| Issue |
A&A
Volume 649, May 2021
|
|
|---|---|---|
| Article Number | A127 | |
| Number of page(s) | 15 | |
| Section | Stellar structure and evolution | |
| DOI | https://doi.org/10.1051/0004-6361/202140413 | |
| Published online | 26 May 2021 | |
Goodness-of-fit test for isochrone fitting in the Gaia era
Statistical assessment of the error distribution
1
Dipartimento di Fisica “Enrico Fermi”, Università di Pisa, Largo Pontecorvo 3, 56127 Pisa, Italy
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
INFN, Sezione di Pisa, Largo Pontecorvo 3, 56127 Pisa, Italy
Received:
25
January
2021
Accepted:
5
March
2021
Abstract
Context. The increasing precision in observational data made available by recent surveys means that the reliability of stellar models can be tested. For this purpose, a firm theoretical basis is crucial for evaluating the agreement of the data and theoretical predictions.
Aims This paper presents a rigorous derivation of a goodness-of-fit statistics for colour-magnitude diagrams (CMD). We discuss the reliability of the underlying assumptions and their validity in real-world testing.
Methods. We derived the distribution of the sum of squared Mahalanobis distances of stellar data and theoretical isochrone for a generic set of data and models. We applied this to the case of synthetic CMDs that were constructed to mimic real data of open clusters in the Gaia sample. Then, we analysed the capability of distinguishing among different sets of input physics and parameters that were used to compute the stellar models. To do this, we generated synthetic clusters from isochrones computed with these perturbed quantities, and we evaluated the goodness-of-fit with respect to the reference unperturbed isochrone.
Results. We show that when r magnitudes are available for each of the N observational objects and p hyperparameters are estimated in the fit, the error distribution follows a χ2 distribution with (r − 1)N − p degrees of freedom. We show that the linearisation of the isochrone between support points introduces negligible deviation from this result. We investigated the possibility of detecting the effects on stellar models that are induced when the following physical quantities were varied: convective core overshooting efficiency, 14N(p, γ)15O reaction rate, microscopic diffusion velocities, outer boundary conditions, and colour transformation (bolometric corrections). We conducted the analysis at three different ages, 150 Myr, 1 Gyr, and 7 Gyr, and accounted for errors in photometry from 0.003 mag to 0.03 mag. The results suggest that it is possible to detect the effect induced by only some of the perturbed quantities. The effects induced by a change in the diffusion velocities or in the 14N(p, γ)15O reaction rate are too small to be detected even when the smallest photometric uncertainty is adopted. A variation in the convective core overshooting efficiency was detectable only for photometric errors of 0.003 mag and only for the 1 Gyr case. The effects induced by the outer boundary conditions and the bolometric corrections are the largest; the change in outer boundary conditions is detected for photometric errors below about 0.01 mag, while the variation in bolometric corrections is detectable in the whole photometric error range. As a last exercise, we addressed the validity of the goodness-of-fit statistics for real-world open cluster CMDs, contaminated by field stars or unresolved binaries. We assessed the performance of a data-driven cleaning of observations, aiming to select only single stars in the main sequence from Gaia photometry. This showed that this selection is possible only for a very precise photometry with errors of few millimagnitudes.
Key words: stars: fundamental parameters / methods: statistical / stars: evolution / stars: interiors / open clusters and associations: general
© ESO 2021
1. Introduction
Open clusters (OCs) have a central role in astrophysical research because they provide an invaluable test bed for our understanding of several processes, from star formation to the physics processes involved in stellar evolution and to galaxy evolution (see e.g., Maeder & Mermilliod 1981; Janes & Adler 1982; Barbaro & Pigatto 1984; Friel 1995; Piskunov et al. 2006; Bonatto et al. 2006; Randich et al. 2007; Miglio et al. 2012; Cantat-Gaudin et al. 2016). They also provide a classical target for calibrating the age scale and other stellar parameters such as the initial helium abundance, superadiabatic convection efficiency, or the convective core overshooting parameter (see e.g., VandenBerg & Stetson 2004; Gennaro et al. 2012; Valle et al. 2018; McKeever et al. 2019; Tognelli et al. 2021).
The analysis of OCs is classically based on fitting the colour-magnitude diagram (CMD) with a set of stellar isochrones (see e.g., Mermilliod 2000 for a review of the adopted fitting methods). This approach mainly relies on maximum-likelihood (ML) or Bayesian techniques and leads to a major advancement in the age determination of OCs and in the possibility of obtaining a sensible calibration of stellar free parameters. However, the method has some systematic errors and observational difficulties that have been problematic to properly address in the past (see e.g., Bica & Bonatto 2011; Netopil et al. 2016; Kos et al. 2018; Cantat-Gaudin et al. 2018). A major problem in the fitting, especially regarding model comparison, are the large errors (dozens of millimagnitudes; mmag) affecting the observational data. These errors blur the sequence of the single and binary stars, and make them indistinguishable.
The large observational uncertainties that blur the cluster sequence affect the capability of fitting procedures to distinguish among theoretical models based on different assumptions of the fundamental input physics, free parameters, or non-standard mechanisms (i.e. rotation, magnetic fields, and spot activity) because such models might fit the data equally well. Ultimately, the magnitude of the observational errors limits the distinguishing power of the data.
It is indeed clear that testing models that account for differences in the prediction of a few mmag in the CMD requires data with higher or at least comparable precision. The advent of the Gaia satellite had a tremendous effect in this research field. The second and early third data releases (hereafter DR2 and EDR3, Gaia Collaboration 2018b, 2021) provide homogeneous photometric data for the whole sky as well as high-precision kinematics and parallax information. This information allows establishing accurate membership and identifying new clusters (see e.g., Cantat-Gaudin et al. 2018, 2019; Castro-Ginard et al. 2018; Ferreira et al. 2019; Bossini et al. 2019).
The Gaia DR2 and EDR3 photometry consists of three broad bands: a G, a GBP, and a GRP magnitude, which are available for the large majority of targets (Evans et al. 2018; Riello et al. 2021). At present, the internal error on individual CCD measurements in the Gaia DR2 can reach a precision as low as 0.002 mag, while systematic effects can account for an additional 0.01 mag uncertainty (Evans et al. 2018). Internal tests revealed a distortion of a few mmag or mag, corresponding to and increasingly brighter GBP for fainter sources (Arenou et al. 2018). The GBP and GRP band flux excess is extensively discussed in Evans et al. (2018); this bias occurs especially frequently in dense fields, binary stars, near bright stars, and fainter sources.
Even with these systematic biases, the Gaia DR2 and EDR3 catalogues provide a clean photometry for the main sequence of most clusters (see e.g., the clusters presented by Bossini et al. 2019). Thanks to the low internal error in the magnitudes, the CMDs clearly show the single-star sequence, accompanied by the equal-mass binary sequence, and a few peculiar sources or contaminating field stars. This scenario is expected to improve even more with the release of Gaia DR3. This catalogue will contain an improved photometry and preliminary source classification, allowing a direct identification of unresolved binaries.
The high-precision photometry in the Gaia DR2 and EDR3 catalogues and the expected improvements in future releases open new possibilities in the framework of validating stellar evolution models. Magnitudes with uncertainties in the mmag range provide the possibility of comparing models computed with different chemical composition and input physics with a sound possibility of distinguishing between them on the basis of the observational data and robust statistical error treatment. In addition to this, the availability of high-quality data allows the possibility of an absolute evaluation of the goodness of the fit for more targets, based on the analysis of the distances from observational data and best-fitting isochrone. This steps has been hampered in the past by the large observational errors: a large uncertainty is reflected in very low values of these residual distances and then in a negligible power in rejecting a fit as unsatisfactory.
A key ingredient needed for this analysis is a deep theoretical understanding of what is expected under the assumption of tiny observational uncertainties. In the light of the previous discussion about the effect of observational errors, it is surprising that this or similar theoretical analysis received little interest in the literature. While many fitting methods have been proposed and validated (see Soderblom 2010; Valls-Gabaud 2014, for a review), only few researches have explored the goodness-of-fit question. As an example, Naylor & Jeffries (2006) proposed an ML method to fit the CMD and derived the expected error distribution, while Tolstoy & Saha (1996) performed a Monte Carlo (MC) analysis on a Bayesian framework. For our aims, the most relevant effort has been made by Flannery & Johnson (1982), who attempted to derive a goodness-of-fit Ψ2 statistics for isochrone fitting, considering the sum of the minimum distances between observed sources and a fitting isochrone. However, they detected a non-negligible discrepancy between the computed statistics and the results obtained with the analysis of synthetic CMD, mainly due to a cut-off in the colours of stars imposed before the fitting. When their method was applied to several clusters, they found that most of them were unlikely at the level of 6σ. The authors noted that merely increasing the error estimates by 50% would reconcile these problems. They concluded that this method requires more sound measurements with known and reliable uncertainty, and accurately ascertained cluster membership.
While previous works have explored some aspects of the question of the goodness-of-fit, a basic theoretical problem is still open: a rigorously derived distribution of the squared distances under the assumption that the observational data were generated by an isochrone. This paper aims to fill this gap. To perform this derivation, we work in an idealised scenario, and we discuss how well the assumptions hold for a real-world fitting.
The paper is organized as follows. Section 2 presents the reference fitting method, that is, a purely geometrical technique based on the squared sum of the minimum distances between observations and a generating isochrone. Section 3 presents a theoretical analysis addressing the computation of the distribution of the chosen statistic, with a specific application to the Gaia magnitude space. We consider in this derivation only single stars, and we do not allow contaminating field stars or peculiar sources. Section 4 explores the foundations of some mathematical assumptions in the distribution derivation. Section 5 investigates the possibility of detecting some input physics modifications in the stellar models, relying on the goodness-of-fit statistics. Section 6 presents some results about the possibility of adopting the computed distribution for real clusters, taking also contaminating sources and unresolved binaries into account. The concluding remarks are collected in Sect. 7.
2. Methods
Let P be a point in the observable hyperspace corresponding to an observed source. Working in the Gaia magnitude space, this corresponds to the observed G, GBP, and GRP values. Let σ = {σG, σGBP, σGRP} be the observational uncertainties in these magnitudes. Let ℐ be a theoretical isochrone, parametrised by a vector θ of latent variables, such as the age, the metallicity, the mixing-length value, and the initial helium content.
In a ML or Bayesian frameworks, it is possible to estimate the posterior distribution of the parameters θ by means of a Monte Carlo Markov chain, for example, or by directly evaluating the likelihood function over a sufficiently dense grid in the parameter space. The evaluation of the likelihood for θ obviously requires a statistic to measure how well an isochrone fits a set of points. Two methods are widely adopted in the literature (see among many Frayn & Gilmore 2002; Pont & Eyer 2004; Jørgensen & Lindegren 2005; von Hippel et al. 2006; Gai et al. 2011; Casagrande et al. 2016; Creevey et al. 2017; Valle et al. 2018), and several aspects of their relative performances are well understood. A first technique aims at minimising the residual distances in the observational space between observed points and isochrone. This purely geometrical approach neglects the different occupation probabilities of the different portions of the isochrone. A second approach assesses the probability that a point comes from an isochrone by cumulating the probabilities that it comes from different portions of the isochrone. It accounts for the different occupation probabilities by considering the evolutionary time step. This second approach uses not only the nearest point on the isochrone, but also a portion of the isochrone near to this minimum. As a result, it usually provides a much narrower error interval on the estimated θ than the first approach. However, this comes at a price. As extensively discussed in Valle et al. (2018), the second approach can provide biased estimates in which the θ posterior credible interval does not cover the true values. In this paper we focus on the first method.
The stellar models were produced using a recent version of the FRANEC stellar evolutionary code (see e.g., Degl’Innocenti et al. 2008; Dell’Omodarme et al. 2012), with the same input physics as described in Tognelli et al. (2018). We computed evolutionary models in the mass range [0.4, 4.6] M⊙ assuming [Fe/H] = 0, with the solar-scaled metal distribution given by Asplund et al. (2009), which leads to an initial helium and metallicity (Y, Z) = (0.274, 0.0130). We used our solar calibrated mixing length parameter for the reference set, namely αml = 2.0. The models with M ≥ 1.2 M⊙ account for convective core overshooting, with a overshooting parameter β = 0.15 as reference. Diffusion was accounted for using the formalism described in Thoul et al. (1994). The outer boundary conditions (boundary conditions, i.e. P and T at the bottom of the atmosphere) were extracted from the AHF11 atmosphere models (Allard et al. 2011).
Theoretical models were converted into the Gaia magnitudes using the MARCS synthetic spectra (Gustafsson et al. 2008) for Teff ≤ 8000 K, completed by the CK03 Castelli & Kurucz (2003) at higher Teff. In both cases, the magnitudes were obtained using the filter transmissions and photometric zero points given in Evans et al. (2018). To explore a wide range of ages and thus of masses, isochrones at three different ages (150 Myr, 1 Gyr, and 7 Gyr) were computed from the evolutionary tracks, following the procedure outlined in Dell’Omodarme et al. (2012).
This paper accounts for stellar evolution up to the central hydrogen exhaustion, but most of the analysis is restricted to the main sequence (MS) phase, where the agreement between different stellar evolutionary codes is better than that for later evolutionary phases. They typically agree to within a few percent in the MS, while the disagreement is even larger than 30% in the helium-burning stages (see e.g., Cassisi 2014). A goodness-of-fit statistics is clearly much more interesting in regions where different evolutionary models agree well and a change in their input physics causes a well-understood and reproducible behaviour.
3. Computing the error distribution
A relevant computational problem arises in defining the minimum distance between the isochrone ℐ and an observational point P in an r dimensional space because isochrones are known as a series of points. The direct computation of the minimum distance between the isochrone support points and P is known to pose several problems (see e.g., Frayn & Gilmore 2002; Valle et al. 2018). In the following, the minimum distance is computed by approximating ℐ with a straight line t between two consecutive points and evaluating the minimum distance between t and P. This approximation is known to be very good as the errors introduced by the linear approximation are totally negligible (see e.g., Harris & Zaritsky 2001; Bergbusch & VandenBerg 2001; Frayn & Gilmore 2002; Valle et al. 2018), especially when the isochrone support points grid is dense.
We parametrised the point Q on the line t between two consecutive isochrone points as
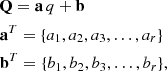 (1)
(1)
where q ∈ [0, 1] is a real parameter. Let P be an observational point. Under the null hypothesis (i.e. the isochrone describes the data), this point lies on t, with parameter q = qp. Let ε ∼ N(0, S) be the observational errors in P determination1. Under the hypothesis of independent errors, the covariance matrix S is diagonal,
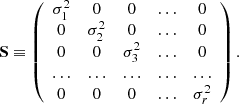 (2)
(2)
Thus,
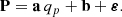 (3)
(3)
The squared distance d2 between P and Q with respect to the metric defined by S−1 is therefore
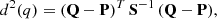 (4)
(4)
corresponding to the standard sum of squared distances weighted by the respective errors, also known as Mahalanobis distance. A vast literature exists on the assessment of its distribution under different assumptions (see e.g., Hardin & Rocke 2005), with applications to linear discriminant analysis and least-squares regression (Gnanadesikan & Kettenring 1972). Because of the nature of the isochrone fitting process, we are interested in a very specific configuration that has been overlooked in the existing literature.
The minimum of this distance over q, corresponding to the distance between P and t, is trivially obtained by imposing the derivative with respect to q to vanish,
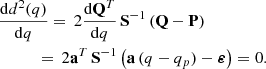 (5)
(5)
Solving Eq. (5) for q gives
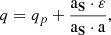 (6)
(6)
where aS is
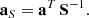 (7)
(7)
Thus the minimum distance from Eq. (4) is given by the quadratic form
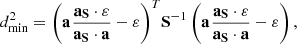 (8)
(8)
which corresponds (because S is diagonal) to the sum of the squares of three correlated Gaussian variables. By defining
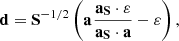 (9)
(9)
we can write
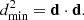 (10)
(10)
We focus on the components of d. The individual distribution of these components is trivially Gaussian, as they result from the sum of the Gaussian random variables ε. Recalling that ε ∼ N(0, S), it follows
![Mathematical equation: $$ \begin{aligned} \mathrm{E}[\mathbf d ] = \mathbf 0 . \end{aligned} $$](/articles/aa/full_html/2021/05/aa40413-21/aa40413-21-eq11.gif) (11)
(11)
The computations of covariance matrix 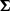 requires a little algebra,
requires a little algebra,
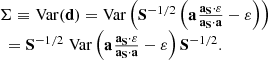 (12)
(12)
By expanding the variance
 (13)
(13)
and with some algebraic steps (see Appendix B), we obtain
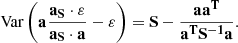 (14)
(14)
Finally, putting Eqs. (12) and (14) together,
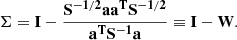 (15)
(15)
The problem of determining the distribution of the minimum distance then reduces to deriving the distribution of the quadratic form d ⋅ d under the assumption d ∼ N(0, Σ). We refer to Provost & Mathai (1992) for a detailed discussion of this and inherent topics; in the following, we present a sketch of the computation for the case under examination.
We consider a random r-variate variable X ∼ N(μ, Σ), and a quadratic form
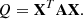 (16)
(16)
We are interested in deriving the distribution of Q. We define
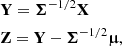 (17)
(17)
with Σ−1/2 the inverse matrix square root of Σ. Then Z ∼ N(0, I), and Eq. (16) can be rewritten as
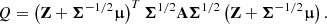 (18)
(18)
By using the spectral theorem, we can write
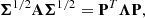 (19)
(19)
where Λ is the diagonal eigenvalues matrix, and PTP = PPT = I. Then we can pose U = PZ, with distribution U ∼ N(0, I). Substituting Eq. (19) into Eq. (18), we obtain
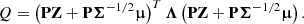 (20)
(20)
We define
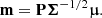 (21)
(21)
Then we have
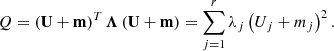 (22)
(22)
Therefore the distribution of Q is given by the linear combination of r non-central 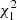 independent variables2, with weights the eigenvalues λj and non-centrality parameters mj. No closed form is known at present for this distribution (see e.g., Castaño-Martínez & López-Blázquez 2005).
independent variables2, with weights the eigenvalues λj and non-centrality parameters mj. No closed form is known at present for this distribution (see e.g., Castaño-Martínez & López-Blázquez 2005).
For our aims, the situation is simplified by the fact that A = I and μ = 0. By imposing the latter constraint, Eq. (22) reduces to a linear combination of 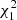 independent variables. In this case, no closed form is known for this distribution either, although different approaches exist in the literature for its computation (see e.g., Imhof 1961; Ruben 1962; Davis 1977; Mathai 1982; Moschopoulos & Canada 1984; Bausch 2013).
independent variables. In this case, no closed form is known for this distribution either, although different approaches exist in the literature for its computation (see e.g., Imhof 1961; Ruben 1962; Davis 1977; Mathai 1982; Moschopoulos & Canada 1984; Bausch 2013).
A further simplification arises by imposing A = I in Eq. (19), so that the matrix Λ contains the eigenvalues of Σ. From Eq. (15) it follows that
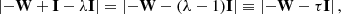 (23)
(23)
where τ = λ − 1 are the eigenvalues of −W. Considering that rank(W) = 13, it follows that τi = 0 for i = 1, …, r − 1, and consequently λi = 1 for i = 1, …, r − 1. As for the last eigenvalue it results λr = 0 because tr(Σ) = r − 1. Therefore the distribution of Q corresponds to the sum of r − 1 independent 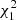 variables, resulting in a
variables, resulting in a 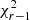 distribution.
distribution.
We can apply this method to the three Gaia magnitudes by defining aT, bT, and S in the following way:
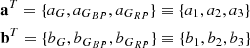 (24)
(24)
and
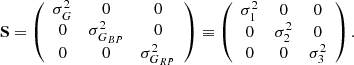 (25)
(25)
In summary, when a cluster of N stars is fitted adopting as observational constraints the Gaia magnitudes, the minimum distance of each star from an isochrone is a random variable with 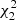 distribution instead of a
distribution instead of a 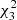 , as might be expected because three independent magnitudes are available. Then the sum of the minimum distances over the whole cluster is a random variable with
, as might be expected because three independent magnitudes are available. Then the sum of the minimum distances over the whole cluster is a random variable with 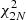 distribution. Because the fit optimises the isochrone over the p hyper-parameters θ (e.g., the age, the metallicity, and the initial helium abundance), the final degrees of freedom for the goodness-of-fit test are 2N − p.
distribution. Because the fit optimises the isochrone over the p hyper-parameters θ (e.g., the age, the metallicity, and the initial helium abundance), the final degrees of freedom for the goodness-of-fit test are 2N − p.
4. Robustness of the error distribution
The theoretical squared distance distribution is derived in Sect. 3 based on some idealised assumptions. A local straight line approximation for the isochrone shape in the magnitude space is adopted. Some deviations from this assumption are obviously expected for a real isochrone. This can be problematic because a synthetic star sampled from a portion of the isochrone may be reconstructed using a portion on the isochrone with somewhat different direction, violating the assumption of Eq. (3). This section is devoted to exploring the robustness of the theoretical approximation.
For this analysis we focused on a reference isochrone for [Fe/H] = 0.0 and an age of 7.0 Gyr; negligible differences arise from different assumptions about the metallicity or the age, as was directly verified. Figure 1 shows the CMD diagram of this isochrone in the G versus GBP − GRP plane (top left hand panel) and the plots of the three pairs of single Gaia magnitudes. From these pairs it is evident that a local straight line approximation is almost valid in the whole magnitude space, although some deviations from a line arise in the late red giant phase, at G ≈ −1.5 mag (see the top right and top left panels of Fig. 1). However, because this is a very rapid evolutionary phase compared to the rest of MS, it will be scarcely populated, and it does not pose a problem for a real-world analysis.
 |
Fig. 1. Top left panel: reference isochrone in the G vs. GBP − GRP plane. Top right panel: isochrone in the G versus GBP plane. Bottom left panel: isochrone in the G vs. GRP plane. Bottom right panel: isochrone in the GBP vs GRP plane. |
The hook at the end of the MS evolution might be more interesting. It is visible at G ∼ 3.5 mag in the panels because the local assumption of a constant direction of the straight line may not hold. However, even in this case, the probability of reconstructing a synthetic star as coming from an incorrect isochrone portion is really small. It is even possible to estimate the difference in the direction of the isochrone and weight it with the evolutionary time step to obtain an idea of the expected angle between the direction of the isochrone for a given step in magnitude. To do this, we computed the angle between two consecutive isochrone portions. Then we computed the weighted mean and median of these values, adopting as a weight the evolutionary time step tracked by the masses on the isochrone. The resulting mean and median angles between consecutive isochrone portions were 3.1 × 10−3 rad and 5.1 × 10−4 rad, implying an overall negligible effect of the direction changes. The goodness of the approximation clearly increases with the number of isochrone support points. For reference the isochrones we used have about 1000 points along the MS.
To further validate the assumption of a 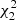 distribution for the minimum P − ℐ distance, we performed a direct evaluation by MC simulations. Several synthetic clusters were generated from the reference isochrone mentioned above assuming different number of stars, from N = 200 to N = 5000. For the purposes of this analysis, the synthetic cluster generation assumes a fraction of binary η = 0.0. An observational error of 0.003 mag in every magnitude was assumed, although this value is proved to be not critical4. A short description of the methods adopted for the synthetic CMD generation is reported in Appendix A. For each observational point of the synthetic cluster, the minimum squared distance d2 was computed with the same technique as detailed in Valle et al. (2018). The procedure was repeated n = 200 times for each N, which is sufficient to achieve a good statistical convergence of the empirical distributions of d2. Then the kernel densities of these distributions were computed and compared with a
distribution for the minimum P − ℐ distance, we performed a direct evaluation by MC simulations. Several synthetic clusters were generated from the reference isochrone mentioned above assuming different number of stars, from N = 200 to N = 5000. For the purposes of this analysis, the synthetic cluster generation assumes a fraction of binary η = 0.0. An observational error of 0.003 mag in every magnitude was assumed, although this value is proved to be not critical4. A short description of the methods adopted for the synthetic CMD generation is reported in Appendix A. For each observational point of the synthetic cluster, the minimum squared distance d2 was computed with the same technique as detailed in Valle et al. (2018). The procedure was repeated n = 200 times for each N, which is sufficient to achieve a good statistical convergence of the empirical distributions of d2. Then the kernel densities of these distributions were computed and compared with a 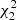 distribution. Figure 2 shows the results for N = 200 and N = 3000. In both cases the agreement is nearly perfect, confirming that the assumption of a straight line approximation holds. To avoid artificial differences at d2 near 0.0 between the two curves due to specific issues in computing a kernel density at the edge of the support range (see e.g., Karunamuni & Alberts 2005; Geenens & Wang 2018), the Jones (1993) correction was applied, as implemented in the evmix library (Hu & Scarrott 2018).
distribution. Figure 2 shows the results for N = 200 and N = 3000. In both cases the agreement is nearly perfect, confirming that the assumption of a straight line approximation holds. To avoid artificial differences at d2 near 0.0 between the two curves due to specific issues in computing a kernel density at the edge of the support range (see e.g., Karunamuni & Alberts 2005; Geenens & Wang 2018), the Jones (1993) correction was applied, as implemented in the evmix library (Hu & Scarrott 2018).
 |
Fig. 2. Left panel: comparison of the empirical distribution of the minimum distance between synthetic observations and isochrone (solid black line) and a |
As a final test, we evaluated the 95th quantile of the empirical distributions for the various N and compared them to the corresponding quantile of the theoretical distribution. This quantile is routinely used in statistical tests as a level of significance. The differences are very small, in the range [−0.3, 0.7]%. This confirms the high accuracy of the approximation.
5. Detecting systematic discrepancies in the input physics
The results presented in the previous sections open the interesting possibility of investigating the actual agreement between isochrones that were computed assuming different sets of input physics. Several ingredients that enter the stellar model computations are still affected by non-negligible uncertainties, so that different legitimate choices are available for the stellar modellers. In particular, this section is devoted to shedding some light on the question whether given a synthetic cluster generated from an isochrone with a given choice of input physics, how well it is fitted, relying on the computed goodness-of-fit, by the reference isochrone. The aim of this exercise is to verify the precision in the magnitude measurements to allow the possibility of rejecting a fit and thus a set of input physics as inadequate to reproduce the data.
We performed this MC experiment by generating synthetic clusters of n = 300 stars. For each assumption in the input physics, we generated 800 synthetic clusters and computed the d2 statistics with respect to the reference isochrone. Then we evaluated the distribution of these statistics and compared with the 95% quantile of the χ2 distribution with 600 degrees of freedom (i.e. 2 × n). The explored scenarios are expected to show different discrepancies in a different mass and age range. Therefore we repeated the MC analysis for three different ages, namely 150 Myr, 1 Gyr, and 7 Gyr. For every set of input physics, the mixing-length value was solar calibrated to avoid artificial discrepancies.
Some words of cautions are needed before we discuss the results. This procedure differs from what would be performed on real data. In that case, the reference statistics would be computed with respect to the best-fit isochrone, and not with respect to a fixed isochrone. Thus the expected statistics under a fit scenario will be lower than or at least equal to that computed with respect to the reference isochrone. Ultimately, the computed statistics represents the maximum possible performance that can be achieved for input physics discrimination. On the other hand, real clusters would contain unresolved binaries, peculiar stars, and contaminating field stars, which have an opposite effect because their presence will artificially increase the computed goodness-of-fit statistics. Moreover, as a further complication, real stars might be not well represented by the current generation of theoretical models because of the lack or not of a fully satisfactory treatment of some potentially important mechanisms such as rotation, spots, additional mixing, and magnetic fields (see e.g., Gallart et al. 2005; Cassisi 2010; Bressan et al. 2015; Salaris & Cassisi 2017). This will introduce a kind of offset in the achievable quality of the fit. Finally, the MC simulations were conducted assuming constant photometric errors in the whole magnitudes range, while for real-world CMDs, a dependence of the error on the magnitudes is expected. However, taking this into account would require a specific assumption both on this dependence and on the range spanned by the error, adding further degrees of freedom to the analysis. Therefore we chose to neglect this variability and only focused on the effect of the absolute error in the possibility of detecting physics discrepancies.
5.1. Examined input physics
We investigated the possibility of detecting the effects induced by a variation of the following physical quantities in stellar models: convective core overshooting efficiency, 14N(p, γ)15O reaction rate, microscopic diffusion velocities, outer boundary conditions (atmospheres), and colour transformation (bolometric corrections). The relevance of each quantity in stellar evolution has largely been discussed by several authors (see e.g., Tognelli et al. 2011, 2018; Valle et al. 2013; Cassisi 2014; Stancliffe et al. 2016).
The efficiency of mixing beyond the classical Schwarzschild border (over- or under-shooting) is still one of the most important sources of uncertainty in stellar evolution theory. Here we analysed only the effect of the core overshooting parameter β, which defines the scale length on which the mixing occurs, adopting a classical instantaneous mixing mechanism. We explored the sensitivity of isochrone fitting to a change of β of ±0.05 around our reference value of 0.15.
Regarding the nuclear network, the main source of uncertainty in the explored evolutionary stages is the 14N(p, γ)15O reaction rate, which sets the efficiency of the CNO cycle. Following Imbriani et al. (2005), we analysed the effect on models when the reaction rate is modified by ±10% around the reference value.
The diffusion velocities of helium and heavy elements was computed with the routine developed by Thoul et al. (1994), who suggested a typical uncertainty in the 10% to 15% range in the computed values. We modified the microscopic diffusion velocities by ±15%.
The choice of the outer boundary conditions is a relevant source of uncertainties in different mass ranges and evolutionary stages. We used as reference the atmosphere models (Allard et al. 2011, herafter AHF11), then we tested the effect on the models of the adoption of other non-grey boundary conditions extracted from Brott & Hauschildt (2005, hereafter BH05) and also by adopting the grey Krishna Swamy (1966) semi-empirical solar T − τ relation (hereafter KS66).
The MARCS plus CK03 synthetic spectra were used as reference to obtain the Gaia magnitudes. To test the effect on the models of different synthetic spectra, we constructed a set of isochrones using only the CK03 colours over the whole temperature range (i.e. Teff ≥ 3500 K).
5.2. Results
Figure 3 shows the isochrones at the three different ages for the various choices of input physics. Qualitatively, all the perturbed models are very similar to the reference model in most of the evolutionary phases, at least for G > 8 mag. This suggests that in many cases, a by-eye comparison between models and data (as was done for years) is not sufficient to correctly distinguish which set of perturbed models achieves the best agreement with data and consequently to reject or prefer some of them. The only exception is the isochrone that is computed with different convective core overshooting efficiency (for ages 150 Myr and 1 Gyr), which as expected, presents the greatest departure from the reference model in the overall contraction zone. However, even in this case, the discrepancy disappears at 7 Gyr because in the mass range relevant for this age, stars have a radiative core and isochrones are no longer sensitive to β.
 |
Fig. 3. Left panel: comparison of isochrones computed for an age of 150 Myr, but with different physics input (see text). Middle: same as in the left panel, but for an age of 1 Gyr. Right panel: same as in the left panel, but for an age of 7 Gyr. |
The capability of an isochrone goodness-of-fit test to distinguish among the considered input physics is shown in Figs. 4 and 5. These figures show for all scenarios we considered the boxplot5 of the 800 d2 statistics as a function of the error multiplier (the baseline observational error, corresponding to a multiplier equal to one, is 0.003 mag). The critical value or a rejection test conducted at the level α = 0.05 (the value that is usually adopted for the significance of statistical tests) is shown by the horizontal dashed line. Values above this threshold lead to the rejection of the hypothesis that the obtained fit is good, thus highlighting an unsatisfactory agreement between models and data.
 |
Fig. 4. Top row, left panel: boxplots of the computed d2 statistics for clusters of n = 300 stars generated by an isochrone at 150 Myr. The overshooting parameter β is changed by ±0.05 with respect to the reference isochrone. The statistics was computed with respect to the reference isochrone at the same age. The dashed blue line marks the significance at the 5% level. Centre: same as in the left panel, but for an age of 1 Gyr. Right panel: same as in the left panel, but for an age of 7 Gyr. Middle row: same as in the top row, but generating synthetic data from an isochrone with modified 14N(p, γ)15O reaction rate. Bottom row: same as in the top row, but generating synthetic data from an isochrone with a modified microscopic diffusion efficiency. |
 |
Fig. 5. Same as in Fig. 4, but for different choices of the synthetic spectra and outer boundary conditions. Top row: effect of adopting different synthetic spectra (CK03 instead of the MARCS2008). Middle row: effect of adopting the BH05 outer boundary conditions. Bottom row: effect of adopting the KS66 outer boundary conditions. |
The results indicate that the considered variations in the efficiency of the microscopic diffusion or in the 14N(p, γ)15O reaction rate are too small to be noted for all combinations of age and error multiplier we analysed. Regarding the convective core overshooting, a discrepancy in the assumed efficiency can be detected only for very precise measurements at a 0.003 mag uncertainty level, and only for the 1 Gyr case. This might appear strange because the effect of β on young isochrones in the overall contraction region is strong. However, the number of stars chosen (n = 300) is sufficiently small that this evolutionary zone, where β modifies the isochrone morphology, hosts fewer than a dozen stars. The same analysis conducted on a much more populated cluster (n = 2000 synthetic stars, data not shown) shows significant differences even for an observational error of 0.03 mag at 1 Gyr.
Regarding the boundary conditions and the colour system, their change largely affects the sequence of low-mass stars, which is a well-populated part of the isochrone. Therefore the difference with respect to the reference isochrone is clearly evident for photometric errors below about 0.01 mag (for boundary conditions) and in the whole photometric error range (for the colour systems).
The results presented so far are largely determined by the fainter stars, for which the differences among the isochrones are larger. However, it is well known that systematic biases in the model-derived bolometric corrections as a function of effective temperature exist in dependence on spectral types and surface gravity. In particular for what concerns the comparison between models and Gaia DR2 data, it has been shown that large systematic differences exist in the regime of low-mass stars (for MG ≳ 7 mag, see e.g., Gagné et al. 2018; Tognelli et al. 2021). This poses a serious problem in using the tail of low-mass stars in the comparison between models and data. Given this situation, we verified whether the adoption of a smaller portion of the isochrone (i.e. MG ≲ 7 mag) would change the results we obtained so far, that is, when the whole isochrone is used. We repeated the analysis using only the portion of the isochrone with MG ≲ 7 mag. The results of these MC experiments are presented in Fig. 6 (only for the 1 Gyr case). As a clear difference from the previous outcomes, in this case, only the overshooting and colour system modifications was detectable, and only for the lowest uncertainty of 0.003 mag.
 |
Fig. 6. Top row, left panel: boxplots of the computed d2 statistics for clusters of n = 300 stars generated by an isochrone at 1 Gyr. The overshooting parameter β changed by ±0.05 with respect to the reference isochrone. The statistics was computed with respect to the reference isochrone at the same age. The generated stars were constrained to have G < 7 mag. The dashed blue line marks the significance at 5% level. Centre: same as in the left panel, but generating synthetic data from an isochrone with modified 14N(p, γ)15O reaction rate. Right panel: same as in the left panel, but generating synthetic data from an isochrone with modified microscopic diffusion efficiency. Bottom row, left panel: same as in the top row, left panel, but for a difference in the colour systems. Centre: same as in the left panel, but generating synthetic data from an isochrone with BH05 boundary condition. Right panel: same as in the left panel, but generating synthetic data from an isochrone with a KS66 boundary condition. |
6. Towards a practical applications in the Gaia era
The goodness-of-fit statistics derived in Sect. 3 assumes in addition to the approximations discussed in Sect. 4 that all the cluster stars are single and that the CMD is not contaminated by the presence of field stars. These are crucial requirements because a clear binary sequence in the CMD would completely modify the final sum of squared distance from a reference isochrone.
Different approaches exist to solve this issue. As an example, it is possible to consider in the fitting not only the single star isochrone, but also the derived isochrones with different mass ratios q (e.g., Randich et al. 2018). This approach requires assuming a distribution for q and an assumed fraction of binary for the clusters. Then it allows computing an equivalent sum of the minimum distances, that is, a distance computed accounting from different probabilities that an observed point comes from the different isochrones. As an example of a similar but slightly different approach, Naylor & Jeffries (2006) derived the expected distribution of a goodness-of-fit statistics computing the probability that an observed stars lies on a particular position of a CMD diagram, integrating over the mass ratio distribution. This approach would require recomputing an ad hoc goodness-of-fit statistic and is therefore considered here no further.
Another possible approach is implementing a rejection technique to select only stars belonging to the single star population from the observed CMD. A data-driven rejection starts by evaluating a fiducial line for the cluster. Then the distances from individual observation and the fiducial line in an appropriate space are evaluated, and observed objects whose distances are greater than a chosen threshold are discarded as unresolved binary or field stars. It is obvious that this approach is only feasible when the observational errors are of few mmag at maximum, otherwise the random observational uncertainty blurs the single-star sequence, making it nearly indistinguishable from the binary sequence. As an example of what can be expected, Fig. 7 shows three synthetic CMD from the same reference isochrone ([Fe/H] = 0.0, age of 7 Gyr), with different assumptions about the observational errors. For the left panel of the figure an uncertainty of 0.003 mag was assumed, while it was 0.01 mag for the central panel and 0.03 mag for the right panel.
 |
Fig. 7. Left panel: synthetic diagram from the reference isochrone, N = 200 synthetic stars were generated assuming an observational uncertainty of 0.003 mag in all the magnitudes. Middle: same as in the left panel, but with observational uncertainty of 0.01 mag. Right panel: same as in the left panel, but with observational uncertainty of 0.03 mag. |
To simulate a difficult scenario, N = 200 artificial stars were generated in all the cases, adopting a fraction of binary η = 0.3. In OCs an average fraction of binaries of about 30% (i.e. η = 0.3) is expected (see e.g., Gizis & Reid 1995; Bouvier et al. 2001; Böhm-Vitense 2007; Boudreault et al. 2010; Khalaj & Baumgardt 2013; Sheikhi et al. 2016; Borodina et al. 2019; Li et al. 2020) even if the distribution of η can be quite large, ranging from about 30% to 70% (Sollima et al. 2010). Moreover, the value of η = 0.3 we adopted is fully suitable for clusters Praesepe (e.g., Bouvier et al. 2001; Khalaj & Baumgardt 2013) and α Per (Sheikhi et al. 2016), which we selected to test the presented rejection method (see Sect. 6). The distribution of the mass for the secondary stars was assumed to be flat from the minimum mass on the isochrone (i.e. 0.4 M⊙) and the mass of the actual companion. The paucity of stars in the synthetic data set makes it harder to correctly evaluate the fiducial line because some portion of the diagram can be unpopulated.
It is evident that the classification of star between single and unresolved binary is a simple task even by eye for the left panel (errors of 0.003 mag), while it is much harder for the right panel (errors of 0.03 mag). We explore in the next section what can be obtained by means of a simple rejection and the relevance of such a technique for a goodness-of-fit test.
With the aim to show what can be achieved with relative simple methods when high precision data are available, we present some results for an automated rejection procedure that was performed assuming different observational errors. The baseline observational error was set at σ = 0.003 mag, and we repeated the analysis considering observational error m σ, with m = 1, …, 10 an error multiplier. Therefore 0.03 mag was the maximum observational error considered in the analysis. The method adopts the distance from the CMD fiducial line as discriminant. Several well-tested and robust procedures exist in literature for this purpose (see among many, Brown et al. 2005; Bernard et al. 2014; Correnti et al. 2016; Wagner-Kaiser et al. 2017); we adopted here a two-step method that is straightforward to implement and that performs very well for our CMD, which mainly contains MS stars.
In detail, the synthetic CMD is divided into 30 bins6 in the G magnitude. For each bin the mode of the G and GBP − GRP magnitudes were computed. These values were subjected to a smoothing by means of the Friedmans Super Smoother (Friedman 1984) implemented in the R function supsmu (R Core Team 2018). For this purpose, the position in the series was used as the x coordinate, and the values of the magnitude as the y coordinate; 20% of the observations around each point were used for the smoothing. Then the distances between the smoothed fiducial line in the G versus GBP − GRP plane of each observation were computed. Because the fiducial line is known only by points, the same procedure as described in Sect. 2 was applied to avoid numerical issues. Then the observational points whose distance is greater than T1 = 30σ were discarded as likely non-single stars or non-cluster members. After these first steps, field stars and obvious binary stars were removed. However, the computed fiducial line are affected by them, therefore a second step was required to obtain a much superior rejection.
The second step, identical to the first, was then performed by adopting a rejection threshold T2 = 6σ. This is possible because most of the obvious outliers were removed after the first step, and the computed fiducial line closely matched the actual single-star sequence. Only stars passing the second selection were retained as likely single stars and cluster members.
A similar method was proposed by Arenou et al. (2018), who evaluated the quality of the Gaia DR2 photometry. They limited the analysis to stars brighter than an apparent G magnitude of about 18 mag, which is the limit above which the quality of photometry and astrometry strongly decreases.
To explore whether we can reject objects based on the proposed two-step procedure, we performed an MC simulation. We generated 100 synthetic CMD with N = 200 stars for each adopted value of the observational error multiplier m. In each case, 20 field stars were randomly generated by selecting 20 cluster single stars and adding a Gaussian observational error with σ = 0.2 mag to them. This is much larger than the error adopted in the observational error simulation (binary stars were added as explained before). A typical result is shown in the left panel of Fig. 8. It was computed assuming an observational uncertainty of 0.006 mag (i.e. m = 2). Then, we applied the two-step fiducial line rejection to each simulated data set. Figure 8 shows for one case that the outlined procedure is able to reject most non-single or non-member stars and thus provides a target suitable for the goodness-of-fit test. The results obtained for the other simulated data sets are similar to result presented in the figure.
 |
Fig. 8. Left panel: synthetic CMD of a cluster with N = 200 stars, binary fraction η = 0.3, and observational uncertainty of 0.006 mag. Another 20 stars were added with a scatter in the magnitude of 0.2 mag. Right panel: same as in the left panel after the two-step rejection (see text). |
We further analysed the classification obtained with the rejection procedure. The so-called confusion matrix was built for each synthetic CMD. This matrix classifies the stars according to two keys: the real status of the star in the MC generation (single, binary) and the status returned by the rejection procedure, as displayed in Fig. 9. In the figure, a number A of cluster stars are correctly classified as single (true positive), while a number B of the single-cluster stars are classified as non-single (false positive). In the same way, D stars are correctly identified as non-single (true negative), and C stars are identified as single when they are not (false negative).
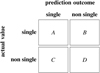 |
Fig. 9. Schematic representation of a confusion matrix for a diagnostic test. |
From this matrix, two indices of the test performance are commonly computed, that is, the sensitivity s and the specificity s′ of the test. The sensitivity corresponds to the proportion of actual positives that are correctly identified as such, while the specificity corresponds to the proportion of actual negatives that are correctly identified as such. After defining A, B, C, and D, the sensitivity s and the specificity s′ are defined as follows:
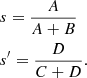 (26)
(26)
The classification in the confusion matrix clearly strictly depends on the values of the thresholds T1 and T2 adopted in the rejection procedure. High threshold values correspond to a low probability of misclassifying a single star, but also to an increased probability of a false-negative result (i.e. a binary classified as single). Ideally, a high value of both is desirable, but in practice, we have to compromise and choose which index to prioritise. In our specific case, the effect on the goodness-of-fit of a poor binary rejection is much more severe than the omission of few good single stars, therefore a high specificity (s′) if far more important than a high sensitivity (s).
The top row in Fig. 10 shows the boxplots for the computed s and s′ from the MC experiment as a function of the observational error multiplier m. It is evident that with the chosen T1 and T2, the sensitivity approaches 1 as the observational error is higher than 0.015–0.020 mag and the specificity decreases. This is caused by the fact that in presence of large errors, the binary and single-star sequences become increasingly harder to distinguish. In this case, both A (single star recovered as a single star) and C (non-single star recovered as single star) therefore increase. Consequently, s approaches 1 and s′ decreases. Ultimately, this means that we cannot obtain a satisfactory rejection, and that both single and binary stars are compatible with a single-star sequence. As an example, for m = 10 (i.e. observational error of 0.03 mag), the median s′ is as low as 0.3.
 |
Fig. 10. Top row, left panel: sensitivity for the detection of single stars from synthetic clusters as a function of the multiplier of the baseline observational error σ = 0.003 mag. The dashed line marks the 95% value. The cluster fiducial lines for the test were data driven (see text for details). Top row, right panel: specificity for the detection of single stars from synthetic clusters (data-driven fiducial line). The dashed green line marks the 90% value and represents a preferred target, while the purple line marks the 80% value and represents a minimum requirement. Bottom row: same as in the top row, but adopting the theoretical isochrone as the fiducial line. |
On the other hand, for low observational errors, a very good specificity is obtained. For m ≤ 4 (i.e. observational errors up to 0.012 mag), we find s′> 0.8.
To confirm the robustness and reliability of the result with respect to the fiducial line computation algorithm, it is mandatory to compare them with another set obtained with a different approach in the fiducial line evaluation. It is in principle possible that superior results can be achieved with a more sophisticated approach. In a perfectly controlled environment in which stars are artificially generated, we had the possibility to test the best ideal performance that can be reached by using the theoretical generating isochrone as single-star fiducial line. Therefore we repeated the sensitivity and specificity evaluation in this configuration. The bottom row in Fig. 10 reports the values we obtained. The comparison shows an increase in the sensitivity for error multipliers below four, implying that a better fiducial line reconstruction can help in this task. However, no improvement is achieved for the specificity, suggesting that even a simple approach performs well in the CMD cleaning.
In summary, even for a scarcely populated CMD, observational errors below 0.006 mag allow a reliable automatic cleaning of the CMD as long as the MS is considered. Further by-eye cleaning can be performed in the turn-off region, where the star number can be too low for a robust automatic classification. As an example, in the right panel of Fig. 8, a star at G ≈ 4 clearly appears to fall off the single-star fiducial line and can be safely rejected as a non-detected binary.
It this section we show some results that can be achieved by the automated rejection described in Sect. 6 for real photometric data. In particular, we analyse the Praesepe (M44, NGC 2632) and the α Persei (Messier 20) OCs. We extracted the photometric data for the two clusters from the online Gaia DR2 catalogue7 (Gaia Collaboration 2016, 2018b) using the filters given in Gaia Collaboration (2018a); we also adopted the parallaxes given in that paper to obtain the absolute magnitudes.
After the selection steps, we had 722 and 565 cluster members for Praesepe and α Persei, respectively. The cleaning steps retained about 50% of the stars as bona fide single sources. The estimated binary rates are, as expected, slightly higher than binarity estimates in Praesepe (from 30% to 50%, Boudreault et al. 2010; Pinfield et al. 2003; Khalaj & Baumgardt 2013) and α Persei clusters (approximately 35%, Sheikhi et al. 2016). As discussed in the previous section, the sensitivity of the selection algorithm is about 80–90% for the nominal error affecting these CMDs, thus implying that 10–20% of the targets are erroneously classified as binary.
The results are displayed in Fig. 11. The top row shows the rejection for the Praesepe cluster. The left panel displays the original data, and the selected single sources are shown in the right panel (339 stars). The strongest selection occurred at the high- and low-luminosity ends. For a G magnitude higher than 9.8, only about 30% of the 278 original sources were selected, while in the near turn-off region, where the algorithm stops, 20 of the 31 sources in the original data set were discarded. Except for the broad sequence at magnitudes higher than about 9, the vast majority of unresolved binaries were removed. For this cluster, a very narrow sequence was identified based on the great precision of the photometric data (median errors in the G, GBP, and GRP bands of 0.0008 mag, 0.0062 mag, and 0.0022 mag, respectively).
 |
Fig. 11. Top row, left panel: Gaia DR2 CMD of the Presepae cluster. Right panel: same as in the left panel, but after the two-step rejection. Bottom row: same as in the top row, but for the α Persei cluster. |
A similar result was obtained for the α Per cluster (bottom row in Fig. 11). In this case, 264 sources passed the cleaning. The photometric nominal errors (median errors in the G, GBP, and GRP bands of 0.0012 mag, 0.01 mag, and 0.0034 mag) are larger than for the Praesepe cluster and broaden the identified sequence. As a difference with the previous case, the features of the sequence for the high-luminosity end were nearly erased by the cleaning, providing more evidence that a very high photometric accuracy is required when source selection is attempted.
7. Conclusions
The outstanding quality of the photometric observations from Gaia enables us to test the reliability of stellar models, and to distinguish in the best possibly way among the poorly constrained free parameters or assumptions that are generally made when stellar models are computed. Therefore it is crucial to have a firm theoretical basis for evaluating the agreement between data and stellar models.
In this framework, we derived the exact analytical expression of the distribution of the sum of squared Mahalanobis distances in a given data set from an OC and a reference isochrone. We obtained it by approximating the isochrone with segments between consecutive support points. We also verified that with N stellar sources with r measured magnitudes each and p hyper-parameters optimised by the fit, the sum of the distances follows a 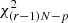 distribution.
distribution.
To confirm the robustness of the idealised assumptions made in deriving this result, we compared the theoretical distribution with that obtained with a controlled simulation, which was a set of CMDs generated from a reference isochrone. As a first point, the approximation with a straight line was supported: the median angle between consecutive isochrone portions was lower than 10−3 rad, which implies an overall negligible effect of the direction changes. Second, we performed a direct evaluation of the distance distribution with MC simulations. Several synthetic clusters were generated from the reference isochrone for N = 200 to N = 5000 stellar objects in the clusters. Observational errors of 0.003 mag in every magnitude were assumed. For each observational point of the synthetic cluster, the minimum squared distance d2 was computed. The procedure was repeated n = 200 times for each N, which is sufficient to achieve a good statistical convergence of the empirical distributions of d2. The agreement between empiric and theoretical χ2 is nearly perfect, confirming that the theoretical assumptions we made hold.
The derivation of the expected distribution can be used as a tool for analysing the possibility of distinguishing between isochrones that are computed assuming different sets of input physics. The aim of this application was to assess the possibility of rejecting a fit, and thus a set of input physics, as inadequate to reproduce the data. We investigated the possibility of detecting the effects induced by a variation (within their current accepted range of variability) of the following physical quantities in stellar models: convective core overshooting efficiency, 14N(p, γ)15O reaction rate, microscopic diffusion velocities, outer boundary conditions (atmospheres), and colour transformations (bolometric corrections). We performed the investigation at three different ages: 150 Myr, 1 Gyr, and 7 Gyr.
The results indicate that the variations in the efficiency of the microscopic diffusion or in the 14N(p, γ)15O reaction rate are too small to be noted even when the smallest uncertainty in the photometry is assumed. Regarding the convective core overshooting, a discrepancy in the assumed efficiency can be detected only for very precise measurements at 0.003 mag uncertainty level, and only for the 1 Gyr case. As for the outer boundary conditions and the colour system, their change largely affects the sequence of low-mass stars, which is a well-populated part of the isochrone. The difference with respect to the reference isochrone is clearly evident for photometric errors below about 0.01 mag. The largest effect is achieved by a change in the bolometric corrections. In this case, the effect is detected in the whole photometric error range.
Finally, we considered that the comparison between models and data is complicated by the presence of outliers because the CMD might be contaminated by field stars or unresolved binaries. These is a crucial issue because a clear binary sequence in the CMD would completely modify the final sum of the squared distance from a reference isochrone. We tested the performance that can be achieved by a simple data-driven rejection technique based on the evaluation of a fiducial line for the cluster and a rejection of objects that lie too far away from it. A two-step rejection technique allowed us to reach a very high rejection rate of non-single stars for observational errors up to 0.012 mag, while the possibility of rejecting binary and fields stars dropped dramatically as the observational errors increased. We found that even for a scarcely populated CMD, observational errors below 0.006 mag allow a reliable automatic cleaning of the CMD as long as the MS is considered. The cleaning procedure was demonstrated to work well on real photometric Gaia DR2 data from the Praesepe (M44, NGC 2632) and the α Persei (Messier 20) OCs, confirming the need of very high photometric accuracy when an automatic source selection is attempted.
By N(μ, S) we indicate a Gaussian density function with mean μ and variance S.
We denote by 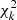 the χ2 distribution with k degrees of freedom.
the χ2 distribution with k degrees of freedom.
The rows of W are linear dependent because W is obtained from the outer product aaT.
We verified that the results are unchanged assuming an observational error of 0.01 mag.
A boxplot is a convenient way to summarise the variability of the data; the thick black lines show the median of the data set, while the box marks the interquartile range; i.e., it extends form the 25th to the 75th percentile of the data. The whiskers extend from the box to the extreme data, but they can only extend to a maximum of 1.5 times the width of the box.
The number of bins is not crucial. Equivalent results were obtained when we varied it from 15 to 80.
Acknowledgments
We thank our anonymous referee for the comments and suggestions. This work has made use of data from the European Space Agency (ESA) mission Gaia (https://www.cosmos.esa.int/gaia), processed by the Gaia Data Processing and Analysis Consortium (DPAC, https://www.cosmos.esa.int/web/gaia/dpac/consortium). Funding for the DPAC has been provided by national institutions, in particular the institutions participating in the Gaia Multilateral Agreement. Praesepe and α Persei clusters data used in this article were retrieved from the Gaia DR2 catalogue available at the url: https://gea.esac.esa.int/archive/.
References
- Allard, F., Homeier, D., & Freytag, B. 2011, in 16th Cambridge Workshop on Cool Stars, Stellar Systems, and the Sun, eds. C. Johns-Krull, M. K. Browning,, & A. A. West, ASP Conf. Ser., 448, 91 [Google Scholar]
- Arenou, F., Luri, X., Babusiaux, C., et al. 2018, A&A, 616, A17 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Asplund, M., Grevesse, N., Sauval, A. J., & Scott, P. 2009, ARA&A, 47, 481 [NASA ADS] [CrossRef] [Google Scholar]
- Barbaro, G., & Pigatto, L. 1984, A&A, 136, 355 [NASA ADS] [Google Scholar]
- Bausch, J. 2013, J. Phys. A: Math. Theor., 46, 505202 [Google Scholar]
- Bergbusch, P. A., & VandenBerg, D. A. 2001, ApJ, 556, 322 [NASA ADS] [CrossRef] [Google Scholar]
- Bernard, E. J., Ferguson, A. M. N., Schlafly, E. F., et al. 2014, MNRAS, 442, 2999 [Google Scholar]
- Bica, E., & Bonatto, C. 2011, A&A, 530, A32 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Böhm-Vitense, E. 2007, AJ, 133, 1903 [NASA ADS] [CrossRef] [Google Scholar]
- Bonatto, C., Kerber, L. O., Bica, E., & Santiago, B. X. 2006, A&A, 446, 121 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Borodina, O. I., Seleznev, A. F., Carraro, G., & Danilov, V. M. 2019, ApJ, 874, 127 [NASA ADS] [CrossRef] [Google Scholar]
- Bossini, D., Vallenari, A., Bragaglia, A., et al. 2019, A&A, 623, A108 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Boudreault, S., Bailer-Jones, C. A. L., Goldman, B., Henning, T., & Caballero, J. A. 2010, A&A, 510, A27 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bouvier, J., Duchêne, G., Mermilliod, J. C., & Simon, T. 2001, A&A, 375, 989 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bressan, A., Girardi, L., Marigo, P., Rosenfield, P., & Tang, J. 2015, Asteroseismology of Stellar Populations in the Milky Way, 39, 25 [Google Scholar]
- Brott, I., & Hauschildt, P. H. 2005, in The Three-Dimensional Universe with Gaia, eds. C. Turon, K. S. O’Flaherty, & M. A. C. Perryman, ESA Spec. Pub., 576, 565 [Google Scholar]
- Brown, T. M., Ferguson, H. C., Smith, E., et al. 2005, AJ, 130, 1693 [NASA ADS] [CrossRef] [Google Scholar]
- Cantat-Gaudin, T., Donati, P., Vallenari, A., et al. 2016, A&A, 588, A120 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cantat-Gaudin, T., Jordi, C., Vallenari, A., et al. 2018, A&A, 618, A93 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cantat-Gaudin, T., Krone-Martins, A., Sedaghat, N., et al. 2019, A&A, 624, A126 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Casagrande, L., Silva Aguirre, V., Schlesinger, K. J., et al. 2016, MNRAS, 455, 987 [NASA ADS] [CrossRef] [Google Scholar]
- Cassisi, S. 2010, in Stellar Populations - Planning for the Next Decade, eds. G. R. Bruzual, & S. Charlot, 262, 13 [Google Scholar]
- Cassisi, S. 2014, EAS Pub. Ser., 65, 17 [Google Scholar]
- Castaño-Martínez, A., & López-Blázquez, F. 2005, TEST, 14, 397 [Google Scholar]
- Castelli, F., & Kurucz, R. L. 2003, in Modelling of Stellar Atmospheres, eds. N. Piskunov, W. W. Weiss, & D. F. Gray, IAU Symp., 210, 20P [Google Scholar]
- Castro-Ginard, A., Jordi, C., Luri, X., et al. 2018, A&A, 618, A59 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Correnti, M., Gennaro, M., Kalirai, J. S., Brown, T. M., & Calamida, A. 2016, ApJ, 823, 18 [CrossRef] [Google Scholar]
- Creevey, O. L., Metcalfe, T. S., Schultheis, M., et al. 2017, A&A, 601, A67 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Davis, A. W. 1977, J. Am. Stat. Assoc., 72, 212 [Google Scholar]
- Degl’Innocenti, S., Prada Moroni, P. G., Marconi, M., & Ruoppo, A. 2008, Ap&SS, 316, 25 [NASA ADS] [CrossRef] [Google Scholar]
- Dell’Omodarme, M., Valle, G., Degl’Innocenti, S., & Prada Moroni, P. G. 2012, A&A, 540, A26 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Evans, D. W., Riello, M., De Angeli, F., et al. 2018, A&A, 616, A4 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ferreira, F. A., Santos, J. F. C., Corradi, W. J. B., Maia, F. F. S., & Angelo, M. S. 2019, MNRAS, 483, 5508 [NASA ADS] [CrossRef] [Google Scholar]
- Flannery, B. P., & Johnson, B. C. 1982, ApJ, 263, 166 [NASA ADS] [CrossRef] [Google Scholar]
- Frayn, C. M., & Gilmore, G. F. 2002, MNRAS, 337, 445 [NASA ADS] [CrossRef] [Google Scholar]
- Friedman, J. H. 1984, A variable span smoother, Tech. Rep. 5, Laboratory for Computational Statistics, Department of Statistics, Stanford University [Google Scholar]
- Friel, E. D. 1995, ARA&A, 33, 381 [NASA ADS] [CrossRef] [Google Scholar]
- Gagné, J., Faherty, J. K., & Mamajek, E. E. 2018, ApJ, 865, 136 [CrossRef] [Google Scholar]
- Gai, N., Basu, S., Chaplin, W. J., & Elsworth, Y. 2011, ApJ, 730, 63 [NASA ADS] [CrossRef] [Google Scholar]
- Gaia Collaboration (Prusti, T., et al.) 2016, A&A, 595, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Brown, A. G. A., et al. 2018a, A&A, 616, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Babusiaux, C., et al.) 2018b, A&A, 616, A10 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Brown, A. G. A., et al.) 2021, A&A, 649, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gallart, C., Zoccali, M., & Aparicio, A. 2005, ARA&A, 43, 387 [NASA ADS] [CrossRef] [Google Scholar]
- Geenens, G., & Wang, C. 2018, J. Comput. Graphical Stat., 27, 822 [Google Scholar]
- Gennaro, M., Prada Moroni, P. G., & Tognelli, E. 2012, MNRAS, 420, 986 [NASA ADS] [CrossRef] [Google Scholar]
- Gizis, J., & Reid, I. N. 1995, AJ, 110, 1248 [NASA ADS] [CrossRef] [Google Scholar]
- Gnanadesikan, R., & Kettenring, J. R. 1972, Biometrics, 28, 81 [CrossRef] [Google Scholar]
- Gustafsson, B., Edvardsson, B., Eriksson, K., et al. 2008, A&A, 486, 951 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hardin, J., & Rocke, D. M. 2005, J. Comput. Graphical Stat., 14, 928 [Google Scholar]
- Harris, J., & Zaritsky, D. 2001, ApJS, 136, 25 [NASA ADS] [CrossRef] [Google Scholar]
- Hu, Y., & Scarrott, C. 2018, J. Stat. Software, 84, 1 [Google Scholar]
- Imbriani, G., Costantini, H., Formicola, A., et al. 2005, Eur. Phys. J. A, 25, 455 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Imhof, J. P. 1961, Biometrika, 48, 417 [Google Scholar]
- Janes, K., & Adler, D. 1982, ApJS, 49, 425 [NASA ADS] [CrossRef] [Google Scholar]
- Jones, M. C. 1993, Stat. Comput., 3, 135 [Google Scholar]
- Jørgensen, B. R., & Lindegren, L. 2005, A&A, 436, 127 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Karunamuni, R. J., & Alberts, T. 2005, Can. J. Stat., 33, 497 [Google Scholar]
- Khalaj, P., & Baumgardt, H. 2013, MNRAS, 434, 3236 [NASA ADS] [CrossRef] [Google Scholar]
- Kos, J., de Silva, G., Buder, S., et al. 2018, MNRAS, 480, 5242 [NASA ADS] [CrossRef] [Google Scholar]
- Krishna Swamy, K. S. 1966, ApJ, 145, 174 [NASA ADS] [CrossRef] [Google Scholar]
- Li, L., Shao, Z., Li, Z.-Z., et al. 2020, ApJ, 901, 49 [Google Scholar]
- Maeder, A., & Mermilliod, J. C. 1981, A&A, 93, 136 [NASA ADS] [Google Scholar]
- Mathai, A. M. 1982, Ann. Inst. Stat. Math., 34, 591 [Google Scholar]
- McKeever, J. M., Basu, S., & Corsaro, E. 2019, ApJ, 874, 180 [NASA ADS] [CrossRef] [Google Scholar]
- Mermilliod, J. C. 2000, in Stellar Clusters and Associations: Convection, Rotation, and Dynamos, eds. R. Pallavicini, G. Micela, & S. Sciortino, ASP Conf. Ser., 198, 105 [Google Scholar]
- Miglio, A., Brogaard, K., Stello, D., et al. 2012, MNRAS, 419, 2077 [Google Scholar]
- Moschopoulos, P., & Canada, W. B. 1984, Comput. Math. Appl., 10, 383 [Google Scholar]
- Naylor, T., & Jeffries, R. D. 2006, MNRAS, 373, 1251 [NASA ADS] [CrossRef] [Google Scholar]
- Netopil, M., Paunzen, E., Heiter, U., & Soubiran, C. 2016, A&A, 585, A150 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pinfield, D. J., Dobbie, P. D., Jameson, R. F., et al. 2003, MNRAS, 342, 1241 [NASA ADS] [CrossRef] [Google Scholar]
- Piskunov, A. E., Kharchenko, N. V., Röser, S., Schilbach, E., & Scholz, R.-D. 2006, A&A, 445, 545 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pont, F., & Eyer, L. 2004, MNRAS, 351, 487 [NASA ADS] [CrossRef] [Google Scholar]
- Provost, S. B., & Mathai, A. M. 1992, Quadratic Forms in Random Variables: Theory and Applications, Statistics: Textbooks and Monographs (Marcel Dekker) [Google Scholar]
- R Core Team 2018, R: A Language and Environment for Statistical Computing (Vienna, Austria: R Foundation for Statistical Computing) [Google Scholar]
- Randich, S., Primas, F., Pasquini, L., Sestito, P., & Pallavicini, R. 2007, A&A, 469, 163 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Randich, S., Tognelli, E., Jackson, R., et al. 2018, A&A, 612, A99 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Riello, M., De Angeli, F., Evans, D. W., et al. 2021, A&A, 649, A3 [Google Scholar]
- Ruben, H. 1962, Ann. Math. Stat., 33, 542 [Google Scholar]
- Salaris, M., & Cassisi, S. 2017, Roy. Soc. Open Sci., 4, 170192 [Google Scholar]
- Salpeter, E. E. 1955, ApJ, 121, 161 [Google Scholar]
- Sheikhi, N., Hasheminia, M., Khalaj, P., et al. 2016, MNRAS, 457, 1028 [NASA ADS] [CrossRef] [Google Scholar]
- Soderblom, D. R. 2010, ARA&A, 48, 581 [NASA ADS] [CrossRef] [Google Scholar]
- Sollima, A., Carballo-Bello, J. A., Beccari, G., et al. 2010, MNRAS, 401, 577 [NASA ADS] [CrossRef] [Google Scholar]
- Stancliffe, R. J., Fossati, L., Passy, J.-C., & Schneider, F. R. N. 2016, A&A, 586, A119 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Thoul, A. A., Bahcall, J. N., & Loeb, A. 1994, ApJ, 421, 828 [NASA ADS] [CrossRef] [Google Scholar]
- Tognelli, E., Prada Moroni, P. G., & Degl’Innocenti, S. 2011, A&A, 533, A109 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tognelli, E., Prada Moroni, P. G., & Degl’Innocenti, S. 2018, MNRAS, 476, 27 [Google Scholar]
- Tognelli, E., Dell’Omodarme, M., Valle, G., Prada Moroni, P. G., & Degl’Innocenti, S. 2021, MNRAS, 501, 383 [Google Scholar]
- Tolstoy, E., & Saha, A. 1996, ApJ, 462, 672 [Google Scholar]
- Valle, G., Dell’Omodarme, M., Prada Moroni, P. G., & Degl’Innocenti, S. 2013, A&A, 549, A50 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Valle, G., Dell’Omodarme, M., Tognelli, E., Prada Moroni, P. G., & Degl’Innocenti, S. 2018, A&A, 619, A158 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Valls-Gabaud, D. 2014, EAS Pub. Ser., 65, 225 [Google Scholar]
- VandenBerg, D. A., & Stetson, P. B. 2004, PASP, 116, 997 [NASA ADS] [CrossRef] [Google Scholar]
- von Hippel, T., Jefferys, W. H., Scott, J., et al. 2006, ApJ, 645, 1436 [NASA ADS] [CrossRef] [Google Scholar]
- Wagner-Kaiser, R., Mackey, D., Sarajedini, A., et al. 2017, MNRAS, 471, 3347 [Google Scholar]
Appendix A: Synthetic CMD generation
All synthetic CMD computations started from a theoretical reference isochrone ℐ. Let ns be the number of single stars, nb the number of unresolved binaries, and nf the number of non-rejected contaminating field stars. The algorithm starts by sampling ns + nb masses from the Salpeter power-law initial mass funtion (Salpeter 1955), adopting 0.4 M⊙ as the lower mass end, and the maximum mass available on ℐ as the upper mass end. We call B1 the set of the last nb objects, with masses Mb, 1. These sources are coupled with corresponding sources with a mass sampled at random in the range [0.4, Mb, 1] M⊙, implying a flat distribution of the mass ratio. We call this second set B2. Then the magnitudes of the unresolved binaries were obtained by combining the fluxes of the two sets B1 and B2. If specified in the input, additional nf stars were generated from the same initial mass function.
Then the photometric errors are accounted for by adding a Gaussian error from the N(0, σ2) distribution to the obtained magnitudes, with σ in the range [0.003, 0.03] mag for all but field stars. For the field stars, σ = 0.2 mag was adopted.
Appendix B: Variance computation
The derivation of Eq. (14) requires some algebraic steps. The three terms in Eq. (13) can be computed as
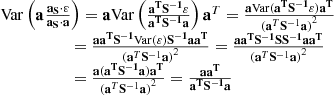 (B.1)
(B.1)
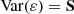 (B.2)
(B.2)
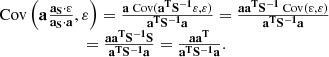 (B.3)
(B.3)
Putting Eqs. (B.1)–(B.3) together, we obtain the final variance in Eq. (14).
All Figures
|
Fig. 1. Top left panel: reference isochrone in the G vs. GBP − GRP plane. Top right panel: isochrone in the G versus GBP plane. Bottom left panel: isochrone in the G vs. GRP plane. Bottom right panel: isochrone in the GBP vs GRP plane. |
| In the text | |
|
Fig. 2. Left panel: comparison of the empirical distribution of the minimum distance between synthetic observations and isochrone (solid black line) and a |
| In the text | |
|
Fig. 3. Left panel: comparison of isochrones computed for an age of 150 Myr, but with different physics input (see text). Middle: same as in the left panel, but for an age of 1 Gyr. Right panel: same as in the left panel, but for an age of 7 Gyr. |
| In the text | |
|
Fig. 4. Top row, left panel: boxplots of the computed d2 statistics for clusters of n = 300 stars generated by an isochrone at 150 Myr. The overshooting parameter β is changed by ±0.05 with respect to the reference isochrone. The statistics was computed with respect to the reference isochrone at the same age. The dashed blue line marks the significance at the 5% level. Centre: same as in the left panel, but for an age of 1 Gyr. Right panel: same as in the left panel, but for an age of 7 Gyr. Middle row: same as in the top row, but generating synthetic data from an isochrone with modified 14N(p, γ)15O reaction rate. Bottom row: same as in the top row, but generating synthetic data from an isochrone with a modified microscopic diffusion efficiency. |
| In the text | |
|
Fig. 5. Same as in Fig. 4, but for different choices of the synthetic spectra and outer boundary conditions. Top row: effect of adopting different synthetic spectra (CK03 instead of the MARCS2008). Middle row: effect of adopting the BH05 outer boundary conditions. Bottom row: effect of adopting the KS66 outer boundary conditions. |
| In the text | |
|
Fig. 6. Top row, left panel: boxplots of the computed d2 statistics for clusters of n = 300 stars generated by an isochrone at 1 Gyr. The overshooting parameter β changed by ±0.05 with respect to the reference isochrone. The statistics was computed with respect to the reference isochrone at the same age. The generated stars were constrained to have G < 7 mag. The dashed blue line marks the significance at 5% level. Centre: same as in the left panel, but generating synthetic data from an isochrone with modified 14N(p, γ)15O reaction rate. Right panel: same as in the left panel, but generating synthetic data from an isochrone with modified microscopic diffusion efficiency. Bottom row, left panel: same as in the top row, left panel, but for a difference in the colour systems. Centre: same as in the left panel, but generating synthetic data from an isochrone with BH05 boundary condition. Right panel: same as in the left panel, but generating synthetic data from an isochrone with a KS66 boundary condition. |
| In the text | |
|
Fig. 7. Left panel: synthetic diagram from the reference isochrone, N = 200 synthetic stars were generated assuming an observational uncertainty of 0.003 mag in all the magnitudes. Middle: same as in the left panel, but with observational uncertainty of 0.01 mag. Right panel: same as in the left panel, but with observational uncertainty of 0.03 mag. |
| In the text | |
|
Fig. 8. Left panel: synthetic CMD of a cluster with N = 200 stars, binary fraction η = 0.3, and observational uncertainty of 0.006 mag. Another 20 stars were added with a scatter in the magnitude of 0.2 mag. Right panel: same as in the left panel after the two-step rejection (see text). |
| In the text | |
|
Fig. 9. Schematic representation of a confusion matrix for a diagnostic test. |
| In the text | |
|
Fig. 10. Top row, left panel: sensitivity for the detection of single stars from synthetic clusters as a function of the multiplier of the baseline observational error σ = 0.003 mag. The dashed line marks the 95% value. The cluster fiducial lines for the test were data driven (see text for details). Top row, right panel: specificity for the detection of single stars from synthetic clusters (data-driven fiducial line). The dashed green line marks the 90% value and represents a preferred target, while the purple line marks the 80% value and represents a minimum requirement. Bottom row: same as in the top row, but adopting the theoretical isochrone as the fiducial line. |
| In the text | |
|
Fig. 11. Top row, left panel: Gaia DR2 CMD of the Presepae cluster. Right panel: same as in the left panel, but after the two-step rejection. Bottom row: same as in the top row, but for the α Persei cluster. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.