| Issue |
A&A
Volume 688, August 2024
|
|
|---|---|---|
| Article Number | A203 | |
| Number of page(s) | 26 | |
| Section | Catalogs and data | |
| DOI | https://doi.org/10.1051/0004-6361/202450032 | |
| Published online | 23 August 2024 | |
The new Herschel/PACS Point Source Catalogue★
1
Konkoly Observatory, Research Centre for Astronomy and Earth Sciences, Hungarian Research Network (HUN-REN),
H-1121
Budapest,
Konkoly Thege Miklós út 15–17.,
Hungary
2
CSFK, MTA Centre of Excellence,
Budapest,
Konkoly Thege Miklós út 15–17.,
1121,
Hungary
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
3
Natural History Museum Vienna,
Burgring 7,
1010
Vienna,
Austria
4
Department of Astrophysics, University of Vienna,
Türkenschanzstrasse 17,
1180
Vienna,
Austria
5
Department of Astronomy, University of Geneva,
Chemin Pegasi 51,
1290
Versoix,
Switzerland
6
California Institute of Technology, IPAC,
Pasadena,
CA,
USA
7
ESAC/ESA,
Camino Bajo del Castillo s/n, Urb. Villafranca del Castillo,
28692
Villanueva de la Cañada, Madrid,
Spain
Received:
19
March
2024
Accepted:
3
June
2024
Abstract
Context. Herschel operated as an observatory, and therefore it did not cover the whole sky, but still observed ~8% of it. The first version of an overall Herschel/PACS Point Source Catalogue (PSC) was released in 2017. The data are still unique and are very important for research using far-infrared information, especially because no new far-infrared mission is foreseen for at least the next decade. In the framework of the NEMESIS project, we revisited all the photometric observations obtained by the PACS instrument on-board the Herschel space observatory, using more advanced techniques than before, including machine learning techniques.
Aims. Our aim was to build the most complete and most accurate Herschel/PACS catalogue to date. Our primary goal was to increase the number of real sources, and decrease the number of spurious sources identified on a strongly variable background, which is due to the thermal emission of the interstellar dust, mostly located in star-forming regions. Our goal was to build a blind catalogue, meaning that source extraction is conducted without relying on prior detections at various wavelengths, allowing us to detect sources never catalogued before.
Methods. The methods for data analysis have evolved continuously since the first release of a uniform Herschel/PACS catalogue. We define a hybrid strategy that includes classical and machine learning source identification and characterisation methods that optimise faint-source detection, providing catalogues at much higher completeness levels than before. Quality assessment also involves machine learning techniques. Our source extraction methodology facilitates a systematic and impartial comparison of sensitivity levels across various Herschel fields, a task that was typically beyond the scope of individual programmes.
Results. We created a high-reliability and a rejected source catalogue for each PACS passband: 70, 100, and 160 μm. With the high-reliability catalogue, we managed to significantly increase the completeness in all bands, especially at 70 μm. At the same time, while the number of high-reliability detections decreased, the number of sources matching with existing catalogues increased, suggesting that the purity is also higher than before. The photometric accuracy of our pipeline is ~1% based on comparison with the standard star models.
Key words: methods: data analysis / space vehicles: instruments / techniques: photometric / catalogs / stars: protostars
A copy of the catalog is available at the CDS via anonymous ftp to cdsarc.cds.unistra.fr (130.79.128.5) or via https://cdsarc.cds.unistra.fr/viz-bin/cat/J/A+A/688/A203
© The Authors 2024
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
The creation of an advanced Herschel/PACS Point Source Catalogue represents an important legacy product that stretches beyond the scope of our project called the Novel Evolutionary Model for the Early Stages of stars with Intelligent Systems (NEMESIS1), providing to the astronomical–star formation community the best far-infrared (FIR) photometric catalogue available until the next far-infrared mission is launched into space. Based on the current schedule of future space missions, this translates into at least a decade or more, making this product even more valuable.
Identifying sources in a strongly variable background is extremely challenging, especially in star-forming regions where dust cloud emission can dominate the background. Here, we define a hybrid strategy that includes classical and machine learning source identification and characterisation methods that optimise faint-source detection, providing catalogues at much higher completeness levels than before.
In the case of Herschel, official and unofficial catalogues were produced based on very different techniques, which meant that the completeness and photometric accuracy of the products were hard to compare. The official ESA Herschel Point Source Catalogues processed all PACS (Marton et al. 2017) and SPIRE (Schulz et al. 2017) photometric observations in a uniform way. However, their method was more tailored for extra-galactic regions, and therefore they had a poor performance in environments with high background emission (i.e. in regions where young stars are mostly located). Nowadays, new methods using machine learning and deep neural networks are able to identify almost any pattern in an amazing variety of images. In this study, we use state-of-the-art techniques to provide accurate and coherent source recognition for point and extended sources on a highly fluctuating background, such as the young stellar objects (YSOs) embedded in dusty clouds.
We analysed the highest-level data products available, including 657 Parallel mode, 13 210 Scan Map (nominal) mode, and 1 240 SSO mode observations. Our methodology for extracting sources allows for a comprehensive and impartial comparison of sensitivity across various Herschel fields, a comparison that individual programmes often cannot offer. The extracted point sources encompass individual YSOs and unresolved YSO clusters within our Galaxy. Additionally, they include dusty extragalactic objects from both the local and distant Universe. This diverse dataset offers a wide array of celestial targets, enabling scientists to delve deeper into the early stages of star formation, examine galaxy properties on local and distant scales, and explore galaxy evolution over cosmic time. Moreover, this dataset not only facilitates statistical analyses of stellar and galaxy clusters but also serves as an exceptional target list for subsequent observations using cutting-edge facilities like ALMA and JWST.
In the following, we detail the main parameters of the mission and the PACS photometer. In Sec. 2, the data used in the generation of the catalogue are described. Section 3 details the steps of the pipeline from the data products to the final catalogue. In Sec. 4, we describe the methods used for source identification, photometry, and quality control, to increase the performance of source finding, and source extraction. In Sec. 5, we describe the final catalogue and its properties. Sec. 6 we discuss the completeness and purity, and compare our catalogue to the previous version and to other user provided data products (UPDPs).
The Herschel Space Observatory (Pilbratt et al. 2010) was the fourth cornerstone mission in the European Space Agency (ESA) science programme. It had a primary mirror of 3.5 m in diameter that allowed for an unprecedented spatial resolution and sensitivity at far-infrared (FIR) and sub-millimetre (smm) wavelengths.
Herschel operated successfully from June 2009 to 29 April 2013 when it ran out of the liquid helium coolant required to maintain the operational temperatures for the instruments’ detectors. The three instruments on board covered the FIR and smm spectral ranges from 55 to 671 μm. The Photodetector Array Camera and Spectrometer (PACS; Poglitsch et al. 2010) and the Spectral and Photometric Imaging REceiver (SPIRE; Griffin et al. 2010) were able to make both spectroscopic and photometric observations, while the Heterodyne Instrument for the Far Infrared (HIFI; de Graauw et al. 2010) was a purely spectroscopic instrument. More than 35000 observations were made during mission that last for more than 25 000 h. The observing time was allocated to both Guaranteed and Open Time Programs, and some source catalogues have already been produced by these observing programmes.
Herschel executed numerous observing programmes with diverse scientific objectives. Due to the varying observing strategies and parameters employed in these programmes, the sky coverage appears quite sporadic. A key objective is to ensure consistent source extraction, allowing for meaningful comparisons. This approach took into consideration factors such as scan speed, sampling rate, and repetition factors. A unified pipeline was applied to all maps, customised to suit the distinct observing bands.
The PACS photometer was a dual-band instrument composed of two filled silicon bolometer arrays. The Blue camera consisted of 32×64 pixels and the Red camera of 16×32 pixels. The Blue camera could be used with two filters centred at 70 μm and 100 μm (BS – blue and BL – green bands), while the Red camera acquired observations at the nominal wavelength 160 μm (R – red band). The filter transmission curves are shown in Fig. 1. The two cameras allowed two-band simultaneous observations: one of the two bands from the Blue camera plus the Red camera, resulting in pairs of observations taken at 70, and 160 or 100, and 160 μm. Both cameras had a field of view of ~1.75′ × 3.50′, with near-Nyquist beam sampling in each band. Throughout the paper we use the BS, BL, and R terms for the three filter bands, as these are the abbreviations also used in the Herschel archives and in the data products.
The shape of the PACS point spread function (PSF) is dominated by a tri-lobe pattern in all three bands. A detailed description can be found in the PACS photometer point spread function technical note. The PSF can be approximated with two-dimensional Gaussian fits, as given in Table 1 below. For low and medium scan speeds the typical full width at half maximum (FWHM) values are 5.5″, 6.7″, and 11″ in the 70, 100, and 160 μm bands, respectively. These beams also define the achievable spatial resolution and set the limit on the separability of nearby sources.
 |
Fig. 1 Filter transmissions of the PACS filter chains. The graph is from the PACS Observer’s Manual and represents the overall transmission of the combined filters with the dichroic and the detector relative response in each of the three bands of the photometer. The dashed vertical lines mark the original intended (design values) of the band edges. |
2 Data
Data were taken from 430 unique observing programmes, including major Guaranteed Time Key Programs and small individual Open Time Programs. The key parameters that characterise the PACS observations are the following:
Observing mode: the observing mode could either be the nominal Scan Map or Parallel mode. In the latter, the observations were acquired together with the SPIRE instrument with a simultaneous five-band photometry of the same field of view. In both modes, the bolometer read-out frequency was 40 Hz, but due to data-rate limitations, an onboard averaging of four frames was performed, except for the BS and BL bands in Parallel mode where the averaging was increased to 8 frames. We emphasise that our catalogue does not contain any extraction from chop-nod observations, as in the chop-nod mode, the same source appears multiple times in the processed images, as described in Nielbock et al. (2013).
Scan speed: the standard satellite scanning speed was 20″ s−1. The highest speed of 60″ s−1 was dedicated to large Galactic surveys and Parallel mode maps. We also included calibration observations where the scan speed was 10″ s−1.
Coverage or depth of the observations: depending on the science goals of the observations, different scanning strategies were applied. The shallowest maps are those acquired in Parallel mode observations, due to the high scan speed and the application of a single repetition. The deepest maps are the ones where low or medium scan speed was selected and the number of repetitions was high. These are typically dedicated observations of point sources. As described in Sec. 2, in many cases the Level 2.5 observations were combined into Level 3 images.
Scan leg separation: the scan leg separation refers to the distance between successive scan lines (or legs) in a raster scan pattern. This parameter is crucial for ensuring uniform coverage and avoiding gaps in the observed sky area. For the Herschel PACS photometric observations, this separation affects the coverage and redundancy of the scanned area, which in turn impacts the sensitivity and reliability of the final data products. A map designed for longer wavelength bands will achieve Nyquist sampling of the PSF for those wavelengths, but the corresponding shorter wavelength map will not be sampled optimally. The separation for the Scan Map mode observations is between 2 and 210 arcsec. In the Parallel mode observations it was 168″ and 155″ in the nominal and orthogonal scan directions, respectively.
The different data products created by the standard product generator (SPG) pipelines are available through the Herschel Science Archive (HSA) and can be downloaded via the web interface or through the HIPE software, specifically developed for Herschel data manipulation2. Several products belonging to different processing levels are generated by the SPG chain (see Fig. 2); they are available in the HSA for users to download (see the PACS Observer’s Manual for a detailed description of the data product levels).
Starting from the raw telemetry, Level 0 frames are generated and processed up to Level 1. In these steps, instrumental effects (1/f noise, common mode drift, cross-talk) are removed, and frames are calibrated in Jy pixel−1. Level 1 frames are the starting point for the mapmakers listed below:
Level 2 maps are generated by using the High-Pass Filtering (HPF) pipeline. Large-scale structures (noise and extended emission) are removed by means of a sliding median filter on an individual bolometer timeline. These maps are not suitable for recovering extended emission.
Level 2.5 maps are generated by combining scan and cross-scan observations of the same sky field (acquired in the same observing mode), by using three different mappers: HPF, Unimap, and JScanam. Level 2.5 HPF maps are the averages of the corresponding Level 2 HPF maps. The Unimap mapper exploits the Generalised Least Square approach with the pixel noise compensation for removing 1/f noise, while the JScanam mappers is a Java implementation of the Scanamorphos de-striper method that does not rely on any noise model nor on filtering and exploits the redundancy to derive the drifts from the data. Unimap and JScanam maps are science-ready, not absolutely calibrated, and are reliable for recovering both extended emission and point-like sources.
Level 3 maps are the average of Unimap and JScanam Level 2.5 maps of any overlapping areas. Additional criteria are that the scan speed is uniform for all the observations; the observations combined are from the same observing programme; they contain at least 180 s worth of data; there is at least one scan and cross-scan observation in all combined observations, and that for the blue channel data only, the filter is the same. For the red channel, all observations are used without regard to the filter used in the blue channel.
Altogether, the number of maps processed is 15 107. Table 2 lists the detailed map numbers according to the different observing modes and filters.
FWHM of the PACS PSF for several important cases.
Number of maps obtained with different observing modes in the 70 μm blue (BS – blue short), 100 μm green (BL – blue long) and 160 μm (R – red) bands.
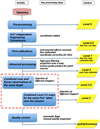 |
Fig. 2 Standard product generator chain from Level 0 to Level 3. The raw data are stored in Level 0 cubes. After numerous levels of noise removal and processing, the Level 2.5 and Level 3 maps are the final products that are used for the PSC generation. |
3 Workflow
The workflow for the generation of the final HPPSC2 catalogues and tables is shown in Fig. 3. The steps are described below, while the details of the methods are discussed in Sec. 4. The workflow starts with reading the list of maps from our data repository.
Reading the next Level 2.5 or Leve l3 JScanam map from our map repository that is flagged as unprocessed, described in Sec. 2. These maps are the input for steps 2, 3 and 5.
Map transformation – structure noise map, calculated as described in Sect. 4.4.4. These maps are essential for the quality assessment of the sources.
-
Source detection – it is done on each map with the following algorithms. At this stage, only the extracted source positions are stored.
HIPE SUSSEXtractor
HIPE Haar-features
AstroPy DAOStarFinder
PyTorch ResidualHerschelNet
Combine the resulting detection lists into one master list. This step creates one list per map.
-
Photometry on the original map at the positions listed in the master list with the algorithms listed below. These algorithms collect all the information necessary for photometry, noise estimation, source characterisation, and other features used in the identification of spurious detections.
Flag the map as processed. Steps 1 to 6 are repeated for every map in our map repository.
Real source identification with Random Forest – details are given in Sect. 4.4.3.
Calculation of signal-to-noise ratio with Support Vector Machine Regressor – detailed in Sect. 4.4.4
Identification of the best detection among multiple detections, as described in Sec. 4.5
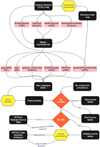 |
Fig. 3 Workflow of the HPPSC2 catalogue generation. |
4 Methods
In this section, we describe the different methods used for source detection and for extracting the brightness of our targets. We also explain the machine learning methods used in the discrimination of real and spurious sources.
The remarkable resolution of Herschel in the FIR and smm wavelengths enabled us to map the dusty Interstellar Medium (ISM) with an unprecedented level of detail. Distinguishing between background fluctuations and semi-extended or point sources posed significant mathematical challenges, leading to the development of specialised algorithms designed specifically for star-forming regions observed by Herschel. These algorithms are highly sophisticated and intricate tools tailored for this specific purpose, rather than for general applications. Despite our efforts to incorporate cutting-edge machine learning techniques, it is important to note that the definition of a ‘source’ itself carries a certain level of uncertainty. We refer to the IRAS Explanatory Supplement and state that the sky at 60–200 μm is dominated by filaments termed “infrared cirrus” which, although concentrated in the Galactic plane, can be found almost all the way up to the Galactic poles. The primary, deleterious effects of the cirrus are that it can generate well-confirmed point and small extended sources that are actually pieces of degree– or arcminute–sized structures rather than isolated, discrete objects and that it can corrupt measurements of true point sources. While Herschel had significantly better angular resolution and sensitivity than IRAS, and could resolve many features of the ISM, due to the turbulent dynamics, self-similar features still appear on smaller scales, still not resolvable for the PACS instrument.
4.1 Source detection
4.1.1 SUSSEXtractor
In the previous version of the PACS PSC, the sourceExtractorSussextractor() task of HIPE (hereafter simply SUSSEXtractor) was used, which is an implementation of the SUSSEXtractor algorithm described in Savage & Oliver (2007). On the basis of its previous successful application to PACS data, we kept it as the basis for our source detection and applied it to the L2.5 and L3 maps with a very low detection threshold. This threshold value was 3 in the first catalogue, but this time we lowered it to the value of 1, to increase the number of detections. We were able to do that without adding false detections to the final products thanks to the real-spurious source classifier we added to the workflow.
4.1.2 HIPE Haar features
A significant improvement in the last version (15.0.1) of HIPE was the implementation of a source finding algorithm based on Haar features. The identifyPointSources() task scans the map pixel by pixel, calculating the average signal in a 3 × 3 or 5 × 5 pixel box, which is selected depending on the PACS PSF and the map pixel size. The average signal value is then compared with the average signal in nearby rectangular regions (left, right, top, bottom, top-left, top-right, etc.). A source is identified if the average signal in that pixel is higher than the average signal in nearby regions, and the difference is always higher than n times the average value of the standard deviation of the pixel. To avoid missing any sources, we chose the n value to be equal to 1, and we executed the task again on the images.
4.1.3 Astropy DAOStarFinder
Next, we complemented the HIPE source detections with additional tools. One of them was the DAOStarFinder task in the AstroPy (Astropy Collaboration 2013; Astropy Collaboration et al. 2018, 2022) Python library, which is an adaptation of the algorithm by Stetson (1987). Because this is a python package, this is the first step that had to be executed outside the HIPE.
4.1.4 Deep learning source detection with PyTorch
In the development of deep learning models for image classification tasks, the use of pre-trained models, such as those available in PyTorch torchvision library (Paszke et al. 2019), has become increasingly popular. These models, including the well-known ResNet (He et al. 2016a), have been pre-trained on large datasets like ImageNet (Deng et al. 2009), which consists of images significantly larger than those we aimed to use in our research. Given our requirement to process 11 × 11 pixel images (cropped from larger maps), the pre-trained models offered by PyTorch are inadequate due to their reliance on larger input dimensions. Also, due to the small size of our input images, we opted not to use pooling layers, which are typically included in convolutional neural networks (CNNs) to reduce the spatial dimensions of the output from one layer to the next.
To address these challenges, we developed a custom architecture, named ResidualHerschelNet, inspired by the principles of ResNet but adapted to our specific requirements. Our model retains the core idea of utilising Residual Units or Blocks (He et al. 2016b). These blocks incorporate convolutional layers followed by batch normalisation (Ioffe & Szegedy 2015) and ReLU activation functions (Nair & Hinton 2010), forming the backbone of our network. In adapting to our specific use case, we employed convolutional layers with a kernel size of 3, a padding size of 1, and a stride of 1. This configuration allows us to maintain the resolution of our small input images throughout the network, enabling detailed analysis of features without spatial reduction. The architecture of ResidualHerschelNet comprises four such Residual Blocks, followed by a Fully Connected Layer, with a single hidden layer consisting of 256 neurons to obtain the network’s predictions.
We trained our ResidualHerschelNet model on labeled 11 × 11 pixel input images for binary classification (see examples in Fig. 4). The aim of this training was to enable the model to accurately detect sources. The training process spanned over 120 epochs, beginning with an initial learning rate of 0.005. We utilised the Adam optimiser (Kingma & Ba 2014) with a weight decay of 0.001 to refine the model’s parameters while preventing overfitting. The Binary Cross-Entropy (BCE) Loss from PyTorch was used to evaluate the model’s performance, suitable for binary classification tasks. To improve the training process, we used a Step Learning Rate (LR) scheduler, reducing the learning rate by half every 20 epochs.
The trained ResidualHerschelNet model predicted the probability of a source’s presence within an 11 × 11 pixel image, producing a value between 0 and 1. This model was employed on our data discussed in Sect. 2, by sliding an 11 × 11 pixel window across the full image, using each window as input to generate the probability. This process resulted in probability maps representing the probability of sources at different locations (see example in Fig. 5).
Once the probability maps were created, the next step was to locate and extract the coordinates of the sources. Our algorithm was designed to recognise sources on probability maps, considering both the probability values and the size of connected regions on thresholded binary masks. A threshold value of 0.5 was set, converting all intensity values above this threshold to 1 (indicative of a source’s presence) and those below to 0. In these binary masks, we identified connected regions of ones, focusing only on those regions with an area comprising at least three ones. This criterion implies that our model predicted a probability exceeding 0.5 for the presence of a source in a minimum of three adjacent positions surrounding the centre of the source. This allowed us to gain insights into the size and shape of a source. A larger and brighter source appeared as a more extensive and brighter area on the probability map.
While the DAOStarFinder method could have been applied to these maps as well, we found that our algorithm was more effective with probability maps as input. We also explored the use of the centroid_sources method from photutils to refine centroid fits but faced constraints due to its fixed box_size parameter. This limitation becomes apparent when two or more sources are close to each other, leading to merged centroids rather than distinct localisations for each source. Consequently, we leveraged our binary masks, applying dilation to enlarge the detected sources’ areas based on their initial dimensions and shapes. We then computed the weighted centres for all sources using the binary masks on the original images. By adopting our method for centroid fitting, we were able to enhance the accuracy of source detection.
 |
Fig. 4 Examples of training sample stamp images in the Scan Map BS band used to train ResidualHerschelNet, our deep learning PyTorch classifier. The top panel shows pictures of the real training sample, while the bottom panel shows stamps for the fake sources. |
 |
Fig. 5 Example of a comparison between the original image (top) and the corresponding probability map (bottom) generated by the ResidualHerschelNet model. The probability map visualises the predicted likelihood of source presence. Brighter areas indicate higher probabilities of source detection. |
4.2 Source photometry
4.2.1 HIPE SUSSEXtractor
SUSSEXtractor, as described in Savage & Oliver (2007), performs a Bayesian source photometry. It adopts the approach of fitting multiple models to the local data, allowing more parameters to vary, and mapping the posterior probability distribution in each case. These include:
Empty sky, uniform background. This model consists solely of a flat, uniform background, described by a single parameter (the level of the background).
Point source, uniform background. This model builds on the empty-sky model, adding a single point source at a given (parameterised) position (X, Y). The point source is modelled as a circularly symmetric 2D Gaussian profile of known FWHM. This model has four parameters: the background level, the X- and Y-positions, and the integrated flux of the source.
Extended source, uniform background. This model is the logical extension of the point-source model and is identical, with the exception that the FWHM is now allowed to vary as a model parameter (giving five in total). This allows us to account for circularly symmetric extended sources or, alternatively, to measure the FWHM of the point-spread function if this is not known.
This task provides us with useful parameters that can be used to distinguish between actual sources and spurious detections, such as flux estimates, error of the flux estimates, background estimation, error of the background, and a quality parameter.
4.2.2 HIPE DAOphot
The SourceExtractorDaophotTask is an implementation of the original DAOPHOT (Stetson 1987). The photometry part of the task works as follows:
The position is refined by fitting a quadratic function to certain pixels in the threshold image. First, using the source pixel and the pixels immediately above and below, and then again using the source pixel and the pixels immediately to the left and right. This gives better accuracy to the source position than simply the centre of a pixel.
The sharpness at each source position is calculated, defined as “delta”/H-image (the threshold filtered image is known as the H-image) at that pixel, where “delta” is calculated from the input image, as the mean of the values of the surrounding pixels subtracted from the value of the pixel itself.
At each source location, the input image is convolved with 1-D horizontal and vertical versions of the DAOPHOT H filter to give hX and hY. Their roundness is computed as (hY-hX)/(hY+hX).
For the background estimation (within an annulus), the pixels in the input map are divided into source pixels and background pixels. Pixels will be marked as “background” if the distance from the nearest source is greater than innerArcsec.
For each source, the annulus between innerArcsec and outerArcsec is searched for background pixels. If there are valid background pixels, the background for the source is set to the median value, and the plus and minus errors for the background are computed using the 95% confidence interval of the values in the annulus.
Aperture photometry is performed to get the source fluxes. The source flux is the sum of the pixels in the aperture (defined by radiusArcsec), with the background value subtracted from each pixel. The flux error is set to be the flux divided by the signal-to-noise ratio.
This task provides us with useful information on the source quality, such as the sharpness and roundness, which are input features for the ML cleaning of the catalogue.
4.2.3 HIPE AnnularSkyAperturePhotometryTask
This task performs a simple aperture photometry of the target, enclosed by a circular aperture. The sky is estimated from a concentric annular aperture with configurable inner and outer radii. The sky estimation algorithm is adapted from the IDL mmm.pro routine. With this task, we perform multiple photometry with different aperture sizes. In the BS and BL bands, the apertures are equal to 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 and 18 arcsec. In the red band, the apertures are 9, 10, 11, 12, 13, 14, 15, 16, 17, 18 and 22 arcsec. The sky annulus is always between 25 and 35 arc-sec. The multiple sizes of the apertures allow us to trace the flux distribution of the detections and differentiate between PSF-like point sources and other sources.
4.2.4 AstroPy aperture_photometry
The AstroPy library of Python offers the aperture_photometry() function and the ApertureStats class tools to perform aperture photometry on an astronomical image for a given set of apertures. In a similar way to the AnnularSkyAperturePhotometryTask in HIPE we used it to measure the flux of the detections in different sizes of apertures. In addition, we estimated two types of background using both mean and median values. These are valuable outputs for the discrimination of false detections.
4.2.5 IDL aper
Compared to the previous methods, IDL offers a very fast computation of the flux values, therefore, we were able to collect even more information on the flux distribution of the sources, with aperture sizes ranging from 3 to 26 arcsec. Before performing the aperture photometry we also used the GCNTRD function to find a more accurate centroid of the sources. The difference between the centroid and the input coordinates was stored as an additional parameter for quality assessment. The efficient processing in IDL also allowed us to calculate the background fluctuation by measuring the flux density in 12 apertures around each source, while also calculating the standard deviation and a robust sigma of these flux values. All these parameters are important to describe the vicinity of our objects and provide quantities that help us in the quality control of the catalogue.
4.2.6 IDL gauss2Dfit
The GAUSS2DFIT function fits a two-dimensional elliptical Gaussian equation to rectilinearly gridded data. The returned values by the algorithm provided useful data on the shape of the fitted detection.
A0 = constant term
A1 = scale factor
a = width of Gaussian in the X direction
b = width of Gaussian in the Y direction
h = centre X location
k = centre Y location.
T = Theta, the rotation of the ellipse from the X axis in radians, counter-clockwise.
For our case, the a and b values, which are the width of the fitted Gaussian, are important indicators of the shape of the source.
4.3 Master lists of sources
Our goal was to create a catalogue that was simultaneously as complete and clean as possible. Therefore, instead of choosing one of the methods over the others, we combined their results. Source extraction was first done on the unmodified Level 2.5 and Leve l3 maps. We applied 4 methods in this order: HIPE SUSSEXtractor, HIPE Haar-like feature-based source finder, AstroPy DAOStarFinder, and finally the image-based deep learning PyTorch finder ResidualHerschelNet. This yielded 4 source lists per map.
In the next step, the 4 source lists per map were combined into one master list per map. The starting point for this master list was the coordinate list provided by SUSSEXtractor. The AstroPy DAOStarFinder list was then matched to the SUSSEXtractor list, and the positions only present in the DAOStarFinder list were appended to the master list. The same procedure was repeated using the Haar features-based findings and also with the resulting lists of our ResidualHerschelNet method. Our own method was the last to be added. This choice provided us with a clearer idea of how many sources would have been missed without using it, and it also reflects the improvement over the previous version of the PACS catalogue. In Table 3, we list a few examples to show how many new detections were added at each step of merging the 4 different lists. To match the sources, we used their respective FWHM as the matching radius.
Number of detections added by the different source finding algorithms that resulted in the master lists in case of some example maps.
4.4 Quality control
4.4.1 Photometric accuracy
Photometric accuracy is characterised as the ratio of the input flux to the measured flux. Photometric errors are derived as the standard deviation of the measured flux values at a given injected flux level. For example, if the injected flux is 60 mJy and the measured flux is 58.74±9.44 mJy, the photometric accuracy is 58.74/60.0 = 0.979, the error is 9.44, and the S/N is 58.74/9.44 = 6.22. Figure 6 shows the photometric accuracy across the different observing modes and filter bands using different methods and aperture sizes. These figures served as a basis for selecting the best methods and aperture size. As a result, we identified the best methods and aperture sizes: for the Scan Map mode observations, we found that the AstroPy aperture_photometry routine gives the best results with aperture sizes of 5, 5, and 10 arcsec in the BS, BL and R band, respectively, while in the Parallel mode observations the HIPE annularAperturePhotometry task had the best performance with aperture sizes of 10, 10 and 13 arcsec in the BS, BL, and R bands. Detailed statistics of the photometric accuracy in comparison with the simulations are listed in Table 4.
4.4.2 Simulations
The quality assessment of any catalogue is a key point. Completeness, flux boosting, and flux error at different sensitivity levels (depending on the depth of the observations) can be evaluated by creating simulations. Table 5 shows the fields we used to create our simulations. For each field 30 different maps were created. In each we injected the number of sources listed in the last column of Table 5. The flux levels were the following: 10.0, 20.0, 30.0, 40.0, 50.0, 60.0, 70.0, 80.0, 90.0, 100.0, 120.0, 140.0, 160.0, 180.0, 200.0, 225.0, 250.0, 275.0, 300.0, 350.0, 400.0, 450.0, 500.0, 600.0, 700.0, 800.0, 900.0, 1000.0, 2000.0 and 3000.0 mJy. We repeated the source injection for each flux level, using the same flux density at all positions. The flux level grid was optimised to have better coverage at the fainter flux levels when detection and accuracy are more of an issue than at the brighter end of the flux distribution. An example of simulations at different flux levels is shown in Fig. 7.
To create realistic simulations, we back-projected sources to the Level 1 observational timeline and executed the map-making algorithm in the same way as in the SPG pipeline. The added sources are the nominal PSFs as described in the PACS Technical Note v2.2. For PACS, the PSF shape is significantly different from a simple 2D Gaussian function, especially in the BS band at high scan speed. Therefore, we had to use actual PSF images and add them to the Level 1 time ordered data (TOD). The process of creating the simulations consisted of the following steps:
Random position generation: Several random positions were generated with the criteria of a minimum separation of 35″. The number of randomly generated sky positions is determined by the extent of the map. In general, for large Parallel mode observations, we were able to generate more positions.
PSF back-projection: to simulate the real sources, we used the official Vesta PSFs that are specific to the observing mode, band, and scan speed. In the first step the PSFs were rotated according to the scan angle of the observation in which the PSF was injected. Then, the Level 1 TOD of the observations was duplicated and emptied. The back-projection from the L2.5 PSF image to the Level 1 TOD was carried out with a dedicated task in HIPE, called Map2signalCubeTask(). We used PSFs that were scaled so that the source flux was exactly 1 Jy. As a result of this process, we were left with a TOD that was of the same length as the observation but contained only 1 Jy flux sources at the randomly generated positions (source-only timelines).
Map projection: The source-only timeline has the advantage that it can be scaled in a linear fashion (e.g. multiplying it by 10 will result in 10 Jy sources, and dividing by 10 results in sources with 100 mJy source flux). After scaling to the desired flux level, we added the PSF data to the actual observational TOD. The combined data was then processed with JScanam SPG14.2.0, so the same algorithm was used for the vast majority of maps in our repository.
Photometric accuracy in comparison with the simulated sources.
 |
Fig. 6 Photometric accuracy for the Scan Map mode observations in the BS (70μm) band. Flux accuracy is the ratio of the measured flux density to the injected flux density. The perfect accuracy is highlighted with the yellow horizontal line at 1. The horizontal axis shows the different methods and aperture sizes used in the exercise. From left to right, the methods are the IDL aper routine with aperture sizes between 3 and 25 arcsec, with one-arcsecond steps; the AstroPy aperture_photometry routine using average background subtraction with aperture sizes of [4, 5, 6, 7, 8, 9, 10, 11, 12, 13, and 18] arcsec; the AstroPy aperture_photometry routine using median background subtraction using the same aperture sizes; the SUSSEXtractor flux determination (one value). The last method is the annularAperturePhotometry task in HIPE with aperture sizes similar to the AstroPy values. Figures for all observing modes and bands are found in Appendix A. HIPE DAOPhot and IDL gauss2dfit are not included because DAOPhot gives the same result as the annularAperturePhotometry given the same aperture size, while gauss2dfit was not used for flux density determination. |
4.4.3 Identification of spurious detections
With the source detection methods described in Sect. 4.1, we identified tens of millions of source candidates and collected information about them with the methods described in Sec. 4.2. To clean the raw source lists, we further tested several supervised ML techniques.
Supervised techniques require training samples and to achieve the best results, we created one for each mapping mode and filter band. In all cases, we collected 1000 visually confirmed sources from both the simulations and from the original observations and 2000 false detections. We prepared the training samples to include 900 randomly picked detections for both categories and 100 for testing. Instead of training only one classifier, for a more robust result, we trained 5 classifiers. We did so by repeating the random picking from the classes. Several ML techniques were used in these tests, including Support Vector Machines (SVM), Naive Bayes (NB), Neural Networks (NN), Random Forests (RF) and eXtreme Gradient Boosting (XGB). The most important details of these techniques are discussed below.
SVM works by finding the hyperplane that best separates the classes in the feature space. It aims to maximise the margin between classes, which helps improve generalisation to unseen data. SVM can handle both linear and non-linear decision boundaries through the use of different kernels, which makes it effective for high-dimensional data and can handle datasets with more features than samples.
NB is a probabilistic classifier based on Bayes’ theorem with the assumption of independence between features. Despite its simplicity, it can be very effective, it is computationally efficient and can handle large datasets with high dimensionality. NB assumes that features are conditionally independent given the class label, which may not always hold true in practice.
NNs are a class of machine learning models inspired by the structure and function of the human brain. They consist of interconnected layers of artificial neurons (nodes) organised into input, hidden, and output layers. NNs can learn complex patterns and relationships in data through a process of forward and backward propagation. The backside of the method is that it requires large amounts of data and computational resources for training, but they can achieve state-of-the-art performance.
RFs are an ensemble learning method based on decision trees, working by training multiple decision trees on random subsets of the data (bootstrap samples) and random subsets of the features. They aggregate the predictions of individual trees to make more accurate and robust predictions. An advantage is that they are less prone to overfitting compared to individual decision trees and can handle both classification and regression tasks. RFs provide feature importance scores, which can help identify the most informative features in the dataset.
XGB is a gradient boosting algorithm known for its speed, scalability, and performance, which sequentially builds an ensemble of weak learners (typically decision trees) and optimises a loss function to minimize prediction errors. XGB uses gradient descent optimisation techniques to improve model performance iteratively, and can handle missing values, regularisation, and custom loss functions, making it highly flexible and customisable.
We also tested if the classification results were better when employing all the raw features of the sources we extracted from the observations or a reduced number of pre-calculated features. The full set of raw features yielded a parameter space with 135 features, including all the flux density values from the different extractors with all the apertures, all parameters of the Gaussian fits and quality features provided by the extractors. In the other classification scenario, we used only 23 features that included the ratio of flux density values measured at different aperture sizes, differences of coordinates provided by the different extractors, FWHM values of the fitted Gaussians and some parameters of the background properties.
We found that the RF and XGB methods provide the best results. A random forest is a meta-estimator that fits a number of decision tree classifiers on various subsamples of the dataset and uses averaging to improve the predictive accuracy and control over-fitting. Gradient boosting refers to a class of ensemble machine learning algorithms that can be used for classification or regression predictive modelling problems. Ensembles are constructed from decision tree models. Trees are added one at a time to the ensemble and are fit to correct the prediction errors made by prior models. This type of ensemble machine learning model is referred to as boosting. Models are fitted using any arbitrary differentiable loss function and gradient descent optimisation algorithm. This gives the technique its name, “gradient boosting”, as the loss gradient is minimised as the model is fitted, much like a neural Network5.
In both cases, we found that using a set of pre-calculated features provides a better cleaning process than using all the raw features. In general, while XGB provides better completeness at lower flux levels and significantly reduces the number of false detections, it still provides a contamination rate higher than desired. RF provides a cleaner but less complete result. The confusion matrices of the classifiers are summarised in Table 6. Finally, the identification of real and spurious sources was done by using RF on the set of pre-calculated features.
Main parameters of the fields used in the simulations.
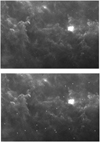 |
Fig. 7 Sources artificially added to the BS Parallel mode observation of the Rosette Molecular Cloud. The top image shows sources with 500 mJy flux density. In the bottom image, sources with 3000 mJy flux density are added at the same sky positions. |
4.4.4 ML determination of the signal-to-noise ratio
The quality control of such an inhomogeneous catalogue as ours is especially difficult. The confusion noise present in the FIR and smm photometric observations is a major limiting factor in sensitivity and photometric accuracy. Confusion noise comes either from the extragalactic background or from the cirrus emission of the Galaxy. Both are mainly due to the presence of cold dust. Additionally, the photometric accuracy is highly dependent on the complexity of the celestial environment. As our goal was to create a homogeneous catalogue, we had to find a way to treat all environments in the same way.
Structure noise (NS) measures the fluctuations of pixels on the map (Kiss et al. 2005). It can be translated into the fluctuation power of neighbouring areas and provides a localised information, instead of a general (regional average) number. For each pixel of the map the NS is calculated as the standard deviation of all flux differences between the pixel and all the surrounding pixels at a fixed distance (see Fig. 8). It includes the spatial noise of the celestial environment, as well as, the noise contribution from the instrument.
The NS maps were generated with an IDL script. The code reads the same maps that were used to generate the catalogue. For each pixel of the map (target pixel, shown as a red square in Fig. 8), we looked for neighbouring pixels in 24 directions (green squares), at 30″ angular distance. If, due to the larger pixel size, fewer than 24 unique pixels are found in the 24 directions, then each pixel is selected only once. The next step is to calculate the absolute difference between the unique neighbouring pixels and the target pixel. When the number of unique data points is greater than three, the standard deviation of these differences is stored as a pixel value in place of the target pixel. The pixel value is calculated according to:
![Mathematical equation: $\\sigma_{\mathrm{strn}}=\sqrt{\frac{1}{24} \sum_{n=1}^{24}\left(d_i-\mu\right)^2},\]$](/articles/aa/full_html/2024/08/aa50032-24/aa50032-24-eq1.png) (1)
(1)
where di are the differences of each of the fluxes of the 24 (or fewer) pixels and that of the central pixel, and is the average of all di. The resulting NS map is then stored as a standard FITS file with the header of the original map.
The distance between the target pixel and the neighbouring pixels corresponds to a spatial frequency that had to be optimised. Choosing a distance too small would mean that the value NS includes the flux from the PSF wings, causing a scaling with the source flux. To minimise this effect, we created NS simulation maps in which we injected sources with 20 Jy flux and increased the angular distance between the target pixel and the neighbouring pixels. On each NS map, the NS value at the position of our artificial sources was calculated and checked as a function of angular separation. We found that at an angular distance of ~30″, the NS values decouple from the source flux and have a minimum value before large-scale structures start to dominate the fluctuation power. We decided to use this angular separation to create our NS maps in all bands and to attach a NS value to each of our detections. An example of a structure noise map is shown in the right panel of Fig. 9.
Pixel values have the same units as the input maps. To avoid the so-called NaN-Donuts, single NaNs in the input map are interpolated before the calculation. The NS value for a given source is calculated as follows: we place an aperture at the extracted position of each source, the diameter of which is 6″ for the blue camera and 12″ for the red camera. The total NS inside the aperture is then converted into units of MJysr−1. Eventually, the resulting NS value is attached to each source in a separate database column.
In the first version of the HPPSC, it was assumed that the photometric accuracy varied as a function of NS. In HPPSC2, we instead aim to predict the photometric uncertainty using regression ML methods. Regression is a type of supervised learning task where the goal is to predict a continuous target variable based on one or more input features. In our case the input features were the mean values of binned NS, the photometric uncertainty of the simulated sources based on the standard deviation of the flux density values associated with those NS values, and the theoretical flux density of the same sources. The target variable was the photometric uncertainty of the real sources given their NS and the measured flux density.
Figure 10 shows, for different flux density levels, examples of how the measured flux density values become scattered as the NS value increases. The figure also indicates that sources with lower flux densities are less likely to be detected in more structured regions and that around brighter sources, the NS values increase due to the extended PSF.
After repeating this for all flux levels, we are able to derive a 2D surface, which gives us the estimated error as a function of NS and the measured flux. The methods we compared are the Random Forest Regressor, the Support Machine Regressor, the MLP Regressor, and the Gradient Boosting Regressor. We found that the best results can be achieved with the Support Machine regression. A short description of these methods is found below.
Random Forest Regressor is an ensemble learning method based on decision trees. It builds multiple decision trees on random subsets of the data (bootstrap samples) and random subsets of features (feature bagging). It aggregates the predictions of individual trees to make more accurate and robust predictions. This type of regressor is effective for handling high-dimensional data, non-linear relationships, and interactions between features.
Support Vector Machine (SVM) Regressor is a supervised learning algorithm used for regression tasks, which works by finding the hyperplane that best fits the data while maximising the margin between data points and the hyperplane. It aims to minimise the error between predicted and actual values while penalising deviations from the margin. It can handle non-linear relationships between features and the target variable through the use of kernel functions. It is effective for small to medium-sized datasets and can handle high-dimensional data well.
MLP Regressor (Multi-layer Perceptron Regressor) is a type of artificial neural network with multiple layers of neurons (nodes). It consists of an input layer, one or more hidden layers, and an output layer, that makes it able to learn complex non-linear relationships in the data through a process of forward propagation and backpropagation. It is highly flexible and can model a wide range of functions, making it suitable for a variety of regression tasks.
Gradient Boosting Regressor builds an ensemble of weak learners (typically decision trees) sequentially. It fits each weak learner to the residuals (errors) of the previous model and combines their predictions to minimise the overall error. Gradient Boosting Regressor aims to improve prediction accuracy by iteratively reducing the residuals of the previous models. Algorithms like XGBoost and LightGBM are known for their speed, scalability, and high predictive performance.
Figure 11 shows the S/N values as a function of NS and flux density for the simulated sources, the predicted S/N on a grid and the predicted S/N for the catalogue sources in the BS band for Scan Map mode maps.
Average confusion matrices of the five RF and XGB classifiers trained for the different observing modes and bands.
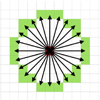 |
Fig. 8 Circular configuration used for NS calculation. The target pixel is shown as a red square. The neighbouring pixels at the predefined angular distance are shown as green squares. |
 |
Fig. 9 RCW79 (OBSID=1342188880), a very structured galactic star-forming region. Left: Original map showing high amplitudes of fluctuations. Right: Structure noise map of the same region. Log scaling was used in both panels. The structure noise map shows that around the bright sources, the fluctuation of the background at a distance of ~30″ is higher than in places where the background is flat. If a pixel has a high value in the structure noise map, it means that in the vicinity of that pixel, the fluctuation of the original map is high. |
4.5 Multiple detections
Source extraction was performed on a map repository that includes the highest processing level available within the HSA for every sky region and does not prevent multiple detections for the same source appearing in different sky maps. To identify single objects with multiple detections on overlapping maps, sources belonging to different observations are grouped. Groups are identified with the Minimum Spanning Tree method using a cutoff length equal to the corresponding PSF FWHM. Within each group, only the source with the highest S/N is included in the final catalogue table. Exceptions were made when both Parallel mode and Scan Map mode observations were obtained for the objects. In these cases, we always chose the highest S/N detection among the Scan Map observations.
 |
Fig. 10 Measured flux density as a function of NS in the Scan Map R observations for sources injected at the 3000 (red), 2000 (blue), 1000 (green), 500 (grey), 100 (black) and 50 (magenta) mJy level. At higher NS values, the flux density values show higher scatter at all flux density levels. The solid lines indicate the respective theoretical flux density values. |
First ten rows of the BS band high-reliability catalogue.
5 Results
As a result of the workflow described in Sec. 3, we created six individual catalogues. This includes a high-reliability catalogue and a rejected source catalogue for each band. High-reliability catalogues are the main products, including detections with S/N ≥3, and, in case of multiple detections, only the best quality measurement is listed. The rejected source catalogue contains those detections that were classified as real detection in the workflow Step 6, but their predicted S/N values are lower than 3, or in case of multiple detections, they are not the best ones belonging to a given object. In this section (and also in Sec. 6), our discussion is focused on the high-reliability catalogues. The first ten rows of the high-reliability catalogue for the BS band are shown in Table 7.
5.1 Catalogue properties
In the three high-reliability catalogues, we list 90 864 (15 347 from Scan Map and 75 517 from Parallel mode), 65 068 (52 588 from Scan Map and 12 480 from Parallel mode), and 152 702 sources(18 284 from Scan Map and 134 418 from Parallel mode) across the 70, 100 and 160 μm (BS, BL and R) bands. The number of sources from product levels L2.5 and L3 is 88 457 and 2407 in the BS band, 41 178 and 23 890 in the BL band, and 130 505 and 22 197 sources in the R band. A more detailed breakdown of the source numbers is listed in Table 8.
The sources of the high-reliability catalogues projected on the sky in galactic frame are shown in Fig. 12. We calculated the coverage of the catalogue in all three bands using HEALPix (Górski et al. 2005) with nside=512. The BS sources cover 1191.58 square degrees (2.89% of the whole sky), the BL sources cover 853.30 square degrees (2.07% of the sky), while the R band covers 2002.53 square degrees (4.85% of the sky). Because R band was used in all the observations, therefore it gives us the total coverage of the catalogue. We have to note that the total coverage of the PACS instrument was ~7%, but some large scale observations were obtained in a way that only Leve l2 products are available, therefore we had to exclude them.
Because of the relatively different angular resolution in the three PACS band we do not attempt to create a band-merged catalogue. Another reason is that the overlap between observations carried out in the BS and BL is very small. Still, we checked the overlap between the different band, using the FWHM of the longer wavelength band as a matching radius. The number of common sources among the BS and BL band, using a 7″ matching radius, is 7767, which is 8.5% of the BS sources and 11.9% of the BL sources. We found 40005 sources that are in both the BS and R catalogues, meaning 44.02% and 26.20% of the BS and R band catalogues, respectively. 23 351 sources are in both the BL and R catalogues, 35.89% of the BL and 15.29% of the total numbers. And finally, the number of sources that were detected in all three bands is 5124 (5.64%, 7.87% and 3.36%).
Figure 13 shows the distribution of flux density values for the high-reliability sources in all three bands. The S/N value distribution for the same sources in all photometric bands are shown in Fig. 14.
 |
Fig. 11 Signal-to-noise ratios in the BS band for the Scan Map mode. Top: signal-to-noise ratio of the simulated sources as a function of NS and the input flux density. Middle: signal-to-noise ratios predicted on a grid by the SVM regression model based on the simulations shown in the top figure. Bottom: signal-to-noise ratios for the real sources predicted by the SVM regression model. In each panel, the signal-to-noise values are shown by the colours on the same logarithmic scale. Figures for all bands and observing modes are shown in Fig. B.2. |
Number of sources in the high-reliability tables of the HPPSC2 in each band, observing mode and data product level.
5.2 Catalogue columns
RA and Dec: right Ascension and Declination coordinates in a J2000.0 reference frame. These are the peak positions of the source detection method that primarily detected the object. The coordinates are in degrees written in double-precision format.
RAerr and Decerr: positional uncertainties of each object. Calculated as the absolute difference of the positions provided by the source-detector method and the result of centroid fitting by the IDL’s GCNTRD routine. Units are in degrees, and the data type is double-precision.
Fν: this is the flux density as provided by the best photometry method task based on the exercises described in Sect. 4.4.1. For all cases, the raw flux density values were corrected for the aperture size, based on the aperture size, based on PACS photometer point spread function technical note. Colour corrections were not applied. Units are mJy, written as double precision.
Fν_err: estimated flux uncertainty. Calculated as the flux density measured over the estimated S/N. The data type is double precision and units are mJy.
S/N: estimated S/N (signal-to-noise ratio) based on a regression-type machine learning approach, trained using simulations. It is calculated as a function of the source flux density and the value of NS (structure noise). The method is described in detail in Sect. 4.4.4.
NS: structure noise value obtained from the structure noise maps as described in Sect. 4.4.4. Double precision, in units of MJysr−1.
FWHMX/FWHMY: these columns contain the FWHM values measured by the 2D Gaussian model in the X and Y directions, fitted by the GAUSS2DFIT routine in IDL. If the Gaussian fit was successful, then both FWHMX and FWHMY are listed. The value is empty if the fit failed in any direction. It is written in double precision format, in units of arcseconds.
OBSID: observation identifier for Herschel observations. It is a 10-digit integer that always starts with 1342. The column lists the first OBSID from the list that built the Level 2.5 or Level 3 map. It corresponds to the meta keyword ob sid001 in the fits file headers.
filter: ‘BS’, ‘BL’, or ‘R’. They correspond to blue short (70 μm), blue long (100 μm) and red (160 μm) bands, respectively.
level: product level as defined in the SPG, described in Sec. 2. Either Level 2.5, or Level 3.
mode: mapping mode as described in Sec. 2. Either Scan Map, Parallel, or SSO.
 |
Fig. 12 All-sky Aitoff projection of the high-reliability catalogue sources across the three PACS bands, presented in the galactic coordinate system. |
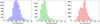 |
Fig. 13 Distribution of the derived flux density values in the three PACS bands. The colours correspond to the individual bands, BS (blue), BL (green) and R (red) from left to right, respectively. |
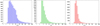 |
Fig. 14 Distribution of the predicted S/N (signal-to-noise ratio) values in the three PACS bands. Colours correspond to the individual bands, BS (blue), BL (green) and R (red) from left to right, respectively. |
6 Discussion
In this section, we discuss our results and compare them to several other catalogues to provide a better understanding of the catalogue. We describe the completeness, accuracy and purity by comparing our results to that of the first verson of the PACS catalogue, to photospheric models, public databases and other Herschel data products. We have to note, that numerous key programmes of the Herschel Space Observatory provided catalogues, but they were all tailored towards the scientific needs of the projects. Therefore, not only the source detection and flux extraction methods were different, but also the way from the raw observational data to the final maps. This can result in significant differences in the size and flux distribution of sources, and in the noise level of the maps and the local background. Also, the goal of the projects was different, therefore more extended sources had been also included in some of the catalogues, not only those that resemble of a true point source.
 |
Fig. 15 Completeness of our new catalogue, HPPSC2 (red) in the three different bands compared to the completeness of the previous HPPSC1 catalogue (black). The completeness curves for the BS, BL and R bands are shown in the left, middle, and right panels, respectively. |
6.1 Completeness and purity
Completeness is calculated as the ratio between the number of sources injected and the number of sources detected by our pipeline and recovered after the cleaning processes described in Sec. 4.4. Figure 15 compares the completeness of the previous catalogue (HPPSC1) and our new catalogue (HPPSC2) in the three photometric bands. The improvement is most visible in the BS band, especially at the bright end of the curve (above ~200 mJy), where the completeness increased by more than 50%. In the green band, the completeness increased both at the faint and bright ends but remained similar to HPPSC1 for flux density levels between 40–200 mJy. In the red band, we consistently achieved higher completeness levels than in HPPSC1, especially above ~80 mJy.
6.2 Effect of the scan leg separation
In Sec. 2, we described that the scan leg separation might have an effect on the resulting maps, therefore could potentially affect the accuracy of the derived positions and the flux density values. To achieve a better understanding of the separation we performed several tests. First, we checked the derived positions of the artificially injected sources and compared that to the theoretical positions. As seen on Fig. 16 there is no clear correlation between the inaccuracy of the derived positions and the separation of the scan legs. We also checked if a significant difference can be seen between the positional accuracy of the Scan Map mode and the Parallel mode observations. We found that the accuracy mostly depends on the observed band, as we found it to be slightly larger in the R band than in the BS and BL bands, but again, the difference was not found to be significant. The mean values (in units of arcseconds) for the Scan Map observations are 1.04 ± 0.39, 1.24 ± 0.53 and 1.52 ± 0.97 in the BS, BL and R bands respectively. The same values for the Parallel mode are 1.06 ± 0.35, 0.91 ± 0.33 and 1.50 ± 0.99.
In a similar fashion we also checked if there is a possible systematic effect of the scan leg separation on the photometric accuracy. Again, we found that the galactic environment in which the sources are located have significantly larger impact on the calculated flux density values than the scan leg separation.
6.3 Comparison with HPPSC1
As a first comparison, we cross-matched the new catalogue (HPPSC2) with the old one (HPPSC1). A comparison between the numbers of sources in the high-reliability catalogues and the numbers of cross-matches are listed in Table 9. In the case of the BS band, 45.5% of the sources were also present in the first version of the catalogue. This ratio is 72.5% and 47.3% in the BL and R bands, respectively. Table 9 also presents statistics of the flux–density ratio for the sources in common between the two catalogues.
In the BS band, as shown in Table 9, we found 41 350 common sources. The median of their flux density value according to the HPPSC1 value is 617.26 mJy, while the median of their HPPSC2 flux density is 685.21 mJy. The number of sources that are only in HPPSC1 and not in HPPSC2 is 66 969, their median flux density is 78.62 mJy. The number of sources that are only in HPPSC2 and not in HPPSC1 is 49 519 with a median flux density value of 2141.36 mJy.
In the BL band (also shown in Table 9), we found 47 145 common sources. The median of their flux density value according to the HPPSC1 value is 49.91 mJy, while the median of their HPPSC2 flux density is 48.68 mJy. The number of sources that are only in HPPSC1 and not in HPPSC2 is 84 234, their median flux density is 39.43 mJy. The number of sources that are only in HPPSC2 and not in HPPSC1 is 17 980 with a median flux density value of 41.74 mJy. The median flux level of sources detected in this band is significantly lower than in the other bands. This is due to the fact that star-forming regions were mostly observed in the BS +R bands, and the detection limit in complex environments is much higher, while the BL+R bands were used for most of the extragalactic observations. In these fields the detection limit is mostly dominated by the confusion noise coming from the presence of other faint extragalaxies, not bright features of the galactic ISM, therefore faint sorces can be easily detected with high S/N ratio.
In the R band (shown in Table 9, too), we found 72 226 common sources. The median of their flux density value according to the HPPSC1 value is 530.0 mJy, while the median of their HPPSC2 flux density is 551.74 mJy. The number of sources that are only in HPPSC1 and not in HPPSC2 is 176 166, their median flux density is 220.75 mJy. The number of sources that are only in HPPSC2 and not in HPPSC1 is 80476 with a median flux density value of 2018.83 mJy.
These numbers clearly show that the sources newly identified in the HPPSC2 are the significantly brighter than the ones identified only in HPPSC1, especially in the BS and R bands. This is in good agreement with the completeness levels described in Sec. 6.1 and with the results shown in Fig. 15. The reason for this difference is that the HPPSC1 was relying on the HIPE SUSSEXtractor source finder, which was mostly tailored for faint, extragalactic sources and missed a large number of objects in galactic regions, where the sources are brighter, meaning that their PSF structure is different from the faint sources as the PSF wings are more dominant, they are located on a more structured background which can also affect their shape and finally, they are prone to be located in clusters, where source crowding becomes an issue. This difference is clearly visible on Fig. 17.
 |
Fig. 16 Difference of the injected position and the derived position as a function of the scan leg separation for the Scan Map BS observations. For each unique separation value the mean and the standard deviation of the positional difference are plotted. There is no clear systematic effect seen on the accuracy of the positions as a function of the scan leg separation. |
Number of sources in the old (HPPSC1) and new (HPPSC2) version of the catalogue.
 |
Fig. 17 Two fields highlighting the differences of HPPSC1 and HPPSC2 in the BS band. The solid black dots show sources that were listed in HPPSC1. HPPSC2 includes both the solid dots and the black squares. |
6.4 Comparison with standard star models
Studies by Balog et al. (2014) and Klaas et al. (2018) have previously examined the flux calibration of the PACS photometer. We used the theoretical fluxes employed in these studies to evaluate the performance of our photometry pipeline. Table 10 summarises the standard stars with well-modelled SEDs of their photospheric emission used in our evaluation. Details of the comparison with models and measured flux density values are also presented in Table 10. Figure 18 illustrates the comparison between measured flux densities and the model flux density as a function of the flux density values. These results demonstrate that our pipeline measures the flux densities of standard stars within an accuracy of 5%. However, note that spectral types are known for these objects, thus we were able to apply a colour correction in our photometric calculations, which improved the accuracy. In Table 11, we present the statistics for the photometric accuracy for each band. The table clearly shows that the deviation from the model is not greater than 1% in any of the bands, and the error is on a scale of a few per cent.
Although our photometric accuracy relative to the photometry of the PACS calibrator stars is maintained within 1%, it is important to note that these values are derived from measurements specifically tailored for flux calibration, involving multiple visits, a scan speed of 20″ s−1, and isolated sources against a flat background. Moreover, the Spectral Energy Distribution of these sources is well understood, enabling accurate colour corrections. It is also crucial to note that these optimal conditions apply only to a limited subset of sources observed by Herschel. Consequently, published values do not incorporate colour corrections, leaving it to the user’s discretion to calculate them. Additionally, it is also essential to keep in mind that the values provided in the catalogue represent in-band flux density values.
Comparison of the theoretical flux density values for PACS standard stars with measured flux densities..
Photometric accuracy in comparison with the standard star models.
6.5 Cross-match with the Simbad database
As a measure of completeness and purity, we also cross-matched our sources with the Simbad database, using their respective FWHM values (5″.5, 7″ and 12″ in the BS, BL, and R bands) as a search radius. We also compared the number of cross-matches in the current catalogue with that of the previous version. Last two columns of Table 9 shows the detailed numbers for each band. We found that although HPPSC2 has 16% less sources in the BS band than HPPSC1, the number of matches with Simbad is 11% higher. In the BL band, the total number of sources is now only 50% of that in the HPPSC1, but the number of Simbad matches is only slightly lower, by 1%. In the R band, we now have 39% less sources, but the number of Simbad matches is just 7% lower. These numbers mean that the current version of the catalogue seems to be cleaner than the first version, because a higher fraction of the sources has a counterpart in the Simbad database.
While number of matching sources might suggest that the new catalogue is less complete, we also have to consider the matches that happen only by chance, because not everything that is listed in Simbad is actually visible for Herschel at FIR wavelengths. To have a better understanding of the cross-matches, we checked the flux distribution of these sources in each band. We found that in the HPPSC1 the median flux density value of the matching sources is 582.45, 48.38 and 261.81 mJy in the BS, BL and R bands, respectively. In the HPPSC2 these numbers are as follows: 1027.36, 49.54 and 1625.48 mJy for the three bands. In the BS and R bands the matching sources are significantly brighter in the new catalogue than before, while in the BL band the median is roughly the same, although the average is again, very different: 1613.08 and 2265.15 in the HPPSC1 and HPPSC2. All these results suggest, that the sources listed in the new HPPSC2 are more reliable than in the previous version. The distribution of the flux density values are shown in Fig. 19. The flux distributions show a double peak in the BL and R bands with the new catalogue. It was the same with HPPSC1 in the BL band, due to the fact that most extragalactic observations were done in this band instead of the BS, and they add a large amount of sources to the faint end of the distribution. In the R band the double peak seems to be caused by a different effect. In this case the extra number of sources appear at the brighter end of the distribution, which is a consequence of the better completeness at higher flux levels compared to HPPSC1.
We have also checked the Simbad main_type of the matching sources to have a better understanding of the nature of sources listed in the catalogue. The top 10 classes for both HPPSC1 and HPPSC2 are listed in Table 12. The comparison shows that in all bands we were able to identify more YSOs and YSO candidates. These sources are located in complex environments, therefore they have to be brighter than the galaxies, for which the detection limit is the extragalactic confusion noise. The increased number of young stars is in agreement with the better completeness achieved towards the bright end of the flux distribution, as shown on Fig. 15. All the main types with at least 10 objects in the sample are shown in the histograms in Appendix C.
As a final test of purity we created 10 Monte-Carlo simulation for both HPPSC1 and HPPSC2 using the R band sources detected on the extragalactic map with OBSID=1342233312. The HPPSC1 lists 7577 sources in the region with 945 matches in Simbad. The HPPSC2 lists 1742 detection in the same field that have 622 counterparts in Simbad. The Monte-Carlo simulations were created by shuffling the RA and Dec coordinates of the sources independently. After each shuffle we checked the number of Simbad counterparts. We found that the HPPSC1 positions have 200.2±18.42 matches, that is 21.19%±1.95% of the matches found with the original positions. In case of the HPPSC2 positions we found that 54.4±3.32 sources have Simbad counterparts by chance, which corresponds to the 8.75%±0.53% of the original matches. In both cases we found that the number of matches are significantly different from that of random positions, but in case of the HPPSC2 it is even more unlikely that the detection is not a real object, but coincides with a position of a source that is within the PSF FWHM, but not visible for Herschel at the FIR wavelengths.
 |
Fig. 18 Comparison of theoretical flux density and measured flux density values in the 70 (top), 100 (middle) and 160 (bottom) μm bands. The accuracy is calculated as a ratio of the measured and model flux, plotted as a function of the theoretical flux density. The 5% error limits are shown as solid grey lines. |
 |
Fig. 19 Flux density distribution comparison for sources listed in both Simbad and in HPPSC1 (light blue) and HPPSC2 (yellow) for the BS (top), BL (middle) and R (bottom) bands. |
The ten most abundant Simbad object types in the different bands in HPPSC2 and HPPSC1.
6.6 Comparison with the Hi-GAL catalogues
The Hi-GAL (Herschel Infrared Galactic Plane Survey) project was a large-scale astronomical survey conducted using the Herschel Space Observatory (Molinari et al. 2010), that obtained observations of the entire galactic mid-plane in the Parallel mode, using the BS and R bands of the PACS camera. Several catalogues were published using the Hi-GAL data and produced by the Hi-GAL team. We use the first public release of high-quality data products (DR1, Molinari et al. 2016) and the 360° clump catalogue (Elia et al. 2021). The goal of the Hi-GAL project was to carry out an unbiased photometric survey of the Galactic plane by mapping a 2° wide strip in five wavebands between 70 μm and 500 μm, to search for the earliest phases of the formation of molecular clouds and high-mass stars, and to use the optimum combination of Herschel wavelength coverage, sensitivity, mapping strategy, and speed to deliver a homogeneous census of star-forming regions and cold structures in the interstellar medium.
The DR1 catalogue lists 120 581 sources in the BS (70 μm) band, and 291 858 in the R (160 μm) band. We cross-matched our catalogue with the Hi-GAL DR1 using the respective PSF FWHM as the matching radius and found that the number of common sources is 35 511 in the BS band and 60 392 in the R band. These numbers are significantly higher than in the case of the HPPSC1 as for the earlier version, the overlap was only 21 501 and 32 756 in the BS and R bands, respectively. Statistics of the photometric accuracy are listed in Table 13.
We also checked the number of counterparts in Simbad. In the BS band 13 333 (37.5%) of the 35 511 common sources have a match in Simbad. There are 85 070 objects that are in the Hi-GAL DR1 but not in the HPPSC2, 8244 (9.7%) of them have a match in Simbad. The number of sources that are in HPPSC2, but not in the Hi-GAL DR1 is 20 624, out of which 2781 (13.5%) has a Simbad pair. In the R band the number of common sources with Simbad match is 16 396 (27.2%). 231 466 sources are in the Hi-GAL DR1 that are not in the HPPSC2, 34 330 (14.8%) with Simbad association, while we found 14 340 sources in the same region that are only in the HPPSC2 and not in the Hi-GAL DR1. 1288 (9.0%) of them has a pain in Simbad. In general we can tell that in the same galactic plane region in the BS band 28.8% of the HPPSC2 sources have a Simbad match, while 28.9% of the Hi-Gal sources. In the R band these ratios are 23.7% and 15.9% for the HPPSC2 and Hi-GAL DR1, respectively.
The Hi-GAL 360° compact source catalogue was released in 2021 (Elia et al. 2021) and is a band-merged catalogue containing 94 604 sources. 34 096 of them were detected in the BS band, and 76 165 in the R band. In the same region the HPPSC2 catalogue lists 75 315 sources in the BS band and 110 121 objects in the R band. The comparison with Hi-GAL 360° shows that the number of cross-matches in the BS band is 20 114 (14 246 with HPPSC1) and 35 898 in the R band (20694 using HPPSC1). Statistics of the ratios of the Hi-GAL 360° and the HPPSC2 photometry are also listed in Table 13.
We also evaluated our catalogue by comparing the number of Simbad matches, and used the number of matching sources of both catalogues a reliability test. In the BS band 10 057 (29.5%) Hi-GAL 360° compact sources have matches, while this number is 20 846 (27.7%) for the HPPSC2. 7702 (38.3%) of the common sources have a counterpart in Simbad. 12 723 sources are only in the Hi-GAL catalogue, 2103 (16.5%) of them has a Simbad association, while 55 201 sources are only in the HPPSC2 catalogue, and 13 128 (23.8%) of them have a Simbad match. In the R band 20 843 (27.4%) of Hi-GAL compact sources have Simbad counterpart, this number is 23 303 (21.2%) for the HPPSC2. The number of sources shared between Hi-GAL 360° and HPPSC2 is 13 975 (38.9%). 40 267 are only in the Hi-GAL with 6868 (17.1%) Simbad matches and 74 223 are only in HPPSC2, with 9044 (12.2%) Simbad matches.
The flux distribution of the sources that are found in both the HPPSC2 and in the Hi-GAL 360° catalogue, also that of only in one of the catalogues, is shown on Fig. 20. As one can see from the figures, the sources common in the catalogues and those found only in the Hi-GAL 360° have a similar flux density distribution, while the sources found only in HPPSC2 have a lower flux density in general.
Comparison of the photometry of the previous and the new versions of the catalogue with that of the flux density values listed in the Hi-GAL DR1, the Hi-GAL 360°, and the PEP catalogues.
6.7 Cross-match with the PACS Evolutionary Probe
The PACS Evolutionary Probe (PEP, Lutz et al. 2011) carried out deep FIR photometric surveys studying galaxy evolution and the nature of the cosmic infrared background are a key strength of the Herschel mission. They provided blind catalogues based on BL and R photometric observations with the PACS instrument, listing 14 550 and 13 473 sources, respectively. We found that 7 851 sources are common in the BL band (6624 with HPPSC1) and 2208 sources are common in the R band (3805 with HPPSC1). Table 13 shows the statistics of the photometry compared to the flux density values listed in the PEP catalogues. It clearly shows that the photometry of the new catalogue has a better agreement with the PEP catalogue than the previous version, as the mean, the median the standard deviation and the median absolute deviation of the flux ratios have improved since the HPPSC1.
We check the biggest field observed by the PEP programme, the Cosmos field, located between 149.3 < RA < 150.9 and 1.4 < Dec < 3 degrees. We made a reliability test in a similar fashion to that in the comparison with the HiGAL 360° catalogue, but instead of comparing the catalogues to Simbad, this time the basis of the comparison was the NASA/IPAC Extragalactic Database (NED).
In the BL band the PEP catalogue lists 7443 sources, 7390 (99.3%) of them has NED counterpart. In the same field and same band HPPSC2 lists 5921 sources, and 5 881 (99.3%) has NED match. There are 1626 sources in this field which were found by our pipeline but are not listed in the PEP catalogue, 1586 (97.5%) of them also listed in NED.
In the R band the PEP survey found 7047 sources in the same region, while our catalogue lists 1428 objects. 7025 (99.7%) PEP sources, and all of the HPPSC2 sources have a NED match. We found 55 sources that are in the HPPSC2 catalogue, but not in the PEP, all of them have a counterpart in NED. The reason why HPPSC2 list so much less sources is two-fold. First, the PEP catalogue was created from high-pass filtered maps, that removed most of the large scale fluctuations from the maps, therefore modifying the noise properties, allowing a lower threshold of detection. Second, the photometry and the noise estimation was tailored for these specific observations, resulting in better signal-to-noise ratios. We would like to note here that in the same field 1272 additional sources are listed in the rejected source lists.
 |
Fig. 20 Flux density distribution comparison for sources listed in both the HPPSC2 and the Hi-GAL 360° compact source catalogue (red), for sources listed only in the HPPSC2 (green), and only in the Hi-GAL 360° (blue) for the BS band (top) and R band (bottom). |
7 Summary and conclusions
In this article, we delivered the second version of the Herschel PACS Point Source Catalogue (HPPSC2). We combined widely used source detection and photometry extraction methods with advanced machine learning techniques through all the processing steps with the aim of creating the cleanest and most complete catalogue of FIR sources observed in the BS, BL and R photometric bands centred at 70, 100 and 160 μm wavelengths, respectively. Our map repository contained the 15 107 highest level processed JScanam maps across the three different bands in three observing modes. These observations were treated according to their observing mode, band, and scanning speed.
Along with ready-to-use methods, such as SUSSEXtractor, DAOStarFinder, and a Haar-feature based method, we developed a deep learning algorithm, the ResidualHerschelNet to identify sources in regions with the most complex environment. We also performed photometry with various algorithms and different set-ups and evaluated the method providing the best overall performance.
In order to test all the different methods in both source identification and photometry, we carried out a large volume of simulations where we added artificial sources with well-controlled flux density levels to real observations, and applied our methodology to re-extract these sources. In total 198 600 sources were added and used as a training to quantify the completeness and photometric accuracy of the catalogue. A subsample of these sources was combined with real objects and fake detections and used as a training sample to discriminate between real and spurious identifications using several machine learning methods. We found that a random forest classifier applied to a set of calculated features gives a more robust result than applying the same method to the ensemble of raw features generated by the methods described in the paper. The expected misclassification in our final methods was between 1 and 5%, depending on the observational mode and the band. This misclassification has a greater impact on completeness than on purity, as the accuracy of the spurious source identification is between 1–2%. Still, we found that the completeness is much better in all bands compared to the first version of the catalogue, with a significant improvement above the 100 mJy level in the BS band, and a 5–10% overall increase in the BL and R bands. The 90% completeness is reached at ~300, ~200, and ~1000 mJy levels, but highly depending on the environment.
We created structure noise maps to describe the environments of our sources, and estimated the photometric uncertainty as a function of the NS parameter using support vector machine regression. This uncertainty and the corresponding S/N helped us to construct the final high-reliability catalogues, which contain sources with S/N ≥3. In case of multiple detection of an object, we kept the detection with the highest S/N value in these products.
Our comparisons with multiple catalogues provided by Herschel key programmes, and with the photospheric models of standard stars show a good agreement in terms of the extracted flux density values. We found that the agreement with the models is within 1% on average, and the uncertainty is within the nominal 5%. Comparison with the Hi-Gal catalogues and the PEP catalogues also show good agreement, even though the observations, methods, and catalogues for both the Hi-GAL and the PEP were tailored for very different scientific needs, one for embedded sources in complex, galactic star-forming regions, and the other for purely extragalactic studies.
As final products, we compiled a high-reliability table and a rejected source table for each PACS photometric band, which are available through the VizieR, ESAsky, and IRSA databases. The high-reliability catalogue outperforms the first version of the HPPSC in terms of completeness, purity, and accuracy. It also adds and delivers large number of objects and valuable data to the catalogues provided by large key programmes. The rejected source catalogues also provide the same type of data as the high-reliability catalogues, but only for sources with lower S/N values, and multiple detections of the same astrophysical object appears.
We are currently in the process of developing a deep learning approach, which will significantly enhance the background estimation of each source, removing the high level of fluctuation in the background annulus of the current aperture photometric method. This method is more to be tailored for sources located in complex environments, and will provide a complementary catalogue, that will be discussed and published in an upcoming paper.
Acknowledgements
Authors would like to acknowledge the former Herschel Point Source Catalogue Working Group as the current work heavily relies on the experience and knowledge collected during the creation of the first catalogue. We also want to thank our referee, B. Vandenbussche, for his useful comments and suggestions that helped improve the paper. This project is funded by the European Union’s Horizon 2020 research and innovation programme under grant agreement No. 101004141. This research was supported by the International Space Science Institute (ISSI) in Bern, through ISSI International Team project #521 (Star Formation with Big Data). G.M. acknowledges support from the János Bolyai Research Scholarship of the Hungarian Academy of Sciences. M.M. acknowledges support from the ESA PRODEX contract nr. 4000129910. This research has made use of the Simbad database, operated at CDS, Strasbourg, France. This research has made use of the VizieR catalogue access tool, CDS, Strasbourg, France (DOI: 10.26093/cds/vizier). This research has also made use of the NASA/IPAC Extragalactic Database (NED), which is operated by the Jet Propulsion Laboratory, California Institute of Technology, under contract with the National Aeronautics and Space Administration. This work made use of software TOPCAT/STILTS (Taylor 2005).
Appendix A Photometric accuracy based on simulations
 |
Fig. A.1 Photometric accuracy for the different bands and observing modes with all the methods and different aperture sizes. Same as Figure 6 but for all bands and modes. |
Appendix B Structure noise based Signal-to-noise ratio
 |
Fig. B.1 Same as Figure 11 but for all bands and modes. Left: Signal-to-noise ratio of the simulated sources as a function of the NS and the input flux density. Middle: Signal-to-noise ratios predicted on a grid by the SVM regression model based on the simulations shown in the top figure. Right: Signal-to-noise ratios for the real sources predicted by the SVM regression model. In each figure the signal-to-noise values are shown by the colours on the same logarithmic scale. Row 1: Scan Map mode BS band, row 2: Scan Map mode BL band, row 3: Scan Map mode R band, row 4: Parallel mode BS band, row 5: Parallel mode BL band, row 6: Parallel mode R band. |
 |
Fig. B.2 (Continued) Same as Figure 11 but for all bands and modes. Left: Signal-to-noise ratio of the simulated sources as a function of the NS and the input flux density. Middle: Signal-to-noise ratios predicted on a grid by the SVM regression model based on the simulations shown in the top figure. Right: Signal-to-noise ratios for the real sources predicted by the SVM regression model. In each figure the signal-to-noise values are shown by the colours on the same logarithmic scale. Row 1: Scan Map mode BS band, row 2: scnmap mode BL band, row 3: Scan Map mode R band, row 4: Parallel mode BS band, row 5: Parallel mode BL band, row 6: Parallel mode R band. |
Appendix C Simbad cross-matches
 |
Fig. C.1 Histogram of the different Simbad main object types of HPPSC2 in the three bands. Only those types with more than ten objects are plotted. |
References
- Astropy Collaboration (Robitaille, T. P., et al.) 2013, A&A, 558, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Astropy Collaboration (Price-Whelan, A. M., et al.) 2018, AJ, 156, 123 [Google Scholar]
- Astropy Collaboration (Price-Whelan, A. M., et al.) 2022, ApJ, 935, 167 [NASA ADS] [CrossRef] [Google Scholar]
- Balog, Z., Müller, T., Nielbock, M., et al. 2014, Exp. Astron., 37, 129 [Google Scholar]
- de Graauw, T., Helmich, F. P., Phillips, T. G., et al. 2010, A&A, 518, L6 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Deng, J., Dong, W., Socher, R., et al. 2009, 2009 IEEE Conference on Computer Vision and Pattern Recognition, 248 [CrossRef] [Google Scholar]
- Elia, D., Merello, M., Molinari, S., et al. 2021, MNRAS, 504, 2742 [NASA ADS] [CrossRef] [Google Scholar]
- Górski, K. M., Hivon, E., Banday, A. J., et al. 2005, ApJ, 622, 759 [Google Scholar]
- Griffin, M. J., Abergel, A., Abreu, A., et al. 2010, A&A, 518, L3 [EDP Sciences] [Google Scholar]
- He, K., Zhang, X., Ren, S., & Sun, J. 2016a, in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770 [CrossRef] [Google Scholar]
- He, K., Zhang, X., Ren, S., & Sun, J. 2016b, in European Conference on Computer Vision, 630 [Google Scholar]
- Ioffe, S., & Szegedy, C. 2015, Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, 37, 448 [Google Scholar]
- Kingma, D. P., & Ba, J. 2014, arXiv e-prints [arXiv:1412.6980] [Google Scholar]
- Kiss, C., Klaas, U., & Lemke, D. 2005, A&A, 430, 343 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Klaas, U., Balog, Z., Nielbock, M., et al. 2018, A&A, 613, A40 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lutz, D., Poglitsch, A., Altieri, B., et al. 2011, A&A, 532, A90 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Marton, G., Calzoletti, L., Perez Garcia, A. M., et al. 2017, arXiv e-prints [arXiv:1705.05693] [Google Scholar]
- Molinari, S., Swinyard, B., Bally, J., et al. 2010, PASP, 122, 314 [Google Scholar]
- Molinari, S., Schisano, E., Elia, D., et al. 2016, A&A, 591, A149 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Nair, V., & Hinton, G. E. 2010, in International Conference on Machine Learning https://api.semanticscholar.org/CorpusID:15539264 [Google Scholar]
- Nielbock, M., Müller, T., Klaas, U., et al. 2013, Exp. Astron., 36, 631 [NASA ADS] [CrossRef] [Google Scholar]
- Paszke, A., Gross, S., Massa, F., et al. 2019, PyTorch: an Imperative Style, High-performance Deep Learning Library (Red Hook, NY, USA: Curran Associates Inc.) [Google Scholar]
- Pilbratt, G. L., Riedinger, J. R., Passvogel, T., et al. 2010, A&A, 518, L1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Poglitsch, A., Waelkens, C., Geis, N., et al. 2010, A&A, 518, A2 [Google Scholar]
- Savage, R. S., & Oliver, S. 2007, ApJ, 661, 1339 [NASA ADS] [CrossRef] [Google Scholar]
- Schulz, B., Marton, G., Valtchanov, I., et al. 2017, arXiv e-prints [arXiv:1706.00448] [Google Scholar]
- Stetson, P. B. 1987, PASP, 99, 191 [Google Scholar]
- Taylor, M. B. 2005, in ASP Conf. Ser., 347, Astronomical Data Analysis Software and Systems XIV, eds. P. Shopbell, M. Britton, & R. Ebert, 29 [NASA ADS] [Google Scholar]
Documentation of the HIPE software, including the algorithms are available on the ESA Cosmos website.
Part of the IDL Astronomy User’s Library, available at IDL Astronomy Library GitHub site
In depth details of the algorithm is available here: https://www.nv5geospatialsoftware.com/docs/using_idl_home.html
All Tables
Number of maps obtained with different observing modes in the 70 μm blue (BS – blue short), 100 μm green (BL – blue long) and 160 μm (R – red) bands.
Number of detections added by the different source finding algorithms that resulted in the master lists in case of some example maps.
Average confusion matrices of the five RF and XGB classifiers trained for the different observing modes and bands.
Number of sources in the high-reliability tables of the HPPSC2 in each band, observing mode and data product level.
Comparison of the theoretical flux density values for PACS standard stars with measured flux densities..
The ten most abundant Simbad object types in the different bands in HPPSC2 and HPPSC1.
Comparison of the photometry of the previous and the new versions of the catalogue with that of the flux density values listed in the Hi-GAL DR1, the Hi-GAL 360°, and the PEP catalogues.
All Figures
|
Fig. 1 Filter transmissions of the PACS filter chains. The graph is from the PACS Observer’s Manual and represents the overall transmission of the combined filters with the dichroic and the detector relative response in each of the three bands of the photometer. The dashed vertical lines mark the original intended (design values) of the band edges. |
| In the text | |
|
Fig. 2 Standard product generator chain from Level 0 to Level 3. The raw data are stored in Level 0 cubes. After numerous levels of noise removal and processing, the Level 2.5 and Level 3 maps are the final products that are used for the PSC generation. |
| In the text | |
|
Fig. 3 Workflow of the HPPSC2 catalogue generation. |
| In the text | |
|
Fig. 4 Examples of training sample stamp images in the Scan Map BS band used to train ResidualHerschelNet, our deep learning PyTorch classifier. The top panel shows pictures of the real training sample, while the bottom panel shows stamps for the fake sources. |
| In the text | |
|
Fig. 5 Example of a comparison between the original image (top) and the corresponding probability map (bottom) generated by the ResidualHerschelNet model. The probability map visualises the predicted likelihood of source presence. Brighter areas indicate higher probabilities of source detection. |
| In the text | |
|
Fig. 6 Photometric accuracy for the Scan Map mode observations in the BS (70μm) band. Flux accuracy is the ratio of the measured flux density to the injected flux density. The perfect accuracy is highlighted with the yellow horizontal line at 1. The horizontal axis shows the different methods and aperture sizes used in the exercise. From left to right, the methods are the IDL aper routine with aperture sizes between 3 and 25 arcsec, with one-arcsecond steps; the AstroPy aperture_photometry routine using average background subtraction with aperture sizes of [4, 5, 6, 7, 8, 9, 10, 11, 12, 13, and 18] arcsec; the AstroPy aperture_photometry routine using median background subtraction using the same aperture sizes; the SUSSEXtractor flux determination (one value). The last method is the annularAperturePhotometry task in HIPE with aperture sizes similar to the AstroPy values. Figures for all observing modes and bands are found in Appendix A. HIPE DAOPhot and IDL gauss2dfit are not included because DAOPhot gives the same result as the annularAperturePhotometry given the same aperture size, while gauss2dfit was not used for flux density determination. |
| In the text | |
|
Fig. 7 Sources artificially added to the BS Parallel mode observation of the Rosette Molecular Cloud. The top image shows sources with 500 mJy flux density. In the bottom image, sources with 3000 mJy flux density are added at the same sky positions. |
| In the text | |
|
Fig. 8 Circular configuration used for NS calculation. The target pixel is shown as a red square. The neighbouring pixels at the predefined angular distance are shown as green squares. |
| In the text | |
|
Fig. 9 RCW79 (OBSID=1342188880), a very structured galactic star-forming region. Left: Original map showing high amplitudes of fluctuations. Right: Structure noise map of the same region. Log scaling was used in both panels. The structure noise map shows that around the bright sources, the fluctuation of the background at a distance of ~30″ is higher than in places where the background is flat. If a pixel has a high value in the structure noise map, it means that in the vicinity of that pixel, the fluctuation of the original map is high. |
| In the text | |
|
Fig. 10 Measured flux density as a function of NS in the Scan Map R observations for sources injected at the 3000 (red), 2000 (blue), 1000 (green), 500 (grey), 100 (black) and 50 (magenta) mJy level. At higher NS values, the flux density values show higher scatter at all flux density levels. The solid lines indicate the respective theoretical flux density values. |
| In the text | |
|
Fig. 11 Signal-to-noise ratios in the BS band for the Scan Map mode. Top: signal-to-noise ratio of the simulated sources as a function of NS and the input flux density. Middle: signal-to-noise ratios predicted on a grid by the SVM regression model based on the simulations shown in the top figure. Bottom: signal-to-noise ratios for the real sources predicted by the SVM regression model. In each panel, the signal-to-noise values are shown by the colours on the same logarithmic scale. Figures for all bands and observing modes are shown in Fig. B.2. |
| In the text | |
|
Fig. 12 All-sky Aitoff projection of the high-reliability catalogue sources across the three PACS bands, presented in the galactic coordinate system. |
| In the text | |
|
Fig. 13 Distribution of the derived flux density values in the three PACS bands. The colours correspond to the individual bands, BS (blue), BL (green) and R (red) from left to right, respectively. |
| In the text | |
|
Fig. 14 Distribution of the predicted S/N (signal-to-noise ratio) values in the three PACS bands. Colours correspond to the individual bands, BS (blue), BL (green) and R (red) from left to right, respectively. |
| In the text | |
|
Fig. 15 Completeness of our new catalogue, HPPSC2 (red) in the three different bands compared to the completeness of the previous HPPSC1 catalogue (black). The completeness curves for the BS, BL and R bands are shown in the left, middle, and right panels, respectively. |
| In the text | |
|
Fig. 16 Difference of the injected position and the derived position as a function of the scan leg separation for the Scan Map BS observations. For each unique separation value the mean and the standard deviation of the positional difference are plotted. There is no clear systematic effect seen on the accuracy of the positions as a function of the scan leg separation. |
| In the text | |
|
Fig. 17 Two fields highlighting the differences of HPPSC1 and HPPSC2 in the BS band. The solid black dots show sources that were listed in HPPSC1. HPPSC2 includes both the solid dots and the black squares. |
| In the text | |
|
Fig. 18 Comparison of theoretical flux density and measured flux density values in the 70 (top), 100 (middle) and 160 (bottom) μm bands. The accuracy is calculated as a ratio of the measured and model flux, plotted as a function of the theoretical flux density. The 5% error limits are shown as solid grey lines. |
| In the text | |
|
Fig. 19 Flux density distribution comparison for sources listed in both Simbad and in HPPSC1 (light blue) and HPPSC2 (yellow) for the BS (top), BL (middle) and R (bottom) bands. |
| In the text | |
|
Fig. 20 Flux density distribution comparison for sources listed in both the HPPSC2 and the Hi-GAL 360° compact source catalogue (red), for sources listed only in the HPPSC2 (green), and only in the Hi-GAL 360° (blue) for the BS band (top) and R band (bottom). |
| In the text | |
|
Fig. A.1 Photometric accuracy for the different bands and observing modes with all the methods and different aperture sizes. Same as Figure 6 but for all bands and modes. |
| In the text | |
|
Fig. B.1 Same as Figure 11 but for all bands and modes. Left: Signal-to-noise ratio of the simulated sources as a function of the NS and the input flux density. Middle: Signal-to-noise ratios predicted on a grid by the SVM regression model based on the simulations shown in the top figure. Right: Signal-to-noise ratios for the real sources predicted by the SVM regression model. In each figure the signal-to-noise values are shown by the colours on the same logarithmic scale. Row 1: Scan Map mode BS band, row 2: Scan Map mode BL band, row 3: Scan Map mode R band, row 4: Parallel mode BS band, row 5: Parallel mode BL band, row 6: Parallel mode R band. |
| In the text | |
|
Fig. B.2 (Continued) Same as Figure 11 but for all bands and modes. Left: Signal-to-noise ratio of the simulated sources as a function of the NS and the input flux density. Middle: Signal-to-noise ratios predicted on a grid by the SVM regression model based on the simulations shown in the top figure. Right: Signal-to-noise ratios for the real sources predicted by the SVM regression model. In each figure the signal-to-noise values are shown by the colours on the same logarithmic scale. Row 1: Scan Map mode BS band, row 2: scnmap mode BL band, row 3: Scan Map mode R band, row 4: Parallel mode BS band, row 5: Parallel mode BL band, row 6: Parallel mode R band. |
| In the text | |
|
Fig. C.1 Histogram of the different Simbad main object types of HPPSC2 in the three bands. Only those types with more than ten objects are plotted. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.