Fig. 5.
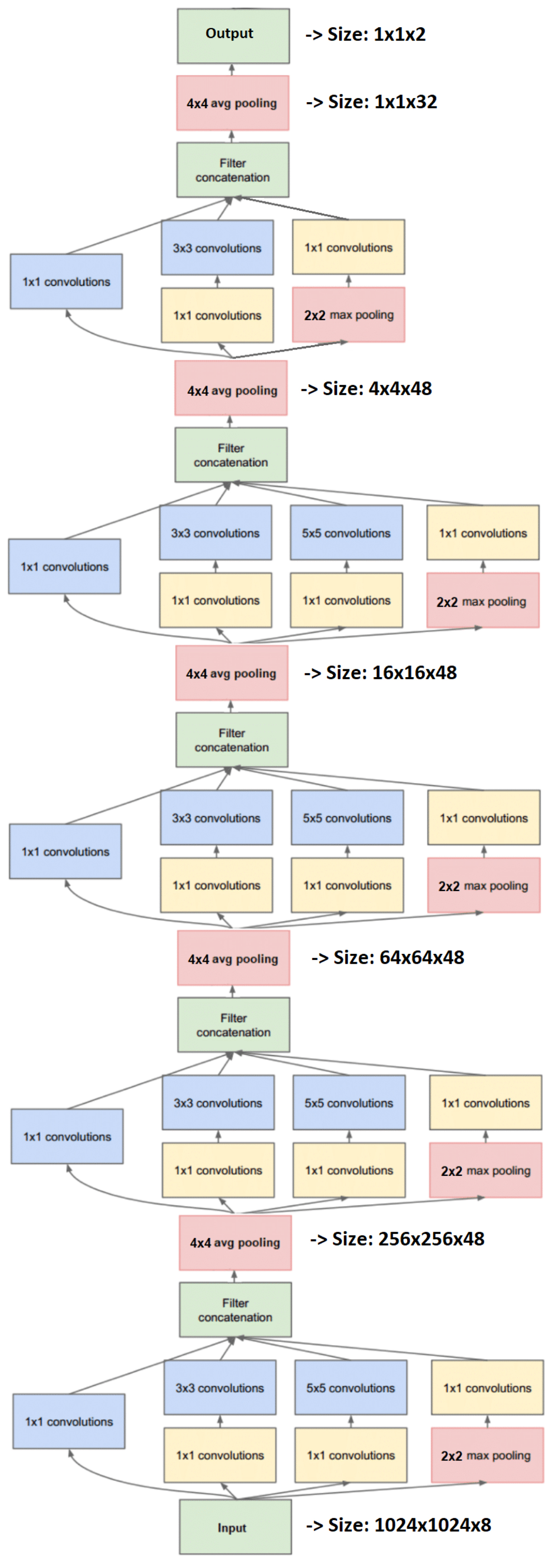
Fully convolutional inception network to perform the compression, see Table 4 for a full description. Each inception block is composed of parallelized convolutions that simultaneously process the same input at different scales to extract different features, then concatenates the full output. After each inception block, the input is compressed with a 4 × 4 pooling layer to decrease the resolution by a factor 4, then we indicate the current size. Finally, the output layer allows a compression down to the number of parameters of the model and is the summary statistics vector of Sect. 3.4.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.