| Issue |
A&A
Volume 690, October 2024
|
|
|---|---|---|
| Article Number | A258 | |
| Number of page(s) | 10 | |
| Section | Extragalactic astronomy | |
| DOI | https://doi.org/10.1051/0004-6361/202450336 | |
| Published online | 14 October 2024 | |
ALMACAL
XII. Data characterisation and products
1
European Southern Observatory, Karl-Schwarzschild-Str. 2, 85748 Garching near Munich, Germany
2
Aix Marseille Univ., CNRS, LAM (Laboratoire d’Astrophysique de Marseille), UMR 7326, F-13388 Marseille, France
3
Space Telescope Science Institute, 3700 San Martin Drive, Baltimore, MD 21218, USA
4
Max-Planck-Institut fúr Extraterrestrische Physik (MPE), Giessenbachstrasse 1, D-85748 Garching, Germany
5
Sydney Institute for Astronomy, School of Physics A28, University of Sydney, NSW 2006, Australia
6
ARC Centre of Excellence for All Sky Astrophysics in 3 Dimensions (ASTRO 3D), Canberra, Australian Capital Territory 2611, Australia
7
ATNF, CSIRO Space and Astronomy, PO Box 76 Epping, NSW 1710, Australia
8
Institute for Astronomy, University of Edinburgh, Royal Observatory, Blackford Hill, Edinburgh EH9 3HJ, UK
9
School of Cosmic Physics, Dublin Institute for Advanced Studies, 31 Fitzwilliam Place, Dublin D02 XF86, Ireland
10
UK Astronomy Technology Centre, Royal Observatory, Blackford Hill, Edinburgh EH9 3HJ, UK
Received:
12
April
2024
Accepted:
26
July
2024
The ALMACAL survey is based on a database of reprocessed ALMA calibration scans suitable for scientific analysis, observed as part of regular PI observations. We present all the data accumulated from the start of ALMA operations until May 2022 for 1047 calibrator fields across the southern sky spanning ALMA Bands 3 to 10 (∼84 − 950 GHz), so-called ALMACAL−22. Encompassing over 1000 square arcmin and accumulating over 2000 hours of integration time, ALMACAL is not only one of the largest ALMA surveys to date, but it continues to grow with each new scientific observation. We outline the methods for processing and imaging a subset of the highest-quality data (‘pruned sample’). Using deconvolution techniques within the visibility data (uv plane), we created data cubes as the final product for further scientific analysis. We describe the properties and shortcomings of ALMACAL and compare its area and sensitivity with other sub-millimetre surveys. Notably, ALMACAL overcomes limitations of previous sub-millimetre surveys, such as small sky coverage and the effects of cosmic variance. Moreover, we discuss the improvements introduced by the latest version of this dataset that will enhance our understanding of dusty star-forming galaxies, extragalactic absorption lines, active galactic nucleus physics, and ultimately the evolution of molecular gas.
Key words: galaxies: evolution / quasars: general / galaxies: star formation
© The Authors 2024
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. Subscribe to A&A to support open access publication.
1. Introduction
Millimetre (mm) and sub-millimetre (sub-mm) observations offer a unique window into various astrophysical processes and phenomena in the Universe. At these wavelengths, key emission lines such as carbon monoxide (CO) and atomic and ionised carbon ([CI], [CII]) emit radiation that reveals essential information about molecular gas content, star-formation activity, and gas dynamics (Carilli & Walter 2013; Tacconi et al. 2020). Sub-mm observations help us explore the cosmic baryon cycle and the complex interplay between cold and dense molecular gas reservoirs, star formation activity, ionised gas, and dust emission (Péroux & Howk 2020).
Modern interferometers have produced large datasets consisting of hundreds to thousands of individual observations. In particular, the Atacama Large Millimeter/submillimeter Array (ALMA) is a pioneering observatory that provides high-resolution observations at mm and sub-mm wavelengths. Transforming the large volume of raw visibility (uv) data from ALMA into scientifically meaningful products is a significant task. This complex process includes several steps: calibration, imaging, and deconvolution.
ALMA has made remarkable progress in automating and ensuring high-quality calibration of interferometric data. These advances have been driven by the diligent efforts of the observatory staff and the success of ALMA’s sophisticated pipeline (Hunter et al. 2023), based on the Common Astronomy Software Applications (CASA) software (McMullin et al. 2007). As a result, ALMA provides its users with meticulously calibrated visibilities, laying the groundwork for further processing and scientific analysis. Despite the effective functionality of the pipeline, certain complications can arise during the calibration process, requiring manual intervention. These complications can include unexpected radio frequency interference, atmospheric anomalies, or misbehaved antennas, all of which affect data quality. In such cases, the expertise of astronomers becomes crucial to correct or flag these problems, ensuring the integrity and reliability of the final scientific products.
Over the years, several large programs (LPs) have exploited the capabilities of ALMA to study the cosmic evolution of gas and stars. In particular, the ASPECS survey in the Hubble Ultra Deep Field (HUDF; Walter et al. 2016; Decarli et al. 2016) aimed to detect CO and [CI] in galaxies without preselection at z = 1 − 3 using Bands 3 and 6. ASPECS covered an area of 4.6 arcmin2 in Band 3 and 2.9 arcmin2 in Band 6. PHANGS–ALMA (Leroy et al. 2021) is a survey of CO(2−1) emission from 90 nearby galaxies with a typical angular resolution of ∼1.5″ and a total survey area of 1050 arcmin2. At higher redshifts, the REBELS survey (Bouwens et al. 2022) targeted 40 UV-bright galaxies at z > 6.5, covering an area of 7 deg2, and aimed to detect the [CII]−158 μm and [OIII]−88 μm lines as well as dust-continuum emission. The ALPINE survey (Le Fèvre et al. 2020) was designed to study 118 star-forming galaxies (SFGs) at 4 < z < 6. This survey targeted the [CII] line and continuum emission, covering an area of 25 arcmin2. The CRISTAL survey (Solimano et al. 2024) selected 25 SFGs with available HST imaging and high stellar masses from the ALPINE sample (log Mstar/M⊙ ≥ 9.5). CRISTAL targets [CII] with a resolution of ∼0.2″, which is higher than its parent sample’s resolution of ∼1″. These surveys have played a key role in constraining the evolution of the molecular gas in galaxies across cosmic epochs. Using different molecular gas tracers shows that the evolution of the molecular gas mass density in the Universe aligns with the cosmic star formation history, providing insights into the process of gas accretion onto galaxies (Walter et al. 2020). In addition to the ALMA LPs, the ALMA Calibrator source catalogue has also been used by Audibert et al. (2022) on a representative sample of the NVSS (when flux limited to 0.4 mJy) to study the CO luminosity function up to redshift z ∼ 2.5 and to assess the role of radioactivity in galaxy evolution. They found that most radio galaxies are more depleted and evolved than the typical simulated halo galaxy.
Other facilities have also been used for surveys of cold gas tracers. The Plateau de Bure High-z Blue Sequence Survey 2 (PHIBSS2) (Guilloteau et al. 1992), is a large observational campaign conducted with the Plateau de Bure Interferometer (PdBI), now part of the Northern Extended Millimeter Array (NOEMA) Observatory. With a frequency range spanning from 80 GHz to 350 GHz, Lenkić et al. (2020) searched for additional background emission lines in the fields of the original PHIBBSS survey. They explored the CO(2 − 1), CO(3 − 2), and CO(6 − 5) emission lines in 110 main-sequence galaxies, covering a total area of ∼130 arcmin2. This survey has been used to derive the molecular gas mass density evolution by converting high−J CO luminosity functions to CO(1 − 0). Additionally, the COLDz survey looked directly for the CO(1 − 0) emission at z = 2 − 3 and CO(2 − 1) at z = 5 − 7 using more than 320 h of VLA time (Pavesi et al. 2018; Riechers et al. 2019, 2020), covering a ∼60 arcmin2 area. However, the large uncertainties of these measurements reflect our limited understanding of the molecular gas content of galaxies across cosmic time.
Our current measurements of the molecular gas mass density (ΩH2) reach redshift z ∼ 7 and show that the density increases from early times, peaks at z ∼ 1 − 3, and decreases to the present day (e.g. Tacconi et al. 2010; Walter et al. 2020; Hamanowicz et al. 2022; Aravena et al. 2024). However, one of the main challenges for the molecular gas surveys is the effect of cosmic variance, which introduces uncertainty on how well the sampled volume represents the Universe (Decarli et al. 2020; Popping et al. 2020; Boogaard et al. 2023). Cosmic variance, caused by natural fluctuations in the Universe’s large-scale structure, results in variations in the number density and distribution of cosmic objects across the sky (Driver & Robotham 2010). Consequently, surveys covering limited sky areas may inadvertently sample regions that are unusually rich or devoid of galaxies, leading to biased estimates of cosmic properties such as the number density of galaxies, clustering, and luminosity function. Small sample sizes exacerbate this issue by introducing statistical uncertainties, which increases the probability of sampling regions with atypical characteristics. Several studies have investigated the effects of field-to-field variance on observables such as the luminosity function and the number density of galaxies (Keenan et al. 2020; Lenkić et al. 2020; Gkogkou et al. 2022; Boogaard et al. 2023). Generally, there is a consensus on the significance of measuring the cosmic variance effect by comparing model predictions with observations and estimates from various sky regions (Popping et al. 2019). This is particularly crucial in deriving the molecular gas mass density of the Universe.
This paper presents a new survey based on ALMA calibrator data accumulated up to May 2022, which we denominated as ALMACAL−22. The original ALMACAL project started in 2016 (Oteo et al. 2016) and has produced several scientific outcomes dedicated to studying molecular gas, dusty star-forming galaxies (DSFGs), absorption lines along the line of sight of quasars, and active galactic nucleus (AGN) physics. ALMACAL−22 was built on the experience of previous pilot ALMACAL surveys, but it has now been expanded to include longer integration times. As part of the strategy to exploit this large dataset, we present the details of processing and imaging data, along with different tests, to ensure the best quality of the sample selection. Here, we provide the characteristics and properties of this new dataset. We compare the strengths of ALMACAL−22 to previous surveys. This new survey covers 1047 fields across the southern sky, intending to alleviate the limitations introduced by Poisson errors due to limited statistics and cosmic variance. We review various studies conducted since ALMA Cycle 1 that have used extragalactic calibration data to explore interesting scientific cases (e.g. Oteo et al. 2017; Klitsch et al. 2019a; Hamanowicz et al. 2022; Chen et al. 2022). We discuss how this new release, ALMACAL−22, can expand our understanding of molecular gas evolution, properties of DSFGs, extragalactic absorption lines, and AGN physics.
This paper is organised as follows. In Sect. 2 we describe the ALMACAL−22 survey, the calibration process (Sect. 2.1), the selection of the pruned sample (Sect. 2.2), and the concatenation and imaging (Sect. 2.3). In Sect. 3 we explore the following properties: spatial distribution (Sect. 3.1), spatial resolution (Sect. 3.2), integration time (Sect. 3.3), and calibrator redshifts (Sect. 3.4). Section 4 compares the strengths of ALMACAL−22 with the previous surveys and discusses the scientific areas where ALMACAL−22 will significantly contribute. In Sect. 5 we summarise our key conclusions. Throughout this paper, we use H0 = 70 km s−1 Mpc−1, ΩM = 0.3, and ΩΛ = 0.7.
2. ALMA calibrator data
The ALMACAL−22 survey comprises archival data compiled from the calibration data used in every science project carried out by ALMA (Zwaan et al. 2022). Each PI-led scientific project involves several observations of a calibrator source that is close to the science field. Most calibrators are bright sub-mm point sources classified as blazars (Bonato et al. 2018) – AGN galaxies with a jet pointing towards the line of sight (Urry & Padovani 1995). Blazars can be divided into two sub-classes: BL Lac objects, which are identified as radio galaxies, and flat-spectrum radio quasars (FSRQs), which are identified as quasars Padovani (2017). When targeting a source with unknown structure and flux, calibration observations are crucial in interferometric astronomy. We used calibrator sources with well-known shapes and flux densities at (sub-)mm and radio wavelengths to adjust the bandpass response, set the flux density scale, and calibrate the amplitude and phase. This ensures we can correct for instrumental and atmospheric corruptions, providing accurate measurements of the target source. These calibration scans have exposure times and setups matching the project’s PI requests. Repeated use of the calibrators for ALMA science observations effectively creates deep observations that often cover a significant fraction of the sub-mm spectrum. The most popular calibrators have data from multiple observations of different ALMA bands. Multiple observations of ALMA calibrators create a high-sensitivity dataset that covers a significant sky area (> 1000 arcmin2).
This paper presents 1047 calibration field data points accumulated from Cycle 1 (July 2012–May 2022) from Band 3 through Band 10, resulting in a dataset of more than 30 Terabytes. These calibrator data are accessible to any user right after the main science dataset has passed quality assurance. In this section we explain the calibration process and subtraction of the calibrator at the centre of the pointing as well as the selection of the so-called pruned sample. Figure 1 shows the ALMACAL−22 field distribution on the sky for the full sample (top) and the pruned sample (bottom).
 |
Fig. 1. Spatial distribution of the calibrator fields for the full ALMACAL−22 (top) and pruned samples (bottom). The distribution of the full sample has no preferred direction, so the position of the calibrators in the sky can be considered homogeneous and only affected by the fact that ALMA observes the sky below δ < 40°. In the pruned sample, two regions exhibit sparse data, possibly attributed to interference, the limited availability of deep fields, and observational difficulties stemming from their proximity to the galactic plane. Further details are provided in Sect. 3.1. |
2.1. Calibration
A dedicated ALMACAL pipeline was created to automate the processing of all delivered datasets. The complete pipeline description is available in Oteo et al. (2016), and the following is a brief overview of its essential components. This pipeline uses the scriptForPI.py script included in every delivered ALMA dataset, which generates fully calibrated data. While ALMA users use this script to create a final dataset, we used it to distinguish the calibrated calibrator data from the science observations. Next, we applied self-calibration to correct the short-time variability of the phase and amplitude during integration, improving the final image’s dynamic range. This process enabled us to create a model and remove the bright calibrator from the visibility data, resulting in the equivalent of blank sky or deep field observations.
During the execution of the ALMA calibration scripts, some bandpass calibrators needed to be consistently calibrated. Unlike with phase calibrators, calibration tables are not always applied to the bandpass calibrators. Most of the time, the bandpass calibrator is also the flux calibrator, so their solutions cannot be applied to themselves. To rectify this, the accurate flux density scale of the bandpass calibrators has to be recovered from the flux calibration table containing standardised values for each calibrator. Applying bandpass calibration tables to bandpass calibrators could, in principle, remove emission and absorption features from cubes that are constructed from these bandpass calibration observations. This could affect emission and absorption features at the phase centre. It should be noted, however, that the bandpass solution is spectrally averaged so that narrow spectral features are not calibrated out. Also, our ability to detect faint emission lines throughout the cubes is unaffected. Because emission lines on top of the quasar continuum are weak compared to the quasar continuum, they do not significantly affect the bandpass solution and do not affect the calibration quality of the data.
The calibration process extends to creating “pseudo-continuum” measurement sets, in which all channels within each spectral window are averaged. The averaging also boosts the signal-to-noise ratio (S/N) for the self-calibration. These files facilitate the implementation of two steps of self-calibration, initially focusing solely on phase and subsequently incorporating both amplitude and phase calibration. The solution interval for the calibration solution is set equal to the integration time. During the intervals of the self-calibration steps, a point source model is applied and fitted to the uv data. This approach offers the advantage of subtracting the point-source model independently for each observation, mitigating the impact of any flux variability in the calibration source. The final step involves deriving the calibrated visibilities and subtracting the continuum of the calibrator source to build line emission data cubes, thereby assembling the ALMACAL−22 dataset.
2.2. Pruned sample selection
While the central bright calibrator enables self-calibration, it introduces challenges to the scientific analysis. Most of the calibrators in our sample are blazars, but a few present extended structures that cannot be modelled as point sources. After subtracting the calibrator’s continuum at the centre of the pointing as a point source, these structures may remain as residuals since they are not taken into account during the cleaning process. These residuals affect the quality of the calibration process, resulting in strong continuum artefacts, interferometric patterns, or extra features that produce high noise values. To overcome this problem, we implemented a sequence of pruning steps to prevent any negative impact on the final combined images.
We analysed key properties, such as the integration time, frequency coverage, bandwidth of each spectral window, spatial resolution, and baseline distribution. We aim to obtain a coherently combined homogeneous sample that will provide broad statistics of the Universe, minimise cosmic variance, and cover the maximum possible volume.
The pruned sample includes only observations made with the 12-metre array. To create the deep cubes, we summed the on-source integration time of observations that covered the same frequency range. We chose bins of 1 GHz to select all the files spanning the same frequency across the extent of the ALMA band’s frequency coverage. To minimise contamination from artefacts, we used a multi-step approach. First, we created the continuum image for each measurement set using CASA and estimated the root-mean-square (RMS) noise. We chose to use the continuum image instead of the data cube because imaging the continuum is much faster and provides a good approximation of the quality of the files. We excluded files with an RMS value higher than 10−5 Jy, which introduced inconsistent noise patterns throughout the cube. Secondly, we estimated the theoretical sensitivity (σtheoretical) associated with each observation by using the apparentsens function of the CASA image toolkit. This function calculates the point source sensitivity in imaged cubes, accounting for image weights and visibility weights, also used in the ALMA Interferometric Pipeline (see Hunter et al. 2023). We insist that the measured RMS of each continuum imaged file compared with the theoretical sensitivity (ALMA pipeline) should not be greater than a factor of 3. We inspected a few files that were removed by the RMS criteria and found that most of them had strong interferometric patterns or errors in calibration. Figure 2 shows the distribution ratio of the measured RMS and the theoretical RMS. The pruned sample extends by up to a factor of 3 with a median value of 1.8, while the full sample has a median value of 2.4. For comparison, the full sample reaches RMS ratios of hundreds. These high-RMS observations could introduce significant noise artefacts in the final data product.
 |
Fig. 2. Distribution of the RMS of measured flux values in maps over the theoretical ones for each file in the full ALMACAL−22 and pruned samples. The pruned sample has a median of 1.8, reaching the imposed limit of 3, whereas the full sample’s median is 2.4. The full sample also includes large values in the hundreds, although we truncate the figure at a ratio of 10. It is necessary and important to remove problematic files that may compromise the final product once these files are combined. |
Despite our efforts with the sample selection, we still found files with strong interferometric patterns, such as image artefacts, baseline stripes, blurring, or distortions in the image. In some cases, these patterns cannot be easily identified from the RMS of the continuum. Several errors can arise when one performs self-calibration using the pipeline, such as poor phase and amplitude calibration. These artefacts are usually caused by baseline errors due to uncertainties in the antenna position when measuring the differences in signal phase and amplitude between pairs of antennas. Artefacts can also appear during imaging, resulting in sidelobes, noise bias, and spatial distortion. The errors in interferometric data are primarily identified in the uv plane during calibration and imaging processes. Considering the large amount of data that the ALMACAL−22 survey contains, it is not possible to visualise all the observations in the uv plane to flag the possible misbehaved antennas. Thanks to our large amounts of data, we can afford to discard corrupted data by checking the continuum map of each observation to determine if it presents strong patterns. We visually identified the presence of stripes, blurring, artificial elongation or shifting of sources, and symmetric or asymmetric patterns, then discarded observations exhibiting these issues to ensure data quality. After removing ∼15% of the files, we combined the data with the same frequency coverage, selecting observations that contribute to a total integration time of at least 10 minutes.
We selected high-quality data to construct the survey. We started from a total of 34909 measurement sets (ms), that is, raw visibility files, of which 25594 add up to at least 10 minutes of integration time. Among these, 15270 files have acceptable RMS levels. After removing visual artefacts and reapplying the integration time criterion, we used 6494 ms files to build the pruned sample. Figure 3 displays the distribution of the number of files in each band for both the full ALMACAL−22 and pruned samples in the left panel. Bands 3, 6, and 7 dominate the full sample, while Bands 3, 4, and 6 dominate the pruned sample. There are no Band 10 data available in the pruned sample. The middle panel shows the distribution of data cubes in both samples, where Bands 3, 4, 6, and 7 dominate (details on how cubes are constructed are discussed in Sect. 2.3). The right panel shows the distribution of calibrators, with 1047 in the full sample and 401 in the pruned sample. For both samples, Band 3 has the most calibration fields, followed by 6 and 4.
 |
Fig. 3. Distribution of the number of ms files (left), cubes (middle), and calibrators (right) for the full ALMACAL−22 and pruned samples across ALMA bands. The full sample contains 34909 ms files, 4547 cubes, and 1047 calibrators, while the pruned sample consists of 6494 ms files, 1508 cubes, and 401 calibrators. Band 6 comprises most files and cubes for the full ALMACAL−22 and pruned samples. Band 3 has the largest variety of calibration fields for both samples, followed by Bands 6 and 4. It should be noted that no data are available in Band 10 for the pruned sample as the quality assurance discarded all the data that contributed sufficient integration time (10 minutes). |
2.3. Building cubes
Data cubes have three dimensions, two of which contain spatial information and one spectral information given by a frequency range. To produce each data cube, we followed a sequence of steps to combine multiple observations. First, we concatenated all the uv observations into a single file to obtain a data cube. We selected the ms files with sequential frequencies to be included in the cube. Then we applied the CASA task statwt to the concatenated file to recalibrate the uv weighting of different observations based on the variance of data. We estimated the beam size using the CASA task getsynthesizedbeam from the analysisUtils package. We sampled each beam with 3 pixels (using a pixel scale = synthesised beam/3) and picked the image size to be ∼1.8 times that of the primary beam, selecting the number of pixels recommended by CASA to maximise the imaging efficiency. We defined the channel width for all cubes to be 31.2 MHz, a value selected to strike a balance between spectral resolution, S/N, and manageable data volume. Finally, we ran tclean in CASA for imaging using linear interpolation, natural weighting to optimise sensitivity, and 0.5 arcsec tapering. We parallelised CASA using eight cores and eight threads, which reduces by a factor of 4 the execution time of tclean for some cubes. The duration of the imaging process depends on how many observations we combine and the cubes’ frequency coverage, ranging from a few minutes to several hours per cube.
The pruned sample is composed of 1508 cubes from Band 3 to Band 9. Table 1 details the number of cubes constructed in each band for the pruned sample and the number of calibrators covered. The distribution of the number of cubes is shown in the middle panel of Fig. 3. The full sample exhibits three times more cubes than the pruned sample. The number of cubes in the full sample refers to the number of data cubes that can be built applying the integration time criterion only, that is, without taking into account the RMS selection and visual inspection that was used to build the pruned sample (see Sect. 2.2).
Number of data cubes and calibrators in the pruned sample.
3. ALMACAL−22 properties
This section explores the inherent properties of the latest data from the ALMACAL−22 survey in both the full and pruned samples. We characterise the fundamental properties of this dataset to provide a clear understanding of the survey’s scope and capabilities. These include the spatial distribution (Sect. 3.1), spatial resolution (Sect. 3.2), integration time (Sect. 3.3), and redshift of the calibrator sources (Sect. 3.4).
3.1. Spatial distribution
The ALMACAL−22 survey comprises calibrators randomly distributed across the southern sky, resulting in a widely dispersed area covering more than 1100 arcmin2. The data collection strategy effectively captures diverse regions with a random distribution. This distribution is advantageous for serendipitous line and continuum detections, providing robustness against the effects of cosmic variance, a challenge often encountered in deep field surveys. The top panel of Fig. 1 shows the spatial distribution for the full ALMACAL−22 sample and bottom panel the pruned sample. In the pruned sample, two areas have relatively sparse data. These regions are near the projection of the galactic plane, likely resulting in fewer observations due to potential interference and the relative paucity of cosmological deep fields in those regions, or challenges associated with observing in those directions. The primary factor influencing the selection of the pruned sample is the minimum integration time, which determines how long observations need to be made to qualify for inclusion in the dataset.
3.2. Spatial resolution
The spatial resolution of the ALMACAL−22 dataset varies depending on the observing frequency and array configuration chosen by PIs based on their scientific goals. Higher-frequency bands generally offer a finer spatial resolution, enabling the detection of more intricate structures and providing valuable insights into the morphology of the observed sources. Conversely, lower-frequency bands offer advantages regarding sensitivity and wider coverage but with a potential sacrifice of some spatial resolution.
Figure 4 shows how each band’s spatial resolution is distributed. In the ALMACAL−22 full sample, the median value in Band 3 is 1.14 arcsec. This consistently decreases for higher-frequency bands, reaching a median spatial resolution of 0.13 arcsec in Band 10. In the case of the pruned sample, Band 4 shows the maximum value in the median spatial resolution of 0.87 arcsec. This value is lower in Band 3, then decreases to a mean value of 0.23 arcsec in Band 9.
 |
Fig. 4. Distribution of the spatial resolution for the full ALMACAL−22 and pruned samples across ALMA bands. The mean values of the full ALMACAL−22 sample decrease consistently towards higher bands, from a median value of 1.15 arcsec in Band 3 to 0.10 arcsec in Band 10. In the pruned sample, Band 4 presents a median value of 0.87 arcsec, followed by Band 3 with 0.59 arcsec, and decreases in higher-frequency bands, reaching 0.23 arcsec in Band 9. |
3.3. Integration time
The integration time reflects the total on-source observation time obtained for the ALMA calibration data. The dataset’s construction requires combining two or more observations if their frequencies overlap by at least 1 GHz. We added up the integration time in a 1 GHz moving window, selecting all the files spanning the same frequency. We imposed a lower limit of 10 minutes for the pruned sample across the whole frequency coverage. Variations in integration time in the cubes arise from the concatenation of short calibration pointings, each lasting several minutes with overlapping spectral coverage. From the varying depths reached, different sensitivity values can be achieved within a cube, but every frequency meets the minimum time criterion. The cube’s frequency range within a cube is chosen to contain sequential frequencies. A calibration field observed several times in the same frequency band may have different frequency ranges observed, creating more than one cube for the same field and band, covering a distinctive frequency extent.
Figure 5 shows the distribution of total integration times for the full ALMACAL−22 dataset and the pruned sample. The median and maximum values of the total integration times for the full ALMACAL−22 dataset and the pruned sample are shown in Table 2. The full sample comprises cubes that achieve more than 10 hours of integration time, while the pruned sample reaches an integration time of up to 7 hours. The median value in the full sample is 0.78 hours; in the pruned sample, it is 0.48 hours. The pruning process has only a slight impact on the median value, suggesting a small effect on the sensitivity. The mean sensitivity value reached in the pruned sample is ∼0.78 mJy/beam (for further discussion see Sect. 4.1).
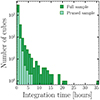 |
Fig. 5. Distribution of the maximum integration time reached in each data cube for the full ALMACAL−22 sample and the pruned sample. The maximum and median values reached in each cube for each band are listed in Table 2. The full sample has a mean value of 0.78 hours, while that of the pruned sample is 0.48 hours. The pruned sample achieves up to 7 hours of integration time, maintaining high sensitivity levels. |
Main properties of the full ALMACAL−22 sample and the pruned sample.
3.4. Redshift
The ALMACAL Redshift Catalogue relies primarily on a redshift database introduced by Bonato et al. (2018) for a substantial portion of the calibrator sample. This compilation was further enriched after cross-matching radio sources with optical sources from NED, SIMBAD (Wenger et al. 2000), and an optical catalogue of bright sources at gigahertz frequencies (Mahony et al. 2011). Team members individually checked each source, noting the redshift and provenance. This catalogue is also supplemented by VLT/X-Shooter observations of calibrator sources (ID 111.253L.001, PI: S. Weng and ID 0101.A-0528, PI: E. Mahony). Out of the initial 1047 sources, 675 have robust redshifts and spectra. For the pruned sample of this work, 390/635 (61%) calibrators have confirmed spectroscopic redshifts. Further details will be presented in a forthcoming paper (Weng et al., in prep.).
The redshift distribution for calibrator sources in the full ALMACAL−22 dataset and the pruned sample is shown in Fig. 6. The full sample of calibrators has a median redshift of z = 0.749, with a maximum of z = 3.788. In the pruned sample, the median redshift value is z = 0.797, and the maximum is z = 3.591. The sources excluded during pruning were likely more concentrated at lower redshifts. However, the redshift distribution in Fig. 6 shows that the higher redshift end is also less populated after pruning. Therefore, we do not expect any significant bias related to redshift in the pruned sample.
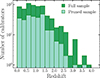 |
Fig. 6. Redshift distribution of calibrators in the full ALMACAL−22 sample and the pruned sample (Weng et al., in prep.). The median redshift is ⟨z⟩ = 0.749 in the full sample, and ⟨z⟩ = 0.797 in the pruned sample. The highest redshift calibrator is at z ∼ 3.8. |
4. Discussion
This section delves into a comparative analysis of ALMACAL−22 and other surveys, emphasising key properties such as sensitivity and survey area. We provide an overview of the scientific goals the ALMACAL survey has achieved so far. We evaluate the unique characteristics of this extensive dataset compared to existing surveys, shedding light on its strengths and potential scientific contributions.
4.1. Survey area and sensitivity
We compared the sensitivity and total area covered by the ALMACAL−22 survey to those of previous large programs. Due to the primary beam response, the sensitivity in each cube decreases as we move away from the phase centre. We considered an area 1.8 times the primary beam size for each field, which we calculated using the primaryBeamArcsec function from the analysisUtils package in CASA. To estimate the sensitivity reached in each data cube, we used the sensitivity task from analysisUtils, which takes the integration time and central frequency as inputs.
ALMACAL−22’s coverage is distinguished by its larger footprint than any previous survey, covering over one thousand square arcminutes. For comparison, the ALMA Spectroscopic Survey in the Hubble Ultra Deep Field (HUDF), ASPECS, (Decarli et al. 2016; Walter et al. 2016; Aravena et al. 2019; Boogaard et al. 2020), covers 4.6 arcmin2 area. The COLDz survey (Pavesi et al. 2018; Riechers et al. 2019, 2020) covers a ∼60 arcmin2 area. The 6 × 15 m IRAM Plateau de Bure High-z Blue-Sequence Survey 2 (PHIBSS2) covers a total area of ∼130 arcmin2 (Tacconi et al. 2018; Lenkić et al. 2020).
Regarding sensitivity, ALMACAL−22 data cubes achieve remarkable sensitivity levels in ALMA bands 3, 4, 5, 8, and 9, comparable to ASPECS and COLDz. Bands 6 and 9 offer a wider range of sensitivities, mainly due to the variety of total integration times obtained in each cube after combining data with overlapping frequencies. Additionally, Audibert et al. (2022) demonstrated that ALMA calibrator data can be used to estimate the molecular gas content of galaxies, reaching sensitivities around 0.482 mJy, comparable to surveys such as COLDz and GOODS-ALMA.
Figure 7 compares the total survey area reached by each band in the pruned ALMACAL−22 sample as a function of the sensitivity. For comparison, we also plotted the sky coverage and sensitivity values reached by other surveys (Lenkić et al. 2023; Riechers et al. 2019; Decarli et al. 2019; Gómez-Guijarro et al. 2022; Stach et al. 2019). Our pruned sample adds up to a total area of 1154 arcmin2, shown as the light green dashed horizontal line, surpassing the total area covered by previous surveys. As the dark dashed horizontal line shows, the full sample area over all bands reaches 1887 arcmin2. The total survey area for both the full and the pruned sample accounts for each calibration field once, prioritising the largest area. Overall, ALMACAL−22’s combination of extensive area coverage and average sensitivity will complement findings from other large surveys, addressing the effect of cosmic variance.
 |
Fig. 7. Total ALMACAL survey area vs the median sensitivity range reached in each band for the pruned sample. For comparison, we plot the area and sensitivity values from the previous surveys, PHIBSS2 (Lenkić et al. 2020), COLDz (Riechers et al. 2019), ASPECS (Decarli et al. 2016) in ALMA Bands 3 and 6, GOODS-ALMA (Gómez-Guijarro et al. 2022) in ALMA Band 6, and AS2UDS (Stach et al. 2019) in ALMA Band 7. The dashed light and dark lines show the total area accumulated by summing up all the bands for the pruned sample and the full sample. The total survey area counts every calibration field once, considering the largest area. |
Despite these strengths, there are challenges to scientific interpretation. For example, since ALMACAL consists of pointed observations of specific sources, it cannot be considered a truly blind survey, raising concerns about potential biases in cosmic overdensities. However, Bonato et al. (2018) classified most calibrators as blazars (∼90%). This property mitigates clustering significance since the jets’ brightness is due to their orientation effects toward the observer rather than their mass. For instance, Sushch & Böttcher (2015) found that clustering effects of a significant number of galaxies (more than five) situated near the line of sight of the blazar beam are absent in the local universe, but they may be possible at higher redshifts (z > 2). Moreover, the lack of correlation in redshifts between continuum- or line-detected galaxies and the calibrators further undermines the impact of having the calibrator source at the centre of each pointing (see Hamanowicz et al. 2022). Additionally, Chen et al. (2023) explored an overdense region in ALMACAL similar to extreme proto-cluster cores and found the most likely explanation to be alignment effects. Furthermore, the smaller primary beams in higher ALMA bands probe smaller volumes at lower redshifts.
4.2. Science projects
The ALMACAL survey covers many scientific studies, focusing on four main areas: (1) molecular gas evolution, (2) properties of DSFGs, (3) extragalactic absorption lines, and (4) AGN physics. We briefly summarise what has been done in these areas and the impact that ALMACAL will have through further analysis of this dataset.
(1) The evolution of molecular gas has been investigated with ALMACAL through the redshifted CO emission line. ALMA observations cover the frequency range of CO lines at different redshifts. Klitsch et al. (2019a) searched for the CO line in absorption in gas-rich galaxies selected via quasar absorption lines. They found multiple CO transitions, revealing that galaxies were associated with optically identified AGN activity. They reported different factors when using the CO spectral energy distributions (CO SLEDs) as a proxy to estimate the amount of molecular gas compared to the widely used galactic values. These findings indicate the galactic values might overestimate the molecular gas masses for some absorption-selected galaxies. This difference highlights the need to construct CO SLEDs in different systems rather than assuming the values measured for typical SFGs. More recently, Hamanowicz et al. (2022) developed an ALMACAL-CO pilot program to detect CO emission lines blindly over 38 calibrator fields, selected to have the longest integration times (> 40 minutes). This pilot program aimed to probe the feasibility of using ALMA calibrator fields to look blindly for CO emitters. Eleven emission lines were detected, providing a consistent estimation of the evolution of molecular gas compared with previous surveys. ALMACAL’s untargeted approach offers the advantage of being less sensitive to cosmic variance than previous deep surveys.
(2) Dusty star-forming galaxies represent more normal SFGs than conventional sub-mm galaxies; such faint systems are usually buried in the confusing noise of sub-mm wavelengths. Early on, Oteo et al. (2016, 2017) exploited the high sensitivity levels achieved by ALMACAL by combining data from multiple visits to 69 ALMA calibrator fields in Bands 6 and 7. They found eight DSFGs and derived the number counts. They discovered systems so faint that even the deepest Herschel surveys would not have detected them. Klitsch et al. (2020) reported the first number counts in ALMA Band 8 over 81 calibrator fields, finding 21 DSFGs. Recently, Chen et al. (2022) extended the number counts estimation using 1001 calibration fields in the ALMA Bands 3, 4, 5, 6, and 7, covering a wavelength range from 3 mm to 870 μm. They report the detection of 186 DSFGs with flux densities comparable to existing large ALMA surveys, but less prone to cosmic variance. Establishing the space density and contribution of DSFGs to the cosmic far-infrared can be a powerful way to validate galaxy formation and evolution models.
(3) The ALMACAL data provide the opportunity to study absorption lines due to galaxies along the line of sight of the calibrators. Klitsch et al. (2019b) reported several galactic absorption lines using 749 calibrators, but no intervening extragalactic molecular absorber was detected. They also used the cosmological hydrodynamical simulation IllustrisTNG (Naiman et al. 2018; Pillepich et al. 2018; Springel et al. 2018; Marinacci et al. 2018) to obtain new upper bounds on the molecular gas mass density. Their results are consistent with an increasing depletion of molecular gas in the present Universe compared to redshift z ∼ 2. In a subsequent study, Klitsch et al. (2023) presented the first constraints on the molecular gas coverage fraction in the circumgalactic medium of low-redshift galaxies using estimates of CO column densities along the line of sight of quasars with intervening galaxies.
(4) As ALMACAL observations are repeated over the years, they allow for multi-year follow-up of the AGN variability. Bonato et al. (2018) examined 754 calibrator data using Bands 3 and 6 in the time domain space, identifying most of them as blazars based on their flat spectrum and low-frequency spectral index. They constructed the light curve of the blazars and found that the median variability index increases steadily with increasing source-to-time lag from 100 to 800 d. Husemann et al. (2019) then studied the morphology and kinematics of the gas surrounding the calibrators. They detected a CO(1 − 0) emission arc structure around the AGN of the quasar 3C 273. This arc morphology of the molecular gas is completely different from that of the ionised gas. This raises the question of whether the molecular gas is bound to a stellar overdensity formed from a recent galaxy interaction or is currently forming in situ due to a density wave and increased ambient pressure caused by the expanding outflow, as predicted in simulations for luminous AGNs (Mukherjee et al. 2018). Komugi et al. (2022) detected extended mm emission associated with the host galaxy of a prototypical radio-loud quasar to investigate the QSO-host interstellar medium (ISM) interaction.
The new ALMACAL−22 dataset, comprising 1047 calibrator fields, promises significant advancements in our current understanding of these science cases. First, the increased calibrator fields will alleviate the field-to-field variance when determining molecular gas evolution. The volume probed by each CO transition will increase by a factor of ∼10 compared to previous surveys, reducing the uncertainties and expanding at different redshift bins. Figure 8 shows an example of a blind search across the calibrator fields, where a prominent emission line was detected. Second, by adding 46 calibrator fields to the last search for DSFGs (Chen et al. 2022) and new observations of the same fields, it will be possible to achieve deeper sensitivity levels, which could improve the estimates of the number counts by detecting the faintest systems in the Universe. Thirdly, there are over 300 calibrator fields where the CO absorption lines have yet to be searched for. This updated version of the ALMACAL survey provides a significantly larger dataset than the data analysed in Klitsch et al. (2019a). Finally, ALMACAL−22 will allow us to study the variability of specific AGN types such as blazars, including both BL Lacs in the nearby Universe and FSRQs at larger distances. Calibrators are usually chosen to be point-like, but some have shown extended large-scale jet structures. Figure 9 illustrates the same calibration field showing extended structures in ALMA Bands 3, 4, and 6. Studying the effect of these powerful jets on star formation could help us to understand the high-energy processes better.
 |
Fig. 8. Example of an ALMACAL−22 data cube from the updated sample with a prominent emission line found in the calibrator field. The top panel shows the full spectral coverage of the region of the data cube where the emission line was found. The lower left panel displays a region of the continuum map of the calibrator field in Band 3, centred on the position of the emission line. The lower right panel shows the emission line, where the shaded region represents the line width reaching a S/N ∼9. |
 |
Fig. 9. Example of three collapsed data cubes for the calibrator field J1225+1253, where jet emission emanates from the central quasar. ALMA Bands 3, 4, and 6 are shown in the top left, top right, and bottom panels. The central quasar in the centre has previously been subtracted in the uv plane. |
5. Conclusion
ALMACAL−22 is a large survey of ALMA calibrator observations, collecting over 30 TB of data and covering 1047 calibrator fields across the southern sky. We have presented all the calibrator data from science projects taken until May 2022, accumulating over 1000 square arcmin and more than 2000 hours of observing time. Here, we provide the characteristics of the survey.
We have presented the selection of a pruned sample, a subset of the highest-quality data. We outline the data processing details from Band 3 to Band 9 to obtain data cubes as final products. The pruned sample contains 401 calibrator fields and 1508 data cubes. We provide an overall review of the main properties of both the full and pruned samples, including the spatial distribution, spatial resolution, integration time, and redshift of the calibrator sources.
In a forthcoming paper, we will revisit the pruned sample to investigate serendipitous detections of the CO emission lines in the calibrator fields. In this way, this survey will provide clues to the evolution of molecular gas in the Universe through an untargeted approach. As ALMACAL−22 is one of the largest surveys to date, it will allow us to make statistical estimates that are less sensitive to potential cosmic variance effects.
Overall, ALMACAL is an ever-growing project, as every scientific project requires calibrator data, and the size of the dataset will continue to grow over the years. A diverse range of catalogues will be established, including the redshift catalogue, extended jets catalogue, and confirmed molecular line catalogue, showcasing the valuable insights ALMACAL−22 will contribute to the scientific community.
Acknowledgments
This research was supported by the International Space Science Institute (ISSI) in Bern, through ISSI International Team project #564 (The Cosmic Baryon Cycle from Space). The ALMA Calibrator Source Catalogue is available here. ALMACAL raw data and processed data cubes are available upon reasonable request. Please contact almacal@eso.org
References
- Aravena, M., Decarli, R., Gónzalez-López, J., et al. 2019, ApJ, 882, 136 [Google Scholar]
- Aravena, M., Heintz, K. E., Dessauges-Zavadsky, M., et al. 2024, A&A, 682, A24 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Audibert, A., Dasyra, K. M., Papachristou, M., et al. 2022, A&A, 668, A67 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bonato, M., Liuzzo, E., Giannetti, A., et al. 2018, MNRAS, 478, 1512 [NASA ADS] [CrossRef] [Google Scholar]
- Boogaard, L. A., van der Werf, P., Weiss, A., et al. 2020, ApJ, 902, 109 [NASA ADS] [CrossRef] [Google Scholar]
- Boogaard, L. A., Decarli, R., Walter, F., et al. 2023, ArXiv e-prints [arXiv:2301.05705] [Google Scholar]
- Bouwens, R. J., Smit, R., Schouws, S., et al. 2022, ApJ, 931, 160 [NASA ADS] [CrossRef] [Google Scholar]
- Carilli, C. L., & Walter, F. 2013, ARA&A, 51, 105 [NASA ADS] [CrossRef] [Google Scholar]
- Chen, J., Ivison, R. J., Zwaan, M. A., et al. 2022, ArXiv e-prints [arXiv:2210.09329] [Google Scholar]
- Chen, J., Ivison, R. J., Zwaan, M. A., et al. 2023, A&A, 675, L10 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Decarli, R., Walter, F., Aravena, M., et al. 2016, ApJ, 833, 69 [Google Scholar]
- Decarli, R., Walter, F., Gónzalez-López, J., et al. 2019, ApJ, 882, 138 [Google Scholar]
- Decarli, R., Aravena, M., Boogaard, L., et al. 2020, ApJ, 902, 110 [Google Scholar]
- Driver, S. P., & Robotham, A. S. G. 2010, MNRAS, 407, 2131 [Google Scholar]
- Gkogkou, A., Béthermin, M., Lagache, G., et al. 2022, ArXiv e-prints [arXiv:2212.02235] [Google Scholar]
- Gómez-Guijarro, C., Elbaz, D., Xiao, M., et al. 2022, A&A, 658, A43 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Guilloteau, S., Delannoy, J., Downes, D., et al. 1992, A&A, 262, 624 [NASA ADS] [Google Scholar]
- Hamanowicz, A., Zwaan, M. A., Péroux, C., et al. 2022, ArXiv e-prints [arXiv:2211.00066] [Google Scholar]
- Hunter, T. R., Indebetouw, R., Brogan, C. L., et al. 2023, PASP, 135, 074501p [NASA ADS] [CrossRef] [Google Scholar]
- Husemann, B., Bennert, V. N., Jahnke, K., et al. 2019, ApJ, 879, 75 [Google Scholar]
- Keenan, R. P., Marrone, D. P., & Keating, G. K. 2020, ApJ, 904, 127 [NASA ADS] [CrossRef] [Google Scholar]
- Klitsch, A., Zwaan, M. A., Péroux, C., et al. 2019a, MNRAS, 482, L65 [NASA ADS] [CrossRef] [Google Scholar]
- Klitsch, A., Péroux, C., Zwaan, M. A., et al. 2019b, MNRAS, 490, 1220 [NASA ADS] [CrossRef] [Google Scholar]
- Klitsch, A., Zwaan, M. A., Smail, I., et al. 2020, MNRAS, 495, 2332 [CrossRef] [Google Scholar]
- Klitsch, A., Davis, T. A., Hamanowicz, A., et al. 2023, ArXiv e-prints [arXiv:2304.12421] [Google Scholar]
- Komugi, S., Toba, Y., Matsuoka, Y., Saito, T., & Yamashita, T. 2022, ApJ, 930, 3 [NASA ADS] [CrossRef] [Google Scholar]
- Le Fèvre, O., Béthermin, M., Faisst, A., et al. 2020, A&A, 643, A1 [Google Scholar]
- Lenkić, L., Bolatto, A. D., Förster Schreiber, N. M., et al. 2020, AJ, 159, 190 [CrossRef] [Google Scholar]
- Lenkić, L., Bolatto, A. D., Fisher, D. B., et al. 2023, ArXiv e-prints [arXiv:2301.05251] [Google Scholar]
- Leroy, A. K., Schinnerer, E., Hughes, A., et al. 2021, ApJS, 257, 43 [NASA ADS] [CrossRef] [Google Scholar]
- Mahony, E. K., Sadler, E. M., Croom, S. M., et al. 2011, MNRAS, 417, 2651 [NASA ADS] [CrossRef] [Google Scholar]
- Marinacci, F., Vogelsberger, M., Pakmor, R., et al. 2018, MNRAS, 480, 5113 [NASA ADS] [Google Scholar]
- McMullin, J. P., Waters, B., Schiebel, D., Young, W., & Golap, K. 2007, ASP Conf. Ser., 376, 127 [Google Scholar]
- Mukherjee, D., Bicknell, G. V., Wagner, A. Y., Sutherland, R. S., & Silk, J. 2018, MNRAS, 479, 5544 [NASA ADS] [CrossRef] [Google Scholar]
- Naiman, J. P., Pillepich, A., Springel, V., et al. 2018, MNRAS, 477, 1206 [Google Scholar]
- Oteo, I., Zwaan, M., Ivison, R., Smail, I., & Biggs, A. 2016, The Messenger, 164, 41 [NASA ADS] [Google Scholar]
- Oteo, I., Zwaan, M. A., Ivison, R. J., Smail, I., & Biggs, A. D. 2017, ApJ, 837, 182 [Google Scholar]
- Padovani, P. 2017, Nat. Astron., 1, 0194 [Google Scholar]
- Pavesi, R., Sharon, C. E., Riechers, D. A., et al. 2018, ApJ, 864, 49 [Google Scholar]
- Péroux, C., & Howk, J. C. 2020, ARA&A, 58, 363 [CrossRef] [Google Scholar]
- Pillepich, A., Nelson, D., Hernquist, L., et al. 2018, MNRAS, 475, 648 [Google Scholar]
- Popping, G., Pillepich, A., Somerville, R. S., et al. 2019, ApJ, 882, 137 [NASA ADS] [CrossRef] [Google Scholar]
- Popping, G., Walter, F., Behroozi, P., et al. 2020, ApJ, 891, 135 [NASA ADS] [CrossRef] [Google Scholar]
- Riechers, D. A., Pavesi, R., Sharon, C. E., et al. 2019, ApJ, 872, 7 [Google Scholar]
- Riechers, D. A., Hodge, J. A., Pavesi, R., et al. 2020, ApJ, 895, 81 [Google Scholar]
- Solimano, M., González-López, J., Aravena, M., et al. 2024, A&A, 689, A145 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Springel, V., Pakmor, R., Pillepich, A., et al. 2018, MNRAS, 475, 676 [Google Scholar]
- Stach, S. M., Dudzevičiūtė, U., Smail, I., et al. 2019, MNRAS, 487, 4648 [Google Scholar]
- Sushch, I., & Böttcher, M. 2015, A&A, 573, A47 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tacconi, L. J., Genzel, R., Neri, R., et al. 2010, Nature, 463, 781 [Google Scholar]
- Tacconi, L. J., Genzel, R., Saintonge, A., et al. 2018, ApJ, 853, 179 [Google Scholar]
- Tacconi, L. J., Genzel, R., & Sternberg, A. 2020, ARA&A, 58, 157 [NASA ADS] [CrossRef] [Google Scholar]
- Urry, C. M., & Padovani, P. 1995, PASP, 107, 803 [NASA ADS] [CrossRef] [Google Scholar]
- Walter, F., Decarli, R., Aravena, M., et al. 2016, ApJ, 833, 67 [Google Scholar]
- Walter, F., Carilli, C., Neeleman, M., et al. 2020, ApJ, 902, 111 [Google Scholar]
- Wenger, M., Ochsenbein, F., Egret, D., et al. 2000, A&AS, 143, 9 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Zwaan, M., Ivison, R., Peroux, C., et al. 2022, ALMACAL: Surveying the Universe with ALMA Calibrator Observations, https://doi.eso.org/10.18727/0722-6691/5256 [Google Scholar]
All Tables
All Figures
|
Fig. 1. Spatial distribution of the calibrator fields for the full ALMACAL−22 (top) and pruned samples (bottom). The distribution of the full sample has no preferred direction, so the position of the calibrators in the sky can be considered homogeneous and only affected by the fact that ALMA observes the sky below δ < 40°. In the pruned sample, two regions exhibit sparse data, possibly attributed to interference, the limited availability of deep fields, and observational difficulties stemming from their proximity to the galactic plane. Further details are provided in Sect. 3.1. |
| In the text | |
|
Fig. 2. Distribution of the RMS of measured flux values in maps over the theoretical ones for each file in the full ALMACAL−22 and pruned samples. The pruned sample has a median of 1.8, reaching the imposed limit of 3, whereas the full sample’s median is 2.4. The full sample also includes large values in the hundreds, although we truncate the figure at a ratio of 10. It is necessary and important to remove problematic files that may compromise the final product once these files are combined. |
| In the text | |
|
Fig. 3. Distribution of the number of ms files (left), cubes (middle), and calibrators (right) for the full ALMACAL−22 and pruned samples across ALMA bands. The full sample contains 34909 ms files, 4547 cubes, and 1047 calibrators, while the pruned sample consists of 6494 ms files, 1508 cubes, and 401 calibrators. Band 6 comprises most files and cubes for the full ALMACAL−22 and pruned samples. Band 3 has the largest variety of calibration fields for both samples, followed by Bands 6 and 4. It should be noted that no data are available in Band 10 for the pruned sample as the quality assurance discarded all the data that contributed sufficient integration time (10 minutes). |
| In the text | |
|
Fig. 4. Distribution of the spatial resolution for the full ALMACAL−22 and pruned samples across ALMA bands. The mean values of the full ALMACAL−22 sample decrease consistently towards higher bands, from a median value of 1.15 arcsec in Band 3 to 0.10 arcsec in Band 10. In the pruned sample, Band 4 presents a median value of 0.87 arcsec, followed by Band 3 with 0.59 arcsec, and decreases in higher-frequency bands, reaching 0.23 arcsec in Band 9. |
| In the text | |
|
Fig. 5. Distribution of the maximum integration time reached in each data cube for the full ALMACAL−22 sample and the pruned sample. The maximum and median values reached in each cube for each band are listed in Table 2. The full sample has a mean value of 0.78 hours, while that of the pruned sample is 0.48 hours. The pruned sample achieves up to 7 hours of integration time, maintaining high sensitivity levels. |
| In the text | |
|
Fig. 6. Redshift distribution of calibrators in the full ALMACAL−22 sample and the pruned sample (Weng et al., in prep.). The median redshift is ⟨z⟩ = 0.749 in the full sample, and ⟨z⟩ = 0.797 in the pruned sample. The highest redshift calibrator is at z ∼ 3.8. |
| In the text | |
|
Fig. 7. Total ALMACAL survey area vs the median sensitivity range reached in each band for the pruned sample. For comparison, we plot the area and sensitivity values from the previous surveys, PHIBSS2 (Lenkić et al. 2020), COLDz (Riechers et al. 2019), ASPECS (Decarli et al. 2016) in ALMA Bands 3 and 6, GOODS-ALMA (Gómez-Guijarro et al. 2022) in ALMA Band 6, and AS2UDS (Stach et al. 2019) in ALMA Band 7. The dashed light and dark lines show the total area accumulated by summing up all the bands for the pruned sample and the full sample. The total survey area counts every calibration field once, considering the largest area. |
| In the text | |
|
Fig. 8. Example of an ALMACAL−22 data cube from the updated sample with a prominent emission line found in the calibrator field. The top panel shows the full spectral coverage of the region of the data cube where the emission line was found. The lower left panel displays a region of the continuum map of the calibrator field in Band 3, centred on the position of the emission line. The lower right panel shows the emission line, where the shaded region represents the line width reaching a S/N ∼9. |
| In the text | |
|
Fig. 9. Example of three collapsed data cubes for the calibrator field J1225+1253, where jet emission emanates from the central quasar. ALMA Bands 3, 4, and 6 are shown in the top left, top right, and bottom panels. The central quasar in the centre has previously been subtracted in the uv plane. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.