| Issue |
A&A
Volume 698, June 2025
|
|
|---|---|---|
| Article Number | A242 | |
| Number of page(s) | 12 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202554311 | |
| Published online | 18 June 2025 | |
Improving the discovery of near-Earth objects with machine-learning methods
Harvard-Smithsonian Center for Astrophysics,
60 Garden St., MS 15,
Cambridge,
MA
02138,
USA
★ Corresponding author: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
28
February
2025
Accepted:
5
May
2025
Abstract
Context. We present a comprehensive analysis of the digest2 parameters for candidates of the Near-Earth Object Confirmation Page (NEOCP) that were reported between 2019 and 2024. Our study proposes methods for significantly reducing the inclusion of non-NEO objects on the NEOCP. Despite the substantial increase in near-Earth object (NEO) discoveries in recent years, only about half of the NEOCP candidates are ultimately confirmed as NEOs. Therefore, much observing time is spent following up on non-NEOs. Furthermore, approximately 11% of the candidates remain unconfirmed because the follow-up observations are insufficient. These are nearly 600 cases per year.
Aims. To reduce false positives and minimize wasted resources on non-NEOs, we refine the posting criteria for NEOCP based on a detailed analysis of all digest2 scores.
Methods. We investigated 30 distinct digest2 parameter categories for candidates that were confirmed as NEOs and non-NEOs. From this analysis, we derived a filtering mechanism based on selected digest2 parameters that were able to exclude 20% of the non-NEOs from the NEOCP while maintaining a minimal loss of true NEOs. We also investigated the application of four machine-learning (ML) techniques, that is, the gradient-boosting machine (GBM), the random forest (RF) classifier, the stochastic gradient descent (SGD) classifier, and neural networks (NN) to classify NEOCP candidates as NEOs or non-NEOs. Based on digest2 parameters as input, our ML models achieved a precision of approximately 95% in distinguishing between NEOs and non-NEOs.
Results. Combining the digest2 parameter filter with an ML-based classification model, we demonstrate a significant reduction in non-NEOs on the NEOCP that exceeds 80%, while limiting the loss of NEO discovery tracklets to 5.5%. Importantly, we show that most follow-up tracklets of initially misclassified NEOs are later correctly identified as NEOs. This effectively reduces the net loss of true NEOs to approximately 1%.
Conclusions. A greater purity of NEO candidates on the NEOCP would allow follow-up observers to allocate more resources to confirming high-priority objects. This would improve the overall observational efficiency and the confirmation rate of NEO discoveries. We suggest that our methods are used as part of the NEOCP pipeline.
Key words: methods: data analysis / methods: numerical / methods: statistical / astronomical databases: miscellaneous / astrometry / minor planets, asteroids: general
These authors contributed equally to this work.
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
Near-Earth objects (NEOs) are natural celestial bodies, including asteroids and comets, on heliocentric orbits with perihelion distances shorter than 1.3 AU. The interest in NEOs has grown significantly throughout the 20th century, driven by the realization that these objects have the potential to impact Earth (Fairchild 1907; Öpik 1916; Opik 1976; Alvarez et al. 1980; Morrison 2006). Although the first NEO, 433 Eros, was discovered in 1898 through photographic plate observations, the systematic discovery and study of these objects did not gain momentum until much later. In 1998, the US Congress mandated NASA to discover 90% of the NEOs that are larger than 1 km (Morrison 1992); in 2005, this target was expanded to include NEOs larger than 140 meters (George E. Brown Act1). Together with advances in technology, in particular, the development of charge-coupled device (CCD) cameras, these legislative efforts sparked a dramatic growth in the number of known NEOs from only a few hundred in 1990 to more than 38 000 today. Dedicated offices at the national space agencies, such as NASA’s Planetary Defense Coordination Office2 and ESA’s Planetary Defense Office in the Space Situational Awareness program3, further reflect the international commitment to planetary defense. This is exemplified by evolving strategies and plans4.
The study of NEOs extends beyond planetary defense initiatives to include exploration, resource utilization, and understanding of the evolution of our Solar System. Recent examples include Hayabusa (Fujiwara et al. 2006), Hayabusa 2 (Watanabe et al. 2017), and OSIRIS-REx (Lauretta et al. 2017), while the DART mission (Rivkin et al. 2021) has successfully demonstrated the kinetic impactor technique for planetary defense. Upcoming missions such as Hera (Michel et al. 2022), Ramses (Kueppers et al. 2023), Tianwen-2 (Cheng & Baoyin 2024), and the commercial AstroForge venture (Meginnis et al. 2024) offer further opportunities to expand our understanding of these celestial bodies.
Despite significant progress and record-breaking NEO discovery rates in the past few years (Figure 1), challenges remain to meet the 2005 mandated objective of identifying 90% of the NEOs that are larger than 140 meters. Current estimates suggest that less than 40% of this population has been discovered (Grav et al. 2023), in contrast to the >90% completion rate for the NEOs that are larger than one kilometer. NASA-funded surveys, such as the Catalina Sky Survey (Christensen et al. 2012), Pan-STARRS (Kaiser et al. 2002), and ATLAS (Tonry et al. 2018), have been instrumental in driving discoveries in the past 15 years. Upcoming initiatives, including the Rubin Observatory (Jones et al. 2009; Vereš & Chesley 2017a; Jones et al. 2018), which is set to begin operations in 2025, and the infrared space telescope NEO Surveyor (Grav et al. 2020), are expected to substantially enhance the detection capabilities and to fulfill the 140-meter discovery objective (Vereš & Chesley 2017a; Mainzer et al. 2023; Wagg et al. 2024).
The process of a NEO discovery relies heavily on the rapid reporting of potential candidates to the Minor Planet Center (MPC5) Near-Earth Object Confirmation Page6 (NEOCP). Follow-up observations allow a quick orbit determination and the formal designation of new NEOs. Central to this process is the use of a tool known as digest2 (Keys et al. 2019), which produces a quasi-probabilistic metric known as the digest2 score. This digest2 score is used to evaluate the likelihood that a single tracklet, that is, a set of detections recorded over a short period, is a NEO. A specific score variant, the NEO noid digest2 score, is used to determine whether a tracklet is eligible for inclusion on the NEOCP. For this, the score must be 65 or greater.
Although the NEO noid digest2 score effectively classifies high-scoring candidates, its reliability diminishes below certain thresholds (Keys et al. 2019). Many non-NEOs therefore appear on the NEOCP. In 2024, for example, roughly 6000 candidates were posted, only about 55% of which proved to be genuine NEOs, while 11% remained unconfirmed. The high proportion of non-NEOs consumes valuable telescope time for follow-up observations. Moreover, previous work by Vereš et al. (2018) suggested that most unconfirmed candidates may still be genuine NEOs. This underscores the need for better screening mechanisms.
To reduce false positives and to minimize wasting resources on non-NEOs, this study proposes refined posting criteria for NEOCP. We explore additional digest2 parameters and employ machine-learning techniques to improve the classification accuracy. The ultimately aim is to allocate follow-up efforts more efficiently and to improve the confirmation rate for true NEOs.
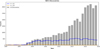 |
Fig. 1 Number of NEO discoveries per year. Large NEOs with a size of >1 km(H<18) and the NASA target (H<22) are displayed as well. |
 |
Fig. 2 Final disposition of the NEOCP tracklets between March 14, 2019 and December 31, 2024. |
2 NEOCP data
We selected initial (discovery) tracklets for each object that appeared on NEOCP between March 14, 2019 and December 31, 2024. Although these six years included a record annual number of NEOCP candidates (Figure 3), the rate of new postings since 2019 was relatively steady compared to previous years (Figure 1). The vast majority of NEOCP candidates were reported by major NEO-dedicated surveys: Pan-STARRS, the Catalina Sky Survey, and ATLAS (Figure 4). In total, the dataset contained 36046 discovery tracklets. The final disposition categories for these NEOCP candidates are illustrated in Figure 2.
A separate section of the NEOCP, the Possible Comet Confirmation Page (PCCP)7, is used for objects exhibiting cometary activity (a coma and/or tail), which are posted regardless of their NEO digest2 scores. Because comets on the PCCP are recognized by their appearance rather than purely by the digest2 scoring, newly discovered comets were excluded from this study. In general, NEOCP objects can have a variety of final dispositions:
New NEO: a genuine new NEO discovery that is eventually announced via an online publication (discovery MPEC).
New non-NEO: a new designation for an object found to be a non-NEO.
Known: a previously identified minor planet (including known NEOs observed at a subsequent apparition).
Artificial: approximately 1% of the NEOCP objects turn out to be human-made satellites or debris.
Deleted: approximately 3% of the postings are removed because they are deemed spurious (e.g., artifacts, stars, or noise).
Unconfirmed: about 11% of candidates remain unconfirmed (i.e., they receive insufficient follow-up) and are declared lost. They are ultimately placed in the isolated tracklet file for potential future recovery or orbit linkage.
Consequently, the main subset of data that we analyzed comprises 19019 new NEOs (including any previously unidentified second-apparition recoveries) and 9306 new non-NEOs. Known objects were not considered, assuming that they were missed by internal MPC attribution mechanisms, but were quickly removed from NEOCP as known.
 |
Fig. 3 Number of NEOCP candidates posted per year. |
 |
Fig. 4 Most productive observatory codes on the NEOCP between 2019–2024. The ATLAS survey has four telescopes: T05, T08, W68, and M22. Pan-STARRS (PS) has two telescopes: F51 and F52. The Catalina Sky Survey (CSS) has five telescopes: G96, 703, I52, V00, and V06. |
 |
Fig. 5 Fraction of NEOs on NEOCP in the NEO noid digest2 score (left) and the score of NEOs and non-NEOs on NEOCP in 2019–2024. |
 |
Fig. 6 NEO noid digest2 score of 3725 unconfirmed (dark) and artificial objects (light) on NEOCP in 2019–2024. |
3 Digest2
The digest2 code (Keys et al. 2019) has been used by the NEO community for almost two decades. Implemented in the C programming language, it is publicly available online8 and processes observations in the MPC1992 astrometric format. An improved version capable of reading ADES-XML astrometry is also publicly available (Vereš et al. 2023). Furthermore, a set of observations can be assessed by digest2 online on the MPC website9.
The digest2 code generates a large set of unperturbed Sun-bound variant orbits that match the end-points of the input tracklet. It then classifies these orbits into distinct orbital categories based on perihelion distance, eccentricity, inclination, and absolute magnitude (H), and it calculates the frequency of orbits within each class. For example, if 90% of the generated orbits correspond to NEO orbits, the resulting NEO score is 90. Thus, digest2 functions as a quasi-probabilistic classification tool.
Traditionally, only a single digest2 value (the NEO noid score) was used to decide whether an object should be posted on the NEOCP. The noid variant of the score represents the likelihood that an object is a NEO relative to the undiscovered fraction of the Solar System population. The NEOCP posting threshold for the NEO noid score has historically been set at 65. Although this cutoff maximizes the number of NEO discoveries, it also results in a high fraction of non-NEOs being posted to the NEOCP. Figure 5 illustrates the sharp decline in the fraction of true NEOs as a function of the NEO noid digest2 score. In recent years, approximately 6000 candidates have appeared on the NEOCP annually, and about 11% remained unconfirmed.
The typical NEO noid digest2 scores for unconfirmed and artificial objects on the NEOCP are shown in Figure 6. The score distribution for unconfirmed objects closely resembles that of all NEOCP candidates (Figure 5), while artificial objects typically exhibit very high digest2 scores. These high scores are often due to their proximity to Earth and to their high apparent rates of motion.
Although the NEO noid score has become the canonical reference, digest2 can generate up to 15 distinct scores for a single tracklet, each corresponding to a different orbit class (see Table 8 in Keys et al. 2019). Each score is produced in two variants: the noid score, based on the undiscovered fraction of the Solar System population, and a raw score, based on the overall Solar System population. The orbital categories are as follows: interesting (Int) objects (high inclination and eccentricity), NEOs, Mars crossers (MC), Hungarias (Hun), Phocaeas (Pho), inner main belt asteroids (MBA1), Pallas family (Pal), Hansa family (Han), central main belt asteroids (MBA2), outer main belt asteroids (MBA3), Hildas (Hil), Jupiter trojans (Jtr), and Jupiter-family comets (JFC). Two additional classes, NEO18 (NEOs with H<18) and NEO22 (NEOs with H<22), are available, but are not used in this work.
4 Digest2 analysis of NEO candidates
Using discovery tracklets from 2019–2024, we computed separate digest2 scores for each of the 13 orbital categories in the raw and noid variants (the suffixes 1 and 2 in the figures, respectively). The histograms in Figures 7, 8, and 9 illustrate how these scores compare for NEOs and non-NEOs in the categories. In some cases, the distinction is fairly strong; for example, most NEOs have a digest2 scores of zero in the Jtr and JFC classes, whereas many non-NEOs show nonzero scores there. Other categories, such as Hildas or Hansa, appear to be less discriminating.
In addition to the visual inspection, we attempted to identify optimal digest2 thresholds within each category to reduce non-NEOs while retaining genuine NEOs. That is, we sought to identify a boundary in each histogram (either above or below a given score) that would exclude zero, one, or two NEOs at most in our data sample, that is, a controlled tolerance for NEO losses. We divided our data samples into a training sample (2019–2023) and a validation sample (2024).
Tables 1, 2, and 3 list the thresholds for three different filter modes (filter0, filter1, and filter2), showing how many NEOs and non-NEOs each filter would remove. For example, filter0 rejected 911 non-NEOs over five years without excluding any NEOs, whereas filter2 eliminated 1557 non-NEOs, but at the cost of 14 NEOs. We then applied these same filters to the 2024 data (Table 4). Depending on the chosen tolerance, between 159 and 278 non-NEOs were selected from the NEOCP, and only three or four genuine NEOs out of 3427 discovered that year were missed. Even though the filters do not classify the majority of the data (Tables 5 and 6), they demonstrate exceptional precision in correctly identifying non-NEOs; it exceeds 98%. This high precision suggests that basic filters can serve as an effective initial screening tool for filtering objects on the NEOCP. This significantly reduces the number of candidates that require further analysis.
5 Machine-learning methods
Although the refined digest2 filters can reduce the number of non-NEOs on the NEOCP, these methods rely on a handful of fixed thresholds. Machine-learning (ML) approaches offer an alternative that can detect nonlinear relationships in high-dimensional data without depending on predefined cutoffs. By training on historical examples of NEO and non-NEO tracklets, ML models potentially classify objects more accurately and lessen the need for follow-up observations on false positives.
This study used observational records in the MPC1992 obs 80-column format, which provides the right ascension (RA), the declination (Dec), the magnitude, the epoch, and the band for each tracklet. Crucially, our dataset consisted exclusively of known NEO and non-NEO tracklets, giving us reliable orbit classifications a priori. The training portion covered five years (2019-2023), comprising 15591 NEO tracklets and 7996 non-NEO tracklets, while all data for 2024, consisting of 4737 tracklets (3428 labeled as NEOs), were used as the test set for the final evaluation.
 |
Fig. 7 Histogram of the Int, MC and Hun and Pho digest2 scores for NEOs and non-NEOs. The number 1 denotes raw, and the number 2 denotes noid. |
5.1 Data preprocessing
The data quality is critical for ML applications, as well as in astronomy, where measurements can be degraded by instrumental limitations and atmospheric conditions or other noise sources. To ensure data integrity, records containing missing values were systematically excluded using a complete case analysis on each row. This preprocessing step resulted in the removal of 6 samples from our training dataset, yielding a final count of 24913 samples. The low proportion of missing data (0.02%) suggests that the completeness of our observational dataset was high, and this minimizes any potential impact on the model training.
In addition to handling missing values, we addressed the class imbalance in our dataset. The initial distribution showed a significant skew, with 16543 NEO tracklets versus 8376 non-NEO tracklets. To mitigate potential classification bias, we implemented a random undersampling strategy that reduced the majority class (NEOs) to match the size of the minority class. This balanced-sampling approach resulted in a final training set of 8375 tracklets per class, ensuring equal representation of NEOs and non-NEOs while maintaining the statistical properties of both populations. A random sampling was performed with a fixed seed value to ensure the reproducibility of our results.
 |
Fig. 8 Histogram of the MBA, Pal, and Han and MBA2 digest2 scores for NEOs and non-NEOs. The number 1 denotes raw, and the number 2 denotes noid. |
5.2 Model architecture and implementation
We implemented four distinct ML methods so that we were able to examine a spectrum of modeling capabilities. First, we adopted a gradient-boosting machine (GBM) based on XGBoost using binary logistic regression as the objective function, a log-loss metric, 100 estimators, a learning rate of 0.1, and a maximum tree depth of 5. This approach sequentially corrected its own errors through boosting, which makes it well suited to complex nonlinear relations in the orbital parameter space. Second, we trained a random forest (RF) classifier using the scikit-learn framework. This algorithm builds multiple decision trees on randomized subsets of the training data and features and then aggregates their predictions. Random forest naturally handles outliers, reduces overfitting by averaging, and quantifies the contribution of each feature to the final classification.
As a simpler alternative, we also employed the code called stochastic gradient descent (SGD) configured as a linear classifier, using binary cross-entropy loss and an adaptive learning rate scheduling. Because it fits a single linear decision boundary, SGD offers computational efficiency and is relatively interpretable: The model coefficients directly indicate which orbital parameters carry the most weight for a classification. To account for any remaining imbalance, we enabled balanced class weights. Finally, we experimented with a feed-forward neural network (NN) containing two hidden layers of 64 ReLU-activated neurons apiece, binary cross-entropy as the loss function, and an Adam optimizer with a learning rate of 0.001. This setup aimed to capture complex relations through nonlinear activation, while validation-based early stopping prevented overfitting.
Filter0. Threshold values and object counts for each digest2 type, showing the number of correctly identified non-NEOs and the maximum number of falsely rejected NEOs (0) in each category based on 2019–2023 NEOCP data.
Filter1. Threshold values and object counts for each digest2 type, showing the number of correctly identified non-NEOs and the maximum number of falsely rejected NEOs (1) in each category based on 2019–2023 NEOCP data.
We evaluated each model performance using accuracy, precision, recall, and F1-score. These metrics were computed on a stratified validation split to preserve the relative frequencies of NEOs and non-NEOs. After we refined the hyperparameters on the validation subset, the models were tested on the 2024 dataset for an unbiased measure of real-world applicability. A correct classification of NEOs is crucial to ensure that follow-up observations are not missed, and the correct rejection of non-NEOs helps us to save telescope time.
Filter2. Threshold values and object counts for each digest2 type, showing the number of correctly identified non-NEOs and the maximum number of falsely rejected NEOs (2) in each category based on 2019–2023 NEOCP data.
Arbitrary filters for individual digest2 thresholds for the 2024 dataset of NEOCP candidates.
To take advantage of the strengths of individual classifiers, we investigated two ensemble strategies. First, we applied a model stacking, where the output of GBM, RF, SGD, and NN was combined by a logistic regression meta-learner, thus capturing the complementary aspects of the predictions of each algorithm. Second, we considered a voting mechanism that aggregated predictions either by majority rule (hard voting) or by averaging class probabilities (soft voting). We tuned the voting weights on the validation data to balance precision and recall. These ensemble methods were designed to mitigate the weaknesses of any single model, with the aim of achieving a more robust overall classification. By comparing threshold-based digest2 filtering and multiple ML classifiers, we hoped to identify the most promising routes to reduce false positives on the NEOCP while retaining the highest fraction of genuine NEOs.
 |
Fig. 9 Histogram of Outer Main Belt (MBA), Hildas, Jupiter Trojans and Jupiter family comets digest2 scores for NEOs. The number 1 denotes raw, and the number 2 denotes noid. |
6 Results
Four machine-learning (ML) models (GBM, RF, SGD, and NN) were trained on NEOCP discovery tracklets (2019–2023) and tested on an independent dataset from 2024. Table 7 summarizes the overall performance of each method in the 2024 test dataset. The results demonstrate that the four methods achieve a broadly comparable performance, with accuracies ranging from 0.9261 (RF) to 0.9329 (NN). The precision is highest for the identification of NEOs (ranging from 0.95 to 0.98) and lower for non-NEOs (0.81-0.86). Despite the similarity of these metrics, the SGD classifier was chosen for the detailed analysis because it produced the fewest misidentified NEOs in the test set. Figure 10 shows the confusion matrices for all four methods. In the SGD matrix, the upper left quadrant represents correctly identified NEOs, the lower right quadrant shows correctly identified nonNEOs, and the off-diagonal cells represent misclassifications. The SGD classifier incorrectly labeled 189 NEOs as non-NEOs and correctly classified 3239 NEOs, along with 884 non-NEOs.
Confusion matrices for filters 0–2 using 2019–2023 NEOCP data.
Confusion matrices for filters 0–2 using 2024 NEOCP data and filters derived from 2019–2023 data.
Model performance metrics.
We investigated the 189 misidentified NEOs in detail. Figures 11, 12, and 13 show the apparent rates of motion and position angle of the motion vector for the matched and unmatched NEOs and non-NEOs from the SGD model. These figures reveal that slow-moving NEOs are more likely to be misclassified, while the orientation of their motion vectors has little impact. We also investigated the sky-plane distribution of correctly and incorrectly classified objects. Figure 14 shows that the opposition-centric ecliptical coordinates do not differentiate the two groups. Thus, incorrect classifications appear to be primarily related to on-sky motion rates and not to location.
 |
Fig. 10 Comparison of the four ML methods we used on 2024 NEOCP data. The SGD method performs best. It misclassified 189 NEOs as nonNEOs. The RF misclassified the most NEOs as non-NEOs. |
 |
Fig. 11 Rate of motion and position angle (top) and histogram of rate of motion (bottom) for correctly identified NEOs and non-NEOs by SGD. There is a clear distinction between NEOs and non-NEOs in rate of motion. |
6.1 Decreasing the false-positive rate
Although a misclassification of 189 of the 3428 NEOs (for 2024) may initially seem significant, it is important to note that our analysis was only applied to the discovery tracklets of objects when they first appeared on the NEOCP. Our previous work (Keys et al. 2019) demonstrated that the NEO digest2 score changes as a function of time and observational geometry, implying that many of these initially missed NEOs could be reidentified when additional data become available. To examine this effect, all follow-up tracklets from the 189 misidentified NEOs were reevaluated using the SGD classifier. Of the 189 objects, 140 were correctly identified as NEOs in at least one follow-up tracklet. As shown in Figure 15, most were correctly reclassified within a few days after the initial discovery tracklet. However, a small number required up to three months to receive a definitive NEO classification.
Four of the remaining 49 NEOs that were consistently misclassified in all available follow-up tracklets were already known (e.g., recoveries), leaving 45 new NEO misidentifications. Table 11 lists the original trksub, packed designation, and basic orbital elements and absolute magnitude (H) of these 45 objects. Most are relatively large and distant. They belong to Amor-class asteroids and have a low NEO noid digest2 score. None qualifies as a potentially hazardous asteroid (PHA; defined as having a minimum orbit intersection distance <0.05 AU and H<22) or as imminent Earth impactors10. Furthermore, since most were discovered toward the end of 2024, their follow-up arcs are very short. We speculate that with additional followup observations, many of these objects might eventually be correctly classified by our model and subsequently reach the NEOCP.
 |
Fig. 12 Rate of motion and position angle (top) and histogram of rate of motion (bottom) for correctly and incorrectly identified NEOs identified by SGD. Misidentified NEOs are slower than the correctly identified ones. |
 |
Fig. 13 Rate of motion and position angle (top) and histogram of rate of motion (bottom) for incorrectly identified NEOs and non-NEOs by SGD. The motion properties of the two orbital types are similar. |
 |
Fig. 14 Opposition-centric ecliptical coordinates of identified and misidentified NEOs by SGD. |
 |
Fig. 15 Histogram of the order of the first follow-up tracklet of initially misclassified NEOs that the ML model identified correctly (left). We also show the histogram of the time that elapsed since the original discovery tracklet (right) until the follow-up tracklet is classified correctly as a NEO for the first time. |
6.2 Follow-up tracklets of misidentified NEOs by filtering
In the 2024 NEOCP dataset, the basic filters misclassified only a few NEOs (three or four) while correctly labeling between 159 and 287 non-NEOs, depending on the filter that was applied. We further examined all 18 NEOs (from 2019–2024) that were misclassified by filter2 and analyzed their follow-up tracklets using the same filter. We found that each of these 18 NEOs had at least one follow-up tracklet that was correctly classified. This was typically by the third follow-up. Additionally, when the original 18 misclassified discovery tracklets were processed through the SGD ML method, they were all misclassified again, indicating a strong correlation between the basic filtering and the SGD ML approach regarding misidentified NEOs. In contrast, the candidates classified as non-NEOs by filter2 were consistently confirmed as non-NEOs by the SGD ML method.
6.3 Analysis of unconfirmed candidates
We analyzed 3725 unconfirmed NEOCP candidates (2019–2024) using the SGD ML method and the basic digest2 filter (filter2). The unconfirmed data were divided into two subsets: 3190 candidates that remained unconfirmed, and 535 candidates that were later attributed to known objects (and thus have known orbital properties).
Within the attributed subset, the SGD ML method achieved a precision of 91%, with approximately 50% of the candidates classified as NEOs. The filter2 correctly identified 79 unconfirmed candidates as non-NEOs, without eliminating any true NEOs. In contrast, when applied to the entire unconfirmed dataset, the SGD ML method indicated that 2620 candidates could be NEOs and only 570 were non-NEOs (see Table 8). This suggests that approximately 83% of the unconfirmed NEOCP candidates are likely NEOs. The observed discrepancy in the NEO/non-NEO ratio of the unconfirmed and attributed subsets can be attributed to a selection effect: Non-NEOs are generally easier to confirm through follow-up observations via linking, which leads to their preferential attribution. filter2 would have eliminated 100 unconfirmed candidates as non-NEOs.
Figure 16 illustrates the relation between the apparent magnitude and rate of motion of the unconfirmed candidates, together with the corresponding NEO noid digest2 scores. It is apparent that the unconfirmed objects generally fall into two categories: those moving extremely fast on the sky, which results in rapidly increasing positional uncertainties that hinder a timely recovery, and those that are very faint, making them difficult to detect with follow-up telescopes. Furthermore, as noted in the left panel of Figure 17, the distribution of observatory codes for tracklets that remain unconfirmed differs from that of attributed tracklets (Figure 17, right), reflecting differences in survey coverage and follow-up capability.
Unconfirmed NEO candidates: SGD ML classification (middle) and already attributed candidates (right) that were initially unconfirmed.
 |
Fig. 16 Rate of motion and mean V-band magnitude of unconfirmed NEO candidates. We highlight NEOs and non-NEOs that were attributed later (left). The histogram shows the NEO noid digest2 score of unconfirmed and attributed NEOCP candidates. |
 |
Fig. 17 Observatory codes of tracklets that remain unconfirmed (left) and those that were later attributed (right). |
7 Discussion
For the past 15 years, a single threshold of NEO noid digest2 (>65) has been used to select candidates, with a brief experiment in mid-2010 where the threshold was lowered in an attempt to identify more NEOs. However, this change resulted in an overwhelming number of non-NEO candidates without a significant increase in genuine NEO discoveries. As shown in Figure 5, the number of NEOs with low digest2 scores is very small. Between 2019 and 2023, only 37 NEOs were found in the digest2 score range of 65 to 70, compared to 826 non-NEOs. In other words, the number of low-score NEOs is lower by an order of magnitude than the annual number of unconfirmed NEOCP candidates. Consequently, our first recommendation is to consider increasing the NEO noid digest2 threshold by a few points.
NEOs that were rejected by digest2 filtering by filter3.
Our second recommendation is to leverage the full range of digest2 parameters and thresholds derived in Section 4. By carefully tuning these thresholds, it is possible to eliminate a substantial fraction of non-NEO candidates from the NEOCP while keeping the misclassification of actual NEOs to a minimum. For example, a conservative filter0 would eliminate no NEOs, while a more aggressive filter filter2 would reject 14 NEOs over a 5-year period, removing approximately 20% of non-NEOs. When we consider that approximately 3000 NEOs are discovered annually and around 600 objects remain unconfirmed, the misclassification of a few NEOs per year appears to be an acceptable compromise.
It is also important to note that more than a dozen NEOs are discovered each year through the lineage of isolated tracklets: the tracklets that never achieve a digest2 score of 65, but still belong to previously unknown NEOs. The Minor Planet Center (MPC) credits these discoveries in MPEC publications, often with a note such as “The following astrometry was found among the isolated tracklets and linked by R. Weryk.” For example, in 2024, 25 discoveries like this were announced (e.g., Chambers et al. 2024).
A detailed analysis of the 14 rejected NEOs in the sample 2019–2023, together with 4 NEOs from 2024 (see Table 9), revealed that four objects lacked a NEO noid digest2 score exceeding 65 and therefore had to be manually added to the NEOCP. The remaining objects exhibited relatively low digest2 scores and a slow to moderate rate of motion typical of newly discovered NEOs. Of these, nine are of the Amor type (usually more distant objects), seven are Apollo, and two are Atira. In particular, all four machine-learning methods consistently identified the objects rejected by the filtering process as NEOs. This suggests that a combined approach using both machine-learning and traditional filtering techniques could offer significant benefits in reducing the non-NEO load on the NEOCP.
Follow-up tracklets of non-NEOs that were correctly classified by SGD ML in 2024.
Implementing filter2 would remove approximately 19% of non-NEOs from the NEOCP for the 2019–2023 period and 21% for 2024. This reduction enables follow-up observers to focus on genuine NEOs instead of expending resources on candidates that are ultimately non-NEOs. Consequently, more NEOs were confirmed than unconfirmed objects.
All four machine-learning methods we evaluated achieved a similar precision and accuracy. We selected the Stochastic Gradient Descent (SGD) classifier as the most appropriate, however. The SGD method correctly labeled 95% of the NEOs and 85% of the non-NEOs. In particular, SGD is capable of reclassifying follow-up tracklets of initially misclassified NEOs as true NEOs, and only about 1% of the NEOs remained misclassified. This high performance is promising, particularly since more than 80% of non-NEOs are correctly identified and therefore excluded from the NEOCP. For example, in 2024, SGD would correctly classify 884 non-NEOs, which would prevent them from being posted to the NEOCP and would save significant follow-up effort. As shown in Table 10, these non-NEOs correspond to 13030 pointings on 4150 tracklets from 104 observatories. Although nearly half of these pointings were incidental (e.g., collected by large-survey telescopes such as Pan-STARRS, the Catalina Sky Survey, and DECAM), the remaining detections represent thousands of valuable exposures that extend the observational arcs of non-NEOs.
With approximately 600 unconfirmed candidates per year and SGD suggesting that roughly half are true NEOs, eliminating non-NEOs from the NEOCP would allow follow-up observers to focus their resources on the most promising candidates. This refined focus would increase the likelihood that genuine NEOs are confirmed instead of expending effort on objects that are eventually ruled out by machine-learning or filtering.
Although modern surveys such as the VRO and NEO Surveyor promise alternative discovery methods, such as inter-night linking (Vereš & Chesley 2017b; Eggl et al. 2020; Heinze et al. 2022), the NEOCP will likely remain in use by current and future survey teams. These new surveys may significantly alter the NEOCP population (e.g., by introducing many very faint objects), and the underlying digest2 score population model might change accordingly. However, the ML and filtering models can both be retrained rapidly to establish new thresholds. This ensures a continued efficiency in the selection of NEO candidates.
NEOs rejected by ML, including on all follow-up tracklets.
Data availability
The GitHub repository11 provides the following data and tools:
data directory: Contains the positions of tracklets in MPC1992 format (.obs extension) for NEOCP data from 2019 to 2024, computed digest2 values (split into 2019–2023 and 2024) in CSV format, the MPC.config configuration file for digest2, optimal thresholds for basic filtering (JSON files), and lists of non-NEOs identified through basic filtering (filtered_pass.csv).
src directory: Contains Python executables: find_filter.py (derives a basic filter from the input data and outputs a JSON file), neocp_filter.py (applies a derived JSON filter to select non-NEOs from an input CSV file), testing_pipeline_formatted.py (uses trained machine learning models from the models directory to classify tracklets as NEOs or non-NEOs), and training_pipeline_formatted.py (trains four distinct machine learning models on an input sample).
models directory: Contains the machine learning models developed in this work, intended for use with the testing_pipeline_formatted.py code.
Acknowledgements
This work was supported by the MPC’s NASA cooperation agreement funding. We also acknowledge support of Oumuamua-Laukien fellowship awarded to the Galileo Project at Harvard University by the Laukien Science Foundation.
References
- Alvarez, L. W., Alvarez, W., Asaro, F., & Michel, H. V., 1980, Science, 208, 1095 [NASA ADS] [CrossRef] [Google Scholar]
- Chambers, K., Lin, C. C., Magnier, E., et al. 2024, Minor Planet Electronic Circulars, 2024-U37 [Google Scholar]
- Cheng, B., & Baoyin, H., 2024, MNRAS, 534, 1376 [Google Scholar]
- Christensen, E., Larson, S., Boattini, A., et al. 2012, in AAS/Division for Planetary Sciences Meeting Abstracts, 44, 210.13 [Google Scholar]
- Eggl, S., Juric, M., Moeyens, J., & Jones, L., 2020, in AAS/Division for Planetary Sciences Meeting Abstracts, 52, 211.01 [Google Scholar]
- Fairchild, H. L., 1907, Geol. Soc. Am. Bull., 18, 493 [Google Scholar]
- Fujiwara, A., Kawaguchi, J., Yeomans, D. K., et al. 2006, Science, 312, 1330 [NASA ADS] [CrossRef] [Google Scholar]
- Grav, T., Mainzer, A., Sonnett, S., et al. 2020, in AAS/Division for Planetary Sciences Meeting Abstracts, 52, 208.03 [Google Scholar]
- Grav, T., Mainzer, A. K., Masiero, J. R., et al. 2023, Planet. Sci. J., 4, 228 [NASA ADS] [CrossRef] [Google Scholar]
- Heinze, A., Eggl, S., Juric, M., et al. 2022, in AAS/Division for Planetary Sciences Meeting Abstracts, 54, 504.04 [Google Scholar]
- Jones, R., Chesley, S., Connolly, A., et al. 2009, Earth Moon Planets, 105, 101 [NASA ADS] [CrossRef] [Google Scholar]
- Jones, R. L., Slater, C. T., Moeyens, J., et al. 2018, Icarus, 303, 181 [NASA ADS] [CrossRef] [Google Scholar]
- Kaiser, N., Aussel, H., Burke, B. E., et al. 2002, in Proc. SPIE, 4836, Survey and Other Telescope Technologies and Discoveries, eds. J. A. Tyson, & S. Wolff, 154 [NASA ADS] [CrossRef] [Google Scholar]
- Keys, S., Vereš, P., Payne, M. J., et al. 2019, PASP, 131, 1 [Google Scholar]
- Kueppers, M., Martino, P., Carnelli, I., & Michel, P., 2023, in AAS/Division for Planetary Sciences Meeting Abstracts, 55, 201.08 [Google Scholar]
- Lauretta, D. S., Balram-Knutson, S. S., Beshore, E., et al. 2017, Space Sci. Rev., 212, 925 [Google Scholar]
- Mainzer, A. K., Masiero, J. R., Abell, P. A., et al. 2023, Planet. Sci. J., 4, 202 [Google Scholar]
- Meginnis, A. D., Acain, J., Helms, C., & Lantukh, D., 2024, in LPI Contributions, 3006, Apophis T-5 Workshop, 2024 [Google Scholar]
- Michel, P., Küppers, M., Bagatin, A. C., et al. 2022, Planet. Sci. J., 3, 160 [NASA ADS] [CrossRef] [Google Scholar]
- Morrison, D., 1992, Mercury, 21, 103 [NASA ADS] [Google Scholar]
- Morrison, D., 2006, Philos. Trans. Roy. Soc. Lond. Ser. A, 364, 2041 [Google Scholar]
- Öpik, E., 1916, Irish Astron. J., 1, 27 [Google Scholar]
- Opik, E. J., 1976, Interplanetary Encounters: Close-Range Gravitational Interactions (Elsevier), 2 [Google Scholar]
- Rivkin, A. S., Chabot, N. L., Stickle, A. M., et al. 2021, Planet. Sci. J., 2, 173 [NASA ADS] [CrossRef] [Google Scholar]
- Tonry, J. L., Denneau, L., Heinze, A. N., et al. 2018, PASP, 130, 064505 [Google Scholar]
- Vereš, P., & Chesley, S. R., 2017a, AJ, 154, 12 [Google Scholar]
- Vereš, P., & Chesley, S. R., 2017b, AJ, 154, 13 [CrossRef] [Google Scholar]
- Vereš, P., Payne, M. J., Holman, M. J., et al. 2018, AJ, 156, 5 [Google Scholar]
- Vereš, P., Cloete, R., Weryk, R., Loeb, A., & Payne, M. J., 2023, PASP, 135, 104505 [Google Scholar]
- Wagg, T., Juric, M., Yoachim, P., et al. 2024, arXiv e-prints [arXiv:2408.12517] [Google Scholar]
- Watanabe, S.-i., Tsuda, Y., Yoshikawa, M., et al. 2017, Space Sci. Rev., 208, 3 [Google Scholar]
K19M00O,K22E05B,K22W01J,K23C01X,K24B01X,K24R01W.
All Tables
Filter0. Threshold values and object counts for each digest2 type, showing the number of correctly identified non-NEOs and the maximum number of falsely rejected NEOs (0) in each category based on 2019–2023 NEOCP data.
Filter1. Threshold values and object counts for each digest2 type, showing the number of correctly identified non-NEOs and the maximum number of falsely rejected NEOs (1) in each category based on 2019–2023 NEOCP data.
Filter2. Threshold values and object counts for each digest2 type, showing the number of correctly identified non-NEOs and the maximum number of falsely rejected NEOs (2) in each category based on 2019–2023 NEOCP data.
Arbitrary filters for individual digest2 thresholds for the 2024 dataset of NEOCP candidates.
Confusion matrices for filters 0–2 using 2024 NEOCP data and filters derived from 2019–2023 data.
Unconfirmed NEO candidates: SGD ML classification (middle) and already attributed candidates (right) that were initially unconfirmed.
Follow-up tracklets of non-NEOs that were correctly classified by SGD ML in 2024.
All Figures
|
Fig. 1 Number of NEO discoveries per year. Large NEOs with a size of >1 km(H<18) and the NASA target (H<22) are displayed as well. |
| In the text | |
|
Fig. 2 Final disposition of the NEOCP tracklets between March 14, 2019 and December 31, 2024. |
| In the text | |
|
Fig. 3 Number of NEOCP candidates posted per year. |
| In the text | |
|
Fig. 4 Most productive observatory codes on the NEOCP between 2019–2024. The ATLAS survey has four telescopes: T05, T08, W68, and M22. Pan-STARRS (PS) has two telescopes: F51 and F52. The Catalina Sky Survey (CSS) has five telescopes: G96, 703, I52, V00, and V06. |
| In the text | |
|
Fig. 5 Fraction of NEOs on NEOCP in the NEO noid digest2 score (left) and the score of NEOs and non-NEOs on NEOCP in 2019–2024. |
| In the text | |
|
Fig. 6 NEO noid digest2 score of 3725 unconfirmed (dark) and artificial objects (light) on NEOCP in 2019–2024. |
| In the text | |
|
Fig. 7 Histogram of the Int, MC and Hun and Pho digest2 scores for NEOs and non-NEOs. The number 1 denotes raw, and the number 2 denotes noid. |
| In the text | |
|
Fig. 8 Histogram of the MBA, Pal, and Han and MBA2 digest2 scores for NEOs and non-NEOs. The number 1 denotes raw, and the number 2 denotes noid. |
| In the text | |
|
Fig. 9 Histogram of Outer Main Belt (MBA), Hildas, Jupiter Trojans and Jupiter family comets digest2 scores for NEOs. The number 1 denotes raw, and the number 2 denotes noid. |
| In the text | |
|
Fig. 10 Comparison of the four ML methods we used on 2024 NEOCP data. The SGD method performs best. It misclassified 189 NEOs as nonNEOs. The RF misclassified the most NEOs as non-NEOs. |
| In the text | |
|
Fig. 11 Rate of motion and position angle (top) and histogram of rate of motion (bottom) for correctly identified NEOs and non-NEOs by SGD. There is a clear distinction between NEOs and non-NEOs in rate of motion. |
| In the text | |
|
Fig. 12 Rate of motion and position angle (top) and histogram of rate of motion (bottom) for correctly and incorrectly identified NEOs identified by SGD. Misidentified NEOs are slower than the correctly identified ones. |
| In the text | |
|
Fig. 13 Rate of motion and position angle (top) and histogram of rate of motion (bottom) for incorrectly identified NEOs and non-NEOs by SGD. The motion properties of the two orbital types are similar. |
| In the text | |
|
Fig. 14 Opposition-centric ecliptical coordinates of identified and misidentified NEOs by SGD. |
| In the text | |
|
Fig. 15 Histogram of the order of the first follow-up tracklet of initially misclassified NEOs that the ML model identified correctly (left). We also show the histogram of the time that elapsed since the original discovery tracklet (right) until the follow-up tracklet is classified correctly as a NEO for the first time. |
| In the text | |
|
Fig. 16 Rate of motion and mean V-band magnitude of unconfirmed NEO candidates. We highlight NEOs and non-NEOs that were attributed later (left). The histogram shows the NEO noid digest2 score of unconfirmed and attributed NEOCP candidates. |
| In the text | |
|
Fig. 17 Observatory codes of tracklets that remain unconfirmed (left) and those that were later attributed (right). |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.