems throughout the cosmos.
Acknowledgements
This work was supported by the MPC’s NASA cooperation agreement funding. We also acknowledge support of the Oumuamua-Laukien fellowship awarded to the Galileo Project at Harvard University by the Laukien Science Foundation. We also thank to Mario Juric´ , Melissa Graham, Jake Andrew Kurlander, Siegfried Eggl for help with the simulated LSST data.
References
- Bannister, M. T., Schwamb, M. E., Fraser, W. C., et al. 2017, ApJ, 851, L38 [NASA ADS] [CrossRef] [Google Scholar]
- Bergner, J. B., & Seligman, D. Z. 2023, Nature, 615, 610 [NASA ADS] [CrossRef] [Google Scholar]
- Bialy, S., & Loeb, A. 2018, ApJ, 868, L1 [Google Scholar]
- Bolin, B. T., Weaver, H. A., Fernandez, Y. R., et al. 2018, ApJ, 852, L2 [NASA ADS] [CrossRef] [Google Scholar]
- Bolin, B. T., Lisse, C. M., Kasliwal, M. M., et al. 2020, AJ, 160, 26 [NASA ADS] [CrossRef] [Google Scholar]
- Bottke, W. F., Durda, D. D., Nesvorný, D., et al. 2005, Icarus, 179, 63 [Google Scholar]
- Bottou, L. 2010, in Proceedings of COMPSTAT’2010: 19th International Conference on Computational StatisticsParis France, August 22-27, 2010 Keynote, Invited and Contributed Papers, Springer, 177 [Google Scholar]
- Breiman, L. 2001, Mach. Learn., 45, 5 [Google Scholar]
- Charnoz, S., & Morbidelli, A. 2003, Icarus, 166, 141 [NASA ADS] [CrossRef] [Google Scholar]
- Chawla, N. V., Bowyer, K. W., Hall, L. O., & Kegelmeyer, W. P. 2002, J. Artific. Intell. Res., 16, 321 [CrossRef] [Google Scholar]
- Cook, N. V., Ragozzine, D., Granvik, M., & Stephens, D. C. 2016, ApJ, 825, 51 [NASA ADS] [CrossRef] [Google Scholar]
- Curran, S. J. 2021, A&A, 649, L17 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dailey, J., Bauer, J., Grav, T., et al. 2010, AAS Meeting Abs., 216, 409.04 [NASA ADS] [Google Scholar]
- Denneau, L., Jedicke, R., Grav, T., et al. 2013, PASP, 125, 357 [NASA ADS] [CrossRef] [Google Scholar]
- Do, A., Tucker, M. A., & Tonry, J. 2018, ApJ, 855, L10 [Google Scholar]
- Engelhardt, T., Jedicke, R., Vereš, P., et al. 2017, AJ, 153, 133 [NASA ADS] [CrossRef] [Google Scholar]
- Fitzsimmons, A., Snodgrass, C., Rozitis, B., et al. 2018, Nat. Astron., 2, 133 [Google Scholar]
- Flekkøy, E. G., & Brodin, J. F. 2022, ApJ, 925, L11 [CrossRef] [Google Scholar]
- Flekkøy, E. G., Luu, J., & Toussaint, R. 2019, ApJ, 885, L41 [CrossRef] [Google Scholar]
- Francis, P. J. 2005, ApJ, 635, 1348 [NASA ADS] [CrossRef] [Google Scholar]
- Fraser, W. C., Pravec, P., Fitzsimmons, A., et al. 2018, Nat. Astron., 2, 383 [NASA ADS] [CrossRef] [Google Scholar]
- Friedman, J. H. 2001, Ann. Stat., 29, 1189 [Google Scholar]
- Grav, T., Jedicke, R., Denneau, L., et al. 2011, PASP, 123, 423 [CrossRef] [Google Scholar]
- He, H., & Garcia, E. A. 2009, IEEE Transac. Knowledge Data Eng., 21, 1263 [CrossRef] [Google Scholar]
- Heinze, A., Eggl, S., Juric, M., et al. 2022, AAS/Division Planet. Sci. Meet. Abs., 54, 504.04 [Google Scholar]
- Hoang, T., & Loeb, A. 2020, ApJ, 899, L23 [NASA ADS] [CrossRef] [Google Scholar]
- Hoang, T., & Loeb, A. 2023, ApJ, 951, L34 [NASA ADS] [CrossRef] [Google Scholar]
- Holman, M. J., Payne, M. J., Blankley, P., Janssen, R., & Kuindersma, S. 2018, AJ, 156, 135 [NASA ADS] [CrossRef] [Google Scholar]
- Hoover, D. J., Seligman, D. Z., & Payne, M. J. 2022, Planet. Sci. J., 3, 71 [NASA ADS] [CrossRef] [Google Scholar]
- Ivezić, Ž., Kahn, S. M., Tyson, J. A., et al. 2019, ApJ, 873, 111 [Google Scholar]
- Jackson, A. P., & Desch, S. J. 2021, J. Geophys. Res. Planets, 126, e06706 [NASA ADS] [CrossRef] [Google Scholar]
- Japkowicz, N., & Stephen, S. 2002, Intell. Data Anal., 6, 429 [Google Scholar]
- Jewitt, D. 2003, Earth Moon Planets, 92, 465 [NASA ADS] [CrossRef] [Google Scholar]
- Jewitt, D., & Seligman, D. Z. 2023, ARA&A, 61, 197 [NASA ADS] [CrossRef] [Google Scholar]
- Jewitt, D., Luu, J., Rajagopal, J., et al. 2017, ApJ, 850, L36 [NASA ADS] [CrossRef] [Google Scholar]
- Jones, R., Chesley, S., Connolly, A., et al. 2009, Earth Moon Planets, 105, 101 [NASA ADS] [CrossRef] [Google Scholar]
- Keys, S., Vereš, P., Payne, M. J., et al. 2019, PASA, 131, 1 [Google Scholar]
- Knight, M. M., Protopapa, S., Kelley, M. S. P., et al. 2017, ApJ, 851, L31 [NASA ADS] [CrossRef] [Google Scholar]
- LeCun, Y., Bengio, Y., & Hinton, G. 2015, Nature, 521, 436 [Google Scholar]
- Levine, W. G., Cabot, S. H. C., Seligman, D., & Laughlin, G. 2021, ApJ, 922, 39 [NASA ADS] [CrossRef] [Google Scholar]
- Loeb, A. 2022, Astrobiology, 22, 1392 [NASA ADS] [CrossRef] [Google Scholar]
- Loeb, A. 2023, Res. Notes Am. Astron. Soc., 7, 43 [Google Scholar]
- Louppe, G., Wehenkel, L., Sutera, A., & Geurts, P. 2013, Adv. Neural Inform. Process. Sys., 26 [Google Scholar]
- Marčeta, D., & Seligman, D. Z. 2023, Planet. Sci. J., 4, 230 [CrossRef] [Google Scholar]
- Masci, F. J., Laher, R. R., Rusholme, B., et al. 2019, PASP, 131, 018003 [Google Scholar]
- Mashchenko, S. 2019, MNRAS, 489, 3003 [NASA ADS] [CrossRef] [Google Scholar]
- Masiero, J. 2017, arXiv e-prints [arXiv:1710.09977] [Google Scholar]
- McGlynn, T. A., & Chapman, R. D. 1989, ApJ, 346, L105 [Google Scholar]
- Meech, K. J., Weryk, R., Micheli, M., et al. 2017, Nature, 552, 378 [Google Scholar]
- Micheli, M., Farnocchia, D., Meech, K. J., et al. 2018, Nature, 559, 223 [Google Scholar]
- Miret-Roig, N., Bouy, H., Raymond, S. N., et al. 2022, Nat. Astron., 6, 89 [NASA ADS] [CrossRef] [Google Scholar]
- Moro-Martín, A., Turner, E. L., & Loeb, A. 2009, ApJ, 704, 733 [CrossRef] [Google Scholar]
- Peña Ramírez, K., Béjar, V. J. S., Zapatero Osorio, M. R., Petr-Gotzens, M. G., & Martín, E. L. 2012, ApJ, 754, 30 [Google Scholar]
- Portegies Zwart, S., Torres, S., Pelupessy, I., Bédorf, J., & Cai, M. X. 2018, MNRAS, 479, L17 [Google Scholar]
- Rafikov, R. R. 2018, ApJ, 867, L17 [NASA ADS] [CrossRef] [Google Scholar]
- Raymond, S. N., Armitage, P. J., & Veras, D. 2018, ApJ, 856, L7 [Google Scholar]
- Raymond, S. N., Kaib, N. A., Armitage, P. J., & Fortney, J. J. 2020, ApJ, 904, L4 [Google Scholar]
- Scholz, A., Muzic, K., Geers, V., et al. 2012, ApJ, 744, 6 [NASA ADS] [CrossRef] [Google Scholar]
- Schwamb, M. E., Jones, R. L., Yoachim, P., et al. 2023, ApJS, 266, 22 [NASA ADS] [CrossRef] [Google Scholar]
- Sen, A. K., & Rana, N. C. 1993, A&A, 275, 298 [NASA ADS] [Google Scholar]
- Siraj, A., & Loeb, A. 2022, New A, 92, 101730 [NASA ADS] [CrossRef] [Google Scholar]
- Sun, Y., Wong, A. K., & Kamel, M. S. 2009, Int. J. Pattern Recog. Artif. Intell., 23, 687 [CrossRef] [Google Scholar]
- Torbett, M. V. 1986, AJ, 92, 171 [NASA ADS] [CrossRef] [Google Scholar]
- Trilling, D. E., Mommert, M., Hora, J. L., et al. 2018, AJ, 156, 261 [Google Scholar]
- Vereš, P., & Chesley, S. R. 2017, AJ, 154, 13 [CrossRef] [Google Scholar]
- Ye, Q.-Z., Zhang, Q., Kelley, M. S. P., & Brown, P. G. 2017, ApJ, 851, L5 [NASA ADS] [CrossRef] [Google Scholar]
All Tables
Confusion matrix results for different models evaluated on ‘Oumuamua and Borisov datasets containing tracklets for one night.
All Figures
|
Fig. 1 Histogram of absolute magnitudes of synthetic ISOs used in this work. |
| In the text | |
|
Fig. 2 Hammer-Aitoff sky-plane projection of synthetic positions of Solar System objects in downloaded LSST data. |
| In the text | |
|
Fig. 3 Digest2 output values ranked in the top nine our of ten features identified as important for ISO classification. |
| In the text | |
|
Fig. 4 Confusion matrices for GBM (upper left), SGD (upper right), RF (botton left), and NN (bottom right). |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.